Область техники
Настоящее изобретение относится к компьютерному способу идентификации пептидов, пригодных для использования в качестве мишеней для лекарственных средств. Более конкретно настоящее изобретение относится к компьютерному способу идентификации инвариантных пептидных мотивов в данных о белковых последовательностях различных организмов, пригодных для использования в качестве возможных мишеней для лекарственных средств. Кроме того, настоящее изобретение предусматривает способ приписывания функции гипотетическим открытым фреймам (белкам) с неизвестной функцией с помощью точной характеристики аминокислотной последовательности.
Настоящее изобретение предусматривает новый подход к идентификации структурных и функциональных характеристик, сохраняющихся инвариантных последовательностей аминокислот белков, которые могут служить в качестве возможных кандидатов в мишени для лекарственных средств. Возможность неожиданного появления штаммов, устойчивых к лекарственным средствам, вызывает необходимость в разработке новых лекарственных средств и мишеней для лекарственных средств. Уникальные инвариантные пептидные мотивы, которые присутствуют в белках патогенного микроорганизма, но отсутствуют в белках хозяина, указывают потенциальные мишени для лекарственных средств. Настоящее изобретение также предусматривает способ для сравнения, подобно геному, большого количества белковых последовательностей одновременно. Еще одним аспектом изобретения является идентификация белковых последовательностей, пригодных для использования в специфической диагностике инфекций.
Предшествующий уровень техники
Известно, что большинство лекарственных средств, которые доступны в настоящее время для лечения инфекций, связываются с конкретными молекулами-мишенями белков в клетке вызывающего болезнь организма, например, некоторые антибиотики, как известно, нарушают функцию рибосом, т.е. воздействуют на трансляцию белков. В этих случаях лекарственные средства связываются либо непосредственно с рибосомальной РНК, либо с комплексами РНК и белков (Wimberly et al., 1999). Эксперименты с химическими зондами показали, что лекарственное средство связывается с определенными нуклеотидными последовательностями рибосомальной РНК, которые являются 'инвариантными' в структурно-аналогичных областях различных организмов (Porse and Garrett, 1999). Другой класс лекарственных средств служит для блокировки других функций, таких как транскрипция (Cutler et al., 1999) или синтез жирных кислот в бактериальной клетке (McCafferty et al., 1999).
В последнее время неожиданно появились несколько устойчивых к лекарственным средствам штаммов (Ghannoum and Rice, 1999) патогенных бактерий, что делает современные способы лечения неэффективными при лечении инфекций, вызываемых бактериальными микроорганизмами. Это вызывает необходимость разработки новых мишеней для лекарственных средств и соответствующих новых лекарственных средств. Доступность полных геномных последовательностей различных микробов дает возможность анализировать все белки, закодированные в данном геноме. Поскольку большинство лекарственных средств, известных в настоящее время, взаимодействует с белками, вероятно, что анализ всех белков в данной бактерии может привести к получению новых работающих мишеней для лекарственных средств.
Информация о новых сохраняющихся инвариантных последовательностях в белке может быть полезной для понимания определенных особенностей архитектуры белков, таких как расположение сегмента в объеме или на поверхности белковой глобулы или присутствие специфических вторичных структурных элементов (Rooman and Wodak, 1988, Presnell et al., 1992). Функциональная роль белка является наиболее важным аспектом сохраняющихся инвариантных последовательностей. Способы обычного анализа последовательностей включают BLAST (Altschul et al., 1990) и FASTA (Wilbur and Lipman, 1983). Эти способы выдают размещение последовательности, качество которой оценивается с помощью матрицы замещения аминокислот. Осуществляются статистические вычисления, и результаты выводятся ранжированным образом, при этом последовательность с наилучшим подобием оценивается как первая. Однако эти способы не создавались для проведения одновременного сравнения, подобно геному, для идентификации пептидных мотивов инвариантных последовательностей, которые особенно важны в этой работе.
В порядке сравнения каждого белка одного организма со всеми другими белками нескольких других организмов либо необходимо использовать BLAST для каждого сравнения, либо должна быть использована BLAST в загрузочном режиме, что требует очень много времени, и поэтому практически неосуществимо. Даже если это сделать, в конце задачи необходимо получить общее подобие множества гомологичных белков и размещений.
Проблема с совмещением множества последовательностей заключается в том, что она переходит на выбор белков. Только белки, которые являются функционально родственными, будут давать четкую картину какого-либо взаимного соответствия между выбранными белками. Такие процедуры являются трудоемкими, занимают много времени и приводят к получению результатов, которые требуют дальнейшей обработки и фильтрации. Однако с помощью этих способов невозможно сравнивать все белки нескольких организмов и получать сохраняющиеся инвариантные пептиды.
Настоящее изобретение предусматривает разработку нового компьютерного способа для поиска пептидного мотива инвариантной последовательности, которая будет иметь разнообразное использование, как указано выше, и устранит недостатки, указанные выше.
Подход авторов основывается на той концепции, что пептидные мотивы последовательностей, инвариантных между различными бактериальными белками, должны быть ответственны за важную роль в структуре и функции белка. Из различных путей, с помощью которых могут быть идентифицированы мишени для лекарственных средств, выбран подход, основывающийся на сравнительной и структурной геномике. В этом случае пептидные мотивы инвариантных последовательностей могут быть вовлечены либо прямо, либо косвенно в функционирование исследуемой молекулы белка. Это является следствием концепции, что пептидные мотивы инвариантных последовательностей, которые остаются неизменными для родственных бактерий либо в близкой, либо в далекой степени, должны быть вовлечены в уникальную структурную характеристику, которая не может быть изменена. Консервативные замещения также не допускаются в этих пептидных мотивах инвариантных последовательностей. В этом случае можно идентифицировать несколько инвариантных пептидных мотивов путем прямого сравнения последовательностей для различных бактериальных геномов без каких-либо предположений "a priori". Этот полностью объективный и лишенный предположений путь изучения последовательностей позволяет получать неидентифицированные свойства последовательностей в различных геномах.
Поскольку пептидные мотивы инвариантных последовательностей могут быть важны для функционирования рассматриваемой белковой молекулы, необходимо разрабатывать эти пептидные мотивы в качестве потенциальных мишеней для антибактериальных лекарственных средств широкого спектра. Вероятно, что маленькая молекула, которая может специфически связываться с инвариантными последовательностями, может вызвать нарушение функционирования рассматриваемой белковой молекулы. Предполагается, что подход "in silico" обеспечит новые пути для экспериментальной оценки с целью установления функций белковых последовательностей, существующих в доступных базах данных.
Краткое изложение существа изобретения
В основу настоящего изобретения поставлена задача создания способа сравнения геномоподобных белковых последовательностей нескольких организмов и идентификации сохраненных инвариантных пептидных мотивов.
Другой задачей настоящего изобретения является создание компьютерного способа сравнения геномоподобных различных организмов путем создания библиотек (хранилищ) пептидов из белковых последовательностей нескольких организмов и последующего сравнения, ведущего к идентификации сохраненных инвариантных пептидных мотивов.
Еще одной задачей настоящего изобретения является создание способа идентификации возможных мишеней для лекарственных средств, и может служить для скрининга лекарственных средств для антибактериальных средств широкого спектра, а также для специфического диагноза инфекций.
Еще одной задачей настоящего изобретения является приписывание соответствующей функции белкам с еще неизвестными функциями.
Еще одной задачей является создание компьютерного способа, использующего инвариантные пептиды или их аналоги для идентификации возможных мишеней для лекарственных средств.
Предложен способ для идентификации инвариантных пептидных мотивов, полученных из миллионов пептидов, присутствующих в белковых последовательностях множества организмов, которые выдержали природную селекцию. Эти последовательности являются структурными детерминантами белков, которые могут быть мишенями или могут быть использованы при скрининге в качестве мишени для нахождения лекарственного средства. Специальные инвариантные характеристики пептидов связаны с конкретным функциональным классом белков.
Настоящий способ позволяет предсказать токсичность, изменение мишени в клетке-хозяине для лекарственного средства, нацеленного против конкретного пептидного мотива патогенного организма, или любого целевого белка, ответственного за болезненный процесс. Настоящий способ может быть расширен на большое количество белков, а также применен для эукариотов и многоклеточных организмов.
Другие аспекты, особенности и преимущества настоящего изобретения станут ясны из нижеследующего описания предпочтительных вариантов воплощений.
Краткое описание компьютерных программ
1. PEPLIB
Цель: Для создания библиотек пептидов организмов из файлов их белков в формате FASTA. Генерируются перекрывающиеся пептиды с длиной, определенной пользователем, а затем только пептиды, удовлетворяющие заданным требованиям, располагаются в алфавитном порядке в выходном файле.
Язык программирования: PERL на платформе IRIX.
2. PEPLIMP
Цель: Эта программа сравнивает библиотеки пептидов организмов, выбранных пользователем, и возвращает последовательности пептидов, которые являются общими среди геномов.
Язык программирования: PERL на платформе IRIX.
3. PEPXTRACT
Цель: Эта программа берет файл с пептидами в качестве входного, осуществляет поиск в файлах белков в формате FASTA (pep файлы) и возвращает подробности относительно пептидов. Подробности включают PID, расположение пептидов в белке, наименование организма и т.п.
Язык программирования: PERL на платформе IRIX.
4. PEPSTITCH
Цель: Эта программа объединяет пептиды в зависимости от определенных критериев (два пептида должны иметь один и тот же PID и должны соседствовать), удаляет перекрывания и сообщает обо всех сохраняющихся инвариантных пептидах.
Язык программирования: PERL на платформе IRIX.
Подробное описание предпочтительных вариантов воплощения изобретения
Теоретически возможно большое количество комбинаций на уровне аминокислот для формирования пептида определенной длины, но в биологических системах наблюдается только ограниченное количество комбинаций. Вне этой ограниченной доли только несколько пептидов остаются инвариантными в геномах различных организмов. В этой заявке рассматривается природа пептидов, которые являются инвариантными среди всех патогенных и непатогенных бактериальных геномов.
В настоящем изобретении показано, что распространенность сохранения аминокислот в белках различных организмов может обеспечить точное различие между различными классами белков. Как правило, эти белки идентифицируются в качестве белков, имеющих фундаментальное значение в выживании организма.
Белковые последовательности нескольких организмов получают с помощью компьютера из существующих баз данных (NCBI, genbank/genomes/bacteria). Затем они разрезаются с помощью компьютера на пептидные фрагменты из 'N' аминокислотных остатков с помощью специально разработанной компьютерной программы PEPLIB. Библиотека пептидов длиной 'N' создается для всех белков каждого организма путем перемещения окна длиной 'N' вдоль последовательности на один остаток за один раз. Полученные с помощью компьютера пептиды сортируются в алфавитном порядке с помощью кода аминокислоты из одной буквы, ненужные данные удаляются путем стирания дублирующихся пептидов. Затем библиотеки пептидов различных организмов сравниваются с помощью компьютера для нахождения общих пептидов. Сравнение осуществляется с использованием специально разработанной компьютерной программы, названной PEPLIMP. Общие пептиды размещаются с помощью компьютера в исходных белках с использованием программы PEPXTRACT и затем метятся с их белками по происхождению и положению. Эти общие пептиды повторно сшиваются с помощью компьютера с получением длинной цепи из общих пептидов. Это делается с использованием программы PEPSTITCH.
Фрагменты из общих пептидов определяются как инвариантные пептиды, поскольку они происходят из белков с сохраняющимися функциями. Все сохраняющиеся инвариантные пептиды, получаемые из одного и того же белка, затем собирают в одну группу. Вторичная структура этих пептидов проверяется с помощью базы данных по кристаллическим структурам белков, а именно, Protein Data Bank (PDB).
В соответствии с настоящим изобретением, предложен компьютерный способ идентификации инвариантных пептидных мотивов для использования в качестве мишеней для лекарственных средств, заключающийся в том, что
i) генерируют с помощью компьютера библиотеки перекрывающихся пептидов из всех белковых последовательностей выбранных организмов, доступных на сайте http://www.ncbi.nlm.nih.gov,
ii) сортируют в алфавитном порядке с помощью компьютера пептиды длиной 'N', полученные как описано выше, согласно коду аминокислоты из одной буквы,
iii) выделяют с помощью компьютера общие пептидные последовательности выбранных бактерий,
iv) размещают с помощью компьютера общие пептиды в исходных белках, а затем метят по их происхождению и положению,
v) соединяют с помощью компьютера перекрывающиеся общие пептиды с получением длинной цепи инвариантных пептидных последовательностей,
vi) проверяют вторичную структуру сохраняющихся пептидов с помощью базы данных по кристаллической структуре,
vii) сравнивают геномы патогенных штаммов с геномами непатогенных штаммов и выбирают последовательности, которые не сохраняются вместе в этих двух группах,
viii) проверяют с помощью компьютера пептидные мотивы инвариантных последовательностей в качестве возможной последовательности - мишени для лекарственных средств путем поиска данных сохраняющихся последовательностей в геноме хозяина и отбрасывают те из них, которые присутствуют в геноме хозяина.
В одном из вариантов воплощения настоящего изобретения длина скользящего окна длиной 'N' может изменяться в пределах от 4 до любой длины аминокислотных остатков.
В одном из вариантов воплощения настоящего изобретения данные о последовательностях белков могут быть взяты от любого организма, но ограничиваются микробами, такими как Mycoplasma pneumoniae, Helicobacter pylori, Hemophillus influenzae, Mycobacterium tuberculosis, Mycoplasma genitalium, Bacillus subtillis, Escherichia coli.
В дополнительном варианте воплощения сохраненный пептидный мотив содержит
1. AAQSIGEPGTQLT
2. AGDGTTTAT
3. AGRHGNKG
4. AHIDAGKTTT
5. CPBETPEG
6. DEPSIGLH
7. DEPISALD
8. DEPTTALDVT
9. DHAGIATQ
10. DHFHGGGEG
11. DLGGGTFD
12. DVLDTWFSS
13. ERERGITI
14. ERGITITSAAT
15. ESRRIDNQLRGR
16. ESGGQRQR
17. GEPGVGKTA
18. GFDYLRDN
19. GHNLQEHS
20. GIDLGTTNS
21. GINLLREGLD
22. GIVGLPNVGKS
23. GKSSLLNA
24. GLTGRKUVDTYG
25. GPPGTGKTLLA
26. GPPGVGKT
27. GSGKTTLL
28. GTRIFGPV
29. IDTPGHVDFT
30. IIAHIDHGKSTL
31. INGFGRIGR
32. IREGGRTVG
33. IVGESGSGKS
34. KFSTYATWWI
35. KMSKSKGN
36. KMSKSLGN
37. KNMITGAAQMDGAILVV
38. KPNSALRK
39. LFGGAGVGKTV
40. LGPSGCGK
41. LHAGGKFD
42. LIDEARTPLnSG
43. LLNRAPTLH
44. LPDKAIDLIDE
45. LPGKLADC
46. LSGGQQQR
47. MGHVDHGKT
48. NADFDGDQMAVH
49. NGAGKSTL
50. NLLGKRVD
51. NTDAEGRL
52. PSAVGYQPTLA
53. QRVAIARA
54. QRYKGLGEM
55. RDGLKPVHRR
56. SALDVSIQA
57. SGGLHGVG
58. SGSGKSSL
59. SGSGKSTL
60. SVFAGVGERTREGND
61. TGRTHQIRVH
62. TGVSGSGKS
63. TLSGGEAQRI
64. TNKYAEGYP
65. TPRSNPATY
66. VEGDSAGG
67. VRKRPGMYIG
В еще одном варианте воплощения настоящего изобретения количество инвариантных пептидных мотивов может изменяться в зависимости от степени родства между организмами и количества организмов, которые сравниваются.
В еще одном варианте воплощения инвариантные последовательности могут принадлежать следующим белкам согласно базе данных http://www.ncbi.nlm.nih.gov, где список белков содержит
I DNA DIRECTED RNA POLYMERASE BETA CHAIN
II EXCINUCLEASE ABC SUBUNIT A
III EXCINUCLEASE ABC SUBUNIT В
IV DNA GYRASE SUBUNIT В
V ATP SYNTHASE BETA CHAIN
VI S-ADENOSYLMETIONINE SYNTHETASE
VII GLYCERALDEHYDE3-PHOSPHATEDEHYDROGENASE
VIII ELONGATION FACTOR G(EF-G)
IX ELONGATION FACTOR TU(EF-TU)
X 30S RIBOSOMAL PROTEIN S12
XI 50S RIBOSOMAL PROTEIN L12
XII 50S RIBOSOMAL PROTEIN
XIII VALYL tRNA SYNTHETASE (VALRS)
XIV CELL DIVISON PROTEIN FtSH HOMOLOG
XV DnaK PROTEIN (HSP70)
XVI GTP BINDING PROTEIN LepA
XVII TRANSPORTER
XVIII OLIGOPEPTIDE TRANSPORT ATP BINDING PROTEIN OPPF
В еще одном варианте воплощения настоящего изобретения указанный способ сравнения библиотек пептидов, как указано на стадии (iii) способа, осуществляется по стадиям, приведенным на фиг.1.
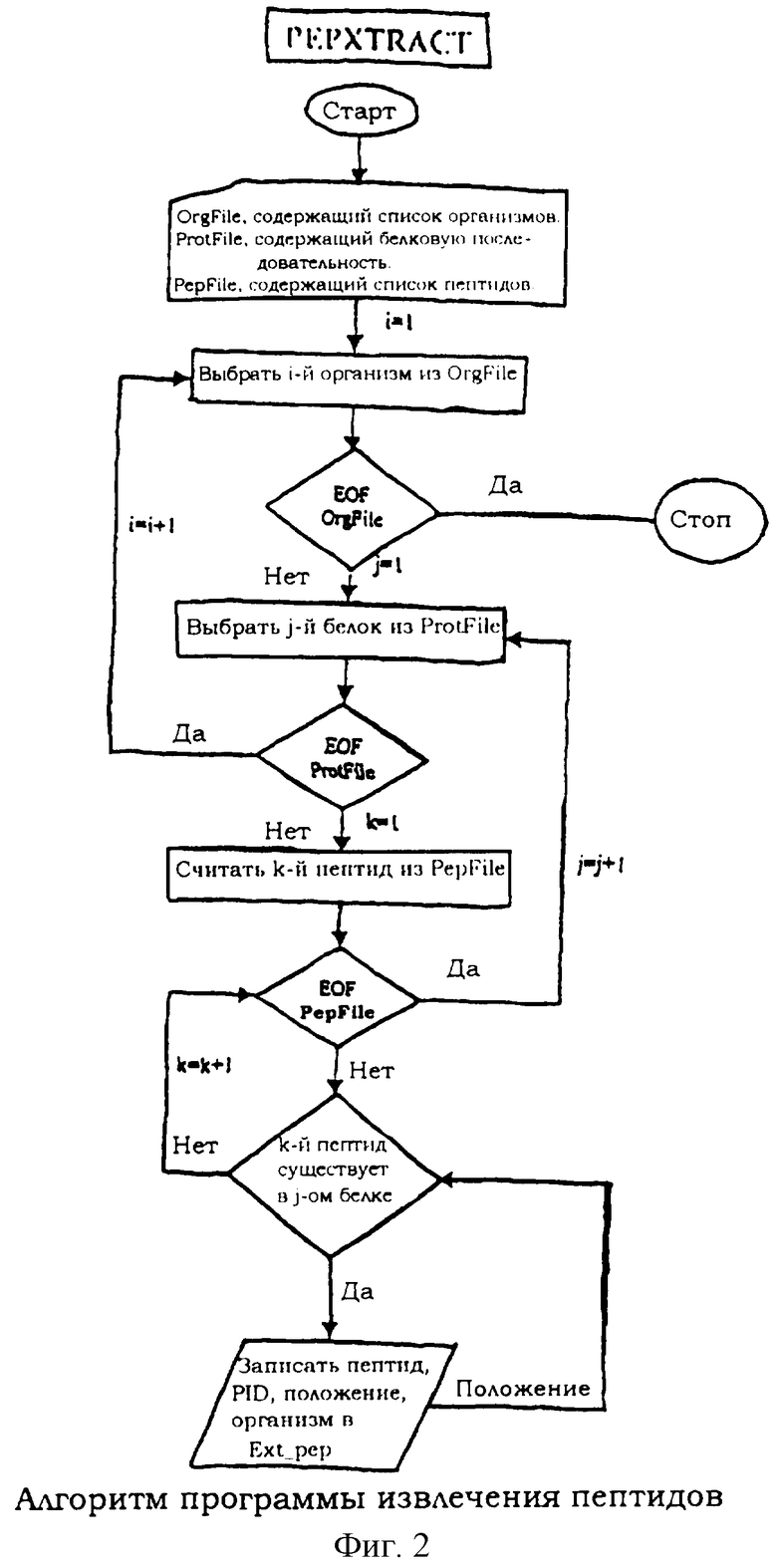
В еще одном варианте воплощения настоящего изобретения указанный способ размещения общих пептидов в исходных белковых последовательностях, как указано на стадии (iv) способа осуществляется по стадиям, приведенным на фиг.2.
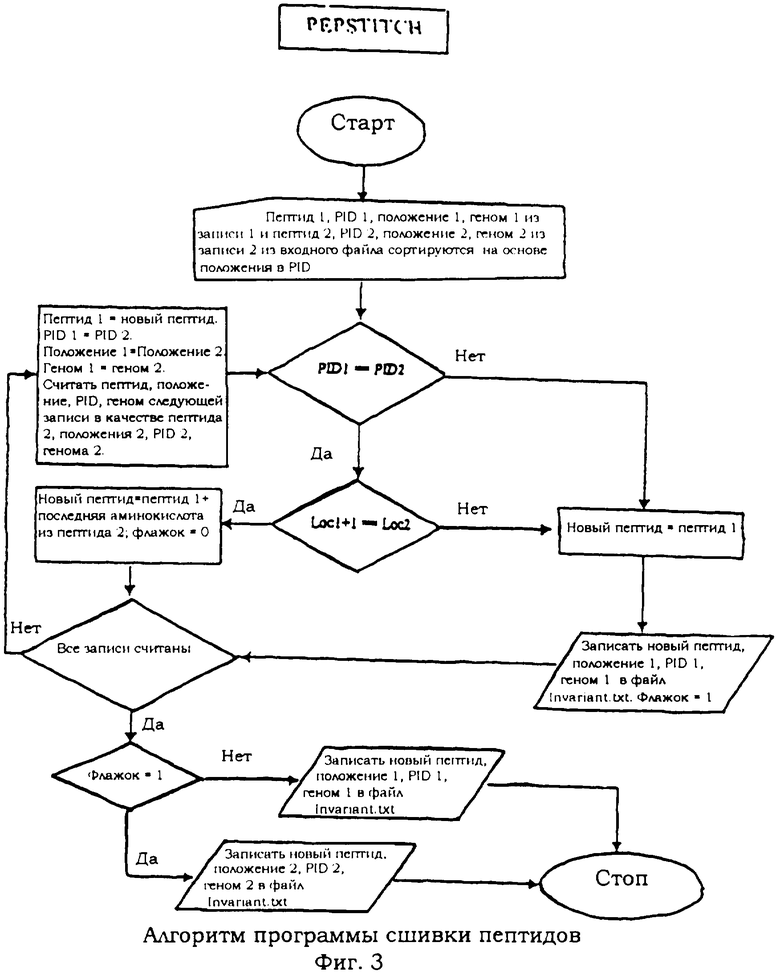
В другом варианте воплощения способ создания общего пептида переменной длины после удаления перекрываний, как указано на стадии (v) способа, осуществляется по стадиям, приведенным на фиг.3.
В еще одном варианте воплощения изобретения система на основе микропроцессора для осуществления способа согласно настоящему изобретению содержит
i) средство для определения окна последовательности аминокислот для создания библиотеки пептидов и последующей сортировки,
ii) средство сравнения библиотеки пептидов,
iii) компьютер для размещения этих общих пептидов в исходных белках и их последующее мечение по происхождению и положению, и
iv) соединение с помощью компьютера перекрывающихся общих пептидов с получением длинной цепи инвариантных пептидных последовательностей.
В другом варианте воплощения изобретения компьютерная система для осуществления способа согласно настоящему изобретению содержит блок центрального процессора, выполняющего программу формирования библиотеки пептидов (PEPLIB), программу сравнения библиотек пептидов (PEPLIMP), программу сшивки пептидов (PEPSTITCH), программу извлечения пептидов (PEPXTRACT), причем все указанные программы хранятся в устройстве памяти, которое доступно для блока центрального процессора, соединенного с дисплеем, на котором блок центрального процессора отображает интерфейсы указанных выше программ в ответ на вводимые пользователем команды с помощью интерфейса.
В еще одном варианте воплощения изобретения способ присвоения функций белку с неизвестными функциями, проявляющему слабую гомологию или ее отсутствие с другими белковыми последовательностями в доступной для всех базе данных (SWISSPROT) может быть осуществлен следующим образом
I. генерируют с помощью компьютера библиотеку перекрывающихся пептидов из белковых последовательностей с неизвестными функциями,
II. сортируют с помощью компьютера пептиды длины 'N' (N представляет собой длину скользящего окна из аминокислот), полученные как указано выше в алфавитном порядке, согласно коду аминокислоты из одной буквы,
III. сравнивают с помощью компьютера эту библиотеку с библиотекой пептидов всех белков с известными функциями для получения общих пептидов,
IV. размещают с помощью компьютера общие пептиды в исходных белках и осуществляют мечение по их происхождению и положению,
V. соединяют с помощью компьютера перекрывающиеся общие пептиды и получают длинную цепь инвариантных пептидных последовательностей,
VI. приписывают функцию неизвестному белку на основе функций белка с максимальной длиной пептидной последовательности, идентичность которой обнаружена, причем чем больше количество соответствий с белками, имеющими подобные функции, тем выше вероятность правильного приписывания функций.
Конкретные параметры организмов, например их наименование, штамм, номер доступа и другие подробности приведены ниже.

Краткое описание чертежей
В дальнейшем изобретение поясняется описанием предпочтительных вариантов его воплощения со ссылками на прилагаемые чертежи, на которых:
фиг.1 изображает блок-схему алгоритма программы сравнения библиотек пептидов согласно изобретению,
фиг.2 - блок-схему алгоритма программы извлечения пептидов согласно изобретению,
фиг.3 - блок-схему алгоритма программы сшивания пептидов согласно изобретению,
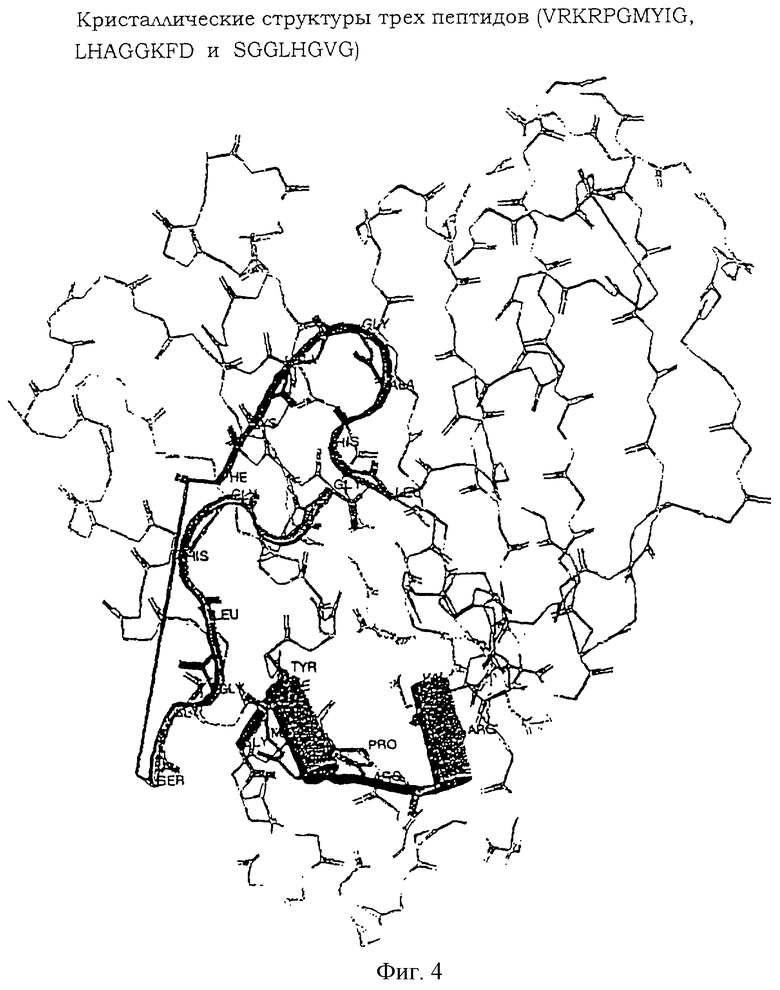
фиг.4 - кристаллические структуры трех инвариантных пептидов (VRKRPGMYIG, LHAGGKFD и SGGLHGVG) из белка ДНК гиразы В согласно изобретению.
Ниже приведены примеры воплощения изобретения, которые не должны рассматриваться как ограничивающие рамки настоящего изобретения.
Пример 1
Программа создания библиотеки пептидов (PEPLIB)
Целью программы является создание библиотеки неизбыточных пептидов с заданным пользователем окном длины 'N' из данного генома путем перемещения окна на одну аминокислоту за один раз.
Программа работает следующим образом:
Выгруженные из Интернета файлы формата FASTA, полученные из http://www.ncbi.nlm.nih.gov, сохраняются под именем <organism_name>.pep и переходят в качестве входных данных в программу PERL, которая создает уникальные заданные пептиды во время своего исполнения.
Формат входного/выходного файла
Выгруженные файлы и их формат:
<organism_name>.pep: файл, который включает и сохраняет описание и белковую последовательность <organism_name> относится к
Тb (Mycobacterium tuberculosis) Bs [Bacillus subtilis) Mg
(Mycoplasma genitalium) Mp (Mycoplasma pneumonia) Ec (Escherichia coli) Hp (Helicobacter pylori) Hi (Haemophilus influenzae)
Формат: FASTA
">gi|"<описание>
<<полная белковая последовательность..................
Например,
>gi |2808711| emb |CAA16238. 1| dnaA
MTDDPGSGFTTVWNAWSELNGDPKVDDGPSSDANLSAPLTPQQRAWLNLVQPL
TIVEGFALLSWSSFVQNEIERHLRAPITDALSRRLGHQIQLGVRIAPPATDEADDTT
VPPSENPATTSPDTTTDNDEIDDSAAARGDNQHSWPV………
>gi |3261513| emb |CAA16239.1| dnaN
MDAATTRVGLTDLTFMIJIESFADAVSWVAKNLPARPAVPVLSGVLLTGSDNGL
CGNARFSLPTMPVEDYPTLPTLPEETGLLPAE.
Выходной файл: <organism_name><peptide_length>.txt
Формат:
<все уникальные пептиды длины, указанной во время исполнения>
например формат Tb8.txt:
АААААААА
AAAAAAAG
AAAAAAAQ
AAAAAAAS
АААААААТ
Пример 2 Программа сравнения библиотек пептидов (PEPLIMP)
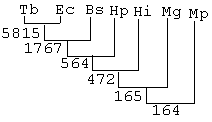
Целью настоящей программы является сравнение определенных пользователем библиотек пептидов друг с другом и сообщение об общих/уникальных пептидах. Выходные файлы программы PEPLIB используются в качестве входных данных для программы PEPLMP. При выполнении программы пользователь осуществляет выбор библиотек, которые должны сравниваться. В зависимости от выбранных библиотек генерируется выходной файл, включающий общие пептиды (фиг.1). Сравнение библиотек 8-мерных пептидов указанных выше семи организмов дает 164 восьмимерных пептида.
Сравнение четырех патогенных организмов, таких как Мусоbacterium tuberculosis, Helicobacter pylori, Mycoplasma pneumonia и Haemophilus influenzas приводит к получению 206 инвариантных пептидов, и сравнение трех непатогенных организмов, таких как Bacillus subtilis, Mycoplasma genitalium и Escherichia coli, приводит к получению 601 инвариантных пептидов. Дерево сравнения выглядит следующим образом
Пример 3
Программа извлечения пептидов (PEPXTRACT)
Эта программа использует выходные данные программы PEPLIMP, то есть все инвариантные пептиды в качестве входных данных, располагает эти пептиды в белковых последовательностях из исходной базы данных и метит их номером идентификации белка (PID) по положению и наименованию организма для дальнейшего анализа. Алгоритм этой программы объясняется на схеме, представленной на фиг.2.
Пример 4
Программа сшивки пептидов (PEPSTITCH)
Эта программа удаляет перекрывающиеся инвариантные пептиды и сообщает обо всем непрерывном расширении инвариантных пептидов, присутствующем в рассматриваемом белке. Это осуществляется путем сначала группировки 'N'-мерных пептидов от того же самого белка организма, а затем, в соответствии с их расположением, они объединяются в длинный одиночный пептид. Алгоритм этой программы представлен на фиг.3.
Пример 5
Предсказание функций гипотетического белка
Инвариантный пептид, имеющий последовательность FSGGQRQR, как обнаружено, существует в белках oppF/dppF шести организмов из семи рассмотренных (за исключением М. tuberculosis). Этот белок функционирует как АТФ-связывающий белок. Поскольку этот инвариантный пептид находится в гипотетическом белке, кодируемом геном Rv1273c в М. tuberculosis, предполагается, что этот белок, кодируемый геном Rv1273c, должен функционировать в качестве АТФ-связывающего белка, поскольку он содержит характеристику этого класса белков.
Пример 6
Предсказание функции гипотетического белка
Другой инвариантный пептид, имеющий последовательность GIVGLPNVGKS, обнаружен в белках, имеющих функцию связывания ГТФ в шести бактериях из семи исследованных (за исключением М. tuberculosis), в то время как такая же инвариантная последовательность присутствует в гипотетическом белке, кодируемом геном Rv1112 в М. tuberculosis. Предполагается, что этот гипотетический белок может иметь свойства связывания ГТФ, поскольку он содержит характеристику этого класса белков.
Пример 7
Идентификация мишени для лекарственных средств на основе инвариантных пептидных мотивов
Фермент ДНК-гираза, как известно, уменьшает суперспирализацию ДНК. Этот белок отсутствует у людей и рассматривается в качестве мишени в течение последних нескольких лет. Однако точная последовательность, на которую должны нацеливаться молекулы лекарственных средств, еще не ясна. Инвариантные пептиды, такие как VRKRPGMYIG, LHAGGKFD, SGGLHGVG, LPGKLADC, VEGDSAGG и QRYKGLGEM, которые являются инвариантными среди бета единиц гиразы множества патогенных и непатогенных бактериальных ДНК, но отсутствуют у хозяина, являются структурными детерминантами, которые могут быть использованы в качестве возможных мишеней для лекарственных средств против бактериальных инфекций. Кристаллические структуры трех из этих пептидов представлены на фиг.4.
Пример 8
Приписывание функции белку с неизвестными функциями
С помощью заявленного способа можно приписывать функцию белку с неизвестными функциями, демонстрирующему слабую гомологию или ее отсутствие по отношению к другим белковым последовательностям в доступной для всех базе данных (SWISSPROT) следующим образом
I. генерируют с помощью компьютера библиотеку перекрывающихся пептидов из белковых последовательностей с неизвестными функциями,
II. сортируют с помощью компьютера пептиды длины 'N' (N представляет собой длину скользящего окна из аминокислот), полученных так, как и выше, в алфавитном порядке, согласно коду аминокислоты из одной буквы,
III. сравнивают с помощью компьютера эту библиотеку с библиотекой пептидов всех белков с известными функциями для получения общих пептидов,
IV. размещают с помощью компьютера общие пептиды в исходных белках и осуществляют их последующее мечение по происхождению и положению,
V. соединяют с помощью компьютера перекрывающиеся общие пептиды с получением длинной цепи инвариантных пептидных последовательностей,
VI. приписывают функции неизвестному белку на основе функций белка с максимальной длиной пептидной последовательности, идентичность которой обнаружена.
Чем больше количество соответствий с белками, имеющими подобные функции, тем выше вероятность правильного приписывания функций.
Технические преимущества заявленного изобретения
Главное преимущество настоящего изобретения представляет собой создание нового способа, который позволяет одновременно сравнивать, подобно геному, большое количество (тысячи) белков одного организма с белками других организмов с получением характеристик пептидных мотивов инвариантных последовательностей.
Изобретение позволяет осуществить быстрый способ идентификации инвариантных пептидных мотивов.
Предусматривается простой и очень точный способ определения инвариантных пептидных мотивов, поскольку способ не включает никаких сложных математических вычислений.
Создается основа для скриннингового исследования антибактериальных соединений широкого спектра.
Изобретение относится к компьютерному способу идентификации пептидов, пригодных для использования в качестве мишеней для лекарственных средств. Сущность способа заключается в том, что создают библиотеки пептидов из белковых последовательностей различных организмов и осуществляют последующее сравнение для идентификации сохраненных консервативных пептидных мотивов, которые идентифицируют с помощью прямого сравнения последовательностей для различных бактериальных организмов и геномов хозяев без каких-либо предположений. Способ пригоден для идентификации возможных мишеней для лекарственных средств и может служить для скрининга антибактериальных лекарственных средств широкого спектра, а также для специфического диагноза инфекций, и в дополнение, для приписывания функций белкам с еще неизвестными функциями с помощью характеристик инвариантных пептидных мотивов. Преимущество изобретения заключается в ускорении способа идентификации пептидных мотивов. 3 с. и 8 з.п. ф-лы, 4 ил.
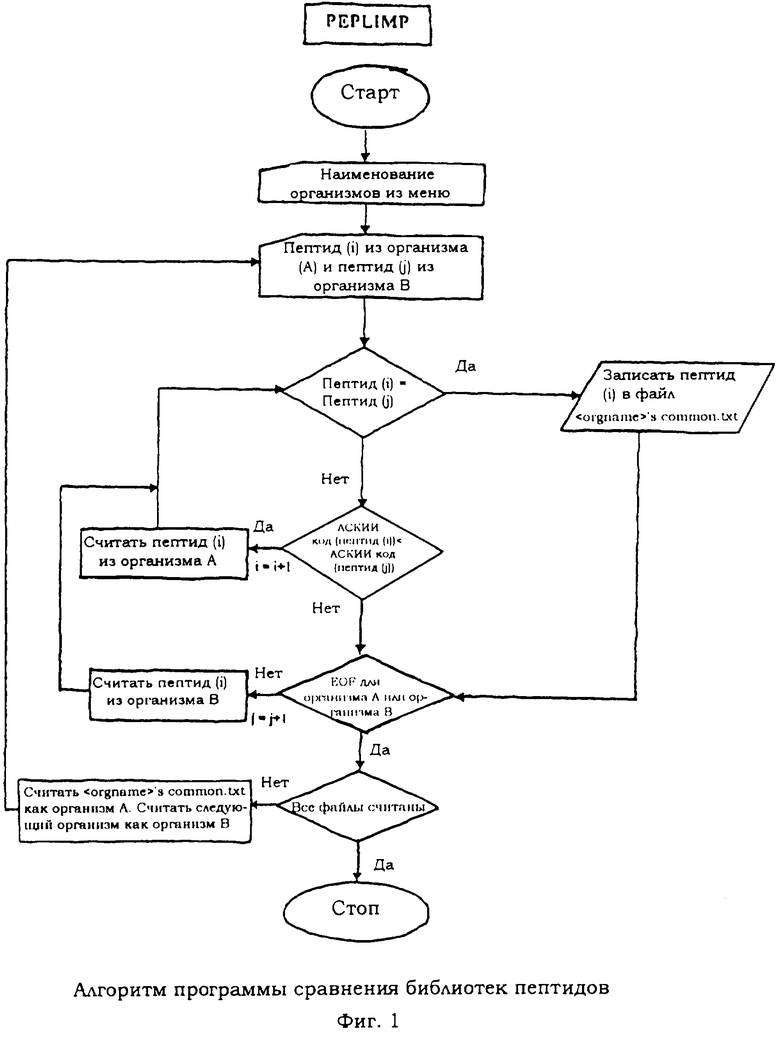
i) генерируют с помощью компьютера библиотеки перекрывающихся пептидов из всех белковых последовательностей выбранных организмов, причем в устройстве памяти компьютера хранятся программы:
формирования библиотеки пептидов (PEPLIB), сравнения библиотек пептидов (PEPLIMP) (фиг.1), сшивки пептидов (PEPSTITCH) (фиг.2), извлечения пептидов (PEPXTRACT) (фиг.3),
при этом программа PEPLIB является программой создания библиотеки неизбыточных пептидов с заданным пользователем окном длины “N” данного генома путем перемещения окна на одну аминокислоту за один раз, и включает
сохранение полученных из сети файлов формата FASTA под именем <organism_name>.pep и переход в качестве входных данных в программу PERL, которая создает уникальные заданные пептиды во время своего исполнения,
причем <organism_name>.pep - это файл, который включает и сохраняет описание и белковую последовательность <organism_name> и относится к Tb (Mycobacterium tuberculosis), Bs (Bacillus subtilis), Mg (Mycoplasma genitalium), Mp (Mycoplasma pneumonia), Ее (Escherichia coli),Hp (Helicobacter pylori), Hi (Haemophilus influenzae)
формат FASTA “gi|”<описание> - “полная белковая последовательность...>, например,
>gi |2808711|emb|CAA16238.1|dnaA
MTDDPGSGFTTVWNAWSELNGDPKVDDGPSSDANLSAPLTPQQRAWLNLVQPL
TIVEGFALLSWSSFVQNEIERHLRAPITDALSRRLGHQIQLGVRIAPPATDEADDTT
VPPSENPATTSPDTTTDNDEIDDSAAARGDNQHSWP.......
>gi |3261513|emb|CAA16239.1|dnaN
MDAATTRVGLTDLTFMIJIESFADAVSWVAKNLPARPAVPVLSGVLL TGSDNGL
CGNARFSLPTMPVEDYPTLPTLPEETGLLPAE,
при этом выходной файл <organism_name><peptide_length>.txt,
формат - <все уникальные пептиды длины, указанной во время исполнения>, например, формат Tb8.txt:
АААААААА
AAAAAAAG
AAAAAAAQ
AAAAAAAS
АААААААТ,
ii) сортируют (классифицируют) в алфавитном порядке с помощью компьютера пептиды длиной “N”, равной длине “скользящего окна”, согласно однобуквенному коду аминокислоты,
iii) выделяют с помощью компьютера общие пептидные последовательности выбранных бактерий,
iv) размещают с помощью компьютера общие пептидные последовательности в исходных белках, а затем осуществляют мечение по их происхождению и положению,
v) соединяют с помощью компьютера перекрывающиеся общие пептидные последовательности с получением длинной цепи инвариантных пептидных последовательностей,
vi) проверяют вторичную структуру консервативных пептидов с помощь базы данных по кристаллической структуре,
vii) сравнивают геномы патогенных штаммов с геномами непатогенных штаммов и выбирают последовательности, которые не сохраняются вместе в этих двух группах, и
viii) проверяют с помощью компьютера пептидные мотивы инвариантных последовательностей в качестве возможной последовательности - мишени для лекарственных средств путем поиска данных сохраняющихся последовательностей в геноме хозяина и отбрасывают те, которые присутствуют в геноме хозяина.
I DNA DIRECTED RNA POLYMERASE BETA CHAIN (бета-цепь ДНК-направленной RNA-полимеразы)
II EXCINUCLEASE ABC SUBUNIT А (субъединица А эксинуклеазы АВС)
III EXCINUCLEASE ABC SUBUNIT В (субъединица В эксинуклеазы АВС)
IV DNA GYRASE SUBUNIT В (субъединица в ДНК-гиразы)
V ATR SYNTHASE BETA CHAIN (бета-цепь АТФ-синтазы)
VI S-ADENOSYLMETHIONINE SYNTHETASE (S-аденозилметионинсинтаза)
VII GLYCERALDEHYDE 3-PHOSPHATE DEHYDROGENASE (глицеральдегид-3-фосфатдегидрогеназа)
VIII ELONGATION FACTOR G (EF-G) (фактор элонгации G(EF-G))
IX ELONGATION FACTOR TU (EF-TU) (фактор элонгации TU (EF-TU))
X 30S RIBOSOMAL PROTEIN S13 (30S - рибосомный белок SI 2)
XI 50S RIBOSOMAL PROTEIN LI 2 (50S - рибосомный белок LI 2)
XII 50S RIBOSOMAL PROTEIN L14 (50S - рибосомный белок L14)
XIII VALYL tRNA SYNTHETASE (VALRS) (валил-tRN-синтетаза)
XIV CELL DIVISON PROTEIN FtSH HOMOLOG (гомолог FtSH белка клеточного деления)
XV DnaK PROTEIN (HSP70) (белок DnaK (HSP70))
XVI GTP BINDING PROTEIN LepA (ГТФ-связывающий белок)
XVII TRANSPORTER (переносчик)
XVIII OLIGOPEPTIDE TRANSPORT ATP BINDING PROTEIN OPPF (АТФ-связывающий белок транспорта олигопептида).
при этом программа PEPLIB является программой создания библиотеки неизбыточных пептидов с заданным пользователем окном длины “N” данного генома путем перемещения окна на одну аминокислоту за один раз, и включает
сохранение полученных из сети файлов формата FASTA под именем <organism__name>.pep и переход в качестве входных данных в программу PERL, которая создает уникальные заданные пептиды во время своего исполнения,
причем <organism_name>.pep - файл, который включает и сохраняет описание и белковую последовательность <organism_name> и относится к Tb (Mycobacterium tuberculosis) Bs (Bacillus subtilis) Mg (Mycoplasma genitalium) Mp (Mycoplasma pneumonia) Ec (Escherichia coli) Hp (Helicobacter pylori) Hi (Haemophilus influenzae)
формат FASTA “>gi|”<описание> - “<<полная белковая последовательность..., например,
>gi |2808711|emb|CAA16238.1|dnaA
MTDDPGSGFTTVWNAWSELNGDPKVDDGPSSDANLSAPLTPQQRAWLNLVQPL
TIVEGFALLSWSSFVQNEIERHLRAPITDALSRRLGHQIQLGVRIAPPATDEADDTT
VPPSENPATTSPDTTTDNDEIDDSAAARGDNQHSWP.......
>gi |3261513|emb|CAA 16239.1| dnaN
MDAATTRVGLTDLTFMIJIESFADAVSWVAKNLPARPAVPVLSGVLLTGSDNGL
CGNARFSLPTMPVEDYPTLPTLPEETGLLPAE,
при этом выходной файл <organism_name><peptide_length>.txt,
формат - <все уникальные пептиды длины, указанной во время исполнения>, например, формат TbS.txt:
АААААААА
AAAAAAAG
AAAAAAAQ
AAAAAAAS
АААААААТ,
программу сравнения библиотеки пептидов (PEPLIMP) (фиг.1), программу сшивки пептидов (PEPSTITCH) (фиг.2), программу извлечения пептидов (PEPXRACT) (фиг.3), причем все указанные программы хранятся в устройстве памяти, которое доступно для блока центрального процессора, соединенного с дисплеем, на котором блок центрального процессора отображает интерфейсы указанных выше программ в ответ на вводимые пользователем команды с помощью интерфейса.
I. генерируют с помощью компьютера библиотеку перекрывающихся пептидов из белковых последовательностей с неизвестными функциями,
причем в устройстве памяти компьютера хранятся программы: формирования библиотеки пептидов (PEPLIB), сравнения библиотек пептидов (PEPLIMP) (фиг.1), сшивки пептидов (PEPSTITCH) (фиг.2), извлечения пептидов (PEPXTRACT) (фиг.3),
при этом программа PEPLIB является программой создания библиотеки неизбыточных пептидов с заданным пользователем окном длины “N” данного генома путем перемещения окна на одну аминокислоту за один раз, и включает
сохранение полученных из сети файлов формата FASTA под именем <organism_name>.pep и переход в качестве входных данных в программу PERL, которая создает уникальные заданные пептиды во время своего исполнения,
причем <organism_name>.pep - это файл, который включает и сохраняет описание и белковую последовательность <organism_name> и относится к Tb (Mycobacterium tuberculosis), Bs (Bacillus subtilis), Mg (Mycoplasma genitalium), Mp (Mycoplasma pneumonia), Eс (Escherichia coli), Hp (Helicobacter pylori), Hi (Haemophilus influenzae)
формат FASTA "gi|”<описание> - <<полная белковая последовательность...>, например,
>gi |2808711|emb|CAA 16238.1|dnaA
MTDDPGSGFTTVWNAWSELNGDPKVDDGPSSDANLSAPLTPQQRAWLNLVQPL
TIVEGFALLSWSSFVQNEIERHLRAPITDALSRRLGHQIQLGVRIAPPATDEADDTT
VPPSENPATTSPDTTTDNDEIDDSAAARGDNQHSWP.......
>gi |3261513|emb|CAA16239.1|dnaN
MDAATTRVGLTDLTFMIJIESFADAVSWVAKNLPARPAVPVLSGVLLTGSDNGL
CGNARFSLPTMPVEDYPTLPTLPEETGLLPAE,
при этом выходной файл <organism_name><peptide_length>.txt,
формат - <все уникальные пептиды длины, указанной во время исполнения>, например, формат Tb8.txt:
АААААААА
AAAAAAAG
AAAAAAAQ
AAAAAAAS
АААААААТ.
II. сортируют с помощью компьютера пептиды длины 'N', равной длине скользящего окна из аминокислот, полученные как указано выше в алфавитном порядке, согласно коду аминокислоты из одной буквы,
III. сравнивают с помощью компьютера эту библиотеку с библиотекой пептидов всех белков с известными функциями для получения общих пептидов,
IV. размещают с помощью компьютера общие пептиды в исходных белках и осуществляют последующее мечение по их происхождению и положению,
V. соединяют с помощью компьютера перекрывающиеся общие пептиды и получают длинную цепь инвариантных пептидных последовательностей,
VI. приписывают функцию неизвестному белку на основе функций белка с максимальной длиной пептидной последовательности, идентичность которой обнаружена, причем чем больше количество соответствий с белками, имеющими подобные функции, тем выше вероятность правильного приписывания функций.
| Прибор, замыкающий сигнальную цепь при повышении температуры | 1918 |
|
SU99A1 |
| ФИГУРНОВ В.Э., IBM для пользователя, М., 1997, ИНФРА-М, стр.31-32. | |||

