Изобретение относится к анализу речи, в частности при распознавании больших словарей в приложениях типа автоматической пишущей машинки.
Известен способ диалогового распознавания речи, при котором для последовательного распознавания используют акустические описания каждого слова, хранимые в словарях, сравниваемые на основе вероятностных моделей [1]
Однако данный способ не обладает высокой эффективностью, поскольку не адаптирован к стационарным шумам канала связи и к артикулярным особенностям произношения диктора.
Известен также способ распознавания изолированных слов, в частности, для очень больших словарей, основанный на определении и хранении для каждого слова в словаре фонетической модели, составленной из последовательности фонетических символов, соответствующих фонемам слова, определении и хранении характеристических параметров, показывающих энергию и спектральный состав фонемы, выборке звукового сигнала, соответствующего каждому изолированному слову, произнесенному диктором, сравнении значений характеристических параметров для всех моделей словаря и выборе посредством алгоритма динамического программирования небольшого количества моделей-кандидатов [2]
Хотя данный способ в некоторой степени адаптирован к диктору, он требует значительных затрат времени и оборудования при обработке алфавита фонем и наборов моделей, а также не адаптирован к шумам и искажениям тракта.
Кроме того, известен способ, реализованный в системе распознавания речи, основанный на выборках речевого сигнала, анализе энергетических и спектральных данных в интервалах выборок, использовании словарей и шаблонов слов, анализе степени подобия между речевыми сигналами и шаблонами, сортировке слов в соответствии со степенью подобия [3]
Однако данный способ также не учитывает в значительной степени артикулярных особенностей дикторов, не адаптирован к шумам и искажениям тракта.
Наиболее близким к предлагаемому является способ распознавания речи, основанный на создании акустических моделей по произношениям слов дикторами, сопоставлении и редактировании текстуальных символов с моделями [4] В процессе создания моделей производится предварительная обработка речевых сигналов с учетом шумовых параметров тракта, дискретизация, сегментация и кодирование сегментов, спектральный и энергетический анализ в различных частотных полосах, сопоставление с эталонами слов в соответствующем словаре, создание акустических описаний, вероятностных и языковых моделей, учитывающих особенности произношений фраз и слов, составление и модификация словарей.
Недостатками данного способа являются возможность существенного влияния на точность распознавания стационарных шумов акустического и электрического каналов, амплитудных модуляций, создаваемым квазипериодическим голосовым источником, не достаточная приспособляемость к артикуляционным особенностям произношения диктора, что не обеспечивает требуемой адаптации к диктору, длительная процедура обработки и сортировки эталонов большого словаря.
Изобретение решает задачу частичного устранения отмеченных выше недостатков известных способов распознавания речи.
Согласно предлагаемому способу распознавания изолированных слов речи с адаптацией к диктору выполняются следующие основные операции обработки речевого сигнала: предискажение речевого сигнала, определение уровня и дисперсии шума канала связи, последовательная сегментация речевого сигнала, кодирование сегментов дискретными элементами, вычисление энергетического спектра, измерение формантных частот и определение амплитуд и энергий в различных частотных полосах, классификация артикулярных событий и состояний при создании акустических моделей, формирование и сортировка эталонов слов, вычисление расстояний между эталонами и реализацией распознаваемого слова, на основе которых принимают решения о распознавании или отказе от распознавания слова.
С целью подавления амплитудных модуляций, создаваемых квазипериодическим голосовым источником, выполняется предискажение речевого сигнала во временной области в виде дифференцирования со сглаживанием.
С целью подавления шумов канала связи число уровней при квантовании энергетического спектра выбирается в зависимости от дисперсии шума канала связи.
Измерение формантных частот выполняется путем последовательного нахождения глобального максимума логарифмического спектра и вычитания из логарифмического спектра некоторой частотно-зависимой функции.
Определение доли периодического и шумового источников возбуждения выполняется путем сравнения с порогом коэффициентов автокорреляции последовательности прямоугольных импульсов в двух частотных полосах (70-900 и 1000-4000 Гц), причем в каждой полосе вычисляется огибающая H(t) по Гильберту, находится ее скользящее среднее  (t)(t) на интервале 10 мс и формируется последовательность прямоугольных импульсов со значениями P(t), равными + 1, 0 и -1, такими, что
(t)(t) на интервале 10 мс и формируется последовательность прямоугольных импульсов со значениями P(t), равными + 1, 0 и -1, такими, что
P(t)= 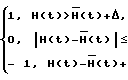
 , где Δ порог, пропорциональный дисперсии скользящего среднего на интервале паузы.
, где Δ порог, пропорциональный дисперсии скользящего среднего на интервале паузы.
Начало и конец артикуляторных движений и соответствующих им акустических процессов детектируются путем сравнения с порогом функции правдоподобия от значений коэффициентов автокорреляции, формантных частот и энергий в специфических частотных полосах, причем эти энергии сглаживаются с различными постоянными времени и отсчитываются в моменты времени, характерные для артикуляторных движений.
Речевой сигнал сегметируется на интервалы между началом и концом акустических процессов, соответствующих специфическим артикуляторным движениям, причем каждый сегмент кодируется множеством гетерархически вложенных дискретных признаков, представленных неравномерно квантованными значениями правдоподобия. Сегментация выполняется последовательно, начиная с гласных звуков, причем сегмент опознается только в том случае, если совпадают типы перехода на его левой и правой границах, а процесс сегментации заканчивается, когда слева и справа по времени опознаются сегменты паузы между словами.
Эталоны слов формируются в виде матриц с бинарными значениями (0 или 1) правдоподобия признаков.
Быстрая сортировка осуществляется путем сравнения старших признаков сегментов неизвестного слова со старшими признаками множества эталонов слов, находящихся в памяти, и выбором для детального анализа только тех эталонов, коды которых по старшим признакам совпадают с признаками неизвестного слова.
Отказ от распознавания происходит в случае, когда нормированная разность расстояний от неизвестной реализации до двух ближайших эталонов, принадлежащих разным словам, ниже установленного порога.
Адаптация к манере артикуляции диктора выполняется путем преобразования матрицы функций правдоподобия слова в бинарную форму и ее включения в словарь эталонов с соответствующим грамматическим описанием, получаемым от пользователя.
Особенности осуществления предлагаемого способа заключается в следующем.
При анализе первичных параметров использован полосовой фильтр (70-6000 Гц) для подавления постоянной составляющей и низкочастотных наводок в сигнале, а также для ограничения спектра сигнала.
Частота отсчетов в аналого-цифровом преобразователе составляет 16 кГц. Крутизна склонов полосового фильтра -60 дБ/окт.
Перед быстрым преобразованием Фурье выполняется предискажение речевого сигнала с целью подавления низкочастотных компонент и уменьшения амплитудной модуляции, вызываемой квазипериодическим возбуждением акустических колебаний в речевом тракте импульсами голосового источника. Речевой сигнал пропускается через скользящее окно Гаусса с шириной, подобранной таким образом, чтобы в спектре сигнала были сглажены неравномерности, создаваемые гармониками основного тона как для низких, так и для высоких голосов. Спектр вычисляется каждые 5 мс. Может быть использовано, например, преобразование Фурье по основанию 4 на 256 точек при частоте отсчетов сигнала 16 кГц.
Адаптация к стационарным шумам акустического и электрического каналов производится посредством определения уровня шума для каждой частотной компоненты на интервале паузы, т.е. отсутствия речи в течении достаточно длительного интервала времени (1-2 с). Этот уровень умножается на коэффициент, зависящий от уровня шума, и вычитается из энергетического спектра сигнала, после чего вычисляется логарифм энергии спектра. Затем логарифмический спектр квантуется по уровню таким образом, что наименьшему кванту соответствует некоторая функция от дисперсии шума канала.
Автокорреляционные функции в заданных частотных полосах предназначены для определения меры периодичности сигнала и вычисления частоты основного тока.
Речевой сигнал пропускается через два полосовых фильтра: 70-600 и 1000-4000 Гц. В каждой полосе вычисляется огибающая по Гильберту, ее скользящее среднее значение (вычисленное на интервале 10 мс) и формируется последовательность прямоугольных импульсов, соответствующих моментам пересечения мгновенной огибающей ее скользящего среднего (квантование на два уровня или три уровня +1, 0, -1, если присутствует заметный шум). Знаковая автокорреляционная функция вычисляется с частотой дискретизации речевого сигнала. Значения коэффициента автокорреляции и периода основного тона считываются каждые 5 мс.
Адаптация к шумам производится путем определения уровня шума на интервале паузы в каждой частотной полосе. Этот уровень служит для вычисления порога квантования.
Период основного тона определяется по максимальным значениям автокорреляционных функций.
Резонансные частоты речевого тракта определяются по положению пиков логарифмического спектра. С этой целью используется итеративная процедура, в которой находится глобальный максимум спектра в диапазоне 150-4000 Гц, с этим глобальным максимумом совмещается пик некоторой функции, умноженной на такой коэффициент, что амплитуда этой функции равна значению глобального максимума, и затем эта функция вычитается из логарифмического спектра. Затем вновь находится глобальный максимум спектра и процедура повторяется до тех пор, пока энергия спектра-остатка не станет ниже некоторого порога. Найденные частоты спектральных пиков сортируются по амплитуде и степени связности их траекторий во времени, и им присваиваются порядковые номера, соответствующие номерам формант.
Артикуляторные движения и соответствующие им акустические процессы характеризуются разной скоростью и длительностью, поэтому для их опознавания используются энергии в специально подобранных частотных полосах, сглаженные с различными постоянными времени.
Процесс детектирования и сегментации может быть реализован следующим образом.
Детекторы определенных типов артикуляторных движений формируются в виде согласованных фильтров или масок, использующих отсчеты в различные моменты времени от энергии в различных частотных полосах, сглаженных с разными постоянными времени. Кроме того, в параметры этих детекторов входят формантные частоты и коэффициенты автокорреляции. В процессе обучения значения этих параметров считываются в моменты времени, определенные с помощью ручной разметки речевых сигналов на характерные сегменты. Затем применяется статистическая процедура поворота и сжатия осей в пространстве измеряемых параметров, в результате которой формируется решающее правило, позволяющее вычислить меру правдоподобия появления того или иного характерного артикуляторного движения по расстоянию от математического ожидания вероятностного распределения, соответствующего этому классу. Иными словами, задача опознавания артикуляторных движений трактуется как задача статистической классификации.
Каждый динамический детектор дает информацию об артикуляторных признаках участка речевого сигнала, причем эти признаки гетерархически вложены друг в друга, т.е. имеется несколько самостоятельных множеств признаков, связанных отношениями вложенности (древесных структур). В число этих признаков входят признаки степени раскрытия речевого тракта-гласный/согласный, типа источника возбуждения голосовой, импульсный или шумовой, подключения носовой полости, места артикуляции гласных по положению частот первой и второй формант относительно границ их вероятностного распределения, высоких и низких фрикативных звуков.
Кроме динамических детекторов, используются статистические детекторы, представляющие собой согласованные фильтры в спектральной области для каждого типа сегмента, обладающего квазистационарным участком, подобно гласным, фрикативным и смычным звукам.
Место артикуляции согласных звуков определяется с помощью специальных детекторов, учитывающих как динамические, так и статические свойства спектров соответствующих участков речи, причем детекторы места артикуляции обучаются по предварительно размеченным границам между сегментами речевого сигнала.
Таким образом, каждый сегмент описывается ограниченным набором кодовых признаков, представленных своими функциями правдоподобия, а каждое слово описывается последовательностью таких сегментов, т.е. матрицей правдоподобия. Количество признаков-около 40, а число сегментов зависит от фонетического состава слова и несколько превышает число фонем.
Процесс распознавания и адаптации сводится к следующему.
Эталоны слов образуются в процессе обучения или адаптации путем квантования матриц правдоподобия на два уровня 0 и 1 путем сравнения правдоподобия каждого кодового признака со своим порогом. Каждому слову может соответствовать некоторое множество эталонов. При быстром поиске в больших словарях используется лишь несколько кодовых признаков, обладающих наибольшей надежностью и обеспечивающих наиболее быстрый отбор наименьшего числа эталонов-претендентов на детальное распознавание. Эти признаки сравниваются с признаками реализации неизвестного слова, также переведенными в бинарную форму. Если расстояние между неизвестной реализацией и эталоном меньше некоторого порога, то это слово отправляется в словарь, в котором и происходит окончательное распознавание. Выигрыш в объеме полученного словаря тем больше, чем больший объем исходного словаря, поскольку процесс отбраковки эталонов происходит почти по дихотомии. Например, для исходного словаря эталонов в несколько десятков тысяч слов окончательный объем словаря обычно не превышает ста эталонов.
С целью ускорения сортировки эталоны упорядочиваются специальным образом по каждому из кодовых признаков, используемых при быстрой сортировке.
После быстрой сортировки распознавание происходит путем вычисления расстояния между реализацией неизвестного слова и оставшимися эталонами. Особенность вычисления расстояний состоит в нелинейном квантовании функций правдоподобия кодовых признаков на небольшие число уровней.
Слово считается распознанным, если минимальное расстояние от неизвестной реализации до одного из эталонов не превышает порога, установленного для этого эталона, и если разница между расстояниями до двух ближайших эталонов, принадлежащих разным словам, выше некоторого фиксированного порога. Если же разница между расстояниями до двух ближайших эталонов мала, а эти эталоны принадлежат разным словам, сигнализируется отказ от распознавания. При этом, в зависимости от режима работы системы распознавания, пользователю может быть предъявлен выбор из нескольких ближайших слов или предложено ввести нераспознанное слово в виде эталона в уже существующий словарь добавлением нового слова. Таким образом осуществляется дополнение словаря и адаптация к особенностям артикуляции конкретного диктора.
| название | год | авторы | номер документа |
|---|---|---|---|
| Биометрический способ идентификации абонента по речевому сигналу | 2020 |
|
RU2742040C1 |
| СПОСОБ ГИБРИДНОЙ ГЕНЕРАТИВНО-ДИСКРИМИНАТИВНОЙ СЕГМЕНТАЦИИ ДИКТОРОВ В АУДИО-ПОТОКЕ | 2013 |
|
RU2530314C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ ГОВОРЯЩЕГО ПО ФОНОГРАММАМ ПРОИЗВОЛЬНОЙ УСТНОЙ РЕЧИ НА ОСНОВЕ ФОРМАНТНОГО ВЫРАВНИВАНИЯ | 2009 |
|
RU2419890C1 |
| СПОСОБ ВЕРИФИКАЦИИ ПОЛЬЗОВАТЕЛЯ В СИСТЕМАХ САНКЦИОНИРОВАНИЯ ДОСТУПА | 2007 |
|
RU2351023C2 |
| МЕТОД РАСПОЗНАВАНИЯ ДИКТОРА И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2002 |
|
RU2230375C2 |
| СПОСОБ РАСПОЗНАВАНИЯ СЛОВ РЕЧИ | 2005 |
|
RU2296376C2 |
| СПОСОБ И УСТРОЙСТВО АВТОМАТИЧЕСКОЙ ВЕРИФИКАЦИИ ЛИЧНОСТИ ПО ГОЛОСУ | 2008 |
|
RU2399102C2 |
| СПОСОБ КОНТАКТНО-РАЗНОСТНОЙ АКУСТИЧЕСКОЙ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ | 2011 |
|
RU2451346C1 |
| СИСТЕМА И СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ | 2011 |
|
RU2466468C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ ПО ФОНОГРАММАМ ПРОИЗВОЛЬНОЙ УСТНОЙ РЕЧИ | 1996 |
|
RU2107950C1 |
Использование: изобретение относится к анализу речи, в частности при распознавании больших словарей в приложениях типа автоматической пишущей машинки. Целью изобретения является повышение точности и надежности распознавания. Сущность изобретения: способ распознавания изолированных слов речи с адаптацией к диктору основан на предискажении речевого сигнала во временной области при дифференцировании со сглаживанием, последовательной сегментации, кодировании сегментов, определении уровня и дисперсии шума канала связи, вычислении энергетического спектра, измерении формальных частот, классификации артикуляторных событий и состояний, формировании и сортировке эталонов слов, вычислении расстояний между эталонами и реализацией неизвестного слова, принятии решений о распознавании или отказе в распознавании с дополнением словаря эталонов в процессе адаптации к диктору. 9 з. п. ф-лы.
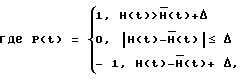
а Δ порог, пропорциональный дисперсии скользящего среднего на интервале паузы и определяемый с учетом уровня шума на интервале паузы в каждой частотной полосе.
| Очаг для массовой варки пищи, выпечки хлеба и кипячения воды | 1921 |
|
SU4A1 |
| ЭЛЕКТРИЧЕСКИЙ УТЮГ | 0 |
|
SU376501A1 |
| Печь-кухня, могущая работать, как самостоятельно, так и в комбинации с разного рода нагревательными приборами | 1921 |
|
SU10A1 |
| Способ приготовления консистентных мазей | 1919 |
|
SU1990A1 |
