Предлагаемое изобретение относится к области вычислительной техники, а именно цифровой обработке сигналов и изображений, решению задач математической физики, моделированию сложных технических систем и природных явлений, и может найти применение в многопроцессорных вычислительных системах с массовым параллелизмом.
Известно устройство: реконфигурируемый вычислитель XPuter (см. статью М.Herz, Т.Hoffmann, U.Nageldinger, С.Schreiber "Interfacing the MoM-PDA to an Internet-based Development System". University of Kaiserslautem. http://xputers.mformatik/unl-kl.de/papers/paper104.pdf и статью R.Hartenstein "Coarse Grain Reconfigurable Architectures" http://xputers.informatik/unl-kl.de/papers/paper110.pdf
XPuter состоит из двумерной распределенной памяти, представляющей собой множество блоков, сопряженной с общим синтезатором потоком данных, и реконфигурируемого АЛУ. Реконфигурируемое АЛУ представляет собой множество АЛУ, каждое из которых содержит коммутатор, позволяющий переключать восемь каналов, попарно соединяющих четыре смежных АЛУ.
Недостатком данного устройства является то, что работает оно эффективно (с производительностью, близкой к пиковой) только на систолических, либо сводимых к ним классах задач.
Причинами недостатка является то, что, во-первых, доступ к памяти данных осуществляется только по шаблонам выборки операндов синтезатором потока данных для конвейеризированнных структур данных, что не позволяет реализовать произвольные процедуры доступа для разного класса задач, во-вторых, выборки из разных блоков памяти осуществляются по общей процедуре, поскольку существует одна, единственная, программа синтезатора потока данных (такая организация характерна для SIMD-машин), в-третьих, коммутатор реконфигурируемого АЛУ является неполно доступным.
Известен ряд вычислительных систем с распределенной памятью, содержащих процессоры, объединенные некоторой коммутационной средой. Среди них можно указать Intel Paragon, IBM SP1/SP2, Cray T3D/T3E и др.
Различие между ними состоит в используемых процессорах и организации коммутационной среды. В качестве аналога рассмотрим компьютер Cray T3D, являющийся суперкомпьютером с массовым параллелизмом и с распределенной памятью. В его состав входят два основных компонента: вычислительные узлы и коммутационная сеть. Каждый вычислительный узел компьютера Cray T3D содержит по два независимых процессорных элемента (ПЭ) и сетевой интерфейс. ПЭ, в свою очередь, содержит процессор и локальную память. Локальная память каждого ПЭ является частью физически распределенной, но логически разделяемой общей памяти всего компьютера. Сетевой интерфейс узла связан с соответствующим сетевым маршрутизатором, который является частью коммутационной сети. Коммутационная сеть компьютера Cray T3D образует трехмерную решетку, соединяя сетевые маршрутизаторы узлов в трех пространственных направлениях. Таким образом, каждый узел имеет шесть непосредственных соседей. Связь между двумя смежными узлами реализована с помощью двух однонаправленных каналов передачи данных, что допускает одновременный обмен данными в противоположных направлениях.
Недостатком этого устройства является низкая реальная производительность при решении задач, требующих большого числа междупроцессорных пересылок.
Причины недостатка: во-первых, коммуникационная сеть является неполно доступной, во-вторых, доступ к памяти данных других процессорных элементов осуществляется дольше и более сложным способом, чем к собственной локальной памяти, за счет того, что обращение осуществляется медленной коммутационной системой, в результате время ожидания данных процессорами возрастает, что приводит к рассинхронизации параллельных вычислений процесса, что, в свою очередь, приводит к снижению реальной производительности системы.
Наиболее близким к предлагаемому изобретению является параллельный процессор Alice (см. "Вычислительные процессоры и системы." / Под редакцией Г.Н.Марчука. Выпуск 7. - М.: Наука. Главная редакция физико-математической литературы, 1990. - С.64-66), содержащий 16 процессорных элементов и 26 элементов памяти для хранения пакетов информации. Каждый процессорный элемент состоит из пяти транспьютеров (процессоров Т414 фирмы Inmos), два из которых осуществляют интерфейс с коммутационной сетью, принимают и передают пакеты, два других производят обработку пакетов, а пятый используется для хранения и выборки программ, соответствующих функциям обрабатываемых пакетов. Каждый элемент памяти, в свою очередь, состоит из двух транспьютеров и динамической памяти. Один транспьютер осуществляет прием посылок от процессорных элементов, модификацию пакетов в памяти и выборку из нее активных пакетов, а другой передает пакеты в коммутационную сеть.
Недостатком этого устройства является низкое быстродействие на определенном классе задач (при реализации сильносвязанных задач, когда число обменов между процессорными элементами сопоставимо с числом операций, выполняемых в процессорных элементах, реальная производительность параллельного процессора Alice будет существенно ниже пиковой). Кроме того, требуется большой объем оборудования для реализации конвейерного функционирования параллельного процессора.
Причина недостатков состоит в том, что обработка информации в транспьютерах выполняется в параллельном коде, а обмен информацией идет в последовательном коде. Транспьютеры будут находиться в состоянии ожидания данных от других транспьютеров, и чем больше будет степень связанности задачи (отношение пересылок к числу операций), тем ниже реальная производительность.
Более того, понижению быстодействия еще способствует тот факт, что в параллельном процессоре Alice интерфейсы коммутационной сети и памяти реализованы не аппаратно, а программно.
Причина недостатка требуемого большого объема оборудования для организации конвейерной обработки информации состоит в том, что в параллельном процессоре Alice используются стандартные процессорные элементы. Так, в процессорном элементе используется пять транспьютеров и только два из них используются непосредственно для обработки информации.
Задача, на решение которой направлено заявленное изобретение, заключается в создании модуля многопроцессорной вычислительной системы, реальная производительность которого близка к пиковой на широком классе задач, в том числе и для сильносвязанных задач.
Технический результат, достигаемый при осуществлении изобретения, состоит в том, что обработка информации и обмен информацией осуществляется согласованно (для одинакового числа разрядов и одинаковой тактовой частоты). Кроме того, за счет аппаратной синхронизации операндов упрощается программирование. Вместо стандартных процессорных элементов введены специальные устройства, обеспечивающие высокоскоростной доступ к памяти и коммутационной сети.
Для достижения указанного технического результата в устройство вместо процессорных элементов введены макропроцессоры (МАП), вместо элементов памяти введены мультиконтроллеры распределенной памяти (МКРП), соединенные с оперативной памятью (ОП), представляющей собой блок стандартных ОЗУ, в качестве коммутационной сети используется матричный коммутатор, причем информационные входы устройства соединены с двунаправленными входами/выходами оперативной памяти и двунаправленными входами/выходами блока мультиконтроллеров распределенной памяти, управляющие входы которых соединены с входом управляющего сигнала устройства, первые информационные входы матричного коммутатора соединены соответственно с первыми выходами блока макропроцессоров, первые информационные входы которых соединены соответственно с первыми выходами матричного коммутатора, вторые выходы которого соединены с информационными входами блока мультиконтроллеров распределенной памяти, информационные выходы которых соединены с вторыми информационными входами и третьими входами матричного коммутатора и вторыми входами блока макропроцессоров, управляющие выходы блока мультиконтроллеров распределенной памяти соединены с управляющими входами оперативной памяти, вторые выходы блока макропроцессоров соединены с выходами устройства.
Причинно-следственная связь между совокупностью существенных признаков заявленного изобретения и достигаемым техническим результатом заключается в следующем: введение в устройство макропроцессоров, структурно выполняющих крупные операции, мультиконтроллеров распределенной памяти, обеспечивающих скоростной обмен информацией между оперативной памятью и макропроцессорами и параллельно-конвейерную обработку информации, матричного коммутатора, обеспечивающего прямые пространственные соединения между всеми компонентами системы, позволяет повысить быстродействие вычислений при решении сильносвязанных задач за счет структурной (аппаратной) реализации крупных математических операций и упростить программирование задач различных проблемных областей, согласованная обработка и передача информации позволяет уменьшить общее время решения сильносвязанных задач.
Изобретение поясняется чертежом, на котором представлена блок-схема устройства модуля многопроцессорной системы.
Устройство содержит информационные входы D1-Dm - входы поступления информации, оперативную память 1, блок 2 мультиконтроллеров распределенной памяти (21-2m), вход 3 устройства - вход поступления управляющего сигнала PUSK, матричный коммутатор 4, блок 5 макропроцессоров (51-5m), выходы 6 устройства - выходы отказа OTK1-OTKm блока макропроцессоров.
Информационные входы D1-Dm устройства соединены с двунаправленными входами/выходами оперативной памяти и двунаправленными входами/выходами D блока 2 мультиконтроллеров распределенной памяти, управляющие входы PUSK которых соединены с входом 3 управляющего сигнала PUSK устройства, первые информационные входы D1-Dm матричного коммутатора 4 соединены соответственно с первыми выходами Z блока 5 макропроцессоров, первые информационные входы Х которых соединены соответственно с первыми выходами Q1-Qm матричного коммутатора 4, вторые выходы Qm+1-Q2m которого соединены с информационными входами Х блока 2 мультиконтроллеров распределенной памяти, информационные выходы Z которых соединены с вторыми информационными входами Dm+1-D2m и третьими входами KOM1-KOMm матричного коммутатора 4 и вторыми входами КОМ блока 5 макропроцессоров, управляющие выходы Y1-Ym блока 2 мультиконтроллеров распределенной памяти соединены с управляющими входами оперативной памяти 1, вторые выходы OTK1-OTKm блока 5 макропроцессоров соединены с выходами 6 устройства.
Модуль многопроцессорной системы включает в себя ОП, содержащую стандартные ОЗУ, m МАП, работающих в формате с плавающей запятой, m МКРП, обеспечивающих передачу данных из/в оперативную память, где m=2-1024, и матричный коммутатор, обеспечивающий соединение по полному графу m макропроцессоров и m мультиконтроллеров распределенной памяти. Соответственно имеется m внешних информационных каналов D1-Dm, m выходов отказа ОТК макропроцессоров, вход управляющего сигнала PUSK.
Параллельная программа для модуля многопроцессорной системы представляет собой последовательность кадров. Каждый кадр является программно-неделимой конструкцией и представляет собой совокупность команд макропроцессоров, коммутационных структур, реализованных в матричном коммутаторе, и процедур обращения (чтения, записи) к блокам распределенной памяти, реализованных в МКРП.
Все устройства системы настраиваются на выполнение нового кадра только тогда, когда все устройства системы завершили процедуры, относящиеся к предыдущему кадру. Выполнение кадров состоит из двух этапов. На первом этапе осуществляется настройка компонентов системы на реализацию кадров, на втором - происходит параллельно-конвейерная обработка информационных потоков в соответствии с настроенной вычислительной структурой.
Предварительно в память программ, расположенную в МКРП, и в ОП по внешним входам D1-Dm помещается соответственно программная и числовая информация. Работа модуля начинается с поступления внешнего сигнала PUSK, по которому осуществляется инициализация процедуры обращения в каждом МКРП и начинает выполняться начальный оператор программы. Мультиконтроллер выполняет следующие операторы: операторы циклического обращения (чтения, записи), операторы пересчета (модификации) параметров и операторы управления. С помощью оператора чтения команды производится запись (настройка) программной информации макропроцессоров. При этом мультиконтроллер настраивается на выдачу команд по выходам Z. В результате по m каналам с выходов Z МКРП разрядностью К обеспечивается последовательная запись команд в макропроцессоры и матричный коммутатор. В формате информации с выходов Z МКРП содержится два старших служебных разряда, кодировка которых определяет назначение поступающей информации, а именно: является ли данная информация командой с разрядностью К или - данными с разрядностью Р. Команда для МАП содержит код операции, выполняемой в МАП, а для матричного коммутатора - адреса операндов, поступающих на входы макропроцессоров.
После загрузки команд начинается непосредственно работа модуля. МКРП обеспечивает поток данных на входы МАП. Данными для МАП может быть либо информация, считанная из оперативной памяти по двунаправленным информационным каналам D через матричный коммутатор в соответствии с заданной адресацией каждого МАП, либо информация, поступающая с выхода любого МАП на матричный коммутатор. Кроме того, результаты всех МАП через матричный коммутатор могут поступать на входы Х МКРП и по двунаправленным каналам D в оперативную память. Сигналы управления Y1-Ym мультиконтроллера управляют чтением/записью информации из/в ОП.
Макропроцессоры в соответствии с поступившими кодами команд настраиваются на структурную реализацию крупных функционально-законченных операций. Структура МАП позволяет реализовать в рамках своей универсальной вычислительной системы различные вычислительные структуры, эффективно реализующие крупные математические операции различных проблемных областей, таких как экспонента, синус, дивергенция, интеграл, фильтр, комплексное умножение, быстрое преобразование Фурье и др.
В случае переполнения разрядной сетки в МАП формируется сигнал отказа ОТК, поступающий на выход модуля.
Блоки заявленного устройства могут быть реализованы средствами вычислительной техники отечественного производства. Так, в модуле используется макропроцессор, описанный в патенте №2210808 на изобретение от 05.01.2001, опубликованный в бюллетене №23 от 20.08.2003 г., мультиконтроллер распределенной памяти, описанный в патенте №220804 от 08.08.2001, опубликованный в бюллетене №23 от 20.08.2003 г., матричный коммутатор, описанный в патенте №2059288 от 05.08.1994 г., опубликованный в бюллетене №12 от 27.04.96 г.
Введение в устройство макропроцессоров, мультиконтроллеров распределенной памяти, матричного коммутатора, соединенных соответствующим образом, позволяет, во-первых, повысить быстродействие вычислений при решении сильносвязанных задач за счет структурной (аппаратной) реализации крупных математических операций и упростить программирование задач различных проблемных областей.
Во-вторых, согласованная обработка и передача информации позволяет уменьшить общее время решения сильносвязанных задач.
В-третьих, позволяет обеспечить равномерный скоростной доступ любого процессора к любому элементу памяти и, как следствие, увеличить скорость обработки информационных структур.
В-четвертых, система команд мультиконтроллера распределенной памяти в сочетании с полнодоступным коммутатором обеспечивает создание эффективных производительных процедур доступа к распределенной памяти, что позволяет сократить время решения задач.
| название | год | авторы | номер документа |
|---|---|---|---|
| МНОГОПРОЦЕССОРНЫЙ МОДУЛЬ | 2008 |
|
RU2397538C1 |
| МНОГОПРОЦЕССОРНАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2012 |
|
RU2502126C1 |
| МНОГОСЛОЙНАЯ МОДУЛЬНАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2008 |
|
RU2398281C2 |
| МАКРОПРОЦЕССОР | 2001 |
|
RU2210808C2 |
| ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2021 |
|
RU2785831C1 |
| СПОСОБ ФИЛЬТРАЦИИ МЕЖПРОЦЕССОРНЫХ ЗАПРОСОВ В МНОГОПРОЦЕССОРНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМАХ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2001 |
|
RU2189630C1 |
| Модуль матричного коммутатора | 1985 |
|
SU1280596A1 |
| СИСТЕМА КОММУТАЦИИ ПРОЦЕССОРНЫХ ЭЛЕМЕНТОВ | 1992 |
|
RU2126990C1 |
| МУЛЬТИКОНТРОЛЛЕР РАСПРЕДЕЛЯЕМОЙ ПАМЯТИ | 2014 |
|
RU2550555C1 |
| ФОТОННАЯ ВЫЧИСЛИТЕЛЬНАЯ МАШИНА | 2017 |
|
RU2639698C1 |
Изобретение относится к области вычислительной техники, а именно цифровой обработке сигналов и изображений, решению задач математической физики, моделированию сложных технических систем, и может найти применение в многопроцессорных вычислительных системах с массовым параллелизмом. Техническим результатом является создание модуля многопроцессорной вычислительной системы, реальная производительность которого близка к пиковой на широком классе задач, в том числе и для сильносвязанных задач. Указанный технический результат достигают тем, что модуль содержит оперативную память, блок мультиконтроллеров распределенной памяти, матричный коммутатор, блок макропроцессоров. 1 ил.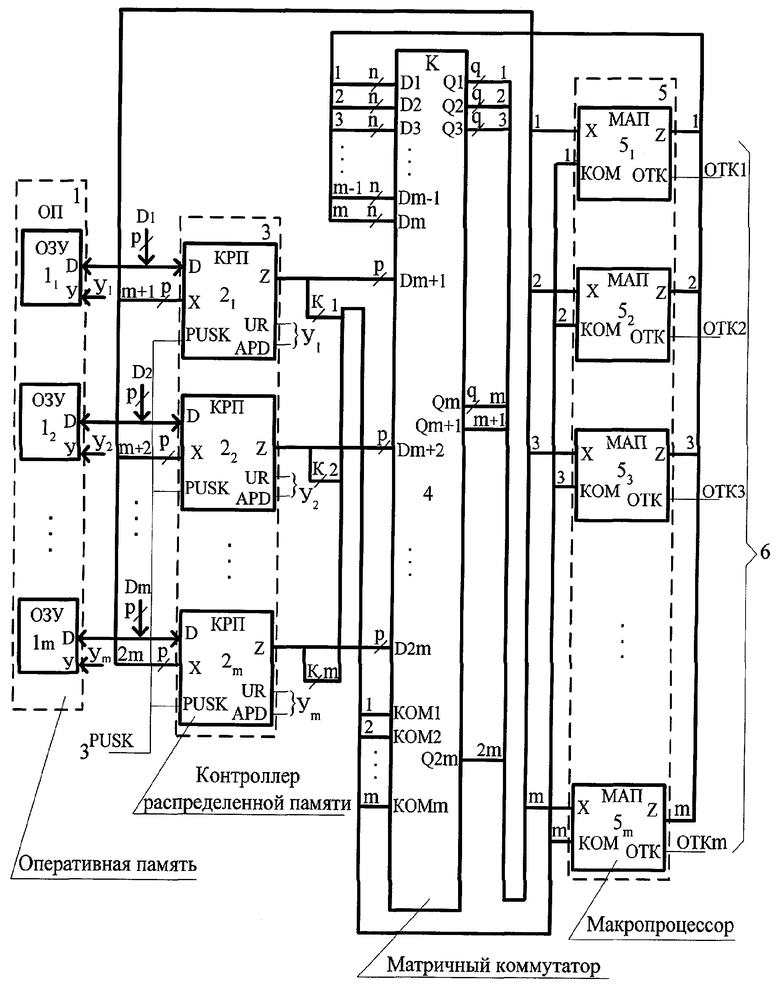
Модуль многопроцессорной системы, предназначенный для построения многопроцессорных систем, отличающийся тем, что содержит группу макропроцессоров, выполняющих крупные математические операции, группу мультиконтроллеров распределенной памяти, обеспечивающих скоростной обмен информацией между оперативной памятью и макропроцессорами и параллельно-конвейерную обработку информации, матричный коммутатор, обеспечивающий прямые пространственные соединения между всеми компонентами системы, причем информационные входы устройства соединены с двунаправленными входами/выходами оперативной памяти и двунаправленными входами/выходами блока мультиконтроллеров распределенной памяти, управляющие входы которых соединены с входом управляющего сигнала устройства, первые информационные входы матричного коммутатора соединены соответственно с первыми выходами блока макропроцессоров, первые информационные входы которых соединены соответственно с первыми выходами матричного коммутатора, вторые выходы которого соединены с информационными входами блока мультиконтроллеров распределенной памяти, информационные выходы которых соединены с вторыми информационными входами и адресными и управляющими входами матричного коммутатора и вторыми входами блока макропроцессоров, управляющие выходы блока мультиконтроллеров распределенной памяти соединены с управляющими входами оперативной памяти, вторые выходы блока макропроцессоров соединены с выходами устройства.
| ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 1991 |
|
RU2042193C1 |
| МАКРОПРОЦЕССОР | 2001 |
|
RU2210808C2 |
| Многопроцессорная вычислительная система | 1979 |
|
SU751238A1 |
| US 2002138550 А, 26.09.2002. | |||

