Предлагаемое изобретение относится к области вычислительной техники, а именно цифровой обработке сигналов и изображений, решению задач математической физики, матричной алгебры и моделированию сложных технических систем.
Известно устройство «Компьютерная система, включающая реконфигурируемое арифметическое устройство» (патент №US2010/0332795(А1), дата публикации 30.12.2010), содержащая центральный процессор, интерфейс внешней оперативной памяти, а также матрицу элементарных процессоров (ЭП). Матрица ЭП может быть реконфигурируема с помощью специальной конфигурационной памяти, которая соединяет процессорные элементы между собой, а также портами ввода-вывода в соответствии с информационной структурой решаемой задачи. Настройку конфигурации выполняет специальный блок управления.
Недостатком системы является малая интенсивность входных и выходных информационных потоков, которая для ряда вычислительных трудоемких задач будет недостаточна, чтобы загрузить в полном объеме ЭП вычислительной системы.
Причина недостатка состоит в том, что отсутствуют блоки распределенной памяти, которые было бы целесообразно интегрировать в вычислительную структуру решаемой задачи. Подключение внешней памяти через порты ввода-вывода приводит к сокращению скорости доступа к информационным данным.
Известно устройство «Процессор с перестраиваемой архитектурой» (патент №US2010/0211747(А1), дата публикации 19.08.2010). Этот процессор с реконфигурируемой (перестраиваемой) архитектурой содержит в себе элементарные процессоры, блоки памяти и коммутационную сеть (структуру).
ЭП соединены в матричную структуру, входы и выходы которой через коммутационную сеть связываются с блоками памяти. При организации вычислительного процесса использована парадигма token, которая позволяет оценивать поток данных и обеспечивать необходимую коммутацию ЭП между собой и ЭП и блоками памяти.
Недостатком этого устройства, во-первых, является необходимость увеличения разрядности операндов путем дополнения информационных бит специальными разрядами, образующими token-идентификатор операнда, а также указания действий над ними.
Для обработки token-идентификаторов необходимо включение дополнительных устройств управления в процессорные элементы, построенных на основе ассоциативной памяти, во-вторых, снижение тактовой частоты работы устройства из-за медленного доступа к конфигурационным данным, соответствующим выбранным номерам ЭП.
Причина данного недостатка заключается в использовании медленной ассоциативной памяти, которая считывает данные не по адресам, а по значениям.
Известно устройство MorphoSys - реконфигурируемая вычислительная система (см. "Design and Implementation of the MorphoSys Reconfigurable Computing Processor", Journal of VLSI and Signal Processing-Systems for Signal, Image and Video Technology, March 2000.
http://www.eng/uci.edu/morphosys/docs/JVSP.pdf).
MorphoSys - это модульная интегральная система на кристалле, предназначенная для вычислительно-емких параллельных вычислений. Она содержит реконфигурируемую матрицу процессорных ячеек (RC), RISC процессор и высокоскоростной интерфейс памяти. RC-матрица с внешней памятью соответствуют реконфигурируемой многопроцессорной системе SIMD. RISC процессор выполняет последовательные задачи, a RC-матрица осуществляет параллельные алгоритмы.
Главным компонентом системы является RC-матрица размером 8×8. Каждая RC содержит 16-битовое АЛУ и умножитель 16×12.
Внешняя память может хранить до 32-х проектов конфигураций. Пользователь может передавать содержимое по строкам или по столбцам. Коммутационная система RC состоит из трех иерархических уровней. Основой - первым уровнем коммутационной системы является двумерная решетка, которая обеспечивает связи по принципу близкодействия. На втором уровне обеспечивается связь по квадрантам (RC-группы 4×4). В RC-массиве содержатся 4 квадранта. В пределах каждого квадранта каждая ячейка может коммутироваться с выходом любой из ячеек своего столбца (строки). На третьем уровне смежные квадранты соединены шинами. Эти шины проходят по строкам и столбцам и передают данные из любой ячейки строки/столбца квадранта в другие ячейки смежного квадранта, но расположенные в той же строке/столбце. Таким образом, до четырех ячеек в строке/столбце могут получить доступ к выходному значению одной из 4-х ячеек той же строки/столбца смежного квадранта.
Недостаток системы - слабая вычислительная мощность в узле RC, отсутствует в RC-ячейке память, что затрудняет доступ к информационным массивам и снижает скорость параллельной обработки. Неслучайно параллельная система MorphoSys эффективно решает определенный класс задач. Единственный управляемый элемент определяет работу в системе как SIMD параллельные вычисления, что еще более ограничивает область применения.
Причина недостатков состоит в том, что в узле RC единственный вычислительный элемент АЛУ, который выполняет арифметические операции сложение (вычитание), умножение и ряд логических операций, отсутствуют пространственные коммутаторы внутри RC-ячеек, а также управляющие элементы, наличие которых позволило бы реализовать в системе MIMD параллельные вычисления.
Наиболее близким к предлагаемому изобретению является параллельный процессор с перепрограммируемой структурой (см. патент №2110088 от 27.04.1998), представляющий собой однородную вычислительную структуру, в состав которой входят матрица арифметико-логических устройств (АЛУ), причем каждая АЛУ матрицы связана с входами и выходами с соседними АЛУ матрицы, и блок управления.
Недостатком этого устройства является низкое быстродействие на определенном классе задач, требующих перестройку структуры вычисления в процессе решения задачи. Кроме того, в матрице АЛУ используются однонаправленные каналы связи, что существенно ограничивает коммуникационные возможности параллельного процесса и, как следствие, снижает эффективность и реальную производительность при решении задач.
Причина недостатков состоит в том, что информационным объектом, с которым оперирует элементарный процессор, является бит. В результате для настройки вычислительной структуры необходимо настроить большое число оборудования (коммутаторов, регистров управления), чтобы синтезировать вычислительную структуру для решения задачи. Большой объем информации, который должен быть передан для настройки вычислительной структуры, не позволяет перепрограммировать вычислительную структуру устройства динамически с каждым операндом.
Задача, на решение которой направлено заявленное изобретение, заключается в создании многопроцессорной вычислительной системы, реальная производительность которой близка к пиковой на широком классе задач, в том числе и для сильносвязанных задач, а также в обеспечении возможности динамической перестройки структуры в процессе решения задачи.
Технический результат, достигаемый при осуществлении изобретения, состоит в том, что обработка информации и обмен информацией осуществляется согласованно и одновременно для всех разрядов числа (а не для бит, как в прототипе). За счет аппаратной синхронизации операндов упрощается программирование. При этом вместо стандартных АЛУ в матрицу введены специальные вычислительные устройства - модули, содержащие макропроцессоры, обеспечивающие высокую скорость обработки информации. Кроме того, в ячейку матрицы введены сегменты распределенной памяти и специальные устройства (мультиконтроллеры), обеспечивающие высокий доступ к памяти и коммутационной сети.
Для достижения указанного технического результата в матрицу устройства вместо арифметико-логических устройств введены многопроцессорные модули, каждый из которых содержит макропроцессоры (МАП), мультиконтроллеры распределенной памяти (МКРП), соединенные с оперативной памятью (ОП), представляющей собой блок стандартных ОЗУ, и пространственный коммутатор, связывающий по полному графу все элементы модуля, а также в устройство введен стандартный блок интерфейса (БИ), при этом внешние двунаправленные выводы модулей, предназначенные для связи модулей в матрице, разбиты на 4 непересекающиеся группы, каждая из которых соответствует определенному пространственному направлению, причем каждый вывод первой группы выводов каждого модуля соответствующей строки матрицы многопроцессорной системы соединен с соответствующим выводом второй группы выводов каждого последующего модуля этой же строки, каждый вывод третьей группы выводов каждого модуля соответствующего столбца матрицы многопроцессорной системы соединен с соответствующим выводом четвертой группы выводов последующего модуля того же столбца, каждый вывод этой же группы выводов первого модуля в каждом столбце матрицы многопроцессорной системы соединен с соответствующим выводом третьей группы выводов последнего модуля в каждом столбце матрицы многопроцессорной системы, выводы второй группы выводов всех модулей первого столбца матрицы многопроцессорной системы соединены соответственно с первыми информационными выводами устройства, вторые информационные выводы устройства соединены соответственно с выводами первой группы выводов всех модулей последнего столбца многопроцессорной системы, внешние двунаправленные выводы каждого модуля матрицы, предназначенные для загрузки в модули программной и числовой информации и выгрузки результатов, соединены соответственно с первыми двунаправленными выводами блока интерфейса, вторые двунаправленные выводы блока интерфейса соединены соответственно с третьими информационными выводами устройства.
Причинно-следственная связь между совокупностью существенных признаков заявляемого изобретения и достигаемым техническим результатом заключается в следующем: введение в устройство матрицы многопроцессорных модулей, каждый из которых содержит макропроцессоры, структурно выполняющие крупные математические операции, блоки распределенной памяти и их мультиконтроллеры, обеспечивающие скоростной обмен информацией между оперативной памятью и макропроцессорами и параллельно-конвейерную обработку информации, пространственный коммутатор, обеспечивающий прямые пространственные соединения между всеми компонентами системы, и введение стандартного блока интерфейса памяти позволяют повысить быстродействие вычислений при решении сильносвязанных задач за счет структурной (аппаратной) реализации крупных математических операций и упростить программирование задач различных проблемных областей, согласованная обработка и передача информации позволяет уменьшить общее время решения сильносвязанных задач.
Изобретение поясняется чертежом, на котором представлена схема многопроцессорной вычислительной системы.
Устройство (см. чертеж) содержит матрицу 1, включающую m*p многопроцессорных модулей, блок 2 интерфейса, первые и вторые информационные двунаправленные выводы устройства соответственно W(W1÷Wpn) и О(O1÷Opn) - выводы для наращивания матрицы многопроцессорной вычислительной системы, третьи L(L1÷Lpn) информационные двунаправленные выводы устройства - выводы для загрузки во все модули матрицы многопроцессорной вычислительной системы цифровой информации и команд и выгрузки результатов.
Внешние выводы каждого модуля матрицы системы, предназначенные для соединения их в матрице, разбиты на четыре непересекающиеся группы, каждая из которых соответствует определенному пространственному направлению и содержит n выводов, а именно: первая группа выводов - (O1÷On), вторая - (W1÷Wn), третья - (S1÷Sn), четвертая - (N1÷Nn), причем каждый вывод первой группы выводов O1÷On каждого модуля соответствующей строки матрицы многопроцессорной системы соединен с соответствующим выводом второй группы выводов W1÷Wn каждого последующего модуля этой же строки, каждый вывод третьей группы выводов S1÷Sn каждого модуля соответствующего столбца матрицы многопроцессорной системы соединен с соответствующим выводом четвертой группы выводов N1÷Nn последующего модуля того же столбца, каждый вывод этой же группы выводов первого модуля в каждом столбце матрицы многопроцессорной системы соединен с соответствующим выводом третьей группы выводов S1÷Sn последнего модуля в каждом столбце матрицы многопроцессорной системы, выводы второй группы выводов W1÷Wn всех модулей первого столбца матрицы многопроцессорной системы соединены соответственно с первыми информационными выводами W1÷Wpn устройства, вторые информационные выводы O1÷Opn устройства соединены соответственно с выводами первой группы выводов О1÷Оn всех модулей последнего столбца многопроцессорной системы, внешние двунаправленные выводы D1÷Dn каждого модуля матрицы устройства, предназначенные для загрузки модуля программной и числовой информации и выгрузки результатов, соединены соответственно с первыми двунаправленными выводами D1÷Dmpn блока интерфейса, вторые двунаправленные выводы блока интерфейса соединены соответственно с третьими информационными выводами L1÷Lpn устройства,
Многопроцессорная вычислительная система представляет собой матрицу m*p модулей многопроцессорной вычислительной системы, каждый из которых содержит оперативную память, содержащую стандартные ОЗУ, m МАП, работающих в формате с плавающей запятой, m КРП, обеспечивающих передачу данных в оперативную память, и пространственный коммутатор, обеспечивающий соединения по полному графу m макропроцессоров и m мультиконтроллеров распределенной памяти. Имеется pn внешних информационных двунаправленных выводов L1÷Lpn для поступления информации в/из системы и pn выводов W1÷Wpn и рn выводов O1÷Opn для наращивания матрицы системы.
Параллельная программа для множества модулей многопроцессорной системы представляет собой последовательность кадров, выполняемых во всех модулях системы, при этом каждый кадр является программно-неделимой конструкцией и представляет собой совокупность команд макропроцессоров, коммутационных структур, реализованных в пространственном коммутаторе, и процедур обращения (чтения, записи) к блокам распределенной памяти, реализованных в МКРП.
Все модули системы настраиваются на выполнение нового кадра только в том случае, если все модули системы завершили процедуры, относящиеся к предыдущему кадру. Выполнение кадров состоит из двух этапов. На первом этапе осуществляется настройка компонентов системы на реализацию кадров, на втором - происходит параллельно-конвейерная обработка информационных потоков в соответствии с настроенной вычислительной структурой.
Предварительно в память программ, расположенную в мультиконтроллерах распределенной памяти всех модулей и в ОП, записывается соответственно программная и числовая информация. Запись осуществляется через БИ последовательно в каждый модуль. Работа всех модулей системы начинается с выполнения инициализации процедуры обращения в каждом МКРП, который выполняет различные операторы. С помощью оператора чтения команды производится запись (настройка) программной информации макропроцессоров.
После загрузки команд начинается непосредственно работа всех модулей системы. Мультиконтроллеры в модулях обеспечивают либо потоки данных на входы МАП через пространственный коммутатор в соответствии с адресацией каждого МАП, либо результаты всех МАП через пространственный коммутатор поступают на входы МКРП и далее в ОП. В МКРП всех модулей формируются сигналы управления чтением/записью информации из/в ОП.
Макропроцессоры всех модулей системы в соответствии с поступившими кодами команд настраиваются на структурную реализацию крупных функционально-законченных операций. Структура МАП модулей позволяет реализовать различные вычислительные структуры, эффективно реализующие крупные математические операции различных проблемных областей, таких как решение систем алгебраических уравнений, быстрое преобразование Фурье, решение систем дифференциальных уравнений, фильтрация изображений, обработка информационных потоков в компьютерных сетях.
Модулем, используемым в заявленном устройстве, является модуль, описанный в патенте №2397538 "Многопроцессорный модуль" авторов Левина И.И., Виневской Л.И., опубликованный 20.08.2010 г., Бюл. №23.
Введение в устройство матрицы модулей, содержащих макропроцессоры, мультиконтроллеры распределенной памяти, пространственный коммутатор, соединенных соответствующим образом, позволяет:
- во-первых, повысить быстродействие вычислений при решении задач, требующих больших информационных обменов, за счет структурной (аппаратной) реализации крупных математических операций и упростить программирование параллельных вычислений для решения задач различных проблемных областей;
- во-вторых, согласованная обработка и обмен информации между компонентами системы позволяет уменьшить время решения сильносвязанных задач;
- в-третьих, позволяет обеспечить равномерный скоростной доступ любого макропроцессора разных модулей к любому элементу памяти разных модулей, и, как следствие, увеличить скорость обработки информации.
| название | год | авторы | номер документа |
|---|---|---|---|
| МОДУЛЬ МНОГОПРОЦЕССОРНОЙ СИСТЕМЫ | 2004 |
|
RU2282236C1 |
| МНОГОПРОЦЕССОРНЫЙ МОДУЛЬ | 2008 |
|
RU2397538C1 |
| ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2021 |
|
RU2785831C1 |
| МНОГОСЛОЙНАЯ МОДУЛЬНАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2008 |
|
RU2398281C2 |
| РЕКОНФИГУРИРУЕМАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2017 |
|
RU2677363C1 |
| Устройство управления ферритовыми фазовращателями модульной фазированной антенной решетки | 2018 |
|
RU2698957C1 |
| Реконфигурируемый вычислительный модуль | 2018 |
|
RU2686017C1 |
| МНОГОУРОВНЕВАЯ МНОГОПРОЦЕССОРНАЯ КОРАБЕЛЬНАЯ ИНФОРМАЦИОННО-УПРАВЛЯЮЩАЯ СИСТЕМА | 2009 |
|
RU2406125C1 |
| МАКРОПРОЦЕССОР | 2001 |
|
RU2210808C2 |
| Устройство для сопряжения многопроцессорной вычислительной системы с внешними устройствами | 1984 |
|
SU1241245A2 |
Изобретение относится к области вычислительной техники. Технический результат заключается в обеспечении высокой производительности для задач, требующих больших информационных обменов между компонентами системы. Указанный технический результат достигается тем, что система содержит матрицу многопроцессорных модулей, каждый из которых содержит взаимосвязанные между собой блок макропроцессоров, блок мультиконтроллеров распределенной памяти, пространственный коммутатор, оперативную память. 1 ил.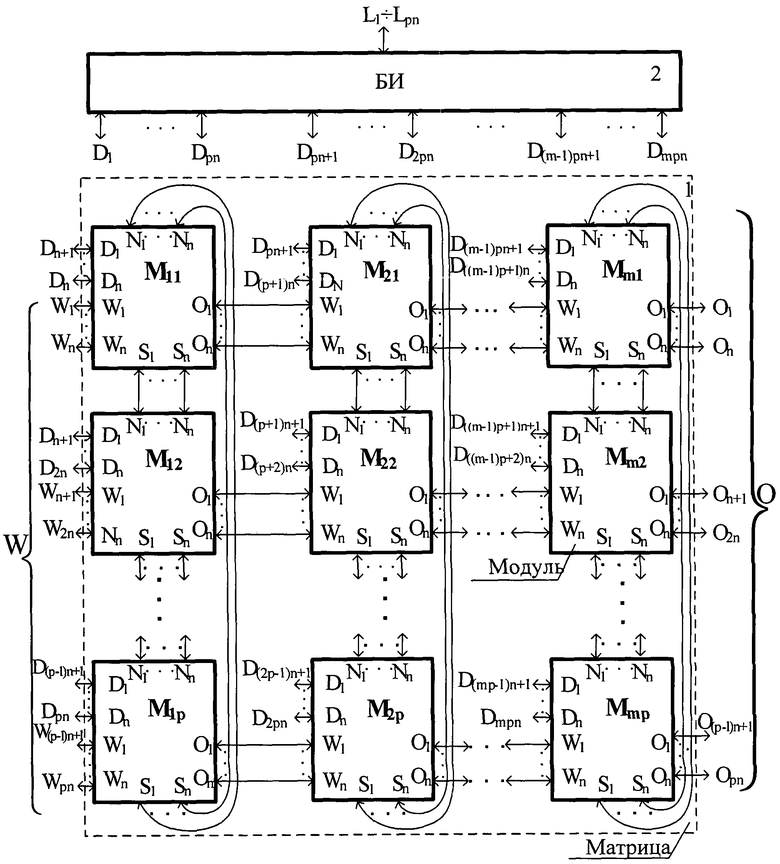
Многопроцессорная вычислительная система, предназначенная для решения широкого класса задач с высокой реальной производительностью, отличающаяся тем, что содержит матрицу многопроцессорных модулей и блок интерфейса, при этом каждый модуль матрицы содержит взаимосвязанные между собой блок макропроцессоров, выполняющих крупные математические операции, блок мультиконтроллеров распределенной памяти, обеспечивающих скоростной обмен информацией между оперативной памятью и макропроцессорами и параллельно-конвейерную обработку информации, пространственный коммутатор, обеспечивающий с помощью четырех групп внешних двунаправленных выводов модулей прямые пространственные соединения между всеми компонентами системы, причем каждый вывод первой группы выводов каждого модуля соответствующей строки матрицы многопроцессорной системы соединен с соответствующим выводом второй группы выводов каждого последующего модуля этой же строки, каждый вывод третьей группы выводов каждого модуля соответствующего столбца матрицы многопроцессорной системы соединен с соответствующим выводом четвертой группы выводов последующего модуля того же столбца, каждый вывод этой же группы выводов первого модуля в каждом столбце матрицы многопроцессорной системы соединен с соответствующим выводом третьей группы выводов последнего модуля в каждом столбце матрицы многопроцессорной системы, выводы второй группы выводов всех модулей первого столбца матрицы многопроцессорной системы соединены соответственно с первыми информационными выводами устройства, вторые информационные выводы которого соединены соответственно с выводами первой группы выводов всех модулей последнего столбца многопроцессорной системы, внешние двунаправленные выводы каждого модуля матрицы, предназначенные для загрузки в модули программной и числовой информации и выгрузки результатов, соединены соответственно с первыми двунаправленными выводами блока интерфейса, вторые двунаправленные выводы которого соединены соответственно с третьими двунаправленными выводами устройства.
| RU 2007102527 A, 27.07.2008 | |||
| МУЛЬТИКОНТРОЛЛЕР РАСПРЕДЕЛЕННОЙ ПАМЯТИ | 2001 |
|
RU2210804C2 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| US 6779086 B2, 17.08.2004 | |||
| МНОГОПРОЦЕССОРНЫЙ МОДУЛЬ | 2008 |
|
RU2397538C1 |
| ПАРАЛЛЕЛЬНЫЙ ПРОЦЕССОР С ПЕРЕПРОГРАММИРУЕМОЙ СТРУКТУРОЙ | 1994 |
|
RU2110088C1 |

