Область техники, к которой относится изобретение
Настоящее изобретение относится в целом к области связи и, в частности, к системе и способу для передачи речевой активности в распределенной системе распознавания голоса.
Уровень техники
Распознавание голоса (VR) представляет собой один из важнейших способов наделения машины искусственным интеллектом для распознавания команд пользователя, подаваемых голосом, и облегчения взаимодействия человека с машиной. VR также является основным способом понимания человеческой речи. Системы, в которых используются способы восстановления лингвистических сообщений из акустического речевого сигнала, называются устройствами распознавания голоса.
Использование VR (которое также часто называют "распознаванием речи") становится все более важным по причинам безопасности. Например, VR можно использовать для замены операций ручного нажатия кнопок на клавиатуре беспроводного телефона. Это особенно важно, когда пользователь инициирует телефонный вызов в процессе управления автомобилем. При использовании автомобильного телефона без VR водитель должен убрать одну руку с рулевого колеса и смотреть на клавиатуру телефона, нажимая кнопки для набора вызываемого номера. Эти действия увеличивают вероятность автодорожного происшествия. Автомобильный телефон, разрешающий речевой ввод (то есть телефон, разработанный для распознавания речи), позволяет водителю заказать разговор по телефону, непрерывно наблюдая за дорогой. Кроме того, автоматическая автомобильная система с комплектом соответствующих средств позволит водителю держать обе руки на рулевом колесе при инициировании телефонного вызова. Примерный словарь для автоматического автомобильного комплекта может включать в себя: десять цифр; ключевые слова "вызов", "посылка", "набор номера", "отмена", "очистка", "добавление", "удаление", "архив", "программа", "да" и "нет"; и набор имен в заданном количестве, куда входят сослуживцы, друзья или члены семьи, вызываемые по телефону чаще других.
Устройство распознавания голоса (речи), то есть система VR, содержит процессор акустических сигналов, называемый также препроцессором устройства распознавания голоса, и декодер слов, называемый также постпроцессором устройства распознавания голоса. Процессор акустических сигналов выполняет функцию выделения признаков. Процессор акустических сигналов выделяет из входящей необработанной речи последовательность признаков (векторов), несущих информацию, которые необходимы для VR. Декодер слов декодирует эту последовательность признаков (векторов) для получения значащего и желаемого формата выходного сигнала, к примеру, последовательность лингвистических слов, соответствующих введенному фрагменту речи.
При реализации устройства распознавания голоса с использованием распределенной системной архитектуры часто требуется возложить задачу декодирования слов на подсистему, которая может взять на себя вычислительную нагрузку и загрузку памяти, что уместно выполнить на сетевом сервере. В то же время процессор акустических сигналов должен находиться как можно ближе к источнику речи, то есть в устройстве пользователя, чтобы уменьшить воздействия вокодеров (используемых для сжатия речи перед передачей), вносимые в процессе обработки сигналов, и/или ошибки, наведенные в канале. Таким образом, в распределенной системе распознавания голоса (DVR) процессор акустических сигналов находится в устройстве пользователя, а декодер слов находится в сети.
Системы DVR позволяют устройствам, таким как сотовые телефоны, персональные средства связи, персональные информационные устройства (PDA) и т.д., получать доступ к информации и услугам от беспроводной сети, такой как Интернет, используя голосовые команды, путем обращения к серверам распознавания голоса в сети.
Использование методов эфирного сопряжения снижает точность систем распознавания голоса в беспроводных прикладных системах. Это ухудшение можно смягчить, возложив выделение признаков из голосовых команд пользователя на такое устройство, как абонентский блок (называемый также абонентской станцией, мобильной станцией, мобильным блоком, удаленной станцией, удаленным терминалом, терминалом доступа и оборудованием пользователя), и передавая признаки VR в трафике данных вместо того, чтобы передавать голосовые команды в голосовом трафике.Таким образом, в системе DVR признаки для препроцессорной обработки выделяются в упомянутом устройстве, после чего они посылаются в сеть. Устройство может быть либо мобильным, либо стационарным и осуществлять связь с одной либо несколькими базовыми станциями (BS) (называемыми также базовыми станциями сотовой связи, сотовыми базовыми станциями, базовыми приемопередающими системами (BTS), базовыми приемопередатчиками, центральными пунктами связи, точками доступа, узлами доступа, узловыми базовыми станциями, приемопередатчиками модемного пула (МРТ)).
Сложные задачи распознавания голоса требуют значительных вычислительных ресурсов. Реализация таких систем в абонентском блоке, имеющем ограниченные ресурсы центрального процессора, памяти и батареи, практически нецелесообразна. Системы DVR опираются на мощь вычислительных ресурсов в сети. В типовой системе DVR к декодеру слов предъявляются более высокие требования в отношении вычислительной мощности и памяти, чем к препроцессору устройства распознавания голоса. Таким образом, система VR на базе сервера в сети служит в качестве постпроцессора системы распознавания голоса и выполняет декодирование слов. Это дает преимущество при выполнении сложных задач VR с использованием ресурсов сети. Примеры систем DVR раскрыты в патенте США №5956683 "Distributed Voice Recognition System", права на который принадлежат правопреемнику настоящего изобретения и содержание которого включено сюда посредством ссылки.
Кроме выделения признаков, выполняемого в абонентском блоке, здесь же могут быть выполнены простые задачи VR, причем в этом случае система распознавания голоса не использует сетевые ресурсы для решения простых задач VR. Следовательно, уменьшается сетевой трафик, в результате чего снижается стоимость предоставления услуг, обеспечивающих возможности речевого ввода.
Несмотря на выполнение простых задач VR в абонентском блоке, перегруженность трафика в сети может привести к тому, что абонентские блоки будут получать некачественное обслуживание от системы VR на базе сервера. Распределенная система VR позволяет получить от пользовательского интерфейса признаки, обладающие широкими возможностями, на основе реализации сложных задач VR, правда, это достигается за счет увеличения сетевого трафика, а иногда за счет задержки передачи. Если локальный механизм VR в абонентском блоке не распознает голосовые команды пользователя, то тогда эти голосовые команды необходимо передавать на механизм VR на основе сервера после препроцессорной обработки, что увеличивает сетевой трафик и приводит к перегруженности сети. Перегруженность сети появляется тогда, когда одновременно от абонентского блока к системе VR на основе сервера передается большой объем сетевого трафика. После интерпретации голосовых команд механизмом VR на основе сервера результаты необходимо передать обратно на абонентский блок, что может привести к значительной задержке, если сеть перегружена.
Таким образом, в системе DVR необходимо иметь систему и способ уменьшения перегрузки сети и уменьшения задержек. Система и способ, уменьшающие перегрузку сети и уменьшающие задержки, позволят повысить эффективность VR.
Сущность изобретения
Описанные варианты ориентированы на создание системы и способа передачи речевой активности, уменьшающие перегрузку и задержки в сети. Система и способ передачи речевой активности в системе распознавания голоса включает в себя модуль обнаружения речевой активности (VAD) и модуль выделения признаков (FE) в абонентском блоке.
Согласно одному аспекту абонентский блок содержит модуль выделения признаков, выполненный с возможностью выделения множества признаков речевого сигнала, модуль обнаружения речевой активности, выполненный с возможностью обнаружения речевой активности в речевом сигнале и обеспечивающий индикацию обнаруженной речевой активности, и передатчик, соединенный с модулем выделения признаков и модулем обнаружения речевой активности и выполненный с возможностью передачи индикации обнаруженной речевой активности перед множеством признаков.
Согласно другому аспекту абонентский блок содержит средство для выделения множества признаков речевого сигнала, средство для обнаружения речевой активности в речевом сигнале и обеспечения индикации обнаруженной речевой активности, и передатчик, соединенный со средством выделения признаков и средством обнаружения речевой активности и выполненный с возможностью передачи индикации обнаруженной речевой активности перед множеством признаков.
Согласно одному аспекту абонентский блок дополнительно содержит средство для объединения множества признаков с индикацией обнаруженной речевой активности, причем индикация обнаруженной речевой активности предшествует множеству признаков.
Согласно одному аспекту способ передачи речевой активности заключается в том, что выделяют множество признаков речевого сигнала, обнаруживают речевую активность с помощью речевого сигнала и обеспечивают индикацию обнаруженной речевой активности, а также передают индикацию обнаруженной речевой активности перед множеством признаков.
Краткое описание чертежей
Фиг.1 - система распознавания голоса, включающая в себя процессор акустических сигналов и декодер слов согласно одному варианту осуществления настоящего изобретения;
фиг.2 - примерный вариант распределенной системы распознавания голоса;
фиг.3 - задержки в примерном варианте осуществления распределенной системы распознавания голоса;
фиг.4 - блок-схема модуля VAD согласно одному варианту осуществления изобретения;
фиг.5 - блок-схема субмодуля VAD согласно одному варианту осуществления изобретения;
фиг.6 - блок-схема модуля FE согласно одному варианту осуществления изобретения;
фиг.7 - диаграмма состояния модуля VAD согласно одному варианту осуществления изобретения; и
фиг.8 - части речи и события VAD на оси времени согласно одному варианту осуществления изобретения.
Подробное описание изобретения
На фиг.1 показана система 2 распознавания голоса, включающая в себя процессор 4 акустических сигналов и декодер 6 слов согласно одному варианту осуществления изобретения. Декодер 6 слов содержит элемент 8 сопоставления с акустическими образцами и элемент 10 моделирования языка. Элемент 10 моделирования языка также называют элементом грамматического описания. Процессор 4 акустических сигналов связан с элементом 8 акустического сопоставления декодера 6 слов. Элемент 8 сопоставления с акустическими образцами соединен с элементом 10 моделирования языка.
Процессор 4 акустических сигналов выделяет признаки из входного речевого сигнала и подает эти признаки в декодер 6 слов. Вообще говоря, декодер 6 слов преобразует акустические признаки из процессора 4 акустических сигналов в оценку исходной последовательности слов говорящего. Это выполняется в два этапа: сопоставление с акустическими образцами и моделирование языка. Моделирования языка можно избежать в приложениях, в которых распознаются выбранные слова. Элемент 8 сопоставления с акустическими образцами обнаруживает и классифицирует возможные акустические образцы, такие как фонемы, слоги, слова и т.п. Образцы-кандидаты подают в элемент 10 моделирования языка, который моделирует правила синтаксических ограничений, определяющих, какие последовательности слов грамматически корректны и имеют смысл. Синтаксическая информация может быть ценным ориентиром для распознавания голоса, когда только акустическая информация допускает неоднозначное толкование. При распознавании голоса на основе моделирования языка последовательно интерпретируются результаты сопоставления акустических признаков, и выдается последовательность оцененных слов.
Как для сопоставления с акустическими образцами, так и для моделирования языка в декодере 6 слов необходимо иметь математическую модель: либо детерминированную, либо стохастическую для описания фонологических и акустико-фонетических вариаций говорящего. Эффективность системы распознавания речи непосредственно связана с качеством этих двух моделей. Среди моделей различных классов для сопоставления с акустическими образцами специалистам в данной области техники наиболее известны две модели: динамической трансформации шкалы времени на базе эталонов (DTW) и скрытая стохастическая марковская модель (HMM).
Процессор 4 акустических сигналов представляет подсистему предварительного анализа речи в устройстве 2 распознавания голоса. В ответ на входной речевой сигнал он обеспечивает соответствующее представление, характеризующее изменяющийся во времени речевой сигнал. Он должен отбрасывать нерелевантную информацию, такую как фоновый шум, канальное искажение, характеристики говорящего и манера речи. Эффективный акустический признак обеспечит устройству распознавания голоса более высокий уровень мощности для акустического различения. Наиболее полезной характеристикой является кратковременная огибающая спектра. При определении параметров кратковременной огибающей спектра обычно используют способ спектрального анализа на основе блока фильтров.
Объединение нескольких систем VR (также называемых механизмами VR) обеспечивает повышенную точность и использование большего количества информации во входном речевом сигнале, чем одна система VR. Система и способ объединения механизмов VR описаны в патентной заявке США №09/618177 "Combined Engine System and Method for Voice Recognition", поданной 18 июля 2000 года, и в патентной заявке США №09/657760 "System and Method for Automatic Voice Recognition Using Mapping", поданной 8 сентября 2000 года, права на которые принадлежат правопреемнику настоящего изобретения и содержание которых полностью включено сюда посредством ссылки.
В одном варианте множество механизмов VR объединено в распределенную систему VR. Таким образом, механизм VR имеется как в абонентском блоке, так и в сетевом сервере. Механизм VR в абонентском блоке является локальным механизмом VR. Механизм VR на сервере является сетевым механизмом VR. Локальный механизм VR содержит процессор для реализации локального механизма VR и память для запоминания речевой информации. Сетевой механизм VR содержит процессор для реализации сетевого механизма VR и память для запоминания речевой информации.
Примерная система DVR раскрыта в патентной заявке США №09/755561 "System and Method For Improving Voice Recognition In A Distributed Voice Recognition System", поданной 5 января 2001 года, права на которую принадлежат правопреемнику настоящего изобретения и содержание которой включено сюда посредством ссылки. На фиг.2 показан примерный вариант осуществления настоящего изобретения. В этом примерном варианте средой является система беспроводной связи, содержащая абонентский блок 40 и центральный пункт связи, называемый сотовой базовой станцией 42. В этом примерном варианте осуществления представлена распределенная система VR. При распределенном VR процессор акустических сигналов или элемент 22 выделения признаков находится в абонентском блоке 40, а декодер 48 слов находится в центральном пункте связи. Если вместо варианта с распределенным VR распознавание голоса реализуется только в абонентском блоке, то такое распознавание будет крайне затруднено даже при наличии словаря среднего размера, поскольку распознавание слов связано с большими затратами на вычисления. С другой стороны, если VR находится только на базовой станции, то может резко снизиться точность из-за ухудшения речевых сигналов, связанного с работой речевых кодеков и канальными эффектами. Очевидно, что вариант с распределенной системой имеет преимущества. Во-первых, уменьшается стоимость абонентского блока, поскольку в этом случае в абонентском блоке 40 отсутствуют аппаратные средства декодера слов. Во-вторых, уменьшается расход батареи (не показана) абонентского блока 40 в результате локального выполнения интенсивных вычислительных операций в декодере слов. В-третьих, повышается точность распознавания дополнительно к гибкости и возможности расширения распределенной системы.
Речь поступает в микрофон 20, который преобразует речевой сигнал в электрические сигналы, подаваемые в элемент 22 выделения признаков. Сигналы от микрофона 20 могут быть аналоговыми или цифровыми. Если сигналы являются аналоговыми, то тогда между микрофоном 20 и элементом 22 выделения признаков может быть предусмотрен аналого-цифровой преобразователь (не показан). Речевые сигналы подаются в элемент 22 выделения признаков. Элемент 22 выделения признаков выделяет релевантные характеристики вводимой речи, которые будут использованы для декодирования лингвистической интерпретации введенной речи. Одним из примеров характеристик, которые можно использовать для оценки речи, являются частотные характеристики введенного речевого кадра. Часто это предусматривают в виде параметров линейного кодирования с предсказанием введенного речевого кадра. Выделенные признаки речи подаются затем в передатчик 24, который кодирует, модулирует и усиливает сигнал с выделенными признаками и подает эти признаки через дуплексер 26 в антенну 28, откуда речевые признаки передаются на сотовую базовую станцию или центральный пункт 42 связи. При этом можно использовать схемы цифрового кодирования, модуляции и передачи различных типов, хорошо известные специалистам в данной области техники.
В центральном пункте 42 связи переданные признаки принимаются антенной 44 и подаются в приемник 46. Приемник 46 может выполнять функции демодуляции и декодирования полученных переданных признаков, которые он предоставляет декодеру 48 слов. Декодер 48 слов, исходя из этих речевых признаков, выполняет лингвистическую оценку речи и подает сигнал воздействия в передатчик 50. Передатчик 50 выполняет функции усиления, модуляции и кодирования сигнала воздействия и подает усиленный сигнал в антенну 52, которая передает оцененные слова или командный сигнал в портативный телефон 40. В передатчике 50 могут также использоваться способы цифрового кодирования, модуляции или передачи, известные специалистам в данной области техники.
В абонентском блоке 40 оцененные слова или командные сигналы принимаются антенной 28, которая через дуплексер 26 передает принятый сигнал в приемник 30, а тот, в свою очередь, демодулирует и декодирует этот сигнал, а затем подает командный сигнал или оцененные слова в управляющий элемент 38. В ответ на принятый командный сигнал или оцененные слова управляющий элемент 38 выдает установленный ответ (например, набор телефонного номера, подача информации на экран дисплея портативного телефона и т.п.).
В одном варианте осуществления изобретения информация, посланная обратно от центрального пункта 42 связи, не обязательно должна представлять собой интерпретацию переданной речи, скорее такая информация, посланная обратно от центрального пункта 42 связи, может представлять собой ответ на декодированное сообщение, посланное портативным телефоном. Например, можно запросить сообщения на удаленном автоответчике (не показан), соединенном через сеть связи с центральным пунктом 42 связи, причем в этом случае сигнал, переданный от центрального пункта 42 связи на абонентский блок 40, может представлять собой сообщение от автоответчика при этом варианте реализации. Второй управляющий элемент 49 находится в центральном пункте связи.
Механизм VR получает речевые данные в виде сигналов импульсно-кодовой модуляции (PCM). Механизм VR обрабатывает сигнал, пока не будет выполнено правильное распознавание, либо пользователь не прекратит говорить, и вся речь не будет обработана. В одном варианте осуществления архитектура DVR включает в себя локальный механизм VR, который получает данные PCM и формирует предварительную информацию. В одном варианте осуществления предварительная информация представляет собой кепстральные параметры. В другом варианте осуществления предварительная информация может представлять собой информацию/признаки любого типа, которая характеризует введенный речевой сигнал. Специалистам в данной области техники понятно, что для определения параметров введенного речевого сигнала можно использовать признаки любого типа, известные специалистам в данной области техники.
Для решения типовой задачи распознавания локальный механизм VR получает набор апробированных эталонов из своей памяти. Локальный механизм VR получает грамматическое описание из приложения. Приложение представляет собой служебную логическую схему, которая позволяет пользователям решить задачу, используя абонентский блок. Эта логическая схема реализуется процессором в абонентском блоке. Она является компонентом модуля пользовательского интерфейса в абонентском блоке.
Система и способ усовершенствования хранения эталонов в системе распознавания голоса описаны в патентной заявке США №09/760076 "System And Method For Efficient Storage Of Voice Recognition Models", поданной 12 января 2001 года, права на которую принадлежат правопреемнику настоящего изобретения и содержание которой целиком включено сюда посредством ссылки. Система и способ для улучшения распознавания голоса в средах с шумами и в условиях несовпадения частот, а также для улучшения хранения эталонов описаны в патентной заявке США №09/703191 "System and Method for Improving Voice Recognition In Noisy Environments and Frequency Mismatch Conditions", поданной 30 октября 2000 года, права на которую принадлежат правопреемнику настоящего изобретения и содержание которой полностью включено сюда посредством ссылки.
Активный словарь, использующий модели субслов, определяется грамматикой. Типовые грамматики включают в себя 7-значные телефонные номера, суммы в долларах и название города из набора названий. Типовые грамматические описания включают в себя состояние "вне словаря (OOV)" для представления состояния в том случае, когда на основе введенного речевого сигнала не удалось обеспечить доверительное распознавание.
В одном варианте осуществления локальный механизм VR локально формирует гипотезу распознавания, если он в состоянии решить задачу VR, определенную данной грамматикой. Когда заданная грамматика слишком сложна для обработки локальным механизмом VR, локальный механизм VR передает входные (предварительные) данные на сервер VR.
Прямая линия связи относится к передаче от сетевого сервера к абонентскому блоку, а обратная линия связи относится к передаче от абонентского блока к сетевому серверу. Время передачи подразделяется на временные единицы (блоки). В одном варианте осуществления время передачи может быть разбито на кадры. В другом варианте осуществления время передачи может быть разбито на временные интервалы (слоты). Согласно одному варианту осуществления данные разбиваются на пакеты данных, причем каждый пакет данных передается в течение одной или нескольких временных единиц. В течение каждой временной единицы базовая станция может вести направленную передачу данных на любой абонентский блок, находящийся на связи с этой базовой станцией. В одном варианте осуществления кадры могут быть дополнительно разбиты на множество временных интервалов. Еще в одном варианте временные интервалы могут быть разбиты дополнительно. Например, временной интервал может быть разбит на половинные интервалы и четвертные интервалы.
На фиг.3 показаны задержки в примерном варианте осуществления распределенной системы 100 распознавания голоса. Система DVR 100 содержит абонентский блок 102, сеть 150 и сервер 160 распознавания речи (SR). Абонентский блок 102 связан с сетью 150, а сеть 150 связана с сервером SR 160. Функция препроцессора (предварительная обработка) в системе DVR 100 реализуется в абонентском блоке 102, который содержит модуль 104 выделения признаков (FE) и модуль 106 обнаружения речевой активности (VAD). FE осуществляет выделение признаков из речевого сигнала и сжатие результирующих признаков. В одном варианте модуль VAD 106 определяет, какие кадры будут передаваться от абонентского блока на сервер SR. Модуль VAD 106 разделяет введенную речь на сегменты, содержащие кадры, в которых обнаружена речь, и соседние кадры перед и после того кадра, в котором была обнаружена речь. В одном варианте осуществления конец каждого сегмента (EOS) отмечается в полезной нагрузке путем передачи нулевого кадра.
Препроцессор VR выполняет предварительную обработку, чтобы определить параметры речевого сегмента. Вектор s - это речевой сигнал, а вектор F и вектор V являются векторами FE и VAD соответственно. В одном варианте осуществления вектор VAD имеет длину в один элемент, а один элемент имеет двоичное значение. В другом варианте осуществления вектор VAD имеет двоичное значение, связанное с дополнительными признаками. В одном варианте дополнительные признаки - это значения энергии полос, позволяющие серверу точно указать конец фрагмента. Указание конца фрагмента - это разграничение речевого сигнала и молчания и разграничение речевых сегментов. Таким образом, сервер может использовать дополнительные вычислительные ресурсы для обеспечения более надежного решения задачи VAD.
Энергии полос соответствуют амплитудам Барка. Шкала Барка - это деформированная частотная шкала критических полос, соответствующих слуховому восприятию человека. Вычисление амплитуд Барка известно специалистам в данной области техники и описано в работе Lawrence Rabiner & Biing Hwang Juang, Fundamentals of Speech Recognition (1993), содержание которой целиком включено сюда посредством ссылки. В одном варианте осуществления оцифрованные речевые сигналы PCM преобразуются в энергии полос.
На фиг.3 показаны задержки в примерном варианте осуществления распределенной системы распознавания голоса. Задержки при вычислении векторов F и V и передачи их по сети показаны с использованием символики Z-преобразования. Задержка выполнения алгоритма, вносимая при вычислении вектора F, равна k, и в одном варианте осуществления диапазон значений k составляет от 100 до 300 мс. Аналогично, задержка выполнения алгоритма при вычислении информации VAD равна j, и в одном варианте диапазон j составляет от 10 до 100 мс. Таким образом, векторы признаков FE предоставляются с задержкой k единиц, а информация VAD предоставляется с задержкой j единиц. Задержка, вносимая при передаче информации по сети, составляет n единиц. Сетевая задержка для векторов F и V одинакова.
На фиг.4 показана блок-схема модуля VAD 400. Модуль 402 кадрирования включает в себя аналого-цифровой преобразователь (не показан). В одном варианте осуществления частота дискретизации выходного речевого сигнала аналого-цифрового преобразователя составляет 8 кГц. Специалистам в данной области техники также должно быть понятно, что можно использовать другие значения выходной частоты дискретизации. Отсчеты речевого сигнала разбиваются на перекрывающиеся кадры. В одном варианте длина кадров составляет 25 мс (200 отсчетов), а частота кадров составляет 10 мс (80 отсчетов).
В одном варианте осуществления каждый кадр формируется в виде окна модулем 404 организации окон с использованием взвешивающей функции Хэмминга. Модуль 406 быстрого преобразования Фурье (FFT) вычисляет амплитудный спектр для каждого кадра в виде окна. В одном варианте осуществления для вычисления амплитудного спектра для каждого кадра в виде окна используют быстрое преобразование Фурье с длиной 256. В одном варианте осуществления первые 129 двоичных отсчетов из амплитудного спектра оставляют для дальнейшей обработки. Модуль 408 спектра мощности (PS) вычисляет спектр мощности путем возведения в квадрат значений амплитудного спектра.
В одном варианте осуществления модуль 409 MEL-фильтрации вычисляет MEL-деформированный спектр, используя весь частотный диапазон (0-4000 Гц). Эта зона делится на 23 канала, равноотстоящих по частотной шкале MEL. Таким образом, имеется 23 значения энергии на кадр. Выходной сигнал модуля 409 MEL-фильтрации является взвешенной суммой значений спектра мощности FFT в каждой зоне. Выходной сигнал модуля 409 MEL-фильтрации проходит через логарифмический модуль 410, который выполняет нелинейное преобразование выходного сигнала модуля MEL-фильтрации. В одном варианте осуществления нелинейное преобразование представляет собой натуральный логарифм. Специалистам в данной области техники понятно, что можно использовать и другие нелинейные преобразования.
Субмодуль 412 детектора речевой активности (VAD) в качестве входного сигнала получает преобразованный выходной сигнал логарифмического модуля 409 и устанавливает различие между речевыми и неречевыми кадрами. Субмодуль VAD 412 обнаруживает присутствие речевой активности в кадре. Субмодуль VAD 412 определяет, имеется или нет в кадре речевая активность. В одном варианте осуществления субмодуль VAD 412 представляет собой трехуровневую нейронную сеть с прямой связью.
На фиг.5 показана блок-схема субмодуля VAD 500. В одном варианте осуществления модуль 420 субдискретизации выполняет субдискретизацию выходного сигнала логарифмического модуля с коэффициентом два.
Модуль 422 дискретного косинусного преобразования (DCT) вычисляет кепстральные коэффициенты, исходя из 23 субдискретизированных логарифмических значений энергии по шкале MEL. В одном варианте осуществления модуль DCT 422 вычисляет 15 кепстральных коэффициентов.
Модуль 424 нейронной сети (NN) предоставляет оценку апостериорной вероятности текущего кадра, являющегося речевым либо неречевым. Пороговый модуль 426 сравнивает оценку из модуля NN 424 с пороговым значением для преобразования оценки в двоичный признак. В одном варианте используют пороговое значение, равное 0,5.
Модуль 427 медианного фильтра сглаживает двоичный признак. В одном варианте осуществления двоичный признак сглаживают, используя 11-точечный медианный фильтр. В другом варианте осуществления модуль 427 медианного фильтра удаляет любые короткие паузы или короткие речевые импульсы длительностью менее 40 мс. В одном варианте осуществления модуль 427 медианного фильтра также добавляет семь кадров перед и после перехода от молчания к речи. В одном варианте осуществления значение бита устанавливают в соответствии с результатом определения того, имеет ли кадр речевую активность, либо представляет молчание.
На фиг.6 показана блок-схема модуля FE 600. Модуль 602 кадрирования, модуль 604 организации окон, модуль FFT 606, модуль PS 608, модуль MF 609 и логарифмический модуль 610 также являются частями FE и выполняют те же функции в модуле FE 600, что и в модуле VAD 400. В одном варианте осуществления эти общие модули используются между модулем VAD 400 и модулем FE 600.
Субмодуль VAD 612 связан с логарифмическим модулем 610. Модуль 428 линейного дискриминантного анализа (LDA) связан с субмодулем VAD 612 и использует полосовой фильтр для выходного сигнала субмодуля VAD 610. В одном варианте осуществления полосовой фильтр представляет собой фильтр RASTA. Примерами полосовых фильтров, которые можно использовать на этапе предварительной обработки для VR, являются фильтры RASTA, описанные в патенте США №5450522 "Auditory Model for Parameterization of Speech", заявка на который подана 12 сентября 1995 года, содержание которого включено сюда посредством ссылки.
Модуль 430 субдискретизации выполняет субдискретизацию выходного сигнала модуля LDA. В одном варианте модуль 430 субдискретизации выполняет субдискретизацию выходного сигнала модуля LDA с коэффициентом два.
Модуль 432 дискретного косинусного преобразования (DCT) вычисляет кепстральные коэффициенты, исходя из 23 субдискретизированных логарифмических значений энергии по шкале MEL. В одном варианте осуществления модуль DCT 422 вычисляет 15 кепстральных коэффициентов.
С целью компенсации шумов модуль 434 онлайновой нормализации (OLN) использует нормализацию среднего значения и дисперсии для кепстральных коэффициентов из модуля DCT 432. Оценки локального среднего значения и дисперсии обновляются для каждого кадра. В одном варианте осуществления к оценкам дисперсии перед нормализацией признаков добавляется экспериментально определенное смещение. Это смещение исключает воздействие оценок дисперсии для слабых шумов в областях длительного молчания. Из нормализованных статических признаков получают динамические признаки. Это позволяет не только сократить объем вычислений, необходимых для нормализации, но также обеспечивает лучшую эффективность распознавания.
Модуль 436 сжатия признаков сжимает векторы признаков. Модуль 438 форматирования и кадрирования потока битов выполняет потоковое форматирование сжатых векторов признаков в битах, подготавливая их для передачи. В одном варианте осуществления модуль 436 сжатия признаков обеспечивает защиту от ошибок форматированного потока битов.
Модуль FE 600 соединяет друг с другом вектор F Z-k и вектор V Z-j. Таким образом, каждый вектор FE содержит соединение вектора F Z-k с вектором V Z-j.
В настоящем изобретении выходной сигнал VAD передается перед полезной нагрузкой, что уменьшает общую задержку в системе DVR, поскольку предварительная обработка VAD короче (j<k), чем предварительная обработка FE.
В одном варианте осуществления приложение, выполняемое на сервере, может определить конец фрагмента речи пользователя, когда вектор V указывает молчание в течение периода времени, большего Shangover. Shangover - это длительность молчания после активной речи для завершения фиксации фрагмента речи. Значение Shangover должно быть больше, чем допустимая длительность молчания внутри фрагмента речи. Если Shangover>k, то задержка на выполнение алгоритма FE не увеличит время отклика. В одном варианте осуществления признаки FE, соответствующие временному интервалу t-k, и признаки VAD, соответствующие временному интервалу t-j, объединяют для формирования расширенных признаков FE. Выходной сигнал VAD передается тогда, когда он имеется, и не зависит от того, когда появляется выходной сигнал FE для передачи. Выходные сигналы VAD и FE синхронизируют с передаваемой полезной нагрузкой. В одном варианте осуществления передается информация, соответствующая каждому сегменту речи, то есть без отбрасывания кадров.
В другом варианте осуществления полоса пропускания канала сужается во время периодов молчания. Вектор F квантуется с более низкой скоростью передачи в битах, когда вектор V указывает на зоны молчания. Это аналогично работе вокодеров с переменной скоростью и многоскоростных вокодеров, в которых скорость передачи битов изменяется на основе определения речевой активности. Выходные сигналы как VAD, так и FE синхронизируются с передаваемой полезной нагрузкой. Передается информация, соответствующая каждому сегменту речи. Таким образом, передается выходной сигнал VAD, но при этом скорость передачи в битах уменьшается в кадрах с молчанием.
Еще в одном варианте осуществления на сервер передаются только кадры с речью. Таким образом, кадры с молчанием полностью опускаются. Поскольку на сервер передаются только речевые кадры, сервер должен каким-то путем определить, что пользователь закончил говорить. Это не зависит от значения задержек k, j и n. Рассмотрим множество слов, к примеру "Portland <пауза> Maine" или "617-555-<пауза>1212". Для передачи информации VAD используют отдельный канал. Признаки FE, соответствующие области <пауза>, в абонентском блоке опускаются, и сервер без отдельного канала не будет иметь информацию для заключения о том, что пользователь закончил говорить. В этом варианте имеется отдельный канал для передачи информации VAD.
В другом варианте осуществления состояние устройства распознавания поддерживается даже при длинных паузах в речи пользователя, согласно диаграмме состояний на фиг.7 и событиям и действиям в таблице 1. При обнаружении речевой активности усредненный вектор модуля FE 600, соответствующий опущенным кадрам и общему количеству опущенных кадров, передается до передачи речевых кадров. Кроме того, когда мобильный абонентский блок определяет, что кадры Shangover молчания зафиксированы, обнаруживается конец фрагмента речи пользователя. В одном варианте осуществления речевые кадры и общее количество опущенных кадров передаются на сервер вместе с усредненным вектором модуля FE 600 по одному и тому же каналу. Таким образом, полезная нагрузка включает в себя как признаки, так и выходной сигнал VAD. В одном варианте осуществления выходной сигнал VAD посылают в полезной нагрузке последним, чтобы указать на конец речи.
Для типового фрагмента речи модуль VAD 400 начинает работу с состояния 702 ожидания и переходит в состояние 704 начального молчания из-за события А. Может быть несколько событий B, которые оставляют этот модуль в состоянии начального молчания. При обнаружении речи событие С вызывает переход в состояние 706 активной речи. Затем модуль 400 переходит из состояния 706 активной речи в состояние 708 "внутреннего" молчания и обратно из-за событий D и Е. Если длительность внутреннего молчания больше Shangover, это трактуется как конец речевого фрагмента, и событие F вызывает переход в состояние 702 ожидания. Событие Z представляет длительное начальное молчание во фрагменте речи. Оно инициирует состояние ошибки TIME_OUT (простой), когда речь пользователя не обнаружена. Событие X прерывает данное состояние и возвращает модуль в состояние 702 ожидания. Это может быть пользователь или событие, инициированное системой.
На фиг.8 показаны части речи и события VAD на оси времени. Обратимся к фиг.8, окну 4 и таблице 2, в которых применительно к модулю VAD 400 показаны события, вызывающие переходы из состояния в состояние.
В таблице 1 Sbefore и Safter - это количество кадров молчания, переданных на сервер перед и после активной речи.
Из диаграммы состояний и таблицы событий, в которых показаны соответствующие действия в мобильной станции, ясно, что имеется ряд пороговых величин, используемых при инициировании переходов из состояния в состояние. Можно использовать определенные значения по умолчанию для этих пороговых величин. Однако специалистам в данной области техники понятно, что можно использовать и другие значения пороговых величин, показанных в таблице 1.
Кроме того, сервер может изменить значения по умолчанию в зависимости от конкретного приложения. Значения по умолчанию являются программируемыми, как это определено в таблице 2.
(i-h)
(h-g)
(j-i)
>(h-e)
В одном варианте осуществления минимальная длительность Smin фрагмента речи составляет порядка 100 мс. В одном варианте осуществления размер области молчания, передаваемой перед активной речью, Sbefore составляет порядка 200 мс. В одном варианте осуществления размер области молчания, передаваемой вслед за активной речью, Safter, составляет порядка 200 мс. В одном варианте осуществления длительность молчания после активной речи для завершения фиксации фрагмента речи, Shangover, лежит в диапазоне от 500 мс до 1500 мс, в зависимости от применения VR. В одном варианте осуществления восьмиразрядный счетчик допускает Smaxsil, равную 2,5 секунды при 100 кадрах в секунду. В одном варианте осуществления минимальная длительность молчания, ожидаемая перед и после активной речи, Sminsil, составляет порядка 200 мс.
Таким образом, здесь был описан новый усовершенствованный способ и устройство для распознавания голоса. Специалистам в данной области техники понятно, что проиллюстрированные здесь различные логические блоки, модули и преобразования данных, описанные вместе с раскрытыми здесь вариантами осуществления, можно реализовать в виде электронных аппаратных средств, компьютерных программных средств или их комбинаций. Проиллюстрированные здесь различные компоненты, блоки, модули, схемы и этапы описаны в целом с точки зрения их функциональных возможностей. То, каким образом реализованы функциональные возможности, в виде аппаратных либо программных средств, зависит от конкретного применения и проектных ограничений, наложенных на всю систему. Специалисты в данной области техники, без сомнения, понимают, что в этих обстоятельствах возможна взаимозаменяемость аппаратных и программных средств, и имеют представление о том, каким образом лучше всего реализовать описанные функциональные возможности для каждого конкретного применения. Например, различные проиллюстрированные здесь логические блоки, модули и преобразования данных, описанные в связи с раскрытыми здесь вариантами осуществления, могут быть реализованы или выполнены с помощью процессора, выполняющего набор встроенных команд, прикладных специализированных интегральных схем (ASIC), вентильной матрицы, программируемой пользователем в условиях эксплуатации (FPGA), либо с помощью другого программируемого логического устройства, дискретной вентильной или транзисторной логики, дискретных аппаратных компонентов, таких как, например, регистры, с помощью любого известного программируемого программного модуля и процессора, либо любой их комбинации, спроектированной для выполнения описанных здесь функций. Модуль VAD 400 и модуль FE 600 могут быть реализованы в микропроцессоре, что является преимущественным вариантом осуществления, а в альтернативном варианте осуществления модуль VAD 400 и модуль FE могут быть выполнены в любом стандартном процессоре, контроллере, микроконтроллере или конечном автомате. Эталоны могут находиться в ОЗУ, флэш-памяти, ПЗУ, СППЗУ (стираемое программируемое ПЗУ), ЭСППЗУ (электрически стираемое программируемое ПЗУ), в регистрах, на жестком диске, съемном диске, в ПЗУ на компакт-диске либо на носителе информации любого вида, известного специалистам в данной области техники. Память (не показана) может составлять единое целое с любым вышеупомянутым процессором (не показан). Процессор (не показан) и память (не показана) могут находиться в ASIC (не показана). ASIC может находиться в телефонном аппарате.
Приведенное описание вариантов осуществления изобретения предложено для того, чтобы дать возможность любому специалисту в данной области техники реализовать или использовать настоящее изобретение. Специалистам в данной области техники очевидны различные модификации этих вариантов осуществления, а также то, что основные определенные здесь принципы могут быть использованы в других вариантах осуществления без необходимости привлечения изобретательских навыков. Таким образом, предполагается, что настоящее изобретение не сводится к продемонстрированным здесь вариантам осуществления, но должно соответствовать самому широкому объему, согласующемуся с изложенными здесь новыми принципами и признаками.







Изобретение относится к системам передачи речевой активности в распределенной системе распознавания голоса. Технический результат - уменьшение перегрузки сети, уменьшение задержки и повышение эффективности распознавания голоса достигается тем, что распределенная система распознавания голоса включает в себя локальный механизм распознавания голоса (VR) в абонентском блоке и серверный механизм VR на сервере, локальный механизм VR содержит модуль выделения признаков (FE), который выделяет признаки из речевого сигнала, и модуль обнаружения речевой активности (VAD), который обнаруживает речевую активность в речевом сигнале, причем индикацию речевой активности передают впереди признаков из абонентского блока на сервер. 3 н.п. ф-лы, 8 ил., 2 табл.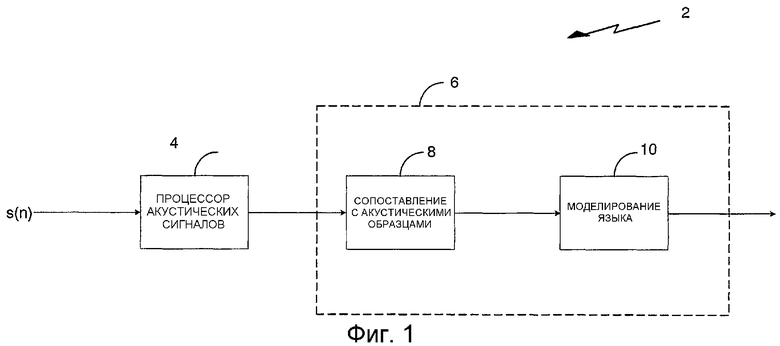
модуль выделения признаков, выполненный с возможностью выделения множества признаков речевого сигнала для представления сигнала с выделенным множеством признаков,
модуль обнаружения речевой активности, выполненный с возможностью обнаружения речевой активности в речевом сигнале и обеспечивающий сигнал индикации обнаруженной речевой активности, и
передатчик, соединенный с модулем выделения признаков и модулем обнаружения речевой активности и выполненный с возможностью передачи сигнала индикации обнаруженной речевой активности перед сигналом, представляющим упомянутое множество признаков.
средство для выделения множества признаков речевого сигнала для представления сигнала с выделенным множеством признаков,
средство для обнаружения речевой активности в речевом сигнале и обеспечения сигнала индикации обнаруженной речевой активности и передатчик, соединенный со средством выделения признаков и средством обнаружения речевой активности и выполненный с возможностью передачи сигнала индикации обнаруженной речевой активности перед сигналом, представляющим упомянутое множество признаков.
выделяют множество признаков из речевого сигнала для представления сигнала с выделенным множеством признаков,
обнаруживают речевую активность в речевом сигнале и обеспечивают сигнал индикации обнаруженной речевой активности, и
передают сигнал индикации обнаруженной речевой активности перед сигналом, представляющим упомянутое множество признаков.
| СПОСОБ СЖАТИЯ РЕЧЕВОГО СИГНАЛА ПУТЕМ КОДИРОВАНИЯ С ПЕРЕМЕННОЙ СКОРОСТЬЮ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ, КОДЕР И ДЕКОДЕР | 1993 |
|
RU2107951C1 |
| СПОСОБ И УСТРОЙСТВО ВОКОДИРОВАНИЯ ПЕРЕМЕННОЙ СКОРОСТИ ПРИ ПОНИЖЕННОЙ СКОРОСТИ КОДИРОВАНИЯ | 1995 |
|
RU2146394C1 |
| US 5956683 A1, 21.09.1999 | |||
| Способ получения трипептидов или их солей | 1973 |
|
SU671721A3 |
| US 6195636 A1, 27.02.2001 | |||
| US 5960399 A1, 28.09.1999 | |||
| ЕР 0784311 А1, 16.07.1997. | |||

