Изобретение относится к системам коммутации. Более точно данное изобретение относится к системам коммутации, имеющим очередь совместно используемой памяти.
АТМ (асинхронный режим передачи данных) рекомендуется в качестве средства транспортировки для BISDN (широкополосной интегрированной сервисной цифровой сети) для того, чтобы передавать различные информационные потоки, такие, как видео, звуковые, потоки данных с помощью CCITT (MKKTT - Международный консультативный комитет по телеграфии и телефонии), являющегося международным центром стандартов. АТМ обеспечивает гибкую полосу пропускания, быструю и динамическую реконфигурацию вызовов, независимость обслуживания и эффективное мультиплексирование разделенных потоков. Идеальный АТМ - коммутатор способен согласовать разделенные потоки, появляющиеся от различных разнородных BISDN сетей обслуживания, не вызывая при этом недопустимых задержек и большой аппаратурной сложности.
В пакетных коммутаторах требуются буферы для временного хранения передаваемых пакетов. Буферизация требуется, в первую очередь, для разрешения внешних и внутренних конфликтов из-за ресурсов. Пример внешнего конфликта из-за ресурсов возникает, когда два пакета должны быть переданы на один и тот же выходной порт. В этом случае обычно один пакет передается, а другой буферизируется. Внутренние конфликты возникают, когда два пакета претендуют на одно и то же внутреннее средство, например внутреннюю шину коммутатора. Средства коммутаций токов встроены либо во входные дискретные буферы, либо в дискретные выходные буферы, либо в систему внутренней буферизации (M.G. Hiuchy and M.J.Karol. "Quening in High-Performance Packet Switching", IEEE Journal on Selected Areas in Communications. Sac-6, hh.1587-1597. Dec. 1988). Для дискретных входных портов очередь связана с каждым входным портом. Поступающие пакеты направляют в низ очереди. Верхний пакет удаляется, если в коммутаторе не возникают внутренние или внешние конфликты с другими пакетами. Выходная буферизация связывает подобную очередь с каждым выходным портом. Внутренняя буферизация связывает дискретные буферы с внутренними структурами (или ступенями) коммутатора. Результаты предыдущих исследований (K. Lutz, "Considerations on ATM switching techniques," International Journal of Digital and Analog Cabled Systems, vol.1, pp. 237-243. 1988; A. Eckberg and T.Hou, "Effects of output buffer sharing on buffer requirements in an ATDM packet switch, " in Proc. of INFOCOM'88, (New Orleans, Louisina), IEEE, Mar. 1988, pp. 459-466; H.Kim and A.Leon-Garcia", A ultistage ATM switch with interstage buffers", International Journal of Digital and Analog Cabled Systems, vol. 2, pp. 289-301; Dec. 1989; H.Kim and A.Leon - Garcia, "Comparative performance study of ATM -switches", in preparation for the Proceedings of the IEEE, 1990) показывают, что совместное использование общего буфера существенно снижает вероятность потери пакета коммутатором. Ожидается, что еще больший эффект будет для разделенных потоков (трафиков).
Размеры и количество буферов, используемых в пакетном коммутаторе, могут оказать существенное влияние на их стоимость и характеристики. Большие размеры и количество буферов отрицательно сказываются на сложности и стоимости. Кроме того, большие буферы могут значительно увеличить задержку, требуемую для передачи пакета от коммутатора. Маленькие дискретные буферы могут привести к выпадению пакетов из-за переполнения. Желательно потребовать использование буферов малого размера, количество которых возрастало бы линейно с возрастанием количества входов и выходов коммутатора.
Переключатели с выходной буферизацией имеют самые лучшие характеристики с точки зрения пропускной способности и задержки прохождения пакета при однородных видах потоков. Однако их высокая аппаратурная сложность приводит к необходимости изучения структуры коммутатора с входной очередью, который имеет меньшую аппаратурную сложность (J.Hue and E.Arthurs, "A broadband packet switch for integrated transport; IEEE Journal on Selected Areas in Communications, Vol. SAC-5, pp. 1264-1273, Oct. 1987). В данном изобретении представлена архитектура коммутатора с организацией входной очереди без блокировки (пакетов) и с входной очередью совместно используемой памяти. Простая очередь совместно используемой памяти позволяет входным портам совместно использовать общий буфер, поглощая таким образом разделенные потоки без возрастания потерь пакетов. Более того, коммутатор гарантирует передачу пакетов в том порядке, в котором они были приняты, снимая проблему восстановления последовательности с конечного пользователя.
Изобретение относится к пакетным коммутаторам. Пакетный коммутатор состоит из общей очереди совместно используемой памяти, имеющей M адресов хранения, по которым хранятся соответствующие пакеты, где M≥3 и целое. Пакетный коммутатор включает также сеть представления данных, имеющую N входных портов для приема пакетов и доставки соответствующих пакетов по требуемым адресам в очереди, где N≥3 и целое. Очередь связана с сетью представления данных для приема пакетов. Пакетный коммутатор также включает распределительную сеть, имеющую J входных портов, где J≥1, для приема пакетов из очереди и доставки их к требуемым выходным портам. Распределительная сеть связана с очередью. Имеется также средство для упорядочения пакетов, получаемых последовательно сетью представления данных, таким образом, что пакеты, принимаемые последовательно сетью представления данных, доставляются сетью представленных данных по соответствующим адресам в очереди. В предпочтительном варианте изобретения M=N=J, причем средство упорядочения включает схему выборки-сложения, связанную с очередью таким образом, что она определяет свободные адреса для хранения пакетов, полученных от сети представления данных, и заставляет пакеты, полученные сетью представления данных, разместиться по последовательно упорядоченным свободным для хранения адресам, при этом сеть представления данных и распределительная сеть является каждая Омега-сетью.
В еще более предпочтительном варианте изобретения пакетный коммутатор имеет возможности тиражирования и сброса (одного пакета на несколько выходных портов).
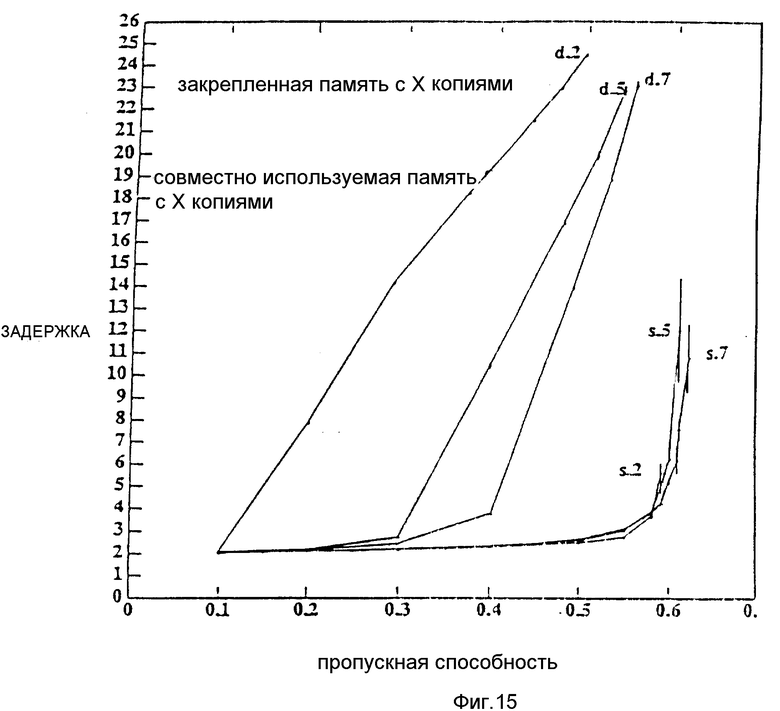
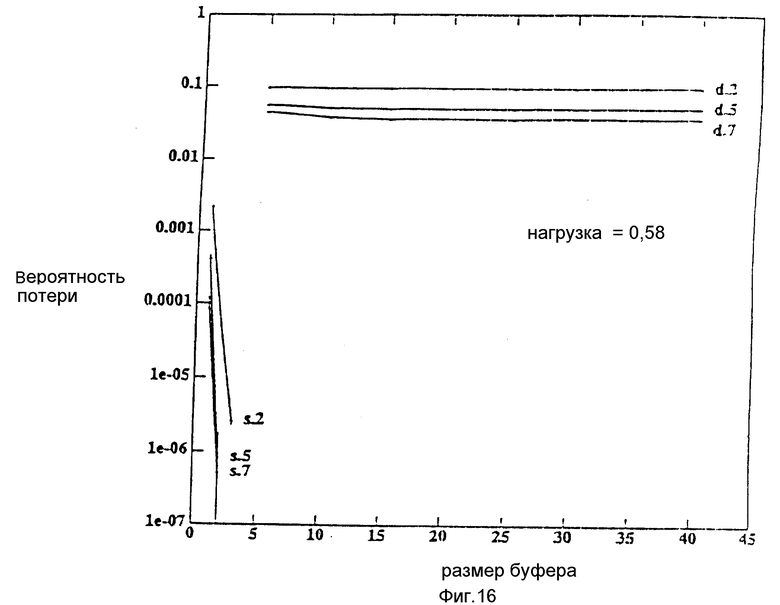
На фиг. 1 схематически представлена архитектура переключателя с совместно используемой памятью; на фиг. 2 и 3 - работа пакетной очереди; на фиг. 4 - пример выполнения комбинированной операции выборки-сложения; на фиг. 5 - структура пакетной очереди; на фиг. 6 - фаза I работы пакетной очереди; на фиг. 7 - фаза II работы пакетной очереди; на фиг. 8 - подробности архитектуры коммутатора с совместно используемой памятью; на фиг. 9 - архитектура сети с совместно используемой памятью и копированием; на фиг.10 - структура пакетной очереди; на фиг. 11 схематически представлено функционирование типовой сети; на фиг. 12 - маршрутизация в стандартной Омега-сети; на фиг. 13 - маршрутизация с тиражированием в Омега-сети; на фиг. 14 схематически представлен альтернативный вариант коммутатора; на фиг. 15 - график зависимости задержки от пропускной способности для потока с тиражированием с 20 буферами в сетях с копиями; с совместно используемой памятью и с закрепленной памятью; на фиг. 16 - график зависимости вероятности потери пакета в зависимости от размера буфера для сетей с копиями: с совместно используемой памятью и с закрепленной памятью; на фиг. 17 - график зависимости вероятности потери пакета в зависимости от заданной нагрузки для сетей с копиями: с закрепленной памятью и совместно используемой памятью.
Теперь будем ссылаться на чертежи, в которых близкие номера ссылок относятся к похожим или тем же самым частям на различных видах, и более подробно на фиг. 8, где дано схематическое представление пакетного коммутатора 10. Пакетный коммутатор 10 состоит из общей очереди совместно используемой памяти 12, имеющей M адресов хранения 14, по которым хранятся соответствующие пакеты, где M≥3 и целое число. Очередь 12 предпочтительно расслоена, как это показано на фиг. 5, и является FIFO ("первый вошел - первый вышел") очередью.
Пакетный коммутатор 10 также включает сеть представления данных 16, имеющую N входных портов 18 для приема пакетов и доставки соответствующих пакетов по требуемым адресам 14 в очередь 12, где N≥3 и целое число. Очередь 12 связана с сетью представления данных для приема пакетов. Кроме того, пакетный коммутатор 10 состоит из распределительной сети 20, имеющей J входных портов 22, где J≥3, для приема пакетов из очереди 12 и доставки их к требуемым выходным портам 24. Распределительная сеть 20 связана с очередью 12. Предпочтительно, чтобы сеть представления данных 16 являлась Омега-сетью. Предпочтительно также, чтобы и распределительная сеть 16 являлась Омега-сетью, но это к тому же не ограничивается. Предпочтительно, чтобы сеть представления данных 16 состояла из LogN ступеней.
Кроме того, пакетный коммутатор 10 включает средство для упорядочения пакетов, принимаемых сетью представления данных 16, таким образом, чтобы пакеты, принимаемые последовательно сетью представления данных, доставлялись сетью представления данных по последовательным адресам 14 в очередь 12. Предпочтительно, чтобы M=N=J, и предпочтительно, чтобы средство упорядочения включало схему выборки-сложения, связанную с очередью 12 таким образом, чтобы она параллельно распознавала свободные адреса для хранения пакетов, принимаемых сетью представленных данных 16, и заставляла принятые сетью представления данных 16 пакеты размещаться последовательно по свободным для хранения адресам 14, как показано на фиг. 6.
Рассматривая функционирование предпочтительного варианта реализации изобретения, допустим, что коммутатор, размерности N•N (N входов, N выходов), имеет распределительную сеть для блокировки (недопускающую блокировку пакетов). Допустим, что пакеты имеют фиксированную длину: такие "пакеты" в оборудовании для АТМ называются "ячейками". АТМ задает пакеты фиксированной длины, включающие 5 байт (октеты по терминологии АТМ) для заголовка и 48 октетов для полезной информационной загрузки. Допустим также, что все входные линии связи в сети сегментирования и синхронизации по скорости передачи данных равной 155 Мбайт/с (или даже большей скорости передачи данных, например 600 Мбайт/с). Результирующее время сегментирования пакета составляет примерно 2,8 мкс. Таким образом, структура коммутатора должна быть устроена так, чтобы он мог обрабатывать примерно 350000 пакетов в секунду от входных портов.
Архитектура коммутатора показана на фиг. 1. Архитектура включает очередь совместно используемой памяти и коммутирующую сеть. Пакеты могут прибывать на N входных портов. Коммутирующая сеть сортирует пакеты по соответствующим выходным портам, необходимым для каждого пакета. Не больше одного пакета назначается к каждому выходному порту. Дополнительные пакеты для каждого выходного порта возвращаются во входную очередь для последующей передачи. Очередь совместно используемой памяти хранит пакеты, которые должны быть направлены в коммутирующую сеть. Доступ к совместно используемой памяти осуществляется в виде FIFO, чтобы поддерживать порядок обработки пакетов.
Любой коммутатор с входной очередью без блокировки (J.Hue and E.Arthurs, "A broadband packet switch for integrated transport", IEEE Journal on Selected Areas in Communications, vol. SAC-5, pp. 1264-1273, Oct. 1987: B.Bingham and H.Bussey, "Reservation-based contention resolution mechanism for Batcher-Banyan packet switchs", Electronics Letters, v. 24, pp. 772-773, June 1988; J. Digan, G. Luderer and A. Vaidya, "Fast packet technology for future switches, "AT & T, Tech. Journal, v. 68, pp. 36-51. March/April, 1989) может быть использован в архитектуре коммутатора. Batcher-Banyan's сеть выбирается в качестве коммутирующей сети. Batcher-Banyan's сеть содержит Batcher's сортировщик (K. Batcher, "Sorting networks and their applications", in AFIPS Proc. of Sprint Joint Comput. Conf., 1968, pp. 307-314), за которым следует Banyans's сеть. Banyans's сеть не блокирует пакеты, когда пакеты на входных портах сортируются в соответствии с их адресами назначения и размещаются последовательно по входным портам. Таким образом пакеты, отсортированные Batcher's сортировщиком, проводятся через Banyan's сеть без блокировки. Однако блокировка все-таки может произойти, если два пакета имеют один и тот же адрес назначения. Пакеты с одним и тем же адресом назначения окажутся ближайшими друг к другу после их сортировки в Batcher's сети. Адреса назначения пакетов во входном порту не могут находиться в порядке возрастания или убывания. Следовательно, необходима схема для отправки только одного пакета из всех пакетов с одним и тем же адресом назначения. J.Hui и E. Arthurs (J.Hui and E.Arthurs, "A broadband packet switch for integrated transport", IEEE Journal on Selected Areas in Communications, vol. SAC-5, pp. 1264-1273. Oct. 1987) предложили архитектуру Batcher-Banyan's коммутатора с трехфазным алгоритмом, чтобы посылать только один пакет к каждому выходному порту. Трехфазный алгоритм используется для того, чтобы устранить конкуренцию, не вводя дополнительного оборудования. Трехфазный алгоритм сначала находит входные пакеты с одинаковыми адресами назначения и затем отбирает один пакет для каждого порта назначения. Таким образом, отобранные пакеты будут все иметь разные адреса назначения. В Hui's коммутаторе пакеты, которые не отобраны во время процедуры выбора, размещаются в выделенных участках памяти. Однако в рассматриваемой архитектуре коммутатора эти пакеты заводятся обратно в очередь совместно используемой памяти через Омега-сеть. Детали функционирования очереди совместно используемой памяти описаны ниже.
Этот раздел касается устройства входной очереди в совместно используемой памяти. Описание входной очереди иллюстрируется на фиг. 2а. Очередь состоит из совместно используемой памяти и двух указателей памяти. Указатели "Верх" и "Низ" содержат адреса пришедшего раньше всех в память пакета и ближайшего имеющегося элемента соответственно. Очередь должна содействовать одновременному вводу вплоть до N входных пакетов, одновременному выводу вплоть до N пакетов в коммутирующую сеть и одновременному возврату обратно вплоть до N-1 заблокированных пакетов из коммутирующей сети. На фиг. 2б P=3 входных пакета вводятся в нижнюю часть очереди и указатель "Низ" последовательно поднимается на P шагов. На фиг. 3а N пришедших раньше всех в очередь пакетов удаляются из очереди для маршрутизации в коммутирующей сети. Верхний указатель поднимается на N шагов. На фиг. 3б F = 2 пакета возвращаются во входную очередь из-за их блокировки в выходных портах. Чтобы не нарушать порядок входных пакетов возвращаемые пакеты должны добавляться в верхнюю часть очереди. Верхний указатель последовательно снижается на F шагов.
Как иллюстрация к вышесказанному, описание входной пакетной очереди содержит три функциональных требования:
Входные пакеты:
Пакеты поступают на P≤N входных портов и добавляются в нижнюю часть очереди. При этом должны быть выполнены следующие функции:
1. Генерирование адресов: для каждого входного пакета должен быть генерирован индивидуальный адрес в совместно используемой памяти. Адреса должны быть индивидуальными и последовательными от "низ" до "низ" +P. Положение указателя "низ" меняется на "низ" +P.
2. Организация пакетов очереди: все входные пакеты должны одновременно храниться в совместно используемой памяти.
Выходные пакеты:
N верхних пакетов одновременно удаляются из входной очереди.
Положение указателя "верх" меняется на "верх" +N
Генерирование адресов для выходных пакетов подразумевается и может быть определено путем использования указателя памяти "верх".
Пакеты обратной связи:
Пакеты обратной связи поступают на F<N каналов и добавляются в верх входной очереди. Как и в случае с входными пакетами должны выполняться следующие функции:
1. Генерирование адресов: Для каждого пакета обратной связи в совместно используемой памяти должен быть сгенерирован индивидуальный адрес. Адреса должны быть индивидуальными и последовательными от "верх" - F до "верх". Положение указателя "верх" меняется на "верх" - F.
2. Организация пакетной очереди: Все пакеты обратной связи должны одновременно храниться в совместно используемой памяти.
Устройство буфера памяти и его интерфейса представлено соответственно во входном и выходном функциональном описаниях. Ключевое требование к устройству очереди состоит в том, что элементы очереди должны храниться в памяти последовательно без пустых промежутков между пакетами. Это требование форсирует связь из заблокированных выходных пакетов, которые должны повторно вводиться по последовательным адресам в верх очереди. Последовательное хранение элементов памяти окажет решающее влияние как на емкость памяти, так и на результаты функционирования, включая пропускную способность.
Чтобы облегчить одновременный вывод N пакетов, память расслаивания на N блоков памяти. Каждый блок памяти подсоединен к порту коммутирующей сети. Благодаря тому, что память расслоена, любой из N последовательных адресов в памяти размещается в собственном блоке памяти и может быть одновременно доступен коммутирующей сети. Таким образом гарантируется одновременный выход в коммутирующей сети.
Одновременный ввод вплоть до N входных пакетов должен быть совершен входной очередью. Ввод очереди требует двух шагов: генерирования адресов и организацию пакетной очереди. Каждый пакет, который требуется ввести в очередь, должен получить собственный адрес в совместно используемой памяти. Кроме того, адреса должны быть последовательными, чтобы гарантировать правильную структуру очереди. После генерирования адресов для хранения пакетов требуется одновременный доступ к очереди. Одновременный доступ может быть обеспечен коммутирующей Омега-сетью. B H. Kim and A. Leon-Garcia, "Non-blocking property of reverse banyan network", accepted for publication in the IEEE trans. in Communications, May 1989 проверено, что одновременный доступ достигается в Омега-сети, если входы упорядочены (последовательны) и выходы последовательны (упорядочены). Так как очередь последовательная, одновременный доступ может иметь место, если генерирование адресов доставляет упорядоченные адреса к входам. Схема генерирования адресов требуется для генерирования правильных адресов на выходных портах.
Схема для генерирования адресов, данная в (G. Almasi and A. Gottlib, Highly Parallel Computing - Redwood City, CA.: The Benjamin-Cummings - Publishing Company, Inc., 1989), допускает генерирование индивидуальных последовательных адресов. В схеме используется операция выборки-сложения с памятью. Операция выборки-сложения осуществляется в одном цикле работы памяти: считывается адрес памяти и одновременно запоминается предыдущее значение плюс смешение по отношению к тому же адресу. Выборка-сложение 3, записываемая как выборка-сложение (3), на адресе ячейки памяти, содержащей значение 9, возвращает 9 и записывается в память 12. Операция сложения-выборки может быть использована для генерирования собственных адресов в последовательной форме. Рассмотрим три входных порта, для которых требуются адреса ближайших имеющихся элементов в памяти очереди. Эти адреса могут быть определены портами путем последовательного выполнения выборки-сложения на нижнем указателе. Хотя эта процедура и обеспечивает правильное функционирование, генерирование адресов осуществляется последовательно, что является "узким местом" системы. Доступ с одновременной выборкой-сложением к адресу ячейки памяти обеспечивается в (A. Gottlib, R. Grishman, C. Kruskal, K. McAuliffe, L. Rudolf and M. Shir, - "The new ultracomputer - designing an mimd - shared memory parallel computer", - IEEE Trans. on Computer pp. 175 - 189, February 1983) путем объединения операций выборки-сложения на каждой ступени Омега-сети. Рассмотрим фиг. 4. Порты 0, 1 и 3 пытаются одновременно выполнить операции выборки-сложения на нижнем указателе. В левом верхнем коммутаторе Омега-сети объединяются операции выборки-сложения в выборку-сложение (2) и записываются al соответственно в наивысший вход сложения-выборки. Объединение происходит на нижнем правом коммутаторе, в результате чего происходит операция выборки-сложения (3) и запись 2 в наивысший вход. В результате выполнения операции сложения-выборки добавляется тройка к нижнему указателю, а 9 возвращается к нижнему правому коммутатору. Коммутатор разделяет на части выборку-сложение (3), возвращая 9 по ее верхнему обратному пути, добавляя 9 к хранимой 2 и возвращая 11 по его нижнему обратному пути. Такое же разделение происходит в верхнем левом коммутаторе, в результате чего происходит одновременное генерирование упорядоченных адресов на портах 0, 1 и 3. В адресах поддерживается порядок, так как более низкий адрес всегда возвращается к адресу более низкого входного порта. Формальное описание комбинированной операции выборки-сложения дано в A. Gottlib, R. Grishman, C. Kruskal, K. McAuliffe, - L. Rudolf and M. Shir, "Thenyu ultracomputer-designing an mimd shared memory - parallel computer", IEEE Trans. on - Computer pp. 175 - 189, February 1983, а устройство компонентов комбинированного коммутатора дано в S. Diskey, R.Kenner, M. Shir and J. Solworth, "A vilsi combining network for the new ultracomputer", in Proc: of the IEEE International Conference on Computer Design, IEEE, at 1985.
Входные пакеты и пакеты обратной связи вводятся в буфер памяти путем использования для генерирования адресов одновременных операций выборки-сложения и затем одновременного доступа к памяти. Адреса входных пакетов генерируются путем доступа к нижнему указателю с выборкой-сложением (1) на каждом входном порте, принимающем пакет. Адреса пакетов обратной связи генерируются путем доступа к верхнему указателю с выборкой-сложением (-1) на каждом порте обратной связи, принимающем пакет. Одновременный доступ к памяти в Омега-сети гарантируется благодаря тому, что пакеты, поступающие на упорядоченные входы, посылаются к последовательно упорядоченным выходам.
Для пакетов обратной связи требуется два прохода через Омега-сеть из-за возможного сворачивания адресов. Как показано в H.Kim and A.Leon-Garcia, "Non-blocking property of reverse banyan network", accepted for publication in the IEEE Trans. on Communications, March 1991, incorporated by reference, Омега-сеть не блокирует потоки с последовательно упорядоченными выходами и упорядоченными входами, что не приводит к сворачиванию пакетов от нижнего входного порта к верхнему порту. Таки как верхний указатель может указывать на произвольный блок памяти, возможно сворачивание на входе канала обратной связи. Чтобы разрешить эту проблему, пакеты обратной связи, передаются за два прохода. Первый проход включает несвернутые входы от верхнего указателя к нижнему порту. Второй проход включает свернутые входы от верхнего порта к верхнему указателю -1.
Фиг. 5 обеспечивает критическую структуру пакетной очереди. Очередь представляет собой совместно используемую расслоенную память, состоящую из N расслоенных блоков. Каждый блок памяти соединен с одним входным портом коммутирующей сети и одним выходным портом Омега-сети. N входов Омега-сети мультиплексированы во времени между входными портами и портами обратной связи, как показано, с помощью мультиплексоров 2:1. Возможны схемы альтернативного мультиплексирования с Омега-сетью, продублированной для каждого набора входов.
Рассмотрим цикл коммутации, чтобы проиллюстрировать работу пакетной очереди. Требуется очередь, чтобы ввести до N входных пакетов и до N-1 пакетов обратной связи и вывести до N пакетов в коммутирующую сеть. Критическим с точки зрения задержки является маршрут из очереди выходных пакетов через коммутирующую сеть и возвращение заблокированных пакетов на входы обратной связи. Для содействия повышению пропускной способности входные пакеты поступают одновременно с распространением выходных пакетов через коммутирующую сеть. С целью обсуждения цикл коммутации иллюстрируется двумя временными фазами. Функционирование фазы 1 охватывает входные пакеты и распределение коммутирующей сети, а фазы 2 - пакеты обратной связи.
Перед фазой 1 память очереди содержит пакеты по местам с 3 до 8 (как показано на фиг. 5). Верхние 4 пакета удаляются из очереди и направляются через коммутирующую сеть. Как показано на фиг. 6, верхний указатель повышается на 4 до 7 и указывает на ближайший, раньше всех пришедший пакет в очереди. Одновременно принимаются входные пакеты через Омега-сеть. На фиг. 6 пакеты принимаются с портов 0, 1 и 3. Каждый из портов выполняет выборку-сложение (1) по нижнему указателю, чтобы одновременно генерировать адреса в пакетную очередь. Нижний указатель поднимается на 3 от 9 до 12. Порты получают адреса 9, 10 и 11, что гарантирует последовательное упорядочение входов. Таким образом все входные пакеты могут быть переданы через Омега-сеть. Благодаря большей задержке в Batcher's сети входы могут храниться до прибытия пакетов обратной связи.
Фаза 2 начинается после того, как Batcher's сеть определит блокирующиеся пакеты и укажет пакеты, которые должны быть возвращены в пакетную очередь. Заблокированные пакеты возвращаются из блоков памяти 1 и 3 на фиг. 7. Пакеты обратной связи возвращаются на порты 1 и 3 Омега-сети и одновременно выполняют выборку-сложение (-1) на верхнем указателе. Верхний указатель снижается на 2 от 7 до 5. Порты получают адреса 5 и 6, и как ранее, могут быть одновременно допущены к пакетной очереди. В завершение цикла три пакета добавляются к пакетной очереди, два пакета успешно передаются и память очереди будет содержать пакеты на местах с 5 до 15. Окончательная архитектура без группового режима представлена на фиг. 8.
Архитектура сети с совместно используемой памятью с копиями для режима тиражирования показана на фиг. 9. Архитектура включает в себя две коммутирующие сети и две очереди совместно используемой памяти. Первая совместно используемая память содержит очередь 12 из всех входных пакетов. Вторая совместно используемая память содержит очередь 58 из всех скопированных пакетов. Коммутирующие сети предпочтительно включают две Омега-сети. Омега-сети передают пакеты между соответствующими входными портами и двумя совместно используемыми памятями. Выходная сеть 40 передает пакеты из выходной очереди для тиражирования 12 к выходным портам 24 и может быть как сетью с блокировкой, так и без блокировки. Типовой входной пакет поступает на входной порт 18, хранится во входной очереди совместно используемой памяти 12, передается в выходную очередь совместно используемой памяти для тиражирования 38 и затем выводится через коммутатор без блокировки 42. Входной пакет, предназначенный к тиражированию, сначала хранится в очереди совместно используемой памяти 12. Отдельный пакет, предназначенный для тиражирования, затем копируется по разу для каждого группового выхода, и каждая копия передается в выходную очередь для тиражирования 38. Скопированные пакеты получают собственные адреса назначения путем поиска по таблице из адресного транслятора и затем посылаются в выходную сеть в соответствии с их адресами назначения.
Омега-сеть имеет 0 (Nlog2N) коммутирующих элементов. Выходная сеть 40 может быть любой коммутирующей сетью без блокирования такой, как матричный, либо Batcher-Banyan's коммутаторы (J.Hui and E.Arthurs, "A broadband packet switch for integrated transport", IEEE Journal on Selected Areas in Communications, vol. SAC-5, pp. 1264-1273. Oct. 1987) или коммутирующей сетью с блокировкой, такой, как Омега-Сеть. Если используется выходная сеть с блокировкой, дополнительные пакеты поступают по обратной связи в групповую очередь благодаря внутренней блокировке. Каждая очередь состоит из совместно используемой расслоенной памяти, включающей N расслоенных адресов, по которым хранятся пакеты. Каждый адрес памяти связан с единственными входным и выходным портами коммутирующей сети. Структуры очереди реализованы в виде памятей с верхним и нижним указателями. Так как памяти расслоены на N путей, любые N элементов последовательной очереди размещаются по своим адресам в последовательно упорядоченной памяти, как показано на фиг. 10. Это свойство используется для недопущения блокировки тиражируемых пакетов. Фиг. 10 раскрывает критические структуры коммутатора и связи между ними.
Типовая работа сети иллюстрируется фиг. 11. Два пакета размещены в коммутаторе 10. Два других пакета группируются из входной очереди 12 с тремя пакетами в выходной очереди для тиражирования 38. Три пакета выводятся, а один возвращается обратно благодаря конструкции в выходной коммутирующей сети. В общем случае, при работе коммутатора должны выполняться следующие функции: 1. ввод пакета; тиражирование; вывод пакета.
Ввод пакетов представлен в первой Омега-сети 42 коммутатора 10. Пакеты поступают на входные порты 18 коммутатора и одновременно им называется маршрут в низ входной пакетной очереди 12. Этим пакетам может быть назначен маршрут с одновременным распределенным управлением путем использования операции "комбинированной выборки-сложения" в Омега-сети и расслоенной совместно используемой памяти. Это тем более требует отсутствия блокировки при размещении входных пакетов во входной очереди совместно используемой памяти 12. Пакеты удаляются из верхней части входной очереди для тиражирования во второй Омега-сети 14.
Тиражирование представлено во второй Омега-сети 44 коммутатора 10. Для тиражирования пакетов каждый пакет из входной очереди 12 многократно копируется во второй Омега-сети 44 для каждого выходного порта тиражируемой совокупности. Например, если пакет должен тиражироваться к трем портам, тогда такой пакет потребует одно место во входной очереди 12 и три места в выходной очереди для тиражирования 38. Как и в случае с алгоритмом для входных пакетов, алгоритм для тиражирования допускает одновременную обработку и выполняется под распределенным управлением. Максимальное количество пакетов, удаляемых из входной очереди и подлежащих тиражированию, таково, что количество скопированных пакетов не превышает количества выходных портов Омега-сети. Выходные пакеты из второй Омега-сети добавляются тогда в низ выходной очереди для тиражирования.
Пакетный вывод представлен в последней коммутирующей сети 40 коммутатора 10. Каждый элемент выходной очереди 38 соответствует пакету, предназначенному для единственного выходного порта. Пакеты удаляются из верха очереди для назначения маршрута к финальным выходным портам. Столько, сколько возможно пакетов удаляется из очереди вплоть до количества входных портов коммутирующей сети. Такие коммутирующие сети, как матричный коммутатор или Batcher Banyan's коммутатор, передают пакеты из выходной очереди для тиражирования 38 к выходным портам. Если имеет место выходная блокировка, первый пакет, предназначенный для данного выходного порта, передается на этот порт, а все другие пакеты отмечаются как заблокированные. Заблокированные пакеты возвращаются во вторую Омега-сеть 44 по каналам обратной связи 50 из выходной очереди для тиражирования 38.
Пакет обратной связи представлен во второй коммутирующей сети 44. Заблокированные пакеты из выходной коммутирующей сети 40 распознаются и возвращаются во вторую Омега-сеть 44 по каналам обратной связи 30. Одновременно заблокированным пакетом назначается маршрут к верху выходной очереди для тиражирования 33, чтобы сохранить последовательность пакетов. Алгоритм, требуемый для выполнения пакетной обратной связи, идентичен алгоритму, требуемому для пакетного ввода. Функционирование входной, выходной сетей и сети обратной связи идентично функционированию пакетного коммутатора без тиражирования. Процесс тиражирования представлен во второй Омега-сети 44 переключателя 10. Верхние элементы входной очереди 12 удаляются, копируются для каждого необходимого выхода, где требуется тиражирование, и хранятся на последовательных вводах в низу выходной очереди для тиражирования 38. Благодаря расслоению памяти все входные и выходные пакеты хранятся по различным и последовательным адресам памяти 18. Функция тиражирования выполняется путем видоизменения стандартной процедуры маршрутизации, выполняемой в Омега-сети.
Пример стандартной процедуры маршрутизации, использованной в Омега-сети, показан на фиг. 12. Для N входов и N выходов, адресованных от 0 до N - 1, Омега-сеть содержит Iog2N ступеней коммутирующих элементов 2х2. Маршрутизация осуществляется для пакета, входящего в любой порт, путем использования требуемого выходного адреса этого пакета. Каждая ступень Омега-сети ответственна за один бит адреса назначения. Выходной адрес пакета подается на коммутирующий элемент 2х2 первой ступени Омега-сети. Самый старший бит выходного адреса удаляется и оставшийся адрес направляется к выходу коммутирующего элемента 2х2, соответствующему удаленному адресному биту. Например, на фиг. 12 пакет, предназначенный для выхода 6 Омега-сети, входит во вход 3. Адрес "110" передается к коммутатору 2х2, подсоединенному к входу 3. Этот коммутатор удаляет самый старший бит "1" и направляет адрес "10" к своему выходу "1". Эта процедура повторяется коммутирующими элементами в последовательных ступенях Омега-сети, пока прибывают пакеты по своему назначению. Используя такую схему маршрутизации, пакет правильно поступит на выход 6 от любого входа Омега-сети.
Чтобы облегчить маршрутизацию для тиражирования, в коммутаторе один вход второй Омега-сети 44 может передавать пакет на множество выходов. В общем случае тиражирование одного входного пакета на множество выходов Омега-сети является сложной проблемой. Общая проблема тиражирования упрощается в данной архитектуре таким образом, что оно происходит только от последовательно упорядоченных отдельных входов к последовательно упорядоченным выходам. Вторая Омега-сеть 44 передает введенные данные из верха входной очереди на последовательные входы низа выходной очереди для тиражирования 38. Благодаря расслоению памяти последовательно вводимые данные в выходную очередь для тиражирования размещаются в последовательно упорядоченных блоках памяти, а значит и в последовательно упорядоченных входах Омега-сети.
Упрощенная проблема маршрутизации при тиражировании данных от одного к множеству выходов решается путем небольшого усовершенствования Омега-сети. Вход, требующий тиражирования, должен быть передан в диапазон последовательно упорядоченных выходных адресов. Так как этот диапазон последовательный, то он может быть описан двумя числами: "верхним" и "нижним", в соответствии с верхним и нижним адресами диапазона. Допустим также, что "нижний" < "верхнего". На практике "нижний" может быть больше "верхнего" в том случае, когда представляется диапазон, который начинается с высокого адреса, продолжается еще выше и возвращается к нижнему адресу. Новая процедура маршрутизации подобна процедуре маршрутизации в стандартной Омега-сети за исключением того, что вместо обращения с одним выходным адресом приходится обращаться с парой ("нижний", "верхний") адресов. Коммутирующий элемент 2х2 получает пару адресов и удаляет самый старший бит в каждом. Если удаленные биты одинаковые, оставшиеся биты "верхнего" и "нижнего" направляются, как и ранее, к выходу коммутирующего элемента 2х2 в соответствии со значением удаленного адресного бита. Если удаленные биты разные, то самый старший бит "нижнего" 0, а самый старший бит "верхнего" 1. В этом случае часть диапазона выходных адресов должна быть направлена к выходу "0" коммутирующего элемента 2х2, а оставшаяся часть - к выходу "1". Пакет будет направлен к обоим выходам. Чтобы облегчить правильную маршрутизацию, генерируются адресные пары ("нижний, 11...1) и (00...0, "верхний") и направляются к портам "0" и "1" соответственно. Используя эту схему маршрутизации, пакетам будут назначаться правильные маршруты ко всем последовательно упорядоченным выходным адресам от нижнего и верхнего.
Пример процедуры маршрутизации при тиражировании представлен на фиг. 13. Один пакет прибывает на вход 3 для направления и тиражирования к входам с 3 по 6. Адресная пара "(011, 110)" передается на коммутатор 2х2, соединенный с входом 3. Этот коммутатор удаляет самые старшие биты "0" и "1" из "верхнего" и "нижнего". Так как самые старшие биты различаются, коммутирующий элемент передает пришедший пакет к обоим своим выходам. Для правильной маршрутизации новая адресная пара "(11, 11)" (("нижний", 11)) направляется к выходу "0", а "(00, 10)" ((00, "верхний")) - к выходу "1". Рассмотрим второй коммутирующий элемент ступени 2. Элемент получает адресную пару "(11, 11)". Самые старшие биты адресной пары одинаковы, оставшаяся пара "(1, 1)" направляется к выходу "1". В завершение процедуры маршрутизации входу 3 назначается правильный маршрут к последовательным выходам с 3 по 6. Такая процедура маршрутизации может быть использована для маршрутизации в стандартной Омега-сети с одним назначением путем установки "верхний" = "нижнему".
Представленная процедура маршрутизации при тиражировании облегчает маршрутизацию одного входа Омега-сети к последовательно упорядоченным выходам. Более того, процедура маршрутизации позволяет каждому из нескольких последовательно упорядоченных портов одновременно связываться маршрутом с множеством последовательно упорядоченных выходов без возврата данных. Маршруты, требуемые для любого входа, не будут блокированы и не будут влиять на маршруты для других входов. Похожая на аналогичную в сети обратной связи двухфазная схема используется, чтобы разрешить свернутые выходы.
Пропускная способность может быть увеличена путем установки во входную очередь 12 генератора числа копий следующим образом. Вместо того, чтобы отбрасывать входные пакеты, подлежащие копированию, когда тиражированный пакет имеет более N пакетов, вплоть до N пакетов могут быть скопированы и число копий в тиражированном пакете уменьшится до числа пакетов, которые не могут быть переданы в первой попытке. Схема для выявления пакетов, которые должны быть посланы через вторую Омега-сеть, реализуется просто путем просмотра адресов, получаемых от операции выборки-сложения, и отбора тех из них, у которых номер меньше N. Пусть Ci - количество копий для i-го пакета во входной очереди 12 от адреса верхнего указателя. K-й пакет, удовлетворяющий условию
может быть найден из операции выборки-сложения. Как только K-й пакет находится,
копий этого пакета будет скопировано через вторую Омега-сеть и число копий K-го пакета изменится до
K-й пакет с новым числом копий остается во входной очереди совместно используемой памяти, чтобы быть посланными в следующем временном такте. Верхний указатель показывает положение K-го пакета в очереди совместно используемой памяти.
Подходящая реализация архитектуры сети с копиями 15 представлена на фиг. 14. Сеть с копиями создана для выполнения пакетных циклов. Пакеты прибывают на входные порты 18 коммутатора 11 с фиксированной частотой, которая определяется максимальной скоростью передачи данных. Минимальный интервал времени между прибытиями (пакетов) определяется как цикл коммутации. Коммутатор 15 должен выполнить все вышеописанные функции в одном цикле. Это может быть выполнено с помощью двух Омега-сетей так, как описано выше, либо с помощью одной Омега-сети 52, которая может передавать данные со скоростью, в четыре раза большей скорости прибытия пакетов. Одна скоростная Омега-сеть является подходящей благодаря ее доступности.
Архитектура коммутатора 15 содержит N процессоров 54, по одному на каждый входной и выходной порты коммутатора. Каждый процессор 54 выполняет все функции, необходимые на каждой степени коммутации. Все очереди совместно используемой памяти реализованы с помощью памяти 56, локальной по отношению к каждому из процессоров 54, определяющей N расслоенных блоков общей памяти. Омега-сеть 52 должна выполнять следующие четыре функции за один цикл переключения: маршрутизацию входного пакета, тиражирование, передачу по обратной связи заблокированных пакетов для входной и для выходной очереди тиражированных пакетов. Как показано, эти функции находятся под распределенным управлением с помощью распределенных процессоров. Входные 18 и выходные порты 24 реализованы на двоичных устройствах 58, которые могут посылать и принимать пакеты с требуемой скоростью передачи и посылать пакеты в память процессора 56.
Детальный анализ функционирования коммутатора следует ниже. В качестве примера моделируется поток с тиражированием пакетов с использованием геометрического распределения промежутков: количество пакетных копий описывается геометрическим распределением. Считаем нагрузку потока на сеть однородной с равной вероятностью поступления пакета на любой из выходных портов 24.
Пусть P - заданная нагрузка и q = (Y1 = y) - вероятность того, что число копий, требуемых приходящим пакетом, равно y. Пусть P(X1 = x) - вероятность того, что число сгенерированных копий равно x. Значит
Таким образом "эффективная заданная нагрузка" = pE(Y1).
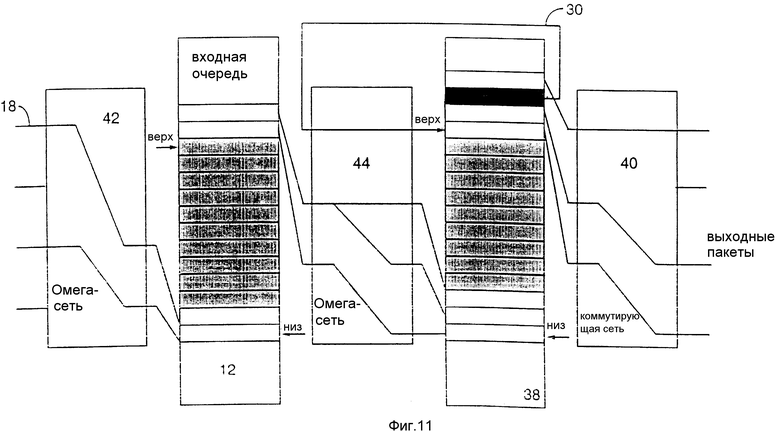
Если принять, что Y1 имеет усеченное геометрическое распределение с параметром q, то тогда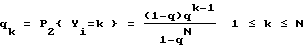
где
N - максимально допустимое количество копий. Так как приходящий пакет будет тиражироваться максимум во все выходные очереди 38, N будет таким же, как и размер сети (т.е. N = 64 для сетки 64Х64).
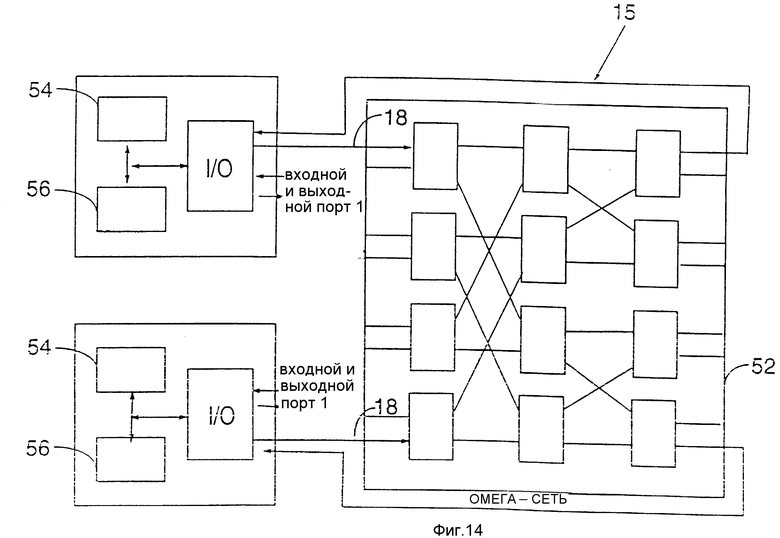
Тогда среднее число копий для приходящего пакета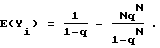
Фигура показывает зависимость задержки (прохождения пакетов) от пропускной способности для различного среднего числа копий для сети с совместно используемой памятью 11 и для сети с копиями и с закрепленной памятью 15. Чтобы сеть копий работала с приемлемой задержкой, заданную нагрузку следует уменьшить до соответственно 0, 1, 0,3 и 0,4 от 0,586 (максимальная пропускная способность коммутатора с входной очередью 12) для тиражированного потока со средним числом копий соответственно 2, 5 и 7. Это существенное снижение по сравнению с максимальной пропускной способностью 0,58 для двухточечных потоков. Однако, если буферы используются совместно, максимальная пропускная способность может быть установлена на том же уровне, что и для двухточечных потоков, как это показано на чертеже. Более того, задержка остается близкой к минимуму вплоть до точки насыщения. Поток с большим числом копий имеет меньшую задержку и большую пропускную способность. Так как заданная нагрузка остается постоянной, когда число копий увеличивается, скорость прибытия тиражированного потока уменьшается и таким образом возрастает пропускная способность и уменьшается задержка.
На фиг. 16 показана зависимость вероятности потери пакета от размера буфера для сетей с копиями: с закрепленной 15 и совместно используемой 11 памятями. Вероятность потери пакета установлена для нагрузки 0,58, близкой к максимуму пропускной способности для двухточечных потоков. Как ожидалось, сеть с совместно используемой памятью 11 требует на несколько порядков меньшую величину буфера, чем сеть с копиями с закрепленной памятью 15. Например, для совместно используемой памяти требуется менее 5 буферов, чтобы поддерживать вероятность потери пакета на уровне 10, в то время как для сети копий с закрепленной памятью потребуется на несколько порядков большая величина буферов, чтобы уменьшить разрыв между ними.
На фиг. 17 показана зависимость вероятности потери пакета от заданной нагрузки для сетей с копиями с закрепленной и с совместно используемой памятями с размерами буфера 8 и 16. Сеть с совместно используемой памятью могла бы работать с нагрузкой вплоть до 0,6 и очень низкой вероятностью потери пакета (порядка 10). Однако сеть с закрепленной памятью могла бы держать более низкую нагрузку (т.е. 0,2 - 0,3), если требовалась бы такая же вероятность потери пакета. Таким образом, когда требуется одна и та же вероятность потери пакета, сеть с копиями и совместно используемой памятью имеет существенно большую пропускную способность, чем сеть с копиями и закрепленной памятью.
Хотя изобретение с целью иллюстрации было подробно описано в предыдущих вариантах, следует учитывать, что эти подробности приведены только с этой целью и что специалисты могут вносить различные изменения, не выходя из сути и объема изобретения, за исключением тех случаев, когда эти изменения описаны в формуле изобретения.












Изобретение относится к пакетному коммутатору, включающему общую очередь совместно используемой памяти, имеющей М адресов хранения, по которым хранятся соответствующие адреса, где M ≥ 3. Коммутатор содержит также сеть представления данных, имеющую N входных портов для приема пакетов и доставки их по требуемым адресам в очередь, где N ≥ 3. Очередь связана с сетью представления данных для приема пакетов. Коммутатор включает также распределительную сеть, имеющую J входных портов, где J ≥ 1, для приема пакетов из очереди и доставки их к требуемым выходным портам. Распределительная сеть связана с очередью. Также имеется средство для упорядочения пакетов, принимаемых сетью представления данных, таким образом, что пакеты, последовательно принимаемые сетью представления данных, доставляются по соответствующим адресам в очередь. 6 с. и 30 з.п.ф-лы, 17 ил.
| M.G.Hiuchi and M.J.Karol | |||
| Quening in High Performens Packet Smitching | |||
| IE EE Journal on Selected Areal in Conmunications | |||
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| Механическая топочная решетка с наклонными частью подвижными, частью неподвижными колосниковыми элементами | 1917 |
|
SU1988A1 |
| I.Hul and Arthurs | |||
| A brodband pacret Switch for integrated transport | |||
| IEEE Journal on Selected Areas IN.Conmunications, p.1264 - 1273, oct.198 7 | |||
| K.Batcher | |||
| Sorting networks and their applications | |||
| AFIPS Prog | |||
| of Spri nt Join Comput | |||
| Conf | |||
| Приспособление для выпечки формового хлеба в механических печах с выдвижным подом без смазки форм жировым веществом | 1921 |
|
SU307A1 |
