Область техники, к которой относится изобретение
Изобретение относится к кодированию по меньшей мере части аудиосигнала.
Предшествующий уровень техники
Среди специалистов широко известно кодирование с линейным предсказанием (LPC) для представления спектрального состава сигнала. Сверх того, было представлено много эффективных схем квантования для таких систем с линейным предсказанием, например, логарифмические отношения площадей (Log Area Ratios) [1], Коэффициенты Отражения (Reflection Coefficients) [2] и Представления Линейного Спектра (Line Spectral Representations), такие как Пары Линейного Спектра (Line Spectral Pairs) или Частоты Линейного Спектра (Line Spectral Freguencies) [3,4,5].
Не вдаваясь в излишние подробности того, как коэффициенты фильтра преобразуются в представление линейного спектра (более детальное описание приведено в [6,7,8,9,10]), результат состоит в том, что идеальный LPC-фильтр М-го порядка H(z) преобразуется в M частот, часто называемых Частотами Линейного Спектра (LSF). Эти частоты уникально представляют фильтр H(z). В качестве примера см. фиг.1. Для лучшего понимания следует заметить, что частоты линейного спектра, показанные на фиг.1 в виде вертикальных линий по направлению к амплитудной характеристике фильтра, являются не более чем частотами, и поэтому не содержат в себе какой бы то ни было информации об амплитуде.
Сущность изобретения
Задачей изобретения является обеспечение усовершенствованного кодирования по меньшей мере части аудиосигнала. Для решения этой задачи согласно изобретению предоставляется способ кодирования, кодер, кодированный аудиосигнал, носитель информации, способ декодирования, декодер, передатчик, приемник и систему, охарактеризованные в независимых пунктах формулы изобретения. Предпочтительные варианты воплощения охарактеризованы в зависимых пунктах.
В соответствии с первым аспектом изобретения, по меньшей мере часть аудиосигнала кодируют с целью получения кодированного сигнала, при этом кодирование, включает в себя кодирование с предсказанием в отношении упомянутой по меньшей мере части аудиосигнала с целью получения коэффициентов предсказания, которые представляют временные характеристики, такие как временная огибающая, упомянутой по меньшей мере части аудиосигнала, преобразование коэффициентов предсказания в набор времен, представляющих коэффициенты предсказания, и включение этого набора времен в кодированный сигнал. Необходимо заметить, что эти времена без какой-либо информации об амплитуде являются достаточными для представления коэффициентов предсказания.
Хотя временная форма сигнала или его компоненты могут быть также непосредственно закодированы в виде набора амплитуд или значений усиления, согласно пониманию изобретателей, более высокое качество может быть получено путем использования кодирования с предсказанием для получения коэффициентов предсказания, которые представляют временные характеристики, такие как временная огибающая, и преобразование этих коэффициентов предсказания в набор времен. Более высокое качество может быть достигнуто вследствие того, что локально (там где нужно) может быть получено разрешение по времени более высокое по сравнению с методиками фиксированной временной шкалы. Кодирование с предсказанием может быть реализовано с использованием амплитудной характеристики LPC-фильтра для представления временной огибающей.
Также, согласно пониманию изобретателей, использование, главным образом, производной во временной области или эквивалента представления линейного спектра является преимущественным при кодировании таких коэффициентов предсказания, представляющих временные огибающие, потому что с помощью данного способа времена или моменты времени являются хорошо определенными, что делает их более подходящими для дальнейшего кодирования. Таким образом, с помощью данного аспекта изобретения достигается эффективное кодирование временных параметров по меньшей мере части аудиосигнала, предназначенное для достижения лучшей степени сжатия по меньшей мере части аудиосигнала.
Варианты воплощения изобретения могут быть интерпретированы как использование LPC-спектра для описания временной огибающей вместо спектральной огибающей, и то, что было временем в случае спектральной огибающей, теперь является частотой, и наоборот, как показано в нижней части фиг.2. Это означает, что использование представления линейного спектра теперь приводит к набору времен или моментов времени вместо частот. Следует заметить, что в данном подходе времена не являются фиксированными по предопределенным интервалам на временной оси, но сами эти времена представляют коэффициенты предсказания.
Изобретатели полагали, что на использовании анализа/синтеза перекрывающихся кадров в отношении временной огибающей можно использовать избыточность представления линейного спектра области перекрытия. Варианты воплощения изобретения используют эту избыточность выгодным образом.
Изобретение и его варианты воплощения являются особенно преимущественными для кодирования временной огибающей шумовой составляющей в аудиосигнале в схемах параметрического аудиокодирования, таких как те, что раскрыты в WO01/69593-A1. В такой схеме параметрического аудиокодирования аудиосигнал может быть разделен на переходные составляющие сигнала, синусоидальные составляющие сигнала и шумовые составляющие. Параметрами, представляющими синусоидальные составляющие, могут быть амплитуда, частота и фаза. Для переходных составляющих дополнение этих параметров описанием огибающей является эффективным представлением.
Необходимо заметить, что изобретение и варианты его воплощения могут быть применены для всей соответствующей полосы частот аудиосигнала или его компонента, но также и для меньшей полосы частот.
Эти и другие аспекты изобретения станут ясны при рассмотрении со ссылкой на сопроводительные чертежи
Перечень чертежей
На чертежах:
Фиг.1 - пример LPC-спектра с 8-ю полюсами с соответствующими 8-ю частотами линейного спектра согласно предшествующему уровню техники;
Фиг.2 - (верхняя часть) использования LPC таким образом, что H(z) представляет частотный спектр, (нижняя часть) использование LPC таким образом, что H(z) представляет временную огибающую;
Фиг.3 - схематический вид иллюстративного применения окон анализа/синтеза;
Фиг.4 - иллюстративная последовательность LSF времен для двух последовательных кадров;
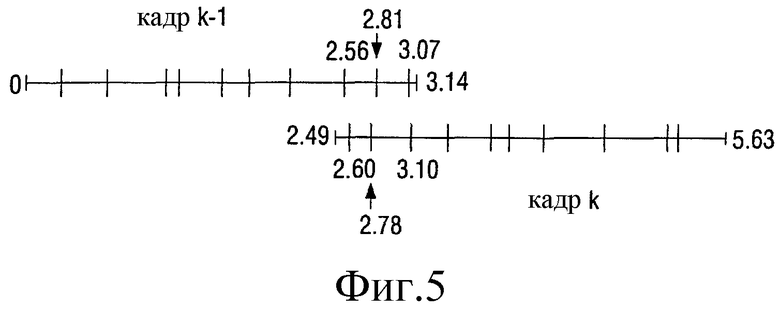
Фиг.5 - согласование LSF времен кадра k относительно предыдущего кадра k-1;
Фиг.6 - весовые функции в качестве функции, используемой в области перекрытия; и
Фиг.7 - система, соответствующая варианту воплощения изобретения.
Чертежи показывают только те элементы, которые необходимы для понимая вариантов воплощения изобретения.
Подробное описание предпочтительных вариантов осуществления
Несмотря на то, что представленное ниже описание ориентировано на использование LPC-фильтра и расчет производных во временной области или эквивалентов частот LSF, изобретение также применимо для других фильтров и представлений, которые попадают в рамки объема, определяемого формулой изобретения.
Фиг.2 показывает, как фильтр с предсказанием, такой как LPC-фильтр, может быть использован для описания временной огибающей аудиосигнала или его компонента. Для того, чтобы было возможно использовать обычный LPC-фильтр, входной сигнал сначала преобразовывают из временной области в частотную область, например, с использованием преобразования Фурье. Поэтому, фактически, временная форма преобразуется в спектральную форму, которую затем кодируют посредством известного LPC-фильтра, который обычно используется для кодирования спектральной формы. Анализ посредством LPC-фильтра обеспечивает коэффициенты предсказания, которые представляют временную форму входного сигнала. Существует компромисс между разрешением по времени и разрешением по частоте. То есть LPC-спектр будет состоять из некоторого количества очень острых пиков (синусоид). Чем слуховая система менее чувствительна к изменениям разрешения по времени, тем меньшее разрешение требуется, иначе говоря, например, для переходного процесса разрешение частотного спектра необязательно должно быть точным. В этом смысле, это может выглядеть как комбинированное кодирование, где разрешение временной области зависит от разрешения частотной области, и наоборот. Также можно использовать несколько кривых LPC для оценки во временной области, например, полосу низких и высоких частот, и в этом случае также разрешение может зависеть от разрешения оценки частоты, и так далее, это также может быть использовано.
LPC-фильтр H(z) может быть, в общем, описан как:
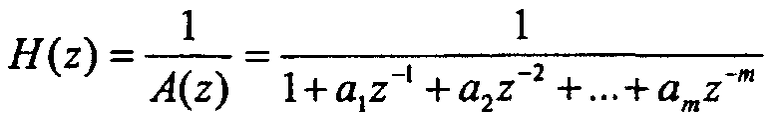
Коэффициенты ai при i от 1 до m являются коэффициентами фильтра с предсказанием, полученными в результате LPC-анализа. Коэффициенты ai определяют H(z).
Для вычисления эквивалентов частот LSF во временной области может быть использована следующая процедура. Эта процедура, по большей части, является действительной как для обычного идеального фильтра, так и для частотной области. Другие известные процедуры, используемые для получения частот LSF в частотной области, также могут быть использованы для вычисления эквивалентов частот LSF во временной области.
Полином A(z) разделен на два полинома P(z) и Q(z) порядка m+1. Полином P(z) образован добавлением коэффициента отражения (в форме решеточного фильтра), равно +1, к A(z), а полином Q(z) образован добавлением коэффициента отражения -1. Существует рекуррентное соотношение между LPC-фильтром в прямой форме (см. уравнение выше) и в решеточной форме:
Ai(z) = Ai-1(z)+kiz-iAi-1(z-1),
где i=1,2,...,m, A0(z)=1 и ki -коэффициент отражения.
Полиномы P(z) и Q(z) получаются следующим образом:
P(z)=Am(z)+z-(m+1)Am(z-1)
Q(z)=Am(z)-z-(m+1)Am(z-1)
Полиномы P(z)=1+p1z-1+p2z-2+...+pmz-m+z-(m+1) и Q(z)=1+q1z-1+q2z-2+...+qmz-m+z-(m+1), полученные указанным путем, обладают четной симметрией и антисимметрией:
Вот некоторые важные свойства этих полиномов:
- Все нули P(z) и Q(z) находятся на единичной окружности в z-плоскости.
- Все нули P(z) и Q(z) чередуются на единичной окружности и не налагаются.
- Свойство минимальной фазы A(z) сохраняется после квантования для обеспечения устойчивости H(z).
Оба полинома P(z) и Q(z) имеют m+1 нулей. Как легко заметить, что z=-1 и z=1 всегда являются нулем в P(z) и Q(z). Поэтому они могут быть удалены делением на 1+z-1 и
1-z-1. Если m четное, то:


Если m нечетное, то:
P'(z)=P(z)
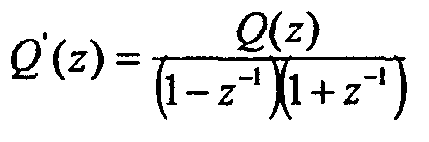
Нули полиномов P'(z) и Q'(z) теперь описываются в виде zi=ejt, поскольку LPC-фильтр применяется во временной области. Нули полиномов P'(z) и Q'(z), таким образом, полностью охарактеризованы их временем t, которое принимает значения от 0 до π по всему кадру, при этом 0 соответствует началу кадра, а π соответствует концу кадра, длина которого может быть фактически любой практически используемой длиной, например 10 или 20 миллисекунд (мс). Времена t, полученные таким образом, можно интерпретировать как эквиваленты временной области для частот линейного спектра, причем эти времена в дальнейшем будут называться LSF-временами. Для вычисления фактических LSF-времен необходимо вычислить корни полиномов P'(z) и Q'(z). В настоящем контексте также могут быть использованы различные методики, которые предложены в [9], [10], [11].
Фиг.3 показывает схематический вид иллюстративной ситуации для анализа и синтеза временных огибающих. В каждом кадре k используется окно, не обязательно прямоугольное, для анализа сегмента с помощью LPC. В результате чего, для каждого кадра, после преобразования, получается набор из N LSF-времен. Следует заметить, что N, в принципе, не обязательно должно быть константой, хотя в большинстве случаев это позволяет достичь более эффективного представления. В этом варианте воплощения предполагается, что LSF-времена квантованы равномерно, однако могут быть также применены и другие методики, например векторное квантование.
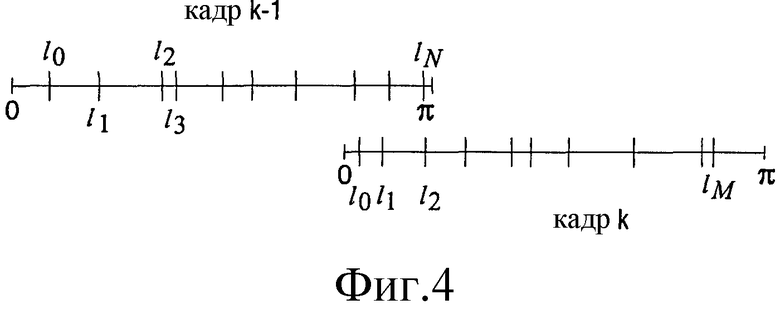
Эксперименты показывают, что в перекрывающихся областях, как показано на фиг.3, часто имеется избыточность между LSF-временами кадра k-1 и между LSF-временами кадра k. См. также фиг.4 и фиг.5. В вариантах воплощения изобретения, которые описаны ниже, эта избыточность используется для более эффективного кодирования LSF-времен, что помогает лучше сжать по меньшей мере часть аудиосигнала. Следует заметить, что фиг.4 и фиг.5 показывают обычные случаи, где LSF-времена кадра k в области перекрытия не идентичны, но достаточно близки к LSF-временам кадра k-1.
Первый вариант воплощения с использованием перекрывающихся кадров
В первом варианте воплощения при использовании перекрывающихся кадров полагается, что различиями между LSF-временами перекрывающихся областей можно, с точки зрения восприятия, пренебречь или они могут привести к допустимой потере качества. Для пары LSF-времен, одно в кадре k-1, другое в кадре k, производное LSF-время вычисляется как взвешенное среднее LSF-времен в упомянутой паре. Взвешенное среднее, в данном случае, может быть истолковано как включающее в себя случай, когда выбирается только одно время из пары LSF-времен. Такой выбор может быть интерпретирован как взвешенное среднее, где вес выбранного LSF-времени равен единице, а вес невыбранного времени равен нулю. Также возможно, что оба LSF-времени в паре имеют одинаковый вес.
Например, примем LSF-времена {l0,l1,l2,...,lN} для кадра k-1 и {l0,l1,l2,...,lM} для кадра k, как показано на фиг.4. LSF-времена в кадре k сдвинуты таким образом, что некоторый уровень l квантования находится в одинаковой позиции в обоих кадрах. Теперь предположим, что есть три LSF-времени в перекрывающейся области для каждого кадра, как в случае на фиг.4 и фиг.5. Затем могут быть сформированы следующие соответствующие пары: {lN-2,k-1 l0,k, lN-1,k-1 l1,k, lN,k-1 l2,k}. В этом варианте воплощения формируется новый набор производных LSF-времен на основании двух исходных наборов из трех LSF-времен. Практический подход состоит в том, чтобы взять LSF-времена кадра k-1 (или k) и вычислить LSF-времена кадра k (или k-1) путем простого сдвига LSF-времен кадра k-1 (или k) для выравнивания кадров во времени. Этот сдвиг выполняется как в кодере, так и в декодере. В кодере LSF-времена правого кадра k сдвигаются до совпадения с LSF-временами в левом кадре k-1. Это необходимо для поиска пар и, в конечном итоге, определения взвешенного среднего.
В предпочтительных вариантах воплощения, производное время или взвешенное среднее кодируется в битовом потоке в виде "уровня представления", который обычно является очисленным значением, например от 0 до 255 (8 бит), представляющим значения от 0 до π. В практических вариантах воплощения также используется кодирование Хаффмана. Для первого кадра первое LSF-время кодируется абсолютно (без опорной точки), а все последующие LSF-времена (включая взвешенные времена в конце) кодируются дифференциально относительно предыдущих. Пусть теперь для кадра k можно воспользоваться описанным «приемом», используя последние три LSF-времени кадра k-1. Тогда при декодировании, кадр k берет последние три уровня представления кадра k-1 (которые находятся в конце диапазона от 0 до 255) и сдвигает их назад по своей собственной временной оси (в начало диапазона от 0 до 255). Все последующие LSF-времена в кадре k будут кодированы дифференциально по отношению к предыдущим, начиная с уровня представления (на оси кадра k), соответствующего последнему LSF в области перекрытия. В случае, если кадр k не может воспользоваться описанным "приемом", то первое LSF-время кадра k будет кодировано абсолютно и все последующие LSF-времена кадра k будут кодированы дифференциально по отношению к предыдущим.
Практическим подходом является вычисление средних величин для каждой пары соответствующих LSF-времен, например:
(lN-2,k-1 +l0,k)/2, (lN-1,k-1 + l1,k)/2, (lN,k-1 + l2,k)/2.
Более выгодный подход принимает во внимание то, что окна обычно показывают плавное нарастание/падение уровня, как показано на фиг.3. В этом способе вычисляется взвешенное среднее для каждой пары, что дает более качественные для восприятия результаты. Процедура вычисления состоит в следующем. Область перекрытия соответствует области (π-r, π). Весовые функции получены как показано на фиг.6. Веса для времен левого кадра k-1 рассчитываются для каждой пары раздельно по формуле:
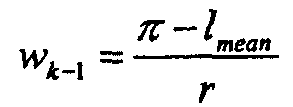
где lmean - среднее пары, например: lmean=(lN-2,k-1+l0,k)/2.
Вес для кадра k вычисляют как wk=1-wk-1
Теперь новые LSF-времена вычисляются как:
lweighted=lk-1wk-1+lkwk
где lk-1 и lk образуют пару. И, наконец, взвешенные LSF-времена равномерно квантуют.
Так как первый кадр в битовом потоке не имеет истории, первый кадр LSF-времен всегда необходимо кодировать без использования способа, описанного выше. Это может быть сделано путем абсолютного кодирования первого LSF-времени с использованием кодирования Хаффмана, и все последующие значения - дифференциально по отношению к предыдущим в кадре с использованием фиксированной таблицы Хаффмана. Все кадры, следующие за первым кадром, могут, в сущности, использовать преимущества вышеописанной методики. Конечно, данная методика не является преимущественной. Например, в случае, когда имеется одинаковое количество LSF-времен в области перекрытия обоих кадров, но с очень плохим совпадением. Вычисление (взвешенного) среднего может в результате дать заметные для восприятия искажения сигнала. Также, случай, когда в кадре k-1 количество LSF-времен не равно количеству LSF-времен в кадре k, не определяется в соответствии с вышеприведенной методикой. Поэтому для каждого кадра LSF-времен, используется индикатор, например, в виде одного бита, включаемый в кодированный сигнал для индикации того, используется ли или нет вышеописанная методика, т.е. должно ли первое количество LSF-времен быть получено из предыдущего кадра или они содержатся в битовом потоке. Например, если бит-индикатор равен 1, то взвешенные LSF-времена кодируют дифференциально относительно предыдущих в кадре k-1, для кадра k первое количество LSF-времен в области перекрытия получают из LSF-времен кадра k-1. Если бит-индикатор равен 0, то первое LSF-время кадра k кодируют абсолютно и все последующие LSF-времена кодируют дифференциально по отношению к предыдущим.
В практическом варианте воплощения кадры LSF-времен являются достаточно длинными, например 1440 отсчетов при 44.1 кГц; в этом случае только около 30 бит в секунду требуются для этого дополнительного бита-индикатора. Эксперименты показывают, что большинство кадров могут с успехом использовать вышеописанную методику, в результате чего сокращается общее количество битов в кадре.
Другой вариант воплощения с использованием перекрывающихся кадров
В соответствии с другим вариантом воплощения изобретения, данные LSF-времен кодируются без потерь. Так, вместо слияния перекрывающихся пар в единые LSF-времена, разности LSF-времен в данном кадре кодируются относительно LSF-времен в другом кадре. Так, в примере на фиг.3, когда значения с l0 до lN получены для кадра k-1, первые три значения с l0 доl3 из кадра k получают путем декодирования разностей по отношению к lN-2, lN-1, lN кадра k-1 соответственно. Кодированием LSF-времени со ссылкой на LSF-время в другом кадре, которое является наиболее близким во времени, чем любое другое LSF-время в упомянутом другом кадре, достигается хорошее использование избыточности, потому что времена могут быть кодированы наилучшим образом со ссылкой на ближайшие времена. Так как их разности обычно достаточно малы, они могут быть закодированы достаточно эффективно с использованием отдельной таблицы Хаффмана. Помимо бита, показывающего, следует ли использовать методику, описанную в первом варианте воплощения, для этого конкретного примера разности l0,k-lN-2,k-1, l1,k-lN-1,k-1, l2,k-lN,k-1 также помещаются в битовый поток в случае, если первый вариант воплощения не используется для рассматриваемой области перекрытия.
Хоть это и менее выгодно, но в качестве альтернативы возможно кодирование разностей по отношению к LSF-временам в предыдущем кадре. Например, можно кодировать только разность первого LSF-времени следующего кадра относительно последнего LSF-времени предыдущего кадра и, далее, кодировать каждое последующее LSF-время в упомянутом последующем кадре относительно предыдущего времени в этом же кадре, например, для кадра k-1: lN-1-ln-2, lN-lN-1, далее для кадра k: l0,k-lN,k-1, l1,k-l0,k и так далее.
Описание системы
Фиг.7 показывает систему в соответствии с одним из вариантов воплощения изобретения. Система включает в себя устройство 1 для передачи или записи кодированного сигнала [S]. Устройство 1 включает в себя блок 10 ввода для приема по меньшей мере части аудиосигнала S, предпочтительно шумовой составляющей аудиосигнала. Блок 10 ввода может быть антенной, микрофоном, сетевым соединением и т.д. Устройство 1 также включает в себя кодер 11 для кодирования сигнала S в соответствии с описанным выше вариантом воплощения изобретения (см. фиг.4, фиг.5 и фиг.6) для получения кодированного сигнала. Возможно, блок 10 ввода принимает полный аудиосигнал и предоставляет его составляющие другим специализированным кодерам. Кодированный сигнал передается блоку 12 вывода, который преобразует кодированный аудиосигнал в битовый поток [S], имеющий подходящий формат для передачи через среду 2 передачи или сохранения на носителе 2 информации. Система также включает в себя приемник или воспроизводящее устройство 3, которое принимает кодированный сигнал [S] в блоке 30 ввода. Блок 30 ввода передает кодированный сигнал [S] декодеру 31. Декодер 31 декодирует кодированный сигнал, выполняя процесс декодирования, который, по существу, является обратной операцией по отношению к кодированию в кодере 11, при этом получается декодированный сигнал S', который соответствует исходному сигналу S, за исключением тех частей, которые были потеряны в процессе кодирования. Декодер 31 передает декодированный сигнал S' в блок 32 вывода, который предоставляет декодированный сигнал S'. Блок 32 вывода может быть воспроизводящим блоком, таким как громкоговоритель, предназначенным для воспроизведения декодированного сигнала S'. Блок 32 вывода также может быть передатчиком для дальнейшей передачи декодированного сигнала S', например, через домашнюю сеть и так далее. В случае, если сигнал S' является реконструкцией составляющей аудиосигнала, такой как шумовая составляющая, тогда блок 32 вывода может включать в себя средства объединения для объединения сигнала S' с другими восстановленными составляющими для предоставления полного аудиосигнала.
Варианты воплощения изобретения могут быть применены, между прочим, в распространении через Интернет, Solid State Audio) твердотельных аудиоустройствах (без механических частей), терминалах связи третьего поколения (3G), общей службе пакетной радиопередачи (GPRS) и их коммерческих реализациях.
Следует заметить, что вышеописанные варианты воплощения скорее иллюстрируют, чем ограничивают изобретение, и специалисты в данной области техники могут создать много альтернативных вариантов воплощения без выхода за рамки объема, определяемого прилагаемой формулой изобретения. В формуле изобретения любые ссылочные символы, помещенные в скобки, не должны восприниматься как ограничение соответствующего пункта. Фраза "включает в себя" не исключает существование других элементов или этапов, чем те, которые перечислены в соответствующем пункте. Изобретение может быть реализовано с помощью аппаратных средств, включающих в себя несколько отдельных элементов, и с помощью подходящим образом запрограммированного компьютера. В пункте, описывающем устройство, где перечислены несколько средств, некоторые из них могут быть воплощены в одном и том же аппаратном элементе. Тот простой факт, что некоторые признаки приведены в различных зависимых пунктах не означает того, что комбинация этих признаков не может быть использована выгодным образом.





Изобретение относится к кодированию аудиосигнала. Техническим результатом является собственно обеспечение усовершенствованного способа кодирования по меньшей мере части аудиосигнала. Указанный технический результат достигается за счет того, что по меньшей мере часть аудиосигнала кодируют для получения кодированного сигнала, при этом кодирование включает в себя кодирование с предсказанием в отношении упомянутой по меньшей мере части аудиосигнала с целью получения коэффициентов предсказания, которые представляют временные характеристики, такие как временная огибающая упомянутой по меньшей мере части аудиосигнала, преобразование коэффициентов предсказания в набор времен, представляющих коэффициенты предсказания, и включение упомянутого набора времен в кодированный сигнал. Для анализа/синтеза перекрывающихся кадров в отношении временной огибающей может быть использована избыточность в представлении линейного спектра для области перекрытия. 2 н. и 12 з.п. ф-лы, 7 ил.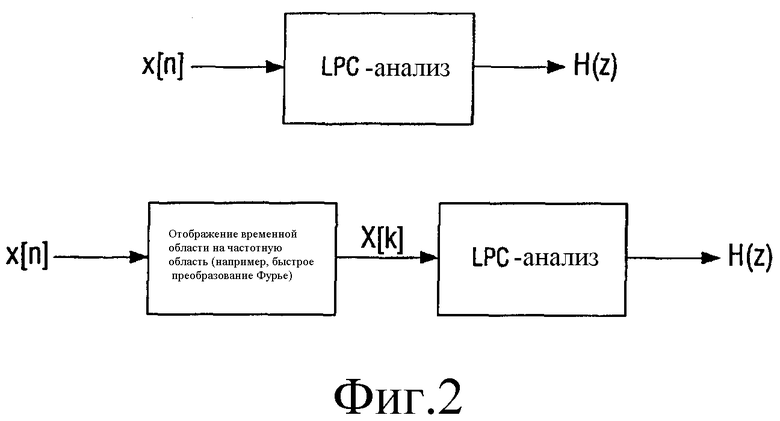
| СПОСОБ СЖАТИЯ ЗВУКОВОЙ ИНФОРМАЦИИ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1998 |
|
RU2144222C1 |
| ПЕРЕДАЮЩАЯ СИСТЕМА НА ПРИНЦИПАХ РАЗЛИЧНОГО КОДИРОВАНИЯ | 1994 |
|
RU2144261C1 |
| US 5749064 A, 05.05.1998 | |||
| WO 9918565 A1, 15.04.1999 | |||
| Катод для электрохимического получения гипохлорита щелочного металла | 1979 |
|
SU899720A1 |
| KUMARESANA R | |||
| et al | |||
| On representing signals using only timing information, Journal of the Acoustical Society of America, vol.110, №5, Nov.2001, USA, c.2421-2439 | |||
| KUMARESANA R | |||
| et al | |||
| On the Duality Between | |||

