Область техники
Настоящее описание относится к способам кэширования целевых адресов команды перехода, в частности к усовершенствованной выборке кэшируемого целевого адреса по отношению к выборке кэшируемой команды перехода, и к процессорам, использующим такие способы.
Уровень техники
Современные микропроцессоры и другие схемы программируемых процессоров часто основаны на конвейерной архитектуре обработки для повышения скорости выполнения. Конвейерный процессор включает в себя множество ступеней обработки для последовательной обработки каждой команды, когда она перемещается через конвейер. В то время как одна ступень обрабатывает команду, другие ступени вдоль конвейера одновременно обрабатывают другие команды.
Каждая ступень конвейера исполняет отличную функцию, необходимую в полной обработке каждой программной инструкции. Хотя порядок и/или функции могут немного изменяться, типичный простой конвейер включает в себя ступень Fetch (выборки) команды, ступень Decode (декодирования) команды, ступень доступа (обращения) к памяти или Readout (считывания), ступень Execute (выполнения) команды и ступень Write-back (обратной записи) результата. Более совершенные конструкции процессоров разбивают некоторые или все эти ступени на несколько отдельных ступеней для выполнения под-частей этих функций. Суперскалярные конструкции дополнительно разбивают эти функции и/или обеспечивают дублированные функции для выполнения операций в параллельных конвейерах аналогичной глубины.
Во время работы ступень выборки команды выбирает следующую команду в выполняемой в настоящее время программе. Часто следующая команда является командой, расположенной в ячейке памяти со следующим последовательным адресом. Обработка некоторых команд может приводить к операции ветвления (перехода), в этом случае следующая команда находится в непоследовательном целевом адресе, полученном посредством декодирования и принятия решения во время выполнения для выбора целевой ветви для последующей обработки.
Существуют два общих класса команд перехода (ветвления), условного и безусловного. Процессор принимает решение, выполнять ли команду условного перехода в зависимости от того, удовлетворено ли условие(я) ветвления во время обработки команды. Процессор выполняет безусловный переход каждый раз, когда процессор выполняет эту команду. Команда, которая должна быть обработана следующей после команды перехода, то есть, скажем, целевой адрес команды, определяется посредством вычисления на основании конкретной команды перехода. В частности, для условного ветвления целевой адрес результата ветвления может не быть определенно известен, пока процессор не примет решение, что условие ветвления удовлетворено.
Для заданной операции выборки ступень выборки первоначально пытается выбрать адресованную команду из кэша команд (iCache). Если команда еще не содержится в iCache, ступень выборки выбирает ее из памяти более высокого уровня, такого как кэш 2-го уровня команд или основной памяти системы. При выборке из памяти более высокого уровня команда загружается в iCache.
Ступень выборки выдает каждую выбранную команду на ступень декодирования команд. Логика ступени декодирования команд декодирует принятые байты команды и выдает результат на следующую ступень конвейера, то есть на Считывание в простом скалярном конвейере. Если команда является командой перехода, то часть обработки декодирования может использовать вычисление целевого адреса ветвления. Логика ступени Считывания обращается к памяти или другим ресурсам, чтобы получить данные операндов для обработки в соответствии с командой. Команду и данные операндов передают к ступени выполнения, которая выполняет конкретную команду над извлеченными данными и формирует результат. Типичная ступень выполнения может реализовывать арифметико-логическое устройство (АЛУ). Пятая ступень записывает результаты выполнения назад в регистр или память.
В таких операциях ступень выполнения время от времени будет принимать и обрабатывать одну из команд перехода. При обработке команды перехода логика ступени выполнения определяет, должна ли быть выбрана (принята) ветвь, например, если условия для условной операции ветвления удовлетворены. Если принимается, то часть этого результата есть целевой адрес (часто вычисленный ступенью декодирования команды), который ступень выборки использует как адрес команды для выборки следующей команды для обработки в конвейере. Для увеличения производительности целевой адрес может быть кэширован способом, аналогичным обработке кэша команд. Например, для принятой ветви вычисленный целевой адрес может быть сохранен в кэше целевого адреса ветвления (КЦАВ, BTAC), обычно вместе с адресом команды перехода, которая сформировала этот целевой адрес.
Для каждой операции выборки ступень выборки использует адрес новой команды и пытается обратиться и к iCache, и к BTAC с этим адресом выборки. Принимая, что команда была загружена в iCache, iCache выдаст адресованную команду на логику ступени выборки. Если адрес соответствует команде перехода и ветвь была предварительно принята, это будет "попаданием" в BTAC, заключающееся в том, что BTAC будет хранить целевой адрес для адреса этой команды и BTAC будет выдавать кэшируемый целевой адрес на логику (логическую схему) Выборки. Если текущий адрес выборки не соответствует команде перехода или ветвь еще не была принята, не имеется "попадания", поскольку BTAC не хранит целевой адрес для текущего адреса команды выборки.
Когда имеется "попадание" в BTAC, логика может предсказывать, должна ли быть эта ветвь, вероятно, снова принята. Если да, то целевой адрес подается на логику Выборки для использования в качестве следующего адреса (вместо следующего последовательного адреса). Поэтому следующая операция выборки после выборки команды перехода использует этот кэшированный целевой адрес, извлеченный из BTAC, чтобы выбрать команду, соответствующую целевому адресу.
Когда скорости процессора увеличиваются, заданная ступень имеет меньшее количество времени, чтобы исполнить свою функцию. Чтобы поддержать или дополнительно повысить производительность, каждая ступень подразделяется. Каждая новая ступень исполняет меньшее количество работы в течение заданного цикла, но имеется большее количество ступеней, работающих одновременно на более высокой тактовой частоте. Поскольку память и процессоры совершенствуются, длина команд и длины адресов команды увеличиваются. Во многих конвейерных процессорах операция выборки разбивается и распределяется среди двух или более ступеней, и выборка команд из iCache и целевых адресов из BTAC занимает два или более циклов обработки. В результате может потребоваться множество циклов, чтобы определить, имеется ли попадание при выборке BTAC, в течение которого ступени, выполняющие выборки из iCache, проходят и начались ли операции выборки в отношении одной или более последующих выборок iCache. В операции выборки, занимающей много циклов, после обнаружения попадания в BTAC последующая обработка выборки должна быть отвергнута, поскольку следующая операция выборки должна использовать адрес, идентифицированный в BTAC. Это отвергание вызывает задержки и снижает выгоду использования кэширования BTAC. Когда количество циклов, требуемых для выборок BTAC, увеличивается, производительность дополнительно ухудшается. Следовательно, существует потребность в дальнейших усовершенствованиях способов кэширования целевого адреса при ветвлении, особенно когда это может помочь уменьшить или устранить ненужную обработку на ступенях iCache в случае попадания в BTAC.
Сущность изобретения
Как должно быть очевидно из описания уровня техники, нормальная операция использует один и тот же адрес, чтобы одновременно обратиться и к кэшу команд, и кэшу целевого адреса ветвления (перехода) (BTAC) во время вызова команды. Чтобы дополнительно повысить производительность, операция выборки BTAC выполняет "просмотр вперед" (упреждающий просмотр), то есть выполняет выборку до выборки команды из кэша команд. В раскрытых примерах выборка BTAC выполняет "просмотр вперед" выборки iCache посредством использования адреса будущей команды или из-за того, что этот адресат был записан в BTAC с более ранним значением адреса. Аспекты этих принципов относятся и к способам и процессорам.
Первый такой способ для выборки команд для использования в конвейерном процессоре использует команды выборки из кэша команд и одновременно осуществляя доступ к кэшу целевого адреса ветвления (BTAC) в течение каждой выборки команды. Обращение к BTAC определяет, хранит ли BTAC целевой адрес ветвления (перехода). Каждое обращение к BTAC занимает по меньшей мере два цикла обработки. Способ также использует смещение операций доступа на заранее определенную величину относительно операций выборки, чтобы начать обращение к BTAC относительно команды перехода по меньшей мере на один цикл прежде инициирования выборки команды перехода.
В различных примерах, подробно описанных ниже, смещение является достаточным, чтобы выбрать целевой адрес ветвления, соответствующий команде перехода, из BTAC для использования в последующей выборке команды, которая начинается в цикле обработки сразу после того цикла обработки, который начал выборку команды перехода. Конкретные примеры этого способа обеспечивают приращение адреса для выборки BTAC как часть операций выборки или обеспечивают уменьшение адреса для записи адресата ветвления в BTAC. Последняя опция не должна быть реализована в самой операции выборки, но может быть реализована в или в ответ на обработку в одном или большем количестве последующих ступеней конвейерной обработки.
Величина смещения является достаточной, чтобы разрешить выборку целевого адреса ветвления, соответствующего команде перехода, из BTAC для использования в выборке последующей команды, которая начинается в цикле обработки сразу после того цикла, который начал выборку команды перехода. В примерах величина смещения охватывает разность адресов между кэшем команд и BTAC, равную величине на единицу меньше, чем количество циклов, требуемых для каждого обращения к BTAC.
Другой способ выборки команд для использования в конвейерном процессоре влечет за собой начало выборки первой команды из кэша команд и одновременно инициирование выборки в BTAC. Обращение к BTAC служит для выборки целевого адреса, соответствующего команде перехода, которая следует за первой командой. Этот способ также использует начало выборки команды перехода из кэша команд. Вслед за началом выборки команды перехода целевой адрес, соответствующий команде перехода, используется, чтобы инициировать выборку целевой команды из кэша команд.
Процессор в соответствии с настоящим раскрытием содержит кэш команд, кэш целевого адреса ветвления и ступени обработки. Одной из сохраненных команд является команда перехода, и кэш целевого адреса ветвления хранит целевой адрес ветвления, соответствующий этой команде. Ступени обработки включают в себя ступень выборки и по меньшей мере одну последующую ступень обработки для выполнения одной или более функций обработки в соответствии с выбранными командами. Ступень выборки выбирает команды из кэша команд и выбирает целевой адрес ветвления из кэша целевого адреса ветвления. Процессор также включает в себя логику смещения. Эта логика обеспечивает смещение выборки из кэша целевого адреса ветвления перед выборкой команд из кэша команд на величину, связанную с количеством циклов обработки, требуемых для завершения каждой выборки из кэша целевого адреса ветвления.
В примерах величина смещения упреждающего просмотра на единицу меньше количества циклов обработки, требуемых для завершения каждой выборки из кэша целевого адреса ветвления. Логика смещения может быть ассоциирована со ступенью выборки, например, чтобы увеличить адрес выборки команды для того, чтобы разрешить этой ступени выборки использовать начальный адрес для осуществления выборки из кэша целевого адреса ветвления. Альтернативно, логика смещения может записывать адресаты ветвления в кэш целевого адреса ветвления, используя уменьшенное значение адреса команды.
Примерные процессоры являются конвейерными процессорами, часто имеющими пять или более ступеней. Последовательно расположенные ступени обработки могут включать в себя ступень декодирования команды, ступень считывания, и ступень выполнения команды, и ступень обратной записи результата. Конечно, каждая из этих ступеней может быть дополнительно разделена или конвейеризована. Также ступень выборки может быть конвейеризована, чтобы содержать множество ступеней обработки.
В одном примере адрес, используемый для выборки BTAC, опережает таковой, использованный при выборке кэша команд, на смещение, предназначенное для компенсации задержки выборки из BTAC в случае попадания. Если это осуществлено в течение выборки, это влечет за собой приращение адреса выборки. Альтернативно, при записи в кэш-памяти адрес записи BTAC может опережать адрес, используемый для хранения команды перехода в кэше команд, на соответствующую величину смещения. Так как это реализовано для операции записи, но предназначено, чтобы вызвать считывание или выборку перед соответствующей выборкой кэша команд, операция записи уменьшает адрес, используемый для записи целевого адреса в BTAC.
Дополнительные задачи, преимущества и новые признаки будут сформулированы частично в описании, которое следует ниже, и частично станет очевидным специалистам после рассмотрения нижеследующего описания и сопроводительных чертежей или может быть изучено посредством реализации или оперирования примерами. Задачи и преимущества настоящего раскрытия могут быть реализованы и достигнуты практикой или использованием методологий, инструментария и комбинаций, конкретно указанных в прилагаемой формуле изобретения.
Краткое описание чертежей
Чертежи изображают один или более вариантов выполнения в соответствии с настоящим раскрытием только посредством примера, а не посредством ограничения. На чертежах аналогичные цифровые ссылочные обозначения относятся к одному и тому же или подобным элементам.
Фиг.1 изображает функциональную блок-схему простого примера конвейерного процессора со смещением упреждающим просмотром для выборки из кэша целевого адреса ветвления перед соответствующей выборкой из кэша команд.
Фиг.2 изображает функциональную блок-схему простого примера ступеней выборки и декодирования конвейерного процессора, реализующего выборку с двумя циклами (или двумя ступенями).
Фиг.3 изображает таблицу, полезную при объяснении синхронизации циклов в ступени выборки согласно фиг.2 без смещения между выборкой из кэша команд и соответствующей выборкой из кэша целевого адреса ветвления.
Фиг.4 изображает таблицу, полезную при объяснении синхронизации циклов в ступени выборки согласно фиг.2 со смещением между выборкой из кэша целевого адреса ветвления и соответствующей выборкой из кэша команд, где смещение относится к (например, на единицу меньше) количеству циклов или количеству ступеней, реализующих выборку целевого адреса.
Фиг.5 изображает функциональную блок-схему простого примера ступеней выборки и декодирования конвейерного процессора, реализующего выборку с тремя циклами (или тремя ступенями).
Фиг.6 изображает таблицу, полезную при объяснении синхронизации циклов в ступени выборки согласно фиг.5 со смещением между выборкой из кэша целевого адреса ветвления и соответствующей выборкой из кэша команд, где смещение относится к (например, на единицу меньше) количеству циклов или количеству ступеней, реализующих выборку целевого адреса.
Фиг.7 изображает частичную блок-схему и последовательность операций, полезных для понимания примера, в котором смещение реализовано как приращение адреса выборки команды.
Фиг.8 изображает частичную блок-схему и последовательность операций, полезных для понимания примера, в котором смещение реализовано в отношении адреса команды, используемого при записи целевого адреса в кэш целевого адреса ветвления.
Подробное описание
В нижеследующем подробном описании многочисленные конкретные подробности сформулированы посредством примеров, чтобы обеспечить полное понимание релевантных вариантов раскрытия. Однако специалистам должно быть очевидно, что настоящее раскрытие может быть реализовано без таких подробностей. В других примерах известные способы, процедуры, компоненты и схема описаны на относительно высоком уровне детализации без подробностей, чтобы избежать излишнего усложнения аспектов настоящего раскрытия.
Различные способы, раскрытые здесь, относятся к выгодной синхронизации выборки целевого адреса ветвления (перехода) перед соответствующей выборкой команды, особенно когда такие выборки выполняются в обработке конвейерного типа. Ниже приводятся ссылки на подробные примеры, проиллюстрированные на сопроводительных чертежах и описанные ниже. Фиг.1 является упрощенной блок-схемой конвейерного процессора 10. Упрощенный конвейер включает в себя пять ступеней.
Первая ступень конвейера в процессоре 10 является ступенью 11 Выборки команд. Эта ступень Выборки получает команды для обработки последующими ступенями. Ступень 11 Выборки подает каждую команду к ступени 13 Декодирования. Логика ступени 13 Декодирования команд декодирует принятые байты команды и выдает результат на следующую ступень конвейера. В простом примере следующей ступенью является ступень 15 доступа (обращения) к данным или Считывания. Логика ступени 15 Считывания обращается к памяти или другим ресурсам (не показаны), чтобы получить данные операнда для обработки в соответствии с командой. Команду и данные операнда передают к ступени 17 Выполнения, который выполняет конкретную команду над извлеченными данными и выдает результат. Пятая ступень 19 записывает результаты обратно в регистр и/или память (не показаны).
Конвейеризация архитектуры обработки таким способом разрешает параллельную работу ступеней 11-19 в отношении последовательных команд. Современные реализации, особенно для высокопроизводительных приложений, обычно разбивают эти ступени на множество под-ступеней. Суперскалярные структуры используют два или более конвейеров, по существу, одинаковой глубины, работающих одновременно параллельно. Для простоты описания, однако, ниже приводятся ссылки на примеры с простым примером конвейера с пятью ступенями, как в процессоре 10.
Логика ступени Выборки часто будет включать в себя или взаимодействовать с кэшем 21 команд (iCache). При выборке команды, идентифицированной адресом, логика (логическая схема) ступени 11 Выборки сначала обратится к iCache 21, чтобы извлечь команду. Если адресованная команда еще не находится в iCache, логика ступени 11 Выборки выберет команду в iCache 21 из других ресурсов, например, кэша 23 уровня два (второго уровня) или основной памяти 25. Команда и адрес сохраняются в iCache 21. Логика ступени Выборки может затем выбирать команду из iCache 21. Команда должна быть также доступна в iCache 21, если необходима впоследствии.
Выполнение многих команд приводит к ветвлениям от текущего местоположения в последовательности программы к другой команде, то есть к команде, сохраненной в отличном местоположении в памяти (и соответствующей непоследующему адресу). Обработка команды перехода использует вычисление ветвления к целевому адресу. Чтобы ускорить операции выборки, логика ступени выборки часто будет включать в себя или осуществлять сопряжение с кэшем целевого адреса ветвления (BTAC) 27 для кэширования целевых адресов способом, аналогичным этой функции в iCache 21. В соответствии с настоящим раскрытием целевой адрес, извлеченный из BTAC 27, смещается (в 29) от такового соответствующей команды в iCache 21, так что обработка просмотра BTAC начинается на один или более циклов прежде просмотра соответствующей команды перехода в iCache 21, чтобы компенсировать любую задержку ожидания при извлечении целевого адреса из BTAC 27.
Смещение, осуществленное в 29, может быть выражено в терминах времени, выражено как один или более тактов или обрабатывающих циклов, выражено как смещение в нумерации адреса, или подобным образом. Ниже описан пример, в котором смещение идентифицирует адрес выборки, несколько опережая (с приращением) во времени или в последовательности команд, по сравнению с адресом выборки, используемым для выборки команды из iCache. Альтернативный пример записывает целевой адрес ветвления в BTAC с соответствующим смещением (уменьшением), так чтобы обе выборки использовали один и тот же адрес, но выборка BTAC все еще опережает выборку iCache на желательную величину смещения. В любом примере, если имеется целевой адрес ветвления в BTAC 27, этот адрес ветвления подается к логике ступени Выборки, чтобы начать выбирать целевую команду немедленно после команды перехода.
Для команды перехода, которая предварительно не была скопирована в iCache 21, BTAC 27 не будет включать в себя целевой адрес для операции ветвления. Могут быть некоторые ситуации, в которых BTAC 27 не будет включать в себя целевой адрес, даже при том, что iCache 21 включает в себя команду перехода, например, потому что обработка еще не выбрала конкретную ветвь. В любом таком случае, когда целевой адрес ветвления не включен в BTAC 27, часть 31 логики декодирования команды будет вычислять целевой адрес во время обработки команды перехода в ступени 13 декодирования.
Процессор может записывать вычисленный целевой адрес в BTAC 27, когда вычислено как часть логики декодирования. Однако не все ветвления выбираются, например, потому что условие для команды условного перехода не выполнено. Логика ступени 17 выполнения будет включать в себя логику 33, чтобы определить, должна ли быть ветвь принята (выбрана). Если да, то обработка должна включать в себя операцию записи (логика, показанная как 35), чтобы записать вычисленный целевой адрес ветвления в BTAC 27. Хотя отдельно не показан, результат выполнения для выбора (приема) конкретной ветви будет использовать выдачу целевого адреса к логике ступени Выборки, чтобы выбрать целевую команду для последующей обработки посредством конвейера.
Нормальная операция или операция, при которой обращение к BTAC занимает один цикл выборки, используют один и тот же адрес, чтобы одновременно обратиться и к iCache 21, и к BTAC 27 в течение выборки команды. Чтобы дополнительно повысить производительность, когда обращение к BTAC требует множества циклов, операция выборки BTAC осуществляет выборку перед командой, выбранной в iCache, на основании Смещения, осуществленного в 29 на фиг.1.
Количество циклов, требуемых для выборки BTAC, определяет количество циклов или длину, требуемую для смещения упреждающего просмотра. Если обращение к BTAC занимает два цикла, то выборка BTAC должна просматривать на один цикл выборки перед выборкой iCache. Если обращение к BTAC занимает три цикла, то выборка BTAC должна просматривать на два цикла выборки прежде выборки iCache, и так далее. Как отмечено, если обращение к BTAC требует только один цикл выборки, смещение может не быть необходимым.
В одном примере адрес, используемый для выборки BTAC, опережает таковой, используемый в выборке iCache, на смещение, предназначенное для компенсации задержки выборки из BTAC в случае попадания. Если реализовано в течение выборки, это влечет за собой приращение в адресе выборки. Альтернативно, при записи в кэш-памяти адрес записи BTAC может опережать адрес, используемый для хранения команды перехода в iCache, на соответствующую величину смещения. Так как это реализовано в отношении операции записи, но предназначено, чтобы вызвать считывание или выборку перед соответствующей выборкой iCache, операция записи уменьшает адрес, используемый для записи целевого адреса в BTAC.
Чтобы полностью оценить операции с упреждающим просмотром, может быть, полезно рассмотреть некоторые примеры. Со ссылками на фиг.2 - 4 предположим, что выборка BTAC требует двух циклов обработки. Хотя циклы для двух выборок могут не всегда быть одинаковыми, для простоты описания в этом примере выборка команды из iCache аналогично требует двух циклов. По существу, ступень 112 выборки может рассматриваться как конвейерная. Хотя ступени выборки могут быть объединены, для этого примера предполагается, что каждый тип выборки выполняется в двух отдельных ступенях конвейера, и конвейер выборки iCache выполняется параллельно со ступенями, формирующими конвейер выборки BTAC. Каждый из конвейеров поэтому состоит из двух ступеней.
Каждая ступень конвейера 112 выборки исполняет различную функцию, необходимую для полной обработки каждой команды программы. Первая ступень, относящаяся к обработке выборки команды (iCache F1), принимает адрес (iAddress) команды, выполняет его функциональную обработку, чтобы начать выборку адресованной команды, и передает свои результаты ко второй ступени, относящейся к обработке выборки команды (iCache F2). В течение следующего цикла iCache F1 принимает адрес другой команды, в то время как iCache F2 завершает обработку выборки в отношении первого адреса и передает результаты, то есть выбранную команду, к ступени 13 Декодирования.
Параллельно первая ступень, относящаяся к обработке выборки целевого адреса (BTAC) (F1 BTAC), принимает адрес выборки BTAC, выполняет его функциональную обработку, чтобы начать выборку из BTAC, и передает свои результаты ко второй ступени, относящейся к обработке выборки команды (F2 BTAC). В течение следующего цикла ступень F1 BTAC принимает адрес другой команды, в то время как iCache F2 завершает обработку выборки в отношении первого адреса и передает результаты, если они есть, к ступени 13 Декодирования. Если обработка BTAC выбирает целевой адрес ветвления из BTAC 27, вторая ступень конвейера BTAC (F2 BTAC) обеспечивает результаты попадания на первую ступень, относящуюся к обработке выборки команды (iCache F1) так, чтобы выборка следующей новой команды использовала соответствующий целевой адрес ветвления из кэша 27.
Фиг.3 является таблицей или диаграммой синхронизации, представляющей синхронизацию циклов и связанную обработку в ступени выборки с 2 циклами, такой как ступень 112, показанная на фиг.2. Алфавитные символы в таблице представляют адреса команд. Например, A, B и C являются последовательным адресом, поскольку они могут быть обработаны в начале прикладной программы. Z представляет целевой адрес, то есть следующую команду, которая должна быть обработана после обработки принятой команды перехода.
В примере согласно фиг.3 для целей описания принимается, что не имеется никакого смещения между обработкой для ступеней выборки iCache и ступеней выборки BTAC. Следовательно, в течение цикла 1 обработки ступень iCache F1 выполняет свою связанную с выборкой обработку в отношении первого адреса A и ступень F1 BTAC выполняет свою связанную с выборкой обработку в отношении первого адреса A. Две ступени F1 передают соответствующие результаты к соответствующим ступеням F2 для обработки во втором цикле. В течение обработки во втором цикле ступень iCache F1 выполняет свою связанную с выборкой обработку в отношении второго адреса B и ступень F1 BTAC выполняет свою связанную с выборкой обработку в отношении второго адреса B. Ступени F2 обе завершают обработку в отношении второго адреса B в конце третьего цикла. Однако в течение этого третьего цикла ступени F1 обе обрабатывают третью последующую команду C.
Теперь предположим, что вторая команда B является командой перехода, для которой BTAC 27 хранит адрес Z целевой ветви. Вторая ступень конвейера BTAC (F2 BTAC) находит попадание и выдает целевой адрес Z в третьем цикле. Целевой адрес Z становится доступным и обрабатывается как адрес выборки команды в ступени iCache F1 в следующем цикле обработки, то есть в четвертом цикле.
Как показано тем не менее, обе ступени F1 начали обрабатывать последующий адрес в третьем цикле (как представлено обведенным в кружок адресом C). Такая обработка является посторонней, и любые результаты должны быть очищены из конвейера. Аналогичная обработка может происходить и должна быть очищенной из ступеней F2 в следующем (четвертом) цикле обработки (снова обведенным в кружок адресом C). Ненужная обработка третьего последовательного адреса является непроизводительной тратой времени обработки, и необходимость очищать ступени от любых связанных данных вносит задержку и снижает производительность.
Фиг.4 является таблицей или временной диаграммой, представляющей синхронизацию циклов и связанную обработку в ступени выборки с 2 циклами, такой как ступени 112, показанные на фиг.2, в котором ступень 112 выборки реализует смещение с упреждающим просмотром выборки BTAC относительно выборки iCache. Таблица согласно фиг.4 аналогична таковой на фиг.3 в том, что обе используют одну и ту же нотацию. Смещение, представленное на фиг.4, однако, устраняет затраченные впустую циклы обработки выборок iCache.
В примере на фиг.4 смещение между обработкой для ступеней выборки iCache и ступеней выборки BTAC соответствует адресу одной команды. Для целей описания смещение представлено приращением адреса выборки. Как отмечено выше, те же самые результаты могут быть достигнуты уменьшающим смещением адреса записи BTAC.
В течение цикла 1 обработки ступень iCache F1 выполняет свою связанную с выборкой обработку в отношении первого адреса A, однако ступень F1 BTAC выполняет свою связанную с выборкой обработку в отношении второго адреса B. Эти две ступени F1 передают соответствующие результаты на соответствующие ступени F2 для обработки, относящейся к А и B соответственно во втором цикле. В течение второго цикла ступень iCache F1 выполняет свою связанную с выборкой обработку в отношении второго адреса B и ступень F1 BTAC выполняет свою связанную с выборкой обработку в отношении третьего адреса C.
Ступень BTAC F2 завершает свою обработку в отношении второго адреса B в конце второго цикла. Так как в этом примере вторая команда B является командой перехода, для которой BTAC 27 хранит адрес Z целевой ветви, ступень BTAC F2 конвейера BTAC находит попадание и выдает целевой адрес Z во втором цикле. Целевой адрес Z становится доступным и обрабатывается как адрес выборки команды на ступени iCache F1 в следующем цикле обработки, то есть в третьем цикле. Следовательно, ступени конвейера iCache могут обрабатывать команду, соответствующую целевому адресу ветвления, немедленно, без необходимости начинать обработку следующего последовательного адреса.
Может все же присутствовать некоторая ненужная обработка следующего последовательного адреса на ступенях конвейера BTAC (как представлено обведенным в кружок адресом C). Однако из-за низкой частоты возникновения команд перехода, в частности сдвоенных принятых (выбранных) команд ветвления, очищение данных для такой ненужной обработки в конвейере BTAC имеет относительно небольшое воздействие на общую производительность процессора.
Должно быть очевидно из рассмотрения этого простого примера согласно фиг.2 и 4, что вначале команды, выбранные из iCache 21 в начальном(ых) цикле(ах), соответствующих смещению, не имеют соответствующей выборки BTAC. Как правило, первая команда не является ветвлением, так что это не является проблематичным. Однако, когда количество циклов выборки BTAC увеличивается и сопровождающее смещение увеличивается, может быть желательно избежать операций ветвления в первой последовательности команд перед первым выполнением (проходом) смещения BTAC.
На фиг.5 и 6 показана конвейерная обработка и ассоциированная синхронизация для процессора, в котором операции выборки BTAC занимают три цикла обработки. Хотя циклы iCache и BTAC не могут быть всегда одинаковыми, для простоты описания выборка команды из iCache аналогично в этом примере требует трех циклов. По существу, ступень 113 Выборки может рассматриваться как конвейерная. Хотя ступени выборки могут быть объединены, для этого примера предполагается, что каждый тип выборки выполняется в двух отдельных ступенях конвейера и конвейер выборки iCache работает параллельно со ступенями, формирующими конвейер выборки BTAC. Каждый из конвейеров поэтому состоит из трех ступеней.
Каждая ступень конвейера выборки 113 выполняет различную функцию, необходимую при полной обработке каждой команды программы. Первая ступень, относящаяся к обработке выборки команды (iCache F1), принимает адрес команды (iAddress), выполняет его функциональную обработку, чтобы начать выборку адресованной команды, и передает свои результаты ко второй ступени, относящейся к обработке выборки команды (iCache F2). В течение следующего цикла ступень iCache F1 принимает адрес другой команды, в то время как ступень iCache F2 выполняет свою обработку выборки в отношении первого адреса и передает результаты к следующей ступени. В течение третьего цикла ступень iCache F1 принимает адрес другой команды, в то время как ступень iCache F2 выполняет свою обработку выборки в отношении второго адреса, и третья ступень, связанная с обработкой выборки команды (iCache F3), завершает обработку в отношении адреса первой команды и передает результаты к ступени 13 Декодирования.
Параллельно первая ступень, связанная с обработкой выборки целевого адреса (BTAC) (F1 BTAC), принимает адрес выборки BTAC, выполняет его функциональную обработку и передает свои результаты ко второй ступени, относящейся к обработке выборки команды (F2 BTAC). В течение следующего цикла ступени BTAC F1 принимает адрес другой команды, в то время как ступень BTAC F2 выполняет свою обработку выборки в отношении первого адреса и передает результаты к следующей ступени. В течение третьего цикла F1 BTAC принимает адрес еще одной команды, в то время как BTAC F2 выполняет свою обработку выборки, связанную со вторым адресом BTAC, и третья ступень, связанная с обработкой выборки команды (F3 BTAC), завершает обработку в отношении первого адреса BTAC и передает результаты к ступени 13 Декодирования.
Фиг.6 является таблицей или временной диаграммой, представляющей синхронизацию циклов и ассоциированную обработку в ступени выборки с 3 циклами, такой как та, что показана на фиг.5, в которой конвейер 113 ступени выборки реализует смещение с упреждающим просмотром для выборки BTAC относительно выборки iCache, соответствующее двум адресам. Таблица фиг.6 аналогична таковой на фиг.4 в том, что использует аналогичную нотацию. В этом примере с 3 циклами для удобства предполагают, что третья последовательная команда C является командой перехода, для которой целевой адрес уже сохранен в BTAC 27.
В примере согласно фиг.6 смещение между обработкой для ступеней выборки iCache и ступеней выборки BTAC соответствует двум адресам команды. Для целей описания смещение представлено приращением адреса выборки. Как отмечено выше, те же самые результаты могут быть достигнуты уменьшенным смещением адреса записи BTAC.
В течение обработки цикла 1 ступень iCache F1 выполняет свою соответствующую выборку, относящуюся к обработке первого адреса A, однако ступень F1 BTAC выполняет свою выборку, относящуюся к обработке первого адреса C. Две ступени F1 передают соответствующие результаты к соответствующим ступеням F2 для обработки в отношении А и C соответственно во втором цикле. В течение второго цикла ступень iCache F1 выполняет свою выборку, связанную с обработкой в отношении второго адреса B, и ступень iCache F2 выполняет свою выборку, связанную с обработкой в отношении первого адреса A. В течение этого же цикла ступень BTAC F2 выполняет свою выборку, связанную с обработкой в отношении адреса C.
В третьем цикле обработки ступень iCache F1 обрабатывает третий адрес C, ступень iCache F2 свою выборку, связанную с обработкой в отношении адреса B, и ступень iCache F3 выполняет свою выборку, связанную с обработкой в отношении адреса A. В то же самое время в конвейере BTAC ступень F3 BTAC завершает обработку в отношении адреса C. В этом примере такая обработка формирует попадание, и выборка BTAC выбирает целевой адрес Z (нижняя строка таблицы).
Так как команда C является командой перехода, для которой BTAC 27 хранит адрес Z целевой ветви, ступень F3 BTAC конвейера BTAC обнаруживает попадание и выдает целевой адрес Z в третьем цикле. Целевой адрес Z становится доступным и обрабатывается как адрес выборки команды в ступени iCache F1 в следующем цикле обработки, то есть в четвертом цикле в нашем примере. Следовательно, ступени конвейера iCache могут обрабатывать команду, соответствующую целевому адресу ветвления, немедленно, без ненужного начала обработки следующего последовательного адреса.
Должно быть отмечено, что выборка BTAC с упреждающим просмотром может быть осуществлена в любом конвейерном процессоре, имеющем iCache и BTAC. Ступень Выборки не должна быть конвейерной, или если она конвейерная, то нет необходимости, чтобы ступень Выборки была конвейеризована способом, показанным в примерах на фиг.2 и 5. Преимущества смещения для обеспечения выборки BTAC с упреждающим просмотром могут быть реализованы в любом процессоре, в котором операция выборки требует двух или более циклов обработки.
В этих примерах циклы обработки, в которых ступень Выборки начинает выборку iCache, влечет за собой соответствующую выборку BTAC (или выборка BTAC влечет за собой выборку iCache) на один или более циклов обработки, определенных смещением, то есть, скажем, на единицу меньше числа циклов обработки, чем требуется для выполнения выборки BTAC. Например, на фиг.4 ступень iCache F1 начинает выборку команды перехода B в цикле 2, через один цикл после соответствующего начала выборки для целевого адреса B ступенью F1 BTAC. В этом первом примере выборка BTAC требует двух циклов. Точно так же на фиг.6 ступень iCache F1 начинает выборку команды перехода C в цикле 3, через два цикла после соответствующего начала выборки для целевого адреса C ступенью F1 BTAC. В примере на фиг.5 и 6 выборка BTAC требует трех циклов обработки. В каждом случае не имеется ненужной промежуточной обработки при обработке выборки iCache.
В примерах на фиг.2-6, описанных выше, принималось, что смещение использовало адрес для выборки BTAC, который был с опережением или впереди адреса, используемого для выборки iCache. Чтобы осуществлять такую операцию в течение обработки выборки, логика выборки будет осуществлять приращение адреса. По существу, когда ступень 11 Выборки принимает адрес для выборки команды, она использует этот адрес как адрес команды iCache, но логика (логическая схема) увеличивает этот адрес, чтобы сформировать адрес для выборки BTAC. Фиг.7 изображает функциональную диаграмму элементов, вовлеченных в такую операцию выборки, используя приращение адреса выборки, чтобы получить адрес для выборки BTAC. Для простоты описания другие элементы конвейера были опущены.
Как показано, логика (логическая схема) 71 в ступени Выборки выдает адрес выборки для использования при обращении как к iCache 21, так и к BTAC 27. Адрес выборки из логики 71 используется непосредственно как адрес для обращения к iCache. При нормальной обработке ступень Выборки выполнит два или более циклов обработки, чтобы получить соответствующую команду из iCache 21. Команда из iCache 21 загружается в регистр 73 и/или выдается к логике 71 для передачи к ступени Декодирования. Как отмечено ранее, часть 31 из логики декодирования команды вычислит целевой адрес в течение обработки команды в ступени 13 Декодирования, и логика ступень 17 выполнения будет включать в себя логику 33 для определения, была ли ветвь принята (выбрана). Если да, то обработка будет включать в себя операцию записи (логика, обозначенная 35 на фиг.1), чтобы записывать вычисленный целевой адрес ветвления в BTAC 27. В этом примере операция записи не изменяется.
Однако ступень Выборки включает в себя логическую схему 291 (включенную в или ассоциированную с логикой 71 ступени выборки) для приращения адреса выборки на соответствующую величину смещения, чтобы сформировать адрес выборки BTAC. В примере выборки с 2 циклами согласно фиг.2 и 4 схема 291 будет увеличивать адрес выборки на одно адресное значение, так чтобы выборка BTAC привела к выборке iCache за один цикл. В примере выборки с 3 циклами на фиг.5 и 6 схема 291 будет увеличивать адрес выборки на два адресных значения, так чтобы выборка BTAC привела к выборке iCache за два цикла. Таким образом, ступень Выборки выполнит два или более циклов обработки, чтобы определить, имеется ли попадание BTAC, соответствующее соответствующей будущей команде, и если да, то извлечет целевой адрес кэшируемого ветвления из BTAC 27. Целевой адрес загружается в регистр 75 и выдается к логике 71. Логика 71 принимает этот целевой адрес ветвления достаточно рано, чтобы использовать этот адрес в качестве следующего адреса выборки в следующем цикле обработки выборки (см. например, фиг.4 и 6). Хотя этот путь не показывается для удобства, результирующий целевой адрес также обычно передается на ступень Декодирования с соответствующей командой перехода, чтобы облегчить дальнейшую обработку команды перехода в конвейере.
В качестве альтернативы приращению адреса в течение операции выборки, обеспечивающей желательную выборку BTAC с упреждающим просмотром, также возможно модифицировать адрес BTAC целевых данных ветвления при записи данных в BTAC 27. Если ассоциированный адрес команды уменьшается, когда этот адрес и целевой адрес ветвления записываются в память, последующая выборка из BTAC на основании текущего адреса команды будет приводить к таковому выборки команды перехода из iCache. Если уменьшение адреса является подходящим, то есть смещение адреса на единицу меньше, чем количество циклов, требуемых для выборки BTAC, то выборка команд из iCache 21 и любых ассоциированных целевых адресов из BTAC 27 будет точно такой же, как в более ранних примерах. На практике часто проще осуществить смещение посредством модификации адреса записи, когда имеется ветвь, выбранная в течение выполнения, вместо приращения адреса выборки каждый раз в течение операций выборки.
Фиг.8 изображает функциональную диаграмму элементов, вовлеченных в такую операцию выборки, используя уменьшение адреса целевых данных при записи вычисленного адресата ветвления BTAC. Для простоты описания другие элементы конвейера были опущены. Как показано, логика 71 в ступени Выборки обеспечивает адрес выборки для использования при обращении и к iCache 21, и к BTAC 27. В этом примере обе выборки используют один и тот же адрес, то есть и для выборки команды из iCache 21, и для обращения к BTAC 27.
Ступень Выборки выполнит два или более циклов обработки, чтобы получить соответствующую команду из iCache 21. Команда из iCache 21 загружается в регистр 73 и/или выдается к логике 71 для передачи к ступени Декодирования. Как отмечено выше, часть 31 логики декодирования команды будет вычислять целевой адрес в течение обработки команды в ступени 13 Декодирования; и логика ступени 17 выполнения будет включать в себя логику 33, чтобы определить, должна ли быть ветвь принята (выбрана). Если да, то обработка будет включать в себя операцию записи, чтобы записывать вычисленный целевой адрес ветвления в BTAC 27.
В этом примере операция записи модифицирована. В частности, логика записи в ступени Выполнения включает в себя логическую схему 292 уменьшения (-) Смещения. Обычно адрес записи, используемый для записи данных целевого адреса в BTAC 27, является адресом команды перехода, которая сформировала адрес ветвления. В примере на фиг.8, однако, схема 292 уменьшает этот адрес на соответствующую величину смещения. Для конвейерного процессора, реализующего выборку с 2 циклами, схема 292 будет уменьшать адрес записи на единичное значение адреса. Для процессора, реализующего выборку с 3 циклами, схема 292 будет уменьшать адрес записи на два адреса.
Теперь снова рассмотрим операцию выборки. Когда логика 71 формирует адрес выборки, этот адрес указывает на текущую желательную команду в iCache 21. Однако из-за уменьшения адреса записи для записи целевых данных в BTAC 27 адрес, используемый в выборке, фактически соответствует адресу более поздней команды, определенной величиной смещения. Если смещение равно одному адресному значению, адрес выборки фактически указывает на потенциальное попадание в BTAC для следующей команды, которая должна быть извлечена из iCache 21. Точно так же, если смещение равно двум адресам, адрес выборки фактически указывает на потенциальное попадание BTAC для двух команд перед адресом, в настоящее время извлекаемым из iCache 21.
Таким образом, ступень Выборки будет выполнять два или более циклов обработки, чтобы определить, имеется ли попадание в BTAC, соответствующее подходящей будущей команде, и если да, извлекать кэшируемый целевой адрес ветвления из BTAC 27. Целевой адрес загружается в регистр 75 и выдается к логике 71. Логика 71 принимает целевой адрес ветвления достаточно рано, чтобы использовать этот адрес в качестве следующего адреса выборки в следующем цикле обработки выборки после того, как она инициализирует выборку iCache для соответствующей команды перехода (см., например, фиг.4 и 6). Хотя путь не показан для удобства, результирующий целевой адрес также обычно передается ступени Декодирования с соответствующей командой перехода, чтобы облегчить обработку команды перехода далее ниже по конвейеру.
Хотя примеры относятся к обработке выборки из BTAC за два и три цикла и соответствующим смещениям, специалистам очевидно, что описание с легкостью адаптируется для обработки выборки, в которой выборка BTAC использует большее количество циклов. В каждом случае оптимальное смещение может быть на единицу меньше, чем количество циклов в выборке BTAC. Однако в начале последовательности выборки некоторое количество команд, соответствующих этому смещению, не должно включать в себя команду перехода, чтобы избежать пропуск попадания BTAC. Если команда перехода включена ранее, первое выполнение программы может обработать команду перехода как ту, для которой не имеется попадания BTAC (ветвь не является предварительно принятой), и программа может работать обычным способом, но без усовершенствования работы, которое иначе должно обеспечиваться при обнаружении попадания в BTAC.
В то время как выше описано то, что, как рассматривается, является наилучшим режимом и/или другими примерами, понимается, что различные модификации могут быть сделаны и что сущность, раскрытая здесь, может быть осуществлена в различных формах и примерах, и что описание может применяться в многочисленных приложениях, только некоторые из которых были описаны здесь. Предполагается нижеследующей формулой изобретения охватывать любое и все приложения, модификации и изменения, которые попадают в объем истинного объема настоящего описания.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБЫ И УСТРОЙСТВА ДЛЯ СОКРАЩЕНИЯ ПОИСКОВ В КЭШЕ ЦЕЛЕВЫХ АДРЕСОВ ВЕТВЛЕНИЙ | 2007 |
|
RU2419835C2 |
| СПОСОБЫ И УСТРОЙСТВА ДЛЯ ПРОАКТИВНОГО УПРАВЛЕНИЯ КЭШЕМ АДРЕСОВ ВЕТВЛЕНИЙ | 2007 |
|
RU2421783C2 |
| ОБРАБОТКА ОШИБОК ПРЕДВАРИТЕЛЬНОГО ДЕКОДИРОВАНИЯ ЧЕРЕЗ КОРРЕКЦИЮ ВЕТВЛЕНИЙ | 2005 |
|
RU2367004C2 |
| ОЧИСТКА СЕГМЕНТИРОВАННОГО КОНВЕЙЕРА ДЛЯ НЕВЕРНО ПРЕДСКАЗАННЫХ ПЕРЕХОДОВ | 2008 |
|
RU2427889C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПРЕДСКАЗАНИЯ ВЕТВЛЕНИЙ | 2012 |
|
RU2602335C2 |
| СХЕМА ОТЛАДКИ, СРАВНИВАЮЩАЯ РЕЖИМ ОБРАБОТКИ НАБОРА КОМАНД ПРОЦЕССОРА | 2007 |
|
RU2429525C2 |
| ВЫБОРКА КОМАНД ПО УКАЗАНИЮ В СРЕДСТВЕ СБОРА СВЕДЕНИЙ О ХОДЕ ВЫЧИСЛЕНИЙ | 2013 |
|
RU2585982C2 |
| УПРАВЛЕНИЕ В РЕЖИМЕ НИЗКИХ ПРИВИЛЕГИЙ РАБОТОЙ СРЕДСТВА СБОРА СВЕДЕНИЙ О ХОДЕ ВЫЧИСЛЕНИЙ | 2013 |
|
RU2585969C2 |
| СПОСОБЫ И УСТРОЙСТВО ДЛЯ МОДЕЛИРОВАНИЯ ПОВЕДЕНИЯ ПРЕДСКАЗАНИЯ ПЕРЕХОДОВ ЯВНОГО ВЫЗОВА ПОДПРОГРАММЫ | 2007 |
|
RU2417407C2 |
| КОМАНДА И ЛОГИЧЕСКАЯ СХЕМА ДЛЯ СОРТИРОВКИ И ВЫГРУЗКИ КОМАНД СОХРАНЕНИЯ | 2014 |
|
RU2663362C1 |
Изобретение относится к способам кэширования целевых адресов команды перехода, в частности к усовершенствованной выборке кэшируемого целевого адреса по отношению к выборке кэшируемой команды перехода. Техническим результатом является повышение производительности процессоров, реализующих эти способы. Конвейерный процессор содержит кэш команд (iCache), кэш целевого адреса ветвления (ВТАС) и ступени обработки, включающие в себя ступень для выборки из iCache и ВТАС. Варианты способов описывают работу указанного процессора. При этом, чтобы компенсировать количество циклов, необходимых для выборки целевого адреса ветвления из ВТАС, выборка из ВТАС приводит к выборке команды перехода из iCache на величину, связанную с количеством циклов, необходимых для выборки из ВТАС. 5 н. и 25 з.п. ф-лы, 8 ил.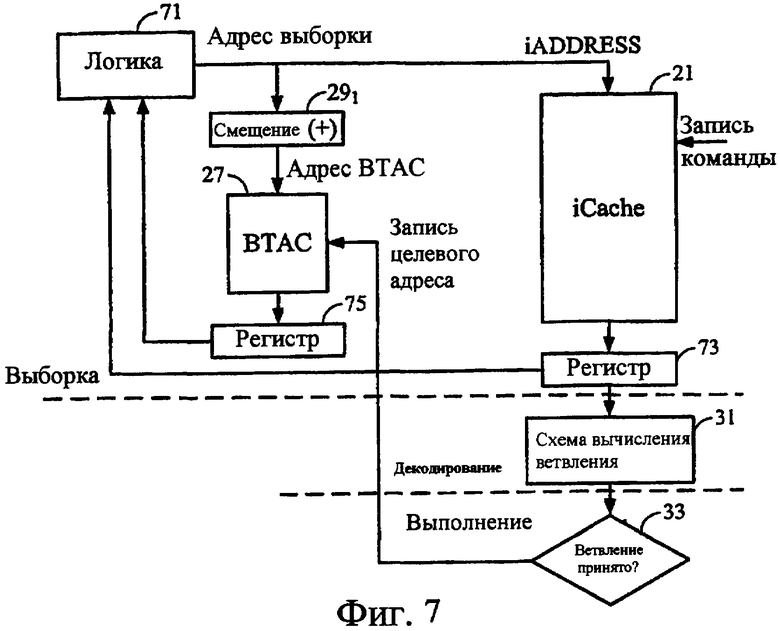
1. Способ выборки команд для использования в конвейерном процессоре, содержащий:
выборку команд из кэша команд;
в течение каждой выборки команды одновременное обращение к кэшу целевого адреса ветвления (ВТАС), чтобы определить, хранит ли ВТАС целевой адрес ветвления, причем каждое обращение к ВТАС содержит по меньшей мере два цикла обработки; и
выполнение смещения операций обращения на заранее определенную величину относительно упомянутых операций выборки, чтобы начать обращение к ВТАС в отношении команды перехода по меньшей мере за один цикл перед инициированием выборки команды перехода из кэша команд.
2. Способ по п.1, в котором:
каждая выборка из кэша команд содержит формирование адреса выборки для команды, которая должна быть выбрана;
причем выполнение смещения содержит приращение каждого адреса выборки на заранее определенную величину; и
каждое обращение к ВТАС содержит выборку из ВТАС, используя увеличенный адрес выборки, полученный в результате смещения.
3. Способ по п.1, в котором:
выполнение смещения содержит уменьшение адреса для команды перехода и запись целевого адреса ветвления и уменьшенного адреса в ВТАС;
способ дополнительно содержит в течение каждого цикла формирование адреса выборки для команды, которая должна быть выбрана; и
выборку и обращение, начатые в каждом цикле, причем оба используют адрес выборки, сформированный в течение цикла.
4. Способ по п.1, в котором заранее определенная величина смещения является достаточной, чтобы разрешить выборку целевого адреса ветвления, соответствующего команде перехода, из ВТАС для использования в последующей выборке команды, начинающейся в цикле обработки, непосредственно после цикла обработки, в котором выборка команды начала выборку команды перехода.
5. Способ по п.4, в котором заранее определенная величина является разностью адресов между выборкой из кэша команд и обращением к ВТАС равной величине, на единицу меньшей, чем количество циклов в каждом обращении к ВТАС.
6. Способ по п.5, в котором: каждое обращение к ВТАС состоит из двух циклов обработки; и заранее определенная величина является разностью адресов между выборкой команд из кэша команд и обращением к ВТАС, равной одному адресу команды.
7. Способ по п.5, в котором: каждое обращение к ВТАС состоит из трех циклов обработки; и заранее определенная величина является разностью адресов между выборкой команд из кэша команд и обращением к ВТАС, равной двум адресам команды.
8. Способ выборки команд для использования в конвейерном процессоре, содержащий этапы:
начинают выборку первой команды из кэша команд;
одновременно с началом выборки первой команды инициируют выборку в кэше целевого адреса ветвления (ВТАС), чтобы выбрать целевой адрес, соответствующий команде перехода, которая следует за первой командой,
начинают выборку команды перехода из кэша команд;
после начала выборки команды перехода используют целевой адрес, соответствующий команде перехода, чтобы начать выборку целевой команды из кэша команд.
9. Способ по п.8, в котором выборка в ВТАС требует два или более циклов обработки.
10. Способ по п.9, в котором инициирование выборки в ВТАС предшествует началу выборки команды перехода из кэша команд на один или более циклов обработки.
11. Способ по п.10, в котором один или более циклов обработки, на которые выборка в ВТАС предшествует началу выборки команды перехода из кэша команд, на единицу меньше, чем два или более циклов обработки, требуемых для выборки в ВТАС.
12. Способ по п.8, в котором: выборка первой команды использует адрес выборки; и выборка в ВТАС использует адрес, увеличенный по отношению к упомянутому адресу выборки.
13. Способ по п.8, в котором: выборка первой команды использует адрес выборки; и
одновременная выборка в ВТАС использует этот адрес выборки, адрес ветвления записан в ВТАС с уменьшенным адресом, чтобы соответствовать упомянутому адресу выборки.
14. Способ выборки команд для использования в конвейерном процессоре, содержащий этапы:
в первом цикле обработки начинают выборку первой команды из кэша команд;
в первом цикле обработки инициирование выборки в кэше целевого адреса ветвления (ВТАС), чтобы выбрать целевой адрес, соответствующий команде перехода, которая следует за первой командой через заранее определенную величину,
во втором цикле обработки после первого цикла обработки начинают выборку команды перехода из кэша команд и завершают выборку целевого адреса из ВТАС;
в третьем цикле обработки после второго цикла обработки используют целевой адрес, соответствующий команде перехода, чтобы начать выборку целевой команды из кэша команд.
15. Способ по п.14, в котором второй цикл обработки следует за первым циклом обработки через один или более циклов обработки, что на единицу меньше, чем количество из двух или более циклов обработки, требуемых для завершения выборки из ВТАС.
16. Способ по п.14, в котором этап инициирования выборки в ВТАС содержит: приращение адреса команды, используемого в начале выборки первой команды из кэша команд в первом цикле обработки, на заранее определенную величину; и
использование упомянутого увеличенного адреса, чтобы начать выборку в ВТАС, чтобы выбрать целевой адрес, соответствующий команде перехода.
17. Способ по п.16, в котором каждое приращение равно величине из одного или более адресов, что на единицу меньше, чем количество из двух или более циклов обработки, требуемых для завершения выборки из ВТАС.
18. Способ по п.14, в котором этап инициирования выборки в ВТАС в первом цикле обработки содержит обращение к ВТАС, используя адрес команды, используемый в начале выборки первой команды из кэша команд в первом цикле обработки; и
адрес, используемый для записи целевого адреса ветвления в ВТАС, был предварительно уменьшен по отношению к адресу команды, используемому для записи команды перехода в кэш команд, на заранее определенную величину, так чтобы адрес целевого адреса в ВТАС соответствовал адресу команды, используемой при начале выборки первой команды из кэша команд в первом цикле обработки.
19. Способ по п.18, в котором уменьшение на величину одного или более адресов на единицу меньше, чем количество из двух или более циклов обработки, требуемых для завершения выборки из ВТАС.
20. Процессор, содержащий:
кэш команд для сохранения команд;
кэш целевого адреса ветвления для сохранения целевого адреса ветвления, соответствующего одной из сохраненных команд, которая является командой перехода;
ступень выборки для выборки команд из кэша команд и для выборки целевого адреса ветвления из кэша целевого адреса ветвления;
по меньшей мере одна ступень последующей обработки для выполнения одной или более функций обработки в соответствии с выбранными командами; и
логику для смещения выборки от кэша целевого адреса ветвления перед выборкой команд из кэша команд на величину, связанную с количеством циклов обработки, требуемых для завершения каждой выборки из кэша целевого адреса ветвления.
21. Процессор по п.20, в котором упомянутая величина является количеством, меньшим на единицу, чем количество циклов обработки, требуемых для завершения каждой выборки из кэша целевого адреса ветвления.
22. Процессор по п.20, в котором: логика содержит логику, связанную со ступенью выборки для приращения адреса, который ступень выборки использует, чтобы осуществить выборку из кэша команд; и
ступень выборки использует этот увеличенный адрес для выполнения выборки из кэша целевого адреса ветвления.
23. Процессор по п.20, в котором: ступень выборки одновременно использует адрес команды как для выборки из кэша команд так и для выборки из кэша целевого адреса ветвления; и эта логика содержит логику для уменьшения адреса команды перехода и использования упомянутого уменьшенного адреса, чтобы записать целевой адрес ветвления в кэш целевого адреса ветвления.
24. Процессор по п.23, в котором логика для уменьшения связана с по меньшей мере одной последующей ступенью обработки.
25. Процессор по п.20, в котором ступень выборки содержит множество конвейерных ступеней обработки.
26. Процессор по п.25, в котором количество циклов обработки, требуемых для завершения каждой выборки из кэша целевого адреса ветвления, равно количеству конвейерных ступеней обработки.
27. Процессор по п.20, в котором по меньшей мере одна последующая ступень обработки содержит: ступень декодирования команд; ступень считывания; ступень выполнения команд; и ступень обратной записи результата.
28. Конвейерный процессор, содержащий:
ступень выборки для выборки команд из кэша команд, в котором одна из команд является командой перехода, и для выборки целевого адреса ветвления, соответствующего команде перехода, из кэша целевого адреса ветвления;
по меньшей мере одна последующая ступень обработки для выполнения одной или более функций обработки в соответствии с выбранными командами; и
средство для смещения выборки из кэша целевого адреса ветвления, так чтобы привести к выборке команд из кэша команд, чтобы компенсировать количество циклов обработки, требуемых для завершения каждой выборки из кэша целевого адреса ветвления.
29. Конвейерный процессор по п.28, в котором ступень выборки содержит множество конвейерных ступеней обработки.
30. Конвейерный процессор по п.28, в котором по меньшей мере одна последующая ступень обработки содержит: ступень декодирования команд; ступень считывания; ступень выполнения команд; и ступень обратной записи результата.
| US 6279105 B1, 21.08.2001 | |||
| АСИНХРОННОЕ УСТРОЙСТВО ОБРАБОТКИ ДАННЫХ | 1997 |
|
RU2182353C2 |
| US 2002188834 A1, 12.12.2002 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ БЛОКИРОВКИ СИГНАЛА СИНХРОНИЗАЦИИ В МНОГОПОТОЧНОМ ПРОЦЕССОРЕ | 2000 |
|
RU2233470C2 |
| МАСШТАБИРУЕМОЕ ИНТЕГРИРОВАННОЕ УСТРОЙСТВО ОБРАБОТКИ ДАННЫХ | 1999 |
|
RU2201015C2 |
| АДРЕСАЦИЯ РЕГИСТРОВ В УСТРОЙСТВЕ ОБРАБОТКИ ДАННЫХ | 1997 |
|
RU2193228C2 |

