Настоящая заявка испрашивает приоритет Корейской заявки номер 10-2004-0071371 на выдачу патента, поданной 7 сентября 2004, которая таким образом включена в настоящие материалы посредством ссылки как полностью в них содержащаяся.
Область техники, к которой относится изобретение
Настоящее изобретение относится к способу и устройству для улучшения качества речи. Хотя настоящее изобретение подходит для широкого круга приложений, оно в особенности подходит для эффективного улучшения качества речи.
Уровень техники
Вообще говоря, предложены различные виды способов улучшения качества речи. Способ спектрального вычитания (ССВ) представляет один из различных видов способов. Способ спектрального вычитания (ССВ) объясняется со ссылкой на Фиг.1 следующим образом.
ССВ является способом прямой оценки кратковременной спектральной амплитуды. В ССВ, речь моделируют в форму, к которой добавлен шум, представленный некоррелированной случайной переменной. Речевое моделирование выражено формулой 1 следующим образом.
[Формула 1]
y[n] = s[n] +d[n]
В формуле 1 y[n] представляет собой входную речь. Кроме того, предполагают, что d[n] представляет собой некоррелированный c s[n] шум. Следовательно, спектральную плотность мощности находят по формуле 2 следующим образом.
[Формула 2]
S y (e jω ) = S s (e jω ) + S d (e jω )
В формуле 2 S y (e jω ) представлен формулой 3 посредством кратковременного дискретного преобразования Фурье (ДПФ).
[Формула 3]

Известно, что фаза сама по себе обнаруживает спектр речевого кадра. Кроме того, доказано, что нет никакого большого различия в определении фазы речевого кадра с использованием фазы речевого сигнала с шумами, который существенно перемешан с шумом. D.L.Wang и J.S.Lim «Несущественность фазы при улучшении речи» (“The unimportance of phase in speech enhancement”), Труды ИИЭР по акустике, речи и обработке сигналов, том l-ASSP.30, стр. 679-681, 1982.
В случае определения фазы речевого кадра с использованием фазы речевого сигнала с шумами, искомое кратковременное ДПФ может быть найдено по Формуле 4.
[Формула 4]

 в формуле 4 находят из Формулы 2. А
в формуле 4 находят из Формулы 2. А  использует фазу речевого сигнала с шумами. Поэтому искомое оцененное значение
использует фазу речевого сигнала с шумами. Поэтому искомое оцененное значение  находят из Формулы 4. Если речи нет, то
находят из Формулы 4. Если речи нет, то 
 оценивают из шума.
оценивают из шума.
Одним из различных способов улучшения качества речи, таким как способ адаптивной линейной фильтрации (АЛФ), раскрыт со ссылкой на Фиг.2 следующим образом. Сначала объяснено использование обычного адаптивного фильтра, в силу развития АЛФ, из схемы, использующей адаптивный фильтр.
При использовании адаптивного фильтра после получения входов от двух микрофонов, то есть получения речи с шумами как входа одного микрофона и чистого шума как входа другого микрофона, вырабатывается функция преобразования и т.п. в силу расстояния между этими двумя микрофонами и т.п. Однако адаптивный фильтр устраняет функцию преобразования для получения чистой речи.
Способ использования адаптивного фильтра является очень эффективным в некоторых случаях и его успешно используют в практических целях. Однако способ требует установки пары микрофонов. Также имеется структурная трудность в решении, как далеко друг от друга должна быть расположена пара микрофонов. Следовательно, трудно применить способ в пользовательском оборудование, таком как подвижный терминал.
АЛФ (адаптивный линейный фильтр) представляет собой усовершенствование способа применения адаптивного фильтра и является схемой для выполнения адаптивной фильтрации по сигналам s[n] и d[n], полученным от одного и того же микрофона посредством оставления разностного эквивалента к периоду основного тона между сигналами. Здесь период основного тона соответствует периоду вокализованной части речи речевого сигнала.
Для вокализованной речи периодическая импульсная последовательность возбуждает речевой тракт. Следовательно, АЛФ оказывает значительное воздействие на вокализованную речь. Однако для невокализованной речи соответствующая речь разрушается.
Один из различных способов улучшения качества речи, такой как схема использования адаптивного гребенчатого фильтра, объясняется следующим образом. Сначала при использовании адаптивного гребенчатого фильтра соответствующая схема, подобная АЛФ, оказывает на вокализованную речь наилучшее воздействие.
В случае вокализованной речи сигнал возбуждения представляет собой периодический сигнал. Даже если преобразование Фурье выполняют по импульсной последовательности, результат указывает, что импульсная последовательность имеет место в частотном домене. Следовательно, в случае вокализованной речи в части, где частота основного тона становится множественной, периодически появляется пик. Само собой очевидно, что контур полного спектра представлен резонансом речевого тракта, называемым формантой.
Когда речевой сигнал с шумами представлен посредством y[n], речь представлена посредством s[n], а речь, из которой удален шум, оценивают как представляемую посредством 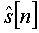 речь, улучшенную адаптивным гребенчатым фильтром, представляют формулой 5.
речь, улучшенную адаптивным гребенчатым фильтром, представляют формулой 5.
[Формула 5]

В формуле 5 Т0 представляет собой извлеченный период основного тона, а ci представляет собой коэффициент гребенчатого фильтра. Здесь как значение L обычно используют малое значение (1~6). Между тем, поскольку шум не является в целом периодическим, адаптивный гребенчатый фильтр является эффективным при удалении шума. Однако известные из уровня техники соответствующие способы улучшения качества речи имеют следующие проблемы или недостатки.
Во-первых, если речь отсутствует, то 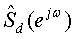 в ССВ оценивают из шума. Однако он не позволяет надежно оценить
в ССВ оценивают из шума. Однако он не позволяет надежно оценить 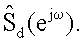 А именно он позволят оценить только, если предполагается, что шум d[n] является постоянным сигналом. Даже если фактически это так, то он не позволяет избежать изменения спектра согласно времени. В особенности в случае подвижного терминала или подобного устройства он не позволяет надежно измерить , поскольку периферическое окружение продолжает изменяться.
А именно он позволят оценить только, если предполагается, что шум d[n] является постоянным сигналом. Даже если фактически это так, то он не позволяет избежать изменения спектра согласно времени. В особенности в случае подвижного терминала или подобного устройства он не позволяет надежно измерить , поскольку периферическое окружение продолжает изменяться.
Во-вторых, АЛФ или схема, использующая адаптивный гребенчатый фильтр, показывают превосходное качество работы по вокализованной речи. Однако эти схемы или способы применимы только к речевому сигналу. В случае применения АЛФ или схемы, использующей адаптивный гребенчатый фильтр, к неречевому сигналу качество работы снижается из-за небольшого несовпадения речевого/неречевого (Р/НР) решения.
В-третьих, в случае некоторой речи речевая характеристика появляется на низкой частоте или неречевая характеристика появляется на высокой частоте, посредством чего качество работы АЛФ ухудшается.
Раскрытие изобретения
Настоящее изобретение направлено на улучшение качества речи.
Дополнительные признаки и преимущества изобретения раскрыты в нижеследующем описании и частично очевидны из описания или могут быть изучены при применении изобретения на практике. Цели и другие преимущества изобретения реализуются и достигаются посредством структуры, конкретно указанной в описании и формуле, а также в приложенных чертежах.
Чтобы достичь эти и другие преимущества и в соответствии с целью настоящего изобретения, как осуществлено и подробно описано, настоящее изобретение осуществлено в способе улучшения качества речи, и этот способ включает в себя разделение входной речи на вокализованную речь и невокализованную речь, выполнение адаптивной фильтрации по вокализованной речи для удаления шума вокализованной речи и выполнение спектрального вычитания по невокализованной речи.
Предпочтительно, способ дополнительно включает в себя выполнение процесса адаптивной линейной фильтрации с использованием адаптивной фильтрации по вокализованной речи для удаления шума вокализованной речи. Среднее значение шумовых спектров, оцененное из заранее заданных кадров, соответствующих предыдущей вокализованной речи, посредством процесса адаптивной линейной фильтрации, используют для спектрального вычитания. Адаптивная фильтрация использует период основного тона, извлеченный из кадра, соответствующего вокализованной речи.
В одном аспекте изобретения способ дополнительно включает в себя выполнение, по меньшей мере, одной из фильтрации нижних частот и фильтрации верхних частот по входной речи и выполнение адаптивной гребенчатой фильтрации по выходу фильтрации верхних частот для удаления шума выхода. Предпочтительно, адаптивную гребенчатую фильтрацию выполняют, когда выход фильтрации верхних частот соответствует вокализованной речи. В другом аспекте изобретения выход фильтрации нижних частот разделен на вокализованную речь и невокализованную речь.
Предпочтительно, шумовые спектральные данные, полученные из части вокализованной речи, используют для спектрального вычитания. Кроме того, шумовые спектральные данные представляют собой значение, получающееся в результате усреднения шумовых спектров, оцененных из заранее заданных кадров, соответствующих предыдущей вокализованной речи, посредством адаптивной фильтрации.
В соответствии с другим вариантом осуществления настоящего изобретения устройство для улучшения качества речи включает в себя блок принятия решения для разделения входной речи на вокализованную речь и невокализованную речь, блок адаптивного линейного фильтра для выполнения процесса адаптивной линейной фильтрации по вокализованной речи, для удаления шума вокализованной речи и блок спектрального вычитания (СВ) для выполнения спектрального вычитания по невокализованной речи.
Предпочтительно, устройство дополнительно включает в себя фильтр нижних частот для выполнения фильтрации нижних частот по входной речи, для вывода на блок принятия решения и фильтр верхних частот для выполнения фильтрации верхних частот по входной речи.
В одном аспекте изобретения устройство дополнительно включает в себя адаптивный гребенчатый фильтр для удаления шума из выхода фильтра верхних частот, если выход фильтра верхних частот соответствует вокализованной речи. Предпочтительно, адаптивный гребенчатый фильтр использует период основного тона, извлеченный из вокализованной речи.
В другом аспекте изобретения устройство дополнительно включает в себя выделитель основного тона для выделения периода основного тона из вокализованной речи, причем выделитель основного тона обеспечивает извлеченный период основного тона блоку АЛФ.
Предпочтительно, блок СВ использует шумовой спектр, оцененный блоком АЛФ. Кроме того, блок СВ использует среднее значение шумовых спектров, оцененных из заранее заданных кадров, соответствующих предыдущей вокализованной речи, посредством блока АЛФ.
В соответствии с другим вариантом осуществления настоящего изобретения способ улучшения качества речи включает в себя получение входной речи, выполнение фильтрации верхних частот по входной речи, выполнение адаптивной гребенчатой фильтрации по выходу фильтрации верхних частот, когда выход фильтрации верхних частот соответствует вокализованной речи, выполнение фильтрации нижних частот по входной речи, выполнение процесса адаптивной линейной фильтрации с использованием адаптивной гребенчатой фильтрации по выходу фильтрации нижних частот, когда выход фильтрации нижних частот соответствует вокализованной речи, и выполнение спектрального вычитания по выходу фильтрации нижних частот, когда выход фильтрации нижних частот соответствует невокализованной речи.
Очевидным является, что и предшествующее общее описание, и далее следующее подробное описание настоящего изобретения являются приводимыми в качестве примера и поясняющими и предназначены для обеспечения дальнейшего раскрытия заявленного изобретения.
Перечень фигур чертежей
Сопроводительные чертежи, которые включены в материалы для обеспечения дальнейшего раскрытия изобретения и составляют часть настоящего описания, иллюстрируют варианты осуществления изобретения и вместе с описанием служат для разъяснения принципов изобретения. Признаки, элементы и аспекты изобретения, которые указаны одними и теми же ссылочными номерами на различных фигурах чертежей, представляют одни и те же эквивалентные или подобные признаки, элементы или аспекты в соответствии с одним или несколькими вариантами осуществления.
Фиг.1 - структурная схема, иллюстрирующая обычный способ спектрального вычитания (ССВ).
Фиг. 2 - структурная схема, иллюстрирующая обычный адаптивный линейный фильтр (АЛФ).
Фиг.3 - структурная схема устройства для улучшения качества речи в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг.4 - блок-схема, иллюстрирующая способ улучшения качества речи, в соответствии с одним вариантом осуществления настоящего изобретения.
Настоящее изобретение относится к улучшению качества речи.
Далее будет приведено подробное описание предпочтительных вариантов осуществления настоящего изобретения, примеры которых представлены на сопроводительных чертежах. Везде, где возможно, одни и те же ссылочные номера использованы в чертежах для указания на одни и те же или подобные части.
В способе улучшения качества речи по одному варианту осуществления настоящего изобретения заданный процесс улучшения качества речи выполняют по вокализованной речи, а способ спектрального вычитания (ССВ) выполняют по невокализованной речи с использованием шумового спектра, достигнутого при выполнении заданного процесса улучшения качества речи.
Устройство для улучшения качества речи в соответствии с одним вариантом осуществления настоящего изобретения раскрыто со ссылкой на Фиг.3.
Как представлено на Фиг.3, устройство для улучшения качества речи включает в себя фильтр 51 нижних частот (ФНЧ), выполняющий фильтрацию нижних частот по введенной речи y[n], и фильтр 50 верхних частот (ФВЧ), выполняющий фильтрацию верхних частот по введенной речи y[n].
Устройство дополнительно включает в себя адаптивный гребенчатый фильтр 56 для обработки высокочастотной компоненты. Устройство также включает в себя блок 52 принятия решения речевой/неречевой (Р/НР), выделитель 53 основного тона и блок 55 спектрального вычитания для обработки низкочастотной компоненты. Кроме того, устройство включает в себя блок 54 адаптивного линейного фильтра (АЛФ). В качестве альтернативы, блок 54 АЛФ может быть заменен средством для выполнения другой схемы улучшения качества речи.
Выход ФВЧ 50 подают на адаптивный гребенчатый фильтр 56. Выход ФНЧ 51 проходит по пути, используя либо АЛФ, либо ССВ в соответствии с вокализованной или невокализованной речью. Блок 52 принятия решения решает, соответствует ли речь, прошедшая через ФНЧ 51, вокализованной или невокализованной речи. Затем принимается решение, использовать ли АЛФ или ССВ в соответствии с результатом решения блока 52 принятия решения В/НВ.
Предпочтительно, блок 52 принятия решения В/НВ доставляет кадр, соответствующий невокализованной речи, из речи, прошедшей через ФНЧ 51, на блок 55 спектрального вычитания с использованием ССВ. В качестве альтернативы, кадр, соответствующий вокализованной речи из речи, прошедшей через ФНЧ 51, доставляют по пути, используя АЛФ. Путь, использующий АЛФ, включает в себя выделитель 53 основного тона и блок 54 АЛФ.
Выделитель 53 основного тона извлекает период Т0 основного тона из кадра, соответствующего вокализованной речи, и затем обеспечивает извлеченный период Т0 основного тона адаптивному гребенчатому фильтру 56. Выделитель 53 основного тона также обеспечивает извлеченный период основного тона блоку 54 АЛФа, причем блок 54 АЛФ использует период Т0 основного тона для АЛФ, чтобы улучшить качество речи для кадра, соответствующего вокализованной речи.
Как упомянуто в предшествующем описании, в настоящем изобретении используют блок 54 АЛФ как средство для улучшения качества речи в соответствии с одним вариантом осуществления настоящего изобретения.
Поскольку диапазон частоты, в пределах которого существует частота основного тона, соответствует 50~400 Гц, частота останова ФНЧ 51 определена так, чтобы в достаточной мере включать в себя диапазон частоты и позволять проходить части речи, имеющей наиболее доминирующее влияние на период основного тона. Предпочтительно, частота останова установлена приблизительно на 800 Гц.
В одном варианте осуществления настоящего изобретения при применении АЛФ речь, имеющая диапазон частот 0~4 кГц, может быть получена рекомбинацией с диапазоном 400~4000 Гц. Это соответствует случаю, когда частота дискретизации составляет 8 кГц. Для приготовления к такому случаю в настоящем изобретении в дальнейшем используют адаптивный гребенчатый фильтр 56.
Адаптивный гребенчатый фильтр 56 по настоящему изобретению удаляет шумы, лежащие между частями, походящими на импульсную последовательность, представленную компонентом основного тона на высокой частоте. Предпочтительно, адаптивный гребенчатый фильтр 56 работает, если существует четкое соответствие сигнала вокализованной речи в высокочастотной компоненте.
Между тем, блок 55 спектрального вычитания, применяющий ССВ, использует шумовые спектральные данные, полученные из части вокализованной речи. Предпочтительно, блок 55 спектрального вычитания использует значение, получаемое в результате усреднения шумовых спектров, оцененных в заданном кадре предыдущей вокализованной речи. Другими словами, шумовые спектральные данные получают из усреднения последовательностей данных шумового спектра заранее определенного числа кадров каждый раз, когда шумовой спектр получают из вокализованной речи.
Поэтому речь  может быть получена посредством удаления шумов из выходов блока 55 спектрального вычитания и адаптивного гребенчатого фильтра 56.
может быть получена посредством удаления шумов из выходов блока 55 спектрального вычитания и адаптивного гребенчатого фильтра 56.
На Фиг.4 представлена блок-схема способа улучшения качества речи в соответствии с одним вариантом осуществления настоящего изобретения. Как представлено на Фиг.4, когда только введена [S1] заданная речь y[n], выполняют фильтрацию [S2] нижних частот и фильтрацию [S3] верхних частот по введенной речи y[n].
Диапазон частоты, в котором существует частота основного тона, обычно составляет 50~400 Гц. Соответственно, часть речи, которая в достаточной степени включает в себя диапазон частоты и которая имеет наиболее доминирующее влияние на период основного тона, подвергают фильтрации нижних частот. Предпочтительно, частоту останова фильтрации нижних частот устанавливают приблизительно на 800 Гц.
Впоследствии идентифицируют, соответствует ли выход фильтрации нижних частот вокализованной речи или невокализованной речи (S4). Если выход фильтрации нижних частот соответствует вокализованной речи, выполняют заданный способ улучшения качества речи по кадру, соответствующему вокализованной речи. Предпочтительно, АЛФ используют как способ улучшения качества речи для вокализованной речи. Следовательно, процесс АЛФ выполняют по кадру, соответствующему вокализованной речи (S6).
Перед процессом АЛФ очевидным является, что период основного тона извлекают из кадра, соответствующего вокализованной речи (S5). Извлеченный период основного тона используют для адаптивной гребенчатой фильтрации (S8), а также для процесса АЛФ (S6).
Однако, если выход фильтрации нижних частот соответствует невокализованной речи, спектральное вычитание выполняют по кадру, соответствующему невокализованной речи (S9). При выполнении спектрального вычитания используют значение, полученное из усреднения шумового спектра, оцененного из заданного кадра предыдущей вокализованной речи, посредством процесса АЛФ. Предпочтительно, используют значение, полученное из усреднения последовательностей данных шумового спектра заранее определенного числа кадров, каждый раз, когда шумовой спектр получают из вокализованной речи посредством процесса АЛФ. Соответствующее значение является шумовыми спектральными данными, полученными из вокализованной речи.
Адаптивную гребенчатую фильтрацию выполняют по выходу, получающемуся в результате выполнения фильтрации верхних частот по введенной речи y[n], для удаления шума выхода (S8). При этом период основного тона, извлеченный из вокализованной речи выхода от фильтрации (S5) нижних частот, используют при выполнении адаптивной гребенчатой фильтрации. Однако перед адаптивной гребенчатой фильтрацией решают, соответствует ли вокализованной речи (S7) выход от фильтрации верхних частот. Если существует четкое соответствие сигнала вокализованной речи, выполняют адаптивную гребенчатую фильтрацию.
Таким образом, речь 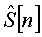 может быть получена посредством удаления шумов из результатов спектрального вычитания и адаптивной гребенчатой фильтрации. В соответствии с раскрытым выше настоящим изобретением ожидается качество работы, лучшее, чем у АЛФ или ССВ.
может быть получена посредством удаления шумов из результатов спектрального вычитания и адаптивной гребенчатой фильтрации. В соответствии с раскрытым выше настоящим изобретением ожидается качество работы, лучшее, чем у АЛФ или ССВ.
В настоящем изобретении после того, как выполнена АЛФ по низкочастотной компоненте, имеющей сильную характеристику основного тона, дополнительно используют адаптивный гребенчатый фильтр, когда высокочастотный компонент соответствует вокализованной речи. Следовательно, настоящее изобретение обеспечивает эффективную работу, если низкие и высокие частоты имеют вокализованные и невокализованные характеристики соответственно.
Поскольку качество речи улучшают на основании характеристики основного тона, которая является универсальной характеристикой речи, настоящее изобретение более устойчиво к перекрестному шуму и т.п., чем другие способы улучшения качества речи (например, фильтрация Виннера, способ спектрального вычитания). Соответственно, настоящее изобретение полезно для удаления шума при использовании единственного микрофона подвижного терминала и для удаления шума при записи речи переносным записывающим устройством. Настоящее изобретение, кроме того, полезно для удаления шума в обычном проводном/беспроводном телефоне или для записи речи в ПЦА (PDA) или подобном устройстве.
Предшествующие варианты осуществления и преимущества приведены только в целях обеспечения примера и не должны рассматриваться как ограничивающие настоящее изобретение. Настоящее изобретение может быть применено и в других типах устройств. Описание настоящего изобретения предназначено для целей раскрытия изобретения и не ограничивает объем формулы изобретения. Для специалистов в данной области техники очевидными являются многочисленные альтернативы, модификации и разновидности. Признаки, характеризующие в формуле изобретения средства с помощью выполняемых им функций, предназначены для обеспечения охраны структуры, описанной в настоящих материалах, как выполняющей раскрытые функции, а также ее структурных эквивалентов и эквивалентных структур.



Изобретение относится к улучшению качества речи, причем деградацию качества речи уменьшают, удаляя шум из невокализованной речи. Способ удаления шума из речевого сигнала включает в себя разделение входной речи на вокализованную речь и невокализованную речь, выполнение адаптивной фильтрации по вокализованной речи для удаления шума вокализованной речи и выполнение спектрального вычитания по невокализованной речи. Технический результат - улучшение качества речевого сигнала. 3 н. и 15 з.п. ф-лы, 4 ил.
1. Способ удаления шума из речевого сигнала, включающий в себя:
выполнение фильтрации нижних частот по входному речевому сигналу в фильтре нижних частот;
получение входного речевого сигнала с фильтрацией нижних частот в модуле принятия решения и
разделение входного речевого сигнала с фильтрацией нижних частот на вокализованный речевой сигнал и невокализованный речевой сигнал;
получение вокализованного речевого сигнала в модуле адаптивной фильтрации и
выполнение адаптивной фильтрации по вокализованному речевому сигналу для удаления шума вокализованного речевого сигнала; и
получение невокализованного речевого сигнала в модуле спектрального вычитания и
выполнение спектрального вычитания по невокализованному речевому сигналу.
2. Способ по п.1, дополнительно включающий в себя выполнение процесса адаптивной линейной фильтрации с использованием модуля адаптивной фильтрации по вокализованному речевому сигналу для удаления шума вокализованного речевого сигнала.
3. Способ по п.2, в котором для спектрального вычитания используют среднее значение шумовых спектров, оцененное из заранее заданных кадров, соответствующих предыдущему вокализованному речевому сигналу, процессом адаптивной линейной фильтрации.
4. Способ по п.1, в котором адаптивная фильтрация использует период основного тона, извлеченный из кадра, соответствующего вокализованному речевому сигналу.
5. Способ по п.1, дополнительно включающий в себя выполнение фильтрации верхних частот по входному речевому сигналу в фильтре верхних частот.
6. Способ по п.5, дополнительно включающий в себя выполнение адаптивной гребенчатой фильтрации по выходу фильтра верхних частот для удаления шума выхода.
7. Способ по п.6, в котором адаптивную гребенчатую фильтрацию выполняют, когда выход фильтра верхних частот соответствует вокализованному речевому сигналу.
8. Способ по п.1, в котором шумовые спектральные данные, полученные из части вокализованного речевого сигнала, используют для спектрального вычитания.
9. Способ по п.8, в котором шумовые спектральные данные являются значением, полученным в результате усреднения шумовых спектров, оцененных из заранее заданных кадров, соответствующих предыдущему вокализованному речевому сигналу, посредством адаптивной фильтрации.
10. Устройство для удаления шума из речевого сигнала, включающее в себя:
фильтр нижних частот для выполнения фильтрации нижних частот по входному речевому сигналу;
модуль принятия решения, получающий входной речевой сигнал с фильтрацией нижних частот,
разделение входного речевого сигнала с фильтрацией нижних частот на вокализованный речевой сигал и невокализованный речевой сигнал;
модуль адаптивного линейного фильтра (АЛФ), получающий вокализованный речевой сигнал и выполняющий процесс адаптивной линейной фильтрации по вокализованному речевому сигналу для удаления шума вокализованного речевого сигнала; и
модуль спектрального вычитания (СВ), получающий невокализованный речевой сигнал для выполнения спектрального вычитания по невокализованному речевому сигналу.
11. Устройство по п.10, дополнительно включающее в себя
фильтр верхних частот, выполняющий фильтрацию верхних частот по входному речевому сигналу.
12. Устройство по п.11, дополнительно включающее в себя адаптивный гребенчатый фильтр для удаления шума из выхода фильтра верхних частот, если выход фильтра верхних частот соответствует вокализованному речевому сигналу.
13. Устройство по п.12, в котором адаптивный гребенчатый фильтр использует период основного тона, извлеченный из вокализованного речевого сигнала.
14. Устройство по п.10, дополнительно включающее в себя выделитель основного тона для извлечения периода основного тона из вокализованного речевого сигнала.
15. Устройство по п.14, в котором выделитель основного тона обеспечивает извлеченный период основного тона модулю АЛФ.
16. Устройство по п.10, в котором модуль СВ использует шумовой спектр, оцененный модулем АЛФ.
17. Устройство по п.10, в котором модуль СВ использует среднее значение шумовых спектров, оцененных из заранее заданных кадров, соответствующих предыдущему вокализованному речевому сигналу, посредством модуля АЛФ.
18. Способ удаления шума из речевого сигнала, включающий в себя:
получение входного речевого сигнала в фильтре верхних частот и выполнение фильтрации верхних частот по входному речевому сигналу;
получение выхода фильтра верхних частот в адаптивном гребенчатом фильтре и выполнение адаптивной гребенчатой фильтрации по выходу фильтра верхних частот, когда выход фильтра верхних частот соответствует вокализованному речевому сигналу;
получение входного речевого сигнала в фильтре нижних частот и выполнение фильтрации нижних частот по входному речевому сигналу;
получение выхода фильтра нижних частот в адаптивном линейном фильтре и выполнение процесса адаптивной линейной фильтрации с использованием адаптивной гребенчатой фильтрации по выходу фильтра нижних частот, когда выход фильтра нижних частот соответствует вокализованному речевому сигналу; и
получение выхода фильтра нижних частот в модуле спектрального вычитания и
выполнение спектрального вычитания по выходу фильтра нижних частот, когда выход фильтра нижних частот соответствует невокализованному речевому сигналу.
| СПОСОБЫ И УСТРОЙСТВА ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ РЕЧЕВЫХ СИГНАЛОВ | 1996 |
|
RU2233010C2 |
| US 6240386 B1, 29.05.2001 | |||
| СПОСОБ И УСТРОЙСТВО ПРЕОБРАЗОВАНИЯ РЕЧЕВОГО СИГНАЛА МЕТОДОМ ЛИНЕЙНОГО ПРЕДСКАЗАНИЯ С АДАПТИВНЫМ РАСПРЕДЕЛЕНИЕМ ИНФОРМАЦИОННЫХ РЕСУРСОВ | 2003 |
|
RU2248619C2 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Двухтактный транзисторный инвертор | 1975 |
|
SU534837A1 |

