Изобретение относится к системам обработки информации и управления, а именно к способам построения систем распознавания речи.
Известен способ проведения двухуровневой обработки речевого сигнала для точного определения границ слова [1]. Способ предполагает сравнивать с анализируемым речевым сигналом эталоны для всех слов словаря системы, ввиду этого способ обладает недостаточным быстродействием.
Известен способ обработки речевого сигнала с использованием блока первого уровня, построенного с применением метода динамического программирования, и блока второго уровня, построенного на основе методов фонемного анализа [2]. Недостатками данного способа является то, что возникновение ошибки блока первого уровня приводит к ошибке всей системы в целом. Способ использует ресурсоемкие, сложные алгоритмы распознавания, что снижает его быстродействие.
Известен способ распознавания изолированных речевых команд [3], содержащий двухуровневую обработку речевого сигнала, с отбором на первом уровне наиболее вероятных кандидатов эталонов для анализируемого слова, выбором на втором уровне наиболее вероятной альтернативы из отобранных кандидатов и анализом результатов распознавания речевого сигнала блоком принятием решения. Блок первого уровня проводит целословный анализ, измеряя расстояние от анализируемого речевого сигнала до эталонов с применением нелинейных функций.
Недостатками такого способа являются его неприменимость для распознавания ключевых слов или команд в потоке слитной речи. Применение нелинейных функций при вычислении расстояний между анализируемым словом и эталонами в блоке первого уровня значительно снижает быстродействие способа.
Наиболее близким к заявляемому является способ распознавания ключевых слов в слитной речи, содержащий двухуровневую обработку речевого сигнала с отбором на первом уровне наиболее вероятных кандидатов эталонов для анализируемого слова, выбором на втором уровне наиболее вероятной альтернативы из отобранных кандидатов и анализ результатов распознавания речевого сигнала с принятием решения, отличающийся тем, что поток слитной речи сегментируют и выделенные отдельные слова подают поочередно на двухуровневую обработку речевого сигнала, при этом анализ и обработка речевого сигнала при сегментации и двухуровневой обработке проводится в частотно-временной области, представленной с помощью вейвлет-преобразования.
При этом при выделении наиболее вероятных кандидатов с применением целословного анализа могут измерять расстояние от анализируемого слова до эталонов с применением линейных функций.
Кроме того, при принятии решения формируют три вида решения: либо о распознанном ключевом слове, либо о переспросе блоку первого уровня на расширение числа кандидатов, либо об отсеве анализируемого слова.
Этот способ осуществляется путем сегментации слов из речевого потока и двухуровневой обработки выделенных слов с отбором на первом уровне наиболее вероятных кандидатов слов для анализируемого сигнала, выбором на втором уровне наиболее вероятной альтернативы из отобранных кандидатов и принятием решения либо о распознанном ключевом слове, либо о переспросе блока первого уровня, либо об отсеве анализируемого слова.
Способ включает основные блоки.
Блок сегментации производит анализ слитной речи на наличие в анализируемый момент времени сигнала-паузы либо сигнала-слова и в результате выделяет множество изолированных слов.
Блок первого уровня распознавания выделяет множество наиболее вероятных кандидатов, наиболее близких к распознаваемому слову. Число кандидатов во множестве, как правило, меньше общего количества слов в словаре.
Блок второго уровня распознавания производит анализ речевого сигнала, с помощью которого определяет наиболее вероятное слово из выбранного множества кандидатов с помощью статистического метода.
Результаты распознавания речевого сигнала на первом и втором уровнях анализируют блоком принятия решения, и, в зависимости от уровня соответствия результатов требованиям, формируют сигнал либо о распознанном ключевом слове, либо о переспросе блока первого уровня, либо об отсеве анализируемого слова.
На этапе сегментации проводится анализ и обработка речевого потока. На первом уровне блок вейвлет-преобразования представляет речевой поток слитной речи в частотно-временной области. Сущность вейвлет-преобразования поясняет формула
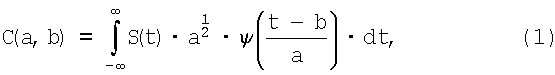
где С(а,b) - вейвлет-коэффициенты;
S(t) - речевой сигнал;
а - коэффициент масштабирования;
ψ(х) - вейвлет-функция;
t - время.
В процессе анализа вычисляют энергетические статистические характеристики речевого сигнала. На основе сравнения вычисленных характеристик с пороговыми значениями принимают решение об отнесении анализируемого сигнала в данный момент времени к сигналу-паузе или к сигналу-слову. В конечном счете на основании полученных данных формируется множество отдельных слов, которые содержались в речевом потоке.
На первом уровне распознавания проводят отбор наиболее вероятных кандидатов с применением целословного анализа.
С помощью блока 2 (фиг.1) первого уровня измеряют расстояние от анализируемого речевого сигнала до эталонов, и величину порога решающего правила для отбора наиболее вероятных кандидатов определяют как постоянную величину, что снижает время работы блока.
Таким образом, решающее правило для определения подмножества слов-претендентов в блоке 1 первого уровня определяется формулой
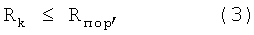
где Rk - расстояние от анализируемого речевого сигнала до эталона, соответствующего k-му слову заданного словаря;
Rпop - постоянное пороговое расстояние.
На втором уровне (блок 3 фиг.1) осуществляют сравнение статистических характеристик анализируемого слова с характеристиками кандидатов эталонов, выбранных на первом уровне.
Результаты сравнения анализируют на третьем уровне (блок 4 фиг.1) и формируют решение либо о распознанном ключевом слове, либо о переспросе блока 2 первого уровня, либо об отсеве анализируемого слова. Переспрос блока 2 заключается в команде на увеличение Rпop (формула 3) и проведение повторного отбора кандидатов уже с увеличенным значением Rпop (формула 3).
Таким образом, применение блока сегментации позволяет распознавать ключевые слова в слитной речи, а также применение линейных функций на первом уровне распознавания при проведении целословного анализа позволяет увеличить быстродействие системы.
Недостатком этого способа системы является то, что непрерывное вейвлет-преобразование выполняется прямым численным интегрированием, что для больших временных последовательностей занимает много времени.
Техническим результатом заявляемого изобретения является повышение быстродействия и точности распознавания слов независимо от громкости и темпа речи.
Быстродействие устройства достигается применением алгоритма быстрого непрерывного вейвлет-преобразования (ВП) акустического сигнала. Разработанный алгоритм позволяет во много раз увеличить быстродействие за счет применения быстрого преобразования Фурье (БПФ). Для малых выборок время выполнения ВП прямым вычислением меньше, чем время выполнения с использованием БПФ, а с увеличением выборки время выполнения ВП прямым интегрированием, наоборот, становится во много раз больше. Алгоритм быстрого непрерывного вейвлет-преобразования можно использовать для анализа и синтеза сигналов в реальном масштабе времени. Непрерывное быстрое вейвлет-преобразование может быть реализовано на базе микроконтроллеров с малым потреблением тока.
Сущность вейвлет-преобразования поясняет формула
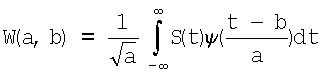 ,
,
где W(a,b) - вейвлет-спектр;
S(t) - речевой сигнал
а - коэффициент масштабирования;
ψ(t) - вейвлет;
t - время.
Пример осуществления способа. Способ может осуществляться с помощью устройства, состоящего из микрофона и ЭВМ. ЭВМ оснащена структурой данных в оперативной памяти. На фиг.1 изображена структурная схема способа. Она состоит из блока акустического анализа представленного 1, блока распознавания фонем 2 и блока распознавания слова 3.
Блок 1 предназначен для вейвлет-преобразования акустического сигнала, сегментации, Фурье преобразования сегментов вейвлет-спектра и сегментов сигнала.
Блок 2 предназначен для сравнения Фурье-спектра вейвлет-коэффициентов сегментов акустического сигнала и эталонов фонем.
Блок 3 предназначен для вычисления энергии сегментов вейвлет-коэффициентов и акустического сигнала, определения границ между гласными и согласными фонемами вейвлет-преобразованием энергии сегментов, подсчета количества гласных фонем, вейвлет-анализа энергии сегментов и распознавания слова.
Блок 1, структурная схема которого представлена на фиг.2, содержит: блок вейвлет-преобразования 4; блок Фурье преобразования 5.
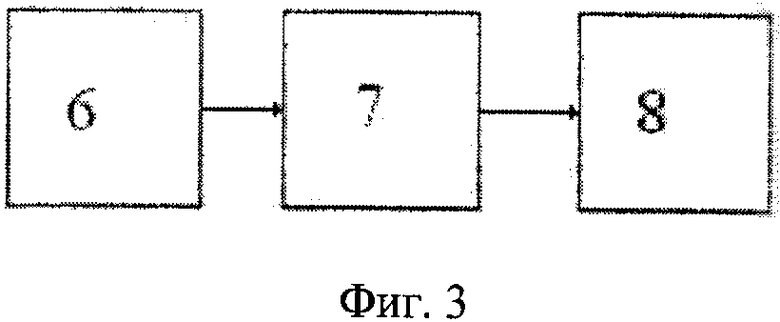
Блок 3, структурная схема которого представлена на фиг.3, содержит: блок вычисления энергетических характеристик сегментов вейвлет-коэффициентов и акустического сигнала 6; блок вейвлет-анализа энергии сегментов 7; блок формирования слова 8.
Способ осуществляют следующим образом. Входное высказывание с микрофона поступает на звуковую карту, преобразуется в цифровую форму с частотой дискретизации, которая может быть равна 8 кгц, и поступает на вход акустического анализатора 1, в блоке 4 которого, предназначенного для дискретной (i = 32768 при частоте дискретизации 8 кгц) временной последовательности S(i) вычисляют вейвлет-коэффициенты (функции) W(1,b) и W(2,b), где b меняется от 1 до 32768.
В блоке 5 акустического анализатора вейвлет-коэффициенты (функции) W(1,b) и W(2,b) разбиваются на сегменты фиксированной длительности (n=128). Общее число сегментов 256. Находится Фурье-спектр функций W(1,b), W(2,b) каждого сегмента. Полученные данные подаются на вход блока 2 для распознавания фонем и на вход блока 3.
В блоке 6 блока 3 вычисляются энергетические характеристики сегментов Е2(n) и Е3(n), функций W(2,b) и S(t) соответственно, где n меняется от 1 до 256. Нормированные энергические характеристики сегментов Е2(n), Е3(n) суммируются и подаются на вход блока 7.
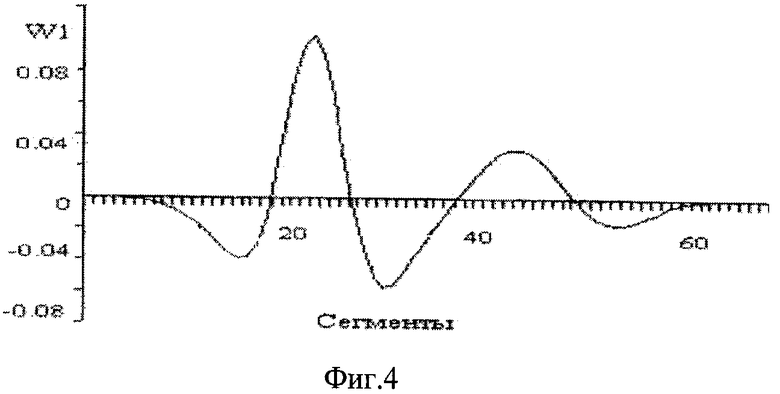
В блоке 7 производят вейвлет-преобразование W1(4,b), с масштабным коэффициентом a=4, где b меняется от 1 до 256. Коэффициент а может меняться от 4 до 8. На фиг.4 представлена функция W1(4,b) слова СИГНАЛ, содержащего две гласные буквы. Положительным значениям функции W1(4, Ь) соответствуют гласные фонемы. Отрицательным значениям - согласные и шипящие фонемы. Если последними буквами в слове являются К, П или Т, то они выделяются в виде максимальных пиков, т.к. впереди этих фонем обычно есть пауза. Если слово содержит одну гласную букву, то выделяется один положительный максимум, если две гласные буквы, то - два положительных максимума и так далее.
Граница между гласными и согласными фонемами или между гласными и шипящими фонемами определяется с точностью до 2-3 сегментов.
В интервале, где выделяются гласные фонемы, подсчитывается количество распознанных букв А. Аналогично, для других гласных букв по отдельности находится количество распознанных букв. Из них выделяются 3 гласные буквы, для которых эти числа наибольшие. Также подсчитываются согласные и шипящие буквы в интервале, где W1(4,b) имеет отрицательное значение. Из них выделяются 3 буквы, также как для гласных букв. Интервал для подсчета согласных букв выбирается шире, чтобы учитывать погрешность определения границ.
Подсчитывается количество положительных пиков в слове.
Для того, чтобы определить, какие фонемы расположены рядом с гласными фонемами речевого сигнала, после подсчета положительных пиков анализ акустического сигнала повторяется в блоках 1 и 3. Вычисляются вейвлет-коэффициенты речевого сигнала с масштабными коэффициентами большими и меньшими 1. Шипящие и свистящие фонемы при малых значениях масштабного коэффициента а имеют энергию W(a,b), сравнимую с энергией гласных букв. При средних значениях а они имеют энергию на уровне шума. Фонемы имеют отличающуюся друг от друга зависимость энергии W(a,b) от масштабного коэффициента а при использовании различного диапазона частот. Это позволяет выделять по отдельности две или три рядом стоящие гласные фонемы. Также можно отделить друг от друга согласные фонемы, если они расположены рядом. Например, фонемы П, Т, К (считаются трудно распознаваемыми) выделяются при больших а в виде кратковременного пика. Фонемы М, Н, Л заметны лишь при средних значениях масштабного множителя а и имеют энергию W(a,b) меньшую, чем гласные звуки. Таким образом, фонемы разделяются на 4 группы: гласные, шипящие, фонемы К, Т, П и остальные согласные, что позволяет увеличить скорость принятия решения в блоке 8.
В блоке 8, если выделяется один пик и выделяется шипящая фонема, выделенные буквы сравнивается с буквами слова в словаре, содержащими одну гласную букву и одну шипящую букву. Если выделяются два пика и выделяется группа фонем К, Т, П, в начале слова, то выделенные буквы сравниваются с буквами слова в словаре, содержащими две гласные буквы, буквы К, Т, П в начале слова. Каждая буква слова из словаря сравнивается с 3 наиболее вероятными буквами, используя логические операции И, ИЛИ. Слова записываются в словарь согласно произношению, а выводятся согласно орфографии. Причем, в словаре можно хранить различные варианты произношения одного слова. Распознанное слово можно выводить и на другом языке.
Источники информации
1. Патент РФ №2297676, МПК8 G10L 15/02, 2006.
2. Патент РФ №2223554, МПК8 G10L 15/14, 2004.
3. Мазуренко И.Л. Компьютерные системы распознавания речи / 1 Интеллектуальные системы. http://nikulchev.milara.ru/files/sbornik.pdf
4. Бойков Ф.Г. Старожилова Т.К. Применение вейвлет-анализа сигнала в системе распознавания речи http://www.dialog-21.ru/Archive/2003/Bojkov.htm.
5. Дремин И.Л., Иванов О.В., Нечитайло В.А. Вейвлеты и их использование. 1 / УФН, т.171, №5, стр. 465-501.
6. Патент РФ №2294024, МПК G10L 15/10, 2006.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ДИКТОРОНЕЗАВИСИМОГО РАСПОЗНАВАНИЯ КЛЮЧЕВЫХ СЛОВ В СЛИТНОЙ РЕЧИ | 2005 |
|
RU2294024C2 |
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ НА ОСНОВЕ ДВУХУРОВНЕВОГО МОРФОФОНЕМНОГО ПРЕФИКСНОГО ГРАФА | 2015 |
|
RU2597498C1 |
| СИСТЕМА И СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ | 2011 |
|
RU2466468C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ИЗОЛИРОВАННЫХ СЛОВ РЕЧИ С АДАПТАЦИЕЙ К ДИКТОРУ | 1994 |
|
RU2047912C1 |
| СПОСОБ ДИКТОРОНЕЗАВИСИМОГО РАСПОЗНАВАНИЯ ИЗОЛИРОВАННЫХ РЕЧЕВЫХ КОМАНД | 1997 |
|
RU2103753C1 |
| Биометрический способ идентификации абонента по речевому сигналу | 2020 |
|
RU2742040C1 |
| СПОСОБ РАСПОЗНАВАНИЯ СЛОВ РЕЧИ | 2005 |
|
RU2296376C2 |
| Способ и устройство классификации сегментов зашумленной речи с использованием полиспектрального анализа | 2014 |
|
RU2606566C2 |
| СПОСОБ ГИБРИДНОЙ ГЕНЕРАТИВНО-ДИСКРИМИНАТИВНОЙ СЕГМЕНТАЦИИ ДИКТОРОВ В АУДИО-ПОТОКЕ | 2013 |
|
RU2530314C1 |
| КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ ЧТЕНИЯ ПЛОСКОПЕЧАТНОГО ТЕКСТА | 1996 |
|
RU2113726C1 |
Изобретение относится к системам обработки информации и управления, в частности к способам построения систем распознавания речи. Техническим результатом является обеспечение возможности распознавания ключевых слов в потоке слитной речи и повышение быстродействия системы. Указанный технический результат достигается тем, что проводят вейвлет-преобразование акустического сигнала с вычислением вейвлет-коэффициентов, которые затем разбивают на сегменты фиксированной длительности, с применением быстрого преобразования Фурье находят Фурье-спектр каждого из сегментов вейвлет-коэффициентов, вычисляют его энергию и определяют границы между гласными и согласными фонемами речевого сигнала, а отбор наиболее вероятных кандидатов слов для анализируемого сигнала производят путем сравнения фонем сигнала с фонемами слова в словаре. 4 ил.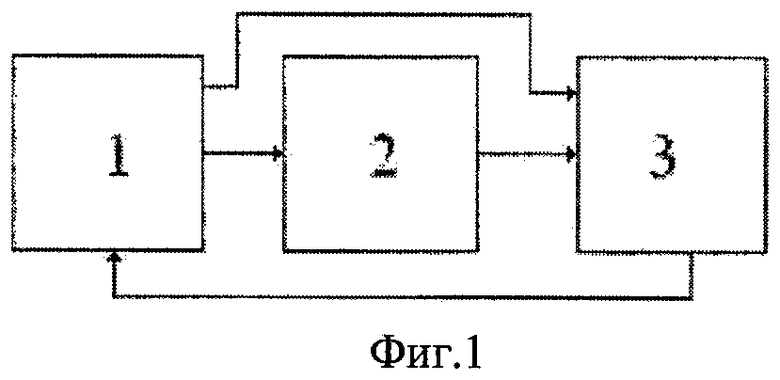
Способ распознавания ключевых слов в слитной речи путем сегментации слов из речевого потока и последующей обработки выделенных слов, включающей отбор наиболее вероятных кандидатов слов для анализируемого сигнала, выбор наиболее вероятной альтернативы из отобранных кандидатов слов, а также принятие решения либо о распознанном ключевом слове, либо о переспросе блока первого уровня, либо об отсеве анализируемого слова, отличающийся тем, что проводят вейвлет-преобразование акустического сигнала с вычислением вейвлет-коэффициентов, которые затем разбивают на сегменты фиксированной длительности, с применением быстрого преобразования Фурье находят Фурье-спектр каждого из сегментов вейвлет-коэффициентов, вычисляют его энергию и определяют границы между гласными и согласными фонемами речевого сигнала, а отбор наиболее вероятных кандидатов слов для анализируемого сигнала производят путем сравнения фонем сигнала с фонемами слова в словаре.
| US 2002116196 A1, 22.08.2002 | |||
| ЩЕТОЧНЫЙ УЗЕЛ ПЫЛЕСОСА (ВАРИАНТЫ) | 2004 |
|
RU2272554C1 |
| US 6253175 В1, 26.06.2001 | |||
| US 6513004 В1, 28.01.2003 | |||
| JP 2008145996 A, 26.06.2008 | |||
| СПОСОБ ДИКТОРОНЕЗАВИСИМОГО РАСПОЗНАВАНИЯ КЛЮЧЕВЫХ СЛОВ В СЛИТНОЙ РЕЧИ | 2005 |
|
RU2294024C2 |

