Изобретение относится к системам обработки информации и управления, а именно к способам построения систем распознавания речи.
Известен способ проведения двухуровневой обработки речевого сигнала для точного определения границ слова (патент США N 4881266). На первом уровне известного способа определяют возможные альтернативы положения границ слова. Ошибка блока первого уровня приводит к снижению вероятности правильного распознавания всей системы в целом. На втором уровне сравнивают полученные альтернативы с эталонами слов. Здесь необходимо сравнивать с анализируемым речевым сигналом эталоны для всех слов словаря системы.
Недостатком известного способа является недостаточное быстродействие.
В качестве ближайшего аналога авторами принят способ обработки речевого сигнала с использованием блока первого уровня, построенного с применением метода динамического программирования и блока второго уровня, построенного на основе методов фонемного анализа (патент США N 5315689). Блоки первого и второго уровней могут меняться местами в зависимости от вероятности правильного распознавания блоков. Блок первого уровня отбирает множество наиболее вероятных кандидатов слов для анализируемого речевого сигнала из всего словаря системы. Блок второго уровня производит анализ речевого сигнала, определяя наиболее вероятную альтернативу из слов, входящих в множество наиболее вероятных кандидатов. Ошибка блока первого уровня приводит к ошибке всей системы в целом. В известном ближайшем аналоге предлагается блок, имеющий большую точность, перемещать на первый уровень, что однако не решает проблемы в целом. Для обеспечения необходимой точности блок первого уровня должен использовать ресурсоемкие алгоритмы распознавания. Это снижает быстродействие системы в целом, т.к. на первом уровне анализируют все слова словаря системы.
Основным недостатком способа по патенту США N 5315689 является недостаточная вероятность правильного распознавания и, кроме того, наблюдается низкое быстродействие.
Перед заявленным изобретением поставлена задача повышения вероятности правильного распознавания и одновременно повышение быстродействия системы распознавания изолированных слов.
Указанная задача решается за счет того, что применяют способ дикторонезависимого распознавания изолированных речевых команд, содержащий двухуровневую обработку речевого сигнала с отбором на первом уровне наиболее вероятных кандидатов слов для анализируемого сигнала и выбором на втором уровне наиболее вероятной альтернативы из отобранных кандидатов, отличающийся тем, что результаты распознавания речевого сигнала на первом и втором уровнях анализируют блоком принятия решения, а в случае не соответствия указанного результата требованиям блока принятия решения формируют сигнал переспроса блока первого уровня.
На первом уровне проводят отбор наиболее вероятных кандидатов с применением целословного анализа.
В блоке первого уровня при проведении целословного анализа измеряют расстояние от анализируемого речевого сигнала до эталонов с применением нелинейных функций.
С помощью блока первого уровня измеряют расстояние от анализируемого речевого сигнала до эталонов блока первого уровня, и величину порога решающего правила для отбора наиболее вероятных кандидатов определяют как нелинейную функцию от минимального расстояния до эталонов блока первого уровня.
Благодаря этому получен технический результат, а именно повышены вероятность правильного распознавания и быстродействие системы распознавания изолированных слов.
На чертеже изображена схема осуществления предлагаемого способа распознавания изолированных речевых команд.
Способ дикторонезависимого распознавания изолированных речевых команд содержит двухуровневую обработку речевого сигнала с отбором на первом уровне наиболее вероятных кандидатов слов для анализируемого сигнала и выбором на втором уровне наиболее вероятной альтернативы из отобранных кандидатов.
Блок 1 первого уровня выделяет множество наиболее вероятных кандидатов, наиболее близких к распознаваемому слову. Число членов в множестве, как правило, меньше общего количества слов в словаре.
Блок 2 второго уровня производит анализ речевого сигнала, с помощью которого определяет наиболее вероятное слово из выбранного множества кандидатов. Здесь могут быть использованы более ресурсоемкие методы (динамическое программирование, скрытое марковское моделирование, нейронные сети и т.п.). Вероятность правильного распознавания блока 2 второго уровня, как правило, возрастает при уменьшении числа анализируемых альтернатив, чем обеспечивается дополнительное повышение точности системы в целом.
Результаты распознавания речевого сигнала на первом и втором уровнях анализируют блоком 3 принятия решения, а в случае не соответствия указанного результата требованиям блока 3 принятия решения формируют сигнал переспроса блока 1 первого уровня.
Блок 3 принятия решения по результатам работы блоков 1 и 2 первого и второго уровней определяет необходимость переспроса. Результатом работы блока 3 является принятое решение либо вызов переспроса. В случае недостаточной степени достоверности решения производят переспрос блока 1 первого уровня. При возникновении переспроса блок 1 первого уровня выдает расширенное множество кандидатов. Алгоритм определения необходимости переспроса использует информацию о распределении расстояний до эталонов блоков 1 и 2 первого и второго уровня (например, расстояние до ближайшего эталона, относительное расстояние между первым и вторым ближайшими эталонами и т.п.).
На первом уровне проводят отбор наиболее вероятных кандидатов с применением целословного анализа.
Применение целословного анализа (использование признаков, характеризующих все слово в целом, например, среднее число пересечений через ноль, положение ударной гласной и т.д.) позволяет кардинально снизить время сравнения с эталонами слов в блоке 1 первого уровня, т.к. отпадает необходимость проведения временной нормализации речевого сигнала.
В блоке 1 при проведении целословного анализа измеряют расстояние от анализируемого речевого сигнала до эталонов с применением нелинейных функций.
Для повышения вероятности правильного распознавания в блоке 1 первого уровня при сравнении с эталонами применяют нелинейную функцию расстояния, например: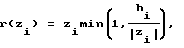 ,
,
где zi - расстояние между значением признака i и эталоном.
hi - пороговая величина.
Для вычисления общего для всех признаков расстояния до каждого эталона используют меру Махаланобиса.
С помощью блока 1 первого уровня измеряют расстояние от анализируемого речевого сигнала до эталонов блока 1 первого уровня, и величину порога решающего правила для отбора наиболее вероятных кандидатов определяют как нелинейную функцию от минимального расстояния до эталонов блока 1 первого уровня.
Используя информацию о распределении расстояний до эталонов слов словаря системы отбирают наиболее вероятные альтернативы (например, расстояние до ближайшего эталона, относительное расстояние между первым и вторым ближайшими эталонами и т.п.), при этом величину порога определяют как нелинейную функцию от минимального расстояния до эталона блока 1 первого уровня (например, кусочно-постоянная функция).
Таким образом, решающее правило для определения подмножества слов-претендентов в блоке 1 первого уровня определяется формулой: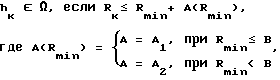 ,
,
A1, A2, B - коэффициенты настройки,
hk - k-ое слова заданного словаря.
Rmin - минимального расстояние от анализируемого речевого сигнала до эталона блока 1 первого уровня.
Rk - расстояние от анализируемого речевого сигнала до эталона, соответствующего k-му слову заданного словаря.
Коэффициенты настройки A1, A2, B находят методами численной оптимизации на основании статистического анализа обучающей выборки.
Среднее время работы двухуровневой системы с переспросом можно определить формулой:
Tср ≈ T1 + Tпр2 + nср • Tср2,
где nср - среднее число проанализированных блоком 2 второго уровня кандидатов.
T1 - время работы блока 1 первого уровня,
Tпр2 - время расчета признаков блока 2 второго уровня,
Tср2 - время анализа одного кандидата блоком 2 второго уровня.
Таким образом, с помощью двухуровневой обработки речевого сигнала с переспросом исправляют ошибки блока 1 первого уровня, что приводит к увеличению вероятности правильного распознавания системы в целом и в то же время за счет применения целословного анализа увеличивают быстродействие системы в целом.
Благодаря этому получен технический результат, а именно повышены вероятность правильного распознавания и быстродействие системы распознавания изолированных слов.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ДИКТОРОНЕЗАВИСИМОГО РАСПОЗНАВАНИЯ КЛЮЧЕВЫХ СЛОВ В СЛИТНОЙ РЕЧИ | 2005 |
|
RU2294024C2 |
| СПОСОБ РАСПОЗНАВАНИЯ КЛЮЧЕВЫХ СЛОВ В СЛИТНОЙ РЕЧИ | 2008 |
|
RU2403628C2 |
| СПОСОБ ДИКТОРОНЕЗАВИСИМОГО РАСПОЗНАВАНИЯ ЗВУКОВ РЕЧИ | 2002 |
|
RU2234746C2 |
| СПОСОБ ГИБРИДНОЙ ГЕНЕРАТИВНО-ДИСКРИМИНАТИВНОЙ СЕГМЕНТАЦИИ ДИКТОРОВ В АУДИО-ПОТОКЕ | 2013 |
|
RU2530314C1 |
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ НА ОСНОВЕ ДВУХУРОВНЕВОГО МОРФОФОНЕМНОГО ПРЕФИКСНОГО ГРАФА | 2015 |
|
RU2597498C1 |
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧЕВЫХ КОМАНД УПРАВЛЕНИЯ | 2003 |
|
RU2271578C2 |
| Способ дикторонезависимого распознавания фонемы в речевом сигнале | 2021 |
|
RU2763124C1 |
| СИСТЕМА И СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ | 2011 |
|
RU2466468C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ИЗОЛИРОВАННЫХ СЛОВ РЕЧИ С АДАПТАЦИЕЙ К ДИКТОРУ | 1994 |
|
RU2047912C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОГО ПОИСКА И КОРРЕКЦИИ ОШИБОК В ТЕКСТАХ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2021 |
|
RU2785207C1 |
Изобретение относится к системам обработки информации и управления, а именно к способам построения систем распознавания речи. Технический результат заявленного изобретения состоит в повышении вероятности правильного распознавания и повышении быстродействия системы распознавания изолированных слов. Указанная задача решается за счет того, что применяют способ дикторонезависимого распознавания изолированных речевых команд, содержащий двухуровневую обработку речевого сигнала с отбором на первом уровне наиболее вероятных кандидатов слов для анализируемого сигнала и выбором на втором уровне наиболее вероятной альтернативы из отобранных кандидатов, отличающийся тем, что результаты распознавания речевого сигнала на первом и втором уровнях анализируют блоком принятия решения, а в случае несоответствия указанного результата требованиям блока принятия решения формируют сигнал переспроса блока первого уровня. На первом уровне проводят отбор наиболее вероятных кандидатов с применением целословного анализа. В блоке первого уровня при проведении целословного анализа измеряют расстояние от анализируемого речевого сигнала до эталонов с применением нелинейных функций. С помощью блока первого уровня измеряют расстояние от анализируемого речевого сигнала до эталонов блока первого уровня, а величину порога решающего правила для отбора наиболее вероятных кандидатов определяют как нелинейную функцию от минимального расстояния до эталонов блока первого уровня. 3 з.п. ф-лы, 1 ил.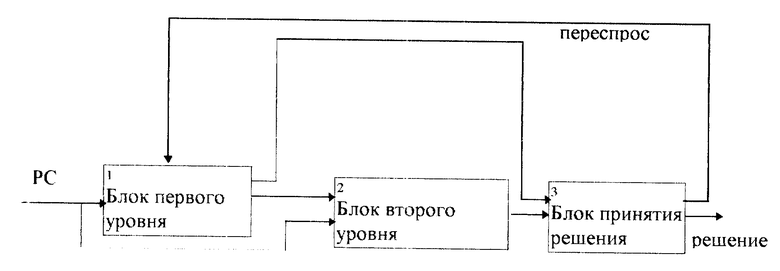
| US, патент, 5315689, кл | |||
| Печь-кухня, могущая работать, как самостоятельно, так и в комбинации с разного рода нагревательными приборами | 1921 |
|
SU10A1 |
