Настоящее изобретение в целом имеет отношение к системам Оптического Распознавания Символов (OCR - Optical Character Recognition), и в частности к способу для автоматической проверки правильности наиболее вероятной версии неоднозначно распознанных слов, которые представляются процессом распознавания.
Существует много предложений в предшествующем уровне техники относительно обеспечения оптического распознавания символов на основании изображений текста. Системы Оптического Распознавания Символов (OCR) довольно хорошо работают с отсканированными с высоким качеством бумажными документами, но обычно терпят неудачу при отсканированном с низким качеством изображении или нечетких шрифтах. Кроме того, иногда имеют место орфографические ошибки в документах, захваченных компонентом OCR-системы. Чтобы иметь возможность повторной печати документов, чтобы иметь возможность электронного поиска в документах (медицинские записи, например с поиском по ключевому слову и т.д., электронные каталоги, базы данных с историческими документами и информацией и т.д.), необходимо преобразование изображений текста к виду, поддающемуся компьютерной обработке (преобразование текста в текст в кодировке ASCII), что обеспечивает высокоэкономичное средство для работы с документами, как известно специалисту в данной области техники. Следовательно, существует потребность в улучшении качества выходных данных компонентов OCR-системы для осуществления способности в полной мере использовать все возможности электронной обработки документов. Внедрение сети Интернет также было фактором, повысившим потребности в более высоком качестве OCR-процесса. Изображения текста, сохраненные на компьютерах в формате PDF, например, доступны для поиска посредством программ-обозревателей сети Интернет. Однако текст, содержащийся в PDF-файлах, должен преобразовываться в компьютерочитаемый цифровой формат, чтобы быть доступным для поиска.
Программные OCR-системы могут разрабатываться с возможностью приспособления к качеству текста и шрифту фактического отсканированного документа. Самонастраивающееся OCR ограничивается теми символами, для которых имеются известные случаи надежного распознавания символов, известная статистика, и/или которые находятся в списках слов или словарях. Некоторые из остающихся неоднозначных символов после процесса распознавания будут символами, которые или редко встречаются, или которые легко перепутать с другим символом в процессе распознавания, предоставляющем символьную группу альтернативных интерпретаций символа. Эти символы не могут быть распознаны (или подтверждены) в рамках существующих интегрированных сред для OCR предшествующего уровня техники. Например, многие из этих символов могут не принадлежать словам в словаре заданного языка, поскольку они могут быть именами собственными, иностранными словами или выражениями, или просто принадлежать другому языку. Выходными данными OCR-системы обычно является строка символов, представляющая текст в виде цифрового текста. Также туда может включаться информация о шрифте, размере и расположении, чтобы иметь возможность восстановления вида исходного документа, например при повторной печати документа. В дополнение, большинство программных OCR-систем используют собственные вероятностные или оценочные величины символов для идентификации неоднозначно распознанных символов или слов, и средство проверки орфографии, которое предусматривает альтернативные слова для этих неоднозначно распознанных слов.
В предшествующем уровне техники есть несколько примеров использования сети Интернет в качестве источника документов и тематической информации и т.д. для организации способа для коррекции ошибок при OCR-обработке документов.
Статья "Использование Всемирной Сети для Получения Повторяемости Новых Биграмм", Франк Келлер (Frank Keller) и Мирелла Лапта (Mirella Lapta), Ассоциация Компьютерной Лингвистики, 2003 год, содержит исследование и подход к преодолению недостаточности данных для трудных слов при OCR-процессе. Один из вопросов, обсуждаемых в этой статье - применима ли повторяемость во Всемирной Сети для вероятностного моделирования.
Статья "Коррекция Текста с Использованием Биграммных Моделей, зависящих от конкретной предметной области, на основании Просмотра Всемирной Сети", Кристофер Рингслеттер (Christoffer Ringsletter) и др., AND, 2007 год, описывает, как повторяемость в сети может использоваться в качестве оценочной величины для изменения существующей упорядоченности кандидатов для существующей коррекционной стратегии. В примерах, описанных в статье, Всемирная Сеть используется в качестве словаря, как понятно специалисту в данной области техники.
Статья "Точная и Эффективная Коррекция Текста с использованием Автоматов Левенштейна, Динамических Словарей Всемирной Сети и Оптимизированных Коррекционных Моделей", Стоян Михов (Stoyan Mihov) и др., Болгарская Академия Наук, 2004 год, описывает способ построения локального словаря, связанного с темой подвергающегося OCR-обработке документа, на основании поисковых запросов в сети. Вывод состоит в том, что небольшие локальные словари обеспечивают лучший результат.
Ни один из этих упомянутых документов, относящихся к предшествующему уровню техники, не обеспечивает значительно улучшенного исчерпывающего способа для коррекции выходных данных OCR. Следовательно, существует потребность в расширенных функциональных возможностях OCR, которые обеспечивают подтверждение наиболее вероятной версии неоднозначно распознанных слов в OCR-системах.
Согласно аспекту настоящего изобретения средство поиска в сети Интернет может обеспечить это подтверждение просто путем измерения количества совпадений, подсчитываемых при использовании неоднозначного слова в качестве аргумента поиска в средстве поиска в сети Интернет. Согласно этому аспекту настоящего изобретения аргумент поиска, обеспечивающий нулевые совпадения, расценивается как безусловное подтверждение того, что неоднозначно распознанное слово не представляет собой эту конкретную версию исследуемого слова. Если измеренное количество совпадений для неоднозначного слова очень велико, то безусловно возможно, что оно является правильной версией. Однако согласно дополнительному аспекту настоящего изобретения поисковые запросы должны выполняться с использованием таких альтернативных слов и/или сочетаний слов, что количество измеренных совпадений равно нулю для всех слов и/или сочетаний, за исключением одного слова и/или одного сочетания. Тогда наиболее вероятной версией неоднозначно распознанных слов является это конкретное слово, идентифицируемое в этой последовательности результатов измерений с помощью ненулевого результата измерения.
Согласно аспекту настоящего изобретения означенные этапы способа могут быть реализованы в программе на сетевом компьютере, который устанавливает связь с сетью Интернет через Интерфейс Прикладных Программ (API - Application Program Interface), взаимодействующий с узлами сети Интернет. Согласно этому аспекту настоящего изобретения реализованная программа принимает входные данные, касающиеся неоднозначно распознанных слов, от OCR-программы, выполняет поисковые запросы, например через API, а затем измеряет количество совпадений, которые представляются программой-обозревателем через API, затем результаты измерений для различных вариантов написания используются для определения наиболее вероятного слова, или используются, чтобы ввести дополнительные результаты измерений относительно вариантов написания с использованием отдельного слова, сочетания нескольких слов, фраз и/или в сочетании с символами-шаблонами в качестве дополнительных измеряемых аргументов поиска.
Согласно примеру варианта осуществления настоящего изобретения есть возможность установить количественный показатель подтверждения для неоднозначно распознанных слов. В примере варианта осуществления, в котором поисковые запросы в сети Интернет выполняются согласно настоящему изобретению, количество измеренных совпадений полностью перенормируются, чтобы можно было сравнить относительное количество совпадений. В альтернативных вариантах осуществления настоящего изобретения предоставляются более детально подготовленные результаты измерений и пороговые уровни, используемые для принятия или отклонения вариантов написания. Количественный показатель подтверждения, основанный на этих относительных количествах, также может сравниваться с верхним пороговым значением подтверждения и нижним пороговым значением подтверждения. Согласно этому примеру варианта осуществления всякий раз, когда количественный показатель подтверждения для неоднозначно распознанного слова больше верхнего порогового значения подтверждения, считается, что оно безусловно идентифицировано. Если количественный показатель подтверждения меньше нижнего порога подтверждения, считается, что оно безусловно не является этой конкретной версией слова. Если количественный показатель подтверждения попадает между верхним и нижним пороговыми значениями подтверждения, необходимо дополнительное исследование неоднозначно распознанного слова путем выполнения дополнительных поисковых запросов и измерений.
Согласно другому аспекту настоящего изобретения могут использоваться различные стратегии предоставления альтернатив слов для неоднозначно распознанного слова, например, на основании альтернатив для неоднозначно распознанного символа, который представляется OCR-функцией, буквенной статистики и т.д., и посредством комбинирования исследуемого слова с другими безусловно распознанными словами в тексте в качестве аргументов поиска. Согласно примеру варианта осуществления настоящего изобретения такие альтернативные слова и/или сочетания слов исследуются с помощью установления количественного показателя подтверждения согласно настоящему изобретению для всех представленных результатов поиска и последующего использования этого количественного показателя, как обрисовано выше, и повторения поисковых запросов с альтернативными аргументами поиска до тех пор, пока не будет достигнуто решение относительно наиболее вероятной версии исследуемого слова (все нули, за исключением одного).
Согласно другому примеру варианта осуществления настоящего изобретения верхнее пороговое значение подтверждения и нижнее пороговое значение подтверждения могут регулироваться, совместно или независимо друг от друга, для обеспечения настройки условий классифицирования исследуемого неоднозначно распознанного слова.
Согласно примеру варианта осуществления настоящего изобретения OCR-функция представляет список неоднозначно распознанных символов и слов, в которых встретились неоднозначно распознанные символы. Более того, также представляются альтернативы, которые являются возможными для каждой вероятной версии символов. На основании этих альтернативных символов создается некоторое количество потенциальных слов, которые являются вероятной правильной версией слова, причем каждое потенциальное слово содержит один из альтернативных символов, соответственно. Согласно аспекту настоящего изобретения идентификация наиболее вероятного правильного потенциального слова может достигаться, используя каждое потенциальное слово в качестве аргумента поиска в средстве поиска в сети Интернет (путем использования API, например), а измеренное количество совпадений по основанию каждой словоформы для принятия решения о наиболее вероятной версии слова. Согласно другому примеру варианта осуществления настоящего изобретения указанный выше количественный показатель подтверждения используется в процессе принятия решения.
Согласно другому примеру варианта осуществления настоящего изобретения, когда результат измерения совпадений приводит к невозможности выбора между кандидатами, например к равному количеству совпадений между двумя кандидатами, потенциальное слово, во-первых, комбинируется со словом, предшествующим исследуемому неоднозначному слову, а затем словосочетания используются в качестве аргумента поиска в сети Интернет, во-вторых, аналогичным образом используется, по меньшей мере, одно слово, следующее за исследуемым словом в той же самой текстовой строке. Дополнительно, в качестве аргумента поиска также используется сочетание, по меньшей мере, одного предшествующего слова, исследуемого слова и, по меньшей мере, одного последующего слова. Количество совпадений для каждого сочетания используется в процессе подтверждения для принятия решения о наиболее вероятной версии слов.
Согласно еще одному примеру варианта осуществления настоящего изобретения, когда сочетания слов обеспечивают неокончательное решение, исследуемое слово комбинируется с более отдаленным словом, предшествующим исследуемому слову. Согласно настоящему примеру варианта осуществления диапазон слов, которые могут быть выбраны в качестве сочетания, может быть ограничен расположением на предварительно заданном удалении, таком, например, как 5 слов от исследуемого слова. Аналогичным образом те же этапы выполняются с последующими словами, например, ограниченными пятым последующим словом. Впрочем, может использоваться любое удаление от исследуемого слова, что является конструктивным признаком настоящего изобретения. Согласно другому конструктивному признаку настоящего изобретения положение, от которого рассчитывается удаление, не обязательно должно принадлежать самому исследуемому слову, а удаление может быть ограниченно областью, которая охватывает исследуемое слово, например. Полученные в результате измеренные совпадения для этих поисковых запросов затем используются как основание для принятия решения о наиболее вероятной версии слова.
Согласно еще одному примеру варианта осуществления настоящего изобретения при выборе предшествующих слов и последующих слов для комбинирования с исследуемым словом учитывается не только положение относительно исследуемого слова, но также и количество содержащихся в слове символов. Согласно аспекту настоящего изобретения длинные слова (например, длиной более 8 символов, но может использоваться любая длина, которая может задаваться предварительно или выбираться пользователем) предпочтительны в качестве уточняющего параметра для исследуемых слов, как описано выше.
Согласно еще одному примеру варианта осуществления настоящего изобретения, по меньшей мере, одно предшествующее слово или, по меньшей мере, одно последующее слово относительно исследуемого слова выбирается на основании частоты встречаемости в определенном языке. Часто встречающиеся слова обычно являются "маленькими словами", такими как "и", "в", "из", и т.д., и вполне могут приниматься как не способствующие процессу проверки правильности. Поэтому предпочтительно использовать предшествующие или последующие слова с низкой частотой встречаемости. В примере варианта осуществления настоящего изобретения количество экземпляров конкретного слова представляется от OCR-функции, и процесс согласно настоящему изобретению проверяет это количество на соответствие пороговому значению. Представленное количество экземпляров и пороговое значение могут быть перенормированы, как понятно специалисту в данной области техники, чтобы обеспечить относительный количественный показатель встречаемости.
Однако слова с высокой повторяемостью в документе, но которые обеспечивают небольшое количество измеренных совпадений при поисковых запросах в сети Интернет, являются хорошими кандидатами для использования в поисковых запросах по сочетаниям с вариантами написания для исследуемого слова.
Согласно еще одному примеру варианта осуществления настоящего изобретения имена собственные могут распознаваться сами по себе, основываясь на сочетании нескольких имен собственных, идентифицированных в тексте. Согласно этому примеру варианта осуществления настоящего изобретения все слова, начинающиеся с заглавной буквы, интерпретируются как имя собственное, при условии, что предшествующий символ не является знаком препинания, которым заканчивается предложение, таким, как ".!?:". Комбинируя, по меньшей мере, два имени собственных, которые встречаются в тексте, процесс подтверждения может возвращать правильное решение. Согласно этому примеру варианта осуществления настоящего изобретения OCR-функция представляет все возможные потенциальные имена собственные процессу подтверждения при выполнении процесса распознавания.
Согласно еще одному аспекту настоящего изобретения OCR-системы часто используются в определенном контексте, например в архивной системе в больнице. Сегодня журналы регистрации пациентов часто заполняются и хранятся в электронном виде, но старые журналы часто существуют в бумажном виде и, следовательно, требуется их сканирование, для встраивания в электронную версию системы. Согласно примеру варианта осуществления настоящего изобретения узлы сети Интернет, которые используются для поисковых запросов в процессе подтверждения, являются выбираемыми. Например, в случае с больничными регистрационными журналами, узлы сети Интернет, содержащие медицинскую информацию, являются лучшим выбором узлов, по которым будет осуществляться поиск.
Согласно другому аспекту настоящего изобретения любые сведения о контексте, связанном с документом, который будет сканироваться в OCR-системе, могут использоваться в качестве уточняющих параметров слов. Медицинский контекст, как описано выше, может дополнительно уточняться медицинскими специальностями, такими как ортопедия и т.д. Другими примерами может служить семейная история, в которой определенная фамилия является преобладающей. Другие примеры могут быть из науки, сельского хозяйства, и т.д. Общим для всех этих "сведений" является то, что просто преобразовать эти "сведения" в адреса для средств поиска, содержащие значимую информацию, связанную с контекстом страниц документа, которые будут распознаваться. Ссылки на эти страницы затем используются при поиске в сети с различными потенциальными словами неоднозначно распознанных слов, и количества совпадений для различных альтернатив затем используются как основание для выбора наиболее вероятного слова. Согласно примеру варианта осуществления настоящего изобретения в качестве средства поиска используется поисковая система Copernic Agent Professional, причем критерии поиска, которые будут использоваться, выбираются в соответствии с содержимым страниц, которые будут распознаваться. В этом примере средства поиска есть возможность выбрать узлы, соответствующие законодательству, трудовым ресурсам, правительству, науке и т.д.
Согласно еще одному аспекту настоящего изобретения, даже если слово неоднозначно распознается из-за неоднозначно распознанных символов в слове, частями таких слов может все же быть достоверно распознанное слово. Например, "домохозяйка" содержит два слова "дом" и "хозяйка". Если неоднозначно распознанная часть слова относится к части слова "хозяйка", поисковые запросы с сочетаниями, содержащими "дом", упростили бы процесс подтверждения. Согласно примеру варианта осуществления настоящего изобретения используется словарь для выделения идентифицируемых главных частей неоднозначно распознанных слов. Это достигается путем принятия первой буквы слова в качестве аргумента для процесса поиска по словарю, и комбинирования затем первой буквы с последующей буквой, пока не будет идентифицировано самое длинное возможное сочетание букв из слова, которое обеспечивает результативный процесс поиска по словарю. Затем эта часть слова используется в процессе поиска в качестве уточняющего параметра для остальной части слова, для которого нужно получить подтверждение как наиболее вероятное слово. Если результат процесса поиска по словарю является неокончательным, процесс продолжается согласно одному из примеров вариантов осуществления, изложенных выше.
Согласно еще одному аспекту настоящего изобретения те же этапы способа согласно настоящему изобретению могут использоваться в процессе проверки орфографии. Алгоритмы проверки орфографии в большинстве случаев будут способны проверять орфографию тех слов, которые входят в состав словаря для определенного языка. Нельзя рассчитывать обнаружить в словаре для определенного языка некоторые категории слов, наподобие слов на иностранных языках и имен собственных, поскольку часто имеются ограничения на размер и согласованность словаря. Используя аспекты настоящего изобретения, которые указаны выше, способ, содержащий этапы согласно настоящему изобретению, может разрешить проблему неверной орфографии слов.
Согласно еще одному аспекту настоящего изобретения неоднозначно распознанные слова часто встречаются также в системах распознавания речи. Всякий раз, когда процесс распознавания, являющийся оптическим распознаванием или процессом распознавания речи и т.д., представляет неоднозначно распознанные слова, устанавливаются возможные варианты неоднозначного слова, например, посредством указаний альтернатив символов для неоднозначно распознанного символа, которые предлагаются самим процессом распознавания, или при помощи идентификации существующих слов как части слова, что описано выше, при этом поиск в сети может обеспечить процесс, идентифицирующий наиболее вероятное слово как правильное распознавание слова.
Согласно еще одному аспекту настоящего изобретения неоднозначно распознанные символы могут представлять собой сочетания двух или более символов. Например, символ "m" может быть сочетанием "r" и "n", или наоборот. То есть неоднозначное распознавание "r" и "n" может быть "m". Вследствие этого в объем настоящего изобретения входит предоставление решений для переменного количества неоднозначно распознанных символов.
Фиг.1 иллюстрирует пример трудного слова "Helligolav".
Фиг.2 иллюстрирует пример сомнительного распознавания букв "N" и "H".
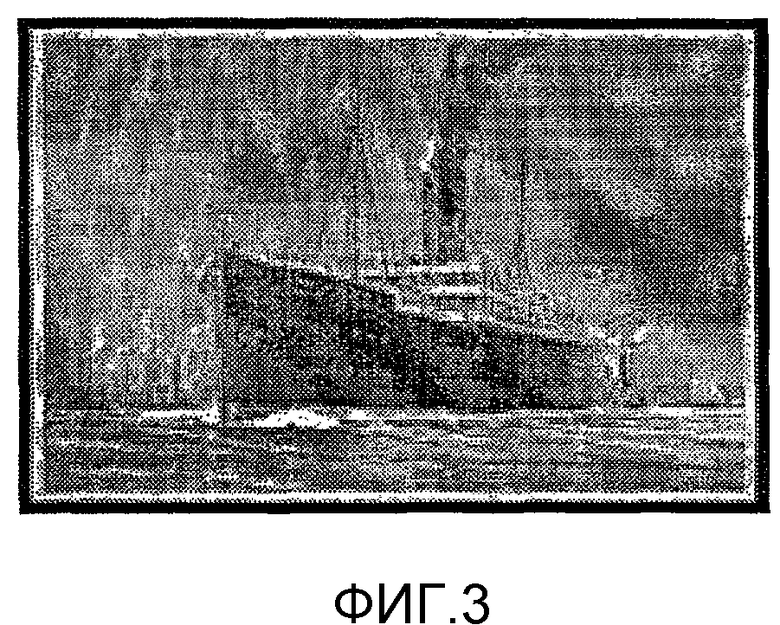
Фиг.3 иллюстрирует изображение судна, встречающееся при поиске в сети Интернет.
Фиг.4 иллюстрирует пример результата поискового запроса, использующего поисковые фразы "Helligolav" и "Nelligolav".
Фиг.5 иллюстрирует другой пример трудно распознаваемого слова.
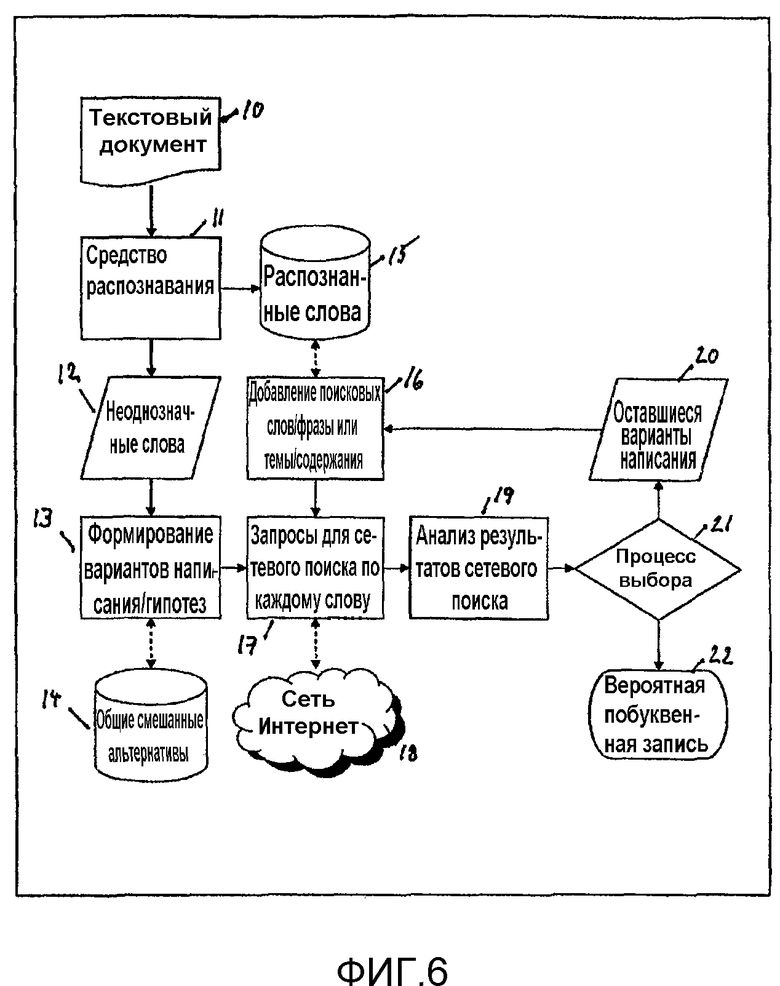
Фиг.6 изображает блок-схему примера способа согласно настоящему изобретению.
Фиг.7 иллюстрирует пример результата работы существующей OCR-программы.
Согласно аспекту настоящего изобретения процесс подтверждения выполняется в три основных этапа. Процесс распознавания, например процесс оптического распознавания (OCR), во-первых, идентифицирует неоднозначно распознанные символы вместе с альтернативами символьной классификации для этого символа. Фиг.7 иллюстрирует пример результата работы коммерческой доступной OCR-программы. Примером OCR-процесса может быть то, что символ "i" может иметь альтернативы "1" и "j". Во-вторых, слово или фраза, частью которых является символ, используется в качестве входных данных для средства сетевого поиска, формируя один поисковый запрос для каждой альтернативной символьной комбинации в этом конкретном слове или фразе. Например, с альтернативами "i", "1" и "j", для исследуемого слова используются три альтернативы. В-третьих, результаты работы средства сетевого поиска анализируются относительно количества экземпляров или вероятности для каждой альтернативной символьной комбинации, и выбирается наиболее вероятная альтернатива. Согласно примеру варианта осуществления настоящего изобретения программа выполняет вышеупомянутые этапы способа, взаимодействуя с сетью Интернет через API для программ-обозревателей сети Интернет, предоставляя варианты написания в качестве аргументов поиска, и измеряет совпадения для вариантов написания. Варианты написания, изображенные на Фиг.7, могут также представляться в виде файла, который может передаваться программе согласно настоящему изобретению, как понятно специалисту в данной области техники.
Пример, который иллюстрирует приложение согласно варианту осуществления в соответствии с настоящим изобретением, взят из письма, написанного в 1926 году, и которое хранится в Национальном Архиве Норвегии (Riksarkivet). Содержание письма связано с отправкой северного оленя через Атлантический Океан пароходами Helligolav и Stavangerfjord. Имена собственные этих двух судов не могут быть найдены ни в одном существующем словаре английского языка. Дополнительно, в этом примере OCR-обработки, как проиллюстрировано на Фиг.2, трудно различить символы "N" и "H". На Фиг.1 проиллюстрировано предложение из письма 1926 года. Соответственно имеются две альтернативы, которые представлены OCR-функцией, "Helligolav" и "Nelligolav". Не существует никакого статистического предпочтения для любой из альтернатив в статистике повторяемости в письме.
При этом, если мы используем эти две альтернативы "Helligolav" и "Nelligolav" в качестве запросов в средстве сетевого поиска, имеется 65 сетевых страниц, содержащих слово "Helligolav", и ни одной, содержащей бессмысленное слово "Nelligolav", явное подтверждение того, что слово должно распознаваться как "Helligolav". Одним из результатов поиска является изображение судна, как проиллюстрировано на Фиг.3.
Согласно другому аспекту настоящего изобретения знание о содержании документа, который будет распознаваться, может использоваться в процессе подтверждения. В вышеприведенном примере знание того, что письмо содержит информацию, связанную с судами, животными и т.д., может использоваться с тем, чтобы запросы подавались на узлы сети Интернет, содержащие информацию, связанную с судами, животными и т.д. В таком случае возвращение изображения из галереи изображений, содержащей иллюстрации судов, является строгой идентификацией значения слова. Одним способом идентификации изображения является идентификация с помощью расширения файла, которое представляет собой, например, ".BMP", ".JPG ", и т.д.
Другой пример использования варианта осуществления настоящего изобретения содержит фразу из популярной книги "Темный Огонь" автора Си Джей Сансом (C.J.Sansom), напечатанной необычным старинным готическим шрифтом, как изображено на Фиг.4. Качество отсканированного изображения этого предложения является превосходным, и поэтому большая часть текста может быть декодирована путем сопоставления аналогичных символов и выполнения расшифровки символов как одноалфавитного шифра замены, который хорошо знаком специалисту по технологиям, используемым в криптоанализе.
Остающиеся нерасшифрованными слова являются такими словами, как имя собственное "Vaughan", поскольку 'V' не поддается расшифровке из-за того, что нет другой заглавной буквы 'V' в тексте и слово "Vaughan" не обнаруживается в словаре. Согласно статистическим данным повторяемости букв, как известно специалисту в данной области техники, возможности смешанных альтернатив для 'V' ограничиваются согласными заглавными буквами 'BCDFGHJKLMNPQRSTVWX'. Измеренные результаты запросов сетевого поиска с использованием этих альтернативных гипотез перечислены в нижеприведенной Таблице 1.
Даже притом, что Vaughan является наиболее вероятным почти с 90% от общего количества совпадений по запросу, не может быть принято окончательное решение, основываясь непосредственно на этих результатах. Есть возможность исключить 'Xaughan' и 'Qaughan' как очень маловероятные из-за очень низкого количества совпадений, но все же остается 10%-ый шанс на ошибочную классификацию, если выбирается альтернатива 'Vaughan'.
Однако, если вместо этого мы используем поисковую фразу "Vaughan livery" (ливрея Вогана), мы найдем только 4 страницы, содержащие фразу, начинающуюся с 'V', а ни одна из других символьных комбинаций не возвращает количественного измерения совпадений по запросу. Объяснением этих результатов является то, что, в то время как семейство Vaughan принадлежит старой английской аристократии и, следовательно, имело слуг в "ливрее Вогана", ни одно из других семейств Baughan, Caughan, Maughan и т.д. не имело служащих в собственных ливреях, поскольку они не относились к титулованному дворянству. Используя сведения о содержании текста, который будет распознаваться, может быть идентифицировано наиболее вероятное слово. В этом примере, слово "livery" является первым последующим словом после исследуемого слова. Поэтому, только при комбинировании этого слова со всеми другими возможными альтернативами в качестве аргументов поиска, словосочетание раскрывает значение содержания и, следовательно, наиболее вероятную версию исследуемого слова.
На Фиг.5 изображен текст, взятый из Энеиды Вергилия, в котором одним из неоднозначно распознанных слов является Danae с вариантом написания Danac. Ни одно из двух слов не обнаруживается в словаре. В том же самом тексте мы имеем безусловно распознанные слова Latinus, Turnus, Rutulian, Argos и Long.
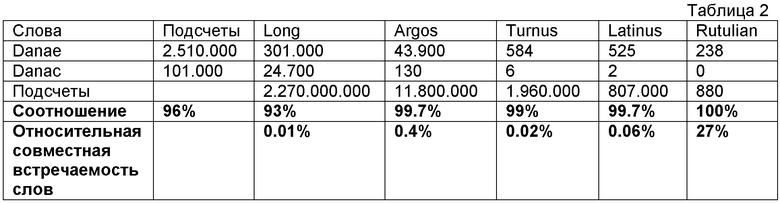
Обратимся к Таблице 2, соотношение совпадений при поиске по запросам в сети между Danae и Danac составляет 96 % в пользу Danae, такое соотношение не может признаваться как решающее. Одна возможная стратегия состоит в том, чтобы использовать поиск в сети, комбинируя искомые слова с другими безусловно распознанными словами. Слово Long является широко распространенным, и только 0.1 документа на тысячу всех документов, содержащих слово Long, содержит или Danae или Danac, и коэффициент совпадения равен 93%. Слова Argos, Turnus и Latinus все выдают в результате коэффициенты совпадения, в сочетании с Danae и Danac, которые свидетельствуют в пользу Danae (>99%), но относительная совместная встречаемость слов остается все еще небольшой. Rutulian является наименее распространенным словом, которое само по себе дает в результате только 880 совпадений, что подводит к окончательному аргументу. Rutulian никогда не сочетается с Danac, но в 27% документов, содержащих слово Rutulian, мы также обнаружим слово Danae, что свидетельствует об устойчивой совместной встречаемости слов.
Обобщением этого принципа является то, что безусловно распознанные слова с низкими значениями повторяемости при поисковых запросах в сети, которые встречаются совместно с одной из альтернатив слова, обеспечивает более достоверное решение, чем безусловно распознанные слова с высокой повторяемостью. В целом, аспектом согласно настоящему изобретению является то, что есть возможность безусловно идентифицировать, какое слово не подходит. Это достигается с помощью идентификации альтернатив, которые возвращают нулевые результаты измерений совпадений, исходя из поиска в сети Интернет. Вообще, количество возвращенных измеренных совпадений может попадать в пределы трех категорий:
1) Итоговое количество измеренных совпадений больше предварительно заданного верхнего порогового значения для одной из альтернатив. Тогда эта альтернатива выбирается.
2) Количество измеренных совпадений меньше нижнего порогового значения. Тогда эта альтернатива отклоняется.
3) Количество измеренных совпадений попадает между верхним и нижним пороговыми значениями. Тогда альтернатива дополнительно исследуется.
Согласно примеру варианта осуществления настоящего изобретения эти три категории могут использоваться как количественный показатель подтверждения вероятной версии исследуемого слова. Согласно иному варианту осуществления настоящего изобретения верхнее пороговое значение и нижнее пороговое значение могут повышаться или понижаться совместно, или независимо. Например, 100% всех совпадений могут разделиться на три группы, определяемые как 10% больше верхнего порогового значения, 10% меньше нижнего порогового значения, из чего следует, что 80% совпадений попадают между пороговыми значениями. Согласно иному варианту осуществления диапазоны могут быть разделены как 5%, 90%, 5% соответственно или как 10%, 70%, 30% соответственно. Любое разделение находится в пределах объема настоящего изобретения.
Согласно примеру варианта осуществления настоящего изобретения способ, содержащий этапы, на которых подтверждают наиболее вероятную версию неоднозначно распознанного слова, содержит следующие этапы:
a) Всякий раз, когда процесс распознавания представляет неоднозначно распознанный символ, слово, содержащее этот символ, записывается так, что альтернативы версий для символа вставляются на место символа в слове, таким образом, формируя список, содержащий альтернативы слова. OCR-функция, как понятно специалисту в данной области техники, предоставляет такую информацию.
b) Затем слова из списка поочередно используются в качестве запросов в программе-обозревателе сети Интернет, как понятно специалисту в данной области техники. Результаты поиска измеряются и сохраняются в списке, например.
c) Затем на следующем этапе нужно исследовать результат в списке отчетов. Процесс выбора подтверждения основывается на наблюдении, что те поисковые запросы, которые возвращают нулевые результаты, обеспечивают безусловное подтверждение того, что слово не подходит. Поэтому процесс будет дополнительно исследовать только те записи, которые обеспечивают отличный от нуля результат поискового запроса. Однако интерпретация количества совпадений связана не только с самым большим количеством совпадений в сети Интернет, но и относительным коэффициентом совпадений относительно других совпадений. Если относительный коэффициент совпадений больше верхнего предварительно заданного порогового значения для определенной альтернативы, эта альтернатива выбирается как наиболее вероятное слово.
d) Если относительный коэффициент совпадений меньше верхнего порогового значения, и относительный коэффициент совпадений больше нижнего порогового значения для коэффициента совпадений, выполняется дополнительное исследование. Если альтернативное слово обладает относительным коэффициентом совпадений за пределами верхнего и нижнего пороговых значений, альтернатива интерпретируется как безусловно не являющаяся словом.
e) Дополнительно, исследование неоднозначно распознанного слова содержит этапы, на которых проверяют, имеет ли слово заглавную букву, и вследствие этого вероятно является именем собственным. Если процесс распознавания возвращает другие вероятные имена собственные, по меньшей мере, два имени собственных используются как объединенный поисковый запрос. И в этом случае комбинация слов, возвращающая нулевые совпадения, исключается из числа кандидатов. Затем остающиеся результаты проверяются на соответствие доверительному интервалу, являющиеся или больше верхнего порогового значения или меньше нижнего порогового значения, или как являющиеся кандидатами на дополнительное исследование, если находятся в пределах ограничений верхнего и нижнего пороговых значений.
f) Если проверка на имя собственное терпит неудачу, на дополнительном этапе выполняют комбинирование найденных в тексте, по меньшей мере, одного предшествующего и, по меньшей мере, одного последующего слова относительно исследуемого слова. Выполняется такая же проверка на достоверность.
g) Если проверки со словосочетаниями на этапе f) терпят неудачу, то выбирается, по меньшей мере, одно предшествующее или, по меньшей мере, одно последующее слово, содержащее количество символов больше предварительно заданного порогового значения, для комбинирования с исследуемым словом. Затем по представленным результатам выполняется проверка достоверности. Используя только слова больше определенной длины, избегают использования маленьких слов, подобных "в", "и" и т.д., в качестве аргументов поиска.
h) Если проверка достоверности на этапе g) терпит неудачу, то выполняются подсчеты относительной повторяемости, по меньшей мере, одного предшествующего или, по меньшей мере, одного последующего слова, и на этапе g) используются только слова с низким подсчитанным значением относительной повторяемости. Затем результаты измерений для различных вариантов написания используются для определения наиболее вероятного слова, или используются, чтобы ввести дополнительные результаты измерений относительно вариантов написания с использованием отдельного слова, сочетания нескольких слов, фраз и/или в сочетании с символами-шаблонами в качестве дополнительных измеряемых аргументов поиска.
i) Если проверка достоверности терпит неудачу на этапе h) и/или g), то первые символы слова используются в качестве входных данных для процесса поиска по словарю. Если достигается комбинация символов, которая возвращает достоверный результат от процесса поиска по словарю, эта часть исследуемого слова представляет собой достоверное слово, которое комбинируется с альтернативами для оставшейся части слова. Затем снова выполняется проверка достоверности.
j) Если любой из этапов c)-i) возвращает неокончательные решения для исследуемого слова, то верхнее пороговое значение и нижнее пороговое значение изменяются для совместных этапов на некоторые предварительно заданные интервалы, и этапы подтверждения c)-i) повторяются.
k) Если этап j) также терпит неудачу, используются случайные выборы верхнего и нижнего пороговых значений, и этапы подтверждения c)-i) повторяются.
l) Если проверка достоверности терпит неудачу на этапе k), альтернатива, получившая наибольший коэффициент совпадений по результатам поисковых запросов на этапе d), выбирается в качестве наиболее вероятного слова.
В вышеописанном примере варианта осуществления настоящего изобретения неоднозначно распознанный символ может быть двумя или более символами, которые являются трудно различимыми. Например, символ "m" может быть комбинацией "r" и "n", например, но для OCR-функции представляется проблематичным различить соответствующие символы. Кроме того, существует возможность того, что OCR-функция отчетливо интерпретирует комбинацию "r" и "m", а символ в действительности представляет собой "m". Во всех вариантах осуществления настоящего изобретения любая ссылка на неоднозначно распознанный символ может содержать один или более неоднозначно распознанных символов, как проиллюстрировано в настоящем описании. В этом контексте выражение "вариант написания" охватывает подстановку вместо неоднозначно распознанного символа одной или более возможной замены одного символа на комбинацию двух других символов, или наоборот.
Согласно другому аспекту настоящего изобретения пороговые величины, используемые, чтобы обусловить принятия варианта написания, связаны с результатами измерений для возможных вариантов написания, как описано выше. Тем не менее, общее количество измеряемых совпадений будет в некотором смысле влиять на фактический уровень используемых пороговых значений. Согласно примеру варианта осуществления настоящего изобретения уровень принятия для i-го варианта написания, обозначенный как принятие(i), может быть выражен следующим образом:

при этом i обозначает один из вариантов написания, #совпаденийi представляет собой измеренное количество совпадений для i-го варианта написания, знаменатель представляет собой общее измеренное количество совпадений для всех вариантов написания, и 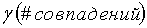 представляет собой пороговый уровень, который является функцией количества совпадений.
представляет собой пороговый уровень, который является функцией количества совпадений.
В другом примере варианта осуществления настоящего изобретения принятие(i) определяется следующим образом:
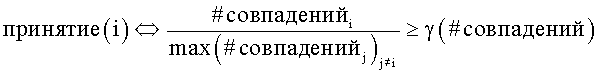
при этом 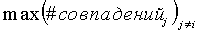 представляет собой общее измеренное количество совпадений для всех вариантов написания, за исключением варианта написания для i, а другие параметры определяются, как изложено выше.
представляет собой общее измеренное количество совпадений для всех вариантов написания, за исключением варианта написания для i, а другие параметры определяются, как изложено выше.
В примере варианта осуществления настоящего изобретения, γ является одной из двух возможных величин, одной для очень большого количества совпадений и другой для обратного случая. В еще одном примере варианта осуществления настоящего изобретения существуют различные величины γ для фраз, отдельных слов и нескольких слов, если поиск содержит символы-шаблоны и т.д., и всякий раз, когда вариант написания замеряется как отдельное слово, как часть поисковых запросов с несколькими словами, или как фраза, соответственно используются различные пороговые уровни для проверки наиболее вероятного варианта написания.
Другая форма величины принятия могла бы сохранять показатель в диапазоне
[0,1], тогда пример порогового значения может быть записан в следующем виде:
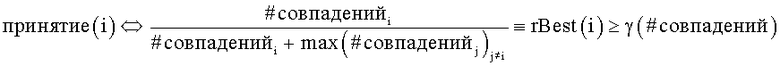
в котором параметры определяются, как изложено выше. Определение порогового значения, также обозначенного как rBest(i), используется в качестве параметра в оценочной функции, задаваемой ниже.
Согласно другому аспекту настоящего изобретения также есть возможность измерить и провести сравнения с пороговыми уровнями, чтобы отклонить вариант написания, например, используя выражение:

в котором параметры определяются, как изложено выше, в то время как нижний пороговый уровень, как функция количества совпадений, обозначается как 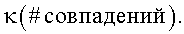
В примере варианта осуществления настоящего изобретения κ является одной из двух возможных величин, одной для очень большого количества совпадений и другой для обратного случая. В еще одном примере варианта осуществления настоящего изобретения существуют различные величины κ для фраз, отдельных слов и нескольких слов, если поиск содержит символы-шаблоны и т.д., и всякий раз, когда вариант написания замеряется как отдельное слово, как часть поисковых запросов с несколькими словами, или как фраза, соответственно используются различные пороговые уровни для проверки наиболее вероятного варианта написания.
Как понятно специалисту в данной области техники, OCR-программы могут также представлять вероятностные или оценочные величины символов, обозначаемые CRS-величина, которые могут использоваться для проектирования оценочной функции, которая включает в себя и CRS, и #совпадений, исходя из сетевых поисковых запросов. Такие оценочные функции могут использоваться как величины принятия или величины отклонения соответственно. Согласно аспекту настоящего изобретения наиболее вероятным словом является то, которое максимизирует оценочную функцию, для слова i:
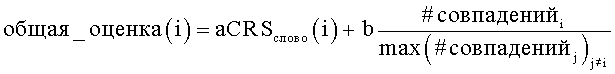
при этом a+b=1, CRSслово(i) представляет собой оценочную величину символа в результате OCR-процесса, имеющего отношение к i-му варианту написания, 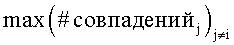 представляет собой общее измеренное количество совпадений для всех вариантов написания, за исключением варианта написания для i. Весовые коэффициенты a и b могут использоваться, чтобы регулировать относительную значимость или вклад в значение функции, исходя из CRS-величины и количества совпадений соответственно.
представляет собой общее измеренное количество совпадений для всех вариантов написания, за исключением варианта написания для i. Весовые коэффициенты a и b могут использоваться, чтобы регулировать относительную значимость или вклад в значение функции, исходя из CRS-величины и количества совпадений соответственно.
Более сложная оценочная функция могла бы быть выражена следующим образом:
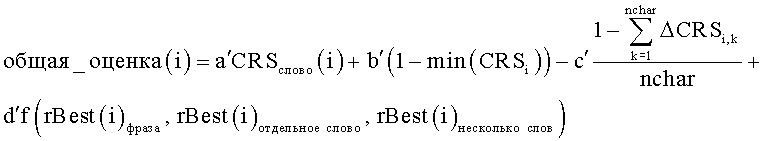
при этом второй член является минимальным CRS для всех символов в слове, третий член является суммой разности CRS между наибольшей CRS для каждого символа и CRS, использующей слово(i). Функция f является или минимальной, или максимальной функцией соответственно различных уровней принятия, которые определены выше относительно отдельного слова i, уровня принятия для фраз, содержащих слово i, и поисковых запросов с несколькими словами, содержащих слово i. В функции a'+b'+c'+d'=1, и используются, чтобы регулировать вклад каждого элемента. nchar представляет собой количество символов в словах i.
Способ согласно настоящему изобретению, который описан выше, может быть реализован в виде программ системы программного обеспечения в существующей OCR-системе, как известно специалисту в данной области техники. Единственным предварительным условием является то, что функция распознавания представляет неоднозначно распознанные символы и слова, содержащие эти символы. Дополнительно функция распознавания должна представлять альтернативы для неоднозначно распознанного символа. Дополнительно этапы подтверждения не обязательно должны выполняться в описанном выше порядке, другими словами этап i) может быть выполнен перед этапом h), как понятно специалисту в данной области техники.
Согласно вариантам осуществления настоящего изобретения всякий раз, когда аргумент поиска комбинируется с другими словами, могут также использоваться части слов. Дополнительно операция комбинирования элементов для предоставления аргумента поиска включает в себя, но не ограничивается этим, использование широко известных поисковых операторов, например "дом AND хозяйка", при этом AND является оператором в форме аргумента поиска, который хорошо знаком специалисту в данной области техники. Дополнительно нужно понимать, что также есть возможность исключить некоторые типы файлов при поиске посредством использования специальных поисковых операторов. Например, добавление "-PDF" после аргумента поиска исключает все файлы формата PDF, которые очень часто содержат отсканированные изображения текста. Вызывая такую команду, процесс поиска избегает исследования документов, содержащих типичные ошибки, процесс поиска направлен на исправление, с помощью этого квалифицируя документы, используемые как основание для проверки, как являющиеся "чистыми" документы.
Дополнительные примеры вариантов осуществления настоящего изобретения содержат процесс подтверждения, который сначала идентифицирует количество совпадений для предшествующих слов и последующих слов, которые предоставляются в качестве аргументов поиска в средстве поиска. Эти последующие слова с низким коэффициентом совпадений, отличным от нуля (меньше первого порогового значения), и которые содержат большое количество символов (больше второго порогового значения), используются в сочетании с исследуемым словом в качестве варианта написания для процесса подтверждения.
Согласно другому примеру варианта осуществления настоящего изобретения верхнее пороговое значение подтверждения и нижнее пороговое значение подтверждения могут изменяться совместно или независимо друг от друга, для обеспечения настройки условий классифицирования исследуемого неоднозначно распознанного слова. Согласно этому примеру варианта осуществления всякий раз, когда изменяются пороговые значения, инициируется новый поиск, и процесс повторяется до завершения, когда или результат превышает верхнее пороговое значение, или, как неокончательный результат, в случае, когда выбранный вариант написания, обеспечивающий наибольшее количество совпадений, выбирается в качестве наиболее вероятной версии исследуемого слова.
Согласно еще одному примеру варианта осуществления настоящего изобретения пользователь может выбирать набор узлов, которые средство поиска будет использовать при выполнении процесса подтверждения. Согласно этому варианту осуществления настоящего изобретения могут выбираться не только узлы сети Интернет, кроме того, могут быть выбраны компьютеры, соединенные с внутренними сетями на базе Интернет-технологии, VPR-сетями, или подобными сетями. Согласно этому примеру варианта осуществления необходимые аутентификация и ассоциации полностью выполняются, исходя из информации, содержащейся в списке, выбранном пользователем при обращении к таким компьютерам, как известно специалисту в данной области техники. Также необходимо обратить внимание, что информационные источники не обязательно ограничиваются хранящим информацию компьютером, соединенным с сетями, но средство поиска согласно настоящему изобретению может также осуществлять поиск на подключенном локально или удаленно жестком диске, содержащем информацию, что подчеркивается в принципах настоящего изобретения. То есть любая файловая система или способ монтирования файловой системы, присущей локальным компьютерам или компьютерам в сети, рассматриваются как находящиеся в пределах объема настоящего изобретения, и как доступные для поиска узлы.
Специалист в данной области техники может легко понять, что те же способ и системы согласно настоящему изобретению могут использоваться в системе распознавания любого типа, например в системах распознавания речи. Процесс подтверждения может основываться на фонемах, вместо отдельных символов, в качестве смешанных альтернатив.
Дополнительно, специалисту в данной области техники также легко понять, что аналогичные этапы согласно настоящему изобретению могут выполняться в программной среде проверки орфографии.
Фиг.6 иллюстрирует пример варианта осуществления системы согласно настоящему изобретению в виде блок-схемы компьютерной программы, выполняющей этапы способа согласно настоящему изобретению, обеспечивающего подтверждение наиболее вероятного слова неоднозначно распознанного слова в OCR-системе, с которой этот вариант осуществления взаимодействует.
Текстовый документ 10 подается на вход средства 11 распознавания, представляющего неоднозначные слова 12 в виде списка неоднозначно распознанных символов вместе со словами, в которых эти символы встречаются. На этапе 13 составляются варианты написания или гипотезы.
Затем варианты написания используются в качестве запросов для сетевого поиска, на этапе 17.
В качестве альтернативы, корректные распознанные слова записываются на этапе 15. На этапе 16 выполняется процесс, добавляющий слова или фразы или тему/содержание к документу. Вместе с вариантами написания из 18, эти комбинации используются в качестве аргументов поиска на этапе 17.
На этапе 19 осуществляется анализ, содержащий этапы подтверждения согласно настоящему изобретению, результатов поиска, предоставленных благодаря этапу 17. Процесс выбора на этапе 21 может использовать количественный показатель подтверждения, как описано выше, чтобы сделать фактический выбор. Однако любой процесс выбора может быть реализован согласно настоящему изобретению. Если процесс выбора является неокончательным, процесс возвращает неокончательные результаты обратно на этап 16, и процесс продолжается, пока не будет достигнут окончательный результат, или не исчерпается количество возможных повторений стратегий и/или корректировок пороговых значений. Тогда процесс 21 выбора завершается выбором альтернативы для исследуемого слова, обеспечивающей наибольший количественный показатель подтверждения, и представлением этой альтернативы обратно OCR-средству, которое порождает полный текст, содержащий все подтвержденные неоднозначно распознанные слова, замененные наиболее вероятной альтернативой для каждого из них.
Согласно другому аспекту настоящего изобретения символ пробела также рассматривается как символ, который может быть неоднозначно распознанным символом. Это происходит в случае, когда слово по ошибке разбито на две половины, например. В пределах объема настоящего изобретения находится Формирование вариантов написания, содержащих удаление символа из слова или фразы.
| название | год | авторы | номер документа |
|---|---|---|---|
| НЕЧЕТКИЙ ПОИСК С ИСПОЛЬЗОВАНИЕМ ФОРМ СЛОВ ДЛЯ РАБОТЫ С БОЛЬШИМИ ДАННЫМИ | 2021 |
|
RU2768233C1 |
| ПРОВЕРКА ОШИБОК СОЧЕТАНИЙ СЛОВ НА БАЗЕ СЕТИ ИНТЕРНЕТ | 2007 |
|
RU2458391C2 |
| СИСТЕМА И СПОСОБ ХРАНЕНИЯ ВАРИАНТА ОТЧЕТА | 2010 |
|
RU2544797C2 |
| АВТОМАТИЧЕСКОЕ ВЕДЕНИЕ КАЛЕНДАРЯ | 2014 |
|
RU2669516C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ВЕРИФИКАЦИИ В ПРОЦЕССЕ ЧТЕНИЯ | 2014 |
|
RU2571396C2 |
| СПОСОБЫ И СИСТЕМЫ ОБРАБОТКИ ИЗОБРАЖЕНИЙ МАТЕМАТИЧЕСКИХ ВЫРАЖЕНИЙ | 2014 |
|
RU2596600C2 |
| МЕТОД И СИСТЕМА ИЗВЛЕЧЕНИЯ ДАННЫХ ИЗ ИЗОБРАЖЕНИЙ СЛАБОСТРУКТУРИРОВАННЫХ ДОКУМЕНТОВ | 2015 |
|
RU2613846C2 |
| СПОСОБ И СИСТЕМА ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ, КОТОРЫЕ СОКРАЩАЮТ ВРЕМЯ ОБРАБОТКИ ИЗОБРАЖЕНИЙ, ПОТЕНЦИАЛЬНО НЕ СОДЕРЖАЩИХ СИМВОЛЫ | 2014 |
|
RU2571616C1 |
| ИДЕНТИФИКАЦИЯ СЕМАНТИЧЕСКИХ ВЗАИМООТНОШЕНИЙ В КОСВЕННОЙ РЕЧИ | 2008 |
|
RU2488877C2 |
| СИСТЕМЫ И СПОСОБЫ ДЛЯ ПОИСКА С ИСПОЛЬЗОВАНИЕМ ЗАПРОСОВ, НАПИСАННЫХ НА ЯЗЫКЕ И/ИЛИ НАБОРЕ СИМВОЛОВ, ОТЛИЧНОМ ОТ ТАКОВОГО, ДЛЯ ЦЕЛЕВЫХ СТРАНИЦ | 2004 |
|
RU2363983C2 |




Настоящее изобретение относится к системам Оптического Распознавания Символов, а в частности к способу и системе для подтверждения неоднозначно распознанных слов, которые представлены процессом оптического распознавания символов, используя варианты написания в качестве аргументов поиска для средства поиска в сети Интернет. Техническим результатом является повышение точности распознавания текстов. Измеренное количество совпадений для каждого варианта написания используется, чтобы предоставить количественный показатель подтверждения для наиболее вероятного варианта написания. Всякий раз, когда количественный показатель подтверждения не является окончательным, используется множество стратегий поиска, чтобы добиться результата измерений, содержащего нулевые совпадения за исключением одного варианта написания, который используется в качестве правильной альтернативы. 2 н. и 54 з.п. ф-лы, 2 табл., 7 ил.
1. Способ для принятия решения относительно противоречивых выходных данных от системы Оптического Распознавания Символов (OCR), причем выходные данные содержат, по меньшей мере, одно слово, по меньшей мере, с одним неоднозначно распознанным символом, причем, по меньшей мере, один неоднозначно распознанный символ представлен в выходных данных вместе с вероятными альтернативами для, по меньшей мере, одного неоднозначно распознанного символа, и словами, в которых, по меньшей мере, один неоднозначно распознанный символ встречается в изображении текста, обрабатываемого OCR-системой, при этом способ содержит этапы, на которых:
используют средство поиска в сети Интернет с аргументами поиска, установленными согласно стратегии поиска, содержащей этапы, на которых:
а) предоставляют начальные аргументы поиска путем формирования вариантов написания для слов, содержащих, по меньшей мере, один неоднозначно распознанный символ, заменяя, по меньшей мере, один неоднозначно распознанный символ поочередно на представленные вероятные альтернативы для, по меньшей мере, одного символа, один по одному и в возможных комбинациях в каждом встречающемся слове, или удаляя символ, тем самым формируя множество вариантов написания, а затем измеряют и записывают количество совпадений для результатов поисковых запросов по каждому соответствующему варианту написания, которые были сформированы таким образом,
b) сравнивают измеренное количество совпадений для каждого из вариантов написания с верхним предварительно заданным относительным пороговым уровнем и нижним предварительно заданным относительным пороговым уровнем, причем каждое из соответствующих сравнений множества результатов измерения принадлежит к одному из трех возможных исходов:
i) если результат измерения для варианта написания больше предварительно заданного относительного верхнего порогового уровня, соответствующий вариант написания для этого результата измерения является правильным вариантом написания для слова, и поиск в сети Интернет завершается,
ii) если результат измерения для варианта написания меньше нижнего предварительно заданного относительного порогового уровня, соответствующий вариант написания для этого результата измерения считается несуществующим, и слово с этим вариантом написания исключается из дополнительных исследований, и продолжают процесс с другими вариантами написания, которые были сформированы в качестве аргументов поиска для средства поиска в сети Интернет,
iii) если результат измерения для варианта написания попадает между верхним относительным пороговым уровнем и нижним относительным пороговым уровнем, завершают работу средства поиска в сети Интернет и изменяют стратегию поиска, с помощью предоставления дополнительных аргументов поиска в виде комбинации элементов множества остающихся вариантов написания и других слов, встречающихся в документе, других символьных альтернатив для этого, по меньшей мере, одного неоднозначно распознанного символа, фраз, настройки верхнего относительного порогового уровня, настройки нижнего относительного порогового уровня, и/или другую информацию, связанную с выходными данными от OCR-системы, перед тем, как продолжить использование стратегии поиска, обеспечивая дополнительные результаты измерений и сравнения для принятия решения относительно противоречивых выходных данных,
с) продолжают выполнение этапа b) некоторое предварительно заданное число раз, или пока не останется только один вариант написания, в зависимости от того, что случится раньше, обеспечивают повторение действий по множеству различных аргументов поиска, используемых в стратегии поиска до завершения этапа b), и используют остающийся вариант написания, обладающий наибольшим результатом измерения больше верхнего относительного порогового уровня в качестве правильного варианта написания.
2. Способ по п.1, в котором стратегия поиска содержит этап, на котором заменяют, по меньшей мере, один неоднозначно распознанный символ на комбинацию, по меньшей мере, двух символов при формировании вариантов написания.
3. Способ по п.1, в котором стратегия поиска содержит этап, на котором заменяют два или более, по меньшей мере, из одного неоднозначно распознанного символа на единственный символ при формировании вариантов написания.
4. Способ по п.1, в котором стратегия поиска содержит этап, на котором идентифицируют, является ли исследуемый вариант написания именем собственным, и если это так, выделяют в OCR-процессе другие распознанные слова, которые являются именами собственными, затем предоставляют в качестве варианта написания комбинацию исследуемого слова, по меньшей мере, с одним другим надежно распознанным именем собственным.
5. Способ по п.1, в котором стратегия поиска содержит этап, на котором используют, по меньшей мере, одно предшествующее слово относительно исследуемого слова в сочетании с исследуемым словом в качестве варианта написания.
6. Способ по п.1, в котором стратегия поиска содержит этап, на котором используют, по меньшей мере, одно последующее слово относительно исследуемого слова в сочетании с исследуемым словом в качестве варианта написания.
7. Способ по п.1, в котором стратегия поиска содержит этап, на котором используют, по меньшей мере, одно более отдаленное предшествующее слово относительно исследуемого слова в сочетании с исследуемым словом в качестве варианта написания.
8. Способ по п.1, в котором стратегия поиска содержит этап, на котором используют, по меньшей мере, одно более отдаленное последующее слово относительно исследуемого слова в сочетании с исследуемым словом в качестве варианта написания.
9. Способ по п.1, в котором стратегия поиска содержит этап, на котором используют, по меньшей мере, одно более отдаленное предшествующее слово относительно исследуемого слова, которое содержит количество символов больше предварительно заданного порогового значения, в сочетании с исследуемым словом в качестве варианта написания.
10. Способ по п.1, в котором стратегия поиска содержит этап, на котором используют, по меньшей мере, одно более отдаленное последующее слово относительно исследуемого слова, которое содержит количество символов больше предварительно заданного порогового значения, в сочетании с исследуемым словом в качестве варианта написания.
11. Способ по п.1, в котором стратегия поиска содержит этапы, на которых:
i) подсчитывают экземпляры слов, встречающихся в изображении текста во время OCR-процесса,
ii) используют, по меньшей мере, одно более отдаленное предшествующее слово относительно исследуемого слова, которое обладает небольшим количеством экземпляров, меньше предварительно заданного порогового значения, в сочетании с исследуемым словом в качестве варианта написания.
12. Способ по п.11, в котором этап ii) стратегии поиска дополнительно содержит этап, на котором:
используют, по меньшей мере, одно более отдаленное последующее слово относительно исследуемого слова, которое обладает небольшим количеством экземпляров, меньше предварительно заданного порогового значения, в сочетании с исследуемым словом в качестве варианта написания.
13. Способ по п.1, в котором стратегия поиска содержит этапы, на которых:
i) подсчитывают экземпляры слов, встречающихся в изображении текста во время OCR-процесса,
ii) используют, по меньшей мере, одно более отдаленное предшествующее слово относительно исследуемого слова, которое обладает большим количеством экземпляров, больше первого предварительно заданного порогового значения, и которое содержит большое количество символов в слове, больше второго порогового значения, в сочетании с исследуемым словом в качестве варианта написания.
14. Способ по п.13, в котором этап ii) стратегии поиска дополнительно содержит этап, на котором:
используют, по меньшей мере, одно более отдаленное последующее слово относительно исследуемого слова, которое обладает большим количеством экземпляров, больше первого предварительно заданного порогового значения, и которое содержит большое количество символов в слове, большее второго порогового значения, в сочетании с исследуемым словом в качестве варианта написания.
15. Способ по п.1, в котором стратегия поиска содержит этапы, на которых:
i) выбирают поочередно более отдаленные предшествующие слова относительно исследуемого слова и составляют список тех предшествующих слов, которые содержат количество символов, большее предварительно заданного порогового значения,
ii) используют выбранные слова, полученные на этапе i), в качестве аргументов поиска в средстве поиска в сети Интернет и идентифицируют слово, которое обеспечивает наименьшее количество совпадений, отличное от нуля, и используют такое слово в сочетании с исследуемым словом в качестве варианта написания.
16. Способ по п.1, в котором стратегия поиска содержит этапы, на которых:
i) выбирают поочередно более отдаленные последующие слова относительно исследуемого слова и составляют список тех последующих слов, которые содержат количество символов, большее предварительно заданного порогового значения,
ii) используют выбранные слова, внесенные в список на этапе i), в качестве аргументов поиска в средстве поиска в сети Интернет и идентифицируют слово, которое обеспечивает наименьшее количество совпадений, отличное от нуля, и используют такое слово в сочетании с исследуемым словом в качестве варианта написания.
17. Способ по п.1, в котором сравнение с верхним пороговым значением и сравнение с нижним пороговым значением основывается на перенормировке пороговых значений и представленного общего количества совпадений.
18. Способ по п.1, в котором верхнее и нижнее пороговые значения изменяются с постепенным увеличением и снижением совместно, и всякий раз, когда выполняется изменение пороговых значений, инициируют новый поиск и процесс подтверждения.
19. Способ по п.1, в котором верхнее и нижнее пороговые значения изменяются с постепенным увеличением и снижением независимо, и всякий раз, когда выполняется изменение пороговых значений, инициируют новый поиск и процесс подтверждения.
20. Способ по п.1, в котором стратегия поиска содержит этапы, на которых:
выбирают поочередно первые символы из исследуемого слова, комбинируют эти символы с увеличением количества первых символов, используют каждый из вариантов, полученных в результате увеличения количества символов, в качестве аргумента для поиска по словарю, и если словарь возвращает истинное слово в результате поиска по словарю, используют это слово в сочетании с исследуемым словом в качестве варианта написания.
21. Способ по п.1, в котором средство поиска, в качестве альтернативы или в дополнение к выполнению поисковых запросов в сети Интернет, осуществляет поисковые запросы по другим информационным источникам, которые не доступны по сети Интернет, но которые доступны через внутреннюю сеть на базе Интернет-технологии, Виртуальную Частную Сеть, или подобные сети, или посредством поиска непосредственно на подсоединенном жестком диске, содержащем информацию.
22. Способ по п.21, в котором пользователь может выбирать из списка, по каким информационным узлам будет производиться поиск во время процесса подтверждения.
23. Способ по п.1, в котором верхнее пороговое значение определяется следующим образом
 ,
,
при этом i обозначает один из вариантов написания, #совпаденийi представляет собой измеренное количество совпадений для i-го варианта написания, знаменатель представляет собой общее измеренное количество совпадений для всех вариантов написания, и γ(# совпадений) представляет собой пороговый уровень, который является функцией количества совпадений.
24. Способ по п.1, в котором верхнее пороговое значение определяется следующим образом
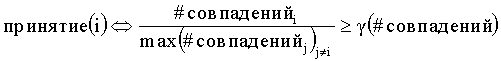 ,
,
при этом i обозначает один из вариантов написания, #совпаденийi представляет собой измеренное количество совпадений для i-го варианта написания, max(# совпаденийj)j≠i представляет собой общее измеренное количество совпадений для всех вариантов написания, за исключением варианта написания для i, и γ(# совпадений) представляет собой пороговый уровень, который является функцией количества совпадений.
25. Способ по п.1, в котором нижнее пороговое значение определяется следующим образом
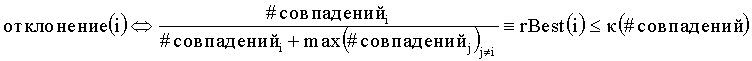
при этом #совпаденийi представляет собой измеренное количество совпадений для i-го варианта написания, max(# совпаденийj)j≠i представляет собой общее измеренное количество совпадений для всех вариантов написания, за исключением варианта написания для i, и κ(# совпадений) представляет собой пороговый уровень, который является функцией количества совпадений.
26. Способ по п.1, в котором оценочная функция используется, чтобы определить результат измерения для количества совпадений, следующим образом:
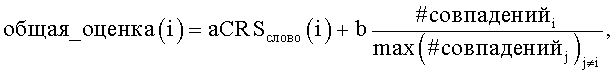
при этом a+b=1, CRSслово(i) представляет собой оценочную величину символа в результате OCR-процесса, имеющего отношение к i-му варианту написания, max(# совпаденийj)j≠i представляет собой общее измеренное количество совпадений для всех вариантов написания, за исключением варианта написания для i.
27. Способ по п.1, в котором оценочная функция используется, чтобы определить результат измерения для количества совпадений, следующим образом:
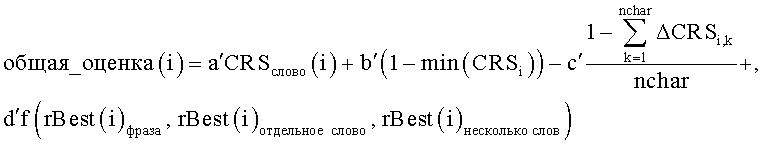
при этом a'+b'+c'+d'=1, CRSслово(i) представляет собой оценочную величину символа в результате OCR-процесса, имеющего отношение к i-му варианту написания, второй член является минимальным CRS для всех символов в слове, третий член является суммой разности CRS между наибольшей CRS для каждого символа и CRS, использующей слово(i), f является минимальной или максимальной функцией величин верхнего порогового значения или нижнего порогового значения, как определено в п.23, и nchar представляет собой количество символов в i-м слове.
28. Способ по любому из пп.1-27, в котором OCR-система является системой распознавания речи, и этот, по меньшей мере, один неоднозначно распознанный символ представляет собой неоднозначную интерпретацию фонемы.
29. Система для принятия решения относительно противоречивых выходных данных от системы Оптического Распознавания Символов (OCR), причем выходные данные содержат, по меньшей мере, одно слово, по меньшей мере, с одним неоднозначно распознанным символом, причем этот, по меньшей мере, один неоднозначно распознанный символ представлен в выходных данных вместе с вероятными альтернативами для этого, по меньшей мере, одного неоднозначно распознанного символа, и словами, в которых этот, по меньшей мере, один неоднозначно распознанный символ встречается в изображении текста, обрабатываемого OCR-системой, при этом система содержит:
системный компонент, использующий средство поиска в сети Интернет с аргументами поиска, установленными согласно стратегии поиска, содержащей этапы, на которых:
a) системный компонент предоставляет начальные аргументы поиска путем формирования вариантов написания для слов, содержащих этот, по меньшей мере, один неоднозначно распознанный символ, заменяя этот, по меньшей мере, один неоднозначно распознанный символ поочередно на представленные вероятные альтернативы для этого, по меньшей мере, одного символа, и в возможных комбинациях в каждом встречающемся слове, или удаляя символ, тем самым формируя множество вариантов написания, а затем измеряет и записывает количество совпадений для результатов поисковых запросов по каждому соответствующему варианту написания, которые были сформированы таким образом,
b) системный компонент сравнивает измеренное количество совпадений для каждого из вариантов написания с верхним предварительно заданным относительным пороговым уровнем и нижним предварительно заданным относительным пороговым уровнем, причем каждое из соответствующих сравнений множества результатов измерения принадлежит к одному из трех возможных исходов:
i) если результат измерения для варианта написания больше предварительно заданного относительного верхнего порогового уровня, соответствующий вариант написания для этого результата измерения является правильным вариантом написания для слова, и поиск в сети Интернет завершается,
ii) если результат измерения для варианта написания меньше нижнего предварительно заданного относительного порогового уровня, соответствующий вариант написания для этого результата измерения считается несуществующим, и слово с этим вариантом написания исключается из дополнительных исследований, и продолжается процесс с другими вариантами написания, которые были сформированы в качестве аргументов поиска для средства поиска в сети Интернет,
iii) если результат измерения для варианта написания попадает между верхним относительным пороговым уровнем и нижним относительным пороговым уровнем, завершается работа средства поиска в сети Интернет и изменяется стратегия поиска с помощью предоставления дополнительных аргументов поиска в виде комбинации элементов множества остающихся вариантов написания и других слов, встречающихся в документе, других символьных альтернатив для этого, по меньшей мере, одного неоднозначно распознанного символа, фраз, настройки верхнего относительного порогового уровня, настройки нижнего относительного порогового уровня, и/или другую информацию, связанную с выходными данными от OCR-системы, перед тем, как продолжить использование стратегии поиска, обеспечивая дополнительные результаты измерений и сравнения для принятия решения относительно противоречивых выходных данных,
с) системный компонент выполняет этап b) некоторое предварительно заданное число раз, или пока не останется только один вариант написания, в зависимости от того, что случится раньше, обеспечивает повторение действий по множеству различных аргументов поиска, используемых в стратегии поиска до завершения этапа b), и использует остающийся вариант написания, обладающий наибольшим результатом измерения больше верхнего относительного порогового уровня в качестве правильного варианта написания.
30. Система по п.29, в которой системный компонент содержит замену этого, по меньшей мере, одного неоднозначно распознанного символа на комбинацию, по меньшей мере, двух символов при формировании вариантов написания.
31. Система по п.29, в которой системный компонент содержит замену двух или более из, по меньшей мере, одного неоднозначно распознанного символа на единственный символ при формировании вариантов написания.
32. Система по п.29, в которой системный компонент содержит модуль, идентифицирующий, является ли исследуемый вариант написания именем собственным, и если это так, предъявляет запрос OCR-процессу на идентификацию других распознанных слов, которые являются именами собственными, и затем комбинируют, по меньшей мере, одно из других надежно распознанных имен собственных с исследуемым именем собственным в качестве варианта написания.
33. Система по п.29, в которой поисковый системный компонент содержит модуль, использующий, по меньшей мере, одно предшествующее слово относительно исследуемого слова в сочетании с исследуемым словом в качестве варианта написания.
34. Система по п.29, в которой системный компонент содержит модуль, использующий, по меньшей мере, одно последующее слово относительно исследуемого слова в сочетании с исследуемым словом в качестве варианта написания.
35. Система по п.29, в которой системный компонент содержит модуль, использующий, по меньшей мере, одно более отдаленное предшествующее слово относительно исследуемого слова в сочетании с исследуемым словом в качестве варианта написания.
36. Система по п.29, в которой системный компонент содержит модуль, использующий, по меньшей мере, одно более отдаленное последующее слово относительно исследуемого слова в сочетании с исследуемым словом в качестве варианта написания.
37. Система по п.29, в которой системный компонент содержит модуль, использующий, по меньшей мере, одно более отдаленное предшествующее слово относительно исследуемого слова, которое содержит количество символов больше предварительно заданного порогового значения, в сочетании с исследуемым словом в качестве варианта написания.
38. Система по п.29, в которой системный компонент содержит модуль, использующий, по меньшей мере, одно более отдаленное последующее слово относительно исследуемого слова, которое содержит количество символов больше предварительно заданного порогового значения, в сочетании с исследуемым словом в качестве варианта написания.
39. Система по п.29, в которой системный компонент содержит модуль который:
i) подсчитывает экземпляры слов, встречающихся в изображении текста во время OCR-процесса, и сохраняет количество экземпляров,
ii) выбирает, по меньшей мере, одно более отдаленное предшествующее слово относительно исследуемого слова, которое обладает небольшим количеством экземпляров, исходя из i), меньше предварительно заданного порогового значения, и комбинирует это слово с исследуемым словом в качестве варианта написания.
40. Система по п.39, в которой системный компонент дополнительно содержит модуль, который:
выбирает, по меньшей мере, одно более отдаленное последующее слово относительно исследуемого слова, которое обладает небольшим количеством экземпляров, меньше предварительно заданного порогового значения, и комбинирует это слово с исследуемым словом в качестве варианта написания.
41. Система по п.29, в которой системный компонент содержит модуль, который:
i) подсчитывает экземпляры слов, встречающихся в изображении текста во время OCR-процесса, и сохраняет количество экземпляров,
ii) выбирает, по меньшей мере, одно более отдаленное предшествующее слово относительно исследуемого слова, которое обладает большим количеством экземпляров, больше первого предварительно заданного порогового значения, и которое содержит большое количество символов в слове, больше второго порогового значения, в сочетании с исследуемым словом в качестве варианта написания.
42. Система по п.41, в которой системный компонент дополнительно содержит модуль, который:
выбирает, по меньшей мере, одно более отдаленное последующее слово относительно исследуемого слова, которое обладает большим количеством экземпляров, больше первого предварительно заданного порогового значения, и которое содержит большое количество символов в слове, больше второго порогового значения, в сочетании с исследуемым словом в качестве варианта написания.
43. Система по п.29, в которой системный компонент содержит модуль, который:
i) выбирает поочередно более отдаленные предшествующие слова относительно исследуемого слова и сохраняет те предшествующие слова, которые содержат количество символов, большее предварительно заданного порогового значения,
ii) использует сохраненные на этапе i) слова в качестве аргументов поиска в средстве поиска в сети Интернет, идентифицирует слово, которое обеспечивает наименьшее количество совпадений, отличное от нуля, и использует такое слово в сочетании с исследуемым словом в качестве варианта написания.
44. Система по п.29, в которой системный компонент содержит модуль, который:
i) выбирает поочередно более отдаленные последующие слова относительно исследуемого слова и сохраняет те предшествующие слова, которые содержат количество символов, большее предварительно заданного порогового значения,
ii) использует сохраненные на этапе i) слова в качестве аргументов поиска в средстве поиска в сети Интернет, идентифицирует слово, которое обеспечивает наименьшее количество совпадений, отличное от нуля, и использует такое слово в сочетании с исследуемым словом в качестве варианта написания.
45. Система по п.29, в которой функция, обеспечивающая сравнение с верхним пороговым значением и сравнение с нижним пороговым значением, основывается на перенормировке пороговых значений и измеренного общего количества совпадений.
46. Система по п.29, в которой верхнее и нижнее пороговые значения изменяются с постепенным увеличением и снижением совместно.
47. Система по п.29, в которой верхнее и нижнее пороговые значения изменяются с постепенным увеличением и снижением независимо.
48. Система по п.29, в которой когда вариант написания является неокончательным, результат побуквенной записи, обеспечивающий наибольшее количество относительных (перенормированных) совпадений, выбирается в качестве наиболее вероятного варианта написания.
49. Система по п.29, в которой системный компонент в качестве альтернативы или в дополнение к выполнению поисковых запросов в сети Интернет осуществляет поисковые запросы по другим информационным источникам, которые не доступны по сети Интернет, но которые доступны через внутреннюю сеть на базе Интернет-технологии, VPR, или подобные сети, или посредством поиска непосредственно на подсоединенном жестком диске, содержащем информацию.
50. Система по п.49, в которой пользователь может выбирать из списка группу информационных узлов, по которым системный компонент будет производить поиск во время процесса подтверждения.
51. Система по п.29, в которой верхнее пороговое значение определяется следующим образом
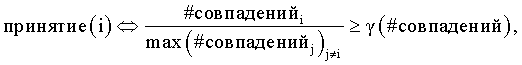
при этом i обозначает один из вариантов написания, #совпаденийi представляет собой измеренное количество совпадений для i-го варианта написания, знаменатель представляет собой общее измеренное количество совпадений для всех вариантов написания, и γ(# совпадений) представляет собой пороговый уровень, который является функцией количества совпадений.
52. Система по п.29, в которой верхнее пороговое значение определяется следующим образом
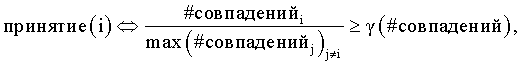
при этом i обозначает один из вариантов написания, #совпаденийi представляет собой измеренное количество совпадений для i-го варианта написания, max(# совпаденийj)j≠i представляет собой общее измеренное количество совпадений для всех вариантов написания, за исключением варианта написания для i, и γ(# совпадений) представляет собой пороговый уровень, который является функцией количества совпадений.
53. Система по п.29, в которой нижнее пороговое значение определяется следующим образом.
при этом #совпаденийi представляет собой измеренное количество совпадений для i-го варианта написания, max(# совпаденийj)j≠i представляет собой общее измеренное количество совпадений для всех вариантов написания, за исключением варианта написания для i, и κ(# совпадений) представляет собой пороговый уровень, который является функцией количества совпадений.
54. Система по п.29, в которой оценочная функция используется, чтобы определить результат измерения для количества совпадений, следующим образом:
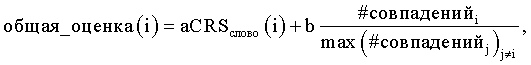
при этом a+b=1, CRSслово(i) представляет собой оценочную величину символа в результате OCR-процесса, имеющего отношение к i-му варианту написания, max(# совпаденийj)j≠i представляет собой общее измеренное количество совпадений для всех вариантов написания, за исключением варианта написания для i.
55. Система по п.29, в которой оценочная функция используется, чтобы определить результат измерения для количества совпадений, следующим образом:
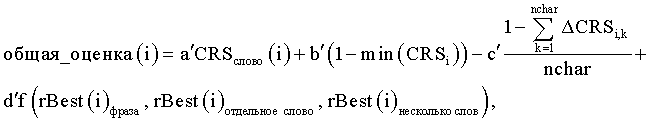
при этом a'+b'+c'+d'=1, СRSслово(i) представляет собой оценочную величину символа в результате OCR-процесса, имеющего отношение к i-му варианту написания, второй член является минимальным CRS для всех символов в слове, третий член является суммой разности CRS между наибольшей CRS для каждого символа и CRS, использующей слово(i), f является минимальной или максимальной функцией величин верхнего порогового значения или нижнего порогового значения, как определено в п.54, и nchar представляет собой количество символов в i-м слове.
56. Система по любому из пп.29-55, в которой OCR-система является системой распознавания речи, и этот, по меньшей мере, один неоднозначно распознанный символ представляет собой неоднозначную интерпретацию фонемы.
| СПОСОБ ИСПОЛЬЗОВАНИЯ ВСПОМОГАТЕЛЬНЫХ МАССИВОВ ДАННЫХ В ПРОЦЕССЕ ПРЕОБРАЗОВАНИЯ И/ИЛИ ВЕРИФИКАЦИИ КОМПЬЮТЕРНЫХ КОДОВ, ВЫПОЛНЕННЫХ В ВИДЕ СИМВОЛОВ, И СООТВЕТСТВУЮЩИХ ИМ ФРАГМЕНТОВ ИЗОБРАЖЕНИЯ | 1999 |
|
RU2166207C2 |
| Приспособление для компенсации деформаций, нарушающих геометрическую правильность работы устройства для рихтовки железнодорожного пути | 1933 |
|
SU42118A1 |
| US 2004086179 A1, 06.05.2004 | |||
| US 2004107406 A1, 03.06.2004 | |||
| Устройство для торможения двухдвигательного электропривода постоянного тока | 1969 |
|
SU649112A1 |
| WO 9962000 A2, 02.12.1999. | |||

