Область техники, к которой относится изобретение
Настоящее изобретение относится к области устройств обработки и к соответствующему программному обеспечению и программным последовательностям, которые выполняют математические операции.
Уровень техники
Компьютерные системы все в большей степени распространяются в нашем обществе. Возможности обработки компьютеров повышают эффективность и производительность работы в широком спектре профессий. По мере того как стоимость покупки и содержания компьютера продолжает падать, все больше потребителей получают возможность использовать преимущество более новых и более быстрых устройств. Кроме того, большое количество людей наслаждается использованием портативных компьютеров, поскольку они обеспечивают свободу. Мобильные компьютеры позволяют пользователям легко транспортировать свои данные и работать с ними вне офиса или во время путешествия. Такой сценарий достаточно привычен для персонала, занимающегося маркетингом, управляющих корпораций и даже студентов.
По мере развития технологии процессора новый программный код также генерируют для работы в устройствах с такими процессорами. Пользователи обычно ожидают и требуют более высоких рабочих характеристик от своих компьютеров независимо от типа используемого программного обеспечения. Одна из таких проблем возникает из видов инструкций и операций, которые фактически выполняются в процессоре. Некоторые типы операций требуют большего времени для окончания из-за сложности операций и/или типа используемых схем. Это обеспечивает возможность оптимизировать способ выполнения некоторых сложных операций внутри процессора.
Мультимедийные приложения представляли собой побудительный мотив развития микропроцессоров более чем в течение десятилетия. Фактически большая часть обновлений вычислительной техники в последние годы была мотивирована мультимедийными приложениями. Такие обновления, прежде всего, возникали в сегментах потребителей, хотя значительный прогресс также можно видеть в сегментах промышленных предприятий, в области образования, построенного на основе развлечений, и в области связи. Тем не менее, будущие мультимедийные приложения предъявят еще более высокие требования к вычислительной технике. В результате работа с персональными компьютерами завтрашнего дня будет еще богаче и будет насыщена аудиовизуальными эффектами, а также будет более простой для использования и, что еще более важно, вычислительные операции сольются с передачей данных.
В соответствии с этим отображение изображений, а также воспроизведение аудио- и видеоданных, которое совместно относятся к содержанию, становятся все более и более популярными приложениями в современных вычислительных устройствах. Операции фильтрации и свертки представляют собой некоторые из наиболее часто выполняемых операций в отношении данных содержания, таких как данные изображения аудио- и видеоданные. Такие операции требуют интенсивных вычислений, но предоставляют высокий уровень параллелизма данных, который можно эксплуатировать, используя эффективное воплощение с применением различных устройств хранения данных, таких как, например, регистры с одним потоком команд и множеством потоков данных (SIMD, ОКМД). В ряде существующих архитектур также требуется, чтобы множество операций, инструкций или подынструкций (часто называются "микрооперациями" или "uops") выполняли различные математические операции по множеству операндов, снижая, таким образом, пропускную способность и увеличивая количество циклов тактовой частоты, требуемых для выполнения математических операций.
Например, последовательность инструкций, состоящая из ряда инструкций, может потребоваться для выполнения одной или больше операций, необходимых для генерирования скалярного произведения, включающего в себя суммирование произведений двух или больше чисел, представленных различными типами данных в пределах устройства обработки, системы или компьютерной программы. Однако такие технологии предшествующего уровня техники могут потребовать множества циклов обработки и могут привести к тому, что процессор или система будут потреблять излишнюю энергию для того, чтобы генерировать скалярное произведение. Кроме того, некоторые технологии предшествующего уровня техники могут быть ограничены по типам данных операнда, с которыми они могут выполнять операции.
Краткое описание чертежей
Настоящее изобретение иллюстрируется в качестве примера, а не для ограничений, на прилагаемых чертежах:
на фиг.1А показана блок-схема компьютерной системы, сформированной с процессором, который включает в себя исполнительные модули, предназначенные для выполнения инструкции для операции скалярного произведения в соответствии с одним вариантом воплощения настоящего изобретения;
на фиг.1В показана блок-схема другой примерной компьютерной системы в соответствии с альтернативным вариантом воплощения настоящего изобретения;
на фиг.1C показана блок-схема еще одной примерной компьютерной системы в соответствии с другим альтернативным вариантом воплощения настоящего изобретения;
на фиг.2 показана блок-схема микроархитектуры для процессора в соответствии с одним вариантом воплощения, который включает в себя логические схемы, предназначенные для выполнения операции скалярного произведения в соответствии с настоящим изобретением;
на фиг.3А иллюстрируются различные типы представлений пакетных данных в мультимедийных регистрах в соответствии с одним вариантом воплощения настоящего изобретения;
на фиг.3В иллюстрируются типы пакетных данных в соответствии с альтернативным вариантом воплощения;
на фиг.3С иллюстрируются различные представления типов пакетных данных со знаком и без знака в мультимедийных регистрах в соответствии с одним вариантом воплощения настоящего изобретения;
на фиг.3D иллюстрируется один вариант воплощения формата кодирования операции (opcode);
на фиг.3Е иллюстрируется альтернативный формат кодирования операции (opcode);
на фиг.3F иллюстрируется еще один альтернативный формат кодирования операции;
на фиг.4 показана блок-схема одного варианта воплощения логической схемы для выполнения операции скалярного произведения по операндам пакетных данных в соответствии с настоящим изобретением;
на фиг.5а показана блок-схема логической схемы для выполнения операции скалярного произведения по операндам пакетных данных с одинарной точностью в соответствии с одним вариантом воплощения настоящего изобретения;
на фиг.5b показана блок-схема логической схемы для выполнения операции скалярного произведения по операндам пакетных данных с двойной точностью в соответствии с одним вариантом воплощения настоящего изобретения;
на фиг.6А показана блок-схема цепи для выполнения операции скалярного произведения в соответствии с одним вариантом воплощения настоящего изобретения;
на фиг.6В показана блок-схема цепи для выполнения операции скалярного произведения в соответствии с другим вариантом воплощения настоящего изобретения;
на фиг.7А показано представление в виде псевдокода операций, которые могут быть выполнены при выполнении инструкции СППО, в соответствии с одним вариантом воплощения;
на фиг.7В показано представление в виде псевдокода операций, которые могут быть выполнены, используя существующую инструкцию СППД, в соответствии с одним вариантом воплощения.
Подробное описание изобретения
В следующем описании описаны варианты воплощения методики выполнения операции скалярного произведения в устройстве обработки, в компьютерной системе или с помощью программы. В следующем описании представлены различные специфичные детали, такие как типы процессоров, состояния микроархитектуры, события, механизмы разблокирования и т.п., для обеспечения более полного понимания настоящего изобретения. Для специалиста в данной области техники, однако, будет понятно, что изобретение может быть выполнено на практике без таких специфичных деталей. Кроме того, некоторые известные структуры, схемы и т.п. не были представлены подробно, чтобы исключить ненужную неясность настоящего изобретения.
Хотя следующие варианты воплощения описаны со ссылкой на процессор, другие варианты воплощения применимы к другим типам интегральных микросхем и логических устройств. Те же самые методики и описания настоящего изобретения можно легко применять к другим типам схем или полупроводниковых устройств, которые могут использовать преимущество более высокой пропускной способности конвейерной обработки и улучшенных рабочих характеристик. Описания настоящего изобретения применимы к любому процессору или устройству, которое выполняет операции с данными. Однако настоящее изобретение не ограничивается процессорами или устройствами, которые выполняют 256-битные, 128-битные, 64-битные, 32-битные или 16-битные операции с данными, и его можно применять к любому процессору и устройству, в котором требуется производить обработку пакетных данных.
В следующем описании с целью пояснения представлены различные специфичные детали для обеспечения полного понимания настоящего изобретения. Однако для специалиста в данной области техники будет понятно, что эти специфичные детали не обязательны для выполнения на практике настоящего изобретения. В других случаях хорошо известные электрические конструкции и схемы не были описаны с представлением конкретных деталей, чтобы не делать излишне неясным настоящее изобретение. Кроме того, в следующем описании представлены примеры и на приложенных чертежах представлены различные примеры с целью иллюстрации. Однако эти примеры не следует рассматривать в смысле ограничения, поскольку они предназначены просто для представления примеров настоящего изобретения вместо предоставления исчерпывающего списка всех возможных вариантов воплощения настоящего изобретения.
Хотя в приведенных ниже примерах описаны обработка и распределение инструкций в контексте исполнительных модулей и логических схем, другие варианты воплощения настоящего изобретения могут быть выполнены с использованием программных средств. В одном варианте воплощения способы настоящего изобретения воплощены в виде исполняемых компьютером инструкций. Инструкции можно использовать для обеспечения выполнения с помощью процессора общего назначения или специализированного процессора, который запрограммирован с инструкциями выполнения этапов настоящего изобретения. Настоящее изобретение может быть представлено как компьютерный программный продукт или программное средство, которое может включать в себя считываемый устройством или компьютером носитель информации, в котором записаны инструкции, которые можно использовать для программирования компьютера (или других электронных устройств) для выполнения способа в соответствии с настоящим изобретением. В качестве альтернативы, этапы настоящего изобретения могут быть выполнены с помощью специфичных аппаратных компонентов, которые содержат аппаратные логические схемы для выполнения этапов или любую комбинацию программируемых компьютерных компонентов и специализированных аппаратных компонентов. Такое программное средство может быть сохранено в запоминающем устройстве системы. Аналогично, код может быть передан через сеть или другие считываемые компьютером носители информации.
Таким образом, считываемый компьютером носитель информации может включать в себя любой механизм, предназначенный для сохранения или передачи информации в форме, считываемой устройством (например, компьютером), но не ограничивается гибкими дисками, оптическими дисками, компакт-диском, постоянным запоминающим устройством (CD-ROM, КД-ПЗУ) и магнитооптическими дисками, постоянным запоминающим устройством (ROM, ПЗУ), оперативным запоминающим устройством (RAM, ОЗУ), стираемым программируемым постоянным запоминающим устройством (EPROM, СППЗУ), электрически стираемым программируемым постоянным запоминающим устройством (EEPROM, ЭСППЗУ), магнитными или оптическими картами, запоминающим устройством типа флэш, передачей через сеть Интернет, электрической, оптической, акустической или другими формами распространения сигналов (например, волнами несущих, инфракрасными сигналами, цифровыми сигналами и т.д.) или тому подобное. В соответствии с этим считываемый компьютером носитель включает в себя любой тип среды/считаемого устройством носителя, пригодного для сохранения или передачи электронных инструкций или информации в форме, считываемой устройством (например, компьютером). Кроме того, настоящее изобретение также может быть загружено как компьютерный программный продукт. При этом программа может быть передана из удаленного компьютера (например, сервера) в запрашивающий компьютер (например, в устройство-клиент). Передача программы может осуществляться в электрической, оптической, акустической или других формах сигналов данных, воплощенных в виде несущей волны, или в другой среде распространения через канал передачи данных (например, модем, сетевое соединение или тому подобное).
Конструкция может использоваться в выполнении различных этапов от конструирования до моделирования и до изготовления. Данные, представляющие конструкцию, могут представлять конструкцию множеством способов. Прежде всего, что полезно при моделировании, аппаратные средства могут быть представлены с использованием языка описания аппаратных средств или другого функционального языка описания. Кроме того, в ходе некоторых этапов процесса конструирования может быть изготовлена модель на уровне схем с логическими и/или транзисторными вентильными схемами. Кроме того, в большинстве конструкций на определенном этапе достигается определенный уровень данных, представляющих физическое размещение различных устройств в аппаратной модели. В случае когда используют обычные технологии изготовления полупроводников, данные, представляющие аппаратную модель, могут представлять собой данные, описывающие наличие или отсутствие различных элементов в различных слоях маски для масок, используемых для изготовления интегральных схем. В любом представлении конструкции данные могут быть сохранены на представленном в любой форме считываемом устройством носителе информации. Оптические или электрические волны, модулированные или генерируемые другим способом для передачи такой информации, запоминающее устройство или магнитный или оптический накопитель информации, такой как диск, могут представлять собой считываемый устройством носитель информации. Любой из этих носителей может "переносить" или "обозначать" конструктивную или программную информацию. Когда передают электрическую волну несущей, обозначающую или переносящую код или конструкцию, в той степени, что выполняют копирование, размещение в буфере или повторную передачу электрического сигнала, получают новую копию. Таким образом, провайдер передачи данных или провайдер сети могут делать копии изделия (волны несущей), которые воплощают технологию настоящего изобретения.
В современных процессорах используют множество различных исполнительных модулей для обработки и выполнения ряда кодов и инструкций. Не все инструкции формируют равными, поскольку некоторые выполняются более быстро, в то время как для других требуется огромное количество циклов тактовой частоты. Чем выше пропускная способность инструкций, тем лучше общие характеристики процессора. Таким образом, было бы предпочтительно иметь как можно большее количество инструкций, выполняемых как можно быстрее. Однако существуют определенные инструкции, которые имеют большую сложность и которые требуют больше времени на исполнение и больше ресурсов процессора. Например, существуют инструкции с плавающей запятой, операции загрузки/сохранения, перемещения данных и т.д.
По мере того как все больше компьютерных систем используют в Интернет и мультимедийных приложениях, с течением времени была введена дополнительная поддержка процессора. Например, инструкции с целым числом/плавающей запятой типа один поток команд и множество потоков данных (ОКМД) и расширения потокового ОКМД (SSE, РПО) представляют собой инструкции, которые уменьшают общее количество инструкций, требуемых для выполнения конкретной программной задачи, что, в свою очередь, может уменьшить потребление энергии. Эти инструкции могут ускорять работу программных средств путем параллельного выполнения операций с множеством элементов данных. В результате может обеспечиваться улучшение рабочих характеристик в широком диапазоне приложений, включающих в себя обработку видеоданных, речевых данных и изображений/фотографий. Воплощение инструкций ОКМД в микропроцессорах и аналогичных типах логических цепей обычно подразумевает целый ряд вопросов. Кроме того, сложность операций ОКМД часто приводит к необходимости использования дополнительной схемы для правильной обработки данных и манипуляции с данными.
В настоящее время инструкция скалярного произведения ОКМД недоступна. Без наличия инструкции скалярного произведения ОКМД может потребоваться большое количество инструкций и регистров данных для выполнения одинаковых результатов в приложениях, таких как сжатие, обработка и манипуляции с аудио/видеоданными. Таким образом, по меньшей мере, одна инструкция скалярного произведения в соответствии с вариантами воплощения настоящего изобретения может уменьшить количество служебных кодов и снизить требования к ресурсам. Варианты воплощения настоящего изобретения обеспечивают способ воплощения операции скалярного произведения в качестве алгоритма, в котором используются аппаратные средства, относящиеся к ОКМД. В настоящее время несколько затруднительно и утомительно выполнять операции скалярного произведения данных, находящихся в регистре ОКМД. Некоторые алгоритмы требуют большего количества инструкций для компоновки данных для арифметических операций, чем фактическое количество инструкций, предназначенных для выполнения этих операций. Благодаря выполнению вариантов воплощения операции скалярного произведения в соответствии с вариантами воплощения настоящего изобретения количество инструкций, требуемых для обеспечения обработки скалярного произведения, можно значительно уменьшить.
Варианты воплощения настоящего изобретения относятся к инструкции для воплощения операции скалярного произведения. Операция скалярного произведения обычно подразумевает умножение, по меньшей мере, двух значений и суммирование результата этого произведения с результатом произведения, по меньшей мере, двух других значений. Другие варианты могут быть выполнены в отношении общего алгоритма скалярного произведения, включающего в себя суммирование результатов различных операций скалярного произведения для генерирования другого скалярного произведения. Например, операция скалярного произведения в соответствии с одним вариантом воплощения, применяемая к элементам данных, в общем, может быть представлена как:
DEST1←SRC1*SRC2;
DEST2←SRC3*SRC4;
DEST3←DEST1+DEST2.
Для операнда пакетных данных ОКМД такой поток может применяться к каждому элементу данных каждого операнда.
В представленном выше потоке "DEST" и "SRC" представляют собой общие члены, представляющие источник и назначение соответствующих данных или операций. В некоторых вариантах воплощения они могут быть воплощены с помощью регистров, запоминающего устройства или других накопителей данных, имеющих другие названия или функции, чем те, которые были представлены. Например, в одном варианте воплощения DEST1 и DEST2 могут представлять собой первую и вторую области временного сохранения (например, регистр "TEMP1" и "ТЕМР2"), SRC1 и SRC3 могут представлять собой первую и вторую области сохранения места назначения (например, регистр "DEST1" и "DEST2") и т.д. В других вариантах воплощения две или больше области сохранения SRC и DEST могут соответствовать разным элементам сохранения данных в пределах одной и той же области сохранения (например, регистр ОКМД). Кроме того, в одном варианте воплощения операция скалярного произведения может генерировать сумму скалярных произведений, сгенерированных описанным выше общим потоком.
На фиг.1А показана блок-схема примерной компьютерной системы, сформированной с процессором, который включает в себя исполнительные модули для выполнения инструкции операции скалярного произведения в соответствии с одним вариантом воплощения настоящего изобретения. Система 100 включает в себя компонент, такой как процессор 102, для воплощения исполнительных модулей, включающий в себя логическую схему для выполнения алгоритмов обработки данных, в соответствии с настоящим изобретением, таких как вариант воплощения, описанный здесь. Система 100 представляет собой систему обработки на основе микропроцессоров типа PENTIUM® III, PENTIUM® 4, Xeon™, Itanium®, XScale™ и/или StrongARM™, поставляемых корпорацией Intel Corporation, г. Санта Клара, Калифорния, хотя также можно использовать другие системы (включающие в себя ПК, имеющие другие микропроцессоры, инженерные рабочие станции, телевизионные приставки и т.п.). В одном варианте воплощения образец системы 100 может выполнить версию операционной системы WINDOWS™, поставляемой компанией Microsoft Corporation, г. Редмонд, штат Вашингтон, хотя также можно использовать другие операционные системы (например, UNIX и Linux), встроенное программное обеспечение и/или графические интерфейсы пользователя. Таким образом, варианты воплощения настоящего изобретения не ограничиваются какой-либо специфичной комбинацией аппаратных схем и программного обеспечения.
Варианты воплощения не ограничиваются компьютерными системами. Альтернативные варианты воплощения настоящего изобретения можно использовать в других устройствах, таких как карманные устройства и встраиваемые приложения. Некоторые примеры карманных устройств включают в себя сотовые телефоны, устройства протокола Интернет, цифровые камеры, карманные персональные компьютеры (КПК) и портативные ПК. Встраиваемые программные приложения могут включать в себя микроконтроллер, цифровой процессор сигналов (DSP, ЦПС), систему на микросхеме, сетевые компьютеры (NetPC), телевизионные приставки, концентраторы сети, коммутаторы глобальной вычислительной сети (WAN, ГВС) или любую другую систему, которая выполняет операции скалярного произведения по операндам. Кроме того, некоторые архитектуры были воплощены для обеспечения возможности выполнения инструкций, обрабатывающих несколько данных одновременно, для улучшения эффективности мультимедийных приложений. По мере того как количество типов и объем данных увеличиваются, компьютеры и их процессоры требуется совершенствовать для обработки этих данных с использованием более эффективных способов.
На фиг.1А показана блок-схема компьютерной системы 100, сформированной с процессором 102, который включает в себя один или больше исполнительных модулей 108, предназначенных для выполнения алгоритма для расчета скалярного произведения элементов данных по одному или больше операндам в соответствии с одним вариантом воплощения настоящего изобретения. Один вариант воплощения может быть описан в контексте настольной или серверной системы с одиночным процессором, но альтернативные варианты воплощения могут быть включены в мультипроцессорную систему. Система 100 представляет собой пример архитектуры концентратора. Компьютерная система 100 включает в себя процессор 102 для обработки сигналов данных. Процессор 102 может представлять собой микропроцессор типа процессора со сложным набором команд (CISC, ПСНК), микропроцессор с архитектурой вычислений с сокращенным набором команд (RISC, BCHK), микропроцессор с командными словами очень большой длины (VLIW, КОБД), процессор, воплощающий комбинацию наборов инструкций или любое другое устройство обработки, такое как, например, цифровой процессор сигналов. Процессор 102 соединен с шиной 110 процессора, по которой можно передавать сигналы данных между процессором 102 и другими компонентами в системе 100. Элементы 100 системы выполняют свои обычные функции, которые хорошо известны специалистам в данной области техники.
В одном варианте воплощения процессор 102 включает в себя запоминающее устройство 104 внутренней кэш Level 1 (L1 (уровень 1)). В зависимости от архитектуры процессор 102 может иметь одиночный внутренний кэш или множество уровней внутренней кэш. В качестве альтернативы, в другом варианте воплощения запоминающее устройство - кэш может быть внешним относительно процессора 102. Другие варианты воплощения могут также включать комбинацию как внутренней, так и внешней кэш, в зависимости от конкретного воплощения и потребностей. Файл 106 регистра может сохранять различные типы данных в различных регистрах, включающих в себя регистры целых чисел, регистры с плавающей запятой, регистры статуса и регистр указателя команд.
Исполнительный модуль 108, включающий в себя логическую схему для выполнения операций с целыми числами и с числами с плавающей запятой, также находится в процессоре 102. Процессор 102 также включает в себя ПЗУ микрокода (ucode), в котором сохранен микрокод для определенных макроинструкций. Для данного варианта воплощения исполнительный модуль 108 включает в себя логические схемы, предназначенные для обработки пакетного набора 109 инструкций. В одном варианте воплощения набор 109 пакетных инструкций включает в себя пакетную инструкцию - скалярное произведение для расчета скалярного произведения по множеству операндов. В результате включения пакетного набора 109 инструкций в набор инструкций процессора 102 общего назначения вместе с соответствующими схемами для выполнения этих инструкций операции, используемые множеством мультимедийных приложений, могут быть выполнены с использованием пакетных данных в процессоре 102 общего назначения. Таким образом, множество мультимедийных приложений могут быть ускорены и могут быть выполнены более эффективно при использовании полной ширины шины данных процессора для выполнения операций с пакетными данными. Это может устранить необходимость передачи малых модулей данных через шину данных процессора для выполнения одной или больше операций с одним элементом данных за один раз.
Альтернативные варианты воплощения исполнительного модуля 108 также можно использовать в микроконтроллерах, встроенных процессорах, графических устройствах, ЦПС и в других типах логических схем. Система 100 включает в себя запоминающее устройство 120. Запоминающее устройство 120 может представлять собой устройство динамического оперативного запоминающего устройства (DRAM, ДОЗУ) устройство статического оперативного запоминающего устройства со случайным доступом (SRAM, СОЗУ), запоминающее устройство типа флэш или другое запоминающее устройство. В запоминающем устройстве 120 могут содержаться инструкции и/или данные, представленные сигналами данных, которые могут быть выполнены процессором 102.
Логическая микросхема 116 системы соединена с шиной 110 процессора и с запоминающим устройством 120. Системная логическая микросхема 116 в представленном варианте выполнения представляет собой концентратор контроллера памяти (МСН, ККП). Процессор 102 может связываться с ККП 116 через шину 110 процессора. ККП 116 обеспечивает тракт 118 запоминающего устройства с большой полосой пропускания в запоминающее устройство 120 для сохранения инструкций и данных и для сохранения графических команд, данных и текстур. ККП 116 предназначен для того, чтобы направлять сигналы данных между процессором 102, запоминающим устройством 120 и другими компонентами в системе 100 и для того, чтобы соединять сигналы данных между шиной 110 процессора, запоминающим устройством 120 и системой 122 ввода/вывода. В некоторых вариантах воплощения логические микросхемы 116 системы могут предоставлять графический порт для соединения с графическим контроллером 112. ККП 116 соединен с запоминающим устройством 120 через интерфейс 118 памяти. Видеокарту 112 соединяют с ККП 116 через взаимное соединение 114 ускоренного графического порта (AGP, УГП).
В системе 100 используется собственная шина 122 интерфейса для соединения ККП 116 с концентратором контроллера ввода/вывода (ICH, ККВ) 130. ККВ 130 предоставляет непосредственные соединения с некоторыми устройствами ввода/вывода через локальную шину ввода/вывода. Локальная шина ввода/вывода представляет собой высокоскоростную шину ввода/вывода, предназначенную для соединения периферийных устройств с запоминающим устройством 120, набором микросхем и процессором 102. Некоторые примеры также представляют собой контроллер звука, концентратор аппаратных средств (BIOS (Базовая система ввода-вывода, БСВВ) типа флэш) 128, беспроводный приемопередатчик 126, накопитель 124 данных, контроллер наследуемого ввода/вывода, содержащий интерфейсы ввода пользователя и клавиатуры, последовательный порт расширения, например универсальную последовательную шину (USB, УПШ), и сетевой контроллер 134. Устройство хранения данных 124 может содержать жесткий диск, накопитель на гибких магнитных дисках, устройство CD-ROM, перепрограммируемое запоминающее устройство или другое устройство - накопитель большого объема.
Для другого варианта воплощения системы исполнительный модуль, предназначенный для выполнения алгоритма с инструкцией скалярного произведения, можно использовать с системой в микросхеме. Один вариант воплощения системы в микросхеме состоит из процессора и запоминающего устройства. Запоминающее устройство для одной такой системы представляет собой запоминающее устройство типа флэш. Запоминающее устройство типа флэш может быть расположено на том же кристалле, что и процессор, и другие системные компоненты. Дополнительно, другие модули логической схемы, например контроллер памяти или графический контроллер, могут также быть расположены в системе на микросхеме.
На фиг.1В иллюстрируется система 140 обработки данных, в которой воплощены принципы одного варианта воплощения настоящего изобретения. Для специалиста в данной области техники будет понятно, что описанные здесь варианты воплощения можно использовать с альтернативными системами обработки без выхода за пределы изобретения.
Компьютерная система 140 содержит ядро 159 обработки, выполненное с возможностью операций ОКМД, включающих в себя операцию скалярного произведения. Для одного варианта воплощения ядро 159 обработки представляет собой модуль обработки любого типа архитектуры, включающий в себя, но без ограничений ПСНК, архитектуру типа ВСНК или КОБД. Ядро 159 обработки также может быть выполнено с возможностью изготовления с использованием одной или больше технологий обработки и, поскольку оно достаточно подробно представлено на считываемых устройством носителях информации, может способствовать такому производству.
Ядро 159 обработки содержит исполнительный модуль 142, набор файла (файлов) 145 регистра и декодер 144. Ядро 159 обработки также включает в себя дополнительную схему (не показана), которая не является необходимой для понимания настоящего изобретения. Исполнительный модуль 142 используется для выполнения инструкций, получаемых ядром 159 обработки. В дополнение к распознаванию типичных инструкций процессора исполнительный модуль 142 может распознавать инструкции в наборе 143 пакетных инструкций для выполнения операций по форматам пакетных данных. Набор 143 пакетных инструкций включает в себя инструкции, предназначенные для поддержки операций скалярного произведения, и также может включать в себя другие пакетные инструкции. Исполнительный модуль 142, соединенный с файлом 145 регистра, может представлять собой внутреннюю шину. Файл 145 регистра представляет собой область сохранения для ядра 159 обработки, предназначенную для сохранения информации, включающей в себя данные. Как упомянуто выше, следует понимать, что область сохранения, используемая для сохранения пакетных данных, не является критичной. Исполнительный модуль 142 соединен с декодером 144. Декодер 144 используется для декодирования инструкций, принятых ядром 159 обработки, и точек входа в сигналы управления и/или микрокод. В ответ на эти сигналы управления и/или точки входа микрокода исполнительный модуль 142 выполняет соответствующие операции.
Ядро 159 обработки соединено с шиной 141 для связи с различными другими устройствами системы, которые могут включать в себя, но не ограничиваются этим, например, управление 146 синхронным динамическим оперативным запоминающим устройством (SDRAM, СДОЗУ), управление 147 статическим оперативным запоминающим устройством (СОЗУ), интерфейс 148 пакетной памяти типа флэш, управление 149 картой в соответствии со стандартом международной ассоциации производителей карт памяти для персональных компьютеров (PCMCIA, МАКППК)/карту compact flash (CF), управление 150 жидкокристаллическим дисплеем (LCD, ЖКД), контроллер 151 прямого доступа к памяти (DMA, ПДП) и альтернативный главный интерфейс 152 шины. В одном варианте воплощения система 140 обработки данных также может содержать мост 154 ввода/вывода, предназначенный для связи с различными устройствами ввода/вывода через шину 153 ввода/вывода. Такие устройства ввода/вывода могут включать в себя, но не ограничиваются этим, например, универсальный асинхронный приемопередатчик (UART, УАПП) 155, универсальную последовательную шину (УПШ) 156, беспроводный УАПП 157 типа Bluetooth и интерфейс 158 расширения ввода/вывода.
В одном варианте воплощения система 140 обработки данных обеспечивает мобильную, сетевую и/или беспроводную передачу данных, и в ней содержится ядро 159 обработки, позволяющее выполнять операции ОКМД, включающие в себя операцию скалярного произведения. Ядро 159 обработки может быть запрограммировано с использованием различных аудио-, видеоданных, алгоритмов формирования изображения и алгоритмов передачи данных, включающих в себя дискретные преобразования, такие как преобразование Уолша-Адамара, быстрое преобразование Фурье (FFT, БПФ), дискретное косинусное преобразование (DCT, ДКП), и их соответствующие обратные преобразования; технологии сжатия/расширения, такие как преобразование цветового пространства, оценка движения при кодировании видеоданных или компенсация движения при декодировании видеоданных; и функции модуляции/демодуляции (MODEM), такие как кодовая импульсная модуляция (РСМ, КИМ). Некоторые варианты воплощения изобретения также можно применять в графических приложениях, таких как трехмерное ("3D") моделирование, рендеринг, детектирование коллизии объектов, преобразование и освещение 3D объектов и т.д.
На фиг.1C иллюстрируется другие альтернативные варианты воплощения системы обработки данных, выполненной с возможностью выполнения операций скалярного произведения ОКМД. В соответствии с одним альтернативным вариантом воплощения система 160 обработки данных может включать в себя основной процессор 166, сопроцессор 161 ОКМД, память 167 кэш и систему 168 ввода/вывода. Система 168 ввода/вывода в случае необходимости может быть соединена с беспроводным интерфейсом 169. Сопроцессор 161 ОКМД выполнен с возможностью выполнения операций ОКМД, включающих в себя операции скалярного произведения. Ядро 170 обработки может быть пригодным для изготовления с использованием одной или больше технологий обработки и может быть достаточно подробно представлено на считываемом устройством носителе информации, что способствует производству всей или части системы 160 обработки данных, включающей в себя ядро 170 обработки.
В одном варианте воплощения сопроцессор 161 ОКМД содержит исполнительный модуль 162 и набор файла (файлов) 164 регистра. В одном варианте воплощения основной процессор 166 содержит декодер 165 для распознавания инструкций из набора 163 инструкций, включающего в себя инструкции расчета скалярного произведения ОКМД, для выполнения исполнительным модулем 162. В альтернативных вариантах воплощения сопроцессор 161 ОКМД также содержит, по меньшей мере, часть декодера 165В для декодирования инструкций, состоящую из набора 163 инструкций. Ядро 170 обработки также включает в себя дополнительную схему (не показана), которая не требуется для понимания вариантов воплощения настоящего изобретения.
Во время работы основной процессор 166 выполняет поток инструкций обработки данных, которые управляют операциями обработки данных общего типа, включая в себя взаимодействие с памятью 167 кэш и систему 168 ввода/вывода. Инструкции, внедряемые в поток инструкций обработки данных, представляют собой инструкции сопроцессора ОКМД. Декодер 165 основного процессора 166 распознает эти инструкции сопроцессора ОКМД как инструкции такого типа, которые должны быть выполнены присоединенным сопроцессором 161 ОКМД. В соответствии с этим основной процессор 166 вырабатывает эти инструкции сопроцессора ОКМД (или сигналы управления, представляющие инструкции сопроцессора ОКМД) в шине 166 сопроцессора, из которой любой присоединенный сопроцессор ОКМД принимает их. В этом случае сопроцессор 161 ОКМД будет принимать и выполнять любые принятые инструкции сопроцессора ОКМД, предназначенные для него.
Данные могут быть приняты через беспроводный интерфейс 169 для обработки с использованием инструкций сопроцессора ОКМД. В качестве одного примера, голосовые данные могут быть приняты в форме цифрового сигнала, который может обрабатываться с помощью инструкций сопроцессора ОКМД, для восстановления цифровых аудиовыборок, представляющих голосовые данные. В другом примере сжатые аудио- и/или видеоданные могут быть получены в форме потока цифровых битов, которые могут быть обработаны с помощью инструкций сопроцессора ОКМД, для восстановления цифровых аудиовыборок и/или кадров движущегося видеоизображения. В одном варианте воплощения ядро 170 обработки, основной процессор 166 и сопроцессор 161 ОКМД интегрированы в виде единого ядра 170 обработки, содержащего исполнительный модуль 162, набор файла (файлов) 164 регистра и декодер 165, для распознавания инструкций из набора 163 инструкций, включающих в себя инструкции скалярного произведения ОКМД.
На фиг.2 показана блок-схема микроархитектуры процессора 200, которая включает в себя логические схемы для выполнения инструкции скалярного произведения в соответствии с одним вариантом воплощения настоящего изобретения. В одном варианте воплощения инструкция скалярного произведения может умножать первый элемент данных на второй элемент данных и суммировать это произведение с произведением третьего и четвертого элемента данных. В некоторых вариантах воплощения инструкция скалярного произведения может быть воплощена для работы с элементами данных, имеющими такие размеры в байтах, как "слово", "двойное слово", "учетверенное слово" и т.д., а также с такими типами данных, как целое число с одиночной и двойной точностью, и с типами данных с плавающей запятой. В одном варианте воплощения соответствующий предварительный процессор 201 составляет часть процессора 200, который делает выборки микроинструкций, предназначенных для выполнения, и подготавливает их для использования в более позднее время в конвейере процессора. Предварительный процессор 201 может включать в себя несколько модулей. В одном варианте воплощения предварительный модуль 226 выборки инструкции выполняет выборку макроинструкций из памяти и передает их в декодер 228 инструкции, который в свою очередь декодирует их, получая примитивы, называемые микрокомандами или микрооперациями (также называемыми micro op или uops), которые может выполнять устройство. В одном варианте воплощения трассовая кэш 230 отбирает декодированные микрооперации и собирает их в программные, упорядоченные последовательности или трассы в очереди 234 микроопераций для выполнения. Когда в трассовую кэш 230 поступает сложная макроинструкция, ПЗУ 232 микрокода предоставляет микрооперации, требуемые для завершения операции.
Большое количество макроинструкций преобразуют в одиночную микрооперацию, в то время как для других требуется несколько микроопераций для завершения всей операции. В одном варианте воплощения если больше чем четыре микрооперации необходимы для завершения макроинструкции, декодер 228 обращается к ПЗУ 232 микрокода для выполнения макроинструкции. В одном варианте воплощения пакетные инструкции скалярного произведения могут быть декодированы в малое количество микроопераций для обработки в декодере 228 инструкций. В другом варианте воплощения инструкция для пакетного алгоритма скалярного произведения может быть сохранена в ПЗУ 232 микрокода в случае, если множество микроопераций необходимо для выполнения операции. Трассовая кэш 230 обращается к программируемой логической матрице (PLA, ПЛМ) точки входа для определения правильного указателя микроинструкций для считывания последовательности микрокода для алгоритма скалярного произведения в ПЗУ 232 микрокода. После того как ПЗУ 232 микрокода закончит установление последовательности микроопераций для текущей макроинструкции, предварительный процессор 201 устройства возобновляет выборку микроопераций из трассовой кэш 230.
Некоторые инструкции ОКМД и другие инструкции мультимедийных типов рассматривают как сложные инструкции. Большинство инструкций, относящихся к операциям с плавающей запятой, также представляют собой сложные инструкции. При этом, когда декодер 228 инструкций сталкивается со сложной макроинструкцией, обращаются к ПЗУ 232 микрокода в соответствующем месте для получения последовательности микрокода для этой макроинструкции. Различные микрооперации, необходимые для выполнения этой макроинструкции, передают в механизм 203 выполнения с изменением последовательности для выполнения соответствующих исполнительных модулей с целым числом и с плавающей запятой.
Механизм 203 выполнения с изменением последовательности используется, когда микроинструкции подготовлены для выполнения. Логическая схема выполнения с изменением последовательности имеет множество буферов для сглаживания выходного потока и изменения порядка потока микроинструкций, для оптимизации рабочей характеристики по мере того, как микроинструкции поступают в конвейер обработки и устанавливается порядок их выполнения. Логическая схема распределения выделяет буферы устройства и ресурсы, которые требуются каждой микрооперации для выполнения. Логическая схема переименования регистра изменяет наименование логических регистров по входам файла регистра. Распределитель также выделяет вход для каждой микрооперации в одной из двух очередей микроопераций по одной для операций памяти и по одной для операций без использования памяти до планировщика инструкции: планировщик памяти, быстрый планировщик 202, медленный/общий планировщик 204 с плавающей запятой и простой планировщик 206 с плавающей запятой. Планировщики 202, 204, 206 микроопераций определяют, когда микрооперация готова для выполнения, на основе готовности их зависимых входных источников операнда регистра и доступности ресурсов выполнения, требуемых для микроопераций, для завершения их операции. Быстрый планировщик 202 микроопераций в данном варианте воплощения может планировать в каждой половине основного цикла тактовой частоты, в то время как другие планировщики могут планировать только в каждом цикле тактовой частоты основного процессора. Планировщики обращаются в порты отправления для планирования микроопераций для выполнения.
Файлы 208, 210 регистра расположены между планировщиками 202, 204, 206 и исполнительными модулями 212, 214, 216, 218, 220, 222, 224 в исполнительном блоке 211. Имеется отдельный файл 208, 210 регистра для операций с целыми числами и с плавающей запятой соответственно. Каждый файл 208, 210 регистра в соответствии с данным вариантом воплощения также включает в себя обходную сеть, которая может осуществлять обход или передавать только завершенные результаты, которые еще не были записаны в файл регистра, в новые зависимые микрооперации. Файл 208 регистра целых чисел и файл 210 регистра с плавающей запятой также выполнены с возможностью передачи данных друг с другом. В одном варианте воплощения файл 208 регистра целых чисел разделен на два отдельных файла регистра, один файл регистра для 32 битов данных низкого порядка и второй файл регистра для 32 битов данных высокого порядка. Фай 210 регистра с плавающей запятой в одном варианте воплощения имеет коды с шириной 128 битов, поскольку инструкции с плавающей запятой обычно имеют операнды с шириной от 64 до 128 битов.
Исполнительный блок 211 содержит исполнительные модули 212, 214, 216, 218, 220, 222, 224, в которых фактически выполняются инструкции. Этот блок включает в себя файлы 208,210 регистра, в которых сохранены значения операнда целочисленных данных и данных с плавающей запятой, которые требуются для выполнения микроинструкции. Процессор 200 в данном варианте воплощения состоит из множества исполнительных модулей: модуля (AGU, МГА) 212 генерирования адреса, МГА 214, быстрого ALU (АЛУ, арифметико-логическое устройство) 216, быстрого АЛУ 218, медленного АЛУ 220, АЛУ 222 с плавающей запятой, модуля 224 перемещения с плавающей запятой. В данном варианте воплощения исполнительные блоки 222, 224 с плавающей запятой выполняют операции с плавающей запятой, ММХ (ММР, мультимедийное расширение), ОКМД и РПО. АЛУ 222 с плавающей запятой в соответствии с данным вариантом воплощения включают в себя делитель с плавающей запятой размером 64 бита на 64 бита для выполнения микроопераций деления, квадратного корня и остатка. В вариантах воплощения настоящего изобретения любое действие, включающее в себя значение с плавающей запятой, происходит в аппаратных средствах с плавающей запятой. Например, преобразования между целочисленным форматом и форматом с плавающей запятой выполняют с привлечением файла регистра с плавающей запятой. Аналогично, операция деления с плавающей запятой происходит в делителе с плавающей запятой. С другой стороны, числа без плавающей запятой и числа целочисленного типа обрабатывают с использованием аппаратных ресурсов для целых чисел. Простые, очень часто используемые операции АЛУ передают исполнительным модулям 216, 218 высокоскоростного АЛУ. Быстрые АЛУ 216, 218 в соответствии с данным вариантом воплощения могут выполнять быстрые операции с эффективной латентностью половина цикла тактовой частоты. В одном варианте воплощения самые сложные операции с целыми числами передают в медленное АЛУ 220, поскольку медленное АЛУ 220 включает в себя исполнительные аппаратные средства для целых чисел, предназначенные для операций с длительной задержкой, таких как умножитель, сдвиги, логика флагов и обработка ответвлений. Операции загрузки/сохранения в памяти выполняют с помощью МГА 212, 214. В данном варианте воплощения АЛУ 216, 218, 220 для целых чисел описаны в контексте выполнения операций с целыми числами для операндов данных размером 64 бита. В альтернативных вариантах воплощения АЛУ 216, 218, 220 могут быть выполнены для поддержки ряда битов данных, включающих в себя 16, 32, 128, 256 и т.д. битов. Аналогично, модули 222, 224 для операций с плавающей точкой могут быть воплощены с возможностью поддержки определенного диапазона операндов, имеющих различную ширину в битах. В одном варианте воплощения модули 222, 224 с плавающей запятой могут работать с операндами пакетных данных шириной 128 битов совместно с ОКМД и мультимедийными инструкциями.
В данном варианте воплощения планировщики 202, 204, 206 микроопераций закончили выполнение операций, зависимых от отправки, до загрузки верхнего уровня. Поскольку микрооперации теоретически планируют и выполняют в процессоре 200, процессор 200 также включает в себя логику для обработки потерь в памяти. Если загрузка данных отсутствует в кэш данных, в данный момент могут выполняться зависимые операции в конвейере, которые оставили для планировщика временно неправильные данные. Механизм повторного выполнения отслеживает и повторно выполняет инструкции, которые используют неправильные данные. Только зависимые операции требуется выполнять повторно, и независимым операциям разрешено заканчиваться. Планировщики и механизм повторного выполнения в одном варианте воплощения процессора также разработаны с возможностью захвата последовательности инструкций для операций скалярного произведения.
Термин "регистры" используется здесь для обозначения мест сохранения внутри процессора, которые используются как часть макроинструкций, для идентификации операндов. Другими словами, регистры, на которые делается здесь ссылка, представляют собой регистры, которые видны снаружи процессора (с точки зрения программиста). Однако регистры варианта воплощения не должны быть ограничены значением определенного типа цепи. Скорее регистр в соответствии с вариантом воплощения должен обеспечивать только возможность сохранения и предоставления данных, и выполнение описанных здесь функций. Регистры, описанные здесь, могут быть воплощены с использованием схем, расположенных внутри процессора, с использованием любого количества различных технологий, таких как выделенные физические регистры, динамически выделяемые физические регистры, с использованием переименования регистра, комбинации выделенных и динамически выделяемых физических регистров и т.д. В одном варианте воплощения регистры для целых чисел содержат данные целого числа размером тридцать два бита. Файл регистра в соответствии с одним вариантом воплощения также содержит шестнадцать ХММ (ДРП, диспетчер расширенной памяти) и регистры общего назначения, восемь мультимедийных (например, добавление "ЕМ64Т") регистров ОКМД для пакетных данных. Для приведенного ниже описания под регистрами понимают регистры данных, предназначенные для сохранения пакетных данных, таких как MMPtm шириной 64 бита (в некоторых случаях также называются регистрами 'mm') в микропроцессорах, в которых обеспечивается технология ММР комании Intel Corporation, г. Санта Клара, Калифорния. Эти регистры ММР, доступные как в целочисленной форме, так и в форме с плавающей запятой, могут работать с элементами пакетных данных, которые сопровождают инструкции ОКМД и РПО. Аналогично, регистры ДРП шириной 128 битов, относящиеся к технологии РПO2, РПО3, РПO4 или далее (в общем обозначены как "РПОх"), также можно использовать для содержания таких операндов пакетных данных. В данном варианте воплощения, при сохранении пакетных данных и данных целого числа регистры не требуется разделять между двумя типами данных.
В примерах на следующих чертежах описан ряд операндов данных. На фиг.3А иллюстрируются различные представления типа пакетных данных в мультимедийных регистрах в соответствии с одним вариантом воплощения настоящего изобретения. На фиг.3А иллюстрируются типы данных для пакетного байта 310, пакетного слова 320 и пакетного двойного слова (dword) 330 для операндов шириной 128 битов. Формат 310 пакетного байта в данном примере имеет длину 128 битов и содержит шестнадцать элементов данных пакетных байтов. Байт определен здесь как 8 битов данных. Информация для каждого элемента данных байта содержится в битах 7-0 для байта 0, в битах 15-8 для байта 1, в бите 23 - бите 16 для байта 2 и, наконец, в бите 120 - бите 127 для байта 15. Таким образом, все доступные биты используются в регистре. Такая компоновка сохранения повышает эффективность сохранения процессора. Также при обращении к шестнадцати элементам данных одна операция теперь может быть выполнена для шестнадцати элементов данных параллельно.
В общем случае элемент данных представляет собой отдельную часть данных, которая сохранена в одиночном регистре или в месте расположения в памяти с другими элементами данных той же длины. В последовательностях пакетных данных, относящихся к технологии РПОх, количество элементов данных, сохраненных в регистре ДРП, составляет 128 битов, разделенных на длину в битах отдельного элемента данных. Аналогично, в последовательностях пакетных данных, относящихся к технологии ММР и РПО, количество элементов данных, сохраненных в регистре ММР, составляет 64 бита, разделенные на длину в битах отдельного элемента данных. Хотя типы данных, иллюстрируемые на фиг.3А, имеют длину 128 битов, варианты воплощения настоящего изобретения также могут работать с операндами шириной 64 бита или с операндами других размеров. Формат 320 пакетного слова в данном примере имеет длину 128 битов и содержит восемь элементов данных пакетного слова. Каждое пакетное слово содержит шестнадцать битов информации. Формат 330 пакетного двойного слова на фиг.3А имеет длину 128 битов и содержит четыре элемента данных пакетного двойного слова. Каждый элемент данных пакетного двойного слова содержит тридцать два бита информации. Пакетное четверное слово имеет длину 128 битов и содержит два элемента данных пакетных четверных слов.
На фиг.3В иллюстрируется альтернативный формат сохранения данных в регистре. Каждые пакетные данные могут включать в себя больше чем один независимый элемент данных. Три формата пакетных данных представлены на иллюстрации: пакетная половина 341, пакетные единичные 342 и пакетные двойные 343 данные. В одном варианте воплощения пакетная половина 341, пакетная единичная 342 и пакетная двойные 343 данные содержат элементы данных с фиксированной запятой. Для альтернативного варианта воплощения одни или больше из пакетной половины 341, пакетной единичной 342 и пакетных двойных 343 данных могут содержать элементы данных с плавающей запятой. В одном альтернативном варианте воплощения пакетная половина 341 имеет длину сто двадцать восемь битов, содержащую восемь элементов данных размером 16 битов. В одном варианте воплощения пакетные единичные 342 данные имеют длину сто двадцать восемь битов и содержат четыре элемента данных размером 32 бита. В одном варианте воплощения пакетные двойные 343 данные имеют длину сто двадцать восемь битов и содержат два элемента данных размером 64 бита. Следует понимать, что такие форматы пакетных данных могут быть дополнительно расширены для других длин регистров, например для 96 битов, 160 битов, 192 битов, 224 битов, 256 битов или больше.
На фиг.3С иллюстрируются различные представления типов пакетных данных со знаком и без знака в мультимедийных регистрах в соответствии с одним вариантом воплощения настоящего изобретения. Представление 344 пакетных байтов без знака иллюстрирует сохранение пакетного байта без знака в регистре ОКМД. Информация для каждого элемента данных байта хранится в бите семь - бите ноль для байта ноль, в бите пятнадцать - бите восемь для байта один, в бите двадцать три - бите шестнадцать для байта два и, наконец, в бите сто двадцать - бите сто двадцать семь для байта пятнадцать. Таким образом, все доступные биты используются в регистре. Такая компоновка сохранения может повышать эффективность сохранения данных процессора. А также при обращении к шестнадцати элементам данных одна операция теперь может быть выполнена параллельно для шестнадцати элементов данных. Представление 345 пакетного байта со знаком иллюстрирует сохранение пакетного байта со знаком. Следует отметить, что восьмой бит каждого элемента данных байта представляет собой индикатор знака. Представление 346 пакетного слова без знака иллюстрирует, как слово семь - слово ноль сохранены в регистре ОКМД. Представление 347 пакетного слова со знаком аналогично представлению 346 в регистре пакетного слова без знака. Следует отметить, что шестнадцатый бит каждого элемента данных слова представляет собой индикатор знака. Представление 348 пакетного двойного слова без знака представляет, как сохраняют элементы данных двойного слова. Представление 349 пакетного двойного слова со знаком аналогично представлению 348 в регистре пакетного двойного слова без знака. Следует отметить, что необходимый бит знака представляет собой тридцать второй бит каждого элемента данных двойного слова.
На фиг.3D представлено описание одного варианта воплощения формата 360 кодирования операции (opcode), который имеет тридцать два бита, и режимов адреса операнда регистра/памяти, соответствующих типу формата операции кодирования, описанному в публикации " IA-32 Intel Architecture Software Developer's Manual Volume 2: Instruction Set Reference," которая представлена компанией Intel Corporation, Санта-Клара, Калифорния на сайте всемирной сети (WWW) по адресу intel.com/design/litcentr. В одном варианте воплощения операция скалярного произведения может быть кодирована одним или больше из полей 361 и 362. Могут быть идентифицированы вплоть до двух мест расположения операнда на инструкцию, включающие в себя вплоть до двух идентификаторов 364 и 365 операнда источника. Для одного варианта воплощения инструкции скалярного произведения идентификатор 366 операнда назначения будет тем же, что и идентификатор 364 операнда источника, тогда как в других вариантах воплощения они могут быть разными. В альтернативном варианте воплощения идентификатор 366 операнда назначения является тем же, что и идентификатор 365 операнда источника, тогда как в других вариантах воплощения они разные. В одном варианте воплощения инструкции скалярного произведения один из операндов источника, идентифицированных по идентификаторам 364 и 365 операнда источника, перезаписывают по результатам операций скалярного произведения, тогда как в других вариантах воплощения идентификатор 364 соответствует элементу регистра источника и идентификатор 365 соответствует элементу регистра назначения. Для одного варианта воплощения инструкции скалярного произведения идентификаторы 364 и 365 операнда можно использовать для идентификации источника размером 32 бита или 64 бита и операндов назначения.
На фиг.3Е представлено описание другого альтернативного формата 370 кодирования операции (opcode), имеющего сорок или больше битов. Формат 370 opcode соответствует формату 360 opcode и содержит необязательный байт 378 префикса. Тип операции скалярного произведения может быть кодирован по одному или больше полям 378, 371 и 372. Вплоть до двух мест расположения операнда на инструкцию могут быть идентифицированы идентификаторами 374 и 375 операнда источника и байтом 378 префикса. Для одного варианта воплощения инструкции скалярного произведения байт 378 префикса можно использовать для идентификации 32-битного или 64-битного операндов источника и назначения. Для одного варианта воплощения инструкции скалярного произведения идентификатор 376 операнда назначения являются такими же, как и идентификатор 374 операнда источника, тогда как в других вариантах воплощения они разные. Для альтернативного варианта воплощения идентификатор 376 операнда назначения является таким же, как и идентификатор 375 операнда источника, тогда как в других вариантах воплощения они разные. В одном варианте воплощения операции скалярного произведения, умножающие один из операндов, идентифицированных идентификаторами 374 и 375 операнда, на другой операнд, идентифицированный идентификаторами 374 и 375 операнда, перезаписывают по результатам операций скалярного произведения, тогда как в других вариантах воплощения скалярное произведение операндов, идентифицированных по идентификаторам 374 и 375, записывают в другой элемент данных в другом регистре. Форматы 360 и 370 opcode обеспечивают возможность адресации регистра в регистр, запоминающее устройство в регистр, регистра по памяти, регистра по регистру, регистра по непосредственному значению, регистра по адресу памяти, как определено частично полями 363 и 373 MOD и с использованием необязательного основания шкала-индекс и байтов смещения.
Рассмотрим теперь фиг.3F, в некоторых альтернативных вариантах воплощения арифметические операции типа один поток команд - много потоков данных (ОКМД) размером 64 бита могут выполняться с использованием инструкции обработки данных сопроцессором (CDP, ОДС). Формат 380 кодирования операции (opcode) представляет одну такую инструкцию ОДС, имеющую поля 382 и 389 opcode ОДС. Тип инструкции ОДС для альтернативных вариантов воплощения операций скалярного произведения может быть кодирован по одному или больше полям 383, 384, 387 и 388. Вплоть до трех мест расположения операнда на инструкцию может быть идентифицировано, включающих в себя до двух идентификаторов 385 и 390 операнда источника и один идентификатор 386 операнда назначения. Для одного варианта воплощения сопроцессор может оперировать 8-, 16-, 32- и 64-битовыми значениями. Для одного варианта выполнения операцию скалярного произведения выполняют по элементам целочисленных данных. В некоторых вариантах воплощения инструкция скалярного произведения могут выполняться в зависимости от условий с использованием поля 381 выбора. Для некоторых инструкций скалярного произведения размеры данных источника инструкций могут быть кодированы полем 383. В некоторых вариантах воплощения детектирование инструкции скалярного произведения, Zero (Z) (ноль), Negative (N) (отрицательное), carry (С) (перенос) и overflow (V) (переполнение) могут быть выполнены по полям ОКМД. Для некоторых инструкций тип режима насыщения может быть кодирован по полю 384.
На фиг.4 показана блок-схема одного варианта воплощения логики для выполнения операции скалярного произведения для операндов пакетных данных в соответствии с настоящим изобретением. Варианты воплощения настоящего изобретения могут быть воплощены для работы с различными типами операндов, такими как описаны выше. В одном варианте воплощения операции скалярного произведения в соответствии с настоящим изобретением воплощены как набор инструкций для работы по специфичным типам данных. Например, инструкция для скалярного произведения пакетных данных с одинарной точностью (DPPS, СППО) предусмотрена для определения скалярного произведения для 32-битных типов данных, включающих в себя целые числа и числа с плавающей запятой. Аналогично, инструкция скалярного произведения для пакетных данных с двойной точностью (СППД, DPPD) предусмотрена для определения скалярного произведения для 64-битных типов данных, включающих в себя целые числа и числа с плавающей запятой. Хотя эти инструкции имеют разные названия, в общем, операции скалярного произведения, которые они выполняют, аналогичны. Для упрощения следующие описания и примеры, приведенные ниже, показаны в контексте инструкции скалярного произведения для обработки элементов данных.
В одном варианте воплощения инструкция скалярного произведения идентифицирует различную информацию, включающую в себя: идентификатор операнда DATA A 410 первых данных и идентификатор второго операнда DATA В 420 вторых данных и идентификатор для RESULTANT 440 (результант) операции скалярного произведения (который может представлять собой тот же идентификатор, что и один из идентификаторов операнда первых данных в одном варианте воплощения). Для следующего описания DATA A, DATA В и для RESULTANT, в общем, называются операндами или блоками данных, но не ограничиваются этим, и также включают в себя регистры, файлы регистров и места расположения в памяти. В одном варианте воплощения каждую инструкцию скалярного произведения (СППО, СППД) декодируют в одну микрооперацию. В альтернативном варианте воплощения каждая инструкция может быть декодирована в различное количество микроопераций для выполнения операции скалярного произведения по операндам данных. Для этого примера операнды 410, 420 представляют собой части информации шириной 128 битов, сохраненные в регистре/запоминающем устройстве источника, имеющем элементы данных шириной "слово". В одном варианте воплощения операнды 410, 420 содержатся в регистрах ОКМД длиной 128 битов, таких как регистры РПОх ДРП длиной 128 битов. В одном варианте воплощения RESULTANT 440 также представляет собой регистр данных ДРП. Кроме того, RESULTANT 440 также может представлять собой тот же регистр или место расположения в памяти, что и у одного из операндов источника. В зависимости от конкретного варианта воплощения операнды и регистры могут иметь другую длину, например 32, 64 и 256 битов, и могут иметь элементы данных размером байт, двойное слово или четверное слово. Хотя элементы данных в этом примере имеют размер "слова", эта же концепция может быть расширена на элементы размером байт и двойное слово. В одном варианте воплощения, где операнды данных имеют ширину 64 бита, регистры ММР используются вместо регистров ДРП.
Первый операнд 410 в этом примере состоит из набора из восьми элементов данных: A3, А2, А1 и А0. Каждый отдельный элемент данных соответствует положению элемента данных в результанте 440. Второй операнд 420 состоит из другого набора из восьми сегментов: В3, В2, В1 и В0 данных. Сегменты данных здесь имеют равную длину, и каждый из них содержит данные размером одно слово (32 бита). Однако элементы данных и положения элементов данных могут содержать другие гранулярности помимо слов. Если бы каждый элемент данных имел размер байт (8 битов), двойное слово (32 бита) или четверное слово (64 бита), операнды размером 128 битов представляли бы собой элементы данных шириной шестнадцать байтов, шириной четыре двойных слова или шириной два четверных слова соответственно. Варианты воплощения настоящего изобретения не ограничиваются операндами данных или сегментами данных с конкретной длиной, и их размер может быть установлен соответственно для каждого варианта воплощения.
Операнды 410, 420 могут находиться или в регистре, или в определенном месте расположения в памяти, или в файле регистра, или могут быть расположены в смешанной форме. Операнды 410, 420 данных передают в логическую схему 430 расчета скалярного произведения исполнительного модуля в процессоре вместе с инструкцией скалярного произведения. К тому моменту времени, когда инструкция скалярного произведения поступает в исполнительный модуль, инструкция должна быть декодирована до этого в конвейере процессора в одном из вариантов воплощения. Таким образом, инструкция скалярного произведения может быть в форме микрооперации (uор) или в некотором другом декодированном формате. Для одного варианта воплощения два операнда 410, 420 данных принимают в логической схеме 430 расчета скалярного произведения. Логическая схема 430 расчета скалярного произведения генерирует первый результат умножения двух элементов данных первого операнда 410 со вторым результатом умножения двух элементов данных в соответствующем положении элемента данных второго операнда 420 и сохраняет сумму первого и второго результатов умножения в соответствующем положении в результанте 440, который может соответствовать тому же местоположению сохранения, что и у первого или второго операнда. В одном варианте воплощения элементы данных из первого и второго операндов представляют собой данные с одиночной точностью (например, 32 бита), в то время как в других вариантах воплощения элементы данных из первого и второго операндов представляют собой данные с двойной точностью (например, 64 бита).
В одном варианте воплощения элементы данных для всех положений данных обрабатывают параллельно. В другом варианте воплощения определенная часть положений элемента данных может быть обработана вместе одновременно. В одном варианте воплощения результант 440 состоит из двух или четырех возможных положений результата скалярного произведения в зависимости от того, выполняют ли СППД или СППО соответственно: DOT-PRODUCTA31-0, DOT-PRODUCTA63-32, DOT-PRODUCTA95-64, DOT-PRODUCTA127-96 (для результатов инструкции СППО) и DOT-PRODUCTA63-0, DOT-PRODUCTA127-64 (для результатов инструкции СППД).
В одном варианте воплощения положение результата скалярного произведения в результанте 440 зависит от поля выбора, ассоциированного с инструкцией скалярного произведения. Например, для инструкций СППО положение результата скалярного произведения в результанте 440 представляет собой DOT-PRODUCTA31-0, если поле выбора равно первому значению, DOT-PRODUCTA63-32, если поле выбора равно второму значению, DOT-PRODUCTA95-64, если поле выбора равно третьему значению, и DOT-PRODUCTA127-64, если поле выбора равно четвертому значению. В случае инструкции СППД положение результата скалярного произведения DOT-PRODUCT в результанте 440 составляет DOT-PRODUCTA63-0, если поле выбора представляет собой первое значение, и DOT-PRODUCTA127-64, если поле выбора представляет собой второе значение.
На фиг.5а иллюстрируется операция инструкции скалярного произведения в соответствии с одним вариантом воплощения настоящего изобретения. В частности, на фиг.5а иллюстрируется операция инструкции СППО в соответствии с одним вариантом воплощения. В одном варианте воплощения операция скалярного произведения в примере, представленном на фиг.5а, по существу, может быть выполнена с помощью логической схемы 430 расчета скалярного произведения по фиг.4. В других вариантах воплощения операция скалярного произведения по фиг.5а может быть выполнена с использованием другой логической схемы, включающей в себя аппаратные средства, программное средство или некоторую их комбинацию.
В других вариантах воплощения операции, представленные на фигурах 4, 5а и 5b, могут быть выполнены в любой комбинации или порядке для получения результата скалярного произведения. В одном варианте воплощения на фиг.5а иллюстрируется 128-битный регистр 501а источника, включающий в себя места расположения сохранения, вплоть до четырех значений с одиночной точностью, с плавающей запятой или целочисленных значений, каждое размером 32 бита, А0-A3. Аналогично, на фиг.5а представлен регистр 505а места назначения размером 128-битов, включающий в себя места сохранения для сохранения вплоть до четырех значений с одиночной точностью с плавающей запятой или целочисленных значений, каждое из которых имеет размер 32 бита, В0-В3. В одном варианте воплощения, каждое значение А0-А3, сохраненное в регистре источника, умножают на соответствующее значение В0-В3, сохраненное в соответствующем положении регистра места назначения, и каждое полученное в результате значение А0·В0, А1·В1, А2·В2, А3·В3 (называются здесь "произведением"), сохраняют в соответствующем месте расположения сохранения первого 128-битного временного регистра ("TEMP1") 510a, включающем в себя места расположения для сохранения вплоть до четырех значений одиночной точностью с плавающей запятой или целочисленных значений, каждое размером 32 бита.
В одном варианте воплощения пары произведений суммируют вместе и каждую сумму (называются здесь "промежуточными суммами") сохраняют в месте сохранения второго 128-битного временного регистра ("ТЕМР2") 515а и третьего 128-битного временного регистра ("ТЕМР3") 520а. В одном варианте воплощения произведения сохраняют в месте сохранения наименьшего значимого 32-битного элемента в местах расположения первого и второго временных регистров. В других вариантах воплощения они могут быть сохранены в других местах расположения элемента первого и второго временных регистров. Кроме того, в некоторых вариантах воплощения произведения могут быть сохранены в одном и том же регистре, например либо в первом, либо во втором временном регистре.
В одном варианте воплощения промежуточные суммы суммируют вместе (называются здесь "конечной суммой") и сохраняют в элементе сохранения четвертого 128-битного временного регистра ("ТЕМР4") 525а. В одном варианте воплощения конечную сумму сохраняют в наименьшем значимом 32-битном элементе сохранения ТЕМР4, тогда как в других вариантах воплощения конечную сумму сохраняют в других элементах сохранения ТЕМР4. Конечную сумму затем сохраняют в элементе сохранения регистра 505а назначения. Точный элемент сохранения, в котором должна быть сохранена конечная сумма, может зависеть от переменных, конфигурируемых в пределах инструкции скалярного произведения. В одном варианте воплощения непосредственное поле ("IMMy [x]"), содержащее множество мест сохранения битов, можно использовать для определения элемента сохранения регистра назначения, в котором должна быть сохранена конечная сумма. Например, в одном варианте воплощения, если поле IMM8 [0] содержит первое значение (например, "1"), конечную сумму сохраняют в элементе В0 сохранения регистра назначения, если поле IMM8 [1] содержит первое значение (например, "1"), конечную сумму сохраняют в элементе В1 сохранения, если поле IMM8 [2] содержит первое значение (например, "1"), конечную сумму сохраняют в элементе В2 сохранения регистра назначения и, если поле IMM8 [3] содержит первое значение (например, "1"), конечную сумму сохраняют в элементе В3 сохранения регистра назначения. В других вариантах воплощения другие непосредственные поля можно использовать для определения элемента сохранения, в котором конечную сумму сохраняют в регистре места назначения.
В одном варианте воплощения непосредственные поля можно использовать для управления, выполняется ли каждая операция умножения и суммирования в операции, представленной на фиг.5а. Например, IMM8 [4] можно использовать для обозначения (например, при установке в "0" или "1"), следует ли А0 умножить на В0 и результат сохранить в TEMP1. Аналогично, IMM8 [5] можно использовать для обозначения (при установке, например, в "0" или "1",), следует ли А1 умножить на В1 и результат сохранить в TEMP1. Аналогично, IMM8 [6] можно использовать для обозначения (при установке, например, в "0" или в "1"), следует ли А2 умножить на В2 и результат сохранить в TEMP1. Наконец, IMM8 [7] можно использовать для обозначения (при установке, например, в "0" или "1"), следует ли A3 умножить на В3 и результат сохранить в TEMP1.
На фиг.5b иллюстрируется операция инструкции СППД в соответствии с одним вариантом воплощения. Одно различие между инструкциями СППО и СППД состоит в том, что СППД работает со значениями с двойной точностью с плавающей запятой и целочисленными значениями (например, значениями размером 64 бита) вместо значений с одиночной точностью. В соответствии с этим меньшее количество элементов данных, которыми требуется управлять, и поэтому меньшее количество промежуточных операций и модулей сохранения (например, регистров) используется при выполнении инструкции СППД, чем инструкции СППО, в одном варианте воплощения.
В одном варианте воплощения на фиг.5b иллюстрируется 128-битный регистр 501b источника, включающий в себя элементы сохранения для сохранения вплоть до двух значений с двойной точностью с плавающей запятой или целочисленных значений, каждое размером 64 бита, А0-А1. Аналогично, на фиг.5b показан регистр 505b назначения размером 128 битов, включающий в себя элементы сохранения, для сохранения вплоть до двух значений с двойной точности с плавающей запятой или целочисленных значений размером 64 бита каждое, В0-В1. В одном варианте воплощения каждое значение А0-А1, сохраненное в регистре источника, умножают на соответствующее значение В0-В1, сохраненное в соответствующем положении регистра назначения, и каждое полученное в результате значение А0·В0, А1·В1 (ниже называются "произведениями") сохраняют в соответствующем элементе сохранения первого 128-битного временного регистра ("TEMP1") 510b, включающего в себя элементы сохранения, для сохранения вплоть до двух значений с двойной точностью с плавающей запятой или целочисленных значений размером 64 бита каждое.
В одном варианте воплощения пары произведений суммируют вместе и каждую сумму (ниже называется "конечной суммой") сохраняют в элементе сохранения второго 128-битного временного регистра ("ТЕМР2") 515b. В одном варианте воплощения произведение и конечную сумму сохраняют в наименее значимом месте сохранения 64-битного элемента первого и второго временных регистров соответственно. В других вариантах воплощения они могут быть сохранены в других местах сохранения элементов первого и второго временных регистров.
В одном варианте воплощения конечную сумму сохраняют в элементе сохранения регистра 505b назначения. Точный элемент сохранения, в котором будет сохранена конечная сумма, может зависеть от переменных, конфигурируемых в пределах инструкции скалярного произведения. В одном варианте воплощения можно использовать непосредственное поле ("IMMy [x]"), содержащее определенное количество бит мест расположения сохранения, для определения элемента сохранения регистра назначения, в котором должна быть сохранена конечная сумма. Например, в одном варианте воплощения, если поле IMM8 [0] содержит первое значение (например, "1"), конечную сумму сохраняют в элементе В0 сохранения регистра назначения, если поле IMM8 [1] содержит первое значение (например, "1"), конечную сумму сохраняют в элементе В1 сохранения. В других вариантах воплощения можно использовать другие непосредственные поля для определения элемента сохранения, в котором сохраняют конечную сумму в регистре назначения.
В одном варианте воплощения непосредственные поля можно использовать для управления, выполняется ли каждая из операций умножения в операциях скалярного произведения, представленных на фиг.5b. Например, IMM8 [4] можно использовать для обозначения (например, путем установки в "0" или "1"), следует ли А0 умножить на В0 и результат сохранить в TEMP1. Аналогично, IMM8 [5] можно использовать для обозначения (путем установки, например, в "0" или "1"), следует ли А1 умножить на В1 и результат сохранить в TEMP1. В других вариантах воплощения можно использовать другие методики управления для определения, следует ли выполнять операции умножения скалярного произведения.
На фиг.6А показана блок-схема схемы 600а выполнения операции скалярного произведения по целочисленным значениям с единичной точностью или значения с плавающей запятой в соответствии с одним вариантом воплощения. Схема 600а в данном варианте воплощения умножает через умножители 610а-613а соответствующие элементы с одиночной точностью двух регистров 601а и 605а, результаты которых могут быть выбраны с помощью мультиплексоров 615а-618а, используя непосредственное поле, IMM8 [7:4]. В качестве альтернативы, мультиплексоры 615а-618а могут выбирать нулевое значение вместо соответствующего произведения операции умножения для каждого элемента. Результаты выбора мультиплексорами 615а-618а затем суммируют вместе с помощью сумматора 620а и результат сохраняют в любом из элементов регистра 630а результата в зависимости от значения непосредственного поля IMM8 [3:0], которое выбирает соответствующий результат суммы сумматора 620а, используя мультиплексоры 625а-628а. В одном варианте воплощения мультиплексоры 625а-628а могут выбирать нули для заполнения элемента регистра 630а результата, если сохраненный результат суммы не будет выбран для сохранения в элементе результата. В других вариантах воплощения можно использовать большее количество сумматоров для генерирования сумм различных результатов умножения. Кроме того, в некоторых вариантах воплощения промежуточные элементы сохранения можно использовать для сохранения результатов произведения или суммирования до тех пор, пока они не будут подвергнуты дальнейшим операциям.
На фиг.6В показана блок-схема схемы 600b для выполнения операции скалярного произведения над целочисленными значениями с одиночной точностью или значениями с плавающей запятой в соответствии с одним вариантом воплощения. Схема 600b данного варианта воплощения умножает через умножители 610b, 612b соответствующие элементы с одиночной точностью двух регистров 601b и 605b, и полученные результаты могут быть выбраны мультиплексорами 615b, 617b, используя непосредственное поле, IMM8 [7:4]. В качестве альтернативы, мультиплексоры 615b, 618b могут выбирать нулевое значение вместо соответствующего произведения операции умножения для каждого элемента. Результат выбора мультиплексорами 615b, 618b затем суммируют вместе с помощью сумматора 620b и результат сохраняют в любом из элементов регистра 630b результата в зависимости от значения непосредственного поля, IMM8 [3:0], которое выбирает соответствующий результат суммы из сумматора 620b, используя мультиплексоры 615b, 627b. В одном варианте воплощения мультиплексоры 625b-627b могут выбирать нули для заполнения элемента регистра 630b результата, если сохраненный результат суммы не будет выбран для сохранения в элементе результата. В других вариантах воплощения большее количество сумматоров можно использовать для генерирования суммы различных результатов умножения. Кроме того, в некоторых вариантах воплощения промежуточные элементы сохранения можно использовать для сохранения результатов произведения или суммирования до тех пор, пока с ними не будут выполнены дополнительные операции.
На фиг.7А показано представление в виде псевдокода операций для выполнения инструкции СППО в соответствии с одним вариантом воплощения. Псевдокод, иллюстрируемый на фиг.7А, обозначает, что значение с одиночной точностью с плавающей запятой или целочисленное значение, сохраненное в регистре источника ("SRC") в битах 31-0, должно быть умножено на значение с одиночной точностью с плавающей запятой или целочисленное значение, сохраненное в регистре назначения ("DEST") в битах 31-0, и результат сохраняют в битах 31-0 временного регистра ("TEMP1"), только если непосредственное значение, сохраненное в непосредственном поле ("IMM8 [4]"), равно "1". В противном случае места расположения битов 31-0 могут содержать нулевое значение, например все нули.
На фиг.7А также представлен псевдокод для обозначения того, что значение с одиночной точностью с плавающей запятой или целочисленное значение, сохраненное в регистре SRC в битах 63-32, должно быть умножено на значение с одиночной точностью с плавающей запятой или целочисленное значение, сохраненное в регистре DEST в битах 63-32, и результат сохраняют в битах 63-32 в регистре TEMP1, только если непосредственное значение, сохраненное в непосредственном поле ("IMM8 [5]"), равно "1". В противном случае места сохранения 63-32 могут содержать нулевое значение, например все нули.
Аналогично, на фиг.7А показан псевдокод, обозначающий, что значение с одиночной точностью с плавающей запятой или целочисленное значение, сохраненное в регистре SRC в битах 95-64, должно быть умножено на значение с одиночной точностью с плавающей запятой или целочисленное значение, сохраненное в регистре DEST в битах 95-64, и результат должен быть сохранен в битах 95-64 регистра TEMP1, только если непосредственное значение, сохраненное в непосредственном поле ("IMM8 [6]"), равно "1". В противном случае места 95-64 сохранения могут содержать нулевое значение, например все нули.
Наконец, на фиг.7А показан псевдокод, обозначающий, что значение с одиночной точностью с плавающей запятой или целочисленное значение, сохраненное в регистре SRC в битах 127-96, должно быть умножено на значение с одиночной точностью с плавающей запятой или целочисленное значение, сохраненное в регистре DEST в битах 127-96, и результат сохраняют в битах 127-96 регистра TEMP1, только если непосредственное значение, сохраненное в непосредственном поле ("IMM8 [7]"), равно "1". В противном случае места 127-96 сохранения могут содержать нулевое значение, например все нули.
Далее, на фиг.7А иллюстрируется, что биты 31-0 суммируют с битами 63-32 TEMP1 и результат сохраняют в местах сохранения битов 31-0 второго временного регистра ("ТЕМР2"). Аналогично, биты 95-64 суммируют с битами 127-96 TEMP1 и результат сохраняют в местах сохранения битов 31-0 третьего временного регистра ("ТЕМР3"). Наконец, биты 31-0 ТЕМР2 суммируют с битами 31-0 ТЕМР3 и результат сохраняют в местах сохранения битов 31-0 четвертого временного регистра ("ТЕМР4").
Данные, сохраненные во временных регистрах, можно затем сохранять в регистре DEST в одном варианте воплощения. Конкретное местоположение в регистре DEST для сохранения данных может зависеть от других полей в инструкции СППО, например поля в IMM8 [х]. В частности, на фиг.7А показано, что в одном варианте воплощения биты 31-0 ТЕМР4 сохранены в местах сохранения битов DEST 31-0, если IMM8 [0] равно "1", в местах сохранения битов DEST 63-32, если IMM8 [1] равно "1", в местах сохранения битов DEST 95-64, если IMM8 [2] равно "1", или в местах сохранения DEST 127-96, если IMM8 [3] равно "1". В противном случае соответствующий элемент бита DEST будет содержать нулевое значение, например все нули.
На фиг.7В показано представление в виде псевдокода операций для выполнения инструкции СППД в соответствии с одним вариантом воплощения. Псевдокод, показанный на фиг.7В, обозначает, что значение с одиночной точностью с плавающей запятой или целочисленное значение, сохраненное в регистре источника ("SRC") в битах 63-0, должно быть умножено на значение с одиночной точностью с плавающей запятой или целочисленное значение, сохраненное в регистре назначения ("DEST") в битах 63-0, и результат сохраняют в битах 63-0 временного регистра ("TEMP1"), только если непосредственное значение, сохраненное в непосредственном поле ("IMM8 [4]"), равно "1". В противном случае места сохранения битов 63-0 могут содержать нулевое значение, например все нули.
Также на фиг.7В показан псевдокод, обозначающий, что значение с одиночной точностью с плавающей запятой или целочисленное значение, сохраненное в регистре SRC в битах 127-64, должно быть умножено на значение с одиночной точностью с плавающей запятой или целочисленное значение, сохраненное в регистре DEST в битах 127-64, и результат должен будет сохранен в битах 127-64 регистра TEMP1, только если непосредственное значение, сохраненное в непосредственном поле ("IMM8 [5]"), равно "1". В противном случае места сохранения битов 127-64 могут содержать нулевое значение, например все нули.
Далее, на фиг.7В, иллюстрируется, что биты 63-0 суммируют с битами 127-64 TEMP1 и результат сохраняют в местах сохранения битов 63-0 второго временного регистра ("ТЕМР2"). Данные, сохраненные во временном регистре, могут затем быть сохранены в регистре DEST, в одном варианте воплощения. Конкретное местоположение, в котором данные будут сохранены в регистре DEST, может зависеть от других полей в инструкции СППО, таких как поля в IMM8 [х]. В частности, на фиг. 7А показано, что в одном варианте воплощения биты 63-0 ТЕМР2 сохранены в месте сохранения битов DEST 63-0, если IMM8 [0] равен "1", или биты 63-0 ТЕМР2 сохраняют в местах сохранения битов DEST 127-64, если IMM8 [1] равен "1". В противном случае соответствующий элемент бита DEST будет содержать нулевое значение, например все нули.
Операции, раскрытые на фиг. 7А и 7В, представляют собой только одно представление операций, которые можно использовать в одном или больше вариантах воплощения изобретения. В частности, псевдокод, показанный на фиг. 7А и 7В, соответствует операциям, выполняемым в соответствии с одной или больше архитектурами процессора, имеющими 128-битные регистры. Другие варианты воплощения могут быть выполнены в архитектурах процессора, имеющих любой размер регистров, или другой тип области сохранения. Кроме того, другие варианты воплощения могут не использовать регистры точно так, как это показано на фиг. 7А и 7В. Например, в некоторых вариантах воплощения можно использовать другое количество временных регистров или ни один из регистров вообще для сохраненных операндов. Наконец, варианты воплощения изобретения могут быть выполнены между множеством процессоров или ядер обработки с использованием любого количества регистров или типов данных.
Таким образом, раскрыты методики для выполнения операции скалярного произведения. Хотя определенные примерные варианты воплощения были описаны и показаны на приложенных чертежах, следует понимать, что такие варианты воплощения представляют собой просто иллюстрацию и не ограничивают широкое изобретение и что данное изобретение не должно быть ограничено конкретными показанными и описанным конструкциями и компоновками, поскольку различные другие модификации могут возникнуть у специалистов в данной области техники после изучения данного раскрытия. В области технологии, такой как эта, которая быстро растет и дальнейшее развитие которой трудно предусмотреть, раскрытые варианты воплощения могут быть легко модифицированы по компоновке и деталям в соответствии с развитием технологии без выхода за пределы принципов настоящего раскрытия или объема приложенной формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ЭФФЕКТИВНАЯ ПАРАЛЛЕЛЬНАЯ ОБРАБОТКА ИСКЛЮЧЕНИЯ С ПЛАВАЮЩЕЙ ЗАПЯТОЙ В ПРОЦЕССОРЕ | 2009 |
|
RU2427897C2 |
| ВЫПОЛНЕНИЕ ОПЕРАЦИЙ ОКРУГЛЕНИЯ В СООТВЕТСТВИИ С ИНСТРУКЦИЕЙ | 2011 |
|
RU2447484C1 |
| ВЫПОЛНЕНИЕ ОПЕРАЦИЙ ОКРУГЛЕНИЯ В СООТВЕТСТВИИ С ИНСТРУКЦИЕЙ | 2007 |
|
RU2420790C2 |
| ЦЕЛОЧИСЛЕННОЕ УМНОЖЕНИЕ ВЫСОКОГО ПОРЯДКА С ОКРУГЛЕНИЕМ И СДВИГОМ В АРХИТЕКТУРЕ С ОДНИМ ПОТОКОМ КОМАНД И МНОЖЕСТВОМ ПОТОКОВ ДАННЫХ | 2003 |
|
RU2263947C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПАРАЛЛЕЛЬНОГО ОБЪЕДИНЕНИЯ ДАННЫХ СО СДВИГОМ ВПРАВО | 2002 |
|
RU2273044C2 |
| СПОСОБ, УСТРОЙСТВО И КОМАНДА ДЛЯ ВЫПОЛНЕНИЯ ЗНАКОВОЙ ОПЕРАЦИИ УМНОЖЕНИЯ | 2003 |
|
RU2275677C2 |
| МОДУЛЬ СОПРОЦЕССОРА КЭША | 2011 |
|
RU2586589C2 |
| УСТРОЙСТВО И СПОСОБ РЕВЕРСИРОВАНИЯ И ПЕРЕСТАНОВКИ БИТОВ В РЕГИСТРЕ МАСКИ | 2014 |
|
RU2636669C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ВЫПОЛНЕНИЯ КОМАНД С ПЛАВАЮЩЕЙ ЗАПЯТОЙ И УПАКОВАННЫХ ДАННЫХ, ИСПОЛЬЗУЯ ОДИНОЧНЫЙ ФАЙЛ РЕГИСТРА | 1996 |
|
RU2179331C2 |
| СПОСОБ И УСТРОЙСТВО ТАСОВАНИЯ ДАННЫХ | 2004 |
|
RU2316808C2 |
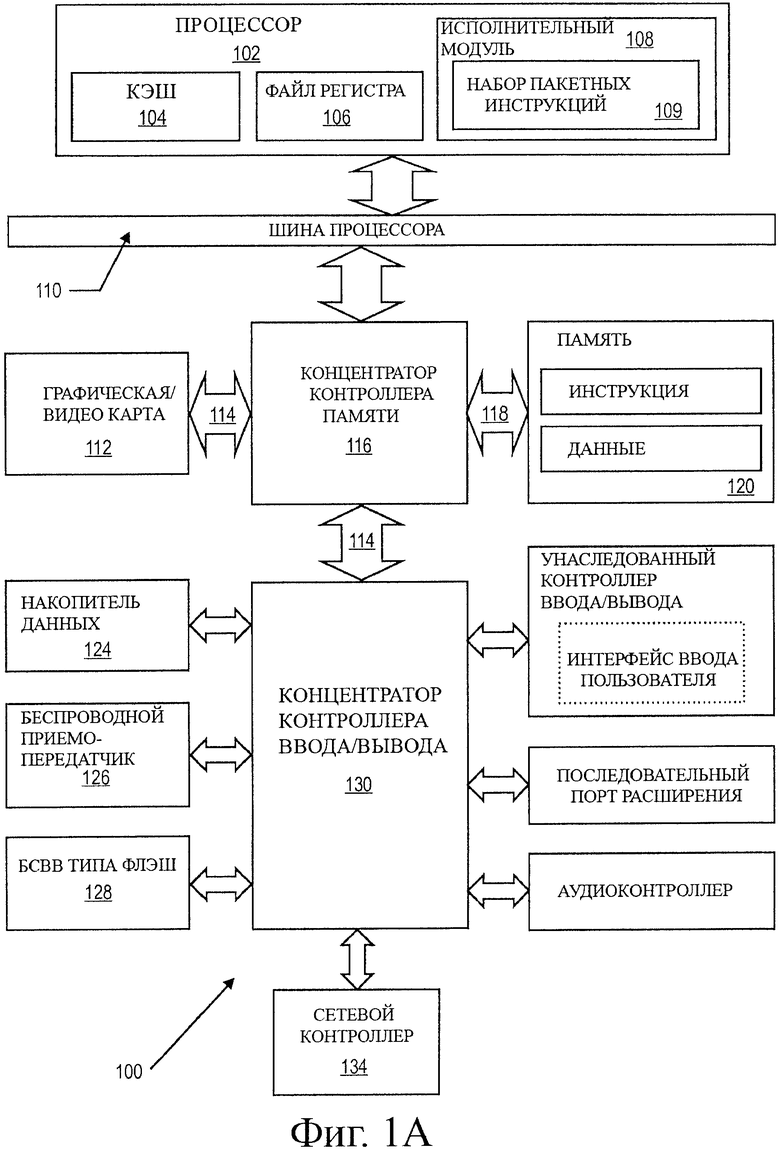
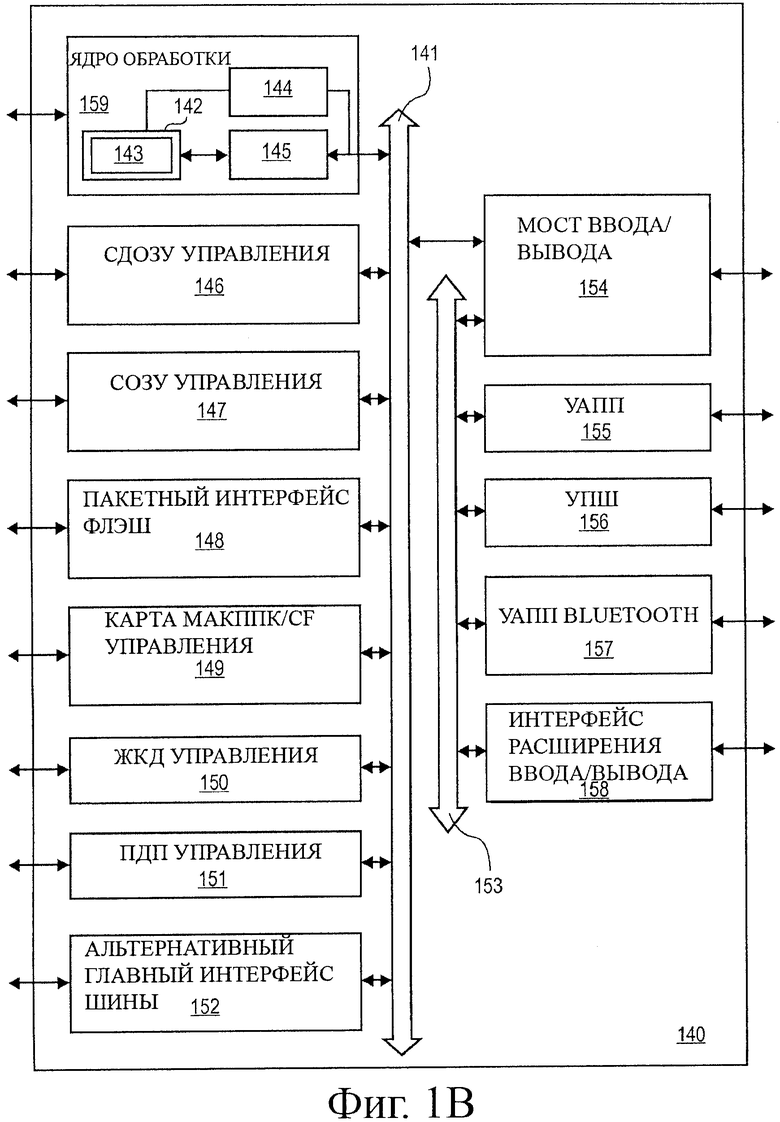
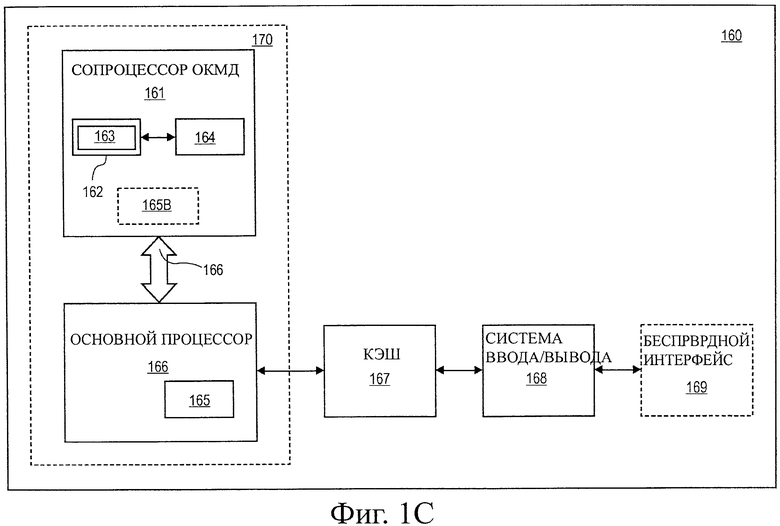
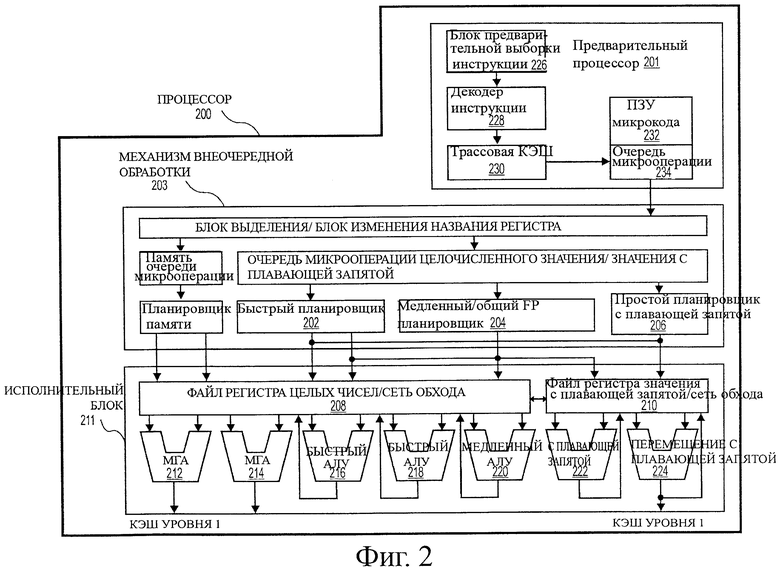
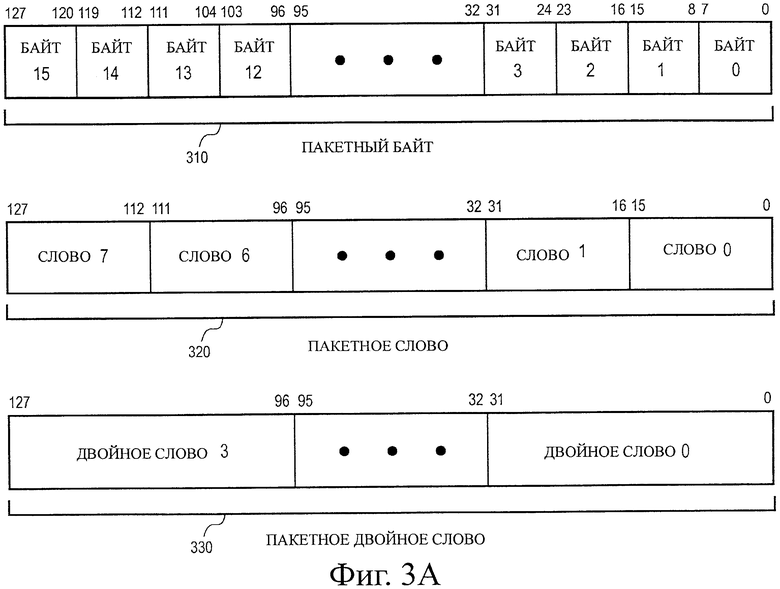
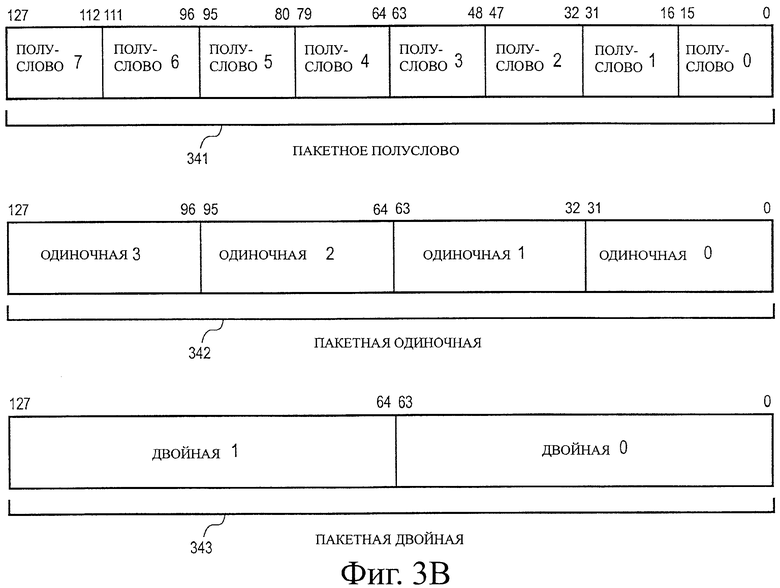
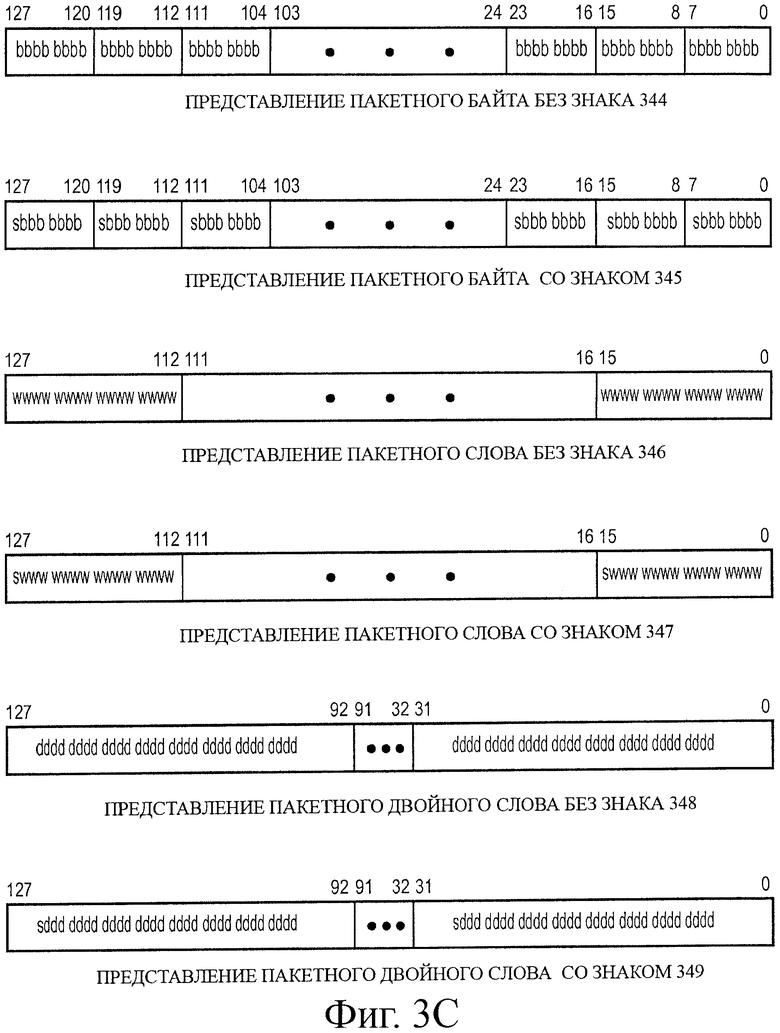
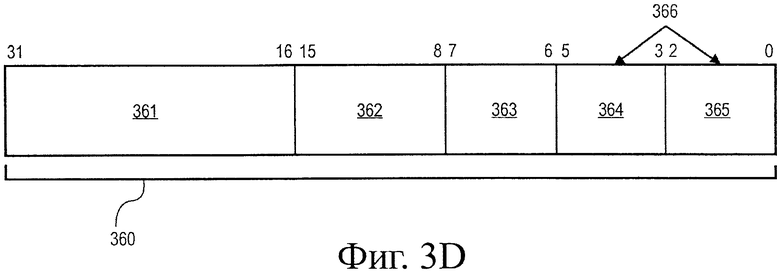
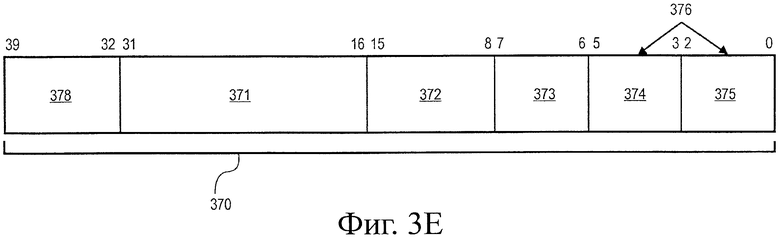
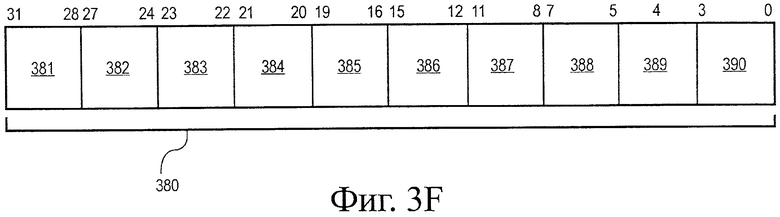
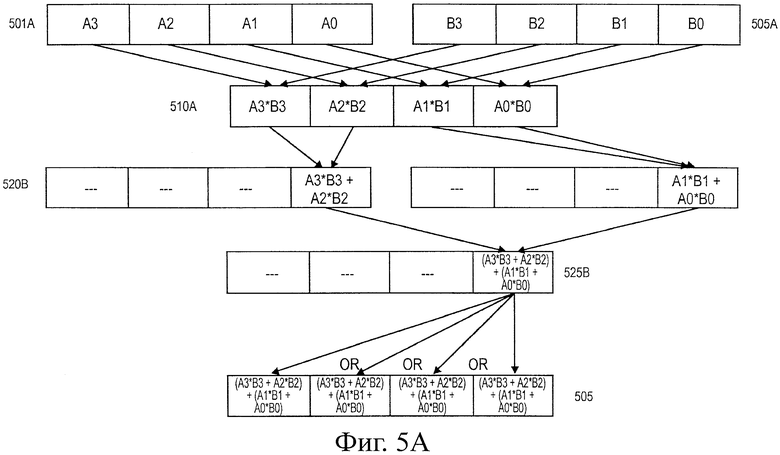
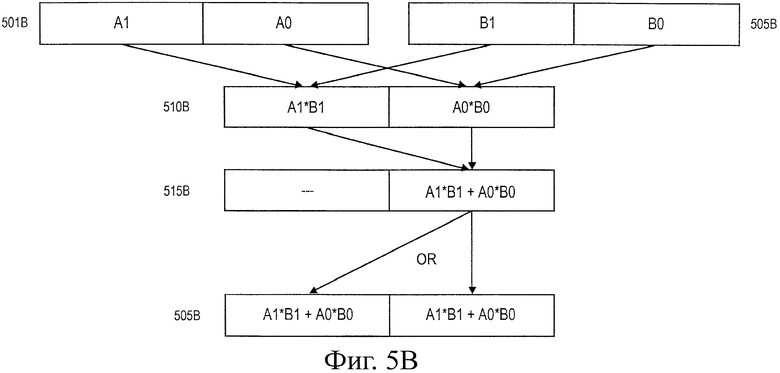
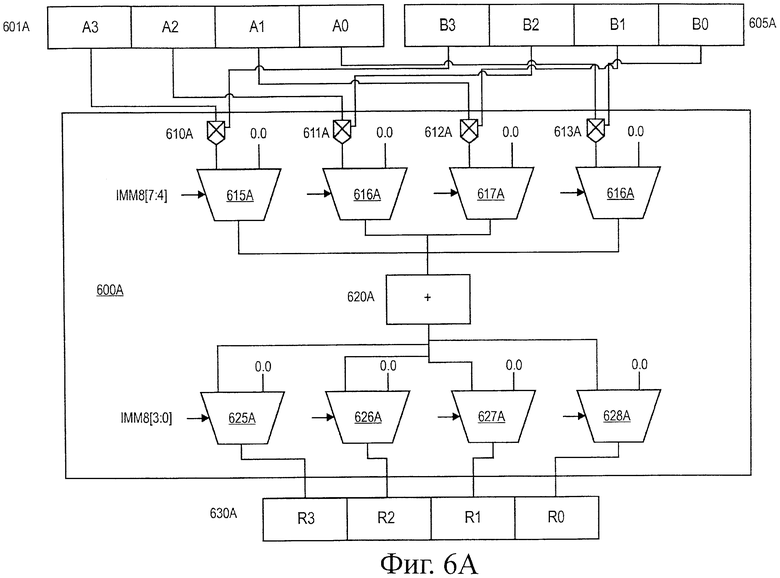
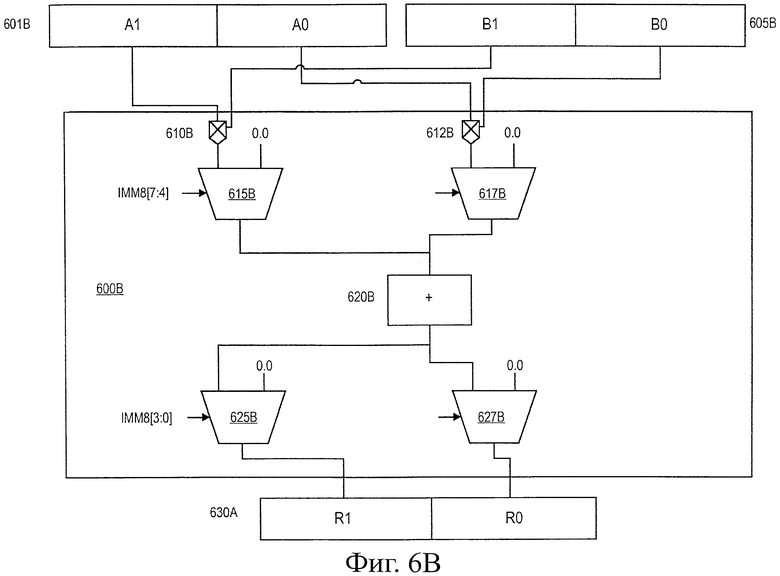


Изобретения относятся к процессорам, предназначенным для выполнения операций скалярного произведения. Техническим результатом является повышение производительности процессора. Система для выполнения операции скалярного произведения содержит: первое запоминающее устройство, предназначенное для сохранения инструкции скалярного произведения типа "один поток команд - много потоков данных" (ОКМД); процессор, соединенный с первым запоминающим устройством для выполнения инструкции скалярного произведения ОКМД, в которой инструкции скалярного произведения типа ОКМД содержат индикатор операнда источника, индикатор операнда назначения, по меньшей мере, один индикатор непосредственного значения, при этом индикатор непосредственного значения включает множество битов управления. 4 н. и 24 з.п. ф-лы, 18 ил.
1. Считываемый устройством носитель информации, на котором сохранена инструкция, которая в случае ее выполнения с помощью устройства обеспечивает выполнение устройством способа, содержащего этапы, на которых
генерируют первое произведение путем умножения первых пакетных данных целочисленного типа данных, которые содержатся в первом операнде, и вторых пакетных данных целочисленного типа, которые содержатся во втором операнде;
генерируют второе произведение путем умножения третьих пакетных данных целочисленного типа данных, которые содержатся в первом операнде, и четвертых пакетных данных целочисленного типа, которые содержатся во втором операнде;
сохраняют первое и второе произведение;
определяют результат скалярного произведения первого операнда и второго операнда путем добавления первого выбранного значения и второго выбранного значения, при этом первое выбранное значение выбирают из первого сохраненного произведения или нулевого значения, а второе выбранное значение выбирают из второго сохраненного произведения или нулевого значения, по меньшей мере, двух операндов, каждый из которых имеет множество пакетных значений первого типа данных;
сохраняют результат скалярного произведения в регистре назначения.
2. Считываемый устройством носитель по п.1, в котором первый тип данных представляет собой целочисленный тип данных.
3. Считываемый устройством носитель по п.1, в котором первый тип данных представляет собой тип данных с плавающей запятой.
4. Считываемый устройством носитель по п.1, в котором каждый из этих, по меньшей мере, двух операндов имеет только два пакетных значения.
5. Считываемый устройством носитель по п.1, в котором каждый из этих, по меньшей мере, двух операндов имеет только четыре пакетных значения.
6. Считываемый устройством носитель по п.1, в котором каждое из множества пакетных значений представляет собой значение с одиночной точностью и должно быть представлено 32 битами.
7. Считываемый устройством носитель по п.1, в котором каждое из множества пакетных значений представляет собой значение с двойной точностью и должно быть представлено 64 битами.
8. Считываемый устройством носитель по п.1, в котором эти, по меньшей мере, два операнда и результат скалярного произведения должны быть сохранены в, по меньшей мере, в двух регистрах, предназначенных для сохранения вплоть 128 битов данных.
9. Устройство для выполнения операции скалярного произведения, содержащее
первую логическую схему для выполнения инструкции скалярного произведения типа "один поток команд, много потоков данных" (ОКМД) по, по меньшей мере, двум пакетным операндам первого типа данных, в котором инструкции скалярного произведения типа ОКМД содержат индикатор операнда источника, индикатор операнда назначения, по меньшей мере, один индикатор непосредственного значения, индикатор операнда источника включает в себя адрес регистра источника, имеющего множество элементов, для сохранения множества пакетных значений, и по меньшей мере множество битов управления для индикации элемента сохранения места назначения, в котором будет сохранен результат.
10. Устройство по п.9, в котором индикатор операнда назначения включает в себя адрес регистра назначения, имеющего множество элементов, для сохранения множества пакетных значений.
11. Устройство по п.10, в котором индикатор непосредственного значения включает в себя множество битов управления.
12. Устройство по п.9, в котором, по меньшей мере, каждый из двух пакетных операндов представляет собой целые числа с двойной точностью.
13. Устройство по п.9, в котором, по меньшей мере, каждый из двух пакетных операндов представляет собой значения с двойной точностью с плавающей запятой.
14. Устройство по п.9, в котором, по меньшей мере, каждый из двух пакетных операндов представляет собой целые числа с одиночной точностью.
15. Устройство по п.9, в котором, по меньшей мере, каждый из двух пакетных операндов представляет собой значения с одиночной точностью с плавающей запятой.
16. Система для выполнения операции скалярного произведения, содержащая
первое запоминающее устройство, предназначенное для сохранения инструкции скалярного произведения типа "один поток команд - много потоков данных" (ОКМД);
процессор, соединенный с первым запоминающим устройством для выполнения инструкции скалярного произведения ОКМД, в которой инструкции скалярного произведения типа ОКМД содержат индикатор операнда источника, индикатор операнда назначения, по меньшей мере, один индикатор непосредственного значения, при этом индикатор непосредственного значения включает множество битов управления.
17. Система по п.16, в которой индикатор операнда источника включает в себя адрес регистра источника, имеющий множество элементов, для сохранения множества пакетных значений.
18. Система по п.17, в которой индикатор операнда назначения включает в себя адрес регистра назначения, имеющий множество элементов, для сохранения множества пакетных значений.
19. Система по п.16, в которой, по меньшей мере, каждый из двух пакетных операндов представляет собой целые числа с двойной точностью.
20. Система по п.16, в которой, по меньшей мере, каждый из двух пакетных операндов представляет собой значения с двойной точностью с плавающей запятой.
21. Система по п.16, в которой, по меньшей мере, каждый из двух пакетных операндов представляет собой целые числа с одиночной точностью.
22. Устройство по п.16, в которой, по меньшей мере, каждый из двух пакетных операндов представляет собой значения с одиночной точностью с плавающей запятой.
23. Процессор для выполнения операции скалярного произведения, содержащий:
регистр источника, предназначенный для сохранения первого пакетного операнда, включающий в себя первое и второе значения данных;
регистр назначения, предназначенный для сохранения второго пакетного операнда, включающий в себя третье и четвертое значения данных;
логическую схему для выполнения инструкции скалярного произведения типа "один поток команд - много потоков данных" (ОКМД) в соответствии со значением управления, обозначенным инструкцией скалярного произведения,
причем логическая схема содержит первый умножитель для умножения первого и третьего значений данных для генерирования первого произведения, второй умножитель, для умножения второго и четвертого значений данных, для генерирования второго произведения, причем логическая схема дополнительно включает в себя, по меньшей мере, один сумматор, для суммирования первого и второго произведений для получения, по меньшей мере, одной суммы, в котором логическая схема дополнительно включает в себя первый мультиплексор для выбора между первым произведением и нулевым значением в зависимости от первого бита значения управления, второй мультиплексор для выбора между вторым произведением и нулевым значением в зависимости от второго бита значения управления, третий мультиплексор для выбора между суммой и нулевым значением для сохранения в первом элементе регистра назначения, и четвертый мультиплексор для выбора между суммой и нулевым значением для сохранения во втором элементе регистра назначения.
24. Процессор по п.23, в котором первое, второе, третье и четвертое значения данных представляют собой 64-битные целочисленные значения.
25. Процессор по п.23, в котором первое, второе, третье, четвертое значения данных представляют собой 64-битные значения с плавающей запятой.
26. Процессор по п.23, в котором первое, второе, третье и четвертое значения данных представляют собой 32-битные целочисленные значения.
27. Процессор по п.23, в котором первое, второе, третье и четвертое значения данных представляют собой 32-битные значения с плавающей запятой.
28. Процессор по п.23, в котором регистры источника и назначения предназначены для сохранения, по меньшей мере, 128 битов данных.
| Перекатываемый затвор для водоемов | 1922 |
|
SU2001A1 |
| JP 2005174298 A, 30.06.2005 | |||
| US 6574651 B1, 03.06.2003 | |||
| СПОСОБ, УСТРОЙСТВО И КОМАНДА ДЛЯ ВЫПОЛНЕНИЯ ЗНАКОВОЙ ОПЕРАЦИИ УМНОЖЕНИЯ | 2003 |
|
RU2275677C2 |

