Область техники
Настоящее изобретение относится к области устройств обработки и соответствующего программного обеспечения и программных последовательностей, которые выполняют математические операции.
Предшествующий уровень техники
Компьютерные системы все больше проникают в жизнь современного общества. Возможности обработки компьютеров повысили эффективность и производительность труда работников в широком спектре профессий. Поскольку стоимость покупок и приобретения в собственность компьютеров продолжает падать, все больше и больше потребителей обретают возможность получения выгод от более новых и более быстродействующих машин. Кроме того, многие люди получают удовольствие от использования портативных компьютеров (ноутбуков) ввиду предоставляемой ими свободы. Мобильные компьютеры позволяют пользователям легко переносить свои данные и работать с ними, когда они покидают офис или находятся в путешествии. Данный сценарий хорошо знаком маркетинговым группам, руководителям корпораций и даже студентам.
По мере развития технологии процессоров происходит создание новых кодов программного обеспечения для исполнения на машинах этими процессорами. Пользователи в общем случае ожидают и требуют более высоких рабочих характеристик от своих компьютеров независимо от типа используемого программного обеспечения. Один такой вопрос может возникнуть из типов команд и операций, которые действительно выполняются в процессоре. Некоторые типы операций требуют больше времени для исполнения ввиду сложности операций и/или типа требующихся схем. Это обеспечивает возможность оптимизировать путь, которым в процессоре исполняются некоторые сложные операции.
Медийные прикладные программы (приложения) стимулируют развитие микропроцессоров уже больше десятка лет. В действительности, большинство компьютерных модернизаций в последние годы стимулировались медийными приложениями. Эти модернизации преобладающим образом происходили в потребительских сегментах, хотя значительный прогресс также наблюдается в производственных сегментах в области развлечений, высшего образования и коммуникации. Тем не менее, будущие медийные приложения сделают необходимыми еще более высокие вычислительные требования. В результате практический опыт персональных компьютеров ближайшего будущего будет отличаться разнообразием аудиовизуальных эффектов, а также они будут проще в использовании и, что более важно, вычисления сольются с коммуникациями.
Соответственно, отображение изображений, а также воспроизведение аудио- и видеоданных, которые совместно определяются понятием «информационное содержание», станут все более популярными приложениями для будущих вычислительных устройств. Операции фильтрации и свертки являются некоторыми из наиболее обычных операций, выполняемых над данными информационного содержания, такими как аудио- и видеоданные изображений. Такие операции требуют высокой вычислительной мощности, но обуславливают высокий уровень параллелизма данных, что может быть использовано за счет эффективной реализации с использованием различных устройств хранения данных, таких, например, как регистры одного потока команд и множества потоков данных (SIMD-регистры). Ряд современных архитектур также требуют ненужного изменения типа данных, что снижает пропускную способность команд и существенно увеличивает число тактовых циклов, требуемых для упорядочивания данных для арифметических операций.
Краткое описание чертежей
Настоящее изобретение иллюстрируется в качестве примера, но не ограничения, на чертежах, на которых одинаковыми ссылочными позициями обозначены сходные элементы.
Фиг.1А - блок-схема компьютерной системы с процессором, который включает в себя исполнительный блок, предназначенный для исполнения команд архитектуры одного потока команд и множества потоков данных (SIMD-команд) для операции целочисленного умножения высокого порядка с округлением и сдвигом в соответствии с одним вариантом осуществления настоящего изобретения;
Фиг.1В - блок-схема другой примерной компьютерной системы, соответствующей альтернативному варианту осуществления настоящего изобретения;
Фиг.1С - блок-схема еще одной примерной компьютерной системы, соответствующей другому альтернативному варианту осуществления настоящего изобретения;
Фиг.2 - блок-схема микроструктуры для процессора одного варианта осуществления, которая включает в себя логические схемы для выполнения операции упакованного целочисленного умножения с округлением и сдвигом в соответствии с настоящим изобретением;
Фиг.3А - представления различных типов упакованных данных в мультимедийных регистрах в соответствии с одним вариантом осуществления настоящего изобретения;
Фиг.3В - типы упакованных данных в соответствии с альтернативным вариантом осуществления настоящего изобретения;
Фиг.3С - вариант осуществления формата кода машинной команды (кода операции) для команды упакованного целочисленного умножения с округлением и сдвигом;
Фиг.3D - альтернативный формат кода операции;
Фиг.3Е - другой альтернативный формат кода операции;
Фиг.4А - блок-схема варианта осуществления логики для выполнения операции SIMD целочисленного умножения высокого порядка с округлением и сдвигом над операндами в памяти в соответствии с настоящим изобретением;
Фиг.4В - блок-схема операции целочисленного умножения высокого порядка с округлением и сдвигом для выбранной позиции элементов данных;
Фиг.5 - блок-схема варианта осуществления схемы для выполнения операции умножения высокого порядка с округлением и сдвигом в соответствии с настоящим изобретением;
Фиг.6А - действие команды упакованного умножения высокого порядка с округлением и сдвигом в соответствии с первым вариантом осуществления настоящего изобретения;
Фиг.6В - дополнительная детализация действия команды упакованного умножения высокого порядка в конкретной позиции элементов данных по фиг.6А;
Фиг.7А - блок-схема, иллюстрирующая вариант осуществления способа для выполнения целочисленного умножения с округлением и сдвигом над операндами упакованных данных для получения части высокого порядка произведений;
Фиг.7В - блок-схема, иллюстрирующая другой вариант способа получения релевантных частей высокого порядка результирующих продуктов операции умножения упакованных целых чисел с округлением и сдвигом.
Детальное описание
Последующее описание раскрывает варианты осуществления целочисленного умножения в архитектуре SIMD с округлением и сдвигом. В последующем описании многочисленные конкретные детали, такие как типы процессоров, микроструктурные условия, события, механизмы разрешения (разблокировки) и тому подобное излагаются для того, чтобы обеспечить более глубокое понимание настоящего изобретения. Однако специалистам в данной области техники должно быть понятно, что изобретение может быть реализовано без таких конкретных деталей. Дополнительно, некоторые хорошо известные структуры, схемы и тому подобное не показаны в деталях, чтобы не затенять сущность изобретения несущественными деталями.
Хотя последующие варианты осуществления описаны со ссылками на процессор, другие варианты осуществления применимы с другими типами интегральных схем и логических устройств. Те же самые методы и указания настоящего изобретения могут быть легко применены в других типах схем или полупроводниковых устройств, которые могут обеспечить выгоды от применения более высокой пропускной способности конвейерной обработки и улучшенных рабочих характеристик. Указания настоящего изобретения применимы к любому процессору или машине, которые исполняют операции над данными. Однако настоящее изобретение не ограничено процессорами и машинами, которые выполняют операции над 256-битовыми, 128-битовыми, 64-битовыми, 32-битовыми или 16-битовыми данными, и может быть применено к любому процессору и машине, в которых необходимо манипулирование с упакованными данными.
В последующем описании, в целях пояснения, изложены различные конкретные детальные особенности, чтобы обеспечить более глубокое понимание настоящего изобретения. Однако специалисту в данной области техники должно быть понятно, что эти конкретные детали не являются необходимыми для практической реализации настоящего изобретения. В других случаях хорошо известные структуры и схемы не поясняются в конкретных деталях, чтобы не затенять сущность настоящего изобретения. Кроме того, в последующем описании приведены примеры, и на чертежах показаны различные примеры в целях иллюстрации. Однако эти примеры не должны трактоваться в ограничительном смысле, так как они приведены только в качестве примеров настоящего изобретения, а не для обеспечения исчерпывающего перечня возможных реализаций настоящего изобретения.Хотя приведенные ниже примеры описывают обработку команд и распределение в контексте исполнительных блоков и логических схем, другие варианты осуществления настоящего изобретения могут быть реализованы с помощью программного обеспечения. В одном варианте осуществления способы, соответствующие настоящему изобретению, реализованы посредством исполняемых машиной команд. Команды могут быть использованы для обеспечения того, чтобы универсальный или специализированный процессор, который программируется командами, выполнял этапы настоящего изобретения. Настоящее изобретение может обеспечиваться как компьютерный программный продукт или программное обеспечение, которое может включать в себя машино- или компьютерно-читаемый носитель, на котором сохранены команды, которые могут быть использованы для программирования компьютера (или иных электронных устройств) для выполнения процесса соответственно настоящему изобретению. Альтернативно, этапы настоящего изобретения могут выполняться конкретными компонентами программного обеспечения, которые содержат логические схемы с жесткими (постоянными) соединениями («зашитую» логику) для выполнения этапов, или любой комбинацией программируемых компьютерных компонентов и заказных аппаратных компонентов. Такое программное обеспечение может быть сохранено в памяти в системе. Аналогичным образом код может распространяться по сети или посредством другого считываемого компьютером носителя.
Данный считываемый машиной носитель может включать в себя любой механизм для хранения или передачи информации в форме, обеспечивающей возможность считывания машиной (например, компьютером), но не ограничен гибкими дискетами, оптическими дисками, постоянной памятью на компакт-дисках (CD-ROM), магнитооптическими дисками, постоянной памятью (ROM, ПЗУ), оперативной памятью (RAM, ОЗУ), стираемой программируемой постоянной памятью (EPROM), электрически стираемой программируемой постоянной памятью (EEPROM), магнитными или оптическими картами, флэш-памятью, передачей по сети Интернет, электрической, оптической, акустической или другими формами передаваемых сигналов (например, несущие колебания, инфракрасные сигналы, цифровые сигналы и т.д.). Соответственно, считываемый компьютером носитель включает в себя любой тип носителя (среды передачи)/считываемого компьютером носителя, пригодного для хранения или передачи электронных команд или информации в форме, считываемой машиной (например, компьютером). Кроме того, настоящее изобретение может также предусматривать загрузку в качестве программного продукта. Как таковая, программа может быть перенесена с удаленного компьютера (например, сервера) в запрашивающий компьютер (например, клиент). Перенос программы может производиться посредством электрической, оптической, акустической или других форм сигналов данных, воплощенных в несущем колебании или в среде распространения, по каналу связи (например, модему, сетевому соединению и т.п.).
Процесс проектирования может проходить различные этапы: от создания, моделирования и до изготовления. Данные, представляющие конструкцию, могут представлять такую конструкцию различными путями. Во-первых, как это полезно при моделировании, аппаратные средства могут быть представлены с использованием языка описания аппаратных средств или другого языка функционального описания. Кроме того, на некоторых этапах процесса проектирования может создаваться модель схемного уровня с логическими и/или транзисторными вентилями. Кроме того, большинство конструкций на некотором этапе достигают уровня данных, представляющих физическое размещение различных устройств в модели аппаратных средств. В случае, когда используются обычные методы изготовления полупроводников, данные, представляющие модель аппаратных средств, могут быть данными, определяющими наличие или отсутствие различных признаков на различных уровнях маски, для масок, используемых в производстве интегральных схем. В любом представлении конструкции данные могут сохраняться на машиночитаемом носителе любой формы. Оптическая или электрическая волна, модулируемая или иным образом генерируемая для передачи такой информации, память или магнитное или оптическое запоминающее устройство, такое как диск, может представлять собой машиночитаемый носитель. Любой из этих носителей может «нести» или «индицировать» информацию о конструкции или информацию программного обеспечения. Если передается колебание электрической несущей, в которой проявляется или которая является носителем кода или разрабатываемого продукта, таким образом, что выполняется копирование, буферизация или повторная передача электрического сигнала, то создается новая копия. Таким образом, провайдер коммуникационного обслуживания или сетевой провайдер может сделать копию изделия (несущего колебания), воплощающего в себе методы настоящего изобретения. В современных процессорах ряд различных исполнительных блоков используется для обработки и исполнения разнообразных кодов и команд. Не все команды создаются одинаковыми, поскольку некоторые являются более быстродействующими для исполнения, в то время как другие могут требовать огромного количества тактовых импульсов. Чем быстрее пропускная способность команд, тем лучшие общие рабочие характеристики процессора. Таким образом, было бы предпочтительным иметь как можно больше команд, исполняемых с максимально возможным быстродействием. Однако имеются некоторые команды, которые имеют более высокую сложность и требуют большего в смысле времени исполнения и ресурсов процессора. Например, имеются команды с плавающей запятой, операции загрузки/сохранения, перемещения данных и т.д.
По мере того как все больше компьютерных систем используется в Интернет-приложениях и мультимедийных приложениях, с течением времени вводится дополнительная поддержка процессоров. Например, команды с плавающей запятой типа «один поток команд и множество потоков данных» (SIMD) и потокового SIMD расширения (SSE) являются командами, которые сокращают общее количество команд, требуемых для исполнения конкретной программной задачи. Эти команды могут ускорять выполнение программного обеспечения за счет операций с множеством элементов данных, осуществляемых параллельно. В результате выигрыш по рабочим характеристикам может быть достигнут в широком диапазоне приложений, включая обработку видео, речи и изображений/фотоснимков. Реализация SIMD-команд в процессорах и логических схемах подобного типа обычно связана с рядом вопросов. Кроме того, сложность SIMD-операций часто приводит к необходимости дополнительных схем, чтобы корректным образом осуществлять обработку и манипулирование данными.
Двумерная запись является эффективным путем представления чисел со знаком. Наиболее значимый бит числа в двоичном дополнительном коде представляет его знак, а остальные биты представляют его модуль. Дробная арифметика с фиксированной запятой позволяет осуществлять умножение чисел в процессоре целочисленных вычислений без возникновения переполнения. Дробная арифметика весьма полезна для программирования цифровой обработки сигналов, так как вопросы, относящиеся к переполнению, в операциях умножения отсутствуют. В то время как умножение двух 16-битовых чисел может потребовать 32 битов для результата, 32-битовый результат, генерируемый путем умножения двух дробных 16-битовых чисел с фиксированной запятой, может быть округлен до 16 битов с введением минимальной ошибки. Преобразование 16-битового целого числа является делением десятичного значения данного целого числа на 32768. В одном варианте осуществления верхние (старшие) 16 битов произведения, полученного в результате умножения двух дробных чисел, являются теми, которые представляют интерес. Однако эти старшие 16 битов результата составляют половину ожидаемого дробного результата. Произведение должно быть сдвинуто на один бит влево для умножения результата на два, чтобы получить корректное окончательное произведение. Дробная арифметика также требует знакового расширения множимых и множителей.
Требование сдвига влево можно также пояснить как выравнивание десятичных разрядов. Например, при умножении десятичных чисел десятичные запятые игнорируются и сдвигаются назад в конец. Десятичная запятая помещается так, чтобы общее число цифр (разрядов) вправо от десятичной запятой в множимом и множителе было равно числу цифр (разрядов) вправо от десятичной запятой в их произведении. Аналогичным образом, «десятичная запятая» для дробной арифметики находится здесь вправо от крайнего левого (знакового) бита, и имеется 15 битов (цифр) вправо от этой запятой. Но в исходных данных всего имеется 30 битов вправо от десятичной запятой. Без сдвига в 32-битовом результате имелся бы 31 бит вправо от десятичной запятой. Сдвиг числа влево на один бит эффективно сокращает число битов вправо от десятичной запятой до 30.
Варианты осуществления настоящего изобретения могут увеличить точность целочисленных SIMD-команд с фиксированной запятой. Формат целого числа с фиксированной запятой подобен формату дробной арифметики с фиксированной запятой. Формат с фиксированной запятой "1,5" в одном варианте осуществления изобретения представляет число, имеющее значение со знаком, причем двоичная запятая расположена между 14 и 15. Для данного и последующего обсуждения позиции битов отсчитываются от крайнего правого бита, начиная с 0. Таким образом, крайний правый или наименее значимый (младший) бит находится в позиции 0. Позиция непосредственно влево от него соответствует биту 1 и т.д. Этот числовой формат 1.N часто используется в приложениях цифровой обработки сигналов. Варианты осуществления, соответствующие настоящему изобретению, могут также обеспечить дополнительную точность и правильность, исходя из методов округления и сдвига. Эта дополнительная точность, достигаемая в вариантах осуществления настоящего изобретения, может способствовать более легкому программированию множества приложений. Кроме того, дополнительная точность может также обеспечить более быстрое исполнение алгоритмов, таких как дискретное косинусное преобразование (DCT), которое часто используется в приложениях обработки видеоданных и изображений.
Примером приложения для SIMD-команды целочисленного умножения высокого порядка с округлением и сдвигом является применение в видео высокого качества. Операция умножения 16 битов на 16 битов (16×16) с получением 16-битового результата является широко распространенной в видеокодерах и декодерах, в особенности в инверсном DCT, DCT, квантовании (Q) и в блоках инверсного квантования (Q). Точность операций умножения может иметь существенное влияние на качество видеоматериала в целом. Улучшение рабочих характеристик и повышение быстродействия в вариантах осуществления настоящего изобретения может иметь особенно большое влияние именно на вычисления инверсного DCT. Вычисления Q и инверсного Q, которые в принципе являются 16-битовыми умножениями, также обеспечивают выигрыш, в дополнение к вычислениям DCT.
В вычислительной индустрии хорошо известны спецификации стандартов 1180-1990 для реализации 8х8 инверсного дискретного косинусного преобразования. Хотя стандарты были созданы в контексте видеоконференции, части спецификации также применимы для кодеров и декодеров, таких как соответствующие различным форматам MPEG. Однако обеспечение совместимости со стандартом IEEE 1180-1190 при поддержании высокой эффективности является трудной задачей. Компромисс часто заключается в выборе между высоким быстродействием при несовместимости или обеспечением совместимости при недостаточном быстродействии. Кроме того, кодирование по стандарту является итеративным процессом, который может потребовать высоких временных затрат, особенно при выборе неверного алгоритма.
Совместимость со стандартом IEEE 1180-1190 может быть облегчена в вариантах осуществления команды умножения высокого порядка с округлением и сдвигом. Варианты осуществления команды целочисленного умножения с одним потоком команд и множеством потоков данных (SIMD) высокого уровня с округлением и сдвигом в соответствии с настоящим изобретением может обеспечить тот же самый формат данных 1.15 для входных и выходных элементов данных в среде пакетной передачи данных. Таким образом, запись кода и программирование с наборами команд, включающих в себя вариант осуществления такой команды умножения высокого порядка с округлением и сдвигом, может быть намного менее сложным. Аналогичным образом, доступность языков высокого уровня и соответствующих компиляторов также может стать возможной. Разработчики могут получить выгоду от языков и компиляторов, возможность использования которых обеспечивается вариантами SIMD-команды с фиксированной запятой, такой как умножение высокого порядка с округлением и сдвигом, для повышения эффективности и точности кодеров/декодеров (кодеков) видео, аудио и изображений. Наборы команд с SIMD-возможностями могут исключить необходимость в алгоритмах большой длины, которые требовались ранее при обработке повторяющихся операций над сходными данными.
Каждые из входных данных для операции умножения в одном из вариантов осуществления представлены в формате 1.15. Для одного варианта осуществления команды умножения высокого порядка с округлением и сдвигом временное (промежуточное) 18-битовое значение, имеющее формат 2.16, создается из верхних (старших) битов 32-битового произведения, полученного умножением двух 16-битовых значений данных. Это промежуточное 18-битовое значение затем округляется для обеспечения точности путем добавления "1" к наименее значимому биту. В то время как в некоторых методах просто отбрасываются все биты низкого порядка, операция округления в данном варианте осуществления настоящего изобретения обеспечивает то, что ошибка попадает в пределы некоторого допустимого порогового значения для инверсного кодирования DCT. Это округленное значение затем сдвигается влево на один бит для дополнительного обеспечения точности и для получения желательного выходного формата. 16-битовый результат, имеющий формат 1.15, выделяется из округленного и сдвинутого 18-битового значения. Округление и сдвиг, выполняемые над промежуточным значением, могут обеспечить два бита дополнительной точности по сравнению с простым взятием 16 битов высшего порядка из 32-битового произведения. Например, в обобщенном варианте осуществления, описанном здесь, округление обеспечивает один бит дополнительной точности, по сравнению с выделением 16 битов высшего порядка из 32-битового произведения. Аналогичным образом сдвиг обеспечивает еще один дополнительный бит точности для округленного произведения. Хотя при данном обсуждении описываются варианты осуществления в контексте целых значений длиной 16 битов, другие варианты осуществления могут применяться к значениям данных любой битовой длины.
На фиг.1А показана блок-схема приведенной для примера компьютерной системы, выполненной с процессором, который включает в себя исполнительные блоки для выполнения команды умножения высокого порядка с округлением и сдвигом в соответствии с одним вариантом осуществления настоящего изобретения. Система 100 включает в себя компонент, такой как процессор 102, для использования исполнительных блоков, включающих в себя логику для выполнения алгоритмов для обработки данных, в соответствии с настоящим изобретением, как в описываемом здесь варианте осуществления. Система 100 представляет системы обработки, основанные на микропроцессорах PENTIUM® III, PENTIUM® 4, XeonTM, Itanium® и/или XScaleTM, доступных от компании Intel Corporation (Santa Clara, California), хотя могут использоваться и другие системы (включая персональные компьютеры с другими микропроцессорами, рабочие станции для проектирования, компьютерные приставки и тому подобные средства). В одном варианте осуществления образцовая система 100 может исполнять версию операционной системы WINDOWSTM, доступной от компании Microsoft Corporation (Redmond, Washington), хотя также могут использоваться и другие операционные системы (например, UNIX и Lunix), встроенное программное обеспечение и/или графические пользовательские интерфейсы. Таким образом, настоящее изобретение не ограничено какой-либо конкретной комбинацией аппаратных схемных средств и программного обеспечения.
Альтернативные варианты осуществления настоящего изобретения могут использоваться в других устройствах, таких как портативные устройства и встроенные прикладные программы. Некоторые примеры портативных устройств включают в себя сотовые телефоны, устройства протокола Интернет, цифровые камеры, персональные цифровые помощники (PDA) и карманные ПК. Встроенные прикладные программы могут включать в себя микроконтроллер, цифровой процессор сигналов, встроенную (накристальную) систему, сетевые компьютеры, компьютерные приставки к телевизорам, сетевые концентраторы, коммутаторы глобальных сетей или любую другую систему, которая выполняет несогласованные копирования или перемещения данных в памяти. Кроме того, некоторые архитектуры реализованы для обеспечения возможности командам воздействовать на различные данные одновременно для улучшения эффективности мультимедийных приложений. По мере того как тип и объем данных увеличивается, компьютеры и их процессоры должны совершенствоваться для манипулирования данными более эффективными способами.
На фиг.1А показана блок-схема компьютерной системы 100 с процессором 102, который включает в себя один или несколько исполнительных блоков 108 для обработки алгоритма, включающего в себя SIMD-команду умножения высокого порядка с округлением и сдвигом в соответствии с настоящим изобретением. Например, процессор 102 может получать программные команды, запрашивающие операции SIMD-умножения высокого порядка над операндами пакетированных данных. Настоящий вариант осуществления описан в контексте однопроцессорной настольной или серверной системы, но альтернативные варианты осуществления могут быть включены в мультипроцессорную систему. Система 100 является примером архитектуры концентратора. Компьютерная система 100 включает в себя процессор 102 для обработки сигналов данных. Процессор 102 может представлять собой, например, микропроцессор компьютера с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор с командными словами сверхбольшой длины (VLIW), процессор, реализующий комбинацию наборов команд или любое другое процессорное устройство, такое как цифровой процессор сигналов (DSP). Процессор 102 связан с процессорной шиной 110, которая может передавать сигналы данных между процессором 102 и другими компонентами в системе 100. Элементы системы 100 выполняют свои обычные функции.
В одном варианте осуществления процессор 102 включает в себя память 104 внутреннего кэша уровня 1 (L1). В зависимости от архитектуры процессор 102 может иметь отдельный внутренний кэш или множество уровней внутреннего кэша. Альтернативно, в другом варианте осуществления память кэша может быть внешней по отношению к процессору 102. Другие варианты осуществления могут также включать в себя комбинацию как внутреннего, так и внешнего кэша, в зависимости от реализации. Регистровый файл 106 может сохранять различные типы данных в различных регистрах, включая целочисленные регистры, регистры с плавающей запятой, регистры статуса и регистры указателей команд.
Исполнительный блок 108, включающий в себя логику для выполнения целочисленных операций и операций с плавающей запятой, также находится в процессоре 102. Процессор 102 также включает в себя ПЗУ микрокода, которое сохраняет микрокод для некоторых макрокоманд. Для данного варианта осуществления исполнительный блок 108 включает в себя логику для обработки набора 109 упакованных команд. В одном варианте осуществления набор 109 упакованных команд включает в себя упакованную команду умножения высокого порядка для получения релевантных частей высокого порядка результирующих произведений. За счет включения упакованного набора 109 команд в набор команд универсального процессора 102, вместе со связанными схемами для выполнения команд, операции, используемые многими мультимедийными приложениями, могут выполняться с использованием упакованных данных в универсальном процессоре 102.
Таким образом, многие мультимедийные приложения могут быть ускорены и исполнены более эффективно за счет использования полной разрядности шины данных процессора для выполнения операций с пакетными данными. Это может исключить необходимость переноса меньших блоков данных по шине данных процессора для выполнения одной или нескольких операций над одним элементом данных в каждый момент времени. В микроконтроллерах, встроенных процессорах, устройствах графики, ЦПБ и других типах логических схем также могут быть использованы альтернативные варианты исполнительного блока 108. Система 100 включает в себя память 120, которая может представлять собой динамическое ОЗУ (DRAM), статическое ОЗУ (SRAM), устройство флэш-памяти или ЗУ иного типа. Память 120 может хранить команды и/или данные, представленные сигналами данных, которые могут выполняться процессором 102.
Микросхема 116 системной логики связана с шиной 110 процессора и памятью 120. Микросхема 116 системной логики в показанном варианте осуществления представляет собой концентратор контроллера памяти (ККП). Процессор 102 может осуществлять информационный обмен с ККП 116 через шину 110 процессора. ККП 116 обеспечивает широкополосный канал 118 памяти к блоку 120 памяти для хранения команд и данных и для хранения команд, данных и текстуры графики. ККП 116 предназначен для пересылки сигналов данных между процессором 102, блоком 120 памяти и другими компонентами в системе 100 и для шунтирования сигналов данных между шиной 110 процессора, блоком 120 памяти и системой 122 ввода/вывода. В некоторых вариантах осуществления микросхема 116 системной логики может обеспечить графический порт для связи с контроллером 112 графики. ККП 116 связан с блоком 120 памяти через интерфейс 118 памяти. Графическая плата 112 связана с ККП 116 через межсоединение 114 ускоренного графического порта.
Система 100 использует специализированную шину 122 интерфейса концентратора для соединения ККП 116 с концентратором контроллера ввода/вывода (ККВВ) 130. ККВВ 130 обеспечивает прямые соединения с некоторыми устройствами ввода/вывода через локальную шину ввода/вывода. Локальная шина ввода/вывода является высокоскоростной шиной ввода/вывода для соединения периферийных устройств с блоком 120 памяти, набором микросхем и процессором 102. В качестве примеров могут служить контроллер аудиоданных, концентратор 128 программно-аппаратных средств (система BIOS, записанная во флэш-памяти), беспроводный приемопередатчик 126, блок 124 хранения данных, традиционный контроллер ввода/вывода, содержащий интерфейсы пользовательского ввода и клавиатуры, последовательный расширительный порт, например, соответствующий универсальной последовательной шине (USB), и сетевой контролер 134. Блок 124 хранения данных может содержать дисковод на жестких дисках, ПЗУ на компакт-дисках (CD-ROM), устройство флэш-памяти или другое устройство массовой памяти.
В другом варианте осуществления системы может быть использован исполнительный блок для исполнения команды умножения упакованных данных высокого порядка с системой на микросхеме. Один вариант осуществления системы на микросхеме содержит процессор и память. В качестве памяти для такой системы может быть использована флэш-память. Флэш-память может находиться на том же кристалле, что и процессор и другие компоненты системы. Дополнительно, другие логические блоки, такие как контроллер памяти или графический контролер, могут также находиться в системе на микросхеме.
На фиг.1В показан альтернативный вариант осуществления системы 140 обработки данных, которая реализует принципы настоящего изобретения. Возможным вариантом системы 140 обработки данных могут быть процессоры прикладных программ Intel®PCA (персональная архитектура Интернет-клиента), основанные на технологии XScaleTM (как описано в WWW, адрес developer.intel.com). Специалистам в данной области техники должно быть понятно, что описанные здесь варианты осуществления могут быть использованы с альтернативными системами обработки без отклонения от сущности настоящего изобретения.
Компьютерная система 140 содержит ядро 159 обработки, обеспечивающее выполнение SIMD-операций, включая умножение высокого порядка с округлением и сдвигом. В одном варианте осуществления ядро 159 обработки представляет собой блок обработки с архитектурой любого типа, включая, но не ограничиваясь, архитектуры CISC, RISC или VLIW. Ядро 159 обработки может также быть пригодным для изготовления по одному или нескольким технологическим процессам и, будучи представленным на машиночитаемых носителях с достаточной детальностью, может быть пригодным для облегчения такого изготовления.
Ядро 159 обработки включает в себя исполнительный блок 142, набор регистровых файлов 145 и декодер 144. Ядро 159 обработки также включает в себя дополнительные схемы (не показаны), что не является существенным для понимания настоящего изобретения. Исполнительный блок 142 используется для исполнения команд, принимаемых ядром 159 обработки. В дополнение к распознаванию типовых команд процессора, исполнительный блок 142 может распознавать команды в наборе 143 упакованных (в упакованном формате) команд для выполнения операций с использованием упакованных форматов данных. Исполнительный блок 142 связан с регистровым файлом 145 внутренней шиной. Регистровый файл 145 представляет область памяти в ядре 159 обработки для хранения информации, включая данные. Как упомянуто выше, понятно, что область памяти, используемая для хранения упакованных данных, не является критичной. Исполнительный блок 142 связан с декодером 144. Декодер 144 используется для декодирования команд, полученных ядром 159 обработки, для получения сигналов управления и/или точек входа в микрокод. В ответ на эти сигналы управления и/или точки входа в микрокод исполнительный блок 142 выполняет соответствующие операции.
Ядро 159 обработки связано с шиной 141 для информационного обмена с различными другими системными устройствами, которые могут включать в себя, не ограничиваясь указанным, например, блок 146 управления синхронным динамическим запоминающим устройством с произвольной выборкой (ЗУПВ) (SDRAM), блок 147 управления статическим ЗУПВ, интерфейс 148 блочной флэш-памяти, блок 149 управления компактной флэш-памятью на плате PCMCIA, блок 150 управления жидкокристаллического дисплея, контроллер 151 прямого доступа к памяти, интерфейс 152 альтернативного устройства управления передачей данных по шине («хозяина» шины). В одном варианте осуществления система 140 обработки данных может также содержать мост 154 ввода/вывода для информационного обмена с различными устройствами ввода/вывода через шину 153 ввода/вывода. Такие устройства ввода/вывода могут включать в себя, без каких-либо ограничений, например, универсальный асинхронный приемопередатчик (UART) 155, универсальную последовательную шину (USB) 156, беспроводный UART 157, выполненный по технологии Bluetooth, и интерфейс 158 расширения ввода/вывода.
Один вариант осуществления системы 140 обработки данных обеспечивает мобильную, сетевую и/или беспроводную связь и ядро 159 обработки, обеспечивающее выполнение SIMD-операций, включая операции объединения (слияния) со сдвигом. Ядро 159 обработки может программироваться с использованием различных алгоритмов передачи аудио, видео, формирования изображений и информационного обмена, включая дискретные преобразования, такие как преобразование Уолша-Адамара, быстрое преобразование Фурье, дискретное косинусное преобразование и их соответствующие инверсные преобразования; методы сжатия/восстановления (сжатых данных), такие как преобразование цветового пространства, анализ движения для кодирования видеоданных или компенсации движения для декодирования видеоданных; и функции модуляции/демодуляции (модем), такие как импульсно-кодовая модуляция (ИКМ).
На фиг.1С показан еще один альтернативный вариант осуществления системы обработки данных, имеющей возможность выполнения SIMD-операций умножения высокого порядка. В соответствии с данным вариантом осуществления, система 160 обработки данных может включать в себя главный процессор 166, SIMD-сопроцессор 161, кэш (быстродействующая буферная память небольшой емкости) 167 и систему 168 ввода/вывода. Система 168 ввода/вывода дополнительно может быть связана с беспроводным интерфейсом 169. SIMD-сопроцессор 161 имеет возможность выполнения SIMD-операций, включая умножение высокого порядка. Ядро 170 обработки может быть пригодным для изготовления по одному или нескольким технологическим процессам и, будучи представленным на машиночитаемых носителях с достаточной детальностью, может быть пригодным для облегчения изготовления всей или части системы 160 обработки данных, включая ядро 170 обработки.
В одном варианте осуществления SIMD-сопроцессор 161 включает в себя исполнительный блок 162, набор регистровых файлов 164. Вариант осуществления главного процессора 166 содержит декодер 165 для распознавания команд из набора 163 команд, включая упакованные SIMD-команды умножения высокого порядка для исполнения исполнительным блоком 162. В альтернативных вариантах, SIMD-сопроцессор 161 также содержит по меньшей мере часть декодера 165В для декодирования команд из набора 163 команд. Ядро 170 обработки также включает в себя дополнительные схемы (не показаны), которые не являются необходимыми для понимания сущности настоящего изобретения.
В процессе работы главный процессор 166 исполняет поток команд обработки данных, которые управляют операциями обработки данных общего типа, включая взаимодействия с кэшем 167 и системой ввода/вывода 168. В поток команд обработки данных встроены команды SIMD-сопроцессора. Декодер 165 главного процессора 166 распознает эти команды SIMD-сопроцессора как команды того типа, которые должны выполняться присоединенным SIMD-сопроцессором 161. Соответственно, главный процессор 166 выдает эти команды SIMD-сопроцессора (или сигналы управления, представляющие команды SIMD-сопроцессора) в шину 166 сопроцессора, из которой они принимаются присоединенными SIMD-сопроцессорами. В этом случае SIMD-сопроцессор 161 будет принимать и исполнять любые принятые команды SIMD-сопроцессора, предназначенные для него.
Данные могут приниматься через беспроводный интерфейс 169 для обработки команд SIMD-сопроцессором. Например, речевая передача может приниматься в форме цифрового сигнала, который может обрабатываться по командам SIMD-сопроцессора для восстановления цифровых аудиовыборок, представляющих речевую передачу. В другом примере, сжатые аудио- и/или видеоданные могут приниматься в форме потока цифровых битов, который может обрабатываться по командам SIMD-сопроцессора для восстановления цифровых выборок аудиоданных и/или кадров видеоданных. В одном варианте осуществления ядро 170 обработки, главный процессор 166 и SIMD-сопроцессор 161 интегрированы в единое ядро 170 обработки, содержащее исполнительный блок 162, набор регистровых файлов 164 и декодер 165 для распознавания команд из набора 163 команд, включающего в себя SIMD-команды умножения высокого порядка.
На фиг.2 представлена блок-схема микроструктуры для процессора 200 в одном варианте осуществления, который включает в себя логические схемы для выполнения операции умножения упакованных целых чисел высокого порядка с округлением и сдвигом, в соответствии с настоящим изобретением. SIMD-операция целочисленного умножения высокого порядка с округлением и сдвигом может также определяться как упакованная операция умножения высокого порядка (PMUL) с округлением и сдвигом или операция умножения высокого порядка. В одном варианте осуществления команды упакованного умножения высокого порядка команда может вызывать получение данных из двух блоков памяти, перемножение соответствующих элементов данных из двух соответствующих блоков памяти для получения набора промежуточных результатов, округление и сдвиг этих промежуточных результатов и усечение этих промежуточных результатов до частей желательного высокого порядка соответствующего произведения для сохранения в результирующем объединенном блоке данных. SIMD-команда умножения высокого порядка может также определяться как PMULHRSW или упакованное умножение высокого порядка с округлением и сдвигом. В данном варианте осуществления команда объединения (слияния) может также быть реализована для работы с элементами данных, имеющими размер байта, слова, слова двойной длины, квадраслова и т.д. Хотя рассмотрение здесь ведется в контексте целочисленных значений и операций с целыми числами, в альтернативных вариантах осуществления изобретения могут использоваться значения с плавающей запятой или операции с плавающей запятой.
Препроцессор (внешний интерфейс) 201 внутреннего порядка является частью процессора 200, который выбирает макрокоманды для исполнения и подготавливает их для использования позднее в конвейерной обработке процессора. Препроцессор 201 в данном варианте осуществления включает в себя различные блоки. Блок 226 упреждающей выборки (из памяти) выбирает с упреждением макрокоманды из памяти и вводит их в декодер 228 команд, который, в свою очередь, декодирует их в примитивы, называемые микрокомандами или микрооперациями (также называемые «микро-оп» или «uops»), понятные машине для исполнения. Трассировочный кэш 230 принимает декодированные микрооперации и собирает их в программно-упорядоченные последовательности или трассы в очереди 234 микроопераций для исполнения. Если трассировочный кэш 230 обнаруживает комплексную макрокоманду, то ПЗУ 232 микрокода обеспечивает микрооперации, необходимые для выполнения операции.
Многие макрокоманды преобразуются в отдельную микрооперацию, а другие требуют нескольких микроопераций для завершения полной операции. В одном варианте осуществления, если для завершения макрокоманды необходимо более четырех микрокоманд, то декодер 228 обращается к ПЗУ 232 микрокода для выполнения макрокоманды. В одном варианте осуществления команда умножения высокого порядка с округлением и сдвигом может декодироваться в небольшое число микроопераций для обработки в декодере 228 команд. В другом варианте осуществления команда для упакованного алгоритма умножения высокого порядка с округлением и сдвигом может быть сохранена в ПЗУ 232 микрокода, если ряд микроопераций необходим для выполнения этой операции. Трассировочный кэш 230 обращается к программируемой логической матрице точек входа для определения корректного указателя микрокоманды для считывания последовательности микрокода для объединения (слияния) алгоритмов в ПЗУ 232 микрокода. После того как ПЗУ 232 микрокода завершит упорядочивание в последовательность микроопераций для текущей макрокоманды, препроцессор 201 машины возобновляет выборку с упреждением микроопераций из трассировочного кэша 230.
Некоторые SIMD и другие команды мультимедийного типа рассматриваются как комплексные команды. Большинство команд, связанных с плавающей запятой, также являются комплексными командами. Когда декодер 228 команд обнаруживает комплексную макрокоманду, к ПЗУ 232 микрокода осуществляется обращение в соответствующей ячейке для извлечения последовательности микрокода для данной макрокоманды. Различные микрооперации, необходимые для выполнения данной макрокоманды, передаются в процессор 203 исполнения с изменением последовательности (в другом порядке) для исполнения в соответствующих исполнительных блоках целочисленных операций и операций с плавающей запятой.
Процессор 203 исполнения с изменением последовательности обеспечивает подготовку микрокоманд для исполнения. Логика исполнения с изменением последовательности имеет ряд буферов для сглаживания и переупорядочивания потока микрокоманд для оптимизации рабочих характеристик, когда они проходят конвейерную обработку и планируются для исполнения. Логика блока распределения распределяет машинные буферы и ресурсы, которые требуются каждой микрооперации для исполнения. Логика переименования регистров переименовывает регистры логики в записи в регистровом файле. Блок распределения также распределяет запись для каждой микрооперации в одну из двух очередей микроопераций, одну для операций с памятью и одну для операций без памяти, перед следующими планировщиками команд: планировщик памяти, скоростной планировщик 202, медленный/общий планировщик 204 микроопераций с плавающей запятой и простой планировщик 206 микроопераций с плавающей запятой. Планировщики 202, 204, 206 определяют, когда микрооперация готова к выполнению, на основе готовности их зависимых источников операндов входных регистров и доступности ресурсов исполнения, которые необходимы микрооперациям для выполнения их операций. Скоростной планировщик 202 в этом варианте осуществления может планировать на каждую половину основного тактового цикла, в то время как другие планировщики могут планировать только один раз на каждый тактовый цикл основного процессора. Планировщики осуществляют арбитраж для портов отсылки для планирования исполнения микроопераций.
Регистровые файлы 208, 210 находятся между планировщиками 202, 204, 206 и исполнительными блоками 212, 214, 216, 218, 220, 222, 224 в исполнительном модуле 211. Имеется отдельный регистровый файл 208, 210 для целочисленных операций и операций с плавающей запятой соответственно. Каждый регистровый файл 208, 210 в этом варианте осуществления также включает в себя шунтирующую цепь, которая может шунтировать или пересылать непосредственно завершенные результаты, которые еще не записаны в регистровый файл, к новым зависимым микрооперациям. Регистровый файл 208 для целочисленных операций и регистровый файл 210 для операций с плавающей запятой также имеют возможность информационного обмена между собой. В одном варианте осуществления регистровый файл 208 для целочисленных операций расщеплен на два отдельных регистровых файла: один регистровый файл для 32 битов данных низкого порядка, а второй регистровый файл для 32 битов данных высокого порядка. Регистровый файл 210 для операций с плавающей запятой в одном варианте осуществления имеет записи длиной 128 битов, поскольку команды с плавающей запятой в типовом случае имеют операнды длиной от 64 до 128 битов.
Исполнительный модуль 211 содержит исполнительные блоки 212, 214, 216, 218, 220, 222, 224, где команды реально исполняются. Эта секция включает в себя регистровые файлы 208, 210, которые сохраняют значения целочисленных операндов и операндов с плавающей запятой, которые необходимы микрооперациям для исполнения. Процессор 200 в данном варианте осуществления содержит ряд исполнительных блоков: блок генерации адреса (БГА) 212, БГА 214, быстродействующее арифметико-логическое устройство (АЛУ) 216, быстродействующее АЛУ 218, медленно действующее АЛУ 220, АЛУ 222 с плавающей запятой, блок 224 перемещения с плавающей запятой. В этом варианте осуществления исполнительные блоки 222, 224 микроопераций с плавающей запятой исполняют операции MMX, SIMD, SSE с плавающей запятой. АЛУ 222 с плавающей запятой в этом варианте осуществления включает в себя делитель с плавающей запятой размером 64 бита × 64 бита для исполнения микроопераций деления, извлечения квадратного корня, определения остатка от деления. В вариантах осуществления настоящего изобретения любое действие, связанное со значением с плавающей запятой, возникает с использованием аппаратного средства с плавающей запятой. Например, преобразования между целочисленным форматом и форматом с плавающей запятой осуществляются с использованием регистрового файла с плавающей запятой. Аналогичным образом, операция деления с плавающей запятой реализуется в делителе с плавающей запятой.
С другой стороны, числа с неплавающей запятой и целые числа обрабатываются ресурсами целочисленных аппаратных средств. Простые часто встречающиеся операции АЛУ реализуются высокоскоростными исполнительными блоками 216, 218 АЛУ. Быстродействующие АЛУ 216, 218 в этом варианте осуществления могут выполнять высокоскоростные операции с эффективной задержкой, равной половине тактового цикла. В одном варианте осуществления наиболее сложные целочисленные операции реализуются медленно действующим АЛУ 220, так как медленно действующее АЛУ 220 включает в себя аппаратные средства исполнения целочисленной арифметики для операций с большим временем ожидания, таких как умножение, сдвиги, флаговая логика, обработка ветвлений. Операции загрузки/хранения в памяти выполняются АЛУ 212, 214. В этом варианте осуществления целочисленные АЛУ 216, 218, 220 описаны в контексте выполнения целочисленных операций над операндами 64-битовых данных. В альтернативных вариантах осуществления АЛУ 216, 218, 220 могут быть реализованы для поддержки разнообразного количества битов данных, включая 16, 32, 128, 256 и т.д. Аналогичным образом, блоки 222, 224 с плавающей запятой могут быть реализованы для поддержки диапазона операндов различной битовой длины. В одном варианте осуществления блоки 222, 224 с плавающей запятой могут работать с операндами упакованных 128-битовых данных во взаимосвязи с SIMD и мультимедийными командами.
Термин «регистры» используется здесь для ссылки на ячейки памяти встроенного процессора (на плате), которые используются в качестве части макрокоманд для идентификации операндов. Иными словами, регистры, упоминаемые здесь, это регистры, «видимые» извне процессора (с точки зрения программиста). Однако регистры в варианте осуществления не должны ограничиваться по своему значению конкретным типом схемы. Напротив, регистр в варианте осуществления должен только иметь возможность сохранять и предоставлять данные и выполнять функции, описанные здесь. Эти регистры могут быть реализованы схемами в процессоре с использованием любого количества различных методов, таких как специализированные физические регистры, динамически распределяемые физические регистры, использующие переименование регистров, комбинации специализированных и динамически распределяемых физических регистров и т.д. В одном варианте осуществления целочисленные регистры сохраняют 32-битовые целочисленные данные. Регистровый файл в одном варианте осуществления также содержит восемь мультимедийных SIMD-регистров для упакованных данных. Для изложенного ниже обсуждения регистры понимаются как регистры данных, предназначенные для хранения упакованных данных, такие как 64-битовые регистры ММХТМ (также называемые в некоторых случаях «mm»-регистрами) в микропроцессорах, реализованных на ММХ (мультимедийное расширение)-технологии, выпускаемых Intel Corporation. Эти ММХ-регистры, доступные как в целочисленной форме, так и в форме регистров с плавающей запятой, могут работать с элементами упакованных данных, которые сопровождают SIMD- и SSE-команды. Аналогичным образом, 128-битовые ХММ (управление расширенной памятью)-регистры, связанные с технологией SSE2, могут также использоваться для поддержки таких операндов упакованных данных. В этом варианте осуществления при сохранении упакованных данных и целочисленных данных для регистров нет необходимости различать эти два типа данных.
На фиг.3А иллюстрируются представления различных типов упакованных данных со знаком и без знака в 128-битовых мультимедийных регистрах в соответствии с одним из вариантов осуществления изобретения. Упакованный формат данных в этом примере содержит шестнадцать упакованных байтовых элементов данных. Байт определен здесь как восемь битов данных. Представление 302 упакованного байта без знака иллюстрирует память упакованного байта без знака в SIMD-регистре. Информация для каждого байтового элемента данных сохранена в битах с бита 7 по бит 0 для байта 0, с бита 15 по бит 8 для байта 1, с бита 23 по бит 16 для байта 2 и, наконец, с бита 128 по бит 120 для байта 15. Таким образом, все имеющиеся биты использованы в данном регистре. Эта конфигурация памяти может также повысить эффективность хранения для процессора. При доступе к 16 элементам данных одна операция может теперь выполняться над 16 элементами данных параллельным способом.
Представление 304 упакованного байта иллюстрирует хранение упакованного байта со знаком. Упакованный формат слова в данном примере содержит восемь упакованных элементов данных слова. Каждое упакованное слово содержит 16 битов информации. Представление 306 упакованного слова без знака иллюстрирует то, каким образом слова от слова 7 по слово 9 сохранены в SIMD-регистре. Представление 308 упакованного слова со знаком аналогично регистровому представлению 306 упакованного слова без знака. Заметим, что 16 битов каждого элемента данных слова являются указателем знака. Упакованный формат слова двойной длины здесь имеет длину 128 битов и содержит 4 упакованных элемента данных слова двойной длины. Каждый упакованный элемент слова двойной длины содержит 32 бита информации. Представление 310 упакованного слова двойной длины без знака показывает то, каким образом сохраняются элементы данных слова двойной длины. Представление 312 упакованного слова двойной длины со знаком аналогично регистровому представлению 310 упакованного слова двойной длины без знака. Заметим, что необходимый знаковый бит является 32 битом каждого элемента данных слова двойной длины. Упакованное квадраслово имеет длину 128 битов и содержит два элемента данных упакованного квадраслова.
В принципе, элемент данных является отдельным фрагментом данных, который сохранен в одном регистре в ячейке памяти с другими элементами данных той же самой длины. В упакованных последовательностях данных, относящихся к технологии SSE2, число элементов данных, сохраненных в ХММ-регистре, равно 128 битам, деленным на длину в битах отдельного элемента данных. Аналогичным образом, в упакованных последовательностях данных, относящихся к технологии MMX и SSE, число элементов данных, сохраненных в ММХ-регистре, равно 64 битам, деленным на длину в битах отдельного элемента данных. Хотя типы данных, показанные на фиг.3А, имеют длину 128 битов, в вариантах осуществления настоящего изобретения могут также использоваться операнды с длиной 64 бита или с другой длиной.
На фиг.3В иллюстрируются альтернативные регистровые форматы хранения данных. Каждые упакованные данные могут включать более одного независимого элемента данных. Показаны три упакованных формата данных: упакованный половинный 341, упакованный единичный 342 и упакованный двойной 343. В одном варианте осуществления упакованный половинный 341, упакованный единичный 342 и упакованный двойной 343 форматы содержат элементы данных с фиксированной запятой. Для альтернативного варианта осуществления упакованный половинный 341, упакованный единичный 342 и упакованный двойной 343 форматы могут содержать элементы данных с плавающей запятой. Один альтернативный вариант осуществления упакованного половинного 341 формата имеет длину 128 битов и содержит восемь 16-битовых элементов данных. Один альтернативный вариант осуществления упакованного единичного 342 формата имеет длину 128 битов и содержит четыре 32-битовых элемента данных. Один альтернативный вариант осуществления упакованного двойного 343 формата имеет длину 128 битов и содержит два 64-битовых элемента данных. Следует иметь в виду, что такие упакованные форматы данных могут быть расширены далее на другие длины регистра, например 96 битов, 160 битов, 192 бита, 224 бита, 256 битов и более.
На фиг.3С показан вариант осуществления формата 360 кода операции (opcode), имеющий 32 или более битов, и способы адресации операнда регистра/памяти в соответствии с типом формата кода операции, описанным в работе "IA-32 Intel Architecture Software Developer's Manual Volume 2: Instruction Set Reference", доступной от Intel Corporation (Santa Clara, CA) во всемирной паутине (www) по адресу intel.com/design/litcentr. Тип операции умножения высокого порядка с округлением и сдвигом может кодироваться одним или несколькими из полей 361 и 362. Может быть идентифицировано до двух ячеек операндов на команду, до двух включительно идентификаторов 364 и 365 операнда источника. В одном варианте осуществления команды объединения (слияния) со сдвигом идентификатор 366 операнда пункта назначения (адресата) является тем же самым, что и идентификатор 364 операнда источника. В альтернативном варианте осуществления идентификатор 366 операнда адресата является тем же самым, что и идентификатор 365 операнда источника. Поэтому для вариантов осуществления операции объединения со сдвигом один из операндов источника, идентифицируемых идентификаторами 364 и 365 операнда источника, перезаписывается результатами операций умножения высокого порядка с округлением и сдвигом. В одном варианте осуществления команды объединения со сдвигом идентификаторы 364 и 365 операндов могут быть использованы для идентификации 64-битовых операндов источника и адресата.
На фиг.3D представлен другой альтернативный формат 370 кода операции, имеющий 40 или более битов. Формат 370 кода операции соответствует формату 360 кода операции и содержит факультативный префиксный байт 378. Тип операции умножения высокого порядка с округлением и сдвигом может кодироваться одним или несколькими из полей 378, 371 и 372. До двух ячеек (местоположений) операндов на команду могут идентифицироваться идентификаторами 374 и 375 операнда источника и префиксным байтом 378. В одном варианте осуществления упакованного умножения высокого порядка с округлением и сдвигом префиксный байт 378 может использоваться для идентификации 128-битовых операндов источника и адресата. В одном варианте осуществления команды умножения высокого порядка идентификатор 376 операнда адресата является тем же самым, что и идентификатор 374 операнда источника. В альтернативном варианте осуществления идентификатор 376 операнда адресата является тем же самым, что и идентификатор 375 операнда источника. Поэтому для вариантов осуществления операций умножения высокого порядка один из операндов источника, идентифицируемых идентификаторами 374 и 375 операнда источника, перезаписывается результатами операций умножения высокого порядка. Форматы 360 и 370 кода операции обеспечивают адресацию из регистра в регистр, из памяти в регистр, регистра памятью, регистра регистром, регистра непосредственным адресом, из регистра в память, в соответствии с тем, как это определено, частично, полями 363 и 373 MOD и факультативными байтами индекса основания системы счисления и смещения.
Согласно фиг.3Е, в некоторых альтернативных вариантах осуществления, 64-битовые арифметические SIMD-операции могут выполняться посредством команды сопроцессорной обработки данных (CDP). Формат 380 кода операции показывает одну такую CDP-команду, имеющую поля 382 и 389 кода операции CDP. Тип CDP-команды в альтернативных вариантах осуществления операций умножения высокого порядка с округлением и сдвигом может кодироваться одним или несколькими полями 383, 384, 387 и 388. Может идентифицироваться до трех ячеек операндов на команду, включая до двух идентификаторов 385 и 390 операндов источника и один идентификатор 386 операнда адресата. Один вариант осуществления сопроцессора может предусматривать операции с 8-, 16-, 32- и 64-битовыми значениями. В одном варианте осуществления операция умножения высокого порядка выполняется над элементами данных с плавающей запятой или с целочисленными элементами данных. В некоторых вариантах осуществления команда объединения может выполняться условным образом с использованием поля 381 условия. Для некоторых команд умножения высокого порядка размер данных источника может кодироваться полем 383. В некоторых вариантах осуществления команды объединения со сдвигом обнаружение нуля (Z), отрицательного значения (N), переноса (С) и переполнения (V) может быть реализовано в SIMD-полях. Для некоторых команд тип насыщения может кодироваться полем 384.
В одном варианте осуществления настоящего изобретения упакованное (в упакованном формате) умножение высокого порядка с округлением и сдвигом может быть представлено следующим форматом команды: PMULHRSW mm1, mm2/m64. PMULHRSW в данном случае означает мнемоническую схему для понятия «упакованное умножение высокого порядка с округлением и сдвигом». Данную команду в этом случае дополняют два операнда источника, а именно mm1 и mm2/m64. Команда в данном варианте реализации действует с 64-битовыми упакованными блоками данных, состоящими из множества меньших элементов данных. В этом случае индивидуальные элементы данных имеют длину 16 битов или длину слова. Таким образом, четыре слова, составляющие в целом 64 бита, могут находиться в каждом упакованном блоке данных. Первый операнд источника, то есть "mm1", в данном случае означает 64-битовый ММХ-регистр. В этом варианте осуществления 64-битовый ММХ-регистр "mm1" из первого операнда источника является также адресатом для результирующего продукта операции упакованного умножения высокого порядка с округлением и сдвигом. Второй операнд источника "mm2/m64" в данном примере может представлять собой 64-битовый ММХ-регистр (mm2) или 64-битовую ячейку памяти (m64).
Хотя приведенные выше примеры описаны в общем случае в контексте операндов и блоков данных длиной 64 бита, варианты осуществления команды умножения высокого порядка с округлением и сдвигом могут действовать и с 128-битовыми упакованными блоками данных. Например, формат команды согласно одному варианту осуществления может быть представлен как PMULHRSW хmm1, хmm2/m128. Два операнда источника в этом случае имеют длину 128 битов, причем каждый содержит восемь элементов данных в виде 16-битовых слов. Первый операнд источника, то есть "хmm1", в данном случае означает 128-битовый ХММ-регистр. В этом варианте осуществления ХММ-регистр "хmm1" является также адресатом для результирующих продуктов. Второй операнд источника "хmm2/m128" в данном примере может представлять собой 128-битовый ХММ-регистр (хmm2) или 128-битовую ячейку памяти (m128). Для данного варианта осуществления каждый из блоков данных может содержать знаковое целочисленное значение. В одном варианте осуществления знаковое целочисленное значение представляет собой формат дополнительного до двух кода.
Кроме того, хотя варианты осуществления, описанные здесь, предусматривают использование упакованных блоков данных, состоящих из элементов данных длиной слова, также могут использоваться элементы данных различных других размеров. Например, в альтернативных вариантах осуществления команды упакованного умножения высокого порядка с округлением и сдвигом могут использоваться отдельные элементы данных, имеющие длину байта, слова двойной длины или квадраслова. Аналогичным образом, длины операндов данных не ограничены значениями 64 и 128. Например, другие варианты осуществления команды могут действовать с упакованными операндами длиной 256 битов. На фиг.4В представлена блок-схема одного варианта осуществления логики для выполнения SIMD-операции целочисленного умножения с округлением и сдвигом над операндами данных в соответствии с настоящим изобретением. PMULHRSW-команда для операции умножения высокого порядка с округлением и сдвигом (также определяемой для краткости как умножение высокого порядка) в данном варианте осуществления начинается с двух элементов информации: первого операнда данных DATA A 410 и второго операнда данных DATA B 420. В одном варианте осуществления PMULHRSW-команда для операции умножения высокого порядка декодируется в одну микрооперацию. В альтернативном варианте осуществления команда может быть декодирована в переменное количество микроопераций для выполнения операции умножения высокого порядка над операндами данных.
Для данного обсуждения DATA A 410, DATA B 420 и RESULTANT 440 в общем случае относятся к операндам или блокам данным, но как таковые не ограничиваются указанным и также включают в себя регистры, регистровые файлы и ячейки памяти. В одном варианте осуществления DATA A 410 и DATA B 420 представляют собой 64-битовые ММХ-регистры (также в некоторых случаях для краткости обозначаемые как "mm". В зависимости от конкретной реализации операнды данных могут быть другой длины, например, 128 или 256 битов. Первый 410 и второй 420 операнды являются блоками данных, включающими в себя х сегментов данных и имеющими полную длину 8х битов каждый, если каждый сегмент данных является байтом (8 битов). Таким образом, каждый из этих сегментов данных имеет длину "x·8" битов. Тогда если х равно 8, то каждый операнд будет иметь длину 8 байтов или 64 бита. Для других вариантов осуществления элемент данных может представлять собой полубайт (4 бита), слово (16 битов), слово двойной длины (32 бита), квадраслово (64 бита) и т.д. В альтернативных вариантах х может иметь величину 16, 32, 64 элемента данных.
Первый упакованный операнд 410 в этом примере содержит четыре элемента данных: А3, А2, А1 и А0. Второй упакованный операнд 420 также содержит четыре элемента данных: В3, В2, В1 и В0. Элементы данных здесь имеют одинаковую длину, и каждый содержит одно слово (16 битов) данных. Однако другой вариант осуществления настоящего изобретения действует с использованием более длинных 128-битовых операндов, где сегменты данных состоят из одного байта (8 битов) каждый, и 128-битовый операнд имел бы 16 сегментов данных байтовой длины. Аналогичным образом, если бы каждый сегмент данных был словом двойной длины (32 бита) или квадрасловом (64 бита), то 128-битовый операнд имел четыре сегмента данных из слов двойной длины или два сегмента данных из квадраслов соответственно. Таким образом, варианты осуществления настоящего изобретения не ограничены операндами или сегментами данных конкретной длины и могут иметь длину, соответствующую конкретной реализации.
Операнды 410, 420 могут находиться либо в регистре, либо в ячейке памяти или в регистровом файле или в их комбинации. Операнды 410, 420 данных посылаются в логический блок 430 вычисления умножения высокого порядка с округлением и сдвигом исполнительного блока в процессоре вместе с командой умножения высокого порядка с умножением и сдвигом. К моменту достижения командой PMULHRSW исполнительного блока команда должна быть декодирована ранее в конвейерной обработке процессора. Таким образом, команда умножения высокого порядка может быть в форме микрооперации (uop) или в некотором другом декодированном формате. Для данного варианта осуществления два операнда 410, 420 данных принимаются логическим блоком 430 вычисления умножения высокого порядка с округлением и сдвигом. Поскольку данный пример работает с 64-битовыми операндами, необходимо промежуточное пространство 431 для хранения промежуточного продукта размером 128 битов. Для 128-битовых операндов потребуется 256-битовое временное пространство для хранения.
Логический блок 430 в данном варианте осуществления сначала перемножает соответствующие значения данных в каждой позиции элемента для получения произведения АЧВ. Каждые промежуточные 32-битовые значения "А×В" для четырех позиций усекаются до 18 битов каждое. В данном варианте осуществления усечение выполняется как сдвиг вправо каждого 32-битового значения на 14 битов для отбрасывания этих битов. При этом остается промежуточное значение из 18 битов. В данном варианте осуществления "1" добавляется к младшему биту для целей округления. Шестнадцать битов непосредственно вправо от наиболее значимого бита каждого округленного значения выводятся в позицию соответствующего элемента данных в результирующем продукте 440. Так для крайней левой позиции элемента данных в данном примере результирующий продукт равен битам [16:1] от выражения '((A3×B3)≫14)+1'. Выбор битов [16:1] результатов округления надлежащим образом масштабирует значение как в дробной арифметике.
Другой вариант осуществления изобретения может действовать с операндами и сегментами данных альтернативной длины, например, с операндами длиной 128/256/512 битов и сегментами данных размером бита/байта/слова/слова двойной длины/квадраслова и отсчетами сдвига на 8/16/32 бита. Таким образом, варианты осуществления настоящего изобретения не ограничены операндами данных, сегментам данных или отсчетами сдвига конкретной длины, и их длины могут быть выбраны соответствующим образом для каждой конкретной реализации.
Команда упакованного умножения высокого порядка с округлением и сдвигом, согласно одному варианту осуществления, при исполнении обуславливает SIMD-(16 битов на 16 битов) умножение упакованных целочисленных слов со знаком в первом операнде источника и втором операнде источника для получения точного 32-битового промежуточного произведения. Это промежуточное произведение в одной реализации сначала усекается до 18 старших битов. Такой выбор этого 18-битового значения обеспечивает 18 битов промежуточной точности. Округление выполняется над этим усеченным значением путем добавления "1" к младшему биту этого 18-битового значения. Иными словами, округление реализует добавление "1" к значению бита, соответствующего биту 14 первоначального 32-битового промежуточного продукта. Окончательное результирующее значение получается путем выбора 16 битов непосредственно вправо от наиболее значимого бита 18-битового значения. В этом варианте осуществления каждое результирующее значение включает в себя один знаковый бит. Каждый элемент данных результирующего продукта в данном примере может иметь целочисленный формат с фиксированной запятой вида '1.15'. Относительно вышеприведенного формата 2.14, где 2 верхних бита являются знаковыми битами, в формате 1.15 может быть достигнуто повышение точности за счет дополнительного бита. Команда умножения высокого порядка с округлением и сдвигом, согласно этому варианту осуществления, сохраняет выбранные 16 битов для каждого округленного и сдвинутого промежуточного 32-битового значения в его соответствующей позиции операнда адресата.
В данном варианте осуществления промежуточные продукты для данной и других позиций элементов данных компонуются вместе в результирующий блок данных, имеющий тот же самый размер, что и элементы данных источника. Например, если упакованные данные операндов источника имеют размер 64 или 128 битов, то соответственно блок данных результирующего продукта также имеет размер 64 или 128 битов. Кроме того, операнды данных источника для знаковой операции могут поступать из регистра или ячейки памяти. Для данного варианта осуществления результирующий упакованный блок данных перезаписывает данные в SIMD-регистре для одного из операндов данных источника.
На фиг.4В представлена блок-схема операции целочисленного умножения высокого порядка с округлением и сдвигом для выбранной позиции элемента данных. DATA ELEMENT (элемент данных) A 450 соответствует первому операнду источника. DATA ELEMENT (элемент данных) В 452 соответствует второму операнду источника. Операция 454 умножения высокого порядка с округлением и сдвигом в данном варианте осуществления начинается с перемножения элементов данных для формирования произведения в виде промежуточного значения TEMP 456. Для двух элементов данных источника размером 16 битов произведение представляет собой промежуточное значение размером 32 бита. В данном варианте осуществления при округлении и масштабировании используются наиболее значимые 18 битов значения TEMP 456. За счет сохранения 18 битов достигается дополнительная точность в вычислениях. Операция 454 умножения высокого порядка с округлением и сдвигом продолжается посредством округления и масштабирования промежуточного значения 456 для получения обновленного промежуточного значения 458. В этом варианте осуществления настоящего изобретения округление реализуется добавлением '1' к биту 14 32-битового промежуточного значения ТЕМР 456. К тому же, бит 14 32-битового значения является также младшим битом 18-битовой части, представляющей интерес. Сдвиг выполняется для 32-битового округленного значения для масштабирования промежуточного значения. Сдвиг влево на один бит выполняется для округленного значения для получения обновленного промежуточного значения 458. Обновленное промежуточное значение 458 усекается для получения результата RESULT 460. Для данного примера представляющими интерес битами являются верхние (старшие) 16 битов 32-битового обновленного промежуточного значения 458, которые сохраняются как результат RESULT 460. Нижние (младшие) 16 битов отбрасываются при усечении.
На фиг.5 показана блок-схема варианта осуществления схемы 500 для выполнения операции умножения высокого порядка с округлением и сдвигом в соответствии с настоящим изобретением. Схема 500 в данном варианте осуществления находится в блоке векторных комплексных целых чисел. Этот блок целых чисел разбивает команду PMULHRSW на восемь частей для реализации 128-битовых операндов, каждый из которых реализует одно умножение 16 битов на 16 битов. Для реализации с 64-битовыми операндами, потребуются четыре части. На фиг.5 элемент SRC Y ELEMENT 502 посылается в блок 504 перекодирования Бута по основанию 4. Элемент SRC Х ELEMENT 506 поступает в умножитель 508 Бута. Умножитель Бута генерирует набор 509 из 9 векторов парциальных (частичных) произведений.
По процедуре умножения вручную процесс начинается с взятия младшего бита операнда (А) и умножения его побитно на разряды другого операнда (В). Таким образом, для каждого бита операнда А, на который производится умножение, генерируется строка результатов. Каждая из этих строк является парциальным произведением. Например,

Поскольку для обработки всех парциальных произведений для умножения больших чисел потребовался бы большой объем аппаратных средств, в одном варианте осуществления для упрощения вычислений реализован метод перекодирования Бута. При перекодировании Бута генерируется немногим более половины (N битов/2 +1) парциальных произведений по сравнению с методом перемножения вручную. Например, вместо четырех парциальных произведений, как указано выше, перекодирование Бута реализуется посредством 3 парциальных произведений. Таким образом, для умножения 16×16 всего имеют место "16/2 +1" или 9 парциальных произведений. Данный способ также называется здесь методом по основанию 4. Каждый 16-битовый массив умножения представляет собой кодированный методом Бута массив по основанию 4. Кодирование методом Бута дает 9 парциальных произведений, сокращение которых достигается древовидной структурой сумматора с переносом суммы (CSA) и сумматором. В одном варианте осуществления полная структура 16-битового массива дерева CSA выглядит следующим образом: 
Данный вариант осуществления имеет возможность обрабатывать отрицательные умножения. Символ "S" относится к знаку, а символ "P" используется для описания самых младших двух битов предыдущего парциального произведения. Например, "pp" в парциальном произведении 1 соответствует самым младшим двум битам парциального произведения 0. Суть знакового расширения наверху состоит в развертывании знакового бита. Это подобно битовой инверсии в дополнении до двух для того, чтобы сделать отрицательные числа положительными перед умножением. Аналогичным образом, суть битов "P" состоит в обеспечении +1 для инверсии дополнением до двух преобразования отрицательного в положительное.
Биты [31:16] могут рассматриваться как биты результата высокого порядка операции умножения. Но в случае умножения высокого порядка с округлением и сдвигом обработка операций округления и сдвига производится перед окончательным результатом. В одном варианте осуществления округление связано с добавлением "1" в битовую позицию 14 в некотором месте в массиве. Однако отсутствует свободная позиция для бита 14 в дереве парциальных произведений, чтобы можно было легко добавить "1". В строке 8 имеются свободные позиции соответственно биту 13, биту 12 и биту 11. Аналогичным образом, также имеется свободная позиция соответственно биту 11 в строке 7. Добавление "1" во все четыре эти местоположения, как показано R битами ниже, приведет к переносу "1" вплоть до битовой позиции 14. С использованием метода округления согласно данному варианту осуществления дерево 510 сжатия CSA выглядит следующим образом:

Варианты осуществления настоящего изобретения используют CSA для сокращения членов парциальных произведений с 9 до 2 перед 32-битовым сумматором 514. В одном варианте осуществления дерево сжатия CSA уменьшает число парциальных произведений сначала с 9 до 6, затем с 6 до 4 и, наконец, с 4 до 2 (с использованием 4:2 CSA). Данный метод обходит необходимость в девяти 32-битовых сумматорах. Выходные результаты дерева 510 CSA в данном варианте осуществления являются двумя сокращенными парциальными членами произведений. Один представляет собой член суммы последнего CSA, а другой - член переноса. Чтобы логически суммировать эти два члена вместе для получения полного результата, член переноса должен быть сдвинут влево на один бит, чтобы обеспечить надлежащее согласование с членом суммы. Например, наименее значимый бит, то есть бит 0, члена переноса следует выровнять с битом 1 члена суммы.
32-битовый сумматор 514 суммирует вместе член суммы SUM 512 и член переноса CARRY 511 для генерации полного результата FULL RESULT 515. SUM 512 в этом варианте осуществления представляет собой SUM[31:0]. CARRY 511 представляет собой CARRY[30:0], сдвинутый влево на одну битовую позицию. Битами релевантности для данного варианта осуществления являются биты [30:15]. Эти 16 битов сдвинуты на один бит относительно произведения приведенного выше умножения. Для данного варианта осуществления схемы 500, сдвиг реализуется с помощью блока 518 результата умножения и блока 516 декодирования результата умножения. Таким образом, результирующий продукт RESULTANT 520 для операции целочисленного со знаком умножения высокого порядка с округлением и сдвигом соответствует 16 битам непосредственно вправо от наиболее значимого бита полного результата FULL RESULT 515, или, иными словами, FULL RESULT [30:16]. Для данного варианта осуществления результирующие продукты от каждой из 8 структур массивов, по одному для каждой пары элементов данных, сцепляются вместе, образуя конечный 128-битовый результат.
Фиг.6А иллюстрирует операцию упакованной команды умножения с округлением и сдвигом в соответствии с первым вариантом осуществления настоящего изобретения. 64-битовый операнд источника DATA A 601 состоит из четырех элементов данных 602, 603, 604, 605, заполненных шестнадцатиричными данными 479С16, 1AF716, C00016 и 020016 соответственно. Аналогичным образом, 64-битовый операнд источника DATA B 611 состоит из четырех элементов данных 612, 613, 614, 615, имеющих шестнадцатиричные значения D76E16, 2BC516, C0FF16 и 022016 соответственно. Упакованная команда умножения высокого порядка с округлением и сдвигом в соответствии с одним вариантом осуществления настоящего изобретения, сопровождаемая элементами данных DATA A 601 и DATA B 611 в качестве операндов источника, даст результирующий операнд RESULTANT 621. Упакованная операция 620 умножения высокого порядка с округлением и сдвигом в данном варианте осуществления генерирует результат для каждой соответствующей пары элементов данных источника. В данном примере четыре элемента данных в операнде RESULTANT 621 имеют шестнадцатиричные значения E94E16 622, 093816 623, 1F8116 624и 000916 625 соответственно.
На фиг.6В показаны дополнительные детали упакованной операции умножения высокого порядка с округлением и сдвигом в конкретной позиции элементов данных согласно фиг.6А. Во взаимосвязи с примером по фиг.6А позиция второго элемента данных слева описана ниже более детально. Значение второго крайнего слева элемента данных 603 элемента DATA A 601 есть 1AF716 (или 001 1010 1111 0111 в двоичной форме). Значение второго крайнего слева элемента данных 613 элемента DATA В 611 есть 2ВС516 (или 0010 1011 1100 0101 в двоичной форме). В процессе осуществления операции упакованного умножения высокого порядка с округлением и сдвигом два значения сначала перемножаются для получения произведения 631 049С 3D1316 (0000 0100 1001 1100 0011 1101 0001 00112). Это произведение 631 обрабатывается как первая версия временного промежуточного значения TEMP 630.
Часть 633 округления этой операции выполняется над произведением 631. В данном варианте осуществления округление 633 связано с добавлением значения "1" к биту "14" 632 произведения 631. Результат 634 округления 633 дает новую версию результата TEMP 630. Результат 634 округления имеет значение 049С 7D1316 (0000 0100 1001 1100 0111 1101 0001 00112). Округленный результат 634 масштабируется для получения желательного результирующего значения в данном варианте осуществления. Масштабирование 636 здесь производится как сдвиг влево на один бит округленного результата 634 в TEMP 630. Таким образом, биты с 30 по 15 сдвигаются до позиций битов с 31 по 16. Результат ТЕМР 630 усекается до 16-битового значения, где наиболее значимые 16 битов (верхняя часть) округленного и сдвинутого значения выводится в качестве результирующего продукта RESULTANT 623. RESULTANT 623 является позицией второго элемента данных слева в упакованном результирующем продукте RESULTANT 621. В данном примере RESULTANT 623 имеет значение 093816 (0000 10001 0011 10002).
Пример такой операции упакованного умножения высокого порядка с округлением основания системы счисления (PMULHRSW) над позициями вторых элементов данных пары 64-битовых операндов может быть проиллюстрирован следующим образом:
В вышеприведенных примерах, один или оба операнда источника данных могут быть 64-битовыми регистрами данных в процессоре, реализованном по технологии MMX/SSE, или 128-битовыми регистрами данных, соответствующими технологии SSE2. В зависимости от реализации эти регистры могут иметь размер 64/128/256 битов. Аналогичным образом, один или оба операнда источника могут быть ячейками памяти, иными, чем регистр. В одном варианте осуществления адресатом для результирующего продукта является также ММХ- или ХММ-регистр данных. Кроме того, адресатом результирующего продукта может быть тот же самый регистр, что и соответствующий операндам источника. Например, в одной архитектуре, команда умножения с округлением и сдвигом имеет первый операнд ММ1 источника и второй операнд ММ2 источника. Предварительно определенный адресат для результирующего продукта может соответствовать регистру для первого операнда источника, в данном случае ММ1.
На фиг.7А показана блок-схема 700, иллюстрирующая вариант осуществления способа для выполнения целочисленного умножения с округлением и сдвигом над упакованными операндами данных для получения верхней части произведений. Значения L длин используются здесь для представления размера операндов и блоков данных. В зависимости от конкретного варианта осуществления L может быть использовано для обозначения размера в терминах количества сегментов данных, битов, байтов, слов и т.д. В блоке 710 первый операнд А данных длины L принимается для использования при выполнении операции упакованного целочисленного умножения высокого порядка с округлением и сдвигом. Второй операнд В данных длины L для операции PMULHRSW также принимается в блоке 720. В блоке 730 производится обработка команды для выполнения умножения высокого порядка с округлением и сдвигом.
Детали операции умножения высокого порядка с округлением и сдвигом в блоке 730 данного варианта осуществления описываются далее в отношении того, что происходит для каждой позиции элемента данных. В одном варианте осуществления операция умножения высокого порядка с округлением и сдвигом для всех позиций элементов данных упакованного результирующего продукта обрабатывается параллельно. В другом варианте осуществления в каждый данный момент времени может обрабатываться определенная часть элементов данных. В блоке 731 вычисляется промежуточное значение TEMP путем перемножения значения элемента из операнда А и значения элемента из операнда В. Промежуточное значение округляется в блоке 732. В одном варианте осуществления верхние 18 битов промежуточного значения используются в вычислениях для достижения лучшей точности. В другом варианте осуществления может представлять интерес другое количество битов данных. После округления в блоке 732, промежуточное значение масштабируется в блоке 733. Для данного варианта осуществления масштабирование связано со сдвигом промежуточного значения влево на один бит. В блоке 734 промежуточное значение усекается до требуемого количества битов и сохраняется в адресате в качестве значения результирующего продукта. Значение результирующего продукта для каждого из отличающейся пары элементов данных источника упорядочивается в надлежащие позиции элементов данных соответственно парам элементов источника в упакованном операнде результирующего продукта.
На фиг.7В показана блок-схема, иллюстрирующая другой вариант осуществления способа для получения релевантных частей высокого порядка результирующих продуктов упакованной операции целочисленного умножения с округлением и сдвигом. В данном варианте осуществления операнды состоят из элементов данных размером в слово. Однако другие варианты осуществления могут быть реализованы с элементами данных альтернативных размеров, включая, например, байт, слово двойной длины или квадраслово. В блоке 742 декодируется сигнал управления для операции умножения высокого порядка с округлением и масштабированием. В блоке 744 осуществляется проверка для определения размера операнда, участвующего в операции. В одном варианте осуществления размер операнда может быть определен с декодированием сигнала управления в блоке 742. Например, размер операнда может быть закодирован с командой. Если размер операнда определен как величина 64 бита, то в блоке 746 осуществляется доступ к регистровому файлу и/или памяти для получения данных операнда в зависимости от того, где находятся данные. В одном варианте осуществления операнды источника могут находиться в SIMD-регистрах и/или в памяти. В случае операндов размером 64 бита, согласно данному варианту осуществления, каждый операнд имеет четыре элемента данных длиной в слово.
Вычисления для этих четырех пар элементов данных источника показаны как четыре набора уравнений в блоке 747. Первое уравнение "TEMP[31:0]=A[15:0] x B[15:0]" представляет умножение элементов данных источника. Второе уравнение "INT(TEMP[31:0]≫14)+1" представляет округление промежуточного результата. Для данного варианта осуществления временное значение сдвигается вправо на 14 битов, и "1" добавляется к наименее значимому биту. Иными словами, верхние 18 битов промежуточного результата сохраняются, и "1" добавляется к тому, что первоначально было битом 14. Третье уравнение "DEST[15:0]=TEMP[16:1]" представляет сдвиг и усечение округленного результата. Каждый элемент данных результирующего продукта также является словом в данном случае, таким образом, необходимы 16 битов. Заметим, что здесь выделяются биты [16:1] из оставшихся 18 битов. В данном варианте осуществления сдвиг влево осуществляется путем взятия 16 битов непосредственно влево от наименее значимого бита. Усеченное значение сохраняется как результирующий продукт для данной позиции элемента данных. Эти три уравнения повторяются для каждой позиции элемента данных в блоке 747, за исключением того, что диапазоны битов заполняются корректными значениями для такой позиции (то есть [15:0], [31:15], [47:32] и [63:48]).
Если размер операнда определен в блоке 744 как 128 битов, то в блоке 748 осуществляется доступ к регистровому файлу и/или памяти для получения требуемых данных операнда. Для операндов длиной 128 битов, согласно данному варианту осуществления, каждый операнд имеет восемь элементов данных длиной в слово. Как в случае 64-битовой ветви обработки, каждая из 8 пар элементов данных источника обрабатывается в блоке 749 с использованием системы из трех уравнений, описанных выше. Корректные диапазоны битов для восьми наборов уравнений в этой 128-битовой ветви обработки являются следующими: [15:0], [31:15], [47:32], [63:48], [79:64], [95:80], [111:96] и [127:112]. Хотя две ветви обработки, описанные в этом примере, связаны с использованием 64-битового и 128-битового операндов, в альтернативных вариантах осуществления могут использоваться операнды различных других длин. Восемь 16-битовых значений, по одному на каждую позицию элемента данных, сохраняются в соответствующих позициях элементов данных в DEST.
Таким образом, выше описаны методы для SIMD целочисленного умножения с округлением и сдвигом. Хотя описаны и показаны на чертежах определенные приведенные для примера варианты осуществления, следует иметь в виду, что такие варианты осуществления являются только иллюстративными, но не ограничивающими объем изобретения, и что данное изобретение не должно ограничиваться конкретными показанными и описанными структурами и конфигурациями, поскольку различные другие модификации могут быть очевидны для специалистов в данной области техники на основе данного раскрытия. В области техники, подобной рассматриваемой, развитие которой осуществляется с высокой скоростью и последующие усовершенствования не просто спрогнозировать, раскрытые варианты осуществления могут легко модифицироваться по форме и в деталях, как это обеспечивается технологическими достижениями, без отклонения от принципов настоящего раскрытия или в объеме пунктов формулы изобретения.
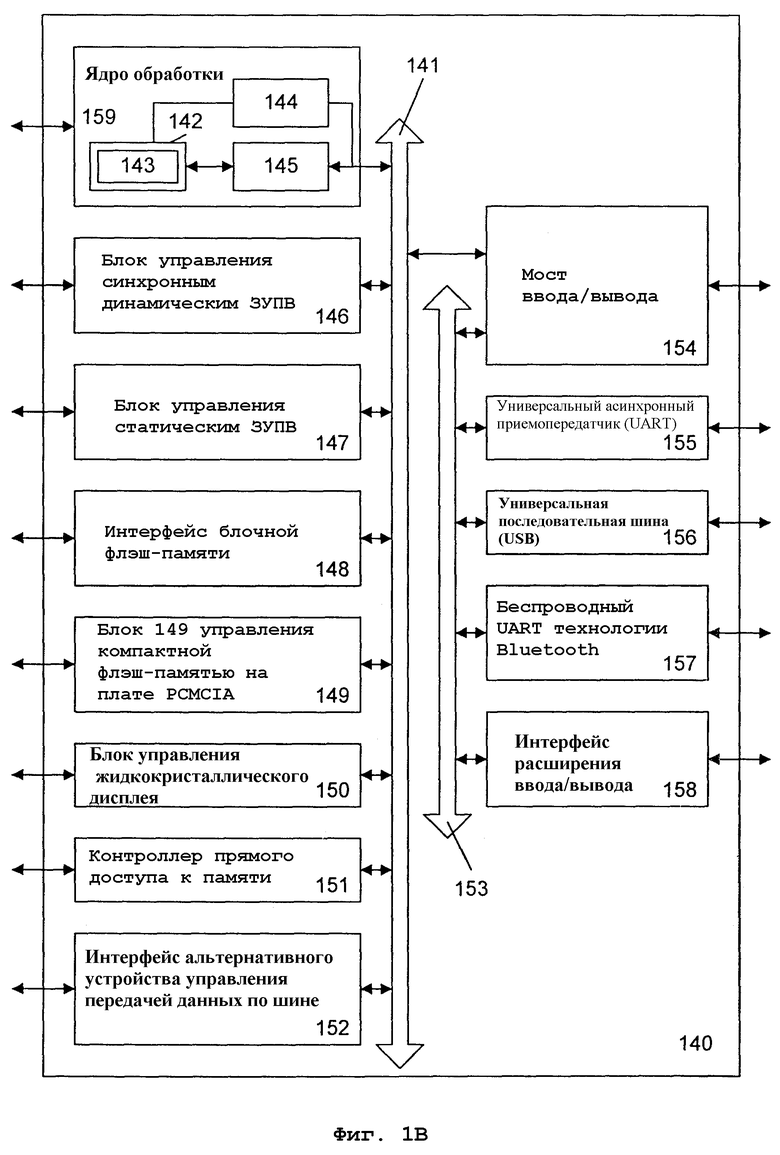
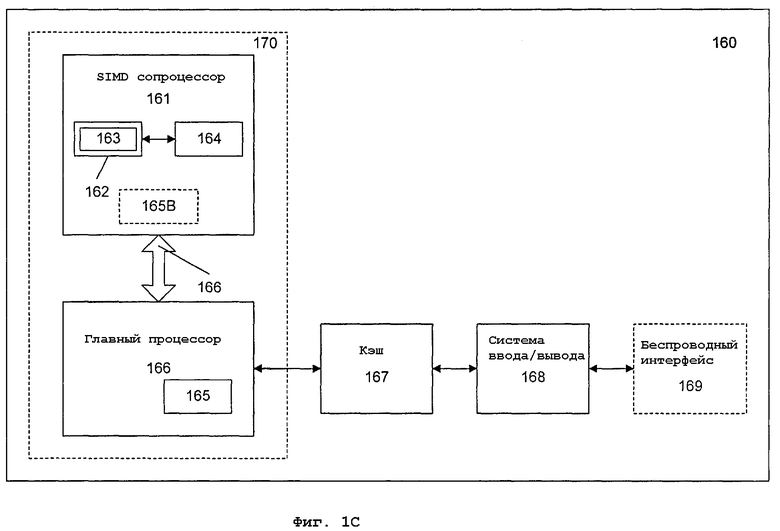
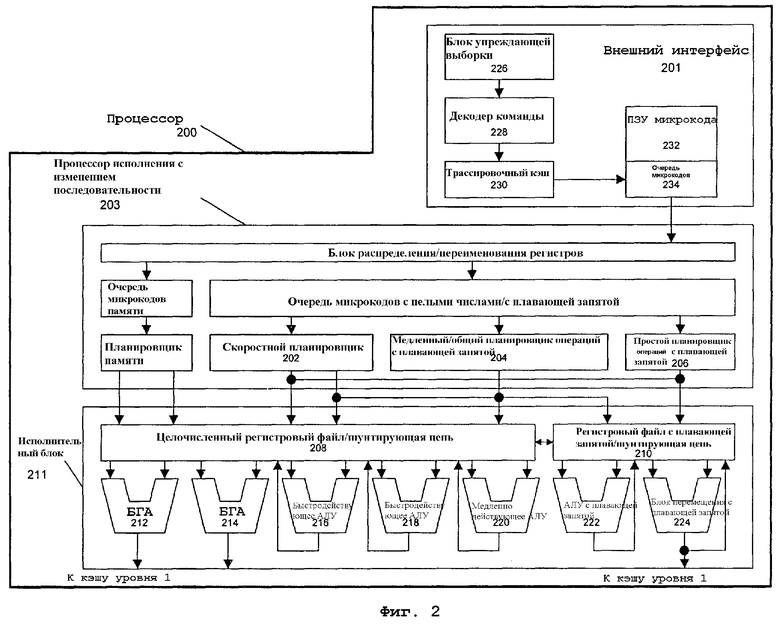

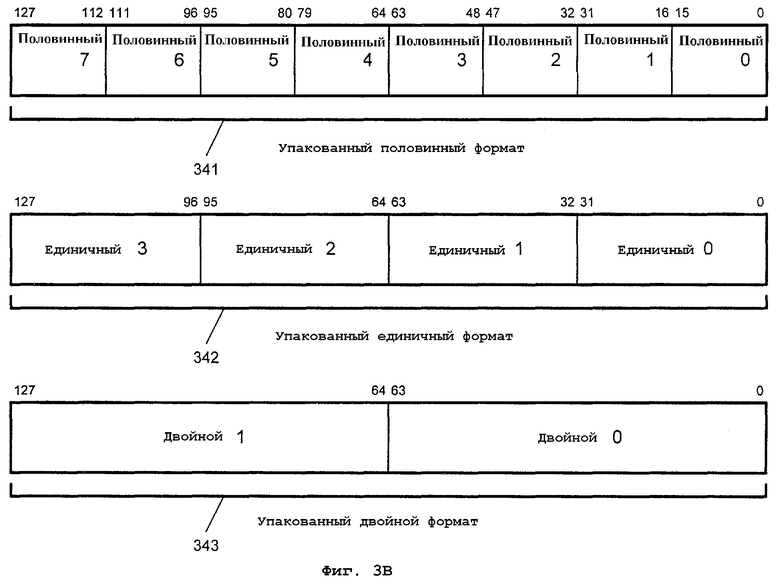
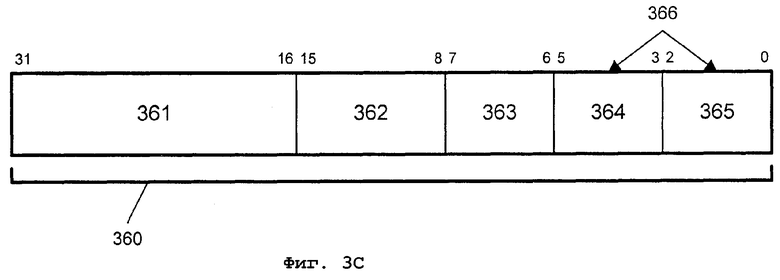
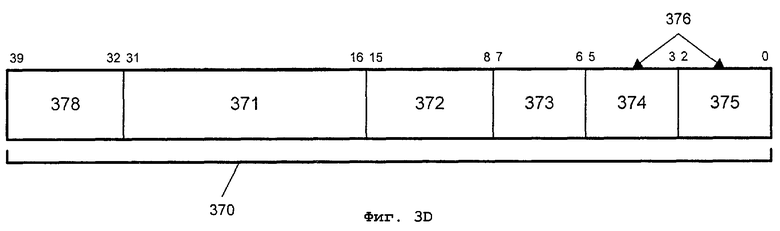
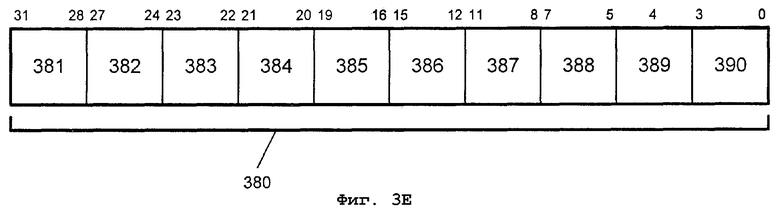
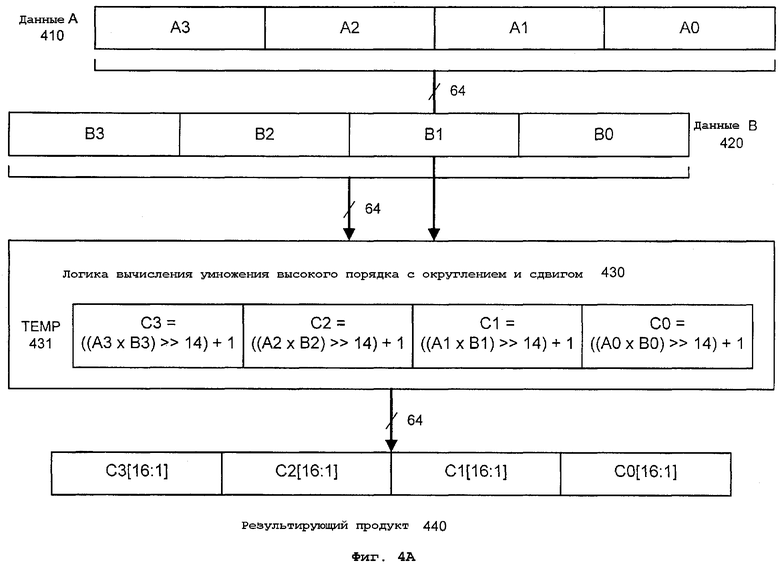
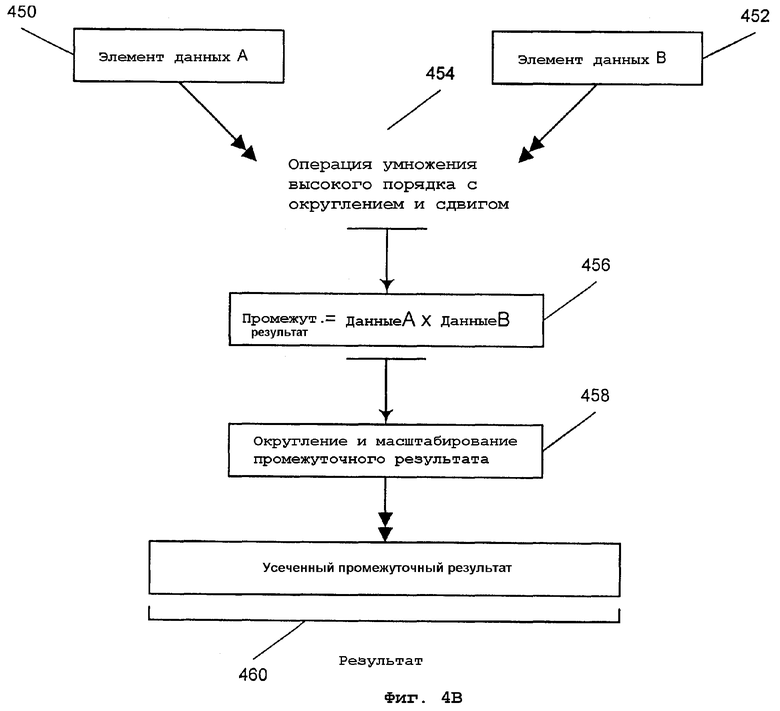
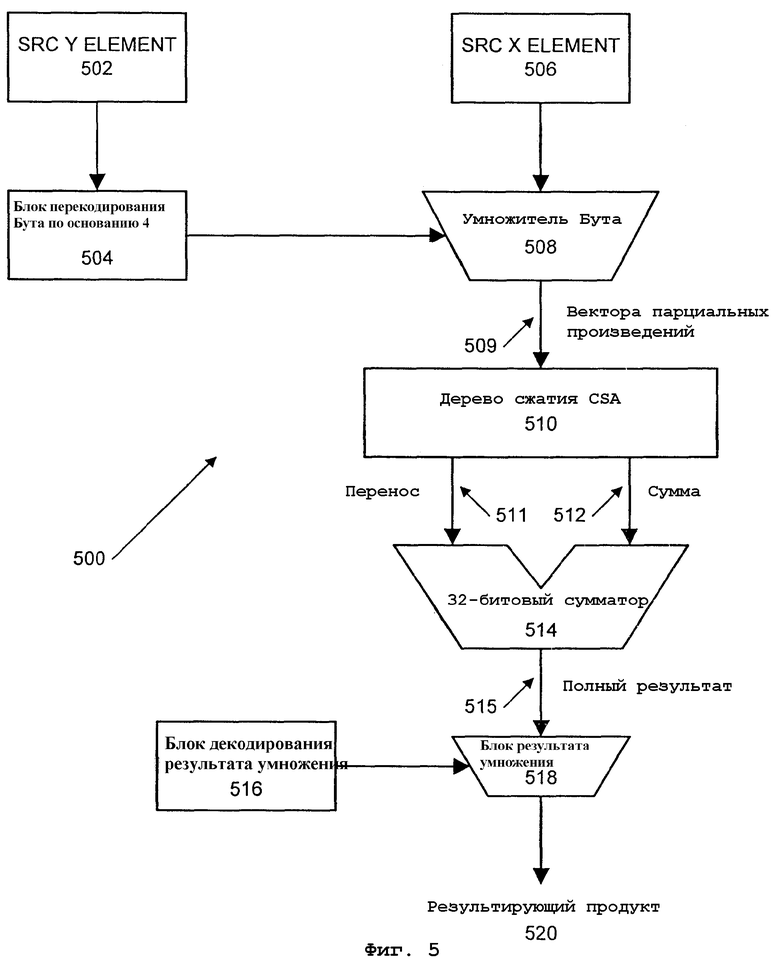
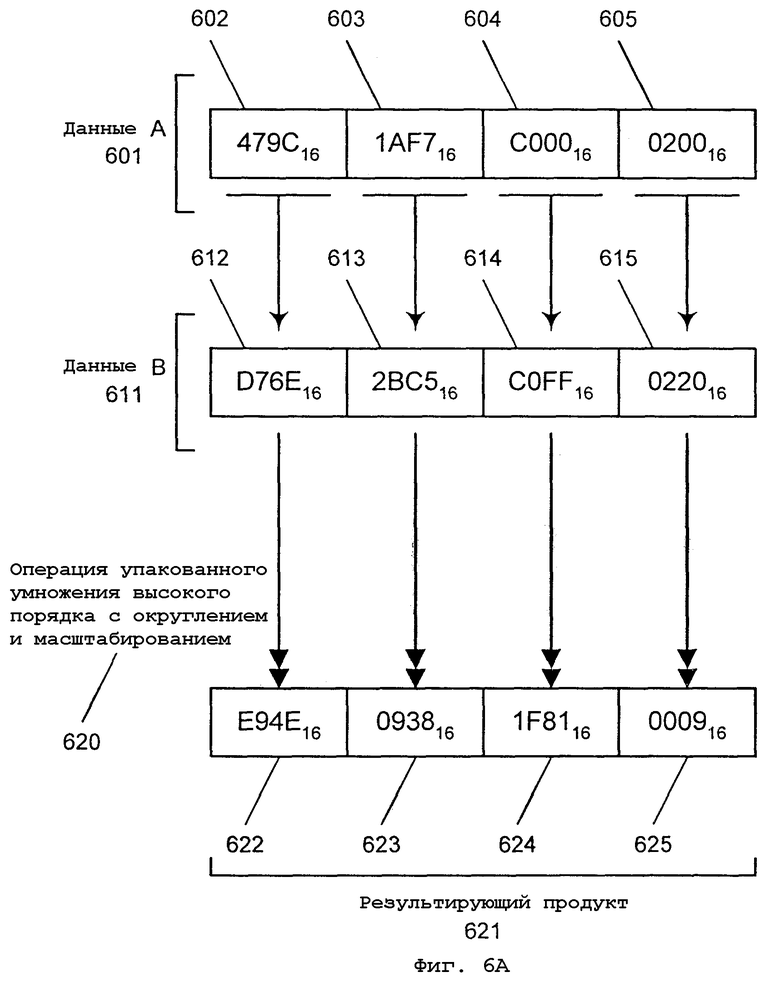
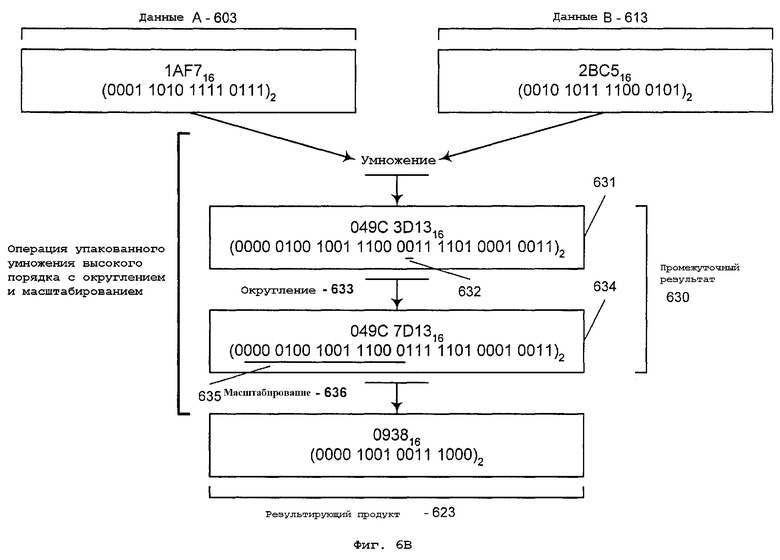
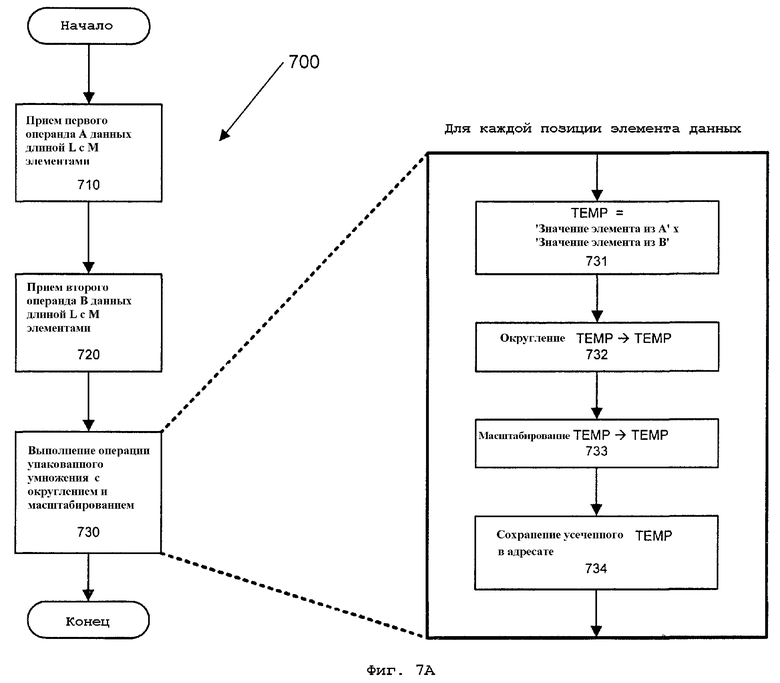
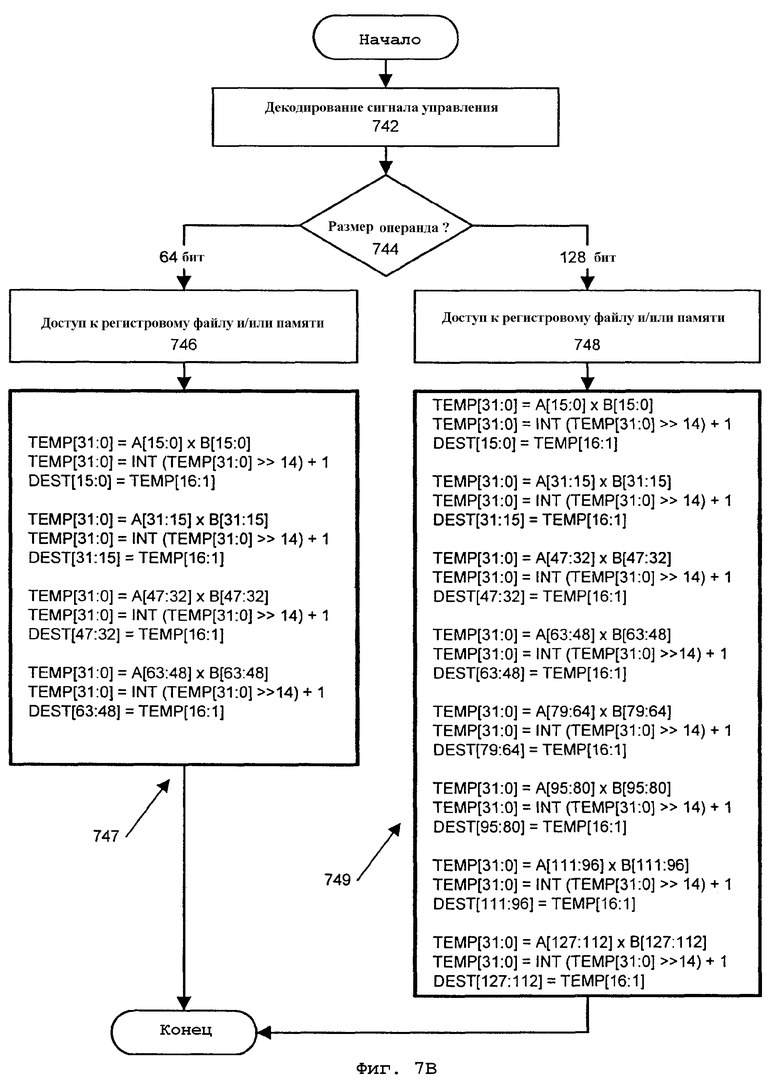
Изобретение относится к области устройств обработки, соответствующего программного обеспечения и программных последовательностей, которые выполняют математические операции. Техническим результатом является повышение быстродействия, увеличение точности вычислений. Указанный результат достигается за счет того, что способ включает прием первого операнда, имеющего первый набор из L элементов данных, прием второго операнда, имеющего второй набор из L элементов данных, и перемножение L пар элементов данных для формирования набора из L произведений, при этом каждая из L пар включает в себя один элемент данных из первого набора и второй элемент данных из соответствующей позиции элемента данных второго набора. Каждое из L произведений округляется для формирования L округленных значений, которые масштабируются для формирования L масштабированных значений, для каждого из которых осуществляется усечение для сохранения в месте назначения, причем каждое усеченное значение должно сохраняться в позиции элемента данных, соответствующей его паре элементов данных. 5 н. и 63 з.п. ф-лы, 16 ил.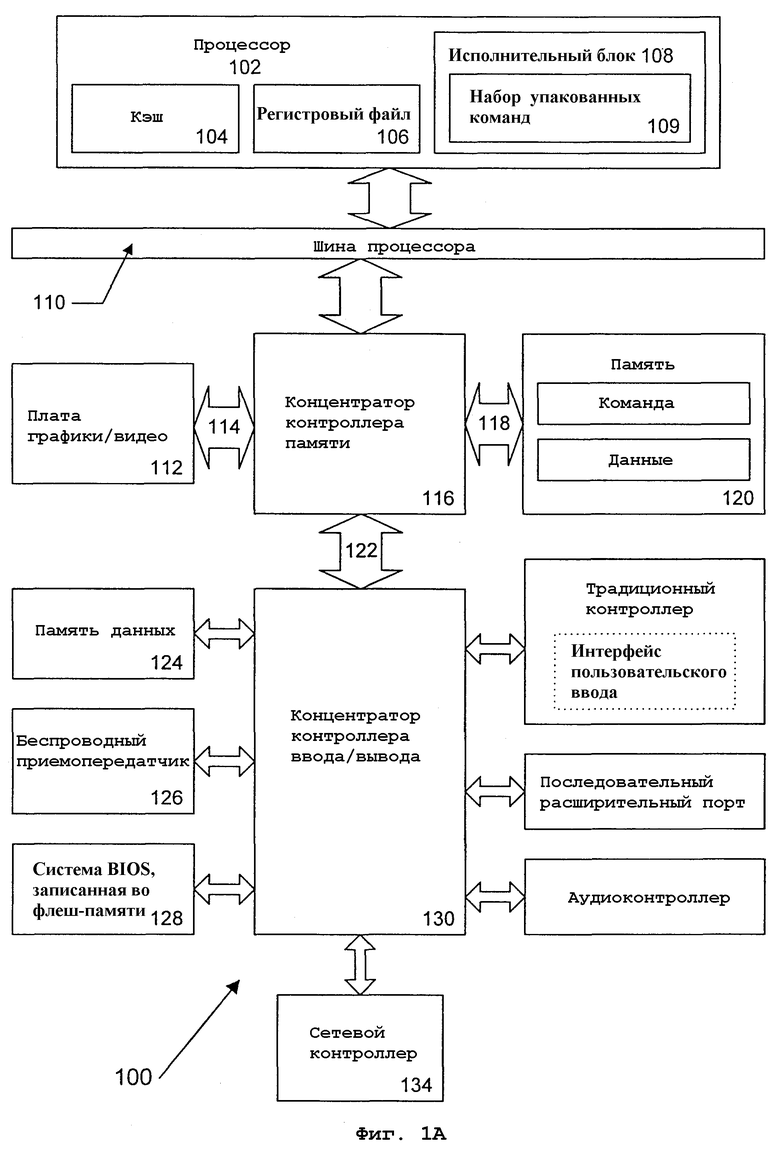
| УСТРОЙСТВО ДЛЯ ВЫПОЛНЕНИЯ ОПЕРАЦИЙ УМНОЖЕНИЯ-СЛОЖЕНИЯ С УПАКОВАННЫМИ ДАННЫМИ | 1996 |
|
RU2139564C1 |

