Предпосылки изобретения
Нейронные сети
Некоторые компьютерные задачи, например, распознавание символов и распознавание изображений, как известно, хорошо решаются методами машинного обучения. Главный из них связан с использованием нейронных сетей. Нейронные сети представляют собой класс алгоритмов, основанных на концепции взаимосвязанных “нейронов”. В обычной нейронной сети нейроны содержат значения данных, каждое из которых влияет на значение присоединенного нейрона согласно связям с заранее заданными весами и на то, отвечает ли сумма связей с каждым конкретным нейроном заранее заданному порогу. Определяя надлежащие веса связей и пороговые значения (процесс также называется “обучением”), нейронная сеть может добиться эффективного распознавания изображений и символов. Зачастую эти нейроны объединяют в “уровни”, чтобы сделать связи между группами более очевидными и вычислять значения для каждого из них.
На фиг.1 показана упрощенная блок-схема нейронной сети, которая интерпретирует образец 100 рукописной буквы “m”. В проиллюстрированном примере значения в изображенных нейронах равны 0 или 1. Это сделано для упрощения иллюстрации и не ограничивает диапазон типов значений, которые могут принимать нейроны в нейронной сети. В проиллюстрированном примере электронное изображение образца рукописного ввода используется для создания множества значений для входного слоя 210, или “слоя 0”. В некоторых реализациях это можно делать, непосредственно отображая каждый пиксель образца 200 на конкретный нейрон в слое 0, в результате чего каждый нейрон показывает 1 или 0 в зависимости от того, включен или выключен пиксель. Другой иллюстративный метод присвоения значений нейронам рассмотрен ниже со ссылкой на сверточные нейронные сети. В зависимости от капризов нейронной сети и проблем, возникающих при ее решении, разные сети могут иметь разные количества нейронов, и они могут быть или не быть связаны с конкретными величинами входных данных.
Согласно фиг.1 различные нейроны в слое 0 связаны с нейронами следующего слоя, слоя 1 (120). В одной реализации, именуемой полносвязной нейронной сетью, каждый из нейронов того или иного слоя связан с нейронами следующего слоя. В примере, показанном на фиг.1, это частично представлено связями двух нейронов слоя 0 с каждым нейроном в слое 1. Затем каждый нейрон слоя 1 принимает входное значение от каждого из нейронов слоя 0. Затем эти входные значения суммируются, и эта сумма сравнивается со смещением или порогом. Если значение превышает порог для конкретного нейрона, то этот нейрон принимает положительное значение, которое можно использовать в качестве входного значения для нейронов в следующем слое нейронов. Это вычисление продолжается по различным слоям нейронной сети, пока не достигнет конечного слоя 130, именуемого здесь “слоем n.” При этом выход процедуры нейронной сети можно считывать из значений в слое n. В одной реализации сети, используемой при распознавании символов, каждое значение в слое присваивается конкретному символу. В этой реализации сеть оканчивается выходным слоем, имеющим только одно большое положительное значение в одном нейроне, которое указывает, какой символ, вычисленный сетью, с наибольшим правдоподобием является рукописным входным символом.
Однако эти соединения дают большую вычислительную сложность, как показано на фиг.2. На фиг.2 показана блок-схема способа вычисления значений нейронов на основании значений, найденных в предыдущем слое. Заметим, что, хотя на фиг.2 показаны различные матрицы, индексы (или размеры) матриц будут меняться от слоя к слою и от сети к сети, и различные реализации могут по-разному ориентировать матрицы или отображать матрицы в память компьютера. Согласно фиг.2 одна реализация нейронных сетей состоит в том, что каждый уровень рассматривается как матрица значений нейронов, которая продемонстрирована матрицей 210 слоя 0. Тогда веса связей можно реализовать в виде матрицы 220 преобразования, которая умножается на матрицу 210 слоя 0. Это умножение позволяет масштабировать каждое значение в предыдущем слое согласно весам связей и затем суммировать их все путем обычного умножения матриц. После осуществления умножения матрица смещения 230 прибавляется к произведению матриц для учета порога каждого нейрона на следующем уровне. Затем сигмоидальная функция (в одной реализации, tanh()) применяется к значению каждого результата для определения соответствия порогу, и результирующие значения помещаются в матрицу для следующего слоя. Это также называется “функцией сплющивания”. Таким образом, согласно фиг.2, связи между последовательными слоями, а, стало быть, во всей сети, можно представить в виде ряда матриц. В этом случае решение задачи обучения нейронной сети сводится к отысканию надлежащих значений для этих матриц.
Хотя на фиг.2 показано, что нейронные сети можно реализовать в виде матриц, вычисление нейронных сетей и обучение нейронных сетей, как описано ниже, предусматривает большое количество математических вычислений. Дополнительно, неполносвязные нейронные сети могут потребовать еще более сложных вычислений.
Сущность изобретения
Программа пиксель-шейдера обеспечивает эффективное обучение сверточной нейронной сети на графическом процессоре. Например, сверточная нейронная сеть реализуется на графическом процессоре в виде ряда текстур. Затем сеть обучается посредством ряда прямых и обратных проходов, причем сверточные ядра и матрицы смещения изменяются в каждом обратном проходе с использованием метода градиентного спуска согласно градиенту функции ошибок.
Реализация опирается на преимущества возможностей параллельной обработки блоков пиксель-шейдера на ГП для эффективного параллельного вычисления прямого и обратного проходов. Она также использует иллюстративное множество формул “от начала до конца” для осуществления вычислений на блоках пиксель-шейдера. В одном примере входом и выходом программы являются текстуры, над которыми также производятся операции в ходе вычисления. В другом примере используется процесс многопроходного суммирования, когда необходимо суммирование по регистрам блоков пиксель-шейдера. Различные методы и системы можно использовать совместно или независимо.
Эта сущность изобретения приведена здесь для ознакомления с рядом концепций в упрощенной форме, которые дополнительно описаны ниже в подробном описании. Эта сущность изобретения не призвана выявлять ключевые признаки или существенные признаки заявленного изобретения, а также не призвана помогать в определении объема заявленного изобретения.
Дополнительные признаки и преимущества явствуют из нижеследующего подробного описания вариантов осуществления, приведенного со ссылкой на прилагаемые чертежи.
Краткое описание чертежей
Фиг.1 - блок-схема традиционной полносвязной нейронной сети.
Фиг.2 - блок-схема матричной реализации связей между двумя слоями полносвязной нейронной сети.
Фиг.3 - блок-схема архитектуры графического процессора.
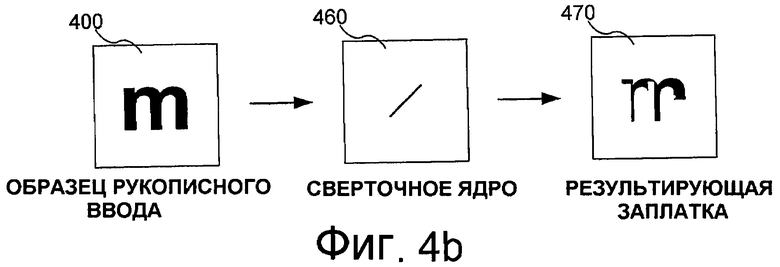
Фиг.4a и 4b - блок-схемы двух примеров действия сверточных ядер на образце рукописного ввода.
Фиг.5 - блок-схема иллюстративного процесса обучения сверточных нейронных сетей на графическом процессоре.
Фиг.6 - блок-схема подпроцесса подготовки данных нейронной сети для вычисления на графическом процессоре.
Фиг.7 - блок-схема примера многопроходного суммирования.
Фиг.8 - блок-схема подходящей вычислительной среды для реализации методов сверточной нейронной сети, показанных на фиг.6.
Подробное описание
Нижеследующее описание относится к обучению сверточных нейронных сетей на архитектурах графического процессора (“ГП”), в частности, для распознавания рукописного ввода. ГП осуществляет повторные прямые проходы и обратные проходы на входных данных, изменяя и упрощая матрицы, которые содержат нейронную сеть, в каждом проходе. Многие из описанных здесь методов призваны извлекать преимущество из эффективностей ГП и использовать программы пиксель-шейдера, предназначенные для эффективного выполнения на ГП.
1. Архитектура ГП
Описанные здесь методы реализуются на графическом процессоре. Один пример графического процессора показан на фиг.1, где в упрощенном виде представлена традиционная ГП архитектура 300. В одной реализации архитектура ГП соответствует ГП 815, показанному на фиг.8. Данные 305 отображения, которые описывают геометрию визуализуемого изображения, вводятся в блоки вершинного шейдера 310, которые генерируют многоугольниковые представления геометрических форм. Эти геометрические формы затем вводятся в растеризатор, который интерполирует многоугольники и отбирает их для построения выборочного множества точек в пространстве изображений, которые затем затушевываются, и к которым добавляется текстура. Затем эти точки поступают на ряд программируемых блоков пиксель-шейдера 330, которые используют методы параллельного вычисления для осуществления затушевывания точек, а также для добавления текстур и манипулирования ими. Именно эта возможность осуществлять параллельные вычисления, а также манипулировать текстуры делает ГП и, в частности, блоки пиксель-шейдера, полезной платформой для вычисления на нейронных сетях. Вычисление блока пиксель-шейдера часто осуществляется под управлением программ пиксель-шейдера, которые являются программами, выполняемыми на ГП, написанными для осуществления преимуществ блоков пиксель-шейдера.
Текстуры, которые ЦП компьютера может заранее загружать в графическую память 350 до обучения, кэшируются в текстурном кэше 340. По завершении этих процессов точки изображения можно помещать в кадровый буфер 360 до переноса в графическую память 350. Однако в различных реализациях описанных здесь методов, входные данные нейронной сети, а также выходные данные будут сохраняться в текстурах. Таким образом, в различных реализациях точка изображения, выведенная в кадровый буфер, игнорируется или не создается вовсе.
2. Сверточные нейронные сети
Хотя вышеописанные полносвязные нейронные сети способны, будучи правильно обученными, распознавать рукописный ввод, им часто не удается пользоваться формой и близостью при обработке ввода. Одна из причин состоит в том, что каждый пиксель обрабатывается независимо, без учета соседних пикселей. По этой причине используются также сверточные нейронные сети, которые связывают с каждым нейроном массив значений, а не одно значение. В принципе, этот массив можно рассматривать как малую заплатку в изображении. Преобразование значения нейрона для следующего слоя обобщается от умножения до свертки. Это подразумевает, что веса 230 связей являются ядрами свертки, а не скалярными значениями. На фиг.4a и 4b показаны два примера сверточных ядер, действующих на образце 400 буквы “m.” На фиг.4a образец объединяется с ядром 410 свертки, представляющим вертикальную линию. Результирующая заплатка пикселей 420 содержит три вертикальные линии, которые присутствуют в образце. Аналогично, на фиг.4b образец рукописного ввода 450 объединяется со сверточным ядром 460, представляющим диагональную линию, идущую направо вверх. Это приводит к заплатке пикселей 460, которая содержит две диагональные линии входного символа. Согласно фиг.4a и 4b две результирующие заплатки демонстрируют разную информацию для символа, в то же время сохраняя соседство пикселей. Это может обеспечивать более эффективное распознавание символов.
Однако для этих более сложных преобразований требуются более сложные матрицы нейронной сети. Таким образом, в то время как матрица полносвязной сети содержит массив числовых значений, в сверточной нейронной сети каждый элемент матрицы представляет собой прямоугольную (или квадратную) заплатку пикселей; аналогично, матрица смещения содержит заплатки, и сигмоидальная функция применяется к каждому элементу каждой заплатки. Дополнительно, вместо вычисления простого умножения матриц, вычисления в сверточных нейронных сетях предусматривают более сложную математику, где требуется больше параллельных вычислений. Один пример вычислений, лежащих в основе реализации сверточной нейронной сети, раскрыт ниже в Разделе 4. Дополнительную информацию по сверточным сетям можно найти в статье P.Y. Simard, D. Steinkaus и J.C. Platt, “Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis,” Proc. International Conference on Document Analysis and Recognition, стр. 958-962, 2003, включенной сюда посредством ссылки.
3. Процедура обучения
На фиг.5 показан иллюстративный процесс 500 обучения сверточной нейронной сети. В различных реализациях процесса 500 этапы можно удалять, объединять или разбивать на подэтапы. Процесс начинается на этапе 510, где процесс принимает нейронную сеть для обучения, а также обучающие образцы. В обычной реализации в сети могут быть заранее заданы образцовые сверточные ядра и смещения, но каждый из них нужно очистить для обеспечения согласованных и эффективных результатов. Обучающие образцы обычно включают в себя много (порядка десятков тысяч) образцов рукописных символов, совместно с указанием правильного символа, в который следует интерпретировать каждый из них. Затем, на этапе 520 данные нейронной сети, например, образцы и матрицы нейронной сети, подготавливаются к обработке в качестве графических данных на блоках пиксель-шейдера 330 в ГП 300. Иллюстративный процесс, выполняемый на этом этапе, более подробно описан ниже со ссылкой на фиг.6. В одной реализации оба этапа 510 и 520 осуществляются ЦП совместно с ГП 815. В другой всю подготовку осуществляет ГП 815.
Согласно фиг.5 каждый из этих образцов вводится в сверточную нейронную сеть, и выходной результат вычисляется для определения, насколько сеть близка или далека от правильного распознавания символов. Это называется “прямой проход”. Затем определяется степень ошибки в отношении каждой из матриц, которые содержат сеть, посредством так называемого “обратного прохода” (обратного распространения ошибки), после чего матрицы изменяются для исправления ошибки. Согласно общепринятой практике программирования ГП общего назначения, описанная здесь реализация записана в виде ряда программ пиксель-шейдера.
Таким образом, на этапе 530 ГП входит в цикл для каждого введенного образца. На этапе 540 нейронная сеть подвергается прямому проходу для определения выходного результата для данного образца. Затем, на этапе 550 функция ошибок используется для вычисления, насколько далека нейронная сеть от ожидаемого выхода. Затем, на этапе 560 определяется функция градиента для функции ошибок. Вычисляя функцию градиента, которая содержит частные производные для каждого элемента каждой матрицы нейронной сети в отношении ошибки, ГП может вычислять, насколько нужно скорректировать каждую матрицу согласно методу градиентного спуска. Затем, на этапе 570 матрицы, включающие в себя сверточные ядра и смещения, изменяются согласно функции градиента. Этапы 550, 560 и 570 носят общее название “обратный проход”, поскольку они берут информацию ошибки выхода и используют ее для определения необходимых изменений для каждой матрицы нейронной сети. Примеры одной реализации уравнений, используемых в этих прямом и обратном проходах, описаны в Разделе 4. Наконец, на этапе 580 этапы прямого/обратного прохода процесса 500 повторяются до тех пор, пока вводятся образцы. По окончании ввода образцов сеть считается обученной на этих вводах и процесс заканчивается.
На фиг.6 показан иллюстративный процесс 600 подготовки данных нейронной сети в качестве графических данных на этапе 520 процесса 500. В различных реализациях процесса 600 этапы можно удалять, объединять или разбивать на подэтапы. Процесс начинается на этапе 610, где процесс создает сцену, состоящую из единичного треугольника, который покрывает все демонстрационное окно. Процесс делает это во избежание влияния растеризатора и других каскадов ГП на результат вычисления, что позволяет процессу сосредоточиться на вычислении пиксель-шейдера.
В предпочтительной реализации каждая переменная параллельных данных сохраняется как двухмерная текстура. Однако некоторые переменные имеют размерность выше двух, поэтому на этапе 620 их можно внедрять в двухмерную текстуру. Например, переменную  можно “сплющить” в
можно “сплющить” в  согласно следующим уравнениям (обозначения описаны ниже в разделе 4):
согласно следующим уравнениям (обозначения описаны ниже в разделе 4):

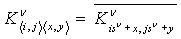

 (3.1)
(3.1)
 (3.2)
(3.2)
Затем, на этапе 630 определяется система координат для текстур. Это необходимо делать, поскольку блоки пиксель-шейдера предназначены для работы с “пикселями”, и, таким образом, нужно определять местоположение каждого “пикселя” (в этом случае, элемента матрицы сверточной сети). Один часто используемый способ состоит в связывании информации “текстурных координат” с вершинами треугольника, который предоставляется к вершинным шейдерам. Тогда ГП может интерполировать значения текстурных координат на каждом выходном пикселе и выдавать интерполированное значение на один из регистров блока пиксель-шейдера. Это можно использовать не только для установления идентичности пикселя, но и для предварительного вычисления значений, необходимых в ходе выполнения программ пиксель-шейдера.
Однако любое нетривиальное использование интерполяционных функций растеризатора приводит к тому, что программам требуется надлежащим образом задавать вершинные данные до каждого прохода. Накладные расходы задания данных могут перевешивать любую выгоду от предварительного вычисления значений. Альтернативная реализация предусматривает использование ShaderModel 3.0 от Microsoft Corporation и ее регистр vPos. Этот регистр содержит в своих компонентах x и y целочисленные сдвиги от левого верхнего угла выходной текстуры. В этом случае адреса, необходимые для поиска значений из входных текстур, являются простыми линейными комбинациями vPos. Определив систему координат, процесс может создавать текстуры на этапе 630. Наконец, на этапе 640 текстуры загружаются в ГП до начала обработки. В одной реализации, максимально возможное количество текстур, если не все, загружаются в графическую память во избежание доступа ГП к системной памяти, что могло бы замедлить вычисление. На этом процесс заканчивается.
4. Реализация и вывод
В каждом приведенном здесь примере используется пиксель-шейдерная система ShaderModel 3.0, хотя в других реализациях можно использовать другие системы. Согласно вышеприведенному рассмотрению нейронная сеть содержит некоторое количество N слоев (уровней) нейронов, где каждый нейрон имеет численное значение. В этом разделе обозначают v-й слой как  .
.  - это вектор, длину которого обозначают как
- это вектор, длину которого обозначают как 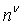 и i-й элемент которого обозначен как
и i-й элемент которого обозначен как  . Каждый слой
. Каждый слой  вычисляется из предыдущего слоя с использованием “выученных параметров”
вычисляется из предыдущего слоя с использованием “выученных параметров” 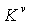 и
и  . Задачей процесса обучения является отыскание хороших значений этих параметров, что, согласно этим методам, делается путем градиентного спуска. Для удобства обозначений используется условный оператор
. Задачей процесса обучения является отыскание хороших значений этих параметров, что, согласно этим методам, делается путем градиентного спуска. Для удобства обозначений используется условный оператор  , который принимает значение 1, если условие c выполняется, и 0 в противном случае. Описанный здесь вывод представляет уравнения для обучения нейронной сети, которые являются упрощенными и объединяются алгебраически для уменьшения количества вызовов программ пиксель-шейдера при осуществлении этих методов обучения.
, который принимает значение 1, если условие c выполняется, и 0 в противном случае. Описанный здесь вывод представляет уравнения для обучения нейронной сети, которые являются упрощенными и объединяются алгебраически для уменьшения количества вызовов программ пиксель-шейдера при осуществлении этих методов обучения.
4.1 Полносвязные сети - прямой проход
Чтобы понять случай сверточной нейронной сети, полезно провести сравнение с относительно простым случаем полносвязной сети, где N, количество слоев, равно 2. В этом случае, при осуществлении прямого прохода, где каждый слой вычисляется из предыдущего, вычисляют  как:
как:
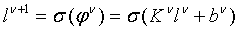

для  . Здесь
. Здесь  - это “функция сплющивания”, представляющая поэлементное применение
- это “функция сплющивания”, представляющая поэлементное применение 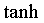 ,
,  - это матрица
- это матрица 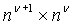 , представляющая веса связей между двумя слоями, и
, представляющая веса связей между двумя слоями, и  - это вектор длиной
- это вектор длиной 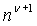 , представляющий смещение.
, представляющий смещение.
4.2 Полносвязные сети - функция ошибок
Чтобы использовать выходной слой  в качестве классификатора символа, мы можем проводить различие между
в качестве классификатора символа, мы можем проводить различие между  классами и использовать
классами и использовать 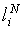 как указатель вероятности
как указатель вероятности 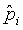 того, что ввод принадлежит классу i. Чтобы преобразовать эти в настоящие вероятности, нормализуем их с использованием функции “softmax”:
того, что ввод принадлежит классу i. Чтобы преобразовать эти в настоящие вероятности, нормализуем их с использованием функции “softmax”:
 .
.
Если мы знаем, что правильная классификация при данном текущем вводе равна t, то идеальное вычисление должно дать  . Суммарное отклонение E от этого идеала можно измерить с использованием формулы для “перекрестной энтропии”:
. Суммарное отклонение E от этого идеала можно измерить с использованием формулы для “перекрестной энтропии”:
 .
.
4.3 Полносвязные сети - обратный проход
Как описано выше, для обучения различных параметров нейронной сети используется градиентный спуск. Это предполагает отыскание частной производной функции ошибок E по каждому из параметров и . В качестве сокращенного обозначения мы вводим следующее:
 ,
,
где  обозначает поэлементное умножение, и
обозначает поэлементное умножение, и  - поэлементное применение
- поэлементное применение 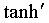 . Затем определение E можно подставить в уравнение (4.4), в результате чего получаем:
. Затем определение E можно подставить в уравнение (4.4), в результате чего получаем:
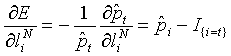
 .
.
Отсюда следует, что для ,
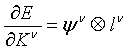
 ,
,
где  обозначает внешнее произведение. Мы также можем заключить, что для ,
обозначает внешнее произведение. Мы также можем заключить, что для ,
 ,
,
где  представляет транспонированную матрицу
представляет транспонированную матрицу  .
.
Предыдущие уравнения можно реализовать для изменения параметров нейронной сети путем обновления параметров следующим образом:


для , где  представляет скорость обучения. В одной реализации эта скорость обучения задана равной
представляет скорость обучения. В одной реализации эта скорость обучения задана равной  .
.
4.4 Сверточные нейронные сети - прямой проход
В отличие от полносвязной нейронной сети в сверточной сети каждый элемент  слоя является не скаляром, а квадратной заплаткой чисел размером
слоя является не скаляром, а квадратной заплаткой чисел размером 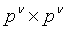 . Соответственно,
. Соответственно, 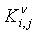 будет использоваться в качестве обозначения ядра свертки размером
будет использоваться в качестве обозначения ядра свертки размером  , и
, и  - для обозначения заплатки смещения размером
- для обозначения заплатки смещения размером  . Отдельные элементы слоев, смещений и ядер будем обозначать как
. Отдельные элементы слоев, смещений и ядер будем обозначать как 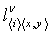 ,
,  и
и  , соответственно.
, соответственно.
Формула для вычисления  аналогична известной формуле для случая полной связности:
аналогична известной формуле для случая полной связности:
 .
.
Однако здесь мы используем символ * для обозначения несколько необычной операции. Интуитивно, она аналогична умножению матрицы на вектор, но самая внутренняя операция представляет собой не умножение скаляров, а свертку и подвыборку (субдискретизацию) заплаток. Точнее говоря, если  - это вектор длиной
- это вектор длиной  для заплаток
для заплаток  и
и  - это матрица размером
- это матрица размером  для ядер
для ядер  , то
, то  означает, что w - это вектор длиной
означает, что w - это вектор длиной  для заплаток
для заплаток 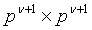 , и
, и

 .
.
Можно показать, что вышеприведенные формулы являются обобщением уравнений для случая полной связности в том смысле, что, если 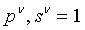 , то уравнения (4.12), (4.13) и (4.14) сводятся к уравнениям для полносвязной сети.
, то уравнения (4.12), (4.13) и (4.14) сводятся к уравнениям для полносвязной сети.
4.5 Сверточные нейронные сети - функция ошибок
Вышеприведенные уравнения для функции ошибок в полносвязной сети применимы и к сверточной сети.
4.6 Сверточные нейронные сети - обратный проход
Как указано выше, при осуществлении обратного прохода отыскивается градиент E с использованием частных производных E по каждой переменной в сети. Начнем с
 ,
,
где  обозначает поэлементное умножение, и
обозначает поэлементное умножение, и  - поэлементное применение tanh, используемое как вышеописанная “функция сплющивания”. Из уравнения (4.15) производные можно выразить в виде:
- поэлементное применение tanh, используемое как вышеописанная “функция сплющивания”. Из уравнения (4.15) производные можно выразить в виде:


 ,
,
где представляет транспонированную матрицу .
Заметим, что операторы  и
и  в данном случае применяются нестандартно. Оператор аналогичен внешнему произведению, но самое внутреннее умножение заменено сверткой и подвыборкой. Если
в данном случае применяются нестандартно. Оператор аналогичен внешнему произведению, но самое внутреннее умножение заменено сверткой и подвыборкой. Если  - это вектор длиной
- это вектор длиной  для заплаток
для заплаток  и
и  - это вектор длиной
- это вектор длиной  для заплаток
для заплаток  , то
, то  означает, что M является матрицей размером
означает, что M является матрицей размером 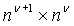 для заплаток
для заплаток 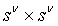 , и что:
, и что:

и
 .
.
Оператор чем-то схож с оператором, обратным оператору ∗, поскольку он раскрывает, а не скрывает аргументы свертки. Если M - это матрица размером  для ядер
для ядер 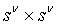 и
и  - это вектор длиной
- это вектор длиной 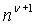 для заплаток
для заплаток 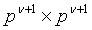 , то
, то 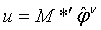 означает, что u является вектором для заплаток
означает, что u является вектором для заплаток  , и
, и

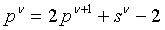 ,
,
где “ ” эквивалентно выполнению всех четырех нижеследующих условий:
” эквивалентно выполнению всех четырех нижеследующих условий:


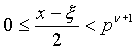
и
 .
.
Как указано выше, когда 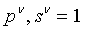 , эти формулы обратного прохода сводятся к формулам для полносвязной сети.
, эти формулы обратного прохода сводятся к формулам для полносвязной сети.
4.7 Моделирование других слоев
На практике сверточная нейронная сеть имеет как сверточные, так и полносвязные слои, т.е. в ней есть слои, где  , и есть слои, где
, и есть слои, где  . Хотя каждый слой можно математически смоделировать как сверточный слой (поскольку это обобщение случая полной связности), с точки зрения вычислений эффективнее выявлять полносвязные слои как особый случай и использовать более простые формулы.
. Хотя каждый слой можно математически смоделировать как сверточный слой (поскольку это обобщение случая полной связности), с точки зрения вычислений эффективнее выявлять полносвязные слои как особый случай и использовать более простые формулы.
Дополнительно, существует другой особый случай, который можно назвать “переходным” слоем. Это случай, когда  , но
, но  . В этом случае прямой проход упрощается до:
. В этом случае прямой проход упрощается до:
 .
.
Аналогично, обратный проход упрощается до:

и
 .
.
4.8 Многопроходное суммирование
Природа параллельных данных блоков пиксель-шейдера затрудняет осуществление суммирования. Поскольку результат в каждом пикселе не может зависеть от результата в других пикселях, для восстановления эффективности предлагается производить суммирование за несколько проходов, где в каждом проходе суммируется некоторое фиксированное количество заплаток, соседствующих по горизонтали. Если A - это матрица размером 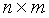 для заплаток
для заплаток  , то функцию
, то функцию  можно задать в виде:
можно задать в виде:
 .
.
Пример этого многопроходного суммирования показан на фиг.7. Согласно фиг.7 матрицу 710 нужно суммировать по каждой строке. Одна строка показана в качестве иллюстративной строки. В примере, показанном на фиг.7, матрица суммируется группами по четыре элемента, так что первые четыре элемента суммируются в первый элемент той же строки переходной суммарной матрицы 720. Аналогично, вторая четверка элементов суммируется во второй элемент строки, и т.д. Затем, во втором проходе, четыре элемента матрицы промежуточной суммы суммируются для получения окончательной суммы для строки.
4.9 Реализация условных операторов
Ввиду того, что архитектура ГП отличается одним потоком команд и многими потоками данных (SIMD), условные операторы могут требовать значительных вычислительных ресурсов. Во многих схемах кодирования программы пиксель-шейдера существует несколько разных способов кодирования этих условных операторов. Однако тестирование показало медленное выполнение оператора if, оператора cmp и предиката (p0).
Чтобы этого не происходило, в случае, когда условный оператор проверяет выполнение краевых условий, было обнаружено, что эффективное решение состоит в полном игнорировании условного оператора и настройки входного каскада ГП на “border color sampling” (выборка цвета по границе). Это позволяет всем обращениям за пределами заданной области текстуры возвращать 0. Для неграничных условных операторов установлено, что эффективнее всего кодировать условие в число с плавающей точкой, которое больше 0, если и только если условие выполняется. Это число можно нормализовать таким образом, чтобы оно принимало точные значения 0 или 1, с использованием оператора mul_sat с достаточно большим коэффициентом. Таким образом, будет восстановлен , используемый в формулах.
4.10 Другие детали реализации
Каждый проход на ГП сопряжен с фиксированными накладными расходами, помимо времени, необходимого для осуществления вычислений. Кроме того, компилятор, содержащийся в драйвере ГП, обычно не имеет возможности оптимизации выполнения программ пиксель-шейдера. Оба эти фактора обуславливают важность объединения как можно большего объема вычислений в каждой программе пиксель-шейдера для обеспечения высокой производительности.
Существующие реализации сверточных нейронных сетей, предназначенные для ЦП, рассматривают каждый принципиальный компонент вычисления как разложимую функцию, например свертку, подвыборку и их производные. Предыдущий аналитический вывод формул “от начала до конца” обеспечивает оптимизацию, специфическую для ГП, которая снижает эти накладные расходы.
Дополнительно, поскольку выделение и отмена выделения на ГП является дорогостоящей операцией, для минимизации затрат в предпочтительной реализации все программы пиксель-шейдера задаются и все текстуры выделяются в начале процесса и повторно используются по его завершении. Передача данных между ЦП и ГП обычно считается дорогостоящей, но поскольку объем данных сравнительно мал, ее можно производить без оптимизации, не жертвуя большим количеством времени. Например, в одной реализации для каждого обучающего образца необходимо передавать только пиксельную заплатку, соответствующую входным данным (обычно 29×29 пикселей), и правильную классификацию.
5. Вычислительная среда
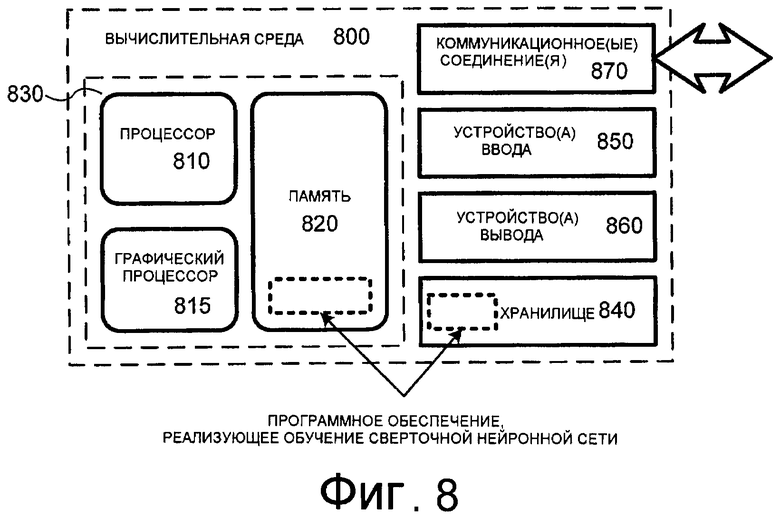
Вышеописанные методы обучения нейронной сети можно осуществлять на самых разнообразных устройствах, в которых осуществляется обработка цифрового медиа-сигнала, включая, помимо прочего, компьютеры; оборудование для записи, передачи и приема изображений и видео; портативные видеопроигрыватели; оборудование для видеоконференций; и т.д. Методы можно реализовать в электронном оборудовании, а также в программном обеспечении обработки цифрового медиа-сигнала, выполняющемся на компьютере или в другой вычислительной среде, например, показанной на фиг.8.
На фиг.8 показан обобщенный пример подходящей вычислительной среды (800), в которой можно реализовать описанные варианты осуществления. Вычислительная среда (800) не призвана налагать каких-либо ограничений на сферу применимости или функциональные возможности изобретения, так как настоящее изобретение можно реализовать в различных вычислительных средах общего или специального назначения.
Согласно фиг.8 вычислительная среда (800) включает в себя, по меньшей мере, один процессор (810), ГП (815) и память (820). На фиг.8 эта наиболее базовая конфигурация (830) ограничена пунктирной линией. Процессор (810) выполняет компьютерно-выполняемые команды и может представлять собой реальный или виртуальный процессор. В многопроцессорной системе несколько процессоров выполняют компьютерно-выполняемые команды для повышения вычислительной мощности. Память (820) может представлять собой энергозависимую память (например, регистры, кэш, ОЗУ), энергонезависимую память (например, ПЗУ, ЭСППЗУ, флэш-память и т.д.), или какую-либо их комбинацию. В памяти (820) хранится программное обеспечение (880), реализующее вышеописанный кодер/декодер и эффективные методы преобразования коэффициентов кодирования/декодирования. ГП (815) может быть объединен с процессором 810 на единой плате или может располагаться отдельно. В одной реализации ГП (815) имеет архитектуру, показанную на фиг.3.
Вычислительная среда может иметь дополнительные особенности. Например, вычислительная среда (800) включает в себя хранилище (840), одно или несколько устройств ввода (850), одно или несколько устройств вывода (860) и одно или несколько коммуникационных соединений (870). Механизм внутреннего соединения (не показан), например, шина, контроллер, или сеть, соединяет между собой компоненты вычислительной среды (800). Обычно, программное обеспечение операционной системы (не показано) обеспечивает операционную среду для другого программного обеспечения, выполняющегося в вычислительной среде (800), и координирует действия компонентов вычислительной среды (800).
Хранилище (840) может быть сменным или стационарным и включает в себя магнитные диски, магнитные ленты или кассеты, CD-ROM, CD-RW, DVD или любой другой носитель, который можно использовать для хранения информации, и к которому можно осуществлять доступ в вычислительной среде (800). В хранилище (840) хранятся команды программного обеспечения (880), реализующие описанные методы обучения нейронной сети.
Устройство(а) ввода (850) может/могут представлять собой устройства ручного ввода, например клавиатуру, мышь, перо или шаровой манипулятор, устройство речевого ввода, сканирующее устройство, или другое устройство, которое обеспечивает ввод в вычислительную среду (800). Для аудиосигнала устройство(а) ввода (850) может/могут представлять собой звуковую карту или аналогичное устройство, которое принимает аудиоввод в аналоговой или цифровой форме, или устройство чтения CD-ROM, которое выдает дискретизированный аудиосигнал в вычислительную среду. Устройство(а) вывода (860) может/могут представлять собой дисплей, принтер, громкоговоритель, устройство записи CD или другое устройство, которое обеспечивает вывод из вычислительной среды (800).
Коммуникационное(ые) соединение(я) (870) обеспечивают связь по среде связи с другой вычислительной сущностью. Среда связи переносит информацию, например, компьютерно-выполняемые команды, сжатую аудио- или видеоинформацию или другие данные в сигнале, модулированном данными. Сигнал, модулированный данными, - это сигнал, одна или несколько характеристик которого изменяется таким образом, чтобы кодировать информацию в сигнале. В порядке примера, но не ограничения, среды связи включают в себя проводные или беспроводные методы, реализуемые посредством электрического, оптического, РЧ, инфракрасного, акустического или иного носителя.
Способы обработки цифрового медиа-сигнала можно описывать в общем контексте компьютерно-считываемых носителей. Компьютерно-считываемые носители представляют собой любые доступные носители, к которым можно осуществлять доступ в вычислительной среде. В порядке примера, но не ограничения, в вычислительной среде (800) компьютерно-считываемые носители включают в себя память (820), хранилище (840), среды связи и комбинации вышеперечисленных примеров.
Методы обучения нейронной сети можно описывать в общем контексте компьютерно-выполняемых команд, например, входящих в состав программных модулей, выполняемых в вычислительной среде на реальном или виртуальном процессоре. В общем случае, программные модули включают в себя процедуры, программы, библиотеки, объекты, классы, компоненты, структуры данных и т.д., которые выполняют определенные задачи или реализуют определенные абстрактные типы данных. Функциональные возможности программных модулей могут объединяться или разделяться между программными модулями, что описано в различных вариантах осуществления. Компьютерно-выполняемые команды для программных модулей могут выполняться в локальной или распределенной вычислительной среде.
В целях представления в подробном описании используются такие термины, как “определяет”, “генерирует”, “регулирует” и “применяет” для описания компьютерных операций в вычислительной среде. Эти термины являются абстракциями высокого уровня для операций, осуществляемых компьютером, и их не следует путать с действиями, производимыми человеком. Фактические компьютерные операции, соответствующие этим терминам, варьируются в зависимости от реализации.
Ввиду большого количества возможных вариаций описанного здесь изобретения в качестве нашего изобретения заявлены все подобные варианты осуществления в той мере, в какой они отвечают объему нижеследующей формулы изобретения и ее эквивалентов.
| название | год | авторы | номер документа |
|---|---|---|---|
| РАСПОЗНАВАНИЕ ЛИЦ С ПОМОЩЬЮ ИСКУССТВЕННОЙ НЕЙРОННОЙ СЕТИ | 2017 |
|
RU2718222C1 |
| РАСПОЗНАВАНИЕ ТЕКСТА С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА | 2017 |
|
RU2691214C1 |
| РАСПОЗНАВАНИЕ РУКОПИСНОГО ТЕКСТА ПОСРЕДСТВОМ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2757713C1 |
| СИСТЕМА МОНИТОРИНГА РЕЖИМОВ ГОРЕНИЯ ТОПЛИВА ПУТЕМ АНАЛИЗА ИЗОБРАЖЕНИЙ ФАКЕЛА ПРИ ПОМОЩИ КЛАССИФИКАТОРА НА ОСНОВЕ СВЁРТОЧНОЙ НЕЙРОННОЙ СЕТИ | 2018 |
|
RU2713850C1 |
| СИСТЕМА РАСПОЗНАВАНИЯ ИЗОБРАЖЕНИЯ: BEORG SMART VISION | 2020 |
|
RU2777354C2 |
| ОБРАБОТКА И АНАЛИЗ ДАННЫХ НА ИЗОБРАЖЕНИЯХ КОМПЬЮТЕРНОЙ ТОМОГРАФИИ | 2017 |
|
RU2667879C1 |
| МЕТОДИКА ПРИМЕНЕНИЯ СРЕДСТВ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА ДЛЯ ИНТЕРПРЕТАЦИИ РЕЗУЛЬТАТОВ, ПОЛУЧЕННЫХ МЕТОДОМ ВЫСОКОРАЗРЕШАЮЩЕЙ КОМПЬЮТЕРНОЙ ТОМОГРАФИИ (ВРКТ), ДЛЯ ДИАГНОСТИКИ ИНТЕРСТИЦИАЛЬНЫХ ЗАБОЛЕВАНИЙ ЛЕГКИХ ЧЕЛОВЕКА (ИЗЛ) | 2023 |
|
RU2827804C1 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ КОМБИНАЦИИ МОДЕЛЕЙ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2768211C1 |
| СПОСОБ ИНТЕРПРЕТАЦИИ ИСКУССТВЕННЫХ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2689818C1 |
| АВТОМАТИЧЕСКОЕ ОПРЕДЕЛЕНИЕ НАБОРА КАТЕГОРИЙ ДЛЯ КЛАССИФИКАЦИИ ДОКУМЕНТА | 2018 |
|
RU2701995C2 |






Изобретения относятся к способу и графическому процессору (ГП) для обучения сверточных нейронных сетей. Техническим результатом является снижение вычислительной сложности. Способ содержит этапы: принимают графические данные, представляющие состояние сверточной нейронной сети и содержащие одну или более текстур, представляющих одну или более переменных нейронной сети, причем упомянутые текстуры содержат текстуру с двумерной адресацией, по меньшей мере одна из упомянутых текстур представляет переменную нейронной сети с адресацией, имеющей размерность более двух, которая была уплощена в двумерную адресацию, при этом сверточная нейронная сеть содержит по меньшей мере один слой, содержащий множество заплаток; выполняют на ГП одну или более программ для осуществления прямого прохода в сверточной нейронной сети, одну или более программ для осуществления обратного прохода в сверточной нейронной сети, причем выполнение включает в себя выполнение сверточных операций в отношении заплаток; одну или более программ для изменения заплаток в сверточной нейронной сети посредством изменения графических данных на основании результатов обратного прохода; повторно выполняют одну или более программ для осуществления прямых проходов, обратных проходов и для изменения графических данных, пока не обучат сверточную нейронную сеть. 3 н. и 14 з.п. ф-лы, 9 ил.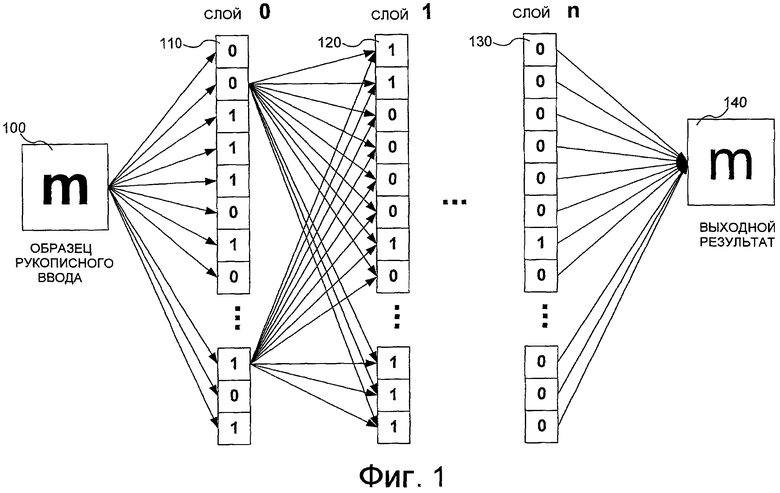
1. Реализуемый компьютером способ обучения сверточной нейронной сети идентифицировать изображения с использованием графических данных, которые могут быть считаны графическим процессором (ГП), и одной или более программ, выполняемых посредством ГП, причем способ содержит этапы:
принимают графические данные, представляющие состояние сверточной нейронной сети и содержащие одну или более текстур, представляющих одну или более переменных нейронной сети, причем упомянутые одна или более текстур содержат текстуру с двумерной адресацией, причем по меньшей мере одна из упомянутых текстур представляет переменную нейронной сети с адресацией, имеющей размерность более двух, которая была уплощена в двумерную адресацию, при этом сверточная нейронная сеть содержит по меньшей мере один слой, содержащий множество заплаток,
выполняют на ГП одну или более программ, выполняемых посредством ГП, для осуществления прямого прохода в сверточной нейронной сети, причем выполнение включает в себя выполнение сверточных операций в отношении заплаток;
выполняют на ГП одну или более программ, выполняемых посредством ГП, для осуществления обратного прохода в сверточной нейронной сети, причем выполнение включает в себя выполнение сверточных операций в отношении заплаток;
выполняют на ГП одну или более программ, выполняемых посредством ГП, для изменения заплаток в сверточной нейронной сети посредством изменения графических данных на основании результатов обратного прохода, и
повторно выполняют одну или более программ, выполняемых посредством ГП, для осуществления прямых проходов, обратных проходов и для изменения графических данных, пока не обучат сверточную нейронную сеть.
2. Способ по п.1, в котором адреса значений, представленных в упомянутой текстуре с двумерной адресацией, определяют через линейные комбинации координат х и у смещения от верхнего левого угла выходной текстуры.
3. Способ по п.1, в котором программы, выполняемые посредством ГП, написаны в виде одной или более программ пиксель-шейдера.
4. Способ по п.1, в котором графические данные настраивают с использованием градиентного спуска.
5. Способ по п.4, в котором
упомянутые одна или более программ используют формулы для вычисления частных производных для определения градиента, и формулы алгебраически объединяют и упрощают для сокращения количества обращений к программам пиксель-шейдера.
6. Способ по п.1, в котором
нейронная сеть содержит один или более полносвязных слоев, и упомянутая одна или более программ, выполняемых посредством ГП, содержат одну или более программ, выполняемых посредством ГП, специфических для одного или более полносвязных слоев, которые используют отдельные формулы для полносвязных слоев.
7. Способ по п.1, в котором
нейронная сеть содержит один или более переходных слоев, и
упомянутые одна или более программ, выполняемых посредством ГП, содержат одну или более программ, выполняемых посредством ГП, специфических для одного или более переходных слоев, которые используют отдельные формулы для переходных слоев.
8. Способ по п.1, в котором графические данные описывают единичный треугольник, покрывающий демонстрационное окно.
9. Способ по п.1, в котором
одна или более программ, выполняемых посредством ГП, содержит одну или более операций суммирования, и
каждую из одной или более операций суммирования разбивают на множество проходов.
10. Способ по п.1, в котором сверточная нейронная сеть осуществляет распознавание рукописного ввода.
11. Считываемый компьютером носитель, содержащий команды, которые при выполнении на графической карте предписывают графической карте осуществлять способ обучения сверточной нейронной сети идентифицировать изображения, причем способ содержит этапы, на которых
принимают множество текстур, при этом это множество текстур по меньшей мере частично представляют сверточные ядра для нейронной сети, причем по меньшей мере некоторые из текстур имеют двумерную адресацию, и представляет сверточные ядра с адресацией, имеющей более двух измерений, которая была уплощена в двумерную адресацию,
вычисляют множество прямых проходов нейронной сети в отношении множества входных данных, включая свертку и субдискретизацию упомянутых сверточных ядер;
для каждого из множества прямых проходов вычисляют обратный проход нейронной сети с использованием функции градиента, и
для каждого обратного прохода на основании результатов функции градиента изменяют информацию, содержащуюся в сверточных ядрах из множества текстур, для оказания влияния на обучение нейронной сети.
12. Считываемый компьютером носитель по п.11, в котором
нейронная сеть обучается распознавать рукописные символы,
множество текстур, по меньшей мере частично, представляет сверточные ядра, и
сверточные ядра оперируют на входных данных, представляющих рукописные символы.
13. Считываемый компьютером носитель по п.11, в котором множество текстур по меньшей мере частично представляет полносвязный уровень и переходный уровень нейронной сети.
14. Графический процессор, выполненный с возможностью выполнять способ обучения сверточной нейронной сети, распознающей рукописный ввод, причем сверточная нейронная сеть содержит один или более слоев, при этом по меньшей мере некоторые из слоев содержат множество квадратных заплаток сверточных ядер, и при этом графический процессор содержит
хранилище данных, способное хранить одну или более графических текстур, причем графические текстуры описывают упомянутые квадратные заплатки сверточных ядер нейронной сети, распознающей рукописный ввод, причем по меньшей мере некоторые из графических текстур имеют двумерную адресацию и представляет квадратные заплатки сверточных ядер, имеющие адресацию с более чем двуми измерениями, которая была уплощена в двумерную адресацию,
множество блоков пиксель-шейдера, настраиваемых посредством программирования пиксель-шейдера, чтобы:
осуществлять повторяющиеся прямые проходы и обратные проходы нейронной сети в отношении данных рукописного ввода, причем проходы включают в себя выполнение сверточных операций в отношении квадратных заплаток сверточных ядер;
сохранять результаты во множестве графических текстур и
изменять квадратные заплатки сверточных ядер упомянутого множества текстур на основании результатов прямых и обратных проходов для обучения нейронной сети.
15. Графический процессор по п.14, в котором нейронная сеть, распознающая рукописный ввод, по меньшей мере частично содержит один сверточный уровень и один полносвязный уровень.
16. Графический процессор по п.14, в котором одна или более графических текстур способны описывать упрощенное изображение треугольника, так что для всей обработки, осуществляемой графическим процессором, требуется вычисление только в отношении части блоков пиксель-шейдера.
17. Графический процессор по п.14, в котором блоки пиксель-шейдера настроены так, что операции суммирования в прямых проходах и обратных проходах нейронной сети разбиваются на множество более мелких операций суммирования.
| US 2005125369 A1, 09.06.2005 | |||
| US 2003174881 A1, 18.09.2003 | |||
| Дорожная спиртовая кухня | 1918 |
|
SU98A1 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА С ПРИМЕНЕНИЕМ НАСТРАИВАЕМОГО КЛАССИФИКАТОРА | 2002 |
|
RU2234126C2 |

