Область техники, к которой относится изобретение
Настоящее изобретение относится к области техники декодирования информационной последовательности из данных, которые были закодированы посредством добавления избыточной последовательности к информационной последовательности и исправления ошибок, используя избыточную последовательность.
Предшествующий уровень техники
Системы обмена данными для спутниковой связи и мобильной связи имеют требования к конфигурациям системы, такие как уменьшенная электрическая мощность и более маленькие антенны. Для того чтобы удовлетворить такие требования, технологии кодирования с исправлением ошибок были введены для достижения большой эффективности кодирования.
Код с малой плотностью проверок на четность известен как код с исправлением ошибок, имеющий очень большую эффективность кодирования, и вводится в различные системы обмена данными и устройства хранения для записи данных. Код с малой плотностью проверок на четность не означает конкретный процесс кодирования с исправлением ошибок, а является общим термином для кодов с исправлением ошибок, имеющих разреженную проверочную матрицу. Разреженная проверочная матрица является проверочной матрицей, в основном состоящей из нулей и имеющей несколько единиц. Код с малой плотностью проверок на четность характеризуется проверочной матрицей.
Выбирая разреженную проверочную матрицу и используя соответствующий процесс декодирования, возможно реализовать процесс кодирования с исправлением ошибок, который близок к теоретическим ограничениям и который имеет очень большую эффективность кодирования (см. Документы 1, 2). Для такого процесса можно использовать алгоритм суммы произведений или алгоритм минимальной суммы.
Документ 4 раскрывает пример процесса декодирования кода с малой плотностью проверок на четность. Устройство декодирования делит принятые данные на блоки, имеющие некоторую длину, в нем находятся принятые данные в которых следует исправить ошибки и данные, называемые сообщением, полученным в процессе декодирования для каждого из блоков, и исправляет ошибки принятых данных во время обновления сообщений, используя проверочную матрицу. Полагается, что один блок содержит N принятых данных (N представляет собой целое число больше 1). Также полагается, что проверочная матрица содержит элементы, каждый представлен матрицей из N строк и R столбцов (R представляет собой положительное целое число, равное N или меньше) из нулей или единиц.
Если каждый элемент из принятых данных выражается b битами (b представляет собой положительное целое число), то требуется область хранения b × N битов, для запоминания блока из N принятых данных. Поскольку запоминается столько же сообщений как количество ненулевых элементов проверочной матрицы, то требуется область хранения из b × (количество ненулевых элементов) для запоминания в ней сообщений. Ненулевые элементы относятся к элементам, имеющим значение 1, но не 0.
Процесс декодирования может выполняться на высокой скорости посредством того, что данные запоминают в RAM (запоминающее устройство с произвольным доступом) и выполнения параллельной обработки над данными во время одновременного осуществления доступа к множеству данных. Для выполнения параллельной обработки над увеличенными данными, к которым можно одновременно осуществить доступ, необходимо разделить и записать данные в множество RAM. Следовательно, устройству декодирования нужен увеличенный масштаб схемы, и процесс создания адресов усложняется.
Проблема, касающаяся количества RAM, может быть решена посредством способа на основе конфигураций устройства (см. Документ 5). Однако такой способ сильно уменьшает коэффициент ошибок процесса декодирования. Хотя существует подход к упрощению компоновки схемы посредством использования регистров сдвига, а не RAM (см. Документ 1), такой подход приводит к увеличенному масштабу схемы, если длина N блока превышает несколько десятков тысяч или если количество избыточных битов больше, а кодовое число значительно меньше.
<Список Документов>
Документ 1: JP 2007-089064 A.
Документ 2: Robert Gallager, “Low-Density Parity-Check Codes”, IEEE Transactions on Information Theory, January 1962, страницы с 21 по 28.
Документ 3: D. J. C. MacKay, “Good Error-Correcting Codes Based on very sparse matrices”, IEEE Transactions on Information Theory, March 1999, страницы с 399 по 431.
Документ 4: Eran Sharon, Simon Litsyn, Jacob Goldberger, “An Efficient Message-Passing Schedule for LDPC Decoding”, Proceedings 2004 IEEE Convention of Electrical and Electronics Engineers in Israel, September 2004, страницы с 223 по 226.
Документ 5: E Yeo, P. Pakzad, B. Nikolic, V Anantharam, “High Throughput Low-Density Parity-Check Decoder Architecture”, 2001 IEEE Global Telecommunications Conference, November 2001, страницы с 3019 по 3024.
Раскрытие изобретения
Если код с малой плотностью проверок на четность декодируется посредством вышеописанного способа, то требуется большая область хранения для хранения данных, которые временно созданы в процессе декодирования. Например, согласно способу декодирования, раскрытому в Документе 4, например, область хранения, чей размер пропорционален количеству ненулевых элементов проверочной матрицы, требуется, чтобы запоминать временно созданные данные (сообщения).
В частности, поскольку спутниковая связь и мобильная связь налагают строгие условия на масштабы устройства и потребление энергии, то существует большой спрос на уменьшение емкости хранения и масштаба схемы. Если используется способ, который не использует данные, которые временно создаются в устройстве декодирования, то область хранения уменьшается, потому что не нужно запоминать никакие данные. Однако такой способ имеет тенденцию к уменьшению коэффициента ошибок процесса декодирования.
Как раскрывается выше, было трудно уменьшить область хранения вместе с поддержанием хорошего коэффициента ошибок в процессе исправления ошибок и декодирования данных.
Задачей настоящего изобретения является предоставление технологии для декодирования кода с малой плотностью проверок на четность, в то же время поддерживая хороший коэффициент ошибок с маленькой емкостью хранения.
Чтобы достичь вышеописанной цели, в соответствии с аспектом настоящего изобретения предоставляется устройство декодирования для исправления ошибок принятых данных, кодированных посредством кода с малой плотностью проверок на четность, содержащее:
первое средство хранения для хранения стольких же элементов данных как количество векторов-столбцов проверочной матрицы упомянутого кода с малой плотностью проверок на четность;
второе средство хранения для хранения того же самого количества данных как в упомянутом первом средстве хранения;
средство преобразования данных; и
средство обработки проверочного узла;
в котором упомянутое средство преобразования данных создает первые промежуточные данные, находящиеся во взаимно-однозначном соответствии с упомянутыми векторами-столбцами, из данных, хранящихся в упомянутом первом средстве хранения, и данных, хранящихся в упомянутом втором средстве хранения;
упомянутое средство обработки проверочного узла создает вторые промежуточные данные для обновления данных, хранящихся в упомянутом первом средстве хранения, основываясь на сумме упомянутых первых промежуточных данных и упомянутых принятых данных;
упомянутое средство преобразования данных обновляет данные, хранящиеся в упомянутом втором средстве хранения, используя упомянутые первые промежуточные данные, и обновляет данные, хранящиеся в упомянутом первом средстве хранения, используя упомянутые вторые промежуточные данные, созданные посредством упомянутого средства обработки проверочного узла; и
декодированные данные создаются посредством процесса, выполняемого посредством упомянутого средства преобразования данных и упомянутого средства обработки проверочного узла.
В соответствии с аспектом настоящего изобретения предоставляется устройство хранения данных, содержащее:
устройство кодирования для кодирования данных, которые следует сохранить в устройстве хранения, согласно коду с малой плотностью проверок на четность; и
устройство декодирования, содержащее первое средство хранения для хранения стольких же элементов данных как количество векторов-столбцов проверочной матрицы упомянутого кода с малой плотностью проверок на четность, второе средство хранения для хранения того же самого количества данных как в упомянутом первом средстве хранения, средство преобразования данных и средство обработки проверочного узла, в котором, упомянутое средство преобразования данных создает первые промежуточные данные, находящиеся во взаимно-однозначном соответствии с упомянутыми векторами-столбцами, из данных, хранящихся в упомянутом первом средстве хранения, и данных, хранящихся в упомянутом втором средстве хранения, упомянутое средство обработки проверочного узла создает вторые промежуточные данные для обновления данных, хранящихся в упомянутом первом средстве хранения, основываясь на сумме упомянутых первых промежуточных данных и упомянутых принятых данных, упомянутое средство преобразования данных обновляет данные, хранящиеся в упомянутом втором средстве хранения, используя упомянутые первые промежуточные данные, и обновляет данные, хранящиеся в упомянутом первом средстве хранения, используя упомянутые вторые промежуточные данные, созданные посредством упомянутого средства обработки проверочного узла; и декодированные данные создаются посредством процесса, выполняемого посредством упомянутого средства преобразования данных и упомянутого средства обработки проверочного узла.
В соответствии с аспектом настоящего изобретения предоставляется система обмена данными, содержащая:
устройство передачи для передачи данных, кодированных посредством кода с малой плотностью проверок на четность;
устройство приема, содержащее первое средство хранения для хранения стольких же элементов данных как количество векторов-столбцов проверочной матрицы упомянутого кода с малой плотностью проверок на четность, второе средство хранения для хранения того же самого количества данных как в упомянутом первом средстве хранения, средство преобразования данных и средство обработки проверочного узла, в котором, упомянутое средство преобразования данных создает первые промежуточные данные, запомненные во взаимно-однозначном соответствии с упомянутыми векторами-столбцами, из данных, хранящихся в упомянутом первом средстве хранения, и данных, хранящихся в упомянутом втором средстве хранения, упомянутое средство обработки проверочного узла создает вторые промежуточные данные для обновления данных, хранящихся в упомянутом первом средстве хранения, основываясь на сумме упомянутых первых промежуточных данных и упомянутых принятых данных, упомянутое средство преобразования данных обновляет данные, хранящиеся в упомянутом втором средстве хранения, используя упомянутые первые промежуточные данные, и обновляет данные, хранящиеся в упомянутом первом средстве хранения, используя упомянутые вторые промежуточные данные, созданные посредством упомянутого средства обработки проверочного узла; и декодированные данные создаются посредством процесса, выполняемого посредством упомянутого средства преобразования данных и упомянутого средства обработки проверочного узла.
В соответствии с аспектом настоящего изобретения предоставляется способ декодирования для исправления ошибок принятых данных, кодированных посредством кода с малой плотностью проверок на четность, содержащий этапы, на которых:
хранят столько же элементов данных как количество векторов-столбцов проверочной матрицы упомянутого кода с малой плотностью проверок на четность в первом средстве хранения;
хранят то же самое количество данных как в упомянутом первом средстве хранения во втором средстве хранения;
создают первые промежуточные данные, запомненные во взаимно-однозначном соответствии с упомянутыми векторами-столбцами, из данных, хранящихся в упомянутом первом средстве хранения, и данных, хранящихся в упомянутом втором средстве хранения;
создают вторые промежуточные данные для обновления данных, хранящихся в упомянутом первом средстве хранения, основываясь на сумме упомянутых первых промежуточных данных и упомянутых принятых данных;
обновляют данные, хранящиеся в упомянутом втором средстве хранения, используя упомянутые первые промежуточные данные, и обновляют данные, хранящиеся в упомянутом первом средстве хранения, используя упомянутые вторые промежуточные данные; и
создают декодированные данные согласно процессу, выполняемому посредством упомянутого средства преобразования данных и упомянутого средства обработки проверочного узла.
Краткое описание чертежей
На фиг.1А изображена блок-схема конфигурационного примера устройства декодирования согласно примерному варианту осуществления настоящего изобретения.
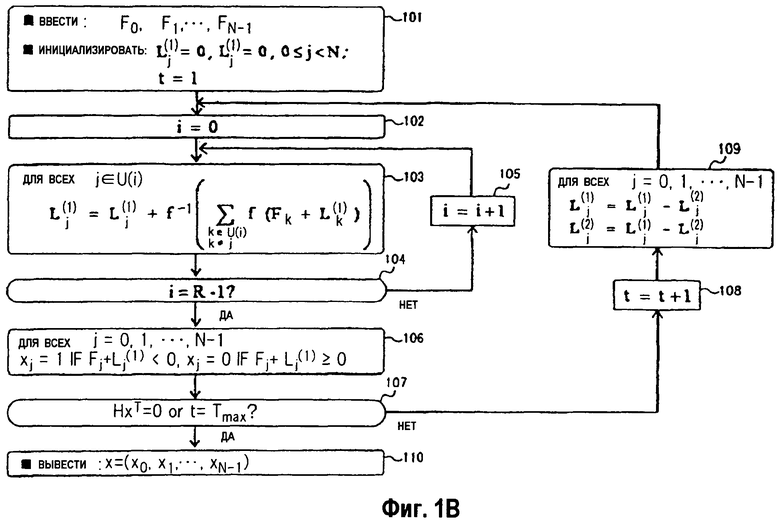
На фиг.1В изображена последовательность операций функционального примера устройства декодирования согласно примерному варианту осуществления.
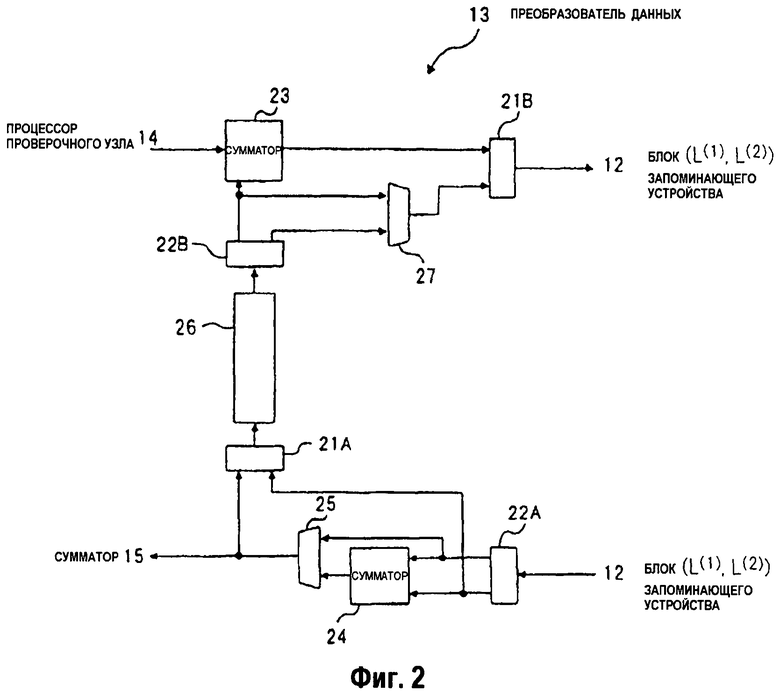
На фиг.2 изображена блок-схема конфигурационного примера преобразователя 13 данных, показанного на фиг.1А.
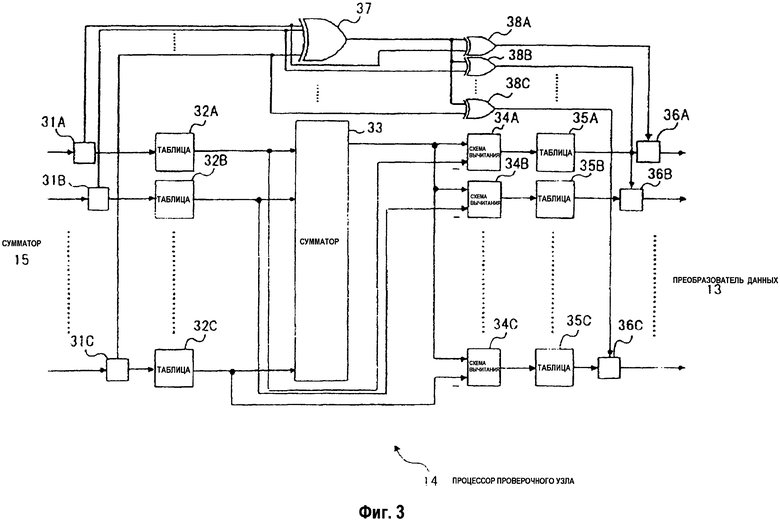
На фиг.3 изображена блок-схема конфигурационного примера процессора 14 проверочного узла, показанного на фиг.1А.
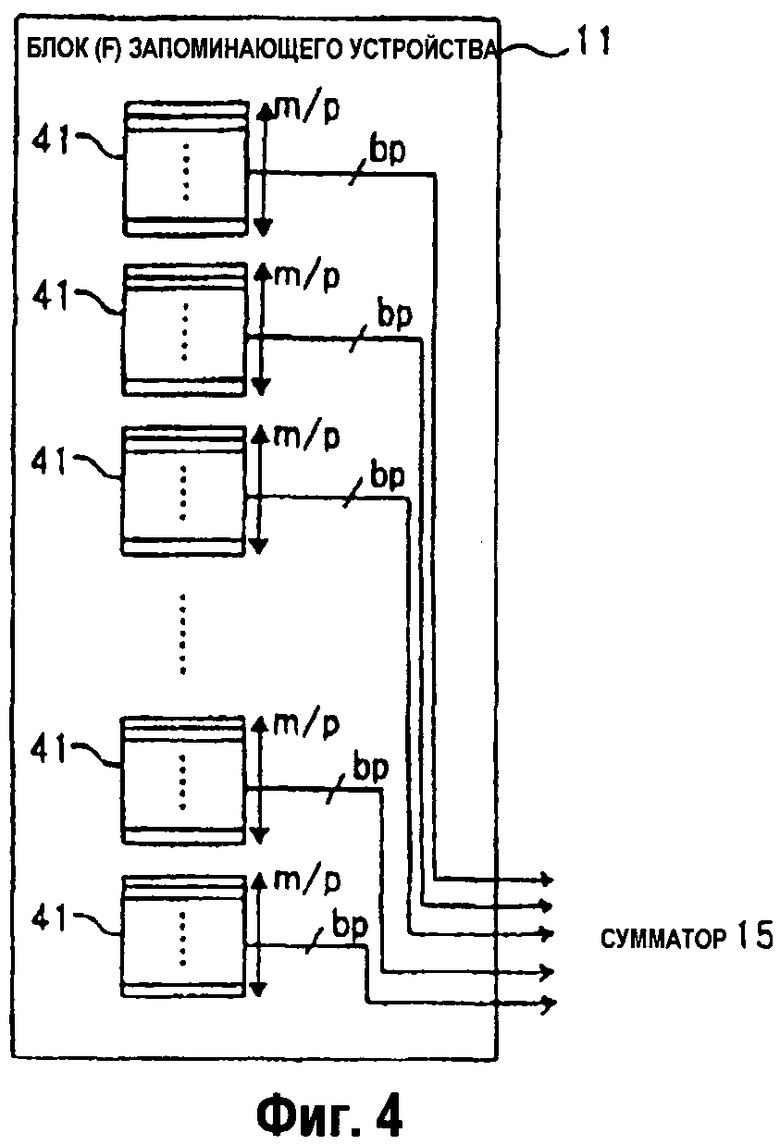
На фиг.4 изображена блок-схема конфигурационного примера блока (F) 11 запоминающего устройства, показанного на фиг.1А.
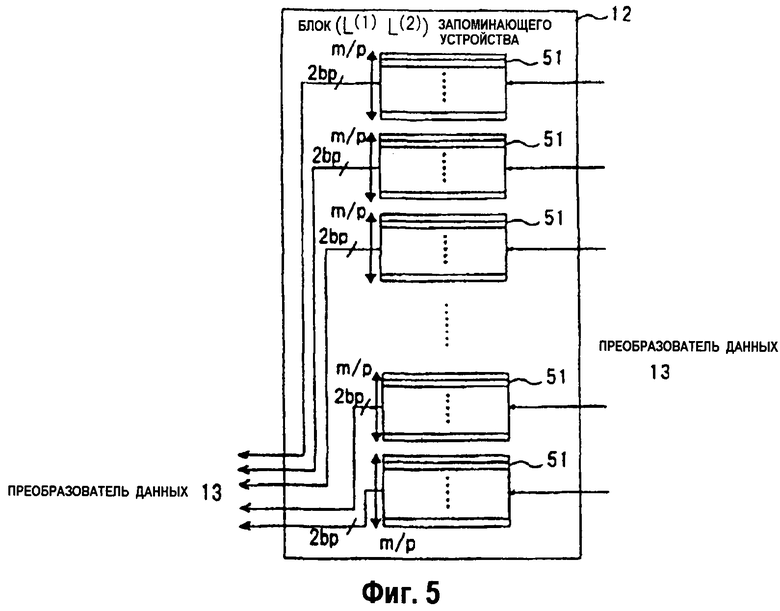
На фиг.5 изображена блок-схема конфигурационного примера блока (L(1), L(2)) 12 запоминающего устройства, показанного на фиг.1А.
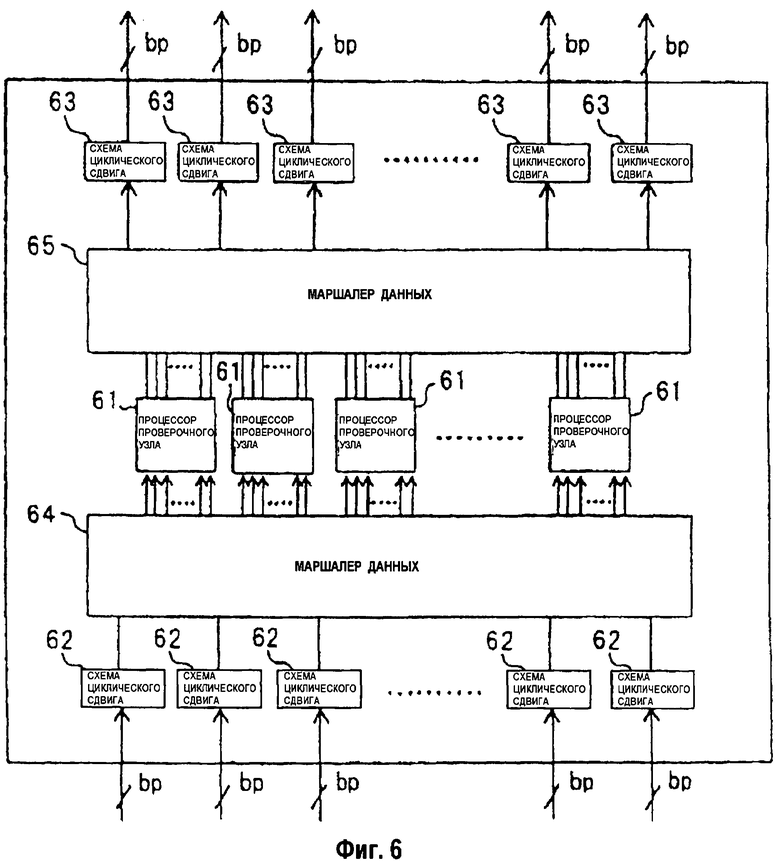
На фиг.6 изображена блок-схема конфигурационного примера процессора параллельных проверочных узлов.
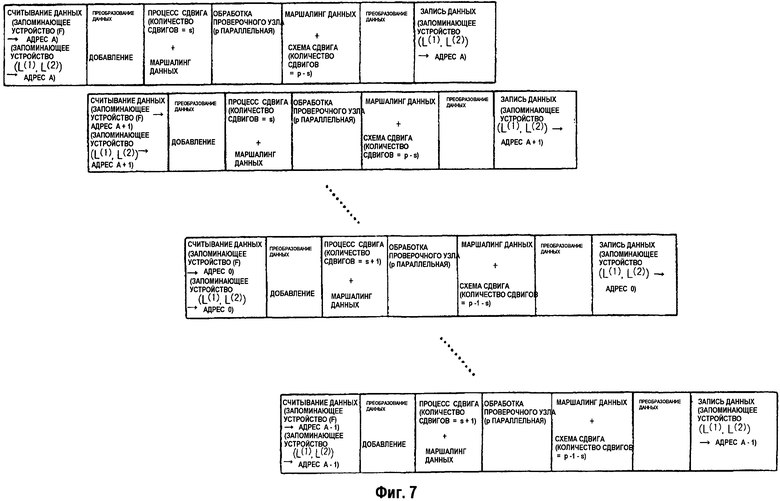
На фиг.7 изображена временная диаграмма, показывающая хронологическую последовательность операций устройства декодирования согласно примерному варианту осуществления.
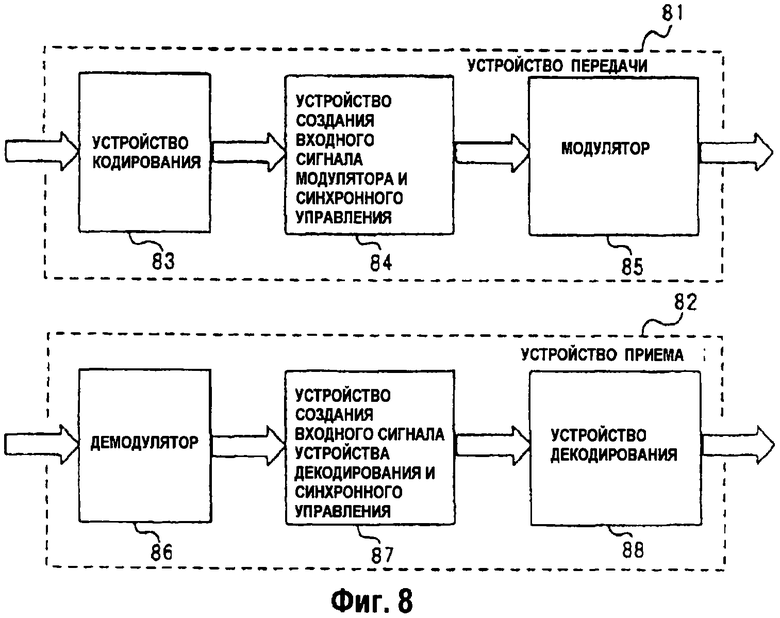
На фиг.8 изображена блок-схема конфигурации системы обмена данными, которая содержит в себе устройство декодирования согласно примерному варианту осуществления.
Лучший вариант для выполнения изобретения
Примерный вариант осуществления настоящего изобретения будет описан в подробностях ниже со ссылкой на чертежи.
На фиг.1А изображена блок-схема конфигурационного примера устройства декодирования согласно примерному варианту осуществления настоящего изобретения. На фиг.1В изображена последовательность операций функционального примера устройства декодирования согласно примерному варианту осуществления. Устройство декодирования согласно примерному варианту осуществления представляет собой устройство для приема данных из устройства кодирования (не показано), которое создает данные кода с малой плотностью проверок на четность, и для декодирования информационной последовательности из данных.
Как показано на фиг.1А, устройство 10 декодирования включает в себя блок (F) 11 запоминающего устройства, блок (L(1), L(2)) 12 запоминающего устройства, преобразователь 13 данных, процессор 14 проверочного узла и сумматор 15. На устройство 10 декодирования подается входной сигнал, содержащий последовательность принятых данных из канала связи (не показан). Последовательность принятых данных закодирована посредством кода с малой плотностью проверок на четность. Обычно принятые данные включают в себя ошибки из-за шума и тому подобного. Устройство 10 декодирования оценивает последовательность битов передачи из принятых данных и выводит оцененную последовательность битов передачи.
Код с малой плотностью проверок на четность характеризуется проверочной матрицей из R строк и N столбцов элементов, каждый имеющий значение 0 или 1, где N представляет собой целое число больше 1, а R - положительное целое число, равное N или меньше, как указано в уравнении (1) ниже:
[Уравнение 1]
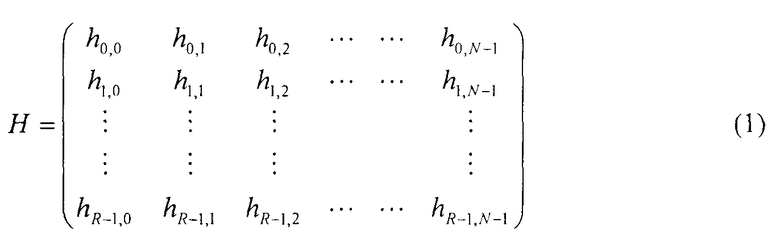
В частности, если проверочную матрицу согласно уравнению (1) можно модифицировать в уравнение (2) ниже посредством перемещения вектора-строки и вектора-столбца, то можно сказать, что код с малой плотностью проверок на четность является одним видом квазициклического кода с малой плотностью проверок на четность.
[Уравнение 2]
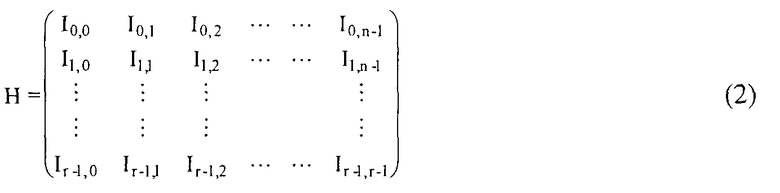
Уравнение (2) представляет собой блочную матрицу r × n (r = R/m, n = N/m), имеющую элементы матрицы m × m (m представляет собой кратный делитель N). Каждая из матриц m × m Is,t(0 ≤ s < r, 0 ≤ t < n) представляет собой матрицу с циклической перестановкой или матрицу, чьи элементы - все нули.
Полагается, что последовательность принятых данных из канала связи представлена посредством F0, F1, …, FN-1, и что каждый символ F1 последовательности принятых данных представлен b битами, где i представляет собой целое число, изменяющееся от 0 до N-1, и b - положительное целое число.
Блок (F) 11 запоминающего устройства является устройством для хранения последовательности F0, F1, …, FN-1 принятых данных, и требуется, чтобы он имел емкость хранения b × N.
Блок (L(1), L(2)) 12 запоминающего устройства является устройством для хранения данных L0 (1), L1 (1), …, LN-1 (1), L0 (2), L1 (2), …, LN-1 (2), которые должны быть временно запомнены в процессе декодирования, и требуется, чтобы он имел емкость хранения 2 × b × N битов. Данные L0 (1), L1 (1), …, LN-1 (1), L0 (2), L1 (2), …, LN-1 (2) будут описаны далее.
Каждый из R векторов-строк (hi,0, hi,1, …, hi,N-1) (i представляет собой целое число в диапазоне 0 ≤ i < R) проверочной матрицы согласно уравнению (1) имеет ненулевые элементы, чьи позиции можно указать согласно уравнению (3) ниже посредством частного множества U(i) множества N целых чисел, изменяющегося от 0 до N-1. Другими словами, U(i) представляет собой множество, указывающее позиции ненулевых элементов i-ого вектора-строки проверочной матрицы. В блоке (L(1), L(2)) 12 запоминающего устройства запомнены данные адресов, определенных посредством U(i). Конкретные операции преобразователя 13 данных, процессора 14 проверочного узла и сумматора 15 будут описаны далее.
[Уравнение 3]
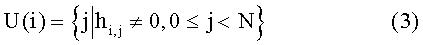
На фиг.2 изображена блок-схема конфигурационного примера преобразователя 13 данных, показанного на фиг.1А. Как показано на фиг.2, преобразователь 13 данных включает в себя соединители 21А, 21В битов, делители 22А, 22В битов, сумматор 23, схему 24 вычитания, схемы 25, 27 выбора и устройство 36 задержки.
На преобразователь 13 данных подаются входные сигналы, представленные посредством 2b-битных данных, считанных из блока (L(1), L(2)) 12 запоминающего устройства, показанного на фиг.1А, и выходные сигналы b-битных данных от процессора 14 проверочного узла. 2b-битные данные, считанные из блока (L(1), L(2)) 12 запоминающего устройства, преобразуются делителем 22А битов, схемой 24 вычитания и схемой 25 выбора в 2b-битные данные, которые выводятся на сумматор 15, показанные на фиг.1А.
b-битные данные доставляются через соединитель 21А, устройство 26 задержки и делитель 22В битов в сумматор 23, который суммирует b-битные данные и b-битные данные, выведенные от процессора 14 проверочного узла. Суммарные данные преобразуются соединителем 21А битов в 2b-битные данные, которые выводятся в блок (L(1), L(2)) 12 запоминающего устройства. 2b-битные данные записываются в блок (L(1), L(2)) 12 запоминающего устройства.
Конфигурация, показанная на фиг.2, применяется там, где 2b-битные данные запомнены по одинаковым адресам в блоке (F) 11 запоминающего устройства, показанном на фиг.1А. Если 2b-битные данные делятся и запомнены в качестве 2b-битных данных, то обходятся без делителей 22А, 22В битов и соединителей 21А, 22А битов.
На фиг.3 изображена блок-схема конфигурационного примера процессора 14 проверочного узла, показанного на фиг.1А. Как показано на фиг.3, процессор 14 проверочного узла включает в себя делители с 31А по 31С битов, таблицы с 32А по 32С преобразования данных, сумматор 33, схемы с 34А по 34С вычитания, таблицы с 35А по 35С преобразования данных, соединители с 36А по 36С битов и арифметические блоки 37, с 38А по 38С исключающего-ИЛИ.
На процессор 14 проверочного узла подается входной сигнал, представленный выходным сигналом от сумматора 15, показанного на фиг.1А. Выходной сигнал от процессора 14 проверочного узла является входным сигналом для преобразователя 13 данных, показанного на фиг.1А. Процессор 14 проверочного узла выполняет обработку этапа 103 в последовательности операций, показанной на фиг.1В.
Согласно примеру функций, используемых при обработке этапа 103, функция f(Z~) представлена уравнением (4) ниже, а обратная функция f-1(Z~) - уравнением (5) ниже.
[Уравнение 4]
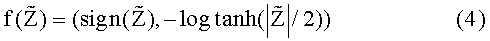
Функция f(Z~) согласно уравнению (4) является функцией для возвращения двух значений, т.е. результата знака функции, который возвращает 1, когда Z~ является Z~ < 0, и возвращает 0 в противном случае, значения, соответствующего логарифму функции гиперболического тангенса. Обратная функция f-1(Z~) функции f(Z~) согласно уравнению (4) является функцией, в которую подаются входные значения, представленные двумя численными значениями S, Z и возвращает значение, представленное правой частью уравнения (5).
[Уравнение 5]
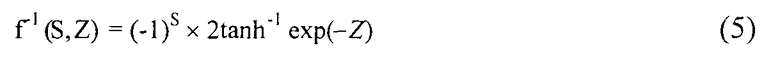
Процессор 14 проверочного узла повторяет обновление данных в блоке (L(1), L(2)) 12 запоминающего устройства заданное количество раз. Логарифм функции гиперболического тангенса в уравнении (4) вычисляется посредством таблицы 32 преобразования данных, а функция правой части уравнения (5) вычисляется посредством таблицы 35 преобразования данных.
Устройство декодирования для кода с малой плотностью проверок на четность, когда применяется для квазициклического кода с малой плотностью проверок на четность, чья проверочная матрица указана в уравнении (2), будет описано ниже. Проверочная матрица, указанная в уравнении (2), является блочной матрицей, имеющей элементы матрицы m × m (m представляет собой кратный делитель N), как описано выше. Полагается, что количество p операций параллельной обработки представлено кратным делителем m.
На фиг.4 изображена блок-схема конфигурационного примера блока (F) 11 запоминающего устройства, показанного на фиг.1А. Как показано на Фиг.4, блок (F) 11 запоминающего устройства содержит n (n = N/m) RAM 41. Каждое из RAM 41 имеет битовую длину в bp с количеством слов, представленных посредством m/p. Полная емкость хранения n RAM 41 представлена bN битами.
По каждому адресу каждого RAM 41 запоминается p принятых данных. По k-му (0 ≤ k < m/p) адресу j-ого (0 ≤ j < n) RAM 41 находится p принятых данных, представленных уравнением (6) ниже.
[Уравнение 6]
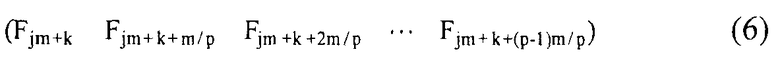
К принятым данным, запомненным в блоке (F) 11 запоминающего устройства, повторно обращаются во время выполнения процесса декодирования. Процесс создания адресов для считывания для каждого RAM 41 будет описан позже.
На фиг.5 изображена блок-схема конфигурационного примера блока (L(1), L(2)) 12 запоминающего устройства, показанного на фиг.1А. Как показано на фиг.5, блок (L(1), L(2)) 12 запоминающего устройства содержит n RAM 51. Каждое из RAM 51 имеет битовую длину в 2bp с количеством слов, представляемых посредством m/p. Полная емкость хранения n RAM 51 представлена bN битами.
По каждому адресу каждого RAM 51 запоминается 2р промежуточных данных. k-ый (0 ≤ k < m/p) адрес j-ого (0 ≤ j < n) RAM запоминает 2p данных, представленных уравнением (7) ниже.
[Уравнение 7]
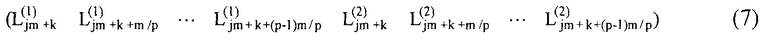
К данным, запомненным в блоке ((L(1), L(2)) 12 запоминающего устройства, повторно обращаются и обновляют их в течение процесса декодирования. Процесс создания адресов для считывания и адресов для записи для каждого RAM 51 будет описан ниже.
Работа устройства декодирования согласно настоящему варианту осуществления описана ниже со ссылкой на последовательность операций на фиг.1В. Сначала описано ниже устройство декодирования для декодирования кода с малой плотностью проверок на четность, имеющего проверочную матрицу, представленную уравнением (1). Затем описано ниже устройство декодирования для декодирования квазициклического кода с малой плотностью проверок на четность, имеющего проверочную матрицу, представленную уравнением (2), в качестве применяемого для параллельной обработки.
Как показано на фиг.1В, устройство 10 декодирования выполняет процесс инициализации (этап 101). При процессе инициализации устройство 10 декодирования записывает последовательность F0, F1, …, FN-1 принятых данных в блок (F) 11 запоминающего устройства. Каждый символ F1 из последовательности принятых данных представлен b битами (0 ≤ i < N, b представляет собой целое число). Устройство 10 декодирования инициализирует все данные L0 (1), L1 (1), …, LN-1 (1), L0 (2), L1 (2), …, LN-1 (2) в блоке (L(1), L(2)) 12 запоминающего устройства как 0. Устройство 10 декодирования инициализирует счетчик для счета количества раз, которое повторяется (t = 1) процесс декодирования. Поскольку структура счетчика очевидна, он пропущен на иллюстрации в блок-схеме фиг.1А для того, чтобы избежать иллюстративных сложностей.
После процесса декодирования устройство 10 декодирования устанавливает переменную i, которая представляет собой индекс векторов-строк проверочной матрицы в начальное значение 0 (этап 102).
Затем устройство 10 декодирования обновляет Lj (1) относительно каждого элемента j в множестве U(i) (см. уравнение (3)), которое указывает позиции ненулевых элементов в i-том векторе (этап 103). В это время устройство 10 декодирования считывает данные Fj из блока (F) 11 запоминающего устройства и считывает данные Lj (1), Lj (2) из блока (L(1), L(2)) 12 запоминающего устройства. Затем устройство 10 декодирования вычисляет Fj + Lj (1), используя сумматор 15. Устройство 10 декодирования вычисляет Fj + Lj (1) относительно всех j, включенных в U(i), и вводит вычисленные суммы в процессор 14 проверочного узла. Процессор 14 проверочного узла обрабатывает все целые числа j, включенные в U(i), и обновляет Lj (1) в обработанные результаты в качестве новых значений. Новые значения записываются в блок (L(1), L(2)) 12 запоминающего устройства. В течение этого времени к данным Fj, Lj (1), Lj (2) осуществляют доступ для каждого j = 0, 1, …, N-1 столько же раз, каково количество ненулевых элементов в j-ом векторе-столбце проверочной матрицы.
Устройство 10 декодирования выполняет обработку этапа 103 успешно относительно i = 0, 1, …, R-1, соответствующих векторам-строкам проверочной матрицы (этапы 104, 105).
Затем устройство 10 декодирования определяет xj так, что xj=1, когда Fj + Lj (1) представляет собой отрицательное значение, и xj = 0 в противном случае (этап 106). Устройство 10 декодирования повторяет обработку этапа с 102 по 106, пока не выполнено (этапы с 107 по 109) одно из двух условий, что произведение НхТ проверочной матрицы и (x0, x1, …, xN-1) является НхТ = 0 и t = Tmax (максимальное значение t).
Операция обработки (этап 109) преобразователя 13 данных, показанного на фиг.2, которая в действительности выполняется за раз, будет описана позже.
Если синдром, вычисленный посредством произведения (x0, x1, …, xN-1) и проверочной матрицы, полученного посредством вышеупомянутой обработки, является 0, то устройство 10 декодирования оценивает (x0, x1, …, xN-1) в качестве последовательности данных передачи, выводит последовательность данных передачи, и завершает процесс декодирования (этап 110). Устройство для вычисления произведения (x0, x1, …, xN-1) и проверочной матрицы пропущено на иллюстрации в блок-схеме на фиг.1А для того, чтобы избежать иллюстративных сложностей.
Работа преобразователя 13 данных на этапе 109 описана ниже.
Обработка этапа 109 является процессом для обновления данных Lj (1), Lj (2) в блоке (L(1), L(2)) запоминающего устройства соответственно в данные Lj (1)-Lj (2), Lj (1)-Lj (2) относительно j = 0, 1, …, N-1. Процесс обновления выполняется однократно каждый раз, когда повторяется процесс декодирования. Каждый раз, когда повторяется процесс декодирования, к данным Lj (1), Lj (2) осуществляют доступ столько же раз, каково количество ненулевых элементов в j-ом векторе-столбце проверочной матрицы. Только когда преобразователь 13 данных считывает данные Lj (1), Lj (2) за один доступ (обращение), преобразователь 13 данных обновляет их в Lj (1) = Lj (1)-Lj (2), Lj (2) = Lj (1)-Lj (2) и выводит обновленные данные.
На фиг.2 изображена конфигурация преобразователя 13 данных, когда в блоке (L(1), L(2)) 12 запоминающего устройства запомнены 2b-битные данные по каждому адресу со старшими b битами, представляемыми посредством Lj (1), и младшими b битами посредством Lj (2). На Фиг.2 2b-битные данные считываются из адресов j (0 ≤ j < N9) блока (L(1), L(2)) 12 запоминающего устройства и вводятся в преобразователь 13 данных, причем 2b-битные данные имеют старшие b битов, представленных посредством Lj (1), и младшие b битов посредством Lj (2). 2b-битные данные делят посредством делителя 22А битов на старшие b битов (Lj (1)) и младшие b битов (Lj (2)). Lj (1) и Lj (1)-Lj (2) из схемы 24 вычитания вводятся в схему 25 выбора.
Как описано выше, каждый раз, когда повторяется процесс декодирования, схема 25 выбора выбирает Lj (1)-Lj (2), когда осуществляют доступ по адресу j в первый раз, и выбирает Lj (1) в противном случае. Выходной сигнал схемы 25 выбора выводится в сумматор 15. Lj (2) соединен с младшими b битами посредством соединителя 21А битов, который вводит соединенные данные в устройство 26 задержки.
Устройство 26 задержки задерживает входной сигнал на время, требуемое операцией обработки процессора 14 проверочного узла, и вводит задержанный сигнал в делитель 22В битов. Делитель 22В битов делит входной сигнал на старшие b биты и младшие b биты и вводит их обоих в схему 27 выбора. Старшие b битов представлены посредством либо Lj (1) или Lj (1)-Lj (2), а младшие b битов посредством Lj (2). Старшие b битов также вводятся в сумматор 23, который добавляет старшие b битов к данным из процессора 14 проверочного узла. Суммарные данные из сумматора 23 и b битов, выведенных из схемы 27 выбора, соединяются друг с другом посредством соединителя 21В битов, и соединенные данные сохраняются по адресу j в блоке (L(1), L(2)) запоминающего устройства.
Таким образом, преобразователь 13 данных создает данные, которые следует отправить в сумматор 15, посредством выбора либо данных Lj (1), либо данных, полученных вычитанием Lj (2) из Lj (1). Преобразователь 13 данных обновляет данные Lj (2) посредством выбора либо данных Lj (1), либо данных, полученных вычитанием Lj (2) из Lj (1).
Согласно настоящему примерному варианту осуществления, как описано выше, данные, запомненные в блоке (L(1), L(2)) 12 запоминающего устройства, преобразуются и обрабатываются для получения декодированного результата. Поскольку только полные 2b-битные данные, сделанные из b-битных данных Lj (1), и поскольку b-битные данные могут запоминаться относительно каждого вектора-столбца проверочной матрицы, то емкость запоминающего устройства для запоминания в ней данных может быть меньше, чем в существующем способе декодирования.
В частности, согласно настоящему примерному варианту осуществления полные 2b-битные данные Lj (1), Lj (2) запоминают относительно j-ого вектора (j = 0, 1, …, N-1), например, и обновляются и обрабатываются. Способ декодирования согласно настоящему примерному варианту осуществления требует меньшей емкости хранения для запоминания в ней данных, чем существующий способ декодирования, в котором запомнены b-битные данные относительно каждого вектора-строки, например i-ый вектор (i = 0, 1, …, R-1), и элементов множества U(i), а также обновляет и обрабатывает данные.
Устройство 10 декодирования согласно настоящему примерному варианту осуществления осуществляет запоминание принятых данных в блоке (F) 11 запоминающего устройства само по себе и обрабатывает принятые данные. Однако настоящее изобретение не ограничивается такой конфигурацией. Согласно другому варианту осуществления носитель записи с записанными на нем данными, кодированными посредством кода с малой плотностью проверок на четность, может загружаться в устройство 10 декодирования, и устройство 10 декодирования может обращаться к данным и декодировать данные, записанные в носителе записи. В этом случае, обходятся без блока (F) 11 запоминающего устройства.
Устройство 10 декодирования согласно настоящему примерному варианту осуществления последовательно повторяет последовательность считывания данных относительно каждого вектора-столбца, выполнения над ними процесса проверочного узла для обновления данных и сохранения данных. Однако настоящее изобретение не ограничивается такой конфигурацией. Согласно другому варианту последовательность параллельной обработки может вводиться для ускорения вышеупомянутого процесса декодирования.
Последовательность параллельной обработки, которая применяется к процессу декодирования для декодирования квазициклического кода с малой плотностью проверок на четность, имеющего проверочную матрицу, указанную посредством уравнения (2), описана ниже. Полагается, что количество p операций параллельной обработки представляется посредством кратного делителя m, который представляет собой размер циклических матриц в качестве элементов проверочной матрицы, указанной посредством уравнения (2). В этом случае блок (F) 11 запоминающего устройства и блок (L(1), L(2)) 12 запоминающего устройства являются идентичными по конфигурации к тем, что показаны на фиг.4 и 5, соответственно. Структуры данных в RAM в блоках запоминающего устройства являются теми же самыми, что те, что представлены уравнениями (6), (7). Количество RAM, включенных в каждый блок запоминающего устройства, равно n. Процесс создания адресов для осуществления доступа к каждому RAM является тем же самым для блока (F) 11 запоминающего устройства и блока (L(1), L(2)) 12 запоминающего устройства как в случае вышеупомянутого примерного варианта осуществления для последовательной обработки. Поэтому только блок (L(1), L(2)) 12 запоминающего устройства будет описываться ниже. Значения A(i,j) r начальных адресов (0 ≤ i < r, 0 ≤ j <n) назначаются каждому из n RAM. Значение A(i,j) i-ого начального адреса j-ого RAM определяется следующим образом:
[Уравнение 8]

где k(i,j) представляет собой целое число, указывающее позиции ненулевых элементов в первом векторе-столбце матрицы Ii,j m × m с циклической перестановкой, которая является (i,j) элементом проверочной матрицы согласно уравнению (2) (0 ≤ k(i,j) < m). Значение A(i,j) адреса находится в соответствии с остатком, полученным от деления k(i,j) на m/p. Адреса для считывания данных из и записи данных в каждый RAM создаются в r образцах. r образцов являются идентичными в том смысле, что только значения начальных адресов отличаются, а последующие адреса создаются просто добавлением 1.
Каждый образец для создания адресов меняется через периоды в единицу времени в m/p. Например, значение первого начального адреса j-ого RAM является A(0,j), и считываются данные согласно уравнению (7), где k = A(0,j). Затем считываются данные по значению A(0,j)+1 адреса согласно уравнению (7), где k = A(0,j)+1. Впоследствии 1 добавляется подобным образом к значению адреса. Однако значение адреса после значения m/p-1 адреса является 0, и соответственно данные одинаково считываются, пока данные не считаются из значения A(0,j)-1 адреса.
Данные, которые считываются следующими, являются данными, соответствующими значению A(1,j) начального адреса. Впоследствии данные считываются согласно процессу, одинаковому с вышеописанным процессом. Тот же самый процесс, который выполняется для значений A(i,j) всех начальных адресов r образцов относительно i = 0, 1, …, r-1, соответствует одному процессу повторного декодирования. После того, как один процесс повторного декодирования закончен, управление затем возвращается в начальную точку, и тот же самый процесс повторяется столько же раз, каково максимальное количество повторений.
Адреса для n RAM могут быть созданы с использованием счетчика MOD(m/p) (по модулю m/p). Счетчик MOD(m/p) выводит 1-битный сигнал за время, когда значение счетчика (значение адреса) изменяется с m/p-1 до 0. Счетчик MOD(m/p) используется в схемах 62, 63 сдвига в процессоре параллельных проверочных узлов, показанном на фиг.6.
Каждый элемент данных согласно уравнению (7), считанных из блока (L(1), L(2)) 12 запоминающего устройства, имеет ширину своих данных, увеличенную от 2b битов до 2bp битов и является входным сигналом для преобразователя параллельных данных. Преобразователь параллельных данных имеет последовательность обработки, которая является одинаковой с последовательностью обработки преобразователя 13 данных, показанного на фиг.2, и включает в себя n преобразователей 13 данных, которых столько же, каково количество RAM. bp-битные данные, соответствующие части L(1), полученной посредством преобразователя параллельных данных, добавляются к bp-битным данным согласно уравнению (6), считанным из блока (F) 11 запоминающего устройства. Добавление выполняется относительно каждого блока из b битов.
n bp-битных данных, которых столько же, каково количество RAM, созданные посредством вышеупомянутой последовательности добавления, все являются входными сигналами для процессора параллельных проверочных узлов.
На фиг.6 изображена блок-схема процессора параллельных проверочных узлов. Процессор параллельных проверочных узлов выполняет обработку этапа 103, показанного на фиг.1В за p параллельных операций.
Как показано на фиг.6, процессор параллельных проверочных узлов включает в себя p процессоров 61 проверочных узлов, 2n схем 62, 63 сдвига и 2 маршалера (блок компоновки) 64, 65 данных. Процессоры 61 проверочных узлов идентичны процессору 14 проверочного узла, показанному на фиг.3. На схемы 62, 63 сдвига подаются входные сигналы, представленные b × p-битной информацией, циклически сдвигают входную информацию для каждого блока из b битов и выводят сдвинутую информацию. Количество сдвигов и схем 62, 63 сдвига определяется в зависимости от проверочной матрицы, представленной уравнением (2).
В процессоре параллельных проверочных узлов, показанном на фиг.6, каждые из n bp-битных данных вводятся в одну из схем 62 сдвига. Процессор параллельных проверочных узлов имеет n схем 62 сдвига, на каждую из которых подаются bp-битные данные. Каждая схема 62 сдвига циклически сдвигает входные bp-битные данные для каждого блока из b битов на предварительно определенное количество и выводит сдвинутые данные. Количество сдвигов определяется согласно уравнению (9) ниже на основе значений начальных адресов (см. уравнение (9)) относительно RAM.
[Уравнение 9]

Количество сдвигов, которое соответствует данным j-ого RAM, которые последовательно считываются со значения A(i,j) начального адреса по значение m/p-1 адреса, согласуется с s(i,j) согласно уравнению (9). Количество сдвигов, которое соответствует данным j-ого RAM, которые последовательно считываются со значения 0 начального адреса по значение A(i,j)+1 адреса, согласуется с s(i,j)+1. Если s(i,j)+1 = p, то количество сдвигов равно 0 и схема сдвига выводит входной сигнал как есть. Как описано выше относительно создания адресов для RAM, количество сдвигов переключается с s(i,j) на s(i,j)+1, используя 1-битовый сигнал за время, когда значение адреса меняется с m/p-1 на 0.
Каждый из выходных сигналов от n схем 62 сдвига состоит из bp битов. Маршалер 64 данных является устройством для создания входных сигналов для p процессоров проверочного узла из выходных сигналов от n схем 62 сдвига. На маршалер 64 данных подаются входные сигналы, представленные bp-битными выходными сигналами от n схем сдвига, маршалер 64 данных компонует n данные (d0 (1), d1 (1), …, dN-1 (1)), где j = 0, 1, …, n-1, которые предоставляются посредством деления bp-битных данных для каждого блока из b битов для создания данных (d0 (1), d1 (1), …, dN-1 (1)), где i = 0, 1, …, p-1, и выводит их на соответствующие процессоры 61 проверочного узла.
На p процессоров 61 проверочного узла подаются входные сигналы, представленные nb-битными данными (d0 (1), d1 (1), …, dN-1 (1)), p процессоров 61 проверочного узла выполняют над ними предварительно определенную обработку и выводят nb-битные данные в качестве обработанных результатов. p выходных данных, каждые соответствующие nb битам, вводятся в маршалер 65 данных. Маршалер 65 данных компонует p nb-битные выходные данные в n bp-битные данные и вводит их в соответствующие схемы 63 сдвигов согласно процессу, который является обратным к процессу, выполняемому маршалером 64 данных. Схемы 63 сдвига служат для отмены процесса циклического сдвига, выполняемого схемами 62 сдвига. Другими словами, сумма количества сдвигов схем 63 сдвигов и количества сдвигов схем 62 сдвигов согласована с p или 0. Данные, выведенные из процессора параллельных проверочных узлов, показанного на фиг.6, обрабатываются посредством процесса, идентичного процессу, выполняемому вышеупомянутым процессором последовательных проверочных узлов согласно примерному варианту осуществления. Однако согласно примерному варианту осуществления n преобразователей 13 данных выполняют операции параллельной обработки.
На фиг.7 изображена временная диаграмма, показывающая хронологическую последовательность операций устройства декодирования согласно примерному варианту осуществления. Процесс декодирования начинается во время запоминания принятых данных в n RAM блока (F) 11 запоминающего устройства. Принятые данные, запомненные в n RAM блока (F) 11 запоминающего устройства, содержат n × p × (m/p) символов, где один символ равен b битам. На фиг.7 показана последовательность операций обработки за один период касательно обновления данных в одном из n RAM в блоке (F) 11 запоминающего устройства и блоке (L(1), L(2)) 12 запоминающего устройства. Последовательность операций обработки для других n-1 RAM является той же самой, как и последовательность операций обработки, показанная на фиг.7. кроме установки значения начального адреса и количества сдвигов схем сдвигов.
В последовательности операций обработки на самой верхней стадии данные из b-битов × p считываются из блока (F) 11 запоминающего устройства, а данные из b-битов × p × 2 считываются из блока (L(1), L(2)) 12 запоминающего устройства, используя установленное значение A начального адреса (см. уравнение (8)), и вводятся через сумматор или преобразователь данных и сумматор в схемы 62 сдвига. Процесс преобразования данных разделяет данные из b-битов × p × 2 на старшие b-битов × p и младшие b-битов × p, вычисляет разницу и соединяет данные. Процесс преобразования данных является в основном тем же самым, что и процесс вышеупомянутого преобразователя 13 данных. Процесс вышеупомянутого преобразователя 13 данных является тем же самым, что и вышеупомянутый процесс преобразования данных, где p = 1.
Количество s начальных сдвигов определяется посредством значения A начального адреса и уравнения (9). Выходные сигналы от схем 62 сдвига и данные, введенные от других n-1 RAM через схемы 62 сдвига, компонуются посредством маршалера 64 данных и вводятся в процессоры 61 проверочного узла. Данные, обработанные процессорами 61 проверочных узлов, компонуются маршалером 65 данных согласно процессу, который является обратным к процессу маршалера 64 данных, и впоследствии сдвигаются схемами 63 сдвига. Данные из b-битов × p соединяются с данными из b-битов × p преобразователем данных. Соединенные данные из b-битов × p × 2 записываются по значению A адреса RAM блока (L(1), L(2)) 12 запоминающего устройства.
Вышеописанный процесс выполняется над данными RAM, запомненными по значениям A+1, A+2, … адреса согласно конвейерной обработке, показанной на фиг.7. Когда первый период, например, заканчивается, значение начального адреса и количество сдвигов устанавливается заново, и выполняется второй период для обновления данных RAM. Процесс выполняется для значений r адресов. Когда весь период r заканчивается, заканчивается один процесс декодирования, чья последовательность повторяется максимальное указанное количество раз.
Согласно вышеупомянутому примерному варианту осуществления при обработке проверочного узла этапа 103, показанного на фиг.1В, используются уравнения (4) и (5) для вычисления Lj (1) на основании логарифма функции гиперболического тангенса. Однако настоящее изобретение не ограничивается таким вычислением. Согласно другому примеру Lj (1) может быть вычислено согласно уравнению (10) ниже.
[Уравнение 10]
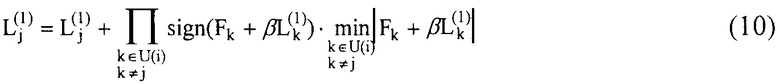
Последовательность обработки проверочного узла согласно уравнению (10) обязательно требует (Fk + βLk (1)) в качестве входного сигнала от сумматора. Поэтому, когда сумматор 15 суммирует данные из запоминающего устройства (F) 11 и данные, полученные из блока (L(1), L(2)) 12 запоминающего устройства через преобразователь 13 данных, он взвешивает данные, полученные из блока (L(1), L(2)) 12 запоминающего устройства через преобразователь 13 данных. В уравнении (10) β представляет весовой коэффициент. Значение β весового коэффициента можно регулировать в зависимости от выбора проверочной матрицы (уравнение (1), уравнение (2)). Значение β весового коэффициента необязательно должно быть постоянным, но может изменяться адаптивно.
Если самые старшие биты входного сигнала представляют положительную или отрицательную полярность, а оставшиеся биты представляют абсолютное значение, то последовательность обработки проверочного узла согласно уравнению (10) может вычислять исключающее-ИЛИ самых старших битов и минимального значения оставшихся битов. Последовательность обработки проверочного узла согласно уравнению (10) таким образом делает ненужным использование таблиц 32, 35, которые требуются использованием логарифмической функцией функции гиперболического тангенса при обработке проверочного узла согласно уравнению (4) и уравнению (5). В результате обработка проверочного узла может реализовываться простой схемой сравнения.
Система обмена данными содержащая в себе вышеописанное устройство декодирования будет описана с помощью иллюстративного примера.
На фиг.8 изображена блок-схема конфигурации системы обмена данными, которая содержит в себе устройство декодирования согласно примерному варианту осуществления. Как показано на фиг.8, система 80 обмена данными содержит устройство 81 передачи и устройство 82 приема.
Устройство 81 передачи включает в себя устройство 83 кодирования, устройство 84 создания входного сигнала модулятора и синхронного управления и модулятор 85. Устройство 83 кодирования выводит данные, кодированные посредством кода с малой плотностью проверок на четность. Устройство 84 создания входного сигнала модулятора и синхронного управления включает в себя кодированные данные, выводимые от устройства 83 кодирования в кадр для синхронизации устройства 82 приема, преобразует кодированные данные в данные, которые соответствуют процессу модуляции модулятора 85, и выводит преобразованные данные. Модулятор 85 модулирует данные от устройства 84 создания входного сигнала модулятора и синхронного управления согласно своему процессу модуляции и выводит модулированные данные. Выходные данные от модулятора 85 передаются по каналу связи и затем принимаются устройством 82 приема.
Устройство 82 приема включает в себя демодулятор 86 декодирования, устройство 87 создания входного сигнала устройства декодирования и синхронного управления и устройство 88 декодирования. Демодулятор 86 принимает сигнал из канала связи, демодулирует сигнал согласно процессу, соответствующему процессу модуляции модулятора 85, и выводит демодулированные данные. Устройство 87 создания входного сигнала устройства декодирования и синхронного управления синхронизируются с кадром данных, выведенных от демодулятора 86, преобразует данные в данные, соответствующие входному сигналу устройства 86 декодирования, и выводит преобразованные данные. Устройство 88 декодирования декодирует код с малой плотностью проверок на четность из данных, выведенных из устройства 87 создания входного сигнала устройства декодирования и синхронного управления, согласно процессу, описанному в вышеупомянутом примерном варианте осуществления, и выводит декодированные данные.
Устройство декодирования согласно вышеописанному варианту осуществления изображено в качестве применяемого в системе обмена данными. Однако устройство декодирования можно использовать в других применениях. Согласно другому примеру вышеописанное устройство декодирования может быть использовано в системе хранения данных. В частности, в системе хранения данных, которая использует технологию исправления ошибок для увеличения надежности сохраненных данных, данные, кодированные посредством кода с малой плотностью проверок на четность, могут быть сохранены в устройстве хранения, а данные, считанные из устройства хранения, могут быть декодированы посредством устройства декодирования.
Частный пример вышеописанного способа декодирования на основе численного примера будет описан ниже.
Полагается, что проверочная матрица согласно уравнению (1) имеет размер из N = 4095 и R = 504. Также полагается, что множество U(i), заданное уравнением (2), имеет i в диапазоне 0 ≤ i < 504 и количество элементов в U(i) все находятся в соответствии с 64. Система обмена данными, например, которая использует способ декодирования, может быть использована в качестве системы для переноса последовательности битов в блоках кадров, имеющих длину кадра в 4095 битов. В общем, около 10% кадров служит в качестве избыточной области для исправления ошибок. Если ширина b битов каждого символа данных, введенных в устройство декодирования, составляет 6 битов, то устройству декодирования требуется иметь емкость хранения в 4095 × 6 битов для блока (F) 11 запоминающего устройства и емкость хранения в 2 × 4095 × 6 битов для блока (L(1), L(2)) 12 запоминающего устройства. Сравнение этих численных примеров с устройством декодирования, использующим существующий способ декодирования, раскрытый в Документе 4, указывает, что емкость хранения согласно численному варианту, снижается на приблизительно 75%. Любое уменьшение в коэффициенте ошибок находится приблизительно от 0,1 до 0,2 дБ.
Настоящее изобретение было описано выше со ссылкой на примерный вариант осуществления. Однако настоящее изобретение не ограничивается вышеописанным примерным вариантом осуществления. Скорее изменения, которые могут быть понятны специалистам в данной области техники, в пределах объема изобретения могут быть сделаны в отношении компоновок и подробностей данного изобретения.
Настоящее изобретение притязает на приоритет на основании Японской патентной заявки №2007-321928, поданной 13 декабря 2007, и содержит ее полное раскрытие в данном документе посредством ссылки.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО ДЕКОДИРОВАНИЯ И УСТРОЙСТВО ПРИЕМА | 2006 |
|
RU2391774C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ДАННЫХ | 2005 |
|
RU2370886C2 |
| УСТРОЙСТВО ОБРАБОТКИ ДАННЫХ И СПОСОБ ОБРАБОТКИ ДАННЫХ | 2012 |
|
RU2595585C2 |
| СПОСОБЫ И УСТРОЙСТВО LDPC-ДЕКОДИРОВАНИЯ | 2005 |
|
RU2392737C2 |
| УСТРОЙСТВО ОБРАБОТКИ ДАННЫХ И СПОСОБ ОБРАБОТКИ ДАННЫХ | 2014 |
|
RU2656830C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ДАННЫХ | 2005 |
|
RU2365034C2 |
| УСТРОЙСТВО ОБРАБОТКИ ДАННЫХ И СПОСОБ ОБРАБОТКИ ДАННЫХ | 2011 |
|
RU2574828C2 |
| УСТРОЙСТВО ОБРАБОТКИ ДАННЫХ И СПОСОБ ОБРАБОТКИ ДАННЫХ | 2014 |
|
RU2656726C2 |
| УСТРОЙСТВО ОБРАБОТКИ ДАННЫХ И СПОСОБ ОБРАБОТКИ ДАННЫХ | 2014 |
|
RU2656725C2 |
| УСТРОЙСТВО ОБРАБОТКИ ДАННЫХ И СПОСОБ ОБРАБОТКИ ДАННЫХ | 2011 |
|
RU2574822C2 |
Изобретение относится к способам декодирования информационной последовательности из данных, закодированных посредством добавления к информационной последовательности избыточной последовательности, используемой для исправления ошибок. Техническим результатом является снижение коэффициента ошибок декодирования при снижении емкости хранения данных. Указанный результат достигается тем, что устройство декодирования для исправления ошибок принятых данных, кодированных посредством кода с малой плотностью проверок на четность, содержит первое и второе средства хранения элементов данных, равных количеству векторов-столбцов проверочной матрицы кода с малой плотностью проверок на четность, средство преобразования данных и средство обработки проверочного узла. Средство преобразования данных создает из данных, хранящихся в первом и втором средствах хранения первые промежуточные данные, запомненные во взаимно-однозначном соответствии с векторами-столбцами. Средство обработки проверочного узла на основе суммы первых промежуточных данных и принятых данных создает вторые промежуточные данные для обновления данных, хранящихся в первом средстве хранения. Средство преобразования данных обновляет данные, хранящиеся во втором средстве хранения, используя первые промежуточные данные, и обновляет данные, хранящиеся в первом средстве хранения, используя вторые промежуточные данные. Декодированные данные создаются посредством средства преобразования данных и средства обработки проверочного узла. 4 н. и 4 з.п. ф-лы, 9 ил.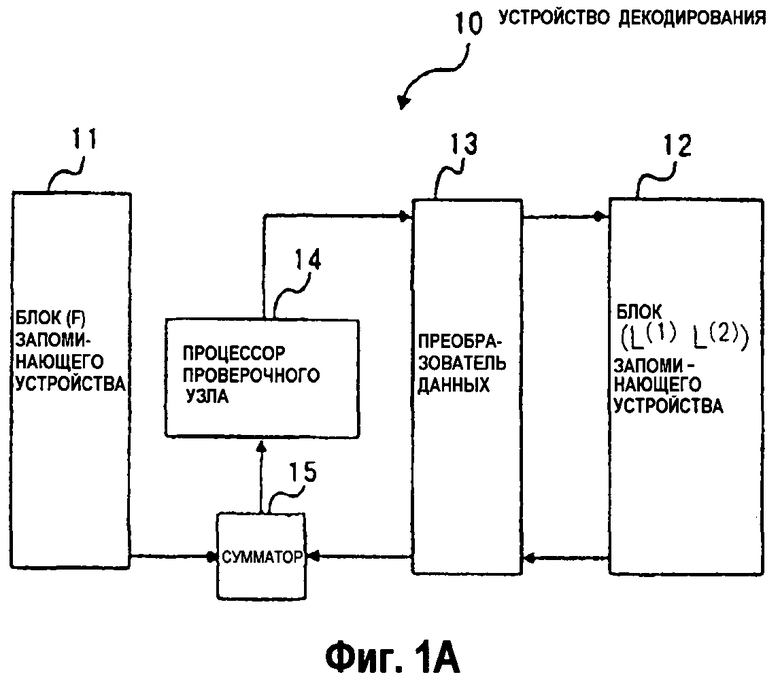
1. Устройство декодирования для исправления ошибок принятых данных, кодированных посредством кода с малой плотностью проверок на четность, содержащее
первое средство хранения для хранения стольких же элементов данных, каково количество векторов-столбцов проверочной матрицы упомянутого кода с малой плотностью проверок на четность;
второе средство хранения для хранения того же самого количества данных, как в упомянутом первом средстве хранения;
средство преобразования данных; и
средство обработки проверочного узла;
в котором упомянутое средство преобразования данных создает первые промежуточные данные, запомненные во взаимно-однозначном соответствии с упомянутыми векторами-столбцами, из данных, хранящихся в упомянутом первом средстве хранения, и данных, хранящихся в упомянутом втором средстве хранения;
упомянутое средство обработки проверочного узла создает вторые промежуточные данные для обновления данных, хранящихся в упомянутом первом средстве хранения, основываясь на сумме упомянутых первых промежуточных данных и упомянутых принятых данных;
упомянутое средство преобразования данных обновляет данные, хранящиеся в упомянутом втором средстве хранения, используя упомянутые первые промежуточные данные, и обновляет данные, хранящиеся в упомянутом первом средстве хранения, используя упомянутые вторые промежуточные данные, созданные посредством упомянутого средства обработки проверочного узла; и
декодированные данные создаются посредством процесса, выполняемого посредством упомянутого средства преобразования данных и упомянутого средства обработки проверочного узла.
2. Устройство декодирования по п.1, в котором процесс, выполняемый посредством упомянутого средства преобразования данных и упомянутого средства обработки проверочного узла, повторяется для повторного обновления данных, хранящихся в упомянутом первом средстве хранения, и данных, хранящихся в упомянутом втором средстве хранения, для создания посредством этого упомянутых декодируемых данных.
3. Устройство декодирования по п.1, в котором упомянутое средство преобразования данных:
создает упомянутые первые промежуточные данные посредством выбора либо данных, хранящихся в упомянутом первом средстве хранения, либо данных, полученных посредством вычитания данных, хранящихся в упомянутом втором средстве хранения, из данных, хранящихся в упомянутом первом средстве хранения; и
обновляет данные, хранящиеся в упомянутом втором средстве хранения, посредством выбора либо данных, хранящихся в упомянутом втором средстве хранения, либо данных, полученных посредством вычитания данных, хранящихся в упомянутом втором средстве хранения, из данных, хранящихся в упомянутом первом средстве хранения.
4. Устройство декодирования по п.1, в котором упомянутое средство обработки проверочного узла создает вторые промежуточные данные для обновления данных, среди данных, хранящихся в упомянутом первом средстве хранения, которые соответствуют упомянутым векторам-столбцам, из суммы упомянутых первых промежуточных данных, запомненных во взаимнооднозначном соответствии с упомянутыми векторами-столбцами, которые пересекают ненулевые элементы каждого из векторов-строк упомянутой проверочной матрицы, и упомянутых принятых данных; и
упомянутое средство преобразования данных выбирает данные, полученные посредством вычитания данных, хранящихся в упомянутом втором средстве хранения, из данных, хранящихся в упомянутом первом средстве хранения, в качестве упомянутых первых промежуточных данных каждый раз, когда обновление данных посредством упомянутого средства обработки проверочного узла заканчивается для всех векторов-строк, и выбирает данные, полученные посредством вычитания данных, хранящихся в упомянутом втором средстве хранения, из данных, хранящихся в упомянутом первом средстве хранения, в качестве обновленных данных для данных, хранящихся в упомянутом втором средстве хранения.
5. Устройство декодирования по п.4, в котором упомянутый код с малой плотностью проверок на четность является квазициклическим кодом с малой плотностью проверок на четность, в котором упомянутая проверочная матрица содержит матрицу с циклической перестановкой, имеющую размер m (m представляет собой положительное целое число) или блочную матрицу из r строк и n столбцов (n, m представляют собой положительные целые числа), имеющую элементы, каждый из нулевой матрицы;
каждое из упомянутого первого средства хранения и упомянутого второго средства хранения содержит n запоминающих устройств с произвольным доступом с количеством слов, представляемым посредством m/р (р представляет собой кратный делитель для m);
упомянутое средство преобразования данных включает в себя максимум n преобразователей данных для параллельной обработки;
при этом упомянутое средство обработки проверочного узла содержит максимум n первых схем сдвига для циклического сдвига данных, имеющих длину р, от упомянутых преобразователей данных, первый маршалер данных для компоновки максимума n данных, имеющих длину р, из упомянутого максимума n первых схем сдвига в р данные, имеющие максимальную длину в n, р процессоров проверочного узла для выполнения параллельной обработки над р данными из упомянутого первого маршалера данных, второй маршалер данных для компоновки р данных, имеющих максимальную длину в n, от упомянутых р процессоров проверочного узла в максимум n данных, имеющих длину р, и максимум n вторых схем сдвига для циклического сдвига максимума n данных от упомянутого второго маршалера данных в процессе, который является обратным к процессу циклического сдвига упомянутых первых схем сдвига; и
упомянутое средство обработки проверочного узла и упомянутое средство преобразования данных обновляет данные, хранящиеся в упомянутом первом средстве хранения, и данные, хранящиеся в упомянутом втором средстве хранения, посредством максимум n данных, параллельных друг другу.
6. Устройство хранения данных, содержащее:
устройство кодирования для кодирования данных, которые следует сохранить в устройстве хранения, согласно коду с малой плотностью проверок на четность; и
устройство декодирования, содержащее первое средство хранения для хранения стольких же элементов данных как количество векторов-столбцов проверочной матрицы упомянутого кода с малой плотностью проверок на четность, второе средство хранения для хранения того же самого количества данных как в упомянутом первом средстве хранения, средство преобразования данных, и средство обработки проверочного узла, в котором упомянутое средство преобразования данных создает первые промежуточные данные, запомненные во взаимно-однозначном соответствии с упомянутыми векторами-столбцами, из данных, хранящихся в упомянутом первом средстве хранения, и данных, хранящихся в упомянутом втором средстве хранения, упомянутое средство обработки проверочного узла создает вторые промежуточные данные для обновления данных, хранящихся в упомянутом первом средстве хранения, основываясь на сумме упомянутых первых промежуточных данных и упомянутых принятых данных, упомянутое средство преобразования данных обновляет данные, хранящиеся в упомянутом втором средстве хранения, используя упомянутые первые промежуточные данные, и обновляет данные, хранящиеся в упомянутом первом средстве хранения, используя упомянутые вторые промежуточные данные, созданные посредством упомянутого средства обработки проверочного узла; и декодированные данные создаются посредством процесса, выполняемого посредством упомянутого средства преобразования данных и упомянутого средства обработки проверочного узла.
7. Система обмена данными, содержащая:
устройство передачи для передачи данных, кодированных посредством кода с малой плотностью проверок на четность;
устройство приема, содержащее первое средство хранения для хранения стольких же элементов данных как количество векторов-столбцов проверочной матрицы упомянутого кода с малой плотностью проверок на четность, второе средство хранения для хранения того же самого количества данных как в упомянутом первом средстве хранения, средство преобразования данных и средство обработки проверочного узла, в котором, упомянутое средство преобразования данных создает первые промежуточные данные, запомненные во взаимно-однозначном соответствии с упомянутыми векторами-столбцами, из данных, хранящихся в упомянутом первом средстве хранения, и данных, хранящихся в упомянутом втором средстве хранения, упомянутое средство обработки проверочного узла создает вторые промежуточные данные для обновления данных, хранящихся в упомянутом первом средстве хранения, основываясь на сумме упомянутых первых промежуточных данных и упомянутых принятых данных, упомянутое средство преобразования данных обновляет данные, хранящиеся в упомянутом втором средстве хранения, используя упомянутые первые промежуточные данные, и обновляет данные, хранящиеся в упомянутом первом средстве хранения, используя упомянутые вторые промежуточные данные, созданные посредством упомянутого средства обработки проверочного узла; и декодированные данные создаются посредством процесса, выполняемого посредством упомянутого средства преобразования данных и упомянутого средства обработки проверочного узла.
8. Способ декодирования для исправления ошибок принятых данных, кодированных посредством кода с малой плотностью проверок на четность, содержащий этапы, на которых:
хранят столько же элементов данных как количество векторов-столбцов проверочной матрицы упомянутого кода с малой плотностью проверок на четность в первом средстве хранения;
хранят то же самое количество данных как в упомянутом первом средстве хранения во втором средстве хранения;
создают первые промежуточные данные, запомненные во взаимнооднозначном соответствии с упомянутыми векторами-столбцами, из данных, хранящихся в упомянутом первом средстве хранения, и данных, хранящихся в упомянутом втором средстве хранения;
создают вторые промежуточные данные для обновления данных, хранящихся в упомянутом первом средстве хранения, основываясь на сумме упомянутых первых промежуточных данных и упомянутых принятых данных;
обновляют данные, хранящиеся в упомянутом втором средстве хранения, используя упомянутые первые промежуточные данные, и обновляют данные, хранящиеся в упомянутом первом средстве хранения, используя упомянутые вторые промежуточные данные; и
создают декодированные данные согласно процессу, выполняемому посредством упомянутого средства преобразования данных и упомянутого средства обработки проверочного узла.
| ЕР 1819054 А2, 15.08.2007 | |||
| ЕР 1699138 A1, 06.09.2006 | |||
| JP 2005051469 A, 24.02.2005 | |||
| US 2007150789 A1, 28.06.2007 | |||
| JP 2007295564 A, 08.11.2007 | |||
| JP 2007081601 A, 29.03.2007 | |||
| KR 20060125501 A, 06.12.2006 | |||
| УСТРОЙСТВО И СПОСОБ КОДИРОВАНИЯ/ДЕКОДИРОВАНИЯ КАНАЛА С ИСПОЛЬЗОВАНИЕМ ПАРАЛЛЕЛЬНОГО КАСКАДНОГО КОДА ПРОВЕРКИ НА ЧЕТНОСТЬ С НИЗКОЙ ПЛОТНОСТЬЮ | 2004 |
|
RU2310274C1 |
| RU 2006109470 A, 10.07.2006. | |||

