Изобретение относится к области молекулярной биологии, молекулярной генетики, биотехнологии и медицины, а именно к способу получения полной кодирующей последовательности гена реналазы 2 человека с ДНК матрицы. Этот способ основан на получении методом полимеразной цепной реакции (ПЦР) с ДНК матрицы отдельных кодирующих последовательностей гена (экзонов), которые затем объединяются методом ПЦР в полноразмерную кодирующую последовательность (кДНК), при помощи комплементарных концевых фрагментов кДНК. С помощью данного метода получены две транскрипционные формы гена реналазы человека: кДНК реналазы 2 и кДНК реналазы 1, используемой в качестве контроля, а также проведена их экспрессия в прокариотической системе.
Структура и особенности экспрессии гена реналазы человека
Ген человеческой реналазы (NC_000010.10) локализован на 10 хромосоме локус q23.33 и включает 309469 пар оснований и имеет 10 экзонов. По данным компьютерного анализа ген реналазы существует, по крайней мере, в виде двух сплайсинговых вариантов - транскрипционных вариантов мРНК 1 и 2. Транскрипционный вариант 1 (мРНК реналазы 1, MN_001031709.2) кодирует белок в 342 аминокислотных остатка (а.о.) и включает 7 экзонов: 1-4, 6, 7 и 9 экзоны (NP_001026879) с расчетной молекулярной массой 37,85 кДа и pI 6,06. Реналаза 1 была открыта в 2005 г. in silico и может служить наглядной иллюстрацией эффективного использования постгеномных технологий (см. обзор [1]).
Экспрессия гена реналазы 1 в тканях человека преимущественно обнаружена в клубочках и проксимальных канальцах почек, а также в кардиомиоцитах, печени и скелетных мышцах [2].
Другие авторы [3] показали, что экспрессия реналазы 1 определяется также в периферических нервах, надпочечниках и жировой ткани человека.
Вторая изоформа (мРНК реналазы 2, MN_0018363.3) также содержит 7 экзонов (1-4, 6, 7 и 10) и отличается от реналазы 1 только последним экзоном. По данным компьютерного предсказания реналаза 2 кодирует белок в 315 а.о. (NP_060833) с расчетной молекулярной массой 34,95 кДа и pI 6,27. Однако до сих пор этот белок в тканях человека так и не был обнаружен [2]. Правда, при помощи метода ПЦР с обратной транскрипцией (RT_PCR) удалось выявить мРНК реналазы 2 в надпочечниках и гипоталамусе [3]. Этим же методом была обнаружена еще одна форма изоформа гена реналазы, т.н. реналаза 3, мРНК которой содержит экзоны 1, 4, 6, 7 и 9 и кодирует теоретически рассчитанную аминокислотную последовательность в 232 а.о. (AK296262) [3]. В принципе сообщалось и о четвертом варианте сплайсинга гена реналазы (мРНК реналазы 4), содержащем 5, 6, 7, 8 и 9 экзоны, которые кодируют теоретически рассчитанную аминокислотную последовательность в 138 а.о. [4].
Однако за исключением реналазы 1 белковые продукты, кодируемые мРНК реналаз 2, 3 и 4, до сих пор не обнаружены и потому их биологическая роль неизвестна.
Традиционно метод клонирования кДНК требует выделения и очистки значительного количества поли-А селективной мРНК из определенной ткани или клеток (ткани/клетки, в которых имеется экспрессионный клонируемый ген). Выделить необходимую мРНК с низким содержанием в клетке особенно трудно, а в случае тканей человека это также сопряжено с соблюдением юридически установленных процедур.
Открытие Taq-полимеразы [5-6] позволило разработать метод полимеразно-цепной реакции (ПЦР), с появлением которого стало возможно амплифицировать интересующий ген непосредственно из выделенной мРНК, что значительно упростило методологию клонирования гена. Несмотря на это все равно остается необходимость выделения специфической мРНК из тканей.
С развитием технологии ПЦР метода и химического синтеза олигонуклеотидов рекомбинантные гены получают непосредственно с кДНК библиотек, к кодирующим областям которых достраивают фланкирующие участки ДНК, содержащие сайты эдонуклеаз рестрикций, необходимые для клонирования в соответствующие вектора [7-8].
Для получения кДНК генов реналазы мы использовали метод получения кодирующей последовательности гена непосредственно с геномной ДНК, что не требует выделения и очистки мРНК и потому существенно упрощает и ускоряет эту процедуру.
Прототип данного метода получения кДНК и экспрессии реналаз 1 и 2 человека в летературе отсутствует. Аналогичные подходы были использованы в работах [9-12]. Так, в работе [9] описан метод получения полной кодирующей последовательности (кДНК) гена PIGR человека (polymeric immunoglobulin receptor), включающего 10 экзонов, посредством объединения единичных экзонов, полученных с матрицы ДНК, методом ПЦР (Genomic DNA Splicing). Вначале авторы получили индивидуальные экзоны в раздельных реакционных средах с применением для каждого экзона прямого и обратного праймеров, оптимизированных компьютерным анализом. Второй раунд амплификации осуществляли после предварительной очистки ПЦР продукта. Во втором раунде амплификации синтезировали отдельные экзоны, используя праймеры, содержавшие нуклеотидные последовательности, перекрывающие соседние экзоны. На конечном этапе экзоны объединяли методом ПЦР, получая таким образом полноразмерную последовательность кДНК. Davies с соавторами [10] предложили метод получения полноразмерной последовательности кДНК гена SWS1, содержащего 5 экзонов, из тотальной ДНК лемура. И в этом случае индивидуальные экзоны получали методом ПЦР в отдельных реакционных средах с матрицы ДНК с использованием прямого и обратного праймеров, содержащих нуклеотидные последовательности, перекрывающие соседние экзоны. После очистки ПЦР продукта экзоны объединяли попарно для получения полноразмерной последовательности кДНК. Фланкирующие праймеры последовательности кДНК включали сайты рестрикции для встраивания в экспрессирующий вектор.
Booth с соавторами [12] амплифицировали индивидуальные экзоны человеческого цилиарного нейротрофического фактора (human ciliary neurotrophic factor - CNTF), содержащего всего два экзона и один интрон. В начале методом ПЦР были отдельно амплифицированы каждый из экзонов, а затем эти экзоны объединяли и встраивали в плазмидный вектор с получением полной кодирующей последовательности CNTF. В этом случае была использована технология так называемого безлигированного клонирования (ligation-independent cloning - без использования эндонуклеаз рестрикций и лигазы), разработанная ранее [13-14]. Она основывается на использовании олигонуклеотидных праймеров, в которых на 5'-конце дезокситимидиновые остатки заменяют дезоксиуроциловыми остатками. После ПЦР ампликоны обрабатывали урацил-ДНК-гликозилазой (uracil DNA glycosylase - UDG), которая генерирует в ампликонах 3'-выступающие «липкие» концы. По этим концам происходит нековалентное объединение ПЦР фрагментов и безковалентное встраивание их в экспрессионный вектор. Однако использование такой технологии объединения трех и более экзонов для получения полной кодирующей последовательности гена в современной литературе не известны, а методические особенности не описаны.
Методы рекомбинантной ПЦР широко используются при клонировании различных генов и создании гибридных генов. Для объединения двух фрагментов ДНК методом ПЦР в начале получают первый ПЦР-фрагмент, у которого с помощью синтетического олигонуклеотида на 5'-конце достраивают участок ДНК (около 20 нуклеотидов), комплементарный второму 3'-концевому фрагменту ДНК. После отжига первого ПЦР фрагмента и второго фрагмента ДНК проводят ПЦР-амплификацию общего фрагмента ДНК с концевыми праймерами для общего фрагмента [15-17].
В последнее время были реализованы проекты, связанные с секвенированием геномов различных эукариот - это проект «Геном человека», направленный на определение нуклеотидной последовательности всего генома человека [18-19], а также проекты по определению полной нуклеотидной последовательности геномов видов. В настоящее время разрабатываются новые подходы по секвенированию ДНК, позволяющие быстро и с минимальными затратами секвенировать геномы различных видов. Анализ геномных последовательностей по определенным алгоритмам (gene prediction method) позволяет с достаточной точностью определять геномные структуры. Наличие полных геномных последовательностей и легкая доступность в получении амплификатов любых фрагментов ДНК из геномной ДНК и объединение ПЦР-фрагментов позволяют конструировать любые генетические конструкции с известной нуклеотидной последовательностью.
Развитие химически автоматического синтеза олигонуклеотидов привело к увеличению синтеза с 30 до несколько десятков, дало возможность удлинять олигонуклеотидную матрицу при помощи ПЦР до несколько сотен нуклеотидов. Стратегия ступенчатого наращивания нуклеотидной последовательности в результате нескольких ПЦР позволила осуществить синтез гена длиной 400 пар оснований (п.о.) [20]. В других исследованиях удалось осуществить химический синтез гена на синтетической матрице длиной более 650 п.о., используя в качестве матрицы для ПЦР две и одну нуклеотидную цепь [21-23]. Однако химический синтез гена на данный момент является трудоемкой и дорогостоящей работой, и для получения полных кодирующих областей генов широко не используется.
Раскрытие изобретения
В доступной научной литературе мы не обнаружили работ по получению кДНК неэкспрессируемого гена реналазы 2 путем прямого синтеза структурных единиц (экзонов) с геномной матрицей ДНК с последующим объединением этих структурных единиц, используя метод ПЦР. Мы применили экзоновый метод для клонирования функционально слабоэкспрессируемого или молчащего гена реналазы 2. Этот метод основан на получении рекомбинантного гена из тотальной ДНК организма по его известным экзонным структурам. Такой способ позволяет быстро «собрать» ген из банка общего числа генов с известными нуклеотидными последовательностями генома эукариот. Для получения неэкспессируемого гена реналазы 2 мы вначале отработали эту методику на экспрессируемом гене реналазы 1. По данным нуклеотидной последовательности банка данных (GenBank www.ncbi. Homo sapiens chromosome [gi:51511726]) locus NC_000010 gene "C10orf59" имеет два транскрипционных варианта: вариант первый - локус NM_001031709 1477 bp mRNA (ген реналазы 1); вариант второй - локус NM_018363 2107 bp mRNA (ген реналазы 2). Ген реналазы 1 человека включает 7 экзонов и содержит 342 а.о. NP_001026879 (гипотетический белок LOC55328 изоформа 1). Ген реналазы 2 также включает 7 экзонов, отличается от транскрипционного варианта 1 седьмым экзоном и содержит 315 а.о. NP_060833.1 (гипотетический белок LOC55328 изоформа 2). В результате были сконструированы экспрессионные плазмидные векторы pET-Ren-I и pET-Ren-II, продуцирующие в клетках Escherichia coli штамм Rosetta рекомбинантную форму реналазы 1 и реналазы 2.
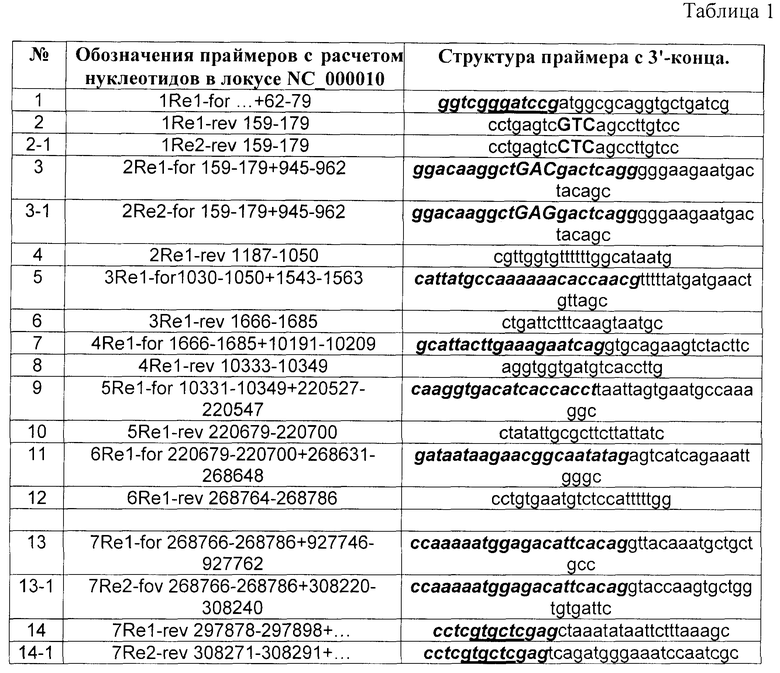
Алгоритм конструирования праймеров для синтеза полной кодирующей области любого гена универсален. В банке данных нуклеотидной последовательности (GenBank www.ncbi.) выбирается последовательность требуемого гена. На примере гена реналазы - локус NC_000010 по данным автоматического вычислительного анализа, использующего метод предсказания гена (gene prediction method), включает две транскрипционные мРНК (NM_001031709 и NM_018363). Транскрипт первый (реналаза 1) включает семь кодирующих областей (экзонов) с номерами нуклеотидов 62-179, 945-1050, 1543-1685, 10191-10349, 220527-220700, 268611-268786, 297746-297898. Следовательно, для синтеза полной кодирующей последовательности реналазы 1 методом ПЦР необходимо синтезировать 14 праймеров (семь «прямых» и семь «обратных» праймеров).
Прямые праймеры (Re1-for - forward) конструируются из двух частей. Первая часть состоит (от 3'-конца) из последовательности (20±3 нуклеотидов) конца предыдущего экзона, т.е. для реналазы 1 номера нуклеотидов, начиная от второго экзона, составляют: 159-179, 1030-1050, 1666-1685, 10331-10349, 220679-220700, 268766-268786 локуса NC_000010. Вариация длины нуклеотидной последовательности зависит от А-Т и G-C состава. Эта часть праймера служит связующим звеном между экзонами (линкерная область). Первая часть прямого праймера первого экзона (прямая фланкирующая область полного структурного гена - 1Re1-for) может содержать до 15 нуклеотидов, служит для встраивания в плазмидный вектор и содержит необходимый для этого сайт рестрикции. В таблице 1 первая часть праймера выделена курсивом и жирным шрифтом. Вторая часть также состоит из 20±3 нуклеотидов, включающих начало экзонов, т.е. номера прямых нуклеотидов, начиная от первого экзона: 62-79, 945-962, 1543-1563 10191-10209, 220527-220547, 268631-268648 и 927746-927762 локуса NC_000010.
Из вышесказанного следует, что, например, прямой праймер второго экзона (2Re1-for) состоит из двадцати одного (159-179) и восемнадцати (945-962) нуклеотидов локуса NC_000010 (см. таблицу 1).
Обратные праймеры (Re1-rev - reverse) конструируются из одной части (20±3 нуклеотидов) комплементарной последовательности, которая состоит из концевой части экзона, т.е. номера с 5'-конца комплементарной последовательности, начиная от первого экзона: 159-179, 1187-1050, 1666-1685, 10333-10349, 220679-220700, 268764-268786, 297878-297898 локуса NC_000010. Обратный праймер последнего экзона (обратная фланкирующая область полного структурного гена 7Re1-rev) содержит дополнительный участок нуклеотидной последовательности (до 15 нуклеотидов), который служит для встраивания в плазмидный вектор и содержит необходимый для этого сайт рестрикции (см. таблицу 1).
Таким образом, структуру праймеров можно создавать автоматически исходя из известной нуклеотидной последовательности гена по данным автоматического вычислительного анализа, использующего метод предсказания гена.
Синтез структурного гена реналазы 1 человека проводили в несколько этапов (см. рис.1).
На первом этапе тотальную ДНК получали из лимфоцитов цельной крови человека модифицированным методом [16]. ДНК выделяли в 2 мл пробирки Eppendorf. К 1 мл крови, содержащему EDTA, добавляли 1 мл буфера-1 (22% сахарозы; 20 мМ MgCl2; 20 мМ Tris-HCl pH 7,5; 1% Triton X-100). Раствор центрифугировали 10 мин при 3800 об/мин на микроцентрифуге Eppendorf Centrifuge 5415 R. Осадок ресуспендировали в 1 мл буфера-1 (разбавленного в два раза) и повторяли центрифугирование. Далее клетки суспендировали в 0,9 мл буфера-2 (10 мМ Tris-HCl; 2 мМ EDTA; 400 мМ NaCl), добавляли 0,1 мл 10% SDS и протеиназу К до концентрации 1 мг/мл. Раствор инкубировали 2-3 часа при 58°C с периодическим перемешиванием. Затем проводили двукратную фенолхлороформную экстракцию, после этого добавляли 0,1 объема 3 М асетата натрия pH 5,0 и 0,6 объема изопропанола. ДНК осаждали при 12000 об/мин (используя туже центрифугу) и осадок промывали 70% холодным этанолом. ДНК растворяли 0,2 мл H2O и хранили при -20°C.
На втором этапе на матрице ДНК человека методом ПЦР получали семь единичных экзонов. Каждый экзон синтезировали отдельно с использованием пары праймеров: для первого экзона 1Re1-for n+62-79 и 1Re1-rev 159-179; второго экзона 2Re1-for 159-179+945-962 и 2Re1-rev 1187-1050; третьего экзона 3Re1-for 1030-1050+1543-1563 и 3Re1-rev 1666-1685; четвертого экзона 4Re1-for 1666-1685+10191-10213 и 4Re1-rev 10333-10349; пятого экзона 5Re1-for 10333-10349+220527-220547 и 5Re1-rev 220679-220700; шестого экзона 6Re1-for 220679-220700+268631-268648 и 6Re1-rev 268764-267886; седьмого экзона 7Re1-for 268766-268786+927746-927762 и 7Re1-rev 297878-297898+n (см. таблицу 1 - с 1 по 14 праймеры). Прямые праймеры (Re1-for …) содержат на 3'-конце последовательность, состоящую примерно из 20±3 нуклеотидов, которая комплементарна обратному праймеру предыдущего экзона (Re1-rev …) - линкерная область ПЦР фрагментов, которая является связующим звеном между экзонами (на рис.1 линкерная область обозначена символом L). В таблице 1 эта область выделена курсивом и жирным шрифтом.
Например, линкерная область прямого праймера 2Re1-for 159-179+945-962 комплементарна обратному праймеру 1Re1-rev 159-179. На рисунке 1 эта область была обозначена как L2 (L(n) - linker, n - номер экзона) - линкерная область, связующее звено между экзонами. Линкерные области фланкирующих экзонов 1R1 и 7R1 гена реналазы - прямой праймер 1Re1-for n+62-79 экзона 1R1 и обратного праймера 7Re1-rev 297878-297898+n экзона 7R1, содержат соответственно сайты рестриктаз BamHI и XhoI (таблица 1 - №1 и 14, подчеркнутые области), которые используются для последующего встраивания структурного гена реналазы в плазмидный вектор рЕТ-28а(+). Обратные праймеры (Re1-rev - reverse) начинаются на границе экзона и их нуклеотидная последовательность входит в структуру этого экзона.
ПЦР проводили в 20 мкл реакционной смеси, содержащей: 4 мкл 5хПЦР раствора (33,5 мМ Tris pH 8,8; 8,3 мМ (NH4)2SO4; 0,1% Twin 20; 5 мМ MgCl2; 0,5 мМ dNTP; 5% глицерин), праймеры (по 400 мкМ каждого в данном объеме), 50-100 нг ДНК и 0,5 ед. Tag-ДНК-полимеразы (модифицированная для теплового старта). Условия ПЦР: 95°C - 5 мин 1 цикл; 92°C - 20 сек, 55°C - 15 сек, 72°C - 10 сек 35 циклов; 72°C - заключительный цикл 3 мин.
При синтезе одиночных экзонов обычно образуются минорные полосы с хорошим выходом продукта (1, 2, 4 и 6 экзоны). Однако 3-й и 7-й экзоны не давали видимую полосу ПЦР продукта или давали низкий выход ПЦР продукта (5-й экзон). В этом случае на первом этапе ПЦР увеличивали в 2-3 раза концентрацию ДНК матрицы или проводили реамплификацию. Реамплификацию проводили в тех же условиях, что и начальную ПЦР. Исключение составляло то, что вместо ДНК матрицы использовали ампликоны от первой ПЦР смеси в количестве 1-2 мкл, а количество циклов уменьшали до 30.
В результате семи раздельных ПЦР были получены ампликоны следующих экзонов: 1Re1, 2Re1, 3Re1, 4Re1, 5Re1, 6Re1, 7Re1 (рис.1 - 2-й этап, рис.2, номера дорожек с 1 по 7).
На третьем этапе методом ПЦР проводили парное объединение экзонов 1Re1 со 2Re1, 3Re1 с 4Re1 и 5Re1 с 6Re1. Линкер L2 служил связующим звеном для экзонов 1Re1 и 2Re1, линкер L4 для экзонов 3Re1 и 4Re1, а линкер L6 для 5Re1 и 6Re1. В качестве матрицы служили ампликоны двух единичных экзонов, а в качестве праймеров для первого объединения экзонов служили 1Re1-for n+62-79 и 2Re1-rev 1187-1050; для второго объединения - 3Re1-for 1030-1050+1543-1563 и 4Re1-rev 10333-10349; третьего объединения - 5Re1-for 10333-10349+220527-220547 и 6Re1-rev 268764-268786. ПЦР проводили в тех же условиях, как и для одиночных экзонов. В качестве матрицы использовали 0,5-1 мкл ПЦР смеси от ампликонов одиночных экзонов. При объединении двух экзонов незначительная примесь праймеров и геномной ДНК, находящаяся в ампликонах одиночных экзонов, не мешала синтезу спаренных экзонов и не давала побочных продуктов.
В результате синтеза трех раздельных ПЦР были получены три фрагмента ДНК для двух объединенных экзонов: 1Re1-2Re1, 3Re1-4Re1, 5Re1-6Re1 (рис.1 - 3-й этап, рис.3 - дорожки 1, 2, 3).
На четвертом этапе проводили объединение двух двойных экзонов ПЦР методом: 1Re1-2Re1 с 3Re1-4Re1 и 5Re1-6Re1 с 7Re1. Линкер L3 служил для связи экзонов 1Re1-2Re1 и 3Re1-4Re1, в качестве матрицы были использованы ампликоны этих экзонов, а праймерами служили 1Re1-for n+62-79 и 4Re1-rev 10333-10349. Линкер L7 связывал двойной объединенный экзон 5Re1-6Re1 и единичный экзон 7Re1, в качестве матрицы были использованы ампликоны этих экзонов, а праймерами служили 5Re1-for 10333-10349+220527-220547 и 7Re1-rev 297878-297898+n.
Условия ПЦР были аналогичны использованным при двойном объединении экзонов. Матрицей служили 0,5-1 мкл ПЦР смеси от ампликонов двойных экзонов. При объединении экзонов методом ПЦР незначительная примесь праймеров, находящаяся в ампликонах двух объединенных экзонов, не мешала при объединении четырех и трех экзонов и не давала побочного продукта.
В результате синтеза методом ПЦР были получены четыре объединенных экзона 1Re1-4Re1 и три объединенных экзона 5Re1-7Re1 (рис.1 - 4-й этап, рис.3 - дорожки 4, 5 и см. табл.2).
На пятом этапе осуществляли синтез полной кодирующей области гена реналазы 1, объединяя с помощью ПЦР все семь экзонов. Для этого четыре объединенных экзона 1Re1-4Re1 соединяли с тремя объединенными экзонами 5Re1-7Re1. Связующим звеном для объединения этих экзонов служил линкер L5, в качестве матрицы были использованы ампликоны этих экзонов, а праймерами служили 1Re1-for n+62-79 и 7Re1-rev 297878-297898+n.
Условия ПЦР была аналогичны использованным на пятом этапе синтеза гена реналазы. В качестве матрицы использовали 0,5-1 мкл ПЦР смеси от ампликонов объединенных экзонов. При объединении экзонов ПЦР методом незначительная примесь праймеров и ампликонов, находящаяся в ПЦР смеси от четвертого этапа синтеза гена, не мешала синтезу всей кодирующей области гена.
В результате ПЦР был получен полный ген реналазы 1, состоящий из семи экзонов (1Re1-7Re1), фланкирующие концы которого содержали линкеры L1 и L8 с сайтами рестрикции для BamHI и XhoI, соответственно (рис.1 - 5-й этап, рис.3 - дорожка 6 и табл.2).
Объединенный фрагмент ДИК был амплифицирован, очищен электрофоретически и выделен из 2% агарозного геля. Для этого в лунку агарозного геля наносили 10 мкл раствора от ПЦР реакции. После электрофореза необходимую полосу вырезали и из геля, а ДНК элюировали по прописи и с применением набора Wizard SV Gel and PCR Clean-Up System (Promega).
Для тестирования целостности кодирующей последовательности структурного гена реналазы 1 объединенный фрагмент ДНК встраивали в плазмидный вектор pGEM-T вектор, предназначенный для клонирования ПЦР продукта. Этот вектор содержит на 3'-концах выступающий единичный Т-остаток, который значительно усиливает лигирование ПЦР продукта. После клонирования объединенного ПЦР продукта были отобраны 10 клонов, которые вначале подвергались рестриктному анализу, а затем - секвенированию ПЦР фрагмента.
Секвенирование ДНК проводили на капиллярном ДНК секвенаторе (Applied Biosystems 310 DNA analyzer) с использованием BigDye Terminator v 3,1 Cycle Sequencing Kit в соответствии с рекомендациями фирмы производителя. Полученную последовательность ДНК соотносили с геном реналазы 1 (locus BC005364 GeneBank), используя программу BLAST, доступную на сайте National Center for Biotechnology Information (http://www.ncbi.nlm.nih.gov).
В результате секвенирования трех клонов было обнаружено, что в клонируемой последовательности имеются три точечные мутации в положении 107, 342 и 723 (на рис.3 они указаны заглавной буквой, выделены жирным шрифтом, и курсивом с подчеркиванием). Эти мутации затрагивают третий нуклеотид вырожденных триплетов и потому не меняют кодируемые данными триплетами аминокислоты.
Ранее было показано, что ПЦР может вводить мутации в амплифицированную ДНК, которые являются результатом недостаточно высокой репликативной точности работы Taq ДНК полимеразы. Для понижения мутационнго давления уменьшают общее количество циклов в амплификации ДНК, либо используют термостабильную ДНК полимеразу с корректирующей активностью [21-23]. Для наших целей мы использовали термостабильную ДНК полимеразу (фирма Евроген), представляющую собой специально разработанную смесь термостабильных ДНК полимераз для эффективной амплификации длинных фрагментов ДНК и обладающую корректирующей 3'->5' экзонуклеазной активностью.
На шестом этапе был получен экспрессионный вектор рекомбинантного гена реналазы 1 pET-Ren-I в результате встраивания в плазмидный вектор pET-28a(f+) по сайтам рестрикции BamHI и XhoI ПЦР фрагмента ДНК, состоящего из семи объединенных между собой экзонов. Для получения этого экспрессионного вектора ПЦР продукт, состоящий из полной кодирующей области гена реналазы 1 (пятый этап схема 1), обрабатывали рестриктазами BamHI и XhoI и лигировали с приготовленным линейным вектором pET-28a(f+), фланкированным этими же участками узнавания рестриктаз. В результате был получен экспрессионный вектор pET-Ren-I (см. рис.1), которым трансформировали клетки Е. coli.
Рубидиевые клетки Е. coli K12 (штамм DE3 Rosetta) готовили по модифицированному методу Kushner [27], аликвоты компетентных клеток (по 0,2 мл) хранили при -70°C. Трансформацию проводили по стандартному методу Cohen [28], используя 0,1 мкг продуктов лигирования. Трансформированные клетки высевали на чашки с LB-агаром, содержащим 100 мкг/мл ампициллина (Ам). После инкубации при 37°C в течение ночи индивидуальную колонию, выросшую на чашке, подращивали в 4 мл LB-среды со 100 мкг/мл Ам в течение ночи. Ночную культуру пересевали в 200 мл этой же LB среды и наращивали культуру клеток до оптической плотности 0,7-0,8 ед. Затем вносили ИПТГ до концентрации 1 мМ и продолжали инкубировать клетки при интенсивном перемешивании еще 3 часа. Биомассу собирали центрифугированием и хранили при -20°C.
Наличие экспрессии гена реналазы 1 анализировали электрофоретически. Образец клеток кипятили в буфере для нанесения (60 мМ Трис-HCl pH 6,8; 1% SDS; 0,2 мМ EDTA; 5% меркаптоэтанол; 8% глицерин; 001% бромфеноловый синий) и анализировали в 0,1% SDS-10% ПААГ. Белок выявляли окрашиванием в кумасси бриллиантовый синий R-250 (см. рис.5). По расчетным данным белок реналазы 1 содержит 342 аминокислотных остатка (а.о.) и соответствует расчетной массе 37,83 кДа и pI 6,06.
Получение полной кодирующей последовательности реналазы 2
Транскрипционный вариант 1 (реналаза 1), также как и транскрипционный вариант 2 (реналаза 2), вначале был выявлен методом предсказания гена (gene prediction method) [2], однако реналаза 2 в клетках человека на данный момент не обнаружена.
Транскрипционный вариант мРНК 2 отличается от транскрипционного варианта мРНК 1 седьмым экзоном. Кроме того, в первом экзоне, кодирующая аминокислотная последовательность реналазы 2 содержит в положении 37 остаток глутаминовой кислоты (кодон - GAC), а реналаза 1 - аспарагиновой кислоты (кодон - GAG). Кодон этой аминокислоты входит в состав праймеров 1Re2-rev и 2Re2-for (на рис.4 и в табл.1 положение этой а.к. выделено заглавными буквами жирным шрифтом (ср. 2, 2-1 и 3, 3-1). С учетом замены аминокислоты в первом экзоне и синтеза нового седьмого экзона были синтезированы четыре дополнительных праймера (см. таблица 1, номера: 2-1, 3-1, 13-1, 14-1). Синтез полной кодирующей последовательности реналазы 2 осуществляли по той же схеме, различие в синтезе проявлялись, начиная со второго этапа (см. рис.1).
На втором этапе на матрице ДНК человека методом ПЦР получали три единичных экзона: 1Re2, 2Re2 и 7Re2 (см. таблицу 2, номера 1-1, 2-1 и 7-1). Единичные экзоны синтезировали с использованием пары праймеров: для 1Re2 экзона - праймеры 1Re1-for n+62-79 и 1Re2-rev 159-179; для 2Re2 экзона - праймеры 2Re2-for 159-179+945-962 и 2Re1-rev 1187-1050; для седьмого экзона - праймеры 7Re2-for 268766-268786+308220-308240 и 7Re2-rev 308271-308291+n (см. таблицу 1 и 2).
На третьем этапе методом ПЦР проводили только парное объединение экзонов 1Re2 с 2Re2. Для объединения этих экзонов праймерами служили 1Re1-for n+62-79 и 2Re1-rev 1187-1050. В результате ПЦР получили фрагмент ДНК 1Re2-2Re2 (см. таблицу 1 и 2).
На четвертом этапе проводили объединение двойных экзонов ПЦР методом: 1Re2-2Re2 с 3Re1-4Re1 и 5Re1-6Re1 с 7Re2. Для объединения до четвертичного экзона 1Re2-4Re2 праймерами служили 1Re1-for n+62-79 и 4Re1-rev 10333-10349, а для третичного 5Re2-7Re2 праймерами служили 5Re1-for 10331-10349+220527-220547 и 7Re2-rev 308271-308291+n (см. рис.1 - 4-й этап и таблицу 1 и 2).
На пятом этапе получали рекомбинантный ген реналазы 2, объединяя с помощью ПЦР все семь экзонов. В результате объединенных четырех экзонов 1Re2-4Re2 с тремя экзонами 5Re2-7Re2 была получена полная кодирующая последовательность реналазы 2 1Re2-7Re2. Для синтеза этой последовательности праймерами служили 1Re1-for n+62-79 и 7Re2-rev 308271-308291+n (см. рис.1 - 5-й этап и таблицу 1 и 2).
На шестом этапе конструировали экспрессионный вектор рекомбинантного гена реналазы 2. Для получения экспрессионного вектора ПЦР продукт из этапа 6 обрабатывали рестриктазами BamHI и XhoI и лигировали с приготовленным линейным вектором pET-28a(f+), фланкированным этими же участками узнавания рестриктаз. В результате был получен экспрессионный вектор pET-Ren-II (см. рис.1-6 - этап), которым трансформировали клетки Е. coli. В результате экспрессии был получен белок реналазы 2, который содержит 315 а.о. и соответствует расчетной массе 34,95 кДа и pI 6,27 (см. рис.6).
Суммируя результаты, полученные при помощи предлагаемого нами экзонового метода клонирования рекомбинантных белков, следует отметить следующие преимущества данного метода: 1 - данный метод является довольно простым методом клонирования рекомбинантных генов, не требующим значительных временных и материальных затрат по сравнению с общепринятыми в настоящее время; 2 - для синтеза кодирующей последовательности гена праймеры подбираются автоматически исходя из банка данных нуклеотидной последовательности клонируемого гена, число праймеров равно удвоенному числу экзонов клонируемого гена; 3 - данный метод не требует выделения мРНК из биологических объектов; 4 - при помощи данного метода был клонирован ген рекомбинантного белок реналазы 2, который относится к белкам с низким уровнем экспрессии или к молчащему гену; 5 - для данного метода не требуются клетки и ткани животных, в которых повышена экспрессия клонируемого гена, труднодоступные в интактном виде ткани человека, получение которых может быть сопряжено (например, в случае посмертного материала) с соблюдением юридически установленных процедур; 6 - данным методом (при постановке его в поточном режиме) можно синтезировать значительное количество рекомбинантных генов за небольшой промежуток времени.
Техническим результатом изобретения является получение рекомбинантных генов - гена реналазы 1, состоящего из 342 а.о., и гена реналазы 2, состоящего из 315 а.о., и их экспрессия в бактериальных клетках (рис.5 и 6).
Краткое описание таблиц и рисунков
Таблица 1. ПЦР праймеры для получения полной кодирующей последовательности генов реналазы 1 и 2.
Примечание. В структуре праймеров, выделенным курсивом и жирным шрифтом, обозначена область перекрывания (L - линкер) (n+1)-го экзона с n-м экзоном, т.е область праймера 2Re1-for 159-179+945-964 комплементарна праймеру 1Re1-rev 159-179. Фланкирующие линкерные области первого экзона прямого праймера первого экзона (1Re1-for n+62-79) и обратного праймера седьмого экзона (7Re1-rev 297878-297898+n) содержат соответственно сайты рестрикции BamHI и XhoI - нуклеотиды выделены жирным шрифтом и курсивом и обозначены знаком "n". Праймеры под номерами 2-1, 3-1, 13-1, 14-1 синтезированы для получения кодирующей последовательности гена реналазы 2. См. пояснение в тексте.
Таблица 2. Размеры экзонов генов реналазы 1 и 2, полученные в результате ПЦР.
Примечания. Re1 и Re2 обозначают экзоны, специфичные для генов реналазы 1 и 2, соответственно, а цифры перед этими символами - порядковый номер экзона.
Рисунок 1. Экзоновый метод получения рекомбинантной реналазы 1 человека.
Рисунок 2. Электрофорез ПЦР фрагментов ДНК одиночных экзонов в 2% агарозном геле. Led - ДНК маркеры размером от 50 п.о. до 500 п.о. с интервалом в 50 п.о.; 1 - экзон 1Re 131 п.о; 2 - экзон 2Re 126 п.о; 3 - экзон 3Re 166 п.о.; 4 - экзон 4Re 179 п.о.; 5 - экзон 5Re 193 п.о.; 6 - экзон 6Re 199 п.о.; 7 - экзон 7Re 188 п.о. Размеры экзонов приведены с учетом размера линкера (см. табл. 2 и схему I). Стрелками обозначены фрагменты ДНК маркера.
Рисунок 3. Электрофорез ПЦР фрагментов ДИК объединенных экзонов в 2% агарозном геле. Led1 - ДНК маркеры размером от 50 п.о. - 500 п.о. с интервалом 50 п.о.; Led2 - ДНК маркеры размером 50 п.о. и от 100 п.о. - 1000 п.о. с интервалом 100 п.о.; 1 - экзоны 1Re-2Re 236 п.о; 2 - экзоны 3Re-4Re 325 п.о; 3 - экзоны 5Re-6Re 370 п.о.; 4 - экзоны 1Re-4Re 538 п.о.; 5 - экзоны 5Re-7Re 535 п.о.; 6 - экзоны 1Re-7Re 1061 п.о. Размеры экзонов приведены с учетом размера линкера (см. табл.2 и рис.1). Стрелками обозначены фрагменты ДНК маркера.
Рисунок 4. Сравнение нуклеотидных последовательностей гена реналазы - транскрипт 1 из NCBI GenBank (код доступа NM 001031709) (А) и клонированная нами нуклеотидная последовательность гена реналазы - (транскрипт 1) (Б).
Рисунок 5. Экспрессия реналазы 1 в клетках E.coli. 1 - тотальный клеточный белок без индукции; 2 - тотальный клеточный белок после идукции ИПТГ; 3 - маркер молекулярной массы белков (фирма Fermentas SM0441) - 19, 25, 34, 49, 85 и 117 кДа.
Рисунок 6. Экспрессия реналазы 1 и 2 в клетках E.coli. 2 и 5 - тотальный клеточный белок без индукции; 1 - тотальный клеточный белок после индукции ИПТГ (реналаза 1); 3 и 4 - тотальный клеточный белок после индукции ИПТГ (реналаза 2); 6 - белок реналазы 1 после очистки на Ni-агарозе; 7 - маркер молекулярной массы белков (фирма Fermentas SM0441) - 19, 25, 34, 49, 85 и 117 кДа.
Данная работа выполнена при поддержке Российского Фонда Фундаментальных Исследований (грант №11-04-01181-а).











Изобретение относится к области генной инженерии и может быть использовано в биотехнологии для получения представляющих практический интерес белков, являющихся продуктами молчащих генов или генов с низким уровнем экспрессии. Предложен способ продуцирования рекомбинантного белка реналазы 2 человека, предусматривающий а) получение полной последовательности кДНК и б) экспрессию полученной последовательности в E.coli, где стадию (а) осуществляют путем ПЦР-амплификации каждого из экзонов с использованием специфических пар праймеров и геномной ДНК в качестве матрицы, и последующего, не предполагающего предварительной очистки, попарного объединения тем же методом сначала соседних экзонов, а затем являющихся продуктами их объединения ампликонов. При этом подбор праймеров, число которых равно удвоенному количеству экзонов, проводят так, чтобы прямые праймеры содержали концевую последовательность предыдущего экзона и начальную последовательность копируемого экзона; обратные праймеры включали только последовательность, комплементарную концу амплифицируемого экзона, а фланкирующие полную кодирующую последовательность прямой и обратный праймеры содержали сайты рестрикции, необходимые для встраивания в плазмидный вектор. 2 табл., 6 ил., 1 пр.
Способ получения и экспрессии полной кДНК последовательности изоформы 2 реналазы человека, который включает стадии:
(1) - получение тотальной ДНК человека, содержащей целевой ген;
(2) - ПЦР амплификация в отдельном реакционном объеме каждого из экзонов с использованием соответственно следующих пар праймеров:
IRe1-for n+62-79, 1Re2-rev 159-179;
2Re2-for 159-179+945-962, 2Re1-rev 1187-1050;
3Re1-for 1030-1050+1543-1563, 3Re1-rev 1666-1685;
4Re1-for 1666-1685+10191-10213, 4Re1-rev 10333-10349;
5Re1-for 10333-10349+220527-220547, 5Re1-rev 220679-220700;
6Re1-for 220679-220700+268631-268648, 6Re1-rev 268764-268786;
7Re2-for 268766-268786+308220-308240, 7Re2-rev 308271-308291+n,
где приводимый интервал значений соответствует положениям нуклеотидов в гене реналазы NC_000010;
(3) - получение полноразмерной кДНК путем попарного объединения без предварительной очистки сначала соседних экзонов, полученных на стадии (2), а затем являющихся продуктами их объединения ампликонов с использованием соответствующих прямого и обратного праймеров, выбранных из вышеприведенного перечня согласно таблице 2;
(4) - конструирование рекомбинантного плазмидного вектора, пригодного для использования в E.coli и содержащего полученную на предыдущей стадии полноразмерную последовательность кДНК;
(5) - трансформация штамма E.coli указанным вектором;
(6) - культивирование трансформированного штамма в условиях, обеспечивающих биосинтез белка изоформы 2 реналазы человека в бактериальных клетках в виде телец включения.
| AN X | |||
| ЕТ AL | |||
| PLoS ONE, 2007, 2(11):e1179 | |||
| WAYNE L.D | |||
| WET AL | |||
| BioTechniques, 43(6), 785-789 | |||
| HENNEBRY ЕТ AL | |||
| Vol | |||
| Psychiatry, 2010, 15, 234-236 | |||
| RU 2008110669 A, 27.09.2009. |

