Изобретение относится к способам анализа текстов, написанных на естественном языке, а именно к способам определения и классификации понятий. Изобретение позволяет выделить существенные определяющие и классифицирующие признаки понятия из словарного контекста, в котором понятие употребляется.
Известен способ определения понятия с помощью математической модели, описанный в работе [1]. При этом способе для определяемого слова модель генерирует фразу на естественном языке, объясняющую его смысл. Математическую модель получают в результате машинного обучения на парах «определяемое слово» - «определяющая фраза», взятых из словарей, с использованием векторного представления текста.
Недостатки этого способа связаны с ограниченными возможностями предложенных математических моделей решать задачу генерации словарных определений - наличием ошибок употребления избыточного количества слов, использованием определяемого слова внутри определения, некорректным использованием частей речи, искажением смысла. В результате подобные решения оказываются более полезными для оценки качества векторного представления текста, чем для формирования определений, вызывающих высокий уровень доверия в профессиональном сообществе. Известен также способ извлечения информации из неструктурированных текстов, написанных на естественном языке (патент RU 2751993 C1) [2]. Данный способ предназначен для извлечения информации из текстовых данных и реализуется с помощью компьютерных программ, однако не содержит специфичных процедур для решения задач определения понятий и их классификации.
Известен также способ построения системы понятий, заключающийся в том, что отбирают источники текстовых данных, содержащих контекст определяемых понятий, составляют множество текстов из всех отобранных источников текстовых данных, относят текстовые данные к разным категориям предметной области и классам важности для решаемой задачи, идентифицируют определяемые понятия и именуют их, находят характеризующие определяемые понятия признаки и находят обобщающие определяемые понятия категории, связывают понятия в систему, проверяют корректность системы понятий с помощью внешних экспертов, пересматривают систему понятий при необходимости [3]. Данный способ позволяет определить определяемое понятие через набор характеризующих его признаков и взаимосвязи с родственными понятиями, определяя тем самым определяемое понятие в системе понятий. Недостатки этого способа заключаются в проведении исключительно качественного анализа для извлечения характеризующих определяемое понятие признаков и их произвольном, субъективный выборе.
Этот способ выбран в качестве прототипа предложенного решения. Технический результат применения изобретения заключается в повышении объективности выбора наименования и обобщающих категорий определяемого понятия, а также в повышении релевантности характеризующих и классифицирующих признаков и функций определяемого понятия, за счет минимизации человеческого фактора с помощью математического моделирования и алгоритмизации анализа контекстных и семантических отношений между определяемым понятием, обобщающими определяемое понятие категориями, характеризующими и классифицирующими признаками и функциями определяемого понятия, реализованных в компьютерных программах.
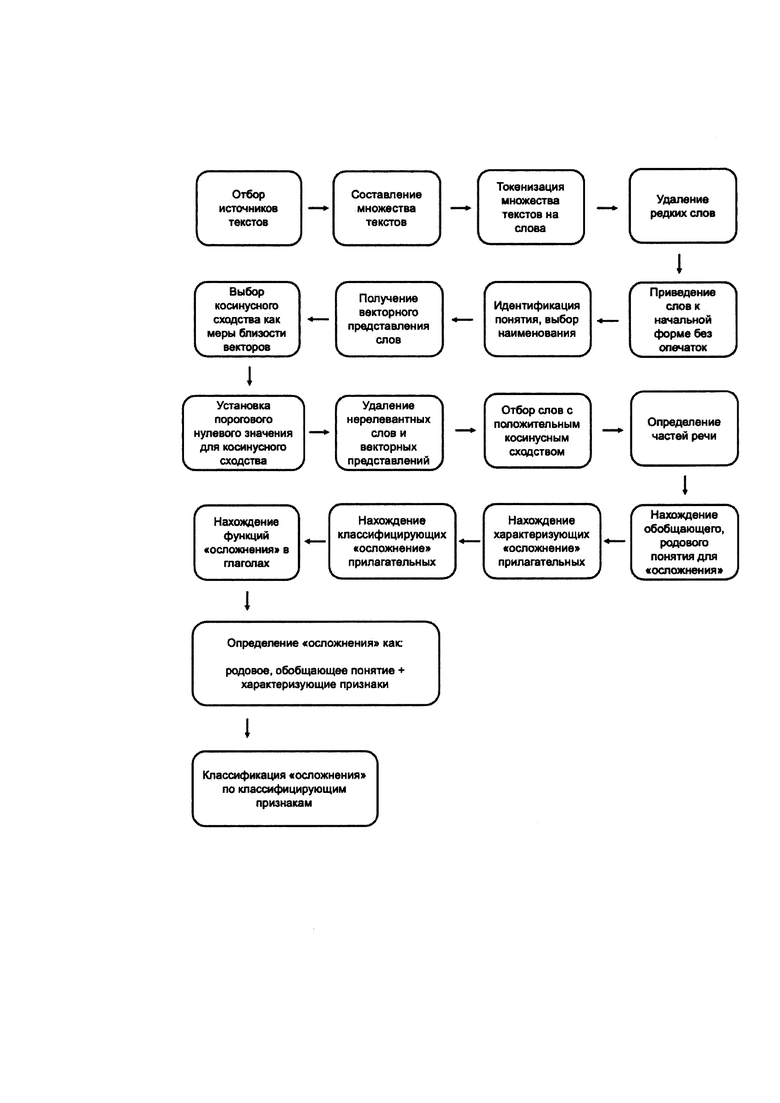
Сущностью изобретения является то и указанный технический результат достигается тем, что в способе определения и классификации понятия исходя из контекста его употребления, заключающемся в том, что отбирают источники текстовых данных, содержащих контекст определяемого понятия, составляют множество текстов из всех отобранных источников текстовых данных, идентифицируют определяемое понятие и именуют его, находят характеризующие определяемое понятие признаки и находят обобщающие определяемое понятие категории, после составления множества текстов из всех отобранных источников текстовых данных токенизируют множество текстов на слова. Далее удаляют слова, встречающиеся во множестве текстов реже заданного числа раз, а все оставшиеся слова приводят к начальной форме и исправляют в них опечатки. Затем идентифицируют определяемое понятие во множестве оставшихся слов и именуют его, выбирая формулировку из множества оставшихся слов. Далее выбирают меру контекстной близости между определяемым понятием и оставшимися словами, после чего задают пороговое значение выбранной меры контекстной близости, превышение которого означает контекстную и смысловую близость слов. Затем удаляют слова, не имеющие отношения к определяемому понятию, а из оставшихся слов отбирают слова, для которых мера контекстной близости с определяемым понятием превышает пороговое значение. Далее определяют части речи отобранных слов. При этом в реализации способа обобщающие определяемое понятие категории находят как обобщающие категории для отобранных существительных и определяемого понятия. Характеризующие определяемое понятие признаки находят в отобранных прилагательных. В отобранных прилагательных также находят классифицирующие определяемое понятие признаки. В отобранных глаголах находят признаки определяемого понятия, указывающие на его функции. Далее дают определение определяемому понятию, используя его наименование, обобщающие категории, характеризующие признаки и функции. Также классифицируют определяемое понятие, используя классифицирующие признаки.
Существует вариант, в котором выбирают меру контекстной близости между определяемым понятием и оставшимися словами, рассчитывая векторные представления слов, отражающие их контекстную близость, и выбирая меру близости между вектором, соответствующим определяемому понятию, и векторами для оставшихся слов.
Существует также вариант, в котором выбирают меру контекстной близости между определяемым понятием и оставшимися словами на основе количества слов между определяемым понятием и оставшимися словами до и/или после определяемого понятия.
Существует также вариант, в котором выбирают меру контекстной близости между определяемым понятием и оставшимися словами на основе статистик совместного употребления определяемого понятия и оставшихся слов. На прилагаемых графических материалах представлена схема реализации изобретения для определения и классификации понятия «осложнение» в нейрохирургии по неструктурированным текстовым записям электронных историй болезни для 90 688 законченных случаев нейрохирургического лечения в условиях стационара.
Осуществление изобретения Способ определения и классификация понятия исходя из контекста его употребления включает следующие этапы. Сначала отбирают источники текстовых данных, содержащих контекст определяемого понятия. Это может быть осуществлено следующим образом. Выбирают электронные и неэлектронные библиотеки, архивы, документы, интернет-ресурсы, информационные системы, телекоммуникационные системы, файлы и любые другие хранилища неструктурированной текстовой информации, а также их внутренние разделы и подразделы, поля баз данных и другие источники, содержащие искомую информацию на любых носителях текстовых данных (бумага, фотопленка, электронные запоминающие устройства, прочие носители). Далее составляют множество текстов из всех отобранных источников текстовых данных, при этом формируют список текстов и для каждого текста указывают источник и другие структурированные метаданные. Идентифицируют определяемое понятие и именуют его. При этом формулировку наименования определяемого понятия находят во множестве текстов как наиболее часто встречающуюся формулировку, написанную без ошибок. Далее находят характеризующие определяемое понятие признаки. Для этого находят основные и близкие по контексту признаки определяемого понятия во множестве текстов. Далее находят обобщающие определяемое понятие категории. Это может быть осуществлено путем оценки семантической близости определяемого понятия с другими понятиями, найденными во множестве текстов. Отличительными признаками предложенного решения является то, что после составления множества текстов из всех отобранных источников текстовых данных токенизируют множество текстов на слова (например, так, как это описано в работе [4]), удаляют слова, встречающиеся во множестве текстов реже заданного числа раз (например, по методам описанным в работе [5]), все оставшиеся слова приводят к начальной форме и исправляют в них опечатки (например, по методам, описанным в работах [6-8]). При этом множество текстов предварительно переводят в электронный текстовый формат с помощью набора текста на клавиатуре, сканирования источника и последующего распознавания программными средствами, диктования компьютеру и последующего распознавания речи и преобразования ее в текстовый формат программными средствами, а также прочими возможными способами. Множество текстов из всех источников формируют в таком виде, в котором для каждого текста указан источник и при необходимости другие идентифицирующие текст структурированные метаданные. Дальнейшую работу с текстами проводят в электронном виде. Токенизацию производят с помощью написанных на языках программирования функций, в том числе, входящих в состав специальных библиотек (например, в языках программирования R, Python). Слова приводят к начальной (нормальной, словарной) форме с помощью программных средств лемматизации, заложенных в возможности языков программирования [4], функций специальных библиотек для языков программирования или специального программного обеспечения (например, MyStem, TreeTagger, UDPipe [9-11]), с помощью словарей и других инструментов для приведения слов к начальной форме [7]. Для исправления опечаток в словах используют методы, основанные на кластеризации по расстоянию Левенштейна в модификациях, фонетических и других правилах, специальные словари, функции, написанные на языках программирования, программное обеспечение (например, Hunspell checker) [6, 7, 12]. Далее идентифицируют определяемое понятие во множестве оставшихся слов и именуют его, выбирая формулировку из множества оставшихся слов. Затем выбирают меру контекстной близости между определяемым понятием и оставшимися словами. Выбор меры контекстной близости основывают на количественных методах анализа неструктурированных текстов, описанных на естественном языке, в том числе из категории «мешка слов» и методах векторного представления текстов [13]. При этом меру контекстной близости формулируют так, чтобы обеспечить линейную зависимость между ее значением и контекстной и смысловой близостью слова, для которого она рассчитывается, с определяемым понятием. Далее задают пороговое значение выбранной меры контекстной близости, превышение которого означает контекстную и смысловую близость слов. Пороговое значение задают в области значений, принимаемых мерой контекстной близости. Далее удаляют слова, не имеющие отношения к определяемому понятию. Для этого проводят скрининг всего списка слов в начальной форме с помощью программного обеспечения, например, описанного в работе [7], и исключают нерелевантные слова из списка. Из оставшихся слов отбирают слова, для которых мера контекстной близости с определяемым понятием превышает пороговое значение. Это осуществляют, рассчитывая выбранную меру контекстной близости слов с определяемым понятием с помощью написанных на языках программирования функций, в том числе, входящих в состав специальных библиотек (например, в языках программирования R, Python). После этого сравнивают рассчитанную меру близости для каждого слова с заданным пороговым значением меры близости. Отбор слов, для которых мера контекстной близости превысила пороговое значение, выполняют с помощью написанных на языках программирования функций, в том числе, входящих в состав специальных библиотек (например, в языках программирования R, Python). Далее определяют части речи отобранных слов с помощью функций специальных библиотек для языков программирования или специального программного обеспечения (например, MyStem, TreeTagger, UDPipe [9-11]). При этом обобщающие определяемое понятие категории находят как обобщающие категории для отобранных существительных и определяемого понятия. Это осуществляют с помощью отнесения отобранных существительных к разным категориям предметной области, в рамках которой определяется понятие, и выбора наиболее часто присваиваемых категорий. Эти часто присваиваемые категории далее относят к более общей категории или нескольким категориям (если возможно) с помощью словарей, профессиональных номенклатур и онтологий, в которых представлена иерархия понятий. Например, отнесение часто встречающихся категорий к категориям более высокого уровня в медицинских предметных областях можно выполнить с помощью международной номенклатуры SNOMED СТ [14]. В общем случае для этой цели можно использовать онтологию WordNet для английского языка, ruWordNet для русского языка или аналоги [15, 16]. При отсутствии готовых онтологий в рамках отдельной предметной области решения об отнесении часто встречающихся категорий понятий к более общим категориям можно принимать на основе консенсуса экспертов. Таким образом, с помощью обобщения наиболее часто встречающихся категорий для существительных, находящихся в одном контексте с определяемым понятием, формируется(-ются) родовые(-ое) понятия(-е), составляющие(-ее) часть определения для определяемого понятия. Характеризующие определяемое понятие признаки находят в отобранных прилагательных. Это осуществляют с помощью скрининга всех отобранных прилагательных, указывающих на специфичные, дифференцирующие определяемое понятие признаки, в программном обеспечении, например, описанном в работе [7]. Далее в отобранных прилагательных находят классифицирующие определяемое понятие признаки. Это осуществляют с помощью скрининга всех отобранных прилагательных, категорирующих определяемое понятие, с помощью программного обеспечения, например, описанного в работе [7]. В отобранных глаголах находят признаки определяемого понятия, указывающие на его функции. Это осуществляют посредством скрининга всех отобранных глаголов, категорирующих определяемое понятие, с помощью программного обеспечения, например, описанного в работе [7]. При этом для уменьшения количества глаголов для скрининга с помощью функций языков программирования, например R или Python, можно исключить глаголы, имеющие одинаковые корни с существительными или прилагательными, однозначно отнесенными к обобщающим категориям на предыдущем этапе. Затем дают определение определяемому понятию, используя его наименование, обобщающие категории, характеризующие признаки и функции. Это осуществляют следующим образом. Наименованию определяемого понятия ставят в соответствие обобщающую(-ие) категорию(-и) (являющую(-ие)ся в определении родовым(-и) понятием(-ями)), к которой(-ым) определяемое понятие относится, и характеризующие признаки (являющиеся в определениями видовым отличием, или дифферентом), которыми определяемое понятие отличается - например, так, как это описано в работе [17]. Далее классифицируют определяемое понятие, используя классифицирующие признаки. Это осуществляется путем формулирования признаков, по которым проводят классификацию понятия, а также набора несовместных классов для каждого признака, по которым понятие делится. При наличии классифицирующих признаков классифицируют определяемое понятие в соответствии с ними.
Существует вариант, в котором выбирают меру контекстной близости между определяемым понятием и оставшимися словами, рассчитывая векторные представления слов, отражающие их контекстную близость, и выбирая меру близости между вектором, соответствующим определяемому понятию, и векторами для оставшихся слов. Это может быть осуществлено следующим образом. Расчет векторных представлений слов выполняют с помощью технологий FastText, word2vec, GloVe, описанных в работах [18-20], или другими способами формирования векторного представления слов, в основе которых лежит «дистрибутивная гипотеза», согласно которой лингвистические единицы, встречающиеся в схожих контекстах, имеют близкие по смыслу значения [21]. Таким образом, для каждого слова рассчитывается последовательность чисел заданной длины (контекстный вектор) в зависимости от его типичного словарного окружения во множестве текстов. В этом случае векторы для слов, употребляемых в схожих контекстах (словарных окружениях), имеют большее сходство в математическом смысле, чем векторы для слов, встречающихся в разных контекстах. Расчет векторных представлений слов выполняется с помощью написанных на языках программирования функций, в том числе, входящих в состав специальных библиотек (например, в языках программирования R, Python). Далее меру контекстной близости выбирают как меру математической близости между вектором, соответствующим определяемому понятию, и векторами для других слов, например, косинусное сходство [22], евклидово расстояние или другую меру [23]. Выбранная мера близости векторов в векторном пространстве определяет меру контекстной и семантической близости соответствующих векторам слов. Таким образом, слова, векторные представления которых схожи, оказываются близки по контексту и смыслу.
Существует также вариант, в котором выбирают меру контекстной близости между определяемым понятием и оставшимися словами на основе количества слов между определяемым понятием и оставшимися словами до и/или после определяемого понятия. Это может быть осуществлено следующим образом. Меру определяют как минимальное абсолютное расстояние, измеряемое в словах, между определяемым понятием и любым из оставшихся слов во множестве текстов до и/или после определяемого слова - с последующим преобразованием. В качестве преобразования, например, можно использовать умножение на -1, что позволит в дальнейшем определить пороговое значение, превышение которого означает контекстную и смысловую близость слов. Существует также вариант, в котором выбирают меру контекстной близости между определяемым понятием и оставшимися словами на основе статистик совместного употребления определяемого понятия и оставшихся слов. Это может быть осуществлено следующим образом. Рассчитывают статистики, отражающие частоту совместное употребления определяемого понятия и оставшихся слов внутри множества текстов, например, статистику TF-IDF (англ. TF - term frequency, IDF - inverse document frequency), коэффициент корреляции и другие.
Предлагаемый способ определения и классификации понятия исходя из контекста его употребления можно также реализовать в комплексном варианте, в котором параллельно выбирают несколько мер контекстной близости, например, на основе близости векторных представлений слов и/или на основе количества слов между определяемым понятием и оставшимися словами до и/или после определяемого понятия, и/или на основе статистик совместного употребления определяемого понятия и оставшихся слов, после чего для каждой меры устанавливают свой порог, превышение которого означает контекстную и смысловую близость слов, далее, после удаления слов, не имеющих отношения к определяемому понятию, для каждой меры контекстной близости формируют отдельное множество слов, для которого соответствующая мера контекстной близости с определяемым понятием превышает соответствующее пороговое значение, затем находят пересечение или объединение множеств слов, полученных с использованием выбранных мер контекстной близости, после чего определяют части речи отобранных слов и продолжают реализовывать способ.
Технические результаты Технический результат применения изобретения заключается в повышении объективности выбора наименования и обобщающих категорий определяемого понятия, а также в повышении релевантности характеризующих и классифицирующих признаков и функций определяемого понятия, за счет минимизации человеческого фактора с помощью математического моделирования и алгоритмизации анализа контекстных и семантических отношений между определяемым понятием, обобщающими определяемое понятие категориями, характеризующими и классифицирующими признаками и функциями определяемого понятия, реализованных в компьютерных программах.
Наименование определяемого понятия находят с помощью программного обеспечения по наиболее часто встречающейся формулировке определяемого слова во множестве слов в начальной форме. Выбор наиболее часто встречающейся формулировки в качестве наименования определяемого понятия является правилом, используемым в реализации изобретения, которое приводит к техническому результату - повышению объективности выбора наименования определяемого понятия.
Нахождение обобщающих категорий для определяемого понятия происходит с помощью программного обеспечения формально, по аналитическому правилу, что нивелирует произвольность и субъективность этого действия. Обобщающие категории находятся исключительно для слов, имеющих контекстную и семантическую близость с определяемым понятием, верифицируемую с помощью меры контекстной близости. Обобщающие категории более высокого уровня иерархии находятся с помощью номенклатур и онтологий, в том числе с возможностью автоматизации с помощью программного обеспечения. Использование данных инструментов приводит к техническому результату - повышению объективности выбора обобщающих категорий для определяемого понятия.
Нахождение характеризующих и классифицирующих признаков определяемого понятия выполняется с помощью программного обеспечения среди прилагательных, имеющих контекстную и семантическую близость с определяемым понятием, верифицируемую с помощью меры контекстной близости. Тем самым минимизируется вероятность отбора признаков, не имеющих отношение к определяемому понятию и не используемых с определяемым понятием в одном контексте. Минимизация такой вероятности приводит к техническому результату - повышению релевантности характеризующих и классифицирующих признаков определяемого понятия. Нахождение функций определяемого понятия выполняется с помощью программного обеспечения по глаголам, имеющим контекстную и семантическую близость с определяемым понятием, верифицируемую с помощью меры контекстной близости в автоматическом режиме. Тем самым минимизируется вероятность отбора функций, не имеющих отношение к определяемому понятию и не используемых с определяемым понятием в одном контексте. Минимизация такой вероятности приводит к техническому результату - повышению релевантности функций определяемого понятия. Выбор меры контекстной близости на основе близости между вектором, соответствующим определяемому понятию, и векторами для оставшихся слов в векторном пространстве и последующий расчет такой меры контекстной близости с помощью программного обеспечения ведет к минимизации человеческого фактора в отборе слов, семантически близких определяемому понятию, что приводит к техническому результату - повышению объективности выбора наименования и обобщающих категорий определяемого понятия, а также повышению релевантности характеризующих и классифицирующих признаков и функций определяемого понятия. Выбор меры контекстной близости на основе количества слов между определяемым понятием и оставшимися словами до и/или после определяемого понятия и последующий расчет такой меры контекстной близости с помощью программного обеспечения ведет к объективности отбора слов, близких определяемому понятию по контексту, что приводит к техническому результату - повышению объективности выбора наименования и обобщающих категорий определяемого понятия, а также к повышению релевантности характеризующих и классифицирующих признаков и функций определяемого понятия.
Выбор меры контекстной близости на основе статистик совместного употребления определяемого понятия и оставшихся слов и последующий расчет такой меры контекстной близости с помощью программного обеспечения ведет к объективности отбора слов, тематически близких определяемому понятию, что приводит к техническому результату -повышении объективности выбора наименования и обобщающих категорий определяемого понятия, а также в повышении релевантности характеризующих и классифицирующих признаков и функций определяемого понятия.
Таким образом, изобретение реализует научно обоснованный подход к лингвистической процедуре определения понятия. Изобретение применимо в любых предметных областях, допускающих программно-реализуемый анализ текстов на естественном языке, в том числе в компьютерной лингвистике, когнитивной психологии, собственно области анализа текстов на естественном языке.
Технический результатом, прямо вытекающим из изложенных выше результатов, является повышение точности идентификации неблагоприятных явлений по неструктурированным текстовым записям истории болезни пациента с помощью алгоритма определения классификации медицинского понятия, характеризующего неблагоприятное явление, исходя из контекста его употребления.
Пример использования изобретения
Изложенный способ определения и классификации понятия исходя из контекста его употребления был применен для определения и классификации понятия «осложнение» в нейрохирургии. Научные работы, посвященные проблеме осложнений в нейрохирургии, демонстрируют нечеткость, размытость понятия «осложнение» в нейрохирургии. Среди нейрохирургов нет единого взгляда на определяющие свойства этого понятия, в результате не сформировано его общепринятое определение. Для лучшего понимания значения термина «осложнение» в нейрохирургии целесообразен анализ контекстов, в котором он употребляется. Для реализации способа были отобраны все источники текстовых данных в электронной истории болезни Национального медицинского исследовательского центра нейрохирургии имени академика Н.Н. Бурденко «е-Med» за период с 2000 г. по 2017 г., потенциально содержащие информацию об осложнениях в нейрохирургии: документы, отражающие данные первичного осмотра, консультаций специалистов, результаты лабораторных и инструментальных исследований, протоколов оперативных вмешательств, этапных эпикризов, клинических заключений, протоколов консилиумов, ежедневных наблюдений, патологоанатомического исследования, заключений об осложнениях, выписного эпикриза. На этапе отбора источников данных были идентифицированы 588 полей из 78 таблиц базы данных электронной истории болезни, в которых содержалось искомое множество текстов. Для 90 688 законченных случаев нейрохирургического лечения из 588 полей базы данных было извлечено и составлено множество текстов, состоящее из 13 060 326 элементов - неструктурированных текстовых записей. После удаления всех символов кроме латинских и кириллических букв, а также продублированных пробелов, множество текстов было токенизировано по пробелу на 229 019 413 токенов-слов. Далее с использованием функции stopwords("russian") пакета "tm" для среды статистического программирования R из полученного множества токенов-слов были удалены 159 стоп-слов, не несущих самостоятельной смысловой нагрузки (предлоги, союзы, частицы, местоимения), а также исключены токены-слова, состоящие после предобработки текста из одной буквы кириллического или латинского алфавита, что сократило множество токенов-слов до 172 158 469 элементов, из которых было выделено множество 614 993 уникальных токенов-слов. Из данного списка уникальных токенов-слов были удалены слова, встречавшиеся в текстах историй болезни за 18 лет не более 5 раз (редко), что привело к списку 176 284 уникальных токенов-слов. Учитывая относительно небольшую долю в этом списке уникальных токенов-слов, содержащих латинские символы (п=8 329; 4,7%), на данном этапе было принято решение продолжить реализацию способа с использованием 167 955 уникальных токенов-слов, написанных на кириллице.
Учитывая большое морфологическое разнообразие русского языка, наличие специальных профессиональных терминов в нейрохирургии, большое число опечаток в машинописных медицинских текстах, на следующем этапе 167 955 уникальных токенов-слов приводили к начальной форме и исправляли опечатки по предложенному нами алгоритму, описанному в работе [7]: для существительных - к единственному числу, именительному падежу, мужскому роду; для прилагательных - к единственному числу, мужскому роду; для глагола - к неопределенной форме. Для этого использовали программное обеспечение «MyStem» от компании «Яндекс» [9]. В результате были получены 91910 уникальных токенов-слов, написанных на кириллице, в начальной форме.
В силу невозможности исправить все опечатки с помощью приведения слова к начальной форме, на данном этапе получали словарь с явно избыточным количеством терминов. Для исправления опечаток использовали расстояние Дамерау-Левенштейна и с помощью функций программной среды R подбирали синтаксически схожие токены-слова в начальной форме, объединяя их под одной наиболее часто встречавшейся начальной формой [24]. Для 95 365 уникальных токенов-слов, у которых корень отличался от корня приписанной ему начальной формы, проводили дополнительные скрининг и при необходимости коррекцию начальной формы с помощью специально разработанного для этого программного обеспечения. В последнем случае для приведения слова к начальной форме руководствовались правилами русского языка и применяли орфографический словарь. В результате описанных процедур из 167 955 уникальных токенов-слов был составлен словарь из 40 121 слова в начальной форме.
Для наименования понятия «осложнения» выбрали слово «осложнение» как наиболее часто встречаемое и правильно написанное идентифицирующее слово в полученном словаре.
Все слова в исходном множестве текстов, встречающиеся более 5 раз, заменяли соответствующими словами в начальной форме из полученного словаря. Преобразованное множество текстов использовали для расчета векторных представлений слов с помощью технологии FastText (модель cbow, размер скользящего окна=5, размер вектора=200), которая продемонстрировала наилучшую способность моделировать контекстную близость между понятиями в условиях данной задачи [25]. В качестве меры близости векторов было выбрано косинусное сходство, при этом пороговое значение косинусного расстояния, превышение которого означает контекстную и смысловую близость соответствующих векторам слов, было установлено равным нулю.
Поскольку понятие «осложнение» употребляется в контексте упоминания неблагоприятных явлений, далее из полученного словаря 40 121 слов отбирали все слова в начальной форме, потенциально обозначающие неблагоприятные медицинские явления, считая, что этот термин используется самостоятельно для обозначения неблагоприятного явления или является специфичным для обозначения нежелательного явления в составе фразы. Для этого удаляли все нерелевантные слова, не имеющие отношение к неблагоприятным медицинским явлениям (в том числе - имена собственные и наименования медицинских процедур), и соответствующие им векторные представления. В результате был получен список из 5853 слов из лексикона неблагоприятных медицинских явлений в начальной форме, которые потенциально могут встречаться в контексте употребления слова «осложнение».
Далее из списка 5853 слов из лексикона неблагоприятных медицинских явлений в начальной форме были отобраны 4416 слов, для которых мера близости соответствующих векторов с вектором для понятия «осложнение» превышала пороговое значение (косинусное сходство было положительным числом). С помощью технологии MyStem (от компании Яндекс) были определены части речи отобранных слов, среди которых оказались 2552 существительных, 1359 прилагательных и 505 глаголов.
Далее для каждого из 2552 существительных было определено, к каким из обобщающих категорий оно относится: симптомы, синдромы, заболевания, неблагоприятные происшествия, синонимы или аналоги термина «осложнение». Данный набор категорий был найден эмпирически в процессе скрининга существительных. Подавляющее большинство отобранных существительных относилось к категории синдромов (1207 слов), симптомов (729 слов) и заболеваний (229 слов). В международной номенклатуре WordNet синдромы и симптомы соотносятся с заболеваниями как «an impairment of health or a condition of abnormal functioning)) (ухудшение здоровья и нормального функционирования). В иерархии понятий номенклатуры SNOMED СТ синдромы отнесены напрямую к заболеваниям, а заболевания и симптомы - к клиническим данным. В англоязычной и русскоязычной медицинской терминологии отклонение от состояния нормального функционирования организма трактуется как «патологическое состояние», «патологический процесс» или «патология», что также согласуется с понятиями «pathology» (any deviation from a healthy or normal condition) и «pathological state» (a state in which you are unable to function normally and without pain). Таким образом, в качестве понятия самого высшего уровня, обобщающего понятие «осложнение» и отобранные существительные, было выбрано понятие «патология как патологический процесс или состояние». Поскольку отобранные существительные, относившиеся к категориям симптомов, синдромов и заболеваний (то есть к обобщающей категории «патология как патологический процесс или состояние»), составили в совокупности 2 165 слов (84,9% всех отобранных существительных), 136 (5,3%) отобранных существительных обозначали аналоги, синонимы или иносказания для понятия «осложнение», а оставшееся 251 (9,8%) существительное нельзя было однозначно отнести к какой-либо категории без знания контекста употребления, то категория «патология как патологический процесс или состояние» как наиболее часто встречающаяся была выбрана в качестве обобщающего, родового понятия в определении понятия «осложнение».
Далее в 1359 отобранных прилагательных осуществили поиск характеризующих и классифицирующих определяемое понятие признаков. К характеризующим признакам отнесли прилагательные, качественно и обобщенно характеризующие определяемое понятие, при этом не описывающие частные варианты реализации определяемого понятия «осложнение»: «не планировавшийся», «непланируемый», «критический», «нежелательный», «тяжелый», «неуточненный», «неустановленный», «сопутствующий», «непонятный», «несчастный», «непредсказуемый», «побочный». Эти прилагательные характеризовали понятие «осложнение» как нечто «вновь возникшее», заранее точно не известное, неблагоприятное, нежелательное, отягощающее.
Часть прилагательных в контексте слова «осложнение» указывали на клиническую форму («симптоматический», «синдромальный»), базовый патологический процесс («ишемический», «воспалительный», «дисциркуляторный», «психотический»), локализацию, распространенность («мультифокальный», «генерализованный»), выраженность («запредельный», «невыраженный», «несильный», «умеренно_выраженный»,
«неярковыраженный», «резковыраженный»), риск для жизни («жизнеугрожающий», «летальный»), период развития, место развития («нозокомиальный», «внутрибольничный»), длительность, сторону поражения, динамику развития («ургентный», «неотложный», «фульминантный», «молниеносный», «рецидивирующий»,), причину, предотвратимость, обратимость («необратимый», «обратимый», «нестойкий») и курабельность («инкурабельный»), по которым осложнения можно классифицировать. Такие прилагательные относили к классифицирующим понятие «осложнение» признакам.
Далее среди 505 отобранных глаголов были отобраны те, что не имеют одинаковых корней слова с отобранными существительными, однозначно отнесенными к обобщающим категориям, и указывают на функции и эффекты определяемого понятия (в порядке уменьшения силы контекстной близости): «рецидивировать», «прогрессировать», «сопутствовать», «не исключаться», «угрожать», «не регрессировать», «повреждать», «нарастать», «настораживать», «изменять», «не выполнять», «усугублять», «инвалидизировать», «сопроводить», «недооценивать», «подозревать», «сопровождаться», «девитализировать», «навредить», «искажать», «утяжелять», «поражать», «пострадать», «обостряться», «скончаться», «нуждаться», «переживать», «страдать», «задерживать», «травмировать», «отягощать», «не стихать», «запаздывать», «не удаваться», «образоваться», «деформировать», «ужесточаться», «дезадаптировать», «ломать», «умирать», «увечить», «затрудняться», «не переносить», «компрометировать», «ухудшаться», «угнетаться», «затруднять», «изменяться», «погибать», «учащаться», «колебаться», «видоизменяться», «истощаться». На первый план в силу контекстной близости выступили глаголы, указывающие на сопутствующий процесс и его негативную динамику. Таким образом, определены важные «функции» осложнения: сопутствовать заболеванию (или медицинскому вмешательству) и ухудшать состояние пациента, причинять вред с довольно широким спектром проявлений.
Таким образом, осложнение - это патология в развитии, патологический процесс, развивающееся патологическое явление, сопутствующее заболеванию или медицинскому вмешательству. Об осложнениях говорят в контексте его «возникновения», что, вероятно, отличает понятие «осложнение» от понятия «сопутствующая патология», о которой чаще говорят при обращении пациента к врачу или поступлении в стационар. Из контекстной связи с симптомами, синдромами и заболеваниями становится очевидно, что «осложнение» реализуется в самых разных клинических вариантах.
На основании вышеизложенного было предложено определение понятия «осложнение» в нейрохирургии, исходя из контекста его употребления:
«Осложнение» (в нейрохирургии) - это интеркуррентная патология, выявляемая нейрохирургом в ходе наблюдения или лечения основного заболевания.
На основе данного определения предложено определение понятия «осложнение» в медицине:
«Осложнение» - это интеркуррентная патология, выявленная в период наблюдения основного заболевания или физиологического процесса, или в результате воздействия на организм человека.
Далее на основании выделенных классифицирующих признаков были сформулированы принципы классификации понятия «осложнение», приведенные ниже.
Классификация осложнений в нейрохирургии на основе признаков, определенных в неструктурированных текстовых записях истории болезни
По варианту клинического проявления:
1. Симптом
2. Синдром
3. Заболевание
По системам организма:
1. Патология нервной системы
2. Патология дыхательной системы
3. Патология пищеварительной системы
4. Патология сердечно-сосудистой системы
5. Патология мочеполовой системы
6. Патология покровной системы
7. Патология опорно-двигательного аппарата
8. Патология иммунной системы
9. Патология эндокринной системы
По органам:
1. С поражением головного мозга
2. С поражением спинного мозга
3. С поражением легких
4. С поражением сердца
5. С поражением... [любого органа]...
По условиям наблюдения:
1. Осложнение внутрибольничное (нозокомиальное)
2. Осложнение внебольничное
По распространенности процесса:
1. Осложнение местное
2. Осложнение системное
По длительности:
1. Осложнение транзиторное (обратимое)
2. Осложнение стойкое
По стороне поражения тела:
1. Осложнение правостороннее
2. Осложнение левостороннее
По количеству пораженных сторон тела:
1. Осложнение одностороннее
2. Осложнение двустороннее
По форме распространения процесса:
1. Осложнение очаговое
2. Осложнение диффузное
По клинической тяжести проявлений:
Конкретные категории в данной градации зависят от патологии, в форме которой реализуется осложнение. В том числе могут быть использованы оценочные шкалы.
По степени клинической компенсации:
1. Осложнение компенсированное
2. Осложнение субкомпенсированное
3. Осложнение декомпенсированное
По динамике развития:
1. Осложнение с острым дебютом
2. Осложнение прогредиентно развивающееся
По динамике течения:
1. Осложнение рецидивирующее
2. Осложнение вялотекущее
3. Осложнение с волнообразным течением
По генезу:
1. Осложнение, потенциально связанное с хирургическим лечением
2. Осложнение, потенциально связанное с лучевым лечением
3. Осложнение, потенциально связанное с медикаментозным лечением
4. Осложнение, потенциально связанное с диагностической процедурой
5. Осложнение без очевидной взаимосвязи с первопричиной
По участию инфекционного агента:
1. Осложнение инфекционное
2. Осложнение неинфекционное
По риску летального исхода:
1. Осложнение жизнеугрожающее
2. Осложнение нежизнеугрожающее
По сроку диагностирования по отношению к хирургическому лечению:
1. Осложнение дооперационное
2. Осложнение интраоперационное
3. Осложнение послеоперационное
По возможности профилактики:
1. Осложнение предотвратимое
2. Осложнение неизбежное
По возможности лечения:
1. Осложнение курабельное
2. Осложнение инкурабельное
По исходу лечения или наблюдения:
1. Осложнение фатальное
2. Осложнение инвалидизирующее
3. Осложнение без явных последствий для здоровья.
Литература
1. Noraset Т. Definition Modeling: Learning to define word embeddings in natural language / Noraset Т., Liang C, Birnbaum L., Downey D. // 31st AAAI Conference on Artificial Intelligence, AAAI 2017 - 2016. - C. 3259-3266.
2. Данилов Г.В. Способ извлечения информации из неструктурированных текстов, написанных на естественном языке (патент RU 2751993 C1) / Данилов Г.В., Шифрин М.А., Потапов А.А., Струнина Ю.В., Цуканова Т.В., Пронкина Т.Е., Косырькова А.В., Мельченко С.А. - 2021.
3. Jabareen Y. Building a Conceptual Framework: Philosophy, Definitions, and Procedure: / Jabareen Y. // http://dx.doi.Org/10.l 177/160940690900800406 -2009. - T. 8 - №4 - C. 49-62.
4. Jurafsky D. Regular Expressions, Text Normalization, Edit Distance,2019. Вып. 3 - 1-98 c.
5. Silge J.Text Mining with R: A tidy approach / J. Silge, D. Robinson - O'Reilly Media, Inc., 2017.
6. Jurafsky D. Spelling Correction and the Noisy Channel, 2019. - 1-14 c.
7. Danilov G. An Information Extraction Algorithm for Detecting Adverse Events in Neurosurgery Using Documents Written in a Natural Rich-in-Morphology Language. / Danilov G., Shifrin M., Strunina U., Pronkina Т., Potapov A. // Studies in health technology and informatics - 2019. - T. 262 - C. 194-197.
8. Sarker A. An unsupervised and customizable misspelling generator for mining noisy health-related text sources / Sarker A., Gonzalez-Hernandez G. // Journal of Biomedical Informatics - 2018. - T. 88 - C. 98-107.
9. MyStem - Технологии Яндекса [Электронный ресурс]. URL: https://yandex.ru/dev/mystern/ (accessed: 14.06.2020).
10. TreeTagger [Электронный ресурс]. URL: https://www.cis.uni-muenchen.de/schmid/tools/TreeTagger/ (accessed: 14.06.2020).
11. UDPipe I UFAL [Электронный ресурс]. URL: http://ufal.mff.cuni.cz/udpipe (accessed: 14.06.2020).
12. Hunspell [Электронный ресурс]. URL: http://hunspell.github.io/ (accessed:14.06.2020).
13. Daniel J. Vector Semantics and Embeddings, 2019. Вып. 3.
14. SNOMED - SNOMED CT Software and Tools [Электронный ресурс]. URL: http://www.snomed.org/snomed-ct/software-tools (accessed: 30.08.2019).
15. WordNet | A Lexical Database for English [Электронный ресурс]. URL: https://wordnet.princeton.edu/ (accessed: 11.01.2021).
16. RuWordNet [Электронный ресурс]. URL: https://ruwordnet.ru/ru (accessed:24.09.2021).
17. Бочаров B.A. М.В.И. Введение в логику. Учебник / Бочаров В.А. М.В.И. // Философские науки - 2012. - №7 - С.136-139.
18. Bojanowski P. Enriching Word Vectors with Subword Information / Bojanowski P., Grave E., Joulin A., Mikolov T. // Transactions of the Association for Computational Linguistics - 2016. - T. 5 - C. 135-146.
19. Mikolov T. Efficient estimation of word representations in vector space International Conference on Learning Representations, ICLR, 2013.
20. Pennington J. GloVe: Global Vectors for Word Representation, 2014. - 1532-1543 c.
21. Sahlgren M. The distributional hypothesis / Sahlgren M.
22. Sidorov G. Soft Similarity and Soft Cosine Measure: Similarity of Features in Vector Space Model / Sidorov G., Sidorov G., Gelbukh A., Gomez-Adorno H., Pinto D. // Computation у Sistemas - 2014. - T. 18 - №3 - C. 491-504.
23. Семинары по метрическим методам классификации Евгений Соколов 1 октября 2013 г.
24. Levenshtein V.I. Binary Codes Capable of Correcting Deletions, Insertions and Reversals / Levenshtein V.I. // SPhD - 1966. - T. 10 - C. 707-710.
25. Danilov G. A Comparison of Word Embeddings to Study Complications in Neurosurgery / Danilov G., Kotik K., Shifrin M., Strunina Y., Pronkina Т., Tsukanova Т., Ishankulov Т., Shults M., Makashova E., Latyshev Y., Sufianov R., Sharipov O., Nazarenko A., Konovalov N., Potapov A. // Studies in health technology and informatics - 2022. - T.289 - C. 5-8. doi:10.3233/SHTI210845.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ извлечения информации из неструктурированных текстов, написанных на естественном языке | 2020 |
|
RU2751993C1 |
| Способ атрибутизации частично структурированных текстов для формирования нормативно-справочной информации | 2020 |
|
RU2750852C1 |
| Автоматическое извлечение именованных сущностей из текста | 2014 |
|
RU2665239C2 |
| СПОСОБ АВТОМАТИЗИРОВАННОЙ СЕМАНТИЧЕСКОЙ КЛАССИФИКАЦИИ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2013 |
|
RU2538304C1 |
| СПОСОБ ОЦЕНКИ СТЕПЕНИ РАСКРЫТИЯ ПОНЯТИЯ В ТЕКСТЕ, ОСНОВАННЫЙ НА КОНТЕКСТАХ, ДЛЯ ПОИСКОВЫХ СИСТЕМ | 2007 |
|
RU2348072C1 |
| Способ автоматизированного анализа текста и подбора релевантных рекомендаций по улучшению его читабельности | 2021 |
|
RU2769427C1 |
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИОННЫХ ОБЪЕКТОВ С ИСПОЛЬЗОВАНИЕМ КОМБИНАЦИИ КЛАССИФИКАТОРОВ, АНАЛИЗИРУЮЩИХ ЛОКАЛЬНЫЕ И НЕЛОКАЛЬНЫЕ ПРИЗНАКИ | 2018 |
|
RU2686000C1 |
| ВОССТАНОВЛЕНИЕ ТЕКСТОВЫХ АННОТАЦИЙ, СВЯЗАННЫХ С ИНФОРМАЦИОННЫМИ ОБЪЕКТАМИ | 2017 |
|
RU2665261C1 |
| СПОСОБ УПРАВЛЕНИЯ АВТОМАТИЗИРОВАННОЙ СИСТЕМОЙ ПРАВОВЫХ КОНСУЛЬТАЦИЙ | 2019 |
|
RU2718978C1 |
| СПОСОБ И СИСТЕМА РАСПОЗНАВАНИЯ ИНФОРМАЦИИ, СОСТАВЛЯЮЩЕЙ КОММЕРЧЕСКУЮ ТАЙНУ | 2024 |
|
RU2841161C1 |
Изобретение относится к информационным технологиям, а именно к способам распознавания и анализа. Технический результат заключается в повышении точности идентификации неблагоприятного явлений по неструктурированным текстовым записям истории болезни пациента. Способ определения неблагоприятных явлений по неструктурированным текстовым записям историй болезни пациентов, заключающийся в том, что анализируют неструктурированные записи электронных историй болезни пациентов с помощью алгоритма определения и классификации медицинского понятия, характеризующего неблагоприятное явление, получают неструктурированные текстовые медицинские данные, и объединяют во множество текстов; осуществляют токенизацию текстов на слова, удаляют слова, встречающиеся реже заданного числа раз, оставшиеся слова приводят к начальной форме и исправляют в них опечатки, идентифицируют определяемое медицинское понятие во множестве оставшихся слов и именуют его, удаляют слова, для которых мера контекстной близости ниже заданного порога, в отобранных существительных, прилагательных, глаголах находят признаки определяемого понятия, указывающие на его функции, на основе вышеуказанного алгоритма выявляют неблагоприятные явления, сопутствующие заболеванию или медицинскому вмешательству, в электронной истории болезни пациента. 3 з.п. ф-лы, 1 ил.
1. Способ определения неблагоприятных явлений по неструктурированным текстовым записям историй болезни пациентов, заключающийся в том, что анализируют неструктурированные текстовые записи электронных историй болезни пациентов с помощью алгоритма определения и классификации медицинского понятия, характеризующего неблагоприятное явление, исходя из контекста его употребления, содержащего следующие этапы:
- из различных источников информации получают неструктурированные текстовые медицинские данные;
- полученные текстовые данные объединяют во множество текстов;
- осуществляют токенизацию текстов на слова;
- удаляют слова, встречающиеся реже заданного числа раз;
- оставшиеся слова приводят к начальной форме и исправляют в них опечатки;
- идентифицируют определяемое медицинское понятие во множестве оставшихся слов и именуют его;
- выбирают меру контекстной близости между определяемым медицинским понятием и оставшимися словами, и задают пороговое значение выбранной меры контекстной близости;
- удаляют слова, для которых мера контекстной близости ниже заданного порога;
- в оставшихся словах, для которых мера контекстной близости выше заданного порога, определяют части речи, при этом:
- в отобранных существительных находят обобщающие определяемое понятие категории;
- в отобранных прилагательных находят характеризующие и классифицирующие определяемое понятие признаки;
- в отобранных глаголах находят признаки определяемого понятия, указывающие на его функции;
- дают определение идентифицируемому медицинскому понятию, используя его наименование и вышеуказанные обобщающие категории, характеризующие признаки и функции;
- классифицируют определяемое медицинское понятие, используя классифицирующие признаки, тем самым формируя классификатор;
на основе вышеуказанного алгоритма выявляют неблагоприятные явления, сопутствующие заболеванию или медицинскому вмешательству, в электронной истории болезни пациента.
2. Способ по п. 1, отличающийся тем, что в алгоритме определения и классификации медицинского понятия, характеризующего неблагоприятное явление, исходя из контекста его употребления, выбирают меру контекстной близости между определяемым понятием и оставшимися словами, рассчитывая векторные представления слов, отражающие их контекстную близость, и выбирая меру близости между вектором, соответствующим определяемому понятию, и векторами для оставшихся слов.
3. Способ по п. 1, отличающийся тем, что в алгоритме определения и классификации медицинского понятия, характеризующего неблагоприятное явление, исходя из контекста его употребления, выбирают меру контекстной близости между определяемым понятием и оставшимися словами на основе количества слов между определяемым понятием и оставшимися словами до и/или после определяемого понятия.
4. Способ по п. 1, отличающийся тем, что в алгоритме определения и классификации медицинского понятия, характеризующего неблагоприятное явление, исходя из контекста его употребления, выбирают меру контекстной близости между определяемым понятием и оставшимися словами на основе статистик совместного употребления определяемого понятия и оставшихся слов.
| Способ извлечения информации из неструктурированных текстов, написанных на естественном языке | 2020 |
|
RU2751993C1 |
| Способ регенерирования сульфо-кислот, употребленных при гидролизе жиров | 1924 |
|
SU2021A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| US 7912705 B2, 22.03.2011 | |||
| ИЗВЛЕЧЕНИЕ СУЩНОСТЕЙ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2626555C2 |
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |

