Изобретение относится к вычислительной технике, в частности к способу организации арифметического ускорителя для решения больших систем линейных уравнений, и может быть использовано для создания новой технологии инженерных расчетов, в том числе объемных интегральных уравнений, электродинамики, гидроакустики, медицинских исследований.
Известен способ организации многопроцессорной ЭВМ, заключающийся в параллельном исполнении нити вычислений по средствам хранимого в виртуальной памяти распределенного представления дескриптора нити, выполнение первичной выборки архитектурных команд по средствам мониторов нитей, формирование графоинформационных зависимостей транзакций, которые выдают через сеть в исполнительные кластеры, переводит активную нить в резидентную очередь ждущих завершения транзакций и выбирают следующую активную нить, принимают транзакции, переписывают их команды, осуществляют выборку и передачу готовых команд кластеру, корректируют граф, передают результат завершения транзакции монитору и переводят нить с коррекцией корня представления дескриптора нити (см., например, патент РФ 2312388, G06F 15/16, 2005 г.).
Известный способ труден в отношении разработки.
Наиболее близким к заявляемому способу является способ организации арифметического ускорителя для решения больших систем линейных уравнений, включающий способ организации арифметического ускорителя для решения больших систем линейных уравнений, включающий общую память, доступную для первичных и одного или более вторичных процессоров, прием множества коэффициентов, связанных с набором линейных уравнений в общую память и разделением их на блоки коэффициентов с использованием одного или более первичных процессоров, выявление доступного вторичного процессора для обработки выбранного блока коэффициентов, передачу его из общей памяти в блок локальной памяти вторичного процессора с последующей обработкой для получения промежуточного результата и передачей его в общую память (см., например, патент РФ №7236998, G06F 7/00).
Основным недостатком известного способа является квадратичный рост числа арифметических операций от числа неизвестных.
Технической задачей, на решение которой направлен заявляемый способ с указанием технического результата, является создание такого способа, который позволил бы уменьшить рост числа арифметических операций и сделать его пропорциональным числу неизвестных.
Технический результат связан с использованием метода быстрого умножения циркулянтных матриц на вектор, основанный на быстром дискретном преобразовании Фурье.
Технический результат достигается путем построения вычислительной среды, позволяющей производить наименьшее количество операций и реализовать рост числа арифметических операций пропорционально числу неизвестных.
Решение технической задачи достигается тем, что способ организации арифметического ускорителя для решения больших систем линейных уравнений, включающий общую память, доступную для первичных и одного или более вторичных процессоров, прием множества коэффициентов, связанных с набором линейных уравнений в общую память и разделением их на блоки коэффициентов с использованием одного или более первичных процессоров, выявление доступного вторичного процессора для обработки выбранного блока коэффициентов, передачу его из общей памяти в блок локальной памяти вторичного процессора с последующей обработкой для получения промежуточного результата и передачей его в общую память, согласно изобретению производят доступ к блоку общей памяти одного или более третичных или четвертичных процессоров, выбранных из произвольного множества разнородных процессоров, выявляют свободный первичный процессор и разделяют промежуточный результат на группы, производят индексирование и записывают значения промежуточного результата в каждой группе в блок общей памяти, выявляют свободный третичный процессор и производят ранжирование индексов и по одному из трех последовательных индексов, выбранных из множества индексов, производят быстрое дискретное преобразование Фурье, записывают результаты преобразования в блок общей памяти, выявляют свободный четвертичный процессор, рассматривают значения элементов матрицы для первого индекса последовательно и производят быстрые дискретные преобразования Фурье по двум другим индексам, затем умножают почленно получившиеся значения по этим двум индексам на Фурье преобразования теплицевой матрицы для этих индексов, затем производят обратное быстрое дискретное преобразование Фурье по этим двум индексам, результаты преобразований записывают в локальную память четвертичного процессора, по окончании процесса производят обратное быстрое дискретное преобразование Фурье по первому индексу, записывают результат в общую память.
На чертеже изображена общая блок-схема по изобретению, показывающая процессоры 1, 2, 3, 4, модуль 5 индексирования, модули 6, 7 Фурье преобразования, модуль 8 обратного Фурье преобразования, блок 9 общей памяти, блоки 10, 11, 12, 13 локальной памяти.
На схеме представлена последовательность действий, отраженная в формуле изобретения, а именно:
Матрица системы линейных уравнений, получающаяся после дискретизации интегральных уравнений, описывающих задачи инженерных расчетов, в том числе объемных интегральных уравнений, электродинамики, гидроакустики, медицинских исследований, например, рассеяние электромагнитных волн на диэлектрических трехмерных структурах имеет форму блочно-теплицевой матрицы. При этом основные вычислительные затраты при умножении матрицы системы линейных уравнений (СЛАУ) на вектор, а это самая затратная вычислительная операция при использовании итерационных алгоритмов, связаны с вычислением сумм вида:
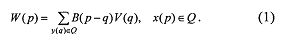 ,
,
где Q - область рассеивающего тела, находящегося внутри параллелепипеда П.
Для вычисления W(p) в узловых точках х(р)∈Q требуется выполнить ~N2 арифметических операций.
Для уменьшения числа арифметических операций будем применять технику быстрого умножения циркулянтных матриц на вектор, основанную на быстром дискретном преобразовании Фурье.
Доопределим величины V(q) нулем в точках x(q) параллелепипеда П, не принадлежащих области Q. Тогда (1) можно записать в виде:
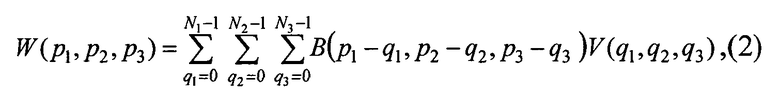
где матричная функция дискретного аргумента В{р) определена для значений:
-(N1-1)≤p1≤(N1-1); -(N2-1)≤p2≤(N2-1); -(N3-1)≤p3≤(N3-1).
Для электромагнитных задач имеем:
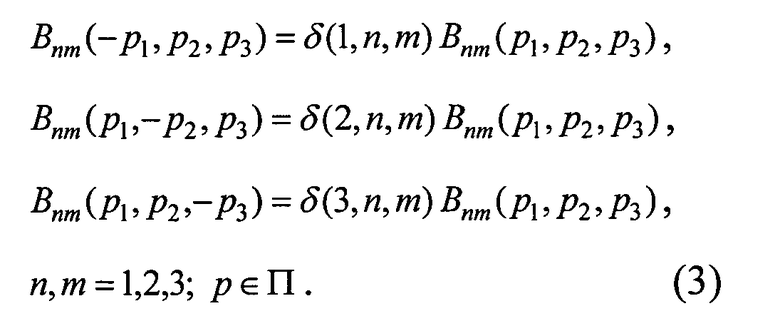
Здесь функция дискретного аргумента δ(k, n, m) определяется формулой
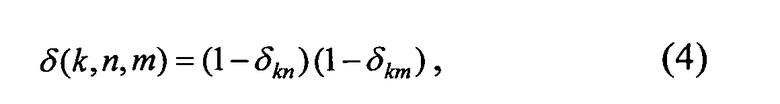
где δkn - символ Кронекера.
Обозначим через П2 параллелепипед со сторонами 2N1h1, 2N2h2 и 2N3h3. Продолжим матричную функцию дискретного аргумента В(р1, р2, р3) на все целочисленные значения р1, р2, p3, полагая ее периодической по каждой переменной с периодами соответственно 2N1, 2N2, 2N3. При этом доопределим В(р1, р2, р3) нулем в точках (N1, p2, p3), (p1, N2, p3), (p1, p2, N3), где p1, p2, p3 - любые целые числа. Далее доопределим вектор функции дискретного аргумента V(p1, p2, p3) нулем во всех узловых точках П2, не принадлежащих П, и продолжим ее на все целочисленные значения р1, р2, р3, полагая ее периодической по каждой переменной с периодами соответственно 2N1, 2N2, 2N3, тогда:
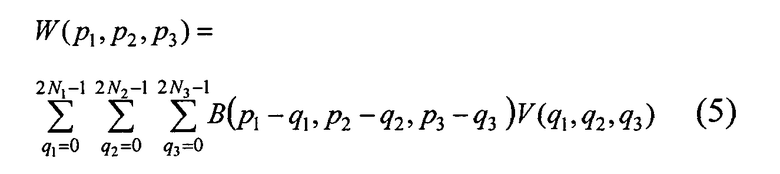
Учитывая изложенное при х(р)∈П функция W(p1, p2, p3) из (5) совпадает со значениями W(p1, p2, p3) из (2). Ниже через П и П2 будем обозначать целочисленные параллелепипеды с числом дискретных аргументов по каждой оси N1, N2, N3 и 2N1, 2N2, 2N3 соответственно. Теперь проводя дискретное преобразование Фурье по каждой переменной от обеих частей (5), получим следующее равенство:
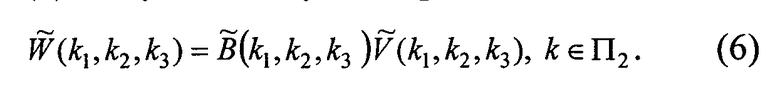
Из (3) и периодичности функций следует, что элементы массива 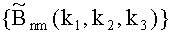
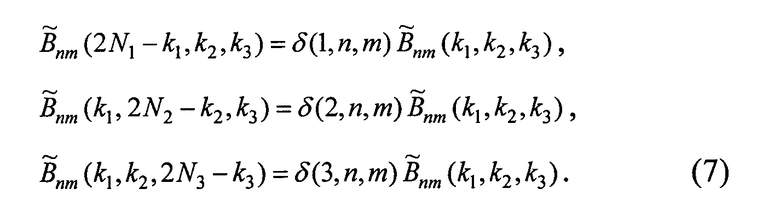
Таким образом, учитывая, что 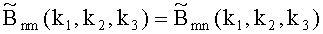
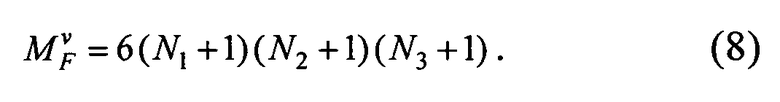
При вычислении W(p), p∈П, основные вычислительные затраты, без учета нахождения 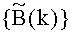
Шаг 1. Проведем ранжирование и расположим N1, N2, N3 в порядке убывания, т.е. N1≥N2≥N3.
Шаг 2. Произведем быстрое дискретное преобразование Фурье по целочисленной переменной р1. Получаем массив чисел Vn(k1, p2, p3), 0≤k1≤2N1-1, 0≤p2≤N2-1, 0≤p3≤N3-1; n=1, 2, 3. Общее количество комплексных чисел в этом массиве равно 6 N1N2N3.
Шаг 3. Для каждого фиксированного k1, 0≤k1≤2N1-1 последовательно производим быстрое дискретное преобразование Фурье по переменным р2, р3. Затем при том же k1, используя формулу (6), получаем значения 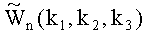
Шаг 4. Произведем быстрое обратное дискретное преобразование Фурье по переменной k1. Получаем требуемые значения Wn(p1, p2, p3), 0≤p1≤N1-1, 0≤p2≤N2-1, 0≤p3≤N3-1.
Для реализации изложенной схемы необходим объем памяти для хранения массива, равного 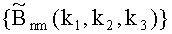
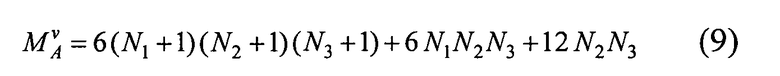
Число арифметических операций, требуемое для вычисления Wn(p), p∈П, оценивается формулой
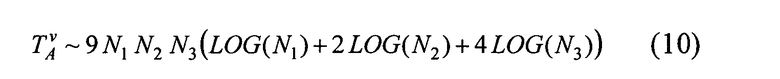
где LOG(N)=N определяется как сумма всех делителей целого числа N с учетом их кратности.
Действительно, при проведении преобразования Фурье вычисления можно проводить в любой последовательности переменных. Поэтому очевидно, что наименьшее количество операций потребуется для приведенной выше последовательности.
Если числа N1, N2, N3 являются степенями числа 2, то можно воспользоваться известным быстрым преобразованием Фурье. Тогда число арифметических операций для вычисления функций дискретного аргумента W(p), p∈П, оценивается формулой
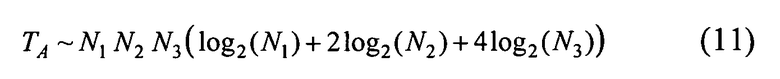
Если для умножения матрицы СЛАУ на вектор использовать (6) без применения рассмотренной схемы, то количество арифметических операций и требуемый объем памяти будут в несколько раз больше.
Обычно при использовании быстрого дискретного преобразования Фурье выбираются значения N, кратные степени 2. Однако при дискретизации интегральных уравнений, это, во многих случаях, может привести к значительным дополнительным вычислительным затратам, поскольку скважность чисел степени 2 весьма велика. Поясним на примере. Пусть N1=N2=N3=N0, т.е. П-куб. Предположим, что для аппроксимации решения с требуемой точностью, достаточно взять значение N0=150. Ближайшие степени двойки - числа 128 и 256. Значение 128 не удовлетворяет требованию аппроксимации решения, поэтому, если мы хотим воспользоваться стандартным БПФ, то необходимо брать значение N0=256. Пусть Т(N0) - число арифметических операций, которое требуется для умножения матрицы СЛАУ на вектор, в зависимости от значений N0. Тогда имеем,
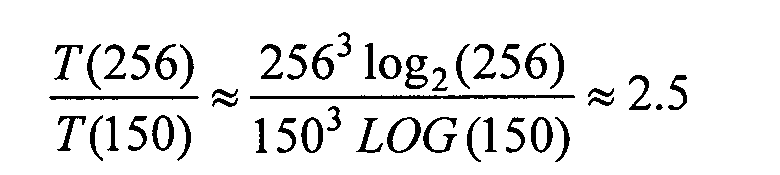
Объем памяти для хранения матрицы СЛАУ при N0=256 в несколько раз больше, чем при N0=150. Значит, использование БПФ для значения N0=150 значительно более эффективно, чем использование БПФ со степенью 2.
Отметим, что использование БПФ дает для числа арифметических операций практически линейную зависимость от размерности СЛАУ по сравнению с квадратичной зависимостью, которая появляется при умножении матрицы на вектор без применения специальных быстрых алгоритмов. Это чрезвычайно важно при численном решении объемных интегральных уравнений, которые после дискретизации сводятся к СЛАУ огромной размерности (больше 106). При этом нужно отметить, что объем памяти также имеет практически линейную зависимость от размерности матрицы. Это обстоятельство очень важно, поскольку без использования эффективных методов дискретизации объем требуемой памяти имеет квадратичную зависимость от размерности.
На этой основе предлагается реализовать способ организации арифметического ускорителя для решения больших систем линейных уравнений.
Проведем ранжирование и расположим N1, N2, N3 в порядке убывания, т.е. N1≥N2≥N3.
Произведем быстрое дискретное преобразование Фурье по целочисленной переменной р1. Получаем массив чисел Vn(k1, p2, p3), 0≤k1≤2N1-1, 0≤p2≤N2-1, 0≤p3≤N3-1; n=1, 2, 3. Общее количество комплексных чисел в этом массиве равно 6 N1N2N3.
Для каждого фиксированного k1, 0≤k1≤2N1-1, последовательно производим быстрое дискретное преобразование Фурье по переменным р2, р3. Затем при том же k1, используя формулу (6), получаем значения
Произведем быстрое обратное дискретное преобразование Фурье по переменной k1. Получаем требуемые значения Wn(p1, p2, p3), 0≤p1≤N1-1, 0≤p2≤N2-1, 0≤p3≤N3-1.
Предложенный способ реализуется следующим образом.
Производят доступ к блоку общей памяти одного или более третичных или четвертичных процессоров, выбранных из произвольного множества разнородных процессоров, затем выявляют свободный первичный процессор и разделяют промежуточный результат на группы, производят индексирование и записывают значения промежуточного результата в каждой группе в блок общей памяти. Далее выявляют свободный третичный процессор и производят ранжирование индексов и по одному из трех последовательных индексов, выбранных из множества индексов, производят быстрое дискретное преобразование Фурье, записывают результаты преобразования в блок общей памяти, затем выявляют свободный четвертичный процессор, рассматривают значения элементов матрицы для первого индекса последовательно и производят быстрые дискретные преобразования Фурье по двум другим индексам, затем умножают почленно получившиеся значения по этим двум индексам на Фурье преобразования теплицевой матрицы для этих индексов, затем производят обратное быстрое дискретное преобразование Фурье по этим двум индексам, результаты преобразований записывают в локальную память четвертичного процессора, по окончании процесса производят обратное быстрое дискретное преобразование Фурье по первому индексу, записывают результат в общую память.
Технический результат заключается в уменьшении роста числа арифметических операций и реализации роста арифметических операций пропорционально числу неизвестных и связан с использованием метода быстрого умножения циркулянтных матриц на вектор, основанный на быстром дискретном преобразовании Фурье.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ КОДИРОВАНИЯ И УСТРОЙСТВО СВЯЗИ | 2020 |
|
RU2796655C1 |
| Способ беспроводной передачи цифровых панорамных аэровидеоизображений | 2018 |
|
RU2707139C1 |
| Способ оценки отношения сигнал-шум на входе приёмного устройства для радиосигнала с цифровой амплитудной модуляцией | 2018 |
|
RU2695953C1 |
| КООРДИНАТНО-ЧУВСТВИТЕЛЬНЫЙ ДАТЧИК МУЛЬТИСКАН | 2009 |
|
RU2399117C1 |
| ВЫСОКОПАРАЛЛЕЛЬНЫЙ СПЕЦПРОЦЕССОР ДЛЯ РЕШЕНИЯ ЗАДАЧ О ВЫПОЛНИМОСТИ БУЛЕВЫХ ФОРМУЛ | 1993 |
|
RU2074415C1 |
| СПОСОБ ОБРАБОТКИ ЗАПРОСОВ, СПОСОБ ФОРМИРОВАНИЯ УВЕДОМЛЕНИЙ И УСТРОЙСТВО ДЛЯ ОБРАБОТКИ ЗАПРОСОВ И ФОРМИРОВАНИЯ УВЕДОМЛЕНИЙ | 2022 |
|
RU2798222C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ХРАНЕНИЯ ИНФОРМАЦИИ О ДВИЖЕНИИ | 2023 |
|
RU2815734C1 |
| ИСТОЧНИК ОПОРНОГО НАПРЯЖЕНИЯ С КАЛИБРОВКОЙ ВЫХОДНОГО НАПРЯЖЕНИЯ | 2019 |
|
RU2715215C1 |
| СПОСОБ ИЗМЕРЕНИЯ РАЗНОСТЕЙ ВРЕМЕНИ ПРИХОДА И ЧАСТОТЫ ПРИЕМА СИГНАЛОВ И УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2003 |
|
RU2256192C2 |
| СПОСОБ (ВАРИАНТЫ) И УСТРОЙСТВО (ВАРИАНТЫ) ОЦЕНИВАНИЯ НЕСУЩЕЙ ЧАСТОТЫ | 1998 |
|
RU2137143C1 |
Изобретение относится к вычислительной технике и может быть использовано для создания арифметического ускорителя для решения больших систем линейных уравнений. Техническим результатом является уменьшение числа арифметических операций. Способ содержит этапы, на которых: производят доступ к блоку общей памяти одного или более третичных или четвертичных процессоров, выбранных из произвольного множества разнородных процессоров, выявляют свободный первичный процессор, разделяют промежуточный результат на группы, производят индексирование и записывают значения промежуточного результата в каждой группе в блок общей памяти, выявляют свободный третичный процессор и производят ранжирование индексов и по одному из трех последовательных индексов, выбранных из множества индексов, производят быстрое дискретное преобразование Фурье, записывают результаты преобразования в блок общей памяти, выявляют свободный четвертичный процессор, рассматривают значения элементов матрицы для первого индекса последовательно, производят быстрые дискретные преобразования Фурье по двум другим индексам, умножают почленно получившиеся значения по этим двум индексам на Фурье преобразования теплицевой матрицы для этих индексов, производят обратное быстрое дискретное преобразование Фурье по этим двум индексам, результаты преобразований записывают в локальную память четвертичного процессора, производят обратное быстрое дискретное преобразование Фурье по первому индексу, записывают результат в общую память. 1 ил.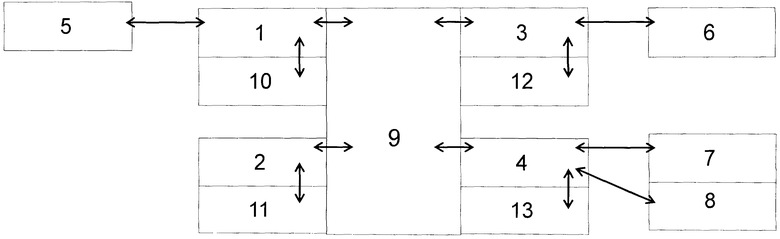
Способ организации арифметического ускорителя для решения больших систем линейных уравнений, включающий общую память, доступную для первичных и одного или более вторичных процессоров, прием множества коэффициентов, связанных с набором линейных уравнений в общую память и разделением их на блоки коэффициентов с использованием одного или более первичных процессоров, выявление доступного вторичного процессора для обработки выбранного блока коэффициентов, передачу его из общей памяти в блок локальной памяти вторичного процессора с последующей обработкой для получения промежуточного результата и передачей его в общую память, отличающийся тем, что производят доступ к блоку общей памяти одного или более третичных или четвертичных процессоров, выбранных из произвольного множества разнородных процессоров, выявляют свободный первичный процессор и разделяют промежуточный результат на группы, производят индексирование и записывают значения промежуточного результата в каждой группе в блок общей памяти, выявляют свободный третичный процессор и производят ранжирование индексов и по одному из трех последовательных индексов, выбранных из множества индексов, производят быстрое дискретное преобразование Фурье, записывают результаты преобразования в блок общей памяти, выявляют свободный четвертичный процессор, рассматривают значения элементов матрицы для первого индекса последовательно и производят быстрые дискретные преобразования Фурье по двум другим индексам, затем умножают почленно получившиеся значения по этим двум индексам на Фурье преобразования теплицевой матрицы для этих индексов, затем производят обратное быстрое дискретное преобразование Фурье по этим двум индексам, результаты преобразований записывают в локальную память четвертичного процессора, по окончании процесса производят обратное быстрое дискретное преобразование Фурье по первому индексу, записывают результат в общую память.
| US 7236998 B2, 26.06.2007 | |||
| JP 62285179 A, 11.12.1987 | |||
| US 2010011039 A1, 14.01.2010 | |||
| US 2012005247 A1, 05.01.2012 | |||
| СПОСОБ ОРГАНИЗАЦИИ МНОГОПРОЦЕССОРНОЙ ЭВМ | 2005 |
|
RU2312388C2 |
| Устройство для разложения теплицевых симметричных матриц | 1990 |
|
SU1755295A2 |
| Устройство для решения дифференциальных уравнений по неявной схеме переменных направлений | 1985 |
|
SU1290347A1 |

