Настоящее изобретение относится к обработке аудиосигналов и, в частности, к устройству и способу для информированной оценки вероятности присутствия многоканальной речи.
Обработка аудиосигналов становится более и более важной. В частности, захват речи без использования рук требуется во многих интерфейсах человек-машина и системах связи. Встроенные акустические датчики обычно принимают смесь полезных звуков (например, речи) и паразитных звуков (например, окружающего шума, голосов говорящих, которые являются помехой, реверберации, и шума датчика). Так как паразитные звуки ухудшают качество и разборчивость полезных звуков, сигналы акустического датчика могут обрабатываться (например, фильтроваться и суммироваться), чтобы извлекать сигнал полезного источника или, формулируя другим образом, чтобы уменьшать сигналы паразитного звука. Чтобы вычислять такие фильтры, обычно требуется точная оценка матрицы спектральной плотности мощности шума (PSD). На практике, сигнал шума является ненаблюдаемым и его матрица PSD должна оцениваться из зашумленных сигналов акустического датчика.
Одноканальные средства оценки вероятности присутствия речи (SPP) используются, чтобы оценивать PSD шума (см., например, [1-5]) и чтобы управлять компромиссным соотношением между уменьшением шума и искажением речи (см., например, [6, 7]). В последнее время используется многоканальная апостериорная SPP, чтобы оценивать матрицу PSD шума (см., например, [8]). В дополнение, оценка SPP может использоваться, чтобы уменьшать потребляемую мощность устройства.
В последующем, рассматривается общепринятая модель сигнала в обработке многоканальной речи, где каждый акустический датчик из M-элементной решетки захватывает аддитивную смесь полезного сигнала и паразитного сигнала. Сигнал, принятый в m-м акустическом датчике может быть описан в частотно-временной области следующим образом:
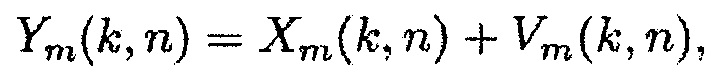 (1)
(1)
где 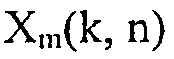 и
и 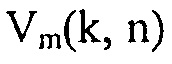 обозначают комплексные спектральные коэффициенты сигнала полезного источника и компонента шума m-го акустического датчика соответственно, и n и k являются индексами времени и частоты соответственно.
обозначают комплексные спектральные коэффициенты сигнала полезного источника и компонента шума m-го акустического датчика соответственно, и n и k являются индексами времени и частоты соответственно.
Полезный сигнал может, например, быть пространственно когерентным по микрофонам и пространственная когерентность шума может, например, соответствовать пространственной когерентности идеального сферически изотропного звукового поля, см. [24].
Другими словами, например, 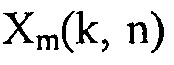 может обозначать комплексные спектральные коэффициенты сигнала полезного источника в m-м акустическом датчике,
может обозначать комплексные спектральные коэффициенты сигнала полезного источника в m-м акустическом датчике, 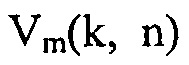 может обозначать комплексные спектральные коэффициенты компонента шума в m-м акустическом датчике, n может обозначать индекс времени и k может обозначать индекс частоты.
может обозначать комплексные спектральные коэффициенты компонента шума в m-м акустическом датчике, n может обозначать индекс времени и k может обозначать индекс частоты.
Наблюдаемые зашумленные сигналы акустического датчика могут быть записаны в векторной системе обозначений как
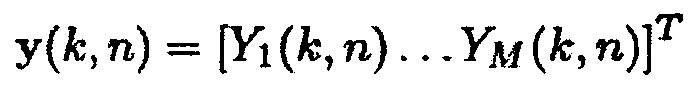 (2)
(2)
и матрица спектральной плотности мощности (PSD) для 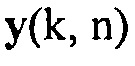 определяется как
определяется как
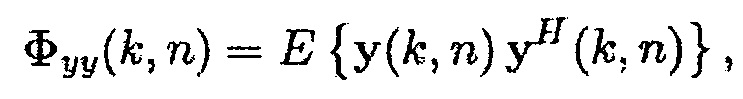 (3)
(3)
где верхний индекс 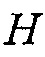 обозначает сопряженное транспонирование матрицы. Векторы
обозначает сопряженное транспонирование матрицы. Векторы 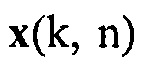 и
и 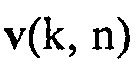 и матрицы
и матрицы 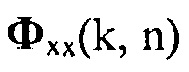 и
и 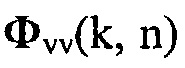 определяются аналогичным образом. Полезные и паразитные сигналы предполагаются некоррелированными и с нулевым средним, так что формула (3) может быть записана как
определяются аналогичным образом. Полезные и паразитные сигналы предполагаются некоррелированными и с нулевым средним, так что формула (3) может быть записана как
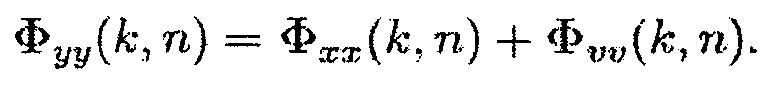 (4)
(4)
Вводятся следующие стандартные гипотезы относительно присутствия полезного сигнала (например, речевого сигнала) в заданном время-частотном интервале:
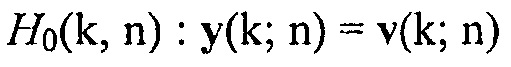 показывает отсутствие речи, и
показывает отсутствие речи, и
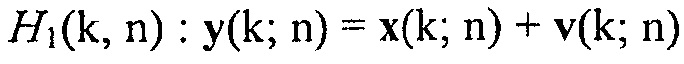 показывает присутствие речи.
показывает присутствие речи.
Может быть, например, предпочтительным оценивать условную апостериорную SPP, т.е. 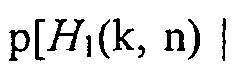
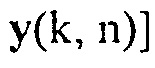 .
.
При предположении, что i-й микрофон решетки берется в качестве эталона, может, например, быть предпочтительным оценивать полезный сигнал 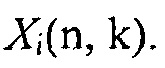
При предположении, что полезные и паразитные компоненты могут моделироваться как комплексные многовариантные гауссовские случайные переменные, оценка многоканальной SPP дается посредством (см. [9]):
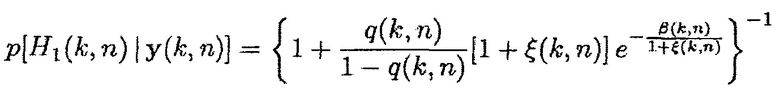 (5)
(5)
где 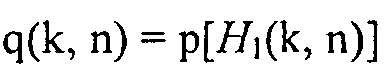 обозначает априорную вероятность присутствия речи (SPP), и
обозначает априорную вероятность присутствия речи (SPP), и
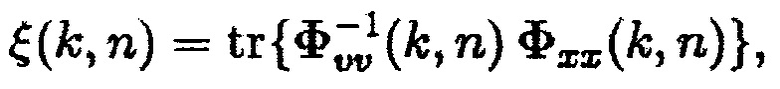 (6)
(6)
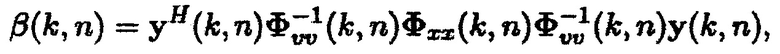 (7)
(7)
где 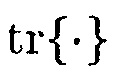 обозначает оператор следа. Также могут выводиться и использоваться альтернативные средства оценки, предполагающие другой тип распределения (например, распределение Лапласа).
обозначает оператор следа. Также могут выводиться и использоваться альтернативные средства оценки, предполагающие другой тип распределения (например, распределение Лапласа).
Только при предположении, что матрица PSD полезного сигнала имеет ранг единицу [например, 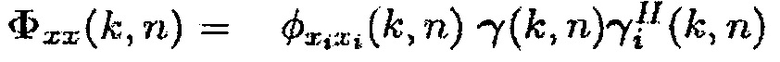 , где
, где 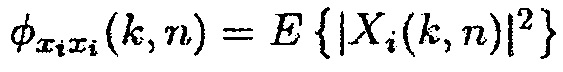 и
и 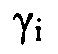 обозначает столбцовый вектор длины M], многоканальная SPP может получаться посредством применения средства оценки одноканальной SPP к выводу формирователя диаграммы направленности отклика без искажений с минимальной дисперсией (MVDR).
обозначает столбцовый вектор длины M], многоканальная SPP может получаться посредством применения средства оценки одноканальной SPP к выводу формирователя диаграммы направленности отклика без искажений с минимальной дисперсией (MVDR).
Подходы данной области техники либо используют фиксированную априорную SPP [4, 9], либо значение, которое зависит от одноканального или многоканального априорного отношения сигнала к шуму (SNR) (см. [2, 8, 10]). Коэн и др. [10], используют три параметра 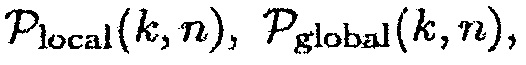 и
и 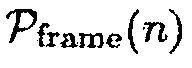 , которые основываются на время-частотном распределении оцененного одноканального априорного SNR, чтобы вычислять априорную SPP, заданную посредством
, которые основываются на время-частотном распределении оцененного одноканального априорного SNR, чтобы вычислять априорную SPP, заданную посредством
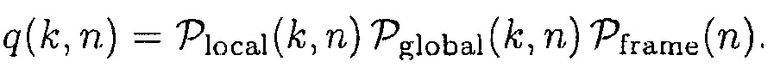 (8)
(8)
Эти параметры используют сильную корреляцию присутствия речи в соседних частотных интервалах последовательных временных кадров. В других подходах данной области техники (см. [11]), параметры вычисляются в логарифмической энергетической области. В дополнительных подходах данной области техники (см. [8]), вместо этого используется многоканальное априорное SNR, чтобы вычислять 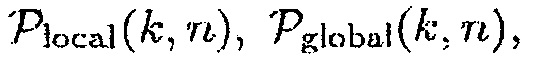 и
и  .
.
Большой недостаток средств оценки SPP данной области техники состоит в том, что они не могут различать между полезными и паразитными звуками.
Цель настоящего изобретения состоит в том, чтобы обеспечить улучшенные концепции для обеспечения информированной оценки вероятности присутствия многоканальной речи. Цель настоящего изобретения решается посредством устройства согласно пункту 1 формулы изобретения, посредством способа согласно пункту 17 формулы изобретения и посредством компьютерной программы согласно пункту 18 формулы изобретения.
В последующем мы будем использовать признак "сцена". Сцена является средой, где генерируется звуковое поле. Пространственная информация о сцене может, например, содержать информацию о положении одного или более источников звука, которые генерируют звуковое поле, информацию о положении акустических датчиков, информацию о расстоянии источников звука до акустических датчиков, информацию о том, обнаружен ли говорящий человек или рот, и/или информацию о том, находится ли говорящий человек или рот в близости к акустическим датчикам.
Звуковое поле может, например, характеризоваться посредством звукового давления в каждом положении в среде, например, среде, где существует звуковое поле. Например, звуковое поле может характеризоваться посредством амплитуд звукового давления в каждом положении в среде, например, среде, где существует звуковое поле. Или звуковое поле может, например, характеризоваться посредством комплексного звукового давления в каждом положении в среде, например, среде, где существует звуковое поле, когда рассматривается спектральная область или частотно-временная область. Например, звуковые давления в положениях в среде, характеризующие звуковое поле, могут, например, записываться посредством одного или более акустических датчиков, например, посредством одного или более микрофонов. Пространственная информация о звуковом поле может, например, содержать направление вектора прибытия или, например, отношение энергии прямого к диффузному, определенное посредством записей упомянутых одного или более акустических датчиков, записывающих звуковые давления в положениях в среде, при этом звуковые давления характеризуют звуковое поле.
Обеспечивается устройство для обеспечения оценки вероятности речи. Устройство содержит первое средство оценки вероятности речи (которое может быть равным средству оценки априорной вероятности присутствия речи) для оценки информации вероятности речи, показывающей первую вероятность в отношении того, содержит ли звуковое поле сцены речь, или в отношении того, не содержит ли звуковое поле сцены речь. Дополнительно, устройство содержит выходной интерфейс для вывода оценки вероятности речи в зависимости от информации вероятности речи. Первое средство оценки вероятности речи сконфигурировано с возможностью оценивать информацию первой вероятности речи на основе, по меньшей мере, пространственной информации о звуковом поле или пространственной информации о сцене.
Обеспечиваются концепции, чтобы преодолевать недостаток предшествующего уровня техники посредством использования предварительной информации, выведенной из сигналов акустического датчика и возможно сигналов неакустического датчика, в вычислении условной апостериорной SPP. В частности, используется пространственная информация о звуковом поле, такая как направленность, близость и местоположение.
Могут определяться параметры 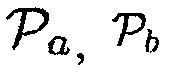 и/или
и/или 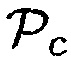 ,
, 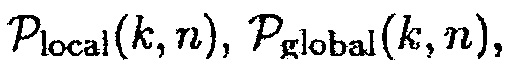 и/или
и/или  .
.
Является важным отметить, что любая комбинация (например, произведение, сумма, взвешенная сумма) параметров 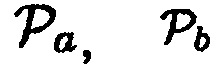 и/или
и/или 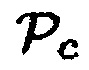 и других известных параметров, например,
и других известных параметров, например, 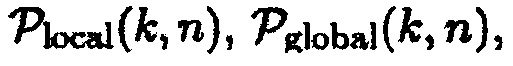 и/или
и/или  , может использоваться для получения информации вероятности речи посредством использования средства комбинирования. Это также означает, что является также возможным использовать только параметры
, может использоваться для получения информации вероятности речи посредством использования средства комбинирования. Это также означает, что является также возможным использовать только параметры 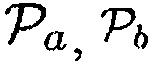 или
или 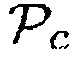 для получения информации вероятности речи.
для получения информации вероятности речи.
Смысл параметров будет объяснен дополнительно ниже.
Может использоваться любая возможная комбинация параметров, например:
a) 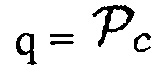 (Например, предположим, что
(Например, предположим, что 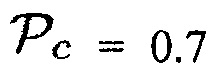 , когда объект находится в близости к датчику. Тогда любой активный источник звука (близкий ли или нет) будет рассматриваться как полезный с априорной SPP, равной 1-0.7=0.3.)
, когда объект находится в близости к датчику. Тогда любой активный источник звука (близкий ли или нет) будет рассматриваться как полезный с априорной SPP, равной 1-0.7=0.3.)
b) 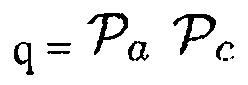 (Например, звук рассматривается как полезный, когда имеется объект, близкий к датчику, и DDR является достаточно высоким.)
(Например, звук рассматривается как полезный, когда имеется объект, близкий к датчику, и DDR является достаточно высоким.)
c) 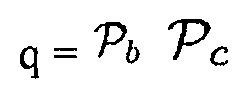 (Например, звук рассматривается как полезный, когда имеется объект, близкий к датчику, и местоположение источника звука находится в пределах области интереса, например, диапазона направления прибытия.)
(Например, звук рассматривается как полезный, когда имеется объект, близкий к датчику, и местоположение источника звука находится в пределах области интереса, например, диапазона направления прибытия.)
d) 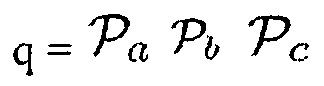 (Например, звук рассматривается как полезный, когда имеется объект, близкий к датчику, DDR наблюдаемого звука является достаточно высоким и местоположение источника звука находится в пределах области интереса.)
(Например, звук рассматривается как полезный, когда имеется объект, близкий к датчику, DDR наблюдаемого звука является достаточно высоким и местоположение источника звука находится в пределах области интереса.)
Согласно одному варианту осуществления, устройство может дополнительно содержать второе средство оценки вероятности речи для оценки вероятности речи, показывающей вторую вероятность в отношении того, содержит ли звуковое поле речь, или в отношении того, не содержит ли звуковое поле речь. Второе средство оценки вероятности речи может быть сконфигурировано с возможностью оценивать вероятность речи на основе информации вероятности речи, оцененной посредством первого средства оценки вероятности речи, и на основе одного или более сигналов акустического датчика, которые зависят от звукового поля.
В другом варианте осуществления первое средство оценки вероятности речи может быть сконфигурировано с возможностью оценивать информацию вероятности речи на основе информации направленности, при этом информация направленности показывает то, насколько направленным является звук звукового поля. Альтернативно или дополнительно, первое средство оценки вероятности речи может быть сконфигурировано с возможностью оценивать информацию вероятности речи на основе информации местоположения, при этом информация местоположения показывает, по меньшей мере, одно местоположение источника звука сцены. Альтернативно или дополнительно, первое средство оценки вероятности речи сконфигурировано с возможностью оценивать информацию вероятности речи на основе информации близости, при этом информация близости показывает, по меньшей мере, одну близость, по меньшей мере, одного (возможного) звукового объекта к, по меньшей мере, одному датчику близости.
Согласно дополнительному варианту осуществления, первое средство оценки вероятности речи может быть сконфигурировано с возможностью оценивать вероятность речи посредством определения оценки отношения прямого к диффузному для отношения прямого к диффузному в качестве пространственной информации, при этом отношение прямого к диффузному показывает отношение прямого звука, содержащегося в сигналах акустического датчика, к диффузному звуку, содержащемуся в сигналах акустического датчика.
В другом варианте осуществления первое средство оценки вероятности речи может быть сконфигурировано с возможностью определять оценку отношения прямого к диффузному посредством определения оценки когерентности комплексной когерентности между первым акустическим сигналом из сигналов акустического датчика, при этом первый акустический сигнал записывается посредством первого акустического датчика p, и вторым акустическим сигналом из сигналов акустического датчика, при этом второй акустический сигнал записывается посредством второго акустического датчика q. Первое средство оценки вероятности речи может дополнительно быть сконфигурировано с возможностью определять отношение прямого к диффузному на основе оценки фазового сдвига для фазового сдвига прямого звука между первым акустическим сигналом и вторым акустическим сигналом.
Согласно одному варианту осуществления, первое средство оценки вероятности речи может быть сконфигурировано с возможностью определять оценку отношения прямого к диффузному 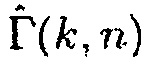 между первым акустическим сигналом и вторым акустическим сигналом посредством применения формулы:
между первым акустическим сигналом и вторым акустическим сигналом посредством применения формулы:
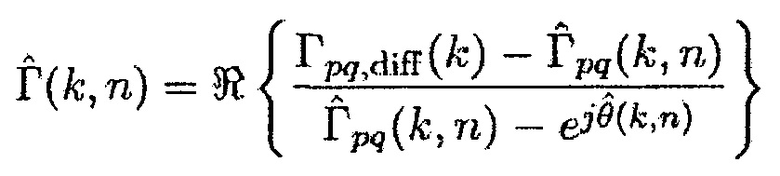
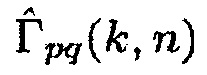 может быть оценкой когерентности комплексной когерентности между первым акустическим сигналом и вторым акустическим сигналом по отношению к время-частотному интервалу (k, n), где n обозначает время и где k обозначает частоту.
может быть оценкой когерентности комплексной когерентности между первым акустическим сигналом и вторым акустическим сигналом по отношению к время-частотному интервалу (k, n), где n обозначает время и где k обозначает частоту.
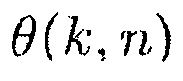 может быть оценкой фазового сдвига для фазового сдвига прямого звука между первым акустическим сигналом и вторым акустическим сигналом по отношению к время-частотному интервалу (k, n), и
может быть оценкой фазового сдвига для фазового сдвига прямого звука между первым акустическим сигналом и вторым акустическим сигналом по отношению к время-частотному интервалу (k, n), и
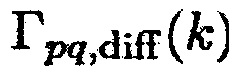 может соответствовать пространственной когерентности между акустическим датчиком p и акустическим датчиком q в чистом поле диффузного звука.
может соответствовать пространственной когерентности между акустическим датчиком p и акустическим датчиком q в чистом поле диффузного звука.
Функция 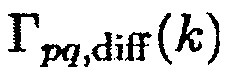 может измеряться или может предварительно вычисляться в зависимости от предполагаемого поля диффузного звука.
может измеряться или может предварительно вычисляться в зависимости от предполагаемого поля диффузного звука.
В другом варианте осуществления первое средство оценки вероятности речи может быть сконфигурировано с возможностью оценивать информацию вероятности речи посредством определения 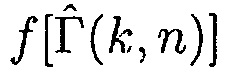 , где
, где 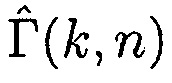 может быть оценкой отношения прямого к диффузному, и где
может быть оценкой отношения прямого к диффузному, и где 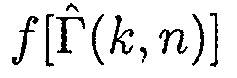 может быть функцией преобразования, представляющей преобразование оценки отношения прямого к диффузному в значение между 0 и 1.
может быть функцией преобразования, представляющей преобразование оценки отношения прямого к диффузному в значение между 0 и 1.
В другом варианте осуществления функция преобразования 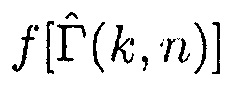 может определяться посредством формулы:
может определяться посредством формулы:
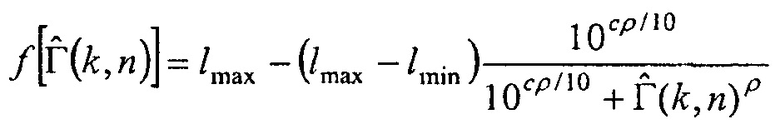
где 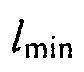 может быть минимальным значением функции преобразования, где
может быть минимальным значением функции преобразования, где 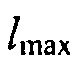 может быть максимальным значением функции преобразования, где c может быть значением для управления смещением вдоль оси
может быть максимальным значением функции преобразования, где c может быть значением для управления смещением вдоль оси 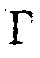 , и где
, и где 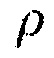 может определять крутизну перехода между
может определять крутизну перехода между 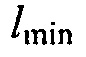 и
и 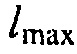 .
.
Согласно дополнительному варианту осуществления, первое средство оценки вероятности речи может быть сконфигурировано с возможностью определять параметр местоположения 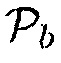 посредством использования формулы
посредством использования формулы
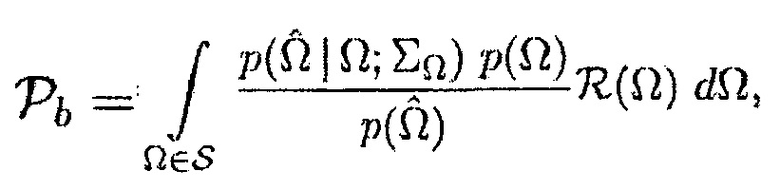
где  является конкретным местоположением, где
является конкретным местоположением, где  является оцененным местоположением,
является оцененным местоположением,
где 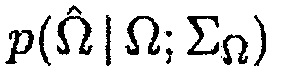 является функцией плотности условной вероятности, и
является функцией плотности условной вероятности, и
где 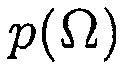 является функцией плотности априорной вероятности для
является функцией плотности априорной вероятности для  , и
, и
где 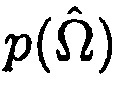 является функцией плотности вероятности для
является функцией плотности вероятности для 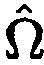 , и
, и
где 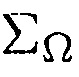 обозначает неопределенность, ассоциированную с оценками для
обозначает неопределенность, ассоциированную с оценками для  , и
, и
где 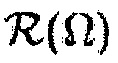 является многомерной функцией, которая описывает область интереса, при этом
является многомерной функцией, которая описывает область интереса, при этом 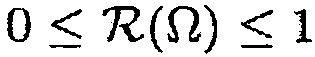 .
.
В другом варианте осуществления первое средство оценки вероятности речи может быть сконфигурировано с возможностью определять информацию вероятности речи q(k, n) посредством применения формулы:
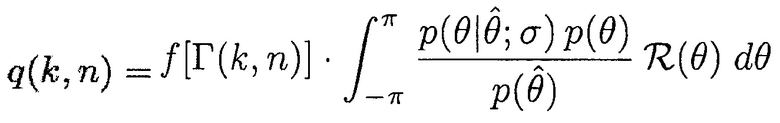
где 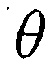 является конкретным направлением прибытия, и где
является конкретным направлением прибытия, и где 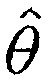 является оцененным направлением прибытия,
является оцененным направлением прибытия,
где 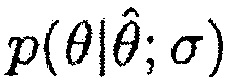 является функцией плотности условной вероятности, и
является функцией плотности условной вероятности, и
где 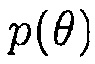 является функцией плотности априорной вероятности для
является функцией плотности априорной вероятности для 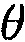 , и
, и
где 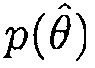 является функцией плотности вероятности для
является функцией плотности вероятности для 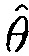 , и
, и
где 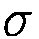 обозначает неопределенность, ассоциированную с оценками для
обозначает неопределенность, ассоциированную с оценками для 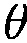 , и
, и
где 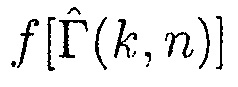 представляет преобразование оценки отношения прямого к диффузному
представляет преобразование оценки отношения прямого к диффузному 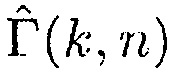 в значение между 0 и 1, и
в значение между 0 и 1, и
где  является многомерной функцией, которая описывает область интереса, при этом
является многомерной функцией, которая описывает область интереса, при этом  .
.
В дополнительном варианте осуществления, первое средство оценки вероятности речи может быть сконфигурировано с возможностью определять параметр близости как пространственную информацию, при этом параметр близости имеет первое значение параметра, когда первое средство оценки вероятности речи обнаруживает один или более возможных источников звука в пределах предварительно определенного расстояния от датчика близости, и при этом параметр близости имеет второе значение параметра, которое является меньшим, чем первое значение параметра, когда первое средство оценки вероятности речи не обнаруживает возможные источники звука в прямой близости от датчика близости. Первое средство оценки вероятности речи сконфигурировано с возможностью определять первое значение вероятности речи в качестве информации вероятности речи, когда параметр близости имеет первое значение параметра, и при этом первое средство оценки вероятности речи сконфигурировано с возможностью определять второе значение вероятности речи в качестве информации вероятности речи, когда параметр близости имеет второе значение параметра, при этом первое значение вероятности речи показывает первую вероятность, что звуковое поле содержит речь, при этом первая вероятность больше, чем вторая вероятность, что звуковое поле содержит речь, при этом вторая вероятность показывается посредством второго значения вероятности речи.
В одном варианте осуществления, обеспечивается устройство для определения оценки спектральной плотности мощности шума, содержащее устройство согласно одному из вышеописанных вариантов осуществления и блок оценки спектральной плотности мощности шума. Устройство согласно одному из вышеописанных вариантов осуществления может быть сконфигурировано с возможностью обеспечивать оценку вероятности речи в блок оценки спектральной плотности мощности шума. Блок оценки спектральной плотности мощности шума сконфигурирован с возможностью определять оценку спектральной плотности мощности шума на основе оценки вероятности речи и множества входных аудиоканалов.
В дополнительном варианте осуществления, обеспечивается устройство для оценки вектора управления, содержащее устройство согласно одному из вышеописанных вариантов осуществления и блок оценки вектора управления. Устройство согласно одному из вышеописанных вариантов осуществления может быть сконфигурировано с возможностью обеспечивать оценку вероятности речи в блок оценки вектора управления. Блок оценки вектора управления может быть сконфигурирован с возможностью оценивать вектор управления на основе оценки вероятности речи и множества входных аудиоканалов.
Согласно другому варианту осуществления, обеспечивается устройство для уменьшения многоканального шума, содержащее устройство согласно одному из вышеописанных вариантов осуществления и блок фильтра. Блок фильтра может быть сконфигурирован с возможностью принимать множество входных каналов аудио. Устройство согласно одному из вышеописанных вариантов осуществления может быть сконфигурировано с возможностью обеспечивать информацию вероятности речи в блок фильтра. Блок фильтра может быть сконфигурирован с возможностью фильтровать множество входных каналов аудио, чтобы получать фильтрованные аудиоканалы на основе информации вероятности речи и множества входных аудиоканалов.
В одном варианте осуществления, первое средство оценки вероятности речи может быть сконфигурировано с возможностью генерировать параметр компромиссного соотношения, при этом параметр компромиссного соотношения зависит от пространственной информации о звуковом поле или пространственной информации о сцене.
Согласно дополнительному варианту осуществления, блок фильтра может быть сконфигурирован с возможностью фильтровать множество входных каналов аудио в зависимости от параметра компромиссного соотношения.
Предложены концепции, чтобы вслепую извлекать звуки, которые являются сильно когерентными на решетке. Обеспечивается средство оценки матрицы PSD многоканального шума, которое основывается на апостериорной SPP. В отличие от состояния данной области техники, оценка DDR используется, чтобы определять априорную SPP. Дополнительно, предлагается использовать оцененное DDR, чтобы управлять параметром компромиссного соотношения PMWF. Дополнительно, продемонстрировано, что предложенный управляемый посредством DDR PWMF превосходит формирователь диаграммы направленности MVDR и MWF в терминах улучшения сегментного SNR и улучшения PESQ.
В одном варианте осуществления, обеспечивается способ для обеспечения оценки вероятности речи. Способ содержит:
- оценку информации вероятности речи, показывающей первую вероятность в отношении того, содержит ли звуковое поле речь, или в отношении того, не содержит ли звуковое поле речь, и
- вывод оценки вероятности речи в зависимости от информации вероятности речи.
Оценка информации первой вероятности речи основывается на, по меньшей мере, пространственной информации о звуковом поле или пространственной информации о сцене.
Дополнительно, обеспечивается компьютерная программа для осуществления вышеописанного способа, когда исполняется на компьютере или сигнальном процессоре.
Варианты осуществления обеспечиваются в зависимых пунктах формулы изобретения.
В последующем, варианты осуществления настоящего изобретения описываются более подробно со ссылкой на чертежи, на которых:
Фиг. 1 иллюстрирует устройство для обеспечения оценки вероятности речи согласно одному варианту осуществления,
Фиг. 2 иллюстрирует устройство для обеспечения оценки вероятности речи согласно другому варианту осуществления,
Фиг. 3 иллюстрирует блок-схему информированного средства оценки многоканальной апостериорной SPP согласно одному варианту осуществления,
Фиг. 4 иллюстрирует блок-схему средства оценки априорной SPP согласно одному варианту осуществления,
Фиг. 5 иллюстрирует преобразование из DDR  в параметр
в параметр 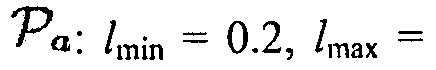
 согласно одному варианту осуществления,
согласно одному варианту осуществления,
Фиг. 6 иллюстрирует блок-схему средства оценки для  с использованием настроек пользователя/приложения, чтобы определять область интереса согласно одному варианту осуществления,
с использованием настроек пользователя/приложения, чтобы определять область интереса согласно одному варианту осуществления,
Фиг. 7 иллюстрирует блок-схему средства оценки для 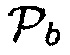 с использованием акустических и неакустических данных, чтобы определять область интереса согласно одному варианту осуществления,
с использованием акустических и неакустических данных, чтобы определять область интереса согласно одному варианту осуществления,
Фиг. 8 иллюстрирует устройство для определения оценки спектральной плотности мощности шума согласно одному варианту осуществления,
Фиг. 9 иллюстрирует блок-схему предложенного средства оценки матрицы PSD шума согласно дополнительному варианту осуществления,
Фиг. 10A иллюстрирует устройство для оценки вектора управления согласно одному варианту осуществления,
Фиг. 10B иллюстрирует блок-схему средства оценки вектора управления согласно одному варианту осуществления,
Фиг. 11 иллюстрирует устройство для уменьшения многоканального шума согласно одному варианту осуществления,
Фиг. 12 иллюстрирует преобразование DDR в параметр компромиссного соотношения 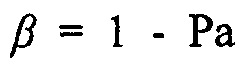 ,
,
Фиг. 13 иллюстрирует улучшение PESQ для стационарного (слева) и перекрестного шума (справа),
Фиг. 14 иллюстрирует усиление SNR для стационарного (слева) и перекрестного шума (справа),
Фиг. 15 иллюстрирует иллюстративные спектрограммы для перекрестного шума (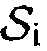 = 11 дБ), и
= 11 дБ), и
Фиг. 16 иллюстрирует оцененное DDR и соответствующую SPP ( = 11 дБ).
= 11 дБ).
Фиг. 1 иллюстрирует устройство для обеспечения оценки вероятности речи согласно одному варианту осуществления. Устройство содержит первое средство 110 оценки вероятности речи для оценки информации вероятности речи, показывающей первую вероятность в отношении того, содержит ли звуковое поле сцены речь, или в отношении того, не содержит ли звуковое поле сцены речь. Дополнительно, устройство содержит выходной интерфейс 120 для вывода оценки вероятности речи в зависимости от информации вероятности речи. Первое средство 110 оценки вероятности речи сконфигурировано с возможностью оценивать информацию первой вероятности речи на основе, по меньшей мере, пространственной информации о звуковом поле или пространственной информации о сцене.
Сцена является средой, где генерируется звуковое поле. Пространственная информация о сцене может, например, содержать информацию о положении одного или более источников звука, которые генерируют звуковое поле, информацию о положении акустических датчиков, информацию о расстоянии источников звука до акустических датчиков, информацию о том, обнаружен ли говорящий человек или рот, и/или информацию о том, находится ли говорящий человек или рот в близости к акустическим датчикам.
Пространственная информация о звуковом поле может, например, быть информацией направленности, показывающей то, насколько направленным является звук звукового поля. Например, информация направленности может быть отношением прямого к диффузному (DDR), как описано ниже.
Фиг. 2 иллюстрирует устройство для обеспечения оценки вероятности речи согласно другому варианту осуществления. Устройство содержит первое средство 210 оценки вероятности речи и выходной интерфейс 220. Более того, устройство дополнительно содержит второе средство 215 оценки вероятности речи, чтобы оценивать оценку вероятности речи, показывающую вторую вероятность в отношении того, содержит ли звуковое поле речь, или в отношении того, не содержит ли звуковое поле речь. Второе средство 215 оценки вероятности речи сконфигурировано с возможностью оценивать оценку вероятности речи на основе информации вероятности речи, оцененной посредством первого средства оценки вероятности речи, и на основе одного или более сигналов акустического датчика, которые зависят от звукового поля.
Для этой цели, первое средство оценки вероятности речи принимает пространственную информацию о звуковом поле и/или пространственную информацию о сцене. Первое средство 210 оценки вероятности речи затем оценивает информацию вероятности речи, которая показывает первую вероятность в отношении того, содержит ли звуковое поле сцены речь, или в отношении того, не содержит ли звуковое поле сцены речь. Первое средство 210 оценки вероятности речи может затем обеспечивать информацию вероятности речи во второе средство 215 оценки вероятности речи. Более того, второе средство 215 оценки вероятности речи может дополнительно принимать один или более сигналов акустического датчика. Второе средство 215 оценки вероятности речи затем оценивает оценку вероятности речи на основе информации вероятности речи, оцененной посредством первого средства 210 оценки вероятности речи, и на основе одного или более сигналов акустического датчика, которые зависят от звукового поля.
В отличие от состояния данной области техники, среди прочего, оценка вероятности речи выполняется на основе пространственной информации. Это значительно улучшает оценку вероятности речи.
Теперь, вводятся следующие гипотезы относительно присутствия полезного речевого сигнала в заданном время-частотном интервале, согласно которым:
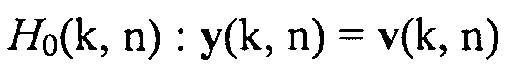 показывает отсутствие полезной речи и
показывает отсутствие полезной речи и
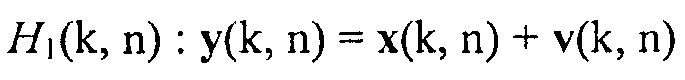 показывает присутствие полезной речи.
показывает присутствие полезной речи.
Другими словами: 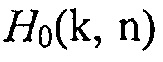 показывает отсутствие полезной речи, в то время как
показывает отсутствие полезной речи, в то время как 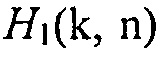 показывает присутствие полезной речи.
показывает присутствие полезной речи.
Фиг. 3 иллюстрирует блок-схему информированного средства оценки многоканальной SPP. Модуль "Вычисления условной апостериорной SPP" может осуществлять формулу (5).
На фиг. 3, модуль 310 реализует осуществление "Вычисления априорной SPP". В варианте осуществления из фиг. 3, модуль 310 "Вычисления априорной SPP" может осуществлять конкретную реализацию первого средства 210 оценки вероятности речи из фиг. 2. Дополнительно, на фиг. 3, модуль 315 реализует осуществление "Вычисления условной апостериорной SPP". В варианте осуществления из фиг. 3, модуль 315 "Вычисления условной апостериорной SPP" может осуществлять конкретную реализацию второго средства 215 оценки вероятности речи из фиг. 2.
Один вариант осуществления модуля 310 "Вычисления априорной SPP" согласно конкретному варианту осуществления показан на фиг. 4. На фиг. 4, настройки пользователя/приложения являются доступными для вычисления параметров в модулях 401, ..., 40P. Настройки пользователя/приложения также могут обеспечиваться в средство 411 комбинирования. Здесь P параметров вычисляются с использованием данных акустического и неакустического датчика также как настроек пользователя/приложения. Параметры  комбинируются (например, взвешенная сумма, произведение, средство комбинирования максимального отношения) посредством средства 411 комбинирования, чтобы вычислять априорную SPP q(k, n).
комбинируются (например, взвешенная сумма, произведение, средство комбинирования максимального отношения) посредством средства 411 комбинирования, чтобы вычислять априорную SPP q(k, n).
В следующих подразделах, представлены три параметра, которые могут использоваться, чтобы вычислять априорную SPP, требуемую для информированной многоканальной SPP.
В последующем, среди прочего, обеспечивается параметр 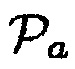 на основе направленности.
на основе направленности.
Является разумным предполагать, что полезные звуки являются направленными, в то время как паразитные звуки являются ненаправленными. Поэтому используется параметр, чтобы показывать то, насколько направленным является наблюдаемый звук. Одной возможностью для измерения направленности звукового поля является отношение прямого к диффузному (DDR). Оценка DDR может получаться посредством комплексной когерентности (CC), как показано в [12]. CC между двумя сигналами, измеренными в акустических датчиках p и q, определяется в частотно-временной области как
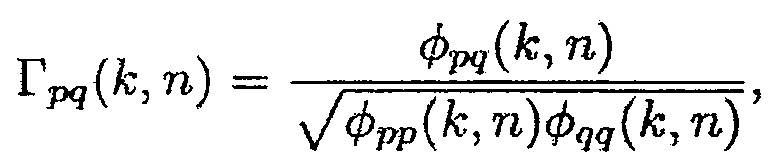 (9)
(9)
где 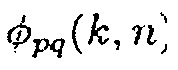 является перекрестной PSD и
является перекрестной PSD и 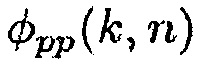 и
и 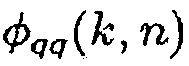 являются авто-PSD упомянутых двух сигналов. Средство оценки DDR в [12] основывается на модели звукового поля, где звуковое давление в любом положении и время-частотном интервале моделируется как суперпозиция прямого звука, представленного посредством одиночной монохроматической плоской волны и идеального диффузного поля. Предполагая всенаправленные акустические датчики, функция CC может быть выражена как
являются авто-PSD упомянутых двух сигналов. Средство оценки DDR в [12] основывается на модели звукового поля, где звуковое давление в любом положении и время-частотном интервале моделируется как суперпозиция прямого звука, представленного посредством одиночной монохроматической плоской волны и идеального диффузного поля. Предполагая всенаправленные акустические датчики, функция CC может быть выражена как
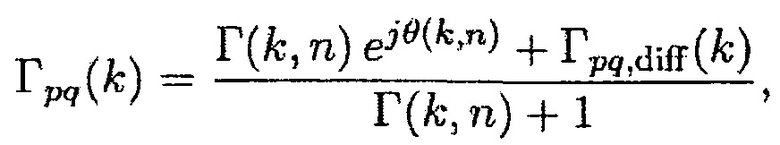 (10)
(10)
где 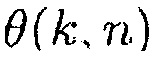 является фазовым сдвигом прямого звука между упомянутыми двумя акустическими датчиками,
является фазовым сдвигом прямого звука между упомянутыми двумя акустическими датчиками, 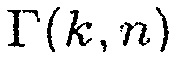 обозначает DDR, и
обозначает DDR, и 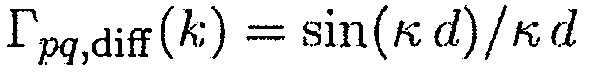 является CC идеального сферически изотропного звукового поля, где
является CC идеального сферически изотропного звукового поля, где 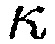 соответствует волновому числу в индексе частоты k, и d расстоянию между акустическими датчиками p и q. Функция
соответствует волновому числу в индексе частоты k, и d расстоянию между акустическими датчиками p и q. Функция 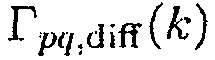 также может получаться в результате измерения. PSD, требуемые, чтобы вычислять
также может получаться в результате измерения. PSD, требуемые, чтобы вычислять 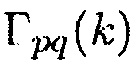 с использованием (9), приближаются посредством временных средних, и фазовый сдвиг
с использованием (9), приближаются посредством временных средних, и фазовый сдвиг 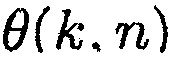 прямого звука может получаться из оцененной зашумленной PSD, т.е.
прямого звука может получаться из оцененной зашумленной PSD, т.е. 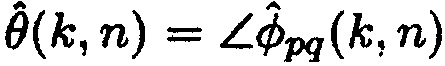 .
.
DDR 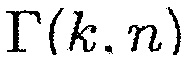 может теперь быть выражено в терминах оцененной CC
может теперь быть выражено в терминах оцененной CC 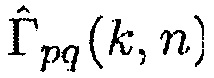 и оцененного фазового сдвига
и оцененного фазового сдвига 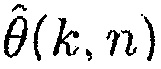 как
как
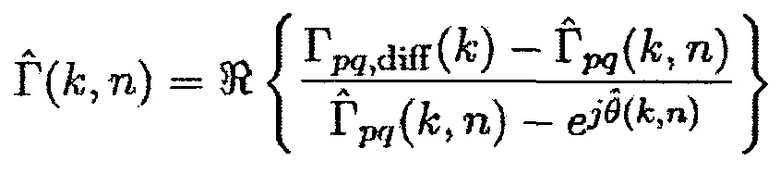 (11)
(11)
В зависимости от применения или акустического сценария (внутри помещений или вне помещений), функция CC 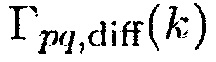 также может заменяться пространственной когерентностью, соответствующей другому полю шума. Когда являются доступными более, чем два акустических датчика, оценка DDR, полученная посредством различных пар акустических датчиков, может комбинироваться.
также может заменяться пространственной когерентностью, соответствующей другому полю шума. Когда являются доступными более, чем два акустических датчика, оценка DDR, полученная посредством различных пар акустических датчиков, может комбинироваться.
Ясно, что низкие значения 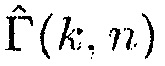 показывают отсутствие направленного источника, тогда как высокие значения
показывают отсутствие направленного источника, тогда как высокие значения 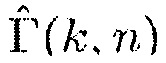 показывают присутствие направленного источника. На основе этого наблюдения,
показывают присутствие направленного источника. На основе этого наблюдения, 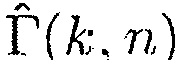 может использоваться, чтобы вычислять параметр, обозначенный посредством Pa, который используется, чтобы получать априорную SPP. Иллюстративная функция преобразования задана посредством
может использоваться, чтобы вычислять параметр, обозначенный посредством Pa, который используется, чтобы получать априорную SPP. Иллюстративная функция преобразования задана посредством
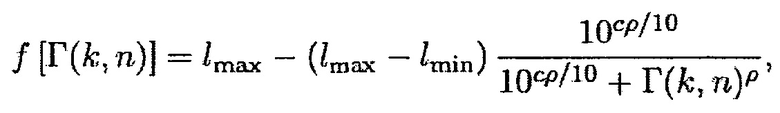 (12)
(12)
где 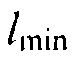 и
и 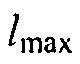 определяют минимальное и максимальное значения, которые функция может достигать, c (в дБ) управляет смещением вдоль оси
определяют минимальное и максимальное значения, которые функция может достигать, c (в дБ) управляет смещением вдоль оси 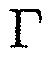 , и
, и 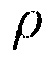 определяет крутизну перехода между
определяет крутизну перехода между 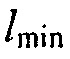 и
и 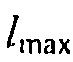 .
.
Фиг. 5 иллюстрирует преобразование (12) из DDR 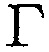 в параметр Pa:
в параметр Pa: 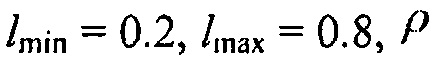
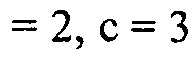 .
.
Наконец, параметр задается посредством
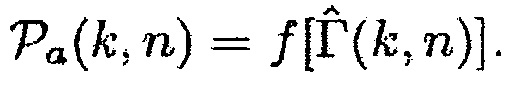 (13)
(13)
Априорная SPP может, например, получаться посредством
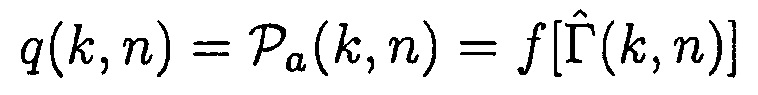 (14)
(14)
или
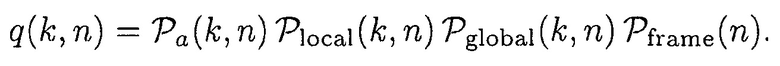 (15)
(15)
Параметры функции преобразования выбираются так, что низкое DDR соответствует низкой SPP, в то время как высокое DDR соответствует высокой SPP.
В последующем, среди прочего, обеспечивается параметр 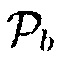 на основе местоположения и неопределенности.
на основе местоположения и неопределенности.
Согласно вариантам осуществления, вычисляется параметр, полученный посредством оценки мгновенного местоположения и ассоциированной неопределенности. Признак "местоположение" указывает на одномерные местоположения (только DOA) так же, как на двух- и трехмерные местоположения. Местоположение может быть описано в декартовых координатах (т.е. положение x, y, и z) или сферических координатах (т.е. азимутальный угол, угол возвышения, и расстояние).
При конкретных условиях, например, DDR, SNR, DOA, геометрия решетки и используемые средства оценки для параметра местоположения и DDR, может быть найдена эмпирическая функция плотности вероятности (PDF), которая описывает распределение вероятностей оцененного местоположения для источника в конкретном местоположении. Фаза обучения используется, чтобы вычислять эту эмпирическую PDF. Аналитическая PDF (например, гауссовская PDF в одномерном случае и многовариантная гауссовская PDF в упомянутом двух- и трехмерном случае) затем подгоняется к оцененным параметрам местоположения для каждого местоположения источника и конкретного условия.
В этом примере, PDF обозначается посредством 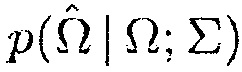 , где матрица
, где матрица 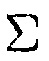 описывает неопределенность, ассоциированную с оценкой для
описывает неопределенность, ассоциированную с оценкой для 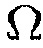 . Из данных выводится многомерная функция преобразования
. Из данных выводится многомерная функция преобразования 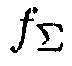 , которая преобразовывает вышеупомянутые условия в неопределенность
, которая преобразовывает вышеупомянутые условия в неопределенность  . Дополнительно, безусловные вероятности
. Дополнительно, безусловные вероятности 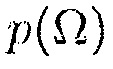 и
и 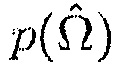 также могут вычисляться на фазе обучения. Например,
также могут вычисляться на фазе обучения. Например, 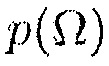 может моделироваться на основе априорной информации о возможных местоположениях источника, тогда как
может моделироваться на основе априорной информации о возможных местоположениях источника, тогда как 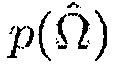 может вычисляться посредством наблюдения оценок в течение фазы обучения.
может вычисляться посредством наблюдения оценок в течение фазы обучения.
В дополнение, область интереса определяется посредством функции 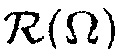 . В случае, когда в качестве параметра местоположения используется расстояние, могут определяться минимальное и максимальное расстояние, которые определяют местоположение полезного источника. Альтернативно, требуемый диапазон расстояний может извлекаться автоматически из датчика глубины или датчика времени пролета. В этом случае, требуемый диапазон может выбираться на основе среднего и дисперсии профиля глубины также как предварительно определенного отклонения и определенных пользователем/приложением пределов.
. В случае, когда в качестве параметра местоположения используется расстояние, могут определяться минимальное и максимальное расстояние, которые определяют местоположение полезного источника. Альтернативно, требуемый диапазон расстояний может извлекаться автоматически из датчика глубины или датчика времени пролета. В этом случае, требуемый диапазон может выбираться на основе среднего и дисперсии профиля глубины также как предварительно определенного отклонения и определенных пользователем/приложением пределов.
Вычисление предложенного параметра является следующим:
1. Оценка условий (например, параметра мгновенного местоположения  , мгновенной направленности
, мгновенной направленности 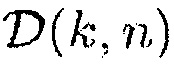 , и SNR) с использованием наблюдаемых акустических сигналов
, и SNR) с использованием наблюдаемых акустических сигналов 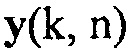 .
.
2. Определение области интереса полезного источника: i) пользователем/приложением, см. фиг. 6, или ii) посредством анализа данных акустического и неакустического датчика, см. фиг. 7. В последнем случае область интереса, обозначенная посредством 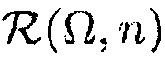 , является переменной по времени. Изображение может, например, анализироваться, чтобы определять местоположение рта говорящего (говорящих). Обнаружение лица и объекта также как идентификация говорящего могут использоваться, чтобы определять источники полезных и паразитных звуков. Приложение обеспечивает возможность выбирать источники/объекты полезных звуков и источники/объекты паразитных звуков интерактивно посредством пользовательского интерфейса. Априорная
, является переменной по времени. Изображение может, например, анализироваться, чтобы определять местоположение рта говорящего (говорящих). Обнаружение лица и объекта также как идентификация говорящего могут использоваться, чтобы определять источники полезных и паразитных звуков. Приложение обеспечивает возможность выбирать источники/объекты полезных звуков и источники/объекты паразитных звуков интерактивно посредством пользовательского интерфейса. Априорная  может определяться пользователем/приложением или посредством анализа неакустических датчиков.
может определяться пользователем/приложением или посредством анализа неакустических датчиков.
3. Определение индикатора неопределенности 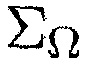 для каждой точки области интереса, на основе условий, вычисленных на этапе 1, и многомерной функции преобразования
для каждой точки области интереса, на основе условий, вычисленных на этапе 1, и многомерной функции преобразования 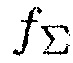 .
.
4. Вычисление параметра посредством
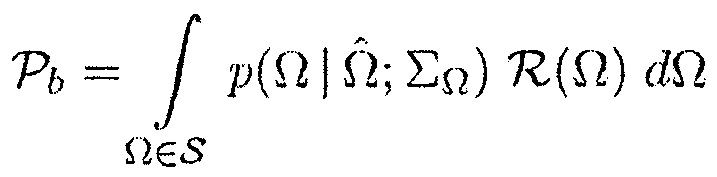 (16)
(16)
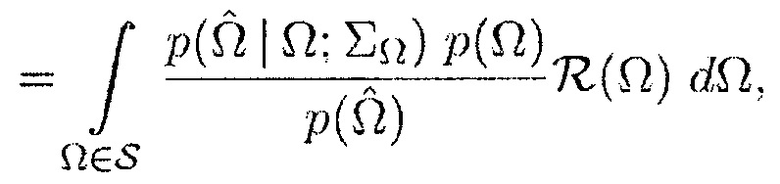 (17)
(17)
где S определяет все возможные местоположения, которые рассматриваются, и 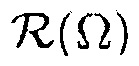 является многомерной функцией (
является многомерной функцией (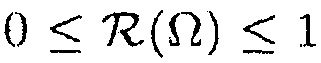 ), которая описывает область интереса. Уравнение (17) следует из (16) напрямую согласно правилу Бейеса, и обеспечивает возможность вычисления
), которая описывает область интереса. Уравнение (17) следует из (16) напрямую согласно правилу Бейеса, и обеспечивает возможность вычисления 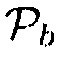 с использованием функций PDF, оцененных на фазе обучения.
с использованием функций PDF, оцененных на фазе обучения.
В одномерном случае, 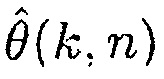 обозначает оцененное мгновенное DOA и
обозначает оцененное мгновенное DOA и 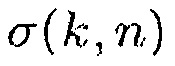 является пропорциональным ассоциированной неопределенности. Например, если используется линейная решетка акустических датчиков, точность оцененного DOA на поперечной стороне решетки является более большой, чем точность оцененного DOA на продольном направлении решетки. Следовательно, неопределенность является более большой и, следовательно,
является пропорциональным ассоциированной неопределенности. Например, если используется линейная решетка акустических датчиков, точность оцененного DOA на поперечной стороне решетки является более большой, чем точность оцененного DOA на продольном направлении решетки. Следовательно, неопределенность является более большой и, следовательно,  больше для продольного направления по сравнению с направлением поперечной стороны. Также известно, что производительность средства оценки DOA зависит от SNR; низкие уровни SNR дают более большую дисперсию оценки и, следовательно, более большую неопределенность по сравнению с высокими уровнями SNR. В одномерном случае, область интереса может, например, определяться как
больше для продольного направления по сравнению с направлением поперечной стороны. Также известно, что производительность средства оценки DOA зависит от SNR; низкие уровни SNR дают более большую дисперсию оценки и, следовательно, более большую неопределенность по сравнению с высокими уровнями SNR. В одномерном случае, область интереса может, например, определяться как
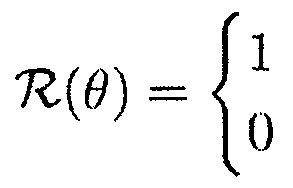
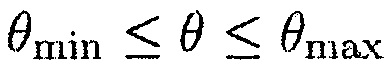 ;
;
так что предполагается, что любой источник, который является активным между 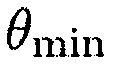 и
и 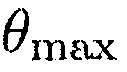 , является полезным.
, является полезным.
Априорная SPP может, например, получаться посредством комбинирования параметров 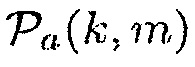 и
и 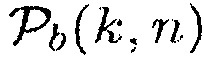
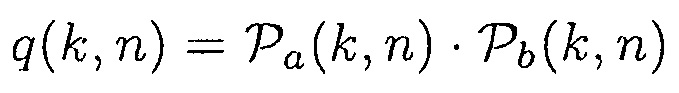
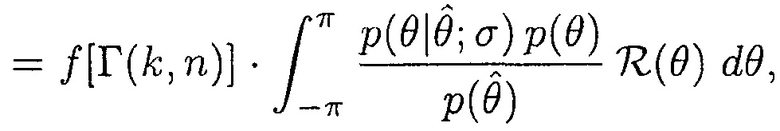 (19)
(19)
где 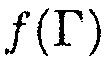 задано посредством (12).
задано посредством (12).
Фиг. 6 иллюстрирует блок-схему средства оценки для 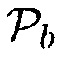 с использованием настроек пользователя/приложения, чтобы определять область интереса. Модуль 610 оценки мгновенного местоположения сконфигурирован с возможностью оценивать мгновенное местоположение. Модуль 620 вычисления неопределенности сконфигурирован с возможностью выполнять вычисление неопределенности. Дополнительно, модуль 630 вычисления параметров сконфигурирован с возможностью выполнять вычисление параметров.
с использованием настроек пользователя/приложения, чтобы определять область интереса. Модуль 610 оценки мгновенного местоположения сконфигурирован с возможностью оценивать мгновенное местоположение. Модуль 620 вычисления неопределенности сконфигурирован с возможностью выполнять вычисление неопределенности. Дополнительно, модуль 630 вычисления параметров сконфигурирован с возможностью выполнять вычисление параметров.
Фиг. 7 иллюстрирует блок-схему средства оценки для 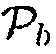 с использованием акустических и неакустических данных, чтобы определять область интереса. Снова, модуль 710 оценки мгновенного местоположения сконфигурирован с возможностью оценивать мгновенное местоположение. Модуль 720 вычисления неопределенности сконфигурирован с возможностью выполнять вычисление неопределенности. Дополнительно, модуль 725 определения области интереса сконфигурирован с возможностью определять область интереса. Модуль 730 вычисления параметров сконфигурирован с возможностью выполнять вычисление параметров.
с использованием акустических и неакустических данных, чтобы определять область интереса. Снова, модуль 710 оценки мгновенного местоположения сконфигурирован с возможностью оценивать мгновенное местоположение. Модуль 720 вычисления неопределенности сконфигурирован с возможностью выполнять вычисление неопределенности. Дополнительно, модуль 725 определения области интереса сконфигурирован с возможностью определять область интереса. Модуль 730 вычисления параметров сконфигурирован с возможностью выполнять вычисление параметров.
В последующем, среди прочего, обеспечивается параметр 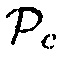 на основе близости.
на основе близости.
Параметр 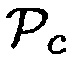 основывается на близости объекта к датчику близости. Здесь данные датчика близости преобразуются в
основывается на близости объекта к датчику близости. Здесь данные датчика близости преобразуются в 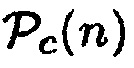 , так что
, так что 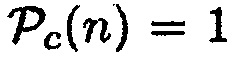 , когда объект находится в прямой близости к датчику близости, и
, когда объект находится в прямой близости к датчику близости, и 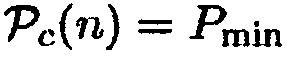 , когда никакие объекты не находятся в близости к датчику, где
, когда никакие объекты не находятся в близости к датчику, где 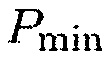 является предварительно определенной нижней границей.
является предварительно определенной нижней границей.
Параметр 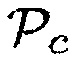 , который показывает близость, может выводиться из классического датчика близости (как используется во многих смартфонах, см. http://en.wikipedia.org/wiki/Proximity_sensor). Альтернативно, параметр может основываться на информации датчика глубины или датчика времени пролета, который может определять, что имеется объект в пределах R метров от датчика.
, который показывает близость, может выводиться из классического датчика близости (как используется во многих смартфонах, см. http://en.wikipedia.org/wiki/Proximity_sensor). Альтернативно, параметр может основываться на информации датчика глубины или датчика времени пролета, который может определять, что имеется объект в пределах R метров от датчика.
В одном конкретном варианте осуществления, 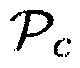 может быть осуществлен как параметр близости. Первое средство оценки вероятности речи может осуществлять преобразование, чтобы преобразовывать параметр близости
может быть осуществлен как параметр близости. Первое средство оценки вероятности речи может осуществлять преобразование, чтобы преобразовывать параметр близости 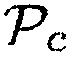 в значение, представляющее информацию вероятности речи, например, значение вероятности речи.
в значение, представляющее информацию вероятности речи, например, значение вероятности речи.
Параметр близости 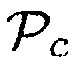 может, например, иметь первое значение параметра, (например,
может, например, иметь первое значение параметра, (например, 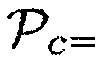 0.60), когда один или более возможных источников звука находится в пределах предварительно определенного расстояния от датчика близости. Дополнительно, параметр близости
0.60), когда один или более возможных источников звука находится в пределах предварительно определенного расстояния от датчика близости. Дополнительно, параметр близости 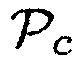 может иметь второе значение параметра (например,
может иметь второе значение параметра (например, 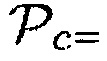 0.40), являющееся меньшим, чем первое значение параметра, когда никакие возможные источники звука не находятся в пределах предварительно определенного расстояния от датчика близости. Параметр близости
0.40), являющееся меньшим, чем первое значение параметра, когда никакие возможные источники звука не находятся в пределах предварительно определенного расстояния от датчика близости. Параметр близости 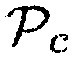 может, например, принимать любое значение между 0 и 1.0, например, в зависимости от близости обнаруженных объектов.
может, например, принимать любое значение между 0 и 1.0, например, в зависимости от близости обнаруженных объектов.
Первое средство оценки вероятности речи может быть сконфигурировано с возможностью определять первое значение вероятности речи в зависимости от 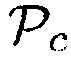 .
.
Теперь, определение информации вероятности речи рассматривается в общем.
Является важным отметить, что любая комбинация (например, произведение, сумма, взвешенная сумма) параметров 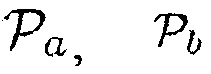 и/или
и/или 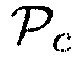 и других известных параметров, например,
и других известных параметров, например, 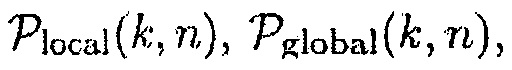 и/или
и/или  , могут использоваться для получения информации вероятности речи посредством использования средства комбинирования. Это также означает, что является также возможным использовать только параметры
, могут использоваться для получения информации вероятности речи посредством использования средства комбинирования. Это также означает, что является также возможным использовать только параметры 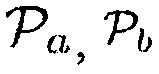 или
или 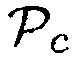 для получения информации вероятности речи.
для получения информации вероятности речи.
Может использоваться любая возможная комбинация параметров, например:
a) 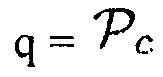 (Например, предполагается, что
(Например, предполагается, что 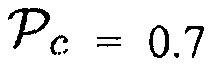 , когда объект находится в близости к датчику. Тогда любой активный источник звука (близкий ли или нет) будет рассматриваться как полезный с априорной SPP, равной 1-0.7=0.3.)
, когда объект находится в близости к датчику. Тогда любой активный источник звука (близкий ли или нет) будет рассматриваться как полезный с априорной SPP, равной 1-0.7=0.3.)
b) 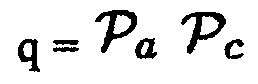 (Например, звук рассматривается как полезный, когда имеется объект, близкий к датчику, и DDR является достаточно высоким.)
(Например, звук рассматривается как полезный, когда имеется объект, близкий к датчику, и DDR является достаточно высоким.)
c) 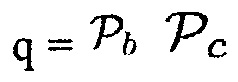 (Например, звук рассматривается как полезный, когда имеется объект, близкий к датчику, и местоположение источника звука находится в пределах области интереса, например, диапазона направления прибытия.)
(Например, звук рассматривается как полезный, когда имеется объект, близкий к датчику, и местоположение источника звука находится в пределах области интереса, например, диапазона направления прибытия.)
d) 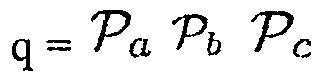 (Например, звук рассматривается как полезный, когда имеется объект, близкий к датчику, DDR наблюдаемого звука является достаточно высоким и местоположение источника звука находится в пределах области интереса.)
(Например, звук рассматривается как полезный, когда имеется объект, близкий к датчику, DDR наблюдаемого звука является достаточно высоким и местоположение источника звука находится в пределах области интереса.)
В последующем, обеспечиваются варианты осуществления применений вышеописанных концепций.
Теперь, описывается оценка матрицы PSD шума.
В [2] было предложено средство оценки PSD шума управляемого минимумом рекурсивного усреднения (MCRA), которое использует правило обновления на основе мягкого решения на основе одноканальной апостериорной SPP. Здесь априорная SPP вычислялась с использованием (8). Аналогичное средство оценки SPP было предложено в [4], где использовались фиксированная априорная SPP и фиксированное априорное SNR, нежели зависящие от сигнала величины как в [2]. Souden и др. [8] предложили средство оценки матрицы PSD многоканального шума, которое использует средство оценки многоканальной SPP [9]. В [8] авторы определяют априорную SPP с использованием априорного SNR способом, аналогичным средству оценки PSD шума MCRA.
Большой недостаток средств оценки многоканальной SPP данной области техники состоит в том, что они полагаются в большой степени на оцененную матрицу PSD шума. Если, например, включается кондиционирование воздуха или люди в отдалении начинают говорить, уровни сигнала увеличиваются, и средство оценки SPP будет показывать, что присутствует речь.
В этом случае, в отличие от предшествующего уровня техники, вариант осуществления все еще обеспечивает возможность принимать точное решение между тем, что является полезным, и тем, что является паразитным.
Учитывая неопределенность присутствия речи, оценка минимальной среднеквадратической ошибки (MMSE) для матрицы PSD шума в некотором время-частотном интервале задается посредством [8]
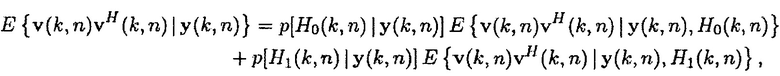 (19)
(19)
где 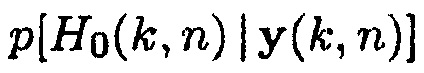 показывает условную вероятность того, что полезная речь отсутствует, и
показывает условную вероятность того, что полезная речь отсутствует, и 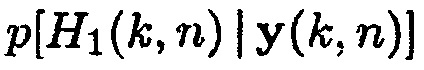 обозначает условную вероятность того, что полезная речь присутствует.
обозначает условную вероятность того, что полезная речь присутствует.
Фиг. 8 иллюстрирует устройство для определения оценки спектральной плотности мощности шума согласно одному варианту осуществления. Устройство для определения оценки спектральной плотности мощности шума содержит устройство 910 для обеспечения оценки вероятности речи согласно одному из вышеописанных вариантов осуществления и блок 920 оценки спектральной плотности мощности шума. Устройство 910 для обеспечения оценки вероятности речи сконфигурировано с возможностью обеспечивать оценку вероятности речи в блок 920 оценки спектральной плотности мощности шума. Блок 920 оценки спектральной плотности мощности шума сконфигурирован с возможностью определять оценку спектральной плотности мощности шума на основе оценки вероятности речи и на основе множества входных аудиоканалов.
Фиг. 9 иллюстрирует блок-схему средства оценки матрицы PSD шума согласно дополнительному варианту осуществления. Средство оценки матрицы PSD шума содержит модуль 912 "Вычисления априорной SPP". Модуль 912 "Вычисления априорной SPP" может быть первым средством оценки вероятности речи устройства для обеспечения оценки вероятности речи. Дополнительно, средство оценки матрицы PSD шума содержит модуль 914 "Вычисления условной апостериорной SPP". Модуль 914 "Вычисления условной апостериорной SPP" может быть вторым средством оценки вероятности речи устройства для обеспечения оценки вероятности речи. Дополнительно, средство оценки матрицы PSD шума содержит блок 920 "Оценки матрицы PSD шума".
Согласно вариантам осуществления, способ оценки шума, чтобы приближать (19), состоит в том, чтобы использовать взвешенную сумму рекурсивно усредненной мгновенной матрицы PSD зашумленного наблюдения, например,  , и оценку PSD шума предыдущего кадра, как описано в [2, 4] для одноканального случая и в [9] для многоканального случая. Этот способ оценки может быть выражен следующим образом:
, и оценку PSD шума предыдущего кадра, как описано в [2, 4] для одноканального случая и в [9] для многоканального случая. Этот способ оценки может быть выражен следующим образом:
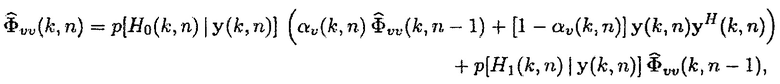 (20)
(20)
где 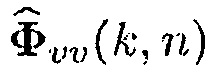 является оцененной матрицей PSD шума и
является оцененной матрицей PSD шума и 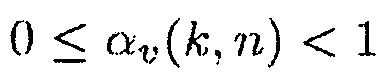 является выбранным параметром сглаживания. После перегруппировки (20), получается следующее правило обновления
является выбранным параметром сглаживания. После перегруппировки (20), получается следующее правило обновления
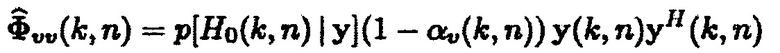 (21)
(21)
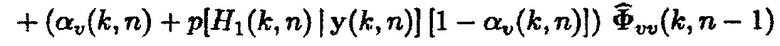
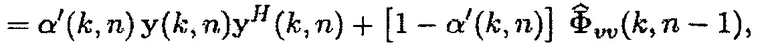 (22)
(22)
так что 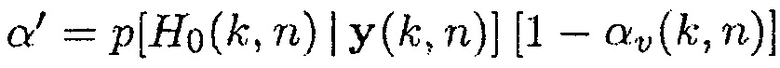 .
.
Чтобы дополнительно уменьшать утечку полезной речи в оценку матрицы PSD шума, мы предлагаем вычислять 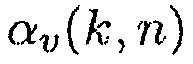 на основе оцененных параметров
на основе оцененных параметров  .
.
В отличие от алгоритма в [4], априорная SPP основывается на параметрах  и использует временную, спектральную и пространственную информацию, выведенную из акустических также как неакустических данных. Предложенное средство оценки матрицы PSD шума резюмировано на фиг. 10.
и использует временную, спектральную и пространственную информацию, выведенную из акустических также как неакустических данных. Предложенное средство оценки матрицы PSD шума резюмировано на фиг. 10.
Теперь, обеспечивается способ для оценки матрицы PSD шума согласно одному варианту осуществления. Средство оценки матрицы PSD шума согласно одному варианту осуществления может быть сконфигурировано с возможностью осуществлять такой способ.
1. Вычисление параметров  .
.
2. Вычисление априорной SPP 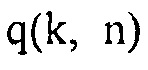 для текущего кадра с использованием параметров
для текущего кадра с использованием параметров  .
.
3. Определение параметра сглаживания 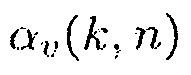 на основе параметров
на основе параметров  .
.
4. Оценка 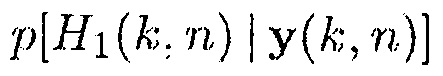 согласно (5), с использованием оцененной матрицы PSD шума из предыдущего кадра [например,
согласно (5), с использованием оцененной матрицы PSD шума из предыдущего кадра [например, 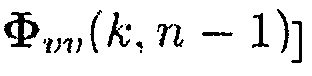 и текущей оценки для
и текущей оценки для 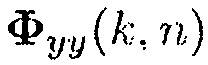 :
:
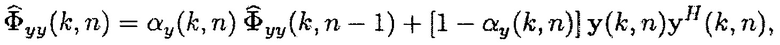 (23)
(23)
где 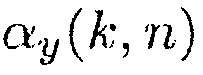 обозначает постоянную сглаживания.
обозначает постоянную сглаживания.
5. Вычисление рекурсивно сглаженной SPP следующим образом
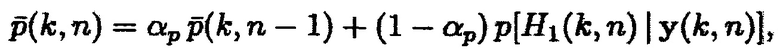 (24)
(24)
где 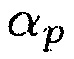 обозначает постоянную сглаживания.
обозначает постоянную сглаживания.
6. Избегание остановки обновления матрицы PSD шума посредством установки 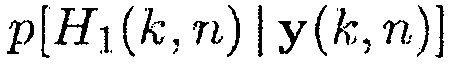 на выбранное максимальное значение
на выбранное максимальное значение 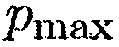 всякий раз, когда
всякий раз, когда  .
.
7. Обновление матрицы PSD шума посредством использования 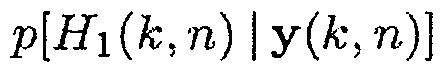 и (22).
и (22).
В последующем, рассматривается оценка вектора управления.
Фиг. 10A иллюстрирует устройство для оценки вектора управления. Устройство для оценки вектора управления содержит устройство 1010 для обеспечения оценки вероятности речи согласно одному из вышеописанных вариантов осуществления и блок 1020 оценки вектора управления. Устройство 1010 для обеспечения оценки вероятности речи сконфигурировано с возможностью обеспечивать оценку вероятности речи в блок 1020 оценки вектора управления. Блок 1020 оценки вектора управления сконфигурирован с возможностью оценивать вектор управления на основе оценки вероятности речи и на основе множества входных аудиоканалов.
Фиг. 10B иллюстрирует блок-схему устройства для оценки вектора управления согласно дополнительному варианту осуществления. Устройство для оценки вектора управления содержит модуль 1012 "Оценки априорной SPP". Модуль 1012 "Оценки априорной SPP" может быть первым средством оценки вероятности речи устройства для обеспечения оценки вероятности речи. Дополнительно, устройство для оценки вектора управления содержит модуль 1014 "Оценки условной апостериорной SPP". Модуль 1014 "Оценки условной апостериорной SPP" может быть вторым средством оценки вероятности речи устройства для обеспечения оценки вероятности речи. Дополнительно, устройство для оценки вектора управления содержит блок 1020 "Оценки вектора управления".
Для некоторых применений, требуется вектор управления полезного направленного источника, в дополнение или вместо матрицы PSD шума. В [13] средство оценки одноканальной SPP использовалось, чтобы вычислять вектор управления для двух акустических датчиков. Вектор управления, относящийся к полезному сигналу, принятому посредством i-го акустического датчика, определяется как
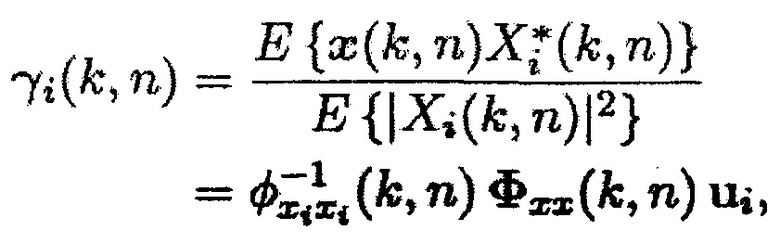 (25)
(25)
где  обозначает оператор сопряжения,
обозначает оператор сопряжения, 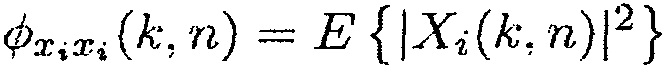 , и
, и
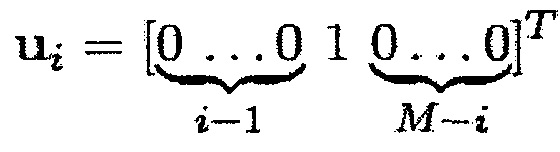 (26)
(26)
Ясно, что вектор управления может получаться посредством взятия i-го столбца 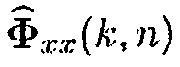 и разделения его на i-й элемент
и разделения его на i-й элемент 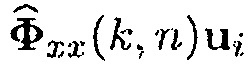 . По определению, i-й элемент вектора управления
. По определению, i-й элемент вектора управления 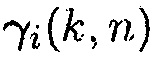 равняется единице.
равняется единице.
С использованием (4), матрица PSD источника может быть выражена как 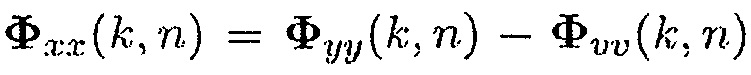 . Поэтому, вектор управления
. Поэтому, вектор управления 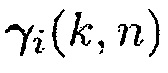 может быть выражен как
может быть выражен как
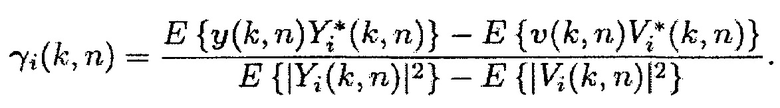 (27)
(27)
Члены в числителе могут получаться как i-й столбец матриц 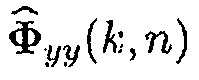 и
и 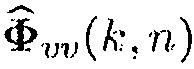 , тогда как члены в знаменателе как i-й элемент столбцовых векторов
, тогда как члены в знаменателе как i-й элемент столбцовых векторов 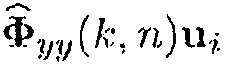 и
и 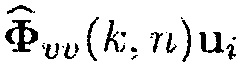 . Альтернативно, вектор управления
. Альтернативно, вектор управления 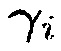 может получаться посредством вычисления разложения по обобщенным собственным значениям пары матриц
может получаться посредством вычисления разложения по обобщенным собственным значениям пары матриц 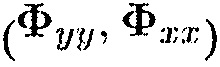 . Для j-го обобщенного собственного значения и пары собственных векторов
. Для j-го обобщенного собственного значения и пары собственных векторов 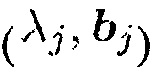 , имеет место следующее:
, имеет место следующее:
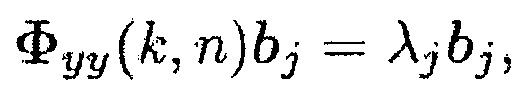 (28)
(28)
что с использованием (4) может быть записано как
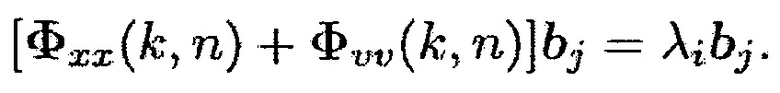 (29)
(29)
Из перегруппировки (29), и учета свойства ранга единица для  (т.е.
(т.е.  ) следует
) следует
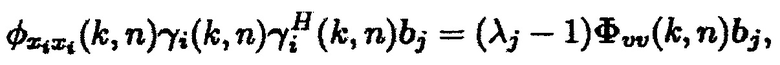 (30)
(30)
что эквивалентно
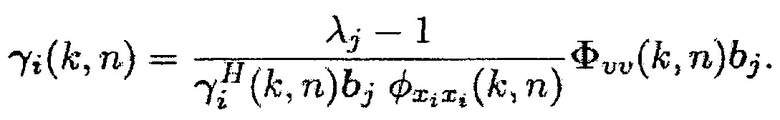 (31)
(31)
Из (31) можно заключить, что если 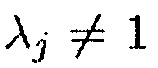 , вектор управления
, вектор управления 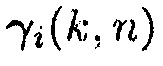 представляет повернутую и масштабированную версию собственного вектора
представляет повернутую и масштабированную версию собственного вектора 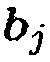 . Однако вследствие предположения ранга единица имеется единственное собственное значение
. Однако вследствие предположения ранга единица имеется единственное собственное значение 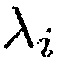 , которое не равно 1 и, следовательно, однозначно определяется собственный вектор
, которое не равно 1 и, следовательно, однозначно определяется собственный вектор 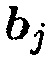 . В конечном счете, чтобы избегать неоднозначности масштабирования,
. В конечном счете, чтобы избегать неоднозначности масштабирования, 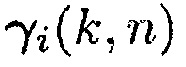 может нормализовываться следующим образом:
может нормализовываться следующим образом:
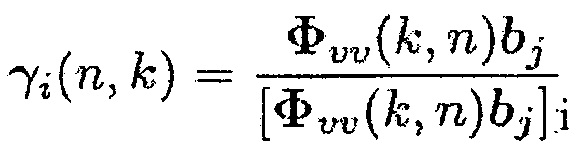 (32)
(32)
где 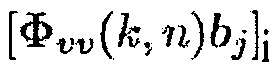 является i-м элементом вектора
является i-м элементом вектора 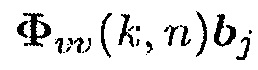 . С использованием информированного средства оценки многоканальной SPP, вектор управления оценивается рекурсивно следующим образом
. С использованием информированного средства оценки многоканальной SPP, вектор управления оценивается рекурсивно следующим образом
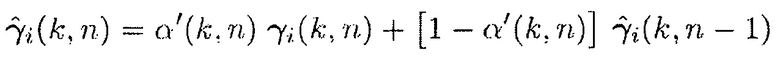 (33)
(33)
где 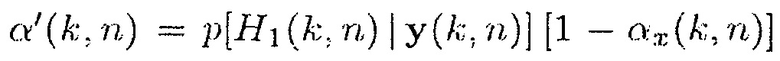 и
и 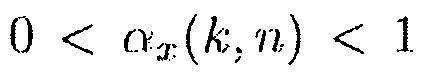 является подходящим образом выбранной постоянной сглаживания. Постоянная сглаживания
является подходящим образом выбранной постоянной сглаживания. Постоянная сглаживания 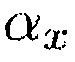 является зависящей от времени и частоты и управляется посредством
является зависящей от времени и частоты и управляется посредством 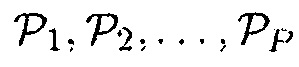 , чтобы минимизировать частоту обновления вектора управления, когда, например, SNR или DDR является слишком низким.
, чтобы минимизировать частоту обновления вектора управления, когда, например, SNR или DDR является слишком низким.
В последующем, объясняется уменьшение многоканального шума.
Фиг. 11 иллюстрирует устройство для уменьшения многоканального шума согласно одному варианту осуществления. Устройство для уменьшения многоканального шума содержит устройство 1110 для обеспечения оценки вероятности речи согласно одному из вышеописанных вариантов осуществления и блок 1120 фильтра. Блок 1120 фильтра сконфигурирован с возможностью принимать множество входных каналов аудио. Устройство 1110 для обеспечения оценки вероятности речи сконфигурировано с возможностью обеспечивать информацию вероятности речи в блок 1120 фильтра. Блок 1120 фильтра сконфигурирован с возможностью фильтровать множество входных каналов аудио, чтобы получать фильтрованные аудиоканалы на основе информации вероятности речи.
Теперь объясняется более подробно уменьшение многоканального шума согласно вариантам осуществления.
Средство оценки SPP часто используется в контексте уменьшения многоканального шума [6, 7, 14]. Информированное средство оценки многоканальной SPP согласно вариантам осуществления может использоваться аналогичным образом. В дополнение, параметры, используемые, чтобы вычислять априорную SPP, могут использоваться, чтобы управлять компромиссным соотношением между уменьшением шума и искажением речи.
Рассматривая i-й акустический датчик в качестве эталона, параметрический многоканальный фильтр Винера (PMWF) частотно-временной области задается посредством [15-17]
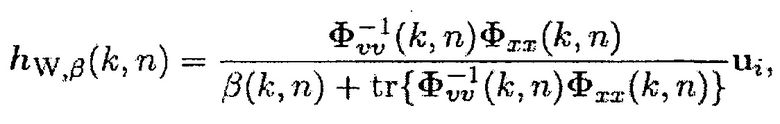 (34)
(34)
где 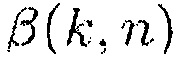 является параметром компромиссного соотношения.
является параметром компромиссного соотношения.
Хорошо известные (пространственные) фильтры являются специальными случаями параметрического многоканального фильтра Винера (PMWF). Например, фильтр отклика без искажений с минимальной дисперсией (MVDR) получается при 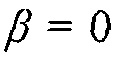 и многоканальный фильтр Винера (MWF) получается при
и многоканальный фильтр Винера (MWF) получается при 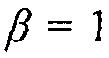 . Следует отметить, что (34) может быть выражено разными способами и может быть разложено на фильтр MVDR и одноканальный параметрический фильтр Винера (см., например, [14, 18] и ссылки там). Дополнительно, пространственный фильтр может быть выражен с использованием вектора управления и матриц PSD. Большое преимущество фильтра в (34) состоит в том, что он не зависит от вектора управления (известного так же, как вектор коллектора решетки или вектор распространения), относящегося к полезному источнику.
. Следует отметить, что (34) может быть выражено разными способами и может быть разложено на фильтр MVDR и одноканальный параметрический фильтр Винера (см., например, [14, 18] и ссылки там). Дополнительно, пространственный фильтр может быть выражен с использованием вектора управления и матриц PSD. Большое преимущество фильтра в (34) состоит в том, что он не зависит от вектора управления (известного так же, как вектор коллектора решетки или вектор распространения), относящегося к полезному источнику.
Оценка полезного сигнала, как принимается посредством i-го акустического датчика, получается посредством
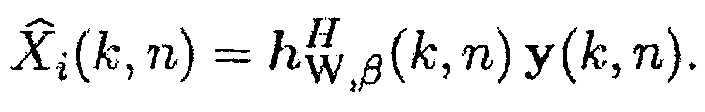 (35)
(35)
При неопределенности присутствия речи, оценка полезного сигнала может получаться согласно
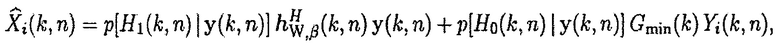 (36)
(36)
где второй член на правой стороне ослабляет искажения речи в случае ложно-отрицательного решения. Коэффициент усиления 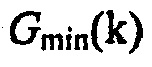 определяет максимальную величину уменьшения шума, когда полезная речь предполагается как неактивная.
определяет максимальную величину уменьшения шума, когда полезная речь предполагается как неактивная.
Если средство оценки MMSE применяется как для случая присутствия речи, так и для отсутствия, и требуется, чтобы в случае присутствия речи, целью была минимизация искажения полезной речи, в то время как в случае отсутствия речи, целью была минимизация остаточного шума на выходе фильтра, то мы находим (34) с помощью параметра [6, 7]
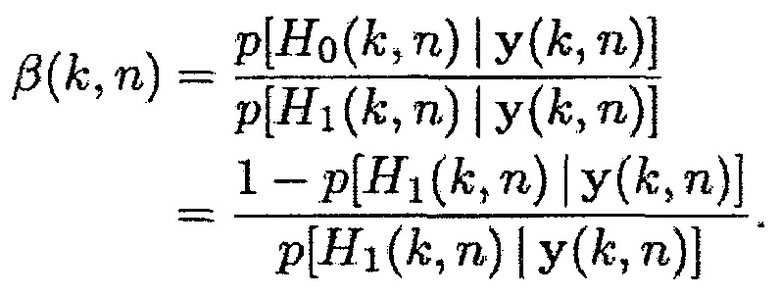 (37)
(37)
так что 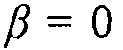 (так что PMWF является равным фильтру MVDR), когда апостериорная SPP
(так что PMWF является равным фильтру MVDR), когда апостериорная SPP 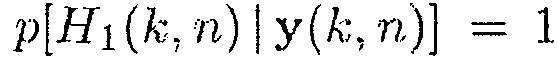 ,
, 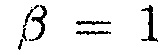 (так что PMWF является равным MWF), когда
(так что PMWF является равным MWF), когда 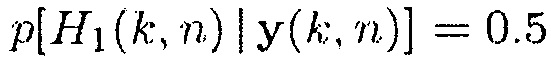 , и
, и 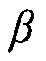 приближается к бесконечности, когда апостериорная SPP
приближается к бесконечности, когда апостериорная SPP 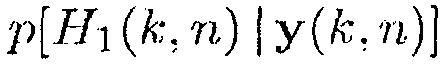 приближается к нулю. Следовательно, в последнем случае, мощность остаточного шума также уменьшается к нулю.
приближается к нулю. Следовательно, в последнем случае, мощность остаточного шума также уменьшается к нулю.
Фиг. 12 иллюстрирует преобразование DDR в параметр компромиссного соотношения с 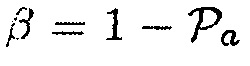
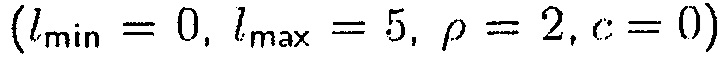 .
.
Прямое применение к априорной SPP может часто приводить к нежелательным слышимым искажениям полезного сигнала. Изобретение включает в себя PMWF, в котором параметр компромиссного соотношения зависит от комбинации (например, взвешенная сумма, произведение, средство комбинирования максимального отношения, и т.д.) параметров 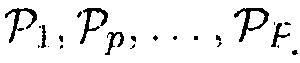 Функции преобразования, используемые, чтобы комбинировать параметры, могут отличаться от функций, используемых, чтобы вычислять априорную SPP.
Функции преобразования, используемые, чтобы комбинировать параметры, могут отличаться от функций, используемых, чтобы вычислять априорную SPP.
Например, можно управлять параметром с использованием параметра 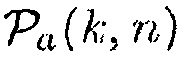 , который отражает направленность наблюдаемого звука, так что
, который отражает направленность наблюдаемого звука, так что 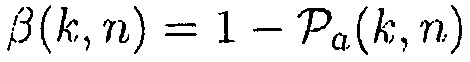 . Параметры
. Параметры 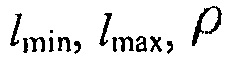 и c выбираются так, что мы получаем
и c выбираются так, что мы получаем 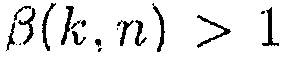 , когда оцененное DDR является низким, чтобы достигать более большой величины уменьшения шума по сравнению со стандартным MWF, и
, когда оцененное DDR является низким, чтобы достигать более большой величины уменьшения шума по сравнению со стандартным MWF, и 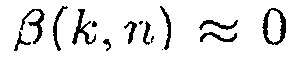 (например, приблизительно равно фильтру MVDR [16]), когда оцененное DDR является высоким, чтобы избегать искажения речи. Пример функции преобразования для параметра
(например, приблизительно равно фильтру MVDR [16]), когда оцененное DDR является высоким, чтобы избегать искажения речи. Пример функции преобразования для параметра  изображен на фиг. 12 с
изображен на фиг. 12 с 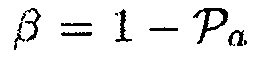
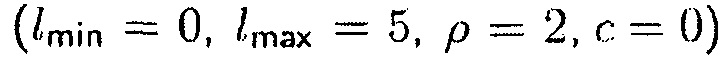 .
.
В одном более общем варианте осуществления, параметр компромиссного соотношения 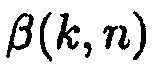 зависит от, по меньшей мере, пространственной информации о звуковом поле или пространственной информации о сцене.
зависит от, по меньшей мере, пространственной информации о звуковом поле или пространственной информации о сцене.
В одном конкретном варианте осуществления, параметр компромиссного соотношения 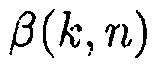 определяется посредством
определяется посредством  , где q обозначает вывод первого средства оценки вероятности речи.
, где q обозначает вывод первого средства оценки вероятности речи.
В одном конкретном варианте осуществления, параметр компромиссного соотношения 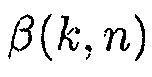 определяется посредством
определяется посредством 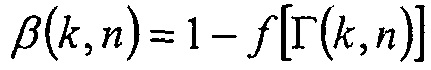 .
.
В последующем, оценивается производительность предложенного алгоритма в терминах достигаемого усиления речи на выходе PMWF. Сначала, описываются меры по установке и выполнению.
Анализ выполнялся для разных отношений SNR и времени реверберации, равного 300 мс. Использовались два разных типа шума: стационарный шум с долгосрочной PSD, равной долгосрочной PSD речи, и нестационарный перекрестный шум. В обоих случаях, CC сигналов шума соответствует CC идеального диффузного поля [21].
Частота дискретизации была 16 кГц, и длина кадра была L = 512 выборок. Моделирование выполнялось для равномерной линейной решетки из M = 4 микрофонов с расстоянием между микрофонами, равным d = 2.3 см. Полезные сигналы получались посредством осуществления свертки 45 с чистой речи с импульсными характеристиками помещения (RIR), которые генерировались с использованием эффективного осуществления модели источника изображений [22]. PSD, требуемые для оценки DDR, приближаются посредством усреднения по 15 временным кадрам. Для этих экспериментов мы использовали преобразования q и 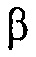 с параметрами, как проиллюстрировано на фиг. 5 и 12a. Параметры сглаживания
с параметрами, как проиллюстрировано на фиг. 5 и 12a. Параметры сглаживания 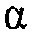 , использовавшиеся в рекурсивном усреднении
, использовавшиеся в рекурсивном усреднении 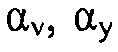 и
и 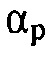 , были выбраны как 0.75, 0.8 и 0.9 соответственно. Изучались улучшение количественной оценки PESQ (перцепционной оценки качества речи) [23] и усиление сегментного SNR на выходе разных формирователей диаграммы направленности, управляемых посредством оцененной матрицы PSD шума. Улучшение PESQ вычисляется как разность в количественной оценке PESQ обратного STFT для
, были выбраны как 0.75, 0.8 и 0.9 соответственно. Изучались улучшение количественной оценки PESQ (перцепционной оценки качества речи) [23] и усиление сегментного SNR на выходе разных формирователей диаграммы направленности, управляемых посредством оцененной матрицы PSD шума. Улучшение PESQ вычисляется как разность в количественной оценке PESQ обратного STFT для 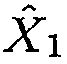 и обратного STFT для
и обратного STFT для 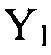 . Сегментное SNR получалось посредством разбиения сигналов на неперекрывающиеся сегменты, равные 10 мс, и усреднения по полученным значениям SNR в дБ. Сегментные SNR на входе и на выходе обозначаются посредством
. Сегментное SNR получалось посредством разбиения сигналов на неперекрывающиеся сегменты, равные 10 мс, и усреднения по полученным значениям SNR в дБ. Сегментные SNR на входе и на выходе обозначаются посредством 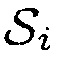 и
и  соответственно. Мы сравниваем производительность стандартных формирователей диаграммы направленности MVDR и Винера, управляемого посредством DDR PMWF, и оценку посредством (36) с i=1.
соответственно. Мы сравниваем производительность стандартных формирователей диаграммы направленности MVDR и Винера, управляемого посредством DDR PMWF, и оценку посредством (36) с i=1.
Теперь, представляются результаты. Улучшение PESQ на выходе формирователей диаграммы направленности проиллюстрировано на фиг. 13 как функция входного SNR 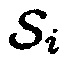 . Можно видеть, что предложенное средство оценки MMSE превосходит стандартные формирователи диаграммы направленности. В дополнение, управляемый посредством DDR PMWF работает более хорошо, чем упомянутые два формирователя диаграммы направленности с фиксированным компромиссным соотношением. Алгоритм ведет к значительному улучшению PESQ в случае перекрестного шума, который вследствие его нестационарности представляет настоящую проблему для многих алгоритмов. Соответствующие усиления сегментного SNR показаны на фиг. 14.
. Можно видеть, что предложенное средство оценки MMSE превосходит стандартные формирователи диаграммы направленности. В дополнение, управляемый посредством DDR PMWF работает более хорошо, чем упомянутые два формирователя диаграммы направленности с фиксированным компромиссным соотношением. Алгоритм ведет к значительному улучшению PESQ в случае перекрестного шума, который вследствие его нестационарности представляет настоящую проблему для многих алгоритмов. Соответствующие усиления сегментного SNR показаны на фиг. 14.
Спектрограммы сигнала полезного источника на первом микрофоне, принятый зашумленный сигнал, стандартный MWF и основывающаяся на MMSE оценка проиллюстрированы на фиг. 15, для отрезка, равного 11 с. Соответствующее преобразование из оцененного DDR в априорную SPP показано на фиг. 16. Можно видеть, что SPP корректно оценивается на высоких частотах также, поэтому обеспечивается сохранение речевого сигнала на этих частотах, где входное SNR является низким.
Хотя некоторые аспекты были описаны в контексте устройства, должно быть ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или признака соответствующего устройства.
Новый разложенный сигнал может сохраняться на цифровом запоминающем носителе или может передаваться по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, такая как сеть Интернет.
В зависимости от конкретных требований реализации, варианты осуществления изобретения могут осуществляться в аппаратном обеспечении или в программном обеспечении. Осуществление может выполняться с использованием цифрового запоминающего носителя, например, гибкого диска, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего электронно-читаемые сигналы управления, сохраненные на нем, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой, так что выполняется соответствующий способ.
Некоторые варианты осуществления согласно изобретению содержат нетранзиторный носитель данных, имеющий электронно-читаемые сигналы управления, которые способны взаимодействовать с программируемой компьютерной системой, так что выполняется один из описанных здесь способов.
В общем, варианты осуществления настоящего изобретения могут осуществляться как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью для выполнения одного из способов, когда компьютерный программный продукт исполняется на компьютере. Программный код может, например, храниться на машинно-читаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из описанных здесь способов, сохраненную на машинно-читаемом носителе.
Другими словами, один вариант осуществления нового способа является, поэтому, компьютерной программой, имеющей программный код для выполнения одного из описанных здесь способов, когда компьютерная программа исполняется на компьютере.
Дополнительный вариант осуществления новых способов является, поэтому, носителем данных (или цифровым запоминающим носителем, или машиночитаемым носителем), содержащим, записанную на нем, компьютерную программу для выполнения одного из описанных здесь способов.
Дополнительный вариант осуществления нового способа является, поэтому, потоком данных или последовательностью сигналов, представляющих компьютерную программу для выполнения одного из описанных здесь способов. Поток данных или последовательность сигналов может, например, быть сконфигурированной с возможностью передаваться посредством соединения передачи данных, например, посредством сети Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер, или программируемое логическое устройство, сконфигурированное с возможностью или адаптированное для выполнения одного из описанных здесь способов.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из описанных здесь способов.
В некоторых вариантах осуществления, может использоваться программируемое логическое устройство (например, программируемая пользователем вентильная матрица), чтобы выполнять некоторые или все из функциональных возможностей описанных здесь способов. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы выполнять один из описанных здесь способов. В общем, способы предпочтительно выполняются посредством любого аппаратного устройства.
Вышеописанные варианты осуществления являются просто иллюстративными для принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и деталей, описанных здесь, должны быть ясными для специалистов в данной области техники. Поэтому предполагается, что изобретение ограничено только объемом приложенной формулы изобретения, а не конкретными деталями, представленными путем описания и объяснения вариантов осуществления.
Ссылки
1. I. Cohen and B. Berdugo. "Noise estimation by minima controlled recursive averaging for robust speech enhancement". IEEE Signal Process. Lett., vol. 9, no. 1, pp. 12-15, Jan. 2002.
2. I. Cohen. "Noise spectrum estimation in adverse environments: Improved minima controlled recursive averaging", IEEE Trans. Speech Audio Process., vol. 11, no. 5, pp. 466-475, Sep. 2003.
3. "Apparatus and method for computing speech absence probability, and apparatus and method removing noise using computation apparatus and method". US Patent No. US 7,080,007 B2, Jul. 18, 2006.
4. T. Gerkmann and R. C. Hendriks. "Noise power estimation base on the probability of speech presence". in Proc. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY, 2011.
5. "Wind noise suppression". US Patent Application Publication Pub. No. US 2011/0103615 A1, May 5, 2011.
6. K. Ngo, A. Spriet, M. Moonen, J. Wouters and S. Jensen. "Incorporating the conditional speech presence probability in multi-channel Wiener filter based noise reduction in hearing aids". EURASIP Journal on Applied Signal Processing, vol. 2009, p. 7, 2009.
7. T. Yu and J. Hansen. "A speech presence microphone array beamformer using model based speech presence probability estimation". in Proc. IEEE Intl. Conf. on Acoustics, Speech and Signal Processing (ICASSP), 2009, pp. 213-216.
8. M. Souden, J. Chen, J. Benesty, and S. Affes. "An integrated solution for online multichannel noise tracking and reduction". IEEE Trans. Audio, Speech, Lang. Process., vol. 19, pp. 2159-2169, 2011.
9. M. Souden, J. Chen, J. Benesty and S. Affes. "Gaussian model-based multichannel speech presence probability". IEEE Transactions on Audio, Speech, and Language Processing, vol. 18, no. 5, pp. 1072-1077, July 2010.
10. I. Cohen and B. Berdugo. "Microphone array post-filtering for non-stationary noise suppression". in Proc. IEEE Intl. Conf. on Acoustics, Speech and Signal Processing (ICASSP), Orlando, Florida, USA, May 2002, pp. 901-904.
11. "Method for estimating priori SAP based on statistical model". US Patent Application Publication Pub. No. US 2008/0082328 A1, Apr. 3, 2008.
12. O. Thiergart, G. D. Galdo and E. A. P. Habets. "Signal-to-reverberant ratio estimation based on the complex spatial coherence between omnidirectional microphones". in Proc. IEEE Intl. Conf. on Acoustics, Speech and Signal Processing (ICASSP), 2012, pp. 309-312.
13. I. Cohen. "Relative transfer function identification using speech signals". IEEE Trans. Speech Audio Process., vol. 12, no. 5, pp. 451-459, Sep. 2004.
14. S. Gannot and I. Cohen. "Adaptive beamforming and postfiltering". in Springer Handbook of Speech Processing, J. Benesty, M. M. Sondhi and Y. Huang, Eds. Springer-Verlag, 2007, ch. 48.
15. A. Spriet, M. Moonen and J. Wouters. "Spatially pre-processed speech distortion weighted multi-channel Wiener filtering for noise reduction". Signal Processing, vol. 84, no. 12, pp. 2367-2387, Dec. 2004.
16. J. Benesty, J. Chen and Y. Huang. Microphone Array Signal Processing. Berlin, Germany: Springer-Verlag, 2008.
17. S. Mehrez, J. Benesty and S. Affes. "On optimal frequency-domain multichannel linear filtering for noise reduction". IEEE Trans. Audio, Speech, Lang. Process., vol. 18, no. 2, pp. 260-276, 2010.
18. J. Benesty, J. Chen and E. A. P. Habets. Speech Enhancement in the STFT Domain, ser. SpringerBriefs in Electrical and Computer Engineering. Springer-Verlag, 2011.
19. Henry Stark, John W. Woods: Probability and Random Processes with Applications to Signal Processing.
20. A. Papoulis, U. Pillai: Probability, Random Variables and Stochastic Processes.
21. E.A.P. Habets, I. Cohen and S. Gannot. "Generating nonstationary multisensor signals under a spatial coherence constraint". Journal Acoust. Soc. of America, vol. 124, no. 5, pp. 2911-2917, Nov. 2008.
22. E.A.P. Habets. "Room impulse response generator". Tech. Rep., Technische Universiteit Eindhoven, 2006.
23. A. Rix, J. Beerends, M. Hollier and A. Hekstra. "Perceptual evaluation of speech quality (PESQ) - a new method for speech quality assessment of telephone networks and codecs". in Proc. IEEE Intl. Conf. on Acoustics, Speech and Signal Processing (ICASSP), 2001, vol. 2, pp. 749-752.
24. G.W. Elko. "Spatial coherence functions". in Microphone Arrays: Signal Processing Techniques and Applications, M. Brandstein and D. Ward, Eds., chapter 4, pp. 61-85. Springer-Verlag, 2001.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОСЛАБЛЕНИЕ ШУМА В СИГНАЛЕ | 2012 |
|
RU2611973C2 |
| ФИЛЬТР И СПОСОБ ДЛЯ ИНФОРМИРОВАННОЙ ПРОСТРАНСТВЕННОЙ ФИЛЬТРАЦИИ, ИСПОЛЬЗУЯ МНОГОЧИСЛЕННЫЕ МГНОВЕННЫЕ ОЦЕНКИ НАПРАВЛЕНИЯ ПРИБЫТИЯ | 2013 |
|
RU2641319C2 |
| ИЗВЛЕЧЕНИЕ РЕВЕРБЕРИРУЮЩЕГО ЗВУКА С ИСПОЛЬЗОВАНИЕМ МИКРОФОННЫХ МАССИВОВ | 2014 |
|
RU2640742C1 |
| СПОСОБ И АППАРАТУРА ДЛЯ ГЕНЕРАЦИИ СИГНАЛА РЕЧИ | 2014 |
|
RU2648604C2 |
| СПОСОБ ГИБРИДНОЙ ГЕНЕРАТИВНО-ДИСКРИМИНАТИВНОЙ СЕГМЕНТАЦИИ ДИКТОРОВ В АУДИО-ПОТОКЕ | 2013 |
|
RU2530314C1 |
| УСТРОЙСТВО И СПОСОБ ОСНОВАННОГО НА ГЕОМЕТРИИ КОДИРОВАНИЯ ПРОСТРАНСТВЕННОГО ЗВУКА | 2011 |
|
RU2556390C2 |
| ПРИЕМ ЗВУКА ПОСРЕДСТВОМ ВЫДЕЛЕНИЯ ГЕОМЕТРИЧЕСКОЙ ИНФОРМАЦИИ ИЗ ОЦЕНОК НАПРАВЛЕНИЯ ЕГО ПОСТУПЛЕНИЯ | 2011 |
|
RU2570359C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ СОВМЕЩЕНИЯ ПОТОКОВ ПРОСТРАНСТВЕННОГО АУДИОКОДИРОВАНИЯ НА ОСНОВЕ ГЕОМЕТРИИ | 2012 |
|
RU2609102C2 |
| ОСЛАБЛЕНИЕ ШУМА ПРИ ПЕРЕДАЧЕ АУДИОСИГНАЛОВ | 2012 |
|
RU2616534C2 |
| ОЦЕНКА МЕСТОПОЛОЖЕНИЯ ИСТОЧНИКА ЗВУКА С ИСПОЛЬЗОВАНИЕМ ФИЛЬТРОВАНИЯ ЧАСТИЦ | 2009 |
|
RU2511672C2 |
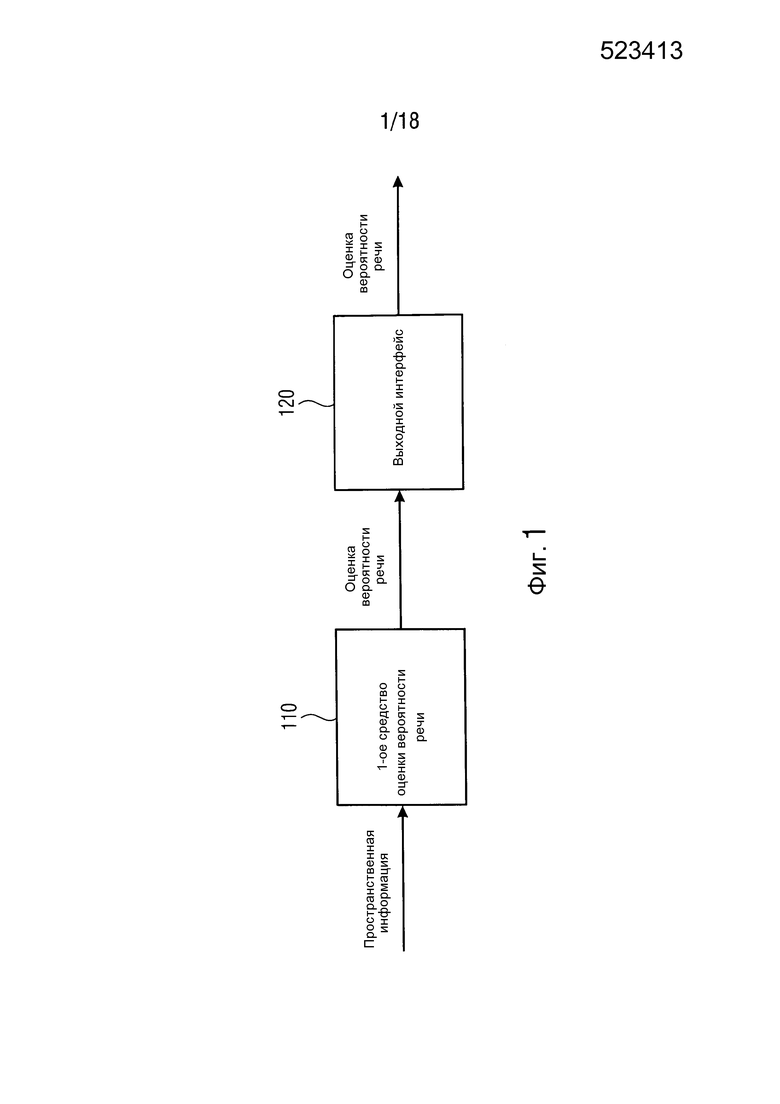
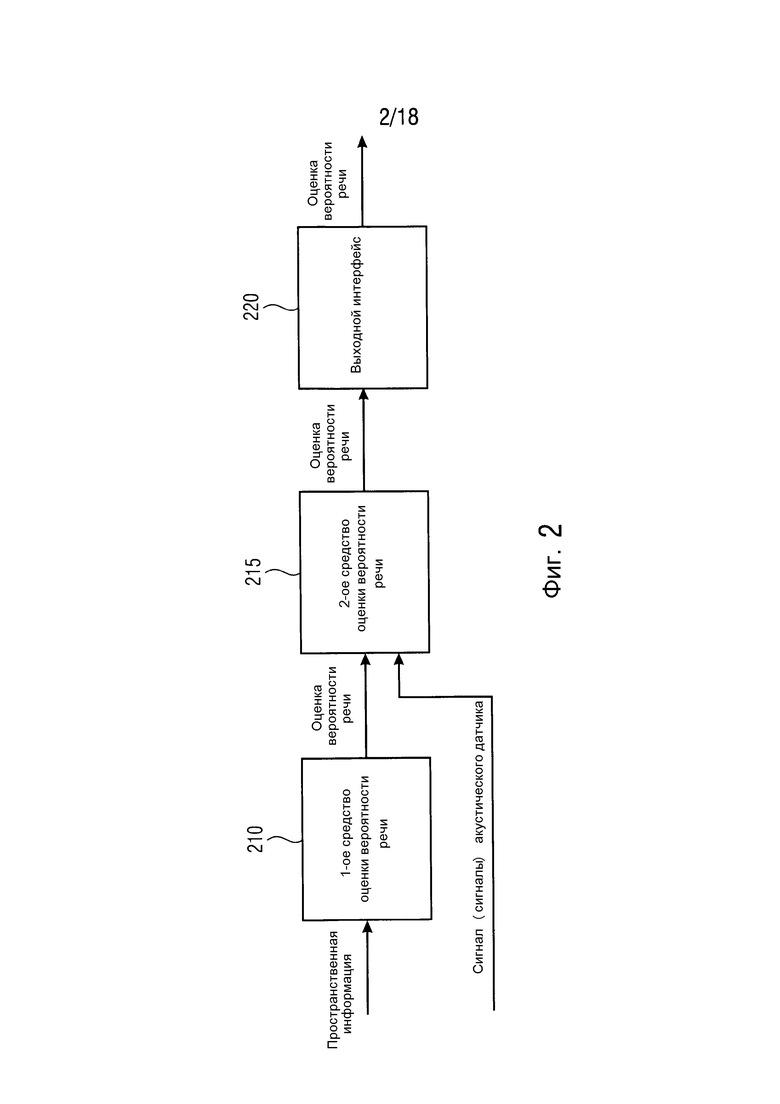
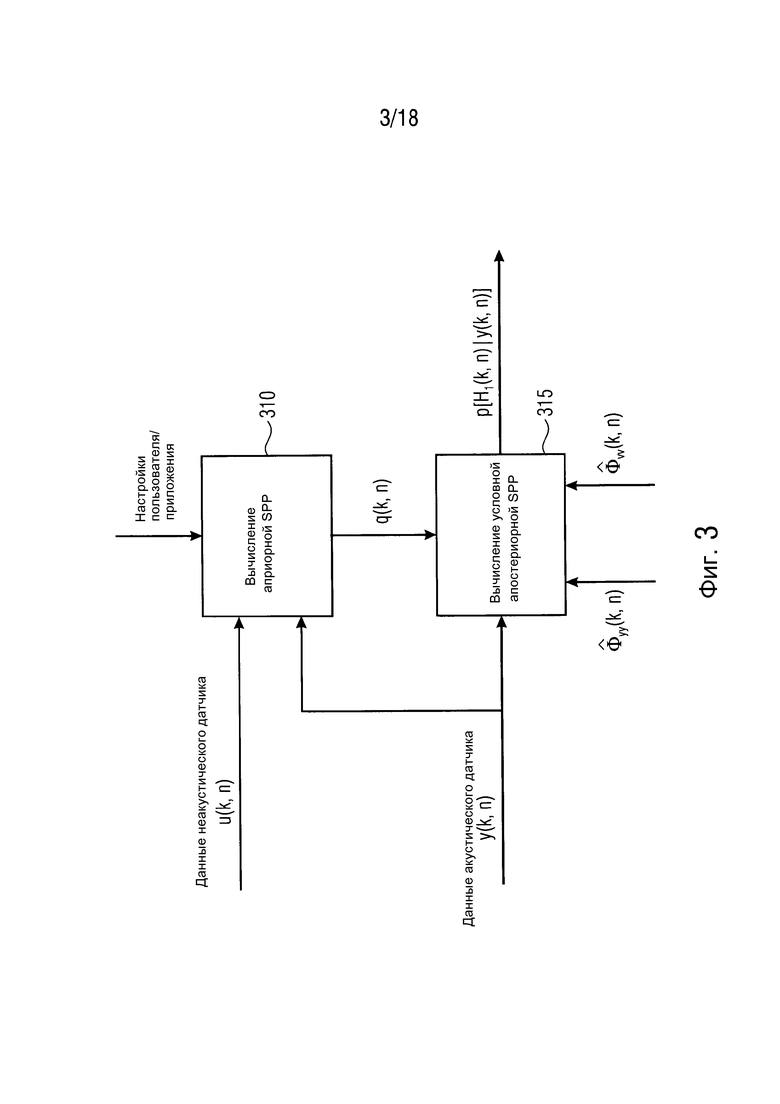
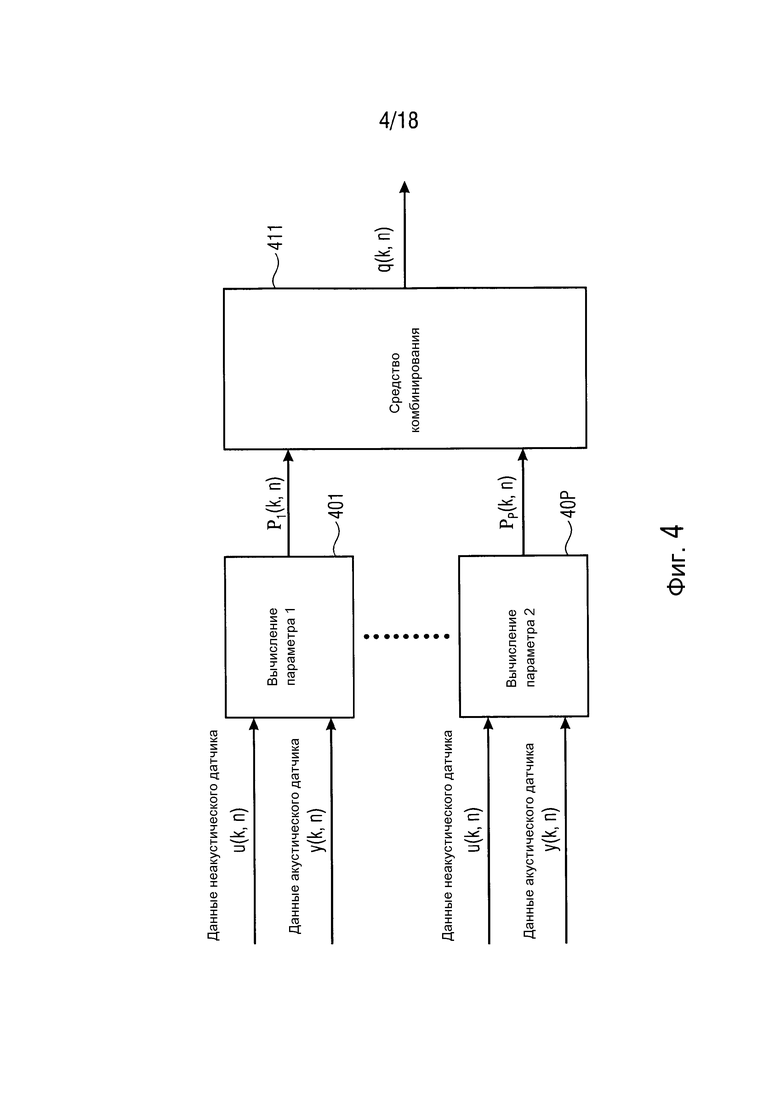
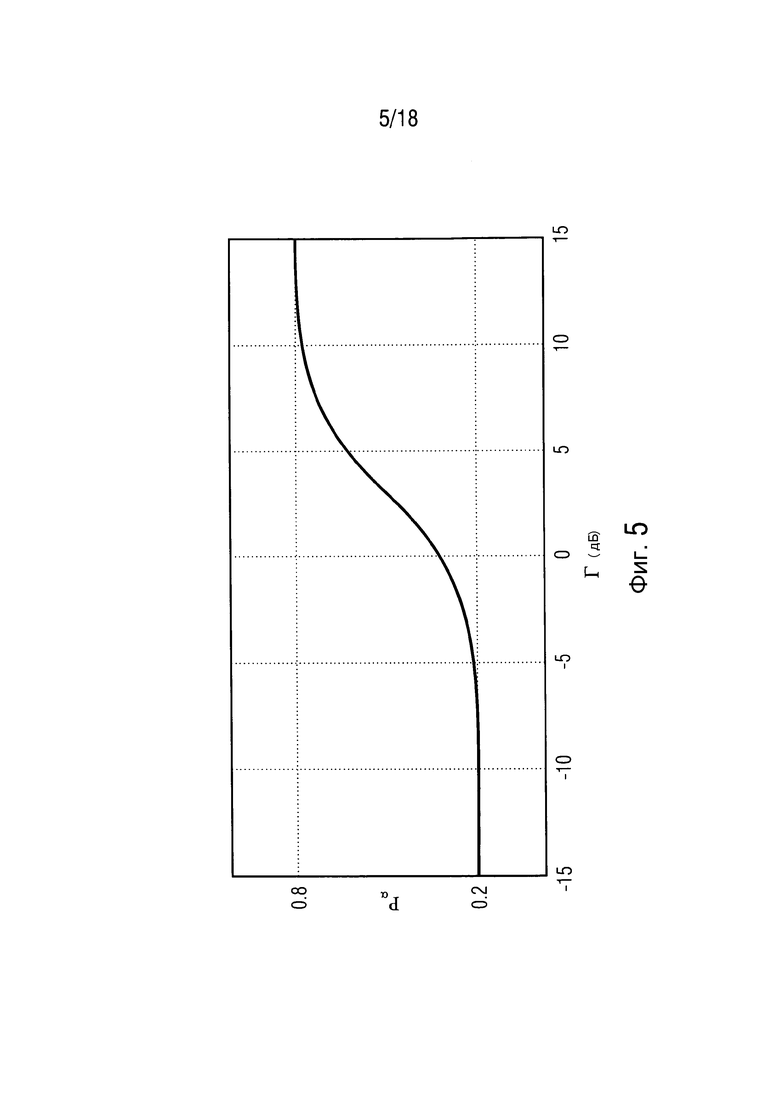
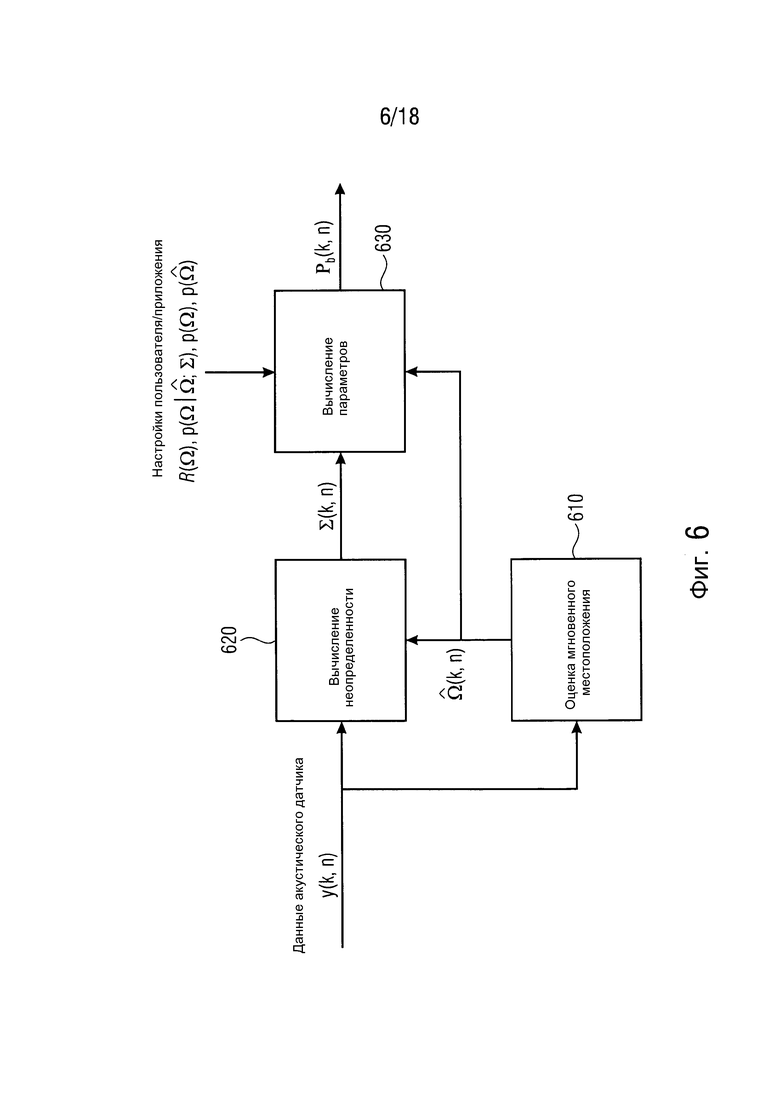
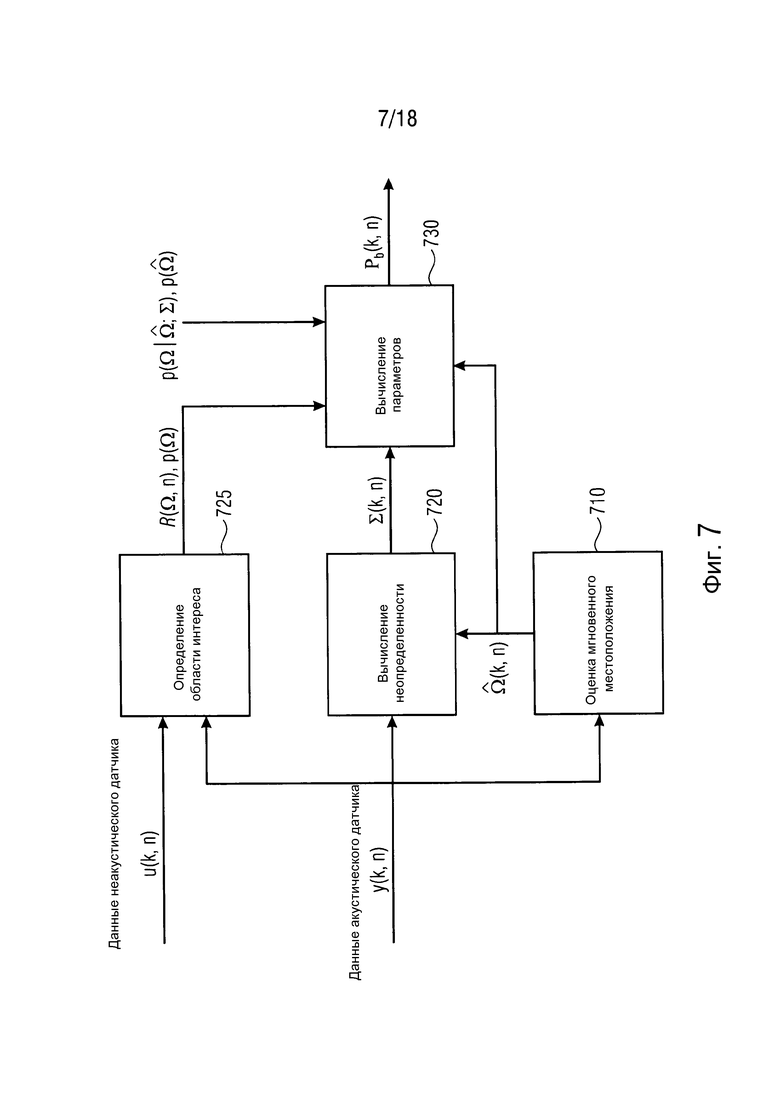
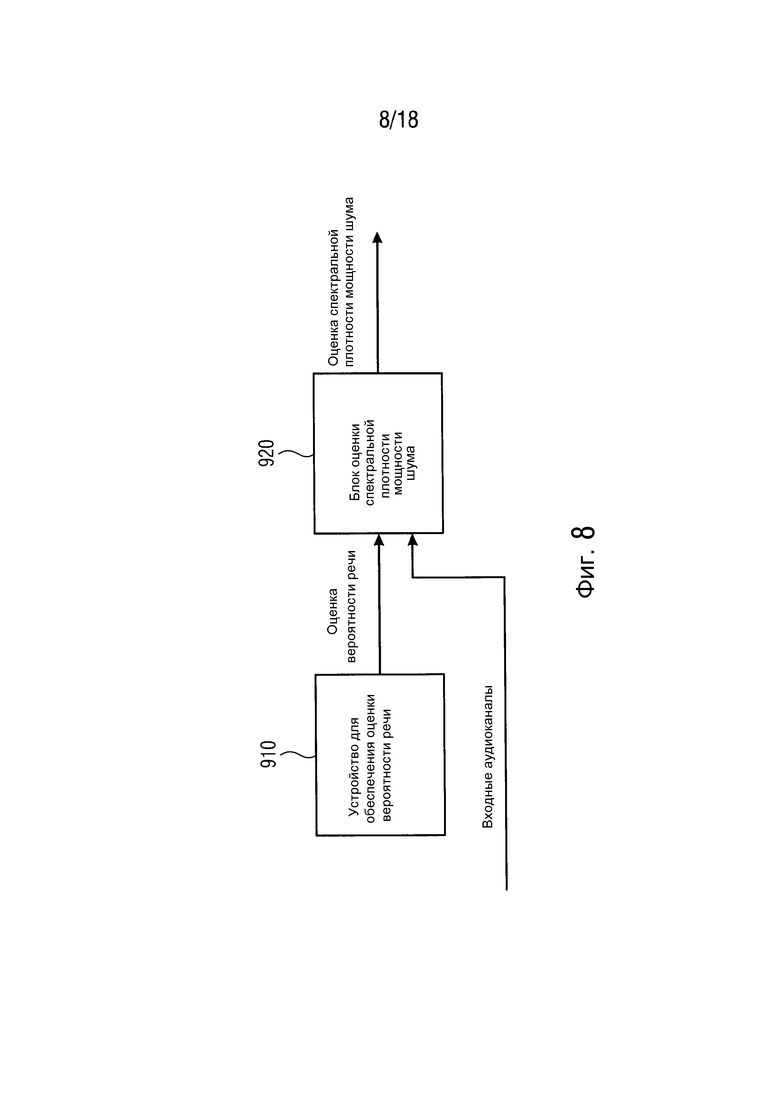
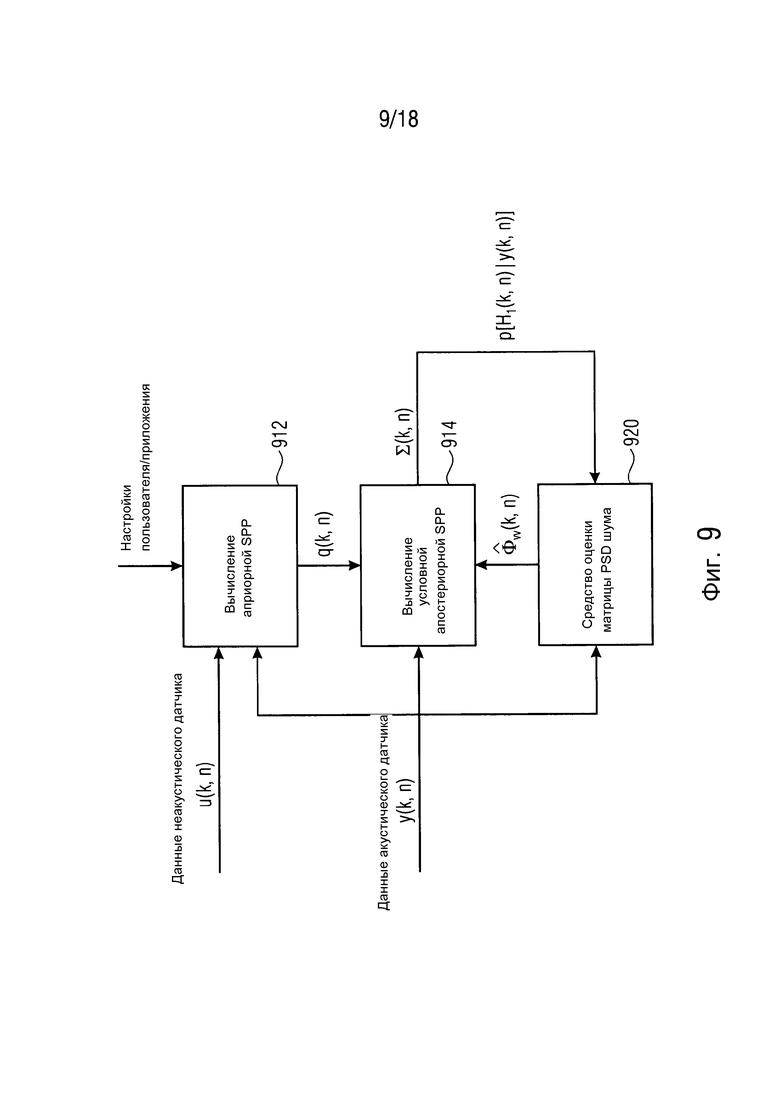
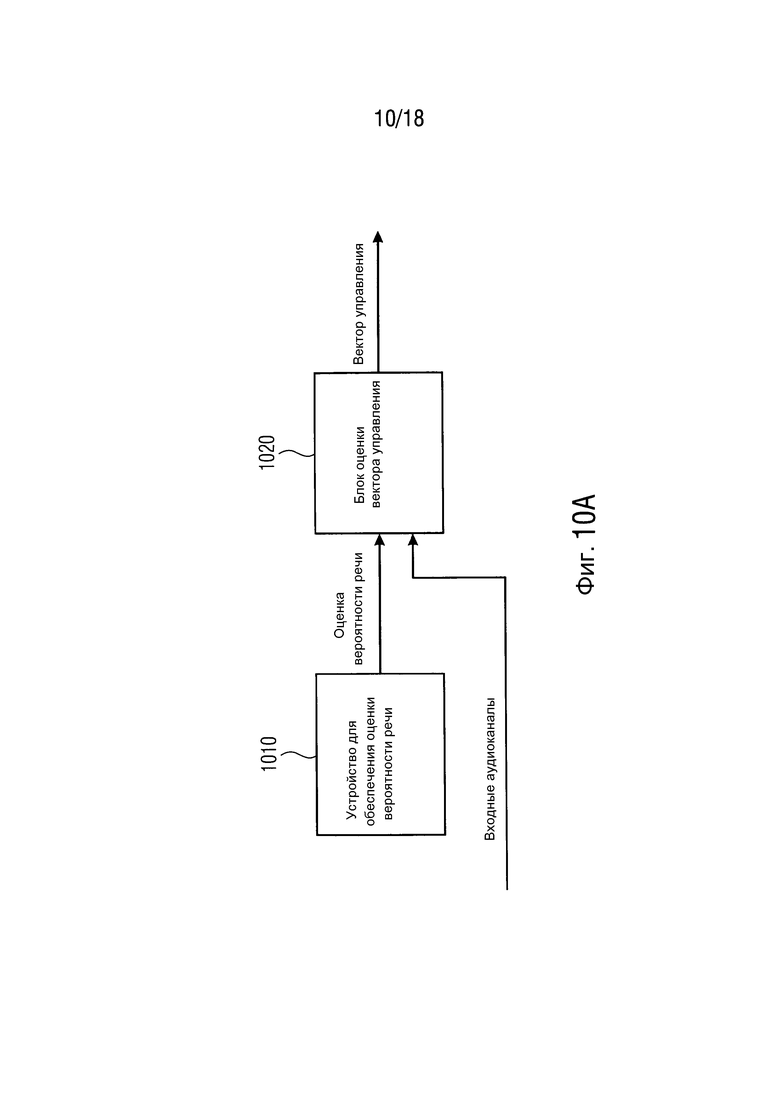
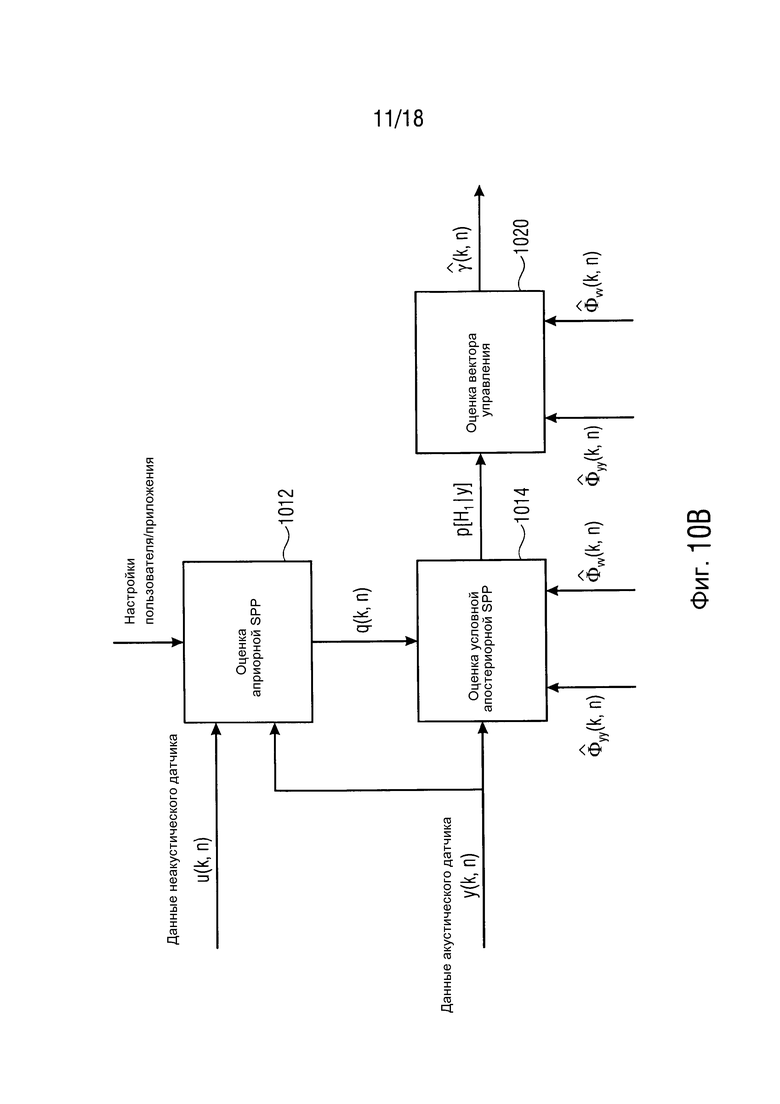
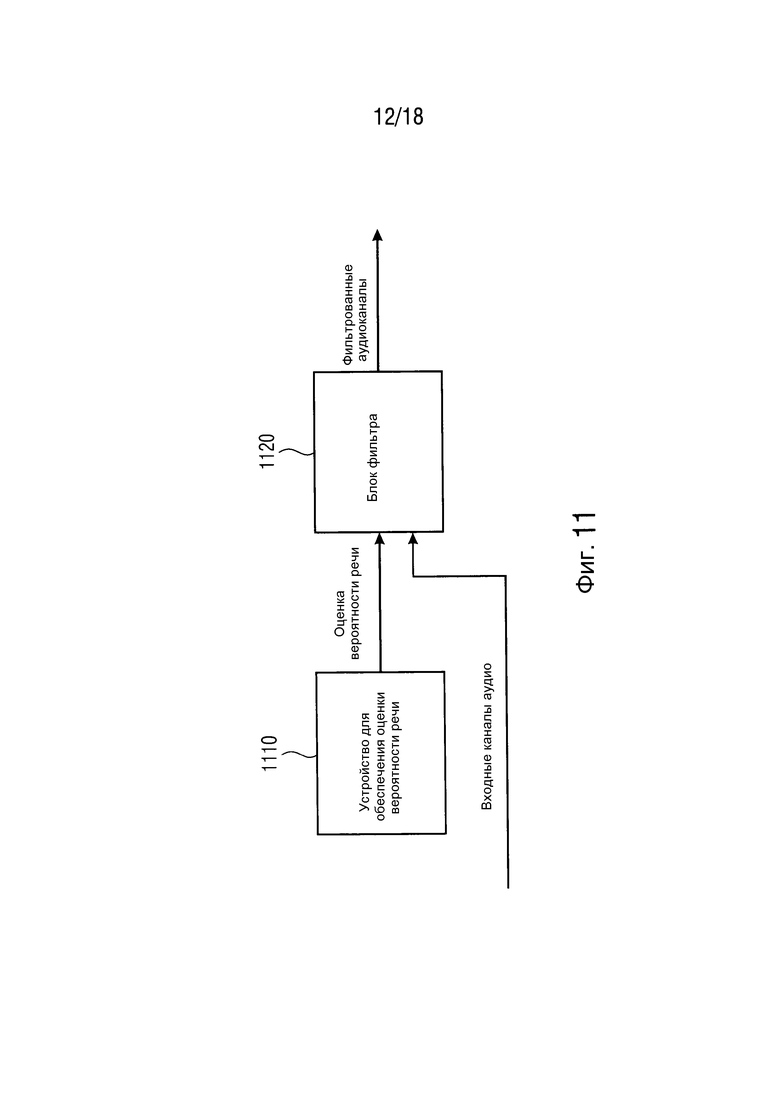
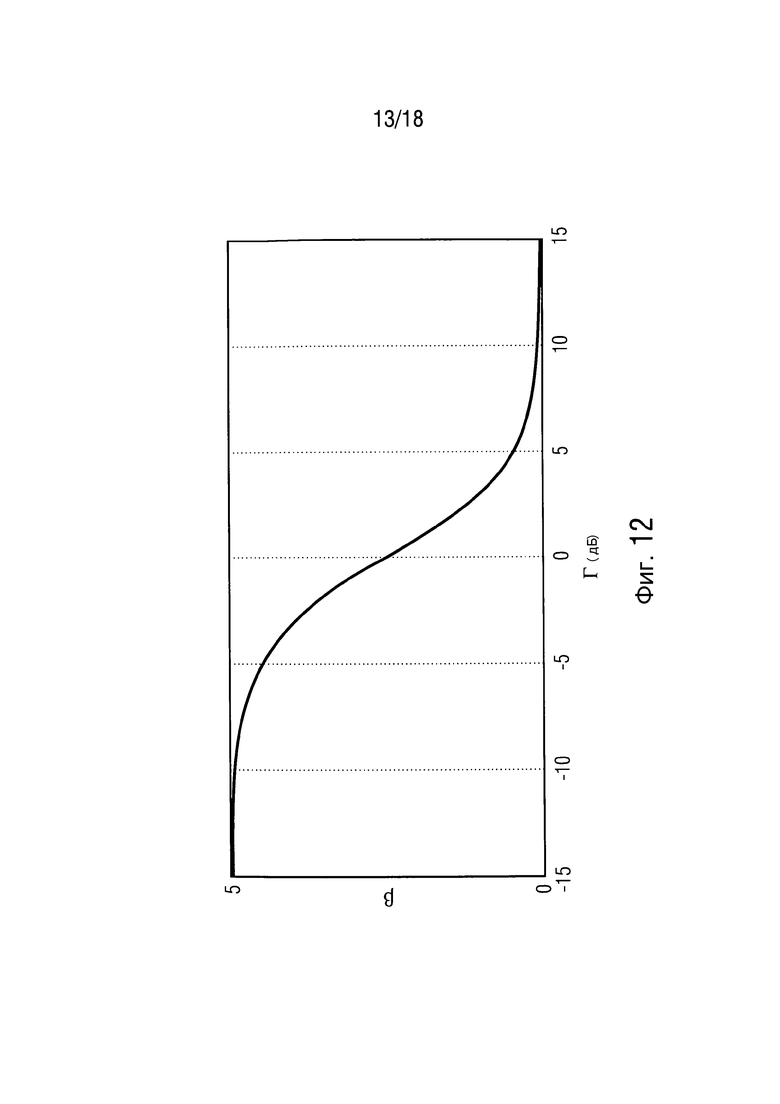
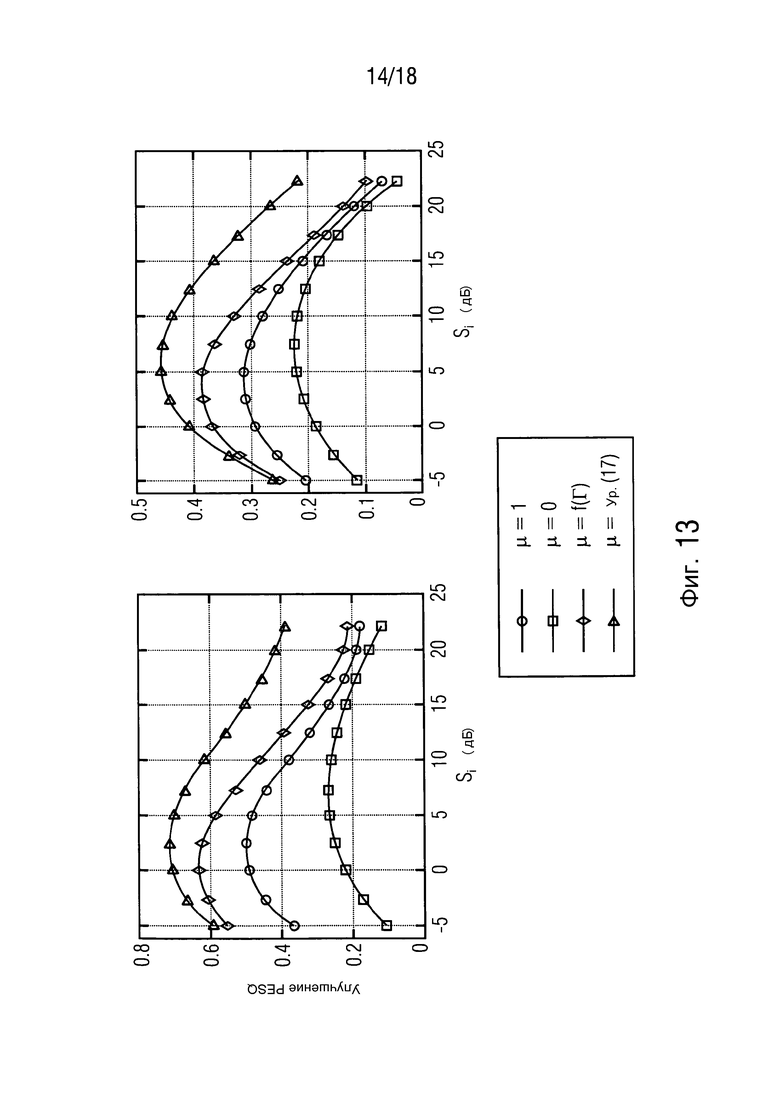
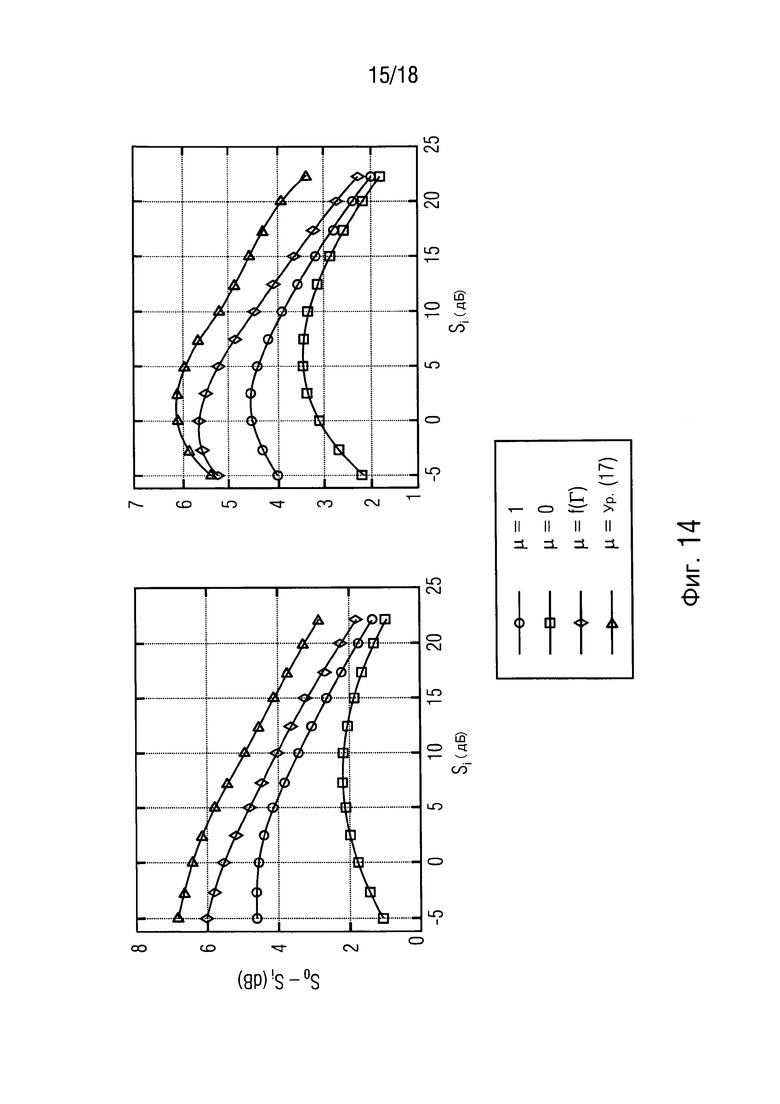
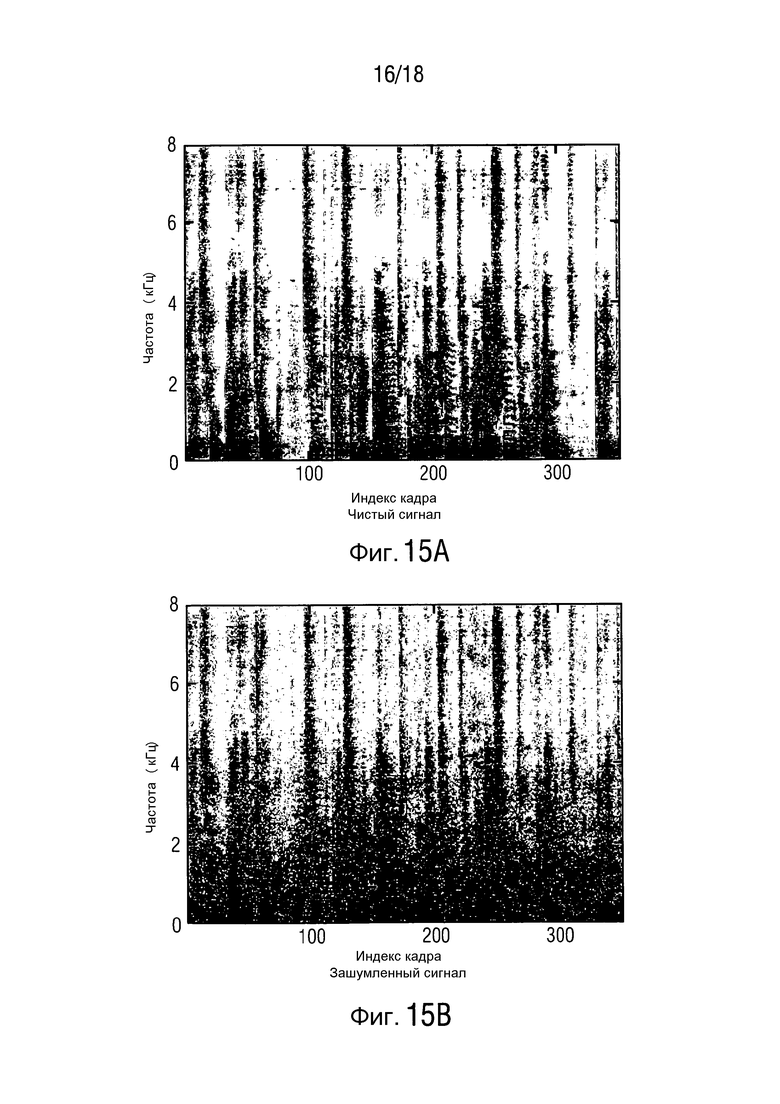
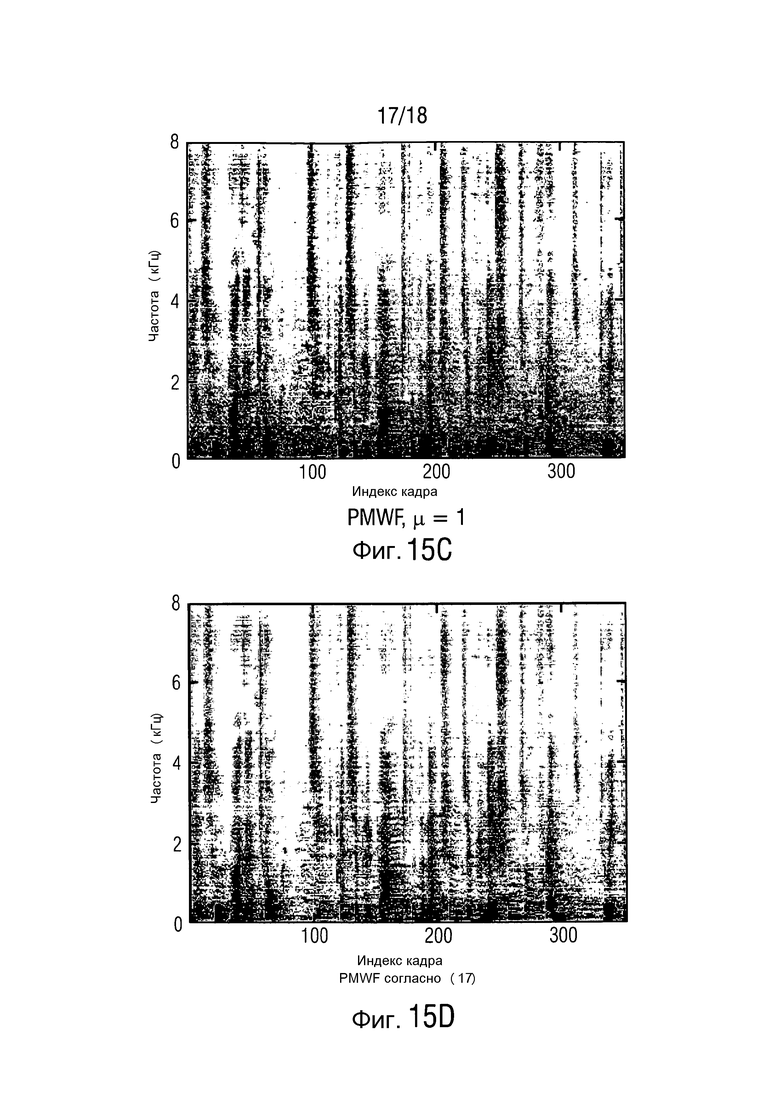
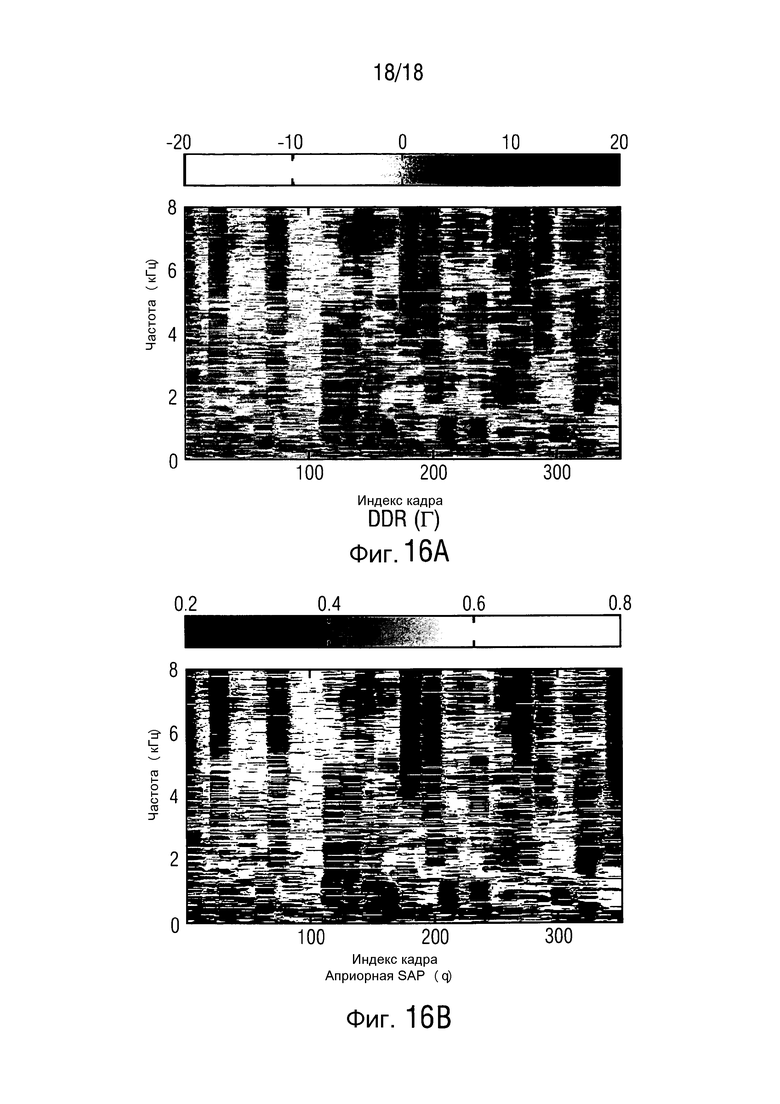
Изобретение относится к средствам для оценки вероятности присутствия многоканальной речи. Технический результат заключается в повышении точности обнаружения полезных и паразитных звуков. Устройство для обеспечения оценки вероятности речи содержит первое средство оценки вероятности речи для оценки информации вероятности речи, показывающей первую вероятность в отношении того, содержит ли звуковое поле сцены речь, или в отношении того, не содержит ли звуковое поле сцены речь. Дополнительно, устройство содержит выходной интерфейс для вывода оценки вероятности речи в зависимости от информации вероятности речи. Первое средство оценки вероятности речи сконфигурировано с возможностью оценивать информацию первой вероятности речи на основе, по меньшей мере, пространственной информации о звуковом поле или пространственной информации о сцене. 6 н. и 12 з.п. ф-лы, 21 ил.
1. Устройство для обеспечения оценки вероятности речи, содержащее:
первое средство (110; 210; 310) оценки вероятности речи для оценки информации вероятности речи, показывающей первую вероятность в отношении того, содержит ли звуковое поле сцены речь, или в отношении того, не содержит ли звуковое поле сцены речь,
при этом первое средство (110; 210; 310) оценки вероятности речи сконфигурировано с возможностью оценивать информацию вероятности речи на основе, по меньшей мере, пространственной информации о звуковом поле или пространственной информации о сцене, и
второе средство (215; 315) оценки вероятности речи для оценивания оценки вероятности речи, показывающей вторую вероятность в отношении того, содержит ли звуковое поле речь, или в отношении того, не содержит ли звуковое поле речь,
при этом второе средство (215; 315) оценки вероятности речи сконфигурировано с возможностью оценивать оценку вероятности речи на основе информации вероятности речи, оцененной посредством первого средства (110; 210; 310) оценки вероятности речи, и на основе одного или более сигналов акустического датчика, которые зависят от звукового поля, и
выходной интерфейс (120; 220) для вывода оценки вероятности речи.
2. Устройство по п. 1,
в котором первое средство (110; 210; 310) оценки вероятности речи сконфигурировано с возможностью оценивать информацию вероятности речи на основе информации направленности, при этом информация направленности показывает то, насколько направленным является звук звукового поля,
при этом первое средство (110; 210; 310) оценки вероятности речи сконфигурировано с возможностью оценивать информацию вероятности речи на основе информации местоположения, при этом информация местоположения показывает по меньшей мере одно местоположение источника звука сцены, или
при этом первое средство (110; 210; 310) оценки вероятности речи сконфигурировано с возможностью оценивать информацию вероятности речи на основе информации близости, при этом информация близости показывает по меньшей мере одну близость по меньшей мере одного возможного звукового объекта к по меньшей мере одному датчику близости.
3. Устройство по п. 1, в котором первое средство (110; 210; 310) оценки вероятности речи сконфигурировано с возможностью оценивать оценку вероятности речи посредством определения оценки отношения прямого к диффузному для отношения прямого к диффузному в качестве пространственной информации, при этом отношение прямого к диффузному показывает отношение прямого звука, содержащегося в сигналах акустического датчика, к диффузному звуку, содержащемуся в сигналах акустического датчика.
4. Устройство по п. 3,
в котором первое средство (110; 210; 310) оценки вероятности речи сконфигурировано с возможностью определять оценку отношения прямого к диффузному посредством определения оценки когерентности для комплексной когерентности между первым акустическим сигналом из сигналов акустического датчика, при этом первый акустический сигнал записывается посредством первого акустического датчика р, и вторым акустическим сигналом из сигналов акустического датчика, при этом второй акустический сигнал записывается посредством второго акустического датчика q, и
при этом первое средство (110; 210; 310) оценки вероятности речи дополнительно сконфигурировано с возможностью определять отношение прямого к диффузному на основе оценки фазового сдвига для фазового сдвига прямого звука между первым акустическим сигналом и вторым акустическим сигналом.
5. Устройство по п. 3, в котором первое средство (110; 210; 310) оценки вероятности речи сконфигурировано с возможностью оценивать информацию вероятности речи посредством определения
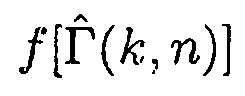
где 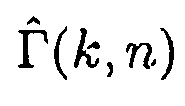 является оценкой отношения прямого к диффузному,
является оценкой отношения прямого к диффузному,
и
где 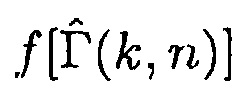 является функцией преобразования,
является функцией преобразования,
представляющей преобразование оценки отношения прямого к диффузному в значение между 0 и 1.
6. Устройство по п. 5, в котором функция преобразования
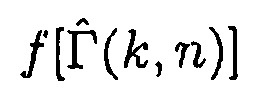 определяется посредством формулы:
определяется посредством формулы:
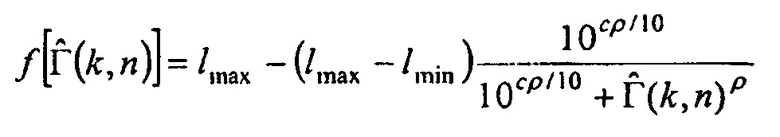
где 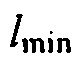 является минимальным значением функции преобразования, где
является минимальным значением функции преобразования, где 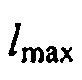 является максимальным значением функции преобразования, где с является значением для управления смещением вдоль оси Г, и где ρ определяет крутизну перехода между
является максимальным значением функции преобразования, где с является значением для управления смещением вдоль оси Г, и где ρ определяет крутизну перехода между 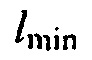 и
и 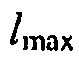 .
.
7. Устройство по п. 1, в котором первое средство (110; 210; 310) оценки вероятности речи сконфигурировано с возможностью определять параметр местоположения 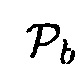 на основе распределения вероятностей оцененного местоположения источника звука и на основе области интереса, чтобы получать информацию вероятности речи.
на основе распределения вероятностей оцененного местоположения источника звука и на основе области интереса, чтобы получать информацию вероятности речи.
8. Устройство по п. 7, в котором первое средство (110; 210; 310) оценки вероятности речи сконфигурировано с возможностью определять параметр местоположения 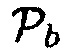 посредством использования формулы
посредством использования формулы
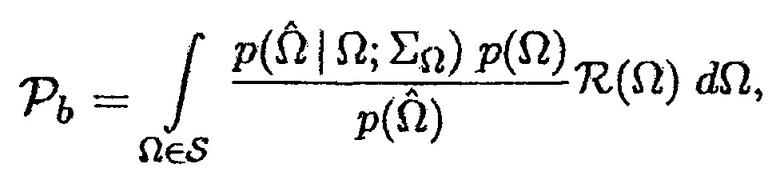
где Ω является конкретным местоположением, где  является оцененным местоположением,
является оцененным местоположением,
где 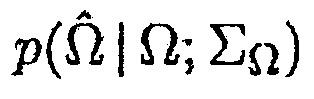 является функцией плотности условной вероятности, и
является функцией плотности условной вероятности, и
где p(Ω) является функцией плотности априорной вероятности для Ω, и
где 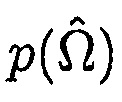 является функцией плотности вероятности для
является функцией плотности вероятности для  , и
, и
где ΣΩ обозначает неопределенность, ассоциированную с оценками для Ω, и
где R(Ω) является многомерной функцией, которая описывает область интереса, при этом 0≤R(Ω)<1.
9. Устройство по п. 3,
в котором первое средство (110; 210; 310) оценки вероятности речи сконфигурировано с возможностью определять априорную вероятность присутствия речи q(k, n) в качестве информации вероятности речи посредством применения формулы:
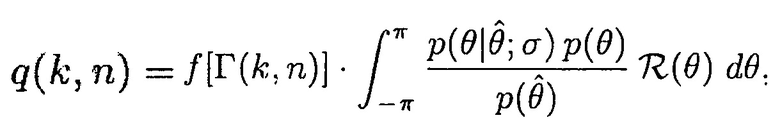
где θ является конкретным направлением прибытия и где 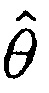 является оцененным направлением прибытия,
является оцененным направлением прибытия,
где 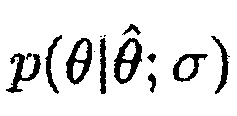 является функцией плотности условной вероятности, и
является функцией плотности условной вероятности, и
где р(θ) является функцией плотности априорной вероятности для 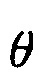 , и
, и
где 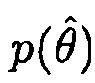 является функцией плотности вероятности для
является функцией плотности вероятности для 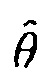 , и
, и
где σ обозначает неопределенность, ассоциированную с оценками для , и
где 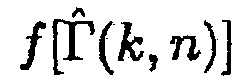 представляет преобразование оценки отношения прямого к диффузному
представляет преобразование оценки отношения прямого к диффузному 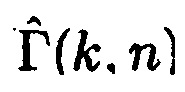 в значение между 0 и 1, и
в значение между 0 и 1, и
где R(θ) является многомерной функцией, которая описывает область интереса, при этом 0≤R(θ)≤1.
10. Устройство по п. 1, в котором первое средство (110; 210; 310) оценки вероятности речи сконфигурировано с возможностью определять параметр близости в качестве пространственной информации,
при этом параметр близости имеет первое значение параметра, когда первое средство (110; 210; 310) оценки вероятности речи обнаруживает один или более возможных источников звука в пределах предварительно определенного расстояния от датчика близости, и при этом параметр близости имеет второе значение параметра, которое является меньшим, чем первое значение параметра, когда первое средство (110; 210; 310) оценки вероятности речи не обнаруживает возможные источники звука в прямой близости к датчику близости, и
при этом первое средство (110; 210; 310) оценки вероятности речи сконфигурировано с возможностью определять первое значение вероятности речи в качестве информации вероятности речи, когда параметр близости имеет первое значение параметра, и при этом первое средство (110; 210; 310) оценки вероятности речи сконфигурировано с возможностью определять второе значение вероятности речи в качестве информации вероятности речи, когда параметр близости имеет второе значение параметра, при этом первое значение вероятности речи показывает первую вероятность того, что звуковое поле содержит речь, при этом первая вероятность больше, чем вторая вероятность того, что звуковое поле содержит речь, при этом вторая вероятность показывается посредством второго значения вероятности речи.
11. Устройство для определения оценки спектральной плотности мощности шума, содержащее:
устройство (910) по п. 1, и
блок (920) оценки спектральной плотности мощности шума,
при этом устройство (910) по п. 1 сконфигурировано с возможностью обеспечивать оценку вероятности речи в блок (920) оценки спектральной плотности мощности шума, и
при этом блок (920) оценки спектральной плотности мощности шума сконфигурирован с возможностью определять оценку спектральной плотности мощности шума на основе оценки вероятности речи и множества входных аудиоканалов.
12. Устройство по п. 11,
в котором устройство (910) по п. 1 сконфигурировано с возможностью вычислять один или более пространственных параметров, при этом упомянутые один или более пространственных параметров показывают пространственную информацию о звуковом поле,
при этом устройство (910) по п. 1 сконфигурировано с возможностью вычислять оценку вероятности речи посредством использования упомянутых одного или более пространственных параметров, и
при этом блок (920) оценки спектральной плотности мощности шума сконфигурирован с возможностью определять оценку спектральной плотности мощности шума посредством обновления предыдущей матрицы спектральной плотности мощности шума в зависимости от оценки вероятности речи, чтобы получать обновленную матрицу спектральной плотности мощности шума в качестве оценки спектральной плотности мощности шума.
13. Устройство для оценки вектора управления, содержащее:
устройство (1010) по п. 1, и
блок (1020) оценки вектора управления,
при этом устройство (1010) по п. 1 сконфигурировано с возможностью обеспечивать оценку вероятности речи в блок (1020) оценки вектора управления, и
при этом блок (1020) оценки вектора управления сконфигурирован с возможностью оценивать вектор управления на основе оценки вероятности речи и множества входных аудиоканалов.
14. Устройство для уменьшения многоканального шума, содержащее:
устройство (1110) по п. 1, и
блок (1120) фильтра,
при этом блок (1120) фильтра сконфигурирован с возможностью принимать множество входных каналов аудио,
при этом устройство (1110) по п. 1 сконфигурировано с возможностью обеспечивать информацию вероятности речи в блок (1120) фильтра, и
при этом блок (1120) фильтра сконфигурирован с возможностью фильтровать множество входных каналов аудио, чтобы получать фильтрованные аудиоканалы на основе информации вероятности речи.
15. Устройство по п. 14, в котором первое средство (110; 210; 310) оценки вероятности речи устройства (1110) по п. 1 сконфигурировано с возможностью генерировать параметр, при этом сгенерированный параметр зависит от по меньшей мере одного пространственного параметра, показывающего пространственную информацию о звуковом поле или пространственную информацию о сцене.
16. Устройство по п. 15, в котором блок (1120) фильтра сконфигурирован с возможностью фильтровать множество входных каналов аудио в зависимости от сгенерированного параметра.
17. Способ для обеспечения оценки вероятности речи, содержащий:
оценку информации вероятности речи, показывающую первую вероятность в отношении того, содержит ли звуковое поле сцены речь, или в отношении того, не содержит ли звуковое поле сцены речь, причем оценка информации вероятности речи осуществляется на основании, по меньшей мере, пространственной информации о звуковом поле или пространственной информации о сцене,
оценку оценки информации вероятности речи, показывающую вторую вероятность в отношении того, содержит ли звуковое поле речь, или в отношении того, не содержит ли звуковое поле речь,
при этом оценка оценки информации вероятности речи осуществляется на основе информации вероятности речи и на основе одного или более сигналов акустического датчика, которые зависят от звукового поля,
и вывод оценки вероятности речи.
18. Машиночитаемый носитель, содержащий компьютерную программу для осуществления способа по п. 17, когда он исполняется на компьютере или сигнальном процессоре.
| Свеклорезка | 1979 |
|
SU901267A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| СИСТЕМА ДЕТЕКТИРОВАНИЯ РЕЧИ | 2004 |
|
RU2363994C2 |

