Область техники, к которой относится изобретение
Настоящее изобретение относится к устройствам для криптографической обработки данных, способам криптографической обработки данных и программам. Более конкретно, настоящее изобретение относится к устройству для криптографической обработки, использующему криптографию с симметричным ключом, способу криптографической обработки данных и программе.
Уровень техники
По мере развития информационно-ориентированного общества возрастает важность технологий информационной безопасности для обеспечения защиты и безопасности обрабатываемой информации. Одним из элементов таких технологий информационной безопасности являются криптографические технологии, вследствие чего такие криптографические технологии сегодня используются, в самых разнообразных продуктах и системах.
Известны самые разнообразные алгоритмы криптографической обработки. Одним из базовых способов является так называемая блочная криптография с симметричным ключом. В блочной криптографии с симметричным ключом один и тот же ключ применяется и для шифрования, и для дешифровки данных. При выполнении обеих операций - операции шифрования и операции дешифровки - ключи генерируют на основе общего ключа и многократно выполняют операцию преобразования данных применительно к единицам в виде блоков данных определенного размера, такого как 64 бит, 128 бит или 256 бит.
К широко известным блочным криптографическим алгоритмам с симметричным ключом относятся DES (стандарт шифрования данных (Data Encryption Standard)), применявшийся в США раньше, и AES (улучшенный стандарт шифрования (Advanced Encryption Standard)), используемый в США сегодня. Сегодня предлагаются и другие разнообразные способы блочной криптографии с симметричным ключом, а стандарт CLEFIA, предложенный корпорацией Sony в 2007, также является одним из способов блочной криптографии с симметричным ключом.
Такой блочный криптографический алгоритм с симметричным ключом реализован главным образом посредством модуля криптографической обработки, содержащего модуль вычисления раундовой функции, который многократно преобразует входные данные, и модуль планирования ключей, который генерирует раундовые ключи для использования в соответствующих раундах в модуле вычисления раундовой функции. Сначала модуль планирования ключей генерирует расширенный ключ с увеличенным числом битов на основе ведущего ключа (главного ключа), представляющего собой секретный ключ, и затем генерирует раундовые ключи (подключи (sub keys)) для использования в соответствующих модулях вычисления раундовой функции с применением модуля криптографической обработки данных на основе сформированного расширенного ключа.
В качестве конкретной структуры, реализующей такой алгоритм, известна структура, многократно вычисляющая раундовую функцию и содержащая модуль линейной трансформации и модуль нелинейной трансформации. Типовой пример такой структуры содержит структуру Файстеля (Feistel) и обобщенную структуру Файстеля. Эти структуры - структура Файстеля и обобщенная структура Файстеля - имеют каждая структуру, преобразующую открытый текст в зашифрованный текст посредством простого многократного применения раундовой функции, включающей F-функции в качестве функций преобразования данных. В каждой F-функции осуществляют линейную трансформацию и нелинейную трансформацию. Непатентный документ 1 и непатентный документ 2 представляют собой примеры документов, рассматривающих криптографическую обработку данных с использованием структуры Файстеля.
Одним из индикаторов, используемых для оценки степени защищенности блочного шифрования, являются диффузионные свойства. Эти свойства можно рассматривать как характеристики распространения (или диффузии) изменений входных данных в выходные данные, и в области защищенного блочного шифрования, ожидается, что влияние таких изменений входных данных будет передано в выходные данные насколько это возможно быстро.
Можно прогнозировать, что для улучшения диффузионных свойств было бы эффективно, например, увеличить число раундов применения раундовой функции. Однако пока не было найдено удобных способов улучшения диффузионных свойств при меньшем числе раундов применения раундовой функции.
Список литературы
Непатентные документы
Непатентный документ 1: К. Найберг, «Обобщенные сети Файстеля» (K. Nyberg, "Generalized Feistel networks", ASIACRYPT 96, SpringerVerlag, 1996, pp.91-104).
Непатентный документ 2: Юлянь Жень, Цутому Мацумото, Нидеки Имаи: О построении доказуемо надежных блочных шифров без опоры на недоказанные гипотезы (Yuliang Zheng, Tsutomu Matsumoto, Hideki Imai: On the Construction of Block Ciphers Provably Secure and Not Relying on Any Unproved Hypotheses. CRYPTO 1989:461-480).
Сущность изобретения
Проблемы, которые должно решать изобретение
Настоящее изобретение было сделано с учетом описанных выше обстоятельств, например, целью изобретения является создание устройства для криптографической обработки данных, обладающего высоким уровнем надежности и защищенности шифрования при улучшенных диффузионных свойствах, способа криптографической обработки данных и программы.
Решение проблем
Первый аспект настоящего изобретения состоит в устройстве для криптографической обработки данных, которое содержит
модуль криптографической обработки данных, который разбивает и вводит составляющие биты данных, подлежащих обработке, в линейки и многократно осуществляет операцию преобразования данных в соответствующих линейках с использованием раундовой функции,
здесь модуль криптографической обработки данных имеет структуру, рассчитанную на ввод n/d-битовых данных, полученных путем разбиения n-битовых входных данных на d сегментов, где d число разбиения, в соответствующие линейки и многократное выполнение вычислений в качестве раундовых вычислений, включая операцию преобразования данных с использованием раундовой функции, и
указанный модуль криптографической обработки данных осуществляет операцию, в ходе которой n/d-битовые данные в каждой линейке, имеющей выходные данные раундовых вычислений, повторно разбивают на сегменты d/2 данных, повторно разбитые данные рекомбинируют для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных после раундовых вычислений на предыдущем этапе, и затем задают реконструированные данные в качестве входных данных для раундовых вычислений на следующем этапе.
Далее, в одном из вариантов устройства для криптографической обработки данных согласно настоящему изобретению раундовая функция включает F-функцию, которая включает в себя вычисления с использованием раундового ключа, нелинейную трансформацию и линейную трансформацию, а также операцию «исключающее ИЛИ» между выходными или входными данными F-функции и данными другой линейки.
Далее, в одном из вариантов устройства для криптографической обработки данных согласно настоящему изобретению модуль криптографической обработки данных задает результат раундовых вычислений предыдущего этапа в качестве входных данных для раундовых вычислений следующего этапа, для чего выполняет операцию, удовлетворяющую следующим условиям распределения с (1) по (3).
(1) Последовательности данных на входной стороне F-функции неизменным способом распределяют в последовательности данных на стороне XOR (функции «исключающее ИЛИ») в составе следующей раундовой функции,
(2) Последовательности данных на стороне функции «исключающее ИЛИ» (XOR) неизменным способом распределяют в последовательности данных на входной стороне F-функции в составе следующей раундовой функции, и
(3) Каждую единицу из последовательности данных, разбитой на сегменты d/2, распределяют в последовательность d/2 данных следующей раундовой функции без наложений.
Далее, в одном из вариантов устройства для криптографической обработки данных согласно настоящему изобретению указанный модуль криптографической обработки данных имеет обобщенную структуру Файстеля, использующую число d разбиения входных данных, равное 4 или более.
Далее, в одном из вариантов устройства для криптографической обработки данных согласно настоящему изобретению указанный модуль криптографической обработки выполняет операцию, в процессе которой генерируют d×(d/2) сегментов повторно разбитых данных путем повторного разбиения n/d-битовых данных в каждой из d линеек, имеющей выходные данные раундовых вычислений на сегменты d/2 данных, затем сегменты d/2 повторно разбитых данных, выбранных из разных линеек из совокупности d линеек, соответствующих числу d разбиения рекомбинируют для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных раундовых вычислений предыдущего этапа, и задают реконструированные данные в качестве входных данных для раундовых вычислений следующего этапа.
Далее, в одном из вариантов устройства для криптографической обработки данных согласно настоящему изобретению, когда все выходные биты находятся в диффузионном состоянии, которое удовлетворяет следующим двум условиям, или когда выходные биты выражены посредством относительного выражения через входные биты, указанный модуль криптографической обработки данных имеет структуру, реализующую полное диффузионное состояние, удовлетворяющее следующим двум условиям:
(Условие 1) все входные биты включены в относительное выражение, и
(Условие 2) все входные биты прошли через раундовую функцию по меньшей мере однажды.
Далее, в одном из вариантов устройства для криптографической обработки данных согласно настоящему изобретению указанный модуль криптографической обработки дополнительно реализует полностью диффузионное состояние посредством четырех раундов выполнения раундовых вычислений.
Далее, в одном из вариантов устройства для криптографической обработки данных согласно настоящему изобретению соединительная структура, определяющая соотношение вход-выход между выходными данными раундовых вычислений предыдущего этапа и повторно разбитыми данными раундовых вычислений следующего этапа, представляет собой соединительную структуру, выбранную из совокупности соединительных структур, имеющих (d/2) сегментов 2n/d-битовых данных в качестве единиц, являющихся данными, генерируемыми путем соединения d×(d/2) сегментов повторно разбитых данных, полученных посредством операции повторного разбиения n/d-битовых данных в линейках, имеющих выходные данные раундовых вычислений.
Далее, в одном из вариантов устройства для криптографической обработки данных согласно настоящему изобретению указанный модуль криптографической обработки обладает инволюционными свойствами.
Далее, в одном из вариантов устройства для криптографической обработки данных согласно настоящему изобретению операция реконструкции повторно разбитых данных от соответствующих раундовых вычислений в модуле криптографической обработки данных включает: распределение повторно разбитых данных последовательностей на входной стороне раундовой функции предыдущего этапа в последовательности на стороне функции «исключающее ИЛИ» (XOR) следующего этапа в соответствии с заданным правилом; и распределение повторно разбитых данных последовательностей на стороне функции «исключающее ИЛИ» (XOR) предыдущего этапа в последовательности на входной стороне раундовой функции следующего этапа в соответствии с заданным правилом.
Далее, в одном из вариантов устройства для криптографической обработки данных согласно настоящему изобретению указанный модуль криптографической обработки осуществляет операцию шифрования для трансформации открытого текста в качестве входных данных в зашифрованный текст или операцию дешифровки для преобразования зашифрованного текста в качестве входных данных в открытый текст.
Далее, второй аспект настоящего изобретения состоит в способе криптографической обработки данных, реализованном в устройстве для криптографической обработки данных,
этот способ криптографической обработки данных включает
этап криптографической обработки данных, на котором разбивают и вводят составляющие биты данных, подлежащих обработке, в линейки и многократно осуществляют операцию преобразования данных в соответствующих линейках с использованием раундовой функции,
здесь этап криптографической обработки данных включает: ввод n/d-битовых данных, полученных путем разбиения n-битовых входных данных согласно числу d разбиения, в соответствующие линейки и многократное выполнение вычислений в качестве раундовых вычислений, включая операцию преобразования данных с использованием раундовой функции, и
указанный этап криптографической обработки данных включает операцию, в ходе которой n/d-битовые данные в каждой линейке, имеющей выходные данные раундовых вычислений, повторно разбивают на сегменты d/2 данных, повторно разбитые данные рекомбинируют для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных после раундовых вычислений на предыдущем этапе, и затем задают реконструированные данные в качестве входных данных для раундовых вычислений на следующем этапе.
Далее, третий аспект настоящего изобретения состоит в программе, в соответствии с которой устройство для криптографической обработки данных осуществляет такую криптографическую обработку данных,
в соответствии с этой программой модуль криптографической обработки данных выполняет
этап криптографической обработки данных, на котором модуль разбивает и вводит составляющие биты данных, подлежащих обработке, в линейки и многократно осуществляет операцию преобразования данных в соответствующих линейках с использованием раундовой функции,
здесь этап криптографической обработки данных включает: ввод n/d-битовых данных, полученных путем разбиения n-битовых входных данных согласно числу d разбиения, в соответствующие линейки и многократное выполнение вычислений в качестве раундовых вычислений, включая операцию преобразования данных с использованием раундовой функции, и
указанный этап криптографической обработки данных включает операцию, в ходе которой n/d-битовые данные в каждой линейке, имеющей выходные данные раундовых вычислений, повторно разбивают на сегменты d/2 данных, повторно разбитые данные рекомбинируют для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных после раундовых вычислений на предыдущем этапе, и затем задают реконструированные данные в качестве входных данных для раундовых вычислений на следующем этапе.
Следует отметить, что программа согласно настоящему описанию представляет собой программу, записанную на носителе записи и затем предоставленную, например, устройству для обработки информации или компьютерной системе, которая может выполнять различные программные коды. Когда модуль для выполнения программ в составе устройства для обработки информации или компьютерной системы исполняет такую программу, происходит выполнение операций в соответствии с этой программой.
Другие цели, признаки и преимущества настоящего изобретения станут ясны из подробного описания, приведенного ниже в сочетании с приведенным позже рассмотрением вариантов настоящего изобретения и прилагаемых чертежей. В настоящем описании система представляет собой логическое объединение устройств, а каждое из составляющих систему устройств не обязательно находится в одном и том же корпусе.
Преимущества изобретения
Согласно одному из вариантов настоящего изобретения реализована криптографическая обработка данных с улучшенными диффузионными свойствами и высоким уровнем защищенности.
В частности, модуль криптографической обработки данных разбивает и вводит биты, составляющие данные, подлежащие обработке, в линейки, и многократно осуществляет операцию преобразования данных с использованием раундовых функций применительно к данным в соответствующих линейках. Этот модуль криптографической обработки данных вводит n/d-битовые данные, полученные путем разбиения n-битовых данных в качестве входных данных в соответствии с числом d разбиения, в каждую линейку и многократно выполняет раундовые вычисления, включая операцию преобразования данных с использованием раундовых функций. Указанные n/d-битовые данные в каждой линейке, имеющей выходные данные раундовых вычислений, разделяют на d/2 сегментов данных и разделенные данные рекомбинируют для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных раундовых вычислений предыдущего этапа. Реконструированные данные задают в качестве входных данных для раундовых вычислений следующего этапа. В такой структуре можно реализовать криптографическую обработку с улучшенными диффузионными свойствами и высоким уровнем защищенности.
Краткое описание чертежей
Фиг.1 представляет схему для пояснения работы n-битового блочного криптографического алгоритма с симметричным ключом, совместимого с длиной ключа k бит.
Фиг.2 представляет схему для пояснения работы алгоритма дешифровки, соответствующего n-битовому блочному криптографическому алгоритму с симметричным ключом, совместимому с длиной ключа k бит и показанному на фиг.1.
Фиг.3 представляет схему для пояснения соотношения между модулем планирования ключей и модулем шифрования данных.
Фиг.4 представляет схему для пояснения примера структуры модуля шифрования данных.
Фиг.5 представляет схему для пояснения примера раундовой функции, имеющей структуру SPN.
Фиг.6 представляет схему для пояснения примера раундовой функции, имеющей структуру Файстеля.
Фиг.7 представляет схему для пояснения примера расширенной структуры Файстеля.
Фиг.8 представляет схему для пояснения примера расширенной структуры Файстеля.
Фиг.9 представляет схему для пояснения примера структуры модуля нелинейной трансформационной обработки данных.
Фиг.10 представляет схему для пояснения примера структуры модуля линейной трансформационной обработки данных.
Фиг.11 представляет схему для пояснения диффузионного состояния при блочном шифровании с использованием структуры Файстеля.
Фиг.12 представляет схему для пояснения диффузионного состояния при блочном шифровании с использованием структуры Файстеля.
Фиг.13 представляет схему для пояснения диффузионного состояния при блочном шифровании с применением имеющей 4 линейки обобщенной структуры Файстеля с использованием двух F-функций на одном этапе.
Фиг.14 представляет схему для пояснения диффузионного состояния при блочном шифровании с применением имеющей 4 линейки обобщенной структуры Файстеля с использованием двух F-функций на одном этапе.
Фиг.15 представляет схему для пояснения диффузионного состояния при блочном шифровании с применением имеющей 4 линейки обобщенной структуры Файстеля с использованием двух F-функций на одном этапе.
Фиг.16 представляет схему для пояснения обычной обобщенной структуры Файстеля в случае, когда число d равно 6.
Фиг.17 представляет схему для пояснения примера путей, которыми достигается полное диффузионное состояние в обычной обобщенной структуре Файстеля в случае, когда число d равно 6.
Фиг.18 представляет схему для пояснения примера структуры, в которой число раундов полной диффузии сделано меньше, чем в обычной структуре, посредством изменения числа межраундовых линеек в случае, где число d разбиения не меньше 6.
Фиг.19 представляет схему для пояснения примера путей, которыми достигается полное диффузионное состояние в структуре, в которой число раундов для достижения полного диффузионного состояния сделано меньше, чем в обычной структуре, посредством изменения числа межраундовых линеек в случае, где число d разбиения не меньше 6.
Фиг.20 представляет схему для пояснения структуры криптографической обработки данных в качестве варианта настоящего изобретения.
Фиг.21 представляет схему для пояснения примера случая, где число d равно 4, в качестве варианта настоящего изобретения.
Фиг.22 показывает пример путей, которыми достигается полное диффузионное состояние с использованием предлагаемого способа для случая, где число d равно 4.
Фиг.23 представляет схему для пояснения примера случая, где число d равно 6, в качестве варианта настоящего изобретения.
Фиг.24 показывает пример путей, которыми достигается полное диффузионное состояние с использованием предлагаемого способа для случая, где число d равно 6.
Фиг.25 представляет схему для пояснения примера структуры, в которой каждый сегмент n/d-битовых данных разделен на 2 в случае, когда число d равно 6.
Фиг.26 представляет диаграмму, показывающую часть соотношения между числом d разбиения n-битовых входных данных, числом р разбиения каждого сегмента n/d-битовых данных и числом раундов для достижения полного диффузионного состояния.
Фиг.27 представляет схему для пояснения примера структуры, в которой последовательности данных на входной стороне F-функции и последовательности данных на стороне функции «исключающее ИЛИ» (XOR) разбиты способами, отличными один от другого.
Фиг.28 представляет схему для пояснения примера структуры, такой же, как структура, показанная на фиг.21, за исключением позиций вставки расширенных ключей.
Фиг.29 представляет схему для пояснения более эффективного способа распределения данных.
Фиг.30 представляет схему для пояснения более эффективного способа распределения данных.
Фиг.31 представляет схему для пояснения более эффективного способа распределения данных.
Фиг.32 представляет схему для пояснения инволюционных свойств структуры Файстеля.
Фиг.33 представляет схему для пояснения инволюционных свойств структуры Файстеля.
Фиг.34 представляет схему, показывающую тип имеющей 4 линейки структуры, где можно добиться превосходных диффузионных свойств.
Фиг.35 представляет схему для пояснения операций с целью достижения инволюционных свойств.
Фиг.36 представляет схему для пояснения примера структуры, обладающей инволюционными свойствами, в имеющей 4 линейки (d=4) структуре.
Фиг.37 представляет схему для пояснения примера структуры, обладающей инволюционными свойствами, в имеющей 6 линеек (d=6) структуре.
Фиг.38 представляет схему для пояснения примера структуры, обладающей инволюционными свойствами.
Фиг.39 представляет схему для пояснения примера структуры, обладающей инволюционными свойствами.
Фиг.40 представляет схему для пояснения примера структуры модуля 700 интегральных схем в качестве устройства для криптографической обработки данных.
Способы осуществления изобретения
Далее следует подробное описание устройства для криптографической обработки данных, способа криптографической обработки данных и программы согласно настоящему изобретению со ссылками на прилагаемые чертежи. Пояснения будут даны в следующем порядке глав.
1. Очерк блочной криптографии с симметричным ключом
2. Очерк диффузионных свойств
(2-1) Описание диффузионных свойств
(2-2) Пример обычной структуры с учетом диффузионных свойств
3. Пример структуры с улучшенными диффузионными свойствами согласно настоящему изобретению
4. Пример структуры с более эффективным распределением данных
5. Пример структуры, обладающей инволюционными свойствами
6. Пример структуры устройства для криптографической обработки данных
7. Краткая характеристика структур согласно настоящему изобретению
[1. Очерк блочной криптографии с симметричным ключом]
Сначала будет вкратце описана блочная криптография с симметричным ключом.
(1-1. Блочная криптография с симметричным ключом)
Блочная криптография с симметричным ключом (далее именуемая «блочное шифрование») определена следующим образом.
В системе блочного шифрования получают в качестве входных сигналов открытый текст Р и ключ K и передают на выход зашифрованный текст С. Длина открытого текста и зашифрованного текста в битах называется размером блока и здесь обозначена n. Хотя величина n может быть равна любому целому числу, обычно эту величину n однозначно определяют для каждого алгоритма блочного шифрования. Блочное шифрование с использованием n в качестве длины блока может также называться «n-битовое блочное шифрование».
Длина ключа в битах обозначена буквой k. Ключ может иметь любую целочисленную величину. Каждый блочный криптографический алгоритм с симметричным ключом совместим с одним или несколькими размерами ключей. Например, некий алгоритм блочного шифрования А имеет размер блока, равный n=128, и может быть совместим с ключами размером k=128, 192 и 256.
Открытый текст Р: n бит
Зашифрованный текст С: n бит
Ключ K: k бит
На фиг.1 представлена схема n-битового алгоритма Е блочного шифрования с симметричным ключом, совместимого с длиной ключа, равной k бит.
Алгоритм D дешифровки, совместимый с алгоритмом Е блочного шифрования, может быть определен обратной функцией Е-1 относительно алгоритма Е шифрования. Зашифрованный текст С и ключ K в этом случае принимают в качестве входных сигналов, а открытый текст Р передают на выход. На фиг.2 представлена схема, показывающая алгоритм D дешифровки, совместимый с алгоритмом Е шифрования, изображенным на фиг.1.
(1-2. Внутренняя структура)
Блочное шифрование может быть разделено между двумя модулями.
Один модуль - "модуль планирования ключей", который получает на вход ключ K и передает на выход расширенный ключ K′ (длина k′ в битах), образованный путем увеличения длины исходного ключа в битах с заданным шагом, а другой модуль - "модуль шифрования данных", который принимает на входы открытый текст Р и расширенный ключ K′ от модуля планирования ключей, преобразует данные и передает на выход зашифрованный текст С.
Соотношение между этими двумя модулями показано на фиг.3.
(1-3. Модуль шифрования данных)
Модуль шифрования данных, используемый в следующих вариантах, может быть разделен на модули обработки данных, именуемые раундовыми функциями. Раундовая функция принимает два сегмента данных в качестве входных данных и передает на выход один сегмент данных после обработки данных в соответствующем модуле. Один из сегментов входных данных представляет собой n-битовые данные, шифрование которых происходит в текущий момент, а выходные данные раундовой функции передают в качестве входных данных следующего раунда. Другой сегмент входных данных представляет собой данные расширенного ключа, поступающие от модуля планирования ключей, так что эти данные ключа называются раундовым ключом. Общее число раундовых функций именуется общим числом раундов и представляет собой величину, задаваемую заранее для каждого алгоритма шифрования. Здесь общее число раундов обозначено R.
Если входные данные первого раунда, считая от входной стороны модуля шифрования данных, обозначены X1, данные, поступающие на вход i-й раундовой функции, обозначены Xi и раундовый ключ обозначен RKi, тогда весь модуль шифрования данных представлен, как показано на фиг.4.
(1-4. Раундовые функции)
Раундовые функции могут принимать разнообразные формы в зависимости от алгоритмов блочного шифрования. Раундовые функции можно классифицировать на основе структур, используемых соответствующими алгоритмами шифрования. Примерами типовых структур являются структура SPN (подстановочно-перестановочная сеть (Substitution-Permutation Network)), структура Файстеля и расширенная структура Файстеля.
(a) Раундовая функция со структурой SPN
Эта структура выполняет операцию «исключающее ИЛИ» с раундовым ключом, нелинейную трансформацию и линейную трансформацию применительно ко всем n-битовым входным данным. Какой-либо конкретный порядок соответствующих операций не задан. На фиг.5 представлен пример раундовой функции, имеющей структуру SPN.
(b) Структура Файстеля
В такой системе n-битовые входные данные разбивают на два сегмента данных по n/2-бит в каждом. Один из этих сегментов данных и раундовый ключ подают на входы функции (F-функция), а над выходными данными этой функции и другим из указанных сегментов данных выполнят операцию «исключающее ИЛИ». После этого правый и левый сегменты данных меняют местами для формирования выходных данных. Внутренняя структура F-функции может быть различной, но обычно эта структура реализует сочетание операции «исключающее ИЛИ» с использованием данных раундового ключа, нелинейной операции и линейной трансформации, как и структура SPN. На фиг.6 представлен пример раундовой функции, имеющей структуру Файстеля.
(c) Расширенная структура Файстеля
Расширенная структура Файстеля отличается от обычной структуры Файстеля в том, что в расширенной структуре число разбиения данных может быть равно 3 или более вместо 2. Если число разбиения данных обозначить буквой d, величина этого числа d может определять различные расширенные структуры Файстеля. Поскольку размер входных/выходных данных для F-функции становится относительно меньше, такая структура считается подходящей для реализации с малой размерностью. На фиг.7 представлен пример расширенной структуры Файстеля для случая числа d, равного 4, и двух F-функций, используемых параллельно в одном раунде. На фиг.8 представлен пример расширенной структуры Файстеля для случая числа d, равного 8, и одной F-функции, используемой в одном раунде.
(1-5. Модуль обработки данных с нелинейной трансформацией)
Модуль обработки данных с нелинейной трансформацией отличается тенденцией к росту стоимости реализации по мере увеличения размера данных, которые должны поступать на вход этого модуля. Во избежание этого целевые данные во многих случаях разбивают на две или более единиц и осуществляют нелинейную трансформацию применительно к каждой из этих единиц. Например, когда входные данные имеют размер ms бит, эти входные данные разбивают на m сегментов s-битовых данных и осуществляют нелинейную трансформацию с размерностью s бит и на входе, и на выходе применительно к каждому из m сегментов s-битовых данных. Такие s-битовые нелинейные трансформации здесь именуются S-ячейки. Пример показан на фиг.9.
(1-6. Модуль обработки данных с линейной трансформацией)
С точки зрения характеристик модуль обработки данных с линейной трансформацией может быть определен в виде матрицы. Элементы этой матрицы могут быть обычно выражены в различных формах, таких как элементы поля Галуа GF(28) или элементы поля Галуа GF(2). На фиг.10 представлен пример модуля обработки данных с линейной трансформацией, получающего ms-битовые входные данные и передающего ms-битовые выходные данные и определенного матрицей размером m×m в поле Галуа GF(2s).
[2. Очерк диффузионных свойств]
Сейчас будут кратко описаны диффузионные свойства, прежде чем перейти к пояснению криптографической обработки согласно настоящему изобретению.
(2-1) Описание диффузионных свойств
Как кратко описано выше, диффузионные свойства применяются в качестве одного из показателей, используемых при оценке защищенности блочного шифрования. Эти свойства можно рассматривать как свойства распространения (или диффузии) изменений входных данных в выходные данные, и в системах защищенного блочного шифрования ожидается, что влияние таких изменений входных данных будет передано выходным данным так быстро, как только возможно.
Далее определены термины «диффузионное состояние» («diffusion state»), «полное диффузионное состояние» («full diffusion state») и «число раундов для достижения полного диффузионного состояния» («number of full diffusion rounds»).
Если выходной бит записан в виде некоторого выражения относительно входных битов и если это относительное выражение удовлетворяет приведенным ниже условиям, состояние выходного бита определено как «диффузионное состояние».
(Условие 1) В это относительное выражение входят все входные биты.
(Условие 2) Все входные биты прошли через раундовую функцию (F-функцию) по меньшей мере однажды.
Далее, состояние, в котором все выходные биты находятся в диффузионном состоянии, определено как «полное диффузионное состояние».
Минимальное число раундов (число повторений), необходимое для достижения полного диффузионного состояния, определено как «число раундов для достижения полного диффузионного состояния».
Указанные определения описаны подробно применительно к блочному шифрованию с использованием структур Файстеля, показанных в конкретных примерах на фиг.11 и 12. Фиг.11 представляет пример структуры раундовой функции при блочном шифровании с использованием структуры Файстеля, а на фиг.12 показана структура, где выполнение раундовой функции повторяется три раза.
Как видно на фиг.12, n/2-битовые данные 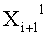
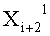
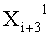
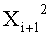

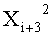
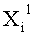
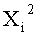

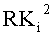
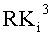
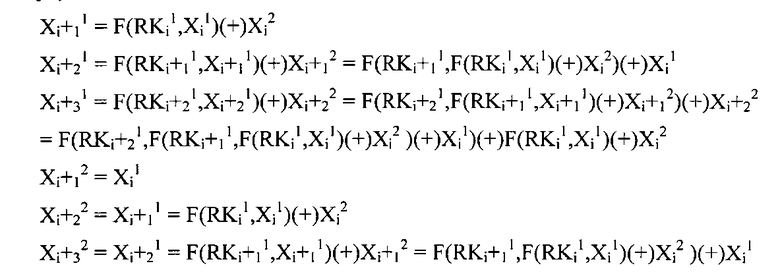
В приведенном выше выражении F(K, X) обозначает данные, получаемые посредством трансформации данных Х с применением F-функции, использующей параметр K, а (+) обозначает операцию «исключающее ИЛИ» над каждым битом.
Результат 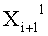
Будучи выражены только через
Согласно приведенным выше результатам все выходные данные
На фиг.13 и 14 представлены другие примеры. Эти чертежи показывают имеющие 4 линейки обобщенные структуры Файстеля с использованием двух F-функций на одном этапе.
На фиг.15 представлено распространение изменений, когда n-битовые входные данные Xi для i-го раунда разбивают на четыре n/4-битовых сегмента данных и вносят изменение только в часть четвертого n/4-битового сегмента данных (обозначен как 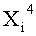
На чертеже толстая штриховая линия обозначает данные, переданные в состоянии, когда изменение входных данных не прошло через F-функцию, а толстые линии обозначают данные, переданные в состоянии, когда изменение входных данных прошло через F-функцию по меньшей мере однажды. Кроме того, предполагается, что каждый выходной бит указанных F-функций испытал воздействие всех входных битов этих F-функций. Как описано выше, число раундов для достижения полного диффузионного состояния может быть определено путем подсчета числа раундов, необходимых прежде, чем все выходные биты испытают воздействия некоего виртуального изменения различных входных битов. Из практики известно, что число раундов для достижения полного диффузионного состояния в обобщенной структуре Файстеля с использованием двух F-функций на одном этапе равно 5, когда число d равно 4.
(2-2) Пример обычной структуры с учетом диффузионных свойств
Далее будет вкратце описана структура обработки данных, учитывающая указанные диффузионные свойства.
Широко известно, что имеющая d линеек обобщенная структура Файстеля с использованием d/2 функций на одном этапе не обладает очень хорошими диффузионными свойствами, а число раундов для достижения полного диффузионного состояния равно d+1. Это описано в непатентном документе 3 (Т. Сузаки и К. Минемацу, «Усовершенствование обобщенной структуры Файстеля» (Т. Suzaki and K. Minematsu, «Improving the Generalized Feistel», FSE 2010, LNCS6147, pp.19-39, 2010)), например.
На фиг.16 представлена обычная обобщенная структура Файстеля, где число d равно 6, а на фиг.17 показан пример путей, по которым структура достигает полного диффузионного состояния.
Для решения указанной выше проблемы непатентный документ 3 предлагает способ структурирования, который может сделать число раундов для достижения полного диффузионного состояния меньше, чем в обычной структуре, в случае, когда число d разбиения не меньше 6, путем изменения межраундовых линеек для каждого сегмента n/d-битовых данных, полученного посредством разбиения данных на d сегментов.
Фиг.18 иллюстрирует этот способ структурирования для случая, когда число d равно 6, а фиг.19 показывает пример путей, по которым такая структура приходит в полное диффузионное состояние.
Реализуемое в этой структуре число раундов, необходимое для достижения полного диффузионного состояния, равно 5, 6, 7, 8, 8 и 8 для случаев, когда число d равно 6, 8, 10, 12, 14 и 16, соответственно. Как можно видеть из этих чертежей, в рассматриваемой структуре достигнуты лучшие диффузионные свойства по сравнению с (d+1) раундами в обычной структуре. Однако предлагаемая структура неэффективна в случае, когда число d равно 4, так что число раундов для достижения полного диффузионного состояния уменьшить не удается.
Непатрентный документ 4 (Сузаки, Цуноо, Кубо и Кавабата, «Предложение структуры, имеющей диффузионный уровень, встроенный в обобщенную структуру Файстеля» (Non-Patent Document 4 (Suzaki, Tsunoo, Kubo, and Kawabata, «Proposal of a structure having diffusion layer incorporated into a generalized Feistel structure», SCIS2008, 2008)) предлагает структуру, делающую диффузионные свойства лучше по сравнению с обычной структурой посредством выполнения линейной операции применительно к каждому сегменту n/d-битовых данных, образованному путем разбиения данных на d сегментов. В такой структуре необходимо, однако, иметь специальные элементы для выполнения линейных операций, что приводит к увеличению стоимости реализации.
[3. Пример структуры с улучшенными диффузионными свойствами согласно настоящему изобретению]
С учетом описанных выше проблем настоящее изобретение предлагает способ структурирования для достижения лучших диффузионных свойств в обобщенной структуре Файстеля без увеличения стоимости реализации.
В имеющей d линеек обобщенной структуре Файстеля согласно этой конфигурации n-битовые входные данные разбивают на d сегментов n/d-битовых данных и осуществляют обработку посредством F-функции и операцию «исключающее ИЛИ» применительно к каждому из этих d сегментов, как и в обычной структуре (этап 1, показанный на фиг.20).
Последовательности данных, поступающие в этом момент на вход F-функций, называются последовательностями данных на входной стороне F-функций, а последовательности данных, применительно к которым выполняется операция «исключающее ИЛИ», называются последовательностями данных на стороне функции «исключающее ИЛИ» (XOR).
После этого каждый сегмент n/d-битовых данных, передаваемый в каждой соответствующей последовательности (каждой соответствующей линейке) дополнительно разбивают на сегменты d/2 (разбиение в этот момент может быть не на равные части).
Данные, дополнительно разбитые на сегменты d/2 в каждой последовательности (каждой линейке), распределяют в соответствии со следующими правилами (этап 2 на фиг.20).
(1) Последовательности данных на входной стороне F-функции неизменным способом распределяют в последовательности данных на стороне XOR (функции «исключающее ИЛИ») в составе следующей раундовой функции,
(2) Последовательности данных на стороне функции «исключающее ИЛИ» (XOR) неизменным способом распределяют в последовательности данных на входной стороне F-функции в составе следующей раундовой функции, и
(3) Каждую единицу из последовательности данных, разбитой на сегменты d/2, распределяют в последовательность d/2 данных следующей раундовой функции без наложений.
После описанного выше распределения каждый из сегментов данных, разбитых на сегменты d/2, интегрируют в один сегмент данных (этап 3 на фиг.20).
Описанную выше процедуру выполняют нужное число раз.
На фиг.20 показан пример структуры, в которой число d разбиения равно 4.
В этой структуре число раундов для достижения полного диффузионного состояния может быть равно 4 независимо от числа d разбиения данных.
Предлагаемый способ удовлетворяет условию, согласно которому число раундов, необходимое для реализации полного диффузионного состояния, равно 4 независимо от числа d разбиения, по следующим причинам.
(1) Любое изменение входных данных для i-го раунда влияет по меньшей мере на одну F-функцию в составе (i+1)-го раунда.
(2) По меньшей мере одна из последовательностей данных на стороне функции «исключающее ИЛИ» (XOR) в составе (i+1)-го раунда находится в диффузионном состоянии.
(3) Данные в диффузионном состоянии в последовательности данных на стороне функции «исключающее ИЛИ» (XOR) в составе (i+1)-го раунда дополнительно разбиты на сегменты d/2 и влияют на все d/2 F-функций в составе (i+2)-го раунда. Соответственно, все последовательности данных на стороне функции «исключающее ИЛИ» (XOR) в составе (i+2)-го раунда находятся в диффузионном состоянии.
(4) Поскольку последовательности данных на стороне функции «исключающее ИЛИ» (XOR) в составе (i+2)-го раунда представляют собой последовательности данных на входной стороне F-функций в составе (i+3)-го раунда, все последовательности данных на входной стороне F-функций в составе (i+3)-го раунда находятся в диффузионном состоянии. Поскольку на входы всех F-функций в составе (i+3)-го раунда поступают данные в диффузионном состоянии, все последовательности данных на стороне функции «исключающее ИЛИ» (XOR) после выполнения применительно к ним этой функции «исключающее ИЛИ» находятся в диффузионном состоянии.
По перечисленным выше причинам полное диффузионное состояние неизменно достигается после (i+3)-го раунда или за четыре раунда. На фиг.21 и 22 представлены конкретные примеры.
Фиг.21 иллюстрирует пример этого способа для случая, когда число d равно 4. Поскольку число d равно 4, каждый сегмент n/4-битовых данных, полученный путем разбиения входных данных на четыре сегмента, дополнительно разделен на 2 (на d/2-сегменты).
Эти два сегмента разделенных данных в качестве выходных данных i-го раунда, соответствующих входным данным 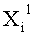
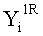
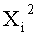
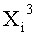
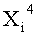
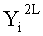
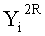
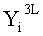

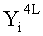
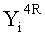
Однако в ходе операции по повторному разбиению данных в каждой линейке не обязательно разбиение производится поровну. Если число входных битов равно 256 и число d разбиения равно 4, например, число битов в каждой линейке равно n/d=256/4=64 бит, и данные, полученные посредством повторного разбиения, представляют собой 32-битовые данные в случае разбиения поровну. В результате получают два 32-битовых сегмента данных.
Однако разбиение поровну не является обязательным, так что сегменты данных, полученные в результате повторного разбиения 64-битовых данных, могут иметь произвольное сочетание размеров, например, сочетание 20-битовых данных и 44-битовых данных.
Однако в момент ввода в модуль для раундовых вычислений следующего раунда четыре сегмента 64-битовых данных согласно числу разбиения d=4 реконструируют путем соединения 20-битовых данных и 44-битовых данных, разделенных по разным линейкам, и вводят в соответствующие линейки для результатов разбиения.
Иными словами, в структуре, имеющей число d разбиения, разделение поровну не является обязательным, однако способы (пропорции разбиения) при повторном разбиении в соответствующих d линейках должны быть идентичны при выполнении операций повторного разбиения в соответствующих d линейках.
Если в какие-либо входные данные i-го раунда внесены изменения, влияние этих изменений проходит на вход по меньшей мере одной из двух F-функций в составе (i+1)-го раунда. Если изменение внесено только в самый младший бит LSB1 в составе данных 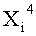
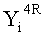
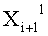
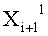
Поскольку изменение во входных данных затронуло по меньшей мере одну F-функцию в составе (i+1)-го раунда, данные, прошедшие операцию «исключающее ИЛИ» с участием выходных данных функции, находятся в диффузионном состоянии. Иными словами гарантировано диффузионное состояние любого сочетания (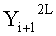
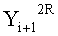
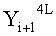
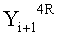
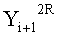
Согласно правилам 2 и 3 рассматриваемого способа выходные данные
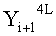
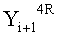

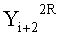
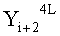
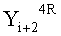
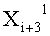
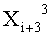
Данные
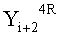
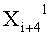
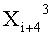
Согласно приведенным выше результатам рассматриваемый способ может удовлетворять условию, что число раундов для достижения полного диффузионного состояния равно 4. На фиг.22 представлен пример путей, с использованием которых полное диффузионное состояние достигается согласно рассматриваемому способу для случая d равно 4. В этом примере структуры полное диффузионное состояние реализовано за четыре раунда, что меньше пяти раундов, необходимых для достижения полного диффузионного состояния в обычной структуре. На фиг.22 показан пример путей, реализующих полное диффузионное состояние в случае, когда число d равно 4 в рассматриваемой структуре.
На фиг.23 представлен пример структуры, где число d равно 6, а на фиг.24 показан пример путей, с использованием которых полное диффузионное состояние достигается в этом примере структуры (числа, показанные до и после перестановки между раундами, представляют индексы, указывающие позиции, в которых соответствующие сегменты данных располагаются после перестановки).
Как очевидно из изложенного выше, структуры согласно настоящему изобретению позволяют достигнуть намного лучших диффузионных свойств по сравнению с обычными структурами. Кроме того, поскольку структуры согласно настоящему изобретению не используют линейные операции, стоимость реализации не увеличивается.
Как описано выше, в рассматриваемом варианте модуль криптографической обработки данных разбивает и вводит составляющие биты данных, подлежащие обработке данных, в линейки и многократно выполняет операцию преобразования данных с использованием раундовых функций применительно к данным в соответствующих линейках. Этот модуль криптографической обработки данных многократно осуществляет раундовые вычисления, в состав которых входят также повторные разбиения и реконструкции данных, как описано ниже.
В частности, модуль криптографической обработки данных вводит n/d-битовые данные, полученные в результате разбиения n-битовых данных в качестве входных данных в соответствии с числом d разбиения, в соответствующие линейки и многократно осуществляет раундовые вычисления, иными словами вычисления, включающие операции преобразования данных с использованием раундовых функций.
Во время работы для многократного выполнения раундовых вычислений n/d-битовые данные каждой линейки, имеющей выходные данные раундовых вычислений, повторно разбивают на сегменты d/2, после чего повторно разбитые данные рекомбинируют для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных раундовых вычислений предшествующего этапа. Реконструированные n/d-битовые данные задают в качестве входных данных для раундовых вычислений следующего этапа.
Конкретнее, выполняют операцию повторного разбиения и реконструкции данных, удовлетворяющую следующим условиям.
(1) Последовательности данных на входной стороне F-функции неизменным способом распределяют в последовательности данных на стороне XOR (функции «исключающее ИЛИ») в составе следующей раундовой функции.
(2) Последовательности данных на стороне функции «исключающее ИЛИ» (XOR) неизменным способом распределяют в последовательности данных на входной стороне F-функции в составе следующей раундовой функции, и
(3) Каждую единицу из последовательности данных, разбитой на сегменты d/2, распределяют в последовательность d/2 данных следующей раундовой функции без наложений.
В системе выполняют операцию, удовлетворяющую таким условиям.
Например, модуль криптографической обработки данных осуществляет операцию, в ходе которой d×(d/2) сегментов повторно поделенных данных генерируют посредством повторного разбиения n/d-битовых данных в каждой из d линеек, имеющих выходные данные раундовых вычислений на сегменты d/2 данных, сегменты d/2 повторно разбитых данных, выбранные из разных линеек из совокупности d линеек, соответствующих числу d разбиения, рекомбинируют для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных раундовых вычислений предыдущего этапа, после чего эти реконструированные данные задают в качестве входных данных для раундовых вычислений следующего этапа.
При выполнении такой операции минимальное число раундов (повторений), необходимое, чтобы войти в описанное выше полное диффузионное состояние, или «число раундов для достижения полного диффузионного состояния» может быть задано равным 4.
Как описано выше, если выходной бит записан в виде некоторого выражения относительно входных битов и если это относительное выражение удовлетворяет приведенным ниже условиям, состояние выходного бита определено как «диффузионное состояние».
(Условие 1) В это относительное выражение входят все входные биты.
(Условие 2) Все входные биты прошли через раундовую функцию (F-функцию) по меньшей мере однажды.
Далее, состояние, в котором все выходные биты находятся в диффузионном состоянии, определено как «полное диффузионное состояние».
В каждом примере структур, описанных в качестве вариантов настоящего изобретения, каждый из сегментов n/d-битовых данных, передаваемых по соответствующим линейкам для передачи данных, полученных в результате разбиения n-битовых входных данных на d, или линеек (d/2) для последовательностей данных на входной стороне F-функций и линеек (d/2) для последовательностей данных на стороне функции «исключающее ИЛИ» (XOR), разбивают на сегменты d/2.
Таковы исходные установки для реализации минимального числа раундов, равного 4, для достижения полного диффузионного состояния.
На фиг.25 показан пример, в котором число d разбиения равно 6, а n/d-битовые данные (n/6-битовые данные) для передачи в соответствующих линейках разделяют на 2 или разделяют на сегменты d/12-битовых данных, которые затем передают между раундами.
Однако число разбиений для реализации полного диффузионного состояния не ограничено (d/2) в каждой линейке, если только число раундов не ограничено 4.
На фиг.26 представлена таблица, показывающая соотношение соответствия между числом d разбиения n-битовых входных данных, числом р разбиения в каждой линейке и числом раундов, необходимых для реализации полного диффузионного состояния.
Если последовательности данных распределены должным образом, число раундов для достижения полного диффузионного состояния можно вычислить с использованием уравнения, приведенного ниже.
Число раундов = 3+[logp(d/2)]
Здесь, [х] это наименьшее целое число не меньше х.
На фиг.27 представлен развернутый пример структуры, в которой последовательности данных на входной стороне F-функций и последовательности данных на стороне функции «исключающее ИЛИ» (XOR) разбиты отлично одни от других.
Структура, показанная на фиг.27, представляет собой пример, в котором число d разбиения равно 6, каждая из трех (=d/2) линеек последовательностей данных на входной стороне F-функций разделена на 2 и каждая из трех (=d/2) линеек последовательностей на стороне функции «исключающее ИЛИ» (XOR) разделена на 3.
В этой структуре число раундов для достижения полного диффузионного состояния также может быть равно 4, если должным образом распределить последовательности данных.
Эффекты, реализуемые рассматриваемым способом, могут быть достигнуты независимо от позиций вставки расширенных ключей (раундовых ключей). На фиг.28 представлен пример структуры, такой же, как пример структуры, показанной на фиг.21, за исключением позиций вставки расширенных ключей (раундовых ключей).
На фиг.21 расширенные ключи (раундовые ключи) вставлены в соответствующие F-функции.
В структуре, показанной на фиг.28, с другой стороны, расширенные ключи (раундовые ключи) вставляют в участки, выполняющие операции «исключающее ИЛИ» на стороне выходов F-функций и над последовательностями данных на стороне функции «исключающее ИЛИ» (XOR).
В такой структуре число раундов для достижения полного диффузионного состояния также может быть уменьшено путем применения механизма передачи, содержащего описанную выше операцию повторного разбиения данных между раундами.
[4. Пример структуры с более эффективным распределением данных]
В рассмотренной выше главе [3. Пример структуры с улучшенными диффузионными свойствами согласно настоящему изобретению] был описан способ структурирования для достижения лучших диффузионных свойств в обобщенной структуре Файстеля без увеличения стоимости реализации системы.
В частности, в структуре, в которой в каждую линейку вводят n/d-битовые данные, полученные путем разбиения n-битовых данных в соответствии с числом d разбиения, и многократно выполняют операцию, такую как раундовые вычисления, включающие операцию преобразования данных с использованием раундовых функций, n/d-битовые данные в каждой линейке, где имеются выходные данные раундовых вычислений, дополнительно повторно разбивают на сегменты d/2 и рекомбинируют эти повторно разбитые данные для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных раундовых вычислений предыдущего этапа. Указанные d сегментов n/d-битовых данных используют в качестве входных данных для раундовых вычислений на следующем этапе.
Далее будет описан более эффективный способ распределения данных по сравнению со способом, рассмотренным в приведенном выше варианте.
Сначала рассмотрим фиг.29, где представлен пример типовой структуры для этого варианта.
В этой структуре n-битовые входные данные разбивают на d сегментов n/d-битовых данных в соответствии с числом d разбиения в d-линеечной обобщенной структуре Файстеля и многократно повторяют операцию, такую как раундовые вычисления, включающие операцию преобразования данных с использованием раундовых функций, как и в варианте, описанном выше в главе [3].
После i-го раунда вычислений последовательности n/d-битовых данных в каждой из d линеек (последовательностей) дополнительно повторно разбивают на сегменты d/2.
Далее, j-й сегмент данных из совокупности сегментов d/2 разбитых выходных данных в каждой линейке (последовательности) после i-го раунда вычислений обозначен как Yi[j] (j целое число не меньше 1 и не больше d2/2).
Аналогично, в совокупности сегментов d/2 данных, полученных путем повторного разбиения n/d-битовых данных в каждой из d линеек в соответствии с числом d разбиения в модуле для раундовых вычислений на (i+1)-м этапе, j-й сегмент данных обозначен Xi+1[j] (j целое число не меньше 1 и не больше d2/2).
При этом, YYi[t] обозначает данные, полученные путем последовательной комбинации данных, удовлетворяющих уравнению j=(d/2)s+t, из совокупности Yi[j].
Здесь, s - целое число не меньше 0 и не больше (d-1), и t - целое число не меньше 1 и не больше d/2.
В частности, удовлетворяются следующие уравнения, например.
YYi[1]=Yi[1]||Yi[1×d/2+1]||Yi[2×d/2+1]|| … ||Yi[(d-1)×d/2+1],
YYi[2]=Yi[2]||Yi[1×d/2+2]||Yi[2×d/2+2]|| … ||Yi[(d-1)×d/2+2],
…
YYi[d/2]=Yi[d/2]||Yi[1×d/2+d/2]||Yi[2×d/2+d/2]|| … ||Yi[(d-1)×d/2+d/2]
Аналогично, XXi[t] обозначает данные, полученные путем последовательной комбинации данных, удовлетворяющих уравнению j=(d/2)s+1, из совокупности Xi[j].
Здесь, Xi[j] обозначает j-й сегмент данных из совокупности сегментов d/2 данных, полученных путем разбиения каждого из d сегментов n/d-битовых данных, являющихся результатом разбиения входных данных на i-м этапе, s - целое число не меньше 0 и не больше (d-1), и t - целое число не меньше 1 и не больше d/2.
Согласно способу, описанному выше в главе [3], имеется большое число распределительных схем, так что соответствующие оценки занимают много времени. В частности, согласно, согласно способу, описанному выше в главе [3], распределительные схемы удовлетворяют следующим условиям с (1) по (3).
(1) Последовательности данных на входной стороне F-функции неизменным способом распределяют в последовательности данных на стороне XOR (функции «исключающее ИЛИ») в составе следующей раундовой функции.
(2) Последовательности данных на стороне функции «исключающее ИЛИ» (XOR) неизменным способом распределяют в последовательности данных на входной стороне F-функции в составе следующей раундовой функции.
(3) Каждую единицу из последовательности данных, разбитой на сегменты d/2, распределяют в последовательность d/2 данных следующей раундовой функции без наложений.
Существует большое число распределительных схем, удовлетворяющих указанным условиям с (1) по (3). В частности, если число d разбиения входных данных велико, число распределительных схем очень велико, вследствие чего нелегко выбрать какую-то одну распределительную схему. Кроме того, стоимость реализации системы может стать выше в зависимости от используемого способа распределения.
В дальнейшем предлагается способ распределения, позволяющий заранее ограничить совокупность распределенных схем, из которых можно выбирать, а также уменьшить стоимость реализации системы. Этот предлагаемый метод разработан путем дальнейшего усовершенствования способа распределения, описанного выше в главе [3].
Сначала, в j-м сегменте данных, обозначенном Xi+1[j], из совокупности сегментов d/2 данных, получаемых путем повторного разбиения каждого из d сегментов n/d-битовых данных, являющихся результатом разбиения входных данных на d сегментов на (i+1)-м этапе, последовательность данных, обозначенную XXi+1[t] и сформированную путем последовательного комбинирования данных, удовлетворяющих уравнению j=(d/2)s+t, циклически сдвигают влево на величину, эквивалентную (2t-1) сегментам данных. Полученные в результате последовательности данных обозначены ZZi+1[t].
В частности,
поскольку ZZi+1[1]=XXi+1[1]<<<1,
установлены следующие соотношения.
ZZi+1[1]=XXi+1[1]<<<1
=(Xi+1[1]||Xi+1[1×d/2+1]||Xi+1[2×d/2+1]|| … ||Xi+1[(d-1)×d/2+1])<<<1
=Xi+1[1×d/2+1]||Xi+1[2×d/2+1]|| … ||Xi+1[(d-1)×d/2+1]||Xi+1[1]
При использовании YYi[j] и ZZi+1[j], определенных, как описано выше, элементы последовательности ZZi+1[j] выбирают один за другим из каждой последовательности YYi[j] без наложений и устанавливают соединений. При таком подходе можно определить перестановку данных от данных i-го раунда к данным (i+1)-го раунда.
На фиг.30 представлен пример случая, когда число d разбиения входных данных равно 6.
Соответствующие промежуточные переменные, изображенные на фиг.30, определены следующим образом.
Промежуточные переменные представляют собой следующие три вида данных.
YYi[t]: Данные, генерируемые путем последовательного комбинирования данных, удовлетворяющих уравнению j=(d/2)s+t (s - целое число не меньше 0 и не больше (d-1), t - целое число не меньше 1 и не больше d/2), в j-m сегменте данных, обозначенном Yi[j] (j - целое число не больше 1 и не меньше d2/2), из совокупности сегментов d/2 данных разбитых выходных данных на i-м этапе.
XXi+1[t]: Данные, генерируемые путем последовательного комбинирования данных, удовлетворяющих уравнению j=(d/2)s+t (s - целое число не меньше 0 и не больше (d-1), t - целое число не меньше 1 и не больше d/2), в j-m сегменте данных, обозначенном Xi+1[j], из совокупности сегментов d/2 данных, полученных путем разбиения каждого из d сегментов n/d-битовых данных, являющихся результатом разбиения входных данных на d сегментов на (i+1)-м этапе.
ZZi+1[t]: Последовательности данных, полученные путем циклического сдвига последовательностей данных XXi+1[t] влево на величину, эквивалентную (2t-1) сегментам данных.
Таковы промежуточные переменные.
Как показано на фиг.30, когда число d разбиения входных данных равно 6, t - целое число не меньше 1 и не больше d/2, причем параметру t присваивают каждое из значений 1, 2 и 3. Промежуточные переменные имеют следующий вид.
Промежуточные переменные YYi[t], соответствующие выходным данным i-го этапа: YYi[1], YYi[2] и YYi[3]
Промежуточные переменные XXi+1[t], соответствующие входным данным перед сдвигом на (i+1)-м этапе: XXi+1[1], XXi+1[2] и XXi+1[3]
Промежуточные переменные ZZi+1[t], соответствующие входным данным после сдвига (i+1)-м этапе: ZZi+1[1], ZZi+1[2] и ZZi+1[3]
Эти переменные вычисляют, как описано ниже.
Промежуточные переменные YYi[t], соответствующие выходным данным i-го этапа: YYi[1], YYi[2] и YYi[3] заданы следующим образом.
YYi[1]=Yi[1]||Yi[4]||Yi[7]||Yi[10]||Yi[13]||Yi[16],
YYi[2]=Yi[2]||Yi[5]||Yi[8]||Yi[11]||Yi[14]||Yi[17],
YYi[3]=Yi[3]||Yi[6]||Yi[9]||Yi[12]||Yi[15]||Yi[18].
Промежуточные переменные XXi+1[t], соответствующие входным данным перед сдвигом на (i+1)-м этапе: XXi+1[1], XXi+1[2] и XXi+1[3] заданы следующим образом.
XXi+1[1]=Xi+1[1]||Xi+1[4]||Xi+1[7]||Xi+1[10]||Xi+1[13]||Xi+1[16],
XXi+1[2]=Xi+1[2]||Xi+1[5]||Xi+1[8]||Xi+1[11]||Xi+1[14]||Xi+1[17],
XXi+1[3]=Xi+1[3]||Xi+1[6]||Xi+1[9]||Xi+1[12]||Xi+1[15]|[Xi+1[18].
Промежуточные переменные ZZi+1[t] соответствующие входным данным после сдвига (i+1)-м этапе: ZZi+1[1], ZZi+1[2] и ZZi+1[3] заданы следующим образом.
ZZi+1[1]=Xi+1[4]||Xi+1[7]||Xi+1[10]||Xi+1[13]||Xi+1[16]||Xi+1[1],
ZZi+1[2]=Xi+1[11]||Xi+1[14]||Xi+1[17]||Xi+1[2]||Xi+1[5]||Xi+1[8],
ZZi+1[3]=Xi+1[18]||Xi+1[3]||Xi+1[6]||Xi+1[9]||Xi+1[12]||Xi+1[15].
Здесь, YYi[1] соединено с ZZi+1[1], YYi[2] соединено с ZZi+1[2] и YYi[3] соединено с ZZi+1[3], например, как показано на фиг.30. В этом случае используется способ распределения данных, показанный в части (а) в верхней половине фиг.31.
Если YYi[1] соединено с ZZi+1[2], YYi[2] соединено с ZZi+1[3] и YYi[3] соединено с ZZi+1[1], например, используется способ распределения данных, показанный в части (b) в нижней половине фиг.31.
Как описано выше, настройку модуля криптографической обработки данных в составе устройства для криптографической обработки данных в рассматриваемом варианте или соединительную структуру, которая определяет соотношение вход-выход между выходными данными раундовых вычислений предыдущего этапа и повторно разбитыми данными для раундовых вычислений следующего этапа, выбирают из совокупности соединительных структур, имеющих сегменты (d/2) из 2n/d-битовых данных в качестве единиц, представляющих собой данные, сформированные посредством комбинирования d×(d/2) сегментов повторно разбитых данных, генерируемых в результате операции повторного разбиения, выполняемой применительно к n/d-битовым данным в линейках, имеющих выходные данные раундовых вычислений.
Способ распределения данных, определяемый рассмотренным выше способом, удовлетворяет условиям, описанным выше в главе [3], а именно:
(1) Последовательности данных на входной стороне F-функции неизменным способом распределяют в последовательности данных на стороне XOR (функции «исключающее ИЛИ») в составе следующей раундовой функции;
(2) Последовательности данных на стороне функции «исключающее ИЛИ» (XOR) неизменным способом распределяют в последовательности данных на входной стороне F-функции в составе следующей раундовой функции; и
(3) Каждую единицу из последовательности данных, разбитой на сегменты d/2, распределяют в последовательность d/2 данных следующей раундовой функции без наложений.
Эти условия с (1) по (3) удовлетворяются.
Соответственно можно улучшить диффузионные свойства.
Кроме того, согласно способу, описанному выше в главе [3], необходимо выбрать и распределить один за другим (d/2×d/2) видов последовательностей данных из совокупности (d/2×d/2) видов последовательностей данных (на практике, эту операцию необходимо повторить еще один раз). Согласно предлагаемому здесь способу, с другой стороны, выбирают и распределяют один за другим d/2 видов последовательностей данных из совокупности d/2 видов последовательностей данных. Таким образом, число схем, из которых нужно делать выбор, резко уменьшается. Далее, каждый способ распределения, выбранный согласно описанному выше способу, характеризуется регулярностью и, соответственно, стоимость реализации можно уменьшить.
[5. Пример структуры, обладающей инволюционными свойствами]
Функция шифрования в обычной структуре Файстеля может быть выражена, как показано на фиг.32. Функция дешифровки в обычной структуре Файстеля может быть выражена, как показано на фиг.33.
Как можно видеть по структурам, представленным на фиг.32 и 33, точно одну и ту же функцию можно использовать и в качестве функции шифрования и в качестве функции дешифровки просто посредством соответствующей перетасовки порядка расширенных ключей (раундовых ключей) для вставки в F-функции. Свойства, при наличии которых функция шифрования и функция дешифровки могут быть реализованы в одной и той же структуре за исключением вставки расширенных ключей (раундовых ключей), называются инволюционными свойствами.
В обладающей инволюционными свойствами структуре для криптографической обработки функция шифрования может служить в качестве функции дешифровки, если должным образом перетасовать порядок расширенных ключей (раундовых ключей), так что нет необходимости отдельно готовить функцию дешифровки. Соответственно, можно сказать, что криптография с использованием инволюционных свойств может быть обычно реализована с меньшими затратами, чем криптография без использования инволюционных свойств.
Кроме того, использование одной и той же функции в качестве функции шифрования и в качестве функции дешифровки обладает тем преимуществом, что затраты на проверку правильности можно сократить наполовину (проверки правильности какой-либо одной функции - функции шифрования или функции дешифровки, будет вполне достаточно) и можно уменьшить вдвое размер кода.
Как описано выше, в показанной на фиг.32 и 33 обычной структуре Файстеля с числом d разбиения, равным 2, в точности одна и та же функция может быть использована и в качестве функции шифрования, и в качестве функции дешифровки, просто посредством соответствующей перетасовки порядка расширенных ключей (раундовых ключей) для вставки в F-функцию, так что может быть легко реализована структура, обладающая инволюционными свойствами.
Однако в обобщенной структуре Файстеля (обобщенные сети Файстеля), имеющей число d разбиения, не равное 2, невозможно легко добиться инволюционных свойств.
Сначала описаны инволюционные свойства имеющей d линеек обобщенной структуры Файстеля, использующей d/2 F-функций на одном этапе (d>2).
Известно, что в имеющей 4 линейки обобщенной структуре Файстеля, такой как описанная выше и показанная на фиг.14 структура, инволюционные свойства могут быть реализованы, если число раундов обработки данных является нечетным числом. Например, имеющая 4 линейки обобщенная структура Файстеля, построенная с тремя раундами (то же самое относится к 5-раундовой структуре). Однако инволюционные свойства реализовать не удается, если число раундов обработки данных является четным числом.
Имеющая d линеек обобщенная структура Файстеля обычно обладает инволюционными свойствами только в тех случаях, когда остаток при делении числа составляющих раундов на число d разбиения равен 1 или (d/2)+1.
Например, имеющая 4 линейки обобщенная структура Файстеля, показанная на фиг.14, обладает инволюционными свойствами только в тех случаях, когда остаток от деления числа составляющих раундов на число d разбиения, равное 4, составляет 1 или (d/2)+1=(4/2)+1=3.
В частности, инволюционные свойства реализуются только в тех случаях, когда число составляющих раундов равно 1, 3, 5, 7, 9, …, или когда число составляющих раундов является нечетным числом.
Кроме того, имеющая 6 линеек обобщенная структура Файстеля с числом d разбиения, равным 6, обладает инволюционными свойствами только в том случае, когда остаток от деления числа составляющих раундов на число d разбиения, равное 6, составляет 1 или (d/2)+1=(6/2)+1=4.
В частности, инволюционные свойства реализуются только в тех случаях, когда число составляющих раундов равно 1, 4, 7, 10, 13, …, или когда число составляющих раундов является одним из указанных чисел.
В общем случае, имеющая d линеек обобщенная структура Файстеля обладает инволюционными свойствами неизменно в зависимости от числа составляющих раундов, как описано выше.
На фиг.34 представлена схема, показывающая в структуре, имеющей 4 линейки, способ, позволяющий реализовать превосходные диффузионные свойства посредством повторного разбиения данных и рекомбинации между раундовыми вычислениями, как описано выше в главе [3. Пример структуры с улучшенными диффузионными свойствами согласно настоящему изобретению].
Согласно этому способу инволюционные свойства достигаются только тогда, когда число составляющих раундов равно 1+3n (n - целое число не меньше 0).
Число составляющих раундов в значительной степени связано с защищенностью и функционированием реализации. В структуре, обладающей инволюционными свойствами, независимо от числа составляющих раундов это число составляющих раундов может быть задано более гибким образом, так что степень защищенности и функционирование реализации можно гибко изменять. Более того, инволюционные свойства позволяют реализовать компактные, малогабаритные устройства.
Описан способ проектирования межраундовых перестановок, позволяющий добиться лучших диффузионных свойств без увеличения стоимости реализации, а также иметь инволюционные свойства независимо от числа составляющих раундов.
Рассматриваемый ниже способ представляет собой способ дополнительного создания инволюционных свойств в структуре, обладающей превосходными диффузионными свойствами, как описано выше в главе [3. Пример структуры с улучшенными диффузионными свойствами согласно настоящему изобретению].
На фиг.35 представлен пример этого способа. Согласно этому способу многократно повторяют процедуры с 1 по 3 этапы, как показано на фиг.35.
(Этап 1)
Сначала, в имеющей d линеек обобщенной структуре Файстеля с таким же числом d разбиения, как и в обычной структуре, n-битовые входные данные, разбитые на d сегментов n/d-битовых данных в соответствии с числом d разбиения, и вводят соответствующие сегменты n/d-битовых данных в соответствующие линейки разбиения. Обработка данных в F-функции и выполнение операции «исключающее ИЛИ» производятся применительно к каждому сегменту n/d-битовых данных.
Последовательности данных, поступающие на входы F-функций в этот момент, называются последовательностями данных на входной стороне F-функций, а последовательности данных, подвергаемые обработке функцией «исключающее ИЛИ» называются последовательностями данных на стороне функции «исключающее ИЛИ» (XOR).
В совокупности последовательностей данных на входной стороне F-функций крайняя левая из таких последовательностей данных на входной стороне F-функций обозначена L(0), а остальные последовательности данных на входной стороне F-функций обозначены последовательно как L(1), …, и L((d/2)-1), начиная слева, например.
Аналогично, последовательности данных на стороне функции «исключающее ИЛИ» (XOR) обозначены последовательно как R(0), …, и R((d/2)-1), начиная слева, например.
(Этап 2)
После этого, n/d-битовые данные, представляющие собой данные, переданные через каждую последовательность данных (линейку), дополнительно повторно разбивают на сегменты d/2 данных. Это повторное разбиение может не быть разбиением поровну.
Повторно разбитые данные из состава последовательностей данных на входной стороне F-функций и повторно разбитые данные из состава последовательностей данных на стороне функции «исключающее ИЛИ» (XOR) обозначены как L(i)j и R(i)j, соответственно.
Здесь, i представляет собой идентификатор (номер) каждой последовательности (линейки) и j представляет собой идентификатор (номер) каждого сегмента повторно разбитых данных в одной последовательности (линейке).
Например, крайние левые данные из состава данных, полученных посредством повторного разбиения крайней левой последовательности данных на входной стороне F-функций на сегменты d/2, обозначены L(0)0, а остальные сегменты данных, полученные в результате повторного разбиения, последовательно обозначены L(0)1, …, и L(0)d/2-1.
Данные, повторно разбитые на сегменты d/2 в каждой из последовательностей (линеек), затем распределяют в соответствии со следующими правилами.
Правило (2-1)
Сначала распределяют крайнюю левую последовательность данных на входной стороне F-функций или данные L(0) (i=0).
Данные L(0)0 распределяют в данные R(0)0 следующей раундовой функции, и данные L(0)1 распределяют в данные R(1)1 следующей раундовой функции. Аналогично, данные L(0)i распределяют в данные R(i)i до тех пор, пока i не станет равным (d/2)-1.
Аналогично, действует следующее правило: L(0)0=R(0)0, L(0)1=R(1)1, L(0)2=R(2)2, ….
Правило (2-2)
Далее распределяют данные L(1).
Данные L(1)0 распределяют в данные R(1)0 следующей раундовой функции, и данные L(1)1 распределяют в данные R(2)1 следующей раундовой функции. Аналогично, данные L(1)i распределяют в данные R((i+1)mod d/2)i до тех пор, пока i не станет равным (d/2)-1.
Правило (2-3)
Операцию, изложенную в описанном выше Правиле 2, повторяют вплоть до данных L((d/2)-1). Иными словами, данные L(i)j распределяют в данные R((i+j)mod d/2)j следующего раунда (i и j не меньше 0 и не больше (d/2)-1).
Правило (2-4)
Такую же операцию, как описано выше, повторяют применительно к последовательностям данных на стороне функции «исключающее ИЛИ» (XOR). В частности, данные R(i)j распределяют в данные L(((d/2)+i-j)mod d/2)j следующей раундовой функции. Здесь, i и j не меньше 0 и не больше (d/2)-1.
(Этап 3)
После выполнения описанного выше распределения каждый сегмент данных, разбитый на сегменты d/2, собирают в один сегмент данных.
Описанную выше операцию повторяют необходимое число раз в соответствии с числом раз, когда выполняют раундовые вычисления.
На фиг.36 показан пример структуры, выполняющей описанную выше операцию в случае 4 линеек (d=4). На фиг.37 показан пример структуры, выполняющей описанную выше операцию в случае 6 линеек (d=6).
В структурах, показанных на фиг.36 и 37, данные, повторно разбитые на сегменты d/2 в каждой последовательности (линейке) перераспределяют для следующего раунда в соответствии с правилами с (2-1) по (2-4), описанными выше для этапа 2. В такой структуре с повторным разбиением и перераспределением данных рассматриваемый способ обеспечивает достижение инволюционных свойств независимо от числа составляющих раундов.
Фиг.38 и 39 иллюстрируют способы структурирования, отличные от описанных выше примеров структур, но обеспечивающие достижение инволюционных свойств независимо от числа составляющих раундов. Способ, описанный выше в главе [3] и иллюстрируемый на фиг.21, является примером структуры, достигающей инволюционных свойств, если число составляющих раундов является нечетным числом.
Как описано выше, в ходе операции реконструкции повторно разбитых данных в составе соответствующих раундовых вычислений в модуле криптографической обработки данных повторно разбитые данные из состава последовательностей на входной стороне раундовых функций предыдущего этапа распределяют в последовательности данных на стороне функции «исключающее ИЛИ» (XOR) следующего этапа в соответствии с описанными выше заданными правилами, а повторно разбитые данные из состава последовательностей на стороне функции «исключающее ИЛИ» (XOR) предыдущего этапа распределяют в последовательности данных на входной стороне раундовых функций следующего этапа в соответствии с описанными выше заданными правилами. Такая структура может обладать инволюционными свойствами, позволяющими одну и ту же структуру использовать как в операциях шифрования, так и в операциях дешифровки.
[6. Пример структуры устройства для криптографической обработки данных]
Наконец, рассмотрим вариант устройства для криптографической обработки данных, осуществляющего криптографическую обработку данных в соответствии с описанными выше вариантами.
Такое устройство для криптографической обработки данных, осуществляющее криптографическую обработку данных в соответствии с описанными выше вариантами, может быть установлено в разнообразных устройствах для обработки информации, которые производят криптографическую обработку данных. В частности, такое устройство для криптографической обработки данных может быть использовано в разнообразных устройствах, которые выполняют операции обработки данных и связи, таких как персональные компьютеры, телевизоры, записывающие устройства, плееры, устройства связи, радио идентификаторы (RFID), микропроцессорные платежные карточки, сенсорные сетевые устройства, модули аутентификации элементов питания/аккумуляторов, оздоровительное/медицинское оборудование и автономные сетевые устройства.
На фиг.40 представлен пример структуры модуля 700 интегральных схем в качестве примера устройства, осуществляющего криптографическую обработку согласно настоящему изобретению. Описанные выше операции могут быть выполнены в разнообразных устройствах для обработки информации, таких как персональные компьютеры, микропроцессорные карточки и устройства чтения/записи. Модуль 700 интегральных схем может быть встроен в любое из таких разнообразных устройств.
Центральный процессор CPU 701, показанный на фиг.40, представляет собой процессор, выполняющий разнообразные программы для начала и окончания криптографической обработки данных, управления передачей/приемом данных, управления передачей данных между соответствующими компонентами и других подобных действий. Запоминающее устройство 702 образовано в составе постоянного запоминающего устройства (ПЗУ (ROM)), сохраняющего программы для выполнения процессором CPU 701 или фиксированные данные, такие как параметры вычислений, и запоминающего устройства с произвольной выборкой (ЗУПВ (RAM)), используемого в качестве области хранения данных и рабочей области для программ, которые должен выполнять процессор CPU 701 в ходе различных операций, и параметров, изменяющихся в процессе выполнения программ, а также другой подобной информации. Запоминающее устройство 702 может быть также использовано в качестве области хранения данных, сохраняющей данные ключей, необходимые для криптографической обработки, таблицу трансформаций (таблицу перестановок) для использования при криптографической обработке, данные для использования в матрицах трансформации и другую подобную информацию. Такая область хранения данных предпочтительно реализована в виде запоминающего устройства, имеющего структуру для защиты от несанкционированного доступа (взлома).
Модуль 703 криптографической обработки данных осуществляет операции шифрования и операции дешифровки с применением описанной выше структуры для криптографической обработки данных или алгоритма блочной криптографической обработки данных с симметричным ключом, использующего обобщенную структуру Файстеля или обычную структуру Файстеля, например.
Хотя модуль криптографической обработки данных описан здесь в качестве индивидуального модуля, такого независимого модуля криптографической обработки данных может и не быть. Вместо этого программа криптографической обработки данных может быть записана в ПЗУ ROM, а процессор CPU 701 может считывать и выполнять программу, записанную в этом ПЗУ ROM, например.
Генератор 704 случайных чисел осуществляет операцию генерации случайных чисел, требуемых для генерации ключей, необходимых для криптографической обработки данных.
Приемопередающий модуль 705 представляет собой модель передачи данных, поддерживающий связь для передачи данных с внешними устройствами. Например, приемопередающий модуль 705 поддерживает связь для передачи данных с модулем интегральных схем, таким как устройство чтения/записи, и передает зашифрованный текст, генерируемый в этом модуле интегральных схем, или принимает входные данные от внешнего устройства чтения/записи или выполняет другие подобные операции
Устройство для криптографической обработки данных, рассматриваемое в приведенном выше варианте, может быть использовано не только в операциях шифрования, выполняемых для шифрования открытых текстов в качестве входных данных, но и в операциях расшифровки для восстановления открытых текстов из зашифрованных текстов в качестве входных данных.
Структура, описанная в приведенном выше варианте, может быть использована и в операциях шифрования, и в операциях дешифровки.
[7. Краткая характеристика структур согласно настоящему изобретению]
Варианты настоящего изобретения были описаны подробно со ссылками на приведенные выше конкретные варианты. Однако специалистам в рассматриваемой области должно быть очевидно, что модификации и изменения могут быть внесены в эти варианты, не выходя за пределы объема настоящего изобретения. Вкратце, настоящее изобретение описано здесь на примерах, но его не следует ограничивать этими примерами. Для понимания объема настоящего изобретения необходимо учитывать Формулу изобретения.
Технология, рассмотренная в настоящем описании, может иметь следующие формы.
(1) Устройство для криптографической обработки данных, включающее
модуль криптографической обработки данных, который разбивает и вводит составляющие биты данных, подлежащих обработке, в линейки и многократно выполняет операцию преобразования данных применительно к данным в соответствующих линейках с использованием раундовой функции,
отличающееся тем, что модуль криптографической обработки данных имеет структуру, рассчитанную на ввод n/d-битовых данных, полученных путем разбиения n-битовых данных в качестве входных данных согласно числу d разбиения, в соответствующие линейки и многократного выполнения вычислений в качестве раундовых вычислений, включая операцию преобразования данных, с использованием раундовой функции, и
этот модуль криптографической обработки данных осуществляет операцию, в ходе которой n/d-битовые данные в каждой линейке, имеющей выходные данные раундовых вычислений, повторно разбивают на сегменты d/2 данных, рекомбинируют повторно разбитые данные для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных раундовых вычислений предыдущего этапа, и задают реконструированные данные в качестве входных данных для раундовых вычислений для следующего этапа.
(2) Устройство для криптографической обработки данных согласно (1), отличающееся тем, что раундовая функция содержит F-функцию, включающую вычисления с использованием раундового ключа, нелинейную трансформацию и линейную трансформацию, и операцию «исключающее ИЛИ» между выходными данными или входными данными F-функции с одной стороны и данными в другой линейке с другой стороны.
(3) Устройство для криптографической обработки данных согласно (1) или (2), отличающееся тем, что модуль криптографической обработки данных задает результат раундовых вычислений предыдущего этапа в качестве входных данных для раундовых вычислении следующего этапа путем выполнения операции, удовлетворяющей следующим условиям распределения с (1) по (3):
(1) Последовательности данных на входной стороне F-функций неизменным способом распределяют в последовательности данных на стороне XOR (функции «исключающее ИЛИ») в составе следующей раундовой функции,
(2) Последовательности данных на стороне функции «исключающее ИЛИ» (XOR) неизменным способом распределяют в последовательности данных на входной стороне F-функций в составе следующей раундовой функции, и
(3) Каждую единицу из последовательности данных, разбитой на сегменты d/2, распределяют в последовательность d/2 данных следующей раундовой функции без наложений.
(4) Устройство для криптографической обработки данных согласно любому (1)-(3), отличающееся тем, что модуль криптографической обработки данных имеет обобщенную структуру Файстеля с числом d разбиения входных данных, равным или больше 4.
(5) Устройство для криптографической обработки данных согласно любому (1)-(4), отличающееся тем, что модуль криптографической обработки данных выполняет операцию, в ходе которой генерируют d×(d/2) сегментов повторно разбитых данных путем повторного разбиения n/d-битовых данных в каждой из d линеек, имеющей выходные данные раундовых вычислений на сегменты d/2 данных, затем сегменты d/2 повторно разбитых данных, выбранных из разных линеек из совокупности d линеек, соответствующих числу d разбиения, рекомбинируют для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных раундовых вычислений предыдущего этапа, и далее реконструированные данные задают в качестве входных данных для раундовых вычислений следующего этапа.
(6) Устройство для криптографической обработки данных согласно любому (1)-(5), отличающееся тем, что, когда все выходные биты находятся в диффузионном состоянии, удовлетворяющем следующим двум условиям, или когда выходные биты связаны неким относительным выражением с входными битами, модуль криптографической обработки данных имеет структуру, реализующую полное диффузионное состояние, удовлетворяющее следующим двум условиям:
(Условие 1) все входные биты входят в указанное рациональное выражение, и
(Условие 2) все входные биты прошли через раундовую функцию по меньшей мере однажды.
(7) Устройство для криптографической обработки данных согласно любому (1)-(6), отличающееся тем, что модуль криптографической обработки данных реализует полное диффузионное состояние за четыре раунда раундовых вычислений.
(8) Устройство для криптографической обработки данных согласно любому (1)-(7), отличающееся тем, что соединительная структура, определяющая соотношение вход-выход между выходными данными раундовых вычислений предыдущего этапа и повторно разбитыми данными, раундовых вычислений следующего этапа, представляет собой соединительную структуру, выбранную из совокупности соединительных структур, имеющих (d/2) сегментов 2n/d-битовых данных в качестве единиц, являющихся данными, генерируемыми путем комбинирования d×(d/2) сегментов повторно разбитых данных, генерируемых посредством операции повторного разбиения, выполняемой применительно к n/d-битовым данным в линейках, имеющих выходные данные раундовых вычислений.
(9) Устройство для криптографической обработки данных согласно любому (1)-(8), отличающееся тем, что модуль криптографической обработки данных обладает инволюционными свойствами, применимыми как для операций шифрования, так и для операций дешифровки.
(10) Устройство для криптографической обработки данных согласно любому (1)-(9), отличающееся тем, что операция реконструкции повторно разбитых данных соответствующих раундовых вычислений в модуле криптографической обработки данных включает: распределение повторно разбитых последовательностей данных на входной стороне раундовых функций предыдущего этапа в последовательности данных на стороне функции «исключающее ИЛИ» (XOR) следующего этапа согласно заданному правилу; и распределение повторно разбитых последовательностей данных на стороне функции «исключающее ИЛИ» (XOR) предыдущего этапа в последовательности данных на входной стороне раундовых функций следующего этапа согласно заданному правилу.
(11) Устройство для криптографической обработки данных согласно любому (1)-(10), отличающееся тем, что модуль криптографической обработки данных выполняет операцию шифрования для трансформации открытого текста в качестве входных данных в зашифрованный текст или операции дешифровки для трансформации зашифрованного текста в качестве входных данных в открытый текст.
Далее, в структуры согласно настоящему изобретению включены способ обработки данных для реализации в описанных выше устройствах и системах и программа для выполнения описанных выше операций.
Последовательность операций, изложенная в настоящем описании, может быть выполнена аппаратным способом, программным способом или посредством сочетания аппаратного и программного способов. Когда какую-либо операцию выполняют программным способом, программа, содержащая соответствующую последовательность обработки данных, может быть инсталлирована в памяти компьютера, встроенного в состав специализированного оборудования, или может быть инсталлирована в компьютере общего назначения, способном выполнять разнообразные операции. Затем программу выполняют. Например, программа может быть предварительно записана на носителе записи. Программа может быть инсталлирована в компьютере не только с носителя записи, а также может быть принята через сеть связи, такую как локальная сеть связи LAN или Интернет, и инсталлирована на носителе записи, таком как внутренний жесткий диск.
Разнообразные операции, рассмотренные в настоящем описании, не обязательно выполнять в указанном последовательном порядке, а можно осуществлять параллельно или независимо одну от другой в зависимости от процессорных мощностей устройства, выполняющего операцию, или по мере необходимости. В настоящем описании система представляет собой логическое объединение устройств, но каждое из этих устройств совсем не обязательно расположено в одном и том же корпусе с другими устройстве.
Применимость в промышленности
Как описано выше, в структуре согласно варианту настоящего изобретения реализована криптографическая обработка данных с улучшенными диффузионными свойствами и высокой степенью защищенности.
В частности, модуль криптографической обработки данных разбивает и вводит составляющие биты данных, подлежащих обработке, в линейки и многократно выполняет операцию преобразования данных с использованием раундовых функций применительно к данным в соответствующих линейках. Этот модуль криптографической обработки данных вводит n/d-битовые данные, полученные путем разбиения n-битовых данных в качестве входных данных согласно числу d разбиения в каждой линейке, и многократно выполняет раундовые вычисления, представляющие собой вычисления, включающие операцию преобразования данных с использованием раундовых функций. Указанные n/d-битовые данные в каждой линейке, имеющей выходные данные раундовых вычислений, разбивают на сегменты d/2 данных и комбинируют разбитые данные для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных раундовых вычислений предыдущего этапа. Реконструированные данные задают в качестве входных данных для раундовых вычислений следующего этапа. В такой структуре может быть реализована криптографическая обработка данных с улучшенными диффузионными свойствами и высоким уровнем защищенности.
Список позиционных обозначений
700 модуль интегральных схем
701 центральный процессор CPU
702 запоминающее устройство
703 модуль криптографической обработки данных
704 генератор случайных чисел
705 приемопередающий модуль.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ИТЕРАТИВНОГО КРИПТОГРАФИЧЕСКОГО ПРЕОБРАЗОВАНИЯ ДАННЫХ | 2012 |
|
RU2504911C1 |
| СПОСОБ БЛОЧНОГО ПРЕОБРАЗОВАНИЯ ЦИФРОВЫХ ДАННЫХ НА ОСНОВЕ РЕГИСТРА СДВИГА ДЛИНЫ ВОСЕМЬ С 32-БИТОВЫМИ ЯЧЕЙКАМИ И С ТРЕМЯ ОБРАТНЫМИ СВЯЗЯМИ | 2022 |
|
RU2796629C1 |
| СПОСОБ БЛОЧНОГО КРИПТОГРАФИЧЕСКОГО ПРЕОБРАЗОВАНИЯ ДВОИЧНОЙ ИНФОРМАЦИИ | 1998 |
|
RU2140713C1 |
| СПОСОБ КРИПТОГРАФИЧЕСКОГО ПРЕОБРАЗОВАНИЯ БЛОКОВ ЦИФРОВЫХ ДАННЫХ | 2007 |
|
RU2359415C2 |
| СПОСОБ КРИПТОГРАФИЧЕСКОГО ПРЕОБРАЗОВАНИЯ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2018 |
|
RU2738321C1 |
| СПОСОБ КРИПТОГРАФИЧЕСКОГО ПРЕОБРАЗОВАНИЯ ЦИФРОВЫХ ДАННЫХ | 2003 |
|
RU2309549C2 |
| УСТРОЙСТВО ОБРАБОТКИ ДАННЫХ, СПОСОБ ОБРАБОТКИ ДАННЫХ И ПРОГРАММА | 2012 |
|
RU2603550C2 |
| СПОСОБ ИТЕРАТИВНОГО ШИФРОВАНИЯ БЛОКОВ ДВОИЧНЫХ ДАННЫХ | 1999 |
|
RU2144268C1 |
| СПОСОБ КРИПТОГРАФИЧЕСКОГО ПРЕОБРАЗОВАНИЯ БЛОКОВ ЦИФРОВЫХ ДАННЫХ | 1997 |
|
RU2140709C1 |
| СПОСОБ ИТЕРАТИВНОГО ШИФРОВАНИЯ БЛОКОВ ДАННЫХ | 1999 |
|
RU2140714C1 |
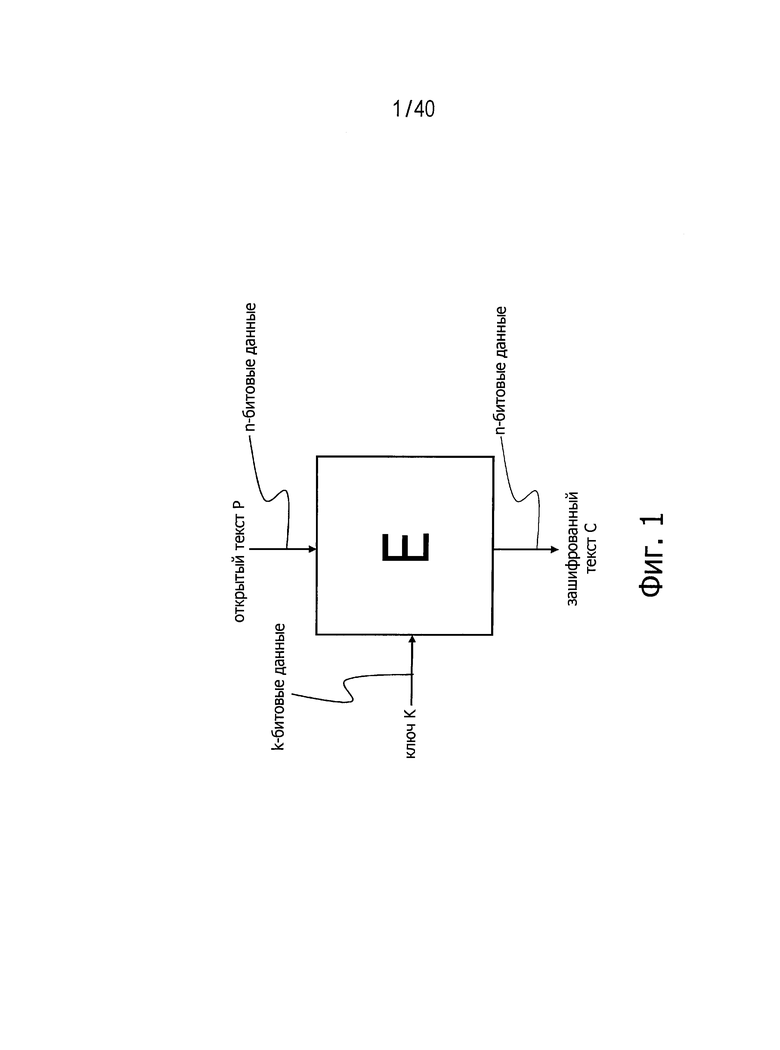
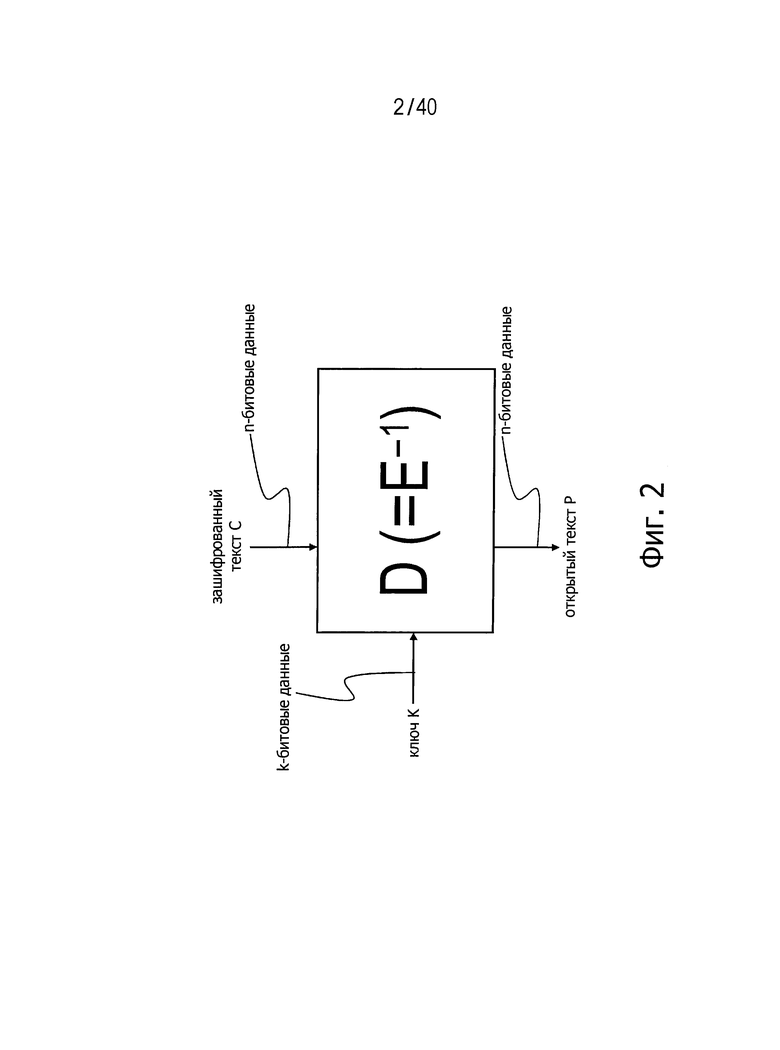
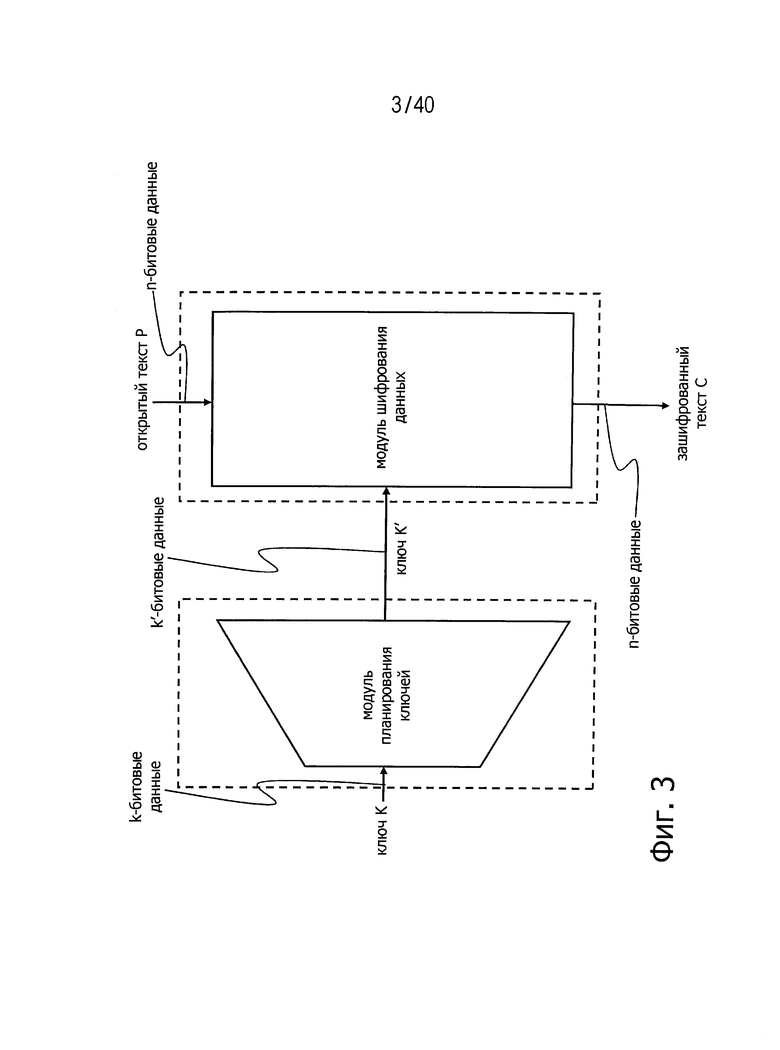
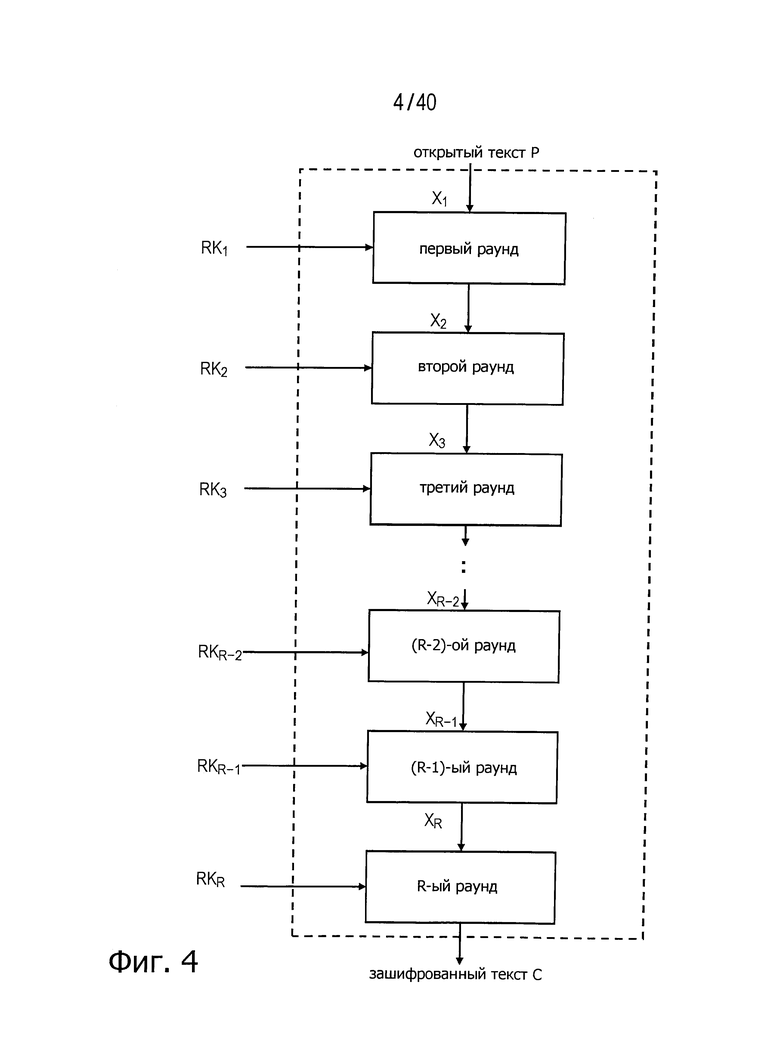
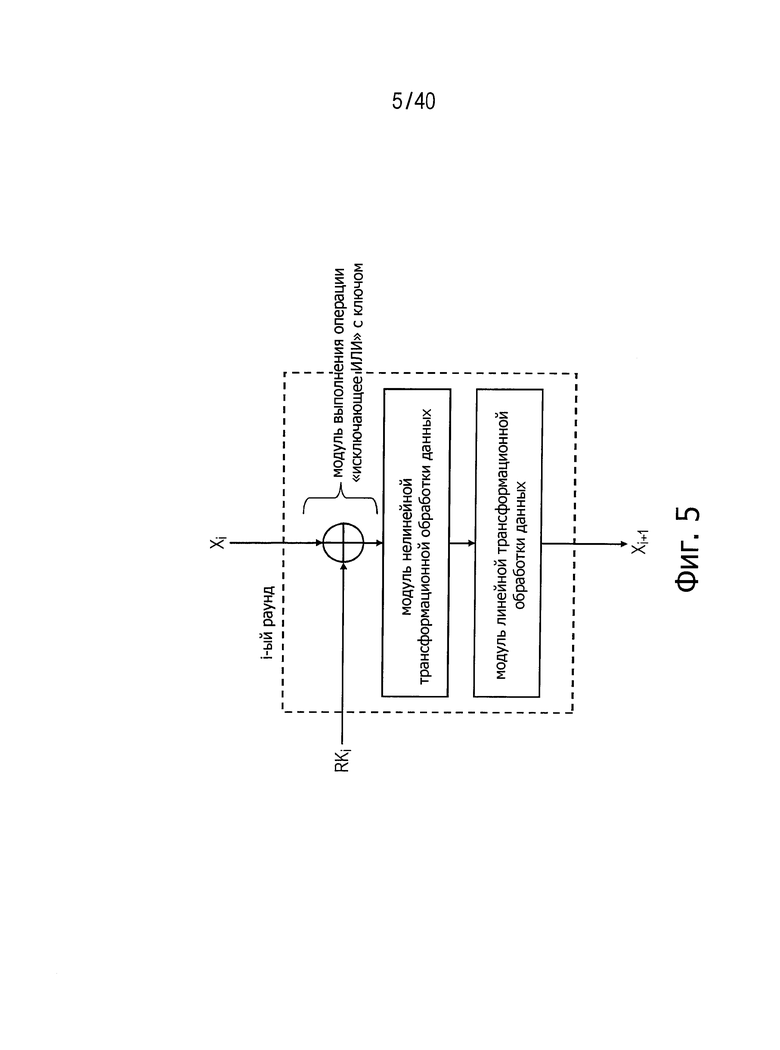
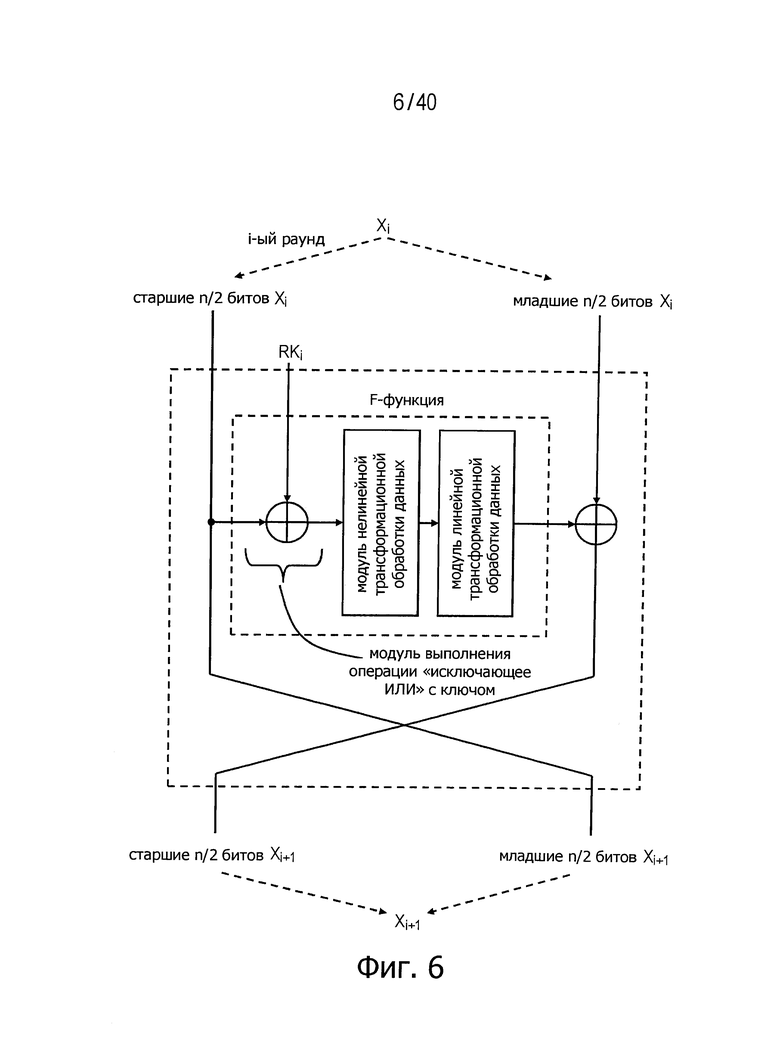
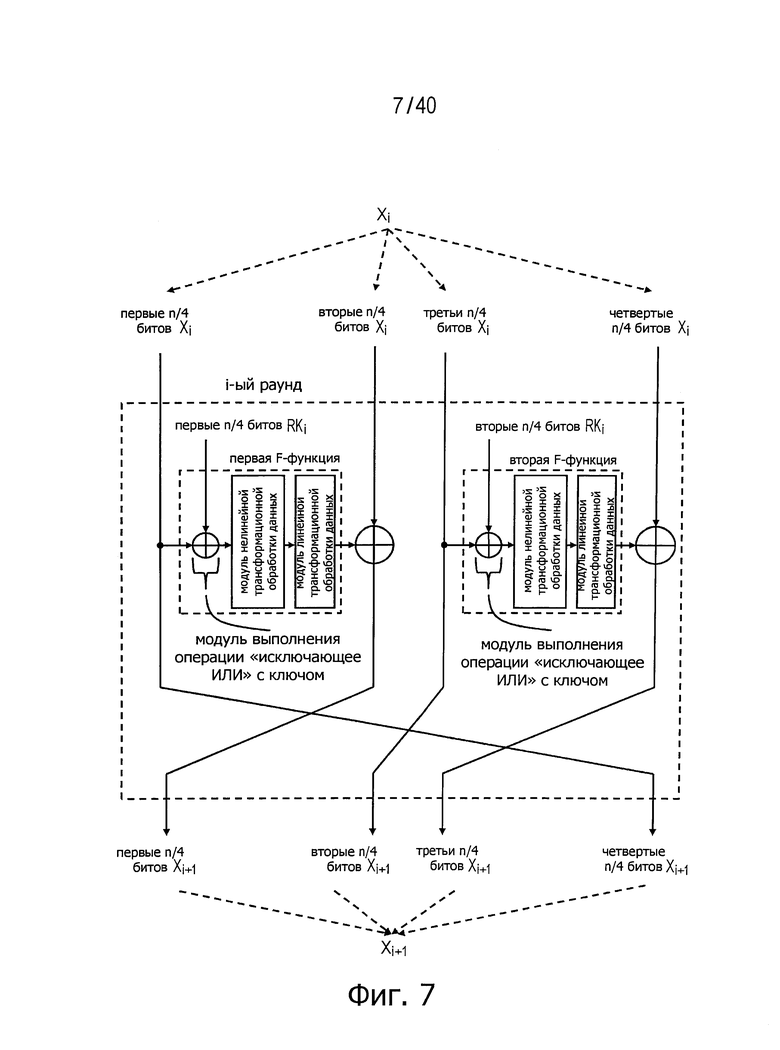
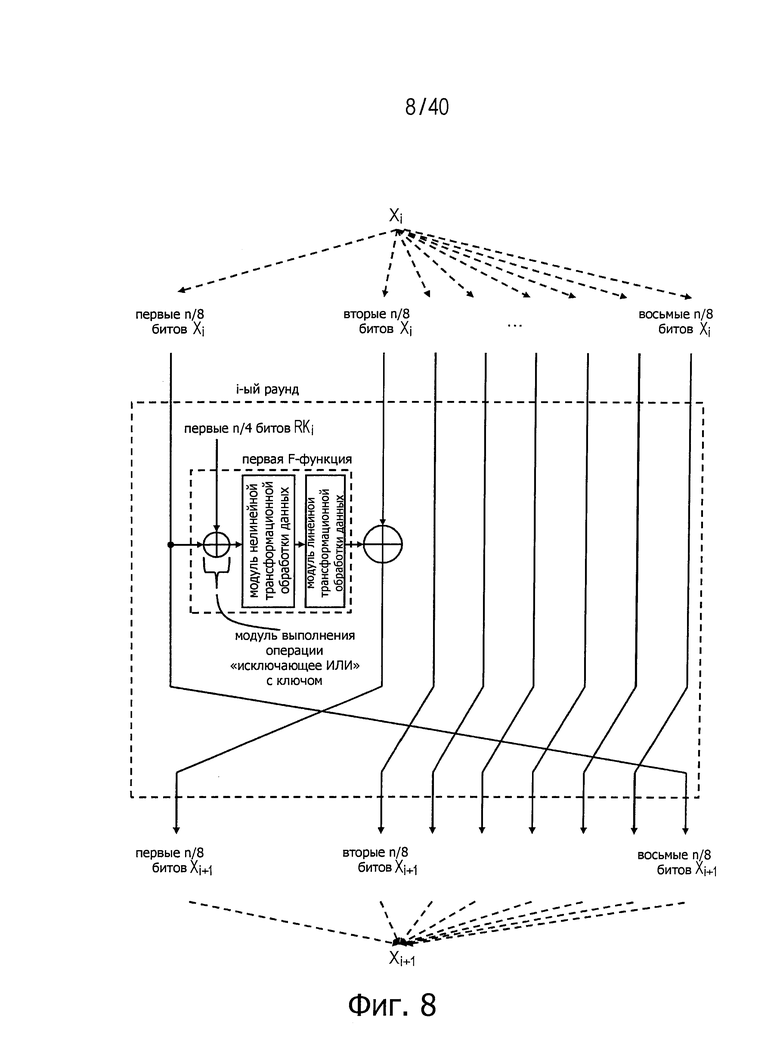
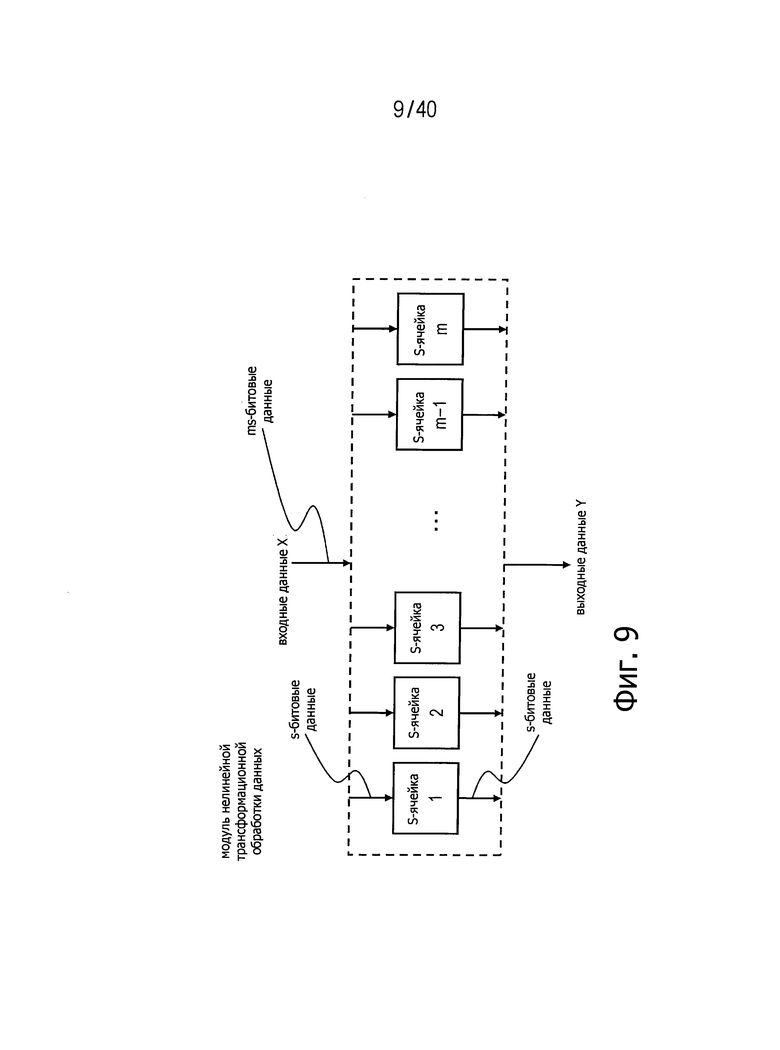
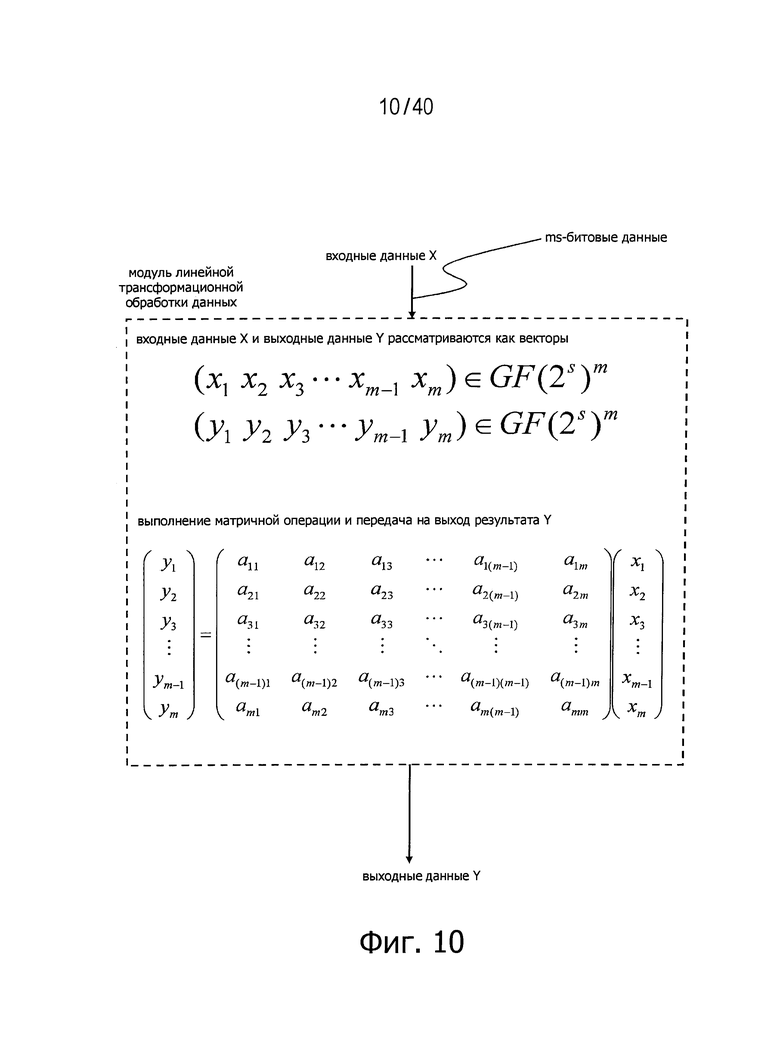
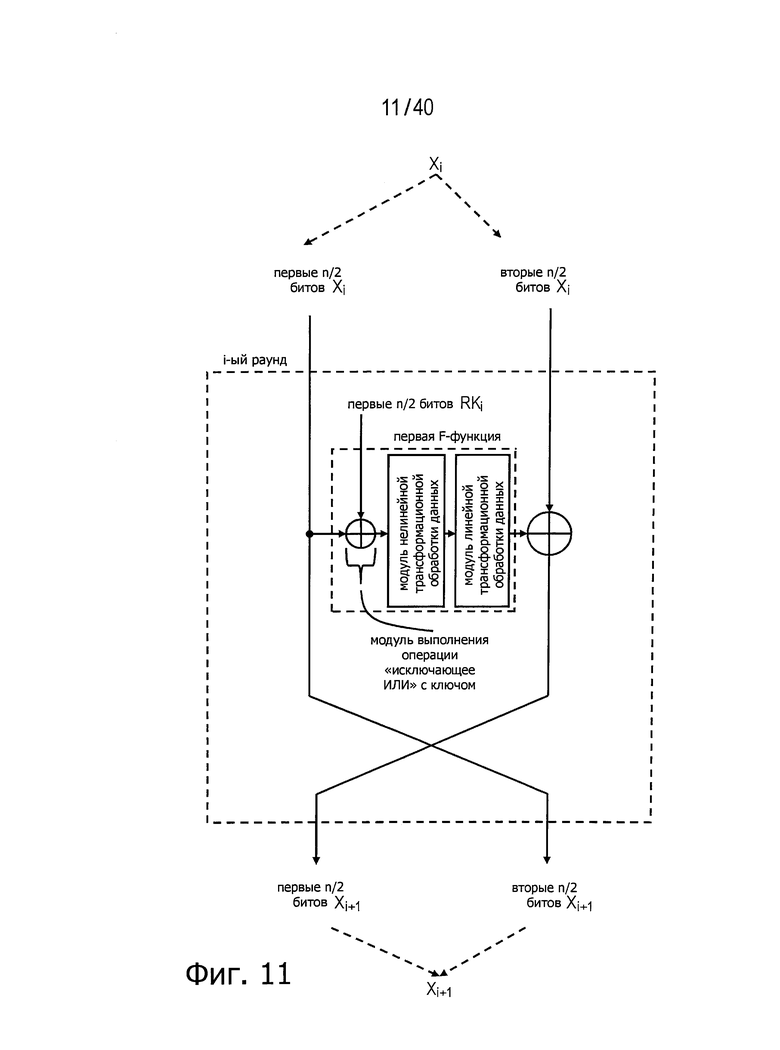
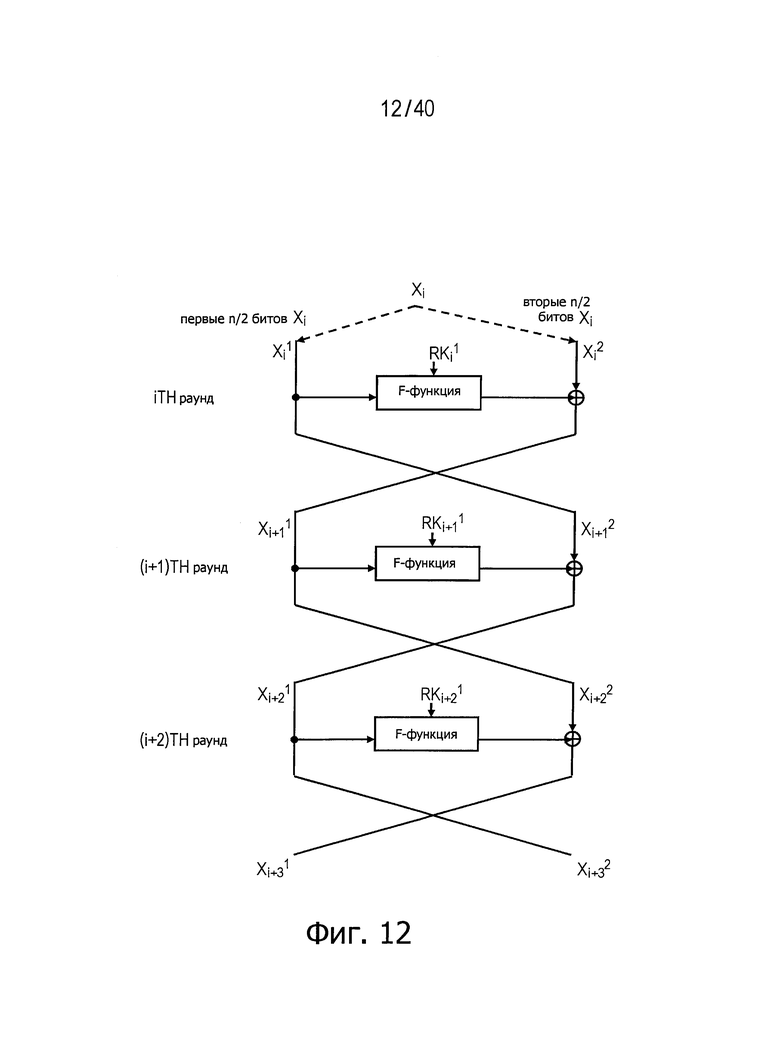
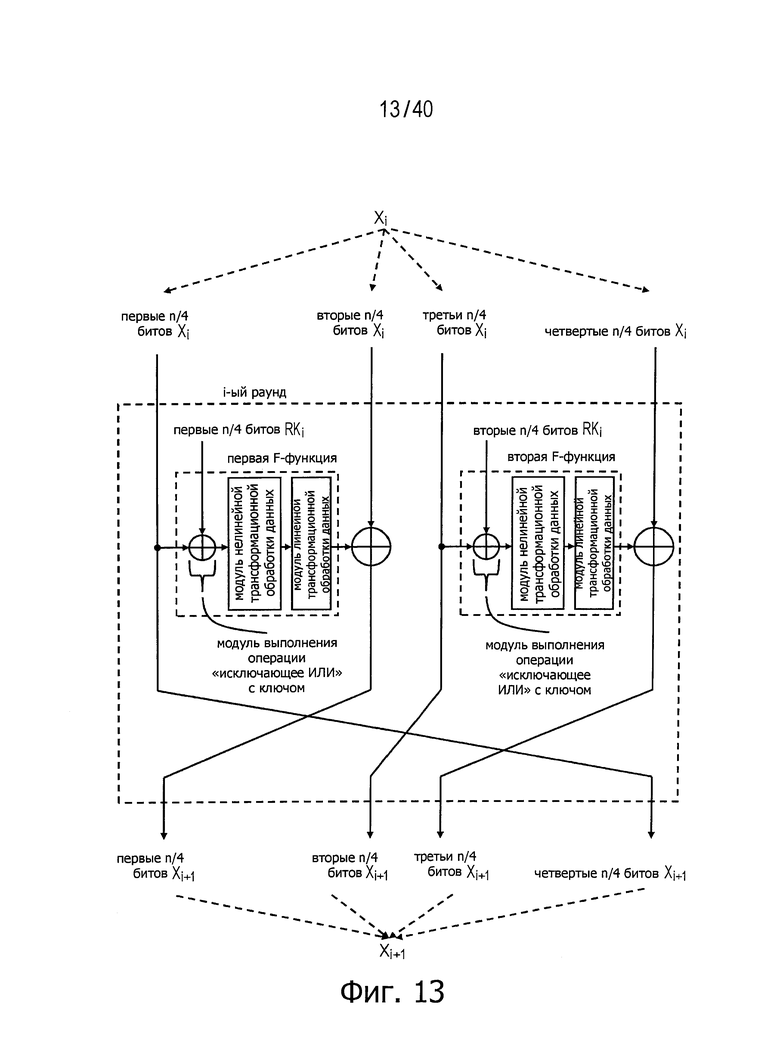
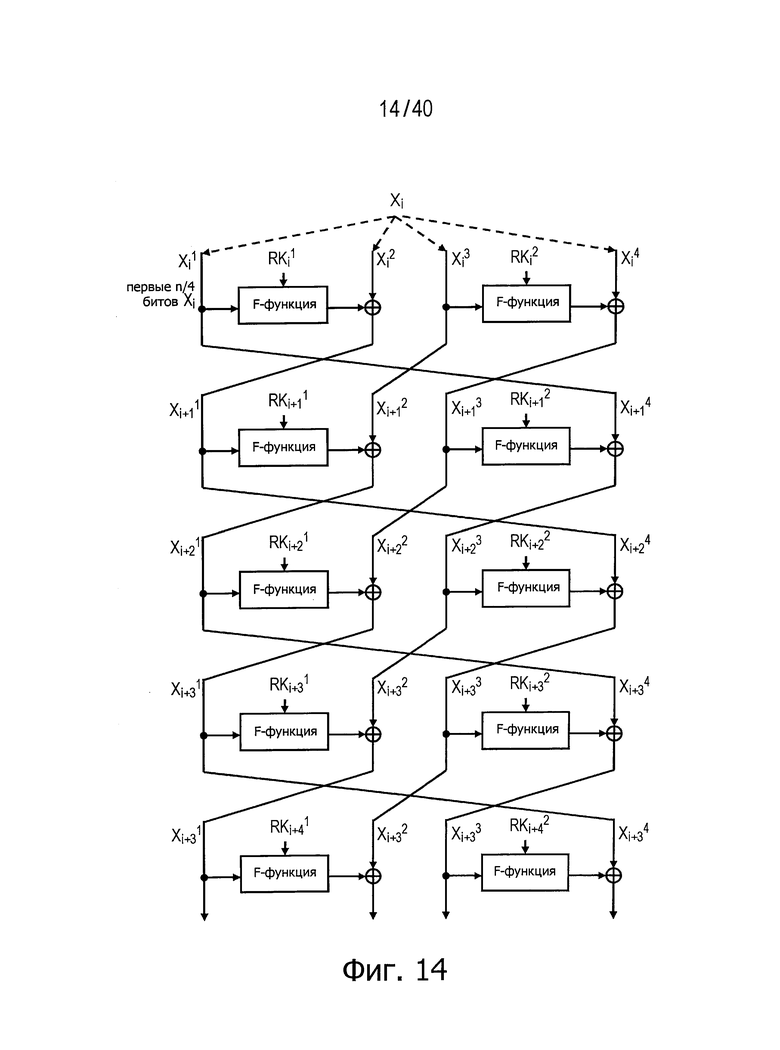
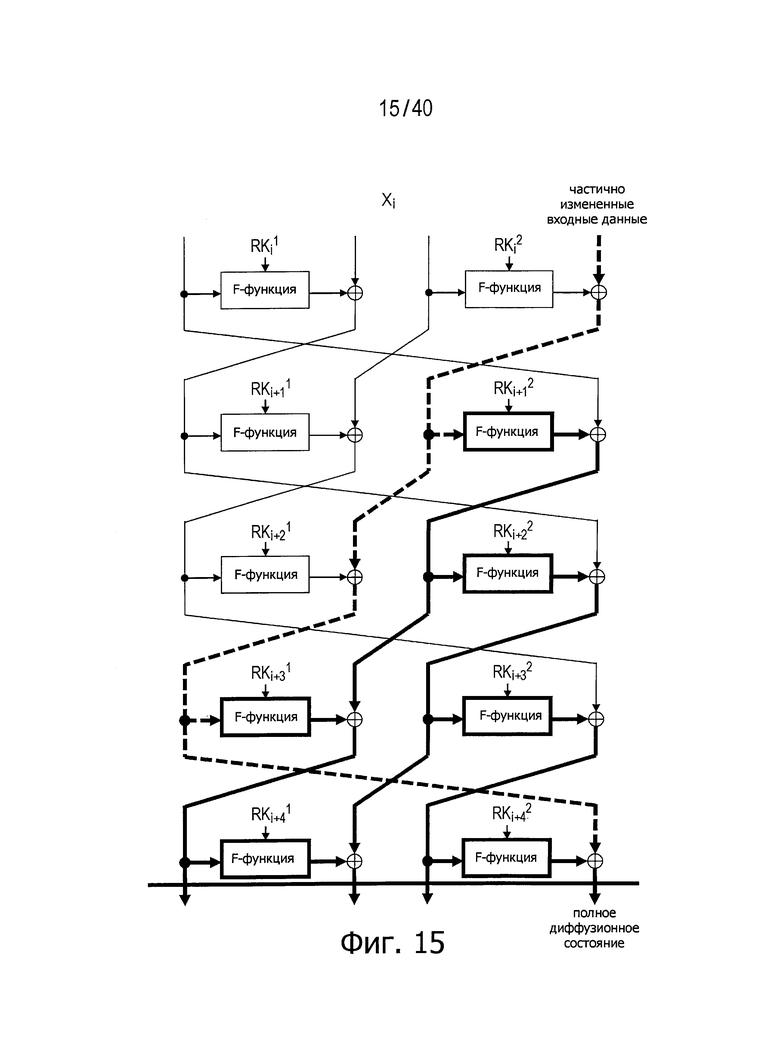
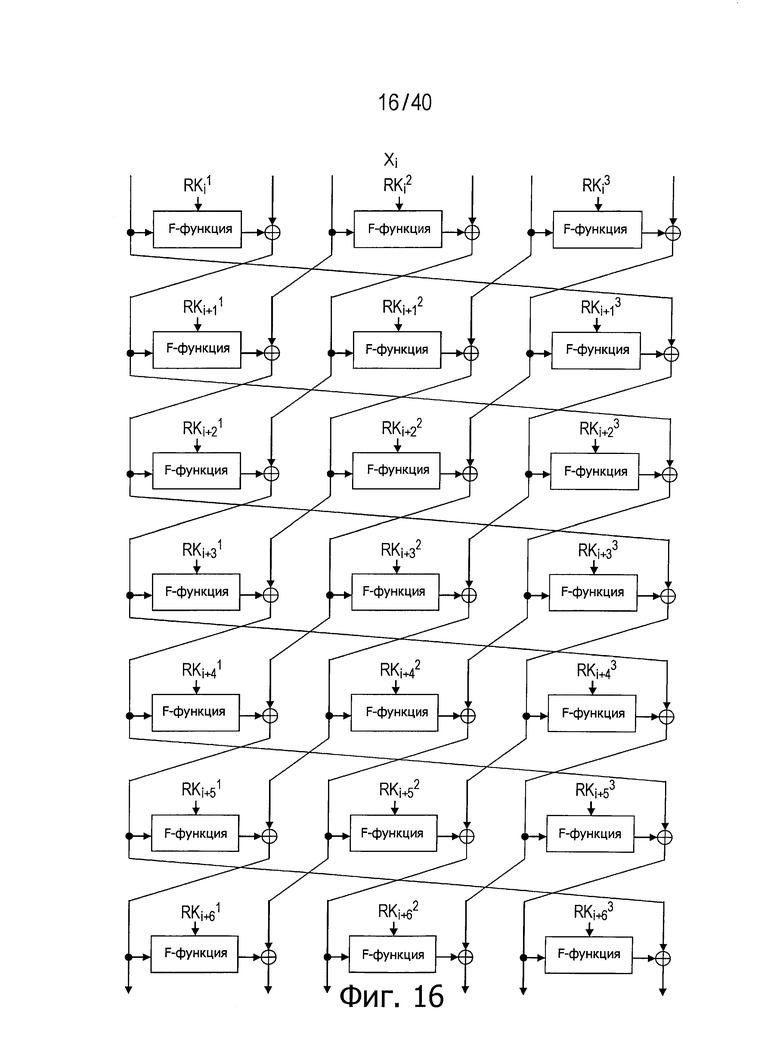
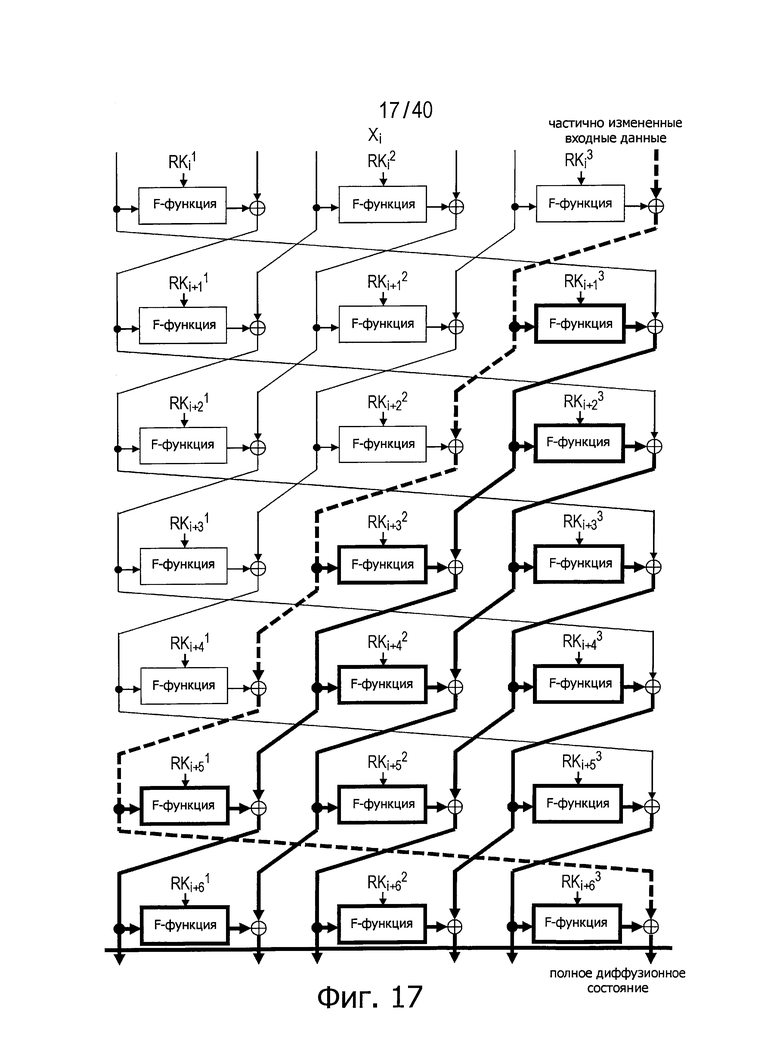
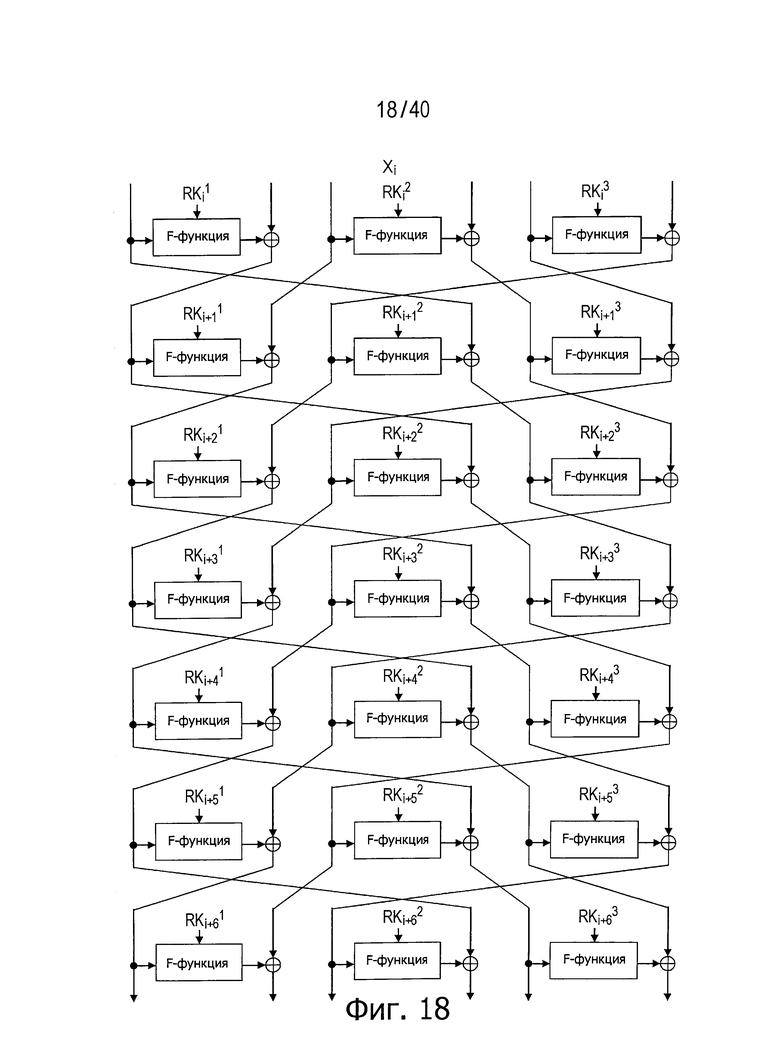
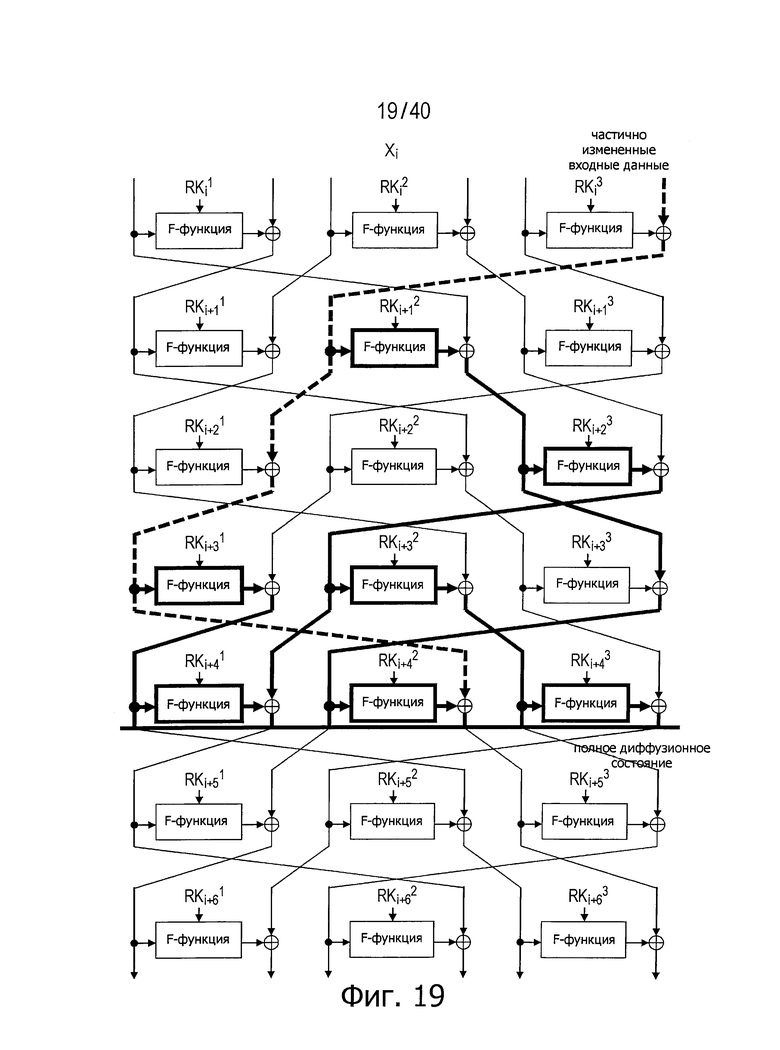
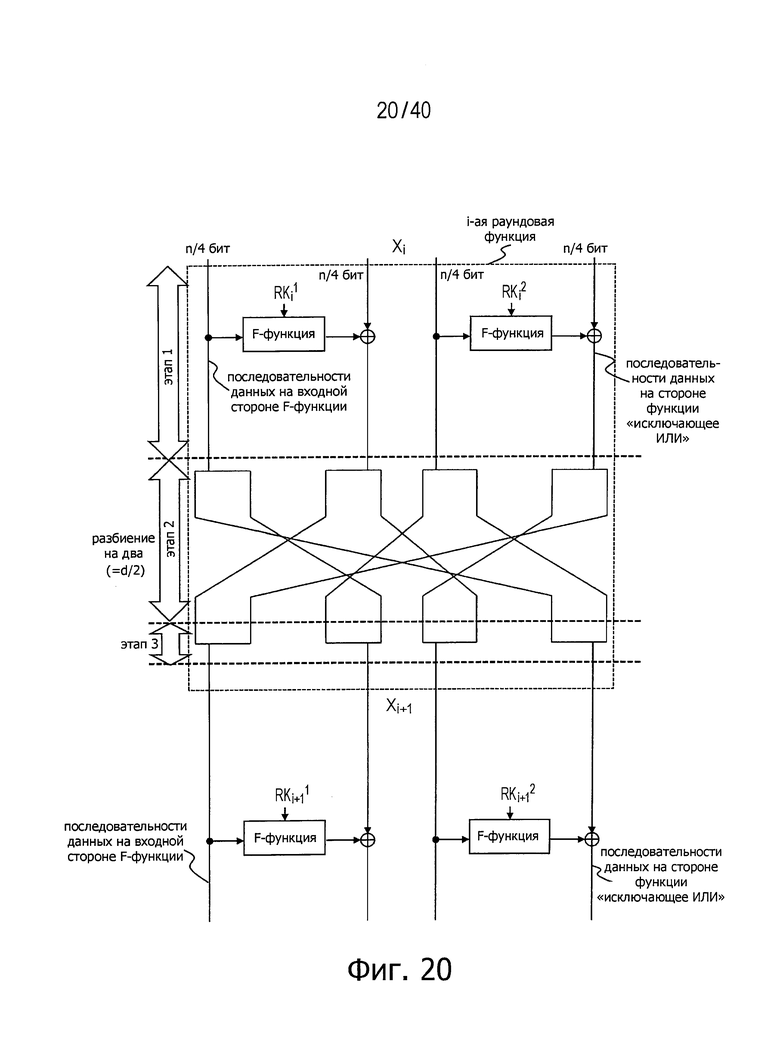
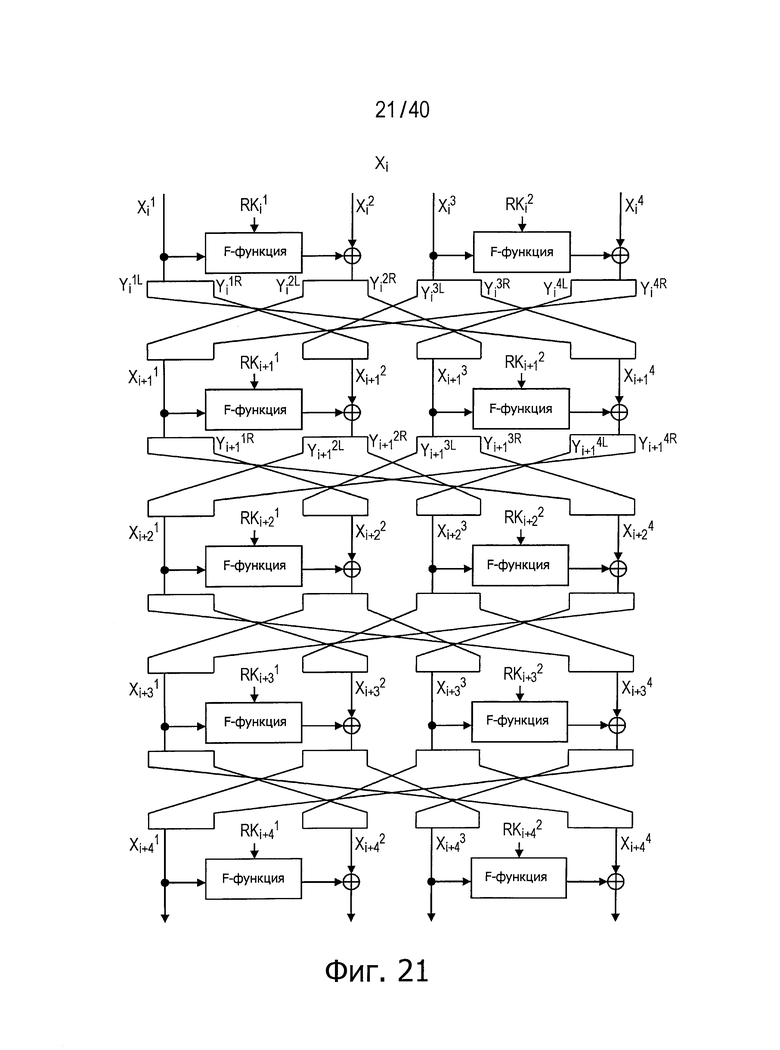
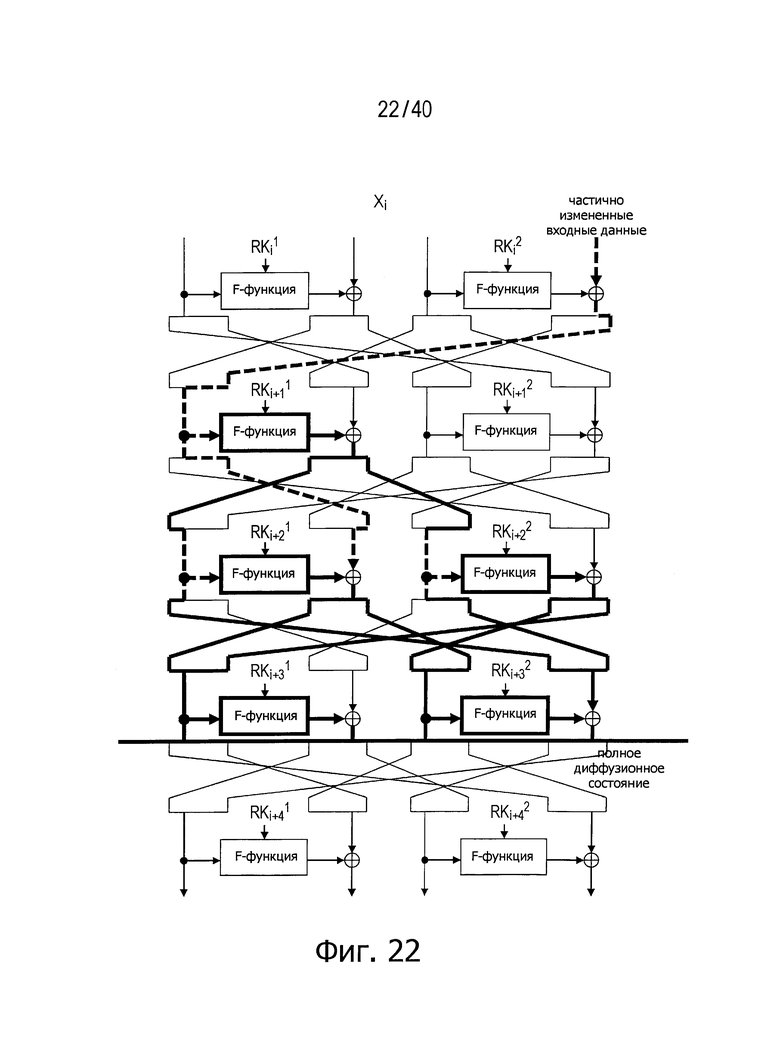
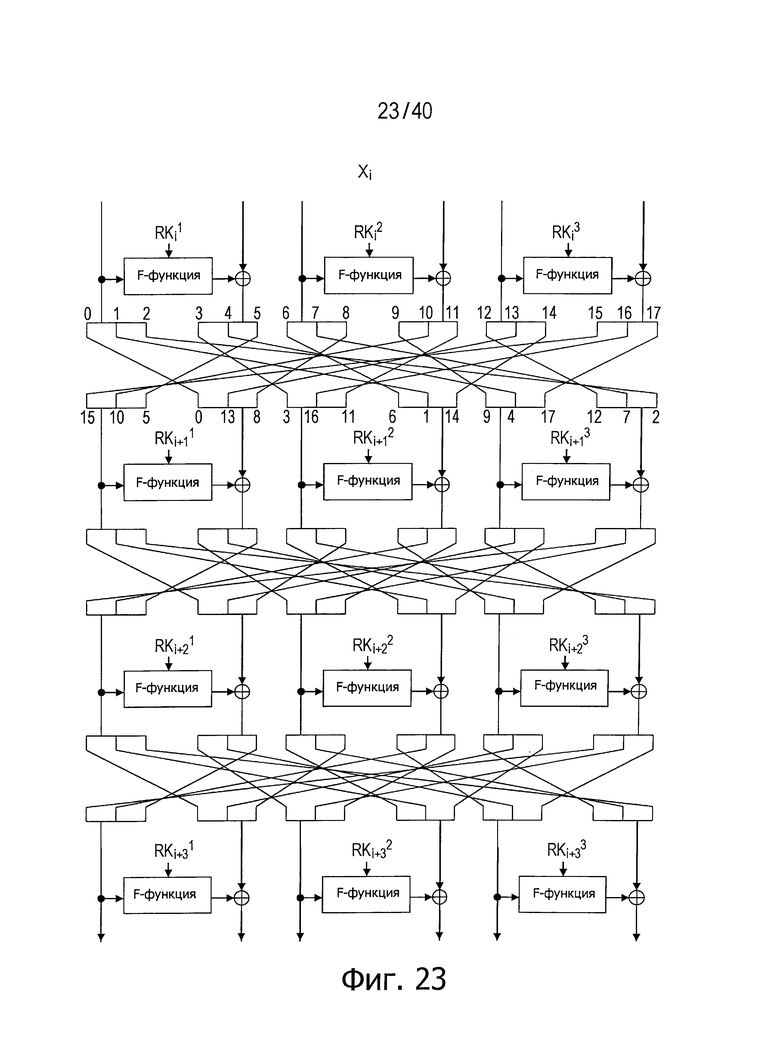
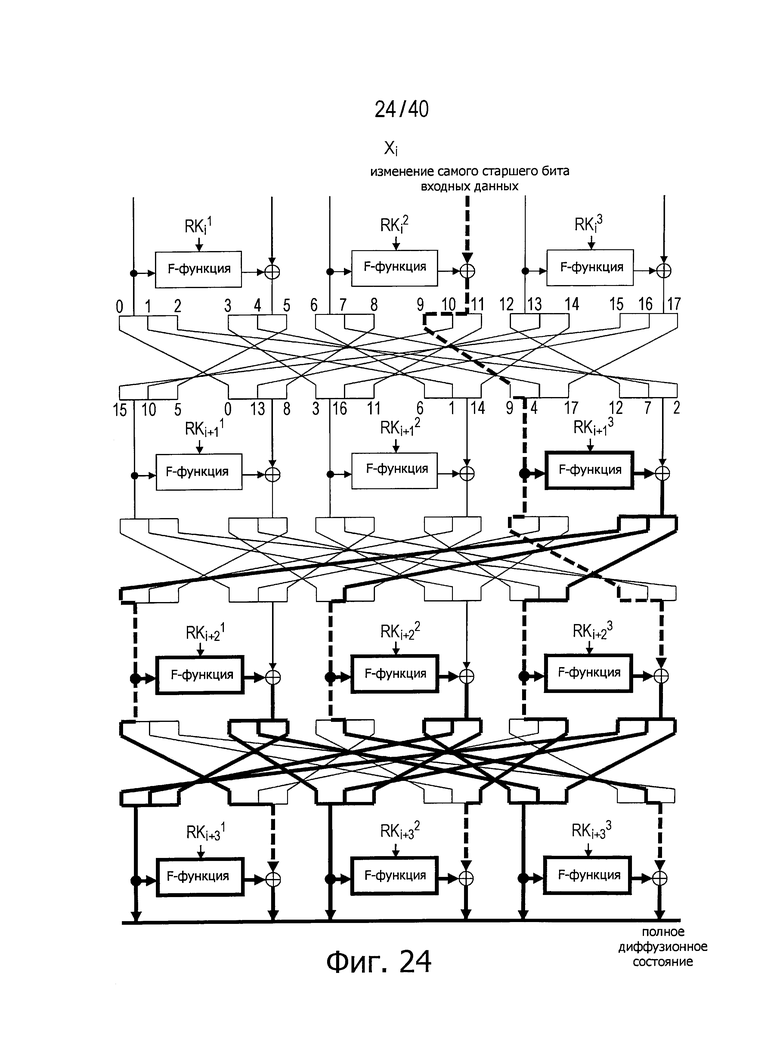
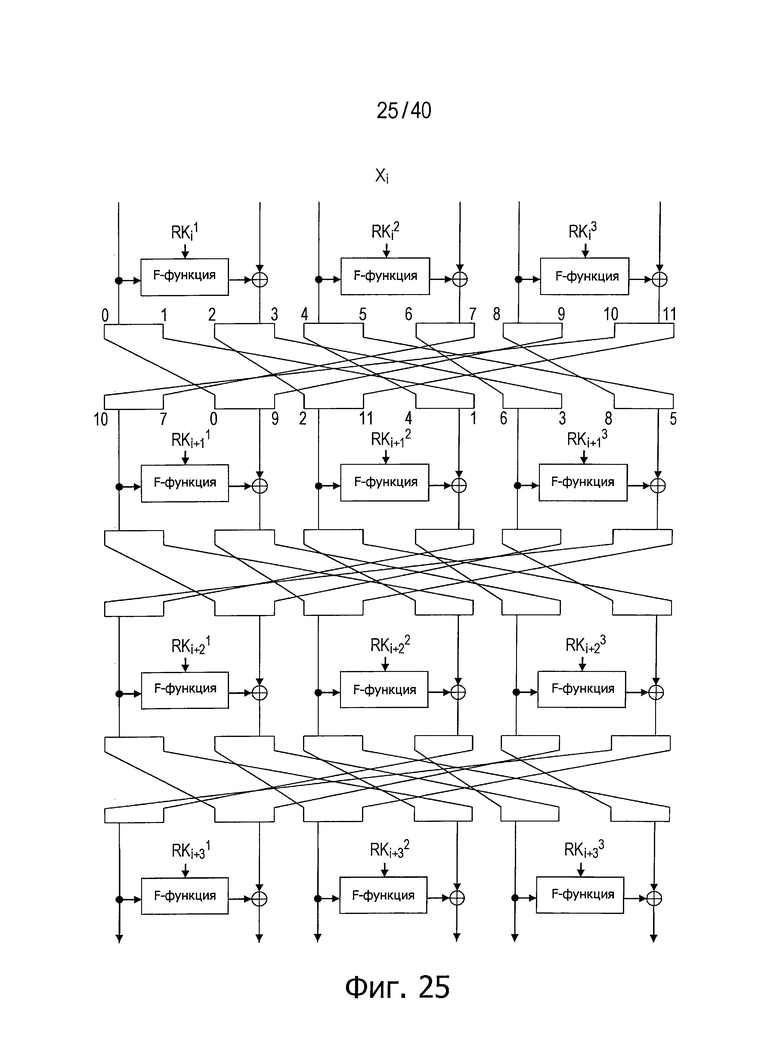
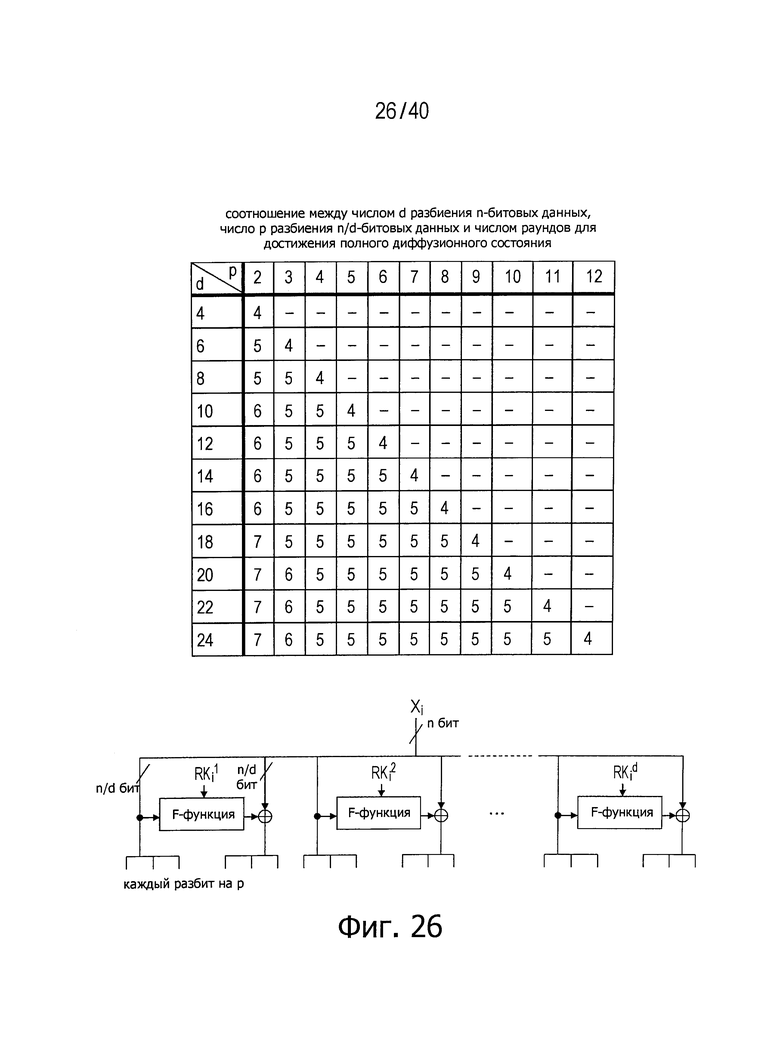
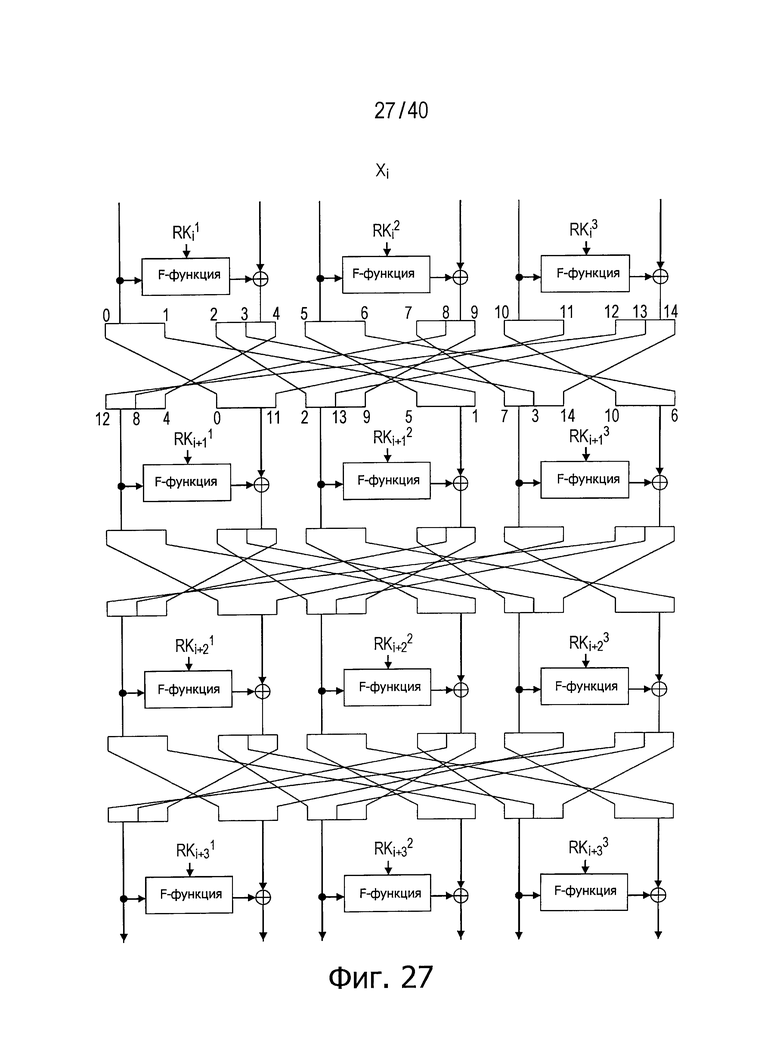
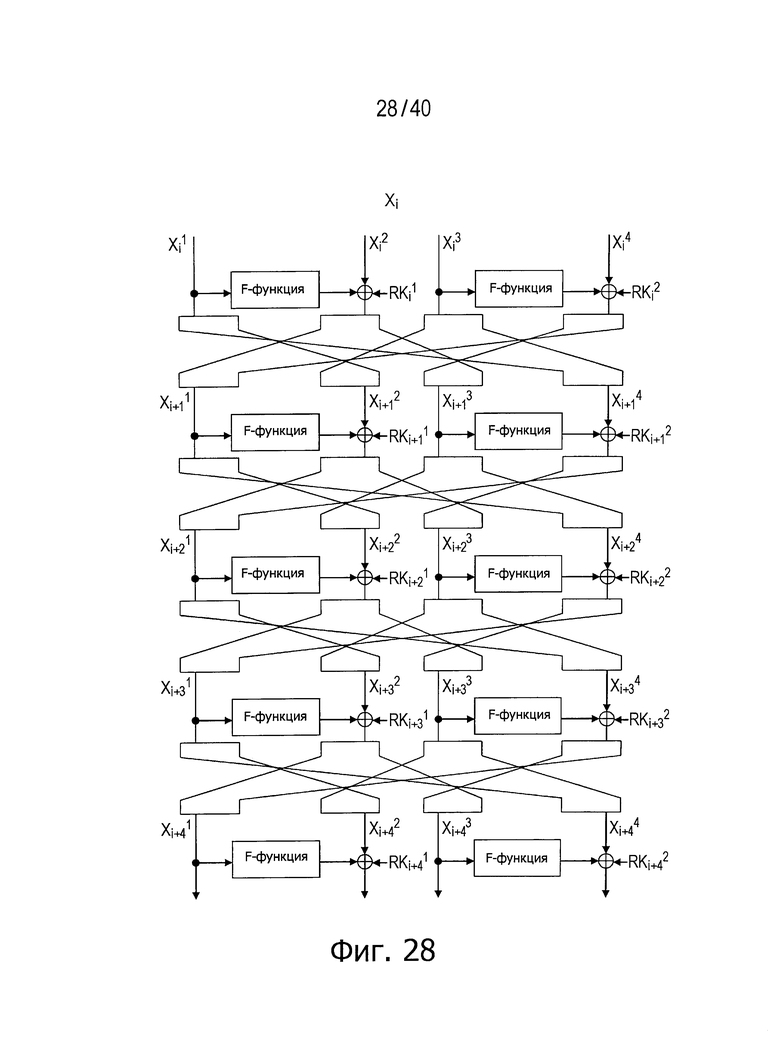
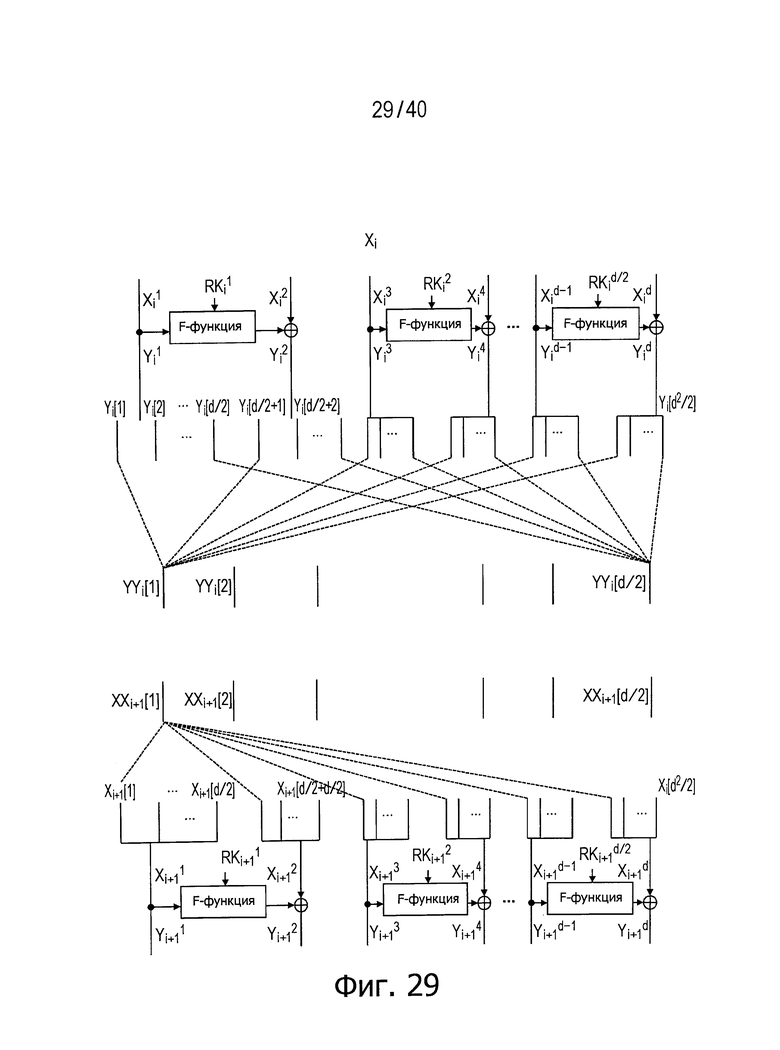
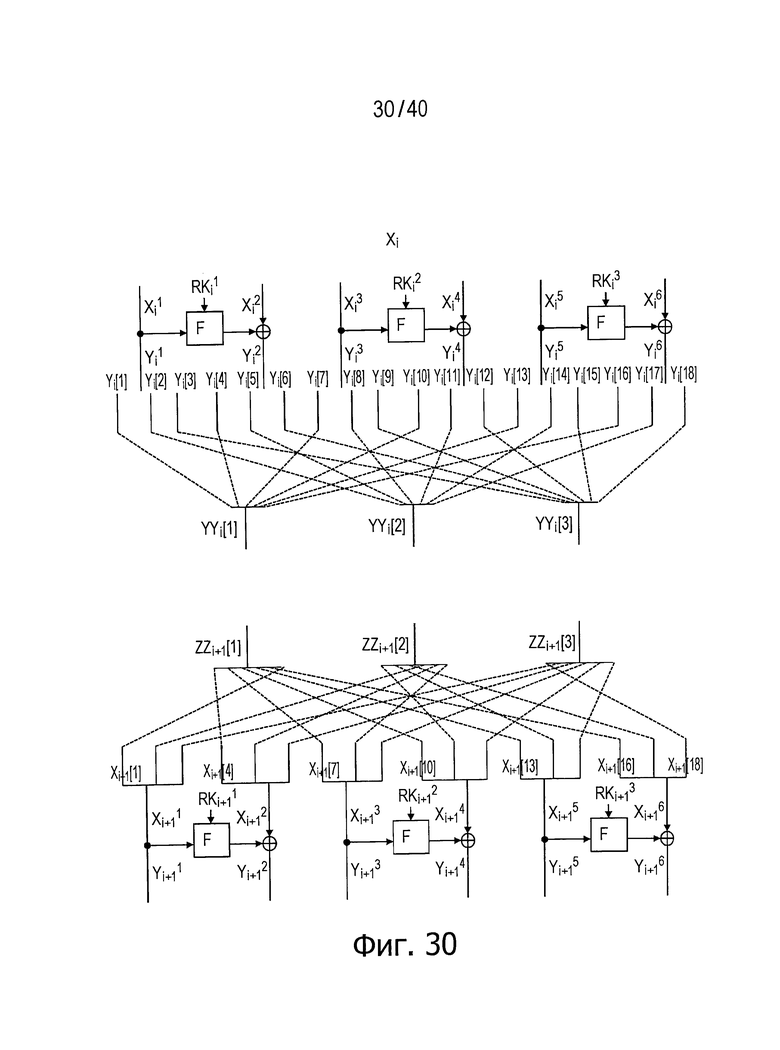
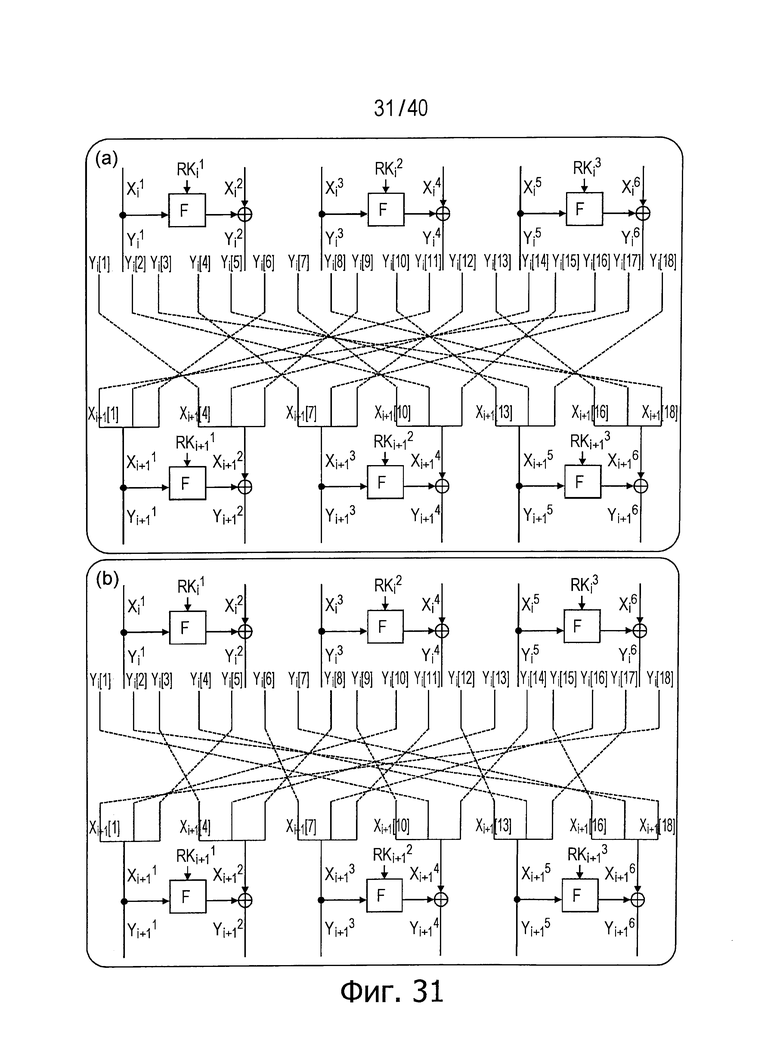

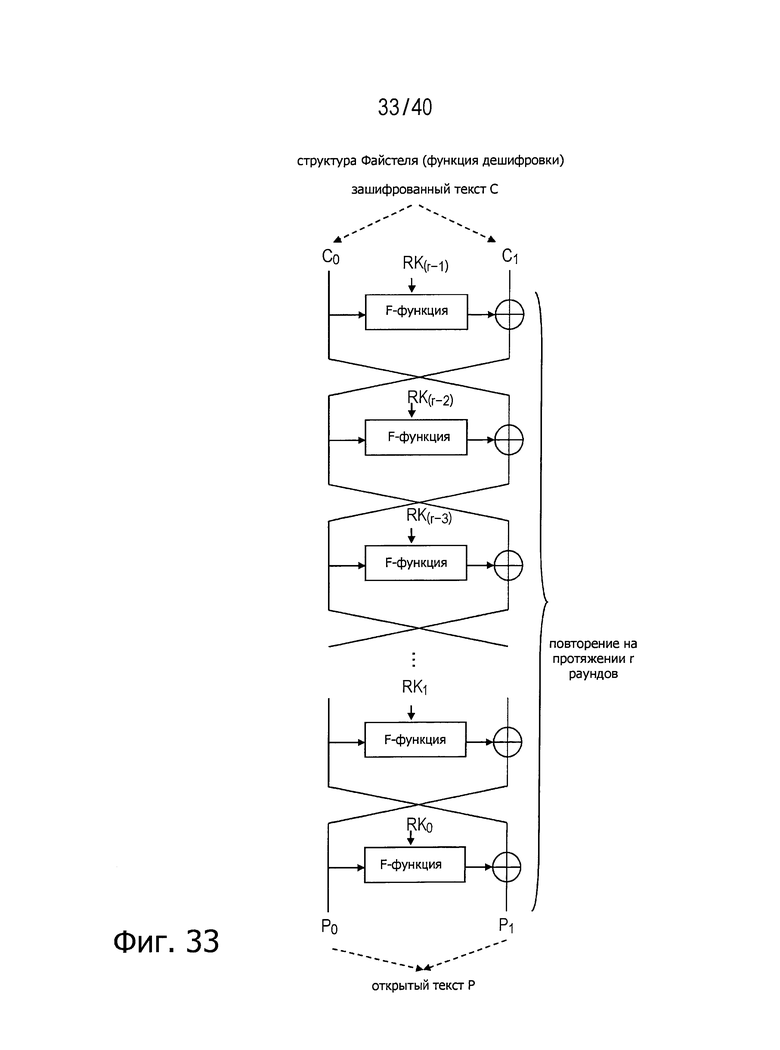

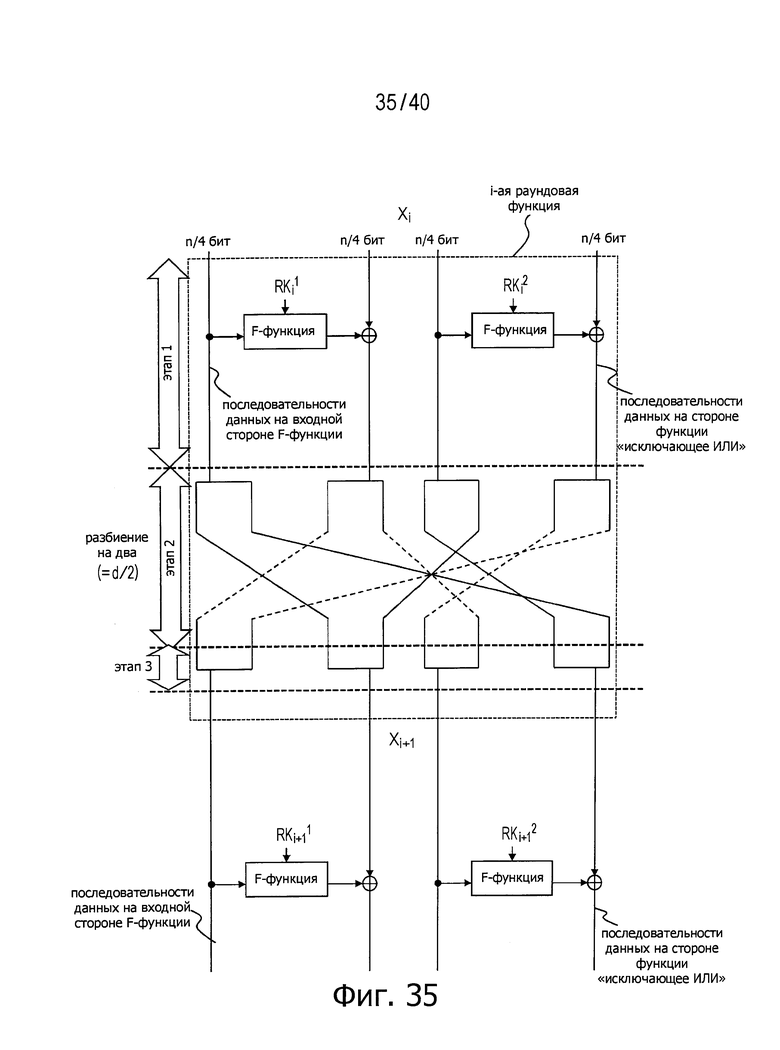
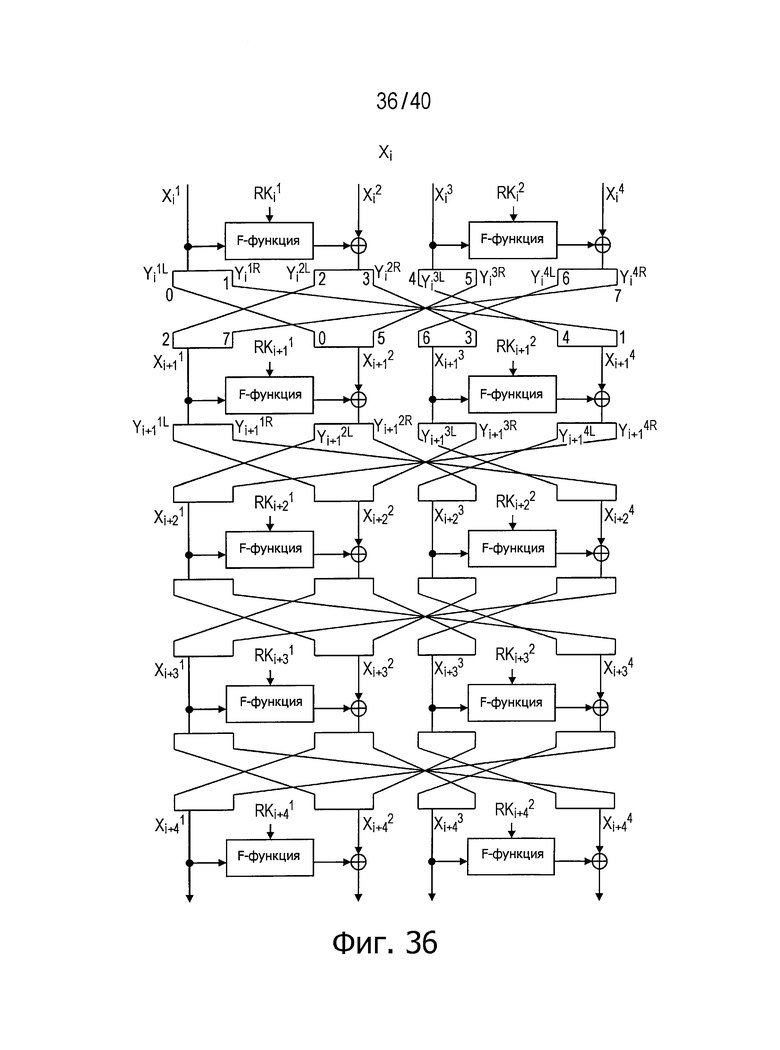
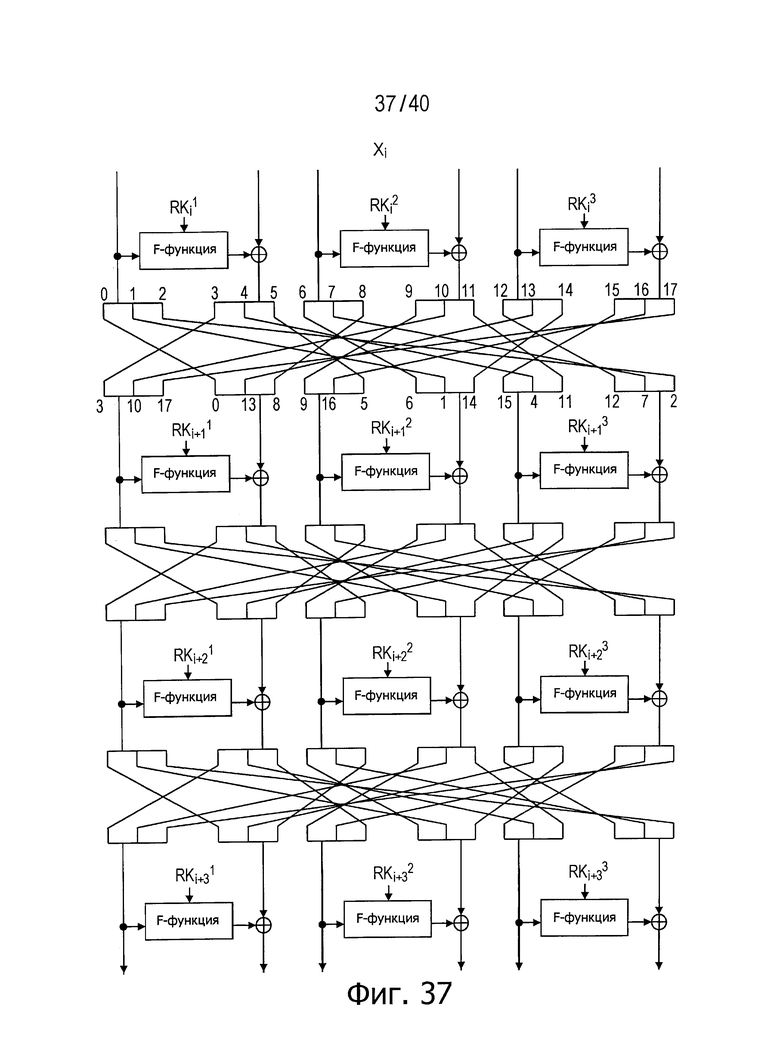
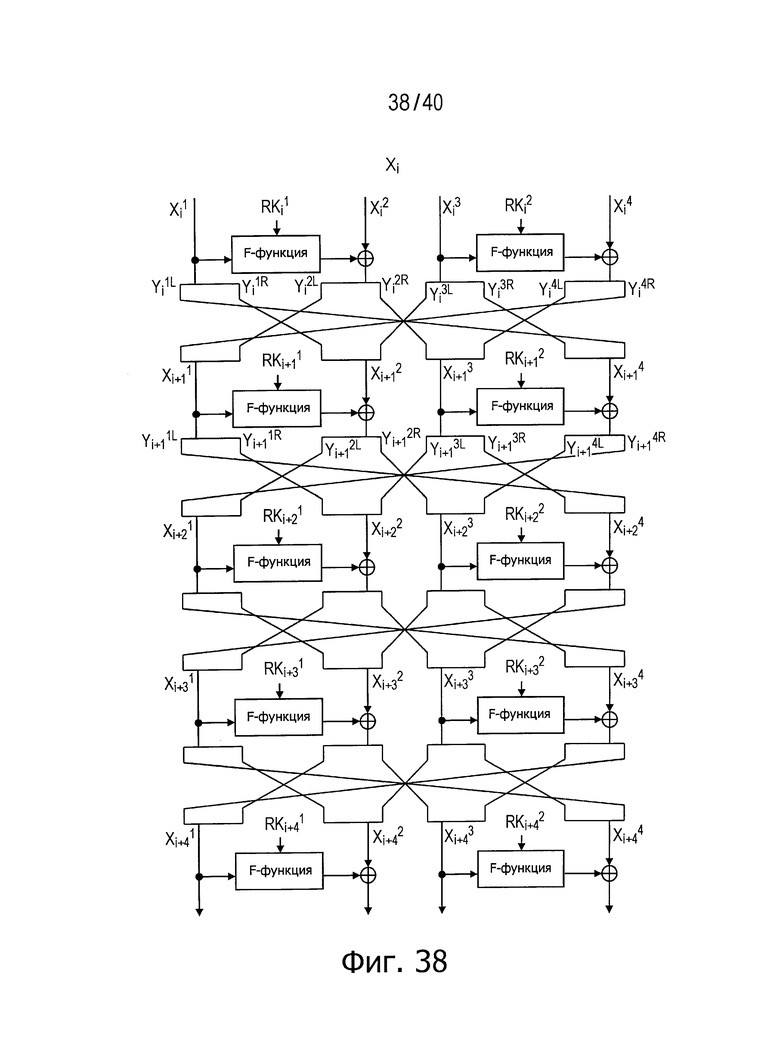
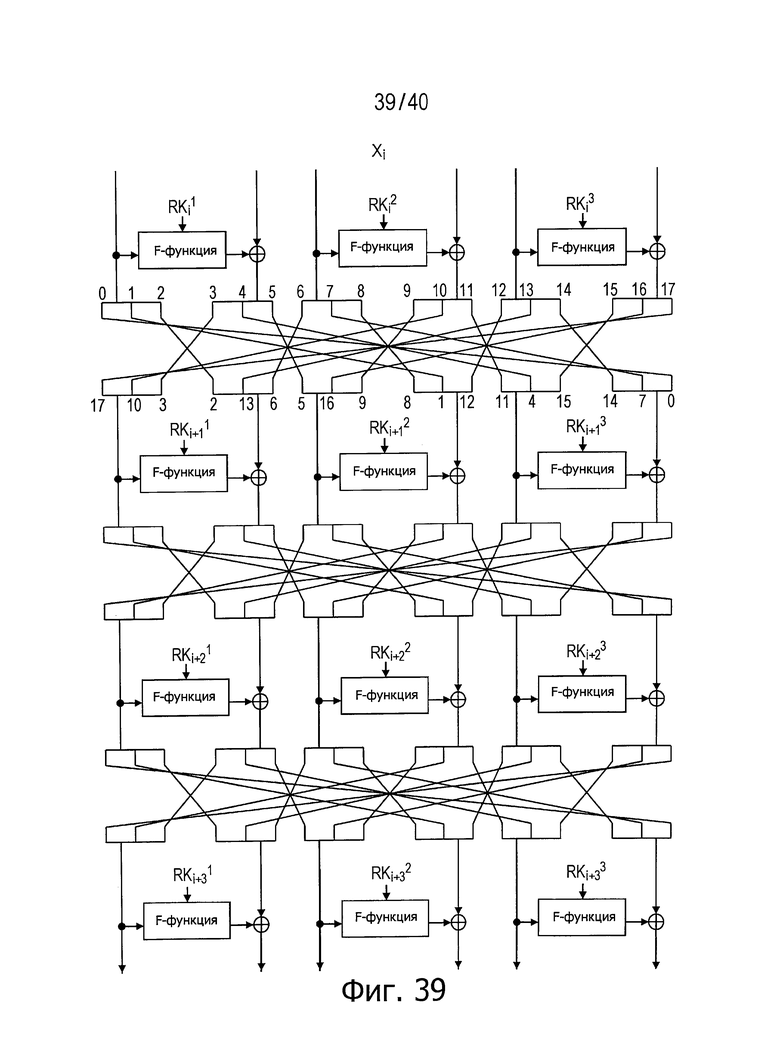
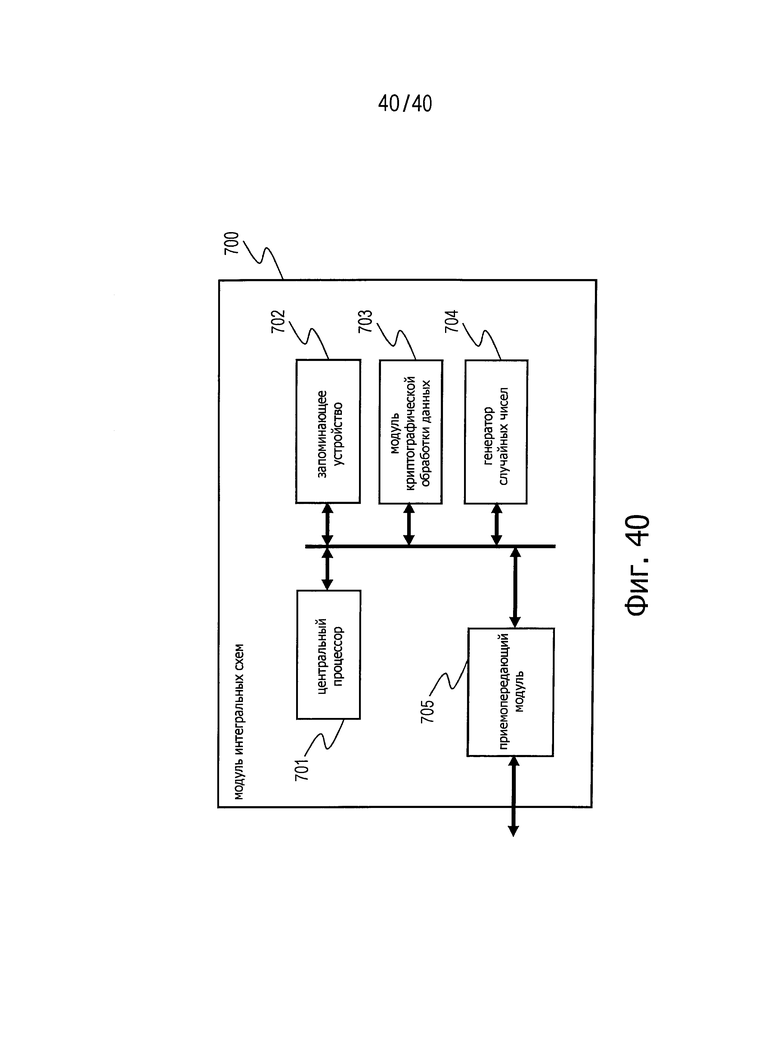
Изобретение относится к области криптографической обработки данных. Технический результат - обеспечение высокого уровня надежности и защиты данных. Реализована криптографическая обработка данных с улучшенными диффузионными свойствами и высоким уровнем защищенности. Модуль криптографической обработки данных разбивает и вводит составляющие биты данных, подлежащих обработке, в несколько линеек и многократно выполняет операцию преобразования данных применительно к данным в соответствующих линейках с использованием раундовой функции. Этот модуль криптографической обработки данных вводит n/d-битовые данные, полученные путем разбиения n-битовых данных в качестве входных данных согласно числу d разбиения, в каждую линейку и многократно выполняет раундовые вычисления, иными словами, вычисления, включающие операцию преобразования данных с использованием раундовых функций. Указанные n/d-битовые данные в каждой линейке, имеющей выходные данные раундовых вычислений, разбивают на сегменты d/2 данных и рекомбинируют разбитые данные для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных раундовых вычислений предыдущего этапа. Реконструированные данные задают в качестве входных данных для раундовых вычислений следующего этапа. 5 н. и 10 з.п. ф-лы, 40 ил.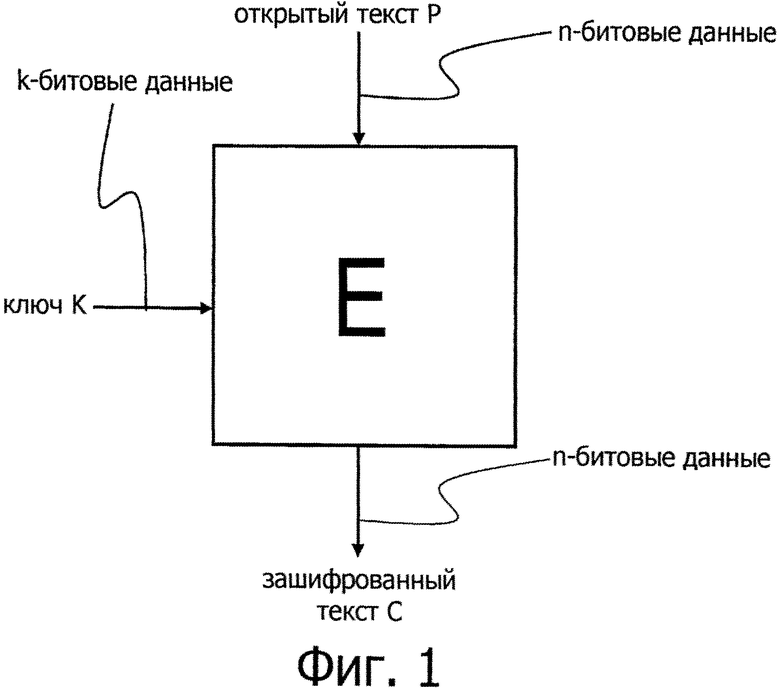
1. Устройство для криптографической обработки данных, содержащее:
модуль криптографической обработки данных, конфигурированный для разбиения и ввода составляющих битов данных, подлежащих обработке, в несколько линеек и многократного выполнения операции преобразования данных применительно к данным в соответствующих линейках с использованием раундовой функции,
отличающееся тем, что
модуль криптографической обработки данных имеет структуру, рассчитанную на ввод n/d-битовых данных, полученных путем разбиения n-битовых данных в качестве входных данных согласно числу d разбиения, в соответствующие линейки и многократного выполнения вычислений в качестве раундовых вычислений, включая операцию преобразования данных, с использованием раундовой функции,
этот модуль криптографической обработки данных осуществляет операцию, в ходе которой n/d-битовые данные в каждой линейке, имеющей выходные данные раундовых вычислений, повторно разбивают на сегменты d/2 данных, рекомбинируют повторно разбитые данные для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных раундовых вычислений предыдущего этапа, и задают реконструированные данные в качестве входных данных для раундовых вычислений для следующего этапа,
раундовая функция содержит F-функцию и операцию «исключающее ИЛИ» между выходными данными или входными данными F-функции с одной стороны и данными в другой линейке с другой стороны, и
модуль криптографической обработки данных задает результат раундовых вычислений предыдущего этапа в качестве входных данных для раундовых вычислений следующего этапа путем выполнения операции, удовлетворяющей следующим условиям распределения с (1) по (3):
(1) Последовательности данных на входной стороне F-функций распределяют в последовательности данных на стороне XOR (функции «исключающее ИЛИ») в составе следующей раундовой функции,
(2) Последовательности данных на стороне функции «исключающее ИЛИ» (XOR) распределяют в последовательности данных на входной стороне F-функций в составе следующей раундовой функции, и
(3) Каждую единицу из последовательности данных, разбитой на сегменты d/2, распределяют в последовательность d/2 данных следующей раундовой функции без наложений.
2. Устройство для криптографической обработки данных по п.1, отличающееся тем, что раундовая функция содержит F-функцию, включающую вычисления с использованием раундового ключа, нелинейную трансформацию и линейную трансформацию, и операцию «исключающее ИЛИ» между выходными данными или входными данными F-функции с одной стороны и данными в другой линейке с другой стороны.
3. Устройство для криптографической обработки данных по п.1, отличающееся тем, что модуль криптографической обработки данных имеет обобщенную структуру Файстеля с числом d разбиения входных данных, равным или больше 4.
4. Устройство для криптографической обработки данных по п.1, отличающееся тем, что модуль криптографической обработки данных выполняет операцию, в ходе которой генерируют d×(d/2) сегментов повторно разбитых данных путем повторного разбиения n/d-битовых данных в каждой из d линеек, имеющей выходные данные раундовых вычислений на сегменты d/2 данных, затем сегменты d/2 повторно разбитых данных, выбранных из разных линеек из совокупности d линеек, соответствующих числу d разбиения, рекомбинируют для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных раундовых вычислений предыдущего этапа, и далее реконструированные данные задают в качестве входных данных для раундовых вычислений следующего этапа.
5. Устройство для криптографической обработки данных по п.1, отличающееся тем, что, когда все выходные биты находятся в диффузионном состоянии, удовлетворяющем следующим двум условиям, или когда выходные биты связаны неким относительным выражением с входными битами, модуль криптографической обработки данных имеет структуру, реализующую полное диффузионное состояние, удовлетворяющее следующим двум условиям:
(Условие 1) все входные биты входят в указанное относительное выражение, и
(Условие 2) все входные биты прошли через раундовую функцию по меньшей мере однажды.
6. Устройство для криптографической обработки данных по п.5, отличающееся тем, что модуль криптографической обработки данных реализует полное диффузионное состояние за четыре раунда раундовых вычислений.
7. Устройство для криптографической обработки данных по п.1, отличающееся тем, что соединительная структура, определяющая соотношение вход-выход между выходными данными раундовых вычислений предыдущего этапа и повторно разбитыми данными раундовых вычислений следующего этапа, представляет собой соединительную структуру, выбранную из совокупности соединительных структур, имеющих (d/2) сегментов 2n/d-битовых данных в качестве единиц, являющихся данными, генерируемыми путем комбинирования d×(d/2) сегментов повторно разбитых данных, генерируемых посредством операции повторного разбиения, выполняемой применительно к n/d-битовым данным в линейках, имеющих выходные данные раундовых вычислений.
8. Устройство для криптографической обработки данных по п.1, отличающееся тем, что модуль криптографической обработки данных обладает инволюционными свойствами.
9. Устройство для криптографической обработки данных по п.8, отличающееся тем, что операция реконструкции повторно разбитых данных соответствующих раундовых вычислений в модуле криптографической обработки данных включает:
распределение повторно разбитых последовательностей данных на входной стороне раундовых функций предыдущего этапа в последовательности данных на стороне функции «исключающее ИЛИ» (XOR) следующего этапа согласно заданному правилу; и
распределение повторно разбитых последовательностей данных на стороне функции «исключающее ИЛИ» (XOR) предыдущего этапа в последовательности данных на входной стороне раундовых функций следующего этапа согласно заданному правилу.
10. Устройство для криптографической обработки данных по п.1, отличающееся тем, что модуль криптографической обработки данных выполняет
операцию шифрования для трансформации открытого текста в качестве входных данных в зашифрованный текст, или
операцию дешифровки для трансформации зашифрованного текста в качестве входных данных в открытый текст.
11. Способ криптографической обработки данных, реализованный в устройстве для криптографической обработки данных,
этот способ криптографической обработки данных содержит
этап криптографической обработки данных, на котором производятся разбиение и ввод составляющих битов данных, подлежащих обработке, в несколько линеек и многократное выполнение операции преобразования данных применительно к данным в соответствующих линейках с использованием раундовой функции,
отличающийся тем, что
этап криптографической обработки данных включает: ввод n/d-битовых данных, полученных путем разбиения n-битовых данных в качестве входных данных согласно числу d разбиения, в соответствующие линейки; и многократное выполнение вычислений в качестве раундовых вычислений, включая операцию преобразования данных, с использованием раундовой функции,
этот этап криптографической обработки данных осуществляет операцию, в ходе которой n/d-битовые данные в каждой линейке, имеющей выходные данные раундовых вычислений, повторно разбивают на сегменты d/2 данных, рекомбинируют повторно разбитые данные для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных раундовых вычислений предыдущего этапа, и задают реконструированные данные в качестве входных данных для раундовых вычислений для следующего этапа,
раундовая функция содержит F-функцию и операцию «исключающее ИЛИ» между выходными данными или входными данными F-функции с одной стороны и данными в другой линейке с другой стороны, и
этап криптографической обработки данных включает задание результата раундовых вычислений предыдущего этапа в качестве входных данных для раундовых вычислений следующего этапа путем выполнения операции, удовлетворяющей следующим условиям распределения с (1) по (3):
(1) Последовательности данных на входной стороне F-функций распределяют в последовательности данных на стороне XOR (функции «исключающее ИЛИ») в составе следующей раундовой функции,
(2) Последовательности данных на стороне функции «исключающее ИЛИ» (XOR) распределяют в последовательности данных на входной стороне F-функций в составе следующей раундовой функции, и
(3) Каждую единицу из последовательности данных, разбитой на сегменты d/2, распределяют в последовательность d/2 данных следующей раундовой функции без наложений.
12. Носитель записи, содержащий записанную на нем программу, в соответствии с которой устройство для криптографической обработки данных осуществляет криптографическую обработку данных,
в соответствии с этой программой модуль криптографической обработки данных выполняет
этап криптографической обработки данных, на котором производятся разбиение и ввод составляющих битов данных, подлежащих обработке, в несколько линеек и многократное выполнение операции преобразования данных применительно к данным в соответствующих линейках с использованием раундовой функции,
отличающийся тем, что
этап криптографической обработки данных включает:
ввод n/d-битовых данных, полученных путем разбиения n-битовых данных в качестве входных данных согласно числу d разбиения, в соответствующие линейки; и многократное выполнение вычислений в качестве раундовых вычислений, включая операцию преобразования данных, с использованием раундовой функции,
этот этап криптографической обработки данных осуществляет операцию, в ходе которой n/d-битовые данные в каждой линейке, имеющей выходные данные раундовых вычислений, повторно разбивают на сегменты d/2 данных, рекомбинируют повторно разбитые данные для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных раундовых вычислений предыдущего этапа, и задают реконструированные данные в качестве входных данных для раундовых вычислений для следующего этапа,
раундовая функция содержит F-функцию и операцию «исключающее ИЛИ» между выходными данными или входными данными F-функции с одной стороны и данными в другой линейке с другой стороны, и
этап криптографической обработки данных включает задание результата раундовых вычислений предыдущего этапа в качестве входных данных для раундовых вычислений следующего этапа путем выполнения операции, удовлетворяющей следующим условиям распределения с (1) по (3):
(1) Последовательности данных на входной стороне F-функций распределяют в последовательности данных на стороне XOR (функции «исключающее ИЛИ») в составе следующей раундовой функции,
(2) Последовательности данных на стороне функции «исключающее ИЛИ» (XOR) распределяют в последовательности данных на входной стороне F-функций в составе следующей раундовой функции, и
(3) Каждую единицу из последовательности данных, разбитой на сегменты d/2, распределяют в последовательность d/2 данных следующей раундовой функции без наложений.
13. Устройство для криптографической обработки данных, содержащее:
модуль криптографической обработки данных, конфигурированный для разбиения и ввода составляющих битов данных, подлежащих обработке, в несколько линеек и многократного выполнения операции преобразования данных применительно к данным в соответствующих линейках с использованием раундовой функции,
отличающееся тем, что
модуль криптографической обработки данных имеет структуру, рассчитанную на ввод n/d-битовых данных, полученных путем разбиения n-битовых данных в качестве входных данных согласно числу d разбиения, в соответствующие линейки и многократного выполнения вычислений в качестве раундовых вычислений, включая операцию преобразования данных, с использованием раундовой функции,
этот модуль криптографической обработки данных осуществляет операцию, в ходе которой n/d-битовые данные в каждой линейке, имеющей выходные данные раундовых вычислений, повторно разбивают на сегменты d/2 данных, рекомбинируют повторно разбитые данные для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных раундовых вычислений предыдущего этапа, и задают реконструированные данные в качестве входных данных для раундовых вычислений для следующего этапа, и
модуль криптографической обработки данных выполняет операцию, в ходе которой генерируют d×(d/2) сегментов повторно разбитых данных путем повторного разбиения n/d-битовых данных в каждой из d линеек, имеющей выходные данные раундовых вычислений на сегменты d/2 данных, затем сегменты d/2 повторно разбитых данных, выбранных из разных линеек из совокупности d линеек, соответствующих числу d разбиения, рекомбинируют для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных раундовых вычислений предыдущего этапа, и далее реконструированные данные задают в качестве входных данных для раундовых вычислений следующего этапа.
14. Устройство для криптографической обработки данных по п.13, отличающееся тем, что:
раундовая функция содержит F-функцию и операцию «исключающее ИЛИ» между выходными данными или входными данными F-функции с одной стороны и данными в другой линейке с другой стороны, и
модуль криптографической обработки данных задает результат раундовых вычислений предыдущего этапа в качестве входных данных для раундовых вычислений следующего этапа путем выполнения операции, удовлетворяющей следующим условиям распределения с (1) по (3):
(1) Последовательности данных на входной стороне F-функций распределяют в последовательности данных на стороне XOR (функции «исключающее ИЛИ») в составе следующей раундовой функции,
(2) Последовательности данных на стороне функции «исключающее ИЛИ» (XOR) распределяют в последовательности данных на входной стороне F-функций в составе следующей раундовой функции, и
(3) Каждую единицу из последовательности данных, разбитой на сегменты d/2, распределяют в последовательность d/2 данных следующей раундовой функции без наложений.
15. Устройство для обработки информации, содержащее:
процессор, конфигурированный для выполнения программ;
запоминающее устройство для сохранения программ; и
модуль криптографической обработки данных, конфигурированный для разбиения и ввода составляющих битов данных, подлежащих обработке, в несколько линеек и многократного выполнения операции преобразования данных применительно к данным в соответствующих линейках с использованием раундовой функции,
отличающееся тем, что
модуль криптографической обработки данных имеет структуру, рассчитанную на ввод n/d-битовых данных, полученных путем разбиения n-битовых данных в качестве входных данных согласно числу d разбиения, в соответствующие линейки и многократного выполнения вычислений в качестве раундовых вычислений, включая операцию преобразования данных, с использованием раундовой функции,
этот модуль криптографической обработки данных осуществляет операцию, в ходе которой n/d-битовые данные в каждой линейке, имеющей выходные данные раундовых вычислений, повторно разбивают на сегменты d/2 данных, рекомбинируют повторно разбитые данные для реконструкции d сегментов n/d-битовых данных, отличных от выходных данных раундовых вычислений предыдущего этапа, и задают реконструированные данные в качестве входных данных для раундовых вычислений для следующего этапа.
раундовая функция содержит F-функцию и операцию «исключающее ИЛИ» между выходными данными или входными данными F-функции с одной стороны и данными в другой линейке с другой стороны, и
модуль криптографической обработки данных задает результат раундовых вычислений предыдущего этапа в качестве входных данных для раундовых вычислений следующего этапа путем выполнения операции, удовлетворяющей следующим условиям распределения с (1) по (3):
(1) Последовательности данных на входной стороне F-функций распределяют в последовательности данных на стороне XOR (функции «исключающее ИЛИ») в составе следующей раундовой функции,
(2) Последовательности данных на стороне функции «исключающее ИЛИ» (XOR) распределяют в последовательности данных на входной стороне F-функций в составе следующей раундовой функции, и
(3) Каждую единицу из последовательности данных, разбитой на сегменты d/2, распределяют в последовательность d/2 данных следующей раундовой функции без наложений.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |

