ПРЕДПОСЫЛКИ
Известно, что на образце для определения его типа может выполняться спектральный анализ. Например, спектральный анализ неизвестного исследуемого образца может включать определение одного или нескольких значений пиковых длин волн. Тщательное сопоставление пиковых длин волн неизвестного образца с сигнатурой пиков известного стандартного образца может указывать, вероятно ли то, что неизвестный образец представляет собой такое же вещество, как и стандартный образец.
В современных многоканальных приборах справочная база данных, которая предназначена для поиска и сопоставления неизвестного образца с известным образцом, может потребовать значительного объема ресурсов для обработки и хранения данных. Например, не является редкостью получение для каждого измерения неизвестного образца спектрального анализа, включающего непрерывный спектр из тысячи или большего количества точек данных.
Более того, в традиционных применениях спектрального поиска не является редкостью то, что справочная база данных включает более 10000 наборов спектральной информации; по одному набору спектральной информации на каждый стандартный образец.
Каждый набор спектральной информации для соответствующего стандартного образца может состоять из тысячи или большего количества точек данных, определяющих пики, впадины и т.д. Сопоставление спектральной информации (например, тысячи или большего количества точек данных) в неизвестном образце с соответствующим одним или несколькими из 10000 наборов спектральной информации (например, из тысячи или большего количества точек данных) может быть вычислительно сложным. Например, если не предпринять меры по использованию вычислительно эффективной методологии поиска, при выполнении поиска неизвестного спектра из 2000 точек в библиотеке из 10000 стандартных спектров (каждый из которых содержит 2000 каналов информации), придется выполнить 20000000 или большее количество операций (поточечных сравнений).
Одним из подходов к тому, чтобы сделать методологию поиска более эффективной, является сжатие спектральных данных перед анализом в двоичный формат. Согласно традиционной спектроскопии, один из предшествующих подходов к преобразованию спектра в двоичную форму заключается в создании оценки в отношении присутствия или отсутствия пика. При сравнении двух спектров, таких, как спектр А и спектр В, одним из подходов является просмотр таблицы пиков для спектра А и присвоение значения 1 любому положению, где спектр В также содержит характерный признак в пределах n волновых чисел (или других подходящих единиц, например, пикселей, m/z и т.д.) этого пика. Любому положению таблицы пиков для спектра А, где спектр В не содержит пик, присваивается нулевое значение. Этот подход был описан Clerc и др. в 1980-х гг.
И хотя этот традиционный подход обеспечивает общее упорядочение подобия, он не представляет какой-либо вероятностной интерпретации. Также следует отметить (и это было отмечено Clerc) то, что согласно этому традиционному подходу, оценки кандидатов на совпадение зависят от направления поиска (результаты являются несимметричными). Например, предположим, что спектр А содержит 10 пиков, спектр В содержит 12 пиков, и обнаружено, что 8 пиков являются общими. Поскольку соответствующие оценки являются нормированными на основе количества присутствующих пиков, то могут генерироваться значения 8/10 или 8/12.
КРАТКОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Как обсуждалось выше, традиционные методики сопоставления неизвестного образца с известным стандартным образцом в базе данных на основе спектрального анализа могут быть сложными из-за количества точек данных, которые требуется сравнить для того, чтобы точно определить истинное совпадение. Во многих случаях, нежелательной является потребность в длительных вычислениях для определения одного или нескольких стандартных значений, которые соответствуют неизвестному образцу для определения его типа.
Кроме того, традиционные методики спектрального сопоставления, как правило, не подходят для быстрого определения совпадений, поскольку такие методики обеспечивают только перечень, указывающий, какое из множества возможных стандартных значений соответствует неизвестному образцу. Традиционный упорядоченный список кандидатов может вводить в заблуждение. Например, согласно традиционным спискам, неизвестно, является ли первый стандартный образец-кандидат (т.е. первый известный образец) в списке более вероятным как являющийся совпадением с исследуемым образцом, чем второй стандартный образец-кандидат (т.е. второй известный образец) в списке. Иными словами, традиционные методики, как правило, не предусматривают какую-либо полезную вероятностную информацию, указывающую, какие из нескольких кандидатов в списке являются более вероятными как являющиеся истинными совпадениями с неизвестным исследуемым образцом.
В отличие от традиционных методик, варианты осуществления настоящего раскрытия, в общем, включают преобразование информации обработки спектральных данных, связанной с одним или несколькими стандартными образцами, в более компактную форму. Кроме того, варианты осуществления настоящего изобретения включают вычислительно эффективную методологию поиска по спектральной библиотеке. Например, по меньшей мере, частично на основе уникального способа управления информацией в спектральной библиотеке (например, сжатия данных), для выполнения спектрального поиска с целью определения поддающегося управлению подмножества стандартных образцов, которые более вероятно соответствуют неизвестному образцу, необходимо меньшее количество математических операций. Следует отметить, что обработка данных, обсуждаемая в настоящем раскрытии, хорошо подходит для использования в спектроскопических применениях любого типа, где ключ к определению неизвестного исследуемого образца предоставляется спектральными пиками.
В частности, согласно одному из вариантов осуществления изобретения, приложение обработки данных принимает информацию, определяющую соответствующие спектральные данные каждого стандартного образца из множества стандартных образцов в библиотеке. Приложение обработки данных (например, процессор спектральных данных) разбивает спектр таким образом, чтобы разбиение включало множество интервалов разной ширины, в дальнейшем именуемых в настоящем документе интервалами диапазона. Спектр можно разбить так, чтобы каждый из пиков от множества стандартных образцов принадлежал одному или нескольким из множества интервалов диапазона разного размера.
В одном из вариантов осуществления изобретения, разбиение спектра на множество интервалов диапазона разного размера включает установление значений ширины и/или границ каждого из множества интервалов диапазона разного размера так, чтобы в каждый из множества интервалов диапазона разного размера попадало равное количество пиков, связанных со стандартными образцами. Для определения кандидатов на совпадение со стандартным образцом, приложение обработки данных, в общем, сравнивает, отображает, индексирует и т.д. пики, связанные с неизвестным образцом в множестве интервалов диапазона разного размера. Совпадение пиков в неизвестном исследуемом образце с одним или несколькими интервалами диапазона позволяет анализатору определять стандартные образцы, которые являются кандидатами на то, чтобы являться хорошим совпадением с неизвестным исследуемым образцом. Иными словами, чем больше количество общих интервалов диапазона совместно используется неизвестным исследуемым образцом и соответствующим стандартным образцом, тем более вероятно то, что неизвестный исследуемый образец совпадает с соответствующим стандартным образцом.
Следует отметить, что, согласно одному из вариантов осуществления изобретения, методики, обсуждаемые в настоящем раскрытии, могут включать анализ и/или сравнение неизвестного образца со всеми возможными стандартными образцами в банке данных. Для каждого из одного или нескольких стандартных образцов в банке данных, варианты осуществления изобретения настоящего раскрытия могут также включать генерирование соответствующего р-значения (например, вероятностной информации) для каждого из какого-либо или всех стандартных образцов. Как обсуждается в настоящем раскрытии, дальнейший анализ вероятностной информации делает возможным определение хороших или наилучших возможных совпадений неизвестного образца со стандартным образцом.
В связи с другим вариантом осуществления изобретения, для каждого соответствующего стандартного образца, определенного как являющегося кандидатом на совпадение, приложение обработки данных, как обсуждается в настоящем раскрытии, генерирует вероятностную информацию. Вероятностная информация может указывать такую информацию, как степень, в которой соответствующий стандартный образец-кандидат относительно близко совпадает с неизвестным исследуемым образцом. Таким образом, варианты осуществления настоящего раскрытия могут включать многоэтапный процесс, в котором определяются потенциальные кандидаты, а затем на наборе кандидатов может выполняться дальнейший анализ с целью определения вероятных совпадений.
Некоторые варианты осуществления настоящего раскрытия включают выработку вероятностной информации, по меньшей мере, частично на основе двоичных арифметических операций с фиксированной запятой.
Согласно дальнейшим вариантам осуществления изобретения, если соответствующий стандартный образец-кандидат с довольно большой вероятностью является совпадением с неизвестным исследуемым образцом, для определения того, какой из стандартных образцов-кандидатов является наилучшим совпадением с неизвестным исследуемым образцом, может выполняться дальнейшая обработка.
Сравнение пиков между неизвестным образцом и соответствующим стандартным образцом может включать определение подмножества множества стандартных образцов, которые являются кандидатами на совпадения с неизвестным образцом, на основе индексации пиков, связанных с неизвестным образцом, в нескольких интервалах диапазона разного размера. Обсуждаемая в настоящем раскрытии индексация может включать любой из примеров методик определения того, какому из множества интервалов диапазона принадлежат пики неизвестного образца.
В качестве дальнейшего неограничивающего примера, разбиение спектра таким образом, чтобы оно включало интервалы диапазона разного размера, может включать выбор границ интервалов диапазона разного размера в соответствии с моделью гипергеометрического распределения.
Выполнение поиска и/или генерирования вероятностной информации может включать реализацию функции гипергеометрической вероятности, предназначенной для генерирования вероятностной информации, указывающей совпадает ли, или в какой степени совпадает, неизвестный образец с соответствующим стандартным образцом из множества стандартных образцов.
Согласно еще одному варианту осуществления изобретения, гипергеометрическое распределение использует коллективные свойства информации пиков, связанной со стандартными образцами (например, известные образцы и соответствующие данные пиков). Анализ, обсуждаемый в настоящем раскрытии, может включать вычисление вероятности того, что совпадение соответствующих пиков представляет собой случайное событие.
Согласно дальнейшим вариантам осуществления изобретения, приложение обработки данных, обсуждаемое в настоящем раскрытии, может конфигурироваться для выработки строки символов для неизвестного образца. Посредством таких символов, как логические единицы или нули, в строке, эта строка для неизвестного образца указывает, какому из множества интервалов диапазона разного размера принадлежит соответствующий пик неизвестного образца. Строка для неизвестного образца также может указывать, какому из множества интервалов диапазона разного размера не принадлежит соответствующий пик неизвестного образца.
Приложение обработки данных также может вырабатывать соответствующую строку символов для каждого из стандартных образцов в библиотеке из множества стандартных образцов. Соответствующая строка указывает, какому из множества интервалов диапазона разного размера принадлежит пик соответствующего стандартного образца. Соответствующая строка для стандартного образца также может указывать, какому из множества интервалов диапазона разного размера не принадлежит пик соответствующего стандартного образца.
Согласно дальнейшим вариантам осуществления изобретения, приложение обработки данных получает вероятностную информацию, по меньшей мере, частично на основе подобия между двоичной строкой для неизвестного образца и соответствующими двоичными строками, связанными со стандартными образцами. То есть, в общем, чем больше количество совпадений между двоичной строкой для неизвестного образца и соответствующей двоичной строкой, связанной с соответствующим стандартным образцом, тем больше вероятность того, что неизвестный образец совпадает с соответствующим стандартным образцом.
Индексация пиков, связанных с неизвестным образцом, в множестве интервалов диапазона разных размеров может включать для каждого соответствующего стандартного образца из множества стандартных образцов: генерирование значения, k, где значение k указывает количество событий того, что пик неизвестного образца попадает в интервал, где соответствующий стандарт также включает пик; генерирование значения N, указывающего общее количество в множестве интервалов диапазона разного размера, на которые делится спектр; генерирование значения, n, указывающего общее количество пиков, присутствующих в соответствующем стандартном образце; и генерирование значения, m, указывающего общее количество пиков, присутствующих в неизвестном образце.
На основе обсужденных выше данных, варианты осуществления настоящего раскрытия включают генерирование вероятностной информации (например, р-значения) для каждого из соответствующих стандартных образцов на основе следующего примера уравнения:
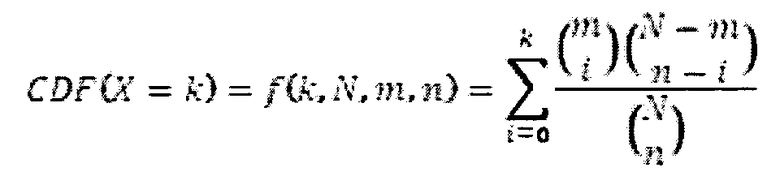
р-значение =1-CDF
Чем ниже р-значение, тем более вероятно то, что неизвестный образец является таким же, как соответствующий стандартный образец.
Один из вариантов осуществления настоящего раскрытия включает вычисление значения вероятности для проверки нулевой гипотезы о том, что совпадение интервала наблюдаемого пика и/или стандарта между стандартным образцом и данным стандартным образцом произошло случайно.
В качестве дальнейшего неограничивающего примера, приложение вычисляет вероятность того, что совпадение между пиком в неизвестном образце и пиком в данном стандартном образце для конкретного интервала диапазона, представляет собой случайное событие. Как упоминалось выше, варианты осуществления настоящего раскрытия являются преимущественными перед традиционными методиками. Например, один из вариантов осуществления настоящего раскрытия включает вычислительно эффективный способ поиска по библиотеке стандартных значений для быстрого ограничения количества кандидатов до меньшего набора стандартных образцов, которые более вероятно совпадают с неизвестным исследуемым образцом. Как упоминалось, в одном из вариантов осуществления изобретения, ресурс обработки данных применяет для определения кандидатов на совпадение двоичные арифметические операции с фиксированной запятой на сокращенном количестве точек данных. Некоторые операции поиска, обсуждаемые в настоящем раскрытии, более чем на порядок быстрее альтернативных компьютерных подходов, и, поскольку указанный подход является вероятностным, вычисления сохраняют высокую степень точности.
Дополнительные варианты осуществления изобретения
Таким же образом, как обсуждалось выше, следует отметить, что варианты осуществления настоящего раскрытия включают генерирование и хранение в памяти информации пиков и интервалов. Например, как обсуждалось выше, процессор спектральных данных может конфигурироваться для приема спектральной информации (например, указывающей набор пиков для каждого стандартного образца из множества стандартных образцов). Процессор спектральных данных разбивает спектр так, чтобы разбиение включало множество интервалов диапазона разного размера. Каждый из пиков (определяемых спектральной информацией) в множестве стандартных образцов принадлежит одному из множества интервалов диапазона разного размера. Процессор спектральных данных сохраняет в памяти информацию пиков и информацию интервалов как информацию пиков и интервалов. Хранящаяся в памяти информация пиков и интервалов включает информацию интервалов, указывающую множество интервалов диапазона разного размера, генерируемых для спектра, подвергнутого разбиению. Хранящаяся в памяти информация пиков из информации пиков и интервалов указывает, какому из множества интервалов диапазона разного размера принадлежат пики в множестве стандартных образцов.
Следует отметить, что варианты осуществления настоящего раскрытия таким же образом, как обсуждалось выше, включают определение возможных совпадений между неизвестным образцом и множеством стандартных образцов. Например, как обсуждалось выше, приложение анализатора может конфигурироваться для получения доступа к информации пиков и интервалов. Конкретнее, в одном из вариантов осуществления изобретения приложение анализатора принимает информацию интервалов диапазона (например, информацию пиков и интервалов). Информация интервалов диапазона указывает множество интервалов диапазона разного размера, на которое был разбит спектр. Приложение анализатора также принимает информацию пиков из информации пиков и интервалов. Информация пиков указывает набор пиков, связанных с каждым из множества стандартных образцов. Информация пиков также указывает, какому из множества интервалов диапазона разного размера принадлежит каждый из пиков. Для определения вероятных кандидатов, которые соответствуют неизвестному образцу, приложение анализатора индексирует местоположения пиков, связанных с неизвестным образцом, во множестве интервалов диапазона разного размера.
Ниже более подробно раскрываются эти и другие более конкретные варианты осуществления изобретения.
Следует отметить, что для осуществления и/или поддержки любой или всех операций способа, раскрываемых в настоящем раскрытии, варианты осуществления настоящего раскрытия могут включать конфигурацию из одного или нескольких вычислительных устройств, серверов, базовых станций, оборудования беспроводной связи, систем управления средствами связи, рабочих станций, карманных компьютеров и ноутбуков и т.п.. Иными словами, для выполнения операций, разъясняемых в настоящем раскрытии, с целью осуществления различных вариантов осуществления изобретения может программироваться и/или конфигурироваться одно или несколько компьютеризированных устройств или процессоров.
Другие варианты осуществления настоящего раскрытия включают программы, реализованные программно, предназначенные для этапов и операций, подытоженных выше и более подробно описываемых ниже. Один такой вариант осуществления изобретения включает компьютерный программный продукт, включающий постоянный машиночитаемый носитель данных (т.е. любой машиночитаемый аппаратный носитель данных), на котором для последующего исполнения закодированы команды программного обеспечения. Указанные команды при исполнении на компьютеризированном устройстве, содержащем процессор, программирует процессор и/или вызывает выполнение процессором операций, раскрываемых в настоящем раскрытии. Такие схемы, как правило, предусматриваются как программное обеспечение, код, команды и/или другие данные (например, структуры данных), упорядоченные или закодированные на постоянном (т.е. не представляющем собой несущую волну) машиночитаемом носителе данных, таком, как оптический носитель (например, CD-ROM), дискета, жесткий диск, карта памяти и т.д., или таком другом носителе, как программно-аппаратное обеспечение или сокращенный код в одном или нескольких носителях из числа ROM, RAM, PROM и т.д., или как специализированная интегральная микросхема (A SIC), и т.д. Программное обеспечение или аппаратно-программное обеспечение, или другие такие конфигурации могут устанавливаться на компьютеризированном устройстве, вызывая выполнение компьютеризированным устройством методик, разъясняемых в настоящем раскрытии.
Соответственно, варианты осуществления настоящего раскрытия направлены на способ, систему, компьютерный программный продукт и т.д., которые поддерживают операции, описываемые в настоящем раскрытии.
Например, один из вариантов осуществления изобретения включает машиночитаемый носитель данных или машиночитаемый аппаратный носитель, содержащий хранящиеся на нем команды. Эти команды при исполнении процессором соответствующего компьютерного устройства вызывают для процессора или нескольких процессоров: прием соответствующих спектральных данных каждого стандартного образца из множества стандартных образцов; разбиение спектра таким образом, чтобы оно включало множество интервалов диапазона разного размера, где каждый из пиков в множестве стандартных образцов принадлежит одному из множества интервалов диапазона разного размера; и сравнение пиков, связанных с неизвестным образцом, с множеством интервалов диапазона разного размера.
Согласно другому варианту осуществления изобретения, машиночитаемый носитель данных или машиночитаемый аппаратный носитель включает хранящиеся на нем команды. Эти команды при исполнении процессором или соответствующим компьютерным устройством вызывают для процессора или нескольких процессоров: прием информации интервалов диапазона, указанная информация интервалов диапазона указывает множество интервалов диапазона разного размера, на которые был разбит спектр; прием информации пиков, указывающей набор пиков, связанных с каждым из множества стандартных образцов, указанная информация пиков также указывает, какому из множества интервалов диапазона разного размера принадлежит каждый из пиков; и индексацию местоположений пиков, связанных с неизвестным образцом, в множестве интервалов диапазона разного размера.
Согласно еще одному варианту осуществления изобретения, машиночитаемый носитель данных или машиночитаемый аппаратный носитель включает хранящиеся на нем команды. Эти команды при исполнении процессором соответствующего компьютерного устройства вызывают для процессора или более процессоров: прием спектральных данных каждого стандартного образца из множества стандартных образцов; разбиение спектра таким образом, чтобы оно включало множество интервалов диапазона разного размера, каждый из указанных пиков в множестве стандартных образцов принадлежит одному из множества интервалов диапазона разного размера; и сохранение информации интервалов, указывающей множество интервалов диапазона разного размера, сгенерированных для спектра, подвергнутого разбиению.
Приведенный выше порядок этапов был добавлен для ясности. Эти этапы могут выполняться в любом подходящем порядке.
Другие варианты осуществления настоящего раскрытия включают программы, реализованные программно, и/или соответствующее аппаратное обеспечение для выполнения любого из этапов и операций осуществления способа, подытоженных выше и более подробно раскрываемых ниже.
Следует понимать, что система, способ, устройство, команды на машиночитаемом носителе данных и т.д., обсуждаемые в настоящем раскрытии, также могут воплощаться строго как программа, реализованная программно, аппаратное обеспечение и/или аппаратно-программное обеспечение, или только как аппаратное обеспечение, как, например, в процессоре или в операционной системе, или в программном приложении.
Как обсуждается в настоящем раскрытии, методики настоящего раскрытия хорошо подходят для использования в таких приложениях, как обработка и использование спектральной информации. Однако следует отметить, что варианты осуществления настоящего раскрытия не ограничиваются использованием в таких приложениях, и что методики, обсуждаемые в настоящем раскрытии, также хорошо подходят и для других приложений.
В дополнение следует отметить, что хотя каждый из различных характерных признаков, методик, конфигураций и т.д. в настоящем раскрытии может обсуждаться в разных местах данного раскрытия, предполагается, что, там, где это является пригодным, каждая из концепций может, необязательно, исполняться независимо от другой, или они могут исполняться в сочетании одна с другой. Соответственно, одно или несколько настоящих изобретений, раскрываемых в настоящем раскрытии, могут воплощаться и рассматриваться множеством различных способов.
Также следует отметить, что данное предварительное обсуждение вариантов осуществления настоящего раскрытия целенаправленно не указывает каждый вариант осуществления изобретения и/или прирастающую новаторскую особенность настоящего раскрытия или заявленного изобретения (изобретений). Вместо этого, данное краткое описание представляет только общие варианты осуществления изобретения и соответствующие пункты новизны относительно традиционных методик. За дополнительными подробностями и/или возможными перспективами (перестановками, элементами, особенностями и т.д.) изобретения (изобретений) читатель направляется к текстовому разделу Подробное описание и соответствующим фигурам настоящего раскрытия, в дальнейшем обсуждаемым ниже. Нижеследующее Подробное описание, в дополнение к представлению сложного описания подробностей изобретения, также представляет дальнейшую сводку особенностей изобретения, или изобретений.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
Вышеупомянутые и другие цели, характерные признаки и преимущества изобретения станут очевидны из нижеследующего более подробного описания предпочтительных вариантов осуществления настоящего раскрытия, иллюстрируемых в сопроводительных графических материалах, в которых похожие ссылочные позиции относятся к одинаковым деталям повсюду в разных видах, Графические материалы необязательно вычерчены в масштабе, вместо этого акцент делается на иллюстрацию вариантов осуществления изобретения, принципов, концепций и т.д.
ФИГ. 1 - один из примеров схемы, иллюстрирующей среду обработки данных, согласно вариантам осуществления настоящего раскрытия.
ФИГ. 2 - один из примеров схемы, иллюстрирующей обработку спектральной информации и генерирование множества интервалов диапазона с переменной шириной, согласно вариантам осуществления настоящего раскрытия.
ФИГ. 3 - один из примеров таблицы, иллюстрирующей информацию пиков, связанную с каждым стандартным образцом из множества стандартных образцов в поисковом банке данных, согласно вариантам осуществления настоящего раскрытия.
ФИГ. 4 - один из примеров схемы, иллюстрирующей индексацию пиков неизвестного образца в соответствующих интервалах диапазона, согласно вариантам осуществления настоящего раскрытия.
ФИГ. 5 - один из примеров схемы, иллюстрирующей таблицу спектральной информации, связанной с неизвестным исследуемым образцом и стандартными образцами, согласно вариантам осуществления настоящего раскрытия.
ФИГ. 6 - один из примеров схемы, иллюстрирующей генерирование двоичных строк, согласно вариантам осуществления настоящего раскрытия.
ФИГ. 7 - один из примеров схемы, иллюстрирующей счетную информацию, связанную со сравнением пиков в неизвестном образце с интервалами диапазона, согласно вариантам осуществления настоящего раскрытия.
ФИГ. 8 - один из примеров схемы, иллюстрирующей разбиение спектра таким образом, чтобы оно включало множество интервалов диапазона равной ширины.
ФИГ. 9 - один из примеров схемы, иллюстрирующей разбиение спектра таким образом, чтобы оно включало множество интервалов диапазона переменной ширины, согласно вариантам осуществления настоящего раскрытия.
ФИГ. 10 - один из примеров схемы, иллюстрирующей информацию пиков, связанную с неизвестным образцом, согласно вариантам осуществления настоящего раскрытия.
ФИГ. 11 - схема, иллюстрирующая пример архитектуры для исполнения способов, согласно вариантам осуществления настоящего раскрытия.
ФИГ. 12-14 - схемы последовательностей операций, иллюстрирующие примеры способов согласно вариантам осуществления настоящего раскрытия.
ПОДРОБНОЕ ОПИСАНИЕ
В качестве неограничивающего примера, приложение спектральной обработки принимает информацию пиков, связанную с множеством стандартных образцов. Приложение спектральной обработки разбивает спектр на множество интервалов диапазона разного размера таким образом, чтобы в каждый из множества интервалов диапазона разного размера попадало по существу равное количество пиков, связанных со стандартными образцами. Для определения стандартных образцов-кандидатов из библиотеки базы данных, которые потенциально соответствуют неизвестному исследуемому образцу, приложение поиска сравнивает пики, связанные с неизвестным образцом, с множеством интервалов диапазона разного размера. В общем, чем больше количество совпадений между неизвестным образцом и соответствующим стандартным образцом, тем больше вероятность того, что неизвестный образец совпадает с соответствующим стандартным образцом.
Конкретнее, ФИГ. 1 представляет собой пример схемы среды обработки данных согласно вариантам осуществления настоящего раскрытия.
Как показано, хранилище 180-1 хранит библиотеку спектральной информации 110, полученной из анализа банка данных известных стандартных образцов. В одном из вариантов осуществления изобретения, спектральная информация 110 указывает спектральную характеристику, полученную в ходе соответствующего анализа каждого из множества стандартных образцов. Спектральная информация 110 может генерироваться на основе спектрального анализа любого подходящего типа.
Спектральная информация 110, связанная с известными стандартными образцами 105, может сохраняться в любом подходящем формате. Например, спектральная информация 110 указывает пики, связанные с каждым из стандартных образцов.
В других вариантах осуществления изобретения, спектральная информация 110 может включать широкий анализ каждого из стандартных образцов. В последнем варианте осуществления изобретения, спектральная информация 110 для каждого из известных стандартных образцов может включать такие данные, как множество дискретных значений данных по спектру длин волн, информацию пиков, связанную с соответствующим известным стандартным образцом, и т.д.
Как обсуждается в настоящем раскрытии, процессор 120 спектральных данных обрабатывает спектральную информацию 110 множества известных стандартных образцов. На основе обработки, процессор 120 спектральных данных вырабатывает и сохраняет в памяти хранилища 180-2 информацию 130 пиков и интервалов диапазона.
В одном из вариантов осуществления изобретения процессор 120 спектральных данных отыскивает спектральную информацию 110 в хранилище 180-1 и обрабатывает спектральную информацию 110 с целью определения соответствующих спектральных данных каждого стандартного образца.
Информация 130 пиков и интервалов, хранящаяся в хранилище 180-2, может сжиматься по сравнению с объемом памяти, необходимым для хранения спектральной информации ПО. Иными словами, емкость запоминающего устройства, требуемая для хранения спектральной информации 110 множества стандартных образцов, может быть существенно больше по размеру, чем емкость запоминающего устройства, необходимая для хранения информации 130 пиков и интервалов.
Варианты осуществления настоящего раскрытия также включают анализатор 135 неизвестного образца. Анализатор 135 неизвестного образца анализирует неизвестный образец и вырабатывает спектральную информацию 150. Спектральная информация 150 включает информацию пиков, предоставляющую ключ к определению неизвестного образца.
Как в дальнейшем будет обсуждено ниже, приложение 140 анализатора сравнивает спектральную информацию 150, полученную из анализа неизвестного образца, с информацией 130 пиков и интервалов диапазона с целью выработки стандартных значений-кандидатов 160 и соответствующей вероятностной информации 170.
Таким образом, в отличие от традиционных способов, которые определяют только список кандидатов на совпадение с неизвестным исследуемым образцом, варианты осуществления настоящего раскрытия включают преобразование и/или сжатие спектральной информации 110 множества известных стандартных образцов 110 в информацию 130 пиков и интервалов диапазона, а затем - генерирование вероятностной информации 170, указывающей степень, в которой стандартные значения-кандидаты 160 являются хорошим совпадением с неизвестным образцом.
В качестве неограничивающего примера, в одном из вариантов осуществления изобретения, приложение 140 анализатора исполняется в мобильном, карманном полевом устройстве. Это переносное устройство может обладать ограниченными ресурсами обработки и хранения данных. Карманное устройство может предназначаться для хранения в памяти информации 130 пиков и интервалов диапазона и для выполнения сравнения спектральной информации 150 со стандартными образцами для выработки стандартных значений-кандидатов 160 и вероятностной информации 170.
ФИГ. 2 представляет собой пример схемы, иллюстрирующей преобразование спектральной информации 110 множества известных стандартных образцов в информацию 130 пиков и интервалов диапазона согласно вариантам осуществления настоящего раскрытия.
Как показано, спектральная информация 110 множества известных стандартных образцов может включать: спектральную информацию 110-1, полученную из анализа стандартного образца А, спектральную информацию 110-2, полученную из анализа стандартного образца В, спектральную информацию 110-3, полученную из анализа стандартного образца С, и т.д.
Как упоминалось ранее, спектральная информация 110 множества известных стандартных образцов 110 может храниться в любой форме, подходящей для представления результатов предшествующего анализа. Например, предшествующий анализ известного стандартного образца А вырабатывает спектральную информацию 110-1, предшествующий анализ известного стандартного образца В вырабатывает спектральную информацию 110-2, предшествующий анализ известного стандартного образца С вырабатывает спектральную информацию 110-3, и т.д. Соответственно, информация пиков известна для каждого из стандартных образцов.
В данном примере, спектральная информация 110-1, связанная со стандартным образцом А, включает пики РА1, РА2, РА3, РА4, РА3, РА6, …; спектральная информация 110-2, связанная со стандартным образцом В, включает пики РВ1, РВ2, РВ3, …; спектральная информация 110-3, связанная со стандартным образцом С, включает пики РС1, РС2, РС3, РС4, …; и т.д.
В качестве неограничивающего примера, процессор 120 спектральных данных обрабатывает спектральную информацию 110 множества известных стандартных образцов для определения общего количества пиков, связанных с сочетанием всех известных стандартных образцов. Как показано, процессор 120 спектральных данных распределяет все пики известных стандартных образцов на едином графике 220.
Вслед за выработкой распределения всех пиков, процессор 120 спектральных данных затем выбирает ширину, или размер, каждого интервала 210 диапазона (например, интервала 210-1 диапазона, интервала 210-2 диапазона, интервала 210-3 диапазона и т.д.) так, чтобы каждому из интервалу 210 диапазона принадлежало по существу равное количество пиков, связанных с известными стандартными образцами. Например, один из вариантов осуществления настоящего раскрытия включает определение положений всех пиков в базе данных, и затем - выработку интервалов диапазона неравной ширины, которые будут давать равномерную вероятность наблюдения пика из поисковой базы данных в любом интервале диапазона.
Ниже в данном описании будут обсуждаться дальнейшие подробности того, как выбирается общее количество интервалов 210 диапазона для соответствующего распределения.
Допустим, что, как показано на ФИГ. 2, все пики стандартных образцов находятся на оси х. В данном примере, интервал 210-1 диапазона включает пик, связанный с каждым из стандартных образцов А, С, D и Н. Например, интервал 210-1 диапазона включает пик РА1, связанный со стандартным образцом А, пик РС1, связанный со стандартным образцом С, пик PD1, связанный со стандартным образцом D, и пик РН1, связанный со стандартным образцом Н.
В данном неограничивающем примере, интервал 210-2 диапазона включает пик, связанный со стандартными образцами F, D, А и К. Например, интервал 210-2 диапазона включает пик PF1, связанный со стандартным образцом F, пик PD2, связанный со стандартным образцом D, пик РА2, связанный со стандартным образцом А, и пик РК1, связанный со стандартным образцом К.
Интервал 210-3 диапазона включает пик, связанный со стандартными образцами К, G и Н. Например, интервал 210-3 диапазона включает пик РК2, связанный со стандартным образцом К, пик PG1, связанный со стандартным образцом G, пик РН2, связанный со стандартным образцом Н, и пик PG2, связанный со стандартным образцом G.
Как упоминалось, распределение пиков, связанных с известными стандартными образцами, изменяется вдоль спектра. Например, разные участки спектра включают разную плотность пиков, поскольку некоторые стандартные образцы дают пики в одной и той же области спектра, в то время как в других областях спектра пики дает очень небольшое количество стандартных образцов.
Как обсуждается в настоящем раскрытии, для учета переменного распределения пиков в спектре, процессор 120 спектральных данных изменяет ширину интервалов 210 диапазона так, чтобы каждый интервал 210 диапазона включал количество пиков, по существу равное каждому из остальных интервалов 210 диапазона.
В одном из неограничивающих примеров, ширина интервалов 210 диапазона может выбираться так, чтобы в спектре не было разрывов. Например, между интервалами 210-1 и 210-2 диапазона отсутствует промежуток, поскольку левая граница интервала 210-2 диапазона начинается на, или находится близко к, правой границе интервала 210-1 диапазона; левая граница интервала 210-3 диапазона начинается на, или находится близко к, правой границе интервала 210-2 диапазона; и т.д.
Согласно альтернативным вариантам осуществления изобретения, может существовать значительный участок спектра, который не включает ни одного пика для любого из известных стандартных образцов. В таком случае, ширина интервалов 210 диапазона может выбираться так, чтобы соответствующие участки спектра не включались в соответствующий интервал диапазона. Иными словами, может существовать промежуток, или нулевой разрыв, между интервалом 210-1 диапазона и интервалом 210-2 диапазона; промежуток между интервалом 210-2 диапазона и интервалом 210-3 диапазона, где не находится ни одного пика; и т.д.
ФИГ. 3 представляет собой пример схемы, иллюстрирующей таблицу 300 известных стандартных образцов и соответствующую информацию пиков, согласно вариантам осуществления настоящего раскрытия.
Следует отметить, что таблица 300 представлена только с иллюстративными целями, и что количество стандартных образцов в библиотеке известных стандартных образцов может изменяться в зависимости от варианта осуществления изобретения.
В данном иллюстративном варианте осуществления изобретения, спектральная информация 110 множества известных стандартных образцов включает информацию пиков, связанных с банком данных известных стандартных образцов А, В, С, D, Е, F, G, H, J и К.
Как обсуждалось ранее, процессор 120 спектральных данных обрабатывает спектральную информацию 110 множества известных стандартных образцов для определения соответствующих пиков, связанных с каждым известным стандартным образцом.
Затем, согласно данному иллюстративному варианту осуществления изобретения, основываясь на спектральной информации 110, процессор 120 спектральных данных определяет, что известный стандартный образец А включает 6 пиков, в их числе РА1, РА2, РА3, РА4, РА5 и РА6; процессор 120 спектральных данных определяет, что известный стандартный образец В включает 3 пика, в их числе РВ1, РВ2 и РВ3; процессор спектральных данных анализатора стандартных образцов определяет, что известный стандартный образец С включает 5 пиков, в их числе РС1, РС2, РС3, РС4 и РС5; и т.д.
Как показано, имеется всего 40 пиков (например, пики РА1, …, РА6, РВ1, …, РВ3, РС1, …, PC5, PD1, …, PD3, PE1, …PE4, …), связанных с сочетанием известных стандартных образцов.
В данном примере, процессор 120 спектральных данных вырабатывает десять интервалов диапазона, в их числе интервалы диапазона 210-1, 210-2, 210-3, 210-4, 210-5, 210-6, 210-7, 210-8, 210-9 и 210-10.
Как обсуждалось ранее, на ФИГ. 3, процессор 120 спектральных данных может разделять спектр на 10 интервалов диапазона так, чтобы в каждый интервал 210 диапазона попадало по существу равное количество пиков. Имеется 40 пиков, связанных с сочетанием известных стандартных образцов, и 10 интервалов 210 диапазона. Таким образом, в данном неограничивающем примере, процессор 120 спектральных данных создает ширину каждого интервала 210 диапазона, достаточную для включения 4 пиков.
ФИГ. 4 представляет собой пример схемы, иллюстрирующей анализ неизвестного исследуемого образца и индексацию (т.е. сравнение) соответствующих пиков неизвестного исследуемого образца во множестве интервалов диапазона, согласно вариантам осуществления настоящего раскрытия. Следует отметить, что соответствующий интервал диапазона может включать несколько пиков для данного образца. Например, интервал 210-3 диапазона включает пик PG1 и пик PG2; и т.д.
В данном примере, допустим, что неизвестный исследуемый образец дает в результате анализа 4 пика. В данном примере, неизвестный исследуемый образец включает пик SP1, пик SP2, пик SP3 и пик SP4. Каждый из пиков, связанных с неизвестным исследуемым образцом, попадает в отдельное местоположение вдоль оси х в спектре, иллюстрируемом как график 400.
Как показано, для содействия генерированию вероятностной информации 170, приложение 140 индексирует пик SP1, пик SP2, пик SP3 и пик SP4 в соответствующих интервалах 210 диапазона. В данном иллюстративном варианте осуществления изобретения, пик SP1 попадает в пределы интервала 210-1 диапазона; пик SP2 попадает в пределы интервала 210-2 диапазона; пик SP3 попадает в пределы интервала 210-6 диапазона; и пик SP4 попадает в пределы интервала 210-10 диапазона.
Следует отметить, что этап индексации, обсуждаемый в настоящем раскрытии, может включать любой из примеров методик определения, отображения, сопоставления и т.д. интервалов диапазона, которым принадлежит множество пиков неизвестного образца.
ФИГ. 5 представляет собой пример схемы, иллюстрирующей дальнейший пример индексации пиков, связанных с неизвестным исследуемым образцом, со стандартными образцами-кандидатами согласно вариантам осуществления настоящего раскрытия.
В качестве неограничивающего примера, приложение 140 вырабатывает для неизвестного образца двоичную строку 510. Двоичная строка 510 указывает, каким из десяти интервалов (например, 210-1, …, 210-10) принадлежит соответствующий пик неизвестного исследуемого образца.
В данном примере, первому двоичному значению (например, местоположению самого левого бита) в двоичной строке 510 присваивается значение 1, указывающее, что неизвестный исследуемый образец включает значение пика (например, SP1) в соответствующем интервале 210-1 диапазона; второму двоичному значению в двоичной строке 510 присваивается значение 1, указывающее, что неизвестный исследуемый образец включает значение пика (например, SP2) в соответствующем интервале 210-2 диапазона; третьему двоичному значению в двоичной строке 510 присваивается значение О, указывающее, что неизвестный исследуемый образец не включает значение пика в соответствующем интервале 210-3 диапазона; четвертому двоичному значению в двоичной строке 510 присваивается значение 0, указывающее, что неизвестный исследуемый образец не включает значение пика в соответствующем интервале 210-4 диапазона; пятому двоичному значению в двоичной строке 510 присваивается значение 0, указывающее, что неизвестный исследуемый образец не включает значение пика в соответствующем интервале 210-5 диапазона; шестому двоичному значению в двоичной строке 510 присваивается значение 1, указывающее, что неизвестный исследуемый образец включает значение пика (например, SP3) в соответствующем интервале 210-6 диапазона; седьмому двоичному значению в двоичной строке 510 присваивается значение 0, указывающее, что неизвестный исследуемый образец не включает значение пика в соответствующем интервале 210-7 диапазона; восьмому двоичному значению в двоичной строке 510 присваивается значение 0, указывающее, что неизвестный исследуемый образец не включает значение пика в соответствующем интервале 210-8 диапазона; девятому двоичному значению в двоичной строке 510 присваивается значение 0, указывающее, что неизвестный исследуемый образец не включает значение пика в соответствующем интервале 210-9 диапазона; и десятому двоичному значению в двоичной строке 510 (например, местоположению самого правого бита) присваивается значение 1, указывающее, что неизвестный исследуемый образец включает значение пика (например, SP4) в соответствующем интервале 210-10 диапазона;
Соответственно, двоичная строка 510 представляет указатель того, каким интервалам диапазона принадлежат пики неизвестного образца.
Как также показано на ФИГ. 5, указанное приложение может конфигурироваться для определения того, какие из множества известных стандартных образцов являются лучшими или наилучшими кандидатами, которые потенциально совпадают с неизвестным исследуемым образцом. В качестве примера, любой из известных стандартных образцов, содержащий пик, попадающий в один и тот же интервал диапазона, что и интервал диапазона, которому также принадлежит по меньшей мере один пик неизвестного исследуемого образца, указывает (известный) стандартный образец-кандидат, который может совпадать с неизвестным исследуемым образцом.
Чем больше пиков неизвестного исследуемого образца попадает в те же интервалы диапазона, что и соответствующий известный стандартный образец, тем более вероятно, что этот соответствующий известный стандартный образец совпадает с неизвестным исследуемым образцом. Как в дальнейшем будет обсуждаться ниже, если частичное совпадение между неизвестным исследуемым образцом и известным стандартным образцом отсутствует, наиболее вероятным является то, что соответствующий известный стандартный образец не совпадает с неизвестным исследуемым образцом.
ФИГ. 6 представляет собой пример схемы, иллюстрирующей генерирование соответствующей двоичной строки для каждого из известных стандартных образцов, согласно вариантам осуществления настоящего раскрытия.
В качестве неограничивающего примера, информация 130 пиков и интервалов может включать двоичные строки 610, связанные с известными стандартными образцами.
Как показано, варианты осуществления настоящего раскрытия вырабатывают двоичную строку для каждого из известных стандартных образцов. Например, двоичная строка 610-1 указывает, какому из десяти интервалов (например, 210-1, …, 210-10) принадлежит соответствующий пик известного стандартного образца А.
В этом примере, первому двоичному значению (например, местоположению самого левого бита) в двоичной строке 610-1 присваивается значение 1, указывающее, что известный стандартный образец А включает значение пика (например, РА1) в соответствующем интервале 210-1 диапазона; второму двоичному значению в двоичной строке 610-1 присваивается значение 1, указывающее, что известный стандартный образец А включает значение пика (например, РА2) в соответствующем интервале 210-2 диапазона; третьему двоичному значению в двоичной строке 610-1 присваивается значение О, указывающее, что известный стандартный образец А не включает значение пика в соответствующем интервале 210-3 диапазона; четвертому двоичному значению в двоичной строке 610-1 присваивается значение 0, указывающее, что известный стандартный образец А не включает значение пика в соответствующем интервале 210-4 диапазона; пятому двоичному значению в двоичной строке 610-1 присваивается значение 1, указывающее, что известный стандартный образец А включает значение пика (например, РА3) в соответствующем интервале 210-5 диапазона; шестому двоичному значению в двоичной строке 610-1 присваивается значение 1, указывающее, что известный стандартный образец А включает значение пика (например, РА4) в соответствующем интервале 210-6 диапазона; седьмому двоичному значению в двоичной строке 610-1 присваивается значение 1, указывающее, что известный стандартный образец А включает значение пика (например, РА3) в соответствующем интервале 210-7 диапазона; восьмому двоичному значению в двоичной строке 610-1 присваивается значение О, указывающее, что известный стандартный образец А не включает значение пика в соответствующем интервале 210-8 диапазона; девятому двоичному значению в двоичной строке 610-1 присваивается значение 0, указывающее, что известный стандартный образец А не включает значение пика в соответствующем интервале 210-9 диапазона; и десятому двоичному значению в двоичной строке 610-1 (например, местоположению самого правого бита) присваивается значение 1, указывающее, что известный стандартный образец А включает значение пика (например, РА6) в соответствующем интервале 210-10 диапазона.
Соответственно, двоичная строка 610-1 представляет указатель того, каким интервалам 210 диапазона принадлежат один или несколько пиков известного образца А.
Для содействия данному примеру, первому двоичному значению (например, местоположению самого левого бита) в двоичной строке 610-2 присваивается значение 1, указывающее, что известный стандартный образец С включает значение пика (например, РС1) в соответствующем интервале 210-1 диапазона; второму двоичному значению в двоичной строке 610-2 присваивается значение 0, указывающее, что известный стандартный образец С не включает значение пика в соответствующем интервале 210-2 диапазона; третьему двоичному значению в двоичной строке 610-2 присваивается значение 0, указывающее, что известный стандартный образец С не включает значение пика в соответствующем интервале 210-3 диапазона; четвертому двоичному значению в двоичной строке 610-2 присваивается значение 1, указывающее, что известный стандартный образец С включает значение пика (например, РС2) в соответствующем интервале 210-4 диапазона; пятому двоичному значению в двоичной строке 610-2 присваивается значение 0, указывающее, что известный стандартный образец С не включает значение пика (например, РС2) в соответствующем интервале 210-5 диапазона; шестому двоичному значению в двоичной строке 610-2 присваивается значение 1, указывающее, что известный стандартный образец С включает значение пика (например, РС3) в соответствующем интервале 210-6 диапазона; седьмому двоичному значению в двоичной строке 610-2 присваивается значение 0, указывающее, что известный стандартный образец С не включает значение пика в соответствующем интервале 210-7 диапазона; восьмому двоичному значению в двоичной строке 610-2 присваивается значение 1, указывающее, что известный стандартный образец С включает значение пика (например, РС4) в соответствующем интервале 210-8 диапазона; девятому двоичному значению в двоичной строке 610-2 присваивается значение 0, указывающее, что известный стандартный образец С не включает значение пика в соответствующем интервале 210-9 диапазона; и десятому двоичному значению (например, местоположению самого правого бита) в двоичной строке 610-2 присваивается значение 1, указывающее, что известный стандартный образец С включает значение пика (например, РС5) в соответствующем интервале 210-10 диапазона.
Соответственно, двоичная строка 610-2 представляет указатель того, каким интервалам 210 диапазона принадлежит один или несколько пиков известного образца С.
Таким образом, строки 610 (например, строка 610-1, строка 610-2, строка 610-3, строка 610-4, строка 610-5, …) в таблице 600 указывают, каким интервалам принадлежат соответствующие один или несколько пиков известного образца.
ФИГ. 7 представляет собой пример схемы, иллюстрирующей таблицу сравнительной информации, согласно вариантам осуществления настоящего раскрытия.
Как обсуждалось ранее, приложение 140 генерирует двоичную строку 510, связанную с неизвестным исследуемым образцом. Для заполнения таблицы 700 значимыми счетными данными, приложение 140 сравнивает двоичную строку 510, связанную с неизвестным исследуемым образцом, с каждой из двоичных строк 610.
Таблица 700 включает значения k, N, m и п.
Значение k представляет количество интервалов диапазона, в которых каждый образец, как неизвестный исследуемый образец, так и соответствующий стандартный образец, включает по меньшей мере один соответствующий пик.
Значение N представляет общее количество интервалов диапазона, на которые разделен спектр.
Величина m представляет количество пиков в неизвестном стандартном образце.
Величина n представляет количество пиков в соответствующем стандартном образце.
Генерирование вероятностной информации
В качестве неограничивающего примера, приложение 140 может, как обсуждается ниже, генерировать вероятностную информацию.
Как упоминалось, после того, как становится доступен исследуемый двоичный спектр (например, двоичная строка 510), он последовательно сравнивается с каждым из двоичных спектров пиков стандартных образцов (например, с двоичными строками 610). В ходе каждого сравнения (т.е. сравнения неизвестного со стандартным образцом А, неизвестного со стандартным образцом В и т.д.) регистрируется количество совпадений пиков между двумя спектрами, подвергаемыми сравнению.
В одном из вариантов осуществления изобретения приведенная ниже гипергеометрическая вероятностная функция масс дает вероятность случайного нахождения к совпадений между неизвестным спектром (например, двоичной строкой 510), содержащим m пиков, и стандартным спектром (например, двоичной строкой 610), содержащим n пиков, для базы данных, содержащей N интервалов.
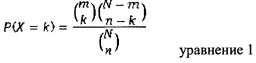
В приведенном выше уравнении 1 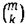 представляет биномиальный коэффициент (который часто читается как «m по k»). Одним из способов вычисления биномиального коэффициента является использование факториальной формулы:
представляет биномиальный коэффициент (который часто читается как «m по k»). Одним из способов вычисления биномиального коэффициента является использование факториальной формулы:

Для того чтобы исключить стандартный материал (например, стандартный образец) как являющийся частью измеренного неизвестного образца, с целью вычисления р-значения и проверки нулевой гипотезы о том, что наблюдаемые совпадения возникают случайно, используется гипергеометрическая кумулятивная функция распределения.
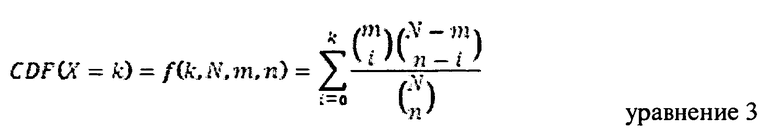
В одном из вариантов осуществления изобретения, р-значение вычисляется как 1-CDF(X=k), и для того, чтобы отвергнуть нулевую гипотезу с доверительной вероятностью 95%, можно использовать любое р-значение <0,05.
При рассмотрении р-значений в таблице 700 на ФИГ. 7 имеют смысл следующие результаты: только одно совпадение из 3 или 4 пиков в результате приводит к более высокому р-значению (известный стандартный образец Н), совпадение всех или почти всех пиков в неизвестном образце со стандартом дает относительно низкое р-значение (известный стандартный образец D), и совпадение малого количества пиков тогда, когда имеется много пиков как в соответствующем стандартном образце, так и в неизвестном исследуемом образце, дает высокие р-значения (известный стандартный образец К).
Как обсуждается ниже, приложение 140 на основе значений k, N, m и n генерирует р-значения для каждого из известных стандартных образцов.
Конкретнее, при сравнении двоичной строки 510 с двоичной строкой 610-1 приложение 140 определяет, что между известным стандартным образцом А и неизвестным исследуемым образцом имеется k=4 общих интервалов диапазона (например, интервал 210-1 диапазона, интервал 210-2 диапазона, интервал 210-6 диапазона и интервал 210-10 диапазона). Например, существует 4 интервала диапазона, включающих пик как из неизвестного исследуемого образца, так и из стандартного образца.
Приложение 140 определяет, что имеется всего N=10 интервалов диапазона (например, интервал 210-1 диапазона, …, интервал 210-10 диапазона).
Приложение 140 определяет, что в неизвестном исследуемом образце имеется m=4 пиков.
Приложение 140 определяет, что в соответствующем стандартном образце А имеется n=6 пиков.
На основе этой информации и приведенного выше уравнения 3, указанное приложение генерирует вероятностную информацию, указывающую, является ли стандартный образец А хорошим совпадением с неизвестным исследуемым образцом.
В данном примере, приложение 140, используя приведенные выше значения и уравнения, генерирует р-значение 0,0714. Такое относительно низкое р-значение указывает, что известный стандартный образец А является вполне хорошим кандидатом на совпадение для неизвестного исследуемого образца.
При сравнении двоичной строки 510 и двоичной строки 610-2, приложение 140 определяет, что имеется к=0 общих интервалов диапазона между известным стандартным образцом В и неизвестным исследуемым образцом. Приложение 140 определяет, что имеется всего N=10 интервалов диапазона (например, интервал 210-1 диапазона, …, интервал 210-10 диапазона). Приложение 140 определяет, что имеется m=4 пиков в неизвестном исследуемом образце. Приложение 140 определяет, что имеется n=6 пиков в соответствующем стандартном образце А.
На основе этой информации указанное приложение генерирует вероятностную информацию, указывающую, является ли стандартный образец В хорошим совпадением с неизвестным исследуемым образцом. В данном примере, приложение генерирует р-значение, равное 1,0. Столь высокое р-значение указывает, что известный стандартный образец В не является хорошим кандидатом на совпадение.
При сравнении двоичной строки 510 и двоичной строки 610-3, приложение 140 определяет, что имеется k=3 общих интервалов диапазона (например, интервал 210-1 диапазона, интервал 210-6 диапазона, интервал 210-10 диапазона) между известным стандартным образцом С и неизвестным исследуемым образцом. Приложение 140 определяет, что имеется всего N=10 интервалов диапазона (например, интервал 210-1 диапазона, …, интервал 210-10 диапазона). Приложение 140 определяет, что имеется m=4 пиков в неизвестном исследуемом образце. Приложение 140 определяет, что имеется n=5 пиков в соответствующем стандартном образце С.
На основе этой информации указанное приложение генерирует вероятностную информацию, указывающую, является ли стандартный образец С хорошим совпадением с неизвестным исследуемым образцом. В данном примере, приложение генерирует для стандартного образца С р-значение, равное 0,0333. Такое относительно низкое р-значение указывает, что известный стандартный образец С является очень хорошим кандидатом на совпадение для неизвестного исследуемого образца. Иными словами, неизвестный исследуемый образец, вероятно, относится к тому же типу, что и известный стандартный образец С.
Таким образом, указанное приложение сравнивает каждую из двоичных строк 610 с двоичной строкой 510, связанной с неизвестным исследуемым образцом. Для каждого из неизвестных стандартных образцов приложение 140 вырабатывает соответствующее р-значение. Как упоминалось, указанное р-значение указывает степень, в которой неизвестный исследуемый образец совпадает с соответствующим известным стандартным образцом в библиотеке. Эта информация может отображаться соответствующему пользователю для извещения пользователя о подмножестве всех стандартных образцов, которые являются наилучшими совпадениями с неизвестным исследуемым образцом.
ФИГ. 8 представляет собой пример графика 800, иллюстрирующего разбиение спектра на интервалы диапазона равного размера для библиотеки из множества стандартных образцов.
Ось х графика 800 указывает длину волны или другую подходящую спектральную измеряемую величину. Ось у графика 800 указывает количество отсчетов, или количество пиков, которые входят в каждый соответствующий интервал. График 800 был сгенерирован на основе базы данных инфракрасных спектров для 10000 химических соединений. Например, спектральное распределение 322468 пиков (связанных с 10000 образцов химических соединений) из данной справочной базы данных, было разделено на 50 интервалов диапазона равной ширины.
Как показано на ФИГ. 8, информация пиков, связанная с библиотекой стандартных образцов, имеет большую или меньшую плотность по спектру длин волн на оси х на графике 800. То есть, при выборе интервалов диапазона равного размера, количество пиков в каждом из интервалов равного размера является чрезвычайно неоднородным.
В общем, на оси х имеет место более высокое вхождение пиков, связанных со стандартными образцами 1000-1500, чем вхождение пиков, связанных со стандартными образцами 2000-2500. Таким образом, разбиение спектра просто на равные значения ширины дает интервалы диапазона, содержащие разные количества пиков.
ФИГ. 9 представляет собой пример графика 900, иллюстрирующего разбиение спектра на интервалы диапазона неравного размера, согласно вариантам осуществления настоящего раскрытия. Ось х графика 900 указывает такой параметр, как величина, основывающаяся на длине волны. Ось у графика 900 указывает такой параметр, как счетное количество, или количество пиков, которые входят в каждый соответствующий интервал.
Как обсуждалось ранее, распределение информации пиков, связанной с библиотекой стандартных образцов, по спектру на оси х графика 900 имеет большую или меньшую плотность. Однако, как обсуждалось ранее, варианты осуществления настоящего раскрытия включают разбиение спектра (например, волнового числа, длины волны, частоты, m/z и т.д.) на интервалы диапазона разного размера таким образом, чтобы каждому данному интервалу диапазона принадлежало по существу равное количество пиков, связанных со стандартными образцами.
Как указывалось выше, один из вариантов осуществления настоящего раскрытия включает характеристику пиков, связанных со стандартными образцами в библиотеке, с целью определения местоположений интервалов, которые при поиске по базе данных будут давать равномерную вероятность наблюдения пика в любом интервале. Как упоминалось выше, выработка интервалов диапазона разного размера может включать начало на одном из краев спектра и определение того, какой должна быть ширина первого интервала (например, самого левого интервала в спектре), чтобы требуемое вхождение пиков (например, Х пиков), связанных со стандартными образцами, попадало в пределы первого интервала.
Исходя из самой правой границы первого интервала (которая потенциально определяет левую границу второго интервала), варианты осуществления настоящего раскрытия могут включать анализ информации пиков, связанной со стандартными образцами в спектре, с целью определения того, какую необходимую ширину должен иметь второй интервал диапазона, чтобы этот второй интервал диапазона включал следующие Х пиков в спектре. Этот процесс повторяется для разделения спектра на требуемой количество интервалов диапазона, где каждый из интервалов диапазона включает по существу равное количество пиков, связанных со стандартными образцами.
В качестве неограничивающего примера, указанная процедура разделения спектра может осуществляться для стандартных образцов так, чтобы имела место вероятность Y% наблюдения пика в любом интервале при использовании любого стандартного спектра. График 900 представляет собой гистограмму, демонстрирующую, что должное задание размеров для разных интервалов диапазона в результате приводит к относительно однородному распределению пиков (т.е. каждый диапазон включает приблизительно одинаковое количество пиков).
Следует, однако, отметить, что, согласно еще одному варианту осуществления изобретения, при использовании гипергеометрического распределения соответствующий интервал диапазона, содержащий более одного пика для образца, можно представить таким же образом, как интервал, содержащий единственный пик для образца. Например, в одном из вариантов осуществления изобретения, в ходе анализа, интервалу, содержащему единственный пик для соответствующего стандартного образца, можно присвоить двоичное значение 1; интервалу, содержащему несколько пиков соответствующего стандартного образца, точно так же можно присвоить двоичное значение 1.
Следует отметить, что, согласно альтернативным вариантам осуществления изобретения, для присвоения более чем 2 значений (например, двоичного 0 или двоичного 1) на каждый интервал, могут использоваться другие функции распределения. Например, число, присваиваемое строке для данного интервала диапазона, может указывать значение 2, если в соответствующем образце имелось два пика, попадавших в указанный интервал диапазона; число, присваиваемое строке для данного интервала диапазона, может указывать значение 3, если в соответствующем образце имелось три пика, попадавших в указанный интервал диапазона; и т.д.
Дополнительные варианты осуществления изобретения
Согласно другому варианту осуществления изобретения, если в один и тот же интервал попадает более одного пика из спектра, то для определения вероятности совпадения пиков может использоваться многомерное гипергеометрическое распределение. Например, если имеется один или два, или три пика, приходящихся на интервал, то вероятность совпадения k1 интервалов с одним пиком и k2 интервалов с двумя пиками представляет собой
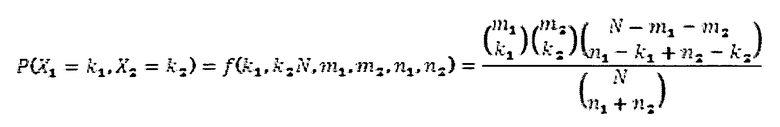
Используя ту же формулу, это можно распространить на три или большее количество пиков, приходящихся на интервал.
ФИГ. 10 представляет собой пример схемы, иллюстрирующей один из примеров обработки данных, согласно вариантам осуществления настоящего раскрытия.
Следует отметить, что для пиков, которые наблюдаются в пределах ошибки длины волны более одного интервала, возникает особый случай. Иными словами, оценочное местоположение пика будет представлять собой единственное значение, однако местоположение с +/- точностью длины волны может лежать в пределах более чем одного интервала. Когда это возникает, варианты осуществления настоящего раскрытия могут включать создание более чем одной двоичной строки для образца (соответствующей переносу местоположения пика между двумя рассматриваемыми интервалами), или предоставление единственному пику возможности занимать более одного интервала. В одном из вариантов осуществления изобретения, приложение 140 выполняет это для исследуемых спектров (например, неизвестного исследуемого образца), а не для стандартных спектров (например, стандартных образцов).
Как показано, в данном примере, допустим, что анализ неизвестного исследуемого образца дает спектральную информацию 1075. Неизвестный исследуемый образец включает значение пика 1050-2, которое попадает между интервалом 1010-2 диапазона и интервалом 1010-3 диапазона. Как указывается спектральной информацией 1075, другие значения пиков, связанные с неизвестным образцом, в общем, не лежат поблизости от края интервала диапазона и поэтому являются заключенными в единственный интервал диапазона.
С обработкой данных, связанной с ситуацией такого типа (например, пик 1050-2 - на краю двух интервалов диапазона), можно поступать несколькими способами. Например, один из вариантов осуществления настоящего раскрытия включает присвоение пика 1050-2 как интервалу 1010-2 диапазона, так и интервалу 1010-3 диапазона, и затем - выполнение анализа так, как это описано выше. В этом случае, приложение обработки данных выполняет анализ, в котором двоичной строкой является 111111011 (например, значение 1050-1 пика принадлежит интервалу 1010-1 диапазона; значение 1050-2 пика принадлежит интервалу 1010-2 диапазона; значение 1050-2 пика принадлежит интервалу 1010-3 диапазона; значение 1050-3 пика принадлежит интервалу 1010-4 диапазона; значение 1050-4 пика принадлежит интервалу 1010-5 диапазона; значение 1050-5 пика принадлежит интервалу 1010-6 диапазона; значение 1050-6 пика принадлежит интервалу 1010-8 диапазона; значение 1050-7 пика принадлежит интервалу 1010-9 диапазона). Вероятностная информация для образца генерируется таким же образом, как это описано выше.
В альтернативном варианте осуществления изобретения, приложение обработки данных может выполнять множество отдельных проходов обработки данных, включающих первых проход и второй проход. На первом проходе приложение обработки данных присваивает значение 1050-2 пика интервалу 1010-2 диапазона (а не интервалу 1010-3 диапазона) и вырабатывает вероятностную информацию для неизвестного исследуемого образца таким же образом, как это описано выше, на основе строки 110111011. На втором проходе приложение обработки данных присваивает значение 1050-2 пика интервалу 1010-3 диапазона (а не интервалу 1010-2 диапазона) и вырабатывает вероятностную информацию для неизвестного исследуемого образца таким же образом, как это описано выше, на основе строки 101111011.
ФИГ. 11 представляет собой пример блок-схемы компьютерной системы 1150, предназначенной для реализации любых операций согласно вариантам осуществления настоящего раскрытия.
Как показано, компьютерная система 1150 согласно настоящему примеру может включать межсоединение 811, которое связывает машиночитаемые носители данных 812, такие, как постоянные запоминающие носители (т.е. аппаратный носитель любого типа), в памяти которого может храниться и отыскиваться цифровая информация, процессор 813, интерфейс 814 ввода-вывода и интерфейс 817 связи.
Интерфейс 814 ввода-вывода обеспечивает возможность подключения к хранилищу 180 (например, хранилищу 180-1, хранилищу 180-2 и т.д.) и к другим устройствам, таким, как экран дисплея, дополнительная клавиатура, компьютерная мышь и т.д., в случае их наличия.
Машиночитаемый носитель данных 812 может представлять собой любое непреходящее устройство хранения данных, такое, как память, оптическое устройство хранения данных, накопитель на жестких дисках, дискета и т.д. В одном из вариантов осуществления изобретения, машиночитаемый носитель данных 812 хранит в памяти команды и/или данные.
Интерфейс 817 связи позволяет компьютерной системе 1500 и процессору 813 устанавливать связь через такой ресурс, как сеть 190, для отыскания информации из отдаленных источников, и устанавливать связь с другими компьютерами. В зависимости от варианта осуществления изобретения, любая или все функциональные возможности, связанные с приложением 140-1 анализатора, могут локально выполняться процессором 813 или посредством ресурсов сети 190, или их сочетанием.
Интерфейс 814 ввода-вывода позволяет процессору 813 отыскивать или предпринимать попытки отыскания информации, хранящейся в хранилище 180.
Как показано, машиночитаемые носители данных 812 кодируются приложением 140-1 анализатора (например, программным обеспечением, программно-аппаратным обеспечением и т.д.), исполняемым процессором 813. Приложение 140-1 анализатора может конфигурироваться для включения команд, предназначенных для реализации любой из операций, связанных с обсужденным выше приложением 140 анализатора.
В ходе работы одного из вариантов осуществления изобретения, процессор 813 получает доступ к машиночитаемым носителям данных 812 посредством использования межсоединения 811 с целью запуска, прогона, исполнения, интерпретации или иного выполнения команд в приложении 140-1 анализатора, хранящемся в памяти машиночитаемого носителя данных 812.
Исполнение приложения 140-1 анализатора предоставляет функциональную возможность обработки данных, такую, как процесс 140-2 анализатора в процессоре 813. Иными словами, процесс 140-2 анализатора, связанный с процессором 813, представляет одну или несколько особенностей исполнения приложения 140-1 анализатора в, или на, процессоре 813 компьютерной системы 1150.
Специалисты в данной области поймут, что компьютерная система 1150 может включать и другие процессы и/или компоненты программного и аппаратного обеспечения, такие, как операционная система, которая управляет назначением и использованием аппаратных ресурсов для исполнения приложения 140-1 анализатора.
Следует отметить, что, согласно различным вариантам осуществления изобретения, компьютерная система может представлять собой устройства любого типа, включающие в качестве неограничивающих примеров персональную компьютерную систему, беспроводное устройство, базовую станцию, телефонное устройство, настольный компьютер, ноутбук, нетбук, большую электронно-вычислительную вычислительную компьютерную систему, карманный компьютер, рабочую станцию, сетевой компьютер, сервер приложений, устройство хранения данных, бытовое электронное устройство, такое, как фотоаппарат, видеокамера, телевизионная приставка, мобильное устройство, игровая видеоприставка, карманное игровое видеоустройство, периферийное устройство, такое, как коммутатор, модем, маршрутизатор, или, в общем, вычислительное или электронное устройство любого типа. Компьютерная система 1150 и/или функциональная возможность, поддерживаемая приложением 140 анализатора, может находиться в любом местоположении или перемещаться в любое местоположение.
Для реализации процессора 120 спектральных данных может использоваться компьютерная система 1150 или архитектура аналогичного типа.
Ниже посредством последовательностей операций по фиг. 12-14 будет обсуждаться функциональность, поддерживаемая процессором 120 спектральных данных и/или приложением 140 анализатора. Следует отметить, что этапы в приводимых ниже последовательностях операций могут исполняться в любом подходящем порядке и в дальнейшем составлять варианты осуществления изобретения, обсуждаемые в настоящем раскрытии.
Фиг. 12 представляет собой последовательность операций 1200, иллюстрирующую один из примеров способа согласно вариантам осуществления настоящего раскрытия. Следует отметить, что в отношении вышеописанных концепций может иметь место некоторое перекрывание.
На этапе 1210 процессор 120 спектральных данных определяет и/или принимает спектральную информацию множества известных стандартных образцов 110. В одном из вариантов осуществления изобретения, спектральная информация 110 множества известных стандартных образцов включает данные, определяющие спектральные данные каждого стандартного образца из множества стандартных образцов.
На этапе 1220 процессор 120 спектральных данных разбивает спектр так, чтобы разбиение включало множество интервалов 210 диапазона разного размера. В одном из вариантов осуществления изобретения, процессор 120 спектральных данных разбивает спектр так, чтобы каждый из пиков в множестве стандартных образцов принадлежал одному из множества интервалов 210 диапазона.
На этапе 1230 приложение 140 индексирует (например, сравнивает, отображает и т.д.) местоположения пиков, связанных с неизвестным образцом, в множестве интервалов 210 диапазона.
Фиг. 13 и 14 объединены, образуя последовательность операций 1300 (например, последовательность операций 1300-1 и последовательность операций 1300-2), иллюстрирующую один из примеров способа согласно вариантам осуществления настоящего раскрытия. Следует отметить, что в отношении вышеописанных концепций может иметь место некоторое перекрывание.
На этапе 1310 процессор 120 спектральных данных принимает соответствующие спектральные данные каждого стандартного образца из множества стандартных образцов.
На этапе 1320 процессор 120 спектральных данных разбивает спектр так, чтобы он включал множество интервалов 210 диапазона. Процессор 120 спектральных данных разбивает спектр так, чтобы каждый из пиков, связанных с множеством стандартных образцов, принадлежал одному из множества интервалов 210 диапазона разного размера.
На подэтапе 1325 процессор 120 спектральных данных определяет значения ширины для каждого из множества интервалов 210 диапазона разного размера так, чтобы в каждый из множества интервалов 210 диапазона разного размера попадало по существу равное количество пиков в стандартных образцах.
На этапе 1330 приложение 140 индексирует, отображает или сравнивает местоположения пиков, связанных с неизвестным образцом, с местоположениями множества интервалов 210 диапазона разного размера в разделенном спектре.
На подэтапе 1335 приложение 140 индексирует пики, связанные с неизвестным образцом, в множестве интервалов 210 диапазона разного размера.
На подэтапе 1340 приложение 140, основываясь на указанной индексации, определяет стандартные образцы, которые являются хорошими кандидатами на совпадение (например, возможными совпадениями) с неизвестным исследуемым образцом.
На этапе 1410 по ФИГ. 14 для каждого соответствующего стандартного образца из числа стандартных образцов, определенных как являющиеся стандартными образцами-кандидатами, или, в альтернативном варианте, для любого или всех стандартных образцов 105 в банке данных, приложение 140 анализатора генерирует вероятностную информацию 170, указывающую степень, в которой каждый из соответствующих стандартных образцов-кандидатов совпадает с неизвестным образцом.
На подэтапе 1420 приложение 140 анализатора вырабатывает двоичную строку 510 для неизвестного образца. Двоичная строка 510 для неизвестного образца указывает, каким из множества интервалов 210 диапазона разного размера принадлежат один или несколько пиков неизвестного образца.
На подэтапе 1430 приложение 140 анализатора вырабатывает соответствующую двоичную строку 610 для каждого из стандартных образцов. Соответствующая двоичная строка 610 указывает, какому из множества интервалов 210 диапазона разного размера принадлежит по меньшей мере один пик из соответствующего стандартного образца.
На подэтапе 1440 приложение 140 анализатора получает вероятностную информацию 170 на основе сравнения двоичной строки 510 с каждой из одной или несколькими соответствующими двоичными строками 610, сгенерированными для стандартных образцов.
Дополнительные варианты осуществления и пункты формулы изобретения
Следует отметить, что варианты осуществления настоящего раскрытия таким же образом, как обсуждалось выше, включают генерирование и сохранение в памяти информации 130 пиков и интервалов. Например, как обсуждалось выше, процессор 120 спектральных данных может конфигурироваться для приема спектральной информации 110 (например, указывающей спектральные данные каждого стандартного образца из множества стандартных образцов). Процессор 120 спектральных данных разбивает спектр так, чтобы он включал множество интервалов 210 диапазона разного размера. Каждый из пиков (указываемых спектральной информацией 110) в множестве стандартных образцов принадлежит одному из множества интервалов 210 диапазона разного размера. Процессор 120 спектральных данных сохраняет информацию пиков и информацию интервалов как информацию 130 пиков и интервалов. Сохраненная информация 130 пиков и интервалов включает информацию интервалов, указывающую множество интервалов диапазона разного размера, сгенерированных для спектра, подвергнутого разбиению. Сохраненная информация пиков из информации 130 пиков и интервалов указывает, какому из множества интервалов 210 диапазона разного размера принадлежат пики в множестве стандартных образцов.
Соответственно, дополнительные приведенные в качестве примера пункты формулы изобретения включают:
31. Способ, включающий:
прием спектральных данных каждого стандартного образца из множества стандартных образцов;
выполнение разбиения спектра таким образом, чтобы оно включало множество интервалов диапазона разного размера, при этом каждый из пиков в множестве стандартных образцов принадлежит одному из множества интервалов диапазона разного размера; и
сохранение информации интервалов, указывающей множество интервалов диапазона разного размера, сгенерированных для спектра, подвергнутого разбиению.
32. Способ по п. 31, дополнительно включающий:
сохранение информации пиков, указывающей, какому из множества интервалов диапазона разного размера принадлежат пики в множестве стандартных образцов.
33. Способ по п. 31, отличающийся тем, что разбиение спектра на множество
интервалов диапазона разного размера включает:
установление значений ширины каждого из интервалов диапазона разного размера так, чтобы в каждый из множества интервалов диапазона разного размера попадало по существу равное количество пиков в стандартных образцах.
34. Способ по п. 31, дополнительно включающий:
прием спектральной информации, связанной с каждым из множества стандартных образцов, указанная спектральная информация включает анализ, охватывающий спектр; и
обработку спектральной информации с целью идентификации сигнатуры пиков каждого стандартного образца.
34. Способ по п. 31, отличающийся тем, что разбиение спектра включает:
выбор границ интервалов диапазона разного размера в соответствии с моделью гипергеометрического распределения.
35. Система, содержащая:
процессор; и
аппаратный ресурс хранения данных, связанный с указанным процессором, при этом аппаратный ресурс хранения данных хранит в памяти команды, которые при их исполнении процессором вызывают выполнение процессором операций:
приема спектральных данных каждого стандартного образца из множества стандартных образцов;
разбиения спектра таким образом, чтобы оно включало множество интервалов диапазона разного размера, при этом каждый из пиков в множестве стандартных образцов принадлежит одному из множества интервалов диапазона разного размера; и
сохранения информации интервалов, указывающей множество интервалов диапазона разного размера, сгенерированных для спектра, подвергнутого разбиению.
36. Система по п. 35, в которой указанный процессор дополнительно выполняет операции:
сохранения информации пиков, указывающей, какому из множества интервалов диапазона разного размера принадлежат пики в множестве стандартных образцов.
37. Система по п. 35, отличающаяся тем, что разбиение спектра на множество интервалов диапазона разного размера включает:
установление значений ширины каждого из интервалов диапазона разного размера так, чтобы в каждый из множества интервалов диапазона разного размера попадало по существу равное количество пиков в стандартных образцах.
38. Система по п. 35, в которой указанный процессор дополнительно выполняет операции:
приема спектральной информации, связанной с каждым из множества стандартных образцов, при этом спектральная информация включает анализ, охватывающий спектр; и
обработки спектральной информации с целью идентификации сигнатуры пиков каждого стандартного образца.
39. Система по п. 35, отличающаяся тем, что разбиение спектра включает:
выбор границ интервалов диапазона разного размера в соответствии с моделью гипергеометрического распределения.
40. Машиночитаемое аппаратное обеспечение хранения данных, содержащее
хранящиеся на нем команды, при этом указанные команды при осуществлении устройством обработки данных вызывают выполнение устройством обработки данных операций:
приема спектральных данных каждого стандартного образца из множества стандартных образцов;
выполнения разбиения спектра таким образом, чтобы оно включало множество интервалов диапазона разного размера, при этом каждый из пиков в множестве стандартных образцов принадлежит одному из множества интервалов диапазона разного размера; и
сохранения информации интервалов, указывающей множество интервалов диапазона разного размера, сгенерированных для спектра, подвергнутого разбиению.
Следует отметить, что варианты осуществления настоящего раскрытия таким же образом, как обсуждалось выше, включают определение возможных совпадений между неизвестным образцом и множеством стандартных образцов. Например, как обсуждалось выше, приложение 140 анализатора может конфигурироваться для получения доступа к информации 130 пиков и интервалов. Конкретнее, в одном из вариантов осуществления изобретения, приложение 140 анализатора принимает информацию интервалов диапазона (например, информацию 130 пиков и интервалов). Информация интервалов диапазона указывает множество интервалов 210 диапазона разного размера, на которые был разбит спектр. Приложение 140 анализатора затем принимает информацию пиков из информации 130 пиков и интервалов. Информация пиков указывает набор пиков, связанных с каждым из множества стандартных образцов. Информация пиков также указывает, какому из множества интервалов 210 диапазона разного размера принадлежит каждый из пиков. Для определения вероятных кандидатов, которые совпадают с неизвестным образцом, приложение 140 анализатора индексирует местоположения пиков, связанных с неизвестным образцом, в множестве интервалов 210 диапазона разного размера.
Соответственно, дополнительные приведенные в качестве примеров пункты формулы изобретения включают:
41. Способ, включающий:
прием информации интервалов диапазона, при этом информация интервалов диапазона указывает множество интервалов диапазона разного размера, на которые был разбит спектр;
прием информации о пиков, указывающей набор пиков, связанных с каждым из множества стандартных образцов, при этом информация пиков также указывает, какому из множества интервалов диапазона принадлежит каждый из пиков; и
индексацию местоположений пиков, связанных с неизвестным образцом, в множестве интервалов диапазона разного размера.
42. Способ по п. 41, дополнительно включающий:
на основе проиндексированных местоположений пиков, связанных с неизвестным образцом, в множестве интервалов диапазона разного размера, определение подмножества множества стандартных образцов, которые являются кандидатами на совпадение с неизвестным образцом.
43. Способ по п. 41, отличающийся тем, что значения ширины каждого из множества интервалов диапазона разного размера определяют так, чтобы в каждый из множества интервалов диапазона разного размера попадало по существу равное количество пиков в стандартных образцах.
44. Способ по п. 41, дополнительно включающий:
для соответствующего стандартного образца из множества стандартных образцов, генерирование вероятностной информации о том, что соответствующий стандартный образец представляет собой совпадение с неизвестным образцом.
45. Способ по п. 44, дополнительно включающий:
генерирование вероятностной информации, по меньшей мере, частично на основе двоичных арифметических операций с фиксированной запятой.
46. Способ по п. 41, дополнительно включающий:
реализацию функции гипергеометрической вероятности для генерирования вероятностной информации, указывающей то, что неизвестный образец совпадает с соответствующим одним из множества стандартных образцов.
47. Способ по п. 41, дополнительно включающий:
определение того, что пик неизвестного образца и пик, связанный с данным стандартным образцом, принадлежат конкретному интервалу диапазона из множества интервалов диапазона; и
вычисление вероятности того, что совпадение между пиком в неизвестном образце и пиком в данном стандартном образце для конкретного интервала диапазона представляет собой случайное событие.
48. Способ по п. 41, дополнительно включающий:
вычисление значения вероятности для проверки нулевой гипотезы о том, что наблюдаемые совпадения пиков между стандартным образцом и данным стандартным образцом происходят случайно.
49. Способ по п. 41, отличающийся тем, что индексация пиков, связанных с неизвестным образцом, в множестве интервалов диапазона включает:
определение пика неизвестного образца;
определение интервала диапазона из множества интервалов диапазона разного размера, в котором лежит пик неизвестного образца; и
определение конкретного стандартного образца из множества стандартных образцов, который включает пик в определенном интервале диапазона.
50. Способ по п. 42, отличающийся тем, что индексация пиков, связанных с неизвестным образцом, в множестве интервалов диапазона включает:
для каждого соответствующего стандартного образца из множества стандартных образцов:
генерирование значения k, указывающего количество событий попадания пика неизвестного образца в интервал, в котором соответствующий стандарт также включает пик;
генерирование значения N, указывающего количество интервалов диапазона разного размера в множестве;
генерирование значения n, указывающего общее количество пиков, присутствующих в соответствующем стандартном образце; и
генерирование значения m, указывающего общее количество пиков, присутствующих в неизвестном образце.
51. Способ по п. 41, отличающийся тем, что индексация включает:
выработку первой двоичной строки, при этом первая двоичная строка указывает, какому из множества интервалов диапазона разного размера принадлежит пик неизвестного образца;
выработку второй двоичной строки, при этом вторая двоичная строка указывает, какому из множества интервалов диапазона разного размера принадлежит пик стандартного образца; и
получение вероятностной информации на основе подобия между первой двоичной и второй двоичной строкой.
52. Система, содержащая:
процессор; и
аппаратный ресурс хранения данных, связанный с процессором, при этом указанный аппаратный ресурс хранения данных хранит в памяти команды, которые при их исполнении процессором вызывают выполнение процессором операций:
приема информации интервалов диапазона, при этом информация интервалов диапазона указывает множество интервалов диапазона разного размера, на которые был разбит спектр;
приема информации о пиках, указывающей набор пиков, связанных с каждым из множества стандартных образцов, при этом информация пиков также указывает, какому из множества интервалов диапазона принадлежит каждый из пиков; и
индексации местоположений пиков, связанных с неизвестным образцом, в множестве интервалов диапазона разного размера.
53. Система по п. 52, в которой процессор дополнительно выполняет операции:
на основе индексации местоположений пиков, связанных с неизвестным образцом, в множестве интервалов диапазона разного размера, определения подмножества множества стандартных образцов, которые являются кандидатами на совпадение с неизвестным образцом.
54. Система по п. 52, отличающаяся тем, что значения ширины каждого из множества интервалов диапазона разного размера определены так, чтобы в каждый из множества интервалов диапазона разного размера попадало по существу равное количество пиков в стандартных образцах.
55. Система по п. 52, в которой процессор дополнительно выполняет операции:
для соответствующего стандартного образца из множества стандартных образцов, генерирования вероятностной информации о том, что соответствующий стандартный образец представляет собой совпадение с неизвестным образцом.
56. Система по п. 55, в которой процессор дополнительно выполняет операции: генерирования вероятностной информации по меньшей мере частично с применением двоичных арифметических операций с фиксированной запятой.
57. Система по п. 52, в которой процессор дополнительно выполняет операции:
реализации функции гипергеометрической вероятности для генерирования вероятностной информации, указывающей то, что неизвестный образец совпадает с соответствующим одним из множества стандартных образцов.
58. Система по п. 52, в которой процессор дополнительно выполняет операции:
определения того, что пик неизвестного образца и пик, связанный с данным стандартным образцом, принадлежат конкретному интервалу диапазона из множества интервалов диапазона; и
вычисления вероятности того, что совпадение между пиком в неизвестном образце и пиком в данном стандартном образце для конкретного интервала диапазона представляет собой случайное событие.
59. Система по п. 52, в которой процессор дополнительно выполняет операции:
вычисления значения вероятности для проверки нулевой гипотезы о том, что наблюдаемые совпадения пиков между стандартным образцом и данным стандартным образцом происходят случайно.
60. Система по п. 52, отличающаяся тем, что индексация пиков, связанных с неизвестным образцом, в множестве интервалов диапазона включает:
определение пика неизвестного образца;
определение интервала диапазона из множества интервалов диапазона разного размера, в котором лежит пик неизвестного образца; и
определение конкретного стандартного образца из множества стандартных образцов, который включает пик в определенном интервале диапазона.
61. Система по п. 52, отличающаяся тем, что индексация пиков, связанных с неизвестным образцом, в множестве интервалов диапазона включает:
для каждого соответствующего стандартного образца из множества стандартных образцов:
генерирование значения k, указывающего количество событий попадания пика неизвестного образца в интервал, в котором соответствующий стандартный образец также включает пик;
генерирование значения N, указывающего количество интервалов диапазона разного размера в множестве;
генерирование значения n, указывающего общее количество пиков, присутствующих в соответствующем стандартном образце; и
генерирование значения m, указывающего общее количество пиков, присутствующих в неизвестном образце.
62. Система по п. 52, отличающаяся тем, что индексация включает:
выработку первой двоичной строки, при этом первая двоичная строка указывает, какому из множества интервалов диапазона разного размера принадлежит неизвестный образец;
выработку второй двоичной строки, при этом вторая двоичная строка указывает, какому из множества интервалов диапазона разного размера принадлежит пик стандартного образца; и
получение вероятностной информации на основе подобия между первой двоичной и второй двоичной строкой.
63. Машиночитаемое аппаратное обеспечение хранения данных, содержащее хранящиеся на нем команды, при этом команды при осуществлении устройством обработки данных вызывают выполнение устройством обработки данных операций:
приема информации интервалов диапазона, при этом указанная информация интервалов диапазона указывает множество интервалов диапазона разного размера, на которые был разбит спектр;
приема информации пиков, указывающей набор пиков, связанных с каждым из множества стандартных образцов, при этом информация пиков также указывает, какому из множества интервалов диапазона принадлежит каждый из пиков; и
индексации местоположений пиков, связанных с неизвестным образцом, в множестве интервалов диапазона разного размера.
Следует снова отметить, что методики настоящего раскрытия хорошо подходят для использования в поисковых приложениях и при сопоставлении неизвестного исследуемого образца с одним или несколькими известными стандартными образцами. Однако следует отметить, что варианты осуществления настоящего раскрытия не ограничиваются использованием в этих приложениях, и что методики, обсужденные в настоящем раскрытии, также хорошо подходят и для других приложений.
Как упоминалось, варианты осуществления настоящего раскрытия полезны в приложениях, где преимущественным является сжатие данных. В качестве неограничивающего примера, в системах, конфигурируемых с очень небольшими ресурсами физической памяти и/или обработки данных, процесс, обсужденный в настоящем раскрытии, может использоваться только для выработки сжатых данных, которые затем направляются куда-либо для дальнейшего анализа. Конкретнее, для хранения информации интервалов диапазона, генерируемой для банка данных стандартных образцов, может конфигурироваться отдаленное устройство. Это отдаленное устройство может принимать информацию пиков для исследуемого образца и сравнивать местоположения пиков, связанных с неизвестным образцом, с целью генерирования двоичной строки, указывающей, в каком из интервалов неизвестный образец содержит соответствующий пик. Отдаленное устройство может конфигурироваться для направления сгенерированной двоичной строки (например, сжатых данных) по каналу связи в другое местоположение, которое выполняет такую обработку данных, как сравнение указанной двоичной строки с двоичными строками, связанными со стандартными образцами, с целью нахождения одного или нескольких совпадений.
На основе изложенного в настоящем раскрытии описания были изложены многочисленные конкретные подробности, обеспечивающие полное понимание заявленного предмета изобретения. Однако специалисты в данной области техники должны понимать, что заявленный предмет изобретения может применяться на практике и без этих конкретных подробностей. В других случаях, способы устройства, системы и т.д., которые могут быть известны среднему специалисту в данной области техники, не были описаны подробно с тем, чтобы не затруднять понимание заявленного предмета изобретения. Некоторые части подробного описания были представлены в выражении алгоритмов или символического представления операций на битах данных или двоичных цифровых сигналах, хранящихся в памяти вычислительной системы, такой, как память компьютера. Эти алгоритмические описания или представления являются примерами методик, используемых средними специалистами в области обработки данных для передачи содержания их работы другим специалистам в данной области техники. Алгоритм, описываемый в настоящем раскрытии, в целом считается самосогласованной последовательностью операций или аналогичной обработки данных, ведущей к требуемому результату. В этом контексте, операции, или обработка данных, включают физическое манипулирование физическими величинами. Как правило, хотя это и не является необходимым, эти величины могут принимать форму электрических или магнитных сигналов, допускающих хранение в памяти, передачу, сочетание, сравнение или другие манипуляции. Временами было удобно, главным образом, по причинам широкого использования, именовать такие сигналы как биты, данные, значения, элементы, символы, буквы, члены, числа, цифры и т.п. Однако следует понимать, что все эти и аналогичные термины должны связываться с соответствующими физическими величинами и являются просто удобными метками. Если конкретно не определено иное, как очевидно из нижеследующего обсуждения, следует принимать во внимание, что повсюду в данном описании обсуждения, использующие такие термины, как «обработка данных», «вычисление», «расчет», «определение» и т.п., относятся к действиям или процессам вычислительной платформы, такой, как компьютер или аналогичное электронно-вычислительное устройство, которое манипулирует данными, или преобразовывает данные, представленные как электронные или магнитные физические величины в запоминающих устройствах, регистрах или других устройствах хранения информации, передающих устройствах или дисплейных устройствах вычислительной платформы.
Несмотря на то, что данное изобретение было особо показано и описано со ссылками на предпочтительные варианты его осуществления, специалистам в данной области техники будет понятно, что в настоящем раскрытии могут делаться различные изменения по форме и в деталях без отступления от духа и объема настоящей заявки, определяемых прилагаемой формулой изобретения. Такие изменения предполагаются как охватываемые объемом данной настоящей заявки. Как таковое, предшествующее описание вариантов осуществления настоящей заявки не предназначено для ограничения. Точнее, любые ограничения изобретения представлены в нижеследующей формуле изобретения.
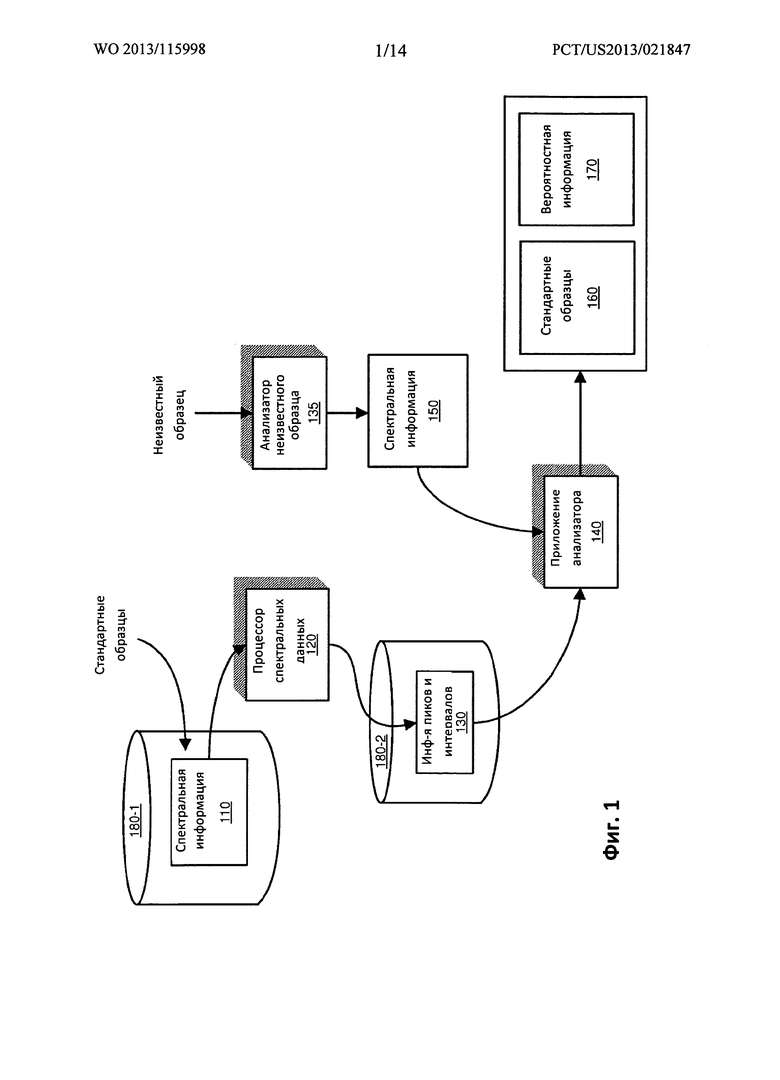
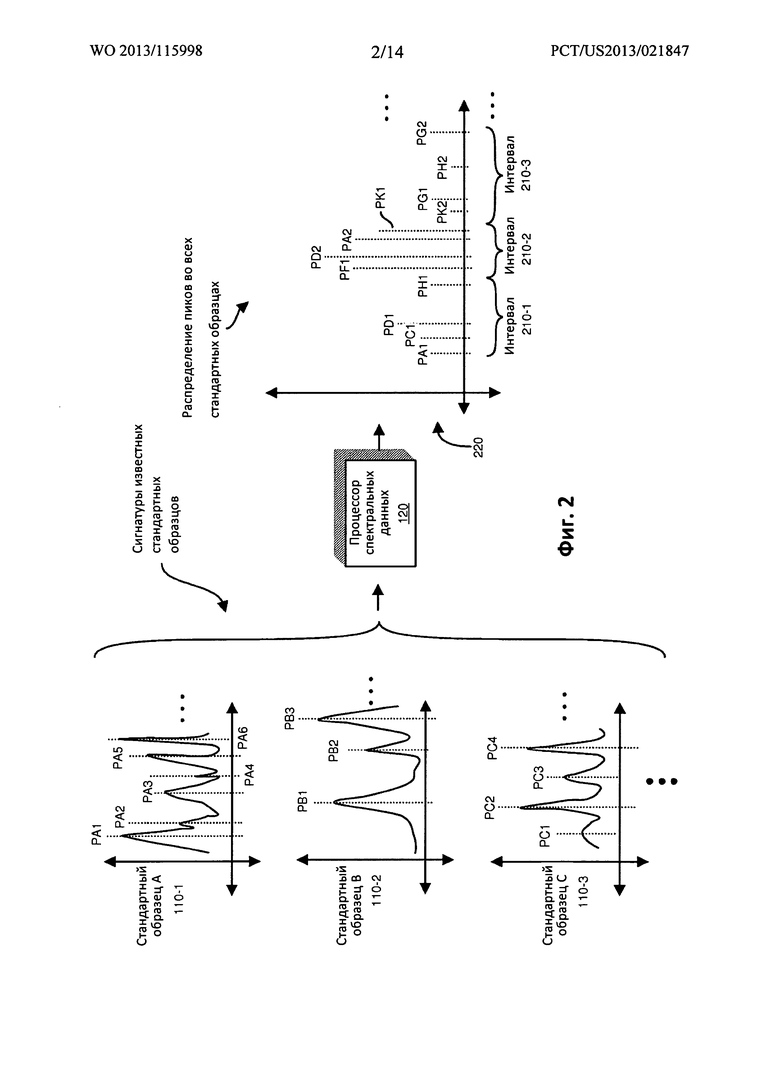


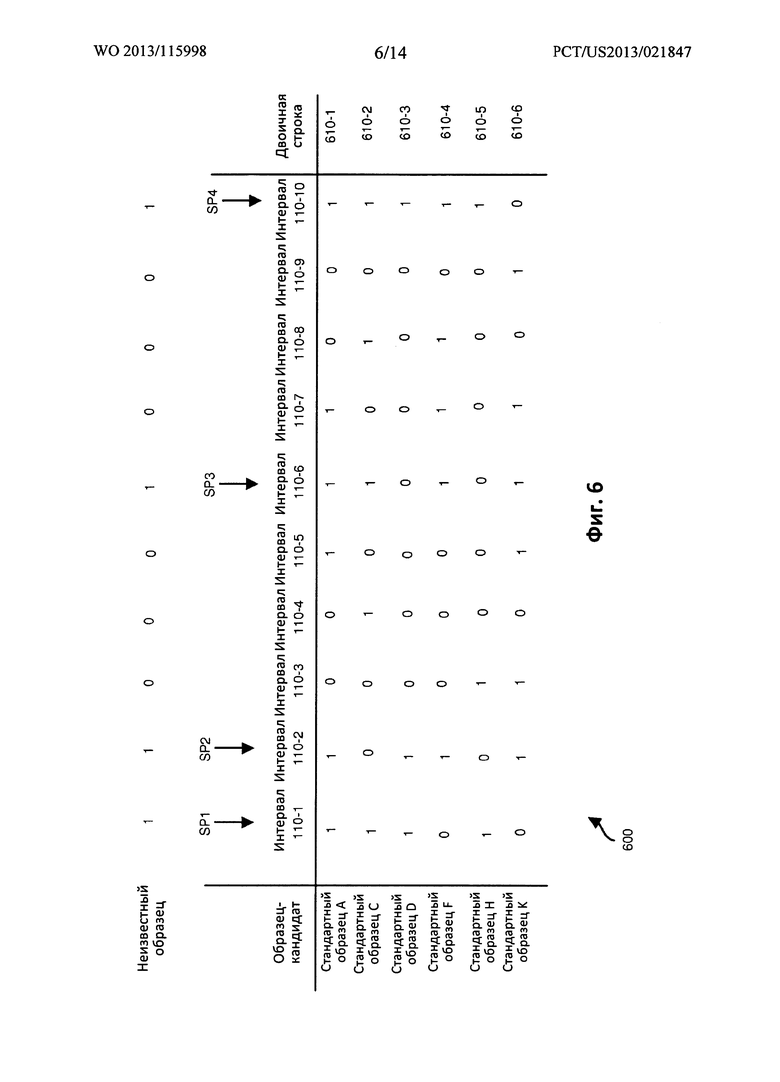

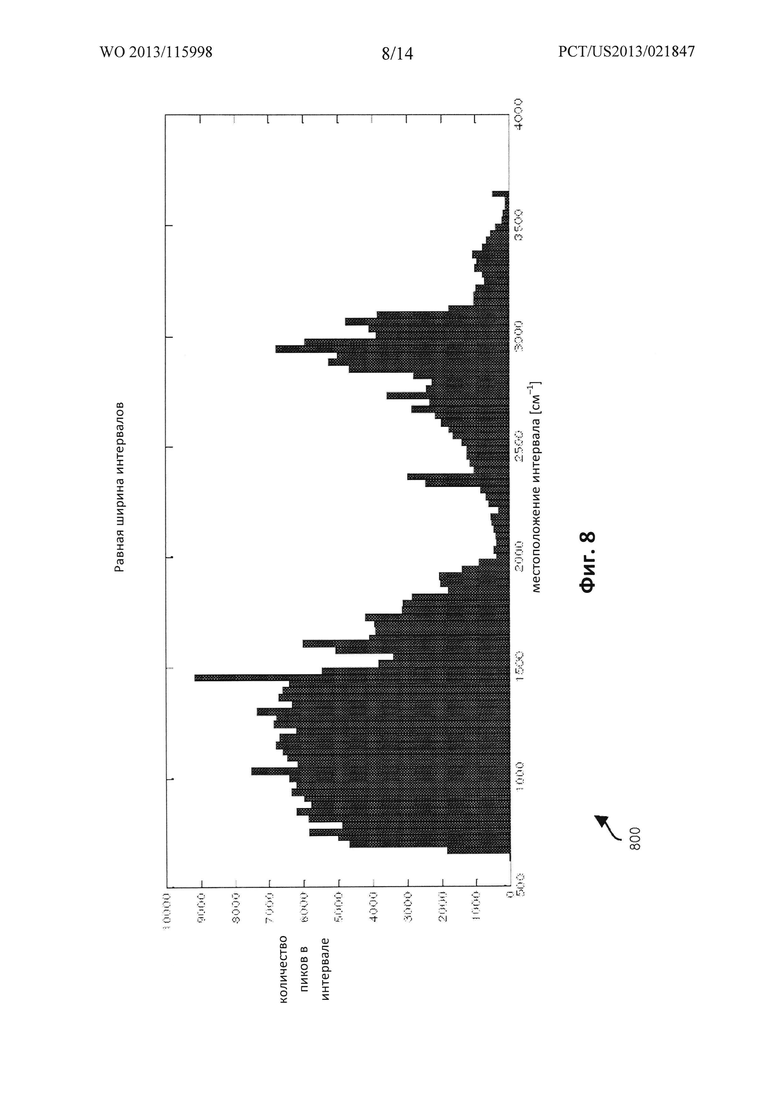
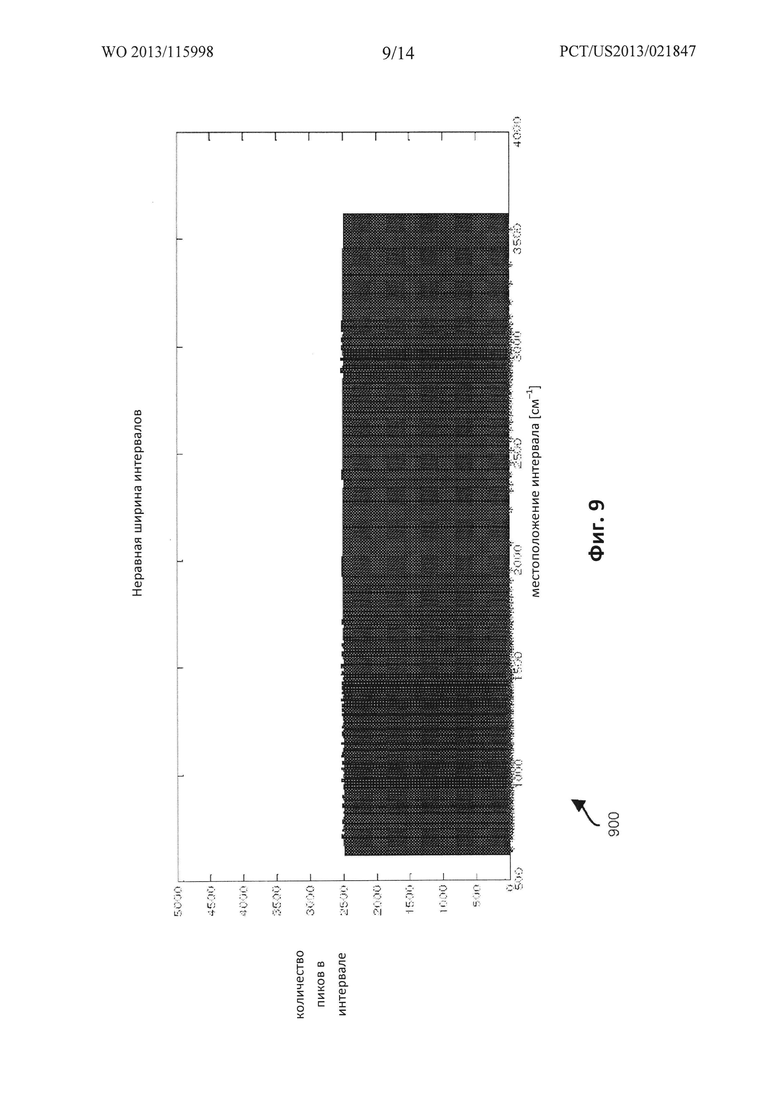
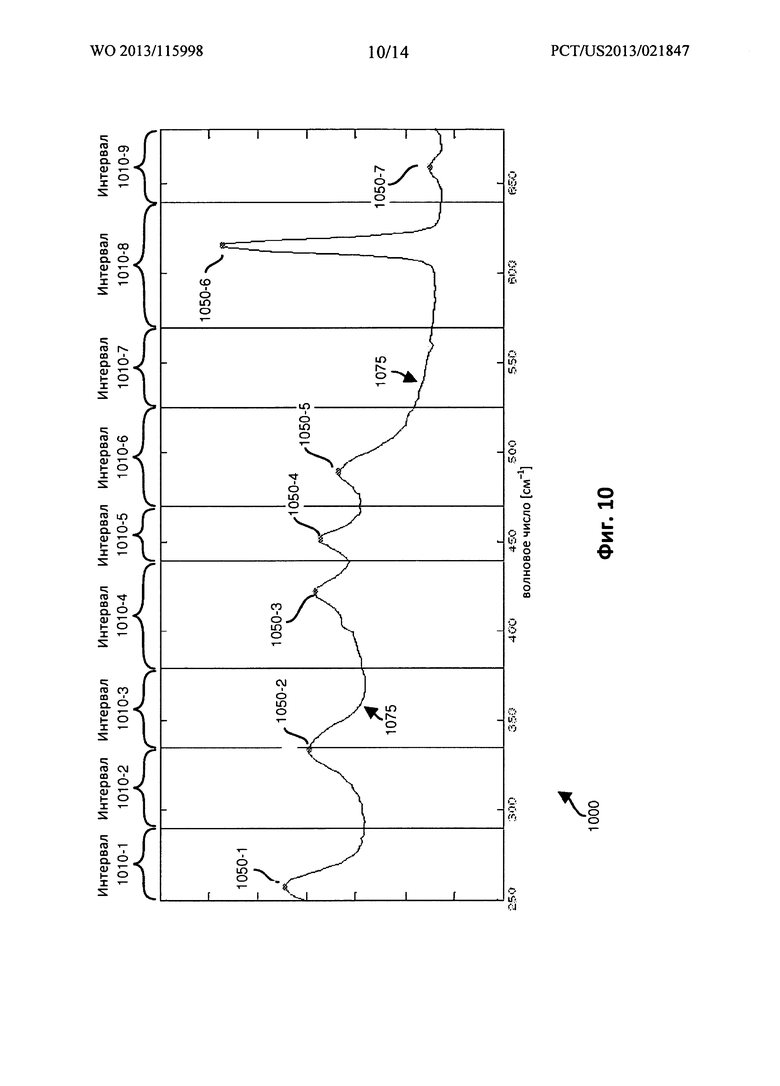
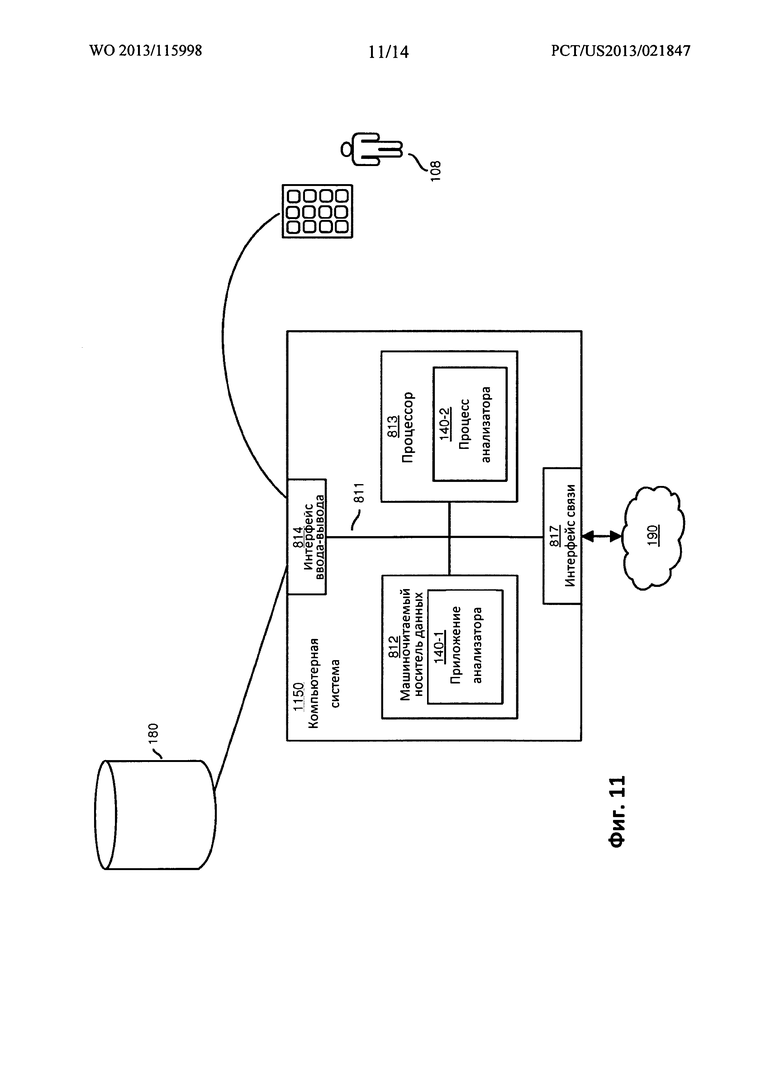
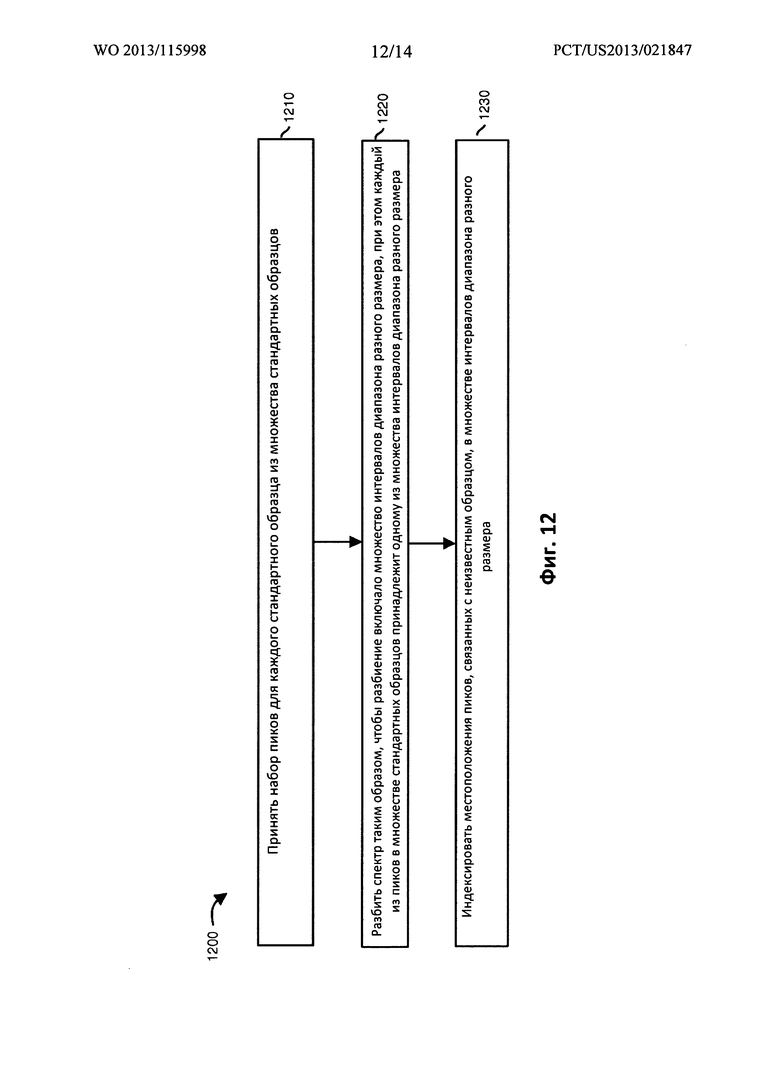
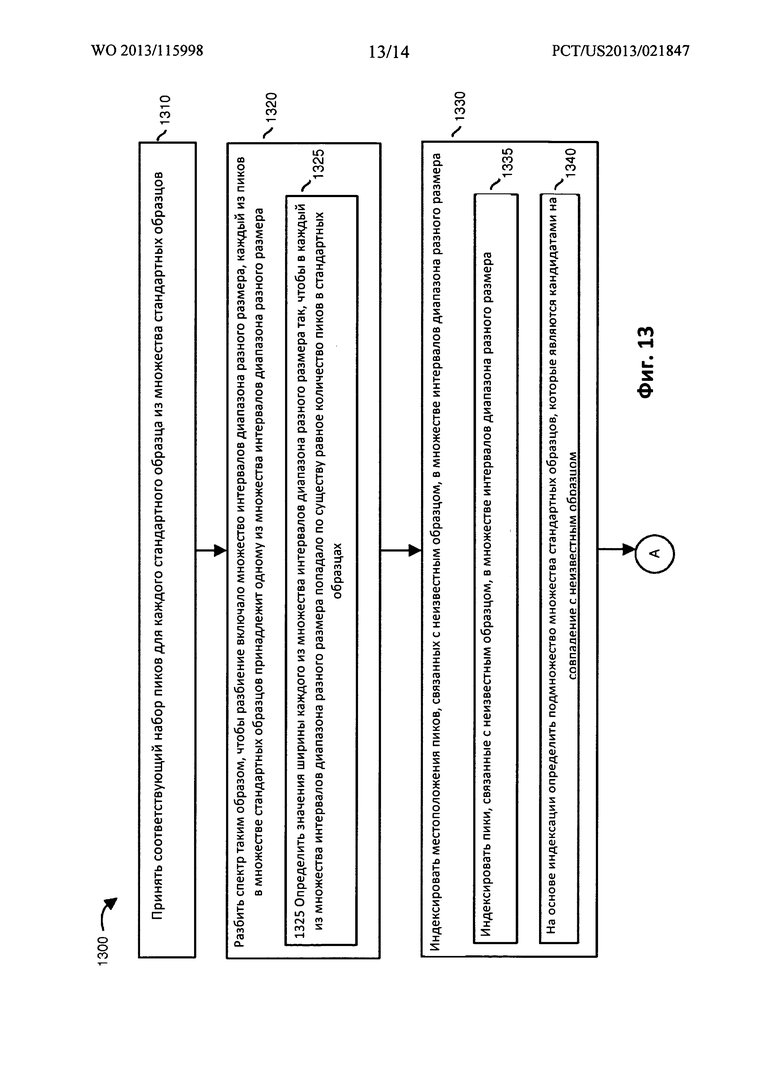
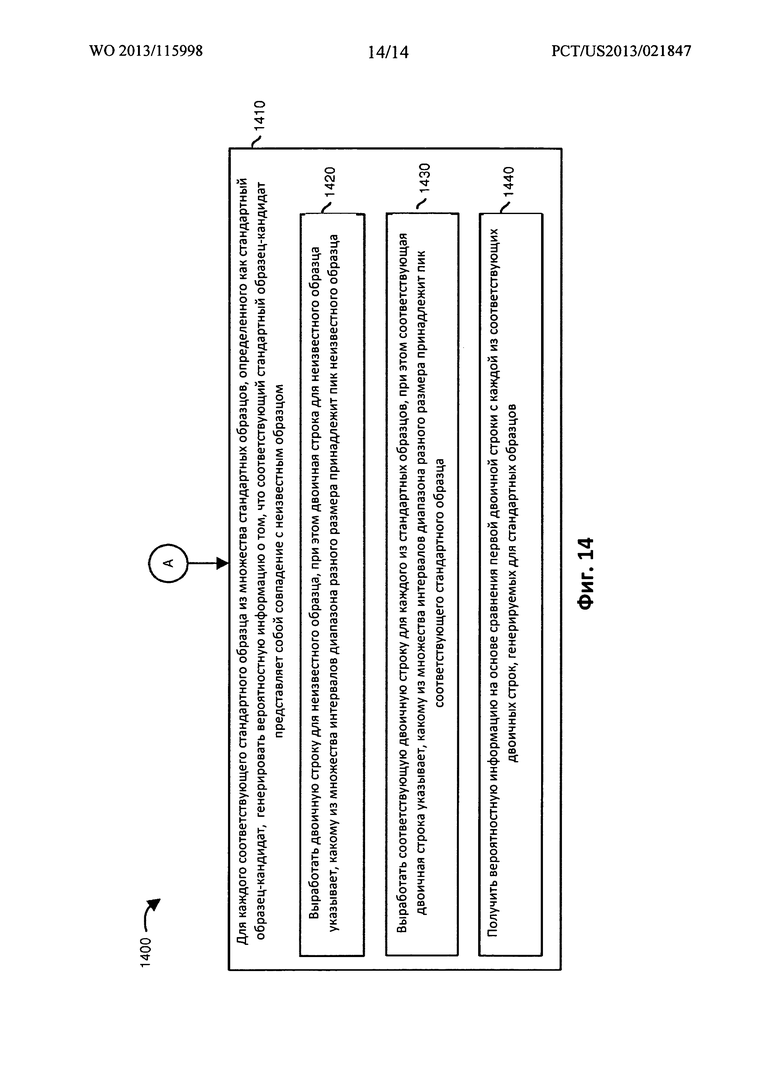
Изобретение относится к средствам обработки спектральных данных. Технический результат заключается в повышении точности определения шаблона спектральных данных, совпадающего с неизвестным образцом. Принимают спектральные данные каждого из множества стандартных образцов, связанных с конкретным материалом и содержащих сигнатуру пиков, распределенных по всему спектру, который идентифицирует упомянутый материал. Уплотняют спектральные данные множества стандартных образцов для осуществления распределения объединенных пиков от множества стандартных образцов по всему спектру. Разбивают распределение объединенных пиков в спектре на множество интервалов диапазона разного размера, каждый из которых содержит по существу одинаковое число объединенных пиков, при этом по меньшей мере один пик от двух или более стандартных образцов. Индексируют множество пиков спектральных данных от неизвестного образца по интервалам диапазона для получения сигнатуры указанных интервалов диапазона, которая включает индексацию каждого интервала диапазона, включающего пик от неизвестного образца. Генерируют вероятностную информацию о совпадении спектральных данных стандартного образца со спектральными данными неизвестного образца посредством сигнатуры интервалов диапазона. 4 н. и 21 з.п. ф-лы, 14 ил.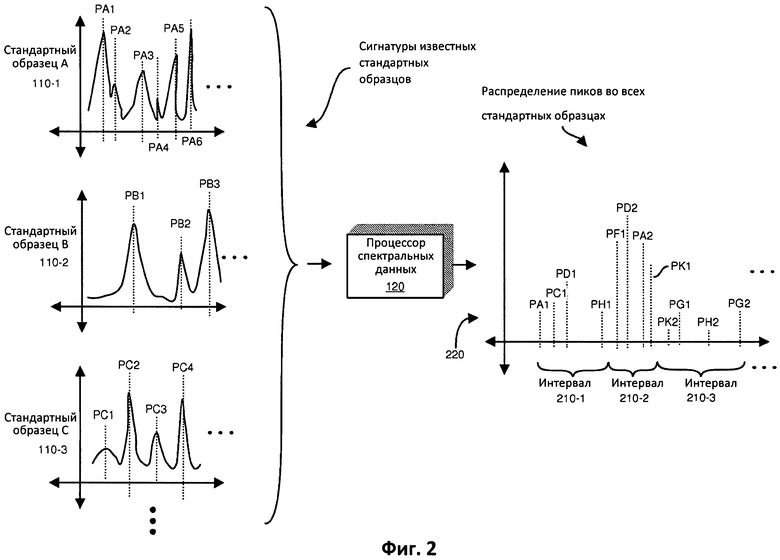
1. Способ обработки спектральных данных, содержащий следующие этапы:
прием спектральных данных каждого из множества стандартных образцов, связанных с конкретным материалом и содержащих сигнатуру пиков, распределенных по всему спектру, который идентифицирует упомянутый материал;
уплотнение спектральных данных множества стандартных образцов для осуществления распределения объединенных пиков от множества стандартных образцов по всему спектру;
разбиение распределения объединенных пиков в спектре на множество интервалов диапазона разного размера, каждый из которых содержит по существу одинаковое число объединенных пиков, при этом по меньшей мере один пик от двух или более стандартных образцов;
индексирование множества пиков спектральных данных от неизвестного образца по интервалам диапазона для получения сигнатуры указанных интервалов диапазона, которая включает индексацию каждого интервала диапазона, включающего пик от неизвестного образца; и
генерирование вероятностной информации о совпадении спектральных данных стандартного образца со спектральными данными неизвестного образца посредством сигнатуры интервалов диапазона.
2. Способ по п. 1, в котором этап генерирования вероятностной информации содержит:
идентификацию подмножества множества стандартных образцов посредством вероятностной информации, которая указывает на совпадение кандидатов с неизвестным образцом.
3. Способ по п. 1, в котором этап разбиения содержит:
установление значений ширины каждого из множества интервалов диапазона разного размера таким образом, чтобы в каждый из множества интервалов диапазона разного размера попадало необходимое количество объединенных пиков.
4. Способ по п. 1, в котором генерирование вероятностной информации осуществляют с применением двоичных арифметических операций с фиксированной запятой.
5. Способ по п. 1, дополнительно содержащий:
обработку спектральных данных множества стандартных образцов с целью идентификации сигнатуры пиков каждого стандартного образца.
6. Способ по п. 1, в котором этап разбиения содержит:
выбор границ интервалов диапазона разного размера в соответствии с моделью гипергеометрического распределения.
7. Способ по п. 1, дополнительно содержащий:
реализацию функции гипергеометрической вероятности для генерирования вероятностной информации.
8. Способ по п. 1, в котором этап индексирования содержит:
идентификацию принадлежности пика неизвестного образца конкретному интервалу диапазона из множества интервалов диапазона и установление индикатора в сигнатуре.
9. Способ по п. 1, в котором этап генерирования вероятности содержит:
вычисление вероятностной информации для проверки нулевой гипотезы о том, что совпадения пиков между стандартным образцом и данным стандартным образцом происходят случайно.
10. Способ по п. 2, в котором этап генерирования вероятностной информации содержит:
для каждого соответствующего стандартного образца из множества стандартных образцов:
генерирование значения k, указывающего количество событий попадания пика неизвестного образца в интервал, в котором находится пик соответствующего стандартного образца;
генерирование значения N, указывающего количество интервалов диапазона разного размера;
генерирование значения n, указывающего общее количество пиков, присутствующих в соответствующем стандартном образце; и
генерирование значения m, указывающего общее количество пиков, присутствующих в неизвестном образце.
11. Способ по п. 10, дополнительно содержащий:
генерирование вероятностной информации для каждого из соответствующих стандартных образцов при помощи следующего уравнения:
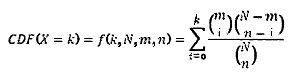
12. Способ по п. 1, в котором сигнатура интервалов диапазона является двоичной строкой, указывающей в каком из интервалов диапазона разного размера находятся пики неизвестного образца, а этап генерирования вероятностной информации основан на подобии между двоичной строкой, указывающей в каком из интервалов диапазона разного размера находится пик неизвестного образца, и двоичной строкой, указывающей в каком из интервалов диапазона разного размера находится пик стандартного образца.
13. Система обработки спектральных данных, содержащая: процессор; и
аппаратный ресурс хранения, связанный с процессором, при этом указанный аппаратный ресурс хранения содержит команды, которые, при их исполнении процессором, приводят к выполнению процессором следующих операций:
прием спектральных данных каждого из множества стандартных образцов, связанных с конкретным материалом и содержащих сигнатуру пиков, распределенных по всему спектру, который идентифицирует упомянутый материал;
уплотнение спектральных данных множества стандартных образцов для осуществления распределения объединенных пиков от множества стандартных образцов по всему спектру;
разбиение распределения объединенных пиков в спектре на множество интервалов диапазона разного размера, каждый из которых содержит по существу одинаковое число объединенных пиков, при этом по меньшей мере один пик от двух или более стандартных образцов;
индексирование множества пиков спектральных данных от неизвестного образца по интервалам диапазона для получения сигнатуры указанных интервалов диапазона, которая включает индексацию каждого интервала диапазона, включающего пик от неизвестного образца; и
генерирование вероятностной информации о совпадении спектральных данных стандартного образца со спектральными данными неизвестного образца посредством сигнатуры интервалов диапазона.
14. Система по п. 13, в которой этап генерирования вероятностной информации содержит:
идентификацию подмножества множества стандартных образцов посредством вероятностной информации, которая указывает на совпадение кандидатов с неизвестным образцом.
15. Система по п. 13, в которой этап разбиения содержит:
установление ширины каждого из множества интервалов диапазона разного размера таким образом, чтобы в каждый из множества интервалов диапазона разного размера попадало необходимое количество объединенных пиков.
16. Система по п. 13, в которой процессор дополнительно выполняет операции по вычислению вероятностной информации с применением двоичных арифметических операций с фиксированной запятой.
17. Машиночитаемое запоминающее аппаратное средство, содержащее хранящиеся в нем команды, которые при их исполнении устройством обработки данных приводят к выполнению указанным устройством обработки данных следующих операций:
прием спектральных данных каждого из множества стандартных образцов, связанных с конкретным материалом и содержащих сигнатуру пиков, распределенных по всему спектру, который идентифицирует упомянутый материал;
уплотнение спектральных данных множества стандартных образцов для осуществления распределения объединенных пиков от множества стандартных образцов по всему спектру;
разбиение распределения объединенных пиков в спектре на множество интервалов диапазона разного размера, каждый из которых содержит по существу одинаковое число объединенных пиков, при этом по меньшей мере один пик от двух или более стандартных образцов;
индексирование множества пиков спектральных данных от неизвестного образца по интервалам диапазона для получения сигнатуры указанных интервалов диапазона, которая включает индексацию каждого интервала диапазона, включающего пик от неизвестного образца; и
генерирование вероятностной информации о совпадении спектральных данных стандартного образца со спектральными данными неизвестного образца посредством сигнатуры интервалов диапазона.
18. Машиночитаемое запоминающее аппаратное средство по п. 17, содержащее хранящиеся в нем команды, которые при их исполнении устройством обработки данных приводят к выполнению указанным устройством обработки данных дополнительной операции:
сохранение двоичной строки для каждого стандартного образца, отображающей, какому из множества интервалов диапазона разного размера принадлежат пики стандартного образца.
19. Машиночитаемое запоминающее аппаратное средство по п. 17, содержащее хранящиеся на нем команды, которые при их исполнении устройством обработки данных приводят к выполнению указанным устройством обработки данных дополнительной операции:
установление ширины каждого из множества интервалов диапазона разного размера так, чтобы в каждый из множества интервалов диапазона разного размера попадало необходимое количество объединенных пиков, осуществляемое при разбиении распределения объединенных пиков в спектре на множество интервалов диапазона разного размера.
20. Машиночитаемое запоминающее аппаратное средство по п. 17, содержащее хранящиеся в нем команды, которые при их исполнении устройством обработки данных приводят к выполнению указанным устройством обработки данных дополнительной операции:
выбор границ интервалов диапазона разного размера в соответствии с моделью гипергеометрического распределения, осуществляемый при разбиении распределения объединенных пиков в спектре на множество интервалов диапазона разного размера.
21. Способ обработки спектральных данных, содержащий:
прием информации об интервалах диапазона, в том числе о множестве интервалов диапазона разного размера, где каждый интервал диапазона содержит по существу равное количество объединенных пиков, взятых из уплотненных спектральных данных от множества стандартных образцов, при этом по меньшей мере один пик взят от двух или более стандартных образцов, каждый стандартный образец относится к уникальному материалу и спектральные данные содержат сигнатуру пиков, распределенных по всему спектру, который идентифицирует упомянутый материал;
индексирование множества пиков в спектральных данных неизвестного образца по интервалам диапазона для получения сигнатуры указанных интервалов диапазона, которая включает индексацию каждого интервала диапазона, включающего пик неизвестного образца; и
генерирование вероятностной информации о совпадении спектральных данных стандартного образца со спектральными данными неизвестного образца посредством сигнатуры интервалов диапазона.
22. Способ по п. 21, дополнительно содержащий:
идентификацию подмножества множества стандартных образцов посредством вероятностной информации, которая указывает на совпадения кандидатов с неизвестным образцом.
23. Способ по п. 21, в котором значения ширины каждого из множества интервалов диапазона разного размера устанавливаются так, чтобы в каждый из множества интервалов диапазона разного размера попадало необходимое количество объединенных пиков.
24. Способ по п. 21, дополнительно содержащий:
генерирование вероятностной информации с применением двоичных арифметических операций с фиксированной запятой.
25. Способ по п. 21, дополнительно содержащий:
реализацию функции гипергеометрической вероятности для генерирования вероятностной информации.
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| СПОСОБ И СИСТЕМА ДЛЯ ОЦЕНКИ ОБРАЗЦОВ | 2005 |
|
RU2389983C2 |

