Область техники, к которой относится изобретение
Варианты осуществления изобретения относятся к оптической связи с системами памяти в главном устройстве. Более конкретно, варианты осуществления изобретения относятся к технологиям обеспечения оптической связи между электронными устройствами (например, ядрами обработки, запоминающими устройствами, контроллерами запоминающего устройства), в соответствии с протоколами, используемыми электронными устройствами.
Уровень техники
По мере повышения вычислительной мощности обработки и увеличения количества ядер обработки, которые могут быть включены в один кристалл, необходимо соответствующее увеличение полосы пропускания запоминающего устройства для поддержания сбалансированных рабочих характеристик системы. Существующая архитектура и технологии обычно не обеспечивают достаточную масштабируемость для обеспечения соответствующего увеличения полосы пропускания запоминающего устройства.
Краткое описание чертежей
Варианты осуществления изобретения представлены в качестве примера, а не для ограничения, и на чертежах одинаковые номера ссылочных позиций обозначают аналогичные элементы.
На фиг. 1 показана блок-схема одного варианта осуществления оптического интерфейса.
На фиг. 2 показана временная диаграмма одного варианта осуществления процесса инициализации сигнала интерфейса уплотнителя.
На фиг. 3 показана блок-схема последовательности операций одного варианта осуществления для операции уплотнителя Q2S в состоянии оптической тренировочной структуры.
На фиг. 4 показана блок-схема последовательности операций одного варианта осуществления для операции уплотнителя S2Q в состоянии оптической тренировочной структуры.
На фиг. 5 показана блок-схема одного варианта осуществления системы расширения оптического запоминающего устройства (ОМЕ).
На фиг. 6 показана схема высокого уровня одного варианта осуществления модуля Q2S.
На фиг. 7 показана блок-схема одного варианта осуществления аналогового входного блока Q2S (Q2SAFE).
На фиг. 8 показана блок-схема одного варианта осуществления Q2S, приемного аналогового входного блока (RxAFE).
На фиг. 9а показана принципиальная схема одного варианта осуществления архитектуры RxAFE для операции с нормальной скоростью.
На фиг. 9b показана принципиальная схема одного варианта осуществления архитектуры RxAFE для операции с высокой скоростью.
На фиг.10 показана блок-схема одного варианта осуществления схемы двухвыводного DFE/сэмплера.
На фиг. 11 показана, в качестве примера, схема выборки для половинной скорости.
На фиг. 12 показана схема одного варианта осуществления полного канала передачи данных Q2S и архитектуры канала тактовой частоты.
На фиг. 13 показана схема высокого уровня одного варианта осуществления модуля S2Q.
На фиг. 14 показана блок-схема одного варианта осуществления логики управления (SCL) S2Q.
На фиг. 15 показана блок-схема одного варианта осуществления аналогового входного блока S2Q.
На фиг. 16 показана блок-схема одного варианта осуществления S2Q, приемного аналогового входного блока (RxAFE).
На фиг. 17а показана принципиальная схема одного варианта осуществления архитектуры RxAFE для операции с нормальной скоростью.
На фиг. 17b показана принципиальная схема одного варианта осуществления архитектуры RxAFE для операции с высокой скоростью.
На фиг. 18, в качестве примера, показана схема выборки с квадратичной частотой.
На фиг. 19 показана блок-схема одного варианта осуществления архитектуры схемы передачи S2Q.
На фиг. 20 показана принципиальная схема одного варианта осуществления полной архитектуры канала передачи данных S2Q и канала тактовой частоты.
На фиг. 21 показаны варианты осуществления многопроцессорных конфигураций, использующих архитектуру взаимного соединения с высокими рабочими характеристиками.
На фиг. 22 показан вариант осуществления многоуровневого стека для архитектуры взаимного соединения с высокими рабочими характеристиками.
Подробное описание изобретения В следующем описании представлены различные конкретные детали. Однако варианты осуществления изобретения могут быть выполнены на практике без этих конкретных деталей. В других случаях хорошо известные схемы, структуры и технологии не были подробно представлены для того, чтобы не усложнять понимание данного описания.
Архитектура и технологии, описанные здесь, предусматривают оптический конечный автомат и секвенсер обучающей последовательности, для обеспечения расширения оптического запоминающего устройства. Используя масштабирование технологии, современные встроенные серверные процессоры и графические процессоры уже содержат десятки сотен ядер на одном кристалле, и количество ядер продолжает увеличиваться до тысяч узлов при использовании технологии 11 нм или 8 нм. Соответствующее увеличение полосы пропускания запоминающего устройства и емкости также требуется для повышения сбалансированных рабочих характеристик системы. Эти архитектуры и технологии нацелены на расширение полосы пропускания запоминающего устройства, используя оптические взаимные соединения, называемыми оптическим расширением запоминающего устройства.
В одном варианте осуществления описанные архитектура и технология могут использоваться для внедрения протокола скоростного канала взаимных соединений (QPI) корпорации Intel с оптическими взаимными соединениями с общепринятыми серверами, клиентами, системами на микросхеме (SoC), компьютерами для высокопроизводительных вычислений (НРС), и платформами информационных центров обработки данных. Взаимное соединение QuickPath компании Intel представляет собой взаимное соединение процессора из "точки-в-точку", разработанное компанией Intel<http://en.wikipedia.org/wiki/Intel>, которое на некоторых платформах заменяет системную шину <http://en.wikipedia.org/wiki/Front-side_bus>(FSB).
Протокол QPI представляет собой высокоскоростной протокол пакетной передачи данных для взаимного соединения из точки в точку, который позволяет с помощью узких высокоскоростных соединений соединять вместе обрабатывающие ядра и другие узлы в архитектуре распределенной платформы, работающей в стиле совместно используемого запоминающего устройства. Протокол QPI предлагает широкую полосу пропускания с малой задержкой. Протокол QPI включает в себя протокол слежения, оптимизированный для малой задержки и обладающий высокой степенью масштабируемости, а также структуры пакетов и структуры линий, обеспечивающие быстрое завершение транзакций.
В одном варианте осуществления уровень протокола QPI управляет когерентностью кэш для интерфейса, используя протокол с обратной записью. В одном варианте осуществления также он имеет набор правил для управления некогерентной передачей сообщений. Уровень протокола обычно соединяется с конечным автоматом когерентности кэш в агентах кэширования, и с собственной логикой агента в контроллерах запоминающего устройства. Уровень протокола также отвечает на функции системного уровня, такие как прерывания, I/O, отображаемые запоминающем устройстве, и фиксацию. Одна основная характеристика уровня протокола представляет собой то, что он работает с сообщениями через множество соединений, включающих в себя множество агентов во множестве устройств.
В одном варианте осуществления архитектура и технологии, описанные здесь, используются для расширения QPI с помощью оптического средства. В одном варианте осуществления конечный автомат и секвенсер, описанные ниже, работают так, чтобы получить протокол QPI без информирования о лежащем в его основе оптическом соединении.
В результате масштабирования технологии современные встроенные процессоры сервера и графические процессоры уже содержат от десятков до сотен ядер на одном кристалле, и количество ядер продолжает увеличиваться даже до тысячи или больше при использовании процессов с технологией производства 11 нм или 8 нм. Такая архитектура, описанная здесь, работает для обеспечения такой полосы пропускания запоминающего устройства, используя оптические взаимные соединения, называемые оптическим расширением запоминающего устройства в протоколе QPI.
Для установления оптического домена соединения с полной скоростью передачи данных, как для тактовой частоты, так и для линий передачи данных, необходима фаза оптического обучения. В одном варианте осуществления после нее следует фаза согласования QPI, в течение которой удаленные и промежуточные компоненты устанавливают протокол передачи данных для линии 0 передачи данных и линии 5 передачи данных, для каждой половины оптического соединения. Сообщения передают по оптическому соединению с полной скоростью передачи данных. В одном варианте осуществления фрейм сообщения синхронизируют с опорной тактовой частотой, и только один фрейм сообщения передают за период опорной тактовой частоты.
В одном варианте осуществления сообщение включает в себя преамбулу, команду, данные и заключительную часть. В одном варианте осуществления преамбула представляет собой 16-битовый поток со структурой данных FFFE, которая помечает начало фрейма сообщения. Другие структуры также можно использовать. В одном варианте осуществления поле команды представляет собой 8-битное поле потока для передачи действия для приема интерфейса, который следует применить. Каждый бит представляет команду для очень простого декодирования. Бит 7 может использоваться для расширенных команд, если необходимо. В одном варианте осуществления поле данных представляет собой поле 8-битного потока, содержащее данные, относящиеся к команде. В одном варианте осуществления заключительная часть представляет собой 4-битный поток, повторяющий структуру 1100 для заполнения остаточной части потока данных до конца периода опорной тактовой частоты. Эта структура заканчивается последними двумя битами в потоке, такими, как 0, таким образом, чтобы можно было идентифицировать преамбулу.
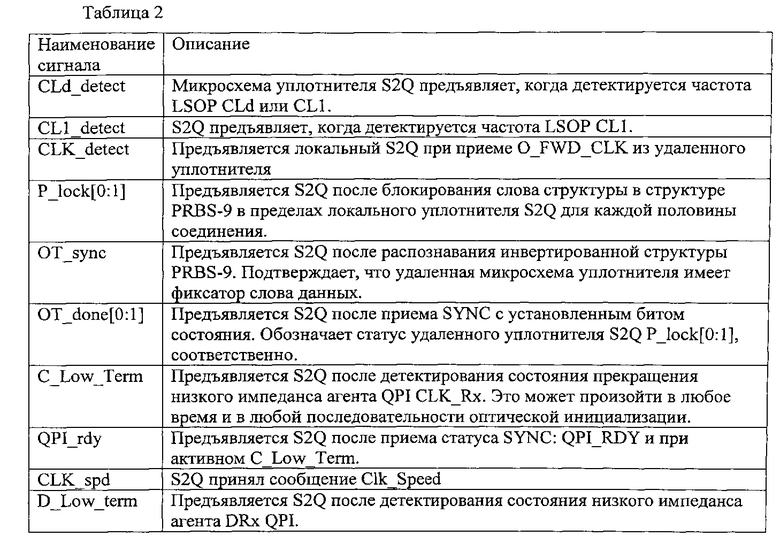
На фиг. 1 показана блок-схема одного варианта осуществления оптического интерфейса. Основные компоненты интерфейса представляют собой следующие: 1) микросхема уплотнителя электро (например, QPI) - оптической (например, на основе кремниевой фотоники, SiP) передачи (Тх), (Q2S) 110; 2) микросхема уплотнителя оптико-электрического приема (Рос), (S2Q) 120; 3) возбуждение модулятора; 4) оптический модуль (SiP) передачи (ТХ) 140; 5) приемный (RX) модуль 150 SiP; и 6) трансимпедансный усилитель (TIA).
В одном варианте осуществления промежуточные компоненты (110, 120) содержат 2:1 параллельно-последовательный/последовательно-параллельный преобразователь (SERDES), который мультиплексирует электрические (например, 20 QPI) линии передачи данных в (например, 10) линии, которые стыкуются с модулем SiP, выполняющим электро-оптическое преобразование. В других вариантах осуществления могут поддерживаться другие отношения и другие количества линий. В одном варианте осуществления оптическая линия разделена на две половины, по нижней половине передают нижние линии 0:9 данных, и по верхней половине передают верхние линии 10:19 данных. В других вариантах осуществления могут поддерживаться другие конфигурации.
Агент 190 представляет собой электрический компонент, который связывается с удаленным компонентом (например, запоминающим устройством), который не показан на фиг. 1. Агент 190 может, например, представлять собой ядро обработки или другой системный компонент. В одном варианте осуществления агент 190 предоставляет сигнал тактовой частоты передачи (ТХ), а также данные ТХ (например, 0-19) в микросхему 110 уплотнителя Q2S. В некоторых вариантах осуществления агент 190 также может предоставлять сигнал системной тактовой частоты, сигнал системного сброса и сигнал I2C в микросхему 110 уплотнителя Q2S. В одном варианте осуществления агент 190 принимает из микросхемы 120 уплотнителя S2Q сигнал опережения тактовой частоты ТХ и принимает (RX) данные (например, 0-19). В некоторых вариантах осуществления агент 190 также может предоставлять сигнал системной тактовой частоты, сигнал системного сброса и сигнал I2C в микросхему 120 уплотнителя S2Q.
В одном варианте осуществления микросхема 110 уплотнителя Q2S и микросхема 120 уплотнителя S2Q соединены так, что микросхема 120 уплотнителя S2Q передает сигналы управления в микросхему 110 уплотнителя Q2S. Выходные сигналы из микросхемы 110 уплотнителя Q2S включают в себя сигнал тактовой частоты ТХ (например, ТХ O_Clk), сигналы данных (например, ТХ O_Data 0:9) и сигналы управления в один или больше передающих оптических модулей 140. Входные сигналы в микросхему 120 уплотнителя S2Q включают в себя сигнал тактовой частоты RX (например, RX O_Clk), сигналы данных (например, RX O_Data 0:9) и сигналы управления из одного или больше приемных оптических модулей 150.
Для установления возможности оптического соединения, конечный автомат, описанный ниже с обучающей последовательностью, используется с оптическим интерфейсом по фиг. 1. В одном варианте осуществления первыми устанавливаются инициирующая последовательность изнутри наружу оптико-электронного соединения, возможность соединения оптического домена. Эта прозрачная оптическая линия затем используется для электрического (например, QPI) согласования параметров связи, и соединение устанавливается между электрическими агентами. Оптический домен имеет 4 основных фазы для последовательности инициализации, представленной в Таблице 1:

В одном варианте осуществления существует локальный интерфейс уплотнителя между микросхемой 110 уплотнителя Q2S и микросхемой 120 уплотнителя S2Q, которая синхронизирует оптические действия Тх и Rx соединений между двумя компонентами. Этот интерфейс управляется из уплотнителя S2Q 120 и обеспечивает соответствующий переход состояния и фаз уплотнителя Q2S110, соответственно. Один вариант осуществления этого интерфейса определен в Таблице 2.
На фиг. 2 показана временная диаграмма одного варианта осуществления процесса инициализации сигнала интерфейса уплотнителя. В одном варианте осуществления, на фазе 210 оптического соединения оптический модуль вводит состояние оптического соединения либо в ходе полного/"холодного" сброса, "горячего" сброса, или из сброса в полосе (IBreset), детектируемого в электронном (например, QPI) интерфейсе. Функция этого состояния состоит в том, чтобы установить оптическую связь по соединению. В одном варианте осуществления, после ввода в фазу 210 оптического соединения, микросхема 120 уплотнителя S2Q отменяет завершение (в состоянии высокого импеданса), всех линий тактовой частоты и Data Rx на электрической стороне.
В одном варианте осуществления, фаза 210 оптического соединения включает в себя три уровня: Отключено, исходное состояние уровня оптического соединения (OCLd) и уровень 1 оптического соединения (OLC1). В одном варианте осуществления, на уровне отключения после приема сигнала получения пихания или "холодного" сброса, оптический домен переходит в отключенное состояние. Микросхема 120 уплотнителя S2Q при этом отменяет завершение (в состоянии высокого импеданса), всех линий интерфейса тактовой частоты и данных RX на электрической стороне. В отключенном состоянии все лазеры выключены. Все логические состояния инициализируют до их состояния сброса при включении питания. После окончания сигнала "сброс" оптический модуль входит в оптическое состояние. В одном варианте осуществления все PLL блокированы, во время состояния отключения.
В одном варианте осуществления, в состоянии OCLd, оптический модуль передает оптические импульсы с низкой скоростью LSOP через оптические линии тактовой частоты O_CLK между оптическими модулями, которые содержат соединение. В одном варианте осуществления LSOP представляет собой LSLE при заданной скорости CLd и рабочем цикле, используя разрешенную работу лазера для передачи с низкой скоростью. В одном варианте осуществления выходной сигнал LSLE включает и выключает лазер вместо использования схемы модулятора высокой мощности. В одном варианте осуществления это осуществляется только в линиях опережения тактовой частоты в этом состоянии, для определения исходной оптической связи по соединению.
В одном варианте осуществления, в этом состоянии микросхема 110 уплотнителя Q2S поддерживает свое состояние завершения Rx в состоянии высокого импеданса для обеих линий тактовой частоты и передачи данных. Это предотвращает выход электрического агента (например, 190 на фиг. 1) за пределы состояния детектирования тактовой частоты протокола инициализации электрического соединения.
В одном варианте осуществления микросхема 120 уплотнителя S2Q при приеме сигнала LSOD выполняют детектирование света из удаленного оптического модуля. В одном варианте осуществления, когда микросхема 120 уплотнителя S2Q принимает три последовательных LSOP, она вырабатывает сигнал CLd_detected для идентификации локальной микросхемы 110 уплотнителя Q2S, которая принимает импульсы. Следует отметить, что возможно принимать LSOP со скоростью CL1, зависящей от порядка, в котором подключены кабели. В этом случае микросхема 120 уплотнителя S2Q будет подсчитывать 16 последовательных импульсов CL1 перед активацией сигнала CLddectect.
В одном варианте осуществления микросхема 110 уплотнителя Q2S остается в состоянии OCLd минимум в течение времени TCLD_sync, которое определено регистром CSR. В этом варианте осуществления микросхема 110 уплотнителя Q2S переходит в состояние OCL1 после выработки сигнала CLd_dectect и по завершению работы таймера TCLD_sync.
В одном варианте осуществления состояние Уровень 1 оптического соединения обозначает, что микросхема 120 уплотнителя S2Q принимает LSOP по линиям тактовой частоты и вырабатывает сигнал CLd_detect. В одном варианте осуществления микросхема 110 уплотнителя Q2S подтверждает CLd_dectect путем передачи LSOP по линиям O_CLK с определенной скоростью CL1. Когда микросхема 120 уплотнителя S2Q принимает два последовательных импульса CL1 (после выработки CLd_detect), она подает сигнал CLl_detect, обеспечивающий переход 110 уплотнителя Q2S в фазу оптического обучения.
В одном варианте осуществления, если микросхема 110 уплотнителя Q2S прекращает принимать LSOP по линиям O_CLK в течение неактивного периода, она формирует сигналы CLd_detect и CLl_detect. Затем микросхема 110 уплотнителя Q2S переходит обратно в состояние OCLd и перестает передавать LSOP в течение периода времени для повторной синхронизации LSOP, для синхронизации последовательности оптического соединения.
В варианте осуществления, в состоянии ОСЫ, микросхема 110 уплотнителя Q2S поддерживает свое завершение Rx в состоянии высокого импеданса для обоих линий передачи тактовой частоты и данных. Это предотвращает выход электрического агента за пределы состояния детектирования тактовой частоты в протоколе инициализации QPI.
Назначение фазы 230 оптического обучения состоит в том, чтобы устанавливать оптический домен соединения с полной скоростью передачи данных по обеим линиям для передачи тактовой частоты и данных. В этой фазе O_FWD_CLK начинает передачу во время состояния восстановления обучения при рабочей тактовой частоте, используя выход модулятора. В то же время микросхема 110 уплотнителя Q2S начинает передачу заранее выбранной структуры (например, структуры PRBS-9) по линиям передачи данных для обучения соединения.
В состоянии восстановления оптического обучения, OTR, оптоволоконное соединение было установлено на обоих концах оптического соединения. В этом состоянии микросхема уплотнителя Q2S прекращает передачу LSOP и начинает передачу O_FWD_CLK, используя модулированный выходной сигнал. Тактовая частота будет передана при рабочей скорости тактовой частоты, (например, 3,2 ГГц), генерируемой из опорной тактовой частоты PLL. Альтернативная операция в медленном режиме будет описана в других местах. Когда микросхема уплотнителя S2Q фиксируется на O_FWD_CLK, она передает сигнал CLK_detect и переходит в состояние структуры оптического обучения.
Цель состояния структуры оптического обучения состоит в том, чтобы обучить оптическое соединение и установить взаимосвязи фаз электрической линии для мультиплексированных данных по оптической линии в соответствии с опережающей оптической тактовой частотой. В одном варианте осуществления это выполняется путем передачи заданной структуры (например, PRBS 9) через линию оптических данных с четными битами (0, 2, 4, …), генерируемыми в линии А для пучка линий передачи данных и нечетных битов (1, 3, 5, …) в линии В для пучка линий передачи данных. В одном варианте осуществления дополнительный бит добавляют к стандартным потокам битов 511, для получения нечетного количества битов. Ориентацию линии демультиплексирования выводят из синхронизации управления высокоскоростного канала передачи данных по структуре фиксирования слова.
В одном варианте осуществления таймер фиксации данных начинает работу, когда подают одну из P_lock [0:1], и выключается, когда подают оба сигнала. В случае окончания работы таймера, микросхема уплотнителя предполагает, что нет возможности обеспечить фиксацию структуры, и отключает половину соединения, по которой не был передан его сигнал фиксации структуры. Затем обработка переходит к оптической инициализации оптического домена в режиме половины соединения. Микросхема уплотнителя останется в состоянии OTP, если не будет подан ни один из сигналов Р_lock.
На фиг. 3 показана блок-схема последовательности операций одного варианта осуществления работы уплотнителя Q2S в течение состояния структуры оптического обучения. В одном варианте осуществления, во время состояния структуры оптического обучения, микросхема уплотнителя Q2S передает заданную структуру обучения 305. В одном варианте осуществления она представляет собой структуру обучения PRBS-9; однако, другие структуры обучения также могут использоваться.
Микросхема уплотнителя Q2S ожидает приема сигнала тактовой частоты из уплотнителя S2Q, 310. В одном варианте осуществления, в состоянии OTP, (подан сигнал Clk_detect), S2Q выполняет обучение по входящему потоку данных, присутствующему в линиях передачи данных. В случае, когда она будет затем зафиксирована по структуре слова по всем линиям передачи данных, содержащимся в половине соединения, 315, микросхема уплотнителя S2Q подает соответствующий сигнал Р_lock [0:1].
В одном варианте осуществления, после подачи сигнала Р_lock, микросхема уплотнителя Q2S передает инвертированную, предварительно выбранную (например, PRBS-9) структуру по одной из линий данных для соответствующей половины соединения, 320. Это действует, как подтверждение для удаленного конца о том, что выполняется приема и была выполнена фиксация потока битов. В одном варианте осуществления Q2S не требуется ожидать обоих сигналов Р_lock или Р_lock по истечению времени для передачи инвертированных данных. Следует отметить, что при этом возможно принимать инвертированную структуру PRBS перед достижением фиксации локальной структуры. Схема фиксации, в этом случае, должна будет различать не инвертированную или инвертированную структуру.
После выработки сигнала OT_sync, 325, микросхема уплотнителя Q2S передает в сообщении Sine синхронизации полосы Р_lock и состояние обучение выполнено, 350. Если микросхема уплотнителя находится в диагностическом режиме, 330, статус выполнено не будет передан. В диагностическом режиме передают команду на запуск, 335, и запускается диагностика, 340, пока не будет принята команда остановки, 345. Статус выполнено передают, 350, после окончания режима диагностики для вывода оптического соединения из фазы обучения. Микросхема уплотнителя Q2S передает сообщение Sine со статусом QPI_rdy, обозначающим, что ее локальный агент QPI готов передавать тактовую частоту FWD и что оптическое обучение закончено (OT_done), 355.
На фиг. 4 показана блок-схема последовательности операций одного варианта осуществления для работы уплотнителя S2Q во время состояния структуры оптического обучения. В одном варианте осуществления S2Q принимает переданный сигнал тактовой частоты из уплотнителя Q2S. После получения фиксации бита по сигналу тактовой частоты, 400, микросхема уплотнителя S2Q передает сигнал Clk_detect, 405, в микросхему уплотнителя Q2S, переходящую в состояние оптического обучения. Микросхема уплотнителя Q2S продолжает передавать структуру обучения (например, PRJBS-9) по линиям передачи данных.
В одном варианте осуществления, в состоянии OTP, (при переданном Clk_detect), микросхема уплотнителя S2Q выполняет обучение по входящему потоку данных, присутствующих в линиях 0_DRx. После ее успешной фиксации по структуре слова для всех линий передачи данных, содержащихся в половине соединения, 410, микросхема уплотнителя S2Q подает соответствующий сигнал Р_lock [0:1], 415. В одном варианте осуществления, после распознавания инвертированной обучающей структуры для минимального числа (например, 2, 3, 4) успешных последовательностей по обеим половинам соединения, 420, микросхема уплотнителя S2Q подает сигнал OT_sync, 425. В одном варианте осуществления, если истекает время для Р_lock, тогда сигнал OT_sync будет передан, и последовательность инициализации продолжается с использованием половины соединения, которая закончила обучение. Выработка OT_sync обозначает, что удаленная микросхема уплотнителя S2Q имеет фиксацию структуры данных и что локальная микросхема уплотнителя приняла подтверждение, как обозначено инвертированной структурой обучения. S2Q принимает сообщение Sine с активным битом статуса выполнено, 430, она передает сигналы OT_done [0:1], 450, в соответствии со статусом Р_lock переданным в сообщении.
В заключение описания фиг. 3 и 4 микросхемы уплотнителя Q2S и S2Q находятся в состоянии выполненного оптического обучения (OTD). Назначение состояния выполненного оптического обучения состоит в том, чтобы синхронизировать готовность электрического агента по окончанию оптического обучения. В одном варианте осуществления микросхема уплотнителя Q2S продолжает находиться в этом состоянии, передавая инвертированную структуру обучения до тех пор, пока она не детектирует, что электрический агент находится в состоянии низкого импеданса. Следует отметить, что электрический агент мог бы включить состояние низкого импеданса в любое время в течение последовательности оптической инициализации.
Что касается фиг. 2, фаза 250 соединения QPI отвечает за установление электрического соединения агента QPI с оптическим доменом, (компоненты уплотнителя). На этой фазе состояние детектирования тактовой частоты QPI из удаленного Агента QPI, синхронизируется с состоянием детектирования тактовой частоты QPI локального агента QPI, как обозначено сигналом QPI_rdy уплотнителя S2Q. В состоянии, готовности приема данных QPI, QPI Drdy, микросхема уплотнителя S2Q будет определять входные данные линии передачи данных из агента QPI. Когда она определяет значение постоянного тока, (1 или 0), она переходит к внутренним линиям передачи данных из генератора структуры к линиям передачи данных от агента QPI. В оптически активном состоянии модуль SiP является прозрачным для соединения QPI.
В альтернативных вариантах осуществления другие протоколы, кроме QPI, можно использовать в обучающих последовательностях с другой длиной, скремблированных с другими структурами PRBS и/или рассеянными с другими структурами, используемыми для обучения и/или быстрой фиксации.
На фиг. 5 показана блок-схема одного варианта осуществления системы расширения оптического запоминающего устройства (ОМЕ). В одном варианте осуществления системная архитектура по фиг. 5 включает в себя конструкцию микроархитектуры уплотнителя для формирования интерфейса для оконечных агентов ядра QPI обработки с оптическим расширением для взаимного соединения со строительными блоками Тх и Rx, и схемами примеров варианта осуществления.
В одном варианте осуществления микросхема уплотнителя имеет два типа модулей. Микросхема уплотнителя 510 Q2S и микросхема уплотнителя 545 Q2S представляют собой модули одного и того же типа, которые принимают сигналы от конечного агента QPI (например, ядро 505, ядро 540), и передают эти сигналы в модуль возбуждения модулятора SiP (например, 515, 550). В следующем описании, модули этого типа называются модулем Q2S (QPI2SIP) или микросхемой уплотнителя Тх.
В одном варианте осуществления модуль Q2S (например, 510, 545) принимает дифференциальные сигналы передачи Данных в 20 линиях с собственной скоростью QPI (например, 6,4 Гбит/с, 8 Гбит/с, 9,6 Гбит/с, 11,2 Гбит/с, 12,8 Гбит/с), и дифференциальные сигналы тактовый частоты с опережением по одной линии тактовой частоты с половинной частотой относительно скорости передачи данных (соответственно, 3,2 ГГц, 4 ГГц, 4,8 ГГц, 5,6 ГГц и 6,4 ГГц) из оконечного агента QPI (например, 505, 540). Другие рабочие частоты также могут поддерживаться. Затем модуль Q2S (например, 510, 545) будет обеспечивать соответствующую выборку данных, используя сэмплеры с половинной частотой, перенастроенные с использованием буфера синхронизации, последовательно включенные (2:1) в потоки данных с удвоенной частотой (соответственно, 12,8 Гбит/с, 16 Гбит/с, 19,2 Гбит/с, 22,4 Гбит/с, 25,6 Гбит/с), и передаваемые в модули возбуждения модулятора SiP (например, 515, 550). Следовательно, в одном варианте осуществления выходы Q2S имеют 10 линий для передачи данных с удвоенной скоростью передачи данных и одну линию передачи тактовой частоты при половинной частоте передачи данных. В альтернативном варианте осуществления линия передачи тактовой частоты может отсутствовать, и любые и все из линий данных можно использовать вместо линии для передачи тактовой частоты.
В одном варианте осуществления модуль S2Q (например, 535, 570) принимает дифференциальные сигналы данных по 10 линиям с удвоенной частотой передачи данных и дифференциальные сигналы тактовой частоты по одной линии тактовой частоты с частотой, составляющей половину частоты, из модуля TIA (например, 530, 565). Аналогично, модули S2Q (например, 535, 570) обеспечивают то, что сигналы будут правильным образом квантованы с использованием сэмплеров с квадратичной частотой, перенастроенные с буферами синхронизации, включенными последовательно (2:1) в потоки данных с полной скоростью передачи данных, и передаваемые в разные оконечные агенты QPI (например, 540, 505). Следовательно, выходы Q2S (например, 535, 570) возвращаются обратно в 20 линии передачи данных при собственной скорости QPI и одной линии передачи тактовой частоты с частотой, составляющей половину скорости передачи данных. В одном варианте осуществления операции между микросхемой уплотнителя Q2S и микросхемой уплотнителя S2Q (например, 510-535 и 545-570) должны быть прозрачными для оконечных агентов QPI (505, 540), за исключением индуцированной задержки.
На фиг. 6 показана схема верхнего уровня одного варианта осуществления модуля Q2S. В одном варианте осуществления модуль 600 Q2S включает в себя два основных участка: цифровая сторона 610 и аналоговая сторона 650. В одном варианте осуществления цифровая сторона 610 включает в себя цепь 615 сканирования, регистры 620 управления и состояния, логические схемы оптического управления (OCL) 625 и логическую схему 630 управления Q2S (QCL). В одном варианте осуществления аналоговая сторона 650 включает в себя систему 655 фазовой автоподстройки частоты (PLL), модуль (VRM) 660 регулятора напряжения, аналоговый генератор 665 и аналоговый входной блок (Q2SAFE) Q2S 670.
Ключевой блок в модуле 600 микросхемы уплотнителя Q2S представляет собой модуль 670 Q2SAFE, который выполняет прием данных восстановления синхронизации, преобразования в последовательные данные 2:1, и передачу данных с удвоенной скоростью в возбуждение модулятора SiP. Качество конструкции Q2SAFE и ее воплощение определяют рабочую скорость, задержку и потребление энергии уплотнителя 600 Q2S.
В одном варианте осуществления QCL 625 представляет собой логическую схему, которая содержит несколько модулей, которые управляют функций Q2SAFE 670. QCL 625 не является частью пути передачи данных, но она обеспечивает установку синхронизации буфера, которая приводит к различной задержке в канале передачи данных. В одном варианте осуществления QCL 625 состоит, по меньшей мере, из следующих функций для управления каналом передачи данных и управления каналом передачи тактовой частоты.
В одном варианте осуществления, при управлении каналом передачи данных, QCL 625 обеспечивает, по меньшей мере, соединение онлайн (описанное ниже), синхронизацию буфера (Sync_FIFO), управление Icomp, управление Rcomp, управление AG и DFE, управление PLL и управление DFX. В одном варианте осуществления, при управлении каналом передачи тактовой частоты, QCL 625 обеспечивает, по меньшей мере, управление CDR, детектирование активности тактовой частоты, переданной с опережением, и управление PLL
На фиг. 7 показана блок-схема одного варианта осуществления аналогового переднего блока предварительной обработки данных по Q2S (Q2SAFE). Q2SAFE 670 представляет собой канал передачи данных по Q2S 600. В одном варианте осуществления Q2SAFE 670 определяет рабочие характеристики модуля 600 с микросхемой Q2S. В одном варианте осуществления Q2SAFE 670 включает в себя 3 основных блока: RxAFE 710, SyncFIFO 730 и TxAFE 750, как показано на фиг. 7. Функция RXAFE 710 состоит в том, чтобы принимать, усиливать для различения дифференциального аналогового сигнала с малым размахом колебаний с входных контактных площадок переходной платы SiP, и для выборки приблизительно в центре данных. Функция SyncFIFO 730 состоит в том, чтобы синхронизировать передаваемые сигналы тактовой частоты и тактовую частоту передачи уплотнителя, для восстановления временных характеристик принимаемых данных, для того, чтобы остановить накопление дрожания и для минимизации дрейфа PVT. Функция TxAFE 750 состоит в том, чтобы преобразовать в последовательную форму (2:1) потоки данных и передать в модуль возбуждения SiP.
На фиг. 8 показана блок-схема одного варианта осуществления Q2S, аналогового приемного блока предварительной обработки (RxAFE) для Q2S. В одном варианте осуществления, схема 820 аналогового приемного блока предварительной обработки (RxAFE) в Q2S работает для приема, усиления, выборки дифференциальных сигналов данных (например, с контактных площадок 810), и выполнения непрерывного поддержания фазового интерполятора (PI). В одном варианте осуществления выход Q2S RxAFE 820 будет передан повторно в блок восстановления тактовой частоты, называемый Sync_FIFO. В одном варианте осуществления блок 820 RxAFE соединен с площадкой 810 массива решетки с шариковыми контактами (BGA) переходной платы SiP через схему 830 защиты ESD. Входные узлы также совместно используются с завершениями Rt 840 и детектором 850 активности соединения.
На фиг. 9а показана принципиальная схема одного варианта осуществления архитектуры RxAFE для работы с нормальной скоростью. На фиг. 9b показана принципиальная схема одного варианта осуществления архитектуры RxAFE для операции с высокой скоростью. Внутренняя архитектура RxAFE показана на фиг. 9а, и 9b, присутствующих в двух вариантах цепей (фиг. 9а) с номинальной скоростью, (например, 6,4 Гб/с); и на (фиг. 9b) с высокой скоростью, (например, 9,6 Гбит/с, вплоть до 12,8 Гбит/с). На фиг. 9а представлена двусторонняя архитектура приемника с перемежением, состоящая из дифференциального буфера 905, после чего следует сэмплер 910, запоминающее устройство 915 CDR для восстановления синхронизации, интерполятор 920 фазы для генерирования тактовой частоты выборки.
На фиг. 9b показана архитектура двустороннего приемника с перемежением, включающая в себя непрерывный эквалайзер 950 с непрерывным временем (CTLE), с автоматическим регулированием 955 усиления (AGC), после которого следует эквалайзер обратной связи для передачи решения (ОРЕ)/сэмплер 960, модуль CDR 970 для восстановления синхронизации, интерполятор 975 фазы для генерирования тактовой частоты выборки. В одном варианте осуществления два варианта выбора могут быть воплощены с использованием перепуска или выбора мультиплексора для выполнения обеих архитектур в одной конструкции.
Технология эквализации может компенсировать эффекты канала, такие как взаимные помехи между символами в области времени (ISI), потери, зависящие от частоты, дисперсию и отражение. В одном варианте осуществления два каскада эквализации используются в архитектуре на фиг. 9b. В одном варианте осуществления первый каскад может представлять собой CTLE, воплощенный с использованием усилителя Черри-Хупера для усиления канала по частоте. Второй каскад представляет собой DFE, в котором используется DFE с программным решением для устранения ISI. Подходы AGC и DFE могут потребовать намного больше времени на проектирование и не настолько критичны для относительно коротких и фиксированных взаимных соединений при номинальной скорости.
На фиг. 10 показана блок-схема одного варианта осуществления схемы двухвыводного DFE/сэмплера. На фиг. 10 иллюстрируется схема примера двухвыводного DFE/сэмплера с половинной частотой. Такая архитектура схемы обеспечивает хороший компромисс между временными характеристиками, мощностью и площадью. Схема 1010 выборки и удержания (S/H) выполняет выборку и удержание данных для 2UI. Ранняя информация, занимаемая в сумматорах 1020 через каналы с поперечным соединением позволяет обеспечить более быстрый переход узла в направлении конечного значения. Требования к скорости цепей могут быть ослаблены, благодаря сумматору. Архитектура DFE с 2 выводами может быть расширена на 4 вывода, на основе требуемых характеристик.
Цикл синхронизации по задержке (DLL) представляет собой систему с замкнутым контуром, которая генерирует сигнал тактовой частоты, который имеет точную взаимосвязь фазы со входной тактовой частотой. В одном варианте осуществления DLL в Q2S RXFAE генерирует дифференциальные квадратурные фазы из дифференциальной тактовой частоты с опережением (fwdclk). Дифференциальные фазы называются I (in-фазой) {0°, 180°} дифференциальной пары тактовой частоты и Q (квадратурной) {90°, 270°} дифференциальной парой тактовой частоты. Конструкция DLL должна разрешать проблемы, такие как усиление дрожания и ошибка квадратурной фазы. Усиление дрожания индуцируется из-за конечной полосы пропускания ячеек линии задержки; в то время как ошибка фазы возникает из-за несоответствия при детектировании фазы. Четыре выхода фазы передают из DLL в фазовые интерполяторы (PI). Выход PI
PI output=iclk × icoef + qclk × qcoef
CDR генерирует icoef и qcoef. B одном варианте осуществления блок схемы CDR воплощает алгоритм Мюллера-Мюллера детектирования фазы. Он генерирует разрешение по фазе 1/64 UI. Выходы интерполяторов фазы обеспечивают тактовую частоту для операции RxAFE. В одном варианте осуществления два бита данных передают на каждый цикл тактовой частоты. В одном варианте осуществления принятые данные подвергают выборке на заднем фронте импульсов тактовой частоты, как показано на фиг. 11.
На фиг. 12 показана принципиальная схема одного варианта осуществления полного канала передачи данных Q2S и архитектуры канала тактовой частоты. Номера ссылочных позиций на фиг. 12 соответствуют отдельным блокам, представленным на описанных выше фигурах. В одном варианте осуществления архитектура уплотнителя, описанная выше, может функционировать для расширения протокола QPI по оптическим соединениям. Это обеспечивает переход без стыков из QPI к оптическому соединению с минимальной задержкой и влиянием на мощность. При таком подходе получают схему восстановления синхронизации для минимизации перекоса, введенного электрическими потоками. Здесь используется преимущество высокоскоростных оптических каналов передачи данных путем последовательной передачи электрических потоков. Конечный автомат соединения в соединении является критичным для электрической и оптической передачи данных. Возможность программирования параметров установок обеспечивает гибкость для этой технологии, которая должна быть адаптирована по различным платформам. Она является очень надежной и простой для воплощения. Она может быть легко расширена на другие протоколы (например, PCI Express) или для большей степени диагностики (например, контура обратной связи) или CRC/ECC.
Представленное выше описание для фиг. 6-12 было представлено для вариантов осуществления функциональности уплотнителя Q2S. Следующее описание направлено на варианты осуществления функциональности уплотнителя S2Q.
На фиг. 13 показана схема высокого уровня одного варианта осуществления модуля S2Q. В одном варианте осуществления модуль 1300 S2Q включает в себя два основных блока: цифровую сторону 1310 и аналоговую сторону 1350. В одном варианте осуществления цифровая сторона 1310 включаете себя цепочку 1315 развертки, регистры 1320 управления и статуса, логическую схему 1325 оптического управления (OCL) и логическую схему 1330 управления S2Q (SCL). В одном варианте осуществления аналоговая сторона 1350 включает в себя PLL 1355, модуль 1360 регулятора напряжения, генератор 1365 аналогового смещения и аналоговый блок 1370 предварительной обработки S2Q (S2QAFE или SAFE). Ключевой блок в этом модуле уплотнителя представляет собой S2QAFE, который выполняет прием данных, восстановление синхронизации, преобразование из последовательной в параллельную форму 2:1, и передачу данных QPI с полной скоростью передачи данных в оконечный агент.
В одном варианте осуществления, каждый из регистров 1320 управления и статуса доступен для считывания-записи из интерфейса I2C. Адресация I2C является одинаковой для компонентов уплотнителя Q2S и S2Q. В одном варианте осуществления регистры зеркально отображены между двумя компонентами, таким образом, запись будет всегда представлять собой запись в оба компонента. Программное обеспечение вначале выполняет запись в регистр выбора компонента уплотнителя, выбирая один из компонентов Q2S или S2Q, для выбора компонента уплотнителя, из которого требуется выполнить считывание. Некоторые значения статуса могут не иметь значения или могут не быть доступными для обоих компонентов Q2S и S2Q. Логический уровень 0 будет возвращен при попытке считывания из не воплощенных регистров или из битов статуса, которые не соответствуют конкретной промежуточной уплотнителя.
На фиг. 14 показана блок-схема одного варианта осуществления логической схемы управления (SCL) для S2Q. В одном варианте осуществления SCL 1330 представляет собой логическую схему, которая управляет несколькими сигналами функций S2QAFE 1370. В одном варианте осуществления SCL 1330 не является частью канала передачи данных, но управляет установкой Sync_FIFO, которая приводит к разной задержке в канале передачи данных. В одном варианте осуществления, SCL 1330 управляет, по меньшей мере, следующими функциями: поддержание 1410 соединения, синхронизация буфера, управление 1455 Icomp, управление 1460 Rcomp, управление 1480PLL, управление (1425 и 1430) AGC и DFE, если используются функции CTLE и DFE, управление 1410 DFX, управление 1470 эквализацией передачи. В одном варианте осуществления SCL 1330 управляет следующими функции в канале передачи тактовой частоты: управление 1415 CDR и детектирование 1420 активности тактовой частоты с опережением.
В одном варианте осуществления один SCL управляет всеми из 10 линий данных и одной линией передачи тактовой частоты в двух разных режимах управления. В одном варианте осуществления SCL 1330 будет работать в нескольких доменах тактовой частоты. Например, цепь развертки может работать при 20+ кГц и модуль детектирования активности перенаправляемой тактовой частоты может работать при половине тактовой частоты, поскольку этот модуль отслеживает передачу сигналов для перенаправляемой тактовой частоты после ее остановки для IBreset. Затем выполняются два действия. Вначале останавливается движение PI во время IBreset. Во-вторых, SCL дублирует сигналы тактовой частоты IBreset в TxClk, для передачи конечному агенту.
На фиг. 15 показана блок-схема одного варианта осуществления аналогового блока предварительной обработки S2Q. В одном варианте осуществления S2QAFE 1370 представляет собой канал передачи данных для S2Q 1300, который определяет характеристики уплотнителя S2Q 1300. В одном варианте осуществления S2QAFE 1370 включает в себя три основных блока: RxAFE 1520, SyncFIFO 1540 и TxAFE 1560. В одном варианте осуществления функция S2Q_RXAFE 1520 состоит в том, чтобы принимать, усиливать, выполнять разрешение дифференциального аналогового сигнала с низким уровнем размаха колебаний на входных контактных площадках шифратора SiP, и для выборки приблизительно в центре данных. В одном варианте осуществления функция S2Q_SyncFIFO 1540 состоит в том, чтобы синхронизировать передаваемую тактовую частоту и область передачи тактовой частоты для восстановления синхронизации принимаемых данных, для прекращения накопления дрожания и для минимизации дрейфа PVT. В одном варианте осуществления функция S2QTxAFE 1560 состоит в том, чтобы мультиплексировать (2:1) потоки данных и передать их в конечный агент.
На фиг. 16 показана блок-схема одного варианта осуществления аналогового блока предварительной обработки (RxAFE) при приеме S2Q. В одном варианте осуществления функция RxAFE 1610 состоит в том, чтобы принимать, усиливать, выполнять выборку дифференциальных сигналов данных и выполнять непрерывное повторное обучение интерполятора фазы (PI). Выход S2Q RxAFE 1610 подают в блок восстановления синхронизации, называемый Sync_FIFO.
В одном варианте осуществления RxAFE 1610 соединен с контактными площадками 1620 переходной печатной платы SiP с шариковыми контактами (BGA), через схему 1630 защиты ESD. Входные узлы также совместно используются с завершением RT 1650 и детектором 1660 активности соединения.
Внутренняя архитектура RxAFE для S2Q показана на фиг. 17а и 17b, которые представляют два варианта выполнения цепей (а) с номинальной скоростью, например, 6,4 Гб/с; (b) с высокой скоростью, например, 9,6 Гбит/с вплоть до 12,8 Гбит/с. Архитектура четырехстороннего приемника с перемежением состоит из: (а) дифференциального буфера, после которого следует сэмплер, CDR восстановления тактовой частоты, интерполятор фазы, для генерирования тактовой частоты выборки; (b) линейный эквалайзер с непрерывным временем (CTLE) с автоматическим регулированием усиления (AGC), после которого следует эквалайзер (DFE) обратной связи для передачи решения/сэмплер, CDR восстановления тактовой частоты, интерполятор фазы, для генерирования тактовой частоты выборки. Два варианта выбора могут быть воплощены путем обхода или выбора мультиплексирования, для выполнения обеих архитектур в одной конструкции.
На фиг. 17а показана принципиальная схема одного варианта осуществления архитектуры RxAFE для работы с нормальной скоростью. На фиг. 17b показана принципиальная схема одного варианта осуществления архитектуры RxAFE для операции с высокой скоростью. Внутренняя архитектура RxAFE, показанная на фиг. 17а и 17b, представляет два варианта схем (фиг. 17а) для номинальной скорости, (например, 6,4 Гб/с); и (фиг. 17b) для высокой скорости, (например, 9,6 Гбит/с вплоть до 12,8 Гбит/с). На фиг. 17а показана архитектура двустороннего приемника с перемежением, состоящая из дифференциального буфера 1705, после чего следует сэмплер 1710, CDR 1715 восстановления тактовой частоты, интерполятор 1720 фазы для генерирования тактовой частоты выборки.
На фиг. 17b показана архитектура двустороннего приемника с перемежением, включающая в себя линейный эквалайзер (CTLE) 1750 с непрерывным временем, с автоматическим регулированием 1755 усиления (AGC), после чего следует эквалайзер обратной связи для передачи решения (ОРЕ)/сэмплер 1760, CDR 1770 восстановления синхронизации, интерполятор 1775 фазы, для генерирования тактовой частоты выборки. В одном варианте осуществления эти два варианта выбора могут быть воплощены путем выбора обхода или мультиплексора, для выполнения обеих архитектур в одной конструкции.
Технология эквализации может компенсировать эффекты канала, такие как взаимные помехи между символами в области времени (ISI), потери в зависимости от частоты, дисперсия и отражение. В одном варианте осуществления два каскада эквализации используются в архитектуре на фиг. 17b. В одном варианте осуществления первый каскад может быть воплощен на основе CTLE с использованием усилителя Черри-Хупера для усиления канала по частоте. Второй каскад представляет собой DFE, в котором используется DFE программного решения для устранения ISI. Подходы AGC и DFE могут занять намного больше времени на конструирование и не являются критичными для относительно коротких и фиксированных взаимных соединений с номинальной скоростью.
Также используют аналогичные DLL, PI и CDR архитектуры, для генерирования тактовой частоты выборки. Основное отличие состоит в том, что эта выборка представляет собой выборку с квадратичной скоростью. Четыре бита данных передают в каждом цикле тактовой частоты. Принятые данные подвергают выборке по заднему фронту импульсов тактовой частоты, как показано на фиг. 18. Существует ряд преимуществ выполнения выборки с квадратичной частотой. Во-первых, можно повторно использовать ту же конструкцию и компоновку схемы приема Q2S. Во-вторых, что еще более важно, проблемы при конструировании CDR, DLL и PI, и DFE/сэмплера будут намного меньшими по сравнению с воплощением с полной скоростью тактовой частоты.
На фиг. 19 показана блок-схема одного варианта осуществления архитектуры схемы передачи S2Q. В этом разделе описан аналоговый блок предварительной обработки (TxAFE) линии передачи данных S2Q для блока схемы (например, 1560). В одном варианте осуществления функция Tx_AFE состоит в том, чтобы мультиплексировать (2:1), усилить и передать дифференциальные сигналы данных, которые были поданы из SyncFIFO. Выходной сигнал Q2S TxAFE будет передан в конечный агент. В одном варианте осуществления, после одного каскада 2:1 преобразователя 1910 параллельных данных в последовательные данные, скорость передачи данных возвращается к скорости линии QPI. Преобразователь из параллельных в последовательные данные и предварительный возбудитель 1920 и возбудитель 1925 могут быть воплощены с использованием схем CML, для удовлетворения требований скорости передачи сигналов. В одном варианте осуществления блок Tx_AFE соединен с контактными площадками 1950 шифратора, полученного с использованием технологии шариковых контактов (BGA) SiP через схему 1960 защиты ESD. В одном варианте осуществления входные узлы также совместно используются с завершением Rx 1970 и схемой 1975 детектирования соединения.
На фиг. 20 показана принципиальная схема одного варианта осуществления полной архитектуры канала передачи данных S2Q и канала тактовой частоты. Номера ссылочных позиций на фиг. 20 соответствуют отдельным блокам, представленным на фиг. 13-19, описанным выше.
Технологии, устройства, способы, системы, описанные здесь, могут быть воплощены с использованием любой архитектуры соединения из точки-в-точку. В качестве примера, может использоваться архитектура взаимного соединения с высокими характеристиками (HPI), в соответствии с любым из следующих вариантов осуществления.
В одном варианте осуществления HPI представляет собой взаимное соединение следующего поколения на основе взаимного соединения с когерентным кэш. В одном примере, HPI может использоваться в вычислительных платформах с высокой производительностью, таких как рабочие станции или серверы, где PCIe обычно используется для соединения ускорителей или устройств I/O. Однако HPI не ограничен этим. Вместо этого, HPI может быть использоваться в любая из систем или платформ, описанных здесь. Кроме того, индивидуально разработанные идеи могут применяться для других взаимных соединений, таких как PCIe. Кроме того, HPI может быть расширен для обеспечения конкурентоспособности на том же рынке, что и другие взаимные соединения, такие как PCIe.
Для поддержания множества устройств, в одном варианте осуществления, HPI включает в себя независимую архитектуру установки инструкций (ISA) (то есть, HPI выполнен с возможностью его воплощения во множестве различных устройств). В другом сценарии HPI также может использоваться для соединения устройств I/O с высокими характеристиками, а не только с процессорами или ускорителями. Например, устройство PCIe с высокими характеристиками может быть соединено с HPI через соответствующий мост трансляции (то есть, HPI с PCIe). Кроме того, в соединении HPI могут использоваться множества устройств на основе HPI, таких как процессоры, различными способами (например, с подключением типа звезда, кольца, сети и т.д.).
На фиг. 21 иллюстрируется вариант осуществления многогнездовых конфигураций с множеством потенциалов. Двухгнездовая конфигурация 2105, как представлено, включает в себя два соединения HPI; однако, в других вариантах осуществления, может использоваться одно соединение HPI. Для более крупных топологий может быть использоваться любая конфигурация, если только ID может быть назначен и присутствует в определенной форме виртуальный канал передачи. Как показано, четырехгнездовая конфигурация 2110 имеет канал HPI от каждого процессора к другому. Но в восьмигнездовом варианте осуществления, показанном в конфигурации 2115, не каждое гнездо непосредственно соединено с каждым другим через соединение HPI. Однако, если виртуальный канал передачи существует между процессорами, такая конфигурация поддерживается. Диапазон поддерживаемых процессоров включает в себя 2-32 в собственном домене. Большее количество процессоров может быть достигнуто при использовании множества доменов или других взаимных соединений между контроллерами узлов.
Архитектура HPI включает в себя определение архитектуры многоуровневого протокола, которая аналогична PCIe тем, что она также включает в себя архитектуру многослойного протокола. В одном варианте осуществления HPI определяет уровни протокола (когерентный, некогерентный, и, в случае необходимости, другие протоколы на основе запоминающего устройства), уровень маршрутизации, уровень соединения и физический уровень. Кроме того, как и множество других архитектур взаимного соединения, HPI включает в себя улучшения, относящиеся к администрированию питанием, конструкции для тестирования и отладки (DFT), обработки неисправности, регистров, безопасности и т.д.
На фиг. 22 иллюстрируется вариант осуществления потенциальных уровней в многоуровневом стеке протокола HPI; однако, эти уровни не требуются и могут быть необязательными в некоторых вариантах выполнения. Каждый уровень работает со своим собственным уровнем гранулярности или квантом информации (уровень 2205а, b протокола с пакетами 2230, уровень 2210а, b соединения с 2235 флитами и физический уровунь 2205а, b с фитами 2240). Следует отметить, что пакет, в некоторых вариантах осуществления, может включать в себя частичные флиты, одиночный флит или множество флитов, на основе варианта осуществления.
В качестве первого примера, ширина фита 2240 включает в себя отображения 1 к 1 ширины соединения на биты (например, ширина соединения 20 битов включает в себя фит размером 20 битов и т.д.). Фиты могут иметь больший размер, такой как 184, 192 или 200 битов. Следует отметить, что, если фит 2240 составляет в ширину 20 битов, и размер флита 2235 составляет 184 бита, тогда требуется дробное число фитов 2240, для передачи одного флита 2235 (например, 9,2 фита размером по 20 бит, для передачи флита 2235 размером 184 бита или 9,6 при 20 битах, для передачи флита размером 192 бита). Следует отметить, что ширина фундаментального соединения на физическом уровне может изменяться. Например, количество линий в одном направлении может включать в себя 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24 и т.д. В одном варианте осуществления в уровень 2210а, b соединения может быть внедрено множество частей различных транзакций в одном флите, и в пределах этого флита может быть внедрено множества заголовков (например, 1, 2, 3, 4) в пределах флита. Здесь HPI разделяет заголовки на соответствующие интервалы, для обеспечения возможности размещения множества сообщений во флите, предназначенных для разных узлов.
Физический уровень 2205а, b, в одном варианте осуществления отвечает за быструю передачу информации через физическую среду (электрическую или оптическую и т.д.). Физическое соединение представляет собой соединения из точки-в-точку между двумя объектами уровня соединения, такими как уровень 2205а и 2205b. Уровень 2210а, b соединения абстрагирует физический уровень 2205а, b из верхних уровней и обеспечивает возможность надежной передачи данных (так же, как запросов) и администрирования регулированием потока между двумя непосредственно соединенными объектами. Он также отвечает за виртуализацию физического канала во множестве виртуальных каналов и классов сообщения. Уровень 2220а, b протокола основан на уровне 2210а, b соединения, для отображения сообщений протокола на соответствующие классы сообщения и виртуальные каналы перед передачей их в физический уровень 2205а, b для передачи через физические соединения. Уровень 2210а, b соединения может поддерживать множество сообщений, таких как запрос, сообщение мониторинга, ответ, обратная запись, некогерентные данные и т.д.
В одном варианте осуществления, для обеспечения надежной передачи предусмотрены проверка циклической избыточности (CRC), проверка ошибок и процедуры восстановления на уровне 2210а, b соединения, для изоляции влияния стандартных ошибок битов, которые возникают при физическом взаимном соединении. Уровень 2210а соединения генерирует CRC в передатчике и выполняет проверку на уровне 2210b соединения приемника.
В некоторых вариантах осуществления уровень 2210а, b соединения использовал схему кредитов для управления потоком. Во время инициализации отправителю предоставляют установленное количество кредитов для передачи пакетов или флитов получателю. Всякий раз, когда пакет или флит передают получателю, отправитель постепенно уменьшает величину подсчета кредитов за один кредит, что представляет собой либо пакет, или флит, в зависимости от типа используемой виртуальной сети. Всякий раз, когда буфер освобождается у получателя, кредит возвращают обратно отправителю для этого типа буфера. Когда кредиты отправителя для заданного канала будут исчерпаны, в одном варианте осуществления, он прекращает передачу каких-либо флитов по этому каналу. По существу, кредиты возвращаются после того, как получатель использует информацию и освободит соответствующие буферы.
В одном варианте осуществления, уровень 2215а, b маршрутизации обеспечивает гибкий и распределенный способ маршрутизации пакетов от источника к месту назначения. В некоторых типах платформы (например, в однопроцессорных и двухпроцессорных системах), этот уровень может не быть явно выраженным, но может составлять часть уровня 2210а, b соединения; в таком случае этот уровень является не обязательным. Он основан на виртуальной сети и абстракции класса сообщения, предусмотренных уровнем 2210а, b соединения как часть функции для определения, как направлять пакеты. Функция маршрутизации, в одном варианте осуществления, определена через осуществления таблицы маршрутизации, специфичные для варианта осуществления. Такое определение разрешает множество моделей использования.
В одном варианте осуществления, уровень 2220а, b протокола воплощает протоколы передачи данных, правило упорядочивания и поддержания когерентности, I/O, прерывания и другую передачу данных на высоком уровне. Следует отметить, что уровень 2220а, b, протокола в одном варианте осуществления предусматривает сообщения для согласования состояний мощности для компонентов и системы. В качестве потенциальной добавки, физический уровень 2205а, b также может независимо или совместно устанавливать состояния мощности отдельных соединений.
Множество агентов могут быть соединены с архитектурой HPI, такой как домашний агент (запросы на упорядочение в запоминающем устройстве), кэширование (запросы по проблемам, связанным с когерентным запоминающим устройством, и ответы, связанные с мониторингом), конфигурация (связана с конфигурацией транзакций), прерывание (прерывания процессов), наследование (имеет дело с транзакциями наследования), некогерентный (имеет дело с некогерентными транзакциями) и другие. Более конкретное описание уровней для HPI представлено ниже.
Обзор нескольких потенциальных свойств HPI включает в себя: не использование предварительного выделения домашнего узла; отсутствие требований по упорядочиванию для множества классов сообщения; упаковка множества сообщений в один флит (заголовок протокола) (то есть, упакованный флит, который может содержать множество сообщений в определенных интервалах); широкое соединение, которое может быть масштабировано по 4, 8, 122, 20, или больше линиям; большая схема проверки на ошибки, которая может использовать 8, 16, 32 или вплоть до 64 битов для защиты от ошибок; и использующая внедренную схему синхронизации.
Физический уровень 2205а, b (или PHY) для HPI установлен выше электрического уровня (то есть электрических проводников, соединяющих два компонента) и ниже уровня 2210а, b соединения, как представлено на фиг. 22. Физический уровень основан на каждом агенте и соединяет уровни соединения по двум агентам (А и В), отделенным друг от друга. Локальные и удаленные электрические уровни соединены через физические среды (например, провода, проводники, оптический канал передачи и т.д.).
Физический уровень 2205а, b, в одном варианте осуществления имеет две основные фазы, инициализации и работы. Во время инициализации соединение является непрозрачным для уровня соединения, и передача сигналов может потребовать включения комбинации синхронизированных по времени состояний и событий согласования параметров связи. Во время операции соединение является прозрачным для уровня соединения, и передача сигналов выполняется с определенной скоростью, по всем линиям, работающим вместе, как одно соединение.
Во время рабочей фазы физический уровень транспортирует флиты от агента А к агенту Б и от агента Б к агенту А. Соединение также называется связью и абстрагирует некоторые физические аспекты, включая в себя среду, ширину и скорость от уровней связи, благодаря обмену флитами и управлению/статусу текущей конфигурации (например, ширины) с уровнем связи. Фаза инициализации включает в себя меньшие фазы, например, опроса, конфигурации. Рабочая фаза также включает в себя меньшие фазы (например, состояния администрирования мощностью связи).
В одном варианте осуществления физический уровень 2205а, b также должен: удовлетворять надежности/стандартам ошибок, быть устойчивым к неисправностям линии связи и переходить в фракции номинальной ширины, поддерживать отдельные неисправности в противоположном направлении связи, поддерживать оперативное подключение/отключение, включение/выключение физических портов, попытки инициализации по истечению времени, когда количество попыток превышает определенный порог и т.д.
В одном варианте осуществления HPI использует вращающуюся структуру битов. Например, когда размер флита не совпадает с множеством линий связи, в HPI, может отсутствовать возможность передачи флитов по целому кратному числу линий (например, 192-битный флит не является целым кратным, например соединения 20 - из линий). Таким образом х20 флитов, может быть размещено с перемежением для исключения неиспользуемой ширины пропускания (то есть, передачи частичного флита в некоторый момент, без использования остальной части линии). Перемежение, в одном варианте осуществления, определяют для оптимизации латентности ключевых полей и мультиплексоров в передатчике (Тх) и приемнике (Rx). Определенная структура также потенциально обеспечивает чистый и быстрый переход на/из меньшей ширины (например, х8) и операции без стыков на новой ширине.
В одном варианте осуществления в HPI используются встроенные часы, такие как 20 битные встроенные часы, или встроенные часы с другим количеством битов. В других интерфейсах с высокими характеристиками может использоваться опережающая тактовая частота или другая тактовая частота для сброса внутри полосы. В результате встраивания часов в HPI, потенциально уменьшается количество используемых выводов. Однако, использование встроенных часов, в некоторых вариантах осуществления, может привести к необходимости использовать разные устройства и способы для обработки сброса внутри полосы. Вначале, после инициализации, используется состояние блокирования соединения для поддержания передачи флитов в состоянии отключенного соединения и обеспечения возможности использования PHY (более подробно описан в Приложении А). В качестве второго примера, электрические упорядоченные наборы, такие как электрически простаивающие упорядоченные наборы (EIOS) могут использоваться во время инициализации.
В одном варианте осуществления HPI выполнен с возможностью использования направления с первой шириной битов, без опережения тактовой частоты и второго соединения с меньшей шириной битов для управления мощностью. В качестве примера, HPI включает в себя состояние передачи с частичной шириной, где используется частичная ширина (например, при х20 полной ширины и х8 частичной ширины); однако, значения ширины являются исключительно иллюстративными и могут отличаться. Здесь PHY может обрабатывать администрирование мощностью с частичной шириной, без помощи уровня соединения или его вмешательства. В одном варианте осуществления протокол состояния блокирующего соединения (BLs) используется для ввода в состояние передачи с частичной шириной (PWTS). Выход PWTS, в одном или больше вариантах осуществления, может использовать протокол BLs или детектирование нарушения автоматической регулировки усиления. Из-за отсутствия опережающей синхронизации, выход PWTLS может включать в себя повторное устранение искажений, которое поддерживает детерминизм соединения.
В одном варианте осуществления HPI использует адаптацию Тх. В качестве примера, используется состояние контура обратной связи и аппаратные средства для адаптации Тх. В качестве одного примера, HPI выполнен с возможностью подсчета фактического количества ошибок битов; что может быть выполнено путем ввода специализированных структур. В результате, HPI должен быть иметь возможность получать лучшие электрические запасы при меньшей мощности. При использовании состояния контура обратной связи одно направление может использоваться, как аппаратные каналы обратной передачи с данными измерений, переданными, как часть полезной нагрузки, содержащей обучающую последовательность (TS).
В одном варианте осуществления HPI выполнен с возможностью предоставления блокирования латентности без обмена значением подсчета синхронизации в TS. Другое взаимное соединение может выполнять фиксацию латентности на основе такого обмена значением подсчета синхронизации в каждом TS. Здесь HPI может использовать периодически повторяющиеся, электрически простаивающие упорядоченные наборы выхода (EIEOS) в качестве прокси для значения подсчета счетчика синхронизации путем выравнивания EIEOS со счетчиком синхронизации. Это потенциально сохраняет пространство полезной нагрузки TS, удаляет помехи дискретизации и проблемы с балансом постоянного тока, а также упрощает расчет латентности, который требуется добавить.
В одном варианте осуществления HPI предоставляет для программного обеспечения и управления таймером машинные транзакции состояния соединения. Другое взаимное соединение может поддерживать семафор (бит удержания), который устанавливается аппаратными средствами при входе в состояние инициализации. Выход из этого состояния происходит, когда программное обеспечение удаляет бит удержания. HPI, в одном варианте осуществления позволяет выполнять управление со стороны программного обеспечения механизмом этого типа, для ввода в состояние передающего соединения или в состояние структуры обратной связи. В одном варианте осуществления HPI позволяет выполнить выход из состояний согласования параметров соединения, который основан на программно-управляемом истечении времени после согласования параметров соединения, что потенциально упрощает тестирующее программное обеспечение.
В одном варианте осуществления HPI использует скремблирование TS псевдослучайной последовательности битов (PRBS). В качестве примера, используется 23-битный PRBS (PRBS23). В одном варианте осуществления PRBS генерируют по самозарождающемуся элементу сохранения с аналогичным размером битов, такому как сдвиговый регистр с линейной обратной связью. В качестве одного примера, может использоваться фиксированная структура UI для скремблирования с обходом до состояния адаптации. Но в результате скремблирования TS с использованием PRBS23, адаптация Rx может выполняться без обхода. Кроме того, смещение и другие ошибки могут быть уменьшены во время восстановления тактовой частоты и выборки. Подход HPI основан на использовании LFSR Фибоначчи, которые могут быть самозарождающимися на определенных участках TS.
В одном варианте осуществления HPI поддерживает эмулированный медленный режим, без изменения тактовой частоты PLL. В некоторых конструкциях могут использоваться отдельные PLL для медленной и быстрой скорости. Также, в одном варианте осуществления, HPI использует эмулированный медленный режим (то есть тактовая частота PLL работает с высокой скоростью; ТХ повторяет биты множество раз; RX выполняет выборку с запасом для установления мест положения кромок и идентификации бита). Это означает, что порты, совместно использующие PLL, могут совместно существовать на медленных и быстрых скоростях. В одном примере, когда произведение представляет собой целочисленное отношение быстрой скорости к медленной скорости, разные быстрые скорости могут работать с одной и той же медленной скоростью, которая может использоваться во время фазы определения оперативного подключения.
В одном варианте осуществления, HPI поддерживает общую частоту медленного режима для оперативного подключения. Эмулированный медленный режим, как описано выше, позволяет одновременно существовать портам HPI, совместно использующим PLL при медленной и быстрой скоростях. Когда разработчик устанавливает кратное значение эмуляции, как целочисленное отношение быстрой скорости к медленной скорости, тогда разные высокие скорости могут работать с одной и той же медленной скоростью. Таким образом, два агента, которые поддерживают, по меньшей мере, одну общую частоту, могут быть оперативно подключены, независимо от скорости, с которой работает порт главного устройства. Программное определение затем может использовать соединение с медленной скоростью для идентификации и установки наиболее оптимальных скоростей соединения.
В одном варианте осуществления HPI поддерживает повторную инициализацию соединения без завершения изменений. При этом может быть предусмотрена повторная инициализация для сброса внутри полосы, в которой произошло изменение завершения линии тактовой частоты для процесса определения, используемого по надежности, готовности и удобству обслуживания (RAS). В одном варианте осуществления повторная инициализация для HPI может быть выполнена без изменения значения завершения, когда HPI включает в себя отсев RX входящих сигналов для идентификации хороших линий.
В одном варианте осуществления HPI поддерживает ввод надежного состояния соединения с низкой мощностью (LPLS). В качестве примера, HPI может включать в себя минимальное пребывание в LPLS (то есть, минимальное количество времени, UI, значения подсчета и т.д., в течение времени, когда соединение остается в LPLS перед выходом). В качестве альтернативы, вход в LPLS может быть согласован, и затем может использоваться сброс внутри полосы для ввода в LPLS. Но это может, в некоторых случаях, маскировать фактический сброс внутри полосы, происходящий от второго агента. HPI, в некоторых вариантах осуществления, разрешает вход в LPLS первому агенту и ввод второго агента в состояние сброса. Первый агент при этом остается нереагирующим в течение некоторого периода времени (то есть, в течение минимального времени пребывания), что позволяет второму агенту завершить сброс и затем разбудить первый агент, обеспечивая намного более эффективный, надежный вход в LPLS.
В одном варианте осуществления HPI поддерживает свойства, такие как детектирование устранения дребезга контактов, пробуждение и непрерывный отсев отказов линий. HPI может выполнять поиск установленной структуры сигналов в течение длительного периода времени для детектирования действительного пробуждения из LPLS, уменьшая, таким образом, шансы эффективного пробуждения. Те же самые аппаратные средства также могут использоваться в фоновом режиме для постоянного отсеивания плохих линии во время процесса инициализации, обеспечивая более надежные свойства RAS.
В одном варианте осуществления HPI поддерживает детерминированный выход для этапа фиксации и повторный запуск - повторное воспроизведение. В HPI некоторые границы TS могут совпадать с границами флита при работе на всю ширину. Таким образом, HPI может идентифицировать и устанавливать границы выхода таким, что может поддерживаться поведение на этапе фиксации с другим соединением. Кроме того, HPI может устанавливать таймеры, которые могут использоваться для поддержания этапа фиксации с парой соединений. После инициализации HPI может также поддерживать операцию с отключенным сбросом внутри полосы для поддержания некоторых преимуществ операции этапа фиксации.
В одном варианте осуществления HPI поддерживает использование заголовка TS вместо полезной нагрузки для ключевых параметров инициализации. В качестве альтернативы, полезная нагрузка TS может использоваться для обмена инициирующими параметрами, такими, как АСК, и номера линий. И уровни постоянного тока для коммуникации полярности линии также можно использовать. Также, HPI может использовать балансированные коды постоянного тока в заголовке TS в качестве ключевых параметров. Это потенциально уменьшает количество байтов, необходимых для полезной нагрузки, и потенциально позволяет использовать всю структуру PRBS23 для скремблирования TS, что уменьшает необходимость в балансировании TS по постоянному току.
В одном варианте осуществления HPI поддерживает меры, для повышения нечувствительности к шумам активных линий во время состояния входа/выхода соединений, передающих с частичным использованием ширины в не простаивающих линиях (PWTLS). В одном варианте осуществления нуль (или другое количество флитов без возможности повторной попытки) можно использовать вокруг точки изменения ширины для повышения нечувствительности к шумам активных линий. Кроме того, HPI может использовать нуль флитов вокруг начала выхода PWTLS (то есть, нуль флитов может быть разбито флитами данных). HPI также может использовать специальные сигналы, формат которых может изменяться для уменьшения шансов фальшивого детектирования переключения в рабочий режим.
В одном варианте осуществления HPI поддерживает использование специализированных структур во время выхода PWTLS для обеспечения возможности неблокирующего выравнивания. В качестве альтернативы, простаивающие линии могут не быть подвергнуты выравниванию на выходе PWTLS, поскольку они могут поддерживать перекос с использованием опережающей тактовой частоты. Также, при использовании встроенных часов, HPI может использовать специальные сигналы, формат которых может изменяться для уменьшения шансов фальшивого детектирования пробуждения, и также обеспечивает возможность выравнивания, без блокирования потока флитов. Это также позволяет получить более надежный RAS, благодаря непрерывному отключению питания линий с ошибками, повторной их адаптации и снова перевода их в режим онлайн, без блокирования потока флитов.
В одном варианте осуществления HPI поддерживает вход в состояние низкого питания соединения (LPLS) без поддержки уровня соединения и более надежный выход LPLS. В качестве альтернативы, согласование на уровне соединения может зависеть от предварительного назначенного входа LPLS главного и вспомогательного устройств из состояния соединения для передачи данных (TLS). В HPI PHY может выполнять согласование, используя коды состояния блокирующего соединения (BLs), и может поддерживать оба агента, которые являются главными устройствами или инициаторами, а также вход в LPLS непосредственно из PWTLS. Выход из LPLS может быть основан на устранении дребезга контактов, при разрыве помехоподавления, используя специфичную структуру, после которой следует согласование параметров связи между двумя сторонами и индуцированный истечением времени сброс внутри полосы, если какая-либо из этих операций не будет правильно выполнена.
В одном варианте осуществления, HPI поддерживает управление непродуктивным образованием контуров во время инициализации. В качестве альтернативы, невозможность инициировать (например, отсутствие хороших линий) может привести к повторной попытке инициации слишком большое количество раз, что потенциально приводит к бесполезному расходу энергии, и это состояние трудно подлежит отладке. В HPI пара соединений может пытаться инициировать установленное количество раз с последующим прекращением этих попыток и отключением питания в состоянии сброса, в случае, когда программное обеспечение может выполнить регулировки перед повторной попыткой этого модуля. Это потенциально улучшает RAS системы.
В одном варианте осуществления HPI поддерживает расширенные варианты выбора IBIST (встроенный тест взаимного соединения). В одном варианте осуществления может использоваться генератор структуры, который позволяет генерировать две нескоррелированные структуры PRBS23 максимальной длины для каждого вывода. В одном варианте осуществления HPI может быть выполнен с возможностью поддержки четырех таких структур, а также обеспечивать возможность управления длиной этих структур (то есть, динамическим изменением тестовой структуры, длины PRBS23).
В одном варианте осуществления HPI обеспечивает расширенную логику для выравнивания линий. В качестве примера, граница TS после фиксации TS может использоваться для выравнивания линий. Кроме того, HPI может выравнивать, выполняя сравнение структуры PRBS линий в LFSR в отдельных точках полезной нагрузки. Такое выравнивание может быть полезным в тестируемых микросхемах, в которых может отсутствовать возможность детектировать TS, или конечных автоматах для администрирования выравниванием.
В одном варианте осуществления выход из режима инициирования в режим передачи по соединению происходит на границе TS с планетарным выравниванием. Кроме того, HPI может поддерживать согласованную задержку, начиная с этой точки. Кроме того, порядком выхода между этими двумя направлениями можно управлять, используя детерминизм главного - вспомогательного устройств, что обеспечивает возможность одного планетарного управления, вместо двух, выравниванием для пары соединений.
В некоторых вариантах осуществления используется фиксированная структура 128UI, для скремблирования TS. Другие используют фиксированный PRBS23 размером 4 к для скремблирования TS. HPI, в одном варианте осуществления, позволяет использовать PRBS любой длины, включая в себя полную последовательность (8М-1) PRBS23.
В некоторых архитектурах адаптация имеет фиксированную длительность. В одном варианте осуществления выход из режима адаптации скорее согласуют, чем устанавливают по времени. Это означает, что моменты времени адаптации могут быть асимметричными между двумя направлениями и могут иметь такую длительность, которая требуется каждой из сторон.
В одном варианте осуществления конечный автомат может обходить состояния, если действия в этих состояниях не требуется повторно выполнять. Однако, это может привести к более сложным конструкциям и уходу от удостоверения. HPI не использует обход - вместо этого он распределяет действия таким образом, что в каждом состоянии могут использоваться короткие таймеры для выполнения действий и исключения обходов. Это потенциально делает переходы конечного автомата более однородными и синхронизированными.
В некоторых архитектурах используется синхронизация с опережением для сброса внутри полосы и на уровне соединения, для подстановки передачи с использованием частичной ширины и для входа в соединение с малой мощностью. HPI использует аналогичные функции кодов состояния соединения блоков. Эти коды потенциально могут иметь ошибки битов, приводящие "к несогласованности" в Rx. HPI включает в себя протокол для работы с такими несовпадениями, а также в качестве средства для обработки асинхронного сброса, запросы состояния соединения с малой мощностью и состояния соединения с частичным использованием ширины.
В одном варианте осуществления используются 128 UI скремблеры для TS по контуру обратной связи. Однако это может привести к наложению спектров для фиксации TS, когда начинается работа контура обратной связи; таким образом, что некоторые архитектуры изменяют полезную нагрузку на 0 в это время. В другом варианте осуществления HPI использует однородную нагрузку и использует периодически возникающие нескремблированные EIEOS для фиксации TS.
В некоторых архитектурах используют скремблированный TS во время инициирования. В одном варианте осуществления HPI определяет сверхпоследовательности, которые представляют собой комбинации скремблированных TS различной длины и скремблированных EIEOS. Это позволяет выполнять более рандомизированные переходы во время инициирования и также упрощает фиксацию TS, фиксацию латентности и другие действия.
Возвращаясь к фиг. 22, можно видеть вариант осуществления логического блока для уровня 2210а, b соединения. В одном варианте осуществления уровень 2210а, b соединения гарантирует надежную передачу данных между двумя протоколами или объектами маршрутизации. Такой подход абстрагирует физический уровень 2205а, b из уровня 2220а, b протокола, отвечает за регулирование потока между двумя агентами (А, В) протокола и предоставляет услуги виртуального канала для уровня протокола (классы сообщения) и уровня маршрутизации (виртуальные сети). Интерфейс между уровнем 2220а, b протокола и уровнем 2210а, b соединения обычно находится на уровне пакета.
В одном варианте осуществления наименьший модуль передачи на уровне соединения называется флит, который имеет установленное количество битов, такое как 192. Уровень 2210а, b соединения основан на физическом уровне 2205а, b, для формирования модуля передачи (фит) физического уровня 2205а, b в модуль передачи (флит) уровня 2210а, b' соединения. Кроме того, уровень 2210а, b соединения может быть логически разбит на две части, передатчика и приемника. Пара передатчик/приемник в одном объекте может быть соединена с парой приемник/передатчик другого объекта. Управление потоком часто выполняют, как на основе флита, так и на основе пакета. Детектирование и коррекцию ошибок также потенциально выполняют на основе уровня флита.
В одном варианте осуществления флиты расширяют на 192 битов. Однако, любой диапазон битов, такой как 81-256 (или больше) можно использовать в разных вариантах. Здесь поле CRC также увеличено (например, 16 битов) для обработки большей полезной нагрузки.
В одном варианте осуществления TID (ID транзакции) составляет 11 битов в длину. В результате, предварительное распределение и включение возможности распределенных собственных агентов может быть устранено. Кроме того, использование 11 битов, в некоторых вариантах осуществления, позволяет использовать TID без необходимости использования расширенного режима TID.
В одном варианте осуществления флиты заголовка разделены на 3 интервала, 2 с равным размером (интервалы 0 и 1) и другой меньший интервал (интервал 2). Плавающее поле может быть доступно для использования в одном из интервала 0 или 1. Сообщения, которые могут использовать интервал 1 и 2, оптимизируют, уменьшая количество битов, необходимых для кодирования кодов операций этих интервалов. Когда для заголовка требуется больше битов, чем обеспечивает интервал 0, выполняют вход на уровень соединения, используя алгоритмы выделения интервалов для обеспечения использования битов полезной нагрузки интервала 1 в качестве дополнительного пространства. Флиты специального управления (например, LLCTRL) могут занимать биты всех 3 интервалов для своих потребностей. Алгоритмы разделения на интервалы могут также существовать, которые обеспечивают возможность использования отдельных интервалов, в то время как по другим интервалам не передается информация для случаев, когда соединение частично занято. Другое взаимное соединение может обеспечить возможность передачи одного сообщения на флит, вместо множества. Размеры интервалов в пределах флита и типы сообщений, которые могут быть размещены в каждом интервале, потенциально обеспечивают увеличенную полосу пропускания HPI даже при уменьшенной скорости передачи флита.
В HPI большая линия основания CRC может улучшить детектирование ошибок. Например, используется CRC размером 16 битов. В результате большого CRC также может использоваться большая полезная нагрузка. 16 битов CRC, в комбинации с многочленом, используемым для этих битов, улучшают детектирование ошибок. В качестве примера, существует минимальное количество шлюзов для обеспечения 1) детектирования ошибок в 1-4 битах, 2) пакетные ошибки длиной 16 или меньше.
В одном варианте осуществления используются чередующиеся CRC на основе двух уравнений CRC 16. Могут использоваться два многочлена размером по 16 бит, многочлен от HPI CRC 16 и второй многочлен. Второй многочлен имеет наименьшее количество шлюзов для воплощения при поддержании свойств 1) всех детектированных ошибок размером 1-7 битов, 2) защиты пакетных ошибок в линии при ширине 3 соединений х8), всех пакетных ошибок длиной 16 или меньше.
В одном варианте осуществления используется уменьшенная максимальная скорость передачи флитов (9,6 вместо 4 UI), но таким образом получают увеличенную пропускную способность соединения. В результате увеличения размера флита, ввода множества интервалов на флит, оптимизированного использования битов полезной нагрузки (измененные алгоритмы для удаления или перемещения нечасто используемых полей) достигается большая эффективность взаимного соединения.
В одном варианте осуществления часть, поддерживающая 3 интервала, включает в себя флит размером 192 бита. Плавающее поле обеспечивает дополнительные 11 битов полезной нагрузки либо для интервала 0, или для интервала 1. Следует отметить, что если будет использоваться больший флит, можно использовать больше плавающих битов. И в отличие от этого, если используется флит с меньшими размерами, обеспечивается меньшее количество плавающих битов. Благодаря обеспечению плавающего поля между двумя интервалами, можно обеспечить дополнительные биты, необходимые для некоторых сообщений, в то же время, все еще оставаясь в пределах 192 битов и обеспечивая максимальное использование полосы пропускания. В качестве альтернативы, предоставление поля HTID размером 11 битов для каждого интервала позволяет использовать дополнительные 11 битов во флите, который невозможно было бы так эффективно использовать.
Некоторые взаимные соединения могут передавать состояние с вирусами в сообщениях на уровне протокола и состояние заражения во флитах данных. В одном варианте осуществления сообщения уровня протокола HPI и состояние заражения перемещают во флиты управления. Поскольку эти биты используются нечасто (только в случае ошибок), удаление их из сообщений уровня протокола потенциально увеличивает степень использования флита. Ввод их, используя флиты управления, все еще позволяет сдерживать ошибки.
В одном варианте осуществления биты CRD и АСК во флите обеспечивают возможность возврата множества кредитов, таких как восемь, или множество ack, таких как 8. Как часть полностью кодированных полей кредита, эти биты используются, как кредит [n] и подтверждение [n], когда интервал 2 кодирован, как LLCRD. Это потенциально улучшает эффективность, обеспечивая для фита возможность возврата множества кредитов VNA и множество подтверждений, используя в сумме всего только 2 бита, но также позволяя оставлять их определение последовательным, когда используется полностью кодированный возврат LLCRD.
В одном варианте осуществления кодирование VNA, по сравнению с кодированием VN0/1, (экономит биты путем выравнивания интервалов для одинакового кодирования). Интервалы во флите заголовка с множеством интервалов могут быть выровнены только по VNA, только по VN0 или только по VN1. В результате принудительного выполнения этого, биты интервала, обозначающие VN, удаляют из каждого интервала. Это повышает эффективность степени использование битов флита и потенциально обеспечивает возможность расширения с 10-битного TID до 11-битного TID.
Некоторые поля позволяют выполнять только возврат с последовательным приращением на 1 (для VN0/1), 02/08/16 (для VNA) и 8 (для подтверждения). Это означает, что при возврате большего количества ожидающих кредитов или подтверждений, можно использовать множество возвратных сообщений. Это также означает, что возвратные значения с нечетным номерами для VNA и подтверждения, могут быть оставлены в ожидании накопления в ожидании четного значения. HPI может иметь полностью кодированные поля возврата кредита и Ack, обеспечивая возврат агентов всех накопленных кредитов или Acks для совокупности с одним сообщением. Это потенциально улучшает эффективность соединения и также потенциально упрощает воплощение логических схем (возвратные логические схемы могут воплощать сигнал "очистить", вместо полного отрицательного приращения).
В одном варианте осуществления уровень 2215а, b маршрутизации обеспечивает гибкий и распределенный способ для маршрутизации транзакций HPI от источника к назначению. Эта схема является гибкой, поскольку алгоритмы маршрутизации для множества топологий могут быть установлены с использованием программируемых таблиц маршрутизации в каждом маршрутизаторе (программирование в одном варианте осуществления выполняется с помощью встроенного программного обеспечения, программного обеспечения или их комбинации).
Функция маршрутизации может быть распределенной; маршрутизация может быть выполнена, используя последовательность этапов маршрутизации, и каждый этап маршрутизации определяют с помощью справочной таблицы в одном из маршрутизаторов источника, промежуточном маршрутизаторе или в маршрутизаторе назначения. Справочная таблица в источнике может использоваться для ввода пакета HPI в ткань HPI. Справочная таблица в промежуточном маршрутизаторе может использоваться для направления пакета HPI из входного порта в выходной порт. Справочная таблица в порту назначения может использоваться для нацеливания агента протокола назначения HPI. Следует отметить, что уровень маршрутизации, в некоторых вариантах осуществления, является тонким, поскольку таблицы маршрутизации и, следовательно, алгоритмы маршрутизации, не определены конкретно спецификацией. Это позволяет применять множество моделей использования, включая в себя архитектурную топологию с гибкой платформой, определяемую при воплощении системы.
Уровень 2215а, b маршрутизации основан на уровне 2210а, b соединения для обеспечения использования вплоть до трех (или больше) виртуальных сетей (VN) - в одном примере, две VN без взаимной блокировки, VN0 и VN1 с несколькими классами сообщения, определенными в каждой виртуальной сети. Совместно используемая адаптивная виртуальная сеть (VNA) может быть определена на уровне соединения, но такая адаптивная есть может не быть непосредственно представлена в концепциях маршрутизации, поскольку каждый класс сообщения и VN может иметь специально выделенные ресурсы и гарантированное развитие вперед.
Неисчерпывающий, примерный список правил маршрутизации включает в себя: (1) (инвариантность класса сообщения): входящий пакет, принадлежащий определенному классу сообщения, может быть направлен по маршруту через исходящий порт HPI / виртуальная сеть в том же классе сообщения; (2) (Переключение) платформы HPI может поддерживать такие типы переключения, как "содержать" и "перенаправлять" и "виртуальное сечение". В другом варианте осуществления HPI может не поддерживать "червоточину" или "переключение" цепей. (3) (Свобода от взаимной блокировки взаимных соединений). Платформы HPI могут не основываться на адаптивных потоках для маршрутизации, свободной от взаимной блокировки.
Используя платформы, на которых одновременно применяют VN0 и VN1, 2 VN вместе могут использоваться для маршрутизации, свободной от взаимной блокировки; и (4) (VN0 для "листовых" маршрутизаторов). На платформах HPI, которые могут одновременно использовать и VN0 и VN1, разрешено использовать VN0 для тех компонентов, маршрутизаторы которых не используют сквозную маршрутизацию; то есть, входные порты имеют места назначения HPI, которые завершаются в этом компоненте. В таком случае пакеты из разных VN могут быть направлены в VN0. Другими правилами (например, движение пакетов между VN0 и VN1) можно управлять с помощью алгоритма маршрутизации, зависимого от платформы.
Этап маршрутизации: этап маршрутизации, в одном варианте осуществления, называется функцией маршрутизации (RF) и функцией выбора (SF). Функция маршрутизации может принимать, в качестве входов, порт HPI, в который поступают пакеты, и NodelD места назначения; он затем вырабатывает, в качестве выходных данных, 2 фрагмента данных - номер порта HPI и виртуальная сеть - и этот пакет должен быть передан по его пути к месту назначения. Также разрешено, чтобы функция маршрутизации дополнительно зависела от входящей виртуальной сети. Кроме того, разрешено привести этап маршрутизации к получению множества пар <порт №, виртуальная сеть>.
Получаемые в результате алгоритмы маршрутизации называются адаптивными. В таком случае функция SF выбора может выбирать одиночный двойной фрагмент данных на основе дополнительной информации о состоянии, которую имеет маршрутизатор (например, используя адаптивные алгоритмы маршрутизации, выбор определенного порта виртуальной сети может зависеть от локальных условий перегруженности). Этап маршрутизации, в одном варианте осуществления, состоит из применения функции маршрутизации и затем функции выбора для получения 2 фрагментов (фрагментов).
Упрощения таблицы маршрутизации: платформы HPI могут воплощать легальные поднаборы виртуальных сетей. Такие поднаборы упрощают размер таблицы маршрутизации (уменьшают количество столбцов), ассоциированный с размещением в буфере виртуального канала и арбитраж на переключателе маршрутизатора. Такие упрощения могут выполняться за счет гибкости и свойств платформы. VN0 и VN1 могут представлять собой сети, свободные от взаимной блокировки, которые обеспечивают свободу от взаимной блокировки либо вместе, или по-отдельности, в зависимости от модели использования, обычно с назначением для них минимальных ресурсов виртуального канала.
Плоская организация таблицы маршрутизации может включать в себя размер, соответствующий максимальному количеству Node/D. При такой организации таблица маршрутизации может быть индексирована по полю места назначения NodelD и, возможно, с использованием поля ID виртуальной сети. Организация таблицы также может быть выполнена иерархически так, что поле места назначения NodelD, подразделено на множество подполей, что зависит от варианта осуществления. Например, при разделении на "локальную" и "нелокальную" части, "нелокальная" часть маршрутизации выполняется перед маршрутизацией "локальной" части. Потенциальное преимущество уменьшения размера таблицы в каждом входном порту обеспечивается за счет потенциальной стоимости, вынуждая назначить NodelD для компонентов HPI в виде иерархической структуры.
Алгоритм маршрутизации: алгоритм маршрутизации, в одном варианте осуществления определяет набор разрешенных частей из модуля источника в модуль назначения. Конкретный путь от источника к месту назначения представляет собой поднабор разрешенных путей, и его получают, как последовательность путей маршрутизации, определенную выше, начиная с маршрутизатора в месте источника, проходя через ноль или большее количество промежуточных маршрутизаторов, и заканчивая маршрутизаторами в месте назначения. Следует отметить, что даже при том, что ткань HPI может иметь множество физических путей от источника к месту назначения, разрешенные пути представляют собой те, которые определены алгоритмом маршрутизации.
В одном варианте осуществления протокол когерентности HPI включен в уровень 2220а, b, предназначенный для поддержки линий кэширования агентов данных из запоминающего устройства. Агент, желающий хэшировать данные в запоминающем устройстве, может использовать протокол когерентности для считывания строки данных, для загрузки в его кэш. Агент, желающий модифицировать строку данных в своем кэш, может использовать протокол когерентности для получения собственности над линией перед модификацией данных. После модификации линий агент может следовать требованиям протокола по содержанию его в своем кэш, до тех пор, пока он либо выполнит запись строки обратно в запоминающее устройство, или включит эту сроку в ответ на внешний запрос. В конечном итоге, агент может заполнить внешние ресурсы, что сделает не рабочей строку в его кэш. Протокол обеспечивает когерентность данных, путем диктовки правил, которым должны следовать все агенты кэширования. Он также обеспечивает средство для агентов без кэш, для когерентного считывания и записи данных в запоминающее устройство.
Два условия могут быть принудительно выполнены для поддержания транзакции, используя протокол когерентности HPI. Во-первых, протокол поддерживает непротиворечивость данных, в качестве примера, на основе для каждого адреса, среди данных в кэш агентов и между этими данными и данными в запоминающем устройстве. Неофициально, непротиворечивость данных может относиться к каждой действительной линии данных в кэш агента, представляющему самое актуальное значение данных, и данных, переданных в пакете протокола когерентности, представляющих самое актуальное значение данных в момент, когда они были переданы. Когда не существует действительная копия данных в кэш или при передаче, протокол может гарантировать, что самое актуальное значение данных находится в запоминающем устройстве. Во-вторых, протокол обеспечивает четко определенные точки обязательств для запросов. Точки обязательств для считывания могут обозначать, когда данные можно использовать; и для записей они могут обозначать, когда для записанных данных может быть выполнено глобальное наблюдение и будет загружено при последующем считывании. Протокол может поддерживать эти точки обязательств, как для кэшируемых так и для некэшируемых (UC) запросов в когерентном пространстве запоминающего устройства.
Протокол когерентности HPI также может обеспечивать прямое продвижение запросов когерентности, поданных агентом по адресу когерентного пространства запоминающего устройства. Конечно, транзакции могут в конечном итоге быть удовлетворены и удалены для правильной работы системы. Протокол когерентности HPI, в некоторых вариантах осуществления, может не иметь значения повторной попытки разрешения конфликтов распределения ресурсов. Таким образом, сам по себе протокол может быть определен таким образом, чтобы он не содержал зависимости от кругового ресурса, и в конструкциях вариантов осуществления могут быть предусмотрены невозможности зависимостей, которые могут привести к взаимной блокировке. Кроме того, протокол может обозначать, когда конструкции выполнены с возможностью предоставления справедливого доступа к ресурсам протокола.
Логично, протокол когерентности HPI, в одном варианте осуществления, состоит из трех пунктов: агенты когерентности (или кэширования), собственные агенты и ткань взаимного соединения HPI, соединяющая агенты. Агенты когерентности и собственные агенты работают вместе для достижения непротиворечивости данных путем обмена сообщениями через взаимное соединение. Уровень 2210а, b соединения и относящееся к нему описание предоставляет детали к ткани взаимного соединения, включающей в себя, как она соотносится с требованиями протокола когерентности, описанными здесь. (Может быть отмечено, что разделение на агентов когерентности и собственных агентов выполнено для ясности представления. Конструкция может содержать множество агентов обоих типов в пределах одного интервала или даже может комбинировать поведение агентов в один конструктивный модуль).
В одном варианте осуществления HPI не выполняет предварительное выделение ресурсов по домашнему агенту. Здесь, принимающий агент, принимающий запрос, выделяет ресурс для его обработки. Агент, передающий запрос, выделяет ресурсы для ответов. В этом сценарии HPI может следовать двум общим правилам, в зависимости от выделения ресурсов. Во-первых, агент, принимающий запрос, может быть ответственным за выделение ресурса для его обработки. Во-вторых, агент, генерирующий запрос, может быть ответственным за выделение ресурсов на отклики процесса на запрос.
Поскольку выделение ресурсов также может продолжаться до НТГО (вместе с RNID/RTID) в запросах на мониторинг с потенциалом уменьшения использования собственного агента и передавать ответы для поддержки ресурсов собственного агента (и передачи данных запрашивающему агенту).
В одном варианте осуществления ресурсы собственного агента также не выделены заранее в запросах на мониторинг и для передачи ответов для поддержания ресурсов для собственного агента (и перенаправления данных запрашивающему агенту).
В одном варианте осуществления отсутствуют возможности собственных ресурсов для "ранней" передачи CmpO прежде, чем домашней агент закончит запрос на обработку, когда он может безопасно просить агента повторно использовать свой ресурс RTID. Общая обработка мониторинга с аналогичным RNID/RTID в системе также составляет часть протокола.
В одном варианте осуществления разрешение конфликтов выполняют, используя заказанный канал отклика. Агент когерентности использует RspCnflt, как запрос для собственного агента, передать FwdCnfltO, который будет заказан с CmpO (если он запланирован) по запросу конфликта с агентом когерентности.
В одном варианте осуществления HPI поддерживает разрешение конфликтов через канал упорядоченного отклика. Агент когерентности, использующий информацию от средств мониторинга для помощи при обработке FwdCnfltO, которая не имеет информации о "типе", и RTID для перенаправления данных в запрашивающий агент.
В одном варианте осуществления агент когерентности блокирует прямые передачи для запросов обратной записи, для поддержания непротиворечивости данных. Но это также позволяет агенту когерентности использовать запрос обратной записи на передачу неразмещенных в кэш (UC) данных перед обработкой, и позволяет агенту когерентности выполнять обратную запись частичных строк, размещенных в кэш, вместо протокола, поддерживающего частичную скрытую обратную запись для прямой передачи.
В одном варианте осуществления поддерживается запрос на недействительность считывания (RdInv), который принимает данные исключительного состояния. Семантика считываний, не помещаемых в кэш (UC), включает в себя сброс модифицированных данных в запоминающее устройство. Определенная архитектура, однако, позволяла передачу М данных в недействительное считывание, что вынуждало запрашивающего агента очищать линию в случае приема М данных. RdInv упрощает поток, но не позволяет перенаправлять вперед данные Е.
В одном варианте осуществления HPI поддерживают InvItoM в функциональности IODC. InvItoM запрашивает исключительные права владения в отношении линий кэш, без приема данных и с намерением выполнения обратной записи вскоре после этого. Требуемое состояние кэш может представлять собой состояние М, и состояние Е, или каждое из них.
В одном варианте осуществления HPI поддерживает WbFlush для постоянного сдвига запоминающего устройства. Вариант осуществления WbFlush представлен ниже. Он может быть передан, как результат настойчивой фиксации. Может выполнять сброс данных для записи в постоянное запоминающее устройство.
В одном варианте осуществления HPI поддерживает дополнительные операции, такие как SnpF, для "разветвленного мониторинга", генерируемого уровнем маршрутизации. Некоторые архитектуры не имеют явно выраженной поддержки для разветвленного мониторинга. Здесь собственный агент HPI генерирует одиночный запрос на "разветвленный мониторинг" и, в ответ, уровень маршрутизации генерирует мониторинг для всех пиринговых агентов в "конусе разветвления". Собственный агент может ожидать ответ на мониторинг из каждой из секции агента.
В одном варианте осуществления HPI поддерживает дополнительные операции, такие как SnpF, для "разветвленного" мониторинга, генерируемого уровнем маршрутизации. Некоторые архитектуры не имеют явной выраженной поддержки для разветвленного мониторинга. Здесь собственный агент HPI генерирует одиночный запрос на "разветвленный" мониторинг и, в ответ, уровень маршрутизации генерирует мониторинг для всех пиринговых агентов в "разветвленном конусе". Собственный агент может ожидать ответ на мониторинг из каждой из секции агента.
В одном варианте осуществления HPI поддерживает явно выраженную обратную запись с возможностью проталкивания в кэш (WbPushMtoI). В одном варианте осуществления агент когерентности выполняет обратную запись модифицируемых данных с возможностью для собственного агента проталкивать модифицируемые данные в "локальный" кэш, сохраняющий их в состоянии М, без записи данных в запоминающее устройство.
В одном варианте осуществления агент когерентности может поддерживать состояние F при прямой передаче совместно используемых данных. В одном примере агент когерентности состояния F, принимает "совместно используемый" мониторинг или прямую передачу данных, после чего такой мониторинг может поддерживать состояние F при передаче состояния S в запрашивающий агент.
В одном варианте осуществления таблицы протокола могут быть выполнены с вложением, таким образом, что одна таблица обращается к другой подтаблице в столбцах в состоянии с "вложением", и таблица с вложением может иметь дополнительные или более тонкие средства защиты, которые устанавливают, какие строки (поведения) разрешены.
В одном варианте осуществления таблицы протокола используют охват рядов, для обозначения в равной степени разрешенного поведения (рядов), вместо добавления битов "смещения", для выбора между вариантами поведения. В одном варианте осуществления таблицы действия организованы для использования в качестве механизма функциональности для BFM (инструмент среды удостоверения), вместо формирования команды BFM своего собственного механизма BFM, основанного на их интерпретации.
В одном варианте осуществления HPI поддерживает некогерентные транзакции. В качестве примера, некогерентная транзакция называется транзакцией, которая не участвует в протоколе когерентности HPI. Некогерентные транзакции содержат запросы и их соответствующие завершения. Для некоторых специальных транзакций, используется механизм широковещательной передачи.
Ссылка в описании на "один вариант осуществления" или "вариант осуществления" означает, что конкретное свойство, структура или характеристика, описанные в связи с вариантом осуществления, включены в, по меньшей мере, один вариант осуществления изобретения. Появление фразы "в одном варианте осуществления" в различных местах в описании не обязательно везде относится к одному и тому же варианту осуществления.
В то время как изобретение было описано со ссылкой на несколько вариантов осуществления, для специалиста в данной области техники будет понятно, что изобретение не ограничено описанными вариантами осуществления, но может быть выполнено на практике с модификацией и изменениями в пределах сущности и объема приложенной формулы изобретения. Описание, таким образом, следует рассматривать, как иллюстративное, а не ограничительное.
| название | год | авторы | номер документа |
|---|---|---|---|
| ФИЗИЧЕСКИЙ УРОВЕНЬ ВЫСОКОПРОИЗВОДИТЕЛЬНОГО МЕЖСОЕДИНЕНИЯ | 2013 |
|
RU2599971C2 |
| ФИЗИЧЕСКИЙ УРОВЕНЬ ВЫСОКОПРОИЗВОДИТЕЛЬНОГО МЕЖСОЕДИНЕНИЯ | 2013 |
|
RU2579140C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ РЕКОНФИГУРИРУЕМОГО ПРОЦЕССОРА | 2001 |
|
RU2283507C2 |
| СПОСОБ РАСШИРЕНИЯ ФИЗИЧЕСКОЙ ОБЛАСТИ ДЕЙСТВИЯ СЕТИ InfiniBand | 2006 |
|
RU2461140C2 |
| Пакетная сеть для мультипроцессорных систем и способ коммутации с использованием такой сети | 2018 |
|
RU2703231C1 |
| СПОСОБЫ И УСТРОЙСТВА ДЛЯ ОСУЩЕСТВЛЕНИЯ КАНАЛА СВЯЗИ ПЕРЕМЕННОЙ РАЗРЯДНОСТИ | 2004 |
|
RU2288542C2 |
| ГЕТЕРОГЕННАЯ СЕТЬ МЕЖСОЕДИНЕНИЙ С УЧЕТОМ ПРОИЗВОДИТЕЛЬНОСТИ И ТРАФИКА | 2011 |
|
RU2566330C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБЕСПЕЧЕНИЯ ПОТОКОВ НА ОСНОВЕ ИДЕНТИФИКАТОРА ЧЕРЕЗ ШИНУ PCI EXPRESS | 2010 |
|
RU2509348C2 |
| НЕЧУВСТВИТЕЛЬНЫЙ К ЗАДЕРЖКЕ БУФЕР ТРАНЗАКЦИИ ДЛЯ СВЯЗИ С КВИТИРОВАНИЕМ | 2014 |
|
RU2598594C2 |
| ЗВЕНО СВЯЗИ МНОГОКРИСТАЛЬНОЙ ИНТЕГРАЛЬНОЙ СХЕМЫ | 2013 |
|
RU2656732C2 |
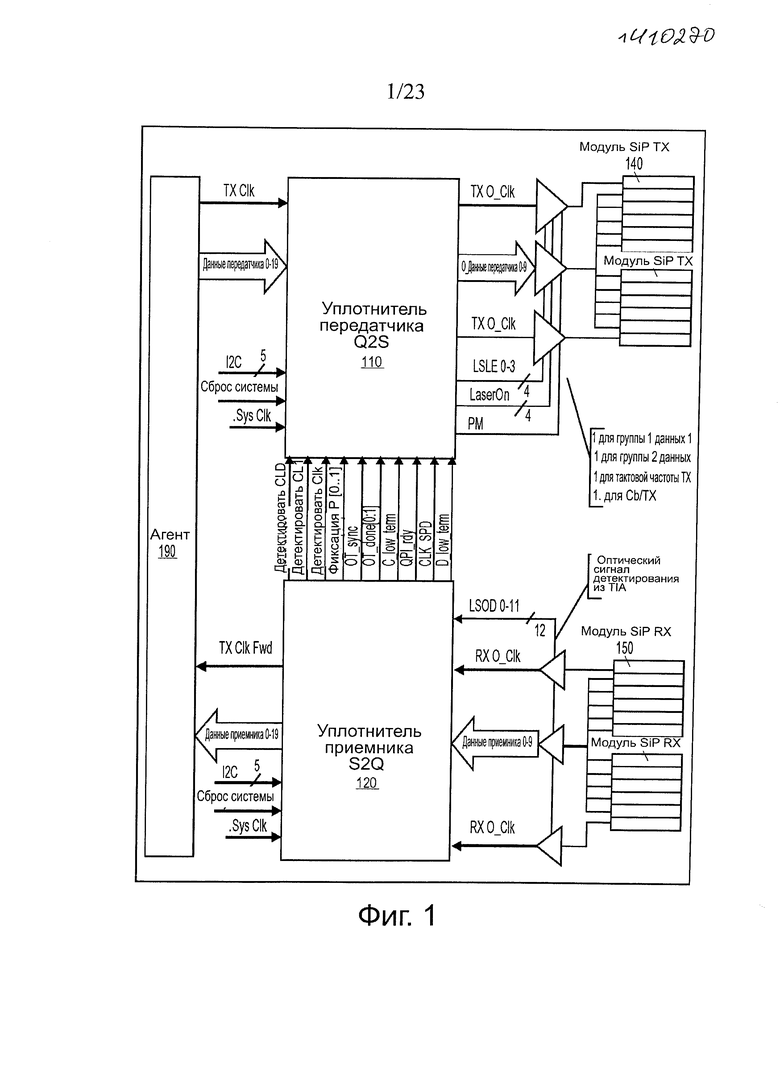

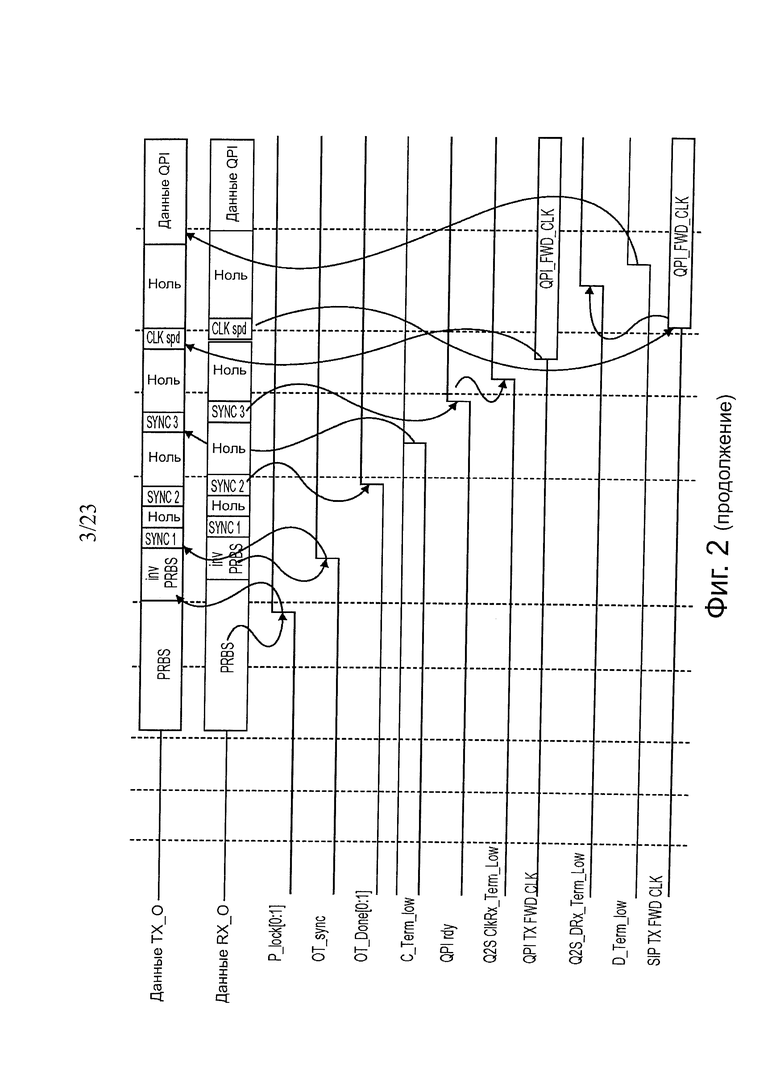
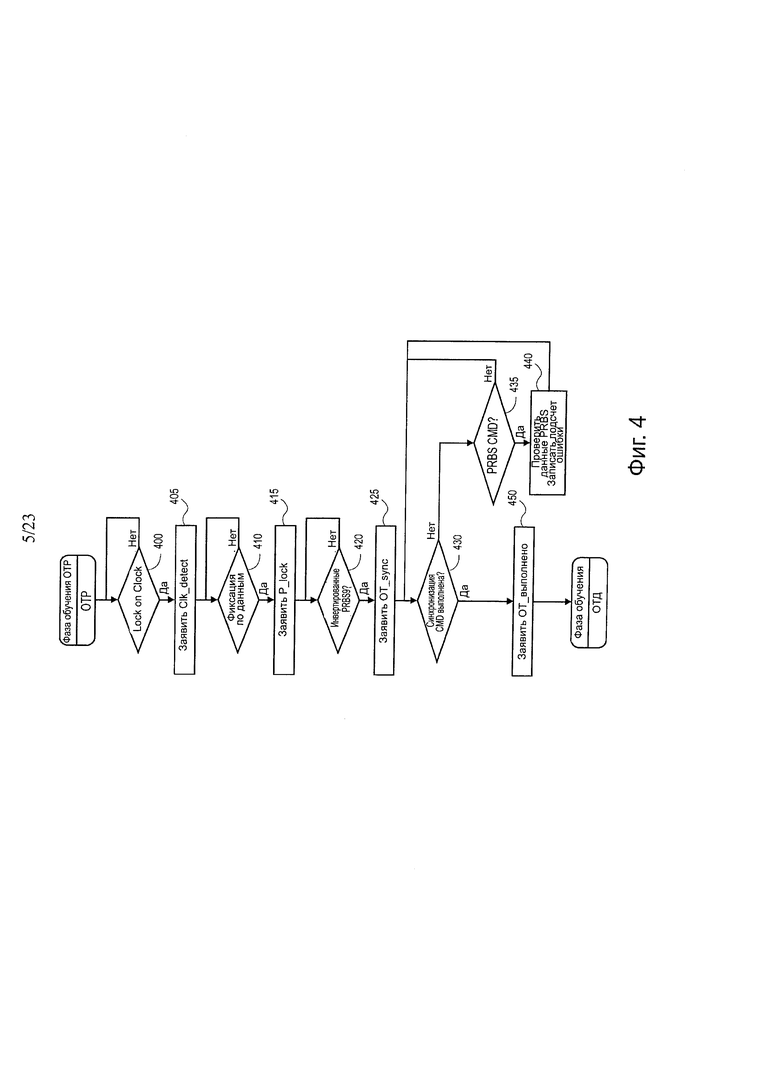
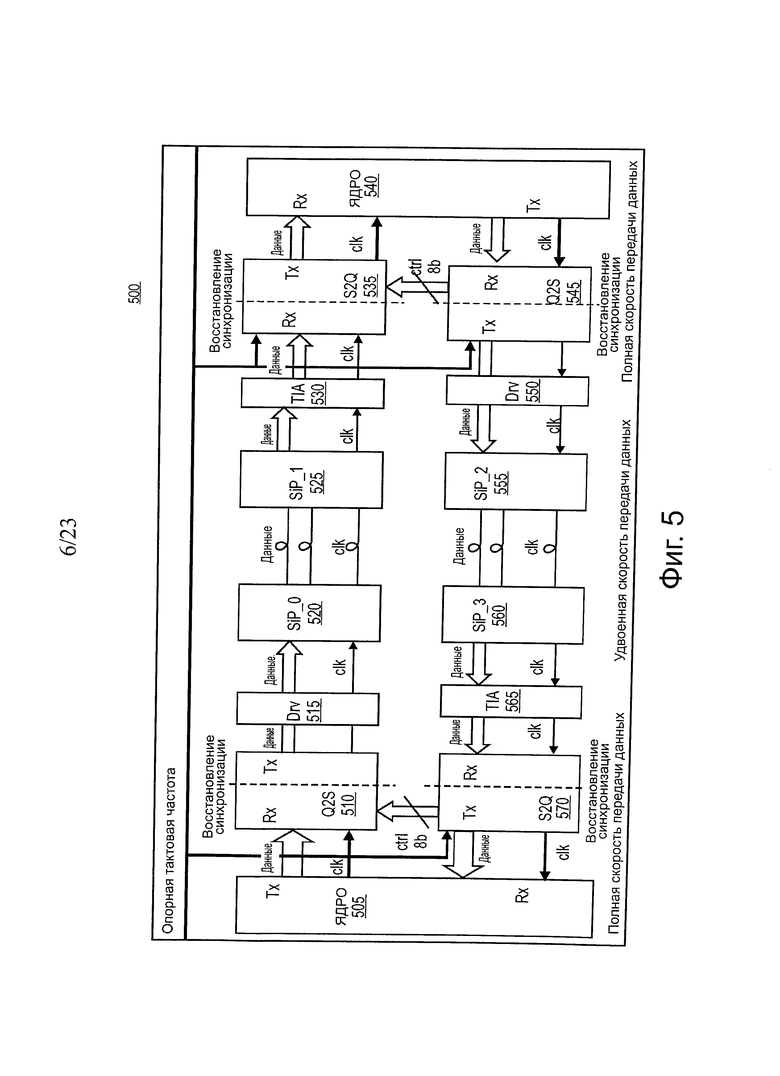
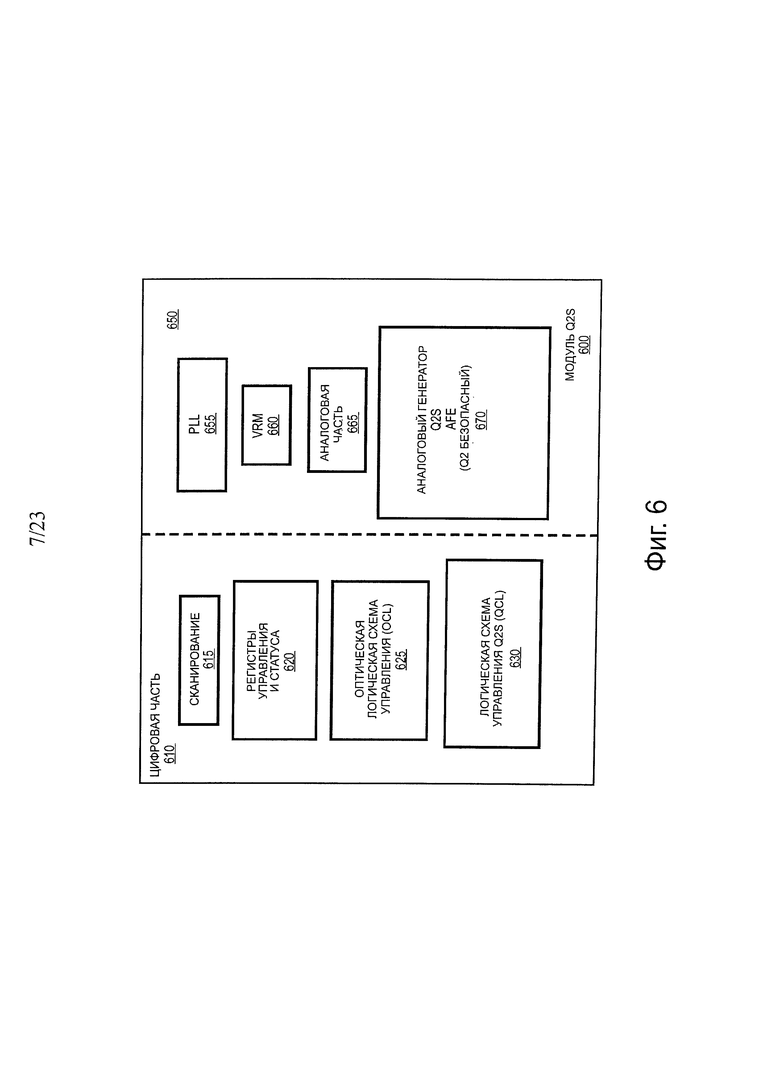

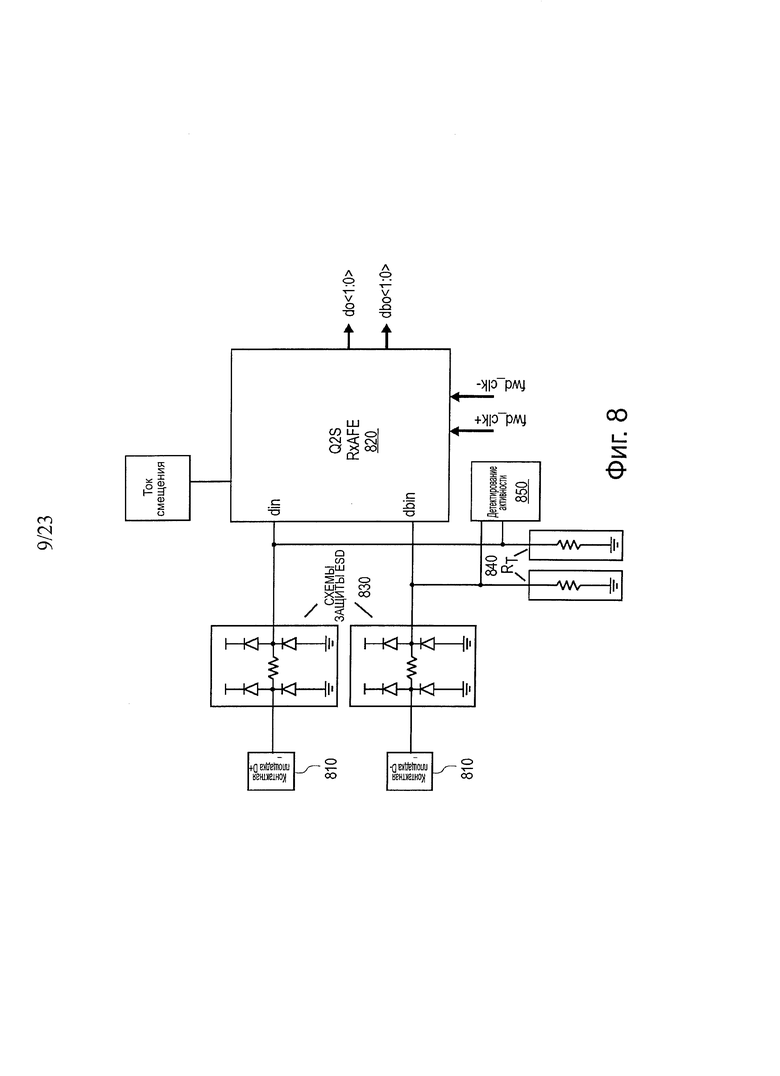
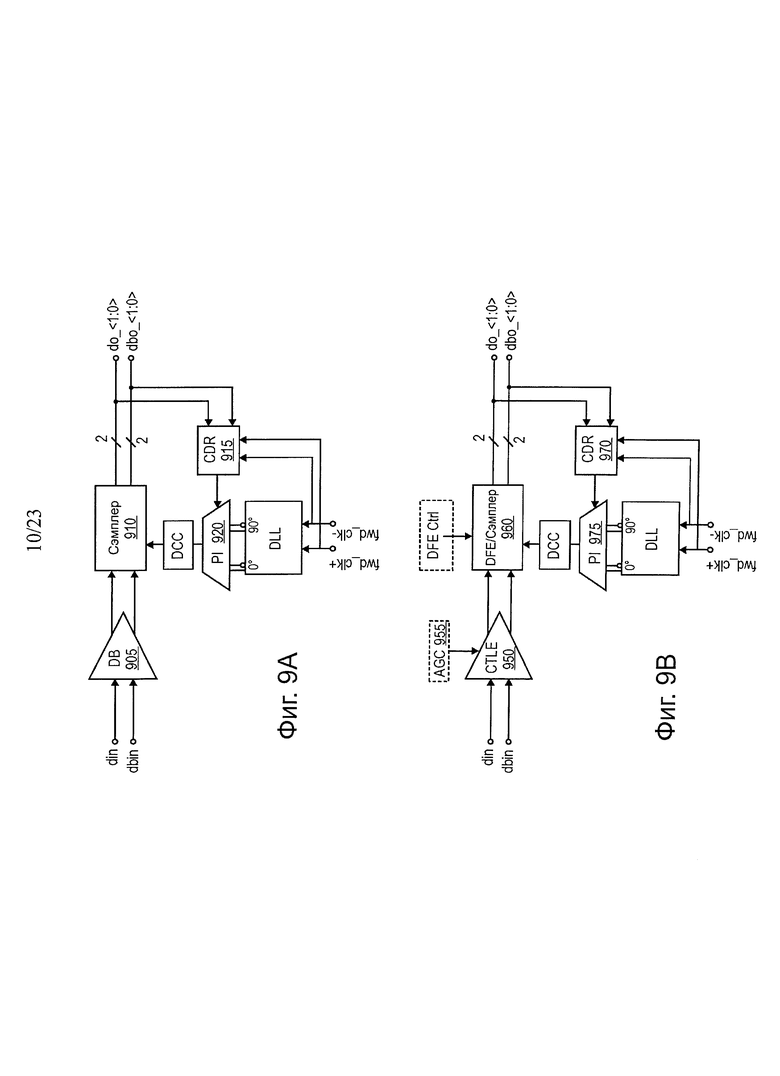

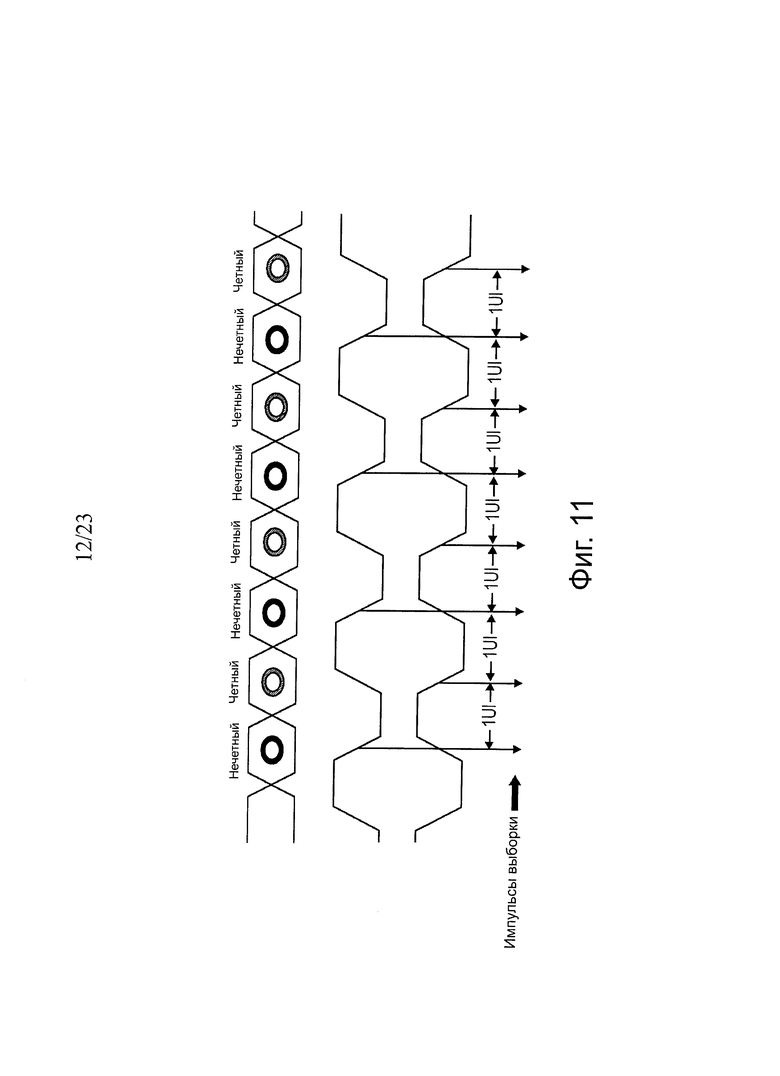
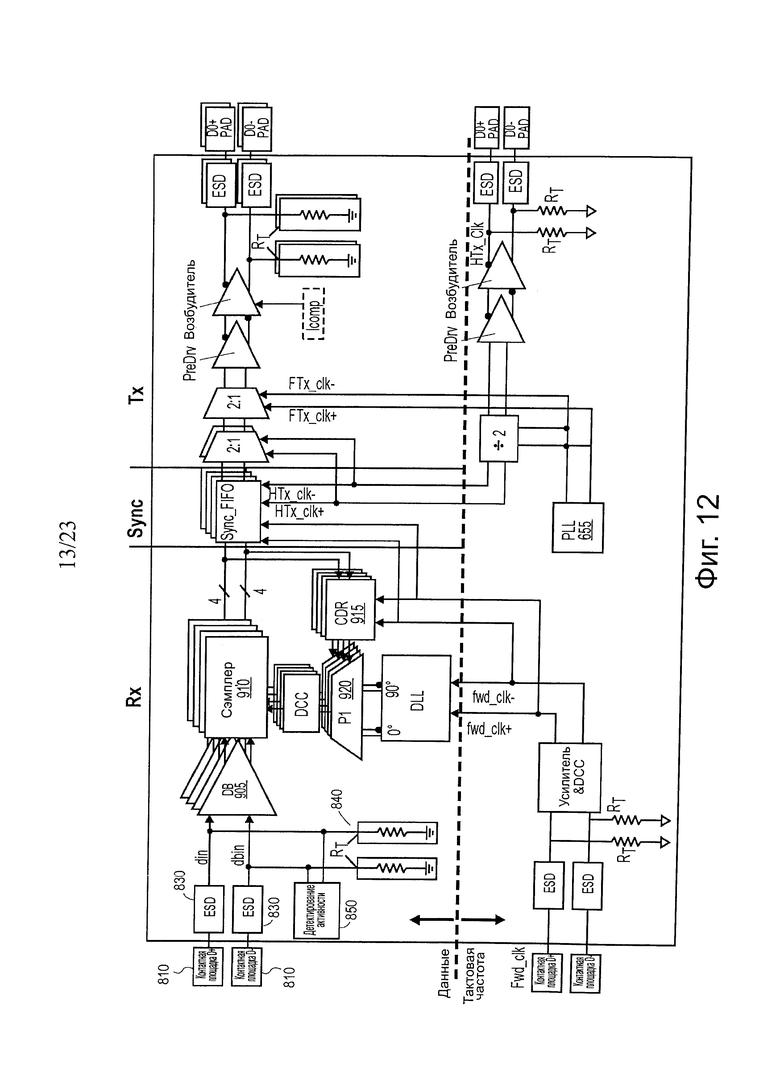
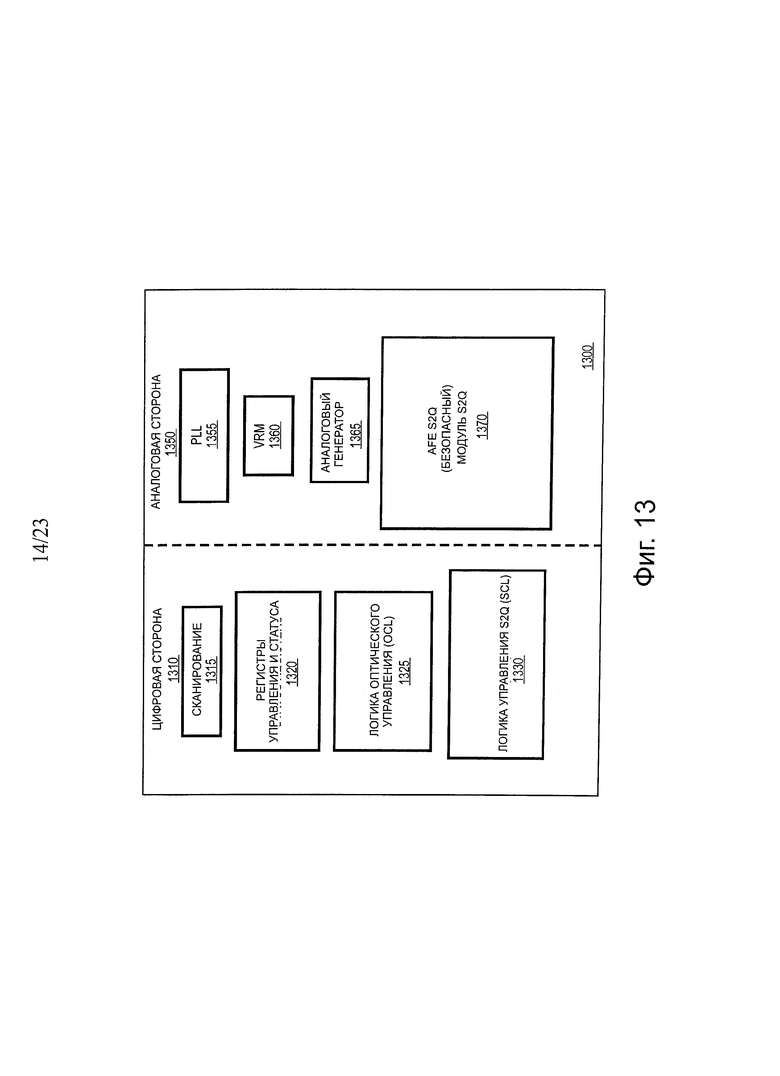
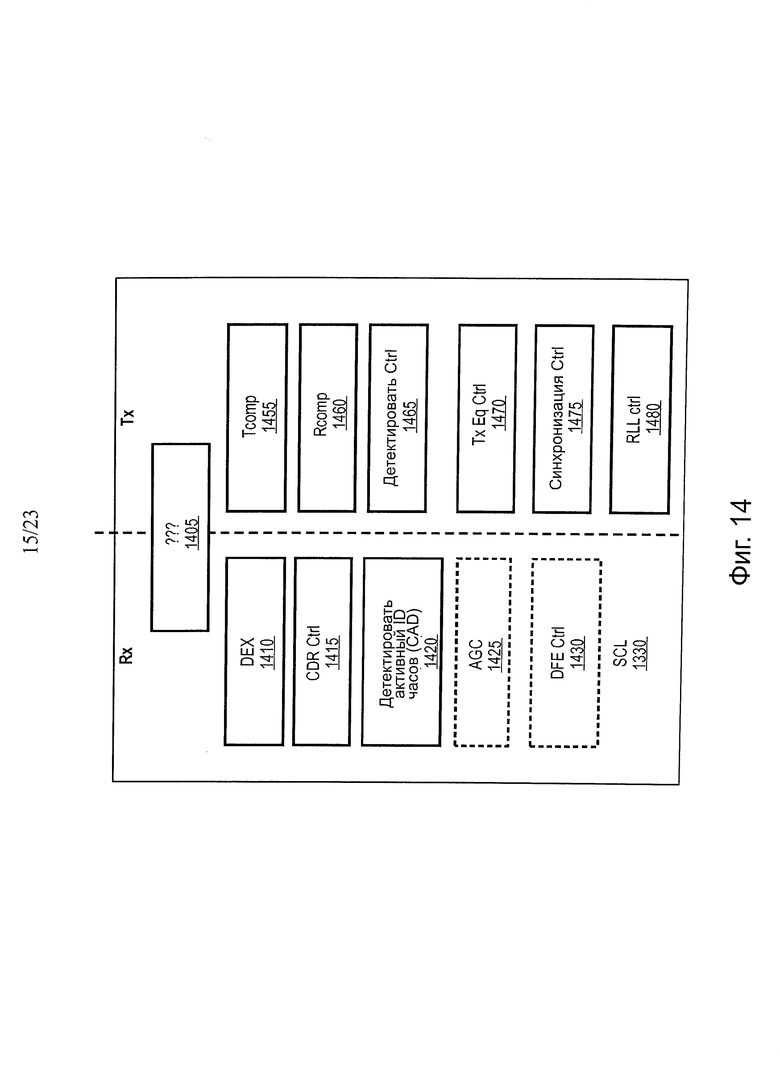
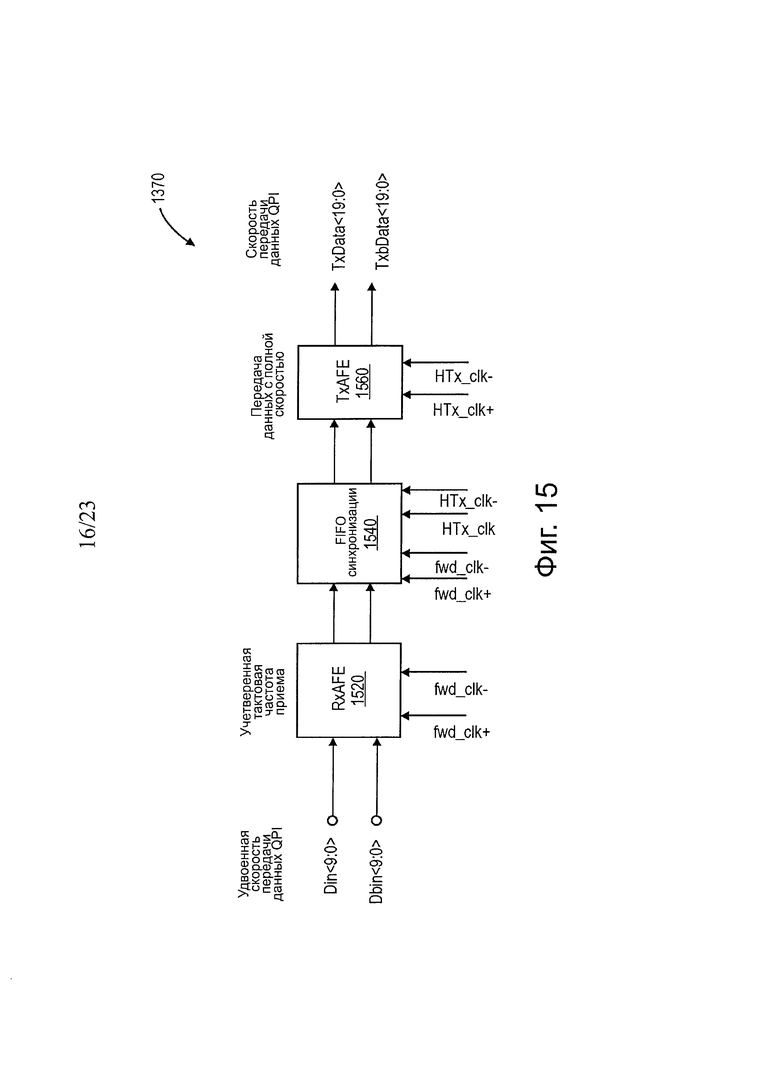

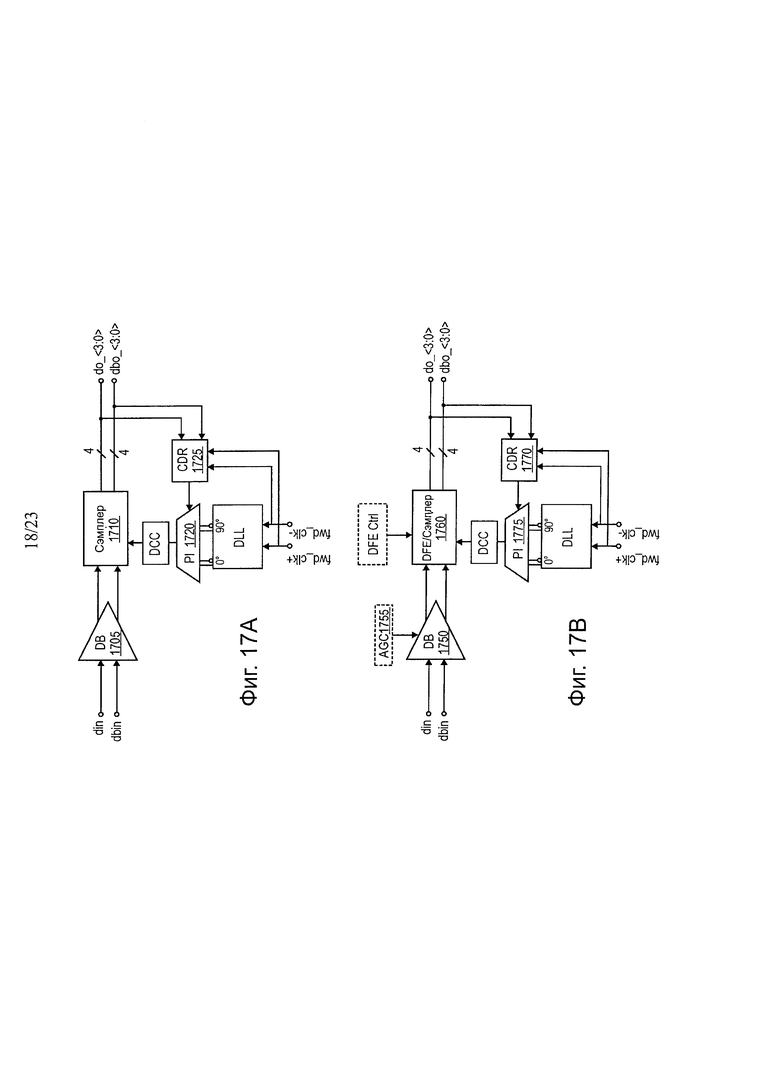

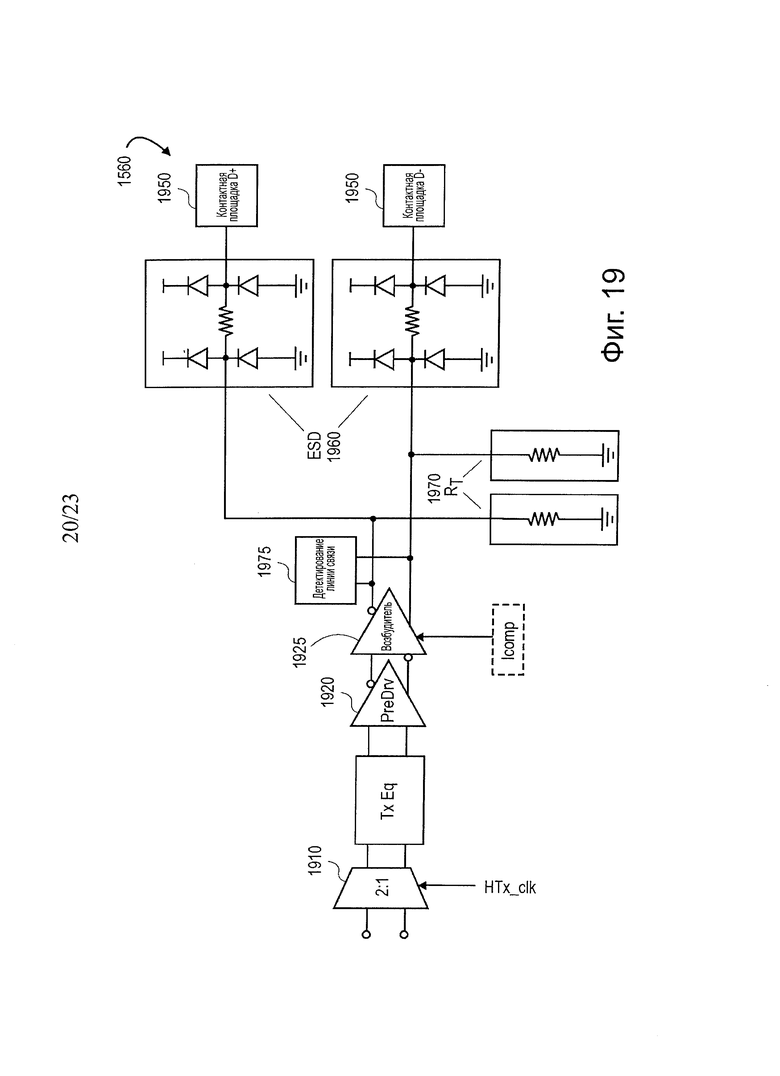
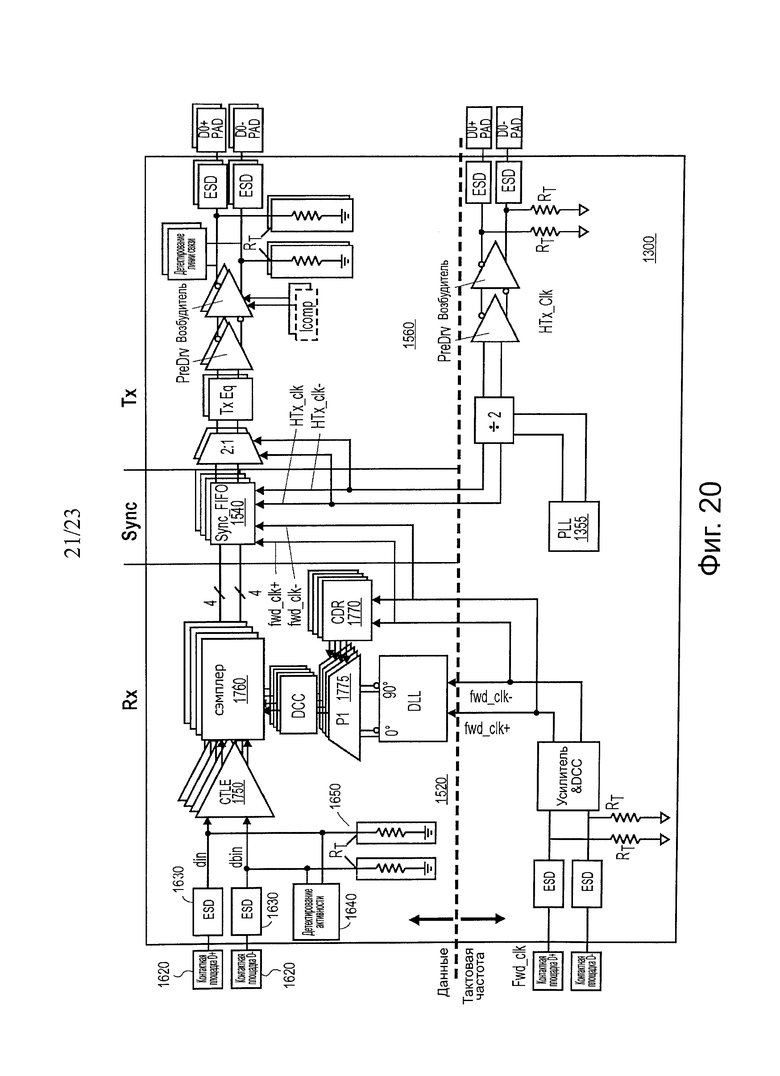
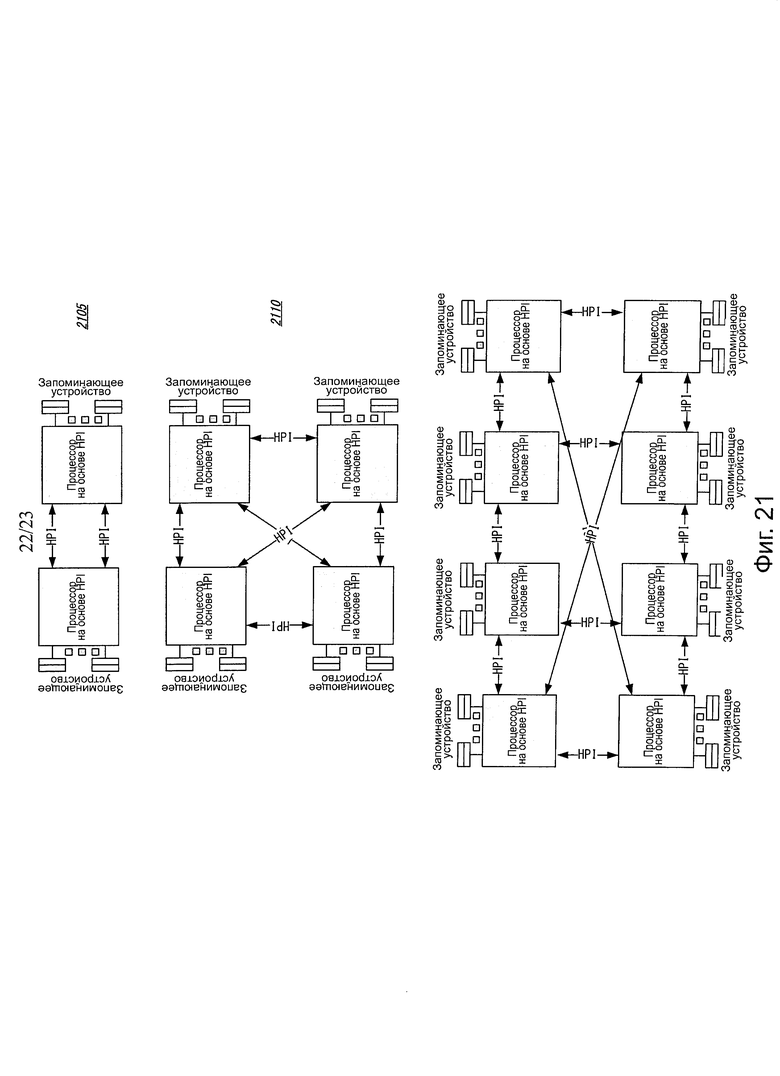

Изобретение относится к вычислительной технике. Технический результат заключается в увеличении полосы пропускания запоминающего устройства. Система расширения оптического запоминающего устройства содержит первую электрическую логическую схему для передачи данных в соответствии с протоколом взаимного межточечного соединения для пакетной передачи данных в соответствии с полной скоростью передачи данных; первую промежуточную схему, соединенную для приема данных от первой электрической логической схемы по электрической линии связи, причем первая промежуточная схема выполнена с возможностью преобразования данных в оптический формат, предназначенный для передачи со скоростью, по меньшей мере в два раза большей полной скорости передачи данных; вторую промежуточную схему, соединенную для приема данных в оптическом формате от первой промежуточной схемы по оптической линии связи, причем вторая промежуточная схема выполнена с возможностью преобразования данных в электрический формат, соответствующий протоколу взаимного межточечного соединения для пакетной передачи данных; и вторую электрическую логическую схему, соединенную для приема данных от первой электрической логической схемы, при этом оптическая линия связи инициализируется в соответствии с оптическими обучающими состояниями. 3 н. и 33 з.п. ф-лы, 24 ил., 2 табл.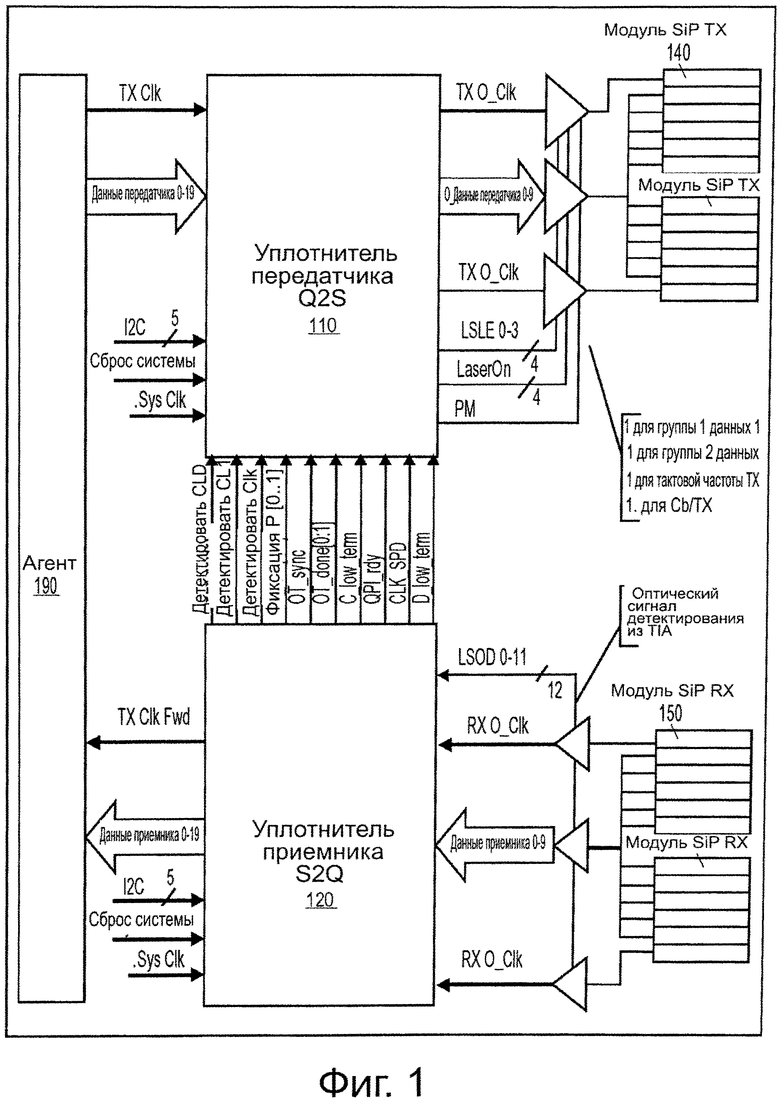
1. Система расширения оптического запоминающего устройства, содержащая:
первую электрическую логическую схему для передачи данных в соответствии с протоколом взаимного межточечного соединения для пакетной передачи данных в соответствии с полной скоростью передачи данных;
первую промежуточную схему, соединенную для приема данных от первой электрической логической схемы по электрической линии связи, причем первая промежуточная схема выполнена с возможностью преобразования данных в оптический формат, предназначенный для передачи со скоростью, по меньшей мере в два раза большей полной скорости передачи данных;
вторую промежуточную схему, соединенную для приема данных в оптическом формате от первой промежуточной схемы по оптической линии связи, причем вторая промежуточная схема выполнена с возможностью преобразования данных в электрический формат, соответствующий протоколу взаимного межточечного соединения для пакетной передачи данных; и
вторую электрическую логическую схему, соединенную для приема данных от первой электрической логической схемы,
при этом оптическая линия связи инициализируется в соответствии с множеством оптических обучающих состояний, и инициализация оптической линии связи выполняется перед инициализацией электрической линии связи.
2. Система по п. 1, в которой протокол взаимного межточечного соединения для пакетной передачи данных включает в себя протокол мониторинга.
3. Система по п. 1, в которой протокол взаимного межточечного соединения для пакетной передачи данных выполнен с возможностью управления когерентностью кэша с использованием протокола обратной записи.
4. Система по п. 1, в которой протокол взаимного межточечного соединения для пакетной передачи данных согласуется с протоколами взамных соединений по скоростному каналу (QPI).
5. Система по п. 1, в которой протокол межточечного соединения для пакетной передачи данных выполнен с возможностью использования встроенного сигнала тактовой частоты.
6. Система по п. 1, в которой первая промежуточная схема и вторая промежуточная схема выполнены с возможностью обеспечивать функционирование оптической линии связи между ними со скоростью передачи данных, соответствующей полной скорости передачи данных, во время инициализации линий связи между первой электрической логической схемой и второй электрической логической схемой.
7. Система по п. 1, в которой первая электрическая логическая схема содержит ядро обработки, а вторая электрическая логическая схема содержит запоминающее устройство.
8. Система по п. 1, дополнительно содержащая:
третью промежуточную схему, соединенную для приема данных от второй электрической логической схемы, причем третья промежуточная схема выполнена с возможностью преобразования данных в оптический формат, предназначенный для передачи со скоростью, по меньшей мере в два раза большей полной скорости передачи данных;
четвертую промежуточную схему, соединенную для приема данных в оптическом формате от третьей промежуточной схемы, причем четвертая промежуточная схема выполнена с возможностью преобразования данных в электрический формат, согласующийся с протоколом взаимного межточечного соединения для пакетной передачи данных, и соединена для подачи электрических данных в первую электрическую логическую схему.
9. Система по п. 8, в которой каждая из первой промежуточной схемы и третьей промежуточной схемы выполнена с возможностью мультиплексировать М линий данных в N линий, взаимодействующих с модулем электрооптического преобразования для выполнения электрооптического преобразования по N линиям.
10. Система по п. 8, в которой каждая из второй промежуточной схемы и четвертой промежуточной схемы выполнена с возможностью принимать N линий данных от модуля оптико-электрического преобразования для выполнения оптико-электрического преобразования по N линиям данных, причем каждая из второй промежуточной схемы и четвертой промежуточной схемы выполнена с возможностью демультиплексировать N линий данных в М линий данных.
11. Система по п. 9, в которой М равно 20, а N равно 10.
12. Система по п. 1, дополнительно содержащая конечный автомат оптического сигнала.
13. Система по п. 12, в которой оптический конечный автомат выполнен с возможностью управления состояниями питания и переходами между состояниями питания.
14. Система по п. 12, в которой оптический конечный автомат выполнен с возможностью управления оптическими обучающими последовательностями.
15. Система по п. 1, в которой первая промежуточная схема и вторая промежуточная схема содержат схему восстановления синхронизации по меньшей мере с одним промежуточным контуром фазовой синхронизации (PLL) для тактовой частоты передачи.
16. Система по п. 1, дополнительно содержащая механизм для содействия операции медленного запуска в соответствии с взаимным соединением по скоростному каналу (QPI).
17. Система по п. 1, дополнительно содержащая одну или более схем динамического регулирования усиления в сочетании со схемами эквалайзера обратной связи (DFE) для самостоятельной адаптации к принимаемым сигналам, при этом не требуется периодическое повторное обучение для выравнивания сигнала.
18. Интегральная схема для расширения оптического запоминающего устройства, содержащая:
первую промежуточную схему, соединенную для приема данных от первой электрической логической схемы по электрической линии связи, причем первая электрическая логическая схема выполнена с возможностью передачи данных в соответствии с протоколом взаимного межточечного соединения для пакетной передачи данных в соответствии с полной скоростью передачи данных, при этом первая промежуточная схема выполнена с возможностью участия в инициализации оптической линии связи, причем инициализация оптической линии связи содержит множество обучающих состояний оптической линии связи, и преобразования данных в оптический формат для передачи со скоростью, по меньшей мере вдвое большей полной скорости передачи данных, причем инициализация оптической линии связи предшествует инициализации электрической линии связи.
19. Интегральная схема по п. 18, в которой первая промежуточная схема соединена для передачи оптических данных во вторую промежуточную схему, причем вторая промежуточная схема соединена для приема данных в оптическом формате от первой промежуточной схемы и выполнена с возможностью преобразования данных в электрический формат, согласующийся с протоколом взаимного межточечного соединения для пакетной передачи данных.
20. Интегральная схема по п. 18, в которой протокол взаимного межточечного соединения для пакетной передачи данных включает в себя протокол мониторинга.
21. Интегральная схема по п. 18, в которой протокол взаимного межточечного соединения для пакетной передачи данных выполнен с возможностью управления когерентностью кэша с использованием протокола обратной записи.
22. Интегральная схема по п. 18, в которой протокол взаимного межточечного соединения для пакетной передачи данных согласуется с протоколами взаимного соединения по скоростному каналу (QPI).
23. Интегральная схема по п. 18, в которой протокол межточечного соединения для пакетной передачи данных выполнен с возможностью использования встроенного сигнала тактовой частоты.
24. Интегральная схема по п. 18, в которой первая промежуточная схема и вторая промежуточная схема выполнены с возможностью обеспечивать функционирования оптической линии связи между ними со скоростью передачи данных, соответствующей полной скорости передачи данных, во время инициализации линий связи между первой электрической логической схемой и второй электрической логической схемой.
25. Интегральная схема по п. 18, в которой первая электрическая логическая схема содержит ядро обработки, а вторая электрическая логическая схема содержит запоминающее устройство.
26. Интегральная схема по п. 18, в которой первая промежуточная схема выполнена с возможностью мультиплексировать М линий данных в N линий, взаимодействующих с модулем электрооптического преобразования для выполнения электрооптического преобразования по N линиям.
27. Интегральная схема по п. 26, в которой вторая промежуточная схема выполнена с возможностью принимать N линий данных от модуля оптико-электрического преобразования для выполнения оптико-электрического преобразования по N линиям данных, причем вторая промежуточная схема выполнена с возможностью демультиплексирования N линий данных в М линий данных.
28. Интегральная схема по п. 27, где М равно 20 и N равно 10.
29. Интегральная схема для расширения оптического запоминающего устройства, содержащая:
первую промежуточную схему, соединенную для приема данных в оптическом формате от второй промежуточной схемы по оптической линии связи, причем первая промежуточная схема выполнена с возможностью преобразования данных в электрический формат, согласующийся с протоколом взаимного межточечного соединения для пакетной передачи данных; и
первую электрическую логическую схему, соединенную для приема данных от удаленной первой электрической логической схемы по электрической линии связи, причем инициализация оптической линии связи предшествует инициализации электрической линии связи, при этом инициализация оптической линии связи содержит множество оптических обучающих состояний.
30. Интегральная схема по п. 29, в которой удаленная электрическая логическая схема выполнена с возможностью передачи данных в соответствии с протоколом взаимного межточечного соединения для пакетной передачи данных в соответствии с полной скоростью передачи данных; а
вторая промежуточная схема соединена для приема данных от первой электрической логической схемы, причем первая промежуточная схема выполнена с возможностью преобразования данных в оптический формат для передачи со скоростью, по меньшей мере в два раза большей полной скорости передачи данных.
31. Интегральная схема по п. 29, в которой протокол взаимного межточечного соединения для пакетной передачи данных включает в себя протокол мониторинга.
32. Интегральная схема по п. 29, в которой протокол взаимного межточечного соединения для пакетной передачи данных выполнен с возможностью управления когерентностью кэша с использованием протокола обратной записи.
33. Интегральная схема по п. 29, в которой протокол взаимного межточечного соединения для пакетной передачи данных согласуется с протоколами взаимного соединения по скоростному каналу (QPI).
34. Интегральная схема по п. 29, в которой первая промежуточная схема и вторая промежуточная схема выполнены с возможностью обеспечивать функционирование оптической линии связи между ними со скоростью передачи данных, соответствующей полной скорости передачи данных, во время инициализации линий связи между первой электрической логической схемой и второй электрической логической схемой.
35. Интегральная схема по п. 29, в которой первая электрическая логическая схема содержит запоминающее устройство.
36. Интегральная схема по п. 29, в которой вторая электрическая логическая схема содержит ядро обработки.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| СИСТЕМА И СПОСОБ СОПРЯЖЕНИЯ ЛОКАЛЬНОГО УСТРОЙСТВА СВЯЗИ | 1997 |
|
RU2189706C2 |

