ОБЛАСТЬ ТЕХНИКИ
Изобретение относится к области вычислительной техники и может быть применено при построении коммутационных средств мультипроцессорных вычислительных и управляющих систем, абонентских систем связи с децентрализованным управлением и информационно-измерительных систем.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Известна сеть iMesh для соединения вычислительных узлов в архитектуре TILEx системы Tilera, (Transferring data in a parallel processing environment US №7461236 B1, МПК G06F 15/00, G06F 15/76, заявлен 21.12.2005, опубликован 2.12.2008), содержащая (FIG 1 и 2A) коммутационный узел 220, включающий входные буфера 222 для временного хранения данных пришедших от соседнего узла и коммуникационную схему 224, передающую данные по портам ввода/вывода по четырем каналам 104 между соседними узлами сети 104 и взаимодействует с процессором 200 через встроенный интегрированный интерфейс коммутатора 232. Коммутационный узел 220 позволяет реализовать различные алгоритмы коммутации и маршрутизации при передаче данных по сети, однако данная особенность приводит к увеличению количества аппаратных ресурсов, требующихся для реализации данного узла.
Недостатком данного решения являются высокие затраты аппаратных ресурсов на реализацию коммутационного узла 220, представляющего собой коммутатор 5 в 5 с буферизацией данных на входных и выходных портах, являющийся настраиваемым и позволяющим реализовать различные виды алгоритмов маршрутизации и коммутации пакетов.
Известна внутрикристальная сеть для соединения 1000 вычислительных ядер в системе Kilocore (Yu Z., Baas В.M. A low-area multi-link interconnect architecture for GALS chip multiprocessors //IEEE transactions on very large scale integration (VLSI) systems. - 2010. - T. 18. - №. 5. - C. 750-762.), содержащая коммутатор 5 в 5 (Fig. 4), включающий в себя модуль буферизации для каждого из выходных каналов, мультиплексоры для коммутации данных между входными и выходными каналами для каждого из каналов (west, south, north, east), мультиплексор для приема данных на входе вычислительного узла, модуль буферизации данных на входе вычислительного узла, обеспечивающий передачу данных через границу частотного домена, причем размер данного буфера увеличен за счет уменьшения относительных размеров других модулей буферизации, что позволяет более эффективно использовать аппаратные ресурсы при решении задач, передачи между вычислительными узлами в которых в большей части являются локальными.
Недостатком данной архитектуры является высокая задержка при передаче данных между абонентами сети при решении задач, распределение трафика по сети в которых является равновероятным.
Наиболее близким к предлагаемой сети по технической сущности является принятая за прототип пакетная сеть для соединения вычислительных узлов FPMAC (Vangal S.R. et al. An 80-tile sub-100-w teraflops processor in 65-nm cmos //IEEE Journal of Solid-State Circuits. - 2008. - T. 43. - №. 1. - C. 29-41.), узел пакетной сети которой (FIG 2) состоит из коммутатора 5 в 5 Crossbar router, состоящего из (FIG 5) модулей синхронизации MSINT, коммутационной логики Crossbar switch и двух очередей для каждого из входных каналов, и модуля интерфейса в коммутатор MB, приемная часть которого состоит из очереди для хранения пришедших флитов (FLITs - flow control digits) пакета и логики для декодирования пришедшего пакета и его последующей обработки, а передающая часть обеспечивает кодирование флитов пакета для передачи их в коммутатор сети.
Доступ к модулю интерфейса в коммутатор RIB в данном устройстве осуществляется непосредственно из регистрового файла процессорного элемента RF, то есть формирование запроса на отправку данных по сети происходит после выполнения определенной инструкции. После выполнения данной инструкции в модуле интерфейса в коммутатор RIB из данных, поступивших от регистрового файла RF и памяти команд IMEM, формируются флиты пакета, и инициируется обмен данными с коммутатором Crossbar router. После этого пакет передается в соответствующую очередь и коммутируется на соответствующий алгоритму коммутации выход коммутатора. Попадая в коммутатор узла назначения, пакет попадает в модуль синхронизации MSINT, буферизация данных в котором реализована как очередь запросов FIFO. Далее пакет буферизируется в соответствующей очереди в коммутаторе и, после успешной коммутации, передается в модуль интерфейса в коммутатор RIB, в котором также реализована промежуточная буферизация данных для обеспечения непрерывности работы процессорного элемента.
Архитектура данного устройства устроена таким образом, что вычислительный узел и коммутатор пакетной сети работают на одной частоте, и, для обеспечения передачи данных между вычислительными узлами, работающими на разных частотах, синхронизация данных осуществлена на входе в коммутатор соответствующего вычислительного узла при помощи модуля синхронизации MSINT. Коммутаторы данной пакетной сети являются коммутаторами 5 в 5 с дополнительной буферизацией данных, для реализации которых требуется значительное количество аппаратных ресурсов. Использование однопортовой локальной памяти данных DMEM и памяти инструкций IMEM приводит к тому, что необходимо буферизовать пришедших по сети пакетов перед их обработкой, если она требует запись в соответствующую память, для обеспечения непрерывной работы процессорного элемента. Модуль интерфейса в коммутатор RIB не имеет отдельного порта для взаимодействия с памятью данных DMEM, чтение данных из этой памяти возможно только при непосредственном участии процессорного элемента, что не позволяет реализовать технологию прямого доступа в память (DMA).
Таким образом, причиной, препятствующей достижению технического результата, является использование коммутаторов 5 в 5 с промежуточной буферизацией данных, наличие модуля синхронизации MSINT, использование в качестве локальной памяти данных DMEM и памяти команд IMEM однопортовой памяти, что приводит к увеличению задержки при передаче данных между вычислительными узлами и увеличению количества аппаратных ресурсов, требующихся для реализации узла пакетной сети. Невозможность независимого от процессорного элемента доступа модуля интерфейса коммутатора RIB в локальную память данных DMEM не позволяет реализовать технологию прямого доступа в память (DMA).
ЗАДАЧА ИЗОБРЕТЕНИЯ
Задача, на решение которой направлено предлагаемое техническое решение, заключается в создании высокопроизводительной, многофункциональной, коммуникационной сети для соединения вычислительных узлов в мультипроцессорных системах, требующей малое количество аппаратных ресурсов для ее реализации.
Техническим результатом изобретения является уменьшение времени задержки при передаче данных между вычислительными узлами и сокращение аппаратных ресурсов, а также расширение функциональных возможностей в части реализации прямого доступа к памяти любого абонента пакетной сети.
КРАТКОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Указанный технический результат при осуществлении изобретения достигается за счет того, что в пакетной сети для мультипроцессорных вычислительных систем, содержащей не менее двух узлов пакетной сети 1, каждый из которых содержит контроллер шины 2 и не менее одного коммутатора канального уровня 31,…3N,
каждый коммутатор канального уровня 31,…3N является коммутатором 2 в 2 без дополнительной буферизации, при этом на канальном уровне между коммутаторами соседних узлов по первым входам и первым выходам обеспечивается принцип передачи данных типа «червь» («wormhole») по канальному интерфейсу 4,
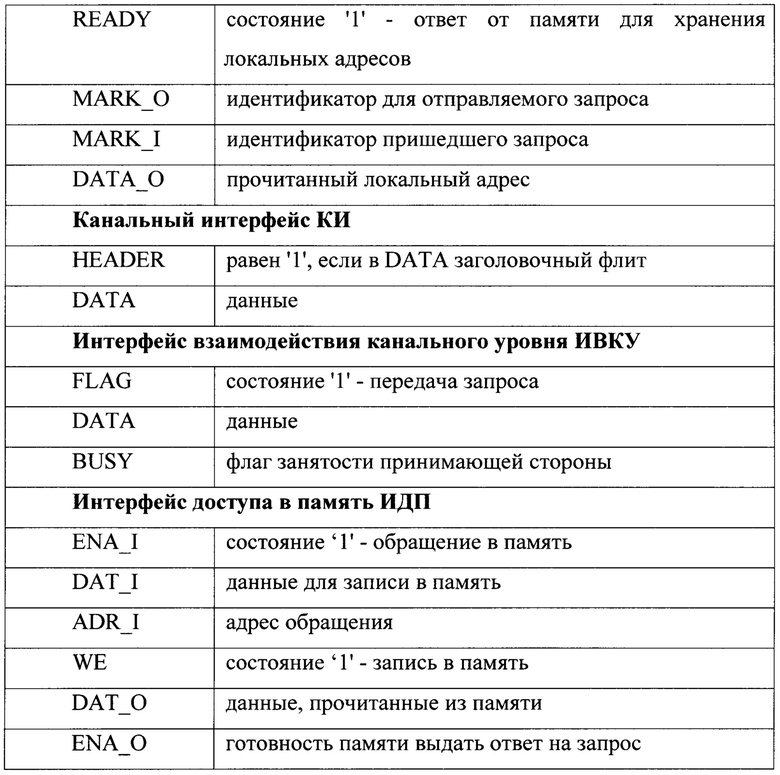
контроллер шины 2 содержит первый блок мультиплексоров 5, локальную память 6 и память кэш инструкций 7, организованных как двухпортовые асинхронные памяти, модуль генерации пакетов канального уровня 8, состоящий из генератора пакетов 9, соединенного с входами второго блока мультиплексоров 10, модуль приема пакетов канального уровня 11, состоящий из приемника пакетов 12, соединенного с выходами третьего блока мультиплексоров 13, входы которого соединены с соответствующими выходами группы буферной памяти 141,…14N FIFO, модуль передачи запросов протокольного уровня 15 и память для хранения локальных адресов 16, а также контроллер шины 2 содержит три внешних порта для организации интерфейсного взаимодействия с вычислительным узлом 17,
причем в контроллере шины 2 к первому внешнему порту подключен модуль передачи запросов протокольного уровня 15 и организован интерфейс взаимодействия протокольного уровня 18, ко второму внешнему порту подключена локальная память 6 и организован интерфейс доступа к памяти 19, а к третьему внешнему порту подключена память кэш инструкций 7 и организован интерфейс доступа к памяти 19,
кроме того, модуль передачи запросов протокольного уровня 15 по второму входу соединен с генератором пакетов 9 по интерфейсу взаимодействия протокольного уровня 18, а по третьему входу по интерфейсу взаимодействия с памятью для хранения локальных адресов 20 соединен с памятью для хранения локальных адресов 16, которая также соединена с приемником пакетов 12 по интерфейсу 20,
блок мультиплексоров 5 соединен с соответствующими входами локальной памяти 6 и памяти кэш инструкций 7, а также с генератором пакетов 9 и приемником пакетов 12 по интерфейсу доступа к памяти 19,
выходы второго блока мультиплексоров 10 соединены со вторым входным портом 1_2 соответствующего коммутатора канального уровня 31,…3N, вторые выходы которых 2_2 соединены с входами соответствующих входов группы буферной памяти 141,…14N FIFO,
при этом в каждом вычислительном узле второй входной 1_2 и второй выходной 2_2 порты коммутаторов канального уровня 31,…3N соединены с соответствующим контроллером шины по интерфейсу взаимодействия канального уровня 21,
причем при передаче данных между узлами пакетной сети используется алгоритм статической распределенной маршрутизации.
Поставленная задача решается тем, что предлагаемый способ с использованием пакетной сети для мультипроцессорных вычислительных систем, содержит следующие этапы, на которых:
- по интерфейсу взаимодействия протокольного уровня 18 формируют запрос на отправку пакета по сети;
- в модуле передачи запросов протокольного уровня 15 подтверждают получение запроса от вычислительного узла по интерфейсу взаимодействия протокольного уровня, передают запрос через границу тактовых доменов вычислительного узла и пакетной сети, и, в соответствии с протоколом интерфейса взаимодействия с памятью для хранения локальных адресов 20, записывают локальный адрес в память для хранения локальных адресов 16, получают от памяти хранения локальных адресов 16 уникальный идентификатор для передаваемого запроса, если соответствует алгоритму работы модуля передачи запросов протокольного уровня, и передают запрос в генератор пакетов 9 модуля по интерфейсу взаимодействия протокольного уровня 18;
- в генераторе пакетов 9 кодируют флиты пакета в соответствии с заданной структурой пакета, исходя из информации, полученной от модуля передачи запросов протокольного уровня 15, и обращаются в локальную память 6 или память кэш инструкций 7 для чтения данных в соответствии с протоколом работы интерфейса доступа к памяти 19, если это необходимо для кодирования пакета заданного типа, передают пакет в один из коммутаторов 31,…3N в порт 1_2 данного узла пакетной сети по интерфейсу взаимодействия канального уровня 21, причем номер коммутатора 31,…3N, в который передают запрос, определяют в соответствии с алгоритмом работы второго блока мультиплексоров 10;
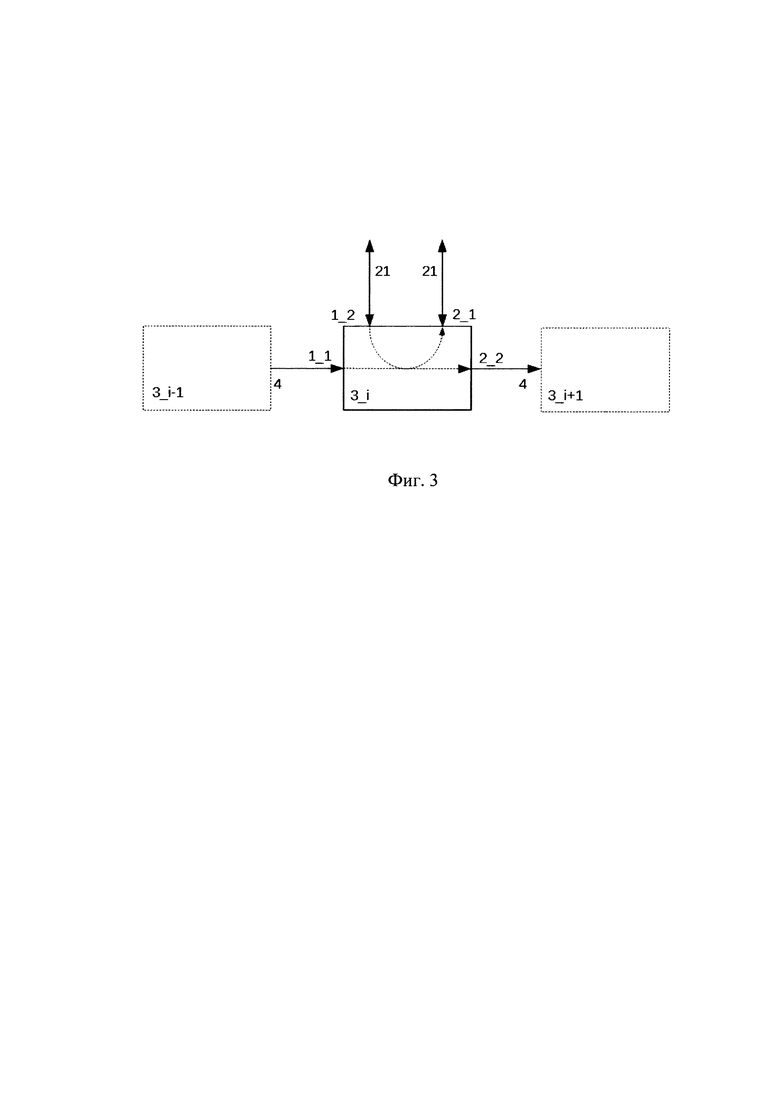
- в коммутаторе 3 производят коммутацию пакета со второго входного порта коммутатора 1_2 на первый выходной порт 2_1 в случае, когда на первом входе находится заголовочный флит пустого пакета, в ином случае - буферизуют пакет до момента, когда коммутацию можно будет провести, причем коммутацию пакета с первого входного порта 1_1 коммутатора 3 производят на второй выходной порт 2_2 коммутатора 3 в случае, когда поле адресата в заголовочном флите пакета содержит номер узла пакетной сети, которому принадлежит данный коммутатор 3, в иных случаях пакет коммутируют на первый выходной порт 2_1 коммутатора 3, который соединен с первым входным портом 1_1 коммутатора 3 соседнего узла пакетной сети;
- после получения контроллером шины 2, а именно модулем приема пакетов канального уровня 11 пакета от одного из коммутаторов 3 данного узла по интерфейсу взаимодействия канального уровня 21, пакет буферизуют в очереди FIFO 141,…14N;
- в соответствии с алгоритмом работы третьего блока мультиплексоров 13, и протоколом работы интерфейса взаимодействия канального уровня 21 между блоком мультиплексоров 13 и приемником пакетов 12, осуществляют чтение из одной из очередей FIFO 141,…14N и передают пакет в приемник пакетов 12;
- в приемнике пакетов 12 декодируют флиты полученного пакета, получают локальный адрес из памяти локальных адресов 16 в соответствии с протоколом работы интерфейса взаимодействия с памятью для хранения локальных адресов 20, если это соответствует алгоритму обработки пакета заданного типа, формируют адрес в локальной памяти 6, в соответствии с алгоритмом обработки пакета заданного типа, и записывают данные из пакета в локальную память 6 или память кэш инструкций 7 в соответствии с протоколом работы интерфейса доступа в память 19.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
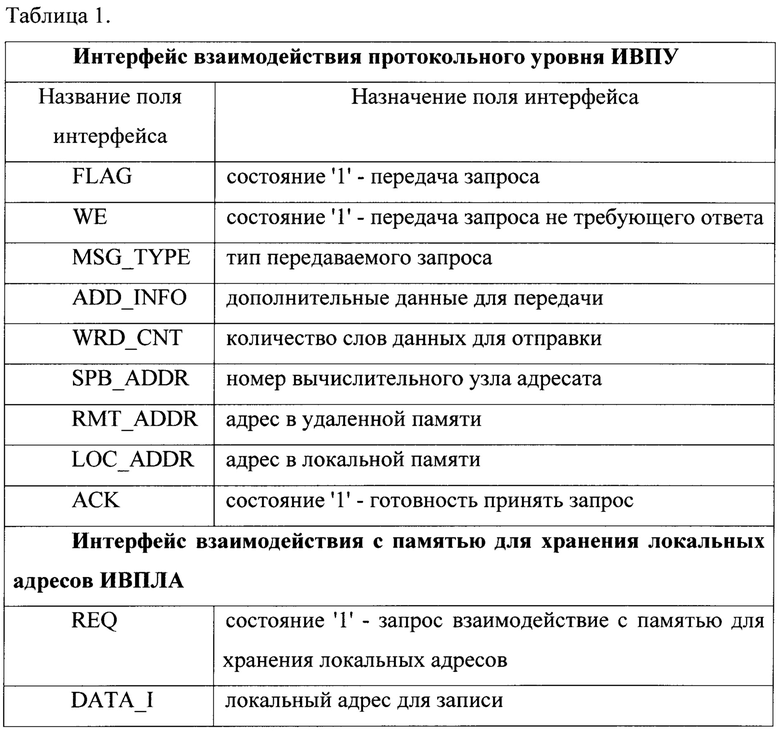
На фиг. 1 представлена блок схема пакетной сети для мультипроцессорных вычислительных систем из трех узлов.
На фиг. 2 представлена блок-схема контроллера шины узла пакетной сети.
На фиг. 3 представлена блок-схема одного из коммутаторов канального уровня узла пакетной сети с нумерацией его входов/выходов.
На фиг. 1, фиг. 2 и фиг. 3 введены следующие обозначения:
1 - узел пакетной сети,
2 - контроллер шины,
3 - общее обозначение коммутаторов,
1_1 - первый входной порт коммутатора 3,
1_2 - второй входной порт коммутатора 3,
2_1 - первый выходной порт коммутатора 3,
2_2 - второй выходной порт коммутатора 3,
31,…3N - группа коммутаторов канального уровня одного узла пакетной сети,
4 - канальный интерфейс,
5, 10, 13 - блоки мультиплексоров,
6 - локальная память,
7 - память кэш инструкций,
8 - модуль генерации пакетов канального уровня,
9 - генератор пакетов,
11 - модуль приема пакетов канального уровня,
12 - приемник пакетов,
141,…14N - группы буферной памяти FIFO очередей запросов,
15 - модуль передачи запросов протокольного уровня,
16 - память для хранения локальных адресов,
17 - вычислительный узел,
18 - интерфейс взаимодействия протокольного уровня,
19 - интерфейс доступа к памяти,
20 - интерфейс взаимодействия с памятью для хранения локальных адресов,
21 - интерфейс взаимодействия канального уровня,
Предлагаемая пакетная сеть осуществляется следующим образом.
Каждый узел пакетной сети содержит коммутаторы 31,…3N и контроллер шины 2, состоящий из модуля передачи запросов протокольного уровня 15, модуля локальной памяти вычислительного узла 6, памяти кэш инструкций вычислительного узла 7, блока мультиплексоров 5, модуля памяти для хранения локальных адресов 16, модуля генерации пакетов канального уровня 8, состоящего из генератора пакетов 9 и блока мультиплексоров 10, модуля приема пакетов канального уровня 11, который состоит из приемника пакетов 12 и блока мультиплексоров 13, и группы буферной памяти 141,…14N FIFO, по одному на каждый подключенный коммутатор 31,…3N.
Коммутаторы 31,…3N соседних узлов взаимодействуют между собой по канальному интерфейсу шины 4. В каждом узле пакетной сети контроллер шины 2 соединен с каждым коммутатором 31,…3N данного узла по интерфейсу взаимодействия канального уровня 21. Доступ в локальную память 6 и память кэш инструкций 7 от модуля генерации пакетов канального уровня 8, модуля приема пакетов канального уровня 11 и вычислительного узла осуществляется по интерфейсу доступа в память 19. Взаимодействие вычислительного узла и контроллера шины осуществляется также по интерфейсу взаимодействия протокольного уровня 18.
Коммутатор 3 имеет два входных порта и два выходных порта, причем первый входной порт 1_1 и первый выходной порт 2_1 коммутатора, соединены по канальному интерфейсу с соответствующими портами соседних коммутаторов, а второй входной порт 1_2 и второй выходной порт 2_2 соединены с контроллером шины вычислительного узла по интерфейсу взаимодействия канального уровня 21. Коммутатор 3 является неполным и осуществляет коммутацию пакетов на первый выходной порт коммутатора 2_1 с первого и второго входных портов 1_1 и 1_2 соответственно, а на второй выходной порт 2_2 только с первого входного порта коммутатора 1_1.
ПОДРОБНОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Пакетная сеть является полностью синхронной и позволяет соединять вычислительные узлы между собой и осуществлять передачу данных от любого узла к любому, причем тактовые частоты работы вычислительных узлов могут отличаться. Узлы пакетной сети можно соединить между собой в топологию типа односторонний или двусторонний конвейер и в топологии более высокой размерности на их основе.
Канальный уровень передачи данных в пакетной сети осуществляется при помощи коммутаторов 31,…3N, являющихся простыми неполными коммутаторами 2 в 2 с пространственным разделением, обеспечивающих червячный метод передачи пакетов («wormhole»). Причем в пакетной сети используется статическая распределенная маршрутизация.
Протокольный уровень передачи осуществляется при помощи контроллеров шины, осуществляющих подключение одного или нескольких коммутаторов канального уровня 31,…3N к вычислительному узлу. По пакетной сети на протокольном уровне могут передаваться пакеты различной длины, причем возможность отправлять пакеты нефиксированной длины присутствует только у абонентов сети, коммутатор которых является крайним в конвейере. Данное ограничение необходимо для обеспечения отсутствия ситуаций взаимной блокировки («deadlock»).
Размер фиксированного пакета составляет 2 флита, размер длинного пакета может содержать до 256 флитов.
Коммутатор канального уровня 3 предназначен для организации канального уровня передачи данных между узлами пакетной сети по канальному интерфейсу 4, причем с контроллером шины коммутатор соединяется по интерфейсу взаимодействия канального уровня 21.
Контроллер шины обеспечивает передачу данных между вычислительными узлами по интерфейсу доступа в память 19 и интерфейсу взаимодействия протокольного уровня 18. Причем модуль локальной памяти 6 и память кэш инструкций 7 предназначены для хранения данных и команд соответствующего вычислительного узла и организованы как двухпортовая асинхронная память.
Модуль передачи запроса протокольного уровня 15 обеспечивает взаимодействие контроллера с одним или несколькими абонентами со стороны вычислительного узла и обеспечивает передачу запроса из тактового домена вычислительного ядра в тактовый домен пакетной шины, причем для синхронизации передачи используется механизм «рукопожатия» (handshake). Также модуль передачи запросов протокольного уровня 15 инициирует запись в память для хранения локальных адресов 16 по интерфейсу взаимодействия с памятью для хранения локальных адресов 20 адрес в локальной памяти 6, по которому будут записаны данные из ответного пакета, если отправляемый запрос имеет тип «чтение удаленной памяти».
Память для хранения локальных адресов 16 организована как память с произвольным доступом и регистр статуса занятости определенной ячейки. Каждому пакету, имеющему тип «чтение удаленной памяти» присваивается уникальный идентификатор, соответствующий адресу ячейки в памяти для хранения локальных адресов 16, в которой хранится адрес ячейки в локальной памяти, в которую нужно записать пришедшие данные. Этот механизм позволяет восстановить локальные адреса для каждого из отправленных пакетов вне зависимости от очередности их прихода и уменьшить тем самым количество передаваемых служебных данных.
Генератор пакетов 9 обрабатывает запросы протокольного уровня, приходящие от модуля передачи запросов 15 по интерфейсу взаимодействия протокольного уровня 18 и обеспечивает их преобразование в пакеты канального уровня. Генератор пакетов 9 имеет доступ в локальную память 6 и память кэш инструкций 7, что позволяет обращаться в локальную память 6 и память кэш инструкций 7 независимо от вычислительного узла. Генератор пакетов 9 обеспечивает кодирование запроса протокольного уровня во флиты пакетов канального уровня. Сформированный пакет передается по интерфейсу взаимодействия канального уровня 21 в один из коммутаторов 31,…3N данного узла пакетной сети, причем требуемый коммутатор 31,…3N выбирается в зависимости от необходимого направления движения пакета по конвейеру.
Модуль приема пакетов канального уровня состоит из приемника пакетов 12 и группы буферной памяти 141,…14N FIFO по одному на каждый коммутатор 31,…3N. Данные модули буферной памяти необходимы для организации приема пакетов от нескольких коммутаторов 31,…3N в приемник пакетов 12. Приемник пакетов 12 обеспечивает декодирование флитов пакетов канального уровня и обеспечивает их последующую обработку. В зависимости от типа пришедшего пакета выбирается способ его дальнейшей обработки. При получении пакета, имеющего тип «ответ на чтение удаленной памяти», соответствующий адрес в локальной памяти 6 или памяти кэш инструкций 7, по которому необходимо записать данные читается из памяти для хранения локальных адресов 16. В случае прихода пакета типа «интерконнект», данные записываются в кольцевой буфер, реализованный в локальной памяти 6. Предусмотрено несколько типов пакетов с таким способом обработки, причем для каждого из них реализован отдельный кольцевой буфер в локальной памяти 6. В случае прихода пакета типа «абонент N занят (свободен)», реализуется блокировка (разблокировка) контроллера шины 2 на отправку запросов к данному абоненту. В случае прихода пакета типа «запись в удаленную память», данные записываются по адресу, указанному в самом пакете. В случае прихода пакета типа «чтение удаленной памяти», данные записываются в кольцевой буфер для последующей обработки генератором пакетов 9. Таким образом, приемник пакетов 12 обеспечивает тегированный прием и передачу данных по сети и позволяет реализовать технологию прямого доступа в память.
Локальная память 6 и память кэш инструкций 7 организованы как двухпортовые памяти, доступные по интерфейсу 19 независимо как со стороны вычислительного узла, так и со стороны модулей контроллера шины. Причем порты могут работать на разных тактовых частотах, что позволяет не использовать отдельные модули синхронизации для передачи данных между вычислительными узлами, работающими на разных частотах.
Предлагаемая пакетная сеть работает следующим образом.
Изначально в коммутаторах сети содержатся только пустые пакеты. На первый вход 1_1 первого коммутатора после пустого пакета готовится к передаче пакет длинной 4 флита, причем адресом его назначения является вычислительный узел второго коммутатора. На второй вход 1_2 второго коммутатора поступил запрос на отправку пакета, однако, в данный момент в коммутаторе находится второй флит пустого пакета. Единственным условием, позволяющим начать передачу пакета со второго входа 1_2 второго коммутатора на первый выход 2_1 второго коммутатора, является наличие флита заголовка пустого пакета на первом входе. Таким образом, после первого такта передача осуществлена не будет. На втором такте во втором коммутаторе оказывается флит заголовка пустого пакета, что позволяет начать передачу пакета от контроллера шины второго коммутатора. На третьем такте флит заголовка длинного пакета попадает в первый коммутатор, но, так как данный пакет был отправлен вычислительному узлу второго коммутатора, флит заголовка на следующем такте передается на первый выход 21 первого коммутатора. Когда флит заголовка попадает во второй коммутатор, данный флит и все остальные флиты данного пакета будут переданы в контроллер шины второго коммутатора, а на первый выход 2_1 второго коммутатора будут передаваться флиты пустого пакета.
Рассмотрим работу пакетной сети на примере запроса типа «чтение удаленной памяти».
(В целях упрощения понимания в таблице 1 в конце описания приведены названия и назначения полей интерфейсов)
На первом этапе вычислительный узел инициирует запрос по интерфейсу взаимодействия протокольного уровня 18 в контроллер шины 2. Для этого он поднимает флаг REQ и присваивает следующие значения полям WE - ’1’, MSG_TYPE = “0x1”, ADD_INFO не используется, WRD_CNT = ’0x01’, SPB_ADDR = адрес абонента, память которого необходимо прочитать, RMT_ADDR = адрес в удаленной памяти, который необходимо прочитать, LOC_ADDR = адрес в локальной памяти вычислительного узла, по которому следует записать прочитанные из удаленной памяти данные. Флаг REQ будет опущен, когда флаг REQ и флаг ACK от модуля передачи запросов протокольного уровня 15 будут подняты в течение одного такта, после этого запрос считается отправленным.
На следующем этапе модуль передачи запросов протокольного уровня осуществляет передачу полученного от вычислительного узла запроса через границу тактовых доменов, причем при передаче используется механизм рукопожатия «handshake», позволяющий избежать метастабильных состояний соответствующих полей интерфейса. После этого модуль передачи запросов протокольного уровня 15 инициирует запись LOC_ADDR в память для хранения локальных адресов 16 по интерфейсу взаимодействия с памятью для хранения локальных адресов 20. Для этого поднимается флаг REQ, а в поле DAT_I выставляется LOC_ADDR. Память для хранения локальных адресов 16 после определения адреса, по которому будет записан запрос, поднимает флаг READY и выставляет в поле MARK_O соответствующий адрес в памяти для хранения локальных адресов 16, который будет использоваться как идентификатор для отправляющегося запроса. Если на данный момент все ячейки памяти локальных адресов 16 заняты, флаг READY поднимется только после того, как одна из ячеек станет свободной. После успешного получения модулем передачи запросов протокольного уровня 15 идентификатора от памяти для хранения локальных адресов 16, данный идентификатор записывается в старшие биты поля ADD_INFO интерфейса 18 между модулем передачи запроса протокольного уровня 15 и генератором пакетов 9. Остальные поля интерфейса заполняются данными, полученными от вычислительного узла.
На следующем этапе, осуществляется передача запроса в генератор пакетов 9 по интерфейсу 18, алгоритм работы интерфейса совпадает с алгоритмом взаимодействия вычислительного узла и модуля передачи запросов протокольного уровня 15. В генераторе пакетов 9 осуществляется кодирование флитов пакета канального уровня в соответствии с видами передаваемых сообщений.
Пакетная сеть поддерживает передачу следующих видов сообщений фиксированной длины: Чтение удаленной памяти, Запись в удаленную память, Интерконнект, абонент N занят/свободен, пустой, а также пакет типа ответ на чтение из удаленной памяти, который имеет нефиксированную длину. Каждый пакет имеет заголовочный флит, в котором передается информация о типе передаваемого пакета (1 байт), номере абонента, которому отправлен пакет (2 байта), количестве флитов в пакете (1 байт), дополнительных данных, назначение которых зависит от типа пакета (4 байта).
Так как выбранный тип пакета - «чтение удаленной памяти» генератору пакетов 9 не нужно обращаться в локальную память 6 и память кэш инструкций 7 для получения данных, которые необходимо отправить. После кодирования, флиты передаются в один из коммутаторов 31,…3N по интерфейсу взаимодействия канального уровня. Причем нужный коммутатор 31,…3N определяется в зависимости от значения поля SPB_ADDR интерфейса взаимодействия протокольного уровня 18 и номера текущего узла пакетной сети в мультиплексоре 10 по заданному алгоритму, позволяющему снизить задержку при передаче пакета путем правильного определения изначального направления движения пакета по сети. Для инициирования передачи по протоколу интерфейса взаимодействия канального уровня 21, генератор пакетов 9 поднимает флаг FLAG, если в текущий момент флаг BUSY от соответствующего коммутатора опущен. Если флаг BUSY поднят, генератор пакетов 9 будет ждать освобождения соответствующего коммутатора. Вместе с поднятием флага FLAG в поле DATA выставляется флит заголовка сформированного пакета. На следующий такт в поле DATA попадает следующий флит пакета, после этого флаг FLAG опускается и пакет считается отправленным.
На следующем этапе, коммутатор 3, получив данные от контроллера шины 2 по интерфейсу взаимодействия канального уровня 21 по второму входному порту 1_2, буферизует полученный пакет. Если на первом входном порту 11 находится заголовочный флит пустого пакета, флит заголовка отправляемого пакета будет передан на первый выходной порт 2_1. На следующий такт, на первый выходной порт 2_1 коммутируется второй флит передаваемого пакета. Если на первом входном порту 1_1 находится любой другой флит, он будет передаваться на первый выход 2_1. Исключение составляет заголовочный флит пакета, который был отправлен вычислительному узлу данного коммутатора. В данном случае, на второй выходной порт 2_2 будут каждый такт передаваться флиты пришедшего пакета, а на первый выходной порт 2_1 будут передаваться флиты пакета, который необходимо отправить. После того, как заголовочный флит передаваемого пакета будет находиться на первом входном порту 11 коммутатора 3 вычислительного узла, адрес которого совпадает с SPB_ADDR, данный флит будет передан на второй выходной порт 2_2 данного коммутатора, и будет инициирован обмен с контроллером шины вычислительного узла по интерфейсу взаимодействия канального уровня 21. Принцип работы совпадает с принципом передачи данных от контроллера шины в коммутатор 3, за исключением того, что контроллер шины всегда готов принять данные от коммутатора 3 и проверка флага BUSY не выполняется.
На следующем этапе флиты пакета, полученные от коммутатора 3, записываются в соответствующую очередь 141,…14N FIFO в модуле приема пакетов канального уровня 11. Флиты хранятся в очереди до тех пор, пока не будет свободен приемник пакетов 12. Для определения готовности приемника пакетов 12 используется сигнал BUSY интерфейса взаимодействия канального уровня 21 между мультиплексором 10 и приемником пакетов 12. Номер очереди, из которой будут передаваться флиты в приемник пакетов 12, при его готовности принять запрос, определяется в 10 исходя из алгоритма, позволяющего организовать равномерный доступ из любой очереди 141,…14N FIFO. Протокол передачи данных по интерфейсу взаимодействия канального уровня 21 между 10 и приемником 12 идентичен протоколу взаимодействия контроллера шины и коммутатора 3. Далее в приемнике пакетов 12 происходит декодирование пакета и его дальнейшая обработка. Для пакета типа «чтение памяти удаленного ядра» осуществляется запись данных необходимых для формирование ответного пакета в соответствующий кольцевой буфер в локальной памяти 6 по интерфейсу доступа в память 19. Протокол работы интерфейса доступа в память 19 является стандартным интерфейсом взаимодействия с памятью с произвольным доступом.
Передача запроса «ответ на чтение удаленной памяти» осуществляется аналогичным образом, за исключением нескольких моментов.
Во-первых, Генератор пакетов 9, как только в соответствующем кольцевом буфере в локальной памяти 6 появляется новый запрос, вычитывает необходимые для кодирования пакета данные по интерфейсу доступа в память 19 из локальной памяти 6 и формирует флиты отправляемого пакета в соответствии со структурой пакета типа «ответ на чтение удаленной памяти».
Когда пакет типа «ответ на чтение удаленной памяти» попадает в приемник пакетов 12 в контроллере шины вычислительного узла, приемник пакетов 12 инициирует запрос в память для хранения локальных адресов 16 по интерфейсу взаимодействия с памятью локальных адресов 20. Для этого поднимается флаг REQ и в поле MARK_IN записывается идентификатор данного пакета, который был получен при записи соответствующего локального адреса в память для хранения локальных адресов 16 при отправке запроса. Память для хранения локальных адресов 16 поднимает флаг READY и заполняет поле DATA_OUT локальным адресом, который хранился в памяти по адресу соответствующему идентификатору из поля MARK_IN. После этого данные из пакета будут записаны приемником пакетов 12 в локальную память 6 или память кэш инструкций 7 в соответствии с локальным адресом по интерфейсу доступа в память 19.
Передача запроса типа «запись в удаленную память» осуществляется также, как и запрос «чтение удаленной памяти» кроме того, что модуль передачи запросов протокольного уровня 15 не записывает локальный адрес в память для хранения локальных адресов 16. Также генератор пакетов 9 для получения данных, которые необходимо отправить, обращается в локальную память 6 или память кэш инструкций 7 в соответствии с адресом, переданным от вычислительного узла в поле LOC_ADDR интерфейса взаимодействия протокольного уровня 18. При получении пакета типа «запись в удаленную память» приемник пакетов 12 записывает полученные данные в локальную память 6 или память кэш инструкций 7 в соответствии с адресом, который был записан вычислительным узлом, являющимся отправителем при формировании запроса на «запись в удаленную память», в поле REMOTE_ADDR интерфейса взаимодействия протокольного уровня 18.
Передача запроса типа «интерконнект» и других зарезервированных типов запросов для тегированной обработки отличается от передачи запроса типа «запись в удаленную память» только на этапе обработки данных в приемнике пакетов 12. После декодирования данные из пакета будут записаны в соответствующий кольцевой буфер, организованный в локальной памяти 6.
ОПИСАНИЕ ПРИМЕРОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Предлагаемая пакетная сеть может быть выполнена на базе ПЛИС Xilinx XC7V585. В состав реализованной пакетной сети входит 16 узлов, по два коммутатора канального уровня в каждом, объединенных между собой в топологию двусторонний конвейер. В качестве вычислительных узлов используются RISC софт-процессоры, дополненные интерфейсными модулями для реализации работы с пакетной сетью. Флит канального уровня имеет ширину 64 бита. Частота работы пакетной сети 300 МГц, а частоты работы вычислительных ядер отличаются, причем восемь из них работают на частоте 50 МГц, а другие восемь - на частоте 100 МГц. Размер локальной памяти каждого узла составляет 4 КБ, память организована как два модуля двухпортовой блочной памяти произвольного доступа с шириной шины данных 36 бит, из которых могут использоваться только младшие 32 разряда. Память кэш инструкций организована таким же образом, но ее размер составляет 2 КБ. Глубины очередей FIFO в модуле приема пакетов канального уровня равны и составляют 16 флитов.
Для оценки количества занимаемых ресурсов для реализации пакетной шины на СБИС была проведена оценка с использованием библиотечных элементов 65 нм технологического процесса в САПР Cadence RTL Compiler. Коммутатор данной сети занимает приблизительно 5000 мкм2, что на несколько порядков меньше, чем площадь коммутатора в рассмотренном прототипе - 0.34 mm2 (Table II).
Задержка при передаче пакета через коммутатор данной сети составляет 2 такта, тогда как задержка при передаче пакета через коммутатор в рассматриваемом прототипе составляет 5 тактов (Table II).
Организация локальной памяти и памяти кэш инструкций в виде двухпортовой асинхронной памяти позволяет исключить из схемы дополнительные модули синхронизации данных, аналогичные модулю MSINT в рассматриваемом прототипе. А также, в совокупности с тегированным приемом и передачей пакетов, реализовать технологию прямого доступа в память (DMA).
Заявленный технический эффект достигается тем, что в отличие от прототипа в качестве коммутаторов используются простые неполные коммутаторы канального уровня 3 2 в 2 без дополнительной буферизации,
синхронизация при передаче данных между вычислительными узлами, работающими на разных частотах, обеспечивается за счет реализации локальной памяти 6 и памяти кэш инструкций 7 как асинхронной двухпортовой памяти, позволяющая исключить из устройства отдельные модули синхронизации,
организация локальной памяти 6 и памяти кэш инструкций 7 в виде двухпортовой памяти, в совокупности с возможностью тегированного приема и передачи пакетов, позволяет реализовать функционал прямого доступа в память.
Вышеизложенные сведения позволяют сделать вывод, что предлагаемая пакетная сеть для соединения абонентов в мультипроцессорных вычислительных системах решает поставленную задачу и соответствует заявляемому техническому результату - уменьшает время задержки при передаче данных между вычислительными узлами, сокращает количество аппаратных ресурсов, требуемых для реализации узла пакетной сети, а также расширяет функциональные возможности в части реализации прямого доступа к памяти любого абонента пакетной сети.
Изобретение относится к области вычислительной техники. Техническим результатом является уменьшение задержки при передаче данных между ядрами и сокращение аппаратных ресурсов, а также расширение функциональных возможностей в части реализации прямого доступа в память любого абонента. Он достигается за счет того, что каждый узел 1 пакетной сети содержит не менее одного коммутатора канального уровня 3 и контроллер шины 2, содержащий блок мультиплексоров 5, локальную память 6 и память кэш инструкций 7, модуль генерации пакетов канального уровня 8, состоящий из генератора 9 и блока мультиплексоров 10, модуль приема пакетов канального уровня 11, состоящий из приемника 12, блока мультиплексоров 13 и группы буферной памяти 141,…14N FIFO, модуль передачи запросов протокольного уровня 15 и память для хранения локальных адресов 16, причем при передаче данных между узлами сети используется принцип передачи типа «червь» («wormhole») и статическая распределенная маршрутизация. 2 н.п. ф-лы, 3 ил., 1 табл.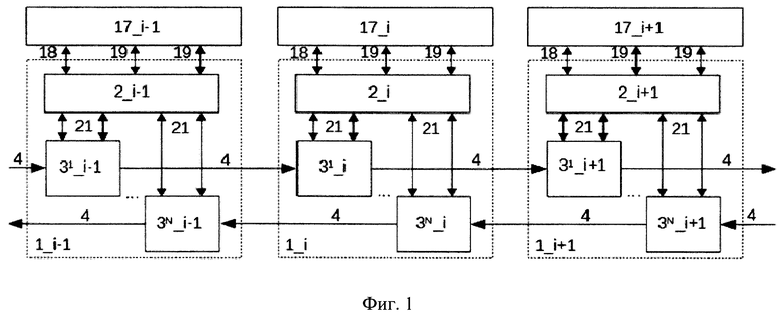
1. Пакетная сеть для мультипроцессорных вычислительных систем, содержащая не менее двух узлов пакетной сети 1, каждый из которых содержит контроллер шины 2 и не менее одного коммутатора канального уровня 31,…3N,
каждый коммутатор канального уровня 31,…3N является коммутатором 2 в 2 без дополнительной буферизации, при этом на канальном уровне между коммутаторами 3 соседних узлов по первым входам и первым выходам обеспечивается принцип передачи данных типа «червь» («wormhole») по канальному интерфейсу 4,
контроллер шины 2 содержит первый блок мультиплексоров 5, локальную память 6 и память кэш инструкций 7, организованных как двухпортовые асинхронные памяти, модуль генерации пакетов канального уровня 8, состоящий из генератора пакетов 9, соединенного с входами второго блока мультиплексоров 10, модуль приема пакетов канального уровня 11, состоящий из приемника пакетов 12, соединенного с выходами третьего блока мультиплексоров 13, входы которого соединены с соответствующими выходами группы буферной памяти 141,…14N FIFO, модуль передачи запросов протокольного уровня 15 и память для хранения локальных адресов 16, а также контроллер шины содержит три внешних порта для организации интерфейсного взаимодействия с вычислительным узлом,
причем в контроллере шины к первому внешнему порту подключен модуль передачи запросов протокольного уровня 15 и организован интерфейс взаимодействия протокольного уровня 18, ко второму внешнему порту подключена локальная память 6 и организован интерфейс доступа к памяти 19, а к третьему внешнему порту подключена память кэш инструкций 7 и организован интерфейс доступа к памяти 19,
кроме того, модуль передачи запросов протокольного уровня 15 по второму входу соединен с генератором пакетов 9 по интерфейсу взаимодействия протокольного уровня 18, а по третьему входу по интерфейсу взаимодействия с памятью для хранения локальных адресов 20 соединен с памятью для хранения локальных адресов 16, которая также соединена с приемником пакетов 12,
блок мультиплексоров 5 соединен с соответствующими входами локальной памяти 6 и памяти кэш инструкций 7, а также с генератором пакетов 9 и приемником пакетов 12 по интерфейсу доступа в память 19,
выходы второго блока мультиплексоров 10 соединены со вторым входным портом соответствующего коммутатора канального уровня 31,…3N, вторые выходы которых соединены с входами соответствующих входов группы буферной памяти 141,…14N FIFO,
при этом в каждом вычислительном узле второй входной 1_2 и второй выходной 2_2 порты коммутаторов канального уровня 31,…3N соединены с соответствующим контроллером шины по интерфейсу взаимодействия канального уровня 21,
причем при передаче данных между узлами пакетной сети используется алгоритм статической распределенной маршрутизации.
2. Способ коммутации с использованием пакетной сети для мультипроцессорных вычислительных систем по п. 1, содержащий следующие этапы, на которых:
по интерфейсу взаимодействия протокольного уровня 18 формируют запрос на отправку пакета по сети,
в модуле передачи запросов протокольного уровня 15 подтверждают получение запроса от вычислительного узла по интерфейсу взаимодействия протокольного уровня 18, передают запрос через границу тактовых доменов вычислительного узла и пакетной сети и, в соответствии с протоколом интерфейса взаимодействия с памятью для хранения локальных адресов 20, записывают локальный адрес в память для хранения локальных адресов 16, получают от памяти хранения локальных адресов 16 уникальный идентификатор для передаваемого запроса, если соответствует алгоритму работы модуля передачи запросов протокольного уровня 15, и передают запрос в генератор пакетов 9 модуля по интерфейсу взаимодействия протокольного уровня 18,
в генераторе пакетов 9 кодируют флиты пакета в соответствии с заданной структурой пакета, исходя из информации, полученной от модуля передачи запросов протокольного уровня 15, и обращаются в локальную память 6 или память кэш инструкций 7 для чтения данных в соответствии с протоколом работы интерфейса доступа в память 19, если это необходимо для кодирования пакета заданного типа, передают пакет в один из коммутаторов 31,…3N в порт 1_2 данного узла пакетной сети по интерфейсу взаимодействия канального уровня 21, причем номер коммутатора 31,…3N, в который передают запрос, определяют в соответствии с алгоритмом работы второго блока мультиплексоров 10,
- в коммутаторе 3 производят коммутацию пакета со второго входного порта коммутатора 1_2 на первый выходной порт 2_1 в случае, когда на первом входе находится заголовочный флит пустого пакета, в ином случае - буферизуют пакет до момента, когда коммутацию можно будет провести, причем коммутацию пакета с первого входного порта 1_1 коммутатора 3 производят на второй выходной порт 2_2 коммутатора 3 в случае, когда поле адресата в заголовочном флите пакета содержит номер узла пакетной сети, которому принадлежит данный коммутатор 3, в иных случаях пакет коммутируют на первый выходной порт 2_1 коммутатора 3, который соединен с первым входным портом 1_1 коммутатора 3 соседнего узла пакетной сети;
- после получения контроллером шины, а именно модулем приема пакетов канального уровня 11 пакета от одного из коммутаторов 3 данного узла по интерфейсу взаимодействия канального уровня 21, пакет буферизуют в очереди FIFO 141,…14N;
- в соответствии с алгоритмом работы третьего блока мультиплексоров 13 и протоколом работы интерфейса взаимодействия канального уровня 21 между блоком мультиплексоров 13 и приемником пакетов 12 осуществляют чтение из одной из очередей FIFO 141,…14N и передают пакет в приемник пакетов 12;
- в приемнике пакетов 12 декодируют флиты полученного пакета, получают локальный адрес из памяти локальных адресов 16 в соответствии с протоколом работы интерфейса взаимодействия с памятью для хранения локальных адресов 20, если это соответствует алгоритму обработки пакета заданного типа, формируют адрес в локальной памяти 6, в соответствии с алгоритмом обработки пакета заданного типа, и записывают данные из пакета в локальную память 6 или память кэш инструкций 7 в соответствии с протоколом работы интерфейса доступа в память 19.
| VANGAL S.R | |||
| et al | |||
| Капельная масленка с постоянным уровнем масла | 0 |
|
SU80A1 |
| Зубчатое колесо со сменным зубчатым ободом | 1922 |
|
SU43A1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Солесос | 1922 |
|
SU29A1 |
| US 7461236 B1, 02.12.2008 | |||
| СПОСОБ ПЕРЕДАЧИ ДАННЫХ | 2017 |
|
RU2651242C1 |
| КОНФИГУРАЦИЯ СЕТИ СИНХРОНИЗАЦИИ | 2010 |
|
RU2504086C1 |

