Область техники, к которой относится изобретение
[0001] Настоящее техническое решение относится к способу и системе транскрипции лексической единицы из первого алфавита во второй.
Уровень техники
[0002] В мире существует множество систем письма. Система письма является традиционным способом визуального представления вербальной коммуникации. Несмотря на то что и письмо и речь удобны для передачи сообщений, письмо отличается тем, что является надежной формой для хранения и передачи информации. Процессы кодирования и декодирования систем письменности предусматривают одинаковое понимание пишущего и читающего значений, которыми обладают наборы символов, составляющие текст.
[0003] Основные признаки систем письма могут быть разделены на большие категории, такие как алфавиты, слоговое письмо и логографическое письмо. Каждая конкретная система может обладать признаками из более чем одной категории. К категории алфавита относится стандартный набор гласных или согласных букв (основные письменные символы или графемы) для кодирования на основе общего принципа, состоящего в том, что буквы (или пары\группы букв) представляют собой звуки речи. В слоговом письме каждый символ соответствует одному слогу или более. В логографическом письме каждый символ представляет собой слово, морфему или другую семантическую единицу. Другие категории включают в себя консонантное письмо (также называемое «абджад»), которое отличается от алфавитов, тем, что в нем не указываются гласные, а также абугиды или альфасилибарии, в которых каждый символ представляет собой пару согласная-гласная. В алфавитах обычно содержится от 20 до 35 символов, которые полностью могут выразить язык, в то время как слоговое письмо может обладать 80-100, а логографическое - несколькими сотнями символов.
[0004] Письмо обычно записывается на жесткий носитель, например, бумагу или электронный носитель, хотя могут быть использованы и менее надежные носители, например, запись на дисплее монитора, на песке или летательным аппаратом в воздухе.
[0005] В компьютерных технологиях пользователям предоставляются услуги на многих языках. Во многих случаях, поставщики услуг переводят пользовательские интерфейсы на различные языки, чтобы пользователи могли читать знаки и другие указатели на родном языке или на известном им иностранном языке. Тем не менее, иногда необходима транскрипция, а не перевод.
[0006] Каждый язык обладает множеством правил и множеством исключений из них. В результате, создание транскрипций хорошего качества может быть затруднительным. Следовательно, существует необходимость в улучшении методик создания транскрипций.
Раскрытие изобретения
[0007] Таким образом, техническим результатом предлагаемого технического решения является достижение заявленных назначений, а именно транскрипции лексической единицы из первого алфавита во второй алфавит.
[0008] Первым объектом настоящего технического решения является способ транскрипции лексической единицы из первого алфавита во второй алфавит, способ выполняется на сервере. Способ включает в себя: (i) получение пары, в которой присутствует (i) лексическая единица, записанная в первом алфавите, и (ii) соответствующая транскрипция лексической единицы, записанная во втором алфавите, причем лексическая единица и транскрипция соответствующей лексической единицы разделяются на соответствующие сегменты таким образом, что в паре каждый сегмент лексической единицы обладает соответствующим сегментом в транскрипции лексической единицы, и таким образом, что каждая лексическая единица включает в себя одно из: (i) последовательность последовательно чередующихся гласного сегмента и согласного сегмента, (ii) один гласный сегмент, (iii) один согласный сегмент; каждый гласный сегмент состоит по меньшей мере из одной гласной, а каждый согласный сегмент состоит по меньшей мере из одной согласной; и (ii) определение, для каждого заданного сегмента лексической единицы, его контекста; (iii) обучение сервера вычислению теоретической частоты по меньшей мере одного символа из второго алфавита, который представляет транскрипцию указанного конкретного заданного сегмента с учетом контекста этого конкретного заданного сегмента лексической единицы.
[0009] В некоторых вариантах осуществления настоящего технического решения, лексическая единица выбирается из: слова или словосочетания.
[0010] В некоторых вариантах осуществления настоящего технического решения, лексическая единица содержит по меньшей мере один специальный символ.
[0011] В некоторых вариантах осуществления настоящего технического решения, по меньшей мере один специальный символ в словосочетании, который расположен между согласной и гласной перед гласной, квалифицируется одним из выбранного из: гласной или согласной, и указанный по меньшей мере один символ, если он квалифицируется гласной, становится частью соседнего гласного сегмента, и указанный по меньшей мере один символ, если он квалифицируется согласной, становится частью соседнего согласного сегмента.
[0012] В некоторых вариантах осуществления настоящего технического решения, по меньшей мере один специальный символ в словосочетании, который расположен между гласной и согласной перед согласной, квалифицируется одним из выбранного из: гласной или согласной, и указанный по меньшей мере один символ, если он квалифицируется гласной, становится частью соседнего гласного сегмента, и указанный по меньшей мере один специальный символ, если он квалифицируется согласной, становится частью соседнего согласного сегмента.
[0013] В некоторых вариантах осуществления настоящего технического решения, по меньшей мере один специальный символ квалифицируется несуществующим.
[0014] В некоторых вариантах осуществления настоящего технического решения, по меньшей мере один специальный символ является любым одним из выбранного: пробел, дефис, разрыв строки, разрыв страницы, и апостроф.
[0015] В некоторых вариантах осуществления настоящего технического решения, контекст лексической единицы выбирается из: предшествующего контекста и последующего контекста.
[0016] В некоторых вариантах осуществления настоящего технического решения, предшествующий контекст заданного сегмента является любым выбранным из: предшествующим соседним сегментом лексической единицы или предшествующим окончанием лексической единицы; последующий контекст заданного сегмента является любым выбранным из: последующим соседним сегментом лексической единицы или последующим окончанием лексической единицы.
[0017] В некоторых вариантах осуществления настоящего технического решения, по меньшей мере один сегмент лексической единицы является немой буквой, и соответствующая транскрипция лексической единицы будет включать в себя символ, представляющий немую букву.
[0018] В некоторых вариантах осуществления настоящего технического решения, второй алфавит представляет собой один из выбранного: (i) алфавит, отличный от первого алфавита; или (ii) фонетический алфавит.
[0019] В некоторых вариантах осуществления настоящего технического решения способ дополнительно включает в себя повторение:
получения пары, в которую входит (i) лексическая единица, записанная в первом алфавите, и (ii) соответствующая транскрипция лексической единицы, записанная во втором алфавите, лексическая единица и транскрипция соответствующей лексической единицы были разделены в соответствующие сегменты, таким образом,
чтобы внутри пары, каждый сегмент лексической единицы обладал соответствующим сегментом в транскрипции лексической единицы, и таким образом,
чтобы каждая лексическая единица содержала одно из выбранного: (i) последовательность последовательно чередующихся гласного и согласного сегмента, (ii) один гласный сегмент, (iii) один согласный сегмент; каждый гласный сегмент состоит по меньшей мере из одной гласной, а каждый согласный сегмент состоит по меньшей мере из одной согласной; и
определения для каждого заданного сегмента лексической единицы его контекста;
обучения сервера вычислению теоретической частоты по меньшей мере одного символа второго алфавита, представляющего собой транскрипцию конкретного заданного сегмента на основе контекста указанного конкретного заданного сегмента лексической единицы,
в отношении множества пар, каждая из которых содержит лексическую единицу и соответствующую транскрипцию, и
обучение сервера вычислению теоретической частоты транскрипции заданного сегмента на основе контекста заданного сегмента представляет собой обучение сервера с помощью алгоритма машинного обучения.
[0020] В некоторых вариантах осуществления настоящего технического решения, способ дополнительно включает в себя: получение от клиентского устройства запроса, который интерпретируется как запрос на транскрипцию второй лексической единицы, записанной в первом алфавите, во второй алфавит; разделение второй лексической единицы на одно выбранное из: (i) один гласный сегмент; (ii) один согласный сегмент; (iii) последовательность последовательно чередующихся гласного сегмента и согласного сегмента; применение теоретической частоты транскрипции каждого сегмента второй лексической единицы, теоретическая частота основана на контексте каждого заданного сегмента во второй лексической единице, и создание транскрипции второй лексической единицы во втором алфавите.
[0021] В некоторых вариантах осуществления настоящего технического решения, способ дополнительно включает в себя передачу клиентскому устройству инструкций отобразить пользователю транскрипцию второй лексической единицы на второй язык.
[0022] В некоторых вариантах осуществления настоящего технического решения, по меньшей мере один сегмент лексической единицы является немой буквой, и инструкции отобразить пользователю транскрипцию второй лексической единицы на второй язык включает в себя инструкцию опустить отображение символа, который представляет немую букву.
[0023] В некоторых вариантах осуществления настоящего технического решения, в которых получение от клиентского устройства запроса на транскрипцию второй лексической единицы, записанной в первом алфавите, во второй алфавит, включает в себя получение поискового запроса, способ дополнительно включает в себя проведение поиска с использованием транскрипции второй лексической единицы во второй алфавит в качестве поискового запроса, и создание страницы результатов поиска.
[0024] В некоторых вариантах осуществления настоящего технического решения, способ дополнительно включает в себя передачу клиентскому устройству инструкций отобразить страницу результатов поиска.
[0025] Другим объектом настоящего технического решения является сервер. Сервер включает в себя носитель информации. Сервер включает в себя процессор. Процессор соединен с носителем информации. Процессор выполнен с возможностью получать доступ к машиночитаемым командам, которые инициируют процессор выполнять этапы, включающие в себя: (i) получение пары, в которой присутствует (i) лексическая единица, записанная в первом алфавите, и (ii) соответствующая транскрипция лексической единицы, записанная во втором алфавите, причем лексическая единица и транскрипция соответствующей лексической единицы разделяются на соответствующие сегменты таким образом, чтобы в паре каждый сегмент лексической единицы обладал соответствующим сегментом в транскрипции лексической единицы, и таким образом, чтобы каждая лексическая единица включала в себя одно из: (i) последовательность последовательно чередующихся гласного сегмента и согласного сегмента, (ii) один гласный сегмент, (iii) один согласный сегмент; каждый гласный сегмент состоит по меньшей мере из одной гласной, а каждый согласный сегмент состоит по меньшей мере из одной согласной; и (ii) определение, для каждого заданного сегмента лексической единицы, его контекста; (iii) обучение сервера вычислению теоретической частоты по меньшей мере одного символа из второго алфавита, который представляет транскрипцию указанного конкретного заданного сегмента с учетом контекста этого конкретного заданного сегмента лексической единицы.
[0026] В некоторых вариантах осуществления настоящего технического решения, лексическая единица выбирается из: слова или словосочетания.
[0027] В некоторых вариантах осуществления настоящего технического решения, лексическая единица содержит по меньшей мере один специальный символ.
[0028] В некоторых вариантах осуществления настоящего технического решения, по меньшей мере один специальный символ в словосочетании, который расположен между согласной и гласной перед гласной, квалифицируется одним выбранным из: гласной или согласной, и указанный по меньшей мере один символ, если он квалифицируется гласной, становится частью соседнего гласного сегмента, и указанный по меньшей мере один символ, если он квалифицируется согласной, становится частью соседнего согласного сегмента.
[0029] В некоторых вариантах осуществления настоящего технического решения, по меньшей мере один специальный символ в словосочетании, который расположен между гласной и согласной перед согласной, квалифицируется одним выбранным из: гласной или согласной, и указанный по меньшей мере один символ, если он квалифицируется гласной, становится частью соседнего гласного сегмента, и указанный по меньшей мере один символ, если он квалифицируется согласной, становится частью соседнего согласного сегмента.
[0030] В некоторых вариантах осуществления настоящего технического решения, по меньшей мере один специальный символ квалифицируется несуществующим.
[0031] В некоторых вариантах осуществления настоящего технического решения, по меньшей мере один специальный символ является любым одним из выбранного: пробел, дефис, разрыв строки, разрыв страницы, и апостроф.
[0032] В некоторых вариантах осуществления настоящего технического решения, контекст лексической единицы выбирается из: предшествующего контекста и последующего контекста.
[0033] В некоторых вариантах осуществления настоящего технического решения, предшествующий контекст заданного сегмента является любым выбранным из: предшествующим соседним сегментом лексической единицы или предшествующим окончанием лексической единицы; последующий контекст заданного сегмента является любым выбранным из: последующим соседним сегментом лексической единицы или последующим окончанием лексической единицы.
[0034] В некоторых вариантах осуществления настоящего технического решения, по меньшей мере один сегмент лексической единицы является немой буквой, и соответствующая транскрипция лексической единицы будет включать в себя символ, представляющий немую букву.
[0035] В некоторых вариантах осуществления настоящего технического решения, второй алфавит представляет собой один из выбранного: (i) алфавит, отличный от первого алфавита; или (ii) фонетический алфавит.
[0036] В некоторых вариантах осуществления настоящего технического решения, процессор дополнительно выполнен с возможностью повторять, в отношении нескольких пар, каждая из которых включает в себя лексическую единицу и соответствующую транскрипцию, этапы:
получения пары, в которую входит (i) лексическая единица, записанная в первом алфавите, и (ii) соответствующая транскрипция лексической единицы, записанная во втором алфавите, лексическая единица и транскрипция соответствующей лексической единицы были разделены в соответствующие сегменты, таким образом,
чтобы внутри пары, каждый сегмент лексической единицы обладал соответствующим сегментом в транскрипции лексической единицы, и таким образом,
чтобы каждая лексическая единица содержала одно из выбранного: (i) последовательность последовательно чередующихся гласного и согласного сегмента, (ii) один гласный сегмент, (iii) один согласный сегмент; каждый гласный сегмент состоит по меньшей мере из одной гласной, а каждый согласный сегмент состоит по меньшей мере из одной согласной; и
определения для каждого заданного сегмента лексической единицы его контекста;
обучения сервера вычислению теоретической частоты по меньшей мере одного символа второго алфавита, представляющего собой транскрипцию конкретного заданного сегмента на основе контекста указанного конкретного заданного сегмента лексической единицы,
и обучение сервера вычислению теоретической частоты транскрипции заданного сегмента на основе контекста заданного сегмента представляет собой обучение сервера с помощью алгоритма машинного обучения.
[0037] В некоторых вариантах осуществления настоящего технического решения, процессор дополнительно выполнен с возможностью выполнять: получение от клиентского устройства запроса, который может быть интерпретирован как запрос на транскрипцию второй лексической единицы, записанной в первом алфавите, во второй алфавит; разделение лексической единицы на одно из выбранного: (i) один гласный сегмент; (ii) один согласный сегмент; (iii) последовательность последовательно чередующихся гласного сегмента и согласного сегмента; применение теоретической частоты транскрипции каждого сегмента второй лексической единицы, теоретическая частота основана на контексте каждого заданного сегмента во второй лексической единице, и создание транскрипции второй лексической единицы во втором алфавите.
[0038] В некоторых вариантах осуществления настоящего технического решения, процессор дополнительно выполнен с возможностью передавать клиентскому устройству инструкции отобразить пользователю транскрипцию второй лексической единицы на второй язык.
[0039] В некоторых вариантах осуществления настоящего технического решения, по меньшей мере один сегмент лексической единицы является немой буквой, и инструкции отобразить пользователю транскрипцию второй лексической единицы на второй язык включает в себя инструкцию опустить отображение символа, который представляет немую букву.
[0040] В некоторых вариантах осуществления настоящего технического решения, в которых получение от клиентского устройства запроса на транскрипцию второй лексической единицы, записанной в первом алфавите, во второй алфавит, включает в себя получение поискового запроса, процессор дополнительно выполнен с возможностью проведения поиска с использованием транскрипции второй лексической единицы во второй алфавит в качестве поискового запроса, и создания страницы результатов поиска.
[0041] В некоторых вариантах осуществления настоящего технического решения, процессор дополнительно выполнен с возможностью передавать клиентскому устройству инструкции отобразить страницу результатов поиска.
[0042] В контексте настоящего описания, если конкретно не указано иное, «сервер» подразумевает под собой компьютерную программу, работающую на соответствующем оборудовании, которая способна получать запросы (например, от клиентских устройств) по сети и выполнять эти запросы или инициировать выполнение этих запросов. Оборудование может представлять собой один физический компьютер или одну физическую компьютерную систему, но ни то, ни другое не является обязательным для настоящего технического решения. В контексте настоящего технического решения использование выражения «сервер» не означает, что каждая задача (например, полученные команды или запросы) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может быть одним сервером или несколькими серверами, оба варианта включены в выражение «по меньшей мере один сервер».
[0043] В контексте настоящего описания, если конкретно не указано иное, «информация» включает в себя любую информацию любого типа, включая информацию, которую можно сохранять на носителе информации. Таким образом, информация включает в себя, без установления ограничений, любые индексы, базы данных, массивы информации, любые файлы, аудиовизуальные произведения (фотографии, фильмы, звукозаписи, презентации и так далее), данные (картографические данные, данные о местоположении, количественные данные и так далее), текст (мнения, комментарии, вопросы, сообщения, слова и словосочетания, записанные в любом алфавите и так далее), документы, таблицы и так далее.
[0044] В контексте настоящего описания, если специально не указано иное, термин «алфавит» означает стандартный набор символов (основные письменные символы или графемы), которые используются для письма на конкретном языке, на основе общего принципа, что буквы представляют собой фонемы (основные важные звуки) разговорного языка. В контексте настоящего описания если специально не указано иное, стандартный набор символов, используемый в двух или более различных языках, означает два или более алфавита, несмотря на то, что эти наборы букв могут быть идентичными. Не ограничивающие примеры алфавитов включают в себя латинский алфавит и алфавиты на основе латинского, например, английский, итальянский, немецкий, французский, польский и другие алфавиты, алфавиты на основе кириллицы, например, русский алфавит, болгарский алфавит, украинский алфавит и так далее, греческий алфавит, армянский алфавит, грузинский алфавит и другие. Некоторые алфавиты, например, английский и итальянский, могут содержать идентичные наборы символов. В контексте настоящего технического решения, два алфавита, которые обладают идентичными наборами символов, являются двумя различными алфавитами.
[0045] В контексте настоящего описания, если специально не указано иное, термин «фонетический алфавит» означает алфавитную систему фонетической транскрипции. Он может быть разработан как стандартное представление звуков разговорного языка. Фонетические символы алфавита созданы из одного или нескольких элементов двух основных типов, букв и диакритических знаков. Например, звук английской буквы (t) в фонетическом алфавите может быть представлен одной буквой [t] или сочетанием буквы и диакритического знака 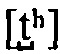 , в зависимости от степени точности. Части используется косая черта для обозначения расширенной или фонетической транскрипции; таким образом, символ /t/ является менее конкретным, и одновременно может подразумевать и
, в зависимости от степени точности. Части используется косая черта для обозначения расширенной или фонетической транскрипции; таким образом, символ /t/ является менее конкретным, и одновременно может подразумевать и 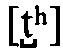 и [t], в зависимости от контекста и языка. Фонетический алфавит является типом алфавита.
и [t], в зависимости от контекста и языка. Фонетический алфавит является типом алфавита.
[0046] В контексте настоящего описания, если специально не указано иное, термин «лексическая единица» означает слово или словосочетание, записанное в конкретном алфавите. Лексическая единица может включать в себя и специальные символы, например, пробел, дефис, разрыв строки, разрыв страницы, апостроф, и другие. Некоторые примеры лексических единиц во французском алфавите: (а) " ", (b) "bonjour", (с) "qu'est-ce qu'un statut", (d) "
", (b) "bonjour", (с) "qu'est-ce qu'un statut", (d) " ", (e) "
", (e) " ". Некоторые примеры лексических единиц в английском алфавите: (a) "a", (b) "statement", (b) "ID", (с) "well-being", (d) "a patent for an invention is the grant of a property right to the inventor".
". Некоторые примеры лексических единиц в английском алфавите: (a) "a", (b) "statement", (b) "ID", (с) "well-being", (d) "a patent for an invention is the grant of a property right to the inventor".
[0047] В контексте настоящего описания, если специально не указано иное, термин «согласная» означает символ алфавита, представляющий звук речи, который выражается в артикуляции с полностью или частично перекрытым вокальным трактом. Примерами являются: звук [р], произносимый с помощью губ; звук [t], произносимый с помощью передней части языка; звук [k], произносимый с помощью задней части языка; звук [h], произносимый с помощью гортани; звуки [f] и [s], произносимые с помощью усиленного пропускания воздуха через узкий канал (фрикативы); и звуки [m] и [n], произносимые с помощью пропускания воздуха через нос (назальные). С согласными контрастируют гласные. В контексте настоящего описания, в некоторых вариантах осуществления настоящего технического решения специальные символы обычно считаются согласными, несмотря на то, что им может не соответствовать никакой звук в разговорной речи.
[0048] В контексте настоящего описания, если специально не указано иное, термин «гласная» означает символ алфавита, представляющий звук разговорного языка, который произносится с открытым вокальным трактом таким образом, что не создается никакого искусственного нагнетания в какой-либо точке выше вокальной щели. С гласными контрастируют согласные. В контексте настоящего описания, в некоторых вариантах осуществления настоящего технического решения специальные символы обычно считаются гласными, несмотря на то, что им может не соответствовать никакой звук в разговорной речи.
[0049] В контексте настоящего описания, если специально не указано иное, термин «гласный сегмент» означает сегмент лексической единицы, который состоит по меньшей мере из одной гласной. Гласный сегмент состоит из всех гласных в лексической единице, примыкающих друг к другу, которые не разделены друг от друга по меньшей мере одной согласной. Если специализированный символ квалифицируется гласной, то он становится частью соседнего гласного сегмента.
[0050] В контексте настоящего описания, если специально не указано иное, термин «согласный сегмент» означает сегмент лексической единицы, который состоит по меньшей мере из одной согласной. Согласный сегмент состоит из всех согласных в лексической единице, примыкающих друг к другу, которые не разделены друг от друга по меньшей мере одной гласной. Если специализированный символ квалифицируется согласной, то он становится частью соседнего согласного сегмента.
[0051] В контексте настоящего описания, если специально не указано иное, термин «транскрипция» означает представление речи или жестов в письменной форме. Источником транскрипции может быть либо высказывание (речь или язык жестов) или ранее существующий текст в другой системе письма, включая ранее существующий текст, записанный на другом языке или записанный с помощью другого алфавита.
[0052] В контексте настоящего описания, если конкретно не указано иное, «компонент» подразумевает под собой программное обеспечение (соответствующее конкретному аппаратному контексту), которое является необходимым и достаточным для выполнения конкретной(ых) указанной(ых) функции(й).
[0053] В контексте настоящего описания, если конкретно не указано иное, термин «носитель информации» подразумевает под собой носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д.
[0054] В контексте настоящего описания, если конкретно не указано иное, слова «первый», «второй», «третий» и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной передачи данных между этими существительными. Так, например, следует иметь в виду, что использование терминов «первый заранее определенный индекс» и «третий заранее определенный индекс» не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) графических объектов/между заранее определенными индексами, равно как и их использование (само по себе) не предполагает, что некий «второй заранее определенный индекс» обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание "первого" элемента и "второго" элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, "первый" сервер и "второй" сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[0055] Каждый вариант осуществления настоящего технического решения преследует по меньшей мере одну из вышеупомянутых целей и/или объектов. Следует иметь в виду, что некоторые объекты настоящего технического решения, полученные в результате попыток достичь вышеупомянутой цели, могут удовлетворять и другим целям, отдельно не указанным здесь.
[0056] Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления настоящего технического решения станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
Краткое описание чертежей
[0057] Для лучшего понимания настоящего технического решения, а также других его аспектов и характерных черт сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[0058] На Фиг. 1 представлена принципиальная схема системы, выполненной в соответствии с вариантом осуществления настоящего технического решения.
[0059] На Фиг. 2 представлен носитель информации системы, показанной на Фиг. 1, носитель информации хранит различные пары лексических единиц, записанные в первом алфавите, и соответствующие транскрипции лексических единиц, записанные во втором алфавите, устройство хранения информации реализовано в соответствии с не ограничивающими вариантами осуществления настоящего технического решения.
[0060] На Фиг. 3 представлена блок-схема исполняемого на компьютере способа, реализованного в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими его объем.
Осуществление изобретения
[0061] На Фиг. 1 представлена схема системы 100, выполненной в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими его объем. Важно иметь в виду, что нижеследующее описание системы 100 представляет собой описание иллюстративных вариантов осуществления настоящего технического решения. Таким образом, все последующее описание представлено только как описание иллюстративного примера настоящего технического решения. Это описание не предназначено для определения объема или установления границ настоящего технического решения. Некоторые полезные примеры модификаций системы 100 также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящего технического решения. Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где это еще не было сделано, т.е. там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным вариантом осуществления этого экземпляра настоящего технического решения. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что система 100 представляет собой в некоторых конкретных проявлениях достаточно простой вариант осуществления настоящего технического решения, и в подобных случаях представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящего технического решения будут обладать гораздо большей сложностью.
[0062] Система 100 включает в себя сервер 102. Сервер 102 может представлять собой обычный компьютерный сервер. В примере варианта осуществления настоящего технического решения, сервер 102 может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сервер 102 может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящего технического решения, не ограничивающем его объем, сервер 102 является одиночным сервером. В других вариантах осуществления настоящего технического решения, не ограничивающих его объем, функциональность сервера 102 может быть разделена, и может выполняться с помощью нескольких серверов.
[0063] Сервер 102 включает в себя носитель 104 информации, который может быть использован сервером 102. В общем случае, носитель 104 информации может быть реализован как носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д. Носитель 104 информации выполнен с возможностью хранения информации, включая машиночитаемые инструкции или другие данные, включая, в качестве не ограничивающего примера, пары лексических единиц, записанные в первом алфавите, и соответствующие транскрипции этих лексических единиц, записанные во втором алфавите, лексические единицы и транскрипции соответствующих лексических единиц разделены на соответствующие сегменты.
[0064] Варианты осуществления сервера 102 хорошо известны в данной области техники. Таким образом, достаточно отметить, что каждый сервер 102 включает в себя, среди прочего, интерфейс 106 сетевой связи (например, модем, сетевую карту и тому подобное) для двусторонней связи по сети ПО передачи данных; и процессор 108, соединенный с интерфейсом 106 сетевой связи и носителем 104 информации, процессор 108 выполнен с возможностью выполнять различные процедуры, включая те, что описаны ниже. С этой целью процессор 108 может иметь доступ к машиночитаемым инструкциям, хранящимся на носителе 104 информации, выполнение которых инициирует процессор 108 выполнять различные описанные здесь процедуры.
[0065] Носитель 104 информации может хранить базу данных (не показана), в которой могут храниться пары лексических единиц и транскрипций.
[0066] Носитель 104 информации может хранить машиночитаемые инструкции, выполнение которых инициирует процессор 108 получать пары лексических единиц, записанных в первом алфавите, и соответствующие транскрипции этих лексических единиц, записанные во втором алфавите. Лексические единицы и транскрипции соответствующей лексической единицы могут быть разделены на соответствующие сегменты таким образом, чтобы в паре каждый сегмент лексической единицы обладал соответствующим сегментом в транскрипции лексической единицы, и таким образом, чтобы каждая лексическая единица включала в себя одно из: (i) последовательность последовательно чередующихся гласного сегмента и согласного сегмента; (ii) один гласный сегмент; (iii) один согласный сегмент. Пары, которые разделены на соответствующие сегменты, могут быть, например, получены от оператора человека. Лексические единицы могут быть разделены на сегменты оператором человеком или любым подходящим вычислительным устройством. Соответствующие транскрипции могут быть разделены на сегменты оператором человеком.
[0067] Процессор 108, например, может получать пару, в которой лексическая единица записана на русском языке с помощью кириллического алфавита, а транскрипции соответствующей лексической единицы записаны в английском алфавите с помощью комбинации английских букв, для связи фонетики русской лексической единицы: "здравствуйте - zdrahstvooytyeh", которая уже разделена на соответствующие сегменты следующим образом: "здр|а|вств|у|йт|е - zdr|ah|stv|oo|yt|yeh". В качестве другого примера, процессор 108 может получать пару, в которой лексическая единица записана на французском языке с помощью французского алфавита, а транскрипции соответствующей лексической единицы записаны в английском алфавите с помощью комбинации английских букв для связи фонетики французской лексической единицы: "bonjour - bonzhoor", которая уже разделена на соответствующие сегменты следующим образом: "b|o|nj|ou|r - b|o|nzh|oo|r". Пары лексических единиц, записанные в первом алфавите, и соответствующие транскрипции этих лексических единиц, записанные во втором алфавите представлены на Фиг. 2, и будут описаны далее более подробно.
[0068] Носитель 104 информации может хранить машиночитаемые инструкции, выполнение которых инициирует процессор 108 определять, для каждого заданного сегмента лексической единицы, ее контекст. Сегменты лексических единиц и их контексты представлены на Фиг. 2 и описаны далее более подробно.
[0069] Носитель 104 информации может хранить машиночитаемые инструкции выполнение которых инициирует процессор 108 вычислять теоретическую частоту по меньшей мере одного символа второго алфавита, который представляет транскрипцию конкретного заданного сегмента на основе контекста конкретного заданного сегмента.
[0070] Например, носитель 104 информации может хранить множество пар французских лексических единиц, записанных во французском алфавите, и соответствующие транскрипции этих лексических единиц, записанных в английском алфавите, лексические единицы и транскрипции соответствующей лексической единицы разделены на соответствующие сегменты. Предположим, что в этих парах конкретный согласный сегмент «s» во множестве лексических единиц был транскрибирован, например, 10,000,000 раз. Когда согласный сегмент «s» находится на конце заданной лексической единицы после гласного сегмента, он транскрибируется как немая буква (например, последняя буква «s» во французском мужском имени собственном « », которая не будет произноситься). Тем не менее, когда согласный сегмент «s» находится между гласными сегментами, он транскрибируется как «z» (например, буква «s» во французском женском имени собственном «
», которая не будет произноситься). Тем не менее, когда согласный сегмент «s» находится между гласными сегментами, он транскрибируется как «z» (например, буква «s» во французском женском имени собственном « »). Таким образом, статистически возможно, что конкретный сегмент может произноситься только одним образом в конкретном контексте (теоретическая частота возможных транскрипций сегмента в заданном контексте составляет 100 процентов). Тем не менее, возможно, что конкретный сегмент в том же контексте может быть транскрибирован двумя или более различными способами. Если существует два или более способа произношения одного и того же сегмента в одном и том же контексте (но часто в различных лексических единицах), процессор 108 может вычислить теоретическую частоту каждой возможной транскрипции сегмента в заданном контексте, и каждая теоретическая частота составляет меньше 100 процентов, а сумма всех значений теоретической частоты составляет 100 процентов.
»). Таким образом, статистически возможно, что конкретный сегмент может произноситься только одним образом в конкретном контексте (теоретическая частота возможных транскрипций сегмента в заданном контексте составляет 100 процентов). Тем не менее, возможно, что конкретный сегмент в том же контексте может быть транскрибирован двумя или более различными способами. Если существует два или более способа произношения одного и того же сегмента в одном и том же контексте (но часто в различных лексических единицах), процессор 108 может вычислить теоретическую частоту каждой возможной транскрипции сегмента в заданном контексте, и каждая теоретическая частота составляет меньше 100 процентов, а сумма всех значений теоретической частоты составляет 100 процентов.
[0071] Процессор 108 может вычислить теоретическую частоту по меньшей мере одного символа второго алфавита, который представляет транскрипцию конкретного заданного сегмента, на основе контекста указанного конкретного заданного сегмента, когда процессор 108 получает доступ по меньшей мере к одной паре лексической единицы, записанной в первом алфавите, и соответствующей транскрипции лексической единицы. Тем не менее, если процессор 108 получает доступ к множеству пар, теоретическая частота по меньшей мере одного символа второго алфавита, который представляет транскрипцию конкретного заданного сегмента, на основе контекста будет более точной.
[0072] Носитель 104 информации может хранить машиночитаемые инструкции, выполнение которых инициирует процессор 108 получать от клиентского устройства 122, которое будет более подробно описано далее, лексические единицы, записанные в первом алфавите, причем первый алфавит не является родным для этих лексических единиц. В качестве не ограничивающего примера, клиентское устройство 122 является персональным компьютером в Интернет-кафе в аэропорту Шёнефельд в Германии, где не установлена русская раскладка клавиатуры. Пользователь 121 пишет с помощью веб-интерфейса своей электронной почты на клиентском устройстве 122 электронное сообщение на русском языке, но с использованием немецкого алфавита, поскольку русская раскладка не установлена. Пользователь 121 активирует в веб-интерфейсе своей электронной почты опцию «транскрибировать». Клиентское устройство 122 может отправлять по сети 110 передачи данных текст в том виде, в котором он написан, одновременно с запросом на транскрипцию текста, и процессор 108 сервера 102 может получать текст для транскрипции. В качестве другого не ограничивающего примера, пользователь 121 печатает на русском языке, но с использованием английского алфавита, поисковый запрос в поисковую строку веб-браузера. Клиентское устройство 122 передает поисковый запрос серверу 102 в том виде, в котором пользователь 121 его ввел.
[0073] Носитель 104 информации может хранить машиночитаемые инструкции, выполнение которых инициирует процессор 108 разделять полученные лексические единицы. Каждая лексическая единица может быть разделена либо на один гласный сегмент, либо на один согласный сегмент, либо на последовательность последовательно чередующихся гласных и согласных сегментов. Например, если полученная лексическая единица является французским словом «eau», которое включает в себя только гласные, эта лексическая единица будет разделена на один гласный сегмент |eau|. Если полученная лексическая единица является русским союзом «в», которое включает в себя только согласные, эта лексическая единица будет разделена на один согласный сегмент |в|. Если полученная лексическая единица является немецким существительным «Bundesverfassungsgericht», которое включает в себя и гласные и согласные, эта лексическая единица будет разделена на последовательность последовательно чередующихся гласных и согласных сегментов: |B|u|nd|e|sv|e|rf|a|ss|u|ngsg|e|r|i|cht|.
[0074] Носитель 104 информации может хранить машиночитаемые инструкции выполнение которых инициирует процессор 108 применять теоретическую частоту транскрипции каждого сегмента второй лексической единицы, теоретическая частота основана на контексте каждого заданного сегмента во второй лексической единице, и создавать транскрипцию второй лексической единицы во втором алфавите. Другими словами, процессор 108 может после разделения полученной лексической единицы на сегменты, определить контекст для каждого из этих сегментов, для извлечения статистики, которая применима для каждого сегмента, включенного в полученное слово, для замены каждого сегмента в полученной лексической единице наиболее подходящей транскрипцией, в соответствии с теоретической частотой транскрипции этого конкретного сегмента в том же самом контексте.
[0075] Носитель 104 информации может хранить машиночитаемые инструкции, выполнение которых инициирует процессор 108 передавать клиентскому устройству 122 инструкции отображать пользователю 121 транскрипцию второй лексической единицы на второй язык. Машиночитаемые инструкции могут дополнительно инициировать процессор 108 передавать клиентскому устройству 122 инструкции опустить отображение символа, который представляет собой немую букву. Таким образом, символ немой буквы может быть виртуальным символом, который существует дополнительно в любом алфавите, который рассматривается в процессе транскрипции, но который не отображается пользователю 121.
[0076] Носитель 104 информации может хранить машиночитаемые инструкции, которые при выполнении инициируют процессор 108, в ответ на получение поискового запроса, транскрибировать поисковый запрос в другой алфавит и далее проводить поиск с помощью транскрипции поискового запроса. Эта функция может быть использована, например, когда пользователь 121 печатает поисковый запрос с помощью алфавита, который не является родным для конкретного языка (например, если пользователь вводит английские слова с помощью русского алфавита).
[0077] Система 100 дополнительно включает в себя клиентское устройство 122. Клиентское устройство 122 может быть связано с пользователем 121. Пользователь 121 может выполнять действия, которые могут быть интерпретированы клиентским устройством 122 как запрос на выполнение действия. Следует отметить, что тот факт, что клиентское устройство 122 может быть связано с пользователем 121, не предполагает и/или реализует конкретный режим работы.
[0078] На Фиг. 1 клиентское устройство 122 реализовано как Dell™ Precision Т1700 МТ CA033PT170011RUWS PC с процессором Intel® Xeon™ 128, частотой ЦП 3300 MHz, видеокартой nVIDIA Quadro K2000, который работает на ОС Windows 7® Pro 64-bit, операционная система установлена и активирована. Клиентское устройство 122, среди прочего, включает в себя интерфейс 126 связи (например, модем, сетевая карта и так далее) для двусторонней связи по сети 110 передачи данных. Как будет понятно специалисту в данной области техники, реализация клиентского устройства 122 никак конкретно не ограничена. Клиентское устройство 122 может быть реализовано как персональный компьютер (настольные компьютеры, ноутбуки, нетбуки и т.п.), устройства беспроводной связи (мобильные телефоны, смартфоны, планшеты и т.п.), а также другое оборудование.
[0079] Клиентское устройство 122 представляет собой пользовательское устройство ввода (не показано). Реализация пользовательского устройства ввода не ограничена и может зависеть от того, какое клиентское устройство 122 используется. Пользовательское устройство ввода может включать в себя любой механизм для предоставления ввода пользователя процессору 128. Пользовательское устройство ввода может представлять собой клавиатуру, мышь и так далее. Устройство ввода не ограничено никакой конкретной методологией ввода, но может быть организовано с помощью виртуальной кнопки на сенсорном экране или, например, физической кнопки на поверхности электронного устройства.
[0080] Исключительно в качестве примера, а не ограничения, в тех вариантах осуществления настоящего технического решения, где клиентское устройство 122 реализовано как беспроводное устройство связи (например, смартфон), пользовательское устройство ввода может быть реализовано как оптическая интерференция на основе пользовательского устройства ввода. Пользовательское устройство ввода в одном примере является сенсорным устройством, воспринимающим движения пальца/объекта, на котором пользователь выполняет жесты и/или нажимает пальцем. Пользовательское устройство ввода может идентифицировать/отслеживать жест и/или определить местоположение пальца пользователя на пользовательском устройстве ввода. В тех случаях, когда пользовательское устройство ввода выполняется как оптическая интерференция на основе пользовательского устройства ввода, например, сенсорного экрана или мультитач экрана, пользовательское устройство ввода может дополнительно выполнять функции экрана (не показано).
[0081] Пользовательское устройство ввода коммуникативно соединено с процессором 128 и передает вводные сигналы (и выходные сигналы, в этом случае оно действует как экран монитора) на основе различных форм пользовательского ввода для обработки и анализа процессором 128.
[0082] Клиентское устройство 122 дополнительно представляет собой экран монитора (не показано). Экран монитора может быть реализован как 21,5'' Dell™ Е2214Н 2214-7803, с разрешением 1920×1080. Экран в общем случае выполнен с возможностью отображать графический интерфейс пользователя (GUI), который предоставляет простой в использовании графический интерфейс между пользователем 121 клиентского устройства 122 и операционной системой или приложением(и), установленными на клиентском устройстве 122. В общем случае графический интерфейс пользователя (GUI) представляет программы, файлы и операционные опции с помощью графических изображений. Графический интерфейс пользователя (GUI) позволяет пользователю 121 ввести запрос на выполнение действия, например, поисковые запросы путем ввода поискового запроса в поисковую строку в графически интерфейс пользователя веб браузера. Запрос может быть введен, например, через устройство ввода, путем набора поискового запроса с помощью любого алфавита.
[0083] Экран монитора также обычно выполнен с возможностью отображать другую информацию, например, пользовательские данные и веб ресурсы, а также карты с текстом, написанным в любом алфавите.
[0084] В альтернативных вариантах осуществления настоящего технического решения экран монитора может быть жидкокристаллическим (ЖК/LCD), светоизлучающим диодом (LED), дисплеем с интерферометрическими модулятором (IMOD) или любым другим подходящим экраном. Экран также может представлять собой сенсорное устройство, например, сенсорный экран. Сенсорный экран является экраном, который определяет наличие и местоположение касаний пользователя. Экран монитора также может быть двойным или мультитач экраном, который может идентифицировать наличие, местоположение и движение сенсорного ввода. В тех случаях, когда экран монитора реализован в виде сенсорного устройства, например, сенсорного экрана или мультитач экрана, экран монитора может выполнять функции пользовательского устройства ввода.
[0085] Экран монитора коммуникативно связан с процессором 128 и получает сигналы от процессора 128. В случаях, когда экран монитора реализован в виде сенсорного устройства, например, сенсорного экрана или мультитач экрана, экран монитора может также передавать сигналы ввода в различных формах пользовательского ввода на обработку и анализ процессору 128.
[0086] Клиентское устройство 122 дополнительно включает в себя носитель 124 информации, который реализован как жесткий диск на 500 Гб и с памятью 8 GB (2×4 GB) 1600 MHz DDR3 Non-ЕСС. Как будет понятно специалисту в данной области техники, носитель 124 информации может быть реализован как носитель информации абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д. и их комбинация. Носитель 124 информации выполнен с возможностью хранить информацию, включая машиночитаемые инструкции и другие данные.
[0087] Носитель 124 информации может хранить программные инструкции, которые реализуют программное обеспечение, выполняющее функции веб-браузера (не показано). В общем случае, целью веб-браузера является предоставление пользователю 121 возможности связываться с сервером 102 и запрашивать различные сервисы, например, картографический поиск с помощью картографических сервисов, общий и вертикальный поиск в Интернете с помощью различных поисковых систем, сервисы электронной почты, сервисы перевода и прочее. В клиентском устройстве 122 браузер реализован как мобильная версия Яндекс™ браузера. Тем не менее, как будет понятно специалисту в данной области техники, реализация браузера никак конкретно не ограничена. В качестве не ограничивающих примеров, подобные браузеры могут представлять собой Яндекс™ браузер, Google Chrome™ браузер, Internet Explorer™ браузер, различные мобильные приложения и так далее. Важно иметь в виду, что любое другое коммерчески доступное или собственное приложение может быть использовано для реализации вариантов осуществления настоящего технического решения, не ограничивающих его объем.
[0088] На Фиг. 2 представлены примеры пар 200 лексических единиц, записанных в первом алфавите (левый столбец) и соответствующих транскрипций (правый столбец) лексических единиц, записанных во втором алфавите. Лексические единицы и транскрипции соответствующих лексических единиц разделены на соответствующие сегменты таким образом, чтобы в паре каждый сегмент лексической единицы обладал соответствующим сегментом в транскрипции лексической единицы, и таким образом, чтобы каждая лексическая единица включала в себя либо последовательность последовательно чередующихся гласных и согласных сегментов, либо один гласный сегмент, либо один согласный сегмент. Сегменты транскрипции могут быть либо гласными сегментами, либо согласными сегментами, либо смешанными сегментами.
[0089] Пара 202 представляет собой пример лексической единицы в первом алфавите и соответствующую транскрипцию лексической единицы, записанную во втором алфавите, в которой лексическая единицы «au» записана во французском алфавите, и соответствующая транскрипция «о» записана в английском алфавите. Лексическая единица «au» является одним французским словом. В других вариантах осуществления настоящего технического решения, лексическая единица, которая представляет собой одно слово, может быть любой частью речи, например, существительным, глаголом, прилагательным и так далее. Лексическая единица «аи» и соответствующая транскрипция «о» разделены на одинаковое число соответствующих сегментов (один сегмент в лексической единице и один соответствующий сегмент в транскрипции), таким образом, в рамках одной пары, один сегмент лексической единицы обладает одним соответствующим сегментом в транскрипции лексической единицы, и, таким образом, лексическая единица «au» содержит один гласный сегмент |au|. Например, оба алфавита - первый алфавит (английский алфавит) и второй алфавит (французский алфавит) основаны на латинском алфавите.
[0090] Пара 204 представляет собой пример лексической единицы в первом алфавите и соответствующую транскрипцию лексической единицы, записанную во втором алфавите, в которой лексическая единицы «в» записана с помощью русского алфавита, и соответствующая транскрипция «v» записана с помощью английского алфавита. Лексическая единица «в» является одним словом, которое является русским предлогом. Лексическая единица «в» и соответствующая транскрипция «v» разделены на одинаковое число соответствующих сегментов (один сегмент в лексической единице и один сегмент в транскрипции), таким образом, в рамках одной пары, один сегмент лексической единицы обладает одним соответствующим сегментом в транскрипции лексической единицы, и, таким образом, лексическая единица «в» содержит один согласный сегмент |v|.
[0091] Пара 208 представляет собой пример лексической единицы в первом алфавите и соответствующую транскрипцию лексической единицы, записанную во втором алфавите, в которой лексическая единицы «bonjour» записана с помощью русского алфавита, и соответствующая транскрипция «bonzhoor» записана с помощью английского алфавита. Лексическая единица «bonjour» является одним французским словом. Лексическая единица «bonjour» и соответствующая транскрипция «bonzhoor» разделены на одинаковое число соответствующих сегментов (пять сегментов в лексической единице и пять соответствующих сегментов в транскрипции), таким образом, в рамках одной пары, каждый сегмент лексической единицы обладает соответствующим сегментом в транскрипции лексической единицы, и, таким образом, лексическая единица «bonjour» содержит последовательность последовательно чередующихся гласных и согласных сегментов. Для целей иллюстрации, на Фиг. 2 все согласные сегменты подчеркнуты в лексической единице «bonjour», а также в других лексических единицах. Все гласные сегменты не подчеркнуты в лексической единице «bonjour», а также в других лексических единицах.
[0092] Пара 210 является примером лексической единицы «time», написанным с помощью английского алфавита, и соответствующей транскрипции «tajm~», записанной с помощью немецкого алфавита. Лексическая единица «|t|i|m|e» и соответствующая транскрипция «|t|aj|m|~|» разделены на одинаковое число соответствующих сегментов (четыре сегмента в лексической единице и четыре соответствующих сегмента в транскрипции), таким образом, в рамках одной пары, каждый сегмент лексической единицы обладает соответствующим сегментом в транскрипции лексической единицы, и, таким образом, лексическая единица «time» содержит последовательность последовательно чередующихся гласных и согласных сегментов. Последняя буква «е» в английском слове «time» является гласной, которая представляет собой немую букву. Гласная, которая является немой, соответствует сегменту в транскрипции, который представлен как |~|. Символ «~» представляет немой звук в некоторых вариантах осуществления настоящего технического решения. Следует иметь в виду, что выбор символа «~» как символа, представляющего немой звук, является случайным. Вместо него может быть использован любой другой символ.
[0093] Транскрипции могут быть показаны пользователю 121 на экране монитора его клиентского устройства 122. Соответственно, сервер 102 может передавать клиентскому устройству 122 инструкции отобразить транскрипцию лексической единицы на второй язык пользователю 121. Эти инструкции могут включать в себя инструкцию опустить отображение символа, который представляет немую букву. Таким образом, немецкая транскрипция английского слова «time» может быть показана пользователю 121 как «tajm» без символа «~», который представляет немую букву.
[0094] Пара 212 является примером, в котором английское слово «metropolitan» транскрибировано в международный фонетический алфавит (IPA), который является одним из существующих фонетических алфавитов.
[0095] Пара 214 является примером лексической единицы «well-being», написанной с помощью английского алфавита, и соответствующей транскрипции «уэлбиин», записанной с помощью русского алфавита. Лексическая единица «well-being» и соответствующая транскрипция «уэлбиин» разделены на одинаковое число соответствующих сегментов (пять сегментов в лексической единице и пять соответствующих сегментов в транскрипции), таким образом, в рамках одной пары, каждый сегмент лексической единицы обладает соответствующим сегментом в транскрипции лексической единицы, и, таким образом, лексическая единица «well-being» содержит последовательность последовательно чередующихся гласных и согласных сегментов. В слове «well-being» есть специальный символ (дефис). В данном варианте осуществления настоящего технического решения, специальный символ, являющийся дефисом, квалифицируется не существующим. Таким образом, разделение лексической единицы выполняется так, будто в слове «well-being» нет дефиса.
[0096] Правила обработки специальных символов могут быть запрограммированы заранее и могут храниться на носителе 104 информации. Эти правила могут относиться к конкретному языку. Например, может существовать правило, согласно которому дефис будет считаться несуществующим для английского языка, если буквы, которые не являются специальными символами, соседствуют с дефисом с обеих сторон. В качестве другого примера, во французском языке дефис может считаться гласной, если следующая за ним буква является гласной, или может считаться согласной, если следующая за ним буква квалифицируется согласной. Это будет подробнее описано ниже, при описании пары 218.
[0097] Пара 216 является примером лексической единицы «vous  », написанным с помощью французского алфавита, и соответствующей транскрипции «voozett», записанной с помощью английского алфавита. Лексическая единица «vous » является словосочетанием из двух слов. В других вариантах осуществления настоящего технического решения, словосочетания содержат несколько слов, предложение, несколько предложений, параграф, несколько параграфов. Лексическая единица «vous » и соответствующая транскрипция «voozett» разделены на одинаковое число соответствующих сегментов (семь сегментов в лексической единице и семь соответствующих сегментов в транскрипции), таким образом, в рамках одной пары, каждый сегмент лексической единицы обладает соответствующим сегментом в транскрипции лексической единицы, и, таким образом, лексическая единица «vous
», написанным с помощью французского алфавита, и соответствующей транскрипции «voozett», записанной с помощью английского алфавита. Лексическая единица «vous » является словосочетанием из двух слов. В других вариантах осуществления настоящего технического решения, словосочетания содержат несколько слов, предложение, несколько предложений, параграф, несколько параграфов. Лексическая единица «vous » и соответствующая транскрипция «voozett» разделены на одинаковое число соответствующих сегментов (семь сегментов в лексической единице и семь соответствующих сегментов в транскрипции), таким образом, в рамках одной пары, каждый сегмент лексической единицы обладает соответствующим сегментом в транскрипции лексической единицы, и, таким образом, лексическая единица «vous  » содержит последовательность последовательно чередующихся гласных и согласных сегментов. В лексической единице «vous
» содержит последовательность последовательно чередующихся гласных и согласных сегментов. В лексической единице «vous  » содержится специальный символ (пробел). В данном варианте осуществления настоящего технического решения, специальный символ, который является пробелом, квалифицируется гласной, если первая буква следующего слова является гласной, и квалифицируется согласной, если первая буква следующего слова является согласной.
» содержится специальный символ (пробел). В данном варианте осуществления настоящего технического решения, специальный символ, который является пробелом, квалифицируется гласной, если первая буква следующего слова является гласной, и квалифицируется согласной, если первая буква следующего слова является согласной.
[0098] Причиной этого является тот факт, что в некоторых языках, например, во французском языке произношение последней согласной предыдущего слова зависит от первой буквы следующего. В подобных языках все или некоторые из специальных символов, которые разделяют слова (пробел, дефисы и прочее) могут считаться принадлежащими к той же группе, что и первая буква следующего слова. Первая буква следующего слова является гласной и, следовательно, пробел квалифицируется гласной. Французская «s» на конце слова произносится как английская «z», если следующее слово начинается с гласной (например « »). С другой стороны, та же французская буква «s» не произносится, если она расположена на конце последнего слова в предложении или если следующее слово начинается с согласной. Например, в последнем слове «
»). С другой стороны, та же французская буква «s» не произносится, если она расположена на конце последнего слова в предложении или если следующее слово начинается с согласной. Например, в последнем слове « » последняя «s» не произносится, поскольку после нее нет гласных.
» последняя «s» не произносится, поскольку после нее нет гласных.
[0099] В других языках, отличных от французского, может применяться другой набор правил для интерпретации специальных символов. В некоторых языках принадлежность всех или некоторых специальных символов к гласным или согласным может быть определена тем, является ли следующая буква гласной или согласной, как во французском. В других языках, принадлежность всех или некоторых специальных символов может определяться предыдущей гласной или согласной. В некоторых других языках принадлежность некоторых специальных символов может быть определена следующей гласной или согласной, а принадлежность других специальных символов может быть определена предыдущей гласной или согласной. В дополнение к приведенным выше примерам, некоторые правила для конкретного языка могут предполагать, что некоторые специальные символы считаются несуществующими.
[00100] Пара 218 является примером лексической единицы «as-tu malade?», написанным с помощью французского алфавита, и соответствующей транскрипции «ahtoomahlahd», записанной с помощью английского алфавита. Лексическая единица «as-tu malade?» является словосочетанием, состоящим из трех слов, первые да из которых рзделены дефисом. Лексическая единица «as-tu malade?» и соответствующая транскрипция «bonzhoor» разделены на одинаковое число соответствующих сегментов (девять сегментов в лексической единице и девять соответствующих сегментов в транскрипции), таким образом, в рамках одной пары, каждый сегмент лексической единицы обладает соответствующим сегментом в транскрипции лексической единицы, и, таким образом, лексическая единица «as-tu malade?» содержит последовательность последовательно чередующихся гласных и согласных сегментов. В лексической единице «as-tu malade?» есть три специальных символа (дефис, пробел и вопросительный знак). В этом варианте осуществления настоящего технического решения, специальные символы, которые являются пробелом и дефисом, считаются связанными с гласными или с согласными в зависимости от первой буквы следующего слова. Вопросительный знак в данном варианте осуществления настоящего технического решения квалифицируется отсутствующим. Сразу после дефиса следующая бука «t» является согласной. Следовательно, дефис квалифицируется согласной. Сразу после пробела следующая бука «т» является согласной. Следовательно, пробел квалифицируется согласной. Дефис, который является согласной, расположен между двумя другими согласными, между «s» и «t». Следовательно, «s», «-» и «t» вместе образуют единый согласный сегмент. Пробел, который является согласной, расположен между гласной и согласной, между «u» и «t». Следовательно, пробел, который является согласной, становится частью согласного сегмента «m» вместе с согласной «m». Вопросительный знак квалифицируется несуществующим и он не представлен в соответствующем сегменте в транскрипции. Знак вопроса не становится отдельным сегментом лексической единицы, поскольку он квалифицируется несуществующим, и согласные и гласные могут являться частью согласного сегмента или гласного сегмента.
[00101] Гласные сегменты и согласные сегменты в лексических единицах обладают контекстом. Контекст конкретного сегмента (согласного сегмента или гласного сегмента) определяется предыдущим контекстом и следующим контекстом. Предыдущий контекст - это то, что расположено прямо перед конкретным сегментом. Следующий контекст - это то, что расположено прямо после конкретного сегмента.
[00102] Предыдущий контекст может включать в себя предыдущий соседний сегмент лексической единицы и предыдущий конец лексической единицы. Следующий контекст может включать в себя следующий соседний сегмент лексической единицы и следующий конец лексической единицы.
[00103] Например, возвращаясь к лексической единице «аи» в паре 202, предыдущий контекст гласного сегмента |au| является предшествующим концом этой лексической единицы, а следующий контекст гласного сегмента |au| является следующим концом этой лексической единицы.
[00104] Другой пример, возвращаясь к лексической единице «bonjour» в паре 208, предыдущий контекст согласного сегмента |b| является предшествующим концом этой лексической единицы, а следующий контекст согласного сегмента |b| является следующим соседним гласным сегментом |о|.
[00105] Обращаясь к той же лексической единице в паре 208, предыдущий контекст гласного сегмента |о| является предшествующим соседним согласным сегментом |b|, а следующий контекст гласного сегмента |о| является следующим соседним согласным сегментом |nj|.
[00106] Обращаясь к той же лексической единице в паре 208, предыдущий контекст согласного сегмента |r| является предшествующим соседним гласным сегментом |ou|, а следующий контекст согласного сегмента |r| является следующим концом лексической единицы.
[00107] В качестве другого примера, обращаясь к лексической единице «vous  » в паре 216, предыдущий контекст согласного сегмента |s| в первом слове «vous» является предыдущим соседним гласным сегментом |ou|, а следующий контекст согласного сегмента |s| является следующим соседним согласным сегментом |
» в паре 216, предыдущий контекст согласного сегмента |s| в первом слове «vous» является предыдущим соседним гласным сегментом |ou|, а следующий контекст согласного сегмента |s| является следующим соседним согласным сегментом | |, соседний гласный сегмент |
|, соседний гласный сегмент | | сдержит пробел, который квалифицируется гласной, и гласную «
| сдержит пробел, который квалифицируется гласной, и гласную « ». Следующий контекст согласного сегмента |s| в первом слове «vous» не является следующим концом лексической единицы, поскольку эта лексическая единица, как было отмечено выше, является словосочетанием, и слово «vous» не является последним словом в лексическом словосочетании.
». Следующий контекст согласного сегмента |s| в первом слове «vous» не является следующим концом лексической единицы, поскольку эта лексическая единица, как было отмечено выше, является словосочетанием, и слово «vous» не является последним словом в лексическом словосочетании.
[00108] На Фиг. 3 представлен исполняемый на компьютере способ 300 транскрипции лексической единицы из первого алфавита во второй, способ 300 выполняется в соответствии с вариантами осуществления настоящего технического решения и исполнятся на сервере 102 системы 100, представленной на Фиг. 1.
[00109] Этап 302 - получение пары, в которую входит лексическая единица, записанная в первом алфавите, и соответствующая транскрипция лексической единицы, записанная во втором алфавите, лексическая единица и транскрипция соответствующей лексической единицы были разделены на соответствующие сегменты.
[00110] Способ 300 начинается на этапе 302, где сервер 102 получает пару, в которую входит лексическая единица, записанная в первом алфавите, и соответствующая транскрипция лексической единицы, записанная во втором алфавите.
[00111] Транскрипция может быть получена из любого подходящего источника. Например, транскрипция может быт подготовлена лингвистом, который специализируется на фонетике исходного языка (на котором записана лексическая единица) и на фонетике целевого языка (на котором нужно подготовить транскрипцию). Например, для транскрипции лексической единицы «vous  » на английский язык, человек или группа людей должны обладать знаниями о фонетике обоих языков.
» на английский язык, человек или группа людей должны обладать знаниями о фонетике обоих языков.
[00112] Первый алфавит может быть родным алфавитом лексической единицы. Например, родным алфавитом для лексической единицы «vous  » является французский.
» является французский.
[00113] Второй алфавит может быть неродным алфавитом лексической единицы. Например, неродным алфавитом для лексической единицы «vous  » является английский.
» является английский.
[00114] Лексическая единица и соответствующая транскрипция лексической единицы поделены на соответствующие сегменты, как было описано выше со ссылками на пару 216 на Фиг. 2.
[00115] В качестве не ограничивающего примера другого источника транскрипций может выступать электронный словарь, если он содержит транскрипции, записанные в фонетическом алфавите. Разделение лексических единиц может выполняться автоматически или вручную. Разделение транскрипций на сегменты может выполняться лингвистами.
[00116] В альтернативных вариантах осуществления настоящего технического решения первый алфавит может быть неродным алфавитом для лексической единицы, а второй алфавит может быть родным для лексической единицы. Например, русское слово «privet» может быть записано с помощью символов английского языка, а транскрипция может быть записана с помощью букв русского алфавита («привет»).
[00117] Способ 300 далее переходит к выполнению этапа 304.
[00118] Этап 304 - определение для каждого заданного сегмента лексической единицы его контекста
[00119] Далее, на этапе 304 сервер 102 определяет для каждого заданного сегмента лексическую единицу его контекста, как было описано выше со ссылкой на пары 200.
[00120] Способ 300 далее переходит к выполнению этапа 306.
[00121] Этап 306 - обучение сервера 102 вычислению теоретической частоты по меньшей мере одного символа второго алфавита, представляющего собой транскрипцию конкретного заданного сегмента на основе контекста указанного конкретного заданного сегмента.
[00122] В результате разделения лексических единиц и транскрипций на сегменты, могут присутствовать различные сегменты транскрипции. Некоторые сегменты транскрипции могут состоять из одного символа второго алфавита (это может быть согласная, гласная или символ, представляющий немую букву). Некоторые сегменты транскрипции могут состоять из двух и более символов второго алфавита. Это может быть комбинация гласной(ых) и/или согласной(ых) и/или символа(ов), представляющих немую букву.
[00123] На этапе 306 сервер 120 вычисляет теоретическую частоту каждого сегмента транскрипции (по меньшей мере одного символа второго алфавита, представляющего собой транскрипцию конкретного заданного сегмента лексической единицы) на основе контекста указанного конкретного заданного сегмента лексической единицы. Возможно, что теоретическая частота конкретной транскрипции конкретной лексической единицы в том же контексте будет выше, поскольку высока вероятность того, что конкретный заданный сегмент лексической единицы в конкретном контексте появляется один раз. Например, для пары 216 |v|ou|s|  |t|e|s| - |v|oo|z|e|tt|~|~|, для каждого элемента теоретическая частота будет 100 процентов. Например, на этом этапе:
|t|e|s| - |v|oo|z|e|tt|~|~|, для каждого элемента теоретическая частота будет 100 процентов. Например, на этом этапе:
согласная «v», расположенная между предыдущим концом и гласным сегментом «ou», будет представлена сегментом |v| в 100 процентах случаев, т.е. в этом единственном случае; согласная «s», расположенная между гласной «е» и следующим концом лексической единицы, будет представлена немой буквой в 100 процентах случаев, т.е. в этом единственном случае, и так далее.
[00124] Тем не менее, теоретическая частота может быть изменена после выполнения этапа 308 способа 300.
[00125] В результате выполнения этапа 306 сервер 102 может создать начальную статистику в отношении транскрипции конкретного гласного и/или согласного сегментов в конкретном контексте.
[00126] Способ 300 далее переходит к выполнению этапа 308.
[00127] Этап 308 - повторение этапов 302-306 способа 300 в отношении множества пар, каждая из которых включает в себя лексическую единицу и соответствующую транскрипцию.
[00128] Далее, на этапе 308 сервер 102 повторяет этапы 302-306 способа 300 в отношении множества пар, каждая из которых включает в себя лексическую единицу и соответствующую транскрипцию. Все лексические единицы записаны в одном первом алфавите. И все транскрипции записаны в одном втором алфавите.
[00129] При повторении этапа 306 с большим числом пар может так случиться, что сервер 102 столкнется в различных лексических единицах с некоторыми гласными и/или согласными сегментами, которые находятся в том же контексте. Возможно, что по меньшей мере некоторые гласные сегменты и/или согласные сегменты в одном и том же контексте всегда транскрибируются одним и тем же способом. Это означает, что теоретическая частота по меньшей мере одного символа второго алфавита, представляющего транскрипцию конкретного заданного сегмента, равна 100 процентов. Тем не менее, возможно также, что по меньшей мере некоторые гласные сегменты и/или согласные сегменты в одном и том же контексте иногда транскрибируются двумя или более способами. В этом случае сервер 102 может вычислить теоретическую частоту по меньшей мере одного символа второго алфавита, представляющего транскрипцию конкретного заданного сегмента, теоретическая частота отличается от 100 процентов для каждого из различных способов транскрипции. Сумма теоретических частот может быть 100 процентов.
[00130] Способ 300 далее переходит к выполнению этапа 310.
[00131] Этап 310 - получение от клиентского устройства 122 запроса, который интерпретируется как запрос на транскрипцию второй лексической единицы, записанной в первом алфавите, во второй алфавит.
[00132] Далее, на этапе 310 сервер 102 получает от клиентского устройства запрос, который интерпретируется как запрос на транскрипцию второй лексической единицы, записанной в первом алфавите, во второй алфавит. Например, это может быть запрос серверу на основе приложения, которое транскрибирует лексические единицы. Такое приложение может быть реализовано, например, как расширение для сервиса электронной почты.
[00133] B альтернативных вариантах осуществления настоящего технического решения, где первый язык является неродным языком для конкретной лексической единицы, а второй язык является родным для лексической единицы, запрос может быть запросом отобразить карту Москвы (Россия), в котором язык операционной системы и веб-браузера, установленного на клиентском устройстве, является английским, и причем пользователь находится в Австралии. Подобный запрос может быть интерпретирован сервером 102 как запрос транскрибировать имена улиц в символы английского алфавита.
[00134] В альтернативных вариантах осуществления настоящего технического решения, где первый язык является неродным языком для конкретной лексической единицы, а второй язык является родным для лексической единицы, запрос может быть поисковым запросом, в котором русские слова были записаны с помощью символов английского алфавита. Подобный запрос может быть интерпретирован сервером 102 как запрос на транскрипцию поискового запроса в символы русского алфавита, что позволяет произвести поиск с помощью русскоязычной транскрипции, или оригинального текста и русскоязычной транскрипции вместе.
[00135] Способ 300 далее переходит к выполнению этапа 312.
[00136] Этап 312 - разделение второй лексической единицы либо на один гласный сегмент, либо на один согласный сегмент, либо на последовательность последовательно чередующихся гласных и согласных сегментов.
[00137] Далее, на этапе 312 сервер 102 разделяет полученную вторую лексическую единицу либо на один гласный сегмент, либо на один согласный сегмент, либо на последовательность последовательно чередующихся гласных и согласных сегментов.
[00138] Вторая лексическая единица может быть получена в рамках текста, который содержит слово или множество слов. Если текст включает в себя два или более вторых лексических единиц, этап 312 может быть выполнен в отношении каждой лексической единицы. В зависимости от языка текста, каждое из слов в тексте может считаться отдельной второй лексической единицей или комбинации слов (например, предложения) могут считаться вторыми лексическими единицами, представляющими собой словосочетания. Выбор может зависеть от специальных правил языка, которые хранятся на носителе 104 информации. Отдельные слова могут быть выбраны для языков, в которых произношение сегментов зависит от контекста в пределах одного и того же слова и не зависит от предыдущих и последующих слов. В других языках, предложения или другие группы слов могут считаться лексической единицей.
[00139] Процессор 108 разделяет вторую лексическую единицу, как было описано со ссылкой на пары 200, представленные на Фиг. 2.
[00140] Способ 300 далее переходит к выполнению этапа 314.
[00141] Этап 314 - применение теоретической частоты транскрипции каждого сегмента второй лексической единицы, теоретическая частота основана на контексте каждого заданного сегмента во второй лексической единице, создание транскрипции второй лексической единицы во втором алфавите.
[00142] Далее, на этапе 314 сервер 102 применяет теоретическую частоту транскрипции каждого сегмента второй лексической единицы, теоретическая частота основана на контексте каждого заданного сегмента во второй лексической единице, и создает транскрипцию второй лексической единицы во втором алфавите. Если конкретный сегмент во второй лексической единице, которая является конкретным содержимым, ранее был транскрибирован тем же способом, в соответствии со статистикой (см. этап 308), он будет транскрибирован тем же способом при выполнении этапа 314. Тем не менее, если один и тот же сегмент в одном и том же контексте был транскрибирован с помощью одной транскрипции в 80 процентах случаев, другой транскрипции в 17 процентах случаев, и третьей транскрипции в 3 процентах случаев, этот сегмент может быть транскрибирован с помощью первой транскрипции, поскольку статистически вероятно, что это наиболее точная транскрипция.
[00143] При выполнении этапа 314 сервер 102 может создать транскрипцию всех лексических единиц полученного текста.
[00144] Способ 300 далее переходит к выполнению этапа 316.
[00145] Этап 316 - передача клиентскому устройству инструкций отобразить пользователю 121 транскрипцию второй лексической единицы на второй язык.
[00146] Далее, на этапе 316, после выполнения транскрипции второй лексической единицы, сервер 102 передает клиентскому устройству 122 инструкции отображать пользователю 121 транскрипцию второй лексической единицы на второй язык. Инструкции отображать пользователю 121 транскрипцию второй лексической единицы на второй язык могут включать в себя инструкцию не отображать символы, представляющие немые буквы.
[00147] Затем способ 300 завершается.
[00148] С некоторой точки зрения, варианты осуществления настоящего технического решения можно изложить следующим образом, в виде пронумерованных пунктов:
[00149] 1. Способ транскрипции лексической единицы из первого алфавита во второй алфавит, способ выполняется на сервере (102), способ включает в себя:
получение (302) пары, в которую входит (i) лексическая единица, записанная в первом алфавите, и (ii) соответствующая транскрипция лексической единицы, записанная во втором алфавите, лексическая единица и транскрипция соответствующей лексической единицы были разделены в соответствующие сегменты, таким образом,
что внутри пары, каждый сегмент лексической единицы обладает соответствующим сегментом в транскрипции лексической единицы, и таким образом,
что каждая лексическая единица содержит одно из выбранного: (i) последовательность последовательно чередующихся гласного и согласного сегмента, (ii) один гласный сегмент, (iii) один согласный сегмент; каждый гласный сегмент состоит по меньшей мере из одной гласной, а каждый согласный сегмент состоит по меньшей мере из одной согласной; и
определение (304) для каждого заданного сегмента лексической единицы его контекста;
обучение (306) сервера (102) вычислению теоретической частоты по меньшей мере одного символа второго алфавита, представляющего собой транскрипцию конкретного заданного сегмента на основе контекста указанного конкретного заданного сегмента лексической единицы.
[00150] 2. Способ по п. 1, в котором лексическая единица выбирается из: слова или словосочетания.
[00151] 3. Способ по любому из пп. 1, 2, в котором тип лексическая единица включает в себя по меньшей мере один специальный символ.
[00152] 4. Способ по п. 3, в котором:
по меньшей мере один специальный символ в словосочетании, который расположен между согласной и гласной перед гласной, квалифицируется одним из выбранного из: гласной и согласной, и в котором,
указанный по меньшей мере один символ, если он квалифицируется гласной, становится частью соседнего гласного сегмента, и
указанный по меньшей мере один символ, если он квалифицируется согласной, становится частью соседнего согласного сегмента.
[00153] 5. Способ по п. 3, в котором:
по меньшей мере один специальный символ в словосочетании, который расположен между гласной и согласной перед согласной, квалифицируется одним из выбранного из: гласной и согласной, и в котором
указанный по меньшей мере один специальный символ, если он квалифицируется гласной, становится частью соседнего гласного сегмента, и
указанный по меньшей мере один специальный символ, если он квалифицируется согласной, становится частью соседнего согласного сегмента.
[00154] 6. Способ по любому из пп. 3-5, в котором по меньшей мере один специальный символ квалифицируется несуществующим.
[00155] 7. Способ по любому из пп. 3-6, в котором по меньшей мере один специальный символ является любым одним из выбранного: пробел, дефис, разрыв строки, разрыв страницы, и апостроф.
[00156] 8. Способ по любому из пп. 1-7, в котором контекст лексической единицы выбирается из: предшествующего контекста и последующего контекста.
[00157] 9. Способ по п. 8, в котором:
предыдущий контекст заданного сегмента является одним выбранным из: предыдущим соседним сегментом лексической единицы или предыдущим концом лексической единицы; и
следующий контекст заданного сегмента является одним выбранным из: следующим соседним сегментом лексической единицы или следующим концом лексической единицы.
[00158] 10. Способ по любому из пп. 1-9, в котором по меньшей мере один сегмент лексической единицы является немой буквой, и соответствующая транскрипция лексической единицы будет включать в себя символ, представляющий немую букву.
[00159] 11. Способ по любому из пп. 1-10, в котором второй алфавит представляет собой одно, выбранное из: (i) алфавит, отличный от первого алфавита; или (ii) фонетический алфавит.
[00160] 12. Способ по любому из пп. 1-11, дополнительно включающий в себя повторение (308) способа по п. 1 в отношении множества пар, каждая из которых представляет собой лексическую единицу и соответствующую транскрипцию, и в котором обучение (306) сервера (102) вычислять теоретическую частоту транскрипции заданного сегмента, которое основано на контексте заданного сегмента, представляет собой обучение сервера (102) с помощью алгоритма машинного обучения.
[00161] 13. Способ по любому из пп. 1-12, дополнительно включающий в себя
получение (310) от клиентского устройства запроса, который интерпретируется как запрос на транскрипцию второй лексической единицы, записанной в первом алфавите, во второй алфавит,
разделение (312) второй лексической единицы на одно, выбранное из:
(i) один гласный сегмент;
(ii) один согласный сегмент;
(iii) последовательность последовательно чередующихся гласных и согласных сегментов;
применение (314) теоретической частоты транскрипции каждого сегмента второй лексической единицы, теоретическая частота основана на контексте каждого заданного сегмента во второй лексической единице, создание транскрипции второй лексической единицы во втором алфавите.
[00162] 14. Способ по п. 13, который дополнительно включает в себя передачу (316) клиентскому устройству инструкций отобразить пользователю (121) транскрипцию второй лексической единицы на второй язык.
[00163] 15. Способ по п. 14, в котором по меньшей мере один сегмент лексической единицы является немой буквой, и в котором инструкции отобразить пользователю (121) транскрипцию второй лексической единицы на второй язык включает в себя инструкцию опустить отображение символа, который представляет немую букву.
[00164] 16. Способ по п. 13, в котором получение (310) от клиентского устройства запроса на транскрипцию второй лексической единицы, записанной в первом алфавите, во второй алфавит, включает в себя получение поискового запроса, способ дополнительно включает в себя проведение поиска с использованием транскрипции второй лексической единицы во второй алфавит в качестве поискового запроса, и создание страницы результатов поиска.
[00165] 17. Способ по п. 16, который дополнительно включает в себя передачу клиентскому устройству инструкций отобразить страницу результатов поиска.
[00166] 18. Сервер (102), обладающий носителем (104) информации и процессором (108), соединенным с носителем (104) информации, процессор (108) выполнен с возможностью доступа к машиночитаемым командам, выполнение которых инициирует процессор (108) выполнять этапы, осуществляющие:
получение (302) пары, в которую входит (i) лексическая единица, записанная в первом алфавите, и (ii) соответствующая транскрипция лексической единицы, записанная во втором алфавите, лексическая единица и транскрипция соответствующей лексической единицы были разделены в соответствующие сегменты, таким образом,
что внутри пары, каждый сегмент лексической единицы обладает соответствующим сегментом в транскрипции лексической единицы, и таким образом,
что каждая лексическая единица содержит одно из выбранного: (i) последовательность последовательно чередующихся гласного и согласного сегмента, (ii) один гласный сегмент, (iii) один согласный сегмент; каждый гласный сегмент состоит по меньшей мере из одной гласной, а каждый согласный сегмент состоит по меньшей мере из одной согласной; и
определение (304) для каждого заданного сегмента лексической единицы его контекста;
обучение (306) сервера (102) вычислению теоретической частоты по меньшей мере одного символа второго алфавита, представляющего собой транскрипцию конкретного заданного сегмента на основе контекста указанного конкретного заданного сегмента лексической единицы.
[00167] 19. Сервер (102) по п. 18, в котором лексическая единица выбирается из: слова или словосочетания.
[00168] 20. Сервер (102) по любому из пп. 18, 19, в котором тип лексическая единица включает в себя по меньшей мере один специальный символ.
[00169] 21. Сервер (102) по п. 20, в котором:
по меньшей мере один специальный символ в словосочетании, который расположен между согласной и гласной перед гласной, квалифицируется одним из выбранного из: гласной и согласной, и в котором
указанный по меньшей мере один специальный символ, если он квалифицируется гласной, становится частью соседнего гласного сегмента, и
указанный по меньшей мере один специальный символ, если он квалифицируется согласной, становится частью соседнего согласного сегмента.
[00170] 22. Сервер (102) по п. 20, в котором:
по меньшей мере один специальный символ в словосочетании, который расположен между гласной и согласной перед согласной, квалифицируется одним из выбранного из: гласной и согласной, и в котором
указанный по меньшей мере один специальный символ, если он квалифицируется гласной, становится частью соседнего гласного сегмента, и
указанный по меньшей мере один специальный символ, если он квалифицируется согласной, становится частью соседнего согласного сегмента.
[00171] 23. Сервер (102) по любому из пп. 20-22, в котором по меньшей мере один специальный символ квалифицируется несуществующим.
[00172] 24. Сервер (102) по любому из пп. 20-23, в котором по меньшей мере один специальный символ является любым одним из выбранного: пробел, дефис, разрыв строки, разрыв страницы, и апостроф.
[00173] 25. Сервер (102) по любому из пп. 18-24, в котором контекст лексической единицы выбирается из: предшествующего контекста и последующего контекста.
[00174] 26. Сервер (102) по п. 25, в котором:
предыдущий контекст заданного сегмента является одним выбранным из: предыдущим соседним сегментом лексической единицы или предыдущим концом лексической единицы; и
следующий контекст заданного сегмента является одним выбранным из: следующим соседним сегментом лексической единицы или следующим концом лексической единицы.
[00175] 27. Сервер (102) по любому из пп. 18-26, в котором по меньшей мере один сегмент лексической единицы является немой буквой, и соответствующая транскрипция лексической единицы будет включать в себя символ, представляющий немую букву.
[00176] 28. Сервер (102) по любому из пп. 18-27, в котором второй алфавит представляет собой одно, выбранное из: (i) алфавит, отличный от первого алфавита; или (ii) фонетический алфавит.
[00177] 29. Сервер (102) по любому из пп. 18-28, в котором процессор (108) дополнительно выполнен с возможностью осуществлять повторение (308) этапов п. 18 в отношении множества пар, каждая из которых представляет собой лексическую единицу и соответствующую транскрипцию, и в котором обучение (306) сервера (102) вычислять теоретическую частоту транскрипции заданного сегмента, которое основано на контексте заданного сегмента, представляет собой обучение сервера (102) с помощью алгоритма машинного обучения.
[00178] 30. Сервер (102) по любому из пп. 18-29, в котором процессор (108) дополнительно выполнен с возможностью осуществлять:
получение (310) от клиентского устройства запроса, который интерпретируется как запрос на транскрипцию второй лексической единицы, записанной в первом алфавите, во второй алфавит,
разделение (312) второй лексической единицы на одно, выбранное из:
(i) один гласный сегмент;
(ii) один согласный сегмент;
(iii) последовательность последовательно чередующихся гласных и согласных сегментов;
применение теоретической частоты (314) транскрипции каждого сегмента второй лексической единицы, теоретическая частота основана на контексте каждого заданного сегмента во второй лексической единице, создание транскрипции второй лексической единицы во втором алфавите.
[00179] 31. Сервер (102) по п. 30, в котором процессор (108) дополнительно выполнен с возможностью осуществлять передачу (316) клиентскому устройству инструкций отобразить пользователю (121) транскрипцию второй лексической единицы на второй язык.
[00180] 32. Сервер (102) по п. 31, в котором по меньшей мере один сегмент лексической единицы является немой буквой, и в котором инструкции отобразить пользователю (121) транскрипцию второй лексической единицы на второй язык включает в себя инструкцию опустить отображение символа, который представляет немую букву.
[00181] 33. Сервер (102) по п. 30, в котором получение (310) от клиентского устройства запроса на транскрипцию второй лексической единицы, записанной в первом алфавите, во второй алфавит, включает в себя получение поискового запроса, процессор (108) дополнительно выполнен с возможностью осуществлять проведение поиска с использованием транскрипции второй лексической единицы во второй алфавит в качестве поискового запроса, и создание страницы результатов поиска.
[00182] 34. Сервер (102) по п. 33, в котором процессор (108) дополнительно выполнен с возможностью осуществлять передачу клиентскому устройству инструкции отобразить страницу результатов поиска.
[00183] Некоторые из этих этапов, а также передача-получение сигнала хорошо известны в данной области техники и поэтому для упрощения были опущены в конкретных частях данного описания. Сигналы могут быть переданы-получены с помощью оптических средств (например, оптоволоконного соединения), электронных средств (например, проводного или беспроводного соединения) и механических средств (например, на основе давления, температуры или другого подходящего параметра).
[00184] Модификации и улучшения вышеописанных вариантов осуществления настоящего технического решения будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не несет никаких ограничений. Таким образом, объем настоящего технического решения ограничен только объемом прилагаемой формулы изобретения.
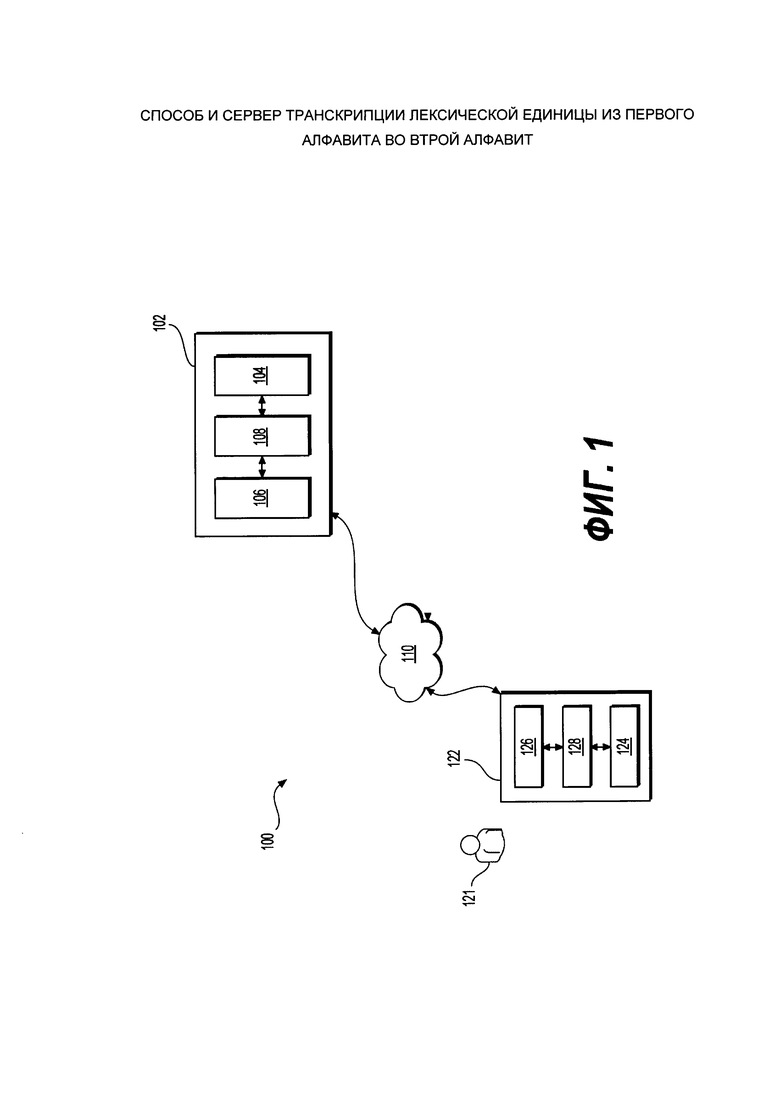
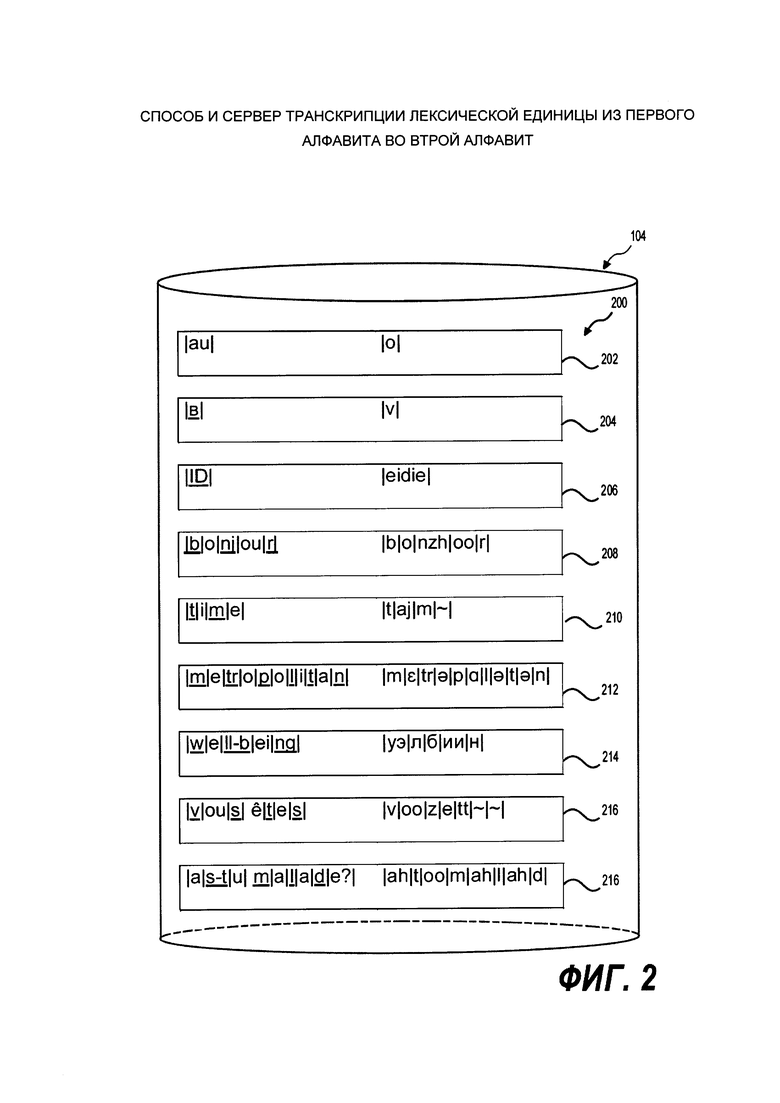
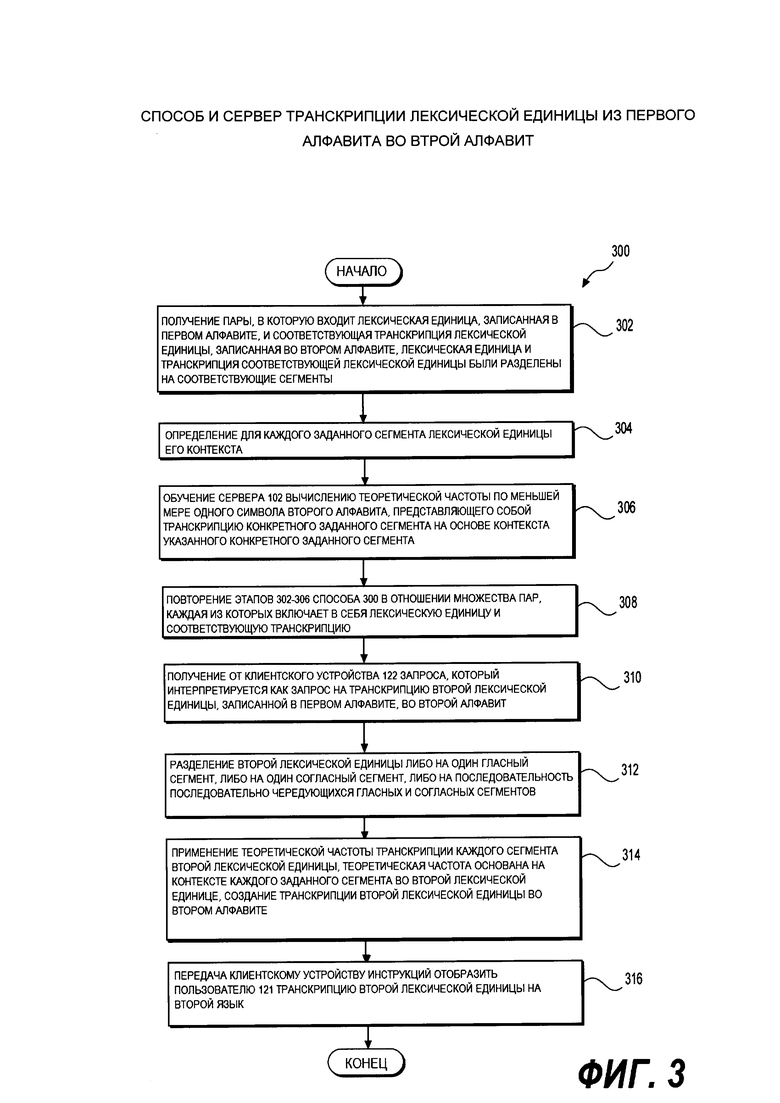
Изобретение относится к способу и системе транскрипции лексической единицы из первого алфавита во второй. Техническим результатом является расширение арсенала технических средств транскрипции лексической единицы из первого алфавита во второй алфавит. В способе транскрипции лексической единицы из первого алфавита во второй алфавит получают пару, содержащую лексическую единицу в первом алфавите и соответствующую ей транскрипцию во втором алфавите. Причем лексическая единица и транскрипция разделены на сегменты. При этом внутри пары каждый сегмент лексической единицы обладает соответствующим сегментом в транскрипции лексической единицы, и каждая лексическая единица представляет собой последовательность последовательно чередующихся гласных и согласных сегментов, один гласный сегмент или один согласный сегмент. Определяют для каждого заданного сегмента лексической единицы его контекст. Обучают сервер вычислению теоретического символа второго алфавита, представляющего собой транскрипцию конкретного заданного сегмента на основе контекста конкретного заданного сегмента лексической единицы. 2 н. и 28 з.п. ф-лы, 3 ил.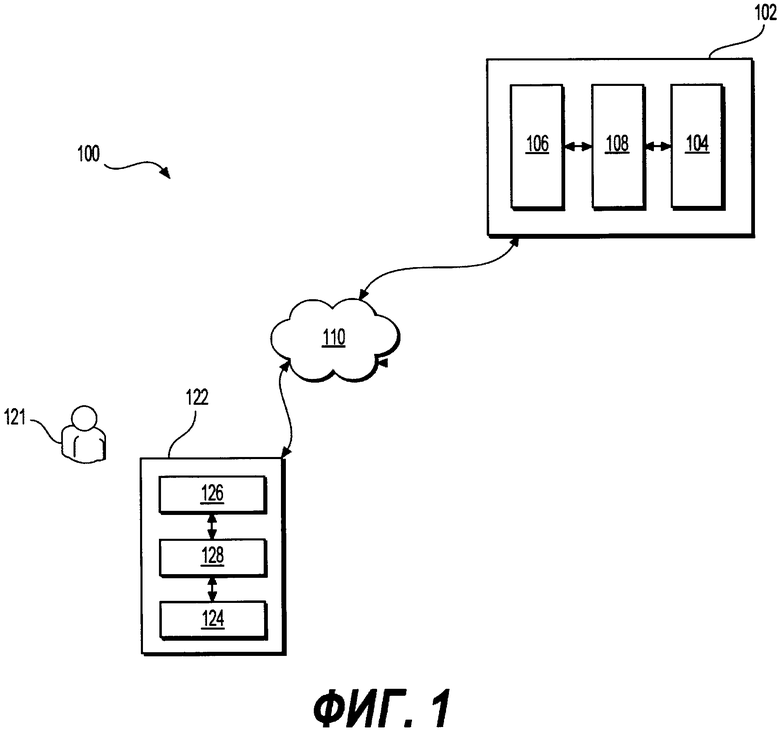
1. Способ транскрипции лексической единицы из первого алфавита во второй алфавит, способ выполняется на сервере, способ включает в себя:
получение пары, в которой присутствует лексическая единица, записанная в первом алфавите, и соответствующая транскрипция лексической единицы, записанная во втором алфавите, лексическая единица и транскрипция соответствующей лексической единицы разделены в соответствующие сегменты таким образом,
что внутри пары каждый сегмент лексической единицы обладает соответствующим сегментом в транскрипции лексической единицы, и таким образом,
что каждая лексическая единица содержит одно из выбранного: последовательность последовательно чередующихся гласного и согласного сегмента, один гласный сегмент, один согласный сегмент; причем каждый гласный сегмент состоит по меньшей мере из одной гласной, а каждый согласный сегмент состоит по меньшей мере из одной согласной; и
определение для каждого заданного сегмента лексической единицы его контекста;
обучение сервера вычислению теоретической частоты по меньшей мере одного символа второго алфавита, представляющего собой транскрипцию конкретного заданного сегмента на основе контекста указанного конкретного заданного сегмента лексической единицы,
получение от клиентского устройства запроса, который интерпретируется как запрос на транскрипцию второй лексической единицы, записанной в первом алфавите, во второй алфавит,
разделение второй лексической единицы на одно, выбранное из:
один гласный сегмент;
один согласный сегмент;
последовательность последовательно чередующихся гласных и согласных сегментов;
применение теоретической частоты транскрипции каждого сегмента второй лексической единицы, теоретическая частота основана на контексте каждого заданного сегмента во второй лексической единице, создание транскрипции второй лексической единицы во втором алфавите.
2. Способ по п. 1, в котором лексическую единицу выбирают из: слова или словосочетания.
3. Способ по п. 1, в котором тип лексическая единица включает в себя по меньшей мере один специальный символ, причем по меньшей мере один специальный символ является любым одним из выбранного: пробел, дефис, разрыв строки, разрыв страницы и апостроф.
4. Способ по п. 3, в котором:
по меньшей мере один специальный символ в словосочетании, который расположен между согласной и гласной перед гласной, квалифицируется одним выбранным из: гласной и согласной, и в котором
указанный по меньшей мере один специальный символ, если он квалифицируется гласной, становится частью соседнего гласного сегмента, и
указанный по меньшей мере один специальный символ, если он квалифицируется согласной, становится частью соседнего согласного сегмента.
5. Способ по п. 3, в котором:
по меньшей мере один специальный символ в словосочетании, который расположен между гласной и согласной перед согласной, квалифицируется одним из выбранного из: гласной и согласной, и в котором
указанный по меньшей мере один специальный символ, если он квалифицируется гласной, становится частью соседнего гласного сегмента, и
указанный по меньшей мере один специальный символ, если он квалифицируется согласной, становится частью соседнего согласного сегмента.
6. Способ по п. 3, в котором по меньшей мере один специальный символ считают несуществующим.
7. Способ по п. 1, в котором контекст лексической единицы выбирают из: предшествующего контекста и последующего контекста.
8. Способ по п. 7, в котором:
предыдущий контекст заданного сегмента выбирают из: предыдущего соседнего сегмента лексической единицы или предыдущего конца лексической единицы; и
следующий контекст заданного сегмента выбирают из: следующего соседнего сегмента лексической единицы или следующего конца лексической единицы.
9. Способ по п. 1, в котором по меньшей мере один сегмент лексической единицы является немой буквой, и соответствующая транскрипция лексической единицы будет включать в себя символ, представляющий немую букву.
10. Способ по п. 1, в котором второй алфавит представляет собой одно, выбранное из: алфавит, отличный от первого алфавита; или фонетический алфавит.
11. Способ по п. 1, в котором дополнительно выполняют повторение способа по п. 1 в отношении множества пар, каждая из которых представляет собой лексическую единицу и соответствующую транскрипцию, и в котором обучение сервера вычислять теоретическую частоту транскрипции заданного сегмента, которое основано на контексте заданного сегмента, представляет собой обучение сервера с помощью алгоритма машинного обучения.
12. Способ по п. 1, в котором дополнительно выполняют передачу клиентскому устройству инструкций отобразить пользователю транскрипцию второй лексической единицы на второй язык.
13. Способ по п. 12, в котором по меньшей мере один сегмент лексической единицы является немой буквой, и в котором инструкции отобразить пользователю транскрипцию второй лексической единицы на второй язык включают в себя инструкцию опустить отображение символа, который представляет немую букву.
14. Способ по п. 1, в котором получение от клиентского устройства запроса на транскрипцию второй лексической единицы, записанной в первом алфавите, во второй алфавит, включает в себя получение поискового запроса, способ дополнительно включает в себя проведение поиска с использованием транскрипции второй лексической единицы во второй алфавит в качестве поискового запроса, и создание страницы результатов поиска.
15. Способ по п. 14, в котором дополнительно выполняют передачу клиентскому устройству инструкций отобразить страницу результатов поиска.
16. Сервер для транскрипции лексической единицы из первого алфавита во второй алфавит, обладающий носителем информации и процессором, соединенным с носителем информации, процессор выполнен с возможностью получать доступ к машиночитаемым командам, выполнение которых инициирует процессор выполнять этапы, осуществляющие:
получение пары, в которой присутствует лексическая единица, записанная в первом алфавите, и соответствующая транскрипция лексической единицы, записанная во втором алфавите, лексическая единица и транскрипция соответствующей лексической единицы разделены в соответствующие сегменты таким образом,
что внутри пары каждый сегмент лексической единицы обладает соответствующим сегментом в транскрипции лексической единицы, и таким образом,
что каждая лексическая единица содержит одно из выбранного: последовательность последовательно чередующихся гласного и согласного сегмента, один гласный сегмент, один согласный сегмент; каждый гласный сегмент состоит по меньшей мере из одной гласной, а каждый согласный сегмент состоит по меньшей мере из одной согласной; и
определение для каждого заданного сегмента лексической единицы его контекста;
обучение сервера вычислению теоретической частоты по меньшей мере одного символа второго алфавита, представляющего собой транскрипцию конкретного заданного сегмента на основе контекста указанного конкретного заданного сегмента лексической единицы;
получение от клиентского устройства запроса, который интерпретируется как запрос на транскрипцию второй лексической единицы, записанной в первом алфавите, во второй алфавит,
разделение второй лексической единицы на одно, выбранное из:
один гласный сегмент;
один согласный сегмент;
последовательность последовательно чередующихся гласных и согласных сегментов;
применение теоретической частоты транскрипции каждого сегмента второй лексической единицы, теоретическая частота основана на контексте каждого заданного сегмента во второй лексической единице, создание транскрипции второй лексической единицы во втором алфавите.
17. Сервер по п. 16, в котором процессор выполнен с возможностью выбора лексической единицы из: слова или словосочетания.
18. Сервер по п. 16, в котором процессор выполнен с возможностью обработки лексической единицы, которая включает в себя по меньшей мере один специальный символ, причем по меньшей мере один специальный символ является любым одним из выбранного: пробел, дефис, разрыв строки, разрыв страницы и апостроф.
19. Сервер по п. 18, в котором процессор выполнен с возможностью:
по меньшей мере один специальный символ в словосочетании, который расположен между согласной и гласной перед гласной, квалифицировать одним из выбранного из: гласной и согласной, и
указанный по меньшей мере один символ, если он квалифицируется гласной, назначать частью соседнего гласного сегмента, и
указанный по меньшей мере один символ, если он квалифицируется согласной, назначать частью соседнего согласного сегмента.
20. Сервер по п. 18, в котором процессор выполнен с возможностью:
по меньшей мере один специальный символ в словосочетании, который расположен между гласной и согласной перед согласной, квалифицировать одним из выбранного из: гласной и согласной, и
указанный по меньшей мере один символ, если он квалифицируется гласной, назначать частью соседнего гласного сегмента, и
указанный по меньшей мере один символ, если он квалифицируется согласной, назначать частью соседнего согласного сегмента.
21. Сервер по п. 18, в котором процессор выполнен с возможностью квалифицировать по меньшей мере один специальный символ несуществующим.
22. Сервер по п. 16, в котором процессор выполнен с возможностью выбора контекста лексической единицы из: предшествующего контекста и последующего контекста.
23. Сервер по п. 22, в котором процессор выполнен с возможностью:
предыдущий контекст заданного сегмента выбирать из: предыдущего соседнего сегмента лексической единицы или предыдущего конца лексической единицы; и
следующий контекст заданного сегмента выбирать из: следующего соседнего сегмента лексической единицы или следующего конца лексической единицы.
24. Сервер по п. 16, в котором процессор выполнен с возможностью обработки по меньшей мере одного сегмента лексической единицы, который является немой буквой, и включать в соответствующую транскрипцию лексической единицы символ, представляющий немую букву.
25. Сервер по п. 16, в котором процессор выполнен с возможностью работы со вторым алфавитом, который представляет собой одно, выбранное из: алфавита, отличного от первого алфавита, или фонетического алфавита.
26. Сервер по п. 16, в котором процессор дополнительно выполнен с возможностью осуществлять повторение этапов по п. 16 в отношении множества пар, каждая из которых представляет собой лексическую единицу и соответствующую транскрипцию.
27. Сервер по п. 26, в котором процессор дополнительно выполнен с возможностью осуществлять передачу клиентскому устройству инструкций отобразить пользователю транскрипцию второй лексической единицы на второй язык.
28. Сервер по п. 27, в котором процессор выполнен с возможностью опустить инструкции на отображение символа, который представляет собой немую букву, когда по меньшей мере один сегмент лексической единицы является немой буквой,
29. Сервер по п. 27, в котором процессор выполнен с возможностью получать от клиентского устройства поискового запроса на транскрипцию второй лексической единицы, записанной в первом алфавите, во второй алфавит, и возможностью осуществлять проведение поиска с использованием транскрипции второй лексической единицы во второй алфавит в качестве поискового запроса, и создание страницы результатов поиска
30. Сервер по п. 29, в котором процессор дополнительно выполнен с возможностью передавать клиентскому устройству инструкции отобразить страницу результатов поиска.

