Настоящая заявка испрашивает приоритет китайской заявки на патент №201510531673.4, поданной 26 августа 2015 г., которая во всей своей полноте включена сюда путем ссылки.
Область техники, к которой относится изобретение
Настоящее изобретение, в общем, относится к обработке данных, а более конкретно к способу, устройству и терминалу для поиска данных.
Уровень техники
В связи с постоянно растущим числом функций, выполняемых мобильным терминалом, все больше и больше данных вырабатывается пользователями мобильных терминалов. Пользователи могут синхронизировать персональные данные с удаленным облачным хранилищем данных для их хранения, чтобы минимизировать память, занимаемую в терминале, и избежать ухудшения производительности, вызванного недостаточным местом хранения. Как правило, облачный сервер может предоставлять пользователям функцию извлечения персональных данных, например поиск сообщения, содержащего ключевое слово, в десятках тысяч сообщений на основании ключевого слова, предоставленного пользователем.
В предшествующем уровне техники облачный сервер может реализовать поиск персональных данных на основании языка структурированных запросов (SQL). Однако принимая во внимание плохую расширяемость SQL, в частности, когда существует большое число пользователей, имеется огромное количество данных, хранящихся в удаленном облачном хранилище данных. В этом случае область поиска сервера предназначена для всех пользователей данных, что приводит к увеличению скорости поиска, повышению эффективности и оптимальному восприятию пользователя.
Сущность изобретения
Принимая во внимание тот факт, что в предшествующем уровне техники поиск пользовательских данных страдает от низкой эффективности и низкой скорости поиска, согласно настоящему изобретению предложены способ, устройство и терминал для поиска данных.
Согласно первому аспекту настоящего изобретения предложен способ поиска данных, включающий в себя извлечение первых сериализованных данных, соответствующих первому идентификатору пользователя в нереляционной базе данных; десериализацию первых сериализованных данных для получения первого индекса; выполнение поиска на основании первого индекса.
В примерном варианте осуществления перед извлечением первых сериализованных данных, соответствующих первому идентификатору пользователя в нереляционной базе данных, способ дополнительно содержит получение первых пользовательских данных и соответствующего первого идентификатора пользователя; установление первого индекса для первых пользовательских данных; сериализацию первого индекса для получения первой двоичной строки; хранение первой двоичной строки в связи с первым идентификатором пользователя в нереляционной базе данных, где первые сериализованные данные включают в себя первую двоичную строку.
В примерном варианте осуществления выполнение поиска на основании первого индекса содержит хранение первого индекса в памяти; выполнение поиска в памяти на основании первого индекса.
В примерном варианте осуществления способ дополнительно содержит: модификацию второго индекса, соответствующего второму идентификатору пользователя в ответ на прием запроса на модификацию, включающего в себя второй идентификатор пользователя.
В примерном варианте осуществления модификация второго индекса, соответствующего второму идентификатору пользователя, в ответ на прием запроса на модификацию, включающего в себя второй идентификатор пользователя, содержит извлечение вторых сериализованных данных, соответствующих второму идентификатору пользователя в нерациональной базе данных; десериализацию вторых сериализованных данных для получения второго индекса; модификацию второго индекса на основании запроса на модификацию; сериализацию модифицированного второго индекса для получения модифицированных вторых сериализованных данных; обновление вторых сериализованных данных, хранящихся в нерациональной базе данных, на модифицированные вторые сериализованные данные.
В примерном варианте осуществления модификация второго индекса на основании запроса на модификацию содержит хранение второго индекса в памяти; модификацию второго индекса в памяти.
Согласно второму аспекту вариантов осуществления настоящего изобретения предложено устройство для поиска данных, включающее в себя первый модуль извлечения, первый модуль обработки и модуль поиска, в котором первый модуль извлечения выполнен с возможностью извлечения первых сериализованных данных, соответствующих первому идентификатору пользователя в нереляционной базе данных; первый модуль обработки выполнен с возможностью десериализации первых сериализованных данных для получения первого индекса; модуль поиска выполнен с возможностью поиска на основании первого индекса.
В примерном варианте осуществления устройство дополнительно содержит модуль получения, модуль установления индекса, второй модуль обработки и модуль хранения, в котором модуль получения выполнен с возможностью получения первых пользовательских данных и соответствующего первого идентификатора пользователя; модуль установления индекса выполнен с возможностью установления первого индекса для первых пользовательских данных; второй модуль обработки выполнен с возможностью сериализации первого индекса для получения первой двоичной строки; модуль хранения выполнен с возможностью хранения первой двоичной строки в связи с первым идентификатором пользователя в нереляционной базе данных, где первые сериализованные данные включают в себя первую двоичную строку.
В примерном варианте осуществления модуль поиска содержит первый подмодуль хранения и подмодуль поиска, причем первый подмодуль хранения выполнен с возможностью хранения первого индекса в памяти; и подмодуль поиска выполнен с возможностью поиска в памяти на основании первого индекса.
В примерном варианте осуществления устройство содержит модуль модификации, причем модуль модификации выполнен с возможностью модификации второго индекса, соответствующего второму идентификатору пользователя, в ответ на прием запроса на модификацию, включающего в себя второй идентификатор пользователя.
В примерном варианте осуществления модуль модификации содержит подмодуль извлечения, первый подмодуль обработки, подмодуль модификации, второй подмодуль обработки и подмодуль обновления, причем подмодуль извлечения выполнен с возможностью извлечения вторых сериализованных данных, соответствующих второму идентификатору пользователя в нерациональной базе данных; первый подмодуль обработки выполнен с возможностью десериализации вторых сериализованных данных для получения второго индекса; подмодуль модификации выполнен с возможностью модификации второго индекса на основании запроса на модификацию; второй подмодуль обработки выполнен с возможностью сериализации модифицированного второго индекса для получения модифицированных вторых сериализованных данных; подмодуль обновления выполнен с возможностью обновления вторых сериализованных данных, хранящихся в нерациональной базе данных, на модифицированные вторые сериализованные данные.
В примерном варианте осуществления подмодуль модификации содержит второй подмодуль хранения и первый подмодуль модификации, причем второй подмодуль хранения выполнен с возможностью хранения второго индекса в памяти; и первый подмодуль модификации выполнен с возможностью модификации второго индекса в памяти.
Согласно третьему аспекту вариантов осуществления настоящего изобретения предложен сервер для поиска данных, включающий в себя процессор; память для хранения исполняемых процессором инструкций; в котором инструкции, при их исполнении процессором, предписывают процессору: извлекать первые сериализованные данные, соответствующие первому идентификатору пользователя в нереляционной базе данных; десериализовать первые сериализованные данные для получения первого индекса; выполнять поиск на основании первого индекса.
Варианты осуществления изобретения могут обеспечить по меньшей мере некоторые из следующих полезных эффектов:
В настоящем изобретении сериализованные данные, соответствующие идентификатору пользователя, можно извлечь и десериализовать в индекс с помощью сервера в базе NoSQL данных, и поиск можно выполнить на основании индекса. Так как поиск выполняется в отношении данных, соответствующих идентификаторам пользователей, а не всех пользователей, область поиска становится намного меньше, что приводит к увеличению скорости поиска, повышению эффективности и оптимальному восприятию пользователя.
В настоящем изобретении сервер устанавливает индексы отдельно для различных пользователей и сериализует индексы отдельно в двоичные строки и затем сохраняет двоичные строки и соответствующие идентификаторы пользователей в базе NoSQL данных для различных пользователей, таким образом можно гарантировать эффективность использования рабочего времени и корректность поиска благодаря более эффективному использованию рабочего времени и корректности, которые имеет непосредственно база NoSQL данных. Кроме того, так как пользовательские данные хранятся в различных строках базы NoSQL данных, поиск выполняется, ориентируясь на данные, соответствующие идентификаторам пользователей, тем самым содействуя защите конфиденциальности пользователей и получая в результате повышенную безопасность. Более того, можно дополнительно обеспечить безопасность поиска благодаря тому факту, что база NoSQL данных может автоматически создавать множество базовых резервных копий. В дополнение, по сравнению с простой схемой поиска может потребоваться меньшее количество серверов при увеличении числа пользователей благодаря характеристике хранения непосредственно базы NoSQL данных.
В настоящем изобретении первый индекс хранится в памяти, и поиск выполняется на основании первого индекса. В данном способе скорость извлечения значительно увеличена по сравнению с поиском на диске, имеющем огромное количество данных.
В настоящем изобретении сервер может также модифицировать индекс, десериализовать двоичную строку, соответствующую идентификатору пользователя, в индекс, модифицировать индекс, сериализовать модифицированный индекс в двоичную строку и обновлять двоичную строку, хранящуюся в базе NoSQL данных. Таким образом, эффективность использования рабочего времени поиска можно гарантировать за счет своевременного обновления данных, хранящихся в базе NoSQL данных, в случае, когда, существует необходимость в добавлении, удалении или модификации пользовательских данных.
В настоящем изобретении модификацию пользовательских данных можно выполнить в памяти для того, чтобы увеличить скорость и повысить эффективность поиска.
Следует понимать, что как предшествующее общее описание, так и последующее подробное описание являются только примерными и не ограничивают настоящее изобретение.
Краткое описание чертежей
Сопроводительные чертежи, которые включены в и образуют часть данного описания, иллюстрируют варианты осуществления в соответствии с изобретением и вместе с описанием служат для объяснения принципов изобретения.
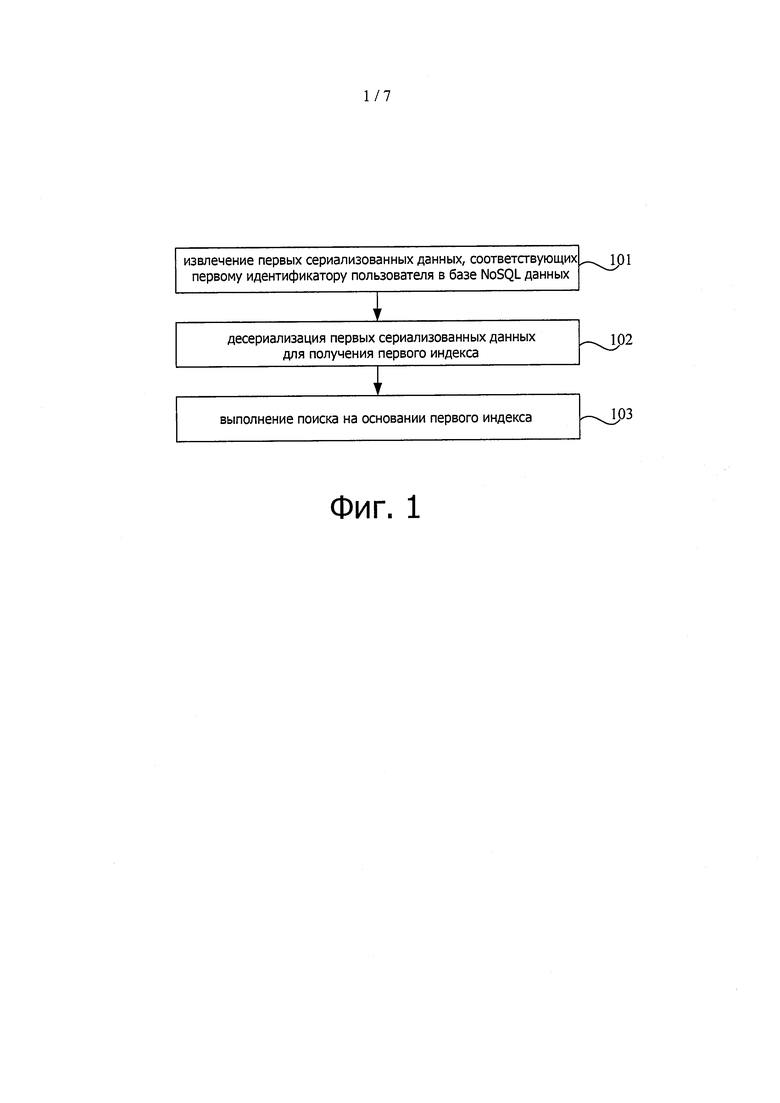
На фиг. 1 показана блок-схема последовательности операций, иллюстрирующая способ поиска данных согласно примерному варианту осуществления.
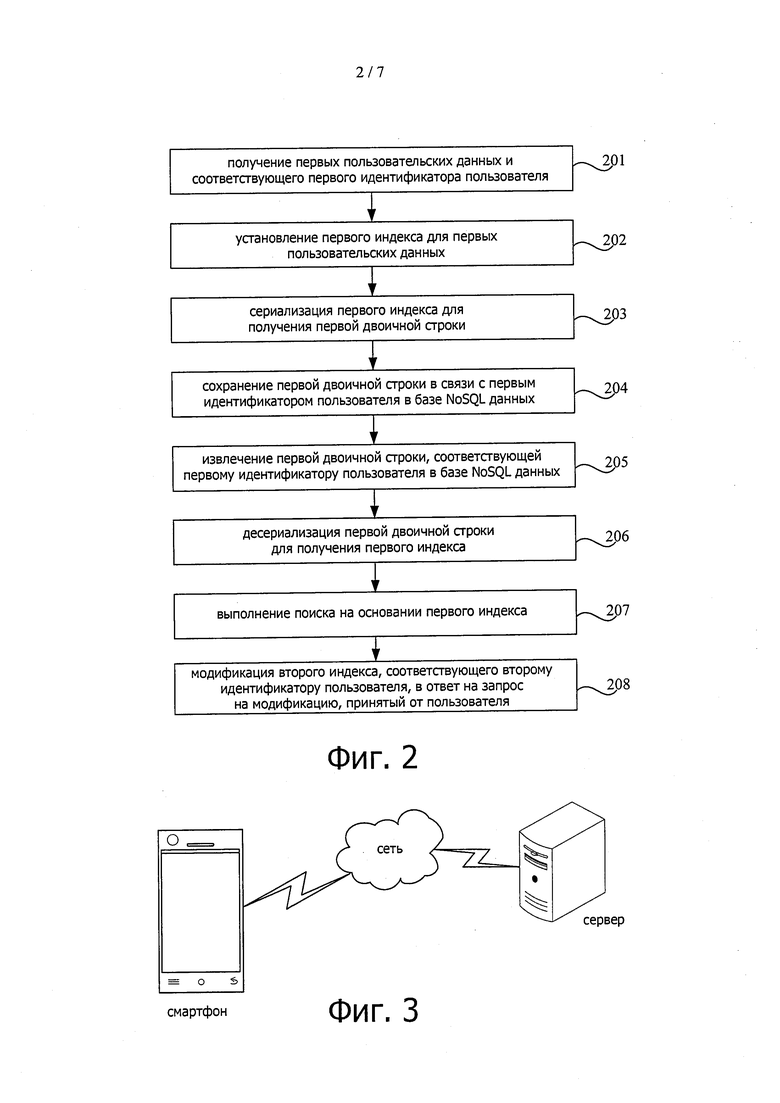
На фиг. 2 показана блок-схема последовательности операций, иллюстрирующая другой способ поиска данных согласно примерному варианту осуществления.
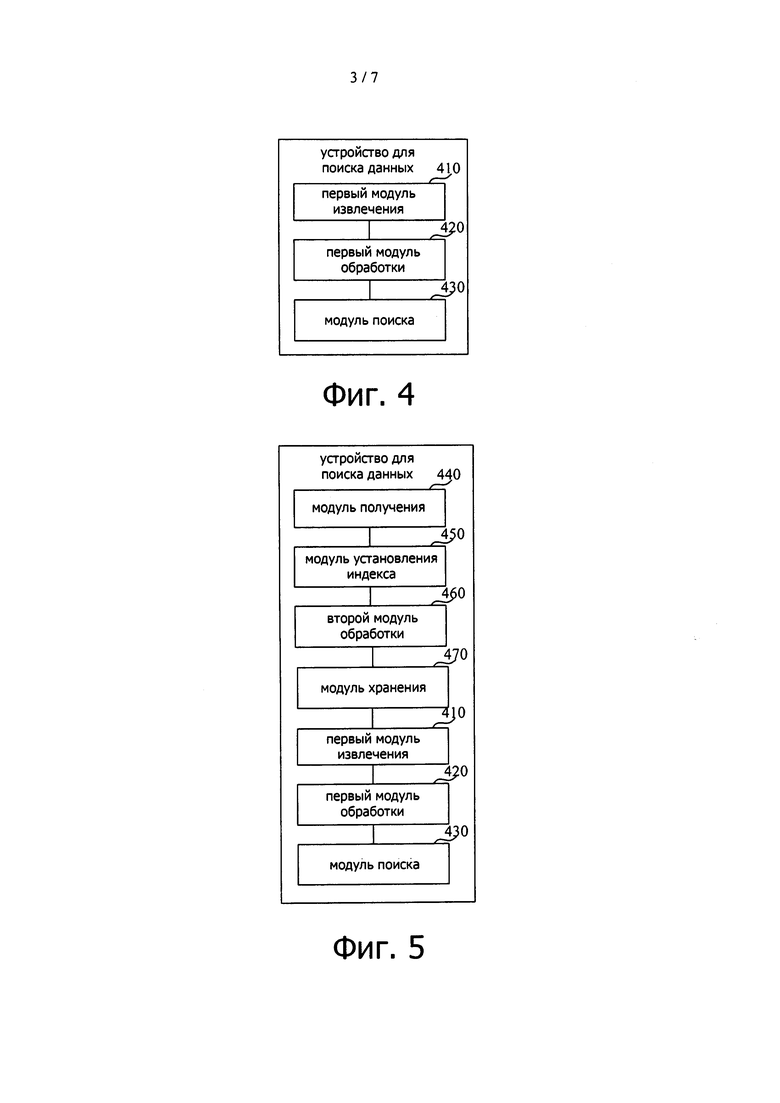
На фиг. 3 схема сценария, иллюстрирующая сценарий применения для поиска данных согласно примерному варианту осуществления.
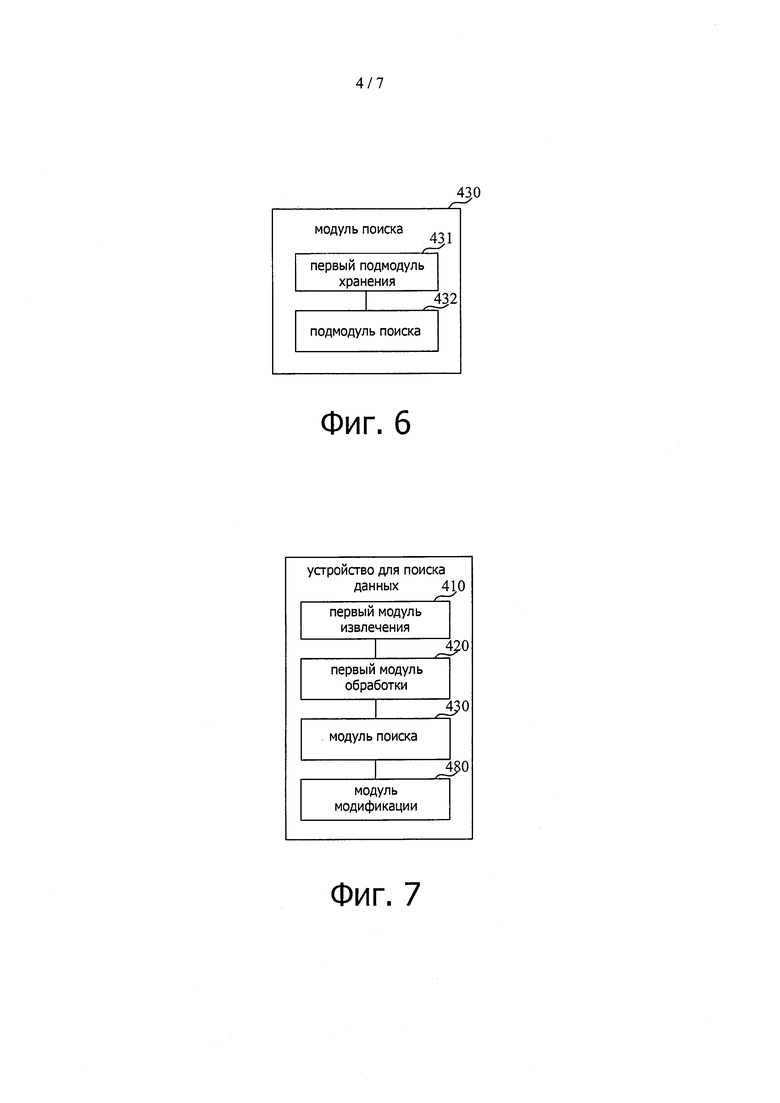
На фиг. 4 показана блок-схема, иллюстрирующая устройство для поиска данных согласно примерному варианту осуществления.
На фиг. 5 показана блок-схема, иллюстрирующая другое устройство для поиска данных согласно примерному варианту осуществления.
На фиг. 6 показана блок-схема, иллюстрирующая другое устройство для поиска данных согласно примерному варианту осуществления.
На фиг. 7 показана блок-схема, иллюстрирующая другое устройство для поиска данных согласно примерному варианту осуществления.
На фиг. 8 показана блок-схема, иллюстрирующая другое устройство для поиска данных согласно примерному варианту осуществления.
На фиг. 9 показана блок-схема, иллюстрирующая другое устройство для поиска данных согласно примерному варианту осуществления.
На фиг. 10 показана структурная схема, иллюстрирующая устройство для поиска данных согласно примерному варианту осуществления.
Подробное описание изобретения
Теперь будет сделана подробная ссылка на примерные варианты осуществления, примеры которых проиллюстрированы на прилагаемых чертежах. Последующее описание опирается на сопроводительные чертежи, на которых одинаковые ссылочные позиции на различных чертежах представляют собой одинаковые или аналогичные элементы, если не указано иное. Реализации, изложенные в последующем описании примерных вариантов осуществления, не представляют собой все одинаковые реализации, соответствующие настоящему изобретению. Вместо этого они являются только примерами устройства и способов, соответствующих аспектам, которые относятся к изобретению, как изложено в формуле изобретения.
Термины, использованные в настоящем раскрытии, предназначены только для описания конкретных вариантов осуществления, а не ограничения настоящего раскрытия. Термины, используемые в форме единственного числа в настоящем раскрытии и в прилагаемой формуле изобретения, включают в себя форму множественного числа, если иное в явном виде не следует из контекста. Следует понимать, что термин "и/или", используемый в данном документе, показывает и содержит любую или все возможные комбинации одного или более связанных с ним элементов, которые были перечислены.
Следует понимать, что термины "первый", "второй" и "третий" можно использовать для описания различной информации, но она не ограничивается этими терминами. Эти термины используются только для разделения одинакового типа информации друг от друга. Например, первая информация может также упоминаться как вторая информация без отклонения от объема настоящего раскрытия, аналогичным образом вторая информация может также упоминаться как первая информация. Слово "если", которое используется в данном документе, можно также интерпретировать как "когда", или "хотя" или "реагировать на определение" в зависимости от контекста.
На фиг. 1 показана блок-схема последовательности операций, иллюстрирующая способ поиска данных согласно примерному варианту осуществления. Как показано на фиг. 1, способ используется в сервере и может включать в себя следующие этапы.
На этапе 101 первые сериализованные данные, соответствующие первому идентификатору пользователя, извлекаются в нереляционной базе данных.
Сервер в настоящем раскрытии может представлять собой облачный сервер, такой как серверы Xiaomi Inc и т.п.Терминал в настоящем раскрытии может представлять собой любой интеллектуальный терминал, поддерживающий Интернет, например мобильный телефон, планшетный компьютер, персональный цифровой помощник (PDA) и т.п.Более конкретно терминал может осуществлять доступ к маршрутизатору через беспроводную локальную сеть LAN и затем получать доступ к серверу в сети общего пользования через маршрутизатор.
В раскрытии нереляционная база данных представляет собой базу данных, использующую нереляционный язык структурированных запросов (NoSQL).
На этапе 102 первый индекс получается путем десериализации первых сериализованных данных.
Среди них сериализация является механизмом поддержки потоковой передачи данных, определяемых пользователем типов в операционной среде.NET. Сериализация должна сохранить объект в виде файла или поля базы данных, в то время как десериализация должна транслировать сериализованный файл в исходный объект.
На этапе 103 поиск выполняется на основании первого индекса.
Из вышеизложенного можно увидеть, что сериализованные данные, соответствующие идентификатору пользователя, можно извлечь и десериализовать в индекс с помощью сервера в базе NoSQL данных, и поиск можно выполнить на основании индекса. Так как поиск выполняется в отношении данных, соответствующих идентификаторам пользователей, а не всех пользователей, область поиска становится намного меньше, что приводит к увеличению скорости поиска, повышению эффективности и оптимальному восприятию пользователя.
На фиг. 2 показана блок-схема последовательности операций, иллюстрирующая другой способ поиска данных согласно примерному варианту осуществления. Как показано на фиг. 2, способ используется в сервере и может включать в себя следующие этапы.
В варианте осуществления раскрытия персональные данные пользователя можно обработать в виде двоичной строки и сохранить в базе NoSQL данных с помощью сервера.
На этапе 201 можно получить первые пользовательские данные и соответствующий идентификатор пользователя.
На данном этапе раскрытия первые пользовательские данные, загруженные первым пользователем, может принимать сервер. В качестве альтернативы пользовательские данные можно получить с помощью сервера в установленных интервалах времени. Первые пользовательские данные могут включать в себя персональные данные, такие как сообщения, сообщения электронной почты, электронные письма, интерактивная переписка и фотографии первого пользователя. Первый идентификатор пользователя можно также принять с помощью сервера в дополнение к первым пользовательским данным. Например, первый идентификатор пользователя, принятый серверами XiaoMi Inc., может представлять собой сведения об учетной записи XiaoMi первого пользователя. Кроме того, идентификатор пользователя может быть также сотовым телефонным номером пользователя, адресом управления доступом к среде (MAC) терминала и т.д.
На этапе 202 первый индекс устанавливается для первого пользователя.
На этом этапе раскрытия первые пользовательские данные инициализируются сервером, и первый индекс устанавливается для первого пользователя через поисковые системы, такие как Lucene. То есть индексы устанавливаются отдельно для различных пользователей с помощью сервера. Индекс может включать в себя множество файлов, таких как инвертированный список и список слов.
На этапе 203 первая двоичная строка получается путем сериализации первого индекса.
На данном этапе раскрытия сервер сериализует первый индекс (то есть инвертированный список, список слов и различные другие файлы) в первую двоичную строку, такую как строка XML, строка JSON, двоичный поток и т.п.согласно базовому формату индекса, например одно название, соответствующее одному элементу. Обычно двоичная строка, такая как индекс, включающий в себя тысячи сообщений или тысячи фотографий, является относительно маленьким или даже не боле 2 Мегабит и занимает маленький объем памяти. Среди них можно выполнить сериализацию с помощью способов, используемых в предшествующем уровне техники, например сериализация XML (XML Serialization), двоичный форматтер (Binary Formatter), форматтер простого протокола доступа к объектам (Soap Formatter) и т.п.
На этапе 204 первая двоичная строка хранится в связи с первым идентификатором пользователя в базе NoSQL данных.
На данном этапе раскрытия сервер хранит идентификатор пользователя и двоичную строку каждого пользователя в соответствующей базе NoSQL данных, например Casssandra, Lucene/Solr, BigTable/Accumulo/Hypertable и т.п.
То есть на данном этапе раскрытия сервер хранит двоичные строки различных пользователей в различных строках базы NoSQL данных, и двоичная строка каждого пользователя физически разделена, таким образом способствуя защите конфиденциальности пользователя и получая в результате повышенную безопасность. Сервер затем выполняет поиск на основании индекса, хранящегося в базе NoSQL данных после приема запроса на поиск от пользователя.
На этапе 205 первая двоичная строка, соответствующая первому идентификатору пользователя, извлекается в базе NoSQL данных.
На данном этапе раскрытия, после приема запроса на поиск, несущего в себе критерии поиска, введенные первым пользователем, сервер может извлечь первый идентификатор пользователя первого пользователя из запроса на поиск и произвести поиск и извлечение соответствующих первых сериализованных данных, причем первые сериализованные данные могут представлять собой двоичную строку.
На этапе 206 первый индекс получается путем десериализации первой двоичной строки.
На данном этапе раскрытия только десериализованные файлы можно считать в сервере и можно использовать с помощью сервера для выполнения следующего этапа поиска. Поэтому сервер получает первый индекс путем десериализации первой двоичной строки, то есть множество файлов, соответствующих персональным данным первого пользователя.
Среди них, так как база NoSQL данных расположена на диске сервера, сервер может извлечь первую двоичную строку с диска в память для запоминающего устройства и затем десериализовать первую двоичную строку в памяти, чтобы выработать первый индекс.
На этапе 207 поиск выполняется на основании первого индекса.
На данном этапе раскрытия различные операции поиска можно выполнить на основании критериев поиска и первого индекса, когда первый индекс вырабатывается в памяти.
Из-за большого пространства памяти для хранения данных и значительно меньшего пространства, занятого индексом отдельного пользователя, индекс пользователя хранится в памяти, в которой будет производиться поиск. По сравнению с поиском на диске, имеющем огромное количество данных, в данном способе скорость извлечения значительно увеличивается. Кроме того, так как в памяти выполняется только операция извлечения, после завершения поиска занимаемое пространство памяти будет освобождаться.
В предшествующем уровне техники сервер вырабатывает индексы для пользовательских данных всех пользователей и хранит все индексы на диске сервера, вырабатывая при этом огромное количество данных (более нескольких десятков гигабит), что приводит к низкой скорости доступа к диску и, таким образом, к низкой скорости поиска и низкой эффективности поиска, что не позволяет удовлетворить потребности заказчика. В варианте осуществления раскрытия индексы устанавливаются отдельно для пользовательских данных различных пользователей, и двоичная строка, соответствующая каждому индексу, сохраняется в связи с идентификатором пользователя, таким образом, когда необходимо осуществлять поиск данных пользователя, поиск для соответствующего индекса можно выполнить просто на основании идентификатора пользователя, значительно сужая область поиска и в то же самое время значительно повышая скорость поиска.
В варианте осуществления раскрытия, когда новые пользовательские данные загружены пользователем, или пользовательские данные модифицированы или удалены, сервер должен модифицировать индекс. В этом случае вариант осуществления раскрытия может дополнительно включать в себя следующий этап.
На этапе 208 второй индекс, соответствующий второму идентификатору пользователя, можно модифицировать в ответ на запрос на модификацию, принятый от пользователя.
На данном этапе раскрытия сервер получает второй идентификатор пользователя в запросе на модификацию, извлекает соответствующую вторую двоичную строку согласно второму идентификатору пользователя и затем извлекает вторую двоичную строку с диска в память и десериализует вторую двоичную строку для получения второго индекса, соответствующего второму идентификатору пользователя, и затем модифицирует второй индекс на основании запроса на модификацию в памяти, наконец, сериализует модифицированный второй индекс в двоичную строку и сохраняет двоичную строку в базе NoSQL данных, то есть вторая двоичная строка, хранящаяся в базе NoSQL данных, обновляется на двоичную строку, соответствующую модифицированному второму индексу.
В вышеупомянутом варианте осуществления раскрытия, так как индекс каждого пользователя является независимым, область поиска является в большей степени целенаправленной и гарантируется эффективность поиска. Поэтому число пользователей, чьи данные можно хранить на сервере, зависит от емкости запоминающего устройства NoSQL. Например, если размер индекса каждого пользователя равен 2 Мбита, и размер дискового пространства сервера составляет 100 гигабитов, то приблизительно 100G/2M=50 тысяч пользователей можно хранить на сервере. Если используется способ поиска, основанный на чистом поиске, таком как Lucene, который используется в предшествующем уровне техники, в котором индексы для 50 тысяч пользователей можно хранить на дисковом пространстве на 100 Гбит, то поиск может сориентироваться на данные всех пользователей, таким образом получая низкую эффективность поиска и продолжительную задержку поиска. Для того чтобы обеспечить эффективность поиска, необходимо уменьшить количество пользовательских данных, хранящихся на сервере, что делает невозможным хранение данных для 50 тысяч пользователей, фактически можно хранить, возможно, только данные 10 тысяч пользователей. Целевой областью поиска раскрытия не являются все пользователи, поэтому можно повысить эффективность поиска. Для одиночного сервера схема, предложенная в раскрытии, позволяет хранить данные для большего количества пользователей, поэтому для схемы, предложенной в раскрытии, требуется меньше серверов, чем в предшествующем уровне техники.
На фиг. 3 показана схема сценария, иллюстрирующая сценарий применения для поиска данных согласно примерному варианту осуществления. Как показано на фиг. 3, сценарий включают сервер и смартфон.
Сервер принимает от пользователя смартфона запрос на поиск, несущий в себе критерии поиска и идентификатор пользователя, извлекает двоичную строку, соответствующую идентификатору пользователя из базы NoSQL данных на основании идентификатора пользователя, затем десериализует извлеченную двоичную строку для получения индекса, соответствующего идентификатору пользователя, и извлекает индекс в памяти и выполняет поиск на основании индекса и критериев поиска.
В сценарии, иллюстрированном на фиг. 3, описание фиг. 1 и фиг. 2 можно использовать для процесса выполнения поиска данных, который не повторяется здесь.
Согласно вариантам осуществления способов поиска данных в данном документе также выполнены варианты осуществления устройств для поиска данных и серверов, используемых в них.
На фиг. 4 показана блок-схема, иллюстрирующая устройство для поиска данных согласно примерному варианту осуществления. Устройство может включать в себя первый модуль 410 извлечения, первый модуль 420 обработки и модуль 430 поиска.
Среди них первый модуль 410 извлечения выполнен с возможностью извлечения первых сериализованных данных, соответствующих первому идентификатору пользователя в базе NoSQL данных; первый модуль 420 обработки выполнен с возможностью получения первого индекса путем десериализации первых сериализованных данных, извлеченных первым модулем извлечения 410; модуль 430 поиска выполнен с возможностью поиска на основании первого индекса, полученного первым модулем 420 обработки.
В вышеупомянутом варианте осуществления сервер может извлекать сериализованные данные, соответствующие идентификатору пользователя в базе NoSQL данных, десериализовать сериализованные данные в индекс и выполнять поиск на основании индекса. Так как поиск выполняется в отношении данных, соответствующих идентификаторам пользователей, а не всех пользователей, область поиска становится намного меньше, что приводит к увеличению скорости поиска, повышению эффективности и оптимальному восприятию пользователя.
На фиг. 5 показана блок-схема, иллюстрирующая другое устройство для поиска данных согласно примерному варианту осуществления. В дополнение к модулям, иллюстрированным на фиг. 4, устройство может дополнительно включать в себя модуль 440 получения, модуль 450 установления индекса, второй модуль 460 обработки и модуль 470 хранения.
Среди них модуль 440 получения выполнен с возможностью получения первых пользовательских данных и соответствующего первого идентификатора пользователя.
Модуль 450 установления индекса выполнен с возможностью установления индекса для первых пользовательских данных, полученных модулем 440 получения.
Второй модуль 460 обработки выполнен с возможностью сериализации индекса, установленного модулем 450 установления индекса для получения двоичной строки.
Модуль 470 хранения выполнен с возможностью хранения двоичной строки, полученной вторым модулем 460 обработки в связи с первым идентификатором пользователя в базе NoSQL данных, где первые сериализованные данные включают двоичную строку.
В вышеупомянутом варианте осуществления сервер устанавливает индексы отдельно для различных пользователей и сериализует индексы отдельно в двоичные строки, и затем хранит двоичные строки и соответствующие идентификаторы пользователей в базе NoSQL данных для различных пользователей, таким образом, можно гарантировать эффективность использования рабочего времени и корректность поиска за счет повышенной эффективности использования рабочего времени и корректности, которые характерны непосредственно для базы NoSQL данных. Кроме того, так как пользовательские данные хранятся в различных строках базы NoSQL данных, поиск выполняется с ориентацией на данные, соответствующие идентификаторам пользователей, тем самым способствуя защите конфиденциальности пользователя и получая в результате повышенную безопасность. Более того, можно дополнительно обеспечить безопасность поиска за счет того, что база NoSQL данных может автоматически создавать множество резервных базовых копий. В дополнение, по сравнению с чистой схемой поиска требуется меньшее количество серверов при увеличении числа пользователей благодаря характеристике хранения непосредственно базы NoSQL данных.
На фиг. 6 показана блок-схема, иллюстрирующая другое устройство для поиска данных согласно примерному варианту осуществления. Модуль 430 поиска, иллюстрированный на фиг. 4, может включать в себя первый подмодуль 431 хранения и подмодуль 432 поиска.
Среди них первый подмодуль 431 хранения выполнен с возможностью хранения первого индекса в памяти; подмодуль 432 поиска выполнен с возможностью поиска в памяти на основании первого индекса, сохраненного первым подмодулем 431 хранения.
В вышеупомянутом варианте осуществления первый индекс может храниться в памяти, и поиск может выполниться в памяти на основании первого индекса. Скорость извлечения может быть значительно повышена для поиска, выполняемого в памяти, по сравнению с поиском, выполняемым на диске, который имеет огромное количество данных.
На фиг. 7 показана блок-схема, иллюстрирующая другое устройство для поиска данных согласно примерному варианту осуществления. В дополнение к модулям, иллюстрированным на фиг. 4, устройство может дополнительно включать в себя модуль 480 модификации.
Среди них модуль 480 модификации выполнен с возможностью модификации второго индекса, соответствующего второму идентификатору пользователя, в ответ на прием запроса на модификацию, причем запрос на модификацию содержит второй идентификатор пользователя.
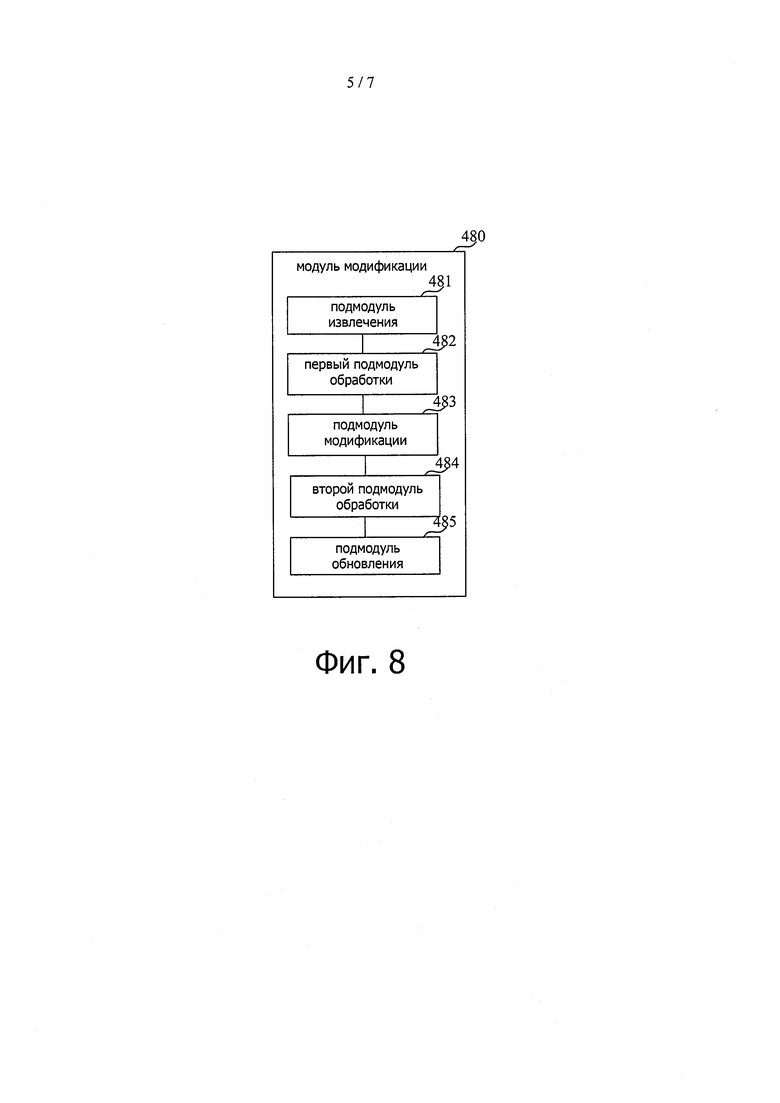
На фиг. 8 показана блок-схема, иллюстрирующая другое устройство для поиска данных согласно примерному варианту осуществления. Модуль 480 модификации, иллюстрированный на фиг. 7, может включать в себя подмодуль 481 извлечения, первый подмодуль 482 обработки, подмодуль 483 модификации, второй подмодуль 484 обработки и подмодуль 485 обновления.
Среди них подмодуль 481 извлечения выполнен с возможностью извлечения сериализованных данных, соответствующих второму идентификатору пользователя в базе NoSQL данных.
Первый подмодуль 482 обработки выполнен с возможностью десериализации вторых сериализованных данных, извлеченных подмодулем 481 извлечения для получения второго индекса.
Подмодуль 483 модификации выполнен с возможностью модификации второго индекса, полученного первым подмодулем 482 обработки на основании запроса на модификацию.
Второй подмодуль 484 обработки выполнен с возможностью сериализации второго индекса, измененного подмодулем 483 модификации для получения вторых сериализованных данных, которые были модифицированы.
Подмодуль 485 обновления выполнен с возможностью обновления вторых сериализованных данных, хранящихся в базе NoSQL данных, на вторые сериализованные данные, которые были модифицированы.
В вышеупомянутом варианте осуществления сервер может также модифицировать индекс, десериализовать двоичную строку, соответствующую идентификатору пользователя, в индекс, модифицировать индекс, сериализовать модифицированный индекс в двоичную строку и обновить двоичную строку, хранящуюся в базе NoSQL данных. Таким образом, эффективность использования рабочего времени поиска можно обеспечить путем своевременного обновления данных, хранящихся в базе NoSQL данных, в том случае когда существует необходимость в добавлении, удалении или модификации пользовательских данных.
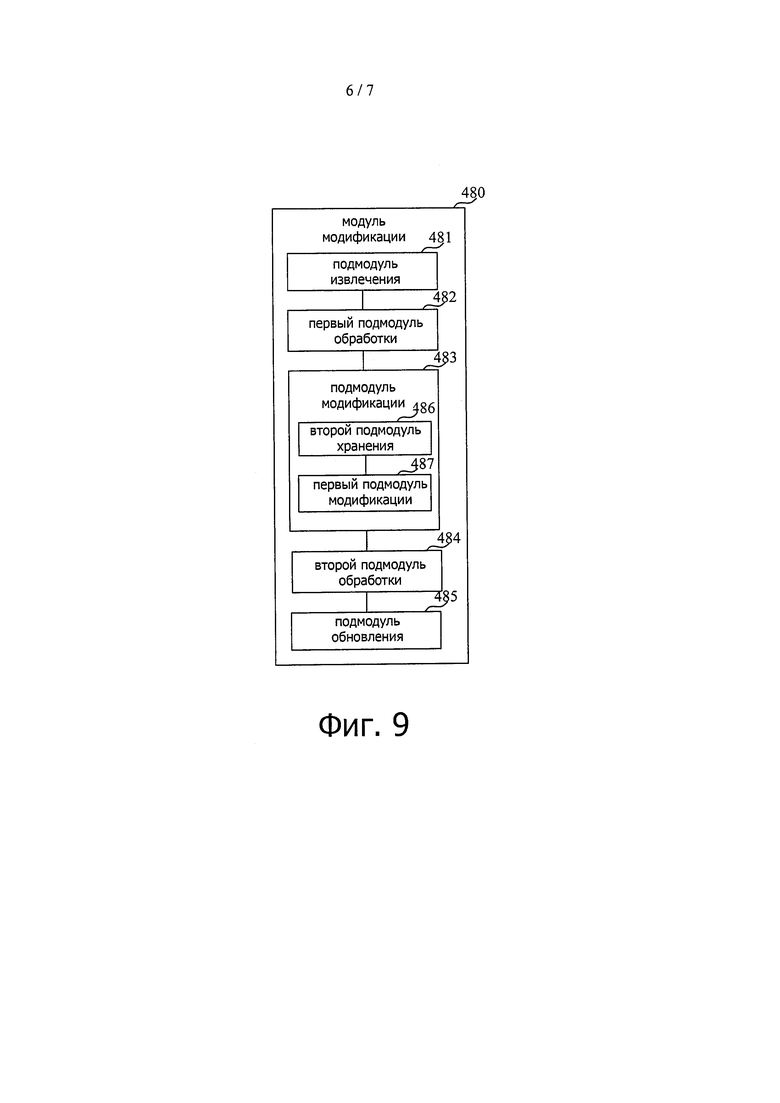
На фиг. 9 показана блок-схема, иллюстрирующая другое устройство для поиска данных согласно примерному варианту осуществления. В дополнение к модулям, иллюстрированным на фиг. 8, устройство может дополнительно включать в себя второй подмодуль 486 хранения и первый подмодуль 487 модификации.
Среди них второй подмодуль 486 хранения выполнен с возможностью хранения второго индекса в памяти.
Первый подмодуль 487 модификации выполнен с возможностью модификации второго индекса, сохраненного вторым подмодулем запоминающего устройства 486 в памяти.
В вышеупомянутом варианте осуществления модификацию пользовательских данных можно также выполнить в памяти для увеличения скорости и повышения эффективности поиска.
Описание соответствующего этапа способа можно использовать для деталей процесса, в котором реализуются назначение и действие соответствующего модуля.
Для вариантов осуществления устройства, так как оно по существу соответствует вариантам осуществления способа, описание некоторой части способа можно использовать для описания соответствующей части устройства. Вышеописанные варианты осуществления устройства представлены только для иллюстративных целей, в которых элементы, описанные в виде отдельных компонентов, могут или не могут быть физически раздельными, и компоненты, иллюстрированные в качестве элементов, могут или не могут быть физическими элементами (то есть эти компоненты могут располагаться в одном и том же месте или рассредоточены в нескольких сетевых элементах). Часть или все модули можно выбрать для реализации целей схемы этого раскрытия в соответствии с реальными потребностями. Специалисты в данной области техники могут понять и осуществить на практике схему без творческих усилий.
Соответственно, в раскрытии выполнен сервер, содержащий процессор; память для хранения исполняемых процессором инструкций; причем процессор выполнен с возможностью извлечения первых сериализованных данных, соответствующих первому идентификатору пользователя в нереляционной базе данных; получения первого индекса путем десериализации первых сериализованных данных; выполнения поиска на основании первого индекса.
На фиг. 10 показана структурная схема, иллюстрирующая устройство 1000 для поиска данных согласно примерному варианту осуществления. Например, устройство 1000 может представлять собой сервер. Устройство 1000 может включать в себя компонент 1022 обработки (например, один или более процессоров) и ресурсы хранения, такие как память 1932 для хранения компонента 1022 обработки, исполняемого инструкции, такие как прикладные программы. Прикладные программы, хранящиеся в памяти 1932, могут включать в себя один или более модулей (не показаны). Каждый модуль может включать в себя набор инструкций для операций, выполняемых на устройстве 1000. Кроме того, компонент 1022 обработки можно выполнить с возможностью исполнения наборов инструкций и выполнения операций на устройстве 1000.
Устройство 1000 может также включать в себя источник 1026 питания, сконфигурированный с возможностью выполнения управления электропитанием для устройства 1000, проводные или беспроводные сетевые интерфейсы 1050, сконфигурированные с возможностью подсоединения устройства 1000 к сети, и/или интерфейсы 1058 ввода/вывода. Устройство 1000 может работать под управлением операционных систем, которые хранятся в памяти 1032, таких как Windows ServerTM, Mac OS XTM, UnixTM, LinuxTM, FreeBSDTM или т.п.
Другие варианты осуществления изобретения будут очевидны для специалистов в данной области техники с учетом описания и практического осуществления раскрытия, представленного в данном документе. Данная заявка предназначена для охвата любых вариаций, использований или адаптаций раскрытия, следующего его общим принципам и включающего в себя такие отклонения от настоящего раскрытия, которые находятся в пределах известной или обычной практики в данной области техники. Предполагается, что описание и примеры рассматриваются только в качестве иллюстрации, причем истинная сущность и объем изобретения указаны в прилагаемой формуле изобретения.
Следует иметь в виду, что изобретательная концепция не ограничивается точной структурой, которая была описана выше и проиллюстрирована на сопроводительных чертежах, и что различные модификации и изменения могут быть сделаны без отступления от объема изобретения. Предполагается, что объем изобретения ограничивается только прилагаемой формулой изобретения.
Изобретение относится к способу, устройству и терминалу для поиска данных. Технический результат заключается в уменьшении области поиска, увеличении скорости поиска, повышении эффективности поиска, обеспечении защиты конфиденциальности пользователей. Способ поиска данных включает извлечение из нереляционной базы данных, сохраненной в запоминающем устройстве, первых сериализованных данных, соответствующих первому идентификатору пользователя; десериализацию первых сериализованных данных для получения первого индекса; выполнение поиска на основании первого индекса. 3 н. и 10 з.п. ф-лы, 10 ил.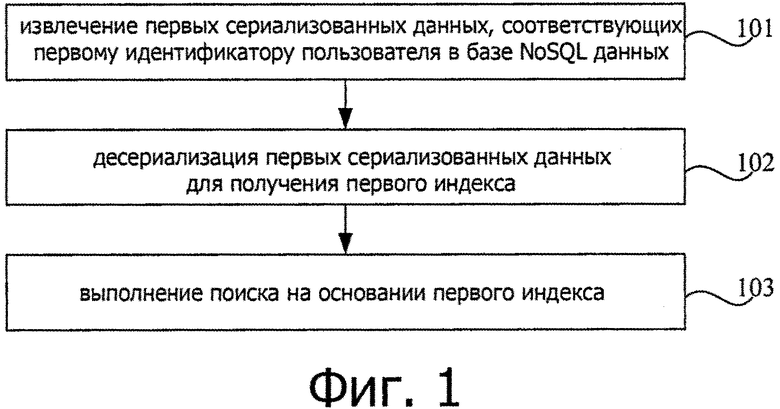
1. Способ поиска данных, содержащий:
извлечение из нереляционной базы данных, сохраненной в запоминающем устройстве, первых сериализованных данных, соответствующих первому идентификатору пользователя;
десериализацию первых сериализованных данных для получения первого индекса;
выполнение поиска на основании первого индекса.
2. Способ по п. 1, в котором перед извлечением из нереляционной базы данных, сохраненной в запоминающем устройстве, первых сериализованных данных, соответствующих первому идентификатору пользователя, способ дополнительно содержит:
получение первых пользовательских данных и соответствующего первого идентификатора пользователя;
установление первого индекса для первых пользовательских данных;
сериализацию первого индекса для получения первой двоичной строки;
хранение первой двоичной строки в связи с первым идентификатором пользователя в нереляционной базе данных, где первые сериализованные данные включают в себя первую двоичную строку.
3. Способ по п. 1, в котором выполнение поиска на основании первого индекса содержит:
хранение первого индекса в памяти;
выполнение поиска в памяти на основании первого индекса.
4. Способ по п. 1, в котором способ дополнительно содержит:
модификацию второго индекса, соответствующего второму идентификатору пользователя, в ответ на прием запроса на модификацию, включающего в себя второй идентификатор пользователя.
5. Способ по п. 4, в котором модификация второго индекса, соответствующего второму идентификатору пользователя, в ответ на прием запроса на модификацию, включающего в себя второй идентификатор пользователя, содержит:
извлечение из нереляционной базы данных, сохраненной в запоминающем устройстве, вторых сериализованных данных, соответствующих второму идентификатору пользователя;
десериализацию вторых сериализованных данных для получения второго индекса;
модификацию второго индекса на основании запроса на модификацию;
сериализацию модифицированного второго индекса для получения модифицированных вторых сериализованных данных;
обновление вторых сериализованных данных, хранящихся в нерациональной базе данных, на модифицированные вторые сериализованные данные.
6. Способ по п. 5, в котором модификация второго индекса на основании запроса на модификацию содержит:
хранение второго индекса в памяти;
модификацию второго индекса в памяти.
7. Устройство для поиска данных, содержащее первый модуль извлечения, первый модуль обработки и модуль поиска, в котором:
первый модуль извлечения выполнен с возможностью извлечения из нереляционной базы данных, сохраненной в запоминающем устройстве, первых сериализованных данных, соответствующих первому идентификатору пользователя;
первый модуль обработки выполнен с возможностью десериализации первых сериализованных данных для получения первого индекса;
модуль поиска выполнен с возможностью поиска на основании первого индекса.
8. Устройство по п. 7, в котором устройство дополнительно содержит модуль получения, модуль установления индекса, второй модуль обработки и модуль хранения, причем:
модуль получения выполнен с возможностью получения первых пользовательских данных и соответствующего первого идентификатора пользователя;
модуль установления индекса выполнен с возможностью установления первого индекса для первых пользовательских данных;
второй модуль обработки выполнен с возможностью сериализации первого индекса для получения первой двоичной строки;
модуль хранения выполнен с возможностью хранения первой двоичной строки в связи с первым идентификатором пользователя в нереляционной базе данных, где первые сериализованные данные включают в себя первую двоичную строку.
9. Устройство по п. 7, в котором модуль поиска содержит первый подмодуль хранения и подмодуль поиска, причем:
первый подмодуль хранения выполнен с возможностью хранения первого индекса в памяти;
подмодуль поиска выполнен с возможностью поиска в памяти на основании первого индекса.
10. Устройство по п. 7, в котором устройство содержит модуль модификации, причем:
модуль модификации выполнен с возможностью модификации второго индекса, соответствующего второму идентификатору пользователя, в ответ на прием запроса на модификацию, включающего в себя второй идентификатор пользователя.
11. Устройство по п. 10, в котором модуль модификации содержит подмодуль извлечения, первый подмодуль обработки, подмодуль модификации, второй подмодуль обработки и подмодуль обновления, причем:
подмодуль извлечения выполнен с возможностью извлечения из нереляционной базы данных, сохраненной в запоминающем устройстве, вторых сериализованных данных, соответствующих второму идентификатору пользователя;
первый подмодуль обработки выполнен с возможностью десериализации вторых сериализованных данных для получения второго индекса;
подмодуль модификации выполнен с возможностью модификации второго индекса на основании запроса на модификацию;
второй подмодуль обработки выполнен с возможностью сериализации модифицированного второго индекса для получения модифицированных вторых сериализованных данных;
подмодуль обновления выполнен с возможностью обновления вторых сериализованных данных, хранящихся в нерациональной базе данных, на модифицированные вторые сериализованные данные.
12. Устройство по п. 11, в котором подмодуль модификации содержит второй подмодуль хранения и подмодуль модификации, причем:
второй подмодуль хранения выполнен с возможностью хранения второго индекса в памяти;
подмодуль модификации выполнен с возможностью модификации второго индекса в памяти.
13. Сервер, содержащий:
процессор;
память для хранения исполняемых процессором инструкций;
причем инструкции, при их исполнении процессором, предписывают процессору:
извлекать из нереляционной базы данных, сохраненной в запоминающем устройстве, первые сериализованные данные, соответствующие первому идентификатору пользователя;
десериализовать первые сериализованные данные для получения первого индекса;
выполнять поиск на основании первого индекса.
| CN 103425785 A, 04.12.2013 | |||
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| СПОСОБ КВАЛИФИКАЦИИ МЕТАЛЛОКОМПОЗИТНЫХ БАКОВ ВЫСОКОГО ДАВЛЕНИЯ | 2015 |
|
RU2650822C2 |
| ИНДЕКСНАЯ СТРУКТУРА МЕТАДАННЫХ, СПОСОБ ПРЕДОСТАВЛЕНИЯ ИНДЕКСОВ МЕТАДАННЫХ, А ТАКЖЕ СПОСОБ ПОИСКА МЕТАДАННЫХ И УСТРОЙСТВО, ИСПОЛЬЗУЮЩЕЕ ИНДЕКСЫ МЕТАДАННЫХ | 2003 |
|
RU2283509C2 |

