Область техники
[01] Настоящее техническое решение относится к системам и способам создания модели прогнозирования и/или определения точности модели прогнозирования. В частности, задачей систем и способов является улучшение точности модели прогнозирования, которая может принимать форму модели дерева принятия решений, причем модель дерева принятия решений используется как часть системы машинного обучения.
Уровень техники
Контекст поисковых систем
[02] Обычно при формировании системы управления набором данных с возможностью поиска, такой как поисковые системы, элементы данных индексируются в соответствии с некоторыми или всеми возможными поисковыми терминами, которые могут включаться в поисковые запросы. Таким образом системой создается, сохраняется и обновляется общеизвестный «инвертированный индекс». Инвертированный индекс включает в себя большое число «списков словопозиций», необходимых для просмотра во время выполнения поискового запроса. Каждый список словопозиций соответствует потенциальному поисковому термину и включает в себя «словопозиций», которые являются ссылками на элементы данных в наборе данных, включающем в себя данный поисковый термин (или иным образом удовлетворяющем некоторым иным условиям, которые выражаются поисковым термином). Например, если элементы данных являются текстовыми документами, что часто встречается в работе поисковых интернет - (или «веб-») систем, то поисковые термины являются индивидуальными словами (и/или некоторыми наиболее часто используемыми их комбинациями), а инвертированный индекс включает в себя один список словопозиций для каждого слова, которое встретилось по меньшей мере в одном документе.
[03] Поисковые запросы, особенно введенные людьми, обычно выглядят как простой список из одного или нескольких слов, которые являются «поисковыми терминами» поискового запроса. Каждый такой поисковый запрос может пониматься как запрос поисковой системе на обнаружение каждого элемента данных в наборе данных, включающем в себя все поисковые термины, указанные в поисковом запросе. Обработка поискового запроса будет включать в себя поиск в одном или нескольких списках словопозиций инвертированного индекса. Как было описано выше, обычно каждому поисковому термину в поисковом запросе будет соответствовать список словопозиций. Поиск производится в списках словопозиций потому, что они могут легко сохраняться и управляться из быстродействующей памяти, в отличие от самих элементов данных (элементы данных обычно хранятся в более медленнодействующей памяти). Это, в общем случае, позволяет осуществлять поисковые запросы с гораздо более высокой скоростью.
[04] Обычно каждый элемент данных в наборе данных пронумерован. Элементы данных в наборе данных упорядочены не хронологически, географически или в алфавитном порядке, а обычно упорядочены (и пронумерованы) в порядке убывания их «независимой от запроса релевантности» ("query-independent relevance QIR"), как известно в данной области техники. Независимая от запроса релевантность QIR является эвристическим параметром, определяемым системой таким образом, что элементы данных с более высоким QIR статистически более вероятно окажутся сочтены релевантными авторами любого поискового запроса. Элементы данных в наборе данных будут упорядочены таким образом, что при завершении поиска элементы с более высоким значением QIR будут расположены сначала. Они, таким образом, появятся в начале (или близко к началу) списка поисковых результатов (который обычно отображается на различных страницах, причем те результаты, что расположены в начале списка поисковых результатов, отображаются на первой странице). Таким образом, каждый список словопозиций в инвертированном индексе будет включать в себя словопозиций, список ссылок на элементы данных, включающий в себя термины, с которыми этот список словопозиций связан, при этом словопозиций расположены в порядке убывания значения QIR. (Такой пример часто встречается в работе поисковых систем).
[05] Однако, должно быть очевидно, что такой эвристический параметр как QIR, может не давать оптимального расположения поисковых результатов в отношении любого данного конкретного запроса, поскольку понятно, что элемент данных, который обычно релевантен во многих поисках (и, получается, имеет высокое значение QIR), может не быть специфично релевантным в любом конкретном случае. Кроме того, релевантность любого конкретного элемента данных будет различаться в разных поисках. Из-за этого обычные поисковые системы применяют различные способы фильтрования, ранжирования и/или реорганизации поисковых результатов, чтобы предоставить их в таком порядке, который представляется релевантным для конкретного создания поисковых результатов для поискового запроса. В данной области техники это известно как «зависимая от запроса релевантность» ("query-specific relevance", здесь и далее упоминаемая как "QSR"). При определении QSR обычно принимается во внимание множество параметров. Такие параметры включают в себя: различные характеристики поискового запроса; поискового параметра; элементов данных для ранжирования; данных, собранных во время прошлых сходных поисковых запросов (или, более широко, определенных «сведений», полученных из прошлых сходных поисковых запросов).
[06] Таким образом, в общем процессе выполнения поискового запроса может быть выделено два основных различных этапа: Первый этап, на котором все поисковые результаты собираются на основе (частично) их значений QIR, сгруппированных и организованных в порядке убывания QIR; и второй этап, на котором по меньшей мере некоторые поисковые результаты перегруппировываются в соответствии с их QSR. После этого создается и отправляется автору запроса новый список поисковых результатов, упорядоченных по их QSR. Список поисковых результатов обычно отправляется частями, начиная с той части, которая включает в себя поисковые результаты с наиболее высоким QSR.
[07] Обычно на первом этапе сбор поисковых результатов прекращается после достижения определенного заранее максимального числа результатов или определенного заранее минимального порогового значения QIR. В данной области техники это называется «прюнинг» (от англ. "pruning" - обрезка); причем при удовлетворении прюнинг-условия весьма вероятно, что релевантные элементы данных уже были обнаружены.
[08] Обычно на втором этапе создается более короткий список (который является подгруппой поисковых результатов с первого этапа), упорядоченный по QSR. Это происходит потому, что обычные поисковые системы при проведении поиска элемента данных, удовлетворяющего данному поисковому запросу, по своему набору данных (который включает в себя несколько миллиардов элементов данных), могут легко создавать список десятка тысяч поисковых результатов (в некоторых случаях даже более). Очевидно, что автору запроса не нужно предоставлять такое количество поисковых результатов. Отсюда понятно огромное значение уменьшения количества поисковых результатов, в итоге предоставляемых автору запроса, до нескольких десятков, которые потенциально имеют высокую релевантность для автора запроса.
[09] Для того, чтобы удовлетворить необходимость ранжирования, требуемую для надлежащей работы поисковых систем, такую, например (без введения ограничений), как создание значений QIR и/или QSR, за последние годы было разработано множество вариантов моделей ранжирования. Эти модели ранжирования могут обеспечить ранжирование документов (например, веб-страниц, текстовых файлов, файлов с изображениями и/или видео-файлов) в соответствии с одним или несколькими параметрами. Некоторые подходы основаны на использовании алгоритмов машинного обучения для создания и функционирования моделей ранжирования; они обычно называются ранжированием на основе машинного обучения (machine-learned ranking, здесь и далее упоминающееся как MLR). Как будет понятно специалисту в данной области техники, MLR не ограничивается поисковыми системами самими по себе и может быть применимо в широком спектре систем информационного поиска.
Раскрытие
Ранжирование с учетом MLR-моделей
[10] В некоторых подходах ранжирование, обеспеченное моделью MLR, может включать в себя значение ранжирования, связанное с документом, которое может называться «параметром интереса» или «меткой», или отношением количества щелчков мышью к количеству показов ("click-through rate (CTR)"). Документ может также называться файлом. Ранжирование может включать в себя «абсолютное ранжирование» в абсолютном порядке: первый документ по отношению ко второму, - например, по значению QIR. Ранжирование может включать в себя «относительное ранжирование» в относительном порядке: первый документ по отношению ко второму в конкретном контексте, - например, по значению QSR. Для связи документа с параметром интереса модели MLR могут в некоторых случаях быть созданы и сохранены с помощью алгоритмов машинного обучения на основе одной или нескольких обучающих выборок. Число моделей MLR, которые требуются для конкретной цели, может варьировать в широких пределах. Известные поисковые системы, такие как Яндекс, могут использовать тысячи моделей MLR параллельно во время обработки поисковых запросов.
[11] В некоторых случаях модели MLR могут основываться на моделях в виде деревьев (древовидных моделях) и векторах признаков, включающих в себя один или несколько параметров, для связывания документа (например, веб-страницы) и параметра интереса (например, значения ранжирования). Один или несколько параметров вектора признаков могут использоваться для определения конкретного пути в древовидной модели, таким образом обеспечивая идентификацию параметра интереса, который должен быть связан с конкретным документом. В некоторых подходах один или несколько параметров могут иметь разные типы, например, бинарный тип, целочисленный тип и/или тип категорий. В качестве примера, в заявке 2015120563 описывается система хранения (хостинга) древовидной модели с целью связывания документа и параметра интереса. Древовидная модель может быть математически описана как включающая в себя одну или несколько функций h (q,d), где q-d связывает «запрос» ("query") и «документ» ("document"). Древовидная модель включает в себя набор факторов. Каждый фактор из набора факторов представлен как один или несколько узлов древовидной модели. Каждый фактор из набора факторов связан с алгоритмом, предоставляющим возможность определения того, по какой ветви, связанной с данным узлом, необходимо следовать для получения данного документа. В качестве примера, один или несколько параметров вектора признаков, связывающих документ и параметр интереса, «сравниваются» для получения набора факторов, чтобы установить путь в древовидной модели на основе значений одного или нескольких параметров. Алгоритмы набора факторов могут предоставить возможность сравнения параметров различных типов, например, бинарного типа, целочисленного типа и/или типа категорий. В некоторых случаях для модели MLR может потребоваться множество древовидных моделей, определяющих модель MLR. В таких случаях модель MLR может быть математически описана как множество функций модели MLR hi (q,d), где q-d связывает «запрос» ("query") и «документ» ("document"), а i связывает функцию с одной древовидной моделью из множества древовидных моделей, определяющих модель MLR. При таких условиях древовидная модель может быть определена функцией hi(q,d), где i соответствует древовидной модели.
Создание древовидных моделей
[12] Древовидные модели, связывающие документ с параметром интереса, могут быть созданы в соответствии с многочисленными методологиями. Эти методологии дают возможность выбора и упорядочивания набора факторов, определяющих древовидную модель (т.е. выбора и упорядочивания узлов относительно друг друга) и/или выбора и упорядочивания набора факторов таким образом, чтобы определить множество древовидных моделей. Для определения модели, например (без введения ограничений) модели MLR, древовидные модели могут быть связаны. Одна из таких методологий для выбора и упорядочивания набора факторов включает в себя использование так называемого «жадного» ("greedy") алгоритма. В соответствии с «жадным» алгоритмом, после создания древовидной модели, фактор выбирается из набора факторов для размещения на конкретном уровне древовидной модели (т.е. для определения узла древовидной модели). Выбор фактора из набора факторов осуществляется с помощью эвристической функции, задачей которой является доведение до максимума «качества» древовидной модели. Другими словами, для конкретного уровня древовидной модели может быть выбран первый фактор, а не второй фактор, потому что «жадный» алгоритм определил, что выбор первого фактора, а не второго фактора, для конкретного уровня древовидной модели позволит создать древовидную модель, которая будет обладать, согласно эвристической функции, лучшим качеством, чем при выборе второго фактора. Следует отметить, что термин «качество» относится к критерию, который позволяет оценить точность древовидной модели. Термин «качество» может, в некоторых случаях, относиться к точности древовидной модели, надежности древовидной модели и/или частоте появления ошибок у древовидной модели. В некоторых случаях качество может быть выражено как точность функции hi(q,d) где / представляет данную древовидную модель (т.е. данную подгруппу факторов, выбранных и упорядоченных так, что они определяют данную древовидную модель). Точность функции h(q,d) может, в некоторых случаях, представлять способность модели машинного обучения делать более точные прогнозы. Другими словами, чем больше точность функции h(q,d), тем более точна модель машинного обучения, и наоборот.
[13] В некоторых случаях «жадный» алгоритм создает древовидную модель с использованием некоторых или всех факторов, которые включены в состав набора факторов. В некоторых случаях «жадный» алгоритм создает первую древовидную модель с использованием первой подгруппы факторов, выбранных из набора факторов, и вторую древовидную модель с использованием подгруппы факторов, выбранных из набора факторов. В некоторых случаях первая подгруппа факторов и вторая подгруппа факторов могут включать в себя по меньшей мере один общий фактор. В некоторых случаях первая подгруппа факторов и вторая подгруппа факторов могут не включать в себя общий фактор. В качестве примера, «жадный» алгоритм выбирает 6 факторов из набора факторов, чтобы создать первую древовидную модель, упоминаемую как h1(q,d), причем 6 факторов выбираются и упорядочиваются относительно друг друга таким образом, чтобы образовать первую древовидную модель. Каждый из 6 факторов представляет собой один или несколько из 6 узлов первой древовидной модели. Затем «жадный» алгоритм выбирает 6 факторов (среди которых некоторые могут быть общими с 6 факторами, выбранными для первой модели, но это не является обязательным) для создания второй древовидной модели, упоминаемой как h2(q,d).
[14] В некоторых подходах модель машинного обучения создается системой на основе обучающего набора и/или тестового набора объектов. Такая модель машинного обучения может быть (без введения ограничений) моделью MLR, используемой для связи документа с параметром интереса. Как было описано выше, система, создающая модель машинного обучения может опираться на различные методологии и/или алгоритмы для создания одной или нескольких древовидных моделей, которые определяют модель машинного обучения. Хотя использование «жадного» алгоритма для создания множественных древовидных моделей может предоставить приемлемые результаты для определенных областей, например, в области поисковых систем, такое решение достаточно ограничено и/или сталкивается с проблемами, по меньшей мере при определенных условиях.
[15] Изобретатель(и) определил(и), что в описанных выше решениях есть по меньшей мере две проблемы, которые будут описаны подробнее ниже. Эти две проблемы могут быть упомянуты как (1) полнота модели машинного обучения, и 2) переобучение модели машинного обучения.
Полнота модели машинного обучения
[16] Полнота модели машинного обучения относится к одной или нескольким комбинациям факторов, выбранных из набора факторов для создания одной или нескольких древовидных моделей, формирующих модели машинного обучения. В общем случае, чем больше в одной или нескольких древовидных моделях комбинаций факторов, тем лучше качество модели машинного обучения и, в результате, тем больше полнота модели машинного обучения. Методологии и/или алгоритмы, используемые для выбора одной или нескольких комбинаций факторов, могут привести, по меньшей мере при некоторых условиях обработки, к полноте, которая не является оптимальной. В качестве примера, такие алгоритмы как, например, «жадный» алгоритм, могут привести к выбору в множестве древовидных моделей, формирующих модели машинного обучения, «слишком схожих» между собой подгрупп факторов из набора факторов. Выражение «слишком схожие» обозначает ситуацию, в которой первая подгруппа факторов, связанная с первой древовидной моделью, и вторая подгруппа факторов включают в себя «слишком много» общих факторов, что также может быть описано как слишком значительное перекрывание между факторами первой древовидной модели и факторами второй древовидной модели. В некоторых случаях некоторые факторы из набора факторов могут быть полностью проигнорированы, и, следовательно, они ни разу не будут выбраны для создания древовидных моделей. Одна из причин, связанная с этой ситуацией, может быть объяснена тем, что некоторые алгоритмы, например, «жадный» алгоритм, созданы для выбора «наилучшего» фактора для данного уровня древовидной модели на основе определения того, что «фактор» с большой вероятностью является «лучшим», хотя такое определение на пофакторной основе может привести к более низкому среднему качеству древовидной модели. Эта ситуация может быть даже более вероятной, когда факторы по своей природе являются «сильными» (т.е. обладающими большим положительным влиянием на качество древовидной модели), хотя и не выбираются как «сильные» с помощью существующих алгоритмов. Такие факторы могут включать в себя факторы целочисленного типа и/или категориального типа, которые обычно связаны более чем с двумя ветвями после того, как они были выбраны как узлы в одной из древовидных моделей (в отличие от факторов бинарного типа, которые обычно связаны не более чем с двумя ветвями после того, как они были выбраны как узлы в одной из древовидных моделей).
Переобучение модели машинного обучения
[17] В некоторых случаях алгоритмы, используемые для создания модели машинного обучения, такие как «жадный» алгоритм, могут создавать так называемую проблему переобучения. Такая проблема может быть выявлена при появлении недостоверных паттернов между значениями, созданными функцией h(q,d) и факторами, связанными с функцией h(q,d). Проблема переобучения может возникнуть, когда алгоритм, создающий одну или несколько древовидных моделей, формирующих модель машинного обучения, начинает выбирать и упорядочивать факторы, с помощью «запоминания» набора обучающих объектов, релевантных только набору обучающих объектов, а не создает закономерность («тренд») на основе набора обучающих объектов, который будет релевантен неизвестным объектам (т.е. тем объектам, которые не являются частью модели машинного обучения), а не только обучающим объектам из набора обучающих объектов.
[18] Настоящее техническое решение предусматривает неограничивающие варианты осуществления, задачей которых является создание моделей прогнозирования, например, моделей машинного обучения, которые обладают более высоким уровнем точности, с помощью решения, по меньшей мере частично, проблемы (1) вычислительной мощности и энергии, необходимых для обучения модели прогнозирования в виде дерева принятия решений с использованием известной перекрестной проверки и/или (2) переобучения модели машинного обучения. Такие улучшенные способы, предоставляя более высокую точность, дают возможность лучшего управления физическими ресурсами системы машинного обучения, в которой создаются одна или несколько моделей машинного обучения. Такие физические ресурсы могут быть устройством обработки данных, например (но без введения ограничений), центральным процессором (CPU) и/или памятью, например (но без введения ограничений), оперативной памятью (ОЗУ).
[19] Настоящее техническое решение основано на первом наблюдении, сделанном изобретателем(ями), что во время создания древовидной модели подгруппа случайных параметров интереса может быть связана с параметрами интереса данного листа предварительной древовидной модели для определения параметра точности предварительной древовидной модели. Подгруппа случайных параметров интереса может быть создана центральным процессором системы, в которой была создана предварительная древовидная модель, поддерживая использования вычислительной мощности процессора ниже допустимого порога. Определение параметра точности предварительной древовидной модели может храниться в ОЗУ системы, и на него может ориентироваться процессор при создании древовидной модели. Определение параметра точности предварительной древовидной модели может быть проведено процессором, поддерживая использование вычислительной мощности процессора ниже допустимого порога.
[20] Настоящее техническое решение, таким образом, приводит, среди прочих преимуществ, к более точному прогнозированию модели машинного обучения, позволяя компьютерной системе (1) более эффективно расходовать вычислительную мощность; и (2) предоставлять конечному пользователю более релевантные прогнозы.
[21] Таким образом, первым объектом настоящего технического решения настоящего технического решения является компьютерный способ определения параметра точности обученной модели прогнозирования в виде дерева принятия решений, способ выполняется в компьютерной системе машинного обучения; способ включает в себя:
доступ, с постоянного машиночитаемого носителя системы машинного обучения, к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса;
создание процессором системы машинного обучения обученной модели прогнозирования в виде дерева принятия решений по меньшей мере частично на основе набора обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса, а обученная модель прогнозирования в виде дерева принятия решений включает в себя узлы, связанные с факторами, и листы, связанные с параметрами интереса обучающих объектов из набора обучающих объектов, и связь между листами и параметрами интереса была определена с помощью выполненного процессором системы машинного обучения сравнения по меньшей мере двух из факторов и признаков обучающих объектов из набора обучающих объектов;
отправку команды процессору системы машинного обучения на выполнение:
создания процессором подгруппы случайных параметров интереса;
связывания в постоянном машиночитаемом носителе подгруппы случайных параметров интереса сданным листом;
определение процессором параметра точности листа на основе (i) параметров интереса, связанных с данным листом и (ii) подгруппы случайных параметров интереса данного листа; и
определение процессором параметра точности обученной модели прогнозирования в виде дерева принятия решений на основе определенного параметра точности листа.
[22] Другим объектом настоящего технического решения является компьютерный способ определения параметра точности обученной модели прогнозирования в виде дерева принятия решений, способ выполняется в компьютерной системе машинного обучения; способ включает в себя:
доступ, с постоянного машиночитаемого носителя, к обученной модели прогнозирования в виде дерева принятия решений, созданной по меньшей мере частично на основе набора обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса, а обученная модель прогнозирования в виде дерева принятия решений включает в себя узлы, связанные с факторами, и листы, связанные с параметрами интереса обучающих объектов из набора обучающих объектов, и связь между листами и параметрами интереса была определена с помощью сравнения по меньшей мере двух из факторов и признаков обучающих объектов из набора обучающих объектов;
создание процессором подгруппы случайных параметров интереса;
связывания в постоянном машиночитаемом носителе подгруппы случайных параметров интереса с данным листом;
определение процессором параметра точности листа на основе (i) параметров интереса, связанных с данным листом и (ii) подгруппы случайных параметров интереса данного листа; и
определение процессором параметра точности обученной модели прогнозирования в виде дерева принятия решений на основе определенного параметра точности листа.
[23] Другим объектом настоящего технического решения является компьютерный способ создания обученной модели прогнозирования в виде дерева принятия решений, способ выполняется в компьютерной системе машинного обучения; способ включает:
осуществление доступа из постоянного машиночитаемого носителя к набору факторов;
идентификацию процессором из набора факторов фактора, связанного с наилучшим параметром точности предварительно обученной модели прогнозирования в виде дерева принятия решений, для данного положения узла, связанного с фактором в предварительно обученной модели прогнозирования в виде дерева принятия решений, причем наилучший параметр точности предварительно обученной модели прогнозирования в виде дерева принятия решений выбирается из множества параметров точности множества предварительных моделей прогнозирования в виде дерева принятия решений, причем множество параметров точности множества предварительных моделей прогнозирования в виде дерева принятия решений было создано в соответствии с одним из описанных выше способов;
связывание процессором фактора с данным положением узла создающейся обученной модели прогнозирования в виде дерева принятия решений; и
создание процессором обученной модели прогнозирования в виде дерева принятия решений, причем обученная модель прогнозирования в виде дерева принятия решений включает в себя узел, связанный с фактором, для данного положения.
[24] Другим объектом настоящего технического решения является компьютерный способ определения параметра точности обученной модели прогнозирования в виде дерева принятия решений, способ выполняется в компьютерной системе машинного обучения; способ включает:
доступ, с постоянного машиночитаемого носителя, к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса;
создание процессором обученной модели прогнозирования в виде дерева принятия решений по меньшей мере частично на основе набора обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса, а обученная модель прогнозирования в виде дерева принятия решений включает в себя узлы, связанные с факторами, и листы, связанные с параметрами интереса обучающих объектов из набора обучающих объектов, и связь между листами и параметрами интереса была определена с помощью сравнения по меньшей мере двух из факторов и признаков обучающих объектов из набора обучающих объектов;
создания процессором подгруппы случайных параметров интереса;
связывания в постоянном машиночитаемом носителе подгруппы случайных параметров интереса с данным листом;
определение процессором параметра точности листа на основе (i) параметров интереса, связанных с данным листом и (ii) подгруппы случайных параметров интереса данного листа; и
определение процессором параметра точности обученной модели прогнозирования в виде дерева принятия решений на основе определенного параметра точности листа.
[25] Другим объектом настоящего технического решения является постоянный машиночитаемый носитель, хранящий программные инструкции для создания модели прогнозирования и/или определения точности модели прогнозирования, при этом программные инструкции выполняются процессором компьютерной системы для осуществления одного или нескольких упомянутых выше способов.
[26] Другим объектом настоящего технического решения является компьютерная система, например (без введения ограничений), электронное устройство, включающее в себя по меньшей мере один процессор и память, хранящую программные инструкции для создания модели прогнозирования и/или определения точности модели прогнозирования; при этом программные инструкции выполняются одним или несколькими процессорами компьютерной системы для осуществления одного или нескольких упомянутых выше способов.
[27] В контексте настоящего описания, если четко не указано иное, «электронное устройство», «пользовательское устройство», «сервер», «удаленный сервер» и «компьютерная система» подразумевают под собой аппаратное и/или системное обеспечение, подходящее к решению соответствующей задачи. Таким образом, некоторые неограничивающие примеры аппаратного и/или программного обеспечения включают в себя компьютеры (серверы, настольные компьютеры, ноутбуки, нетбуки и так далее), смартфоны, планшеты, сетевое оборудование (маршрутизаторы, коммутаторы, шлюзы и так далее) и/или их комбинацию.
[28] В контексте настоящего описания, если четко не указано иное, «машиночитаемый носитель» и «память» подразумевает под собой носитель абсолютно любого типа и характера, не ограничивающие примеры включают в себя ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB-ключи, флеш-карты, твердотельные накопители и накопители на магнитной ленте.
[29] В контексте настоящего описания, если четко не указано иное, «указание» информационного элемента может представлять собой сам информационный элемент или указатель, отсылку, ссылку или другой косвенный способ, позволяющий получателю указания найти сеть, память, базу данных или другой машиночитаемый носитель, из которого может быть извлечен информационный элемент. Например, указание на документ может включать в себя сам документ (т.е. его содержимое), или же оно может являться уникальным дескриптором документа, идентифицирующим файл по отношению к конкретной файловой системе, или каким-то другими средствами передавать получателю указание на сетевую папку, адрес памяти, таблицу в базе данных или другое место, в котором можно получить доступ к файлу. Как будет понятно специалистам в данной области техники, степень точности, необходимая для такого указания, зависит от степени первичного понимания того, как должна быть интерпретирована информация, которой обмениваются получатель и отправитель указателя. Например, если до установления связи между отправителем и получателем понятно, что указание информационного элемента принимает вид ключа базы данных для записи в конкретной таблице заранее установленной базы данных, включающей в себя информационный элемент, то передача ключа базы данных - это все, что необходимо для эффективной передачи информационного элемента получателю, несмотря на то, что сам по себе информационный элемент не передавался между отправителем и получателем указания.
[30] В контексте настоящего описания, если конкретно не указано иное, слова «первый», «второй», «третий» и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной связи между этими существительными. Так, например, следует иметь в виду, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий «второй сервер» обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание «первого» элемента и «второго» элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, «первый» сервер и «второй» сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[31] Каждый вариант осуществления настоящего технического решения преследует по меньшей мере одну из вышеупомянутых целей и/или объектов. Следует иметь в виду, что некоторые объекты настоящего технического решения, полученные в результате попыток достичь вышеупомянутой цели, могут удовлетворять и другим целям, отдельно не указанным здесь. Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления настоящего технического решения станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
Краткое описание чертежей
[32] Для лучшего понимания настоящего технического решения, а также других его аспектов и характерных черт, сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[33] На Фиг. 1 представлена схема компьютерной системы, которая подходит для реализации настоящего технического решения, и/или которая используется в сочетании с вариантами осуществления настоящего технического решения;
[34] На Фиг. 2 представлена схема сетевой вычислительной среды, выполненной в соответствии с вариантом осуществления настоящего технического решения;
[35] На Фиг. 3 представлена схема, показывающая древовидную модель частично, и два примера векторов признаков в соответствии с вариантом осуществления настоящего технического решения;
[36] На Фиг. 4 представлена схема полной древовидной модели в соответствии с вариантом осуществления настоящего технического решения;
[37] На Фиг. 5 представлена схема, показывающая части предварительной древовидной модели и полную предварительную древовидную модель в соответствии с другим вариантом осуществления настоящего технического решения;
[38] На Фиг. 6 представлена схема, показывающая части предварительной древовидной модели в соответствии с другим вариантом осуществления настоящего технического решения;
[39] На Фиг. 7 представлена схема полной предварительной древовидной модели в соответствии с другим вариантом осуществления настоящего технического решения;
[40] На Фиг. 8 представлена схема, показывающая первый компьютерный способ, являющийся вариантом осуществления настоящего технического решения.
[41] На Фиг. 9 представлена схема, показывающая второй компьютерный способ, являющийся вариантом осуществления настоящего технического решения.
[42] На Фиг. 10 представлена схема, показывающая третий компьютерный способ, являющийся вариантом осуществления настоящего технического решения.
[43] На Фиг. 11 представлена схема, показывающая четвертый компьютерный способ, являющийся вариантом осуществления настоящего технического решения.
[44] Также следует отметить, что чертежи выполнены не в масштабе, если специально не указано иное.
Осуществление
[45] Все примеры и используемые здесь условные конструкции предназначены, главным образом, для того, чтобы помочь читателю понять принципы настоящего технического решения, а не для установления границ его объема. Следует также отметить, что специалисты в данной области техники могут разработать различные схемы, отдельно не описанные и не показанные здесь, но которые, тем не менее, воплощают собой принципы настоящего технического решения и находятся в границах его объема.
[46] Кроме того, для ясности в понимании, следующее описание касается достаточно упрощенных вариантов осуществления настоящего технического решения. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящего технического решения будут обладать гораздо большей сложностью.
[47] Некоторые полезные примеры модификаций настоящего технического решения также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящего технического решения. Эти модификации не представляют собой исчерпывающего списка, и специалисты в данной области техники могут создавать другие модификации, остающиеся в границах объема настоящего технического решения. Кроме того, те случаи, в которых не были описаны примеры модификаций, не должны интерпретироваться как то, что никакие модификации невозможны, и/или что то, что было описано, является единственным вариантом осуществления этого элемента настоящего технического решения.
[48] Более того, все заявленные здесь принципы, аспекты и варианты осуществления настоящего технического решения, равно как и конкретные их примеры, предназначены для обозначения их структурных и функциональных основ. Таким образом, например, специалистами в данной области техники будет очевидно, что представленные здесь блок-схемы представляют собой концептуальные иллюстративные схемы, отражающие принципы настоящего технического решения. Аналогично, любые блок-схемы, диаграммы, псевдокоды и т.п. представляют собой различные процессы, которые могут быть представлены на машиночитаемом носителе и, таким образом, использоваться компьютером или процессором, вне зависимости от того, показан явно подобный компьютер или процессор или нет.
[49] Функции различных элементов, показанных на фигурах, включая функциональный блок, обозначенный как «процессор» или «графический процессор», могут быть обеспечены с помощью специализированного аппаратного обеспечения или же аппаратного обеспечения, способного использовать подходящее программное обеспечение. Когда речь идет о процессоре, функции могут обеспечиваться одним специализированным процессором, одним общим процессором или множеством индивидуальных процессоров, причем некоторые из них могут являться общими. В некоторых вариантах осуществления настоящего технического решения процессор может являться универсальным процессором, например, центральным процессором (CPU) или специализированным для конкретной цели процессором, например, графическим процессором (GPU). Более того, использование термина «процессор» или «контроллер» не должно подразумевать исключительно аппаратное обеспечение, способное поддерживать работу программного обеспечения, и может включать в себя, без установления ограничений, цифровой сигнальный процессор (DSP), сетевой процессор, интегральная схема специального назначения (ASIC), программируемую пользователем вентильную матрицу (FPGA), постоянное запоминающее устройство (ПЗУ) для хранения программного обеспечения, оперативное запоминающее устройство (ОЗУ) и энергонезависимое запоминающее устройство. Также может быть включено другое аппаратное обеспечение, обычное и/или специальное.
[50] Программные модули или простые модули, представляющие собой программное обеспечение, могут быть использованы здесь в комбинации с элементами блок-схемы или другими элементами, которые указывают на выполнение этапов процесса и/или текстовое описание. Подобные модели могут быть выполнены на аппаратном обеспечении, показанном напрямую или косвенно.
[51] С учетом этих примечаний, далее будут рассмотрены некоторые неограничивающие варианты осуществления аспектов настоящего технического решения.
[52] На Фиг. 1 представлена схема компьютерной системы 100, которая подходит для некоторых вариантов осуществления настоящего технического решения, причем компьютерная система 100 включает в себя различные аппаратные компоненты, включая один или несколько одно - или многоядерных процессоров, которые представлены процессором 110, графическим процессором (GPU) 111, твердотельным накопителем 120, ОЗУ 130, интерфейсом 140 монитора, и интерфейсом 150 ввода/вывода.
[53] Связь между различными компонентами компьютерной системы 100 может осуществляться с помощью одной или нескольких внутренних и/или внешних шин 160 (например, шины PCI, универсальной последовательной шины, высокоскоростной шины IEEE 1394, шины SCSI, шины Serial ATA и так далее), с которыми электронно соединены различные аппаратные компоненты. Интерфейс 140 монитора может быть соединен с монитором 142 (например, через HDMI-кабель 144), видимым пользователю 170, интерфейс 150 ввода/вывода может быть соединен с сенсорным экраном (не изображен), клавиатурой 151 (например, через USB-кабель 153) и мышью 152 (например, через USB-кабель 154), как клавиатура 151, так и мышь 152 используются пользователем 170.
[54] В соответствии с вариантами осуществления настоящего технического решения твердотельный накопитель 120 хранит программные инструкции, подходящие для загрузки в ОЗУ 130, и использующиеся процессором 110 и/или графическим процессором GPU 111 для обработки показателей активности, связанных с пользователем. Например, программные инструкции могут представлять собой часть библиотеки или приложение.
[55] На Фиг. 2 показана сетевая компьютерная среда 200, подходящая для использования с некоторыми вариантами осуществления настоящего технического решения, причем сетевая компьютерная среда 200 включает в себя ведущий сервер 210, обменивающийся данными с первым ведомым сервером 220, вторым ведомым сервером 222 и третьим ведомым сервером 224 (также здесь и далее упоминаемыми как ведомые серверы 220, 222, 224) по сети (не изображена), предоставляя этим системам возможность обмениваться данными. В некоторых вариантах осуществления решения, не ограничивающих его объем, сеть может представлять собой Интернет. В других вариантах осуществления настоящего технического решения сеть может быть реализована иначе - в виде глобальной сети передачи данных, локальной сети передачи данных, частной сети передачи данных и т.п.
[56] Сетевая компьютерная среда 200 может включать в себя большее или меньшее количество ведомых серверов, что не выходит за границы настоящего технического решения. В некоторых вариантах осуществления настоящего технического решения конфигурация «ведущий сервер - ведомый сервер» не является обязательной; может быть достаточно одиночного сервера. Следовательно, число серверов и тип архитектуры не является ограничением объема настоящего технического решения.
[57] В одном варианте осуществления настоящего решения между ведущим сервером 210 и ведомыми серверами 220, 222, 224 может быть установлен канал передачи данных (не показан), чтобы обеспечить возможность обмена данными. Такой обмен данными может происходить на постоянной основе или же, альтернативно, при наступлении конкретных событий. Например, в контексте сбора данных с веб-страниц и/или обработки поисковых запросов обмен данными может возникнуть в результате контроля ведущим сервером 210 обучения моделей машинного обучения, осуществляемого сетевой компьютерной средой. В некоторых вариантах осуществления настоящего решения ведущий сервер 210 может получить набор обучающих объектов и/или набор тестирующих объектов и/или набор факторов от внешнего сервера поисковой системы (не изображен) и отправить набор обучающих объектов и/или набор тестирующих объектов и/или набор факторов одному или нескольким ведомым серверам 220, 222, 224. После получения от ведущего сервера 210 один или несколько ведомых серверов 220, 222, 224 могут обработать набор обучающих объектов и/или набор тестирующих объектов и/или набор факторов в соответствии с настоящим решением для создания одной или нескольких моделей машинного обучения, причем каждая модель машинного обучения включает в себя в некоторых случаях одну или несколько древовидных моделей. В некоторых вариантах осуществления решения одна или несколько древовидных моделей моделируют связь между документом и параметром интереса. Созданная модель машинного обучения может быть передана ведущему серверу 210 и, таким образом, ведущий сервер 210 может создать прогноз, например, в контексте поискового запроса, полученного от внешнего сервера поисковой системы, на основе поискового запроса. После обработки поискового запроса созданной моделью машинного обучения ведущий сервер 210 может передать один или несколько соответствующих результатов внешнему серверу поисковой системы. В некоторых альтернативных вариантах осуществления решения один или несколько ведомых серверов 220, 222, 224 может напрямую сохранять созданную модель машинного обучения и обрабатывать поисковый запрос, полученный от внешнего сервера поисковой системы через ведущий сервер 210.
[58] Ведущий сервер 210 может быть выполнен как обычный компьютерный сервер и может включать в себя некоторые или все характеристики компьютерной системы 100, изображенной на Фиг. 1. В примере варианта осуществления настоящего технического решения ведущий сервер 210 может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что ведущий сервер 210 может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящего технического решения, не ограничивающем его объем, ведущий сервер 210 является одиночным сервером. В других вариантах осуществления настоящего технического решения, не ограничивающих его объем, функциональность ведущего сервера 210 может быть разделена, и может выполняться с помощью нескольких серверов.
[59] Варианты осуществления ведущего сервера 210 широко известны среди специалистов в данной области техники. Тем не менее, для краткой справки: ведущий сервер 210 включает в себя интерфейс передачи данных (не показан), который настроен и выполнен с возможностью устанавливать соединение с различными элементами (например, с внешним сервером поисковой системы и/или ведомыми серверами 220, 222, 224 и другими устройствами, потенциально соединенными с сетью) по сети. Ведущий сервер 210 дополнительно включает в себя по меньшей мере один компьютерный процессор (например, процессор 110 ведущего сервера 210), функционально соединенный с интерфейсом передачи данных и настроенный и выполненный с возможностью выполнять различные процессы, описанные здесь.
[60] Основной задачей ведущего сервера 210 является координация создания моделей машинного обучения ведомыми серверами 220, 222, 224. Как было описано ранее, в одном варианте осуществления настоящего решения набор обучающих объектов и/или набор тестирующих объектов и/или набор факторов может быть передан некоторым или всем ведомым серверам 220, 222, 224, и таким образом, ведомые серверы 220, 222, 224 могут создавать одну или несколько моделей машинного обучения на основе набора обучающих объектов и/или набора тестирующих объектов и/или набора факторов. В некоторых вариантах осуществления решения, модель машинного обучения может включать в себя одну или несколько древовидных моделей. Каждая из древовидных моделей может быть сохранена на одном или нескольких ведомых серверах 220, 222, 224. В некоторых альтернативных вариантах осуществления решения древовидные модели могут быть сохранены по меньшей мере на двух серверах из ведомых серверов 220, 222, 224. Как будет понятно специалистам в данной области техники, то, где сохраняются модель машинного обучения и/или древовидные модели, формирующие модель машинного обучения, не является важным для настоящего решения, и может быть предусмотрено множество вариантов без отклонения от объема настоящего технического решения.
[61] В некоторых вариантах осуществления настоящего решения после того, как ведомые серверы 220, 222, 224 сохранили одну или несколько моделей машинного обучения, ведомые серверы 220, 222, 224 могут получить инструкции на проведение связей между документом и параметром интереса, причем документ отличается от обучающих объектов из набора обучающих объектов и включает набор параметров, соответствующих значениям, связанным с некоторыми факторами, выбранными из набора факторов, определяющих структуру по меньшей мере одной древовидной модели. Как только связывание между документом и параметром интереса было завершено ведомыми серверами 220, 222, 224, ведущий сервер 210 может получить от ведомых серверов 220, 222, 224 параметр интереса, который должен быть связан с документом. В некоторых других вариантах осуществления настоящего решения ведущий сервер 210 может отправлять документ и/или набор параметров, связанный с документом, не получая параметра интереса в ответ. Этот сценарий может возникнуть после определения одним или несколькими ведомыми серверами 220, 222, 224 того, что документ и/или набор параметров, связанный с документом, приводят к модификации одной из древовидных моделей, хранящихся на ведомых серверах 220, 222, 224. В некоторых вариантах осуществления настоящего решения ведущий сервер 210 может включать в себя алгоритм, который может создавать инструкции для модификации одной или нескольких моделей, хранящихся на ведомых серверах 220, 222, 224, с параметром интереса для связи с документом. В таких примерах одна из древовидных моделей, хранящаяся на ведомых серверах 220, 222, 224, может быть модифицирована таким образом, что документ может быть связан с параметром интереса в древовидной модели. В некоторых вариантах осуществления настоящего решения после того, как одна из древовидных моделей, хранящаяся на ведомых серверах 220, 222, 224, была модифицирована, ведомые серверы 220, 222, 224 могут передать сообщение ведущему серверу 210, причем сообщение указывает на модификацию, осуществленную в одной из древовидных моделей. Могут быть предусмотрены другие варианты того, как ведущий сервер 210 взаимодействует с ведомыми серверами 220, 222, 224, что не выходит за границы настоящего решения и может быть очевидным специалисту в данной области техники. Кроме того, важно иметь в виду, что для упрощения вышеприведенного описания конфигурация ведущего сервера 210 была сильно упрощена. Считается, что специалисты в данной области техники смогут понять подробности реализации ведущего сервера 210 и его компонентов, которые могли быть опущены в описании с целью упрощения.
[62] Ведомые серверы 220, 222, 224 могут быть выполнены как обычные компьютерные серверы и могут включать в себя некоторые или все характеристики компьютерной системы 100, изображенной на Фиг. 1. В примере варианта осуществления настоящего технического решения ведомые серверы 220, 222, 224 могут представлять собой серверы Dell™ PowerEdge™, на которых используется операционная система Microsoft™ Windows Server™. Излишне говорить, что ведомые серверы 220, 222, 224 могут представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящего решения, не ограничивающем его объем, ведомые серверы 220, 222, 224 функционируют на основе распределенной архитектуры. В альтернативных вариантах настоящего технического решения, не ограничивающих его объем, настоящее техническое решение может осуществляться единственным ведомым сервером.
[63] Варианты осуществления ведомых серверов 220, 222, 224 широко известны среди специалистов в данной области техники. Тем не менее, для краткой справки: каждый из ведомых серверов 220, 222, 224 может включать в себя интерфейс передачи данных (не показан), который настроен и выполнен с возможностью устанавливать соединение с различными элементами (например, с внешним сервером поисковой системы и/или ведущим сервером 210 и другими устройствами, потенциально соединенными с сетью) по сети. Каждый из ведомых серверов 220, 222, 224 дополнительно включает в себя по меньшей мере один компьютерный процессор (например, сходный с процессором 110, изображенным на Фиг. 1), функционально соединенный с интерфейсом обмена данных, настроенный и выполненный с возможностью выполнять различные описанные здесь процессы. Каждый из ведомых серверов 220, 222, 224 дополнительно может включать в себя одно или несколько устройств памяти (например, аналогичных твердотельному накопителю 120, и/или ОЗУ 130, изображенным на Фиг. 1.
[64] Общей задачей ведомых серверов 220, 222, 224 является создание одной или нескольких моделей машинного обучения. Как было описано ранее, в одном варианте осуществления, модель машинного обучения может включать в себя одну или несколько древовидных моделей. Каждая из древовидных моделей включает в себя набор факторов (которые также могут упоминаться как подгруппа факторов, если факторы, образующие подгруппу, были выбраны из набора факторов). Каждый фактор из набора факторов соответствует одному или нескольким узлам соответствующей древовидной модели. Во время создания одной или нескольких моделей машинного обучения для выбора и упорядочивания факторов таким образом, чтобы создать древовидную модель, ведомые серверы 220, 222, 224 могут исходить из набора обучающих объектов и/или набора тестирующих объектов. Этот процесс выбора и упорядочивания факторов может быть повторен с помощью многочисленных итераций таким образом, что ведомые серверы 220, 222, 224 создают множество древовидных моделей, причем каждая из древовидных моделей соответствует различным выборам и/или порядкам (после упорядочивания) факторов. В некоторых вариантах осуществления набор обучающих объектов и/или набор тестирующих объектов и/или набор факторов может быть получен от ведущего сервера 210 и/или внешнего сервера. После создания моделей машинного обучения ведомые серверы 220, 222, 224 могут передать ведомому серверу 210 указание на то, что модели машинного обучения были созданы и могут использоваться для создания прогнозов, например (но не вводя ограничений), в контексте классификации документов во время процесса сбора данных в сети («веб-кроулинга») и/или после обработки поискового запроса, полученного от внешнего сервера поисковой системы.
[65] В некоторых вариантах осуществления настоящего технического решения ведомые серверы 220, 222, 224 могут также получать документ и набор параметров, связанных с документом, вместе с параметром интереса, который должен быть связан с документом. В некоторых других вариантах осуществления ведомые серверы 220, 222,224 могут не передавать параметр интереса ведущему серверу 210. Этот сценарий может возникнуть после определения ведомыми серверами 220, 222, 224 того, что параметр интереса, который должен быть связан с документом, приводит к модификации одной из древовидных моделей, хранящихся на этих серверах. В некоторых вариантах осуществления настоящего технического решения после того, как одна из древовидных моделей, хранящаяся на ведомых серверах 220, 222, 224, была модифицирована, ведомые серверы 220, 222,224 могут передать сообщение ведущему серверу 210, причем сообщение указывает на модификацию, осуществленную в одной из древовидных моделей. Могут быть предусмотрены другие варианты того, как ведомые серверы 220, 222, 224 взаимодействует с ведущим сервером 210, что не выходит за границы настоящего решения и может быть очевидным специалисту в данной области техники. Кроме того, важно иметь в виду, что для упрощения вышеприведенного описания конфигурация ведомых серверов 220, 222, 224 была сильно упрощена. Считается, что специалисты в данной области техники смогут понять подробности реализации ведомых серверов 220, 222, 224 и его компонентов, которые могли быть опущены в описании с целью упрощения.
[66] На Фиг. 2 показано, что ведомые серверы 220, 222, 224 могут быть функционально соединены с базой данных 230 «хэш-таблицы 1», базой данных 232 «хэш-таблицы 2» и базой данных 234 «хэш-таблицы n» (здесь и далее упоминаемых как «базы данных 230, 232, 234»). Базы данных 230, 232, 234 могут быть частью ведомых серверов 220, 222, 224 (например, они могут быть сохранены в устройствах памяти ведомых серверов 220, 222, 224, таких как твердотельный накопитель 120 и/или ОЗУ 130) или могут быть сохранены на отдельных серверах баз данных. В некоторых вариантах осуществления настоящего технического решения может быть достаточно единственной базы данных, доступной ведомым серверам 220, 222, 224. Следовательно, число баз данных и организация баз данных 230, 232, 234 не является ограничением объема настоящего технического решения. Базы данных 230, 232, 234 могут быть использованы для доступа и/или хранения данных, относящихся к одной или нескольким хэш-таблицам, представляющим модели машинного обучения, например (но без введения ограничений) древовидные модели, созданные в соответствии с настоящим техническим решением. В некоторых вариантах осуществления настоящего решения ведомые серверы 220, 222, 224 могут получить доступ к базам данных 230, 232, 234, чтобы идентифицировать параметр интереса, который будет связан с документом и далее обработать набор параметров, связанный с документом, в соответствии с настоящим техническим решением. В некоторых других вариантах осуществления настоящего технического решения ведомые серверы 220, 222, 224 могут получить доступ к базам данных 230, 232, 234, чтобы сохранить новую запись (здесь и далее также упоминаемую как «хэшированный комплексный вектор» и/или «ключ») в одной или нескольких хэш-таблицах, причем новая запись была создана после обработки набора параметров, связанных с документом; она представляет параметр интереса, который будет связан с документом. В таких вариантах осуществления новая запись может представлять модификацию древовидных моделей, представленных хэш-таблицей. Хотя в примере на Фиг. 2 представлен вариант осуществления настоящего технического решения, в котором базы данных 230, 232, 234 включают в себя хэш-таблицы, следует понимать, что могут быть предусмотрены альтернативные варианты сохранения моделей машинного обучения без отклонения от объема настоящего технического решения.
[67] Больше подробностей обработки древовидных моделей, формирующих модель машинного обучения, будут предоставлены в описаниях Фиг. 3-7.
[68] На Фиг. 3 изображены часть древовидной модели 300, первый набор 330 параметров и второй набор 340 параметров. Первый набор 330 параметров и второй набор 340 параметров могут также упоминаться как векторы признаков. Часть древовидной модели 300 могла быть создана в соответствии с настоящим техническим решением и может представлять связь между документом и параметром интереса. Древовидная модель 300 может быть упомянута как модель машинного обучения или часть модели машинного обучения (например, для вариантов осуществления настоящего технического решения, в которых модель машинного обучения опирается на множество древовидных моделей). В некоторых случаях древовидная модель 300 может быть упомянута как модель прогнозирования или часть модели прогнозирования (например, для вариантов осуществления настоящего технического решения, в которых модель прогнозирования опирается на множество древовидных моделей).
[69] Документ может быть различных форм, форматов и может иметь разную природу, например, без введения ограничений, документ может быть текстовым файлом, текстовым документом, веб-страницей, аудио файлом, видео файлом и так далее. Документ может также упоминаться как файл, что не выходит за границы настоящего технического решения. В одном варианте осуществления настоящего технического решения файл может быть документом, который может быть найден поисковой системой. Однако, могут быть предусмотрены другие варианты осуществления настоящего технического решения, что не выходит за границы настоящего технического решения и может быть очевидным специалисту в данной области техники. Как было упомянуто ранее, параметр интереса может быть разных форм и форматов, например (без введения ограничений), он представляет указание на порядок ранжирования документа, такое как отношение количества щелчков мышью к количеству показов ("click-through rate (CTR)"). В некоторых вариантах осуществления настоящего технического решения параметр интереса может упоминаться как метка и/или ранжирование, в частности в контексте поисковых систем. В некоторых вариантах осуществления параметр интереса может быть создан алгоритмом машинного обучения с использованием документа обучения. В некоторых альтернативных вариантах осуществления могут быть использованы другие способы, например (без введения ограничений), определение параметра интереса вручную. Следовательно, то, как создается параметр интереса, никак не ограничивается, и могут быть предусмотрены другие варианты осуществления, что не выходит за границы настоящего технического решения и может быть очевидным специалисту в данной области техники.
[70] Путь в части древовидной модели 300 может быть определен первым набором 330 параметров и/или вторым набором 340 параметров. Первый набор 330 параметров и второй набор 340 параметров могут также быть связаны с тем же самым документом или с различными документами. Часть древовидной модели 300 включает в себя множество узлов, каждый из которых соединен с одной или несколькими ветвями. В варианте осуществления, изображенном на Фиг. 3, представлены первый узел 302 (также упоминаемый как первый фактор 302), второй узел 304 (также упоминаемый как второй фактор 304), третий узел 306 (также упоминаемый как третий фактор 306), четвертый узел 308 (также упоминаемый как четвертый фактор 308) и пятый узел 310 (также упоминаемый как четвертый фактор 310). Каждый узел (первый узел 302, второй узел 304, третий узел 306, четвертый узел 308 и пятый узел 310) связан с условием, таким образом определяя так называемый фактор. Первый узел 302 связан с условием "if Page_rank<3" (значение ранжирования страницы), связанным с двумя ветками (т.е. значение «истина» представлено бинарным числом «0», а значение «ложь» представлено бинарным числом «1»); второй узел 304 связан с условием "Is main page?" («Главная страница?»), связанным с двумя ветками (т.е. Значение «истина» представлено бинарным числом «0», а значение «ложь» представлено бинарным числом «1»); третий узел 306 связан с условием "if Number_clicks<5,000" (число щелчков), связанным с двумя ветками (т.е. значение «истина» представлено бинарным числом «0», а значение «ложь» представлено бинарным числом «1»); четвертый узел 308 связан с условием "which URL?" («Какой URL?»), которое связано более чем с двумя ветками (т.е. каждая ветка связана со своим URL, например, с URL "yandex.ru"); и пятый узел 310 связан с условием "which Search query?" («Какой поисковый запрос?»), которое связано более чем с двумя ветками (т.е. каждая ветка связана со своим поисковым запросом, например, поисковый запрос «посмотреть Эйфелеву башню»). В одном варианте осуществления каждое из условий, установленных выше, может определять отдельный фактор (т.е. первый фактор 302 определяется условием "if Page_rank<3" (значение ранжирования страницы), второй фактор 304 определяется условием "Is main page?" («Главная страница?»), третий фактор 306 определяется условием "if Number_clicks<5,000" (число щелчков), четвертый фактор 308 определяется условием "which URL?" («Какой URL?»), пятый фактор 310 определяется условием "which Search query?" («Какой поисковый запрос?»). Кроме того, пятый узел 310 по ветке «посмотреть Эйфелеву башню» связан с листом 312. В некоторых вариантах осуществления лист 312 может указывать на параметр интереса.
[71] Согласно описанной выше конфигурации, древовидная модель 300, определенная конкретным выбором и порядком первого фактора 302, второго фактора 304, третьего фактора 306, четвертого фактора 308 и пятого фактора 310, может связывать документ (например, без введения ограничений, веб-страницу в формате html) с параметром интереса, связанным с листом 312, причем связь определяется путем в части древовидной модели 300 на основе первого набора 330 параметров и/или второго набора 340 параметров. Следует учитывать, что с целью упрощения понимания приведена только часть древовидной модели 300. Специалисту в области настоящего технического решения может быть очевидно, что число узлов, ветвей и листов фактически не ограничено и зависит исключительно от сложности древовидной модели. Кроме того, в некоторых вариантах осуществления древовидная модель может быть «небрежной» (от англ. oblivious) древовидной моделью, включающей в себя набор узлов, каждый из которых включает в себя две ветви (т.е. значение «истина» представлено бинарным числом «0», а значение «ложь» представлено бинарным числом «1»). Однако настоящее решение не ограничивается «небрежной» древовидной моделью, и может быть предусмотрено множество вариаций, что может быть очевидно специалисту в данной области техники: например, древовидная модель, состоящая из первой части, определяющей «небрежную» древовидную модель, и второй части, определяющей древовидную модель, которая не является «небрежной», что проиллюстрировано на древовидной модели 300 (первая часть определяется первым узлом 302, вторым узлом 304, третьим узлом 306, а вторая часть определяется четвертым узлом 308 и пятым узлом 310).
[72] Первый набор 330 параметров - пример параметров, определяющих путь, проиллюстрированный на древовидной модели 300. Набор 330 параметров может быть связан с документом и может предоставить возможность определить путь в древовидной модели 300, описанной выше. По меньшей мере один параметр из набора параметров может быть бинарного типа и/или типа вещественных чисел (например, типа целых чисел, типа чисел с плавающей запятой). В некоторых вариантах осуществления первая часть данных может представлять путь в «небрежной» части древовидной модели, как в случае, изображенном на Фиг. 3. В пределах объема настоящего технического решения могут быть возможны другие варианты. В примере, представленном на Фиг. 3, набор параметров включает в себя первый компонент 332, связанный со значением «01» и второй компонент 334, связанный со значением «3500». Хотя в настоящем описании используется термин «компонент», следует иметь в виду, что можно с равным успехом использовать термин «переменная», который можно рассматривать как эквивалент слова «компонент». Первый компонент 332 включает в себя бинарную последовательность «01», которая при переводе на древовидную модель 300 представляет первую часть пути. В примере, представленном на Фиг. 3, первая часть пути представлена с помощью применения первой бинарной цифры «0» из последовательности «01» к первому узлу 302 (т.е. первому фактору 302), а затем второй бинарной цифры «1» последовательности «01» ко второму узлу 304 (т.е. ко второму фактору 304). Второй компонент 332 при переводе на древовидную модель 300 представляет вторую часть пути. В примере, представленном на Фиг. 3, вторая часть пути представлена с помощью применения числа «3500» к третьему узлу 306 (т.е. третий фактор 306). Хотя в примере на Фиг. 3 приведена первая часть данных как включающая в себя первый компонент 332 и второй компонент 334, число компонентов и число цифр, включенное в один из компонентов, не ограничено и может быть предусмотрено множество вариантов, что не выходит за границы настоящего технического решения.
[73] В примере, представленном на Фиг. 3, первый набор параметров также включает в себя третий компонент 336, связанный со значением "yandex.ru" и четвертый компонент 338, связанный со значением «посмотреть Эйфелеву башню». Третий компонент 336 и четвертый компонент 338 могут быть категориального типа. В некоторых вариантах осуществления третий компонент 336 и четвертый компонент 338 также могут упоминаться как характеристики категорий и могут включать в себя, например (без введения ограничений), хост, URL, доменное имя, IP-адрес, поисковой запрос и/или ключевое слово. В некоторых вариантах осуществления настоящего технического решения третий компонент 336 и четвертый компонент 338 могут быть в общем охарактеризованы как включающие в себя категории меток, которые предоставляют возможность категоризировать информацию. В некоторых вариантах осуществления третий компонент 336 и четвертый компонент 338 могут принимать форму последовательности и/или строки символов и/или цифр. В других вариантах осуществления настоящего технического решения третий компонент 336 и четвертый компонент 338 могут включать в себя параметр, который может принимать более чем два значения, как в случае, изображенном на Фиг. 3, что приводит к тому, что древовидная модель 300 имеет столько ветвей, соединенных с узлом, сколько есть возможных значений у параметра. Может быть предусмотрено множество других вариантов того, что включают в себя третий компонент 336 и четвертый компонент 338, что не выходит за границы настоящего технического решения. В некоторых вариантах осуществления третий компонент 336 и четвертый компонент 338 могут представлять путь в части древовидной модели, причем эта часть не является «небрежной», как в случае, изображенном на Фиг. 3. В пределах объема настоящего технического решения могут быть возможны другие варианты.
[74] Третий компонент 336 включает в себя строку символов "yandex.ru", которая, при переводе на древовидную модель 300 представляет четвертую часть пути. В примере, представленном на Фиг. 3, четвертая часть пути представлена с помощью применения строки символов "yandex.ru" к четвертому узлу 308. Четвертый компонент 338 при переводе на древовидную модель 300 представляет пятую часть пути. В примере, представленном на Фиг. 3, пятая часть пути представлена с помощью применения строки символов «посмотреть Эйфелеву башню» к пятому узлу 310, приводя к узлу 312 и параметру интереса, связанному с ним. Хотя в примере на Фиг. 3 приведены третий компонент 336 и четвертый компонент 338, число компонентов и число цифр и/или символов, включенное в один из компонентов, не ограничено и может быть предусмотрено множество вариантов, что не выходит за границы настоящего решения.
[75] Обратимся ко второму набору 340 параметров, который являет собой другой пример параметров, определяющих путь, проиллюстрированный на древовидной модели 300. Как и в случае первого набора 330 параметров, второй набор 340 параметров может быть связан с документом и может предоставить возможность определить путь в древовидной модели 300, описанной выше. Второй набор параметров 340 аналогичен по всем аспектам первому набору параметров 330 за исключением того, что второй набор 340 параметров включает в себя первый компонент 342, а не первый компонент 332, и второй компонент 334 из первого набора 330 параметров. Первый компонент 342 включает в себя последовательность цифр «010», причем первый компонент 332 связан со значением «01» и второй компонент 334 связан со значением «3500». Как будет понятно специалисту в области настоящего технического решения в первом компоненте 342 значение «3500» представлено бинарной цифрой «0», которая является результатом значения «3500», примененного к условию, связанному с третьим узлом 306 (т.е. "Number_clicks <5,000", число щелчков мышью). В итоге первый компонент 342 может быть рассмотрен как альтернативное представление первого компонента 332 и второго компонента 334 того же пути в древовидной модели 300. В итоге в некоторых вариантах осуществления значение вещественного числа может быть переведено в бинарное значение, в частности, в случаях, в которых узел древовидной модели, к которому нужно применить целочисленное значение, соответствует «небрежной» части древовидной модели. Также возможны другие варианты; примеры второго набора 340 параметров не должны рассматриваться как ограничивающие объем настоящего технического решения. Второй набор параметров 340 также включает в себя второй компонент 344 и третий компонент 346, которые идентичны третьему компоненту 336 и четвертому компоненту 338 первого набора 330 параметров.
[76] На Фиг. 4 приведен пример полной древовидной модели 400. Задачей древовидной модели 400 является иллюстрация типовой древовидной модели, которая может быть модифицирована таким образом, чтобы отвечать требованиям конкретной модели прогнозирования. Такие модификации могут включать в себя, например (но без введения ограничений), добавление или удаление одного или нескольких уровней дерева, добавление или удаление узлов (т.е. факторов), добавление или удаление ветвей, соединяющих узлы, и/или листов дерева. Древовидная модель 400 может быть частью модели машинного обучения или моделью машинного обучения. Древовидная модель может быть предварительной древовидной моделью или обученной древовидной моделью. В некоторых вариантах осуществления древовидная модель 400 после создания может быть обновлена и/или модифицирована, например, для повышения уровня точности модели машинного обучения и/или расширения объема применения модели машинного обучения. В некоторых вариантах осуществления настоящего технического решения древовидная модель 400 может браться за основу для обработки, например (но без введения ограничений), поисковых запросов. Без отклонения от объема настоящего технического решения могут быть предусмотрены другие области, в которых может браться за основу древовидная модель 400.
[77] Древовидная модель 400 включает в себя первый узел 402, связанный с первым фактором "f1". Первый узел 402 определяет первый уровень древовидной модели 400. Первый узел 402 соединен ветвями со вторым узлом 404 и третьим узлом 406. Второй узел 404 и третий узел 406 связаны со вторым фактором "f2". Второй узел 404 и третий узел 406 определяют второй уровень древовидной модели 400. В одном варианте осуществления настоящего технического решения первый фактор "f1" был выбран в наборе факторов для размещения на первом уровне древовидной модели 400 на основе набора обучающих объектов. Более подробное описание того, как осуществляется выбор факторов из набора факторов, будет приведено ниже. Первый фактор "f1" определен таким образом, что, для данного объекта, значение параметра, связанного с первым фактором "f1" определяет то, связан ли объект со вторым узлом 404 или третьим узлом 406. В качестве примера, если значение меньше, чем значение "f1", то объект связан со вторым узлом 404. В другом примере, если значение больше, чем значение "f1", то объект связан с третьим узлом 406.
[78] В свою очередь, второй узел 404 связан с четвертым узлом 408, связанным с третьим фактором "f3", и пятый узел 410 связан с третьим фактором "f3". Третий узел 406 связан с шестым узлом 412, связанным с третьим фактором "f3", и седьмой узел 414 связан с третьим фактором "f3". Четвертый узел 408, пятый узел 410, шестой узел 412 и седьмой узел 414 определяют третий уровень древовидной модели 400. Как было описано ранее по отношению к первому узлу 402, для данного объекта, значение параметра, связанного со вторым фактором "f2" определяет то, будет ли связан объект с четвертым узлом 408, или с пятым узлом 410 (если объект связан со вторым узлом 404), или с шестым узлом 412 или седьмым узлом 414 (если объект связан с третьим узлом 406).
[79] В свою очередь, каждый узел из: четвертый узел 408, пятый узел 410, шестой узел 412 и седьмой узел 414 связан с наборами параметров интереса. В примере на Фиг. 4 наборы параметров интереса включают в себя первый набор 420, второй набор 422, третий набор 424 и четвертый набор 426. Каждый из наборов параметров интереса включает в себя три параметра интереса, а именно "С1", "С2" и "С3".
[80] Как будет понятно специалистам в данной области техники, древовидная модель 400 иллюстрирует вариант осуществления настоящего технического решения, в котором конкретный уровень древовидной модели 400 связан с одним фактором. В примере, представленном на Фиг. 4, первый уровень включает в себя первый узел 402 и связан с первым фактором "f1"; второй уровень включает в себя второй узел 404 и третий узел 406, и связан со вторым фактором "f2"; а третий уровень включает в себя четвертый узел 408, пятый узел 410, шестой узел 412 и седьмой узел 414, и связан с третьим фактором "f3". Другими словами, в варианте осуществления настоящего технического решения на Фиг. 4 первый уровень связан с первым фактором "f1", второй уровень связан со вторым фактором "f2", и третий уровень связан с третьим фактором "f3". Могут быть, однако, предусмотрены другие варианты осуществления настоящего решения. В частности, в альтернативном варианте осуществления созданная древовидная модель может включать в себя различные факторы для данного уровня древовидной модели. Например, первый уровень такой древовидной модели может включать в себя первый узел, связанный с первым фактором "f1", второй уровень может включать в себя второй узел, связанный со вторым фактором "f2" и третий узел, связанный с третьим фактором "f3". Как будет понятно специалистам в области настоящего технического решения, можно предусмотреть множество вариантов того, какие факторы могут быть связаны с данным уровнем, не выходя за границы настоящего технического решения.
[81] Релевантные этапы создания варианта модели прогнозирования в виде дерева принятия решений (также упоминаемой как «обученное дерево принятия решений», «древовидная модель», и/или «модель дерева принятия решений») будут описаны с учетом Фиг. 5, Фиг. 6 и Фиг. 7.
[82] На Фиг. 5 представлены этапы создания варианта модели прогнозирования в виде дерева принятия решений. На Фиг. 6 и Фиг. 7 представлены наборы первичных деревьев (также упоминаемых как «предварительные древовидные модели» или «предварительные модели прогнозирования в виде деревьев принятия решений», используемые для выбора первого фактора и второго фактора, которые используются в варианте осуществления обученной модели прогнозирования.
[83] На Фиг. 5 представлен процесс создания обученной модели прогнозирования в виде дерева принятия решений на основе набора факторов и обучающих объектов. Следует отметить, что следующее описание обученной модели прогнозирования, как представлено на Фиг. 5, является только одним неограничивающим вариантом осуществления обученной модели прогнозирования в виде дерева принятия решений, и предусматривается, что другие неограничивающие варианты осуществления могут иметь больше или меньше узлов, факторов, уровней и листов.
[84] Как проиллюстрировано первым деревом 510 принятия решений, создание обученной модели прогнозирования в виде дерева принятия решений начинается с выбора первого фактора, связанного здесь с первым узлом 511. Способ, с помощью которого выбираются факторы на каждом уровне, будет описан подробнее ниже.
[85] На окончании пути от первого узла 511 по ветви первого дерева принятия решений есть два листа 512 и 513. Каждый лист, лист 512 и лист 513, имеет «значения листа», которые связаны с параметрами интереса. В некоторых вариантах осуществления настоящего технического решения первый фактор "f1" был выбран для узла 511 первого уровня древовидной модели 510 на основе набора обучающих объектов и/или параметра точности дерева 510 принятия решений. Более подробное описание того, как определяется параметр точности листа и/или параметр точности дерева 510 принятия решений, будет приведено ниже, в связи с описанием способов 800, 900 и 1000.
[86] Второй фактор "f2" выбирается следующим и добавляется к дереву 510 принятия решений, что создает дерево 520 принятия решений. Второй узел 522 и третий узел 523, связанные со вторым фактором, добавляются к двум ветвям, исходящим из первого узла 511. В альтернативном варианте осуществления второй узел 522 и третий узел 523 могут быть связаны с различными факторами. В вариантах осуществления настоящего технического решения, показанных на Фиг. 5, первый узел 511 дерева 520 принятия решений остается таким же, как и в дереве 510 принятия решений, потому что первый фактор был выбран и назначен на первый уровень, и связан с первым узлом 511. Листы 524-528 теперь связаны с окончаниями путей в дереве 520 принятия решений. Второй узел 522 имеет два листа, лист 524 и лист 525, исходящие из второго узла 522. Третий узел 523 имеет три листа, лист 526, лист 527 и лист 528, исходящие из третьего узла 523. Число листов, исходящих из любого данного узла, может зависеть, например, от факторов, выбранных в любом данном узле, и признаков обучающих объектов, с помощью которых была создана древовидная модель.
[87] Также на Фиг. 5, показано, что затем выбирается третий фактор "f3" и добавляется к дереву 520 принятия решений, что создает дерево 530 принятия решений. Первый узел 511, второй узел 522 и третий узел 523 остаются теми же самыми, что и в дереве 510 принятия решения и в дереве 520 принятия решений. Первый фактор и второй фактор (и связанные с ними узлы) также остаются теми же самыми факторами (и узлами), выбранными и назначенными ранее. Новые узлы 534-538 добавляются к ветвям, исходящим из второго узла 522 и третьего узла 523. Новые листы (540, 541, 542, 543, 545, 546, 547, 548, 549, 550, 551), связанные с окончаниями путей дерева 530 принятия решения, исходят из новых узлов 534-538. Каждый лист из новых листов (540, 541, 542, 543, 545, 546, 547, 548, 549, 550, 551) имеет соответствующее значение листа, связанное с одним или несколькими параметрами интереса. В этом примере варианта осуществления во время создания обученной модели прогнозирования в виде дерева принятия решений было выбрано три фактора. Предусматривается, что в различных вариантах осуществления обученной модели прогнозирования в виде дерева принятия решений может быть больше или меньше трех факторов. Следует отметить, что создаваемая древовидная модель может обладать числом уровней, созданных так, как описано выше, которое больше или меньше трех.
[88] Способ выбора факторов для обученной модели прогнозирования в виде дерева принятия решений, который проиллюстрирован на Фиг. 4 и Фиг. 5, теперь будет описан с учетом Фиг. 6 и Фиг. 7.
[89] Для выбора в качестве первого фактора «наилучшего» фактора создается набор «первичных деревьев» («прото-деревьев») с первым узлом. На Фиг. 6 показаны три первичных дерева 610, 620 и 630 как типичная выборка из набора первичных деревьев. В каждом отдельном первичном дереве 610, 620 и 630 первый узел связан с отдельным фактором из набора доступных факторов. Например, узел 611 первичного дерева 610 связан с одним из факторов, "fa", а узел 621 первичного дерева 620 связан с фактором "fb", а в первичном дереве 630 узел 631 связан с фактором "fn". В некоторых вариантах осуществления настоящего технического решения для каждого из факторов, из которых должен быть выбран первый фактор, создается одно первичное дерево. Все первичные деревья отличаются друг от друга, и они могут не учитываться после выбора наилучшего фактора для использования в качестве узла первого уровня.
[90] В некоторых вариантах осуществления такие факторы как, например, "fa", "fb" и "fn", будут связаны с признаками, которые являются численными или категориальными. Например, возможно не только наличие двух листов на узел (как в случае с использованием только бинарных данных), но и наличие большего количества листов (и ветвей, к которым могут быть добавлены дополнительные узлы). Например, как показано на Фиг. 6, первичное дерево 610, включающее в себя узел 611, имеет ветви, идущие в три листа 612-614, а первичное дерево 620 и первичное дерево 630 имеет два (622, 623) листа и четыре листа (632-635), соответственно.
[91] Набор первичных деревьев, изображенных на Фиг. 6, затем используется для выбора «наилучшего» первого фактора для добавления к создаваемой обученной модели прогнозирования в виде дерева принятия решений. В каждом дереве из первичных деревьев по меньшей мере к некоторым листам, исходящему из одного или нескольких узлов, применяется эвристическая функция, упомянутая выше и описанная подробнее ниже. Например, параметр точности определяется для первичных деревьев 610, 620 и 630. В некоторых вариантах осуществления настоящего технического решения параметры точности листа определяются по меньшей мере для некоторых листов, например, для листов 612, 613, и 614 первичного дерева 610. В некоторых вариантах осуществления параметры точности листа могут быть комбинированы для определения параметра точности. Более подробное описание того, как определяется параметр точности листа и/или параметр точности первичного дерева, будет приведено ниже, в связи с описанием способов 800, 900 и 1000.
[92] Первый фактор для использования при создании древовидной модели затем может быть выбран с помощью выбора первичного дерева «наилучшего качества» на основе параметров точности для каждого первичного дерева. Фактор, связанный с первичным деревом «наилучшего качества» затем выбирается как первый фактор для создания обученной модели прогнозирования в виде дерева принятия решений.
[93] С целью иллюстрации выберем первичное дерево 620 как «наилучшее» первичное дерево, например, на основе определения того, что первичное дерево 620 связано с наивысшим параметром точности. На Фиг. 7 показан созданный второй набор первичных деревьев для выбора «наилучшего» фактора второго фактора для добавления к создаваемой обученной модели прогнозирования в виде дерева принятия решений. Узел 621 и его соответствующие ветви сохраняются от первичного дерева 620. Остальное первичное дерево 620 и первый набор первичных деревьев может не учитываться.
[94] Те же самые обучающие объекты затем используются для тестирования второго набора первичных деревьев, включающих в себя узел 621, связанный с «наилучшим» первым фактором (назначенным с помощью описанного выше процесса) и двух узлов, связанных со вторым фактором, причем второй фактор из набора факторов для каждого первичного дерева свой. В этом примере присутствуют два узла второго уровня, потому что с узлом 621 связаны две ветви. Если бы «наилучшим» первичным деревом было первичное дерево 630, присутствовало бы четыре узла, связанных с четырьмя ветвями, исходящими из узла 631. Как показано в трех типичных примерах первичных деревьев 640, 660 и 680 из второго набора первичных деревьев, показанных на Фиг. 7, первый узел каждого первичного дерева - это узел 621 от наилучшего первого первичного дерева, и в деревьях присутствуют, добавленные к двум ветвям, исходящим от узла 621, два узла 642, 643 (для первичного дерева 640), два узла 662, 663 (для первичного дерева 660) и два узла 682, 683 (для первичного дерева 680). Каждое из окончаний первичных деревьев 640, 660 и 680 связано с листами 644-647; 664-668 и 684-688, соответственно.
[95] «Наилучший» второй фактор теперь выбирается таким же образом, как описано выше для «наилучшего» первого фактора, причем первичное дерево, состоящее из первого фактора и второго фактора, будет иметь, в соответствии с эвристической функцией, «более высокое качество» (обладая более высоким параметром точности), чем другие первичные деревья, которые не были выбраны. Затем второй фактор, связанный со вторыми узлами первичного дерева, обладающими более высоким параметром точности, выбирается как второй фактор для того, чтобы быть присвоенным создающейся обученной модели прогнозирования в виде дерева принятия решений. Например, если первичное дерево 660 определяется как первичное дерево с наивысшим параметром точности, узел 662 и узел 663 будут добавлены к создающейся обученной модели прогнозирования в виде дерева принятия решений.
[96] Аналогично, если добавляются последующие факторы и уровни, будет создаваться новый набор первичных деревьев с использованием узла 621, узла 662, и узла 663, с новыми узлами, добавленным к пяти ветвям, исходящим из узла 662 и узла 663. Способ будет проводиться для какого угодно количества уровней и связанных факторов при создании обученной модели прогнозирования в виде дерева принятия решений. Следует отметить, что обученная модель прогнозирования в виде дерева принятия решений может обладать числом уровней, созданных так, как описано выше, которое больше или меньше трех.
[97] Когда создание обученной модели прогнозирования в виде дерева принятия решений завершено, для законченной модели прогнозирования может быть осуществлено определение параметра точности. В некоторых вариантах осуществления определение модели прогнозирования может основываться на наборе обученных моделей прогнозирования в виде деревьев принятия решений, а не на единственной обученной модели прогнозирования в виде дерева принятия решений, причем каждая обученная модель прогнозирования в виде дерева принятия решений из набора может быть создана в соответствии со способом, описанным выше. В некоторых вариантах осуществления факторы могут быть выбраны из того же самого набора факторов, и может быть использован тот же самый набор обучающих объектов.
[98] С учетом Фиг. 1 - Фиг. 7 были описаны некоторые не ограничивающие примеры систем и компьютерных способов, используемые в связи с проблемой создания обученной модели прогнозирования в виде дерева принятия решений и/или установки параметра точности обученной модели прогнозирования в виде дерева принятия решений, далее следует описание общих решений этой проблемы со ссылкой на Фиг. 8 - Фиг. 11.
[99] Конкретнее, на Фиг. 8 показана блок-схема первого компьютерного способа 800 определения параметра точности обученной модели прогнозирования в виде дерева принятия решений. В некоторых вариантах осуществления способ 800 может быть (полностью или частично) реализован на ведущем сервере 210 и/или ведомых серверах 230, 232 и 234.
[100] Способ 800 начинается на этапе 802, на котором осуществляется доступ, с постоянного машиночитаемого носителя системы машинного обучения, к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса. Затем, на этапе 804 способа 800 происходит создание процессором системы машинного обучения обученной модели прогнозирования в виде дерева принятия решений по меньшей мере частично на основе набора обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса, а обученная модель прогнозирования в виде дерева принятия решений включает в себя узлы, связанные с факторами, и листы, связанные с параметрами интереса обучающих объектов из набора обучающих объектов, и связь между листами и параметрами интереса была определена с помощью выполненного процессором системы машинного обучения сравнения по меньшей мере двух из факторов и признаков обучающих объектов из набора обучающих объектов.
[101] На этапе 806 способа 800 осуществляется передача команды системе машинного обучения на выполнение этапов 808, 810, 812 и 814. На этапе 808 процессор осуществляет создание процессором подгруппы случайных параметров интереса. На этапе 810 процессор осуществляет связывание в постоянном машиночитаемом носителе подгруппы случайных параметров интереса с данным листом. На этапе 812 процессор выполняет определение процессором параметра точности листа на основе (i) параметров интереса, связанных с данным листом и (ii) подгруппы случайных параметров интереса данного листа. На этапе 814 процессор осуществляет определение процессором параметра точности обученной модели прогнозирования в виде дерева принятия решений на основе определенного параметра точности листа.
[102] На Фиг. 9 показана блок-схема второго компьютерного способа 900 определения параметра точности обученной модели прогнозирования в виде дерева принятия решений. В некоторых вариантах осуществления способ 900 может быть (полностью или частично) реализован на ведущем сервере 210 и/или ведомых серверах 230, 232 и 234. Как будет понятно специалисту в данной области техники, некоторые или все аспекты и альтернативные варианты осуществления настоящего технического решения, перечисленные в связи со способом 900 могут в равной степени быть применимы или адаптированы к способам 800, 1000 и 1100.
[103] Способ 900 начинается на этапе 902, на котором происходит доступ, с постоянного машиночитаемого носителя, к обученной модели прогнозирования в виде дерева принятия решений, созданной по меньшей мере частично на основе набора обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса, а обученная модель прогнозирования включает в себя узлы, связанные с факторами, и листы, связанные с параметрами интереса обучающих объектов из набора обучающих объектов, и связь между листами и параметрами интереса была определена с помощью сравнения по меньшей мере двух из факторов и признаков обучающих объектов из набора обучающих объектов. В некоторых вариантах осуществления сравнение по меньшей мере двух факторов и признаков обучающих объектов включает в себя сравнение процессором условий, связанных по меньшей мере с двумя факторами и по меньшей мере двумя значениями, связанными с признаками соответствующего обучающего объекта. В некоторых вариантах осуществления признаки могут указывать по меньшей мере либо на число щелчков мышью, либо на число просмотров, либо на ранжирование документов, либо на URL, либо на доменное имя, либо на IP-адрес, либо на поисковой запрос, либо на ключевое слово. В некоторых вариантах осуществления настоящего технического решения параметр интереса может указывать по меньшей мере либо на прогнозирование поискового результата, либо на вероятность щелчка мышью, либо на релевантность документа, либо на пользовательский интерес, либо на URL, либо на число щелчков, либо на отношение количества щелчков мышью к количеству показов (CTR). В некоторых вариантах осуществления настоящего технического решения каждый из факторов может быть связан либо с (i) условием, применимым к бинарному признаку, либо с (ii) условием, применимым к численному признаку, либо с (iii) условием, применимым к категориальному признаку.
[104] На этапе 904 способа 900 осуществляется создание процессором подгруппы случайных параметров интереса. В некоторых вариантах осуществления настоящего технического решения создание процессором подгруппы случайных параметров интереса включает в себя создание случайных значений целевой функции, связанной с обученной моделью прогнозирования в виде дерева принятия решений. В некоторых вариантах осуществления настоящего технического решения случайные значения выбираются таким образом, чтобы увеличить ошибку, связанную с наилучшим из факторов фактором, поддерживая при этом созданный ранее параметр точности обученной модели прогнозирования в виде дерева принятия решений ниже минимального порога. Наилучший из факторов фактор может быть определен как фактор, оказывающий наиболее положительное влияние на созданный ранее параметр точности обученной модели прогнозирования в виде дерева принятия решений. Случайные значения могут быть выбраны на основе значений параметров интереса, связанных сданным листом. Случайные значения могут быть выбраны таким образом, что они будут включены в состав диапазона, включающего в себя минимальное значение, определенное как самое низкое из значений параметра интереса, связанного с данным листом, и самое высокое из значений, определенное как самое высокое значение параметра интереса, связанного с данным листом. Подгруппа случайных параметров интереса может включать в себя число случайных параметров интереса, равное числу параметров интереса данного листа, с которым подгруппа случайных параметров интереса связана.
[105] На этапе 906 способа 900 осуществляется связывание в постоянном машиночитаемом носителе подгруппы случайных параметров интереса с данным листом.
[106] На этапе 908 способа 900 осуществляется определение процессором параметра точности листа на основе (i) параметров интереса, связанных с данным листом и (ii) подгруппы случайных параметров интереса данного листа.
[107] Затем на этапе 910 способа 900 осуществляется определение процессором параметра точности обученной модели прогнозирования в виде дерева принятия решений на основе определенного параметра точности листа. В некоторых вариантах осуществления определение процессором параметра точности обученной модели прогнозирования в виде дерева принятия решений, основанное на определенном параметре точности листа, включает в себя определение общей ошибки листов в соответствии с формулой:
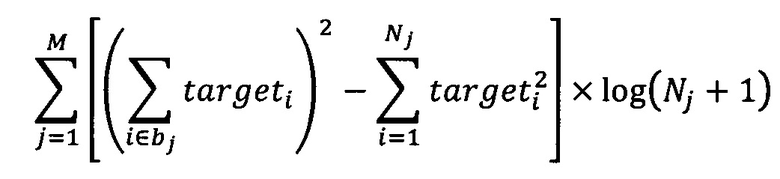 ,
,
где М - число листов, Nj является числом параметров интереса, связанных с j-м листом.
[108] В некоторых вариантах осуществления число параметров интереса, связанное с j-м листом, равно числу обучающих объектов, связанных с j-м листом. Кроме того, определение процессором параметра точности обученной модели прогнозирования в виде дерева принятия решений может быть основано на множестве определенных параметров точности листа, причем каждый из множества определенных параметров листа связан с отдельным листом. В некоторых вариантах осуществления настоящего технического решения параметр точности обученной модели прогнозирования в виде дерева принятия решений может показывать точность целевой функции, связанной с обученной моделью прогнозирования в виде дерева принятия решений.
[109] На Фиг. 10 показана блок-схема третьего компьютерного способа 1000 определения параметра точности обученной модели прогнозирования в виде дерева принятия решений. В некоторых вариантах осуществления настоящего технического решения способ 1000 может быть (полностью или частично) реализован на ведущем сервере 210 и/или ведомых серверах 230, 232 и 234.
[110] Способ 1000 начинается на этапе 1002, на котором осуществляется доступ, с постоянного машиночитаемого носителя к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса. Затем, на этапе 1004 способа 1000 происходит создание процессором обученной модели прогнозирования в виде дерева принятия решений по меньшей мере частично на основе набора обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса, а обученная модель прогнозирования в виде дерева принятия решений включает в себя узлы, связанные с факторами, и листы, связанные с параметрами интереса обучающих объектов из набора обучающих объектов, и связь между листами и параметрами интереса была определена с помощью сравнения по меньшей мере двух из факторов и признаков обучающих объектов из набора обучающих объектов.
[111] На этапе 1006 способа 1000 осуществляется создание процессором подгруппы случайных параметров интереса. Затем, на этапе 1008 способа 1000 осуществляется связывание в постоянном машиночитаемом носителе подгруппы случайных параметров интереса с данным листом. На этапе 1010 способа 1000 осуществляется определение процессором параметра точности листа на основе (i) параметров интереса, связанных с данным листом и (ii) подгруппы случайных параметров интереса данного листа. Затем на этапе 1012 способа 1000 осуществляется определение процессором параметра точности обученной модели прогнозирования в виде дерева принятия решений на основе определенного параметра точности листа.
[112] На Фиг. 11 показана блок-схема четвертого компьютерного способа 1100 создания обученной модели прогнозирования в виде дерева принятия решений. В некоторых вариантах осуществления настоящего технического решения способ 1100 может быть (полностью или частично) реализован на ведущем сервере 210 и/или ведомых серверах 230, 232 и 234.
[113] Способ 1100 начинается на этапе 1102, с осуществления доступа из постоянного машиночитаемого носителя к набору факторов. Затем, на этапе 1104 способа 1100 осуществляется идентификация процессором из набора факторов фактора, связанного с наилучшим параметром точности предварительно обученной модели прогнозирования в виде дерева принятия решений, для данного положения узла, связанного с фактором в предварительно обученной модели прогнозирования в виде дерева принятия решений, причем наилучший параметр точности предварительно обученной модели прогнозирования в виде дерева принятия решений выбирается из множества параметров точности множества предварительных моделей прогнозирования в виде дерева принятия решений, причем множество параметров точности множества предварительных моделей прогнозирования в виде дерева принятия решений было создано в соответствии со способами 800, 900 или 1000. Специалистом в данной области техники могут быть предусмотрены и другие варианты, основанные на способах 800, 900 или 1000, без отклонения от объема настоящего технического решения.
[114] На этапе 1106 способа 1100 осуществляется связывание процессором фактора с данным положением узла создающейся обученной модели прогнозирования в виде дерева принятия решений. На этапе 1108 способа 1100 осуществляется создание процессором обученной модели прогнозирования в виде дерева принятия решений, причем обученная модель прогнозирования в виде дерева принятия решений включает в себя узел, связанный с фактором, для данного положения. В некоторых вариантах осуществления каждый из множества параметров точности связан с соответствующей моделью из множества предварительных моделей прогнозирования в виде дерева принятия решений.
[115] В некоторых вариантах осуществления способ 1100 также включает в себя первый дополнительный этап и второй дополнительный этап. Первый дополнительный этап включает в себя идентификацию процессором другого фактора из набора факторов, причем этот другой фактор связан с наилучшим параметром точности другой предварительно обученной модели прогнозирования в виде дерева принятия решений для другого данного положения другого узла, связанного с другим фактором в другой предварительно обученной модели прогнозирования в виде дерева принятия решений. Второй дополнительный этап включает в себя связывание процессором другого фактора с другим данным положением другого узла создающейся обученной модели прогнозирования в виде дерева принятия решений.
[116] В некоторых вариантах осуществления настоящего технического решения обученная модель прогнозирования в виде дерева принятия решений также включает в себя другой узел, связанный с другим фактором, для другого данного положения.
[117] С учетом вышеописанных вариантов осуществления настоящего технического решения, которые были описаны и показаны со ссылкой на конкретные этапы, выполненные в определенном порядке, следует иметь в виду, что эти этапы могут быть совмещены, разделены, обладать другим порядком выполнения - все это не выходит за границы настоящего технического решения. Соответственно, порядок и группировка этапов не является ограничением для настоящего технического решения.
[118] Таким образом, способы и системы, реализованные в соответствии с некоторыми неограничивающими вариантами осуществления настоящего технического решения, могут быть представлены следующим образом, представленными в пронумерованных пунктах.
[119] [Пункт 1] Способ (800) определения параметра точности обученной модели (400) прогнозирования в виде дерева принятия решений, способ выполняется в компьютерной системе (210, 230, 232, 234) машинного обучения; способ (800) включает в себя:
доступ (802), с постоянного машиночитаемого носителя (120, 130) системы машинного обучения, к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса;
создание (804) процессором (110) системы машинного обучения обученной модели (400) прогнозирования в виде дерева принятия решений по меньшей мере частично на основе набора обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса, а обученная модель (400) прогнозирования в виде дерева принятия решений включает в себя узлы (402, 404, 406, 408, 410, 412, 414), связанные с факторами, и листы (420, 422, 424, 426), связанные с параметрами интереса обучающих объектов из набора обучающих объектов, и связь между листами (420, 422, 424, 426) и параметрами интереса была определена с помощью выполненного процессором (110) системы машинного обучения сравнения по меньшей мере двух из факторов и признаков обучающих объектов из набора обучающих объектов;
отправку (806) команды процессору (110) системы машинного обучения на выполнение:
создания (808) процессором (110) подгруппы случайных параметров интереса;
связывания (810) в постоянном машиночитаемом носителе (120, 130) подгруппы случайных параметров интереса сданным листом;
определение (812) процессором (110) параметра точности листа на основе (i) параметров интереса, связанных с данным листом и (ii) подгруппы случайных параметров интереса данного листа; и
определение (814) процессором (110) точности обученной модели прогнозирования в виде дерева принятия решений на основе определенного параметра точности листа.
[120] [Пункт 2] Способ (900) определения параметра точности обученной модели (400) прогнозирования в виде дерева принятия решений, способ (900) выполняется в компьютерной системе (210, 230, 232, 234) машинного обучения; способ (900) включает в себя:
доступ (902) из постоянного машиночитаемого носителя (120, 130) к обученной модели (400) прогнозирования в виде дерева принятия решений, созданной по меньшей мере частично на основе набора обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса, а обученная модель (400) прогнозирования в виде дерева принятия решений включает в себя узлы (402, 404, 406, 408, 410, 412, 414), связанные с факторами, и листы (420, 422, 424, 426), связанные с параметрами интереса обучающих объектов из набора обучающих объектов, и связь между листами (420, 422, 424, 426) и параметрами интереса была определена с помощью сравнения по меньшей мере двух из факторов и признаков обучающих объектов из набора обучающих объектов;
создание (904) процессором (110) подгруппы случайных параметров интереса;
связывания (906) в постоянном машиночитаемом носителе (120, 130) подгруппы случайных параметров интереса сданным листом;
определение (908) процессором (110) параметра точности листа на основе (i) параметров интереса, связанных с данным листом и (ii) подгруппы случайных параметров интереса данного листа; и
определение (910) процессором (110) точности обученной модели прогнозирования в виде дерева принятия решений на основе определенного параметра точности листа.
[121] [Пункт 3] Способ (900) по п. 2, в котором сравнение по меньшей мере двух факторов и признаков обучающих объектов включает в себя сравнение процессором (110) условий, связанных по меньшей мере с двумя факторами и по меньшей мере двумя значениями, связанными с признаками соответствующего обучающего объекта.
[122] [Пункт 4] Способ по любому из пп. 2 и 3, в котором создание процессором (110) подгруппы случайных параметров интереса включает в себя создание случайных значений целевой функции, связанной с обученной моделью (400) прогнозирования в виде дерева принятия решений.
[123] [Пункт 5] Способ по п. 4, в котором и случайные значения выбираются таким образом, чтобы увеличить ошибку, связанную с наилучшим из факторов фактором, поддерживая при этом созданный ранее параметр точности обученной модели (400) прогнозирования в виде дерева принятия решений ниже минимального порога.
[124] [Пункт 6] Способ по п. 5, в котором наилучший из факторов фактор определен как фактор, оказывающий наиболее положительное влияние на созданный ранее параметр точности обученной модели (400) прогнозирования в виде дерева принятия решений.
[125] [Пункт 7] Способ по любому из пп. 4-6, в котором случайные значения выбираются на основе значений параметров интереса, связанных с данным листом.
[126] [Пункт 8] Способ по п. 7, в котором случайные значения выбираются таким образом, что они будут включены в состав диапазона, включающего в себя минимальное значение, определенное как самое низкое из значений параметра интереса, связанного с данным листом, и самое высокое из значений, определенное как самое высокое значение параметра интереса, связанного с данным листом.
[127] [Пункт 9] Способ по любому из пп. 2-8, в котором подгруппа случайных параметров интереса включает в себя число случайных параметров интереса, равное числу параметров интереса данного листа, с которым подгруппа случайных параметров интереса связана.
[128] [Пункт 10] Способ по любому из пп. 2-9, в котором определение процессором (110) параметра точности обученной модели (400) прогнозирования в виде дерева принятия решений, основанное на определенном параметре точности листа, включает в себя определение общей ошибки листов в соответствии с формулой:
где М - число листов, Nj является числом параметров интереса, связанных с j-м
листом.
[129] [Пункт 11] Способ по п. 10, в котором число параметров интереса, связанное c j-м листом, равно числу обучающих объектов, связанных с j-м листом.
[130] [Пункт 12] Способ по любому из пп. 2-11, в котором определение процессором (110) параметра точности обученной модели прогнозирования в виде дерева принятия решений основано на множестве определенных параметров точности листа, причем каждый из множества определенных параметров листа связан с отдельным листом.
[131] [Пункт 13] Способ по п. 2, в котором признаки указывают по меньшей мере либо на число щелчков мышью, либо на число просмотров, либо на ранжирование документов, либо на URL, либо на доменное имя, либо на IP-адрес, либо на поисковой запрос, либо на ключевое слово.
[132] [Пункт 14] Способ по п. 2, в котором параметр интереса указывает по меньшей мере либо на прогнозирование поискового результата, либо на вероятность щелчка мышью, либо на релевантность документа, либо на пользовательский интерес, либо на URL, либо на число щелчков мышью, либо на отношение количества щелчков мышью к количеству показов (CTR).
[133] [Пункт 15] Способ по любому из пп. 2-14, в котором параметр точности обученной модели прогнозирования в виде дерева принятия решений показывает точность целевой функции, связанной с обученной моделью (400) прогнозирования в виде дерева принятия решений.
[134] [Пункт 16] Способ по любому из пп. 2-15, в котором каждый из факторов связан либо с (i) условием, применимым к бинарному признаку, либо с (ii) условием, применимым к численному признаку, либо (iii) условием, применимым к категориальному признаку.
[135] [Пункт 17] Способ (1100) создания обученной модели (400) прогнозирования в виде дерева принятия решений, способ (1100) выполняется в компьютерной системе (210, 230, 232, 234) машинного обучения; способ (1100) включает в себя:
осуществление доступа (1102) из постоянного машиночитаемого носителя (120, 130) к набору факторов;
идентификацию (1104) процессором (110) из набора факторов фактора, связанного с наилучшим параметром точности предварительно обученной модели (510, 520, 530, 610, 620, 630, 640, 660, 680) прогнозирования в виде дерева принятия решений, для данного положения узла, связанного с фактором в предварительно обученной модели (510, 520, 530, 610, 620, 630, 640, 660, 680) прогнозирования в виде дерева принятия решений, причем наилучший параметр точности предварительно обученной модели (510, 520, 530, 610, 620, 630, 640, 660, 680) прогнозирования в виде дерева принятия решений выбирается из множества параметров точности множества предварительных моделей прогнозирования в виде дерева принятия решений, причем множество параметров точности множества предварительных моделей прогнозирования в виде дерева принятия решений было создано в соответствии со способом по любому из пп. 2-16 и 21;
связывание (1106) процессором (110) фактора с данным положением узла создающейся обученной модели (400) прогнозирования в виде дерева принятия решений; и
создание (1108) процессором (110) обученной модели (400) прогнозирования в виде дерева принятия решений, причем обученная модель (400) прогнозирования в виде дерева принятия решений включает в себя узел, связанный с фактором, для данного положения.
[136] [Пункт 18] Способ по п. 17, в котором каждый из множества параметров точности связан с соответствующей моделью из множества предварительных моделей прогнозирования в виде дерева принятия решений.
[137] [Пункт 19] Способ по любому из пп. 17-18, в котором способ (1100) также включает в себя:
идентификацию процессором (110) другого фактора из набора факторов, причем этот другой фактор связан с наилучшим параметром точности другой предварительно обученной модели (510, 520, 530, 610, 620, 630, 640, 660, 680) прогнозирования в виде дерева принятия решений для другого данного положения другого узла, связанного с другим фактором в другой предварительно обученной модели (510, 520, 530, 610, 620, 630, 640, 660, 680) прогнозирования в виде дерева принятия решений; и
связывание процессором (110) другого фактора с другим данным положением другого узла создающейся обученной модели (400) прогнозирования в виде дерева принятия решений.
[138] [Пункт 20] Способ по любому из пп. 17-19, в котором обученная модель (400) прогнозирования в виде дерева принятия решений также включает в себя другой узел, связанный с другим фактором, для другого данного положения.
[139] [Пункт 21] Способ (1000) определения параметра точности обученной модели (400) прогнозирования в виде дерева принятия решений, способ выполняется в компьютерной системе (210, 230, 232, 234) машинного обучения; способ (1000) включает в себя:
доступ (1002), с постоянного машиночитаемого носителя (120, 130), к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса;
создание (1004) процессором (110) обученной модели (400) прогнозирования в виде дерева принятия решений по меньшей мере частично на основе набора обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса, а обученная модель прогнозирования в виде дерева принятия решений включает в себя узлы (402, 404, 406, 408, 410, 412, 414), связанные с факторами, и листы (420, 422, 424, 426), связанные с параметрами интереса обучающих объектов из набора обучающих объектов, и связь между листами (420, 422, 424, 426) и параметрами интереса была определена с помощью сравнения по меньшей мере двух из факторов и признаков обучающих объектов из набора обучающих объектов;
создание (1006) процессором (110) подгруппы случайных параметров интереса;
связывания (1008) в постоянном машиночитаемом носителе (120, 130) подгруппы случайных параметров интереса сданным листом;
определение (1010) процессором (110) параметра точности листа на основе (i) параметров интереса, связанных с данным листом и (ii) подгруппы случайных параметров интереса данного листа; и
определение (1012) процессором (110) точности обученной модели (400) прогнозирования в виде дерева принятия решений на основе определенного параметра точности листа.
[140] [Пункт 22] Компьютерная система (210, 230, 232, 234), выполненная с возможностью выполнять способ по любому из пп. 1-21.
[141] [Пункт 23] Постоянный машиночитаемый носитель (120, 130), включающий в себя исполнимые на компьютере инструкции, которые инициируют выполнение системой ((210, 230, 232, 234) способа по любому из пп. 1-21.
[142] Важно иметь в виду, что варианты осуществления настоящего технического решения могут быть реализованы с проявлением и других технических результатов.
[143] Некоторые из этих этапов, а также передача-получение сигнала хорошо известны в данной области техники и поэтому для упрощения были опущены в конкретных частях данного описания. Сигналы могут быть переданы-получены с помощью оптических средств (например, оптоволоконного соединения), электронных средств (например, проводного или беспроводного соединения) и механических средств (например, на основе давления, температуры или другого подходящего параметра).
[144] Модификации и улучшения вышеописанных вариантов осуществления настоящего технического решения будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не несет никаких ограничений. Таким образом, объем настоящего технического решения ограничен только объемом прилагаемой формулы изобретения.
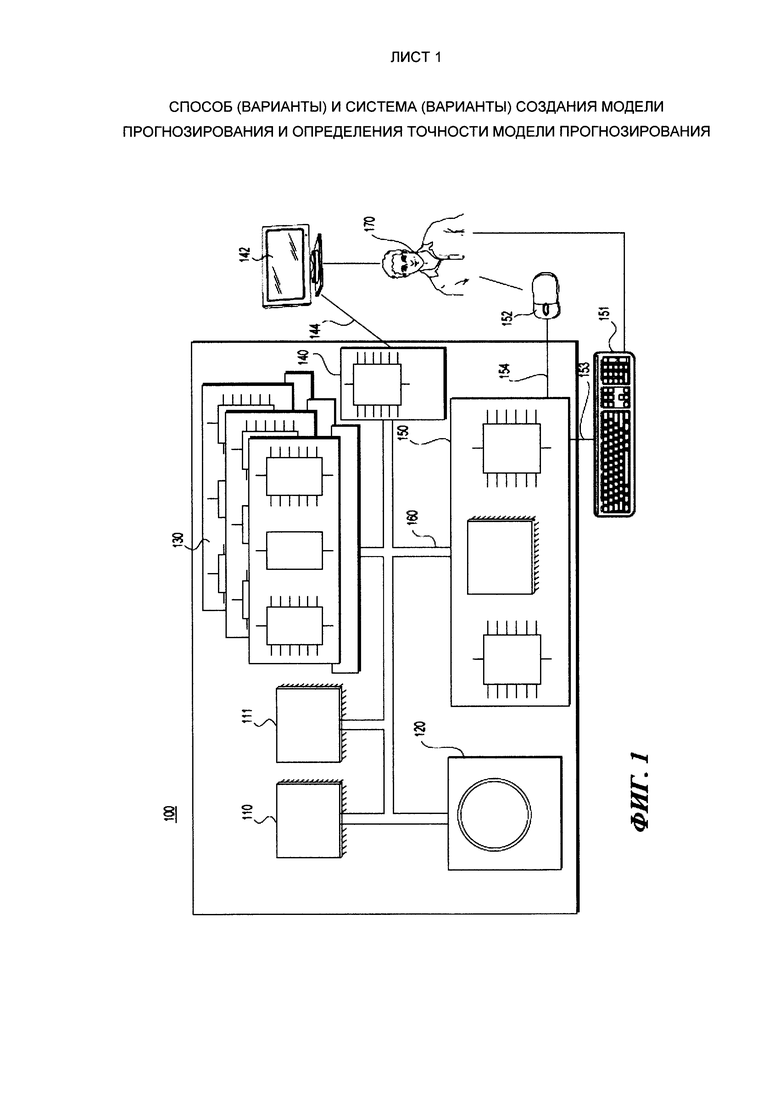



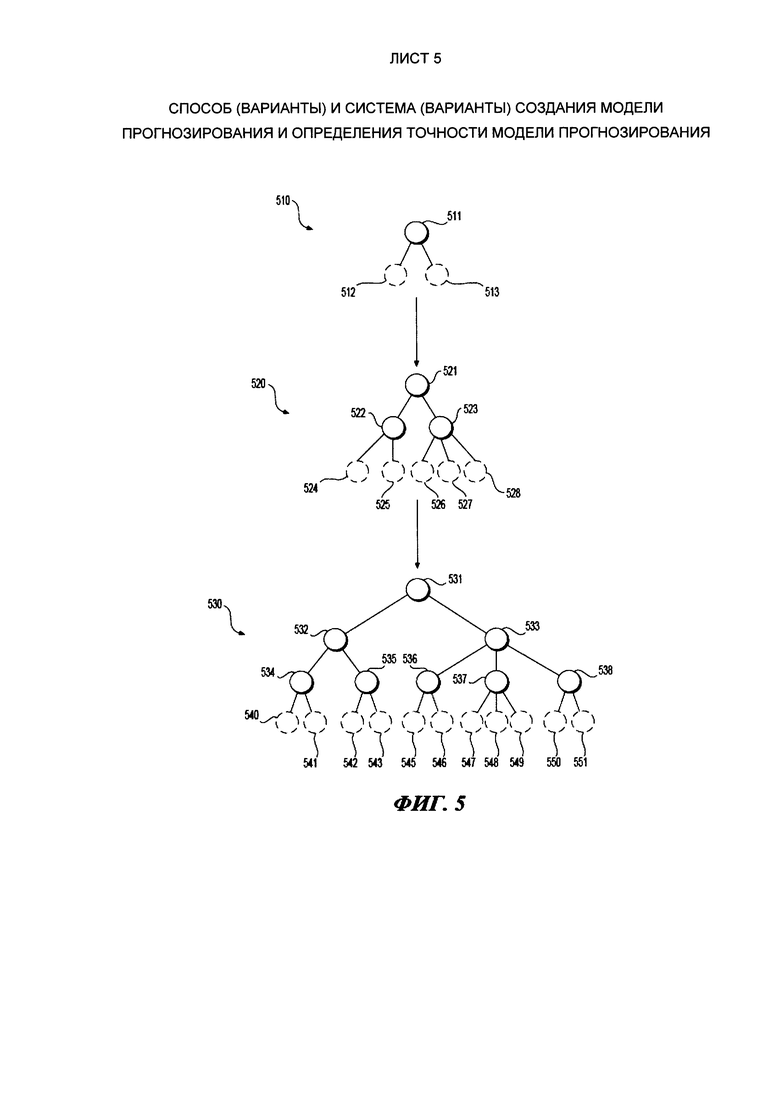




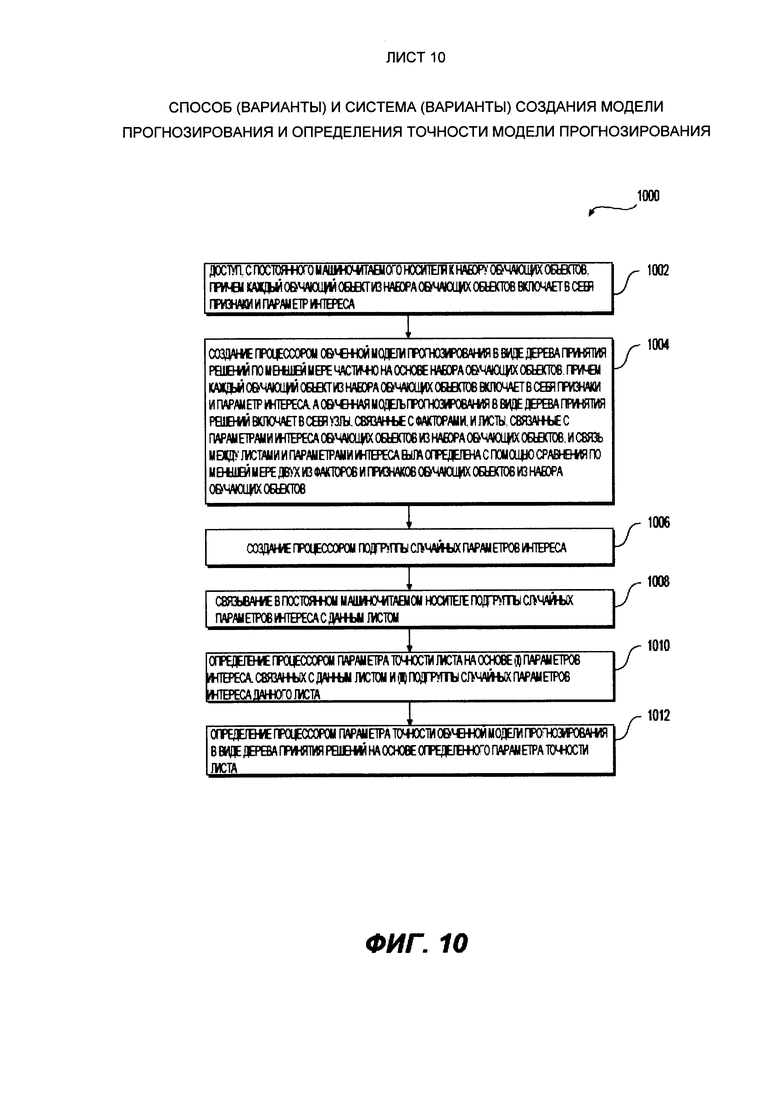

Изобретение относится к способу и системе создания модели прогнозирования и определения параметра точности обученной модели прогнозирования в виде дерева принятия решений. Технический результат заключается в повышении точности модели прогнозирования. Способ включает в себя доступ к обученной модели прогнозирования в виде дерева принятия решений, созданной по меньшей мере частично на основе набора обучающих объектов; создание подгруппы случайных параметров интереса; связывание подгруппы случайных параметров интереса с листом дерева принятия решений; определение параметра точности листа на основе параметров интереса, связанных с данным листом и подгруппы случайных параметров интереса данного листа; определение параметра точности обученной модели прогнозирования в виде дерева принятия решений на основе определенного параметра точности листа. 7 н. и 34 з.п. ф-лы, 11 ил.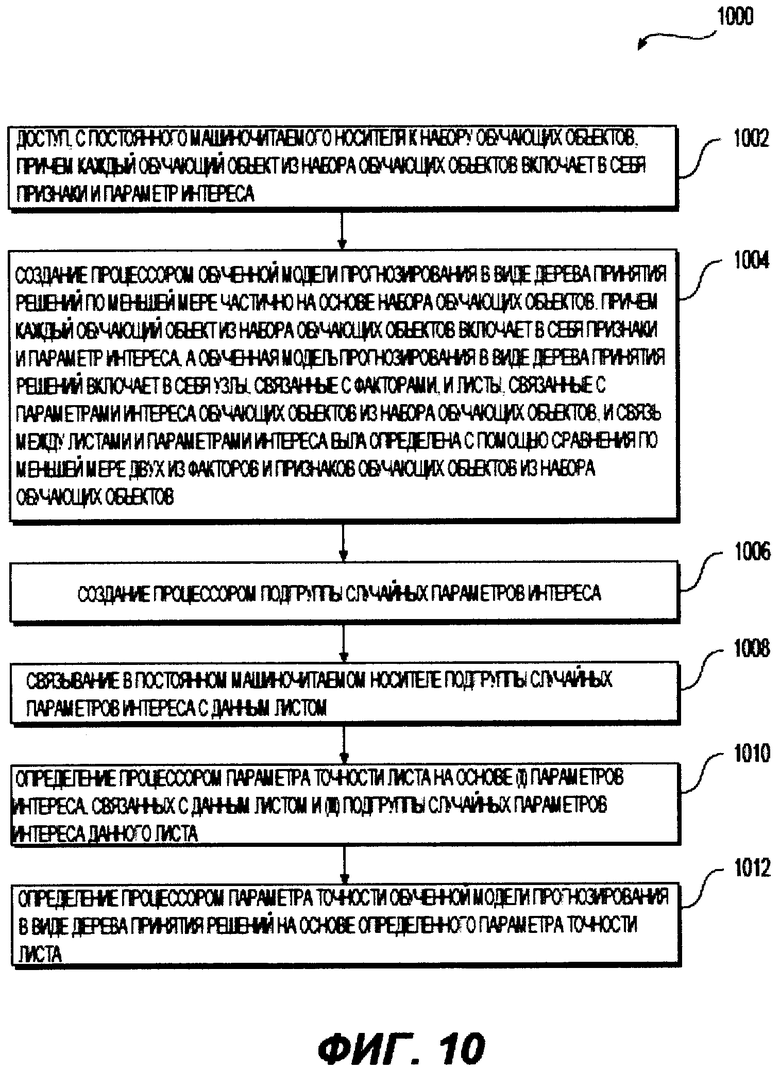
1. Способ определения параметра точности обученной модели прогнозирования в виде дерева принятия решений, выполняемый в компьютерной системе машинного обучения и включающий:
доступ с постоянного машиночитаемого носителя системы машинного обучения к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса;
создание процессором системы машинного обучения обученной модели прогнозирования по меньшей мере частично на основе набора обучающих объектов, причем обученная модель прогнозирования включает в себя узлы, связанные с факторами, и листы, связанные с параметрами интереса обучающих объектов, а связь между листами и параметрами интереса определена с помощью выполненного процессором сравнения по меньшей мере двух из факторов и признаков обучающих объектов;
отправку команды процессору на выполнение:
создания процессором подгруппы случайных параметров интереса;
связывания в постоянном машиночитаемом носителе подгруппы случайных параметров интереса сданным листом;
определение процессором параметра точности листа на основе параметров интереса, связанных с данным листом, и подгруппы случайных параметров интереса данного листа; и
определение процессором параметра точности обученной модели прогнозирования на основе определенного параметра точности листа.
2. Способ определения параметра точности обученной модели прогнозирования в виде дерева принятия решений, выполняемый в компьютерной системе машинного обучения и включающий:
доступ с постоянного машиночитаемого носителя к обученной модели прогнозирования, созданной по меньшей мере частично на основе набора обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса, а обученная модель прогнозирования включает в себя узлы, связанные с факторами, листы, связанные с параметрами интереса обучающих объектов, и связь между листами и параметрами интереса, определенную с помощью сравнения по меньшей мере двух из факторов и признаков обучающих объектов;
создание процессором подгруппы случайных параметров интереса;
связывания в постоянном машиночитаемом носителе подгруппы случайных параметров интереса с данным листом;
определение процессором параметра точности листа на основе параметров интереса, связанных с данным листом, и подгруппы случайных параметров интереса данного листа; и
определение процессором параметра точности обученной модели прогнозирования на основе определенного параметра точности листа.
3. Способ по п. 2, в котором при сравнении по меньшей мере двух факторов и признаков обучающих объектов выполняют сравнение процессором условий, связанных по меньшей мере с двумя факторами и по меньшей мере двумя значениями, связанными с признаками соответствующего обучающего объекта.
4. Способ по п. 2, в котором при создании процессором подгруппы случайных параметров интереса выполняют создание случайных значений целевой функции, связанной с обученной моделью прогнозирования.
5. Способ по п. 4, в котором случайные значения выбирают таким образом, чтобы увеличить ошибку, связанную с наилучшим из факторов фактором, поддерживая при этом созданный ранее параметр точности обученной модели ниже минимального порога.
6. Способ по п. 5, в котором наилучший из факторов фактор определяют как фактор, оказывающий наиболее положительное влияние на созданный ранее параметр точности обученной модели прогнозирования.
7. Способ по п. 4, в котором случайные значения выбирают на основе значений параметров интереса, связанных с данным листом.
8. Способ по п. 7, в котором случайные значения выбирают таким образом, что они включены в состав диапазона, включающего в себя минимальное значение, определенное как самое низкое из значений параметра интереса, связанного с данным листом, и самое высокое из значений, определенное как самое высокое значение параметра интереса, связанного сданным листом.
9. Способ по п. 2, в котором подгруппа случайных параметров интереса включает в себя число случайных параметров интереса, равное числу параметров интереса данного листа, с которым подгруппа случайных параметров интереса связана.
10. Способ по п. 2, в котором при определении процессором параметра точности обученной модели прогнозирования, основанном на определенном параметре точности листа, выполняют определение общей ошибки листов в соответствии с формулой:
 ,
,
где М - число листов, Nj является числом параметров интереса, связанных с j-м листом.
11. Способ по п. 10, в котором число параметров интереса, связанное с j-м листом, равно числу обучающих объектов, связанных с j-м листом.
12. Способ по п. 2, в котором определение процессором параметра точности обученной модели прогнозирования основано на множестве определенных параметров точности листа, причем каждый из множества определенных параметров листа связан с отдельным листом.
13. Способ по п. 2, в котором признаки указывают по меньшей мере либо на число щелчков мышью, либо на число просмотров, либо на ранжирование документов, либо на URL, либо на доменное имя, либо на IP-адрес, либо на поисковой запрос, либо на ключевое слово.
14. Способ по п. 2, в котором параметр интереса указывает по меньшей мере либо на прогнозирование поискового результата, либо на вероятность щелчка мышью, либо на релевантность документа, либо на пользовательский интерес, либо на URL, либо на число щелчков мышью, либо на отношение количества щелчков мышью к количеству показов (CTR).
15. Способ по п. 2, в котором параметр точности модели прогнозирования показывает точность целевой функции, связанную с моделью прогнозирования.
16. Способ по п. 2, в котором каждый из факторов связан либо с условием, применимым к бинарному признаку, либо с условием, применимым к численному признаку, либо с условием, применимым к категориальному признаку.
17. Способ создания обученной модели прогнозирования в виде дерева принятия решений, выполняемый в компьютерной системе машинного обучения и включающий:
осуществление доступа из постоянного машиночитаемого носителя к набору факторов;
идентификацию процессором из набора факторов фактора, связанного с наилучшим параметром точности предварительно обученной модели прогнозирования в виде дерева принятия решений для данного положения узла, связанного с фактором в предварительно обученной модели прогнозирования, причем наилучший параметр точности предварительно обученной модели прогнозирования выбирается из множества параметров точности множества предварительных моделей прогнозирования, причем множество параметров точности множества предварительных моделей прогнозирования создано в соответствии со способом по п. 2;
связывание процессором фактора с данным положением узла создающейся обученной модели прогнозирования в виде дерева принятия решений; и
создание процессором обученной модели прогнозирования в виде дерева принятия решений, включающей в себя узел, связанный с фактором, для данного положения.
18. Способ по п. 17, в котором каждый из множества параметров точности связан с соответствующей моделью из множества предварительных моделей прогнозирования.
19. Способ по п. 17, в котором дополнительно выполняют:
идентификацию процессором другого фактора из набора факторов, связанного с наилучшим параметром точности другой предварительно обученной модели прогнозирования для другого данного положения другого узла, связанного с другим фактором в другой предварительно обученной модели прогнозирования; и
связывание процессором другого фактора с другим данным положением другого узла создающейся обученной модели прогнозирования.
20. Способ по п. 17, в котором обученная модель прогнозирования дополнительно включает в себя другой узел, связанный с другим фактором, для другого данного положения.
21. Способ определения параметра точности обученной модели прогнозирования в виде дерева принятия решений, выполняемый в компьютерной системе машинного обучения и включающий:
доступ с постоянного машиночитаемого носителя к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса;
создание процессором обученной модели прогнозирования по меньшей мере частично на основе набора обучающих объектов, причем обученная модель прогнозирования включает в себя узлы, связанные с факторами, листы, связанные с параметрами интереса обучающих объектов, а связь между листами и параметрами интереса определена с помощью сравнения по меньшей мере двух из факторов и признаков обучающих объектов;
создание процессором подгруппы случайных параметров интереса;
связывание в постоянном машиночитаемом носителе подгруппы случайных параметров интереса с данным листом;
определение процессором параметра точности листа на основе параметров интереса, связанных с данным листом, и подгруппы случайных параметров интереса данного листа; и
определение процессором параметра точности обученной модели прогнозирования на основе определенного параметра точности листа.
22. Компьютерная система для определения параметра точности обученной модели прогнозирования в виде дерева принятия решений, включающая в себя:
постоянный машиночитаемый носитель;
процессор, выполненный с возможностью осуществлять:
доступ с постоянного машиночитаемого носителя к обученной модели прогнозирования, созданной по меньшей мере частично на основе набора обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса, а обученная модель прогнозирования включает в себя узлы, связанные с факторами, и листы, связанные с параметрами интереса обучающих объектов, а связь между листами и параметрами интереса определена с помощью сравнения по меньшей мере двух из факторов и признаков обучающих объектов;
создание процессором подгруппы случайных параметров интереса;
связывание в постоянном машиночитаемом носителе подгруппы случайных параметров интереса сданным листом;
определение процессором параметра точности листа на основе параметров интереса, связанных с данным листом, и подгруппы случайных параметров интереса данного листа; и
определение процессором параметра точности обученной модели прогнозирования на основе определенного параметра точности листа.
23. Система по п. 22, в которой при сравнении по меньшей мере двух факторов и признаков обучающих объектов процессор выполнен с возможностью осуществлять сравнение условий, связанных по меньшей мере с двумя факторами и по меньшей мере двумя значениями, связанными с признаками соответствующего обучающего объекта.
24. Система по п. 22, в которой при создании процессором подгруппы случайных параметров интереса процессор выполнен с возможностью осуществлять создание случайных значений целевой функции, связанной с обученной моделью прогнозирования.
25. Система по п. 24, в которой процессор выполнен с возможностью осуществлять выбор случайных значений таким образом, чтобы увеличить ошибку, связанную с наилучшим из факторов фактором, поддерживая при этом созданный ранее параметр точности обученной модели прогнозирования ниже минимального порога.
26. Система по п. 25, в которой процессор выполнен с возможностью осуществлять определение наилучшего из факторов фактора как фактора, оказывающего наиболее положительное влияние на созданный ранее параметр точности обученной модели прогнозирования.
27. Система по п. 24, в которой процессор выполнен с возможностью осуществлять выбор случайных значений на основе значений параметров интереса, связанных с данным листом.
28. Система по п. 27, в которой процессор выполнен с возможностью осуществлять выбор случайных значений таким образом, что они включены в состав диапазона, включающего в себя минимальное значение, определенное как самое низкое из значений параметра интереса, связанного с данным листом, и самое высокое из значений, определенное как самое высокое значение параметра интереса, связанного сданным листом.
29. Система по п. 22, в которой процессор выполнен с возможностью осуществлять определение параметра точности листа на основе параметров интереса, связанных с данным листом, и подгруппы случайных параметров интереса данного листа причем, подгруппа случайных параметров интереса включает в себя число случайных параметров интереса, равное числу параметров интереса данного листа, с которым подгруппа случайных параметров интереса связана.
30. Система по п. 22, в которой процессор выполнен с возможностью осуществлять определение параметра точности обученной модели прогнозирования, основанного на определенном параметре точности листа, и процессор дополнительно выполнен с возможностью осуществлять определение общей ошибки листов в соответствии с формулой:
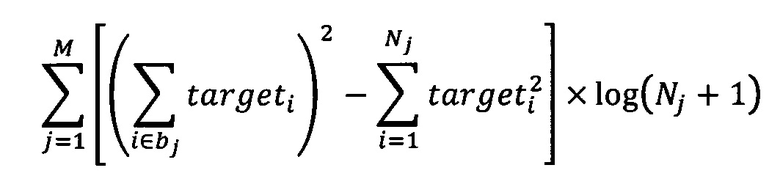 ,
,
где М - число листов, Nj является числом параметров интереса, связанных с j-м листом.
31. Система по п. 30, в которой число параметров интереса, связанное с j-м листом, равно числу обучающих объектов, связанных с j-м листом.
32. Система по п. 22, в которой процессор выполнен с возможностью осуществлять определение параметра точности обученной модели прогнозирования на основе множества определенных параметров точности листа, причем каждый из множества определенных параметров листа связан с отдельным листом.
33. Система по п. 22, в которой признаки указывают по меньшей мере либо на число щелчков мышью, либо на число просмотров, либо на ранжирование документов, либо на URL, либо на доменное имя, либо на IP-адрес, либо на поисковой запрос, либо на ключевое слово.
34. Система по п. 22, в которой процессор выполнен с возможностью осуществлять определение параметра интереса, который указывает по меньшей мере либо на прогнозирование поискового результата, либо на вероятность щелчка мышью, либо на релевантность документа, либо на пользовательский интерес, либо на URL, либо на число щелчков мышью, либо на отношение количества щелчков мышью к количеству показов (CTR).
35. Система по п. 22, в которой процессор выполнен с возможностью осуществлять определение параметра точности модели прогнозирования, который показывает точность целевой функции, связанную с моделью прогнозирования в виде дерева принятия решений.
36. Система по п. 22, в которой каждый из факторов связан либо с условием, применимым к бинарному признаку, либо с условием, применимым к численному признаку, либо с условием, применимым к категориальному признаку.
37. Компьютерная система для создания обученной модели прогнозирования в виде дерева принятия решений, включающая:
постоянный машиночитаемый носитель;
процессор, выполненный с возможностью осуществлять:
осуществление доступа из постоянного машиночитаемого носителя к набору факторов;
идентификацию процессором из набора факторов фактора, связанного с наилучшим параметром точности предварительно обученной модели прогнозирования в виде дерева принятия решений для данного положения узла, связанного с фактором в предварительно обученной модели прогнозирования, причем наилучший параметр точности предварительно обученной модели прогнозирования выбирается из множества параметров точности множества предварительных моделей прогнозирования в виде дерева принятия решений, причем множество параметров точности множества предварительных моделей прогнозирования создано в соответствии со способом по п. 2;
связывание процессором фактора с данным положением узла создающейся обученной модели прогнозирования; и
создание процессором обученной модели прогнозирования в виде дерева принятия решений, включающей в себя узел, связанный с фактором, для данного положения.
38. Система по п. 37, в которой каждый из множества параметров точности связан с соответствующей моделью из множества предварительных моделей прогнозирования.
39. Система по п. 37, в которой процессор дополнительно выполнен с возможностью осуществлять:
идентификацию процессором другого фактора из набора факторов, причем этот другой фактор связан с наилучшим параметром точности другой предварительно обученной модели прогнозирования для другого данного положения другого узла, связанного с другим фактором в другой предварительно обученной модели прогнозирования; и
связывание процессором другого фактора с другим данным положением другого узла создающейся обученной модели прогнозирования.
40. Система по п. 37, в которой обученная модель прогнозирования дополнительно включает в себя другой узел, связанный с другим фактором, для другого данного положения.
41. Компьютерная система для определения параметра точности обученной модели прогнозирования в виде дерева принятия решений, включающая:
постоянный машиночитаемый носитель;
процессор, выполненный с возможностью осуществлять:
доступ с постоянного машиночитаемого носителя к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов включает в себя признаки и параметр интереса;
создание процессором обученной модели прогнозирования в виде дерева принятия решений по меньшей мере частично на основе набора обучающих объектов, причем обученная модель прогнозирования включает в себя узлы, связанные с факторами, и листы, связанные с параметрами интереса обучающих объектов, а связь между листами и параметрами интереса определена с помощью сравнения по меньшей мере двух из факторов и признаков обучающих объектов;
создание процессором подгруппы случайных параметров интереса;
связывание в постоянном машиночитаемом носителе подгруппы случайных параметров интереса с данным листом;
определение процессором параметра точности листа на основе параметров интереса, связанных с данным листом, и подгруппы случайных параметров интереса данного листа; и
определение процессором параметра точности обученной модели прогнозирования на основе определенного параметра точности листа.
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| US 8136025 B1, 13.03.2012 | |||
| СБОР ДАННЫХ О ПОЛЬЗОВАТЕЛЬСКОМ ПОВЕДЕНИИ ПРИ ВЕБ-ПОИСКЕ ДЛЯ ПОВЫШЕНИЯ РЕЛЕВАНТНОСТИ ВЕБ-ПОИСКА | 2007 |
|
RU2435212C2 |

