Изобретение относится к области информационных технологий, а именно к области автоматического анализа данных средствами программ для ЭВМ, и может быть использовано для быстрой группировки документов по смыслу и быстрого поиска смысловых дубликатов выбранного документа.
Известны система и метод дифференцированного анализа и хранения документов. В частности, система может быть сконфигурирована для выполнения одного или нескольких дифференциальных анализов набора документов для обнаружения и измерения изменений языка во всех наборах документов аналогичного типа, а также изменений языка в конкретных объектах (например, разделах документа, параграфах, статьях) документов. Система состоит из трех основных компонентов: синтаксический анализ документов, обнаружение текстовых дубликатов и морфологический анализ. Компонент синтаксического анализа документов разбивает документы на объекты и создает индексы для каждого полного документа и компонентов документа. Эти индексы позволяют сравнивать документы и объекты на сходство с помощью компонента обнаружения почти дубликатов, который реализует различные алгоритмы анализа сходства. Компонент морфологического анализа настроен на поиск документов по определенному языку или разделам и сравнение документов, в которых присутствует искомый язык (по патенту US20190236102, кл. G06F 16/901, G06F 16/93, G06F 17/22, G06F 17/27, опубл. 01.08.19).
Недостатком данного решения является сложность процесса анализа, включающего в себя синтаксический, морфологический анализ, анализ по размеру. Алгоритмы хеширования используются ограничено.
Известна разновидность асимметричного метода хеширования текста (по патенту CN106776553, кл. G06F 17/27, G06F 17/30, опубл. 31.05.17), основанная на глубоком обучении, которая характеризуется тем, что включает в себя следующие этапы:
- S1: извлекается семантическая метка текста обучающего набора, вычисляется семантическое сходство между образцами
- S2: хеш-кодирование двоичной системы в соответствии с образцом семантической метки обучающего набора и текстом обучающего набора для измерения семантического сходства, это двухсистемное хеш-кодирование должно поддерживаться в обучающем наборе с оптимальной семантической производительностью для сохранения, то есть ожидаемого хеш-кодирования
- S3: при вводе обучающего набора текста в нейтральную сеть будет вычислен текст, соответствующий хеш-кодировке;
- S4: отклонение для ожидаемого хеш-кодирования, полученное в хеш-кодировании и S2, которые вычисляют нейтральный сетевой результат, и с помощью алгоритма обратной трансляции биографии для обучения параметра нейронной сети.
В известном патенте описывается только способ хеширования текста. Не упоминается возможность его применения для поиска и сортировки документов.
Наиболее близким техническим решением является метод обучения хешированию коротких текстов, основанных на тематических моделях с большей степенью детализации. Модель обучается с использованием внешнего крупномасштабного корпуса. Оптимальные тематические признаки с большей степенью детализации могут быть выбраны в соответствии с типом набора данных и присвоен вес. Предпочтительно различие по тематическим моделям с большей степенью детализации, которые выбирает этот способ, вносит вклад в хеш-функцию для обучения, в то время как сходная семантика связана между построением разреженного короткого текста. Способ настоящего изобретения использует два вида стратегий обучения хешированию, основанных на многопоточной модели: независимый метод обучения с хеш-функцией, характеризующийся более детализированным объединением тематических функций, изучением хеш-кодов, и объединенный метод обучения при изучении хеш-кодов с хеш-функцией с более детализированными тематическими функциями. Метод основан на простой степени детализации тематических функций, при этом показатели многочленной оценки такие, как точность и скорость запоминания, значительно повышаются (по патенту CN104408153, кл. G06F 17/30, опубл. 31.07.18).
Недостатком данного метода является применение бинарных хешей, т.е. состоящих из 32..128 бит. Для получения хеша используется нейронная сеть, которую необходимо тренировать на корпусе документов, что менее удобно по сравнению с использованием предобученных моделей. На вход нейронной сети подаются TF-IDF вектора, что с одной стороны может улучшить качество за счёт более правильного учитывания частотности слов, но с другой стороны из-за большого размера входного вектора TF-IDF и, соответственно, большого размера нейросети может занимать длительное время на обработку каждого документа. Для получения векторов TF-IDF необходимо оперировать сразу всей коллекцией документов, что усложняет работу, когда в систему постоянно поступают новые документы.
Технический результат, на достижение которого направлено предлагаемое изобретение, заключается в автоматизации и ускорении процесса группировки и поиска документов по смысловому значению посредством использования семантического хеша.
Указанный технический результат достигается тем, что способ семантического хеширования текстовых данных реализуется программно-аппаратным комплексом с помощью специального программного обеспечения, в которое загружается текстовый документ, для которого вычисляется семантический (смысловой) вектор посредством осреднения семантических векторов слов, составляющих текстовый документ, далее из семантического вектора документа вычисляется семантический хеш текстового документа в следующей последовательности:
- выбор длины L итогового хеша и количества символов алфавита N;
- осреднение групп компонент семантического вектора с получением сжатого вектора, состоящего из L вещественных чисел;
- масштабирование и сдвиг сжатого вектора с получением масштабированного и смещенного вектора, состоящего из вещественных чисел в диапазоне 0…N;
- округление масштабированного и смещенного вектора с заменой вещественных чисел на ближайшие целые числа в диапазоне 0…N с получением квантизированного вектора;
- получение семантического хеша путем замены целых чисел символами алфавита.
Предлагаемое изобретение поясняется схемой (фиг. 1), на которой показан порядок получения семантического хеша.
Описанный способ реализуется специальной программой, установленной на ЭВМ. В программу загружается какой-либо текстовый документ. Для данного документа вычисляется семантический (смысловой) вектор. Семантическим (смысловым) вектором является форма представления текстового документа в виде набора вещественных чисел. Преобразование может осуществляться посредством следующих технологий: FastText, Word2Vec для отдельных слов с последующим осреднением векторов слов документа. При этом вектора слов представляют собой набор чисел. Например, для модели FastText это могут быть вектора по 100 или 300 чисел:
ω 1 = υ11, υ12, υ13, … υ1n
ω 2 = υ21, υ22, υ23, … υ2n
…
ω k = υk1, υk2, υk3, … υkn
где ω1,… ωk – вектора слов, полученные из модели класса FastText или Word2Vec, υij – вещественные компоненты векторов, k – количество слов документе.
Вектор документа ωd вычисляется следующим способом:
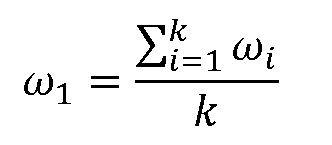
После чего вектор документа нормируется:
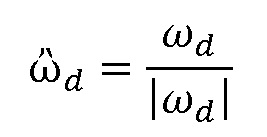
Из семантического вектора вычисляется семантический хеш. Семантическим хешем является представление текстового документа в виде короткого набора символов, например, цифр и букв. Семантический хеш отличается от семантического вектора более сжатым представлением: вместо последовательности нескольких сотен вещественных чисел используется короткая последовательность символов. Семантический хеш получается с помощью следующей последовательности действий (фиг. 1):
1. Выбираются длина L итогового хеша и размер (количество символов) алфавита N. Размер алфавита определяет символы, которые можно использовать для записи хешей. Например, если использовать все арабские цифры 0…9 и все заглавные латинские буквы A…Z, то длина алфавита будет равняться 10+26=36 символов. Выбор длины хеша и размера алфавита влияет на степень схожести документов при совпадении их семантических хешей. Семантический вектор документа может состоять, например, из 300 вещественных чисел из диапазона -1…1.
2. Осреднение групп компонент семантического вектора с получением сжатого вектора, состоящего из L вещественных чисел в диапазоне -1…1, для снижения размерности. На этом шаге из вектора длиной, например, 300 чисел получаем методом осреднения вектор длиной, например, 17 символов.
3. Масштабирование и сдвиг с получением масштабированного и смещенного вектора, состоящего из вещественных чисел в диапазоне 0…N, т.е. отображение диапазонов -1..1 в 0..N.
4. Квантование – округление масштабированного и смещенного вектора с заменой вещественных чисел на ближайшие целые числа в диапазоне 0…N с получением квантизированного вектора.
5. Получение семантического хеша путем замены целых чисел символами алфавита. Замена чисел символами осуществляется для получения более короткой формы записи.
После создания программным обеспечением семантического хеша он используется для быстрой группировки похожих документов (если хеши похожи, то и документы похожи) и для быстрого поиска похожих по смыслу документов для выбранного документа.
Пример хеширования трех текстов
Первый и второй текст отличаются только одним словосочетанием, а третий отличается полностью.
text_1 = """Обработка текстов на естественном языке (Natural Language Processing, NLP) — общее направление искусственного интеллекта и математической лингвистики. Оно изучает проблемы компьютерного анализа синтеза текстов на естественных языках. Применительно к искусственному интеллекту анализ означает понимание языка, а синтез — генерацию грамотного текста."""
# Словосочетание "искусственный интеллект" заменено на "машинное обучение"
text_2 = """Обработка текстов на естественном языке (Natural Language Processing, NLP) — общее направление машинного обучения и математической лингвистики. Оно изучает проблемы компьютерного анализа и синтеза текстов на естественных языках. Применительно к машинному обучению анализ означает понимание языка, а синтез — генерацию грамотного текста."""
text_3 = """Информационный поиск (англ. information retrieval) — процесс поиска неструктурированной документальной информации, удовлетворяющей информационные потребности, и наука об этом поиске."""
vec_1 = text_semantic_vector(text_1)
vec_2 = text_semantic_vector(text_2)
vec_3 = text_semantic_vector(text_3)
# Попарные косинусные сходства семантических векторов
print(
f"косинусное сходство смысловых векторов 1 и 2: {np.dot(vec_1, vec_2):.4f}",
f"косинусное сходство смысловых векторов 1 и 3: {np.dot(vec_1, vec_3):.4f}",
f"косинусное сходство смысловых векторов 2 и 3: {np.dot(vec_2, vec_3):.4f}",
sep="\n",
)
# Семантические хеши векторов
semantic_hashes = [
hash_from_doc_vector(vec, hash_length=10, alphabet_size=20)
for vec in (vec_1, vec_2, vec_3)
]
for i, s_hash in enumerate(semantic_hashes, start=1):
print(f"семантический хеш текста {i}: {s_hash}")
Текстовый вывод программного кода:
косинусное сходство смысловых векторов 1 и 2: 0.9909
косинусное сходство смысловых векторов 1 и 3: 0.8191
косинусное сходство смысловых векторов 2 и 3: 0.8243
семантический хеш текста 1: 6C8C8A6829
семантический хеш текста 2: 6C8C8A6829
семантический хеш текста 3: 7D7C7A5938
В результате для похожих текстов 1 и 2, которые отличаются заменой словосочетания на синонимичное, семантические хеши одинаковые, а для текста 3 семантический хеш отличается значительно, т.к. значительно отличается и исходный текст.
Таким образом, предложенный в изобретении способ обеспечивает автоматизацию и ускорение процесса группировки и поиска документов по смысловому значению посредством использования семантического хеша.
| название | год | авторы | номер документа |
|---|---|---|---|
| ТЕМАТИЧЕСКИЕ МОДЕЛИ С АПРИОРНЫМИ ПАРАМЕТРАМИ ТОНАЛЬНОСТИ НА ОСНОВЕ РАСПРЕДЕЛЕННЫХ ПРЕДСТАВЛЕНИЙ | 2018 |
|
RU2719463C1 |
| Способ атрибутизации частично структурированных текстов для формирования нормативно-справочной информации | 2020 |
|
RU2750852C1 |
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ФОРМАЛИЗОВАННЫХ ДОКУМЕНТОВ В СИСТЕМЕ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА | 2013 |
|
RU2546555C1 |
| Система автоматического определения тематики текстовых документов на основе объяснимых методов искусственного интеллекта | 2023 |
|
RU2823436C1 |
| СПОСОБ ПОИСКА ПОХОЖИХ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ, РАЗМЕЩЕННЫХ НА УСТРОЙСТВАХ ХРАНЕНИЯ ДАННЫХ | 2014 |
|
RU2571539C2 |
| СПОСОБ ПОИСКА ПОХОЖИХ ПО СМЫСЛОВОМУ СОДЕРЖИМОМУ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ, РАЗМЕЩЕННЫХ НА УСТРОЙСТВАХ ХРАНЕНИЯ ДАННЫХ | 2009 |
|
RU2420800C2 |
| СПОСОБ ОЦЕНКИ СТЕПЕНИ РАСКРЫТИЯ ПОНЯТИЯ В ТЕКСТЕ, ОСНОВАННЫЙ НА КОНТЕКСТАХ, ДЛЯ ПОИСКОВЫХ СИСТЕМ | 2007 |
|
RU2348072C1 |
| СПОСОБ УПРАВЛЕНИЯ АВТОМАТИЗИРОВАННОЙ СИСТЕМОЙ ПРАВОВЫХ КОНСУЛЬТАЦИЙ | 2019 |
|
RU2718978C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ОТВЕТА НА ПОИСКОВЫЙ ЗАПРОС | 2024 |
|
RU2834217C1 |
| ПОДБОР ПАРАМЕТРОВ ТЕКСТОВОГО КЛАССИФИКАТОРА НА ОСНОВЕ СЕМАНТИЧЕСКИХ ПРИЗНАКОВ | 2016 |
|
RU2628431C1 |

Изобретение относится к вычислительной технике. Технический результат заключается в автоматизации и ускорении процесса группировки и поиска документов по смысловому значению посредством использования семантического хеша. Способ семантического хеширования текстовых данных реализуется программно-аппаратным комплексом с помощью специального программного обеспечения, в которое загружается текстовый документ, для которого вычисляется семантический вектор посредством осреднения семантических векторов слов, составляющих текстовый документ, далее из семантического вектора документа вычисляется семантический хеш текстового документа в определенной последовательности. 1 ил.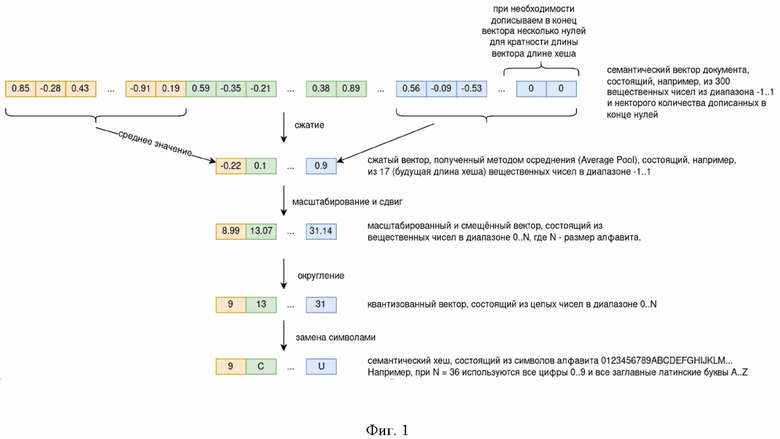
Способ семантического хеширования текстовых данных, реализующийся программно-аппаратным комплексом с помощью специального программного обеспечения, в которое загружается текстовый документ, для которого вычисляется семантический вектор посредством осреднения семантических векторов слов, составляющих текстовый документ, далее из семантического вектора документа вычисляется семантический хеш текстового документа в следующей последовательности:
- выбор длины L итогового хеша и количества символов алфавита N;
- осреднение групп компонент семантического вектора с получением сжатого вектора, состоящего из L вещественных чисел;
- масштабирование и сдвиг сжатого вектора с получением масштабированного и смещенного вектора, состоящего из вещественных чисел в диапазоне 0…N;
- округление масштабированного и смещенного вектора с заменой вещественных чисел на ближайшие целые числа в диапазоне 0…N с получением квантизированного вектора;
- получение семантического хеша путем замены целых чисел символами алфавита.
| CN 113392180 A, 14.09.2021 | |||
| US 8676725 B1, 18.03.2014 | |||
| US 20150074117 A1, 12.03.2015 | |||
| US 20040220944 A1, 04.11.2004 | |||
| US 20190121873 A1, 25.04.2019 | |||
| СПОСОБ И СИСТЕМА СЕМАНТИЧЕСКОГО ПОИСКА ЭЛЕКТРОННЫХ ДОКУМЕНТОВ | 2011 |
|
RU2473119C1 |

