УРОВЕНЬ ТЕХНИКИ ИЗОБРЕТЕНИЯ
Область техники, к которой относится изобретения
[0001] Настоящее изобретение относится, в общем, к области компьютерной графики и, в частности, к способу генерации анимационной модели головы по речевому сигналу и электронному вычислительному устройству, реализующему упомянутый способ.
Описание предшествующего уровня техники
[0002] В настоящее время дополненную и виртуальную реальность все более часто используют в современных устройствах для получения эффекта присутствия путем анимации различных персонажей. Например, есть потребность в решении для генерации анимационной модели головы по речевому сигналу, обеспечивающем выполнение в реальном времени с хорошим качеством и малой задержкой между приемом речевого сигнала и движениями модели головы, а также уменьшение потребления вычислительных ресурсов, например, для создания персонализированных трехмерных (3D) моделей голов и использования их во время телефонных звонков или в виртуальных чатах, отображения головы при дублировании речи на другом языке.
[0003] В предшествующем уровне техники известны решения, которые направлены на анимацию головы, например, такие как нижеописанные решения.
[0004] Патент США US 10169905 B2, выданный 01.01.2019 под названием «SYSTEMS AND METHODS FOR ANIMATING MODELS FROM AUDIO DATA», раскрывает систему и способы компьютерной анимации 3D моделей голов, сформированных из изображений лиц. Захваченное двумерное (2D) изображение, которое включает в себя изображение лица, может быть получено и использовано для формирования статической 3D модели головы. Средство анимации может быть приспособлено для статической 3D модели, чтобы генерировать готовую к анимации 3D генеративную модель. Наборы средств анимации могут быть параметрами, каждый из которых сопоставлен с конкретными звуками. Эти сопоставления могут использоваться для генерации списков воспроизведения наборов параметров средства анимации на основе принятого аудиоконтента. Эти сопоставления используются для обучения сети для сопоставления аудиоконтента с параметрами средства анимации. Техническое решение, раскрытое в данном патенте США, имеет следующие недостатки. Для обучения сети используются обучающие данные, содержащие глубину изображения и модель лица, которые не всегда возможно получить из общедоступных источников, таких как, например, видеосигнал, полученный видеокамерой, или видеосигнал, извлеченный из Интернета. Получение и использование глубины изображения и модели лица приводит к увеличению вычислительной нагрузки.
[0005] В публикации «Audio–driven animator–centric speech animation», VisemeNet, Zhou и др. 2018г. раскрыта модель, которая обучалась на основе созданных вручную анимационных кривых, построенных для некоторого общедоступного набора данных с четырехмерным (4D) сканированием профессиональным аниматором. В этой модели используется многозадачная подсеть для предсказания перемещения опорных точек лица (лендмарок) и фонем из аудиосигнала. Техническое решение, раскрытое в данной публикации, имеет недостатки, которые заключаются в том, что анимация, выполняемая этой моделью, зависит от предпочтений аниматора и имеет большую задержку.
[0006] В публикации «A Deep Learning Approach for Generalized Speech Animation», Taylor и др. 2017г. раскрыто средство предсказания с функцией скользящего окна для анимации речи. Средство предсказания обучают на фонемах и коэффициентах, полученных путем обработки лендмарок методом главных компонент (PCA). Техническое решение, раскрытое в данной публикации, имеет недостатки, которые заключаются в том, что анимация, выполняемая этим средством предсказания, имеет большую задержку и обучение этого средства предсказания нужно выполнять для каждого персонажа отдельно.
[0007] В публикации «Audio–Driven Facial Animation by Joint End–to–End Learning of Pose and Emotion», Nvidia, Karras и др., 2017г. раскрыта модель для анимации лица по речевому сигналу. Эта модель была обучена на основе данных движения, полученных с помощью очень качественного и затратного 4D сканирования, для речи одного человека. В модели используются коэффициенты, вычисленные путем обработки методом PCA обучающего набора данных, полученного сканированием. Функцией потерь во время обучения является только ошибка коэффициентов PCA. Техническое решение, раскрытое в данной публикации, имеет следующие недостатки. Набор данных для обучения получают слишком затратным способом. Возможны проблемы с обобщением данных для генерации разных лиц, поскольку обучение необходимо выполнять для каждого человека отдельно. В данном техническом решении невозможно использовать более простой способ обработки визем по 3D данным, например, систему кодирования лицевых движений (FACS).
[0008] В публикации «Synthesizing Obama: Learning Lip Sync from Audio», Washington university, S. SUWAJANAKORN и др., 2017г. раскрыто техническое решение, в котором обучение выполнено только на 3D–видео Барака Обамы, чтобы обеспечить 2D лендмарки лица на основе входного речевого сигнала Обамы. Для построения видеовыхода на основе лендмарок используются не методы на основе максимального правдоподобия (ML). Техническое решение, раскрытое в данной публикации, имеет следующие недостатки. Данное техническое решение может генерировать только 2D видео с тем человеком, на котором производилось обучение модели, в данном случае – Обамой. Данное техническое решение не поддерживает анимацию любых виртуальных персонажей.
[0009] В целом, существующие технические решения для анимации головы имеют следующие недостатки:
– получение данных для обучения, как правило, требует высоких вычислительных затрат или большого количества труднодоступных данных;
– способы, основанные на двухмерных лендмарках в качестве описания движений лица, обычно дают очень плоские результаты анимации из–за недостатка трехмерной информации;
– получение анимации виртуального персонажа с высоким качеством изображения на основе движений человеческого лица требует высоких вычислительных затрат из–за разницы в форме лица;
– трудно обобщить данные для анимации на голос любого пользователя;
– модель для анимации с высоким качеством изображения имеет большую задержку.
[0010] Настоящее изобретение создано для устранения, по меньшей мере, одного из вышеописанных недостатков и для обеспечения, по меньшей мере, одного из нижеописанных преимуществ.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0011] Целью настоящего изобретения является обеспечение способа генерации анимационной модели головы по речевому сигналу и электронного вычислительного устройства, реализующего упомянутый способ, способных обеспечить анимацию головы по речевому сигналу в реальном времени с низкой задержкой и высоким качеством изображения. Такое преимущество достигается за счет того, что обученное средство искусственного интеллекта выдает поток фонем и поток визем, соответствующих фонемам в потоке фонем, путем обработки признаков речевого сигнала и определяет анимационные кривые для визем в полученном потоке визем на основе соответствующих им фонем. Затем поток фонем и поток визем объединяют путем наложения полученного потока фонем и полученного потока визем друг на друга с учетом определенных анимационных кривых и формируют анимацию модели головы путем анимации визем в объединенном потоке фонем и визем с использованием определенных анимационных кривых.
[0012] Кроме того, настоящее изобретение позволяет дополнительно получить, по меньшей мере, одно из следующих преимуществ:
– использование широко доступных данных для обучения;
– генерация анимационной модели головы по голосу любого персонажа;
– генерация анимационной модели головы для любого персонажа.
[0013] Один аспект настоящего изобретения обеспечивает способ генерации анимационной модели головы по речевому сигналу, при этом упомянутый способ выполняется одним или более процессорами и содержит этапы, на которых: принимают речевой сигнал; преобразуют речевой сигнал в набор признаков речевого сигнала; извлекают признаки речевого сигнала из набора признаков речевого сигнала; получают последовательность фонем и последовательность визем, соответствующих фонемам в последовательности фонем, путем обработки признаков речевого сигнала обученным средством искусственного интеллекта; вычисляют обученным средством искусственного интеллекта анимационные кривые для визем в полученной последовательности визем на основе соответствующих им фонем; объединяют полученную последовательность фонем и полученную последовательность визем путем наложения полученной последовательности фонем и полученной последовательности визем друг на друга с учетом вычисленных анимационных кривых; и формируют анимацию модели головы путем анимации визем в объединенной последовательности фонем и визем с использованием вычисленных анимационных кривых.
[0014] В дополнительном аспекте обучение средства искусственного интеллекта содержит этапы, на которых: принимают набор обучающих данных, содержащий речевой сигнал, субтитры для речевого сигнала и видеосигнал, соответствующий речевому сигналу; выявляют последовательность фонем из субтитров для речевого сигнала; преобразуют речевой сигнал в набор признаков речевого сигнала; извлекают признаки речевого сигнала из набора признаков речевого сигнала; получают последовательность фонем и последовательность визем, соответствующих фонемам в последовательности фонем, на основании признаков речевого сигнала; вычисляют функцию формирования последовательности фонем путем сравнения последовательности фонем, выявленной из субтитров для речевого сигнала, и последовательности фонем, полученной на основании признаков речевого сигнала; вычисляют анимационные кривые для визем в последовательности визем, полученной на основании признаков речевого сигнала; применяют вычисленные анимационные кривые к заранее заданному набору визем; выявляют траектории перемещения опорных точек лица на заранее заданном наборе визем с примененными вычисленными анимационными кривыми; выявляют траектории перемещения опорных точек лица в видеосигнале, соответствующем речевому сигналу; накладывают траектории перемещения опорных точек лица в видеосигнале, соответствующем речевому сигналу, на заранее заданное нейтральное лицо; вычисляют функцию формирования последовательности визем и функцию вычисления анимационных кривых путем сравнения траекторий перемещения опорных точек лица в видеосигнале, соответствующем речевому сигналу, наложенных на заранее заданное нейтральное лицо, и выявленных траекторий перемещения опорных точек лица на заранее заданном наборе визем; и вычисляют функцию выбора визем на основании последовательности фонем, полученной на основании признаков речевого сигнала, последовательности визем, полученной на основании признаков речевого сигнала, и вычисленных анимационных кривых.
[0015] В другом дополнительном аспекте этап преобразования речевого сигнала в набор признаков речевого сигнала и этап извлечения признаков речевого сигнала из набора признаков речевого сигнала выполняют одним из способа мел–частотных кепстральных коэффициентов (MFCC) или дополнительным предварительно обученным средством искусственного интеллекта.
[0016] В еще одном дополнительном аспекте дополнительное предварительно обученное средство искусственного интеллекта является по меньшей мере одним из рекуррентной нейронной сети, долгой краткосрочной памяти (LSTM), управляемым рекуррентным блоком (GRU), их модификациями или комбинацией любых из них.
[0017] В еще одном дополнительном аспекте обученное средство искусственного интеллекта содержит по меньшей мере два блока, при этом первый блок из упомянутых меньшей мере двух блоков обученного средства искусственного интеллекта выполняет этап, на котором получают последовательность фонем и последовательность визем, соответствующих фонемам в последовательности фонем, путем обработки признаков речевого сигнала, и второй блок из упомянутых меньшей мере двух блоков обученного средства искусственного интеллекта выполняет этап, на котором вычисляют обученным средством искусственного интеллекта анимационные кривые для визем в полученной последовательности визем на основе соответствующих им фонем.
[0018] В еще одном дополнительном аспекте первый блок из упомянутых меньшей мере двух блоков обученного средства искусственного интеллекта является по меньшей мере одним из сверточной нейронной сети, рекуррентной нейронной сети, долгой краткосрочной памяти (LSTM), управляемым рекуррентным блоком (GRU), их модификациями или комбинацией любых из них.
[0019] В еще одном дополнительном аспекте второй блок из упомянутых меньшей мере двух блоков обученного средства искусственного интеллекта является по меньшей мере одним из сверточной нейронной сети, рекуррентной нейронной сети, долгой краткосрочной памяти (LSTM), управляемым рекуррентным блоком (GRU), их модификациями или комбинацией любых из них.
[0020] В еще одном дополнительном аспекте этап вычисления анимационных кривых для визем в последовательности визем, полученной на основании признаков речевого сигнала выполняют с помощью системы кодирования лицевых движений (FACS).
[0021] Другой аспект настоящего изобретения обеспечивает электронное вычислительное устройство, содержащее: по меньшей мере один процессор; и память хранящую числовые параметры по меньшей мере одного обученного средства искусственного интеллекта и инструкции, которые при исполнении по меньшей мере одним процессором побуждают по меньшей мере один процессор выполнять способ генерации анимационной модели головы по речевому сигналу.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0022] Вышеописанные и другие аспекты, признаки и преимущества настоящего изобретения будут более понятны из последующего подробного описания, приведенного в сочетании с прилагаемыми чертежами, на которых:
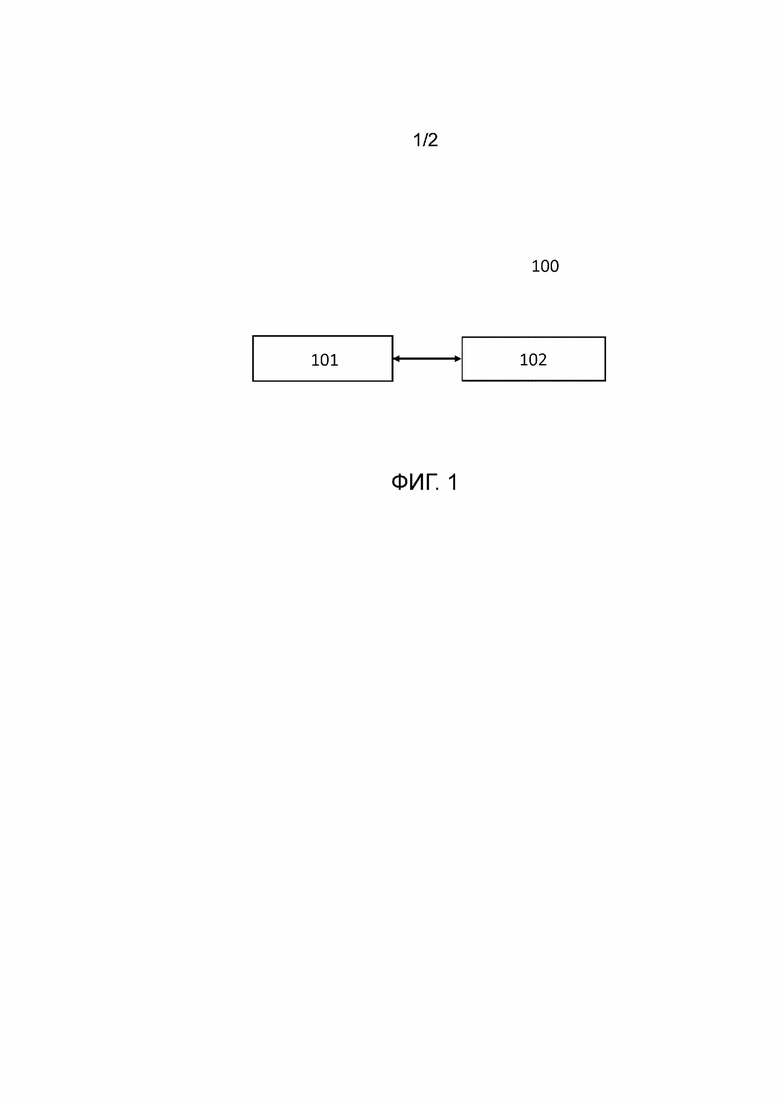
[0023] Фиг. 1 – блок–схема, иллюстрирующая электронное вычислительное устройство.
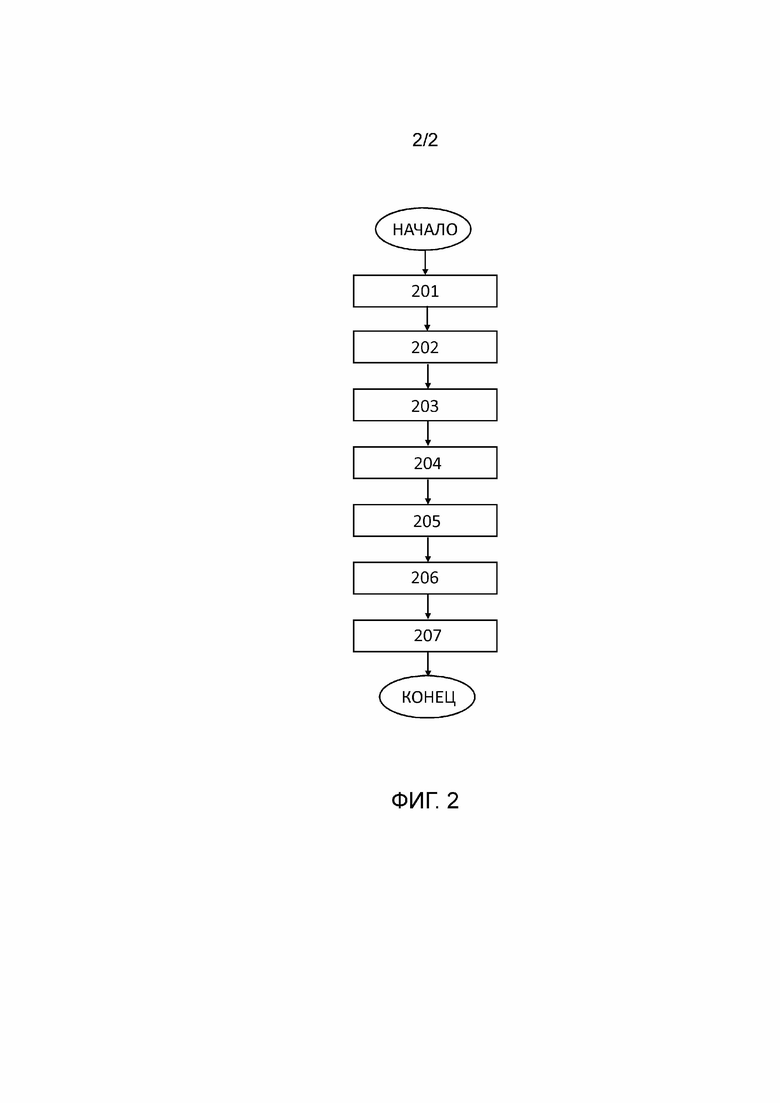
[0024] Фиг. 2 – блок–схема последовательности операций, иллюстрирующая предпочтительный вариант осуществления способа генерации анимационной модели головы по речевому сигналу.
[0025] В последующем описании, если не указано иное, одинаковые ссылочные позиции используются для одинаковых элементов, когда они изображены на разных чертежах, и их параллельное описание не приводится.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ НАСТОЯЩЕГО ИЗОБРЕТЕНИЯ
[0026] Нижеследующее описание со ссылкой прилагаемые чертежи приведено, чтобы облегчить полное понимание различных вариантов осуществления настоящего изобретения, заданного формулой изобретения, и его эквивалентов. Описание включает в себя различные конкретные подробности, чтобы облегчить такое понимание, но данные подробности следует считать только примерными. Соответственно, специалисты в данной области техники обнаружат, что можно разработать различные изменения и модификации различных вариантов осуществления, описанных в настоящей заявке, без выхода за пределы объема настоящего изобретения. Кроме того, описания общеизвестных функций и конструкций могут быть исключены для ясности и краткости.
[0027] Термины и формулировки, используемые в последующем описании и формуле изобретения не ограничены библиографическим значениями, а просто использованы создателем настоящего изобретения, чтобы обеспечить четкое и последовательное понимание настоящего изобретения. Соответственно, специалистам в данной области техники должно быть ясно, что последующее описание различных вариантов осуществления настоящего изобретения предлагается только для иллюстрации.
[0028] Следует понимать, что формы единственного числа включают в себя множественность, если контекст явно не указывает иное.
[0029] Дополнительно следует понимать, что термины «содержит», «содержащий», «включает в себя» и/или «включающий в себя», при использовании в настоящей заявке, означают присутствие изложенных признаков, значений, операций, элементов и/или компонентов, но не исключают присутствия или добавления одного или более других признаков, значений, операций, элементов, компонентов и/или их групп.
[0030] В дальнейшем, различные варианты осуществления настоящего изобретения описаны более подробно со ссылкой на прилагаемые чертежи.
[0030] На фиг.1 показана блок–схема, иллюстрирующая электронное вычислительное устройство 100, способное выполнять генерацию анимационной модели головы по речевому сигналу.
[0031] Электронное вычислительное устройство 100 включает в себя по меньшей мере один процессор 101 и память 102. Память 102 хранит числовые параметры по меньшей мере одного обученного средства искусственного интеллекта. Память 102 также хранит инструкции, которые при исполнении по меньшей мере одним процессором 101 побуждают по меньшей мере один процессор 101 выполнять способ генерации анимационной модели головы по речевому сигналу.
[0032] Электронное вычислительное устройство 100 может быть любым вычислительным устройством, например, таким как смартфон, мобильный телефон, настольный компьютер, ноутбук, игровая приставка, диктофон, портативный музыкальный проигрыватель и т.д.
[0033] На фиг.2 показана блок–схема последовательности операций, иллюстрирующая предпочтительный вариант осуществления способа генерации анимационной модели головы по речевому сигналу.
[0034] Способ генерации анимационной модели головы по речевому сигналу выполняется электронным вычислительным устройством 100, содержащим один или более процессоров и память.
[0035] На этапе 201 электронное вычислительное устройство 100 принимает речевой сигнал. Речевой сигнал может быть принят из любого доступного источника, такого как Интернет, телевизионная или радио передача, смартфон, мобильный телефон, диктофон, настольный компьютер, ноутбук и т.д.
[0036] На этапе 202 речевой сигнал, принятый на этапе 201, преобразуют в набор признаков речевого сигнала. На этапе 203 из набора признаков речевого сигнала, полученного на этапе 202, извлекают признаки речевого сигнала. Преобразование речевого сигнала в набор признаков речевого сигнала и извлечение признаков речевого сигнала из набора признаков речевого сигнала может быть выполнено любым подходящим способом.
[0037] В одном из вариантов осуществления этапы 202 и 203 выполняют способом мел–частотных кепстральных коэффициентов (MFCC). Поскольку способ MFCC известен в уровне техники, его подробное описание опущено.
[0038] В другом из вариантов осуществления этапы 202 и 203 выполняют дополнительным предварительно обученным средством искусственного интеллекта, которое сохранено в памяти электронного вычислительного устройства 100. Дополнительным предварительно обученным средством искусственного интеллекта может быть по меньшей мере одно из рекуррентной нейронной сети, долгой краткосрочной памяти (LSTM), управляемого рекуррентного блока (GRU) и их модификациями. Дополнительным предварительно обученным средством искусственного интеллекта также может быть комбинация любых из выщеприведенных средств искусственного интеллекта.
[0039] На этапе 204 обученное средство искусственного интеллекта обрабатывает признаки речевого сигнала, полученные на этапе 203, для получения последовательности фонем и последовательности визем, соответствующих фонемам в последовательности фонем. На этапе 205 обученное средство искусственного интеллекта вычисляет анимационные кривые для визем в последовательности визем, полученной на этапе 204, на основе соответствующих им фонем. Анимационные кривые задают параметры движения лица в анимации и длительность анимации визем.
[0040] В одном из вариантов осуществления обученное средство искусственного интеллекта содержит по меньшей мере два блока. Первый блок из упомянутых меньшей мере двух блоков обученного средства искусственного интеллекта выполняет этап 204, а второй блок из упомянутых меньшей мере двух блоков обученного средства искусственного интеллекта выполняет этап 205.
[0041] Первым блоком из упомянутых меньшей мере двух блоков обученного средства искусственного интеллекта может быть по меньшей мере одно из сверточной нейронной сети, рекуррентной нейронной сети, долгой краткосрочной памяти (LSTM), управляемым рекуррентным блоком (GRU), их модификациями или комбинацией любых из них.
[0042] Вторым блоком из упомянутых меньшей мере двух блоков обученного средства искусственного интеллекта может быть по меньшей мере одно из сверточной нейронной сети, рекуррентной нейронной сети, долгой краткосрочной памяти (LSTM), управляемым рекуррентным блоком (GRU), их модификациями или комбинацией любых из них.
[0043] На этапе 206 последовательность фонем и последовательность визем, полученные на этапе 204, объединяют путем наложения полученной последовательности фонем и полученной последовательности визем друг на друга с учетом анимационных кривых, вычисленных на этапе 205. В объединенной последовательности фонем и визем каждой фонеме в объединенной последовательности сопоставлена соответственная визема. Длительность каждой фонемы и сопоставленной соответственной виземы в объединенной последовательности, задается анимационной кривой для данной виземы.
[0044] На этапе 207 формируют анимацию модели головы путем анимации визем в объединенной последовательности фонем и визем с использованием параметров движения лица и длительности анимации визем, заданных анимационными кривыми, вычисленными на этапе 205.
[0045] Числовые параметры обученного средства искусственного интеллекта и дополнительного обученного средства искусственного интеллекта могут быть приняты из любого доступного источника, такого как Интернет, настольный компьютер, ноутбук и т.д., и сохранены в памяти 102 электронного вычислительного устройства 100. Средство искусственного интеллекта и дополнительное средство искусственного интеллекта также может быть обучено в электронном вычислительном устройстве 100.
[0046] Обучение средства искусственного интеллекта выполняют на наборе обучающих данных, который содержит речевой сигнал, субтитры для речевого сигнала и видеосигнал, соответствующий речевому сигналу. Такой набор обучающих данных может быть принят из любого доступного источника, такого как Интернет, телевизионная передача, смартфон, мобильный телефон, диктофон, настольный компьютер, ноутбук и т.д. Затем речевой сигнал, субтитры для речевого сигнала и видеосигнал отдельно обрабатывают. Обработка речевого сигнала, обработка субтитров для речевого сигнала и обработка видеосигнала может выполняться как параллельно, так и последовательно в зависимости от компоновки электронного вычислительного устройства 100 и его вычислительной способности.
[0047] Из субтитров для речевого сигнала выявляют последовательность фонем. Эта операция может быть выполнена любым известным способом, поэтому подробное описание этой операции опущено.
[0048] Речевой сигнал преобразуют в набор признаков речевого сигнала, и затем извлекают признаки речевого сигнала из набора признаков речевого сигнала. Как и для генерации анимационной модели головы по речевому сигналу преобразование речевого сигнала в набор признаков речевого сигнала и извлечение признаков речевого сигнала из набора признаков речевого сигнала может быть выполнено любым подходящим способом.
[0049] Последовательность фонем и последовательность визем, соответствующих фонемам в последовательности фонем, получают средством искусственного интеллекта на основании признаков речевого сигнала.
[0050] Для того, чтобы обученное средство искусственного интеллекта могло формировать последовательность фонем, средство искусственного интеллекта обучают функции формирования последовательности фонем. Функцию формирования последовательности фонем вычисляют с использованием функции потерь путем сравнения последовательности фонем, выявленной из субтитров для речевого сигнала, и последовательности фонем, полученной на основании признаков речевого сигнала. Функция потерь является известной функцией, поэтому подробное описание этой операции опущено.
[0051] Анимационные кривые для визем в последовательности визем, полученной на основании признаков речевого сигнала, могут быть вычислены с помощью системы кодирования лицевых движений (FACS). Однако настоящее изобретение не ограничено только применением FACS для вычисления анимационных кривых. Для вычисления анимационных кривых могут быть использованы любые подходящие способы.
[0052] Вычисленные анимационные кривые применяют к заранее заданному набору визем. Анимационные кривые задают параметры движения лица в анимации и длительность анимации визем. Применение анимационных кривых к заранее заданному набору визем вызывает анимацию/движение визем.
[0053] Затем выявляют траектории перемещения опорных точек лица на заранее заданном наборе визем с примененными вычисленными анимационными кривыми. Опорные точки лица выявляют детектором опорных точек лица. Детектор опорных точек лица может быть любым известным детектором. Параметры движения, заданные анимационными кривыми, задают анимацию/движение визем и, следовательно, траектории перемещения опорных точек лица.
[0054] Траектории перемещения опорных точек лица также выявляют в видеосигнале, соответствующем речевому сигналу. Опорные точки лица выявляют также, как и в описанной выше операции выявления траектории перемещения опорных точек лица на заранее заданном наборе визем. Затем при воспроизведении видеосигнала с выявленными опорными точками лица выявляют траектории перемещения опорных точек лица путем отслеживания перемещения опорных точек.
[0055] Выявленные траектории перемещения опорных точек лица в видеосигнале, соответствующем речевому сигналу, накладывают на заранее заданное нейтральное лицо.
[0056] Для того, чтобы обученное средство искусственного интеллекта могло формировать последовательность визем и вычислять анимационные кривые, средство искусственного интеллекта обучают функции формирования последовательности визем и функции вычисления анимационных кривых. Функцию формирования последовательности визем и функцию вычисления анимационных кривых вычисляют с использованием функции потерь путем сравнения траекторий перемещения опорных точек лица в видеосигнале, соответствующем речевому сигналу, наложенных на заранее заданное нейтральное лицо, и выявленных траекторий перемещения опорных точек лица на заранее заданном наборе визем. Функция потерь является известной функцией, поэтому подробное описание этой операции опущено.
[0057] Существуют похожие виземы, которые могут частично соответствовать одной фонеме, поэтому средство искусственного интеллекта обучают для правильного выбора виземы для каждой фонемы. Функцию выбора визем для обученного средства искусственного интеллекта вычисляют с использованием метода регуляризации на основании последовательности фонем, полученной на основании признаков речевого сигнала, последовательности визем, полученной на основании признаков речевого сигнала, и вычисленных анимационных кривых. Регуляризация, как метод решения некорректно поставленной задачи или предотвращения переобучения, является известным методом, поэтому подробное описание этой операции опущено.
[0058] Способ, раскрытый в данной заявке, может быть реализован посредством по меньшей мере одного процессора, интегральной схемы специального назначения (ASIC), программируемой пользователем вентильной матрицы (FPGA), или как система на кристалле (SoC). Кроме того, способ, раскрытый в данной заявке, может быть реализован посредством считываемого компьютером носителя, на котором хранятся числовые параметры множества обученных интеллектуальных систем и исполняемые компьютером инструкции, которые, при исполнении процессором компьютера, побуждают компьютер к выполнению раскрытого способа. Обученное средство искусственного интеллекта и инструкции по выполнению заявленного способа могут быть загружены в мобильное устройство по сети или с носителя.
[0059] Вышеприведенные описания вариантов осуществления изобретения являются иллюстративными, и модификации конфигурации и реализации не выходят за пределы объема настоящего описания. Например, хотя варианты осуществления изобретения описаны, в общем, в связи с фигурами 1–2, приведенные описания являются примерными. Хотя предмет изобретения описан на языке, характерном для конструктивных признаков или методологических операций, понятно, что предмет изобретения, определяемый прилагаемой формулой изобретения, не обязательно ограничен конкретными вышеописанными признаками или операциями. Более того, конкретные вышеописанные признаки и операции раскрыты как примерные формы реализации формулы изобретения. Изобретение не ограничено также показанным порядком этапов способа, порядок может быть видоизменен специалистом без новаторских нововведений. Некоторые или все этапы способа могут выполняться последовательно или параллельно.
[0060] Соответственно предполагается, что объем варианта осуществления изобретения ограничивается только нижеследующей формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ МНОГОМОДАЛЬНОГО БЕСКОНТАКТНОГО УПРАВЛЕНИЯ МОБИЛЬНЫМ ИНФОРМАЦИОННЫМ РОБОТОМ | 2020 |
|
RU2737231C1 |
| СЕТЬ СВЯЗИ И УСТРОЙСТВА ДЛЯ ПРЕОБРАЗОВАНИЯ ТЕКСТА В РЕЧЬ И ТЕКСТА В АНИМАЦИЮ ЛИЦА | 2007 |
|
RU2488232C2 |
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ НА ОСНОВЕ ДВУХУРОВНЕВОГО МОРФОФОНЕМНОГО ПРЕФИКСНОГО ГРАФА | 2015 |
|
RU2597498C1 |
| СПОСОБ АУДИОВИЗУАЛЬНОГО РАСПОЗНАВАНИЯ СРЕДСТВ ИНДИВИДУАЛЬНОЙ ЗАЩИТЫ НА ЛИЦЕ ЧЕЛОВЕКА | 2022 |
|
RU2791415C1 |
| СПОСОБ СОЗДАНИЯ МОДЕЛИ АНАЛИЗА ДИАЛОГОВ НА БАЗЕ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА ДЛЯ ОБРАБОТКИ ЗАПРОСОВ ПОЛЬЗОВАТЕЛЕЙ И СИСТЕМА, ИСПОЛЬЗУЮЩАЯ ТАКУЮ МОДЕЛЬ | 2019 |
|
RU2730449C2 |
| АДАПТИВНОЕ УЛУЧШЕНИЕ АУДИО ДЛЯ РАСПОЗНАВАНИЯ МНОГОКАНАЛЬНОЙ РЕЧИ | 2016 |
|
RU2698153C1 |
| Способ определения признаков паркинсонизма по голосу с использованием искусственного интеллекта | 2023 |
|
RU2841464C2 |
| Способ 3D-реконструкции человеческой головы для получения рендера изображения человека | 2022 |
|
RU2786362C1 |
| СПОСОБ ИНТЕРАКТИВНОЙ СЕГМЕНТАЦИИ ОБЪЕКТА НА ИЗОБРАЖЕНИИ И ЭЛЕКТРОННОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2020 |
|
RU2742701C1 |
| ИНТЕРФЕЙС ПОЛЬЗОВАТЕЛЯ С УПРЕЖДАЮЩИМ ДЕЙСТВИЕМ | 2003 |
|
RU2353068C2 |
Изобретение относится к области вычислительной техники. Технический результат настоящего изобретения заключается в обеспечении способа генерации анимационной модели головы по речевому сигналу и электронного вычислительного устройства, реализующего упомянутый способ, способных обеспечить анимацию головы по речевому сигналу в реальном времени с низкой задержкой и высоким качеством изображения. Способ генерации анимационной модели головы по речевому сигналу: принимают речевой сигнал; преобразуют речевой сигнал в набор признаков речевого сигнала; извлекают признаки речевого сигнала из набора признаков речевого сигнала; получают последовательность фонем и последовательность визем; вычисляют обученным средством искусственного интеллекта анимационные кривые; объединяют полученную последовательность фонем и полученную последовательность визем путем наложения полученной последовательности фонем и полученной последовательности визем друг на друга с учетом вычисленных анимационных кривых; и формируют анимацию модели головы путем анимации визем в объединенной последовательности фонем и визем с использованием вычисленных анимационных кривых. 2 н. и 7 з.п. ф-лы, 2 ил.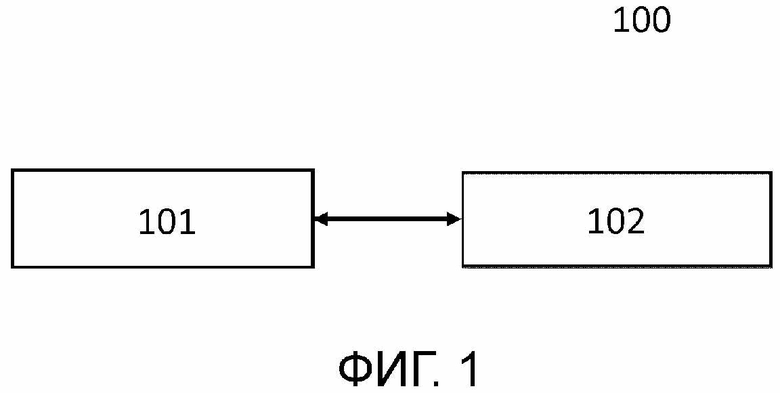
1. Способ генерации анимационной модели головы по речевому сигналу, при этом упомянутый способ выполняется одним или более процессорами и содержит этапы, на которых:
принимают речевой сигнал;
преобразуют речевой сигнал в набор признаков речевого сигнала;
извлекают признаки речевого сигнала из набора признаков речевого сигнала;
получают последовательность фонем и последовательность визем, соответствующих фонемам в последовательности фонем, путем обработки признаков речевого сигнала обученным средством искусственного интеллекта;
вычисляют обученным средством искусственного интеллекта анимационные кривые для визем в полученной последовательности визем на основе соответствующих им фонем;
объединяют полученную последовательность фонем и полученную последовательность визем путем наложения полученной последовательности фонем и полученной последовательности визем друг на друга с учетом вычисленных анимационных кривых; и
формируют анимацию модели головы путем анимации визем в объединенной последовательности фонем и визем с использованием вычисленных анимационных кривых.
2. Способ по п.1, в котором обучение средства искусственного интеллекта содержит этапы, на которых:
принимают набор обучающих данных, содержащий речевой сигнал, субтитры для речевого сигнала и видеосигнал, соответствующий речевому сигналу;
выявляют последовательность фонем из субтитров для речевого сигнала;
преобразуют речевой сигнал в набор признаков речевого сигнала;
извлекают признаки речевого сигнала из набора признаков речевого сигнала;
получают последовательность фонем и последовательность визем, соответствующих фонемам в последовательности фонем, на основании признаков речевого сигнала;
вычисляют функцию формирования последовательности фонем путем сравнения последовательности фонем, выявленной из субтитров для речевого сигнала, и последовательности фонем, полученной на основании признаков речевого сигнала;
вычисляют анимационные кривые для визем в последовательности визем, полученной на основании признаков речевого сигнала;
применяют вычисленные анимационные кривые к заранее заданному набору визем;
выявляют траектории перемещения опорных точек лица на заранее заданном наборе визем с примененными вычисленными анимационными кривыми;
выявляют траектории перемещения опорных точек лица в видеосигнале, соответствующем речевому сигналу;
накладывают траектории перемещения опорных точек лица в видеосигнале, соответствующем речевому сигналу, на заранее заданное нейтральное лицо;
вычисляют функцию формирования последовательности визем и функцию вычисления анимационных кривых путем сравнения траекторий перемещения опорных точек лица в видеосигнале, соответствующем речевому сигналу, наложенных на заранее заданное нейтральное лицо, и выявленных траекторий перемещения опорных точек лица на заранее заданном наборе визем; и
вычисляют функцию выбора визем на основании последовательности фонем, полученной на основании признаков речевого сигнала, последовательности визем, полученной на основании признаков речевого сигнала, и вычисленных анимационных кривых.
3. Способ по п.1 или 2, в котором этап преобразования речевого сигнала в набор признаков речевого сигнала и этап извлечения признаков речевого сигнала из набора признаков речевого сигнала выполняют одним из способа мел–частотных кепстральных коэффициентов (MFCC) или дополнительным предварительно обученным средством искусственного интеллекта.
4. Способ по п.3, в котором дополнительное предварительно обученное средство искусственного интеллекта является по меньшей мере одним из рекуррентной нейронной сети, долгой краткосрочной памяти (LSTM), управляемым рекуррентным блоком (GRU), их модификациями или комбинацией любых из них.
5. Способ по п.1, в котором обученное средство искусственного интеллекта содержит по меньшей мере два блока,
при этом первый блок из упомянутых по меньшей мере двух блоков обученного средства искусственного интеллекта выполняет этап, на котором получают последовательность фонем и последовательность визем, соответствующих фонемам в последовательности фонем, путем обработки признаков речевого сигнала, и второй блок из упомянутых по меньшей мере двух блоков обученного средства искусственного интеллекта выполняет этап, на котором вычисляют обученным средством искусственного интеллекта анимационные кривые для визем в полученной последовательности визем на основе соответствующих им фонем.
6. Способ по п.5, в котором первый блок из упомянутых по меньшей мере двух блоков обученного средства искусственного интеллекта является по меньшей мере одним из сверточной нейронной сети, рекуррентной нейронной сети, долгой краткосрочной памяти (LSTM), управляемым рекуррентным блоком (GRU), их модификациями или комбинацией любых из них.
7. Способ по п.5, в котором второй блок из упомянутых по меньшей мере двух блоков обученного средства искусственного интеллекта является по меньшей мере одним из сверточной нейронной сети, рекуррентной нейронной сети, долгой краткосрочной памяти (LSTM), управляемым рекуррентным блоком (GRU), их модификациями или комбинацией любых из них.
8. Способ по п.2, в котором этап вычисления анимационных кривых для визем в последовательности визем, полученной на основании признаков речевого сигнала выполняют с помощью системы кодирования лицевых движений (FACS).
9. Электронное вычислительное устройство, содержащее:
по меньшей мере один процессор; и
память, хранящую числовые параметры по меньшей мере одного обученного средства искусственного интеллекта и инструкции, которые при исполнении по меньшей мере одним процессором побуждают по меньшей мере один процессор выполнять способ генерации анимационной модели головы по речевому сигналу по любому из пп. 1–8.
| US2018174348 A1, 21.06.2018 | |||
| DE102004059051 A1, 08.06.2006 | |||
| US2009184967 A1, 23.07.2009 | |||
| US2006122834 A1, 08.06.2006 | |||
| RU2013158054 A, 10.08.2015. |

