ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННУЮ ЗАЯВКУ
[0001] Настоящая заявка испрашивает приоритет патентной заявки США № 62/312,053, поданной 23 марта 2016, содержание которой включено в настоящий документ посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ
[0002] Настоящая заявка относится к обработке многоканальных волновых форм аудио.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
[0003] Различные методы могут быть использованы для распознавания речи. Некоторые методы используют акустическую модель, которая получает акустические признаки, выведенные из аудиоданных.
КАТКОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
[0004] В некоторых реализациях, система распознавания речи может выполнять адаптивные методы улучшения аудио для улучшения распознавания многоканальной речи, например, путем повышения его надежности и/или точности. Например, адаптивное формирование луча (диаграммы направленности) может выполняться с использованием нейронных сетей. Несколько каналов аудио, например, аудио информация от разных микрофонов, могут быть поданы на модуль нейронной сети, который адаптивно изменяет фильтры, используемые для улучшения аудио, например, пространственной фильтрации или формирования диаграммы направленности. В некоторых реализациях, система может динамически оценивать набор фильтров для каждого входного фрейма с использованием нейронной сети. Например, многоканальные сигналы исходных (необработанных) волновых форм могут быть переданы в модуль долгой краткосрочной памяти (LSTM) предсказания фильтра (FP) для генерации фильтров временной области для каждого канала. Затем выполняется свертка этих фильтров с аудиоданными для соответствующих каналов и их суммирование вместе для формирования одноканальной улучшенной речи, которая предоставляется в акустическую модель, используемую для выполнения распознавания речи.
[0005] Хотя некоторые системы автоматического распознавания речи (ASR) могут работать приемлемо в некоторых ситуациях, например, когда пользователь находится рядом с микрофоном, качество функционирования таких систем ASR может ухудшаться в условиях дальней зоны, когда между пользователем и микрофоном имеются большие расстояния, например, когда динамик предоставляет команды на телевизор или термостат. В таких условиях, речевые сигналы подвергаются деградации из-за реверберации и аддитивного шума. Эти системы часто используют несколько микрофонов для повышения точности распознавания, улучшения речевых сигналов и уменьшения эффектов, обусловленных реверберацией и шумом.
[0006] Некоторые многоканальные системы ASR используют два отдельных модуля для выполнения распознавания. Во-первых, применяется улучшение (усиление) речи решетки микрофонов, как правило, посредством формирования диаграммы направленности. Затем усиленный сигнал передается на акустическую модель. Методы часто включают формирование диаграммы направленности на основе задержки и суммирования, что включает в себя прием сигналов от разных микрофонов для регулирования задержки от целевого динамика до каждого из микрофонов. Затем выровненные по времени сигналы суммируются для усиления сигнала с целевого направления и ослабления шума, исходящего из других направлений. Другие формы улучшения сигнала включают в себя отклик без искажений с минимальной дисперсией (MVDR) и многоканальную винеровскую (Wiener) фильтрацию (MWF).
[0007] Подход к обработке улучшения как отдельной от акустического моделирования может не привести к наилучшему решению для улучшения характеристик ASR. Кроме того, многие методы улучшения включают подход, основанный на модели, который требует итерационной оптимизации параметров для акустической модели и/или модели улучшения аудио. Например, подходы часто сначала оценивают параметры формирования луча, а затем оценивают параметры акустической модели. Эти итерационные подходы не просто комбинировать с другими типами моделей, которые не используют итерационное обучение. Например, акустические модели, основанные на нейронных сетях, часто оптимизируются с использованием градиентного алгоритма обучения, а не итерационных методов обучения, используемых с моделью гауссовой смеси (GMM) и другими моделями.
[0008] Система распознавания речи может быть усовершенствована путем совместного обучения пространственных фильтров и параметров акустической модели. В одном из способов выполнения улучшения аудио используются многоканальные фильтры ʺвременной сверткиʺ, каждый из которых независимо фильтрует каждый канал входа и затем суммирует выходы в процессе, аналогичном формированию диаграммы направленности на основе фильтрации и суммирования. Другие методы могут обучать множество пространственных фильтров, чтобы адаптироваться к целевому сигналу, приходящему в разных пространственных направлениях, при большом увеличении вычислительной сложности. Хотя оба этих способа показали улучшения по сравнению с традиционными методами обработки сигналов на основе задержки и суммирования и на основе фильтрации и суммирования, одним недостатком является то, что оцененные пространственные и спектральные фильтры, определенные во время обучения, являются фиксированными для декодирования. То есть, фильтры не изменяются или не адаптируются во время использования в распознавании речи. В результате, в подходах фиксированного фильтра, фиксированные фильтры могут не соответствовать фактическому положению пользователя относительно микрофонов.
[0009] Соответственно, инновационный аспект изобретения, описанного в настоящей заявке, относится к автоматизированной системе распознавания речи, которая может адаптировать фильтры, используемые для улучшения аудио, по мере приема речевых данных. Например, по мере обнаружения речи, система распознавания речи может динамически изменять параметры фильтров, используемых для выполнения пространственной фильтрации. В некоторых реализациях, фильтры адаптируются для каждого входного речевого фрейма. Кроме того, каждый фильтр может быть определен с использованием информации о множестве аудиоканалов. Вместо того чтобы определять каждый фильтр независимо на основе одного аудиоканала, фильтр для каждого аудиоканала может быть определен с использованием входов от всех аудиоканалов.
[0010] Система распознавания речи может выполнять адаптивное улучшение аудио с использованием одной или нескольких нейронных сетей. Например, система распознавания речи может включать в себя две нейронные сети, одна из которых адаптивно генерирует пространственные фильтры, а другая действует как акустическая модель. Первая нейронная сеть генерирует параметры фильтра на основе множества каналов аудиоданных, соответствующих произношению (речевому фрагменту). Параметры фильтра определяют характеристики нескольких фильтров, например, одного фильтра для каждого канала аудиоданных. Параметры фильтра для каждого канала подаются на отличающийся фильтр. Каждый фильтр затем применяется к соответствующему ему каналу аудиоданных, и результаты для каждого канала суммируются вместе. Суммированные выходы фильтров предоставляются во вторую нейронную сеть, которая ранее была обучена, чтобы идентифицировать акустические фонемы речевого фрагмента. Затем система может использовать идентифицированные фонемы для генерации конкурирующей транскрипции речевого фрагмента.
[0011] В соответствии с инновационным аспектом изобретения, описанного в настоящей заявке, способ адаптивного улучшения аудио для многоканального распознавания речи включает в себя действия приема первого канала аудиоданных, соответствующих речевому фрагменту, и второго канала аудиоданных, соответствующих речевому фрагменту; генерирования, с использованием обученной рекуррентной нейронной сети, (i) первого набора параметров фильтра для первого фильтра на основе первого канала аудиоданных и второго канала аудиоданных и (ii) второго набора параметров фильтра для второго фильтра на основе первого канала аудиоданных и второго канала аудиоданных; генерирования единого объединенного канала аудиоданных путем объединения (i) аудиоданных первого канала, который был отфильтрован с использованием первого фильтра, и (ii) аудиоданных второго канала, который был отфильтрован с использованием второго фильтра; ввода аудиоданных для единого объединенного канала в нейронную сеть, обученную в качестве акустической модели; и обеспечения транскрипции для речевого фрагмента, которая определяется, по меньшей мере, на основе выхода, который нейронная сеть выдает в ответ на получение объединенных выходов свертки.
[0012] Эта и другие реализации могут включать в себя один или несколько следующих дополнительных признаков. Рекуррентная нейронная сеть содержит один или несколько слоев долгой краткосрочной памяти. Рекуррентная нейронная сеть включает в себя первый слой долгой краткосрочной памяти, который принимает как первый, так и второй каналы аудио; и второй слой долгой краткосрочной памяти, соответствующий первому каналу, и третий слой долгой краткосрочной памяти, соответствующий второму каналу, второй слой долгой краткосрочной памяти и третий слой долгой краткосрочной памяти, каждый, принимают выход первого слоя долгой краткосрочной памяти и предоставляют набор параметров фильтра для соответствующего канала. Слои долгой краткосрочной памяти имеют параметры, которые были изучены во время процесса обучения, который совместно обучает слои долгой краткосрочной памяти и нейронную сеть, которая обучается как акустическая модель. Действия дополнительно включают в себя изменение или генерирование новых параметров фильтра для каждого входного фрейма аудиоданных. Действия дополнительно включают в себя, для каждого аудио фрейма в последовательности аудио фреймов речевого фрагмента, генерирование нового набора параметров фильтра и свертку аудиоданных для фрейма с фильтром с новым набором параметров фильтра. Первый фильтр и второй фильтр представляют собой фильтры с конечным импульсным откликом. Первый фильтр и второй фильтр имеют различные параметры.
[0013] Различные микрофонные выходы свертываются с различными фильтрами. Первый и второй каналы аудиоданных представляют собой первый и второй каналы данных волновых форм аудио для речевого фрагмента. Первый и второй каналы волновой формы аудио являются записями речевого фрагмента различными микрофонами, находящимися на расстоянии друг от друга. Нейронная сеть, обученная как акустическая модель, содержит сверточный слой, один или несколько слоев долгой краткосрочной памяти и несколько скрытых слоев. Сверточный слой нейронной сети, обученной как акустическая модель, сконфигурирован для выполнения свертки временной области. Нейронная сеть, обученная как акустическая модель, сконфигурирована так, что выходы сверточного слоя накапливаются для генерации набора накопленных значений. Нейронная сеть, обученная в качестве акустической модели, сконфигурирована вводить накопленные значения в один или несколько слоев долгой краткосрочной памяти в нейронной сети, обученной в качестве акустической модели. Первый и второй фильтры сконфигурированы для выполнения как пространственной, так и спектральной фильтрации. Действия дополнительно включают в себя свертку аудиоданных для первого канала с первым фильтром, имеющим первый набор параметров фильтра, для генерации первых выходов свертки; свертку аудиоданных для второго канала со вторым фильтром, имеющим второй набор параметров фильтра, для генерации вторых выходов свертки; и объединение первых выходов свертки и вторых выходов свертки.
[0014] Другие варианты осуществления этого аспекта включают в себя соответствующие системы, устройства и компьютерные программы, записанные на компьютерных запоминающих устройствах, каждая из которых сконфигурирована для выполнения операций этих способов.
[0015] В некоторых реализациях, описанные здесь способы могут быть осуществлены для реализации одного или нескольких из следующих преимуществ. Например, система распознавания речи может динамически изменять параметры фильтра, используемые для улучшения аудио, что может привести к большей надежности и точности распознавания речи. Усовершенствованное улучшение аудио, как обсуждается здесь, может обеспечить более четкие речевые данные для акустической модели, что позволяет повысить точность распознавания речи. Система распознавания речи может генерировать фильтры, которые соответствуют фактическому положению пользователя, более точно, чем фиксированные предопределенные фильтры. Кроме того, адаптация фильтров может настраиваться на изменения в положении пользователя относительно микрофонов, например, когда пользователь ходит по комнате во время разговора. В некоторых реализациях, вычислительная сложность улучшения аудио снижается с использованием системы нейронной сети, описанной ниже, по сравнению с моделями, которые пытаются адаптироваться к сигналам, приходящим с множества разных предопределенных пространственных направлений. Также можно получить улучшенную точность распознавания речи с помощью других методов, рассмотренных ниже, включая совместное обучение модели предсказания фильтра с акустической моделью, обучение модели предсказания фильтра с использованием обратной связи от акустической модели. В некоторых реализациях, многозадачные стратегии обучения используются для установки нескольких целей обучения, например, точного предсказания как состояний акустической модели, так и признаков чистого аудио. Использование многозадачного обучения может повысить точность распознавания зашумленного аудио, а также может улучшить предсказание фильтра и упорядочить обучение.
[0016] Детали одного или нескольких вариантов осуществления изобретения, раскрытого в настоящем описании, приведены на прилагаемых чертежах и в описании ниже. Другие признаки, аспекты и преимущества заявленного изобретения станут очевидными из описания, чертежей и формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0017] Фиг. 1 иллюстрирует примерную архитектуру для адаптивного улучшения аудио.
[0018] Фиг. 2 иллюстрирует примерные отклики формирователя диаграммы направленности.
[0019] Фиг. 3 иллюстрирует пример системы распознавания речи с использованием нейронных сетей.
[0020] Фиг. 4 иллюстрирует примерный процесс адаптивного улучшения аудио для распознавания многоканальной речи.
[0021] Фиг. 5 иллюстрирует пример вычислительного устройства и мобильного вычислительного устройства.
[0022] На чертежах, одинаковые ссылочные позиции обозначают соответствующие элементы.
ПОДРОБНОЕ ОПИСАНИЕ
[0023] Совместное многоканальное усиление и акустическое моделирование с использованием нейронных сетей могут использоваться для выполнения распознавания речи. В некоторых предыдущих подходах, фильтры, обучаемые на этапе обучения, были фиксированными для декодирования, что потенциально влияло на способность этих моделей адаптироваться к ранее не наблюдавшимся или изменяющимся условиям. Изобретение, описанное в настоящей заявке, описывает методику адаптивного формирования диаграммы направленности нейронной сети (NAB) для решения этой проблемы. Вместо обучения конкретных фильтров на этапе обучения, модель нейронной сети может обучаться, чтобы динамически генерировать параметры фильтров по мере того, как аудиоданные принимаются во время распознавания речи. Это позволяет системе выполнять более точное формирование диаграммы направленности, которое не ограничено предопределенным количеством фиксированных направлений прихода сигнала.
[0024] В некоторых реализациях, система распознавания речи использует слои долгой краткосрочной памяти (LSTM) для предсказания коэффициентов фильтра формирования диаграммы направленности во временной области на каждом входном фрейме. Выполняется свертка фильтров с фреймовым входным сигналом временной области и их суммирование по каналам, по существу выполняя формирование диаграммы направленности на основе фильтрации фильтром с конечным импульсным откликом (FIR) и суммирования с использованием динамически адаптируемых фильтров. Выход формирователя диаграммы направленности передается в акустическую модель сверточной, с долгой краткосрочной памятью глубокой нейронной сети (CLDNN), которая обучается совместно со слоями LSTM предсказания фильтра. В одном примере, система распознавания речи с предлагаемой моделью NAB достигает относительного улучшения частоты ошибок слов (WER) 12,7% по сравнению с одноканальной моделью и достигает такой же производительности, что и архитектура ʺфакторизованнойʺ модели, которая использует несколько фиксированных пространственных фильтров, с уменьшением вычислительных затрат на 17,9%.
[0025] Несмотря на то, что в последние годы производительность автоматического распознавания речи (ASR) значительно улучшилась, особенно с появлением глубокого обучения, производительность в реалистичных зашумленных сценариях и сценариях дальней зоны по-прежнему значительно отстает от условий чистой речи. Для повышения надежности, решетки микрофонов обычно используются для улучшения речевого сигнала и устранения нежелательных шумов и реверберации.
[0026] Система распознавания речи может использовать метод многоканальной обработки сигналов, представляющий собой формирование диаграммы направленности на основе задержки и суммирования (DS), в котором сигналы из разных микрофонов выравниваются во времени, чтобы скорректировать задержку распространения от целевого говорящего до каждого микрофона, а затем смешиваются в единый канал. Это приводит к усилению сигнала с целевого направления и ослаблению шума, приходящего с других направлений. Однако может быть трудно точно оценить временную задержку прихода в средах с реверберацией, и формирование диаграммы направленности DS не учитывает влияние пространственно-коррелированного шума. Можно повысить производительность, используя более обобщенный метод фильтрации и суммирования (FS), где перед суммированием в каждом канале применяется линейный фильтр. Такие фильтры обычно выбираются для оптимизации целей сигнального слоя, например SNR, которые отличаются от цели обучения акустической модели (AM).
[0027] Совместное обучение стадий усиления и АМ повышает производительность, как для модели гауссовой смеси, так и для акустических моделей нейронной сети. Например, в некоторых реализациях, система распознавания речи может обучать нейронные сети работать непосредственно на многоканальных волновых формах сигналов, используя один слой многоканальных фильтров FIR ʺвременной сверткиʺ, каждый из которых независимо фильтрует каждый канал входа, а затем суммирует выходы в процессе, аналогичном формированию диаграммы направленности FS. После обучения, фильтры в этом многоканальном банке фильтров обучаются совместно выполнять пространственную и спектральную фильтрацию с типовыми фильтрами, имеющими отклик полосы пропускания по частоте, но управляемыми для усиления или ослабления сигналов, поступающих с различных направлений. В некоторых реализациях, система распознавания речи может использовать факторизованную модель многоканальной волновой формы, которая разделяет поведение пространственной и спектральной фильтрации на отдельные слои и повышает производительность, но может увеличить вычислительную сложность. Хотя обе эти архитектуры продемонстрировали улучшения по сравнению с традиционными методами обработки сигналов DS и FS, одним из недостатков является то, что оцененные пространственные и спектральные фильтры являются фиксированными во время декодирования.
[0028] Чтобы устранить ограниченную адаптивность и уменьшить вычислительную сложность моделей, описанных выше, изобретение, описанное в настоящей заявке, включает в себя модель адаптивного формирования диаграммы направленности нейронной сети (NAB), которая повторно оценивает набор коэффициентов пространственного фильтра на каждом входном фрейме с использованием нейронной сети. В частности, необработанные многоканальные сигналы волновых форм передаются в LSTM предсказания фильтра (FP), выходы которой используются в качестве коэффициентов пространственного фильтра. Эти пространственные фильтры для каждого канала затем подвергаются свертке с соответствующим входом волновой формы, и выходы суммируются вместе для формирования одноканальной выходной волновой формы, содержащей улучшенный речевой сигнал. Полученный одноканальный сигнал передается на акустическую модель необработанной волновой формы, которая обучается совместно со слоями FP LSTM. В некоторых реализациях, фильтрация может выполняться в частотной области, в противоположность обработке сигналов временной области. Настоящее раскрытие иллюстрирует ниже, что выполнение NAB во временной области требует оценки намного меньшего количества коэффициентов фильтра и приводит к лучшей WER по сравнению с предсказанием фильтра частотной области.
[0029] Кроме того, изобретение, описанное в настоящей заявке, включает в себя другие усовершенствования в модели NAB. Во-первых, раскрытие описывает явный ввод активаций верхних слоев акустической модели с предыдущего временного шага, которые захватывают информацию высокого уровня об акустических состояниях в качестве дополнительного входа в слои FP. Механизм стробирования далее применяется для ослабления потенциальных ошибок в этих предсказаниях. Он анализирует предсказания вместе с входами и состояниями модели для вывода доверительной оценки, которая при необходимости масштабирует с понижением векторы обратной связи. Во-вторых, раскрытие описывает включение стратегии многозадачного обучения (MTL) для регуляризации обучения и помощи в предсказании фильтра. Это работает путем обучения модели NAB для совместного предсказания состояний акустической модели и чистых признаков, что может улучшить акустические модели, обучаемые на зашумленных данных.
[0030] Пример модели адаптивного формирования диаграммы направленности нейронной сети (NAB) изображен на фиг. 1, которая включает в себя блоки предсказания фильтра (FP), формирования диаграммы направленности путем фильтрации и суммирования (FS), акустического моделирования (AM) и многозадачного обучения (MTL). Показаны два канала, но может использоваться большее количество каналов. В каждом временном фрейме k, система принимает в малом окне М выборок волновой формы для каждого канала c из входов С каналов, обозначенных как x1(k)[t], x2(k)[t], …, xс(k)[t] для t∈{1,…,M}.
[0031] Адаптивная пространственная фильтрация может быть выполнена следующим образом. Формирователь диаграммы направленности на основе фильтра с конечной импульсной характеристикой (FIR) и суммирования может быть записан как:
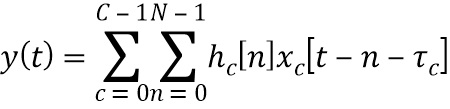 Уравнение 1
Уравнение 1
где hc[n] - n-й отвод фильтра, ассоциированного с микрофоном c, xc[t] - сигнал, принимаемый микрофоном c в момент времени t, τс - задержка управления (по направлению), вводимая в сигнал, принимаемый микрофоном, чтобы выравнивать его с другими каналами решетки, и y[t] - выходной сигнал. N - длина фильтра.
[0032] Алгоритмы улучшения, которые оптимизируют Уравнение 1, могут потребовать оценки задержки управления τс, которая может быть получена из отдельной модели локализации. Коэффициенты фильтра могут быть получены путем оптимизации целей сигнального уровня. В модели NAB, система оценивает коэффициенты фильтра совместно с параметрами AM путем прямой минимизации кросс-энтропии или функции потерь последовательности. Вместо явного оценивания задержки управления для каждого микрофона, τс может неявно содержаться в оцениваемых коэффициентах фильтра. Результирующая адаптивная фильтрация в каждом временном фрейме k задается Уравнением 2, где hc(k)[t] - оцениваемый фильтр для канала c во временном фрейме k.
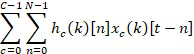 Уравнение 2
Уравнение 2
[0033] Для оценки hc(k)[t], система обучает FP LSTM предсказывать N коэффициентов фильтра для каждого канала. Вход в модуль FP представляет собой конкатенацию фреймов необработанных входных выборок xc(k)[t] из всех каналов и может также включать в себя признаки для локализации, такие как признаки взаимной корреляции.
[0034] Нижеследующее раскрытие более подробно описывает архитектуру модуля FP. Следуя Уравнению 2, оцененные коэффициенты фильтра hc(k)[t] подвергаются свертке с входными выборками xc(k)[t] для каждого канала. Выходы свертки суммируются, например, в блоке FS по каналам для получения одноканального сигнала y(k)[t].
[0035] Затем акустическое моделирование выполняется с использованием блока АМ. Одноканальный улучшенный сигнал y(k)[t] передается в модуль AM, показанный на фиг. 1. Волновая форма одноканального сигнала передается на слой ʺвременной сверткиʺ, обозначенный как tConv, который действует как банк фильтров временной области, содержащий некоторое число фильтров. Например, может использоваться 128 фильтров. Выход tConv прореживается во времени посредством max-накопления (max-pooling) по длине входного фрейма. В некоторых реализациях, max-накопление спектрального выхода во времени помогает отбросить кратковременную информацию. Наконец, нелинейность выпрямителя и стабилизированное логарифмическое сжатие применяются для каждого выхода фильтра, чтобы создать вектор признаков фреймового уровня во фрейме k.
[0036] В некоторых реализациях, система не включает в себя частотный сверточный слой. Вектор признаков, сгенерированный временным сверточным слоем, непосредственно передается на три слоя LSTM с 832 ячейками и 512-мерный проекционный слой, за которым следует полностью связанный слой DNN из 1024 скрытых единиц. 512-мерный проекционный слой низкого ранга линейных выходов используется перед слоем softmax, чтобы уменьшить количество параметров, необходимых для классификации выходных целей 13522 контекстно-зависимых состояний. После обработки фрейма k, система сдвигает окно общего входного сигнала на интервал 10 мс и повторяет этот процесс.
[0037] Модули AM и FP могут обучаться совместно. В некоторых реализациях, блок FS не имеет обучаемых параметров. Модель развернута на 20 временных шагах для обучения с использованием усеченного обратного распространения во времени. Метка выходного состояния задерживается на 5 фреймов, поскольку использование информации о будущих фреймах часто улучшает предсказание текущего фрейма.
[0038] Процесс обучения может быть усовершенствован с использованием управляемой (стробируемой) обратной связи. Информация распознавания из акустической модели отображает содержание речи и, как считается, помогает более ранним слоям сети. Расширение сетевого входа в каждом фрейме с предсказанием из предыдущего фрейма может повысить производительность. Чтобы исследовать преимущества обратной связи в модели NAB, предсказание AM в фрейме k-1 может быть передано обратно в модель FP во временном фрейме k (самая правая вертикальная линия на фиг. 1). Поскольку предсказание softmax является многомерным, то система возвращает обратно активации низкого ранга, предшествующие softmax, на модуль FP, чтобы ограничить увеличение параметров модели.
[0039] Данное соединение обратной связи дает модулю FP информацию высокого слоя о фонематическом содержании сигнала, чтобы помочь в оценке коэффициентов фильтра формирования диаграммы направленности. Например, соединение может предоставлять вероятную контекстно-зависимую информацию о состоянии в сигнале для использования при генерации фильтров формирования диаграммы направленности. Эта обратная связь состоит из модельных предсказаний, которые могут содержать ошибки, в частности, в начале обучения и поэтому могут привести к плохому обучению моделей. Поэтому в соединение вводится механизм стробирования (избирательного пропускания) для модуляции степени обратной связи. В отличие от обычных гейтов (механизмов избирательного пропускания информации) LSTM, которые контролируют каждую размерность независимо друг от друга, мы используем глобальный скалярный гейт для смягчения обратной связи. Гейт gfb(k) во временном фрейме k вычисляется из входных выборок волновой формы x(k), состояния первого слоя FP LSTM s(k-1) и вектора обратной связи v(k-1) следующим образом:
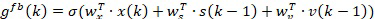 Уравнение 3
Уравнение 3
где wx, ws и wv - соответствующие весовые векторы и σ - поэлементная нелинейность. Система использует логическую функцию для σ, которая выводит значения в диапазоне [0,1], где 0 отключает соединение обратной связи, а 1 прямо пропускает обратную связь. Следовательно, эффективный вход FP имеет вид [hx(k), gfb(k)v(k-1)].
[0040] Многозадачное обучение может обеспечить улучшенную устойчивость. Система включает в себя модуль MTL при обучении путем конфигурирования сети, чтобы иметь два выхода, один выход распознавания, который предсказывает состояния CD, и второй выход шумоподавления, который восстанавливает 128 log-mel признаков, полученных из основного чистого сигнала. Выход шумоподавления используется только для обучения, чтобы упорядочить параметры модели; ассоциированные слои отбрасываются во время вывода. В модели NAB, модуль MTL ответвляется от первого слоя LSTM модуля AM, как показано на фиг. 1. Модуль MTL состоит из двух полностью соединенных слоев DNN, за которыми следует линейный выходной слой, который предсказывает чистые признаки. Во время обучения, обратно распространяемые градиенты с двух выходов взвешиваются с помощью α и 1-α для выходов распознавания и шумоподавления, соответственно.
[0041] Это раскрытие описывает эксперименты, проведенные примерно на 2000 часов зашумленных данных обучения, включающих в себя 3 миллиона речевых фрагментов на английском языке. Этот набор данных создается путем искусственного искажения чистых речевых фрагментов с использованием симулятора помещения с добавлением варьирующихся степеней шума и реверберации. Чистые речевые фрагменты являются анонимными и вручную транскрибированными голосовыми поисковыми запросами и являются характерными для голосового поискового интернет-трафика. Шумовые сигналы, которые включают в себя музыку и окружающий шум, отобранные с веб-сайтов для обмена видео, и записи окружений ʺповседневной жизниʺ, добавляются к чистым речевым фрагментам при SNR в диапазоне от 0 до 20 дБ со средним значением 12 дБ. Реверберация моделируется с использованием модели изображения с размерностями помещения и положениями решетки микрофонов, из которых случайным образом берутся выборки из 100 возможных конфигураций помещений с временами T60 в диапазоне от 400 до 900 мс со средним значением примерно 600 мс. Используются первый и последний канал 8-канальной линейной решетки микрофонов с расстоянием 14 см между микрофонами. Местоположения шума и целевого говорящего варьируются по речевым фрагментам; расстояние между источником звука и решеткой микрофонов выбирается в пределах от 1 до 4 метров. Азимуты речи и шума соответствовали равномерным выборкам в диапазоне ±45 градусов и ±90 градусов для каждого зашумленного речевого фрагмента. Изменение в местоположениях источника шума и говорящего может способствовать повышению надежности системы.
[0042] Оценочный набор включает в себя отдельный набор из примерно 30000 речевых фрагментов (более 200 часов). Он создается аналогично обучающему набору с подобными настройками SNR и реверберации. В некоторых реализациях, конфигурации помещения, значения SNR, времена T60, а также позиции целевого говорящего и помех в оценочном набора не идентичны таковым в обучающем наборе, хотя геометрия решетки микрофонов между обучающим и тестовым наборами иногда идентична.
[0043] Входные признаки для моделей необработанных волновых форм вычисляются с использованием входного окна размером 35 мс, и переходом (скачком) 10 мс между фреймами. Если не указано иное, то все сети обучаются с 128 фильтрами tConv и с критерием кросс-энтропии с использованием асинхронного стохастического градиентного спуска (ASGD). Эксперименты обучения последовательностей могут также использовать распределенный ASGD, который более подробно описан в [29]. Все сети имеют 13522 CD выходных цели. Веса для слоев CNN и DNN инициализируются при помощи использования стратегии Glorot-Bengio, а все параметры LSTM равномерно инициализируются, чтобы находиться в пределах от -0,02 до 0,02. Мы используем экспоненциально затухающую скорость обучения, которая начинается с 4e-3 и имеет скорость затухания в 0,1 на 15 миллиардов фреймов.
[0044] В одном примере, базовая модель NAB включает в себя CLDNN AM необработанной волновой формы и модуль FP без MTL и обратной связи. Модуль FP имеет два 512-элементных слоя LSTM и один линейный выходной слой для генерации коэффициентов фильтра 5 мс (например, 81 отвод с частотой дискретизации 16 кГц) для каждого входного канала. Это дает коэффициент ошибок в словах (WER), равный 22,2%, тогда как для CLDNN одноканальной необработанной волновой формы имеет место 23,5%. В следующих разделах описываются эксперименты с использованием вариантов этой базовой модели, чтобы найти усовершенствованную настройку FP.
[0045] Для модуля FP могут использоваться несколько различных архитектур (например, фиг. 1). Каждый модуль FP имеет первые S ʺсовместно используемыхʺ 512-элементных слоев LSTM, за которым следует разделенный стек из P ʺразделенныхʺ канально-зависимых 256-элементных слоев LSTM, чтобы стимулировать изучение независимой модели предсказания фильтра для каждого канала. Канально-зависимые линейные выходные слои затем суммируются для генерации коэффициентов фильтра. Следовательно, базовая модель имеет S=2 и P=0.
[0046] Повышенная производительность может быть достигнута с использованием одного совместно используемого и одного канально-зависимого слоя LSTM. В некоторых реализациях, дальнейшее увеличение общего количества слоев LSTM не может повысить производительность, независимо от конфигурации.
[0047] Признаки кросс-корреляции могут использоваться для локализации и могут использоваться для предсказания фильтров формирования диаграммы направленности в частотной области. В результате, эти признаки кросс-корреляции могут быть предоставлены в блок FP. Для сравнения, также обучалась двухканальная модель NAB, передающая не взвешенные признаки кросс-корреляции, извлеченные из 100 мс фреймов со сдвигом 10 мс, в качестве входов в модуль FP. При той же базовой структуре (S=2, P=0), эта модель дала WER 22,3%, что аналогично 22,2%, полученным с использованием выборок волновой формы в качестве входов. Предоставление более явной информации о локализации в форме признаков кросс-корреляции не помогает, в предположении, что модуль FP способен обучаться хорошим пространственным фильтрам непосредственно из выборок волновой формы.
[0048] Максимальная задержка между двумя микрофонами, расположенными на расстоянии 14 см друг от друга, может составлять менее 0,5 мс, предполагая, что для выравнивания двух каналов должно быть достаточно фильтров не короче 0,5 мс. В этом разделе описывается изменение длины предсказанных фильтров с базовым модулем FP (S=2 и P=0). Повышенная производительность может быть достигнута с использованием фильтра 1,5 мс. Также можно видеть, что слишком большой размер фильтра ухудшает производительность.
[0049] Модель NAB может использовать многозадачное обучение для повышения надежности посредством обучения части сети для восстановления 128-мерных чистых log-mel признаков в качестве вторичной цели для первичной задачи предсказания состояния CD. Чтобы сбалансировать обе цели, используется интерполяционный вес α=0,9. С использованием MTL, базовая модель NAB (S=2, P=0 и 5,0 мс фильтр) уменьшает WER с 22,2% до 21,2%. Для дальнейшего повышения производительности добавляется соединение управляемой (стробируемой) обратной связи, что приводит к дополнительному абсолютному снижению на 0,2%, давая в результате конечный показатель WER 21,0%.
[0050] Окончательная модель NAB с улучшенными конфигурациями имеет: а) структуру FP с S=1 и P=1; b) входы необработанной волновой формы; c) размер выходного фильтра 1,5 мс; d) целевой интерполяционный вес MTL α=0,9; e) соединения управляемой обратной связи. Вместо использования 128 фильтров для слоя спектральной фильтрации (tConv на фиг. 1) система использует 256 фильтров, поскольку было показано, что это дает дополнительные улучшения. В окончательной конфигурации, модель NAB достигает WER 20,5%, что составляет 7,7% относительного улучшения по сравнению с исходной моделью NAB при 22,2% без этих модификаций. Среди них, MTL и управляемая обратная связь вместе дают наибольшее снижение ошибок. Фиг. 2 иллюстрирует частотные отклики предсказанных фильтров формирования диаграммы направленности в направлениях целевой речи и мешающих шумов. Другими словами, фиг. 2 иллюстрирует визуализации предсказанных откликов формирователя диаграммы направленности на разных частотах (ось Y) во времени (ось X) в направлении целевой речи (3-е) и направлении мешающих шумов (4-е) для зашумленной (1-я) и чистой (2-я) речевых спектрограмм.
[0051] SNR для речевого фрагмента в примере на фиг. 2 равно 12 дБ. Отклики в направлении целевой речи имеют относительно более зависящие от речи вариации, чем таковые в направлении шума. Это может указывать на то, что предсказанные фильтры присутствуют в речевом сигнале. Кроме того, отклики в областях с высокой речевой энергией, как правило, ниже, чем другие, что предполагает эффект автоматической регулировки усиления предсказанных фильтров.
[0052] Поскольку адаптивное формирование луча иногда выполняется в частотной области, можно рассмотреть возможность использования модели NAB как во временной, так и в частотной области. В настройке NAB в частотной области, имеется LSTM, которая предсказывает комплексные фильтры FFT (CFFT) для обоих каналов. Для данного входа 257-точечного FFT, это означает предсказание 4×257 частотных точек для реальных и мнимых компонентов для 2 каналов. После того, как комплексные фильтры предсказаны для каждого канала, поэлементное произведение вычисляется с FFT входа для каждого канала, что эквивалентно свертке в Уравнении 2 во временной области. Результат этого подается в одноканальную CLDNN в частотной области, что предполагает как спектральное разложение с комплексной линейной проекцией (CLP), так и акустическое моделирование. Хотя использование признаков CFFT значительно снижает вычислительную сложность, производительность может быть хуже, чем модель необработанной волновой формы в некоторых реализациях. Это может быть связано с тем, что CFFT требует предсказания фильтра с более высокой размерностью.
[0053] Производительность модели NAB также может быть сопоставлена с нефакторизованными и факторизованными моделями необработанных волновых форм, которые, как было показано, обеспечивают превосходную производительность для одноканальных моделей и других методов обработки сигналов, таких как DS и FS. По сравнению с нефакторизованной моделью, предсказание фильтров на каждый временной фрейм для обработки различных пространственных направлений в данных, как обсуждалось выше, может повысить производительность. Хотя факторизованная модель потенциально может обрабатывать разные направления, пересчитывая многие направления поиска в слое пространственной фильтрации, адаптивная модель может достичь подобной производительности с меньшей вычислительной сложностью.
[0054] Как отмечено выше, архитектура NAB для многоканальных сигналов волновых форм может реализовать адаптивное формирование диаграммы направленности на основе фильтрации и суммирования совместно с обучением AM. В отличие от предыдущих систем, фильтры формирования диаграммы направленности адаптируются к текущему входному сигналу, а также учитывают предыдущие предсказания АМ через соединения управляемой обратной связи. Чтобы улучшить обобщение модели, MTL может быть принято для регуляризации обучения. Экспериментальные результаты показывают, что включение явной структуры FS выгодно, и предлагаемое NAB имеет сходную производительность с факторизованной моделью, но с более низкими вычислительными затратами.
[0055] Возвращаясь к фигурам, фиг. 1 иллюстрирует примерную систему 100 для адаптивного формирования диаграммы направленности нейронной сети (NAB). Вкратце и, как описано более подробно ниже, система 100 принимает множество каналов аудиоданных 103 и 106, которые могут быть приняты от разных микрофонов. Система 100 обрабатывает аудиоданные 103 и 106 посредством стадии 109 предсказания фильтра, стадии 112 фильтрации и суммирования, стадии акустической модели 115 и стадии 118 многозадачного обучения для идентификации фонем в аудиоданных 103 и 106.
[0056] На стадии 109 предсказания фильтра, система 100 принимает множество каналов аудиоданных 103 и 106. Хотя система 100 показывает прием двух каналов аудиоданных, система 100 может принимать дополнительные аудиоканалы, которые будут обрабатываться так же, как и аудиоданные 103 и 106. Стадия 109 предсказания фильтра включает в себя два слоя LSTM, которые генерируют параметры фильтра для стадии 112 фильтрации и суммирования. Первый слой LSTM 121 совместно используется двумя каналами аудиоданных 103 и 106. Первый слой LSTM 121 используется для формирования диаграммы направленности и получения выгоды от данных из двух каналов аудиоданных 103 и 106. Данные из одного канала влияют на формирование диаграммы направленности другого канала. Второй слой LSTM со слоями LSTM 124 и 127 является канально-зависимым. Слои LSTM 124 и 127 генерируют параметры, которые корректируют размерность последующих фильтров.
[0057] Во время стадии 112 фильтрации и суммирования, система 100 использует два фильтра 130 и 133, а затем суммирует выходы из этих двух фильтров в сумматоре 136. Фильтр 130 принимает аудиоданные 103 и параметры фильтра от слоя LSTM 124. Параметры фильтра применяются к фильтру, который затем выполняет свертку с аудиоданными 103. Аналогично, фильтр 133 принимает аудиоданные 106 и параметры фильтра от слоя LSTM 127. Параметры фильтра применяются к фильтру, который затем выполняет свертку с аудиоданными 106. В некоторых реализациях, фильтры 130 и 133 представляют собой фильтры с конечным импульсным откликом. В некоторых реализациях, длина фильтров 130 и 133 является фиксированной и может быть одинаковой или может отличаться одна от другой. В некоторых реализациях, коэффициенты фильтров 130 и 133 основаны на параметрах, принятых от слоев LSTM 130 и 133. Выходы из двух фильтров 130 и 133 суммируются вместе в сумматоре 136. Выход 139 сумматора подается на слой 115 акустической модели.
[0058] На стадии 115 акустической модели, система 100 использует слой 142 временной свертки, слой 145 постобработки, множество слоев LSTM 148, 151 и 154 и глубокую нейронную сеть 157. Слой 142 временной свертки принимает выход сумматора 139 и очищает и дополнительно фильтрует сигнал путем удаления высоких частот. В некоторых реализациях, система 100 только выполняет временную свертку и не выполняет частотную свертку. Слой 142 временной свертки может включать в себя один сверточный слой с множеством карт признаков. Например, слой 142 временной свертки может включать в себя 256 карт признаков. Стратегия накопления, ассоциированная с уровнем 142 временной свертки, может включать в себя неперекрывающееся max-накопление, например, с размером накопления, равным 3.
[0059] Выход слоя 142 временной свертки предоставляется в постпроцессор 145. В некоторых реализациях, постпроцессор 145 выполняет max-накопление выходного сигнала слоя 142 временной свертки по всей длине выходного сигнала. Затем постпроцессор 145 применяет выпрямленную нелинейность с последующим стабилизированным логарифмическим выражением для создания вектора признаков фреймового уровня. При выпрямлении, постпроцессор 145 заменяет отрицательные значения нулевым значением и сохраняет положительные значения. В некоторых реализациях, постпроцессор 145 уменьшает размерность вектора признаков. Уменьшение размерности уменьшает необходимость в дополнительных последующих слоях LSTM.
[0060] Выход постпроцессора 145 передается на слои LSTM 148, 151 и 154, которые подходят для моделирования сигнала по времени. В некоторых реализациях, для моделирования сигнала может использоваться три слоя LSTM. В некоторых реализациях, каждый слой LSTM может включать в себя 832 ячейки и 512- единичный проекционный слой для уменьшения размерности. В некоторых реализациях, альтернативно может использоваться более трех слоев LSTM, включая меньшее количество ячеек. Выход слоев LSTM 148, 151 и 154 предоставляется на один или более слоев глубокой нейронной сети (DNN) 157.
[0061] Выход 160 DNN 157 представляет выход акустической модели. Этот выход может представлять вероятностные оценки для каждого из различных состояний акустической модели, например фонем или скрытых состояний марковской модели (HMM) фонем. Когда обученная система используется для выполнения распознавания речи, выход 160 указывает, какие фонемы наиболее вероятны, и эта информация используется для транскрипции речевого фрагмента, который соответствует аудиоданным 103 и 106. Например, информация может быть предоставлена в модель языка или другую модель для определения слов и фраз, которые лучше всего соответствуют вероятным фонемам.
[0062] Слои, которые включены в один или несколько слоев DNN 157, могут быть полностью соединенными, и, в некоторых реализациях, каждый слой может иметь 1024 скрытых единиц. Другие слои системы 100 могут быть совместно обучены с акустической моделью 139.
[0063] Во время обучения, акустическая модель 139 может быть развернута в течение 20 временных шагов для обучения с усеченным обратным распространением во времени (BPTT). В некоторых реализациях, метка состояния выхода может задерживаться на один или несколько фреймов, поскольку информация о будущих фреймах может повысить точность предсказаний, ассоциированных с текущим фреймом. Во время обучения, выходные цели могут быть заданы как выход 160 и использованы для обратного распространения.
[0064] Система 100 включает в себя механизм 163 управляемой (стробируемой) обратной связи. Как правило, управляемая обратная связь используется только во время обучения. Управляемая обратная связь 163 предоставляет лингвистическую информацию высокого уровня выходных целей на стадию 109 предсказания фильтра. С лингвистической информацией, слой 109 предсказания фильтра может корректировать последующие параметры фильтра, основываясь на предыдущей фонеме. В некоторых реализациях, сигнал управляемой обратной связи содержит доверительное значение. Если доверительное значение не удовлетворяет порогу, то управляемая обратная связь 163 не влияет на последующие параметры фильтра. Если доверительное значение удовлетворяет порогу, то управляемая обратная связь 163 влияет на последующие параметры фильтра. Например, если порог равен 0,5, то при доверительном значении, равном единице, стадия 109 предсказания фильтра будет использовать выходную цель 160 для настройки параметров фильтра. Если доверительное значение было равным нулю, то стадия 109 предсказания фильтра не будет использовать выходную цель 160 для настройки параметров фильтра.
[0065] Система включает в себя слой 118 многозадачного обучения. Слой 118 многозадачного обучения включает в себя слои DNN 166 и 169. Слой DNN 169 выводит чистые признаки 172, которые являются очищенным от шума выходом и используются системой 100 во время фазы обучения для генерации чистых log-mel признаков. Как показано на фиг. 1, слой 118 многозадачного обучения принимает данные из первого слоя LSTM 148. Для того чтобы слой 118 многозадачного обучения обрабатывал принятые данные, данные из первого слоя LSTM 148 включают в себя низкие уровни шума.
[0066] Фиг. 3 является блок-схемой, иллюстрирующей примерную систему 300 для распознавания речи с использованием нейронных сетей. Система 300 включает в себя клиентское устройство 310, вычислительную систему 320 и сеть 330. В этом примере, вычислительная система 320 предоставляет информацию о речевом фрагменте и дополнительную информацию в нейронные сети 323. Компьютерная система 320 использует выход из нейронной сети 327, чтобы идентифицировать транскрипцию для речевого фрагмента.
[0067] В системе 300, клиентское устройство 310 может быть, например, настольным компьютером, переносным компьютером, планшетным компьютером, носимым компьютером, сотовым телефоном, смартфоном, музыкальным проигрывателем, устройством чтения электронных книг, навигационной системой или любым другим соответствующим вычислительным устройством. Функции, выполняемые вычислительной системой 320, могут выполняться отдельными компьютерными системами или могут быть распределены между несколькими компьютерными системами. Сеть 330 может быть проводной или беспроводной или их комбинацией и может включать в себя Интернет.
[0068] В некоторых реализациях, вычислительная система 320 принимает набор из выборок 321 волновых форм аудио. Эти выборки 321 могут включать в себя выборки для множества аудиоканалов, например, выборки из аудио, обнаруженного разными микрофонами одновременно. Вычислительная система 320 использует выборки 321 для генерации параметров фильтра, которые используются для пространственной фильтрации. Затем пространственно отфильтрованный выход предоставляется в акустическую модель, например нейронную сеть 327. Вычислительная система 320 может определять транскрипцию-кандидат для речевого фрагмента, основываясь по меньшей мере на выходе нейронной сети 327.
[0069] В проиллюстрированном примере, пользователь 302 клиентского устройства 310 говорит, а клиентское устройство 310 записывает аудио, которое включает в себя речь. Клиентское устройство 310 записывает несколько каналов аудио при обнаружении речи. Клиентское устройство 310 передает записанные аудиоданные 312 для нескольких каналов в вычислительную систему 320 по сети 330.
[0070] Вычислительная система 320 принимает аудиоданные 312 и получает выборки 321 волновой формы аудио. Например, вычислительная система 320 может идентифицировать набор выборок 321 волновой формы аудио, которые представляют аудио в течение определенного периода времени, например, в течение 25 мс периода аудиосигнала 312. Эти выборки волновой формы аудио могут быть подобными тем, которые были описаны выше со ссылкой на фиг. 1.
[0071] Вычислительная система 320 может предоставлять выборки 321 волновых форм аудио в нейронную сеть 323, которая действует как модель предсказания фильтра. Нейронная сеть 323 может соответствовать стадии 109 предсказания фильтра, как описано со ссылкой на фиг. 1. Таким образом, нейронная сеть 323 может быть рекуррентной нейронной сетью, которая была обучена, чтобы генерировать параметры фильтра на основе выборок 321 волновых форм аудио.
[0072] Вычислительная система 320 может предоставлять выход нейронной сети 323 в модуль 325 фильтрации и суммирования. Модуль 325 фильтрации и суммирования может соответствовать стадии 112 фильтрации и суммирования, как описано со ссылкой на фиг. 1. Таким образом, модуль 323 фильтрации и суммирования может применять фильтры с параметрами фильтра, полученными из нейронной сети 323, к выборкам 321 волновых форм аудио и суммировать выходы.
[0073] В проиллюстрированном примере, вычислительная система 320 предоставляет выход модуля 325 фильтрации и суммирования в нейронную сеть 327. Нейронная сеть 327 была обучена действовать как акустическая модель. Например, нейронная сеть 327 указывает вероятность того, что частотно-временные представления признаков соответствуют разным речевым единицам, когда частотно-временные представления признаков выводятся модулем 325 фильтрации и основаны на выборках 321 волновых форм аудио. Нейронная сеть 327 может, например, соответствовать стадии 115 акустической модели, как описано со ссылкой на фиг. 1 выше. В некоторых реализациях, нейронная сеть 327 также может включать в себя слои начальной временной свертки и постобработки, которые первоначально обрабатывают выходы из модуля 325 фильтрации.
[0074] Нейронная сеть 327 создает выходы 329 нейронной сети, которые вычислительная система 320 использует для идентификации транскрипции 330 для аудиосигнала 312. Выходы 329 нейронной сети указывают вероятность того, что речь в конкретном окне соответствует конкретным фонетическим единицам. В некоторых реализациях, используемыми фонетическими единицами являются фоны (элементарные речевые звуки) или компоненты фон, также называемые фонемами. В этом примере, потенциальные фоны также упоминаются как s0 … sm. Фоны могут быть любыми из различных фон в речи, таких как фона ʺahʺ, фона ʺaeʺ, фона ʺzhʺ и т.д. Фоны s0 … sm могут включать в себя все возможные фоны, которые могут встретиться в выборках 321 волновых форм аудио, или меньше, чем все возможные фоны, которые могут встретиться. Каждая фона может быть разделена на три акустических состояния.
[0075] Выходы 327 нейронной сети могут предоставлять предсказания или вероятности акустических состояний при условии данных, включенных в выборки 322 волновых форм аудио. Выходы 329 нейронной сети могут предоставлять значение, для каждого состояния каждой фоны, которое указывает вероятность того, что вектор v1 акустических признаков представляет конкретное состояние конкретной фоны. Например, для первой фоны, s0, выходы 329 нейронной сети могут предоставить первое значение, которое указывает вероятность P(s0_1|X), которая указывает вероятность того, что окно w1 включает в себя первое акустическое состояние фоны s0, при условии набора входа X, предоставленного в выборках 321 волновых форм аудио. Для первой фоны, s1, выходы 329 нейронной сети 329 могут предоставить второе значение, указывающее вероятность P(s0_2|X), указывающее вероятность того, что окно w1 включает в себя второе акустическое состояние фоны s0, при условии набора входа X, предоставленного в выборках 321 волновых форм аудио. Подобные результаты могут быть предоставлены для всех состояний всех фон s0 … sm.
[0076] Вычислительная система 320 предоставляет различные наборы выборок 321 в нейронную сеть 327 для приема предсказаний или вероятностей акустических состояний в разных окнах. Вычислительная система 320 может обеспечивать последовательность входов, один за другим, представляющих различные временные окна речевого фрагмента. Путем последовательного ввода каждого фрейма аудиоданных в систему, вычислительная система 320 получает оценки фонем, которые, вероятно, могли встретиться во время речевого фрагмента.
[0077] Вычислительная система 320 может предоставить выходы 329 нейронной сети, например, на взвешенные преобразователи конечного состояния, которые аппроксимируют скрытую марковскую модель (HMM), которая может включать в себя информацию о лексиконе, указывающую фонетические единицы слов, грамматику и модель языка, которая указывает вероятные последовательности слов. Выход HMM может быть решеткой слов, из которой может быть выведена транскрипция 330. Затем, вычислительная система 320 предоставляет транскрипцию 330 на клиентское устройство 310 по сети 330.
[0078] Обучение нейронных сетей 323, 327 может быть выполнено, как описано выше. Прямое распространение через нейронную сеть 327 производит выходы в выходном слое нейронной сети. Выходы могут сравниваться с данными, указывающими корректные или желательные выходы, которые указывают, что полученное представление частотно-временных признаков соответствует известному акустическому состоянию. Определяется мера ошибки между действительными выходами нейронной сети и корректными или желательными выходами. Затем ошибка распространяется обратно через нейронную сеть для обновления весов в нейронной сети 327. Нейронная сеть 323 предсказания фильтра может совместно обучаться с нейронной сетью 327.
[0079] Этот процесс обучения может быть повторен для данных представления частотно-временных признаков, сгенерированных для выборок волновых форм аудиосигналов множества различных речевых фрагментов в наборе обучающих данных. Во время обучения, фреймы, выбранные для обучения, могут выбираться случайным образом из большого набора, так что фреймы из одного и того же речевого фрагмента не обрабатываются последовательно.
[0080] В некоторых реализациях, обработка системы распознавания речи может выполняться на устройстве, которое первоначально обнаруживает или записывает речь. Например, обработка, описанная как выполняемая вычислительным устройством 320, может выполняться на пользовательском устройстве 310 без отправки аудиоданных по сети в некоторых реализациях.
[0081] Фиг. 4 иллюстрирует примерный процесс 400 для адаптивного формирования диаграммы направленности нейронной сети для распознавания многоканальной речи. В общем, процесс 400 получает речевой фрагмент и идентифицирует, с использованием нейронной сети, вероятные фонемы, которые соответствуют словам речевого фрагмента. Процесс 400 будет описан как выполняемый компьютерной системой, содержащейся на одном или нескольких компьютерах, например, системой 100, показанной на фиг. 1, или системой 300, показанной на фиг. 3.
[0082] Система принимает первый канал аудиоданных, соответствующий речевому фрагменту, и второй канал аудиоданных, соответствующий речевому фрагменту (410). В некоторых реализациях, система принимает первый и второй каналы через разные микрофоны. Например, система может иметь один микрофон с правой стороны системы и второй микрофон, расположенный примерно в пяти сантиметрах от первого микрофона с правой стороны системы. Когда пользователь говорит, оба микрофона принимают слегка различающиеся аудиоданные речи пользователя. В некоторых реализациях, система может иметь более двух микрофонов, каждый из которых принимает аудиоданные, когда пользователь говорит.
[0083] При помощи обученной рекуррентной нейронной сети, система генерирует (i) первый набор параметров фильтра на основе нескольких каналов аудиоданных и (ii) второй набор параметров фильтра на основе нескольких каналов аудиоданных (420). В некоторых реализациях, обученная рекуррентная нейронная сеть включает в себя один или несколько слоев LSTM. В некоторых реализациях, один слой LSTM принимает аудиоданные из каждого из каналов. Например, первый слой LSTM принимает данные из первого канала и второго канала. В некоторых реализациях, специфические для каналов слои LSTM принимают выход слоя LSTM, который принимает данные из каждого канала. В этом случае, первая LSTM анализирует данные из обоих каналов для формирования диаграммы направленности. В некоторых реализациях, выходами специфических для каналов слоев LSTM являются параметры фильтра для соответствующего аудиоканала. В некоторых реализациях, каждый специфический для канала слой LSTM генерирует различные параметры фильтра. В некоторых реализациях, система сегментирует аудиоданные на несколько фреймов и генерирует новые, а иногда и разные параметры фильтра для каждого фрейма.
[0084] Система выполняет свертку аудиоданных для первого канала с первым фильтром, имеющим первый набор параметров фильтра, для генерации первых выходов свертки (430). Система выполняет свертку аудиоданных для второго канала со вторым фильтром, имеющим второй набор параметров фильтра, для генерации вторых выходов свертки (440). В некоторых реализациях, где система сегментирует аудиоданные на сегменты в разные фреймы, система выполняет свертку каждого фрейма аудиоданных с соответствующими параметрами. В некоторых реализациях, первый и второй фильтры представляют собой фильтры с конечным импульсным откликом. В некоторых реализациях, когда система принимает несколько аудиоканалов, система фильтрует каждый аудиоканал в соответствии с его соответствующими параметрами фильтра. В некоторых реализациях, первый и второй фильтры выполняют как пространственную, так и спектральную фильтрацию.
[0085] Система объединяет первые выходы свертки и вторые выходы свертки (450). В некоторых реализациях, система суммирует первые и вторые выходы свертки. В некоторых реализациях, где система принимает несколько аудиоканалов, система суммирует несколько выходов свертки из нескольких фильтров.
[0086] Система вводит объединенные выходы свертки в нейронную сеть, обученную в качестве акустической модели (460). В некоторых реализациях, акустическая модель идентифицирует фонемы, которые соответствуют речевому фрагменту. В некоторых реализациях, нейронная сеть, обученная как акустическая модель, включает в себя несколько слоев LSTM, например три слоя LSTM. В некоторых реализациях, нейронная сеть, обученная как акустическая модель, включает в себя сверточный слой и несколько скрытых слоев. В некоторых реализациях, сверточный слой выполняет временную свертку. В некоторых реализациях, система не выполняет частотную свертку. В некоторых реализациях, система накапливает выход сверточного слоя для генерации набора накопленных значений. В некоторых реализациях, система подает набор накопленных значений в слои LSTM нейронной сети, обученной в качестве акустической модели. Система обеспечивает транскрипцию для речевого фрагмента, которая определяется, по меньшей мере, на основе выхода, который нейронная сеть предоставляет в ответ на получение объединенных выходов свертки (470).
[0087] В некоторых реализациях, система обеспечивает механизм обратной связи от выхода нейронной сети, обученной в качестве акустической модели, в рекуррентную нейронную сеть. Механизм обратной связи позволяет системе использовать информацию предыдущей фонемы для воздействия на параметры фильтра. В некоторых реализациях, обратная связь является управляемой в том смысле, что обратная связь передается в рекуррентную нейронную сеть, только если доверительное значение для фонемы удовлетворяет порогу.
[0088] В некоторых реализациях, система включает в себя стадию многозадачного обучения, которую система использует во время фазы обучения. Стадия многозадачного обучения принимает данные из слоя LSTM нейронной сети, обученной в качестве акустической модели, например, первого слоя LSTM. В некоторых реализациях, стадия многозадачного обучения включает в себя несколько слоев глубокой нейронной сети, например, два слоя глубокой нейронной сети и может включать в себя несколько скрытых слоев. Стадия многозадачного обучения генерирует чистые признаки для использования в фазе обучения нейронной сети, обучаемой в качестве акустической модели, и рекуррентной нейронной сети.
[0089] На фиг. 5 показан пример вычислительного устройства 500 и мобильного вычислительного устройства 550, которые могут использоваться для реализации описанных здесь методов. Вычислительное устройство 500 предназначено для представления различных форм цифровых компьютеров, таких как ноутбуки, настольные компьютеры, рабочие станции, персональные цифровые помощники, серверы, блейд-серверы, мэйнфреймы и другие подходящие компьютеры. Мобильное вычислительное устройство 550 предназначено для представления различных форм мобильных устройств, таких как персональные цифровые помощники, сотовые телефоны, смартфоны и другие подобные вычислительные устройства. Компоненты, показанные здесь, их соединения и отношения и их функции предназначены только для примеров и не предназначены для ограничения.
[0090] Вычислительное устройство 500 включает в себя процессор 502, память 504, устройство 506 хранения, высокоскоростной интерфейс 508, соединяющий память 504 и несколько высокоскоростных портов 510 расширения, и низкоскоростной интерфейс 512, соединяющий низкоскоростной порт 514 расширения и устройство 506 хранения. Процессор 502, память 504, устройство 506 хранения, высокоскоростной интерфейс 508, высокоскоростные порты 510 расширения и низкоскоростной интерфейс 512 соединены между собой различными шинами и могут быть установлены на общей материнской плате или, в случае необходимости, другими способами. Процессор 502 может обрабатывать инструкции для исполнения в вычислительном устройстве 500, включая инструкции, хранящиеся в памяти 504 или устройстве 506 хранения, для отображения графической информации для GUI на внешнем устройстве ввода/вывода, таком как дисплей 516, связанный с высокоскоростным интерфейсом 508. В других реализациях, могут использоваться, по мере необходимости, несколько процессоров и/или несколько шин вместе с несколькими модулями памяти и типами памяти. Кроме того, могут быть подключены несколько вычислительных устройств, причем каждое устройство обеспечивает части необходимых операций (к примеру, в качестве серверного банка, группы блейд-серверов или многопроцессорной системы).
[0091] Память 504 хранит информацию в вычислительном устройстве 500. В некоторых реализациях, память 504 является энергозависимым блоком или блоками памяти. В некоторых реализациях, память 504 является энергонезависимым блоком или блоками памяти. Память 504 также может быть другой формой считываемого компьютером носителя, такого как магнитный или оптический диск.
[0092] Устройство 506 хранения способно обеспечивать массовую память для вычислительного устройства 500. В некоторых реализациях, устройство 506 хранения может представлять собой или содержать считываемый компьютером носитель, например, такой как устройство на гибком диске, устройство на жестком диске, устройство на оптическом диск или устройство на магнитном диске, флэш-память или другое подобное твердотельное устройство памяти или массив устройств, включая устройства в сети хранения данных или другие конфигурации. Инструкции могут храниться на носителе информации. Инструкции, исполняемые одним или несколькими устройствами обработки (например, процессором 502), выполняют один или несколько способов, таких, как описано выше. Инструкции также могут быть сохранены одним или несколькими устройствами хранения, такими как считываемые компьютером или машиночитаемые носители (например, память 504, устройство 506 хранения или память на процессоре 502).
[0093] Высокоскоростной интерфейс 508 управляет интенсивными по полосе пропускания операциями для вычислительного устройства 500, в то время как низкоскоростной интерфейс 512 управляет менее интенсивными по полосе пропускания операциями. Такое распределение функций является только примером. В некоторых реализациях, высокоскоростной интерфейс 508 связан с памятью 504, дисплеем 516 (например, через графический процессор или ускоритель) и с высокоскоростными портами 510 расширения, которые могут принимать различные карты расширения. В данной реализации, низкоскоростной интерфейс 512 соединен с устройством 506 хранения и с низкоскоростным портом 514 расширения. Низкоскоростной порт 514 расширения, который может включать в себя различные порты связи (например, USB, Bluetooth, Ethernet, беспроводной Ethernet) может быть связан с одним или несколькими устройствами ввода/вывода, такими как клавиатура, координатно-указательное устройство, сканер или сетевое устройство, такое как коммутатор или маршрутизатор, например, через сетевой адаптер.
[0094] Вычислительное устройство 500 может быть реализовано в нескольких различных формах, как показано на чертеже. Например, оно может быть реализовано как стандартный сервер 520 или многократно в группе таких серверов. Кроме того, оно может быть реализовано на персональном компьютере, таком как портативный компьютер 522. Оно также может быть реализовано как часть системы 524 серверной стойки. В качестве альтернативы, компоненты из вычислительного устройства 500 могут быть объединены с другими компонентами в мобильном устройстве, таком как мобильное вычислительное устройство 550. Каждое из таких устройств может содержать одно или несколько из вычислительного устройства 500 и мобильного вычислительного устройства 550, и вся система может состоять из нескольких вычислительных устройств, взаимодействующих друг с другом.
[0095] Мобильное вычислительное устройство 550 включает в себя процессор 552, память 564, устройство ввода/вывода, такое как дисплей 554, интерфейс 566 связи и приемопередатчик 568, а также другие компоненты. Мобильное вычислительное устройство 550 также может быть снабжено устройством хранения, таким как устройство типа micro-drive или другое устройство, для обеспечения дополнительной памяти. Процессор 552, память 564, дисплей 554, интерфейс 566 связи и приемопередатчик 568 соединены между собой с использованием различных шин, а некоторые из компонентов могут быть установлены на общей материнской плате или по мере необходимости другими способами.
[0096] Процессор 552 может исполнять инструкции в мобильном вычислительном устройстве 550, включая инструкции, хранящиеся в памяти 564. Процессор 552 может быть реализован в виде набора микросхем, которые включают в себя отдельные и множественные аналоговые и цифровые процессоры. Процессор 552 может обеспечивать, например, координацию других компонентов мобильного вычислительного устройства 550, такими как управление пользовательскими интерфейсами, приложения, выполняемые мобильным вычислительным устройством 550, и беспроводная связь посредством мобильного вычислительного устройства 550.
[0097] Процессор 552 может осуществлять связь с пользователем через интерфейс 558 управления и интерфейс 556 дисплея, связанный с дисплеем 554. Дисплей 554 может представлять собой, например, дисплей TFT (жидкокристаллический дисплей на тонкопленочных транзисторах) или дисплей OLED (на органических светоизлучающих диодах) или другую подходящую технологию отображения. Интерфейс 556 дисплея может содержать соответствующую схему для управления дисплеем 554 для представления графической и другой информации пользователю. Интерфейс 558 управления может принимать команды от пользователя и преобразовывать их для отправки в процессор 552. Кроме того, внешний интерфейс 562 может обеспечивать связь с процессором 552, чтобы обеспечивать возможность связи в ближней зоне мобильного вычислительного устройства 550 с другими устройствами. Внешний интерфейс 562 может предусматривать, например, проводную связь в некоторых реализациях или беспроводную связь в других реализациях, а также может использоваться несколько интерфейсов.
[0098] Память 564 хранит информацию в мобильном вычислительном устройстве 550. Память 564 может быть реализована в виде одного или нескольких считываемых компьютером носителей, блока или блоков энергозависимой памяти или блока или блоков энергонезависимой памяти. Память 574 расширения также может быть предусмотрена и соединена с мобильным вычислительным устройством 550 через интерфейс 572 расширения, который может включать в себя, например, интерфейс карты SIMM (модуля памяти с односторонним расположением выводов). Память 574 расширения может обеспечивать дополнительное пространство хранения для мобильного вычислительного устройства 550 или также может хранить приложения или другую информацию для мобильного вычислительного устройства 550. В частности, память 574 расширения может включать в себя инструкции для осуществления или дополнения процессов, описанных выше, и также может включать информацию безопасности. Таким образом, например, память 574 расширения может быть предоставлена в качестве защитного модуля для мобильного вычислительного устройства 550 и может быть запрограммирована с инструкциями, которые обеспечивают безопасное использование мобильного вычислительного устройства 550. Кроме того, защищенные приложения могут предоставляться через SIMM-карты вместе с дополнительной информацией, например, размещение идентифицирующей информации на SIMM-карте в защищенном режиме.
[0099] Память может включать в себя, например, флэш-память и/или память NVRAM (энергонезависимая память с произвольной выборкой), как обсуждается ниже. В некоторых реализациях, на носителе информации сохранены инструкции, которые, при выполнении одним или несколькими устройствами обработки (например, процессором 552), выполняют один или несколько способов, как те, которые были описаны выше. Инструкции также могут храниться одним или несколькими устройствами хранения, такими как один или несколько считываемых компьютером или машиночитаемых носителей (например, память 564, память 574 расширения или память на процессоре 552). В некоторых реализациях, инструкции могут приниматься в распространяемом сигнале, например, приемопередатчиком 568 или внешним интерфейсом 562.
[0100] Мобильное вычислительное устройство 550 может осуществлять беспроводную связь через интерфейс 566 связи, который может включать в себя, в случае необходимости, схему цифровой обработки сигналов. Интерфейс 566 связи может обеспечивать связь в различных режимах или протоколах, таких, как голосовые вызов GSM (Глобальная система мобильной связи), SMS (Служба коротких сообщений), EMS (Улучшенная служба передачи сообщений) или MMS (Служба мультимедийных сообщений), CDMA (Множественный доступ с кодовым разделением), TDMA (Множественный доступ с ременным разделением), PDC (Персональная цифровая сотовая связь), WCDMA (Широкополосный множественный доступ с кодовым разделением), CDMA2000 или GPRS (Пакетная радиосвязь общего пользования), в числе других. Такая связь может осуществляться, например, с помощью приемопередатчика 568 с использованием радиочастоты. Кроме того, может осуществляться связь в ближней зоне, например, с использованием Bluetooth, Wi-Fi или другого подобного приемопередатчика. Кроме того, модуль 570 приемника GPS (Системы глобального позиционирования) может предоставлять дополнительные беспроводные данные, связанные с навигацией и местоположением, на мобильное вычислительное устройство 550, которые могут использоваться соответствующими приложениям, работающими на мобильном вычислительном устройстве 550.
[0101] Мобильное вычислительное устройство 550 может также осуществлять связь прослушиваемым образом с использованием аудиокодека 560, который может принимать проговариваемую информацию от пользователя и преобразовывать ее в полезную цифровую информацию. Аудиокодек 560 может также генерировать прослушиваемый звуковой сигнал для пользователя, к примеру, через динамик в телефонной трубке мобильного вычислительного устройства 550. Такой звук может включать в себя звук из голосовых телефонных вызовов, может включать в себя записанный звук (например, голосовые сообщения, музыкальные файлы и т.д.), а также может включать в себя звук, генерируемый приложениями, работающими на мобильном вычислительном устройстве 550.
[0102] Мобильное вычислительное устройство 550 может быть реализовано в нескольких различных формах, как показано на чертежах. Например, оно может быть реализовано как сотовый телефон 580. Оно также может быть реализовано как часть смартфона 582, персонального цифрового помощника или другого подобного мобильного устройства.
[0103] Различные реализации описанных здесь систем и методов могут быть осуществлены в цифровых электронных схемах, интегральных схемах, специально разработанных ASIC (специализированных интегральных схемах), компьютерных аппаратных средствах, встроенном программном обеспечении, программном обеспечении и/или их комбинациях. Эти различные реализации могут включать в себя реализацию в одной или нескольких компьютерных программах, которые являются исполняемыми и/или интерпретируемыми в программируемой системе, включающей себя по меньшей мере один программируемый процессор, который может быть специализированным процессором или процессором общего назначения, подключенным для приема данных и инструкций и для передачи данных и инструкций на систему хранения, по меньшей мере одно устройства ввода и по меньшей мере одно устройство вывода.
[0104] Эти компьютерные программы (также известные как программы, программное обеспечение, программные приложения или код) включают в себя машинные инструкции для программируемого процессора и могут быть реализованы на высокоуровневом процедурном и/или объектно-ориентированном языке программирования и/или языке ассемблирования/машинном языке. Как используется здесь, термины ʺмашиночитаемый носительʺ и ʺсчитываемый компьютером носительʺ относятся к любому компьютерному программному продукту, прибору и/или устройству (например, магнитным дискам, оптическим дискам, памяти, программируемым логическим устройствам (PLD)), используемым для предоставления машинных инструкций и/или данных в программируемый процессор, включая машиночитаемый носитель, который принимает машинные инструкции как машиночитаемый сигнал. Термин ʺмашиночитаемый сигналʺ относится к любому сигналу, используемому для предоставления машинных инструкций и/или данных программируемому процессору.
[0105] Для обеспечения взаимодействия с пользователем, системы и способы, описанные здесь, могут быть реализованы на компьютере, имеющем устройство отображения (например, монитор на CRT (электронно-лучевой трубке) или LCD (жидкокристаллическом устройстве отображения)) для отображения информации пользователю, а также клавиатуру и координатно-указательное устройство (например, мышь или трекбол), с помощью которых пользователь может предоставить ввод в компьютер. Другие виды устройств также могут использоваться для обеспечения взаимодействия с пользователем; например, обратная связь, предоставляемая пользователю, может быть любой формой сенсорной обратной связи (например, визуальная обратная связь, слуховая обратная связь или осязательная обратная связь); и ввод от пользователя может приниматься в любой форме, включая акустический, речевой или тактильный ввод.
[0106] Системы и способы, описанные здесь, могут быть реализованы в вычислительной системе, которая включает в себя серверный (внешний) компонент (например, в качестве сервера данных), которая включает в себя компонент промежуточного программного обеспечения (например, сервер приложений), или которая включает в себя клиентский (внутренний) компонент (например, клиентский компьютер, имеющий графический пользовательский интерфейс или веб-браузер, через который пользователь может взаимодействовать с реализацией описанных здесь систем и методов) или любую комбинацию внешних компонентов, промежуточного программного обеспечения или внутренних компонентов. Компоненты системы могут быть связаны между собой любой формой или средой цифровой передачи данных (например, сетью связи). Примеры сетей связи включают в себя локальную сеть (LAN), глобальную сеть (WAN) и Интернет.
[0107] Вычислительная система может включать в себя клиенты и серверы. Клиент и сервер, как правило, удалены друг от друга и обычно взаимодействуют через сеть связи. Отношение клиента и сервера возникает в связи с компьютерными программами, исполняющимися на соответствующих компьютерах и имеющими отношение клиент-сервер друг к другу.
[0108] Хотя несколько реализаций были подробно описаны выше, возможны и другие модификации. Например, в то время, как клиентское приложение описывается как осуществляющее доступ к представителю(ям), в других реализациях представитель(и) может (могут) быть использован(ы) другими приложения, реализованными одним или несколькими процессорами, такими как приложение, выполняемое на одном или нескольких серверах. К тому же, логические потоки, изображенные на чертежах, не требуют определенного показанного порядка или последовательного порядка для достижения желательных результатов. К тому же, могут быть предоставлены другие действия, или действия могут быть устранены из описанных потоков, а другие компоненты могут быть добавлены или удалены из описанных систем. Соответственно, другие реализации находятся в пределах следующей формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ТЕХНОЛОГИЯ АНАЛИЗА АКУСТИЧЕСКИХ ДАННЫХ НА НАЛИЧИЕ ПРИЗНАКОВ ЗАБОЛЕВАНИЯ COVID-19 | 2021 |
|
RU2758649C1 |
| Способ улучшения речевого сигнала с низкой задержкой, вычислительное устройство и считываемый компьютером носитель, реализующий упомянутый способ | 2023 |
|
RU2802279C1 |
| ИНДИВИДУАЛЬНО НАСТРОЕННЫЙ ВЫВОД, КОТОРЫЙ ОПТИМИЗИРУЕТСЯ ДЛЯ ПОЛЬЗОВАТЕЛЬСКИХ ПРЕДПОЧТЕНИЙ В РАСПРЕДЕЛЕННОЙ СИСТЕМЕ | 2020 |
|
RU2821283C2 |
| СПОСОБ АУДИОВИЗУАЛЬНОГО РАСПОЗНАВАНИЯ СРЕДСТВ ИНДИВИДУАЛЬНОЙ ЗАЩИТЫ НА ЛИЦЕ ЧЕЛОВЕКА | 2022 |
|
RU2791415C1 |
| СПОСОБ МНОГОМОДАЛЬНОГО БЕСКОНТАКТНОГО УПРАВЛЕНИЯ МОБИЛЬНЫМ ИНФОРМАЦИОННЫМ РОБОТОМ | 2020 |
|
RU2737231C1 |
| УСТРОЙСТВО, СПОСОБ ИЛИ КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ ГЕНЕРАЦИИ АУДИОСИГНАЛА С РАСШИРЕННОЙ ПОЛОСОЙ С ИСПОЛЬЗОВАНИЕМ ПРОЦЕССОРА НЕЙРОННОЙ СЕТИ | 2018 |
|
RU2745298C1 |
| ВЕРИФИКАЦИЯ ГОВОРЯЩЕГО | 2017 |
|
RU2697736C1 |
| ОБУЧЕНИЕ НЕЙРОННЫХ СЕТЕЙ С ИСПОЛЬЗОВАНИЕМ ФУНКЦИЙ ПОТЕРЬ, ОТРАЖАЮЩИХ ЗАВИСИМОСТИ МЕЖДУ СОСЕДНИМИ ТОКЕНАМИ | 2018 |
|
RU2721190C1 |
| ГЕНЕРАТОР АУДИОДАННЫХ И СПОСОБЫ ФОРМИРОВАНИЯ АУДИОСИГНАЛА И ОБУЧЕНИЯ ГЕНЕРАТОРА АУДИОДАННЫХ | 2021 |
|
RU2823015C1 |
| РАСПОЗНАВАНИЕ СМЕШАННОЙ РЕЧИ | 2015 |
|
RU2686589C2 |
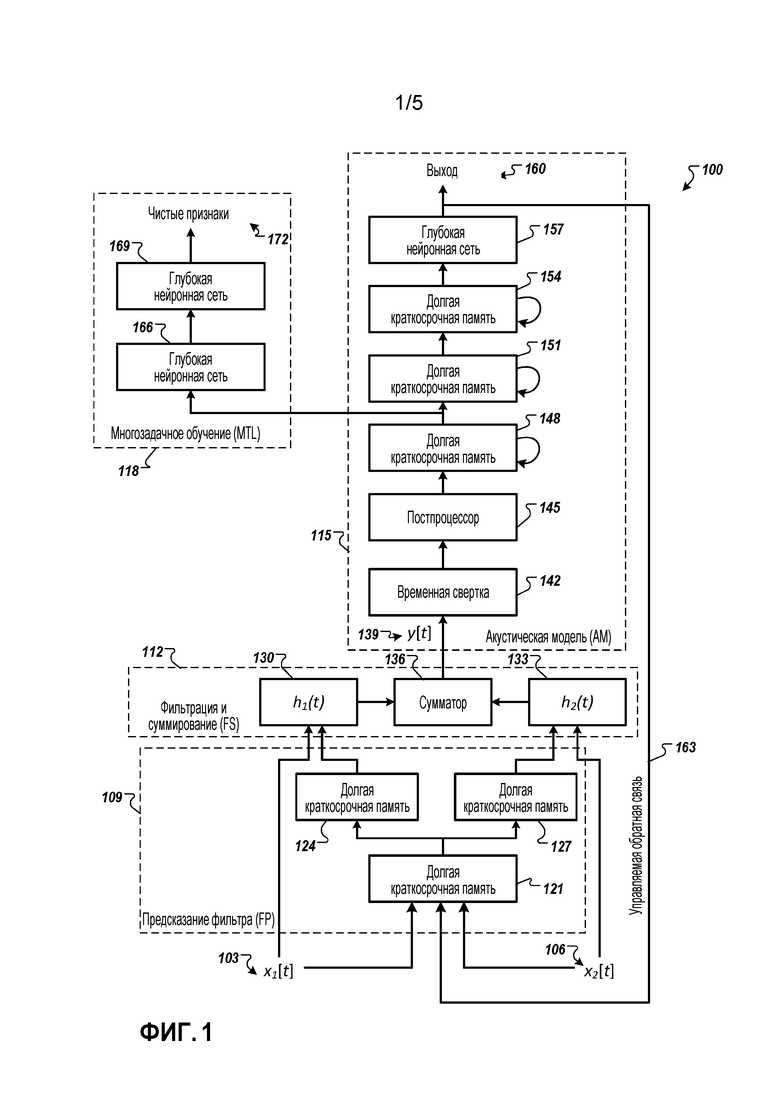
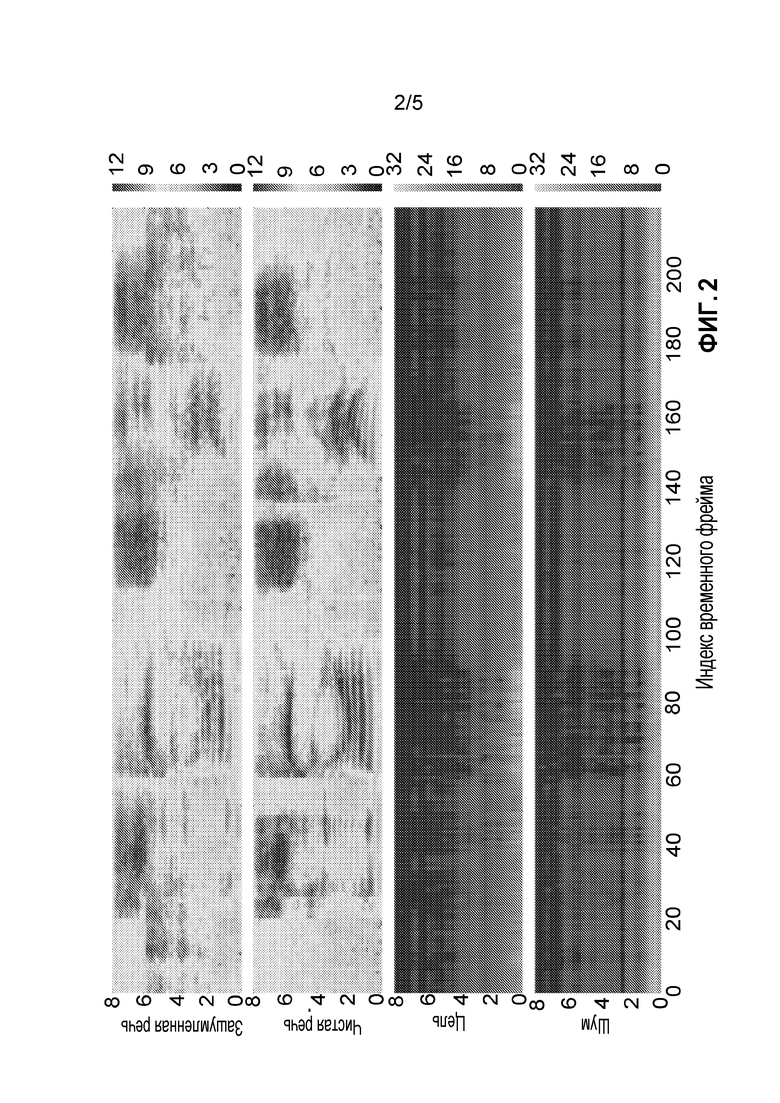
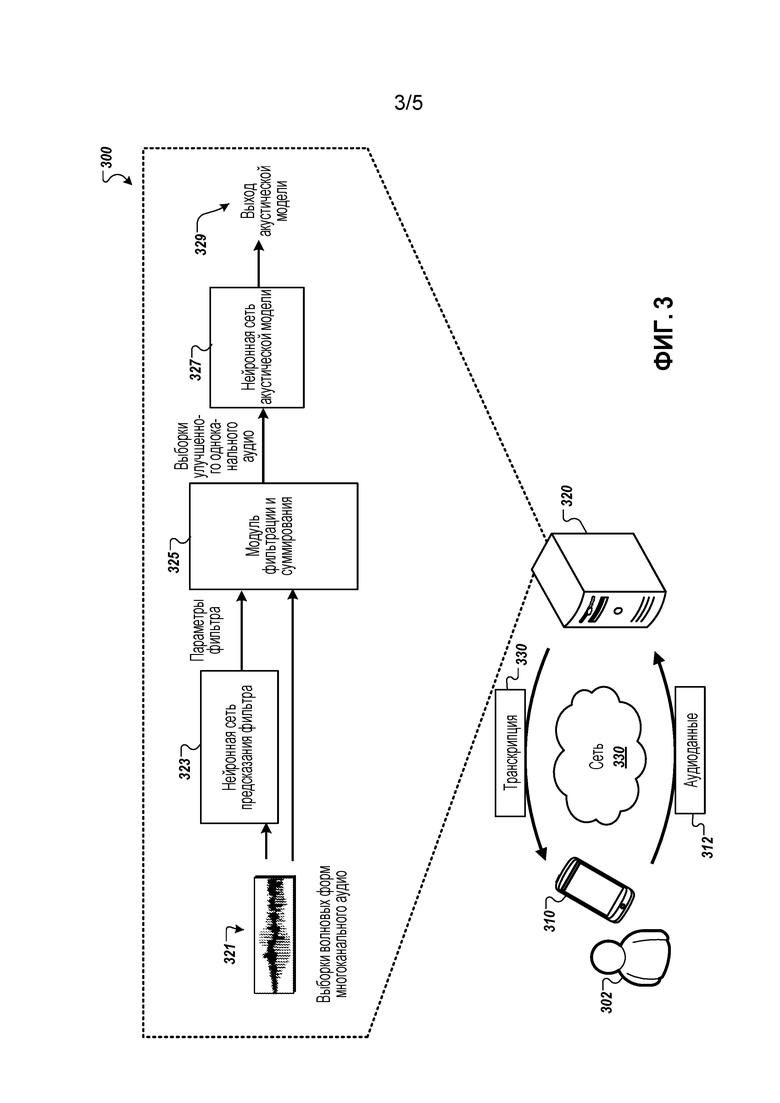

Раскрыты средства для адаптивного формирования диаграммы направленности нейронной сети для многоканального распознавания речи. Технический результат заключается в повышении эффективности распознавания речи. Принимают первый канал аудиоданных, соответствующих речевому фрагменту, и второй канал аудиоданных, соответствующих этому речевому фрагменту. Генерируют, с использованием обученной рекуррентной нейронной сети, первый набор параметров фильтра для первого фильтра на основе первого канала аудиоданных и второго канала аудиоданных и второй набор параметров фильтра для второго фильтра на основе первого канала аудиоданных и второго канала аудиоданных. Генерируют единый объединенный канал аудиоданных путем объединения аудиоданных первого канала, который был отфильтрован с использованием первого фильтра, и аудиоданных второго канала, который был отфильтрован с использованием второго фильтра. Вводят аудиоданные для единого объединенного канала в нейронную сеть, обученную в качестве акустической модели. 3 н. и 17 з.п. ф-лы, 5 ил.
1. Компьютерно-реализуемый способ распознавания многоканальной речи, содержащий:
прием первого канала аудиоданных, соответствующих речевому фрагменту, и второго канала аудиоданных, соответствующих этому речевому фрагменту;
генерирование, с использованием обученной рекуррентной нейронной сети, (i) первого набора параметров фильтра для первого фильтра на основе первого канала аудиоданных и второго канала аудиоданных и (ii) второго набора параметров фильтра для второго фильтра на основе первого канала аудиоданных и второго канала аудиоданных;
генерирование единого объединенного канала аудиоданных путем объединения (i) аудиоданных первого канала, который был отфильтрован с использованием первого фильтра, и (ii) аудиоданных второго канала, который был отфильтрован с использованием второго фильтра;
ввод аудиоданных для единого объединенного канала в нейронную сеть, обученную в качестве акустической модели; и
предоставление транскрипции для речевого фрагмента, которая определяется, по меньшей мере, на основе выхода, который нейронная сеть выдает в ответ на прием аудиоданных для единого объединенного канала.
2. Способ по п.1, в котором рекуррентная нейронная сеть содержит один или более слоев долгой краткосрочной памяти.
3. Способ по п.1, в котором рекуррентная нейронная сеть содержит:
первый слой долгой краткосрочной памяти, который принимает как первый, так и второй каналы аудио; и
второй слой долгой краткосрочной памяти, соответствующий первому каналу, и третий слой долгой краткосрочной памяти, соответствующий второму каналу, причем каждый из второго слоя долгой краткосрочной памяти и третьего слоя долгой краткосрочной памяти принимает выход первого слоя долгой краткосрочной памяти и предоставляет набор параметров фильтра для соответствующего канала.
4. Способ по п.3, в котором слои долгой краткосрочной памяти имеют параметры, которые были изучены во время процесса обучения, который совместно обучает слои долгой краткосрочной памяти и нейронную сеть, которая обучается в качестве акустической модели.
5. Способ по п.1, содержащий изменение или генерирование новых параметров фильтра для каждого входного фрейма аудиоданных.
6. Способ по п.1, содержащий, для каждого аудиофрейма в последовательности аудиофреймов речевого фрагмента, генерирование нового набора параметров фильтра и выполнение свертки аудиоданных для фрейма с фильтром с этим новым набором параметров фильтра.
7. Способ по п.1, в котором первый фильтр и второй фильтр представляют собой фильтры с конечным импульсным откликом.
8. Способ по п.1, в котором первый фильтр и второй фильтр имеют разные параметры.
9. Способ по п.1, в котором для разных микрофонных выходов свертка выполняется с разными фильтрами.
10. Способ по п.1, в котором первый и второй каналы аудиоданных представляют собой первый и второй каналы волновой формы аудио для речевого фрагмента, причем первый и второй каналы волновой формы аудио являются записями речевого фрагмента различными микрофонами, которые находятся на расстоянии друг от друга.
11. Способ по п.1, в котором нейронная сеть, обученная в качестве акустической модели, содержит сверточный слой, один или более слоев долгой краткосрочной памяти и множество скрытых слоев.
12. Способ по п.11, в котором сверточный слой нейронной сети, обученной в качестве акустической модели, сконфигурирован для выполнения свертки временной области.
13. Способ по п.11, в котором нейронная сеть, обученная в качестве акустической модели, сконфигурирована так, что выход сверточного слоя накапливается для генерации набора накопленных значений.
14. Способ по п.13, в котором нейронная сеть, обученная в качестве акустической модели, сконфигурирована вводить накопленные значения в один или более слоев долгой краткосрочной памяти в нейронной сети, обученной в качестве акустической модели.
15. Способ по п.1, в котором первый и второй фильтры сконфигурированы выполнять как пространственную, так и спектральную фильтрацию.
16. Способ по п.1, содержащий:
свертку аудиоданных для первого канала с первым фильтром, имеющим первый набор параметров фильтра, для генерации первых выходов свертки;
свертку аудиоданных для второго канала со вторым фильтром, имеющим второй набор параметров фильтра, для генерации вторых выходов свертки; и
объединение первых выходов свертки и вторых выходов свертки.
17. Система для распознавания многоканальной речи, содержащая:
один или более компьютеров и одно или более запоминающих устройств, хранящих инструкции, которые приспособлены при их исполнении одним или более компьютерами предписывать одному или более компьютерам выполнять операции, содержащие:
прием первого канала аудиоданных, соответствующих речевому фрагменту, и второго канала аудиоданных, соответствующих этому речевому фрагменту;
генерирование, с использованием обученной рекуррентной нейронной сети, (i) первого набора параметров фильтра для первого фильтра на основе первого канала аудиоданных и второго канала аудиоданных и (ii) второго набора параметров фильтра для второго фильтра на основе первого канала аудиоданных и второго канала аудиоданных;
генерирование единого объединенного канала аудиоданных путем объединения (i) аудиоданных первого канала, который был отфильтрован с использованием первого фильтра, и (ii) аудиоданных второго канала, который был отфильтрован с использованием второго фильтра;
ввод аудиоданных для единого объединенного канала в нейронную сеть, обученную в качестве акустической модели; и
предоставление транскрипции для речевого фрагмента, которая определяется, по меньшей мере, на основе выхода, который нейронная сеть выдает в ответ на прием аудиоданных для единого объединенного канала.
18. Система по п.17, в которой рекуррентная нейронная сеть содержит:
первый слой долгой краткосрочной памяти, который принимает как первый, так и второй каналы аудио; и
второй слой долгой краткосрочной памяти, соответствующий первому каналу, и третий слой долгой краткосрочной памяти, соответствующий второму каналу, причем каждый из второго слоя долгой краткосрочной памяти и третьего слоя долгой краткосрочной памяти принимает выход первого слоя долгой краткосрочной памяти и предоставляет набор параметров фильтра для соответствующего канала.
19. Система по п.17, в которой операции дополнительно содержат:
свертку аудиоданных для первого канала с первым фильтром, имеющим первый набор параметров фильтра, для генерации первых выходов свертки;
свертку аудиоданных для второго канала со вторым фильтром, имеющим второй набор параметров фильтра, для генерации вторых выходов свертки; и
объединение первых выходов свертки и вторых выходов свертки.
20. Долговременный машиночитаемый носитель, на котором сохранено программное обеспечение, исполняемое одним или более компьютерами, которое при его исполнении предписывает одному или более компьютерам выполнять операции, содержащие:
прием первого канала аудиоданных, соответствующих речевому фрагменту, и второго канала аудиоданных, соответствующих этому речевому фрагменту;
генерирование, с использованием обученной рекуррентной нейронной сети, (i) первого набора параметров фильтра для первого фильтра на основе первого канала аудиоданных и второго канала аудиоданных и (ii) второго набора параметров фильтра для второго фильтра на основе первого канала аудиоданных и второго канала аудиоданных;
генерирование единого объединенного канала аудиоданных путем объединения (i) аудиоданных первого канала, который был отфильтрован с использованием первого фильтра, и (ii) аудиоданных второго канала, который был отфильтрован с использованием второго фильтра;
ввод аудиоданных для единого объединенного канала в нейронную сеть, обученную в качестве акустической модели; и
предоставление транскрипции для речевого фрагмента, которая определяется, по меньшей мере, на основе выхода, который нейронная сеть выдает в ответ на прием аудиоданных для единого объединенного канала.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| US 9263036 B1, 16.02.2016 | |||
| US 9239828 B2, 19.01.2016 | |||
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| US 6202049 B1, 13.03.2001 | |||
| EP 1450350 A1, 25.08.2004 | |||
| КЛАССИФИКАТОР НА ОСНОВЕ НЕЙРОННЫХ СЕТЕЙ ДЛЯ ВЫДЕЛЕНИЯ АУДИО ИСТОЧНИКОВ ИЗ МОНОФОНИЧЕСКОГО АУДИО СИГНАЛА | 2006 |
|
RU2418321C2 |

