Перекрестные ссылки на связанные с изобретением патентные заявки
Настоящая заявка испрашивает приоритет заявки по китайской патентной заявке №201510818653.5, поданной 20 ноября 2015 г., содержание которой полностью включено в настоящий документ посредством ссылки.
Область техники, к которой относится изобретение
Настоящее изобретение относится, в целом, к области интернет технологий, в частности, к способу извлечения тематических предложений веб-страниц и к устройству извлечения тематических предложений веб-страниц.
Уровень техники
С бурным развитием интернет технологий, сеть Интернет стала для человека важным каналом получения информации. В частности, пользователь может ввести в поисковую систему запрашиваемое выражение, и поисковая система в ответ на данный запрашиваемое выражение может отобрать для пользователя определенное количество веб-страниц для их выборочного просмотра. Следует отметить, что для облегчения просмотра поисковая система может ранжировать отобранные веб-страницы по степени соответствия веб-страницы запрашиваемому выражению.
Такое соответствие может указывать на сходство между тематическим предложением одной отобранной веб-страницы и запрашиваемым выражением. Например, запрашиваемое выражение это «симптомы гепатита В», при этом тематическое предложение отобранной веб-страницы №1 является «каковы симптомы гепатита В», а тематическое предложение отобранной страницы №2 является «способы передачи вируса гепатита В».
Поскольку тематическое предложение отобранной веб-страницы №1 имеет большее сходство с упомянутым запрашиваемым выражением, отобранная страница №1 в большей степени соответствует запрашиваемому выражению, в результате чего она находится выше в результатах поиска. Таким образом, тематическое предложение веб-страницы может непосредственно влиять на порядок ранжирования отобранных веб-страниц и, таким образом, влиять на степень удовлетворенности пользователя результатами поиска.
В настоящее время извлечение тематических предложений веб-страниц основано на некоторых обобщенных вручную правилах извлечения для произвольных веб-страниц, и впоследствии эти правила применяются для определения тематического предложения конкретной веб-страницы. Однако точность тематических предложений, извлеченных с веб-страниц с применением таких способов извлечения, является относительно низкой.
Упомянутые способ и устройство согласно настоящему изобретению направлены на решение по меньшей мере одной вышеупомянутой проблемы, а также других проблем.
Раскрытие сущности изобретения
Способ и устройство извлечения тематических предложений веб-страниц раскрыты посредством различных предпочтительных вариантов осуществления настоящего изобретения.
Настоящее изобретение в одном из своих аспектов относится к способу извлечения тематических предложений веб-страниц, включающему в себя этапы, на которых: получают множество возможных веб-страниц и предварительно построенную модель машинного обучения, причем каждая из множества возможных веб-страниц содержит множество предварительно отобранных возможных тематических предложений, причем каждое возможное тематическое предложение включает в себя множество словесных сегментов; определяют значение словесной характеристики для каждого словесного сегмента, причем значение словесной характеристики показывает уровень важности словесного сегмента в каждой из возможных веб-страниц; вводят соответствующие множеству словесных сегментов значения словесных характеристик в модель машинного обучения для получения значения важности для каждого словесного сегмента; для каждой возможной веб-страницы определяют значение частичного порядка для каждого возможного тематического предложения в соответствии с упомянутыми значениями важности словесных сегментов, содержащихся в возможном тематическом предложении; и для каждой возможной веб-страницы выбирают одно из множества возможных тематических предложений, связанных со значением частичного порядка, превышающим предварительно заданное пороговое значение, в качестве целевого тематического предложения возможной веб-страницы.
В некоторых варианта осуществления настоящего изобретения упомянутый способ дополнительно включает в себя процесс предварительного построения модели машинного обучения, включающий в себя: получение заголовков страниц множества образцов веб-страниц, причем каждый образец веб-страницы соответствует по меньшей мере одному запрашиваемому выражению для отбора образца веб-страницы, причем каждое запрашиваемое выражение связано с взвешенным значением для обозначения степени корреляции между запрашиваемым выражением и отобранным образцом веб-страницы; вычисление значения метки для каждого словесного сегмента, содержащегося в каждом заголовке страницы; определение величины словесной характеристики для каждого словесного сегмента, содержащегося в каждом заголовке страницы, причем значение словесной характеристики указывает на степень важности словесного сегмента в соответствующем образцы веб-страницы; и применение предварительно заданного алгоритма машинного обучения для изучения значений меток и значений словесных характеристик словесных сегментов в каждом заголовке страницы для получения модели машинного обучения.
В некоторых вариантах осуществления настоящего изобретения значение метки для каждого словесного сегмента, содержащегося в каждом заголовке страницы, вычисляют по следующей формуле: 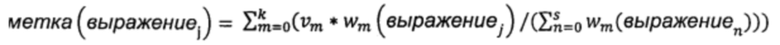 ,
,
причем выражениеj обозначает содержащийся в заголовке страницы j-й словесный сегмент, метка (выражениеj) представляет собой значение метки словесного сегмента выражениеj, m представляет собой запрашиваемое выражение, k представляет собой суммарное количество запрашиваемых выражений, 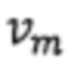 представляет собой взвешенное значение запрашиваемого выражения m, wm (выражениеj представляет собой взвешенное значение словесного сегмента выражениеj для запрашиваемого выражения m, n представляет собой словесный сегмент в заголовке страницы, a s представляет собой суммарное количество словесных сегментов в заголовке страницы.
представляет собой взвешенное значение запрашиваемого выражения m, wm (выражениеj представляет собой взвешенное значение словесного сегмента выражениеj для запрашиваемого выражения m, n представляет собой словесный сегмент в заголовке страницы, a s представляет собой суммарное количество словесных сегментов в заголовке страницы.
В одном из вариантов осуществления настоящего изобретения, предварительно заданный алгоритм машинного обучения представляет собой алгоритм обучения «GBRank», причем способ сравнения частичного порядка в упомянутом алгоритме обучения «GBRank» представляет собой попарное сравнение частичного порядка; причем функция потерь в алгоритме обучения «GBRank» представляет собой перекрестную энтропию.
В некоторых вариантах осуществления настоящего изобретения определение значения частичного порядка для каждого возможного тематического предложения включает в себя: вычисление для каждого возможного тематического предложения взвешенной суммы множества значений важности словесных сегментов, содержащихся в возможном тематическом предложении, в качестве значения частичного порядка возможного тематического предложения.
В некоторых вариантах осуществления настоящего изобретения способ дополнительно содержит этапы, на которых: устанавливают отношение соответствия между множеством целевых тематических предложений и множеством возможных веб-страниц; и сохраняют упомянутое отношение соответствия в предварительно заданной базе данных.
В некоторых вариантах осуществления настоящего изобретения способ дополнительно содержит этапы, на которых: в ответ на поисковый запрос поисковой системы, определяют множество веб-страниц, отобранных поисковой системой, причем множество отобранных веб-страниц входит во множество возможных веб-страниц; отбирают целевое тематическое предложение каждой отобранной веб-страницы из предварительно заданной базы данных, и сопоставляют целевое тематическое предложение с поисковым запросом для получения для каждой отобранной веб-страницы значения соответствия; и ранжируют множество отобранных веб-страниц на основе соответствующих значений соответствия.
В некоторых вариантах осуществления настоящего изобретения, определение значения словесной характеристики для каждого словесного сегмента включает в себя вычисление частоты слова, обратной частоты документа, постоянного коэффициента попаданий и близости каждого словесного сегмента.
Настоящее изобретение в другом своем аспекте относится к устройству для извлечения тематических предложений веб-страниц, содержащему по меньшей мере один процессор, запоминающее устройство и по меньшей мере один программный модуль, хранящийся на запоминающем устройстве и предназначенный для исполнения посредством упомянутого по меньшей мере одного процессора, причем упомянутый по меньшей мере один программных модуль содержит: модуль получения веб-страницы и модели, выполненный с возможностью получения возможной веб-страницы и предварительного построения модели машинного обучения, причем каждая возможная веб-страница содержит множество предварительно отобранных возможных тематических предложений, причем каждое возможное тематическое предложение включает в себя множество словесных сегментов; модуль определения значения важности словесного сегмента, выполненный с возможностью определения значений словесных характеристик, указывающих на уровни важности словесных сегментов в каждой возможной веб-странице, и ввода значений словесных характеристик в модель машинного обучения для получения значения важности для каждого словесного сегмента; модуль определения значения частичного порядка тематических предложений, выполненный с возможностью определения, для каждой возможной веб-страницы, значения частичного порядка для каждого возможного тематического предложения в соответствии со значениями важности словесных сегментов возможного тематического предложения, и модуль определения тематического предложения, выполненный с возможностью выбора, для каждой возможной веб-страницы, одного из множества возможных тематических предложений, связанного со значением частичного порядка, превышающим предварительно заданное пороговое значение, в качестве целевого тематического предложения возможной веб-страницы.
Согласно другому аспекту в настоящем изобретении предложена энергонезависимая машиночитаемое запоминающее устройство, содержащая машиночитаемую программу, хранящуюся в ней, причем, во время исполнения, упомянутая машиночитаемая программа обеспечивает реализацию компьютером способа извлечения тематических предложений веб-страниц, причем упомянутый способ содержит этапы, на которых: получают множество возможных веб-страниц и предварительно построенную модель машинного обучения, причем каждая возможная веб-страница содержит множество предварительно отобранных возможных тематических предложений, причем каждое возможное тематическое предложение включает в себя множество словесных сегментов; определяют значение словесной характеристики для каждого словесного сегмента, причем значение словесной характеристики указывает на уровень важности словесного сегмента в каждой возможной веб-странице, причем значение словесной характеристики включает в себя частоту слова, обратную частоту документа, постоянный коэффициент попаданий и близость каждого словесного сегмента; вводят значения словесных характеристик, соответствующие множеству словесных сегментов, в модель машинного обучения для получения значения важности для каждого словесного сегмента; для каждой возможной веб-страницы определяют значение частичного порядка для каждого возможного тематического предложения в соответствии со значениями важности словесных сегментов, содержащихся в возможном тематическом предложении; и для каждой возможной веб-страницы выбирают одно из множества возможных тематических предложений, связанное со значением частичного порядка, превышающим предварительно заданное пороговое значение, в качестве целевого тематического предложения возможной веб-страницы.
Другие аспекты настоящего изобретения станут понятны для специалистов в данной области техники из нижеследующего описания, пунктов формулы изобретения и прилагаемых чертежей.
Краткое описание чертежей
Различные задачи, признаки и преимущества настоящего изобретения раскрыты более подробно из нижеследующего подробного описания настоящего изобретения при его рассмотрении совместно с прилагаемыми чертежами, на которых одинаковые номера позиций служат для обозначения схожих элементов. Следует отметить, что прилагаемые чертежи приведены лишь в качестве примеров для иллюстрации различных раскрытых вариантов осуществления настоящего изобретения и не ограничивают объем настоящего изобретения.
На фиг. 1 показана блок-схема примера способа извлечения тематических предложений с веб-страницы в соответствии с некоторыми вариантами осуществления настоящего изобретения;
на фиг. 2 показана блок-схема примера способа построения модели машинного обучения в соответствии с некоторыми вариантами осуществления настоящего изобретения;
на фиг. 3 показана структурная схема примера устройства для извлечения тематических предложений с веб-страниц в соответствии с некоторыми вариантами осуществления настоящего изобретения;
на фиг. 4 показана структурная схема другого примера устройства для извлечения тематических предложений с веб-страниц в соответствии с некоторыми вариантами осуществления настоящего изобретения;
на фиг. 5 показана схема аппаратного оборудования примера устройства для извлечения тематических предложений с веб-страниц в соответствии с некоторыми вариантами осуществления настоящего изобретения;
на фиг. 6 показана структурная схема примера системы, включающей в себя конкретные аспекты раскрытых вариантов осуществления настоящего изобретения.
Осуществление изобретения
Далее приведено подробное описание примеров вариантов осуществления настоящего изобретения, показанных на прилагаемых чертежах. Варианты осуществления, соответствующие настоящему изобретению, раскрыты далее со ссылками на чертежи. По возможности, одинаковые номера позиций использованы на всех чертежах для обозначения одинаковых или схожих элементов. Очевидно, что раскрытые варианты осуществления представляют собой часть (но не все) возможных вариантов осуществления настоящего изобретения. На основании раскрытых вариантов осуществления специалистами в данной области техники могут быть получены другие варианты осуществления согласно настоящему изобретению, причем все они входят в объем настоящего изобретения.
В соответствии с различными вариантами осуществления, настоящее изобретение относится к способу и устройству извлечения тематических предложений веб-страниц.
На фиг. 1 показана блок-схема примера процесса извлечения тематических предложений с веб-страниц в соответствии с некоторыми вариантами осуществления настоящего изобретения. Как показано на упомянутом чертеже, способ извлечения тематических предложений согласно настоящему изобретению может включать в себя этапы S101-S104.
На этапе S101 получают по меньшей мере одну возможную веб-страницу и могут обеспечить наличие предварительно построенной модели машинного обучения. При этом упомянутая по меньшей мере одна возможная веб-страница может содержать несколько предварительно отобранных возможных тематических предложений, причем каждое возможное тематическое предложение может содержать множество словесных сегментов.
Модель машинного обучения, например, модель контролируемого машинного обучения может быть предварительно построена до выполнения этапа S101. Модель машинного обучения представляет собой модель, построенную с применением предварительно заданного способа обучения. Предварительно заданный способ обучения может использовать несколько веб-страниц, отобранных в ответ на запрашиваемое выражение, в качестве обучающих образцов.
В частности, пользователь может ввести запрашиваемое выражение в поисковую систему. Поисковая система может отобрать несколько веб-страниц, соответствующих упомянутому запрашиваемому выражению. Если пользователь выясняет, что по меньшей мере одна из отобранных веб-страниц полностью соответствует запрашиваемому выражению, пользователь может получить доступ к этой по меньшей мере одной из отобранных веб-страниц. Посредством отслеживания истории доступа пользователя к веб-страницам может быть получено суммарное число доступов к каждой веб-странице, которое затем может быть преобразовано во взвешенное значение веб-страницы.
Далее, могут быть собраны несколько запрашиваемых выражений, соответствующих каждой веб-странице. При этом может быть получено суммарное число доступов к каждой веб-странице (то есть, общее число доступов к каждой веб-странице), соответствующее конкретному выражению, которое затем может быть преобразовано во взвешенное значение веб-страницы, соответствующее упомянутому конкретному выражению.
Таким образом, обучающие образцы, используемые в предварительно заданном способе обучения, представляют собой несколько веб-страниц, соответственно связанных с распределением взвешенных значений и запрашиваемых выражений. Каждое взвешенное значение может быть получено посредством отслеживания истории доступа пользователя к соответствующей отобранной веб-странице в ответ на конкретное запрашиваемое выражение. Таким образом, взвешенное значение может указывать на степень корреляции между соответствующей веб-страницей и конкретным запрашиваемым выражением. Кроме того, взвешенное значение может отражать степень удовлетворенности пользователя соответствующей веб-страницей с учетом конкретного запрашиваемого выражения.
Следует отметить, что предварительно построенная модель машинного обучения может использовать образцы доступа крупных пользователей для того, чтобы отметить ключевые слова на веб-страницах так, чтобы модель машинного обучения могла изучить степени важности слов и фраз из данных об образцах доступа крупных пользователей, а также могла выразить степени важности слов и фраз в форме моделей.
По меньшей мере одна возможная веб-страница может быть отобрана из сети, например, сети Интернет, с применением поискового робота. Упомянутая по меньшей мере одна возможная веб-страниц может представлять собой по меньшей мере одну возможную веб-страницу, а также может представлять собой множество возможных веб-страниц. Целевое тематическое предложение может быть определено для каждой веб-страницы посредством применения способа согласно некоторым вариантам осуществления настоящего изобретения.
Следует отметить, что каждая возможная веб-страница может содержать большое количество предложений. Во-первых, небольшое количество предложений может быть выбрано в качестве возможных тематических предложений. И затем, на последующих этапах, из упомянутого небольшого количества возможных тематических предложений может быть определено целевое тематическое предложение. При этом эффективность определения тематических предложений веб-страниц может быть увеличена.
Отобранные возможные тематические предложения могут представлять собой предложения, которые с большой вероятностью содержат целевое тематическое предложение. Например, некоторые области или домены веб-страницы, содержащие заголовок страницы, заголовок статьи, точку привязки, иерархию и метаданные веб-сайта и так далее, с большой вероятностью содержат ключевые слова всего содержания веб-страницы. Таким образом, возможные тематические предложения могут быть извлечены из упомянутых доменов. В частности, заголовок страницы может представлять собой заголовок страницы с проставленными знаками препинания. Следует отметить, что вышеупомянутые домены приведены лишь в качестве примеров. Возможные тематические предложения быть отобраны из любых подходящего домена.
После получения возможных тематических предложений, возможно применение инструмента разделения на словесные сегменты для разделения возможных тематических предложений и получения множества словесных сегментов. Упомянутое множество словесных сегментов можно также принять в качестве возможных ключевых слов. Например, возможное тематическое предложение это «гепатит В вызывает лихорадку», при этом словесными сегментами могут быть «гепатит В», «вызывает» и «лихорадка».
На этапе S102, для каждого словесного сегмента может быть определено значение словесной характеристики. При этом значение словесной характеристики может указывать на степень важности словесного сегмента в упомянутой возможной веб-странице. Множество значений словесных характеристик, соответствующих упомянутому множеству словесным сегментам, могут быть введены в модель машинного обучения для получения значений важности словесных сегментов.
В некоторых вариантах осуществления настоящего изобретения, возможно применение предварительно заданного алгоритма определения значения характеристики для определения значения словесной характеристики для каждого словесного сегмента. Значение словесной характеристики может указывать на степень важности соответствующего словесного сегмента в возможной веб-странице.
В частности, множество алгоритмов определения значений характеристики может быть предварительно задано заранее для определения различных видов значений словесных характеристик соответственно. Таким образом, для вычисления конкретного типа словесной характеристики словесных сегментов может быть предварительно задан соответствующий алгоритм определения значения характеристики.
Например, различные типы словесных характеристик могут включать в себя, помимо прочего: частоту слова (TF, term frequency), обратную частоту документа ОЧД (IDF, inverse document frequency), постоянный коэффициент попаданий, близость, длину заголовка страницы, тип страницы и так далее. При этом словесная характеристика словесного сегмента может представлять собой любую подходящую комбинацию упомянутых параметров.
В некоторых вариантах осуществления настоящего изобретения в качестве алгоритма определения значений характеристик для конкретного типа словесной характеристики возможно применение любого подходящего алгоритма.
Пример алгоритма определения частоты слова может включать в себя следующие этапы: определение суммарного количества словесных сегментов веб-страницы; определение числа вхождений конкретного словесного сегмента в веб-страницу; получение частоты слова словесного сегмента веб-страницы посредством деления числа вхождения словесного сегмента на суммарное количество словесных сегментов.
Пример алгоритма определения обратной частоты документа может включать в себя следующие этапы: определение суммарного количества параграфов веб-страницы; определение количества параграфов, содержащих конкретный словесный сегмент; определение обратной частоты документа словесного сегмента в качестве логарифма отношения суммарного количества параграфов веб-страницы к количеству параграфов, содержащих словесный сегмент.
Пример алгоритма определения постоянного коэффициента попаданий может включать в себя следующие этапы: задание интервала слова, начинающегося с конкретного словесного сегмента и имеющего предварительно заданную длину; и определение частоты попаданий в интервал слова на веб-странице в качестве постоянного коэффициента попаданий.
Пример алгоритма определения близости может представлять собой вычисление степени грамматической корреляции между конкретным словесным сегментом и другими словесными сегментами; пример алгоритма определения длины заголовка страницы может представлять собой вычисление заданного количества слов в заголовке страницы; и пример алгоритма для определения типа страницы может представлять собой распределение содержания веб-страницы по предварительно заданным категориям.
Следует отметить, что вышеописанные типы словесных характеристик приведены лишь в качестве примеров, которые не ограничивают объем настоящего изобретения. Любые другие подходящие типы словесных могут быть применены для обозначения степени важности словесного сегмента на возможной веб-странице.
После определения значений словесных характеристик словесных сегментов значения характеристик каждого словесного сегмента могут быть введены в модель машинного обучения для получения значений важности словесных сегментов соответственно.
В частности, в модель машинного обучения могут быть введены значения словесных характеристик словесных сегментов в возможных тематических предложениях, а выходными данными могут быть значения важности словесных сегментов. В некоторых вариантах осуществления настоящего изобретения для каждого словесного сегмента в возможных тематических предложениях в модель машинного обучения может быть введено значение характеристики словесного сегмента. Модель машинного обучения выполнена с возможностью вычислять значение важности словесного сегмента в зависимости от значения характеристики словесного сегмента. В результате может быть получено значение важности каждого словесного сегмента в возможных тематических предложениях.
На этапе S103 определяют значение частичного порядка каждого возможного тематического предложения в соответствии со значениями важности словесных сегментов, содержащихся в каждом возможном тематическом предложении.
Как правило, каждое возможное тематическое предложение содержит множество словесных сегментов, причем каждый словесный сегмент имеет соответствующее значение важности. Используя значения важности словесных сегментов, может быть получено значение частичного порядка возможного тематического предложения. Например, значение частичного порядка возможного тематического предложения может представлять собой непосредственное суммирование значений важности каждого словесного сегмента возможного тематического предложения. В другом примере значение частичного порядка возможного тематического предложения может представлять собой взвешенное суммирование значений важности каждого словесного сегмента возможного тематического предложения, что подробно раскрыто ниже.
Следует отметить, что каждая возможная веб-страница может содержать множество возможных тематических предложений. Для каждого возможного тематического предложения может быть определено соответствующее значение частичного порядка.
На этапе S104 возможное тематическое предложение, соответствующее значению частичного порядка, превышающему предварительно заданное пороговое значение, определяют в качестве целевого тематического предложения веб-страницы.
В некоторых вариантах осуществления настоящего изобретения пороговое значение частичного порядка может быть задано заранее. Если одно из возможных тематических предложений соответствует значению частичного порядка, превышающему пороговое значение частичного порядка, то в качестве целевого тематического предложения веб-страницы может быть определено упомянутое одно возможное тематическое предложение.
Соответственно, согласно раскрытому способу извлечения тематических предложений с веб-страниц, сначала получают по меньшей мере одну возможную веб-страницу, причем каждая возможная веб-страница может содержать множество возможных тематических предложений, причем каждое возможное тематическое предложение может содержать множество словесных сегментов. Затем для каждого словесного сегмента может быть определено значение словесной характеристики. Множество значений словесных характеристик, соответствующих множеству словесных сегментов, могут быть введены в предварительно заданную модель машинного обучения для получения значений важности словесных сегментов. Затем может быть определено значение частичного порядка каждого возможного тематического предложения в соответствии со значениями важности словесных сегментов, содержащихся в каждом возможном тематическом предложении. И наконец, возможное тематическое предложение, соответствующее значению частичного порядка, превышающему предварительно заданное пороговое значение, может быть определено в качестве целевого тематического предложения веб-страницы.
Следует отметить, что в раскрытом способе для получения значений частичного порядка возможных тематических предложений может использоваться модель машинного обучения. Поскольку образцы веб-страниц, используемые в процессе обучения модели машинного обучения, могут отражать степень корреляции с запрашиваемым выражением, полученная модель машинного обучения может быть более точной. В результате, может быть повышена точность выбора целевого тематического предложения.
В частности, тематическое предложение конкретной веб-страницы, главным образом, определяют на основе обобщенных вручную правил извлечения с применением произвольных веб-страниц. Таким образом, точность выбора целевого тематического предложения является относительно низкой.
Следует отметить, что обобщенные искусственно вручную правила извлечения формируют на основе произвольных веб-страниц, поэтому правила извлечения представляют собой лишь совокупность простых условий, например, является ли конкретное слово важным или неважным при конкретном условии. При использовании простых условий трудно точно определить степень важности слова на веб-странице.
Однако в некоторых вариантах осуществления способа построенная модель машинного обучения может использовать веб-страницы, отобранные в ответ на запрашиваемое выражение, в качестве образцов веб-страниц, поэтому образцы веб-страниц могут отображать степени корреляции с запрашиваемым выражением. Степени корреляции могут быть определены посредством использования статистики доступа к отобранным веб-страницам. Таким образом, модель машинного обучения, построенная в способе согласно настоящему изобретению, может формировать более точные правила извлечения по сравнению с существующими правилами, и целевое тематическое предложение веб-страницы, извлеченное с применением раскрытого способа, может являться более точным.
В некоторых вариантах реализации для повышения точности определений целевого тематического предложения возможной веб-страницы может быть применяться внешняя ссылка возможной веб-страницы для формирования выборки возможных тематических предложений. В частности, внешние ссылки возможной веб-страницы могут быть получены перед этапом S104. Внешняя ссылка может представлять собой часть текстового содержания.
Возможно определение степени схожести между внешней ссылкой и каждым подходящим тематическим предложением. В зависимости от степени схожести для возможного тематического предложения может быть задан поправочный коэффициент. Поправочный коэффициент может превышать 0, или быть меньше или равным 1. Более высокая степень схожести соответствует большему поправочному коэффициенту. Значение частичного порядка возможного тематического предложения может быть вычислено с учетом упомянутого поправочного коэффициента.
В этом случае этап S104 может быть осуществлен с применением значений частичного порядка, обработанных с учетом соответствующих поправочных коэффициентов. То есть, если обработанное значение частичного порядка с учетом поправочного коэффициента превышает пороговое значение, соответствующее возможное тематическое предложение может быть определено в качестве целевого тематического предложения.
Например, имеют место два возможных тематических предложения возможной веб-страницы, в частности, одним из возможных тематических предложений является: «Гепатит В вызывает лихорадку», а вторым возможным тематическим предложением является: «Что такое гепатит В и как охладить тело при лихорадке?». Значения частичного порядка этих двух возможных тематических предложений составляют 0,5 и 0,7 соответственно.
Внешней ссылкой на возможную веб-страницу является «Гепатит В вызывает лихорадку». Очевидно, что первое возможное тематическое предложение более сходно с внешней ссылкой, поэтому поправочный коэффициент первого возможного тематического предложения равен 1, при этом поправочный коэффициент второго возможного тематического предложения составляет 0,5. Значение частичного порядка первого возможного тематического предложения может быть вычислено как 0,5*1=0,5, и значение частичного порядка второго возможного тематического предложения может быть вычислено как 0,7*0,5=0,35.
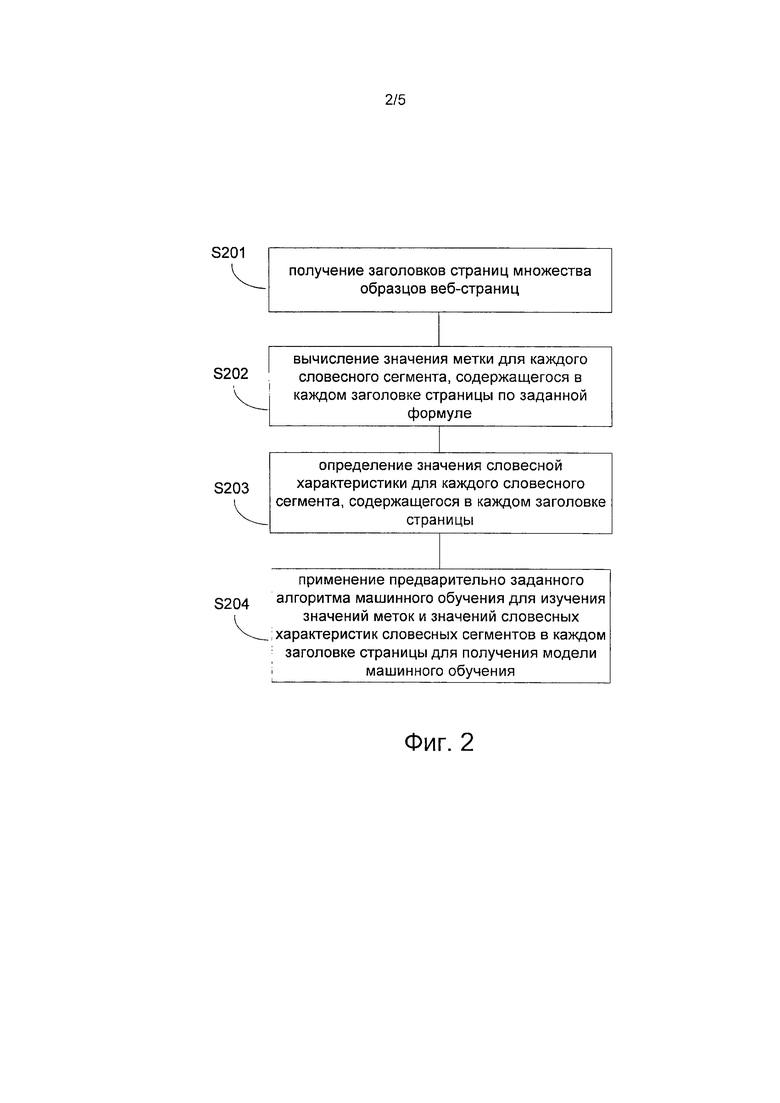
На фиг. 2 показана блок-схема примера способа построения модели машинного обучения согласно некоторым вариантам осуществления настоящего изобретения. Как показано на упомянутом чертеже, способ построения модели машинного обучения может включать в себя этапы S201-S204, которые подробно раскрыты ниже.
На этапе S201 могут быть получены заголовки страниц множества образцов веб-страниц. Каждый образец веб-страницы соответствует по меньшей мере одному запрашиваемому выражению для отбора образца веб-страницы. Каждое запрашиваемое выражение может быть связано с взвешенным значением. Взвешенное значение может применяться для обозначения степени корреляции между запрашиваемым выражением и отобранным образцом веб-страницы.
Следует отметить, что построение модели машинного обучения требует обучающих образцов, причем обучающие образцы могут представлять собой образцы веб-страниц, полученные на этапе S201. Образцы веб-страниц могут быть отобраны из сети, например, сети Интернет, с применением поискового робота.
Также следует отметить, что для повышения удовлетворенности пользователя определенным целевым тематическим предложением при построении модели машинного обучения каждый образец веб-страницы соответствует взвешенному значению. Взвешенное значение может отражать степень корреляции между запрашиваемым выражением и отобранным образцом веб-страницы, причем степень корреляции может отражать удовлетворенность пользователя.
В частности, запрашиваемое выражение может быть введено в поисковую систему и в ответ на запрашиваемое выражение может быть отобрано множество образцов веб-страниц. Заголовки страниц образцов веб-страниц могут быть отображены в поисковой системе. Если пользователя удовлетворит содержанием по меньшей мере одного образца веб-страницы, то пользователь может выбрать упомянутый по меньшей мере один образец веб-страницы, кликнув на заголовок страницы по меньшей мере одного образца веб-страниц. В результате, можно осуществляться текущий контроль за количеством кликов на образцы веб-страниц для определения взвешенного значения образцов веб-страниц. Взвешенное значение может быть получено при делении количества кликов на некоторое предварительно заданное конкретное значение.
Как описано выше, в некоторых вариантах осуществления настоящего изобретения, взвешенное значение образцов веб-страниц может быть определено в отношении запрашиваемых выражений. В некоторых прочих вариантах осуществления настоящего изобретения взвешенное значение образцов веб-страниц может быть определено в отношении образца веб-страницы, как подробно описано ниже.
В частности, запрашиваемое выражение может обеспечить отбор множества образцов веб-страниц. Предполагая, что заголовки страницы нескольких образцов веб-страниц в отношении запрашиваемого выражения qi имеют вид {ti1, ti2,…, tik}, и взвешенные значения множества образцов веб-страниц имеют следующий вид {vi1, vi2,…, vik}. Корреляция данных запрашиваемого выражения может быть выражена в виде {(qi, ((ti1, vi1), (ti2, vi2),…, (tik, vik)))}.
И наоборот, образец веб-страницы также может соответствовать множеству запрашиваемых выражений. Если пользователь вводит запрашиваемое выражение и затем кликает на образец веб-страницы, то это может означать, что образец веб-страницы точно соответствует запрашиваемому выражению. Таким образом, тематическое предложение образца веб-страницы может быть описано с применением слов, содержащихся в запрашиваемом выражении.
После инверсии корреляции данных запрашиваемого выражения, корреляция данных образца веб-страницы может быть выражена как {(tm, ((qm1, vm1), (qm2, vm2),…,(qmk, vmk)))}, где tm представляет собой произвольный заголовок страницы из {ti1, ti2,…, tik}, {qm1, qm2,…, qmk} представляют собой множество запрашиваемых выражений, a {vm1, vm2,…, vmk} представляют собой взвешенные значения для образцов веб-страниц.
Из полученной корреляции данных образцов веб-страниц {(tm, ((qm1, vm1), (qm2, vm2),…,(qmk, vmk)))} можно видеть, что любой образец tm веб-страницы соответствует множеству запрашиваемым выражениям {qm1,qm2,…,qmk} соответственно. Применительно к этим запрашиваемым выражениям взвешенные значения образца веб-страницы имеют вид {vml,vm2,…,vmk} соответственно. На этапе S202 для каждого заголовка страницы вычисляют значение метки каждого содержащегося в заголовке страницы словесного сегмента с использованием следующей формулы: 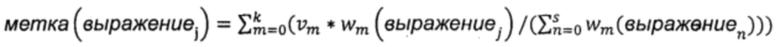 ,
,
в которой выражениеj обозначает j-й словесный сегмент, содержащийся в заголовке страницы, метка (выражениеj) представляет собой значение метки словесного сегмента выражениеj, m представляет собой запрашиваемое выражение, k представляет собой суммарное количество запрашиваемых выражений, 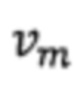 представляет собой взвешенное значение запрашиваемого выражения m, wm (выражениеj) представляет собой взвешенное значение словесного сегмента выражениеj для запрашиваемого выражения m, n представляет собой словесный сегмент в заголовке страницы, a s представляет собой суммарное количество словесных сегментов в заголовке страницы.
представляет собой взвешенное значение запрашиваемого выражения m, wm (выражениеj) представляет собой взвешенное значение словесного сегмента выражениеj для запрашиваемого выражения m, n представляет собой словесный сегмент в заголовке страницы, a s представляет собой суммарное количество словесных сегментов в заголовке страницы.
В частности, если имеет место множество образцов веб-страниц, то может быть получено множество соответствующих заголовков страниц. Каждый заголовок страницы может содержать множество словесных сегментов. Для каждого заголовка страницы может быть вычислено значение метки каждого из словесных сегментов, содержащихся в заголовке страницы, в соответствии с вышеприведенной формулой для значения метки. Следует отметить, что параметр wm (выражениеj) в формуле для значения метки может быть вычислен посредством инструмента разбиения слова.
Например, заголовок страницы образца веб-страницы выглядит как «Вызывает ли гепатит В лихорадку?». В соответствии с отслеживаемыми данными о количестве кликов, на образец страницы кликнули при ответе на запрашиваемое выражение №1: «гепатит В вызывает лихорадку» и при ответе на запрашиваемое выражение №2: «симптомы гепатита В». Согласно упомянутым данным, взвешенные значения vm двух запрашиваемых выражений могут быть вычислены, как 1,5 и 0,5 соответственно.
Используя инструмент разбиения слов, можно вычислить взвешенные значения словесных сегментов запрашиваемого выражения №1: «гепатит В вызывает лихорадку». Взвешенное значение словесного сегмента «гепатит Вюю» составляет 97, взвешенное значение словесного сегмента «вызывает» составляет 73, а взвешенное значение словесного сегмента «лихорадка» составляет 85.
Взвешенные значения словесных сегментов запрашиваемого выражения №2 «симптомы у гепатита В» могут быть вычислены с применением инструмента разбиения слов. Взвешенное значение словесного сегмента «гепатит В» составляет 105, взвешенное значение словесного сегмента «у» составляет 5, а взвешенное значение словесного сегмента «симптом» составляет 85.
На основе вышеприведенных данных может быть вычислено значение меток словесных сегментов, содержащихся в образце веб-страницы «вызывает ли гепатит В лихорадку?». В частности, образец веб-страницы содержит четыре словесных сегмента «гепатит В», «ли», «вызывает» и «лихорадку».
Значение метки словесного сегмента «гепатит В» составляет: 1,5*97/(97+73+85)+0,5*105/(105+5+85)=0,839; значение метки словесного сегмента «ли» составляет: 1,5*0/(97+73+85)+0,5*0/(105+5+85)=0; значение метки словесного сегмента «вызывает» составляет: 1,5*73/(97+73+85)+0,5*0/(105+5+85)=0,42, а значение метки словесного сегмента «лихорадка» составляет: 1,5*85/(97+73+85)+0,5*0/(105+5+85)=0,5.
После вышеприведенного вычисления для каждого образца веб-страницы могут быть получены значения меток для всех словесных сегментов, содержащихся в заголовке страницы образца веб-страницы. Корреляция данных значений метки образца веб-страницы может быть представлена в 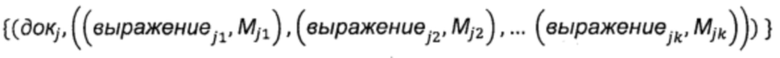 ,
,
где 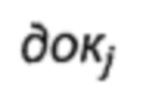 представляет собой образец страницы, {выражениеj1, выражениеj2,…, выражениеjk} представляют собой содержащиеся в образце веб-страницы словесные сегменты, а {Mj1, Mj2,…, Mjk] представляют собой значения меток каждого словесного сегмента соответственно.
представляет собой образец страницы, {выражениеj1, выражениеj2,…, выражениеjk} представляют собой содержащиеся в образце веб-страницы словесные сегменты, а {Mj1, Mj2,…, Mjk] представляют собой значения меток каждого словесного сегмента соответственно.
На этапе S203 определяют для каждого заголовка страницы значение словесной характеристики каждого словесного сегмента, содержащегося в заголовке страницы. Значение словесной характеристики указывает на степень важности словесного сегмента в соответствующем образце веб-страницы.
Определение значений словесных характеристик словесных сегментов в заголовках страниц может относиться к этапу S102 способа извлечения тематических предложений с веб-страниц, описанного выше со ссылкой на фиг. 1.
На этапе S204, используя предварительно заданный алгоритм машинного обучения, могут быть получены значения меток и значения словесных характеристик словесных сегментов каждого заголовка страницы для обучения модели машинного обучения.
Алгоритм машинного обучения может содержать неизвестные величины. Исходные значения неизвестных величин могут быть заданы предварительно. После ввода значений словесных характеристик словесных сегментов в алгоритм машинного обучения могут быть получены ожидаемые значения меток словесных сегментов. Ожидаемые значения меток могут быть сравнены с текущими значениями меток, вычисленными на этапе S202, причем неизвестные величины могут непрерывно исправляться на основании результатов сравнения для получения конечных значений неизвестных величин. Конечные значения неизвестных величин можно подставить в алгоритм машинного обучения для получения модели машинного обучения.
В некоторых вариантах осуществления настоящего изобретения алгоритм машинного обучения представляет собой алгоритм обучения «GBRank». Способ сравнения частичного порядка в упомянутом алгоритме обучения «GBRank» может представлять собой попарное сравнение частичного порядка. Функция потерь в алгоритме, обучения «GBRank» может представлять собой перекрестную энтропию.
Следует отметить, что алгоритм обучения «GBRank» включает в себя процесс сравнения частичного порядка. Процесс сравнения частичного порядка может представлять собой попарное сравнение частичного порядка. То есть значения словесных характеристик двух словесных сегментов могут быть использованы в качестве входных данных, при этом могут быть получены ожидаемые значения меток двух словесных сегментов и сравнены с рассчитанными фактическими значениями меток двух словесных сегментов.
Формула сравнения частичного порядка может иметь следующий вид: 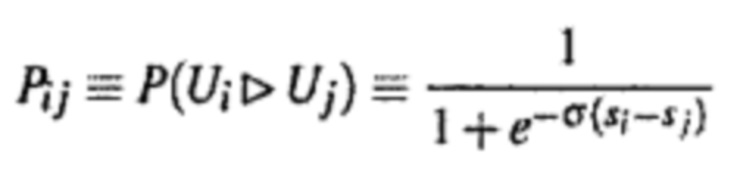 . Эта формула может быть преобразована как
. Эта формула может быть преобразована как 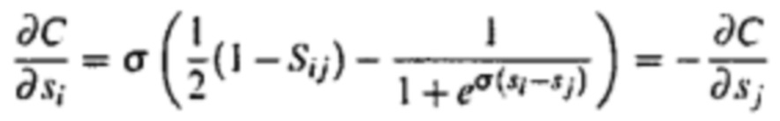 . При этом Pij обозначает вероятность того, что один словесный сегмент лучше другого словесного сегмента; e представляет собой предварительно заданное фиксированное значение; σ является предварительно заданным фиксированным значением, обычно равным 0,1, причем оно может иметь другое значение, при этом большее значение σ указывает на большую погрешность; Sj представляет собой прогнозированное значение метки выражениеi словесного сегмента, при этом Sj представляет собой ожидаемое значение метки словесного сегмента выражениеj.
. При этом Pij обозначает вероятность того, что один словесный сегмент лучше другого словесного сегмента; e представляет собой предварительно заданное фиксированное значение; σ является предварительно заданным фиксированным значением, обычно равным 0,1, причем оно может иметь другое значение, при этом большее значение σ указывает на большую погрешность; Sj представляет собой прогнозированное значение метки выражениеi словесного сегмента, при этом Sj представляет собой ожидаемое значение метки словесного сегмента выражениеj.
Формула функции потерь может иметь следующий вид: 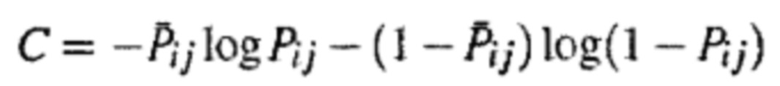 . И если удовлетворено условие
. И если удовлетворено условие 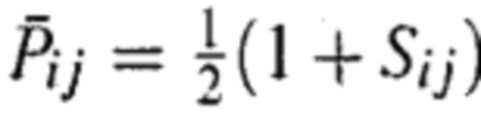 , то могут быть составлены следующие формулы:
, то могут быть составлены следующие формулы:
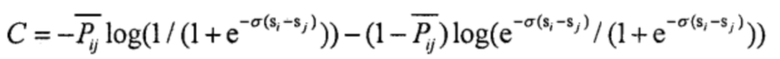
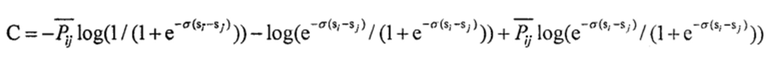
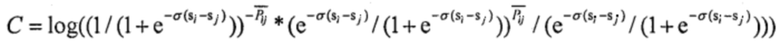
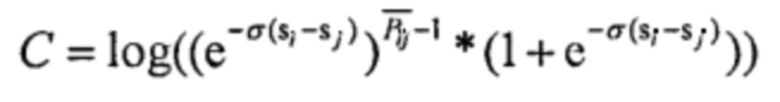
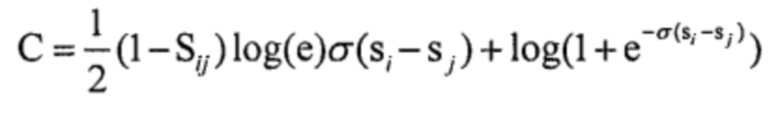
Поскольку σ и loge представляют собой константы, функция потерь может быть преобразована до следующей формулы: 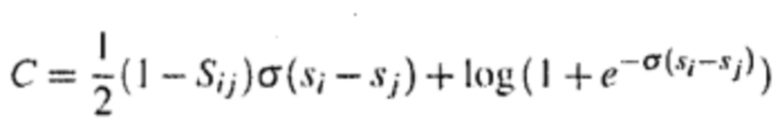 ,
,
где Sij вычисляется из отношения между значениями меток двух словесных сегментов. Если значение метки словесного сегмента выражениеi превышает значение метки словесного сегмента выражениеj, то Sij может быть принято за 1. Если значение метки словесного сегмента выражениеi меньше значения метки словесного сегмента выражениеj, то Sij может быть принято за -1. Если значение метки словесного сегмента выражениеi равно значению метки словесного сегмента выражениеj, то Sij может быть принято за 0. Следует принять во внимание, что другие параметра в формуле могут иметь отсылку к приведенному выше описанию.
После выполнения вышеописанного процесса машинного обучения, конечная модель машинного обучения может иметь три структуры, выстроенные посредством набора условий оценки. Например, определенная структура может представлять собой дерево принятия решений.
Возвращаясь к фиг. 1, конкретный вариант этапа 103 для определения значения частичного порядка каждого возможного тематического предложения может включать в себя следующие этапы.
В зависимости от значений частичного порядка словесных сегментов, содержащихся в одном возможном тематическом предложении, можно вычислить взвешенную сумму множества значений важности словесных сегментов в виде значения частичного порядка возможного тематического предложения.
В частности, каждое возможное тематическое предложение может содержать множество словесных сегментов. Каждый словесный сегмент связан со значением важности и взвешенным значением. Взвешенное значение каждого словесного сегмента может быть умножено на соответствующее значение важности. Сумма результатов умножения множества словесных сегментов возможного тематического предложения может использоваться в качестве значения частичного порядка возможного тематического предложения.
В некоторых вариантах реализации полученные целевые тематические предложения веб-страниц могут храниться в базе данных для обеспечения возможности ранжирования веб-страниц при выполнении поиска веб-страниц.
Конкретные этапы хранения могут включать в себя установление отношения соответствия между возможными веб-страницами и целевыми тематическими предложениями и сохранение установленного отношения соответствия в заданной базе данных.
В частности, может быть определено множество возможных веб-страниц, причем каждая возможная веб-страница может содержать по меньшей мере одно целевое тематическое предложение. Для каждой возможной веб-страницы может быть установлено соответствующее отношение между возможной веб-страницей и упомянутым по меньшей мере одним целевым тематическим предложением.
Следует отметить, что возможная веб-страница может быть представлена посредством любого подходящего способа однозначной идентификации, например, посредством унифицированного указателя ресурса (URL) веб-страницы. Таким образом, одно или несколько целевых тематических предложений каждой возможной веб-страницы можно хранить в базе данных, связанной с соответствующим указателем URL возможной веб-страницы.
Например, возможная веб-страницей является «Sina Sports», указателем URL которой является «url=sport.sina.com». Два полученных целевых тематических предложения, в частности, имеют вид «Sina Sports storm» и «Sina Sports». Таким образом, предварительно заданная база данных может содержать указатель URL в виде «url= sport.sina.com» и два соответствующих целевых тематических предложения «Sina Sports storm» и «Sina Sports».
Установленную базу данных можно использовать для ранжирования возможной веб-страницы в ответ на поиск пользователя. В частности, процесс ранжирования может включать в себя этапы А1-A3.
На этапе А1 в ответ на запрашиваемое выражение, введенное пользователем в поисковую систему, определяют несколько веб-страниц, отобранных поисковой системой. При этом отобранные веб-страницы могут входить в возможные веб-страницы.
Когда пользователю необходимо осуществить поиск конкретных аспектов информации, в поисковую систему может быть введено запрашиваемое выражение, относящееся к упомянутой информации, и поисковая система может отобрать множество релевантных веб-страниц. Отобранные релевантные веб-страницы могут быть приняты в качестве отобранных веб-страниц.
Следует отметить, что может иметь место множество возможных веб-страниц, при этом может иметь место несколько отобранных веб-страниц. Отобранные веб-страницы входят в возможные веб-страницы. Используя вышеописанный способ извлечения тематических предложений с веб-страниц, могут быть получены целевые тематические предложения возможных веб-страниц, которые могут быть сохранены в предварительно заданной базе данных. Таким образом, целевые тематические предложения отобранных веб-страниц также хранятся в предварительно заданной базе данных.
На этапе А2 из предварительно заданной базы данных может быть получено по меньшей мере одно целевое тематическое предложение каждой отобранной веб-страницы, причем запрашиваемое выражение может быть сопоставлено с определенными целевыми тематическими предложениями каждой отобранной веб-страницы для получения значений соответствия.
В предварительно заданной базе данных может быть выполнен поиск целевых тематических предложений для каждой отобранной веб-страницы. Отобранная веб-страница может храниться в предварительно заданной базе данных в форме формы указателя URL. Таким образом, может быть осуществлен поиск указателя URL отобранной веб-страницы, после чего может быть получено по меньшей мере одно целевое тематическое предложение, соответствующее упомянутому указателю URL.
Введенное пользователем запрашиваемое выражение может быть соответствующим образом сопоставлено с целевыми тематическими предложениями отобранных веб-страниц для получения значений соответствия. Следует отметить, что если отобранная веб-страница имеет несколько целевых тематических предложений, запрашиваемое выражение может быть сопоставлено с каждым целевым тематическим предложением для получения значения соответствия каждого целевого тематического предложения соответственно. Максимальное значение соответствия может быть применено в качестве значения соответствия запрашиваемого выражения отобранной веб-странице.
Например, запрашиваемое выражение, введенное пользователем в поисковую систему, имеет вид «Sina Sports». Одна из веб-страниц, отобранная поисковой системой, имеет указатель URL «url= sport.sina.com». В предварительно заданной базе данных могут быть найдены два соответствующих целевых тематических предложения, представляющих собой, в частности, «Sina Sports storm» и «Sina Sports».
Запрашиваемое выражение «Sina Sports» может быть сопоставлено с двумя целевыми тематическими предложениями «Sina Sports storm» и «Sina Sports». Два результата сопоставления равняются 0,8 и 1. Максимальное значение, равное 1, представляет собой значение соответствия запрашиваемого выражения «Sina Sports» и отобранной веб-страницей «url= sport.sina.com».
Если отобрано множество веб-страниц, значение соответствия может быть вычислено между каждой отобранной веб-страницей и запрашиваемым выражением с использованием вышеописанного способа.
На этапе A3 может быть выполнено ранжирование отобранных веб-страниц в соответствии со значениями соответствия, при этом они могут быть отображены в поисковой системе.
Более высокое значение соответствия между отобранной веб-страницей и запрашиваемым выражением указывает на более высокую степень корреляции между отобранной веб-страницей и запрашиваемым выражением. Используя значения соответствия, отобранные веб-страницы могут быть ранжированы и сформированы в список в поисковой системе на основании упомянутого порядка ранжирования. При этом отобранные веб-страницы, имеющие более высокую степень корреляции с запрашиваемым выражением, могут быть расположены в начале списка, что может упростить для пользователя процесс нахождения более релевантных веб-страниц.
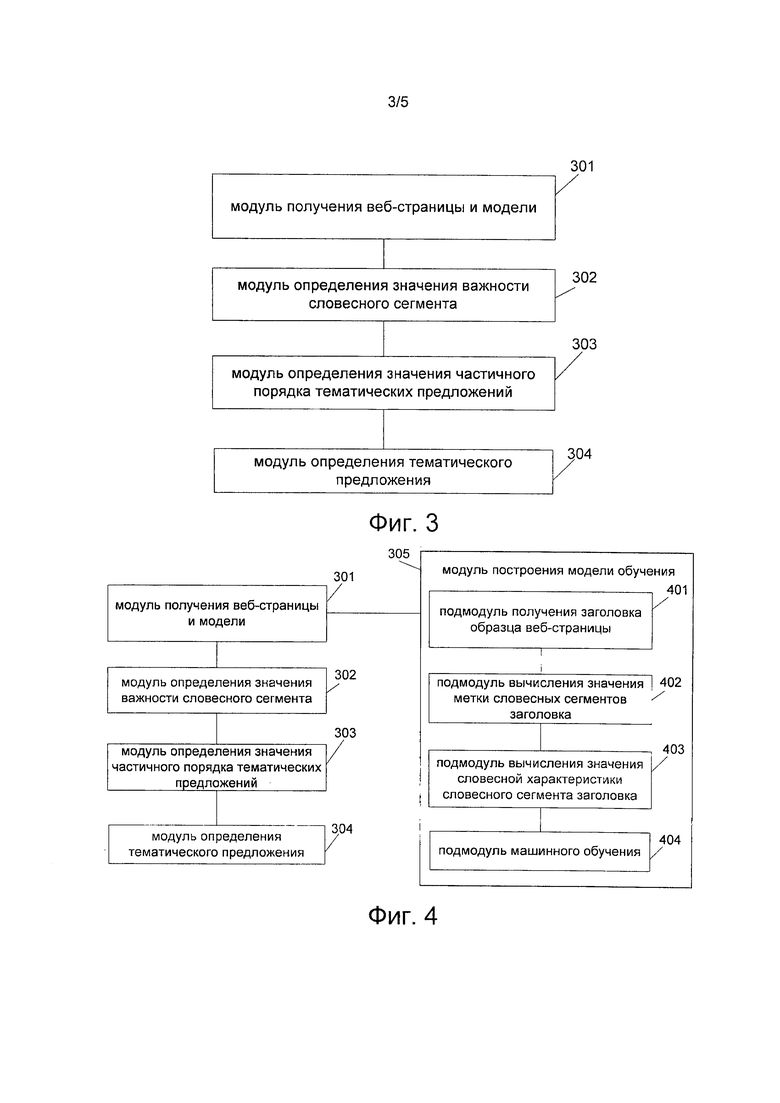
На фиг. 3 показана структурная схема примера устройства для извлечения тематических предложений с веб-страниц в соответствии с одним из вариантов осуществления настоящего изобретения. В одном из вариантов устройство для извлечения тематических предложений с веб-страниц может содержать модуль 301 получения веб-страницы и модели, модуль 302 определения значения важности словесного сегмента, модуль 303 определения значения частичного порядка тематического предложения и модуль 304 определения тематического предложения.
Модуль 301 получения веб-страницы и модели выполнен с возможностью получения по меньшей мере одной возможной веб-страницы и предварительного построения модели машинного обучения. По меньшей мере одна возможная веб-страница может содержать несколько предварительно отобранных возможных тематических предложений, причем каждое возможное тематическое предложение может содержать несколько словесных сегментов.
Модуль 302 определения значения важности словесного сегмента выполнен с возможностью ввода значений словесных характеристик нескольких словесных сегментов в модель машинного обучения для получения значений важности словесных сегментов. Значение словесной характеристики указывает на степень важности словесного сегмента в возможной вебстранице.
Модуль 303 определения значения частичного порядка тематического предложения выполнен с возможностью определения значения частичного порядка каждого возможного тематического предложения в соответствии со значениями важности словесных сегментов, содержащихся в каждом возможном тематическом предложении.
Модуль 304 определения тематического предложения выполнен с возможностью определения возможного тематического предложения, связанного со значением частичного порядка, превышающим предварительно заданное пороговое значение, в качестве целевого тематического предложения веб-страницы.
Таким образом, в устройстве для извлечения тематических предложений с веб-страниц согласно настоящему изобретению сначала посредством модуля 301 получения веб-страницы и модели может быть получена по меньшей мере одна возможная веб-страница, причем каждая возможная веб-страница может содержать несколько возможных тематических предложений, причем каждое возможное тематическое предложение может содержать несколько словесных сегментов. Далее, для каждого словесного сегмента может быть определено значение словесной характеристики. Модуль 302 определения значения важности словесного сегмента выполнен с возможностью ввода множества значений словесных характеристик, соответствующих множеству словесных сегментов, в предварительно заданную модель машинного обучения для получения значений важности словесных сегментов, после чего может быть определено значение частичного порядка каждого возможного тематического предложения посредством модуля 303 определения значения частичного порядка тематического предложения в соответствии со значениями важности словесных сегментов, содержащихся в каждом возможном тематическом предложении. И наконец, может быть определено возможное тематическое предложение, связанное со значением частичного порядка, превышающим предварительно заданное пороговое значение, в качестве целевого тематического предложения веб-страницы посредством модуля 304 определения тематического предложения.
Следует отметить, что в упомянутом устройстве может использоваться модель машинного обучения для получения значений частичного порядка возможных тематических предложений. Поскольку используемые в процессе обучения модели машинного обучения образцы веб-страниц могут отражать степени корреляции с запрашиваемым выражением, полученная модель машинного обучения может быть более точной. Таким образом, может быть повышена точность выбора целевого тематического предложения.
На фиг. 4 показана структурная схема другого примера устройства для извлечения тематических предложений с веб-страниц согласно некоторым вариантам осуществления настоящего изобретения. Как показано на упомянутом чертеже, устройство для извлечения тематических предложений с веб-страниц может дополнительно содержать модуль 305 построения модели обучения для предварительного построения модели машинного обучения.
Модуль 305 построения модели обучения может включать в себя подмодуль 401 получения заголовка образца веб-страницы, подмодуль 402 вычисления значения метки словесного сегмента заголовка, подмодуль 403 вычисления значения словесной характеристики словесного сегмента заголовка и подмодуль 404 машинного обучения.
Подмодуль 401 получения заголовка образца веб-страницы выполнен с возможностью получения заголовков веб-страниц множества образцов веб-страниц. Каждый образец веб-страницы может соответствовать по меньшей мере одному запрашиваемому выражению для отбора образца веб-страницы. Каждое запрашиваемое выражение может быть связано с взвешенным значением. Взвешенное значение может быть применено для обозначения степени корреляции между запрашиваемым выражением и отобранным образцом веб-страницы.
Подмодуль 402 вычисления значения метки словесного сегмента заголовка выполнен с возможностью вычисления значения метки каждого словесного сегмента, содержащегося в каждом заголовке страницы, с применением следующей формулы: 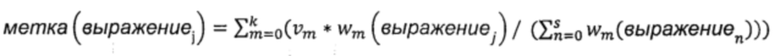 ,
,
в которой выражениеj обозначает j-й словесный сегмент, содержащийся в заголовке страницы, метка (выражениеj) представляет собой значение метки словесного сегмента выражениеj, m представляет собой запрашиваемое выражение, k представляет собой суммарное количество запрашиваемых выражений, 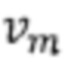 представляет собой взвешенное значение запрашиваемого выражения m, wm (выражениеj) представляет собой взвешенное значение словесного сегмента выражениеj для запрашиваемого выражения m, n представляет собой словесный сегмент в заголовке страницы, a s представляет собой суммарное количество словесных сегментов в заголовке страницы.
представляет собой взвешенное значение запрашиваемого выражения m, wm (выражениеj) представляет собой взвешенное значение словесного сегмента выражениеj для запрашиваемого выражения m, n представляет собой словесный сегмент в заголовке страницы, a s представляет собой суммарное количество словесных сегментов в заголовке страницы.
Подмодуль 403 вычисления значения словесной характеристики словесного сегмента заголовка выполнен с возможностью определения значения словесной характеристики каждого словесного сегмента, содержащегося в каждом заголовке страницы. Значение словесной характеристики может указывать на степень важности словесного сегмента в соответствующем образце веб-страницы.
Подмодуль 404 машинного обучения выполнен с возможностью применения предварительно заданного алгоритма машинного обучения для изучения значений меток и значений словесных характеристик словесных сегментов в каждом заголовке страницы для получения модели машинного обучения.
В некоторых вариантах осуществления настоящего изобретения, алгоритм машинного обучения представляет собой алгоритм обучения «GBRank». При этом способ сравнения частичного порядка в упомянутом алгоритме обучения «GBRank» представляет собой попарное сравнение частичного порядка. При этом функция потерь в алгоритме обучения «GBRank» может представлять собой перекрестную энтропию.
Как показано на фиг. 3, модуль 303 определения значения частичного порядка тематического предложения может включать в себя подмодуль определения значения частичного порядка взвешенной суммы. Упомянутый подмодуль определения значения частичного порядка взвешенной суммы выполнен с возможностью вычисления взвешенной суммы нескольких значений важности словесных сегментов, содержащихся в каждом возможном тематическом предложении в зависимости от значений важности словесных сегментов. Вычисленная взвешенная сумма каждого возможного тематического предложения может быть применена в качестве значения частичного порядка возможного тематического предложения.
В некоторых вариантах осуществления настоящего изобретения вышеописанное устройство для извлечения тематических предложений с веб-страниц может дополнительно содержать модуль хранения тематических предложений. Модуль хранения тематических предложений выполнен с возможностью устанавливать отношение соответствия между целевыми тематическими предложениями и возможными веб-страницами и сохранять упомянутые отношения соответствия между целевыми тематическими предложениями и возможными веб-страницами в предварительно заданной базе данных.
Кроме того, устройство для извлечения тематических предложений с веб-страниц может содержать модуль определения отобранных веб-страниц, модуль сопоставления тематических предложений веб-страниц и модуль ранжирования отобранных веб-страниц.
Модуль определения отобранных веб-страниц выполнен с возможностью определения нескольких веб-страниц, отобранных в ответ на запрашиваемое выражение, введенное пользователем в поисковую систему. Отобранные веб-страницы могут быть включены в возможные веб-страницы.
Модуль сопоставления тематических предложений веб-страниц выполнен с возможностью сопоставления одного или нескольких целевых тематических предложений каждой отобранной веб-страницы, полученной из предварительно заданной базы данных, с запрашиваемым выражением для получения значений соответствия.
Модуль ранжирования отобранных веб-страниц выполнен с возможностью ранжирования отобранных веб-страниц в соответствии с значений соответствия и отображения отобранных веб-страниц в поисковой системе в соответствии с порядком ранжирования.
На фиг. 6 показан пример системы для извлечения тематических предложений веб-страниц в соответствии с одним из вариантов осуществления настоящего изобретения. Как показано на упомянутом чертеже, упомянутая система может содержать один или несколько серверов 610, коммуникационную сеть 620, по меньшей мере одно пользовательское устройство 630, и/или любой другой подходящий компонент.
Пользовательские устройства 630 могут быть соединены посредством одного или нескольких коммуникационных каналов 643 с коммуникационной сетью 620, так что обеспечена возможность их связи через коммуникационный канал 641 с сервером 610.
В некоторых вариантах осуществления настоящего изобретения один или несколько этапов, или все из этапов, способа извлечения тематических предложений веб-страниц, раскрытого выше со ссылкой на фиг. 1-2, можно реализовать посредством одного или нескольких возможных аппаратных процессоров сервера (или серверов) 610, пользовательского устройства (устройств) 630 и/или другого подходящего компонента системы.
Сервер (серверы) 610 и/или пользовательское устройство (устройства) 630 могут включать в себя любые подходящие модули, раскрытые выше со ссылкой на фиг. 3 и 4.
В некоторых вариантах осуществления настоящего изобретения коммуникационная сеть 620 может представлять собой любую подходящую комбинацию по меньшей мере одной проводной и/или беспроводной сети, например, Интернет, внутренней сети, глобальной вычислительной сети («WAN»), локальной вычислительной сети («LAN»), беспроводной сети, сети цифровой абонентской линии связи («DSL»), сети ретрансляции кадров, сети режима асинхронной передачи («АТМ»), виртуальной частотной сети («VPN»), сети Wi-Fi, сети WiMax, сети спутниковой связи, сети мобильной связи, сети мобильных данных, кабельной сети, сети телефонной связи, волоконно-оптической сети и/или любой другой подходящей коммуникационной сети, или любой комбинации любых таких сетей.
Пользовательское устройство (или устройства) 630 может представлять собой любое подходящее устройство, которое может сообщаться с одним или несколькими серверами через коммуникационную сеть 620, принимать запрос пользователя, обрабатывать и передавать данные, и/или отображать веб-страницы, и/или выполнять любую другую подходящую функцию. Например, пользовательское устройство 630 может представлять собой мобильный телефон 631, планшетный компьютер 633, портативный компьютер 635, настольный компьютер 637, телевизионную приставку, телевизор 639, проигрыватель мультимедийных потоков, игровую приставку, и/или любое другое подходящее устройство.
Не смотря на то, что на фиг. 6 показано только пять типов пользовательских устройств 631, 633, 635, 637 и 639 для того, чтобы избежать чрезмерного усложнения чертежа, в различных вариантах осуществления настоящего изобретения возможно применение любого подходящего количества таких терминалов и любых возможных типов таких терминалов.
Раскрытое устройство для проверки и обновления данных на пользовательском устройстве может представлять собой одно или несколько пользовательских устройств 630 и может быть реализовано с применением подходящих аппаратных средств согласно одному из вариантов осуществления настоящего изобретения. Например, на фиг. 5 показаны примеры аппаратных средств 600, причем такие аппаратные средства могут содержать аппаратный процессор 504, запоминающее устройство и/или накопитель 501, шину 502 и интерфейс (или интерфейсы) 503 связи.
В некоторых вариантах осуществления настоящего изобретения запоминающее устройство и/или накопитель 501 может представлять собой любое запоминающее устройство и/или накопитель для хранения программ, данных, мультимедийного контента, указателей URL веб-страниц, первоначальных данных ресурсов веб-страниц, информации пользователей и/или любого подходящего контента. Например, запоминающее устройство и/или накопитель 501 может представлять собой оперативную память (RAM), постоянную память, флэш-память, например, накопитель на жестких дисках, оптический носитель, и/или любое другое подходящее устройство хранения.
В некоторых вариантах осуществления настоящего изобретения, интерфейс (или интерфейсы) 503 связи может представлять собой любую подходящую схему для взаимодействия с одной или несколькими коммуникационными сетями, например, коммуникационной сетью 620. Например, интерфейс (или интерфейсы) 514 может представлять собой схему сетевой интерфейсной карты, схему беспроводной связи, и/или любую другую подходящую схему для взаимодействия с одной или несколькими коммуникационными сетями, например, сетью Интернет, глобальной вычислительной сетью, локальной сетью, городской вычислительной сетью и т.д.
Шина 502 может представлять собой любой подходящий механизм для обеспечения связи между двумя или более компонентами устройства обнаружения ресурса веб-страницы. Шина 502 может представлять собой шину ISA, шину PCI, шину EISA или любую другую подходящую шину. Шина 502 может бать разделена на адресную шину, шину данных, управляющую шину и т.д. Шина 205 представлена на фиг. 5 в виде двунаправленной стрелки, но это не значит, что возможен только один вид шины или что может быть предусмотрена только одна шина.
Запоминающее устройство и/или накопитель 501 выполнен с возможностью хранения программ. Аппаратный процессор 504 может запускать программу в ответ на прием рабочей инструкции. В некоторых вариантах осуществления настоящего изобретения один или несколько этапов, или все этапы, способа проверки и обновления данных в пользовательском устройстве, раскрытого выше со ссылкой на фиг. 1-2, могут быть реализованы посредством аппаратных процессоров 504.
Аппаратный процессор 504 может представлять собой любой подходящий аппаратный процессор, например, микропроцессор, микроконтроллер, центральный процессор (CPU), сетевой процессор (NP), процессор цифровой обработки сигналов (DSP), специализированную интегральную микросхему (ASIC), программируемую пользователем вентильную матрицу (FPGA), или другое программируемое логическое устройство, логический элемент на дискретных компонентах или устройство с транзисторной логикой, дискретные аппаратные компоненты. Аппаратный процессор 504 может реализовать или исполнить различные варианты осуществления настоящего изобретения, в том числе один или несколько способов, этапов и логических схем. Универсальный процессор может представлять собой микропроцессор или любые другие известные из уровня техники процессоры.
Этапы раскрытого способа в различных вариантах осуществления настоящего изобретения можно непосредственно реализовать посредством аппаратного декодирующего процессора или декодирующего процессора в комбинации с аппаратным модулем и программным модулем. Программный модуль может быть предусмотрен в любом подходящем запоминающем устройстве/носителе, например, в оперативной памяти, флэш-памяти, постоянной памяти, программируемой постоянной памяти, электрически-стираемой программируемой памяти, регистре и т.д. Носитель может находиться в запоминающем устройстве и/или накопителе 501. Аппаратный процессор 504 может реализовать этапы раскрытого выше способа путем комбинации аппаратного обеспечения и информации, считанной с памяти и/или накопителя 501.
Кроме того, структурные схемы и блок-схемы, представленные на чертежах, иллюстрируют различные варианты раскрытых способа и системы, а также архитектуры, функции и операции, которые могут быть реализованы посредством компьютерного программного продукта. В данном случае, каждый блок структурной схемы или блок-схемы может представлять модуль, кодовый сегмент, участок программного кода. Каждый модуль, каждый кодовый сегмент и каждый участок программного кода может включать в себя одну или несколько исполняемых инструкций для реализации предварительно определенных логических функций.
Также следует отметить, что в некоторых альтернативных реализациях, функции, проиллюстрированные в блоках, могут быть реализованы или выполнены в любом порядке или последовательности, которые не ограничены порядком и последовательностью, показанной и раскрытой со ссылкой на чертежи. Например, два последовательных блока могут быть в действительно исполнены по существу одновременно, где это целесообразно, или параллельно для уменьшения времени запаздывания и времени обработки, или даже выполнены в обратном порядке в зависимости от связанной функциональной возможности.
Также следует отметить, что каждый блок в блок-схеме и/или структурной схеме, а также комбинации блоков в блок-схемах и/или структурных схемах, может быть реализован посредством аппаратно выделенной системы для выполнения конкретных функций, или может быть реализован посредством выделенной системы, скомбинированной с аппаратными средствами и компьютерными инструкциями.
В настоящем изобретения предложен компьютерный программный продукт для выполнения способа извлечения тематических предложений веб-страниц. Компьютерный программный продукт включает в себя машиночитаемый носитель данных, в котором хранятся программные коды. Программный код включает в себя инструкции для выполнения раскрытого способа. Конкретные реализации раскрытого способа могут относиться к различным вариантам осуществления, раскрытым со ссылкой на фиг. 1-2. Соответственно, в раскрытом способе и устройстве для извлечения тематических предложений с веб-страниц, может быть получена по меньшей мере одна возможная веб-страница, причем каждая возможная веб-страница может содержать несколько возможных тематических предложений, причем каждое возможное тематическое предложение может содержать несколько словесных сегментов. Далее, может быть определено значение словесной характеристики для каждого словесного сегмента. Несколько значений словесных характеристик, соответствующих нескольким словесным сегментам, могут быть введены в предварительно заданную модель машинного обучения для получения значений важности словесных сегментов. Далее, можно определить значение частичного порядка каждого возможного тематического предложения в соответствии со значениями важности словесных сегментов, содержащихся в каждом возможном тематическом предложении. И наконец, возможное тематическое предложение, связанное со значением частичного порядка, превышающим предварительно заданное пороговое значение, может быть определено в качестве целевого тематического предложения веб-страницы.
В способе и устройстве согласно настоящему изобретению может использоваться модель машинного обучения для получения значений частичного порядка возможных тематических предложений. Поскольку образцы веб-страниц, используемые в процессе обучения модели машинного обучения, могут отражать степени корреляции с запрашиваемым выражением, полученная модель машинного обучения может быть более точной. Таким образом, может быть повышена точность выбора целевого тематического предложения.
Следует отметить, что термины отношения, используемые в настоящем описании, такие как «первый», «второй» и т.д. приведены лишь для того, чтобы отделить одну операцию/объект от другой операции/объекта, что необязательно требует или подразумевает, что эти объекты или операции имеют такое отношение или порядок. Кроме того, предполагается, что термины «содержащий», «включающий в себя» или другая их вариация, охватывают неисключительные ссылки, например, процесс, способ, изделие или устройство, в том числе набор элементов, и включает в себя не только эти элементы, но также включает в себя другие неоднозначно перечисленные элементы, или дополнительно включает в себя некоторые свойственные элементы такого процесса, способа, изделия или устройства. Без дополнительных ограничений, элемент, заданный выражением «включает в себя.…» не исключает наличие другого такого же элемента в таком процессе, способе, изделии или устройстве.
Хотя настоящее изобретение раскрыто и проиллюстрировано применительно к предшествующим иллюстративным предпочтительным вариантам, должно быть понятно, что настоящее описание приведено лишь в качестве примера и что возможны многочисленные изменения в признаках предпочтительных вариантов настоящего изобретения, которые не выходят за пределы объема защиты и сущности настоящего изобретения, которые ограничены лишь пунктами прилагаемой формулы. Признаки раскрытых вариантов могут быть объединены и перегруппированы различным образом. Специалистам в данной области техники очевидно, что в настоящее изобретение могут быть внесены различные изменения, и возможны различные эквиваленты или улучшения, не выходящие за пределы объема защиты и сущности настоящего изобретения, при этом они будут подпадать под объем притязаний настоящего изобретения. Также следует отметить, что одинаковые номера позиций и буквенные обозначения соответствуют одинаковым элементам на чертежах, и, таким образом, если какой-либо элемент определен на одном из чертежей, то он может не быть определен и описан на последующих чертежах.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПОСТРОЕНИЕ И ПРИМЕНЕНИЕ ВЕБ-КАТАЛОГОВ ДЛЯ ФОКУСИРОВАННОГО ПОИСКА | 2005 |
|
RU2382400C2 |
| СИСТЕМА И СПОСОБ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА В ПОИСКОВОЙ СИСТЕМЕ | 2024 |
|
RU2839310C1 |
| СПОСОБ И СИСТЕМА СОЗДАНИЯ ВЕКТОРОВ АННОТАЦИИ ДЛЯ ДОКУМЕНТА | 2017 |
|
RU2720074C2 |
| СПОСОБ ОБРАБОТКИ ЦЕЛЕВОГО СООБЩЕНИЯ, СПОСОБ ОБРАБОТКИ НОВОГО ЦЕЛЕВОГО СООБЩЕНИЯ И СЕРВЕР (ВАРИАНТЫ) | 2014 |
|
RU2589856C2 |
| СБОР ДАННЫХ О ПОЛЬЗОВАТЕЛЬСКОМ ПОВЕДЕНИИ ПРИ ВЕБ-ПОИСКЕ ДЛЯ ПОВЫШЕНИЯ РЕЛЕВАНТНОСТИ ВЕБ-ПОИСКА | 2007 |
|
RU2435212C2 |
| СПОСОБ ОПРЕДЕЛЕНИЯ ПРОФИЛЯ ПОЛЬЗОВАТЕЛЯ МОБИЛЬНОГО УСТРОЙСТВА НА САМОМ МОБИЛЬНОМ УСТРОЙСТВЕ И СИСТЕМА ДЕМОГРАФИЧЕСКОГО ПРОФИЛИРОВАНИЯ | 2016 |
|
RU2647661C1 |
| СПОСОБ ОПРЕДЕЛЕНИЯ ПОСЛЕДОВАТЕЛЬНОСТИ ПРОСМОТРА ВЕБ-СТРАНИЦ И СЕРВЕР, ИСПОЛЬЗУЕМЫЙ В НЕМ | 2014 |
|
RU2634218C2 |
| СПОСОБ И СИСТЕМА ОБРАБОТКИ ПОИСКОВОГО ЗАПРОСА | 2015 |
|
RU2640639C2 |
| СПОСОБ ПРОВЕРКИ ВЕБ-СТРАНИЦ НА СОДЕРЖАНИЕ В НИХ ЦЕЛЕВОГО АУДИО И/ИЛИ ВИДЕО (AV) КОНТЕНТА РЕАЛЬНОГО ВРЕМЕНИ | 2013 |
|
RU2530671C1 |
| СПОСОБ ОТБОРА ЭФФЕКТИВНЫХ ВАРИАНТОВ В ПОИСКОВЫХ И РЕКОМЕНДАТЕЛЬНЫХ СИСТЕМАХ (ВАРИАНТЫ) | 2013 |
|
RU2543315C2 |

Изобретение относится к средствам извлечения тематических предложений веб-страниц. Технический результат заключается в повышении точности тематических предложений, извлеченных с веб-страниц. Получают возможные веб-страницы и предварительно построенную модель машинного обучения, причем каждая возможная веб-страница содержит множество предварительно отобранных возможных тематических предложений, причем каждое возможное тематическое предложение содержит несколько словесных сегментов. Определяют значения словесных характеристик, указывающие на уровни важности словесных сегментов в каждой возможной веб-странице соответственно, и вводят упомянутые значения словесных характеристик в модель машинного обучения для получения значения важности для каждого словесного сегмента. Для каждой возможной веб-страницы определяют значение частичного порядка для каждого возможного тематического предложения в соответствии со значениями важности словесных сегментов, содержащихся в возможном тематическом предложении. Для каждой возможной веб-страницы, выбирают одно из множества возможных тематических предложений, связанное со значением частичного порядка, превышающим предварительно заданное пороговое значение, в качестве целевого тематического предложения возможной веб-страницы. 3 н. и 17 з.п. ф-лы, 6 ил.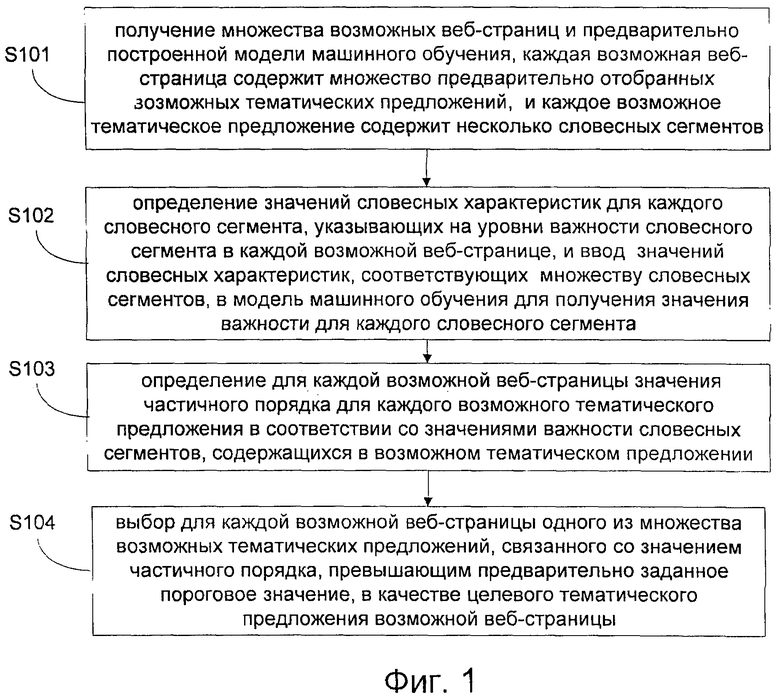
1. Способ извлечения тематических предложений веб-страниц, включающий в себя этапы, на которых:
получают возможные веб-страницы и предварительно построенную модель машинного обучения, причем каждая возможная веб-страница содержит множество предварительно отобранных возможных тематических предложений, причем каждое возможное тематическое предложение содержит несколько словесных сегментов;
определяют значения словесных характеристик, указывающие на уровни важности словесных сегментов в каждой возможной веб-странице соответственно, и вводят упомянутые значения словесных характеристик в модель машинного обучения для получения значения важности для каждого словесного сегмента;
для каждой возможной веб-страницы определяют значение частичного порядка для каждого возможного тематического предложения в соответствии со значениями важности словесных сегментов, содержащихся в возможном тематическом предложении; и
для каждой возможной веб-страницы выбирают одно из множества возможных тематических предложений, связанное со значением частичного порядка, превышающим предварительно заданное пороговое значение, в качестве целевого тематического предложения возможной веб-страницы.
2. Способ по п. 1, дополнительно включающий в себя процесс предварительного построения модели машинного обучения, включающий в себя:
получение заголовков страниц множества образцов веб-страниц, причем каждый образец веб-страницы соответствует по меньшей мере одному запрашиваемому выражению для отбора образца веб-страницы, причем каждое запрашиваемое выражение связано с взвешенным значением для обозначения степени корреляции между запрашиваемым выражением и отобранным образцом веб-страницы;
вычисление значения метки для каждого словесного сегмента, содержащегося в каждом заголовке страницы;
определение значения словесной характеристики для каждого словесного сегмента, содержащегося в каждом заголовке страницы, причем значение словесной характеристики указывает на степень важности словесного сегмента в соответствующем образце веб-страницы; и
применение предварительно заданного алгоритма машинного обучения для изучения значений меток и значений словесных характеристик словесных сегментов в каждом заголовке страницы для получения модели машинного обучения.
3. Способ по п. 2, в котором
значение метки для каждого словесного сегмента, содержащегося в каждом заголовке страницы, вычисляют с применением следующей формулы:
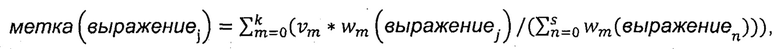
в которой выражениеj обозначает j-й словесный сегмент, содержащийся в заголовке страницы, метка (выражениеj) представляет собой значение метки словесного сегмента выражениеj, m представляет собой запрашиваемое выражение, k представляет собой суммарное количество запрашиваемых выражений, νm представляет собой взвешенное значение запрашиваемого выражения m, wm (выражениеj) представляет собой взвешенное значение словесного сегмента выражениеj для запрашиваемого выражения m, n представляет собой словесный сегмент в заголовке страницы, a s представляет собой суммарное количество словесных сегментов в заголовке страницы.
4. Способ по п. 2, в котором
предварительно заданный алгоритм машинного обучения представляет собой алгоритм обучения «GBRank»,
способ сравнения частичного порядка в упомянутом алгоритме обучения «GBRank» представляет собой попарное сравнение частичного порядка; и
функция потерь в алгоритме обучения «GBRank» представляет собой перекрестную энтропию.
5. Способ по п. 1, в котором определение значения частичного порядка для каждого возможного тематического предложения включает в себя:
вычисление для каждого возможного тематического предложения взвешенной суммы множества значений важности словесных сегментов, содержащихся в возможном тематическом предложении, в качестве значения частичного порядка возможного тематического предложения.
6. Способ по п. 1, дополнительно содержащий этапы, на которых:
устанавливают отношение соответствия между множеством целевых тематических предложений и множеством возможных веб-страниц; и
сохраняют упомянутое отношение соответствия в предварительно заданной базе данных.
7. Способ по п. 6, дополнительно содержащий этапы, на которых:
в ответ на поисковый запрос поисковой системы, определяют множество веб-страниц, отобранных поисковой системой, причем множество отобранных веб-страниц входит во множество возможных веб-страниц;
отбирают целевое тематическое предложение каждой отобранной веб-страницы из предварительно заданной базы данных и сопоставляют целевое тематическое предложение с поисковым запросом для получения для каждой отобранной веб-страницы значения соответствия; и
ранжируют множество отобранных веб-страниц на основе соответствующих значений соответствия.
8. Способ по п. 1, в котором определение значения словесной характеристики для каждого словесного сегмента включает в себя:
вычисление частоты выражения, обратной частоты документа, постоянного коэффициента попаданий и близости каждого словесного сегмента.
9. Устройство для извлечения тематических предложений веб-страниц, содержащее по меньшей мере один процессор, запоминающее устройство и по меньшей мере один программный модуль, хранящийся на запоминающем устройстве и предназначенный для исполнения посредством упомянутого по меньшей мере одного процессора, причем упомянутый по меньшей мере один программный модуль содержит:
модуль получения веб-страницы и модели, выполненный с возможностью получения возможной веб-страницы и предварительного построения модели машинного обучения, причем каждая возможная веб-страница содержит множество предварительно отобранных возможных тематических предложений, причем каждое возможное тематическое предложение включает в себя множество словесных сегментов;
модуль определения значения важности словесного сегмента, выполненный с возможностью определения значений словесных характеристик, указывающих на уровни важности словесных сегментов в каждой возможной веб-странице, и ввода значений словесных характеристик в модель машинного обучения для получения значения важности для каждого словесного сегмента;
модуль определения значения частичного порядка тематических предложений, выполненный с возможностью определения, для каждой возможной веб-страницы, значения частичного порядка для каждого возможного тематического предложения в соответствии со значениями важности словесных сегментов возможного тематического предложения, и
модуль определения тематического предложения, выполненный с возможностью выбора, для каждой возможной веб-страницы, одного из множества возможных тематических предложений, связанного со значением частичного порядка, превышающим предварительно заданное пороговое значение, в качестве целевого тематического предложения возможной веб-страницы.
10: Устройство по п. 9, в котором упомянутый по меньшей мере один программный модуль дополнительно содержит:
модуль построения модели обучения, выполненный с возможностью предварительного построения модели машинного обучения, причем упомянутый модуль построения модели обучения содержит:
подмодуль получения заголовка образца веб-страницы, выполненный с возможностью получения заголовков веб-страниц множества образцов веб-страниц, причем каждый образец веб-страницы соответствует одному или нескольким запрашиваемым выражениям для отбора образца веб-страницы, причем каждое запрашиваемое выражение связано с взвешенным значением для обозначения степени корреляции между запрашиваемым выражением и отобранным образцом веб-страницы;
подмодуль вычисления значения метки словесных сегментов заголовка, выполненный с возможностью вычисления значения метки для каждого словесного сегмента, содержащегося в каждом заголовке страницы,
подмодуль вычисления значения словесной характеристики словесного сегмента заголовка, выполненный с возможностью определения значения словесной характеристики для каждого словесного сегмента, содержащегося в каждом заголовке страницы, причем значение словесной характеристики указывает на степень важности словесного сегмента в соответствующем образце веб-страницы, и
подмодуль машинного обучения, выполненный с возможностью применения предварительно заданного алгоритма машинного обучения для изучения значений меток и значений словесных характеристик словесных сегментов в каждом заголовке страницы для получения модели машинного обучения.
11. Устройство по п. 10, в котором:
значение метки для каждого словесного сегмента, содержащегося в каждом заголовке страницы, вычисляется с применением следующей формулы
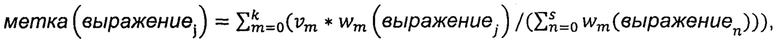
в которой выражениеj обозначает j-й словесный сегмент, содержащийся в заголовке страницы, метка (выражениеj) представляет собой значение метки словесного сегмента выражениеj, m представляет собой запрашиваемое выражение, k представляет собой суммарное количество запрашиваемых выражений, νm представляет собой взвешенное значение запрашиваемого выражения m, wm (выражениеj) представляет собой взвешенное значение словесного сегмента выражениеj для запрашиваемого выражения m, n представляет собой словесный сегмент в заголовке страницы, a s представляет собой суммарное количество словесных сегментов в заголовке страницы.
12. Устройство по п. 10, в котором:
предварительно заданный алгоритм машинного обучения представляет собой алгоритм обучения «GBRank»,
способ сравнения частичного порядка в упомянутом алгоритме обучения «GBRank» представляет собой попарное сравнение частичного порядка; и
функция потерь в алгоритме обучения «GBRank» представляет собой перекрестную энтропию.
13. Устройство по п. 10, в котором модуль определения значения частичного порядка тематических предложений включает в себя:
подмодуль определения значения частичного порядка взвешенной суммы, выполненный с возможностью вычисления для каждого возможного тематического предложения взвешенной суммы множества значений важности словесных сегментов, содержащихся в возможном тематическом предложении, в качестве значения частичного порядка возможного тематического предложения.
14. Устройство по п. 10, в котором упомянутый по меньшей мере один программный модуль дополнительно содержит:
модуль хранения тематических предложений, выполненный с возможностью:
установления отношения соответствия между множеством целевых тематических предложений и множеством возможных веб-страниц, и
сохранения упомянутого отношения соответствия в предварительно заданной базе данных.
15. Устройство по п. 14, в котором упомянутый по меньшей мере один программный модуль дополнительно содержит:
модуль определения отобранных веб-страниц, выполненный с возможностью определения, в ответ на поисковый запрос поисковой системы, множества веб-страниц, отобранных поисковой системой, причем множество отобранных веб-страниц входит во множество возможных веб-страниц,
модуль сопоставления тематических предложений веб-страниц, выполненный с возможностью отбора целевого тематического предложения каждой отобранной веб-страницы из предварительно заданной базы данных, и сопоставления целевого тематического предложения с поисковым запросом для получения значения соответствия для каждой отобранной веб-страницы, и
модуль ранжирования отобранных веб-страниц, выполненный с возможностью ранжирования множества отобранных веб-страниц на основе соответствующих значений соответствия.
16. Устройство по п. 9, в котором модуль определения значения важности словесного сегмента дополнительно выполнен с возможностью:
вычисления частоты выражения, обратной частоты документа, постоянного коэффициента попаданий и близости каждого словесного сегмента.
17. Долговременное машиночитаемое запоминающее устройство, содержащее машиночитаемую программу, хранящуюся в нем, причем упомянутая машиночитаемая программа при исполнении обеспечивает осуществление компьютером способа извлечения тематических предложений веб-страниц, причем упомянутый способ содержит этапы, на которых:
получают возможные веб-страницы и предварительно построенную модель машинного обучения, причем каждая возможная веб-страница содержит множество предварительно отобранных возможных тематических предложений, причем каждое возможное тематическое предложение включает в себя множество словесных сегментов;
определяют значения словесных характеристик, указывающие на уровни важности словесных сегментов в каждой возможной веб-странице соответственно, причем значение словесной характеристики включает в себя частоту выражения, обратную частоту документа, постоянный коэффициент попадания и близость каждого словесного сегмента;
вводят упомянутые значения словесных характеристик в модель машинного обучения для получения значения важности для каждого словесного сегмента;
для каждой возможной веб-страницы определяют значение частичного порядка для каждого возможного тематического предложения в соответствии со значениями важности словесных сегментов, содержащихся в возможном тематическом предложении; и
для каждой возможной веб-страницы выбирают одно из множества возможных тематических предложений, связанное со значением частичного порядка, превышающим предварительно заданное пороговое значение, в качестве целевого тематического предложения возможной веб-страницы.
18. Долговременное машиночитаемое запоминающее устройство по п. 17, дополнительно содержащее процесс предварительного построения модели машинного обучения, включающий в себя:
получение заголовков страниц множества образцов веб-страниц, причем каждый образец веб-страницы соответствует по меньшей мере одному запрашиваемому выражению для отбора образца веб-страницы, причем каждое запрашиваемое выражение связано с взвешенным значением для обозначения степени корреляции между запрашиваемым выражением и отобранным образцом веб-страницы;
вычисление значения метки для каждого словесного сегмента, содержащегося в каждом заголовке страницы с применением следующей формулы:
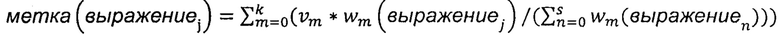 ,
,
в которой выражениеj обозначает j-й словесный сегмент, содержащийся в заголовке страницы, метка (выражениеj) представляет собой значение метки словесного сегмента выражениеj, m представляет собой запрашиваемое выражение, k представляет собой суммарное количество запрашиваемых выражений, νm представляет собой взвешенное значение запрашиваемого выражения m, wm (выражениеj) представляет собой взвешенное значение словесного сегмента выражениеj для запрашиваемого выражения m, n представляет собой словесный сегмент в заголовке страницы, a s представляет собой суммарное количество словесных сегментов в заголовке страницы;
определение значения словесной характеристики для каждого словесного сегмента, содержащегося в каждом заголовке страницы, причем значение словесной характеристики указывает на степень важности словесного сегмента в соответствующем образце веб-страницы; и
применение предварительно заданного алгоритма машинного обучения для изучения значений меток и значений словесных характеристик словесных сегментов в каждом заголовке страницы для получения модели машинного обучения.
19. Долговременное машиночитаемое запоминающее устройство по п. 18, в котором
предварительно заданный алгоритм машинного обучения представляет собой алгоритм обучения «GBRank»,
способ сравнения частичного порядка в упомянутом алгоритме обучения «GBRank» представляет собой попарное сравнение частичного порядка;
функция потерь в алгоритме обучения «GBRank» представляет собой перекрестную энтропию;
для каждого возможного тематического предложения предусмотрено вычисление взвешенной суммы множества значений важности словесных сегментов, содержащихся в возможном тематическом предложении, в качестве значения частичного порядка возможного тематического предложения.
20. Долговременное машиночитаемое запоминающее устройство по п. 17, отличающееся тем, что упомянутый способ дополнительно предусматривает:
установление отношения соответствия между множеством целевых тематических предложений и множеством возможных веб-страниц, и
сохранение упомянутого отношения соответствия в предварительно заданной базе данных,
в ответ на поисковый запрос поисковой системы, определение множества веб-страниц, отобранных поисковой системой, причем множество отобранных веб-страниц входит во множество возможных веб-страниц;
отбирание целевого тематического предложения каждой отобранной веб-страницы из предварительно заданной базы данных и сопоставление целевого тематического предложения с поисковым запросом для получения для каждой отобранной веб-страницы значения соответствия; и
ранжирование множества отобранных веб-страниц на основе соответствующих значений соответствия.
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| US 9015151 B1, 21.04.2015 | |||
| СПОСОБ СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ЕСТЕСТВЕННОГО ЯЗЫКА С ИСПОЛЬЗОВАНИЕМ ГРАФИЧЕСКОГО ЯЗЫКА-ПОСРЕДНИКА | 2009 |
|
RU2509350C2 |

