Область техники
Изобретение относится к архитектуре многослойного персептрона, который может быть использован для генерации изображений.
Описание известного уровня техники
Современный уровень безусловной генерации изображений достигается при использовании крупномасштабных сверточных генераторов, обученных состязательным образом [9, 10, 1]. Хотя в последнее время этот современный уровень был дополнен множеством нюансов и идей, в течение многих лет с момента появления DCGAN [21] такие генераторы базируются на пространственных сверточных слоях, иногда также с использованием блоков пространственного самовнимания [30]. В других популярных генеративных архитектурах для изображений, включая автокодировщики [13], авторегрессионные генераторы [28] или потоковые модели [3, 12], также всегда присутствуют пространственные свертки. Поэтому может показаться, что пространственные свертки (или, по крайней мере, пространственное самовнимание) являются неизбежным строительным блоком современных генераторов изображений.
Ранее в широко известной методике CoordConv [17] в качестве дополнительного ввода в нейронную сеть успешно использовалась подача координат пикселей, чтобы ввести пространственно-реляционное смещение. Не так давно та же идея была использована COCO-GAN [16] для генерации изображений по частям или создания "циклических" изображений, таких как сферические панорамы. Однако в этих моделях по-прежнему используются стандартные свертки в качестве основной операции синтеза. Следовательно, процесс синтеза соседних пикселей в таких архитектурах не является независимым.
Насколько известно авторам изобретения, проблема регрессии данного изображения из координат пикселей с помощью перцептрона (который вычисляет значение каждого пикселя независимо) возникла при создании композиционных шаблонов с помощью эволюционного метода [26]. Эти шаблоны, привлекательные для художников компьютерной графики, также рассматривались как своего рода дифференцируемая параметризация изображения [20]. Однако этот метод оказался неспособным создавать фотореалистичные результаты с высоким разрешением (см., например, демонстрацию [8]).
В некоторых блогах, посвященных машинному обучению, сообщалось об экспериментах с GAN, в которых генератором был перцептрон, принимающий на входе случайный вектор и координаты пикселей и выдающий на выходе значение этого пикселя [5, 6]. Описанная модель успешно обучалась на MNIST, но не масштабировалась для более сложных данных изображения.
Сети представления сцен [25] и позднее сети полей нейронного излучения (NeRF) [19] продемонстрировали, как можно поразительно точно закодировать 3D содержание отдельных сцен, используя глубокие перцептронные сети. В этой реализации в системах [24] и [27] рассматривалось применение периодических функций активации и так называемых признаков Фурье для кодирования координат пикселей (или вокселей), вводимых в многослойный персептрон. В частности, была продемонстрирована возможность кодирования таким способом отдельных изображений с высоким разрешением. Однако во всех этих работах не рассматривалась задача обучения генераторов изображений, которую решают авторы в данном изобретении.
Самая недавняя (и независимая) система Generative Radiance Fields (GRAF) [23] показала многообещающие результаты при встраивании генератора NeRF в генератор изображений для совместимого с 3D синтеза изображений. Результаты для такого совместимого с 3D синтеза (все еще ограниченного в разнообразии и разрешении) были достоверно продемонстрированы. В настоящем изобретении авторы не рассматривают совместимый с 3D синтез, а вместо этого исследуют, могут ли архитектуры на базе перцептрона достичь высокого качества синтеза 2D изображений.
Сущность изобретения
В последнее время в ряде работ было показано, что отдельные изображения или коллекции изображений одной и той же сцены можно кодировать/синтезировать, используя весьма разные глубокие архитектуры (глубокие многослойные перцептроны) особого типа [19, 24]. В таких архитектурах не используются пространственные свертки или пространственное самовнимание, но они, тем не менее, способны достаточно хорошо воспроизводить изображения. Однако эти архитектуры ограничены отдельными сценами. Проводились исследования, можно ли построить глубокие генераторы для безусловного синтеза классов изображений, используя идеи аналогичных архитектур, и, что более важно, можно ли довести качество таких генераторов до современного уровня.
Положительный ответ был получен (фиг.1) по меньшей мере для изображения со средним разрешением (256х256). Фиг.1: образцы из предложенных генераторов, обученных на нескольких сложных наборах данных (LSUN Churches, FFHQ, Landscapes, Satellite-Buildings, Satellite-Landscapes) с разрешением 256×256. Эти изображения созданы без пространственных сверток, повышающей дискретизации или операций самовнимания. Во время логического вывода между пикселями не происходит никакого взаимодействия.
На фиг.1 показаны образцы, созданные генератором согласно изобретению, обученным на четырех различных наборах данных. Первые два столбца изображений слева были созданы моделью, обученной на наборе данных LSUN Churches, следующие два столбца изображений созданы моделью, обученной на наборе данных FFHQ, далее два столбца изображений созданы моделью, обученной на наборе данных изображений пейзажей и следующие два последних столбца изображений созданы моделью, обученной на наборе данных спутниковых снимков. На фиг.1 показано, что можно применить одну и ту же архитектуру и процедуру обучения к очень разным наборам данных и получить хорошие результаты.
Таким образом, предложены разработанные и обученные глубокие генеративные архитектуры для различных классов изображений, которые достигают такого же качества генерации, как современный сверточный генератор StyleGANv2 [10], и даже превосходят это качество с некоторыми наборами данных. Важно отметить, что предлагаемые генераторы не используют в своих магистралях какие-либо формы пространственных сверток или пространственного внимания. Вместо этого они используют кодирование координат отдельных пикселей, а также косвенное мультипликативное согласование (весовую модуляцию) на случайных векторах. Кроме такого согласования в предлагаемой архитектуре независимо прогнозируется цвет каждого пикселя, поэтому архитектуру предлагаемого генератора изображений назвали генератором условно независимого синтеза пикселей (CIPS).
Помимо предложения данного класса генераторов изображений и сравнения его качества с современными сверточными генераторами, также исследовалась дополнительная гибкость, обеспечиваемая независимой обработкой пикселей. Она включает в себя легкость распространения синтеза на нетривиальные топологии (например, цилиндрические панорамы), в отношении которых известно, что распространение пространственных сверток является нетривиальным [16, 2]. Более того, тот факт, что пиксели синтезируются в предлагаемых генераторах независимо, позволяет осуществлять последовательный синтез для вычислительных архитектур с ограничением памяти. Благодаря этому предлагаемая модель способна улучшить качество фотографий, а также генерировать больше значений пикселей в определенных областях изображения (т.е. для выполнения фовеального синтеза).
Предлагаемое изобретение представляет собой новую, основанную на стиле архитектуру многослойного персептрона, которая может использоваться для генерации изображений и которая обеспечивает качество, сопоставимое с современными GAN с точки зрения общих показателей при разрешении до 2562.
Данная модель, обладающая высокой степенью распараллеливания, также может быть обучена генерировать изображения по частям во время обучения и, следовательно, полезна для специалистов-практиков, имеющих ограниченные ресурсы графических процессоров.
Генератор оценивался на различных наборах данных и показал, что он лучше всего работает в областях без явной пространственной ориентации (например, на спутниковых снимках).
Чтобы осуществлять постепенный синтез от грубых изображений к точным, существующие сети генераторов изображений основаны в значительной степени на пространственных свертках и, необязательно, на блоках самовнимания. Предложена новая архитектура для генераторов изображений, в которой значение цвета для каждого пикселя вычисляется независимо при наличии значения случайного скрытого вектора и координаты этого пикселя. Во время синтеза не используются пространственные свертки или аналогичные операции, которые распространяют информацию по пикселям. Были проанализированы возможности моделирования таких генераторов при состязательном обучении, и исследовалась способность этих новых генераторов достичь качества генерации, подобного качеству, обеспечиваемому современными сверточными генераторами.
Предложено аппаратное обеспечение, содержащее программные продукты, которые реализуют способ генерации изображений с фиксированным разрешением  посредством условно независимого синтеза пикселей, заключающийся в том, что:
посредством условно независимого синтеза пикселей, заключающийся в том, что:
берут многослойным персептроном G случайный вектор  и координаты пикселей с плавающей запятой
и координаты пикселей с плавающей запятой  в качестве ввода;
в качестве ввода;
обрабатывают координаты пикселей с плавающей запятой набором синусов с различными частотами для получения приемлемого для сети кодирования координат;
осуществляют, используя координаты пикселей с плавающей запятой, поиск предварительно обученных вложений координат в веса сети;
преобразуют случайный вектор сетью отображения, выход которой влияет на веса в полносвязном слое (ModFC);
возвращают многослойным перцептроном значения RGB каждого пикселя;
оценивают генератор перцептрона G (x;y;z) на каждой паре (x, y) координатной сетки, сохраняя при этом случайную часть z фиксированной;
вычисляют полное выходное изображение согласно оценке:

где
 - набор целочисленных координат пикселей.
- набор целочисленных координат пикселей.
При этом сеть отображения и перцептрон преобразуют z в вектор стиля, и из этого компонента стиля исходит вся стохастичность в процессе генерации. Также сгенерированные изображения могут быть изображениями с произвольным разрешением. Генерируемые изображения могут быть картами окружающей среды или цилиндрическими панорамами. Координаты пикселей с плавающей запятой могут быть цилиндрическими координатами для синтеза прямоугольных изображений. Координаты пикселей с плавающей запятой представляют собой выборочную нерегулярную сетку координат, более плотную в области, на которую предполагается направить взгляд, и более разреженную за пределами этой области.
Информация о точном расположении элемента может быть представлена несколькими способами, некоторые из которых более дружественные к нейронной сети. Одним из способов является использование абсолютных координат пикселей (например, (243, 432)), другим - масштабирование координат так, чтобы они находились в интервале (-1, 1). Более дружественным к нейронным сетям способом является использование так называемого "позиционного кодирования", которое впервые было введено для задач обработки естественного языка в https://arxiv.org/abs/1706.03762. Идея применения такого кодирования к более широкой области была разработана в https://arxiv.org/abs/2006.09661, https://arxiv.org/ abs/2006.10739.
Изобретение может быть реализовано с помощью модели искусственного интеллекта (AI). Функция, связанная с AI, может выполняться посредством энергонезависимой памяти, энергозависимой памяти и процессора.
Процессор может включать в себя один или несколько процессоров. При этом один или несколько процессоров могут быть процессором общего назначения, например центральным процессором (CPU), процессором приложений (AP) или т.п., блоком обработки только графики, таким как блок обработки графики (GPU), блоком визуальной обработки (VPU) и/или специальным процессором AI, таким как нейронный процессор (NPU).
Упомянутые один или несколько процессоров управляют обработкой входных данных в соответствии с заранее определенным рабочим правилом или моделью искусственного интеллекта (AI), хранящимися в энергонезависимой памяти и энергозависимой памяти. Заранее определенное рабочее правило или модель искусственного интеллекта предоставляется посредством обучения.
В данном контексте предоставление посредством обучения означает, что путем применения алгоритма обучения к множеству обучающих данных создается заранее определенное рабочее правило или модель AI с желаемой характеристикой. Обучение может осуществляться в самом устройстве, в котором выполняется AI согласно варианту осуществления, и/или оно может быть реализовано отдельным сервером/системой.
Модель AI может состоять из множества уровней нейронной сети. Каждый уровень имеет множество значений весов и выполняет операцию уровня посредством вычисления предыдущего уровня и операции с множеством весов. Примеры нейронных сетей включают в себя, без ограничения перечисленным, сверточную нейронную сеть (CNN), глубокую нейронную сеть (DNN), рекуррентную нейронную сеть (RNN), ограниченную машину Больцмана (RBM), сеть глубинного доверия (DBN), двунаправленную рекуррентную глубокую нейронную сеть (BRDNN), генеративные состязательные сети (GAN) и глубокие Q-сети.
Алгоритм обучения - это метод обучения заранее определенного целевого устройства (например, робота) с использованием множества обучающих данных, который побуждает целевое устройство, разрешает ему или управляет им при выполнении определения или прогнозирования. Примеры алгоритмов обучения включают в себя, без ограничения, обучение с учителем, обучение без учителя, обучение с частичным привлечением учителя или обучение с подкреплением.
Согласно изобретению, при выполнении способа генерации изображений с помощью условно-независимого процессора синтеза пикселей можно выполнять операцию предварительной обработки данных для преобразования их в форму, подходящую для использования в качестве ввода для модели искусственного интеллекта. Модель искусственного интеллекта может быть получена путем обучения. В данном контексте "полученный путем обучения" означает, что заранее определенное рабочее правило или модель искусственного интеллекта, сконфигурированные для выполнения заданной функции (или цели), получают путем обучения базовой модели искусственного интеллекта множеством частями обучающих данных с помощью обучающего алгоритма. Модель искусственного интеллекта может включать в себя множество уровней нейронной сети. Каждый из множества уровней нейронной сети включает в себя множество значений весов и выполняет вычисления нейронной сети путем вычисления между результатом вычисления предыдущего уровня и множеством значений весов.
Предсказание на основе рассуждений - это метод логических рассуждений и прогнозирования путем определения информации, который включает в себя, например, рассуждение на основе знаний, прогнозирование оптимизации, планирование на основе предпочтений или рекомендацию.
Описание чертежей
Фиг.1 - образцы из предложенных генераторов, обученных на нескольких сложных наборах данных (LSUN Churches, FFHQ, Landscapes, Satellite-Buildings, Satellite-Landscapes) с разрешением 256×256.
Фиг.2 а, b - случайные выборки из генератора CIPS, обученного на наборе данных FFHQ.
Фиг.3 - архитектура генератора условно-независимого синтеза пикселей (CIPS).
Фиг.4 - изображение, соответствующее среднему вектору стиля в пространстве  для генераторов CIPS (слева) и CIPS-NE (без вложений) (справа).
для генераторов CIPS (слева) и CIPS-NE (без вложений) (справа).
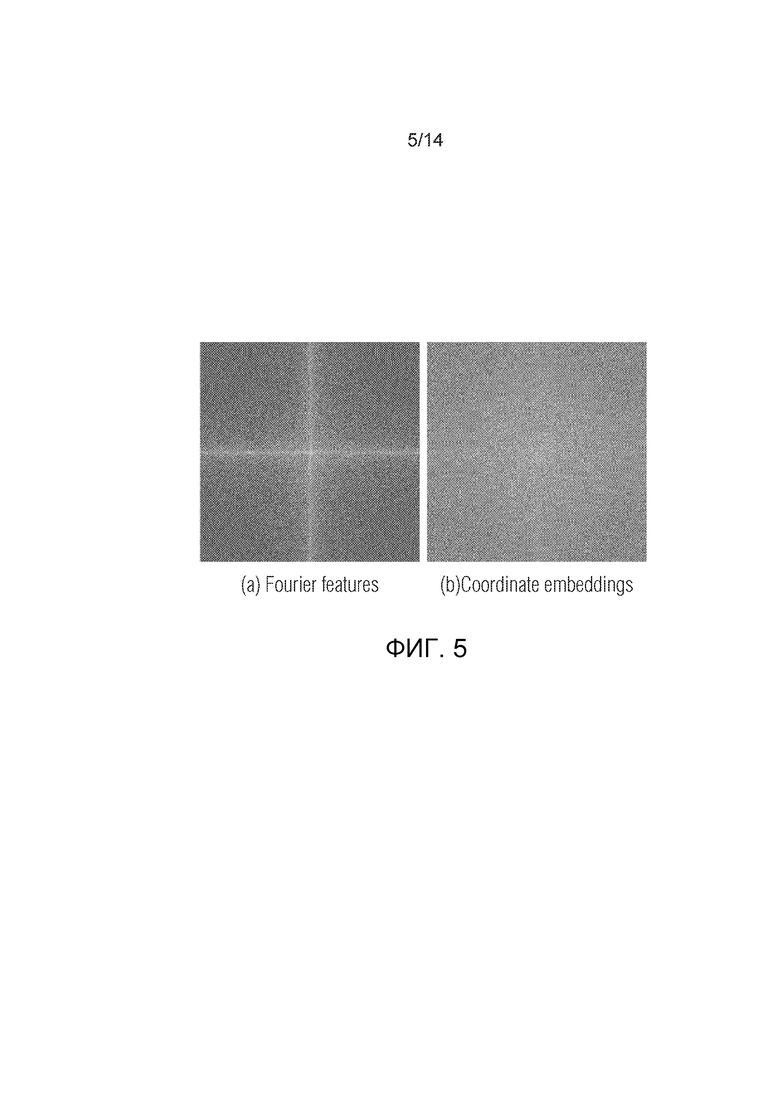
Фиг.5 - величина спектра для двух видов предложенного позиционного кодирования (цветовая шкала одинакова для обоих графиков), (а) признаки Фурье, (b) вложения координат.
Фиг.6 - график PCA (3 компонента) для двух видов позиционного кодирования на основе CIPS, (a) признаки Фурье, (b) вложения координат.
Фиг.7 - влияние различных типов позиционного кодирования на полученное изображение. Слева (а) исходное изображение. Центр (b) обнулены вложения координат. Справа (c) обнулены признаки Фурье.
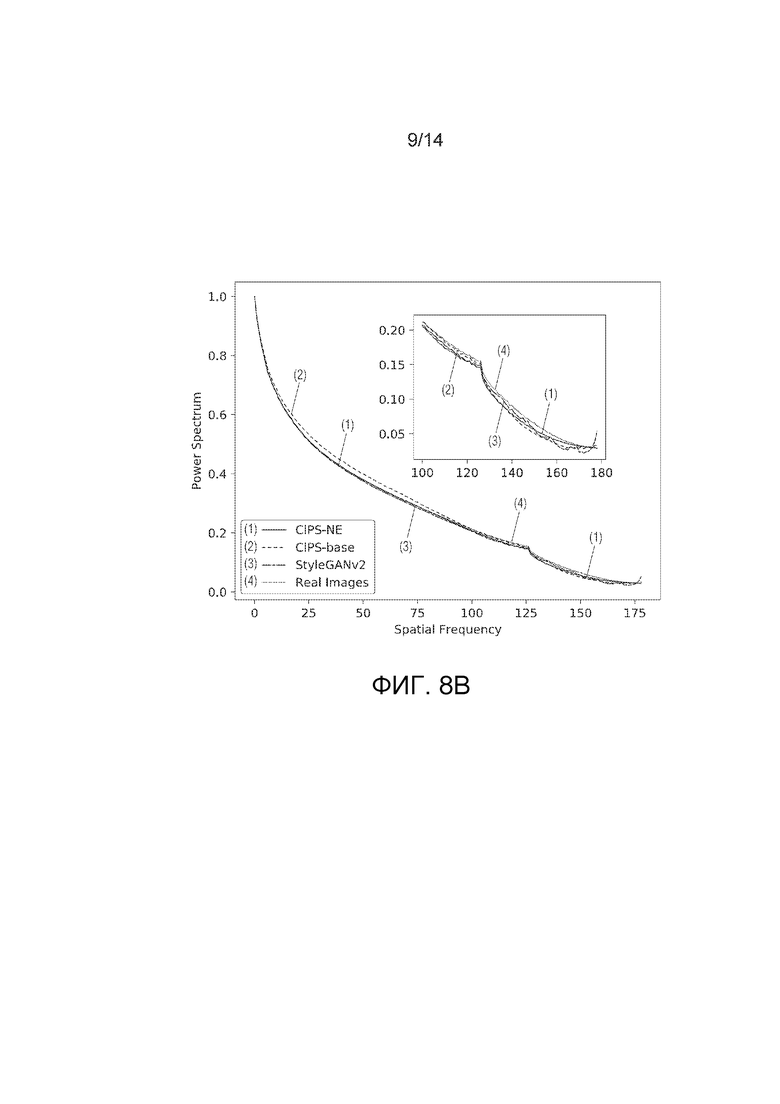
Фиг.8A - амплитудные спектры. Предлагаемые модели создают меньше артефактов в высокочастотных компонентах (обратите внимание на сетчатый рисунок на StyleGANv2).
Фиг.8B - азимутальное интегрирование по спектральной функции Фурье.
Фиг.9 - изображения, созданные с применением фовеального синтеза.
Фиг.10 - слева (а) - сгенерированное изображение с разрешением 256×256, увеличенное по схеме Ланцоша с повышением частоты дискретизации [15]. Справа (b) - изображение, синтезированное CIPS.
Фиг.11 - скрытый линейный морфинг между двумя выбранными изображениями - крайним левым и крайним правым.
Фиг.12 - слияние панорамы.
Фиг.13: Примеры наиболее распространенных видов артефактов на разных наборах данных.
Подробное описание
Предлагаемое решение может найти применение в области обработки изображений и использоваться для:
- создания модели, которая может генерировать изображения с произвольным разрешение;
- создания модели, которая может синтезировать непрямоугольные объекты типа карт окружающей среды или цилиндрических панорам.
Предлагаемое решение может использоваться в различных сценариях обработки изображений, и варианты его применения могут включать в себя (но без ограничения перечисленным):
- программное обеспечение для редактирования изображений,
- синтез фона для мобильного телефона или ТВ,
- синтез карт окружения для компьютерной графики и VR.
Предлагаемая модель способна создавать естественно выглядящие изображения из желаемой области с переменным разрешением, например, одна модель может создавать изображения размером как 16×16 пикселей, так и 4096×4096 пикселей без ее переобучения.
На фиг.2 показаны восемь случайных образцов, сгенерированных предложенным генератором, обученным на наборе данных человеческих лиц. Фиг.2 демонстрирует хорошее качество генерации, а также разнообразие сгенерированных лиц.
Рассматривалась проблема генерации изображений с помощью многослойного персептрона G, который берет случайный вектор z∈Z и координаты пикселей с плавающей запятой (x, y)∈[-1,1] в качестве ввода и возвращает значение RGB c∈[0,1] этого пикселя. Чтобы вычислить полное выходное изображение, необходимо оценить генератор G в каждой паре (x, y) координатной сетки. Процесс генерации можно рассматривать как порождающее обратное дискретное преобразование Фурье.
Предлагаемое изобретение представляет собой новую, основанную на стиле многослойную архитектуру персептрона, использующую предложенное позиционное кодирование и весовую модуляцию, которую можно применить для генерации изображений и которая обеспечивает качество, сопоставимое с современными GAN с точки зрения общих показателей при разрешении до 256×256.
Было продемонстрировано, что данную модель, которая является хорошо распараллеливаемой, можно также обучить генерировать изображения по частям во время обучения, и поэтому она полезна для специалистов-практиков, имеющих ограниченные ресурсы графического процессора.
В случае аппаратной реализации целевым устройством может быть любой мобильный телефон с достаточными вычислительными ресурсами или любое другое потребительское устройство, которому может потребоваться такой синтез изображения (например, телевизионный приемник). Для корректной работы такое устройство должно иметь центральный процессор, внутреннюю память с изображениями, оперативную память. Для ускорения вычислений в нем также может быть предусмотрен нейронный процессор.
Предлагаемая сеть генератора синтезирует изображения с фиксированным разрешением и имеет архитектуру типа многослойного перцептрона G (см. фиг.3). Конкретно, при синтезе каждого пикселя в качестве ввода берутся случайный вектор , общий для всех пикселей, а также координаты пикселей  . На выходе выдается значение RGB
. На выходе выдается значение RGB  данного пикселя
данного пикселя 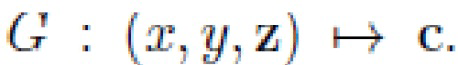
На фиг.3 показана архитектура генератора условно независимого синтеза пикселей (CIPS). В верхней части показан конвейер генерации, в котором координаты (x;y) каждого пикселя кодируются (поля "Признаки Фурье" и "Вложения координат") и обрабатываются полносвязной (FC) сетью с весами, модулированными скрытым вектором w, общим для всех пикселей (поля "ModFC"). Сеть возвращает значение RGB каждого пикселя. В нижней части показана архитектура модулированного полносвязного слоя (ModFC).
Скрытый Z - это случайный вектор, который выбирается из нормального распределения Гаусса с нулевым средним и единичной дисперсией.
Нормализация - масштабирует скрытый Z так, чтобы его L2 норма была равна единице (Z/norm(Z)).
Признаки Фурье - это обучаемый линейный слой с синусоидальной активационной функцией:
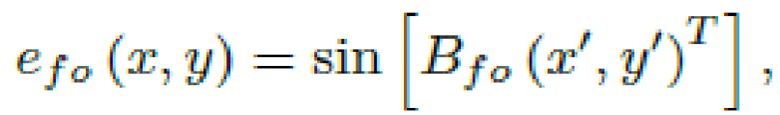
Вложения координат - это обучаемый попиксельный вектор, который обучается для всего набора данных. Его можно рассматривать как некоторые признаки всего набора данных, в данном случае оказалось, что он содержит высокочастотные компоненты, такие как волосы и детали глаз.
Сеть отображения - это полностью сверточная нейронная сеть, которая перерабатывает скрытый вектор Z в некоторое обучаемое распределение перед передачей его основному генератору.
A - небольшая нейронная сеть (простое линейное отображение, различное для каждого слоя) обрабатывает выход сети отображения для создания масштабного вектора.
ModFC - модуль модуляции, принимающий ввод и масштабирующий вектор A, а также выполняющий следующие действия (нижняя часть фиг.3 - Архитектура модулированного полносвязного слоя (ModFC)):
Mod+demod - принимает вывод A (обозначенный как s) и ввод (обозначенный как B) и применяет следующую операцию
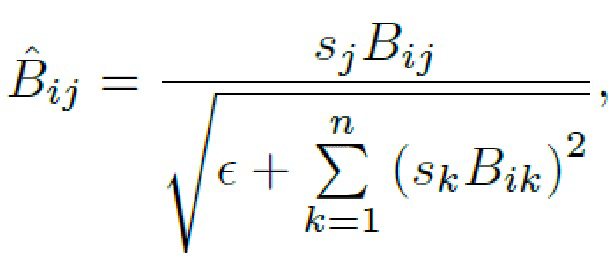
FC+LeakyReLU - обучаемый линейный слой, за которым следует активация LeakyReLU.
Примечание. Предлагаемая конфигурация по умолчанию также включает пропуск подключений к выходу (здесь не показан).
Следовательно, чтобы вычислить полное выходное изображение I, генератор G оценивается в каждой паре (x;y) координатной сетки, сохраняя при этом случайную часть z фиксированной:
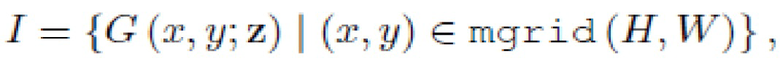
где
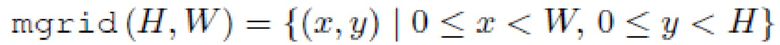
- набор целочисленных координат пикселей.
Следуя [9], сеть M отображения (также перцептрон) превращает z в вектор стиля 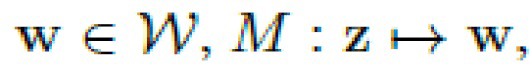 и из этого компонента стиля вытекает вся стохастичность в процессе генерации.
и из этого компонента стиля вытекает вся стохастичность в процессе генерации.
Затем следует метод StyleGANv2 [10], в котором стиль w вводится в процесс генерации посредством весовой модуляции. Любой модулированный полносвязный (ModFC) слой генератора (см. фиг.3) можно записать в виде  где
где  - ввод,
- ввод,  - обучаемая матрица весов
- обучаемая матрица весов  , модулированная стилем,
, модулированная стилем,  - обучаемое смещение, и
- обучаемое смещение, и 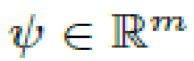 - выход. Модуляция происходит следующим образом: сначала вектор стиля w преобразуется небольшой сетью (обозначенной как A на фиг.3) в вектор масштаба
- выход. Модуляция происходит следующим образом: сначала вектор стиля w преобразуется небольшой сетью (обозначенной как A на фиг.3) в вектор масштаба  . Затем вычисляется (i;j)-ый ввод как
. Затем вычисляется (i;j)-ый ввод как

где 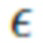 - небольшая константа. После этого линейного отображения к
- небольшая константа. После этого линейного отображения к  применяется функция LeakyReLU.
применяется функция LeakyReLU.
В предлагаемой конфигурации предусмотрены пропуски подключений для каждых двух слоев от промежуточных карт признаков до значений RGB и суммируются вклады выходов RGB, соответствующих различным слоям. Эти пропуски подключений естественным образом добавляют значения, соответствующие тому же самому пикселю, и не вызывают взаимодействия между пикселями.
Независимость процесса генерации пикселей делает модель доступной для распараллеливания во время логического вывода, а также обеспечивает гибкость в скрытом пространстве z.
Например, в некоторых модифицированных вариантах синтеза каждый пиксель может быть вычислен с другим вектором шума z, хотя для получения согласованно выглядящих изображений необходимо постепенное изменение z.
Позиционное кодирование
Для достижения современного качества синтеза описанная выше архитектура нуждается в важной модификации. В литературе описаны две немного отличающиеся версии позиционного кодирования для координатно-ориентированных многослойных персептронов (MLP), создающих изображения. Во-первых, в работе SIREN [24] предложен перцептрон с принципиальной инициализацией весов и синусоидой в качестве функции активации, используемый на всех уровнях. Во-вторых, признаки Фурье, введенные в [27], используют функцию периодической активации только в самом первом слое. В предлагаемом изобретении применена схема несколько промежуточного типа: синусоидальная функция используется для получения вложения Фурье 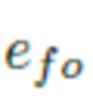 , тогда как другие слои используют стандартную функцию LeakyReLU:
, тогда как другие слои используют стандартную функцию LeakyReLU:

где 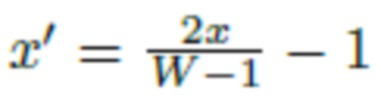 и
и  - координаты пикселей, одинаково отображенные в интервале [-1;1], и весовая матрица
- координаты пикселей, одинаково отображенные в интервале [-1;1], и весовая матрица 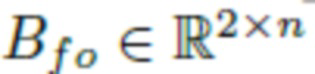 является обучаемой, как в работе SIREN.
является обучаемой, как в работе SIREN.
Однако использование только позиционного кодирования Фурье оказалось недостаточным для получения приемлемых изображений. В частности, было обнаружено, что результаты синтеза обычно содержат множество волновых артефактов. Поэтому для каждого пространственного положения обучается отдельный вектор 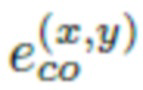 , которые называются вложениями координат. Они в целом представляют собой обучаемые векторы . Для сравнения этих двух вложений со спектральной точки зрения полное позиционное кодирование e (x;y) представляет собой конкатенацию функций Фурье и вложения координат
, которые называются вложениями координат. Они в целом представляют собой обучаемые векторы . Для сравнения этих двух вложений со спектральной точки зрения полное позиционное кодирование e (x;y) представляет собой конкатенацию функций Фурье и вложения координат
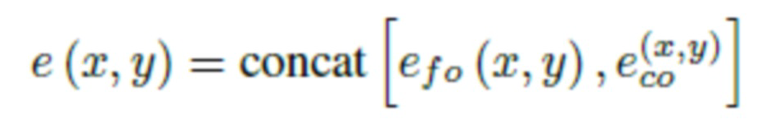
и служит в качестве ввода для следующего слоя перцептрона:
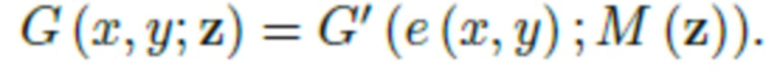
Детали архитектуры
В предлагаемых экспериментах как признаки Фурье, так и вложения координат имели размерность 512. Генератор имел 14 модулированных полносвязных слоев шириной 512. Авторы использовали активацию LeakyReLU с наклоном 0,2. Предложенные эксперименты были реализованы на основе общедоступного кода для StyleGANv2. Предлагаемая модель обучается со стандартной ненасыщающей логистической потерей GAN со штрафом R1 [18], применяемым к дискриминатору D. Этот дискриминатор имеет остаточную архитектуру, описанную в [10] (авторы намеренно сохранили архитектуру дискриминатора нетронутой). Сети обучались оптимизатором Adam [11] со скоростью обучения  и гиперпараметрами:
и гиперпараметрами:
 .
.
Оценка
Генераторы CIPS и их варианты оценивались на ряде наборов данных. Для эффективности большинство оценок были ограничены разрешением 256X256. Анализировались следующие наборы данных (см. фиг.1):
Набор данных Flickr Faces-HQ (FFHQ) [9] содержит 70 000 высококачественных, хорошо выровненных, в основном практически фронтальных снимков человеческих лиц. Этот набор данных является наиболее регулярным с точки зрения геометрического выравнивания, и известно, что варианты StyleGAN очень хорошо работают в этой схеме.
Набор данных LSUN Churches [29] содержит 126 000 наружных снимков церквей весьма разнообразного архитектурного стиля. Этот набор данных регулярный, причем все изображения имеют вертикальную ориентацию.
Набор данных Landscapes содержит 60 000 пейзажных снимков, собранных вручную с веб-сайта Flickr.
Набор данных Satellite-Buildings содержит 280 741 снимков размером 300 300 пикселей (которые авторы обрезали до разрешения 256×256 и поворачивали случайным образом). Этот набор данных имеет большой размер и приблизительно выровнен по масштабу, но не имеет единообразной ориентации.
И наконец, набор данных Satellite-Landscapes содержит менее тщательно подобранную коллекцию из 2 608 изображений с разрешением 512×512 спутниковых снимков различных эффектных пейзажей, найденных в Google Earth (авторы кадрировали их до разрешения 256х256). Это наиболее "текстурный" набор данных, в котором отсутствует единообразный масштаб или ориентация.
Для оценки применяись обычно используемые метрики для генерации изображений: Frechet Inception Distance (расстояние Фреше) (FID) [7], а также недавно введенные генеративные меры Precision (точность) и Recall (отклик) [22, 14].
Таким образом, предлагаемая основная оценка осуществляется в сравнении с современным генератором StyleGANv2 [10]. В предлагаемом изобретении реализация StyleGANv2 обучается на всех четырех наборах данных. StyleGANv2 обучается без смешивания стилей и регуляризации пути генератора, эти изменения не влияют на метрику FID. Результаты данного ключевого сравнения представлены в таблицах 1 и 2. Ни один из двух вариантов генератора не доминирует над другим, при этом StyleGANv2 имеет более низкий (лучший) показатель FID на FFHQ, Landscapes и (незначительно) Satellite-Buildings, в то время как генератор CIPS получил более низкий показатель на LSUN Churches и Satellite-Landscapes.
LSUN Churches
Landscapes
Satellite-Buildings
Satellite-Landscapes
3,86
2,81
76,33
51,54
3,58
3,61
76,8
48,47
Таблица 1: FID для нескольких наборов данных с разрешением 2562 для модели CIPS с пропусками. Следует отметить, что качество CIPS сопоставимо с современным StyleGANv2 и лучше для Churches. Значение для модели CIPS на FFHQ отличается от значения, указанного в таблице 3, поскольку авторы обучали эту модель в течение более продолжительного времени и с большим размером пакета.
CIPS
0,613
0,493
Таблица 2: Точность и отклик, измеренные на FFHQ при 2562.
Достигнутое качество предложенной модели выше с точки зрения точности (соответствует правдоподобию изображений) и ниже по отклику (на это указывает большее количество пропущенных мод).
Абляции
Важность различных частей предложенной модели оценивалась путем ее абляции на наборе данных FFHQ (таблица 3). При этом рассматривались удаление признаков Фурье, вложений координат (конфигурация, называемая CIPS-NE) и замена активации LeakyReLU синусоидальной функцией на всех уровнях. Также сравнивались варианты с остаточными связями (реализация Style-GANv2 [10], регулирующая дисперсию остаточных блоков с делением на 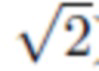 ) с основным выбором кумулятивных проекций в RGB. Дополнительно рассматривалась конфигурация "base" без пропусков подключений и остаточных подключений. В этом сравнении все модели обучались на 300K итерациях с размером пакета 16.
) с основным выбором кумулятивных проекций в RGB. Дополнительно рассматривалась конфигурация "base" без пропусков подключений и остаточных подключений. В этом сравнении все модели обучались на 300K итерациях с размером пакета 16.
Как показывают результаты, вложения координат, остаточные блоки и совокупная проекция в RGB значительно улучшают качество модели. Удаление вложений координат сильнее всего ухудшает значение FID и влияет на качество генерируемых изображений (фиг.4 справа). Исследовалась важность вложений координат для модели CIPS ниже. Фиг.4: представлено изображение, соответствующее среднему вектору стиля в пространстве  для генераторов CIPS (слева) и CIPS-NE (без вложений) (справа). Левое изображение имеет более правдоподобные детали, такие как волосы, что подтверждает результаты в таблице 3.
для генераторов CIPS (слева) и CIPS-NE (без вложений) (справа). Левое изображение имеет более правдоподобные детали, такие как волосы, что подтверждает результаты в таблице 3.
(NE)"
Вложения координат
Остаточные блоки
Пропуск подключений
Синусоидальная активация
+
-
-
-
-
-
-
-
+
-
-
-
+
-
+
-
+
+
-
-
+
-
-
+
Таблица 3: Влияние модификаций генератора CIPS на набор данных FFHQ с точки зрения оценки расстояния Фреше (FID). Каждый столбец соответствует определенной конфигурации, а строки соответствуют присутствующим/отсутствующим признакам. Одновременное использование признаков Фурье и вложений координат необходимо для хорошего результата FID. Кроме того, как остаточные соединения, так и совокупные пропуски подключений (конфигурация по умолчанию) к выходу превосходят по производительности простой многослойный персептрон.
Влияние позиционных кодировок
Для анализа разницы между признаками Фурье  и вложениями координат
и вложениями координат  авторы построили график спектра этих кодов для генератора CIPS-base, обученного на FFHQ.
авторы построили график спектра этих кодов для генератора CIPS-base, обученного на FFHQ.
Как показано на фиг.5, кодирование Фурье обычно несет низкочастотные компоненты, тогда как вложения координат напоминают более высокочастотные детали. Фиг.5: Величина спектра для предложенных двух видов позиционного кодирования (цветовая шкала одинакова для обоих графиков). Вложения координат на выходе явно имеют более высокие частоты. На фиг.5 показано, что вложение координат имеет более высокочастотную составляющую, а признаки Фурье сфокусированы на компонентах с низким разрешением.
Этот же вывод подтверждает анализ главных компонентов (PCA) этих двух кодирований (фиг.6). Фиг.6: График PCA (3 компонента) для двух видов позиционного кодирования CIPS-base (признаки Фурье и вложения координат). Эти изображения были получены путем применения метода уменьшения размерности PCA (анализа главных компонентов) к размеру канала для получения матрицы формы Высота*Ширина*3. Данные 3 канала можно интерпретировать как цвета RGB в целях иллюстрации. На фиг.6(a) видно, что график PCA фактически не поддается обработке, так как эти вложения были взяты из модели, обученной на наборе данных пейзажей, который не содержит повторяющихся шаблонов, а на фиг.6(b) вложения были взяты из генератора, обученного на хорошо выровненных лицах, и можно четко видеть глаза, губы, нос, брови и т.д. Вложения координат содержат не только более мелкие детали, но и ключевые точки усредненного лица. Возможно это объясняется просто: вложения координат обучаются для каждого пикселя независимо, в то время как 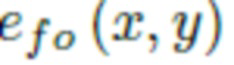 - обученная функция этих координат. Однако следующие уровни сети могут преобразовывать позиционные коды и, например, в конечном итоге создавать более мелкие детали на основе признаков Фурье.
- обученная функция этих координат. Однако следующие уровни сети могут преобразовывать позиционные коды и, например, в конечном итоге создавать более мелкие детали на основе признаков Фурье.
Чтобы продемонстрировать, что это не так, был проведен следующий эксперимент. Был обнулен вывод либо признаков Фурье (a), либо вложений координат (b), и полученные изображения показаны на фиг.7. Можно заметить, что информация деталей волос на лице, а также пряди волос на лбу, находится во вложениях координат. Это доказывает, что именно вложения координат (b) служат ключом к высокочастотным деталям получаемого изображения. В левой части (а) показано исходное изображение. В центре (b) обнулены вложения координат (изображение не содержит мелких деталей). В правой части (c) обнулены признаки Фурье (присутствуют только высокочастотные детали).
Спектральный анализ созданных изображений
Обычные операции сверточной повышающей дискретизации могут привести к невозможности обучения спектрального распределения реальных изображений независимо от любой архитектуры генератора [4]. CIPS же, напротив, явно работает с координатной сеткой и не имеет модулей увеличения масштаба, что должно улучшить воспроизведение спектра. Действительно, авторы сравнили спектр своих моделей (CIPS-"base" без остаточных и пропускаемых подключений; CIPS-NE) с Style-GANv2 и продемонстрировали, что конструкция генераторов CIPS имеет преимущество в спектральной области.
На фиг.8A, 8B представлен спектральный анализ моделей, обученных на FFHQ, с разрешением 2562. Все результаты усреднены по 5000 выборкам. Продемонстрировано, что наибольшее сходство с реальными изображениями дает CIPS-NE.
На фиг.8А показаны амплитудные спектры. Понятно, что предлагаемые модели CIPS-NE, CIPS-base дают меньше артефактов в высокочастотных компонентах. Спектр StyleGANv2 имеет артефакты в высокочастотных областях (сетчатый узор в StyleGANv2, который проявляется в виде светлых точек по краям спектра), отсутствующие в обоих рассматриваемых генераторах CIPS.
В соответствии с предыдущими работами [4] также использовалось азимутальное интегрирование (AI) по спектральной функции Фурье; на фиг.8B показано азимутальное интегрирование по спектральной функции Фурье. Кривая StyleGANv2 имеет сильные искажения в большинстве высокочастотных компонентов. Удивительно, но CIPS-NE демонстрирует более реалистичный и гладкий хвост, чем CIPS-base, но хуже с точки зрения FID (Frechet Inception Distance, https://en.wikipedia.org/ wiki/Fr%C3%A9chet_inception_distance). Стоит отметить, что статистика AI по CIPS-NE очень близка к статистике по реальным изображениям. Однако добавление вложений координат ухудшает реалистичный спектр, одновременно улучшая качество с точки зрения FID (таблица 3). Введение пропусков подключений фактически делает спектры менее похожими на спектры естественных изображений.
Интерполяция
В завершение экспериментальной части демонстрируется гибкость CIPS. Как и многие другие генераторы, генераторы CIPS обладают способностью интерполяции между скрытыми векторами со значимым морфингом (фиг.11). На фиг.11 показан скрытый линейный морфинг между двумя выбранными изображениями - крайним левым и крайним правым.
Как и ожидалось, изменение между этими крайними изображениями происходит плавно и позволяет использовать это свойство так же, как и в оригинальных работах (например, [10]).
Фовеальный рендеринг и интерполяция
Одним из вдохновляющих применений предложенного попиксельного генератора является фовеальный синтез. Способность к фовеальному синтезу может быть полезна для компьютерной графики и других приложений, а также в качестве имитации зрительной системы человека. При фовеальном синтезе сначала выбирается нерегулярная координатная сетка, более плотная в той области, на которую предполагается направить взгляд, и более разреженная за пределами этой области. Затем на этой сетке оценивается CIPS (его размер меньше, чем полное разрешение), и цвет для недостающих пикселей изображения заполняется с помощью интерполяции. Демонстрация этого метода представлена на фиг.9. Фиг.9: изображения, полученные с использованием фовеального синтеза. В каждом случае выборка генератора CIPS производилась на двухмерном распределении Гаусса, сконцентрированном в центре изображения (стандартное отклонение=0:4*размер изображения). Слева направо: выбранный шаблон покрывает 5% всех пикселей, 25%, 50%, 100% (полную координатную сетку). Недостающие значения цвета были заполнены с помощью бикубической интерполяции.
Наряду с фовеальным рендерингом также можно интерполировать изображение за пределами обучающего разрешения, просто путем выбора более плотных сеток. Здесь используется модель, обученная на изображениях с разрешением 256×256 для обработки сетки 1024×1024 пикселей, которая сравнивается с результатами повышающей дискретизации изображения, синтезированного с разрешением 256×256 с фильтром Ланцоша [15]. Как видно на фиг.10, более правдоподобные детали получаются при более плотном синтезе, чем при использовании фильтра Ланцоша. Фиг.10, левая часть (а): сгенерированное изображение с разрешением 256×256, увеличенное с помощью схемы повышения дискретизации Ланцоша [15] до 1024×1024. Правая часть (b): изображение, синтезированное CIPS, обученным с разрешением 256×256 на координатной сетке с разрешением 1024×1024. Следует отметить резкость/правдоподобность века и более корректную форму зрачка при использовании предлагаемого изобретения. Как показано на фиг.10 при использовании предложенного изобретения (b) получено более резкое изображение справа, форма зрачка ближе к окружности, и складка над глазом имеет более ровную форму, а на левом изображении (а) зрачок находит на радужку, а складка над глазом размыта.
Панорамный синтез
Поскольку CIPS строится на координатной сетке, он может относительно легко использовать недекартовы сетки. Чтобы показать это, была принята цилиндрическая система для создания пейзажных панорам. Схема обучения такова. Обрезка 256×256 из цилиндрической координатной сетки подвергалась равномерной выборке, и генератор обучался создавать изображения с использованием этих координатных обрезок в качестве ввода. Подобная идея также исследовалась в [16]. Однако в настоящем изобретении во время обучения авторы не использовали никаких реальных панорам в отличие от другой координатной модели COCOGAN [16]. На фиг.12(а) и 12(b) представлены примеры образцов панорамы, полученных с помощью полученной модели.
Поскольку каждый пиксель генерируется только из его координат и вектора стиля, предложенная архитектура допускает попиксельную интерполяцию стиля (фиг.12 (c)). В этих примерах осуществляется линейное смешивание вектора стиля между центральной частью (стиль на фиг.12(a)) и внешней частью (стиль на фиг.12(b)). Реализовано линейное смешивание двух верхних изображений из генератора CISP, обученного на наборе данных Landscapes с цилиндрической системой координат. Полученное изображение содержит элементы обеих исходных панорам: здания и вода объединены естественным образом. При синтезе панорамы вместо них используются цилиндрические координаты, что позволяет синтезировать прямоугольные изображения. В остальном метод такой же.
Типичные артефакты
В заключение, представлены типичные артефакты, постоянно повторяющиеся в результатах генераторов CIPS (фиг.13). На фиг.13 представлены примеры наиболее распространенных видов артефактов в разных наборах данных. Лучше всего их можно описать как волнистые текстуры на волосах, фоне, и светящиеся пятна. Волнистая текстура (на волосах) и узор повторяющихся линий (на зданиях) объясняются периодическим характером синусоидальной активационной функции в признаках Фурье. Также иногда CIPS создает реалистичное изображение, небольшая часть которого несовместима с остальным изображением и выходит за пределы области. Предполагается, что такое поведение вызвано функцией активации LeakyReLU, которая делит координатную сетку на части. Для каждой части CIPS эффективно применяет собственное обратное дискретное преобразование Фурье. Поскольку генераторы CIPS не используют повышающую дискретизацию или другую координацию пикселей, генератору сложнее защититься от такого поведения.
5. Заключение
Представленная новая модель генератора, именуемая CIPS, является высококачественной архитектурой с условно независимым синтезом пикселей, в которой значение цвета вычисляется с использованием только случайного шума и положения координат.
Основная идея состоит в том, что предлагаемая архитектура без пространственных сверток, операций внимания или повышающей дискретизации способна конкурировать на рынке моделей и обеспечивать достойное качество с точки зрения FID, точности и отклика; о подобных результатах для моделей на основе персептрона ранее не сообщалось. Кроме того, в спектральной области результаты на выходе CIPS труднее отличить от реальных изображений. Интересно, что модификация CIPS-NE слабее с точки зрения правдоподобия, но имеет более реалистичный спектр.
Прямое использование координатной сетки позволяет работать с более сложными структурами, такими как цилиндрические панорамы, просто путем замены базовой системы координат.
В заключение можно констатировать, что предлагаемый генератор демонстрирует качество на уровне современной модели StyleGANv2; кроме того, он может найти применение в самых различных сценариях. Было показано, что рассматриваемую модель можно успешно применять в задачах фовеального рендеринга и сверхразрешения в их генерирующих интерпретациях. Дальнейшее развитие предложенного принципа предполагает изучение этих задач, сформулированных как "создание изображения из другого изображения".
Представленные выше примерные варианты осуществления являются лишь примерами и не должны рассматриваться как ограничивающие. Кроме того, описание этих примерных вариантов осуществления предназначено для иллюстрации, а не для ограничения объема формулы изобретения, и многие альтернативы, модификации и вариации будут очевидны специалистам в данной области техники
ЛИТЕРАТУРА
[1] A. Brock, J. Donahue, and K. Simonyan. Large scale GAN training for high fidelity natural image synthesis. In International Conference on Learning Representations, 2019.
[2] T. S. Cohen, M. Geiger, J. K¨ohler, and M.Welling. Spherical cnns. In International Conference on Learning Representations, 2018. 2
[3] L. Dinh, J. Sohl-Dickstein, and S. Bengio. Density estimation using real nvp. arXiv preprint arXiv:1605.08803, 2016.
[4] R. Durall, M. Keuper, and J. Keuper. Watch Your Up-Convolution: CNN Based Generative Deep Neural Networks Are Failing to Reproduce Spectral Distributions. In Proc. CVPR, pages 7887-7896, 2020.
[5] D. Ha. Generating large images from latent vectors. blog.otoro.net, 2016.
[6] D. Ha. Generating large images from latent vectors - part two. blog.otoro.net, 2016.
[7] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Proc. NIPS, NIPS’17, page 6629-6640, Red Hook, NY, USA, 2017. Curran Associates Inc.
[8] A. Karpathy. Convnetjs demo: Image ”painting”. https://cs.stanford.edu/people/karpathy/convnetjs/demo/image_regression.html.
Accessed: 2020-11-05.
[9] T. Karras, S. Laine, and T. Aila. A style-based generator architecture for generative adversarial networks. In Proc. CVPR, pages 4396-4405, 2019.
[10] T. Karras, S. Laine, M. Aittala, J. Hellsten, J. Lehtinen, and T. Aila. Analyzing and improving the image quality of stylegan. In Proc. CVPR, pages 8107-8116, 2020.
[11] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. In International Conference on Learning Representations, ICLR, 2015.
[12] D. P. Kingma and P. Dhariwal. Glow: Generative flow with invertible 1×1 convolutions. In Proc. NeurIPS, pages 10215-10224, 2018.
[13] D. P. Kingma and M. Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
[14] T. Kynk¨a¨anniemi, T. Karras, S. Laine, J. Lehtinen, and T. Aila. Improved precision and recall metric for assessing generative models. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alch'e-Buc, E. Fox, and R. Garnett, editors, Proc. NeurIPS, volume 32, pages 3927-3936. Curran Associates, Inc., 2019.
[15] C. Lanczos. An iteration method for the solution of the eigenvalue problem of linear differential and integral operators. United States Governm. Press Office Los Angeles, CA, 1950.
[16] C. H. Lin, C. Chang, Y. Chen, D. Juan, W.Wei, and H. Chen. Coco-gan: Generation by parts via conditional coordinating. In Proc. ICCV, pages 4511-4520, 2019.
[17] R. Liu, J. Lehman, P. Molino, F. Petroski Such, E. Frank, A. Sergeev, and J. Yosinski. An intriguing failing of convolutional neural networks and the CoordConv solution. In S. Bengio, H.Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Proc. NeurIPS, pages 9627-9638. Curran Associates, Inc., 2018.
[18] L. Mescheder, A. Geiger, and S. Nowozin. Which Training Methods for GANs do actually Converge? In J. Dy and A. Krause, editors, Proc. ICML, volume 80 of Proceedings of Machine Learning Research, pages 3481-3490, Stockholmsmassan, Stockholm Sweden, July 2018. PMLR.
[19] B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In A. Vedaldi, H. Bischof, T. Brox, and J.-M. Frahm, editors, Proc. ECCV, pages 405-421, Cham, 2020. Springer International Publishing.
[20] A. Mordvintsev, N. Pezzotti, L. Schubert, and C. Olah. Differentiable image parameterizations. Distill, 2018.
https://distill.pub/2018/differentiable-parameterizations.
[21] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. In International Conference on Learning Representations, 2016.
[22] M. S. M. Sajjadi, O. Bachem, M. Lucic, O. Bousquet, and S. Gelly. Assessing generative models via precision and recall. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Proc. NIPS, volume 31, pages 5228-5237. Curran Associates, Inc., 2018.
[23] K. Schwarz, Y. Liao, M. Niemeyer, and A. Geiger. GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis. In Proc. NeurIPS. Curran Associates, Inc., 2020.
[24] V. Sitzmann, J. N. P. Martel, A. W. Bergman, D. B. Lindell, and G. Wetzstein. Implicit Neural Representations with Periodic Activation Functions. In Proc. NeurIPS. Curran Associates, Inc., 2020.
[25] V. Sitzmann, M. Zollh¨ofer, and G. Wetzstein. Scene representation networks: Continuous 3d-structure-aware neural scene representations. In Proc. NeurIPS. 2019.
[26] K. O. Stanley. Compositional pattern producing networks: A novel abstraction of development. Genetic Programming and Evolvable Machines, 8(2):131-162, Jun 2007.
[27] M. Tancik, P. P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Raghavan, U. Singhal, R. Ramamoorthi, J. T. Barron, and R. Ng. Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains. In Proc. NeurIPS. Curran Associates, Inc., 2020.
[28] A. Van Den Oord, N. Kalchbrenner, and K. Kavukcuoglu. Pixel recurrent neural networks. In Proc. ICML, pages 1747-1756, 2016.
[29] F. Yu, A. Seff, Y. Zhang, S. Song, T. Funkhouser, and J. Xiao. LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop. 2016.
[30] H. Zhang, I. J. Goodfellow, D. N. Metaxas, and A. Odena. Self-attention generative adversarial networks. In Proc. ICML, 2019.
| название | год | авторы | номер документа |
|---|---|---|---|
| МОДЕЛИРОВАНИЕ ЧЕЛОВЕЧЕСКОЙ ОДЕЖДЫ НА ОСНОВЕ МНОЖЕСТВА ТОЧЕК | 2021 |
|
RU2776825C1 |
| Быстрый двухслойный нейросетевой синтез реалистичных изображений нейронного аватара по одному снимку | 2020 |
|
RU2764144C1 |
| СПОСОБ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ ФОРМИРОВАНИЯ ПРАВДОПОДОБНОГО ОТОБРАЖЕНИЯ ТЕЧЕНИЯ ВРЕМЕНИ СУТОЧНОГО МАСШТАБА | 2020 |
|
RU2745209C1 |
| Повторный синтез изображения, использующий прямое деформирование изображения, дискриминаторы пропусков и основанное на координатах реконструирование | 2019 |
|
RU2726160C1 |
| НЕЙРОСЕТЕВОЙ ПЕРЕНОС ВЫРАЖЕНИЯ ЛИЦА И ПОЗЫ ГОЛОВЫ С ИСПОЛЬЗОВАНИЕМ СКРЫТЫХ ДЕСКРИПТОРОВ ПОЗЫ | 2020 |
|
RU2755396C1 |
| Способ построения представления сцены с прямой коррекцией для синтеза изображения в реальном времени | 2022 |
|
RU2799237C1 |
| Способ синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора, и электронное вычислительное устройство для его реализации | 2020 |
|
RU2749749C1 |
| СПОСОБ СОЗДАНИЯ АНИМИРУЕМОГО АВАТАРА ЧЕЛОВЕКА В ПОЛНЫЙ РОСТ ИЗ ОДНОГО ИЗОБРАЖЕНИЯ ЧЕЛОВЕКА, ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2023 |
|
RU2813485C1 |
| Способ локального генерирования и представления потока обоев и вычислительное устройство, реализующее его | 2020 |
|
RU2768551C1 |
| ОБУЧЕНИЕ GAN (ГЕНЕРАТИВНО-СОСТЯЗАТЕЛЬНЫХ СЕТЕЙ) СОЗДАНИЮ ПОПИКСЕЛЬНОЙ АННОТАЦИИ | 2019 |
|
RU2735148C1 |












Настоящее техническое решение относится к области вычислительной техники. Технический результат заключается в улучшении качества изображений при ограниченных ресурсах графических процессоров. Технический результат достигается за счёт генерации изображений с разрешением посредством условно независимого синтеза пикселей, где извлекают многослойным персептроном случайный вектор z ∈ Z и координаты пикселей (x, y) ∈ {0 … W-1}×{0 … H-1} изображения с плавающей запятой, обрабатывают координаты пикселей изображения с плавающей запятой набором синусов с различными частотами, осуществляют, используя координаты пикселей изображения с плавающей запятой, поиск предварительно обученных вложений координат в весах сети, используя координаты пикселей изображения с плавающей запятой, преобразуют случайный вектор сетью отображения, выход которой влияет на веса в полносвязном слое, возвращают многослойным перцептроном значения RGB каждого пикселя изображения, оценивают генератор перцептрона G(x; y; z) на каждой паре (x, y), вычисляют полное выходное изображение согласно оценке I = {G(x, y; z)|(x, y) ∈ mgrid (H, W)}. 5 з.п. ф-лы, 3 табл., 13 ил.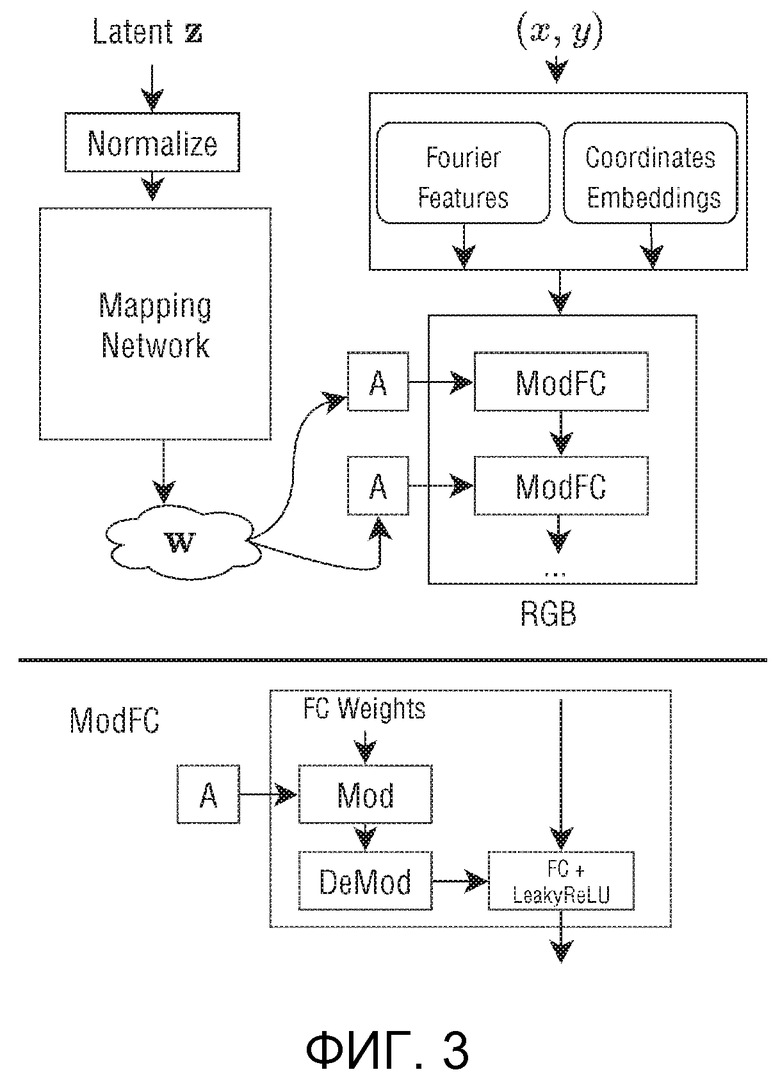
1. Способ генерации изображений с разрешением  посредством условно независимого синтеза пикселей, выполняющийся на устройстве, содержащем аппаратное обеспечение в виде центрального процессора, внутренней памяти, содержащей изображения, оперативной памяти, причем аппаратное обеспечение содержит программное обеспечение для редактирования изображений, реализующее указанный способ, заключающийся в том, что:
посредством условно независимого синтеза пикселей, выполняющийся на устройстве, содержащем аппаратное обеспечение в виде центрального процессора, внутренней памяти, содержащей изображения, оперативной памяти, причем аппаратное обеспечение содержит программное обеспечение для редактирования изображений, реализующее указанный способ, заключающийся в том, что:
извлекают из внутренней памяти упомянутого устройства многослойным персептроном G случайный вектор  и координаты пикселей изображения с плавающей запятой
и координаты пикселей изображения с плавающей запятой 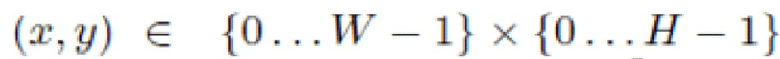 в качестве ввода;
в качестве ввода;
обрабатывают координаты пикселей изображения с плавающей запятой набором синусов с различными частотами для получения приемлемых для сети кодирования координат;
осуществляют, используя координаты пикселей изображения с плавающей запятой, поиск предварительно обученных вложений координат в весах сети, используя координаты пикселей изображения с плавающей запятой;
преобразуют случайный вектор сетью отображения, выход которой влияет на веса в полносвязном слое (ModFC);
возвращают многослойным перцептроном значения RGB каждого пикселя изображения;
оценивают генератор перцептрона G(x;y;z) на каждой паре (x, y) координатной сетки, сохраняя при этом случайную часть z фиксированной;
вычисляют полное выходное изображение согласно оценке:
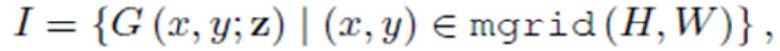
где  - набор целочисленных координат пикселей выходного изображения для упомянутого устройства.
- набор целочисленных координат пикселей выходного изображения для упомянутого устройства.
2. Способ по п. 1, в котором сеть отображения и перцептрон преобразуют z в вектор стиля, и из этого вектора стиля исходит вся стохастичность в процессе генерации.
3. Способ по п. 1, в котором сгенерированные изображения являются изображениями с произвольным разрешением.
4. Способ по п. 1, в котором сгенерированные изображения представляют собой карты окружающей среды или цилиндрические панорамы.
5. Способ по п. 1, в котором координаты пикселей с плавающей запятой представляют собой цилиндрические координаты для синтеза прямоугольных изображений.
6. Способ по любому из пп. 1-3, в котором
координаты пикселей с плавающей запятой представляют собой выборочную нерегулярную сетку координат, более плотную в области, на которую предполагается направить взгляд, и более разреженную за пределами этой области.
| Tero Karras et al | |||
| Analyzing and Improving the Image Quality of StyleGAN, опубл | |||
| Прибор для равномерного смешения зерна и одновременного отбирания нескольких одинаковых по объему проб | 1921 |
|
SU23A1 |
| US 10825219 B2, 03.11.2020 | |||
| US 10824909 B2, 03.11.2020 | |||
| US 10839259 B2, 17.11.2020 | |||
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Повторный синтез изображения, использующий прямое деформирование изображения, дискриминаторы пропусков и основанное на координатах реконструирование | 2019 |
|
RU2726160C1 |

