Предлагаемое изобретение относится к области обработки геномных данных в целом и, более конкретно, к приложениям секвенирования следующего поколения.
Известен способ и система для сжатия последовательностей генома c использованием графических блоков обработки (см., например, патент (US 20180011870) Method and system for compressing genome sequences using graphic processing units WO/2016/125154, IL).
Недостатком данного способа является возможность случайной утечки конфиденциальной геномной информации в процессе поиска данных. Из-за отсутстивия шифрования, в случае утечки, геномная информация может быть использована различными способами, например, для отказа в приеме на работу и медицинского страхования, шантажа или даже генетической дискриминации.
Известен способ управления необработанными геномными данными с способом сохранения конфиденциальности в биобанке. (см., например, патент (WO 2014202615) Method to manage raw genomic data in a privacy preserving manner in a biobank № WO/2014/202615, C0048)
Недостатком данного способа является необходимость исопльзования дополнительных затрат на хранение и обработку большого объема не сжатой информации. Из-за отсутсвия предварительного сжатия геномных данных, при использовании данного метода возникают дополнительные экономические и технологические требования, что делает способ непрактичным для использования в клинических геномных приложенях.
За прототип принят способ сжатия/декомпресси и устройство для вызова данных геномных вариантов (см., например, патент (EP 3430551) Compression/decompression method and apparatus for genomic variant call data № H03M 7/30, GB), заключающийся в том, в одной схеме генерируется сжатое представление последовательности, по меньшей мере, части генома индивидуума. Способ включает получение входного файла, содержащего представление последовательности, по меньшей мере, части генома индивидуума в форме последовательности вариантов, определенных при сравнении с эталонным геномом; способ позволяет получать доступ к справочной базе биоданных, содержащей множество списков ссылок генетических вариантов разных людей; список ссылок содержит последовательность генетических вариантов из одного гаплотипа; список ссылок представлят собой двойные мозаики, которые соответствуют части генома индивида с точностью до порогового значения; каждая мозаика представляет один из двух гаплотипов генома индивида для которой должно быть создано сжатое представление; сжатое представление создается путем кодирования самих мозаик и кодирования отклонений от этих мозаик.
Недостатком способа-прототипа является то, что в нем производится только сжатие данных и не предусмотрено их шифрование. Это не обеспечивает конфиденциальность данных, что может привести к случайной или преднамеренной утечки информации о генетических особенностях индивида из баз биоданных.
Техническая задача изобретения - совметное сжатие и шифрование информации выравнивания геномных данных для уменьшения объема информации, что уменьшает экономические и технологические требования к хранению и обработки информации, а также обеспечивает сохранение конфиденциальности индивидуальных особенностей геномных данных человека на всех этапах взаимиодействия с базами биоданных.
Техническая задача достигается тем, что в способе сжатия геномных данных, информацию выравнивания геномных данных, организованную как поток данных выравнивания на основе чтения, преобразуют в поток данных выравнивания на основе положения. Информацию выравнивания на основе положения кодируют в поток данных выравнивания на основе ссылок. Поток данных выравнивания на основе ссылок зашифровывают комбинацией сохраняющего порядок шифрования информации о геномном положении и симметричного шифрования разностных данных выравнивания на основе ссылок. Результирующий сжатый и зашифрованный поток индексируют и сохраняют в блоке хранения биобанка в базе данных.
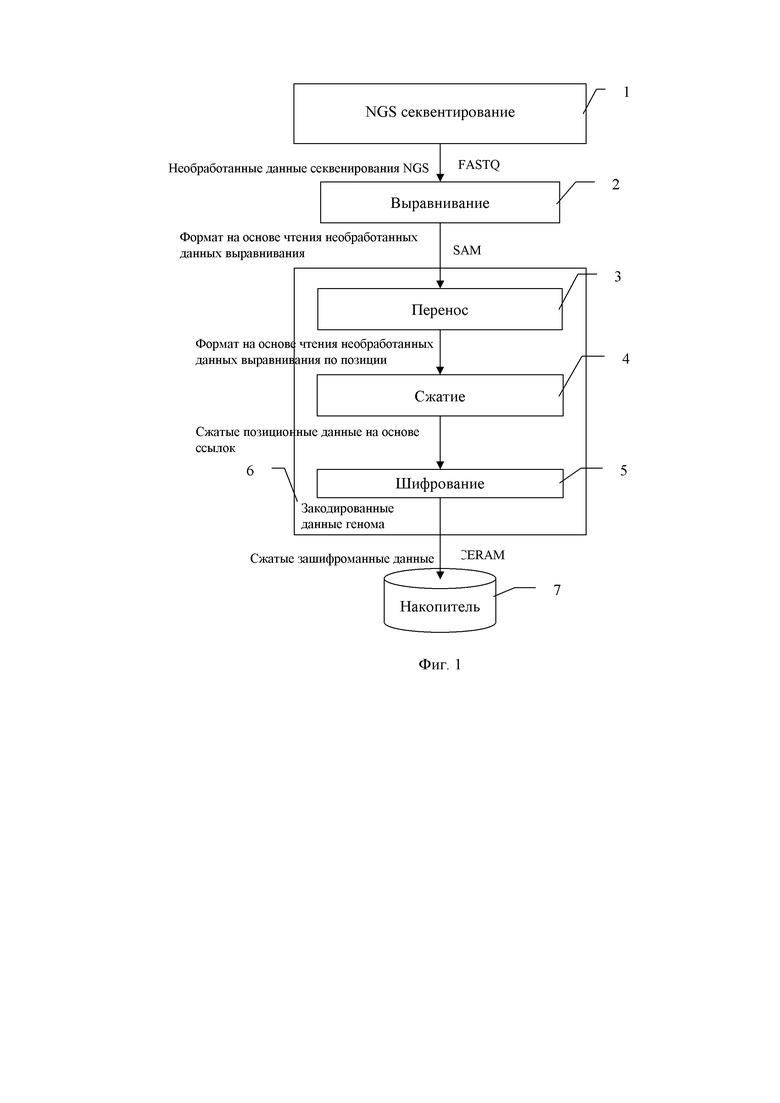
Сущность предлагаемого изобретения заключается в следующем. На фиг. 1 показана схема обработки геномных данных, содержащая кодер геномных данных 6, секвенсор следующего поколения (NGS) 1 и блок хранения биобанка 7. В секвенсоре 1 следующего поколения с процессором генерируют необработанные данные последовательности NGS в один или несколько файлов данных. Файл необработанных данных секвенирования генерируют в формате FASTQ.
В процессоре выравнивания (модуль 2) принимают в качестве входных данных необработанные данные секвенирования NGS, выравнивают краткие чтения по эталонному геному и генерируют файл необработанных данных выравнивания. Файл необработанных данных выравнивания имеет формат SAM или формат BAM, двоичный эквивалент формата SAM.
Модуль выравнивания 2 программируют для реализации различных способов выравнивания геномных данных. Модуль выравнивания 2 является компьютерной системой или частью компьютерной системы, включающей в себя центральный процессор (CPU, «процессор» или «компьютерный процессор»), память, такую как RAM, и модули хранения, такие как жесткий диск, и интерфейсы связи для связи с другими компьютерные системы через сеть связи, например, Интернет или локальную сеть.
В кодере геномных данных 6 принимают в качестве входных данных исходные данные выравнивания из модуля выравнивания 2; транспонируют его с помощью модуля транспонирования 3 в файл исходных данных выравнивания на основе позиции; сжимают с помощью модуля сжатия 4 файл необработанных данных выравнивания на основе положения в файл сжатых данных положения на основе ссылок; и шифруют, в модуле шифрования 5, в файл данных, что позволяет производить выборочный поиск по зашифрованной и сжатой эталонной карте выравнивания (формат файла «SECRAM»). Из кодера геномных данных 6 записывают результирующий зашифрованный файл данных SECRAM со сжатым выравниванием в блок 6 хранения биобанка.
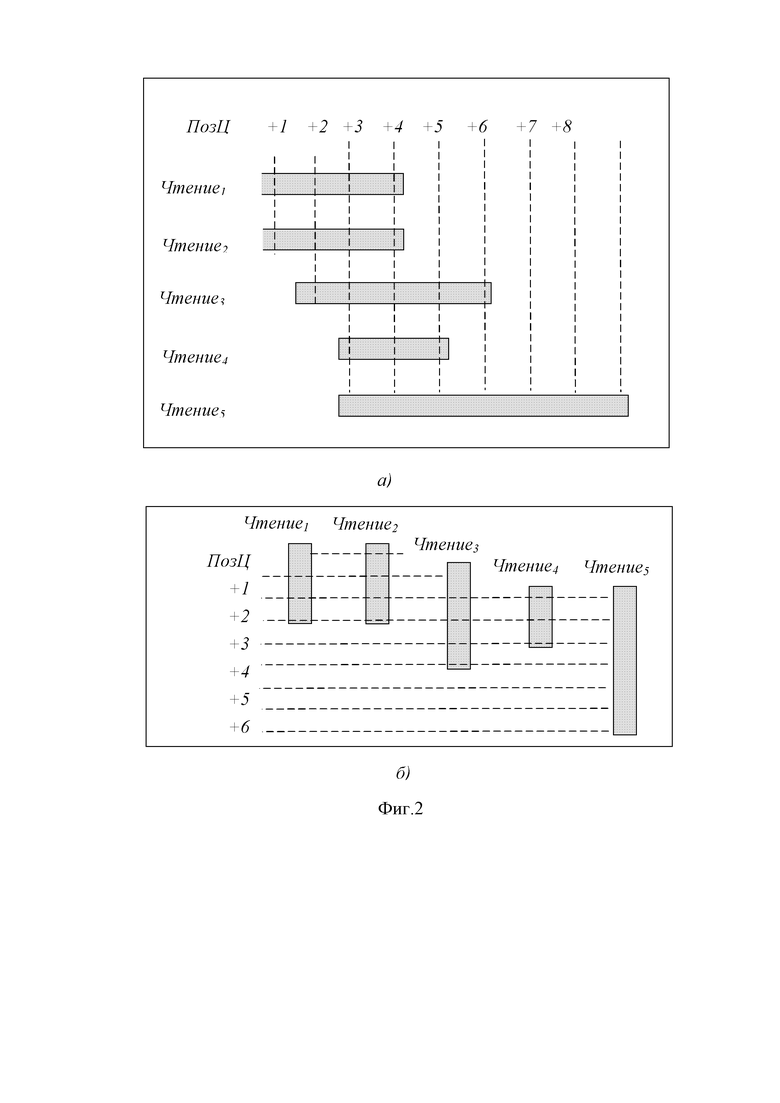
В модуле транспонирования 3 преобразуют информацию о геномном выравнивании из структуры данных на основе чтения, в структуру данных на основе позиции, как показано на фиг. 2. В основанном на чтении формате выровненные данные, представленные краткими считываниями, последовательно сохраняются, как сгенерированные секвенсором 1, чтение-чтение-чтение, в файле необработанных данных выравнивания.
Основанные на чтении форматов включают формат SAM, формат BAM и формат CRAM. В формате на основе позиции (фиг. 2) информация об одной позиции сгруппирована вместе в непрерывное хранилище, следовательно, выровненные данные сохраняются по позициям в файле.
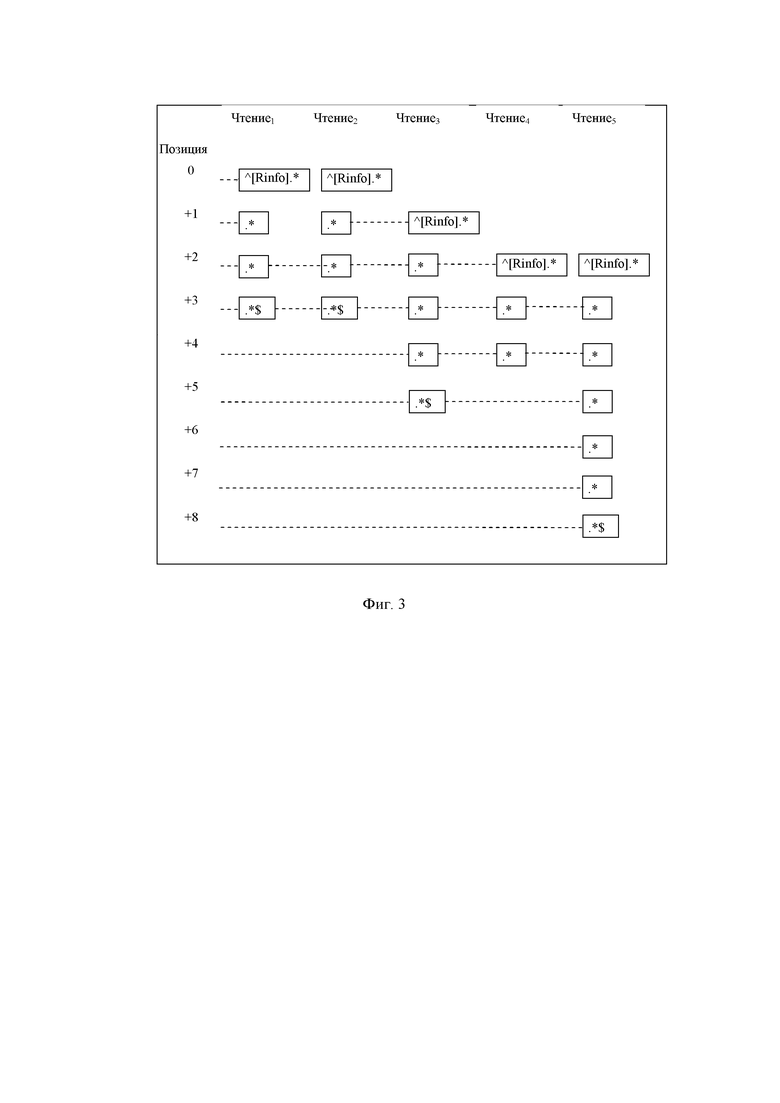
На фиг. 3 показана структура файла данных на основе позиции для 5 операций чтения (чтение 1, чтение 2, чтение 3, чтение 4, чтение 5), перекрывающих 9 позиций с индексами от 0 до 8. В позиции 0 записывается начальный маркер чтения 1 и чтения 2. Как показано на фиг. 3, символ * используют в качестве начального маркера для каждого начала короткого чтения в текстовом файле данных, за которым следует информация метаданных, относящаяся к короткому чтению, такая как его имя или идентификатор, цепочка и/или качество отображения, и нуклеотидное основание, идентифицированное в этом положении (A, T, C или G, обозначенное «.*» на фиг. 3) с соответствующим показателем качества. В положении +1 продолжение Чтение1 и Чтение2, то есть следующее нуклеотидное основание, идентифицированное в этом положении (A, T, C или G, обозначенное «.*» На фиг. 3 ), а также начало Чтение3, записаны. В позиции +3 последнее основание Чтение1 и Чтение2, за которым следует маркер конца Чтение1 и Чтение2, а также продолжение Чтение3, Чтение4 и Чтение5 соответственно, то есть следующее нуклеотидное основание, идентифицированное в этой позиции (A, T, C или G, обозначенные «.*» На фиг. 3) для Чтение3, Чтение4 и Чтение5 соответственно, записываются. В возможном варианте осуществления, как показано на фиг. 3 символ «.* $» используют в качестве конечного маркера для каждого короткого конца чтения в текстовом файле данных, но возможны и другие варианты осуществления. В целях иллюстрации, только ультракороткие чтения, перекрывающие позиции от 3 (чтение 4) до 7 (чтение 5), показаны на фиг. 3, но предложенная структура данных применима к коротким чтениям от 100 бит/с и выше, что обычно выводится секвенсорами NGS. Чем дольше считывание, тем короче издержки метаданных RInfo в результирующей структуре файла данных на основе позиции. В возможном варианте осуществления (не показан) информация Rinfo считывания также может включать в себя длину считывания, так что маркер конца не нужно записывать.
Сжатие данных осуществляется в модуле сжатия 4. В модуле сжатия 4 сжимают файл необработанных данных выравнивания на основе положения в файл сжатых данных положения на основе ссылки.
Правильно выровненные короткие чтения должны иметь значительную избыточность, так как большая часть операций чтения, будет соответствовать ссылке. Например, на фиг. 2 Данные Чтение1 и Чтение2 должны быть очень похожими. В предложенном варианте осуществления эталонного сжатия, значение позиции (ПозЦ) извлекают из исходных данных выравнивания на основе позиции. Для данной позиции все операции чтения, которые охватывают эту позицию, могут быть упорядочены по их начальным позициям, затем каждое чтение прикрепляется с уникальным порядком. Одному чтению может быть присвоен другой порядок для разных позиций, потому что соответствующие списки покрытых чтений в этих позициях различаются. В любой отдельной позиции строки ПозЦ захватывают один или несколько из трех различных примитивных разностных операторов выравнивания, таких как:
1. ЗАМЕНА - Порядок //'S'// [A | T | C | G]: чтение (указанное Порядком) для замены указанной буквой по сравнению со ссылкой.
2. ВСТАВКА - Порядок //'I'//i// {A, T, C, G}i: чтение содержит вставку из i букв, которые перечислены.
3. УДАЛЕНИЕ - Порядок //'D': чтение для удаления.
1. ЗАМЕНА - Порядок //'S'// [A | T | C | G]: чтение (указанное Порядком) имеет замену указанной буквой по сравнению со ссылкой.
2. ВСТАВКА - Порядок //'I'//i// {A, T, C, G}i : чтение содержит вставку из i букв, которые перечислены.
3. УДАЛЕНИЕ - Порядок //'D': чтение имеет удаление.
Например, ПозЦ, который выглядит как «9I4ATIG…23SA…57D », означает:
9I4ATG: вставка 4 букв «ATTG» в 9
23SA: замена буквой «А» в 23
57D: удаление в 57
9I4ATG: вставка 4 букв «ATTG» 9
23SA: замена буквой «А» в 23
57D: удаление в 57
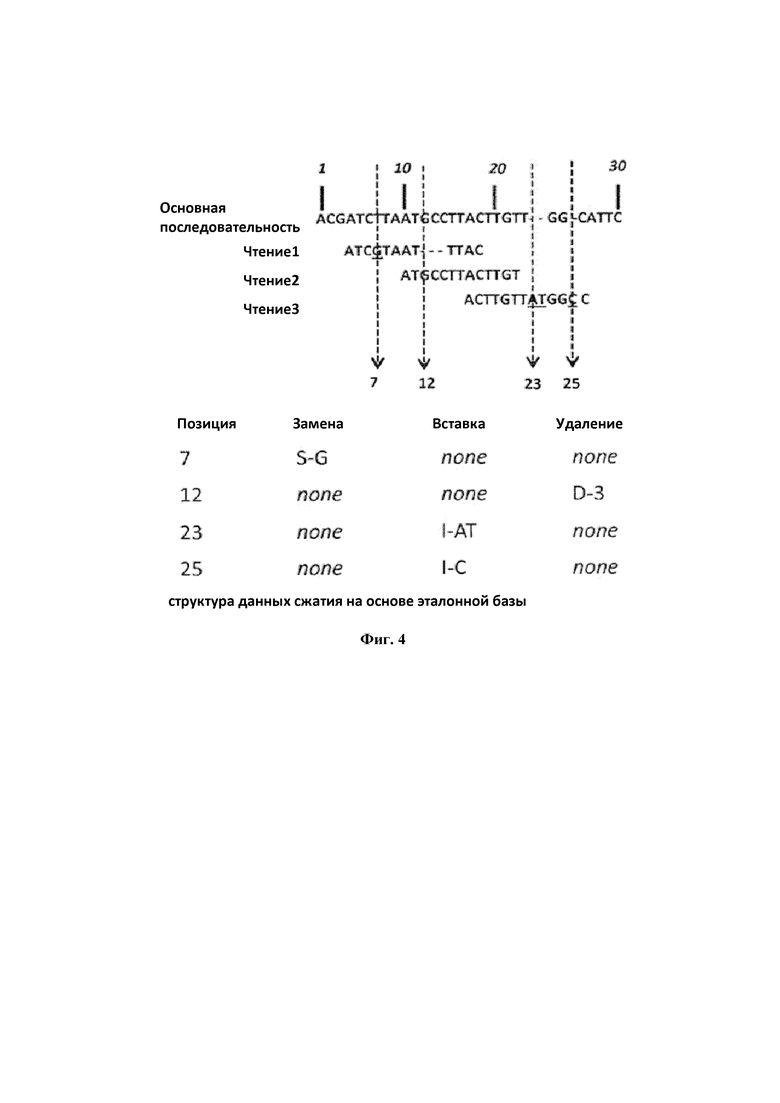
Простой пример предложенной ссылочной структуры данных сжатия показан на фиг. 4 где:
ПозЦ в позиции 7 относится к 1SG (замена на базу 'G' в Чтение1, упорядоченную как чтение # 1 в этой позиции)
ПозЦ в позиции 12 относится к 1D3 (удаление 3 баз в Чтение1, упорядоченных как чтение # 1 в этой позиции)
ПозЦ в позиции 23 относится к 1IAT (вставка двух оснований 'A', 'T' в Чтение3 упорядочена как чтение # 1 в этой позиции)
ПозЦ в позиции 25 относится к 1IC (вставка базы 'C' в Чтение3 упорядочена как чтение # 1 в этой позиции)
ПозЦ в позиции 7 относится к 1SG (замена на базу 'G' в Чтение1, упорядоченную как чтение # 1 в этой позиции)
ПозЦ в позиции 12 относится к 1D3 (удаление 3 баз в Чтение1, упорядоченных как чтение # 1 в этой позиции)
ПозЦ в позиции 23 относится к 1IAT (вставка двух оснований 'A', 'T' в Чтение3 упорядочена как чтение # 1 в этой позиции)
ПозЦ в позиции 25 относится к 1IC (вставка базы 'C' в Чтение3 упорядочена как чтение # 1 в этой позиции)
Более сложные операторы разности выравнивания (например, мягкое ограничение, жесткое ограничение, область пропуска …) также могут быть закодированы вышеупомянутыми операторами примитивов или их комбинацией, как будет очевидно для специалистов в данной области техники.
Список заголовков для чтения содержит список операций чтения, которые начинаются с этой позиции. Он раскладывается как (Order//RInfo) *, где «*» означает произвольное количество таких заголовков. В возможном варианте осуществления информация считывания RInfo также может включать в себя длину считывания, так что нам не нужно сохранять маркер конца.
Показатели качества записывают показатели качества для основ этой позиции.
ПозЦ записывает информацию о вариантах относительно эталонной последовательности.
Размер строки - это длина (измеряемая байтами) строки позиции;
Список заголовков для чтения содержит список операций чтения, которые начинаются с этой позиции. Он раскладывается как (Order//RInfo) *, где «*» означает произвольное количество таких заголовков. В возможном варианте осуществления информация считывания RInfo также может включать в себя длину считывания, так что нам не нужно сохранять маркер конца.
Показатели качества записывают показатели качества для основ этой позиции.
ПозЦ записывает информацию о вариантах относительно эталонной последовательности.
После того как исходные данные выравнивания на основе позиции преобразуют в справочную структуру сжатых данных о положении, специалист в области кодирования данных может применять дополнительные методы кодирования данных, такие как энтропийное кодирование и/или алгоритмы кодирования текста, для дополнительного сжатия данных в компактный двоичный справочный файл сжатых данных о местоположении. В возможном варианте осуществления кодирование с переменной длиной может использоваться для дополнительного сжатия различий, обнаруженных в ссылочном сжатии, а также метаданных чтения, таких как показатели качества отображения.
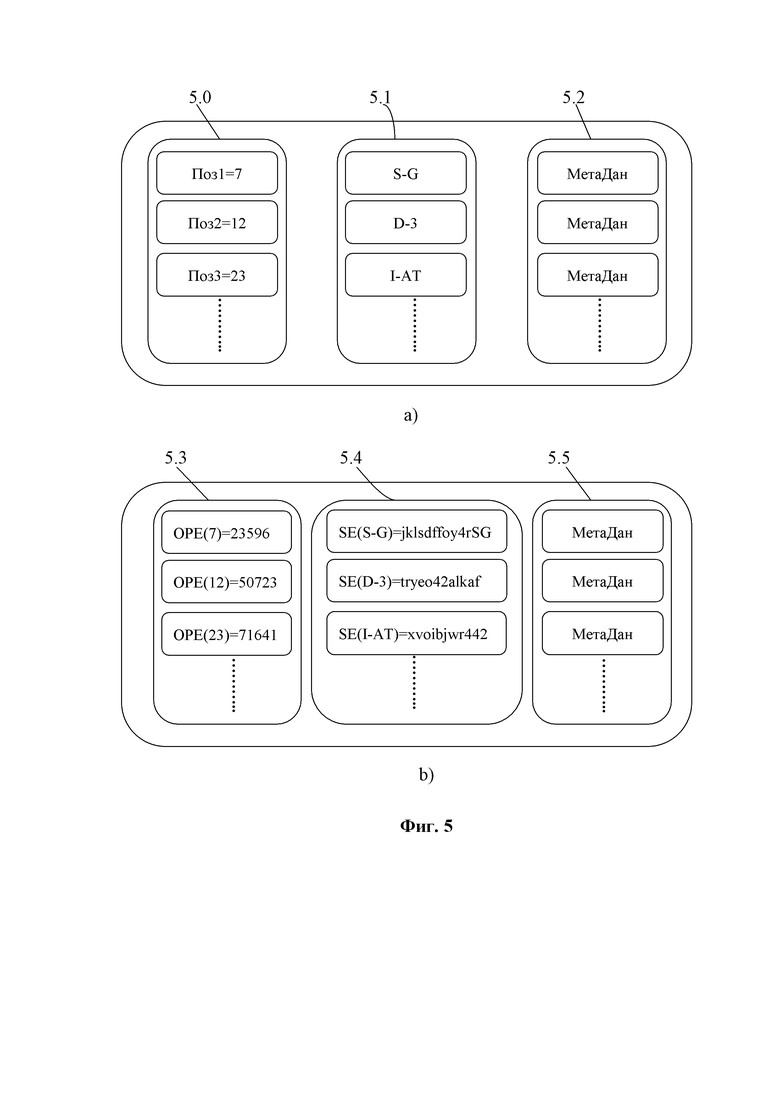
Шифрование данных осуществляют в модуле шифрования 5. Модуль шифрованя назначают мастер-ключ Km каждому пациенту, который может использоваться для получения различных ключей шифрования для разных этапов шифрования. В модуле шифрования 5 независимо шифруют информацию о вариантах для каждой позиции, то есть каждой строки в структуре данных на фиг. 3 для обеспечения детального контроля конфиденциальности путем частичного извлечения данных о геномном выравнивании при одновременном устранении общих угроз утечки информации о геномном выравнивании. Таким образом, ограничивают поиск данных только интересующими позициями из результирующего файла данных (например, в формате файла «SECRAM») без утечки какой-либо информации из позиций вне интересующей области, даже если исходные считанные данные выравнивания (например, в формате файла SAM/BAM) охватывают как релевантные, так и нерелевантные позиции.
В модуль шифрования 5 кодируют формат файла сжатых геномных данных по фиг. 5) в зашифрованный сжатый формат файла SECRAM, как показано на фиг. 5) в два этапа. На первом этапе из модуля шифрования 5 извлекают сохраняющий порядок ключ шифрования из главного ключа Km пациента и шифруют поля позиции Поз1, Поз2, Поз3… в сохраняющий порядок зашифрованный блок позиций 5.3 из блока 5.0 сжатых файлов геномных данных с использованием схемы шифрования с сохранением порядка (OPE) с ключом шифрования с сохранением порядка OPE. Эта схема шифрования с сохранением порядка позволяет извлекать результирующие зашифрованные данные 5.3 в заданной строке, соответствующей определенной позиции (OPE (Поз1), OPE (Поз2) или OPE (Поз3) … на фиг. 5), не требуя дешифрование всего блока данных 5.3 (например, блок из 50000 строк данных) на этапе декодирования.
На втором этапе со ссылкой на формат по фиг. 5, модуль 5 шифрования шифруют конфиденциальную информацию в каждой позиции, такую как блок 5.1 данных ПозЦ SG, D-3 I-AT… закодированных коротких разностей чтения относительно эталонной последовательности в зашифрованный блок 5.4 данных ПозЦ с помощью современного метода SE шифрования безопасности. Модуль шифрования 5 выводит ключ Ksc из главного ключа Km пациента. Для i-го блока 5.1 покрывая несколько строк позиции в своем входном файле сжатых данных о позициях, связанном с пациентом m, модуль 5 шифрования генерирует случайное число Ri. Для каждой строки позиции в сжатом блоке i модуль шифрования 5 шифрует сцепленные данные 5.1 ПозЦ с помощью потокового шифра с использованием симметричного ключа шифрования Ksc и случайного значения Ri для генерации симметрично зашифрованных данных 5.4 ПозЦ. В предложенном варианте для шифрования используют режим потокового шифра XOR. В возможном варианте осуществления используется AES в режиме шифрования потока CTR. В возможном варианте осуществления модуль 5 шифрования сохраняет случайную соль Ri в индексном файле (не показан). В другом возможном варианте осуществления (не показан) модуль 5 шифрования сохраняет случайную соль Ri в заголовке блока зашифрованных данных.
Общая схема обеспечения безопасности и обеспечения соблюдения конфиденциальности сильно зависит от базовой системы управления ключами.
Таким образом разработанный способ совместного сжатия и шифрования данных при геномном выравнивании, генерирующий сжатое представление последовательности генома в форме последовательности вариантов, полученных на основе сравнения с эталонным геномом, что уменьшает экономические и технологические требования к хранению и обработке информации, а также повышает сохранность конфиденциальности индивидуальных геномных данных за счет устранения интервала времени между сжатиеме геномных данных после секветирования и шифрованием, что повышает защищенность данных.
Изобретение относится к области компьютерных технологий, а именно к обработке геномных данных. Технический результат заключается в повышении надежности хранения данных. Компьютерно реализуемый способ совместного сжатия и шифрования данных при геномном выравнивании, генерирующий сжатое представление последовательности генома в форме последовательности вариантов, полученных на основе сравнения с эталонным геномом, а также принимают в качестве входных данных необработанные данные секвенирования (NGS) с помощью процессора выравнивания, на кодер геномных данных поступают исходные данные от процессора выравнивания, транспонируют с помощью процессора данные в файл исходных данных на основе позиции выравнивания, затем процессор осуществляет шифрование в файл данных с учетом позиции, что позволяет производить выборочный поиск по зашифрованной и сжатой эталонной карте выравнивания, и из кодера данных записывают результирующий зашифрованный файл данных в формате SECRAM со сжатым выравниванием в блок хранения биобанка. 7 ил.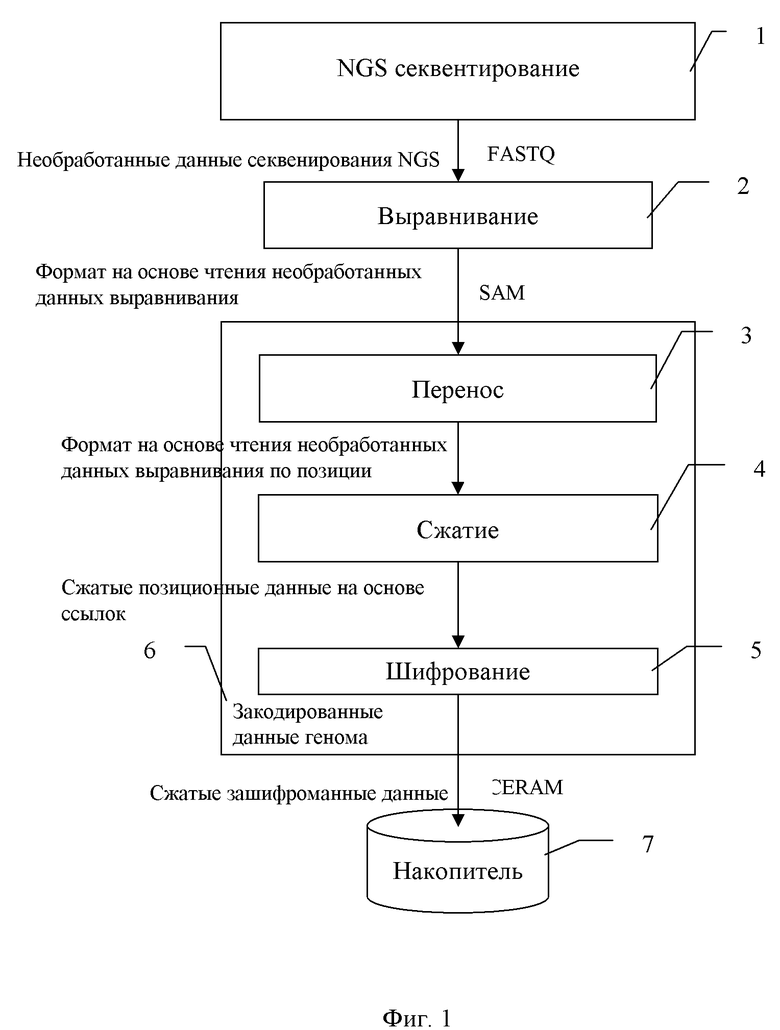
Компьютерно-реализуемый способ совместного сжатия и шифрования данных при геномном выравнивании, генерирующий сжатое представление последовательности генома в форме последовательности вариантов, полученных на основе сравнения с эталонным геномом, о т л и ч а ю щ и й с я тем, что принимают в качестве входных данных необработанные данные секвенирования (NGS) с помощью процессора выравнивания, выравнивают краткие чтения по эталонному геному и генерируют файл необработанных данных выравнивания, при этом файл необработанных данных имеет формат SAM или BAM, на кодер геномных данных поступают исходные данные от процессора выравнивания, транспонируют с помощью процессора данные в файл исходных данных на основе позиции выравнивания, после чего с помощью процессора сжимают файл необработанных данных выравнивания на основе положения в файл с учетом позиции выравнивания, затем процессор осуществляет шифрование в файл данных с учетом позиции, что позволяет производить выборочный поиск по зашифрованной и сжатой эталонной карте выравнивания, и из кодера данных записывают результирующий зашифрованный файл данных в формате SECRAM со сжатым выравниванием в блок хранения биобанка.
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Gregory W | |||
| Vurture et al | |||
| "GENOMESCOPE: FAST REFERENCE-FREE GENOME PROFILING FROM SHORT READS", GENOMSCOPE, Pub | |||
| Видоизменение прибора с двумя приемами для рассматривания проекционные увеличенных и удаленных от зрителя стереограмм | 1919 |
|
SU28A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| WO 2014202615 A2, 24.12.2014 | |||
| EP 3430551 A1, 23.01.2019 | |||
| СПОСОБЫ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ИНФОРМАЦИИ | 2017 |
|
RU2659025C1 |

