ОБЛАСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к области иммунотерапии или диагностики опухоли, и в частности к полностью человеческим антителам к мезотелину и иммунным эффекторным клеткам, нацеленным на мезотелин.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Роль иммунных эффекторных клеток в опухолевом иммунном ответе все больше и больше привлекает внимание. Адоптивная иммунотерапия на основе иммунных эффекторных клеток достигла некоторых эффектов для некоторых видов опухолей, и такой способ иммунотерапии может преодолеть недостатки лечения антителами, однако терапевтические эффекты в отношении большинства опухолей все еще неудовлетворительны [Grupp SA, et al. Adoptive cellular therapy. Curr Top Microbiol Immunol., 2011; 344: 149-72.]. В последние годы было раскрыто, что специфичность цитотоксических лимфоцитов (CTL) к распознаванию клеток-мишеней зависит от Т-клеточных рецепторов (TCR), scFv антитела к ассоциированным с опухолевыми клетками антигенам и внутриклеточные сигнал-активирующие мотивы рецептора Т-лимфоцитов CD3ζ, или FcεRIγ сливали с химерным антигенным рецептором (CAR), и Т-лимфоцит генетически модифицировали химерными антигенными рецепторами на его поверхности посредством, например, лентивирусной инфекции. Такие CAR Т-лимфоциты способны избирательно нацеливать Т-лимфоциты на опухолевые клетки, и в частности специфически уничтожать опухоль неограничивающим образом с помощью главного комплекса гистосовместимости (МНС). CAR Т-лимфоцит представляет собой новую стратегию иммунотерапии в области опухолевой иммунотерапии. Естественные клетки-киллеры (NK) или естественные киллерные Т-клетки (NKT), модифицированные CAR, также проявляют противоопухолевую активность в доклинических исследованиях.
При разработке иммунных эффекторных клеток, модифицированных CAR, особенно Т-клеток, выбор генов целевых антигенов на самом деле играет ключевую роль. Учитывая сложность экспрессии генов in vivo и различные неконтролируемые факторы, выбор подходящих генов для CAR очень затруднен. Более того, для многих опухолеспецифических антигенов трудно найти определенную нацеленную против них молекулу, подходящую для конструирования иммунных эффекторных клеток, модифицированных CAR.
Мезотелин представляет собой гликопротеин клеточной поверхности, молекулярная масса которого составляет 40 кДа. Он экспрессируется на высоком уровне в различных опухолях, таких как рак поджелудочной железы, рак яичников и мезотелиома тимуса. В нормальных тканях он экспрессируется только на нормальных мезотелиальных клетках плевры, перикарда и брюшины. Мезотелин синтезируется в виде белка-предшественника массой 71 кДа, зрелая часть которого экспрессируется на поверхности клетки. Белок-предшественник протеолитически расщепляется фурином на отщепляемую часть массой 31 кДа (называемую химерный фактор мегакариоцитов или MPF) и фракцию мезотелина массой 40 кДа. Последний компонент может оставаться связанным с поверхностью клетки с помощью гликозилфосфатидилинозитольной связи, а также может быть отщеплен протеолитическим ферментом.
Сообщалось об антителах к мезотелину или других направленных способах терапии. В клинических исследованиях также сообщалось о CAR-T (Maus MV, Haas AR, Beatty GL, Albelda SM, Levine BL, Liu X, Zhao Y, Kalos M, June CH. T cells expressing chimeric antigen receptors can cause anaphylaxis in humans. Cancer Immunol Res. 2013; 1 (1): 26-31; Beatty GL, Haas AR, Maus MV, Torigian DA, Soulen MC, Plesa G, Chew A, Zhao Y, Levine BL, Albelda SM, Kalos M, June CH. Mesothelin-specific chimeric antigen receptor mRNA-engineered T cells induce anti-tumor activity in solid malignancies. Cancer Immunol Res. 2014 Feb; 2 (2): 112-20). Однако было также установлено, что CAR-T, сконструированный с помощью мышиного антитела к мезотелину человека, в клинических условиях демонстрирует побочные эффекты, такие как антимышиное антитело и аллергия, что указывает на то, что мезотелин может быть потенциальной терапевтической мишенью, но свойства самого антитела могут повлиять на его эффективность и побочные эффекты. Таким образом, в данной области техники все еще существует потребность в поиске решений, с помощью которых можно преодолеть проблемы, связанные с антителами, которые не являются оптимальными или которые вызывают токсические побочные эффекты.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Целью настоящего изобретения является обеспечение полностью человеческих антител к мезотелину, а также иммунных эффекторных клеток, нацеленных на мезотелин.
В первом аспекте изобретения предложено полностью человеческое антитело, которое специфически связывается с мезотелином, выбранное из группы, состоящей из:
(а) антитела, содержащего вариабельную область тяжелой цепи, имеющую CDR1, содержащую аминокислотную последовательность SEQ ID NO: 54, CDR2, содержащую аминокислотную последовательность SEQ ID NO: 55, CDR3, содержащую аминокислотную последовательность SEQ ID NO: 56;
(b) антитела, содержащего вариабельную область легкой цепи, имеющую CDR1, содержащую аминокислотную последовательность SEQ ID NO: 51, CDR2, содержащую аминокислотную последовательность SEQ ID NO: 52, CDR3, содержащую аминокислотную последовательность SEQ ID NO: 53;
(c) антитела, содержащего вариабельную область тяжелой цепи указанного антитела (а) и вариабельную область легкой цепи указанного антитела (b);
(d) антитела, содержащего вариабельную область тяжелой цепи, имеющую CDR1, содержащую аминокислотную последовательность SEQ ID NO: 60, CDR2, содержащую аминокислотную последовательность SEQ ID NO: 61, CDR3 аминокислотной последовательности SEQ ID NO: 62;
(e) антитела, содержащего вариабельную область легкой цепи, имеющую CDR1, содержащую аминокислотную последовательность SEQ ID NO: 57, CDR2, содержащую аминокислотную последовательность SEQ ID NO: 58, CDR3 аминокислотной последовательности SEQ ID NO: 59;
(f) антитела, содержащего вариабельную область тяжелой цепи указанного антитела (d) и вариабельную область легкой цепи антитела (е);
(g) антитела, которое распознает ту же антигенную детерминанту, которую распознает любое из антител (а) - (f).
В предпочтительном варианте осуществления полностью человеческое антитело содержит вариабельную область тяжелой цепи и вариабельную область легкой цепи, при этом аминокислотная последовательность вариабельной области тяжелой цепи представлена в положениях с 1 по 123 SEQ ID NO: 6; и аминокислотная последовательность вариабельной области легкой цепи представлена в положениях с 139 по 254 SEQ ID NO: 6; или
полностью человеческое антитело содержит вариабельную область тяжелой цепи и вариабельную область легкой цепи, при этом аминокислотная последовательность вариабельной области тяжелой цепи представлена в положениях с 1 по 124 SEQ ID NO: 8; и аминокислотная последовательность вариабельной области легкой цепи представлена в положениях с 140 по 247 SEQ ID NO: 8.
В другом предпочтительном варианте осуществления полностью человеческое антитело, которое специфически связывается с мезотелином, может представлять собой одноцепочечное антитело (scFV), моноклональное антитело, доменное антитело, Fab-фрагмент, Fd-фрагмент, Fv-фрагмент, F(ab')2-фрагмент и его производное, или другие формы антител; предпочтительно одноцепочечное антитело.
В другом аспекте изобретения предложена нуклеиновая кислота, кодирующая антитело.
В другом аспекте изобретения предложен вектор экспрессии, содержащий нуклеиновую кислоту.
В другом аспекте изобретения предложена клетка-хозяин, которая содержит вектор экспрессии или имеет нуклеиновую кислоту, интегрированную в геном.
В другом аспекте настоящего изобретения предложено применение вышеуказанных антител для получения лекарственного средства направленного действия, конъюгата антитела с лекарственным средством или многофункционального антитела, специфически нацеленного на опухолевые клетки, экспрессирующие мезотелин; или для получения средства для диагностики опухоли, экспрессирующей мезотелин; или для получения иммунных клеток, модифицированных химерным антигенным рецептором.
В другом аспекте настоящего изобретения предложен химерный антигенный рецептор (CAR) антитела, содержащий последовательно связанные антитело по настоящему изобретению, трансмембранную область и внутриклеточную сигнальную область.
В предпочтительном варианте осуществления внутриклеточная сигнальная область выбрана из группы, состоящей из последовательностей внутриклеточных сигнальных областей CD3ζ, FcεRIγ, CD27, CD28, CD137, CD134, MyD88, CD40 или их комбинации.
В другом предпочтительном варианте осуществления трансмембранная область содержит трансмембранную область CD8 или CD28.
В другом предпочтительном варианте осуществления химерный антигенный рецептор содержит следующие последовательно связанные антитело, трансмембранную область и внутриклеточную сигнальную область:
Антитело, CD8 и CD3ζ
Антитело, CD8, CD137 и CD3ζ
Антитело, трансмембранную область молекулы CD28, внутриклеточную сигнальную область молекулы CD28 и CD3ζ; или
Антитело, трансмембранную область молекулы CD28, внутриклеточную сигнальную область молекулы CD28, CD137 и CD3ζ.
В другом предпочтительном варианте осуществления антитело представляет собой одноцепочечное антитело или доменное антитело.
В другом предпочтительном варианте осуществления химерный антигенный рецептор имеет:
SEQ ID NO: 41 или аминокислотную последовательность, представленную в ее положениях с 22 по 353;
SEQ ID NO: 42 или аминокислотную последовательность, представленную в ее положениях с 22 по 454;
SEQ ID NO: 43 или аминокислотную последовательность, представленную в ее положениях с 22 по 498;
SEQ ID NO: 44 или аминокислотную последовательность, представленную в ее положениях с 22 по 501;
SEQ ID NO: 45 или аминокислотную последовательность, представленную в ее положениях с 22 по 543;
SEQ ID NO: 46 или аминокислотную последовательность, представленную в ее положениях с 22 по 346;
SEQ ID NO: 47 или аминокислотную последовательность, представленную в ее положениях с 22 по 447;
SEQ ID NO: 48 или аминокислотную последовательность, представленную в ее положениях с 22 по 491;
SEQ ID NO: 49 или аминокислотную последовательность, представленную в ее положениях с 22 по 494; или
SEQ ID NO: 50 или аминокислотную последовательность, представленную в ее положениях с 22 по 536.
В другом аспекте изобретения предложена нуклеиновая кислота, кодирующая химерный антигенный рецептор.
В другом предпочтительном варианте осуществления нуклеиновая кислота, кодирующая химерный антигенный рецептор, имеет:
SEQ ID NO: 31 или нуклеотидную последовательность, указанную в ее положениях с 473 по 1468;
SEQ ID NO: 32 или нуклеотидную последовательность, указанную в ее положениях с 473 по 1771;
SEQ ID NO: 33 или нуклеотидную последовательность, указанную в ее положениях с 473 по 1903;
SEQ ID NO: 34 или нуклеотидную последовательность, указанную в ее положениях с 473 по 1912;
SEQ ID NO: 35 или нуклеотидную последовательность, указанную в ее положениях с 473 по 2038;
SEQ ID NO: 36 или нуклеотидную последовательность, указанную в ее положениях с 473 по 1447;
SEQ ID NO: 37 или нуклеотидную последовательность, указанную в ее положениях с 473 по 1750;
SEQ ID NO: 38 или нуклеотидную последовательность, указанную в ее положениях с 473 по 1882;
SEQ ID NO: 39 или нуклеотидную последовательность, указанную в ее положениях с 473 по 1891;
SEQ ID NO: 40 или нуклеотидную последовательность, указанную в ее положениях с 473 по 2017.
В другом аспекте настоящего изобретения предложен вектор экспрессии, содержащий нуклеиновую кислоту.
В другом предпочтительном варианте осуществления вектор экспрессии получают из лентивирусной плазмиды pWPT (или pWPT-eGFP).
В другом аспекте настоящего изобретения предложен вирус, содержащий указанный вектор.
В другом аспекте изобретения предложено применение химерного антигенного рецептора, или нуклеиновой кислоты, или вектора экспрессии, или вируса для получения генетически модифицированных иммунных клеток, нацеленных на опухолевые клетки, экспрессирующие мезотелин.
В предпочтительном варианте осуществления опухоль, экспрессирующая мезотелин, включает, но не ограничивается указанными, рак поджелудочной железы, рак яичника и мезотелиому тимуса.
В другом аспекте настоящего изобретения предложена генетически модифицированная иммунная клетка, которая трансдуцирована нуклеиновой кислотой, или вектором экспрессии, или вирусом; или экспрессирует химерный антигенный рецептор на своей поверхности.
В предпочтительном варианте осуществления иммунная клетка дополнительно содержит кодирующую последовательность экзогенного цитокина; и предпочтительно цитокин включает IL-12, IL-15 или IL-21.
В другом предпочтительном варианте осуществления иммунная клетка дополнительно экспрессирует другой химерный антигенный рецептор, который не содержит CD3ζ, но содержит внутриклеточный сигнальный домен CD28, внутриклеточный сигнальный домен CD137 или их комбинацию.
В другом предпочтительном варианте иммунная клетка дополнительно экспрессирует хемокиновый рецептор; и предпочтительно хемокиновый рецептор включает CCR2.
В другом предпочтительном варианте иммунная клетка дополнительно экспрессирует миРНК, которая может снижать экспрессию PD-1, или белок, который блокирует PD-L1.
В другом предпочтительном варианте осуществления иммунная клетка дополнительно экспрессирует предохранитель; предпочтительно предохранитель включает индуцируемую каспазу-9, усеченный EGFR или RQR8.
В другом предпочтительном варианте осуществления иммунные клетки включают Т-лимфоциты, NK-клетки или NKT-клетки.
В другом аспекте изобретения предложено применение генетически модифицированных иммунных клеток для получения лекарственного средства, ингибирующего опухоль, и опухоль представляет собой опухоль, экспрессирующую мезотелин.
В другом аспекте настоящего изобретения предложен многофункциональный иммуноконъюгат, включающий любое из вышеописанных антител; и связанную с ним функциональную молекулу (включая ковалентно связанные, конъюгированные, присоединенные, адсорбированные); при этом функциональная молекула выбрана из группы, состоящей из молекулы, которая нацелена на маркер поверхности опухоли, молекулы, подавляющей опухоль, молекулы, которая нацелена на маркер поверхности иммунной клетки, или детектируемой метки.
В предпочтительном варианте осуществления в многофункциональном иммуноконъюгате молекула, которая нацелена на маркер поверхности опухоли, представляет собой антитело или лиганд, который связывается с маркером поверхности опухоли; или молекула, подавляющая опухоль, представляет собой противоопухолевый цитокин или противоопухолевый токсин; и предпочтительно цитокины включают, но не ограничиваются указанными IL-12, IL-15, IFN-бета, TNF-альфа.
В другом предпочтительном варианте осуществления в многофункциональном иммуноконъюгате детектируемая метка включает флуоресцентную метку или хромогенную метку.
В другом предпочтительном варианте осуществления в многофункциональном иммуноконъюгате антитело, которое связывается с маркером поверхности опухоли, относится к антителу, которое распознает антиген, отличный от мезотелина, при этом другой антиген включает EGFR, EGFRvIII, мезотелин, HER2, EphA2, Her3, ЕрСАМ, MUC1, MUC16, СЕА, клаудин 18.2, рецептор фолиевой кислоты, клаудин 6, CD3, WT1, NY-ESO-1, MAGE 3, ASGPR1 или CDH16.
В другом предпочтительном варианте осуществления в многофункциональном иммуноконъюгате молекула, которая нацелена на маркер поверхности иммунной клетки, представляет собой антитело, которое связывается с маркером поверхности Т-клетки и образует с вышеописанным антителом бифункциональное антитело, активирующее Т-клетку (биспецифический активатор Т-клетки, BiTE).
В другом предпочтительном варианте осуществления в многофункциональном иммуноконъюгате антитело, которое связывается с маркером поверхности Т-клетки, представляет собой антитело к CD3.
В другом предпочтительном варианте осуществления антитело к CD3 представляет собой одноцепочечное антитело (scFV), моноклональное антитело, Fab-фрагмент, Fd-фрагмент, Fv-фрагмент, F(ab')2-фрагмент и его производное; предпочтительно одноцепочечное антитело.
В другом предпочтительном варианте осуществления антитело к CD3 представляет собой гуманизированное, полностью человеческое, химерное или мышиное антитело.
В другом предпочтительном варианте осуществления многофункциональный иммуноконъюгат представляет собой слитый полипептид и дополнительно содержит линкерный пептид (линкер) между вышеописанным антителом по изобретению и связанной с ним функциональной молекулой.
В другом предпочтительном варианте осуществления линкерный пептид имеет последовательность (GlyGlyGlyGlySer)n, где n представляет собой целое число от 1 до 5; более предпочтительно n равно 3.
В другом предпочтительном варианте осуществления многофункциональный иммуноконъюгат вводят в виде полипептида или способом введения гена.
В другом аспекте изобретения предложена нуклеиновая кислота, кодирующая многофункциональный иммуноконъюгат.
В другом аспекте настоящего изобретения предложено применение многофункционального иммуноконъюгата для получения противоопухолевого средства или средства для диагностики опухолей, которые экспрессируют мезотелин; или для получения иммунных клеток, модифицированных химерным антигенным рецептором; и предпочтительно иммунные клетки включают Т-лимфоцит, NK-клетку или NKT-лимфоцит.
В другом аспекте изобретения предложена фармацевтическая композиция (включая лекарственное средство или средство для диагностики), включающая:
антитело или нуклеиновую кислоту, кодирующую антитело; или
иммуноконъюгат или нуклеиновую кислоту, кодирующую конъюгат; или
химерный антигенный рецептор или нуклеиновую кислоту, кодирующую химерный антигенный рецептор; или
генетически модифицированную иммунную клетку.
В другом аспекте изобретения предложено антитело, которое способно конкурировать за связывание с мезотелином с антителом по изобретению.
В другом аспекте изобретения предложено антитело, которое способно связываться с эпитопом мезотелина, представленным SEQ ID NO: 66. В предпочтительном варианте осуществления также предложено антитело, которое связывается с эпитопом мезотелина, представленным SEQ ID NO: 72.
Другие аспекты изобретения будут очевидны специалисту в данной области техники в контексте представленного раскрытия.
ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
Фигура 1. Связывание антител Р1А6Е и P3F2 с мезотелином человека и контролем BSA (бычий сывороточный альбумин) в анализе ELISA с единичным фагом. Значения для антител Р1А6Е и P3F2 к мезотелину человека и отрицательного контроля BSA продемонстрировали, что два выбранных антитела могут специфически связываться с мезотелином человека.
Фигура 2. Связывание двух разных одноцепочечных антител Р1А6Е и P3F2 с мезотелином человека и BSA, детектируемое с помощью ELISA.
Фигура 3. Электрофорез в очищенном полиакриламидном геле в присутствии додецилсульфата натрия (SDS-PAGE) антител к мезотелину человека.
Фигура 4. Электрофорез в SDS-PAGE моноклональных антител P1A6E и P3F2.
Фигура 5. Кривые связывания моноклонального антитела Р1А6Е с различными концентрациями мезотелина человека в Biacore.
Фигура 6. Кривая связывания моноклонального антитела P3F2 с различными концентрациями мезотелина человека в Biacore.
Фигура 7. Анализ специфического связывания четырех одноцепочечных антител (Р1А6Е, P3F2 и контрольных антител SS, С10) с клетками PANC-1-MSLN с помощью клеточного сортера с возбуждением флуоресценции (FACS).
Фигура 8. Анализ специфического связывания четырех моноклональных антител (Р1А6Е, P3F2 и контрольных антител SS, С10) с клетками PANC-1-MSLN с помощью клеточного сортера с возбуждением флуоресценции (FACS).
Фигура 9. ELISA, демонстрирующий связывание антител scFv-P1A6E-Fc и scFv-P3F2-Fc с областями R1, R2, R3.
Фигура 10. ELISA, демонстрирующий связывание антител scFv-P1A6E-Fc и scFv-P3F2-Fc с областями R1A, R1B, R1C, R1AB, R1BC.
Способ осуществления изобретения
Авторы настоящего изобретения исследовали множество видов опухолеспецифических генов на ранней стадии и обнаружили, что значительная часть этих генов также экспрессируется в нормальных клетках некоторых тканей, и применение этих генов относительно затруднено в способе модификации иммунных эффекторных клеток химерными антигенными рецепторами. Некоторые опухолеспецифические гены демонстрируют лучшие опухолеспецифические характеристики экспрессии, однако иммунные эффекторные клетки, модифицированные CAR, на их основе не обладают активностью по уничтожению опухолевых клеток или обладают низкой активностью, поскольку мишень может индуцировать секрецию факторов, ингибирующих иммунные эффекторные клетки, таких как PD-L1, опухолевыми клетками.
После повторных исследований и скрининга авторы настоящего изобретения обнаружили, что в качестве мишени для конструирования CAR среди многих молекул-кандидатов может использоваться мезотелин. Авторы настоящего изобретения продемонстрировали, что Т-клетки, модифицированные CAR, полученные на основе антител к мезотелину, избирательно нацелены на мезотелин-положительные опухолевые клетки и являются высокоцитотоксичными по отношению к опухолевым клеткам. Авторы предполагают, что соответствующие иммунные эффекторные клетки, модифицированные CAR, особенно Т-клетки, должны быть применимы для лечения опухолей человека.
Антитела к мезотелину
Специфические антитела, которые обладают хорошими свойствами связывания с мезотелином и пригодны для получения генетически модифицированных иммунных эффекторных клеток, были скринированы и получены авторами настоящего изобретения в библиотеках естественных полностью человеческих антител, также авторами изобретения были обнаружены их ключевые области CDR для выявления их свойств связывания.
Антитела по изобретению могут быть интактными молекулами иммуноглобулина или антигенсвязывающими фрагментами, включая, но не ограничиваясь указанными, Fab-фрагменты, Fd-фрагменты, Fv-фрагменты, F(ab')2 фрагменты, фрагменты области, определяющей комплементарность (CDR), одноцепочечное антитело (scFv), доменное антитело, двухвалентное одноцепочечное антитело, одноцепочечное фаговое антитело, биспецифическое диатело, трехцепочечное антитело, четырехцепопчечное антитело.
Антигенсвязывающие свойства антитела могут быть описаны тремя специфическими областями, расположенными в вариабельных областях тяжелой и легкой цепей, называемыми областями, определяющими комплементарность (CDR), которые разделяют вариабельные области на четыре каркасные области (FR), а аминокислотные последовательности четырех FR являются относительно консервативными и непосредственно не вовлечены в связывание. Эти CDR образуют петлевую структуру, в которой β-складки, образованные FR, расположены близко друг к другу в пространстве, а антигенсвязывающий сайт антитела состоит из CDR на тяжелой цепи и CDR на соответствующей легкой цепи. Можно определить, какие аминокислоты составляют области FR или CDR, сравнивая аминокислотные последовательности того же типа антител. Области CDR представляют собой последовательности иммунологически примечательных белков, a CDR области антител по изобретению являются совершенно новыми. Антитело может содержать два, три, четыре, пять или все шесть областей CDR, описанных в данном документе.
Другой аспект изобретения включает функциональные варианты антител, описанных в данном документе. Если вариант способен конкурировать с исходным антителом за специфическое связывание с мезотелином 1, и его способность распознавать мезотелин, экспрессируемый опухолевыми клетками, близка к таковой для специфических антител, представленных в примерах настоящего изобретения. Функциональные варианты могут иметь модификации консервативных последовательностей, включая нуклеотидные и аминокислотные замены, добавления и делеции. Такие модификации могут быть введены стандартными способами, известными в данной области техники, такими как направленный мутагенез и случайный ПЦР-опосредованный мутагенез, и могут включать как природные, так и неприродные нуклеотиды и аминокислоты. Предпочтительно модификация последовательности происходит вне области CDR антитела.
Антитела по настоящему изобретению могут быть применены для получения различных противоопухолевых лекарственных средств направленного действия и лекарственных средств для диагностики опухолей, и в частности для получения иммунных эффекторных клеток, нацеленных на мезотелин.
Химерный антигенный рецептор и генетически модифицированная иммунная клетка
В настоящем изобретении предложен химерный антигенный рецептор, экспрессируемый на поверхности иммунной эффекторной клетки (иммунной клетки), где химерный антигенный рецептор содержит последовательно связанные внеклеточную область связывания, трансмембранную область и внутриклеточную сигнальную область, при этом внеклеточная область связывания содержит антитело по изобретению. Путем экспрессии химерного антигенного рецептора на поверхности иммунных эффекторных клеток, последние могут оказывать высокоспецифическое цитотоксическое действие на опухолевые клетки, экспрессирующие мезотелин.
В контексте настоящего изобретения термины «иммунные клетки» и «иммунные эффекторные клетки» используются взаимозаменяемо и включают Т-лимфоцит, NK-клетки или NKT-клетки и т.п.
В качестве предпочтительного варианта осуществления настоящего изобретения антитело, содержащееся в химерном антигенном рецепторе, представляет собой одноцепочечное антитело, которое связано с CD8 или трансмембранной областью CD28 через шарнирную область CD8, и за трансмембранной областью сразу же следует внутриклеточная сигнальная область.
Изобретение также включает нуклеиновые кислоты, кодирующие химерные антигенные рецепторы. Настоящее изобретение также относится к вариантам вышеописанных полинуклеотидов, которые кодируют полипептид или фрагмент, аналог и производное полипептида, имеющего ту же аминокислотную последовательность, что и настоящее изобретение.
Трансмембранная область химерного антигенного рецептора может быть выбрана из трансмембранной области белка, такого как CD8 или CD28. Белок CD8 человека представляет собой гетеродимер, состоящий из двух цепей, αβ или γδ. В одном варианте осуществления изобретения трансмембранная область выбрана из трансмембранной области CD8a или CD28. Кроме того, шарнирная область CD8α является гибкой областью, так что CD8 или CD28 и трансмембранная область, а также шарнирная область используются для соединения домена распознавания целевого scFv химерного антигенного рецептора CAR с внутриклеточной сигнальной областью.
Внутриклеточная сигнальная область может быть выбрана из группы, состоящей из внутриклеточной сигнальной области белка CD3ζ, FcεRIγ, CD27, CD28, CD137, CD134, MyD88, CD4 и их комбинаций. Молекула CD3 состоит из пяти субъединиц, в которых субъединица CD3ζ (также известная как CD3 zeta, сокращенно Z) содержит 3 мотива ITAM (иммунорецепторных тирозиновых активирующих мотива), которые являются важными областями сигнальной трансдукции в комплексе TCR-CD3. CD38Z представляет собой усеченную последовательность CD3ζ, без мотива ITAM, и она, как правило, сконструирована в настоящем изобретении в качестве отрицательного контроля. FcεRIγ в основном распределен на поверхности тучных клеток и базофилов и содержит мотив ITAM, который похож на CD3ζ по структуре, распределению и функции. Кроме того, как упоминалось выше, CD28, CD137 и CD134 являются ко-стимулирующими сигнальными молекулами. Ко-стимулирующий эффект их внутриклеточных сигнальных сегментов при связывании с соответствующими лигандами приводит к продолжительной пролиферации иммунных эффекторных клеток, прежде всего Т-лимфоцитов, и увеличению уровня цитокинов, таких как IL-2 и IFN-γ, секретируемых иммунными эффекторными клетками, а также увеличению периода выживания и противоопухолевого действия иммунных эффекторных клеток, модифицированных CAR, in vivo.
Химерный антигенный рецептор по настоящему изобретению может быть последовательно соединен следующим образом:
Антитело по изобретению, CD8 и CD3ζ;
Антитело по изобретению, CD8, CD137 и CD3ζ;
Антитело по изобретению, трансмембранная область молекулы CD28, внутриклеточная сигнальная область молекулы CD28 и CD3ζ; или
Антитела по изобретению, трансмембранная область молекулы CD28, внутриклеточная сигнальная область молекулы CD28, CD137 и CD3.
И их комбинации, где CD28a в соответствующем белке химерного антигенного рецептора представляет собой трансмембранную область молекулы CD28, a CD28b представляет собой внутриклеточную сигнальную область молекулы CD28. Различные описанные выше химерные антигенные рецепторы в совокупности называются scFv (мезотелин)-CAR.
В настоящем изобретении также предложен вектор, содержащий вышеуказанную нуклеиновую кислоту, кодирующую белок химерного антигенного рецептора, экспрессируемый на поверхности иммунной эффекторной клетки. В конкретном варианте осуществления вектор, применяемый в настоящем изобретении, представляет собой лентивирусный плазмидный вектор pWPT-eGFP. Данная плазмида относится к третьему поколению самоинактивирующейся лентивирусной векторной системы. Система имеет три плазмиды, упаковочная плазмида psPAX2, кодирующая белок Gag/Pol, кодирующая белок Rev; плазмида оболочки PMD2.G, кодирующая белок VSV-G (гликопротеин вируса везикулярного стоматита); и пустой вектор pWPT-eGFP, который может быть применен для рекомбинантного введения представляющей интерес последовательности нуклеиновой кислоты, т.е. нуклеиновой кислоты, кодирующей CAR. В пустом векторе pWPT-eGFP экспрессия усиленного зеленого флуоресцентного белка (eGFP) регулируется промотором фактора элонгации-1α (EF-1α). В рекомбинантном векторе экспрессии pWPT-eGFP-F2A-CAR, содержащем последовательность нуклеиновой кислоты, кодирующую CAR, совместная экспрессия eGFP и CAR достигается с помощью последовательности 2А (сокращенно F2A) вируса ящура (FMDV), индуцирующей рибосомальный пропуск. Следует понимать, что также применимы другие векторы экспрессии.
Изобретение также включает вирусы, содержащие векторы, описанные выше. Вирусы по изобретению включают упакованные инфекционные вирусы, а также вирусы, подлежащие упаковке, которые содержат необходимые компоненты для упаковки в инфекционные вирусы. Другие вирусы, известные в данной области техники, которые могут быть использованы для трансдукции экзогенных генов в иммунные эффекторные клетки и их соответствующие плазмидные векторы также применимы в настоящем изобретении.
Настоящее изобретение дополнительно включает генетически модифицированный Т-лимфоцит, который трансдуцируют нуклеиновой кислотой по настоящему изобретению или трансдуцируют вышеуказанной рекомбинантной плазмидой, содержащей нуклеиновую кислоту по настоящему изобретению, или вирусной системой, содержащей плазмиду. В настоящем изобретении могут быть применены обычные в данной области техники способы трансдукции нуклеиновой кислоты, включая способы невирусной и вирусной трансдукции. Способы невирусной трансдукции включают способы электропорации и транспозона. В последнее время, для достижения высокоэффективной трансдукции целевых генов стало возможным непосредственно вводить чужеродные гены в ядро с помощью нуклеофектора, аппарата для ядерной трансфекции, разработанного Amaxa. Кроме того, по сравнению с обычной электропорацией, эффективность трансдукции системы транспозонов на основе системы Sleeping Beauty или транспозона PiggyBac была значительно улучшена. Сообщалось о комбинировании аппарата для ядерной трансфекции и системы транспозона SB Sleeping Beauty [Davies JK., et al. Combining CD19 redirection and alloanergization to generate tumor-specific human T cells for allogeneic cell therapy of B-cell malignancies. Cancer Res, 2010, 70(10): OF1-10.], и с помощью этого способа может быть достигнута высокая эффективность трансдукции и сайт-направленная интеграция целевых генов. В одном варианте осуществления изобретения способ трансдукции Т-лимфоцитов, модифицированных геном химерного антигенного рецептора, представляет собой способ трансдукции на основе вируса, такого как ретровирус или лентивирус. Преимущества способа заключаются в высокой эффективности трансдукции и стабильной экспрессии экзогенного гена, а также возможности уменьшения времени культивирования Т-лимфоцитов in vitro до клинического уровня. Трансдуцированная нуклеиновая кислота экспрессируется, проходя этапы транскрипции и трансляции, на поверхности трансгенных Т-лимфоцитов. Анализ цитотоксичности in vitro, проведенный на различных культивированных опухолевых клетках, показал, что иммунные эффекторные клетки по настоящему изобретению обладают высокоспецифическими эффектами уничтожения опухолевых клеток (также известными как цитотоксичность). Таким образом, нуклеиновая кислота, кодирующая белок химерного антигенного рецептора по настоящему изобретению, плазмида, содержащая нуклеиновую кислоту, вирус, содержащий плазмиду, и трансгенные иммунные эффекторные клетки, трансфицированные нуклеиновой кислотой, плазмидой или вирусом, описанными выше, могут эффективно применяться в опухолевой иммунотерапии.
Иммунные клетки по настоящему изобретению также могут нести экзогенные кодирующие последовательности для цитокинов, включая, но не ограничиваясь указанными, IL-12, IL-15 или IL-21. Эти цитокины обладают иммуномодулирующей или противоопухолевой активностью, усиливают функцию эффекторных Т-клеток и активированных NK-клеток или непосредственно оказывают противоопухолевое действие. Таким образом, специалистам в данной области техники будет понятно, что применение этих цитокинов поможет иммунным клеткам лучше функционировать.
В дополнение к химерному антигенному рецептору, описанному выше, иммунные клетки по настоящему изобретению могут также экспрессировать другой химерный антигенный рецептор, который не содержит CD3ζ, но содержит внутриклеточный сигнальный домен CD28 и внутриклеточный сигнальный домен CD137 или их комбинацию.
Иммунные клетки по настоящему изобретению могут также экспрессировать хемокиновые рецепторы, включая, но не ограничиваются указанными, CCR2. Специалисту в области техники будет понятно, что хемокиновый рецептор CCR2 может конкурентно связывать CCR2 в организме и эффективно применяться для блокировки метастазирования опухоли.
Иммунные клетки по настоящему изобретению могут также экспрессировать миРНК, которые могут уменьшить экспрессию PD-1, или белки, блокирующие PD-L1. Специалисту в области техники будет понятно, что конкурентная блокировка взаимодействий между PD-L1 и его рецептором PD-1 будет способствовать восстановлению противоопухолевых Т-клеточных ответов, тем самым ингибируя рост опухоли.
Иммунные клетки по настоящему изобретению могут также экспрессировать предохранитель; предпочтительно, предохранитель включает индуцируемую каспазу-9, усеченный EGFR или RQR8.
Иммуноконъюгат
В настоящем изобретении также предложен многофункциональный иммуноконъюгат, содержащий антитела, описанные в настоящем документе, и дополнительно содержащий по меньшей мере одну функциональную молекулу другого типа. Функциональная молекула выбрана из, но не ограничиваясь указанными, молекулы, которая нацелена на маркер поверхности опухоли, молекулы, подавляющей опухоль, молекулы, которая нацелена на маркер поверхности иммунной клетки, или детектируемой метки. Антитело и функциональная молекула могут образовывать конъюгат путем ковалентного связывания, спаривания, связывания, сшивания и т.п.
В качестве предпочтительного варианта иммуноконъюгат может содержать антитело по изобретению и по меньшей мере одну молекулу, которая нацелена на маркер поверхности опухоли, или молекулу, подавляющую опухоль. Молекула, подавляющая опухоль, может представлять собой противоопухолевые цитокины или противоопухолевые токсины. Предпочтительно, цитокины включают, но не ограничиваясь указанными, IL-12, IL-15, IFN-бета, TNF-альфа. Молекулы, которые нацелены на маркеры поверхности опухоли, например, могут действовать синергетически с антителами по изобретению для более точного нацеливания на опухолевые клетки.
В качестве предпочтительного варианта иммуноконъюгат может содержать антитело по настоящему изобретению и детектируемую метку. Такие детектируемые метки включают, но не ограничиваясь указанными, флуоресцентные метки, хромогенные метки, такие как ферменты, простетические группы, флуоресцентные материалы, люминесцентные материалы, биолюминесцентные материалы, радиоактивные материалы, позитрон-излучающие металлы и нерадиоактивный парамагнитный ион металла. Также можно быть включен более чем один маркер. Метка, применяемая для маркировки антитела с целью обнаружения, и/или анализа, и/или диагностики, зависит от применяемой конкретной техники и/или способа обнаружения/анализа/диагностики, например, иммуногистохимическое окрашивание образцов (ткани), проточная цитометрия и т.п. Специалистам в данной области техники хорошо известны подходящие метки для техник и/или способов обнаружения/анализа/диагностики, известных в данной области техники.
В качестве предпочтительного варианта иммуноконъюгат может содержать антитело по изобретению, а также молекулу, которая нацелена на маркер поверхности иммунной клетки. Молекула, которая нацелена на маркеры поверхности иммунных клеток, может распознавать иммунные клетки и переносить антитела по изобретению к иммунным клеткам, так что антитела по изобретению могут нацеливать иммунные клетки на опухолевые клетки и тем самым запускать иммуноциты для специфического уничтожения опухоли.
В качестве средств химического получения иммуноконъюгата путем конъюгации, напрямую или косвенно (например, с помощью линкера), иммуноконъюгат может быть получен в виде слитого белка, содержащего антитело по изобретению и другие подходящие белки. Слитый белок может быть получен способом, известным в данной области техники, например, рекомбинантно, путем конструирования и последующей экспрессии молекулы нуклеиновой кислоты, которая содержит нуклеотидную последовательность, кодирующую антитело, в рамке с нуклеотидной последовательностью, кодирующей подходящую метку.
В другом аспекте изобретения предложена молекула нуклеиновой кислоты, кодирующая по меньшей мере одно антитело по изобретению, функциональный вариант или его иммуноконъюгат. После получения соответствующей последовательности для получения соответствующей последовательности в больших количествах может быть применен рекомбинантный способ. Обычно это осуществляют путем ее клонирования в вектор, переноса его в клетку и последующего выделения соответствующей последовательности из пролиферирующих клеток-хозяев стандартными способами.
Настоящее изобретение также относится к векторам, содержащим подходящие последовательности ДНК, описанные выше, а также подходящие промоторы или контрольные последовательности. Эти векторы могут быть применены для трансформации подходящей клетки-хозяина, чтобы обеспечить экспрессию белка. Клетка-хозяин может представлять собой прокариотическую клетку, такую как бактериальная клетка; или низшую эукариотическую клетку, такую как дрожжевая клетка; или высшую эукариотическую клетку, такую как клетка млекопитающего.
Фармацевтическая композиция
Антитела, иммуноконъюгаты, содержащие антитела, и генетически модифицированные иммунные клетки по настоящему изобретению могут быть применены для получения фармацевтической композиции или средства для диагностики. В дополнение к эффективному количеству антитела, иммунологического конъюгата или иммунной клетки, композиция может дополнительно содержать фармацевтически приемлемый носитель. Термин «фармацевтически приемлемый» означает, что, когда молекулярные субстанции и композиции вводят животным или людям надлежащим образом, они не вызывают неблагоприятных, аллергических или других нежелательных реакций.
Конкретными примерами некоторых веществ, которые могут быть применены в качестве фармацевтически приемлемых носителей или их компонентов, являются сахара, такие как лактоза, декстроза и сахароза; крахмалы, такие как кукурузный крахмал и картофельный крахмал; целлюлоза и ее производные, такие как карбоксиметилцеллюлоза натрия, этилцеллюлоза и метилцеллюлоза; трагант; солод; желатин; тальк; твердые смазывающие вещества, такие как стеариновая кислота и стеарат магния; сульфат кальция; растительные масла, такие как арахисовое масло, хлопковое масло, кунжутное масло, оливковое масло, кукурузное масло и масло какао; многоатомные спирты, такие как пропиленгликоль, глицерин, сорбит, маннит и полиэтиленгликоль; альгиновая кислота; эмульгаторы, такие как Tween®; смачивающие агенты, такие как лаурилсульфат натрия; красители; ароматизаторы; таблетки, стабилизаторы; антиоксиданты; консерванты; апирогенная вода; изотонические солевые растворы; и фосфатные буферы и т.п.
Композиция по настоящему изобретению может быть получена в различных лекарственных формах по мере необходимости, и дозировка, которую нужно вводить пациенту, может быть определена врачом в соответствии с факторами, такими как тип, возраст, масса тела и общее медицинское состояние пациента, способ введения и т.п.Например, можно применять инъекцию или другой способ лечения.
Далее настоящее изобретение описано со ссылкой на конкретные варианты осуществления. Следует понимать, что эти примеры предназначены только для иллюстрации настоящего изобретения и не предназначены для ограничения объема настоящего изобретения. В нижеследующих примерах экспериментальные процедуры, там, где не указаны конкретные условия, обычно выполняются в соответствии с условиями, описанными в стандартных положениях, такими как составленные J. Sambrook et al., Molecular Cloning Experiments Guide, Third Edition, Science Press, 2002, или согласно условиям, предлагаемым изготовителем.
Пример 1. Конструирование линий клеток, стабильно экспрессирующих мезотелин
1.1. Конструирование плазмидного вектора
Применяемая в этом примере векторная система относится к третьему поколению самоинактивирующейся лентивирусной векторной системы. В системе три плазмиды, упаковочная плазмида psPAX2, кодирующая белок Gag/Pol, кодирующая белок Rev; плазмида оболочки PMD2.G, кодирующая белок VSV-G; и рекомбинантная плазмида pWPT-MSLN, кодирующая внеклеточную и трансмембранную область целевого гена мезотелина человека на основе пустого вектора pWPT (от Addgene).
В соответствии с учетным номером NMB005823 в GenBank фрагмент целевого гена (SEQ ID NO: 1 (нуклеотидная), 2 (аминокислотная)), содержащий сигнальный пептид, Flag-маркер, внеклеточный домен и трансмембранную область мезотелина человека, синтезировали с применением способа синтеза гена, основанного на мостиковой ПЦР. ПЦР-амплификацию проводили с применением пар праймеров pWmslnF (SEQ ID NO: 3, GCTTACGCGTCCTAGCGCTACCGGTCGCCACCATGAGGGCCTGGATC) и pWmslnR (SEQ ID NO: 4, CGAGGTCGACCTAGGCCAGGGTGGAGGCTAGGAGCAGTGCCAGGACGG) при следующих условиях: предварительная денатурация: 94°С в течение 4 мин; денатурация: 94°С в течение 30 с; отжиг: 58°С в течение 30 с; элонгация: 68°С в течение 80 с; 30 циклов. Теоретический размер полученного фрагмента составлял 1113 пар оснований. Продукт амплификации подтверждали электрофорезом в агарозном геле, и он соответствовал теоретическому размеру. Сайты рестрикции MluI и SalI вводили выше по цепи и ниже по цепи к открытой рамке считывания. Целевой ген, полученный выше, дважды расщепляли с помощью MluI и SalI и лигировали в один и тот же дважды расщепленный вектор pWPT для конструирования эффективного лентивирусного вектора pWPT-MSLN. Сконструированный вектор идентифицировали с помощью расщепления MluI и SalI и секвенировали по корректным последовательностям, чтобы он был готов к лентивирусной упаковке.
1.2. Трансфицированные плазмидой клетки 293Т для упаковки лентивируса
Клетки 293Т (АТСС: CRL-11268), культивированные от пассажа 6 к пассажу 10, высевали с плотностью 6×106 в чашках по 10 см и культивировали в течение ночи при 37°С в 5% СО2 для трансфекции. В качестве среды использовали DMEM (Invitrogen), содержащую 10% фетальную бычью сыворотку (Sigma). И на следующие сутки среду заменяли на бессывороточную DMEM за 2 часа до трансфекции.
Стадии трансфекции заключались в следующем:
1) 5 мкг плазмиды целевого гена pWPT-MSLN растворяли в 500 мкл воды MillQ с 7,5 мкг упаковочной плазмиды РАХ2 и 2,5 мкг плазмиды оболочки pMD2.G, соответственно, и смешивали,
2) По каплям добавляли 62 мкл 2,5 М CaCl2 (Sigma) и перемешивали при 1200 об/мин на вортексе,
3) Наконец, по каплям добавляли 500 мкл 2×HBS (280 мМ NaCl, 10 мМ KCl, 1,5 мМ Na2HPO4, 12 мМ глюкозы, 50 мМ Hepes (Sigma), рН 7,05 и стерилизовали через фильтр 0,22 мкМ) и перемешивали встряхиванием при 1200 об/мин в течение 10 с,
4) Сразу же помещали в культуральную чашку, осторожно встряхивали при 37°С, 5% СО2, культивировали в течение от 4 до 6 часов, заменяли DMEM, содержащей 10% фетальную бычью сыворотку.
Через 48 ч или 72 ч трансфекции клеточный дебрис удаляли центрифугированием и вирус собирали фильтрованием с применением фильтра 0,45 мкм (Millipore).
1.3. Инфицирование клеток PANC-1 рекомбинантным лентивирусом
Собранный вирусный раствор концентрировали и титровали, а клетки PANC-1 (от АТСС), высеянные на чашки размером 6 см, инфицировали. Через трое суток после инфицирования клетки собирали, часть смешанных клонов отбирали и лизировали жидкостью для лизиса клеток. И затем 40 мкг клеточного белка подвергали гель-электрофорезу в SDS-PAGE с последующим иммуноблоттингом и окрашиванием мышиными антителами к Flag-маркеру. После промывания PBS белок инкубировали с козьим антимышиным антителом, мечеными пероксидазой хрена, промывали и, наконец, детектировали с помощью ECL-реагента (реагент электрохимического лизиса). Результаты вестерн-блоттинга показали, что полоса с молекулярной массой приблизительно 38 кДа была обнаружена в клетках PANC-1, инфицированных мезотелином человека MSLN (т.е. PANC-1-MSLN), в то время как соответствующая полоса не была обнаружена в неинфицированных пустых клетках. Остальные клетки были размножены, заморожены и сохранены для последующих экспериментов.
Пример 2. Получение антигена мезотелина человека
В соответствии с учетным номером NM_005823 в GenBank фрагмент гена мезотелина человека (положения с 88 по 942 последовательности SEQ ID NO: 1 (нуклеотидная), положения с 30 по 314 последовательности SEQ ID NO: 12 (аминокислотная)) синтезировали с применением способа синтеза гена, основанного на мостиковой ПЦР, и выполняли ПЦР-амплификацию. Амплифицированный продукт вводили в плазмидный вектор pCMV-V5 (вектор имеет 6 His-маркеров, слитых и экспрессируемых ниже по цепи с сайтом множественного клонирования, от Shanghai Rui Jin Biotechnology Co., Ltd.) с помощью NheI/BglII, и трансформировали в штамм-хозяин ТОР10. Положительные клоны выделяли, идентифицировали с помощью ПЦР и подтверждали секвенированием с получением рекомбинантной плазмиды экспрессии V5-MSLN.
Вышеуказанные плазмиды экспрессии трансфицировали в хорошо растущие клетки HEK-293F и непрерывно культивировали при 37°С, 5% СО2, 12,5 об/мин при встряхивании в течение 7 суток, и центрифугировали при 4000 об/мин в течение 10 мин, осадки удаляли, супернатант собирали и фильтровали через мембранный фильтр 0,45 мкм, обработанный образец очищали на колонке для аффинной хроматографии HisTrap (от GE), чтобы в конечном итоге получить очищенный белок мезотелина человека, а результаты идентификации представлены на фиг. 1.
Пример 3. Скрининг одноцепочечного антитела к мезотелину человека
3.1. Скрининг связывающих антител специфических к мезотелину человека на основе фагового дисплея
Применяя технологию фагового дисплея, специфическое к мезотелину человека антитело скринировали из библиотеки естественных полностью человеческих антител. Для этой цели бактерии в глицерине (приобретаемые у Shanghai Rui Jin Biotechnology Co., Ltd.) из естественной библиотеки фагового дисплея полностью человеческих одноцепочечных антител инокулировали в 400 мл среды 2×YT (триптон с дрожжевым экстрактом)/ампициллин, до достижения плотности клеток OD600=0,1 и инкубировали при 37°С и 200 об/мин до достижения плотности клеток OD600=0,5. Для инфицирования клеток применяли 1012 БОЕ (бляшкообразующие единицы) вспомогательного фага M13LO7 (от Invitrogen) и инкубировали при 30°С и 50 об/мин в течение 30 минут. После добавления 50 мг/л канамицина и культивирования при встряхивании при 37°С и 200 об/мин в течение 30 минут осадок отделяли центрифугированием (15 минут, 1600×g, 4°С) и ресуспендировали в 400 мл среды 2×YT/пенициллин/канамицин и встряхивали в течение 16 ч при 37°С и 200 об/мин. Наконец, осадок отделяли центрифугированием (5000 об/мин, 4°С в течение 20 минут) и отбрасывали. Супернатант фильтровали через фильтр 0,45 мкм и добавляли 1/4 объема 20% (мас./об.) ПЭГ 8000, 2,5 М раствор NaCl и инкубировали на ледяной бане в течение 1 часа для осаждения бактериофага. Затем осадок осаждали центрифугированием (20 мин, 8000×g, 4°С) и супернатант отбрасывали. Фаг ресуспендировали в 25 мл предварительно обработанного PBS (137 мМ NaCl, 2,7 мМ KCl, 8 мМ Na2HPO4, 2 мМ KH2PO4) и центрифугировали (5 мин, 20000×g, 4°С). Добавляли к супернатанту 1/4 объема 20% (мас./об.) ПЭГ 8000, 2,5 М раствор NaCl и снова инкубировали на ледяной бане в течение 30 минут для осаждения фаговых частиц. Осадок центрифугировали (30 мин, 20000×g, 4°С) и фаговые частицы снова ресуспендировали в 2 мл предварительно обработанного PBS, выдерживали на льду в течение 30 мин и центрифугировали (30 мин, 17000×g, 4°С). Супернатанты смешивали с 4% (мас./об.) BSA в PBS при 1:1, помещали на роторный смеситель и инкубировали в течение 30 минут при комнатной температуре, а затем непосредственно использовали для скрининга.
Используя вышеупомянутую библиотеку фаговых антител, выполняли четыре раунда направленного скрининга на биотинилированном рекомбинантном белке мезотелина человека по следующей схеме: библиотеку фаговых антител инкубировали с антигеном мезотелина, меченым биотином, при комнатной температуре в течение 2 часов, а затем инкубировали с блокированными 2% (мас./об.) BSA магнитными частицами, покрытыми стрептавидином, MyOne Cl (от Invitrogen) при комнатной температуре в течение 30 минут. Затем частицы промывали буфером PBST (фосфатно-солевой буфер, содержащий 0,1% Tween-20) для удаления фагов, которые не были специфически связаны или имели слабую связывающую способность. Фаги с высокой связывающей способностью отделяли от магнитных частиц глицином-HCl (рН 2,2), нейтрализовали нейтрализующим раствором Триса (рН 9,1) и применяли для инфицирования Е. coli ER2738 в средней логарифмической фазе роста для следующего раунда скрининга. В четырех раундах скрининга количество магнитных частиц составляло 50 мкл, 20 мкл, 10 мкл и 10 мкл, а концентрации мезотелина человека, меченного биотином, составляли 100 нМ, 10 нМ, 5 нМ и 1 нМ, соответственно, и PBST применяли для промывки в течение 10, 10, 15 и 20 раз, соответственно.
3.2. Идентификация связывающих антител специфических к мезотелину человека Случайным образом выбирали 96 клонов из клонов, полученных в четвертом раунде скрининга, и анализировали их связывающую способность с мезотелином человека с применением ELISA (ферментный иммуносорбентный анализ) с единичным фагом. Для этой цели каждую отдельную колонию инокулировали в 300 мкл среды 2×YT/ампициллин (содержащей 2% глюкозу) на 96-луночном планшете с глубокими лунками и культивировали при встряхивании при 37°С и 250 об/мин в течение 16 часов. 20 мкл культуры инокулировали в 500 мкл среды 2×YT/ампициллин (содержащей 0,1% глюкозу) и встряхивали при 37°С и 250 об/мин в течение 1,5 часов. Для получения
раствора вспомогательного фага отбирали 75 мкл M13KO7 (титр 3×1012 БОЕ/мл) и смешивали в 15 мл среды 2×YT и добавляли в культуральный планшет по 50 мкл/лунку и инкубировали при 37°С и 150 об/мин в течение 30 минут. Затем готовый раствор канамицина (брали 180 мкл канамицина 50 мг/мл и добавляли в 15 мл среды 2×YT) добавляли по 50 мкл/лунку и инкубировали при встряхивании в течение 16 часов при 37°С и 250 об/мин. Наконец, клетки осаждали центрифугированием (30 минут, 5000×g, 4°С) и супернатант переносили в новый 96-луночный планшет с глубокими лунками.
Для проведения ELISA с единичным фагом в 96-луночный планшет MediSorp ELISA (приобретен у Nunc) размещали 100 нг/лунку антигена мезотелина человека и белка отрицательного контроля BSA (100 мкл/лунку) и покрывали, оставляя в течение ночи при 4°С. Каждую лунку блокировали PBST, содержащим 2% (мас./об.) BSA. Затем лунки трижды промывали PBST и последний отбрасывали. Затем каждый раствор фага, полученный выше, добавляли в каждую лунку планшета по 100 мкл/лунку. После инкубации при 37°С в течение 2 часов планшет трижды промывали PBST. Для обнаружения связанного фага конъюгат супероксиддисмутазы и антитела к М13 (приобретен у GE Healthcare) разводили в соотношении 1:5000 в PBST и в каждую лунку добавляли по 100 мкл. После инкубации при 37°С в течение 1 часа лунки трижды промывали PBST, а затем трижды промывали PBS. Наконец, 50 мкл тетраметилбензидинового субстрата (ТМВ) добавляли в лунки и проводили визуализацию в течение 10 минут при комнатной температуре с последующим добавлением 50 мкл 2М H2SO4 на лунку для остановки реакции окрашивания. Значения экстинкции измеряли при 450 нм с помощью иммуносорбента с иммобилизованными ферментами (Bio-Rad). При секвенировании обнаруживали два разных одноцепочечных антитела Р1А6Е (SEQ ID NO: 5 (нуклеотидная), 6 (аминокислотная)) и P3F2 (SEQ ID NO: 7 (нуклеотидная), 8 (аминокислотная)), которые проявляли достаточно сильное связывание с мезотелином человека (hu-мезотелин) при проведении анализа ELISA, при этом не связываясь с BSA (фиг. 2).
SEQ ID NO: 5 (нуклеотидная)

SEQ ID NO: 6 (аминокислотная)

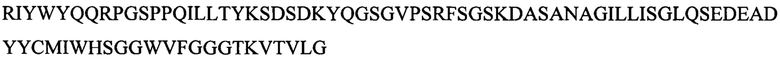
Где аминокислотная последовательность вариабельной области тяжелой цепи представлена в положениях с 1 по 123 SEQ ID NO: 6, и аминокислотная последовательность вариабельной области легкой цепи представлена в положениях с 139 по 254 SEQ ID NO: 6.
Где аминокислотная последовательность CDR1 легкой цепи представляет собой TLRSGINVGIYRIY (SEQ ID NO: 51), аминокислотная последовательность CDR2 легкой цепи представляет собой YKSDSDKYQGS (SEQ ID NO: 52), аминокислотная последовательность CDR3 легкой цепи представляет собой MIWHSGGWV (SEQ ID NO: 53); аминокислотная последовательность CDR1 тяжелой цепи представляет собой GDTVSSDSAAWN (SEQ ID NO: 54), аминокислотная последовательность CDR2 тяжелой цепи представляет собой RTYYRSKWFNDYAVSVKG (SEQ ID NO: 55), а аминокислотная последовательность CDR3 тяжелой цепи представляет собой SNSYYYYAMDV (SEQ ID NO: 56).
SEQ ID NO: 7 (нуклеотидная)

SEQ ID NO: 8 (аминокислотная)

Где аминокислотная последовательность вариабельной области тяжелой цепи представлена в положениях с 1 по 124 SEQ ID NO: 8; аминокислотная последовательность вариабельной области легкой цепи представлена в положениях с 140 по 247 SEQ ID NO: 8.
Где аминокислотная последовательность CDR1 легкой цепи представляет собой RASQVISRALA (SEQ ID NO: 57), аминокислотная последовательность CDR2 легкой цепи представляет собой DASNLQS (SEQ ID NO: 58), аминокислотная последовательность CDR3 легкой цепи представляет собой QQFNSYPLT (SEQ ID NO: 59); аминокислотная последовательность CDR1 тяжелой цепи представляет собой GYTFTSYYMH (SEQ ID NO: 60), аминокислотная последовательность CDR2 тяжелой цепи представляет собой IINPSGGSTSYAQKFQG (SEQ ID NO: 61), а аминокислотная последовательность CDR3 тяжелой цепи представляет собой SRSGTTVVNHDAFDI (SEQ ID NO: 62).
Пример 4. Получение одноцепочечного антитела и моноклонального антитела
4.1. Получение одноцепочечного антитела к мезотелину человека
Фрагмент scFv-P1A6E амплифицировали из полученных клонов с применением пары праймеров V5-P1A6E-F (SEQ ID NO: 9) и V5-P1A6E-R (SEQ ID NO: 10); фрагмент scFv-P3F2 амплифицировали с применением пары праймеров V5-P3F2-F (SEQ ID NO: 11) и V5-P3F2-R (SEQ ID NO: 12), расщепляли рестриктазой Nhel/BamHI, соединяли с векторной плазмидой pCMV-V5-Fc, дважды расщепленной Nhel/BamHI (в векторе Fc-фрагмент человеческого антитела IgG1 гибридизировали ниже по цепи с сайтами множественного клонирования, именуемый далее как V5-Fc, приобретенный у Shanghai Rui Jin Biotech Co., Ltd.), с помощью ДНК-лигазы T4, и трансформировали в штамм-хозяин TOP10. Клоны отбирали, и положительные клоны идентифицировали с помощью ПЦР и подтверждали секвенированием с получением эукариотических плазмид экспрессии V5-scFv-P1A6E-Fc и V5-scFv-P3F2-Fc, соответственно.
SEQ ID NO: 9: ACAGTGCTAGCACAGGTACAGCTGGAACAG;
SEQ ID NO: 10: TTGTCGGATCCACCTAGGACGGTGACC;
SEQ ID NO: 11: ACAGTGCTAGCACAGATGCAGCTAGTGC;
SEQ ID NO: 12: TTGTCGGATCCACGTTTGATCTCCAGC.
Вышеуказанные плазмиды экспрессии трансфицировали в хорошо растущие клетки HEK-293F, соответственно, культивировали при 37°С, 5% CO2, 125 об/мин при встряхивании непрерывно в течение 7 суток, центрифугировали при 4000 об/мин в течение 10 мин. Осадок удаляли и супернатант собирали и фильтровали с помощью мембраны 0,45 мкм. Обработанный образец аффинно очищали с помощью колонки с иммобилизованным белком А (от GE) с получением окончательно очищенных слитых белков антитело-Fc scFv-P1A6E-Fc и scFv-P3F2-Fc. Результаты идентификации представлены на фиг. 3.
4.2. Получение моноклонального антитела к мезотелину человека
В этом примере моноклональное антитело экспрессировали с применением двухплазмидной системы. Ген вариабельной области тяжелой цепи антитела подлежал внесению в плазмиду pIH, содержащую ген IgGl CH человека, и ген вариабельной области легкой цепи антитела подлежал внесению в плазмиду PIK, содержащую ген IgG CL человека (плазмида приобретена у Shanghai Rui Jin Biotechnology Co., Ltd.).
Фрагмент VH-P1A6E амплифицировали из матричной плазмиды V5-scFv-PlA6E-Fc с применением пары праймеров P1A6E-HF (SEQ ID NO: 13, gcctttcctggtttcctgtctcaggtacagctgg aacagtc) и P1A6E-HR (SEQ ID NO: 14, GATGGGCCCTTGGTGGAGGCACTCGAGACGGTGACCAG). Фрагмент HF1 амплифицировали из матричной плазмиды pIH с применением пары праймеров HF1F (SEQ ID NO: 15, ggctaactagagaacccactgc) и HF1R (SEQ ID NO: 16, AGACAGGAAACCAGGAAAGGC); и фрагмент HF3 амплифицировали из матричной плазмиды pIH с применением пары праймеров HF3F (SEQ ID NO: 17, gcctccaccaagggcccatc) и HF3R (SEQ ID NO: 18, gacaatcttagcgcagaagtc). Три фрагмента смешивали в эквимолярном соотношении, а затем осуществляли ПЦР сплайсинг. Фрагменты выделяли с помощью рестрикционной эндонуклеазы двойного расщепления NheI/NotI и соединяли с векторной плазмидой pIH, дважды расщепленной NheI/NotI, с помощью ДНК-лигазы Т4, и трансформировали в штамм-хозяин ТОР10. Клоны отбирали и положительные клоны идентифицировали с помощью ПЦР и подтверждали секвенированием с получением эукариотической плазмиды экспрессии pIH-Р1А6Е. Аналогичным образом получали эукариотическую плазмиду экспрессии pIH-P3F2.
Для получения эукариотической плазмиды экспрессии pIK-Р1А6Е фрагмент VL1-Р1А6Е получали из матричной плазмиды V5-scFv-PlA6E-Fc с применением пары праймеров P1A6E-LF (SEQ ID NO: 19, ctttggtttccaggtgcaagatgtcaggctgtgctgactcag) и Р1А6Е-LR (SEQ ID NO: 20, GAAGACAGATGGTGCAGCCACCGTACCTAGGACGGTGACCTTG); фрагмент LF1 амплифицировали из матричной плазмиды pIK с применением пары праймеров LF1F (SEQ ID NO: 21, ggctaactagagaacccactgc) и LF1R (SEQ ID NO: 22, ACATCTTGCACCTGGAAACCAAAG); фрагмент LF3 амплифицировали из матричной плазмиды pIK с применением пары праймеров LF3F (SEQ ID NO: 23, acggtggctgcaccatctgtcttc) и LF3R (SEQ ID NO: 24, GACAATCTTAGCGCAGAAGTC). Три фрагмента смешивали в эквимолярном соотношении для ПЦР сплайсинга. После выделения фрагменты расщепляли рестрикционными эндонуклеазами EcoRV/NotI и лигировали в векторную плазмиду pIK, дважды расщепленную EcoRI/NotI, с помощью ДНК-лигазы Т4, и трансформировали в штамм-хозяин ТОР10. Клоны отбирали, и положительные клоны идентифицировали с помощью ПЦР и подтверждали секвенированием. Аналогично получали эукариотическую плазмиду экспрессии pIK-P3F2.
Плазмиды экспрессии pIH-Р1А6Е и pIK-Р1А6Е смешивали в эквимолярном соотношении, pIH-P3F2 и pIK-P3F2 смешивали в эквимолярном соотношении и трансфицировали в хорошо растущие клетки HEK-293F, соответственно. Клетки культивировали при 37°С, 5% СО2, 125 об/мин при встряхивании непрерывно в течение 7 суток, центрифугировали при 4000 об/мин в течение 10 мин. Осадок удаляли и супернатант собирали и фильтровали с помощью мембраны 0,45 мкм. Обработанный образец аффинно очищали с помощью колонки с иммобилизованным белком А с получением окончательно очищенных антител Р1А6Е и P3F2. Результаты идентификации представлены на фиг. 4.
Пример 5. Аффинность антитела к мезотелину человека
Для количественного анализа связывания антитела с мезотелином человека аффинность и кинетические параметры одноцепочечного антитела и моноклонального антитела Р1А6Е и P3F2 измеряли способом с захватом с применением системы Biacore Т200 (от GE). Антитело к человеческому IgG (Fc) (от GE) иммобилизировали на поверхности оптического чипа СМ5, покрытого карбоксиметилированным декстраном, за первичную аминогруппу с помощью NHS/EDC (1-этил-3-3-диметиламинопропил карбодиимид) связывания в соответствии с инструкциями производителя. Измерения проводили в 1×HBS-EP плюс рабочий буфер при 25°С, 30 мкл/мин, при условиях регенерации: 3 М MgCl2, 10 мкл/мин в течение 30 с. В каждом раунде цикла тестирования антитело, подлежащее тестированию, сначала захватывается на чипе. Аналит (мезотелин человека) определенной концентрации пропускали по поверхности чипа. Благодаря получаемому сигналу SPR (поверхностный плазменный резонанс) можно обнаружить взаимодействие между мезотелином человека и захваченным антителом. Обнаруженный сигнал регистрировали в резонансных единицах (RU) и представляли в виде графика, показывающего его изменение во времени (второй), чтобы получить соответствующую кривую связывания и кривую диссоциации. В разных циклах тестирования концентрации мезотелина человека составляли 10 нМ, 20 нМ, 40 нМ, 80 нМ и 160 нМ, соответственно. Полученные кривые оценивали с применением программного обеспечения Biacore Т200 и рассчитывали значения аффинности KD. На фиг. 5 и фиг. 6 показаны кинетические кривые моноклональных антител Р1А6Е и P3F2 при анализе аффинности Biacore, соответственно. Данные связывания для одноцепочечного антитела и моноклонального антитела Р1А6Е и P3F2 к мезотелину человека приведены в таблице 1.
Таблица 1. Параметры аффинности одноцепочечных антител и моноклональных антител Р1А6Е и P3F2 к мезотелину человека

Пример 6. Свойства связывания антитела к мезотелину человека на поверхности клетки (одноцепочечное антитело и моноклональное антитело)
Каждое антитело scFv-P1A6E-Fc и scFv-P3F2-Fc анализировали на способность связывания с мезотелином на поверхности клетки с помощью клеточного сортера с возбуждением флуоресценции (FACS) (Guava 8НТ, поставляемого Millipore).
Конкретные способы заключаются в следующем:
1) инокуляция PANC-1-MSLN и PANC-1 в логарифмической фазе роста в чашку диаметром 6 см, соответственно, с плотностью посева приблизительно 90% и инкубация при 37°С в инкубаторе в течение ночи.
2) расщепление клеток с помощью 10 мМ ЭДТА, сбор клеток центрифугированием при 200 g в течение 5 мин и ресуспендирование клеток в 1% фосфатно-солевом буфере (NBS PBS), содержащем телячью сыворотку в концентрации от 1×10 до 1×10 /мл, в цитометрической пробирке в количестве 100 мкл на пробирку.
3) центрифугирование при 200 g в течение 5 мин и отбрасывание супернатанта.
4) антитела Р1А6Е и P3F2, подлежащие тестированию, добавляли в две экспериментальные группы, соответственно, добавочные антитела SS и С10 (от Shanghai Rui Jin Biotechnology Co., Ltd.) добавляли в две положительные контрольные группы, представленные в качестве положительных контролей, и другую контрольную группу представлял собой PBS без антитела. Конечная концентрация каждого антитела составляла 20 мкг/мл. В каждую пробирку добавляли 100 мкл и помещали на ледяную баню в течение 45 минут.
5) Добавление в каждую пробирку 2 мл 1% NBS PBS и центрифугирование при 200 g в течение 5 мин дважды.
6) Отбрасывание супернатанта и добавление меченых флуоресцином козьих античеловеческих антител (Shanghai Karrie Biotech Co., Ltd.) в разведении 1:100, с добавлением 100 мкл в каждую пробирку, и инкубирование на ледяной бане в течение 45 минут.
7) Добавление в каждую пробирку 2 мл 1% NBS PBS и центрифугирование при 200 g в течение 5 мин дважды.
8) Отбрасывание супернатанта, ресуспендирование в 300 мкл 1% NBS PBS и детектирование способом проточной цитометрии.
9) Анализ данных с применением программного обеспечения для анализа данных проточной цитометрии Flowjo7.6.
Результаты проточной цитометрии показали, что четыре антитела, Р1А6Е и P3F2, а также контрольные антитела SS и С10, либо в формате одноцепочечного антитела (фиг. 7), либо в формате моноклональном полного антитела (фиг. 8, пик флуоресценции клеток PANC-1-MSLN значительно отличался от такового для контроля (PBS) (фиг. 7В, фиг. 8В), в то же время нет существенных отличий по сравнению с клетками PANC-1 (фиг. 7А, фиг. 8А)), могут специфически распознавать клетки PANC-1-MSLN, стабильно экспрессирующие мезотелин человека, но не связываются с мезотелин-отрицательными клетками PANC-1, что указывает на то, что четыре антитела могут специфически распознавать мезотелин человека. Пики флуоресценции антител Р1А6Е и P3F2 были значительно сильнее по сравнению с таковыми для контрольных антител SS и С10, что указывает на то, что эффективность связывания P1A6E и P3F2 с клетками PANC-1-MSLN выше, чем у SS и С10.
Пример 7. Получение CAR Т. содержащего антитело к мезотелину человека Для конструирования химерного антигенного рецептора порядок соединения частей химерного антигенного рецептора, приведенного в качестве примера в настоящем изобретении, представлен в таблице 2.
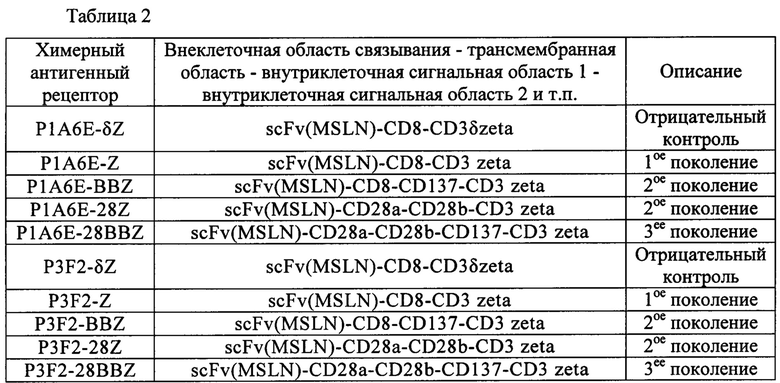
Примечание: CD28a представляет собой трансмембранную область молекулы CD28, a CD28b представляет собой внутриклеточную сигнальную область молекулы CD28.
Лентивирусная плазмидная векторная система, применяемая в настоящем примере, относится к лентивирусной 4-плазмидной системе третьего поколения, которая имеет 4 плазмиды, а именно плазмиду оболочки pCMV-VSV-G, кодирующую белок VSV-G (от Addgene), упаковочную плазмиду pRSV-REV, кодирующую белок Rev (от Addgene); pMDLg/pRRE, кодирующую Gal и Pol (от Addgene) и рекомбинантный вектор экспрессии, кодирующий представляющий интерес ген CAR на основе пустого вектора pRRLSIN-cPPT.PGK-GFP.WPRE (от Addgene). В качестве промотора во всех векторах гена CAR применяли фактора элонгации-1α (EF-1α) вектора, раскрытого в 201310164725.X. Конкретный способ конструирования заключается в следующем:
(1) Получение промоторного фрагмента: фрагмент с промотором EF-la амплифицировали с помощью ПЦР с применением вектора pWPT-eGFP-F2A-CAR, праймеров pwpxlF (SEQ ID NO: 25, 5'-gcaggggaaagaatagtagaca-3') и pWPT-MluIR (SEQ ID NO: 26, 5'-aggccagcggcaggagcaaggcggtcactggtaaggccatggtggcgaccggtagc-3').
(2) Получение фрагмента целевого CAR: часть P1A6E и часть P3F2 целевого фрагмента CAR амплифицировали с применением полученных выше V5-scFv-P1A6E-Fc и V5-scFv-P3F2-Fc в качестве матриц и с применением праймеров P1A6E-F (SEQ ID NO: 27, 5'-ctcctgccgctggccttgctgctccacgccgccaggccgcaggtacagctggaaca-3') и праймера P1A6E-R (SEQ ID NO: 28, 5'-gcggcgctggcgtcgtggtacctaggacggtgacc-3'), праймера P3F2-F (SEQ ID NO: 29, 5'ctcctgccgctggccttgctgctccacgccgccaggccgcagatgcagctagtgca-3') и P3F2-R (SEQ ID NO: 30, 5'gcggcgctggcgtcgtggtacgtttgatctccag-3').
(3) Первое, второе, третье поколение консенсусной последовательности и последовательности отрицательного контроля CAR получали с помощью ПЦР: фрагменты последовательностей CD8-CD36 zeta (5Z), CD8-CD3 zeta (Z), CD28a-CD28b-CD3 zeta (28Z) и CD28a-CD28b-CD137-CD3 zeta (28BBZ) получали с применением pWPT-eGFP-F2A-GPC3-5Z, pWPT-eGFP-F2A-GPC3-Z, pWPT-eGFP-F2A-GPC3-28Z и pWPT-eGFP-F2A-GPC3-28BBZ, раскрытых в 201310164725.X, в качестве матриц, и праймера HF (SEQ ID NO: 63, 5'accacgacgccagcgccgcgaccac) и праймера pwpxlR (SEQ ID NO: 64, 5'-tagcgtaaaaggagcaacatag), соответственно.
(4) фрагменты консенсусной последовательности CD8-CD137-CD3 zeta (BBZ) синтезировали с применением способа синтеза генов на основе мостиковой ПЦР со ссылкой на последовательность BBZ, раскрытую в US 8,911,993 В2 (COMPOSITIONS FOR TREATMENT OF CANCER).
(5) После полученного выше промоторного фрагмента целевые фрагменты CAR и фрагменты консенсусной последовательности CD8-CD38 zeta (SZ), CD8-CD3 zeta (Z), CD8-CD137-CD3 zeta (BBZ), CD28a-CD28b-CD3 zeta (28Z) и CD28a-CD28b-CD137-CD3 zeta (28BBZ) были соответственно соединены мостиковой связью обычным способом, праймеры pwpxlF и pwpxlR применяли для амплификации с получением фрагментов, содержащих EF-1α и целевой ген CAR, которые соответственно носят названия:
P1A6E-8Z (SEQ ID NO: 31); P1A6E-Z (SEQ ID NO: 32); P1A6E-BBZ (SEQ ID NO: 33); P1A6E-28Z (SEQ ID NO: 34); P1A6E-28BBZ (SEQ ID NO: 35). P3F2-5Z (SEQ ID NO: 36); P3F2-Z (SEQ ID NO: 37); P3F2-BBZ (SEQ ID NO: 38); P3F2-28Z (SEQ ID NO: 39); P3F2-28BBZ (SEQ ID NO: 40).
(6) Фрагмент CAR с промотором и целевым геном CAR, полученный на стадии выше, дважды расщепляли ClaI и SalI и лигировали в тот же расщепленный вектор pRRLSIN.cPPT.PGK-GFP.WPRE для конструирования лентивирусного вектора, экспрессирующего каждый химерный антигенный рецептор. Успешно сконструированный вектор идентифицировали расщеплением Mlu и Sal и подтверждали секвенированием для упаковки лентивирусов.
Полученные векторы, содержащие каждый целевой CAR, представляют собой следующие:
pRRLSIN-EF1α-P1A6E-8Z; pRRLSIN-EF1α-P1A6E-Z; pRRLSIN-EF1α-P1A6E-BBZ; pRRLSIN-EF1α-P1A6E-28Z; pRRLSIN-EF1α-P1A6E-28BBZ; pRRLSIN-EF1α-P3F2-8Z; pRRLSIN-EF1α-P3F2-Z; pRRLSIN-EF1α-P3F2-BBZ; pRRLSIN-EF1α-P3F2-28Z; pRRLSIN-EF1α-P3F2-28BB.
Благодаря применению вышеуказанной конструкции могут быть получены 10 полипептидных последовательностей CAR, которые носят названия: P1A6E-5Z (SEQ ID NO: 41); P1A6E-Z (SEQ ID NO: 42); P1A6E-BBZ (SEQ ID NO: 43); P1A6E-28Z (SEQ ID NO: 44); P1A6E-28BBZ (SEQ ID NO: 45). P3F2-8Z (SEQ ID NO: 46); P3F2-Z (SEQ ID NO: 47); P3F2-BBZ (SEQ ID NO: 48); P3F2-28Z (SEQ ID NO: 49); P3F2-28BBZ (SEQ ID NO: 50).
Трансфекция клеток 293T плазмидой для упаковки лентивируса Клетки НЕК-293Т (АТСС: CRL-11268), культивированные от пассажа 6 к пассажу 10, высевали с плотностью 6×106 в чашках по 10 см и культивировали в течение ночи при 37°С в 5% СО2 для трансфекции. В качестве среды использовали DMEM, содержащую 10% фетальную бычью сыворотку.
Стадии трансфекции заключаются в следующем:
Получение жидкости А: растворение 10 мкг требуемых генных плазмид pRRLSIN-cPPT.EF-1α-CAR (выбранные из pRRLSIN-EF1α-P1A6E-5Z, pRRLSIN-EF1α-P1A6E-Z, pRRLSIN-EF1α-P1A6E-BBZ, pRRLSIN-EF1α-P1A6E-28Z, pRRLSIN-EF1α-P1A6E-28BBZ, pRRLSIN-EF1α-P3F2-Z, pRRLSIN-EF1α-P3F2-BBZ, pRRLSIN-EF1α-P3F2-28Z, pRRLSIN-EF1α-P3F2-28BBZ) и 7,5 мкг упаковочной плазмиды pMDLg RRE и pRSV-REV и 3 мкг плазмиды оболочки pCMV-VSV-G в 800 мкл свободной от сыворотки среды DMEM и тщательное перемешивание.
Получение жидкости В: растворение 60 мкг PEI (полиэтиленимин 1 мкг/мкл, от Polysciences) в 800 мкл свободной от сыворотки среды DMEM, осторожное перемешивание и инкубирование при комнатной температуре в течение 5 минут.
Формирование комплекса трансфекции: добавление жидкости А в жидкость В и осторожное перемешивание, встряхивание или осторожное перемешивание сразу после добавления, инкубирование при комнатной температуре в течение 20 мин.
Добавление по каплям 1,6 мл трансфекционного комплекса к клеткам НЕК-293Т и через 4-5 ч замена среды на DMEM с 2% фетальной бычьей сывороткой для трансфицированных 293Т клеток.
Через 72 ч после трансфекции вирус собирали фильтрованием с применением фильтра 0,45 мкм и центрифугировали при 28000 об/мин с применением ультрацентрифуги Beckman Optima L-100XP в течение 2 часов при 4°С. Супернатант отбрасывали и полученный осадок центрифугировали при от 1/10 до 1/50 исходного раствора AIM-V (от Invitrogen) и ресуспендировали по 100 мкл/пробирку при -80°С для титрования вируса или инфицирования Т-лимфоцитов.
Пример 8. Инфицирование цитотоксических Т-лимфоцитов (CTL) рекомбинантным лентивирусом
Мононуклеарные клетки периферической крови человека получали из периферической крови здорового человека путем центрифугирования в градиенте плотности (от Shanghai Blood Center), а клетки CTL получали из мононуклеарных клеток периферической крови способом отрицательной сортировки с применением магнитных гранул CTL (приобретены у Stem Cell Technologies). Сортированные клетки CTL подвергали проточной цитометрии для определения чистоты клеток CTL. Коэффициент позитивности клеток CTL 95% или более был подходящим для следующей стадии. Клетки добавляли в лимфоцитарную среду Quantum 007 (от РАА) при плотности приблизительно 1×106/мл. Магнитные гранулы, покрытые антителами к CD3 и CD28 (Invitrogen), добавляли в соотношении клеток к магнитным гранулам 1:1, и добавляли рекомбинантный человеческий IL-2 (приобретен у Shanghai Huaxin Biotechnology Co., Ltd.) в конечной концентрации 300 ед./мл для стимуляции и культивирования в течение 24 часов. И затем клетки CTL инфицировали вышеуказанным рекомбинантным лентивирусом при MOI (множественность заражения) приблизительно равной 5. Инфицированные клетки пересевали через сутки при плотности 5×105/мл и добавляли рекомбинантный человеческий IL-2 в конечной концентрации 300 ед./мл в культуральной среде лимфоцитов.
Инфицированные клетки CTL детектировали проточной цитометрией на 8 сутки культивирования по экспрессии различных химерных антигенных рецепторов. Во-первых, инфицированные CAR Т-клетки инкубировали с биотинилированным рекомбинантным белком мезотелина человека в течение 1 часа при 37°С, дважды промывали фосфатно-солевым буфером Дульбекко (D-PBS) и затем инкубировали с меченым фикоэритрином стрептавидином в течение 40 мин при 37°С. После трехкратного промывания фосфатно-солевым буфером Дульбекко отношение положительных клеток определяли проточной цитометрией. В качестве отрицательного контроля применяли неинфицированные Т-лимфоциты, коэффициенты позитивности инфицированных вирусом Т-клеток, экспрессирующих различные химерные антигенные рецепторы, представлены в таблице 3.
Результаты коэффициента позитивности показывают, что при использовании лентивирусной инфекции может быть получен определенный коэффициент позитивности Т-клеток с CAR.

Клетки CTL инфицировали вирусами, упакованными с разными химерными антигенными рецепторами, и затем субкультивировали при плотности клеток 5×105/мл через сутки, подсчитывали и дополняли IL-2 (конечная концентрация 300 ед./мл). На 11-ый сутки культивирования было получено приблизительно от 20 до 40 раундов амплификации, что указывает на то, что клетки CTL, экспрессирующие различные химерные антигенные рецепторы, могут быть размножены в определенном количестве in vitro, что обеспечивает проведение последующих тестов на токсичность in vitro и проведение экспериментов in vivo.
Пример 9. Тест in vitro по токсичности Т-лимфоцитов, экспрессирующих химерные антигенные рецепторы
В экспериментах по токсичности in vitro применяли следующие материалы:
В качестве клеток-мишеней применяли мезотелин-отрицательную клеточную линию рака поджелудочной железы (PANC-1) и (PANC-1-MSLN) клеточную линию PANC-1 (PANC-1-MSLN), трансфицированную геном мезотелина, как показано в таблице 4, и эффекторные клетки, представляющие собой CTL, культивированные в течение 12 суток in vitro, были проверены в примере 4 и показали положительную экспрессию химерного антигенного рецептора с помощью способа FACS. Эффективные целевые соотношения составляли 3:1, 1:1 и 1:3, соответственно. Количество клеток-мишеней составляло 10000/лунку, а эффекторные клетки соответствовали разным эффективным целевым соотношениям. В каждой группе было 5 повторных лунок, в среднем было рассчитано 5 лунок, а время обнаружения составило 18 часов.
Каждая экспериментальная группа и каждая контрольная группа представлены в следующем порядке:
Каждая экспериментальная группа: каждая клетка-мишень плюс CTL, экспрессирующие различные химерные антигенные рецепторы;
Контрольная группа 1: клетки-мишени с максимальным высвобождением ЛДГ (лактадегидрогеназы);
Контрольная группа 2: клетки-мишени со спонтанным высвобождением ЛДГ;
Контрольная группа 3: эффекторные клетки со спонтанным высвобождением ЛДГ.
Способ детектирования: применяли CytoTox 96® для анализа нерадиоактивной цитотоксичности (Promega), представляющий собой колориметрический анализ, который может заменить тест на высвобождение 51Cr. С помощью анализа CytoTox 96® определяли количественный выход лактатдегидрогеназы (ЛДГ). ЛДГ является стабильным цитозольным ферментом, который высвобождается при лизисе клеток и высвобождается аналогично высвобождению радиоактивного 51Cr. Супернатант с высвобожденной средой ЛДГ может быть обнаружен 30-минутной связанной ферментативной реакцией, в течение которой ЛДГ превращает соль тетразолия (INT) в красный формазан. Количество полученного красного продукта пропорционально количеству лизированных клеток. Подробности можно найти в инструкциях набора для обнаружения нерадиоактивной цитотоксичности CytoTox 96.
Цитотоксичность рассчитывается следующим образом:
% цитотоксичности = [(экспериментальная группа - контрольная группа 2 - контрольная группа 3)/(контрольная группа 1 - контрольная группа 2)] × 100
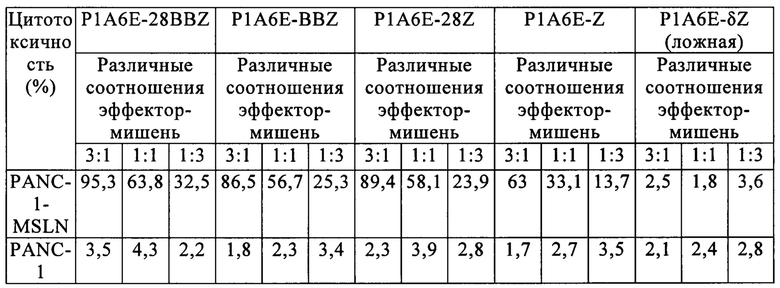
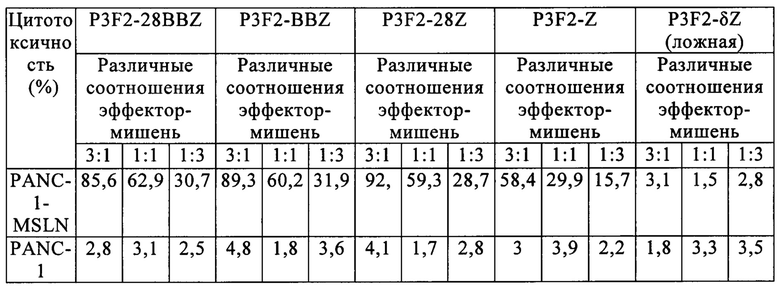
В частности, как показано в таблице 4, CAR одноцепочечного антитела к мезотелину (Р1А6Е, P3F2) по настоящему изобретению показали значительную уничтожающую активность в отношении мезотелин-положительных клеток рака поджелудочной железы, а противоопухолевая активность второго и третьего поколений Т-клеток с CAR против мезотелина была немного сильнее по сравнению с первым поколением. Существенной уничтожающей активности в группе, трансфицированной пустым вектором, не обнаружили. Кроме того, все Т-клетки с CAR не проявляли цитотоксической активности в отношении мезотелин-отрицательных клеток рака поджелудочной железы PANC-1. Эти результаты показывают, что Т-клетки с CAR против мезотелина по изобретению (включая 1-е, 2-е и 3-е поколения Т-клеток с CAR) могут избирательно нацеливаться на мезотелин-положительные клетки рака поджелудочной железы и эффективно уничтожать их. Кроме того, первое, второе и третье поколение Т-клеток с CAR против мезотелина по настоящему изобретению проявляли градиентную зависимость соотношения эффектор-мишень, то есть чем выше соотношение эффектор-мишень, тем сильнее цитотоксические эффекты.
Таблица 4. Противоопухолевая активность in vitro Т-клеток с CAR, имеющих слитое и экспрессируемое одноцепочечное антитело
Пример 10. Анализ эпитопа антитела к мезотелину человека
Фрагмент гена мезотелина человека амплифицировали с помощью ПЦР из SEQ ID NO: 1 и лигировали в эукариотический вектор экспрессии pCMV-V5-muFc, содержащий мышиный Fc-фрагмент, с помощью двойного расщепления NheI/BamHI. Клетки НЕК-293F временно трансфицировали в соответствии с примером 4, и супернатант культуры клеток обрабатывали и аффинно очищали с помощью колонки с иммобилизованным белком G (от GE) с получением окончательно очищенного слитого белка мезотелина человека и muFc-фрагмента, и связывание антител scFv-P1A6E-Fc и scFv-P3F2-Fc идентифицировали с помощью ELISA. Зрелый мезотелин человека разделяли на три области: область R1 (Е296-Т390, SEQ ID NO: 66), область R2 (S391-Q486, SEQ ID NO: 67), область R3 (N487-G581, SEQ ID NO: 68) в соответствии с учетным номером в Genbank NP_001170826.1 (SEQ ID NO: 65). Результаты ELISA показали, что оба антитела scFv-P1A6E-Fc и scFv-P3F2-Fc связываются только с областью 1 (Е296-Т390). Область 1 дополнительно делили на 5 мелких фрагментов и сливали и экспрессировали с muFc, соответственно. Область R1A (296E-337D, SEQ ID NO: 69), область RIB (328D-369I, SEQ ID NO: 70), область R1C (360Y-405T, SEQ ID NO: 71), область R1AB (296E-359L, ID NO: 72), R1BC (328D-405T, SEQ ID NO: 73). Результаты ELISA представлены на фиг. 9 и фиг. 10, где антитела scFv-P1A6E-Fc и scFv-P3F2-Fc в значительной степени связаны с областью R1AB, слабо связаны с областью R1A и не связаны с областью R1B. Следовательно, сайты связывания антител scFv-P1A6E-Fc и scFv-P3F2-Fc должны быть расположены вокруг сайтов, где перекрываются R1A и R1B. Эта область содержит 10 аминокислот «DAALLATQMD», на основе которых 10 аминокислот или 5 аминокислот были расширены с обоих концов с образованием двух пептидов R1J10: «YKKWELEACVDAALLATQMDRVNAIPFTYE (SEQ ID NO: 74)» и R1J5: «LEACVDAALLATQMDRVNAI (SEQ ID NO: 75)» и слиты и экспрессированы с muFc, соответственно. Результаты ELISA показали, что антитела scFv-P1A6E-Fc и scFv-P3F2-Fc не связываются с R1J10 или R1J5. Исходя из приведенных выше результатов, эпитопы антител scFv-P1A6E-Fc и scFv-P3F2-Fc должны представлять собой конформационные эпитопы, расположенные в области R1AB (SEQ ID NO: 72).
Все ссылки, упомянутые в настоящем изобретении, включены в настоящий документ посредством ссылки, как если бы каждая ссылка была индивидуально включена посредством ссылки. Кроме того, следует понимать, что после прочтения вышеприведенных положений настоящего изобретения специалисты в данной области техники смогут вносить различные модификации или изменения в настоящее изобретение, и такие эквивалентные формы также входят в объем прилагаемой формулы настоящего изобретения.
--->
Перечень последовательностей
<110> Carsgen therapeutics, limited
<120> ПОЛНОСТЬЮ ЧЕЛОВЕЧЕСКИЕ АНТИТЕЛА К МЕЗОТЕЛИНУ И ИММУННЫЕ ЭФФЕКТОРНЫЕ КЛЕТКИ,
НАЦЕЛЕННЫЕ НА МЕЗОТЕЛИН
<130> P2016-1262
<150> CN201510519214.4
<151> 2015-08-21
<160> 75
<170> PatentIn version 3.3
<210> 1
<211> 1068
<212> DNA
<213> Homo Sapiens
<400> 1
atgagggcct ggatcttctt tctcctttgc ctggccggga gggctctggc agccccgcta 60
gcagattaca aagacgatga cgacaaggaa gtggagaaga cagcctgtcc ttcaggcaag 120
aaggcccgcg agatagacga gagcctcatc ttctacaaga agtgggagct ggaagcctgc 180
gtggatgcgg ccctgctggc cacccagatg gaccgcgtga acgccatccc cttcacctac 240
gagcagctgg acgtcctaaa gcataaactg gatgagctct acccacaagg ttaccccgag 300
tctgtgatcc agcacctggg ctacctcttc ctcaagatga gccctgagga cattcgcaag 360
tggaatgtga cgtccctgga gaccctgaag gctttgcttg aagtcaacaa agggcacgaa 420
atgagtcctc aggtggccac cctgatcgac cgctttgtga agggaagggg ccagctagac 480
aaagacaccc tagacaccct gaccgccttc taccctgggt acctgtgctc cctcagcccc 540
gaggagctga gctccgtgcc ccccagcagc atctgggcgg tcaggcccca ggacctggac 600
acgtgtgacc caaggcagct ggacgtcctc tatcccaagg cccgccttgc tttccagaac 660
atgaacgggt ccgaatactt cgtgaagatc cagtccttcc tgggtggggc ccccacggag 720
gatttgaagg cgctcagtca gcagaatgtg agcatggact tggccacgtt catgaagctg 780
cggacggatg cggtgctgcc gttgactgtg gctgaggtgc agaaacttct gggaccccac 840
gtggagggcc tgaaggcgga ggagcggcac cgcccggtgc gggactggat cctacggcag 900
cggcaggacg acctggacac gctggggctg gggctacagg gcggcatccc caacggctac 960
ctggtcctag acctcagcat gcaagaggcc ctctcgggga cgccctgcct cctaggacct 1020
ggacctgttc tcaccgtcct ggcactgctc ctagcctcca ccctggcc 1068
<210> 2
<211> 356
<212> PRT
<213> Homo Sapiens
<400> 2
Met Arg Ala Trp Ile Phe Phe Leu Leu Cys Leu Ala Gly Arg Ala Leu
1 5 10 15
Ala Ala Pro Leu Ala Asp Tyr Lys Asp Asp Asp Asp Lys Glu Val Glu
20 25 30
Lys Thr Ala Cys Pro Ser Gly Lys Lys Ala Arg Glu Ile Asp Glu Ser
35 40 45
Leu Ile Phe Tyr Lys Lys Trp Glu Leu Glu Ala Cys Val Asp Ala Ala
50 55 60
Leu Leu Ala Thr Gln Met Asp Arg Val Asn Ala Ile Pro Phe Thr Tyr
65 70 75 80
Glu Gln Leu Asp Val Leu Lys His Lys Leu Asp Glu Leu Tyr Pro Gln
85 90 95
Gly Tyr Pro Glu Ser Val Ile Gln His Leu Gly Tyr Leu Phe Leu Lys
100 105 110
Met Ser Pro Glu Asp Ile Arg Lys Trp Asn Val Thr Ser Leu Glu Thr
115 120 125
Leu Lys Ala Leu Leu Glu Val Asn Lys Gly His Glu Met Ser Pro Gln
130 135 140
Val Ala Thr Leu Ile Asp Arg Phe Val Lys Gly Arg Gly Gln Leu Asp
145 150 155 160
Lys Asp Thr Leu Asp Thr Leu Thr Ala Phe Tyr Pro Gly Tyr Leu Cys
165 170 175
Ser Leu Ser Pro Glu Glu Leu Ser Ser Val Pro Pro Ser Ser Ile Trp
180 185 190
Ala Val Arg Pro Gln Asp Leu Asp Thr Cys Asp Pro Arg Gln Leu Asp
195 200 205
Val Leu Tyr Pro Lys Ala Arg Leu Ala Phe Gln Asn Met Asn Gly Ser
210 215 220
Glu Tyr Phe Val Lys Ile Gln Ser Phe Leu Gly Gly Ala Pro Thr Glu
225 230 235 240
Asp Leu Lys Ala Leu Ser Gln Gln Asn Val Ser Met Asp Leu Ala Thr
245 250 255
Phe Met Lys Leu Arg Thr Asp Ala Val Leu Pro Leu Thr Val Ala Glu
260 265 270
Val Gln Lys Leu Leu Gly Pro His Val Glu Gly Leu Lys Ala Glu Glu
275 280 285
Arg His Arg Pro Val Arg Asp Trp Ile Leu Arg Gln Arg Gln Asp Asp
290 295 300
Leu Asp Thr Leu Gly Leu Gly Leu Gln Gly Gly Ile Pro Asn Gly Tyr
305 310 315 320
Leu Val Leu Asp Leu Ser Met Gln Glu Ala Leu Ser Gly Thr Pro Cys
325 330 335
Leu Leu Gly Pro Gly Pro Val Leu Thr Val Leu Ala Leu Leu Leu Ala
340 345 350
Ser Thr Leu Ala
355
<210> 3
<211> 47
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 3
gcttacgcgt cctagcgcta ccggtcgcca ccatgagggc ctggatc 47
<210> 4
<211> 48
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 4
cgaggtcgac ctaggccagg gtggaggcta ggagcagtgc caggacgg 48
<210> 5
<211> 762
<212> DNA
<213> Homo Sapiens
<400> 5
caggtacagc tggaacagtc aggtctagga ctggtgaagc cctcgcagac cctctctctc 60
acctgtgcca tctccgggga cactgtctct agcgacagtg ctgcttggaa ctggatcagg 120
cagtccccat cgagaggcct tgagtggctg ggaaggacat actacaggtc caagtggttt 180
aatgattatg cagtatctgt gaaaggtcga ataaccatca actcagacac atccaagaac 240
cagttctccc tgcagttgaa ctctgtgact cccgaggaca cggctgtgta ttattgtgca 300
agaagtaata gttactacta ctacgctatg gacgtctggg gccaaggcac cctggtcacc 360
gtctcgagtg gtggaggcgg ttcaggcgga ggtggttctg gcggtggcgg atcgcaggct 420
gtgctgactc agccgtcttc cctctctgca tctcctggag catcagccag tctcacctgc 480
accttgcgca gtggcatcaa tgttggtatc tacaggatat actggtacca acagaggcca 540
gggagtcctc cccagattct cctgacttac aaatcagact cagataagta ccagggctct 600
ggagtcccca gtcgcttctc tggatccaaa gatgcttcgg ccaatgcagg gattttactc 660
atctctgggc tccagtctga agatgaggct gactattact gcatgatttg gcacagcggc 720
ggttgggtgt tcggcggagg gaccaaggtc accgtcctag gt 762
<210> 6
<211> 254
<212> PRT
<213> Homo Sapiens
<220>
<221> MISC_FEATURE
<223> primer
<400> 6
Gln Val Gln Leu Glu Gln Ser Gly Leu Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp Thr Val Ser Ser Asp
20 25 30
Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp Phe Asn Asp Tyr Ala
50 55 60
Val Ser Val Lys Gly Arg Ile Thr Ile Asn Ser Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Ser Asn Ser Tyr Tyr Tyr Tyr Ala Met Asp Val
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Ala Val Leu Thr Gln
130 135 140
Pro Ser Ser Leu Ser Ala Ser Pro Gly Ala Ser Ala Ser Leu Thr Cys
145 150 155 160
Thr Leu Arg Ser Gly Ile Asn Val Gly Ile Tyr Arg Ile Tyr Trp Tyr
165 170 175
Gln Gln Arg Pro Gly Ser Pro Pro Gln Ile Leu Leu Thr Tyr Lys Ser
180 185 190
Asp Ser Asp Lys Tyr Gln Gly Ser Gly Val Pro Ser Arg Phe Ser Gly
195 200 205
Ser Lys Asp Ala Ser Ala Asn Ala Gly Ile Leu Leu Ile Ser Gly Leu
210 215 220
Gln Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Met Ile Trp His Ser Gly
225 230 235 240
Gly Trp Val Phe Gly Gly Gly Thr Lys Val Thr Val Leu Gly
245 250
<210> 7
<211> 741
<212> DNA
<213> Homo Sapiens
<400> 7
cagatgcagc tagtgcagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtt 60
tcctgcaagg catctggata caccttcacc agctactata tgcactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaata atcaacccta gtggtggtag cacaagctac 180
gcacagaagt tccagggcag agtcaccatg accagggaca cgtccacgag cacagtctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtgc gagtagtcgg 300
agtgggacta cggtggtaaa tcatgatgct tttgatatct gggggaaagg gaccacggtc 360
accgtctcga gtggtggagg cggttcaggc ggaggtggtt ctggcggtgg cggatcggac 420
atccagttga cccagtctcc atcctccctg tctgcgtctg taggagacag agtcaccatc 480
acttgccggg caagccaggt cattagccgt gctttagcct ggtatcaaca aacaccaggg 540
aaacctccta aactcctgat ctatgatgcc tccaatttgc agagtggggt cccatcaagg 600
ttcagcggca gtggatctgg gacagatttc actctcacca tcagccgcct gcagcctgaa 660
gattttgcaa cttattactg tcaacagttt aatagttacc ctctcacttt cggcggaggg 720
accaagctgg agatcaaacg t 741
<210> 8
<211> 247
<212> PRT
<213> Homo Sapiens
<400> 8
Gln Met Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Asn Pro Ser Gly Gly Ser Thr Ser Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ser Ser Arg Ser Gly Thr Thr Val Val Asn His Asp Ala Phe Asp
100 105 110
Ile Trp Gly Lys Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Gln Leu Thr
130 135 140
Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile
145 150 155 160
Thr Cys Arg Ala Ser Gln Val Ile Ser Arg Ala Leu Ala Trp Tyr Gln
165 170 175
Gln Thr Pro Gly Lys Pro Pro Lys Leu Leu Ile Tyr Asp Ala Ser Asn
180 185 190
Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr
195 200 205
Asp Phe Thr Leu Thr Ile Ser Arg Leu Gln Pro Glu Asp Phe Ala Thr
210 215 220
Tyr Tyr Cys Gln Gln Phe Asn Ser Tyr Pro Leu Thr Phe Gly Gly Gly
225 230 235 240
Thr Lys Leu Glu Ile Lys Arg
245
<210> 9
<211> 30
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 9
acagtgctag cacaggtaca gctggaacag 30
<210> 10
<211> 27
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 10
ttgtcggatc cacctaggac ggtgacc 27
<210> 11
<211> 28
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 11
acagtgctag cacagatgca gctagtgc 28
<210> 12
<211> 27
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 12
ttgtcggatc cacgtttgat ctccagc 27
<210> 13
<211> 41
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 13
gcctttcctg gtttcctgtc tcaggtacag ctggaacagt c 41
<210> 14
<211> 38
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 14
gatgggccct tggtggaggc actcgagacg gtgaccag 38
<210> 15
<211> 22
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 15
ggctaactag agaacccact gc 22
<210> 16
<211> 21
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 16
agacaggaaa ccaggaaagg c 21
<210> 17
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 17
gcctccacca agggcccatc 20
<210> 18
<211> 21
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 18
gacaatctta gcgcagaagt c 21
<210> 19
<211> 42
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 19
ctttggtttc caggtgcaag atgtcaggct gtgctgactc ag 42
<210> 20
<211> 43
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 20
gaagacagat ggtgcagcca ccgtacctag gacggtgacc ttg 43
<210> 21
<211> 22
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 21
ggctaactag agaacccact gc 22
<210> 22
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 22
acatcttgca cctggaaacc aaag 24
<210> 23
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 23
acggtggctg caccatctgt cttc 24
<210> 24
<211> 21
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 24
gacaatctta gcgcagaagt c 21
<210> 25
<211> 22
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 25
gcaggggaaa gaatagtaga ca 22
<210> 26
<211> 56
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 26
aggccagcgg caggagcaag gcggtcactg gtaaggccat ggtggcgacc ggtagc 56
<210> 27
<211> 56
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 27
ctcctgccgc tggccttgct gctccacgcc gccaggccgc aggtacagct ggaaca 56
<210> 28
<211> 35
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 28
gcggcgctgg cgtcgtggta cctaggacgg tgacc 35
<210> 29
<211> 56
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 29
ctcctgccgc tggccttgct gctccacgcc gccaggccgc agatgcagct agtgca 56
<210> 30
<211> 34
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 30
gcggcgctgg cgtcgtggta cgtttgatct ccag 34
<210> 31
<211> 1566
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> P1A6E-¦ДZ polynucleotide
<400> 31
gcaggggaaa gaatagtaga cataatagca acagacatac aaactaaaga attacaaaaa 60
caaattacaa aaattcaaaa ttttccgatc acgagactag cctcgagaag cttgatcgat 120
ggctccggtg cccgtcagtg ggcagagcgc acatcgccca cagtccccga gaagttgggg 180
ggaggggtcg gcaattgaac cggtgcctag agaaggtggc gcggggtaaa ctgggaaagt 240
gatgtcgtgt actggctccg cctttttccc gagggtgggg gagaaccgta tataagtgca 300
gtagtcgccg tgaacgttct ttttcgcaac gggtttgccg ccagaacaca ggtgtcgtga 360
cgcggatcca ggcctaagct tacgcgtcct agcgctaccg gtcgccacca tggccttacc 420
agtgaccgcc ttgctcctgc cgctggcctt gctgctccac gccgccaggc cgcaggtaca 480
gctggaacag tcaggtctag gactggtgaa gccctcgcag accctctctc tcacctgtgc 540
catctccggg gacactgtct ctagcgacag tgctgcttgg aactggatca ggcagtcccc 600
atcgagaggc cttgagtggc tgggaaggac atactacagg tccaagtggt ttaatgatta 660
tgcagtatct gtgaaaggtc gaataaccat caactcagac acatccaaga accagttctc 720
cctgcagttg aactctgtga ctcccgagga cacggctgtg tattattgtg caagaagtaa 780
tagttactac tactacgcta tggacgtctg gggccaaggc accctggtca ccgtctcgag 840
tggtggaggc ggttcaggcg gaggtggttc tggcggtggc ggatcgcagg ctgtgctgac 900
tcagccgtct tccctctctg catctcctgg agcatcagcc agtctcacct gcaccttgcg 960
cagtggcatc aatgttggta tctacaggat atactggtac caacagaggc cagggagtcc 1020
tccccagatt ctcctgactt acaaatcaga ctcagataag taccagggct ctggagtccc 1080
cagtcgcttc tctggatcca aagatgcttc ggccaatgca gggattttac tcatctctgg 1140
gctccagtct gaagatgagg ctgactatta ctgcatgatt tggcacagcg gcggttgggt 1200
gttcggcgga gggaccaagg tcaccgtcct aggtaccacg acgccagcgc cgcgaccacc 1260
aacaccggcg cccaccatcg cgtcgcagcc cctgtccctg cgcccagagg cgtgccggcc 1320
agcggcgggg ggcgcagtgc acacgagggg gctggacttc gcctgtgata tctacatctg 1380
ggcgcccttg gccgggactt gtggggtcct tctcctgtca ctggttatca ccagagtgaa 1440
gttcagcagg agcgcagacg cccccgcgta ggtcgacctc gagggaattc cgataatcaa 1500
cctctggatt acaaaatttg tgaaagattg actggtattc ttaactatgt tgctcctttt 1560
acgcta 1566
<210> 32
<211> 1869
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> P1A6E-Z polynucleotide
<400> 32
gcaggggaaa gaatagtaga cataatagca acagacatac aaactaaaga attacaaaaa 60
caaattacaa aaattcaaaa ttttccgatc acgagactag cctcgagaag cttgatcgat 120
ggctccggtg cccgtcagtg ggcagagcgc acatcgccca cagtccccga gaagttgggg 180
ggaggggtcg gcaattgaac cggtgcctag agaaggtggc gcggggtaaa ctgggaaagt 240
gatgtcgtgt actggctccg cctttttccc gagggtgggg gagaaccgta tataagtgca 300
gtagtcgccg tgaacgttct ttttcgcaac gggtttgccg ccagaacaca ggtgtcgtga 360
cgcggatcca ggcctaagct tacgcgtcct agcgctaccg gtcgccacca tggccttacc 420
agtgaccgcc ttgctcctgc cgctggcctt gctgctccac gccgccaggc cgcaggtaca 480
gctggaacag tcaggtctag gactggtgaa gccctcgcag accctctctc tcacctgtgc 540
catctccggg gacactgtct ctagcgacag tgctgcttgg aactggatca ggcagtcccc 600
atcgagaggc cttgagtggc tgggaaggac atactacagg tccaagtggt ttaatgatta 660
tgcagtatct gtgaaaggtc gaataaccat caactcagac acatccaaga accagttctc 720
cctgcagttg aactctgtga ctcccgagga cacggctgtg tattattgtg caagaagtaa 780
tagttactac tactacgcta tggacgtctg gggccaaggc accctggtca ccgtctcgag 840
tggtggaggc ggttcaggcg gaggtggttc tggcggtggc ggatcgcagg ctgtgctgac 900
tcagccgtct tccctctctg catctcctgg agcatcagcc agtctcacct gcaccttgcg 960
cagtggcatc aatgttggta tctacaggat atactggtac caacagaggc cagggagtcc 1020
tccccagatt ctcctgactt acaaatcaga ctcagataag taccagggct ctggagtccc 1080
cagtcgcttc tctggatcca aagatgcttc ggccaatgca gggattttac tcatctctgg 1140
gctccagtct gaagatgagg ctgactatta ctgcatgatt tggcacagcg gcggttgggt 1200
gttcggcgga gggaccaagg tcaccgtcct aggtaccacg acgccagcgc cgcgaccacc 1260
aacaccggcg cccaccatcg cgtcgcagcc cctgtccctg cgcccagagg cgtgccggcc 1320
agcggcgggg ggcgcagtgc acacgagggg gctggacttc gcctgtgata tctacatctg 1380
ggcgcccttg gccgggactt gtggggtcct tctcctgtca ctggttatca ccagagtgaa 1440
gttcagcagg agcgcagacg cccccgcgta ccagcagggc cagaaccagc tctataacga 1500
gctcaatcta ggacgaagag aggagtacga tgttttggac aagagacgtg gccgggaccc 1560
tgagatgggg ggaaagccgc agagaaggaa gaaccctcag gaaggcctgt acaatgaact 1620
gcagaaagat aagatggcgg aggcctacag tgagattggg atgaaaggcg agcgccggag 1680
gggcaagggg cacgatggcc tttaccaggg tctcagtaca gccaccaagg acacctacga 1740
cgcccttcac atgcaggccc tgccccctcg ctaggtcgac ctcgagggaa ttccgataat 1800
caacctctgg attacaaaat ttgtgaaaga ttgactggta ttcttaacta tgttgctcct 1860
tttacgcta 1869
<210> 33
<211> 2001
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> P1A6E-BBZ polynucleotide
<400> 33
gcaggggaaa gaatagtaga cataatagca acagacatac aaactaaaga attacaaaaa 60
caaattacaa aaattcaaaa ttttccgatc acgagactag cctcgagaag cttgatcgat 120
ggctccggtg cccgtcagtg ggcagagcgc acatcgccca cagtccccga gaagttgggg 180
ggaggggtcg gcaattgaac cggtgcctag agaaggtggc gcggggtaaa ctgggaaagt 240
gatgtcgtgt actggctccg cctttttccc gagggtgggg gagaaccgta tataagtgca 300
gtagtcgccg tgaacgttct ttttcgcaac gggtttgccg ccagaacaca ggtgtcgtga 360
cgcggatcca ggcctaagct tacgcgtcct agcgctaccg gtcgccacca tggccttacc 420
agtgaccgcc ttgctcctgc cgctggcctt gctgctccac gccgccaggc cgcaggtaca 480
gctggaacag tcaggtctag gactggtgaa gccctcgcag accctctctc tcacctgtgc 540
catctccggg gacactgtct ctagcgacag tgctgcttgg aactggatca ggcagtcccc 600
atcgagaggc cttgagtggc tgggaaggac atactacagg tccaagtggt ttaatgatta 660
tgcagtatct gtgaaaggtc gaataaccat caactcagac acatccaaga accagttctc 720
cctgcagttg aactctgtga ctcccgagga cacggctgtg tattattgtg caagaagtaa 780
tagttactac tactacgcta tggacgtctg gggccaaggc accctggtca ccgtctcgag 840
tggtggaggc ggttcaggcg gaggtggttc tggcggtggc ggatcgcagg ctgtgctgac 900
tcagccgtct tccctctctg catctcctgg agcatcagcc agtctcacct gcaccttgcg 960
cagtggcatc aatgttggta tctacaggat atactggtac caacagaggc cagggagtcc 1020
tccccagatt ctcctgactt acaaatcaga ctcagataag taccagggct ctggagtccc 1080
cagtcgcttc tctggatcca aagatgcttc ggccaatgca gggattttac tcatctctgg 1140
gctccagtct gaagatgagg ctgactatta ctgcatgatt tggcacagcg gcggttgggt 1200
gttcggcgga gggaccaagg tcaccgtcct aggtaccacg acgccagcgc cgcgaccacc 1260
aacaccggcg cccaccatcg cgtcgcagcc cctgtccctg cgcccagagg cgtgccggcc 1320
agcggcgggg ggcgcagtgc acacgagggg gctggacttc gcctgtgata tctacatctg 1380
ggcgcccttg gccgggactt gtggggtcct tctcctgtca ctggttatca ccctttactg 1440
caaacggggc agaaagaaac tcctgtatat attcaaacaa ccatttatga gaccagtaca 1500
aactactcaa gaggaagatg gctgtagctg ccgatttcca gaagaagaag aaggaggatg 1560
tgaactgaga gtgaagttca gcaggagcgc agacgccccc gcgtacaagc agggccagaa 1620
ccagctctat aacgagctca atctaggacg aagagaggag tacgatgttt tggacaagag 1680
acgtggccgg gaccctgaga tggggggaaa gccgagaagg aagaaccctc aggaaggcct 1740
gtacaatgaa ctgcagaaag ataagatggc ggaggcctac agtgagattg ggatgaaagg 1800
cgagcgccgg aggggcaagg ggcacgatgg cctttaccag ggtctcagta cagccaccaa 1860
ggacacctac gacgcccttc acatgcaggc cctgccccct cgctaggtcg acctcgaggg 1920
aattccgata atcaacctct ggattacaaa atttgtgaaa gattgactgg tattcttaac 1980
tatgttgctc cttttacgct a 2001
<210> 34
<211> 2010
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> P1A6E-28Z polynucleotide
<400> 34
gcaggggaaa gaatagtaga cataatagca acagacatac aaactaaaga attacaaaaa 60
caaattacaa aaattcaaaa ttttccgatc acgagactag cctcgagaag cttgatcgat 120
ggctccggtg cccgtcagtg ggcagagcgc acatcgccca cagtccccga gaagttgggg 180
ggaggggtcg gcaattgaac cggtgcctag agaaggtggc gcggggtaaa ctgggaaagt 240
gatgtcgtgt actggctccg cctttttccc gagggtgggg gagaaccgta tataagtgca 300
gtagtcgccg tgaacgttct ttttcgcaac gggtttgccg ccagaacaca ggtgtcgtga 360
cgcggatcca ggcctaagct tacgcgtcct agcgctaccg gtcgccacca tggccttacc 420
agtgaccgcc ttgctcctgc cgctggcctt gctgctccac gccgccaggc cgcaggtaca 480
gctggaacag tcaggtctag gactggtgaa gccctcgcag accctctctc tcacctgtgc 540
catctccggg gacactgtct ctagcgacag tgctgcttgg aactggatca ggcagtcccc 600
atcgagaggc cttgagtggc tgggaaggac atactacagg tccaagtggt ttaatgatta 660
tgcagtatct gtgaaaggtc gaataaccat caactcagac acatccaaga accagttctc 720
cctgcagttg aactctgtga ctcccgagga cacggctgtg tattattgtg caagaagtaa 780
tagttactac tactacgcta tggacgtctg gggccaaggc accctggtca ccgtctcgag 840
tggtggaggc ggttcaggcg gaggtggttc tggcggtggc ggatcgcagg ctgtgctgac 900
tcagccgtct tccctctctg catctcctgg agcatcagcc agtctcacct gcaccttgcg 960
cagtggcatc aatgttggta tctacaggat atactggtac caacagaggc cagggagtcc 1020
tccccagatt ctcctgactt acaaatcaga ctcagataag taccagggct ctggagtccc 1080
cagtcgcttc tctggatcca aagatgcttc ggccaatgca gggattttac tcatctctgg 1140
gctccagtct gaagatgagg ctgactatta ctgcatgatt tggcacagcg gcggttgggt 1200
gttcggcgga gggaccaagg tcaccgtcct aggtaccacg acgccagcgc cgcgaccacc 1260
aacaccggcg cccaccatcg cgtcgcagcc cctgtccctg cgcccagagg cgtgccggcc 1320
agcggcgggg ggcgcagtgc acacgagggg gctggacttc gcctgtgatt tttgggtgct 1380
ggtggtggtt ggtggagtcc tggcttgcta tagcttgcta gtaacagtgg cctttattat 1440
tttctgggtg aggagtaaga ggagcaggct cctgcacagt gactacatga acatgactcc 1500
ccgccgcccc gggccaaccc gcaagcatta ccagccctat gccccaccac gcgacttcgc 1560
agcctatcgc tccagagtga agttcagcag gagcgcagac gcccccgcgt accagcaggg 1620
ccagaaccag ctctataacg agctcaatct aggacgaaga gaggagtacg atgttttgga 1680
caagagacgt ggccgggacc ctgagatggg gggaaagccg cagagaagga agaaccctca 1740
ggaaggcctg tacaatgaac tgcagaaaga taagatggcg gaggcctaca gtgagattgg 1800
gatgaaaggc gagcgccgga ggggcaaggg gcacgatggc ctttaccagg gtctcagtac 1860
agccaccaag gacacctacg acgcccttca catgcaggcc ctgccccctc gctaggtcga 1920
cctcgaggga attccgataa tcaacctctg gattacaaaa tttgtgaaag attgactggt 1980
attcttaact atgttgctcc ttttacgcta 2010
<210> 35
<211> 2136
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> P1A6E-28BBZ polynucleotide
<400> 35
gcaggggaaa gaatagtaga cataatagca acagacatac aaactaaaga attacaaaaa 60
caaattacaa aaattcaaaa ttttccgatc acgagactag cctcgagaag cttgatcgat 120
ggctccggtg cccgtcagtg ggcagagcgc acatcgccca cagtccccga gaagttgggg 180
ggaggggtcg gcaattgaac cggtgcctag agaaggtggc gcggggtaaa ctgggaaagt 240
gatgtcgtgt actggctccg cctttttccc gagggtgggg gagaaccgta tataagtgca 300
gtagtcgccg tgaacgttct ttttcgcaac gggtttgccg ccagaacaca ggtgtcgtga 360
cgcggatcca ggcctaagct tacgcgtcct agcgctaccg gtcgccacca tggccttacc 420
agtgaccgcc ttgctcctgc cgctggcctt gctgctccac gccgccaggc cgcaggtaca 480
gctggaacag tcaggtctag gactggtgaa gccctcgcag accctctctc tcacctgtgc 540
catctccggg gacactgtct ctagcgacag tgctgcttgg aactggatca ggcagtcccc 600
atcgagaggc cttgagtggc tgggaaggac atactacagg tccaagtggt ttaatgatta 660
tgcagtatct gtgaaaggtc gaataaccat caactcagac acatccaaga accagttctc 720
cctgcagttg aactctgtga ctcccgagga cacggctgtg tattattgtg caagaagtaa 780
tagttactac tactacgcta tggacgtctg gggccaaggc accctggtca ccgtctcgag 840
tggtggaggc ggttcaggcg gaggtggttc tggcggtggc ggatcgcagg ctgtgctgac 900
tcagccgtct tccctctctg catctcctgg agcatcagcc agtctcacct gcaccttgcg 960
cagtggcatc aatgttggta tctacaggat atactggtac caacagaggc cagggagtcc 1020
tccccagatt ctcctgactt acaaatcaga ctcagataag taccagggct ctggagtccc 1080
cagtcgcttc tctggatcca aagatgcttc ggccaatgca gggattttac tcatctctgg 1140
gctccagtct gaagatgagg ctgactatta ctgcatgatt tggcacagcg gcggttgggt 1200
gttcggcgga gggaccaagg tcaccgtcct aggtaccacg acgccagcgc cgcgaccacc 1260
aacaccggcg cccaccatcg cgtcgcagcc cctgtccctg cgcccagagg cgtgccggcc 1320
agcggcgggg ggcgcagtgc acacgagggg gctggacttc gcctgtgatt tttgggtgct 1380
ggtggtggtt ggtggagtcc tggcttgcta tagcttgcta gtaacagtgg cctttattat 1440
tttctgggtg aggagtaaga ggagcaggct cctgcacagt gactacatga acatgactcc 1500
ccgccgcccc gggccaaccc gcaagcatta ccagccctat gccccaccac gcgacttcgc 1560
agcctatcgc tccaaacggg gcagaaagaa actcctgtat atattcaaac aaccatttat 1620
gagaccagta caaactactc aagaggaaga tggctgtagc tgccgatttc cagaagaaga 1680
agaaggagga tgtgaactga gagtgaagtt cagcaggagc gcagacgccc ccgcgtacca 1740
gcagggccag aaccagctct ataacgagct caatctagga cgaagagagg agtacgatgt 1800
tttggacaag agacgtggcc gggaccctga gatgggggga aagccgcaga gaaggaagaa 1860
ccctcaggaa ggcctgtaca atgaactgca gaaagataag atggcggagg cctacagtga 1920
gattgggatg aaaggcgagc gccggagggg caaggggcac gatggccttt accagggtct 1980
cagtacagcc accaaggaca cctacgacgc ccttcacatg caggccctgc cccctcgcta 2040
ggtcgacctc gagggaattc cgataatcaa cctctggatt acaaaatttg tgaaagattg 2100
actggtattc ttaactatgt tgctcctttt acgcta 2136
<210> 36
<211> 1545
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> P3F2-¦ДZ polynucleotide
<400> 36
gcaggggaaa gaatagtaga cataatagca acagacatac aaactaaaga attacaaaaa 60
caaattacaa aaattcaaaa ttttccgatc acgagactag cctcgagaag cttgatcgat 120
ggctccggtg cccgtcagtg ggcagagcgc acatcgccca cagtccccga gaagttgggg 180
ggaggggtcg gcaattgaac cggtgcctag agaaggtggc gcggggtaaa ctgggaaagt 240
gatgtcgtgt actggctccg cctttttccc gagggtgggg gagaaccgta tataagtgca 300
gtagtcgccg tgaacgttct ttttcgcaac gggtttgccg ccagaacaca ggtgtcgtga 360
cgcggatcca ggcctaagct tacgcgtcct agcgctaccg gtcgccacca tggccttacc 420
agtgaccgcc ttgctcctgc cgctggcctt gctgctccac gccgccaggc cgcagatgca 480
gctagtgcag tctggggctg aggtgaagaa gcctggggcc tcagtgaagg tttcctgcaa 540
ggcatctgga tacaccttca ccagctacta tatgcactgg gtgcgacagg cccctggaca 600
agggcttgag tggatgggaa taatcaaccc tagtggtggt agcacaagct acgcacagaa 660
gttccagggc agagtcacca tgaccaggga cacgtccacg agcacagtct acatggagct 720
gagcagcctg agatctgagg acacggccgt gtattactgt gcgagtagtc ggagtgggac 780
tacggtggta aatcatgatg cttttgatat ctgggggaaa gggaccacgg tcaccgtctc 840
gagtggtgga ggcggttcag gcggaggtgg ttctggcggt ggcggatcgg acatccagtt 900
gacccagtct ccatcctccc tgtctgcgtc tgtaggagac agagtcacca tcacttgccg 960
ggcaagccag gtcattagcc gtgctttagc ctggtatcaa caaacaccag ggaaacctcc 1020
taaactcctg atctatgatg cctccaattt gcagagtggg gtcccatcaa ggttcagcgg 1080
cagtggatct gggacagatt tcactctcac catcagccgc ctgcagcctg aagattttgc 1140
aacttattac tgtcaacagt ttaatagtta ccctctcact ttcggcggag ggaccaagct 1200
ggagatcaaa cgtaccacga cgccagcgcc gcgaccacca acaccggcgc ccaccatcgc 1260
gtcgcagccc ctgtccctgc gcccagaggc gtgccggcca gcggcggggg gcgcagtgca 1320
cacgaggggg ctggacttcg cctgtgatat ctacatctgg gcgcccttgg ccgggacttg 1380
tggggtcctt ctcctgtcac tggttatcac cagagtgaag ttcagcagga gcgcagacgc 1440
ccccgcgtag gtcgacctcg agggaattcc gataatcaac ctctggatta caaaatttgt 1500
gaaagattga ctggtattct taactatgtt gctcctttta cgcta 1545
<210> 37
<211> 1848
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> P3F2-Z polynucleotide
<400> 37
gcaggggaaa gaatagtaga cataatagca acagacatac aaactaaaga attacaaaaa 60
caaattacaa aaattcaaaa ttttccgatc acgagactag cctcgagaag cttgatcgat 120
ggctccggtg cccgtcagtg ggcagagcgc acatcgccca cagtccccga gaagttgggg 180
ggaggggtcg gcaattgaac cggtgcctag agaaggtggc gcggggtaaa ctgggaaagt 240
gatgtcgtgt actggctccg cctttttccc gagggtgggg gagaaccgta tataagtgca 300
gtagtcgccg tgaacgttct ttttcgcaac gggtttgccg ccagaacaca ggtgtcgtga 360
cgcggatcca ggcctaagct tacgcgtcct agcgctaccg gtcgccacca tggccttacc 420
agtgaccgcc ttgctcctgc cgctggcctt gctgctccac gccgccaggc cgcagatgca 480
gctagtgcag tctggggctg aggtgaagaa gcctggggcc tcagtgaagg tttcctgcaa 540
ggcatctgga tacaccttca ccagctacta tatgcactgg gtgcgacagg cccctggaca 600
agggcttgag tggatgggaa taatcaaccc tagtggtggt agcacaagct acgcacagaa 660
gttccagggc agagtcacca tgaccaggga cacgtccacg agcacagtct acatggagct 720
gagcagcctg agatctgagg acacggccgt gtattactgt gcgagtagtc ggagtgggac 780
tacggtggta aatcatgatg cttttgatat ctgggggaaa gggaccacgg tcaccgtctc 840
gagtggtgga ggcggttcag gcggaggtgg ttctggcggt ggcggatcgg acatccagtt 900
gacccagtct ccatcctccc tgtctgcgtc tgtaggagac agagtcacca tcacttgccg 960
ggcaagccag gtcattagcc gtgctttagc ctggtatcaa caaacaccag ggaaacctcc 1020
taaactcctg atctatgatg cctccaattt gcagagtggg gtcccatcaa ggttcagcgg 1080
cagtggatct gggacagatt tcactctcac catcagccgc ctgcagcctg aagattttgc 1140
aacttattac tgtcaacagt ttaatagtta ccctctcact ttcggcggag ggaccaagct 1200
ggagatcaaa cgtaccacga cgccagcgcc gcgaccacca acaccggcgc ccaccatcgc 1260
gtcgcagccc ctgtccctgc gcccagaggc gtgccggcca gcggcggggg gcgcagtgca 1320
cacgaggggg ctggacttcg cctgtgatat ctacatctgg gcgcccttgg ccgggacttg 1380
tggggtcctt ctcctgtcac tggttatcac cagagtgaag ttcagcagga gcgcagacgc 1440
ccccgcgtac cagcagggcc agaaccagct ctataacgag ctcaatctag gacgaagaga 1500
ggagtacgat gttttggaca agagacgtgg ccgggaccct gagatggggg gaaagccgca 1560
gagaaggaag aaccctcagg aaggcctgta caatgaactg cagaaagata agatggcgga 1620
ggcctacagt gagattggga tgaaaggcga gcgccggagg ggcaaggggc acgatggcct 1680
ttaccagggt ctcagtacag ccaccaagga cacctacgac gcccttcaca tgcaggccct 1740
gccccctcgc taggtcgacc tcgagggaat tccgataatc aacctctgga ttacaaaatt 1800
tgtgaaagat tgactggtat tcttaactat gttgctcctt ttacgcta 1848
<210> 38
<211> 1980
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> P3F2-BBZ
<400> 38
gcaggggaaa gaatagtaga cataatagca acagacatac aaactaaaga attacaaaaa 60
caaattacaa aaattcaaaa ttttccgatc acgagactag cctcgagaag cttgatcgat 120
ggctccggtg cccgtcagtg ggcagagcgc acatcgccca cagtccccga gaagttgggg 180
ggaggggtcg gcaattgaac cggtgcctag agaaggtggc gcggggtaaa ctgggaaagt 240
gatgtcgtgt actggctccg cctttttccc gagggtgggg gagaaccgta tataagtgca 300
gtagtcgccg tgaacgttct ttttcgcaac gggtttgccg ccagaacaca ggtgtcgtga 360
cgcggatcca ggcctaagct tacgcgtcct agcgctaccg gtcgccacca tggccttacc 420
agtgaccgcc ttgctcctgc cgctggcctt gctgctccac gccgccaggc cgcagatgca 480
gctagtgcag tctggggctg aggtgaagaa gcctggggcc tcagtgaagg tttcctgcaa 540
ggcatctgga tacaccttca ccagctacta tatgcactgg gtgcgacagg cccctggaca 600
agggcttgag tggatgggaa taatcaaccc tagtggtggt agcacaagct acgcacagaa 660
gttccagggc agagtcacca tgaccaggga cacgtccacg agcacagtct acatggagct 720
gagcagcctg agatctgagg acacggccgt gtattactgt gcgagtagtc ggagtgggac 780
tacggtggta aatcatgatg cttttgatat ctgggggaaa gggaccacgg tcaccgtctc 840
gagtggtgga ggcggttcag gcggaggtgg ttctggcggt ggcggatcgg acatccagtt 900
gacccagtct ccatcctccc tgtctgcgtc tgtaggagac agagtcacca tcacttgccg 960
ggcaagccag gtcattagcc gtgctttagc ctggtatcaa caaacaccag ggaaacctcc 1020
taaactcctg atctatgatg cctccaattt gcagagtggg gtcccatcaa ggttcagcgg 1080
cagtggatct gggacagatt tcactctcac catcagccgc ctgcagcctg aagattttgc 1140
aacttattac tgtcaacagt ttaatagtta ccctctcact ttcggcggag ggaccaagct 1200
ggagatcaaa cgtaccacga cgccagcgcc gcgaccacca acaccggcgc ccaccatcgc 1260
gtcgcagccc ctgtccctgc gcccagaggc gtgccggcca gcggcggggg gcgcagtgca 1320
cacgaggggg ctggacttcg cctgtgatat ctacatctgg gcgcccttgg ccgggacttg 1380
tggggtcctt ctcctgtcac tggttatcac cctttactgc aaacggggca gaaagaaact 1440
cctgtatata ttcaaacaac catttatgag accagtacaa actactcaag aggaagatgg 1500
ctgtagctgc cgatttccag aagaagaaga aggaggatgt gaactgagag tgaagttcag 1560
caggagcgca gacgcccccg cgtacaagca gggccagaac cagctctata acgagctcaa 1620
tctaggacga agagaggagt acgatgtttt ggacaagaga cgtggccggg accctgagat 1680
ggggggaaag ccgagaagga agaaccctca ggaaggcctg tacaatgaac tgcagaaaga 1740
taagatggcg gaggcctaca gtgagattgg gatgaaaggc gagcgccgga ggggcaaggg 1800
gcacgatggc ctttaccagg gtctcagtac agccaccaag gacacctacg acgcccttca 1860
catgcaggcc ctgccccctc gctaggtcga cctcgaggga attccgataa tcaacctctg 1920
gattacaaaa tttgtgaaag attgactggt attcttaact atgttgctcc ttttacgcta 1980
<210> 39
<211> 1989
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> P3F2-28Z polynucleotide
<400> 39
gcaggggaaa gaatagtaga cataatagca acagacatac aaactaaaga attacaaaaa 60
caaattacaa aaattcaaaa ttttccgatc acgagactag cctcgagaag cttgatcgat 120
ggctccggtg cccgtcagtg ggcagagcgc acatcgccca cagtccccga gaagttgggg 180
ggaggggtcg gcaattgaac cggtgcctag agaaggtggc gcggggtaaa ctgggaaagt 240
gatgtcgtgt actggctccg cctttttccc gagggtgggg gagaaccgta tataagtgca 300
gtagtcgccg tgaacgttct ttttcgcaac gggtttgccg ccagaacaca ggtgtcgtga 360
cgcggatcca ggcctaagct tacgcgtcct agcgctaccg gtcgccacca tggccttacc 420
agtgaccgcc ttgctcctgc cgctggcctt gctgctccac gccgccaggc cgcagatgca 480
gctagtgcag tctggggctg aggtgaagaa gcctggggcc tcagtgaagg tttcctgcaa 540
ggcatctgga tacaccttca ccagctacta tatgcactgg gtgcgacagg cccctggaca 600
agggcttgag tggatgggaa taatcaaccc tagtggtggt agcacaagct acgcacagaa 660
gttccagggc agagtcacca tgaccaggga cacgtccacg agcacagtct acatggagct 720
gagcagcctg agatctgagg acacggccgt gtattactgt gcgagtagtc ggagtgggac 780
tacggtggta aatcatgatg cttttgatat ctgggggaaa gggaccacgg tcaccgtctc 840
gagtggtgga ggcggttcag gcggaggtgg ttctggcggt ggcggatcgg acatccagtt 900
gacccagtct ccatcctccc tgtctgcgtc tgtaggagac agagtcacca tcacttgccg 960
ggcaagccag gtcattagcc gtgctttagc ctggtatcaa caaacaccag ggaaacctcc 1020
taaactcctg atctatgatg cctccaattt gcagagtggg gtcccatcaa ggttcagcgg 1080
cagtggatct gggacagatt tcactctcac catcagccgc ctgcagcctg aagattttgc 1140
aacttattac tgtcaacagt ttaatagtta ccctctcact ttcggcggag ggaccaagct 1200
ggagatcaaa cgtaccacga cgccagcgcc gcgaccacca acaccggcgc ccaccatcgc 1260
gtcgcagccc ctgtccctgc gcccagaggc gtgccggcca gcggcggggg gcgcagtgca 1320
cacgaggggg ctggacttcg cctgtgattt ttgggtgctg gtggtggttg gtggagtcct 1380
ggcttgctat agcttgctag taacagtggc ctttattatt ttctgggtga ggagtaagag 1440
gagcaggctc ctgcacagtg actacatgaa catgactccc cgccgccccg ggccaacccg 1500
caagcattac cagccctatg ccccaccacg cgacttcgca gcctatcgct ccagagtgaa 1560
gttcagcagg agcgcagacg cccccgcgta ccagcagggc cagaaccagc tctataacga 1620
gctcaatcta ggacgaagag aggagtacga tgttttggac aagagacgtg gccgggaccc 1680
tgagatgggg ggaaagccgc agagaaggaa gaaccctcag gaaggcctgt acaatgaact 1740
gcagaaagat aagatggcgg aggcctacag tgagattggg atgaaaggcg agcgccggag 1800
gggcaagggg cacgatggcc tttaccaggg tctcagtaca gccaccaagg acacctacga 1860
cgcccttcac atgcaggccc tgccccctcg ctaggtcgac ctcgagggaa ttccgataat 1920
caacctctgg attacaaaat ttgtgaaaga ttgactggta ttcttaacta tgttgctcct 1980
tttacgcta 1989
<210> 40
<211> 2115
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> P3F2-28BBZ polynucleotide
<400> 40
gcaggggaaa gaatagtaga cataatagca acagacatac aaactaaaga attacaaaaa 60
caaattacaa aaattcaaaa ttttccgatc acgagactag cctcgagaag cttgatcgat 120
ggctccggtg cccgtcagtg ggcagagcgc acatcgccca cagtccccga gaagttgggg 180
ggaggggtcg gcaattgaac cggtgcctag agaaggtggc gcggggtaaa ctgggaaagt 240
gatgtcgtgt actggctccg cctttttccc gagggtgggg gagaaccgta tataagtgca 300
gtagtcgccg tgaacgttct ttttcgcaac gggtttgccg ccagaacaca ggtgtcgtga 360
cgcggatcca ggcctaagct tacgcgtcct agcgctaccg gtcgccacca tggccttacc 420
agtgaccgcc ttgctcctgc cgctggcctt gctgctccac gccgccaggc cgcagatgca 480
gctagtgcag tctggggctg aggtgaagaa gcctggggcc tcagtgaagg tttcctgcaa 540
ggcatctgga tacaccttca ccagctacta tatgcactgg gtgcgacagg cccctggaca 600
agggcttgag tggatgggaa taatcaaccc tagtggtggt agcacaagct acgcacagaa 660
gttccagggc agagtcacca tgaccaggga cacgtccacg agcacagtct acatggagct 720
gagcagcctg agatctgagg acacggccgt gtattactgt gcgagtagtc ggagtgggac 780
tacggtggta aatcatgatg cttttgatat ctgggggaaa gggaccacgg tcaccgtctc 840
gagtggtgga ggcggttcag gcggaggtgg ttctggcggt ggcggatcgg acatccagtt 900
gacccagtct ccatcctccc tgtctgcgtc tgtaggagac agagtcacca tcacttgccg 960
ggcaagccag gtcattagcc gtgctttagc ctggtatcaa caaacaccag ggaaacctcc 1020
taaactcctg atctatgatg cctccaattt gcagagtggg gtcccatcaa ggttcagcgg 1080
cagtggatct gggacagatt tcactctcac catcagccgc ctgcagcctg aagattttgc 1140
aacttattac tgtcaacagt ttaatagtta ccctctcact ttcggcggag ggaccaagct 1200
ggagatcaaa cgtaccacga cgccagcgcc gcgaccacca acaccggcgc ccaccatcgc 1260
gtcgcagccc ctgtccctgc gcccagaggc gtgccggcca gcggcggggg gcgcagtgca 1320
cacgaggggg ctggacttcg cctgtgattt ttgggtgctg gtggtggttg gtggagtcct 1380
ggcttgctat agcttgctag taacagtggc ctttattatt ttctgggtga ggagtaagag 1440
gagcaggctc ctgcacagtg actacatgaa catgactccc cgccgccccg ggccaacccg 1500
caagcattac cagccctatg ccccaccacg cgacttcgca gcctatcgct ccaaacgggg 1560
cagaaagaaa ctcctgtata tattcaaaca accatttatg agaccagtac aaactactca 1620
agaggaagat ggctgtagct gccgatttcc agaagaagaa gaaggaggat gtgaactgag 1680
agtgaagttc agcaggagcg cagacgcccc cgcgtaccag cagggccaga accagctcta 1740
taacgagctc aatctaggac gaagagagga gtacgatgtt ttggacaaga gacgtggccg 1800
ggaccctgag atggggggaa agccgcagag aaggaagaac cctcaggaag gcctgtacaa 1860
tgaactgcag aaagataaga tggcggaggc ctacagtgag attgggatga aaggcgagcg 1920
ccggaggggc aaggggcacg atggccttta ccagggtctc agtacagcca ccaaggacac 1980
ctacgacgcc cttcacatgc aggccctgcc ccctcgctag gtcgacctcg agggaattcc 2040
gataatcaac ctctggatta caaaatttgt gaaagattga ctggtattct taactatgtt 2100
gctcctttta cgcta 2115
<210> 41
<211> 353
<212> PRT
<213> Artificial sequence
<220>
<221> MISC_FEATURE
<223> P1A6E-¦ДZ amino acid sequence
<400> 41
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gln Val Gln Leu Glu Gln Ser Gly Leu Gly Leu
20 25 30
Val Lys Pro Ser Gln Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp
35 40 45
Thr Val Ser Ser Asp Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro
50 55 60
Ser Arg Gly Leu Glu Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp
65 70 75 80
Phe Asn Asp Tyr Ala Val Ser Val Lys Gly Arg Ile Thr Ile Asn Ser
85 90 95
Asp Thr Ser Lys Asn Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro
100 105 110
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Ser Asn Ser Tyr Tyr Tyr
115 120 125
Tyr Ala Met Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln
145 150 155 160
Ala Val Leu Thr Gln Pro Ser Ser Leu Ser Ala Ser Pro Gly Ala Ser
165 170 175
Ala Ser Leu Thr Cys Thr Leu Arg Ser Gly Ile Asn Val Gly Ile Tyr
180 185 190
Arg Ile Tyr Trp Tyr Gln Gln Arg Pro Gly Ser Pro Pro Gln Ile Leu
195 200 205
Leu Thr Tyr Lys Ser Asp Ser Asp Lys Tyr Gln Gly Ser Gly Val Pro
210 215 220
Ser Arg Phe Ser Gly Ser Lys Asp Ala Ser Ala Asn Ala Gly Ile Leu
225 230 235 240
Leu Ile Ser Gly Leu Gln Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Met
245 250 255
Ile Trp His Ser Gly Gly Trp Val Phe Gly Gly Gly Thr Lys Val Thr
260 265 270
Val Leu Gly Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro
275 280 285
Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro
290 295 300
Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp
305 310 315 320
Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu Leu
325 330 335
Ser Leu Val Ile Thr Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro
340 345 350
Ala
<210> 42
<211> 454
<212> PRT
<213> Artificial sequence
<220>
<221> MISC_FEATURE
<223> P1A6E-Z amino acid sequence
<400> 42
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gln Val Gln Leu Glu Gln Ser Gly Leu Gly Leu
20 25 30
Val Lys Pro Ser Gln Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp
35 40 45
Thr Val Ser Ser Asp Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro
50 55 60
Ser Arg Gly Leu Glu Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp
65 70 75 80
Phe Asn Asp Tyr Ala Val Ser Val Lys Gly Arg Ile Thr Ile Asn Ser
85 90 95
Asp Thr Ser Lys Asn Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro
100 105 110
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Ser Asn Ser Tyr Tyr Tyr
115 120 125
Tyr Ala Met Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln
145 150 155 160
Ala Val Leu Thr Gln Pro Ser Ser Leu Ser Ala Ser Pro Gly Ala Ser
165 170 175
Ala Ser Leu Thr Cys Thr Leu Arg Ser Gly Ile Asn Val Gly Ile Tyr
180 185 190
Arg Ile Tyr Trp Tyr Gln Gln Arg Pro Gly Ser Pro Pro Gln Ile Leu
195 200 205
Leu Thr Tyr Lys Ser Asp Ser Asp Lys Tyr Gln Gly Ser Gly Val Pro
210 215 220
Ser Arg Phe Ser Gly Ser Lys Asp Ala Ser Ala Asn Ala Gly Ile Leu
225 230 235 240
Leu Ile Ser Gly Leu Gln Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Met
245 250 255
Ile Trp His Ser Gly Gly Trp Val Phe Gly Gly Gly Thr Lys Val Thr
260 265 270
Val Leu Gly Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro
275 280 285
Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro
290 295 300
Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp
305 310 315 320
Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu Leu
325 330 335
Ser Leu Val Ile Thr Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro
340 345 350
Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly
355 360 365
Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro
370 375 380
Glu Met Gly Gly Lys Pro Gln Arg Arg Lys Asn Pro Gln Glu Gly Leu
385 390 395 400
Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile
405 410 415
Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr
420 425 430
Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met
435 440 445
Gln Ala Leu Pro Pro Arg
450
<210> 43
<211> 498
<212> PRT
<213> Artificial sequence
<220>
<221> MISC_FEATURE
<223> P1A6E-BBZ amino acid sequence
<400> 43
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gln Val Gln Leu Glu Gln Ser Gly Leu Gly Leu
20 25 30
Val Lys Pro Ser Gln Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp
35 40 45
Thr Val Ser Ser Asp Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro
50 55 60
Ser Arg Gly Leu Glu Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp
65 70 75 80
Phe Asn Asp Tyr Ala Val Ser Val Lys Gly Arg Ile Thr Ile Asn Ser
85 90 95
Asp Thr Ser Lys Asn Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro
100 105 110
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Ser Asn Ser Tyr Tyr Tyr
115 120 125
Tyr Ala Met Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln
145 150 155 160
Ala Val Leu Thr Gln Pro Ser Ser Leu Ser Ala Ser Pro Gly Ala Ser
165 170 175
Ala Ser Leu Thr Cys Thr Leu Arg Ser Gly Ile Asn Val Gly Ile Tyr
180 185 190
Arg Ile Tyr Trp Tyr Gln Gln Arg Pro Gly Ser Pro Pro Gln Ile Leu
195 200 205
Leu Thr Tyr Lys Ser Asp Ser Asp Lys Tyr Gln Gly Ser Gly Val Pro
210 215 220
Ser Arg Phe Ser Gly Ser Lys Asp Ala Ser Ala Asn Ala Gly Ile Leu
225 230 235 240
Leu Ile Ser Gly Leu Gln Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Met
245 250 255
Ile Trp His Ser Gly Gly Trp Val Phe Gly Gly Gly Thr Lys Val Thr
260 265 270
Val Leu Gly Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro
275 280 285
Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro
290 295 300
Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp
305 310 315 320
Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu Leu
325 330 335
Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys Lys Leu Leu
340 345 350
Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu
355 360 365
Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys
370 375 380
Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Lys
385 390 395 400
Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu
405 410 415
Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly
420 425 430
Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu
435 440 445
Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly
450 455 460
Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser
465 470 475 480
Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro
485 490 495
Pro Arg
<210> 44
<211> 501
<212> PRT
<213> Artificial sequence
<220>
<221> MISC_FEATURE
<223> P1A6E-28Z amino acid sequence
<400> 44
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gln Val Gln Leu Glu Gln Ser Gly Leu Gly Leu
20 25 30
Val Lys Pro Ser Gln Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp
35 40 45
Thr Val Ser Ser Asp Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro
50 55 60
Ser Arg Gly Leu Glu Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp
65 70 75 80
Phe Asn Asp Tyr Ala Val Ser Val Lys Gly Arg Ile Thr Ile Asn Ser
85 90 95
Asp Thr Ser Lys Asn Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro
100 105 110
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Ser Asn Ser Tyr Tyr Tyr
115 120 125
Tyr Ala Met Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln
145 150 155 160
Ala Val Leu Thr Gln Pro Ser Ser Leu Ser Ala Ser Pro Gly Ala Ser
165 170 175
Ala Ser Leu Thr Cys Thr Leu Arg Ser Gly Ile Asn Val Gly Ile Tyr
180 185 190
Arg Ile Tyr Trp Tyr Gln Gln Arg Pro Gly Ser Pro Pro Gln Ile Leu
195 200 205
Leu Thr Tyr Lys Ser Asp Ser Asp Lys Tyr Gln Gly Ser Gly Val Pro
210 215 220
Ser Arg Phe Ser Gly Ser Lys Asp Ala Ser Ala Asn Ala Gly Ile Leu
225 230 235 240
Leu Ile Ser Gly Leu Gln Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Met
245 250 255
Ile Trp His Ser Gly Gly Trp Val Phe Gly Gly Gly Thr Lys Val Thr
260 265 270
Val Leu Gly Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro
275 280 285
Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro
290 295 300
Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp
305 310 315 320
Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu
325 330 335
Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser
340 345 350
Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly
355 360 365
Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala
370 375 380
Ala Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
385 390 395 400
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
405 410 415
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
420 425 430
Met Gly Gly Lys Pro Gln Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr
435 440 445
Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly
450 455 460
Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln
465 470 475 480
Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln
485 490 495
Ala Leu Pro Pro Arg
500
<210> 45
<211> 543
<212> PRT
<213> Artificial sequence
<220>
<221> MISC_FEATURE
<223> P1A6E-28BBZ amino acid sequence
<400> 45
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gln Val Gln Leu Glu Gln Ser Gly Leu Gly Leu
20 25 30
Val Lys Pro Ser Gln Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp
35 40 45
Thr Val Ser Ser Asp Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro
50 55 60
Ser Arg Gly Leu Glu Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp
65 70 75 80
Phe Asn Asp Tyr Ala Val Ser Val Lys Gly Arg Ile Thr Ile Asn Ser
85 90 95
Asp Thr Ser Lys Asn Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro
100 105 110
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Ser Asn Ser Tyr Tyr Tyr
115 120 125
Tyr Ala Met Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln
145 150 155 160
Ala Val Leu Thr Gln Pro Ser Ser Leu Ser Ala Ser Pro Gly Ala Ser
165 170 175
Ala Ser Leu Thr Cys Thr Leu Arg Ser Gly Ile Asn Val Gly Ile Tyr
180 185 190
Arg Ile Tyr Trp Tyr Gln Gln Arg Pro Gly Ser Pro Pro Gln Ile Leu
195 200 205
Leu Thr Tyr Lys Ser Asp Ser Asp Lys Tyr Gln Gly Ser Gly Val Pro
210 215 220
Ser Arg Phe Ser Gly Ser Lys Asp Ala Ser Ala Asn Ala Gly Ile Leu
225 230 235 240
Leu Ile Ser Gly Leu Gln Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Met
245 250 255
Ile Trp His Ser Gly Gly Trp Val Phe Gly Gly Gly Thr Lys Val Thr
260 265 270
Val Leu Gly Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro
275 280 285
Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro
290 295 300
Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp
305 310 315 320
Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu
325 330 335
Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser
340 345 350
Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly
355 360 365
Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala
370 375 380
Ala Tyr Arg Ser Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys
385 390 395 400
Gln Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys
405 410 415
Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val
420 425 430
Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn
435 440 445
Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val
450 455 460
Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Gln
465 470 475 480
Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp
485 490 495
Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg
500 505 510
Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr
515 520 525
Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
530 535 540
<210> 46
<211> 346
<212> PRT
<213> Artificial sequence
<220>
<221> MISC_FEATURE
<223> P3F2-¦ДZ amino acid sequence
<400> 46
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gln Met Gln Leu Val Gln Ser Gly Ala Glu Val
20 25 30
Lys Lys Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr
35 40 45
Thr Phe Thr Ser Tyr Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln
50 55 60
Gly Leu Glu Trp Met Gly Ile Ile Asn Pro Ser Gly Gly Ser Thr Ser
65 70 75 80
Tyr Ala Gln Lys Phe Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser
85 90 95
Thr Ser Thr Val Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr
100 105 110
Ala Val Tyr Tyr Cys Ala Ser Ser Arg Ser Gly Thr Thr Val Val Asn
115 120 125
His Asp Ala Phe Asp Ile Trp Gly Lys Gly Thr Thr Val Thr Val Ser
130 135 140
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
145 150 155 160
Asp Ile Gln Leu Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
165 170 175
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Val Ile Ser Arg Ala
180 185 190
Leu Ala Trp Tyr Gln Gln Thr Pro Gly Lys Pro Pro Lys Leu Leu Ile
195 200 205
Tyr Asp Ala Ser Asn Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
210 215 220
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Gln Pro
225 230 235 240
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Phe Asn Ser Tyr Pro Leu
245 250 255
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Thr Thr Pro
260 265 270
Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu
275 280 285
Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His
290 295 300
Thr Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu
305 310 315 320
Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val Ile Thr Arg Val
325 330 335
Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
340 345
<210> 47
<211> 447
<212> PRT
<213> Artificial sequence
<220>
<221> MISC_FEATURE
<223> P3F2-Z amino acid sequence
<400> 47
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gln Met Gln Leu Val Gln Ser Gly Ala Glu Val
20 25 30
Lys Lys Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr
35 40 45
Thr Phe Thr Ser Tyr Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln
50 55 60
Gly Leu Glu Trp Met Gly Ile Ile Asn Pro Ser Gly Gly Ser Thr Ser
65 70 75 80
Tyr Ala Gln Lys Phe Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser
85 90 95
Thr Ser Thr Val Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr
100 105 110
Ala Val Tyr Tyr Cys Ala Ser Ser Arg Ser Gly Thr Thr Val Val Asn
115 120 125
His Asp Ala Phe Asp Ile Trp Gly Lys Gly Thr Thr Val Thr Val Ser
130 135 140
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
145 150 155 160
Asp Ile Gln Leu Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
165 170 175
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Val Ile Ser Arg Ala
180 185 190
Leu Ala Trp Tyr Gln Gln Thr Pro Gly Lys Pro Pro Lys Leu Leu Ile
195 200 205
Tyr Asp Ala Ser Asn Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
210 215 220
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Gln Pro
225 230 235 240
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Phe Asn Ser Tyr Pro Leu
245 250 255
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Thr Thr Pro
260 265 270
Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu
275 280 285
Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His
290 295 300
Thr Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu
305 310 315 320
Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val Ile Thr Arg Val
325 330 335
Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn
340 345 350
Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val
355 360 365
Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Gln
370 375 380
Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp
385 390 395 400
Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg
405 410 415
Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr
420 425 430
Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
435 440 445
<210> 48
<211> 491
<212> PRT
<213> Artificial sequence
<220>
<221> MISC_FEATURE
<223> P3F2-BBZ amino acid sequence
<400> 48
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gln Met Gln Leu Val Gln Ser Gly Ala Glu Val
20 25 30
Lys Lys Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr
35 40 45
Thr Phe Thr Ser Tyr Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln
50 55 60
Gly Leu Glu Trp Met Gly Ile Ile Asn Pro Ser Gly Gly Ser Thr Ser
65 70 75 80
Tyr Ala Gln Lys Phe Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser
85 90 95
Thr Ser Thr Val Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr
100 105 110
Ala Val Tyr Tyr Cys Ala Ser Ser Arg Ser Gly Thr Thr Val Val Asn
115 120 125
His Asp Ala Phe Asp Ile Trp Gly Lys Gly Thr Thr Val Thr Val Ser
130 135 140
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
145 150 155 160
Asp Ile Gln Leu Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
165 170 175
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Val Ile Ser Arg Ala
180 185 190
Leu Ala Trp Tyr Gln Gln Thr Pro Gly Lys Pro Pro Lys Leu Leu Ile
195 200 205
Tyr Asp Ala Ser Asn Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
210 215 220
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Gln Pro
225 230 235 240
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Phe Asn Ser Tyr Pro Leu
245 250 255
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Thr Thr Pro
260 265 270
Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu
275 280 285
Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His
290 295 300
Thr Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu
305 310 315 320
Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr
325 330 335
Cys Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe
340 345 350
Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg
355 360 365
Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser
370 375 380
Arg Ser Ala Asp Ala Pro Ala Tyr Lys Gln Gly Gln Asn Gln Leu Tyr
385 390 395 400
Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys
405 410 415
Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn
420 425 430
Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu
435 440 445
Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly
450 455 460
His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr
465 470 475 480
Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
485 490
<210> 49
<211> 494
<212> PRT
<213> Artificial sequence
<220>
<221> MISC_FEATURE
<223> P3F2-28Z amino acid sequence
<400> 49
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gln Met Gln Leu Val Gln Ser Gly Ala Glu Val
20 25 30
Lys Lys Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr
35 40 45
Thr Phe Thr Ser Tyr Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln
50 55 60
Gly Leu Glu Trp Met Gly Ile Ile Asn Pro Ser Gly Gly Ser Thr Ser
65 70 75 80
Tyr Ala Gln Lys Phe Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser
85 90 95
Thr Ser Thr Val Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr
100 105 110
Ala Val Tyr Tyr Cys Ala Ser Ser Arg Ser Gly Thr Thr Val Val Asn
115 120 125
His Asp Ala Phe Asp Ile Trp Gly Lys Gly Thr Thr Val Thr Val Ser
130 135 140
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
145 150 155 160
Asp Ile Gln Leu Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
165 170 175
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Val Ile Ser Arg Ala
180 185 190
Leu Ala Trp Tyr Gln Gln Thr Pro Gly Lys Pro Pro Lys Leu Leu Ile
195 200 205
Tyr Asp Ala Ser Asn Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
210 215 220
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Gln Pro
225 230 235 240
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Phe Asn Ser Tyr Pro Leu
245 250 255
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Thr Thr Pro
260 265 270
Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu
275 280 285
Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His
290 295 300
Thr Arg Gly Leu Asp Phe Ala Cys Asp Phe Trp Val Leu Val Val Val
305 310 315 320
Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu Val Thr Val Ala Phe Ile
325 330 335
Ile Phe Trp Val Arg Ser Lys Arg Ser Arg Leu Leu His Ser Asp Tyr
340 345 350
Met Asn Met Thr Pro Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln
355 360 365
Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala Tyr Arg Ser Arg Val Lys
370 375 380
Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln
385 390 395 400
Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu
405 410 415
Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Gln Arg
420 425 430
Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys
435 440 445
Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg
450 455 460
Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys
465 470 475 480
Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
485 490
<210> 50
<211> 536
<212> PRT
<213> Artificial sequence
<220>
<221> MISC_FEATURE
<223> P3F2-28BBZ amino acid sequence
<400> 50
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gln Met Gln Leu Val Gln Ser Gly Ala Glu Val
20 25 30
Lys Lys Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr
35 40 45
Thr Phe Thr Ser Tyr Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln
50 55 60
Gly Leu Glu Trp Met Gly Ile Ile Asn Pro Ser Gly Gly Ser Thr Ser
65 70 75 80
Tyr Ala Gln Lys Phe Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser
85 90 95
Thr Ser Thr Val Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr
100 105 110
Ala Val Tyr Tyr Cys Ala Ser Ser Arg Ser Gly Thr Thr Val Val Asn
115 120 125
His Asp Ala Phe Asp Ile Trp Gly Lys Gly Thr Thr Val Thr Val Ser
130 135 140
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
145 150 155 160
Asp Ile Gln Leu Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
165 170 175
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Val Ile Ser Arg Ala
180 185 190
Leu Ala Trp Tyr Gln Gln Thr Pro Gly Lys Pro Pro Lys Leu Leu Ile
195 200 205
Tyr Asp Ala Ser Asn Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
210 215 220
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Gln Pro
225 230 235 240
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Phe Asn Ser Tyr Pro Leu
245 250 255
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Thr Thr Pro
260 265 270
Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu
275 280 285
Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His
290 295 300
Thr Arg Gly Leu Asp Phe Ala Cys Asp Phe Trp Val Leu Val Val Val
305 310 315 320
Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu Val Thr Val Ala Phe Ile
325 330 335
Ile Phe Trp Val Arg Ser Lys Arg Ser Arg Leu Leu His Ser Asp Tyr
340 345 350
Met Asn Met Thr Pro Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln
355 360 365
Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala Tyr Arg Ser Lys Arg Gly
370 375 380
Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val
385 390 395 400
Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu
405 410 415
Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp
420 425 430
Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn
435 440 445
Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg
450 455 460
Asp Pro Glu Met Gly Gly Lys Pro Gln Arg Arg Lys Asn Pro Gln Glu
465 470 475 480
Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser
485 490 495
Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly
500 505 510
Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu
515 520 525
His Met Gln Ala Leu Pro Pro Arg
530 535
<210> 51
<211> 14
<212> PRT
<213> Homo Sapiens
<400> 51
Thr Leu Arg Ser Gly Ile Asn Val Gly Ile Tyr Arg Ile Tyr
1 5 10
<210> 52
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 52
Tyr Lys Ser Asp Ser Asp Lys Tyr Gln Gly Ser
1 5 10
<210> 53
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 53
Met Ile Trp His Ser Gly Gly Trp Val
1 5
<210> 54
<211> 12
<212> PRT
<213> Homo Sapiens
<400> 54
Gly Asp Thr Val Ser Ser Asp Ser Ala Ala Trp Asn
1 5 10
<210> 55
<211> 18
<212> PRT
<213> Homo Sapiens
<400> 55
Arg Thr Tyr Tyr Arg Ser Lys Trp Phe Asn Asp Tyr Ala Val Ser Val
1 5 10 15
Lys Gly
<210> 56
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 56
Ser Asn Ser Tyr Tyr Tyr Tyr Ala Met Asp Val
1 5 10
<210> 57
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 57
Arg Ala Ser Gln Val Ile Ser Arg Ala Leu Ala
1 5 10
<210> 58
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 58
Asp Ala Ser Asn Leu Gln Ser
1 5
<210> 59
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 59
Gln Gln Phe Asn Ser Tyr Pro Leu Thr
1 5
<210> 60
<211> 10
<212> PRT
<213> Homo Sapiens
<400> 60
Gly Tyr Thr Phe Thr Ser Tyr Tyr Met His
1 5 10
<210> 61
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 61
Ile Ile Asn Pro Ser Gly Gly Ser Thr Ser Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 62
<211> 15
<212> PRT
<213> Homo Sapiens
<400> 62
Ser Arg Ser Gly Thr Thr Val Val Asn His Asp Ala Phe Asp Ile
1 5 10 15
<210> 63
<211> 25
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 63
accacgacgc cagcgccgcg accac 25
<210> 64
<211> 22
<212> DNA
<213> Artificial sequence
<220>
<221> misc_feature
<223> primer
<400> 64
tagcgtaaaa ggagcaacat ag 22
<210> 65
<211> 622
<212> PRT
<213> Homo Sapiens
<400> 65
Met Ala Leu Pro Thr Ala Arg Pro Leu Leu Gly Ser Cys Gly Thr Pro
1 5 10 15
Ala Leu Gly Ser Leu Leu Phe Leu Leu Phe Ser Leu Gly Trp Val Gln
20 25 30
Pro Ser Arg Thr Leu Ala Gly Glu Thr Gly Gln Glu Ala Ala Pro Leu
35 40 45
Asp Gly Val Leu Ala Asn Pro Pro Asn Ile Ser Ser Leu Ser Pro Arg
50 55 60
Gln Leu Leu Gly Phe Pro Cys Ala Glu Val Ser Gly Leu Ser Thr Glu
65 70 75 80
Arg Val Arg Glu Leu Ala Val Ala Leu Ala Gln Lys Asn Val Lys Leu
85 90 95
Ser Thr Glu Gln Leu Arg Cys Leu Ala His Arg Leu Ser Glu Pro Pro
100 105 110
Glu Asp Leu Asp Ala Leu Pro Leu Asp Leu Leu Leu Phe Leu Asn Pro
115 120 125
Asp Ala Phe Ser Gly Pro Gln Ala Cys Thr Arg Phe Phe Ser Arg Ile
130 135 140
Thr Lys Ala Asn Val Asp Leu Leu Pro Arg Gly Ala Pro Glu Arg Gln
145 150 155 160
Arg Leu Leu Pro Ala Ala Leu Ala Cys Trp Gly Val Arg Gly Ser Leu
165 170 175
Leu Ser Glu Ala Asp Val Arg Ala Leu Gly Gly Leu Ala Cys Asp Leu
180 185 190
Pro Gly Arg Phe Val Ala Glu Ser Ala Glu Val Leu Leu Pro Arg Leu
195 200 205
Val Ser Cys Pro Gly Pro Leu Asp Gln Asp Gln Gln Glu Ala Ala Arg
210 215 220
Ala Ala Leu Gln Gly Gly Gly Pro Pro Tyr Gly Pro Pro Ser Thr Trp
225 230 235 240
Ser Val Ser Thr Met Asp Ala Leu Arg Gly Leu Leu Pro Val Leu Gly
245 250 255
Gln Pro Ile Ile Arg Ser Ile Pro Gln Gly Ile Val Ala Ala Trp Arg
260 265 270
Gln Arg Ser Ser Arg Asp Pro Ser Trp Arg Gln Pro Glu Arg Thr Ile
275 280 285
Leu Arg Pro Arg Phe Arg Arg Glu Val Glu Lys Thr Ala Cys Pro Ser
290 295 300
Gly Lys Lys Ala Arg Glu Ile Asp Glu Ser Leu Ile Phe Tyr Lys Lys
305 310 315 320
Trp Glu Leu Glu Ala Cys Val Asp Ala Ala Leu Leu Ala Thr Gln Met
325 330 335
Asp Arg Val Asn Ala Ile Pro Phe Thr Tyr Glu Gln Leu Asp Val Leu
340 345 350
Lys His Lys Leu Asp Glu Leu Tyr Pro Gln Gly Tyr Pro Glu Ser Val
355 360 365
Ile Gln His Leu Gly Tyr Leu Phe Leu Lys Met Ser Pro Glu Asp Ile
370 375 380
Arg Lys Trp Asn Val Thr Ser Leu Glu Thr Leu Lys Ala Leu Leu Glu
385 390 395 400
Val Asn Lys Gly His Glu Met Ser Pro Gln Val Ala Thr Leu Ile Asp
405 410 415
Arg Phe Val Lys Gly Arg Gly Gln Leu Asp Lys Asp Thr Leu Asp Thr
420 425 430
Leu Thr Ala Phe Tyr Pro Gly Tyr Leu Cys Ser Leu Ser Pro Glu Glu
435 440 445
Leu Ser Ser Val Pro Pro Ser Ser Ile Trp Ala Val Arg Pro Gln Asp
450 455 460
Leu Asp Thr Cys Asp Pro Arg Gln Leu Asp Val Leu Tyr Pro Lys Ala
465 470 475 480
Arg Leu Ala Phe Gln Asn Met Asn Gly Ser Glu Tyr Phe Val Lys Ile
485 490 495
Gln Ser Phe Leu Gly Gly Ala Pro Thr Glu Asp Leu Lys Ala Leu Ser
500 505 510
Gln Gln Asn Val Ser Met Asp Leu Ala Thr Phe Met Lys Leu Arg Thr
515 520 525
Asp Ala Val Leu Pro Leu Thr Val Ala Glu Val Gln Lys Leu Leu Gly
530 535 540
Pro His Val Glu Gly Leu Lys Ala Glu Glu Arg His Arg Pro Val Arg
545 550 555 560
Asp Trp Ile Leu Arg Gln Arg Gln Asp Asp Leu Asp Thr Leu Gly Leu
565 570 575
Gly Leu Gln Gly Gly Ile Pro Asn Gly Tyr Leu Val Leu Asp Leu Ser
580 585 590
Met Gln Glu Ala Leu Ser Gly Thr Pro Cys Leu Leu Gly Pro Gly Pro
595 600 605
Val Leu Thr Val Leu Ala Leu Leu Leu Ala Ser Thr Leu Ala
610 615 620
<210> 66
<211> 95
<212> PRT
<213> Artificial sequence
<220>
<223> human mesothelin fragment
<400> 66
Glu Val Glu Lys Thr Ala Cys Pro Ser Gly Lys Lys Ala Arg Glu Ile
1 5 10 15
Asp Glu Ser Leu Ile Phe Tyr Lys Lys Trp Glu Leu Glu Ala Cys Val
20 25 30
Asp Ala Ala Leu Leu Ala Thr Gln Met Asp Arg Val Asn Ala Ile Pro
35 40 45
Phe Thr Tyr Glu Gln Leu Asp Val Leu Lys His Lys Leu Asp Glu Leu
50 55 60
Tyr Pro Gln Gly Tyr Pro Glu Ser Val Ile Gln His Leu Gly Tyr Leu
65 70 75 80
Phe Leu Lys Met Ser Pro Glu Asp Ile Arg Lys Trp Asn Val Thr
85 90 95
<210> 67
<211> 95
<212> PRT
<213> Artificial sequence
<220>
<223> human mesothelin fragment
<400> 67
Ser Leu Glu Thr Leu Lys Ala Leu Leu Glu Val Asn Lys Gly His Glu
1 5 10 15
Met Ser Pro Gln Val Ala Thr Leu Ile Asp Arg Phe Val Lys Gly Arg
20 25 30
Gly Gln Leu Asp Lys Asp Thr Leu Asp Thr Leu Thr Ala Phe Tyr Pro
35 40 45
Gly Tyr Leu Cys Ser Leu Ser Pro Glu Glu Leu Ser Ser Val Pro Pro
50 55 60
Ser Ser Ile Trp Ala Val Arg Pro Gln Asp Leu Asp Thr Cys Asp Pro
65 70 75 80
Arg Gln Leu Asp Val Leu Tyr Pro Lys Ala Arg Leu Ala Phe Gln
85 90 95
<210> 68
<211> 95
<212> PRT
<213> Artificial sequence
<220>
<223> human mesothelin fragment
<400> 68
Asn Met Asn Gly Ser Glu Tyr Phe Val Lys Ile Gln Ser Phe Leu Gly
1 5 10 15
Gly Ala Pro Thr Glu Asp Leu Lys Ala Leu Ser Gln Gln Asn Val Ser
20 25 30
Met Asp Leu Ala Thr Phe Met Lys Leu Arg Thr Asp Ala Val Leu Pro
35 40 45
Leu Thr Val Ala Glu Val Gln Lys Leu Leu Gly Pro His Val Glu Gly
50 55 60
Leu Lys Ala Glu Glu Arg His Arg Pro Val Arg Asp Trp Ile Leu Arg
65 70 75 80
Gln Arg Gln Asp Asp Leu Asp Thr Leu Gly Leu Gly Leu Gln Gly
85 90 95
<210> 69
<211> 42
<212> PRT
<213> Artificial sequence
<220>
<223> human mesothelin fragment
<400> 69
Glu Val Glu Lys Thr Ala Cys Pro Ser Gly Lys Lys Ala Arg Glu Ile
1 5 10 15
Asp Glu Ser Leu Ile Phe Tyr Lys Lys Trp Glu Leu Glu Ala Cys Val
20 25 30
Asp Ala Ala Leu Leu Ala Thr Gln Met Asp
35 40
<210> 70
<211> 42
<212> PRT
<213> Artificial sequence
<220>
<223> human mesothelin fragment
<400> 70
Asp Ala Ala Leu Leu Ala Thr Gln Met Asp Arg Val Asn Ala Ile Pro
1 5 10 15
Phe Thr Tyr Glu Gln Leu Asp Val Leu Lys His Lys Leu Asp Glu Leu
20 25 30
Tyr Pro Gln Gly Tyr Pro Glu Ser Val Ile
35 40
<210> 71
<211> 31
<212> PRT
<213> Artificial sequence
<220>
<223> human mesothelin fragment
<400> 71
Tyr Pro Gln Gly Tyr Pro Glu Ser Val Ile Gln His Leu Gly Tyr Leu
1 5 10 15
Phe Leu Lys Met Ser Pro Glu Asp Ile Arg Lys Trp Asn Val Thr
20 25 30
<210> 72
<211> 64
<212> PRT
<213> Artificial sequence
<220>
<223> human mesothelin fragment
<400> 72
Glu Val Glu Lys Thr Ala Cys Pro Ser Gly Lys Lys Ala Arg Glu Ile
1 5 10 15
Asp Glu Ser Leu Ile Phe Tyr Lys Lys Trp Glu Leu Glu Ala Cys Val
20 25 30
Asp Ala Ala Leu Leu Ala Thr Gln Met Asp Arg Val Asn Ala Ile Pro
35 40 45
Phe Thr Tyr Glu Gln Leu Asp Val Leu Lys His Lys Leu Asp Glu Leu
50 55 60
<210> 73
<211> 63
<212> PRT
<213> Artificial sequence
<220>
<223> human mesothelin fragment
<400> 73
Asp Ala Ala Leu Leu Ala Thr Gln Met Asp Arg Val Asn Ala Ile Pro
1 5 10 15
Phe Thr Tyr Glu Gln Leu Asp Val Leu Lys His Lys Leu Asp Glu Leu
20 25 30
Tyr Pro Gln Gly Tyr Pro Glu Ser Val Ile Gln His Leu Gly Tyr Leu
35 40 45
Phe Leu Lys Met Ser Pro Glu Asp Ile Arg Lys Trp Asn Val Thr
50 55 60
<210> 74
<211> 30
<212> PRT
<213> Artificial sequence
<220>
<223> human mesothelin fragment
<400> 74
Tyr Lys Lys Trp Glu Leu Glu Ala Cys Val Asp Ala Ala Leu Leu Ala
1 5 10 15
Thr Gln Met Asp Arg Val Asn Ala Ile Pro Phe Thr Tyr Glu
20 25 30
<210> 75
<211> 20
<212> PRT
<213> Artificial sequence
<220>
<223> human mesothelin fragment
<400> 75
Leu Glu Ala Cys Val Asp Ala Ala Leu Leu Ala Thr Gln Met Asp Arg
1 5 10 15
Val Asn Ala Ile
20
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| АНТИТЕЛА К МЕЗОТЕЛИНУ | 2019 |
|
RU2837574C2 |
| МОЛЕКУЛЫ, СВЯЗЫВАЮЩИЕ МЕЗОТЕЛИН И CD137 | 2019 |
|
RU2815066C2 |
| АНТИ-МЕЗОТЕЛИН АНТИТЕЛО И ЕГО КОНЪЮГАТ С ЛЕКАРСТВЕННЫМИ СРЕДСТВАМИ | 2019 |
|
RU2747995C1 |
| ПОЛИСПЕЦИФИЧЕСКИЕ СВЯЗЫВАЮЩИЕ БЕЛКИ, НАЦЕЛЕННЫЕ НА CAIX, ANO1, МЕЗОТЕЛИН, TROP2, СEA ИЛИ КЛАУДИН-18.2 | 2018 |
|
RU2792671C2 |
| ХИМЕРНЫЕ РЕЦЕПТОРЫ АНТИГЕНА ПРОТИВ МЕЗОТЕЛИНА ЧЕЛОВЕКА И ИХ ПРИМЕНЕНИЕ | 2014 |
|
RU2714902C2 |
| МЕЗОТЕЛИНОВЫЕ CAR-РЕЦЕПТОРЫ И ИХ ПРИМЕНЕНИЕ | 2020 |
|
RU2822193C2 |
| АНТИТЕЛО ПРОТИВ ГЛИПИКАНА-3 И ЕГО ПРИМЕНЕНИЕ | 2016 |
|
RU2744245C2 |
| АНТИТЕЛО К IL-13RA2 И ЕГО ПРИМЕНЕНИЕ | 2018 |
|
RU2756623C2 |
| АНТИТЕЛО К B7-H4, ЕГО АНТИГЕНСВЯЗЫВАЮЩИЙ ФРАГМЕНТ И ЕГО ФАРМАЦЕВТИЧЕСКОЕ ПРИМЕНЕНИЕ | 2019 |
|
RU2792748C2 |
| ПОЛИСПЕЦИФИЧЕСКИЕ СВЯЗЫВАЮЩИЕ БЕЛКИ, НАЦЕЛЕННЫЕ НА NKG2D, CD16 И TROP2 | 2018 |
|
RU2820629C2 |
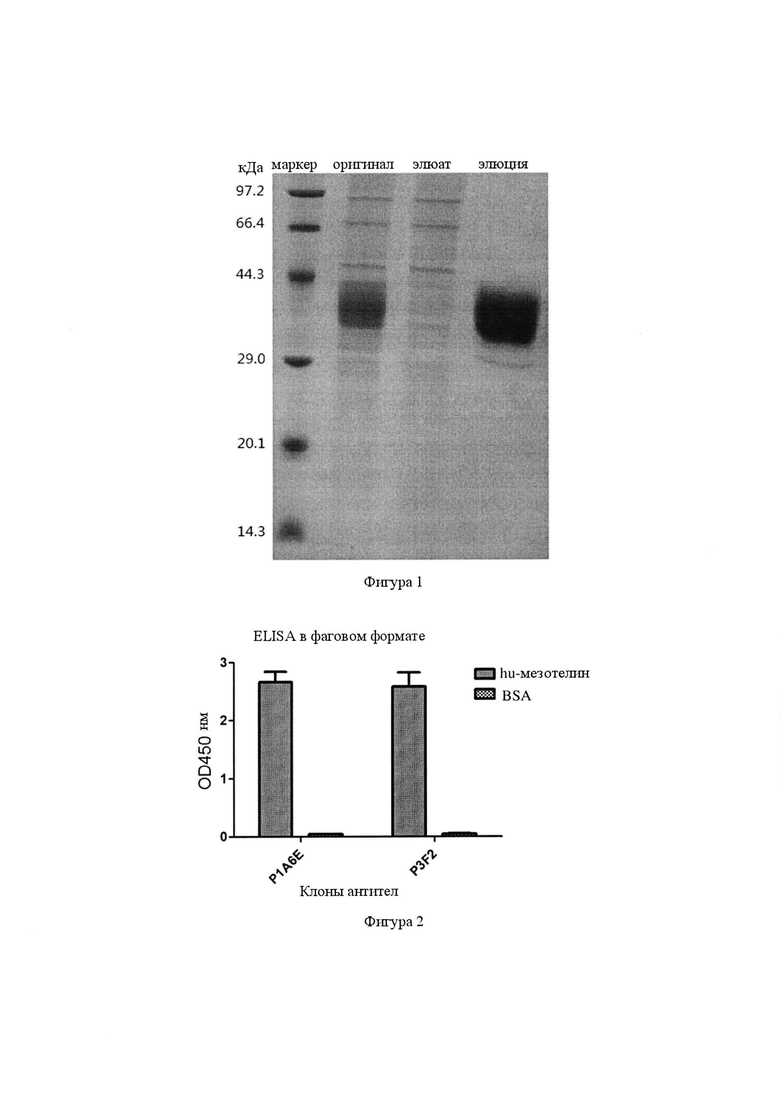

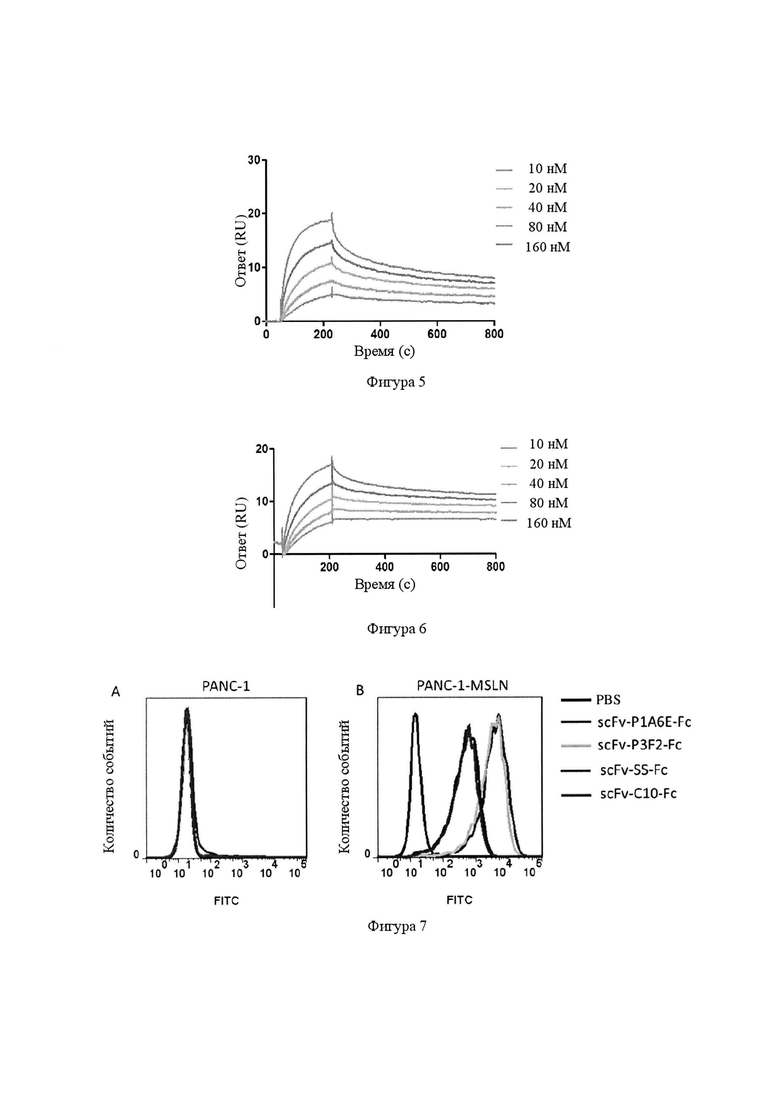

Изобретение относится к области биохимии, в частности к антителу, которое специфически связывается с мезотелином. Также раскрыты нуклеиновая кислота, кодирующая указанное антитело, вектор экспрессии и клетка-хозяин, содержащие указанную нуклеиновую кислоту; химерный антигенный рецептор, содержащий указанное антитело; иммуноконъюгат и фармацевтическая композиция, содержащие указанное антитело. Раскрыто применение указанного антитела. Изобретение позволяет эффективно лечить опухоли, ассоциированные с мезотелином. 14 н. и 18 з.п. ф-лы, 4 табл., 10 ил., 10 пр.
1. Полностью человеческое антитело, которое специфически связывается с мезотелином, выбранное из группы, состоящей из:
(а) антитела, содержащего вариабельную область тяжелой цепи, имеющую CDR1, содержащую аминокислотную последовательность SEQ ID NO: 54, CDR2, содержащую аминокислотную последовательность SEQ ID NO: 55, CDR3, содержащую аминокислотную последовательность SEQ ID NO: 56, и содержащего вариабельную область легкой цепи, имеющую CDR1, содержащую аминокислотную последовательность SEQ ID NO: 51, CDR2, содержащую аминокислотную последовательность SEQ ID NO: 52, CDR3, содержащую аминокислотную последовательность SEQ ID NO: 53,
(b) антитела, содержащего вариабельную область тяжелой цепи, имеющую CDR1, содержащую аминокислотную последовательность SEQ ID NO: 60, CDR2, содержащую аминокислотную последовательность SEQ ID NO: 61, CDR3 с аминокислотной последовательностью SEQ ID NO: 62, и содержащего вариабельную область легкой цепи, имеющую CDR1, содержащую аминокислотную последовательность SEQ ID NO: 57, CDR2, содержащую аминокислотную последовательность SEQ ID NO: 58, CDR3 с аминокислотной последовательностью SEQ ID NO: 59.
2. Полностью человеческое антитело по п. 1, содержащее вариабельную область тяжелой цепи и вариабельную область легкой цепи, при этом аминокислотная последовательность вариабельной области тяжелой цепи представлена в положениях с 1 по 123 SEQ ID NO: 6 и аминокислотная последовательность вариабельной области легкой цепи представлена в положениях с 139 по 254 SEQ ID NO: 6, или
содержащее вариабельную область тяжелой цепи и вариабельную область легкой цепи, при этом аминокислотная последовательность вариабельной области тяжелой цепи представлена в положениях с 1 по 124 SEQ ID NO: 8 и аминокислотная последовательность вариабельной области легкой цепи представлена в положениях с 140 по 247 SEQ ID NO: 8.
3. Нуклеиновая кислота, кодирующая антитело по п. 1 или 2.
4. Вектор экспрессии, содержащий нуклеиновую кислоту по п. 3.
5. Клетка-хозяин для экспрессии антитела по п. 1 или 2, содержащая вектор экспрессии по п. 4 или включающая нуклеиновую кислоту по п. 3, интегрированную в геном.
6. Применение антитела по п. 1 или 2 для получения лекарственного средства направленного действия, конъюгата антитела с лекарственным средством или многофункционального антитела, специфически нацеленного на опухолевые клетки, экспрессирующие мезотелин.
7. Применение антитела по п. 1 или 2 для получения средства для диагностики опухоли, экспрессирующей мезотелин.
8. Применение антитела по п. 1 или 2 для получения иммунных клеток, модифицированных химерным антигенным рецептором.
9. Химерный антигенный рецептор, специфически связывающийся с опухолевыми клетками, экспрессирующими мезотелин, содержащий последовательно связанные антитело по п. 1 или 2, трансмембранную область и внутриклеточную сигнальную область.
10. Химерный антигенный рецептор по п. 9, где внутриклеточная сигнальная область выбрана из группы, состоящей из последовательностей внутриклеточных сигнальных областей CD3ζ, FcεRIγ, CD27, CD28, CD137, CD134, MyD88, CD40 или их комбинации.
11. Химерный антигенный рецептор по п. 9, где трансмембранная область содержит трансмембранную область CD8 или CD28.
12. Химерный антигенный рецептор по п. 9, содержащий следующие последовательно связанные антитело, трансмембранную область и внутриклеточную сигнальную область:
антитело по п. 1 или 2, CD8 и CD3ζ,
антитело по п. 1 или 2, CD8, CD137 и CD3ζ,
антитело по п. 1 или 2, трансмембранную область молекулы CD28, внутриклеточную сигнальную область молекулы CD28 и CD3ζ, или
антитело по п. 1 или 2, трансмембранную область молекулы CD28, внутриклеточную сигнальную область молекулы CD28, CD137 и CD3ζ.
13. Химерный антигенный рецептор по п. 9, где антитело представляет собой одноцепочечное антитело.
14. Химерный антигенный рецептор по п. 9, имеющий:
SEQ ID NO: 41 или аминокислотную последовательность, представленную в ее положениях с 22 по 353,
SEQ ID NO: 42 или аминокислотную последовательность, представленную в ее положениях с 22 по 454,
SEQ ID NO: 43 или аминокислотную последовательность, представленную в ее положениях с 22 по 498,
SEQ ID NO: 44 или аминокислотную последовательность, представленную в ее положениях с 22 по 501,
SEQ ID NO: 45 или аминокислотную последовательность, представленную в ее положениях с 22 по 543,
SEQ ID NO: 46 или аминокислотную последовательность, представленную в ее положениях с 22 по 346,
SEQ ID NO: 47 или аминокислотную последовательность, представленную в ее положениях с 22 по 447,
SEQ ID NO: 48 или аминокислотную последовательность, представленную в ее положениях с 22 по 491,
SEQ ID NO: 49 или аминокислотную последовательность, представленную в ее положениях с 22 по 494, или
SEQ ID NO: 50 или аминокислотную последовательность, представленную в ее положениях с 22 по 536.
15. Генетически модифицированная Т-клетка, содержащая нуклеиновую кислоту по п. 3 или вектор экспрессии по п. 4 и экспрессирующая химерный антигенный рецептор по любому из пп. 9-14 на своей поверхности.
16. Т-клетка по п. 15, дополнительно содержащая кодирующую последовательность для экзогенного цитокина, при этом цитокин предпочтительно включает IL-12, IL-15 или IL-21.
17. Т-клетка по п. 15, дополнительно экспрессирующая другой химерный антигенный рецептор, который не содержит CD3ζ, но содержит внутриклеточный сигнальный домен CD28, внутриклеточный сигнальный домен CD137 или их комбинацию.
18. Т-клетка по п. 15, дополнительно экспрессирующая хемокиновый рецептор, при этом хемокиновый рецептор предпочтительно включает CCR2.
19. Т-клетка по п. 15, дополнительно экспрессирующая миРНК, которая может снижать экспрессию PD-1, или белок, блокирующий PD-L1.
20. Т-клетка по п. 15, дополнительно экспрессирующая предохранитель (safety switch), включающий индуцируемую каспазу-9, усеченный EGFR или RQR8.
21. Т-клетка по п. 15, включающая Т-лимфоцит, естественную клетку-киллер (NK) или естественный киллерный Т-лимфоцит (NKT).
22. Иммуноконъюгат для лечения опухоли, содержащий:
антитело по п. 1 или 2, и
связанную с ним функциональную молекулу, выбранную из молекулы, которая нацелена на маркер поверхности опухоли, молекулы, подавляющей опухоль, молекулы, которая нацелена на маркер поверхности иммунной клетки, или детектируемой метки.
23. Иммуноконъюгат для обнаружения опухоли, содержащий:
антитело по п. 1 или 2, и
связанную с ним функциональную молекулу, выбранную из молекулы, которая нацелена на маркер поверхности опухоли, молекулы, подавляющей опухоль, молекулы, которая нацелена на маркер поверхности иммунной клетки, или детектируемой метки.
24. Иммуноконъюгат для анализа опухоли, содержащий:
антитело по п. 1 или 2, и
связанную с ним функциональную молекулу, выбранную из молекулы, которая нацелена на маркер поверхности опухоли, молекулы, подавляющей опухоль, молекулы, которая нацелена на маркер поверхности иммунной клетки, или детектируемой метки.
25. Иммуноконъюгат для диагностики опухоли, содержащий:
антитело по п. 1 или 2, и
связанную с ним функциональную молекулу, выбранную из молекулы, которая нацелена на маркер поверхности опухоли, молекулы, подавляющей опухоль, молекулы, которая нацелена на маркер поверхности иммунной клетки, или детектируемой метки.
26. Иммуноконъюгат по любому из пп. 22-25, где молекула, которая нацелена на маркер поверхности опухоли, представляет собой антитело или лиганд, который связывается с маркером поверхности опухоли, или
молекула, подавляющая опухоль, представляет собой противоопухолевый цитокин или противоопухолевый токсин, и предпочтительно цитокин включает IL-12, IL-15, IFN-бета, TNF-альфа.
27. Иммуноконъюгат по любому из пп. 22-25, где детектируемая метка включает флуоресцентную метку или хромогенную метку.
28. Иммуноконъюгат по п. 26, где антитело, которое связывается с маркером поверхности опухоли, относится к антителу, которое распознает другой антиген, отличный от мезотелина, при этом другой антиген включает EGFR, EGFRvIII, мезотелин, HER2, EphA2, Her3, EpCAM, MUC1, MUC16, CEA, клаудин 18.2, рецептор фолиевой кислоты, клаудин 6, CD3, WT1, NY-ESO-1, MAGE 3, ASGPR1 или CDH16.
29. Иммуноконъюгат по любому из пп. 22-25, где молекула, которая нацелена на маркер поверхности иммунной клетки, представляет собой антитело, которое связывается с маркером поверхности Т-клетки и образует с антителом по п. 1 или 2 бифункциональное антитело, активирующее Т-клетку.
30. Иммуноконъюгат по п. 29, где антитело, которое связывается с маркером поверхности Т-клетки, представляет собой антитело к CD3.
31. Иммуноконъюгат по п. 30, представляющий собой слитый полипептид и дополнительно содержащий линкерный пептид между антителом по п. 1 или 2 и связанной с ним функциональной молекулой.
32. Фармацевтическая композиция для лечения заболеваний, ассоциированных с мезотелином, включающая эффективное количество:
антитела по п. 1 или 2 или нуклеиновой кислоты, кодирующей антитело, или
иммуноконъюгата по любому из пп. 22-31, или
генетически модифицированной иммунной клетки по любому из пп. 15-21.
| Приспособление для изготовления дранки | 1929 |
|
SU18396A1 |
| RU 2004109149 A, 10.05.2005 | |||
| СПОСОБ ФОРМИРОВАНИЯ ЭПИТАКСИАЛЬНОГО МАССИВА МОНОКРИСТАЛЛИЧЕСКИХ НАНООСТРОВКОВ КРЕМНИЯ НА САПФИРОВОЙ ПОДЛОЖКЕ В ВАКУУМЕ | 2015 |
|
RU2600505C1 |
| US 20100028336 A1, 04.02.2010 | |||
| WO 2009045957 A1, 09.04.2009. | |||

