Область техники, к которой относится изобретение
[0001] Настоящее изобретение относится, в общем, к областям компьютерного зрения и компьютерной графики для создания двумерных изображений трехмерной сцены, видимых из различных точек обзора, и более конкретно, к способу синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора, и к электронному вычислительному устройству для реализации данного способа.
Описание известного уровня техники
[0002] В последние годы было предложено несколько принципов нейронной отрисовки изображений геометрически и фотометрически сложных сцен [16, 31, 28, 29]. В основу этих принципов положен дифференцируемый рендеринг (отрисовка) определенных геометрических представлений, и процесс отрисовки обычно реализуется процедурой обучения, в которой последовательно выполняются операции отрисовки и обратного распространения ошибки, задаваемой функцией потерь между отрисованными изображениями и истинными изображениями на обучаемые параметры.
[0003] В этом контексте было исследовано несколько типов геометрических представлений. Например, в работе [31] допускается, что геометрия сцены моделируется с помощью треугольной сетки, которая предоставляется в процесс обучения, и оцениваются нейронные текстуры, чтобы захватить фотометрические свойства различных частей поверхности. В качестве альтернативы, в нескольких работах [9, 22, 15] была предпринята попытка обучать как треугольную сетку, так и текстуру (или цвета поверхности) посредством процесса обратного распространения ошибки, однако это оказалось слишком сложным из-за недифференцируемого характера растеризации сетки вблизи границ взаимного перекрытия объектов. В другой серии работ [16, 21] исследовались явные и неявные объемные представления, обучаемые вместе с сетью отрисовки.
[0004] Настоящее изобретение является развитием платформы нейронной точечной графики [2], в которой используется нейронное моделирование на основе представления геометрии «облако точек». Облака точек обладают рядом привлекательных свойств по сравнению с сеточными представлениями и волюметрическими представлениями. Во-первых, в отличие от волюметрических представлений, они хорошо масштабируются на большие сцены, поскольку нет необходимости в равномерном или почти равномерном распределении точек в облаке. Во-вторых, в то время как треугольные сетки могут быть непригодны для представления различных сложных явлений, таких как тонкие объекты, облака точек позволяют их эффективно моделировать. Как правило, легче получить облака точек для естественных сцен, чем их треугольные сетки, так как процесс создания сетки является одним из самых неустойчивых этапов традиционных алгоритмов моделирования на основе изображений. С другой стороны, облака точек возникают как промежуточное представление на ранних этапах таких алгоритмов каждый раз, когда сцена захватывается с использованием датчика глубины, генерирующего коллекцию сканов глубины, или с помощью пассивного многовидового стереопредставления, которое обычно также генерирует коллекцию плотных или полуплотных карт глубины.
[0005] Хотя исходная платформа [2] продемонстрировала ряд высоко реалистичных результатов отрисовки, она ограничена в нескольких аспектах. Например, алгоритм отрисовки [2] начинается с "жесткой" растеризации точек с использованием z-буферизации OpenGL. Это может внести значительный шум и переобучение в процессе обучения, когда облако точек зашумлено, так как точки-выбросы перекрывают истинные точки поверхности. Хотя, в принципе, процесс обучения может выявлять такие точки выброса и обучаться их "закрашивать", это требует дополнительной производительности сети и может привести к переобучению, когда выбросы наблюдаются в очень немногих видах. Во-вторых, успех работы [2] зависит от выбора радиуса точек, используемого для их растеризации. Если выбранный радиус не совпадает примерно с плотностью точек, то результаты могут значительно ухудшиться так, что либо будут потеряны мелкие детали, либо сквозь видимые поверхности "проступят" невидимые поверхности.
Трехмерное представление сцены
[0006] На сегодняшний день существует множество представлений 3D сцен с различными свойствами, и многие из них можно использовать для автоматической обработки. К ним относятся облака точек, сетки, функции расстояний со знаком (Signed Distance Functions, SDF) [21], воксельные представления и октадеревья [18, 30] и т.п. Облака точек просты в обработке, поскольку они хранятся в виде двух принимающих действительные значения массивов - координат точек относительно некоторой мировой системы координат и точек цветов. Их выразительные возможности зависят только от количества точек и могут отражаться облака с различной пространственной плотностью. В настоящее время существуют многочисленные исследования, оперирующие с облаками точек для классификации, сегментации и генерации трехмерных моделей [13, 11, 20, 10, 24, 25]. Естественно, что воксельные представления также можно изучать и использовать для любого вида обработки, однако они занимают большую часть памяти и их невозможно адаптировать к неоднородному разрешению. Сетки, являющиеся, по существу, облаками точек с недифференцируемыми треугольниками, гораздо сложнее в обработке и используются в основном для отрисовки [19, 5]. Существует большой объем работ по синтезу проекций с использованием различных аппаратных и программных методов, в которых имеет место компромиссное соотношение между фотореализмом и скоростью [1, 3, 19, 23].
Дифференцируемая отрисовка
[0007] Платформы дифференцируемого рендеринга позволяют генерировать градиенты относительно различных параметров сцены, таких как внутренние параметры и внешние параметры камеры, пространственные и физические свойства данного трехмерного представления (например, положения вершин сетки, цвета или отражающая способность) и освещения. Значительный объем работ посвящен отрисовке по сетке, поскольку топология сетки позволяет оптимизировать деформацию геометрии и использовать общие априорные распределения для различных задач реконструкции. Soft Rasterizer [15] предлагает вероятностное сглаживание операции дискретной выборки, тогда как OpenDR [17] и Kato [9] явно выводят приближенные частные производные, которые, однако, основаны на численных методах. Авторы работы [32] решают эту проблему путем вычисления градиентов посредством интегрирования функции интенсивности пикселей. Pix2Vex [22] характеризуется наличием полупрозрачного Z-буфера и циклического обучающего конвейера изображения/геометрии. Аналогичным образом можно расширить дифференцируемым образом трассировку лучей при растеризации треугольников, в частности, метод [12] обеспечивает выборку границ с дальнейшим интегрированием в приближенные градиенты для точной обработки взаимного перекрытия. Облака точек, хотя и являются более простым представлением для автоматической обработки, чем сетки, благодаря отсутствию недифференцируемой топологии, значительно труднее поддаются реалистичной отрисовке. Метод дифференцируемой растеризации поверхности (Differentiable Surface Splatting) [33] оценивает отрисованное изображение, проецируя точки на холст (элемент для создания 2D изображения, плоскость изображения) и смешивая их с усеченными гауссовыми ядрами. Из-за усечения, введенного для эффективности, производные рассчитываются приблизительно.
Нейронная отрисовка
[0008] В отличие от физических конвейеров нейронная отрисовка подразумевает обучение произвольному представлению сцены для генерации реалистичных изображений и манипулирования их видом (от манипуляции атрибутами сцены до врисовки). Например, метод Neural Volumes [16] основан на прогнозе 4D объема (RGB+непрозрачность) для модели, основанной на нескольких фотографиях, с применением вариационного автокодировщика, деформации объема и его интегрирования с учетом непрозрачности. Отложенная нейронная отрисовка (Deferred Neural Rendering) [31] обучается оценивать нейронную текстуру объекта на основе его координатных UV карт и нацелена на синтез изображения на основе этих выборок глубокой текстуры. В DeepVoxels [28] используется аналогичный принцип и оценивается объемный скрытый нейронный код объекта по комбинации CNN и RNN (GRU), а в более поздней работе – сети представления сцен (Scene Representation Networks) [29] —используется только RNN для обучения глубин точек. В алгоритме нейронной точечной графики (Neural Point-Based Graphics) [2] используется промежуточный принцип: она включает в себя обучение векторных представлений точек в облаке, набрасывает видимые точки с большим ядром на холст с помощью быстрого Z-буфера и устраняет разреженность результата с помощью CNN на базе U-Net. Тем не менее, из-за жесткого Z-буфера этот алгоритм не является полностью дифференцируемым.
[0009] Настоящее изобретение было создано в целях устранения по меньшей мере одного из вышеуказанных недостатков и обеспечения по меньшей мере одного из преимуществ, описанных ниже.
СПИСОК ЛИТЕРАТУРЫ
[1] T. Aila and S. Laine. Understanding the efficiency of ray traversal on gpus. In Proceedings of the conference on high performance graphics 2009, pages 145-149. ACM, 2009. 2
[2] K.-A. Aliev, D. Ulyanov, and V. Lempitsky. Neural point-based graphics. arXiv preprint arXiv:1906.08240, 2019. 1, 2
[3] F. C. Crow. A comparison of antialiasing techniques. IEEE Computer Graphics and Applications, (1):40-48, 1981. 2
[4] J. M. Cychosz. An introduction to ray tracing. Computers & Graphics, 17(1):107, 1993. 3
[5] K. Dempski and D. S. Dietrich. Real-time rendering tricks and techniques in directx. Premier Press, 2002. 2
[6] J. Deng, W. Dong, R. Socher, L. Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248-255, June 2009. 5
[7] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural computation, 9(8):1735-1780, 1997. 2, 3
[8] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In Proc. ECCV, pages 694-711, 2016. 5
[9] H. Kato, Y. Ushiku, and T. Harada. Neural 3d mesh renderer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3907-3916, 2018. 1, 2
[10] L. Landrieu and M. Simonovsky. Large-scale point cloud semantic segmentation with superpoint graphs. In Proceed¬ings ofthe IEEE Conference on Computer Vision and Pattern Recognition, pages 4558-4567, 2018. 2
[11] C.-L. Li, M. Zaheer, Y. Zhang, B. Poczos, and R. Salakhutdinov. Point cloud gan. arXiv preprint arXiv:1810.05795, 2018. 2
[12] T.-M. Li, M. Aittala, F. Durand, and J. Lehtinen. Differentiable monte carlo ray tracing through edge sampling. In SIGGRAPH Asia 2018 Technical Papers, page 222. ACM, 2018. 2
[13] C.-H. Lin, C. Kong, and S. Lucey. Learning efficient point cloud generation for dense 3d object reconstruction. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018. 2
[14] G. Liu, F. A. Reda, K. J. Shih, T.-C. Wang, A. Tao, and B. Catanzaro. Image inpainting for irregular holes using partial convolutions. In Proceedings of the European Conference on Computer Vision (ECCV), pages 85-100, 2018. 5
[15] S. Liu, T. Li, W. Chen, and H. Li. Soft rasterizer: A differentiable renderer for image-based 3d reasoning. arXiv preprint arXiv:1904.01786, 2019. 1, 2
[16] S. Lombardi, T. Simon, J. M. Saragih, G. Schwartz, A. M. Lehrmann, and Y. Sheikh. Neural volumes: learning dynamic renderable volumes from images. ACM Trans. Graph., 38(4):65:1-65:14, 2019. 1, 2
[17] M. M. Loper and M. J. Black. Opendr: An approximate differentiable renderer. In European Conference on Computer Vision, pages 154-169. Springer, 2014. 2
[18] D. Meagher. Geometric modeling using octree encoding. Computer graphics and image processing, 19(2):129-147, 1982. 2
[19] J. Neider, T. Davis, and M. Woo. OpenGL programming guide, volume 14. Addison-Wesley Reading, MA, 1993. 2
[20] A. Nguyen and B. Le. 3d point cloud segmentation: A sur¬vey. In 2013 6th IEEE conference on robotics, automation and mechatronics (RAM), pages 225-230. IEEE, 2013. 2
[21] J. J. Park, P. Florence, J. Straub, R. Newcombe, and S. Lovegrove. Deepsdf: Learning continuous signed dis¬tance functions for shape representation. arXiv preprint arXiv:1901.05103, 2019. 1,2
[22] F. Petersen, A. H. Bermano, O. Deussen, and D. Cohen-Or. Pix2vex: Image-to-geometry reconstruction using a smooth differentiable renderer. arXiv preprint arXiv:1903.11149, 2019. 1, 2
[23] T. Porter and T. Duff. Compositing digital images. In ACM Siggraph Computer Graphics, volume 18, pages 253-259. ACM, 1984. 2, 4
[24] C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 652-660, 2017. 2
[25] C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Advances in neural information processing systems, pages 5099-5108, 2017. 2
[26] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolu¬tional networks for biomedical image segmentation. CoRR, abs/1505.04597, 2015. 5
[27] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. CoRR, abs/1409.1556, 2014. 5
[28] V. Sitzmann, J. Thies, F. Heide, M. NieBner, G. Wetzstein, and M. Zollhofer. Deepvoxels: Learning persistent 3d feature embeddings. In Proc. CVPR, 2019. 1, 2
[29] V. Sitzmann, M. Zollhofer, and G. Wetzstein. Scene representation networks: Continuous 3d-structure-aware neural scene representations. CoRR, abs/1906.01618, 2019. 1,2
[30] R. Szeliski. Rapid octree construction from image sequences. CVGIP: Image understanding, 58(1):23-32, 1993. 2
[31] J. Thies, M. Zollhofer, and M. NieBner. Deferred neural rendering: Image synthesis using neural textures. In Proc. SIG- GRAPH, 2019. 1, 2
[32] Z. Wu and W. Jiang. Analytical derivatives for differentiable renderer: 3d pose estimation by silhouette consistency. arXiv preprint arXiv:1906.07870, 2019. 2
[33] W. Yifan, F. Serena, S. Wu, C. Oztireli, and O. Sorkine-Hornung. Differentiable surface splatting for point-based geometry processing. arXiv preprint arXiv:1906.04173, 2019. 2, 3
[34] M. Zwicker, H. Pfister, J. Van Baar, and M. Gross. Surface splatting. In Proc. SIGGRAPH, pages 371-378. ACM, 2001. 3
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0010] В настоящем изобретении вводится дифференцируемый нейронный отрисовщик (рендерер) облаков точек, полученных из сканов сцен, реконструированных из изображений реального мира. Эта система способна синтезировать реалистичные и высококачественные изображения трехмерных сцен, представленных в виде облаков точек, даже при наличии взаимных перекрытий, шума, отражений и других проблем. Предлагаемая нейронная архитектура состоит из рекуррентной нейронной сети для последовательной обработки точек, сгруппированных по воображаемым лучам, образующим пирамиду видимости камеры, и полносверточной нейронной сети, которая уточняет полученное изображение. Отрисовщик обучается на ряде трехмерных сцен, снятых в реальном мире, с соответствующим набором их фотографий из нескольких точек обзора, и после обучения может создавать новые фотореалистичные виды новой сцены, как они воспринимаются произвольно расположенной камерой в реальном мире. Представлены достаточно качественные результаты для сцен, снятых стандартными сканерами RGB-D, и для облаков точек, составленных из фотографий RGB.
[0011] Созданное с использованием лучевой отрисовки, настоящее изобретение нацелено на повышение гибкости представления облака точек в целиком обучаемой единой процедурой, полностью дифференцируемой системе, которая позволяет решать различные задачи компьютерной графики наряду с обработкой дефектов, возникающих естественным образом в сканах реального мира.
[0012] В настоящем изобретении в алгоритм нейронной точечной графики [2] введено два усовершенствования, позволяющих решить две проблемы. Во-первых, процесс жесткой растеризации заменен рекуррентной растеризацией, при которой сеть LSTM [7] реализует нейронный аналог алгоритма z-буфера. Эта замена позволяет более плавно обрабатывать точки выбросов, поскольку сеть LSTM можно обучить отрисовывать их как полностью прозрачные. При данном подходе такая отрисовке LSTM предшествует сверточной отрисовке и может обучаться вместе с ней.
[0013] Второе усовершенствование заключается в том, что устранена проблема выбора радиуса точки благодаря использованию нейронного аналога классического алгоритма Mipmapping из компьютерной графики. Предложена сверточная архитектура MipMapNet, которая растеризует облако точек несколько раз с различным разрешением, причем для растеризации точек всегда используется однопиксельный радиус. Получающиеся растеризации сливаются внутри MipMapNet, так что процесс слияния безусловно выбирает оптимальный радиус точки на основе локальной плотности точек.
[0014] Настоящее изобретение демонстрирует оба усовершенствования (нейронный z-буфер и нейронное Mipmapping) платформы нейронной точечной графики, которые вместе позволяют получить более адекватные отрисовки, которые стабильны во времени и менее подвержены искажениям в присутствии зашумленных точек.
[0015] Предложенные методы позволяют синтезировать из облаков точек двумерное изображение сцены, просматриваемой с требуемой точки обзора, с высоким качеством и низкими вычислительными затратами.
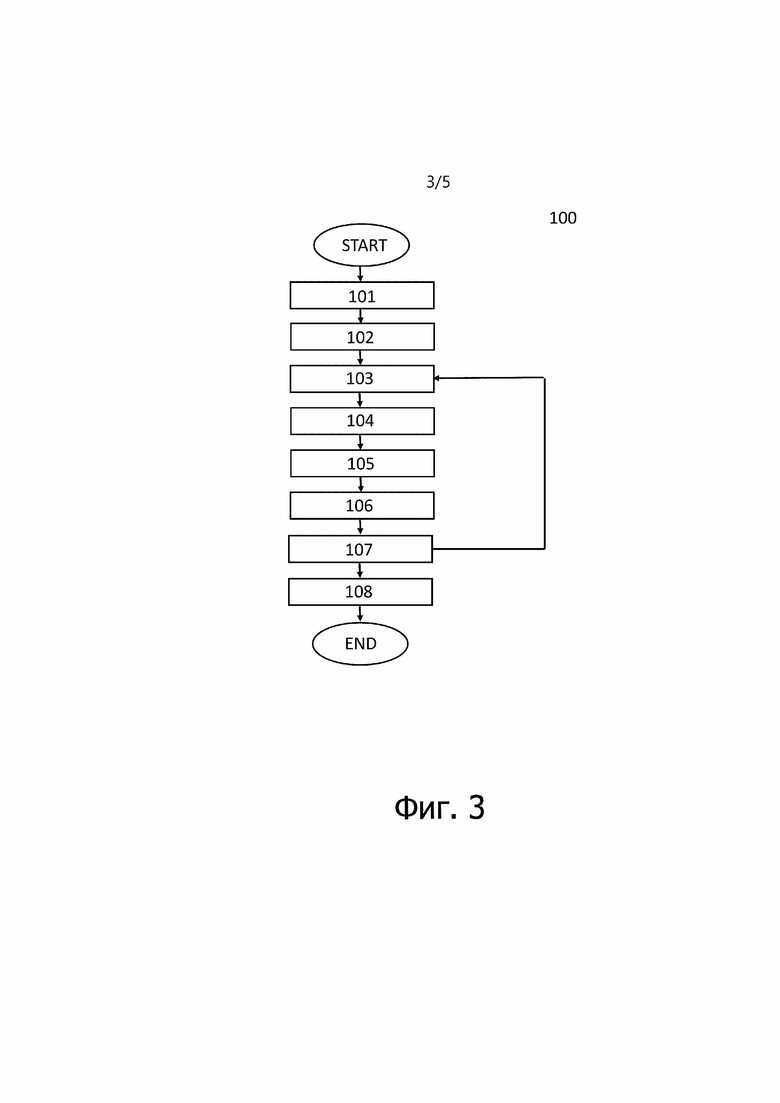
[0016] Согласно одному аспекту настоящего изобретения предложен способ синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора, заключающийся в том, что: принимают (S101) трехмерное облако точек, полученное из множества двумерных изображений одной и той же сцены, причем каждую точку облака задают трехмерными координатами в мировой системе координат и векторным представлением точки; задают (S102) точку обзора как камеру, имеющую внутренние параметры и внешние параметры; преобразуют (S103) трехмерные координаты каждой точки в двумерные координаты и глубину каждой точки в системе координат экранного пространства камеры, используя внутренние параметры и внешние параметры; задают (S104) множество лучей, расходящихся от точки обзора, причем лучи заданы координатами экранного пространства и внутренними параметрами и внешними параметрами; группируют (S105) точки в наборы точек, ассоциированные с лучами, причем каждый набор точек содержит точки, через которые проходит один луч, и в каждом наборе точек точки располагаются в порядке уменьшения их глубины относительно точки обзора; вычисляют (S106) для каждого луча векторное представление луча путем агрегирования векторных представлений точек и глубин соответствующего набора точек с помощью обученного предиктора (средства предсказания) машинного обучения; проецируют (S107) векторные представления лучей на плоскость изображения, причем этапы (S103)-(S107) выполняют для заданного множества масштабов; осуществляют слияние (S108) плоскостей изображения во множестве масштабов с помощью обученного предиктора машинного обучения в двумерное изображение.
[0017] В дополнительном аспекте обучение предиктора машинного обучения включает в себя два последовательных этапа: этап предобучения, выполняемый на первом наборе обучающих данных, причем первый набор обучающих данных включает в себя: наборы двумерных изображений разных сцен одного и того же типа, где каждый набор двумерных изображений представляет одну сцену и каждое двумерное изображение в наборе снято с разной точки обзора, точки обзора, и трехмерные облака точек, каждое из которых получено из соответствующего набора двумерных изображений; и этап точной настройки, выполняемый на втором наборе обучающих данных, причем второй набор обучающих данных включает в себя: наборы двумерных изображений разных сцен одного и того же типа, где каждый набор двумерных изображений представляет одну сцену, каждое двумерное изображение в наборе снято с разной точки обзора, причем сцены во втором наборе обучающих данных отличаются от сцен в первом наборе обучающих данных, точки обзора, и трехмерные облака точек, каждое из которых получено из соответствующего набора двумерных изображений.
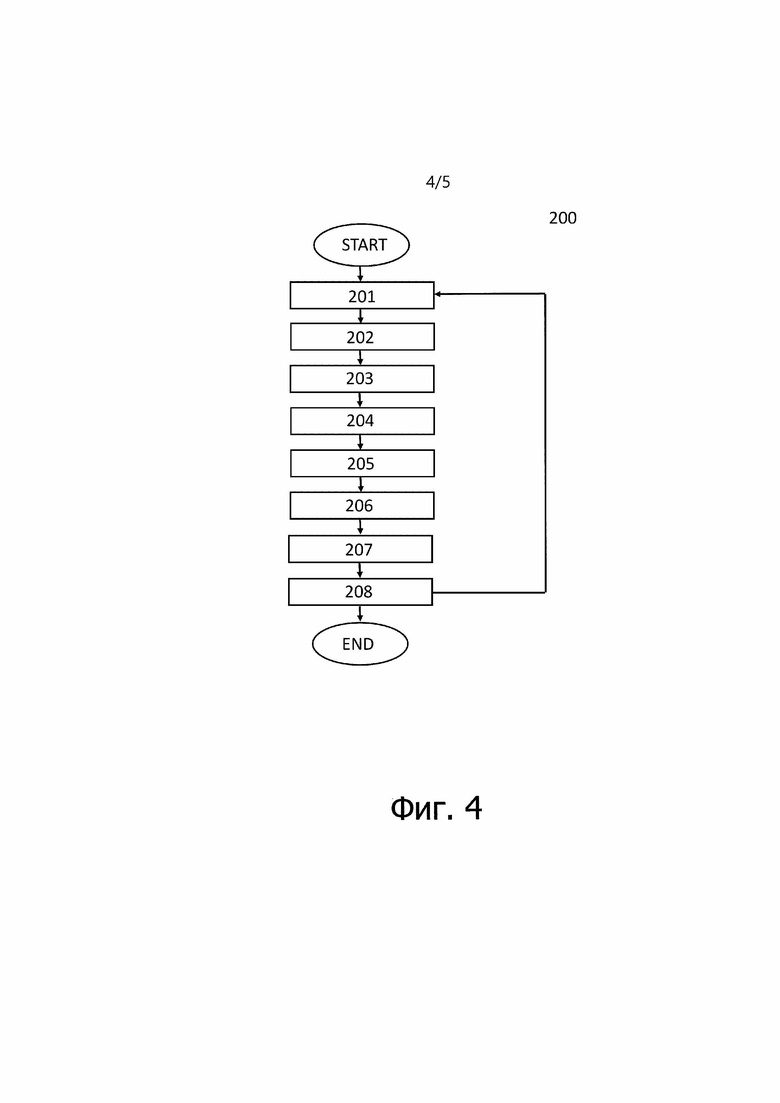
[0018] В другом дополнительном аспекте каждый из двух этапов обучения предиктора машинного обучения заключается в том, что: произвольно выбирают (S201) из соответствующего набора обучающих данных обучающие данные случайно выбранной сцены, содержащие трехмерное облако точек, точку обзора и двумерное изображение, захваченное с упомянутой точки обзора; преобразуют (S202) трехмерные координаты каждой точки трехмерного облака точек в двумерные координаты и глубину каждой точки в системе координат экранного пространства камеры, используя внутренние параметры и внешние параметры камеры, с которыми был захвачен данный набор двумерных изображений; задают (S203) множество лучей, расходящихся от точки обзора, причем лучи заданы координатами экранного пространства и внутренними параметрами и внешними параметрами; группируют (S204) точки в наборы точек, ассоциированные с лучами, причем каждый набор точек содержит точки, через которые проходит один луч, и в каждом наборе точек точки располагаются в порядке уменьшения их глубины относительно точки обзора; вычисляют (S205) для каждого луча векторное представление луча путем агрегирования векторных представлений точек и глубин соответствующего набора точек; обрабатывают (S206) с помощью предиктора машинного обучения векторные представления лучей для получения суммы значений функции потерь; оценивают (S207) градиент полученной суммы относительно каждого скалярного веса предиктора машинного обучения и векторных представлений точек; изменяют (S208) каждый скалярный вес предиктора машинного обучения и векторные представления всех точек в соответствии с заданным правилом оптимизатора на основании оцененного градиента, причем этапы (S201)-(S208) повторяют заданное количество раз.
[0019] В другом дополнительном аспекте обученный предиктор машинного обучения содержит две части, причем первая часть обученного предиктора машинного обучения выполняет этап (S106), а вторая часть обученного предиктора машинного обучения выполняет этап (S108).
[0020] В другом дополнительном аспекте первая часть обученного предиктора машинного обучения является по меньшей мере одной из рекуррентной нейронной сети, а вторая часть предиктора обученного машинного обучения является нейронной сетью на базе U-net.
[0021] В другом аспекте настоящего изобретения предложено электронное вычислительное устройство, содержащее: по меньшей мере процессор и память, в которой хранятся числовые параметры обученного предиктора машинного обучения и инструкции, которые при их исполнении по меньшей мере одним процессором побуждают по меньшей мере один процессор выполнять способ синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0022] Описанные выше и другие аспекты, признаки и преимущества настоящего изобретения будут более очевидны из следующего подробного описания в совокупности с прилагаемыми чертежами, на которых:
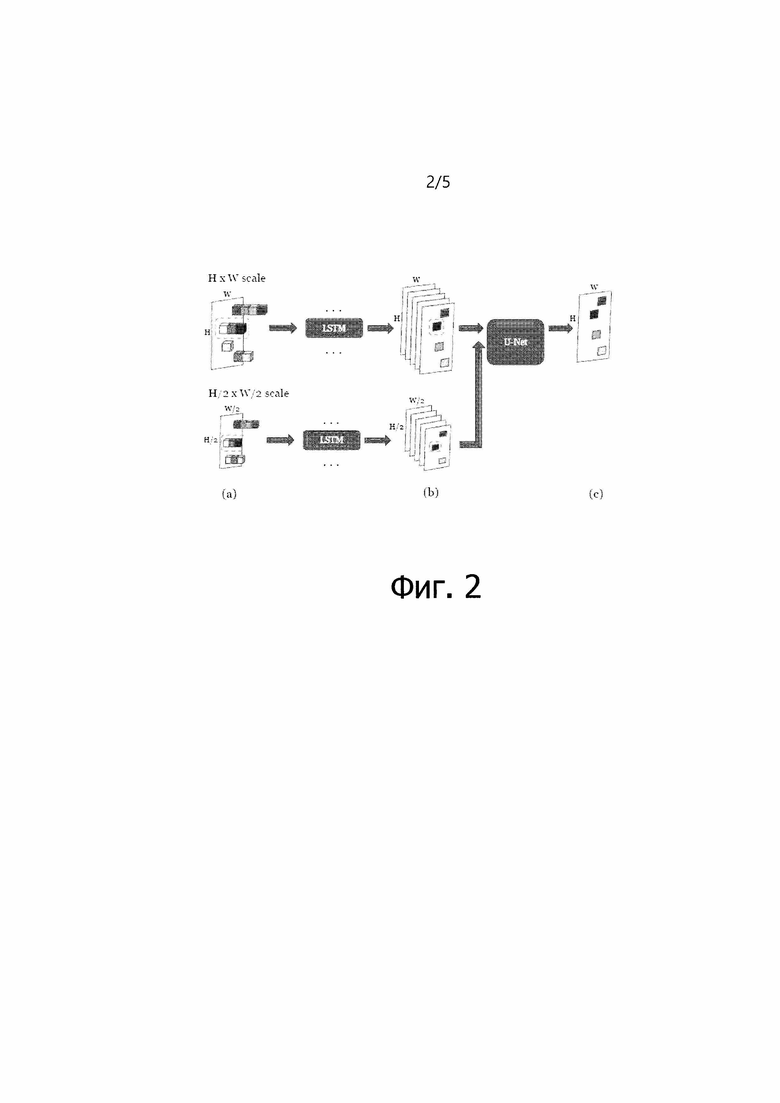
[0023] Фиг. 1 - схематическое изображение, иллюстрирующее процесс лучевой группировки.
[0024] Фиг. 2 - схематическое изображение, иллюстрирующее операции предиктора машинного обучения.
[0025] Фиг. 3 - блок-схема, иллюстрирующая предпочтительный вариант осуществления способа синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора.
[0026] Фиг. 4 - блок-схема, иллюстрирующая процесс обучения предиктора машинного обучения в соответствии с настоящим изобретением.
[0027] Фиг. 5 - схематическое изображение, иллюстрирующее электронное вычислительное устройство в соответствии с настоящим изобретением.
[0028] В последующем описании, если не указано иное, одни и те же ссылочные номера используются для одинаковых элементов, изображенных на разных чертежах, и их параллельное описание не приводится.
ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0029] Следующее описание со ссылками на прилагаемые чертежи представлено для того, чтобы облегчить полное понимание различных вариантов осуществления настоящего изобретения, охарактеризованных формулой изобретения и ее эквивалентами. Для облегчения такого понимания описание включает в себя различные конкретные детали, однако эти детали следует рассматривать только как примерные. Соответственно, специалистам в данной области техники будет понятно, что можно разработать различные изменения и модификации различных вариантов осуществления, описанных в данном документе, не выходя за рамки объема настоящего изобретения. Кроме того, описания известных функций и структур могут быть опущены для ясности и краткости.
[0030] Термины и формулировки, используемые в последующем описании и формуле изобретения, не ограничиваются их библиографическими значениями, а просто используются автором изобретения для того, чтобы обеспечить ясное и последовательное понимание настоящего изобретения. Соответственно, специалистам в данной области техники будет понятно, что последующее описание различных вариантов осуществления настоящего изобретения представлено только для иллюстрации.
[0031] Следует понимать, что формы единственного числа включают в себя множественное число, если только в контексте нет явного указания на иное.
[0032] Следует понимать, что хотя термины "первый", "второй" и т.д. могут использоваться в данном документе в отношении элементов настоящего раскрытия, эти элементы не следует истолковывать как ограниченные данными терминами. Эти термины используются только для того, чтобы отличить один элемент от других элементов.
[0033] Также следует понимать, что термины "содержит", "содержащий", "включает" и/или "включающий", используемые в данном документе, означают наличие упомянутых признаков, значений, операций, элементов и/или компонентов, но не исключают наличие или добавление одного или нескольких других признаков, значений, операций, элементов, компонентов и/или их групп.
[0034] В различных вариантах настоящего раскрытия "модуль" или "блок" может выполнять по меньшей мере одну функцию или операцию и может быть реализован в форме аппаратного обеспечения, программного обеспечения или их комбинации. "Множество модулей" или "множество блоков" можно реализовать по меньшей мере с одним процессором (не показан) посредством его интеграции с по меньшей мере одним модулем, отличным от "модуля" или "блока", который должен быть реализован в форме конкретного аппаратного обеспечения.
[0035] Далее будут более подробно описаны различные варианты осуществления настоящего изобретения со ссылками на прилагаемые чертежи.
[0036] 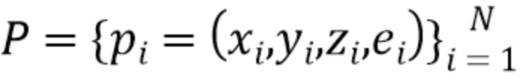 - это трехмерное облако точек, заданное координатами точек
- это трехмерное облако точек, заданное координатами точек 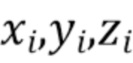 относительно выбранной мировой системы координат и векторными представлениями точек - векторами
относительно выбранной мировой системы координат и векторными представлениями точек - векторами 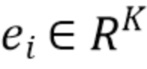 , ассоциированными с каждой точкой.
, ассоциированными с каждой точкой.  представляет собой трехмерный объект или сцену, которую желательно отрисовать реалистичным образом, и векторные представления
представляет собой трехмерный объект или сцену, которую желательно отрисовать реалистичным образом, и векторные представления 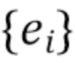 будут описаны далее как обучаемые параметры сцены. Кроме того, предусмотрена камера, параметризованная ее внутренними параметрами
будут описаны далее как обучаемые параметры сцены. Кроме того, предусмотрена камера, параметризованная ее внутренними параметрами 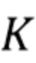 и внешними параметрами
и внешними параметрами 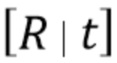 в соответствии с моделью камеры-обскуры [4]. Внутренние параметры камеры включают в себя фокусное расстояние, формат датчика изображения и главную точку. Внешние параметры камеры включают в себя местоположение и ориентацию камеры относительно мировой системы координат. Эти величины задают правило перспективного преобразования координат из мировой системы координат в соответствующую систему координат экранного пространства:
в соответствии с моделью камеры-обскуры [4]. Внутренние параметры камеры включают в себя фокусное расстояние, формат датчика изображения и главную точку. Внешние параметры камеры включают в себя местоположение и ориентацию камеры относительно мировой системы координат. Эти величины задают правило перспективного преобразования координат из мировой системы координат в соответствующую систему координат экранного пространства:
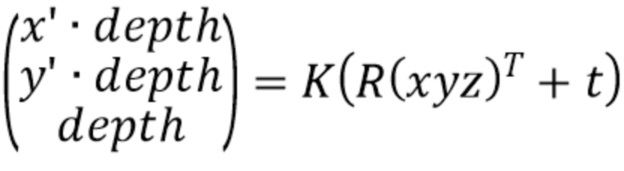 (1)
(1)
[0037] С помощью перспективной проекции (1) получают координаты экранного пространства 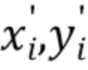 и их расстояния
и их расстояния 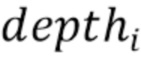 от камеры для всех точек в :
от камеры для всех точек в :
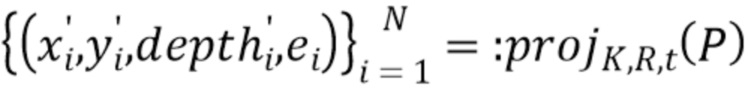 (2)
(2)
[0038] Если точки охарактеризованы не векторными представлениями, а цветами RGB, то изображение облака точек, воспринимаемое камерой, можно воссоздать методом растризации (splatting) [34, 33] точек на холст 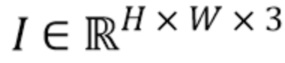 , т.е. установкой цвета каждой точки
, т.е. установкой цвета каждой точки 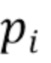 как цвета пикселя
как цвета пикселя 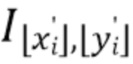 жестким способом (прямое назначение) или мягким способом (дополнительной установкой цвета точки для соседних пикселей и слиянием цветов соседних точек для обеспечения плавности).
жестким способом (прямое назначение) или мягким способом (дополнительной установкой цвета точки для соседних пикселей и слиянием цветов соседних точек для обеспечения плавности).
[0039] Тем не менее, несмотря на эффективность описанного подхода к отрисовке облаков точек, он не позволяет решить многие важные проблемы, которые естественным образом возникают при реалистичной отрисовке, такие как наличие дыр в изображении между проецируемыми точками, учет видимости (чаще всего, если несколько точек накладывается на один и тот же пиксель, то на цвет пикселя влияет только цвет ближайшей к камере точки), световые эффекты и многое другое.
Лучевая группировка
[0040] На фиг. 1 представлен процесс лучевой группировки. Показанный на изображении кролик является примером образца трехмерной модели, которая отрисовывается и сохраняется в виде облака точек. Камера в левом нижнем углу воспринимает изображение кролика, собранное на желтой плоскости поблизости. Красно-зелено-желтая трапеция - это срез бесконечной пирамиды, представляющий собой пирамиду видимости камеры, т.е. пространство всех возможных точек, которые могут влиять на изображение. Холст изображения будет сохранен дискретным образом и будет содержать H×W пикселей. Рассмотрим луч (синий), который проходит через пиксель 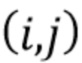 на изображении. Одна точка на груди кролика и другая точка на его лапе будут считаться принадлежащими этому лучу, поскольку они проецируются в то же самое целое положение на изображении.
на изображении. Одна точка на груди кролика и другая точка на его лапе будут считаться принадлежащими этому лучу, поскольку они проецируются в то же самое целое положение на изображении.
[0041] Чтобы представить правило отрисовки более наглядно, на первом этапе конвейера точки в группируются в соответствии с их округленными координатами экранного пространства. Точнее говоря, воображаемые лучи считаются выходящими из камеры. Каждый луч 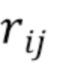 берет начало в местоположении камеры и проходит через соответствующий пиксель
берет начало в местоположении камеры и проходит через соответствующий пиксель 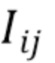 холста изображения. Координаты экранного пространства
холста изображения. Координаты экранного пространства 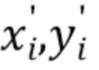 каждой точки в арифметически округляются и рассматриваются как принадлежащие лучу
каждой точки в арифметически округляются и рассматриваются как принадлежащие лучу 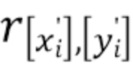 . Результатом процесса группировки является взаимно-однозначное распределение точек между наборами (лучами), и затем точки сортируются в порядке уменьшения их глубины относительно камеры (см. фиг. 1). После этой процедуры различные наборы (лучи) будут хранить различное количество упорядоченных точек
. Результатом процесса группировки является взаимно-однозначное распределение точек между наборами (лучами), и затем точки сортируются в порядке уменьшения их глубины относительно камеры (см. фиг. 1). После этой процедуры различные наборы (лучи) будут хранить различное количество упорядоченных точек 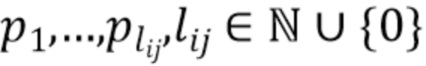 , и некоторые из наборов могут остаться пустыми, если в них не были помещены точки (см. фиг.1).
, и некоторые из наборов могут остаться пустыми, если в них не были помещены точки (см. фиг.1).
Нейронная архитектура
[0042] На фиг. 2 показаны основные части предложенного алгоритма. Хотя на фиг. 2 показана обработка с применением двух масштабов, эти масштабы и их количество могут быть любыми и задаваться заранее. На этапе (а) в каждом масштабе облако точек P, сгруппированное в некоторое количество лучей, передается в сеть LSTM с весами, общими для всех пикселей и всех масштабов. LSTM принимает векторное представление и глубину каждой точки в луче последовательно в порядке уменьшения глубины. На этапе (b) для каждого луча LSTM выдает агрегированное векторное представление луча - вектор с скалярами. Расположив векторные представления лучей на холсте, получают тензор 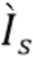 размера
размера 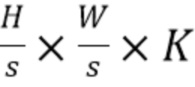 . На этапе (c) сеть с архитектурой U-Net собирает тензоры
. На этапе (c) сеть с архитектурой U-Net собирает тензоры 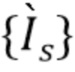 из всех масштабов с соответствующими уровнями разрешения и осуществляет их слияние в окончательное изображение RGB.
из всех масштабов с соответствующими уровнями разрешения и осуществляет их слияние в окончательное изображение RGB.
[0043] В результате лучевой группировки получают распределение N точек в по 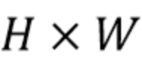 лучам
лучам 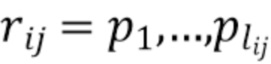 переменной длины
переменной длины 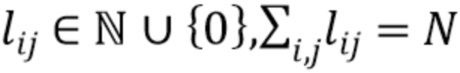 . Рассмотрим рекуррентную нейронную сеть (RNN)
. Рассмотрим рекуррентную нейронную сеть (RNN) 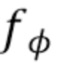 с обучаемыми параметрами
с обучаемыми параметрами 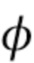 , состоящую из рекуррентных ячеек, например, ячеек LSTM [7], но не ограниченную ими. Этот метод будет описан для RNN, состоящей из ячеек LSTM. Получив ввод, последнее скрытое состояние и последнее состояние ячейки
, состоящую из рекуррентных ячеек, например, ячеек LSTM [7], но не ограниченную ими. Этот метод будет описан для RNN, состоящей из ячеек LSTM. Получив ввод, последнее скрытое состояние и последнее состояние ячейки 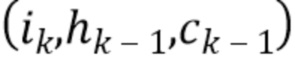 , эта RNN преобразует данную информацию в логически вытекающие скрытые состояния и состояния ячейки
, эта RNN преобразует данную информацию в логически вытекающие скрытые состояния и состояния ячейки 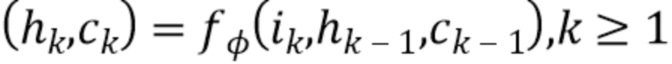 .
. 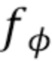 используется для последовательной обработки точек в каждом луче
используется для последовательной обработки точек в каждом луче 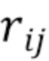 и агрегирования этой совокупной информации в выходной признак соответствующего пикселя изображения) (см. фиг. 2).
и агрегирования этой совокупной информации в выходной признак соответствующего пикселя изображения) (см. фиг. 2).
[0044] Более конкретно, для каждого луча строятся векторы признаков его точек 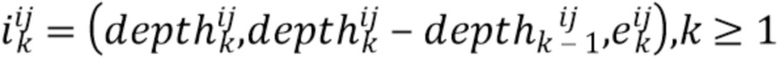 (при
(при 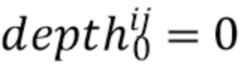 ). Если точки в имеют больше признаков, чем только мировые координаты и векторные представления, например, цвет точки, семантическую сегментацию и т.п., то эти признаки можно спроецировать на экранные координаты и включить их в
). Если точки в имеют больше признаков, чем только мировые координаты и векторные представления, например, цвет точки, семантическую сегментацию и т.п., то эти признаки можно спроецировать на экранные координаты и включить их в 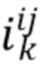 . Получив признаки новой точки, RNN выдает обновленную оценку
. Получив признаки новой точки, RNN выдает обновленную оценку 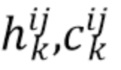 параметров всего луча:
параметров всего луча:
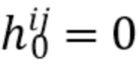 (3)
(3)
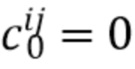 (4)
(4)
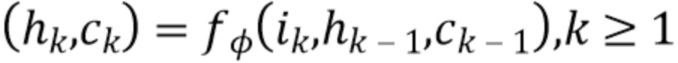 (5)
(5)
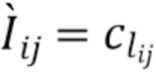 (6)
(6)
[0045] Такая конструкция позволяет смешивать точки вдоль луча в обратном порядке, эффективно игнорируя несущественные кластеры точек и идентифицируя фронтальную поверхность лежащей в основе трехмерной структуры относительно выбранной камеры. Результирующее состояние ячейки 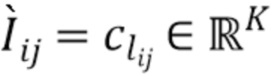 интерпретируется как агрегированный признак луча, который содержит релевантную информацию о цвете пикселя, подлежащего оценке (например, одним из возможных решений для RNN было бы воспроизведение векторного представления передней точки), и он называется векторным представлением луча. В основу этого подхода положено интуитивное представление, что ячейка LSTM способна имитировать как простые, так и сложные правила смешивания прозрачности, такие как оператор OVER [23], независимое от порядка наложение и т.п. Поэтапные выводы LSTM не используются, так как выражение для состояния ячейки LSTM больше похоже на формулы смешивания прозрачности, чем на выражение для выходных переменных. Для тех пикселей , которые соответствуют пустым лучам, устанавливается
интерпретируется как агрегированный признак луча, который содержит релевантную информацию о цвете пикселя, подлежащего оценке (например, одним из возможных решений для RNN было бы воспроизведение векторного представления передней точки), и он называется векторным представлением луча. В основу этого подхода положено интуитивное представление, что ячейка LSTM способна имитировать как простые, так и сложные правила смешивания прозрачности, такие как оператор OVER [23], независимое от порядка наложение и т.п. Поэтапные выводы LSTM не используются, так как выражение для состояния ячейки LSTM больше похоже на формулы смешивания прозрачности, чем на выражение для выходных переменных. Для тех пикселей , которые соответствуют пустым лучам, устанавливается 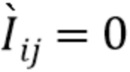 и
и 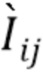 рассматривается далее как тензор многоканального изображения.
рассматривается далее как тензор многоканального изображения.
[0046] Таким образом, 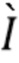 содержит набор векторных представлений лучей для всех непустых лучей, которые отражают агрегированную информацию о точках на луче, но не зависят от точек соседних лучей. Вводится обозначение
содержит набор векторных представлений лучей для всех непустых лучей, которые отражают агрегированную информацию о точках на луче, но не зависят от точек соседних лучей. Вводится обозначение 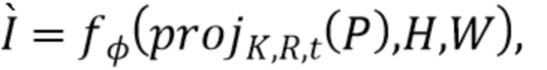 представляющее вышеупомянутую процедуру группировки по
представляющее вышеупомянутую процедуру группировки по 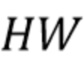 лучам, обработки RNN и построения холста размера
лучам, обработки RNN и построения холста размера 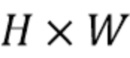 с векторными представлениями лучей.
с векторными представлениями лучей.
[0047] После нескольких повторений этой операции строится пирамида тензоров различного разрешения:
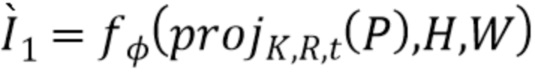 ,
,
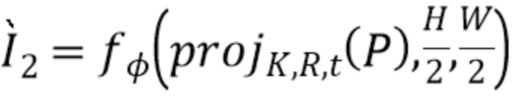 ,
,
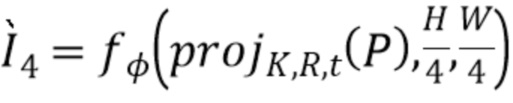 ,
,
[0048] По мере уменьшения масштаба снижается степень детализации и "резкости", однако отдельные лучи начинают содержать больше точек. Это приводит к лучшей контекстной обработке посредством RNN и меньшему количеству дыр в тензоре  соответствующих пустым лучам при меньших масштабах.
соответствующих пустым лучам при меньших масштабах.
[0049] На последнем этапе алгоритма векторные представления лучей сливаются и преобразуются в конечное изображение RGB полносверточной сетью (FCN)  . Архитектура, лежащая в основе
. Архитектура, лежащая в основе 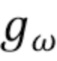 , в основном вдохновлена U-Net [26], которая была расширена добавлением пирамиды многомасштабных входных изображений (см. фиг. 2). На каждом разрешении сжимающего пути
, в основном вдохновлена U-Net [26], которая была расширена добавлением пирамиды многомасштабных входных изображений (см. фиг. 2). На каждом разрешении сжимающего пути 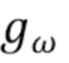 принимает
принимает 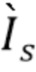 , где
, где 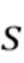 =1,2,4,… - коэффициент понижения разрешения для соответствующего уровня, и конкатенирует с картами признаков из уровня более высокого разрешения. Это позволяет сети заполнить недостающие области и использовать информацию о более широком контексте одновременно из нескольких разрешений. В качестве замены простых сверток в этой сжимающей части использовались частичные свертки [14]. Эти слои получают входной тензор и маску и обрабатывают только значения в немаскированных позициях ввода, осуществляя соответствующее повторное взвешивание результата с учетом заданной маски. Это делается для того, чтобы придать уточняющей сети меньшую зависимость от возможной разреженности ввода, вызванной дырами в тензорах .
=1,2,4,… - коэффициент понижения разрешения для соответствующего уровня, и конкатенирует с картами признаков из уровня более высокого разрешения. Это позволяет сети заполнить недостающие области и использовать информацию о более широком контексте одновременно из нескольких разрешений. В качестве замены простых сверток в этой сжимающей части использовались частичные свертки [14]. Эти слои получают входной тензор и маску и обрабатывают только значения в немаскированных позициях ввода, осуществляя соответствующее повторное взвешивание результата с учетом заданной маски. Это делается для того, чтобы придать уточняющей сети меньшую зависимость от возможной разреженности ввода, вызванной дырами в тензорах .
[0050] Во время обучения вместе настраиваются независящие от точки обзора векторные представления точек 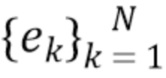 , параметры и
, параметры и 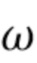 обеих сетей и вспомогательные параметры
обеих сетей и вспомогательные параметры 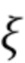 (см. ниже).
(см. ниже).
Функции потерь
[0051] Система обучается посредством оптимизации суммы двух функций потерь. Обе потери задействуют перцептивную функцию потерь 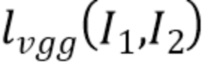 между двумя изображениями
между двумя изображениями 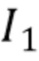 and
and 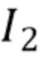 на базе VGG-19 [27], предварительно обученной на ImageNet [6]:
на базе VGG-19 [27], предварительно обученной на ImageNet [6]:
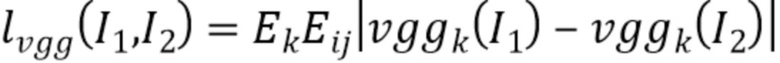 ,
,
при этом 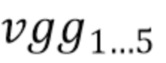 соответствуют картам признаков из слоев VGG -19 relu1_2; relu2_2; relu3_4; relu4_4; relu5_4. Данный выбор слоев обычно обосновывается как репрезентативное подмножество перцептивных признаков VGG в передаче стиля и смежных областях [8].
соответствуют картам признаков из слоев VGG -19 relu1_2; relu2_2; relu3_4; relu4_4; relu5_4. Данный выбор слоев обычно обосновывается как репрезентативное подмножество перцептивных признаков VGG в передаче стиля и смежных областях [8].
[0052] Первая функция потерь ограничивает RNN созданием холста векторных представлений лучей 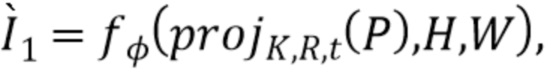 семантически согласованных с истинной картиной
семантически согласованных с истинной картиной 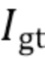 .Более конкретно, наряду с RNN и CNN обучается один слой свертки 1˟1
.Более конкретно, наряду с RNN и CNN обучается один слой свертки 1˟1  , и результат сравнивается с настоящим изображением:
, и результат сравнивается с настоящим изображением:
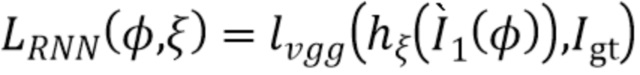 .
.
[0053] Вторая потеря ограничивает уточняющую сеть созданием окончательного прогноза 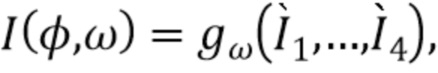 близкого к истинной картине
близкого к истинной картине 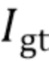 :
:
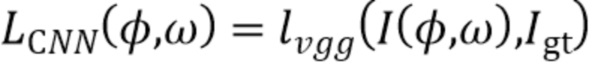 ).
).
[0054] Процедура обучения состоит из двух этапов. На первом этапе, называемом предобучением, на который подается набор облаков точек сцен аналогичного типа, векторные представления точек каждой сцены и параметры 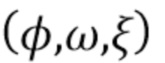 всех сверточных сетей полностью оптимизируются в соответствии с суммой всех функций потерь во всех сценах. Эта оптимизация выполняется по алгоритму ADAM и включает в себя обратное распространение градиента функции потерь. На втором этапе, называемом точной настройкой, имея предоставленное облако точек по меньшей мере для одной сцены, обучение направлено на оптимизацию только векторных представлений точек для этой сцены или набора сцен по отношению к замороженным, ранее предобученным сверточным сетям. В начале этого этапа процесс обучения начинается с нулевых значений дескриптора для данной новой сцены или набора сцен.
всех сверточных сетей полностью оптимизируются в соответствии с суммой всех функций потерь во всех сценах. Эта оптимизация выполняется по алгоритму ADAM и включает в себя обратное распространение градиента функции потерь. На втором этапе, называемом точной настройкой, имея предоставленное облако точек по меньшей мере для одной сцены, обучение направлено на оптимизацию только векторных представлений точек для этой сцены или набора сцен по отношению к замороженным, ранее предобученным сверточным сетям. В начале этого этапа процесс обучения начинается с нулевых значений дескриптора для данной новой сцены или набора сцен.
[0055] Один вариант осуществления способа синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора, будет описан более подробно со ссылкой на фиг. 3. Способ 100 содержит этапы S101-S108.
[0056] На этапе S101 принимают трехмерное облако точек. Трехмерное облако точек может быть сохранено в памяти устройства или получено с любого удаленного устройства по проводной или беспроводной связи. Трехмерное облако точек можно получить из множества 2D изображений одной и той же сцены любым известным способом. Каждая точка облака задана 3D координатами в мировой системе координат и векторным представлением точки.
[0057] На этапе S102 задают требуемую точку обзора как камеру, имеющую внутренние параметры и внешние параметры.
[0058] На этапе S103 3D координаты каждой точки преобразуют в 2D координаты и глубину каждой точки в системе координат экранного пространства камеры, используя внутренние параметры и внешние параметры. Внутренние параметры и внешние параметры задают правило перспективного преобразования координат из мировой системы координат в соответствующую систему координат экранного пространства. Такое преобразование известно из уровня техники и описано выше. Поэтому подробное описание этого преобразования здесь опущено.
[0059] На этапе S104 задают множество лучей, расходящихся от точки обзора. Лучи задаются координатами экранного пространства, внутренними параметрами и внешними параметрами. Задание множества лучей подробно описано выше со ссылкой на фиг. 1.
[0060] На этапе S105 точки группируют в наборы точек, ассоциированные с лучами. Каждый набор точек содержит точки, через которые проходит один луч, и в каждом наборе точек точки располагаются в порядке уменьшения их глубины относительно точки обзора. Подробное описание группировки точек приведено выше в разделе "Лучевая группировка".
[0061] На этапе S106 для каждого луча обученный предиктор машинного обучения вычисляет векторное представление луча путем агрегирования векторных представлений точек и глубин соответствующего набора точек. На этапе S107 векторные представления лучей проецируются на плоскость изображения. Этапы (S103)-(S107) выполняются для множества масштабов. Множество масштабов задают заранее. На этапе S108 обученный предиктор машинного обучения сливает плоскости изображений во множестве масштабов в 2D изображение. Этапы S106, S107, S108 подробно описаны выше со ссылкой на фиг. 2.
[0062] Обученный предиктор машинного обучения состоит из двух частей. Первая часть обученного предиктора машинного обучения выполняет этап (S106), а его вторая часть выполняет этап (S108).
[0063] Первая часть обученного предиктора машинного обучения представляет собой по меньшей мере одну из рекуррентных нейронных сетей. Вторая часть обученного предиктора машинного обучения - это нейронная сеть на базе U-net.
[0064] Предиктор машинного обучения обучается в два последовательных этапа. Первый этап является этапом предобучения. Второй этап - это этап точной настройки. Первый этап выполняется на первом наборе обучающих данных. Первый набор данных обучающих данных включает в себя: наборы 2D изображений разных сцен одного и того же типа, причем каждый набор 2D изображений представляет одну сцену и каждое 2D изображение в наборе снято из различных точек обзора; точки обзора и 3D облака точек, каждое из которых получено из соответствующего набора 2D изображений.
[0065] Второй этап выполняют на втором наборе обучающих данных. Второй набор обучающих данных включает в себя: наборы 2D изображений разных сцен одного и того же типа, причем каждый набор 2D изображений представляет одну сцену и каждое 2D изображение в наборе снято из различных точек обзора, при этом сцены во втором наборе обучающих данных отличаются из сцен в первом наборе обучающих данных; точки обзора и 3D облака точек, каждое из которых получено из соответствующего набора 2D изображений.
[0066] На фиг. 4 показан процесс 200 обучения предиктора машинного обучения. Каждый из двух этапов обучения предиктора машинного обучения содержит этапы S201-S208.
[0067] На этапе S201 из соответствующего набора обучающих данных произвольно выбираются обучающие данные. Для этапа предобучения обучающие данные выбираются произвольно из первого набора обучающих данных. Для этапа точной настройки обучающие данные выбираются произвольно из второго набора обучающих данных. Обучающие данные принадлежат произвольно выбранной сцене и содержат 3D облако точек, точку обзора и 2D изображение, захваченное с указанной точки обзора.
[0068] На этапе S202 3D координаты каждой точки 3D облака точек преобразуют в 2D координаты и глубину каждой точки в системе координат экранного пространства камеры, используя внутренние параметры и внешние параметры камеры, с помощью которой был снят данный набор 2D изображений.
[0069] На этапе S203 задают множество лучей. Лучи расходятся от точки обзора. Лучи задают координатами экранного пространства, внутренними параметрами и внешними параметрами.
[0070] На этапе S204 точки облака точек группируют в наборы точек, ассоциированные с лучами. Каждый набор точек содержит точки, через которые проходит один луч, и в каждом наборе точек точки располагаются в порядке уменьшения их глубины относительно точки обзора.
[0071] На этапе S205 для каждого луча вычисляют векторное представление луча путем агрегирования векторных представлений точек и глубин соответствующего набора точек.
[0072] На этапе S206 предиктор машинного обучения обрабатывает векторные представления лучей, чтобы получить сумму значений функции потерь. Процесс, связанный с функциями потерь, подробно описан выше в разделе "Функции потерь".
[0073] На этапе S207 оценивается градиент полученной суммы относительно каждого скалярного веса предиктора машинного обучения и векторных представлений точек.
[0074] На этапе S208 каждый скалярный вес предиктора машинного обучения и векторные представления всех точек изменяются в соответствии с заданным правилом оптимизатора на основе оцененного градиента. Этапы (S201)-(S208) повторяют заданное количество раз.
[0075] На фиг. 5 представлена структурная схема, иллюстрирующая электронное вычислительное устройство в соответствии с настоящим изобретением. Электронное вычислительное устройство 300 содержит по меньшей мере один процессор 301 и память 302.
[0076] Память 302 хранит числовые параметры обученного предиктора машинного обучения и инструкции. По меньшей мере один процессор 301 исполняет инструкции, хранящиеся в памяти 302, для выполнения способа 100 синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора.
[0077] Способ, раскрытый в данном документе, может быть реализован по меньшей мере одним процессором, таким как центральный процессор (CPU), графический процессор (GPU), реализованный по меньшей мере на одной из специализированной интегральной схемы (ASIC), программируемой пользователем вентильной матрицы (FPGA), но без ограничения ими. Кроме того, способ, раскрытый в данном документе, может быть реализован на машиночитаемом носителе, который хранит числовые параметры обученного предиктора машинного обучения и исполняемые компьютером инструкции, которые при их исполнении процессором побуждают компьютер выполнять предложенный способ. Обученный предиктор машинного обучения и инструкции для реализации настоящего способа могут быть загружены в электронное вычислительное устройство через сеть или с носителя.
[0078] Настоящее изобретение может применяться в гарнитурах виртуальной реальности, очках дополненной реальности, очках смешанной реальности, смартфонах и других устройствах и системах виртуальной и/или дополненной реальности.
[0079] Приведенные выше описания вариантов осуществления изобретения являются иллюстративными, и модификации, внесенные в конфигурации и реализации не выходят за пределы объема настоящего описания. Например, несмотря на то, что варианты осуществления изобретения описаны в общем виде со ссылками на фиг. 1 и 2, эти представленные выше описания являются примерными. Хотя предмет изобретения описан на языке, характеризующем конструктивные признаки или этапы способа, понятно, что он не обязательно ограничен описанными признаками или этапами. Кроме того, конкретные описанные выше признаки и этапы раскрыты как примерные формы реализации формулы изобретения. Изобретение не ограничивается проиллюстрированной последовательностью этапов способа, специалист сможет изменить эту последовательность без применения творческих усилий. Некоторые или все этапы способа могут выполняться последовательно или параллельно.
[0080] Соответственно, подразумевается, что объем варианта осуществления изобретения ограничен только следующей формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ТЕКСТУРИРОВАННЫЕ НЕЙРОННЫЕ АВАТАРЫ | 2019 |
|
RU2713695C1 |
| НЕЙРОННАЯ ТОЧЕЧНАЯ ГРАФИКА | 2019 |
|
RU2729166C1 |
| Способ обеспечения компьютерного зрения | 2022 |
|
RU2791587C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЗИРОВАННОГО ПОСТРОЕНИЯ ВИРТУАЛЬНОЙ 3D-СЦЕНЫ НА ОСНОВАНИИ ДВУМЕРНЫХ СФЕРИЧЕСКИХ ФОТОПАНОРАМ | 2024 |
|
RU2826369C1 |
| Способ и электронное устройство для обнаружения трехмерных объектов с помощью нейронных сетей | 2021 |
|
RU2776814C1 |
| СПОСОБ ВИЗУАЛИЗАЦИИ 3D ПОРТРЕТА ЧЕЛОВЕКА С ИЗМЕНЕННЫМ ОСВЕЩЕНИЕМ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ НЕГО | 2021 |
|
RU2757563C1 |
| Способ построения представления сцены с прямой коррекцией для синтеза изображения в реальном времени | 2022 |
|
RU2799237C1 |
| Способ формирования архитектуры нейросети для классификации объекта, заданного в виде облака точек, способ ее применения для обучения нейросети и поиска семантически схожих облаков точек | 2017 |
|
RU2674326C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ СТЕПЕНИ УХУДШЕНИЯ ЛИДАРНЫХ ДАННЫХ | 2021 |
|
RU2826476C1 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ ОПРЕДЕЛЕНИЯ КОМПЬЮТЕРОМ НАЛИЧИЯ ДИНАМИЧЕСКИХ ОБЪЕКТОВ | 2019 |
|
RU2767955C1 |

Изобретение относится к средствам создания двумерных изображений трехмерной сцены, видимых из различных точек обзора. Технический результат заключается в синтезировании из облаков точек двумерного изображения сцены, просматриваемой с требуемой точки обзора, с высоким качеством и низкими вычислительными затратами. Принимают трехмерное облако точек, полученное из множества двумерных изображений одной и той же сцены, причем каждую точку облака задают трехмерными координатами в мировой системе координат и векторным представлением точки. Задают точку обзора как камеру, имеющую внутренние параметры и внешние параметры. Преобразуют трехмерные координаты каждой точки в двумерные координаты и глубину каждой точки в системе координат экранного пространства камеры, используя внутренние параметры и внешние параметры; задают множество лучей, расходящихся от точки обзора, причем лучи заданы координатами экранного пространства и внутренними параметрами и внешними параметрами. Группируют точки в наборы точек, ассоциированные с лучами, причем каждый набор точек содержит точки, через которые проходит один луч, и в каждом наборе точек точки располагаются в порядке уменьшения их глубины относительно точки обзора. Вычисляют для каждого луча векторное представление луча путем агрегирования векторных представлений точек и глубин соответствующего набора точек с помощью обученного предиктора машинного обучения. Проецируют векторные представления лучей на плоскость изображения, причем предыдущие этапы выполняют для заданного множества масштабов. Осуществляют слияние плоскостей изображения во множестве масштабов с помощью обученного предиктора машинного обучения в двумерное изображение. 2 н. и 4 з.п. ф-лы, 5 ил.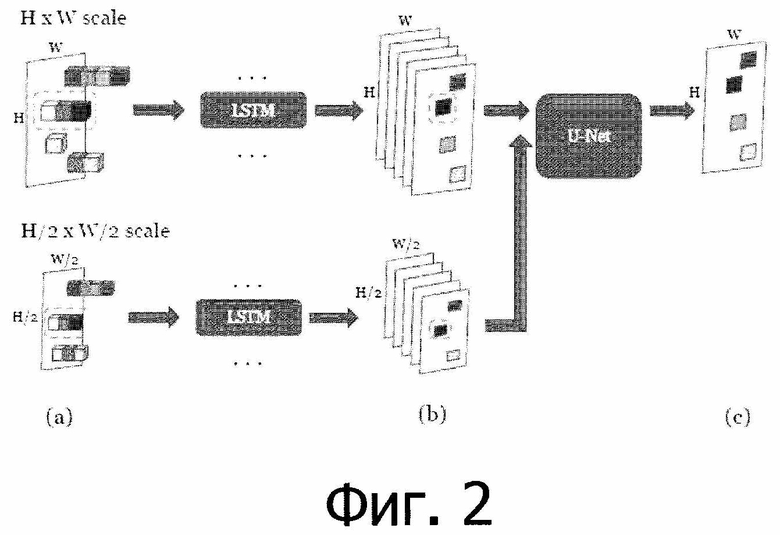
1. Способ синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора, при этом упомянутый способ содержит этапы, на которых:
принимают (S101) трехмерное облако точек, полученное из множества двумерных изображений одной и той же сцены, причем каждую точку облака задают трехмерными координатами в мировой системе координат и векторным представлением точки;
задают (S102) точку обзора как камеру, имеющую внутренние параметры и внешние параметры, при этом внутренние параметры содержат фокусное расстояние, формат датчика изображения и главную точку, а внешние параметры содержат местоположение и ориентацию камеры относительно мировой системы координат;
преобразуют (S103) трехмерные координаты каждой точки в двумерные координаты и глубину каждой точки в системе координат экранного пространства камеры, используя внутренние параметры и внешние параметры;
задают (S104) множество лучей, расходящихся от точки обзора, причем лучи заданы координатами экранного пространства и внутренними параметрами и внешними параметрами;
группируют (S105) точки в наборы точек, ассоциированные с лучами, причем каждый набор точек содержит точки, через которые проходит один луч, и в каждом наборе точек точки расположены в порядке уменьшения их глубины относительно точки обзора;
вычисляют (S106) для каждого луча векторное представление луча путем агрегирования векторных представлений точек и глубин соответствующего набора точек с помощью обученного предиктора машинного обучения;
проецируют (S107) векторные представления лучей на плоскость изображения,
причем этапы (S103)-(S107) выполняют для заданного множества масштабов;
осуществляют слияние (S108) плоскостей изображения во множестве масштабов с помощью обученного предиктора машинного обучения в двумерное изображение.
2. Способ по п.1, в котором обучение предиктора машинного обучения включает в себя два последовательных этапа:
этап предобучения, выполняемый на первом наборе обучающих данных, причем первый набор обучающих данных включает в себя:
- наборы двумерных изображений разных сцен одного и того же типа, причем каждый набор двумерных изображений представляет одну сцену и каждое двумерное изображение в наборе снято с разной точки обзора,
- точки обзора и
- трехмерные облака точек, каждое из которых получено из соответствующего набора двумерных изображений; и
этап точной настройки, выполняемый на втором наборе обучающих данных, причем второй набор обучающих данных включает в себя:
- наборы двумерных изображений разных сцен одного и того же типа, причем каждый набор двумерных изображений представляет одну сцену, каждое двумерное изображение в наборе снято с разной точки обзора, причем сцены во втором наборе обучающих данных отличаются от сцен в первом наборе обучающих данных,
- точки обзора и
- трехмерные облака точек, каждое из которых получено из соответствующего набора двумерных изображений.
3. Способ по п. 2, в котором каждый из двух этапов обучения предиктора машинного обучения содержит этапы, на которых:
произвольно выбирают (S201) из соответствующего набора обучающих данных обучающие данные случайно выбранной сцены, содержащие трехмерное облако точек, точку обзора и двумерное изображение, захваченное с упомянутой точки обзора;
преобразуют (S202) трехмерные координаты каждой точки трехмерного облака точек в двумерные координаты и глубину каждой точки в системе координат экранного пространства камеры, используя внутренние параметры и внешние параметры камеры, с которыми был захвачен данный набор двумерных изображений;
задают (S203) множество лучей, расходящихся от точки обзора, причем лучи заданы координатами экранного пространства и внутренними параметрами и внешними параметрами;
группируют (S204) точки в наборы точек, ассоциированные с лучами, причем каждый набор точек содержит точки, через которые проходит один луч, и в каждом наборе точек точки расположены в порядке уменьшения их глубины относительно точки обзора;
вычисляют (S205) для каждого луча векторное представление луча путем агрегирования векторных представлений точек и глубин соответствующего набора точек;
обрабатывают (S206) с помощью предиктора машинного обучения векторные представления лучей для получения суммы значений функции потерь;
оценивают (S207) градиент полученной суммы относительно каждого скалярного веса предиктора машинного обучения и векторных представлений точек;
изменяют (S208) каждый скалярный вес предиктора машинного обучения и векторные представления всех точек в соответствии с заданным правилом оптимизатора на основании оцененного градиента,
причем этапы (S201)-(S208) повторяют заданное количество раз.
4. Способ по любому из пп. 1-3, в котором обученный предиктор машинного обучения содержит две части, причем первая часть обученного предиктора машинного обучения выполняет этап (S106), а вторая часть обученного предиктора машинного обучения выполняет этап (S108).
5. Способ по п. 4, в котором первая часть обученного предиктора машинного обучения является по меньшей мере одной из рекуррентных нейронных сетей, а вторая часть обученного предиктора машинного обучения является нейронной сетью на базе U-net.
6. Электронное вычислительное устройство для синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора, содержащее:
по меньшей мере процессор и
память, в которой хранятся числовые параметры обученного предиктора машинного обучения и инструкции, которые при их исполнении по меньшей мере одним процессором побуждают по меньшей мере один процессор выполнять способ синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора, по любому из пп. 1-5.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| МОРФОЛОГИЧЕСКОЕ СГЛАЖИВАНИЕ (МС) ПРИ ПОВТОРНОМ ПРОЕЦИРОВАНИИ ДВУХМЕРНОГО ИЗОБРАЖЕНИЯ | 2011 |
|
RU2562759C2 |

