Область техники, к которой относится изобретение
Изобретение относится к компьютерному зрению, в частности к навигации мобильных роботов, для мобильных приложений, которые осуществляют понимание сцены и распознавание объектов.
Описание предшествующего уровня техники
Обнаружение 3D объектов из облаков точек направлено на одновременное определение местоположения и распознавание 3D объектов по предоставленному набору 3D точек. Этот метод широко применяется в автономном вождении, робототехнике и дополненной реальности в качестве основного метода понимания 3D сцен.
В то время как 2D методы ([26], [32]) работают с плотными массивами фиксированного размера, 3D методы должны работать с нерегулярными неструктурированными 3D данными произвольного объема. Поэтому методы обработки 2D данных невозможно применить напрямую для обнаружения 3D объектов, и в методах обнаружения 3D объектов ([10], [22], [19]) используются инновационные подходы к обработке 3D данных.
Проблемой сверточных методов обнаружения 3D объектов является масштабируемость: для обработки крупномасштабных сцен требуется либо нерационально большой объем вычислительных ресурсов, либо слишком много времени. В других методах прибегают к представлению данных вокселей и используют разреженные свертки; однако эти методы решают проблемы масштабируемости в ущерб точности обнаружения. Иными словами, не существует метода обнаружения 3D объектов, который бы обеспечивал точные оценки и при этом обладал хорошим масштабированием.
Современные методы обнаружения 3D объектов проектируются для применения либо внутри, либо вне помещений.
Методы для применения внутри и вне помещений разрабатываются практически независимо друг от друга с использованием методов обработки данных, специфичных для предметной области. Многие современные методы для применения вне помещений [30], [13], [35] проецируют 3D точки на плоскость общей перспективы, тем самым сводя задачу обнаружения 3D объектов к обнаружению 2D объектов. Эти методы, конечно же, используют преимущества быстро развивающихся алгоритмов обнаружения 2D объектов. При наличии проекции общей перспективы в работе [14] ее обрабатывают полностью сверточным методом, а в работе [31] используется безъякорный 2D подход. К сожалению, эти подходы, оказавшиеся эффективными как для обнаружения 2D объектов, так и для обнаружения 3D объектов вне помещений, сложно адаптировать для помещений, так как это бы потребовало нерационально большого объема памяти и вычислительных ресурсов. Для решения проблем производительности предлагались различные стратегии обработки 3D данных. В настоящее время в области обнаружения 3D объектов преобладают три подхода - на основе голосования, на основе преобразователя и 3D свертки. Далее подробно обсуждается каждый из этих подходов; также представлен краткий обзор безъякорных методов.
Методы на основе голосования
Первым методом, в который было введено голосование по точкам для обнаружения 3D объектов, был метод VoteNet [22]. VoteNet обрабатывает 3D точки с помощью Point-Net [23], присваивает группу точек каждому объекту-кандидату в соответствии с их центром голосования и вычисляет признаки объекта из каждой группы точек. Из многочисленных последователей VoteNet основной прогресс связан с современными стратегиями группировки и голосования, применяемыми к признакам PointNet. BRNet [4] уточняет результаты голосования с помощью репрезентативных точек из центров голосования, что улучшает захват мелких локальных структурных признаков. MLCVNet [29] вводит три контекстных модуля в этапы голосования и классификации VoteNet для кодирования контекстной информации на разных уровнях. H3DNet [33] усовершенствует процедуру генерации группы точек путем прогнозирования гибридного набора геометрических примитивов.
VENet [28] содержит механизм внимания и вводит модуль взвешивания голосов, обучаемый с помощью новой потери привлекательности голосов.
Все методы на основе голосования типа VoteNet ограничены проектным решением. Во-первых, они плохо масштабируются: поскольку их производительность зависит от объема входных данных, они имеют свойство замедляться при увеличении сцен. Кроме того, многие методы на основе голосования реализуют стратегии голосования и группировки в виде настраиваемых слоев, что затрудняет воспроизведение или отладку этих методов или перенос их на мобильные устройства.
Методы на основе преобразователя
Недавно появившиеся методы на основе преобразователя используют сквозное обучение и прямое распространение на логический вывод вместо эвристики и оптимизации, что делает их менее предметно-ориентированными. В GroupFree [16] "голова" VoteNet заменена модулем-преобразователем, итеративно обновляющим положения запросов объектов и собирающим промежуточные результаты обнаружения. 3DETR [19] был первым методом обнаружения 3D объектов, реализованным в виде сквозного обучаемого преобразователя. Однако более продвинутые методы на основе преобразователя по-прежнему имеют проблемы с масштабируемостью, аналогичные ранним методам на основе голосования. В отличие от них, предлагаемый метод является полностью сверточным, поэтому он более быстрый и простой в реализации, чем методы на основе голосования и на основе преобразователя.
3D сверточные методы
Воксельное представление позволяет эффективно обрабатывать кубически растущие разреженные 3D данные. Методы обнаружения 3D объектов на основе вокселей ([12], [18]) преобразуют точки в воксели и обрабатывают их с помощью 3D сверточных сетей. Однако плотные объемные признаки по-прежнему потребляют много памяти, а 3D свертки требуют больших вычислительных ресурсов. В общем, обработка больших сцен требует много ресурсов и не может быть выполнена за один проход.
GSDN [10] решает проблемы производительности с помощью разреженных 3D сверток. Он имеет архитектуру кодер-декодер, в которой обе части, кодер и декодер, построены из разреженных 3D сверточных блоков. По сравнению со стандартными сверточными подходами на основе голосования и преобразователя, GSDN значительно более эффективно использует память и масштабируется на большие сцены без ущерба для плотности точек. Основным недостатком GSDN является его точность: этот метод сопоставим по качеству с VoteNet, но значительно уступает современному уровню развития [16].
GSDN использует 15 соотношений сторон для ограничивающих рамок 3D объектов в качестве якорей (анкоров). Если GSDN обучается в безъякорных установках с одним соотношением сторон, то его точность снижается на 12%. В отличие от GSDN, предлагаемый метод не содержит якоря, но использует преимущества разреженных 3D сверток.
Безъякорное обнаружение объектов на основе RGB
При обнаружении 2D объектов безъякорные методы составляют конкуренцию стандартным якорным методам. FCOS [26] осуществляет обнаружение 2D объектов методом попиксельного прогнозирования и демонстрирует значительное улучшение по сравнению с его предшественником на основе якорей - RetinaNet [15]. FCOS3D [27] тривиально адаптирует FCOS путем добавления дополнительных целей для монокулярного обнаружения 3D объектов. ImVoxelNet [24] решает ту же проблему с "головой" типа FCOS, построенной из стандартных (неразреженных) 3D сверточных блоков. Предлагаемое изобретение адаптирует идеи упомянутых безъякорных методов для обработки разреженных нерегулярных данных.
Помимо масштабируемости и точности, идеальный метод обнаружения 3D объектов должен обладать способностью работать с объектами произвольной формы и размера без дополнительных хаков и настраиваемых вручную гиперпараметров. Использовавшиеся ранее допущения по ограничивающим рамкам 3D объектов (например, соотношения сторон или абсолютные размеры) ограничивают обобщение и увеличивают количество гиперпараметров и обучаемых параметров.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В последнее время все больше внимания уделяется обнаружению 3D объектов из 3D облаков точек (компьютерному зрению) ввиду возможности его применения в таких перспективных областях, как робототехника и дополненная реальность.
Предлагается безъякорный метод, в котором не задаются априоры на объектах, и обнаружение 3D объектов осуществляется исключительно на основе данных. Кроме того, вводится новая параметризация ориентированной ограничивающей рамки (OBB), инспирированная лентой Мебиуса, которая уменьшает количество гиперпараметров. Чтобы доказать эффективность параметризации, авторы провели эксперименты на SUN RGB-D с несколькими методами обнаружения 3D объектов и предоставили сведения об улучшении результатов для всех этих методов.
Предложен способ обеспечения компьютерного зрения робототехнического устройства, реализуемый в вычислительном устройстве робототехнического устройства, причем робототехническое устройство имеет камеру с датчиками глубины и RGB-камеру, центральный процессор, внутреннюю память, оперативную память, при этом способ включает этапы, на которых:
захватывают реальную сцену с объектами в сцене, используя камеру с датчиками глубины и RGB-камеру;
представляют захваченную реальную сцену в виде облака из набора N точек, каждая из которых представлена своей координатой и цветом, и
вводят облако из набора N точек в качестве данных в нейронную сеть, причем нейронная сеть состоит из части "скелет", части "шея" и части "голова",
где часть "скелет", часть "шея" и часть "голова" являются 3D разреженными сверточными частями нейронной сети;
в нейронной сети выполняют следующие этапы:
посредством части "скелет" представляют облако точек в виде объемного пиксельного представления входных данных;
посредством части "скелет" обрабатывают объемное пиксельное представление входных данных для получения четырехмерных тензоров;
посредством сверточной части "шея" обрабатывают четырехмерные тензоры для извлечения выраженных в числовой форме признаков объектов в сцене;
посредством части "голова" обрабатывают извлеченные признаки объектов в сцене для получения прогнозов положений и категорий объектов в сцене, причем для каждого объекта в сцене часть "голова" выдает прогнозы, где прогноз содержит:
вероятность классификации объекта, параметры регрессии ограничивающей рамки объекта и центрированность объекта внутри ограничивающей рамки объекта;
посредством части "голова" фильтруют все полученные прогнозы путем сравнения прогнозов по вероятности классификации объекта для выбора наиболее вероятного прогноза, при этом наиболее вероятный прогноз считается окончательной оценкой положения и категории объекта в сцене и характеризуется данными, касающимися положения и категории объекта в сцене;
выводят из нейронной сети данные, касающиеся положения, ориентации и категории объекта в сцене в виде числового представления сцены, представляющего компьютерное зрение для робототехнического устройства.
При этом способ может содержать дополнительный этап, на котором: преобразуют числовое представление сцены в изображение сцены, причем компьютерное устройство дополнительно содержит экран, и изображение сцены отображается на экране для пользователя.
Предложен компьютерно-читаемый носитель, содержащий программный код, который воспроизводит способ по п. 1 при его реализации в компьютерном устройстве.
При этом описанный выше способ, выполняемый электронным устройством, может выполняться с использованием искусственного интеллекта (ИИ). Функция, связанная с ИИ, может выполняться посредством энергонезависимой памяти, энергозависимой памяти и процессора.
Процессор может включать в себя один или множество процессоров. В настоящее время один или несколько процессоров могут быть процессорами общего назначения, такими как центральный процессор (CPU), процессор приложений (АР) и т.п., блоком обработки только графики, таким как графический процессор (GPU), процессор компьютерного зрения (VPU) и/или специальный процессор для искусственного интеллекта, такой как нейронный процессор (NPU).
Эти один или несколько процессоров управляют обработкой входных данных в соответствии с предварительно определенным рабочим правилом или искусственным интеллектом (ИИ), хранящимся в энергонезависимой памяти и энергозависимой памяти. Предварительно определенное рабочее правило или искусственный интеллект обеспечиваются посредством обучения.
В данном контексте обеспечение посредством обучения означает, что путем применения алгоритма обучения к множеству обучающих данных создается предварительно определенное рабочее правило или ИИ с требуемой характеристикой. Обучение может выполняться непосредственно в том устройстве, в котором выполняется ИИ согласно варианту осуществления, и/или может быть реализовано отдельным сервером/системой.
ИИ может состоять из множества слоев нейронной сети. Каждый слой имеет множество весовых значений и выполняет операцию слоя посредством вычисления предыдущего слоя и операции множества весовых коэффициентов. Примеры нейронных сетей включают в себя, без ограничения, сверточную нейронную сеть (CNN), глубокую нейронную сеть (DNN), рекуррентную нейронную сеть (RNN), ограниченную машину Больцмана (RBM), глубокую сеть доверия (DBN), двунаправленную рекуррентную глубокую нейросеть (BRDNN), генеративно-состязательные сети (GAN) и глубокие Q-сети. Нейронная сеть может быть реализована аппаратными или программно-аппаратными средствами.
Алгоритм обучения представляет собой способ обучения заданного целевого устройства (например, робота) с использованием множества обучающих данных, чтобы побудить, разрешить или контролировать целевое устройство выполнять определение или прогнозирование. Примеры алгоритмов обучения включают, без ограничения перечисленным, обучение с привлечением учителя, обучение без учителя, обучение с частичным привлечением учителя или обучение с подкреплением.
Согласно изобретению, способ распознавания объектов может получать выходные данные распознавания путем использования данных изображения в качестве входных данных для искусственного интеллекта. Искусственный интеллект можно получить путем обучения. В данном контексте "полученный путем обучения" означает, что предварительно определенное рабочее правило или искусственный интеллект, обеспечивающий выполнение требуемой функции (или цели), получают путем обучения базового искусственного интеллекта на множестве частей обучающих данных с помощью обучающего алгоритма. Искусственный интеллект может включать в себя множество слоев нейронной сети. Каждый из множества слоев нейронной сети включает множество значений весов и выполняет вычисления нейронной сети путем вычисления между результатом вычисления предыдущего слоя и множеством значений весов.
Визуальное понимание - это метод распознавания и обработки вещей аналогично человеческому зрению, и оно включает, например, распознавание объекта, отслеживание объекта, поиск изображений, распознавание людей, распознавание сцен, 3D реконструкцию/локализацию или улучшение изображения.
Согласно изобретению в предлагаемом способе может использоваться искусственный интеллект, выполняемый путем использования данных. Процессор может выполнять на данных операцию предварительной обработки для их преобразования в форму, подходящую для применения в качестве ввода для модели искусственного интеллекта. Искусственный интеллект можно получить путем обучения. В данном контексте "полученный путем обучения" означает, что предварительно определенное рабочее правило или искусственный интеллект, обеспечивающий выполнение требуемой функции (или цели), получают путем обучения базового искусственного интеллекта с помощью нескольких частей обучающих данных, применяя обучающий алгоритм. Искусственный интеллект может включать в себя множество слоев нейронной сети. Каждый из множества слоев нейронной сети включает в себя множество значений весов и выполняет вычисления нейронной сети путем вычисления между результатом вычисления предыдущим слоем и множеством значений весов.
Прогнозирование рассуждений - это метод формирования логических рассуждений и получения прогнозов путем определения информации, который включает, например, формирование рассуждений на основе знаний, прогнозирование оптимизации, планирование на основе предпочтений или рекомендации.
Краткое описание чертежей
Представленные выше и/или другие аспекты станут более очевидными из описания примерных вариантов осуществления со ссылками на прилагаемые чертежи, на которых изображено следующее:
Фиг. 1 - общая схема предлагаемого способа.
Фиг. 2 - примеры объектов с неопределенным путевым углом.
Фиг. 3 - результат предложенного метода с датасетом ScanNet.
Фиг. 4 - зависимость точности обнаружения от скорости логического вывода, измеренной в кадрах в секунду, для исходного и модифицированного FCAF3D в сравнении с известными методами обнаружения 3D объектов.
Подробное описание
Предлагаемое изобретение относится к компьютерному зрению и представляет собой первый в своем классе полностью сверточный безъякорный метод обнаружения 3D объектов внутри помещений, названный FCAF3D. FCAF3D - это простой, эффективный и масштабируемый метод обнаружения 3D объектов из облаков точек.
Предлагается способ обеспечения компьютерного зрения робототехнического устройства. Этот способ может быть реализован в компьютерном устройстве робототехнического устройства. Робототехническое устройство содержит камеру с датчиками глубины и RGB-камеру, центральный процессор, внутреннюю память, оперативную память. Камера с датчиками глубины и RGB-камера осуществляют захват реальной сцены с 3D объектами в этой сцене. Предлагаемый метод позволяет обнаруживать и распознавать категорию и положение 3D объектов в захваченной сцене.
Предлагаемое решение спроектировано для анализа сцены и распознавания объектов. Полученные результаты могут использоваться в широком круге задач, где решения принимаются на основе сцены и ее объектов. Например, программное обеспечение, основанное на предлагаемом способе, может предоставлять мобильным робототехническим устройствам (например, мобильным роботам-навигаторам) пространственную информацию для планирования траектории, захвата объектов и манипулирования ими. Кроме того, предлагаемое решение может использоваться в мобильном приложении для автоматической генерации подсказок о сцене.
Предлагаемое решение предназначено для обнаружения и распознавания 3D объектов и оценки их пространственного положения. Формулировка задачи соответствует классической постановке задачи обнаружения 3D объектов, сформулированной научным сообществом компьютерного зрения.
Предлагаемое решение предполагается реализовать в мобильных робототехнических устройствах, имеющих компьютерное устройство. Компьютерное устройство робототехнического устройства содержит камеру с датчиками глубины и RGB-камеру, центральный процессор, внутреннюю память, оперативную память, экран.
Также изобретение может быть реализовано в смартфонах в составе мобильного приложения. Для реализации предлагаемого способа может использоваться носитель, например компьютерно-читаемый носитель. При этом компьютерно-читаемый носитель содержит программный код, который воспроизводит предлагаемый способ при реализации в компьютерном устройстве. В частности, компьютерно-читаемый носитель должен иметь достаточный объем оперативной памяти и вычислительных ресурсов. Требуемый объем ресурсов зависит от функции устройства, параметров камеры и требований к производительности.
Следует отметить, что при обнаружении 3D объектов традиционно используется предварительно определенный набор ограничивающих рамок 3D объектов, называемых якорями. Такой набор можно рассматривать как набор априорных гипотез о положении объектов в пространстве (объектов в сцене) и их размерах. Использование такого набора гипотез позволяет обнаруживать объекты в 3D пространстве путем выбора наиболее вероятных гипотез и их уточнения. Однако априорные гипотезы не всегда хорошо описывают реальные объекты в конкретной сцене, поэтому использование якорей ограничивает применимость метода обнаружения объектов. Вначале во всех методах обнаружения объектов использовались якоря. Недавно был описан новый подход, позволяющий не использовать якоря при решении задачи обнаружения объектов; это позволяет разработать более универсальное решение. За последние несколько лет сформировался целый класс методов, не использующих якоря - их можно назвать "безъякорными". Теперь они составляют конкуренцию традиционным "якорным" методам.
Предлагаемый сверточный безъякорный способ обнаружения 3D объектов внутри помещений является простым, но эффективным способом, в котором используется воксельное представление облака точек (входные данные) и применяется обработка вокселей разреженными свертками.
В соответствии с предложенным способом осуществляется захват точек Npts в цветах RGB и на выходе выдается набор ограничивающих рамок 3D объектов. Точки Npts в цветах RGB представляют собой набор из N точек, каждая из которых представлена своей координатой и цветом в предлагаемом способе, выполняемом на компьютере. Каждая точка трехмерного пространства (точка) определяется тремя координатами в пространстве, а также цветом в палитре RGB (точка в цветах RGB). Набор точек в трехмерном пространстве также называют облаком точек. Это облако из набора N точек, каждая из которых представлена своей координатой и цветом, можно получить путем обработки захваченной реальной сцены с имеющимися в ней объектами. Облако из набора N точек вводится в нейронную сеть в качестве данных. Координаты точки являются действительными числами. Воксель - это общепринятое сокращение объемного пикселя, т.е. трехмерного пикселя. Обычно "2D" пиксель в 2D изображении является базовой "ячейкой" изображения. Пиксель является элементом дискретизации изображения: изображение делится на равные секции (элементы) регулярной сеткой. Каждый такой элемент имеет форму квадрата, выровненного по сторонам изображения. По аналогии с пикселем воксель является частью трехмерного пространства, ограниченной параллелепипедом, выровненным по координатным осям и разделенным по сетке на элементы сетки. Однако воксель определяется более гибко, чем пиксель. Так, не обязательно делить пространство на элементы регулярной трехмерной сеткой: элементы сетки могут располагаться в пространстве произвольным образом. То есть, пространство делится на элементы сетки произвольно. Центр вокселя определяется путем усреднение всех координат точек из облака точек, попадающих в один элемент сетки (т.е. усредняются координаты x, координаты y и координаты z). Это значит, что каждый элемент сетки соответствует своему вокселю. В результате получается набор вокселей, такой же разреженный и нерегулярный, как и исходный набор точек в 3D пространстве.
Если воксели организованы в регулярную сетку, то говорят о воксельном объеме, а при отсутствии регулярной структуры говорят о воксельном представлении. Кроме того, воксель не обязательно имеет одинаковые пространственные размеры по всем трем осям: это может быть не куб, а произвольный параллелепипед, однако для удобства расчетов часто используются кубические воксели.
Предлагаемый метод FCAF3D способен обрабатывать крупномасштабные сцены, используя минимальное время выполнения и память, за один полностью сверточный проход с прямым распространением и не требует этапа эвристической постобработки. Существующие методы обнаружения 3D объектов используются предварительные предположения о геометрии объектов. Любые геометрические приоры ограничивают обобщающую способность метода. Вместо этого авторы изобретения предлагают новую параметризацию ориентированных ограничивающих рамок (OBB), которая позволяет получать лучшие результаты без каких-либо приоров. Предлагаемый метод обеспечивает соответствующие современному уровню результаты обнаружения 3D объектов в единицах mAP@0,5 на датасетах ScanNet V2 (+4,5), SUN RGB-D (+3,5) и S3DIS (+20,5). mAP@0,5 - это стандартный показатель для оценки качества обнаружения 3D объектов. Возможные значения mAP@0,5 находятся в диапазоне от 0 до 100. Чем выше значение mAP@0,5, тем выше качество. На датасете S3DIS FCAF3D превосходит конкурентов с огромным отрывом.
Таким образом, настоящее изобретение обеспечивает следующий вклад в современный уровень техники:
- предложен первый в своем классе полностью сверточный безъякорный способ обнаружения 3D объектов (FCAF3D) для сцен внутри помещений;
- представлена новая параметризация OBB и доказано, что она повышает точность нескольких существующих методов обнаружения 3D объектов на SUN RGB-D;
- предложенный способ существенно превосходит известный уровень техники на сложных крупномасштабных датасетах ScanNet, SUN RGB-D и S3DIS для помещений в единицах mAP, и при этом он имеет более высокую скорость логического вывода.
Задача обнаружения 3D объектов (компьютерного зрения) заключается в обнаружении и распознавании трехмерных объектов и оценке их пространственного положения в сцене. 3D объекты имеют сложную, разнообразную и иногда изменяемую форму, которую часто невозможно описать параметрически (уравнениями). Поэтому в стандартной постановке задачи обнаружения объектов форма, размеры и положение объектов моделируются простой объемной фигурой - параллелепипедом, "рамкой". Такие рамки называются 3D ограничивающими рамками. Они определяются трехмерными координатами центра рамки, а также шириной, высотой и длиной рамки. Для простоты допускается, что все такие параллелепипеды ориентированы по координатным осям трехмерного пространства, т.е. все их ребра и грани направлены по одной из осей. Иногда они решают задачу в более сложной постановке, где параллелепипеды поворачиваются в горизонтальной плоскости, тогда задача обнаружения объекта дополнительно включает определение ориентации объекта, т.е. угла поворота. Также у каждого объекта есть метка категории.
Категория объекта указывается в разметке (аннотации) датасетов. Аннотация является эталоном, достоверной информацией, содержащейся в исходных датасетах. В этом случае аннотация представляет собой набор трехмерных ограничивающих рамок объектов, при этом определенные категории объектов для каждого облака точек содержатся в датасете. Аннотацию получают с привлечением специалистов-оценщиков при создании датасета его авторами. Аннотация используется для обучения нейронной сети: чтобы научиться делать прогнозы на основе входных данных, необходимо просмотреть ряд обучающих примеров данной формы (входные данные - эталонные истинные выходные данные, содержащиеся в разметке) и найти паттерн, позволяющий установить взаимосвязь между входными и выходными данными.
Категории получают в результате экспертной оценки специалистом-оценщиком, которому на этапе сбора обучающих данных предоставляются трехмерные облака точек. Такие трехмерные облака точек получают из набора изображений RGB и их соответствующих карт глубины, т.е. измерений датчика глубины. Для разметки используется специальное программное обеспечение, позволяющее визуализировать облака точек на экране, манипулировать ими, не внося изменений в исходные данные (поворачивать, перемещать и масштабировать их для просмотра с разных сторон), путем нажатия на нужную область пространства или иного указания положения объектов в пространстве в виде охватывающих их параллелепипедов, т.е. 3D ограничивающих рамок.
Предлагаемая архитектура FCAF3D состоит из части "скелет", части "шея" и части "голова", эти термины являются общепринятыми терминами в данной области техники. Обозначения частей нейронной сети обнаружения объектов как части "скелет", "шея" и "голова" используются в статьях, описывающих такие методы обнаружения двумерных/трехмерных объектов, как FCOS, ATSS, ImVoxelNet, FCOS3D. Части "скелет", "шея" и "голова" представляют собой разреженные 3D сверточные части нейронной сети.
Под частью "скелет" нейронной сети подразумевается предварительно обученная нейронная сеть или часть предварительно обученной нейронной сети. Нейронные сети, используемые в качестве "скелета", обучаются на больших объемах визуальных данных, обычно путем решения задачи классификации изображений. В результате такого обучения они приобретают способность захватывать паттерны в визуальных данных. Эту способность можно использовать не только для решения задачи классификации изображений, но и для решения многих других задач компьютерного зрения. Стандартный подход при проектировании нейронной сети для решения задач компьютерного зрения заключается в использовании предварительно обученного "скелета", но с заменой в нем некоторых слоев, предназначенных для решения задачи классификации, другими слоями, предназначенными для решения целевой задачи.
Часть "шея" нейронной сети принимает в качестве ввода вывод "скелета" - четырехмерный тензор, и также возвращает четырехмерные тензоры.
Часть "голова" нейронной сети - это последний, заключительный слой нейронной сети для получения прогнозов положения, ориентации и категорий объектов в сцене. Часть "голова" выдает прогнозы для каждого из объектов сцены. Каждый прогноз содержит вероятность классификации объекта, параметры регрессии ограничивающей рамки объекта и центрированность объекта внутри ограничивающей рамки объекта.
Деление на части "шея" и "голова" является условным и формальным, так как каждая из этих частей состоит из сходных по типу и назначению слоев нейросети. В случае настоящего изобретения слои нейронной сети представляют собой разреженные сверточные слои.
При разработке предлагаемого FCAF3D для масштабируемости была выбрана разреженная сверточная сеть типа GSDN. Чтобы улучшить обобщение, в этой сети уменьшено количество гиперпараметров, которые необходимо настраивать вручную; в частности, упрощена обрезка разреженности в шее. Кроме того, в часть "голова" введено простое многоуровневое присвоение положения. И наконец, обсуждаются ограничения существующих параметризаций 3D ограничивающих рамок, и предлагается новая параметризация, которая повышает как точность, так и способность к обобщению.
ResNet - это семейство архитектур нейронных сетей, широко используемое для решения задач компьютерного зрения. Семейство ResNet имеет как облегченные архитектуры, так и более мощные архитектуры с большим количеством настраиваемых параметров. Облегченные архитектуры предназначены для использования в тех случаях, когда вычислительные ресурсы ограничены и/или важна скорость. Более мощные архитектуры с большим количеством настраиваемых параметров показывают лучшее качество решения целевой задачи по сравнению с облегченными. Такие мощные архитектуры выбираются в тех случаях, когда основным приоритетом является качество и имеется значительный объем вычислительных ресурсов. Все эти архитектуры устроены по одному и тому же принципу: они содержат одинаковые или похожие вычислительные блоки, определенным образом связанные между собой. В результате семейство ResNet формируется архитектурами нейронных сетей с разным количеством таких вычислительных блоков. Недавно был описан метод модификации архитектуры нейронной сети семейства ResNet, позволяющий адаптировать эту архитектуру для обработки разреженных трехмерных данных (таких как облака точек), хотя первоначальные архитектуры семейства ResNet были предназначены для обработки двумерных данных (изображений). Вычислительные блоки нейросетевой архитектуры семейства ResNet (как и любой другой нейросетевой архитектуры) состоят из слоев. В архитектуре нейронной сети семейства ResNet в вычислительных блоках присутствуют двумерные сверточные слои. Метод модификации заключается в замене всех 2D сверточных слоев на 3D сверточные слои. Если подобную модификацию применить ко всем нейросетевым архитектурам семейства ResNet, то можно получить семейство трехмерных разреженных нейросетевых архитектур семейства ResNet. Предлагаемый способ реализован в модифицированной нейронной сети семейства ResNet.
Чтобы реализовать способ компьютерного зрения, с помощью камеры с датчиками глубины и RGB-камерой захватывается реальная сцена с объектами в этой сцене. Захваченная реальная сцена представляется компьютерным устройством в виде облака из набора N точек, каждая из которых представлена своей координатой и цветом (облако точек Npts в цветах RGB). Облако из набора N точек вводится в нейронную сеть в качестве данных.
Датчик глубины (камера глубины) измеряет расстояние до точек в сцене и выдает результаты измерений в виде плотной двумерной карты, каждый пиксель которой содержит расстояние от камеры глубины до некоторой точки в сцене. Далее необходимо определить, как соотносятся координаты пикселей на карте глубины и координаты точек в трехмерном пространстве, иначе говоря, определить, как карта глубины преобразуется в трехмерное пространство. Для этого необходимо знать параметры камеры глубины, которые определяют тип данного дисплея. Параметры камеры явно указаны в наборах данных, используемых для экспериментов в данной работе. В реальных условиях применения предлагаемого способа обнаружения 3D объектов параметры камеры могут оцениваться отдельно любым способом оценки параметров камеры (это стандартная процедура, также известная как калибровка камеры), либо задаваться непосредственно в явном виде, например, как характеристики конкретной модели камеры глубины.
Реальная сцена с объектами в ней захватывается камерой с датчиками глубины и RGB-камерой в виде набора N точек, каждая из которых дополнительно представлена своей координатой и цветом. Для этого требуется, чтобы пиксели изображения RGB и пиксели карты глубины отображались в одни и те же точки в 3D пространстве. Соответственно, необходимо согласовать пиксели RGB-изображения с пикселями карты глубины. Для этого пиксели карты глубины отображаются в 3D пространстве (с использованием настроек камеры глубины), а затем проецируются на плоскость изображения (с использованием настроек RGB-камеры). Результатом этой процедуры является карта глубины, попиксельно выровненная с изображением RGB. Каждой точке в 3D пространстве, отображенной из пикселя карты глубины, присваиваются значения RGB, которые были записаны в пикселе изображения RGB, соответствующем данному пикселю карты глубины.
Выше была описана процедура получения облака точек из одного изображения RGB и одной карты глубины. Измерения любого датчика глубины неточны. Однако точность измерений можно повысить при наличии нескольких измерений области 3D пространства, полученных из разных точек. В этом случае можно агрегировать информацию из нескольких измерений и тем самым скорректировать измерения на отдельных картах глубины или, например, выделить некоторые измерения как случайные выбросы, обусловленные несовершенством измерительного прибора, и удалить эти выбросы. Также такая агрегация измерений позволяет повысить согласованность измерений в одной 3D сцене и получить не набор отдельных облаков точек для каждого RGB-изображения и карты глубины, а одно облако точек, полностью описывающее всю сцену. Разработан ряд методов агрегирования RGB-изображений и карт глубины, они включают в себя методы одновременной локализации и построения карты (SLAM), методы интегрирования усеченной функции расстояния со знаком (TSDF) и другие методы. Захваченное облако точек Npts в цветах RGB вводится в нейронную сеть.
Нейронная сеть состоит из слоев, каждый из которых принимает в качестве ввода тензор, вычисляет на нем функцию, и возвращает результат, также являющийся тензором. Слои могут быть последовательными и/или параллельными. Метод "сборки" слоев в нейронную сеть также называют архитектурой нейронной сети.
На фиг. 1 показаны слои нейронной сети. Облако точек Npts в цветах RGB вводится в слои нейронной сети; на фиг. 1 сверточный слой обозначен как "Conv0", этот слой вычисляет функцию, называемую "сверткой" (обычный математический термин). Слой объединения обозначен как "Объединение" на фиг. 1, слой объединения вычисляет локальный максимум. Результатом "Conv0" и "Объединения" является разреженный 3D тензор.
Разреженная нейронная сеть для предлагаемого способа FCAF3D показана на фиг. 1. Далее описывается ее работа.
Часть "скелет"
Часть "скелет" в FCAF3D представляет собой разреженную модификацию ResNet [11], в которой все 2D свертки заменены 3D разреженными свертками. Семейство разреженных многомерных версий ResNet впервые было представлено в [5], для краткости авторы называют их HDResNet.
Часть "скелет" реализует следующее:
представление облака точек в виде объемного пиксельного (воксельного) представления входных данных, облако точек Npts в цветах RGB представляется как воксельное представление в слоях "Conv0" и "Объединение";
обработку объемного пиксельного представления входных данных с получением четырехмерных тензоров остаточными блоками.
Как следует из фиг. 1, блок 1, блок 2, блок 3, блок 4 - это остаточные блоки. Остаточный блок - это вычислительная единица архитектуры нейронной сети семейства ResNet. Она состоит из нескольких слоев различного типа: сверточных слоев, слоев, выполняющих нормализацию внутри минипакета, слоя активации. Отличительным признаком этого вычислительного блока является специально организованная связь между слоями, называемая пропускным соединением, или остаточным соединением (что и дало название как вычислительному блоку - остаточный блок, так и семейству нейросетевых архитектур ResNet - остаточные сети).
Остаточные блоки - это пропускные блоки, которые изучают остаточные функции на основании вводов в слои вместо изучения несвязанных функций. Они были представлены как часть архитектуры ResNet. Формально, обозначая желаемое базовое отображение как H(x), авторы позволяют расположенным в стеке нелинейным слоям соответствовать другому отображению H(x) - x. Исходное отображение преобразуется в F(x) + x. F(x) действует как остаток, отсюда и название "остаточный блок". Интуиция подсказывает, что легче оптимизировать остаточное отображение, чем исходное несвязанное отображение. В крайнем случае, если бы отображение идентичности было оптимальным, было бы легче подтолкнуть остаток к нулю, чем соответствовать отображению идентичности стеком нелинейных слоев. Наличие пропускных соединений облегчает изучение сетью подобных идентичности отображений.
Часть "шея"
Признаки объектов сцены, выраженные в числовой форме, извлекаются из разных слоев "скелета" с помощью части "шея". Часть "шея" обрабатывает четырехмерные тензоры из части "скелет", чтобы извлечь выраженные в числовой форме признаки объектов сцены. Под признаками подразумеваются описания, представления, дескрипторы объектов в формате, с которым может работать компьютерное устройство, т.е. в числовой форме, в виде набора чисел. Эти числа могут быть организованы в виде многомерных матриц, т.е. тензоров.
Значения этих чисел трудно интерпретировать, они не являются наглядными: в общем, невозможно указать конкретное число и утверждать, что оно кодирует определенное свойство объекта. Согласно этому формату, признаки, извлеченные "шеей", являются четырехмерными тензорами.
Предлагаемая часть "шея" является упрощенным декодером GSDN. Признаки на каждом слое части "шея" обрабатываются посредством одной операции разреженной транспонированной 3D свертки и одной операции 3D разреженной свертки.
Каждая операция транспонированной 3D разреженной свертки с размером ядра 2 может увеличить количество ненулевых значений в 23 раза. Чтобы предотвратить быстрое увеличение объема памяти, GSDN использует слой обрезки, который фильтрует ввод с помощью маски вероятности.
В GSDN вероятности на уровнях признаков рассчитываются с помощью дополнительного сверточного слоя оценки. Этот слой обучается со специальной потерей, обеспечивающей согласованность между прогнозируемой разреженностью и якорями. В частности, разреженность вокселей устанавливается положительной, если любой из последующих якорей, связанных с текущим вокселем, является положительным. Однако использование этой потери может быть неоптимальным, так как удаленные воксели объекта могут присваиваться с низкой вероятностью.
Для простоты слой оценки с соответствующей потерей удален и вместо него используются вероятности из слоя классификации в "голове". Порог вероятности не настраивается, но поддерживается на большинстве вокселей Nvox для управления уровнем разреженности, где Nvox равно количеству входных точек Npts. Это простой, но изящный способ предотвратить рост разреженности, поскольку повторное использование одного и того же гиперпараметра делает этот процесс более прозрачным и последовательным.
Как следует из фиг. 1, каждый из слоев Conv1, Conv2, Conv3, Conv4 является сверточным слоем. Сверточные слои нейронной сети сворачивают ввод и передают результат следующему слою. Каждый сверточный нейрон обрабатывает данные только для своего рецептивного поля. Сверточные нейронные сети широко используются для обработки данных с топологией типа сетки (например, изображений), поскольку свертка учитывает пространственные отношения между отдельными признаками.
Сверточные слои нейронной сети осуществляют свертку ввода и передают результат следующему слою. Каждый сверточный слой обрабатывает данные только для своего рецептивного поля. Сверточные нейронные сети широко используются для обработки данных с топологией типа сетки (например, изображений), поскольку свертка учитывает пространственные отношения между отдельными объектами.
Как следует из фиг. 1, TransConv1, TransConv2, TransConv3 являются транспонированными сверточными слоями. Транспонированный сверточный слой - это стандартный транспонированный сверточный слой. Он принимает тензор в качестве ввода, вычисляет на нем функцию свертки, и возвращает результат свертки, также являющийся тензором. У него есть параметры - так называемое ядро свертки, настраиваемое во время обучения нейронной сети. По сути, это сверточный слой, но он способен увеличивать размерность входного тензора путем, увеличивая его разреженность или дублируя значения.
Как следует из фиг. 1, "обрезка" - это слой обрезки. Слой обрезки - это нестандартный слой, используемый в GSDN. Он принимает разреженный 3D тензор и фильтрует его с помощью вероятностной маски. Вероятности на уровне признаков рассчитываются с помощью дополнительного сверточного слоя оценки.
Общая часть "голова". Часть "голова" безъякорного FCAF3D состоит из трех параллельных разреженных сверточных слоев (см. фиг. 1) с общими весами для уровней признаков.
Извлеченные признаки, полученные на предыдущем этапе, обрабатываются 3D разреженной сверточной "головой" с весами, общими для разных уровней признаков. "Голова" обеспечивает обработку извлеченных признаков объектов сцены для получения прогнозов положений, ориентаций и категорий объектов в сцене, при этом "голова" выводит прогнозы для каждого из объектов сцены. Прогноз включает в себя вероятность классификации объекта, параметры регрессии ограничивающей рамки объекта и центрированность объекта внутри ограничивающей рамки объекта. Полученные прогнозы фильтруются путем сравнения прогнозов по вероятности классификации объекта, чтобы выбрать наиболее вероятный прогноз. Выбор наиболее вероятного прогноза рассматривается как окончательная оценка положения, ориентации и категории объекта в сцене и характеризуется данными положения, ориентации и категории объекта в сцене. Такое числовое представление сцены используется робототехническим устройством.
В любой момент вычислений внутри нейронной сети происходит обработка набора координат точек в трехмерном пространстве. На вход подается набор координат точек, на входе и выходе каждого слоя нейронной сети имеются данные, представленные в виде трехмерных разреженных тензоров. Все точки находятся в одном и том же 3D пространстве. Но количество точек и координаты точек изменяются в процессе вычислений. Положения - это координаты точек, которые появляются в процессе вычислений. Они не являются точно теми же координатами точек, которые поступили как ввод, но они находятся где-то между координатами входных точек, примерно в той же области пространства.
Система координат (координатная сетка) определяется через координаты точек в трехмерном пространстве и разметку ограничивающих рамок объектов: все координаты определяются в некоторой системе координат. В этой системе координат ось y должна иметь одинаковое направление с вектором силы тяжести, в этом случае трехмерные ограничивающие рамки объектов вида OBB и AABB будут располагаться горизонтально. AABB - это сокращение от Axis-Aligned Bounding Box (ограничивающая рамка выровнена по координатным осям). Это общий термин для 3D ограничивающей рамки какого-либо объекта, все ребра и плоскости которого направлены по координатным осям 3D пространства. OBB - это сокращение от Oriented Bounding Box (ориентированная ограничивающая рамка). Это общий термин для 3D ограничивающей рамки объекта определенного вида, расположенного горизонтально в пространстве и произвольно повернутого в горизонтальной плоскости.
Для каждого положения  три параллельных разреженных сверточных слоя "головы" этой архитектуры выводят вероятности
три параллельных разреженных сверточных слоя "головы" этой архитектуры выводят вероятности  классификации, параметры δ регрессии ограничивающей рамки и центрированность
классификации, параметры δ регрессии ограничивающей рамки и центрированность  , соответственно. Эта схема подобна простой и облегченной "голове" FCOS [26], но адаптирована для 3D данных.
, соответственно. Эта схема подобна простой и облегченной "голове" FCOS [26], но адаптирована для 3D данных.
Вероятности классификации означают, что для каждой категории объекта (стол, стул, и т.д.) оценивается вероятность того, что данное положение находится внутри трехмерной ограничивающей рамки объекта этой категории ("данная точка принадлежит объекту этой категории").
Что касается параметров регрессии ограничивающей рамки, то здесь необходимо уточнить, что все существующие методы обнаружения 3D объектов не дают прямого прогноза 3D ограничивающей рамки объекта в явном виде. Обычно вместо этого оцениваются параметры 3D ограничивающей рамки, зависящие от положения: например, расстояния от данного положения до 6 граней 3D ограничивающей рамки. Ограничивающая рамка - это 3D ограничивающая рамка объекта.
Центрированность 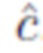 описывает близость положения к центру эталонной (истинной) 3D ограничивающей рамки объекта, в которую попадает это положение. Центрированность - это относительная величина, которая может принимать значения от 0 до 1; чем ближе к центру, тем больше значение и тем ближе оно к 1.
описывает близость положения к центру эталонной (истинной) 3D ограничивающей рамки объекта, в которую попадает это положение. Центрированность - это относительная величина, которая может принимать значения от 0 до 1; чем ближе к центру, тем больше значение и тем ближе оно к 1.
Иными словами, часть "голова" возвращает вероятности классификации, параметры регрессии ограничивающей рамки, оценку центрированности для каждого положения.
Как следует из фиг. 1, часть "голова" относится к сверточному слою. При этом часть "голова" содержит слои регрессии, центрированности, классификации. Для каждого положения слой классификации выводит вероятности классификации, слой регрессии выводит параметры δ регрессии ограничивающей рамки, а слой центрированности выводит оценку центрированности , соответственно.
Как следует из фиг. 1, "Объединение" относится к слою объединения. Слой объединения - это слой, который вычисляет локальный максимум или локальный средний стандартный слой. Слой объединения принимает тензор на входе, возвращает пространственно упорядоченный набор локальных максимумов/локальных средних значений этого тензора, который также является тензором.
Слои объединения уменьшают размерность данных, объединяя выходы кластеров нейронов на одном слое в один нейрон на следующем слое. Локальное объединение объединяет небольшие кластеры, обычно используются тайлы размером 2×2. Глобальное объединение действует на все нейроны карты признаков. Широко используются два распространенных типа объединения: максимальное и среднее. Максимальное объединение использует максимальное значение каждого локального кластера нейронов на карте объектов, а среднее объединение использует среднее значение.
Во время обучения FCAF3D выводит положения для различных уровней признаков, которые должны быть присвоены истинным рамкам {b}.
На вход поступают точки Npts в цветах RGB, а выходе выдаются вероятность классификации объектов, параметры регрессии ограничивающей рамки, показатель центрированности для каждого положения (то есть для некоторого набора точек в 3D пространстве). На этапе тестирования из вероятностей классификации, параметров регрессии ограничивающей рамки, показателя центрированности вычисляются 3D ограничивающие рамки объектов. Примеры таких 3D ограничивающих рамок представлены на фиг. 3. Прогнозы положения, ориентации объекта в пространстве, а также его категории доступны в числовом представлении, представляющем компьютерное зрение для робототехнического устройства, и могут использоваться им в соответствии с поставленной задачей. Также реализуется способ визуализации прогнозов, полученных с помощью предлагаемого способа. Пользователь может видеть изображение сцены с размещенными в ней 3D ограничивающими рамками объектов. Эти 3D ограничивающие рамки окрашены по-разному, чтобы кодировать различные категории объектов. Цветовое кодирование фиксированное (один и тот же цвет всегда соответствует одной и той же категории) и произвольное.
В методе обнаружения 3D объектов ImVoxelNet выходные положения (локации) прогнозируются на трех уровнях, и для уровня заранее определены максимальные расстояния от положения до краев 3D ограничивающей рамки объекта, которые могут быть присвоены этому положению. Для трех масштабов установлены пороги 75 см, от 75 см до 1,5 м и более 1,5 м, соответственно.
Настоящее изобретение предлагает упрощенную стратегию для разреженных данных, которая не требует настройки гиперпараметров, специфичных для набора данных. Для каждой ограничивающей рамки (примеры 3D ограничивающих рамок объектов показаны на фиг. 3) выбирается последний уровень признака, на котором эта ограничивающая рамка покрывает по меньшей мере Nloc положений. Если такого уровня признака нет, выбирается первый. Положения фильтруются путем выборки по центру [26], учитывая только точки рядом с центром ограничивающей рамки как положительные совпадения.
Путем присвоений некоторые положения  спариваются с ограничивающими прямоугольниками
спариваются с ограничивающими прямоугольниками 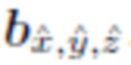 . - это эталонная (истинная) 3D ограничивающая рамка объекта, ассоциированная с положением . Эталонные ограничивающие рамки объекта содержатся в разметке набора данных или могут быть получены непосредственно из этой разметки.
. - это эталонная (истинная) 3D ограничивающая рамка объекта, ассоциированная с положением . Эталонные ограничивающие рамки объекта содержатся в разметке набора данных или могут быть получены непосредственно из этой разметки.
Соответственно, эти положения ассоциируются с истинными метками 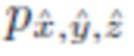 и значениями
и значениями  3D центрированности.
3D центрированности.
 (истинные метки) означают эталонные категории объектов, которые известны или могут быть непосредственно получены для каждой ограничивающей рамки объекта из разметки набора данных.
(истинные метки) означают эталонные категории объектов, которые известны или могут быть непосредственно получены для каждой ограничивающей рамки объекта из разметки набора данных.
 (3D центрированность) означает центрированность. Центрированность описывает близость какого-либо положения к центру эталонной (истинной) 3D ограничивающей рамки объекта, в который попадает это положение. Центрированность - это относительная величина, которая может принимать значения от 0 до 1; чем ближе к центру, тем больше значение и тем ближе оно к 1.
(3D центрированность) означает центрированность. Центрированность описывает близость какого-либо положения к центру эталонной (истинной) 3D ограничивающей рамки объекта, в который попадает это положение. Центрированность - это относительная величина, которая может принимать значения от 0 до 1; чем ближе к центру, тем больше значение и тем ближе оно к 1.
Во время логического вывода оценки  умножаются на 3D центрированность
умножаются на 3D центрированность 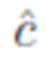 непосредственно перед NMS, как предложено в [24].
непосредственно перед NMS, как предложено в [24].
Общая функция потерь формулируется следующим образом:

В данном случае количество согласованных положений Npos равно  . Потеря классификации Lcls представляет собой фокальную потерю, потеря регрессии Lreg представляет собой IoU, а потеря центрированности Lcntr представляет собой бинарную кросс-энтропию. Для каждой потери прогнозируемые значения обозначены крышечкой.
. Потеря классификации Lcls представляет собой фокальную потерю, потеря регрессии Lreg представляет собой IoU, а потеря центрированности Lcntr представляет собой бинарную кросс-энтропию. Для каждой потери прогнозируемые значения обозначены крышечкой.
Потеря классификации Lcls представляет собой фокальную потерю, потеря регрессии Lreg представляет собой IoU, а потеря центрированности Lcntr представляет собой бинарную кросс-энтропию. Фокальная потеря, IoU, бинарная кросс-энтропия - это общие термины для различных штрафных функций, используемых для обучения нейронных сетей.
Параметризация ограничивающей рамки (на фиг. 3 для наглядности показан пример 3D ограничивающих рамок объектов).
3D ограничивающие рамки объектов могут быть выровненными по координатным осям (AABB) или ориентированными (OBB).
Следовательно, AABB горизонтальный и не повернут, а OBB горизонтальный и повернут произвольным образом. AABB может определяться центральной точкой (3 координаты), длиной, шириной и высотой. Для OBB также необходимо установить угол поворота в горизонтальной плоскости - путевой угол θ.
AABB можно описать как  , тогда как описание OBB включает в себя путевой угол θ: bOBB=(x, y, z, w, l, h, θ). В обеих формулах x, y, z обозначают координаты центра ограничивающей рамки, а w, l, h - его ширину, длину и высоту, соответственно.
, тогда как описание OBB включает в себя путевой угол θ: bOBB=(x, y, z, w, l, h, θ). В обеих формулах x, y, z обозначают координаты центра ограничивающей рамки, а w, l, h - его ширину, длину и высоту, соответственно.
Параметризация AABB. Параметризация для AABB была предложена в [24]. В частности, для истинного AABB (x, y, z, w, l, h) и положения  δ можно сформулировать как набор из 6 элементов:
δ можно сформулировать как набор из 6 элементов:
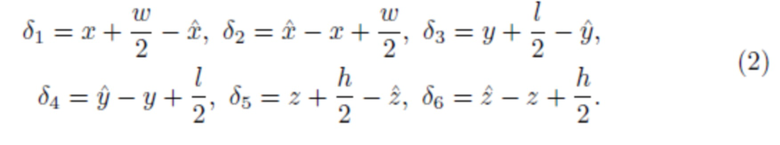
Спрогнозированный AABB  может быть тривиально получен из δ.
может быть тривиально получен из δ.
Путевой угол - это угол поворота 3D ограничивающей рамки объекта в горизонтальной плоскости, который определяет ориентацию объекта ("куда обращен объект"). Это один из параметров, который определяет ориентированная 3D ограничивающая рамка OBB (определение OBB включает путевой угол θ).
Все современные методы обнаружения 3D объектов из облаков точек решают задачу оценки путевого угла как классификацию с последующей регрессией. Путевой угол разбивается на бины; затем точный путевой угол регрессируется в бине. Для сцен в помещении диапазон от 0 до 2π обычно делится на 12 равных бинов [22], [21], [33], [19]. Для сцен вне помещения обычно используется всего два бина [30], [13], так как объекты на дороге могут быть либо параллельны, либо перпендикулярны дороге.
Оценка значения путевого угла осуществляется в два этапа. Сначала делается приблизительная оценка: определяется диапазон значений, в которые попадает данный путевой угол. Затем на втором этапе уточняется значение путевого угла в этом интервале. Эти интервалы называются бином.
После выбора бина путевого угла оценивается значение путевого угла посредством регрессии. VoteNet и другие методы на основе голосования прямо оценивают значение θ. Методы для использования вне помещения исследуют более сложные подходы, например, прогнозирование значений тригонометрических функций. Например, SMOKE [17] оценивает sin θ и cos θ и использует предсказанные значения для восстановления путевого угла.
На фиг. 2 изображены объекты в помещении, где путевой угол имеет точно выраженное значение. На фиг. 2 приведены примеры объектов, которые одинаково выглядят с нескольких сторон: квадратный стол, круглый стол, еще один круглый стол.
Следует отметить, что путевой угол - это угол поворота 3D ограничивающей рамки 3D объекта в горизонтальной плоскости, который определяет ориентацию объекта ("куда обращен объект"). Один из параметров, который определяет ориентированная 3D ограничивающая рамка истинного угла OBB - это угол, характеризующий эталонные, истинные значения любого из параметров объекта, оцениваемых данным методом. Желательно, чтобы значения параметров, оцениваемых данным методом (прогнозируемых, оцениваемых, выдаваемых методом), были максимально приближены к истинным значениям параметров объекта. В данном контексте истинный угол следует понимать, как истинный путевой угол, т.е. эталонное, истинное значение путевого угла, заранее известное из маркировки набора данных.
Соответственно, аннотации истинного угла можно выбирать для этих объектов произвольно, что делает классификацию бинов путевого угла бессмысленной. Чтобы избежать выбраковки корректных прогнозов, не совпадающих с аннотациями, используется повернутая потеря IoU, так как ее значение одинаково для всех возможных вариантов выбора путевого угла. Следовательно, предлагается параметризация OBB, учитывающая неоднозначность поворота. Следует уточнить, что не всегда можно однозначно определить ориентацию предмета, так как некоторые предметы выглядят одинаково с нескольких сторон: например, круглая табуретка, круглый стол, квадратный стол, см. фиг. 2. Поэтому любое значение путевого угла, принятое в качестве эталона, будет выбрано до некоторой степени случайно. Это называется неоднозначностью поворота.
Параметризация для OBB основана на отображении ленты Мебиуса, поэтому авторы говорят о параметризации Мебиуса OBB.
Рассматривая OBB с параметрами (x, y, z, w, l, h, θ), обозначим q=w/l. Если x, y, z, w+l, h постоянные, то оказывается, что OBB с
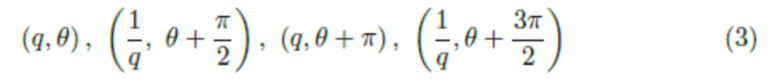
определяют одну и ту же ограничивающую рамку. Набор (q, θ), где θ ∈ (0, 2π], q ∈ (0,+inf), топологически эквивалентен ленте Мебиуса [20] с точностью до этого отношения эквивалентности. Следовательно, авторы могут переформулировать задачу оценки (q, θ) как задачу прогнозирования точки на ленте Мебиуса. Естественным способом вложения ленты Мебиуса, являющейся двумерным многообразием, в евклидово пространство является:
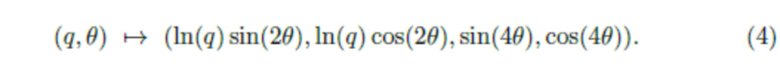
Легко проверить, что четыре точки из уравнения 3 отображаются в евклидовом пространстве в одну точку. Однако эксперименты показывают, что прогнозирование только ln(q)sin(2θ) и ln(q)cos(2θ) дает лучшие результаты, чем прогнозирование всех четырех значений. Поэтому авторы сделали выбор в пользу псевдовложения ленты Мебиуса в R2. Оно называется "псевдо", поскольку отображает всю центральную окружность ленты Мебиуса, определяемую ln(q)=0 до (0,0). Соответственно, невозможно различить точки с In <7=0. Однако In(q)=0 подразумевает строгое равенство w и I, что редко встречается в реальных сценариях. Кроме того, выбор угла мало влияет на IoU, если w=l; поэтому этот редкий случай игнорируется ради точности обнаружения и простоты метода. В итоге, получена новая параметризация OBB:

В стандартной параметризации уравнения 2  тривиально выводится из δ. В предложенной параметризации w, l, θ нетривиальны и могут быть получены следующим образом:
тривиально выводится из δ. В предложенной параметризации w, l, θ нетривиальны и могут быть получены следующим образом:

где отношение 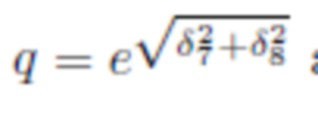 и размер
и размер  .
.
И наконец, данные положения, ориентации и категории объекта в сцене выводятся из нейронной сети в виде числового представления сцены. Числовое представление сцены представляется в виде изображения сцены.
Робототехнические устройства могут использовать положение, ориентацию и категорию объектов в числовом представлении для планирования путей внутри сцены, позволяющих обойти эти объекты. Категории объектов могут использоваться для манипулирования только объектами, принадлежащими к требуемым категориям, например, для загрузки и транспортировки требуемых объектов в соответствии с инструкциями пользователя, для чистки предметов мебели заданных категорий и т.п.
Положение, ориентация и категория объектов в числовом представлении могут использоваться для автоматического предоставления статистики об объектах, присутствующих в сцене, например, для отслеживания количества имеющихся в настоящее время товаров в торговой зоне или для создания текстового описания данной сцены в приложениях-помощниках, например, для помощи незрячим людям.
Числовое представление сцены может быть преобразовано (с помощью известных методов) в изображение сцены, при этом компьютерное устройство дополнительно содержит экран, и изображение сцены отображается на экране для пользователя.
Изображение сцены может использоваться для наглядной демонстрации результатов применения предлагаемого метода человеку в приложениях искусственной реальности (AR), в приложениях для мониторинга или учета объектов и т.д. Потребителем результатов в виде изображений является человек.
Положение, ориентация и категория объектов в представлении изображения могут использоваться в AR для предоставления пользователю информации об объектах, присутствующих в сцене, и для дополнения захваченного изображения сцены сгенерированной аннотацией объектов, присутствующих в сцене.
Эксперименты
Предлагаемый способ оценивался на трех бенчмарках для обнаружения 3D объектов: ScanNet V2 [7], SUN RGB-D [25] и S3DIS [1]. Для всех датасетов в качестве метрики использовалась именованная средняя точность (mAP) при пороговых значениях IoU, равных 0,25 и 0,5.
Датасет ScanNet содержит 1513 реконструированных 3D сканов в помещении с поточечными частными и семантическими метками 18 категорий объектов. При наличии такой аннотации AABB вычисляется по стандартному принципу [22]. Обучающее подмножество состоит из 1201 сканов, а 312 сканов оставлены для проверки.
SUN RGB-D - это датасет для понимания монокулярных 3D сцен, содержащий более 10 000 изображений RGB-D внутри помещений. Аннотация состоит из поточечных семантических меток и OBB 37 категорий объектов. Как предложено в [22], эксперименты проводились с объектами 10 наиболее распространенных категорий. Части, выделенные для обучения и проверки, содержат 5285 и 5050 облаков точек, соответственно.
S3DIS. Датасет Stanford Large-Scale 3D Indoor Spaces содержит 3D сканы 272 комнат из 6 зданий с 3D частными и семантическими аннотациями. Следуя [10], предлагаемый метод оценивался на категориях мебели. AABB получены из 3D семантики. Использовалось официальное разделение, в котором 68 комнат из зоны 5 были предназначены для проверки, а остальные 204 комнаты составили обучающее подмножество.
Для всех датасетов использовались одни и те же гиперпараметры, за исключением следующего. Во-первых, размер выходного слоя классификации был равен количеству категорий объектов, которое составляло 18, 10 и 5 для ScanNet, SUN RGB-D и S3DIS.
Во-вторых, SUN RGB-D содержит OBB, поэтому для этого датасета прогнозировались дополнительные цели δ7 и δ8; следует отметить, что функция потерь не затрагивалась. И наконец, ScanNet, SUN RGB-D и S3DIS содержат различное количество сцен, поэтому каждая сцена повторялась 10, 3 и 13 раз за эпоху, соответственно.
Подобно GSDN [10], в качестве "скелета" использовалась разреженная 3D модификация ResNet34, названная HDResNet34. Часть "шея" и часть "голова" использовали выводы части "скелет" на всех уровнях признаков. В исходной вокселизации облака точек были установлены размер вокселя 0,01 м и количество точек Npts 100000. Соответственно, Nvox равно 100000. Как ATSS [32], так и FCOS [26] устанавливают Nloc равным 32 для обнаружения 2D объектов. Соответственно, был выбран такой уровень признаков, при котором ограничивающая рамка покрывает по меньшей мере Nloc=33 положения. 18 положений было получено выборкой по центру. Порог NMS IoU равен 0,5.
Обучение. Был реализован метод FCAF3D с использованием фреймворка MMdetection3D [6]. Процедура обучения соответствовала стандартной схеме MMdetection [3]: обучение занимало 12 эпох, и скорость обучения снижалась на 8-й и 11-й эпохах. Использовался оптимизатор Адама с начальной скоростью обучения 0,001 и снижением веса 0,0001. Все нейронные сети обучались на двух NVidia V100 с размером пакета 8. Оценка и тесты производительности выполнялись на одной NVidia GTX1080Ti.
В настоящем изобретении используется протокол оценки, представленный в [16]. Обучение и оценка рандомизированы, так как входные Npt выбираются из облака точек произвольно. Для получения статистически значимых результатов обучение проводят 5 раз и каждую обученную нейронную сеть тестируют независимо 5 раз.
Сообщаются как лучшие, так и средние метрики для 5×5 тестов: это позволяет сравнивать FCAF3D с методами обнаружения 3D объектов, которые сообщают либо об одном лучшем, либо о среднем значении.
Был реализован метод FCAF3D с использованием фреймворка MMdetection3D [6].
Процедура обучения соответствовала стандартной схеме MMdetection [3]: обучение занимало 12 эпох, и скорость обучения снижалась на 8-й и 11-й эпохах.
Использовался оптимизатор Адама с начальной скоростью обучения 0,001 и снижением веса 0,0001. Все нейронные сети обучались на двух NVidia V100 с размером пакета 8. Оценка и тесты производительности выполнялись на одной NVidia GTX1080Ti.
Результаты
Сравнение с современными методами
В таблице 1 FCAF3D сравнивается с известными современными методами на трех бенчмарках для помещений.
В таблице 1 представлены результаты FCAF3D и существующих методов обнаружения 3D объектов внутри помещений, которые принимают облака точек. Лучшие значения метрик выделены жирным шрифтом. FCAF3D превосходит предыдущие современные методы: GroupFree (на ScanNet и SUN RGB-D) и GSDN (на S3DIS). Сообщаемое значение метрики является лучшим для 25 тестов; в скобках указано среднее значение.
Таблица 1
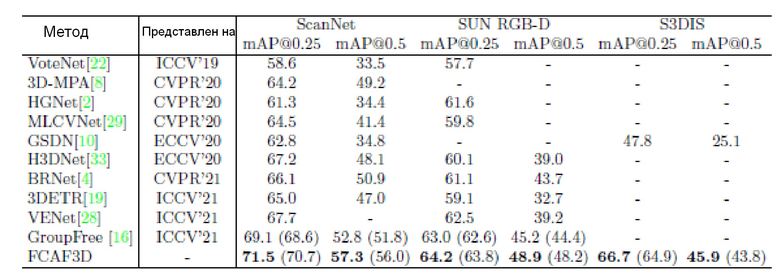
Предлагаемый метод оценивался на датасетах ScanNet [7], SUN RGB-D [25] и S3DIS [1] и продемонстрировал убедительное превосходство над известным уровнем техники на всех бенчмарках (среднее значение приведено в скобках). На SUN RGB-D и ScanNet предлагаемый метод превосходит другие методы по меньшей мере на 3,5% mAP@0,5. На датасете ScanNet предлагаемый метод обнаружения 3D объектов на 4,5 пункта выше, чем лучший конкурирующий метод обнаружения 3D объектов. На датасете SUN RGB-D он выше на 3,5 пункта. На датасете S3DIS он выше на 20,5 пункта. Такие же отличные результаты можно увидеть для стандартной метрики оценки качества mAP@0,25.
На фиг. 3 представлен пример облаков точек ScanNet с прогнозируемыми ограничивающими рамками. На фиг. 3 изображено облако точек из ScanNet с AABB. Цвет ограничивающей рамки обозначает категорию объекта. Слева: оценка по предложенному методу (FCAF3D), справа - истина. Каждая категория объектов имеет свой цвет ограничивающей рамки. Категории имеют цветовую кодировку, а именно: синий (обозначен как C) - стул, оранжевый (обозначен как O) - стол, зеленый (обозначен как G) - дверь, красный (обозначен как R) - шкаф. Можно заметить, что 3D ограничивающие рамки, спрогнозированные предложенным методом (слева), аналогичны истинным ограничивающим рамкам (справа). Этот результат наглядно иллюстрирует именно предлагаемый метод.
Аналогичные результаты были получены для облака точек из SUN RGB-D с OBB, а также для облака точек из S3DIS с AABB.
Для изучения геометрических приоров обучались и оценивались существующие методы с предлагаемыми модификациями. Проводились эксперименты с методами обнаружения 3D объектов, принимающими данные различных модальностей: облака точек, изображения RGB или и то, и другое, чтобы увидеть, заменили ли в FCAF3D вышеупомянутые потери повернутыми потерями IoU с параметризацией Мебиуса по уравнению 5. Для получения полной картины использовалась параметризация sin-cos, используемая в методе обнаружения 3D объектов вне помещений SMOKE [17].
Повернутая потеря IoU уменьшает количество обучаемых параметров и гиперпараметров, включая геометрические приоры и веса потерь. Эта потеря уже использовалась при обнаружении 3D объектов вне помещений [34]. Недавно в работе [6] сообщалось о результатах обучения VoteNet с выровненными по осям координат потерями IoU на ScanNet.
В таблице 2 показано, что замена стандартной параметризации на параметризацию Мебиуса повышает mAP@0,5 VoteNet и ImVoteNet примерно на 4%.
В ImVoxelNet не используется схема "классификация + регрессия" для оценки путевого угла, а прогнозируется его значение напрямую за один шаг. Поскольку исходный ImVoxelNet использует повернутые потери IoU, авторам потребовалось только изменять параметризацию без необходимости удаления избыточных потерь. И снова параметризация Мебиуса помогла получить лучшие результаты, хотя это превосходство незначительно.
Таблица 2
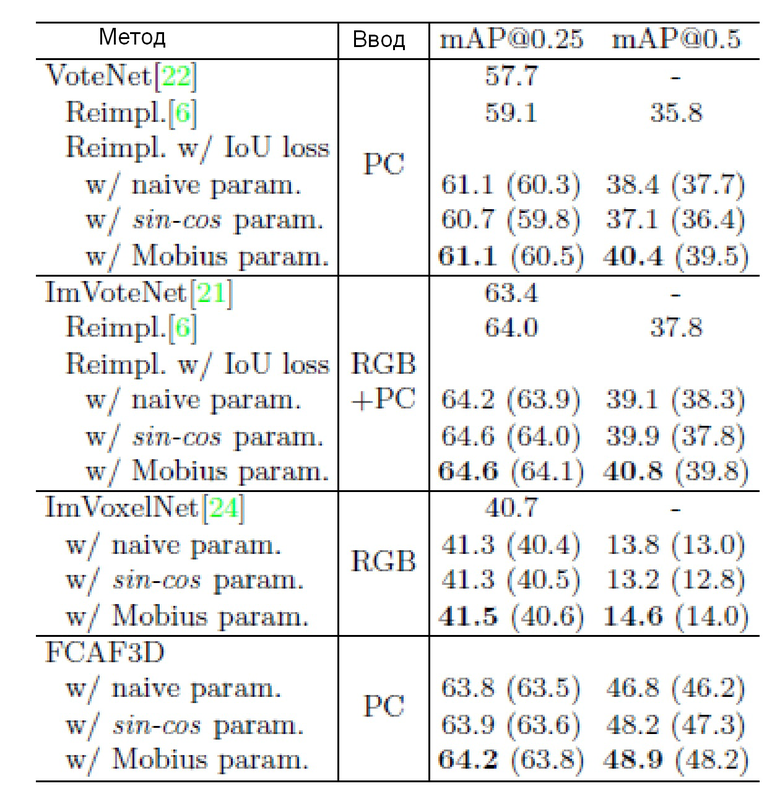
Таблица 2 иллюстрирует результаты нескольких методов обнаружения 3D объектов, принимающих на входе различные модальности, с различной параметризацией OBB на SUN RGB-D. Значение метрики FCAF3D является лучшим для 25 тестов; среднее значение указано в скобках. Для других методов представлены результаты из оригинальных статей, а также результаты, полученные в ходе предлагаемых экспериментов с повторными внедрениями (обозначены как Reimpl) на основе MMdetection3D. "РС" - облако точек. "RGB" - изображение RGB или набор изображений RGB. "RGB+PC" - изображение RGB и облако точек или набор изображений RGB и облако точек. VoteNet - основанный на голосовании метод обнаружения 3D объектов, который принимает облако точек в цветах RGB. ImVoteNet - основанный на голосовании метод обнаружения 3D объектов, который принимает изображение RGB и облако точек или набор изображений RGB и облако точек. ImVoxelNet - метод обнаружения 3D объектов, который принимает изображение RGB или набор изображений RGB. "Reimpl." означает повторное внедрение. VoteNet и ImVoteNet были повторно внедрены для экспериментов, поскольку исходный код этих методов не был опубликован. Приводятся как результаты, представленные в оригинальных статьях, так и результаты, полученные с помощью повторно внедренных методов. Эти результаты доказывают правильность повторного внедрения и обеспечивают точность, сравнимую с точностью, указанной в исходных статьях.
“w/naive param.” означает наивную параметризацию OBB, где каждый параметр OBB оценивается напрямую. Эта параметризация используется в оригинальном VoteNet.
“w/sin-cos param.” означает параметризацию sin-cos OBB. Параметризация sin-cos сформулирована в методе SMOKE обнаружения 3D объектов вне помещений.
“w/Mobius param.” означает параметризацию Mobius OBB.
Как видно, все исследованные методы, в частности, VoteNet, ImVoteNet, ImVoxelNet, FCAF3D, выигрывают от использования предложенной параметризации Мебиуса OBB. Результаты, полученные с помощью параметризации Мебиуса, лучше, чем результаты, полученные как с "наивной" параметризацией, так и с параметризацией sin-cos, описанной авторами метода SMOKE. Наблюдаемое улучшение одинаково для различных методов обнаружения 3D объектов, которые принимают различные типы входных данных.
Затем изучались якоря GSDN, чтобы доказать, что слои на основе якорей имеют ограниченную способность к обобщению. Согласно таблице 3, mAP@0,5 резко падает на 12%, если GSDN обучается без якорей (что эквивалентно использованию одного якоря). Иными словами, GSDN демонстрирует низкую производительность без специфичного для предметной области наведения в форме якорей; следовательно, этот метод негибкий и необобщенный. Все FCAF3D, представленные в таблице 3, соответствуют предложенному методу и имеют различные модификации ResNet (HDResNet34, HDResNet34:3, HDResNet34:2) и разный размер вокселей.
Для сравнения оценивался FCAF3D с таким же "скелетом", и он с огромным отрывом превзошел GSDN, достигнув вдвое большего значения mAP.
Таблица 3

В таблице 3 представлены результаты полностью сверточных методов обнаружения 3D объектов, которые принимают облака точек в ScanNet.
Сообщаются результаты GSDN, полученные с вокселями 0,05 м. Хотя меньшие воксели обеспечивают более детальное представление данных, зависимость между размером вокселя и точностью не является прямой. Изменение размера вокселя по-разному влияет на GSD и FCAF3D из-за разных стратегий присвоения. В FCAF3D авторы стремились плотно "покрыть" 3D пространство положениями. Расстояние между положениями пропорционально размеру вокселя, поэтому чем меньше размер вокселя, тем плотнее покрытие и, следовательно, выше отклик. GSDN "покрывает" 3D пространство якорями. Линейные размеры якорей пропорциональны размеру вокселей. При присваивании игнорировались якоря с небольшим пересечением с ограничивающими рамками. При уменьшении размера вокселей уменьшаются якоря; соответственно, некоторые якоря будут игнорироваться, что приведет к более низкому отклику.
Таким образом, FCAF3D в общем выигрывает от меньших вокселей, а GSDN - нет. В целом ожидается, что производительность GSDN упадет при уменьшении размера вокселей с 0,05 до 0,01.
Далее обсуждается проектное решение нейронной сети для предлагаемого метода (FCAF3D) и исследуется его влияние на метрики при независимом применении в абляционных исследованиях. Эксперименты проводились с различным размером вокселей, количеством точек в облаке точек Npts, количеством положений, выбранных путем выборки по центру, а также с центрированностью и без нее. Результаты абляционных исследований сведены в таблицу 4 для всех бенчмарков.
Таблица 4

В таблице 4 представлены результаты абляционных исследований на размере вокселей, количестве точек (которое равно количеству вокселей Nvox при обрезке), центрированности и выборке по центру в FCAF3D. Лучшие варианты выделены жирным шрифтом (на самом деле это опции по умолчанию, использованные для получения результатов в таблице 1 выше). Представленное значение метрики является лучшим для 25 тестов; в скобках указано среднее значение.
Размер вокселей. Как и следовало ожидать, с увеличением размера вокселей снижается точность. Использовались воксели размером 0,03, 0,02 и 0,01 мкм. Заметный разрыв в mAP между размерами вокселей 0,01 и 0,02 мкм объясняется присутствием почти плоских объектов, таких как двери, картины и доски. В частности, при размере вокселей 2 см "голова" будет выводить положения с допуском 16 см, но почти плоские объекты могут быть меньше 16 см по одному из измерений. Наблюдается снижение точности для больших размеров вокселя.
Количество точек. Подобно 2D изображениям, прореженные облака точек иногда называют облаками с низким разрешением. Соответственно, они содержат меньше информации, чем их версии с высоким разрешением. Как и следовало ожидать, чем меньше точек, тем ниже точность обнаружения. В этой серии экспериментов было выбрано 20 тысяч, 40 тысяч и 100 тысяч точек из всего облака точек, и полученные значения метрик выявили четкую зависимость между количеством точек и mAP. Авторы не считают, что большие значения Npts соответствуют уровню существующих методов (в частности, GSDN [10] использует все точки в облаке точек, GroupFree [16] выбирает 50 тысяч точек, VoteNet [22] выбирает 40 тысяч точек для ScanNet и 20 тысяч для SUN RGB-D). Для направления обрезки в "шее" используется Nvox=Npts. Когда Nvox превышает 100 тысяч, время логического вывода увеличивается из-за растущей разреженности в шее, при этом точность повышается незначительно. Поэтому поиск по сетке был ограничен для Npts 100 тысяч и использовался как значение по умолчанию для полученных результатов.
Центрированность. Использование центрированности улучшает mAP для датасетов ScanNet и SUN RGB-D. Для S3DIS результаты противоречивы: лучшее значение mAP@0,5 компенсируется незначительным снижением mAP@0,25. Тем не менее, авторы проанализировали все результаты и поэтому могут считать центрированность полезной функцией с небольшим положительным влиянием на mAP, почти достигающим 1% от mAP@0,5 в ScanNet.
Выборка по центру. И наконец, авторы изучили количество положений, полученных в выборке по центру. Выбрано 9 положений, как предложено в FCOS [26], весь набор из 27 положений, как в ImVoxelNet [24], и 18 положений. Последний выбор оказался наилучшим по mAP на всех бенчмарках.
Центрированность. Использование центрированности улучшает mAP для датасетов ScanNet и SUN RGB-D. Для S3DIS результаты противоречивы: лучшее mAP@0,5 компенсируется незначительным снижением mAP@0,25. Тем не менее были проанализированы все результаты, и центрированность признана полезной функцией с небольшим положительным эффектом на mAP, почти достигающим 1% от mAP@0,5 в ScanNet.
Выборка по центру. И наконец, было изучено количество положений, выбранных в выборке по центру. Было выбрано 9 положений, как предложено в FCOS [26], весь набор из 27 положений, как в ImVoxelNet [24], и 18 положений. Последний выбор оказался наилучшим по mAP на всех бенчмарках.
Скорость логического вывода
По сравнению со стандартными свертками, разреженные свертки рационально используют время и память. Авторы GSDN утверждают, что с помощью разреженных сверток они обрабатывают сцену с 78 миллионами точек, охватывающую около 14000 м3, за один полностью сверточный проход с прямым распространением, используя всего 5 ГБ памяти графического процессора. FCAF3D использует те же разреженные свертки и тот же "скелет", что и GSDN. Однако, как видно из таблицы 3, FCAF3D по умолчанию работает медленнее, чем GSDN. Это объясняется меньшим размером вокселей: авторы используют 0,01 м для надлежащего многоуровневого назначения, в то время как GSDN использует 0,05 м.
Для создания самого быстрого метода авторы использовали "скелеты" HDResNet34:3 и HDResNet34:2 всего с тремя и двумя уровнями признаков, соответственно. С этими модификациями FCAF3D имеет более высокую скорость логического вывода, чем GSDN (фиг. 4). На фиг. 4 показана зависимость точности обнаружения от скорости логического вывода, измеренная в сценах в секунду, для исходного и модифицированного FCAF3D в сравнении с существующими методами обнаружения 3D объектов. На фиг. 4 показан показатель mAP@0,5 на ScanNet относительно количества сцен в секунду. Модификации FCAF3D имеют разное количество уровней признаков "скелета". Для каждого существующего метода имеется модификация FCAF3D, превосходящая этот метод как по точности обнаружения, так и по скорости логического вывода. Согласно графику предлагаемый метод FCAF3D без ускоряющих модификаций является наиболее точным из всех методов обнаружения 3D объектов; однако он медленнее, чем некоторые другие методы. Тем не менее, для каждого существующего метода имеется модификация FCAF3D, превосходящая этот метод как по точности обнаружения, так и по скорости логического вывода.
На фиг. 4 представлено сравнение ключевых характеристик предлагаемого метода FCAF3D и двух его модификаций (FCAF3D с 3 уровнями и FCAF3D с 2 уровнями) с существующими методами, решающими аналогичную задачу: GroupFree, H3DNet, BRNet, 3DETR, 3DETR-m, VoteNet, GSDN. Сравнение выполнялось на датасете ScanNet. Каждая точка на графике соответствует какому-то способу обнаружения 3D объектов.
Ось Y: Производительность (mAP) - mAP@0,5, метрика точности обнаружения 3D объектов. Более высокие значения соответствуют более высокой точности; соответственно, чем выше расположены методы на графике, тем они лучше.
По оси абсцисс: Сцен в секунду - это количество сцен, обрабатываемых в секунду. Более высокие значения соответствуют более высокой скорости; соответственно, чем правее расположены методы на графике, тем они лучше.
Для каждого из существующих методов существует модификация предлагаемого способа, которая одновременно показывает лучшую точность и является более быстрой (иными словами, точка которой расположена на графике выше и правее). Для GroupFree, H3DNet, BRNet, 3DETR, 3DETR-m, VoteNet это FCAF3D и FCAF3D с тремя уровнями. Для GSDN - FCAF3D с двумя уровнями.
Для объективного сравнения авторы повторно измерили скорость логического вывода для методов GSDN и методов на основе голосования, поскольку операция группировки точек и разреженные свертки стали намного быстрее с момента появления этих методов. В тестах производительности авторы выбрали реализации, основанные на фреймворке MMdetection3D [6], чтобы уменьшить различия в кодовой базе. Сообщаемая скорость логического вывода для всех методов измерялась на одном и том же графическом процессоре, поэтому их можно сравнивать напрямую.
Предлагается FCAF3D, первый в своем классе полностью сверточный безъякорный метод обнаружения 3D объектов для сцен внутри помещений. Предлагаемый метод значительно превосходит известный уровень техники на сложных бенчмарках SUN RGB-D, ScanNet и S3DIS для помещений как в значениях mAP, так и скорости логического вывода. Также предложена новая ориентированная параметризация ограничивающей рамки, и продемонстрировано, что она повышает точность для нескольких методов обнаружения 3D объектов. Кроме того, предлагаемая параметризация позволяет исключить какие-либо предварительные допущения об объектах, тем самым уменьшая количество гиперпараметров. В общем, FCAF3D с предложенной параметризацией ограничивающей рамки является точным, масштабируемым и в то же время обобщаемым методом. Предлагаемое программное решение предполагается исполнять в мобильных робототехнических устройствах или запускать на смартфонах в составе мобильного приложения. Для реализации предлагаемого способа устройство-носитель должно соответствовать техническим требованиям. В частности, оно должно иметь достаточный объем оперативной памяти и вычислительных ресурсов. Требуемый объем ресурсов зависит от функции устройства, параметров камеры и требований к производительности.
Представленные выше варианты осуществления изобретения являются примерами и не должны рассматриваться как ограничивающие. Кроме того, описание примерных вариантов осуществления изобретения предназначено для иллюстрации, а не для ограничения объема формулы изобретения, и специалистам в данной области техники будут очевидны многие альтернативы, модификации и варианты.
Литература
1. Armeni, I., Sener, O., Zamir, A.R., Jiang, H., Brilakis, I., Fischer, M., Savarese, S.: 3d semantic parsing of large-scale indoor spaces. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 1534-1543 (2016).
2. Chen, J., Lei, B., Song, Q., Ying, H., Chen, D.Z., Wu, J.: A hierarchical graph network for 3d object detection on point clouds. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 392-401 (2020).
3. Chen, K., Wang, J., Pang, J., Cao, Y., Xiong, Y., Li, X., Sun, S., Feng, W., Liu, Z., Xu, J., et al.: Mmdetection: Open mmlab detection toolbox and benchmark. arXiv preprint arXiv:1906.07155 (2019).
4. Cheng, B., Sheng, L., Shi, S., Yang, M., Xu, D.: Back-tracing representative points for voting-based 3d object detection in point clouds. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8963-8972 (2021).
5. Choy, C., Gwak, J., Savarese, S.: 4d spatio-temporal convnets: Minkowski convolutional neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 3075-3084 (2019).
6. Contributors, M.: MMDetection3D: OpenMMLab next-generation platform for general 3D object detection. (2020)
https://github.com/open-mmlab/mmdetection3d.
7. Dai, A., Chang, A.X., Savva, M., Halber, M., Funkhouser, T., Niesner, M.: Scannet: Richly-annotated 3d reconstructions of indoor scenes. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5828-5839 (2017).
8. Engelmann, F., Bokeloh, M., Fathi, A., Leibe, B., Niesner, M.: 3d-mpa: Multiproposal aggregation for 3d semantic instance segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9031-9040 (2020).
9. Ge, Z., Liu, S., Li, Z., Yoshie, O., Sun, J.: Ota: Optimal transport assignment for object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 303-312 (2021).
10. Gwak, J., Choy, C., Savarese, S.: Generative sparse detection networks for 3d single-shot object detection. In: Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part IV 16. pp. 297-313. Springer (2020).
11. He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770-778 (2016).
12. Hou, J., Dai, A., Niesner, M.: 3d-sis: 3d semantic instance segmentation of rgbd scans. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4421-4430 (2019).
13. Lang, A.H., Vora, S., Caesar, H., Zhou, L., Yang, J., Beijbom, O.: Pointpillars: Fast encoders for object detection from point clouds. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12697-12705 (2019).
14. Li, B.: 3d fully convolutional network for vehicle detection in point cloud. In: 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 1513-1518. IEEE (2017).
15. Lin, T.Y., Goyal, P., Girshick, R., He, K., Doll'ar, P.: Focal loss for dense object detection. In: Proceedings of the IEEE international conference on computer vision. pp. 2980-2988 (2017).
16. Liu, Z., Zhang, Z., Cao, Y., Hu, H., Tong, X.: Group-free 3d object detection via transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 2949-2958 (2021).
17. Liu, Z., Wu, Z., T'oth, R.: Smoke: Single-stage monocular 3d object detection via keypoint estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. pp. 996-997 (2020).
18. Maturana, D., Scherer, S.: Voxnet: A 3d convolutional neural network for realtime object recognition. In: 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 922-928. IEEE (2015).
19. Misra, I., Girdhar, R., Joulin, A.: An end-to-end transformer model for 3d object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2906-2917 (2021)
20. Munkres, J.R.: Topology (2000).
21. Qi, C.R., Chen, X., Litany, O., Guibas, L.J.: Imvotenet: Boosting 3d object detection in point clouds with image votes. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4404-4413 (2020).
22. Qi, C.R., Litany, O., He, K., Guibas, L.J.: Deep hough voting for 3d object detection in point clouds. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9277-9286 (2019).
23. Qi, C.R., Su, H., Mo, K., Guibas, L.J.: Pointnet: Deep learning on point sets for 3d classification and segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 652-660 (2017).
24. Rukhovich, D., Vorontsova, A., Konushin, A.: Imvoxelnet: Image to voxels projection for monocular and multi-view general-purpose 3d object detection. arXiv preprint arXiv:2106.01178 (2021).
25. Song, S., Lichtenberg, S.P., Xiao, J.: Sun rgb-d: A rgb-d scene understanding benchmark suite. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 567-576 (2015).
26. Tian, Z., Shen, C., Chen, H., He, T.: Fcos: Fully convolutional one-stage object detection. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9627-9636 (2019).
27. Wang, T., Zhu, X., Pang, J., Lin, D.: Fcos3d: Fully convolutional one-stage monocular 3d object detection. arXiv preprint arXiv:2104.10956 (2021).
28. Xie, Q., Lai, Y.K., Wu, J., Wang, Z., Lu, D., Wei, M., Wang, J.: Venet: Voting enhancement network for 3d object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3712-3721 (2021).
29. Xie, Q., Lai, Y.K., Wu, J., Wang, Z., Zhang, Y., Xu, K., Wang, J.: Mlcvnet: Multilevel context votenet for 3d object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10447-10456 (2020).
30. Yan, Y., Mao, Y., Li, B.: Second: Sparsely embedded convolutional detection. Sensors 18(10), 3337 (2018).
31. Yin, T., Zhou, X., Krahenbuhl, P.: Center-based 3d object detection and tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11784-11793 (2021).
32. Zhang, S., Chi, C., Yao, Y., Lei, Z., Li, S.Z.: Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9759-9768 (2020).
33. Zhang, Z., Sun, B., Yang, H., Huang, Q.: H3dnet: 3d object detection using hybrid geometric primitives. In: European Conference on Computer Vision. pp. 311-329. Springer (2020).
34. Zhou, D., Fang, J., Song, X., Guan, C., Yin, J., Dai, Y., Yang, R.: Iou loss for 2d/3d object detection. In: 2019 International Conference on 3D Vision (3DV). pp. 85-94. IEEE (2019).
35. Zhou, Y., Tuzel, O.: Voxelnet: End-to-end learning for point cloud based 3d object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4490-4499 (2018).
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ и электронное устройство для обнаружения трехмерных объектов с помощью нейронных сетей | 2021 |
|
RU2776814C1 |
| ВИЗУАЛИЗАЦИЯ РЕКОНСТРУКЦИИ 3D-СЦЕНЫ С ИСПОЛЬЗОВАНИЕМ СЕМАНТИЧЕСКОЙ РЕГУЛЯРИЗАЦИИ НОРМАЛЕЙ TSDF ПРИ ОБУЧЕНИИ НЕЙРОННОЙ СЕТИ | 2023 |
|
RU2825722C1 |
| НЕЙРОННАЯ ТОЧЕЧНАЯ ГРАФИКА | 2019 |
|
RU2729166C1 |
| МОДЕЛИРОВАНИЕ ЧЕЛОВЕЧЕСКОЙ ОДЕЖДЫ НА ОСНОВЕ МНОЖЕСТВА ТОЧЕК | 2021 |
|
RU2776825C1 |
| Способ синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора, и электронное вычислительное устройство для его реализации | 2020 |
|
RU2749749C1 |
| СПОСОБ ИНТЕРАКТИВНОЙ СЕГМЕНТАЦИИ ОБЪЕКТА НА ИЗОБРАЖЕНИИ И ЭЛЕКТРОННОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2020 |
|
RU2742701C1 |
| Способ 3D-реконструкции человеческой головы для получения рендера изображения человека | 2022 |
|
RU2786362C1 |
| СПОСОБ И СИСТЕМА ДЛЯ УТОЧНЕНИЯ ПОЗЫ КАМЕРЫ С УЧЕТОМ ПЛАНА ПОМЕЩЕНИЯ | 2022 |
|
RU2794441C1 |
| ТЕКСТУРИРОВАННЫЕ НЕЙРОННЫЕ АВАТАРЫ | 2019 |
|
RU2713695C1 |
| Способ управления бортовыми системами беспилотных транспортных средств при помощи нейронных сетей на основе архитектуры трансформеров | 2024 |
|
RU2841111C1 |
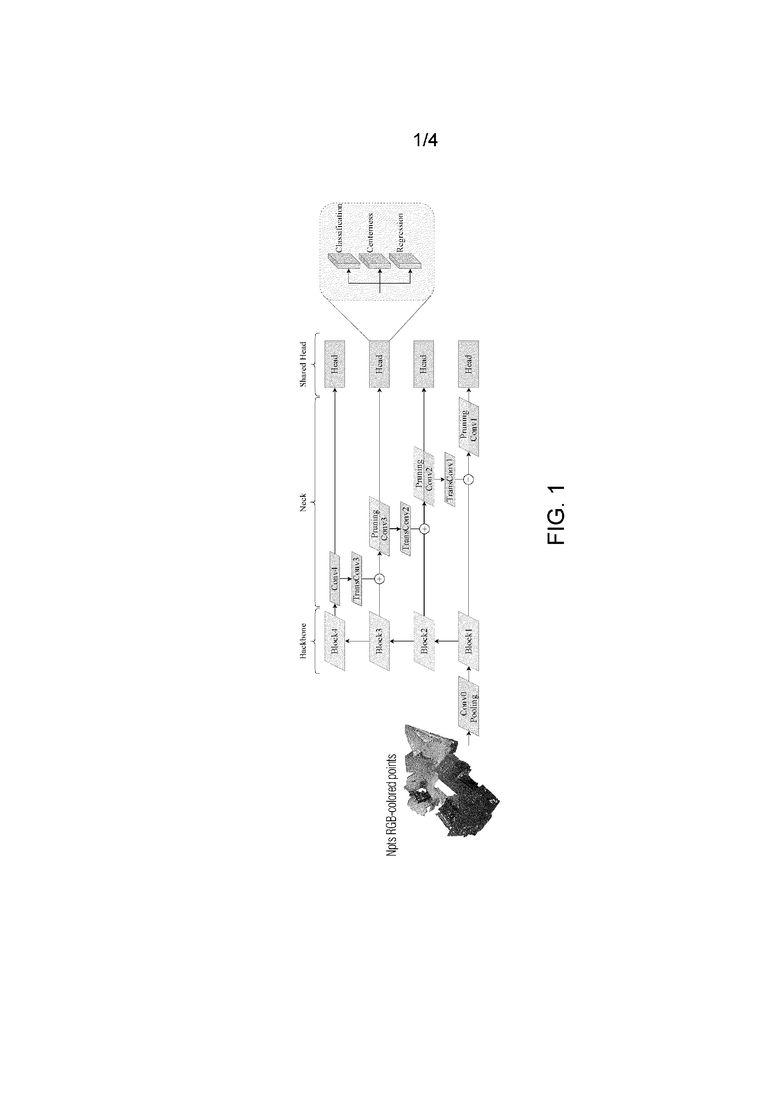

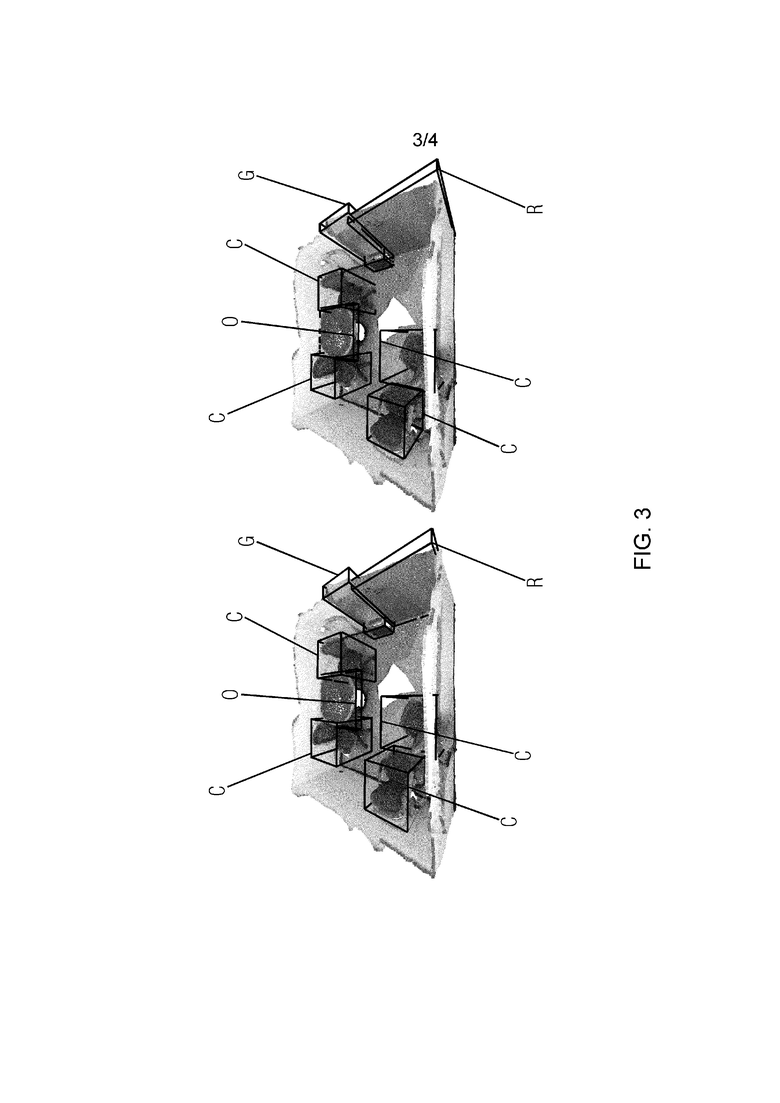
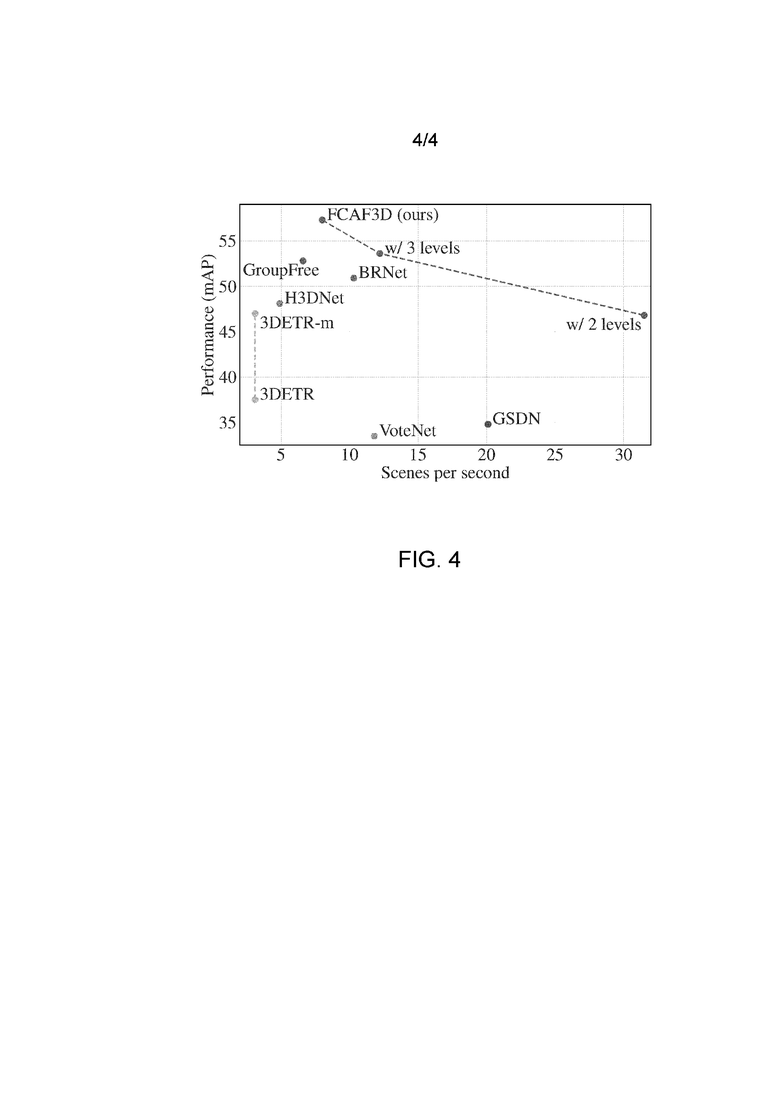
Изобретение относится к навигации мобильных роботов, для мобильных приложений, выполняющих понимание сцены и распознавание объектов. Технический результат заключается в повышении точности обнаружения объектов и уменьшении времени обработки сцены. Предложен способ, в котором принимают облако точек, реконструированное или полученное от датчиков глубины. Сначала данное облако точек представляют в виде воксельного представления. Затем воксельное представление обрабатывают с помощью 3D разреженного сверточного "скелета". Далее применяют 3D разреженную сверточную "шею" для извлечения признаков на разных уровнях "скелета". Полученные признаки обрабатывают посредством 3D разреженной сверточной "головы" с весами, общими для разных уровней признаков. На каждом уровне признаков "голова" отвечает за прогнозирование объектов определенного масштаба. "Голова" выдает параметры ограничивающей рамки для каждого положения. И наконец, все полученные прогнозы фильтруются, чтобы выбрать наиболее вероятные. 2 н. и 1 з.п. ф-лы, 4 ил., 4 табл.
1. Способ обеспечения компьютерного зрения робототехнического устройства, реализуемый в компьютерном устройстве робототехнического устройства, причем робототехническое устройство имеет камеру с датчиками глубины и RGB-камеру, центральный процессор, внутреннюю память, оперативную память, при этом способ включает этапы, на которых:
захватывают реальную сцену с объектами в сцене, используя камеру с датчиками глубины и RGB-камеру;
представляют захваченную реальную сцену в виде облака из набора N точек, каждая из которых представлена своей координатой и цветом, и
вводят облако из набора N точек в качестве данных в нейронную сеть, причем нейронная сеть состоит из части "скелет", части "шея" и части "голова",
причем часть "скелет", часть "шея" и часть "голова" являются 3D разреженными сверточными частями нейронной сети;
в нейронной сети выполняют следующие этапы:
А) посредством части "скелет" представляют облако точек в виде объемного пиксельного представления входных данных;
В) посредством части "скелет" обрабатывают объемное пиксельное представление входных данных для получения четырехмерных тензоров;
С) посредством части "шея" обрабатывают четырехмерные тензоры для извлечения выраженных в числовой форме признаков объектов в сцене;
D) посредством части "голова" обрабатывают извлеченные признаки объектов в сцене для получения прогнозов положений, ориентаций и категорий объектов в сцене, причем для каждого объекта в сцене часть "голова" выдает прогнозы, причем прогноз содержит:
вероятность классификации объекта, параметры регрессии ограничивающей рамки объекта и центрированность объекта внутри ограничивающей рамки объекта;
Е) посредством части "голова" фильтруют все полученные прогнозы путем сравнения прогнозов по вероятности классификации объекта для выбора наиболее вероятного прогноза, при этом наиболее вероятный прогноз считается окончательной оценкой положения, ориентации и категории объекта в сцене и характеризуется данными, касающимися положения, ориентации и категории объекта в сцене;
выводят из нейронной сети данные, касающиеся положения, ориентации и категории объекта в сцене, в виде числового представления сцены, представляющего компьютерное зрение для робототехнического устройства.
2. Способ по п.1, дополнительно содержащий этап, на котором:
преобразуют числовое представление сцены в изображение сцены, при этом компьютерное устройство дополнительно содержит экран, и изображение сцены отображается на экране для пользователя.
3. Компьютерно-читаемый носитель, содержащий программный код, воспроизводящий способ по п.1 при его реализации в компьютерном устройстве.
| Способ регенерирования сульфо-кислот, употребленных при гидролизе жиров | 1924 |
|
SU2021A1 |
| Способ регенерирования сульфо-кислот, употребленных при гидролизе жиров | 1924 |
|
SU2021A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| CN 111243017 A, 05.06.2020 | |||
| CN 110392897 A, 29.10.2019 | |||
| Способ распознавания объектов на изображении | 2018 |
|
RU2693267C1 |

