УРОВЕНЬ ТЕХНИКИ ИЗОБРЕТЕНИЯ
Область техники, к которой относится изобретение
[0001] Настоящее изобретение относится, в общем, к областям компьютерного зрения и компьютерной графики для формирования структуры многоплоскостного изображения (MPI) или структуры многослойного изображения (MLI) в качестве представления сцены из произвольного набора изображений, в частности, к способам построения представления сцены и электронным вычислительным устройствам, выполняющим эти способы.
[0002] Настоящая заявка относится к заявке на патент Российской Федерации 2021132877, поданной 12.11.2021 и озаглавленной «СПОСОБ ПОСТРОЕНИЯ МНОГОПЛОСКОСТНОГО ИЗОБРАЖЕНИЯ (MPI) С ПРЯМОЙ КОРРЕКЦИЕЙ ДЛЯ СИНТЕЗА ИЗОБРАЖЕНИЯ В РЕАЛЬНОМ ВРЕМЕНИ» (METHOD FOR BUILDING MULTI-PLANE IMAGE (MPI) REPRESENTATION WITH FEED-FORWARD CORRECTION FOR REAL-TIME VIEW SYNTHESIS), которая принадлежит тому же заявителю и включена в настоящий документ по ссылке.
Описание предшествующего уровня техники
[0003] Проблема синтеза фотореалистичных новых представлений (NVS) стала чрезвычайно популярной в сообществе глубокого обучения за последние несколько лет. Эта задача предполагает, что при заданном наборе входных изображений сцены и соответствующих камер необходимо предсказать изображение сцены с новой камеры. Как правило, решение состоит из двух этапов: сначала строится промежуточное представление (прокси) геометрии сцены, а затем это представление визуализируется для получения нового изображения. Недавно разработанные способы нейронного рендеринга (получения изображения) достигли фотореалистичного качества для синтеза новых изображений, однако у них есть ограничения во время обучения или логического вывода. Оптимизация для каждой сцены или низкая частота кадров при логическом выводе являются критическими ограничениями для использования существующих современных решений в приложениях.
[0004] В то же время сложность задачи сильно зависит от количества входных кадров. Если предоставляется один кадр, алгоритм должен много раз выполнять вычисления, чтобы разрешить окклюзии, и возможно лишь небольшое изменение ориентации изображения (если только модель не позиционируется как генеративная [17]). Наоборот, если доступно множество исходных изображений, то проблема в основном сводится к интерполяции между ними. Предлагаемое решение направлено на последний случай в качестве настройки по умолчанию, предполагая, что 4-8 изображений служат в качестве входных данных для системы новых изображений, и ориентировано на представление, используемое в реальных задачах.
[0005] Наиболее многообещающим способом моделирования сцены для данного случая является представление многоплоскостного изображения (MPI), рассматривающее сцену как ряд равномерно расположенных полупрозрачных плоскостей. Недавно предложенная система слияния локальных световых полей (Local lightfield fusion system, LLFF) [13], использующая MPI [26] для рендеринга на основе изображений, имеет решение для сформулированной выше проблемы. Ограничение представления результатов заключается в строгом количестве изображений и структуре, используемых во время обучения. Пять исходных изображений были спроецированы на эти плоскости и объединены с помощью нейронной сети для получения цвета RGB и непрозрачности. После построения ориентированного на источник MPI LLFF может отображать новые изображения с помощью любого стандартного графического механизма, например, OpenGL. Однако, чтобы расширить поле зрения, предлагается смешать пять ближайших MPI для каждой новой камеры. Такой подход уже позволяет полностью погрузиться в сцену при условии, что сгенерирован весь набор MPI.
[0006] Чтобы улучшить качество рендеринга, LiveView [7] предложил построить отдельное ориентированное на цель MPI в усеченной пирамиде каждой новой камеры. Авторы утверждают, что упрощенные архитектуры позволяют сделать логический вывод их подхода в реальном времени, несмотря на объем вычислений, необходимых для вычисления каждого представления MPI.
[0007] С другой стороны, NeRF [14] с рядом последующих работ неявно «запекает» геометрию сцены в веса многослойного персептрона, который принимает координаты вокселей в качестве входных данных и возвращает его цвет и объемную плотность. Новый кадр вычисляется с использованием процедуры приближенного лучевого марширования (ray marching), которая интегрирует цвета вокселов вдоль луча в соответствии с предсказанной плотностью. Этот подход, хотя и дает отличные результаты, требует длительного обучения для каждой новой сцены. Чтобы преодолеть эту проблему, в нескольких решениях [3, 4, 11, 21, 24] реализована стратегия смешивания: нейронная сеть обучается предсказывать цвет и плотность для каждой точки на луче путем смешивания проекции этой точки на исходные изображения. Как замечено во всех этих способах, дополнительная тонкая настройка для каждой сцены является решающим этапом от более или менее качественного к приемлемо хорошему. Производимое качество предварительно обученных сетей, включающих поле яркости, на практике создает довольно большое количество артефактов. Поэтому произведенное представление, в отличие от ориентированного на источник MPI, не готово к немедленному рендерингу и требует дополнительных вычислительных ресурсов для синтеза нового изображения.
[0008] Предлагаемый подход, называемый MPI с механизмом самовнимания, направлен на представление сцены путем объединения представления, подходящего для приложений, с качеством новых изображений, превосходящим ориентированные на цель способы.
[0009] Предлагается применять модули самовнимания для поддержки различного количества исходных изображений, в отличие от LLFF, которая была разработана только для фиксированного количества. Для построения MPI из исходных изображений применяется многоэтапная процедура, аналогичная по духу Deep-View [6], но не требующая обратного распространения во время логического вывода.
Представление сцены
[0010] Выбор представления сцены чаще всего основывается на требованиях логического вывода, все они имеют неодинаковые вычислительные ресурсы. Отмечаются такие прокси, которые могут визуализироваться стандартными графическими механизмами в качестве визуализируемых представлений. Как правило, этот подход обеспечивает скорость рендеринга в реальном времени, а сложные вычисления требуются только при построении геометрии прокси. Следует отметить, что процедура построения выполняется в зависимости только от заданного исходного изображения, что мотивирует называть ее ориентированной на источник. Сетки и облака точек являются хорошо известными примерами такого рода. В предыдущих документах [9, 16] нейронные сети успешно применялись для предсказания текстуры сетки или цветов вершин на основе исходных изображений. Система StereoMag [26] предложила использовать многоплоскостную геометрию (MPI) с полупрозрачными плоскостями, расположенными в усеченной пирамиде одной из исходных камер (весь конвейер предполагал две исходных камеры, и выбор между ними был случайным). Это представление может быть визуализировано комбинацией простой деформации гомографии и операции компоновки поверх (compose-over, наложения изображения на фоновое изображение) [15]. Одним из способов уменьшить проблему, заключающуюся в ограниченной возможности представления зависящих от изображения эффектов, например, зеркальные отражения, является представление, настроенное для каждой новой камеры. Например, LiveView [7] строит новое ориентированное на цель MPI в усеченной пирамиде каждой новой камеры. С другой стороны, LLFF [13] предложил построить MPI в усеченной пирамиде каждой исходной камеры и использовать эвристику для смешивания разных предварительных новых изображений, полученных с использованием этих MPI, для получения результирующего изображения. IBR-Net [21] вычисляет поле яркости сцены с точки обзора новой камеры посредством смешивания признаков, извлеченных из исходных фотографий. Примечательно, что для вычисления объемной плотности точек вдоль луча применяется операция самовнимания. Поэтому это представление является только ориентированным на цель.
[0011] Другой способ заключается в использовании отсроченных представлений. Они могут быть определены как представления, использующие некоторые предсказанные признаки, а не только цвет RGB, в качестве свойства прокси сцены. Поэтому для этой группы требуется декодирующая сеть, которая либо корректирует представление в соответствии с направлением обзора, либо переводит уже полученное изображение из домена признаков в домен RGB. Было продемонстрировано, что этот подход обеспечивает лучшее качество как для сеток [19], облаков точек [1, 22], так и для многоплоскостных изображений [23], а также для нейронных полей яркости [14, 24]. Например, MVSNeRF [3] вычисляет ориентированный на источник объем затрат, состоящий из признаков. Чтобы рассчитать яркость и плотность RGB, персептрон преобразует интерполированные признаки из объема, принимая во внимание координаты вокселя и направление обзора.
[0012] Однако большинство способов, хотя и предварительно обучены на наборе данных, показывают свои наилучшие результаты только после процедуры тонкой настройки на каждой новой сцене. Этот этап является дорогостоящим в вычислительном отношении, несмотря на то, что было приложено много усилий, чтобы сделать его быстрее и проще [3, 21].
[0013] В отличие от вышеприведенного, настоящее изобретение предлагает подход, который представляет сцену как ориентированное на источник MPI, что позволяет быстро и дешево получать новые изображения. В то же время новая сетевая архитектура приводит к лучшему качеству, чем основанный на MPI конвейер LLFF и ориентированные на цель IBRNet и MSNeRF (до тонкой настройки).
Выбор архитектуры
[0014] Основанные на MPI способы использовали разные типы архитектур для получения RGB и непрозрачности их многоуровневого представления. Система стереоувеличения [26] сначала проецировала два исходных изображения на плоскости, чтобы получить объем развертки плоскостей (plane-sweep volume, PSV). После этого плоскости объединялись поканально и обрабатывались двумерной (2D) сверточной сетью для получения полупрозрачных текстур. В последующих документах [13, 18] сети реализовывались с использованием трехмерных (3D) сверток для более естественной обработки измерения глубины. В NeX [23] обучено два многослойных персептрона на одной сцене: один персептрон возвращает непрозрачность и коэффициенты для базовых функций RGB на основе координаты пикселя и глубины плоскости. Другой персептрон обучается необходимым базовым функциям, которые зависят только от направления обзора.
[0015] Успех операций внимания и блоков преобразования как в языковых задачах [20], так и в компьютерном зрении [5, 25] мотивировал их использование в конвейерах новых изображений. Как упоминалось выше, в IBRNet использован механизм внимания вдоль луча, чтобы обеспечить взаимодействие друг с другом вокселов вдоль одного и того же луча новой камеры. Этот блок также включен в предложенный подход, но таким образом, что он не зависит от изображения.
[0016] Поскольку восстановление сцены по набору исходных изображений представляет собой сложную обратную задачу, в DeepView [2, 6] применен обученный алгоритм градиентного спуска для обновления представления сцены на основе разницы между исходными изображениями и проекциями на них предполагаемой геометрии. Будучи чрезвычайно эффективным, этот способ требует обратного распространения ошибки во время логического вывода. В предложенном решении принята идея коррекции представления на основе вычисления ошибки, но упрощена процедура для избавления от дорогостоящих вычислений.
[0017] Задача синтеза новых изображений состоит в предсказании изображения сцены с новой камеры с учетом набора входных изображений (также называемых исходными изображениями) для этой сцены и соответствующих параметров камеры. Двумя естественными источниками таких входных изображений являются выполненные портативной камерой видео статических сцен [32, 21, 31] и снимки с многокамерной установки [6, 13]. Многие недавние подходы [32, 34, 27, 33] основаны на оценке поля яркости сцены на основе кадров исходного видео, наиболее близких к новому положению камеры. Примечательно, что они также требуют тонкой настройки модели для новой сцены для достижения наилучших результатов. Эти ограничения не позволяют использовать такие модели в настройках, где требуется быстрый рендеринг.
[0018] В отличие от вышеприведенного, способы, основанные на многоплоскостных изображениях (MPI) [26], позволяют представить сцену набором фронто-параллельных плоскостей, заданных несколькими входными изображениями. В некоторых документах [13, 6] показаны полноценные возможности использования этого представления для применений в реальном времени благодаря высокой скорости рендеринга и хорошему обобщению для различных сцен. Одним из ограничений является относительно большое количество полупрозрачных плоскостей, необходимых для аппроксимации геометрии сцены, тогда как недостаточное количество приводит к визуальным артефактам. В недавно предложенных документах [2, 30] формируется плотный набор плоскостей (например, 128), а затем они объединяются в многослойное изображение (MLI) с помощью необучаемой операции постобработки. В другом документе [29] адаптивная к сцене геометрия оценивается непосредственно нейронной сетью, однако она рассматривает только случай для двух входных изображений, при этом их обрабатывают асимметрично.
[0019] Настоящее раскрытие обеспечивает новый способ синтеза фотореалистичных изображений, который оценивает многослойную геометрию сцены в форме MLI, учитывая произвольный набор изображений, отобранных из входного видео. Предлагаемая структура способна генерировать геометрию прокси для новой сцены с прямым распространением, обеспечивая при этом качество рендеринга изображения наравне с предыдущими способами. В отличие от предыдущих решений, предложенное решение не требует предварительно заданного количества входных изображений или каких-либо нейронных вычислений во время рендеринга.
СПИСОК ЦИТИРУЕМЫХ ДОКУМЕНТОВ
[1] Kara-Ali Aliev, Artem Sevastopolsky, Maria Kolos, Dmitry Ulyanov, and Victor Lempitsky. Neural point-based graphics. In Proc. ECCV, 2020. 2
[2] Michael Broxton, John Flynn, Ryan Overbeck, Daniel Erickson, Peter Hedman, Matthew Duvall, Jason Dourgarian, Jay Busch, Matt Whalen, and Paul Debevec. Immersive light field video with a layered mesh representation. In Proc. ACM SIGGRAPH, 2020. 3
[3] Anpei Chen, Zexiang Xu, Fuqiang Zhao, Xiaoshuai Zhang, Fanbo Xiang, Jingyi Yu, and Hao Su. Mvsnerf: Fast generalizable radiance field reconstruction from multi-view stereo. In Proc. ICCV, pages 14124-14133, October 2021. 2
[4] Julian Chibane, Aayush Bansal, Verica Lazova, and Gerard Pons-Moll. Stereo radiance fields (srf): Learning view synthesis for sparse views of novel scenes. In Proc. CVPR, pages 7911-7920, June 2021. 2
[5] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021. 3
[6] John Flynn, Michael Broxton, Paul Debevec, Matthew Du-Vall, Graham Fyffe, Ryan Styles Overbeck, Noah Snavely, and Richard Tucker. Deepview: High-quality view synthesis by learned gradient descent. In Proc. CVPR, 2019. 2, 3
[7] Sushobhan Ghosh, Zhaoyang Lv, Nathan Matsuda, Lei Xiao, Andrew Berkovich, and Oliver Cossairt. Liveview: Dynamic target-centered mpi for view synthesis, 2021. 1, 2
[8] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, June 2016. 4
[9] Ronghang Hu and Deepak Pathak. Worldsheet: Wrapping the world in a 3d sheet for view synthesis from a single image. In arXivpreprint arXiv:2012.09854, 2020. 2
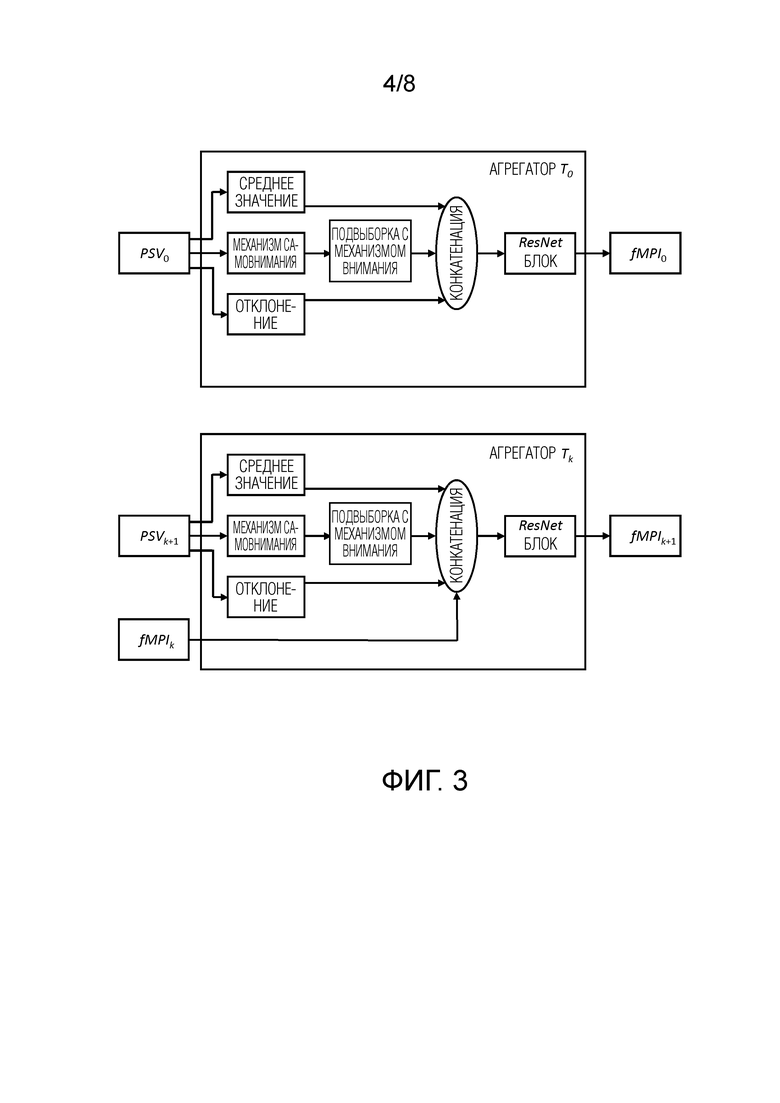
[10] Juho Lee, Yoonho Lee, Jungtaek Kim, Adam Kosiorek, Seungjin Choi, and Yee Whye Teh. Set transformer: A framework for attention-based permutation-invariant neural networks. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, ICML, volume 97 of Proceedings of Machine Learning Research, pages 3744-3753. PMLR. 4
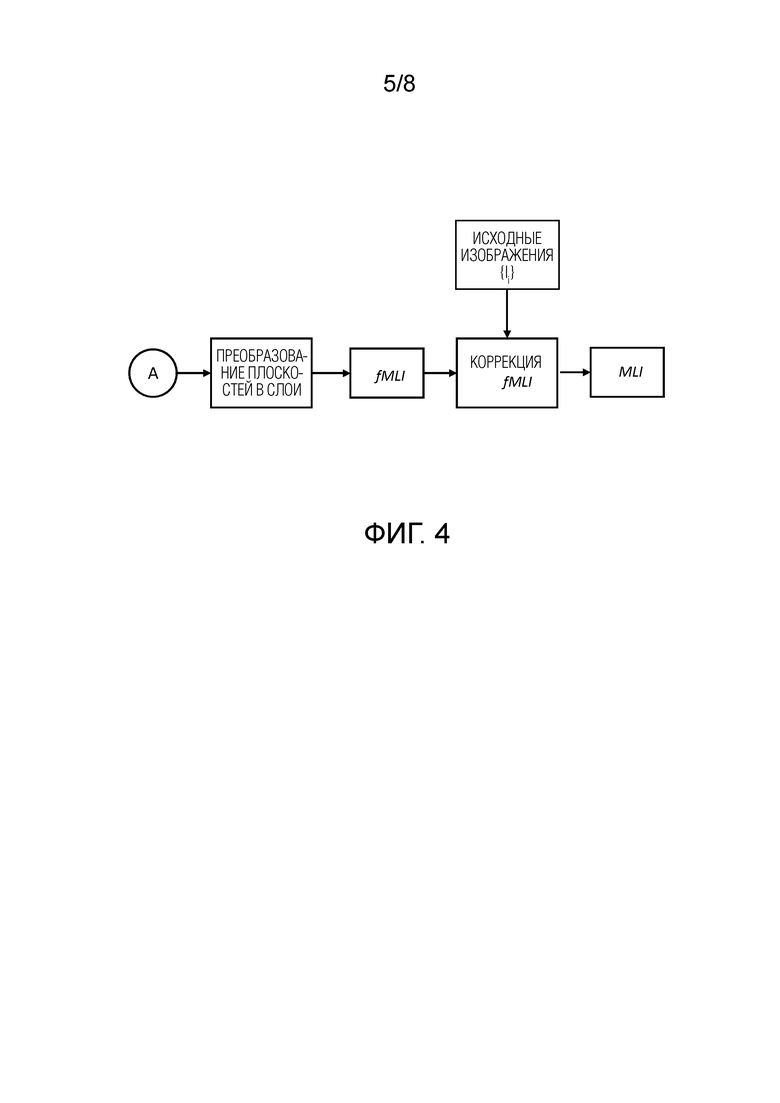
[11] Yuan Liu, Sida Peng, Lingjie Liu, Qianqian Wang, Peng Wang, Christian Theobalt, Xiaowei Zhou, and Wenping Wang. Neural Rays for Occlusion-aware Image-based Ren-dering. arXiv:2107.13421 [cs], July 2021. 2
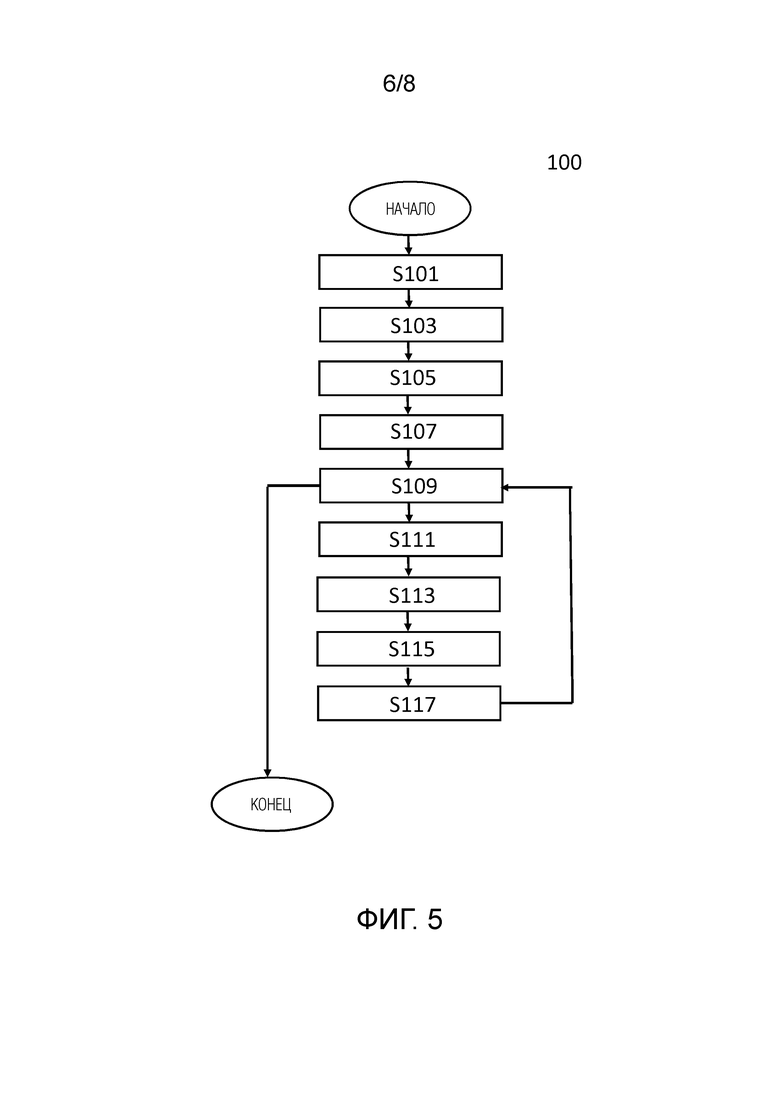
[12] F Landis Markley, Yang Cheng, John L Crassidis, and Yaakov Oshman. Averaging quaternions. 30(4):1193-1197. 3
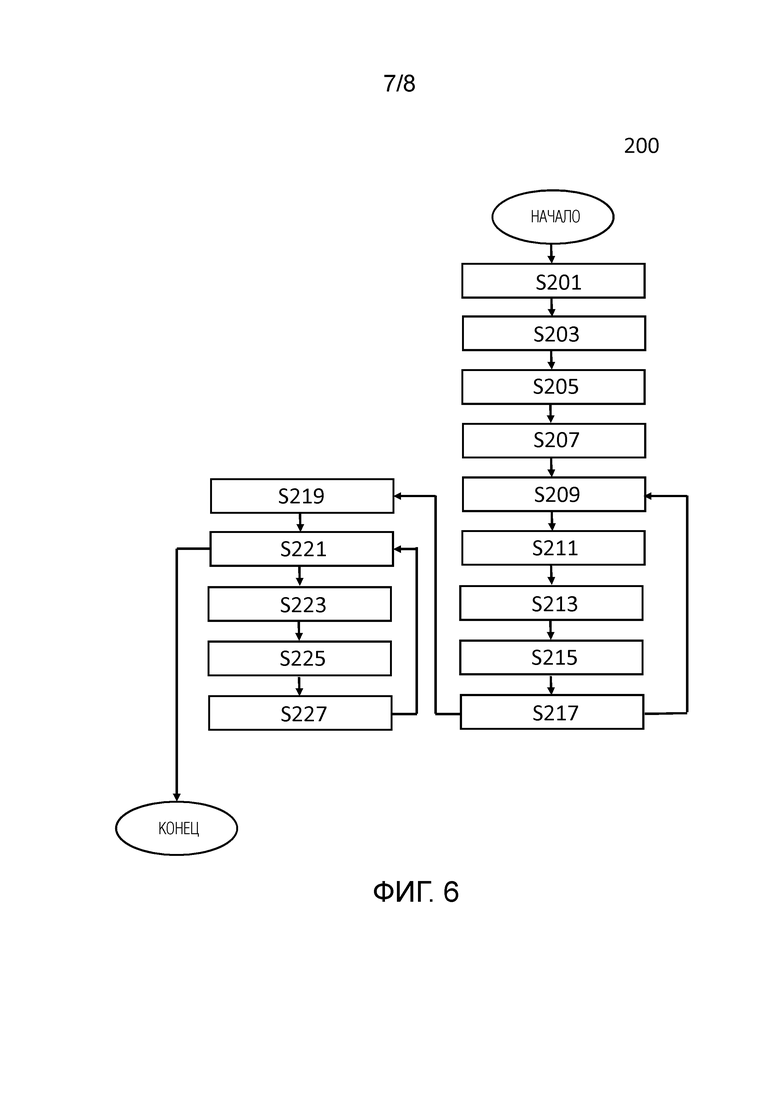
[13] Ben Mildenhall, Pratul P. Srinivasan, Rodrigo Ortiz-Cayon, Nima Khademi Kalantari, Ravi Ramamoorthi, Ren Ng, and Abhishek Kar. Local light field fusion: Practical view synthesis with prescriptive sampling guidelines. In SIGGRAPH, 2019. 1, 2, 3
[14] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view syn-thesis. In Proc. ECCV, 2020. 1, 2
[15] Thomas Porter and Tom Duff. Compositing digital images. In Proc. ACM SIGGRAPH, 1984. 2, 3
[16] Gernot Riegler and Vladlen Koltun. Free view synthesis. In Proc. ECCV, 2020. 2
[17] Robin Rombach, Patrick Esser, and Bjorn Ommer. Geometry-free view synthesis: Transformers and no 3d priors, 2021. 1
[18] P. P. Srinivasan, R. Tucker, J. T. Barron, R. Ramamoorthi, R. Ng, and N. Snavely. Pushing the boundaries of view extrapolation with multiplane images. In Proc. CVPR, 2019. 3
[19] Justus Thies, Michael Zollhofer, and Matthias NieBner. Deferred neural rendering: Image synthesis using neural textures. In Proc. ACM SIGGRAPH, 2019. 2
[20] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, L ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. 3
[21] Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul P. Srinivasan, Howard Zhou, Jonathan T. Barron, Ricardo Martin-Brualla, Noah Snavely, and Thomas Funkhouser. Ibr-net: Learning multi-view image-based rendering. In Proc. CVPR, pages 4690-4699, June 2021. 2
[22] O. Wiles, G. Gkioxari, R. Szeliski, and J. Johnson. Synsin: End-to-end view synthesis from a single image. In Proc. CVPR, 2020. 2
[23] Suttisak Wizadwongsa, Pakkapon Phongthawee, Jiraphon Yenphraphai, and Supasorn Suwajanakorn. Nex: Real-time view synthesis with neural basis expansion. In Proc. CVPR, pages 8534-8543, June 2021. 2, 3
[24] Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. pixelnerf: Neural radiance fields from one or few images. In Proc. CVPR, pages 4578-4587, June 2021. 2
[25] Han Zhang, Ian Goodfellow, Dimitris Metaxas, and Augustus Odena. Self-attention generative adversarial networks, 2019. 3
[26] Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: Learning view synthesis using multiplane images. In Proc. ACM SIGGRAPH, 2018. 1, 2, 3
[27] Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields (2021)
[28] Hu, R., Ravi, N., Berg, A.C., Pathak, D.: Worldsheet: Wrapping the world in a 3d sheet for view synthesis from a single image. In: Proc. ICCV (2021)
[29] Khakhulin, T., Korzhenkov, D., Solovev, P., Sterkin, G., Ardelean, T., Lempitsky, V.: Stereo magnification with multi-layer images. In: Proc. CVPR (2022)
[30] Lin, K.E., Xu, Z., Mildenhall, B., Srinivasan, P.P., Hold-Geoffroy, Y., DiVerdi, S., Sun, Q., Sunkavalli, K., Ramamoorthi, R.: Deep multi depth panoramas for view synthesis. In: Proc. ECCV (2020)
[31] Liu, Y., Peng, S., Liu, L., Wang, Q., Wang, P., Theobalt, C., Zhou, X., Wang, W.: Neural Rays for Occlusion-aware Image-based Rendering (2021)
[32] Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: NeRF: Representing scenes as neural radiance fields for view synthesis. In: Proc. ECCV (2020)
[33] Neff, T., Stadlbauer, P., Parger, M., Kurz, A., Mueller, J.H., Chaitanya, C.R.A., Kaplanyan, A.S., Steinberger, M.: DONeRF: Towards Real-Time Rendering of Compact Neural Radiance Fields using Depth Oracle Networks. Computer Graphics Forum 40(4) (2021)
[34] Xian, W., Huang, J.B., Kopf, J., Kim, C.: Space-time neural irradiance fields for free-viewpoint video. In: Proc. CVPR (2021)
[35] Laine, S., Hellsten, J., Karras, T., Seol, Y., Lehtinen, J., Aila, T.: Modular primitives for high-performance differentiable rendering. ACM Transactions on Graphics 39(6) (2020)
[36] Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition (2015)
[37] Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: Proc. ECCV (2016)
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0020] Задачей настоящего изобретения является обеспечение способов построения представления сцены, такого как структура многоплоскостного изображения (MPI) или структура многослойного изображения (MLI), и электронных вычислительных устройств, реализующих эти способы. Предложенное решение решает практическую задачу синтеза обобщаемого нового изображения в реальном времени из заданного набора изображений. Предложенные способы позволяют генерировать структуру MPI или структуру MLI из произвольного набора изображений и не требуют какой-либо оптимизации или тонкой настройки во время логического вывода. Основная часть способа заключается в прямом распространении несоответствия между исходными изображениями и визуализированными изображениями для улучшения предполагаемого представления. Предложенный подход превосходит представленные в уровне техники способы синтеза новых изображений на контрольных наборах данных, при этом обеспечивая возможность рендеринга в реальном времени.
[0021] Основные этапы предложенного подхода следующие. Во-первых, геометрия сцены оценивается в виде MPI, которое сквозным образом преобразуется в MLI. Кроме того, каждое промежуточное представление, MPI или MLI, проходит через процедуру прямой коррекции ошибок, аналогичную той, что описана в документе DeepView [6]. Вкратце, во время этой процедуры расхождение между исходными изображениями и текущим представлением, полученным для исходных камер, вычисляется и передается в модель искусственного интеллекта (ИИ), которая обновляет представление сцены с учетом этой информации.
[0022] Результирующая геометрия прокси имеет вид многослойной сетки [28, 29], что позволяет выполнять быстрый рендеринг в реальном времени на этапе логического вывода с помощью стандартных графических механизмов, таких как OpenGL. В соответствии с настоящим решением необходимое количество слоев для представления сцены может составлять всего четыре.
[0023] Один аспект настоящего изобретения обеспечивает способ построения представления сцены, содержащий этапы, на которых: принимают (S101) набор изображений одной и той же сцены, снятых разными камерами, и внутренние и внешние параметры упомянутых камер; получают (S103) тензоры признаков для каждого изображения из принятого набора изображений посредством извлечения признаков из каждого изображения из принятого набора изображений с помощью блока извлечения признаков обученной модели искусственного интеллекта (ИИ); выполняют построение (S105) объема развертки плоскостей (PSV) посредством конкатенации полученных тензоров признаков в направлении глубины PSV с использованием принятых внутренних и внешних параметров камер; выполняют построение (S107) многоплоскостного изображения (MPI) посредством агрегирования признаков построенного PSV с помощью агрегатора PSV-MPI обученной модели ИИ; получают (S109) MPI с текстурой RGBA посредством обработки признаков каждой плоскости MPI с помощью преобразователя MPI-RGBA обученной модели ИИ; получают (S111) набор изображений, соответствующий принятому набору изображений, из MPI с текстурой RGBA с использованием принятых внутренних и внешних параметров камер; вычисляют (S113) разности между соответствующими изображениями из принятого набора изображений и соответствующими изображениями из набора изображений, полученного из MPI с текстурой RGBA, с использованием функции ошибки; выполняют построение (S115) PSV посредством конкатенации вычисленных разностей в направлении глубины PSV с использованием принятых внутренних и внешних параметров камер; обновляют (S117) MPI посредством агрегирования признаков MPI и признаков текущего PSV с помощью агрегатора PSV-MPI обученной модели ИИ; при этом этапы (S109)-(S117) повторяют заданное количество раз для получения MPI с текстурой RGBA в качестве представления сцены, и при этом обученная модель ИИ содержит множество агрегаторов PSV-MPI и множество преобразователей MPI-RGBA, каждый соответствующий агрегатор PSV-MPI из множества агрегаторов PSV-MPI используется на соответствующем этапе построения или обновление MPI, и каждый соответствующий преобразователь MPI-RGBA из множества преобразователей MPI-RGBA используется на соответствующем этапе получения MPI с текстурой RGBA.
[0024] В дополнительном аспекте блок извлечения признаков представляет собой либо любую нейронную сеть, выполненную с возможностью применения к изображениям, либо блоки извлечения для компьютерного зрения, подобные SIFT или KAZE, агрегаторы PSV-MPI представляют собой любые нейронные сети, выполненные с возможностью обработки последовательностей с произвольной входной длиной, и преобразователи MPI-RGBA представляют собой любые нейронные сети, выполненные с возможностью применения к двумерным или трехмерным тензорам.
[0025] В другом дополнительном аспекте агрегаторы PSV-MPI выполняют подвыборку с механизмом внимания для обработки признаков PSV.
[0026] Другой аспект настоящего изобретения обеспечивает электронное вычислительное устройство, содержащее: по меньшей мере один процессор; и память, в которой хранятся числовые параметры обученной модели ИИ и инструкции, которые при выполнении по меньшей мере одним процессором заставляют по меньшей мере один процессор выполнять способ построения представления сцены по любому из вышеприведенных вариантов осуществления.
[0027] Еще один аспект настоящего изобретения обеспечивает способ построения представления сцены, содержащий этапы, на которых: принимают (S201) набор изображений одной и той же сцены, снятых разными камерами, и внутренние и внешние параметры упомянутых камер; получают (S203) тензоры признаков для каждого изображения из принятого набора изображений посредством извлечения признаков из каждого изображения из принятого набора изображений с помощью блока извлечения признаков обученной модели искусственного интеллекта (ИИ); выполняют построение (S205) объема развертки плоскостей (PSV) посредством конкатенации полученных тензоров признаков в направлении глубины PSV с использованием принятых внутренних и внешних параметров камер; выполняют построение (S207) многоплоскостного изображения (MPI) посредством агрегирования признаков построенного PSV с помощью агрегатора PSV-MPI обученной модели ИИ; получают (S209) MPI с текстурой RGBA посредством обработки признаков каждой плоскости MPI с помощью преобразователя MPI-RGBA обученной модели ИИ; получают (S211) набор изображений, соответствующий принятому набору изображений, из MPI с текстурой RGBA с использованием принятых внутренних и внешних параметров камер; вычисляют (S213) разности между соответствующими изображениями из принятого набора изображений и соответствующими изображениями из набора изображений, полученного из MPI с текстурой RGBA, с использованием функции ошибки; выполняют построение (S215) PSV посредством конкатенации вычисленных разностей в направлении глубины PSV с использованием принятых внутренних и внешних параметров камер; обновляют (S217) MPI посредством агрегирования признаков MPI и признаков текущего PSV с помощью агрегатора PSV-MPI обученной модели ИИ; при этом этапы (S209)-(S217) повторяют заданное количество раз для получения MPI; преобразуют (S219) MPI в многослойное изображение (MLI) с помощью агрегатора MPI-MLI обученной модели ИИ с использованием подвыборки с механизмом внимания для разделения плоскостей MPI на группы и агрегирования тензоров признаков соответствующей группы в соответствующий слой MLA, при этом количество плоскостей больше, чем количество групп; получают (S221) MLI с текстурой RGBA посредством обработки признаков каждого слоя MLI с помощью преобразователя MLI-RGBA обученной модели ИИ; получают (S223) набор изображений, соответствующий принятому набору изображений, из MLI с текстурой RGBA с использованием принятых внутренних и внешних параметров камер; вычисляют (S225) разности между соответствующими изображениями из принятого набора изображений и соответствующими изображениями из набора изображений, полученного из MLI с текстурой RGBA, с использованием функции ошибки; обновляют (S227) MLI посредством проецирования разностей на слои MLI, конкатенации спроецированных разностей с признаками MLI и агрегирования конкатенированных разностей и признаков с помощью агрегатора разности-MLI обученной модели ИИ; при этом этапы (S221)-(S227) повторяют заданное количество раз для получения MLI с текстурой RGBA в качестве представления сцены, и при этом обученная модель ИИ содержит множество агрегаторов PSV-MPI, множество преобразователей MPI-RGBA, множество агрегаторов разности-MLI и множество преобразователей MLI-RGBA, каждый соответствующий агрегатор PSV-MPI из множества агрегаторов PSV-MPI используется на соответствующем этапе построения или обновления MPI, каждый соответствующий преобразователь MPI-RGBA из множества преобразователей MPI-RGBA используется на соответствующем этапе получения MPI c текстурой RGBA, каждый соответствующий агрегатор разности-MLI из множества агрегаторов разности-MLI используется на соответствующем этапе обновления MLI, и каждый соответствующий преобразователь MLI-RGBA из множества преобразователей MLI-RGBA используется на соответствующем этапе получения MLI с текстурой RGBA.
[0028] В дополнительном аспекте блок извлечения признаков представляет собой либо любую нейронную сеть, выполненную с возможностью применения к изображениям, либо блоки извлечения для компьютерного зрения, подобные SIFT или KAZE, агрегаторы PSV-MPI, агрегатор MPI-MLI и агрегаторы разности-MLI представляют собой любые нейронные сети, выполненные с возможностью обработки последовательностей с произвольной входной длиной, и преобразователи MPI-RGBA и преобразователи MLI-RGBA представляют собой любые нейронные сети, выполненные с возможностью применения к двумерным или трехмерным тензорам.
[0029] В другом дополнительном аспекте агрегаторы PSV-MPI выполняют подвыборку с механизмом внимания для обработки признаков PSV.
[0030] Еще один аспект настоящего изобретения обеспечивает электронное вычислительное устройство, содержащее: по меньшей мере один процессор; и память, в которой хранятся числовые параметры обученной модели ИИ и инструкции, которые при выполнении по меньшей мере одним процессором заставляют по меньшей мере один процессор выполнять способ построения представления сцены по любому из вышеприведенных вариантов осуществления.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0031] Фиг. 1А иллюстрирует принцип построения MPI с текстурой RGBA.
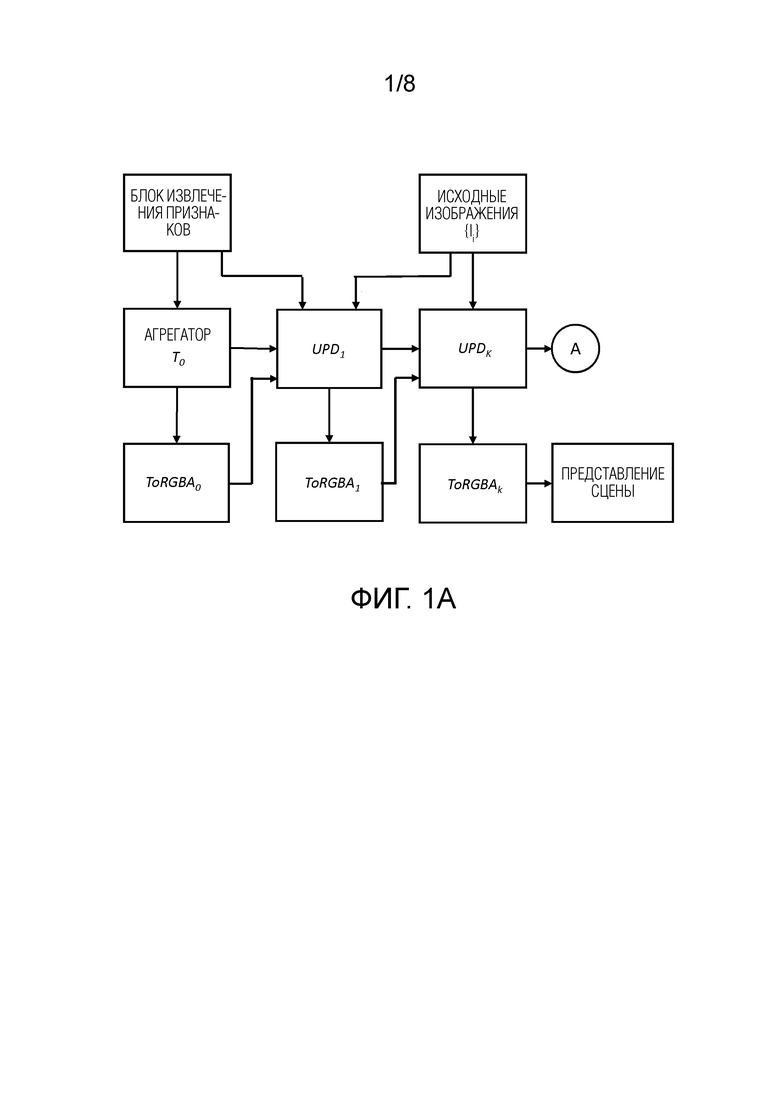
[0032] Фиг. 1В иллюстрирует блоки ToRGBA.
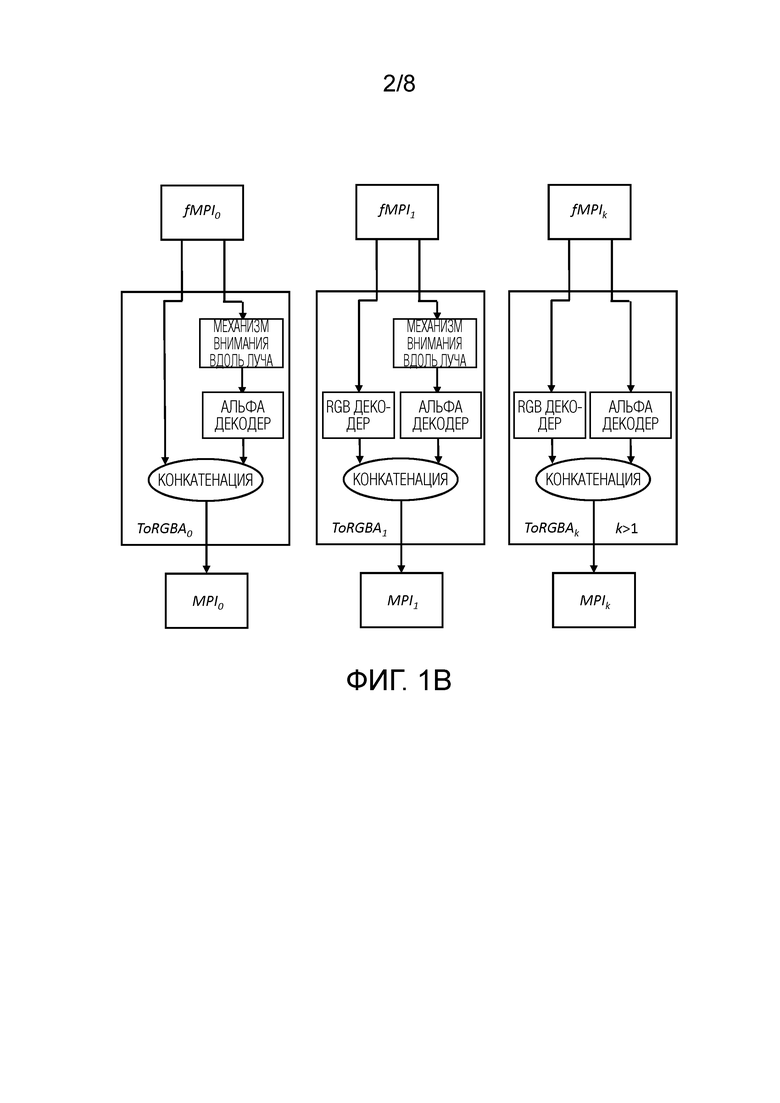
[0033] Фиг. 2 иллюстрирует процедуры UPD.
[0034] Фиг. 3 иллюстрирует блоки Т агрегирования.
[0035] Фиг. 4 иллюстрирует принцип построения MLI с текстурой RGBA.
[0036] Фиг. 5 является блок-схемой последовательности операций способа построения MPI с текстурой RGBA в качестве представления сцены.
[0037] Фиг. 6 является блок-схемой последовательности операций способа построения MLI с текстурой RGBA в качестве представления сцены.
[0038] Фиг. 7 является блок-схемой, иллюстрирующей электронное вычислительное устройство, выполненное с возможностью выполнения способа построения MPI с текстурой RGBA в качестве представления сцены.
[0039] Фиг. 8 является блок-схемой, иллюстрирующей электронное вычислительное устройство, выполненное с возможностью выполнения способа построения MLI с текстурой RGBA в качестве представления сцены.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ НАСТОЯЩЕГО ИЗОБРЕТЕНИЯ
[0040] Нижеследующее описание со ссылкой на прилагаемые чертежи приведено, чтобы облегчить полное понимание различных вариантов осуществления настоящего изобретения, заданного формулой изобретения, и его эквивалентов. Описание включает в себя различные конкретные подробности, чтобы облегчить такое понимание, но данные подробности следует считать только примерными. Соответственно, специалисты в данной области техники обнаружат, что можно разработать различные изменения и модификации различных вариантов осуществления, описанных в настоящей заявке, без выхода за пределы объема настоящего изобретения. Кроме того, описания общеизвестных функций и конструкций могут быть исключены для ясности и краткости.
[0041] Термины и формулировки, используемые в последующем описании и формуле изобретения не ограничены библиографическим значениями, а просто использованы создателем настоящего изобретения, чтобы обеспечить четкое и последовательное понимание настоящего изобретения. Соответственно, специалистам в данной области техники должно быть ясно, что последующее описание различных вариантов осуществления настоящего изобретения предлагается только для иллюстрации.
[0042] Следует понимать, что формы единственного числа включают в себя множественность, если контекст явно не указывает иное.
[0043] Следует понимать, что хотя термины «первый», «второй» и т.д. могут использоваться здесь в отношении элементов настоящего раскрытия, такие элементы не следует толковать как ограниченные этими терминами. Термины используются только для того, чтобы отличить один элемент от других элементов.
[0044] Дополнительно следует понимать, что термины «содержит», «содержащий», «включает в себя» и/или «включающий в себя», при использовании в настоящей заявке, означают присутствие изложенных признаков, значений, операций, элементов и/или компонентов, но не исключают присутствия или добавления одного или более других признаков, значений, операций, элементов, компонентов и/или их групп.
[0045] В различных вариантах осуществления настоящего раскрытия «модуль» или «блок» может выполнять по меньшей мере одну функцию или операцию и может быть реализован с помощью аппаратного обеспечения, программного обеспечения или их комбинации. «Множество модулей» или «множество блоков» может быть реализовано по меньшей мере с одним процессором (не показан) посредством его интеграции по меньшей мере с одним модулем, отличным от «модуля» или «блока», который необходимо реализовать с помощью специального аппаратного обеспечения.
[0046] Принцип построения MPI с текстурой RGBA, или MLI с текстурой RGBA в качестве представления сцены, будет описан со ссылкой на фиг. 1А, 1В, 2, 3, 4.
Представление
[0047] Учитывая набор исходных изображений 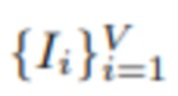 формы 3xHxW с соответствующими положениями камеры {πi} и внутренними параметрами {Ki}, оценивается изображение In, соответствующее изображению новой камеры с известным положением и внутренними параметрами (π’,K’). Чтобы гарантировать обобщение и быстрый логический вывод для такой задачи, используется представление MPI [26]. А именно, положения исходной камеры усредняются с использованием формулировки оптимизации, описанной в [12], и строится виртуальная опорная камера. L плоскостей с разрешением h×w размещены в усеченной пирамиде опорной камеры с равномерным несоответствием по глубине в диапазоне от 1 до 100. Показано, что количество плоскостей связано с частотой дискретизации Найквиста [13, 18]. В большинстве экспериментов выбирается L = 40, в то время как LLFF [13] обычно использует 32 плоскости. Рендеринг нового изображения прост: нужно просто деформировать MPI на новую камеру и скомпоновать поверх [15] деформированные текстуры в отношении его непрозрачности. Критический вопрос здесь заключается в том, как оценить текстуру RGB и непрозрачность представления MPI для всех этих плоскостей. Стоит отметить, что после построения MPI рендеринг произвольного количества новых изображений становится чрезвычайно дешевым и не требует использования каких-либо нейронных сетей.
формы 3xHxW с соответствующими положениями камеры {πi} и внутренними параметрами {Ki}, оценивается изображение In, соответствующее изображению новой камеры с известным положением и внутренними параметрами (π’,K’). Чтобы гарантировать обобщение и быстрый логический вывод для такой задачи, используется представление MPI [26]. А именно, положения исходной камеры усредняются с использованием формулировки оптимизации, описанной в [12], и строится виртуальная опорная камера. L плоскостей с разрешением h×w размещены в усеченной пирамиде опорной камеры с равномерным несоответствием по глубине в диапазоне от 1 до 100. Показано, что количество плоскостей связано с частотой дискретизации Найквиста [13, 18]. В большинстве экспериментов выбирается L = 40, в то время как LLFF [13] обычно использует 32 плоскости. Рендеринг нового изображения прост: нужно просто деформировать MPI на новую камеру и скомпоновать поверх [15] деформированные текстуры в отношении его непрозрачности. Критический вопрос здесь заключается в том, как оценить текстуру RGB и непрозрачность представления MPI для всех этих плоскостей. Стоит отметить, что после построения MPI рендеринг произвольного количества новых изображений становится чрезвычайно дешевым и не требует использования каких-либо нейронных сетей.
Построение PSV
[0048] Здесь задана процедура построения объема развертки плоскостей 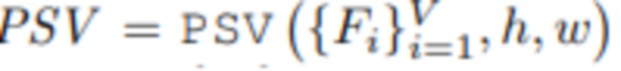 с заданным набором тензоров исходных признаков {Fi}, состоящем из C каналов, и с разрешением плоскостей h×w. Обратите внимание, что признаки {Fi} могут либо совпадать с исходными изображениями {Ii}, либо быть выходами какой-либо сети кодирования. Чтобы построить упомянутый объем, каждый из тензоров признаков «не проецируется» на плоскости с использованием искривления гомографии. Никакая процедура исправления искажений изображения не применяется в случае, если разрешение плоскостей и признаков не равны. Таким образом, выходом процедуры является тензор формы V×L×C×h×w. Как правило, для получения MPI из построенного PSV необходимо исключить ось V, т.е. все исходные признаки необходимо агрегировать, а затем спроецировать в область RGBA [26, 6].
с заданным набором тензоров исходных признаков {Fi}, состоящем из C каналов, и с разрешением плоскостей h×w. Обратите внимание, что признаки {Fi} могут либо совпадать с исходными изображениями {Ii}, либо быть выходами какой-либо сети кодирования. Чтобы построить упомянутый объем, каждый из тензоров признаков «не проецируется» на плоскости с использованием искривления гомографии. Никакая процедура исправления искажений изображения не применяется в случае, если разрешение плоскостей и признаков не равны. Таким образом, выходом процедуры является тензор формы V×L×C×h×w. Как правило, для получения MPI из построенного PSV необходимо исключить ось V, т.е. все исходные признаки необходимо агрегировать, а затем спроецировать в область RGBA [26, 6].
Обновление
[0049] Для простоты раскрывается обновление представления MPI, но эта процедура также применима к MLI.
Инициализация
[0050] В начале предложенного подхода каждое из исходных изображений предварительно обрабатывается с помощью блока извлечения признаков, подобного U-Net, 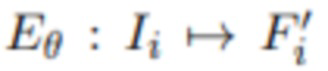 , что дает тензоры V того же разрешения, что и исходные изображения HxW, которые конкатенируются с Ii вдоль оси канала. Эти признаки используются для построения объема развертки плоскостей PSV0 с разрешением h0×w0, который служит входом для сети T0. Результатом этих сетей является начальная версия MPI в области признаков, называемая fMPI0.
, что дает тензоры V того же разрешения, что и исходные изображения HxW, которые конкатенируются с Ii вдоль оси канала. Эти признаки используются для построения объема развертки плоскостей PSV0 с разрешением h0×w0, который служит входом для сети T0. Результатом этих сетей является начальная версия MPI в области признаков, называемая fMPI0.
[0051] Общая схема предложенного подхода представлена на фиг. 1А. Он состоит из четырех этапов, и для всех этапов, кроме начального, сеть ToRGBAk, k≥1, проецирует признаки в область RGBA, 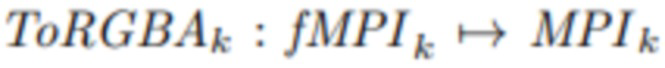 , тогда как ToRGBA0 просто добавляет на ее вход канал непрозрачности. Выходом ToRGBAk является представление сцены. Фиг. 1В демонстрирует архитектуру этих модулей.
, тогда как ToRGBA0 просто добавляет на ее вход канал непрозрачности. Выходом ToRGBAk является представление сцены. Фиг. 1В демонстрирует архитектуру этих модулей.
Коррекция ошибок
[0052] Поскольку реконструкция сцены из набора входных изображений является сложной задачей, настоящий подход использует многоэтапную прямую схему коррекции ошибок, которую побудил использовать документ DeepView [6]. В этом подходе текущее представление сцены, либо MPI, либо MLI, уточняется на основе несоответствия между полученными исходными изображениями и опорными исходными изображениями.
[0053] В частности, текущее состояние представления визуализируется относительно полученных исходных камер и сгенерированных исходных изображений {Îi}. Затем вычисленные ошибки между полученными (визуализированными) изображениями и исходными изображениями пропускаются через модуль агрегирования ошибок, и представление обновляется. Стоит подчеркнуть, что эта процедура реализована чистым прямым способом и не требует никакого обратного распространения (автоматического дифференцирования) во время логического вывода.
Коррекция ошибок MPI
[0054] Важнейшей составляющей предложенного способа является распространение ошибок. Как только будут получены текущая версия многоплоскостного представления fMPIk и MPIk, k≥1 с разрешением hk×wk, можно отобразить состояние RGBA на исходных камерах и получить тензоры 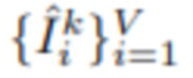 размером H×W. Функция ошибки Δ вычисляет разность между исходным изображением Ii и полученным изображением
размером H×W. Функция ошибки Δ вычисляет разность между исходным изображением Ii и полученным изображением 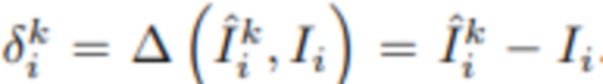 . После этого к набору ошибок применяется процедура PSV, а полученный результат
. После этого к набору ошибок применяется процедура PSV, а полученный результат 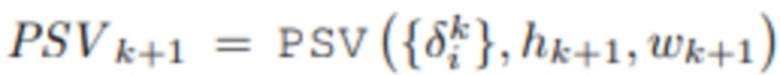 используется для вычисления нового состояния MPI с помощью блока Tk+1 агрегирования (фиг. 3)
используется для вычисления нового состояния MPI с помощью блока Tk+1 агрегирования (фиг. 3) 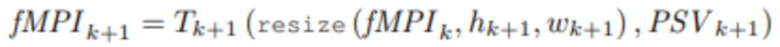 .
.
[0055] Отметим, что при этом обновлении также возможно увеличить разрешение MPI с hk×wk до hk+1×wk+1, что дает возможность строить представление от грубого к точному. В опытах используется способ 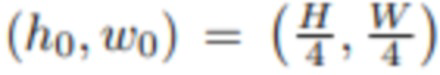 , а для
, а для 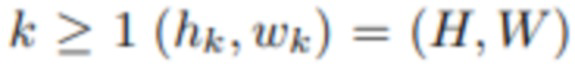 . Операция изменения размера реализована с помощью билинейной интерполяции. Вся процедура обозначена как UPDk+1, т.е.
. Операция изменения размера реализована с помощью билинейной интерполяции. Вся процедура обозначена как UPDk+1, т.е. 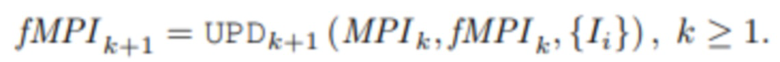
Чтобы обновить состояние MPI в первый раз, та же процедура применяется к извлеченным признакам {Fi} вместо изображений RGB {Ii}.
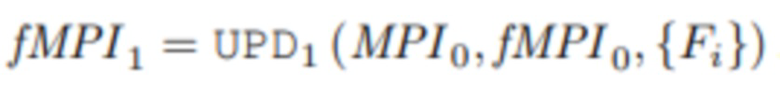 .
.
Схема процедур UPDk представлена на фиг. 2. Выходом предложенного подхода является состояние MPI4.
Сетевые архитектуры
Модули обновления
[0056] Модуль Tk+1 обновления принимает объем развертки плоскостей PSVk+1 формы 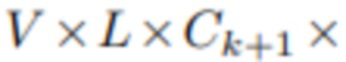
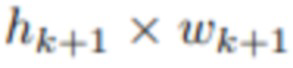 . Во-первых, вычисляется среднее значение признаков изображения и отклонение признаков изображения по оси V. Однако в некоторых случаях этих выборочных статистических данных может быть недостаточно для агрегирования имеющейся информации. Поэтому может быть также необязательно применена операция самовнимания, такая как подвыборка с механизмом внимания [10], в отношении того же размера. Среднее значение, отклонение и (для k≥1) предыдущее состояние fMPIk вдоль оси каналов конкатенируются и обрабатываются 2D-блоками ResNet [8] (каждая из L плоскостей обрабатывается независимо). Выход подвыборки может быть необязательно конкатенирован со средним значением, отклонением. Это производит обновленную версию fMPIk+1.
. Во-первых, вычисляется среднее значение признаков изображения и отклонение признаков изображения по оси V. Однако в некоторых случаях этих выборочных статистических данных может быть недостаточно для агрегирования имеющейся информации. Поэтому может быть также необязательно применена операция самовнимания, такая как подвыборка с механизмом внимания [10], в отношении того же размера. Среднее значение, отклонение и (для k≥1) предыдущее состояние fMPIk вдоль оси каналов конкатенируются и обрабатываются 2D-блоками ResNet [8] (каждая из L плоскостей обрабатывается независимо). Выход подвыборки может быть необязательно конкатенирован со средним значением, отклонением. Это производит обновленную версию fMPIk+1.
Проецирование в RGB
[0057] Чтобы получить цвет RGB из признаков, ToRGBAk, k≥1, применяет многослойный персептрон. Процесс предсказания непрозрачности (k≥0) более сложен, так как именно прозрачность отвечает за обработку окклюзий сцены. Для обеспечения взаимодействия между разными слоями используется операция самовнимания вдоль оси L тензора признаков формы L×Ck×hk×wk, обозначенная на фиг. 1В как механизм внимания вдоль луча. После этого персептрон с финальной сигмовидной активацией завершает расчет альфа-канала.
Преобразование MPI в MLI
[0058] Преобразование MPI в MLI и дальнейшая обработка MLI показаны на фиг. 4. Основная идея многослойного представления (MLI) заключается в оценке набора слоев адаптивной к сцене сетки с полупрозрачными текстурами. Хотя MPI способно отображать детали сцены в высоком качестве, для получения правдоподобных результатов требуется довольно большое количество плоскостей. Более того, существует теоретическая нижняя граница необходимого числа плоскостей [18, 13, 2]. Представление MLI более компактно, так как оно может использовать значительно меньше слоев для достижения аналогичного качества. Таким образом, оно обеспечивает чрезвычайно быстрый рендеринг с заметно меньшим объемом памяти для хранения данных. Кроме того, эта геометрия прокси свободна от упомянутых теоретических ограничений.
[0059] В некоторых предыдущих документах [2] преобразование MPI в MLI выполнялось с помощью процедуры постобработки, основанной на эвристике. В отличие от них, эта структура напрямую генерируется на основе идей, исследованных в документе StereoLayeres [29] для случая только двух входных кадров. Этот подход дает стабильные результаты и при компоновке множества изображений, даже если исходные изображения разрежены. Подробно набор плоскостей MPI подразделяется на группы одинакового размера, и каждая группа объединяется в один деформируемый слой, т.е. предсказывается соответствующая карта глубины и текстура. Чтобы преобразовать карту глубины в сетку, каждый пиксель упомянутой карты обрабатывается как вершина и соединяется с соседними шестью вершинами с помощью граней. Таким образом, каждый четырехугольник (блок пикселей 2×2) состоит из двух треугольников. Средство рендеринга nvdiffrast [35] может быть использовано для того, чтобы сделать процесс растеризации дифференцируемым по сравнению с геометрией многослойной сетки и обучать конвейер с помощью стандартных способов глубокого обучения.
Коррекция ошибок MLI
[0060] После получения многослойной геометрии fMLI проводится этап коррекции, аналогичный тому, который применялся к MPI, но теперь несоответствие вычисляется в области RGB только при разрешении H×W. После обновления fMLI оно преобразуется из области признаков в RGBA и это окончательное представление представляет собой MLI.
Подвыборка с механизмом внимания
[0061] Операция подвыборки с механизмом внимания [10] применяется в конвейере для выполнения слияния из различного количества входных данных в предопределенное количество выходных данных. По сути, это модуль внимания [20], где вопросы представлены обучаемыми векторами, называемыми точками привязки, независимыми от входных данных, а указания к решению и значения равны входным векторам.
[0062] В случае MPI рендеринг выполняется с помощью деформации гомографии, тогда как MLI требует использования дифференцируемого средства рендеринга. Кроме того, в случае MLI операция unproj «не проецирует» входные данные на предопределенные деформируемые слои вместо жестких плоскостей. Поскольку коррекция MLI выполняется в полном разрешении, для экономии памяти предсказанный цвет не конкатенируется с признаками перед рендерингом и вычисляется ошибка только в области RGB.
Обучение
[0063] Процесс обучения представленной модели типичен для конвейеров NVS. Однако обратите внимание, что предлагаемая система обучается на наборе данных сцен, в отличие от некоторых других подходов [32, 16, 19, 23], которые требуют специального обучения для каждой сцены. Сначала отбираются исходные изображения V, и они используются для построения представления MLI с помощью процедуры, описанной выше. После того, как MLI построено, оно визуализируется на N новых (контрольных) камерах, отобранных из той же сцены, что и исходные камеры, и сгенерированные изображения 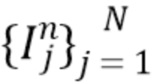 сравниваются с опорными изображениями с использованием следующих потерь:
сравниваются с опорными изображениями с использованием следующих потерь:
Потери изображения
Пиксельная потеря ℓ1: 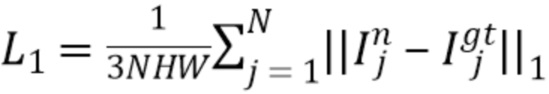 и потеря восприятия [37]
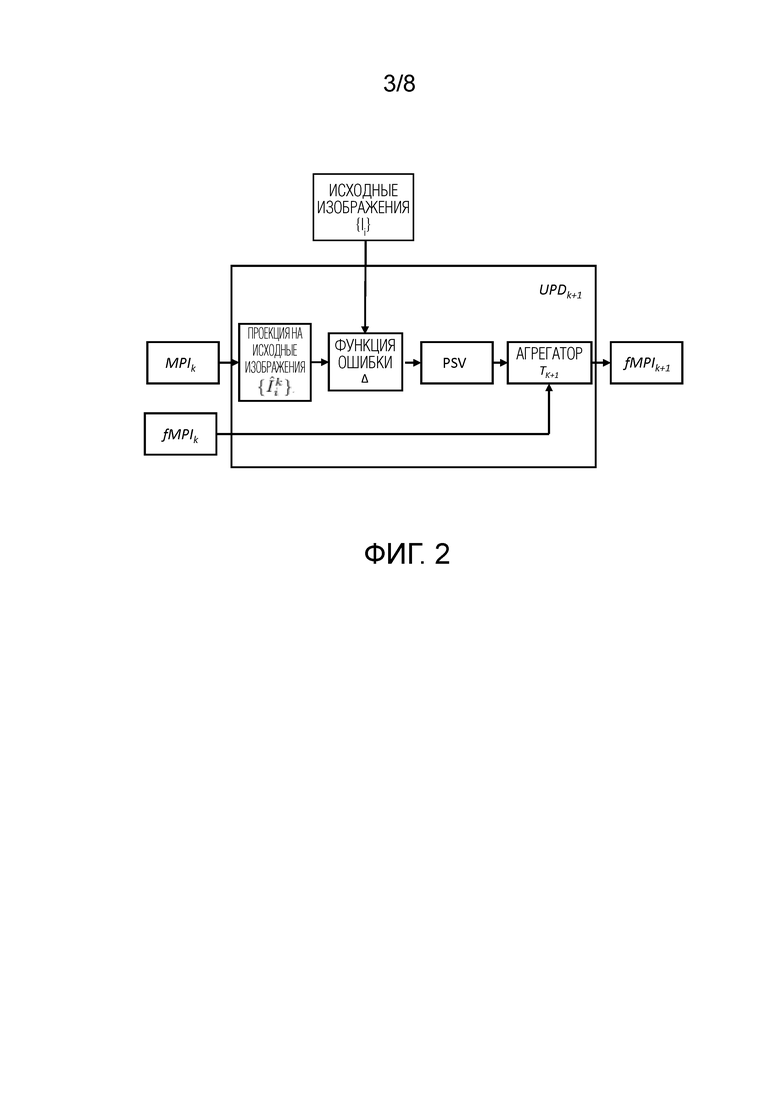
и потеря восприятия [37] 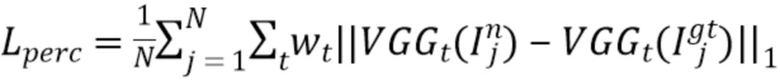 применяются к визуализированным изображениям для новых положений, где веса wt соответствуют разным слоям сети VGG [36].
применяются к визуализированным изображениям для новых положений, где веса wt соответствуют разным слоям сети VGG [36].
Полная вариация
Чтобы сделать геометрию деформируемых слоев более гладкой, на глубину каждого слоя накладывают полные вариационные (TV) потери (потери вычисляются для каждой из L-карт независимо).
Веса
Суммарно функция потерь равна L = λ1L1 + λpercLperc + λtvLtv, и по умолчанию λ1 = 1, λperc = 2, λtv = 0,1.
[0064] По меньшей мере один из множества модулей может быть реализован посредством модели искусственного интеллекта (ИИ). Функция, связанная с ИИ, может выполняться посредством энергонезависимой памяти, энергозависимой памяти и процессора.
[0065] Процессор может включать в себя один или множество процессоров. В то же время один или множество процессоров могут быть процессором общего назначения, таким как центральный процессор (ЦП), процессор приложений (AP) или подобный, процессором для графики, таким как графический процессор (GPU), процессор обработки изображений (VPU) и/или специализированным процессором искусственного интеллекта (ИИ), таким как нейронный процессор (NPU).
[0066] Один или более процессоров управляют обработкой входных данных в соответствии с заданным правилом работы или моделью ИИ, хранящимися в энергонезависимой памяти или энергозависимой памяти. Заданное правило работы или модель искусственного интеллекта обеспечивается посредством обучения.
[0067] В данном случае обеспечение посредством обучения означает, что, применяя алгоритм обучения ко множеству обучающих данных, создается заданное правило работы или модель ИИ требуемой характеристики. Обучение может быть выполнено в самом устройстве, которое содержит ИИ в соответствии с вариантом осуществления, и/или может быть реализовано через отдельный сервер/систему.
[0068] Модель ИИ может состоять из множества слоев нейронной сети. Каждый слой имеет множество весовых значений и выполняет операцию слоя с использованием вычисления предыдущего слоя и множества весов. Примеры нейронных сетей включают в себя, но не ограничиваются ими, сверточную нейронную сеть (CNN), глубокую нейронную сеть (DNN), рекуррентную нейронную сеть (RNN), ограниченную машину Больцмана (RBM), глубокую сеть доверия (DBN), двунаправленную рекуррентную глубокую нейронную сеть (BRDNN), генеративные состязательные сети (GAN) и глубокие Q-сети.
[0069] Алгоритм обучения является способом обучения заранее заданного целевого устройства (например, автоматического устройства) с использованием множества обучающих данных, чтобы заставлять, позволять или управлять целевым устройством для выполнения определения или предсказания. Примеры алгоритмов обучения включают, но не ограничиваются этим, обучение с учителем, обучение без учителя, обучение частично с учителем или обучение с подкреплением.
[0070] Способ 100 построения представления сцены более подробно описан со ссылкой на фиг. 5. Представление сцены, построенное способом 100, представляет собой MPI с текстурой RGBA. Способ 100 содержит этапы S101-S117.
[0071] На этапе S101 принимают набор изображений одной и той же сцены, снятых разными камерами, и внутренние и внешние параметры упомянутых камер. Набор изображений может быть принят из памяти, сервера, Интернета и т. д. в виде видео статических сцен [32, 21, 31], снимков с многокамерной установки [6, 13] и т.д. Внутренние параметры камеры включают в себя фокусное расстояние, формат датчика изображения и главную точку. Внешние параметры камеры включают в себя местоположение и ориентацию камеры относительно мировой системы координат.
[0072] На этапе S103 тензоры признаков для каждого изображения из принятого набора изображений получают посредством извлечения признаков из каждого изображения из принятого набора изображений с помощью блока извлечения признаков обученной модели искусственного интеллекта (ИИ). Извлечение признаков может быть выполнено любыми известными способами. Поэтому подробное описание извлечения признаков здесь опущено.
[0073] На этапе S105 выполняют построение объема развертки плоскостей (PSV) посредством конкатенации полученных тензоров признаков в направлении глубины PSV с использованием принятых внутренних и внешних параметров камер.
[0074] На этапе S107 выполняют построение многоплоскостного изображения (MPI) посредством агрегирования признаков построенного PSV с помощью агрегатора PSV-MPI обученной модели ИИ. Агрегатор PSV-MPI представляет собой агрегатор T, описанный выше и показанный на фиг. 1А, 2, 3. MPI представляет собой fMPI, описанное выше и проиллюстрированное на фиг. 1В, 2, 3.
[0075] На этапе S109 получают MPI с текстурой RGBA посредством обработки признаков каждой плоскости MPI с помощью преобразователя MPI-RGBA обученной модели ИИ. Преобразователь MPI-RGBA представляет собой ToRGBA, описанный выше и проиллюстрированный на фиг. 1А, 1В. MPI с текстурой RGBA представляет собой MPI, описанное выше и проиллюстрированное на фиг. 1B, 2.
[0076] На этапе S111 получают набор изображений, соответствующий принятому набору изображений, из MPI с текстурой RGBA с использованием принятых внутренних и внешних параметров камер.
[0077] На этапе S113 вычисляют разности между соответствующими изображениями из принятого набора изображений и соответствующими изображениями из набора изображений, полученного из MPI с текстурой RGBA, с использованием функции ошибки.
[0078] На этапе S115 выполняют построение PSV посредством конкатенации вычисленных разностей в направлении глубины PSV с использованием принятых внутренних и внешних параметров камер.
[0079] На этапе S117 обновляют MPI посредством агрегирования признаков MPI и признаков текущего PSV с помощью агрегатора PSV-MPI обученной модели ИИ.
[0080] Этапы S109-S117 повторяют заданное количество раз для получения MPI с текстурой RGBA в качестве представления сцены. Заданное количество раз для повторения этапов S109-S117 задается заранее в зависимости от требуемого качества представления сцены. Чем больше повторений, тем выше качество представления сцены.
[0081] Обученная модель ИИ содержит множество агрегаторов PSV-MPI и множество преобразователей MPI-RGBA, каждый соответствующий агрегатор PSV-MPI из множества агрегаторов PSV-MPI используется на соответствующем этапе построения или обновление MPI, и каждый соответствующий преобразователь MPI-RGBA из множества преобразователей MPI-RGBA используется на соответствующем этапе получения MPI с текстурой RGBA.
[0082] Блок извлечения признаков может быть либо любой нейронной сетью, выполненной с возможностью применения к изображениям, либо блоками извлечения для компьютерного зрения, подобными SIFT или KAZE. Агрегаторы PSV-MPI могут быть любыми нейронными сетями, выполненными с возможностью обработки последовательностей с произвольной входной длиной. Преобразователи MPI-RGBA могут любыми нейронными сетями, выполненными с возможностью применения к двумерным или трехмерным тензорам.
[0083] В одном варианте осуществления способа 100 агрегаторы PSV-MPI выполняют подвыборку с механизмом внимания для обработки признаков PSV.
[0084] Способ 200 построения представления сцены более подробно описан со ссылкой на фиг. 6. Представление сцены, построенное способом 200, представляет собой MLI с текстурой RGBA. Способ 100 содержит этапы S201-S227. Этапы S201-S217 те же, что и этапы S101-S117, соответственно.
[0085] Этапы S209-S217 повторяют заданное количество раз для получения MPI. Заданное количество раз для повторения этапов S209-S217 задается заранее в зависимости от требуемого качества представления сцены. Чем больше повторений, тем выше качество представления сцены.
[0086] На этапе S219 преобразуют MPI в многослойное изображение (MLI) с помощью агрегатора MPI-MLI обученной модели ИИ с использованием подвыборки с механизмом внимания для разделения плоскостей MPI на группы и агрегирования тензоров признаков соответствующей группы в соответствующий слой MLA, при этом количество плоскостей больше, чем количество групп. MPI представляет собой fMPI, описанное выше и проиллюстрированное на фиг. 1В, 2, 3. MLI представляет собой fMLI, описанное выше и проиллюстрированное на фиг. 4.
[0087] На этапе S221 получают MLI с текстурой RGBA посредством обработки признаков каждого слоя MLI с помощью преобразователя MLI-RGBA обученной модели ИИ. MLI с текстурой RGBA представляет собой MLI, описанное выше и проиллюстрированное на фиг. 4.
[0088] На этапе S223 получают набор изображений, соответствующий принятому набору изображений, из MLI с текстурой RGBA с использованием принятых внутренних и внешних параметров камер.
[0089] На этапе S225 вычисляют разности между соответствующими изображениями из принятого набора изображений и соответствующими изображениями из набора изображений, полученного из MLI с текстурой RGBA, с использованием функции ошибки.
[0090] На этапе S227 обновляют MLI посредством проецирования разностей на слои MLI, конкатенации спроецированных разностей с признаками MLI и агрегирования конкатенированных разностей и признаков с помощью агрегатора разности-MLI обученной модели ИИ.
[0091] Этапы S221-S227 повторяют заданное количество раз для получения MLI с текстурой RGBA в качестве представления сцены. Заданное количество раз для повторения этапов S221-S227 задается заранее в зависимости от требуемого качества представления сцены. Чем больше повторений, тем выше качество представления сцены.
[0092] Обученная модель ИИ содержит множество агрегаторов PSV-MPI, множество преобразователей MPI-RGBA, множество агрегаторов разности-MLI и множество преобразователей MLI-RGBA, каждый соответствующий агрегатор PSV-MPI из множества агрегаторов PSV-MPI используется на соответствующем этапе построения или обновления MPI, каждый соответствующий преобразователь MPI-RGBA из множества преобразователей MPI-RGBA используется на соответствующем этапе получения MPI c текстурой RGBA, каждый соответствующий агрегатор разности-MLI из множества агрегаторов разности-MLI используется на соответствующем этапе обновления MLI, и каждый соответствующий преобразователь MLI-RGBA из множества преобразователей MLI-RGBA используется на соответствующем этапе получения MLI с текстурой RGBA.
[0093] Блок извлечения признаков может быть либо любой нейронной сетью, выполненной с возможностью применения к изображениям, либо блоками извлечения для компьютерного зрения, подобными SIFT или KAZE. Агрегаторы PSV-MPI, агрегатор MPI-MLI и агрегаторы разности-MLI могут быть любыми нейронными сетями, выполненными с возможностью обработки последовательностей с произвольной входной длиной. Преобразователи MPI-RGBA и преобразователи MLI-RGBA могут любыми нейронными сетями, выполненными с возможностью применения к двумерным или трехмерным тензорам.
[0094] В одном варианте осуществления способа 200 агрегаторы PSV-MPI выполняют подвыборку с механизмом внимания для обработки признаков PSV.
[0095] Блок-схема, иллюстрирующая электронное вычислительное устройство 300 в соответствии с настоящим изобретением, показана на фиг. 7. Электронное вычислительное устройство 300 выполнено с возможностью выполнения способа 100. Электронное вычислительное устройство 300 содержит по меньшей мере один процессор 301 и память 302.
[0096] Память 302 хранит числовые параметры обученной модели ИИ и инструкции. По меньшей мере один процессор 301 исполняет инструкции, хранящиеся в памяти 302, чтобы выполнять способ 100 построения представления сцены.
[0097] Блок-схема, иллюстрирующая электронное вычислительное устройство 400 в соответствии с настоящим изобретением, показана на фиг. 8. Электронное вычислительное устройство 400 выполнено с возможностью выполнения способа 200. Электронное вычислительное устройство 400 содержит по меньшей мере один процессор 401 и память 402.
[0098] Память 402 хранит числовые параметры обученной модели ИИ и инструкции. По меньшей мере один процессор 401 исполняет инструкции, хранящиеся в памяти 402, чтобы выполнять способ 200 построения представления сцены.
[0099] Способы, раскрытые в настоящем документе, могут быть реализованы по меньшей мере одним процессором, таким как центральный процессор (CPU), графический процессор (GPU), реализованным на по меньшей мере одной из специализированной интегральной схеме (ASIC), программируемой пользователем матрице логических элементов (FPGA), но изобретение не ограничено ими. Кроме того, способы, раскрытые в настоящем документе, могут быть реализованы с помощью считываемого компьютером носителя, в котором хранятся числовые параметры модели ИИ и исполняемые компьютером инструкции, которые при выполнении процессором компьютера заставляют компьютер выполнять способ согласно изобретению. Модель ИИ и инструкции по реализации настоящего способа могут быть загружены в электронное вычислительное устройство через сеть или с носителя.
[0100] Настоящее изобретение может применяться в 3D-фотографии, устройствах виртуальной реальности, устройствах дополненной реальности, смартфонах, компьютерах, 2D- и 3D-дисплеях, телевизорах, а также других вычислительных устройствах и системах.
[0101] Вышеприведенные описания вариантов осуществления изобретения являются иллюстративными, и модификации конфигурации и реализации не выходят за пределы объема настоящего описания. Например, хотя варианты осуществления изобретения описаны, в общем, в связи с фигурами 5-8, приведенные описания являются примерными. Хотя предмет изобретения описан на языке, характерном для конструктивных признаков или методологических операций, понятно, что предмет изобретения не обязательно ограничен конкретными вышеописанными признаками или операциями. Более того, конкретные вышеописанные признаки и операции раскрыты как примерные формы реализации формулы изобретения. Изобретение не ограничено также показанным порядком этапов способа, порядок может быть видоизменен специалистом без новаторских нововведений. Некоторые или все этапы способа могут выполняться последовательно или параллельно.
[0102] Соответственно предполагается, что объем вариантов осуществления изобретения ограничивается только нижеследующей формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ создания многослойного представления сцены и вычислительное устройство для его реализации | 2021 |
|
RU2787928C1 |
| Способ синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора, и электронное вычислительное устройство для его реализации | 2020 |
|
RU2749749C1 |
| СИСТЕМА ДЛЯ ГЕНЕРАЦИИ ВИДЕО С РЕКОНСТРУИРОВАННОЙ ФОТОРЕАЛИСТИЧНОЙ 3D-МОДЕЛЬЮ ЧЕЛОВЕКА, СПОСОБЫ НАСТРОЙКИ И РАБОТЫ ДАННОЙ СИСТЕМЫ | 2024 |
|
RU2834188C1 |
| СПОСОБ СОЗДАНИЯ АНИМИРУЕМОГО АВАТАРА ЧЕЛОВЕКА В ПОЛНЫЙ РОСТ ИЗ ОДНОГО ИЗОБРАЖЕНИЯ ЧЕЛОВЕКА, ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2023 |
|
RU2813485C1 |
| СПОСОБ ВИЗУАЛИЗАЦИИ 3D ПОРТРЕТА ЧЕЛОВЕКА С ИЗМЕНЕННЫМ ОСВЕЩЕНИЕМ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ НЕГО | 2021 |
|
RU2757563C1 |
| Устройство создания многомерных виртуальных изображений органов дыхания человека и способ создания объёмных изображений с применением устройства | 2021 |
|
RU2783364C1 |
| НЕЙРОННАЯ ТОЧЕЧНАЯ ГРАФИКА | 2019 |
|
RU2729166C1 |
| Способ и электронное устройство для обнаружения трехмерных объектов с помощью нейронных сетей | 2021 |
|
RU2776814C1 |
| ВИЗУАЛИЗАЦИЯ РЕКОНСТРУКЦИИ 3D-СЦЕНЫ С ИСПОЛЬЗОВАНИЕМ СЕМАНТИЧЕСКОЙ РЕГУЛЯРИЗАЦИИ НОРМАЛЕЙ TSDF ПРИ ОБУЧЕНИИ НЕЙРОННОЙ СЕТИ | 2023 |
|
RU2825722C1 |
| Быстрый двухслойный нейросетевой синтез реалистичных изображений нейронного аватара по одному снимку | 2020 |
|
RU2764144C1 |
Изобретение относится к области компьютерного зрения. Техническим результатом является повышение скорости и качества обработки изображений. Для достижения технического результата в заявленном решении принимают набор изображений одной и той же сцены, снятых разными камерами; получают тензоры признаков для каждого изображения; выполняют построение объема развертки плоскостей (PSV) посредством конкатенации полученных тензоров признаков в направлении глубины PSV с использованием принятых внутренних и внешних параметров камер; выполняют построение многоплоскостного изображения (MPI); получают MPI с текстурой RGBA; вычисляют разности между соответствующими изображениями из принятого набора изображений и соответствующими изображениями из набора изображений, полученного из MPI с текстурой RGBA, с использованием функции ошибки; выполняют построение PSV посредством конкатенации вычисленных разностей в направлении глубины PSV; обновляют MPI посредством агрегирования признаков MPI и признаков текущего PSV. 4 н. и 4 з.п. ф-лы, 9 ил.
1. Способ построения представления сцены, содержащий этапы, на которых:
принимают (S101) набор изображений одной и той же сцены, снятых разными камерами, и внутренние и внешние параметры упомянутых камер;
получают (S103) тензоры признаков для каждого изображения из принятого набора изображений посредством извлечения признаков из каждого изображения из принятого набора изображений с помощью блока извлечения признаков обученной модели искусственного интеллекта (ИИ);
выполняют построение (S105) объема развертки плоскостей (PSV) посредством конкатенации полученных тензоров признаков в направлении глубины PSV с использованием принятых внутренних и внешних параметров камер;
выполняют построение (S107) многоплоскостного изображения (MPI) посредством агрегирования признаков построенного PSV с помощью агрегатора PSV-MPI обученной модели ИИ;
получают (S109) MPI с текстурой RGBA посредством обработки признаков каждой плоскости MPI с помощью преобразователя MPI-RGBA обученной модели ИИ;
получают (S111) набор изображений, соответствующий принятому набору изображений, из MPI с текстурой RGBA с использованием принятых внутренних и внешних параметров камер;
вычисляют (S113) разности между соответствующими изображениями из принятого набора изображений и соответствующими изображениями из набора изображений, полученного из MPI с текстурой RGBA, с использованием функции ошибки;
выполняют построение (S115) PSV посредством конкатенации вычисленных разностей в направлении глубины PSV с использованием принятых внутренних и внешних параметров камер;
обновляют (S117) MPI посредством агрегирования признаков MPI и признаков текущего PSV с помощью агрегатора PSV-MPI обученной модели ИИ;
при этом этапы (S109)-(S117) повторяют заданное количество раз для получения MPI с текстурой RGBA в качестве представления сцены, и
при этом обученная модель ИИ содержит множество агрегаторов PSV-MPI и множество преобразователей MPI-RGBA, каждый соответствующий агрегатор PSV-MPI из множества агрегаторов PSV-MPI используется на соответствующем этапе построения или обновления MPI, и каждый соответствующий преобразователь MPI-RGBA из множества преобразователей MPI-RGBA используется на соответствующем этапе получения MPI с текстурой RGBA.
2. Способ по п. 1, в котором блок извлечения признаков представляет собой либо любую нейронную сеть, выполненную с возможностью применения к изображениям, либо блоки извлечения для компьютерного зрения, подобные SIFT или KAZE, агрегаторы PSV-MPI представляют собой любые нейронные сети, выполненные с возможностью обработки последовательностей с произвольной входной длиной, и преобразователи MPI-RGBA представляют собой любые нейронные сети, выполненные с возможностью применения к двумерным или трехмерным тензорам.
3. Способ по п. 1 или 2, в котором агрегаторы PSV-MPI выполняют подвыборку с механизмом внимания для обработки признаков PSV.
4. Электронное вычислительное устройство для построения представления сцены, содержащее:
по меньшей мере один процессор; и
память, в которой хранятся числовые параметры обученной модели ИИ и инструкции, которые при выполнении по меньшей мере одним процессором заставляют по меньшей мере один процессор выполнять способ построения представления сцены по любому из пп. 1-3.
5. Способ построения представления сцены, содержащий этапы, на которых:
принимают (S201) набор изображений одной и той же сцены, снятых разными камерами, и внутренние и внешние параметры упомянутых камер;
получают (S203) тензоры признаков для каждого изображения из принятого набора изображений посредством извлечения признаков из каждого изображения из принятого набора изображений с помощью блока извлечения признаков обученной модели искусственного интеллекта (ИИ);
выполняют построение (S205) объема развертки плоскостей (PSV) посредством конкатенации полученных тензоров признаков в направлении глубины PSV с использованием принятых внутренних и внешних параметров камер;
выполняют построение (S207) многоплоскостного изображения (MPI) посредством агрегирования признаков построенного PSV с помощью агрегатора PSV-MPI обученной модели ИИ;
получают (S209) MPI с текстурой RGBA посредством обработки признаков каждой плоскости MPI с помощью преобразователя MPI-RGBA обученной модели ИИ;
получают (S211) набор изображений, соответствующий принятому набору изображений, из MPI с текстурой RGBA с использованием принятых внутренних и внешних параметров камер;
вычисляют (S213) разности между соответствующими изображениями из принятого набора изображений и соответствующими изображениями из набора изображений, полученного из MPI с текстурой RGBA, с использованием функции ошибки;
выполняют построение (S215) PSV посредством конкатенации вычисленных разностей в направлении глубины PSV с использованием принятых внутренних и внешних параметров камер;
обновляют (S217) MPI посредством агрегирования признаков MPI и признаков текущего PSV с помощью агрегатора PSV-MPI обученной модели ИИ;
при этом этапы (S209)-(S217) повторяют заданное количество раз для получения MPI;
преобразуют (S219) MPI в многослойное изображение (MLI) с помощью агрегатора MPI-MLI обученной модели ИИ с использованием подвыборки с механизмом внимания для разделения плоскостей MPI на группы и агрегирования тензоров признаков соответствующей группы в соответствующий слой MLA, при этом количество плоскостей больше, чем количество групп;
получают (S221) MLI с текстурой RGBA посредством обработки признаков каждого слоя MLI с помощью преобразователя MLI-RGBA обученной модели ИИ;
получают (S223) набор изображений, соответствующий принятому набору изображений, из MLI с текстурой RGBA с использованием принятых внутренних и внешних параметров камер;
вычисляют (S225) разности между соответствующими изображениями из принятого набора изображений и соответствующими изображениями из набора изображений, полученного из MLI с текстурой RGBA, с использованием функции ошибки;
обновляют (S227) MLI посредством проецирования разностей на слои MLI, конкатенации спроецированных разностей с признаками MLI и агрегирования конкатенированных разностей и признаков с помощью агрегатора разности-MLI обученной модели ИИ;
при этом этапы (S221)-(S227) повторяют заданное количество раз для получения MLI с текстурой RGBA в качестве представления сцены, и
при этом обученная модель ИИ содержит множество агрегаторов PSV-MPI, множество преобразователей MPI-RGBA, множество агрегаторов разности-MLI и множество преобразователей MLI-RGBA, каждый соответствующий агрегатор PSV-MPI из множества агрегаторов PSV-MPI используется на соответствующем этапе построения или обновления MPI, каждый соответствующий преобразователь MPI-RGBA из множества преобразователей MPI-RGBA используется на соответствующем этапе получения MPI c текстурой RGBA, каждый соответствующий агрегатор разности-MLI из множества агрегаторов разности-MLI используется на соответствующем этапе обновления MLI, и каждый соответствующий преобразователь MLI-RGBA из множества преобразователей MLI-RGBA используется на соответствующем этапе получения MLI с текстурой RGBA.
6. Способ по п. 5, в котором блок извлечения признаков представляет собой либо любую нейронную сеть, выполненную с возможностью применения к изображениям, либо блоки извлечения для компьютерного зрения, подобные SIFT или KAZE, агрегаторы PSV-MPI, агрегатор MPI-MLI и агрегаторы разности-MLI представляют собой любые нейронные сети, выполненные с возможностью обработки последовательностей с произвольной входной длиной, и преобразователи MPI-RGBA и преобразователи MLI-RGBA представляют собой любые нейронные сети, выполненные с возможностью применения к двумерным или трехмерным тензорам.
7. Способ по п. 5 или 6, в котором агрегаторы PSV-MPI выполняют подвыборку с механизмом внимания для обработки признаков PSV.
8. Электронное вычислительное устройство для построения представления сцены, содержащее:
по меньшей мере один процессор; и
память, в которой хранятся числовые параметры обученной модели ИИ и инструкции, которые при выполнении по меньшей мере одним процессором заставляют по меньшей мере один процессор выполнять способ построения представления сцены по любому из пп. 5-7.
| TINGHUI ZHOU et al.: "Stereo Magnification: Learning view synthesis using multiplane images", 2018, [найдено: 03.02.2022] Найдено в: "https://arxiv.org/abs/1805.09817" | |||
| HSIN-PING HUANG et al: "Semantic View Synthesis", 2020, [найдено: 03.02.2022] Найдено в: https://arxiv.org/pdf/2008.10598v1.pdf#page=3 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПРЕДОСТАВЛЕНИЯ МНОГОСЛОЙНОЙ МОДЕЛИ СЦЕНЫ С ГЛУБИНОЙ И СИГНАЛ, СОДЕРЖАЩИЙ МНОГОСЛОЙНУЮ МОДЕЛЬ СЦЕНЫ С ГЛУБИНОЙ | 2009 |
|
RU2513894C2 |
| KARA-ALI ALIEV | |||
