ПЕРЕКРЕСТНЫЕ ССЫЛКИ НА РОДСТВЕННЫЕ ЗАЯВКИ
Настоящая заявка не является предварительной и испрашивает приоритет на основе Предварительной Заявки на патент США № 62/510,256, поданной 23 мая 2017, и Предварительной Заявки на патент США № 62/541,594, поданной 4 августа 2017. Содержание вышеуказанных заявок тем самым полностью включается в настоящую заявку посредством ссылки.
УРОВЕНЬ ТЕХНИКИ
Настоящее описание изобретения имеет отношение к преобразованию последовательностей с использованием нейронных сетей.
Нейронные сети представляют собой модели машинного обучения, которые задействуют один или несколько слоев нелинейных блоков, чтобы прогнозировать вывод для принятого ввода. Некоторые нейронные сети включают в себя один или несколько скрытых слоев в дополнение к выходному слою. Вывод каждого скрытого слоя используются в качестве ввода для следующего слоя в сети, т.е. следующего скрытого слоя или выходного слоя. Каждый слой сети генерирует вывод исходя из принятого ввода в соответствии с текущими значениями соответственного набора параметров.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Настоящее описание изобретения описывает систему, реализованную в виде компьютерных программ на одном или нескольких компьютерах в одном или нескольких местоположениях, которая генерирует выходную последовательность, которая включает в себя соответственный вывод в каждой из множественных позиций в порядке вывода, исходя из входной последовательности, которая включает в себя соответственный ввод в каждой из множественных позиций в порядке ввода, т.е. преобразовывает входную последовательность в выходную последовательность. В частности, система генерирует выходную последовательность, используя нейронную сеть кодировщика и нейронную сеть декодировщика, обе на основе внимания.
Конкретные варианты осуществления изобретения, описанного в настоящем описании изобретения, могут быть реализованы таким образом, чтобы воплощать одно или несколько из следующих преимуществ.
Многие существующие подходы к преобразованию последовательности с использованием нейронных сетей используют рекуррентные нейронные сети как в кодировщике, так и в декодировщике. Хотя сети такого вида могут достигать хорошей эффективности на задачах преобразования последовательностей, их вычисления имеют последовательный характер, т.е. рекуррентная нейронная сеть генерирует вывод на текущем временном шаге, обусловленном скрытым состоянием рекуррентной нейронной сети на предыдущем временном шаге. Этот последовательный характер исключает распараллеливание, что приводит к длительному времени обучения и логического вывода и, соответственно, рабочим нагрузкам, которые расходуют большой объем вычислительных ресурсов.
С другой стороны, поскольку кодировщик и декодировщик описанной нейронной сети с преобразованием последовательности основаны на внимании, нейронная сеть с преобразованием последовательности может преобразовывать последовательности быстрее, обучаться быстрее, или и то и другое, так как работу сети легче можно распараллелить. То есть, поскольку описанная нейронная сеть с преобразованием последовательности полностью полагается на механизм внимания для получения глобальных зависимостей между вводом и выводом и не задействует какие-либо слои рекуррентной нейронной сети, проблемы с длительным временем обучения и логического вывода и высоким использованием ресурсов, вызванные последовательным характером слоев рекуррентной нейронной сети, ослабляются.
Более того, нейронная сеть с преобразованием последовательности может преобразовывать последовательности более точно, чем существующие сети, которые основываются на сверточных слоях или рекуррентных слоях, несмотря на то, что времена обучения и логического вывода короче. В частности, в традиционных моделях количество операций, необходимых для соотнесения сигналов из двух произвольных позиций ввода или вывода, растет с расстоянием между позициями, например, линейно или логарифмически, в зависимости от архитектуры модели. Это затрудняет изучение зависимостей между удаленными позициями во время обучения. В описываемой сейчас нейронной сети с преобразованием последовательности это количество операций сводится к постоянному количеству операций благодаря использованию внимания (и, в частности, самовнимания), не полагаясь на рекурсию или свертки. Самовнимание, иногда называемое внутренним вниманием, представляет собой механизм внимания, связывающий разные позиции одной последовательности для того, чтобы вычислить представление последовательности. Использование механизмов внимания позволяет нейронной сети с преобразованием последовательности эффективно изучать зависимости между удаленными позициями во время обучения, повышая точность нейронной сети с преобразованием последовательности на различных задачах преобразования, например, машинном переводе. Фактически, описанная нейронная сеть с преобразованием последовательности может достигать результатов существующего уровня техники на задаче машинного перевода несмотря на то, что она проще обучается и быстрее генерирует выводы, чем традиционные нейронные сети машинного перевода. Нейронная сеть с преобразованием последовательности также может демонстрировать улучшенную производительность по сравнению с традиционными нейронными сетями машинного перевода без настройки под конкретную задачу, благодаря механизму внимания.
Подробная информация об одном или нескольких вариантах осуществления изобретения в настоящем описании изобретения приводится на прилагаемых чертежах и описании ниже. Другие признаки, аспекты и преимущества изобретения станут очевидными из описания, чертежей и формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 показывает иллюстративную систему нейронной сети.
Фиг. 2 является схемой, показывающей механизмы внимания, которые применяются подслоями внимания в подсетях нейронной сети кодировщика и нейронной сети декодировщика.
Фиг. 3 является блок-схемой последовательности операций иллюстративного технологического процесса для генерирования выходной последовательности из входной последовательности.
Одинаковые ссылочные позиции и обозначения на различных чертежах обозначают одинаковые элементы.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Настоящее описание изобретения описывает систему, реализованную в виде компьютерных программ на одном или нескольких компьютерах в одном или нескольких местоположениях, которая генерирует выходную последовательность, которая включает в себя соответственный вывод в каждой из множественных позиций в порядке вывода, исходя из входной последовательности, которая включает в себя соответственный ввод в каждой из множественных позиций в порядке ввода, т.е. преобразовывает входную последовательность в выходную последовательность.
Например, система может быть системой нейронного машинного перевода. То есть, если входная последовательность представляет собой последовательность слов на исходном языке, например, предложение или фразу, выходная последовательность может быть переводом входной последовательности на целевой язык, т.е. последовательностью слов на целевом языке, которая отражает последовательность слов на исходном языке.
В качестве другого примера, система может быть системой распознавания речи. То есть, если входная последовательность представляет собой последовательность аудиоданных, отражающих произносимый фрагмент речи, выходная последовательность может быть последовательностью графем, символов или слов, которая отражает речевой фрагмент, т.е. является текстовой расшифровкой входной последовательности.
В качестве другого примера, система может быть системой обработки естественного языка. Например, если входная последовательность представляет собой последовательность слов на исходном языке, например, предложение или фразу, выходная последовательность может быть кратким изложением входной последовательности на исходном языке, т.е. последовательностью, которая содержит меньше слов, чем входная последовательность, но сохраняет основной смысл входной последовательности. В качестве другого примера, если входная последовательность представляет собой последовательность слов, которые формулируют вопрос, выходная последовательность может быть последовательностью слов, которые формулируют ответ на этот вопрос.
В качестве другого примера, система может быть частью компьютеризированной системы медицинской диагностики. Например, входная последовательность может быть последовательностью данных из электронной медицинской карты, а выходная последовательность может быть последовательностью прогнозируемого курса лечения.
В качестве другого примера, система может быть частью системы обработки изображений. Например, входная последовательность может быть изображением, т.е. последовательностью значений цвета из изображения, а вывод может быть последовательностью текста, который описывает изображение. В качестве другого примера, входная последовательность может быть последовательностью текста или другого контекста, а выходная последовательность может быть изображением, которое описывает этот контекст.
В частности, нейронная сеть включает в себя нейронную сеть кодировщика и нейронную сеть декодировщика. Как правило, и кодировщик и декодировщик основаны на внимании, т.е. оба применяют механизм внимания к своим соответственным принятым вводам при преобразовании входной последовательности. В некоторых случаях ни кодировщик, ни декодировщик не включают в себя какие-либо сверточные слои или какие-либо рекуррентные слои.
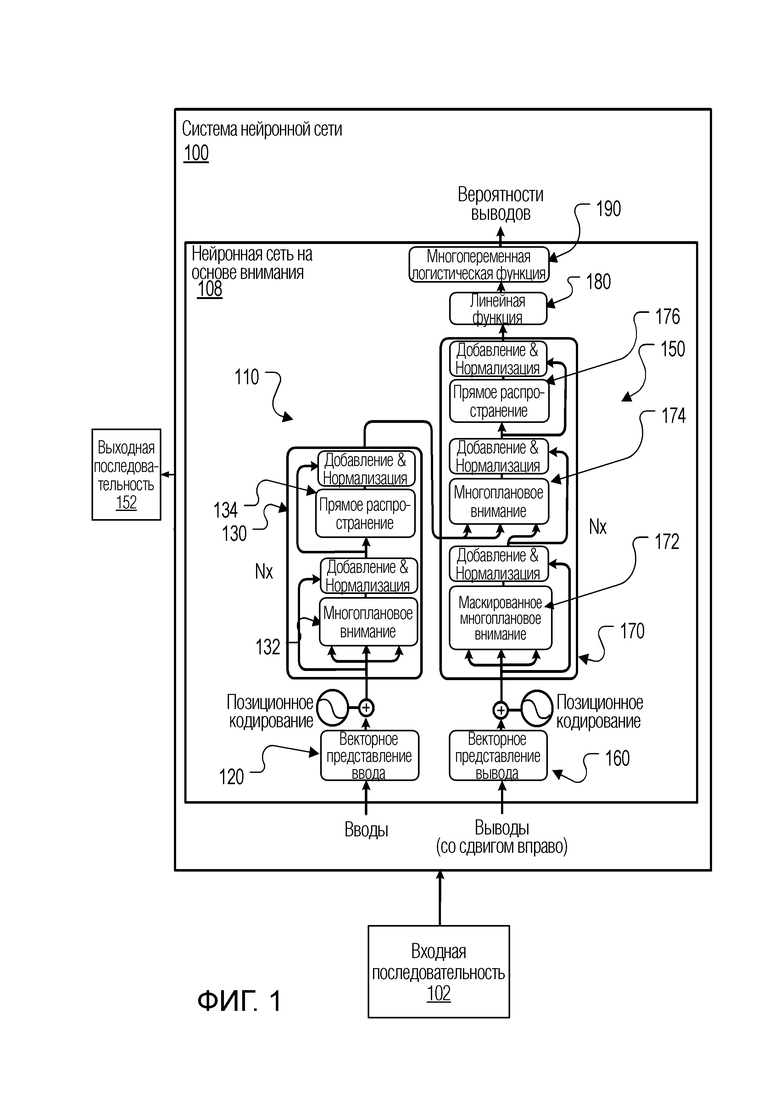
Фиг. 1 показывает иллюстративную систему 100 нейронной сети. Система 100 нейронной сети является примером системы, реализованной в виде компьютерных программ на одном или нескольких компьютерах в одном или нескольких местоположениях, в которой могут быть реализованы описанные ниже системы, компоненты и методы.
Система 100 нейронной сети принимает входную последовательность 102 и обрабатывает входную последовательность 102, чтобы преобразовать входную последовательность 102 в выходную последовательность 152.
Входная последовательность 102 имеет соответственный сетевой ввод в каждой из множественных позиций ввода в порядке ввода, а выходная последовательность 152 имеет соответственный сетевой вывод в каждой из множественных позиций вывода в порядке вывода. То есть, входная последовательность 102 имеет множественные вводы, расположенные согласно порядку ввода, а выходная последовательность 152 имеет множественные выводы, расположенные согласно порядку вывода.
Как описано выше, система 100 нейронной сети может выполнять любую из множества задач, которые требуют обработки последовательных вводов для генерирования последовательных выводов.
Система 100 нейронной сети включает в себя нейронную сеть 108 с преобразованием последовательности на основе внимания, которая, в свою очередь, включает в себя нейронную сеть 110 кодировщика и нейронную сеть 150 декодировщика.
Нейронная сеть 110 кодировщика выполняется с возможностью приема входной последовательности 102 и генерирования соответственного кодированного представления каждого из сетевых вводов во входной последовательности. Как правило, кодированное представление является вектором или иначе упорядоченной совокупностью числовых значений.
Далее, нейронная сеть 150 декодировщика выполняется с возможностью использования кодированных представлений сетевых вводов для генерирования выходной последовательности 152.
Как правило, и как будет подробнее описано ниже, и кодировщик 110 и декодировщик 150 основаны на внимании. В некоторых случаях ни кодировщик, ни декодировщик не включают в себя какие-либо сверточные слои или какие-либо рекуррентные слои.
Нейронная сеть 110 кодировщика включает в себя слой 120 векторного представления и последовательность из одной или нескольких подсетей 130 кодировщика. В частности, как показано на Фиг. 1, нейронная сеть кодировщика включает в себя N подсетей 130 кодировщика.
Слой 120 векторного представления выполняется с возможностью, для каждого сетевого ввода во входной последовательности, отобрать сетевой ввод в числовое представление сетевого ввода в пространстве векторных представлений, например, в вектор в пространстве векторных представлений. Затем слой 120 векторного представления предоставляет числовые представления сетевых вводов в первую подсеть в последовательности подсетей 130 кодировщика, т.е. в первую подсеть 130 кодировщика из N подсетей 130 кодировщика.
В частности, в некоторых реализациях, слой 120 векторного представления выполняется с возможностью отображения каждого сетевого ввода в векторизованное представление сетевого ввода и последующего объединения, например, суммирования или усреднения, векторизованного представления сетевого ввода с позиционным векторным представлением позиции ввода сетевого ввода в порядке ввода для генерирования объединенного векторизованного представления сетевого ввода. То есть, каждая позиция во входной последовательности имеет соответствующее векторное представление, и для каждого сетевого ввода слой 120 векторного представления объединяет векторизованное представление сетевого ввода с векторным представлением сетевого ввода во входной последовательности. Такие позиционные векторные представления может позволить модели полностью использовать порядок входной последовательности, не полагаясь на рекурсию или свертки.
В некоторых случаях позиционные векторные представления являются изученными. Как используется в настоящем описании изобретения, термин "изученный" означает, что операция или значение были скорректированы во время обучения нейронной сети 108 с преобразованием последовательности. Обучение нейронной сети 108 с преобразованием последовательности описывается ниже со ссылкой на Фиг. 3.
В некоторых других случаях позиционные векторные представления фиксированы и различны для каждой позиции. Например, векторные представления могут образовываться из функций синуса и косинуса различных частот и могут удовлетворять:
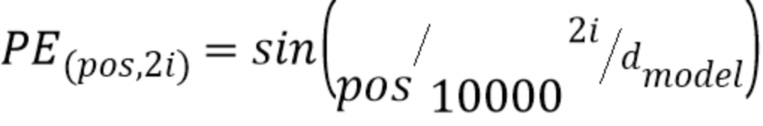
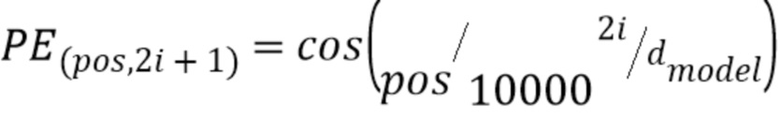 ,
,
где pos является позицией, i является числом измерений в пределах позиционного векторного представления, и dmodel является размерностью векторного представления (и других векторов, обрабатываемых нейронной сетью 108). Использование синусоидальных позиционных векторных представлений может позволить модели проводить экстраполяцию на большие длины последовательностей, что может увеличить диапазон приложений, для которых может быть задействована модель.
Объединенное векторизованное представление затем используется в качестве числового представления сетевого ввода.
Каждая из подсетей 130 кодировщика выполняется с возможностью приема соответственного ввода подсети кодировщика для каждой из множества позиций ввода и генерирования соответственного вывода подсети для каждой из множества позиций ввода.
Выводы подсети кодировщика, сгенерированные последней подсетью кодировщика в последовательности, затем используются в качестве кодированных представлений сетевых вводов.
Для первой подсети кодировщика в последовательности ввод подсети кодировщика является числовыми представлениями, сгенерированными слоем 120 векторного представления, а для каждой подсети кодировщика, отличной от первой подсети кодировщика в последовательности, ввод подсети кодировщика является выводом подсети кодировщика предыдущей подсети кодировщика в последовательности.
Каждая подсеть 130 кодировщика включает в себя подслой 132 самовнимания кодировщика. Подслой 132 самовнимания кодировщика выполняется с возможностью приема ввода подсети для каждой из множества позиций ввода, и, для каждой конкретной позиции ввода в порядке ввода, применения механизма внимания к вводам подсети кодировщика в позициях ввода с использованием одного или нескольких запросов, извлеченных из ввода подсети кодировщика в конкретной позиции ввода, чтобы сгенерировать соответственный вывод для конкретной позиции ввода. В некоторых случаях механизм внимания является многоплановым механизмом внимания. Механизм внимания и то, как механизм внимания применяется подслоем 132 самовнимания кодировщика, будет более подробно описано ниже со ссылкой на Фиг. 2.
В некоторых реализациях каждая из подсетей 130 кодировщика также включает в себя слой остаточного соединения, который объединяет выводы подслоя самовнимания кодировщика с вводами для подслоя самовнимания кодировщика, чтобы сгенерировать остаточный вывод самовнимания кодировщика, и слой нормализации слоя, который применяет нормализацию слоя к остаточному выводу самовнимания кодировщика. Эти два слоя вместе обозначены на Фиг. 1 как операция "Добавление и Нормализация".
Некоторые или все подсети кодировщика также могут включать в себя слой 134 попозиционного прямого распространения, который выполняется с возможностью работы отдельно по каждой позиции во входной последовательности. В частности, для каждой позиции ввода, слой 134 прямого распространения выполняется с возможностью приема ввода в позиции ввода и применения последовательности трансформаций к вводу в позиции ввода для генерирования вывода для позиции ввода. Например, последовательность трансформаций может включать в себя две или более изученных линейных трансформаций, каждая из которых отделена функцией активации, например, нелинейной поэлементной функцией активации, например, функцией активации ReLU, которая может позволить обеспечить более быстрое и более эффективное обучение на больших и сложных наборах данных. Вводы, принимаемые слоем 134 попозиционного прямого распространения, могут быть выводами слоя нормализации слоя, когда предусмотрены остаточный слой и слой нормализации слоя, или выводами подслоя 132 самовнимания кодировщика, когда остаточный слой и слой нормализации слоя не предусмотрены. Трансформации, применяемые слоем 134, как правило, будут одинаковыми для каждой позиции ввода (но разные слои прямого распространения в разных подсетях будут применять разные трансформации).
В случаях, когда подсеть 130 кодировщика включает в себя слой 134 попозиционного прямого распространения, подсеть кодировщика может также включать в себя слой остаточного соединения, который объединяет выводы слоя попозиционного прямого распространения с вводами для слоя попозиционного прямого распространения, чтобы сгенерировать попозиционный остаточный вывод кодировщика, и слой нормализации слоя, который применяет нормализацию слоя к попозиционному остаточному выводу кодировщика. Эти два слоя вместе также обозначены на Фиг. 1 как операция "Добавление и Нормализация". Выводы этого слоя нормализации слоя затем могут использоваться в качестве выводов подсети 130 кодировщика.
Так как нейронная сеть 110 кодировщика сгенерировала кодированные представления, нейронная сеть 150 декодировщика выполняется с возможностью генерирования выходной последовательности авторегрессионным методом.
То есть, нейронная сеть 150 декодировщика генерирует выходную последовательность, на каждом из множества временных шагов генерирования, генерируя сетевой вывод для соответствующей позиции вывода, обусловленный (i) кодированными представлениями и (ii) сетевыми выводами в позициях вывода, предшествующих этой позиции вывода в порядке вывода.
В частности, для заданной позиции вывода нейронная сеть декодировщика генерирует вывод, который устанавливает распределение вероятностей по возможным сетевым выводам в заданной позиции вывода. Затем нейронная сеть декодировщика может выбрать сетевой вывод для позиции вывода, производя выборку из распределения вероятностей или выбирая сетевой вывод с наибольшей вероятностью.
Поскольку нейронная сеть 150 декодировщика является авторегрессионной, на каждом временном шаге генерирования декодировщик 150 работает с сетевыми выводами, которые уже были сгенерированы перед этим временным шагом генерирования, т.е. сетевыми выводами в позициях вывода, предшествующих соответствующей позиции вывода в порядке вывода. В некоторых реализациях, чтобы гарантировать, что это имеет место как во время логического вывода, так и во время обучения, на каждом временном шаге генерирования нейронная сеть 150 декодировщика сдвигает уже сгенерированные сетевые выводы вправо на одну позицию порядка вывода (т.е. вносит смещение на одну позицию в уже сгенерированную выходную последовательность сети) и (как будет подробнее описано ниже) маскирует определенные операции, чтобы позиции могли уделять внимание только позициям до этой позиции включительно в выходной последовательности (а не последующим позициям). Хотя в остальной части описания ниже описывается, что при генерировании заданного вывода в заданной позиции вывода различные компоненты декодировщика 150 работают с данными в позициях вывода, предшествующих заданным позициям вывода (а не с данными в любых других позициях вывода), будет понятно, что этот тип согласования может быть эффективно реализован с использованием описанного выше сдвига.
Нейронная сеть 150 декодировщика включает в себя слой 160 векторного представления, последовательность подсетей 170 декодировщика, линейный слой 180 и слой 190 с многопеременной логистической функцией. В частности, как показано на Фиг. 1, нейронная сеть декодировщика включает в себя N подсетей 170 декодировщика. Однако, хотя пример на Фиг. 1 и показывает кодировщик 110 и декодировщик 150, включающие в себя одинаковое количество подсетей, в некоторых случаях кодировщик 110 и декодировщик 150 включают в себя разное количество подсетей. То есть, декодировщик 150 может включать в себя больше или меньше подсетей, чем кодировщик 110.
Слой 160 векторного представления выполняется с возможностью, на каждом временном шаге генерирования, для каждого сетевого вывода в позиции вывода, которая предшествует текущей позиции вывода в порядке вывода, отображать сетевой вывод в числовое представление сетевого вывода в пространстве векторных представлений. Затем слой 160 векторного представления предоставляет числовые представления сетевых выводов в первую подсеть 170 в последовательности подсетей декодировщика, т.е. в первую подсеть 170 декодировщика из N подсетей декодировщика.
В частности, в некоторых реализациях, слой 160 векторного представления выполняется с возможностью отображения каждого сетевого вывода в векторизованное представление сетевого вывода и объединения векторизованного представления сетевого вывода с позиционным векторным представлением позиции вывода сетевого вывода в порядке вывода, чтобы сгенерировать объединенное векторизованное представление сетевого вывода. Затем объединенное векторизованное представление используется в качестве числового представления сетевого вывода. Слой 160 векторного представления генерирует объединенное векторизованное представление таким же образом, как описано выше в отношении слоя 120 векторного представления.
Каждая подсеть 170 декодировщика выполняется с возможностью, на каждом временном шаге генерирования, принимать соответственный ввод подсети декодировщика для каждой из множества позиций вывода, предшествующих соответствующей позиции вывода, и генерировать соответственный вывод подсети декодировщика для каждой из множества позиций вывода, предшествующих соответствующей позиции вывода (или, что то же самое, если выходная последовательность была сдвинута вправо, каждого сетевого вывода в позиции до текущей позиции вывода включительно).
В частности, каждая подсеть 170 декодировщика включает в себя два разных подслоя внимания: подслой 172 самовнимания декодировщика и подслой 174 внимания кодировщика-декодировщика.
Каждый подслой 172 самовнимания декодировщика выполняется с возможностью, на каждом временном шаге генерирования, принимать ввод для каждой позиции вывода, предшествующей соответствующей позиции вывода, и, для каждой конкретной позиции вывода, применять механизм внимания к вводам в позициях вывода, предшествующих соответствующей позиции, с использованием одного или нескольких запросов, извлеченных из ввода в конкретной позиции вывода, чтобы сгенерировать обновленное представление для конкретной позиции вывода. То есть, подслой 172 самовнимания декодировщика применяет механизм внимания, который маскирован таким образом, чтобы он не уделял внимания или иным образом не обрабатывал никакие данные, которые не находятся в позиции, предшествующей текущей позиции вывода в выходной последовательности.
Каждый подслой 174 внимания кодировщика-декодировщика, с другой стороны, выполняется с возможностью, на каждом временном шаге генерирования, принимать ввод для каждой позиции вывода, предшествующей соответствующей позиции вывода, и, для каждой из позиций вывода, применять механизм внимания к кодированным представлениям в позициях ввода с использованием одного или нескольких запросов, извлеченных из ввода для позиции вывода, чтобы сгенерировать обновленное представление для позиции вывода. Таким образом, подслой 174 внимания кодировщика-декодировщика применяет внимание к кодированным представлениям, в то время как подслой 172 самовнимания кодировщика применяет внимание к вводам в позициях вывода.
Механизм внимания, применяемый каждым из этих подслоев внимания, будет подробнее описан ниже со ссылкой на Фиг. 2.
На Фиг. 1 подслой 172 самовнимания декодировщика показан как находящийся перед подслоем внимания кодировщика-декодировщика в порядке обработки в пределах подсети 170 декодировщика. Однако в других примерах подслой 172 самовнимания декодировщика может находиться после подслоя 174 внимания кодировщика-декодировщика в порядке обработки в пределах подсети 170 декодировщика, или разные подсети могут иметь разные порядки обработки.
В некоторых реализациях каждая подсеть 170 декодировщика включает в себя, после подслоя 172 самовнимания декодировщика, после подслоя 174 внимания кодировщика-декодировщика, или после каждого из этих двух подслоев, слой остаточного соединения, который объединяет выводы подслоя внимания с вводами для подслоя внимания, чтобы сгенерировать остаточный вывод, и слой нормализации слоя, который применяет нормализацию слоя к остаточному выводу. Фиг. 1 показывает эти два слоя, вставленные после каждого из двух подслоев, оба обозначены как операция "Добавление и Нормализация".
Некоторые или все подсети 170 декодировщика также включают в себя слой 176 попозиционного прямого распространения, который выполняется с возможностью работы таким же образом, как и слой 134 попозиционного прямого распространения из кодировщика 110. В частности, слой 176 выполняется с возможностью, на каждом временном шаге генерирования: для каждой позиции вывода, предшествующей соответствующей позиции вывода: принимать ввод в позиции вывода и применять последовательность трансформаций к вводу в позиции вывода, чтобы сгенерировать вывод для позиции вывода. Например, последовательность трансформаций может включать в себя две или более изученных линейных трансформаций, каждая из которых отделена функцией активации, например, нелинейной поэлементной функцией активации, например, функцией активации ReLU. Вводы, принимаемые слоем 176 попозиционного прямого распространения, могут быть выводами слоя нормализации слоя (следующего за последним подслоем внимания в подсети 170), когда предусмотрены остаточный слой и слой нормализации слоя, или выводами последнего подслоя внимания в подсети 170, когда остаточный слой и слой нормализации слоя не предусмотрены.
В случаях, когда подсеть 170 декодировщика включает в себя слой 176 попозиционного прямого распространения, подсеть декодировщика также может включать в себя слой остаточного соединения, который объединяет выводы слоя попозиционного прямого распространения с вводами для слоя попозиционного прямого распространения, чтобы сгенерировать попозиционный остаточный вывод декодировщика, и слой нормализации слоя, который применяет нормализацию слоя к попозиционному остаточному выводу декодировщика. Эти два слоя вместе также обозначены на Фиг. 1 как операция "Добавление и Нормализация". Выводы этого слоя нормализации слоя затем могут использоваться в качестве выводов подсети 170 декодировщика.
На каждом временном шаге генерирования линейный слой 180 применяет изученную линейную трансформацию к выводу последней подсети 170 декодировщика для того, чтобы спроецировать вывод последней подсети 170 декодировщика в приемлемое пространство для обработки слоем 190 с многопеременной логистической функцией. Затем слой 190 с многопеременной логистической функцией применяет многопеременную логистическую функцию к выводам линейного слоя 180, чтобы сгенерировать распределение вероятностей по возможным сетевым выводам на временном шаге генерирования. Как описано выше, декодировщик 150 может затем выбрать сетевой вывод из возможных сетевых выводов, используя распределение вероятностей.
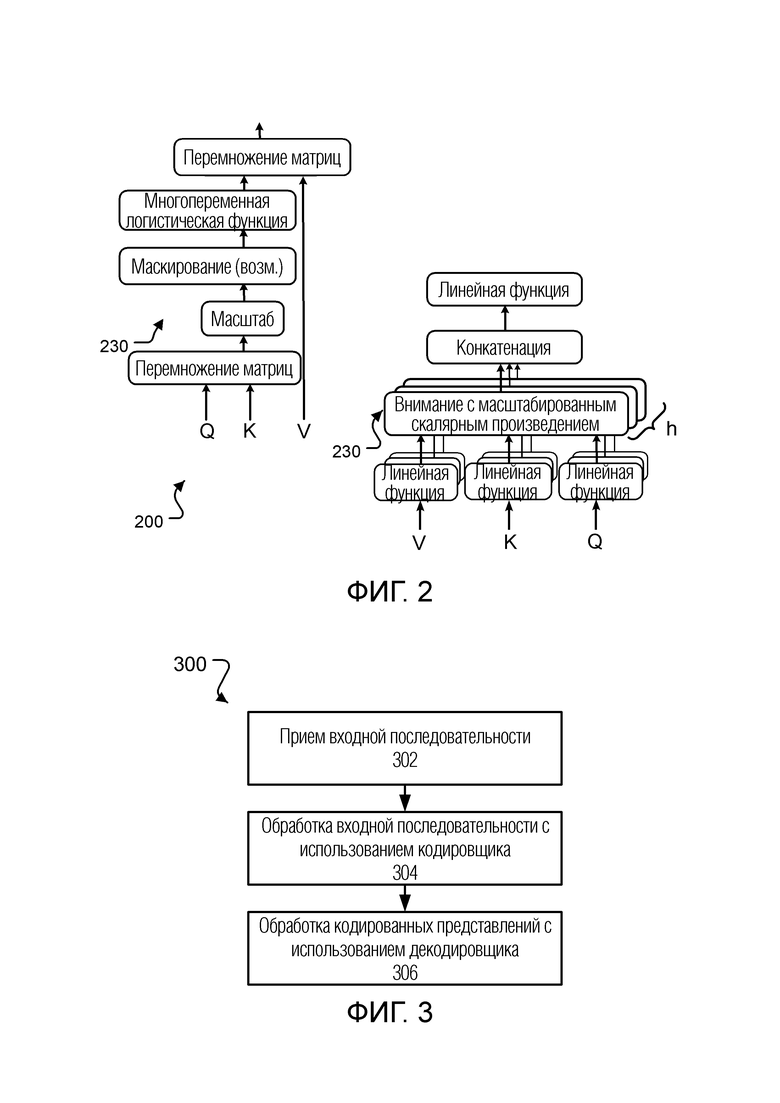
Фиг. 2 является схемой 200, показывающей механизмы внимания, которые применяются подслоями внимания в подсетях нейронной сети 110 кодировщика и нейронной сети 150 декодировщика.
Как правило, механизм внимания отображает запрос и набор пар ключ-значение в вывод, где запрос, ключи и значения все являются векторами. Вывод вычисляется как взвешенная сумма значений, где вес, назначенный каждому значению, вычисляется функцией совместимости запроса с соответствующим ключом.
Более конкретно, каждый подслой внимания применяет механизм 230 внимания с масштабированным скалярным произведением. При внимании с масштабированным скалярным произведением, для заданного запроса, подслой внимания вычисляет скалярные произведения запроса со всеми ключами, делит каждое из скалярных произведений на коэффициент масштабирования, например, квадратный корень из размерностей запросов и ключей, а затем применяет многопеременную логистическую функцию к масштабированным скалярным произведениям, чтобы получить веса значений. Затем подслой внимания вычисляет взвешенную сумму значений в согласии с этими весами. Таким образом, для внимания с масштабированным скалярным произведением функция совместимости является скалярным произведением, а вывод функции совместимости дополнительно масштабируется с помощью коэффициента масштабирования.
При работе, и как показано в левой части Фиг. 2, подслой внимания вычисляет внимание по набору запросов одновременно. В частности, подслой внимания упаковывает запросы в матрицу Q, упаковывает ключи в матрицу K и упаковывает значения в матрицу V. Чтобы упаковать набор векторов в матрицу, подслой внимания может генерировать матрицу, которая включает в себя векторы в качестве строк матрицы.
Затем подслой внимания выполняет перемножение матриц (MatMul) между матрицей Q и матрицей, транспонированной к матрице K, чтобы сгенерировать матрицу выводов функции совместимости.
Затем подслой внимания масштабирует матрицу выводов функции совместимости, а именно, путем деления каждого элемента матрицы на коэффициент масштабирования.
Затем подслой внимания применяет многопеременную логистическую функцию к масштабированной матрице выводов, чтобы сгенерировать матрицу весов, и выполняет перемножение матриц (MatMul) между матрицей весов и матрицей V, чтобы сгенерировать матрицу выводов, которая включает в себя вывод механизма внимания для каждого из значений.
Что касается подслоев, которые используют маскирование, т.е. подслоев внимания декодировщика, подслой внимания маскирует масштабированную матрицу выводов перед применением многопеременной логистической функции. То есть, подслой внимания заглушает (устанавливает на отрицательную бесконечность) все значения в масштабированной матрице выводов, которые соответствуют позициям после текущей позиции вывода.
В некоторых реализациях, чтобы позволить подслоям внимания совместно уделять внимание информации из разных подпространств представлений в разных позициях, подслои внимания задействуют многоплановое внимание, как в правой части Фиг. 2.
В частности, для реализации многопланового внимания, подслой внимания параллельно применяет h разных механизмов внимания. Другими словами, подслой внимания включает в себя h разных слоев внимания, причем каждый слой внимания в пределах одного и того же подслоя внимания, принимает одни и те же исходные запросы Q, исходные ключи K и исходные значения V.
Каждый слой внимания выполняется с возможностью трансформирования исходных запросов, ключей и значений, используя изученные линейные трансформации, и последующего применения механизма 230 внимания к трансформированным запросам, ключам и значениям. Каждый слой внимания, как правило, будет изучать разные трансформации из каждого другого слоя внимания в одном и том же подслое внимания.
В частности, каждый слой внимания выполняется с возможностью применения изученной линейной трансформации запроса к каждому исходному запросу, чтобы сгенерировать специфичный для конкретного слоя запрос для каждого исходного запроса, применения изученной линейной трансформации ключа к каждому исходному ключу, чтобы сгенерировать специфичный для конкретного слоя ключ для каждого исходного ключа, и применения изученной линейной трансформации значения к каждому исходному значению, чтобы сгенерировать специфичные для конкретного слоя значения для каждого исходного значения. Затем слой внимания применяет описанный выше механизм внимания, используя эти специфичные для слоя запросы, ключи и значения, чтобы сгенерировать начальные выводы для слоя внимания.
Затем подслой внимания объединяет начальные выводы слоев внимания, чтобы сгенерировать окончательный вывод подслоя внимания. Как показано на Фиг. 2, подслой внимания последовательно связывает (конкатенирует) выводы слоев внимания и применяет изученную линейную трансформацию к этому составному выводу, чтобы сгенерировать вывод подслоя внимания.
В некоторых случаях изученные трансформации, применяемые подслоем внимания, уменьшают размерность исходных ключей и значений и, при необходимости, запросов. Например, когда размерность исходных ключей, значений и запросов равна d, и в подслое имеется h слоев внимания, подслой может уменьшить размерность исходных ключей, значений и запросов до d/h. Это сохраняет затраты на вычисления многопланового механизма внимания близкими затратам на выполнение механизма внимания с полной размерностью, в то же время повышая репрезентативные возможности подслоя внимания.
Хотя механизм внимания, применяемый каждым подслоем внимания, является одним и тем же, запросы, ключи и значения отличаются для разных типов внимания. То есть, разные типы подслоев внимания используют разные источники для исходных запросов, ключей и значений, которые принимаются в качестве ввода подслоем внимания.
В частности, когда подслой внимания является подслоем самовнимания кодировщика, все ключи, значения и запросы поступают из одного и того же места, в данном случае, вывода предыдущей подсети в кодировщике, или, для подслоя самовнимания кодировщика в первой подсети, векторных представлений вводов, и каждая позиция в кодировщике может уделять внимание всем позициям в порядке ввода. Таким образом, есть соответственный ключ, значение и запрос для каждой позиции в порядке ввода.
Когда подслой внимания является подслоем самовнимания декодировщика, каждая позиция в декодировщике уделяет внимание всем позициям в декодировщике, предшествующим этой позиции. Таким образом, все ключи, значения и запросы поступают из одного и того же места, в данном случае, вывода предыдущей подсети в декодировщике, или, для подслоя самовнимания декодировщика в первой подсети декодировщика, векторных представлений уже сгенерированных выводов. Таким образом, есть соответственный ключ, значение и запрос для каждой позиции в порядке вывода перед текущей позицией.
Когда подслой внимания является подслоем внимания кодировщика-декодировщика, запросы поступают из предыдущего компонента в декодировщике, а ключи и значения поступают из вывода кодировщика, т.е. из кодированных представлений, генерируемых кодировщиком. Это позволяет каждой позиции в декодировщике уделять внимание всем позициям во входной последовательности. Таким образом, есть соответственный запрос для каждой позиции в порядке вывода перед текущей позицией, а также соответственный ключ и соответственное значение для каждой позиции в порядке ввода.
Более подробно, когда подслой внимания является подслоем самовнимания кодировщика, для каждой конкретной позиции ввода в порядке ввода, подслой самовнимания кодировщика выполняется с возможностью применения механизма внимания к вводам подсети кодировщика в позициях ввода с использованием одного или нескольких запросов, извлеченных из ввода подсети кодировщика в конкретной позиции ввода, чтобы сгенерировать соответственный вывод для конкретной позиции ввода.
Когда подслой самовнимания кодировщика реализует многоплановое внимание, каждый слой самовнимания кодировщика в подслое самовнимания кодировщика выполняется с возможностью: применения изученной линейной трансформации запроса к каждому вводу подсети кодировщика в каждой позиции ввода, чтобы сгенерировать соответственный запрос для каждой позиции ввода, применения изученной линейной трансформации ключа к каждому вводу подсети кодировщика в каждой позиции ввода, чтобы сгенерировать соответственный ключ для каждой позиции ввода, применения изученной линейной трансформации значения к каждому вводу подсети кодировщика в каждой позиции ввода, чтобы сгенерировать соответственное значение для каждой позиции ввода, и последующего применения механизма внимания (т.е. описанного выше механизма внимания с масштабированным скалярным произведением) с использованием запросов, ключей и значений для определения начального вывода самовнимания кодировщика для каждой позиции ввода. Затем подслой объединяет начальные выводы слоев внимания, как описано выше.
Когда подслой внимания является подслоем самовнимания декодировщика, подслой самовнимания декодировщика выполняется с возможностью, на каждом временном шаге генерирования: принимать ввод для каждой позиции вывода, предшествующей соответствующей позиции вывода, и, для каждой из конкретных позиций вывода, применять механизм внимания к вводам в позициях вывода, предшествующих соответствующей позиции, с использованием одного или нескольких запросов, извлеченных из ввода в конкретной позиции вывода, чтобы сгенерировать обновленное представление для конкретной позиции вывода.
Когда подслой самовнимания декодировщика реализует многоплановое внимание, каждый слой внимания в подслое самовнимания декодировщика выполняется с возможностью, на каждом временном шаге генерирования, применять изученную линейную трансформацию запроса к вводу в каждой позиции вывода, предшествующей соответствующей позиции вывода, чтобы сгенерировать соответственный запрос для каждой позиции вывода, применения изученной линейной трансформации ключа к каждому вводу в каждой позиции вывода, предшествующей соответствующей позиции вывода, чтобы сгенерировать соответственный ключ для каждой позиции вывода, применения изученной линейной трансформации значения к каждому вводу в каждой позиции вывода, предшествующей соответствующей позиции вывода, чтобы сгенерировать соответственный ключ для каждой позиции вывода, и последующего применения механизма внимания (т.е. описанного выше механизма внимания с масштабированным скалярным произведением) с использованием запросов, ключей и значений для определения начального вывода самовнимания декодировщика для каждой позиции вывода. Затем подслой объединяет начальные выводы слоев внимания, как описано выше.
Когда подслой внимания является подслоем внимания кодировщика-декодировщика, подслой внимания кодировщика-декодировщика выполняется с возможностью, на каждом временном шаге генерирования: принимать ввод для каждой позиции вывода, предшествующей соответствующей позиции вывода, и, для каждой из позиций вывода, применять механизм внимания к кодированным представлениям в позициях ввода с использованием одного или нескольких запросов, извлеченных из ввода для позиции вывода, чтобы сгенерировать обновленное представление для позиции вывода.
Когда подслой внимания кодировщика-декодировщика реализует многоплановое внимание, каждый слой внимания выполняется с возможностью, на каждом временном шаге генерирования: применять изученную линейную трансформацию запроса к вводу в каждой позиции вывода, предшествующей соответствующей позиции вывода, чтобы сгенерировать соответственный запрос для каждой позиции вывода, применять изученную линейную трансформацию ключа к каждому кодированному представлению в каждой позиции ввода, чтобы сгенерировать соответственный ключ для каждой позиции ввода, применять изученную линейную трансформацию значения к каждому кодированному представлению в каждой позиции ввода, чтобы сгенерировать соответственное значение для каждой позиции ввода, и впоследствии применять механизм внимания (т.е. описанный выше механизм внимания с масштабированным скалярным произведением) с использованием запросов, ключей и значений для определения начального вывода внимания кодировщика-декодировщика для каждой позиции ввода. Затем подслой объединяет начальные выводы слоев внимания, как описано выше.
Фиг. 3 является блок-схемой последовательности операций иллюстративного технологического процесса для генерирования выходной последовательности из входной последовательности. Для удобства технологический процесс 300 будет описан как выполняемый системой из одного или нескольких компьютеров, расположенных в одном или нескольких местоположениях. Скажем, система нейронной сети, например, система 100 нейронной сети, изображенная на Фиг. 1, надлежащим образом запрограммированная в соответствии с настоящим описанием изобретения, может выполнять технологический процесс 300.
Система принимает входную последовательность (этап 310).
Система обрабатывает входную последовательность, используя нейронную сеть кодировщика, чтобы сгенерировать соответственное кодированное представление каждого из сетевых вводов во входной последовательности (этап 320). В частности, система обрабатывает входную последовательность посредством слоя векторного представления, чтобы сгенерировать векторизованное представление каждого сетевого ввода и затем обработать векторизованные представления посредством последовательности подсетей кодировщика для генерирования кодированных представлений сетевых вводов.
Система обрабатывает кодированные представления с использованием нейронной сети декодировщика, чтобы сгенерировать выходную последовательность (этап 330). Нейронная сеть декодировщика выполняется с возможностью генерирования выходной последовательности из кодированных представлений авторегрессионным методом. То есть, нейронная сеть декодировщика генерирует один вывод из выходной последовательности на каждом временном шаге генерирования. На заданном временном шаге генерирования, на котором генерируется заданный вывод, система обрабатывает выводы перед заданным выводом в выходной последовательности посредством слоя векторного представления в декодировщике, чтобы сгенерировать векторизованные представления. Затем система обрабатывает векторизованные представления посредством последовательности подсетей декодировщика, линейного слоя и слоя с многопеременной логистической функцией, чтобы сгенерировать заданный вывод. Поскольку подсети декодировщика включают в себя подслои внимания кодировщика-декодировщика, а также подслои самовнимания декодировщика, декодировщик использует как уже сгенерированные выводы, так и кодированные представления, когда генерирует заданный вывод.
Система может выполнять технологический процесс 300 для входных последовательностей, для которых ожидаемый вывод, т.е. выходная последовательность, которая должна быть сгенерирована системой для входной последовательности, не известен.
Система также может выполнять технологический процесс 300 на входных последовательностях в наборе обучающих данных, т.е. наборе вводов, для которых известна выходная последовательность, которая должна быть сгенерирована системой, чтобы обучать кодировщик и декодировщик определять выученные значения для параметров кодировщика и декодировщика. Технологический процесс 300 может многократно выполняться на вводах, выбранных из набора обучающих данных в рамках традиционного обучающего метода машинного обучения, чтобы обучать начальные слои нейронной сети, например, обучающий метод градиентного спуска с обратным распространением, который использует традиционный алгоритм оптимизации, например, алгоритм оптимизации Adam. Во время обучения система может включать в себя любое количество методов, чтобы повысить скорость, эффективность, или и то и другое, обучающего процесса. Например, система может использовать исключающую регуляризацию, сглаживание меток, или и то и другое, чтобы уменьшить переобучение. В качестве другого примера, система может выполнять обучение, используя распределенную архитектуру, которая параллельно обучает множество экземпляров нейронной сети с преобразованием последовательности.
В настоящем описании изобретения используется термин "выполненный с возможностью" в отношении систем и компонентов компьютерных программ. Для системы из одного или нескольких компьютеров, которая выполнена с возможностью выполнения конкретных операций или действий, это означает, что система имеет установленное на ней программное обеспечение, встроенное программное обеспечение, аппаратное обеспечение, или их комбинацию, которые при работе заставляют систему выполнять операции или действия. Для одной или нескольких компьютерных программ, которые выполнены с возможностью выполнения конкретных операций или действий, это означает, что одна или несколько программ включают в себя инструкции, которые, при исполнении устройством обработки данных, заставляют устройство выполнять операции или действия.
Варианты осуществления изобретения и функциональные операции, описанные в настоящем описании изобретения, могут быть реализованы в цифровых электронных схемах, в материально воплощенном компьютерном программном обеспечении или встроенном программном обеспечении, в компьютерном аппаратном обеспечении, включающих в себя структуры, раскрытые в настоящем описании изобретения, и их структурные эквиваленты, или в комбинациях одного или нескольких из них. Варианты осуществления изобретения, описанного в настоящем описании изобретения, могут быть реализованы в виде одной или нескольких компьютерных программ, т.е. одного или нескольких модулей компьютерных программных инструкций, закодированных на материальном долговременном средстве хранения для исполнения устройством обработки данных, или для управления его работой. Компьютерное средство хранения может быть машиночитаемым устройством хранения, машиночитаемым информационным носителем, запоминающим устройством с произвольным или последовательным доступом, или комбинацией одного или нескольких из них. В качестве альтернативы или в дополнение, программные инструкции могут быть закодированы в искусственно сгенерированном распространяемом сигнале, например, сгенерированном машиной электрическом, оптическом или электромагнитном сигнале, который генерируется, чтобы закодировать информацию для передачи в подходящее принимающее устройство для исполнения устройством обработки данных.
Термин "устройство обработки данных" относится к аппаратным средствам обработки данных и охватывает все виды устройств, аппаратов и машин для обработки данных, в том числе, к примеру, программируемое обрабатывающее устройство, компьютер, либо несколько обрабатывающих устройств или компьютеров. Устройство также может представлять собой, или дополнительно включать в себя, логические схемы специального назначения, например, ППВМ (программируемая пользователем вентильная матрица) или СИС (специализированная интегральная схема). В некоторых случаях устройство может включать в себя, в дополнение к аппаратному обеспечению, код, который создает среду исполнения для компьютерных программ, например, код, который составляет встроенное программное обеспечение обрабатывающего устройства, набор протоколов, систему управления базами данных, операционную систему, или комбинацию одного или нескольких из них.
Компьютерная программа, которая также может упоминаться или описываться как программа, программное обеспечение, программное приложение, приложение, модуль, программный модуль, сценарий или код, может быть написана на любом языке программирования, включая сюда компилируемые либо интерпретируемые языки, или декларативные либо процедурные языки; и она может быть развернута в любой форме, в том числе как автономная программа или как модуль, компонент, подпрограмма или другой блок, подходящий для использования в вычислительной среде. Программа может, но не обязательно, соответствовать файлу в файловой системе. Программа может храниться в части файла, который заключает в себе другие программы или данные, например, один или несколько сценариев, хранящиеся в документе на языке разметки, в отдельном файле, предназначенном для рассматриваемой программы, или в нескольких совместно согласованных файлах, например, файлах, в которых хранится один или несколько модулей, подпрограмм или частей кода. Компьютерная программа может быть развернута для исполнения на одном компьютере или на нескольких компьютерах, которые расположены на одной площадке или распределены по нескольким площадкам и взаимосвязаны с помощью сети передачи данных.
В настоящем описании изобретения термин "база данных" используется широко, для обозначения любой совокупности данных: данные не должны быть структурированы каким-то конкретным образом, или вообще структурированы, и они могут храниться на устройствах хранения в одном или нескольких местоположениях. Таким образом, например, индексная база данных может включать в себя множественные совокупности данных, каждая из которых может быть организована и доступна по-разному.
Аналогично, в настоящем описании изобретения термин "машина" используется широко, для обозначения основанной на программном обеспечении системы, подсистемы или технологического процесса, который запрограммирован для выполнения одной или нескольких определенных функций. Как правило, машина будет реализована в виде одного или нескольких программных модулей или компонентов, установленных на одном или нескольких компьютерах в одном или нескольких местоположениях. В некоторых случаях один или несколько компьютеров будут выделены для конкретной машины; в других случаях множественные машины могут быть установлены и запущены на одном и том же компьютере или компьютерах.
Технологические процессы и логические потоки, описанные в настоящем описании изобретения, могут выполняться одним или несколькими программируемыми компьютерами, исполняющими одну или несколько компьютерных программ, чтобы выполнять функции, работая с входными данными и генерируя вывод. Технологические процессы и логические потоки также могут выполняться логическими схемами специального назначения, например, ППВМ или СИС, либо с помощью комбинации логических схем специального назначения и одного или нескольких программируемых компьютеров.
Компьютеры, подходящие для исполнения компьютерной программы, могут быть основаны на микропроцессорах общего или специального назначения, или на том и другом, либо на центральном блоке обработки любого другого вида. Как правило, центральный блок обработки будет принимать инструкции и данные из постоянного запоминающего устройства или оперативного запоминающего устройства, или из обоих. Основными элементами компьютера являются центральный блок обработки для выполнения или исполнения инструкций, и одно или несколько запоминающих устройств для хранения инструкций и данных. Центральный блок обработки и запоминающее устройство могут быть дополнены логическими схемами специального назначения, или внедрены в них. Как правило, компьютер также будет включать в себя, или будет функционально связан с ними, чтобы принимать данные из них или передавать данные в них, или и то и другое, одно или несколько устройств хранения большой емкости для хранения данных, например, магнитные, магнитооптические диски или оптические диски. Однако компьютеру не обязательно иметь такие устройства. Более того, компьютер может быть встроен в другое устройство, например, подвижный телефон, карманный персональный компьютер (КПК), подвижный звуковой или видео проигрыватель, игровая приставка, приемник Системы глобального позиционирования (GPS - Global Positioning System), или переносное устройство хранения, например, флэш-накопитель с универсальной последовательной шиной (USB - universal serial bus), и это лишь несколько примеров.
Читаемые с помощью компьютера носители, подходящие для хранения компьютерных программных инструкций и данных, включают в себя все формы энергонезависимой памяти, носители и запоминающие устройства, в том числе, для примера, полупроводниковые запоминающие устройства, например, СППЗУ, ЭСППЗУ и ЭСППЗУ с параллельным стиранием; магнитные диски, например, внутренние жесткие диски или съемные диски; магнитооптические диски; а также диски CD-ROM и DVD-ROM.
Чтобы обеспечить взаимодействие с пользователем, варианты осуществления изобретения, описанного в настоящем описании изобретения, могут быть реализованы на компьютере, имеющем устройство отображения, например, монитор на ЭЛТ (электронно-лучевая трубка) или ЖК-монитор (жидкокристаллическое устройство отображения), для отображения информации пользователю, а также клавиатуру и координатно-указательное устройство, например, манипулятор мышь или шаровой манипулятор, с помощью которых пользователь может обеспечить ввод в компьютер. Другие виды устройств также могут использоваться для обеспечения взаимодействия с пользователем; например, обратная связь, предоставляемая пользователю, может представлять собой любую форму сенсорной обратной связи, например, визуальную обратную связь, слуховую обратную связь или тактильную обратную связь; и ввод от пользователя может приниматься в любой форме, включая сюда акустический, речевой или тактильный ввод. Помимо этого, компьютер может взаимодействовать с пользователем, отправляя документы на устройство, которое используется пользователем, и принимая документы от него; например, отправляя сетевые страницы сетевому обозревателю на устройстве пользователя в ответ на запросы, принимаемые от сетевого обозревателя. Кроме того, компьютер может взаимодействовать с пользователем, отправляя текстовые сообщения или сообщения в другой форме на персональное устройству, например, интеллектуальный телефон, на котором запущено приложение обмена сообщениями, и принимая со своей стороны ответные сообщения от пользователя.
Устройство обработки данных для реализации моделей машинного обучения также может включать в себя, например, аппаратные ускорители специального назначения для обработки общих и требующих большого объема вычислений частей обучения или производства в задаче машинного обучения, т.е. логического вывода, рабочих нагрузок.
Модели машинного обучения могут быть реализованы и развернуты с использованием инфраструктурной платформы машинного обучения, например, платформы TensorFlow, платформы Microsoft Cognitive Toolkit, платформы Apache Singa или платформы Apache MXNet.
Варианты осуществления изобретения, описанного в настоящем описании изобретения, могут быть реализованы в вычислительной системе, которая включает в себя серверный компонент, как, например, сервер данных, или которая включает в себя компонент промежуточного программного обеспечения, например, сервер приложений, или которая включает в себя клиентский компонент, например, клиентский компьютер, имеющий графический интерфейс пользователя, сетевой обозреватель или приложение, через которое пользователь может взаимодействовать с реализацией изобретения, описанного в настоящем описании изобретения, или любую комбинацию одного или нескольких таких серверных компонентов, компонентов промежуточного программного обеспечения, или клиентских компонентов. Компоненты системы могут быть взаимосвязаны любой формой или средой передачи цифровых данных, например, сетью связи. Примеры сетей связи включают в себя локальную вычислительную сеть (ЛВС) и глобальную вычислительную сеть (ГВС), например, сеть Интернет.
Вычислительная система может включать в себя клиентские и серверные части. Клиент и сервер обычно удалены друг от друга и, как правило, взаимодействуют через сеть связи. Взаимоотношения клиента и сервера возникают благодаря компьютерным программам, запущенным на соответственных компьютерах и имеющим друг с другом взаимоотношение клиент-сервер. В некоторых вариантах осуществления сервер передает данные, например, страницу HTML, на пользовательское устройство, например, с целью отображения данных пользователю, взаимодействующему с устройством, которое выступает в роли клиента, и приема пользовательского ввода от него. Данные, сгенерированные на пользовательском устройстве, например, результат взаимодействия с пользователем, могут приниматься на сервере от устройства.
Хотя настоящее описание изобретения и содержит много конкретных деталей реализации, они не должны истолковываться как ограничения объема какого-либо изобретения или объема того, что может быть заявлено, а скорее как описания признаков, которые могут быть специфичными для конкретных вариантов осуществления конкретных изобретений. Некоторые признаки, которые описаны в настоящем описании изобретения в контексте отдельных вариантов осуществления, также могут быть реализованы в комбинации в одном варианте осуществления. И наоборот, различные признаки, которые описаны в контексте одного варианта осуществления, также могут быть реализованы в нескольких вариантах осуществления по отдельности или в любой подходящей подкомбинации. Более того, хотя признаки могут быть описаны выше как действующие в некоторых комбинациях, и даже первоначально быть заявлены как таковые, один или несколько признаков из заявленной комбинации в некоторых случаях могут быть исключены из комбинации, а заявленная комбинация может быть отнесена к подкомбинации или вариации подкомбинации.
Аналогично, хотя операции изображены на чертежах и перечислены в формуле изобретения в конкретном порядке, это не следует понимать как требование того, чтобы такие операции выполнялись в конкретном показанном порядке или в последовательном порядке, или того, чтобы выполнялись все проиллюстрированные операции, для достижения желаемых результатов. При определенных обстоятельствах могут быть выгодны многозадачность и параллельная обработка. Более того, разделение различных системных модулей и компонентов в описанных выше вариантах осуществления не следует понимать как требование такого разделения во всех вариантах осуществления, и нужно понимать, что описанные программные компоненты и системы, как правило, могут быть объединены вместе в одном программном продукте или упакованы в несколько программных продуктов.
Были описаны конкретные варианты осуществления изобретения. Другие варианты осуществления находятся в пределах объема следующей формулы изобретения. Например, действия, перечисленные в формуле изобретения, могут выполняться в другом порядке и при этом достигать желаемых результатов. В качестве одного примера, технологические процессы, изображенные на прилагаемых чертежах, не обязательно требуют конкретного показанного порядка или последовательного порядка для достижения желаемых результатов. В некоторых случаях могут быть выгодны многозадачность и параллельная обработка.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ПОЛУЧЕНИЯ ВЕКТОРНЫХ ПРЕДСТАВЛЕНИЙ ДАННЫХ В ТАБЛИЦЕ С УЧЁТОМ СТРУКТУРЫ ТАБЛИЦЫ И ЕЁ СОДЕРЖАНИЯ | 2024 |
|
RU2839037C1 |
| СПОСОБ СИНТЕЗА ВИДЕО ИЗ ВХОДНОГО КАДРА АВТОРЕГРЕССИОННЫМ МЕТОДОМ, ПОЛЬЗОВАТЕЛЬСКОЕ ЭЛЕКТРОННОЕ УСТРОЙСТВО И СЧИТЫВАЕМЫЙ КОМПЬЮТЕРОМ НОСИТЕЛЬ ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2023 |
|
RU2829010C1 |
| СПОСОБ ГЕНЕРАЦИИ ТРЁХМЕРНЫХ ОБЛАКОВ ТОЧЕК | 2020 |
|
RU2745445C1 |
| СПОСОБ АВТОМАТИЗАЦИИ СКВОЗНОГО (END-TO-END) ТЕСТИРОВАНИЯ С ПОМОЩЬЮ МОДЕЛИ МАШИННОГО ОБУЧЕНИЯ | 2024 |
|
RU2839253C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОПРЕДЕЛЕНИЯ МОШЕННИЧЕСКИХ ТРАНЗАКЦИЙ ПОЛЬЗОВАТЕЛЯ | 2024 |
|
RU2839053C1 |
| РАСПОЗНАВАНИЕ ТЕКСТА С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА | 2017 |
|
RU2691214C1 |
| СПОСОБ И УСТРОЙСТВО ГЕНЕРИРОВАНИЯ ВИДЕОКЛИПА ПО ТЕКСТОВОМУ ОПИСАНИЮ И ПОСЛЕДОВАТЕЛЬНОСТИ КЛЮЧЕВЫХ ТОЧЕК, СИНТЕЗИРУЕМОЙ ДИФФУЗИОННОЙ МОДЕЛЬЮ | 2024 |
|
RU2823216C1 |
| СИСТЕМА РАСПОЗНАВАНИЯ ИЗОБРАЖЕНИЯ: BEORG SMART VISION | 2020 |
|
RU2777354C2 |
| Способ управления бортовыми системами беспилотных транспортных средств при помощи нейронных сетей на основе архитектуры трансформеров | 2024 |
|
RU2841111C1 |
| УСТРАНЕНИЕ РАЗМЫТИЯ ИЗОБРАЖЕНИЯ | 2020 |
|
RU2742346C1 |
Изобретение относится к системе, носителю данных и способу преобразования последовательности на основе внимания. Технический результат заключается в повышении быстродействия преобразования последовательности. В способе принимают входную последовательность, имеющую соответственный ввод в каждой из множества позиций ввода в порядке ввода; обрабатывают входную последовательность посредством нейронной сети кодировщика, чтобы сгенерировать соответственное кодированное представление каждого из вводов во входной последовательности, при этом нейронная сеть кодировщика содержит последовательность из одной или более подсетей кодировщика, причем каждая подсеть кодировщика выполнена с возможностью принимать соответственный ввод подсети кодировщика для каждой из множества позиций ввода и генерировать соответственный вывод подсети для каждой из множества позиций ввода, и при этом каждая подсеть кодировщика содержит подслой самовнимания кодировщика, который выполнен с возможностью принимать ввод подсети для каждой из множества позиций ввода и, для каждой конкретной позиции ввода в порядке ввода, применять механизм самовнимания к вводам подсети кодировщика в множестве позиций ввода, чтобы сгенерировать соответственный вывод для данной конкретной позиции ввода, при этом применение механизма самовнимания содержит этапы, на которых: определяют запрос из ввода подсети в упомянутой конкретной позиции ввода, определяют ключи, полученные из вводов подсети в множестве позиций ввода, определяют значения, полученные из вводов подсети в множестве позиций ввода, и используют упомянутые определенные запрос, ключи и значения для генерирования упомянутого соответственного вывода для конкретной позиции ввода; и обрабатывают кодированные представления посредством нейронной сети декодировщика, чтобы сгенерировать выходную последовательность, имеющую соответственный вывод в каждой из множества позиций вывода в порядке вывода. 3 н. и 27 з.п. ф-лы, 3 ил.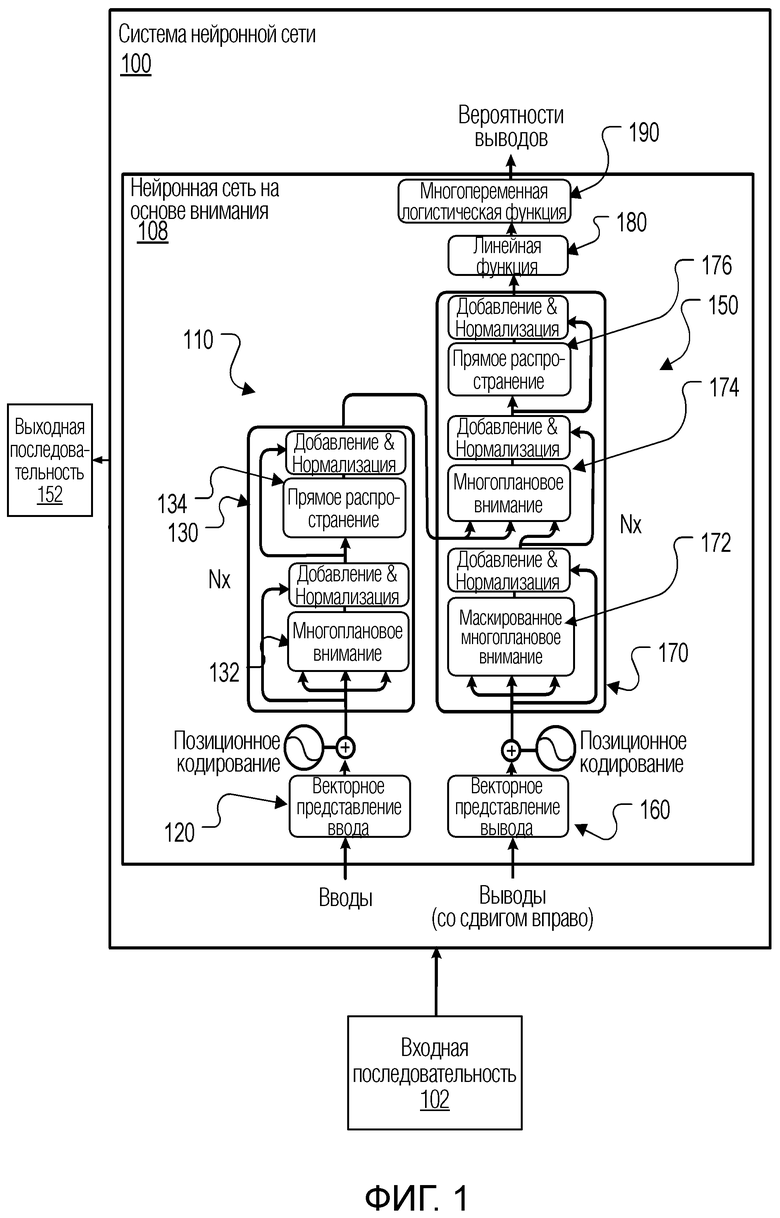
1. Вычислительная система, выполненная с возможностью преобразования последовательности на основе внимания и содержащая один или более компьютеров и одно или более запоминающих устройств, хранящих инструкции, которые при их исполнении одним или более компьютерами предписывают одному или более компьютерам реализовывать нейронную сеть с преобразованием последовательности для преобразования входной последовательности, имеющей соответственный сетевой ввод в каждой из множества позиций ввода в порядке ввода, в выходную последовательность, имеющую соответственный сетевой вывод в каждой из множества позиций вывода в порядке вывода, при этом нейронная сеть с преобразованием последовательности содержит:
нейронную сеть кодировщика, выполненную с возможностью принимать входную последовательность и генерировать соответственное кодированное представление каждого из сетевых вводов во входной последовательности, при этом нейронная сеть кодировщика содержит последовательность из одной или более подсетей кодировщика, причем каждая подсеть кодировщика выполнена с возможностью принимать соответственный ввод подсети кодировщика для каждой из множества позиций ввода и генерировать соответственный вывод подсети для каждой из множества позиций ввода, и при этом каждая подсеть кодировщика содержит подслой самовнимания кодировщика, который выполнен с возможностью принимать ввод подсети для каждой из множества позиций ввода и, для каждой конкретной позиции ввода в порядке ввода, применять механизм самовнимания к вводам подсети кодировщика в множестве позиций ввода, чтобы сгенерировать соответственный вывод для данной конкретной позиции ввода, при этом применение механизма самовнимания содержит: определение запроса из ввода подсети в упомянутой конкретной позиции ввода, определение ключей, полученных из вводов подсети в множестве позиций ввода, определение значений, полученных из вводов подсети в множестве позиций ввода, и использование упомянутых определенных запроса, ключей и значений для генерирования упомянутого соответственного вывода для конкретной позиции ввода; и
нейронную сеть декодировщика, выполненную с возможностью принимать кодированные представления и генерировать выходную последовательность.
2. Система по п.1, в которой нейронная сеть кодировщика дополнительно содержит слой векторного представления, выполненный с возможностью:
для каждого сетевого ввода во входной последовательности,
отображать сетевой ввод в векторизованное представление сетевого ввода, и
объединять векторизованное представление сетевого ввода с позиционным векторным представлением позиции ввода сетевого ввода в порядке ввода, чтобы сгенерировать объединенное векторизованное представление сетевого ввода; и
предоставлять объединенные векторизованные представления сетевых вводов в качестве вводов подсети кодировщика для первой подсети кодировщика в последовательности подсетей кодировщика.
3. Система по п.1, в которой соответственные кодированные представления сетевых вводов являются выводами подсети кодировщика, сгенерированными последней подсетью кодировщика в упомянутой последовательности.
4. Система по п.1, в которой последовательность из одной или более подсетей кодировщика включает в себя по меньшей мере две подсети кодировщика, при этом, для каждой подсети кодировщика, отличной от первой подсети кодировщика в упомянутой последовательности, ввод подсети кодировщика является выводом подсети кодировщика предыдущей подсети кодировщика в данной последовательности.
5. Система по п.1, в которой по меньшей мере одна из подсетей кодировщика дополнительно содержит слой попозиционного прямого распространения, который выполнен с возможностью, для каждой позиции ввода:
принимать ввод в этой позиции ввода, и
применять последовательность трансформаций к вводу в данной позиции ввода, чтобы сгенерировать вывод для этой позиции ввода.
6. Система по п.5, в которой упомянутая последовательность содержит две изученные линейные трансформации, отделенные функцией активации.
7. Система по п.5, в которой упомянутая по меньшей мере одна подсеть кодировщика дополнительно содержит:
слой остаточного соединения, который объединяет выводы слоя попозиционного прямого распространения с вводами для слоя попозиционного прямого распространения, чтобы сгенерировать попозиционный остаточный вывод кодировщика, и
слой нормализации слоя, который применяет нормализацию слоя к попозиционному остаточному выводу кодировщика.
8. Система по п.1, в которой каждая подсеть кодировщика дополнительно содержит:
слой остаточного соединения, который объединяет выводы подслоя самовнимания кодировщика с вводами для подслоя самовнимания кодировщика, чтобы сгенерировать остаточный вывод самовнимания кодировщика, и
слой нормализации слоя, который применяет нормализацию слоя к остаточному выводу самовнимания кодировщика.
9. Система по п.1, в которой каждый подслой самовнимания кодировщика содержит множество слоев самовнимания кодировщика.
10. Система по п.9, в которой каждый слой самовнимания кодировщика выполнен с возможностью:
применять изученную линейную трансформацию запроса к каждому вводу подсети кодировщика в каждой позиции ввода, чтобы сгенерировать соответственный запрос для каждой позиции ввода,
применять изученную линейную трансформацию ключа к каждому вводу подсети кодировщика в каждой позиции ввода, чтобы сгенерировать соответственный ключ для каждой позиции ввода,
применять изученную линейную трансформацию значения к каждому вводу подсети кодировщика в каждой позиции ввода, чтобы сгенерировать соответственное значение для каждой позиции ввода, и
для каждой позиции ввода,
определять соответственный индивидуальный для позиции ввода вес для данной позиции ввода путем применения функции совместимости между запросом для этой позиции ввода и ключами, сгенерированными для множества позиций ввода, и
определять начальный вывод самовнимания кодировщика для данной позиции ввода путем определения взвешенной суммы значений, взвешенных посредством соответствующих весов, индивидуальных для позиций ввода, для множества позиций ввода, каковые значения генерируются для множества позиций ввода.
11. Система по п.10, в которой подслой самовнимания кодировщика выполнен с возможностью, для каждой позиции ввода, объединять начальные выводы самовнимания кодировщика для этой позиции ввода, сгенерированные слоями самовнимания кодировщика, чтобы сгенерировать вывод для подслоя самовнимания кодировщика.
12. Система по п.9, в которой слои самовнимания кодировщика работают параллельно.
13. Система по п.1, в которой нейронная сеть декодировщика авторегрессионным методом генерирует выходную последовательность посредством того, что, на каждом из множества временных шагов генерирования, генерирует сетевой вывод в позиции вывода, соответствующей этому временному шагу генерирования, обусловленный кодированными представлениями и сетевыми выводами в позициях вывода, предшествующих этой позиции вывода в порядке вывода.
14. Система по п.13, в которой нейронная сеть декодировщика содержит последовательность подсетей декодировщика, при этом каждая подсеть декодировщика выполнена с возможностью, на каждом временном шаге генерирования, принимать соответственный ввод подсети декодировщика для каждой из множества позиций вывода, предшествующих упомянутой соответствующей позиции вывода, и генерировать соответственный вывод подсети декодировщика для каждой из множества позиций вывода, предшествующих этой соответствующей позиции вывода.
15. Система по п.14, в которой нейронная сеть декодировщика дополнительно содержит слой векторного представления, выполненный с возможностью, на каждом временном шаге генерирования,
для каждого сетевого вывода в позициях вывода, предшествующих упомянутой соответствующей позиции вывода в порядке вывода:
отображать этот сетевой вывод в векторизованное представление сетевого вывода, и
объединять векторизованное представление сетевого вывода с позиционным векторным представлением упомянутой соответствующей позиции вывода сетевого вывода в порядке вывода, чтобы сгенерировать объединенное векторизованное представление сетевого вывода; и
предоставлять объединенные векторизованные представления сетевого вывода в качестве ввода для первой подсети декодировщика в последовательности подсетей декодировщика.
16. Система по п.14, в которой по меньшей мере одна из подсетей декодировщика содержит слой попозиционного прямого распространения, который выполнен с возможностью, на каждом временном шаге генерирования, для каждой конкретной позиции вывода, предшествующей упомянутой соответствующей позиции вывода:
принимать ввод в этой конкретной позиции вывода и
применять последовательность трансформаций к вводу в данной конкретной позиции вывода, чтобы сгенерировать вывод для этой конкретной позиции вывода.
17. Система по п.16, в которой последовательность содержит две изученные линейные трансформации, отделенные функцией активации.
18. Система по п.16, в которой упомянутая по меньшей мере одна подсеть декодировщика дополнительно содержит:
слой остаточного соединения, который объединяет выводы слоя попозиционного прямого распространения с вводами для слоя попозиционного прямого распространения, чтобы сгенерировать остаточный вывод, и
слой нормализации слоя, который применяет нормализацию слоя к остаточному выводу.
19. Система по п.14, в которой каждая подсеть декодировщика содержит подслой внимания кодировщика-декодировщика, который выполнен с возможностью, на каждом временном шаге генерирования: принимать ввод для каждой конкретной позиции вывода, предшествующей соответствующей позиции вывода, и, для каждой из этих конкретных позиций вывода, применять механизм внимания к кодированным представлениям в позициях ввода с использованием одного или более запросов, извлеченных из ввода для этой конкретной позиции вывода, чтобы сгенерировать обновленное представление для данной конкретной позиции вывода.
20. Система по п.19, в которой каждый подслой внимания кодировщика-декодировщика содержит множество слоев внимания кодировщика-декодировщика, и в которой каждый слой внимания кодировщика-декодировщика выполнен с возможностью, на каждом временном шаге генерирования:
применять изученную линейную трансформацию запроса к вводу в каждой из упомянутых конкретных позиций вывода, предшествующей упомянутой соответствующей позиции вывода, чтобы сгенерировать соответственный запрос для каждой конкретной позиции вывода,
применять изученную линейную трансформацию ключа к каждому кодированному представлению в каждой позиции ввода, чтобы сгенерировать соответственный ключ для каждой позиции ввода,
применять изученную линейную трансформацию значения к каждому кодированному представлению в каждой позиции ввода, чтобы сгенерировать соответственное значение для каждой позиции ввода, и
для каждой конкретной позиции вывода, предшествующей упомянутой соответствующей позиции вывода,
определять соответственный индивидуальный для позиции вывода вес для каждой из позиций ввода путем применения функции совместимости между запросом для этой конкретной позиции вывода и ключами, и
определять начальный вывод внимания кодировщика-декодировщика для данной конкретной позиции вывода путем определения взвешенной суммы значений, взвешенных посредством соответствующих весов, индивидуальных для позиций вывода, для этой позиции ввода.
21. Система по п.20, в которой подслой внимания кодировщика-декодировщика выполнен с возможностью, на каждом временном шаге генерирования, объединять выводы внимания кодировщика-декодировщика, сгенерированные слоями внимания кодировщика-декодировщика, чтобы сгенерировать вывод для подслоя внимания кодировщика-декодировщика.
22. Система по п.20, в которой слои внимания кодировщика-декодировщика работают параллельно.
23. Система по п.19, в которой каждая подсеть декодировщика дополнительно содержит:
слой остаточного соединения, который объединяет выводы подслоя внимания кодировщика-декодировщика с вводами для подслоя внимания кодировщика-декодировщика, чтобы сгенерировать остаточный вывод, и
слой нормализации слоя, который применяет нормализацию слоя к остаточному выводу.
24. Система по п.14, в которой каждая подсеть декодировщика содержит подслой самовнимания декодировщика, который выполнен с возможностью, на каждом временном шаге генерирования: принимать ввод для каждой конкретной позиции вывода, предшествующей упомянутой соответствующей позиции вывода и, для каждой конкретной позиции вывода, применять механизм внимания к вводам в позициях вывода, предшествующих упомянутой соответствующей позиции вывода, с использованием одного или более запросов, извлеченных из ввода в этой конкретной позиции вывода, чтобы сгенерировать обновленное представление для данной конкретной позиции вывода.
25. Система по п.24, в которой каждый подслой самовнимания декодировщика содержит множество слоев самовнимания декодировщика и в которой каждый слой самовнимания декодировщика выполнен с возможностью, на каждом временном шаге генерирования:
применять изученную линейную трансформацию запроса к вводу в каждой конкретной позиции вывода, предшествующей упомянутой соответствующей позиции вывода, чтобы сгенерировать соответственный запрос для каждой конкретной позиции вывода,
применять изученную линейную трансформацию ключа к каждому вводу в каждой конкретной позиции вывода, предшествующей упомянутой соответствующей позиции вывода, чтобы сгенерировать соответственный ключ для каждой конкретной позиции вывода,
применять изученную линейную трансформацию значения к каждому вводу в каждой конкретной позиции вывода, предшествующей упомянутой соответствующей позиции вывода, чтобы сгенерировать соответственный ключ для каждой конкретной позиции вывода, и
для каждой из упомянутых конкретных позиций вывода, предшествующей упомянутой соответствующей позиции вывода,
определять соответственный индивидуальный для позиции вывода вес для каждой конкретной позиции вывода путем применения функции совместимости между запросом для этой конкретной позиции вывода и ключами, и
определять начальный вывод внимания декодировщика для данной конкретной позиции вывода путем определения взвешенной суммы значений, взвешенных посредством соответствующих весов, индивидуальных для позиций вывода, для этой конкретной позиции вывода.
26. Система по п.25, в которой подслой самовнимания декодировщика выполнен с возможностью, на каждом временном шаге генерирования, объединять выводы внимания декодировщика, сгенерированные слоями самовнимания декодировщика, чтобы сгенерировать вывод для подслоя самовнимания декодировщика.
27. Система по п.25, в которой слои внимания декодировщика работают параллельно.
28. Система по п.24, в которой каждая подсеть декодировщика дополнительно содержит:
слой остаточного соединения, который объединяет выводы подслоя самовнимания декодировщика с вводами для подслоя самовнимания декодировщика, чтобы сгенерировать остаточный вывод, и
слой нормализации слоя, который применяет нормализацию слоя к остаточному выводу.
29. Долговременный компьютерный носитель информации, хранящий инструкции, которые при их исполнении одним или более компьютерами предписывают одному или более компьютерам реализовывать нейронную сеть с преобразованием последовательности для преобразования входной последовательности, имеющей соответственный сетевой ввод в каждой из множества позиций ввода в порядке ввода, в выходную последовательность, имеющую соответственный сетевой вывод в каждой из множества позиций вывода в порядке вывода, при этом нейронная сеть с преобразованием последовательности содержит:
нейронную сеть кодировщика, выполненную с возможностью принимать входную последовательность и генерировать соответственное кодированное представление каждого из сетевых вводов во входной последовательности, при этом нейронная сеть кодировщика содержит последовательность из одной или более подсетей кодировщика, причем каждая подсеть кодировщика выполнена с возможностью принимать соответственный ввод подсети кодировщика для каждой из множества позиций ввода и генерировать соответственный вывод подсети для каждой из множества позиций ввода, и при этом каждая подсеть кодировщика содержит подслой самовнимания кодировщика, который выполнен с возможностью принимать ввод подсети для каждой из множества позиций ввода и, для каждой конкретной позиции ввода в порядке ввода, применять механизм самовнимания к вводам подсети кодировщика в множестве позиций ввода, чтобы сгенерировать соответственный вывод для данной конкретной позиции ввода, при этом применение механизма самовнимания содержит: определение запроса из ввода подсети в упомянутой конкретной позиции ввода, определение ключей, полученных из вводов подсети в множестве позиций ввода, определение значений, полученных из вводов подсети в множестве позиций ввода, и использование упомянутых определенных запроса, ключей и значений для генерирования упомянутого соответственного вывода для конкретной позиции ввода; и
нейронную сеть декодировщика, выполненную с возможностью принимать кодированные представления и генерировать выходную последовательность.
30. Компьютерно-реализуемый способ преобразования последовательности на основе внимания, содержащий этапы, на которых:
принимают входную последовательность, имеющую соответственный ввод в каждой из множества позиций ввода в порядке ввода;
обрабатывают входную последовательность посредством нейронной сети кодировщика, чтобы сгенерировать соответственное кодированное представление каждого из вводов во входной последовательности, при этом нейронная сеть кодировщика содержит последовательность из одной или более подсетей кодировщика, причем каждая подсеть кодировщика выполнена с возможностью принимать соответственный ввод подсети кодировщика для каждой из множества позиций ввода и генерировать соответственный вывод подсети для каждой из множества позиций ввода, и при этом каждая подсеть кодировщика содержит подслой самовнимания кодировщика, который выполнен с возможностью принимать ввод подсети для каждой из множества позиций ввода и, для каждой конкретной позиции ввода в порядке ввода, применять механизм самовнимания к вводам подсети кодировщика в множестве позиций ввода, чтобы сгенерировать соответственный вывод для данной конкретной позиции ввода, при этом применение механизма самовнимания содержит этапы, на которых: определяют запрос из ввода подсети в упомянутой конкретной позиции ввода, определяют ключи, полученные из вводов подсети в множестве позиций ввода, определяют значения, полученные из вводов подсети в множестве позиций ввода, и используют упомянутые определенные запрос, ключи и значения для генерирования упомянутого соответственного вывода для конкретной позиции ввода; и
обрабатывают кодированные представления посредством нейронной сети декодировщика, чтобы сгенерировать выходную последовательность, имеющую соответственный вывод в каждой из множества позиций вывода в порядке вывода.
| JIANPENG CHENG et al, "Long Short-Term Memory-Networks for Machine Reading", 20.09.2016, доступно: https://arxiv.org/pdf/1601.06733 | |||
| ZHOUHAN LIN et al, "A Structured Self-attentive Sentence Embedding", 09.03.2017, доступно: https://arxiv.org/pdf/1703.03130 | |||
| KYUNGHYUN CHO et al, "Learning Phrase Representations using RNN Encoder-Decoder for |

