Область техники, к которой относится изобретение
[0001] Настоящее изобретение относится к авторегрессионному синтезу высококачественных видео из одного кадра (изображения) с использованием полностью сверточной диффузионной модели.
Уровень техники
[0002] Синтез видео, представляющий собой важнейшую область исследований в области компьютерного зрения и графики, имеет широкий ряд возможных применений - от создания персонализированного контента до эффектов компьютерной графики (CGI). Хотя последние достижения позволили улучшить качество синтеза изображений, преобразование изображения в видео с высоким разрешением остается сложной задачей. Основная причина заключается в том, что существующие модели требуют крупномасштабных наборов видеоданных и значительных вычислительных ресурсов, что делает их обучение дорогостоящим и ограничивает их практичность.
Сущность изобретения
[0003] Для решения проблем, присущих известным решениям, предложенные и раскрытые в данном документе технические решения используют диффузионную модель перехода от кадра к следующему кадру, которая фактически представляет собой диффузионную модель перехода от кадра к видео с рекурсивной схемой выборки кадров и явным управлением движением синтезируемых видео с помощью общего скрытого кода движения. Преимущество предложенных и раскрытых технических решений состоит в том, что они позволяют поддерживать временную когерентность синтезируемых видео. Более того, применение диффузионной модели перехода от кадра к видео с рекурсивной схемой выборки кадров и явным управлением движением позволяет обучать модель на видео с более низким разрешением, используя меньший объем видеопамяти с произвольным доступом (VRAM), а затем, когда она обучена, использовать ее для вывода (inference) в более высоком разрешении (например, вплоть до 2048 × 1280) без значительного снижения качества изображения.
[0004] Согласно первому аспекту изобретения предложен способ синтеза видео (последовательности кадров) авторегрессионным методом, включающий в себя: прогнозирование с использованием обученной диффузионной модели перехода от кадра к следующему кадру следующего кадра 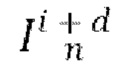 на основе входного кадра
на основе входного кадра 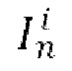 , одновременно с обуславливанием движения между кадрами синтезируемого видео с помощью общего скрытого кода m движения.
, одновременно с обуславливанием движения между кадрами синтезируемого видео с помощью общего скрытого кода m движения.
[0005] В качестве развития первого аспекта способ дополнительно включает в себя этап, на котором прогнозируют с использованием обученной диффузионной модели перехода от кадра к следующему кадру еще один следующий кадр на основе ранее спрогнозированного кадра 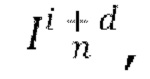 также при одновременном обуславливании движения между кадрами синтезируемого видео с помощью упомянутого общего скрытого кода m движения.
также при одновременном обуславливании движения между кадрами синтезируемого видео с помощью упомянутого общего скрытого кода m движения.
[0006] В качестве еще большего развития первого аспекта движение между кадрами синтезируемого видео обуславливают (явно контролируют) с помощью общего скрытого кода m движения путем ввода упомянутого общего скрытого кода m движения в один или несколько слоев основанного на U-Net диффузионного предиктора диффузионной модели перехода от кадра к следующему кадру.
[0007] В качестве еще большего развития первого аспекта общий скрытый код m движения получают путем выполнения следующих этапов, на которых: получают векторное представление сети сравнительного обучения языка и изображений (CLIP) для входного кадра 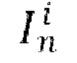 путем пропускания входного кадра
путем пропускания входного кадра 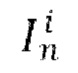 через кодировщик обученной нейронной сети CLIP; осуществляют поиск одного или нескольких векторных представлений CLIP, ближайших к полученному векторному представлению CLIP, используя k-ближайших соседей (kNN), причем поиск выполняют в базе данных векторных представлений CLIP, полученных для одного или нескольких кадров одного или нескольких обучающих видео, содержащихся в обучающем наборе данных, используемом для обучения диффузионной модели перехода от кадра к следующему кадру; и осуществляют выборку общего скрытого кода m движения из банка М выученных векторных представлений движения, соответствующих одному или нескольким кадрам одного или нескольких обучающих видео, которые использовались для получения одного или нескольких найденных векторных представлений CLIP.
через кодировщик обученной нейронной сети CLIP; осуществляют поиск одного или нескольких векторных представлений CLIP, ближайших к полученному векторному представлению CLIP, используя k-ближайших соседей (kNN), причем поиск выполняют в базе данных векторных представлений CLIP, полученных для одного или нескольких кадров одного или нескольких обучающих видео, содержащихся в обучающем наборе данных, используемом для обучения диффузионной модели перехода от кадра к следующему кадру; и осуществляют выборку общего скрытого кода m движения из банка М выученных векторных представлений движения, соответствующих одному или нескольким кадрам одного или нескольких обучающих видео, которые использовались для получения одного или нескольких найденных векторных представлений CLIP.
[0008] В качестве еще большего развития первого аспекта метрику расстояния для kNN вычисляют как расстояние между векторным представлением CLIP кадра обучающего видео, содержащегося в обучающем наборе данных, и векторным представлением CLIP входного кадра 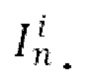
[0009] В качестве еще большего развития первого аспекта диффузионную модель перехода от кадра к следующему кадру обучают путем многократного выполнения до сходимости следующих этапов, на которых: осуществляют случайную выборку пары кадров 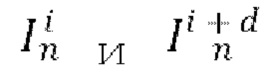 из обучающего видео обучающего набора данных, где d обозначает разность времени видео между этими кадрами; пропускают кадры
из обучающего видео обучающего набора данных, где d обозначает разность времени видео между этими кадрами; пропускают кадры 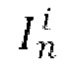 и
и 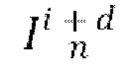 через кодировщик Е предварительно обученного вариационного автокодировщика (VAE) для получения соответствующих скрытых представлении xi и xi+d этих кадров; вычисляют остаток
через кодировщик Е предварительно обученного вариационного автокодировщика (VAE) для получения соответствующих скрытых представлении xi и xi+d этих кадров; вычисляют остаток 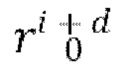 путем вычитания скрытого представления xi из скрытого представления xi+d; получают общий скрытый код m движения обучающего видео, обозначенного индексом n, из которого были выбраны кадры
путем вычитания скрытого представления xi из скрытого представления xi+d; получают общий скрытый код m движения обучающего видео, обозначенного индексом n, из которого были выбраны кадры 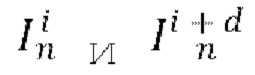 , и сохраняют полученный общий скрытый код m движения в базе данных обучаемых векторных представлений движения; осуществляют случайную выборку индекса t временного шага диффузии, соответствующего порядковому номеру временных шагов диффузии от 1 до где Т - общее количество временных шагов диффузии, и вводят индекс t временного шага диффузии в диффузионную модель перехода от кадра к следующему кадру посредством синусного и/или косинусного позиционного кодирования; осуществляют случайную выборку тензора ∈ шума из N(0,I); и обновляют веса основанного на U-Net диффузионного предиктора, содержащегося в диффузионной модели перехода от кадра к следующему кадру, путем выполнения шага градиентного спуска на потере L2 между выбранным тензором ∈ шума и тензором ∈ шума, прогнозируемым основанным на U-Net диффузионным предиктором, обуславливаемым выбранным общим скрытым кодом m движения, индексом t временного шага диффузии, скрытым представлением xi и вычисленным остатком
, и сохраняют полученный общий скрытый код m движения в базе данных обучаемых векторных представлений движения; осуществляют случайную выборку индекса t временного шага диффузии, соответствующего порядковому номеру временных шагов диффузии от 1 до где Т - общее количество временных шагов диффузии, и вводят индекс t временного шага диффузии в диффузионную модель перехода от кадра к следующему кадру посредством синусного и/или косинусного позиционного кодирования; осуществляют случайную выборку тензора ∈ шума из N(0,I); и обновляют веса основанного на U-Net диффузионного предиктора, содержащегося в диффузионной модели перехода от кадра к следующему кадру, путем выполнения шага градиентного спуска на потере L2 между выбранным тензором ∈ шума и тензором ∈ шума, прогнозируемым основанным на U-Net диффузионным предиктором, обуславливаемым выбранным общим скрытым кодом m движения, индексом t временного шага диффузии, скрытым представлением xi и вычисленным остатком 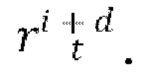
[0010] В качестве еще большего развития первого аспекта на временном шаге t диффузии для кадра 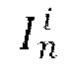 прогнозируемый тензор ∈ шума получают путем пропускания через основанный на U-Net диффузионный предиктор выбранного общего скрытого кода m движения, индекса t временного шага диффузии, скрытого представления xi и вычисленного остатка
прогнозируемый тензор ∈ шума получают путем пропускания через основанный на U-Net диффузионный предиктор выбранного общего скрытого кода m движения, индекса t временного шага диффузии, скрытого представления xi и вычисленного остатка 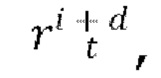 зашумленного случайно выбранным тензором ∈ шума.
зашумленного случайно выбранным тензором ∈ шума.
[0011] В качестве еще большего развития первого аспекта два кадра 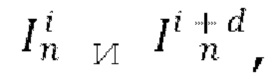 выбранные из обучающего видео, представляют собой кадры, расположенные смежно или рядом друг с другом в последовательности кадров обучающего видео, диффузионную модель перехода от кадра к следующему кадру, обуславливаемую выборочным общим скрытым кодом m движения, индексом t временного шага диффузии, скрытым представлением xi и вычисленным остатком
выбранные из обучающего видео, представляют собой кадры, расположенные смежно или рядом друг с другом в последовательности кадров обучающего видео, диффузионную модель перехода от кадра к следующему кадру, обуславливаемую выборочным общим скрытым кодом m движения, индексом t временного шага диффузии, скрытым представлением xi и вычисленным остатком 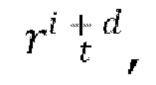 обучают путем минимизации потери L2 между прогнозируемым тензором ∈ шума и выбранным тензором ∈ шума.
обучают путем минимизации потери L2 между прогнозируемым тензором ∈ шума и выбранным тензором ∈ шума.
[0012] В качестве еще большего развития первого аспекта два кадра 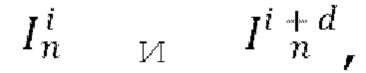 которые пропускают через кодировщик Е предварительно обученного VAE для получения соответствующих скрытых представлении xi и xi+d кадров, пропускают в виде фрагментов (crops) упомянутых кадров, при этом способ дополнительно содержит этап получения упомянутых фрагментов из каждого кадра, причем фрагменты каждого кадра включают в себя центр и один или более из четырех углов этого кадра.
которые пропускают через кодировщик Е предварительно обученного VAE для получения соответствующих скрытых представлении xi и xi+d кадров, пропускают в виде фрагментов (crops) упомянутых кадров, при этом способ дополнительно содержит этап получения упомянутых фрагментов из каждого кадра, причем фрагменты каждого кадра включают в себя центр и один или более из четырех углов этого кадра.
[0013] В качестве еще большего развития первого аспекта способ дополнительно включает в себя один или более этапов получения дополнительных пар кадров, подлежащих использованию на стадии обучения, путем выполнения горизонтального переворота и/или инверсии времени пар кадров, случайно выбираемых из обучающих видео, содержащихся в обучающем наборе данных.
[0014] В качестве еще большего развития первого аспекта прогнозирование следующего кадра Ii на основе предыдущего кадра Ii-1 с использованием обученной диффузионной модели перехода от кадра к следующему кадру, при одновременном обуславливании движения между кадрами синтезируемого видео с помощью общего скрытого кода m движения включает этапы, на которых: получают векторное представление CLIP для предыдущего кадра Ii-1 , осуществляют поиск одного или нескольких векторных представлений CLIP, ближайших к полученному векторному представлению CLIP, с использованием kNN, причем поиск осуществляют в базе данных векторных представлений CLIP, полученных ранее для одного или нескольких кадров одного или нескольких обучающих видео, содержащихся в обучающем наборе данных, используемом для обучения диффузионной модели перехода от кадра к следующему кадру; осуществляют выборку общего скрытого кода m движения из банка М выученных векторных представлений движения, соответствующих одному или более кадрам одного или более обучающих видео, которые использовались для получения одного или более найденных векторных представлений CLIP; пропускают предыдущий кадр Ii-1 через кодировщик Е предварительно обученного VAE для получения соответствующего скрытого представления xi-1; для каждого кадра видео, синтезируемого обученной диффузионной моделью перехода от кадра к следующему кадру, начиная со второго кадра: осуществляют выборку исходного зашумленного остатка 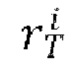 из N(0,I); получают обесшумленный остаток
из N(0,I); получают обесшумленный остаток 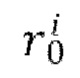 путем выполнения Т шагов диффузии основанным на U-Net диффузионным предиктором, при этом на шаге t диффузии: вычитают из зашумленного остатка
путем выполнения Т шагов диффузии основанным на U-Net диффузионным предиктором, при этом на шаге t диффузии: вычитают из зашумленного остатка 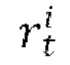 выходное значение обученного основанного на U-Net диффузионного предиктора, содержащегося в диффузионной модели перехода от кадра к следующему кадру
выходное значение обученного основанного на U-Net диффузионного предиктора, содержащегося в диффузионной модели перехода от кадра к следующему кадру 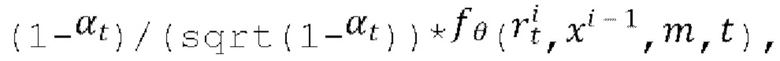 где αt - гиперпараметр обученного основанного на U-Net диффузионного предиктора; получают скрытое представление xi синтезируемого следующего кадра Ii путем добавления обесшумленного остатка
где αt - гиперпараметр обученного основанного на U-Net диффузионного предиктора; получают скрытое представление xi синтезируемого следующего кадра Ii путем добавления обесшумленного остатка 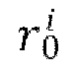 к скрытому представлению xi-1 предыдущего кадра; получают синтезированный следующий кадр Ii путем пропускания скрытого представления xi+d упомянутого кадра через декодировщик D предварительно обученного VAE; и получают синтезированное видео V путем объединения всех синтезированных кадров {I}N.
к скрытому представлению xi-1 предыдущего кадра; получают синтезированный следующий кадр Ii путем пропускания скрытого представления xi+d упомянутого кадра через декодировщик D предварительно обученного VAE; и получают синтезированное видео V путем объединения всех синтезированных кадров {I}N.
[0015] Согласно второму аспекту изобретения предложено пользовательское электронное устройство, выполненное с возможностью синтезировать видео из кадра авторегрессионным методом, причем устройство включает в себя процессор и память, хранящую исполняемые компьютером инструкции, которые при их исполнении процессором побуждают устройство выполнять способ согласно первому аспекту или согласно любому развитию первого аспекта.
[0016] Согласно третьему аспекту настоящего изобретения предложен считываемый компьютером носитель, хранящий исполняемые компьютером инструкции, которые при их исполнении устройством побуждают его выполнять способ согласно первому аспекту или согласно любому развитию первого аспекта.
Краткое описание чертежей
[ФИГ. 1] Фиг. 1 - схематическое изображение архитектуры диффузионной модели перехода от кадра к следующему кадру согласно варианту осуществления настоящего изобретения, предложенного в настоящей заявке.
[ФИГ. 2] Фиг. 2 - схематическое изображение структуры основанного на U-Net диффузионного предиктора, содержащегося в диффузионной модели перехода от кадра к следующему кадру, согласно варианту осуществления настоящего изобретения.
[ФИГ. 3] Фиг. 3 - схематическое изображение процесса выборки скрытого кода движения, выполняемый диффузионной моделью перехода от кадра к следующему кадру согласно варианту осуществления настоящего изобретения, предложенного в настоящей заявке.
[ФИГ. 4] Фиг. 4 - примеры кадров, синтезированных авторегрессионным методом, начиная с входного кадра, диффузионной моделью перехода от кадра к следующему кадру, согласно варианту осуществления настоящего изобретения.
Подробное описание изобретения
[0017] Предложенные и раскрытые в настоящем документе технические решения решают задачу синтеза видео авторегрессионным методом путем обуславливания синтеза следующего кадра предыдущим кадром и, дополнительно, общим (shared) скрытым кодом движения, определяемым однократно для входного кадра и сохраняемым постоянным для всех синтезируемых кадров. Общий скрытый код движения - это обучаемый вектор, который выучивает динамику движения видео. Архитектуре диффузионной модели перехода от кадра к следующему кадру, синтезирующей кадры, требуется всего лишь текущий видеокадр для синтеза следующего кадра и, таким образом, обеспечивается эффективное с точки зрения данных и вычислений обучение при высоких разрешениях. Кроме того, благодаря обуславливанию всех синтезируемых кадров общим скрытым кодом движения диффузионная модель перехода от кадра к следующему кадру обеспечивает временную согласованность, не прибегая к интенсивно потребляющим память слоям временной свертки или временного внимания.
[0018] Эффективность предложенной диффузионной модели перехода от кадра к следующему кадру была подтверждена экспериментально на известных наборах данных для синтеза видео, таких как SkyTimeLapse и DeepLandscape, с использованием расстояния Фреше для видео (FVD) и начального расстояния Фреше (FID) в качестве основных оценочных метрик. Полученные экспериментальные данные приведены в конце данного подробного описания. Благодаря обучению на видео с разрешением 1280×720 предлагаемая диффузионная модель перехода от кадра к следующему кадру может создавать видео с разрешением почти в 2 раз выше, чем у современных методов, при незначительной потере в FVD.
[0019] Основной вклад настоящего изобретения по сравнению с предшествующим уровнем техники составляют предложенные и раскрытые в настоящем документе технические решения, которые разработаны с пониманием того, что сложные механизмы временной когерентности, такие как слои временного внимания и временной свертки, не являются необходимыми для небольших наборов видеоданных, и что более легкие модели с рекурсивной схемой выборки могут конкурировать с более мощными моделями на меньших обучающих наборах данных. Таким образом, диффузионная модель перехода от кадра к следующему кадру, используемая в предложенных и раскрытых в настоящем документе технических решениях, представляет собой новый класс диффузионных моделей для видео, который состоит из модели скрытой диффузии (LDM), которая обуславливается предыдущим кадром синтезируемого видео и общим скрытым кодом движения, который выучивается совместно для каждого видео.
[0020] Диффузионные модели представляют собой класс моделей, часто используемых в генеративном моделировании изображений. Согласно одной из существующих формулировок, диффузионные вероятностные модели устранения шума (DDPM) представляют собой модели скрытых переменных вида 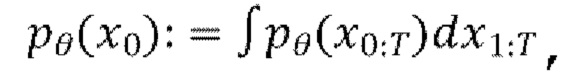 где
где 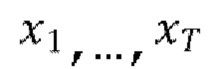 - скрытые переменные той же размерности, что и данные
- скрытые переменные той же размерности, что и данные 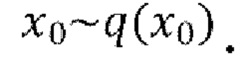 Процесс диффузии, или прямой процесс, представляет собой цепь Маркова с гауссовскими переходами. Он постепенно добавляет к данным гауссовский шум в соответствии с планом дисперсии β1, …, βT:
Процесс диффузии, или прямой процесс, представляет собой цепь Маркова с гауссовскими переходами. Он постепенно добавляет к данным гауссовский шум в соответствии с планом дисперсии β1, …, βT:
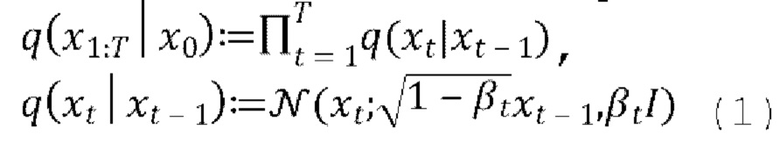
[0021] Выборку xt на произвольном временном шаге t во время прямого процесса также можно выполнять в закрытом виде:
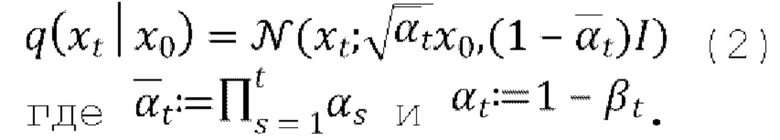
[0022] Генеративный процесс, или обратный процесс, представляет собой совместное распределение 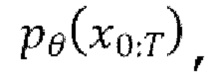 также определяемое как цепь Маркова с выучиваемыми гауссовскими переходами, начинающимися с р(xT)=N(xT; 0,I):
также определяемое как цепь Маркова с выучиваемыми гауссовскими переходами, начинающимися с р(xT)=N(xT; 0,I):
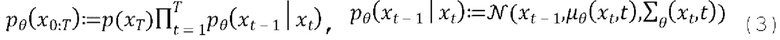
[0023] Обучение обратному процессу равносильно обучению устранению шума 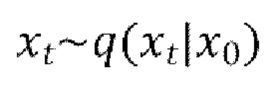 для получения оценки для
для получения оценки для 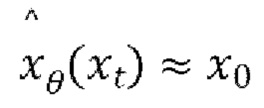 всех временных шагов t. Таким образом, предлагаемая диффузионная модель перехода от кадра к следующему кадру оптимизируется (обучается) путем минимизации потери среднеквадратической ошибки прогнозирования шума (также называемой потерей L2):
всех временных шагов t. Таким образом, предлагаемая диффузионная модель перехода от кадра к следующему кадру оптимизируется (обучается) путем минимизации потери среднеквадратической ошибки прогнозирования шума (также называемой потерей L2):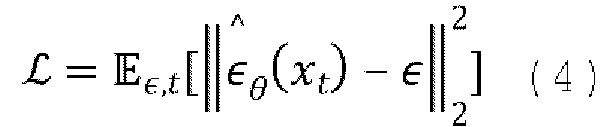
в течение периодов времени tr равномерно выбираемых из [1, …, T], где 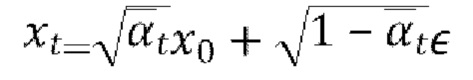 и
и 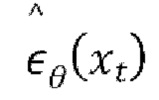 - это добавленный шум ∈, прогнозируемый оценкой модели.
- это добавленный шум ∈, прогнозируемый оценкой модели.
[0024] Для создания видео с более высоким разрешением в данном случае используется подход LDM. Используя кодировщик Е предварительно обученного VAE из Stable Diffusion, все данные, обработанные (как на стадии обучения, так и на стадии вывода) диффузионной моделью перехода от кадра к следующему кадру, кодируются для уменьшения пространственного разрешения. В конкретной неограничивающей реализации кодирования пространственное разрешение уменьшается на ×8. Используя выученное скрытое пространство, скрытые представления кадров, синтезированные диффузионной моделью перехода от кадра к следующему кадру, затем декодируются декодировщиком D того же самого VAE обратно в пиксельное пространство (т.е. в фактически синтезированные кадры). Эта особенность обеспечивает возможность реализации предлагаемых технических решений на устройствах с ограниченными ресурсами процессора и памяти.
[0025] Кроме безусловной генерации, диффузионные модели способны моделировать условные распределения и решать такие задачи, как обусловленный классом синтез изображений, преобразование текста в изображение или текста в видео, дорисовка изображений и различные другие задачи преобразования изображения в изображение. Для синтеза видео с последовательными кадрами предложенная диффузионная модель перехода от кадра к следующему кадру обуславливается предыдущим кадром и, дополнительно, специфичным для видео скрытым кодом движения. Более конкретно, обуславливающий кадр объединяется со скрытым представлением xt и они вместе подаются в диффузионную модель перехода от кадра к следующему кадру, обученную синтезировать скрытое представление xt+1, декодируемое декодировщиком D VAE в следующий кадр.
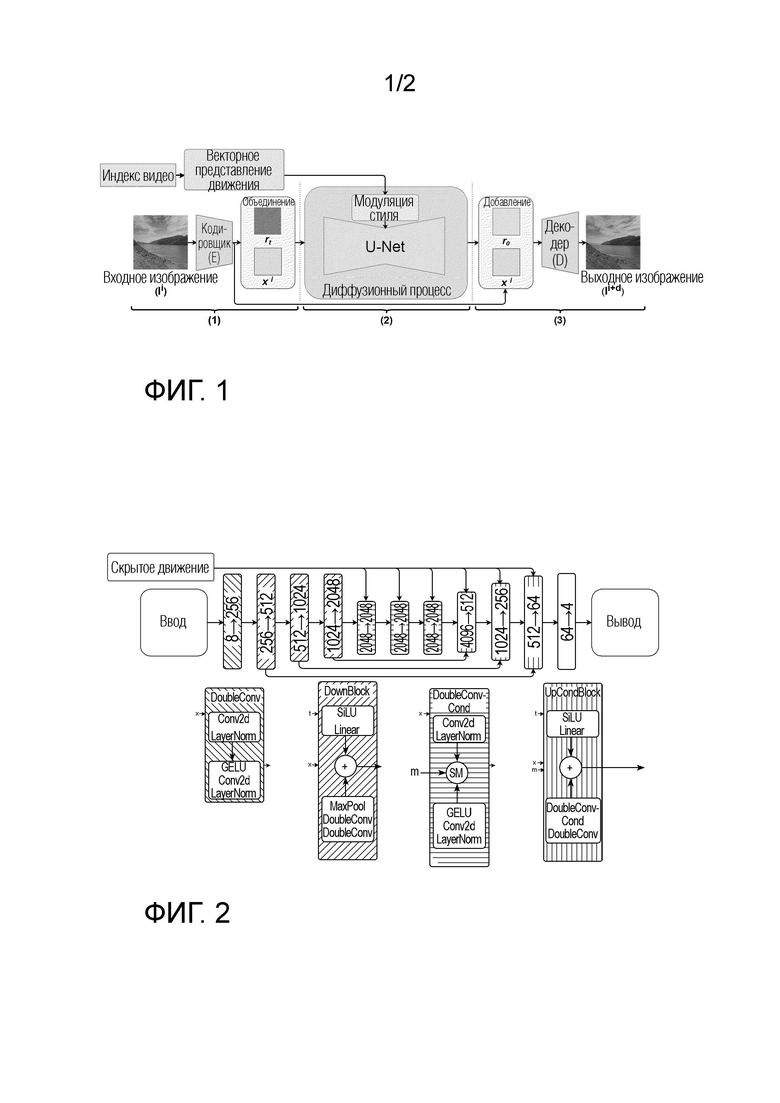
[0026] Далее со ссылкой на фиг. 1 будет подробно описана архитектура диффузионной модели перехода от кадра к следующему кадру согласно неограничивающему варианту осуществления настоящего изобретения, предлагаемому в настоящей заявке. Диффузионная модель перехода от кадра к следующему кадру содержит кодировщик Е и декодировщик D предварительно обученного VAE, основанный на U-Net диффузионный предиктор и модуляцию стиля векторным представлением (m) движения. Архитектура предлагаемого основанного на U-Net диффузионного предиктора будет подробно описана со ссылкой на фиг. 2.
[0027] Предложенная диффузионная модель перехода от кадра к следующему кадру не полагается на временное внимание, временную свертку или любую другую операцию, которая явно распространяет информацию по видеокадрам. Для сохранения временной когерентности видео синтезируется авторегрессионным методом, покадрово, путем прогнозирования следующего кадра Ii+d на основе предыдущего кадра Ii и общего скрытого кода m движения, который одинаков для всех кадров в одном видео. При выводе I0 является исходным кадром, вводимым в диффузионную модель перехода от кадра к следующему кадру. Для синтеза видео высокого разрешения диффузионная модель перехода от кадра к следующему кадру сконфигурирована с возможностью работы в низкоразмерном скрытом пространстве предварительно обученного VAE, являющегося моделью перцептивного сжатия. Этот VAE состоит из кодировщика Е и декодировщика D. VAE предварительно обучается на задаче автокодирования случайных кадров, т.е. входной обучающий кадр пропускается через кодировщик E, становится скрытым представлением и возвращается обратно в свое исходное пиксельное пространство после его пропускания через декодировщик D. Кодировщик и декодировщик можно обучать, без ограничения перечисленным, с помощью функции потерь, вычисляемой между исходным эталонным кадром и реконструированным кадром, полученным декодировщиком D. Альтернативно, VAE, включающий в себя кодировщик Е и декодировщик D, можно обучать сквозным методом (end-to-end) с помощью основанного на U-Net диффузионного предиктора, содержащегося в диффузионной модели перехода от кадра к следующему кадру, осуществлять сжатие входных кадров и реконструкцию синтезируемых кадров. Для обучения диффузионной модели перехода от кадра к следующему кадру при каждом проходе модели из обучающего видео обучающего набора данных произвольно выбираются пары кадров 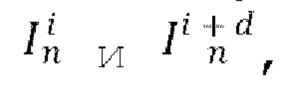 где d обозначает разность времени видео между выбранными кадрами. Обучающий набор данных может содержать любые доступные видео, например, видео людей, облаков, волн, листвы деревьев и т.п.
где d обозначает разность времени видео между выбранными кадрами. Обучающий набор данных может содержать любые доступные видео, например, видео людей, облаков, волн, листвы деревьев и т.п.
[0028] Известно, что, по меньшей мере, некоторые соседние кадры (например, кадры по существу одной и той же сцены) в видео часто похожи друг на друга и будут накапливать изменения по мере их удаления от начального (исходного) кадра соседних кадров. Учитывая это, в предложенном техническом решении скрытое представление xi+d следующего (синтезируемого) кадра моделируется как сумма скрытого представления xi предыдущего кадра и остатка 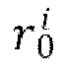 , прогнозируемого основанным на U-Net диффузионным предиктором (обозначенным как U-Net на фиг. 1), содержащимся в диффузионной модели перехода от кадра к следующему кадру:
, прогнозируемого основанным на U-Net диффузионным предиктором (обозначенным как U-Net на фиг. 1), содержащимся в диффузионной модели перехода от кадра к следующему кадру:
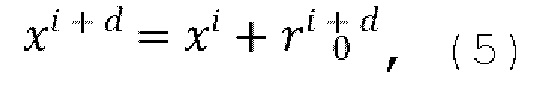
где d - разность времени видео между входным кадром 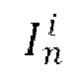 и спрогнозированным кадром
и спрогнозированным кадром 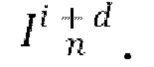 Остаток прогнозируется основанным на U-Net диффузионным предиктором (LDM) следующим образом:
Остаток прогнозируется основанным на U-Net диффузионным предиктором (LDM) следующим образом:
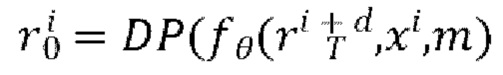
где DP - процесс диффузии, описанный выше со ссылкой на приведенные математические выражения (1)-(4) и реализуемый с помощью основанного на U-Net диффузионного предиктора ƒ; θ - полученные в результате обучения веса ƒ; 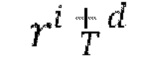 - начальный шум, выбранный из нормального распределения ~N(0,I); xi - скрытое представление обуславливающего предыдущего кадра, и m - общий скрытый код движения.
- начальный шум, выбранный из нормального распределения ~N(0,I); xi - скрытое представление обуславливающего предыдущего кадра, и m - общий скрытый код движения.
[0029] Хотя характер движения, обнаруживаемого в видео, может значительно различаться в разных областях, например, в анимации лица и ландшафтной анимации, в рамках настоящего изобретения предполагается, что характер движения объектов в видео из одной области, т.е. людей, облаков, волн, листвы деревьев и т.д., описывается низкоразмерным скрытым кодом m движения, который выучивается совместно для каждого видео в обучающем наборе данных и применяется в ƒθ с модуляцией стиля. В неограничивающей реализации низкоразмерный скрытый код m движения может быть реализован в виде вектора размера k. Экспериментальные данные, приведенные ниже в конце настоящего описания, получены при значении k=16. Однако в зависимости от различных обстоятельств (например, в зависимости от доступной в данный момент памяти или ресурсов процессора) размер k вектора скрытого низкоразмерного кода m движения может быть установлен на большее или меньшее значение, чем 16. Применение общего скрытого кода m движения важно для синтеза видео хорошего качества, в которых тип, скорость и направление движения поддерживаются (благодаря обуславливанию вывода с помощью общего скрытого кода m движения) согласованными во всех синтезируемых кадрах.
[0030] В соответствии с приведенным выше описанием на фиг. 1 схематически показан общий вид архитектуры диффузионной модели перехода от кадра к следующему кадру согласно варианту осуществления настоящего изобретения, предлагаемого в настоящей заявке. Как следует из фиг. 1, этот конвейер содержит по меньшей мере следующие операции: проецирование входного кадра Ii из пиксельного пространства в скрытое векторное пространство путем пропускания входного кадра Ii через кодировщик Е VAE, в результате этой операции получают скрытое представление xi входного кадра Ii; затем объединение исходного зашумленного остатка rt (представляющего собой шум, выбранный из нормального распределения) со скрытым представлением xi входного кадра Ii, и пропускание результата этого объединения через основанный на U-Net диффузионный предиктор при одновременном обуславливании движения между кадрами синтезируемого видео посредством общего скрытого кода m движения (что обозначено на фиг. 1 как блок "Модуляция стиля"); в результате этой операции основанный на U-Net диффузионный предиктор прогнозирует обесшумленный остаток r0; затем спрогнозированный обесшумленный остаток r0 добавляется к скрытому представлению xi входного кадра Ii для моделирования xi+d следующего кадра Ii+d; и наконец, смоделированное скрытое представление xi+d проецируется обратно в пиксельное пространство декодировщиком D VAE для получения синтезированного следующего кадра Ii+d.
[0031] Подробная, но не ограничивающая реализация архитектуры основанного на U-Net диффузионного предиктора, содержащегося в диффузионной модели перехода от кадра к следующему кадру согласно варианту осуществления настоящего изобретения, предложенному в настоящем документе, проиллюстрирована на фиг. 2 и описана детально ниже. Специалисту в данной области техники будет понятно, что количество блоков и каналов в проиллюстрированном основанном на U-Net диффузионном предикторе может изменяться в целях облегчения модели или повышения ее мощности для выучивания более обширного набора данных.
[0032] Основанный на U-Net диффузионный предиктор содержит блоки пяти типов: (1) блок DoubleConv, (2) блок DownBlock, (3) блок DoubleConvCond, (4) блок UpCondBlock, (5) блок 64→4.
[0033] Первый блок (с левой стороны фиг. 2) основанного на U-Net диффузионного предиктора, а именно (1) блок DoubleConv, работает со скрытым представлением xi входного кадра xi, объединенным с исходным зашумленным остатком rt. Блок DoubleConv включает в себя субблок 2D-свертки 3×3 (Conv2d) с нормализацией слоя (LayerNorm), за которым следует субблок функции активации линейного модуля ошибки Гаусса (GELU) с дополнительной 2D-сверткой 3×3 (Conv2d) и нормализации слоя (LayerNorm). Размер входного канала блока DoubleConv равняется 8, размер выходного канала блока DoubleConv равняется 256.
[0034] Второй блок (с левой стороны фиг. 2) основанного на U-Net диффузионного предиктора, а именно блок (2) DownBlock, работает с выводом первого блока и дополнительно с текущим индексом t временного шага диффузии, который вводится в блок DownBlock посредством синусного и/или косинусного позиционного кодирования. Блок DownBlock содержит субблок функции активации сигмовидной линейной единицы (SiLU) и субблок максимального пулинга (подвыборки) (MaxPool), за которым следует х2 DoubleConv, содержимое которого соответствует содержимому блока DoubleConv, описанного выше. Полученные данные субблоков суммируются и передаются в следующий блок основанного на U-Net диффузионного предиктора. Размер входного канала второго блока DownBlock равняется 256, размер выходного канала второго блока DownBlock равняется 512.
[0035] Третий и четвертый блоки (с левой стороны фиг. 2) основанного на U-Net диффузионного предиктора аналогичны описанному выше блоку DownBlock. Таким образом, описание содержимого этих блоков здесь опущено. Размер входного канала третьего блока DownBlock равняется 512, размер выходного канала третьего блока DownBlock равняется 1024. Размер входного канала четвертого блока DownBlock, таким образом, равняется 1024, размер выходного канала четвертого блока DownBlock равняется 204 8. Каждый из второго, третьего и четвертого блоков DownBlock дополнительно соединяется соответствующим skip-соединением 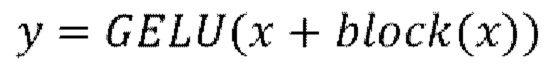 с описываемыми ниже восьмым, девятым и десятым блоками UpCondBlock, соответственно.
с описываемыми ниже восьмым, девятым и десятым блоками UpCondBlock, соответственно.
[0036] Пятый блок (с левой стороны фиг. 2) основанного на U-Net диффузионного предиктора, а именно (3) блок DoubleConvCond, работает с выводом четвертого блока и дополнительно со скрытым кодом дВИЖения. DoubleConvCond содержит имеет то же содержимое, что и блок DoubleConv, описанный выше, и дополнительно субблок модуляции стиля (в том числе движения) (SM). Описание содержимого субблоков блока DoubleConv здесь опущено. Субблок SM используется в блоке DoubleConvCond для конкатенации обуславливающего скрытого кода m движения к результатам работы субблоков блока DoubleConv. Размер входного канала пятого блока DoubleConvCond равняется 2048, размер выходного канала пятого блока DoubleConvCond равняется 2048.
[0037] Шестой и седьмой блоки (с левой стороны фиг. 2) основанного на U-Net диффузионного предиктора аналогичны описанному выше DoubleConvCond. Поэтому описание содержимого этих блоков здесь опущено. Размер входного канала шестого блока DoubleConvCond равняется 2048, размер выходного канала шестого блока DoubleConvCond равняется 2048. Размер входного канала седьмого блока DoubleConvCond равняется 2048, размер выходного канала седьмого блока DoubleConvCond равняется 2048.
[0038] Восьмой блок (с левой стороны фиг.2) основанного на U-Net диффузионного предиктора, а именно (4) блок UpCondBlock, работает с выводом седьмого блока и дополнительно со скрытым кодом m движения и текущим индексом t временного шага диффузии, вводимым в блок UpCondBlock посредством синусного и/или косинусного позиционного кодирования. Блок UpCondBlock содержит субблок функции активации сигмовидной линейной единицы (SiLU) и субблок DoubleConvCond и DoubleConv, содержимое которых соответственно соответствует содержимому блока DoubleConvCond и блока DoubleConv, описанных выше. Полученные данные этих субблоков суммируются и передаются в следующий блок основанного на U-Net диффузионного предиктора. Размер входного канала восьмого блока UpCondBlock равняется 4096, размер выходного канала восьмого блока UpCondBlock равняется 512.
[0039] Девятый и десятый блоки (с левой стороны фиг. 2) основанного на U-Net диффузионного предиктора аналогичны описанному выше блоку UpCondBlock. Поэтому описание содержимого этих блоков здесь опущено. Размер входного канала девятого блока UpCondBlock равняется 1024, размер выходного канала девятого блока UpCondBlock равняется 256. Размер входного канала десятого блока UpCondBlock равняется 512, размер выходного канала десятого блока UpCondBlock равняется 64.
[0040] Последний блок 64→4 представляет собой полносвязный блок с 2D-сверткой 1×1 (Conv2d).
[0041] Процедура обучения, применяемая к диффузионной модели перехода от кадра к следующему кадру, подробно описана в следующем псевдокоде 1:
Псевдокод 1: процедура обучения диффузионной модели от кадра к следующему кадру (без потери общности здесь предполагается, что размер пакета (batch) равен 1)
повторить
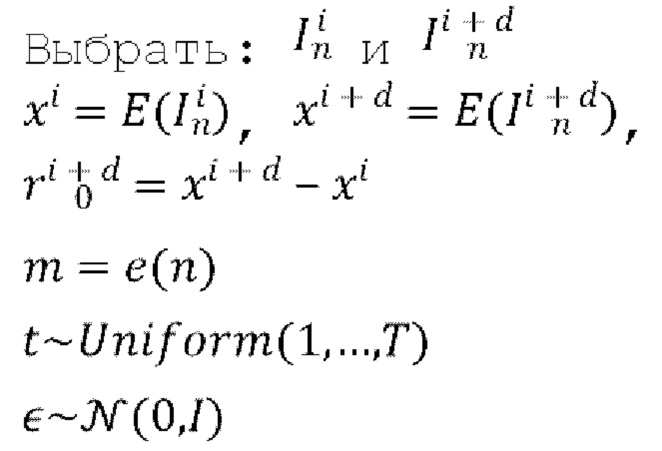
Сделать шаг градиентного спуска на
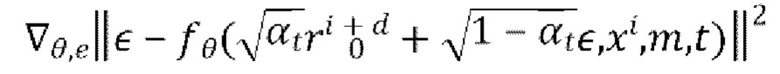
до схождения (т.е. до тех пор, пока не будет получено глобальное оптимальное значение функции потерь)
где 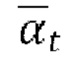 - гиперпараметр ƒθ.
- гиперпараметр ƒθ.
[0042] Диффузионную модель перехода от кадра к следующему кадру можно обучать не на целых кадрах, а на их фрагментах. В конкретной неограничивающей реализации диффузионная модель перехода от кадра к следующему кадру обучается на 5 фрагментах каждого из одного или нескольких кадров одного или нескольких обучающих видео с полным разрешением, содержащихся в обучающем наборе данных: центр и четыре угла, чтобы сделать скрытые представления движения ошибкоустойчивыми. Эти 5 фрагментов имеют один и тот же скрытый код движения. Это помогает снизить зависимость от пространственного расположения движущихся пикселей в видео. Кроме того, разнообразие движений в обучающем наборе данных можно дополнительно увеличить путем следующих дополнений: горизонтального переворота и инверсии времени, применяемых к обучающим кадрам/фрагментам. В результате количество уникальных скрытых движений увеличивается в 4 раза. В результате обучения ƒθ получается банк М выученных векторных представлений движения, хранящихся на уровне е векторного представления движения. Уровень е векторного представления движения представляет собой массив векторов, из которого желаемое векторное представление получают с помощью индекса видео. Изначально для каждого видео вектор инициализируется произвольно. На каждой итерации обучения из массива по индексу берется один вектор m, соответствующий видео, кадры которого участвуют в этой итерации. Затем m участвует в процессе диффузии и обновляется градиентным спуском, как и все остальные веса.
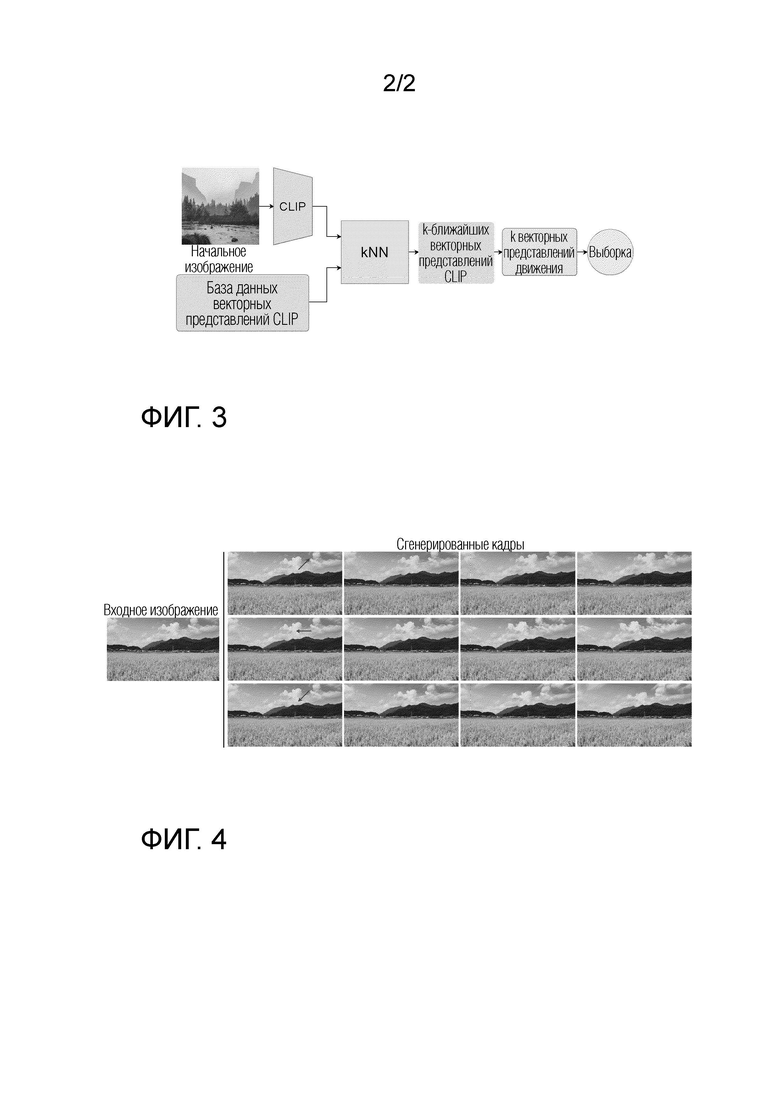
[0043] В конкретном неограничивающем варианте реализации схемы выборки общего скрытого кода движения получение общего скрытого кода m движения, который подлежит использованию при выводе диффузионной модели перехода от кадра к следующему кадру, для обуславливания динамики движения, подлежащей отражению в синтезируемых кадрах, применяется подход сравнительного обучения языка и изображений (CLIP), как показано на фиг. 3. Однако настоящее изобретение не ограничено применением CLIP, поскольку для сравнения содержимого кадра можно использовать различные предобученные кодировщики изображений. Общий скрытый код m движения следует выбирать правильно, чтобы управлять направлением и характером движения в синтезируемом видео. Наивный подход заключается в выборке скрытого кода m движения из одного или нескольких скрытых кодов движения произвольных видео, которые хранятся в банке М выученных векторных представлений движения. Однако было обнаружено, что синтез изображения при его обуславливании скрытым кодом m движения, выбираемым из совершенно другого видео с точки зрения содержимого (т.е. в этом случае скрытый код m движения не будет общим), может привести к визуальным артефактам, нереалистичным движениям и неестественно выглядящим объектам. Векторное представление кадров - это набор карт признаков, получаемых посредством Е из кадра, а векторное представление движения - это вектор, получаемый из массива обучаемых векторов М по индексу видео.
[0044] На фиг. 3 показана схема выборки общего скрытого кода m движения, согласно которой скрытый код m движения видео с наиболее близкими показателями CLIP используется повторно в качестве общего скрытого кода m движения. Это приводит к более плавному и более связному синтезу/анимации видео. Как показано на фиг. 3, для получения общего скрытого кода m движения для кадра синтезируемого видео предлагается сначала получить векторное представление CLIP для этого кадра путем пропускания этого кадра через кодировщик обученной нейронной сети CLIP, известной как продукт OpenAI. Затем осуществляется поиск одного или нескольких векторных представлений CLIP, ближайших к полученному векторному представлению CLIP, с использованием k-ближайших соседей (kNN) в базе данных векторных представлений CLIP, полученных заранее для одного или нескольких кадров одного или нескольких обучающих видео, содержащихся в используемом обучающем наборе данных для обучения диффузионной модели перехода от кадра к следующему кадру. kNN выбран в качестве основного используемого алгоритма, поскольку его проще всего реализовать. Однако настоящее изобретение не ограничено применением kNN, поскольку в нем также могут использоваться любые доступные более сложные алгоритмы. Векторные представления CLIP можно получать и сохранять в базе данных векторных представлений CLIP заранее, чтобы каждый раз при выводе не пересчитывать векторные представления CLIP. И в завершение, общий скрытый код m движения получают из банка выученных векторных представлений движения, соответствующих одному или более кадрам одного или более обучающих видео, которые использовались для получения одного или более найденных векторных представлений CLIP. В одном конкретном неограничивающем варианте осуществления общий скрытый код движения одного или более начальных кадров одного или более обучающих видео, которые использовались для получения одного или более ближайших векторных представлений CLIP, переиспользуется в качестве общего скрытого кода m движения. Альтернативно, в другом примере можно применить усреднение к общим скрытым кодам движения одного или нескольких обучающих видео, которые использовались для получения одного или нескольких ближайших векторных представлений CLIP, и этот усредненный скрытый код m движения можно использовать в качестве общего скрытого кода m движения.
[0045] Процедура вывода (инференса), выполняемая обученной диффузионной моделью перехода от кадра к следующему кадру, подробно описана в следующем псевдокоде 2:
Псевдокод 2: Процедура логического вывода обученной диффузионной модели перехода от кадра к следующему кадру.
Ввести I0 - начальный кадр.
Выбрать общий скрытый код движения из банка М выученных векторных представлений движения (как описано со ссылкой на фиг. 3 выше).
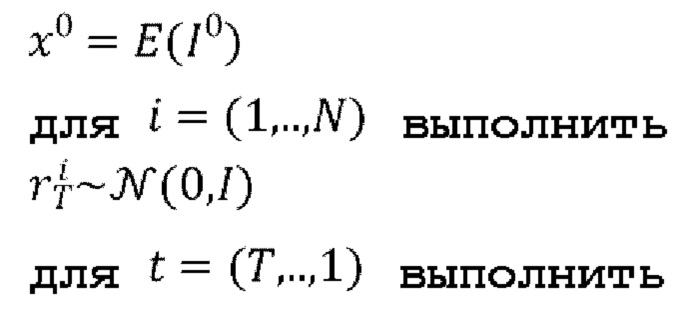
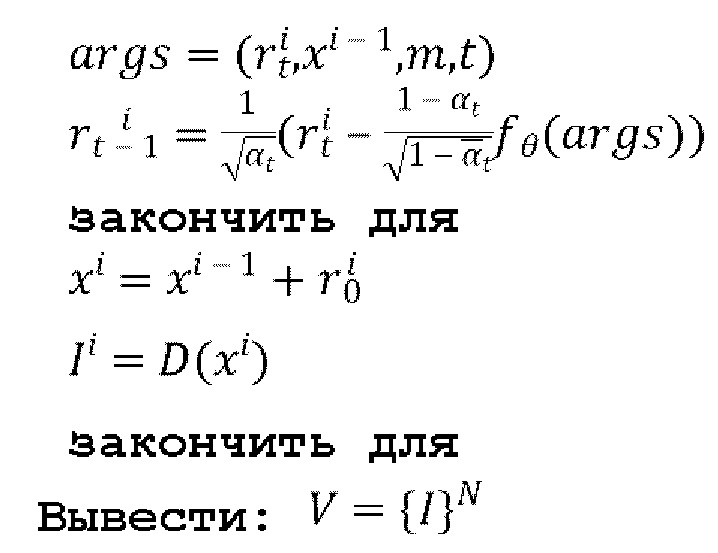
[0046] Таким образом, ƒθ используется при выводе для генерации авторегрессионным методом видеопоследовательности V={I}N при обеспечении начального (обуславливающего) кадра I0. Поскольку диффузионная модель перехода от кадра к следующему кадру является полностью сверточной, при выводе можно успешно использовать начальный кадр более высокого разрешения, чем кадры, использованные при обучении упомянутой модели.
[0047] Описанный выше способ синтеза видео может выполняться пользовательским электронным устройством (не показано). Таким устройством может быть, без ограничения перечисленным, смартфон, планшет, ноутбук, ПК, гарнитура AR/VR и так далее. Пользовательское электронное устройство может содержать, по меньшей мере, процессор и память, в которой хранятся исполняемые компьютером инструкции, которые при исполнении процессором вынуждают устройство выполнять способ согласно первому аспекту или согласно любому развитию первого аспекта. Память может дополнительно непосредственно хранить веса и смещения диффузионной модели перехода от кадра к следующему кадру, в том числе основанного на U-Net диффузионного предиктора и VAE. Кроме того, память может дополнительно непосредственно хранить веса и смещения нейронной сети CLIP.
[0048] В качестве альтернативы, пользовательское электронное устройство, оснащенное блоком связи, может отправлять запрос на один или несколько серверов, реализующих диффузионную модель перехода от кадра к следующему кадру, которая включает в себя основанный на U-Net диффузионный предиктор и VAE, и нейронной сети CLIP, для приема в ответ на упомянутый запрос одного или нескольких или всех синтезированных внешними средствами кадров видеопоследовательности(й). В этом случае предложенные и описанные здесь технические решения могут быть реализованы на таком одном или нескольких компьютеризованных серверах. Кроме того, обучение диффузионной модели перехода от кадра к следующему кадру, включающей в себя основанный на U-Net диффузионный предиктор и VAE, а также, при необходимости, модели на основе CLIP, можно осуществлять в режиме онлайн (т.е. на самом устройстве) или в автономном режиме (т.е. на одном или нескольких внешних серверах).
[0049] Процессор может быть любого типа, например, он может представлять собой, без ограничения, один или несколько из следующих процессоров: процессор общего назначения (CPU), процессор цифровых сигналов (DSP), процессор приложений (АР), графический процессор (GPU), блок видеообработки (VPU), специальный процессор ИИ, например, нейронный процессор (NPU) и т.д. Процессор может быть реализован в виде системы на кристалле (SOC), специализированной интегральной схемы (ASIC), программируемой пользователем вентильной матрицы (FPGA) или другого программируемого логического устройства (PLD), дискретного логического элемента, транзисторной логики, дискретных аппаратных компонентов, или любой их комбинации.
[0050] Память может быть любого типа, например, она может представлять собой, но без ограничения, одно или несколько из запоминающих устройств: оперативного запоминающего устройства (RAM), оперативной видеопамяти (VRAM), динамического ОЗУ (DRAM), статического RAM (SRAM), SDRAM с двойной скоростью передачи данных (DDR SRAM), синхронного динамического RAM с двойной скоростью передачи данных 4 (DDR4 RAM), динамического RAM Rambus (DRDRAM), постоянного запоминающего устройства (ROM),
программируемого ROM (PROM), стираемого PROM (EPROM), электрически стираемого PROM (EEPROM), виртуальной памяти. Память может быть реализована в виде твердотельного накопителя (SSD), жесткого диска (HDD), USB-накопителя и т.д.
[0051] Пользовательское электронное устройство может работать на любой операционной системе (например, Android, iOS, Harmony OS, Windows, Linux и т.д.) и может включать в себя любое другое необходимое программное, программно-аппаратное и/или аппаратное обеспечение (например, блок связи, интерфейс I/O, камеру (например, для захвата начального кадра I0), источник питания и т.д.). Неограничивающие примеры вычислительного устройства 50 включают смартфон, умные часы, планшет, слуховой аппарат, компьютер, ноутбук, гарнитуру AR/VR и так далее.
[0052] Настоящее изобретение также предусматривает считываемый компьютером (энергонезависимый) носитель, хранящий исполняемые компьютером инструкции, которые при их исполнении устройством побуждают устройство выполнять данный способ (или функционировать как устройство, выполняющее этот способ) в соответствии с первым аспектом или согласно любому развитию первого аспекта. В качестве считываемого компьютером носителя могут использоваться любые типы носителей или устройств для хранения данных.
[0053] Экспериментальные данные и другие неограничивающие особенности предлагаемых технических решений. Ниже представлены количественные и качественные результаты экспериментов. Флагманская модель обучалась на наборе данных DeepLandscape. Этот набор данных состоит из 999 обучающих ландшафтных видео с разрешением 1280×720 в обучающем разделе и 57 тестовых видео. Для сравнения с существующими количественными решениями для генерации изображения в видео диффузионную модель перехода от кадра к следующему кадру, предложенную и раскрытую в настоящем документе, обучали и оценивали на наборе данных SkyTimelapse, состоящем из клипов различной длины, содержащих динамические сцены неба. Он содержит 35392 обучающих видеоклипа и 2815 тестовых видеоклипов в разрешении 640×360. Сцены включают в себя различные условия дневного времени и погоды. Обе диффузионные модели перехода от кадра к следующему кадру обучались на графическом процессоре Nvidia А100 80 ГБ (×4 графических процессора для набор данных DeepLandscape) с размером пакета 256 и оптимизатором AdamW со скоростью обучения, установленной на 5×10-5. Модели SkyTimelapse обучались на фрагментах 256×256, а модели DeepLandscape - на фрагментах 512×512. Во всех экспериментах разность d времени видео была установлена на 1, и модель обучалась на 150 тысяч эпох, где одна эпоха составляет один полный проход через набор данных.
[0054] Количественные результаты представлены ниже в таблице 1: Количественные результаты качества и разнообразия генерации изображения в видео на наборе данных SkyTimelapse:
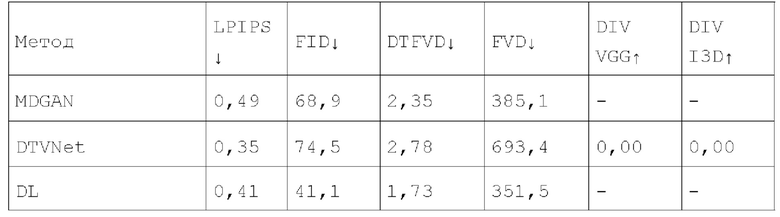

[0055] Обусловленная генерация видео. Качество синтезированных кадров оценивалось с помощью LPIPS и FID. Для оценки качества видео сообщаются FVD и DTFVD, что полезно для измерения других типов динамики, не фиксируемых FVD. Затем измерялось разнообразие сгенерированных видео с помощью DIV VGG и DIV I3D. Поскольку диффузионная модель перехода от кадра к следующему кадру способна генерировать несколько различных видео из данного начального кадра, обе метрики измеряют их среднее взаимное расстояние в пространстве признаков сетей VGG-16 и I3D, предварительно обученных на ImageNet и Kinetics, соответственно. Для справедливого сравнения с конкурентами были взяты методы расчета метрик из Michael Dorkenwald, Timo Milbich, Andreas Blattmann, Robin Rombach, Konstantinos G. Derpanis, and Bjorn Ommer "Stochastic image-to-video synthesis using cinns" in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021. Оценка выполнялась на видео с разрешением 128×128 и длиной 32 кадра.
[0056] Из результатов, приведенных в таблице 1 выше, видно, что, хотя диффузионная модель перехода от кадра к следующему кадру, предложенная и раскрытая в настоящем документе, достигает качества, сопоставимого с качеством конкурентов, она генерирует более разнообразные видео и значительно превосходит другие модели по обеим метрикам разнообразия. Более того, в отличие от существующих подходов, диффузионная модель перехода от кадра к следующему кадру может создавать видео с более высоким разрешением, чем видео в обучающем наборе.
[0057] Безусловная генерация видео. Несмотря на то, что большинство моделей генерации видео решают безусловные задачи генерации видео, важно сравнивать с ними результаты, достигнутые данной диффузионной моделью перехода от кадра к следующему кадру. Для этого в экспериментах первый кадр генерировался генератором StyleGAN-V, а затем анимировался предложенной и описанной диффузионной моделью перехода от кадра к следующему кадру. Эти эксперименты также проводились на наборе данных SkyTimelapse. Оценивалось 162 сгенерированных видео с разрешением 256×256 и длиной 16 и 128 кадров. Полученные количественные результаты безусловной генерации качества видео на наборе данных SkyTimelapse представлены в таблице 2 ниже:
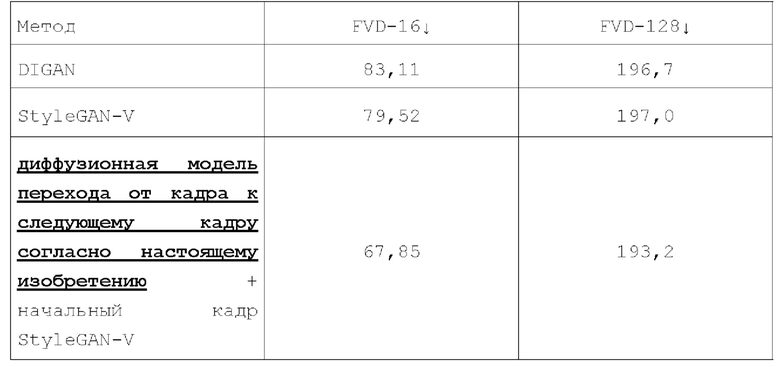
[0058] Результаты, приведенные выше в таблице 2, демонстрируют, что с теми же самыми начальными кадрами диффузионная модель перехода от кадра к следующему кадру генерирует лучшие видео исходя из FVD, чем StyleGAN-V. Причем преимущество остается за видео в 128 кадров, хотя диффузионная модель перехода от кадра к следующему кадру является авторегрессионной по сравнению с конкурентом. На фиг. 4 показаны примеры различных последовательностей кадров, сгенерированных для одного входного изображения диффузионной моделью перехода от кадра к следующему кадру, обученной на наборе данных DeepLandscape с разрешением 1280×704. Показаны 1-й, 6-й, 11-й и 16-й сгенерированные кадры. Используя различные скрытые коды движения из банка М выученных векторных представлений движения, можно изменять направление и характер движения на видео.
[0059] В целях генерации видео высокого разрешения и из-за ограничений памяти из предлагаемой диффузионной модели перехода от кадра к следующему кадру исключены слои самовнимания, которые изначально использовались в DDPM. Это делает предлагаемую диффузионную модель перехода от кадра к следующему кадру полностью сверточной и позволяет генерировать видео с более высоким разрешением, чем те, на которых модель обучалась. Эксперименты, проведенные авторами настоящего изобретения, показывают, что такое упрощение не приводит к потере качества. Метрики также подтверждают, что использование модуляции стиля (с помощью общего скрытого кода m движения) для обуславливания сопоставимо с методом перекрестного внимания (cross-attention), который является популярным для диффузионных моделей. Однако преимуществом является то, что модуляция стиля более эффективно использует память, чем перекрестное внимание, и сохраняет диффузионную модель перехода от кадра к следующему кадру полностью сверточной.
[0060] Диффузионная модель перехода от кадра к следующему кадру обучается с использованием некоторого количества фрагментов (например, 5 фрагментов) видео с общим скрытым кодом движения. Этот тип дополнения данных регуляризирует модель и предотвращает зависимость выученных скрытых кодов движения от пространственных областей обучающих кадров. Модель, обученная на одном центральном фрагменте, генерирует отдельные кадры хорошего качества, но при этом страдает согласованность видео. Это можно заметить по значительному повышению метрик FVD и разнообразия. Также видно, что схема выборки скрытого кода движения на основе kNN повышает качество и разнообразие видео по сравнению со случайной выборкой скрытого кода движения.
[0061] Таким образом, предложен новый класс диффузионных моделей обработки видео, которые генерируют видео с разрешением выше в 2 раза, чем у современных передовых подходов, достигая сопоставимого качества видео на небольших наборах данных видео. Было показано, что рекурсивная выборка кадров в сочетании с общим обуславливающим стиль/движение вектором m приводит к лучшей временной согласованности данных и ресурсоэкономным конфигурациям по сравнению с более сложными известными архитектурами. Предложенная архитектура диффузионной модели перехода от кадра к следующему кадру с ограниченным числом параметров позволяет достичь высокого качества изображения при высоких разрешениях без обучения на частных крупномасштабных наборах видеоданных, что открывает новые возможности в исследованиях и разработках генеративного видео даже относительно более эффективных моделей, которые применяют альтернативные методы к популярным и дорогостоящим в вычислительном отношении временному вниманию и временной свертке. Было также доказано, что простая схема согласования содержимого с использованием предварительно обученного кодировщика изображений Е значительно повышает визуальную привлекательность синтезированных видео за счет выбора общих скрытых кодов движения, которые создают более плавную анимацию без чрезмерной зависимости от семантических структур конкретных видео.
[0062] Во всех материалах настоящего документа упоминание элемента в единственном числе не исключает наличия множества таких элементов в фактической реализации изобретения, и, наоборот, упоминание элемента во множественном числе не исключает наличие всего одного такого элемента в реальной реализации изобретения. Любое конкретное значение или диапазон значений, упомянутые выше, не следует интерпретировать в ограничительном смысле, напротив, такое конкретное значение или диапазон значений следует рассматривать как представляющее среднюю точку определенного большего диапазона, примерно до 50% с обеих сторон упомянутого значения или специально упомянутого меньшего диапазона.
[0063] Хотя данное изобретение было проиллюстрировано и описано со ссылкой на различные варианты его осуществления, специалистам в данной области техники будет понятно, что можно внести различные изменения в форму и содержимое без выхода за рамки сущности и объема настоящего изобретения, определяемых прилагаемой формулой изобретения и ее эквивалентами. Другими словами, приведенное выше подробное описание основано на конкретных примерах и возможных реализациях настоящего изобретения, но его не следует интерпретировать так, что осуществимы только явно раскрытые реализации. Предполагается, что любое изменение или замена, которые могут быть внесены в раскрытие специалистом с обычной квалификацией без внесения творческого и/или технического вклада в этот способ, подпадают под объем охраны с учетом эквивалентов, предусмотренный формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ СОЗДАНИЯ АНИМИРУЕМОГО АВАТАРА ЧЕЛОВЕКА В ПОЛНЫЙ РОСТ ИЗ ОДНОГО ИЗОБРАЖЕНИЯ ЧЕЛОВЕКА, ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2023 |
|
RU2813485C1 |
| НЕЙРОСЕТЕВОЙ ПЕРЕНОС ВЫРАЖЕНИЯ ЛИЦА И ПОЗЫ ГОЛОВЫ С ИСПОЛЬЗОВАНИЕМ СКРЫТЫХ ДЕСКРИПТОРОВ ПОЗЫ | 2020 |
|
RU2755396C1 |
| МОДЕЛИРОВАНИЕ ЧЕЛОВЕЧЕСКОЙ ОДЕЖДЫ НА ОСНОВЕ МНОЖЕСТВА ТОЧЕК | 2021 |
|
RU2776825C1 |
| СПОСОБ И УСТРОЙСТВО ГЕНЕРИРОВАНИЯ ВИДЕОКЛИПА ПО ТЕКСТОВОМУ ОПИСАНИЮ И ПОСЛЕДОВАТЕЛЬНОСТИ КЛЮЧЕВЫХ ТОЧЕК, СИНТЕЗИРУЕМОЙ ДИФФУЗИОННОЙ МОДЕЛЬЮ | 2024 |
|
RU2823216C1 |
| Способ синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора, и электронное вычислительное устройство для его реализации | 2020 |
|
RU2749749C1 |
| Способ локального генерирования и представления потока обоев и вычислительное устройство, реализующее его | 2020 |
|
RU2768551C1 |
| СПОСОБ ПОСТРОЕНИЯ КАРТЫ ГЛУБИНЫ ПО ПАРЕ ИЗОБРАЖЕНИЙ | 2022 |
|
RU2806009C2 |
| ОБРАБОТКА ОККЛЮЗИЙ ДЛЯ FRC C ПОМОЩЬЮ ГЛУБОКОГО ОБУЧЕНИЯ | 2020 |
|
RU2747965C1 |
| СПОСОБ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ ФОРМИРОВАНИЯ ПРАВДОПОДОБНОГО ОТОБРАЖЕНИЯ ТЕЧЕНИЯ ВРЕМЕНИ СУТОЧНОГО МАСШТАБА | 2020 |
|
RU2745209C1 |
| УСТРАНЕНИЕ РАЗМЫТИЯ ИЗОБРАЖЕНИЯ | 2020 |
|
RU2742346C1 |
Изобретение относится к обработке видеоданных, а именно к авторегрессионному синтезу высококачественных видео из одного кадра (изображения) с использованием полностью сверточной диффузионной модели. Технический результат направлен на получение видео более высокого разрешения. Способ синтеза видео авторегрессионным методом содержит: прогнозирование с использованием обученной диффузионной модели перехода от кадра к следующему кадру следующего кадра на основе входного кадра при одновременном обуславливании движения между кадрами синтезируемого видео с помощью общего скрытого кода m движения, выбранного в соответствии со схемой выборки скрытого кода движения на основе k-ближайших соседей (kNN). Предложенные технические решения также пригодны для работы на устройствах с ограниченными ресурсами процессора/памяти, по меньшей мере, благодаря тому, что слои самовнимания, изначально используемые в диффузионно-вероятностных моделях устранения шума (DDPM), заменены обуславливанием общим скрытым кодом движения. 3 н. и 11 з.п. ф-лы. 4 ил., 2 табл.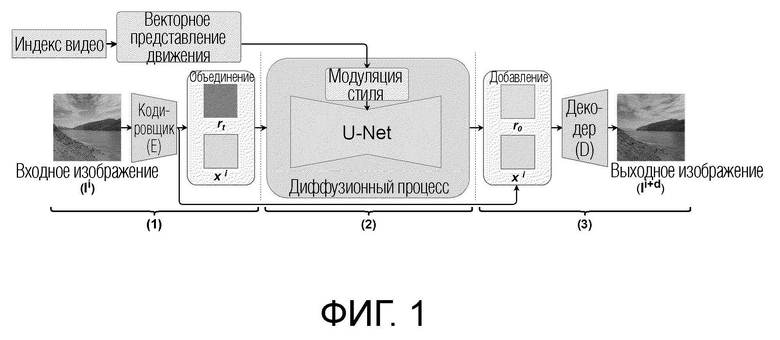
1. Способ синтеза видео, причем способ включает в себя:
получение общего скрытого кода движения, соответствующего движению между кадрами видео, путем ввода входного кадра в первый кодировщик;
получение первого скрытого представления путем ввода входного кадра во второй кодировщик, при этом первым скрытым представлением являются данные входного кадра в низкоразмерном скрытом пространстве;
прогнозирование с использованием обученной нейросетевой модели следующего кадра на основе входного кадра на основе упомянутого общего скрытого кода движения и первого скрытого представления.
2. Способ по п. 1, в котором первым кодировщиком является кодировщик сети сравнительного обучения языка и изображений (CLIP); вторым кодировщиком является предварительно обученный вариационный автокодировщик (VAE); и обученной нейросетевой моделью является основанный на U-Net диффузионный предиктор.
3. Способ по п. 1 или 2, в котором прогнозирование следующего кадра включает в себя:
прогнозирование с использованием обученной нейросетевой модели еще одного следующего кадра на основе ранее спрогнозированного следующего кадра, основываясь на общем скрытом коде движения и первом скрытом представлении.
4. Способ по любому из пп. 1-3, в котором движение между кадрами синтезируемого видео основывают на общем скрытом коде движения путем ввода упомянутого общего скрытого кода движения в один или несколько слоев обученной нейросетевой модели.
5. Способ по любому из пп. 1-4, в котором получение общего скрытого кода движения включает в себя:
получение векторного представления сети сравнительного обучения языка и изображений (CLIP) для входного кадра путем ввода входного кадра в первый кодировщик;
идентификацию одного или нескольких векторных представлений CLIP, ближайших к полученному векторному представлению CLIP, используя k-ближайших соседей (kNN) и метрику расстояния для kNN, на основе базы данных векторных представлений CLIP, полученных для одного или нескольких кадров одного или нескольких обучающих видео, содержащихся в обучающем наборе данных, используемом для обучения нейросетевой модели; и
получение общего скрытого кода движения из банка выученных векторных представлений движения, соответствующих одному или нескольким кадрам одного или нескольких обучающих видео, которые использовались для получения одного или нескольких векторных представлений CLIP.
6. Способ по п. 5, в котором метрику расстояния для kNN вычисляют как расстояние между векторным представлением CLIP кадра обучающего видео, содержащегося в обучающем наборе данных, и векторным представлением CLIP входного кадра.
7. Способ по любому из пп. 1-6, в котором обучаемую нейросетевую модель обучают путем многократного выполнения следующих этапов, на которых:
получают пару кадров, включающую в себя входной кадр и следующий кадр, из обучающего видео обучающего набора данных;
получают первое скрытое представление и второе скрытое представление для упомянутой пары кадров путем ввода пары кадров во второй кодировщик, при этом вторым скрытым представлением являются данные следующего кадра в низкоразмерном скрытом пространстве;
вычисляют остаток путем вычитания первого скрытого представления из второго скрытого представления;
получают общий скрытый код движения обучающего видео, обозначенного индексом, из которого была получена упомянутая пара кадров, и сохраняют полученный общий скрытый код движения в базе данных векторных представлений CLIP;
получают индекс временного шага диффузии, соответствующий порядковому номеру временных шагов диффузии, при этом индекс временного шага диффузии вводится в нейросетевую модель на основе синусной или косинусной функции;
получают получаемый выборкой тензор шума путем выборки тензора шума на основе нормального распределения;
получают прогнозируемый тензор шума на основе общего скрытого кода движения, индекса временного шага диффузии, первого представления и остатка; и
обновляют, основываясь на полученном выборкой тензоре шума, спрогнозированном тензоре шума, веса нейросетевой модели.
8. Способ по п. 7, в котором получение прогнозируемого тензора шума включает в себя:
получение, на временном шаге диффузии, прогнозируемого тензора шума путем ввода общего скрытого кода движения, индекса временного шага диффузии, первого скрытого представления и вычисленного остатка в нейросетевую модель.
9. Способ по любому из пп. 7, 8, в котором парой кадров, полученной из обучающего видео, являются кадры, расположенные смежно или рядом друг с другом в последовательности кадров обучающего видео,
при этом обновление весов нейросетевой модели включает в себя минимизацию функции потерь между спрогнозированным тензором шума и полученным выборкой тензором шума с использованием градиентного спуска.
10. Способ по любому из пп. 7-9, в котором получение первого скрытого представления и второго скрытого представления включает в себя:
получение фрагментов каждого кадра из упомянутой пары кадров, включающих в себя центр и один или более из четырех углов кадров упомянутой пары; и
получение первого скрытого представления и второго скрытого представления кадров упомянутой пары путем ввода упомянутой пары кадров во второй кодировщик в форме упомянутых фрагментов упомянутой пары кадров.
11. Способ по любому из пп. 7-10, в котором получение пары кадров дополнительно включает в себя:
получение дополнительных пар кадров путем выполнения по меньшей мере одного из горизонтального переворота и/или инверсии времени пары кадров из обучающих видео, содержащихся в обучающем наборе данных.
12. Способ по любому из пп. 1-11, в котором прогнозирование следующего кадра из входного кадра включает в себя:
получение векторного представления CLIP для входного кадра,
идентификацию одного или нескольких векторных представлений CLIP, ближайших к полученному векторному представлению CLIP, с использованием kNN, на основе базы данных векторных представлений CLIP, полученных ранее для одного или нескольких обучающих видео, содержащихся в обучающем наборе данных, используемом для обучения нейросетевой модели;
получение общего скрытого кода движения на основе банка выученных векторных представлении движения, соответствующих одному или более кадрам одного или более обучающих видео, которые использовались для получения одного или более векторных представлений CLIP;
получение первого скрытого представления путем ввода входного кадра во второй кодировщик;
для каждого кадра видео, синтезируемого с использованием обученной нейросетевой модели, начиная со следующего кадра:
получают исходный зашумленный остаток;
получают обесшумленный остаток путем выполнения шагов диффузии обученной нейросетевой моделью, при этом для каждого из шагов диффузии: вычитают из зашумленного остатка выходное значение обученной модели;
получают второе скрытое представление следующего кадра путем добавления обесшумленного остатка к первому скрытому представлению входного кадра;
получают следующий кадр путем ввода второго скрытого представления в декодировщик, соответствующий второму кодировщику; и
получают синтезированное видео путем объединения всех полученных кадров.
13. Электронное устройство для синтеза видео, причем устройство содержит процессор и память, хранящую исполняемые компьютером инструкции, которые при их исполнении процессором побуждают устройство выполнять способ по любому из пп. 1-12.
14. Считываемый компьютером носитель, хранящий исполняемые компьютером инструкции, которые при их исполнении электронным устройством побуждают электронное устройство выполнять способ по любому из пп. 1-12.
| Способ синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора, и электронное вычислительное устройство для его реализации | 2020 |
|
RU2749749C1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| ABHISHEK AICH, et al | |||
| Солесос | 1922 |
|
SU29A1 |
| Насос | 1917 |
|
SU13A1 |

