ОБЛАСТЬ ТЕХНИКИ
[01] Настоящая технология относится к системам интеллектуальных персональных помощников и, в частности, к способам и электронным устройствам для идентификации пользовательского высказывания по цифровому аудиосигналу.
УРОВЕНЬ ТЕХНИКИ
[02] Электронные устройства, такие как смартфоны и планшеты, могут осуществлять доступ к растущему и разнообразному количеству приложений и служб обработки и/или доступа к информации различных типов.
[03] Однако начинающие пользователи и/или пользователи с ограниченными возможностями и/или пользователи, управляющие транспортным средством, могут быть не в состоянии эффективно взаимодействовать с такими устройствами, главным образом, из-за разнообразия функций, предоставляемых этими устройствами, или невозможности использовать человеко-машинные интерфейсы, предоставляемые такими устройствами (например, клавиатуру). Например, пользователь, который управляет транспортным средством, или пользователь с нарушениями зрения, может не иметь возможности использовать клавиатуру сенсорного экрана, связанную с некоторыми из этих устройств. В дополнение к вышеупомянутым ситуациям, когда пользователь не может эффективно взаимодействовать с устройством через сенсорные интерфейсы, на рынке появляется множество устройств «громкой связи», которыми можно управлять с помощью голосовых команд.
[04] Системы личных помощников с элементами искусственного интеллекта (IPA) реализованы на некоторых устройствах и были разработаны для выполнения задач в ответ на пользовательские голосовые команды. Например, системы IPA могут использоваться для поиска информации и/или навигации. Традиционная система IPA, такая как, например, система IPA Siri®, может принимать цифровой аудиосигнал, содержащий пользовательское высказывание, и выполнять в ответ на него большое разнообразие задач. Например, система IPA может быть сконфигурирована с возможностью анализа цифрового аудиосигнала для распознавания пользовательской речи, которая может указывать голосовую команду, произносимую пользователем.
[05] Традиционные системы IPA в основном направлены на извлечение текстовых данных (распознавание речи) из цифрового аудиосигнала для выполнения задач. Например, система IPA может определять, что пользовательское высказывание в цифровом аудиосигнале является голосовой командой для предоставления пользователю текущей погоды, для предоставления пользователю местоположения ближайшего торгового центра, для запуска некоторого приложения на устройстве и тому подобного.
[06] Однако традиционные системы IPA могут требовать значительного времени перед выполнением задачи в ответ на голосовую команду пользователя. Удовлетворенность пользователей системой IPA может меняться в зависимости от того, насколько «отзывчивой» является система IPA, то есть пользователи могут предпочесть системы IPA, которые реагируют на их голосовые команды быстрее.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[07] Разработчики настоящей технологии осознали некоторые технические проблемы, связанные с существующими системами IPA. Системы IPA обычно сконфигурированы с возможностью захвата аудиоданных до тех пор, пока не истечет некоторый предопределенный период времени после того, как пользователь перестал говорить. Например, системы IPA могут захватывать 1 секунду аудиоданных после того, как пользователь перестал говорить, чтобы убедиться, что пользователь завершил произношение своей команды. Однако это приводит к значительной задержке, и, следовательно, предоставление пользователю логической информации в ответ на данную пользовательскую команду также будет задерживаться.
[08] В первом обширном аспекте настоящей технологии предоставляется способ идентификации пользовательского высказывания по цифровому аудиосигналу. Цифровой аудиосигнал содержит аудиозапись пользовательского высказывания. Способ исполняется электронным устройством. Способ содержит получение электронным устройством набора признаков для соответствующего сегмента цифрового аудиосигнала. Каждый набор признаков содержит по меньшей мере признаки акустического типа, извлекаемые из соответствующего сегмента цифрового аудиосигнала. Сегменты цифрового аудиосигнала связаны с соответствующими временными интервалами некоторой предопределенной длительности. Способ содержит получение электронным устройством указания момента времени завершения высказывания в цифровом аудиосигнале, соответствующего некоторому моменту времени, после которого пользовательское высказывание завершено. Способ содержит определение электронным устройством скорректированного момента времени завершения высказывания путем добавления некоторого предопределенного временного смещения к моменту времени завершения высказывания. Способ содержит определение электронным устройством меток для соответствующих наборов признаков на основе скорректированного момента времени завершения высказывания и временных интервалов соответствующих сегментов цифрового аудиосигнала. Метка указывает, завершилось ли пользовательское высказывание во время соответствующего сегмента цифрового аудиосигнала, связанного с соответствующим набором признаков. Способ содержит использование электронным устройством наборов признаков и соответствующих меток для обучения нейронной сети (NN) прогнозировать, во время какого сегмента цифрового аудиосигнала пользовательское высказывание завершилось.
[09] В некоторых вариантах осуществления способа, набор признаков дополнительно содержит признаки лингвистического типа для соответствующего сегмента цифрового аудиосигнала.
[10] В некоторых вариантах осуществления способа признаки лингвистического типа определяются на основе текстового представления пользовательского высказывания. Текстовое представление содержит по меньшей мере одно слово и по меньшей мере одну паузу.
[11] В некоторых вариантах осуществления способа указание момента времени завершения высказывания определяют по меньшей мере одним из осуществляющего оценку человека и алгоритма автоматического выравнивания речи с текстом (ASA).
[12] В некоторых вариантах осуществления способа использование наборов признаков и соответствующих меток для обучения NN содержит организацию наборов признаков и соответствующих меток в том же порядке, что и порядок, в котором соответствующие сегменты встречаются в цифровом аудиосигнале.
[13] В некоторых вариантах осуществления способа способ дополнительно содержит, во время фазы использования NN, получение электронным устройством по меньшей мере некоторой части цифрового аудиосигнала в процессе использования. Способ дополнительно содержит определение электронным устройством первого набора признаков для первого сегмента цифрового аудиосигнала в процессе использования. Первый сегмент включает в себя самую последнюю полученную часть цифрового аудиосигнала в процессе использования. Цифровой аудиосигнал в процессе использования записывается в режиме реального времени во время высказывания в процессе использования. Первый набор признаков содержит по меньшей мере признаки акустического типа, извлекаемые из первого сегмента цифрового аудиосигнала. Способ дополнительно содержит использование электронным устройством NN для определения на основе первого набора признаков первого значения, указывающего вероятность того, что пользовательское высказывание в процессе использования завершилось во время первого сегмента цифрового аудиосигнала в процессе использования. В ответ на то, что первое значение превышает предопределенный порог, способ дополнительно содержит определение электронным устройством того, что пользовательское высказывание в процессе использования завершилось во время первого сегмента цифрового аудиосигнала в процессе использования.
[14] В некоторых вариантах осуществления способа способ дополнительно содержит генерирование электронным устройством триггера для остановки записи цифрового аудиосигнала в процессе использования.
[15] В некоторых вариантах осуществления способа способ дополнительно содержит обеспечение электронным устройством алгоритму автоматического распознавания речи (ASR) по меньшей мере некоторой части цифрового аудиосигнала в процессе использования для определения текстового представления высказывания в процессе использования и генерирование электронным устройством триггера для остановки обеспечения алгоритму ASR цифрового аудиосигнала в процессе использования.
[16] В некоторых вариантах осуществления способа способ дополнительно содержит в ответ на то, что первое значение находится ниже предопределенного порога, определение электронным устройством второго набора признаков для второго сегмента цифрового аудиосигнала в процессе использования. Второй сегмент является продолжением первого сегмента в цифровом аудиосигнале в процессе использования. Второй набор признаков содержит по меньшей мере признаки акустического типа, извлекаемые из второго сегмента цифрового аудиосигнала. Способ дополнительно содержит использование электронным устройством NN для определения на основе первого набора признаков и второго набора признаков второго значения, указывающего вероятность того, что пользовательское высказывание в процессе использования завершилось во время второго сегмента цифрового аудиосигнала в процессе использования. В ответ на то, что второе значение превышает предопределенный порог, способ дополнительно содержит определение электронным устройством того, что пользовательское высказывание в процессе использования завершилось во время первого сегмента цифрового аудиосигнала в процессе использования.
[17] В некоторых вариантах осуществления способа электронным устройством является одно из пользовательского электронного устройства и сервера, соединенного с пользовательским электронным устройством посредством сети связи.
[18] Во втором обширном аспекте настоящей технологии предоставляется электронное устройство для идентификации пользовательского высказывания по цифровому аудиосигналу. Цифровой аудиосигнал содержит аудиозапись пользовательского высказывания. Электронное устройство сконфигурировано с возможностью получения набора признаков для соответствующего сегмента цифрового аудиосигнала. Каждый набор признаков содержит по меньшей мере признаки акустического типа, извлекаемые из соответствующего сегмента цифрового аудиосигнала. Сегменты цифрового аудиосигнала связаны с соответствующими временными интервалами некоторой предопределенной длительности. Электронное устройство сконфигурировано с возможностью получения указания момента времени завершения высказывания в цифровом аудиосигнале, соответствующего некоторому моменту времени, после которого пользовательское высказывание завершено. Электронное устройство сконфигурировано с возможностью определения скорректированного момента времени завершения высказывания путем добавления предопределенного временного смещения к моменту времени завершения высказывания. Электронное устройство сконфигурировано с возможностью определения меток для соответствующих наборов признаков на основе скорректированного момента времени завершения высказывания и временных интервалов соответствующих сегментов цифрового аудиосигнала. Метка указывает, завершилось ли пользовательское высказывание во время соответствующего сегмента цифрового аудиосигнала, связанного с соответствующим набором признаков. Электронное устройство сконфигурировано с возможностью использования наборов признаков и соответствующих меток для обучения нейронной сети (NN) прогнозировать, во время какого сегмента цифрового аудиосигнала пользовательское высказывание завершилось.
[19] В некоторых вариантах осуществления электронного устройства, набор признаков дополнительно содержит признаки лингвистического типа для соответствующего сегмента цифрового аудиосигнала.
[20] В некоторых вариантах осуществления электронного устройства признаки лингвистического типа определяются на основе текстового представления пользовательского высказывания, причем текстовое представление содержит по меньшей мере одно слово и по меньшей мере одну паузу.
[21] В некоторых вариантах осуществления электронного устройства указание момента времени завершения высказывания определяется по меньшей мере одним из осуществляющего оценку человека и алгоритма автоматического выравнивания речи с текстом (ASA).
[22] В некоторых вариантах осуществления электронного устройства то, что электронное устройство сконфигурировано с возможностью использования наборов признаков и соответствующих меток для обучения NN, содержит то, что электронное устройство сконфигурировано с возможностью организации наборов признаков и соответствующих меток в том же порядке, что и порядок, в котором соответствующие сегменты встречаются в цифровом аудиосигнале.
[23] В некоторых вариантах осуществления электронного устройства электронное устройство дополнительно сконфигурировано с возможностью, во время фазы использования NN, получения по меньшей мере некоторой части цифрового аудиосигнала в процессе использования. Электронное устройство дополнительно сконфигурировано с возможностью определения первого набора признаков для первого сегмента цифрового аудиосигнала в процессе использования. Первый сегмент включает в себя самую последнюю полученную часть цифрового аудиосигнала в процессе использования. Цифровой аудиосигнал в процессе использования записывается в режиме реального времени во время высказывания в процессе использования. Первый набор признаков содержит по меньшей мере признаки акустического типа, извлекаемые из первого сегмента цифрового аудиосигнала. Электронное устройство дополнительно сконфигурировано с возможностью использования NN для определения на основе первого набора признаков первого значения, указывающего вероятность того, что пользовательское высказывание в процессе использования завершилось во время первого сегмента цифрового аудиосигнала в процессе использования. В ответ на то, что первое значение превышает предопределенный порог, электронное устройство дополнительно сконфигурировано с возможностью определения того, что пользовательское высказывание в процессе использования завершилось во время первого сегмента цифрового аудиосигнала в процессе использования.
[24] В некоторых вариантах осуществления электронного устройства электронное устройство дополнительно сконфигурировано с возможностью генерирования триггера для остановки записи цифрового аудиосигнала в процессе использования.
[25] В некоторых вариантах осуществления электронного устройства электронное устройство дополнительно сконфигурировано с возможностью обеспечения алгоритму автоматического распознавания речи (ASR) по меньшей мере некоторой части цифрового аудиосигнала в процессе использования для определения текстового представления высказывания в процессе использования и генерирования триггера для остановки обеспечения алгоритму ASR цифрового аудиосигнала в процессе использования.
[26] В некоторых вариантах осуществления электронного устройства электронное устройство дополнительно сконфигурировано с возможностью в ответ на то, что первое значение находится ниже предопределенного порога, определения второго набора признаков для второго сегмента цифрового аудиосигнала в процессе использования. Второй сегмент является продолжением первого сегмента в цифровом аудиосигнале в процессе использования. Второй набор признаков содержит по меньшей мере признаки акустического типа, извлекаемые из второго сегмента цифрового аудиосигнала. Электронное устройство дополнительно сконфигурировано с возможностью использования NN для определения на основе первого набора признаков и второго набора признаков второго значения, указывающего вероятность того, что пользовательское высказывание в процессе использования завершилось во время второго сегмента цифрового аудиосигнала в процессе использования. Электронное устройство дополнительно сконфигурировано с возможностью, в ответ на то, что второе значение превышает предопределенный порог, определения того, что пользовательское высказывание в процессе использования завершилось во время второго сегмента цифрового аудиосигнала в процессе использования.
[27] В некоторых вариантах осуществления электронного устройства электронным устройством является одно из пользовательского электронного устройства и сервера, соединенного с пользовательским электронным устройством посредством сети связи.
[28] В контексте настоящего описания «сервер» представляет собой компьютерную программу, которая работает на соответствующем аппаратном обеспечении и способна принимать запросы (например, от устройств) по сети и выполнять эти запросы или вызывать выполнение этих запросов. Аппаратное обеспечение может быть одним физическим компьютером или одной физической компьютерной системой, но ни то, ни другое не является обязательным для настоящей технологии. В настоящем контексте использование выражения "сервер" не предполагает, что каждая задача (например, принятые инструкции или запросы) или какая-либо конкретная задача будут приняты, выполнены или вызваны для выполнения одним и тем же сервером (т.е. тем же самым программным обеспечением и/или аппаратным обеспечением); данное выражение предполагает, что любое количество программных элементов или аппаратных устройств может быть задействовано в приеме/отправке, выполнении или вызове для выполнения любой задачи или запроса, или последствий любой задачи или запроса; и все это программное обеспечение и аппаратное обеспечение может быть одним сервером или многочисленными серверами, причем оба данных случая включены в выражение "по меньшей мере один сервер".
[29] В контексте настоящего описания "устройство" представляет собой любое компьютерное оборудование, которое способно выполнять программное обеспечение, которое является надлежащим для релевантной поставленной задачи. Таким образом, некоторые (неограничивающие) примеры устройств включают в себя персональные компьютеры (настольные ПК, ноутбуки, нетбуки и т.д.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что устройство, выступающее в качестве устройства в настоящем контексте, не исключается из возможности выступать в качестве сервера для других устройств. Использование термина "устройство" не исключает использования многочисленных устройств при приеме/отправке, выполнении или вызове выполнения какой-либо задачи или запроса, или последствий любой задачи или запроса, или этапов любого описанного в данном документе способа.
[30] В контексте настоящего описания "база данных" представляет собой любую структурированную совокупность данных, независимо от ее конкретной структуры, программное обеспечение для администрирования базы данных, или компьютерное оборудование, на котором данные хранятся, реализуются или их делают доступными для использования иным образом. База данных может находиться на том же аппаратном обеспечении, что и процесс, который хранит или использует информацию, хранящуюся в базе данных, или она может находиться на отдельном аппаратном обеспечении, например, на выделенном сервере или множестве серверов.
[31] В контексте настоящего описания термин "информация" включает в себя информацию любого характера или вида, которая может быть сохранена в базе данных любым образом. Таким образом, информация включает в себя, но без ограничения, аудиовизуальные произведения (изображения, фильмы, звуковые записи, презентации и т.д.), данные (данные о местоположении, численные данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д.
[32] В контексте настоящего описания, если специально не указано иное, подразумевается, что термин «компонент» включает в себя программное обеспечение (соответствующее конкретному аппаратному контексту), которое является как необходимым, так и достаточным для реализации конкретной функции (функций), на которую ссылаются.
[33] В контексте настоящего описания предполагается, что выражение "используемый компьютером носитель информации" включает в себя носители любого характера и вида, в том числе RAM, ROM, диски (CD-ROM, DVD, дискеты, накопители на жестких дисках и т.д.), USB-ключи, твердотельные накопители, ленточные накопители и т.д.
[34] В контексте настоящего описания слова "первый", "второй", "третий" и т.д. используются в качестве прилагательных только для того, чтобы позволить отличать существительные, которые они модифицируют, друг от друга, а не для описания какой-либо особой взаимосвязи между такими существительными. Таким образом, например, следует понимать, что использование терминов "первый сервер" и "третий сервер" не подразумевает какого-либо конкретного порядка, типа, хронологии, иерархии или ранжирования (например) таких серверов, равно как и их использование (само по себе) не означает, что какой-либо "второй сервер" должен обязательно существовать в любой определенной ситуации. Кроме того, как обсуждается в других контекстах данного документа, ссылка на "первый" элемент и "второй" элемент не исключает того, что эти два элемента фактически являются одним и тем же элементом реального мира. Таким образом, например, в некоторых случаях "первый" сервер и "второй" сервер могут быть одним и тем же программным обеспечением и/или аппаратным обеспечением, в других случаях они могут представлять собой разное программное обеспечение и/или аппаратное обеспечение.
[35] Каждая из реализаций настоящей технологии обладает по меньшей мере одним (одной) из вышеупомянутых аспектов и/или целей, но не обязательно имеет их все. Следует понимать, что некоторые аспекты настоящей технологии, которые возникли в попытке достичь вышеупомянутой цели, могут не удовлетворять этой цели и/или удовлетворять другим целям, которые в данном документе явным образом не описаны.
[36] Дополнительные и/или альтернативные признаки, аспекты и преимущества реализаций настоящей технологии станут очевидными из нижеследующего описания, сопроводительных чертежей и приложенной формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[37] Для лучшего понимания настоящей технологии, а также других аспектов и ее дополнительных признаков, ссылка приводится на нижеследующее описание, которое должно использоваться в сочетании с сопроводительными чертежами, на которых:
[38] Фигура 1 иллюстрирует систему, подходящую для реализации неограничивающих вариантов осуществления настоящей технологии;
[39] Фигура 2 иллюстрирует по меньшей мере некоторые данные, которые могут храниться в базе данных системы с Фигуры 1 в неограничивающих вариантах осуществления настоящей технологии;
[40] Фигура 3 иллюстрирует цифровой аудиосигнал и множество наборов связанных с ним признаков в соответствии с неограничивающими вариантами осуществления настоящей технологии;
[41] Фигура 4 иллюстрирует некоторую итерацию обучения нейронной сети (NN), реализуемую системой с Фигуры 1 в неограничивающих вариантах осуществления настоящей технологии;
[42] Фигура 5 иллюстрирует фазу использования NN с Фигуры 4 в неограничивающих вариантах осуществления настоящей технологии; и
[43] Фигура 6 представляет собой схематичную блок-схему, иллюстрирующую схему последовательности операций способа, исполняемого электронным устройством в соответствии с неограничивающими вариантами осуществления настоящей технологии.
ПОДРОБНОЕ ОПИСАНИЕ
[44] Со ссылкой на Фигуру 1 проиллюстрировано схематичное представление системы 100, причем система 100 подходит для реализации неограничивающих вариантов осуществления настоящей технологии. Следует четко понимать, что изображенная система 100 является лишь иллюстративной реализацией настоящей технологии. Таким образом, нижеследующее описание предназначено лишь для того, чтобы использоваться в качестве описания иллюстративных примеров настоящей технологии. Это описание не предназначено для определения объема или ограничения настоящей технологии. В некоторых случаях то, что считается полезными примерами модификаций системы 100, также может быть изложено ниже. Это делается лишь для облегчения понимания и, опять же, не для определения объема или ограничения настоящей технологии.
[45] Эти модификации не являются исчерпывающим списком и, как будет понятно специалисту в данной области техники, вероятно возможны другие модификации. Кроме того, те случаи, когда это не было сделано (т.е. когда не было представлено примеров модификаций), не следует интерпретировать так, что никакие модификации не являются возможными и/или что описанное является единственным способом реализации такого элемента настоящей технологии. Специалисту в данной области будет понятно, что это, вероятно, не так. Кроме того, следует понимать, что в некоторых случаях система 100 может предоставлять простые реализации настоящей технологии, и что в таких случаях они представлены для помощи в понимании. Специалисты в данной области поймут, что различные реализации настоящей технологии могут иметь большую сложность.
[46] Вообще говоря, система 100 может позволить пользователю 102 взаимодействовать с электронным устройством 104 посредством голосовых команд. С этой целью система 100 содержит электронное устройство 104 (или просто «устройство 104»), сеть 110 связи и сервер 106.
[47] Как проиллюстрировано на Фигуре 1, пользователь 102 может произносить голосовые команды устройству 104. Устройство 104 сконфигурировано с возможностью записи цифрового аудиосигнала 160, когда пользователь 102 произносит голосовую команду в форме пользовательского высказывания 150. Другими словами, устройство 104 выполнено с возможностью записи цифрового аудиосигнала 160 в режиме реального времени, когда пользователь 102 произносит пользовательское высказывание 150 вблизи устройства 104.
[48] Устройство 104 выполнено с возможностью передачи данных, указывающих части цифрового аудиосигнала 160, в систему 108 обработки IPA по мере записи цифрового аудиосигнала 160. Это означает, что устройство 104 выполнено с возможностью передачи данных, указывающих части цифрового аудиосигнала 160, в систему 108 обработки IPA в режиме реального времени, пока пользователь 102 говорит.
[49] Предположим, что части цифрового аудиосигнала 160 (данные которого должны быть переданы в систему 108 обработки IPA) имеют длительность 50 мс. В этом примере длительность 50 мс может соответствовать временным интервалам записи, с которыми части цифрового аудиосигнала 160 записываются и передаются в систему 108 обработки IPA. В этом примере для каждых 50 мс записываемого цифрового аудиосигнала 160 устройство 104 может быть сконфигурировано с возможностью передачи данных в систему 108 обработки IPA, указывающих эти 50 мс цифрового аудиосигнала 160 в режиме реального времени.
[50] Другими словами, в этом примере система 108 обработки IPA может принимать данные, указывающие последовательные части по 50 мс цифрового аудиосигнала 160 по мере записи цифрового аудиосигнала 160. Следует отметить, что составляющая 50 мс длительность для части цифрового аудиосигнала 160 приведена в вышеописанном неисчерпывающем примере исключительно в целях иллюстрации и не предназначена для ограничения объема настоящей технологии.
[51] Во время приема данных, указывающих последовательные части цифрового аудиосигнала 160, в общем, система 108 обработки IPA сконфигурирована с возможностью, среди прочего, определения, завершилось ли пользовательское высказывание 150 во время самой последней принятой части цифрового аудиосигнала 160.
[52] Таким образом, если система 108 обработки IPA определяет, что пользовательское высказывание 150 завершилось во время самой последней принятой части цифрового аудиосигнала 160, система 108 обработки IPA может определить, что дополнительные части цифрового аудиосигнала 160 могут не требоваться (i) для определения пользовательской голосовой команды, произнесенной пользователем 102 (в качестве пользовательского высказывания 150), и (ii) для выполнения задач в ответ на эту голосовую команду.
[53] Разработчики настоящей технологии осознали, что разработка системы 108 обработки IPA так, чтобы она позволяла определять, когда пользовательское высказывание 150 завершается в цифровом аудиосигнале 160, может быть полезной по многим причинам. В некоторых случаях это может позволить системе 108 обработки IPA быстрее определять голосовые команды, произносимые пользователем 102, и в ответ на эти голосовые команды выполнять задачи раньше.
[54] В результате, определение того, когда пользовательское высказывание 150 завершается в цифровом аудиосигнале 160, как это будет описано в данном документе, может улучшить «отзывчивость» системы 108 обработки IPA, то есть оно может сократить время между (i) моментом времени окончания произношения пользователем 102 голосовой команды в форме пользовательского высказывания 150 (то есть моментом времени завершения пользовательского высказывания 150) и (ii) моментом времени выполнения системой 108 обработки IPA задачи в ответ на эту голосовую команду.
[55] Следует отметить, что, хотя система 108 обработки IPA проиллюстрирована на Фигуре 1 как реализованная сервером 106, в других вариантах осуществления настоящей технологии один (одна) или несколько (или все) компонентов и/или функциональных возможностей системы 108 обработки IPA может быть реализован (реализована) устройством 104 (например, система 108 обработки IPA может быть реализована локально на устройстве 104) без выхода за рамки объема настоящей технологии. Далее будут описаны различные компоненты системы 100 и то, как эти компоненты могут быть сконфигурированы с возможностью определения конца пользовательского высказывания 150. Устройство
[56] Как упоминалось ранее, система 100 содержит устройство 104. Реализация устройства 104 конкретным образом не ограничена, но, в качестве примера, устройство 104 может быть реализовано в виде персонального компьютера (настольные ПК, ноутбуки, нетбуки и т.д.), устройства беспроводной связи (такого как смартфон, сотовый телефон, планшет, умная колонка и т.д.). Как таковое, устройство 104 иногда может именоваться «электронным устройством», «конечным пользовательским устройством», «клиентским электронным устройством», «пользовательским электронным устройством» или просто «устройством». Следует отметить, что тот факт, что устройство 104 связано с пользователем 102, не обязательно предполагает или подразумевает какой-либо режим работы - например необходимость входа в систему, необходимость регистрации или тому подобное.
[57] Предполагается, что устройство 104 содержит аппаратное обеспечение и/или программное обеспечение и/или микропрограммное обеспечение (или их комбинацию) для обнаружения пользовательского высказывания 150 и/или записи цифрового аудиосигнала 160. Вообще говоря, цифровой аудиосигнал 160 представляет собой результат (выходные данные) аудиозаписи, выполняемой устройством 104, когда пользователь 102 произносит пользовательское высказывание 150. Как таковой, цифровой аудиосигнал 160 представляет звуковые волны, которые обнаруживаются, записываются и преобразуются в цифровую форму в режиме реального времени, пока пользователь 102 говорит.
[58] В некоторых вариантах осуществления устройство 104 также может содержать аппаратное обеспечение и/или программное обеспечение и/или микропрограммное обеспечение (или их комбинацию) для исполнения приложения IPA. Вообще говоря, назначением приложения IPA, также известного как «чат-бот», является предоставление пользователю 102 возможности взаимодействовать с устройством 104 посредством речи. Приложение IPA может обеспечивать возможность речевого взаимодействия между пользователем 102 и устройством 104 посредством использования системы 108 обработки IPA. Таким образом, можно сказать, что приложение IPA связано с системой 108 обработки IPA.
[59] Следует отметить, что в некоторых вариантах осуществления настоящей технологии устройство 104 также может реализовывать компоненты и/или функциональные возможности сервера 106. Например, устройство 104 может содержать аппаратное обеспечение и/или программное обеспечение и/или микропрограммное обеспечение (или их комбинацию), как известно в данной области техники, для локальной реализации системы 108 обработки IPA. В таком случае, как приложение IPA, так и система 108 обработки IPA могут быть реализованы локально на устройстве 104 без отклонения от объема настоящей технологии.
[60] В некоторых вариантах осуществления настоящей технологии, в которых система 108 обработки IPA реализована сервером 106, устройство 104 может быть сконфигурировано с возможностью передачи данных, указывающих части цифрового аудиосигнала 160, как упомянуто выше, на сервер 106.
[61] Например, устройство 104 может быть сконфигурировано с возможностью генерирования первого пакета 162 данных, содержащего данные, указывающие первую часть цифрового аудиосигнала 160, и может отправлять (в режиме реального времени) первый пакет 162 данных на сервер 106, в то время как вторая часть цифрового аудиосигнала 160 записывается.
[62] Устройство 104 может быть сконфигурировано с возможностью генерирования второго пакета 164 данных, содержащего данные, указывающие вторую часть цифрового аудиосигнала 160, и может отправлять (в режиме реального времени) второй пакет 164 данных на сервер 106, в то время как третья часть цифрового аудиосигнала 160 записывается.
[63] Устройство 104 может быть сконфигурировано с возможностью генерирования третьего пакета 166 данных, содержащего данные, указывающие третью часть цифрового аудиосигнала 160, и может отправлять (в режиме реального времени) третий пакет 166 данных на сервер 106, в то время как другая часть цифрового аудиосигнала 160 записывается.
[64] Следовательно, можно сказать, что в некоторых вариантах осуществления настоящей технологии, в которых система 108 обработки IPA реализована сервером 106, устройство 104 может быть сконфигурировано с возможностью передачи потока пакетов данных на сервер 106, причем эти пакеты данных содержат данные, указывающие последовательные части цифрового аудиосигнала 160.
[65] В других вариантах осуществления настоящей технологии, в которых система 108 обработки IPA реализована устройством 104, устройство 104 может быть сконфигурировано с возможностью локальной передачи потока пакетов данных в систему 108 обработки IPA, причем эти пакеты данных содержат данные, указывающие последовательные части цифрового аудиосигнала 160.
Сеть связи
[66] В иллюстративном примере системы 100 устройство 104 соединено с возможностью связи с сетью 110 связи для доступа к и передачи пакетов данных (таких как, например, первый пакет 162 данных, второй пакет 164 данных и третий пакет 166 данных) на/от сервера 106. В некоторых неограничивающих вариантах осуществления настоящей технологии сеть 110 связи может быть реализована как Интернет. В других вариантах осуществления настоящей технологии сеть 110 связи может быть реализована иначе, например, как какая-либо глобальная сеть связи, локальная сеть связи, частная сеть связи и тому подобное. То, как реализована линия связи (отдельно не пронумерована) между устройством 104 и сетью 110 связи, будет зависеть, среди прочего, от того, как реализовано устройство 104.
[67] Просто как пример, а не как ограничение, в тех вариантах осуществления настоящей технологии, в которых устройство 104 реализовано как устройство беспроводной связи (например, как смартфон), линия связи может быть реализована как линия беспроводной связи (такая как, но без ограничения, линия сети связи 3G, линия сети связи 4G, Wireless Fidelity или WiFi® для краткости, Bluetooth® и тому подобные). В тех примерах, в которых устройство 104 реализовано как ноутбук, линия связи может быть либо беспроводной (такой как Wireless Fidelity или WiFi® для краткости, Bluetooth® или тому подобное), либо проводной (такой как Ethernet-соединение).
[68] В некоторых вариантах осуществления настоящей технологии, в которых система 108 обработки IPA реализована устройством 104, сеть 110 связи может быть опущена без отклонения от объема настоящей технологии.
Сервер
[69] Как упоминалось ранее, система 100 также содержит сервер 106, который может быть реализован как обычный компьютерный сервер. В примере варианта осуществления настоящей технологии сервер 106 может быть реализован как сервер Dell™ PowerEdge™, работающий под управлением операционной системы Microsoft™ Windows Server™. Само собой разумеется, сервер 106 может быть реализован в любом другом подходящем аппаратном, программном и/или микропрограммном обеспечении или в их комбинации. В проиллюстрированных неограничивающих вариантах осуществления настоящей технологии сервер 106 является единственным сервером. В альтернативных неограничивающих вариантах осуществления настоящей технологии функциональные возможности сервера 106 могут быть распределены и могут быть реализованы посредством многочисленных серверов.
[70] Вообще говоря, сервер 106 сконфигурирован с возможностью получения (в режиме реального времени) данных, указывающих части цифрового аудиосигнала 160, и использования системы 108 обработки IPA для выполнения различных задач для пользователя 102. Однако в дополнение к использованию системы 108 обработки IPA для выполнения различных задач для пользователя 102 сервер 106 может быть сконфигурирован с возможностью «обучения» по меньшей мере некоторых компонентов системы 108 обработки IPA.
[71] Компоненты и функциональные возможности системы 108 обработки IPA и то, как сервер 106 сконфигурирован с возможностью «обучения» по меньшей мере некоторых компонентов системы 108 обработки IPA, будет описано более подробно ниже в настоящем документе.
База данных
[72] Сервер 106 также соединен с возможностью связи с базой 124 данных. На представленной иллюстрации база 124 данных проиллюстрирована как единый физический объект. Это не обязательно должно быть так в каждом варианте осуществления настоящей технологии. По существу, база 124 данных может быть реализована как множество отдельных баз данных. Опционально, база 124 данных может быть разделена на несколько распределенных хранилищ.
[73] База 124 данных сконфигурирована с возможностью хранения информации, обрабатываемой или используемой сервером 106. Вообще говоря, база 124 данных может принимать данные от сервера 106 для их временного и/или постоянного хранения и может предоставлять сохраненные данные серверу 106 для их обработки.
[74] В некоторых вариантах осуществления база 124 данных может хранить данные, которые могут использоваться сервером 106, чтобы генерировать по меньшей мере некоторые обучающие данные для обучения по меньшей мере некоторых компонентов системы 108 обработки IPA. В других вариантах осуществления база 124 данных может хранить сами обучающие данные, которые сервер 106 может использовать для обучения по меньшей мере некоторых компонентов системы 108 обработки IPA.
[75] В одном варианте осуществления база 124 данных может хранить множество цифровых аудиосигналов. Например, со ссылкой на Фигуру 2 проиллюстрировано множество 200 цифровых аудиосигналов, которые могут быть сохранены в базе 124 данных. База 124 данных может хранить большое количество цифровых аудиосигналов, например, 10000, 100000, 1000000 и т.п.
[76] Множество 200 цифровых аудиосигналов может быть собрано и сохранено в базе 124 данных многими различными способами. Однако, лишь в качестве примеров, множество 200 цифровых аудиосигналов может быть записано ответственными за оценку людьми и/или получено с помощью краудсорсинга.
[77] В одном примере множество 200 цифровых аудиосигналов может представлять собой аудиозаписи высказываний, которые указывают типичные пользовательские высказывания, выполняемые пользователями при взаимодействии с устройствами, аналогичными устройству 104. В случае, когда устройство 104 представляет собой устройство типа «умной колонки», типичными пользовательскими высказываниями могут быть, но без ограничения: «Выключи», «Воспроизведи музыку», «Сделай меньшую громкость», «Какая сейчас погода», «Где находится ближайшая заправочная станция», «Спящий режим», «Позвони Илье», «Установи напоминание на семь утра» и так далее.
[78] В некоторых вариантах осуществления база 124 данных может хранить текстовые представления пользовательских высказываний, связанных с соответствующими из множества 200 цифровых аудиосигналов. Например, база 124 данных может хранить множество 220 текстовых представлений. В этом примере каждый из множества 200 цифровых аудиосигналов связан с соответствующим одним из множества 220 текстовых представлений.
[79] Рассмотрим в качестве примера цифровой аудиосигнал 202 из множества 200 цифровых аудиосигналов, хранящихся в базе 124 данных. Цифровой аудиосигнал 202 связан с текстовым представлением 222 из множества 220 текстовых представлений. Текстовое представление 222 содержит по меньшей мере одно слово и, возможно, паузы и представляет собой текстовую форму высказывания, записанного в цифровом аудиосигнале 202. Например, если цифровой аудиосигнал 202 является аудиозаписью человека, произносящего «Воспроизведи музыку», текстовое представление 222 является текстовой формой этого высказывания.
[80] Множество 220 текстовых представлений может быть собрано и сохранено в базе 124 данных многими различными способами. Однако, лишь в качестве примеров, множество 220 текстовых представлений может быть сгенерировано ответственными за оценку людьми и/или получено с помощью краудсорсинга теми, кто записал цифровые аудиосигналы 200, и/или сгенерировано посредством обработки речи из цифровых аудиосигналов 200 в текст посредством компьютерной системы.
[81] Например, цифровой аудиосигнал 202 может быть предоставлен некоторому ответственному за оценку человеку, который может прослушать этот цифровой аудиосигнал 202, воспринять соответствующее пользовательское высказывание и воспроизвести текстовую форму этого высказывания для генерирования текстового представления 222. Ответственных за оценку людей можно попросить выполнить аналогичную задачу для каждого из множества 200 цифровых аудиосигналов для генерирования соответствующего одного из множества 220 текстовых представлений. Альтернативно, текстовое представление 222 может быть исходным текстом, который использовался ответственным за оценку человеком или ответственным за оценку участником краудсорсинга для генерирования цифрового аудиосигнала 202.
[82] В другом примере сервер 106 может применять алгоритм автоматического распознавания речи (ASR) для генерирования множества 220 текстовых представлений на основе множества 200 цифровых аудиосигналов. Вообще говоря, алгоритмы ASR, иногда упоминаемые как «алгоритмы преобразования речи в текст (STT)», позволяют компьютерным системам распознать и перевести разговорный язык в текстовую форму.
[83] В этом примере сервер 106 может вводить цифровой аудиосигнал 202 в алгоритм ASR, который сконфигурирован с возможностью вывода, в ответ, текстового представления 222. Таким образом, сервер 106 может итеративно вводить цифровые аудиосигналы из множества 200 цифровых аудиосигналов в алгоритм ASR, который в ответ может генерировать соответствующие представления из множества 220 текстовых представлений.
[84] В некоторых вариантах осуществления настоящей технологии база 124 данных может хранить временные отметки в связи с цифровыми аудиосигналами. Например, база 124 данных может хранить множество 24 0 временных меток. В этом примере каждый из множества 200 цифровых аудиосигналов связан с соответствующей одной из множества 240 временных меток.
[85] В примере цифрового аудиосигнала 202 цифровой аудиосигнал 202 связан с временной отметкой 242. Временная отметка 242 указывает момент времени в цифровом аудиосигнале 202, после которого пользовательское высказывание в цифровом аудиосигнале 202 завершилось.
[86] В контексте настоящей технологии этот момент времени является моментом времени «завершения высказывания» в цифровом аудиосигнале 202. Другими словами, в цифровом аудиосигнале 202 аудиозапись пользовательского высказывания завершается в момент времени «завершения высказывания». В одном примере этот момент времени завершения высказывания в цифровом аудиосигнале 202 может совпадать с моментом времени, когда пользователь прекращает говорить. Можно сказать, что моментом времени завершения высказывания является некоторый момент времени в цифровом аудиосигнале 202, после которого пользовательское высказывание завершено.
[87] Множество 240 временных меток может быть собрано и сохранено в базе 124 данных многими различными способами. Лишь в качестве примеров, множество 240 временных меток может быть сгенерировано ответственными за оценку людьми и/или краудсорсингом и/или компьютерной системой.
[88] Например, цифровой аудиосигнал 202 может быть предоставлен некоторому ответственному за оценку человеку, который может прослушать этот цифровой аудиосигнал 202 и отметить некоторый момент времени цифрового аудиосигнала 202, после которого пользовательское высказывание, записанное в цифровом аудиосигнале 202, завершилось. Ответственных за оценку людей можно попросить выполнить аналогичную задачу для каждого из множества 200 цифровых аудиосигналов для генерирования соответствующей отметки из множества 240 временных отметок.
[89] В другом примере сервер 106 может применять алгоритм автоматического выравнивания речи с текстом (ASA) для генерирования множества 240 временных меток на основе множества 200 цифровых аудиосигналов и множества 220 текстовых представлений. Вообще говоря, алгоритмы ASA позволяют компьютерным системам сгенерировать выровненный по времени индекс слов на основе (i) цифрового аудиосигнала, содержащего аудиозапись человеческой речи (например, пользовательское высказывание), и (ii) текстового представления этой речи. Другими словами, алгоритмы ASA сконфигурированы с возможностью выполнения автоматического выравнивания аудиозаписи человеческой речи с ее транскрипцией на уровне слов.
[90] В этом примере сервер 106 может вводить цифровой аудиосигнал 202 и текстовое представление 222 в алгоритм ASA, который сконфигурирован с возможностью автоматического «выравнивания по времени» слов из текстового представления 222, чтобы получить временные интервалы цифрового аудио сигнал 202, во время которых произносятся соответствующие слова из текстового представления 222.
[91] В результате для каждого слова из текстового представления 222 алгоритм ASA может выводить две временные отметки: (i) первую, указывающую момент времени в цифровом аудиосигнале 202, когда произнесение некоторого определенного слова начинается, и (ii) вторую, указывающую момент времени в цифровом аудиосигнале 202, когда произнесение соответствующего слова завершается. Следовательно, сервер 106 может определить, что вторая временная отметка, связанная с последним словом текстового представления 222, указывает момент времени завершения высказывания для цифрового аудиосигнала 202.
[92] Таким образом, сервер 106 может итеративно вводить цифровые аудиосигналы из множества 200 цифровых аудиосигналов и соответствующие текстовые представления из множества 220 текстовых представлений в алгоритм ASA, который может использоваться для определения соответствующих временных меток из множества 240 временных меток.
[93] База 124 данных также может сохранять наборы признаков в связи с соответствующим одним из множества 200 цифровых аудиосигналов. Эти наборы признаков могут быть определены сервером 106. То, как наборы характеристик для цифрового аудиосигнала 202 могут быть определены сервером 106, будет описано далее со ссылкой на Фигуру 3.
[94] На Фигуре 3 проиллюстрирован цифровой аудиосигнал 202 и соответствующее текстовое представление 222. Предположим, что текстовой формой (например, текстовым представлением 222) пользовательского высказывания, записанного как часть цифрового аудиосигнала 202, является «'Воспроизведи' 'музыку'». Там также проиллюстрирован момент времени завершения высказывания, соответствующий временной отметке 242, связанной с цифровым аудиосигналом 202.
[95] В некоторых вариантах осуществления при определении наборов признаков для цифрового аудиосигнала 202 сервер 106 может быть сконфигурирован с возможностью сегментации цифрового аудиосигнала 202 на множество 300 сегментов, а именно: первый сегмент 302, второй сегмент 304, третий сегмент 306, четвертый сегмент 308, пятый сегмент 310 и шестой сегмент 312.
[96] Сервер 106 может сегментировать цифровой аудиосигнал 202 на сегменты предопределенной длительности. Например, сегменты во множестве 300 сегментов могут иметь длительность 100 мс. Однако предопределенная длительность, которая определяется оператором сервера 106, может отличаться от приведенного выше неисчерпывающего примера в других реализациях и не выходить за рамки объема настоящей технологии.
[97] Предполагается, что сервер 106 может быть сконфигурирован с возможностью определения соответствующего набора признаков для каждого сегмента из множества 300 сегментов. В некоторых вариантах осуществления определенный набор признаков может содержать признаки акустического типа. В других вариантах осуществления определенный набор признаков может содержать признаки акустического типа, а также признаки лингвистического типа.
[98] Чтобы лучше это проиллюстрировать, рассмотрим в качестве примера первый сегмент 302 из множества 300 сегментов. В некоторых вариантах осуществления для определения набора признаков для первого сегмента 302 сервер 106 может быть сконфигурирован с возможностью дополнительной сегментации первого сегмента 302 на множество суб-сегментов (не проиллюстрированы). Например, если первый сегмент 302 имеет длительность 100 мс, сервер 106 может дополнительно сегментировать этот первый сегмент 302 на десять суб-сегментов, каждый из которых имеет длительность 10 мс.
[99] Предполагается, что сервер 106 может получать/извлекать, для каждого суб-сегмента первого сегмента 302, признаки акустического типа, применяя один или несколько алгоритмов обработки сигналов. Признаки акустического типа, получаемые/извлекаемые сервером 106, применяющим один или несколько алгоритмов обработки сигналов для соответствующего суб-сегмента, могут указывать, но без ограничения: уровень громкости, уровень основного тона, уровень энергии, гармоничность (например, автокорреляция основного тона), спектральные особенности и тому подобное.
[100] Как только сервер 106 получает/извлекает признаки акустического типа для каждого суб-сегмента, сервер 106 может группировать признаки акустического типа соответствующих суб-сегментов, тем самым определяя первый набор 322 признаков для первого сегмента 302. Предполагается, что признаки акустического типа для некоторого суб-сегмента могут быть извлечены не только из данного суб-сегмента, но также из по меньшей мере части соседних суб-сегментов у данного суб-сегмента.
[101] Предполагается, что признаки акустического типа для суб-сегмента могут быть скомпонованы в векторную форму. Следовательно, группировка признаков акустического типа соответствующих суб-сегментов может включать в себя группировку векторов, связанных с соответствующими суб-сегментами, в группу векторов (или в матрицу), которая соответствует первому набору 322 признаков.
[102] Этот первый набор 322 признаков содержит признаки акустического типа для первого сегмента 302.
[103] В дополнительных вариантах осуществления настоящей технологии, в дополнение к признакам акустического типа, сервер 106 может получать/извлекать признаки лингвистического типа для соответствующих сегментов из множества 300 сегментов. Например, сервер 106 может применять вышеупомянутый алгоритм ASR для получения/извлечения признаков лингвистического типа для соответствующих сегментов из множества 300 сегментов.
[104] Это означает, что в некоторых вариантах осуществления, в дополнение к признакам акустического типа, первый набор 322 признаков может дополнительно содержать признаки лингвистического типа, которые могут быть получены/извлечены из первого сегмента 302 сервером 106, применяющим алгоритм ASR. Признаки лингвистического типа могут указывать, но без ограничения: часть речи (POS) слова, вероятность биграммы и униграммы слова, соотношение акцентов ("accent ratio"). Кроме того, паралингвистические признаки, такие как тембр голоса и среднестатистическая речь, также могут использоваться вместе или отдельно с признаками лингвистического типа.
[105] Сервер 106 может быть сконфигурирован с возможностью определения множества 320 наборов признаков для множества 300 сегментов аналогично тому, как сервер 106 определяет первый набор 322 признаков для первого сегмента 302. Следовательно, сервер 106 может быть сконфигурирован с возможностью генерирования:
- второго набора 324 признаков для второго сегмента 304;
- третьего набора 326 признаков для третьего сегмента 306;
- четвертого набора 328 признаков для четвертого сегмента 308;
- пятого набора 330 признаков для пятого сегмента 310;
- шестого набора 332 признаков для шестого сегмента 312.
[106] Предполагается, что сервер 106 может хранить множество 320 наборов признаков в связи с соответствующими сегментами из множества 300 сегментов цифрового аудиосигнала 202 в базе 124 данных.
[107] Предполагается, что множество 320 наборов признаков может использоваться сервером 106 для обучения по меньшей мере некоторых компонентов системы 108 обработки IPA. То, как эти наборы функций могут быть использованы для обучения по меньшей мере некоторых компонентов системы 108 обработки IPA, будет более подробно описано ниже.
[108] Сервер 106 также может быть сконфигурирован с возможностью определения меток для наборов признаков из множества 320 наборов признаков. Определенная метка для набора признаков может указывать, завершилось ли пользовательское высказывание в цифровом аудиосигнале 202 во время соответствующего сегмента цифрового аудиосигнала 202.
[109] Сервер 106 может определять эти метки на основе скорректированного момента времени завершения высказывания, соответствующего временной отметке 350, проиллюстрированной на Фигуре 3. Сервер 106 сконфигурирован с возможностью определения скорректированного момента времени завершения высказывания на основе момента времени завершения высказывания (соответствующего временной отметке 242, также проиллюстрированной на Фигуре 3).
[110] Предполагается, что сервер 10 6 может определять скорректированный момент времени завершения высказывания путем добавления некоторого предопределенного временного смещения 340 к моменту времени завершения высказывания. Например, сервер 106 может добавить временное смещение, равное 100 мс, к моменту времени завершения высказывания, чтобы определить скорректированный момент времени завершения высказывания.
[111] Причина, по которой метки (указывающие, завершилось ли пользовательское высказывание в цифровом аудиосигнале 202 во время соответствующего сегмента цифрового аудиосигнала 202) для наборов признаков основаны на скорректированном моменте времени завершения высказывания, а не на моменте времени завершения высказывания, станет ясна из приведенного ниже описания.
[112] Тем не менее, как только скорректированный момент времени завершения высказывания (соответствующий временной отметке 350) определен, сервер 106 может определить метки для соответствующих наборов признаков из множества 320 наборов признаков.
[113] Например, сервер 106 может определить, что меткой для первого набора 322 признаков является «0», поскольку скорректированный момент времени завершения высказывания наступает после соответствующего первого сегмента 302. Другими словами, метка указывает, что пользовательское высказывание в цифровом аудиосигнале 202 не завершилось во время первого сегмента 302.
[114] Аналогично, сервер 106 может определить, что соответствующими метками для второго набора 324 признаков и для третьего набора 326 признаков также являются «0», поскольку скорректированный момент времени завершения высказывания наступает после второго сегмента 304 и третьего сегмента 306. Другими словами, соответствующие метки для второго набора 324 признаков и третьего набора 326 признаков указывают, что пользовательское высказывание в цифровом аудиосигнале 202 не завершилось во время второго сегмента 304 и третьего сегмента 306.
[115] Сервер 106 может определить, что меткой для четвертого набора 328 признаков является «0», поскольку скорректированный момент времени завершения высказывания наступает после четвертого сегмента 308. Следует отметить, что, хотя момент времени завершения высказывания (соответствующий временной отметке 242) происходит во время четвертого сегмента 308, сервер 106 использует скорректированный момент времени завершения высказывания в качестве опорного момента времени для определения того, завершилось ли пользовательское высказывание в цифровом аудиосигнале 202 во время некоторого сегмента цифрового аудиосигнала 202. Как упомянуто выше, причина, по которой метки основаны на скорректированном моменте времени завершения высказывания, а не на моменте времени завершения высказывания, станет понятной из приведенного ниже описания.
[116] Сервер 106 может определить, что меткой для пятого набора 330 признаков является «1», поскольку скорректированный момент времени завершения высказывания наступает во время пятого сегмента 310. Другими словами, эта метка указывает, что пользовательское высказывание в цифровом аудиосигнале 202 завершилось во время пятого сегмента 310.
[117] Аналогично, сервер 106 может определить, что меткой для шестого набора 332 признаков также является «1», поскольку скорректированный момент времени завершения высказывания наступает до шестого сегмента 312. Другими словами, эта метка указывает, что пользовательское высказывание в цифровом аудиосигнале 202 завершилось во время шестого сегмента 312.
[118] Таким образом, сервер 106 может быть сконфигурирован с возможностью определения множества 320 наборов признаков, как объяснено выше, для множества сегментов цифрового аудиосигнала 202. Сервер 106 также сконфигурирован с возможностью определения соответствующих меток для множества 320 наборов признаков, при этом метка указывает, завершилось ли пользовательское высказывание во время соответствующего сегмента в цифровом аудиосигнале 202.
[119] Следует отметить, что сервер 106 может быть сконфигурирован с возможностью хранения множества 320 наборов признаков в связи с соответствующими метками в базе 124 данных. Сервер 106 может быть сконфигурирован с возможностью определения меток для наборов признаков других аудиосигналов из множества 200 цифровых аудиосигналов, хранящихся в базе 124 данных, аналогично тому, как сервер 106 сконфигурирован определять метки для множества 320 наборов признаков цифрового аудиосигнала 202.
[120] Сервер 106 может использовать множество наборов признаков и соответствующих меток для обучения по меньшей мере некоторых компонентов системы 108 обработки IPA. Теперь будет описано то, как сервер 106 сконфигурирован с возможностью обучения по меньшей мере некоторых компонентов системы 108 обработки IPA.
[121] Со ссылкой на Фигуру 4, система 108 обработки IPA содержит нейронную сеть (NN) 400. NN 400 является по меньшей мере одним компонентом системы 108 обработки IPA, который может быть обучен сервером 106. Другими словами, сервер 106 может быть сконфигурирован с возможностью обучения NN 400 системы 108 обработки IPA.
Нейронная сеть
[122] Вообще говоря, определенная NN состоит из взаимосвязанной группы искусственных «нейронов», которые обрабатывают информацию, используя коннекционистский подход к вычислению. NN используются для моделирования сложных взаимосвязей между входными и выходными данными (без фактического знания этих взаимосвязей) или для поиска закономерностей в данных. NN сначала подготавливаются во время фазы обучения, во время которой им предоставляется некоторый известный набор «входных данных» и информации для адаптации NN к генерированию надлежащих выходных данных (для некоторой определенной ситуации, которую пытаются смоделировать). Во время этой фазы обучения эта NN адаптируется к изучаемой ситуации и меняет свою структуру так, чтобы данная NN могла обеспечивать разумные прогнозные выходные данные для определенных входных данных во время некоторой новой ситуации (на основе того, что было изучено). Таким образом, вместо того, чтобы пытаться определить сложные статистические схемы или математические алгоритмы для некоторой определенной ситуации, определенная NN пытается дать «интуитивный» ответ, основанный на «восприятии» ситуации. Таким образом, определенная NN является своего рода обученным «черным ящиком», который может быть использован в ситуации, когда то, что находится в этом «ящике», важным не является; важно лишь, что «ящик» дает разумные ответы на определенные входные данные.
[123] NN обычно используются во многих таких ситуациях, в которых важно знать лишь выходные данные, основанные на некоторых определенных входных данных, но то, как именно эти выходные данные были получены, имеет меньшее значение или значения не имеет. Например, NN обычно используются для оптимизации распределения веб-трафика между серверами и при обработке данных, в том числе фильтрации, кластеризации, разделении сигналов, сжатии, генерировании вектора, распознавании речи и тому подобном.
[124] Следует понимать, что NN могут быть классифицированы на различные классы NN. Один из этих классов содержит рекуррентные нейронные сети (RNN). Эти конкретные NN приспособлены использовать свои «внутренние состояния» (хранимую память) для обработки последовательностей входных данных. Это делает RNN хорошо подходящими для таких задач, как, например, распознавание несегментированного рукописного ввода и распознавание речи. Этими внутренними состояниями RNN можно управлять, и они именуются «управляемыми» (gated) состояниями или «управляемыми» воспоминаниями.
[125] Также следует отметить, что сами RNN также могут быть классифицированы на различные подклассы RNN. Например, RNN могут быть реализованы в виде сетей с долгой краткосрочной памятью (LSTM), управляемых рекуррентных блоков (GRU), двунаправленных RNN (BRNN) и т.п.
[126] Сети с LSTM представляют собой системы глубокого обучения, которые могут обучаться задачам, требующим, в некотором смысле, «воспоминаний» о событиях, которые произошли ранее в течение очень коротких и дискретных временных интервалов. Топологии сетей с LSTM могут меняться в зависимости от конкретных задач, которые их "обучают" выполнять. Например, сети с LSTM могут обучаться выполнять задачи, при которых относительно длительные задержки происходят между событиями или когда события происходят вместе с низкой и высокой частотой.
[127] В некоторых вариантах осуществления настоящей технологии предполагается, что NN 400 может быть реализована как данная сеть с LSTM. Можно сказать, что NN 400 может быть реализована в некоторых вариантах осуществления с некоторой топологией сети, которая позволяет хранить «воспоминания» о событиях, которые произошли ранее.
[128] Подводя итог, можно сказать, что реализация NN 400 системой 108 обработки IPA может быть в общем разделена на две фазы: фаза обучения и фаза использования.
[129] Сначала, NN 400 обучают во время фазы обучения. Во время фазы обучения сервер 106 может выполнять большое количество итераций обучения в отношении NN 400. Вообще говоря, во время определенной итерации обучения в NN 400 вводят наборы признаков, связанных с общим цифровым аудиосигналом, и она, в некотором смысле, «обучается» тому, какой из этих наборов признаков соответствует сегменту этого цифрового аудиосигнала, во время которого пользовательское высказывание в этом цифровом аудиосигнале завершилось (используя скорректированный момент времени завершения высказывания, соответствующий временной отметке 350, проиллюстрированной на Фигуре 3, в качестве его представительной переменной).
[130] Затем, во время фазы использования, когда NN 400 знает, какие данные следует ожидать в качестве входных данных (например, наборы признаков) и какие данные следует предоставлять в качестве выходных данных (например, прогнозы для наборов признаков), NN 4 00 фактически работает используя данные в процессе использования (in-use data). Вообще говоря, во время использования, в NN 400 вводят наборы признаков, связанных с цифровым аудиосигналом в процессе использования (например, таким как цифровой аудиосигнал 160), и используют ее для определения вероятности соответствующего сегмента цифрового аудиосигнала в процессе использования, во время которого пользовательское высказывание завершилось.
[131] Далее со ссылкой на Фигуру 4 будет описано то, как сервер 106 может выполнять итерацию обучения NN 400. На Фигуре 4 проиллюстрировано схематичное представление итерации обучения NN 400. Предположим, что данная итерация обучения NN 400 выполняется на основе данных, связанных с цифровым аудиосигналом 202. Однако следует отметить, что в отношении NN 400 во время фазы ее обучения выполняется большее количество итераций обучения, как упомянуто выше, используя данные, связанные с другими аудиосигналами из множества 200 цифровых аудиосигналов, аналогично выполнению данной итерации обучения, проиллюстрированной на Фигуре 4.
[132] Для данной итерации обучения NN 400, сервер 106 может извлечь обучающие данные 402 из базы 124 данных. Обучающие данные 402 содержат (i) множество 320 наборов признаков для цифрового аудиосигнала 202 и (ii) соответствующие связанные метки. Как упомянуто выше, в некоторых вариантах осуществления настоящей технологии обучающие данные 402 могут быть предопределены сервером 106, то есть сервер 106 мог определить и сохранить эти обучающие данные 402 до фазы обучения NN 400.
[133] Сервер 106 сконфигурирован с возможностью ввода множества 320 наборов признаков в NN 400 в той же последовательности, что и последовательность, в которой соответствующие сегменты из множества 300 сегментов встречаются в цифровом аудиосигнале 202. Другими словами, во время данной итерации обучения сервер 106 сконфигурирован с возможностью ввода множества 320 наборов признаков в NN 400 в следующем порядке: первый набор 322 признаков, второй набор 324 признаков, третий набор 326 признаков, четвертый набор 328 признаков, пятый набор 330 признаков и шестой набор 332 признаков.
[134] Когда сервер 106 вводит первый набор 322 признаков в NN 400, NN 400 сконфигурирована с возможностью вывода первого выходного значения 422, указывающего вероятность того, что пользовательское высказывание в цифровом аудиосигнале 202 завершилось во время первого сегмента 302 цифрового аудиосигнала 202. Как проиллюстрировано на Фигуре 4, предположим, что первое выходное значение 422 равно «0,1» (или 10%, например). Можно сказать, что NN 400 определяет первое выходное значение «0,1» для первого сегмента 302 на основе первого набора 322 признаков.
[135] Сервер 106 затем вводит второй набор 324 признаков в NN 400. NN 400 сконфигурирована с возможностью вывода второго выходного значения 424, указывающего вероятность того, что пользовательское высказывание в цифровом аудиосигнале 202 завершилось во время второго сегмента 304 цифрового аудиосигнала 202. Как проиллюстрировано на Фигуре 4, предположим, что второе выходное значение 424 равно «0,3».
[136] Как упоминалось ранее, NN 400 может иметь топологию сети, которая позволяет NN 400 хранить «воспоминания» о событиях, которые произошли ранее. Другими словами, NN 400 может быть сконфигурирована с возможностью вывода второго выходного значения «0,3» на основе (i) второго набора 324 признаков, а также на основе «памяти», что ранее введенным набором признаков является (ii) первый набор 322 признаков. Это означает, что NN 400 может определять второе выходное значение 424 «0,3» для второго сегмента 304 на основе обоих (i) второго набора 324 признаков и (ii) первого набора 322 признаков.
[137] Сервер 106 затем вводит третий набор 326 признаков в NN 400, а NN 400 выводит третье выходное значение 426 «0,1». NN 400 может определять третье выходное значение 426 «0,1» для третьего сегмента 306 на основе (i) третьего набора 326 признаков, (ii) второго набора 324 признаков и (iii) первого набора 322 признаков.
[138] Сервер 106 затем вводит четвертый набор 328 признаков в NN 400, а NN 400 выводит четвертое выходное значение 428 «0,4». NN 400 может определять четвертое выходное значение 428 «0,4» для четвертого сегмента 308 на основе (i) четвертого набора 328 признаков, (ii) третьего набора 326 признаков, (iii) второго набора 324 признаков и (iv) первого набора 322 признаков.
[139] Сервер 106 затем вводит пятый набор 330 признаков в NN 400, а NN 400 выводит пятое выходное значение 430 «0,9». NN 400 может определять пятое выходное значение 430 «0,9» для пятого сегмента 310 на основе (i) пятого набора 330 признаков, (ii) четвертого набора 328 признаков, (iii) третьего набора 326 признаков, (iv) второго набора 324 признаков и (v) первого набора 322 признаков.
[140] Сервер 106 затем вводит шестой набор 332 признаков в NN 400, а NN 400 выводит шестое выходное значение 432 «0,8». NN 400 может определять шестое выходное значение 432 «0,8» для шестого сегмента 312 на основе (i) шестого набора 332 признаков, (ii) пятого набора 330 признаков, (iii) четвертого набора 328 признаков, (iv) третьего набора 326 признаков, (v) второго набора 324 признаков и (vi) первого набора 322 признаков.
[141] Таким образом, как поясняется выше, во время данной итерации обучения NN 400, проиллюстрированной на Фигуре 4, NN 400 прогнозирует, что:
существует вероятность «0,1», что пользовательское высказывание завершилось во время первого сегмента 302 цифрового аудиосигнала 202;
существует вероятность «0,3», что пользовательское высказывание завершилось во время второго сегмента 304 цифрового аудиосигнала 202;
существует вероятность «0,1», что пользовательское высказывание завершилось во время третьего сегмента 306 цифрового аудиосигнала 202;
существует вероятность «0,4», что пользовательское высказывание завершилось во время четвертого сегмента 308 цифрового аудиосигнала 202;
существует вероятность «0,9», что пользовательское высказывание завершилось во время пятого сегмента 310 цифрового аудиосигнала 202; и
существует вероятность «0,8», что пользовательское высказывание завершилось во время шестого сегмента 312 цифрового аудиосигнала 202.
[142] Затем, во время данной итерации обучения, сервер 106 может быть сконфигурирован с возможностью выполнения сравнительного анализа между выходными значениями, выданными посредство NN 400, и метками, связанными с соответствующими наборами признаков из множества 320 наборов признаков. На основе этого сравнения сервер 106 может быть сконфигурирован с возможностью определения множества 440 отдельных штрафных значений.
[143] Рассмотрим пример сравнительного анализа для (i) метки для первого набора 322 признаков и (ii) первого выходного значения 422. С одной стороны, метка для первого набора 322 признаков указывает, что пользовательское высказывание в цифровом аудиосигнале 202 не завершилось во время первого сегмента 302, связанного с первым набором 322 признаков, или, другими словами, существует вероятность «0», что пользовательское высказывание в цифровом аудиосигнале 202 завершилось во время первого сегмента 302. С другой стороны, первое выходное значение 422 является прогнозом, сделанным посредством NN 400, который указывает вероятность «0,1», что пользовательское высказывание в цифровом аудиосигнале 202 завершилось во время первого сегмента 302.
[144] Сравнивая метку для первого набора 322 признаков и первое выходное значение 422, сервер 106 может определять, что прогноз NN 400 для первого сегмента 302 цифрового аудиосигнала 202 не соответствует соответствующей метке. Следовательно, сервер 106 может быть сконфигурирован с возможностью генерирования первого отдельного штрафного значения 442, указывающего прогнозную ошибку, допущенную посредством NN 400 для первого сегмента 302 цифрового аудиосигнала 202.
[145] Например, в этом случае первое отдельное штрафное значение 442 может быть разностью между значением метки для первого набора 322 признаков и первым выходным значением 422, то есть первое отдельное штрафное значение 442 может составлять «0,1».
[146] Теперь рассмотрим пример сравнительного анализа для (i) метки для пятого набора 330 признаков и (ii) пятого выходного значения 430. С одной стороны, метка для пятого набора 332 признаков указывает, что пользовательское высказывание в цифровом аудиосигнале 202 завершилось во время пятого сегмента 310, связанного с пятым набором 330 признаков, или, другими словами, существует вероятность «1», что пользовательское высказывание в цифровом аудиосигнале 202 завершилось во время пятого сегмента 310. С другой стороны, пятое выходное значение 430 является прогнозом, сделанным посредством NN 400, который указывает вероятность «0,9», что пользовательское высказывание в цифровом аудиосигнале 202 завершилось во время пятого сегмента 310.
[147] Сравнивая метку для пятого набора 330 признаков и пятое выходное значение 430, сервер 106 может определять, что прогноз NN 400 для пятого сегмента 310 цифрового аудиосигнала 202 не соответствует соответствующей метке. Следовательно, сервер 106 может быть сконфигурирован с возможностью генерирования пятого отдельного штрафного значения 450, указывающего прогнозную ошибку, допущенную посредством NN 400 для пятого сегмента 310 цифрового аудиосигнала 202.
[148] Например, в этом случае пятое отдельное штрафное значение 450 может быть разностью между значением метки для пятого набора 330 признаков и пятым выходным значением 430, то есть пятое отдельное штрафное значение 450 может составлять «0,1».
[149] Сервер 106 может быть сконфигурирован с возможностью генерирования других штрафных значений из множества 440 отдельных штрафных значений аналогично тому, как сервер 106 сконфигурирован генерировать первое отдельное штрафное значение 442 и пятое отдельное штрафное значение 450.
[150] Как только множество 440 отдельных штрафных значений сгенерировано, сервер 106 может быть сконфигурирован с возможностью определения объединенного штрафного значения 460 для данной итерации обучения NN 400. Сервер 106 может определить объединенное штрафное значение 460 посредством объединения множества 440 отдельных штрафных значений. В одном примере объединенное штрафное значение 460 может быть суммой множества 440 отдельных штрафных значений.
[151] Сервер 106 сконфигурирован с возможностью использования объединенного штрафного значения 460 для обучения NN 400 во время данной итерации обучения. Например, сервер 106 может использовать методы обратного распространения ошибки для корректировки связей между искусственными «нейронами» NN 400 на основе объединенного штрафного значения 460.
[152] Следовательно, сервер 106 сконфигурирован с возможностью подготовки NN 400 таким образом, что NN 400 выводит выходные значения в ответ на наборы признаков, так что различия между значениями соответствующих меток и соответствующими выходными значениями сводятся к минимуму. Чем больше различия между значениями соответствующих меток и соответствующими выходными значениями, тем выше будет объединенное штрафное значение 460 и, следовательно, тем большей может быть корректировка связей между искусственными «нейронами» NN 400. Точно так же, чем меньше различия между значениями соответствующих меток и соответствующими выходными значениями, тем ниже будет объединенное штрафное значение 460 и, следовательно, тем меньшей может быть корректировка связей между искусственными «нейронами» NN 400.
[153] В некоторых вариантах осуществления настоящей технологии отдельным штрафным значениям во множестве 440 отдельных штрафных значений могут быть назначены веса для определения объединенного штрафного значения 460. Назначение весов некоторым из отдельных штрафных значений во время определения объединенного штрафного значения 460 может сократить количество «ложноположительных» прогнозов, выполняемых посредством NN 400.
[154] При «ложноположительном» прогнозе NN 400 определяет, что существует высокая вероятность того, что некоторый сегмент, который возникает до завершения (конца) пользовательского высказывания в цифровом аудиосигнале, содержит это завершение упомянутого пользовательского высказывания. Сокращение количества ложноположительных прогнозов может быть полезным во время использования, поскольку ложноположительный прогноз может привести к тому, что система 108 обработки IPA ошибочно определит, что пользовательское высказывание завершилось во время самой последней полученной части цифрового аудиосигнала 160, когда, в действительности, пользователь 102 еще не прекратил говорить.
[155] Например, ложноположительные прогнозы могут с большей вероятностью происходить для сегментов, во время которых возникает пауза в пользовательском высказывании. Другими словами, ложноположительный прогноз более вероятно происходит во время сегментов, в которых пользователь приостанавливает пользовательское высказывание (например, во время паузы между двумя произносимыми пользователем словами).
[156] Количество ложноположительных прогнозов NN 400 может быть сокращено путем назначения весов отдельным штрафным значениям, связанным с сегментами цифрового аудиосигнала 202, которые возникают до скорректированного момента времени завершения высказывания, чтобы увеличить их вклад в объединенное штрафное значение 460.
[157] Например, на данной итерации обучения с Фигуры 4 первое отдельное штрафное значение 442, второе отдельное штрафное значение 444, третье отдельное штрафное значение 44 6 и четвертое отдельное штрафное значение 448 могут быть умножены на вес сокращения ложноположительных прогнозов во время определения объединенного штрафного значения 460. Это приводит к тому, что объединенное штрафное значение 460 увеличивается больше для определенной прогнозной ошибки, допускаемой NN 400 для любого из первого сегмента 302, второго сегмента 304, третьего сегмента 306 и четвертого сегмента 308, чем для аналогичной прогнозной ошибки, допускаемой NN 400 для любого из пятого сегмента 310 и шестого сегмента 312.
[158] Как упоминалось ранее, сервер 106 может использовать скорректированный момент времени завершения высказывания вместо момента времени завершения высказывания для определения меток для соответствующих наборов признаков. Причиной использования скорректированного момента времени завершения высказывания является то, что разработчики настоящей технологии осознали, что подготовка NN 400 к генерированию высокого выходного значения для сегмента, во время которого возникает момент времени завершения высказывания, является сложной задачей.
[159] Чтобы лучше это проиллюстрировать, обратимся теперь к Фигурам 3 и 4. Следует напомнить, что момент времени завершения высказывания возникает во время четвертого сегмента 308 цифрового аудиосигнала 202, в то время как скорректированный момент времени завершения высказывания возникает во время пятого сегмента 310 цифрового аудиосигнала 202. Как видно на Фигуре 3, человек говорит во время одной части четвертого сегмента 308 и не говорит во время другой части четвертого сегмента 308. Что касается пятого сегмента 310, пользователь уже завершил высказывание, и, следовательно, пользователь не говорит во время пятого сегмента 310.
[160] В результате у NN 400 в некотором смысле возникает больше трудностей с (i) «обучением» тому, что с соответствующим сегментом цифрового аудиосигнала 202, во время которого пользовательское высказывание завершилось, связан четвертый набор 328 признаков, чем с (ii) «обучением» тому, что с соответствующим сегментом цифрового аудиосигнала 202, во время которого пользовательское высказывание завершилось, связан пятый набор 330 признаков. Например, это может быть одной из причин того, почему (i) четвертое выходное значение 428, определенное посредством NN 400 для четвертого сегмента 308, меньше, чем (ii) пятое выходное значение 430, определенное посредством NN 400 для пятого сегмента 310.
[161] В некоторых вариантах осуществления настоящей технологии также предполагается, что добавление предопределенного временного смещения 340 к моменту времени завершения высказывания, чтобы тем самым определить скорректированный момент времени завершения высказывания, и использование этого скорректированного момента времени завершения высказывания для пометки наборов признаков может помочь NN 400 в сокращении количества ложноположительных прогнозов во время фазы ее использования. Следует отметить, что подготовка NN 400 с помощью меток, определяемых на основе скорректированного момента времени завершения высказывания (в отличие от их определения на основе момента времени завершения высказывания), приводит к большей вероятности того, что NN 400 (i) определит спрогнозированный во время использования момент времени завершения высказывания, который возникает немного позже во времени, чем фактический момент времени завершения высказывания во время использования, чем (ii) определит спрогнозированный во время использования момент времени завершения высказывания, который возникает немного раньше во времени, чем фактический момент времени завершения высказывания во время использования.
[162] Таким образом, во время данной итерации обучения NN 400 сервер 106 сконфигурирован с возможностью ввода множества 320 наборов признаков в NN 400 в той же последовательности, что и последовательность, в которой соответствующие сегменты цифрового аудиосигнала 202 встречаются в цифровом аудиосигнале 202. NN 400 сконфигурирована с возможностью генерировать соответствующее выходное значение после ввода соответствующего набора признаков, при этом выходное значение указывает вероятность того, что пользовательское высказывание в цифровом аудиосигнале 202 завершилось во время соответствующего сегмента соответствующего набора признаков. Как только соответствующие выходные значения определены для множества 320 наборов признаков, сервер 106 сконфигурирован с возможностью выполнения сравнительного анализа между соответствующими выходными значениями и соответствующими метками каждого набора из множества 320 наборов признаков. Сервер 106 может выполнить сравнительный анализ и, таким образом, определить множество отдельных штрафных значений для соответствующих наборов из множества 320 наборов признаков. Отдельное штрафное значение указывает прогнозную ошибку, сделанную NN 400 для соответствующего сегмента соответствующего набора признаков из множества 320 наборов признаков. Множеству 440 отдельных штрафных значений потенциально могут быть назначены веса, а затем они могут быть объединены для определения объединенного штрафного значения 4 60 для данной итерации обучения NN 400. Сервер 106 может затем использовать методы обратного распространения ошибки на основе объединенного штрафного значения 460 для корректировки связей между искусственными «нейронами» NN 400, тем самым позволяя NN 400 в некотором смысле учиться на данном обучающем примере, который был ей предоставлен.
[163] Теперь будет описано, как сервер 106 может использовать систему 108 обработки IPA, и более конкретно, как в настоящий момент обученная NN 400 системы 108 обработки IPA может использоваться во время фазы ее использования.
[164] Как упомянуто выше, во время фазы использования сервер 106 может получать (в режиме реального времени) данные, указывающие (характеризующие) части цифрового аудиосигнала 160 (то есть цифрового аудиосигнала во время использования). Со ссылкой на Фигуру 5, давайте предположим, что в первый определенный момент времени у сервера 106 имеется две части цифрового аудиосигнала 160 по 50 мс - другими словами, на данный момент времени у сервера 106 имеется 100 мс цифрового аудиосигнала 160.
[165] Следует отметить, что, как упомянуто выше в одном неограничивающем примере, части цифрового аудиосигнала 160 записываются и передаются в систему 108 обработки IPA и могут соответствовать интервалам в 50 мс. Также следует отметить, что, как упомянуто выше в другом неограничивающем примере, NN 400 была обучена на основе сегментов по 100 мс. В таком случае сервер 106 может быть сконфигурирован с возможностью использования NN 400 во время фазы ее использования для каждых 100 мс цифрового аудиосигнала 160.
[166] В этом случае, как упомянуто выше, в первый определенный момент времени у сервера 106 имеется 100 мс (две последовательные части по 50 мс) цифрового аудиосигнала 160. Следовательно, у сервера 106 может иметься первый сегмент 502 в процессе использования, составляющий 100 мс цифрового аудиосигнала 160.
[167] Сервер 106 может быть сконфигурирован с возможностью определения первого набора 512 признаков в процессе использования для первого сегмента 502 в процессе использования аналогично тому, как сервер 106 сконфигурирован определять множество 320 наборов признаков для множества 300 сегментов. Следует отметить, однако, что сервер 106 может начать определять по меньшей мере некоторые признаки из первого набора 512 признаков в процессе использования до первого определенного момента времени. Например, как только первая из двух частей цифрового аудиосигнала 160 принята, сервер 106 может начать определять по меньшей мере некоторые признаки из первого набора 512 признаков в процессе использования. Как только вторая из двух частей цифрового аудиосигнала 160 принята, сервер 106 может начать определять другие признаки из первого набора 512 признаков в процессе использования.
[168] Как только первый набор 512 признаков в процессе использования определен, сервер 106 может затем ввести первый набор 512 признаков в NN 400. NN 400 сконфигурирована с возможностью вывода первого выходного значения 522 в процессе использования. Предположим, что первое выходное значение 522 в процессе использования равно «0,1» (или 10%, например), как проиллюстрировано на Фигуре 5. Это означает, что NN 400 может определить, что существует вероятность «0,1» (или 10%), что пользовательское высказывание 150 пользователя 102 завершилось во время первого сегмента 502 цифрового аудиосигнала 160 в процессе использования.
[169] Сервер 106 может быть сконфигурирован с возможностью сравнения первого выходного значения 522 в процессе использования с предопределенным порогом 550 прогнозирования. Предопределенный порог 550 прогнозирования может быть определен оператором системы 108 обработки IPA. Предположим, что, как проиллюстрировано на Фигуре 5, предопределенный порог 500 прогнозирования равен «0,7» (или 70%, например).
[170] Таким образом, сервер 106 может определить, что первое выходное значение 522 в процессе использования ниже упомянутого предопределенного порога 550 прогнозирования. Это означает, что вероятность (определенная посредством NN 400) того, что пользовательское высказывание 150 завершилось во время первого сегмента 502 в процессе использования, слишком мала для определения системой 108 обработки IPA, что пользовательское высказывание 150 завершилось во время первого сегмента 502 в процессе использования. Можно сказать, что, если определенное выходное значение в процессе использования ниже предопределенного порога 550 прогнозирования, система 108 обработки IPA может определить, что пользовательское высказывание 150 не завершилось во время соответствующего сегмента в процессе использования.
[171] В то время как система 108 обработки IPA обрабатывает первый сегмент 502 в процессе использования, сервер 106 может получать дополнительные части цифрового аудиосигнала 160. Таким образом, как только система 108 обработки IPA определяет, что пользовательское высказывание 150 не завершилось во время первого сегмента 502 в процессе использования, система 108 обработки IPA может быть сконфигурирована с возможностью приема следующих 100 мс цифрового аудиосигнала 160 для повторения вышеупомянутой обработки в процессе использования.
[172] Например, следующие 100 мс цифрового аудиосигнала 160 могут быть доступны во второй определенный момент времени. Следующие 100 мс цифрового аудиосигнала могут быть вторым сегментом 504 в процессе использования, проиллюстрированным на Фигуре 5. Второй сегмент 504 в процессе использования может быть следующим сегментом относительно первого сегмента 502 в процессе использования цифрового аудиосигнала 160.
[173] Следовательно, во второй определенный момент времени второй сегмент 504 в процессе использования может использоваться сервером 106 для определения второго набора 514 признаков в процессе использования. Второй набор 514 признаков в процессе использования затем может быть введен в NN 400. В этом случае, как пояснено выше, NN 400 может быть сконфигурирована с возможностью определения второго выходного значения 524 в процессе использования на основе (i) второго набора 514 признаков в процессе использования и (ii) первого набора 512 признаков в процессе использования (ранее введенного набора признаков в процессе использования). Предположим, что второе выходное значение 524 в процессе использования равно «0,8» (или 80%, например).
[174] Таким образом, сервер 106 может определить, что второе выходное значение 524 в процессе использования выше упомянутого предопределенного порога 550 прогнозирования. Это означает, что вероятность (определенная посредством NN 400) того, что пользовательское высказывание 150 завершилось во время второго сегмента 504 в процессе использования, является достаточно высокой для определения системой 108 обработки IPA, что пользовательское высказывание 150 завершилось во время второго сегмента 504 в процессе использования.
[175] В ответ на определение того, что пользовательское высказывание 150 было завершено во время второго сегмента 504 в процессе использования цифрового аудиосигнала 160, система 108 обработки IPA может сгенерировать триггер для устройства 104, чтобы остановить запись цифрового аудиосигнала 160, поскольку пользователь 102 перестал говорить.
[176] В некоторых вариантах осуществления, хотя система 108 обработки IPA сконфигурирована с возможностью определения того, завершилось ли пользовательское высказывание 150 пользователя 102, алгоритм ASR может применяться системой 108 обработки IPA для определения текстового представления в процессе использования пользовательского высказывания 150. Таким образом, как только система 108 обработки IPA определяет, что пользовательское высказывание 150 завершилось во время второго сегмента 504 в процессе использования, система 108 обработки IPA может сгенерировать триггер для алгоритма ASR, чтобы остановить обработку цифрового аудиосигнала 160 в процессе использования после упомянутого второго сегмента 504 в процессе использования.
[177] В некоторых вариантах осуществления настоящей технологии сервер 106 и/или устройство 104 могут быть сконфигурированы с возможностью исполнения способа 600 идентификации пользователя по цифровому аудиосигналу, схематичное представление которого проиллюстрировано на Фигуре 6. Теперь будет описан способ 600.
ЭТАП 602: получение набора признаков для соответствующего сегмента цифрового аудиосигнала;
[178] Способ 600 начинается на этапе 602, на котором электронное устройство сконфигурировано получать набор признаков для соответствующего сегмента цифрового аудиосигнала. В некоторых вариантах осуществления электронное устройство, выполняющее этап 602, может быть устройством 104. В других вариантах осуществления электронным устройством может быть сервер 106. Предполагается, что по меньшей мере некоторые этапы способа 600 могут быть исполнены устройством 104, тогда как другие этапы способа 600 могут быть исполнены сервером 106.
[179] Например, электронное устройство (такое как, например, сервер 106 и/или устройство 104) может получить множество 320 наборов признаков (см. Фигуру 3) для соответствующих сегментов из множества 300 сегментов цифрового аудиосигнала 202. Следует отметить, что в некоторых вариантах осуществления множество 320 наборов признаков может быть определено и получено от устройства 104 и/или сервера 106 и/или других компьютерных объектов (которые могут быть сконфигурированы с возможностью определения множества 320 наборов признаков аналогично тому, что было описано выше), соединенных с возможностью связи с сервером 106 и/или устройством 104.
[180] Каждый набор признаков из множества 320 наборов признаков содержит по меньшей мере признаки акустического типа, извлекаемые из соответствующего сегмента из множества 300 сегментов цифрового аудиосигнала 202. Как объяснено выше, в других вариантах осуществления настоящей технологии наборы признаков также могут включать в себя, в дополнение к признакам акустического типа, признаки лингвистического типа. Следует отметить, что признаки лингвистического типа могут быть определены на основе текстового представления 222, связанного с цифровым аудиосигналом 202.
[181] Следует отметить, что множество 300 сегментов цифрового аудиосигнала 202 имеют временные интервалы, имеющие предопределенную длительность. В неограничивающем примере с Фигуры 3 множество 300 сегментов содержит сегменты по 100 мс каждый.
ЭТАП 604: получение указания момента времени завершения высказывания в цифровом аудиосигнале, соответствующего некоторому моменту времени, после которого пользовательское высказывание завершено;
[182] Способ 600 переходит на этап 604, на котором электронное устройство сконфигурировано получать указание момента времени завершения высказывания в цифровом аудиосигнале 202. Момент времени завершения высказывания соответствует некоторому моменту времени, после которого пользовательское высказывание в цифровом аудиосигнале 202 завершено.
[183] Например, электронное устройство (такое как, например, сервер 106 и/или устройство 104) может получить временную отметку 242, которая указывает момент времени в цифровом аудиосигнале 202, после которого пользовательское высказывание в цифровом аудиосигнале 202 завершено. Следует отметить, что временная отметка 242 может быть получена от устройства 104 и/или сервера 106 и/или других компьютерных объектов (которые могут быть сконфигурированы с возможностью предоставления временной отметки 242 аналогично тому, что было описано выше), соединенных с возможностью связи с сервером 106 и/или устройством 104.
[184] В некоторых вариантах осуществления указание момента времени завершения высказывания (например, временная отметка 242) может быть определено ответственным за оценку человеком, в то время как в других вариантах осуществления оно может определяться устройством 104 и/или сервером 106 и/или другими компьютерными объектами, применяющими алгоритм ASA, как описано выше.
ЭТАП 606: определение скорректированного момента времени завершения высказывания путем добавления некоторого предопределенного временного смещения к моменту времени завершения высказывания;
[185] Способ 600 переходит на этап 606, на котором электронное устройство сконфигурировано определять скорректированный момент времени завершения высказывания путем добавления некоторого предопределенного временного смещения к моменту времени завершения высказывания. Например, электронное устройство может быть сконфигурировано с возможностью определения скорректированного момента времени завершения высказывания путем добавления предопределенного временного смещения 340 к моменту времени завершения высказывания, что показано на Фигуре 3.
[186] Предопределенное временное смещение 340 может быть определено оператором NN 400. Например, предопределенное временное смещение 34 0 может составлять 100 мс. Предполагается, что определение длительности предопределенного временного смещения 340 оператором может зависеть, среди прочего, от различных реализаций настоящей технологии.
ЭТАП 608: определение меток для соответствующих наборов признаков на основе скорректированного момента времени завершения высказывания и временных интервалов соответствующих сегментов цифрового аудиосигнала;
[187] Способ 600 переходит на этап 608, на котором электронное устройство сконфигурировано определять отметки для соответствующих наборов из множества 320 наборов признаков. Электронное устройство определяет эти отметки на основе (i) скорректированного момента времени завершения высказывания и (ii) временных интервалов соответствующих сегментов из множества 300 сегментов.
[188] Следует отметить, что отметка указывает, завершилось ли пользовательское высказывание во время соответствующего сегмента цифрового аудиосигнала 202, связанного с соответствующим набором из множества 320 наборов признаков.
[189] Другими словами, электронное устройство может определять эти метки следующим образом:
если временной интервал, связанный с определенным сегментом из множества 300 сегментов, наступает до скорректированного момента времени завершения высказывания, электронное устройство определяет метку для соответствующего набора из множества 320 наборов признаков, которая указывает, что пользовательское высказывание не завершилось во время упомянутого сегмента из множества 300 сегментов; и
если (i) временной интервал, связанный с определенным сегментом из множества 300 сегментов, включает в себя скорректированный момент времени завершения высказывания, или (ii) временной интервал, связанный с определенным сегментом из множества 300 сегментов, наступает после скорректированного момента времени завершения высказывания, электронное устройство определяет метку для соответствующего набора из множества 320 наборов признаков, которая указывает, что пользовательское высказывание завершилось во время упомянутого сегмента из множества 300 сегментов.
ЭТАП 610: использование наборов признаков и соответствующих меток для обучения нейронной сети (NN) прогнозировать, во время какого сегмента цифрового аудиосигнала пользовательское высказывание завершилось;
[190] Способ 600 переходит на этап 610, на котором электронное устройство сконфигурировано с возможностью использования множества 320 наборов признаков и соответствующих меток для обучения NN 400. В одном неограничивающем примере этап 610 может соответствовать выполнению электронным устройством определенной итерации обучения во время фазы обучения NN 400.
[191] NN 400 обучают прогнозировать, во время какого сегмента из множества 300 сегментов цифрового аудиосигнала 202 пользовательское высказывание завершилось.
[192] В некоторых вариантах осуществления на этапе 610 электронное устройство может быть сконфигурировано организовывать множество наборов признаков и соответствующие метки в том же порядке, что и порядок, в котором соответствующие сегменты из множества 300 сегментов встречаются в цифровом аудиосигнале 202. Это может иметь место, например, когда NN 400 имеет топологию сети, которая позволяет NN 400 хранить «воспоминания» о событиях, которые произошли ранее. Таким образом, множество 320 наборов признаков может быть введено в NN 400 в той же последовательности, что и последовательность, в которой множество 300 сегментов встречается в цифровом аудиосигнале 202.
[193] В некоторых вариантах осуществления настоящей технологии электронное устройство может быть сконфигурировано с возможностью выполнения дополнительных этапов относительно этапов, проиллюстрированных на Фигуре 6. Например, электронное устройство может быть сконфигурировано с возможностью выполнения по меньшей мере некоторых этапов во время фазы использования NN 400.
[194] В некоторых вариантах осуществления электронное устройство может быть сконфигурировано с возможностью получения по меньшей мере некоторой части цифрового аудиосигнала в процессе использования. Например, электронное устройство (такое как, например, устройство 104 или сервер 106) может быть сконфигурировано с возможностью получения по меньшей мере некоторой части цифрового аудиосигнала 160. Получение по меньшей мере некоторой части цифрового аудиосигнала 160 может происходить в режиме реального времени. Например, цифровой аудиосигнал 160 может быть записан в режиме реального времени во время пользовательского высказывания 150. В результате части цифрового аудиосигнала 160 могут быть получены электронным устройством в режиме реального времени по мере их записи.
[195] Электронное устройство также может быть сконфигурировано с возможностью определения первого набора 512 признаков в процессе использования для первого сегмента 502 в процессе использования. Следует отметить, что первый сегмент 502 в процессе использования включает в себя самую последнюю полученную часть цифрового аудиосигнала 160 в процессе использования. Например, первый набор 512 признаков в процессе использования может быть определен для первого сегмента 502 в процессе использования, который может представлять собой самые последние 100 мс цифрового аудиосигнала 160, которые были получены электронным устройством.
[196] Первый набор 512 признаков в процессе использования может содержать признаки акустического типа, извлекаемые из первого сегмента 502 в процессе использования. Другими словами, аналогично тому, что было описано выше, электронное устройство может быть сконфигурировано с возможностью извлечения признаков акустического типа из первого сегмента 502 в процессе использования. В других вариантах осуществления настоящей технологии первый набор 512 признаков в процессе использования также может включать в себя признаки лингвистического типа, как объяснено выше, без отклонения от объема настоящей технологии. Таким образом, в других вариантах осуществления, аналогично тому, что было описано выше, электронное устройство может применять алгоритмы (такие как алгоритмы ASR и ASA) для определения признаков лингвистического типа, связанных с первым сегментом 502 в процессе использования.
[197] Также предполагается, что электронное устройство может быть сконфигурировано с возможностью использования NN 400 для определения, на основе первого набора 512 признаков в процессе использовании, первого выходного значения 522 в процессе использования, указывающего вероятность завершения пользовательского высказывания 150 (пользовательского высказывания в процессе использования) в цифровом аудиосигнале 160 во время первого сегмента 502 в процессе использования.
[198] Электронное устройство может сравнивать первое выходное значение 522 в процессе использования с предопределенным порогом 550 прогнозирования. В ответ на определение того, что первое выходное значение 522 в процессе использования выше предопределенного порога 550 прогнозирования, электронное устройство может определять, что пользовательское высказывание 150 завершилось во время первого сегмента 502 в процессе использования цифрового аудиосигнала 160.
[199] В некоторых вариантах осуществления, если электронное устройство определяет, что пользовательское высказывание 150 завершилось во время первого сегмента 502 в процессе использования цифрового аудиосигнала 160, электронное устройство может быть сконфигурировано с возможностью генерирования триггера для остановки записи цифрового аудиосигнала 160.
[200] В других вариантах осуществления электронное устройство может предоставлять по меньшей мере некоторую часть цифрового аудиосигнала 160 алгоритму ASR для определения текстового представления пользовательского высказывания 150. Предполагается, что в ответ на определение, что пользовательское высказывание 150 завершилось во время первого сегмента 502 в процессе использования цифрового аудиосигнала 160, электронное устройство может генерировать триггер для остановки предоставления цифрового аудиосигнала 160 к ASR.
[201] Следует также отметить, что в ответ на определение того, что первое выходное значение 522 в процессе использования ниже предопределенного порога 550 прогнозирования, электронное устройство может быть сконфигурировано с возможностью определения второго набора 514 признаков в процессе использования для второго сегмента 504 в процессе использования. Например, второй сегмент 504 в процессе использования может быть следующим сегментом по отношению к первому сегменту 502 в процессе использования в по меньшей мере некоторой части цифрового аудиосигнала 160, получаемого электронным устройством. Второй набор 514 признаков в процессе использования может быть определен аналогично тому, как может быть определен первый набор 512 признаков в процессе использования.
[202] Электронное устройство также может использовать NN 400 для определения, на основании первого набора 512 признаков в процессе использования и второго набора 514 признаков в процессе использования, второго выходного значения 524 в процессе использования, указывающего вероятность завершения пользовательского высказывания 150 во время второго сегмента 504 в процессе использования цифрового аудиосигнала 160.
[203] Предполагается, что NN 400 может иметь топологию сети, которая позволяет NN 400 хранить «воспоминания» о событиях, которые произошли ранее, и, следовательно, когда электронное устройство вводит второй набор 514 признаков в процессе использования, NN 400 имеет «воспоминания» о первом наборе 512 признаков в процессе использования, который был введен в NN 400 ранее.
[204] Электронное устройство может сравнивать второе выходное значение 524 в процессе использования с предопределенным порогом 550 прогнозирования, и в ответ на определение, что второе выходное значение 524 превышает предопределенный порог 550 прогнозирования, электронное устройство может определять, что пользовательское высказывание 150 завершилось во время второго сегмента 504 в процессе использования цифрового аудиосигнала 160. В ответ на это электронное устройство может генерировать триггеры аналогично тому, что было описано выше.
[205] Модификации и улучшения вышеописанных реализаций настоящей технологии могут стать очевидными для специалистов в данной области техники. Предшествующее описание предназначено для того, чтобы быть примерным, а не ограничивающим. Поэтому подразумевается, что объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
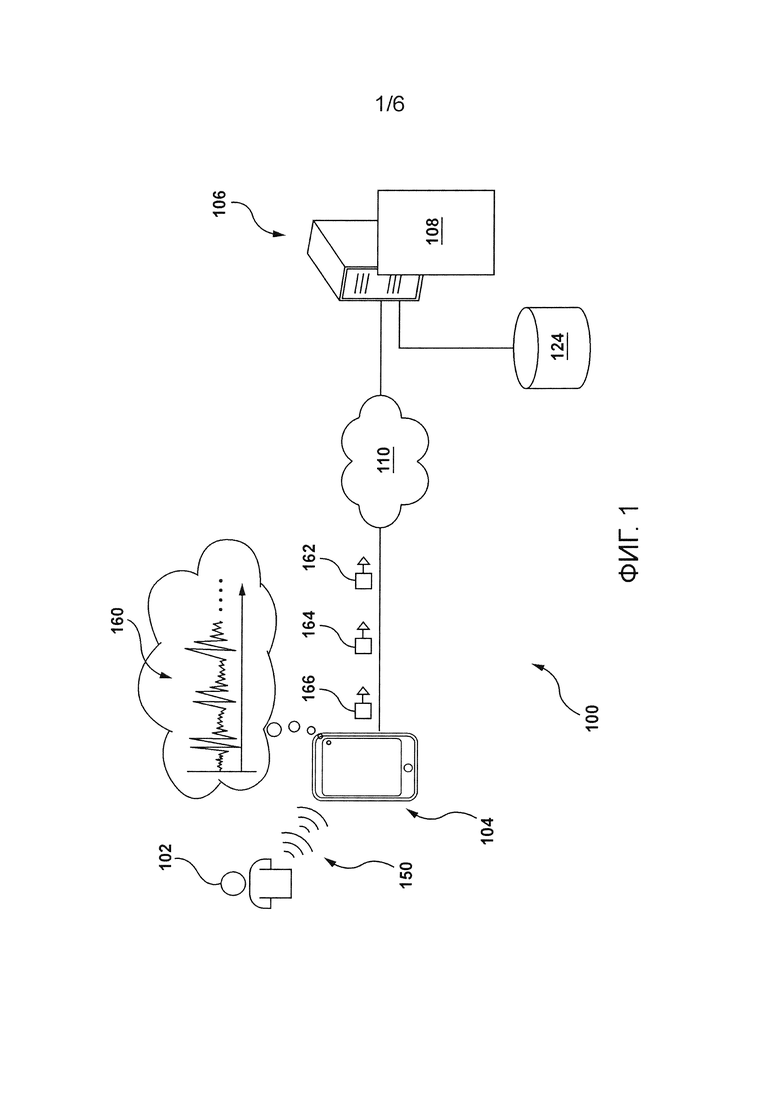
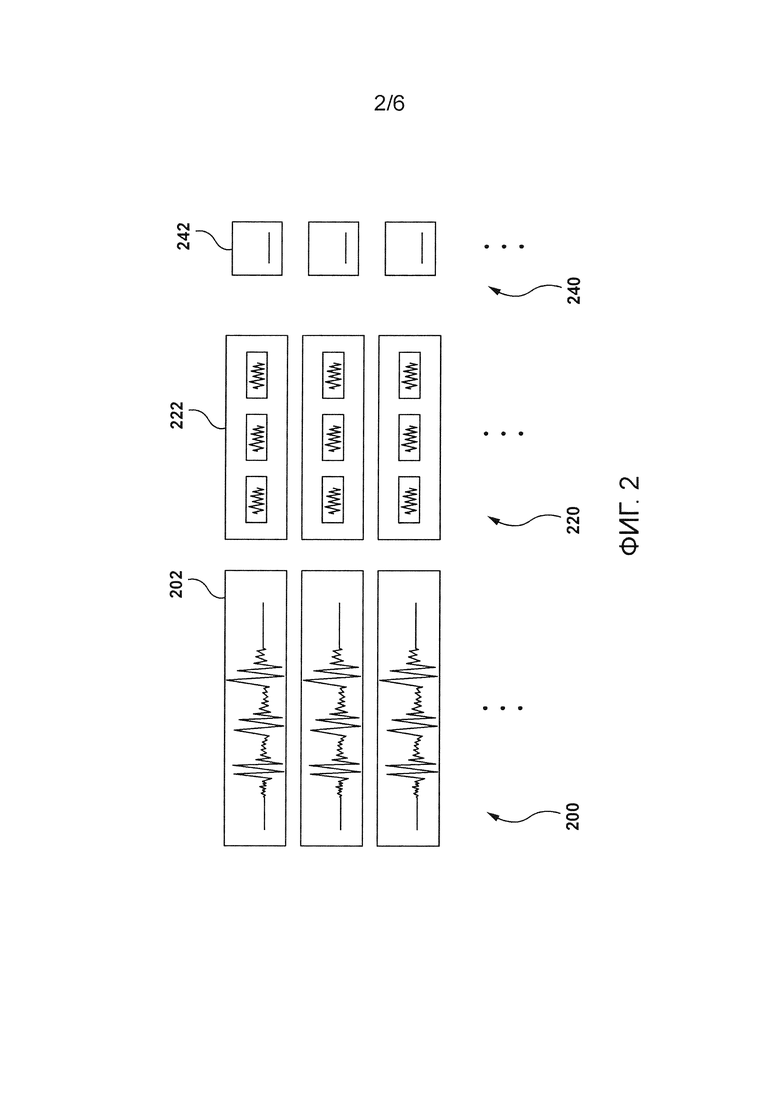
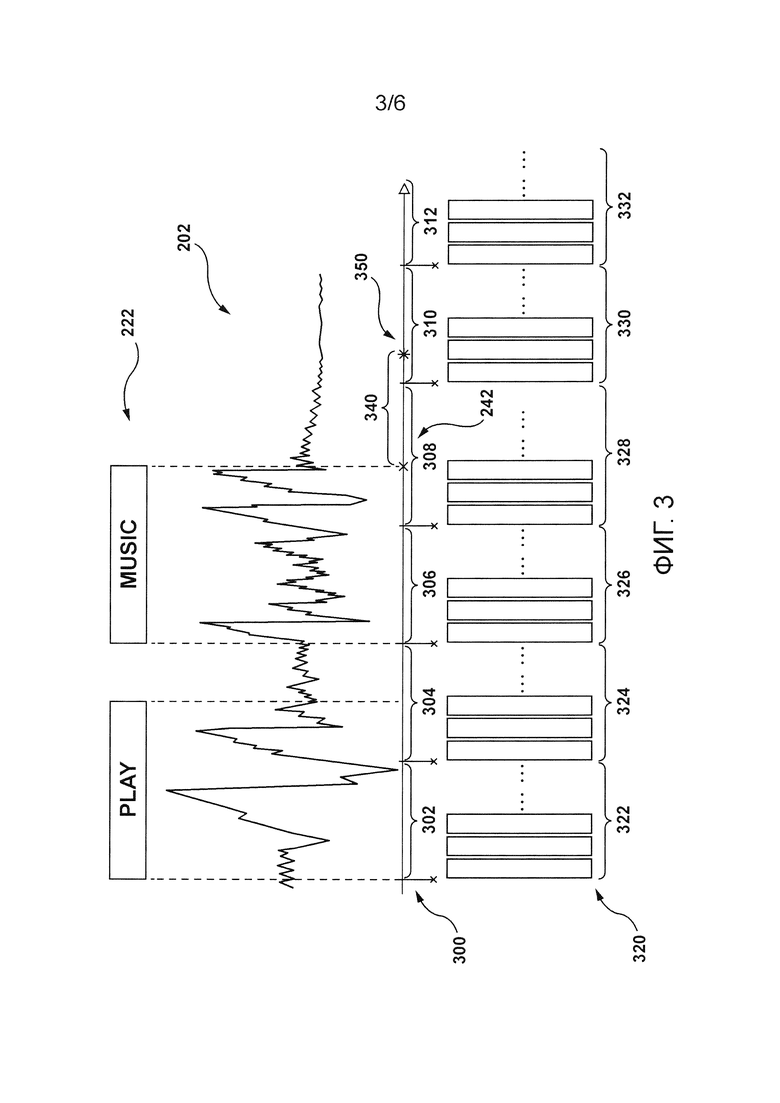
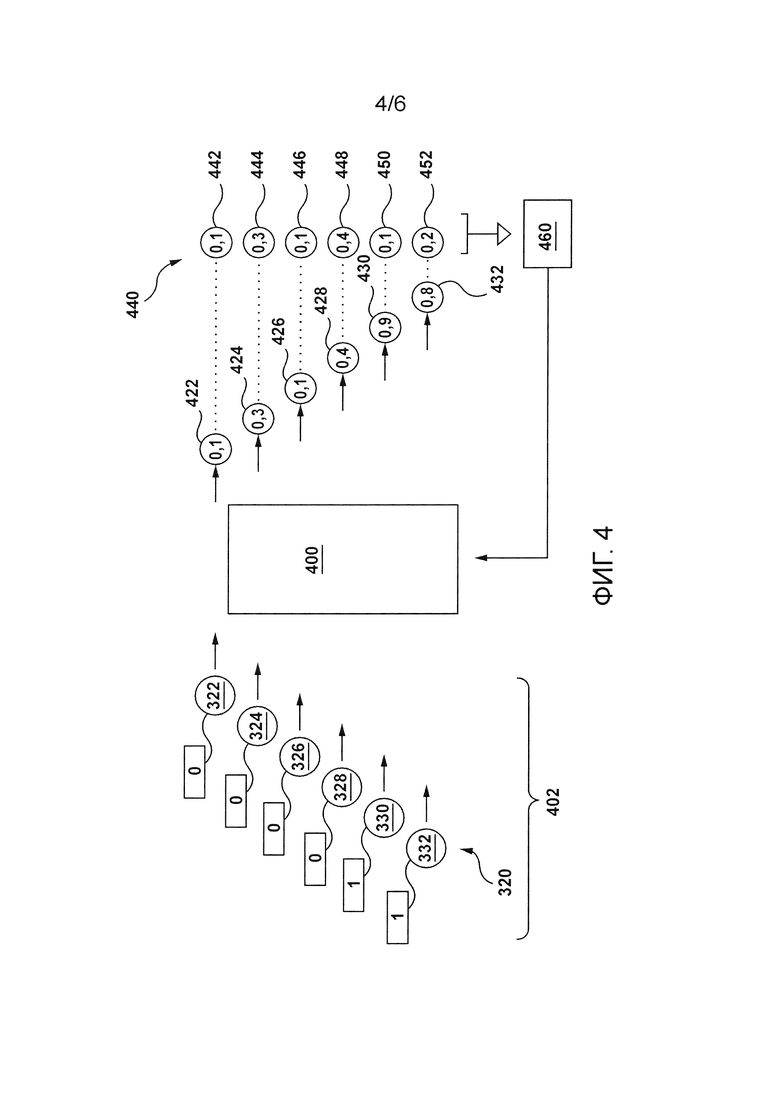
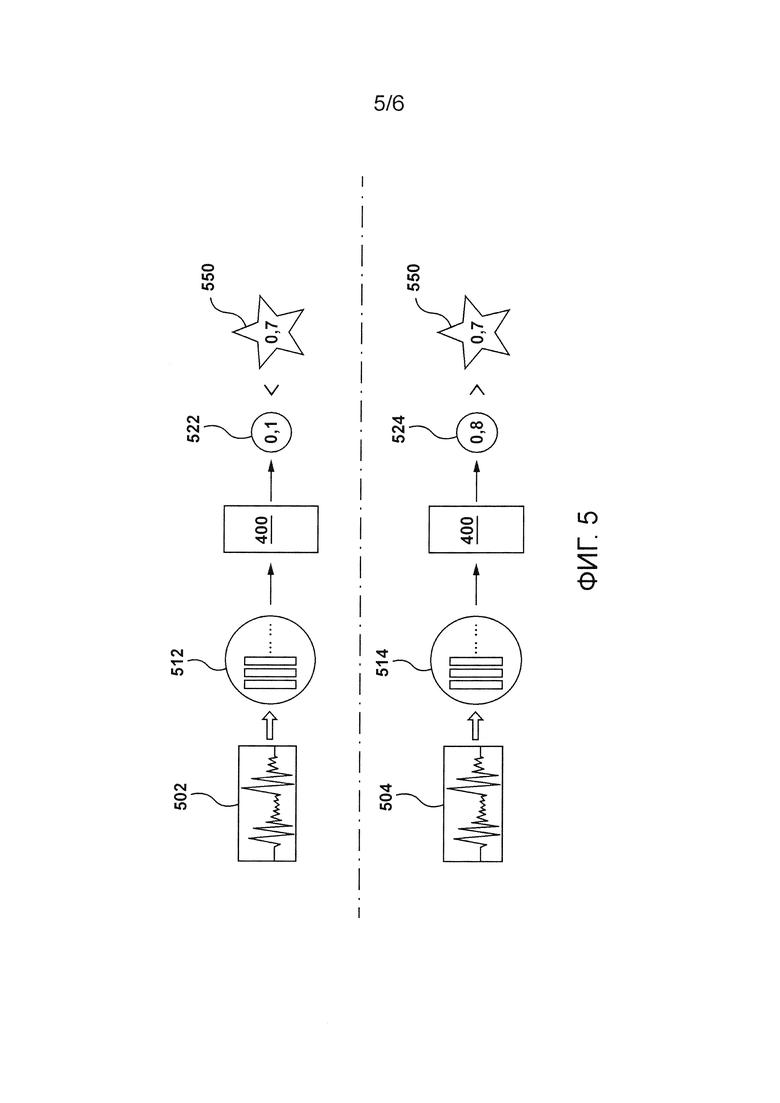
Изобретение относится к способу и системе идентификации завершения пользовательского высказывания по цифровому аудиосигналу. Технический результат заключается в повышении точности идентификации завершения пользовательского высказывания. В способе выполняют получение электронным устройством набора признаков для соответствующего сегмента цифрового аудиосигнала, причем каждый набор признаков содержит по меньшей мере признаки акустического типа, извлекаемые из соответствующего сегмента цифрового аудиосигнала, причем сегменты цифрового аудиосигнала связаны с соответствующими временными интервалами предопределенной длительности; получение электронным устройством указания момента времени завершения высказывания в цифровом аудиосигнале, соответствующего некоторому моменту времени, после которого пользовательское высказывание завершено; определение электронным устройством скорректированного момента времени завершения высказывания путем добавления предопределенного временного смещения к моменту времени завершения высказывания; определение электронным устройством меток для соответствующих наборов признаков на основе скорректированного момента времени завершения высказывания и временных интервалов соответствующих сегментов цифрового аудиосигнала, причем метка указывает, завершилось ли пользовательское высказывание во время соответствующего сегмента цифрового аудиосигнала, связанного с соответствующим набором признаков; использование электронным устройством наборов признаков и соответствующих меток для обучения нейронной сети (NN) прогнозировать, во время какого сегмента цифрового аудиосигнала пользовательское высказывание завершилось. 2 н. и 18 з.п. ф-лы, 6 ил.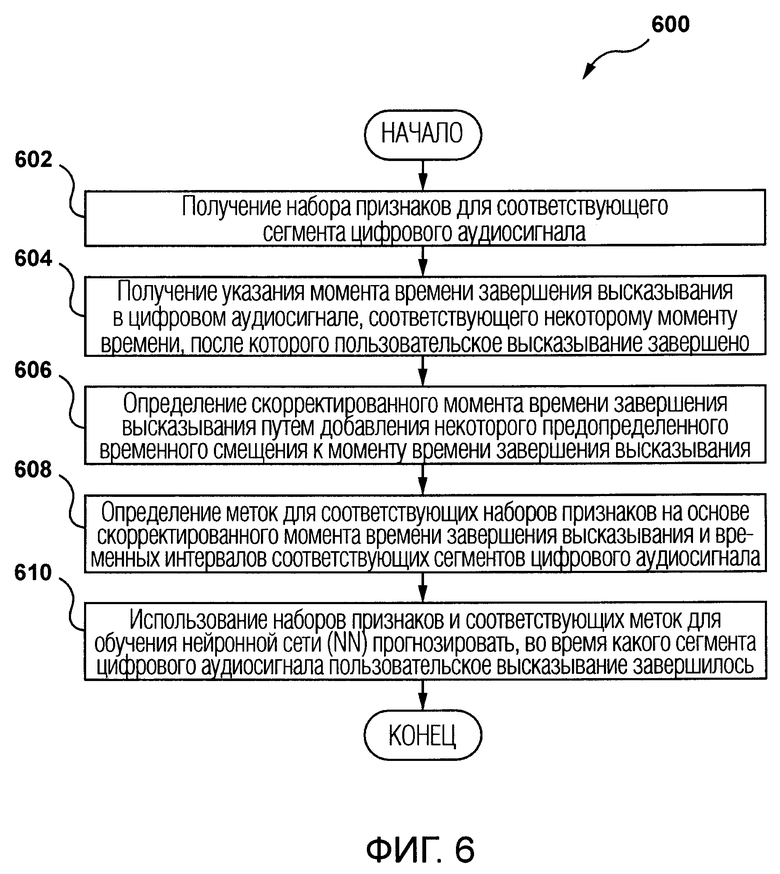
1. Способ идентификации завершения пользовательского высказывания по цифровому аудиосигналу, причем цифровой аудиосигнал содержит аудиозапись пользовательского высказывания, причем способ исполняется электронным устройством и содержит:
- получение электронным устройством набора признаков для соответствующего сегмента цифрового аудиосигнала,
причем каждый набор признаков содержит по меньшей мере признаки акустического типа, извлекаемые из соответствующего сегмента цифрового аудиосигнала,
причем сегменты цифрового аудиосигнала связаны с соответствующими временными интервалами предопределенной длительности;
получение электронным устройством указания момента времени завершения высказывания в цифровом аудиосигнале, соответствующего некоторому моменту времени, после которого пользовательское высказывание завершено;
определение электронным устройством скорректированного момента времени завершения высказывания путем добавления предопределенного временного смещения к моменту времени завершения высказывания;
определение электронным устройством меток для соответствующих наборов признаков на основе скорректированного момента времени завершения высказывания и временных интервалов соответствующих сегментов цифрового аудиосигнала,
- причем метка указывает, завершилось ли пользовательское высказывание во время соответствующего сегмента цифрового аудиосигнала, связанного с соответствующим набором признаков;
- использование электронным устройством наборов признаков и соответствующих меток для обучения нейронной сети (NN) прогнозировать, во время какого сегмента цифрового аудиосигнала пользовательское высказывание завершилось.
2. Способ по п. 1, в котором набор признаков дополнительно содержит признаки лингвистического типа для соответствующего сегмента цифрового аудиосигнала.
3. Способ по п. 1, в котором признаки лингвистического типа определяются на основе текстового представления пользовательского высказывания, причем текстовое представление содержит по меньшей мере одно слово и по меньшей мере одну паузу.
4. Способ по п. 1, в котором указание момента времени завершения высказывания определяют по меньшей мере одним из осуществляющего оценку человека и алгоритма автоматического выравнивания речи с текстом (ASA).
5. Способ по п. 1, в котором использование наборов признаков и соответствующих меток для обучения NN содержит:
- организацию наборов признаков и соответствующих меток в том же порядке, что и порядок, в котором соответствующие сегменты встречаются в цифровом аудиосигнале.
6. Способ по п. 1, в котором способ дополнительно содержит, во время фазы использования NN:
- получение электронным устройством по меньшей мере некоторой части цифрового аудиосигнала в процессе использования;
- определение электронным устройством первого набора признаков для первого сегмента цифрового аудиосигнала в процессе использования, причем первый сегмент включает в себя самую последнюю полученную часть цифрового аудиосигнала в процессе использования, причем цифровой аудиосигнал в процессе использования записан в режиме реального времени во время высказывания в процессе использования;
- причем первый набор признаков содержит по меньшей мере признаки акустического типа, извлекаемые из первого сегмента цифрового аудиосигнала;
- использование электронным устройством NN для определения на основе первого набора признаков первого значения, указывающего вероятность того, что пользовательское высказывание в процессе использования завершилось во время первого сегмента цифрового аудиосигнала в процессе использования;
- в ответ на то, что первое значение превышает предопределенный порог,
определение электронным устройством того, что пользовательское высказывание в процессе использования завершилось во время первого сегмента цифрового аудиосигнала в процессе использования.
7. Способ по п. 6, при этом способ дополнительно содержит:
- генерирование электронным устройством триггера для остановки записи цифрового аудиосигнала в процессе использования.
8. Способ по п. 6, при этом способ дополнительно содержит:
- обеспечение электронным устройством алгоритму автоматического распознавания речи (ASR) по меньшей мере некоторой части цифрового аудиосигнала в процессе использования для определения текстового представления высказывания в процессе использования; и
- генерирование электронным устройством триггера для остановки обеспечения алгоритму ASR цифрового аудиосигнала в процессе использования.
9. Способ по п. 6, при этом способ дополнительно содержит в ответ на то, что первое значение находится ниже предопределенного порога:
- определение электронным устройством второго набора признаков для второго сегмента цифрового аудиосигнала в процессе использования, причем второй сегмент является продолжением первого сегмента в цифровом аудиосигнале в процессе использования,
причем второй набор признаков содержит по меньшей мере признаки акустического типа, извлекаемые из второго сегмента цифрового аудиосигнала;
- использование электронным устройством NN для определения на основе первого набора признаков и второго набора признаков второго значения, указывающего вероятность того, что пользовательское высказывание в процессе использования завершилось во время второго сегмента цифрового аудиосигнала в процессе использования;
- в ответ на то, что второе значение превышает предопределенный порог,
- определение электронным устройством того, что пользовательское высказывание в процессе использования завершилось во время второго сегмента цифрового аудиосигнала в процессе использования.
10. Способ по п. 1, в котором электронным устройством является одно из:
- пользовательского электронного устройства; и
- сервера, соединенного с пользовательским электронным устройством посредством сети связи.
11. Электронное устройство для идентификации завершения пользовательского высказывания по цифровому аудиосигналу, причем цифровой аудиосигнал содержит аудиозапись пользовательского высказывания, причем электронное устройство сконфигурировано с возможностью:
- получения набора признаков для соответствующего сегмента цифрового аудиосигнала,
причем каждый набор признаков содержит по меньшей мере признаки акустического типа, извлекаемые из соответствующего сегмента цифрового аудиосигнала,
причем сегменты цифрового аудиосигнала связаны с соответствующими временными интервалами предопределенной длительности;
- получения указания момента времени завершения высказывания в цифровом аудиосигнале, соответствующего некоторому моменту времени, после которого пользовательское высказывание завершено;
- определения скорректированного момента времени завершения высказывания путем добавления предопределенного временного смещения к моменту времени завершения высказывания;
- определения меток для соответствующих наборов признаков на основе скорректированного момента времени завершения высказывания и временных интервалов соответствующих сегментов цифрового аудиосигнала,
причем метка указывает, завершилось ли пользовательское высказывание во время соответствующего сегмента цифрового аудиосигнала, связанного с соответствующим набором признаков;
- использования наборов признаков и соответствующих меток для обучения нейронной сети (NN) прогнозировать, во время какого сегмента цифрового аудиосигнала пользовательское высказывание завершилось.
12. Электронное устройство по п. 11, в котором набор признаков дополнительно содержит признаки лингвистического типа для соответствующего сегмента цифрового аудиосигнала.
13. Электронное устройство по п. 11, в котором признаки лингвистического типа определяются на основе текстового представления пользовательского высказывания, причем текстовое представление содержит по меньшей мере одно слово и по меньшей мере одну паузу.
14. Электронное устройство по п. 11, в котором указание момента времени завершения высказывания определяется по меньшей мере одним из осуществляющего оценку человека и алгоритма автоматического выравнивания речи с текстом (ASA).
15. Электронное устройство по п. 11, при этом то, что электронное устройство сконфигурировано с возможностью использования наборов признаков и соответствующих меток для обучения NN, содержит то, что электронное устройство сконфигурировано с возможностью:
- организации наборов признаков и соответствующих меток в том же порядке, что и порядок, в котором соответствующие сегменты встречаются в цифровом аудиосигнале.
16. Электронное устройство по п. 11, при этом электронное устройство дополнительно сконфигурировано с возможностью, во время фазы использования NN:
- получения по меньшей мере некоторой части цифрового аудиосигнала в процессе использования;
- определения первого набора признаков для первого сегмента цифрового аудиосигнала в процессе использования, причем первый сегмент включает в себя самую последнюю полученную часть цифрового аудиосигнала в процессе использования, причем цифровой аудиосигнал в процессе использования записан в режиме реального времени во время высказывания в процессе использования;
- причем первый набор признаков содержит по меньшей мере признаки акустического типа, извлекаемые из первого сегмента цифрового аудиосигнала;
- использования NN для определения на основе первого набора признаков первого значения, указывающего вероятность того, что пользовательское высказывание в процессе использования завершилось во время первого сегмента цифрового аудиосигнала в процессе использования;
- в ответ на то, что первое значение превышает предопределенный порог,
определения того, что пользовательское высказывание в процессе использования завершилось во время первого сегмента цифрового аудиосигнала в процессе использования.
17. Электронное устройство по п. 16, при этом электронное устройство дополнительно сконфигурировано с возможностью:
- генерирования триггера для остановки записи цифрового аудиосигнала в процессе использования.
18. Электронное устройство по п. 16, при этом электронное устройство дополнительно сконфигурировано с возможностью:
- обеспечения алгоритму автоматического распознавания речи (ASR) по меньшей мере некоторой части цифрового аудиосигнала в процессе использования для определения текстового представления высказывания в процессе использования; и
- генерирования триггера для остановки обеспечения алгоритму ASR цифрового аудиосигнала в процессе использования.
19. Электронное устройство по п. 16, при этом электронное устройство дополнительно сконфигурировано с возможностью, в ответ на то, что первое значение находится ниже предопределенного порога:
- определения второго набора признаков для второго сегмента цифрового аудиосигнала в процессе использования, причем второй сегмент является продолжением первого сегмента в цифровом аудиосигнале в процессе использования,
причем второй набор признаков содержит по меньшей мере признаки акустического типа, извлекаемые из второго сегмента цифрового аудиосигнала;
- использования NN для определения на основе первого набора признаков и второго набора признаков второго значения, указывающего вероятность того, что пользовательское высказывание в процессе использования завершилось во время второго сегмента цифрового аудиосигнала в процессе использования;
- в ответ на то, что второе значение превышает предопределенный порог,
определения того, что пользовательское высказывание в процессе использования завершилось во время второго сегмента цифрового аудиосигнала в процессе использования.
20. Электронное устройство по п. 11, при этом электронным устройством является одно из:
- пользовательского электронного устройства; и
- сервера, соединенного с пользовательским электронным устройством посредством сети связи.
| СПОСОБ И УСТРОЙСТВО ДЛЯ РАСПОЗНАВАНИЯ РЕЧИ | 2006 |
|
RU2393549C2 |
| СПОСОБ И ДИСКРИМИНАТОР ДЛЯ КЛАССИФИКАЦИИ РАЗЛИЧНЫХ СЕГМЕНТОВ СИГНАЛА | 2009 |
|
RU2507609C2 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| US 8924209 B2, 30.12.2014 | |||
| US 6839670 B1, 04.01.2005 | |||
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| US 9922640 B2, 20.03.2018 | |||
| KR 20010093334 A, 27.10.2001 | |||
| CN 1950882 B, 16.06.2010 | |||
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| US 10134425 B1, 20.11.2018. | |||

