ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящая технология относится к способу и системе синтеза речи из текста. Конкретнее, настоящая технология относится к способам и системам для обучения алгоритма машинного обучения (MLA) созданию искусственных высказываний в виде текста и способу использования таким образом обученного MLA созданию искусственных высказываний.
УРОВЕНЬ ТЕХНИКИ
[0002] В системах преобразования текста в речь (от англ. text-to-speech (TTS) - текст-в-речь) часть текста (или текстовый файл) преобразовывается в аудио-речь (или речевой аудио-файл). Такие системы используются в широком диапазоне приложений, например, в электронных играх, устройствах для чтения электронных книг, устройствах, выполненных с возможностью чтения электронных писем, спутниковой навигации, автоматизированных телефонных системах и автоматизированных системах оповещения. Например, некоторые системы мгновенных сообщений (instant messaging (IM)) используют синтез TTS для преобразования текстового чата в речь. Это может быть очень удобно для людей, которым трудно читать, людям, за рулем, или людям, которые просто не хотят отвлекаться от своего занятия, чтобы переключать внимание на окно IM.
[0003] Другой областью применения систем TTS являются "личные помощники". Подобные личные помощники реализованы либо в виде программного обеспечения, внедренного в устройство (например, помощник SIRI™, встроенный в устройства компании APPLE™), либо в виде отдельных аппаратных устройств с соответствующим программным обеспечением (например, устройство AMAZON™ ECHO™). Личные помощники предоставляют интерфейс на основе высказываний между электронным устройством и пользователем. Пользователь может давать команды с помощью голоса (например, произнеся "Какая сегодня погода в Нью-Йорке, Америка?").
[0004] Электронное устройство выполнено с возможностью улавливать высказывание, преобразовывать высказывание в текст для обработки созданной пользователем команды. В этом примере, электронное устройство выполнено с возможностью выполнять поиск и определять текущий прогноз погоды в Нью-Йорке. Электронное устройство далее выполнено с возможностью создавать искусственное высказывание, представляющее собой ответ на пользовательский запрос. В этом примере электронное устройство может быть выполнено с возможностью создавать голосовое высказывание: "Сейчас пять градусов Цельсия, ветер северо-восточный".
[0005] Одной из главных сложностей, связанных с системами TTS является создание машинных высказываний, которые "звучат естественно". Другими словами, главной сложностью является создание искусственного высказывания, которое звучало бы максимально похоже на то, как звучал бы человек. Обычно, системы TTS выполняют алгоритмы машинного обучения (MLA), которые обучены создавать машинные высказывания для данного текста, которые необходимо преобразовать в искусственное высказывание с помощью корпуса заранее записанных высказываний.
[0006] Эти высказывания записаны заранее человеком (как правило, актером с хорошей дикцией). MLA далее выполнен с возможностью "вырезать и вставлять" различные части корпуса заранее записанных высказываний для создания требуемого машинного высказывания. Другими словами, MLA системы TTS создает искусственную речь путем "конкатенации" частей записанной речи, которые хранятся в базе данных.
[0007] Например, если часть текста, который необходимо обработать, представляет собой "ma", MLА выбирает максимально подходящий кусок из заранее записанных высказываний для создания соответствующей части искусственного высказывания. Очевидно, что если человек будет произносить высказывание "ma", оно будет звучать по-разному в зависимости от множества условий - окружающих фонем (т.е. "контекста"), является ли оно частью ударного слога или нет, является ли это началом или концом слова и т.д. Таким образом, данный корпус заранее записанных высказываний может обладать множеством высказываний, представляющий текст "ma", некоторые из них звучат отлично от других и, следовательно, некоторые из них являются более (или менее) подходящими для создания конкретных вариантов искусственного высказывания, представляющего собой «ma».
[0008] Следовательно, одна из сложностей состоит в определении того, какие части заранее записанных высказываний использовать для данного искусственного высказывания, чтобы оно звучало максимально естественно. Есть два параметра, которые обычно используются для выбора данного куска для добавления его в текущее искусственное высказывание - целевой показатель и показатель объединения (конкатенации).
[0009] В общем случае, целевой показатель указывает на то, является ли данный кусок заранее записанных высказываний подходящим для обработки данной части текста. Показатель объединения указывает на то, насколько хорошо два соседних куска (из потенциального выбора соседних частей) заранее записанных высказываний будут звучать вместе (т.е. насколько естественным будет переход между одним заранее записанным высказыванием и следующими звуками соседнего высказывания).
[0010] Целевой показатель может быть вычислен с помощью Формулы 1:
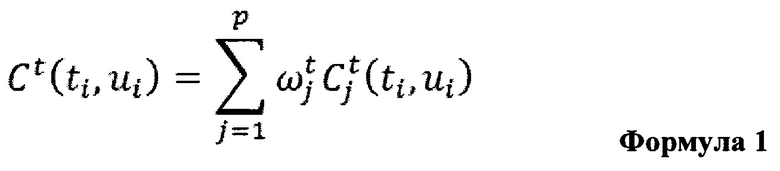
[0011] Другими словами, целевой показатель может быть вычислен как взвешенная сумма разницы в свойствах части текста, которая предназначена для обработки в искусственное высказывание, и одним конкретным из заранее записанных высказываний, которое предназначено для обработки этой части текста. Свойства, которые могут быть обработаны с помощью MLA для определения целевого показателя, включают в себя: частоту главного тона, длительность, контекст, позиция элемент в слоге, число ударных слогов во фразе, и т.д.
[0012] Показатель объединения может быть вычислен с помощью Формулы 2:
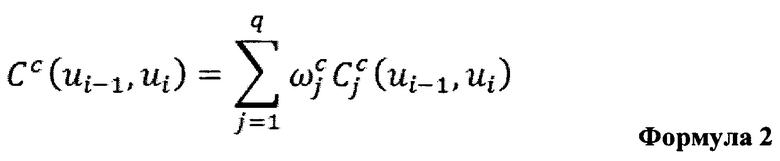
[0013] Другими словами, показатель объединения вычисляется как взвешенная сумма свойств двух потенциальных соседних элементов заранее записанных высказываний.
[0014] Общий показатель может быть вычислен с помощью Формулы 3:
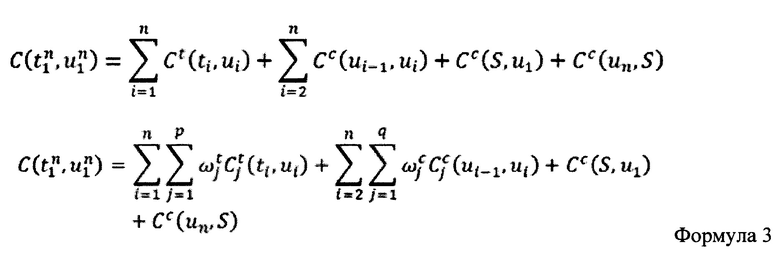
[0015] Общий показатель может вычисляться как сумма целевого показателя и показателя объединения, связанных с данным элементов заранее записанных высказываний. Следовательно, для того чтобы обработать текст, предназначенный для обработки в машинное высказывание, серверу, который выполняет MLA, необходимо выбрать набор U1, U2, …, UN таким образом, чтобы общий показатель, вычисленный в соответствии с Формулой 3, был минимальным.
[0016] Американская патентная заявка 7,308,407 (опубликована 11 декабря, 2007 компанией IBM) описывает способ создания искусственной речи, который может включать в себя определение записи разговорной речи и создание транскрипции разговорной речи. Используя транскрипцию, а не заранее определенный сценарий, запись может анализироваться и могут извлекаться акустические элементы. Каждый акустический элемент может включать в себя фонему и/или суб-фонему. Акустические единицы могут храниться таким образом, что конкатенативный движок преобразования текста-в-речь может далее соединять акустические элементы вместе для создания искусственной речи.
[0017] Американская патентная заявка 5,809,462 (опубликована 15 сентября, 1998 компанией Ericsson Messaging Systems) описывает систему автоматического распознавания речи, которая преобразует голосовой сигнал в компактную, закодированную форму, которая коррелирует с набором разговорных фонем. Для выполнения необходимого кодирования речи может быть использован ряд различных схем сопоставления паттерном нейронной сети. Интегрированный пользовательский интерфейс помогает пользователю, который незнаком с деталями распознавания речи или нейронными сетями, быстро настроить и протестировать нейронную сеть для распознавания фонем. Для обучения нейронной сети, интегрированным пользовательским интерфейсом обрабатываются оцифрованные голосовые данные, содержащие известные фонемы, распознавание которых нейронной сетью желательно для пользователя. Оцифрованная речь сегментируется на фонемы, и каждый сегмент помечается соответствующим кодом фонемы. На основе выбранного пользователем способа преобразования и параметров преобразования, каждый сегмент преобразуется на серию многомерных векторов, которые представляют характеристики речи этого сегмента. Эти векторы итеративно представляются нейронной сети для обучения/настройки этой нейронной для постоянного различия и распознавания этих векторов и назначению каждому вектору подходящего кода фонемы. Одновременное отображение оцифрованной речи, сегментов, наборов векторов и представления обученной нейронной сети помогает пользователю визуально подтверждать допустимость обучающего набора фонем. Пользователь может также выборочно голосом подтверждать допустимость схемы оцифровки, сегментов и векторов преобразования таким образом, чтобы допустимые обучающие данные поступали в нейронную сеть. Если пользователь считает, что конкретный этап или параметр приводит к недопустимому результату, пользователь может модифицировать один или несколько параметров и проверять, приводит ли модификация к улучшению работы. Обученная нейронная сеть также автоматически тестируется путем представления текстового речевого сигнала в интегрированный пользовательский интерфейс и наблюдения за звуковой и визуальной автоматической сегментацией речи, преобразования на многомерные вектора и итогового назначения нейронной сетью кодов фонем. Также описан способ декодирования таких кодов фонем с использованием нейронной сети.
РАСКРЫТИЕ ТЕХНОЛОГИИ
[0018] Таким образом, задачей предлагаемого технического решения является устранение по меньшей мере некоторых недостатков, присущих известному уровню техники.
[0019] Варианты осуществления настоящей технологии были разработаны с учетом определения разработчиками по меньшей мере одной проблемы, связанной с известными подходами к обучению и использованию систем TTS. Без установления ограничений какой-либо конкретной теорией, разработчики выделили две проблемы в существующем уровне техники. Во-первых, создание обучающих объектов для MLA может быть ресурсозатратным, как в плане числа необходимых людей-асессоров, так и в плане связанных с этим показателей. Во-вторых, поскольку создание машинных высказываний обычно выполняется в режиме "реального времени" (поскольку взаимодействие между пользователем и электронным устройством выполняется "на ходу", существует необходимость в создании машинных высказываний без значительно заметной для пользователя задержки), функция показателей должна вычисляться быстро.
[0020] Таким образом, система TTS, реализующая MLA, который выполнен в соответствии с неограничивающими вариантами осуществления настоящей технологии, создает (или ей доступен) корпус заранее записанных высказываний (и соответствующего им текстового представления). Корпус заранее записанных высказываний обычно создается актером, зачитывающим текст, который записывается и далее обрабатывается в его текстовое представление.
[0021] Система TTS далее осуществляет парсинг текстового представления каждого слова из словарного корпуса по меньшей мере на одну фонему. Затем система TTS, для каждых выбранных двух таким образом подвергнутых парсингу слов, которые обладают общей фонемой между ними: осуществляет создание искусственного слова на основе объединения раздельных фонем из каждого из двух слов, объединение выполняется с помощью общей фонемы как связующей точки, и объединение приводит по меньшей мере к двум искусственным словам. В некоторых вариантах осуществления настоящей технологии, объединение осуществляется по одной связующей точке.
[0022] Таким образом созданные искусственные слова далее обрабатываются в высказывания из искусственных слов, которые предоставляются асессорам. От асессоров требуется назначить отметку высказыванию из искусственных слов, которая будет показывать, звучит ли оно натурально или нет. В некоторых вариантах осуществления настоящей технологии, асессорам не нужно оценивать, звучат ли высказывания из искусственных слов осмысленно или нет - только естественность звучания. Таким образом, назначенная отметка может быть бинарной - например, "хорошо" или "плохо". В альтернативном варианте осуществления технологии, назначенная отметка может быть выбрана по школе от нуля до единицы (где ноль -неестественное звучание, а единица - естественное).
[0023] Система TTS далее обучает классификатор прогнозировать оценку для созданных высказываний из искусственных слов, оценки представляют собой параметр человеческой оценки паттерна перехода фонем возле связующей точки, параметр человеческой оценки указывает на то, естественно ли звучит паттерн перехода. Другими словами, классификатор обучается прогнозировать отметку, которая была бы назначена искусственному слову асессором.
[0024] Классификатор обучается использовать акустические свойства. Акустические свойства могут включать в себя по меньшей мере одно из: основную частоту и плотность мощности (mel-frequency cepstrum). В некоторых вариантах осуществления настоящей технологии, классификатор использует свойства данной фонемы и окружающих фонем. В некоторых вариантах осуществления настоящей технологии, классификатор использует среднее значение акустических свойств, которые усреднены для данной фонемы. В некоторых вариантах осуществления настоящей технологии, классификатор реализован как модель дерева на основе градиентного бустинга. Тем не менее, также могут быть использованы другие модели.
[0025] После обучения классификатора, он используется для создания обучающих объектов для MLA. В некоторых вариантах осуществления настоящей технологии, MLA реализован как MLA на основе Deep Similarity Learning (DSL). MLA на основе DSL может обладать двумя подсетями, и обучение MLА включает в себя: подачу на первую подсеть: множества левых частей нового искусственного слова на основе фонемы и соответствующих параметров качества; подачу на вторую подсеть множества правых частей нового искусственного слова на основе фонемы и соответствующих параметров качества; обучение MLА на основе DSL созданию векторов таким образом, чтобы векторы данной левой части и правой части, которые связаны со сравнительно более высокими параметрами качества, также были связаны со сравнительно более высоким значением скалярного умножения. В некоторых неограничивающих вариантах осуществления технологии, конкретный тип MLA на основе DSL может включать в себя MLA на основе DSSM и MLA на основе мультимодальной модели Deep Similarity, MLA на основе обучения сходству классификации и MLА на основе обучения регрессионному сходству.
[0026] В некоторых вариантах осуществления настоящей технологии, MLA на основе DSL создает векторы путем использования встроенного алгоритма для преобразования акустических свойств в представление заранее определенной длины (размера) К (представление создается как для "левого", так и для "правого" размера связующей точки.
[0027] Таким образом, во время фазы использования MLA на основе DSL необходимо высчитать показатели объединения для всех кандидатов (левая часть обладает числом М кандидатов, а правая часть обладает числом N кандидатов), ML А на основе DSL перемножает две матрицы размерами М×K и K×N, что позволяет снизить время, необходимое для вычисления общего показателя.
[0028] Первым объектом настоящей технологии является способ создания обучающего набора для преобразования текста-в-речь (TTS) для обучения алгоритма машинного обучения (MLA) созданию воспроизводимых машиной высказываний, представляющих введенный текст. Способ выполняется сервером. Способ включает в себя: получение корпуса слов, причем каждое слово из которого обладает: текстовым представлением; голосовым представлением; парсинг текстового представления каждого слова из корпуса слов по меньшей мере на одну фонему; для каждых выбранных двух слов, которые обладают общей фонемой между ними: создание искусственного слова на основе объединения отдельных фонем из каждого из двух слов, объединение выполняется с использованием общей фонемы как связующей точки, причем объединение приводит к созданию по меньшей мере двух искусственных слов; создание высказываний из искусственных слов на основе созданных по меньшей мере двух искусственных слов; получение оценок для созданных высказываний из искусственных слов, причем оценки представляют собой параметр человеческой оценки паттерна перехода фонем возле связующей точки, причем параметр человеческой оценки указывает на то, естественно ли звучит паттерн перехода; определение акустических свойств созданных высказываний из искусственных слов; и обучение классификатора на основе созданных высказываний из искусственных слов, акустических свойств и оценок для создания: параметра качества, связанного с новым искусственным словом на основе фонем, причем параметр качества указывает на то, естественно ли звучит новое искусственное слово на основе фонем.
[0029] В некоторых вариантах осуществления способа, способ далее включает в себя: создание обучающего набора TTS для обучения MLA, причем обучающий набор TTS включает в себя множество обучающих объектов, причем каждый из множества обучающих объектов включает в себя: соответствующее новое искусственное слово на основе фонем; соответствующий параметр качества, созданный классификатором.
[0030] В некоторых вариантах осуществления способа, MLA представляет собой алгоритм машинного обучения на основе Deep Similarity Learning ().
[0031] В некоторых вариантах осуществления способа, MLA на основе DSL обладает двумя подсетями, и при этом обучение MLА включает в себя: подачу на первую подсеть: множества левых частей нового искусственного слова на основе фонемы и соответствующих параметров качества; подачу на вторую подсеть множества правых частей нового искусственного слова на основе фонемы и соответствующих параметров качества; обучение MLA на основе DSL созданию векторов таким образом, чтобы векторы данной левой части и правой части, которые связаны со сравнительно более высокими параметрами качества, также были связаны со сравнительно более высоким значением скалярного умножения.
[0032] В некоторых вариантах осуществления способа, каждое новое искусственное слово на основе фонем обрабатывается как потенциальная левая сторона и потенциальная правая сторона.
[0033] В некоторых вариантах осуществления способа, обучение MLA на основе DSL созданию векторов далее включает в себя обучение MLA на основе DSL таким образом, что вектора другой левой стороны и другой правой стороны, которые связаны со сравнительно более низким параметром качества, также связаны со сравнительно более низким значением скалярного умножения.
[0034] В некоторых вариантах осуществления способа, способ далее включает в себя: обработку всей совокупности фонем из словарного корпуса через первую подсеть и вторую подсеть для создания соответствующего вектора левой стороны и вектора правой стороны каждой из совокупности фонем; сохранение множества созданных векторов левой стороны и векторов правой стороны в хранилище памяти.
[0035] В некоторых вариантах осуществления способа, обработка всей совокупности фонем включает в себя выполнение встроенного алгоритма для создания вектора на основе фонемы.
[0036] В некоторых вариантах осуществления способа, множество созданных векторов левой стороны и векторов правой стороны используется во время фазы использования для создания функции показателя воспроизведенных машиной высказываний во время обработки введенного текста.
[0037] В некоторых вариантах осуществления способа, способ далее включает в себя, во время фазы использования, вычисление функции показателя путем умножения первой матрицы на вторую матрицу, причем первая матрица включает в себя векторы левой стороны, а вторая матрица включает в себя векторы правой стороны.
[0038] В некоторых вариантах осуществления способа, акустические свойства включают в себя по меньшей мере одно из: основную частоту и плотность мощности (mel-frequency cepstrum).
[0039] В некоторых вариантах осуществления способа, данное акустическое свойство данной фонемы создается на основе данной фонемы и ее контекста.
[0040] В некоторых вариантах осуществления способа, контекст данной фонемы представляет собой по меньшей мере одну соседнюю другую фонему.
[0041] В некоторых вариантах осуществления способа, классификатор реализуется как MLA на основе дерева решений.
[0042] В некоторых вариантах осуществления способа, искусственное слово обладает только одной связующей точкой.
[0043] Другим объектом настоящей технологии является вычислительное устройство для создания обучающего набора для преобразования текста-в-речь (TTS) для обучения алгоритма машинного обучения (MLA) созданию воспроизводимых машиной высказываний, представляющих введенный текст, причем MLA выполняется на вычислительном устройстве. Вычислительное устройство обладает процессором, который выполнен с возможностью осуществлять: получение корпуса слов, причем каждое слово из которого обладает: текстовым представлением; голосовым представлением; парсинг текстового представления каждого слова из корпуса слов по меньшей мере на одну фонему; для каждых выбранных двух слов, которые обладают общей фонемой между ними: создание искусственного слова на основе объединения отдельных фонем из каждого из двух слов, объединение выполняется с использованием общей фонемы как связующей точки, причем объединение приводит к созданию по меньшей мере двух искусственных слов; создание высказываний из искусственных слов на основе созданных по меньшей мере двух искусственных слов; получение оценок для созданных высказываний из искусственных слов, причем оценки представляют собой параметр человеческой оценки паттерна перехода фонем возле связующей точки, причем параметр человеческой оценки указывает на то, естественно ли звучит паттерн перехода; определение акустических свойств созданных высказываний из искусственных слов; и обучение классификатора на основе созданных высказываний из искусственных слов, акустических свойств и оценок для создания: параметра качества, связанного с новым искусственным словом на основе фонем, причем параметр качества указывает на то, естественно ли звучит новое искусственное слово на основе фонем.
[0044] В некоторых вариантах осуществления вычислительного устройства, вычислительное устройство является сервером. В других вариантах осуществления вычислительного устройства, вычислительное устройство может представлять собой электронное устройство пользователя.
[0045] В контексте настоящего описания «сервер» подразумевает под собой компьютерную программу, работающую на соответствующем оборудовании, которая способна получать запросы (например, от клиентских устройств) по сети и выполнять эти запросы или инициировать выполнение этих запросов. Оборудование может представлять собой один физический компьютер или одну физическую компьютерную систему, но ни то, ни другое не является обязательным для данной технологии. В контексте настоящей технологии использование выражения «сервер» не означает, что каждая задача (например, полученные команды или запросы) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может быть одним сервером или несколькими серверами, оба варианта включены в выражение «по меньшей мере один сервер».
[0046] В контексте настоящего описания, если конкретно не указано иное, «клиентское устройство» подразумевает под собой электронное устройство, связанное с пользователем и включающее в себя любое аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. Таким образом, примерами клиентских устройств (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует иметь в виду, что компьютерное устройство, ведущее себя как клиентское устройство в настоящем контексте, может вести себя как сервер по отношению к другим клиентским устройствам. Использование выражения «клиентское устройство» не исключает возможности использования множества клиентских устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного способа.
[0047] В контексте настоящего описания, если конкретно не указано иное, «компьютерное устройство» подразумевает под собой любое электронное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. Компьютерное устройство может являться сервером, клиентским устройством и так далее.
[0048] В контексте настоящего описания, если конкретно не указано иное, термин «база данных» подразумевает под собой любой структурированный набор данных, не зависящий от конкретной структуры, программного обеспечения по управлению базой данных, аппаратного обеспечения компьютера, на котором данные хранятся, используются или иным образом оказываются доступны для использования. База данных может находиться на том же оборудовании, выполняющем процесс, на котором хранится или используется информация, хранящаяся в базе данных, или же база данных может находиться на отдельном оборудовании, например, выделенном сервере или множестве серверов.
[0049] В контексте настоящего описания, если конкретно не указано иное, «информация» включает в себя любую информацию любого типа, включая информацию, которую можно хранить в базе данных. Таким образом, информация включает в себя, среди прочего, аудиовизуальные произведения (фотографии, видео, звукозаписи, презентации и т.д.), данные (картографические данные, данные о местоположении, цифровые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, таблицы и т.д.
[0050] В контексте настоящего описания, если конкретно не указано иное, «компонент» подразумевает под собой программное обеспечение (соответствующее конкретному аппаратному контексту), которое является необходимым и достаточным для выполнения конкретной(ых) указанной(ых) функции(й).
[0051] В контексте настоящего описания, если конкретно не указано иное, термин «носитель информации» подразумевает под собой носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д.
[0052] В контексте настоящего описания, если конкретно не указано иное, термин «текст» подразумевают под собой последовательность символов и слов, которые эти символы образуют, причем эта последовательность может быть прочитана человеком. Текст может, в общем случае, быть кодированным в машиночитаемые форматы, например, ASCII. Текст в общем случае отличается бессимвольных закодированных данных, например, графических изображений в форме растровых изображений, и программного кода. Текст может быть в различных формах, например, он может быть написан или напечатан, например, в виде книги или документа, электронного сообщения, текстового сообщения (например, отправленного в системе мгновенных сообщений) и т.д.
[0053] В контексте настоящего описания, если конкретно не указано иное, термин «акустический» подразумевает под собой звуковую энергию в форме волн, обладающих частотой, в общем случае находящейся в диапазоне, слышимом человеком. «Аудио» подразумевает под собой звук в акустическом диапазоне, слышимом человеком. Термины «речь» и «синтезированная речь» в общем случае используются здесь, подразумевая под собой аудио- или акустические (например, озвученные) представления текста. Акустические данные и аудио-данные могут иметь много различных форм, например, он могут быть записями, песнями и т.д. Акустические данные и аудио-данные могут быть сохранены в файле, например, в МРЗ файле, который может быть сжат для хранения или более быстрой передачи.
[0054] В контексте настоящего описания, если конкретно не указано иное, выражение «нейронная сеть» подразумевает под собой систему программ и структур данных, созданных для приближенного моделирования процессов в человеческом мозге. Нейронные сети в общем случае включают в себя серию алгоритмов, которые могут идентифицировать лежащие в основе отношения и связи в наборе данных, используя процесс, который имитирует работу человеческого мозга. Расположения и веса связей в наборе данных в общем случае определяют вывод. Нейронная сеть, таким образом, в общем случае открыта для всех данных ввода или параметров одновременно, во всей их полноте, и, следовательно, способна моделировать их взаимозависимость. В отличие от алгоритмов машинного обучения, которые используют деревья принятия решений и, следовательно, имеют свои ограничения, нейронные сети не ограничиваются и, следовательно, подходят для моделирования взаимозависимостей.
[0055] В контексте настоящего описания, если конкретно не указано иное, слова «первый», «второй», «третий» и и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной взаимосвязи между этими существительными. Так, например, следует иметь в виду, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий "второй сервер" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание «первого» элемента и «второго» элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, «первый» сервер и «второй» сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[0056] Каждый вариант осуществления настоящей технологии преследует по меньшей мере одну из вышеупомянутых целей и/или объектов, но наличие всех не является обязательным. Следует иметь в виду, что некоторые объекты данной технологии, полученные в результате попыток достичь вышеупомянутой цели, могут не удовлетворять этой цели и/или могут удовлетворять другим целям, отдельно не указанным здесь.
[0057] Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления настоящей технологии станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0058] Для лучшего понимания настоящей технологии, а также других ее аспектов и характерных черт, сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
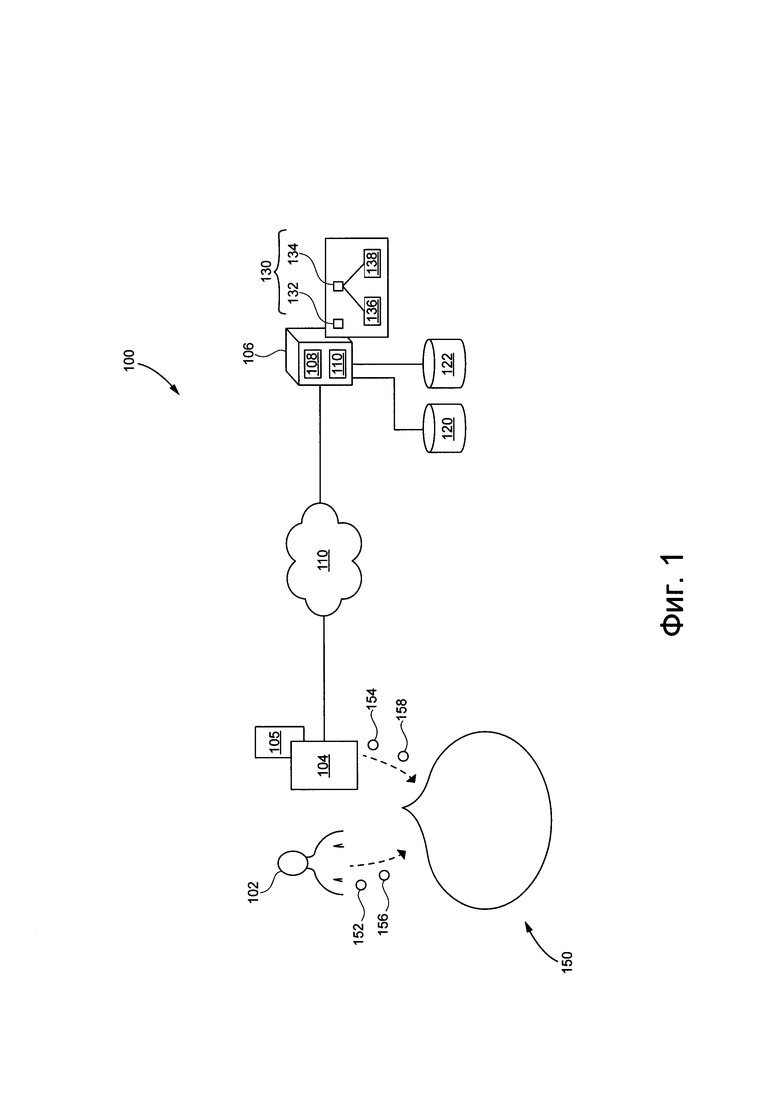
[0059] На Фиг. 1 представлена принципиальная схема системы, выполненной в соответствии с вариантом осуществления настоящей технологии, не ограничивающим ее объем.
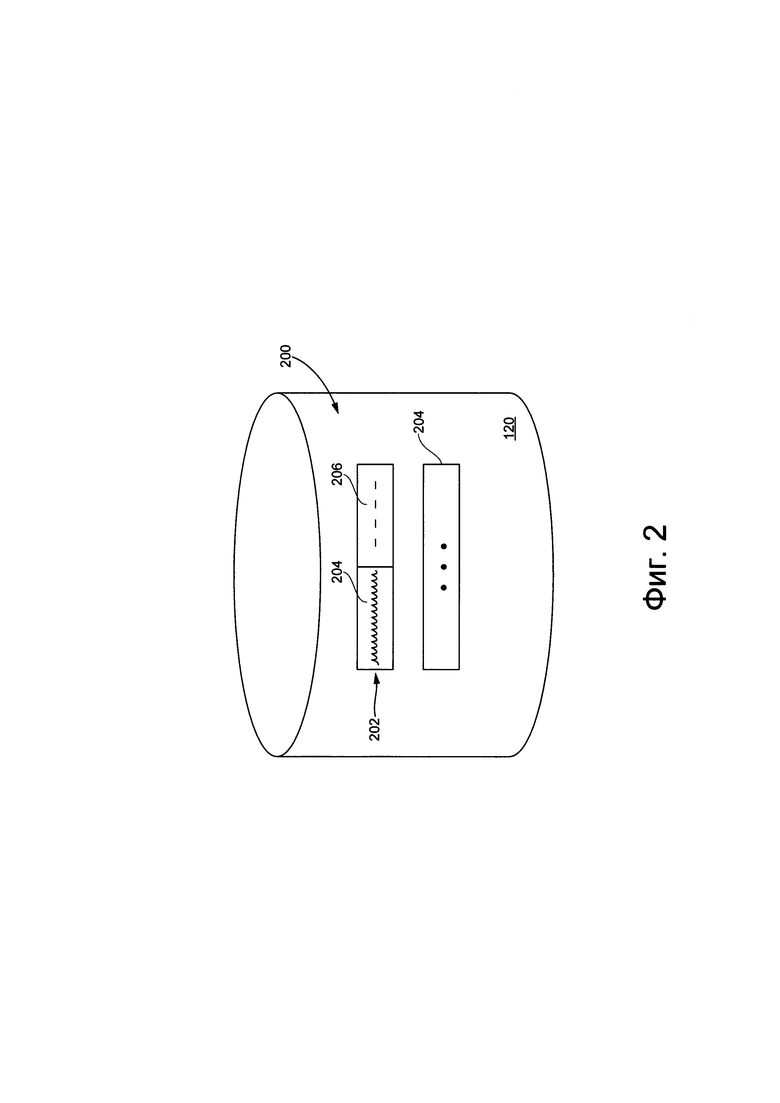
[0060] На Фиг. 2 представлена схематическая иллюстрация содержимого базы данных заранее записанных высказываний, относящейся к системе, которая показана на Фиг. 1.
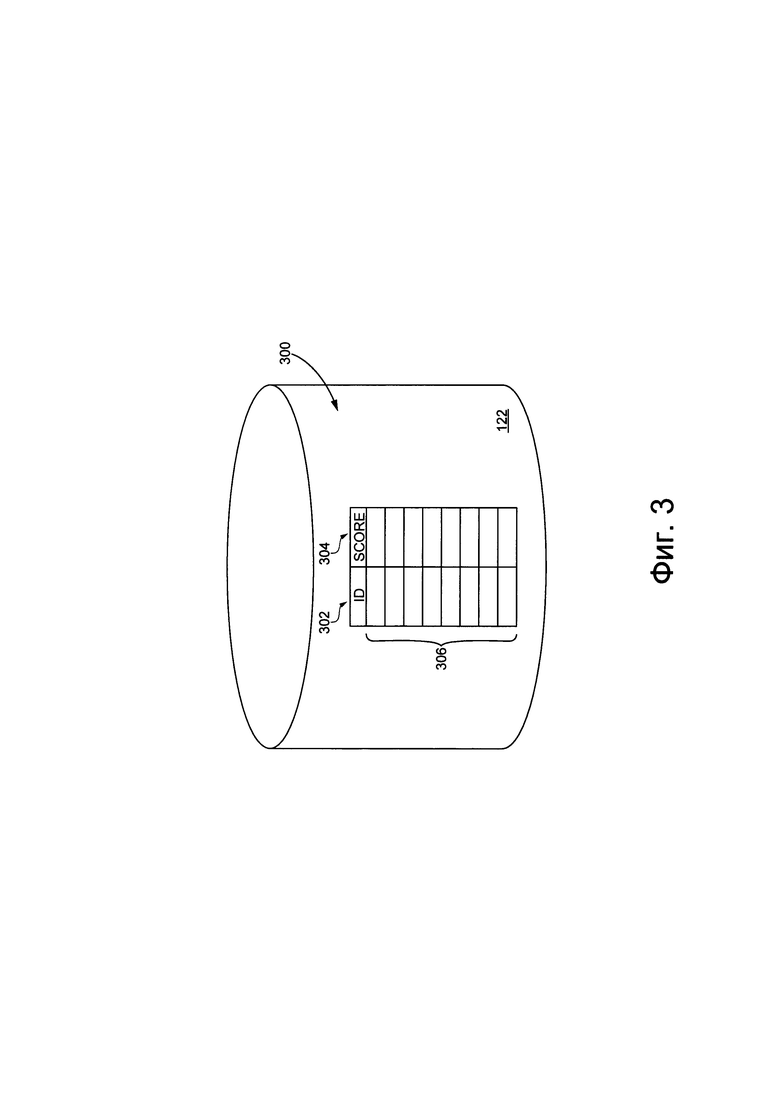
[0061] На Фиг. 3 представлено содержимое базы данных оценок асессоров системы, показанной на Фиг. 1.
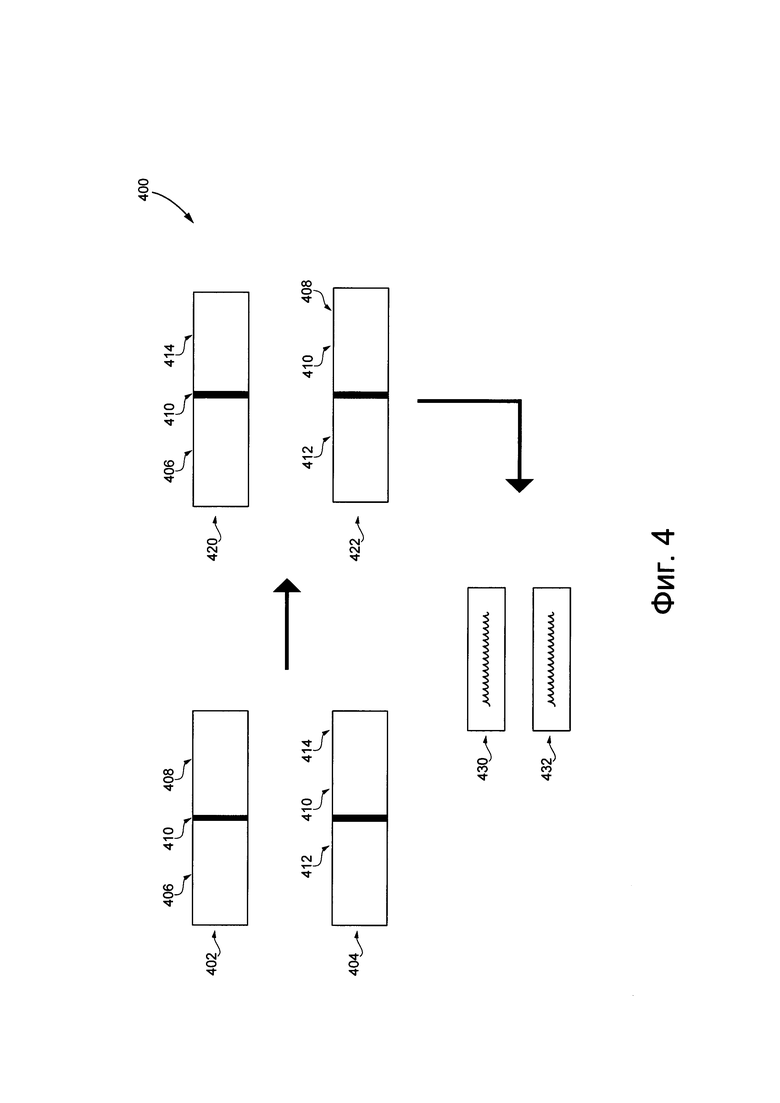
[0062] На Фиг. 4 представлено схематическое представление процедуры создания искусственного слова, которая реализуется в системе, показанной на Фиг. 1.
[0063] На Фиг. 5 представлен процесс обучения второго MLA, выполняемого системой, изображенной на Фиг. 1.
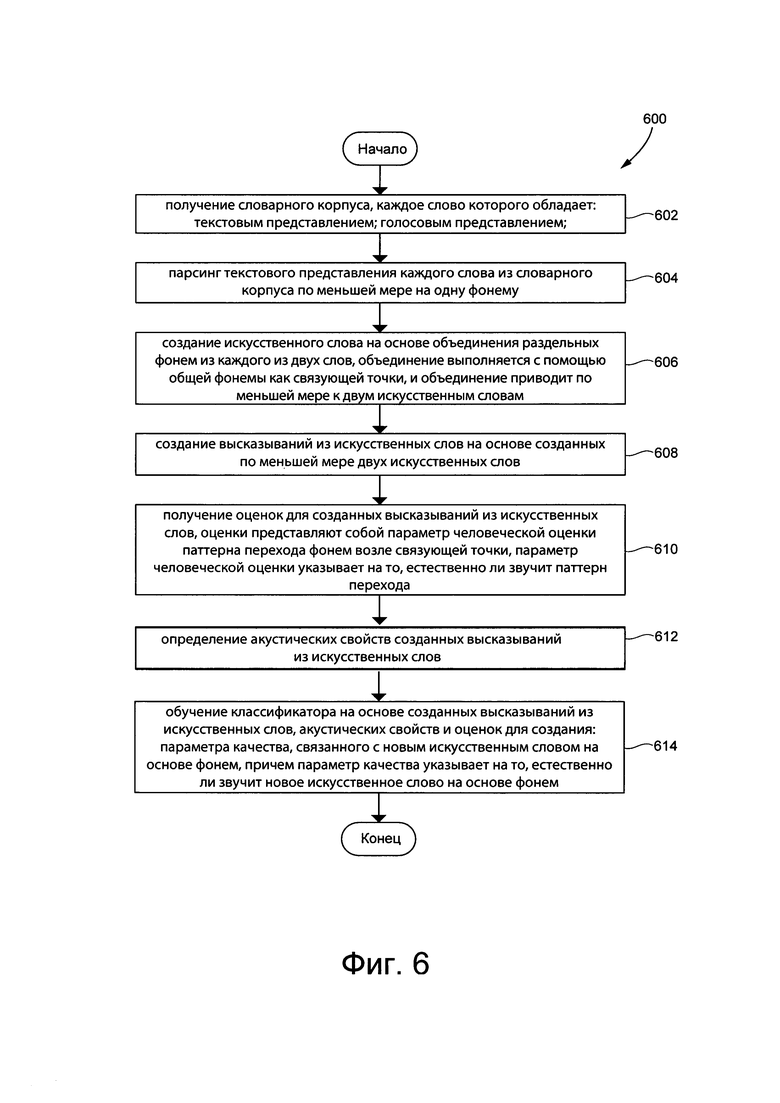
[0064] На Фиг. 6 представлена блок-схема способа, реализованного в соответствии с неограничивающими вариантами осуществления настоящей технологии в системе, представленной на Фиг. 1.
ОСУЩЕСТВЛЕНИЕ
[0065] На Фиг. 1 представлена принципиальная схема системы 100, выполненной в соответствии с вариантами осуществления настоящей технологии, не ограничивающими ее объем. Важно иметь в виду, что нижеследующее описание системы 100 представляет собой описание иллюстративных вариантов осуществления настоящего технического решения. Таким образом, все последующее описание представлено только как описание иллюстративного примера настоящей технологии. Это описание не предназначено для определения объема или установления границ настоящей технологии. Некоторые полезные примеры модификаций системы 100 также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящей технологии.
[0066] Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где это еще не было сделано, т.е. там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным вариантом осуществления этого элемента настоящего технического решения. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что система 100 представляет собой в некоторых конкретных проявлениях достаточно простой вариант осуществления настоящей технологии, и в подобных случаях этот вариант представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящей технологии будут обладать гораздо большей сложностью.
[0067] В общем случае, система 100 выполнена с возможностью создавать искусственные высказывания из текста, предназначенного для обработки. Пример реализации системы 100 нацелен на среду, где взаимодействие между пользователем и электронным устройством реализовано с помощью интерфейса на основе высказываний. Тем не менее, важно отметить, что варианты осуществления сигналов никак конкретно не ограничены. Таким образом, способы и процедуры, описанные здесь, могут быть реализованы в любом варианте системы 100, где желательно создание машинных высказываний.
[0068] На Фиг. 1 система 100 предоставляет искусственные ответы на пользовательские запросы, что приводит к "разговору" между пользователем и электронным устройством. Например, звуковые указания 152 и 156 (например, произнесенные высказывания) от пользователя 102 могут улавливаться электронным устройством 104 (или просто "устройством 104"), которое, в свою очередь, выполнено с возможностью предоставлять звуковые указания 154 и 158 (например, воспроизведенные высказывания или "искусственные высказывания"). Таким образом, можно сказать, что это приводит к разговору 150 между пользователем 102 и устройством 104, причем разговор 150 состоит из (i) звуковых указаний 152 и 156 и (ii) звуковых указаний 154 и 158.
[0069] Далее будут описаны различные компоненты системы 100 и то, как эти компоненты могут быть выполнены с возможностью предоставления звуковых указаний 154 и 158.
Пользовательское устройство
[0070] Как было упомянуто ранее, система 100 включает в себя устройство 104. Варианты осуществления устройства 104 конкретно не ограничены, но в качестве примера устройства 104 могут использоваться персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), устройства беспроводной связи (смартфон, мобильный телефон, планшет, умный динамик и т.п.), а также сетевое оборудование (маршрутизаторы, коммутаторы или шлюзы). Таким образом, устройство 104 может иногда упоминаться как "электронное устройство", "устройство конечного пользователя", "клиентское электронное устройство" или просто "устройство". Следует отметить, что тот факт, что устройство 104 связано с пользователем 102, не подразумевает какого-либо конкретного режима работы, равно как и необходимости входа в систему, быть зарегистрированным, или чего-либо подобного.
[0071] Подразумевается, что устройство 104 включает в себя аппаратное и/или прикладное программное обеспечение и/или системное программное обеспечение (или их комбинацию), как известно в данной области техники, для того, чтобы (i) обнаружить или уловить звуковые указания 152 и 156 и (ii) предоставить или воспроизвести звуковые указания 154 и 158. Например, устройство 104 может включать в себя один или несколько микрофонов для обнаружения или улавливания звуковых указаний 152 и 156 и один или несколько динамиков для предоставления или воспроизведения звуковых указаний 154 и 158.
[0072] Устройство 104 также включает в себя аппаратное и/или прикладное программное, и/или системное программное обеспечение (или их комбинацию), как известно в данной области техники, для использования приложения 105 умного личного помощника (IPА). В общем случае, целью приложения 105 IPA, также известного как "чатбот" является возможность (i) позволить пользователю 102 вводить запросы в форме голосовых высказываний (например, звуковых указаний 152 и 156) и, в ответ, (ii) предоставлять пользователю 102 зависящие от намерения ответы в форме голосовых высказываний (например, звуковых указаний 154 и 158). Ввод запросов и предоставление зависящих от намерения ответов может выполняться приложением 105 IPA с помощью пользовательского интерфейса на естественном языке.
[0073] В общем случае, пользовательский интерфейс приложения 105 IP А на естественном языке может представлять собой интерфейс взаимодействия человека и компьютера любого типа, в котором лингвистические элементы, такие как глаголы, фразы, падежи и т.д. используются для управления пользовательским интерфейсом с целью извлечения, выбора, модификации или создания данных в приложении 105 IPA.
[0074] Например, когда голосовые высказывания пользователя 102 (например, звуковые указания 152 и 156) обнаруживаются (т.е. улавливаются) устройством 104, приложение 105 IP А может использовать свой пользовательский интерфейс на естественном языке для анализа голосовых высказываний пользователя 102 и извлечения данных из них, которые указываются на запросы пользователя 102. Также, данные, которые указывают на зависящие от намерения ответы, которые могут быть получены устройством 104, анализируются пользовательским интерфейсом на естественном языке приложения 105 IPA для предоставления или воспроизведения голосовых высказываний (например, звуковые указания 154 и 158) указывают на зависящие от намерения ответы.
Сеть передачи данных;
[0075] В примерном варианте системы 100, устройство 104 коммуникативно соединено с сетью 110 передачи данных для доступа и передачи пакетов данных к серверу 106/от сервера 106 и/или другим веб-ресурсам (не показано). В некоторых вариантах осуществления настоящей технологии, не ограничивающих ее объем, сеть 110 передачи данных может представлять собой Интернет. В других неограничивающих вариантах осуществления настоящей технологии, сеть 110 передачи данных может быть реализована иначе - в виде глобальной сети связи, локальной сети связи, частной сети связи и т.п. Реализация линии передачи данных (отдельно не пронумерована) между устройством 104 и сетью 110 передачи данных будет зависеть среди прочего от того, как именно реализовано устройство 104.
[0076] В качестве примера, но не ограничения, в данных вариантах осуществления настоящей технологии в случаях, когда устройство 104 представляет собой беспроводное устройство связи (например, смартфон), линия передачи данных представляет собой беспроводную сеть передачи данных (например, среди прочего, линия передачи данных 3G, линия передачи данных 4G, беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п.). В тех примерах, где устройство 104 представляет собой портативный компьютер, линия связи может быть как беспроводной (беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п) так и проводной (соединение на основе сети Ethernet).
Сервер
[0077] Как уже ранее упоминалось, система 100 также включает в себя сервер 106, который может быть реализован как обычный сервер. В примере варианта осуществления настоящей технологии, сервер 106 может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сервер 106 может представлять собой любое другое подходящее аппаратное, прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящей технологии, не ограничивающем ее объем, сервер 106 является одиночным сервером. В других вариантах осуществления настоящей технологии, не ограничивающих ее объем, функциональность сервера 106 может быть разделена, и может выполняться с помощью нескольких серверов.
[0078] В общем случае, сервер 106 выполнена с возможностью (i) получать данные, указывающие на запросы от устройства 104, (ii) анализировать данные, указывающие на запросы и, в ответ, (iii) создавать данные, указывающие на искусственные ответы и (iv) передавать данные, указывающие на искусственные ответы, устройству 104. С этой целью, сервер 106 размещает сервис 108 IPA, связанный с приложением 105 IPA.
[0079] Сервис 108 IPА включает в себя различные компоненты, которые могут позволить реализовать вышеупомянутые функции. Например, сервис 108 IPА может реализовать, среди прочего, множество алгоритмов машинного обучения (MLA) 130, включающих в себя первый MLA 132 и второй MLA 134. В общем случае, данный MLА из множества MLА 130 (например, первый MLА 132 и второй MLА 134) и компьютерный алгоритм, который может "учиться" из обучающих данных и делать прогнозы на основе используемых данных. Данный MLA обычно обучается во время фазы обучения, на основе обучающих данных для, "обучения" связям и/или шаблонам в обучающих данных для создания прогнозов, во время фазы их использования, на основе используемых данных.
[0080] В соответствии с неограничивающими вариантами осуществления настоящей технологии, первый MLA 132 может быть реализован как классификатор. Первый MLА 132 может быть реализован с помощью модели дерева с использованием градиентного бустинга. Тем не менее, другие модели также могут быть использованы для реализации первого MLА 132.
[0081] Второй MLA 134 может быть реализован с помощью MLA на основе нейронной сети. В неограничивающем варианте осуществления настоящей технологии, второй MLA 134 может быть реализован как MLА на основе Deep Structured Semantic Model (). Они также могут иногда упоминаться специалистами в данной области техники как Deep Semantic Similarity Model.
[0082] Следует отметить, что второй MLA 134 также может быть реализован с использованием других моделей. В представленном варианте осуществления технологии, второй MLA 134 обладает двумя подсетями - первой подсетью 136 и второй подсетью 138.
[0083] Сервер 106 также далее выполнен с возможностью выполнять процедуру 112 обучения. В общем случае, задачей процедуры 112 обучения является обучение множества MLА 130.
[0084] В соответствии с неограничивающими вариантами осуществления настоящей технологии, процедура 112 обучения выполнена с возможностью получать доступ к корпусу заранее записанных высказываний (и связанного с ними текстового представления), как будет описано далее ниже. Корпус заранее записанных высказываний обычно создается актером, зачитывающим текст, который записывается и далее обрабатывается в его текстовое представление.
[0085] Процедура 112 обучения далее выполнена с возможностью осуществлять парсинг текстового представления каждого слова из словарного корпуса по меньшей мере на одну фонему. Парсинг может выполняться с помощью известных методик парсинга.
[0086] Процедура 112 обучения далее, для каждых выбранных двух слов, которые обладают общей фонемой между ними: осуществляет создание искусственного слова на основе объединения раздельных фонем из каждого из двух слов, объединение выполняется с помощью общей фонемы как связующей точки, и объединение приводит по меньшей мере к двум искусственным словам. В некоторых вариантах осуществления настоящей технологии, объединение осуществляется по одной связующей точке.
[0087] На Фиг. 4 представлена схема представления процедуры 400 создания искусственного слова. В показанном примере представлено два слова - первое слово 402 и второе слово 404, каждое из них обладает общей фонемой 410. Следует отметить, что первое слово 402 и второе слово 404 могут представлять собой слова, фразы или предложения.
[0088] Первое слово 402 может быть разделено на две фонемы общей фонемой 410 - первой фонемой 406 первого слова и второй фонемой 408 первого слова. Аналогичным образом, второе слово 404 может быть разделено на две фонемы общей фонемой 410 -первой фонемой 412 второго слова и второй фонемой 414 второго слова.
[0089] Процедура 112 обучения создает два искусственных слова - первое искусственное слово 420 и второе искусственное слово 422. Первое искусственное слово 420 - созданное из двух объединенных фонем - первой фонемы 406 первого слова и второй фонемы 414 второго слова, объединенных общей фонемой 410 (которая используется как точка связывания). Второе искусственное слово 422 - созданное из двух других объединенных фонем - первой фонемы 412 второго слова и второй фонемы 408 первого слова, объединенных общей фонемой 410 (которая используется как точка связывания).
[0090] Следует отметить, что каждое из искусственных слов создается с помощью одной точки связывания (т.е. общей фонемы 410). Также следует отметить, что первое слово 402 и второе слово 404 не обязаны обладать одинаковой длиной или обладать сходством в семантическом значении. Главное, чтобы первое слово 402 и второе слово 404 обладали общей фонемой 410.
[0091] Процедура 112 обучения повторяет процесс объединения с помощью множества пар слов, каждая часть из множества пар слов выбрана таким образом, что имеется общая фонема. В некоторых вариантах осуществления настоящей технологии каждая часть из множества пар слов, выбранных таким образом, что они обладают одной общей фонемой, которая используется как связующая точка.
[0092] Таким образом созданные искусственные слова (например, первое искусственное слово 420, второе искусственное слово 422, а также другие созданные искусственные слова) далее обрабатываются в высказывания из искусственных слов (например, путем объединения соответствующих частей корпуса заранее записанных высказываний), показанных на Фиг. 4, как высказывание 430 из первого искусственного слова и высказывание 432 из второго искусственного слова. Высказывания из искусственных слов (т.е. высказывание 430 из первого искусственного слова и высказывание 432 из второго искусственного слова и другие созданные высказывания из искусственных слов) представляются людям-асессорам.
[0093] Асессорам необходимо назначить метку данному высказыванию из искусственного слова, т.е. высказыванию 430 из первого искусственного слова и высказыванию 432 из второго искусственного слова и другим созданным высказываниям из искусственных слов), отметка отражает, звучит ли естественно высказывание из искусственных слов (т.е. высказывание 430 из первого искусственного слова и высказывание 432 из второго искусственного слова и другие созданные высказывания из искусственных слов). В некоторых вариантах осуществления настоящей технологии, асессорам не нужно оценивать, звучат ли высказывания из искусственных слов осмысленно или нет - только естественность звучания. Таким образом, назначенная отметка может быть бинарной - например, "хорошо" или "плохо". В альтернативном варианте осуществления технологии, назначенная отметка может быть выбрана по школе от нуля до единицы (где ноль -неестественное звучание, а единица - естественное).
[0094] Процедура 112 обучения далее обучает первый MLA 132 прогнозировать оценку для созданных высказываний из искусственных слов, оценки представляют собой параметр человеческой оценки паттерна перехода фонем возле связующей точки, параметр человеческой оценки указывает на то, естественно ли звучит паттерн перехода. Другими словами, классификатор обучается прогнозировать отметку, которая была бы назначена искусственному слову асессором.
[0095] Первый MLА 132 обучается использовать акустические свойства. Акустические свойства могут включать в себя по меньшей мере одно из: основную частоту и плотность мощности (mel-frequency cepstrum).
[0096] В некоторых вариантах осуществления настоящей технологии, первый MLA 132 использует свойства данной фонемы и окружающих фонем. В некоторых вариантах осуществления настоящей технологии, первый MLA 132 использует среднее значение акустических свойств, которые усреднены для данной фонемы.
[0097] После обучения первого MLA 132, первый MLA 132 используется для создания обучающих объектов для второго MLА 134. Конкретнее, процедура 112 обучения создает множество высказываний из искусственных слов и передает множество высказываний из искусственных слов первому MLА 132. Первый MLА 132 назначает оценку каждому из созданного множества высказываний из искусственных слов. Оценка, в некотором смысле, является прогнозом параметра человеческой оценки паттерна перехода фонем возле связующей точки, параметр человеческой оценки указывает на то, естественно ли звучит что паттерн перехода. Множество таким образом оцененных высказываний из искусственных слов далее используется для обучения второго MLA.
[0098] На Фиг. 5 представлен процесс обучения второго MLA 134. Конкретнее, на Фиг. 5 представлена первая подсеть 136 и вторая подсеть 138. Процедура 112 обучения подает левую часть высказываний 502 первой подсетью 136 и правую часть высказываний 504 второй подсети 138. Множество заранее записанных высказываний подвергается парсингу для создания левой части высказываний 502 и правой части высказываний 504. Следует отметить, что каждая левая сторона (т.е. первая фонема 406 первого слова и первая фонема 412 второго слова, и т.д.) и правая фонема (т.е. вторая фонема 408 первого слова и вторая фонема 415 второго слова, и т.д.) оцененного множества высказываний из искусственных слов используются для левой части высказываний 502 и правой части высказываний 504.
[0099] В качестве примера и со ссылкой на Фиг. 4, первая фонема 406 первого слова, вторая фонема 414 второго слова, первая фонема 412 второго слова и вторая фонема 408 первого слова используются для создания каждой из левой стороны высказываний 502 и правой стороны высказываний 504.
[00100] Каждая из первой фонемы 406 первого слова, второй фонемы 414 второго слова, первой фонемы 412 второго слова и второй фонемы 408 первого слова далее преобразуются, соответствующей одной из первой подсети 136 и второй подсети 138 в вектор заранее определенного размера К (например, используя способы внедрения и так далее).
[00101] Второй MLА 134 обучается созданию результирующего вектора 506 данной левой стороны и правой стороны, результирующий вектор 506 является результатом скалярного умножения соответствующего вектора левой стороны и вектора правой стороны, и значение результирующего вектора 506 пропорционально значениям оценки, назначенным первым MLA 132 соответствующей паре левой стороны и правой стороны.
[00102] Другими словами, чем выше значение назначенной оценки для данной пары фонем левой стороны и правой стороны, тем выше значение результирующего вектора.
[00103] Второй MLA 134 далее используется для создания множества векторов для каждой возможной левой стороны и каждой возможной правой стороны, используя множество высказываний из искусственных слов.
[00104] Возвращаясь к Фиг. 1, сервер 106 также коммуникативно соединен с базой 120 данных заранее записанных высказываний и базой 122 данных оценок асессоров.
[00105] В представленном варианте осуществления, база 120 данных заранее записанных высказываний и база 120 данных оценок асессоров представлены в виде отдельных физических элементов. Но это не является обязательным для каждого варианта осуществления настоящей технологии. Таким образом, база 120 данных заранее записанных высказываний и база 120 данных оценок асессоров могут быть реализованы в виде единой базы данных. Кроме того, любая из базы 120 данных заранее записанных высказываний и базы 120 данных оценок асессоров может быть разделена на несколько отдельных хранилищ.
База 120 данных заранее записанных высказываний
[00106] В общем случае, база 120 данных заранее записанных высказываний выполнена с возможностью сохранять корпус заранее записанных высказываний. Эти высказывания записаны заранее человеком (как правило, актером с хорошей дикцией). Как было упомянуто ранее, и как будет более подробно описано далее, множество MLА 130 далее выполняется с возможностью использовать корпус заранее записанных высказываний для опции "вырезать и копировать" различные части заранее записанного корпуса высказываний для создания требуемого искусственного высказывания.
[00107] На Фиг. 2 представлена принципиальная схема содержимого базы 120 данных заранее определенных высказываний. База 120 данных заранее записанных высказываний хранит корпус заранее записанных высказываний 200. Каждая запись 202 связана с данным из заранее записанных высказываний (т.е. каждым словом или группой слов). Каждая запись 202 сопоставляет голосовое представление 204 с текстовым представлением 206. Следует отметить, что текстовое представление 206 может быть создано с помощью любого подходящего способа преобразования речи в текст.
[00108] База 120 данных заранее записанных высказываний содержит ряд дополнительных записей 208, которые структурированы аналогично записи 202.
База 122 данных оценок асессоров
[00109] Со ссылкой на Фиг. 3 будет описано содержимое базы 122 данных оценок асессоров. База 122 данных оценок асессоров используется для хранения вышеупомянутых оценок асессоров.
[00110] Резюмируя, созданные процедурой 112 обучения искусственные слова далее обрабатываются в высказывания из искусственных слов, которые предоставляются асессорам. От асессоров требуется назначить отметку высказыванию из искусственных слов, которая будет показывать, звучит ли оно натурально или нет. В некоторых вариантах осуществления настоящей технологии, асессорам не нужно оценивать, звучат ли высказывания из искусственных слов осмысленно или нет -только естественность звучания. Таким образом, назначенная отметка может быть бинарной - например, "хорошо" или "плохо". В альтернативном варианте осуществления технологии, назначенная отметка может быть выбрана по школе от нуля до единицы (где ноль - неестественное звучание, а единица - естественное).
[00111] С учетом описанной архитектуры, возможно осуществлять способ создания обучающего набора для преобразования текста-в-речь (TTS) для обучения алгоритма машинного обучения (MLA) созданию воспроизводимых машиной высказываний, представляющих введенный текст. Способ выполняется множеством MLA 130. На Фиг. 6 представлена диаграмма блок-схемы способа 600, который выполняется в соответствии с неограничивающими вариантами осуществления настоящей технологии. Способ 600 может выполняться процедурой 112 обучения и/или множеством MLA 130 (или ее частями).
[00112] Этап 602 - получение словарного корпуса, причем каждое слово из словарного корпуса обладает: текстовым представлением и голосовым представлением
[00113] Способ 600 начинается на этапе 602, где процедура 112 обучения и/или множество MLA 130 получает словарный корпус, причем каждое слово из словарного корпуса обладает: текстовым представлением и голосовым представлением.
[00114] Этап 604 - парсинг текстового представления каждого слова из словарного корпуса по меньшей мере на одну фонему
[00115] На этапе 604, процедура 112 обучения и/или множество MLA 130 осуществляют парсинг текстового представления каждого слова из словарного корпуса по меньшей мере на одну фонему.
[00116] Следующие этапы способа 600 выполняются для каждого из выбранных двух слов, которые обладают общей фонемой между собой.
[00117] Этап 606 - создание искусственного слова на основе объединения раздельных фонем из каждого из двух слов, объединение выполняется с помощью общей фонемы как связующей точки, и объединение приводит по меньшей мере к двум искусственным словам
[00118] На этапе 606, процедура 112 обучения и/или множество MLA 130 осуществляют создание искусственного слова на основе объединения раздельных фонем из каждого из двух слов, объединение выполняется с помощью общей фонемы как связующей точки, и объединение приводит по меньшей мере к двум искусственным словам.
[00119] Этап 608 - создание высказываний из искусственных слов на основе созданных по меньшей мере двух искусственных слов
[00120] На этапе 608, процедура 112 обучения и/или множество MLA 130 осуществляют создание высказываний из искусственных слов на основе созданных по меньшей мере двух искусственных слов.
[00121] Этап 610 - получение оценок для созданных высказываний из искусственных слов, оценки представляют собой параметр человеческой оценки паттерна перехода фонем возле связующей точки, параметр человеческой оценки указывает на то, естественно ли звучит паттерн перехода
[00122] На этапе 610, процедура 112 обучения и/или множество MLA 130 осуществляют получение оценки для созданных высказываний из искусственных слов, оценки представляют собой параметр человеческой оценки паттерна перехода фонем возле связующей точки, параметр человеческой оценки указывает на то, естественно ли звучит паттерн перехода.
[00123] Этап 612 - определение акустических свойств созданных высказываний из искусственных слов
[00124] На этапе 612, процедура 112 обучения и/или множество MLA 130 осуществляют определение акустических свойств созданных высказываний из искусственных слов.
[00125] Этап 614 - обучение классификатора на основе созданных высказываний из искусственных слов, акустических свойств и оценок для создания: параметра качества, связанного с новым искусственным словом на основе фонем, причем параметр качества указывает на то, естественно ли звучит новое искусственное слово на основе фонем
[00126] На этапе 614, процедура 112 обучения и/или множество MLA 130 осуществляют обучение классификатора (т.е. второго MLA 134) на основе созданных высказываний из искусственных слов, акустических свойств и оценок для создания: параметра качества, связанного с новым искусственным словом на основе фонем, причем параметр качества указывает на то, естественно ли звучит новое искусственное слово на основе фонем.
[00127] В некоторых вариантах осуществления способа 600, способ 600 далее включает в себя: создание обучающего набора TTS для обучения MLА (т.е. второго MLА 134), причем обучающий набор TTS включает в себя множество обучающих объектов, причем каждый из множества обучающих объектов включает в себя: соответствующее новое искусственное слово на основе фонем; соответствующий параметр качества, созданный классификатором (т.е. первым MLA 132).
[00128] С учетом того, что второй MLA 134 может быть реализован как MLA на основе Deep Similarity Learning (DSL) и что второй MLA 134 обладает двумя подсетями (т.е. первой подсетью 136 и второй подсетью 138), обучение MLA включает в себя: подачу на первую подсеть: множества левых частей нового искусственного слова на основе фонемы и соответствующих параметров качества; подачу на вторую подсеть множества правых частей нового искусственного слова на основе фонемы и соответствующих параметров качества; обучение MLА на основе DSL созданию векторов таким образом, чтобы векторы данной левой части и правой части, которые связаны со сравнительно более высокими параметрами качества, также были связаны со сравнительно более высоким значением скалярного умножения.
[00129] Как было описано ранее, в некоторых вариантах осуществления способа 600, каждое новое искусственное слово на основе фонем обрабатывается как потенциальная левая сторона и потенциальная правая сторона.
[00130] Из представленного выше описания должно быть понятно, что обучение MLA на основе DSL созданию векторов далее включает в себя обучение MLA на основе DSL таким образом, что вектора другой левой стороны и другой правой стороны, которые связаны со сравнительно более низким параметром качества, также связаны со сравнительно более низким значением скалярного умножения.
[00131] После выполнения способа 600 для обучения второго MLA 134, способ 600 далее включает в себя обработку всей совокупности фонем из словарного корпуса через первую подсеть и вторую подсеть для создания соответствующего вектора левой стороны и вектора правой стороны каждой из совокупности фонем; сохранение множества созданных векторов левой стороны и векторов правой стороны в хранилище памяти.
[00132] В некоторых вариантах осуществления способа 600, обработка всей совокупности фонем включает в себя выполнение встроенного алгоритма для создания вектора на основе фонемы.
[00133] Таким образом созданные векторы левой стороны и векторы правой стороны используются во время фазы использования для создания функции показателя воспроизведенных машиной высказываний во время обработки введенного текста. Таким образом, во время фазы использования, способ 600 далее включает в себя вычисление функции показателя путем умножения первой матрицы на вторую матрицу, причем первая матрица включает в себя векторы левой стороны, а вторая матрица включает в себя векторы правой стороны.
[00134] Некоторые из описанных выше этапов, а также передача-получение сигнала хорошо известны в данной области техники и поэтому для упрощения были опущены в конкретных частях данного описания. Сигналы могут быть переданы/получены с помощью оптических средств (например, опто-волоконного соединения), электронных средств (например, проводного или беспроводного соединения) и механических средств (например, на основе давления, температуры или другого подходящего параметра).
[00135] Некоторые технические эффекты неограничивающих вариантов осуществления настоящей технологии могут включать предоставление пользователю быстроисполнимого, эффективного, многофункционального и/или доступного способа синтеза речи в текст. Варианты осуществления настоящей технологии могут предоставлять TTS, который обеспечивает более "естественное звучание" искусственных высказываний по сравнению с известными в данной области техники подходами. Это может быть связано, по меньшей мере, частично, с более эффективным процессом обучения MLA.
[00136] Важно иметь в виду, что не все упомянутые здесь технические результаты могут проявляться в каждом варианте осуществления настоящей технологии. Например, варианты осуществления настоящей технологии могут быть выполнены без проявления некоторых технических результатов, другие могут быть выполнены с проявлением других технических результатов или вовсе без них.
[00137] Модификации и улучшения вышеописанных вариантов осуществления настоящей технологии будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не устанавливает никаких ограничений. Таким образом, объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.

Изобретение относится к вычислительной технике. Технический результат – создание машинных высказываний без видимой для пользователя задержки. Способ создания обучающего набора преобразования текста в речь (TTS) для обучения алгоритма машинного обучения (MLA) для создания воспроизведенных машиной высказываний, представляющих собой введенный текст, включает: получение словарного корпуса; парсинг текстового представления слов из словарного корпуса на фонемы; для каждых двух выбранных слов: создание искусственного слова на основе объединения раздельных фонем из каждого из двух слов; создание высказываний из искусственных слов на основе созданных двух искусственных слов; получение оценок для созданных высказываний из искусственных слов, оценки представляют собой параметр человеческой оценки паттерна перехода фонем возле связующей точки; определение акустических свойств созданных высказываний из искусственных слов; и обучение классификатора на основе созданных высказываний из искусственных слов, акустических свойств и оценок для создания: параметра качества, связанного с новым искусственным словом на основе фонем, причем параметр качества указывает на то, естественно ли звучит новое искусственное слово на основе фонем. 2 н. и 14 з.п. ф-лы, 6 ил.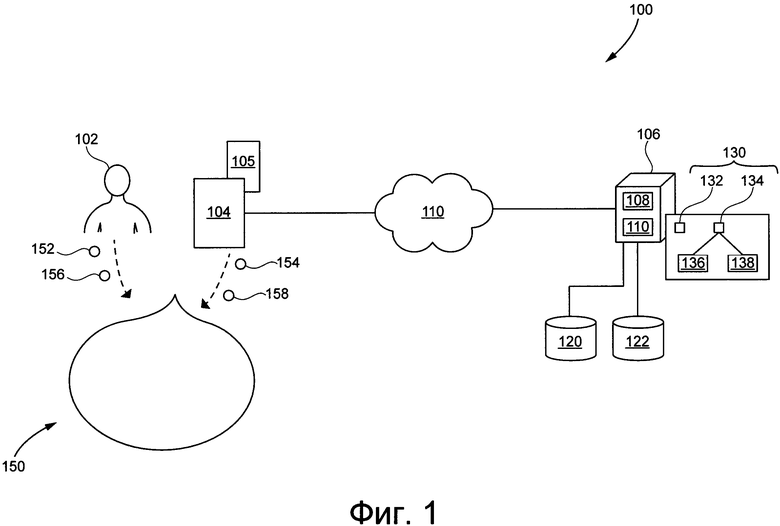
1. Способ создания обучающего набора преобразования текста в речь (TTS) для обучения алгоритма машинного обучения (MLA) для создания воспроизведенных машиной высказываний, представляющих собой введенный текст, причем способ выполняется на сервере и включает в себя:
получение словарного корпуса, каждое слово которого обладает:
текстовым представлением;
голосовым представлением;
парсинг текстового представления каждого слова из словарного корпуса по меньшей мере на одну фонему;
для каждых двух выбранных слов, два слова обладают общей фонемой между ними:
создание искусственного слова на основе объединения раздельных фонем из каждого из двух слов, объединение выполняется с помощью общей фонемы как связующей точки, и объединение приводит по меньшей мере к двум искусственным словам;
создание высказываний из искусственных слов на основе созданных по меньшей мере двух искусственных слов;
получение оценок для созданных высказываний из искусственных слов, оценки представляют собой параметр человеческой оценки паттерна перехода фонем возле связующей точки, параметр человеческой оценки указывает на то, естественно ли звучит паттерн перехода;
определение акустических свойств созданных высказываний из искусственных слов; и
обучение классификатора на основе созданных высказываний из искусственных слов, акустических свойств и оценок для создания:
параметра качества, связанного с новым искусственным словом на основе фонем, причем параметр качества указывает на то, естественно ли звучит новое искусственное слово на основе фонем.
2. Способ по п. 1, способ дополнительно включает в себя:
создание обучающего набора TTS для обучения MLA, обучающий набор TTS включает в себя множество обучающих объектов, причем каждый из множества обучающих объектов включает в себя:
соответствующее новое искусственное слово на основе фонем;
соответствующий параметр качества, созданный классификатором.
3. Способ по п. 2, в котором MLА представляет собой алгоритм машинного обучения на основе Deep Similarity Learning (DSL).
4. Способ по п. 3, в котором MLA на основе DSL обладает двумя подсетями, причем обучение MLА включает в себя:
передачу первой подсети: множества левых частей нового искусственного слова на основе фонем и соответствующих параметров качества;
передачу второй подсети: множества правых частей нового искусственного слова на основе фонем и соответствующих параметров качества;
обучение MLA на основе DSL созданию векторов таким образом, что вектора данной левой стороны и данной правой стороны, которые связаны со сравнительно более высоким параметром качества, также связаны со сравнительно более высоким значением скалярного умножения.
5. Способ по п. 4, в котором каждое новое искусственное слово на основе фонем обрабатывается как потенциальная левая сторона и потенциальная правая сторона.
6. Способ по п. 4, в котором обучение MLA на основе DSL созданию векторов далее включает в себя обучение MLA на основе DSL таким образом, что вектора другой левой стороны и другой правой стороны, которые связаны со сравнительно более низким параметром качества, также связаны со сравнительно более низким значением скалярного умножения.
7. Способ по п. 6, способ дополнительно включает в себя:
обработку всей совокупности фонем из словарного корпуса через первую подсеть и вторую подсеть для создания соответствующего вектора левой стороны и вектора правой стороны каждой из совокупности фонем;
сохранение множества созданных векторов левой стороны и векторов правой стороны в хранилище памяти.
8. Способ по п. 7, в котором обработка всей совокупности фонем включает в себя выполнение встроенного алгоритма для создания вектора на основе фонемы.
9. Способ по п. 7, в котором множество созданных векторов левой стороны и векторов правой стороны используется во время фазы использования для создания функции показателя воспроизведенных машиной высказываний во время обработки введенного текста.
10. Способ по п. 9, в котором способ далее включает в себя, во время фазы использования, вычисление функции показателя путем умножения первой матрицы на вторую матрицу, причем первая матрица включает в себя векторы левой стороны, а вторая матрица включает в себя векторы правой стороны.
11. Способ по п. 1, в котором акустические свойства включают в себя по меньшей мере одно из: основную частоту и плотность мощности (mel-frequency cepstrum).
12. Способ по п. 11, в котором данное акустическое свойство данной фонемы создается на основе данной фонемы и ее контекста.
13. Способ по п. 11, в котором контекст данной фонемы представляет собой по меньшей мере одну соседнюю другую фонему.
14. Способ по п. 1, в котором классификатор реализуется как MLА на основе дерева решений.
15. Способ по п. 1, в котором искусственное слово обладает только одной связующей точкой.
16. Вычислительное устройство для создания обучающего набора преобразования текста в речь (TTS) для обучения алгоритма машинного обучения (MLA) для создания воспроизведенных машиной высказываний, MLA выполняется вычислительным устройством, причем вычислительное устройство включает в себя процессор, который выполнен с возможностью выполнять:
получение словарного корпуса, каждое слово которого обладает:
текстовым представлением;
голосовым представлением;
парсинг текстового представления каждого слова из словарного корпуса по меньшей мере на одну фонему;
для каждых двух выбранных слов, два слова обладают общей фонемой между ними:
создание искусственного слова на основе объединения раздельных фонем из каждого из двух слов, объединение выполняется с помощью общей фонемы как связующей точки, и объединение приводит по меньшей мере к двум искусственным словам;
создание высказываний из искусственных слов на основе созданных по меньшей мере двух искусственных слов;
получение оценок для созданных высказываний из искусственных слов, оценки представляют собой параметр человеческой оценки паттерна перехода фонем возле связующей точки, параметр человеческой оценки указывает на то, естественно ли звучит что паттерн перехода;
определение акустических свойств созданных высказываний из искусственных слов; и
обучение классификатора на основе созданных высказываний из искусственных слов, акустических свойств и оценок для создания:
параметра качества, связанного с новым искусственным словом на основе фонем, причем параметр качества указывает на то, естественно ли звучит новое искусственное слово на основе фонем.
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| US 5809462 A1, 15.09.1998 | |||
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| ПРЕОБРАЗОВАНИЕ БУКВЫ В ЗВУК ДЛЯ СИНТЕЗИРОВАННОГО ПРОИЗНОШЕНИЯ СЕГМЕНТА ТЕКСТА | 2004 |
|
RU2320026C2 |

