ОБЛАСТЬ ТЕХНИКИ
[01] Настоящая технология относится к системе умного персонального помощника и, конкретнее, к способу и компьютерному устройству для выбора текущего зависящего от контекста ответа для текущего пользовательского запроса.
УРОВЕНЬ ТЕХНИКИ
[02] Электронные устройства, такие как смартфоны и планшеты, способны получать доступ к огромному и различному числу приложений и сервисов для обработки и/или доступа к различным типам информации. Тем не менее, новые пользователи и/или пользователи с нарушениями и/или пользователи, ведущие автомобиль, могут не быть способны эффективно взаимодействовать с подобными устройствами, в основном из-за множества функций, предоставляемых этими устройствами, или невозможности использования человеко-машинного интерфейса, предоставляемого подобными устройствами (например, клавиатурой). Например, пользователь, который ведет автомобиль, или пользователь, который плохо видит, может не быть способен использовать сенсорную клавиатуру, связанную с некоторыми из этих устройств.
[03] Были разработаны системы умного личного помощника (IPA) для выполнения функций в ответ на пользовательские запросы. Подобные системы IPA могут быть использованы, например, для извлечения информации и навигации. Обычная система IP А, например, Siri®, может воспринимать обычный ввод на естественном человеческом языке от устройства и выполнять большое количество различных задач для пользователя. Например, пользователь может связываться с Siri® путем произнесения высказываний (через голосовой интерфейс Siri®) с вопросом, например, о текущей погоде, о ближайшем торговом центре и так далее. Пользователь также может выполнять различные приложения, установленные на электронном устройстве.
[04] Обычные системы IPA в основном сфокусированы на анализе пользовательского запроса и предоставлении на него логичного ответа. Тем не менее, различные пользователи обладают различными стилями речи, которые ранжируются от очень формального до очень разговорного или неформального стиля речи. По этой причине, сложной задачей является предоставление логических ответов, которые подражают стилю речь пользователя.
РАСКРЫТИЕ ТЕХНОЛОГИИ
[05] Разработчики настоящей технологии обратили внимание на некоторые технические недостатки, связанные с существующими системами IPA. Обычные системы IPA сфокусированы на предоставлении логичных ответов на запросы, введенные пользователями. Тем не менее, следует отметить, что некоторые запросы, введенные пользователями, являются "зависящими от контекста", т.е. введены с учетом "контекста", в котором находятся эти запросы. Например, некоторые запросы могут быть введены в формальном контексте, например, во время беседы с коллегой, или в разговорном общении, например, во время беседы с другом или членом семьи. Таким образом, стиль речи пользователя может изменяться и, следовательно, запросы и/или ответы в данной беседе будут зависеть от контекста данной беседы.
[06] Задачей предлагаемой технологии является устранение по меньшей мере некоторых недостатков, присущих известному уровню техники. Разработчики настоящей технологии предлагают систему, которая учитывает (i) логическое сходство между ответом и беседой, которую ведет пользователь и (ii) лигнвистическое сходство между ответом и беседой, которую ведет пользователь. Таким образом, возможно выбрать зависящий от контекста ответ, который будет предоставляться пользователю, и который "логически" связан с беседой (т.е. зависящий от контекста ответ, подходящий для беседы, и запрос, для которого он предоставляется), и который "лингвистически" связан с беседой (т.е. ответ и беседа относятся к одному стилю речи).
[07] Первым объектом настоящей технологии является способ выбора текущего зависящего от контекста ответа для текущего пользовательского запроса. Способ выполняется сервером, коммуникативно соединенным с базой данных, которая хранит множество векторов. Каждый вектор связан с соответствующим сниппетом беседы, который включает в себя соответствующий сниппет контекста и соответствующий сниппет ответа. Каждый вектор обладает (i) соответствующим вектором контекста, указывающим на свойства соответствующего сниппета контекста и (ii) соответствующим вектором ответа, указывающим на свойства соответствующего сниппета ответа. Вектор контекста и вектор ответа каждого из множества векторов создается нейронной сетью. Нейронная сеть была обучена: на основе первого сниппета контекста и первого сниппета ответа, которые находятся в общем сниппете беседы, и второго сниппета контекста и второго сниппета ответа, которые не находятся в общем первом сниппете контекста. Нейронная сеть была обучена таким образом, чтобы значение положительного примера сходства векторов между (i) первым вектором ответа, созданным на основе первого сниппета ответа и (ii) первым вектором контекста, созданным на основе первого сниппета контекста, превышало значение отрицательного примера сходства векторов между (i) вторым вектором ответа, созданным на основе второго сниппета ответа и (ii) первым вектором контекста. Способ включает в себя: получение сервером текущего сниппета контекста, включающего в себя текущий пользовательский запрос; создание нейронной сетью сервера текущего вектора контекста на основе текущего сниппета контекста, причем текущий вектор контекста указывает на свойства текущего сниппета контента; для каждого сниппета ответа, связанного с соответствующим вектором, создание сервером соответствующей оценки ранжирования, которая представляет собой сумму: соответствующего первого значения сходства векторов между (i) текущим вектором контекста и (ii) соответствующим вектором контекста, причем каждое первое значение сходства векторов указывает на лингвистическое сходство между (i) текущим сниппетом контекста и (ii) соответствующим сниппетом контекста; и соответствующего второго значения сходства векторов между (i) текущим вектором контекста и (ii) соответствующим вектором ответа, причем каждое второе значение сходства векторов указывает на лингвистическое и логическое сходство между (i) текущим сниппетом контекста и (ii) соответствующим сниппетом ответа; и выбор сервером текущего зависящего от контекста ответа среди сниппетов ответа на основе соответствующих оценок ранжирования.
[08] В некоторых вариантах осуществления настоящей технологии, способ далее включает в себя ранжирование сервером сниппетов ответа на основе соответствующих оценок ранжирования. Выбор текущего зависящего от контента ответа включает в себя выбор сервером наиболее высоко ранжированного сниппета ответа в качестве текущего зависящего от контекста ответа для текущего пользовательского запроса.
[09] В некоторых вариантах осуществления способа, нейронная сеть включает в себя: подсеть контекста, которая создает первый вектор контекста на основе первого сниппета контекста; и подсеть ответа, которая создает (i) первый вектор ответа, созданный на основе первого сниппета ответа и (ii) второй вектора ответа, созданный на основе второго сниппета ответа.
[10] В некоторых вариантах осуществления настоящей технологии, создание текущего вектора контекста на основе текущего сниппета контекста выполняется подсетью контекста.
[11] В некоторых вариантах осуществления способа, нейронная сеть была обучена таким образом, что значение положительного примера сходства векторов превышает по меньшей мере заранее определенное пороговое значение значения отрицательного примера сходства векторов.
[12] В некоторых вариантах осуществления способа, нейронная сеть была обучена создавать первый вектор контекста и первый и второй векторы ответа таким образом, чтобы максимизировать разницу между значением положительного примера сходства векторов и значением отрицательного примера сходства векторов.
[13] В некоторых вариантах осуществления способа, значение положительного примера сходства векторов указывает на векторное расстояние между (i) первым вектором ответа и (ii) первым вектором контекста. Значение отрицательного примера сходства векторов указывает на векторное расстояние между (i) вторым вектором ответа и (ii) первым вектором контекста.
[14] В некоторых вариантах осуществления способа, значение положительного примера сходства векторов является скалярным произведением (i) первого вектора ответа и (ii) первого вектора контекста. Значение отрицательного примера сходства векторов является скалярным произведением (i) второго вектора ответа и (ii) первого вектора контекста.
[15] В некоторых вариантах осуществления способа, данное первое значение сходства векторов является скалярным произведением (i) текущего вектора контекста и (ii) соответствующего вектора контекста. Данное второе примерное значение сходства векторов является скалярным произведением (i) текущего вектора контекста и (ii) соответствующего вектора ответа.
[16] В некоторых вариантах осуществления способа, способ далее включает в себя выбор сервером множества векторов на основе текущего сниппета контекста среди всех векторов, хранящихся в базе данных.
[17] В некоторых вариантах осуществления способа, данная оценка ранжирования является взвешенной суммой соответствующего первого значения сходства векторов и соответствующего второго значения сходства векторов.
[18] В некоторых вариантах осуществления способа, вектор контекста и вектор ответа каждого из множества векторов, которые были созданы нейронной сетью, были конкатенированы в соответствующий один из множества векторов.
[19] Вторым объектом настоящей технологии является компьютерное устройство для выбора текущего зависящего от контекста ответа для текущего пользовательского запроса. Компьютерное устройство коммуникативно соединено с базой данных, хранящих множество векторов. Каждый вектор связан с соответствующим сниппетом беседы, который включает в себя соответствующий сниппет контекста и соответствующий сниппет ответа. Каждый вектор обладает (i) соответствующим вектором контекста, указывающим на свойства соответствующего сниппета контекста и (ii) соответствующим вектором ответа, указывающим на свойства соответствующего сниппета ответа. Вектор контекста и вектор ответа каждого из множества векторов создается нейронной сетью. Нейронная сеть была обучена на основе первого сниппета контекста и первого сниппета ответа, которые находятся в общем сниппете беседы, и второго сниппета ответа, который не находится в первом сниппете контекста, таким образом, чтобы значение положительного примера сходства векторов между (i) первым вектором ответа, созданным на основе первого сниппета ответа и (ii) первым вектором контекста, созданным на основе первого сниппета контекста, превышало значение отрицательного примера сходства векторов между (i) вторым вектором ответа, созданным на основе второго сниппета ответа, и (ii) первым вектором контекста. Компьютерное устройство выполнено с возможностью осуществлять: получение текущего сниппета контекста, включающего в себя текущий пользовательский запрос; создание нейронной сетью текущего вектора контекста на основе текущего сниппета контекста, причем текущий вектор контекста указывает на свойства текущего сниппета контента; для каждого сниппета ответа, связанного с соответствующим вектором, создание соответствующей оценки ранжирования, которая представляет собой сумму: соответствующего первого значения сходства векторов между (i) текущим вектором контекста и (ii) соответствующим вектором контекста, причем каждое первое значение сходства векторов указывает на лингвистическое сходство между (i) текущим сниппетом контекста и (ii) соответствующим сниппетом контекста; и соответствующего второго значения сходства векторов между (i) текущим вектором контекста и (ii) соответствующим вектором ответа, причем каждое второе значение сходства векторов указывает на лингвистическое и логическое сходство между (i) текущим сниппетом контекста и (ii) соответствующим сниппетом ответа; и выбор текущего зависящего от контекста ответа среди сниппетов ответа на основе соответствующих оценок ранжирования.
[20] В некоторых вариантах осуществления вычислительного устройства, вычислительное устройство является сервером.
[21] В некоторых вариантах осуществления технического решения, электронное устройство является клиентским устройством, связанным с пользователем.
[22] В некоторых вариантах осуществления компьютерного устройства, оно далее выполнено с возможностью осуществлять ранжирование сниппетов ответа на основе соответствующих оценок ранжирования. Компьютерное устройство, которое выполнено с возможностью осуществлять выбор текущего зависящего от контента ответа, включает в себя компьютерное устройство, которое выполнено с возможностью осуществлять выбор наиболее высоко ранжированного сниппета ответа в качестве текущего зависящего от контекста ответа для текущего пользовательского запроса.
[23] В некоторых вариантах осуществления компьютерного устройства, нейронная сеть включает в себя: подсеть контекста, которая создает первый вектор контекста на основе первого сниппета контекста; и подсеть ответа, которая создает (i) первый вектор ответа, созданный на основе первого сниппета ответа и (ii) второй вектора ответа, созданный на основе второго сниппета ответа.
[24] В некоторых вариантах осуществления компьютерного устройства, оно выполнено с возможностью осуществлять создание текущего вектора контекста на основе текущего сниппета контекста путем использования подсети контекста.
[25] В некоторых вариантах осуществления компьютерного устройства, нейронная сеть была обучена таким образом, что значение положительного примера сходства векторов превышает по меньшей мере заранее определенное пороговое значение значения отрицательного примера сходства векторов.
[26] В некоторых вариантах осуществления компьютерного устройства, значение положительного примера сходства векторов указывает на векторное расстояние между (i) первым вектором ответа и (ii) первым вектором контекста. Значение отрицательного примера сходства векторов указывает на векторное расстояние между (i) вторым вектором ответа и (ii) первым вектором контекста.
[27] В некоторых вариантах осуществления компьютерного устройства, значение положительного примера сходства векторов является скалярным произведением (i) первого вектора ответа и (ii) первого вектора контекста. Значение отрицательного примера сходства векторов является скалярным произведением (i) второго вектора ответа и (ii) первого вектора контекста.
[28] В некоторых вариантах осуществления компьютерного устройства, данное первое значение сходства векторов является скалярным произведением (i) текущего вектора контекста и (ii) соответствующего вектора контекста. Данное второе значение сходства векторов является скалярным произведением (i) текущего вектора контекста и (ii) соответствующего вектора ответа.
[29] В контексте настоящего описания «сервер» подразумевает под собой компьютерную программу, работающую на соответствующем оборудовании, которая способна получать запросы (например, от клиентских устройств) по сети и выполнять эти запросы или инициировать выполнение этих запросов. Оборудование может представлять собой один физический компьютер или одну физическую компьютерную систему, но ни то, ни другое не является обязательным для данной технологии. В контексте настоящей технологии использование выражения «сервер» не означает, что каждая задача (например, полученные команды или запросы) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может быть одним сервером или несколькими серверами, оба варианта включены в выражение «по меньшей мере один сервер».
[30] В контексте настоящего описания «устройство» подразумевает под собой аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. Таким образом, примерами устройств (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует иметь в виду, что устройство, ведущее себя как устройство в настоящем контексте, может вести себя как сервер по отношению к другим устройствам. Использование выражения «клиентское устройство» не исключает возможности использования множества клиентских устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного способа.
[31] В контексте настоящего описания, «база данных» подразумевает под собой любой структурированный набор данных, не зависящий от конкретной структуры, программного обеспечения по управлению базой данных, аппаратного обеспечения компьютера, на котором данные хранятся, используются или иным образом оказываются доступны для использования. База данных может находиться на том же оборудовании, выполняющем процесс, на котором хранится или используется информация, хранящаяся в базе данных, или же база данных может находиться на отдельном оборудовании, например, выделенном сервере или множестве серверов.
[32] В контексте настоящего описания «информация» включает в себя информацию любую информацию, которая может храниться в базе данных. Таким образом, информация включает в себя, среди прочего, аудиовизуальные произведения (изображения, видео, звукозаписи, презентации и т.д.), данные (данные о местоположении, цифровые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, таблицы, списки слов и т.д.
[33] В контексте настоящего описания «компонент» подразумевает под собой программное обеспечение (соответствующее конкретному аппаратному контексту), которое является необходимым и достаточным для выполнения конкретной(ых) указанной(ых) функции(й).
[34] В контексте настоящего описания «используемый компьютером носитель компьютерной информации» подразумевает под собой носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д.
[35] В контексте настоящего описания слова «первый», «второй», «третий» и и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной взаимосвязи между этими существительными. Так, например, следует иметь в виду, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий "второй сервер" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание «первого» элемента и «второго» элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, «первый» сервер и «второй» сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[36] Каждый вариант осуществления настоящей технологии преследует по меньшей мере одну из вышеупомянутых целей и/или объектов, но наличие всех не является обязательным. Следует иметь в виду, что некоторые объекты данной технологии, полученные в результате попыток достичь вышеупомянутой цели, могут не удовлетворять этой цели и/или могут удовлетворять другим целям, отдельно не указанным здесь.
[37] Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления настоящей технологии станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[38] Для лучшего понимания настоящей технологии, а также других ее аспектов и характерных черт, сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[39] На Фиг. 1 представлена система, подходящая для реализации неограничивающих вариантов осуществления настоящей технологии;
[40] На Фиг. 2 представлен иллюстративный пример данных, хранящихся в базе данной сниппетов из системы, показанной на Фиг. 1, в соответствии с некоторыми вариантами осуществления настоящей технологии;
[41] На Фиг. 3 представлена схема итерации обучения нейронной сети системы, показанной на Фиг. 1, в соответствии с некоторыми вариантами осуществления настоящей технологии;
[42] На Фиг. 4 представлен пример процедуры создания вектора для заполнения базы данных векторов из системы, показанной на Фиг. 1, в соответствии с некоторыми вариантами осуществления настоящей технологии;
[43] На Фиг. 5 представлен иллюстративный пример создания оценок ранжирования для выбора данного зависящего от контекста ответа в соответствии с некоторыми вариантами осуществления настоящей технологии; и
[44] На Фиг. 6 представлена блок-схема способа выбора текущего зависящего от контекста ответа для текущего пользовательского запроса в соответствии с некоторыми вариантами осуществления настоящей технологии.
ОСУЩЕСТВЛЕНИЕ
[45] На Фиг. 1 представлена принципиальная схема системы 100, выполненной в соответствии с вариантами осуществления настоящей технологии, не ограничивающими ее объем. Важно иметь в виду, что нижеследующее описание системы 100 представляет собой описание показательных вариантов осуществления настоящей технологии. Таким образом, все последующее описание представлено только как описание иллюстративного примера настоящей технологии. Это описание не предназначено для определения объема или установления границ настоящей технологии. Некоторые полезные примеры модификаций системы 100 также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящей технологии.
[46] Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где это еще не было сделано, т.е. там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным вариантом осуществления этого элемента настоящего технического решения. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что система 100 представляет собой в некоторых конкретных проявлениях достаточно простой вариант осуществления настоящей технологии, и в подобных случаях этот вариант представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящей технологии будут обладать гораздо большей сложностью.
[47] В общем случае, система 100 выполнена с возможностью предоставлять зависящие от контекста ответы на пользовательские запросы, что приводит к "беседе" между пользователем и электронным устройством. Например, звуковые указания 152 и 156 (например, произнесенные высказывания) от пользователя 102 могут улавливаться электронным устройством 104 (или просто "устройством 104"), которое, в свою очередь, выполнено с возможностью предоставлять звуковые указания 154 и 158 (например, воспроизведенные высказывания или "искусственные высказывания"). Таким образом, можно сказать, что это приводит к беседе 150 между пользователем 102 и устройством 104, причем беседа 150 состоит из (i) звуковых указаний 152 и 156 и (ii) звуковых указаний 154 и 158.
[48] Далее будут описаны различные компоненты системы 100 и то, как эти компоненты могут быть выполнены с возможностью предоставления звуковых указаний 154 и 158.
Пользовательское устройство
[49] Как было упомянуто ранее, система 100 включает в себя устройство 104. Варианты осуществления устройства 104 конкретно не ограничены, но в качестве примера устройства 104 могут использоваться персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), устройства беспроводной связи (смартфон, мобильный телефон, планшет, умный динамик и т.п.), а также сетевое оборудование (маршрутизаторы, коммутаторы или шлюзы). Таким образом, устройство 104 может иногда упоминаться как "электронное устройство", "устройство конечного пользователя", "клиентское электронное устройство" или просто "устройство". Следует отметить, что тот факт, что устройство 104 связано с пользователем 102, не подразумевает какого-либо конкретного режима работы, равно как и необходимости входа в систему, быть зарегистрированным, или чего-либо подобного.
[50] Подразумевается, что устройство 104 включает в себя аппаратное и/или прикладное программное обеспечение и/или системное программное обеспечение (или их комбинацию), как известно в данной области техники, для того, чтобы (i) обнаружить или уловить звуковые указания 152 и 156 и (ii) предоставить или воспроизвести звуковые указания 154 и 158. Например, устройство 104 может включать в себя один или несколько микрофонов для обнаружения или улавливания звуковых указаний 152 и 156 и один или несколько динамиков для предоставления или воспроизведения звуковых указаний 154 и 158.
[51] Устройство 104 также включает в себя аппаратное и/или прикладное программное, и/или системное программное обеспечение (или их комбинацию), как известно в данной области техники, для использования приложения 105 умного личного помощника (IPA). В общем случае, целью приложения 105 IPA, также известного как "чатбот" является возможность (i) позволить пользователю 102 вводить запросы в форме голосовых высказываний (например, звуковых указаний 152 и 156) и, в ответ, (ii) предоставлять пользователю 102 зависящие от намерения ответы в форме голосовых высказываний (например, звуковых указаний 154 и 158). Ввод запросов и предоставление зависящих от намерения ответов может выполняться приложением 105 IPA с помощью пользовательского интерфейса на естественном языке.
[52] В общем случае, пользовательский интерфейс приложения 105 IPA на естественном языке может представлять собой интерфейс взаимодействия человека и компьютера любого типа, в котором лингвистические элементы, такие как глаголы, фразы, падежи и т.д. используются для управления пользовательским интерфейсом с целью извлечения, выбора, модификации или создания данных в приложении 105 IPA.
[53] Например, когда голосовые высказывания пользователя 102 (например, звуковые указания 152 и 156) обнаруживаются (т.е. улавливаются) устройством 104, приложение 105 IPA может использовать свой пользовательский интерфейс на естественном языке для анализа голосовых высказываний пользователя 102 и извлечения данных из них, которые указываются на запросы пользователя 102. Также, данные, которые указывают на зависящие от намерения ответы, которые могут быть получены устройством 104, анализируются пользовательским интерфейсом на естественном языке приложения 105 IPA для предоставления или воспроизведения голосовых высказываний (например, звуковые указания 154 и 158) указывают на зависящие от намерения ответы.
[54] Альтернативно или дополнительно, подразумевается, что приложение 105 IPA может исполнять человеком-машинный интерфейс, который (i) позволяет пользователю 102 вводить указания на запросы в текстовой форме и, в ответ, (ii) предоставляет пользователю 102 указания на зависящие от контекста ответы в текстовой форме.
Сеть передачи данных
[55] В примерном варианте системы 100, устройство 104 коммуникативно соединено с сетью 110 передачи данных для доступа и передачи пакетов данных к серверу 112/от сервера 106 и/или другим веб-ресурсам (не показано). В некоторых вариантах осуществления настоящей технологии, не ограничивающих ее объем, сеть 110 передачи данных может представлять собой Интернет. В других неограничивающих вариантах осуществления настоящей технологии, сеть 110 передачи данных может быть реализована иначе - в виде глобальной сети связи, локальной сети связи, частной сети связи и т.п. Реализация линии передачи данных (отдельно не пронумерована) между устройством 104 и сетью 110 передачи данных будет зависеть среди прочего от того, как именно реализовано устройство 104.
[56] В качестве примера, но не ограничения, в данных вариантах осуществления настоящей технологии в случаях, когда устройство 104 представляет собой беспроводное устройство связи (например, смартфон), линия передачи данных представляет собой беспроводную сеть передачи данных (например, среди прочего, линия передачи данных 3G, линия передачи данных 4G, беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п.). В тех примерах, где устройство 104 представляет собой портативный компьютер, линия связи может быть как беспроводной (беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п.) так и проводной (соединение на основе сети Ethernet).
Сервер
[57] Как уже ранее упоминалось, система 100 также включает в себя сервер 106, который может быть реализован как обычный сервер. В примере варианта осуществления настоящей технологии, сервер 106 может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сервер 106 может представлять собой любое другое подходящее аппаратное, прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящей технологии, не ограничивающем ее объем, сервер 106 является одиночным сервером. В других неограничивающих вариантах осуществления настоящей технологии, функциональность сервера 106 может быть разделена, и может выполняться с помощью нескольких серверов.
[58] В общем случае, сервер 106 выполнен с возможностью (i) получать данные, указывающие на запросы от устройства 104, (ii) анализировать данные, указывающие на запросы и, в ответ, (iii) создавать данные, указывающие на искусственные ответы и (iv) передавать данные, указывающие на искусственные ответы, устройству 104. С этой целью, сервер 106 размещает сервис 108 IPA, связанный с приложением 105 IPA.
[59] Сервис 108 IPA включает в себя различные компоненты, которые могут позволить реализовать вышеупомянутые функции. Например, сервис 180 IPA может выполнять, среди прочего, нейронную сеть 130, содержащую подсеть 132 контекста и подсеть 134 ответа.
[60] В общем случае, данная нейронная сеть содержит взаимосвязанную группу искусственных "нейронов", которая обрабатывает информацию с использованием коннекционистского подхода к вычислению. Нейронные сети используются для моделирования сложных взаимосвязей между вводами и выводами (без фактических знаний об этих взаимосвязях) или для поиска паттернов в данных. Нейронные сети сначала описываются в фазе обучения, в которой они предоставляются с известным набором "вводов" и информацией для адаптации нейронной сети для создания подходящих выводов (для данной ситуации, для которой происходит моделирование). Во время фазы обучения, данная нейронная сеть адаптируется под изучаемую ситуацию и изменяет свою структуру таким образом, что данная нейронная сеть будет способна предоставлять подходящие прогнозированные выводы для данных вводов с учетом новой ситуации (на основе того, что было выучено). Таким образом, вместо попыток определения сложных статистических механизмов или математических алгоритмов для данной ситуации; данная нейронная сеть пытается предоставить "интуитивный" ответ на основе "ощущения" для ситуации. Данная нейронная сеть, таким образом, представляет собой что-то наподобие "черного ящика", который может использоваться в ситуации, когда само содержимое "ящика" не является существенным; но важно, что "ящик" предоставляет логичные ответы на данный ввод.
[61] Нейронные сети часто используются во многих подобных ситуациях (где важен только вывод, основывающийся на данном вводе, но то, как именно был получен этот вывод значительно менее важно или неважно вовсе). Например, нейронные сети часто используются для оптимизации распределения веб-трафика между серверами и обработкой данных, включая, фильтрацию, кластеризацию, разделение сигналов, сжатие, создание векторов и так далее.
[62] Подразумевается, что некоторые нейронные сети могут быть сформированы более чем одной подсетью "нейронов", причем каждая подсеть получает некоторые вводы от данной нейронной сети и адаптирует, в сочетании с другим подсетями данной нейронной сети, для создания подходящих выводов. Например, в этом случае, нейронная сеть 130 включает в себя подсеть 132 контекста и подсеть 134 ответа, которые обучены в сочетании для предоставления подходящих выводов нейронной сети 130.
[63] Суммируя, использование нейронной сети 130 может быть в широком смысле разделено на две фазы - фазу обучения и фазу использования. Сначала нейронная сеть 130 (например, подсеть 132 контекста и подсеть 134 ответа) должна быть обучена в фазе обучения (т.е. "машинное обучение"). Далее, после того, как подсети 132 и 134 контекста и ответа знают, какие данные ожидаются в виде ввода и какие данные предоставлять в виде вывода, нейронная сеть 130 фактически работает, используя рабочие данные в фазе использования.
[64] То, как реализованы, обучены и используются нейронная сеть 130 (например, подсеть 132 и 134 контекста и ответа) и другие компоненты сервиса 108 IPA для осуществления по меньшей мере некоторых вышеописанных функций сервиса 108 IP А, будет более подробно описано далее.
[65] Сервер 106 также коммуникативно соединен с базой 120 данных сниппетов, базой 122 векторов и базой 124 данных обработки. В представленном варианте осуществления технологии, база 120 данных сниппета, база 122 данных векторов и база 124 данных обработки представлены в виде отдельных физических элементов. Но это не является обязательным для каждого варианта осуществления настоящей технологии. Таким образом, некоторые или все из базы 120 данных сниппета, базы 122 данных векторов и базы 124 данных обработки могут быть реализованы в виде одной базы данных. Кроме того, любая из базы 120 данных сниппета, базы 122 данных векторов и базы 124 данных обработки может быть разделена на несколько отдельных баз данных. Аналогичным образом, все (или любая их комбинация) из базы 120 данных сниппета, базы 122 данных векторов и базы 124 данных обработки могут быть реализованы в виде аппаратного устройства.
База данных обработки
[66] База 124 данных обработки выполнена с возможностью сохранять информацию, извлеченную или иным образом определенную или созданную сервером 106 во время обработки. В общем случае, база 124 данных обработки может получать данные с сервера 106, которые были извлечены или иным образом определены или созданы сервером 106 во время обработки для временного и/или постоянного хранения, и могут предоставлять сохраненные данные серверу 106 для их использования.
База данных сниппетов
[67] Со ссылкой на Фиг. 2, представлен иллюстративный пример множества сниппетов 200 беседы, хранящихся в базе 120 данных сниппетов, которые были собраны из различных источников. Например, множество сниппетов 200 беседы может быть собрано с сайтов социальных медиа, из чатов, электронных писем, текстовых сообщений и так далее. В представленном на Фиг. 2 примере, множество сниппетов 200 беседы включает в себя первый сниппет 202 беседы, второй сниппет 204 беседы и третий сниппет 206 беседы. Тем не менее, следует иметь в виду, что большее число сниппетов беседы, например, 10000, 100000, 1000000 и так далее, может быть собрано и сохранено в базе 120 данных сниппетов, не выходя за пределы настоящей технологии.
[68] Каждый из множества сниппетов 200 беседы связан с соответствующей беседой, которая включает в себя запросы и ответы, введенные "оратором" (человеком или машиной) в соответствующей беседе. Таким образом, каждый из множества сниппетов 200 беседы включает в себя (i) сниппеты запроса, представляющие запросы соответствующей беседы и (ii) сниппеты ответа, представляющие собой ответы из соответствующей беседы.
[69] Например, первый сниппет 202 беседы включает в себя сниппеты 210 и 214 запросов, а также сниппеты 212 и 216 ответов. В другом примере, второй сниппет 204 беседы включает в себя сниппеты 218, 222, 226 запросов и сниппеты 220, 224 и 228 ответов. В другом примере, третий сниппет 206 беседы включает в себя сниппет 230 запроса, а также сниппет 232 ответа.
[70] Следует отметить, что данный ответ в данной беседе может предоставляться (соответствующим пользователем) (i) в ответ на данный запрос и (ii) с учетом конкретного "контекста". Например, данный ответ в данной беседе предоставляется в ответ на то, что данный запрос предшествует данному ответу в данной беседе. Таким образом, можно сказать, что данный ответ "логически" связан с данным запросом, который предшествует данному ответу, поскольку данный ответ предоставляется в ответ на него, и включает в себя ту же логическую информацию, связанную с данным запросом. Тем не менее, данный ответ также предоставляется с учетом контекста данной беседы. Например, данный запрос может быть в формальном контексте, например, беседы с коллегой, или в разговорном общении, например, беседы с другом или членом семьи. Таким образом, можно сказать, что данный ответ "лингвистически" связан с контекстом данной беседы, поскольку данный ответ может предоставляться с помощью формальной лексики или знакомой лексики, в зависимости от контекста данной беседы, в которой предоставляется данный ответ.
[71] Контекст для данного ответ в данной беседе может быть получен из всех из запросов и ответов, которые предшествуют данному ответу, поскольку данный ответ будет, в некотором смысле, подражать "лингвистической" природе, посредством конкретного использования лексики или сленга предыдущих запросов и ответов в данной беседе.
[72] Таким образом, можно сказать, что контекст, связанный с данным ответом, включает в себя часть соответствующей беседы, которая предшествует соответствующему ответу. Например, в первом сниппете 202 беседы, сниппет контекста для сниппета 216 ответа включает в себя (i) сниппеты 210 и 214 запросов и (ii) сниппет 212 ответа. Также, в первом сниппете 202 беседы, сниппет контекста для сниппета 212 ответа включает в себя сниппет 210 запроса. В другом примере, во втором сниппете 204 беседы, сниппет контекста для сниппета 228 ответа включает в себя (i) сниппеты 218, 222 и 226 запросов и (ii) сниппеты 220 и 224 ответов. Также, во втором сниппете беседы, сниппет контекста для сниппета 224 ответа включает в себя (i) сниппеты 218 и 222 запросов и (ii) сниппет 220 ответа. Также, во втором сниппете беседы, сниппет контекста для сниппета 220 ответа включает в себя сниппет 218 запроса. В другом примере, в третьем сниппете 206 беседы, сниппет контекста для сниппета 232 ответа представляет собой сниппет 230 запроса.
[73] Сервер 106 может быть выполнен с возможностью использовать по меньшей мере некоторые из множества сниппетов 200 беседы, хранящихся в базе 120 данных сниппетов для обучения нейронной сети 130. Сервер 106 также может быть выполнен с возможностью использовать по меньшей мере некоторые из множества сниппетов 200 беседы, хранящихся в базе 120 данных сниппетов во время фазы использования нейронной сети 130. То, как сервер 106 может использовать по меньшей мере некоторые из множества сниппетов 200 беседы, хранящихся в базе 120 данных сниппетов для обучения и использования нейронной сети 130, будет описано далее более подробно.
База данных векторов
[74] В общем случае, база 122 данных векторов выполнена с возможностью сохранять множество векторов, связанных с соответствующими сниппетами, хранящимися в базе 120 данных сниппетов. Множество векторов может быть создано сервером 106, выполняющим нейронную сеть 130 во время ее фазы использования. Сервер 106 может также использовать множество векторов, хранящихся в базе 122 данных векторов для выбора зависящих от контекста ответов на новые пользовательские запросы (в фазе использования). Другими словами, база 122 данных векторов выполнена с возможностью осуществлять сохранение одной или нескольких коллекций векторных данных, связанных с соответствующими сниппетами беседы и/или соответствующими сниппетами контекста и ответа из базы 120 данных сниппетов, и причем одна или несколько коллекций векторных данных (i) создается нейронной сетью 130 и (ii) используется сервером 106 для выбора зависящих от контекста ответов.
[75] То, как обучается нейронная сеть 130 во время фазы использования, на основе по меньшей мере некоторых из множества сниппетов 200 беседы, хранящихся в базе 120 данных сниппета, и как используется нейронная сеть 130, используется во время первой фазы использования для заполнения базы 122 данных векторов на основе по меньшей мере некоторых из множества сниппетов 200 беседы, будет описано далее. Тем не менее, следует отметить, что по меньшей мере некоторых из множества сниппетов 200 беседы, используемых во время фазы обучения, может включать или не включать в себя по меньшей мере некоторые из множества сниппетов 200 беседы, используемых во время фазы использования нейронной сети 130, не выходя за границы настоящей технологии.
[76] На Фиг. 3 представлен иллюстративный пример одной итерации обучения нейронной сети 130 в соответствии с некоторыми вариантами осуществления настоящей технологии. Следует отметить, что несмотря на то, что будет описана только итерация обучения, следует иметь в виду, что во время фазы обучения нейронной сети 130, может выполняться большое число итераций обучения аналогично тому, как выполняется одна итерация обучения, показанная на Фиг. 3, для обучения нейронной сети 130, не выходя на границы настоящей технологии.
[77] Итерация обучения нейронной сети 130, показанной на Фиг. 3, включает в себя первую суб-итерацию 302 и вторую суб-итерацию. Во время первой суб-итерации 302, выполняется процедура 306 прямого распространения, во время которой (i) обучающий объект 310 вводится в нейронную сеть 130 и (ii) множество обучающих векторов 310 выводится нейронной сетью 130. Обучающий объект 310 создан сервером 106 на основе информации, хранящейся в базе 120 данных сниппетов. Обучающий объект 310 включает в себя сниппет 314 обучающего контекста, сниппет 316 первого обучающего ответа и сниппет 318 второго обучающего ответа.
[78] Первый обучающий сниппет 316 ответа находится в первом обучающем сниппете 316 ответа в общей обучающей беседе среди множества сниппетов 200 беседы, хранящихся в базе 120 данных сниппета. Например, обучающий сниппет 314 контекста может включать в себя сниппет 210 запроса, сниппет 212 ответа и сниппет 214 запроса первого сниппета 202 беседы, а первый обучающий сниппет 316 может быть сниппетом 216 ответа первого сниппета 202 беседы (см. Фиг. 2). Таким образом, может сказать, что обучающий сниппет 314 контекста представляет контекст ответа, представленный первым обучающим сниппетом 316 ответа.
[79] С другой стороны, второй обучающий сниппет 318 ответа не находится в обучающем сниппете 314 контекста в любом из множества сниппетов 200 бесед, хранящихся в базе 120 данных сниппетов. Сервер 106 может быть выполнен с возможностью выбирать любой сниппет ответа как второй обучающий сниппет 318 ответа, поскольку никакой из сниппетов ответа не находится в обучающем сниппете 314 контекста в общем сниппете беседы среди множества сниппетов 200 беседы.
[80] Обучающий сниппет 314 контекста вводится в подсеть 132 контекста нейронной сети 130, а первый и второй обучающие сниппеты 316 и 318 ответа вводятся в подсеть 134 ответа. Таким образом, подсеть 132 контекста создает обучающий вектор 320 контекста на основе обучающего сниппета 314 контекста, а подсеть 134 ответа создает первый и второй обучающие векторы 322 и 324 ответа на основе первого и второго обучающего сниппетов 316 и 318 ответа соответственно. По того, как множество обучающих векторов 312, содержащих обучающий вектор 320 контекста и первый и второй обучающие векторы 322 и 324 ответа выводятся нейронной сетью 130, первая суб-итерация 302 завершается, и может начаться вторая суб-итерация 304. Следует отметить, что все обучающие векторы во множестве обучающих векторов 312 обладают одинаковым числом измерений или, другими словами, одинаковой размерностью.
[81] В общем случае, во время второй суб-итерации 304, выполняется процедура 308 обратного распространения, за время которой подсети 132 контекста и 134 ответа могут адаптироваться к изучаемой ситуации и могут менять свои структуры (например, взаимосвязи между искусственными "нейтронами").
[82] Во время второй суб-итерации 304, значение 350 положительного примера сходства векторов и значение 360 отрицательного примера сходства векторов создается сервером 106 на основе множества обучающих векторов 312. Значение 350 положительного примера сходства векторов создается на основе обучающего вектора 320 контекста и первого обучающего вектора 322 ответа. Значение 350 положительного примера сходства векторов указывает на сходство обучающего вектора 320 контекста и первого обучающего вектора 322 ответа. Значение 360 отрицательного примера сходства векторов создается на основе обучающего вектора 320 контекста и второго обучающего вектора 324 ответа. Значение 360 отрицательного примера сходства векторов указывает на сходство обучающего вектора 320 контекста и второго обучающего вектора 324 ответа.
[83] Следует отметить, что значение 350 положительного примера сходства векторов и значение 360 отрицательного примера сходства векторов может создаваться различными путями и будет зависеть, среди прочего, от различных вариантов осуществления настоящей технологии. Например, данное значение сходства векторов может создаваться как значение, которое обратно пропорционально векторному расстоянию между соответствующей парой векторов. Таким образом, данное значение сходства векторов может указывать на векторное расстояние между соответствующей парой векторов. В другом примере, данное векторное сходство может создаваться как скалярное произведение между соответствующей парой векторов.
[84] Для целей иллюстрации, описанных далее, предположим, что значение 350 положительного примера сходства векторов создается как скалярное произведение обучающего вектора 320 контекста и первый обучающий вектор 322 ответа, и что значение 360 отрицательного примера сходства векторов создается как скалярное произведение обучающего вектора 320 контекста и второго обучающего вектора 324 ответа. Тем не менее, как уже упоминалось ранее, подразумевается, что значение 350 положительного примера сходства векторов и значение 360 отрицательного примера сходства векторов может создаваться различными путями в различных вариантах осуществления настоящей технологии.
[85] Также следует иметь в виду, что значение 350 положительного примера сходства векторов связано с обучающим сниппетом 314 контекста и первым обучающим сниппетом 316 ответа, который находится в обучающем сниппете беседы. Также, значение 360 отрицательного примера сходства векторов связано с обучающим сниппетом 314 контекста и вторым обучающим сниппетом 318 ответа, который не находится в обучающем сниппете беседы. Следовательно, можно сказать, что значение 350 положительного примера сходства векторов определяется оператором сервера 106 как "положительный пример" для нейронной сети 130 и, следовательно, должен превосходить значение 360 отрицательного примера сходства векторов, которое определяется оператором сервера 106 как "отрицательный пример" для нейронной сети 130. В самом деле, обучающий вектор 320 контекста и первый обучающий вектор 322 ответа должны быть более похожими друг на друга, чем обучающий вектор 320 контекста и второй обучающий вектор 324 ответа, поскольку обучающий сниппет 314 контекста и первый обучающий сниппет 316 ответа находятся в общем сниппете беседы. В самом деле, оператор сервера 106 может определять "положительные и отрицательные примеры" (комбинации наличия или отсутствия сниппетов) для нейронной сети 130 таким образом, что нейронная сеть 130 обучена создавать значения сходства векторов для "положительных примеров", которые превышают значения сходства векторов "отрицательных примеров".
[86] Во время второй суб-итерации 304 сервер 106 может быть выполнен с возможностью создавать штрафное значение 370 для обучения нейронной сети 130 на основе значения 350 положительного примера сходства векторов и отрицательного примерного значения 360 сходства векторов.
[87] В общем случае, во время процедуры 308 обратного распространения, штрафное значение 370 может "распространяться", если есть таковая необходимость, через нейронную сеть 130 (в обратном направлении), чтобы поменять или адаптировать взаимосвязи между "нейронами" и подсетями 132 контекста и 134 ответа для адаптации к изучаемой ситуации, если есть такая необходимость.
[88] В некоторых вариантах осуществления настоящей технологии, если значение 350 положительного примера сходства векторов больше отрицательного примерного значения 360 сходства векторов, штрафное значение 370 может составлять "ноль" или незначительно для текущей итерации обучения. В самом деле, сервер 106 может определять, что, поскольку обучающий вектор 320 контекста и первый обучающий вектор 322 ответа больше похожи друг на друга, чем обучающий вектор 320 контекста и второй обучающий вектор 324 ответа, нет необходимости "распространять" какие-либо штрафные значения по нейронной сети 130, поскольку нейронная сеть 130 адаптирована под изучаемую ситуацию.
[89] Тем не менее, если значение 350 положительного примера сходства векторов меньше значения 360 отрицательного примера сходства векторов, штрафное значение 370 может составлять разницу между значением 350 положительного примера сходства векторов и значением 360 отрицательного примера сходства векторов. В этом случае, сервер 106 может определять, что, поскольку обучающий вектор 320 контекста и первый обучающий вектор 322 ответа меньше похожи друг на друга, чем обучающий вектор 320 контекста и второй обучающий вектор 324 ответа, есть необходимость "распространять" штрафное значение 370, поскольку нейронная сеть 312 не создала множества обучающих векторов 312, которые соответствуют или подходят для изучаемое ситуации.
[90] Следовательно, в некоторых вариантах осуществления настоящей технологии, можно сказать, что нейронная сеть 130 была обучена на основе первого данного обучающего сниппета контекста и первого данного обучающего сниппета ответа, которые находятся в общем сниппете беседы, и второго данного обучающего сниппета ответа, который не находится в первом сниппете контекста, таким образом, чтобы данное значение положительного примера сходства векторов между (i) первым данным обучающим вектором ответа, созданным на основе первого данного сниппета ответа и (ii) первым данным обучающим вектором контекста, созданным на основе первого данного обучающего сниппета контекста, превышало данное значение отрицательного примера сходства векторов между (i) вторым данным обучающим вектором ответа, созданным на основе второго данного обучающего сниппета ответа, и (ii) первым данным обучающим вектором контекста.
[91] Как было упомянуто ранее, в некоторых вариантах осуществления настоящей технологии, если значение 350 положительного примера сходства векторов больше, по меньшей мере на заранее определенное пороговое значение, значения 360 отрицательного примера сходства векторов, штрафное значение 370 может составлять "ноль" или незначительно для текущей итерации обучения. Тем не менее, если значение 350 положительного примера сходства векторов не больше, по меньшей мере на заранее определенное пороговое значение, значения 360 отрицательного примера сходства векторов, штрафное значение 370 может составлять разницу между значением 350 положительного примера сходства векторов и значением 360 отрицательного примера сходства векторов. Заранее определенное пороговое значение может быть определено оператором сервера 106 и будет зависеть, среди прочего, от различных вариантов осуществления настоящей технологии.
[92] Следовательно, в других вариантах осуществления настоящей технологии, можно сказать, что нейронная сеть 130 была обучена на основе первого данного обучающего сниппета контекста и первого данного обучающего сниппета ответа, которые находятся в общем сниппете беседы, и второго данного обучающего сниппета ответа, который не находится в первом сниппете контекста, таким образом, чтобы данное значение положительного примера сходства векторов между (i) первым данным обучающим вектором ответа, созданным на основе первого данного сниппета ответа и (ii) первым данным обучающим вектором контекста, созданным на основе первого данного обучающего сниппета контекста, превышало, по меньшей мере на заранее определенное пороговое значение, данное значение отрицательного примера сходства векторов между (i) вторым данным обучающим вектором ответа, созданным на основе второго данного обучающего сниппета ответа, и (ii) первым данным обучающим вектором контекста.
[93] В общем, можно сказать, что нейронная сеть 130 (например, подсеть 132 контекста и подсеть 134 ответа) обучается для создания векторов контекста и ответа таким образом, что различия между значениями положительного примера сходства векторов и значениями отрицательного примера сходства векторов максимизированы. В самом деле, нейронная сеть 130 обучается созданию данных векторов контекста и данных векторов ответа таким образом, что (i) векторы контекста и векторы ответа, связанные со сниппетами контекста и сниппетами ответа соответственно, которые находятся в общих сниппетах беседы и более похожи на (ii) векторы контекста и векторы ответа, связанные со сниппетами контекста и сниппетами ответа соответственно, которые не находятся в общих сниппетах беседы.
[94] После завершения второй суб-итерации 304, следующая итерация обучения нейронной сети 130 может выполняться сервером 106 аналогично тому, как выполняется одна итерация обучения, показанная на Фиг. 3.
[95] После обучения нейронной сети 130 во время ее фазы обучения, сервер 106 может использовать нейронную сеть 130 во время ее первой фазы использования для заполнения базы 122 данных векторов. На Фиг. 4 представлен иллюстративный пример процесса 400 создания векторов для заполнения векторной базы 122 данных.
[96] Сервер 106 извлекает данные, указывающие на сниппет 412 беседы, из базы 120 данных сниппетов. Сервер 106 анализирует сниппет 412 беседы и извлекает сниппет 414 контекста и сниппет 416 ответа. Сниппет 414 контекста вводится в подсеть 132 контекста, а сниппет 416 ответа вводится в подсеть 134 ответа. Подсеть 132 контекста выводит вектор 420 контекста, а подсеть 134 ответа выводит вектор 422 ответа. В некоторых вариантах осуществления настоящей технологии, вектор 420 контекста и вектор 422 ответа конкатенированы сервером 106 для создания вектора 424, который включает в себя (i) вектор 420 контекста и вектор 422 ответа. Вектор 424 далее сохраняется в базе 122 данных векторов, причем вектор 424 связан со сниппетом 412 беседы.
[97] Подразумевается, что в других вариантах осуществления настоящей технологии сервер 106 может сохранять вектор 420 контекста и вектор 422 ответа, как в связи со сниппетом 412 беседы в базе 122 данных векторов, без конкатенации вектора 420 контекста и вектора 422 ответа в вектор 424.
[98] Следует отметить, что вектор 420 контекста, который создается подсетью 132 контекста, указывает на свойства сниппета 414 контекста, а вектор 422 ответа, который создается с помощью подсети 134 ответа, указывает на свойства сниппета 416 ответа. В самом деле, вектор 420 контекста указывает на свойства сниппета 414 контекста, поскольку он был создан на основе сниппета 414 контекста, а вектор 244 ответа указывает на свойства сниппета 416 ответа, поскольку он был создан на основе сниппета 416 ответа. Тем не менее, как уже упоминалось ранее, нейронная сеть 130 (например, подсеть 132 и 134 контекста и ответа) старается предоставлять "интуитивный" ответ на основе "ощущений" от ситуации. Нейронная сеть 130, таким образом, представляет собой что-то наподобие "черного ящика", который может использоваться в ситуации, когда само содержимое "ящика" не является существенным; но важно, что "ящик" предоставляет логичные ответы на данный ввод.
[99] Таким образом, можно сказать, что неважно на какие конкретно свойства сниппета 414 контекста указывает вектор 420 контекста, тем не менее, важно, что вектор 420 контекста указывает по меньшей мере на некоторые лингвистические и логические свойства сниппета 414 контекста, например, на то, что данное значение сходства между вектором 420 контекста и вектором 422 ответа превышает данное значение сходства вектора 420 контекста и другого вектора ответа, связанного со сниппетом ответа, который не находится в сниппете 414 контекста.
[100] Также можно сказать, что неважно на какие конкретно свойства сниппета 416 ответа указывает вектор 422 ответа, тем не менее, важно, что вектор 422 ответа указывает по меньшей мере на некоторые лингвистические и логические свойства сниппета 416 ответа, например, на то, что данное значение сходства между вектором 420 контекста и вектором 422 ответа превышает данное значение сходства вектора 422 ответа и другого вектора контекста, связанного со сниппетом ответа, который не находится в сниппете 416 ответа.
[101] Предположение о том, что (i) вектор 420 контекста указывает по меньшей мере на некоторые лингвистические и логические свойства сниппета 414 контекста и (ii) вектор 422 ответа указывает по меньшей мере на некоторые лингвистические и логические свойства сниппета 416 ответа, может быть сделано по причине того, что, как обсуждалось ранее, сниппеты контекста и сниппеты ответа, которые находятся в общем сниппете беседы, "логически" и "лингвистически" связаны друг с другом. Следовательно, обучение нейронной сети 130 созданию векторов контекста и векторов ответа для соответствующего контекста и сниппетов ответа, которые находятся вместе таким образом, что эти векторы контекста и ответа аналогичны, приводит к обучению нейронной сети 130 созданию этих векторов контекста и ответа таким образом, что они указывают по меньшей мере на некоторые лингвистические и логические свойства, поскольку эти свойства должны быть аналогичными из-за нахождения соответствующих сниппетов контекста и ответа.
[102] Соответствующий процесс создания вектора может выполняться для каждого сниппета беседы, хранящегося в базе 120 данных сниппета, аналогично тому, как выполняется процесс 400 создания вектора сервером 106 для сниппета 412 беседы.
[103] На Фиг. 1, как упоминалось ранее, на сервере 106 находится сервис 108 IPA, и сервер 106 выполнен с возможностью (i) получать данные, указывающие на запросы от устройства 104, (ii) анализировать данные, указывающие на запросы и, в ответ, (iii) создавать данные, указывающие на искусственные ответы и (iv) передавать данные, указывающие на искусственные ответы, устройству 104. То, как реализованы некоторые из функций сервера 106, будет описано далее.
[104] Предположим, что звуковое указание 152 (например, произнесенное высказывание пользователя 102) обнаружено или зафиксировано устройством 104. Приложение 105 IPA извлекает из звукового указания 152 данные, указывающие на первый запрос "Эй, ты здесь?"
[105] Предположим, что сервис 108 IPA создает первый зависящий от контекста ответ "Да", по меньшей мере частично основанный на (i) первом запросе (в данном случае, первый сниппет запроса также является сниппетом контекста для первого зависящего от контекста ответа). Сервер 106 далее передает устройству 104 данные, указывающие на первый зависящий от контекста ответ. Подразумевается, что данные, указывающие на первый зависящий от контекста ответ может храниться в базе 124 данных обработки в связи в первым запросом.
[106] Также предполагается, что устройство 104 создает, на основе данных, указывающий на первый зависящий от контекста ответ, звуковое указание 154 (например, "произнесенное высказывание" приложения 105 сервиса IPA) и предоставляет или воспроизводит его пользователю 102.
[107] Также предположим, что звуковое указание 156 (например, другое произнесенное высказывание пользователя 102) далее обнаружено или зафиксировано устройством 104. Приложение 105 IPA извлекает из звукового указания 152 данные, указывающие на второй запрос "Как дела?" Другими словами, в этот момент времени, беседа 150 может выглядеть следующим образом:
 "Эй, ты тут?"
"Эй, ты тут?"
"Да".
"Как дела?"
[108] Устройство 104 может быть выполнено с возможностью создавать пакет 180 данных, который включает в себя данные, указывающие на беседу 150, например, данные, указывающие на (i) первый запрос, (ii) первый зависящий от контекста ответ и (iii) второй запрос. Устройство 104 выполнено с возможностью передавать пакет 180 данных по сети 110 передачи данных серверу 106. Подразумевается, что содержимое пакета 180 данных может храниться в базе 124 данных обработки сервером 106 при получении.
[109] При получении пакета 180 данных, сервер 106 может передавать свое содержимое сервису 108 IPA для обработки. В общем случае, сервис 108 IPA выполнен с возможностью выбирать, на основе по меньшей мере некоторого содержимого пакета 180 данных, данный зависящий от контекста ответ для второго запроса. С этой целью, сервис 108 IPA может выполнять подсеть 132 контекста нейронной сети 130 во время второй фазы использования.
[110] На Фиг. 5 представлен иллюстративный пример того, как может использоваться подсеть 132 контекста сервером 106 для выбора данного зависящего от контекста ответа для второго запроса.
[111] Когда содержимое пакета 180 данных передается сервису 108 IPA, сервис 108 IPA может извлекать из него данные, указывающие на текущий сниппет 500 контекста. Текущий сниппет 500 контекста представляет собой беседу 150, в данный момент, между пользователем 102 и приложением 105 IPA устройства 104. Следует отметить, что текущий сниппет контекста включает в себя текущий запрос "Как дела?" (т.е. второй запрос), для которого необходимо предоставить текущий зависящий от контекста ответ (например, данный зависящий от контекста ответ). Текущий сниппет 500 контекста вводится в подсеть 132 контекста, которая в ответ создает текущий вектор 502 контекста. В некоторых вариантах осуществления настоящей технологии, сервер 106 может быть выполнен с возможностью создавать двойной текущий вектор 504 контекста путем конкатенации текущего вектора 502 контекста с его копией.
[112] Сервер 106 может извлекать из базы 122 данных векторов, которая была заполнена во время первой фазы использования нейронной сети 130, множеством векторов 512. Следует отметить, что каждый из множества векторов 512 связан с соответствующим сниппетом (например, соответствующим сниппетом контекста и соответствующим сниппетом ответа). Например, множество векторов 512 включает в себя вектор 424, который содержит вектор 420 контекста и вектор 422 ответа, и вектор 510, который включает в себя вектор 506 контекста и вектор 508 ответа. Тем не менее, следует иметь в виду, что множество векторов 512 может содержать большее число векторов, например, 100, 10000, 100000, 1000000 и так далее.
[113] В некоторых вариантах осуществления настоящей технологии, множество векторов 512 может включать в себя все векторы, хранящиеся в базе 122 данных векторов. В других вариантах осуществления настоящей технологии, множество векторов может представлять собой подмножество векторов, выбранных из всех векторов, хранящихся в базе 122 данных векторов. Например, выбор подмножества векторов из всех векторов может выполняться сервером 106 на основе данного алгоритма поиска сходства ближайших соседей, как будет понятно из дальнейшего описания.
[114] Сервер 106 также выполнен с возможностью создавать, для каждого из множества векторов 512, соответствующую оценку ранжирования. Каждая оценка ранжирования является суммой соответствующего первого значения сходства векторов и соответствующего второго значения сходства векторов.
[115] Например, сервер 106 может быть выполнен с возможностью создавать первое значение 512 сходства векторов и второе значение 516 сходства векторов на основе вектора 424 и двойного текущего вектора 504 контекста. Сервер 106 может быть выполнен с возможностью создавать оценку 522 ранжирования для вектора 424 в качестве скалярного произведения между вектором 424 и двойным вектором 504 контекста. Сумма первого значения 514 сходства векторов и второго значения 516 сходства векторов равна оценке 522 ранжирования.
[116] Первое значение 514 сходства векторов является скалярным произведением вектора 420 контекста и текущего вектора 502 контекста. Чем выше первое значение 514 сходства векторов, тем более схожими являются вектор 420 контекста и текущий вектора 502 контекста. Поскольку данный контекст данной беседы может указывать на лингвистическую "природу" (например, стиль речи) данной беседы, чем выше первое значение 514 сходства векторов, тем более лингвистически схожи сниппет 414 контекста и текущий сниппет 500 контекста. Таким образом, можно сказать, что первое значение 514 сходства вектора указывает на лингвистическое сходство между сниппетом 414 контекста (см. Фиг. 4), связанным с вектором 420 контекста и текущим сниппетом 500 контекста, связанным с текущим вектором 502.
[117] Второе значение 516 сходства векторов является скалярным произведением вектора 422 ответа и текущего вектора 502 контекста. Чем выше второе значение 516 сходства векторов, тем более схожими являются вектор 422 ответа и текущий вектора 502 контекста. Другими словами, чем выше второе значение 516 сходства векторов, тем более лингвистически и логически сходны сниппет 416 ответа и текущий сниппет 500 контекста, исходя из того как была обучена нейронная сеть 130 во время фазы обучения. Таким образом, можно сказать, что второе значение 516 сходства вектора указывает на логическое и лингвистическое сходство между сниппетом 416 ответа (см. Фиг. 4), связанным с вектором 422 ответа и текущим сниппетом 500 контекста, связанным с текущим вектором 502.
[118] В другом примере, сервер 106 может быть выполнен с возможностью создавать первое значение 518 сходства векторов и второе значение 520 сходства векторов на основе вектора 510 и двойного текущего вектора 504 контекста. Сервер 106 может быть выполнен с возможностью создавать оценку 524 ранжирования для вектора 510 в качестве скалярного произведения между вектором 510 и двойным вектором 504 контекста. Сумма первого значения 518 сходства векторов и второго значения 520 сходства векторов равна оценке 524 ранжирования.
[119] Первое значение 518 сходства векторов является скалярным произведением вектора 506 контекста и текущего вектора 502 контекста. Таким образом, можно сказать, что первое значение 518 сходства векторов указывает на лингвистическое сходство между данным сниппетом 414 контекста, связанным с вектором 506 контекста и текущим сниппетом 500 контекста, связанным с текущим вектором 502 контекста. Второе значение 520 сходства векторов является скалярным произведением вектора 508 ответа и текущего вектора 502 контекста. Таким образом, можно сказать, что второе значение 520 сходства вектора указывает на логическое сходство между данным сниппетом ответа, связанным с вектором 508 ответа и текущим сниппетом 500 контекста, связанным с текущим вектором 502 контекста.
[120] Как показано на Фиг. 5, сервер 106 может быть выполнен с возможностью создавать множество первых значений 526 сходства векторов и множество вторых значений 528 сходства векторов. Например, каждый из множества векторов 512 связан с соответствующим одним из первых значений 526 сходства векторов с соответствующим одним из вторых значений 528 сходства векторов.
[121] Сервер 106 также выполнен с возможностью создавать множество оценок 530 ранжирования. Подразумевается, что в некоторых вариантах осуществления настоящей технологии, данная оценка ранжирования может являться взвешенной суммой соответствующего первого значения сходства векторов и соответствующего второго значения сходства векторов. Это может придать, в некотором смысле, больше важности во время выбора текущего зависящего от контекста ответа, логическому сходству текущего зависящего от контекста ответа с текущим запросом или лингвистическому сходству текущего зависящего от контекста ответа в текущем контексте.
[122] В некоторых вариантах осуществления настоящей технологии, сервер 106 может также быть выполнен с возможностью создавать ранжированное множество векторов (не показано), содержащее множество векторов 512, ранжированных в соответствии с их соответствующими оценками ранжирования из множества оценок 530 ранжирования. Также подразумевается, что сервер 106 может быть выполнен с возможностью выбирать данный сниппет ответа, связанный с наиболее высоко ранжированным вектором, из ранжированного множества векторов.
[123] Например, предположим, что оценка 522 ранжирования, связанная с вектором 424, превышает любую оценку ранжирования среди множества оценок 530 ранжирования. Также предположим, что вектор 424 и, конкретнее, вектор 422 ответа связан с соответствующим сниппетом 416 ответа, представляющим собой "Все хорошо, я в порядке". Таким образом, сервер 106 может быть выполнен с возможностью выбирать сниппет 416 ответа в качестве текущего зависящего от контекста ответа для текущего запроса "Как твои дела?". Следует отметить, что вместо выбора ответа, например "Мои дела отлично, спасибо", который не связан с лингвистическим стилем текущего сниппета 500 контекста, текущий зависящий от контекста ответ, выбранный сервисом 108 IPA, может "подражать" знакомому контексту текущего сниппета 500 контекста, одновременно оставаясь логически связанным с текущим запросом.
[124] Сервер 106 выполнен с возможностью создавать пакет 185 данных, содержащий данные, указывающие на текущий зависящий от контекста ответ "Все хорошо, я в порядке." и передавать его через сеть 110 передачи данных устройству 104. Приложение 105 IPA может далее анализировать содержимое пакета 185 данных для создания звукового указания 158, которое указывает на текущий зависящий от контекста ответ, и предоставлять или воспроизводить его для пользователя 102.
[125] Следует отметить, что подразумевается, что предоставление подобных зависящих от контекста ответов может быть полезным для пользователя 102. Следует отметить, что предоставление более "подходящих ответов" пользователю 102, то есть "подражание" стилю речи пользователя 102, может делать пользовательское взаимодействие с устройством 104 более простым и удобным. Более эффективное пользовательское взаимодействие может быть полезным для пользователя 102 во множестве различных ситуаций, например, если пользователь ведет транспортное средство, пользователь с нарушениями или не может взаимодействовать по какой-либо другой причине с устройством 104 с помощью какого-либо модуля пользовательского взаимодействия временно и/или постоянно.
[126] В других вариантах осуществления настоящей технологии, следует отметить, что предоставление такого "более подходящего ответа" пользователю 102 может снизить вычислительную мощность и/или время, которые необходимы устройству 104 и/или приложению 105 IPA для завершения задачи, запрашиваемой у него после запуска приложения 105 IPA устройством 104. Это может снизить энергопотребление и расход батареи устройства 104, а также сэкономить вычислительную мощность, позволяя выполнять другие приложения, установленные и/или работающие на устройстве 104.
[127] На Фиг. 5 представлена блок-схема способа 600 выбора текущего зависящего от контекста ответа для текущего пользовательского запроса в соответствии с некоторыми вариантами осуществления настоящей технологии. Несмотря на то, что способ 600 будет описан как выполняемый сервером 106, следует отметить, что устройство 104 может быть выполнено с возможностью выполнять способ 600 аналогично тому, как сервер 106 выполнен с возможностью выполнять способ 600, не выходя за пределы настоящей технологии.
ЭТАП 602: Получение текущего сниппета контекста, включающего в себя текущий пользовательский запрос
[128] Способ 600 начинается на этапе 602, когда сервер 106 получает текущий сниппет 500 контекста, содержащий текущий запрос "Как дела?". Например, сервер 106 может быть выполнен с возможностью получать пакет 180 данных (см. Фиг. 1), содержащий данные, указывающие на текущий сниппет 500 контекста.
[129] Подразумевается, что сервер 106 может быть выполнен с возможностью сохранять данные, указывающие на текущий сниппет 500 контекста в базе 124 данных обработки для будущего использования.
ЭТАП 604: Создание нейронной сетью текущего вектора контекста на основе текущего сниппета контекста
[130] Способ 600 продолжается на этапе 602, где сервер 106 выполнен в возможностью осуществлять создание, путем использования нейронной сети 130, текущего вектора 502 контекста на основе текущего сниппета 500 контекста. Подразумевается, что создание текущего вектора 502 контекста на основе текущего сниппета 500 контекста выполняется подсетью 132 контекста нейронной сети 130. Следует отметить, что, как упоминалось ранее, текущий вектор 502 контекста указывает по меньшей мере на некоторые лингвистические и логические свойства текущего сниппета контекста.
[131] Со ссылкой на Фиг. 3, подразумевается, что нейронная сеть 130 включает в себя подсеть 132 контекста и подсеть 134 ответа. Подсеть 132 контекста во время своей обучающей фазы, создает обучающий вектор 320 контекста на основе обучающего сниппета 314 контекста. Подсеть 134 ответа, во время своей фазы обучения, создает первый и второй обучающие векторы 322 и 324 ответа на основе первого и второго обучающих сниппетов 316 и 318 ответа соответственно. Подразумевается, что во время фазы обучения нейронной сути 130, она может быть обучена таким образом, что значение 350 положительного примера сходства векторов превышает по меньшей мере заранее определенное пороговое значение (определено оператором сервера 106) значения 360 отрицательного примера сходства векторов.
[132] Также подразумевается, что нейронная сеть 130 может обучаться сервером 106 для создания обучающего вектора 320 контекста и первого и второго обучающих векторов 322 и 324 ответа таким образом, чтобы максимизировать разницу между значением 350 положительного примера сходства векторов и значением 360 отрицательного примера сходства векторов.
[133] В некоторых вариантах осуществления настоящей технологии, нейронная сеть 130 может быть обучена на основе по меньшей мере на некоторых данных, хранящихся в базе 120 данных сниппета. Также подразумевается, что по меньшей мере некоторые данные, хранящиеся в базе 120 данных сниппетов, которая используется во время фазы обучения нейронной сети 130, могут включать или не включать в себя по меньшей мере некоторые данные, хранящиеся в базе 120 данных сниппетов, которая используется во время первой и второй фаз использования нейронной сети 130.
ЭТАП 606: Для каждого сниппета ответа, связанного с соответствующим вектором, создается соответствующая оценка ранжирования, которая является суммой соответствующего первого значения сходства векторов и соответствующего второго значения сходства векторов
[134] Способ 600 продолжается на этапе 606, где сервер 106 выполнен с возможностью, для каждого сниппета ответа, связанного с соответствующим одним из множества векторов 512 (см. Фиг. 5), создавать соответствующую оценку ранжирования, которая является суммой соответствующего первого значения сходства векторов и соответствующего второго значения сходства векторов.
[135] Подразумевается, что сервер 106 может быть выполнен с возможностью выбирать множество векторов 512 среди всех векторов, хранящихся в базе 122 данных векторов, заполненных нейронной сетью 130 во время ее первой фазы использования. Например, выбор данного подмножества векторов (например, множество векторов 512) из всех векторов может выполняться сервером 106 на основе данного алгоритма поиска сходства с ближайшим соседом.
[136] Подразумевается, что сервер 106 может создавать для множества векторов 512 (i) множество первых значений 526 сходства векторов, (ii) множество вторых значений 528 сходства векторов и (iii) множество оценок 530 ранжирования.
[137] В некоторых вариантах осуществления настоящей технологии, соответствующая оценка ранжирования каждого из множества векторов 512 может представлять собой взвешенную сумму соответствующего первого значения сходства векторов и соответствующего второго значения сходства векторов.
[138] Например, первое значение 514 сходства векторов может являться скалярным произведением вектора 420 контекста и текущего вектора 502 контекста. Чем выше первое значение 514 сходства векторов, тем более схожими являются вектор 420 контекста и текущий вектора 502 контекста. Поскольку данный контекст данной беседы может указывать на лингвистическую "природу" (например, стиль речи) данной беседы, чем выше первое значение 514 сходства векторов, тем более лингвистически схожи сниппет 414 контекста и текущий сниппет 500 контекста. Таким образом, можно сказать, что первое значение 514 сходства вектора указывает на лингвистическое сходство между сниппетом 414 контекста (см. Фиг. 4), связанным с вектором 420 контекста и текущим сниппетом 500 контекста, связанным с текущим вектором 502.
[139] В другом примере, второе значение 514 сходства векторов может являться скалярным произведением вектора 420 ответа и текущего вектора 502 контекста. Чем выше второе значение 516 сходства векторов, тем более схожими являются вектор 422 ответа и текущий вектора 502 контекста. Другими словами, чем выше второе значение 516 сходства векторов, тем более лингвистически и логически сходны сниппет 416 ответа и текущий сниппет 500 контекста, исходя из того, как была обучена нейронная сеть 130 во время фазы обучения. Таким образом, можно сказать, что второе значение 516 сходства вектора указывает на логическое и лингвистическое сходство между сниппетом 416 ответа (см. Фиг. 4), связанным с вектором 422 ответа и текущим сниппетом 500 контекста, связанным с текущим вектором 502.
[140] В некоторых вариантах осуществления настоящей технологии, подразумевается, что (i) множество первых значений 526 сходства векторов, (ii) множества вторых значений 528 сходства векторов и (iii) множество оценок 530 ранжирования могут сохраняться сервером 106 в базе 124 данных обработки для будущего использования.
ЭТАП 608: выбор текущего зависящего от контекста ответа среди сниппетов ответа на основе соответствующих оценок ранжирования
[141] Способ 600 завершается на этапе 608, где сервер 106 выполнен с возможностью осуществлять выбор текущего зависящего от контекста ответа среди сниппетов ответа, связанного с соответствующими векторами из множества векторов 512 на основе соответствующих оценок ранжирования.
[142] Подразумевается, что сервер 106 может ранжировать сниппеты ответа, связанные с соответствующими векторами из множества векторов 512 на основе соответствующих оценок ранжирования во множестве оценок 530 ранжирования. Сервер 106 может также быть выполнен с возможностью выбирать текущий зависящий от контекста ответ в качестве наиболее высоко ранжированного сниппета ответа среди таким образом ранжированных сниппетов ответа на текущий запрос.
[143] Модификации и улучшения вышеописанных вариантов осуществления настоящей технологии будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не устанавливает никаких ограничений. Таким образом, объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ НЕЙРОННОЙ СЕТИ ФОРМИРОВАНИЮ ТЕКСТОВОЙ ВЫХОДНОЙ ПОСЛЕДОВАТЕЛЬНОСТИ | 2020 |
|
RU2798362C2 |
| Способ и система для синтеза речи из текста | 2017 |
|
RU2692051C1 |
| СПОСОБ И КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ ОПРЕДЕЛЕНИЯ НАМЕРЕНИЯ, СВЯЗАННОГО С ЗАПРОСОМ ДЛЯ СОЗДАНИЯ ЗАВИСЯЩЕГО ОТ НАМЕРЕНИЯ ОТВЕТА | 2017 |
|
RU2711104C2 |
| СПОСОБ И СИСТЕМА ВЫБОРА ДЛЯ РАНЖИРОВАНИЯ ПОИСКОВЫХ РЕЗУЛЬТАТОВ С ПОМОЩЬЮ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2731658C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ПРОВЕРКИ МЕДИАКОНТЕНТА | 2022 |
|
RU2815896C2 |
| СПОСОБ И СИСТЕМА СОЗДАНИЯ ВЕКТОРОВ АННОТАЦИИ ДЛЯ ДОКУМЕНТА | 2017 |
|
RU2720074C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРИРОВАНИЯ ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТА | 2018 |
|
RU2733481C2 |
| СПОСОБ И СИСТЕМА ДЛЯ РАСШИРЕНИЯ ПОИСКОВЫХ ЗАПРОСОВ С ЦЕЛЬЮ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2018 |
|
RU2720905C2 |
| Способ и система для хранения множества документов | 2018 |
|
RU2744028C2 |
| Способы и электронные устройства для идентификации пользовательского высказывания по цифровому аудиосигналу | 2018 |
|
RU2761940C1 |
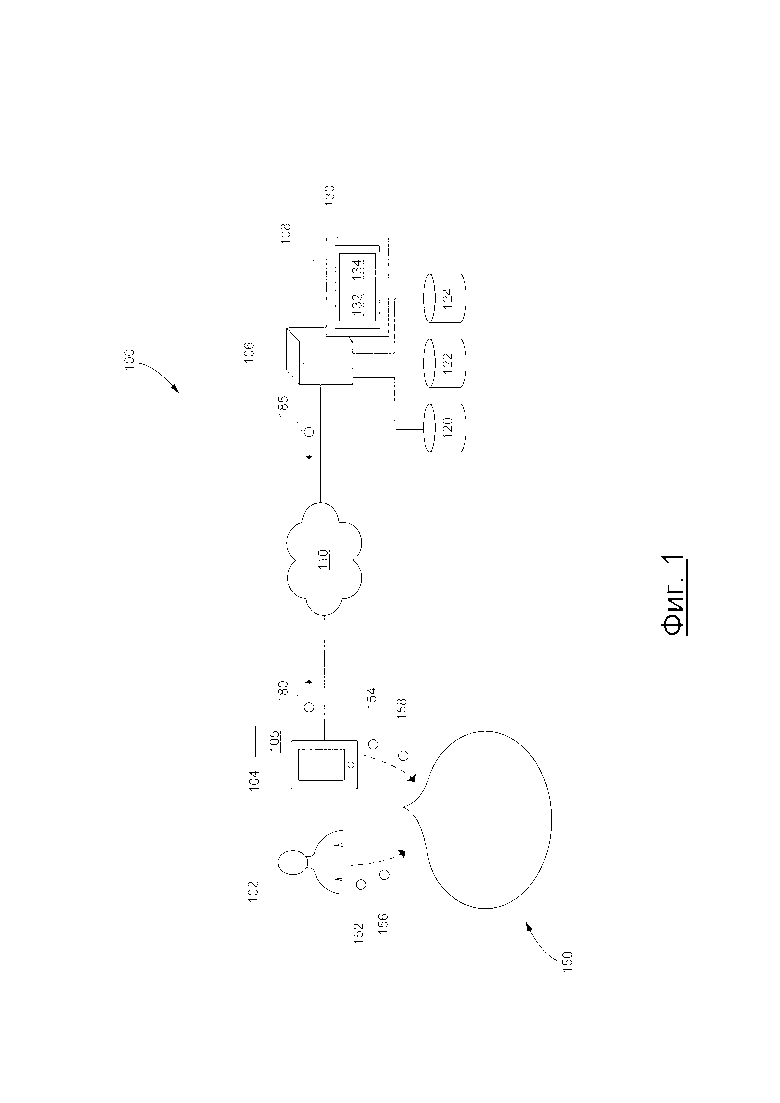

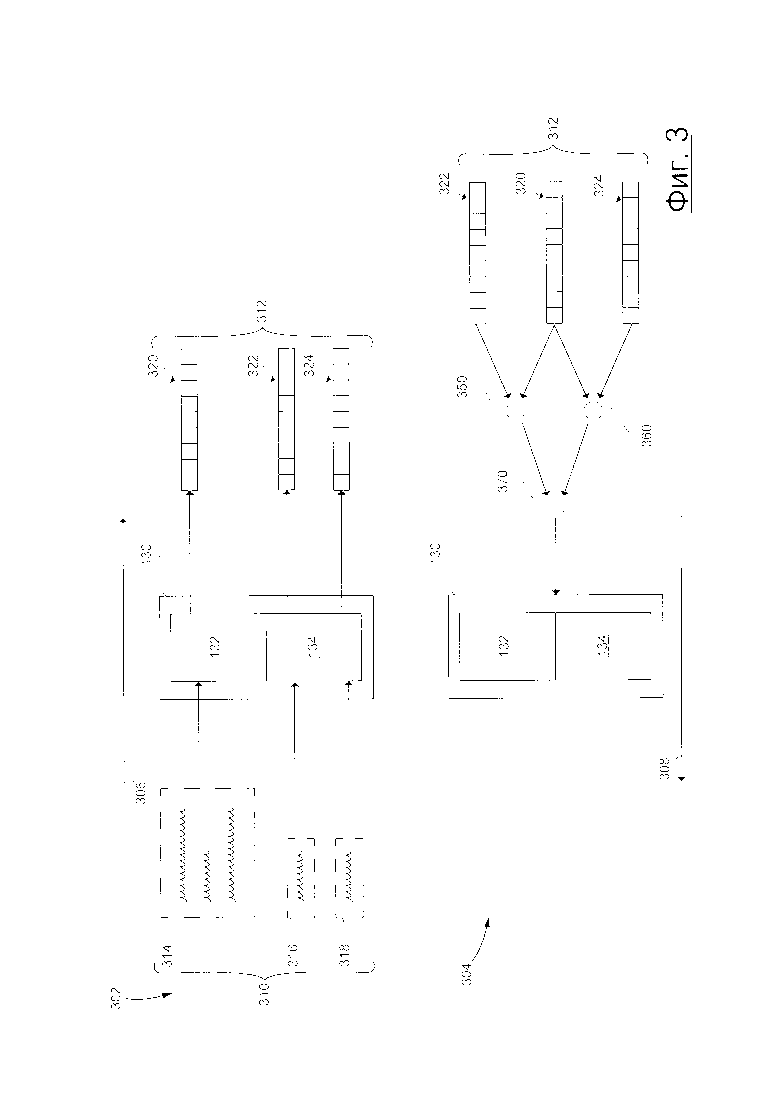
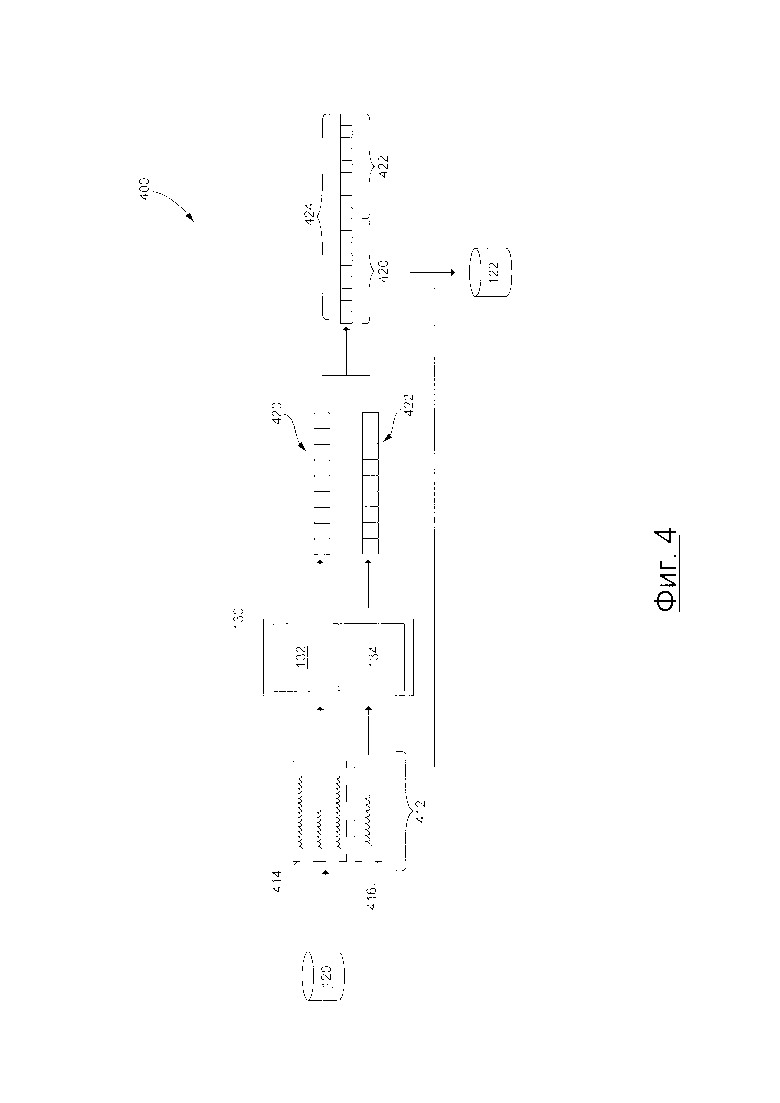
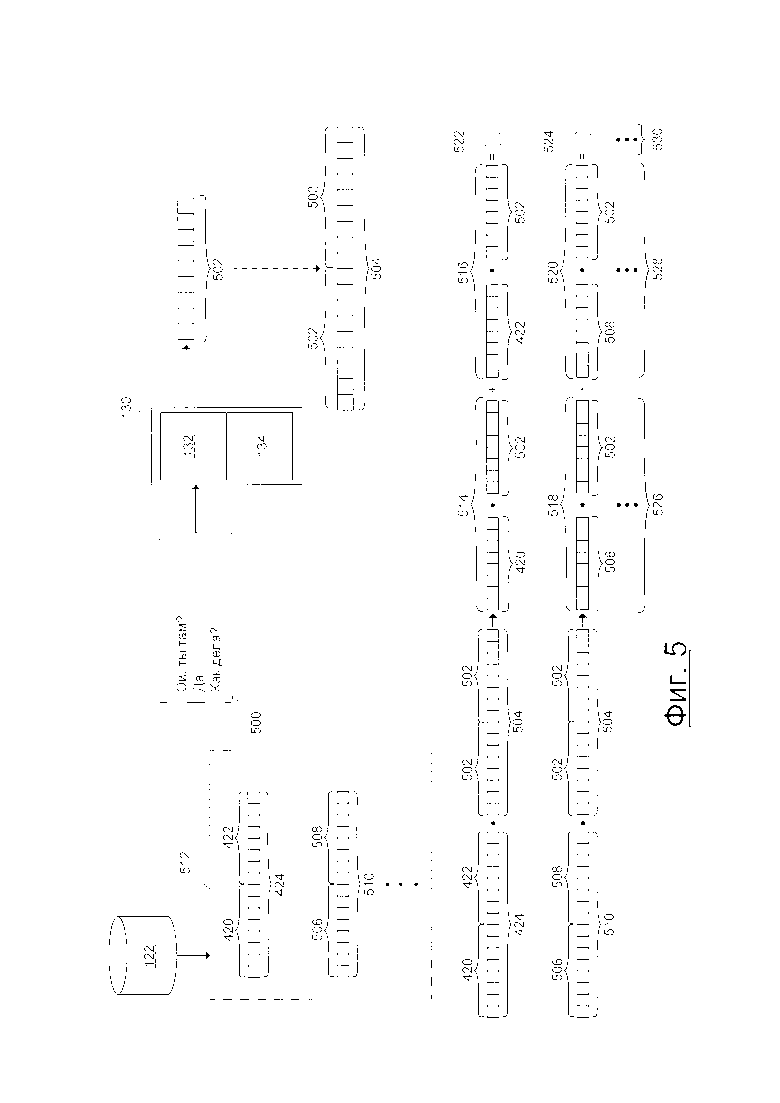
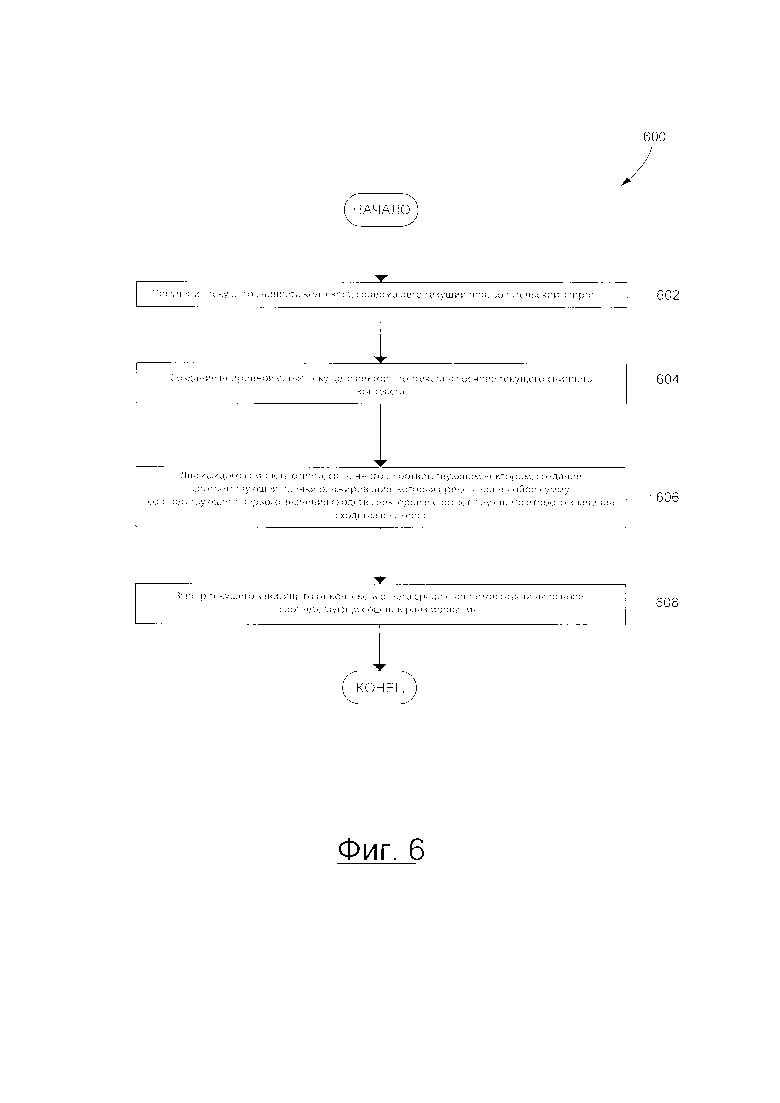
Изобретение относится к вычислительной технике. Технический результат – предоставление логических ответов, которые подражают стилю речи пользователя. Способ выбора текущего зависящего от контекста ответа для текущего пользовательского запроса, который выполняется сервером, коммуникативно соединенным с базой данных, которая хранит множество векторов, причем каждый вектор связан с соответствующим сниппетом беседы, который включает в себя соответствующий сниппет контекста и соответствующий сниппет ответа, при этом каждый вектор обладает соответствующим вектором контекста, указывающим на свойства соответствующего сниппета контекста и соответствующим вектором ответа, указывающим на свойства соответствующего сниппета ответа, причем вектор контекста и вектор ответа каждого из множества векторов создается нейронной сетью. 2 н. и 18 з.п. ф-лы, 6 ил.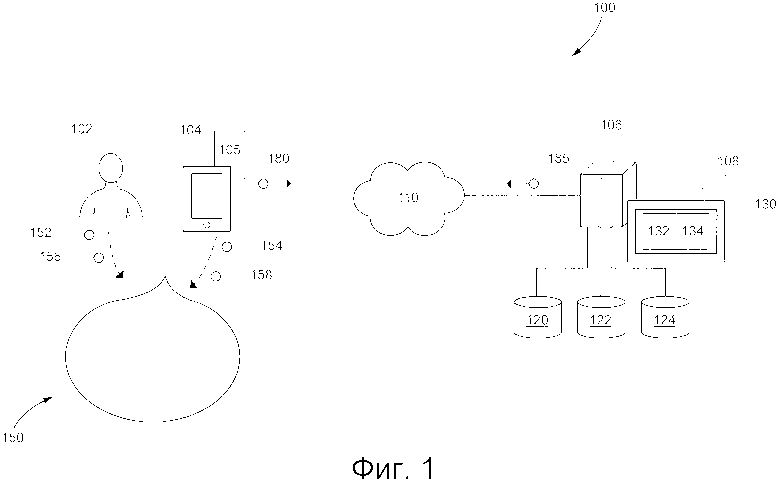
1. Способ выбора текущего зависящего от контекста ответа для текущего пользовательского запроса, который выполняется сервером, коммуникативно соединенным с базой данных, которая хранит множество векторов, причем каждый вектор связан с соответствующим сниппетом беседы, который включает в себя соответствующий сниппет контекста и соответствующий сниппет ответа, при этом каждый вектор обладает соответствующим вектором контекста, указывающим на свойства соответствующего сниппета контекста и соответствующим вектором ответа, указывающим на свойства соответствующего сниппета ответа, причем вектор контекста и вектор ответа каждого из множества векторов создается нейронной сетью,
которая была обучена:
на основе первого сниппета контекста и первого сниппета ответа, которые находятся в общем сниппете беседы, и второго сниппета контекста и второго сниппета ответа, которые не находятся в общем первом сниппете контекста,
таким образом, что значение положительного примера сходства векторов между первым вектором ответа, созданным на основе первого сниппета ответа и первым вектором контекста, созданным на основе первого сниппета контекста, превышает значение отрицательного примера сходства векторов между вторым вектором ответа, созданным на основе второго сниппета ответа, и первым вектором контекста,
причем способ включает в себя:
получение сервером текущего сниппета контекста, включающего в себя текущий пользовательский запрос;
создание нейронной сетью сервера текущего вектора контекста на основе текущего сниппета контекста, причем текущий вектор контекста указывает на свойства текущего сниппета контента;
для каждого сниппета ответа, связанного с соответствующим вектором, создание сервером соответствующей оценки ранжирования, которая является суммой:
соответствующего первого значения сходства векторов между текущим вектором контекста и соответствующим вектором контекста, причем каждое первое значение сходства векторов указывает на лингвистическое сходство между текущим сниппетом контекста и соответствующим сниппетом контекста; и
соответствующего второго значения сходства векторов между текущим вектором контекста и соответствующим вектором ответа, причем каждое второе значение сходства векторов указывает на лингвистическое и логическое сходство между текущим сниппетом контекста и соответствующим сниппетом ответа; и
выбор текущего зависящего от контекста ответа среди сниппетов ответа на основе соответствующих оценок ранжирования.
2. Способ по п. 1, в котором способ далее включает в себя ранжирование сервером сниппетов ответа на основе соответствующих оценок ранжирования, причем выбор текущего зависящего от контента ответа включает в себя выбор сервером наиболее высоко ранжированного сниппета ответа в качестве текущего зависящего от контекста ответа для текущего пользовательского запроса.
3. Способ по п. 1, в котором нейронная сеть включает в себя:
подсеть контекста, которая создает первый вектор контекста на основе первого сниппета контекста; и
подсеть ответа, которая создает первый вектор ответа, созданный на основе первого сниппета ответа и второй вектор ответа, созданный на основе второго сниппета ответа.
4. Способ по п. 3, в котором создание текущего вектора контекста на основе текущего сниппета контекста выполняется подсетью контекста.
5. Способ по п. 1, в котором нейронная сеть была обучена таким образом, что значение положительного примера сходства векторов превышает по меньшей мере заранее определенное пороговое значение значения отрицательного примера сходства векторов.
6. Способ по п. 1, в котором нейронная сеть была обучена создавать первый вектор контекста и первый и второй вектора ответа таким образом, чтобы максимизировать разницу между значением положительного примера сходства векторов и значением отрицательного примера сходства векторов.
7. Способ по п. 1, в котором значение положительного примера сходства векторов указывает на векторное расстояние между первым векторов ответа и первым векторов контекста, и причем значение отрицательного примера сходства векторов указывает на векторное расстояние между вторым вектором ответа и первым вектором контекста.
8. Способ по п. 1, в котором значение положительного примера сходства векторов является скалярным произведением первого вектора ответа и первого вектора контекста, и причем значение отрицательного примера сходства векторов является скалярным произведением второго вектора ответа и первого вектора контекста.
9. Способ по п. 1, в котором данное первое значение сходства векторов является скалярным произведением текущего вектора контекста и соответствующего вектора контекста, и причем данное второе значение сходства векторов является скалярным произведением текущего вектора контекста и соответствующего вектора ответа.
10. Способ по п. 1, в котором способ далее включает в себя выбор сервером множества векторов на основе текущего сниппета контекста среди всех векторов, хранящихся в базе данных.
11. Способ по п. 1, в котором данная оценка ранжирования является взвешенной суммой соответствующего первого значения сходства векторов и соответствующего второго значения сходства векторов.
12. Способ по п. 1, в котором вектор контекста и вектор ответа каждого из множества векторов, которые были созданы нейронной сетью, были конкатенированы в соответствующий один из множества векторов.
13. Компьютерное устройство для выбора текущего зависящего от контекста ответа для текущего пользовательского запроса, коммуникативно соединенное с базой данных, которая хранит множество векторов, причем каждый вектор связан с соответствующим сниппетом беседы, который включает в себя соответствующий сниппет контекста и соответствующий сниппет ответа, при этом каждый вектор обладает соответствующим вектором контекста, указывающим на свойства соответствующего сниппета контекста и соответствующим вектором ответа, указывающим на свойства соответствующего сниппета ответа, причем вектор контекста и вектор ответа каждого из множества векторов создается нейронной сетью,
которая была обучена:
на основе первого сниппета контекста и первого сниппета ответа, которые находятся в общем сниппете беседы, и второго сниппета контекста и второго сниппета ответа, которые не находятся в общем первом сниппете контекста,
таким образом, что значение положительного примера сходства векторов между первым вектором ответа, созданным на основе первого сниппета ответа и первым вектором контекста, созданным на основе первого сниппета контекста, превышает значение отрицательного примера сходства векторов между вторым вектором ответа, созданным на основе второго сниппета ответа, и первым вектором контекста,
компьютерное устройство выполнено с возможностью осуществлять:
получение текущего сниппета контекста, включающего в себя текущий пользовательский запрос;
создание нейронной сетью текущего вектора контекста на основе текущего сниппета контекста, причем текущий вектор контекста указывает на свойства текущего сниппета контента;
для каждого сниппета ответа, связанного с соответствующим вектором, создание соответствующей оценки ранжирования, которая является суммой:
соответствующего первого значения сходства векторов между текущим вектором контекста и соответствующим вектором контекста, причем каждое первое значение сходства векторов указывает на лингвистическое сходство между текущим сниппетом контекста и соответствующим сниппетом контекста; и
соответствующего второго значения сходства векторов между текущим вектором контекста и соответствующим вектором ответа, причем каждое второе значение сходства векторов указывает на лингвистическое и логическое сходство между текущим сниппетом контекста и соответствующим сниппетом ответа; и
выбор текущего зависящего от контекста ответа среди сниппетов ответа на основе соответствующих оценок ранжирования.
14. Компьютерное устройство по п. 13, в котором компьютерное устройство далее выполнено с возможностью осуществлять ранжирование сниппетов ответа на основе соответствующих оценок ранжирования, причем компьютерное устройство выполнен с возможностью осуществлять выбор текущего зависящего от контента ответа включает в себя компьютерное устройство, выполненное с возможностью осуществлять выбор наиболее высоко ранжированного сниппета ответа в качестве текущего зависящего от контекста ответа для текущего пользовательского запроса.
15. Компьютерное устройство по п. 13, в котором нейронная сеть включает в себя:
подсеть контекста, которая создает первый вектор контекста на основе первого сниппета контекста; и
подсеть ответа, которая создает первый вектор ответа, созданный на основе первого сниппета ответа и второй вектор ответа, созданный на основе второго сниппета ответа.
16. Компьютерное устройство по п. 15, которое выполнено с возможностью осуществлять создание текущего вектора контекста на основе текущего сниппета контекста путем использования подсети контекста.
17. Компьютерное устройство по п. 13, в котором нейронная сеть была обучена таким образом, что значение положительного примера сходства векторов превышает по меньшей мере заранее определенное пороговое значение значения отрицательного примера сходства векторов.
18. Компьютерное устройство по п. 13, в котором значение положительного примера сходства векторов указывает на векторное расстояние между первым вектором ответа и первым векторов контекста, и причем значение отрицательного примера сходства векторов указывает на векторное расстояние между вторым вектором ответа и первым вектором контекста.
19. Компьютерное устройство по п. 13, в котором значение положительного примера сходства векторов является скалярным произведением первого вектора ответа и первого вектора контекста, и причем значение отрицательного примера сходства векторов является скалярным произведением второго вектора ответа и первого вектора контекста.
20. Компьютерное устройство по п. 13, в котором данное первое значение сходства векторов является скалярным произведением текущего вектора контекста и соответствующего вектора контекста, и причем данное второе значение сходства векторов является скалярным произведением текущего вектора контекста и соответствующего вектора ответа.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| СИСТЕМА, СПОСОБ И ИНТЕРФЕЙС ДЛЯ ОБЕСПЕЧЕНИЯ ПЕРСОНАЛИЗИРОВАННОГО ПОИСКА И ДОСТУПА К ИНФОРМАЦИИ | 2005 |
|
RU2419858C2 |
| ТЕКСТОЗАВИСИМЫЙ СПОСОБ КОНВЕРСИИ ГОЛОСА | 2010 |
|
RU2427044C1 |

