ОБЛАСТЬ ТЕХНИКИ
Настоящее техническое решение относится к области вычислительной техники, в частности к системе и способу автоматизации обработки голосовых обращений клиентов в сервисные службы компании.
УРОВЕНЬ ТЕХНИКИ
Высокий уровень конкуренции и нестабильная экономическая ситуация в мире требуют от компаний непрерывной оптимизации своих расходов, одной из ключевых статей традиционно являются затраты на сервисное обслуживание клиентов. Это влечет за собой необходимость снижения себестоимости обслуживания контакта клиента при сохранении заданного уровня качества, что в свою очередь формирует потребность в автоматизации указанных процессов.
Мировые тенденции к развитию голосовых сервисов и совершенствование современных средств голосовых каналов (протоколы голосовой связи через Интернет VoIP и других технологий передачи голосовой информации) и технологий анализа и обработки голосовой информации приводят к росту числа систем автоматизации обработки голосовых запросов клиентов и, как следствие, рост числа затрат компаний на их разработку.
Из уровня техники известно значительное количество систем автоматизации голосовых обращений клиентов, в части такие решения описаны в заявках: US2013246053A1, опубл. 19.09.2013; US2011010173A1, опубл. 13.01.2011.
В известных из уровня техники решениях используется следующая система объектов:
- Сообщение системы: вопрос, приглашение или какой-то иной звуковой сигнал системы клиенту. Например, вопрос «Чем я могу помочь Вам?»;
- Реплика/реакция клиента: Ответ, команда, вопрос, уточнение или другой ответ клиента. Например, «Скажи мне баланс по моей карте»;
- Диалог между клиентом и системой – это последовательность сообщений системы и реплики/реакции клиента. Диалог может иметь целью задать вопрос клиенту с целью получения от него информации или предоставить информацию по запросу клиента;
- Коммуникация – это непрерывная последовательность диалогов одного клиента с системой. Диалоги могут быть как логически связанны между собой, так и содержать разные тематические блоки.
Ключевой показатель качества автоматических и автоматизированных систем обслуживания голосовых запросов клиентов является точность распознавания ответа клиента в каждом диалоге и коммуникации в целом. Точность распознавания в коммуникации (P(right)) можно измерить как отношение числа правильно распознанных ответов клиента во всей коммуникации (Nright) к общему числу ответов клиента в этой коммуникации (N).
P(right) = Nright/N*100%.
Точность распознавания зависит от двух составляющих: точность перевода звука в текст и точность выявления смысла из распознанного текста.
Точность выявления смысла из распознанного текста связана с количеством слов в ответе клиента и синтаксической сложностью предложения клиента. Универсальных методик для оценки качества данного показателя на текущий момент не существует.
Данные ограничения приводят к невозможности достижения 100% уровня вероятности распознавания ответов клиента в автоматических и автоматизированных системах и возможности полноценного конкурирования с качеством распознавания речи человеком. Причем, чем более сложен ответ клиента, тем больше вероятность ошибки в распознавании ответа системой.
Это приводит к следующим основным недостаткам имеющихся в настоящее время систем:
1. Сервис всегда должен учитывать, что могла произойти ошибка при распознавании, так как точность распознавания речи менее 100%, а в среднем составляет от 80 до 93%. Для решения данной проблемы существующие системы включают шаг уточнения (переспрашивания) информации у клиента, что приводит к удлинению времени обслуживания, росту негативного отношения клиента к системе и, как следствие, прекращению взаимодействия с системой (разрывает соединения, бросает трубку и т.д.).
2. Упрощение диалогов между клиентом и системой. Как следствие, увеличивается количество диалогов в рамках коммуникации из-за того, что система задает более простые вопросы и получает информацию от клиента постепенно. Это также приводит к удлинению времени обслуживания и увеличивает вероятность неверного распознавания ответов клиента.
3. Ограничение списка тематик и голосовых сервисов, которые могут быть автоматизированы. Это приводит к отходу от концепции «человеческого» общения клиента и системы, к решению задачи снижения вероятности некорректного распознавания или некорректного выделения смысла.
Перечисленные выше ограничения негативно влияют на ключевые показатели качества работы автоматических и автоматизированных систем и компании в целом:
- общее снижение качества корректно обработанных голосовых запросов клиентов за счет исключения человека из системы;
- снижение процента автоматизации, который измеряется, как отношение количества клиентов, получивших обслуживание в системе, к общему количеству клиентов, обратившихся в систему;
- рост расходов на обслуживание голосовых запросов клиентов за счет удлинения времени обслуживания;
- снижение возможностей развития и самообучения систем из-за ограничения автоматизированного списка тематик и голосовых сервисов.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Технической проблемой, на решение которой направлено заявленное техническое решение, является создание системы, способа и машиночитаемого носителя автоматизации обработки голосовых обращений клиентов в сервисные службы компании, которые охарактеризованы в независимых пунктах формулы. Дополнительные варианты реализации настоящего изобретения представлены в зависимых пунктах изобретения.
Технический результат заключается в динамическом выборе способа обработки голосового обращения клиента в зависимости от переданных параметров голосового отрезка (voice sample), качества автоматического распознавания речи и доступности оператора. Указанный технический результат достигается за счет функции маршрутизации звонков между системой ASR и модулем службы OSR, учитывающей такие параметры, как качество распознавания речи, цену/критичность ошибки в бизнес-процессе заказчика, доступность оператора, категорию клиента и т.д.
В предпочтительном варианте реализации заявлена система автоматизации голосовых обращений клиентов в сервисные службы компании, содержащая:
сервер взаимодействия (CORE), обеспечивающий:
• взаимодействие с сервером Голосовых приложений посредством Voice XML интерпретатора и MRCP клиента;
• получение от него аудиопотока/аудиофайла для транскрибирования;
• осуществляет выбор способа обработки - системой автоматического распознавания речи (ASR) или модулем службы оператора (OSR) аудиопотока/аудиофайла в соответствии с переданными настройками;
• маршрутизацию аудиопотока/аудиофайла последовательно в систему ASR;
• обработку ответа от системы ASR и проверку уровня доверия к транскрибированному тексту, при уровне доверия выше минимально установленного осуществляет передачу текста в службу Sematic для выделения семантических тэгов, при уровне доверия ниже минимально установленного осуществляет маршрутизацию обращения в модуль службы OSR;
• получение от модуля службы OSR массива транскрибированного текста и семантических тэгов;
• передачу результатов распознавания голосового обращения клиента и выделенных семантических тэгов в сервер Голосовых приложений;
сервер OSR, обеспечивающий:
• маршрутизацию обращений клиентов в АРМ Оператора;
• передачу результатов обработки обращений в сервер взаимодействия;
• регистрацию и выбор оператора для обработки обращения;
АРМ Оператора, содержащий web-интерфейс для обработки голосового обращения клиента с преднастроенными шаблонами ответов и обеспечивающий проигрывание Оператору звукового отрывка (Voice Sample);
АРМ Конфигуратор OSR, содержащий web-интерфейс для настройки АРМ оператора и модуля службы OSR;
службу Semantic, выполняющую выделение ключевых слов из транскрибированного текста по заданной грамматике, переданной сервером взаимодействия (CORE), на основе настроенной статистической модели;
службу Logger, осуществляющую логирование результатов распознавания голосовых обращений, клиентов и выделенных семантических тэгов;
службу статистики (Statistics), осуществляющую сохранение информации обо всех стадиях диалога:
 дату и время начала сессии;
дату и время начала сессии;
дату и время окончания сессии;
URL аудиопотока/аудиофайла;
настройки статистики сервера Голосовых приложений, для дальнейшего использования в АРМ Статистика;
АРМ Специалиста по мониторингу, содержащий web-интерфейс для просмотра отчетов по работе системы и контроля корректности распознавания голосовых обращений клиентов.
В частном варианте сервер взаимодействия (CORE) в зависимости от уровня критичности диалога производит маршрутизацию функции распознавания обращения клиента в модуль службы OSR без предварительного обращения в систему ASR, в которой производят прослушивание переданного звукового отрезка (VS) и отмечают выбор правильного варианта распознавания текста, после чего модуль службы OSR возвращает в сервер взаимодействия (CORE) массив транскрибированного текста и семантические тэги.
В другом частном варианте сервер взаимодействия (CORE) осуществляет маршрутизацию аудиопотока/аудиофайла только в систему ASR, обработку ответа от системы ASR и проверку уровня доверия к транскрибированному тексту, маршрутизацию в службу Sematic для выделения семантических тэгов при уровне доверия выше минимально установленного, формирование отрицательного ответа при уровне доверия ниже минимально установленного, передачу результатов распознавания голосового обращения клиента и выделенных семантических тэгов в сервер Голосовых приложений.
В другом частном варианте сервер взаимодействия (CORE) вначале отправляет звуковой отрезок (VS) в систему ASR, а после получения результатов автоматического распознавания в модуль службы OSR, где производят прослушивание звукового отрезка (VS) и проверяют/дополняют результаты автоматического распознавания речи клиента, в зависимости от качества автоматического распознавания подтверждают данные системы ASR, или вносят соответствующие корректировки, после чего модуль службы OSR возвращает в сервер взаимодействия (CORE) массив транскрибированного текста и семантические тэги.
В другом частном варианте сервер взаимодействия (CORE) одновременно отправляет звуковой отрезок (VS) и в систему ASR, и в модуль службы OSR, в случае, если первый по времени приходит ответ от модуля службы OSR, то в сервер Голосовых приложений передаются результат распознавания текста и семантические теги от модуля службы OSR, в случае, если первый по времени приходит ответ от системы ASR, то дополнительно проверяется вероятность распознавания текста, если она больше заданного уровня в системе, то сервер взаимодействия (CORE) передает в сервер Голосовых приложений результат автоматического распознавания системой ASR, если уровень доверия менее заданного уровня в сервере взаимодействия (CORE), то ожидается ответ от модуля службы OSR.
В другом частном варианте после обработки речи клиента и выделения семантических тегов, сервер взаимодействия (CORE) осуществляет обращение через терминал клиента в ИТ-системы заказчика и получает текст для синтеза речи, далее производит обращение с полученным текстом в систему синтеза речи (TTS) и возвращает в терминал клиента аудиофайл с синтезированным сообщением по запрошенной клиентом информации.
Заявленное решение также осуществляется за счет способа автоматизации голосовых обращений клиентов в сервисные службы компании, содержащий этапы, на которых:
устанавливают соединение с помощью терминала клиента по протоколу управления медиа-ресурсами (MRCP) c сервером Голосовых приложений и отправляют запрос, содержащий идентификатор (ID) диалога и аудиопоток;
осуществляют с помощью сервера Голосовых приложений предварительную обработку вызова, определяют начало речи с помощью функции Voice Activity Detection (VAD) и таймаутов;
осуществляют передачу ID-диалога и уникальный указатель ресурса (URL) на аудиопоток/аудиофайл (VS) в сервер взаимодействия (CORE), а также обеспечивают взаимодействие с системами Заказчика;
принимают с помощью сервера взаимодействия (CORE) из терминала клиента ID-диалога, уникальный указатель ресурса (URL) на аудиопоток/аудиофайл и передают в систему автоматического распознавания речи (ASR) аудиопоток/аудиофайл и настройки распознавания текста;
осуществляют транскрибирование и оценку вероятности правильного распознавания звука с помощью системы ASR;
возвращают с помощью системы ASR в сервер взаимодействия (CORE) массив транскрибированного текста и уровень доверия распознавания звука;
оценивают с помощью сервера взаимодействия (CORE) уровень доверия к распознаванию голосового отрезка (VS);
при уровне доверия выше минимально установленного осуществляют передачу текста и требуемую грамматику в службу Sematic для выделения семантических тэгов;
выделяют службой Semantic из переданного текста по указанной грамматике семантические тэги;
при уровне доверия ниже минимально установленного осуществляется маршрутизацию обращения в модуль службы OSR,
производят с помощью модуля службы OSR прослушивание звукового отрезка (VS) и фиксируют выбор правильного варианта распознавания текста;
возвращают с помощью модуля службы OSR в сервер взаимодействия (CORE) массив транскрибированного текста и семантические тэги;
передают с помощью сервера взаимодействия (CORE) в сервер Голосовых приложений массив транскрибированного текста и семантические тэги;
осуществляют с помощью сервер взаимодействия (CORE) логирование результатов распознавания в службе Logger;
осуществляют запись и хранение информации обо всех стадиях диалога:
дата и время начала сессии;
дата и время окончания сессии;
URL аудиопотока/аудиофайла;
настройки статистики сервера Голосовых приложений, в службе статистики (Statistics) для дальнейшего использования в АРМ Статистика.
В частном варианте производят с помощью сервера взаимодействия (CORE) маршрутизацию функции распознавания обращения клиента в модуль службы OSR без предварительного обращения в систему ASR, при этом в модуле службы OSR осуществляют прослушивание переданного звукового отрезка (VS) и фиксируют выбор правильного варианта распознавания текста, возвращают с помощью модуля службы OSR в сервер взаимодействия (CORE) массив транскрибированного текста и семантические тэги.
В другом частном варианте дополнительно:
производят с помощью сервера взаимодействия (CORE) маршрутизацию функции распознавания обращения клиента в систему ASR;
осуществляют транскрибирование и оценку вероятности правильного распознавания звука с помощью системы ASR;
оценивают с помощью сервера взаимодействия (CORE) уровень доверия к распознаванию голосового отрезка VS;
при уровне доверия выше минимально установленного осуществляют передачу текста и требуемой грамматики в службу Sematic для выделения семантических тэгов;
выделяют службой Semantic из переданного текста по указанной грамматике семантические тэги;
передают с помощью сервера взаимодействия (CORE) в сервер Голосовых приложений массив транскрибированного текста и семантические тэги;
при уровне доверия ниже минимально установленного осуществляют формирование отрицательного ответа в сервер Голосовых приложений.
В другом частном варианте дополнительно:
производят с помощью сервера взаимодействия (CORE) последовательную отправку звукового отрезка (VS) в систему ASR, а после получения результатов автоматического распознавания в модуль службы OSR;
производят с помощью модуля службы OSR прослушивание звукового отрезка (VS) и проверку результатов автоматического распознавания речи клиента;
подтверждают или корректируют в модуле службы OSR результаты автоматического транскрибирования звука в текст с помощью системы ASR;
передают с помощью модуля службы OSR в сервер взаимодействия (CORE) массив транскрибированного текста и семантические тэги.
В другом частном варианте дополнительно:
производят одновременную отправку звукового отрезка (VS) и в систему ASR, и в модуль службы OSR;
при получении ответа от системы ASR или модуля службы OSR в сервере взаимодействия (CORE) производят оценку очередности полученных ответов в соответствии со следующим порядком: если первый по времени приходит ответ от модуля службы OSR, то передают в сервер Голосовых приложений результат распознавания и семантические тэги службы OSR; если первый по времени приходит ответ от системы ASR и переданная вероятность распознавания текста больше заданного уровня в сервере взаимодействия (CORE), то осуществляют передачу в сервер Голосовых приложений результат автоматического распознавания системой ASR; если первый по времени приходит ответ от системы ASR и вероятность распознавания текста меньше заданного уровня в сервере взаимодействия (CORE), то ожидается ответ от модуля службы OSR.
В другом частном варианте дополнительно:
после обработки речи клиента и выделения семантических тегов осуществляют обращение с помощью сервере взаимодействия (CORE) через сервер Голосовых приложений в ИТ-систему заказчика и получают текст для синтеза речи;
производят с помощью сервера взаимодействия (CORE) передачу полученного из ИТ-системы Заказчика текст в систему синтеза речи (TTS);
возвращают с помощью сервера взаимодействия (CORE) в терминал клиента аудиофайл с синтезированным сообщением по запрошенной клиентом информации.
Заявленное решение также осуществляется за счет машиночитаемого носителя для автоматизации голосовых обращений клиентов в сервисные службы компании, содержащий исполняемые процессором инструкции, которые побуждают взаимодействовать аппаратные средства для выполнения способа автоматизации голосовых обращений клиентов в сервисные службы компании.
В частном варианте производят с помощью сервера взаимодействия (CORE) маршрутизацию функции распознавания обращения клиента к модулю службы OSR без предварительного обращения в систему ASR;
производят с помощью модуля службы OSR прослушивание оператором переданного звукового отрезка (VS) и фиксируют выбор правильного варианта распознавания текста;
возвращают с помощью модуля службы OSR в сервер взаимодействия (CORE) массив транскрибированного текста и семантические тэги.
В другом частном варианте дополнительно:
производят с помощью сервера взаимодействия (CORE) маршрутизацию функции распознавания обращения клиента в систему ASR;
осуществляют транскрибирование и оценку вероятности правильного распознавания звука с помощью системы ASR;
оценивают с помощью сервера взаимодействия (CORE) уровень доверия к распознаванию голосового отрезка VS;
при уровне доверия выше минимально установленного осуществляют передачу текста и требуемой грамматики в службу Sematic для выделения семантических тэгов;
выделяют службой Semantic из переданного текста по указанной грамматике семантические тэги;
передают с помощью сервера взаимодействия (CORE) в сервер Голосовых приложений массив транскрибированного текста и семантические тэги;
при уровне доверия ниже минимально установленного осуществляется формирование отрицательного ответа в сервер Голосовых приложений.
В другом частном варианте дополнительно:
производят с помощью сервера взаимодействия (CORE) последовательную отправку звукового отрезка (VS) в систему ASR, а после получения результатов автоматического распознавания в модуль службы OSR.;
производят с помощью модуля службы OSR прослушивание оператором звукового отрезка (VS) и проверку результатов автоматического распознавания речи клиента;
подтверждают или корректируют в модуле службы OSR результаты автоматического транскрибирования звука в тексте с помощью системы ASR;
передают с помощью модуля службы OSR в сервер взаимодействия (CORE) массив транскрибированного текста и семантические тэги.
В другом частном варианте дополнительно:
производят одновременную отправку звукового отрезка (VS) и в систему ASR, и в модуль службы OSR;
при получении ответа от системы ASR или от модуля службы OSR c помощью сервера взаимодействия (CORE) производят оценку очередности полученных ответов в соответствии со следующим порядком:
если первый по времени приходит ответ от модуля службы OSR, то передают в сервер Голосовых приложений результат распознавания и семантические тэги модуля службы OSR; если первый по времени приходит ответ от системы ASR и переданная вероятность распознавания текста больше заданного уровня в сервере взаимодействия (CORE), то осуществляют передачу в сервер Голосовых приложений результата автоматического распознавания системой ASR;
если первый по времени приходит ответ от системы ASR и вероятность распознавания текста меньше заданного уровня в сервере взаимодействия (CORE), то ожидают ответ от службы OSR.
В другом частном варианте дополнительно:
после обработки речи клиента и выделения семантических тегов осуществляют обращение с помощью сервера взаимодействия (CORE) через сервер Голосовых сообщений в ИТ-систему Заказчика и получают текст для синтеза речи;
производят с помощью сервера взаимодействия (CORE) передачу полученного из ИТ-системы Заказчика текста в систему синтеза речи (TTS);
возвращают с помощью сервера взаимодействия (CORE) в терминал клиента аудиофайл с синтезированным сообщением по запрошенной клиентом информации.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения. К заявке прилагаются следующие чертежи:
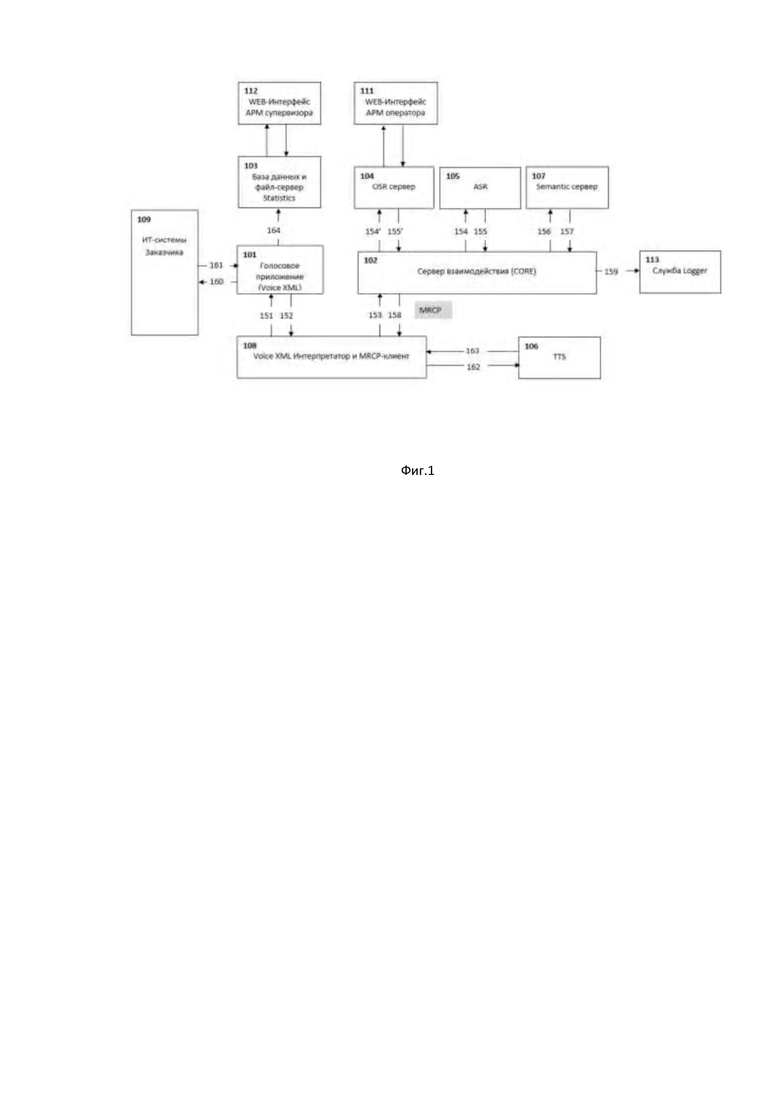
Фиг. 1 иллюстрирует аппаратно-программный комплекс автоматизации голосовых обращений клиентов в сервисные службы;
Фиг. 2-6 иллюстрируют примеры интерфейсов взаимодействия с системой, в котором предоставлена возможность просмотра списков настроенных сценариев диалогов и формирования нового сценария диалога;
Фиг. 7 иллюстрирует пример интерфейса взаимодействия с системой, в котором представлена технологическая схема процесса анализа голоса во время звонка в реальном времени и определения выбора следующей ветки скрипта диалога в зависимости от анализа голоса;
Фиг. 8 иллюстрирует пример вариант интерфейса работы специалиста по мониторингу с детальной информацией по обращению клиента.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако, квалифицированному в предметной области специалисту, будет очевидно каким образом можно использовать настоящее изобретение, как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять понимание особенностей настоящего изобретения.
Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
Настоящее изобретение направлено на обеспечение системы, способа и машиночитаемого носителя автоматизации обработки голосовых обращений клиентов в сервисные службы компании, которые объединяют в себе систему автоматического распознавания речи (ASR) и модуль службы оператора (OSR).
Ниже приведены термины и сокращения, которые используются в заявленном решении:
NoInput - событие, при котором система не получает от клиента голосовой команды (клиент молчит или говорит слишком тихо);
NoMatch - событие, при котором клиент вводит значение, которое не определяется системой на основе заложенной грамматики;
Агрегированный диалог - верхний уровень агрегации диалогов в службе OSR, отражает бизнес-логику объединения тематик обращений клиентов;
Тематика - агрегирует диалоги с клиентом с единой причиной обращения;
Диалог - Сообщение, проигрываемое клиенту в рамках разговора. Диалоги, относящиеся к одному вопросу, объединяются в тематики;
Навык оператора - характеристика оператора, отражающая его специализацию и уровень подготовленности;
Глобальный ответ - пред настроенный вариант действия для оператора на голосовую команду клиента, позволяющий переключить клиента в ветку меню вне пред настроенной логики диалога;
Локальный ответ - преднастроенный вариант действия для оператора на голосовую команду клиента, позволяющий переключить клиента на следующий шаг диалога;
АС - автоматизированная система;
АРМ - автоматизированное рабочее место;
АТС - автоматическая телефонная станция;
БД - база данных;
СУБД - система управления базами данных;
ПО - программное обеспечение;
ASR (Automation speech recognition) – автоматическое распознавание речи;
IVR (Interactive Voice Response) - система предварительно записанных голосовых сообщений, выполняющая функцию маршрутизации звонков внутри контактного центра;
NFS (Network File System) - протокол сетевого доступа к файловым системам;
TCP/IP (Transmission Control Protocol (TCP)) - протокол управления передачей данных и Internet Protocol (IP) – межсетевой протокол, описывающий формат пакета данных, передаваемого по сети;
TTS (Text-To-Speech) – синтез речи.
В заявленном решении система обработки голосового обращения абонента заменяет сотрудника сервисной службы компании (оператора контактного центра, продавца в магазине, официанта в ресторане и т.д.) на автоматический (при полной автоматизации) или автоматизированный (при использовании службы OSR) сервис. В решении максимально используются возможности современной технологии распознавания речи, что позволяет не использовать возможности оператора, и подключать человеческий ресурс только в самых необходимых случаях.
В заявленном решении используются следующие технологические решения:
1. Запись разговора в online-режиме обрабатывают и обнаруживают начало разговора клиента.
2. Голос клиента записывают и создают Voice Sample (VS - фрагмент диалога Клиент – Система, который содержит только ответ клиента на вопрос системы).
3. VS передают на обработку оператору посредством модуля службы Operator Speech Recognition (OSR).
В зависимости от настроек системы, перевод осуществляется сразу в online-режиме, или может быть обработана в off-line в случае, если система ASR не распознала речь клиента.
В одном из вариантов работы системы предусмотрено одновременное применение системы ASR и модуля службы OSR.
Для формирования звукового отрезка VS выполняют: определение начала разговора клиента;
выделяют ответ клиента и отрезают тишину вначале и в конце разговора.
Отправляют VS в систему ASR. Оценивают вероятность правильного распознавания отрезка VS и, если получен ответ с уровнем вероятности правильного распознавания более заданного в настройках системы, распознанный текст передается в службу Semantic.
Если уровень распознавания меньше заданного порогового значения, то VS передается в модуль службы OSR. Выполняют распознавание переданного VS оператором. В наушниках у оператора инициируется короткий звуковой сигнал, и далее проигрывается VS (с той же скоростью или в N (по умолчанию равный 1,3) раз быстрее). При этом указатель позиции проигрывания перемещается в соответствии с VS. Оператор, прослушав VS, нажимает на кнопку/строку, соответствующую ответу клиента, или набирает текст/цифры и передает результат обратно на сервер взаимодействия (CORE), который в соответствии с заданными настройками маршрутизирует данные на сервер Голосовых приложений.
В одном из альтернативных вариантов работы системы используют только модуль службы OSR. При этом выполняют формирование звукового отрезка VS. Определяют начало разговора клиента, выделяют ответ клиента и отрезают тишину в начале и в конце разговора. Отправляют VS в модуль службы OSR. Выполняют распознавание переданного VS оператором. В наушниках у оператора инициируется короткий звуковой сигнал, и далее проигрывается VS (с той же скоростью или в N (по умолчанию равный 1,3) раз быстрее). При этом указатель позиции проигрывания перемещается в соответствии с VS. Оператор, прослушав VS, нажимает на кнопку/строку, соответствующую ответу клиента, или набирает текст/цифры и передает результат обратно на сервер взаимодействия (CORE), который маршрутизирует данные на сервер Голосовых приложений.
В заявленном решении система обработки голосовых обращений клиентов в сервисные службы компании позволяет привлекать оператора в случаях:
1. на этапе диалога, где автоматическая система распознавания речи не может распознать слова клиента.
2. только в критичных шагах диалога, когда необходима 100% уверенность в правильном распознавании ответа клиента (подтверждение заказа, проверка пароля/кодового слова и т.д.).
Данный подход, в отличие от обычного диалога Оператор – Клиент, допускает оператору условно одновременно обрабатывать до 10-14 вызовов, что позволяет до 80% уменьшить затраты на содержание соответствующей службы компании. Дополнительно сохраняются результаты транскрибирования текста и выделенных семантических тэгов по 100% полученных голосовых сообщений (как обработанных автоматической службой, так и обработанных оператором), что позволяет использовать полученные данные для улучшения работы службы Semantic.
Как представлено на Фиг.1 аппаратно-программный комплекс автоматизации голосовых обращений клиентов в сервисные службы состоит из серверных модулей и клиентских модулей.
Состав серверных модулей:
102. Сервер взаимодействия (CORE), отвечает за взаимодействие всех компонентов модулей и подмодулей между собой, передачи запросов, в том числе к службе статистики. Осуществляет прием запросов от Сервера Голосовых приложений по протоколу управления медиа-ресурсами (MRCP), передачу вызовов в службу OSR, в том числе обработку и предпостроение json форм, получение и маршрутизация результатов распознавание из модуля службы OSR в MRCP. Обращается к серверу Semantic для выделения смысла из распознанного текста.
104. Модуль службы оператора OSR (Operator Speech Recognition) отвечает за передачу запросов и получение ответов в АРМ Оператора. Осуществляет управление регистрацией операторов (присвоение и снятие статуса Busy), отслеживает статус оператора (перерыв, готов, занят) и маршрутизирует вызовы в зависимости от скилл-групп операторов, его занятости и истории обработанных звонков.
107. Служба Semantic, отвечает за выделение смысла (ключевых слов) из распознанного текста на основе статистической модели.
103. Служба статистики (Statistic) отвечает за сохранение информации обо всех стадиях диалога, для дальнейшего использования в АРМ Статистика.
Клиентские модули:
111. Автоматизированное рабочее место оператора (АРМ Оператора) – рабочее место оператора, на который поступают запросы от службы MRCP. При получении запроса АРМ автоматически открывает окно запроса и проигрывает звуковой отрывок. Оператор имеет возможность выбрать вариант, которому соответствует звуковой отрывок. Ответ оператора возвращается в сервер взаимодействия (CORE).
112. АРМ Конфигуратор – рабочее место администратора Аппаратно-программного комплекса, позволяет настроить интерфейс работы оператора (модуль службы OSR), параметры распознавания (система ASR) и синтеза речи (служба TTS), настройки веб-сервисов для обращения к системам Заказчика.
113. АРМ Статистики - рабочее место специалиста по мониторингу. Предоставляет отчеты, на основе сформированной статистики.
Для обеспечения работы аппаратно-программного комплекса также необходима техническая среда, состоящая из следующих модулей:
101. Сервер Голосовых приложений (Voice XML): поддерживает основную логику работы сервиса и адаптируется под специфику работы Заказчика. Отвечает за взаимодействие с ИТ-системами Заказчика, предварительную обработку вызова, определение начала речи с помощью функции VAD и таймаутов. Осуществляет передачу звука в сервер взаимодействия (CORE).
108. Voice XML интерпретатор и MRCP клиент осуществляет передачу запросов между сервером взаимодействия (CORE) и сервером Голосовых приложений.
105. Система ASR (Automation Speech Recognition), отвечает за взаимодействие с серверами распознавания речи различных производителей, в т.ч. Nuance ASR, Yandex Speech Kit и т.д.
106. Служба TTS (Text-To-Speech), отвечает за взаимодействие с серверами произнесения речи различных производителей, в т.ч. TTS Nuance, TTS Yandex Speech Kit и т.д.
Ниже представлена логика взаимодействия между компонентами системы:
151. Голосовое обращение клиента через ИТ-системы Заказчика маршрутизируется в сервер Голосовых приложений.
152. Сервер Голосовых приложений: фиксирует в службе Statistics начало вызова; осуществляет передачу запроса на обработку аудиопотока/аудиофайла на сервер CORE.
Запрос на обработку включает в себя:
идентификатор вызова;
URL на аудиопоток/аудиофайл;
тип обработки (ASR/ OSR/ ASR+OSR);
грамматику для проставления семантических тэгов.
153. Voice XML интерпретатор и MRCP клиент осуществляет передачу запроса на сервер CORE.
154. В зависимости от переданных настроек сервер CORE осуществляет маршрутизацию аудиопотока/аудиофайла на распознавание:
в систему ASR (154) (аудиопоток/аудиофайл и настройки распознавания текста);
в модуль службы OSR (154’) (аудиопоток/аудиофайл, при наличии распознанный текст от службы ASR и название диалога);
одновременно в модуль службы OSR и систему ASR.
155. система ASR (155) производит обработку аудиопотока/ аудиофайла и формирует массив распознанного текста с указанием уровня доверия.
155’ Модуль службы OSR (155’) при получении запроса на обработку аудиопотока/аудиофайла осуществляет поиск и приоритезацию свободных операторов и маршрутизирует аудиопоток/аудиофайл на выбранного сотрудника.
Результатом обработки запроса OSR/ASR является:
- выделенная семантика из аудиозаписи;
- транскрибированная оператором аудиозапись диалога с клиентом.
При отсутствии свободных сотрудников формирует ответ в CORE со статусом BUSY.
156. После распознавания текста системой ASR или транскрибирование записи оператором сервер CORE осуществляет передачу данной информации на сервер Semantic для выделения семантических тэгов.
В случае, если в процессе обработки аудиозаписи оператор использовал преднастроенные ответы диалога, то модуль службы OSR передает уже выделенные семантические тэги и обращения на сервер Semantic не происходит.
157. Сервер Semantic осуществляет выделение семантических тэгов в переданном тексте с помощью указанной грамматики.
158. После получения от сервера Semantic массива семантических тэгов сервер CORE передает данную информацию в сервер Голосовых приложений для определения дальнейших шагов обработки диалога с клиентом.
В случае, если семантические тэги не были выделены или при обработке аудиопотока/аудиофайла произошли ошибки, то сервер CORE передает один из следующих типов событий: No Match, No Input, Error.
159. После передачи результатов распознавания в сервер Голосовых приложений посредством протокола MRCP, также происходит их логирование в службе Logger.
160. По результатам анализа распознанного текста от клиента сервер Голосовых приложений может осуществить запрос в ИТ-системы Заказчика для получения дополнительной информации для ответа клиенту (запрос баланса, статуса заказа, информации о работе отделений/магазинов и т.д.)
161. ИТ-системы Заказчика формируют необходимую информацию по запросу клиента.
162. В случае, если информация носит динамический характер и для ее озвучивания необходимо провести синтез речи, то сервер Голосовых приложений направляет запрос в службу TTS (в зависимости от выбранного Заказчиком подрядчика TTS запрос идет напрямую или через MRCP-клиент).
163. По заданному тексту служба TTS осуществляет синтез речи и передает созданный аудиофайл для проигрывания в ИТ-системы заказчика.
164. По завершению обработки голосового вызова от клиента сервер Голосовых приложений осуществляет запись об окончании диалога на сервер Statistic.
При необходимости анализа результатов распознавания и мониторинга качества работы службы специалист по мониторингу посредством web-интерфейса службы Statistic осуществляет поиск и анализ аудиозаписей и результатов распознавания.
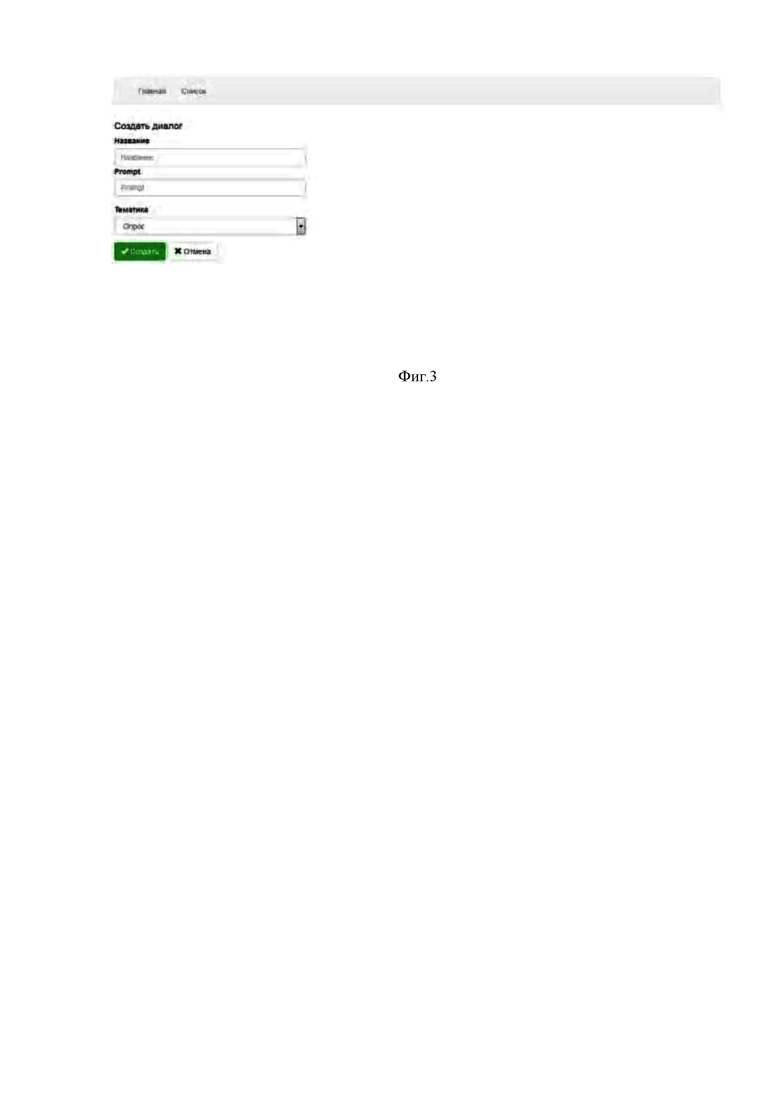
На фигурах 2-5 представлены примеры интерфейсов взаимодействия с системой, в которых предоставлена возможность просмотра списков настроенных сценариев диалогов и формирования нового сценария диалога.
Администрирование диалогов
Для перехода в просмотр настроенных диалогов для обработки Оператором необходимо на главном экране выбрать раздел «Диалоги».
Данное окно позволяет:
1. Просмотреть список настроенных диалогов
2. Создать новый диалог
3. Изменить существующий диалог.
Для создания нового диалога в системе необходимо нажать на кнопку «Создать» в верхней части диалогового окна. В открывшемся диалоговом окне необходимо указать название диалога; в разделе Promt ввести полный текст диалога, зачитываемый клиенту в IVR; выбрать тематику и нажать на кнопку «Создать».
Для редактирования ранее созданного диалога необходимо выбрать нужную запись из списка и перейти по гиперссылке в окно просмотра диалога. В открывшемся окне нажать на кнопку «Изменить». Открывается диалоговое окно редактирования параметров диалога, в котором доступно:
- Изменить название диалога
- Изменить описание диалога
- Выбрать тематику, к которой относится данный диалог, из списка доступных тематик.
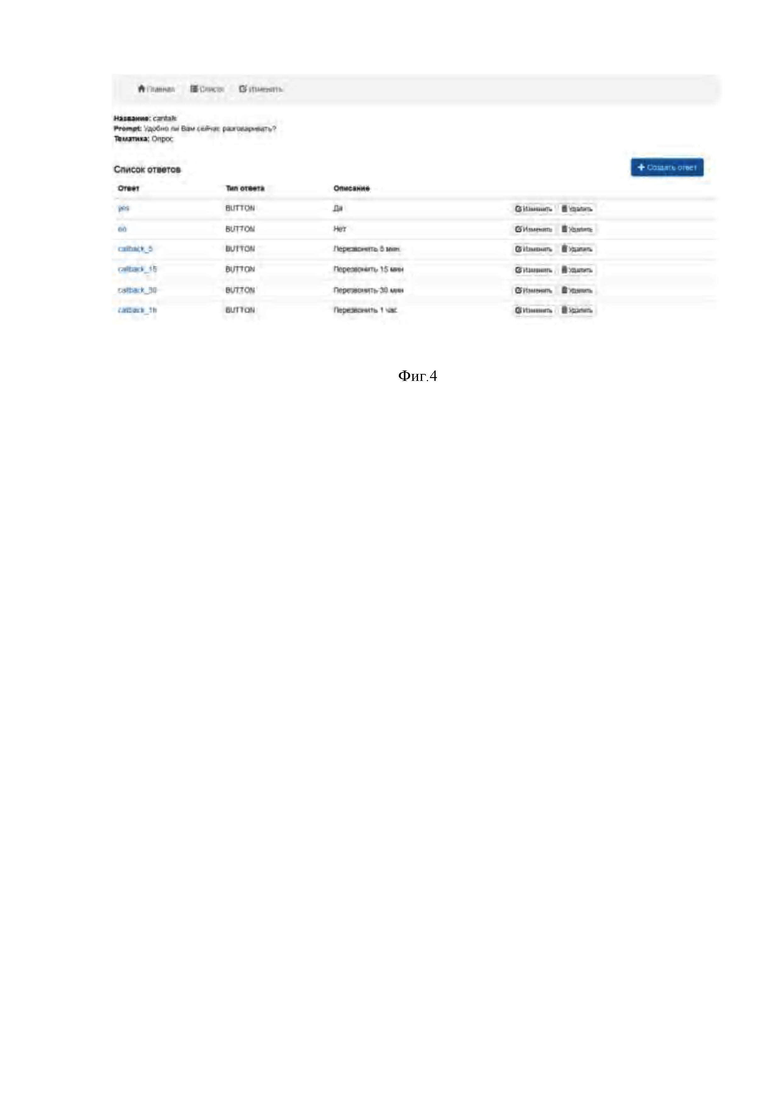
Для создания и редактирования списка ответов диалога необходимо выбрать нужную запись из списка диалогов и перейти по гиперссылке. Открывается диалоговое окно, позволяющее:
1. Просмотреть и скорректировать список ответов в рамках данного диалога (добавить, изменить или удалить);
2. Изменить параметры диалога (название, описание и тематику).
Для создания ответа необходимо нажать на кнопку «Создать ответ» в верхней правой части диалогового окна. В открывшемся диалоговом окне необходимо указать:
- название ответа на латинице;
- тип отображения ответа. Доступные варианты: BUTTON – кнопка, ADDRESS – поле для ввода адреса, TEXT – поле для ввода текста, NUMBER – поле для ввода числа, DATE – поле для выбора даты;
- описание ответа, которое будет отображаться оператору
Для редактирования ответа необходимо выбрать нужную запись из списка и нажать на кнопку «Изменить»:
Для удаления ответа необходимо выбрать нужную запись из списка и нажать на кнопку «Удалить».
На фигуре 6 приведен вариант интерфейса работы при поступлении вызова оператору.
При поступлении вызова оператору открывается окно диалога для выбора вариантов ответа клиента.
Окно диалога включает в себя:
• Название диалога (601) – в данном поле отображается название диалога, с которого был переведен ответ клиента на оператора. Выводится в верхней части диалогового окна.
• Оставшееся время (602) – в данном поле отображается время, доступное оператору для ответа, выраженное в миллисекундах. После истечения отведенного времени при отсутствии ответа оператора диалоговое окно автоматически закрывается, в системе фиксируется событие BUSY.
• Поле для ввода текста (603) – предназначено для ввода ответа клиента на текущий диалог.
Заполняется в случае, если диалог предполагает расширенный (имеет множество вариантов ответа: ввод названий, адреса, ФИО) или уникальный (комментарий, пароли и кодовые слова) ответ клиента на заданный вопрос.
• Локальные кнопки (604) – переводят диалог с клиентом на следующий шаг в рамках стандартного, преднастроенного маршрута.
Название кнопок и логика перехода настраивается администратором системы при создании диалога (Администрирование диалогов).
• Глобальные кнопки (605) – позволяют управлять диалогом с клиентом по нестандартному сценарию:
перевод звонка на несколько шагов вперед или назад;
проигрывание предзаписанной фразы на ответ/комментарий клиента и возврат на этот же шаг диалога;
проигрывание предзаписанной фразы на ответ/комментарий клиента и завершение диалога с фиксированным событием.
Глобальные кнопки настраиваются в рамках тематики и одинаковые для всех диалогов в рамках данной тематики.
• Кнопка «Отправить» - при нажатии на кнопку в системе фиксируется ответ клиента, введенный оператором в текстовом поле. Диалог переводится на следующий шаг в соответствии с настроенным маршрутом.
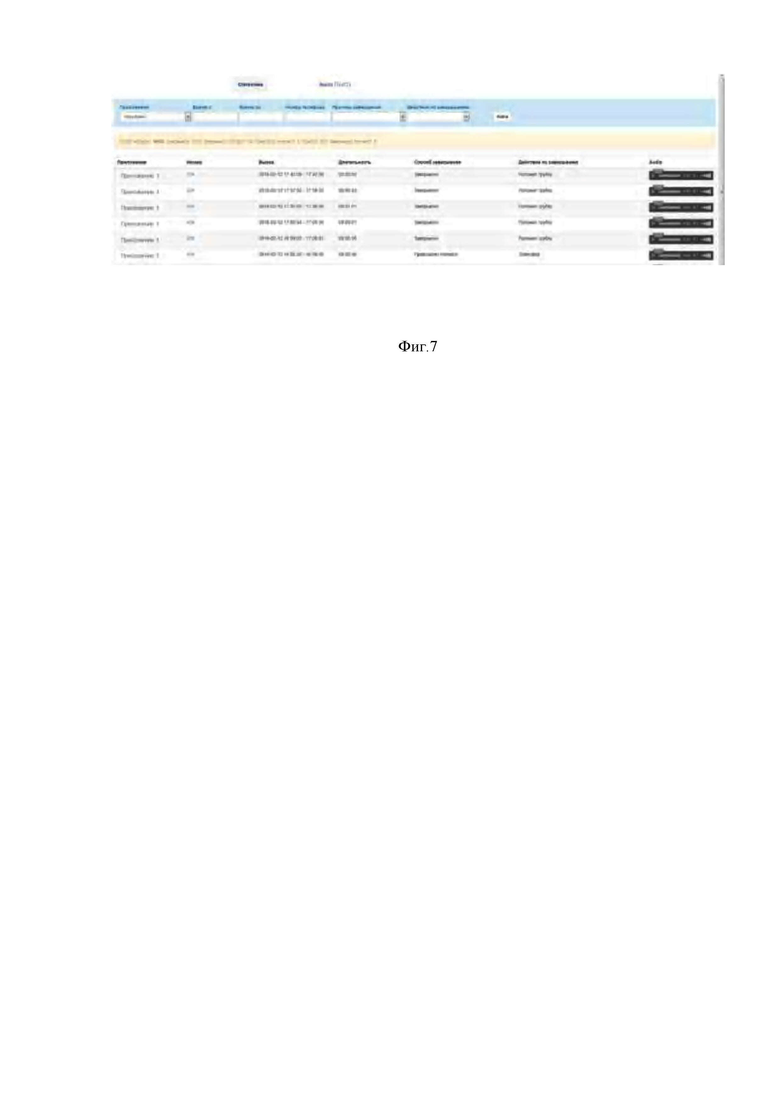
На фигуре 7 приведен вариант интерфейса работы специалиста по мониторингу.
Окно диалога включает в себя:
• Область для поиска и отбора голосовых обращений клиентов (701) – в данном поле возможен поиск по параметрам время с… по, номер телефона, причина завершения, действие по завершению.
• Статистика поиска (702) – сколько всего обращений по указанным параметрам найдено, в том числе в разбивке по причинам и действиям по завершению.
• Список найденных диалогов (703) – в списке отображается информация по номеру, с которого осуществлялось обращение, дате и времени вызова, длительности, способу завершения, действия по завершению.
• Переход к детальной информации по выбранному обращению (704)
• Прослушивание обращения (705) – прослушивание аудиозаписи обращения клиента.
Для отбора обращений пользователь может указать следующие параметры:
- Приложение – выбор заданного приложения из списка настроенных в системе
- Время обращения – период, в интервале которого произошло обращение клиента.
- Номер телефона – номер телефона, с которого обращался клиент, только для обращений по телефонной линии.
- Причина завершения – причина окончания разговора с клиентом.
- Действие по завершению – зафиксированное действие в системе по завершению разговора с клиентом.
После заполнения параметров поиска обращений необходимо нажать кнопку «Найти». Система отобразит:
Статистику по результатам поиска обращений: общее количество обращений, соответствующее введенным критериям, и в разбивке по статусу завершения.
Список обращений, соответствующий введенным критериям, с указанием:
- название приложения
- номер, с которого был осуществлен вызов (для обращений посредством телефонной связи)
- дата и время обращения
- длительность обращения
- способ завершения обращения (причина завершения обращения)
- действие по завершении.
В данном интерфейсе пользователю доступны операции:
- Прослушать весь выбранный звонок клиента, нажав кнопку Play в пункте Audio
- Просмотреть детальную информацию по выбранному обращению. Для этого необходимо перейти по гиперссылке в пункте «Номер» для выбранного звонка.
На фигуре 8 приведен вариант интерфейса работы специалиста по мониторингу с детальной информацией по обращению клиента.
Окно диалога включает в себя:
1. Список диалогов в рамках выбранного звонка.
2. По каждому диалогу отображается следующая информация:
a. Дата и время диалога;
b. Уровень доверия к распознанному тексту – принимает значения от 0 до 1, где 1 – высокая степень точности распознавания, 0 – текст не распознан;
c. Транскрипция – содержит распознанный текст ответа клиента в рамках диалога;
d. Результат – содержит правило, описывающее дальнейшее действие программы после распознавания;
e. Статус – результат сравнения распознанной фразой с грамматикой приложения;
f. Кто ответил – указан источник распознавания текста: сервис ASR или оператор
g. Этап диалога – название диалога
По выбранному обращению пользователь может:
- Просмотреть список диалогов в рамках выбранного обращения;
- Прослушать выбранный диалог;
По каждому диалогу отображается следующая информация:
- Дата и время диалога;
- Уровень доверия к распознанному тексту – принимает значения от 0 до 1, где 1 – высокая степень точности распознавания, 0 – текст не распознан;
- Транскрипция – содержит распознанный текст ответа клиента в рамках диалога;
- Результат – содержит правило, описывающее дальнейшее действие программы после распознавания;
- Статус – результат сравнения распознанной фразой с грамматикой приложения;
- Кто ответил – указан источник распознавания текста: сервис ASR или оператор;
- Этап диалога – название диалога.
В настоящих материалах заявки было представлено предпочтительное раскрытие осуществление заявленного технического решения, которое не должно использоваться как ограничивающее иные, частные воплощения его реализации, которые не выходят за рамки испрашиваемого объема правовой охраны и являются очевидными для специалистов в соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| МАШИННОЕ ОБУЧЕНИЕ | 2005 |
|
RU2391791C2 |
| ПРЕДСТАВЛЕНИЕ ДАННЫХ НА ОСНОВЕ ВВЕДЕННЫХ ПОЛЬЗОВАТЕЛЕМ ДАННЫХ | 2004 |
|
RU2360281C2 |
| СИНХРОННОЕ ПОНИМАНИЕ СЕМАНТИЧЕСКИХ ОБЪЕКТОВ, РЕАЛИЗОВАННОЕ С ПОМОЩЬЮ ТЭГОВ РЕЧЕВОГО ПРИЛОЖЕНИЯ | 2004 |
|
RU2349969C2 |
| СИНХРОННОЕ ПОНИМАНИЕ СЕМАНТИЧЕСКИХ ОБЪЕКТОВ ДЛЯ ВЫСОКОИНТЕРАКТИВНОГО ИНТЕРФЕЙСА | 2004 |
|
RU2352979C2 |
| КОНЕЧНЫЙ АВТОМАТ УНИФИЦИРОВАННОГО ОБМЕНА СООБЩЕНИЯМИ | 2008 |
|
RU2470364C2 |
| Способ эмуляции голосового бота при обработке голосового вызова (варианты) | 2022 |
|
RU2792405C2 |
| ИНТЕЛЛЕКТУАЛЬНОЕ РАБОЧЕЕ МЕСТО ОПЕРАТОРА И СПОСОБ ЕГО ВЗАИМОДЕЙСТВИЯ ДЛЯ ОСУЩЕСТВЛЕНИЯ ИНТЕРАКТИВНОЙ ПОДДЕРЖКИ СЕССИИ ОБСЛУЖИВАНИЯ КЛИЕНТА | 2020 |
|
RU2755781C1 |
| ГОЛОСОВАЯ СВЯЗЬ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ МЕЖДУ ЧЕЛОВЕКОМ И УСТРОЙСТВОМ | 2014 |
|
RU2583150C1 |
| Платформа автоматизации контакт-центров с использованием речевой аналитики | 2021 |
|
RU2787530C1 |
| СПОСОБЫ И УСТРОЙСТВО ДЛЯ ОСУЩЕСТВЛЕНИЯ РАСПРЕДЕЛЕННЫХ МНОГОМОДАЛЬНЫХ ПРИЛОЖЕНИЙ | 2008 |
|
RU2494444C2 |




Изобретение относится к системе и способу автоматизации обработки голосовых обращений клиентов в сервисные службы компаний. Технический результат заключается в динамическом выборе способа обработки голосового обращения клиента в зависимости от переданных параметров голосового отрезка. Система содержит: сервер взаимодействия (CORE), АРМ Оператора, содержащий web-интерфейс для обработки голосового обращения клиента с преднастроенными шаблонами ответов и обеспечивающий проигрывание Оператору звукового отрывка (Voice Sample); АРМ Конфигуратор OSR, содержащий web-интерфейс для настройки АРМ оператора и модуля службы OSR; службу Semantic, выполненную с возможностью выделения ключевых слов из транскрибированного текста по заданной грамматике; службу Logger, выполненную с возможностью логирования результатов распознавания голосовых обращений, клиентов и выделенных семантических тэгов; службу статистики (Statistics), выполненную с возможностью сохранения информации обо всех стадиях диалога; АРМ Специалиста по мониторингу, содержащий web-интерфейс для просмотра отчетов по работе системы и контроля корректности распознавания голосовых обращений клиентов. 3 н. и 15 з.п. ф-лы, 8 ил.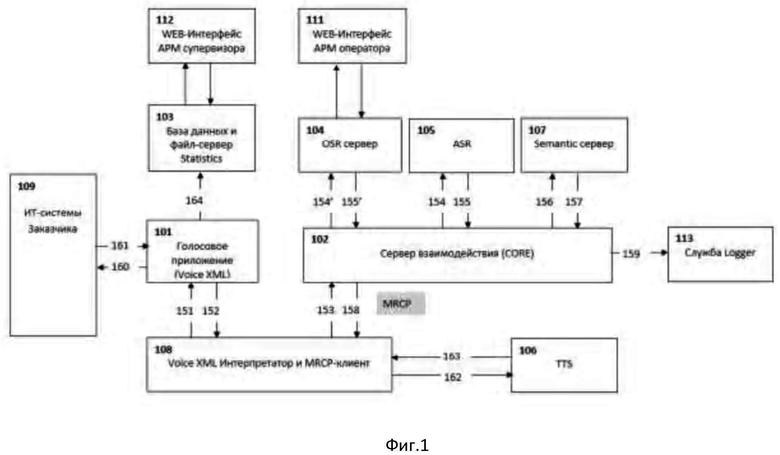
1. Система автоматизации голосовых обращений клиентов в сервисные службы компании, содержащая:
сервер взаимодействия (CORE), выполненный с возможностью:
• взаимодействия с сервером Голосовых приложений посредством Voice XML интерпретатора и MRCP клиента;
• получения от него аудиопотока/аудиофайла для транскрибирования;
• осуществления выбора способа обработки – системой автоматического распознавания речи (ASR) или модулем службы оператора (OSR) аудиопотока/аудиофайла в соответствии с переданными настройками;
• маршрутизации аудиопотока/аудиофайла последовательно в систему ASR;
• обработки ответа от системы ASR и проверки уровня доверия к транскрибированному тексту, при уровне доверия выше минимально установленного осуществляет передачу текста в службу Sematic для выделения семантических тэгов, при уровне доверия ниже минимально установленного осуществляет маршрутизацию обращения в модуль службы OSR;
• получения от модуля службы OSR массива транскрибированного текста и семантических тэгов;
• передачи результатов распознавания голосового обращения клиента и выделенных семантических тэгов в сервер Голосовых приложений;
сервер OSR, выполненный с возможностью:
• маршрутизации обращений клиентов в АРМ Оператора;
• передачи результатов обработки обращений в сервер взаимодействия;
• регистрации и выбора оператора для обработки обращения;
АРМ Оператора, содержащий web-интерфейс для обработки голосового обращения клиента с преднастроенными шаблонами ответов и обеспечивающий проигрывание Оператору звукового отрывка (Voice Sample);
АРМ Конфигуратор OSR, содержащий web-интерфейс для настройки АРМ оператора и модуля службы OSR;
службу Semantic, выполненную с возможностью выделения ключевых слов из транскрибированного текста по заданной грамматике, переданной сервером взаимодействия (CORE), на основе настроенной статистической модели;
службу Logger, выполненную с возможностью логирования результатов распознавания голосовых обращений, клиентов и выделенных семантических тэгов;
службу статистики (Statistics), выполненную с возможностью сохранения информации обо всех стадиях диалога:
 дату и время начала сессии;
дату и время начала сессии;
дату и время окончания сессии;
URL аудиопотока/аудиофайла;
настройки статистики сервера Голосовых приложений, для дальнейшего использования в АРМ Статистика;
АРМ Специалиста по мониторингу, содержащий web-интерфейс для просмотра отчетов по работе системы и контроля корректности распознавания голосовых обращений клиентов.
2. Система по п.1, характеризующаяся тем, что сервер взаимодействия (CORE) в зависимости от уровня критичности диалога производит маршрутизацию функции распознавания обращения клиента в модуль службы OSR без предварительного обращения в систему ASR, в которой производят прослушивание переданного звукового отрезка (VS) и отмечают выбор правильного варианта распознавания текста, после чего модуль службы OSR возвращает в сервер взаимодействия (CORE) массив транскрибированного текста и семантические тэги.
3. Система по п.1, характеризующаяся тем, что сервер взаимодействия (CORE) осуществляет маршрутизацию аудиопотока/аудиофайла только в систему ASR, обработку ответа от системы ASR и проверку уровня доверия к транскрибированному тексту, маршрутизацию в службу Sematic для выделения семантических тэгов при уровне доверия выше минимально установленного, формирование отрицательного ответа при уровне доверия ниже минимально установленного, передачу результатов распознавания голосового обращения клиента и выделенных семантических тэгов в сервер Голосовых приложений.
4. Система по п.1, характеризующаяся тем, что сервер взаимодействия (CORE) вначале отправляет звуковой отрезок (VS) в систему ASR, а после получения результатов автоматического распознавания в модуль службы OSR, где производят прослушивание звукового отрезка (VS) и проверяют/дополняют результаты автоматического распознавания речи клиента, в зависимости от качества автоматического распознавания подтверждают данные системы ASR, или вносят соответствующие корректировки, после чего модуль службы OSR возвращает в сервер взаимодействия (CORE) массив транскрибированного текста и семантические тэги.
5. Система по п.1, характеризующаяся тем, что сервер взаимодействия (CORE) одновременно отправляет звуковой отрезок (VS) и в систему ASR, и в модуль службы OSR, в случае, если первый по времени приходит ответ от модуля службы OSR, то в сервер Голосовых приложений передаются результат распознавания текста и семантические теги от модуля службы OSR, в случае, если первый по времени приходит ответ от системы ASR, то дополнительно проверяется вероятность распознавания текста, если она больше заданного уровня в системе, то сервер взаимодействия (CORE) передает в сервер Голосовых приложений результат автоматического распознавания системой ASR, если уровень доверия менее заданного уровня в сервере взаимодействия (CORE), то ожидается ответ от модуля службы OSR.
6. Система по п.1, характеризующаяся тем, что после обработки речи клиента и выделения семантических тегов, сервер взаимодействия (CORE) осуществляет обращение через терминал клиента в ИТ-системы заказчика и получает текст для синтеза речи, далее производит обращение с полученным текстом в систему синтеза речи (TTS) и возвращает в терминал клиента аудиофайл с синтезированным сообщением по запрошенной клиентом информации.
7. Способ автоматизации голосовых обращений клиентов в сервисные службы компании, содержащий этапы, на которых:
устанавливают соединение с помощью терминала клиента по протоколу управления медиа-ресурсами (MRCP) c сервером Голосовых приложений и отправляют запрос, содержащий идентификатор (ID) диалога и аудиопоток;
осуществляют с помощью сервера Голосовых приложений предварительную обработку вызова, определяют начало речи с помощью функции Voice Activity Detection (VAD) и таймаутов;
осуществляют передачу ID-диалога и уникальный указатель ресурса (URL) на аудиопоток/аудиофайл (VS) в сервер взаимодействия (CORE), а также обеспечивают взаимодействие с системами Заказчика;
принимают с помощью сервера взаимодействия (CORE) из терминала клиента ID-диалога, уникальный указатель ресурса (URL) на аудиопоток/аудиофайл и передают в систему автоматического распознавания речи (ASR) аудиопоток/аудиофайл и настройки распознавания текста;
осуществляют транскрибирование и оценку вероятности правильного распознавания звука с помощью системы ASR;
возвращают с помощью системы ASR в сервер взаимодействия (CORE) массив транскрибированного текста и уровень доверия распознавания звука;
оценивают с помощью сервера взаимодействия (CORE) уровень доверия к распознаванию голосового отрезка (VS);
при уровне доверия выше минимально установленного осуществляют передачу текста и требуемую грамматику в службу Sematic для выделения семантических тэгов;
выделяют службой Semantic из переданного текста по указанной грамматике семантические тэги;
при уровне доверия ниже минимально установленного осуществляется маршрутизацию обращения в модуль службы OSR,
производят с помощью модуля службы OSR прослушивание звукового отрезка (VS) и фиксируют выбор правильного варианта распознавания текста;
возвращают с помощью модуля службы OSR в сервер взаимодействия (CORE) массив транскрибированного текста и семантические тэги;
передают с помощью сервера взаимодействия (CORE) в сервер Голосовых приложений массив транскрибированного текста и семантические тэги;
осуществляют с помощью сервера взаимодействия (CORE) логирование результатов распознавания в службе Logger;
осуществляют запись и хранение информации обо всех стадиях диалога:
дата и время начала сессии;
дата и время окончания сессии;
URL аудиопотока/аудиофайла;
настройки статистики сервера Голосовых приложений, в службе статистики (Statistics) для дальнейшего использования в АРМ Статистика.
8. Способ по п.7, характеризующийся тем, что производят с помощью сервера взаимодействия (CORE) маршрутизацию функции распознавания обращения клиента в модуль службы OSR без предварительного обращения в систему ASR, при этом в модуле службы OSR осуществляют прослушивание переданного звукового отрезка (VS) и фиксируют выбор правильного варианта распознавания текста, возвращают с помощью модуля службы OSR в сервер взаимодействия (CORE) массив транскрибированного текста и семантические тэги.
9. Способ по п.7, характеризующийся тем, что дополнительно:
производят с помощью сервера взаимодействия (CORE) маршрутизацию функции распознавания обращения клиента в систему ASR;
осуществляют транскрибирование и оценку вероятности правильного распознавания звука с помощью системы ASR;
оценивают с помощью сервера взаимодействия (CORE) уровень доверия к распознаванию голосового отрезка VS;
при уровне доверия выше минимально установленного осуществляют передачу текста и требуемой грамматики в службу Sematic для выделения семантических тэгов;
выделяют службой Semantic из переданного текста по указанной грамматике семантические тэги;
передают с помощью сервера взаимодействия (CORE) в сервер Голосовых приложений массив транскрибированного текста и семантические тэги;
при уровне доверия ниже минимально установленного осуществляют формирование отрицательного ответа в сервер Голосовых приложений.
10. Способ по п.7, характеризующийся тем, что дополнительно:
производят с помощью сервера взаимодействия (CORE) последовательную отправку звукового отрезка (VS) в систему ASR, а после получения результатов автоматического распознавания в модуль службы OSR;
производят с помощью модуля службы OSR прослушивание звукового отрезка (VS) и проверку результатов автоматического распознавания речи клиента;
подтверждают или корректируют в модуле службы OSR результаты автоматического транскрибирования звука в текст с помощью системы ASR;
передают с помощью модуля службы OSR в сервер взаимодействия (CORE) массив транскрибированного текста и семантические тэги.
11. Способ по п.7, характеризующийся тем, что дополнительно:
производят одновременную отправку звукового отрезка (VS) и в систему ASR, и в модуль службы OSR;
при получении ответа от системы ASR или модуля службы OSR в сервере взаимодействия (CORE) производят оценку очередности полученных ответов в соответствии со следующим порядком: если первый по времени приходит ответ от модуля службы OSR, то передают в сервер Голосовых приложений результат распознавания и семантические тэги службы OSR; если первый по времени приходит ответ от системы ASR и переданная вероятность распознавания текста больше заданного уровня в сервере взаимодействия (CORE), то осуществляют передачу в сервер Голосовых приложений результат автоматического распознавания системой ASR; если первый по времени приходит ответ от системы ASR и вероятность распознавания текста меньше заданного уровня в сервере взаимодействия (CORE), то ожидается ответ от модуля службы OSR.
12. Способ по по пп.7-11, характеризующийся тем, что дополнительно:
после обработки речи клиента и выделения семантических тегов осуществляют обращение с помощью сервере взаимодействия (CORE) через сервер Голосовых приложений в ИТ-систему заказчика и получают текст для синтеза речи;
производят с помощью сервера взаимодействия (CORE) передачу полученного из ИТ-системы Заказчика текст в систему синтеза речи (TTS);
возвращают с помощью сервера взаимодействия (CORE) в терминал клиента аудиофайл с синтезированным сообщением по запрошенной клиентом информации.
13. Машиночитаемый носитель для автоматизации голосовых обращений клиентов в сервисные службы компании, содержащий исполняемые процессором инструкции, которые побуждают взаимодействовать аппаратные средства для выполнения способа по любому из пп. 7-12.
14. Машиночитаемый носитель по п.13, характеризующийся тем, что производят с помощью сервера взаимодействия (CORE) маршрутизацию функции распознавания обращения клиента к модулю службы OSR без предварительного обращения в систему ASR;
производят с помощью модуля службы OSR прослушивание оператором переданного звукового отрезка (VS) и фиксируют выбор правильного варианта распознавания текста;
возвращают с помощью модуля службы OSR в сервер взаимодействия (CORE) массив транскрибированного текста и семантические тэги.
15. Машиночитаемый носитель по п.13, характеризующийся тем, что дополнительно:
производят с помощью сервера взаимодействия (CORE) маршрутизацию функции распознавания обращения клиента в систему ASR;
осуществляют транскрибирование и оценку вероятности правильного распознавания звука с помощью системы ASR;
оценивают с помощью сервера взаимодействия (CORE) уровень доверия к распознаванию голосового отрезка VS;
при уровне доверия выше минимально установленного осуществляют передачу текста и требуемой грамматики в службу Sematic для выделения семантических тэгов;
выделяют службой Semantic из переданного текста по указанной грамматике семантические тэги;
передают с помощью сервера взаимодействия (CORE) в сервер Голосовых приложений массив транскрибированного текста и семантические тэги;
при уровне доверия ниже минимально установленного осуществляется формирование отрицательного ответа в сервер Голосовых приложений.
16. Машиночитаемый носитель по п.13, характеризующийся тем, что дополнительно:
производят с помощью сервера взаимодействия (CORE) последовательную отправку звукового отрезка (VS) в систему ASR, а после получения результатов автоматического распознавания в модуль службы OSR;
производят с помощью модуля службы OSR прослушивание оператором звукового отрезка (VS) и проверку результатов автоматического распознавания речи клиента;
подтверждают или корректируют в модуле службы OSR результаты автоматического транскрибирования звука в тексте с помощью системы ASR;
передают с помощью модуля службы OSR в сервер взаимодействия (CORE) массив транскрибированного текста и семантические тэги.
17. Машиночитаемый носитель по п.13, характеризующийся тем, что дополнительно:
производят одновременную отправку звукового отрезка (VS) и в систему ASR, и в модуль службы OSR;
при получении ответа от системы ASR или от модуля службы OSR c помощью сервера взаимодействия (CORE) производят оценку очередности полученных ответов в соответствии со следующим порядком:
если первый по времени приходит ответ от модуля службы OSR, то передают в сервер Голосовых приложений результат распознавания и семантические тэги модуля службы OSR; если первый по времени приходит ответ от системы ASR и переданная вероятность распознавания текста больше заданного уровня в сервере взаимодействия (CORE), то осуществляют передачу в сервер Голосовых приложений результата автоматического распознавания системой ASR;
если первый по времени приходит ответ от системы ASR и вероятность распознавания текста меньше заданного уровня в сервере взаимодействия (CORE), то ожидают ответ от службы OSR.
18. Машиночитаемый носитель по пп.13-17, характеризующийся тем, что дополнительно:
после обработки речи клиента и выделения семантических тегов осуществляют обращение с помощью сервера взаимодействия (CORE) через сервер Голосовых сообщений в ИТ-систему Заказчика и получают текст для синтеза речи;
производят с помощью сервера взаимодействия (CORE) передачу полученного из ИТ-системы Заказчика текста в систему синтеза речи (TTS);
возвращают с помощью сервера взаимодействия (CORE) в терминал клиента аудиофайл с синтезированным сообщением по запрошенной клиентом информации.
| US 7676371 B2, 09.03.2010 | |||
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Агрегат для сушки хромовых кож внаклейку | 1957 |
|
SU113598A1 |

