Перекрестные ссылки на родственные заявки
[0001] Настоящая заявка испрашивает приоритет на основании предварительной заявки на патент США №62/443,294, поданной 6 января 2017 г. и озаглавленной «PHASING CORRECTION» (КОРРЕКЦИЯ ФАЗИРОВАНИЯ), которая полностью и для любых целей включена в настоящий документ посредством ссылки.
УРОВЕНЬ ТЕХНИКИ
[0002] Настоящее раскрытие относится к секвенированию нуклеиновых кислот. Более конкретно, настоящее раскрытие относится к системам и способам для секвенирования в реальном времени с коррекцией фазирования.
[0003] На определенном участке проточной ячейки или другой подложки совместно анализируют множество копий молекулы нуклеиновой кислоты, имеющих одинаковую последовательность (возможно, с ограниченными вариациями, непреднамеренно внесенными при обработке образца). Используют достаточное количество копий, чтобы сгенерировать достаточный сигнал для обеспечения надежного распознавания оснований. Набор молекул нуклеиновой кислоты на участке называют кластером.
[0004] Фазирование представляет собой нецелевой артефакт, который возникает в результате секвенирования множества молекул нуклеиновых кислот в кластере. Фазирование представляет собой степень, с которой сигналы, такие как, флуоресценция от отдельных молекул в кластере, теряют синхронизацию друг с другом. Часто термин «фазирование» применяют для обозначения помехи от некоторых молекул, которые характеризуются отставанием, а термин «пре-фазирование» (опережающее) используют для обозначения помехи от других молекул, которые характеризуются опережением. Совместно, фазирование и опережающее фазирование определяют, насколько хорошо работает устройство для секвенирования (секвенатор) и выполняется химический анализ.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0005] Некоторые аспекты этого раскрытия относятся к способам определения скорректированных значений цвета по данным изображения, полученным с помощью секвенатора нуклеиновых кислот в ходе осуществления цикла распознавания оснований, причем секвенатор содержит систему получения изображения, один или более процессоров и запоминающее устройство. Такие способы могут характеризоваться следующими операциями: (а) получение изображения подложки (например, части проточной ячейки), содержащей множество участков, на которых считывают нуклеиновые основания; (b) измерение значений цвета множества участков по изображению подложки, (с) сохранение значений цвета в буфере процессора одного или более процессоров секвенатора; (d) получение (возвращение) значений цвета с частичной коррекцией фазирования для множества участков, причем значения цвета с частичной коррекцией фазирования были сохранены в запоминающем устройстве секвенатора в ходе осуществления непосредственно предшествующего цикла распознавания оснований; (е) определение коррекции опережающего фазирования; и (f) определение скорректированных значений цвета. В различных вариантах реализации все указанные операции выполняют в течение одного цикла распознавания оснований. В некоторых вариантах осуществления способы также включают применение скорректированных значений цвета для распознавания оснований для множества участков.
[0006] В процессе секвенирования участки имеют цвета, представляющие типы оснований нуклеиновых кислот. Измеренные и сохраненные значения цвета могут представлять собой значения интенсивности или другие значения величины при определенной длине волны или диапазоне длин волн. В некоторых вариантах реализации значения цвета определяют только по двум каналам секвенатора. В некоторых вариантах реализации значения цвета получают с применением четырех каналов секвенатора. Хотя настоящее раскрытие сфокусировано на коррекции фазирования цветовых сигналов, эти концепции применимы и в отношении сигналов других типов, генерируемых в процессе секвенирования кластеров нуклеиновых кислот, имеющих идентичные последовательности. Примеры таких других сигналов включают излучение вне видимого спектра, концентрирование ионов и т.д.
[0007] В некоторых вариантах осуществления для определения скорректированных значений цвета в операции (f) применяют (i) значения цвета в буфере процессора, (ii) значения с частичной коррекцией фазирования, сохраненные в ходе осуществления непосредственно предшествующего цикла, и (iii) коррекцию опережающего фазирования. В некоторых вариантах осуществления для определения коррекции опережающего фазирования в операции (е) применяют (i) значения цвета с частичной коррекцией фазирования, сохраненные в ходе осуществления непосредственно предшествующего цикла распознавания оснований, и (ii) значения цвета, сохраненные в буфере процессора.
[0008] В некоторых вариантах осуществления коррекция опережающего фазирования включает весовой коэффициент (вес). В таких вариантах осуществления операция определения скорректированных значений цвета может включать умножение весов на значения цвета множества участков, измеренные по изображению подложки.
[0009] В некоторых вариантах реализации способы также включают определение коррекции фазирования для непосредственно следующего цикла распознавания оснований. В качестве примера, определение коррекции фазирования для непосредственно следующего цикла распознавания оснований включает анализ (i) значений цвета с частичной коррекцией фазирования, хранимых в запоминающем устройстве секвенатора, и (ii) значений цвета, хранимых в буфере процессора. В некоторых вариантах осуществления, включающих определение коррекции фазирования для непосредственно следующего цикла распознавания оснований, способы также включают (i) получение значений цвета с частичной коррекцией фазирования для непосредственно следующего цикла распознавания оснований путем применения коррекции фазирования в отношении значений цвета множества участков, хранимых в запоминающем устройстве секвенатора; и (ii) сохранение значений цвета с частичной коррекцией фазирования для непосредственно следующего цикла распознавания оснований в запоминающем устройстве секвенатора. В некоторых вариантах осуществления получение значений цвета с частичной коррекцией фазирования для непосредственно следующего цикла распознавания оснований также включает суммирование (i) значений цвета со скорректированным фазированием множества участков и (ii) значений цвета множества участков из изображения подложки, измеренной в п. (b). В некоторых вариантах реализации при сохранении значений цвета с частичной коррекцией фазирования для непосредственно следующего цикла распознавания оснований частично скорректированные значения цвета сохраняют в буферах сегмента запоминающего устройства секвенатора.
[0010] В некоторых вариантах осуществления способы выполняют в реальном времени в ходе получения считываний последовательностей секвенатором нуклеиновых кислот. В некоторых вариантах осуществления секвенатор нуклеиновых кислот осуществляет секвенирование путем синтеза нуклеиновых кислот на множестве участков. В некоторых вариантах осуществления, в которых подложка содержит проточную ячейку, проточную ячейку логически разделяют на сегменты и каждый сегмент представляет собой область проточной ячейки, содержащую подмножество участков, причем это подмножество фиксируют в одном изображении с помощью системы получения изображения.
[0011] В некоторых вариантах осуществления с применением таких систем в операции (d) (извлечение значений цвета с частичной коррекцией фазирования для множества участков) значения цвета с частичной коррекцией фазирования были предварительно сохранены в буферах сегмента запоминающего устройства секвенатора, причем буферы сегмента выполнены с возможностью хранения данных, представляющих изображения отдельных сегментов на подложке. В некоторых вариантах осуществления емкость запоминающего устройства составляет около 512 Гигабайт или менее или около 256 Гигабайт или менее. В некоторых вариантах осуществления, например, запоминающее устройство имеет емкость, которая в два раза меньше емкости, необходимой для хранения данных, содержащихся во всех сегментах в двух проточных ячейках. В некоторых вариантах осуществления обработка, описанная в данном документе, позволяет сэкономить по меньшей мере около 50 Гигабайт; а в некоторых вариантах осуществления по меньшей мере около 100 Гигабайт.
[0012] В некоторых вариантах реализации перед выполнением операции (а) (получение изображения подложки) способы также включают помещение (обеспечение наличия) реагентов в проточную ячейку и обеспечение возможности взаимодействия реагентов с участками, в результате чего участки будут иметь цвета, соответствующие типам нуклеиновых оснований, в ходе осуществления цикла распознавания оснований. В таких вариантах реализации способ также может включать после операции (f) (определения скорректированных значений цвета): (i) помещение свежих реагентов в проточную ячейку и обеспечение возможности взаимодействия свежих реагентов с участками, в результате чего участки будут иметь цвета, соответствующие типам нуклеиновых оснований, для следующего цикла распознавания оснований; и (ii) повторное выполнение операций (a)-(e) следующего цикла распознавания оснований. Такие способы также могут включать создание первого потока процессора для выполнения операций (a)-(f) для цикла распознавания оснований и создание второго потока процессора для выполнения операций (a)-(f) для следующего цикла распознавания оснований. В некоторых вариантах осуществления указанные способы также включают выделение буфера процессора и второго буфера процессора, причем второй буфер процессора используют для определения скорректированных значений цвета в п. (f).
[0013] Некоторые другие аспекты раскрытия относятся к секвенаторам нуклеиновых кислот, которые могут характеризоваться следующими элементами: системы получения изображения; запоминающего устройства; и одного или более процессоров, выполненных с возможностью или сконфигурированных для: (а) получения данных, представляющих изображение подложки, содержащей множество участков, на которых считывают нуклеиновые основания (на указанных участках проявляются, например, цвета, соответствующие типам нуклеиновых оснований); (b) получения значений цвета для множества участков из изображения подложки; (с) сохранения значений цвета в буфере процессора; (d) извлечения значений цвета с частичной коррекцией фазирования для множества участков для цикла распознавания оснований (значения цвета с частичной коррекцией фазирования были сохранены в запоминающем устройстве секвенатора в ходе осуществления непосредственно предшествующего цикла распознавания оснований); (е) определения коррекции опережающего фазирования; и (f) определения скорректированных значений цвета по, например, (i) значениям цвета в буфере процессора, (ii) значений с частичной коррекцией фазирования, сохраненных в течение непосредственно предшествующего цикла, и (iii) коррекции опережающего фазирования.
[0014] Команды или другая конфигурация (вариант выполнения) для определения коррекции опережающего фазирования могут включать конфигурацию для определения коррекции опережающего фазирования из (i) значений цвета с частичной коррекцией фазирования, сохраненных в ходе осуществления непосредственно предшествующего цикла распознавания оснований, и (ii) значений цвета, сохраненных в буфере процессора.
[0015] В некоторых вариантах осуществления запоминающее устройство разделяют на множество буферов сегмента, каждый из которых выполнен с возможностью хранения данных, представляющих одно изображение сегмента на подложке. В некоторых вариантах осуществления запоминающее устройство имеет емкость менее приблизительно 550 Гигабайт (в некоторых примерах, что в два раза меньше объема, необходимого для хранения данных, содержащихся во всех сегментах в двух проточных ячейках).
[0016] Процессоры могут быть сконфигурированы для осуществления описанных операций различными способами, например, путем получения исполняемых машиночитаемых команд. В некоторых случаях процессоры программируют с помощью аппаратно реализованного программного обеспечения или ядер для специализированной обработки, например, ядер цифровой обработки сигналов. В различных вариантах осуществления процессор (-ы) выполнены с возможностью или сконфигурированы для осуществления (и/или управления) любой одной или более операциями способа, описанными выше.
[0017] В некоторых вариантах реализации раскрытые в данном документе функции коррекции фазирования позволяют существенно снизить стоимость прибора для секвенирования за счет более эффективного использования запоминающего устройства (например, оперативного запоминающего устройства (ОЗУ)). В некоторых вариантах осуществления эти функции коррекции фазирования используют в контексте анализа в реальном времени (RTA) на платформах секвенирования.
[0018] Эти и другие признаки раскрытия будут представлены более подробно ниже со ссылкой на соответствующие чертежи.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0019] На фиг. 1 представлена блок-схема секвенатора с аппаратным обеспечением для анализа в реальном времени данных изображения, полученных из кластеров нуклеиновой кислоты.
[0020] На фиг. 2 представлена иллюстрация данных двухканального секвенирования для иллюстрации концепций фазирования и опережающего фазирования.
[0021] На фиг. 3 изображена архитектура проточной ячейки, содержащей множество сегментов, каждый из которых содержит множество кластеров.
[0022] На фиг. 4 показан массив данных, содержащий данные величины для кластеров в сегменте или другого отображаемого фрагмента проточной ячейки; причем данные величины могут представлять собой значения интенсивности света для каждого из двух или более цветовых каналов.
[0023] На фиг. 5 схематично изображены первая конфигурация обработки и способ проведения коррекции фазирования в реальном времени.
[0024] На фиг. 6 представлена блок-схема процесса распознавания оснований, в котором может быть использована конфигурация процессора и запоминающего устройства, показанная на фиг. 5.
[0025] На фиг. 7 схематично изображены вторая конфигурация обработки и способ проведения коррекции фазирования в реальном времени. Эта конфигурация позволяет снизить требования к системному запоминающему устройству.
[0026] На фиг. 8 схематично изображены третья конфигурация обработки и способ проведения коррекции фазирования в реальном времени. Эта конфигурация позволяет дополнительно снизить требования к системному запоминающему устройству.
[0027] На фиг. 9 представлена высокоуровневая блок-схема первых нескольких циклов обработки, которые могут быть использованы с конфигурацией процессора и запоминающего устройства, показанной на фиг. 8, и, в некоторых вариантах реализации, показанной на фиг. 7.
[0028] На фиг. 10 представлена блок-схема циклов обработки, в которых распознавание оснований проводят с полностью скорректированным фазированием. Такой цикл может быть выполнен в третьем и последующих циклах обработки при секвенировании кластеров сегмента.
[0029] На фиг. 11 представлены сравнительные данные для способов коррекции фазирования с использованием алгоритма применения уменьшенного объема основного запоминающего устройства.
ПОДРОБНОЕ ОПИСАНИЕ
ОПРЕДЕЛЕНИЯ
[0030] Числовые диапазоны включают числа, определяющие диапазон. Предполагается, что каждое максимальное числовое ограничение, приведенное в данном описании, включает каждое меньшее числовое ограничение, как если бы такие меньшие числовые ограничения были непосредственно указаны в данном документе. Предполагается, что каждое минимальное числовое ограничение, приведенное в данном описании, будет включать каждое большее числовое ограничение, как если бы такие большие числовые ограничения были явным образом указаны в данном документе. Каждый числовой диапазон, приведенный в данном описании, будет включать каждый более узкий числовой диапазон, относящийся к такому более широкому числовому диапазону, как если бы все такие более узкие числовые диапазоны были явным образом указаны в данном документе.
[0031] Заголовки, представленные в данном документе, не предназначены для ограничения раскрытия.
[0032] Если в данном документе не указано иное, все технические и научные термины, используемые в данном документе, имеют то же значение, которое обычно понятно для специалистов в данной области техники. Различные научные словари, которые включают термины, включенные в данный документ, хорошо известны и доступны специалистам в данной области. Хотя любые способы и материалы, подобные или эквивалентные способам и материалам, описанным в данном документе, находят применение на практике или при испытании вариантов осуществления, раскрытых в данном документе, для некоторых способов и материалов приведено описание.
[0033] Термины, определенные ниже, более подробно описаны со ссылкой на полное описание. Следует понимать, что данное раскрытие не ограничено конкретным описанным способом, протоколами и реагентами, поскольку они могут варьироваться в зависимости от контекста их использования специалистами в данной области техники.
[0034] Используемые в данном документе грамматические формы единственного числа подразумевают ссылку на множественное число, если контекст явно не указывает на иное. Термин «множество» относится к более чем одному элементу. Например, указанный термин использован в данном документе применительно к количеству считываний для получения фазированного островка с использованием способов, раскрытых в данном документе.
[0035] Термин «фрагмент» использован в данном документе в отношении количества информации о последовательности генома, хромосомы или гаплотипа в биологическом образце, которое в сумме меньше количества информации о последовательности одного полного генома, одной полной хромосомы или одного полного гаплотипа, как явствует из контекста.
[0036] Термин «образец» в данном документе относится к образцу, как правило, полученному из биологической жидкости, клетки, ткани, органа или организма и содержащему нуклеиновую кислоту или смесь нуклеиновых кислот, содержащих по меньшей мере одну последовательность нуклеиновой кислоты, подлежащую секвенированию. Такие образцы включают, без ограничений, мокроту/жидкость ротовой полости, околоплодную жидкость, спинномозговую жидкость, кровь, фракцию крови (например, сыворотку или плазму), образцы, полученные при биопсии тонкой иглой (например, хирургической биопсии, биопсии тонкой иглой и т.д.), мочу, слюну, сперму, пот, слезы, жидкость брюшной полости, плевральную жидкость, эксплантатную ткань в жидкости для промывания, культуру органа и любой другой тканевый или клеточный препарат, или их фракцию, или производное, или выделение из них.
[0037] Хотя образец часто берут у человека (например, пациента), образцы могут быть взяты из любого организма, имеющего хромосомы, включая, без ограничений, собак, кошек, лошадей, коз, овец, крупный рогатый скот, свиней и т.д. Образец может быть использован непосредственно при получении из биологического источника или после предварительной обработки для изменения свойств образца. Например, такая предварительная обработка может включать приготовление плазмы из крови, разбавление вязких жидкостей и т.д. Способы предварительной обработки также могут включать, без ограничений, фильтрацию, осаждение, разбавление, дистилляцию, смешивание, центрифугирование, замораживание, лиофилизацию, концентрирование, амплификацию, фрагментацию нуклеиновой кислоты, инактивацию нежелательных компонентов, добавление реагентов, лизирование и т.д. Если такие способы предварительной обработки применяют к образцу, в таких способах предварительной обработки исследуемая нуклеиновая кислота (-ы) обычно остается в исследуемом образце, иногда в концентрации, пропорциональной концентрации в необработанном исследуемом образце (например, именно в образце, в к которому не применяли какой-либо подобный способ (-ы) предварительной обработки). Такие «обработанные» или «подготовленные» образцы по-прежнему считаются биологическими «исследуемыми» образцами в контексте способов, описанных в настоящем документе.
[0038] Термины «полинуклеотид», «нуклеиновая кислота» и «молекулы нуклеиновой кислоты» используют взаимозаменяемо, и они относятся к ковалентно связанной последовательности нуклеотидов (т.е. рибонуклеотидов в случае РНК и дезоксирибонуклеотидов в случае ДНК), в которой 3'-положение пентозы одного нуклеотида соединено фосфодиэфирной группой с 5'-положением пентозы следующего нуклеотида. Нуклеотиды включают последовательности любой формы нуклеиновой кислоты, включая, без ограничений, молекулы РНК и ДНК. Термин «полинуклеотид» включает, без ограничений, одноцепочечный и двухцепочечный полинуклеотид.
[0039] Одноцепочечные молекулы полинуклеотид а могут образовываться в одноцепочечной форме, в виде ДНК или РНК, или образовываться в форме двухцепочечной ДНК (дцДНК) (например, сегментов геномной ДНК, продуктов полимеразной цепной реакции (ПНР) и амплификации, и т.п). Таким образом, одноцепочечный полинуклеотид может быть кодирующей или некодирующей цепью двухцепочечного полинуклеотида. Способы получения одноцепочечных молекул полинуклеотида, подходящих для использования в описанных способах, с использованием стандартных способов хорошо известны в данной области техники. Точная последовательность первичных полинуклеотидных молекул, как правило, несущественна для раскрытых вариантов осуществления и может быть известна или неизвестна. Одноцепочечные молекулы полинуклеотида могут представлять собой молекулы геномной ДНК (например, геномной ДНК человека), включая как интронные, так и экзонные последовательности (кодирующие последовательности), а также некодирующие регуляторные последовательности, такие как промоторные и энхансерные последовательности.
[0040] Описанная в данном документе нуклеиновая кислота может иметь любую длину, подходящую для использования в предоставленных способах. Например, целевые нуклеиновые кислоты могут иметь длину по меньшей мере 10, по меньшей мере 20, по меньшей мере 30, по меньшей мере 40, по меньшей мере 50, по меньшей мере 75, по меньшей мере 100, по меньшей мере 150, по меньшей мере 200, по меньшей мере 250, по меньшей мере 500 или по меньшей мере 1000 тысяч пар нуклеотидов (килобаз = тысяч пар оснований) или более.
[0041] В контексте проточной ячейки или другой подложки (субстрата) для секвенирования термин «участок» относится к небольшой области, где осуществляют секвенирование. Во многих вариантах осуществления участок содержит множество, как правило, большое множество копий одной последовательности нуклеиновой кислоты, по которой получают данные секвенирования. Данные последовательности, полученные с участка, могут представлять собой «риды» (считывания).
[0042] Термин «полиморфизм» или «генетический полиморфизм» в данном документе использованы для обозначения наличия в одной и той же популяции двух или более аллелей в одном генетическом локусе. Различные формы полиморфизма включают однонуклеотидные полиморфизмы, тандемные повторы, микроделеции, вставки, инсерционно-делеционные мутации и другие полиморфизмы.
[0043] Термин «распознавание оснований» относится к назначенному основанию (типу нуклеотида) для данных последовательности для конкретного положения в полинуклеотидной последовательности. Распознанное основание может выводиться секвенатором для каждого положения в секвенируемой нуклеиновой кислоте. Иногда распознавание оснований характеризуется качеством распознавания.
[0044] Термин «рид» относится к последовательности, считанной с фрагмента образца нуклеиновой кислоты. Как правило, хотя и не обязательно, рид представляет короткую последовательность соседних пар оснований в образце. Рид может быть символически представлено последовательностью пар оснований (как ATCG)) фрагмента образца. Она может храниться в запоминающем устройстве и обрабатываться соответствующим образом для определения того, соответствует ли она референсной последовательности или другим критериям. Рид может быть получен непосредственно с устройства для секвенирования или косвенно из хранимой информации о последовательности, относящейся к образцу. В некоторых случаях рид представляет собой последовательность ДНК достаточной длины (например, по меньшей мере приблизительно 25 пар оснований), которая может использоваться для идентификации большей последовательности или области, например, которая может выравниваться и быть специфично связана с хромосомой, или геномной областью или геном.
[0045] Термин «секвенирование следующего поколения (NGS)» в данном документе относится к методам секвенирования, которые обеспечивают массовое параллельное секвенирование кольнально амплифицированных молекул и отдельных молекул нуклеиновой кислоты. Неограничивающие примеры секвенирования следующего поколения включают секвенирование путем синтеза с использованием обратимых меченых красителем терминаторов и секвенирование путем лигирования.
[0046] Термин «параметр» в данном документе относится к числовому значению, которое характеризует физическое свойство или представление этого свойства. В некоторых ситуациях параметр численно характеризует набор количественных данных и/или числовое соотношение между наборами количественных данных. Например, среднее значение и дисперсия аппроксимации стандартного распределения для гистограммы являются параметрами.
[0047] Термины «порог» (пороговое значение) в данном документе относятся к любому числу, используемому в качестве предельной величины для характеристики образца, нуклеиновой кислоты или их фрагмента (например, рида). Пороговое значение можно сравнивать с измеренным или вычисленным значением для определения того, следует ли классифицировать источник такого значения определенным образом. Пороговые значения могут определяться эмпирически или аналитически. Выбор порогового значения зависит от уровня достоверности, который пользователь будет использовать при классификации. Иногда их выбирают для конкретной цели (например, чтобы сбалансировать чувствительность и избирательность).
[0048] Анализ в реальном времени относится к процессу и системе, в которых обработку и анализ данных выполняют в фоновом режиме относительно сбора данных в ходе секвенирования ДНК. Пример системы анализа в реальном времени описан в патенте США №8,965,076, который полностью включен в настоящее описание посредством ссылки.
КОНТЕКСТ ДЛЯ ФА ЗИРОВАНИЯ
Устройство для секвенирования
[0049] На фиг. 1 представлена блок-схема некоторых компонентов типового секвенатора 100 нуклеиновой кислоты или системы, включающей такой секвенатор. В частности, система 100 содержит проточную ячейку 101 и систему 103 получения изображения, один или более процессоров 105 с одним или более буферами 107 и системное запоминающее устройство (иногда называемое основным запоминающим устройством) 109, содержащее множество буферов 111 сегмента. Как правило, системное запоминающее устройство 109 находится в устройстве, которое не является частью интегральной схемы, содержащей какой-либо из одного или более процессоров 105. В некоторых вариантах осуществления системное запоминающее устройство представляет собой энергозависимое запоминающее устройство, такое как оперативное запоминающее устройство или ОЗУ, например, динамическое запоминающее устройство с произвольной выборкой (DRAM), твердотельный накопитель или накопитель на жестком диске.
[0050] Проточная ячейка и система получения изображений содержат компоненты, выполненные или сконфигурированные в соответствии с принципами, понятными в области секвенирования нуклеиновых кислот, и они не будут подробно описаны в данном документе. Подходящие системы анализа изображений и соответствующие проточные ячейки используют в секвенаторах нуклеиновой кислоты, например, секвенаторах серий MiSeq и HiSeq, производимых компанией Illumina, Inc., Сан-Диего, Калифорния. Для получения дополнительной информации см. патент США №8,241,573, патент США №9,193,996 и патент США №8,951,781, каждый из которых полностью включен в настоящее описание посредством ссылки.
[0051] Обычно, последовательности нуклеиновой кислоты, подходящие для применения с раскрытыми способами, обеспечивают быстрое и эффективное одновременное обнаружение множества целевых нуклеиновых кислот. Они могут включать жидкостные компоненты, способные доставлять реагенты для амплификации и/или реагенты для секвенирования к одному или более фрагментам иммобилизованной ДНК, причем система содержит такие компоненты, как насосы, клапаны, резервуары, жидкостные линии и т.п. Проточная ячейка может быть установлена и/или использована в интегрированной системе для обнаружения целевых нуклеиновых кислот. Типовые проточные ячейки описаны, например, в 2010/0111768 А1 (США) и №13/273,666 (США), каждый из которых полностью включен в настоящее описание посредством ссылки. Как показано для проточных ячеек, один или более жидкостных компонентов интегрированной системы можно использовать как для способа амплификации, так и для способа обнаружения (детектирования). Например, один или более жидкостных компонентов интегрированной системы можно использовать для способа амплификации и для доставки реагентов для секвенирования в способе секвенирования. В качестве альтернативы, интегрированная система может содержать отдельные жидкостные системы для осуществления способов амплификации и для осуществления способов обнаружения.
[0052] Для целей настоящего раскрытия достаточно понимать, что проточная ячейка сначала принимает и иммобилизует или иным способом фиксирует образец нуклеиновой кислоты, подлежащий секвенированию, а затем подвергает его воздействию различных реагентов, связанных с процессом секвенирования. В некоторых вариантах осуществления процесс секвенирования представляет собой последовательность процесса синтеза, хотя могут быть использованы другие технологии секвенирования.
[0053] Система 103 получения изображения содержит оптические компоненты, например, компоненты возбуждения флуоресценции (например, лазер и соответствующие зеркала и линзы) для освещения участков проточной ячейки, в которых происходит секвенирование, и компоненты фиксации изображения для фиксации изображений флуоресценции фрагментов проточной ячейки, имеющей множество участков. Данные, полученные системой сбора изображений, содержат информацию, которую можно применять для определения того, какой нуклеотид считывают в любом данном участке в любом данном цикле секвенирования.
[0054] Для проведения анализа в реальном времени секвенатор 100 обычно содержит встроенные процессоры и запоминающее устройство, которые интерпретируют и сохраняют данные изображения от системы получения изображения 103. Примеры подходящих процессоров для секвенатора включают процессоры, относящиеся к классу Intel Xeon E5. Как правило, процессор 105 содержит множество буферов 107, которые временно хранят данные изображения, полученные в течение одного цикла получения изображения. В показанном варианте осуществления буферы процессора выделены в системном запоминающем устройстве. Данный буфер процессора может быть связан с конкретным потоком процессора, созданным для анализа данных изображения области проточной кюветы в ходе выполнения анализа в реальном времени. В некоторых вариантах осуществления данные изображения, анализируемые в виде потока, представляют собой данные одного сегмента (описанного ниже), зафиксированные в течение одного цикла получения изображения. В некоторых вариантах осуществления буфер может хранить около 400 Гигабайт данных. В контексте данного документа поток представляет собой упорядоченную последовательность команд, которая указывает процессору, какие операции следует выполнить. Команды конфигурируют процессор с использованием исполняемого машинного кода, выбранного из определенного набора команд на машинном языке, или «собственных команд», встроенных в аппаратный процессор.
[0055] Набор команд на машинном языке или набор собственных команд известен аппаратному процессору (-ам) или центральным процессорам и по существу встроен в них. Это «язык», с помощью которого система и прикладная программа взаимодействуют с аппаратными процессорами. Каждая собственная команда представляет собой дискретный код, распознаваемый архитектурой обработки и который может указывать конкретные регистры для арифметических, адресных или управляющих функций; конкретные области запоминающего устройства или значения смещения; и конкретные режимы адресации, используемые для интерпретации операндов. Более сложные операции создают путем объединения этих простых собственных команд, выполняемых последовательно или, в иных случаях, как указано в командах потока управления.
[0056] Системное запоминающее устройство 109 содержит множество буферов 111 сегмента, каждый из которых выполнен с возможностью хранения фрагмента данных изображения, полученных из проточной ячейки в течение одного цикла получения изображения. Буферы сегмента в этом примере имеют такое название, поскольку они выполнены с возможностью хранения данных изображения одного сегмента. Как более подробно объяснено ниже, сегмент представляет собой область проточной ячейки, которая может быть захвачена в одном изображении, полученном в течение одного цикла получения изображения. Буферы 111 сегмента выполнены с возможностью хранения данных изображения в течение более длительного периода времени по сравнению с буферами 107 процессора. В некоторых вариантах осуществления буферы 111 сегмента хранят данные изображения в течение по меньшей мере двух циклов получения изображения. Хотя в настоящей заявке описаны буферы, которые буферизуют данные сегмента проточной ячейки, раскрытые варианты осуществления не ограничиваются буферами, хранящими указанный объем данных. Если не указано иное или если контекст явно не указывает на иное, подразумевается, что упоминания «буферы сегмента» включают буфер любого типа, хранящего данные изображения фрагмента проточной ячейки, причем указанные данные изображения обрабатывают как одно целое, как описано в данном документе.
[0057] Для выполнения распознавания оснований один или более процессоров 105 задействуют данные, полученные от системного запоминающего устройства 109, и данные, хранимые в буферах 107 процессора. Как правило, одно распознавание оснований выполняют для одного участка в течение одного цикла получения изображения.
[0058] Как показано на фигуре, один или более процессоров 105 и основное запоминающее устройство 109 совместно используют данные в двух направлениях. Кроме того, один или более процессоров 105 принимают данные изображения от системы 103 получения изображения. В некоторых вариантах осуществления система 103 получения изображения получает данные от проточной ячейки 101 путем возбуждения участков секвенирования в проточной ячейке 101 и приема оптических сигналов от этих участков. В некоторых вариантах осуществления сигнал, принятый системой 103 получения изображения, является сигналом флуоресценции, создаваемым при освещении системой 103 проточной ячейки 101 светом с соответствующими длинами волн. В таких вариантах осуществления получают сигнал флуоресценции в виде значений интенсивности для множества цветов.
[0059] Понятие цикла используется во всем этом раскрытии. Один цикл секвенирования включает считывание одного нуклеотида на каждом одном или более участках, захваченных на изображении. Считывание называют распознаванием оснований. В различных вариантах осуществления, описанных в данном документе, в одном вычислительном цикле - в контексте функционирования процессора (-ов) и запоминающего устройства - выполняют как распознавание оснований, так и фиксацию изображения, но для разных нуклеотидов, причем распознавание оснований запаздывает относительно фиксации изображения в последовательности считываемых или распознаваемых нуклеотидов. Например, в одном вычислительном цикле один или более процессоров проводят распознавание оснований для нуклеотида в цикле n секвенирования и одновременно осуществляют фиксацию изображения для нуклеотида в цикле n+1 секвенирования. Таким образом, в одном вычислительном цикле секвенатор (а) сохраняет и обрабатывает неизмененные данные изображения для нуклеотидов в цикле n+1 секвенирования и (b) выполняет распознавание оснований для нуклеотидов в цикле n секвенирования. Использование буферов процессора и буферов сегмента в этой поцикловой обработке будет описано более подробно ниже.
Общая информация о фазировании
[0060] На определенном участке проточной ячейки или другой подложки одновременно анализируют множество копий молекулы нуклеиновой кислоты, имеющих одинаковую последовательность (возможно, с ограниченными вариациями, непреднамеренно внесенными при обработке образца). Используют достаточное количество копий, чтобы сгенерировать достаточный сигнал для обеспечения надежного распознавания оснований. Набор молекул нуклеиновой кислоты на участке называют кластером. В некоторых случаях несеквенированный кластер содержит только одноцепочечные молекулы нуклеиновой кислоты.
[0061] Фазирование представляет собой нецелевой артефакт, который возникает в результате секвенирования множества молекул нуклеиновых кислот в кластере. Фазирование представляет собой степень, с которой сигналы, такие как, флуоресценция от отдельных молекул в кластере, теряют синхронизацию друг с другом. Часто термин «фазирование» применяют для обозначения помехи от некоторых молекул, которые характеризуются отставанием, а термин «пре-фазирование» (опережающее) используют для обозначения помехи от других молекул, которые характеризуются опережением. Совместно, фазирование и опережающее фазирование определяют, насколько хорошо работает устройство для секвенирования и выполняется химический анализ.
[0062] Меньшие значения лучше. Значения 0,10/0,10 означают, что 0,10% молекул в кластере характеризуются отставанием, а 0,10% характеризуются опережением в каждом цикле распознавания оснований. Другими словами, 0,20% истинного сигнала теряется в каждом цикле и, следовательно, будут вносить шум. В другом примере 0,20/0,20 означает, что за цикл теряется 0,4% истинного сигнала, и в этом случае после 250 циклов (без коррекции) шум будет равен сигналу.
[0063] Компонент анализа в реальном времени секвенатора может определять фазирование и опережающее фазирование для применения правильного уровня коррекции фазирования по мере прохождения последовательности. Это осуществляется путем искусственной принудительного направления сигнала в каждый канал секвенатора или из него на основании распознаваний оснований до или после текущего цикла.
[0064] Ранее фазирование и опережающее фазирование оценивали по определенному количеству циклов (например, первые 12 циклов каждого рида), а затем применяли ко всем последующим циклам. В некоторых современных секвенаторах используется алгоритм, называемый эмпирической коррекцией фазирования, для оптимизации коррекции фазирования в каждом цикле путем подбора диапазона коррекции для выбора диапазона, обеспечивающего наивысшую достоверность (чистоту сигнала). Хотя эмпирическая коррекция фазирования обеспечивает повышенную производительность, она требует применения большего количества вычислительных ресурсов.
[0065] В обычных секвенаторах каждое основание имеет уникальный цвет флуоресцентного красителя; например, зеленый для тимина, красный для цитозина, синий для гуанина и желтый для аденина. Чтобы получить информацию для распознавания оснований, четырехканальный секвенатор получает четыре изображения сегмента или другого фрагмента проточной ячейки. Некоторые секвенаторы теперь имеют только два канала и, таким образом, получают только два изображения одного и того же фрагмента проточной ячейки. В двухканальном секвенаторе используют смесь красителей для каждого основания и используют красный и зеленый фильтры для двух изображений. В примере с двухканальным секвенатором кластеры, видимые на красном или зеленом изображениях, интерпретируют как, соответственно, основания С и Т. Кластеры, наблюдаемые как на красном, так и на зеленом изображениях, отмечены как основания А, а немаркированные кластеры определяют как основания G.
[0066] На фиг. 2 показано фазирование в ходе секвенирования нуклеинового кластера, имеющего последовательность … ACGTAAG …. Как показано на фигуре, в течение цикла распознавания оснований для первого основания G 98,4% сигнала флуоресценции порождены последовательностями, генерирующими в данный момент сигнал для G, в то время как 1,5% сигнала флуоресценции порождены последовательностями, генерирующими в данный момент сигнал для предшествующего основания С, а 1,1% сигнала флуоресценции порождены последовательностями, генерирующими в данный момент сигнал для следующего основания Т. В сигнал для предшествующего основания С вносит вклад фазирование, а в сигнал для следующего основания Т вносит вклад опережающее фазирование.
[0067] Коррекция фазирования для распознавания этого нуклеотидного основания G отражена на графике в правой части фиг. 2. Как показано для двухканального секвенатора, сигнал флуоресценции может быть представлен на двумерном графике с сигналом максимальной интенсивности на «зеленой оси», представляющей основание Т, максимальной интенсивностью на «красной оси», представляющей основание С, максимальной интенсивностью на середине между осями, представляющей основание А, и минимальной интенсивностью на обеих осях, представляющих основание G. При отсутствии ошибок фазирования сигнал для основания G должен иметь нулевую интенсивность как на красной, так и на зеленой осях. Вместо этого, при обсуждаемой ошибке фазирования сигнал флуоресценции характеризуется некоторым увеличением интенсивности как на зеленой, так и на красной осях. В этом примере коррекция опережающего фазирования приводит к уменьшению интенсивности сигнала до нуля по зеленой оси, а коррекция фазирования приводит к уменьшению интенсивности сигнала до нуля по красной оси. Аналогичная коррекция может быть выполнена при распознавании оснований для оснований Т, С и А.
Сегменты и проточные ячейки
[0068] Как было объяснено выше, проточная ячейка содержит множество участков, на которых собирают информацию о последовательности. В некоторых вариантах осуществления каждый участок проточной ячейки содержит кластер одноцепочечных нуклеиновых кислот, имеющих одинаковую последовательность. Одно изображение, используемое при секвенировании в реальном времени, может содержать миллионы таких кластеров. Типовая проточная ячейка настолько велика, что для охвата всей ее площади требуются сотни или даже тысячи отдельных изображений. В некоторых вариантах осуществления процессор и связанное с ним запоминающее устройство, используемые для анализа в реальном времени, обрабатывают все эти изображения текущим образом, чтобы выполнить распознавания оснований для одного цикла. В некоторых вариантах реализации процессор и запоминающее устройство одновременно обрабатывают все изображения, полученные в двух или более проточных ячейках в течение одного цикла распознавания оснований. На фиг. 3 схематично показана архитектура проточной ячейки, используемой в некоторых секвенаторах, производимых компанией Illumina, Inc. В показанном примере секвенатор выполняет одновременное распознавание оснований в двух проточных ячейках, Проточной ячейке 1 и Проточной ячейке 2. В некоторых вариантах осуществления каждая проточная ячейка имеет участки секвенирования на каждой из двух поверхностей, верхней поверхности и нижней поверхности. В таких случаях секвенатор отображает как верхнюю, так и нижнюю поверхности в ходе каждого цикла распознавания оснований. Как показано на фиг. 3, каждая поверхность проточной ячейки содержит четыре дорожки, L1, L2, L3 и L4; конечно, возможно и другое их количество. Каждая дорожка каждой поверхности может иметь множество секций, называемых полосами. Каждая полоса в свою очередь разделена на множество сегментов. Например, одна полоса может содержать приблизительно 120 сегментов. Для двух проточных ячеек, причем каждая проточная ячейка имеет две поверхности, на каждой из которых имеется четыре дорожки, каждая дорожка содержит шесть полос, а каждая полоса содержит 120 сегментов, необходимо проанализировать данные нескольких тысяч сегментов за цикл. В различных вариантах осуществления изображение каждого сегмента (или другое изображение из фрагмента проточной ячейки) задействует один поток процессора. В некоторых вариантах осуществления секвенатор, в котором используют проточную ячейку, имеющую архитектуру, изображенную на фиг. 3, обрабатывает данные 8000 или более сегментов в каждом цикле распознавания оснований. В таких случаях логические схемы для обработки в реальном времени будут использовать 8000 или более потоков процессора в каждом цикле распознавания оснований.
[0069] Данные из одного сегмента, зафиксированные в течение одного цикла, могут быть сохранены в запоминающем устройстве в виде массива, причем каждая запись в массиве представляет собой значение цвета для каждого канала отдельного кластера в сегменте. Массив для двухканальной конфигурации изображен на фиг. 4. В качестве примера, детектор интенсивности цвета может генерировать от 400 до 1500 сигналов для каждого канала. Буфер сегмента в системном запоминающем устройстве выполнен с возможностью хранения всей информации в массиве, другими словами, значений цвета всех кластеров на сегменте за один цикл распознавания оснований. Буфер процессора может быть аналогичным образом выполнен с возможностью хранения всей информации в массиве.
Процесс фазирования
[0070] Значительная нагрузка на запоминающее устройство при анализе данных последовательности в реальном времени обусловлена необходимостью коррекции фазирования, поэтому два или три цикла интенсивностей для кластера необходимо сохранить для каждого сегмента на полную длину цикла. На Illumina HiSeqX с 700-нм проточной ячейкой это занимает 73 Гигабайта в запоминающем устройстве. Эта нагрузка является достаточно большой, так что большая часть данных (на этой платформе) помещается в кэш на твердотельном накопителе.
[0071] Как было объяснено выше, коррекция фазирования обеспечивает корректировку значений интенсивности изображения для устранения чередования фазы некоторых оснований нуклеиновых кислот в кластере. Для этого коррекцию фазирования начинают с измеренных значений интенсивности цвета кластера (или других сигналов, измеренных в способе секвенирования) для текущего цикла распознавания оснований и добавляют или вычитают корректирующее значение, используя измеренные значения интенсивности из предыдущего цикла распознавания оснований и/или используя измеренные значения интенсивности из последующего цикла распознавания оснований. В различных вариантах реализации значение интенсивности со скорректированным фазированием для выполнения распознавания оснований определяют с помощью выражения, показанного в нижней части фиг. 5. Как показано на фигуре, значения интенсивности со скорректированным фазированием для текущего цикла распознавания оснований на изображении равны измеренным значениям интенсивности для текущего цикла распознавания оснований за вычетом произведения первого коэффициента и измеренных значений интенсивности в непосредственно предшествующем цикле распознавания оснований и за вычетом произведения второго коэффициента и измеренных значений интенсивности в непосредственно следующем цикле распознавания оснований:
Скорректированная интенсивность = -a⋅In-1+In - b⋅In+1
где In-1, In и In+1 представляют собой значения интенсивности кластеров в сегменте в непосредственно предшествующем цикле распознавания оснований, в текущем цикле распознавания оснований и в следующем цикле распознавания оснований. Коэффициенты а и b представляют собой, соответственно, коэффициенты фазирования и опережающего фазирования (иногда называемые весовыми коэффициентами(весами)). Их могут вычислять заново для каждого цикла распознавания оснований для сегмента.
[0072] Возвращаясь к фиг. 2, измеренное значение интенсивности для третьего основания в изображенной последовательности (для одного кластера на изображении) показано в виде точки на графике, с правой стороны фиг. 2. Коррекция опережающего фазирования этого измеренного значения интенсивности представлена вертикальной стрелкой от измеренного значения интенсивности до горизонтальной оси. В выражении для значений интенсивности со скорректированным фазированием указанная коррекция опережающего фазирования представлена произведением коэффициента b и значения интенсивности, измеренного для следующего последовательного цикла распознавания оснований. Кроме того, измеренное значение интенсивности корректируют с помощью коррекции фазирования, представленной горизонтальной стрелкой на графике. Эту коррекцию фазирования осуществляют путем вычитания из измеренного значения интенсивности произведения коэффициента а и измеренного значения интенсивности для непосредственно предшествующего цикла распознавания оснований. Коэффициенты а и b могут быть определены множеством способов, но во многих вариантах реализации их вычисляют заново для каждого цикла распознавания оснований. Описание способов определения коэффициентов, которые будут использованы при коррекции фазирования, приведено в международной заявке на патент с номером публикации WO 2015/084985, Belitz и др., опубликованной 11 июня 2015 г., которая полностью включена в настоящий документ посредством ссылки.
[0073] В некоторых вариантах осуществления алгоритм фазирования определяет коэффициенты фазирования эмпирически, максимизируя совокупную достоверность (или аналогичный показатель) данных интенсивности кластера в ходе цикла распознавания оснований. Согласно одной реализации алгоритма выполняют итерацию по всем или многим коэффициентам фазирования и определяют, какие из них обеспечивают наилучшие результаты. Например, алгоритм фазирования может обеспечивать оптимизацию а и b в каждом цикле с использованием поиска по шаблону, используя критерий оптимальности, согласно которому подсчитывают количество кластеров, которые не прошли фильтр достоверности. Таким образом, а и b выбирают таким образом, чтобы максимизировать качество данных.
[0074] В некоторых вариантах осуществления определение коэффициентов фазирования происходит как постоянный анализ на протяжении всего цикла секвенирования (например, в ходе генерации рида). В результате применения такого подхода неточная оценка фазирования, полученная на более ранних циклах, не окажет негативного влияния на более поздние циклы.
[0075] Согласно некоторым способам достоверность значения интенсивности кластера определяют как функцию относительных расстояний до гауссовских центроидов для других значений интенсивности кластера, определенных для того же цикла распознавания оснований. Центроиды идеально совпадают с ожидаемыми местоположениями интенсивностей А, Т, С и G для двух каналов (см. фиг. 2) при условии использования двухканальной системы. В некоторых вариантах осуществления достоверность может быть вычислена с использованием следующего выражения:
достоверность = 1-D1/(D1+D2),
где D1 представляет собой расстояние до ближайшего гауссовского центроида, а D2 представляет собой расстояние до следующего ближайшего центроида. При использовании этого подхода, когда средняя достоверность (качество) значений интенсивности максимизирована, выбирают правильные значения а и b. Когда эти значения будут определены, может быть применена коррекция ко всем значениям кластера и может быть непосредственно осуществлено распознавание оснований. Способы аппроксимации гауссовых распределений для двухканального набора данных описаны в международной заявке на патент с номером публикации WO 2015/084985, ранее включенной посредством ссылки.
[0076] В некоторых вариантах осуществления коррекцию фазирования вычисляют почти в каждом цикле в ходе осуществления секвенирования. В некоторых вариантах осуществления коррекцию фазирования вычисляют в каждом цикле в ходе осуществления секвенирования. В некоторых вариантах осуществления отдельную коррекцию фазирования вычисляют для разных местоположений отображаемой поверхности в одном и том же цикле. Например, в некоторых вариантах осуществления отдельную коррекцию фазирования вычисляют для каждой отдельной дорожки отображаемой поверхности, например, отдельной дорожки проточной ячейки. В некоторых вариантах осуществления отдельную коррекцию фазирования вычисляют для каждого подмножества дорожек, например, полосы отображения в дорожке проточной ячейки. В некоторых вариантах осуществления отдельную коррекцию фазирования вычисляют для каждого отдельного изображения, такого как, например, каждый сегмент. В некоторых вариантах осуществления отдельную коррекцию фазирования вычисляют для каждого сегмента в каждом цикле.
[0077] Поскольку считывания становится более длинными, члены более высокого порядка могут стать более важными при коррекции фазирования. Таким образом, в конкретных вариантах осуществления, чтобы исправить это, может быть вычислена эмпирическая коррекция фазирования второго порядка. Например, в некоторых вариантах осуществления способ включает коррекцию фазирования второго порядка, определяемую следующим образом:
I(цикл.)=-а*I(цикл.-2)-А*I(цикл.-I)+I(цикл.)-В*I(цикл.+1)-b*I(цикл.+2)
где I представляет собой интенсивность, а, А, В и b представляют собой члены первого и второго порядка для коррекции фазирования. В конкретных вариантах осуществления вычисление оптимизируют по а, А, В и b.
[0078] На фиг. 5 схематично изображены конфигурация обработки и способ проведения коррекции фазирования в реальном времени. В изображенном варианте осуществления процессор 502 создает новый поток 503 обработки, когда процессор вызывают для выполнения распознавания оснований в кластерах на изображении, например, изображении сегмента. Новый поток может быть сгенерирован для каждого цикла распознавания оснований для каждого сегмента. В изображенном варианте осуществления процессор 502 обеспечивает доступность одного буфера 505 процессора в течение каждого цикла распознавания оснований для сегмента (и назначенного потока обработки). Буфер процессора временно хранит значения интенсивности, которые процессор использует в ходе вычислений для выполнения коррекции фазирования для текущего цикла n распознавания оснований. В изображенном варианте осуществления процессор взаимодействует с системным запоминающим устройством 507, содержащим три буфера, по одному для хранения данных изображения, зафиксированных для конкретного цикла распознавания оснований. В случае применения архитектуры проточной ячейки, изображенной на фиг. 3, каждый буфер хранит данные изображения для кластеров одного сегмента; таким образом, указанные буферы называют буферами сегмента. Конечно, для других архитектур проточных ячеек и/или систем получения изображений указанные буферы могут хранить больше или меньше данных кластера. Для удобства в настоящем описании будет применен термин «буфер сегмента». Каждый буфер сегмента хранит данные для одного сегмента (или другого фрагмента проточной ячейки), захваченные в течение одного цикла распознавания оснований. Данные изображения могут быть представлены в виде массива данных, например, показанного на фиг. 4.
[0079] Как показано, системное запоминающее устройство 507 содержит буфер 509 сегмента, который временно хранит значения интенсивности для непосредственно предшествующего цикла распознавания оснований (по сравнению с текущим циклом распознавания оснований, обрабатываемым процессором), буфер 511 сегмента, который хранит значения интенсивности, измеренные для текущего цикла распознавания оснований, и буфер 513 сегмента, который хранит значения интенсивности для непосредственно следующего цикла распознавания оснований. Опять же, каждый из буферов 509, 511 и 513 сегмента содержит данные, измеренные для одного сегмента для одного цикла n распознавания оснований.
[0080] Как показано, в потоке 503 используют значения интенсивности, хранимые в каждом из буферов 509, 511 и 513 сегмента в течение одного цикла распознавания оснований. Значения интенсивности последовательно загружаются в буфер 505 процессора и обрабатываются для реализации вычисления согласно выражению коррекции фазирования, представленному в нижней части фиг. 5. После завершения процесса распознавания оснований, как показано в конфигурации процессора и запоминающего устройства на фиг. 5, в буфере процессора содержатся скорректированные значения интенсивности, используемые для выполнения распознавания оснований с коррекцией фазирования.
[0081] На фиг. 6 представлена блок-схема процесса распознавания оснований, в котором может быть использована конфигурация процессора и запоминающего устройства, показанная на фиг. 5. Как показано на фиг. 6, процесс 601 инициирует новый цикл распознавания оснований путем создания потока процессора и выделения буфера процессора для этого потока. См. блок 603 процесса. После этого процессор извлекает данные интенсивности из изображения сегмента проточной ячейки (или другого подходящего фрагмента проточной ячейки), полученного одновременно с текущим циклом обработки. В изображенной реализации зафиксированное изображение и соответствующие значения интенсивности являются первичными значениями интенсивности для следующего последовательного цикла распознавания оснований, а не текущего цикла распознавания оснований (текущей итерации обработки). Другими словами, в текущем цикле обработки выполняют распознавание оснований для данных изображения, собранных в непосредственно предшествующем цикле обработки. Таким образом, как показано в блоке 605 процесса 601, извлеченные значения интенсивности указаны с помощью обозначения In+1, где n представляет текущий цикл распознавания оснований. Другими словами, в цикле обработки (i) происходит распознавание оснований для цикла n распознавания оснований и (ii) фиксация данных изображения для цикла n+1 распознавания оснований.
[0082] Вновь извлеченные данные интенсивности, которые могут быть предоставлены в форме массива, как показано на фиг. 4, сохраняются в доступном буфере сегмента в системном запоминающем устройстве (например, в буфере 513 сегмента). В некоторых вариантах осуществления указанный буфер сегмента представляет собой буфер, в котором хранятся данные интенсивности, которые были использованы ранее, но больше не нужны для распознавания оснований.
[0083] В текущем цикле обработки в ходе процесса 601 также извлекают данные интенсивности, сохраненные в течение вычислительного цикла, предшествующего текущему вычислительному циклу. См. блок 607 процесса. Извлеченные данные интенсивности относятся к текущему циклу распознавания оснований и обозначены In. Извлеченные данные интенсивности получают из соответствующего буфера сегмента, такого как буфер 511 сегмента системного запоминающего устройства, как показано на фиг. 5.
[0084] Кроме того, в ходе процесса 601 извлекают данные интенсивности, которые были сохранены за два цикла до текущего цикла распознавания оснований. См. блок 609 процесса. В качестве примера, со ссылкой на фиг. 5, такие данные интенсивности могут быть получены из буфера 509 сегмента системного запоминающего устройства. Массив значений интенсивности, извлеченных в операции 609, обозначен In-1.
[0085] Хотя операции 605, 607 и 609 показаны как происходящие последовательно, указанный порядок операций является гибким и процесс может быть реализован таким образом, что любой порядок будет приемлемым, при условии, что он согласуется с распознаванием оснований, которое включает коррекцию фазирования.
[0086] После извлечения значений интенсивности для текущего цикла распознавания оснований (блок 607 процесса) и значений интенсивности для непосредственно предшествующего цикла распознавания оснований (блок 609 обработки) процессор имеет все значения интенсивности, требуемые для выполнения коррекции фазирования. Процессор осуществляет коррекцию фазирования путем определения сначала весового коэффициента b коррекции опережающего фазирования и весового коэффициента а коррекции фазирования для текущего цикла распознавания оснований. См. блок 611 процесса, который иллюстрирует, что это может быть выполнено с использованием извлеченных значений интенсивности для следующего цикла распознавания оснований вместе со значениями интенсивности для текущего и непосредственно предшествующих циклов распознавания оснований. Затем, используя весовые коэффициенты коррекции фазирования и опережающего фазирования, процессор вычисляет значения интенсивности со скорректированным фазированием для текущего цикла распознавания оснований, как показано в блоке 613 процесса. Скорректированные значения относятся к кластерам в рассматриваемом сегменте. При вычислении может быть использовано выражение, приведенное в блоке 613. Используя значения интенсивности со скорректированным фазированием процессор выполняет распознавание в течение текущего цикла распознавания оснований, как показано в блоке 615 процесса.
[0087] На этом этапе обработка для текущего цикла распознавания оснований завершена и может быть выполнена следующая итерация распознавания оснований. Принятие решения о том, следует ли проводить другой цикл распознавания оснований, изображено в блоке 617, в ходе которого определяют, имеются ли какие-либо дополнительные подлежащие секвенированию нуклеотиды в кластерах рассматриваемого сегмента. В случае их отсутствия процесс завершается, как показано в блоке 619. Если таковые имеются, управление процессом передается в блок 621 процесса, в котором процессор увеличивает значение счетчика циклов. Это позволяет эффективно индексировать значения интенсивности для текущего цикла In распознавания оснований по отношению к значениям интенсивности для непосредственно предшествующего цикла In-1 распознавания оснований. В то же время значения интенсивности для непосредственно следующего базового (In+1) распознавания оснований становятся значениями интенсивности для текущего цикла (In) распознавания оснований. Эти приращения выполняют в отношении индексов, применяемых для данных интенсивности, хранимых в буферах сегмента.
Процесс фазирования (с уменьшенными требованиями к основному запоминающему устройству)
[0088] Подход, показанный на фиг. 5 и 6, может нормально работать при том условии, что секвенатор и связанная с ним система анализа в реальном времени не ограничены в отношении объема запоминающего устройства. Однако, учитывая объем данных, которые необходимо обрабатывать в некоторых современных секвенаторах, например, секвенаторах, которые используют для выполнения полногеномногосеквенирования, объем запоминающего устройства может быть недостаточным, в частности, по коммерчески выгодной стоимости. Таким образом, хранение в три раза большего объема данных, соответствующего полному изображению проточной ячейки (или проточных ячеек) в течение цикла распознавания оснований, может привести к серьезной нехватке ресурсов.
[0089] Алгоритм для фазирования, например, представленный на фиг. 5 и 6, является значительно способствует выполнению анализа в реальном времени, поскольку он существенно улучшает результаты секвенирования, в частности, на нестандартных образцах, например, образцах с низким генетическим разнообразием. Однако нагрузка на запоминающее устройство увеличивается с ростом производительности систем секвенирования следующего поколения. Нижеследующие варианты осуществления позволяют снизить нагрузку на запоминающее устройство с использованием весов фазирования, полученных из данных, которые уже были частично скорректированы в отношении фазирования. Весовые коэффициенты фазирования и опережающего фазирования могут быть получены независимо и все же обеспечивать высококачественные результаты секвенирования. В некоторых примерах требования к основному запоминающему устройству включают в два раза меньший объем, необходимый для хранения данных, содержащихся во всех сегментах в двух проточных ячейках.
[0090] В некоторых вариантах осуществления конфигурацию процессора и запоминающего устройства для распознавания оснований со скорректированным фазированием устанавливают таким образом, чтобы уменьшить требования к системному запоминающему устройству. Один пример осуществления этого показан на фиг. 7. Значения интенсивности корректируют, как описано выше, например, весовые коэффициенты фазирования и опережающего фазирования вычисляют и применяют в отношении непосредственно предшествующих и непосредственно следующих циклов. Однако в примере, показанном на фиг. 7, системное запоминающее устройство 707 использует только два буфера сегмента для коррекции фазирования: буфер 709 сегмента и буфер 711 сегмента. В этом примере процессор 702 использует поток 703 обработки, для которого, в отличие от примера, показанного на фиг. 5, используют два связанных буфера процессора: буфер 705 процессора для хранения извлеченных из запоминающего устройства 707 значений интенсивности и оперирования ними и буфер 706 процессора для хранения и использования значений In+1; интенсивности вновь захваченных изображений. В изображенном примере буферы процессора выделены в основном запоминающем устройстве, но это не всегда является обязательным. В некоторых вариантах осуществления буферы процессора выделяют в другом физическом запоминающем устройстве или даже в микросхеме процессора.
[0091] Замена буферов сегмента на буферы процессора позволяет существенно снизить общие требования к памяти. При использовании множества процессоров и/или многопоточной обработки несколько процессоров обрабатывают данные множества сегментов. Например, количество сегментов в системе может составлять порядка 1000 2000, в то время как число процессоров, обрабатывающих все эти сегменты, равно приблизительно двадцати. Теоретически, такая система способна обеспечить сокращение применения объема запоминающего устройства приблизительно в 50 раз. В некоторых вариантах реализации уменьшение составляет порядка 20 раз.
[0092] В этом варианте реализации значения интенсивности, полученные по изображениям сегмента в текущем цикле (In+1) обработки, хранятся локально на процессоре и используются для вычисления весов фазирования и опережающего фазирования и последующего выполнения распознавания оснований. В некоторых вариантах реализации самые последние полученные значения (In+1) интенсивности сохраняются в буфере сегмента в системном запоминающем устройстве 707 только после завершения этого процесса.
[0093] В некоторых вариантах осуществления процессор и системное запоминающее устройство выполнены, как показано на фиг. 8. Как и в конфигурации процессора/запоминающего устройства, показанной на фиг. 7, процессор 802 использует потоки 803 обработки, каждый из которых связан с двумя буферами процессора: буфером 805 процессора для временного хранения значений интенсивности из системного запоминающего устройства 807 (буфера 811 сегментов) и буфера 806 процессора для временного хранения значений интенсивности, полученных в течение текущего цикла (In+1) обработки. Для обеспечения эффективного и результативного применения этой конфигурации для значений интенсивности, хранимых в буфере 811 сегмента, необходимо частично выполнить коррекцию фазирования. Примеры способов осуществления этого описаны ниже. Буфер 705 процессора на фиг. 7 и буфер 805 процессора на фиг. 8 загружают значения интенсивности из основного запоминающего устройства и затем используют их для генерации скорректированных значений интенсивности, используемых для распознавания оснований. В показанном примере буферы процессора выделены в основном запоминающем устройстве, но это не всегда является обязательным. В некоторых вариантах осуществления буферы процессора выделяют в другом физическом запоминающем устройстве или даже в микросхеме процессора.
[0094] На фиг. 9 представлено высокоуровневое представление процесса 901, который может быть использован с конфигурацией процессора и запоминающего устройства, показанной на фиг. 8, и, в некоторых вариантах реализации, показанной на фиг. 7. Как показано на фиг. 9, первый и второй циклы обработки используют не всю информацию для проведения полной коррекции фазирования в кластерах, отображаемых в сегменте. Однако в первых циклах фазирование не является существенной проблемой.
[0095] Для проведения полной коррекции фазирования секвенатору требуются три последовательных цикла получения данных по изображению. В первом цикле обработки секвенатор не выполняет распознавание оснований; он лишь сохраняет данные интенсивности для следующей обработки, т.е. цикла, в котором будет выполнено первое распознавание оснований.
[0096] Как показано, процесс 901 начинается в блоке 903 процесса, в котором создают поток для первого цикла обработки. Команды в этом потоке управляют извлечением данных интенсивности из изображения кластеров в течение первого цикла (I1) секвенирования, т.е. цикла, в течение которого считываются первые нуклеотиды кластеров. См. блок 905 процесса. Данные изображения сохраняются в буфере сегмента в системном запоминающем устройстве. На этом этапе по существу завершается первый цикл обработки.
[0097] Процесс продолжается в блоке 907 процесса, в котором создается новый поток при подготовке ко второму циклу обработки. В этом процессе первый и второй буферы процессора выделяют для второго цикла обработки. См. блок 907. Блоки 907, 909, 911, 913, 915, 917, 919, 921 и 923 процесса выполняют в ходе осуществления второго цикла обработки, который выполняют с использованием потока и буферов процессора, сгенерированных в блоке 907 процесса.
[0098] Как показано, процессор извлекает данные интенсивности из изображения для следующего цикла (b) распознавания оснований и сохраняет эти данные в первом буфере процессора. См. блок 909 процесса. Затем, в ходе осуществления второго цикла обработки процессор извлекает данные интенсивности, сохраненные в буфере сегмента в ходе осуществления первого цикла обработки, которые представляют собой данные интенсивности для текущего цикла (I1) распознавания оснований. См. блок 911. Используя данные интенсивности, собранные в ходе осуществления первого и второго циклов обработки, процессор может вычислить весовой коэффициент b опережающего фазирования для текущего цикла распознавания оснований (т.е. первых распознаваний оснований в ридах). См. блок 913 процесса. С помощью значений интенсивности для первых двух циклов и весового коэффициента опережающего фазирования процессор вычисляет скорректированные значения данных интенсивности для второго цикла (b) распознавания оснований. Скорректированные значения данных интенсивности могут быть сохранены во втором буфере процессора. См. блок 915 процесса. Затем процессор выполняет распознавания оснований для второго цикла распознавания оснований с использованием скорректированных значений данных интенсивности, полученных в блоке 915. См. блок 917 процесса.
[0099] На этом этапе процесс секвенирования готов начать подготовку к следующему циклу распознавания оснований. Он начинается в блоке 919 процесса определением весового коэффициента а коррекции фазирования с использованием данных (b) интенсивности следующего (или второго) цикла распознавания оснований и текущих данных (I1) цикла распознавания оснований, которые были сохранены в буфере сегмента. Используя весовой коэффициент а коррекции фазирования, процессор затем вычисляет значения данных интенсивности со скорректированным фазированием (но не скорректированным опережающим фазированием) по текущим нескорректированным данным (b) интенсивности, извлеченным в ходе осуществления этого второго цикла обработки, и значениям данных интенсивности для первого цикла (I1) обработки согласно выражению, приведенному в блоке 921 процесса. Это приводит к получению массива частично скорректированных значений интенсивности (I2(частично скорректированных)) для второго цикла распознавания оснований. Для выполнения коррекции опережающего фазирования секвенатор должен будет дождаться следующего цикла обработки. Однако на этом этапе большая часть вычислений завершена и данные массива для одного изображения могут быть сохранены в буфере сегмента для использования в следующем цикле распознавания оснований. С этой целью процессор сохраняет данные интенсивности со скорректированным фазированием (но не скорректированным опережающим фазированием) в буфере сегмента (таким образом, что I2 (частично скорректированные) заменяют I1 в буфере сегмента). См. блок 923 процесса.
[0100] На этом этапе первый и второй циклы обработки завершаются и выполняют распознавания оснований для первого цикла распознавания оснований, который является вторым циклом обработки. Последующие циклы распознавания оснований могут быть выполнены с полной коррекцией фазирования, как описано на фиг. 10. См. блок 925 процесса.
[0101] На фиг. 10 показана последовательность операций, которые могут быть выполнены в ходе цикла обработки, при котором проводят распознавание оснований со скорректированным фазированием. Такой цикл может быть выполнен в третьем и последующих циклах обработки при секвенировании кластеров сегмента. В некоторых вариантах осуществления последовательность операций, изображенная на фиг. 10, соответствует блоку 925 процесса, показанному на фиг. 9.
[0102] Как показано на фигуре, процесс начинается с выделения потока и связанных с ним первого и второго буферов процессора. См. блок 1003 процесса. Затем, процессор извлекает значения данных интенсивности из изображения для следующего цикла (In+1) распознавания оснований и сохраняет эти значения в первом буфере процессора. См. блок 1005 процесса. Одновременно процессор извлекает частично скорректированные значения данных интенсивности, которые были сохранены в ходе предшествующего цикла распознавания оснований (в качестве неограничивающего примера, I2(частично скорректированные) в варианте осуществления, показанном на фиг. 9, или In-a(In-1)). Теперь эти значения представляют собой значения интенсивности для текущего цикла распознавания оснований (In). Ранее они были сохранены в буфере сегмента запоминающего устройства системы и теперь извлечены из него. См. блок 1007 процесса. С частично скорректированными значениями данных интенсивности для текущего цикла распознавания оснований, для которых была скорректировано фазирование, процессору необходимо лишь выполнить коррекцию опережающего фазирования, чтобы завершить коррекцию данных интенсивности и выполнить необходимые распознавания оснований для текущего цикла распознавания оснований. С этой целью процессор определяет весовой коэффициент b коррекции опережающего фазирования для текущего цикла распознавания оснований. Для выполнения этого процессор использует извлеченные данные интенсивности, только что извлеченные им из данных изображения, для следующего цикла (In+1) вместе с частично скорректированными ранее данными интенсивности для текущего цикла распознавания оснований. Напомним, что эти частично скорректированные данные только что были извлечены из буфера сегмента. Частично скорректированные данные интенсивности могут быть представлены следующим выражением: In-a(In-1). См. блок 1009 процесса.
[0103] С учетом весового коэффициента b коррекции опережающего фазирования, вычисленного для текущего цикла распознавания оснований, процессор имеет все необходимые данные для вычисления массива данных интенсивности с полностью скорректированным фазированием для текущего цикла (In) распознавания оснований. Вычисление проводят, как показано в блоке 1009 процесса. Результирующие полностью скорректированные значения данных интенсивности сохраняют во втором буфере процессора. См. блок 1011 процесса. После этого процессор выполняет распознавания оснований для текущего цикла распознавания оснований с использованием скорректированных значений данных интенсивности, сохраненных во втором буфере процессора. См. блок 1013 процесса.
[0104] В текущем цикле обработки может быть начата подготовка к следующему циклу распознавания оснований, который будет выполнен в ходе следующего цикла обработки. В изображенном варианте осуществления процессор определяет весовой коэффициент а коррекции фазирования для следующего цикла распознавания оснований с использованием данных интенсивности, доступных для текущего цикла распознавания оснований. См. блок 1015 процесса. Напомним, что данные интенсивности следующего цикла распознавания оснований были извлечены и сохранены в первом буфере процессора при выполнении операции 1005 процесса. Частично скорректированные значения интенсивности для текущего цикла распознавания оснований были извлечены из буфера сегмента в целях выполнения текущих распознаваний оснований. Те же частично скорректированные значения интенсивности теперь используются для вычисления весового коэффициента а коррекции фазирования для следующего цикла распознавания оснований. Теперь, с применением вычисленного весового коэффициента коррекции фазирования для следующего цикла распознавания оснований процессор вычисляет значения данных интенсивности со скорректированным фазированием (но не скорректированным опережающим фазированием), как показано в блоке 1017 процесса. Затем процессор сохраняет эти значения данных интенсивности со скорректированным фазированием для следующего цикла распознавания оснований в буфере сегмента. См. блок 1019 процесса.
[0105] До создания этого изобретения предполагалось, что точность распознавания оснований ухудшится при определении весов опережающего фазирования по значениям интенсивности со скорректированным фазированием. Однако результаты, приведенные в настоящем документе, указывают на наличие небольшого количества неточных результатов или их отсутствие. В некоторых вариантах реализации данные изображения сжимают (например, путем сжатия с потерями) и даже сжимают данные с частичной коррекцией фазы. В обоих случаях было продемонстрировано, что сжатие может быть выполнено без потери точности. Например, без сжатия в реализации используют два буфера плавающего типа для каждого сегмента (размер буфера плавающего типа составляет 4 байта). В случае применения сжатия в реализации используют однобайтовый буфер, таким образом, используя в 4 раза меньший объем памяти.
[0106] На этом этапе текущий цикл обработки по существу завершен, поэтому процессор определяет, необходимо ли выполнить еще какие-либо циклы при секвенировании кластеров текущего сегмента. См. блок 1021 принятия решения. Если из кластеров больше не требуется считывать основания, процесс завершается и дальнейшие циклы обработки не осуществляют. Однако, если требуется один или более дополнительных циклов секвенирования, управление процессом передается в блок 1023 процесса, в котором процессор увеличивает номер текущего цикла, и на этом этапе частично скорректированные значения данных интенсивности, хранимые в буфере сегмента, становятся текущими; т.е. они становятся значениями для нового цикла распознавания оснований. Затем управление процессом возвращается к блоку 1003 процесса, в котором начинается следующий цикл обработки.
ПРИМЕР
[0107] Как было объяснено выше, некоторые варианты осуществления позволяют снизить нагрузку на запоминающее устройство с использованием весов фазирования, полученных по данным, которые уже были частично скорректированы по фазированию. Однако не было понятно, что весовые коэффициенты фазирования и опережающего фазирования могут быть получены независимо и при этом могут быть обеспечены высококачественные результаты секвенирования. Из примера, представленного на фиг. 11, видно, что это возможно.
[0108] Как показано на фигуре, было проведено два сравнения, в каждом из которых был использован базовый процесс (например, процесс, показанный на фиг. 5 и 6) и новый процесс, который был оптимизирован для уменьшения требований к основному запоминающему устройству (например, процесс, показанный на фиг. 8 и 10). В каждом сравнении использовали одни и те же секвенатор и образец. В частности, прибор Illumina HiSeqX был преобразован для использования химического состава из 2 красителей. Выходные изображения секвенатора были сохранены и оба алгоритма фазирования были испытаны на одних и тех же изображениях секвенирования, что позволило обеспечить полностью управляемое испытание. В столбце «Производительность по кластерам» указана производительность, обеспечиваемая секвенатором; в столбце «% согласованных» указано количество кластеров, которые успешно согласованы с эталонным геномом, а в столбце «% частота появления ошибок» указана средняя частота появления ошибок последовательностей, вызванных программным обеспечением, по сравнению с эталонным геномом.
[0109] Как видно из результатов секвенирования, алгоритм фазирования с эффективным использованием запоминающего устройства сопоставим с базовым алгоритмом. В этом примере применение процесса с эффективным использованием запоминающего устройства привело к увеличению частоты появления ошибок приблизительно на 3%, что компенсируется уменьшением применяемого объема основного запоминающего устройства (в некоторых вариантах реализации оцениваемым от 420 Гигабайт до 340 Гигабайт).
СПОСОБЫ СЕКВЕНИРОВАНИЯ
[ОНО] Как указано выше, настоящее раскрытие относится к секвенированию образцов нуклеиновых кислот. Может быть использован любая из множества технологий секвенирования с использованием одного или более каналов информации для распознавания оснований, в частности, оптических каналов. В частности, могут быть применены способы, согласно которым нуклеиновые кислоты присоединены в фиксированных местоположениях в массиве (например, в виде кластера) и согласно которым для массива многократно получают изображение. В частности, могут быть применены варианты осуществления, в которых изображения получают в разных цветовых каналах, например, соответствующих разным меткам, используемым для различения одного типа нуклеотидного основания от другого. В некоторых вариантах осуществления процесс определения нуклеотидной последовательности целевой нуклеиновой кислоты может представлять собой автоматизированный процесс. Некоторые варианты осуществления включают способы секвенирования путем синтеза (SBS). Хотя в данном документе особо выделено секвенирование путем синтеза, могут быть использованы и другие технологии секвенирования.
[0111] Во многих вариантах реализации способы секвенирования путем синтеза включают ферментативное удлинение образующейся цепи нуклеиновой кислоты путем итеративного сложения нуклеотидов и некодирующей цепи. В традиционных способах секвенирования путем синтеза для целевого нуклеотида при каждой доставке может быть обеспечен единичный нуклеотидный мономер в присутствии полимеразы. Однако согласно описанным в данном документе способам для целевой нуклеиновой кислоты в присутствии полимеразы при доставке может быть обеспечен нуклеотидный мономер более, чем одного типа.
[0112] При секвенировании путем синтеза могут быть использованы нуклеотидные мономеры, которые имеют терминаторный компонент или которые не имеют терминаторный компонент. Способы с использованием нуклеотидных мономеров, в которых отсутствуют терминаторы, включают, например, пиросеквенирование и секвенирование с использованием меченных γ-фосфатом нуклеотидов. В способах с использованием нуклеотидных мономеров, в которых отсутствуют терминаторы, количество нуклеотидов, добавляемых в каждом цикле, как правило, является переменным и зависит от матричной последовательности и способа доставки нуклеотидов. Для способов секвенирования путем синтеза, в которых используют нуклеотидные мономеры с терминаторный компонентом, терминатор может быть по существу необратимым в используемых условиях секвенирования, как в случае традиционного секвенирования по Сенгеру, при котором используют дидезоксинуклеотиды, или терминатор может быть обратимым, как в случае способов секвенирования, разработанных компанией Solexa (сейчас Illumina, Inc.).
[0113] Согласно способам секвенирования путем синтеза могут использовать нуклеотидные мономеры, которые имеют меченый компонент или не имеют меченый компонент. Соответственно, события включения могут быть обнаружены на основании характеристики метки, например, флуоресценции метки; характеристики нуклеотидного мономера, например, молекулярной массы или молекулярного заряда; побочного продукта включения нуклеотида, например, высвобождения пирофосфата; или т.п. В вариантах осуществления, в которых в реагенте для секвенирования присутствуют два или более разных нуклеотидов, разные нуклеотиды могут отличимыми друг от друга или, В качестве альтернативы, две или более разных меток могут быть неотличимыми при используемых методах обнаружения. Например, разные нуклеотиды, присутствующие в реагенте для секвенирования, могут иметь разные метки, и их можно различить с использованием подходящих оптических устройств, примером чего являются способы секвенирования, разработанные компанией Solexa (в настоящее время Illumina, Inc.).
[0114] Некоторые варианты осуществления включают способы пиросеквенирования. С применением пиросеквенирования обнаруживают высвобождение неорганического пирофосфата (PPi), когда конкретные нуклеотиды включены в образующуюся цепь (Ronaghi, М., Karamohamed S., Pettersson, В., Uhlen, М., Nyren, P. (1996) «Real-time DNA sequencing using detection of pyrophosphate release». Analytical Biochemistry 242(1), 84-9; Ronaghi, M. (2001) «Pyrosequencing sheds light on DNA sequencing)). Genome Res. 11(1), 3-11; Ronaghi, M., Uhlen, M., Nyren, P. (1998) «A sequencing method based on real-time pyrophosphate)). Science 281(5375), 363; патент США №6,210,891; патент США №6,258,568 и патент США №6,274,320, раскрытие которых полностью включено в настоящее описание посредством ссылки). При пиросеквенировании высвобождаемый пирофосфат PPi может быть обнаружен путем прямого превращения в аденозинтрифосфат (АТФ) под действием АТФ-сульфурилазы, а уровень генерируемого АТФ определяют по фотонам, вырабатываемым люциферазой. Нуклеиновые кислоты, подлежащие секвенированию, могут быть присоединены к элементам в массиве и может осуществляться визуализация этого массива для фиксации хемилюминесцентных сигналов, которые вырабатываются в результате включения нуклеотидов в элементы массива. Изображение может быть получено после обработки массива с применением нуклеотидов определенного типа (например, А, Т, С или G). Изображения, полученные после добавления нуклеотидов каждого типа, будут отличаться в зависимости от того, какие элементы обнаружены в массиве. Эти различия в изображении отражают различное содержимое последовательности элементов массива. Однако относительные местоположения каждого элемента останутся неизменными на изображениях. Указанные изображения могут быть сохранены, обработаны и проанализированы с использованием способов, описанных в данном документе. Например, изображения, полученные после обработки массива с применением нуклеотидов каждого различного типа, могут быть обработаны таким же образом, как показано в данном документе в качестве примера для изображений, полученных из разных каналов обнаружения для способов секвенирования на основе обратимых терминаторов].
[0115] Согласно другому иллюстративному типу секвенирования путем синтеза цикл секвенирования осуществляют путем последовательного добавления нуклеотидов, содержащих обратимые терминаторы, например, отщепляемую метку или метку из фотообесцвечиваемого красителя, как описано, например, в WO 04/018497 и патенте США №7,057,026, раскрытие которого включено в настоящее описание посредством ссылки. Этот подход коммерциализирован компанией Solexa (в настоящее время Illumina Inc.) и описан в WO 91/06678 и WO 07/123,774, каждый из которых включен в настоящее описание посредством ссылки. Наличие флуоресцентно-меченных терминаторов, для которых терминация могут быть обращена, а флуоресцентная метка расщеплена, способствует эффективному секвенированию с циклически обратимой терминацией (CRT). Кроме того, полимеразы могут быть разработаны с возможностью их эффективного включения и распространения из этих измененных нуклеотидов.
[0116] В вариантах осуществления секвенирования на основе обратимого терминатора метки могут по существу не препятствовать удлинению в условиях реакции секвенирования путем синтеза. Однако метки для обнаружения могут быть удаляемыми, например, путем расщепления или разложения. Изображения могут быть захвачены после включения меток в элементы массива нуклеиновых кислот. В конкретных вариантах осуществления каждый цикл включает одновременную доставку нуклеотидов четырех разных типов в массив, причем каждый тип нуклеотида имеет спектрально отличную метку. Затем могут быть получены четыре изображения, для каждого из которых используют канал обнаружения, который является избирательным для одной из четырех разных меток. В качестве альтернативы нуклеотиды различных типов можно добавлять последовательно и получать изображение массива между этапами добавления. В таких вариантах осуществления на каждом изображении будут представлены элементы нуклеиновой кислоты, которые включают нуклеотиды определенного типа. Различные элементы будут присутствовать или отсутствовать на разных изображениях вследствие разного содержимого последовательности каждого элемента. Однако относительные положения элементов останутся неизменными на изображениях. Изображения, полученные с помощью таких способов секвенирования путем синтеза на основе обратимого терминатора, могут быть сохранены, обработаны и проанализированы, как описано в данном документе. После этапа фиксации изображения метки могут быть удалены и обратимые терминаторные компоненты могут быть удалены для осуществления последующих циклов добавления и обнаружения нуклеотидов. Удаление меток после их обнаружения в определенном цикле и перед последующим циклом, может обеспечить преимущество уменьшения фонового сигнала и перекрестных взаимодействий между циклами.
[0117] В конкретных вариантах осуществления некоторые или все нуклеотидные мономеры могут включать обратимые терминаторы. В таких вариантах осуществления обратимые терминаторы/расщепляемые флуорофоры могут включать фтор, связанный с рибозным компонентом 3'-сложноэфирной связью (Metzker, Genome Res. 15:1767-1776 (2005), который включен в настоящее описание посредством ссылки). Согласно другим подходам химический анализ терминатора отделяют от расщепления флуоресцентной метки (Ruparel и др., Ргос Natl Acad Sci USA 102: 5932-7 (2005), которая полностью включена в настоящее описание посредством ссылки). Ruparel и др. описали разработку обратимых терминаторов с использованием небольшой 3'-аллильной группы для блокирования удлинения, но которую можно было легко разблокировать с помощью короткой обработки с применением палладиевого катализатора. Флуорофор был прикреплен к основанию фоторасщепляемым линкером, который легко расщепляется при 30-секундном воздействии длинноволнового ультрафиолетового света. Таким образом, в качестве расщепляемого связывания можно использовать либо дисульфидное восстановление, либо фоторасщепление. Другим подходом к обратимой терминации является использование естественной терминации, которая происходит после помещения объемного красителя на дезоксирибонуклеозидтрифосфат (dNTP). Присутствие заряженного объемного красителя на дезоксирибонуклеозидтрифосфате может действовать как эффективный терминатор за счет стерического несоответствия и/или электростатической помехи. Наличие одного события включения предотвращает дальнейшие включения, пока краситель не будет удален. При расщеплении красителя происходит удаление фтора и эффективное обращение терминации. Примеры измененных нуклеотидов также описаны в патенте США №7,427,673 и патенте США №7,057,026, раскрытия которых полностью включены в настоящее описание посредством ссылки.
[0118] Дополнительные иллюстративные системы и способы секвенирования путем синтеза, которые могут применяться с описанными в данном документе способами и системами, описаны в публикации заявки на патент США №2007/0166705, публикации заявки на патент США №2006/0188901, патенте США №7,057,026, публикации заявки на патент США №2006/0240439, публикации заявки на патент США №2006/0281109, публикации РСТ №WO 05/065814, публикации заявки на патент США №2005/0100900, публикации РСТ №WO 06/064199, публикации РСТ №WO 07/010,251, публикации заявки на патент США №2012/0270305 и публикации заявки на патент США №2013/0260372, раскрытия которых полностью включены в настоящий документ посредством ссылки.
[0119] В некоторых вариантах осуществления можно использовать обнаружение (детектирование) четырех разных нуклеотидов с использованием менее четырех разных меток. Например, секвенирование путем синтеза может быть выполнено с использованием способов и систем, описанных в используемых материалах публикации заявки на патент США №2013/0079232. В качестве первого примера, пара типов нуклеотидов может детектироваться на одной и той же длине волны, но их различают на основании разницы в интенсивности для одного члена пары по сравнению с другим или на основании изменения одного члена пары (например, путем химического изменения, фотохимического изменения или физического изменения), которая обуславливает появление или исчезновение наблюдаемого сигнала по сравнению с сигналом, обнаруженным для другого члена пары. В качестве второго примера, нуклеотиды, относящиеся к трем из четырех различных типов могут детектироваться при определенных условиях, в то время как у нуклеотидов четвертого типа отсутствует метка, которая может быть обнаружена в этих условиях или является минимально обнаруживаемой в этих условиях (например, возможно ее минимальное обнаружение вследствие наличия фоновой флуоресценции и т.д.). Включение нуклеотидов первых трех типов в нуклеиновую кислоту может быть определено на основании наличия соответствующих им сигналов, а включение нуклеотида четвертого типа в нуклеиновую кислоту может быть определено на основании отсутствия или минимального обнаружения какого-либо сигнала. В качестве третьего примера, нуклеотид одного типа может включать метку (-и), которую обнаруживают в двух разных каналах, тогда как нуклеотиды других типов обнаруживают не более чем в одном из каналов. Вышеупомянутые три примера конфигурации не считаются взаимоисключающими и могут быть использованы в различных комбинациях. Пример осуществления, в котором объединены все три примера, представляет собой способ секвенирования путем синтеза на основе флуоресценции, согласно которому используют нуклеотид первого типа, который обнаруживают в первом канале (например, дезоксиаденозина трифосфат (dATP) с меткой, которую обнаруживают в первом канале при возбуждении с применением первой длины волны возбуждения), нуклеотид второго типа, который обнаруживают во втором канале (например, дезоксицитидина трифосфат (dCTP) с меткой, которую обнаруживают во втором канале при возбуждении с применением второй длины волны возбуждения), нуклеотид третьего типа, который обнаруживают как в первом, так и во втором канале (например, тримидина трифосфат (dTTP) с по меньшей мере одной меткой, которую обнаруживают в обоих каналах при возбуждении с применением первой и/или второй длины волны возбуждения), и нуклеотид четвертого типа, в котором отсутствует метка и который не обнаруживается или минимально обнаруживается в любом канале (например, дезоксигуанозина трифосфат (dGTP) без метки).
[0120] Кроме того, как описано во включенных в настоящий документ материалах публикации заявки на патент США №2013/0079232, данные секвенирования могут быть получены с использованием одного канала. В таких так называемых подходах секвенирования с одним красителем нуклеотид первого типа имеет метку, но указанную метку удаляют после того, как будет сгенерировано первое изображение, а нуклеотид второго типа метят только после того, как будет сгенерировано первое изображение. Нуклеотид третьего типа сохраняет свою метку на первом и на втором изображениях, а нуклеотид четвертого типа не содержит метки на обоих изображениях.
[0121] В некоторых вариантах осуществления могут использовать секвенирование с применением способов лигирования. В таких способах используют ДНК-лигазу для включения олигонуклеотидов и идентификации включения указанных олигонуклеотидов. Олигонуклеотиды обычно имеют разные метки, которые сопоставлены идентичности конкретного нуклеотида в последовательности, с которым гибридизуют олигонуклеотиды. Как и в случае других способов секвенирования путем синтеза, изображения могут быть получены после обработки массива элементов нуклеиновых кислот помеченными реагентами для секвенирования. На каждом изображении будут представлены элементы нуклеиновой кислоты, которые включают метки нуклеотидов определенного типа. Различные элементы будут присутствовать или отсутствовать на разных изображениях вследствие разного содержимого последовательности каждого элемента, но относительное положение элементов останется неизменным на изображениях. Изображения, полученные с помощью способов секвенирования на основе лигирования, могут быть сохранены, обработаны и проанализированы, как описано в данном документе. Типовые системы и способы секвенирования путем синтеза, которые могут быть использованы со способами и системами, описанными в данном документе, описаны в патенте США №6,969,488, патенте США №6,172,218 и патенте США №6,306,597, раскрытие которых полностью включено в настоящий документ посредством ссылки.
[0122] В некоторых вариантах осуществления может применяться секвенирование с использованием нанопор (Deamer, D.W. & Akeson, М. «Nanopores and nucleic acids: prospects for ultrarapid sequencing)). Trends Biotechnol. 18, 147-151 (2000); Deamer, D. и D. Branton, «Characterization of nucleic acids by nanopore analysis)). Acc. Chem. Res. 35:817-825 (2002); Li, J., M. Gershow, D. Stein, E. Brandin и J.A. Golovchenko, «DNA molecules and configurations in a solid-state nanopore microscope)) Nat. Mater. 2:611-615 (2003), раскрытие которых полностью включено в настоящий документ посредством ссылки). В таких вариантах осуществления целевая нуклеиновая кислота проходит через нанопоры. Нанопора может представлять собой синтетическую пору или биологический мембранный белок, такой как α-гемолизин. Когда целевая нуклеиновая кислота проходит через нанопоры, каждую пару оснований можно идентифицировать путем измерения флуктуаций электропроводимости поры, (патент США №7,001,792; Soni, G.V. и Meller, «А. Progress toward ultrafast DNA sequencing using solid-state nanopores». Clin. Chem. 53, 1996-2001 (2007); Healy, K. «Nanopore-based single-molecule DNA analysis)). Nanomed. 2, 459-481 (2007); Cockroft, S. L., Chu, J., Amorin, M. и Ghadiri, M.R. «A single-molecule nanopore device detects DNA polymerase activity with single-nucleotide resolution)). J. Am. Chem. Soc. 130, 818-820 (2008), раскрытие которых полностью включено в настоящее описание посредством ссылки). Данные, полученные с помощью секвенирования с использованием нанопор, могут быть сохранены, обработаны и проанализированы, как описано в данном документе. В частности, данные могут быть обработаны как изображение в соответствии с типовой обработкой оптических изображений и других изображений, которая описана в данном документе.
[0123] В некоторых вариантах осуществления могут применяться способы, включающие контроль активности ДНК-полимер азы в реальном времени. Включения нуклеотидов могут быть обнаружены посредством взаимодействий при резонансном переносе энергии флуоресценции (FRET) между флуорофорсодержащей полимеразой и нуклеотидами помеченными γ-фосфатом, как описано, например, в патенте США №7,329,492 и патенте США №7,211,414 (каждый из которых включен в настоящее описание посредством ссылки) или включения нуклеотидов могут быть обнаружены с помощью волноводов с нулевой модой, как описано, например, в патенте США №7,315,019 (который включен в настоящее описание посредством ссылки) и с использованием флуоресцентных нуклеотидных аналогов и сконструированных полимераз, как описано, например, в патенте США №7,405,281 и публикации заявки на патент США №2008/0108082 (каждое из которых включено в настоящее описание посредством ссылки). Освещение может быть ограничено объемом порядка цептолитра вокруг поверхностно-связанной полимеразы, так что включение флуоресцентно-помеченных нуклеотидов можно наблюдать при низком фоне (Levene, MJ и др. «Zero-mode waveguides for single-molecule analysis at high concentrations)). Science 299, 682-686 (2003); Lundquist, P. M. и др. «Parallel confocal detection of single molecules in real time)). Opt. Lett. 33, 1026-1028 (2008); Korlach, J. и др. «Selective aluminum passivation for targeted immobilization of single DNA polymerase molecules in zero-mode waveguide nano structures)). Proc. Natl. Acad. Sci. USA 105, 1176-1181 (2008), раскрытие которых полностью включено в настоящее описание посредством ссылки). Изображения, полученные с помощью таких способов, могут быть сохранены, обработаны и проанализированы, как описано в данном документе.
[0124] Некоторые варианты осуществления секвенирования путем синтеза включают обнаружение протона, высвобожденного при включении нуклеотида в продукт удлинения. Например, для секвенирования, основанного на обнаружении высвобожденных протонов, может быть использован электрический детектор и связанные с ним способы, которые коммерчески доступны от компании Ion Torrent (Guilford, СТ, дочерняя компания Life Technologies), или способы и системы секвенирования, описанные в 2009/0026082 А1 (США); 2009/0127589 А1 (США); 2010/0137143 А1 (США) или 2010/0282617 А1 (США), каждый из которых включен в настоящий документ посредством ссылки. Описанные в данном документе способы амплификации целевых нуклеиновых кислот с использованием кинетического исключения могут быть легко применены для подложек, используемых для обнаружения протонов. В частности, описанные в данном документе способы могут быть использованы для получения клональных популяций ампликонов, которые используют для обнаружения протонов.
[0125] Вышеуказанные способы секвенирования путем синтеза могут в предпочтительных вариантах осуществляться в мультиплексных форматах таким образом, что одновременно используют множество разных целевых нуклеиновых кислот. В конкретных вариантах осуществления разные целевые нуклеиновые кислоты могут быть обработаны в общем реакционном резервуаре или на поверхности конкретной подложки. Это позволяет удобно доставлять реагенты для секвенирования, удалять непрореагировавшие реагенты и обнаруживать события включения мультиплексным способом. В вариантах осуществления с использованием поверхностно-связанных целевых нуклеиновых кислот, указанные кислоты могут иметь формат массива. В формате массива целевые нуклеиновые кислоты, как правило, могут быть связаны с поверхностью пространственно различимым способом. Целевые нуклеиновые кислоты могут быть связаны путем прямого ковалентного присоединения, присоединения к микроносителю или другой частице или путем связывания с полимеразой или другой молекулой, которая прикреплена к поверхности. Массив может включать одну копию целевой нуклеиновой кислоты на каждом участке (также называемом элементом) или множество копий с одинаковой последовательностью могут присутствовать на каждом участке или в каждом элементе. Множество копий может быть получено с применением способов амплификации, такими как мостиковая амплификация или эмульсионная полимеразная цепная реакция.
[0126] В способах, описанным в данном документе, могут применяться массивы, имеющие элементы с любым из множества значений плотности, включая, например, по меньшей мере приблизительно 10 элементов/см2, 100 элементов/см2, 500 элементов/см2, 1000 элементов/см2, 5000 элементов/см2, 10000 элементов/см2, 50000 элементов/см2, 100000 элементов/см2, 1000000 элементов/см2, 5000000 элементов/см2 или выше.
[0127] Описанные в данном документе способы могут обеспечить быстрое и эффективное одновременное обнаружение (детектирование) множества целевых нуклеиновых кислот. Соответственно, в настоящем раскрытии предложены интегрированные системы, способные подготавливать и обнаруживать нуклеиновые кислоты с использованием способов, известных в данной области техники, например, способов, приведенных выше в качестве примеров. Таким образом, интегрированная система согласно настоящему раскрытию может содержать жидкостные компоненты, способные доставлять реагенты для амплификации и/или реагенты для секвенирования к одному или более фрагментам иммобилизованной ДНК, причем система содержит такие компоненты, как насосы, клапаны, резервуары, жидкостные линии и т.п. Проточная ячейка может быть установлена и/или использована в интегрированной системе для обнаружения целевых нуклеиновых кислот. Типовые проточные ячейки описаны, например, в 2010/0111768 А1 (США) и №13/273,666 (США), каждый из которых включен в настоящее описание посредством ссылки. Как показано для проточных ячеек, один или более жидкостных компонентов интегрированной системы можно использовать для способа амплификации и для способа обнаружения. Если рассмотреть в качестве примера вариант осуществления секвенирования нуклеиновой кислоты, один или более жидкостных компонентов интегрированной системы можно использовать для описанного в данном документе способа амплификации и для доставки реагентов для секвенирования в способе секвенирования, например, способе, приведенном в качестве примера выше. В качестве альтернативы, интегрированная система может содержать отдельные жидкостные системы для осуществления способов амплификации и для осуществления способов обнаружения. Примеры интегрированных систем секвенирования, которые способны создавать амплифицированные нуклеиновые кислоты, а также определять последовательность нуклеиновых кислот, включают, без ограничения, платформу MiSeq™ (Illumina, Inc., Сан-Диего, Калифорния) и устройства, описанные в патенте США №13/273,666, который включен в настоящее описание посредством ссылки.
[0128] В некоторых вариантах осуществления способов, описанных в данном документе, метки картируемой последовательности содержат риды последовательностей приблизительно в 20 парах оснований, приблизительно в 25 парах оснований, приблизительно в 30 парах оснований, приблизительно в 35 парах оснований, приблизительно в 40 парах оснований, приблизительно в 45 парах оснований, приблизительно в 50 парах оснований, приблизительно в 55 парах оснований, приблизительно в 60 парах оснований, приблизительно в 65 парах оснований, приблизительно в 70 парах оснований, приблизительно в 75 парах оснований, приблизительно в 80 парах оснований, приблизительно в 85 парах оснований, приблизительно в 90 парах оснований, приблизительно в 95 парах оснований, приблизительно в 100 парах оснований, приблизительно в 110 парах оснований, приблизительно в 120 парах оснований, приблизительно в 130 парах оснований, приблизительно в 140 парах оснований, приблизительно в 150 парах оснований, приблизительно в 200 парах оснований, приблизительно в 250 парах оснований, приблизительно в 300 парах оснований, приблизительно в 350 парах оснований, приблизительно в 400 парах оснований, приблизительно в 450 парах оснований или приблизительно в 500 парах оснований. В некоторых случаях одно-концевые риды свыше 500 пар оснований используют для ридов свыше приблизительно 1000 пар оснований при генерировании парно-концевого рида. Картирование меток последовательности обеспечивают путем сравнения последовательности для метки с эталонной последовательностью для определения хромосомного происхождения секвенируемой молекулы нуклеиновой кислоты, причем информация о конкретной генетической последовательности не требуется. Небольшая степень несоответствия (0-2 несоответствия на метку последовательности) может быть разрешена для учета незначительных полиморфизмов, которые могут существовать между эталонным геномом и геномами в смешанном образце.
СИСТЕМЫ И УСТРОЙСТВА ДЛЯ АНАЛИЗА ДАННЫХ СЕКВЕНИРОВАНИЯ В РЕАЛЬНОМ ВРЕМЕНИ
[0129] Анализ данных секвенирования, как правило, выполняют с использованием различных алгоритмов и программ, исполняемых с помощью компьютера. Таким образом, в некоторых вариантах осуществления используют процессы, включающие хранение данных в одной или более компьютерных системах или других системах обработки или передачу данных посредством одной или более компьютерных систем или других систем обработки. Раскрытые в данном документе варианты осуществления также относятся к устройству для выполнения указанных операций. Указанное устройство может быть, в частности, выполнено с возможностью решения требуемых задач или может представлять собой компьютер (или группу компьютеров) общего назначения, выборочно активируемый или реконфигурируемый с помощью компьютерной программы и/или структуры данных, хранимой в компьютере. В некоторых вариантах осуществления группа процессоров выполняет некоторые или все описанные аналитические операции совместно (например, посредством сети или облачных вычислений) и/или параллельно. Процессор или группа процессоров для выполнения способов, описанных в данном документе, могут относиться к различным типам, включая микроконтроллеры и микропроцессоры, например, программируемые устройства (например, сложную программируемую логическую интегральную схему (CPLD) и программируемую логическую интегральную схему (FPGA)), и непрограммируемые устройства, например, интегральную схему специального назначения (ASIC) матрицы логических элементов или микропроцессоры общего назначения.
[0130] Кроме того, некоторые варианты осуществления относятся к материальным и/или машиночитаемым носителям, предназначенным для долговременного хранения информации, или к компьютерным программным продуктам, которые включают программные команды и/или данные (включая структуры данных) для выполнения различных операций, реализуемых с помощью компьютера. Примеры машиночитаемых носителей включают в себя, без ограничений, полупроводниковые запоминающие устройства, магнитные носители, такие как дисковые накопители, магнитную ленту, оптические носители, такие как компакт-диски, магнитооптические носители, и аппаратные устройства, которые, в частности, выполнены с возможностью хранения и выполнения программных команд, такие как постоянное запоминающее устройство (ПЗУ) и оперативное запоминающее устройство (ОЗУ). Конечный пользователь может непосредственно или опосредованно управлять машиночитаемым носителем. Примеры непосредственно управляемых носителей включают носители, расположенные на пользовательском оборудовании, и/или носители, которые не используют совместно. Примеры опосредованно управляемых носителей включают носители, которые опосредованно доступны пользователю посредством внешней сети и/или посредством службы, предоставляющий совместно используемые ресурсы, например, «облачной вычислительной среды». Примеры программных команд включают как машинный код, например, созданный компилятором, так и файлы, содержащие код более высокого уровня, который может быть выполнен компьютером с использованием интерпретатора.
[0131] В различных вариантах осуществления данные или информацию, используемые в раскрытых способах и устройстве, обеспечивают в электронном формате. Такие данные или информация могут включать риды, полученные из образца нуклеиновой кислоты, количества или плотности меток, которые совпадают с конкретными областями эталонной последовательности (например, которые совпадают с хромосомой или сегментом хромосомы), разделяющие расстояния между соседними ридами или фрагментами, распределения таких разделяющих расстояний, диагнозы и т.п. В контексте данного документа данные или другая информация, предоставленная в электронном формате, доступна для сохранения на машине и передачи между машинами. Обычно данные в электронном формате получают в цифровом виде и их можно хранить в виде битов и/или байтов в различных структурах данных, списках, базах данных и т.д. Данные могут быть записаны электронным, оптическим способами и т.д.
[0132] В одном варианте осуществления предложен компьютерный программный продукт для определения коэффициентов фазирования и опережающего фазирования, а также значений величины со скорректированным фазированием и связанных распознаваний оснований. Компьютерный продукт может содержать команды для выполнения любого одного или более из вышеописанных способов для фазирования и распознавания оснований. Как объяснено выше, компьютерный продукт может включать предназначенный для долговременного хранения информации и/или материальный машиночитаемый носитель с записанной на нем исполняемой на компьютере или компилируемой логической процедурой (например, командами) для обеспечения возможности для процессора выравнивать риды, идентифицировать фрагменты и/или островки выровненных ридов, идентифицировать аллели, включая аллели, возникшие вследствие инсерционно-делеционных мутаций, гетерозиготные полиморфизмы, фазовые фрагменты хромосом, а также хромосомы и геномы гаплотипов. В одном примере компьютерный продукт включает (1) машиночитаемый носитель, на котором хранится исполняемая компьютером или компилируемая логическая процедура (например, команды) для обеспечения возможности для процессора выполнять коррекцию фазирования для данных величины (например, данных интенсивности цвета из двух или более каналов) на образцах нуклеиновой кислоты; (2) выполняемую с применением компьютера логическую процедуру для осуществления распознаваний оснований образцов нуклеиновой кислоты; и (3) процедуру вывода для генерирования выходных данных, характеризующих образцы нуклеиновой кислоты.
[0133] Следует понимать, что человеку без посторонней помощи будет нецелесообразно или даже в большинстве случаев невозможно выполнять вычислительные операции согласно способам, раскрытым в данном документе. Например, для генерации коэффициентов фазирования даже для одного сегмента в течение одного цикла распознавания оснований могут потребоваться годы работы без применения вычислительного устройства. Конечно, проблема усугубляется тем, что для надежного NGS-секвенирования (секвенирование следующего поколения), как правило, требуется коррекция фазирования и распознавание оснований по меньшей мере для тысяч или даже миллионов ридов.
[0134] Раскрытые в данном документе способы могут быть выполнены с использованием системы секвенирования образцов нуклеиновой кислоты. Система может содержать: (а) секвенатор для приема нуклеиновых кислот из исследуемого образца, обеспечивающий информацию о последовательности нуклеиновой кислоты из образца; (б) процессор; и (с) один или более машиночитаемых носителей, на которых хранятся команды для выполнения в процессоре для оценки данных из секвенатора. Машиночитаемый носитель также может хранить данные величины с частичной коррекцией фазирования из кластеров в проточной ячейке.
[0135] В некоторых вариантах осуществления команды по выполнению способов поступают с машиночитаемого носителя, на котором хранятся машиночитаемые команды для осуществления способа определения фазы последовательности. Таким образом, один вариант осуществления предусматривает, что компьютерный программный продукт использует один или более машиночитаемых предназначенных для долговременного хранения информации носителей, на которых хранятся исполняемые компьютером команды, при выполнении которых одним или более процессорами компьютерной системы компьютерная система реализует способ секвенирования образца ДНК. Способ включает: (а) получение данных, представляющих изображение (например, само изображение) подложки, содержащей множество участков, на которых считывают основания нуклеиновых кислот; (b) получение значений цвета (или других значений, представляющие отдельные основания/нуклеотиды) для множества участков из изображения подложки; (с) сохранение значений цвета в буфере процессора; (d) извлечение значений цвета с частичной коррекцией фазирования для множества участков для цикла распознавания оснований, причем значения цвета с частичной коррекцией фазирования были сохранены в запоминающем устройстве секвенатора в течение непосредственно предшествующего цикла распознавания оснований; (е) определение коррекции опережающего фазирования из (i) значений цвета с частичной коррекцией фазирования, сохраненных в течение непосредственно предшествующего цикла распознавания оснований, и (ii) значений цвета, сохраненных в буфере процессора; и (f) определение скорректированных значений цвета из (i) значений цвета в буфере процессора, (ii) значений с частичной коррекцией фазирования, сохраненных в течение непосредственно предшествующего цикла, и (iii) коррекции опережающего фазирования.
[0136] Последовательность или другие данные могут быть введены в компьютер или сохранены на машиночитаемом носителе непосредственно или опосредованно. В различных вариантах осуществления компьютерная система является встроенной или непосредственно соединена с устройством секвенирования, которое считывает и/или анализирует последовательности нуклеиновых кислот из образцов. Последовательности или другую информацию от таких приборов передают в компьютерную систему (или просто на встроенное аппаратное обеспечение обработки) посредством интерфейса передачи данных. Кроме того, запоминающее устройство может хранить риды, информацию о качестве распознавания оснований, информацию о коэффициентах фазирования и т.д. Запоминающее устройство также может хранить различные процедуры и/или программы для анализа и предоставления данных последовательности. Такие программы/процедуры могут включать программы для выполнения статистического анализа и т.д.
[0137] В одном примере пользователь обеспечивает помещение образца в устройство для секвенирования. Устройство для секвенирования, подключенное к компьютеру, собирает и/или анализирует данные. Программное обеспечение, установленное на компьютере, позволяет собирать и/или анализировать данные. Данные могут быть сохранены, отображены (с помощью монитора или другого подобного устройства) и/или отправлены в другое местоположение. Компьютер может быть подключен к Интернету, который используют для передачи данных на мобильное устройство, используемое удаленным пользователем (например, врачом, ученым или аналитиком). Понятно, что данные могут быть сохранены и/или проанализированы до осуществления передачи. В некоторых вариантах осуществления необработанные данные собирают и отправляют удаленному пользователю или на устройство, которое будет анализировать и/или хранить указанные данные. Например, риды могут передавать по мере их генерирования или вскоре после этого и согласовывать, а другие удаленно анализировать. Передача может происходить по Интернету, но также может осуществляться посредством спутникового или другого соединения. В качестве альтернативы, данные могут храниться на машиночитаемом носителе и носитель может быть отправлен конечному пользователю (например, по почте). Удаленный пользователь может находиться в том же или другом географическом местоположении, включая, без ограничений, здание, город, штат, страну или континент.
[0138] В некоторых вариантах осуществления способы также включают сбор данных, относящихся к множеству полинуклеотидных последовательностей (например, риды), и отправку указанных данных в компьютер или другую вычислительную систему. Например, компьютер может быть подключен к лабораторному оборудованию, например, устройству для сбора образцов, устройству амплификации полинуклеотидов или устройству секвенирования нуклеотидов. Собранные или сохраненные данные могут быть переданы с компьютера в удаленное местоположение, например, по локальной сети или глобальной сети, такой как Интернет. В удаленном местоположении в отношении переданных данных могут быть выполнены различные операции.
[0139] В некоторых вариантах осуществления любой из представленных в данном документе систем секвенатор выполнен с возможностью осуществления секвенирования следующего поколения (NGS). В некоторых вариантах осуществления секвенатор выполнен с возможностью осуществления массового параллельного секвенирования с использованием секвенирования путем синтеза с применением обратимых терминаторов красителя. В других вариантах осуществления секвенатор выполнен с возможностью осуществления секвенирования одной молекулы.
ЗАКЛЮЧЕНИЕ
[0140] Настоящее раскрытие может быть воплощено в других конкретных формах без отступления от его сущности или существенных характеристик. Описанные варианты осуществления следует рассматривать во всех отношениях только как иллюстративные, а не ограничивающие. Таким образом, объем раскрытия определяется прилагаемой формулой изобретения, а не в приведенным выше описанием. Все изменения, которые подходят по смыслу и диапазону эквивалентности формулы изобретения, должны быть включены в его объем.
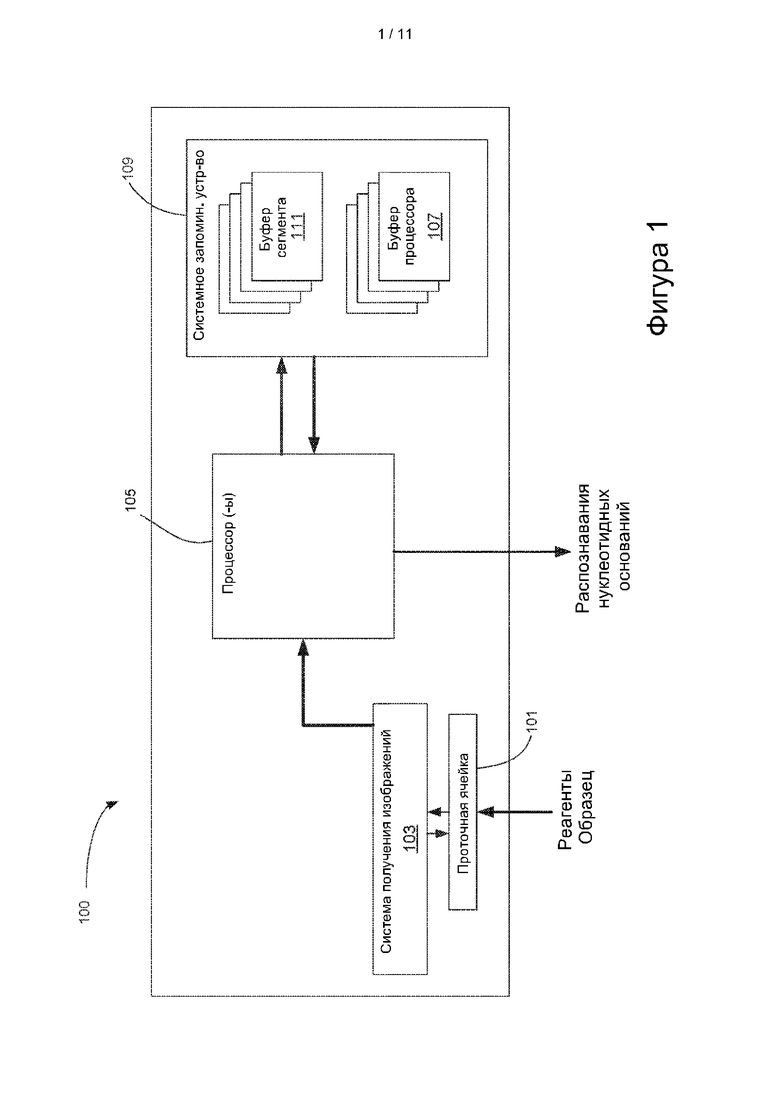
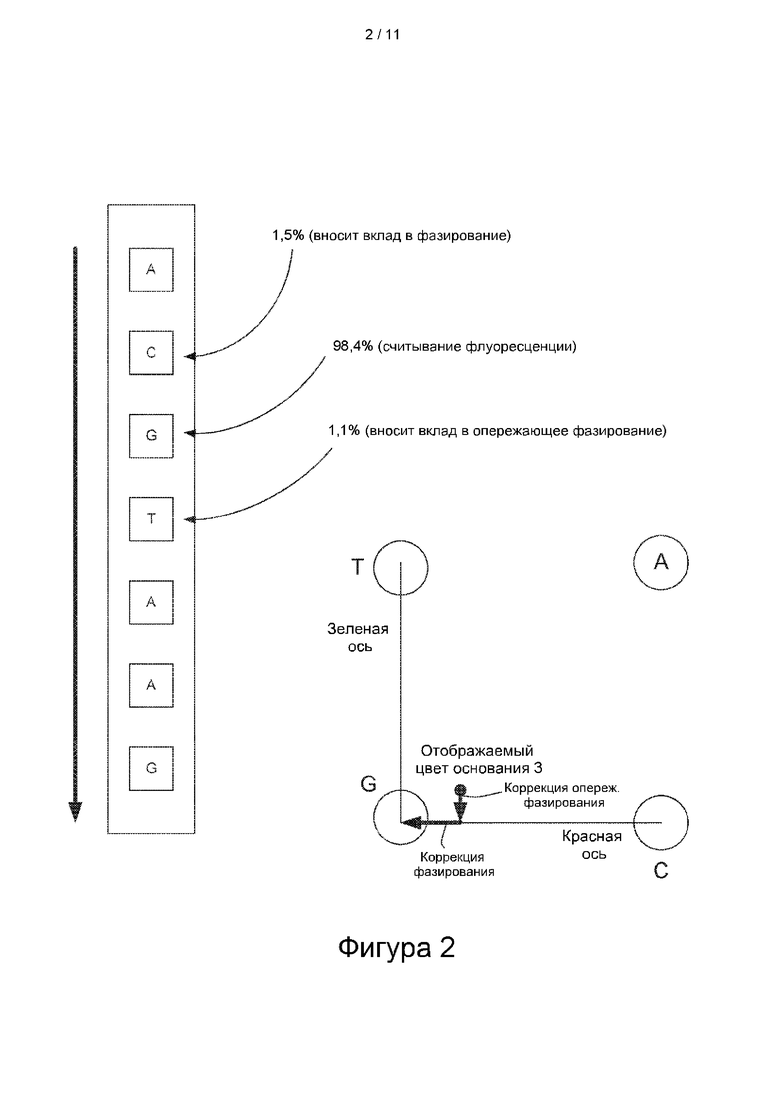
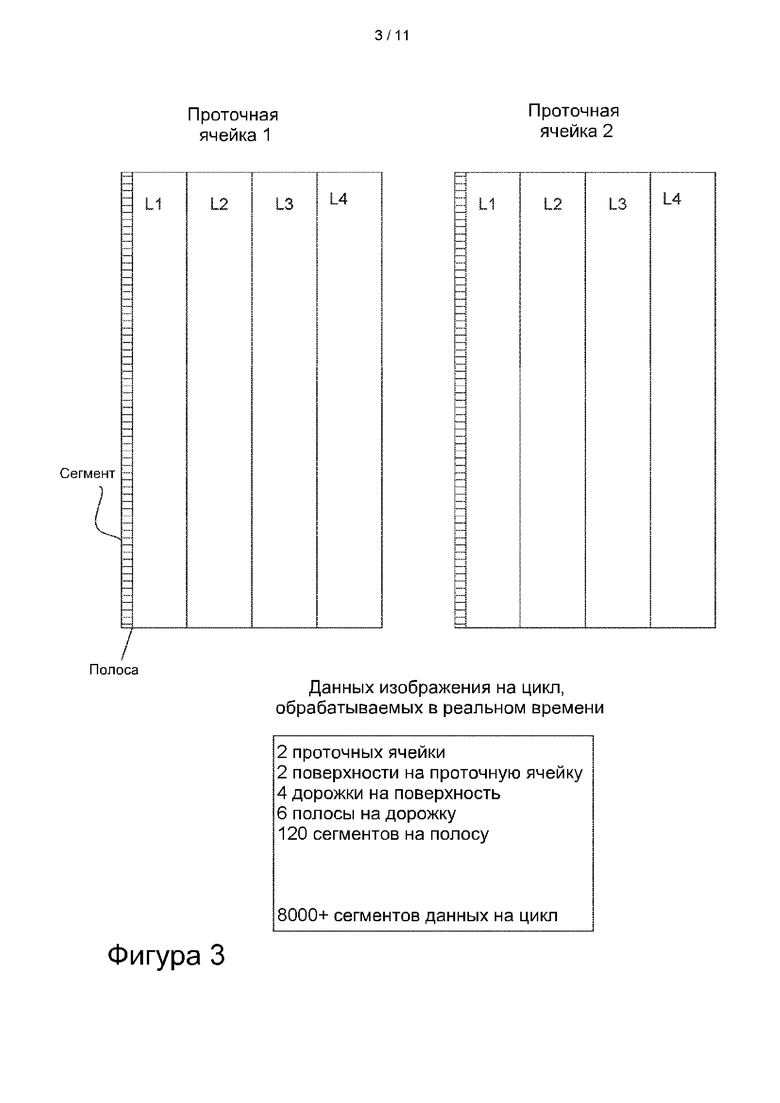
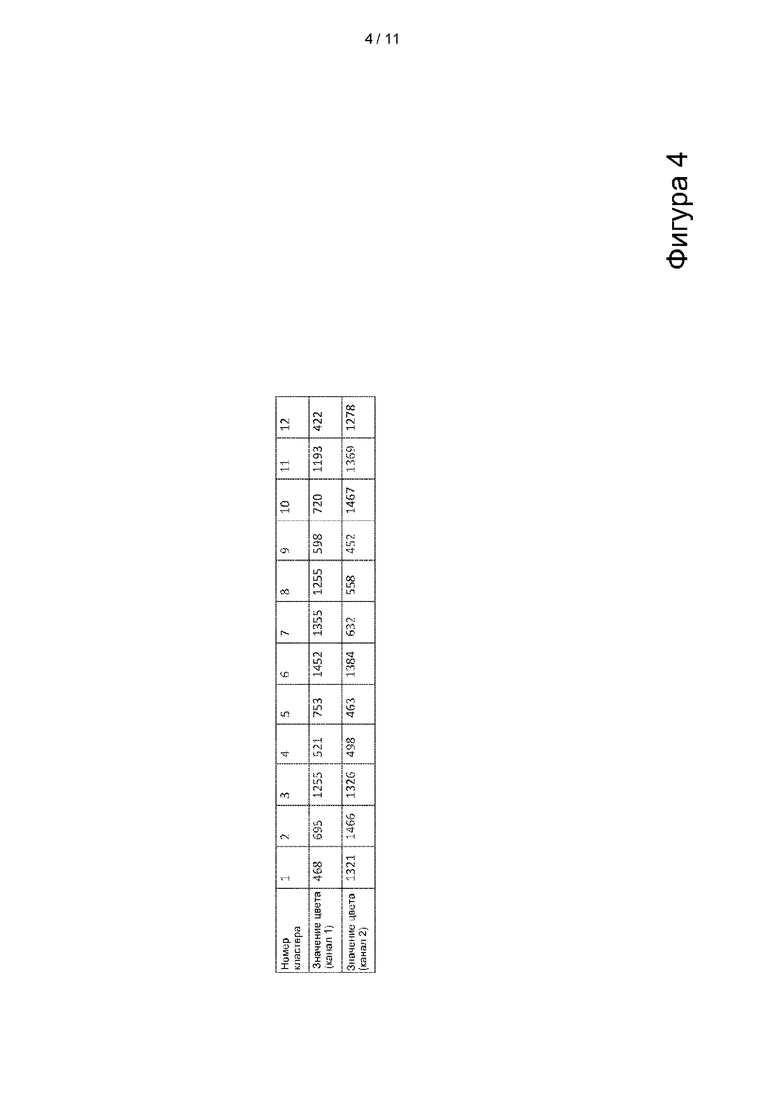
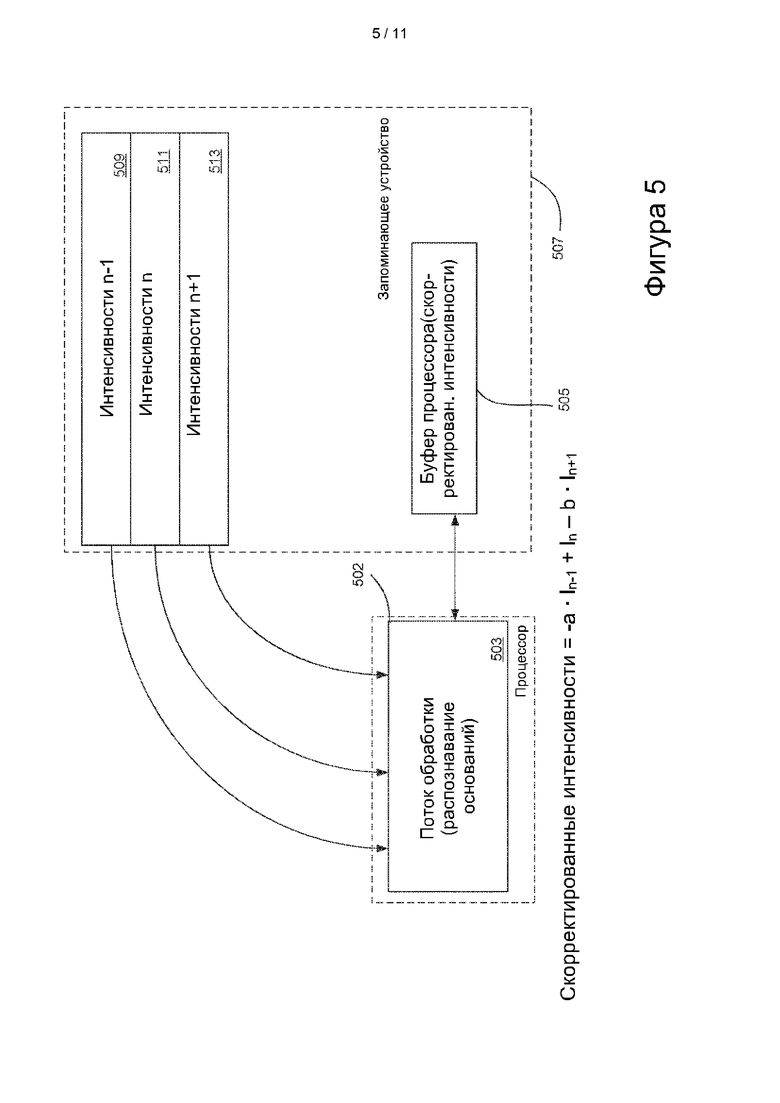
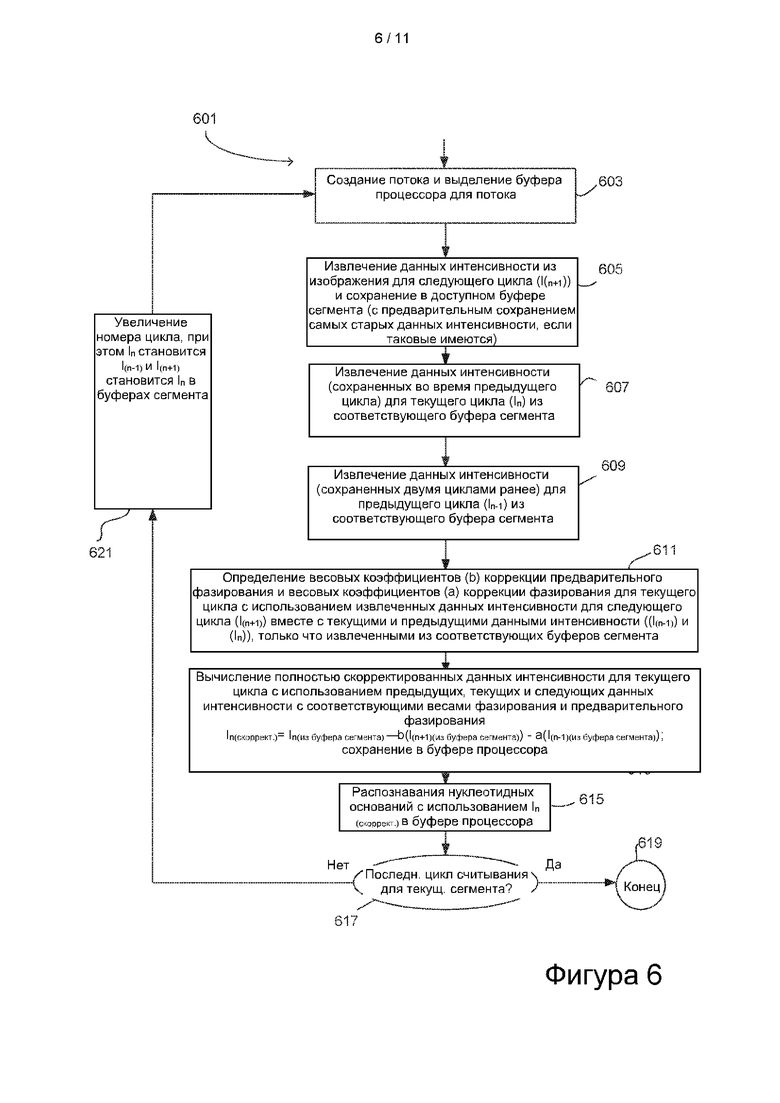
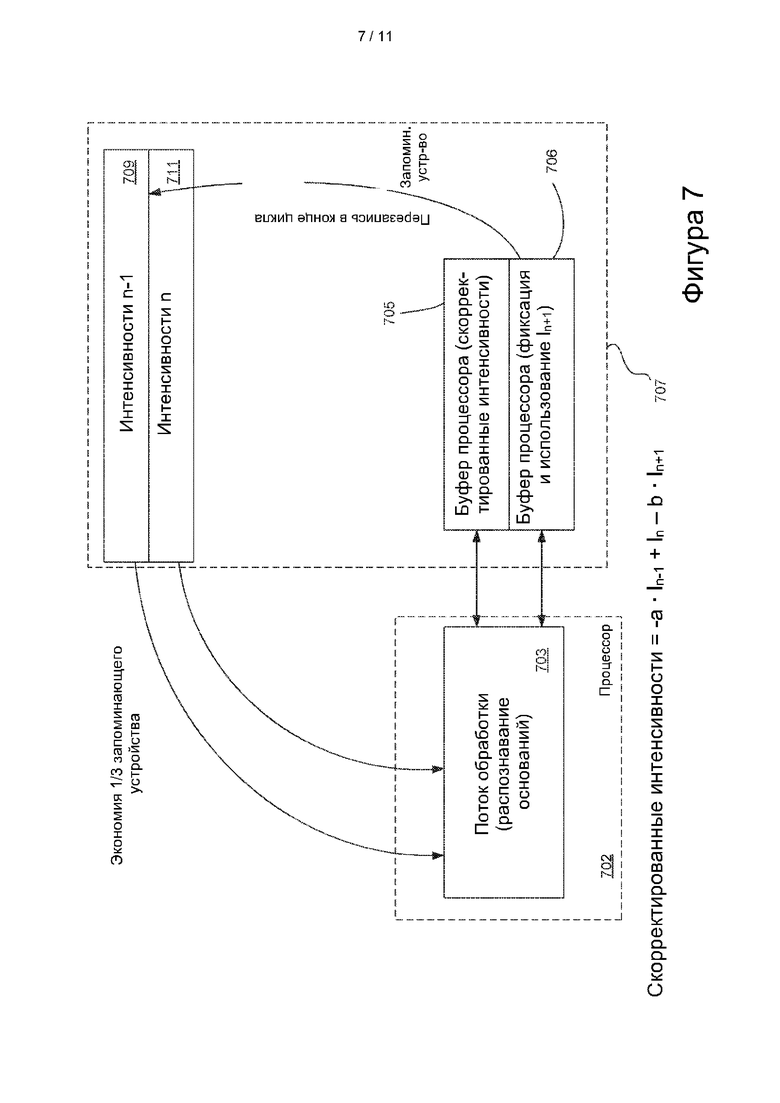
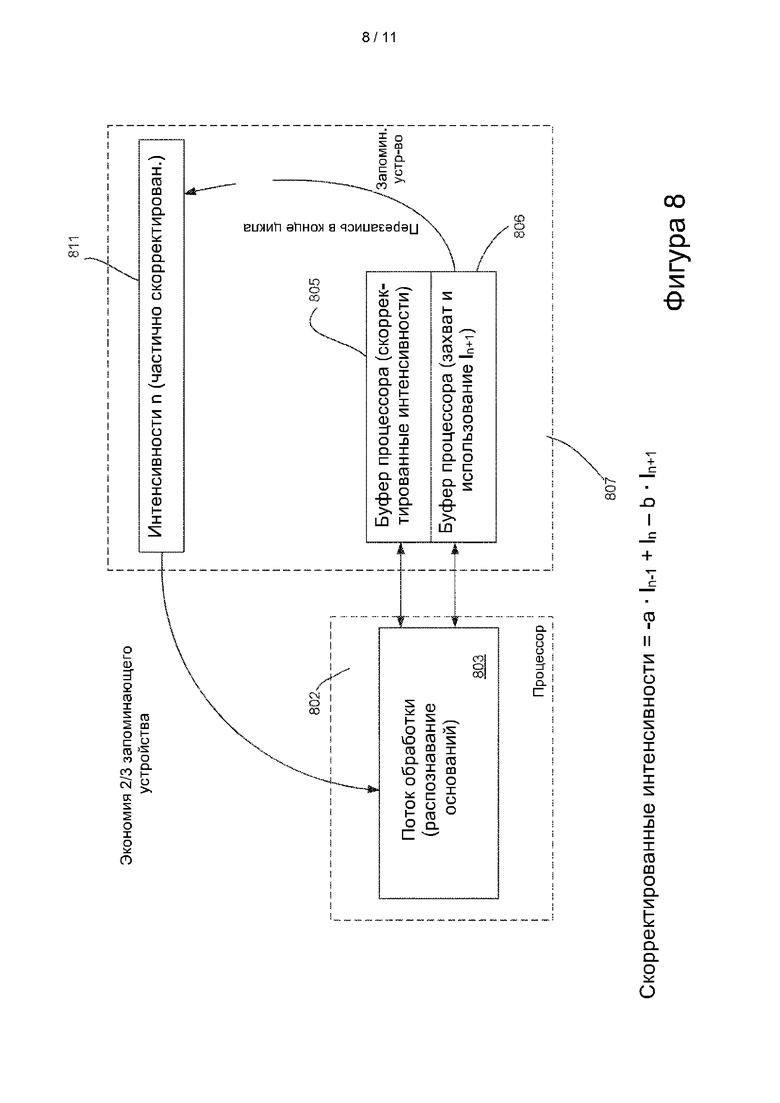
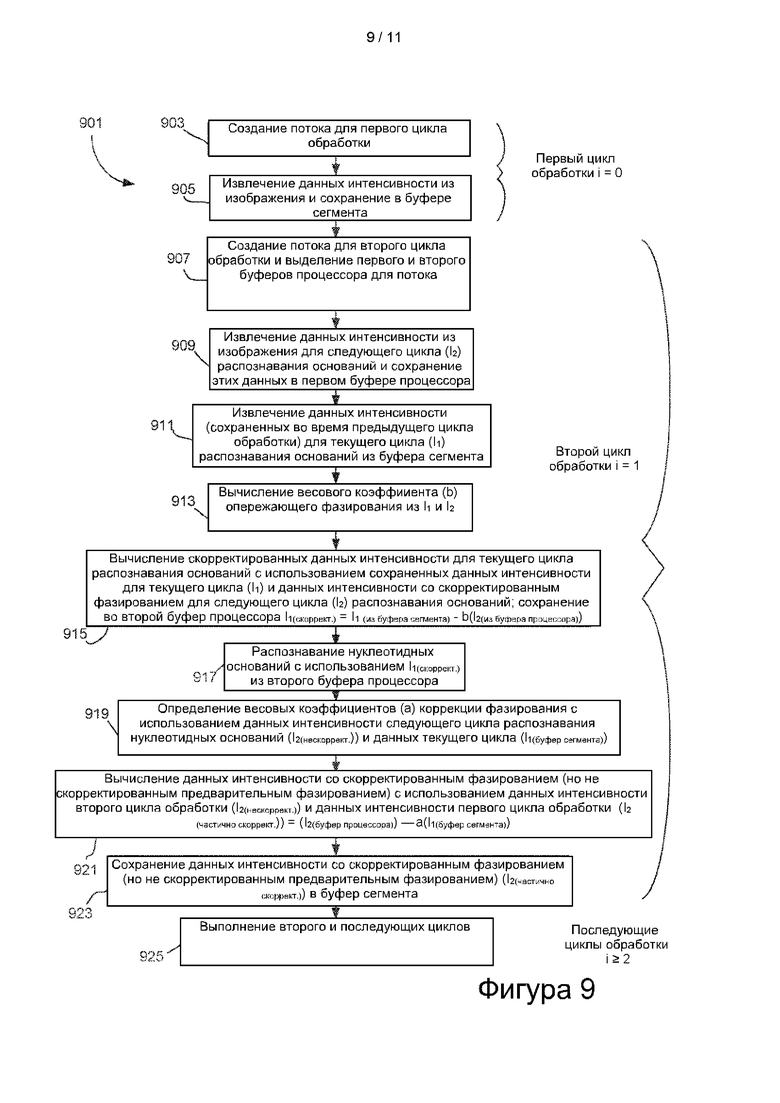
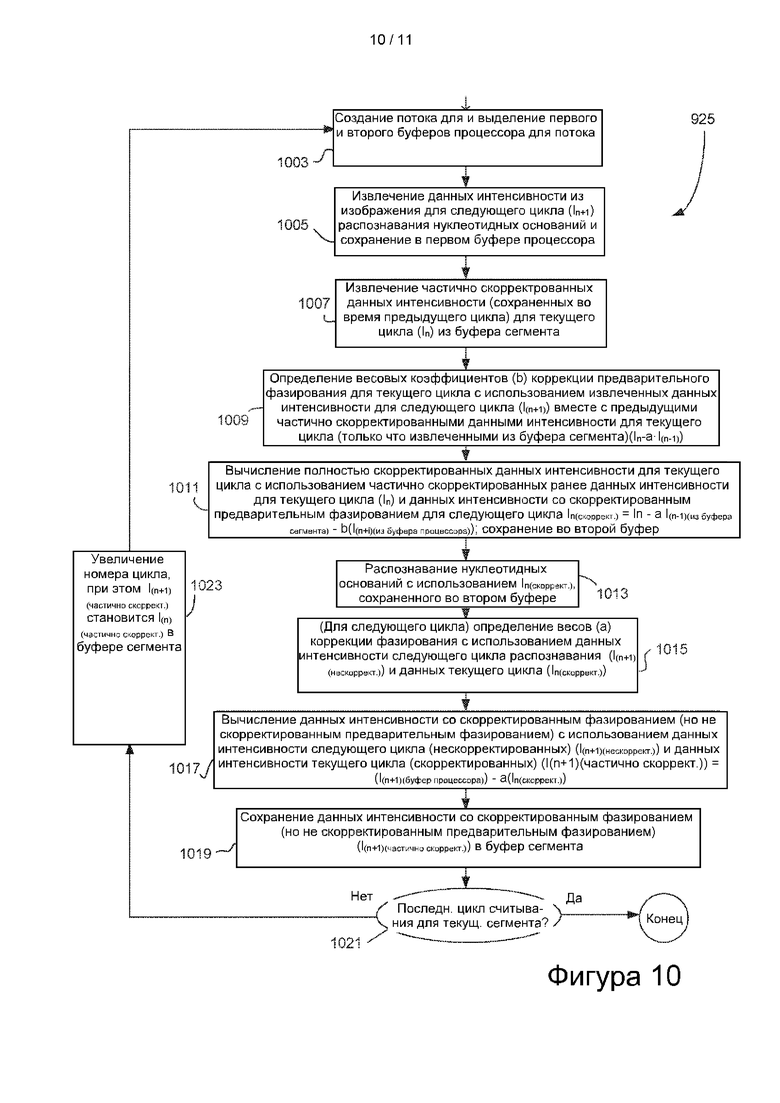
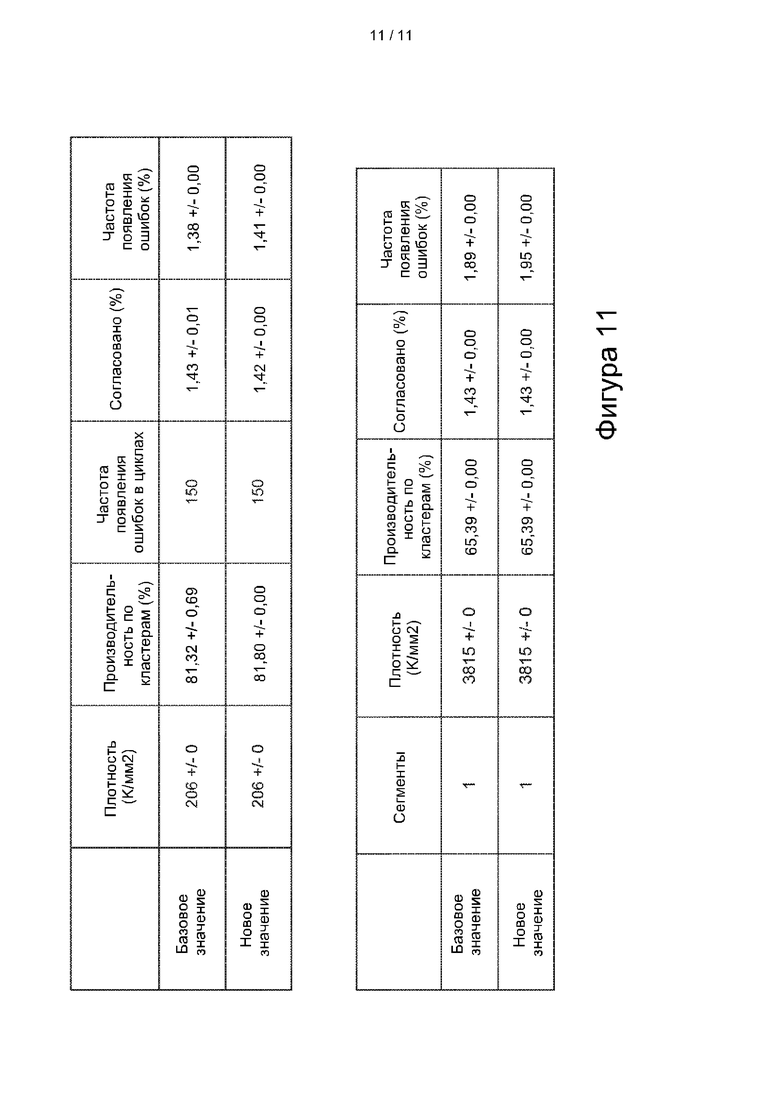
Группа изобретений относится к области биотехнологии. Предложен способ определения скорректированных значений цвета из данных изображения, полученных в ходе осуществления цикла распознавания оснований с помощью секвенатора и секвенатор нуклеиновых кислот. Способ включает (a) получение изображения подложки, содержащей множество участков, на которых считывают основания нуклеиновых кислот, причем эти участки имеют цвета, представляющие типы нуклеиновых оснований; (b) измерение значений цвета множества участков по указанному изображению подложки;(c) сохранение значений цвета в буфере процессора одного или более процессоров секвенатора; (d) извлечение значений цвета с частичной коррекцией фазирования множества участков, где указанные значения цвета с частичной коррекцией фазирования были сохранены в запоминающем устройстве секвенатора в ходе осуществления непосредственно предшествующего цикла распознавания оснований; (е) определение коррекции опережающего фазирования по значениям цвета с частичной коррекцией фазирования, сохраненным в ходе осуществления непосредственно предшествующего цикла распознавания оснований, и значениям цвета, сохраненным в буфере процессора; и (f) определение скорректированных значений цвета по значениям цвета в буфере процессора, значениям цвета с частичной коррекцией фазирования, сохраненным в ходе осуществления непосредственно предшествующего цикла, и коррекции опережающего фазирования. Секвенатор содержит систему получения изображений, запоминающее устройство и процессоров, выполненный с возможностью указанный действий способа. Изобретения обеспечивают снижение нагрузки на запоминающее устройство. 2 н. и 37 з.п. ф-лы, 11 ил.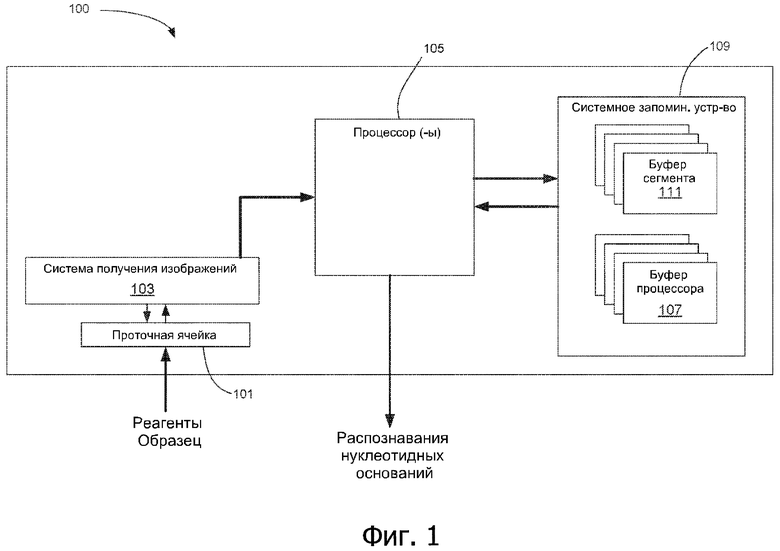
1. Способ определения скорректированных значений цвета из данных изображения, полученных в ходе осуществления цикла распознавания оснований с помощью секвенатора нуклеиновых кислот, содержащего систему получения изображения, один или более процессоров и запоминающее устройство, включающий:
(a) получение изображения подложки, содержащей множество участков, на которых считывают основания нуклеиновых кислот, причем эти участки имеют цвета, представляющие типы нуклеиновых оснований;
(b) измерение значений цвета множества участков по указанному изображению подложки;
(c) сохранение значений цвета в буфере процессора одного или более процессоров секвенатора;
(d) извлечение значений цвета с частичной коррекцией фазирования множества участков, где указанные значения цвета с частичной коррекцией фазирования были сохранены в запоминающем устройстве секвенатора в ходе осуществления непосредственно предшествующего цикла распознавания оснований;
(е) определение коррекции опережающего фазирования по
значениям цвета с частичной коррекцией фазирования, сохраненным в ходе осуществления непосредственно предшествующего цикла распознавания оснований, и
значениям цвета, сохраненным в буфере процессора; и
(f) определение скорректированных значений цвета по
значениям цвета в буфере процессора,
значениям цвета с частичной коррекцией фазирования, сохраненным в ходе осуществления непосредственно предшествующего цикла, и
коррекции опережающего фазирования.
2. Способ по п. 1, который также включает применение скорректированных значений цвета для выполнения распознавания оснований для множества участков.
3. Способ по п. 1 или 2, в котором коррекция опережающего фазирования включает определение веса, и при этом определение скорректированных значений цвета включает умножение весов на значения цвета множества участков, измеренных по изображению подложки.
4. Способ по любому из предшествующих пунктов, который также включает определение коррекции фазирования для непосредственно следующего цикла распознавания оснований.
5. Способ по п. 4, в котором определение коррекции фазирования для непосредственно следующего цикла распознавания оснований включает анализ
значений цвета с частичной коррекцией фазирования, хранимых в запоминающем устройстве секвенатора, и
значений цвета, хранимых в буфере процессора.
6. Способ по п. 4, который также включает:
генерирование значений цвета с частичной коррекцией фазирования для непосредственно следующего цикла распознавания оснований путем применения коррекции фазирования к значениям цвета множества участков, хранимых в запоминающем устройстве секвенатора; и
сохранение значений цвета с частичной коррекцией фазы для непосредственно следующего цикла распознавания оснований в запоминающем устройстве секвенатора.
7. Способ по п. 6, в котором получение значений цвета с частичной коррекцией фазирования для непосредственно следующего цикла распознавания оснований также включает суммирование
значений цвета со скорректированным фазированием множества участков и
значений цвета множества участков из изображения подложки, измеренных на этапе (b).
8. Способ по п. 6, в котором при сохранении значений цвета с частичной коррекцией фазирования для непосредственно следующего цикла распознавания оснований частично скорректированные значения цвета сохраняют в буферах сегмента запоминающего устройства секвенатора.
9. Способ по любому из предшествующих пунктов, в котором способ выполняют в реальном времени в ходе получения ридов последовательностей секвенатором нуклеиновых кислот.
10. Способ по любому из предшествующих пунктов, в котором секвенатор нуклеиновых кислот синтезирует нуклеиновые кислоты на множестве участков.
11. Способ по любому из предшествующих пунктов, в котором значения цвета определяют с применением только двух каналов секвенатора.
12. Способ по любому из пп. 1–10, в котором значения цвета получают с применением четырех каналов секвенатора.
13. Способ по любому из предшествующих пунктов, в котором подложка содержит проточную ячейку, причем проточную ячейку логически разделяют на сегменты и каждый сегмент представляет собой область проточной ячейки, содержащую подмножество участков, причем указанное подмножество фиксируют в одном изображении от системы получения изображения.
14. Способ по п. 13, в котором в операции (d) значения цвета с частичной коррекцией фазирования были сохранены в буферах сегмента запоминающего устройства секвенатора, причем буферы сегмента выполнены с возможностью хранения данных, представляющих изображения отдельных сегментов на подложке.
15. Способ по п. 14, в котором емкость запоминающего устройства составляет 512 Гигабайт или менее.
16. Способ по п. 13, который также включает перед операцией (а) помещение реагентов в проточную ячейку и обеспечение возможности взаимодействия реагентов с участками, в результате чего участки будут иметь цвета, соответствующие типам нуклеиновых оснований, в ходе осуществления цикла распознавания оснований.
17. Способ по п. 16, который также включает после операции (f):
помещение свежих реагентов в проточную ячейку и обеспечение возможности взаимодействия свежих реагентов с участками, в результате чего участки будут иметь цвета, соответствующие типам нуклеиновых оснований, для следующего цикла распознавания оснований; и
повторное выполнение операций (а)–(е) для следующего цикла распознавания оснований.
18. Способ по п. 17, который также включает создание первого потока процессора для выполнения операций (a)–(f) для цикла распознавания оснований и создание второго потока процессора для выполнения операций (a)–(f) для следующего цикла распознавания оснований.
19. Способ по любому из предшествующих пунктов, который также включает выделение буфера процессора и второго буфера процессора, причем второй буфер процессора используют для определения скорректированных значений цвета в п. (f).
20. Секвенатор нуклеиновых кислот, содержащий:
систему получения изображений;
запоминающее устройство; и
один или более процессоров, выполненных или сконфигурированных с возможностью:
(а) получения данных, представляющих изображение подложки, содержащей множество участков, на которых считывают нуклеиновые основания, причем указанные участки имеют цвета, соответствующие типам нуклеиновых оснований;
(b) получения значений цвета для множества участков по изображению подложки;
(c) сохранения значений цвета в буфере процессора;
(d) извлечения значений цвета с частичной коррекцией фазирования множества участков для цикла распознавания оснований, причем значения цвета с частичной коррекцией фазирования были сохранены в запоминающем устройстве в ходе осуществления непосредственно предшествующего цикла распознавания оснований;
(e) определения коррекции опережающего фазирования по
значениям цвета с частичной коррекцией фазирования, сохраненным в ходе осуществления непосредственно предшествующего цикла распознавания оснований, и
значений цвета, сохраненных в буфере процессора; и
(f) определение скорректированных значений цвета по
значениям цвета в буфере процессора,
значений с частичной коррекцией фазирования, сохраненных в ходе осуществления непосредственно предшествующего цикла, и
коррекции опережающего фазирования.
21. Секвенатор нуклеиновых кислот по п. 20, в котором запоминающее устройство разделено на множество буферов сегмента, каждый из которых выполнен с возможностью хранения данных, представляющих одно изображение сегмента на подложке.
22. Секвенатор нуклеиновых кислот по п. 20 или 21, в котором емкость запоминающего устройства составляет 512 Гигабайт или менее.
23. Секвенатор нуклеиновых кислот по любому из пп. 20–22, в котором один или более процессоров также выполнены или сконфигурированы с возможностью применения скорректированных значений цвета для выполнения распознавания оснований для множества участков.
24. Секвенатор нуклеиновых кислот по любому из пп. 20–23, в котором коррекция опережающего фазирования включает определение веса, и при этом один или более процессоров выполнены или сконфигурированы с возможностью определения скорректированных значений цвета путем умножения веса на значения цвета множества участков, измеренные на изображении подложки.
25. Секвенатор нуклеиновых кислот по любому из пп. 20–24, в котором один или более процессоров также выполнены или сконфигурированы с возможностью определения коррекции фазирования для непосредственно следующего цикла распознавания оснований.
26. Секвенатор нуклеиновых кислот по п. 25, в котором один или более процессоров выполнены или сконфигурированы с возможностью определения коррекции фазирования для непосредственно следующего цикла распознавания оснований путем анализа
значений цвета с частичной коррекцией фазирования, хранимых в запоминающем устройстве, и
значений цвета, хранимых в буфере процессора.
27. Секвенатор нуклеиновых кислот по п. 25, в котором один или более процессоров также выполнены или сконфигурированы с возможностью:
получения значений цвета с частичной коррекцией фазирования для непосредственно следующего цикла распознавания оснований путем применения коррекции фазирования к значениям цвета множества участков, хранимых в запоминающем устройстве; и
сохранения значений цвета с частичной коррекцией фазирования для непосредственно следующего цикла распознавания оснований в запоминающем устройстве.
28. Секвенатор нуклеиновых кислот по п. 27, в котором один или более процессоров выполнены или сконфигурированы с возможностью получения значений цвета с частичной коррекцией фазирования для непосредственно следующего цикла распознавания оснований путем суммирования
значений цвета со скорректированным фазированием множества участков и
значений цвета множества участков по изображению подложки, измеренных в операции (b).
29. Секвенатор нуклеиновых кислот по п. 27, в котором один или более процессоров выполнены или сконфигурированы с возможностью сохранения значений цвета с частичной коррекцией фазирования для непосредственно следующего цикла распознавания оснований путем сохранения значений цвета с частичной коррекцией фазирования в буферах сегмента запоминающего устройства.
30. Секвенатор нуклеиновых кислот по любому из пп. 20–29, в котором один или более процессоров также выполнены или сконфигурированы с возможностью осуществления операций (a)–(f) в реальном времени в ходе распознавания оснований.
31. Секвенатор нуклеиновых кислот по любому из пп. 20–30, дополнительно содержащий систему для синтеза нуклеиновых кислот на множестве участков.
32. Секвенатор нуклеиновых кислот по любому из пп. 20–31, в котором один или более процессоров также выполнены или сконфигурированы с возможностью получения значений цвета с применением только двух каналов.
33. Секвенатор нуклеиновых кислот по любому из пп. 20–31, в котором один или более процессоров также выполнены или сконфигурированы с возможностью получения значений цвета с применением четырех каналов.
34. Секвенатор нуклеиновых кислот по любому из пп. 20–33, в котором подложка содержит проточную ячейку, причем проточную ячейку логически разделяют на сегменты, и каждый сегмент представляет собой область проточной ячейки, содержащую подмножество участков, причем указанное подмножество фиксируют в одном изображении от системы получения изображения.
35. Секвенатор нуклеиновых кислот по п. 34, в котором в операции (d) значения цвета с частичной коррекцией фазирования были сохранены в буферах сегмента запоминающего устройства секвенатора, причем буферы сегмента выполнены или сконфигурированы с возможностью хранения данных, представляющих изображения отдельных сегментов на подложке.
36. Секвенатор нуклеиновых кислот по п. 34, в котором один или более процессоров также выполнены или сконфигурированы с возможностью перед выполнением операции (а) помещения реагентов в проточную ячейку и обеспечения возможности взаимодействия реагентов с участками, в результате чего участки будут иметь цвета, соответствующие типам нуклеиновых оснований, в ходе осуществления цикла распознавания оснований.
37. Секвенатор нуклеиновых кислот по п. 36, в котором один или более процессоров также выполнены или сконфигурированы с возможностью после операции (f):
помещения свежих реагентов в проточную ячейку и обеспечения возможности взаимодействия свежих реагентов с участками, в результате чего участки будут иметь цвета, соответствующие типам нуклеиновых оснований, для следующего цикла распознавания оснований; и
повторного выполнения операций (а)–(е) для следующего цикла распознавания оснований.
38. Секвенатор нуклеиновых кислот по п. 37, в котором один или более процессоров также выполнены или сконфигурированы с возможностью создания первого потока процессора для выполнения операций (a)–(f) для цикла распознавания оснований и создания второго потока процессора для выполнения операций (a)–(f) для следующего цикла распознавания оснований.
39. Секвенатор нуклеиновых кислот по любому из пп. 20–38, в котором один или более процессоров также выполнены или сконфигурированы с возможностью выделения буфера процессора и второго буфера процессора для определения скорректированных значений цвета в операции (f).
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| СПОСОБ СЕКВЕНИРОВАНИЯ ПОЛИНУКЛЕОТИДОВ | 2002 |
|
RU2291197C2 |

