Область техники
Изобретение, среди прочего, относится к новому вирусу рыб, обозначенному как Totivirus, который вызывает гибель рыб, и к способам обнаружения указанного вируса в рыбе и защите рыб от заражения указанным вирусом, и к связанным (ре)агентам и применениям.
Уровень техники
Рыба является одним из основных источников питания человека, и рыбоводство стало важной отраслью, особенно в связи с тем, что уровень вылова диких рыб является невысоким или снижается в результате чрезмерного вылова рыбы и потери среды обитания. Примеры выращиваемой рыбы включают атлантический лосось (Salmo salar) и пинагор (Cyclopterus lumpus).
Однако инфекционные заболевания в аквакультуре угрожают производству рыбы и также могут влиять на популяции диких рыб. Например, известно, что воспаление сердечных и скелетных мышц (HSMI) является часто смертельным заболеванием у выращиваемого на фермах атлантического лосося. У пораженных рыб часто снижается прием корма, что приводит к аномальному поведению при плавании и, в некоторых случаях, к внезапному падежу. Обычно внешние поражения не распознаются. При вскрытии сердце часто выглядит бледным и несколько рыхлым. В некоторых случаях перикардиальный мешок наполнен кровью. Гистологические исследования показывают, что у большинства рыб в пораженных сетчатых садках обнаруживаются серьезные повреждения, хотя они кажутся здоровыми. Впервые обнаруженное в Норвегии в 1999 г. (Kongtorp et al., J. Fish Dis., 27, 2004), впоследствии HSMI было вовлечено в нескольких вспышках инфекции на других фермах Норвегии и Великобритании. Полагается, что рыбный реовирус (PRV), реовирус рыб относится к семейству Reoviridae, подсемейству Spinareovirinae, и является вероятным возбудителем HSMI (Kibenge et al., Virol. J., 10, 2013). С 1999 г. наблюдается рост числа вспышек инфекции, и полагается, что данное заболевание оказывает пагубное экономическое влияние на лососеводство.
Кардиомиопатический синдром (CMS) представляет собой тяжелое заболевание сердца, поражающее главным образом крупного атлантического лосося на второй год пребывания в морской воде в преддверии отлова. Больные рыбы могут внезапно пасть, не проявляя внешних признаков заболевания, или у них могут проявляться такие симптомы, как аномальное плавание и анорексия. Заболевание было впервые выявлено у выращиваемого атлантического лосося в Норвегии в 1985 году, и затем у выращиваемого лосося на Фарерских островах, в Великобритании и Ирландии. CMS также был описан у дикого атлантического лосося в Норвегии. В 2010 г. двухцепочечный РНК-вирус семейства Totiviridae, названный вирусом рыбного миокардита (PMCV), был описан как возбудитель CMS (Haugland et al., J. Virol., 85, 2011). PMCV считается одной из самых больших проблем в производстве атлантического лосося, приводящей к крупным экономическим потерям для компаний-производителей лосося.
Проблемы, связанные с болезнями при производстве пинагора (Cyclopterus lumpus), в определенной степени обусловлены бактериальными инфекциями. Среди них Aeromonas salmonicida subsp. (возбудитель атипичного фурункулеза), Pasteurella sp., Vibrio anguillarum и Tenacibaculum sp. были наиболее значимыми видами. Применение программ целевой вакцинации, систематический мониторинг заболевания и совершенствование производства привели к постепенному снижению числа случаев атипичного фурункулеза, вибриоза и пастереллеза. Однако несколько видов вирусов были обнаружены у диких пинагор, включая вирусную геморрагическую септицемию (VHSV) (Guðmundsdóttir et al., J. Fish Dis., 42, 2019), вирусный нервный некроз (VNN) и новый ранавирус. Недавно был идентифицирован вирус, поражающий выращиваемого пинагора: флавивирус пинагора (LFV/CLuV) (Skoge et al., Arch. Virol., 163, 2018). LFV/CLuV демонстрирует низкое, но отчетливое сходство с неотнесенным вирусом летучих мышей Tamana (TABV). Было обнаружено, что LFV/CLuV присутствует во всех видах тканей пинагора у пораженных рыб, но патологию в основном наблюдали в печени и почках. Вирус ассоциируется с тяжелым заболеванием пинагора. После того, как LFV/CLuV был охарактеризован, результаты картирования распространения вируса и определения его связи с заболеванием показали, что он широко распространен с относительно высокой ассоциированной распространенностью.
В некоторых рыбоводческих хозяйствах в настоящее время наблюдается высокий уровень смертности - например, до 80% в некоторых популяциях пинагора, несмотря на то, что ОТ-ПЦР в режиме реального времени и гистологические исследования не позволяют обнаружить любые известные патогены в рыбе.
Таким образом, существует постоянная потребность в идентификации новых патогенов, которые инфицируют и приводят к гибели рыб, в частности, на фермах выращивания пинагора. Кроме того, существует постоянная потребность в способах мониторинга производства выращиваемой рыбы на предмет наличия инфекции патогенами, чтобы избежать вспышек инфекции и, возможно, лечить инфицированную рыбу.
Сущность изобретения
В соответствии с настоящим изобретением неожиданно был обнаружен новый вирус у рыбы пинагор, названный здесь Totivirus Cyclopterus lumpus (CLuTV). Длина и организация генома вместе с анализом последовательности показывают, что CLuTV является тотирусом, ближайшим представителем которого является вирус атлантического лосося PMCV.
Следовательно, один аспект изобретения относится к нуклеиновой кислоте, содержащей по меньшей мере последовательность одной открытой рамки считывания (ORF), выбранной из группы, состоящей из ORF-1, ORF-2, ORF-X, ORF-Y и ORF-Z; где:
ORF-1 по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 1,
ORF-2 по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 2,
ORF-X по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 3,
ORF-Y по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 4, и
ORF-Z по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 5.
Другой аспект изобретения относится к нуклеиновой кислоте, где (а) последовательность указанной нуклеиновой кислоты комплементарна SEQ ID NO: 1 и/или SEQ ID NO: 2; и/или (b) последовательность указанной нуклеиновой кислоты комплементарна SEQ ID NO: 6.
Еще один аспект изобретения относится к вирусному полипептиду, содержащему аминокислотную последовательность, которая по меньшей мере на 80%, по меньшей мере на 90% или по меньшей мере на 95% идентична любой из SEQ ID NO: 7-11, или которая представляет собой любую из SEQ ID NO: 7-11 или ее консервативно замещенный вариант.
Еще один аспект изобретения относится к вирусу, который инфицирует и способен приводить к гибели рыбы пинагор (Cyclopterus lumpus), где геном вируса содержит последовательность нуклеиновой кислоты, раскрытую здесь, где указанная последовательность нуклеиновой кислоты содержит основание урацил (U) вместо основания тимин (Т), и/или вирус содержит вирусный полипептид, содержащий аминокислотную последовательность, которая по меньшей мере на 80%, по меньшей мере на 90%, или по меньшей мере на 95% идентична любой из SEQ ID NO: 7-11, или которая представляет собой любую из SEQ ID NO: 7-11 или ее консервативно замещенный вариант.
Еще один аспект изобретения относится к олигонуклеотидному праймеру, который содержит последовательность по меньшей мере из 9 нуклеотидов, где указанная последовательность комплементарна последовательности нуклеиновой кислоты, которая содержится в геноме вируса, раскрытого здесь.
Еще один аспект изобретения относится к олигонуклеотидному праймеру, который (а) содержит последовательность по меньшей мере из 9 последовательных нуклеотидов, где указанная последовательность комплементарна последовательности нуклеиновой кислоты, которая содержится в геноме вируса, раскрытого здесь, (b) содержит по меньшей мере 9 последовательных нуклеотидов последовательности, которая представляет собой или комплементарна фрагменту референсной последовательности нуклеиновой кислоты, выбранной из группы, состоящей из SEQ ID NO: 1, SEQ ID NO: 2, SEQ ID NO: 3, SEQ ID NO: 4, SEQ ID NO: 5 или SEQ ID NO: 6, или (c) содержит по меньшей мере 9 последовательных нуклеотидов последовательности, которая по меньшей мере на 80% идентична последовательности, которая представляет собой последовательность или комплементарна последовательности, выбранной из группы, состоящей из SEQ ID NO: 12 - SEQ ID NO: 40; предпочтительно при условии, что указанный олигонуклеотидный праймер не содержит последовательность, выбранную из группы, состоящей из SEQ ID NO: 41 - SEQ ID NO: 49.
Еще один аспект изобретения относится к способу обнаружения вируса, который инфицирует и способен приводить к гибели рыбы, включающему стадии:
(а) контактирование нуклеиновой кислоты, экстрагированной из биологического образца рыбы по меньшей мере с одним олигонуклеотидным праймером, с образованием смеси, где по меньшей мере один олигонуклеотидный праймер комплементарен последовательности нуклеиновой кислоты, которая содержится в геноме вируса, раскрытого здесь, и
(b) определение того, присутствует ли продукт амплификации при подвергании смеси а) амплификации, где присутствие продукта амплификации указывает на присутствие РНК, ассоциированной с вирусом, и следовательно, на присутствие вируса в биологическом образце.
Еще один аспект изобретения относится к способу обнаружения вируса, который инфицирует и способен приводить к гибели рыбы, включающему стадии:
(а) секвенирование нуклеиновой кислоты, экстрагированной из биологического образца рыбы, и
(b) сравнение полученной последовательности нуклеиновой кислоты с последовательностью нуклеиновой кислоты, которая представляет собой или является комплементарной референсной последовательности, выбранной из группы, состоящей из SEQ ID NO: 1, SEQ ID NO: 2, SEQ ID NO: 3, SEQ ID NO: 4, SEQ ID NO: 5 и SEQ ID NO: 6, где по меньшей мере 80% идентичность последовательности между двумя последовательностями указывает на присутствие вируса в биологическом образце.
Еще один аспект изобретения относится к способу обнаружения вируса, который инфицирует и способен приводить к гибели рыбы, включающему стадии:
(а) секвенирование нуклеиновой кислоты, экстрагированной из биологического образца рыбы, и
(b) трансляцию полученной последовательности нуклеиновой кислоты в аминокислотную последовательность или трансляцию последовательности нуклеиновой кислоты, комплементарной указанной полученной последовательности нуклеиновой кислоты, в аминокислотную последовательность, и
(c) сравнение полученной аминокислотной последовательности с референсной последовательностью, выбранной из группы, состоящей из SEQ ID NO: 7-11, где по меньшей мере 80% идентичность последовательности между двумя последовательностями указывает на присутствие вируса в биологическом образце.
Еще один аспект изобретения относится к антителу, которое связывается с полипептидом, где полипептид кодируется последовательностью нуклеиновой кислоты, которая содержится в геноме вируса, раскрытого здесь, и/или где полипептид содержит аминокислотную последовательность, которая по меньшей мере на 80%, по меньшей мере на 90%, или по меньшей мере на 95% идентична любой из SEQ ID NO: 7-11, или которая представляет собой любую из SEQ ID NO: 7-11 или ее консервативно замещенный вариант.
Еще один аспект изобретения относится к набору для обнаружения вируса в биологическом образце рыбы, где набор включает олигонуклеотидный праймер, раскрытый здесь, и/или антитело, описанное здесь.
Еще один аспект изобретения относится к антителу для применения в лечении рыб, инфицированных вирусом, раскрытым здесь.
Еще один аспект изобретения относится к применению вируса, раскрытого здесь, для получения вакцины.
Еще один аспект изобретения относится к вакцине, содержащей:
(i) последовательность нуклеиновой кислоты, которая содержится в геноме вируса, раскрытого здесь;
(ii) последовательность нуклеиновой кислоты, раскрытую здесь;
(iii) вирусный полипептид, кодируемый последовательностью нуклеиновой кислоты, которая содержится в геноме вируса, раскрытого здесь;
(iv) вирусный полипептид, содержащий аминокислотную последовательность, которая по меньшей мере на 80%, по меньшей мере на 90% или по меньшей мере на 95% идентична любой из SEQ ID NO: 7-11, или которая представляет собой любую из SEQ ID NO: 7-11 или ее консервативно замещенный вариант; или
(v) вирус, раскрытый здесь.
Еще один аспект изобретения относится к молекуле интерферирующей РНК (iRNA) для применения в лечении рыбы, инфицированной вирусом, где молекула iРНК содержит по меньшей мере 12 последовательных нуклеотидов, или комплементарна последовательности нуклеиновой кислоты, содержащейся в геноме вируса, раскрытого здесь.
Краткое описание фигур
На фиг. 1: представлено схематическое изображение последовательности CLuTV, идентифицированной здесь, которая имеет длину 6353 нуклеотида и содержит пять возможных открытых рамок считывания (ORF).
На фиг. 2: представлена нуклеотидная последовательность генома CLuTV.
На фиг. 3: представлена нуклеотидная последовательность ORF-1 CLuTV.
На фиг. 4: представлена нуклеотидная последовательность ORF-2 CLuTV.
На фиг. 5: представлены нуклеотидные последовательности ORF-X, ORF-Y и ORF-Z CLuTV.
На фиг. 6: представлена аминокислотная последовательность ORF-1 CLuTV.
На фиг. 7: представлена аминокислотная последовательность ORF-2 CLuTV.
На фиг. 8: представлены аминокислотные последовательности ORF-X, ORF-Y и ORF-Z CLuTV.
На фиг. 9: показано окрашивание гематоксилином и эозином полного среза пораженного пинагора, показывающее скопление жидкости в желудке (стрелка).
На фиг. 10: показано окрашивание гематоксилином и эозином среза кишечника пинагора, показывающее скопление слизи и клеточные выделения (стрелки).
На фиг. 11: показано окрашивание гематоксилином и эозином среза кишечника пинагора, показывающее скопление слизи (стрелка) и клеточные выделения.
На фиг. 12: показано окрашивание гематоксилином и эозином среза кишечника пинагора, показывающее скопление слизи (стрелка).
Подробное описание изобретения
Определения
Для облегчения понимания настоящего изобретения ниже приведены некоторые определения терминов, используемых в описании изобретения.
В рамках настоящего изобретения, термин «пинагор» или «рыба-воробей» предназначен для обозначения любого вида, выбранного из полного семейства Cyclopteridae. Наиболее предпочтительным видом согласно изобретению является Cyclopterus lumpus.
Термин «нуклеиновая кислота» включает молекулы ДНК (например, кДНК или геномную ДНК), молекулы РНК (например, мРНК), аналоги ДНК или РНК, полученные с использованием аналогов нуклеотидов (например, пептидные нуклеиновые кислоты и не встречающиеся в природе аналоги нуклеотидов), и их гибриды. Таким образом, несмотря на то, что в последовательностях нуклеиновых кислот, представленных на фиг. 2-5 и SEQ ID NO: 1-6, используются основания гуанин, цитозин, аденин и тимин, варианты осуществления изобретения относятся к их соответствующим последовательностям РНК, в которых используются основания гуанин, цитозин, аденин и урацил (т.е. с урацилом вместо тимина), следовательно, эти последовательности РНК, также обеспечиваются здесь. Молекула нуклеиновой кислоты может представлять собой одноцепочечную или двухцепочечную. Если не указано иное, то левый конец любой одноцепочечной последовательности нуклеиновой кислоты, обсуждаемой здесь, представляет собой 5’-конец. Направление добавления от 5’ к 3’ растущих транскриптов РНК является направлением транскрипции.
Термин «олигонуклеотид» означает нуклеиновую кислоту, содержащую 200 или меньше нуклеотидов. Олигонуклеотиды могут быть одноцепочечными, например, для использования в качестве праймеров, праймеров для клонирования или гибридизационных зондов, или они могут быть двухцепочечными, например, для использования в конструировании мутантного гена. Олигонуклеотиды могут быть смысловыми или антисмысловыми олигонуклеотидами. Олигонуклеотид может включать метку, включая радиоактивную метку, флуоресцентную метку, гаптен или антигенную метку, для анализов детектирования.
В рамках настоящего изобретения, термин «олигонуклеотидный праймер» или «праймер» следует понимать как относящийся к последовательности нуклеиновой кислоты (например по меньшей мере длиной из 9 нуклеотидов, и длиной меньше чем 60 нуклеотидов), подходящей для направления активности на область нуклеиновой кислоты, например, для амплификации целевой последовательности нуклеиновой кислоты с помощью полимеразной цепной реакции (ПЦР) или для гибридизации in situ.
В рамках настоящего изобретения, термин «комплементарные» в контексте последовательностей нуклеиновых кислот означает последовательности нуклеиновых кислот, которые образуют двухцепочечную структуру посредством совпадения пар оснований (от A до T (или U) и от G до C). Например, последовательность нуклеиновой кислоты, комплементарная G-T-A-C, представляет собой C-A-T-G. Другими примерами комплементарных последовательностей нуклеиновых кислот являются следующими:
Комплементарная последовательность нуклеиновой кислоты (например, если нуклеиновая кислота представляет собой ДНК):
5’-ATTCGCTTAACGCAA-3’
3’-TAAGCGAATTGCGTT-5’
Соответствующие комплементарные последовательности, в которых урацил заменен на тимин (например, в случае, если нуклеиновая кислота представляет собой РНК):
5’-AUUCGCUUAACGCAA-3’
3’-UAAGCGAAUUGCGUU-5’
В рамках настоящего изобретения, термин «аминокислота» относится к одной из 20 встречающихся в природе аминокислот или любых неприродных аналогов. Предпочтительно термин «аминокислота» относится к одной из 20 встречающихся в природе аминокислот.
Термины «полипептид» или «белок» означают макромолекулу, состоящую из последовательности аминокислот. Белок может быть нативным белком, т.е. белком, продуцированным природной и нерекомбинантной клеткой; или он может продуцироваться сконструированной или рекомбинантной клеткой и содержать молекулы, имеющие аминокислотную последовательность нативного белка, или молекулы, содержащие делеции, добавления и/или замены одной или более аминокислот нативной последовательности. Термины также включают аминокислотные полимеры, в которых одна или более аминокислот являются химическими аналогами соответствующего встречающегося в природе аминокислотного полимера.
Термин «идентичность последовательностей» указывает количественное измерение степени гомологии между двумя последовательностями, которые могут представлять собой последовательности нуклеиновых кислот (также называемыми нуклеотидами) или аминокислотными последовательностями. Если две сравниваемые последовательности не имеют равной длины, то они должны выравниваться для обеспечения наилучшего соответствия, позволяя вставку гэпов или, альтернативно, усечение на концах последовательностей нуклеиновых кислот или аминокислотных последовательностей.
В случае нуклеотидной последовательности, например, термин «по меньшей мере на 80% идентична» означает, таким образом, что по меньшей мере 80% нуклеотидов по всей последовательности можно выравнить с идентичными нуклеотидами из другой последовательности. Определенный процент нуклеотидов можно обозначить, например, как 80% идентичных, 85% идентичных, 90% идентичных, 95% идентичных, 99% идентичных или более в указанной области при сравнении и выравнивании для максимального соответствия. Например, последовательность длиной 10 нуклеотидов, например GGGAAACCTT, может быть на 80% идентична непрерывной последовательности (например, GGGAAACCGG) или прерывистой последовательности (например, GGGACCCCTT):
Пример 100% идентичности:
GGGAAACCTT
││││││││││
GGGAAACCTT
Пример 80% идентичности:
GGGAAACCTT
││││││││
GGGAAACCGG
Пример 80% идентичности:
GGGAAACCTT
││││ ││││
GGGACCCCTT
Специалисту в данной области понятно, что доступны различные методы для сравнения последовательностей (см. ниже).
В рамках настоящего изобретения, термин «консервативно замещенная» по отношению к аминокислоте означает, что аминокислота может быть замещена другой аминокислотой из своей соответствующей группы в соответствии со следующими шестью группами: [1] аланин (A), серин (S), треонин (T); [2] аспарагиновая кислота (D), глутаминовая кислота (E); [3] аспарагин (N), глутамин (Q); [4] аргинин (R), лизин (K); [5] изолейцин (I), лейцин (L), метионин (M), валин (V); и [6] фенилаланин (F), тирозин (Y), триптофан (W). «Консервативно замещенный вариант» применительно к полипептиду или белку означает, что любая из аминокислот в указанном полипептиде или белке может подвергнуться консервативной замене, как здесь определено выше.
В рамках настоящего изобретения, термин «антитело» относится к гликопротеину, содержащему по меньшей мере две тяжелые (H) цепи и две легкие (L) цепи, соединенные дисульфидными связями, или его фрагменту (антигенсвязывающий участок) антитела. Каждая тяжелая цепь состоит из вариабельной области тяжелой цепи (VH) и константной области тяжелой цепи (CH). Константная область тяжелой цепи состоит из трех доменов: СН1, СН2 и СН3. Каждая легкая цепь состоит из вариабельной области легкой цепи (VL) и константной области легкой цепи (CL). Константная область легкой цепи состоит из одного домена CL. Области VH и VL могут быть дополнительно подразделены на области гипервариабельности, называемые участками, определяющими комплементарность (CDR), между которыми находятся более консервативные области, называемые каркасными областями (FR). Каждая VH и VL состоит из трех CDR и четырех FR, расположенных от аминоконца к карбоксиконцу в следующем порядке: FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4. Вариабельные области тяжелой и легкой цепей содержат связывающий домен, который взаимодействует с антигеном. Константные области антител могут опосредовать связывание иммуноглобулина с клетками-хозяевами или факторами, включая различные клетки иммунной системы (например, эффекторные клетки) и первый компонент (C1q) классической системы комплемента. Антитела по изобретению включают моноклональные антитела (включая полноразмерные моноклональные антитела) и поликлональные антитела, полные антитела, химерные антитела, гуманизированные антитела, человеческие антитела или гибридные антитела с двойной или множественной антигенной или эпитопной специфичностью, фрагменты антител и субфрагменты антител, например, фрагменты Fab, Fab', F(ab')2 и т.п., включая гибридные фрагменты любого иммуноглобулина или любого природного, синтетического или сокнструированного белка, который функционирует в качестве антитела, связываясь со специфическим антигеном с образованием комплекса. Антитела по изобретению также могут представлять собой Fc-слитые белки.
«Вектор» представляет собой нуклеиновую кислоту, которую можно использовать для введения другой нуклеиновой кислоты (или «конструкции»), связанной с ней, в клетку. Одним из типов вектора является «плазмида», которая относится к линейной или кольцевой двухцепочечной молекуле ДНК, в которую могут быть лигированы дополнительные сегменты нуклеиновой кислоты. Другим типом вектора является вирусный вектор (например, дефектные по репликации ретровирусы, аденовирусы и аденоассоциированные вирусы), где дополнительные сегменты ДНК могут быть вставлены в вирусный геном. Некоторые векторы способны к автономной репликации в клетке-хозяине, в которую они введены (например, бактериальные векторы, содержащие бактериальный ориджин репликации и эписомальные векторы млекопитающих). Другие векторы (например, неэписомальные векторы млекопитающих) интегрируются в геном клетки-хозяина после введения в клетку-хозяин и культивирования под селективным давлением и, таким образом, реплицируются вместе с геномом хозяина. Вектор можно использовать для направления экспрессии выбранной нуклеиновой кислоты в клетке.
«Клетка-хозяин» представляет собой клетку, которую можно использовать для экспрессии нуклеиновой кислоты, например, нуклеиновой кислоты, описанной здесь. Клеткой-хозяином может быть прокариотическая клетка, например, E. coli, или эукариотическая клетка, например, одноклеточный эукариот (например, дрожжи или другой гриб), растительная клетка (например, клетка растения табака или помидора), клетка животного (например, клетка человека, клетка обезьяны, клетка хомяка, клетка крысы, клетка мыши или клетка насекомого) или гибридома. Примеры клеток-хозяев включают клеточные линии яичника китайского хомячка (СНО) или их производные. Обычно клетка-хозяин представляет собой культивируемую клетку, которую можно трансформировать или трансфицировать нуклеиновой кислотой, кодирующей полипептид, которая затем может быть экспрессирована в клетке-хозяине. Понятно, что термин «клетка-хозяин» относится не только к конкретной рассматриваемой клетке, но и к потомству или потенциальному потомству такой клетки. Поскольку определенные модификации могут происходить в последующих поколениях в результате, например, мутации или влияния окружающей среды, то такое потомство может фактически не быть идентичным родительской клетке, но все же оно включается в объем термина, используемого здесь.
Термины «лечить» и «лечение» включают терапевтическое лечение, профилактическое лечение и применения, которые ослабляют симптомы расстройства или снижают риск того, что у субъекта (например, рыбы) разовьется расстройство (например, симптомы вирусной инфекции).
В рамках настоящего изобретения, термин «вакцина» относится к материалу, который может индуцировать иммунный ответ, который блокирует инфекционность, частично или полностью, инфекционного агента, которым по отношению к настоящему изобретению является вирус, поражающий рыбу, например, пинагор. Таким образом, при введении рыбам вакцина по изобретению иммунизирует рыбу против заболевания, вызываемого вирусом. Иммунизирующий компонент вакцины может представлять собой, ДНК, как, например, в ДНК-вакцине, РНК, как, например, в РНК-вакцине, рекомбинантный белок или его фрагмент по настоящему изобретению, или живой или аттенуированный рекомбинантный вирус.
В рамках настоящего изобретения, «iРНК-средство» (аббревиатура «средства на основе интерферирующей РНК») представляет собой РНК-средство, которое может подавлять (снижать) экспрессию гена-мишени, например белка, кодированного ORF-1, ORF-2, ORF-X, ORF-Y или ORF-Z. iРНК-средство может функционировать посредством одного или нескольких механизмов, включая посттранскрипционное расщепление мРНК-мишени, иногда называемое в данной области как «РНКi», или претранскрипционные или претрансляционные механизмы. iРНК-средство может быть двухцепочечным (ds) iРНК-средством. iРНК-средство также может быть «малой интерферирующей РНК» (siРНК).
В рамках настоящего изобретения, термины «по изобретению» или «согласно изобретению» предназначены для обозначения всех аспектов и вариантов осуществления изобретения, раскрытых и/или заявленных здесь. И наоборот, любые аспекты, элементы или варианты осуществления, упомянутые в данном документе как «раскрытые в данном документе» или «описанные в данном документе», следует понимать как аспекты, элементы или варианты осуществления «по изобретению» или «согласно изобретению».
В рамках настоящего изобретения, термин «содержащий» следует толковывать как охватывающий термины как «включающий», так и «состоящий из», где оба значения специально предназначены и, следовательно, индивидуально раскрывают варианты осуществления согласно настоящему изобретению.
В данном контексте форма единственного числа элемента или компонента также включает множественное число, если только число явно не подразумевается как единственное число.
В рамках настоящего изобретения, термин «приблизительно», модифицирующий количество используемого вещества, ингредиента, компонента или параметра, относится к изменению числового количества, которое может происходить, например, посредством типичных процедур измерения и обработки, например, используемых процедур обращения с жидкостью для приготовления концентратов или растворов. Кроме того, изменение может происходить из-за непреднамеренной ошибки в процедурах измерения, различий в производстве, источнике или чистоте ингредиентов, используемых для выполнения методов, и т.п. В одном варианте осуществления термин «приблизительно» означает в пределах 10% от указанного числового значения. В более конкретном варианте осуществления термин «приблизительно» означает в пределах 5% от указанного числового значения.
Последовательности вирусных нуклеиновых кислот и вирусные полипептиды
Один аспект изобретения относится к нуклеиновой кислоте, содержащей по меньшей мере последовательность одной открытой рамки считывания (ORF), выбранной из группы, состоящей из ORF-1, ORF-2, ORF-X, ORF-Y и ORF-Z; где:
ORF-1 по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 1,
ORF-2 по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 2,
ORF-X по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 3,
ORF-Y по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 4, и
ORF-Z по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 5.
В некоторых вариантах осуществления:
ORF-1 по меньшей мере на 85% идентична последовательности нуклеиновой кислоты SEQ ID NO: 1,
ORF-2 по меньшей мере на 85% идентична последовательности нуклеиновой кислоты SEQ ID NO: 2,
ORF-X по меньшей мере на 85% идентична последовательности нуклеиновой кислоты SEQ ID NO: 3,
ORF-Y по меньшей мере на 85% идентична последовательности нуклеиновой кислоты SEQ ID NO: 4, и
ORF-Z по меньшей мере на 85% идентична последовательности нуклеиновой кислоты SEQ ID NO: 5.
В предпочтительных вариантах осуществления:
ORF-1 по меньшей мере на 90% идентична последовательности нуклеиновой кислоты SEQ ID NO: 1,
ORF-2 по меньшей мере на 90% идентична последовательности нуклеиновой кислоты SEQ ID NO: 2,
ORF-X по меньшей мере на 90% идентична последовательности нуклеиновой кислоты SEQ ID NO: 3,
ORF-Y по меньшей мере на 90% идентична последовательности нуклеиновой кислоты SEQ ID NO: 4, и
ORF-Z по меньшей мере на 90% идентична последовательности нуклеиновой кислоты SEQ ID NO: 5.
В более предпочтительных вариантах осуществления:
ORF-1 по меньшей мере на 95% идентична последовательности нуклеиновой кислоты SEQ ID NO: 1,
ORF-2 по меньшей мере на 95% идентична последовательности нуклеиновой кислоты SEQ ID NO: 2,
ORF-X по меньшей мере на 95% идентична последовательности нуклеиновой кислоты SEQ ID NO: 3,
ORF-Y по меньшей мере на 95% идентична последовательности нуклеиновой кислоты SEQ ID NO: 4, и
ORF-Z по меньшей мере на 95% идентична последовательности нуклеиновой кислоты SEQ ID NO: 5.
В еще более предпочтительных вариантах осуществления:
ORF-1 по меньшей мере на 98% идентична последовательности нуклеиновой кислоты SEQ ID NO: 1,
ORF-2 по меньшей мере на 98% идентична последовательности нуклеиновой кислоты SEQ ID NO: 2,
ORF-X по меньшей мере на 98% идентична последовательности нуклеиновой кислоты SEQ ID NO: 3,
ORF-Y по меньшей мере на 98% идентична последовательности нуклеиновой кислоты SEQ ID NO: 4, и
ORF-Z по меньшей мере на 98% идентична последовательности нуклеиновой кислоты SEQ ID NO: 5.
В еще более предпочтительных вариантах осуществления:
ORF-1 по меньшей мере на 99% идентична последовательности нуклеиновой кислоты SEQ ID NO: 1,
ORF-2 по меньшей мере на 99% идентична последовательности нуклеиновой кислоты SEQ ID NO: 2,
ORF-X по меньшей мере на 99% идентична последовательности нуклеиновой кислоты SEQ ID NO: 3,
ORF-Y по меньшей мере на 99% идентична последовательности нуклеиновой кислоты SEQ ID NO: 4, и
ORF-Z по меньшей мере на 99% идентична последовательности нуклеиновой кислоты SEQ ID NO: 5.
В особенно предпочтительных вариантах осуществления:
ORF-1 представляет собой последовательность нуклеиновой кислоты SEQ ID NO: 1,
ORF-2 представляет собой последовательность нуклеиновой кислоты SEQ ID NO: 2,
ORF-X представляет собой последовательность нуклеиновой кислоты SEQ ID NO: 3,
ORF-Y представляет собой последовательность нуклеиновой кислоты SEQ ID NO: 4, и
ORF-Z представляет собой последовательность нуклеиновой кислоты SEQ ID NO: 5.
В конкретных вариантах осуществления нуклеиновая кислота, раскрытая здесь, содержит по меньшей мере ORF-1 и/или ORF-2 согласно любому из их вариантов осуществления, раскрытых здесь.
Последовательность нуклеиновой кислот, раскрытая здесь, может быть по меньшей мере на 80% идентична вирусному геному согласно SEQ ID NO: 6. В некоторых вариантах осуществления последовательность нуклеиновой кислоты, раскрытая здесь, по меньшей мере на 85% идентична вирусному геному согласно SEQ ID NO: 6. В предпочтительных вариантах осуществления последовательность нуклеиновой кислоты, раскрытая здесь, по меньшей мере на 90% идентична вирусному геному согласно SEQ ID NO: 6. В более предпочтительных вариантах осуществления последовательность нуклеиновой кислоты, раскрытая здесь, по меньшей мере на 95% идентична вирусному геному согласно SEQ ID NO: 6. В еще более предпочтительных вариантах осуществления последовательность нуклеиновой кислоты, раскрытая здесь, по меньшей мере на 98% идентична вирусному геному согласно SEQ ID NO: 6. В еще более предпочтительных вариантах осуществления последовательность нуклеиновой кислоты, раскрытая здесь, по меньшей мере на 99% идентична вирусному геному согласно SEQ ID NO: 6. В особенно предпочтительных вариантах осуществления последовательность нуклеиновой кислоты, раскрытая здесь, имеет 100% идентичность с последовательностью вирусного генома согласно SEQ ID NO: 6 (CLuTV).
Настоящее изобретение также относится к нуклеиновой кислоте, последовательность которой комплементарна последовательности любой из нуклеиновых кислот, раскрытых здесь.
Последовательность указанной нуклеиновой кислоты может быть комплементарной ORF-1, ORF-2, ORF-X, ORF-Y или ORF-Z согласно любому из их вариантов осуществления, раскрытых здесь. Последовательность нуклеиновой кислоты также может быть комплементарной последовательности нуклеиновой кислоты, которая по меньшей мере на 80% идентична, в некоторых вариантах осуществления по меньшей мере на 85% идентична, в предпочтительных вариантах осуществления по меньшей мере на 90% идентична, в более предпочтительных вариантах осуществления по меньшей мере на 95% идентична, в еще более предпочтительных вариантах осуществления, на 98% идентична, в еще более предпочтительных вариантах осуществления по меньшей мере на 99% идентична, и в особенно предпочтительных вариантах осуществления на 100% идентична последовательности вирусного генома согласно SEQ ID NO: 6 (CLuTV).
Следовательно, изобретение также относится к нуклеиновой кислоте, где (а) последовательность указанной нуклеиновой кислоты комплементарна любой из SEQ ID NO: 1 - SEQ ID NO: 5; и/или (b) последовательность указанной нуклеиновой кислоты комплементарна SEQ ID NO: 6.
Следовательно, изобретение также относится к нуклеиновой кислоте, где (а) последовательность указанной нуклеиновой кислоты комплементарна SEQ ID NO: 1 и/или SEQ ID NO: 2; и/или (b) последовательность указанной нуклеиновой кислоты комплементарна SEQ ID NO: 6.
В предпочтительных вариантах осуществления последовательности нуклеиновой кислоты, раскрытые здесь, представляют собой последовательности нуклеиновой кислоты РНК, т.е. они содержат основание урацил (U) вместо основания тимин (T). Соответственно, вирусы, раскрытые здесь, содержат их генетическую информацию в форме таких нуклеиновокислотных последовательностей РНК.
Специалист в данной области также понимает, что изменения последовательности нуклеиновой кислоты, приводящие к модификациям аминокислотной последовательности белка, который она кодирует, могут иметь незначительное влияние, если оно вообще имеет место, на результирующую трехмерную структуру белка. Например, кодон аминокислоты аланин, гидрофобной аминокислоты, может быть заменен кодоном, кодирующим другой менее гидрофобный остаток, такой как глицин, или более гидрофобный остаток, такой как валин, лейцин или изолейцин. Аналогично можно ожидать, что изменения, которые приводят к замене одного отрицательно заряженного остатка на другой, такого как аспарагиновая кислота на глутаминовую кислоту, или одного положительно заряженного остатка на другой, например лизин на аргинин, также могут привести к образованию белка с практически такой же функциональной активностью.
Каждая из следующих шести групп содержит аминокислоты, которые являются типичными консервативными заменами друг друга: [1] аланин (A), серин (S), треонин (T); [2] аспарагиновая кислота (D), глутаминовая кислота (E); [3] аспарагин (N), глутамин (Q); [4] аргинин (R), лизин (K); [5] изолейцин (I), лейцин (L), метионин (M), валин (V); и [6] фенилаланин (F), тирозин (Y), триптофан (W) (см., например, публикацию заявки на патент США 20100291549).
Предпочтительно ORF-1, ORF-2, ORF-X, ORF-Y и ORF-Z кодируют вирусные полипептиды, содержащие аминокислотные последовательности SEQ ID NO: 7-11 соответственно, или аминокислотные последовательности, которые по меньшей мере на 80% идентичны (например по меньшей мере на 85% идентичны или по меньшей мере на 90% идентичны, или по меньшей мере на 91% идентичны по меньшей мере на 92% идентичны по меньшей мере на 93% идентичны по меньшей мере на 94% идентичны по меньшей мере на 95% идентичны по меньшей мере на 96% идентичны по меньшей мере на 97% идентичны по меньшей мере на 98% идентичны или по меньшей мере на 99% идентичны) аминокислотным последовательностям SEQ ID NO: 7-11 соответственно. В некоторых вариантах осуществления ORF-1, ORF-2, ORF-X, ORF-Y и ORF-Z кодируют вирусные полипептиды, которые являются консервативно замещенными вариантами SEQ ID NO: 7-11 соответственно, как описано выше.
Следовательно, в еще одном аспекте настоящее изобретение относится к вирусным полипептидам, содержащим аминокислотные последовательности SEQ ID NO: 7-11 соответственно, или аминокислотные последовательности, которые по меньшей мере на 80% идентичны (например по меньшей мере на 85% идентичны или по меньшей мере на 90% идентичны или по меньшей мере на 91% идентичны по меньшей мере на 92% идентичны по меньшей мере на 93% идентичны по меньшей мере на 94% идентичны по меньшей мере на 95% идентичны по меньшей мере на 96% идентичны по меньшей мере на 97% идентичны по меньшей мере на 98% идентичны или по меньшей мере на 99% идентичны) аминокислотным последовательностям SEQ ID NO: 7-11 соответственно. В некоторых вариантах осуществления вирусные полипептиды представляют собой консервативно замещенные варианты SEQ ID NO: 7-11 соответственно, как описано выше. Также настоящее изобретение относится к векторам, например, плазмидным векторам или вирусным векторам, содержащим последовательности нуклеиновых кислот, кодирующие вирусные полипептиды по изобретению, описанные выше.
Идентичность (гомологию) последовательностей белков и/или нуклеиновых кислот можно оценить с использованием любого из множества алгоритмов и программ сравнения последовательностей, известных в данной области. Для сравнения последовательностей обычно одна последовательность функционирует в качестве референсной последовательности (например, последовательности, описанной здесь), с которой сравнивают тестовые последовательности. Затем с помощью алгоритма сравнения последовательностей рассчитывают процент идентичности последовательностей для тестовых последовательностей относительно референсной последовательности на основе параметров программы.
Процент идентичности двух аминокислотных последовательностей можно определить, например, сравнением информации о последовательности с использованием компьютерной программы «GAP», т.е. Висконсинский пакет программ Генетической Компьютерной Группы (GCG, Madison, Wisconsin) (Devereux, et al., (1984), Nucl. Acids Res., 12: 387-395). При расчете процентной идентичности сравниваемые последовательности выравнивают таким образом, чтобы обеспечить наибольшее сопоставление между последовательностями. Предпочтительные значения параметров по умолчанию для программы «GAP» включают: (1) использование GCG унарной матрицы сравнения (содержащей значение «1» для идентичностей и значение «0» для отсутствия идентичности) для нуклеотидов, и взвешенную матрицу сравнения аминокислот Gribskov and Burgess, ((1986) Nucl. Acids Res., 14: 6745), как описано в «Atlas of Polypeptide Sequence and Structure», Schwartz и Dayhoff, eds., National Biomedical Research Foundation, pp. 353-358 (1979) или другие аналогичные матрицы сравнения; (2) штраф за наличие любого гэпа - 8 и дополнительный штраф за каждый символ в гэпе - 2 для аминокислтных последовательностей, или штраф за наличие любого гэпа - 50, и дополнительный штраф за каждый символ в гэпе - 3 для нуклеотидных последовательностей; (3) отсутствие штрафа за концевые гэпы; и (4) отсутствие максимального штрафа за длинные гэпы.
Идентичность и/или сходство последовательностей также можно определить с использованием алгоритма локальной идентичности последовательностей Смита-Уотермана, 1981, Adv. Appl. Math. 2:482, алгоритм идентичности последовательности Нидлмана-Вунша, 1970, J. Mol. Biol. 48:443, поиск сходства последовательностей методом Пирсона-Липмана, 1988, Proc. Nat. Acad. Sci. U.S.A. 85:2444, компьютеризованные варианты данных алгоритмов (BESTFIT, FASTA, and TFASTA in the Wisconsin Genetics Software Package, Genetics Computer Group, 575 Science Drive, Madison, Wis.).
Еще одним примером подходящего алгоритма является PILEUP. Алгоритм PILEUP позволяет осуществлять выравнивание множества последовательностей из группы родственных последовательностей путем последовательного попарного выравнивания. Для осуществления выравнивания может быть также построена древовидная схема, иллюстрирующая кластерные взаимосвязи. В программе PILEUP используется упрощенный метод последовательного выравнивания, описанный Feng и Doolittle, 1987, J. Mol. Evol. 35:351-360; метод аналогичен описанному Higgins and Sharp, 1989, CABIOS 5: 151-153. Подходящими параметрами PILEUP являются: «цена» гэпа 3,00 по умолчанию, «цена» длины гэпа 0,10 по умолчанию и взвешенные значения концевых гэпов.
Еще одним примером подходящего алгоритма является алгоритм BLAST, описанный в публикациях: Altschul et al., 1990, J. Mol. Biol. 215:403-410; Altschul et al., 1997, Nucleic Acids Res. 25:3389-3402; and Karin et al., 1993, Proc. Natl. Acad. Sci. U.S.A. 90:5873-5787. Особенно пригодной программой BLAST является программа WU-BLAST-2, полученная от Altschul et al., 1996, Methods in Enzymology 266: 460-480. В программе WU-BLAST-2 используется несколько параметров поиска, большинство из которых имеют значения по умолчанию. В программе WU-BLAST-2 используется несколько параметров поиска, большинство из которых принимаются как величины по умолчанию. Корректируемые параметры установлены со следующими величинами по умолчанию: охват с перекрыванием=1, перекрывающаяся фракция=0,125, предельная длина слова (T) = 11. Параметрами HSP S и HSP S2 являются динамические величины, и эти параметры устанавливаются самой программой в зависимости от состава конкретной последовательности и состава конкретной базы данных, в которой осуществляется поиск представляющей интерес последовательности; однако для повышения чувствительности эти величины могут быть скорректированы.
Дополнительным применяемым алгоритмом является gapped BLAST, описанный в публикации Altschul et al., 1993 год, Nucl. Acids Res. 25:3389-3402. В программе gapped BLAST используется матрица весовых оценок замен BLOSUM-62; пороговый параметр Т установлен на 9; метод двух совпадений для запуска продлений без гэпов, затраты на длину гэпа к стоимостью 10+k; Xu установлен на 16, и Xg установлен на 40 на стадии поиска в базе данных и на 67 на выходной стадии алгоритмов. Выравнивание с гэпами запускается при оценке, соответствующей приблизительно 22 битам.
Способы получения вирусных полипептидов, описанных здесь, хорошо известны специалистам в данной области. Например, и без ограничений, последовательности нуклеиновых кислот, кодирующие вирусные полипептиды, содержащие SEQ ID NO: 7-11, или последовательности по меньшей мере на 80% идентичные им, включая консервативно замещенные варианты SEQ ID NO: 7-11, можно клонировать в вектор, например, такой как плазмидный или вирусный вектор, и экспрессировать в подходящем хозяине, таком как клетки рыб, клетки млекопитающих, бактериальные клетки, клетки растений и клетки насекомых, и выделить экспрессированные вирусные полипептиды из них.
Вирусы
Еще один аспект изобретения относится к вирусу, который инфицирует и способен приводить к гибели рыбы пинагор (Cyclopterus lumpus), где геном вируса содержит последовательность нуклеиновой кислоты, раскрытую здесь, где указанная последовательность нуклеиновой кислоты содержит основание урацил (U) вместо основания тимин (Т).
Еще один аспект изобретения относится к вирусу, который инфицирует и способен вызывать гибель рыбы пинагор (Cyclopterus lumpus), где вирус содержит вирусный полипептид, содержащий аминокислотную последовательность, которая по меньшей мере на 80%, по меньшей мере на 90% или по меньшей мере на 95% идентична любой из SEQ ID NO: 7-11, или которая представляет собой любую из SEQ ID NO: 7-11 или ее консервативно замещенный вариант.
Еще один аспект изобретения относится к вирусу, который инфицирует и способен вызывать гибель рыбы пинагор (Cyclopterus lumpus), где геном вируса содержит последовательность нуклеиновой кислоты, раскрытую здесь, где указанная последовательность нуклеиновой кислоты содержит основание урацил (U) вместо основания тимин (T), и вирус содержит вирусный полипептид, содержащий аминокислотную последовательность, которая по меньшей мере на 80%, по меньшей мере на 90% или по меньшей мере на 95% идентична любой из SEQ ID NO: 7-11, или которая представляет собой любую из SEQ ID NO: 7-11 или ее консервативно замещенный вариант.
В предпочтительных вариантах осуществления нуклеиновая кислота, содержащаяся в вирусе, находится в форме двухцепочечной РНК (дцРНК).
В некоторых вариантах осуществления геном вируса содержит последовательность нуклеиновой кислоты, содержащую по меньшей мере одну из ORF-1, ORF-2, ORF-X, ORF-Y или ORF-Z согласно любому из их вариантов осуществления, раскрытых здесь. В предпочтительных вариантах осуществления последовательность вирусного генома включает по меньшей мере ORF-1 и ORF-2 согласно любому из их вариантов осуществления, раскрытых здесь. В некоторых вариантах осуществления геном вируса содержит последовательность нуклеиновой кислоты, которая представляет собой или комплементарна последовательности нуклеиновой кислоты, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, даже более предпочтительно по меньшей мере на 95%, еще более предпочтительно на 98%, особенно предпочтительно на 99% или даже на 100% идентична последовательности вирусного генома согласно SEQ ID NO: 6 (CLuTV).
В некоторых вариантах осуществления вирус включает ORF-1, ORF-2, ORF-X, ORF-Y и ORF-Z; где:
ORF-1 по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 1,
ORF-2 по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 2,
ORF-X по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 3,
ORF-Y по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 4, и
ORF-Z по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 5;
и где ORF-1, ORF-2, ORF-X, ORF-Y и ORF-Z кодируют вирусные полипептиды, содержащие SEQ ID NO: 7-11 соответственно, или последовательности, которые по меньшей мере на 80% идентичны SEQ ID NO: 7-11 соответственно.
В некоторых вариантах осуществления геном вируса кодирует вирусные полипептиды, содержащие соответствующие аминокислотные последовательности, содержащие SEQ ID NO: 7-11, или последовательности, которые по меньшей мере на 80% (например по меньшей мере на 85%, по меньшей мере на 90%, по меньшей мере на 91%, по меньшей мере на 92%, по меньшей мере на 93%, по меньшей мере на 94%, по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98% или по меньшей мере на 99% идентичны SEQ ID NO: 7-11). Предпочтительно вирус содержит ORF-1, ORF-2, ORF-X, ORF-Y и ORF-Z, как здесь определено, где указанные ORF-1, ORF-2, ORF-X, ORF-Y и ORF-Z кодируют вирусные полипептиды, которые по меньшей мере на 95% идентичны SEQ ID NO 7-11 соответственно. Более предпочтительно, вирус содержит ORF-1, ORF-2, ORF-X, ORF-Y и ORF-Z, как здесь определено, где указанные ORF-1, ORF-2, ORF-X, ORF-Y и ORF-Z кодируют вирусные полипептиды, которые представляют собой консервативно замещенные варианты SEQ ID NO: 7-11 соответственно, или вирусные полипептиды, содержащие аминокислотные последовательности SEQ ID NO: 7-11 соответственно.
В некоторых вариантах осуществления геном вируса кодирует по меньшей мере SEQ ID NO: 7 и 8 или последовательности, которые идентичны им по меньшей мере на 80% (например по меньшей мере на 85%, по меньшей мере на 90%, по меньшей мере на 91%, по меньшей мере на 92%, по меньшей мере на 93%, по меньшей мере на 94%, по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98% или по меньшей мере на 99%), включая консервативно замещенные варианты SEQ ID NO: 7 и 8.
В некоторых вариантах осуществления инфицирование рыбы пинагор вирусом, раскрытым здесь, вызывает у рыб следующие симптомы:
(i) повреждение тканей в кишечнике и/или
(ii) диарею; или
(iii) кардиомиопатию.
В предпочтительных вариантах осуществления инфицирование рыбы пинагор вирусом, раскрытым здесь, вызывает кардиомиопатию.
Повреждение тканей в кишечнике можно диагностировать с помощью гистологии или электронной микроскопии, чтобы видеть разрушение ткани кишечника, например, разрушение структуры ворсинок, увеличение толщины других слоев. Предпочтительно, тканевые срезы окрашивают с использованием гистологического красителя гематоксилин и эозин (H&E). При использовании такого красителя у инфицированных особей можно наблюдать скопление жидкости и непереваренных частиц корма в желудке и в кишечнике (см., например, фиг. 9-12), что приводит к диарее у этих рыб. Кроме того, может наблюдаться повреждение стенки кишечника с клеточными выделениями и повышенным образованием слизи (см., например, фиг. 10-12). Диарею у рыб можно наблюдать в водных резервуарах с выращиваемой рыбой.
Изменения компонентов биомакромолекул (белков в общем, сидерофильных белков, нейтральных мукополисахаридов, гликогена и кислых мукополисахаридов) также можно увидеть в образцах ткани кишечника с помощью обычных методов, например, вестерн-блоттинга, ELISA, окрашивания тканевых срезов и т. д.
Кардиомиопатию можно диагностировать с помощью гистопатологии, с наличием тяжелого воспаления и дегенерацией губчатого слоя миокарда (желудочка) и с аналогичными изменениями в предсердии, также предпочтительно с использованием гистологического окрашивания гематоксилином и эозином (H&E). Дегенерация миоцитов и воспалительные изменения не часто наблюдаются в компактном слое сердца и всегда возникают позднее, чем изменения губчатых слоев. Также возможно нарушение кровообращения с мультифокальным некрозом печени. У рыб, страдающих CMS, могут проявляться такие симптомы, как аномальное плавание. При вскрытии обнаруживается тампонада сердца с кровью в перикардиальном мешке и умеренный или выраженный асцит (Haugland et al., J. Virol., 85, 2011).
В некоторых вариантах осуществления вирус представляет собой вирус без оболочки. В отличие от вирусов с оболочкой, вирусы без оболочки характеризуются более высокой устойчивостью к химическим и физическим воздействиям, например, они являются термостойкими.
В предпочтительных вариантах осуществления вирус представляет собой Totivirus. Такие вирусы не имеют оболочки, имеют икосаэдрическую симметрию и архитектуру T=2. Диаметр обычно составляет приблизительно 40 нм.
В некоторых вариантах осуществления вирус, описанный здесь, содержит 5'-нетранслируемую область (5'-UTR), которая функционирует в качестве внутреннего сайта входа в рибосому (IRES).
В предпочтительных вариантах осуществления ORF-1 и ORF-2 кодируют капсидный белок (CP) и РНК-зависимую РНК-полимеразу (RDRP).
Настоящее изобретение также относится к вектору, содержащему нуклеиновую кислоту, кодирующую по меньшей мере одну открытую рамку считывания, как здесь раскрыто во всех их вариантах осуществления. В некоторых вариантах осуществления вектор содержит нуклеиновую кислоту, которая кодирует полный вирус, раскрытый здесь. Вектор можно использовать для введения указанной нуклеиновой кислоты(т) в клетку, такую как клетка-хозяин.
Настоящее изобретение также относится к клетке-хозяину, содержащей вирус, описанный здесь. Клетка-хозяин может быть бактериальной клеткой, клеткой рыбы или клеткой млекопитающего.
Олигонуклеотидные праймеры
Еще один аспект изобретения относится к олигонуклеотидному праймеру, который содержит последовательность по меньшей мере из 9 нуклеотидов, где указанная последовательность комплементарна последовательности нуклеиновой кислоты, которая содержится в геноме вируса, раскрытого здесь.
Еще один аспект изобретения относится к олигонуклеотидному праймеру, который (а) содержит последовательность по меньшей мере из 9 последовательных нуклеотидов, где указанная последовательность комплементарна последовательности нуклеиновой кислоты, которая содержится в геноме вируса, раскрытого здесь, (b) содержит по меньшей мере 9 последовательных нуклеотидов последовательности, которая представляет собой или комплементарна фрагменту референсной последовательности нуклеиновой кислоты, выбранной из группы, состоящей из SEQ ID NO: 1, SEQ ID NO: 2, SEQ ID NO: 3, SEQ ID NO: 4, SEQ ID NO: 5 или SEQ ID NO: 6, или (c) содержит по меньшей мере 9 последовательных нуклеотидов последовательности, которая по меньшей мере на 80% идентична последовательности, которая представляет собой или комплементарна последовательности, выбранной из группы, состоящей из SEQ ID NO: 12 - SEQ ID NO: 40; предпочтительно при условии, что указанный олигонуклеотидный праймер не содержит последовательность, выбранную из группы, состоящей из SEQ ID NO: 41 - SEQ ID NO: 49.
В некоторых вариантах осуществления олигонуклеотидный праймер имеет длину от 9 до 60 нуклеотидов. В предпочтительных вариантах осуществления олигонуклеотидный праймер имеет длину от 12 до 40 нуклеотидов. В более предпочтительных вариантах осуществления олигонуклеотидный праймер имеет длину от 15 до 30 нуклеотидов. В еще более предпочтительных вариантах воплощения олигонуклеотидный праймер имеет длину от 18 до 25 нуклеотидов.
Специалист в данной области легко поймет, что олигонуклеотидный праймер, комплементарный последовательности нуклеиновой кислоты, будет гибридизоваться с этой последовательностью в жестких условиях. «Жесткие условия» относятся к условиям по температуре, ионной силе и присутствию других соединений, таких как органические растворители, при которых проводят гибридизацию нуклеиновых кислот. В жестких условиях спаривание оснований нуклеиновых кислот будет происходить только между последовательностями нуклеиновых кислот, имеющими высокую частоту комплементарных оснований. Жесткие условия гибридизации известны специалистам в данной области (см., например, Green M. R., Sambrook, J. Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory Press; 4th edition, 2012 г.). Точные условия жесткой гибридизации обычно зависят от последовательности и будут различаться в разных обстоятельствах, что легко поймет специалист в данной области. Более длинные последовательности гибридизуются при более высоких температурах по сравнению с более короткими последовательностями. Обычно выбираются жесткие условия, которые приблизительно на 5°C ниже температуры плавления (Tm) для конкретной последовательности. Tm определяется как температура, при которой 50% дуплексных молекул диссоциировали на составляющие их одиночные цепи. Поскольку последовательности-мишени обычно присутствуют в избытке, то при Tm 50% праймеров нуклеиновых кислот обычно будут заняты при равновесии. Как правило, жесткими условиями будут такие, в которых концентрация соли ниже приблизительно 1,0 М ионов натрия, обычно приблизительно от 0,01 до 1,0 М ионов натрия (или других солей) при рН от 6,8 до 8,3, и температура составляет по меньшей мере приблизительно 30°C для коротких праймеров (например, от 10 нуклеотидов до 50 нуклеотидов) и по меньшей мере приблизительно 60°C для более длинных праймеров. Жесткие условия также могут быть достигнуты добавлением дестабилизирующих агентов, таких как формамид. Специалист в данной области легко поймет, что за счет комплементарности последовательностей олигонуклеотидный праймер по изобретению, следовательно, гибридизуется с последовательностью нуклеиновой кислоты, которая содержится в геноме вируса, раскрытого здесь.
Олигонуклеотидный праймер по настоящему изобретению можно метить молекулярным маркером для обеспечения визуализации гибридизации с последовательностью-мишенью или количественной оценки амплификации последовательности-мишени. Специалисту в данной области известны различные молекулярные маркеры или метки.
В конкретном варианте осуществления в настоящем документе обеспечивается олигонуклеотидный праймер, который содержит по меньшей мере 9 последовательных нуклеотидов последовательности, которая представляет собой или комплементарна фрагменту (например, длиной от 9 до 60 нуклеотидов, предпочтительно длиной от 12 до 40 нуклеотидов, более предпочтительно от 15 до 30 нуклеотидов, еще более предпочтительно от 18 до 25 нуклеотидов) референсной последовательности нуклеиновой кислоты, выбранной из группы, состоящей из SEQ ID NO: 1, SEQ ID NO: 2, SEQ ID NO: 3, SEQ ID NO: 4, SEQ ID NO: 5 или SEQ ID NO: 6; предпочтительно при условии, что указанный олигонуклеотидный праймер не содержит последовательности, выбранной из группы, состоящей из SEQ ID NO: 41 - SEQ ID NO: 49. В особенно предпочтительном варианте осуществления последовательность указанного олигонуклеотидного праймера состоит из указанной последовательности из последовательных нуклеотидов.
В еще одном конкретном варианте осуществления в настоящем документе обеспечивается олигонуклеотидный праймер, который содержит по меньшей мере 9 (предпочтительно по меньшей мере 12, более предпочтительно по меньшей мере 15, еще более предпочтительно по меньшей мере 18) последовательных нуклеотидов последовательности, которая по меньшей мере на 80% идентична последовательности, которая представляет собой или комплементарна последовательности, выбранной из группы, состоящей из SEQ ID NO: 12 - SEQ ID NO: 40; предпочтительно при условии, что указанный олигонуклеотидный праймер не содержит последовательности, выбранной из группы, состоящей из SEQ ID NO: 41 - SEQ ID NO: 49.
Еще один аспект изобретения относится к применению по меньшей мере одного олигонуклеотидного праймера в способе обнаружения вируса, раскрытого здесь, где по меньшей мере один праймер содержит последовательность по меньшей мере из 9 нуклеотидов, например, 9 последовательных нуклеотидов (предпочтительно по меньшей мере 12, более предпочтительно по меньшей мере 15, еще более предпочтительно по меньшей мере 18), и где указанная последовательность комплементарна последовательности нуклеиновой кислоты, которая содержится в геноме указанного вируса.
В некоторых вариантах осуществления по меньшей мере один олигонуклеотидный праймер представляет собой пару праймеров, т.е. два праймера, один прямой праймер и один обратный праймер, которые комплементарны двум областям последовательности нуклеиновой кислоты и которые можно использовать для амплификации последовательности между двумя указанными областями. Это хорошо известно специалисту в данной области, и в пределах его/ее навыков найти олигонуклеотидные праймеры, подходящие для образования пары. Согласно применению по изобретению, «пара праймеров» может использоваться для амплификации последовательности нуклеиновой кислоты, которая содержится в геноме вируса, описанного здесь.
В некоторых вариантах осуществления изобретения используется синтез кДНК в способе обнаружения вируса, раскрытого здесь. Например, случайные олигонуклеотидные праймеры (например, гексануклеотиды) используются для синтеза кДНК из последовательности нуклеиновой кислоты, которая содержится в геноме указанного вируса.
В некоторых вариантах осуществления изобретения используется ПЦР в способе обнаружения вируса, раскрытого здесь. В некоторых вариантах осуществления изобретения используется ОТ-ПЦР в способе обнаружения вируса, раскрытого здесь. В некоторых вариантах осуществления изобретения используется ОТ-кПЦР в способе обнаружения вируса, раскрытого здесь. В некоторых вариантах осуществления используется случайная мультиплексная ОТ-ПЦР в способе обнаружения вируса, раскрытого здесь; в данном способе используется смесь праймеров, разработанных таким образом, чтобы быть устойчивыми к амплификации праймер-димер (см. Clem et al., Virol. J, 4, 2007). В некоторых вариантах осуществления изобретения используется опосредованная транскрипцией амплификация (TMA) в способе обнаружения вируса, раскрытого здесь. В некоторых вариантах осуществления изобретения используется амплификация замещением цепей (SDA) в способе обнаружения вируса, раскрытого здесь.
В некоторых вариантах осуществления изобретения используется детектирование in situ, также называемое гибридизацией in situ (ISH) в способе обнаружения вируса, раскрытого здесь, например флуоресцентная гибридизация in situ (FISH). В методе ISH используется меченная комплементарная ДНК, РНК или модифицированная последовательность олигонуклеотидного праймера (зонд) для визуализации специфических нуклеиновых кислот в морфологически сохраненных клетках и тканевых срезах. Зонд можно метить радиоактивными, флуоресцентными или антигенными метками (например, дигоксигенином), которые затем можно локализовать и количественно определить в ткани с помощью авторадиографии, флуоресцентной микроскопии или иммуногистохимии соответственно.
Диагностические способы
Еще один аспект изобретения относится к способу обнаружения вируса, который инфицирует и способен вызывать гибель рыбы, включающему стадии:
(а) контактирование нуклеиновой кислоты, экстрагированной из биологического образца рыбы по меньшей мере с одним олигонуклеотидным праймером с образованием смеси, где по меньшей мере один олигонуклеотидный праймер комплементарен последовательности нуклеиновой кислоты, которая содержится в геноме вируса, раскрытого здесь, и
(b) определение того, присутствует ли продукт амплификации при подвергании смеси а) амплификации, где присутствие продукта амплификации указывает на присутствие РНК, ассоциированной с вирусом, и, следовательно, на присутствие вируса в биологическом образце.
В некоторых вариантах осуществления нуклеиновую кислоту на стадии (а) способа, например РНК, экстрагируют из биологических образцов с использованием твердофазной экстракции, например, очистки на колонке с использованием твердой фазы из силикагелевой мембраны. В некоторых вариантах осуществления нуклеиновую кислоту на стадии (а) способа, например РНК, экстрагируют из биологических образцов с использованием экстракции смесью фенол/хлороформ.
В способе можно использовать любой подходящий олигонуклеотидный праймер, раскрытый здесь. Обычно по меньшей мере один олигонуклеотидный праймер на стадии (а) способа выбирают для получения продукта амплификации согласно стадии (b), который имеет длину от 45 нуклеотидов до 3000 нуклеотидов. Однако продукты амплификации, даже меньшей или большей длины, могут быть соответственно получены с использованием способов и олигонуклеотидного праймера, раскрытых здесь.
В некоторых вариантах осуществления по меньшей мере один олигонуклеотидный праймер на стадии (а) способа выбирается для получения продукта амплификации согласно стадии (b) для анализа ПЦР или ОТ-ПЦР, который имеет длину от 100 нуклеотидов до 2500 нуклеотидов. В предпочтительных вариантах осуществления по меньшей мере один олигонуклеотидный праймер на стадии (а) способа выбирается для получения продукта амплификации согласно стадии (b) для анализа ПЦР или ОТ-ПЦР, который имеет длину от 200 нуклеотидов до 1500 нуклеотидов. В более предпочтительных вариантах осуществления по меньшей мере один олигонуклеотидный праймер на стадии (а) способа выбирается для получения продукта амплификации согласно стадии (b) для анализа ПЦР или ОТ-ПЦР, который имеет длину от 300 нуклеотидов до 1000 нуклеотидов.
В некоторых вариантах осуществления по меньшей мере один олигонуклеотидный праймер на стадии (а) способа выбирается для получения продукта амплификации согласно стадии (b) для анализа ОТ-ПЦР в режиме реального времени, который имеет длину от 45 нуклеотидов до 500 нуклеотидов. В предпочтительных вариантах осуществления по меньшей мере один олигонуклеотидный праймер на стадии (а) способа выбирается для получения продукта амплификации согласно стадии (b) для анализа ОТ-ПЦР в режиме реального времени, который имеет длину от 50 нуклеотидов до 350 нуклеотидов. В более предпочтительных вариантах осуществления по меньшей мере один олигонуклеотидный праймер на стадии (а) способа выбирается для получения продукта амплификации согласно стадии (b) для анализа ОТ-ПЦР в режиме реального времени, который имеет длину от 55 до 250 нуклеотидов.
В некоторых вариантах осуществления для амплификации на стадии (b) способа используется ПЦР. В некоторых вариантах осуществления для амплификации на стадии (b) способа используется ОТ-ПЦР. В некоторых вариантах осуществления амплификация на стадии (b) способа используется ОТ-кПЦР.
В некоторых вариантах осуществления продукт амплификации на стадии (b) способа определяют с помощью саузерн-блоттинга. В некоторых вариантах осуществления продукт амплификации на стадии (b) способа определяют с помощью нозерн-блоттинга. В некоторых вариантах осуществления продукт амплификации на стадии (b) способа определяют спектрофотометрией. В некоторых вариантах осуществления продукт амплификации на стадии (b) способа определяется с использованием красителя для ДНК. В некоторых вариантах осуществления продукт амплификации на стадии (b) способа определяют количественной оценкой присутствия меченого олигонуклеотидного праймера, например, количественным определением присутствия флуоресцентно меченого олигонуклеотидного праймера.
Еще один аспект изобретения относится к способу обнаружения вируса, который инфицирует и способен приводить к гибели рыбы, включающему стадии:
(а) секвенирование нуклеиновой кислоты, экстрагированной из биологического образца рыбы, и
(b) сравнение полученной последовательности нуклеиновой кислоты с последовательностью нуклеиновой кислоты, которая представляет собой или комплементарна референсной последовательности, выбранной из группы, состоящей из SEQ ID NO: 1, SEQ ID NO: 2, SEQ ID NO: 3, SEQ ID NO: 4, SEQ ID NO: 5 и SEQ ID NO: 6, где по меньшей мере 80% идентичность последовательностей между двумя последовательностями указывает на присутствие вируса в биологическом образце.
В некоторых вариантах осуществления нуклеиновую кислоту на стадии (а) способа, например РНК, экстрагируют из биологических образцов с использованием твердофазной экстракции, например, очистки на колонке с использованием твердой фазы из силикагелевой мембраны. В некоторых вариантах осуществления нуклеиновую кислоту на стадии (а) способа, например РНК, экстрагируют из биологических образцов с использованием экстракции смесью фенол/хлороформ.
В некоторых вариантах осуществления секвенирование на стадии (а) способа выполняется секвенированием по Сэнгеру (метод обрыва цепи). В предпочтительных вариантах осуществления секвенирование на стадии (а) способа выполняется секвенированием нового поколения (NGS), предпочтительно секвенированием Illumina (Solexa), секвенированием Roche 454, ионным полупроводниковым секвенированием или секвенированием через лигирование SOLiD (Goodwin S, et al., (2016) Goodwin S, et al., (2016) Coming of age: Ten years of next-generation sequencing technologies. Nature reviews, Genetics, 17, 333-351).
В предпочтительных вариантах осуществления секвенирование на стадии (а) способа обеспечивает последовательность ДНК, которую можно напрямую сравнивать с референсными последовательностями ДНК, выбранными из группы, состоящей из SEQ ID NO: 1, SEQ ID NO: 2, SEQ ID NO: 3, SEQ ID NO: 4, SEQ ID NO: 5 и SEQ ID NO: 6.
В некоторых вариантах осуществления изобретения по меньшей мере 85% идентичность последовательности между двумя последовательностями на стадии (b) способа указывает на присутствие вируса в биологическом образце.
В предпочтительных вариантах осуществления по меньшей мере 90% идентичность последовательности между двумя последовательностями на стадии (b) способа указывает на присутствие вируса в биологическом образце.
В более предпочтительных вариантах осуществления по меньшей мере 95% идентичность последовательности между двумя последовательностями на стадии (b) способа указывает на присутствие вируса в биологическом образце.
В еще более предпочтительных вариантах осуществления по меньшей мере 98% идентичность последовательности между двумя последовательностями на стадии (b) способа указывает на присутствие вируса в биологическом образце.
В еще более предпочтительных вариантах осуществления по меньшей мере 99% идентичность последовательности между двумя последовательностями на стадии (b) способа указывает на присутствие вируса в биологическом образце.
В особенно предпочтительном варианте осуществления 100% идентичность последовательности двух последовательностей на стадии (b) способа указывает на присутствие вируса в биологическом образце.
Еще один аспект изобретения относится к способу обнаружения вируса, который инфицирует и способен вызывать гибель рыбы, включающему стадии:
(а) секвенирование нуклеиновой кислоты, экстрагированной из биологического образца рыбы, и
(b) трансляцию полученной последовательности нуклеиновой кислоты в аминокислотную последовательность или трансляцию последовательности нуклеиновой кислоты, комплементарной указанной полученной последовательности нуклеиновой кислоты, в аминокислотную последовательность, и
(c) сравнение полученной аминокислотной последовательности с референсной последовательностью, выбранной из группы, состоящей из SEQ ID NO: 7-11, где по меньшей мере 80% идентичность последовательности между двумя последовательностями указывает на присутствие вируса в биологическом образце.
Антитела
Еще один аспект изобретения относится к антителу, которое связывается с полипептидом, где полипептид кодируется последовательностью нуклеиновой кислоты, которая содержится в геноме вируса, раскрытого здесь, и/или где полипептид содержит аминокислотную последовательность, которая по меньшей мере на 80%, по меньшей мере на 90% или по меньшей мере на 95% идентична любой из SEQ ID NO: 7-11, или представляет собой любую из SEQ ID NO 7-11 или ее консервативно замещенный вариант.
В некоторых вариантах осуществления полипептид выбран из группы, состоящей из:
(i) полипептида, содержащего аминокислотную последовательность, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95%, еще более предпочтительно по меньшей мере на 98%, особенно предпочтительно по меньшей мере на 99% или даже на 100% идентична или представляет собой SEQ ID NO: 7;
(ii) полипептида, содержащего аминокислотную последовательность, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95%, еще более предпочтительно по меньшей мере на 98%, особенно предпочтительно по меньшей мере на 99% или даже на 100% идентична или представляет собой SEQ ID NO: 8;
(iii) полипептида, содержащего аминокислотную последовательность, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95%, еще более предпочтительно по меньшей мере на 98%, особенно предпочтительно по меньшей мере на 99% или даже на 100% идентична или представляет собой SEQ ID NO: 9;
(iv) полипептида, содержащего аминокислотную последовательность, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95%, еще более предпочтительно по меньшей мере на 98%, особенно предпочтительно по меньшей мере на 99% или даже на 100% идентична или представляет собой SEQ ID NO: 10; и
(v) полипептида, содержащего аминокислотную последовательность, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95%, еще более предпочтительно по меньшей мере на 98%, особенно предпочтительно по меньшей мере на 99% или даже на 100% идентична или представляет собой SEQ ID NO: 11.
В некоторых вариантах осуществления антитело представляет собой поликлональное антитело. В некоторых вариантах осуществления антитело представляет собой моноклональное антитело.
Антитела, раскрытые здесь, можно получить методами генетической иммунизации, в которых нативные белки экспрессируются in vivo с нормальными посттранскрипционными модификациями, избегая выделения или синтеза антигена. Например, гидродинамическую доставку экспрессионных векторов плазмидной ДНК в вену хвоста или конечности можно использовать для получения представляющего интерес антигена in vivo у мышей, крыс и кроликов и, таким образом, индукции антигенспецифических антител (Tang et al., Nature 356 (6365): 152-4 (1992); Tighe et al., Immunol. Today, 19 (2) 89-97 (1998); Bates et al., Biotechniques, 40 (2) 199-208 (2006)). Данная процедура позволяет эффективно генерировать антигенспецифические антитела с высоким титром. Антитела также можно получить методами in vitro. Подходящие примеры включают, не ограничиваясь этим, гибридомные технологии, фаговый дисплей, дрожжевой дисплей и т.п.
Наборы
Еще один аспект изобретения относится к набору для обнаружения вируса в биологическом образце рыбы, где набор содержит олигонуклеотидный праймер, раскрытый здесь, и/или антитело, раскрытое здесь.
В некоторых вариантах осуществления набор представляет собой набор для анализа ОТ-ПЦР в режиме реального времени, например, набор представляет собой набор для анализа ОТ-кПЦР в режиме реального времени.
В некоторых вариантах осуществления набор предназначен для обнаружения тотивируса в биологическом образце рыбы. В предпочтительных вариантах осуществления набор предназначен для обнаружения тотивируса в биологическом образце рыбы пинагор.
Лечебные применения и вакцины
В еще одном аспекте изобретение относится к антителу для лечения рыб, в частности, рыбы пинагор, против заболевания, вызванного тотивирусной инфекцией. В предпочтительном варианте осуществления антитело предназначено для применения в лечении рыб, в частности рыбы пинагор, страдающей заболеванием, вызванным вирусом, описанным здесь (CLuTV). Антитело связывается с полипептидом, кодированным последовательностью нуклеиновой кислоты, содержащейся в геноме вируса, раскрытого здесь.
В предпочтительных вариантах осуществления рыба представляет собой рыбу пинагор.
В некоторых вариантах осуществления у рыбы проявляются следующие симптомы:
(i) повреждение тканей кишечника и/или
(ii) диарея; или
(iii) кардиомиопатия.
Симптомы можно определить, как описано выше. В предпочтительных вариантах осуществления у рыб проявляются симптомы кардиомиопатии.
В еще одном аспекте изобретение относится к применению вируса, раскрытого здесь, для получения вакцины против заболевания, вызываемого указанным вирусом.
В еще одном аспекте изобретение относится к вакцине, содержащей:
(i) последовательность нуклеиновой кислоты, которая содержится в геноме вируса, раскрытого здесь;
(ii) последовательность нуклеиновой кислоты, раскрытой здесь;
(iii) вирусный полипептид, кодируемый последовательностью нуклеиновой кислоты, которая содержится в геноме вируса, раскрытого здесь;
(iv) вирусный полипептид, содержащий аминокислотную последовательность, которая по меньшей мере на 80%, по меньшей мере 90% или по меньшей мере на 95% идентична любой из SEQ ID NO: 7-11, или которая представляет собой любую из SEQ ID NO: 7-11 или его консервативно замещенный вариант; или
(v) вирус, раскрытый здесь.
В некоторых вариантах осуществления вакцина содержит несколько вирусных полипептидов, например, первый полипептид, который содержит аминокислотную последовательность, которая по меньшей мере на 80% идентична SEQ ID NO: 7, и второй полипептид, который содержит аминокислотную последовательность, которая по меньшей мере 80% идентична SEQ ID NO: 8. Вакцина может содержать один, два, три, четыре или пять вирусных полипептидов.
Вакцина предназначена для защиты рыб, в частности, рыбы пинагор, от болезней, вызванных тотивирусной инфекцией. В предпочтительном варианте осуществления вакцина предназначена для защиты рыб, в частности, рыбы пинагор, от заболевания, вызванного инфицированием вирусом, раскрытым здесь (CLuTV).
В некоторых вариантах осуществления, где вакцина содержит последовательность нуклеиновой кислоты, содержащуюся в геноме вируса, раскрытого здесь, указанная последовательность нуклеиновой кислоты содержит по меньшей мере одну из ORF-1, ORF-2, ORF-X, ORF-Y или ORF-Z, согласно любому из их вариантов осуществления, раскрытых здесь. В предпочтительных вариантах осуществления, где вакцина содержит последовательность нуклеиновой кислоты, содержащуюся в геноме вируса, раскрытого здесь, указанная последовательность нуклеиновой кислоты содержит по меньшей мере ORF-1 и ORF-2 согласно любому из их вариантов осуществления, раскрытых здесь. В некоторых вариантах осуществления, где вакцина содержит последовательность нуклеиновой кислоты, содержащуюся в геноме вируса, раскрытого здесь, указанная последовательность нуклеиновой кислоты представляет собой или комплементарна последовательности нуклеиновой кислоты, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95%, еще более предпочтительно по меньшей мере на 98%, особенно предпочтительно по меньшей мере на 99% или даже на 100% идентична последовательности вирусного генома согласно SEQ ID NO: 6 (CLuTV).
Нуклеиновая кислота может представлять собой ДНК или РНК.
В некоторых вариантах осуществления, где вакцина содержит вирусный полипептид, кодируемый последовательностью нуклеиновой кислоты, которая содержится в геноме вируса, раскрытого здесь, где указанный полипептид выбран из группы, состоящей из:
(i) полипептида, содержащего аминокислотную последовательность, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95%, еще более предпочтительно по меньшей мере на 98%, особенно предпочтительно по меньшей мере на 99% или даже на 100% идентична или представляет собой SEQ ID NO: 7;
(ii) полипептида, содержащего аминокислотную последовательность, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95%, еще более предпочтительно по меньшей мере на 98%, особенно предпочтительно по меньшей мере на 99% или даже на 100% идентична или представляет собой SEQ ID NO: 8;
(iii) полипептида, содержащего аминокислотную последовательность, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95%, еще более предпочтительно по меньшей мере на 98%, особенно предпочтительно по меньшей мере на 99% или даже на 100% идентична или представляет собой SEQ ID NO: 9;
(iv) полипептида, содержащего аминокислотную последовательность, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95%, еще более предпочтительно по меньшей мере на 98%, особенно предпочтительно по меньшей мере на 99% или даже на 100% идентична или представляет собой SEQ ID NO: 10; и
(v) полипептида, содержащего аминокислотную последовательность, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95%, еще более предпочтительно по меньшей мере на 98%, особенно предпочтительно по меньшей мере на 99% или даже на 100% идентична или представляет собой SEQ ID NO: 11.
В некоторых вариантах осуществления, где вакцина содержит вирус, раскрытый здесь, геном указанного вируса включает последовательность нуклеиновой кислоты, которая представляет собой последовательность нуклеиновой кислоты РНК, содержащую по меньшей мере одну из ORF-1, ORF-2, ORF-X, ORF-Y или ORF-Z согласно любому из их вариантов осуществления, раскрытых здесь. В некоторых вариантах осуществления, где вакцина содержит вирус, раскрытый здесь, геном указанного вируса содержит последовательность нуклеиновой кислоты, которая представляет собой последовательность нуклеиновой кислоты РНК, которая представляет собой или которая комплементарна последовательности нуклеиновой кислоты, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95%, еще более предпочтительно, на 98%, особенно предпочтительно на 99% или даже на 100% идентична последовательности вирусного генома согласно SEQ ID NO: 6 (CLuTV).
В некоторых вариантах осуществления вакцина содержит количество антигена в диапазоне от 0,05 до 1,0 мг/мл, например от 0,1 до 0,5 мг/мл, от 0,15 до 0,4 мг/мл или от 0,2 до 0,3 мг/мл. Вакцину можно вводить в дозах от 0,005 до 0,5 мг/особь, предпочтительно от 0,01 до 0,05 мг/особь, более предпочтительно от 0,01 до 0,02 мг/особь.
В некоторых вариантах осуществления вакцина содержит количество антигена, соответствующее TCID50 от 105 до 1010 на дозу, предпочтительно TCID50 от 106 до 109 на дозу.
Вакцина может находиться в форме суспензии вируса или может быть лиофилизирована. В лиофилизированную вакцину может полезным добавить один или более стабилизаторов. Подходящими стабилизаторами являются, например, углеводы, такие как сорбит, маннит, крахмал, сахароза, декстран; белок-содержащие агенты, такие как бычья сыворотка или обезжиренное молоко; и буферы, такие как фосфаты щелочных металлов.
Вакцина по изобретению может дополнительно находиться в составе, содержащем адъювант. Примерами адъювантов, часто используемых при выращивании рыбы и моллюсков, являются мурамилдипептиды, липополисахариды, некоторые глюканы и гликаны, минеральное масло, Montanide™ и Carbopol®. Обзор адъювантов, подходящих для рыбных вакцин, приведен в обзорной статье Sommerset (Expert Rev. Vaccines, 4 (1), 89-101 (2005)).
Вакцина по изобретению может дополнительно содержать подходящий фармацевтический носитель. В некоторых вариантах осуществления вакцина формулирована в виде эмульсии «вода в масле». Вакцина также может содержать так называемый «носитель». Носитель представляет собой материал, к которому антиген прикрепляется, но не связывается с ним ковалентно. Такие носители, среди прочего, представляют собой биоразлагаемые нано/ микрочастицы или капсулы из PLGA (сополимера лактида и гликолевой кислоты), альгината или хитозана, липосомы, ниосомы, мицеллы, множественные эмульсии и макросоли, все известные в данной области техники. Особой формой такого носителя, в котором антиген частично встроен в носитель, является так называемый иммуностимулирующий комплекс ISCOM.
Кроме того, вакцина может содержать одно или более подходящих поверхностно-активных соединений или эмульгаторов, например Cremophore®, Tween® и Span®. Также можно использовать адъюванты, такие как интерлейкин, CpG и гликопротеины.
В некоторых вариантах осуществления вакцина вводится в корм для рыб, где указанный корм может представлять собой, например, гранулированный или экструдированный корм.
Еще в одном аспекте изобретение относится к молекуле интерферирующей РНК (iРНК) для применения в лечении рыб, в частности, рыбы пинагор, страдающей заболеванием, вызванным тотивирусной инфекцией. В предпочтительном варианте осуществления iРНК предназначена для применения в лечении рыб, в частности рыбы пинагор, страдающей заболеванием, вызванным вирусом, раскрытым здесь (CLuTV). В конкретном варианте осуществления молекула iРНК содержит по меньшей мере 12 (предпочтительно смежных) нуклеотидов или комплементарных последовательности нуклеиновой кислоты, содержащейся в геноме вируса, раскрытого здесь.
В предпочтительных вариантах осуществления рыба представляет собой рыбу пинагор.
В некоторых вариантах осуществления у рыбы проявляются следующие симптомы:
(i) повреждение тканей кишечника и/или
(ii) диарея; или
(iii) кардиомиопатия.
Симптомы можно определить, как описано выше. В предпочтительных вариантах осуществления у рыб проявляются симптомы кардиомиопатии.
В некоторых вариантах осуществления молекула iРНК содержит по меньшей мере 12 (предпочтительно смежных) нуклеотидов последовательности нуклеиновой кислоты, содержащей ORF-1, ORF-2, ORF-X, ORF-Y или ORF-Z, или комплементарная ей, в соответствии с любым их вариантов осуществления, раскрытых здесь. В некоторых вариантах осуществления молекула iРНК содержит по меньшей мере 12 (предпочтительно смежных) нуклеотидов или комплементарных последовательности нуклеиновой кислоты, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, даже более предпочтительно по меньшей мере на 95%, еще более предпочтительно на 98%, особенно предпочтительно на 99% или даже на 100% идентична последовательности вирусного генома согласно SEQ ID NO: 6 (CLuTV).
Последовательности
Последовательности, приведенные в настоящем раскрытии, представляют собой следующие (см. также фигуры и список последовательностей):
Другие подходящие олигонуклеотидные праймеры, приведенные в данном документе, представлены в таблице 2:
Дополнительные олигонуклеотидные праймеры, приведенные в данном документе, представлены в таблице 3:
Примеры
Следующие ниже примеры иллюстрируют настоящее изобретение. Они предназначены для помощи в понимании изобретения, и их не следует истолковывать в качестве ограничения объема изобретения.
Пример 1: идентификация CLuTV
Образцы рыбы были отобраны с места выращивания пинагора (Cyclopterus lumpus), где наблюдалась высокая смертность рыбы (60-80%). Образцы анализировали с использованием стандартной ОТ-ПЦР в режиме реального времени и гистологии. С помощью ОТ-ПЦР в режиме реального времени не было выявлено известных патогенов. Гистологический анализ показал признаки повреждения тканей кишечника у пораженных рыб, но не было обнаружено ни потенциально патогенных бактерий, ни микропаразитов.
Общую фракцию РНК экстрагировали из умирающей рыбы в соответствии с протоколом экстракции смесью фенол/хлороформ (набор для высокопроизводительного выделения РНК из тканей Qiagen RNeasy® 96), и данную РНК использовали в качестве матрицы в анализе секвенирования нового поколения (NGS). NGS-анализ проводили в компании BaseClear (https://www.baseclear.com/), и он дал приблизительно 98 миллионов считываний последовательностей, большинство из которых были получены из транскриптома хозяина. В GenBank Национального центра биотехнологической информации (NCBI) было обнаружено, что приблизительно 28600 считываний из анализа NGS не имеют значимого нуклеотидного совпадения. На основании этих считываний изобретателями была идентифицирована и охарактеризована новая вирусная последовательность, названная здесь Cyclopterus lumpus Totivirus или CLuTV. Последовательности ДНК, полученные в результате анализа NGS, представлены на фиг. 2-5 (см. также SEQ ID NO: 1-6). Однако следует понимать, что соответствующие последовательности РНК присутствуют в вирусе CLuTV.
Последовательность CLuTV, идентифицированная здесь, имеет длину 6353 нуклеотида и содержит пять возможных открытых рамок считывания (ORF). Схема приведена на фиг. 1. Связь между CLuTV и другими известными вирусами можно определить только сравнением транслированных аминокислотных последовательностей. Длина и организация генома вместе с последующим анализом последовательности показали, что это новый вирус в семействе Totiviridae, ближайшим представителем которого является вирус атлантического лосося PMCV.
Предварительные результаты показывают, что по меньшей мере в Норвегии, CLuTV широко распространен среди выращиваемых на фермах пинагоров.
Патология, связанная с CLuTV у пинагора, показана на фиг. 9-12. Срезы тканей пинагора окрашивали с использованием гистологического красителя гематоксилина и эозина (H&E). На фиг. 9 представлен полный срез пораженного пинагора, показывающий скопление жидкости в желудке (стрелка). На фиг. 10 представлен срез кишечника пинагора, показывающий скопление слизи и клеточные выделения (стрелки). На фиг. 11 представлен срез кишечника пинагора, показывающий скопление слизи (стрелка) и клеточные выделения. На фиг. 12 представлен срез кишечника пинагора, показывающий скопление слизи (стрелка).
Пример 2: анализ нуклеотидной последовательности CLuTV
Нуклеотидная последовательность CLuTV по данным анализа NGS была подтверждена стандартным секвенированием по Сэнгеру продуктов ОТ-ПЦР, полученных из общей фракции РНК, экстрагированной из умирающих рыб.
При выполнении стандартного поиска нуклеотидов BLAST с использованием последовательности CLuTV совпадений в NCBI GeneBank обнаружено не было. Если параметры поиска изменяли для включения в поиск более непохожих последовательностей, то были идентифицированы некоторые участки последовательностей других известных вирусов. Процент идентичности нуклеотидных последовательностей («Seq. Id.») между этими областями CLuTV и областями других известных вирусов показан в таблице 4.
Наилучшее совпадение нуклеотидов, обнаруженное между CLuTV и известными вирусами в NCBI GeneBank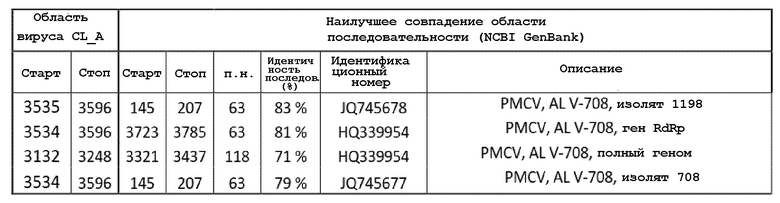
PMCV, ближайший представитель для CLuTV, содержит в своем геноме три ORF. ORF3 из PMCV находится в той же области, что и ORFX-Y в CLuTV.
Пример 3: анализ аминокислотной последовательности CLuTV
Трансляция ORF CLuTV дает в общей сложности пять потенциальных белков. Аминокислотная идентичность ORF CLuTV и других известных белков из других вирусов показана в таблице 5. Приведено только наилучшее совпадение для каждой ORF.
Наилучшее совпадение аминокислотной последовательности, обнаруженное между CLuTV и известными вирусами в NCBI GeneBank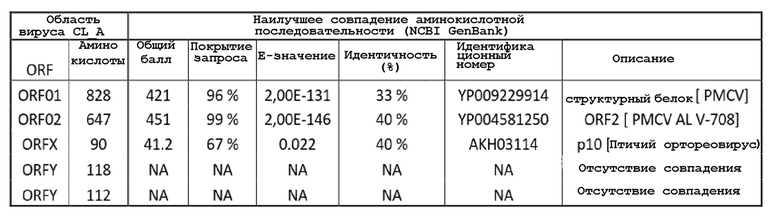
Пример 4: оценка присутствия CLuTV в выращиваемых популяциях пинагора
Были разработаны три отдельных анализа ОТ-ПЦР в режиме реального времени (CLP01, CLP02 и CLP03) с использованием праймеров согласно SEQ ID NO: 12-14, 15-17 и 18-20 соответственно. CLP01 нацелен на ORF-1, CLP02 нацелен на ORF-2 и CLP03 нацелен на ORF-Y. Исходный материал образца рыбы был подтвержден как положительный на CLuTV с использованием всех данных трех анализов.
Для более обширного исследования был выбран анализ CLP01 для оценки присутствия CLuTV в имеющихся популяциях пинагора. Результаты скрининга различных популяций пинагора в Норвегии приведены в таблице 6.
Результаты тестирования материала NGS и полевого материала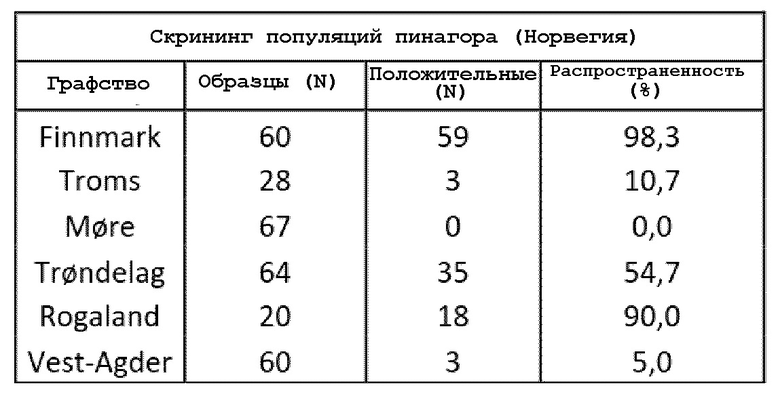
Как следует из данных таблицы, в некоторых популяциях пинагора, в частности в округах Finnmark и Rogaland, распространенность CLuTV превышает 90%.
Принимая во внимание раскрытие, представленное здесь, следует понимать, что настоящее изобретение также включает следующие пункты:
1. Нуклеиновая кислота, где последовательность указанной нуклеиновой кислоты включает:
(а) по меньшей мере, последовательность одной открытой рамки считывания (ORF), выбранной из группы, состоящей из ORF-1, ORF-2, ORF-X, ORF-Y и ORF-Z, или
(b) последовательность, комплементарную ей;
где:
ORF-1 по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 1,
ORF-2 по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 2,
ORF-X по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 3,
ORF-Y по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 4, и
ORF-Z по меньшей мере на 80% идентична последовательности нуклеиновой кислоты SEQ ID NO: 5.
2. Нуклеиновая кислота по п.1, где:
ORF-1 по меньшей мере на 85% идентична последовательности нуклеиновой кислоты SEQ ID NO: 1,
ORF-2 по меньшей мере на 85% идентична последовательности нуклеиновой кислоты SEQ ID NO: 2,
ORF-X по меньшей мере на 85% идентична последовательности нуклеиновой кислоты SEQ ID NO: 3,
ORF-Y по меньшей мере на 85% идентична последовательности нуклеиновой кислоты SEQ ID NO: 4, и
ORF-Z по меньшей мере на 85% идентична последовательности нуклеиновой кислоты SEQ ID NO: 5.
3. Нуклеиновая кислота по пп.1 или 2, где:
ORF-1 по меньшей мере на 90% идентична последовательности нуклеиновой кислоты SEQ ID NO: 1,
ORF-2 по меньшей мере на 90% идентична последовательности нуклеиновой кислоты SEQ ID NO: 2,
ORF-X по меньшей мере на 90% идентична последовательности нуклеиновой кислоты SEQ ID NO: 3,
ORF-Y по меньшей мере на 90% идентична последовательности нуклеиновой кислоты SEQ ID NO: 4, и
ORF-Z по меньшей мере на 90% идентична последовательности нуклеиновой кислоты SEQ ID NO: 5.
4. Нуклеиновая кислота по любому из пп.1-3, где:
ORF-1 по меньшей мере на 95% идентична последовательности нуклеиновой кислоты SEQ ID NO: 1,
ORF-2 по меньшей мере на 95% идентична последовательности нуклеиновой кислоты SEQ ID NO: 2,
ORF-X по меньшей мере на 95% идентична последовательности нуклеиновой кислоты SEQ ID NO: 3,
ORF-Y по меньшей мере на 95% идентична последовательности нуклеиновой кислоты SEQ ID NO: 4, и
ORF-Z по меньшей мере на 95% идентична последовательности нуклеиновой кислоты SEQ ID NO: 5.
5. Нуклеиновая кислота по любому из пп. 1-4, где:
ORF-1 по меньшей мере на 98% идентична последовательности нуклеиновой кислоты SEQ ID NO: 1,
ORF-2 по меньшей мере на 98% идентична последовательности нуклеиновой кислоты SEQ ID NO: 2,
ORF-X по меньшей мере на 98% идентична последовательности нуклеиновой кислоты SEQ ID NO: 3,
ORF-Y по меньшей мере на 98% идентична последовательности нуклеиновой кислоты SEQ ID NO: 4, и
ORF-Z по меньшей мере на 98% идентична последовательности нуклеиновой кислоты SEQ ID NO: 5.
6. Нуклеиновая кислота по любому из пп.1-5, где:
ORF-1 по меньшей мере на 99% идентична последовательности нуклеиновой кислоты SEQ ID NO: 1,
ORF-2 по меньшей мере на 99% идентична последовательности нуклеиновой кислоты SEQ ID NO: 2,
ORF-X по меньшей мере на 99% идентична последовательности нуклеиновой кислоты SEQ ID NO: 3,
ORF-Y по меньшей мере на 99% идентична последовательности нуклеиновой кислоты SEQ ID NO: 4, и
ORF-Z по меньшей мере на 99% идентична последовательности нуклеиновой кислоты SEQ ID NO: 5.
7. Нуклеиновая кислота по любому из пп.1-6, где:
ORF-1 на 100% идентична последовательности нуклеиновой кислоты SEQ ID NO: 1,
ORF-2 на 100% идентична последовательности нуклеиновой кислоты SEQ ID NO: 2,
ORF-X на 100% идентична последовательности нуклеиновой кислоты SEQ ID NO: 3,
ORF-Y на 100% идентична последовательности нуклеиновой кислоты SEQ ID NO: 4, и
ORF-Z на 100% идентична последовательности нуклеиновой кислоты SEQ ID NO: 5.
8. Нуклеиновая кислота, где последовательность указанной нуклеиновой кислоты по меньшей мере на 80% идентична соответствующей последовательности, присутствующей в SEQ ID NO: 6, предпочтительно по меньшей мере на 85% идентична, более предпочтительно по меньшей мере на 90% идентична, еще более предпочтительно по меньшей мере на 95% идентична, еще более предпочтительно по меньшей мере на 98% идентична, еще более предпочтительно по меньшей мере на 99% идентична и особенно предпочтительно на 100% идентична.
9. Нуклеиновая кислота, где последовательность указанной нуклеиновой кислоты по меньшей мере на 80% идентична соответствующей последовательности, присутствующей в последовательности, комплементарной SEQ ID NO: 6, предпочтительно по меньшей мере на 85% идентична, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95% идентична, еще более предпочтительно по меньшей мере на 98% идентична, еще более предпочтительно по меньшей мере 99% идентична и особенно предпочтительно на 100% идентична.
10. Нуклеиновая кислота по пп.8 или 9, где последовательность указанной нуклеиновой кислоты содержит 200 нуклеотидов или менее.
11. Нуклеиновая кислота по любому из пп.8-10, где последовательность указанной нуклеиновой кислоты содержит по меньшей мере 60 нуклеотидов.
12. Нуклеиновая кислота по п.11, где последовательность указанной нуклеиновой кислоты содержит по меньшей мере 100 нуклеотидов, предпочтительно по меньшей мере 150 нуклеотидов.
13. Нуклеиновая кислота по п.8 или 9, где последовательность указанной нуклеиновой кислоты содержит по меньшей мере 200 нуклеотидов.
14. Применение нуклеиновой кислоты по любому из пп.1-13:
(а) в качестве гибридизационного зонда;
(b) для обнаружения вируса, раскрытого здесь, в биологическом образце рыбы, в частности, рыбы пинагор;
(c) в способе обнаружения вируса, который инфицирует и способен приводить к гибели рыбы, в частности, рыбы пинагор;
(d) в способе обнаружения вируса, который инфицирует и способен приводить к гибели рыбы, в частности рыбы пинагор, согласно любому из соответствующих способов, раскрытых здесь;
(e) для приготовления вакцины для защиты рыб, в частности, рыбы пинагор, от болезней, вызванных инфекцией Totivirus; или
(f) для приготовления вакцины для защиты рыб, в частности рыбы пинагор, от болезни, вызванной вирусом, раскрытым здесь, например, вирусом по пп.18-25 ниже.
15. Нуклеиновая кислота по п.1, где последовательность указанной нуклеиновой кислоты включает по меньшей мере ORF-1 и ORF-2, как определено в любом из пп.1-7, или последовательность, комплементарную им.
16. Нуклеиновая кислота по п.1, где последовательность указанной нуклеиновой кислоты по меньшей мере на 80% идентична геному вируса согласно SEQ ID NO: 6, предпочтительно по меньшей мере на 85% идентична, более предпочтительно по меньшей мере на 90% идентична, но все же более предпочтительно по меньшей мере на 95% идентична, еще более предпочтительно по меньшей мере на 98% идентична, еще более предпочтительно по меньшей мере 99% идентична и особенно предпочтительно на 100% идентична.
17. Нуклеиновая кислота по п.1, где последовательность указанной нуклеиновой кислоты по меньшей мере на 80% идентична последовательности, комплементарной SEQ ID NO: 6, предпочтительно по меньшей мере на 85% идентична, более предпочтительно по меньшей мере на 90% идентична, но более предпочтительно по меньшей мере на 95% идентична, еще более предпочтительно по меньшей мере на 98% идентична, еще более предпочтительно по меньшей мере на 99% идентична и особенно предпочтительно на 100% идентична.
18. Вирус, в частности вирус, который инфицирует и способен приводить к гибели рыбы пинагор (например, Cyclopterus lumpus), где геном вируса содержит последовательность нуклеиновой кислоты по любому из пп.1-13 и 15-17, где указанная последовательность нуклеиновой кислоты, содержащаяся в геноме вируса, содержит основание урацил (U) вместо основания тимин (T).
19. Вирус по п.18, где инфицирование этим вирусом рыбы пинагор вызывает у рыб следующие симптомы:
(i) повреждение тканей кишечника и/или
(ii) диарею; или
(iii) кардиомиопатию.
20. Вирус, который содержит одну или более, предпочтительно две или более, более предпочтительно три или более, более предпочтительно четыре или более, еще более предпочтительно пять из ORF 1, 2, X, Y и Z, где указанные ORF 1, 2 , X, Y, Z кодируют вирусные полипептиды согласно SEQ ID NO: 7-11 соответственно или вирусные полипептиды, которые по меньшей мере на 80% идентичны SEQ ID NO: 7-11 соответственно.
21. Вирус по п.20, где указанные ORF 1, 2, X, Y и Z кодируют вирусные полипептиды согласно SEQ ID NO: 7-11 соответственно или вирусные полипептиды, которые по меньшей мере на 90% идентичны SEQ ID NO: 7-11 соответственно.
22. Вирус по п.20, где указанные ORF 1, 2, X, Y и Z кодируют вирусные полипептиды согласно SEQ ID NO: 7-11 соответственно или вирусные полипептиды, которые по меньшей мере на 95% идентичны SEQ ID NO: 7-11 соответственно.
23. Вирус по любому из пп.20-22, где указанные ORF 1, 2, X, Y и Z кодируют вирусные полипептиды, которые являются консервативно замещенными вариантами SEQ ID NO: 7-11 соответственно.
24. Вирус по любому из пп.18-23, где вирус является вирусом без оболочки.
25. Вирус по любому из пп.18-24, где вирус представляет собой Totivirus.
26. Олигонуклеотидный праймер, который содержит последовательность по меньшей мере из 9 последовательных нуклеотидов, предпочтительно по меньшей мере 12 последовательных нуклеотидов, более предпочтительно по меньшей мере 15 последовательных нуклеотидов, и особенно предпочтительно по меньшей мере 18 последовательных нуклеотидов, где указанная последовательность содержится в геноме вируса по любому из пп.18-25, предпочтительно при условии, что указанный праймер не содержит SEQ ID NO: 41-49.
27. Олигонуклеотидный праймер, который содержит последовательность по меньшей мере из 9 последовательных нуклеотидов, предпочтительно по меньшей мере 12 последовательных нуклеотидов, более предпочтительно по меньшей мере 15 последовательных нуклеотидов и особенно предпочтительно по меньшей мере 18 последовательных нуклеотидов, где указанная последовательность комплементарна последовательности нуклеиновой кислоты, содержащейся в геноме вируса по любому из пп.18-25, предпочтительно при условии, что указанный праймер не содержит SEQ ID NO: 41-49.
28. Олигонуклеотидный праймер, который содержит последовательность по меньшей мере из 9 последовательных нуклеотидов, предпочтительно по меньшей мере 12 последовательных нуклеотидов, более предпочтительно по меньшей мере 15 последовательных нуклеотидов и особенно предпочтительно по меньшей мере 18 последовательных нуклеотидов, где указанная последовательность по меньшей мере на 80% идентична последовательности, содержащейся в SEQ ID NO: 6, предпочтительно при условии, что указанный праймер не содержит SEQ ID NO: 41-49.
29. Олигонуклеотидный праймер, который содержит последовательность по меньшей мере из 9 последовательных нуклеотидов, предпочтительно по меньшей мере 12 последовательных нуклеотидов, более предпочтительно по меньшей мере 15 последовательных нуклеотидов, и особенно предпочтительно по меньшей мере 18 последовательных нуклеотидов, где указанная последовательность по меньшей мере на 80% идентична последовательности, содержащейся в последовательности, комплементарной SEQ ID NO: 6, предпочтительно при условии, что указанный праймер не содержит SEQ ID NO: 41-49.
30. Олигонуклеотидный праймер по п.28 или 29, где указанная процентная идентичность последовательностей составляет по меньшей мере 85%, предпочтительно по меньшей мере 90%, более предпочтительно по меньшей мере 95%, еще более предпочтительно по меньшей мере 98%, еще более предпочтительно по меньшей мере, 99% и особенно предпочтительно 100%.
31. Олигонуклеотидный праймер по любому из пп.22-26, где указанный олигонуклеотидный праймер имеет от 9 до 60 нуклеотидов в длину, предпочтительно от 12 до 40 нуклеотидов в длину, более предпочтительно от 15 до 30 нуклеотидов в длину, особенно предпочтительно от 18 до 25 нуклеотидов в длину.
32. Олигонуклеотидный праймер по любому из пп.22-24, где указанная последовательность, содержащаяся в нем, представляет собой или комплементарна фрагменту референсной последовательности нуклеиновой кислоты, выбранной из группы, состоящей из SEQ ID NO: 1, SEQ ID NO: 2, SEQ ID NO: 3, SEQ ID NO: 4, SEQ ID NO: 5 или SEQ ID NO: 6.
33. Олигонуклеотидный праймер, который содержит по меньшей мере 9 последовательных нуклеотидов, предпочтительно по меньшей мере 12 последовательных нуклеотидов, более предпочтительно по меньшей мере 15 последовательных нуклеотидов, и особенно предпочтительно по меньшей мере 18 последовательных нуклеотидов, последовательности, которая по меньшей мере на 80% идентична последовательности, которая представляет собой последовательность, выбранную из группы, состоящей из SEQ ID NO: 12 - SEQ ID NO: 40, или комплементарной ей, предпочтительно при условии, что указанный праймер не содержит SEQ ID NO: 41-49.
34. Применение по меньшей мере одного олигонуклеотидного праймера в способе обнаружения вируса по любому из пп.18-25, где по меньшей мере один праймер содержит последовательность по меньшей мере из 9 последовательных нуклеотидов, предпочтительно по меньшей мере 12 последовательных нуклеотидов, более предпочтительно по меньшей мере 15 последовательных нуклеотидов, и особенно предпочтительно по меньшей мере 18 последовательных нуклеотидов, и где указанная последовательность комплементарна последовательности нуклеиновой кислоты, которая содержится в геноме указанного вируса, предпочтительно при условии, что указанный праймер не содержит SEQ ID NO: 41-49.
35. Применение по меньшей мере одной нуклеиновой кислоты по любому из пп.1-13 или 15-17, или по меньшей мере одного олигонуклеотидного праймера по любому из пп.26-34 в способе обнаружения вируса рыб, где необязательно вирус инфицирует и приводит к гибели рыбы пинагор.
36. Применение по п.35, где указанная нуклеиновая кислота или указанный олигонуклеотидный праймер используются в способе обнаружения вируса по любому из пп.18-25.
37. Способ обнаружения вируса, который инфицирует и может привести к гибели рыбы, в частности, рыбы пинагор, включающий следующие стадии:
(а) контактирование нуклеиновой кислоты, экстрагированной из биологического образца рыбы по меньшей мере с одним олигонуклеотидным праймером с образованием смеси, где по меньшей мере один олигонуклеотидный праймер комплементарен последовательности нуклеиновой кислоты, которая содержится в геноме вируса по любому из пп.18-25,
(b) определение того, присутствует ли продукт амплификации при подвергании смеси а) амплификации, где присутствие продукта амплификации указывает на присутствие РНК, ассоциированной с вирусом, и, следовательно, на присутствие вируса в биологическом образце.
38. Способ по п.37, где олигонуклеотидный праймер представляет собой олигонуклеотидный праймер по любому из пп. 26-34.
39. Способ по п.37 или 38, где нуклеиновую кислоту на стадии (а) способа, например РНК, экстрагируют из биологических образцов с использованием твердофазной экстракции, например, очистки на колонке с использованием твердой фазы из силикагелевой мембраны.
40. Способ по любому из пп.37, 38, где нуклеиновую кислоту на стадии (а) способа, например РНК, экстрагируют из биологических образцов с использованием экстракции смесью фенол/хлороформ.
41. Способ обнаружения вируса, который инфицирует рыбу и способен приводит к гибели рыбы, в частности, рыбу пинагор, включающий следующие стадии:
(а) секвенирование нуклеиновой кислоты, экстрагированной из биологического образца рыбы, и
(b) сравнение полученной последовательности нуклеиновой кислоты с последовательностью нуклеиновой кислоты, которая представляет собой или комплементарна референсной последовательности, выбранной из группы, состоящей из SEQ ID NO: 1, SEQ ID NO: 2, SEQ ID NO: 3, SEQ ID NO: 4, SEQ ID NO: 5 и SEQ ID NO: 6, где по меньшей мере 80% идентичность последовательности между двумя последовательностями указывает на присутствие вируса в биологическом образце.
42. Способ по п.41, где процент идентичности последовательности между двумя последовательностями, который указывает на присутствие вируса в биологическом образце, составляет по меньшей мере 85%, предпочтительно по меньшей мере 90%, более предпочтительно по меньшей мере 95%, еще более предпочтительно по меньшей мере 98%, еще более предпочтительно по меньшей мере 99% и особенно предпочтительно 100%.
43. Вирусный полипептид, содержащий аминокислотную последовательность, которая по меньшей мере на 80% идентична любой из SEQ ID NO: 7-11.
44. Вирусный полипептид по п.43, содержащий аминокислотную последовательность, которая по меньшей мере на 90% идентична любой из SEQ ID NO: 7-11.
45. Вирусный полипептид по п.43 или 44, содержащий аминокислотную последовательность, которая по меньшей мере на 95% идентична любой из SEQ ID NO: 7-11.
46. Вирусный полипептид по любому из пп.43-45, содержащий аминокислотную последовательность, содержащую любую из SEQ ID NO: 7-11 или ее консервативно замещенный вариант.
47. Вирусный полипептид по любому из пп.43-45, содержащий аминокислотную последовательность, содержащую SEQ ID NO: 7-11.
48. Антитело, которое связывается с полипептидом, где полипептид кодируется последовательностью нуклеиновой кислоты, которая содержится в геноме вируса по любому из пп.18-25, или представляет собой вирусный полипептид, кодируемый нуклеиновой кислотой по любому из пп.1-13 и 15-17.
49. Антитело, которое связывается с полипептидом, выбранным из группы, состоящей из:
(i) полипептида, содержащего аминокислотную последовательность, которая по меньшей мере на 80%, предпочтительно по меньшей мере 85%, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95%, еще более предпочтительно по меньшей мере на 98%, особенно предпочтительно по меньшей мере на 99% или даже на 100% идентична или представляет собой SEQ ID NO: 7;
(ii) полипептида, содержащего аминокислотную последовательность, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95%, еще более предпочтительно по меньшей мере на 98%, особенно предпочтительно, по меньшей мере на 99% или даже на 100% идентична или представляет собой SEQ ID NO: 8;
(iii) полипептида, содержащего аминокислотную последовательность, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95%, еще более предпочтительно по меньшей мере на 98%, особенно предпочтительно по меньшей мере на 99% или даже на 100% идентична или представляет собой SEQ ID NO: 9;
(iv) полипептида, содержащего аминокислотную последовательность, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95%, еще более предпочтительно по меньшей мере на 98%, особенно предпочтительно, по меньшей мере на 99% или даже на 100% идентична или представляет собой SEQ ID NO: 10; и
(v) полипептида, содержащего аминокислотную последовательность, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95%, еще более предпочтительно по меньшей мере на 98%, особенно предпочтительно по меньшей мере на 99% или даже на 100% идентична или представляет собой SEQ ID NO: 11.
50. Набор для обнаружения вируса в биологическом образце рыбы, где набор включает нуклеиновую кислоту по любому из пп.1-13 или 15-17, олигонуклеотидный праймер по любому из пп.26-34 и/или антитело по п.48 или 49.
51. Набор по п.50, где набор подходит для проведения или предназначен для применения в проведении анализа ОТ-ПЦР в режиме реального времени.
52. Антитело по п.48 или 49 для применения в лечении рыбы, инфицированной вирусом, в частности рыбы пинагор.
53. Антитело по п.52, где вирус представляет собой вирус по любому из пп.18-25.
54. Применение вируса по любому из пп.18-21 для получения вакцины.
55. Вакцина, содержащая:
(i) последовательность нуклеиновой кислоты, которая содержится в геноме вируса по любому из пп.18-25;
(ii) последовательность нуклеиновой кислоты по любому из пп.1-13 или 15-17;
(iii) вирусный полипептид, кодируемый последовательностью нуклеиновой кислоты, содержащейся в геноме вируса по любому из пп.18-25;
(iv) вирусный полипептид, кодируемый последовательностью нуклеиновой кислоты по любому из пп.1-13 или 15-17;
(v) вирусный полипептид по любому из пп.43-47, или
(vi) вирус по любому из пп.18-25.
56. Вакцина по п.55, где последовательность нуклеиновой кислоты представляет собой последовательность нуклеиновой кислоты, указанную в любом из пп.1-13 или 17, где указанная последовательность нуклеиновой кислоты содержит основание урацил (U) вместо основания тимин (Т).
57. Молекула интерферирующей РНК (iРНК) для применения в лечении рыб, инфицированных вирусом, в частности, рыбы пинагор, где молекула iРНК содержит по меньшей мере 12 (предпочтительно смежных) нуклеотидов или комплементарна последовательности нуклеиновой кислоты, содержащейся в геноме вируса по любому из пп.18-25.
58. Молекула интерферирующей РНК (iРНК) для применения в лечении рыб, инфицированных вирусом, в частности рыбы пинагор, где молекула iРНК содержит по меньшей мере 12 (предпочтительно смежных) нуклеотидов или комплементарна последовательности нуклеиновой кислоты, которая по меньшей мере на 80%, предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, еще более предпочтительно по меньшей мере на 95%, еще более предпочтительно на 98%, особенно предпочтительно на 99% или даже на 100% идентична последовательности вирусного генома согласно SEQ ID NO: 6 (CLuTV).
59. Интерферирующая РНК по п.57 или 58, где указанная молекула iРНК содержит по меньшей мере 15, и более предпочтительно по меньшей мере 18 указанных (предпочтительно смежных) нуклеотидов.
Специалисты в данной области понимают или смогут определить, используя не более чем рутинные эксперименты и/или общеизвестные общие знания, многочисленные эквиваленты конкретных аспектов, элементов и вариантов осуществления, раскрытых здесь как в примерах, так и в основной части полного описания патента. Такие эквиваленты считаются входящими в объем данного изобретения и предназначены для охвата следующей формулой изобретения или любой формулой изобретения, которая может быть реализована на основе настоящего раскрытия.
--->
Список последовательностей
<110> Pharmaq Analytiq
<120> Новый Totivirus рыб
<130> ZOE20234PCT
<160> 49
<170> BiSSAP 1.3.6
<210> 1
<211> 2484
<212> ДНК
<213> Вирусы
<220>
<223> Нуклеотидная последовательность ORF-1
<400> 1
atggacgcaa acaaagaaac acaaataaca gaggagaaag taggagagga ggttacctta 60
caggtggaag taagggagga agatacggga ttactccaag acccaacgag taaagaagcc 120
ctgacaaaac tgatcaccga cctagccaaa aaacaaaggg aggtggtctc tgatgcaacc 180
gatttcgggt tggacatcgc aacaactcta cagtcaagac agtcaaacag tcagttccac 240
gtgttgagag aaggaaatgt agataccagg atagcatcgg agagaggatc aacaacacac 300
acaagaaggc ttgccactat tggtaacgtg gagccatgct ggttcagaac agcaccgggt 360
gttagggggg ggatattgat tgaaccctca aacgctgttc tggctctgaa acctctcttc 420
cagggtgcag accccggacc tctttcaagt agtgcccgtt tggatattaa caactattca 480
tcccagacgg cccttggctt catgaacagc attggagcag acatcgaaag taacagggtt 540
tcattttctg agccgttgat tcgcgccttc atcttctcaa ttgatgatca tataagaggt 600
gaatcacccc tctcgtggtt ggggaacaga acgacgcttt tgccgcgccc acttggtaca 660
ttacctagtg gggattactt tccagcatct gtaagatcag ctggatgggt ggcgggagac 720
acacaggcta tgattgtgaa cgctgaagac tttgcaaggg aggcaagggg cgaggagagg 780
ttcaatgacg gttggggggc aacagtatgg aatgtaccag gagtagaagg tgtggcagtt 840
gttcccatta aactcgcaga ccaaggagat ccagcaatca attctatctg gatgctcatg 900
cacatggaaa atccaatccg tacaaggttt gttgaggttg atgaggttga catgttgctg 960
gatgatcctc aggtgggttc agaatggaca aatctttcaa catctgttgt tccgggaccg 1020
tcaaagaagg ttctcttcgt gatcactgac atgaacaaca accagagtgg ggacatactc 1080
ctggacgatt tcaacggtgc tgttgacaac atcgaccaag cagccaacgt cataggagga 1140
gtgccggtcg acatcggagc actaatacct gcctggatgg ggttggatcc tgatcgtcgg 1200
tcagagttgg ggattgctgg agtgaggaga tggacaaggt actatgggaa cacacaggac 1260
tgggaggctt cactagccat cgtgagtgag atgctcgtca ctttccctgg acaggtacag 1320
aggtcaggaa gaacaggtgc tgagaatcac tatgctgatg caggaggagg gattgcccaa 1380
tacccactga atggtattga tgtggtgttg tatgatgggt tgacggctgc agagaagtta 1440
gcattagctg gaagagagtc tgacatcatg actacaccag cttcgggcta caggcagcga 1500
tcaaacaatc caaacacttc gcctccaatg ctcctatact gtcggttttc ctcagaagca 1560
gccgtggctg taagtgctct actctataag cccaggttca caatgaccat cggaaatgag 1620
ttgagacctg ccatcctggc tgataacatc tacaggagag gaaagagaac agcagtcatg 1680
gtggacatca tcgcaggcca gataggtgca gtttctagga tgaccaacac cccagggaac 1740
tcagaacaac cagcagtggc tcaagccatt gttcgtcaac tagcaggctg tgccacacgt 1800
ctacatcagg aaacttgtgc tggtgagcta gtgaacatca ctgtctctgg gtggaataac 1860
caacaaggtc agattgcatg gagaaacctt tacacggatg gccgtgacag aacactgagc 1920
tgcagggtac cacggatgga gtacaactcg ctgggatttg atggaaggat ggaaatcgat 1980
gacctctaca acttcaaaac agagggattc gacgcacttg acattgatgg gcagcagtgg 2040
gatcacatga attggaaaac tccacatcaa aaggaagacg gacaggtcac cgcacgaagg 2100
ctgacttcag cagcaggatg gacaagggct cttgttccac ttgacaacat cggtcttgta 2160
agggctaacg gagcagagtt cgcaccactc ggagtacatg tcctaaaccc aacagttgga 2220
agaggaaagg aagtaagata ttccaactat ggatttgtac cactcgcaag cgagatccga 2280
gagttgccac tggtcacaca ggtaccttca cagaacgatg ccaatcacat cattcaccct 2340
gcagttcgcg gtggaaggcc tctggtgtta ggaaacatgg gaatgttcaa tccaatcttc 2400
atggacagaa ctccgggaca aagagcatcc cagaatccca caaccgacac acagaccgtg 2460
aacaacgcca ccgtcctgga tttc 2484
<210> 2
<211> 1941
<212> ДНК
<213> Вирусы
<220>
<223> Нуклеотидная последовательность ORF-2
<400> 2
atgacaattt taatcaattt tattagagaa aacaaacttg acccatcaaa ggtgttcaaa 60
aatttaacaa acaaggtaaa gttggctggt gagggattca gtagtgactg gaggtattat 120
gtgaactggg aattacttgg tggataccag gatctcgagg aacacgacat gattgaggaa 180
gtaagggctt ttacaacgca ggaagcaaag tcggcagagt tcggagggcc ggttgttaaa 240
gcattggaag aacttcttgc ccctttatca ggagtggtac gttcaaagag aactttggag 300
gagttcctac tggacagaga tgcatgggcg aagaatacat caggttttgt tacaagtaac 360
atcaagaaag gaaagaacaa gattgaggtt gcagagaaca tggacatcaa agagctactg 420
gagatagttt accttggaga atatcaaaac aggccattta taaaacaaga accaggaaaa 480
gccaggccgg tagttaattc aaacttaccg ccctaccttt tcatgagttg ggttttcgaa 540
caaatcgagc ccattttgag gaaaaacttt tcatcaaaaa ctaccatctt cgattcagca 600
tggacaaaga gtgagttgtg gcatcaaatg acagacgacg tcaggtataa gaaaggaatt 660
ttcgttccgc ttgactattc gagattcgat tcaacaatta gtaaagaact agctgtaaca 720
gcattcaata tgctagttga catactcgtc gacatcccct ctgatctgcg aaggtcagcc 780
aaatacaggt tcaggaatca agtgattctg acgggtgagg aaagttggac gtggaacaat 840
gccgttcttt cgggatggcg ttggactgct ctgattacat cattagtcaa tctcgcaatc 900
ctagaagctg cagaggttac cagaacaggg acgggaatta gagtacaagg ggacgacgtg 960
cgtgttttct ttcaaaagaa aggagatgca gaaattgcaa ttgcgaaaat caactcattc 1020
ggtttcgaaa tcaatccaac aaaagtcttt tgctcgaaaa ggagagatga gtatctaaga 1080
atggtagcaa cggatgaatt acgtggttac ccaattaggt cactcccaaa aatattgttt 1140
gtgggaccaa ctgaaacact taccgacaga tcagaagaca gagtaaatgg aatagtcaac 1200
aaatggacaa cactggtgtc aagaggagga aatgagagta ggtgctggaa gatgcttgtt 1260
accgatattg cgggtttaac ccaatggtca cgtgataaca tcaagaagtg gcttcaaaca 1320
ccttcagcac tgggtggtgc aggactgttc cagaacacaa cgtcacaagg aattagactc 1380
aaaatcaaaa cagagattaa ggaggatttg ggaacttaca agctggcgag tgattacccg 1440
ggagacttgg gaaatttatg ggccagaggt aggaactcaa aatccaagct attgtctgca 1500
caattagaag aaatccacat tccacagcca ttaggagttt ggccaaacgc tttcatcttt 1560
acaaagaaga agaagcccac agttaggttc aaagaagaag cattaggatc cacaaaacgt 1620
gacgccttga ttagggataa ggattgggat gcacttgaag atttggttga gaataagtct 1680
gaggtattgt tttggaagag agtgctcccc agatttttct atcgtatgtt gcttgtcgaa 1740
ggaggttttt caactcctat tccaaaaaca ctcgtgaata atgaaatagt tgctacggtc 1800
tcagctttcg tagcgtggta tacttttgaa aagatcatga agtataatgg aatattgagt 1860
ggtgaaaagc tccagagact tcaacttggg gcagagtact attcaagatt cttactggac 1920
tcattcaaac gctttggtaa a 1941
<210> 3
<211> 270
<212> ДНК
<213> Вирусы
<220>
<223> Нуклеотидная последовательность ORF-X
<400> 3
atggaaaatg aaaagaacgt aagagtaggt agttgttaca gtgtaagtgc tgtgtttgga 60
tctacaatct gtacagcaca agacaacact gcaggtggag atttggaggc taagcagagc 120
tgggattcac cagttgtgac ggcgatgata gtgatcggag tcgtggcatt cattctgatg 180
gtggtgtgga tgttgagagg agcctgcaag ggctacaccg ttgtgaagag accgcatggg 240
aacgaagagg ctctccaact tcaggacgta 270
<210> 4
<211> 354
<212> ДНК
<213> Вирусы
<220>
<223> Нуклеотидная последовательность ORF-Y
<400> 4
atgtcagtga tgtgggataa cgaatggata aggttgagta gggttagcag gagttctgtt 60
gccgtgaaaa gaaatatata cggtgaacgg gttgaacgct tactactcag ctttggatca 120
gaggcttctg tcttcgaatg gtttggagta gaggaagaag attaccacag gatacgtctg 180
gcattcagag ttattgccca ctgggttatt cactctgaac ttttggaagt aggaggaggg 240
tatacagtct ggagaaatga agatgaccct cgtgaccggg atgcggagtg ggagttctgt 300
tacaccttaa gagttcatgg gagaatggct aactcttcag gcagaagatc agga 354
<210> 5
<211> 336
<212> ДНК
<213> Вирусы
<220>
<223> Нуклеотидная последовательность ORF-Z
<400> 5
atgatagttt actctttcaa aaaccacaac cagttgacct ttgcactgga agagcagggt 60
gtggctaatg tcatagttca actagatgac aagtggaagg aggtaacatt tcaacaccat 120
gagaggaaag agttggttca gtttctactc actctcggta aatatgtcga taaagaatta 180
tgtacaacag tactcgactt ggaaattacc gaagaagatg atcttgagta tgaaaaggaa 240
taccaggtga atggtgaaat cttgaccttt tggtctgcag aggttgaagg gaaagaagtc 300
attaatgcaa tgacaatgga gatggaatgt ctcaat 336
<210> 6
<211> 6353
<212> ДНК
<213> Вирусы
<220>
<223> Нуклеотидная последовательность генома
<400> 6
gttagatttg ttttccagtg aggttggttg acggcgcctc accgtaacac tccgtcgggt 60
tcacacgccg ccacgtgtgt cccacccacc actccctccg gtagagtgga ccggttttcg 120
ctggccagat tgagccctgg tcggtagtcg ggtaacatcg cttaaagggt actgtaggcg 180
tctgaaagca cggattcgac actgtgccgt atggcggtcc tgtccacggt actctactta 240
acttcgcccc cttggaggac cgtacaggtc tgacgtgagg aacttctctg aagtgaccac 300
aagcgtcgca gtaattgcta gagggaaaga gctgacgggt tgttgagtat tcagtttcta 360
atataccatg gacgcaaaca aagaaacaca aataacagag gagaaagtag gagaggaggt 420
taccttacag gtggaagtaa gggaggaaga tacgggatta ctccaagacc caacgagtaa 480
agaagccctg acaaaactga tcaccgacct agccaaaaaa caaagggagg tggtctctga 540
tgcaaccgat ttcgggttgg acatcgcaac aactctacag tcaagacagt caaacagtca 600
gttccacgtg ttgagagaag gaaatgtaga taccaggata gcatcggaga gaggatcaac 660
aacacacaca agaaggcttg ccactattgg taacgtggag ccatgctggt tcagaacagc 720
accgggtgtt agggggggga tattgattga accctcaaac gctgttctgg ctctgaaacc 780
tctcttccag ggtgcagacc ccggacctct ttcaagtagt gcccgtttgg atattaacaa 840
ctattcatcc cagacggccc ttggcttcat gaacagcatt ggagcagaca tcgaaagtaa 900
cagggtttca ttttctgagc cgttgattcg cgccttcatc ttctcaattg atgatcatat 960
aagaggtgaa tcacccctct cgtggttggg gaacagaacg acgcttttgc cgcgcccact 1020
tggtacatta cctagtgggg attactttcc agcatctgta agatcagctg gatgggtggc 1080
gggagacaca caggctatga ttgtgaacgc tgaagacttt gcaagggagg caaggggcga 1140
ggagaggttc aatgacggtt ggggggcaac agtatggaat gtaccaggag tagaaggtgt 1200
ggcagttgtt cccattaaac tcgcagacca aggagatcca gcaatcaatt ctatctggat 1260
gctcatgcac atggaaaatc caatccgtac aaggtttgtt gaggttgatg aggttgacat 1320
gttgctggat gatcctcagg tgggttcaga atggacaaat ctttcaacat ctgttgttcc 1380
gggaccgtca aagaaggttc tcttcgtgat cactgacatg aacaacaacc agagtgggga 1440
catactcctg gacgatttca acggtgctgt tgacaacatc gaccaagcag ccaacgtcat 1500
aggaggagtg ccggtcgaca tcggagcact aatacctgcc tggatggggt tggatcctga 1560
tcgtcggtca gagttgggga ttgctggagt gaggagatgg acaaggtact atgggaacac 1620
acaggactgg gaggcttcac tagccatcgt gagtgagatg ctcgtcactt tccctggaca 1680
ggtacagagg tcaggaagaa caggtgctga gaatcactat gctgatgcag gaggagggat 1740
tgcccaatac ccactgaatg gtattgatgt ggtgttgtat gatgggttga cggctgcaga 1800
gaagttagca ttagctggaa gagagtctga catcatgact acaccagctt cgggctacag 1860
gcagcgatca aacaatccaa acacttcgcc tccaatgctc ctatactgtc ggttttcctc 1920
agaagcagcc gtggctgtaa gtgctctact ctataagccc aggttcacaa tgaccatcgg 1980
aaatgagttg agacctgcca tcctggctga taacatctac aggagaggaa agagaacagc 2040
agtcatggtg gacatcatcg caggccagat aggtgcagtt tctaggatga ccaacacccc 2100
agggaactca gaacaaccag cagtggctca agccattgtt cgtcaactag caggctgtgc 2160
cacacgtcta catcaggaaa cttgtgctgg tgagctagtg aacatcactg tctctgggtg 2220
gaataaccaa caaggtcaga ttgcatggag aaacctttac acggatggcc gtgacagaac 2280
actgagctgc agggtaccac ggatggagta caactcgctg ggatttgatg gaaggatgga 2340
aatcgatgac ctctacaact tcaaaacaga gggattcgac gcacttgaca ttgatgggca 2400
gcagtgggat cacatgaatt ggaaaactcc acatcaaaag gaagacggac aggtcaccgc 2460
acgaaggctg acttcagcag caggatggac aagggctctt gttccacttg acaacatcgg 2520
tcttgtaagg gctaacggag cagagttcgc accactcgga gtacatgtcc taaacccaac 2580
agttggaaga ggaaaggaag taagatattc caactatgga tttgtaccac tcgcaagcga 2640
gatccgagag ttgccactgg tcacacaggt accttcacag aacgatgcca atcacatcat 2700
tcaccctgca gttcgcggtg gaaggcctct ggtgttagga aacatgggaa tgttcaatcc 2760
aatcttcatg gacagaactc cgggacaaag agcatcccag aatcccacaa ccgacacaca 2820
gaccgtgaac aacgccaccg tcctggattt ctagtaaggg ggagcacgct tcctccttac 2880
cgcgtggacc tacgattcga cccattcttc aaaaattgac aaagaatttc taaaaagaac 2940
aattaggtac taaaatcgac aattgggaag ataacataac atttggaaca acggagaaat 3000
ttaagagtag tggagaacta cctggttggg gaaaaagtgg gtggagaaga ggactgtggt 3060
tggcgttaca agttgttccc cgtgaagtaa aaaatgagat gacaatttta atcaatttta 3120
ttagagaaaa caaacttgac ccatcaaagg tgttcaaaaa tttaacaaac aaggtaaagt 3180
tggctggtga gggattcagt agtgactgga ggtattatgt gaactgggaa ttacttggtg 3240
gataccagga tctcgaggaa cacgacatga ttgaggaagt aagggctttt acaacgcagg 3300
aagcaaagtc ggcagagttc ggagggccgg ttgttaaagc attggaagaa cttcttgccc 3360
ctttatcagg agtggtacgt tcaaagagaa ctttggagga gttcctactg gacagagatg 3420
catgggcgaa gaatacatca ggttttgtta caagtaacat caagaaagga aagaacaaga 3480
ttgaggttgc agagaacatg gacatcaaag agctactgga gatagtttac cttggagaat 3540
atcaaaacag gccatttata aaacaagaac caggaaaagc caggccggta gttaattcaa 3600
acttaccgcc ctaccttttc atgagttggg ttttcgaaca aatcgagccc attttgagga 3660
aaaacttttc atcaaaaact accatcttcg attcagcatg gacaaagagt gagttgtggc 3720
atcaaatgac agacgacgtc aggtataaga aaggaatttt cgttccgctt gactattcga 3780
gattcgattc aacaattagt aaagaactag ctgtaacagc attcaatatg ctagttgaca 3840
tactcgtcga catcccctct gatctgcgaa ggtcagccaa atacaggttc aggaatcaag 3900
tgattctgac gggtgaggaa agttggacgt ggaacaatgc cgttctttcg ggatggcgtt 3960
ggactgctct gattacatca ttagtcaatc tcgcaatcct agaagctgca gaggttacca 4020
gaacagggac gggaattaga gtacaagggg acgacgtgcg tgttttcttt caaaagaaag 4080
gagatgcaga aattgcaatt gcgaaaatca actcattcgg tttcgaaatc aatccaacaa 4140
aagtcttttg ctcgaaaagg agagatgagt atctaagaat ggtagcaacg gatgaattac 4200
gtggttaccc aattaggtca ctcccaaaaa tattgtttgt gggaccaact gaaacactta 4260
ccgacagatc agaagacaga gtaaatggaa tagtcaacaa atggacaaca ctggtgtcaa 4320
gaggaggaaa tgagagtagg tgctggaaga tgcttgttac cgatattgcg ggtttaaccc 4380
aatggtcacg tgataacatc aagaagtggc ttcaaacacc ttcagcactg ggtggtgcag 4440
gactgttcca gaacacaacg tcacaaggaa ttagactcaa aatcaaaaca gagattaagg 4500
aggatttggg aacttacaag ctggcgagtg attacccggg agacttggga aatttatggg 4560
ccagaggtag gaactcaaaa tccaagctat tgtctgcaca attagaagaa atccacattc 4620
cacagccatt aggagtttgg ccaaacgctt tcatctttac aaagaagaag aagcccacag 4680
ttaggttcaa agaagaagca ttaggatcca caaaacgtga cgccttgatt agggataagg 4740
attgggatgc acttgaagat ttggttgaga ataagtctga ggtattgttt tggaagagag 4800
tgctccccag atttttctat cgtatgttgc ttgtcgaagg aggtttttca actcctattc 4860
caaaaacact cgtgaataat gaaatagttg ctacggtctc agctttcgta gcgtggtata 4920
cttttgaaaa gatcatgaag tataatggaa tattgagtgg tgaaaagctc cagagacttc 4980
aacttggggc agagtactat tcaagattct tactggactc attcaaacgc tttggtaaat 5040
aatgcaatgt acgggagtcg gtcaggaccg tacagtatca acacgaatgt agatttgttc 5100
tacgacggtg ggcaaatagt tgctaaacgg taagtccatc cgaggcggct tacctgtagt 5160
taccctggag acaaagggaa taaacacgaa gtgtgaccct cctagtaagg cccaggaacg 5220
tgccgcgtaa ctatgggtat cggcaataca tgacaaaatg gaaaatgaaa agaacgtaag 5280
agtaggtagt tgttacagtg taagtgctgt gtttggatct acaatctgta cagcacaaga 5340
caacactgca ggtggagatt tggaggctaa gcagagctgg gattcaccag ttgtgacggc 5400
gatgatagtg atcggagtcg tggcattcat tctgatggtg gtgtggatgt tgagaggagc 5460
ctgcaagggc tacaccgttg tgaagagacc gcatgggaac gaagaggctc tccaacttca 5520
ggacgtataa tgtcagtgat gtgggataac gaatggataa ggttgagtag ggttagcagg 5580
agttctgttg ccgtgaaaag aaatatatac ggtgaacggg ttgaacgctt actactcagc 5640
tttggatcag aggcttctgt cttcgaatgg tttggagtag aggaagaaga ttaccacagg 5700
atacgtctgg cattcagagt tattgcccac tgggttattc actctgaact tttggaagta 5760
ggaggagggt atacagtctg gagaaatgaa gatgaccctc gtgaccggga tgcggagtgg 5820
gagttctgtt acaccttaag agttcatggg agaatggcta actcttcagg cagaagatca 5880
ggatgatagt ttactctttc aaaaaccaca accagttgac ctttgcactg gaagagcagg 5940
gtgtggctaa tgtcatagtt caactagatg acaagtggaa ggaggtaaca tttcaacacc 6000
atgagaggaa agagttggtt cagtttctac tcactctcgg taaatatgtc gataaagaat 6060
tatgtacaac agtactcgac ttggaaatta ccgaagaaga tgatcttgag tatgaaaagg 6120
aataccaggt gaatggtgaa atcttgacct tttggtctgc agaggttgaa gggaaagaag 6180
tcattaatgc aatgacaatg gagatggaat gtctcaatta attctctctt atagagaggc 6240
acagcatcac acaacacaca ctcacacaca ccaacgcaca cactaggctg gcgggcctat 6300
aggagtaccc ctgactccga atataaatct aatgggggcc tgtagttaag cac 6353
<210> 7
<211> 828
<212> БЕЛОК
<213> Вирусы
<220>
<223> Аминокислотная последовательность ORF-1
<400> 7
Met Asp Ala Asn Lys Glu Thr Gln Ile Thr Glu Glu Lys Val Gly Glu
1 5 10 15
Glu Val Thr Leu Gln Val Glu Val Arg Glu Glu Asp Thr Gly Leu Leu
20 25 30
Gln Asp Pro Thr Ser Lys Glu Ala Leu Thr Lys Leu Ile Thr Asp Leu
35 40 45
Ala Lys Lys Gln Arg Glu Val Val Ser Asp Ala Thr Asp Phe Gly Leu
50 55 60
Asp Ile Ala Thr Thr Leu Gln Ser Arg Gln Ser Asn Ser Gln Phe His
65 70 75 80
Val Leu Arg Glu Gly Asn Val Asp Thr Arg Ile Ala Ser Glu Arg Gly
85 90 95
Ser Thr Thr His Thr Arg Arg Leu Ala Thr Ile Gly Asn Val Glu Pro
100 105 110
Cys Trp Phe Arg Thr Ala Pro Gly Val Arg Gly Gly Ile Leu Ile Glu
115 120 125
Pro Ser Asn Ala Val Leu Ala Leu Lys Pro Leu Phe Gln Gly Ala Asp
130 135 140
Pro Gly Pro Leu Ser Ser Ser Ala Arg Leu Asp Ile Asn Asn Tyr Ser
145 150 155 160
Ser Gln Thr Ala Leu Gly Phe Met Asn Ser Ile Gly Ala Asp Ile Glu
165 170 175
Ser Asn Arg Val Ser Phe Ser Glu Pro Leu Ile Arg Ala Phe Ile Phe
180 185 190
Ser Ile Asp Asp His Ile Arg Gly Glu Ser Pro Leu Ser Trp Leu Gly
195 200 205
Asn Arg Thr Thr Leu Leu Pro Arg Pro Leu Gly Thr Leu Pro Ser Gly
210 215 220
Asp Tyr Phe Pro Ala Ser Val Arg Ser Ala Gly Trp Val Ala Gly Asp
225 230 235 240
Thr Gln Ala Met Ile Val Asn Ala Glu Asp Phe Ala Arg Glu Ala Arg
245 250 255
Gly Glu Glu Arg Phe Asn Asp Gly Trp Gly Ala Thr Val Trp Asn Val
260 265 270
Pro Gly Val Glu Gly Val Ala Val Val Pro Ile Lys Leu Ala Asp Gln
275 280 285
Gly Asp Pro Ala Ile Asn Ser Ile Trp Met Leu Met His Met Glu Asn
290 295 300
Pro Ile Arg Thr Arg Phe Val Glu Val Asp Glu Val Asp Met Leu Leu
305 310 315 320
Asp Asp Pro Gln Val Gly Ser Glu Trp Thr Asn Leu Ser Thr Ser Val
325 330 335
Val Pro Gly Pro Ser Lys Lys Val Leu Phe Val Ile Thr Asp Met Asn
340 345 350
Asn Asn Gln Ser Gly Asp Ile Leu Leu Asp Asp Phe Asn Gly Ala Val
355 360 365
Asp Asn Ile Asp Gln Ala Ala Asn Val Ile Gly Gly Val Pro Val Asp
370 375 380
Ile Gly Ala Leu Ile Pro Ala Trp Met Gly Leu Asp Pro Asp Arg Arg
385 390 395 400
Ser Glu Leu Gly Ile Ala Gly Val Arg Arg Trp Thr Arg Tyr Tyr Gly
405 410 415
Asn Thr Gln Asp Trp Glu Ala Ser Leu Ala Ile Val Ser Glu Met Leu
420 425 430
Val Thr Phe Pro Gly Gln Val Gln Arg Ser Gly Arg Thr Gly Ala Glu
435 440 445
Asn His Tyr Ala Asp Ala Gly Gly Gly Ile Ala Gln Tyr Pro Leu Asn
450 455 460
Gly Ile Asp Val Val Leu Tyr Asp Gly Leu Thr Ala Ala Glu Lys Leu
465 470 475 480
Ala Leu Ala Gly Arg Glu Ser Asp Ile Met Thr Thr Pro Ala Ser Gly
485 490 495
Tyr Arg Gln Arg Ser Asn Asn Pro Asn Thr Ser Pro Pro Met Leu Leu
500 505 510
Tyr Cys Arg Phe Ser Ser Glu Ala Ala Val Ala Val Ser Ala Leu Leu
515 520 525
Tyr Lys Pro Arg Phe Thr Met Thr Ile Gly Asn Glu Leu Arg Pro Ala
530 535 540
Ile Leu Ala Asp Asn Ile Tyr Arg Arg Gly Lys Arg Thr Ala Val Met
545 550 555 560
Val Asp Ile Ile Ala Gly Gln Ile Gly Ala Val Ser Arg Met Thr Asn
565 570 575
Thr Pro Gly Asn Ser Glu Gln Pro Ala Val Ala Gln Ala Ile Val Arg
580 585 590
Gln Leu Ala Gly Cys Ala Thr Arg Leu His Gln Glu Thr Cys Ala Gly
595 600 605
Glu Leu Val Asn Ile Thr Val Ser Gly Trp Asn Asn Gln Gln Gly Gln
610 615 620
Ile Ala Trp Arg Asn Leu Tyr Thr Asp Gly Arg Asp Arg Thr Leu Ser
625 630 635 640
Cys Arg Val Pro Arg Met Glu Tyr Asn Ser Leu Gly Phe Asp Gly Arg
645 650 655
Met Glu Ile Asp Asp Leu Tyr Asn Phe Lys Thr Glu Gly Phe Asp Ala
660 665 670
Leu Asp Ile Asp Gly Gln Gln Trp Asp His Met Asn Trp Lys Thr Pro
675 680 685
His Gln Lys Glu Asp Gly Gln Val Thr Ala Arg Arg Leu Thr Ser Ala
690 695 700
Ala Gly Trp Thr Arg Ala Leu Val Pro Leu Asp Asn Ile Gly Leu Val
705 710 715 720
Arg Ala Asn Gly Ala Glu Phe Ala Pro Leu Gly Val His Val Leu Asn
725 730 735
Pro Thr Val Gly Arg Gly Lys Glu Val Arg Tyr Ser Asn Tyr Gly Phe
740 745 750
Val Pro Leu Ala Ser Glu Ile Arg Glu Leu Pro Leu Val Thr Gln Val
755 760 765
Pro Ser Gln Asn Asp Ala Asn His Ile Ile His Pro Ala Val Arg Gly
770 775 780
Gly Arg Pro Leu Val Leu Gly Asn Met Gly Met Phe Asn Pro Ile Phe
785 790 795 800
Met Asp Arg Thr Pro Gly Gln Arg Ala Ser Gln Asn Pro Thr Thr Asp
805 810 815
Thr Gln Thr Val Asn Asn Ala Thr Val Leu Asp Phe
820 825
<210> 8
<211> 647
<212> БЕЛОК
<213> Вирусы
<220>
<223> Аминокислотная последовательность ORF-2
<400> 8
Met Thr Ile Leu Ile Asn Phe Ile Arg Glu Asn Lys Leu Asp Pro Ser
1 5 10 15
Lys Val Phe Lys Asn Leu Thr Asn Lys Val Lys Leu Ala Gly Glu Gly
20 25 30
Phe Ser Ser Asp Trp Arg Tyr Tyr Val Asn Trp Glu Leu Leu Gly Gly
35 40 45
Tyr Gln Asp Leu Glu Glu His Asp Met Ile Glu Glu Val Arg Ala Phe
50 55 60
Thr Thr Gln Glu Ala Lys Ser Ala Glu Phe Gly Gly Pro Val Val Lys
65 70 75 80
Ala Leu Glu Glu Leu Leu Ala Pro Leu Ser Gly Val Val Arg Ser Lys
85 90 95
Arg Thr Leu Glu Glu Phe Leu Leu Asp Arg Asp Ala Trp Ala Lys Asn
100 105 110
Thr Ser Gly Phe Val Thr Ser Asn Ile Lys Lys Gly Lys Asn Lys Ile
115 120 125
Glu Val Ala Glu Asn Met Asp Ile Lys Glu Leu Leu Glu Ile Val Tyr
130 135 140
Leu Gly Glu Tyr Gln Asn Arg Pro Phe Ile Lys Gln Glu Pro Gly Lys
145 150 155 160
Ala Arg Pro Val Val Asn Ser Asn Leu Pro Pro Tyr Leu Phe Met Ser
165 170 175
Trp Val Phe Glu Gln Ile Glu Pro Ile Leu Arg Lys Asn Phe Ser Ser
180 185 190
Lys Thr Thr Ile Phe Asp Ser Ala Trp Thr Lys Ser Glu Leu Trp His
195 200 205
Gln Met Thr Asp Asp Val Arg Tyr Lys Lys Gly Ile Phe Val Pro Leu
210 215 220
Asp Tyr Ser Arg Phe Asp Ser Thr Ile Ser Lys Glu Leu Ala Val Thr
225 230 235 240
Ala Phe Asn Met Leu Val Asp Ile Leu Val Asp Ile Pro Ser Asp Leu
245 250 255
Arg Arg Ser Ala Lys Tyr Arg Phe Arg Asn Gln Val Ile Leu Thr Gly
260 265 270
Glu Glu Ser Trp Thr Trp Asn Asn Ala Val Leu Ser Gly Trp Arg Trp
275 280 285
Thr Ala Leu Ile Thr Ser Leu Val Asn Leu Ala Ile Leu Glu Ala Ala
290 295 300
Glu Val Thr Arg Thr Gly Thr Gly Ile Arg Val Gln Gly Asp Asp Val
305 310 315 320
Arg Val Phe Phe Gln Lys Lys Gly Asp Ala Glu Ile Ala Ile Ala Lys
325 330 335
Ile Asn Ser Phe Gly Phe Glu Ile Asn Pro Thr Lys Val Phe Cys Ser
340 345 350
Lys Arg Arg Asp Glu Tyr Leu Arg Met Val Ala Thr Asp Glu Leu Arg
355 360 365
Gly Tyr Pro Ile Arg Ser Leu Pro Lys Ile Leu Phe Val Gly Pro Thr
370 375 380
Glu Thr Leu Thr Asp Arg Ser Glu Asp Arg Val Asn Gly Ile Val Asn
385 390 395 400
Lys Trp Thr Thr Leu Val Ser Arg Gly Gly Asn Glu Ser Arg Cys Trp
405 410 415
Lys Met Leu Val Thr Asp Ile Ala Gly Leu Thr Gln Trp Ser Arg Asp
420 425 430
Asn Ile Lys Lys Trp Leu Gln Thr Pro Ser Ala Leu Gly Gly Ala Gly
435 440 445
Leu Phe Gln Asn Thr Thr Ser Gln Gly Ile Arg Leu Lys Ile Lys Thr
450 455 460
Glu Ile Lys Glu Asp Leu Gly Thr Tyr Lys Leu Ala Ser Asp Tyr Pro
465 470 475 480
Gly Asp Leu Gly Asn Leu Trp Ala Arg Gly Arg Asn Ser Lys Ser Lys
485 490 495
Leu Leu Ser Ala Gln Leu Glu Glu Ile His Ile Pro Gln Pro Leu Gly
500 505 510
Val Trp Pro Asn Ala Phe Ile Phe Thr Lys Lys Lys Lys Pro Thr Val
515 520 525
Arg Phe Lys Glu Glu Ala Leu Gly Ser Thr Lys Arg Asp Ala Leu Ile
530 535 540
Arg Asp Lys Asp Trp Asp Ala Leu Glu Asp Leu Val Glu Asn Lys Ser
545 550 555 560
Glu Val Leu Phe Trp Lys Arg Val Leu Pro Arg Phe Phe Tyr Arg Met
565 570 575
Leu Leu Val Glu Gly Gly Phe Ser Thr Pro Ile Pro Lys Thr Leu Val
580 585 590
Asn Asn Glu Ile Val Ala Thr Val Ser Ala Phe Val Ala Trp Tyr Thr
595 600 605
Phe Glu Lys Ile Met Lys Tyr Asn Gly Ile Leu Ser Gly Glu Lys Leu
610 615 620
Gln Arg Leu Gln Leu Gly Ala Glu Tyr Tyr Ser Arg Phe Leu Leu Asp
625 630 635 640
Ser Phe Lys Arg Phe Gly Lys
645
<210> 9
<211> 90
<212> БЕЛОК
<213> Вирусы
<220>
<223> Аминокислотная последовательность ORF-X
<400> 9
Met Glu Asn Glu Lys Asn Val Arg Val Gly Ser Cys Tyr Ser Val Ser
1 5 10 15
Ala Val Phe Gly Ser Thr Ile Cys Thr Ala Gln Asp Asn Thr Ala Gly
20 25 30
Gly Asp Leu Glu Ala Lys Gln Ser Trp Asp Ser Pro Val Val Thr Ala
35 40 45
Met Ile Val Ile Gly Val Val Ala Phe Ile Leu Met Val Val Trp Met
50 55 60
Leu Arg Gly Ala Cys Lys Gly Tyr Thr Val Val Lys Arg Pro His Gly
65 70 75 80
Asn Glu Glu Ala Leu Gln Leu Gln Asp Val
85 90
<210> 10
<211> 118
<212> БЕЛОК
<213> Вирусы
<220>
<223> Аминокислотная последовательность ORF-Y
<400> 10
Met Ser Val Met Trp Asp Asn Glu Trp Ile Arg Leu Ser Arg Val Ser
1 5 10 15
Arg Ser Ser Val Ala Val Lys Arg Asn Ile Tyr Gly Glu Arg Val Glu
20 25 30
Arg Leu Leu Leu Ser Phe Gly Ser Glu Ala Ser Val Phe Glu Trp Phe
35 40 45
Gly Val Glu Glu Glu Asp Tyr His Arg Ile Arg Leu Ala Phe Arg Val
50 55 60
Ile Ala His Trp Val Ile His Ser Glu Leu Leu Glu Val Gly Gly Gly
65 70 75 80
Tyr Thr Val Trp Arg Asn Glu Asp Asp Pro Arg Asp Arg Asp Ala Glu
85 90 95
Trp Glu Phe Cys Tyr Thr Leu Arg Val His Gly Arg Met Ala Asn Ser
100 105 110
Ser Gly Arg Arg Ser Gly
115
<210> 11
<211> 112
<212> БЕЛОК
<213> Вирусы
<220>
<223> Аминокислотная последовательность ORF-Z
<400> 11
Met Ile Val Tyr Ser Phe Lys Asn His Asn Gln Leu Thr Phe Ala Leu
1 5 10 15
Glu Glu Gln Gly Val Ala Asn Val Ile Val Gln Leu Asp Asp Lys Trp
20 25 30
Lys Glu Val Thr Phe Gln His His Glu Arg Lys Glu Leu Val Gln Phe
35 40 45
Leu Leu Thr Leu Gly Lys Tyr Val Asp Lys Glu Leu Cys Thr Thr Val
50 55 60
Leu Asp Leu Glu Ile Thr Glu Glu Asp Asp Leu Glu Tyr Glu Lys Glu
65 70 75 80
Tyr Gln Val Asn Gly Glu Ile Leu Thr Phe Trp Ser Ala Glu Val Glu
85 90 95
Gly Lys Glu Val Ile Asn Ala Met Thr Met Glu Met Glu Cys Leu Asn
100 105 110
<210> 12
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Прямой праймер CLP01
<400> 12
ctgtggctgt aagtgctcta c 21
<210> 13
<211> 25
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Зонд CLP01 Taqman
<400> 13
tttccgatgg tcattgtgaa cctgg 25
<210> 14
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Обратный праймер CLP01
<400> 14
gctgttctct ttcctctcct g 21
<210> 15
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Прямой праймер CLP02
<400> 15
tcagccaaat acaggttcag g 21
<210> 16
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Зонд CLP02 Taqman
<400> 16
ccaactttcc tcacccgtca gaat 24
<210> 17
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Обратный праймер CLP02
<400> 17
tgtaatcaga gcagtccaac g 21
<210> 18
<211> 22
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Прямой праймер CLP03
<400> 18
agtgatgtgg gataacgaat gg 22
<210> 19
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Зонд CLP03 Taqman
<400> 19
aggttgagta gggttagcag gagt 24
<210> 20
<211> 22
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Обратный праймер CLP03
<400> 20
cctctgatcc aaagctgagt ag 22
<210> 21
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_F1
<400> 21
atggacgcaa acaaagaaac a 21
<210> 22
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_R1
<400> 22
ccaatgctgt tcatgaaacc 20
<210> 23
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_F2
<400> 23
ccggacctct ttcaagtagt g 21
<210> 24
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_R2
<400> 24
gcatctcact cacgatggct 20
<210> 25
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_F3
<400> 25
tgggaacaca caggactggg 20
<210> 26
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_R3
<400> 26
ctccatgcaa tctgaccttg 20
<210> 27
<211> 22
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_F4
<400> 27
acttgtgctg gtgagctagt ga 22
<210> 28
<211> 17
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_R4
<400> 28
atccaggacg gtggcgt 17
<210> 29
<211> 25
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_F5
<400> 29
ttagagaaaa caaacttgac ccatc 25
<210> 30
<211> 25
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_R5
<400> 30
cgacgagtat gtcaactagc atatt 25
<210> 31
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_F6
<400> 31
caaatgacag acgacgtcag g 21
<210> 32
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_R6
<400> 32
ccagtgctga aggtgtttga 20
<210> 33
<211> 22
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_F7
<400> 33
ccgatattgc gggtttaacc ca 22
<210> 34
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_R7
<400> 34
cgctacgaaa gctgagaccg 20
<210> 35
<211> 25
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_F8
<400> 35
gttgttacag tgtaagtgct gtgtt 25
<210> 36
<211> 25
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_R8
<400> 36
ttaccgagag tgagtagaaa ctgaa 25
<210> 37
<211> 17
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_F9
<400> 37
acgccaccgt cctggat 17
<210> 38
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_R9
<400> 38
cctgacgtcg tctgtcattt g 21
<210> 39
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_F10
<400> 39
cggtctcagc tttcgtagcg 20
<210> 40
<211> 25
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PCL_R10
<400> 40
aacacagcac ttacactgta acaac 25
<210> 41
<211> 25
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Seq_41
<400> 41
cctacactta cagccacaga gtgcc 25
<210> 42
<211> 37
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Seq_42
<400> 42
tggtggcggc gctagctgtc aggagaggaa agagaag 37
<210> 43
<211> 122
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Seq_43
<400> 43
actcaacata aagttatact catggctaaa atttattaca ctacaggaac agcaggaaaa 60
cgatgggtgt aggtgaaggc tagagaagcc aaatacaggt tttcttatct tccttttgtg 120
gg 122
<210> 44
<211> 25
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Seq_44
<400> 44
tgcaggtatt tcctcacccg tcagc 25
<210> 45
<211> 54
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Seq_45
<400> 45
agtacatcat acaatacatg atcaactgct ctgattacat tattaattga aatt 54
<210> 46
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Seq_46
<400> 46
caggttcaca atgaccacct cat 23
<210> 47
<211> 25
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Seq_47
<400> 47
cgatgtggga taacgaaccg ggtaa 25
<210> 48
<211> 121
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Seq_48
<400> 48
ttacagggtt cctgcctaaa tgaatcatca tccaaggatt tacaaaaaat tatagccttg 60
kcaccccaac cattatagct atcataaccc tactcaacct gtactcttac atacacctca 120
t 121
<210> 49
<211> 97
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Seq_49
<400> 49
tatcacatcc acttgatcca aagctgagtt gaggttctga atacctttgt taattttctg 60
tctcaatgac ctaatattgt cagtggagtg ttaaatc 97
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| НОВЫЙ КОРОНАВИРУС РЫБ | 2020 |
|
RU2813731C2 |
| ГОМОЛОГ ГЛИЦЕРОЛ-3-ФОСФАТ-АЦИЛТРАНСФЕРАЗЫ И ЕГО ИСПОЛЬЗОВАНИЕ | 2011 |
|
RU2545375C2 |
| ИММУНОГЕННЫЕ КОМПОЗИЦИИ ДЛЯ ИММУНИЗАЦИИ СВИНЕЙ ПРОТИВ ЦИРКОВИРУСА ТИПА 3 И СПОСОБЫ ИХ ПОЛУЧЕНИЯ И ПРИМЕНЕНИЯ | 2016 |
|
RU2771533C2 |
| ВАКЦИННАЯ КОМПОЗИЦИЯ ДЛЯ ЛЕЧЕНИЯ РАКА | 2018 |
|
RU2782261C2 |
| АТТЕНУИРОВАННЫЙ ШТАММ ВИРУСА РЕПРОДУКТИВНО-РЕСПИРАТОРНОГО СИНДРОМА СВИНЕЙ (РРСС) И ЕГО ВОЗМОЖНОЕ ПРИМЕНЕНИЕ В СРЕДСТВАХ ДЛЯ ИММУНИЗАЦИИ | 2015 |
|
RU2723040C2 |
| ИММУНОГЕННЫЕ КОМПОЗИЦИИ ДЛЯ ИММУНИЗАЦИИ СВИНЕЙ ПРОТИВ ЦИРКОВИРУСА ТИПА 3 И СПОСОБЫ ИХ ПОЛУЧЕНИЯ И ПРИМЕНЕНИЯ | 2022 |
|
RU2803427C1 |
| КОМПОЗИЦИЯ БЕЛКОВ С АКТИВНОСТЬЮ ПОЛИМЕРИЗАЦИИ ИЗОПРЕНА И ЕЕ ПРИМЕНЕНИЕ | 2021 |
|
RU2811542C1 |
| Кодон-оптимизированная нуклеиновая кислота, которая кодирует белок SMN1, и ее применение | 2020 |
|
RU2742837C1 |
| РЕКОМБИНАНТНЫЕ КЛЕТКИ, ПРОДУЦИРУЮЩИЕ ГИАЛУРОНОВУЮ КИСЛОТУ | 2022 |
|
RU2839983C2 |
| ВАРИАНТЫ, НА ОСНОВЕ АДЕНОАССОЦИИРОВАННОГО ВИРУСА, СОСТАВЫ И СПОСОБЫ ДЛЯ ПУЛЬМОНАЛЬНОЙ ДОСТАВКИ | 2021 |
|
RU2829874C1 |
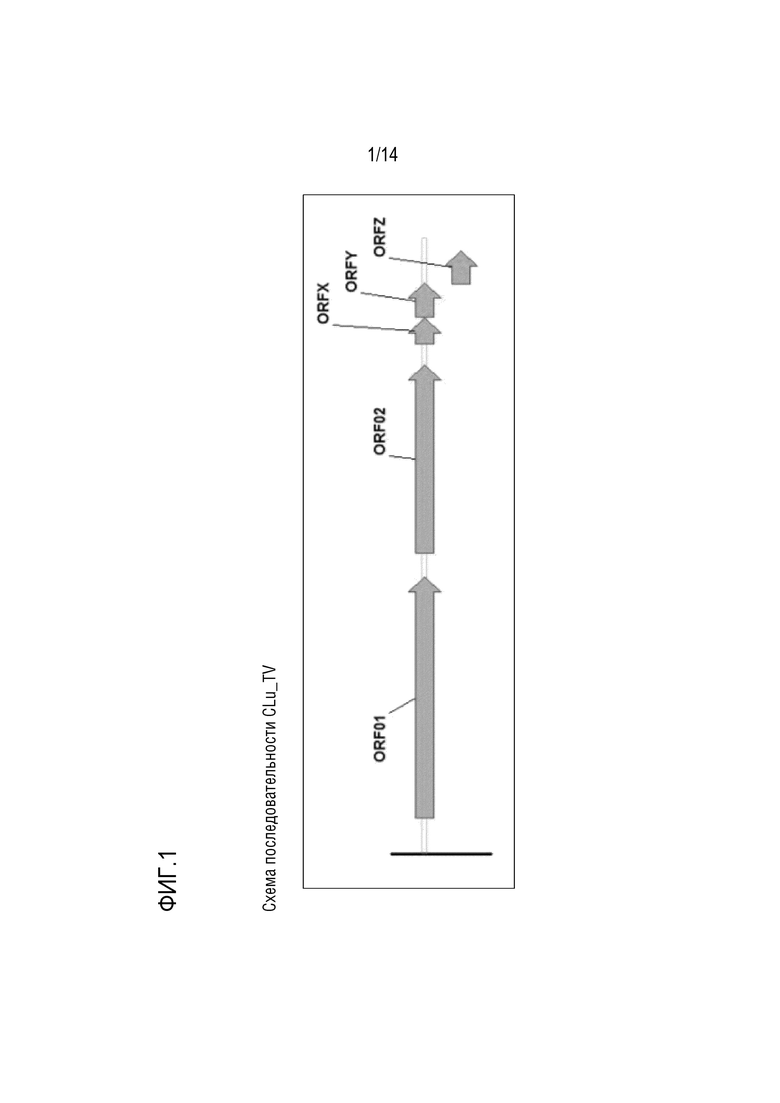









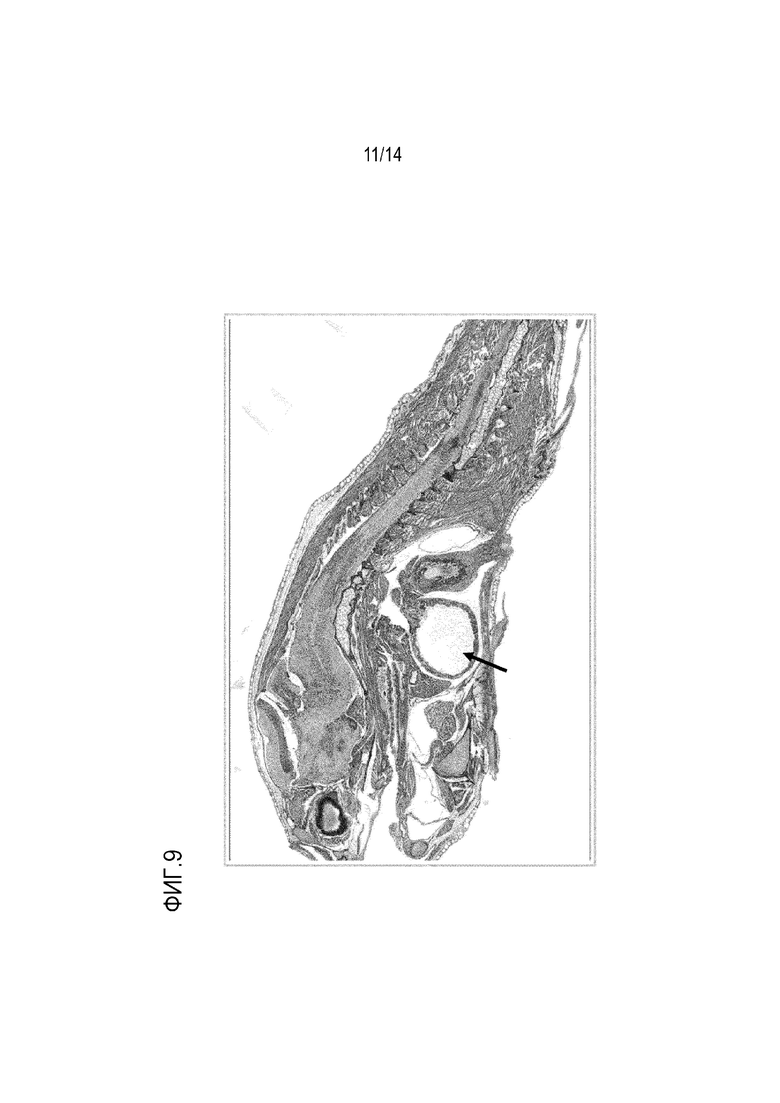
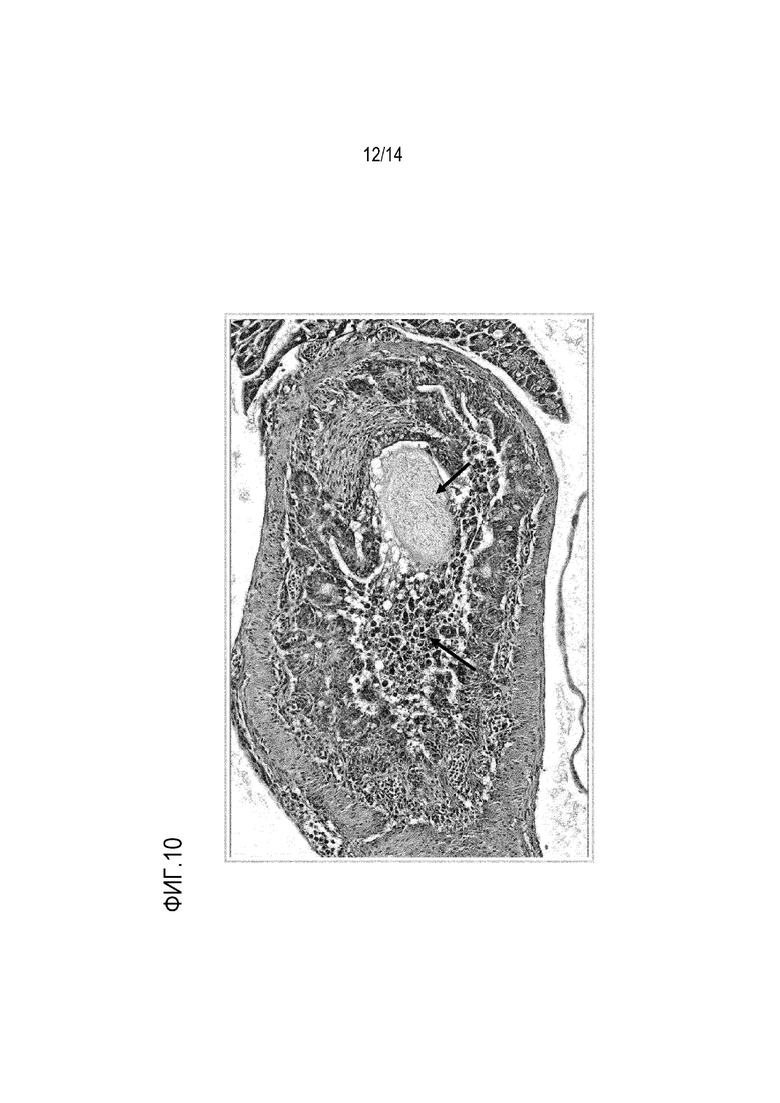
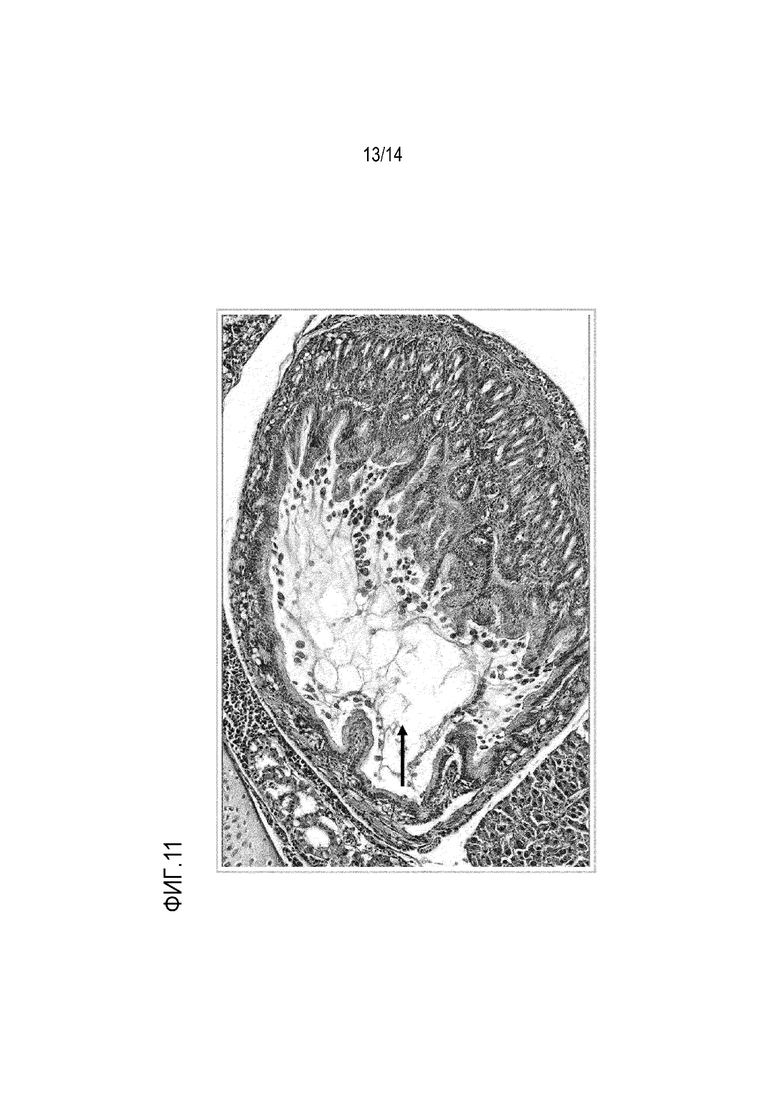
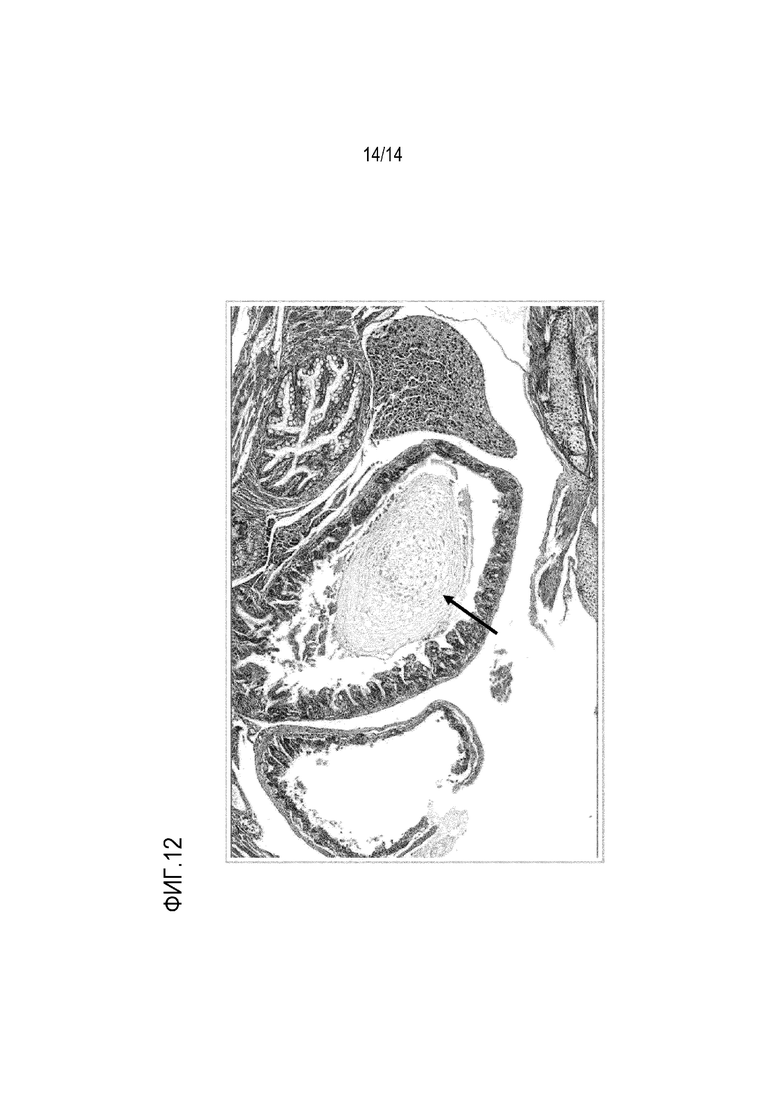
Изобретение относится к биотехнологии. Предложено применение по меньшей мере одного олигонуклеотидного праймера в способе обнаружения вируса в биологическом образце рыбы. Геном указанного вируса содержит SEQ ID NO: 6 или последовательность нуклеиновой кислоты, по меньшей мере на 80% идентичную ей, или по меньшей мере одну из SEQ ID NO: 1-5 или последовательность, которая по меньшей мере на 80% идентична ей. Геном указанного вируса содержит основание урацила (U) вместо основания тимина (T). Праймер содержит последовательность из по меньшей мере 12-40 последовательных нуклеотидов, и причем указанная последовательность комплементарна последовательности нуклеиновой кислоты, которая содержится в геноме указанного вируса. Предложен способ обнаружения вируса и набор для обнаружения вируса в биологическом образце рыбы. Изобретение позволяет обнаружить биологическом образце рыбы вирус, геном которого содержит SEQ ID NO: 6 или последовательность нуклеиновой кислоты, по меньшей мере на 80% идентичную ей, или по меньшей мере одну из SEQ ID NO: 1-5 или последовательность, которая по меньшей мере на 80% идентична ей. 4 н. и 3 з.п. ф-лы, 12 ил., 6 табл., 4 пр.
1. Применение по меньшей мере одного олигонуклеотидного праймера в способе обнаружения вируса в биологическом образце рыбы, где геном указанного вируса содержит SEQ ID NO: 6 или последовательность нуклеиновой кислоты, по меньшей мере на 80% идентичную ей, или по меньшей мере одну из SEQ ID NO: 1-5 или последовательность, которая по меньшей мере на 80% идентична ей, причем геном указанного вируса содержит основание урацила (U) вместо основания тимина (T), причем по меньшей мере один праймер содержит последовательность из по меньшей мере 12-40 последовательных нуклеотидов, и причем указанная последовательность комплементарна последовательности нуклеиновой кислоты, которая содержится в геноме указанного вируса.
2. Способ обнаружения вируса, в котором геном указанного вируса содержит SEQ ID NO: 6 или последовательность нуклеиновой кислоты, по меньшей мере на 80% идентичную ей, или по меньшей мере одну из SEQ ID NO: 1-5, или последовательность, которая по меньшей мере на 80% идентична ей, причем указанная последовательность нуклеиновой кислоты содержит основание урацила (U) вместо основания тимина (T), причем способ включает стадии:
(a) контактирования нуклеиновой кислоты, выделенной из биологического образца рыбы, с по меньшей мере одним олигонуклеотидным праймером с образованием смеси, где по меньшей мере один олигонуклеотидный праймер комплементарен последовательности нуклеиновой кислоты, содержащейся в геноме вируса, и
(b) определения того, присутствует ли при амплификации смеси a) продукт амплификации, где присутствие продукта амплификации указывает на присутствие РНК, связанной с вирусом, и следовательно, на присутствие вируса в биологическом образце,
причем олигонуклеотидный праймер представляет собой олигонуклеотидный праймер указанный в п.1.
3. Способ обнаружения вируса, включающий стадии:
(a) секвенирования нуклеиновой кислоты, выделенной из биологического образца рыбы, и
(b) сравнения полученной последовательности нуклеиновой кислоты с последовательностью нуклеиновой кислоты, которая представляет собой или комплементарна референсной последовательности, выбранной из группы, состоящей из SEQ ID NO:1, SEQ ID NO:2, SEQ ID NO:3, SEQ ID NO:4, SEQ ID NO:5 и SEQ ID NO:6, где по меньшей мере 80% идентичности последовательности между двумя последовательностями указывает на присутствие вируса в биологическом образце.
4. Набор для обнаружения вируса в биологическом образце рыбы, содержащий олигонуклеотидный праймер по п.1.
5. Применение по п.1, или способ по п.2, или набор по п.4, где указанный олигонуклеотидный праймер содержит по меньшей мере 9 последовательных нуклеотидов последовательности, которая по меньшей мере на 80% идентична последовательности, которая представляет собой или комплементарна последовательности, выбранной из группы, состоящей из SEQ ID NO:12 - SEQ ID NO:40;
при условии, что указанный олигонуклеотидный праймер не содержит последовательность, выбранную из группы, состоящей из SEQ ID NO:41 - SEQ ID NO:49.
6. Набор по п.4, где указанный набор представляет собой тест ОТ-ПЦР в режиме реального времени.
7. Применение по п.1, или способ по п.2, или набор по п.4, где указанный олигонуклеотидный праймер имеет длину 18-25 нуклеотидов.
| WO 2011131600 A1, 27.10.2011 | |||
| WO 2018224516 A1, 13.122018 | |||
| DATABASE BLAST, 11 октября 2018 г., LOCUS MI928367.1 | |||
| DATABASE BLAST, LOCUS JB492210.1, 11 июня 2014 г. | |||
| DATABASE BLAST, LOCUS FW549500.1, 27 декабря 2010 г. | |||
| DATABASE BLAST, LOCUS MM166065.1, 7 декабря 2018 г. | |||
| РЕБРИКОВ Д.В | |||
| и др., ПЦР в реальном времени, 6-е издание, БИНОМ, лаборатория |
