ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к области биопродукции гиалуроновой кислоты.
УРОВЕНЬ ТЕХНИКИ
Гиалуроновая кислота, также известная как гиалуронан или HA, представляет собой встречающийся в природе высокомолекулярный полисахарид, состоящий из D-глюкуроновой кислоты и N-ацетил-D-глюкозамина, связанных через чередующиеся β-(1→4) и β-(1→3) гликозидные связи, и имеющий химическую формулу (C14H21NO11)n. Гиалуроновая кислота может иметь длину 25000 дисахаридных повторов. Размер полимеров гиалуроновой кислоты может составлять от 5000 до 20000000 Да in vivo.
HA имеет множество применений в медицинской и косметической областях, включая поддерживающий материал для тканевой инженерии, дерматологические наполнители и добавки, улучшающие вязкость, для лечения остеоартрита. В частности, снижение массы или молекулярной массы HA посредством разложения или замедления синтеза влияет на физические и химические свойства, такие как объем ткани, вязкость и эластичность. Поэтому существует постоянная потребность в продукции HA.
Сегодня основными известными источниками HA являются человеческие пуповины, петушиные гребни и ферментация некоторых микроорганизмов.
Способы ферментации для получения HA из микроорганизмов представляют особый интерес, поскольку они облегчают продукцию большого количества HA путем возможного увеличения масштаба при меньших затратах. В отличие от выделения HA из животных источников, которые обеспечивают получение гиалуроновой кислоты с очень высокой молекулярной массой, микробная ферментация позволяет в определенной степени контролировать размер исходной молекулярной массы. Это позволяет избежать необходимости дальнейших стадий фракционирования механическими, физическими или химическими средствами.
С этой целью было показано, что бактериальные культуры, такие как гемолитические стрептококки группы A и C, представляют собой хорошие источники HA (US 5316926, US 4801539, JP 2009011315). Однако такие бактерии, и, в частности, Streptococcus zooepidemicus, который в основном используется в данной области техники, обычно не признаются безопасными. Рекомбинантные клетки-хозяева Bacillus также продемонстрировали способность продуцировать HA в диапазоне от 20 до 800 кДа (US2008038780). В US2006168690 также было продемонстрировано, что трансформация растительных клеток для включения ДНК, кодирующей синтазу гиалуроновой кислоты, успешно позволила продуцировать HA. Наконец, продукция малых молекул HA также была продемонстрирована у дрожжей, таких как рекомбинантные Pichia pastoris, в CN 104263666.
В отличие от других микроорганизмов, которые обычно используются для получения биологических молекул, дрожжи обычно признаются безопасными. Они могут быстро расти и культивироваться при более высокой плотности по сравнению с бактериями и не требуют асептической среды. Кроме того, дрожжевые клетки могут быть легче отделены от среды для культивирования, чем бактерии, что значительно упрощает процесс экстракции и очистки продукта. Наконец, дрожжи обладают преимуществом с точки зрения большей устойчивости к изменениям рН в среде для культивирования и как таковые представляют собой более сильные ферментационные системы.
Однако среди дрожжей отличительные признаки между видами также могут представлять определенные проблемы. Это в основном связано с разницей в метаболизме между видами. Например, интеграции генома в P. pastoris стабильны, но часто встречается высокая вариабельность клонов от одной трансформации, отображающая различные характеристики продуктивности или изменения в их физиологии. Для этого требуется длительный процесс скрининга, чтобы найти клон с оптимальными признаками для желаемого применения. Эта клональная изменчивость является важным недостатком для дальнейшего развития P. pastoris в качестве платформы для получения химических веществ с дополнительными положительными характеристиками. Еще одним недостатком использования P. pastoris является то, что это метанотрофный организм.
Напротив, Saccharomyces cerevisiae особенно полезны в качестве инструмента для получения молекул, представляющих интерес, поскольку они имеют длительную безопасную историю, когда дело доходит до использования людьми (например, в вине, пиве или хлебе), и как таковые являются хорошо известной моделью, генетическая информация о которой хорошо известна в данной области техники. S. cerevisiae также обладают тем преимуществом, что в целом признаны безопасными для людей и животных. Более того, подкисление среды, которое происходит при культивировании этих дрожжей, снижает возможность загрязнения биоферментеров и, следовательно, устраняет необходимость добавления антибиотиков в среду. Наконец, было разработано много генетических инструментов, позволяющих стабильно модифицировать их геном (интеграция в хромосому).
Соответственно, в данной области техники все еще существует потребность в дополнительных способах продукции гиалуроновой кислоты, позволяющих ее высокоэффективный синтез и секрецию. В частности, все еще существует потребность в способах продукции, которые являются экономически эффективными и обеспечивают получение гиалуроновой кислоты, которая безопасна для применения человеком.
В конкретном случае в данной области техники все еще существует потребность в способах продукции гиалуроновой кислоты, позволяющих получать большие количества гиалуроновой кислоты определенного и контролируемого размера.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Соответственно, настоящее изобретение относится к следующим элементам:
Пункт 1: дрожжевая клетка, продуцирующая гиалуроновую кислоту (HA), где рекомбинантная клетка содержит:
(a) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы;
(b) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP (уридинтрифосфат)-глюкозодегидрогеназы (UDP-GlcDH или HASB);
(c) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, где указанный полипептид, имеющий активность гиалуронидазы, содержит сигнал секреции, так что рекомбинантная дрожжевая клетка продуцирует гиалуроновую кислоту, в частности, имеющую желаемую молекулярную массу (HAMW), и
(d) (i) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутаминсинтетазы (GLN1); и/или
(ii) одну или более нарушенных эндогенных нуклеиновых кислот, кодирующих глутаматсинтазу (GLT1);
где указанная рекомбинантная дрожжевая клетка относится к роду Saccharomyces, или роду Candida, или роду Kluyveromyces, или роду Ogataea, или роду Yarrowia, или роду Debaryomyces, или роду Ashbya.
Как проиллюстрировано в примерах, рекомбинантные дрожжи по изобретению позволяют продуцировать гиалуроновую кислоту в дрожжевой клетке, которая естественным образом не способна продуцировать гиалуроновую кислоту. Кроме того, в примерах продемонстрировано, что размер гиалуроновой кислоты, продуцируемой рекомбинантными дрожжами, может быть контролируемым.
Указанные предпочтительные свойства могут быть дополнительно улучшены путем рекомбинации дрожжей с дополнительными модификациями, описанными в настоящем документе ниже.
Пункт 2: рекомбинантная клетка-хозяин, продуцирующая гиалуроновую кислоту (HA), где рекомбинантная клетка-хозяин содержит:
(a) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы;
(b) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы (UDP-GlcDH или HASB);
(c) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, где указанный полипептид, имеющий активность гиалуронидазы, содержит сигнал секреции и якорный сигнал, так что клетка-хозяин продуцирует гиалуроновую кислоту, в частности, имеющую желаемую молекулярную массу (HAMW); и
(d) (i) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутаминсинтетазы (GLN1); и/или
(ii) одну или более нарушенных эндогенных нуклеиновых кислот, кодирующих глутаматсинтазу (GLT1).
Пункт 3: Рекомбинантная клетка по пункту 1 или 2, где молекулярная масса HA находится в диапазоне менее 50 кДа, предпочтительно в диапазоне от около 20 до около 50 кДа.
Пункт 4: Рекомбинантная клетка по пункту 1 или 2, где молекулярная масса HA находится в диапазоне более 50 кДа, предпочтительно в диапазоне от около 50 до около 250 кДа.
Пункт 5: Рекомбинантная клетка по пункту 1 или 2, где молекулярная масса HA находится в диапазоне более 100 кДа, предпочтительно в диапазоне от около 100 до около 1500 кДа.
Пункт 6: Рекомбинантная клетка по любому из пунктов 1-5, где нуклеиновая кислота, кодирующая полипептид, имеющий активность глутаминсинтетазы, получена или происходит из Saccharomyces cerevisiae.
Пункт 7: Рекомбинантная клетка по любому из пунктов 1-6, где нуклеиновая кислота, кодирующая полипептид, имеющий активность гиалуронидазы, получена или происходит из по меньшей мере одного из Cupiennius salei, Loxosceles intermedia, Hirudo nipponia, Bothrops atrox или Tityus serrulatus.
Пункт 8: Рекомбинантная клетка по любому из пунктов 1-7, где нуклеиновая кислота, кодирующая полипептид, имеющий активность гиалуронан-синтазы, получена или происходит из по меньшей мере одного из Streptococcus zooepidemicus, вируса хлореллы PBCV1, вируса хлореллы CviKl, вируса хлореллы IL-5-2s1, вируса хлореллы CZ-2, вируса хлореллы CVG-1, Xenopus laevis или Pasteurella multocida, и, в частности, получена или происходит из по меньшей мере одного из Streptococcus zooepidemicus, вируса хлореллы PBCV1, вируса хлореллы CviKl, вируса хлореллы IL-5-2s1, вируса хлореллы CZ-2, вируса хлореллы CVG-1 или Xenopus laevis.
Пункт 9: Рекомбинантная клетка по любому из пунктов 1-8, где нуклеиновая кислота, кодирующая полипептид, имеющий активность UDP-глюкозодегидрогеназы, получена или происходит из по меньшей мере одного из Arabidopsis thaliana, вируса хлореллы PBCV1 или Streptococcus zooepidemicus и, в частности, из Arabidopsis thaliana или вируса хлореллы PBCV1.
Пункт 10: Рекомбинантная клетка по любому из пунктов 1-9, где рекомбинантная клетка содержит рекомбинантную нуклеиновую кислоту, кодирующую одно или более из:
(i) полипептида, имеющего активность глутамин-фруктозо-6-фосфатамидотрансферазы (GFA1); и/или
(ii) полипептида, имеющего активность UDP-N-ацетилглюкозаминпирофосфорилазы (QRI1).
Пункт 11: Рекомбинантная клетка по любому из пунктов 1-10, где рекомбинантная клетка содержит по меньшей мере одну рекомбинантную нуклеиновую кислоту, кодирующую одно или более из:
(i) полипептида, имеющего активность фосфоглюкомутазы-1 (PGM1); и/или
(ii) полипептида, имеющего активность UTP (уридинтрифосфат)-глюкозо-1-фосфат-уридилилтрансферазы (UGP1); и/или
(iii) полипептида, имеющего активность глюкозамин-6-фосфат-N-ацетилтрансферазы (GNA1); и/или
(iv) полипептида, имеющего активность фосфоацетилглюкозаминмутазы (PCM1).
Пункт 12: Рекомбинантная дрожжевая клетка по любому из пунктов 1 и 3-11, выбранная из группы, состоящей из Saccharomyces cerevisiae, Saccharomyces boulardii, Saccharomyces bayanus, Saccharomyces paradoxus, Saccharomyces mikatae, Saccharomyces castelli, Candida albicans, Candida glabrata, Candida tropicalis, Kluyveromyces lactis, Kluyveromyces marxianus, Kluyveromyces polysporus, Kluyveromyces thermotolerens, Ogataea polymorpHa, Yarrowia lypolytica, Debaryomyces hansenii и Ashbya gossypii, и предпочтительно представляющая собой Saccharomyces cerevisiae.
Пункт 13: Рекомбинантная клетка-хозяин по любому из пунктов 2-11, относящаяся к порядку Saccharomycetales, в частности, к семейству Saccharomycetales, и, в частности, выбранная из группы, состоящей из Saccharomyces cerevisiae, Saccharomyces boulardii, Saccharomyces bayanus, Saccharomyces paradoxus, Saccharomyces mikatae, Saccharomyces castelli, Candida albicans, Candida glabrata, Candida tropicalis, Kluyveromyces lactis, Kluyveromyces marxianus, Kluyveromyces polysporus, Kluyveromyces thermotolerens, Ogataea polymorpHa, Yarrowia lypolytica, Debaryomyces hansenii и Ashbya gossypii, и предпочтительно представляющая собой Saccharomyces cerevisiae.
Пункт 14: Способ продуцирования гиалуроновой кислоты (HA), имеющей желаемую молекулярную массу (HAMW), включающий:
(a) культивирование рекомбинантной клетки, как определено в любом из пунктов 1-13, в среде для культивирования в течение времени, достаточного для продуцирования гиалуроновой кислоты (HA), имеющей желаемую молекулярную массу; и
(b) необязательно выделение или извлечение гиалуроновой кислоты (HA) из рекомбинантной клетки и/или из среды для культивирования.
Пункт 15: Способ по пункту 14, где HA имеет молекулярную массу от около 20 до около 50 кДа и предпочтительно от около 20 до около 30 кДа.
Пункт 16: Способ по пункту 15, где HA имеет молекулярную массу от около 30 до около 50 кДа.
Пункт 17: Способ по пункту 14, где молекулярная масса HA составляет от около 50 до около 150 кДа.
Пункт 18: Способ по пункту 14, где молекулярная масса HA составляет от около 150 до около 1500 кДа.
Пункт 19: Способ по любому из пунктов 14-18, где рекомбинантная клетка содержит по меньшей мере одну рекомбинантную нуклеиновую кислоту, кодирующую одно или более из:
(i) полипептида, имеющего активность глутамин-фруктозо-6-фосфатамидотрансферазы (GFA1); и/или
(ii) полипептида, имеющего активность UDP-N-ацетилглюкозаминпирофосфорилазы (QRI1).
Пункт 20: Способ по любому из пунктов 14-19, где рекомбинантная клетка содержит по меньшей мере одну рекомбинантную нуклеиновую кислоту, кодирующую одно или более из:
(i) полипептида, имеющего активность фосфоглюкомутазы-1 (PGM1);
(ii) полипептида, имеющего активность UTP-глюкозо-1-фосфат-уридилилтрансферазы (UGP1);
(iii) полипептида, имеющего активность глюкозамин-6-фосфат-N-ацетилтрансферазы (GNA1); и/или
(iv) полипептида, имеющего активность фосфоацетилглюкозаминмутазы (PCM1).
Пункт 21: Способ по любому из пунктов 14-20, где рекомбинантная клетка является членом рода Saccharomyces и, в частности, представляет собой Saccharomyces cerevisiae.
Пункт 22: Способ по любому из пунктов 14-21, где время, достаточное для продуцирования гиалуроновой кислоты (HA), имеющей желаемую молекулярную массу, представляет собой период от около 35 до около 50 часов, предпочтительно от около 40 до около 50 часов, предпочтительно около 48 часов.
Пункт 23: Способ по любому из пунктов 14-22, где молекулярную массу гиалуроновой кислоты контролируют путем регулирования pH среды для культивирования.
Пункт 24: Способ по любому из пунктов 14-23, где способ осуществляют в промышленном масштабе, предпочтительно, где среда для культивирования составляет по меньшей мере около 100 л, более предпочтительно в диапазоне от около 1000 до около 3000 л, еще более предпочтительно около 10000 л, еще более предпочтительно около 100000 л или даже около 250000 л.
Пункт 25: Гиалуроновая кислота (HA), получаемая из рекомбинантной клетки по любому из пунктов 1-10 или способом по любому из пунктов 14-24.
Пункт 26: Среда для культивирования, содержащая HA по пункту 25.
Пункт 27: Композиция, содержащая гиалуроновую кислоту (HA) по пункту 24.
Пункт 28: Промышленное изделие, или потребительский продукт, или расходный материал, содержащий (i) HA по пункту 25, (ii) среду для культивирования по пункту 26 или (iii) композицию по пункту 27.
Пункт 29: Промышленное изделие, или потребительский продукт, или расходный материал по пункту 27, представляющий собой косметический продукт, вкусо-ароматическое вещество, парфюмерный продукт, пищевой продукт, продукт питания, напиток, текстурант, фармацевтическую композицию, биологически активную добавку, нутрицевтик, чистящее средство и/или стоматологическую композицию и/или композицию для гигиены полости рта.
Пункт 30: Применение рекомбинантной клетки, как определено в любом из пунктов 1-13, для продуцирования гиалуроновой кислоты (HA), имеющей молекулярную массу в диапазоне от около 20 до около 50 кДа или от около 50 до около 1000 кДа.
Пункт 31: Способ продуцирования гиалуроновой кислоты, включающий стадии:
(a) культивирования рекомбинантных дрожжей, как определено в любом из пунктов 1 и 3-12, в среде для культивирования; и
(b) извлечения гиалуроновой кислоты из указанной среды для культивирования,
где гиалуроновая кислота, извлеченная на стадии (b), имеет молекулярную массу, контролируемую путем выбора:
- природы и происхождения нуклеиновой кислоты, кодирующей гиалуронидазу, рекомбинантных дрожжей,
- природы и происхождения промотора, контролирующего экспрессию нуклеиновой кислоты, кодирующей гиалуронидазу(-ы), рекомбинантных дрожжей,
- наличия якорного сигнала и/или сигнала секреции, связанного с кодируемой(-ыми) гиалуронидазой(-ами), рекомбинантных дрожжей,
- pH среды для культивирования в процессе стадии культивирования рекомбинантных дрожжей, и/или
- продолжительности культивирования рекомбинантных дрожжей.
Некоторые варианты осуществления настоящего изобретения могут обеспечить одно или более из следующих преимуществ:
способ продуцирования гиалуроновой кислоты с контролируемой молекулярной массой;
способ продуцирования гиалуроновой кислоты с контролируемой молекулярной массой в дрожжевой клетке Saccharomyces; и
способ продуцирования гиалуроновой кислоты с контролируемой молекулярной массой путем изменения генетических параметров (например, регуляторных последовательностей) и/или параметров способа (pH или времени ферментации).
Подробности, примеры и предпочтения, представленные в отношении любого конкретного одного или более заявленных аспектов настоящего изобретения, будут дополнительно описаны в настоящем документе и в равной степени применимы ко всем аспектам настоящего изобретения. Любая комбинация вариантов осуществления, примеров и предпочтений, описанных в настоящем документе, во всех их возможных вариантах охватывается настоящим изобретением, если в настоящем документе не указано иное, или иным образом явно противоречит контексту.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
На фиг. 1 показан схематический путь продуцирования гиалуроновой кислоты
На фиг. 2A и 2B показаны агарозные гели, используемые для определения молекулярной массы гиалуроновой кислоты, продуцируемой штаммами согласно изобретению (например, штамм YA5235-1 (фиг. 2A) и штамм YA5359-10 (фиг. 2B)). Агарозные гели получают после прогона аликвоты супернатанта рассматриваемого штамма и окрашивания его «универсальным красителем» (номер CAS 7423-31-6). Стандарты молекулярной массы HA присутствуют в каждом геле для референса.
КРАТКОЕ ОПИСАНИЕ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
SEQ ID NO: 1 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (HASA), происходящую из вируса хлореллы PBCV-1
SEQ ID NO: 2 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (HASA), происходящую из вируса хлореллы PBCV-1
SEQ ID NO: 3 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (HASA), происходящую из Pasteurella multocida
SEQ ID NO: 4 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (HASA), происходящую из Pasteurella multocida
SEQ ID NO: 5 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (HASA), происходящую из Pasteurella multocida
SEQ ID NO: 6 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (HASA), происходящую из Xenopus laevis
SEQ ID NO: 7 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (HASA), происходящую из Streptococcus zooepidemicus
SEQ ID NO: 8 представляет собой аминокислотную последовательность гиалуронан-синтазы (HASA), происходящую из вируса хлореллы PBCV-1
SEQ ID NO: 9 представляет собой аминокислотную последовательность гиалуронан-синтазы (HASA), происходящую из Pasteurella multocida
SEQ ID NO: 10 представляет собой аминокислотную последовательность гиалуронан-синтазы (HASA), происходящую из Xenopus laevis
SEQ ID NO: 11 представляет собой аминокислотную последовательность гиалуронан-синтазы (HASA), происходящую из Streptococcus zooepidemicus
SEQ ID NO: 12 представляет собой нуклеотидную последовательность UDP-глюкозодегидрогеназы (HASB), происходящую из Arabidopsis thaliana
SEQ ID NO: 13 представляет собой перекодированную нуклеотидную последовательность UDP-глюкозодегидрогеназы (HASB), происходящую из вируса хлореллы PBCV-1
SEQ ID NO: 14 представляет собой перекодированную нуклеотидную последовательность UDP-глюкозодегидрогеназы (HASB), происходящую из вируса хлореллы PBCV-1
SEQ ID NO: 15 представляет собой перекодированную нуклеотидную последовательность UDP-глюкозодегидрогеназы (HASB), происходящую из Streptococcus zooepidemicus
SEQ ID NO: 16 представляет собой аминокислотную последовательность UDP-глюкозодегидрогеназы (HASB), происходящую из Arabidopsis thaliana
SEQ ID NO: 17 представляет собой аминокислотную последовательность UDP-глюкозодегидрогеназы (HASB), происходящую из вируса хлореллы PBCV1
SEQ ID NO: 18 представляет собой аминокислотную последовательность UDP-глюкозодегидрогеназы (HASB), происходящую из Streptococcus zooepidemicus
SEQ ID NO: 19 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Bothrops atrox, с N-концевым сигналом секреции
SEQ ID NO: 20 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Bothrops atrox, с N-концевым сигналом секреции и С-концевым якорным сигналом
SEQ ID NO: 21 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Cupiennius salei, с N-концевым сигналом секреции
SEQ ID NO: 22 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Cupiennius salei, с N-концевым сигналом секреции и С-концевым якорным сигналом
SEQ ID NO: 23 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Hirudo Nipponia, с N-концевым сигналом секреции
SEQ ID NO: 24 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Hirudo Nipponia, с N-концевым сигналом секреции и С-концевым якорным сигналом
SEQ ID NO: 25 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Loxosceles intermedia, с N-концевым сигналом секреции
SEQ ID NO: 26 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Loxosceles intermedia, с N-концевым сигналом секреции и С-концевым якорным сигналом
SEQ ID NO: 27 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Tityus serrulatus, с N-концевым сигналом секреции
SEQ ID NO: 28 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Tityus serrulatus, с N-концевым сигналом секреции и С-концевым якорным сигналом
SEQ ID NO: 29 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Vespa magnifica, с N-концевым сигналом секреции
SEQ ID NO: 30 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Vespa magnifica, с N-концевым сигналом секреции и С-концевым якорным сигналом
SEQ ID NO: 31 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Bothrops atrox, с N-концевым сигналом секреции
SEQ ID NO: 32 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Bothrops atrox, с N-концевым сигналом секреции и С-концевым якорным сигналом
SEQ ID NO: 33 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Cupiennius salei, с N-концевым сигналом секреции
SEQ ID NO: 34 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Cupiennius salei, с N-концевым сигналом секреции и С-концевым якорным сигналом
SEQ ID NO: 35 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Hirudo Nipponia, с N-концевым сигналом секреции
SEQ ID NO: 36 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Hirudo Nipponia, с N-концевым сигналом секреции и С-концевым якорным сигналом
SEQ ID NO: 37 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Loxosceles intermedia, с N-концевым сигналом секреции
SEQ ID NO: 38 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Loxosceles intermedia, с N-концевым сигналом секреции и С-концевым якорным сигналом
SEQ ID NO: 39 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Tityus serrulatus, с N-концевым сигналом секреции
SEQ ID NO: 40 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Tityus serrulatus, с N-концевым сигналом секреции и С-концевым якорным сигналом
SEQ ID NO: 41 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Vespa magnifica, с N-концевым сигналом секреции
SEQ ID NO: 42 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Vespa magnifica, с N-концевым сигналом секреции и С-концевым якорным сигналом
SEQ ID NO: 43 представляет собой нуклеотидную последовательность последовательности секреции, добавленной в 5’
SEQ ID NO: 44 представляет собой аминокислотную последовательность последовательности секреции, добавленной в N-конце
SEQ ID NO: 45 представляет собой нуклеотидную последовательность якорной последовательности, добавленной в 3’
SEQ ID NO: 46 представляет собой аминокислотную последовательность якорной последовательности, добавленной в C-конце
SEQ ID NO: 47 представляет собой нуклеотидную последовательность глутамин-фруктозо-6-фосфатамидотрансферазы (GFA1), происходящую из Saccharomyces cerevisiae
SEQ ID NO: 48 представляет собой перекодированную нуклеотидную последовательность глутамин-фруктозо-6-фосфатамидотрансферазы (GFA1), происходящую из вируса хлореллы 1 (PBCV-1)
SEQ ID NO: 49 представляет собой перекодированную нуклеотидную последовательность глутамин-фруктозо-6-фосфатамидотрансферазы (GFA1), происходящую из вируса хлореллы 1 (PBCV-1)
SEQ ID NO: 50 представляет собой аминокислотную последовательность глутамин-фруктозо-6-фосфатамидотрансферазы (GFA1), происходящую из Saccharomyces cerevisiae
SEQ ID NO: 51 представляет собой аминокислотную последовательность глутамин-фруктозо-6-фосфатамидотрансферазы (GFA1), происходящую из вируса хлореллы 1 (PBCV-1)
SEQ ID NO: 52 представляет собой нуклеотидную последовательность UDP-N-ацетилглюкозаминпирофосфорилазы (QRI1), происходящую из Saccharomyces cerevisiae
SEQ ID NO: 53 представляет собой аминокислотную последовательность UDP-N-ацетилглюкозаминпирофосфорилазы (QRI1), происходящую из Saccharomyces cerevisiae
SEQ ID NO: 54 представляет собой нуклеотидную последовательность фосфоглюкомутазы-1 (PGM1), происходящую из Saccharomyces cerevisiae
SEQ ID NO: 55 представляет собой аминокислотную последовательность фосфоглюкомутазы-1 (PGM1), происходящую из Saccharomyces cerevisiae
SEQ ID NO: 56 представляет собой нуклеотидную последовательность UTP-глюкозо-1-фосфат-уридилилтрансферазы (UGP1), происходящую из Saccharomyces cerevisiae
SEQ ID NO: 57 представляет собой аминокислотную последовательность UTP-глюкозо-1-фосфат-уридилилтрансферазы (UGP1), происходящую из Saccharomyces cerevisiae
SEQ ID NO: 58 представляет собой нуклеотидную последовательность глюкозамин-6-фосфат-N-ацетилтрансферазы (GNA1), происходящую из Saccharomyces cerevisiae
SEQ ID NO: 59 представляет собой аминокислотную последовательность глюкозамин-6-фосфат-N-ацетилтрансферазы (GNA1), происходящую из Saccharomyces cerevisiae
SEQ ID NO: 60 представляет собой нуклеотидную последовательность фосфоацетилглюкозаминмутазы (PCM1), происходящую из Saccharomyces cerevisiae
SEQ ID NO: 61 представляет собой аминокислотную последовательность фосфоацетилглюкозаминмутазы (PCM1), происходящую из Saccharomyces cerevisiae
SEQ ID NO: 62 представляет собой нуклеотидную последовательность промотора pTDH3
SEQ ID NO: 63 представляет собой нуклеотидную последовательность промотора pTDH3.Sk
SEQ ID NO: 64 представляет собой нуклеотидную последовательность промотора pTDH3-1.sba
SEQ ID NO: 65 представляет собой нуклеотидную последовательность промотора pTDH3.Sar
SEQ ID NO: 66 представляет собой нуклеотидную последовательность промотора pENO2
SEQ ID NO: 67 представляет собой нуклеотидную последовательность промотора pTEF3
SEQ ID NO: 68 представляет собой нуклеотидную последовательность промотора pTEF1
SEQ ID NO: 69 представляет собой нуклеотидную последовательность промотора pTEF1.ago
SEQ ID NO: 70 представляет собой нуклеотидную последовательность промотора pTEF1.Sba
SEQ ID NO: 71 представляет собой нуклеотидную последовательность промотора pPDC1
SEQ ID NO: 72 представляет собой нуклеотидную последовательность промотора pCCW12
SEQ ID NO: 73 представляет собой нуклеотидную последовательность промотора pCCW12.Sm
SEQ ID NO: 74 представляет собой нуклеотидную последовательность промотора pCCW12.Sk
SEQ ID NO: 75 представляет собой нуклеотидную последовательность промотора pCCW12.Sba
SEQ ID NO: 76 представляет собой нуклеотидную последовательность промотора pCCW12.Sar
SEQ ID NO: 77 представляет собой нуклеотидную последовательность промотора pNUP57
SEQ ID NO: 78 представляет собой нуклеотидную последовательность промотора pCCW10.ago
SEQ ID NO: 79 представляет собой нуклеотидную последовательность промотора pCWP2
SEQ ID NO: 80 представляет собой нуклеотидную последовательность промотора pRPLA1
SEQ ID NO: 81 представляет собой нуклеотидную последовательность промотора pCUP1
SEQ ID NO: 82 представляет собой нуклеотидную последовательность промотора pMET6
SEQ ID NO: 83 представляет собой нуклеотидную последовательность промотора pMET25
SEQ ID NO: 84 представляет собой нуклеотидную последовательность промотора pSAM1
SEQ ID NO: 85 представляет собой нуклеотидную последовательность терминатора tTPI1
SEQ ID NO: 86 представляет собой нуклеотидную последовательность терминатора tMET25
SEQ ID NO: 87 представляет собой нуклеотидную последовательность терминатора tDIT1
SEQ ID NO: 88 представляет собой нуклеотидную последовательность терминатора tRPL3
SEQ ID NO: 89 представляет собой нуклеотидную последовательность терминатора tRPL3.sm
SEQ ID NO: 90 представляет собой нуклеотидную последовательность терминатора tRPL3.sba
SEQ ID NO: 91 представляет собой нуклеотидную последовательность терминатора tRPL41B
SEQ ID NO: 92 представляет собой нуклеотидную последовательность терминатора tRPL15A
SEQ ID NO: 93 представляет собой нуклеотидную последовательность терминатора tRPL15A.sba
SEQ ID NO: 94 представляет собой нуклеотидную последовательность терминатора tIDP1
SEQ ID NO: 95 представляет собой нуклеотидную последовательность терминатора tTEF1.sba
SEQ ID NO: 96 представляет собой нуклеотидную последовательность глутаминсинтетазы (GLN1), происходящую из Saccharomyces cerevisiae
SEQ ID NO: 97 представляет собой аминокислотную последовательность глутаминсинтетазы (GLN1), происходящую из Saccharomyces cerevisiae
SEQ ID NO: 98 представляет собой нуклеотидную последовательность глутаматсинтазы (GLT1), происходящую из Saccharomyces cerevisiae
SEQ ID NO: 99 представляет собой аминокислотную последовательность глутаматсинтазы (GLT1), происходящую из Saccharomyces cerevisiae
SEQ ID NO: 100 представляет собой нуклеотидную последовательность терминатора tTDH3.
SEQ ID NO: 101 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (HASA), происходящую из вируса хлореллы CviKl
SEQ ID NO: 102 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (HASA), происходящую из вируса хлореллы IL-5-2s1
SEQ ID NO: 103 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (HASA), происходящую из вируса хлореллы CZ-2
SEQ ID NO: 104 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (HASA), происходящую из вируса хлореллы CVG-1
SEQ ID NO: 105 представляет собой аминокислотную последовательность гиалуронан-синтазы (HASA), происходящую из вируса хлореллы CviKl
SEQ ID NO: 106 представляет собой аминокислотную последовательность гиалуронан-синтазы (HASA), происходящую из вируса хлореллы IL-5-2s1
SEQ ID NO: 107 представляет собой аминокислотную последовательность гиалуронан-синтазы (HASA), происходящую из вируса хлореллы CZ-2
SEQ ID NO: 108 представляет собой аминокислотную последовательность гиалуронан-синтазы (HASA), происходящую из вируса хлореллы CVG-1
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Авторы изобретения разработали генетически модифицированные клетки, и, в частности, генетически модифицированные дрожжи, обладающие способностью продуцировать гиалуроновую кислоту по сравнению с родительскими клетками, и особенно по сравнению с родительскими дрожжами, которые естественным образом на это не способны.
Эти генетически модифицированные клетки описаны в настоящем описании.
Определения
Термин «гиалуроновая кислота», также известная как гиалуронан или HA, представляет собой полисахарид, состоящий из D-глюкуроновой кислоты и N-ацетил-D-глюкозамина, связанных через чередующиеся β-(1→4) и β-(1→3) гликозидные связи, и имеющий химическую формулу (C14H21NO11)n.
Гиалуроновая кислота может продуцироваться в рекомбинантной клетке.
В данном контексте термин «рекомбинантный», при использовании в отношении клетки, указывает на то, что клетка была модифицирована путем введения эндогенной и/или гетерологичной нуклеиновой кислоты или белка в клетку или изменения нативной клетки или что клетка получена из клетки, модифицированной таким образом. Таким образом, например, рекомбинантные клетки экспрессируют гены или нуклеиновую кислоту, которые не обнаружены в нативной (нерекомбинантной) форме клетки, или экспрессируют нативные (например, эндогенные) гены на другом уровне, чем их нативный уровень, или экспрессируют добавочные или дополнительные копии нативных (например, эндогенных) на другом уровне, чем их нативный уровень.
В данном контексте термин «рекомбинантный», при использовании в отношении нуклеиновой кислоты или вектора, представляет собой последовательности, образованные/полученные методами генной инженерии, хорошо известными специалисту в данной области техники. Соответственно, руководящие принципы Национального института здравоохранения (NIH) США указывают, что:
«рекомбинантные […] нуклеиновые кислоты определены как:
i. молекулы, которые (а) сконструированы путем соединения молекул нуклеиновой кислоты и (b) которые могут реплицироваться в живой клетке, то есть рекомбинантные нуклеиновые кислоты»,
что отражает общепринятое использование слова «рекомбинантный», применительно к нуклеотидным последовательностям, для обозначения рекомбинированного после вставки или соединения с другой нуклеиновой кислотой.
Белки, которые являются результатом экспрессии рекомбинантной ДНК или рекомбинантного вектора в живых клетках, также называют рекомбинантными белками.
Соответственно, термин «рекомбинантный» является синонимом термина «генетически модифицированный». Термин «ген» является синонимом термина «нуклеиновая кислота» или «нуклеотидная последовательность».
Рекомбинантная нуклеотидная последовательность для применения в рекомбинантной клетке и, в частности, в рекомбинантных дрожжах согласно настоящему изобретению, может быть предоставлена в форме конструкции нуклеиновой кислоты. Термин «конструкция нуклеиновой кислоты» относится к молекуле нуклеиновой кислоты, одно- или двухцепочечной, которая выделена или получена из нативного (например, эндогенного) гена, встречающегося в природе, или представляет собой гетерологичную нуклеиновую кислоту, или которая была модифицирована, чтобы содержать сегменты нуклеиновой кислоты, которые объединены и сопоставлены таким образом, который в противном случае не существовал бы в природе. Термин «конструкция нуклеиновой кислоты» является синонимом термина «экспрессионная кассета» или «экспрессионная кассета гетерологичной нуклеиновой кислоты», когда конструкция нуклеиновой кислоты содержит один или более регуляторных элементов, необходимых для экспрессии кодирующей последовательности, где указанные контрольные последовательности функционально связаны с указанной кодирующей последовательностью. Неограничивающие примеры регуляторных элементов включают промоторы, энхансеры, сайленсеры, терминаторы и поли-А сигналы.
Рекомбинантная нуклеотидная последовательность для применения в рекомбинантной клетке согласно настоящему изобретению может быть предоставлена в форме экспрессионного вектора, где полинуклеотидная последовательность функционально связана с по меньшей мере одной контрольной последовательностью для экспрессии полинуклеотидной последовательности в рекомбинантной клетке.
Термины «полученный из», или «происходящий из», или «который происходит из» микроорганизма или животного обычно означают, что вещество (например, молекула нуклеиновой кислоты или полипептид), происходящее из микроорганизма или животного, является нативным для этого микроорганизма или животного.
Термин «полученный из» микроорганизма или животного обычно означает, что вещество (например, молекула нуклеиновой кислоты или полипептид), полученное из микроорганизма или животного, является результатом модификаций, внесенных в вещество, нативное для (т.е. присутствующее как таковое) этого микроорганизма или животного. Например, в отношении нуклеотидной последовательности, полученной из микроорганизма или животного, указанная нуклеотидная последовательность может соответствовать перекодированной и/или усеченной версии нативной нуклеотидной последовательности из этого микроорганизма или животного. Другие модификации, хорошо известные специалисту в данной области техники, могут быть внесены в нативное вещество микроорганизма или животного, что приводит к тому, что используемое вещество является «полученным из» указанного микроорганизма или животного.
В данном контексте термин «полипептид» относится к молекуле, содержащей аминокислотные остатки, связанные пептидными связями, и содержащей более пяти аминокислотных остатков. Аминокислоты идентифицируются либо однобуквенными, либо трехбуквенными обозначениями. Термин «белок» в данном контексте является синонимом термина «полипептид» и может также относиться к двум или более полипептидам. Таким образом, термины «белок», «пептид» и «полипептид» могут быть использованы взаимозаменяемо. Полипептиды могут быть необязательно модифицированы (например, гликозилированные, фосфорилированные, ацилированные, фарнезилированные, пренилированные, сульфированные и тому подобное) для добавления функциональности. Полипептиды, проявляющие активность, могут называться ферментами. Следует понимать, что в результате вырожденности генетического кода может быть получено множество нуклеотидных последовательностей, кодирующих данный полипептид.
Полипептид, кодируемый рекомбинантной нуклеиновой кислотой для применения в рекомбинантной клетке и, в частности, в рекомбинантных дрожжах согласно настоящему изобретению, может содержать сигнальный пептид и/или пропептидную последовательность. В случае, если полипептид, экспрессируемый рекомбинантной клеткой, и, в частности, рекомбинантными дрожжами согласно настоящему изобретению, содержит сигнальный пептид и/или пропептид, идентичность последовательности может быть рассчитана по зрелой полипептидной последовательности.
В данном контексте термин «функционально связанный» относится к двум или более элементам нуклеотидной последовательности, которые физически связаны и находятся в функциональной взаимосвязи друг с другом. Например, промотор функционально связан с кодирующей последовательностью, если промотор способен инициировать или регулировать транскрипцию или экспрессию кодирующей последовательности, и в этом случае кодирующую последовательность следует понимать как находящуюся «под контролем» промотора. Как правило, когда две нуклеотидные последовательности функционально связаны, они будут находиться в одной и той же ориентации и, как правило, также в одной и той же рамке считывания. Обычно они будут по существу смежными, хотя это может и не потребоваться.
Термин «нативный» или «эндогенный», используемый в настоящем документе в отношении молекул, и, в частности, ферментов и нуклеиновых кислот, обозначает молекулы, которые экспрессируются в организме, из которого они происходят, или встречаются в природе.
Термин «эндогенный ген» означает, что ген присутствовал в клетке до любой генетической модификации в штамме дикого типа. Эндогенные гены могут быть сверхэкспрессированы путем введения гетерологичных последовательностей в дополнение к или для замены эндогенных регуляторных элементов или путем введения одной или более добавочных или дополнительных копий гена в хромосому или плазмиду (указанные добавочные или дополнительные копии обозначены как «экзогенные или гетерологичные гены», или «гетерологичные нуклеотидные последовательности», или «гетерологичные нуклеиновые кислоты», как определено в настоящем документе). Эндогенные гены также могут быть модифицированы для модуляции их экспрессии и/или активности. Например, мутации могут быть введены в кодирующую последовательность для модификации продукта гена, или гетерологичные последовательности могут быть введены в дополнение к или для замены эндогенных регуляторных элементов. Модуляция эндогенного гена может приводить к повышенной регуляции и/или усилению активности продукта гена или, альтернативно, к пониженной регуляции и/или ослаблению активности продукта эндогенного гена. Другим способом усиления экспрессии эндогенных генов является введение одной или более добавочных или дополнительных копий гена на хромосому или плазмиду (указанные дополнительные копии обозначены как «экзогенные или гетерологичные гены», или «гетерологичные нуклеотидные последовательности», или «гетерологичные нуклеиновые кислоты», как определено в настоящем документе).
Под «одной или более добавочными или дополнительными копиями гена» согласно изобретению в настоящем изобретении, например, понимается от 1 до 50 копий, в частности от 1 до 30 копий, более конкретно от 1 до 20 копий и предпочтительно от 1 до 10 копий. Указанные копии могут быть вставлены в один и тот же локус или в разные локусы рекомбинантной клетки согласно изобретению.
Термин «экзогенный ген» означает, что ген был введен в клетку средствами, хорошо известными специалисту в данной области техники, принимая во внимание, что этот ген встречается или не встречается в природе в клетке дикого типа. Клетки могут экспрессировать экзогенные гены, если эти гены вводятся в клетку со всеми элементами, обеспечивающими их экспрессию в клетке. Трансформация клеток с помощью экзогенной ДНК является рутинной задачей для специалиста в данной области техники. Экзогенные гены могут быть интегрированы в хромосому-хозяина или экспрессироваться вне хромосом из плазмид или векторов. В данной области техники известны различные плазмиды, которые различаются с точки зрения начала их репликации и количества их копий в клетке. Последовательность экзогенных генов может быть адаптирована для ее экспрессии в клетке. Действительно, специалисту в данной области техники известно понятие предпочтения кодонов и то, как адаптировать нуклеотидные последовательности для конкретного предпочтения кодонов без модификации выведенного белка. В частных вариантах осуществления оптимизированные по кодонам гены экспрессируют нативные ферменты.
Термин «гетерологичный ген» или «гетерологичная нуклеотидная последовательность» относится к гену или нуклеотидной последовательности, которые обычно не встречаются в данной клетке в природе. Таким образом, гетерологичная нуклеотидная последовательность может быть: (a) чужеродной для своей клетки-хозяина (т.е. «экзогенной» для клетки); (b) естественным образом обнаруженной в клетке-хозяине (т.е. «эндогенной»), но присутствующей в неестественном количестве в клетке (т.е. в большем или меньшем количестве, чем естественно обнаруженная в клетке-хозяине); или (c) естественным образом обнаруженной в клетке-хозяине, но расположенной вне ее естественного локуса.
В настоящей заявке все гены обозначены их общими названиями и ссылками на их нуклеотидные последовательности и, в случае возникновения, на их аминокислотные последовательности. Используя ссылки, приведенные в номере доступа для известных генов, специалисты в данной области техники могут определить эквивалентные гены в других организмах, бактериальных штаммах, дрожжах, грибах, млекопитающих, растениях и т. д. Эта рутинная работа предпочтительно выполняется с использованием консенсусных последовательностей, которые могут быть определены путем выравнивания последовательностей с генами, полученными из других клеток, и конструирования вырожденных зондов для клонирования соответствующего гена в другом организме.
Специалисту в данной области техники известны различные способы модуляции и, в частности, повышенной регуляции или пониженной регуляции экспрессии эндогенных генов. Например, способ усиления экспрессии или сверхэкспрессии эндогенных генов заключается во введении одной или более добавочных или дополнительных копий гена в хромосому или плазмиду.
Другой способ заключается в замене эндогенного промотора гена более сильным промотором. Эти промоторы могут быть гомологичными или гетерологичными. Промоторы, особенно интересные в настоящем изобретении, более подробно описаны в другом месте настоящего описания.
Экспрессионная конструкция нуклеиновой кислоты может дополнительно содержать 5'- и/или 3'-последовательности распознавания и/или селективные маркеры.
Термин «индуцибельный промотор» используется для квалификации промотора, активность которого индуцирована, то есть повышена:
- в присутствии одного или более конкретных метаболитов. Чем выше концентрация метаболита в среде, тем сильнее активность промотора; или
- в присутствии низкой концентрации или в отсутствие одного или более метаболитов. Эти метаболиты отличаются от тех, увеличение присутствия которых индуцирует активность промотора. Чем ниже концентрация метаболита в среде, тем сильнее активность промотора.
Термин «репрессируемый промотор» используется для квалификации промотора, активность которого репрессируется, то есть снижается:
- в присутствии одного или более конкретных метаболитов. Чем выше концентрация метаболита в среде, тем слабее активность промотора; или
- в присутствии низкой концентрации или в отсутствие одного или более метаболитов. Эти метаболиты отличаются от тех, увеличение присутствия которых подавляет активность промотора. Чем ниже концентрация метаболита в среде, тем слабее активность промотора.
В данном контексте термин «якорный сигнал» при использовании в сочетании с белком или полипептидом, таким как фермент (такой как, например, гиалуронидаза), означает, например, первую нуклеиновую кислоту, кодирующую белок, которая функционально связана со второй нуклеиновой кислотой, кодирующей белок или полипептид, или первый белок или полипептид, который функционально связан со вторым белком или полипептидом, таким как фермент (такой как, например, гиалуронидаза с образованием, например, слитого белка), и который позволяет клеточному транспортному механизму клетки, в частности клетки S. cerevisiae, правильно закреплять и/или располагать в мембране клетки второй белок, функционально связанный с первым белком.
В данном контексте термин «сигнал секреции» при использовании в сочетании с белком или полипептидом, таким как фермент (такой как, например, гиалуронидаза), означает, например, первую нуклеиновую кислоту, кодирующую пептид или белок, которая функционально связана со второй нуклеиновой кислотой, кодирующей белок, или первый белок, который связан со вторым белком, таким как фермент (такой как, например, гиалуронидаза с образованием, например, слитого белка), и который позволяет клеточному транспортному механизму клетки, в частности клетки S. cerevisiae, локализовать по меньшей мере второй белок на мембране клетки и секретировать второй белок за пределами клетки после того, как первый белок был, например, отщеплен от второго белка.
В данном контексте термины «сигнал секреции» и «якорный сигнал» при использовании в сочетании с белком или полипептидом, таким как фермент (такой как, например, гиалуронидаза), означают, например, первую нуклеиновую кислоту, кодирующую пептид или белок, которая функционально связана со второй нуклеиновой кислотой, кодирующей белок, или первый белок, который функционально связан со вторым белком, таким как фермент (такой как, например, гиалуронидаза), и который позволяет клеточному транспортному механизму клетки, в частности клетки S. cerevisiae, локализовать по меньшей мере второй белок на мембране клетки, где, если второй белок также функционально связан с «якорным сигналом», второй белок не секретируется, но остается прикрепленным к мембране клетки. В некоторых случаях сигнал секреции-якорный сигнал может обеспечивать двойную функцию сигнала секреции и якорного сигнала.
Последовательности сигналов секреции и якорного сигнала, способы экспрессии, закрепления и/или секреции гетерологичных белков, таких как ферменты (такие как, например, гиалуронидаза), на поверхности клетки (такой как, например, дрожжевая клетка) хорошо известны в данной области техники (см., например, Ast et al (2013) Cell 152: 1134-1145, Ast and Schuldiner (2013) Crit Rev Biochem Mol Biol 48(3) 273-288, Van der Vaart et al (1997) Applied Environmental Microbiology 63(2) 615-620, и все содержание каждой из этих публикаций включено в настоящий документ посредством ссылки).
«Активность» фермента используется взаимозаменяемо с термином «функция» и обозначает в контексте настоящего изобретения способность фермента катализировать желаемую реакцию. Количество фермента в клетке-хозяине может быть изменено путем модификации транскрипции гена, кодирующего фермент. Это может быть достигнуто, например, путем модификации числа копий нуклеотидной последовательности, кодирующей фермент (например, путем использования экспрессионного вектора с более высоким или более низким числом копий, содержащего нуклеотидную последовательность, или путем введения дополнительных копий нуклеотидной последовательности в геном клетки-хозяина, или путем делеции или нарушения нуклеотидной последовательности в геноме клетки-хозяина), путем изменения порядка кодирующих последовательностей на полицистронной мРНК оперона или разделения оперона на отдельные гены, каждый из которых имеет свои собственные контрольные элементы, или путем увеличения силы промотора или оператора, с которым функционально связана нуклеотидная последовательность.
Альтернативно или дополнительно, количество копий фермента в клетке-хозяине может быть изменено путем модификации уровня трансляции мРНК, кодирующей фермент. Это может быть достигнуто, например, путем модификации стабильности мРНК, модификации последовательности сайта связывания рибосомы, модификации расстояния или последовательности между сайтом связывания рибосомы и стартовым кодоном последовательности, кодирующей фермент, модификации всей межцистронной области, расположенной «против хода транскрипции» или прилегающей к 5’-стороне стартового кодона области, кодирующей фермент, стабилизации 3’-конца транскрипта мРНК с использованием «шпилек» и специализированных последовательностей, модификации частоты использования кодонов фермента, изменения экспрессии редких кодоновых тРНК, используемых в биосинтезе фермента, и/или повышения стабильности фермента, например, посредством мутации его кодирующей последовательности.
Активность фермента в клетке-хозяине может быть изменена несколькими способами, включая, но не ограничиваясь, экспрессию модифицированной формы фермента, которая проявляет повышенную или пониженную растворимость в клетке-хозяине, экспрессию измененной формы фермента, которая не имеет домена, через который ингибируется активность фермента, экспрессию модифицированной формы фермента, которая имеет более высокий или более низкий Kcat или более низкий или более высокий Km для субстрата, или экспрессию измененной формы фермента, которая более или менее подвержена обратной или упреждающей регуляции другой молекулой в пути.
Термины «кодирующий» или «кодирующий для» относятся к способу, посредством которого полинуклеотид, посредством механизмов транскрипции и трансляции, продуцирует аминокислотную последовательность.
Ген(-ы), кодирующий(-ие) фермент(-ы), рассматриваемый(-ые) в настоящем изобретении, может быть экзогенным или эндогенным.
Способы, осуществленные в настоящем изобретении, предпочтительно требуют применения одной или более конструкций хромосомной интеграции для стабильного введения гетерологичной нуклеотидной последовательности в определенное место на хромосоме или для функционального нарушения одного или более генов-мишеней в генетически модифицированной клетке. В некоторых вариантах осуществления нарушение гена-мишени предотвращает экспрессию родственного функционального белка. В некоторых вариантах осуществления нарушение гена-мишени приводит к экспрессии нефункционального белка из нарушенного гена.
Соответственно, «нарушенная эндогенная нуклеиновая кислота» в настоящем изобретении относится к эндогенной нуклеиновой кислоте или гену, неспособному кодировать функциональный или полностью функциональный белок или полипептид, который он кодирует, до его нарушения. Нуклеиновая кислота может быть, например, нарушена введением интеграционной конструкции в нуклеиновую кислоту, как проиллюстрировано в примерах. Указанная интеграция может, например, предотвращать экспрессию родственного функционального белка или полипептида или приводить к экспрессии нефункционального или не полностью функционального белка или полипептида из нарушенного гена.
Параметры конструкций хромосомной интеграции, которые могут варьироваться в практике настоящего изобретения, включают, но не ограничиваются, длины гомологичных последовательностей; нуклеотидную последовательность гомологичных последовательностей; длину интегрирующей последовательности; нуклеотидную последовательность интегрирующей последовательности; и нуклеотидную последовательность локуса-мишени. В некоторых вариантах осуществления эффективный диапазон длины каждой гомологичной последовательности составляет от 20 до 5000 пар оснований, предпочтительно от 50 до 100 пар оснований. В конкретных вариантах осуществления длина каждой гомологичной последовательности составляет около 50 пар оснований. Для получения дополнительной информации о длине гомологии, необходимой для нацеливания генов, см. D. Burke et al., Methods in yeast Genetics - A Cold Spring Harbor Laboratory Course Manual (2000).
В некоторых вариантах осуществления (а) нарушенный(-ые) ген(-ы), в который(-ые) вышеупомянутая(-ые) конструкция(-ии) ДНК предназначена(-ы) для вставки, может предпочтительно содержать один или более селектируемых маркеров, пригодных для выбора трансформированных клеток. Предпочтительно, указанный селектируемый(-ые) маркер(-ы) содержится в конструкции(-ях) ДНК согласно настоящему изобретению.
В некоторых вариантах осуществления селектируемый маркер представляет собой маркер устойчивости к антибиотикам. Иллюстративные примеры маркеров устойчивости к антибиотикам включают, но не ограничиваются, продукты гена NAT1, AURl-C, HpH, DSDA, KAN<R> и SH BLE. Продукт гена NAT1 из S. noursei придает устойчивость к норсеотрицину; продукт гена AURl-C из Saccharomyces cerevisiae придает устойчивость к ауреобазидину A (AbA); продукт гена HpH из Klebsiella pneumoniae придает устойчивость к гигромицину B; продукт гена DSDA из E. coli позволяет клеткам расти на планшетах с D-серином в качестве единственного источника азота; ген KAN<R> транспозона Tn903 придает устойчивость к G418; и продукт гена SH BLE из Streptoalloteichus hindustanus придает устойчивость к зеоцину (блеомицину).
В некоторых вариантах осуществления маркер устойчивости к антибиотикам удаляют после выделения генетически модифицированной клетки согласно изобретению. Специалист в данной области техники способен выбрать подходящий маркер в конкретном генетическом контексте.
В конкретном варианте осуществления рекомбинантная клетка согласно изобретению лишена какого-либо маркера устойчивости к антибиотикам. Это преимущественно предотвращает необходимость добавления антибиотиков в селекционную среду.
В некоторых вариантах осуществления селектируемый маркер сохраняет ауксотрофию (например, питательную ауксотрофию) в генетически модифицированной клетке. В таких вариантах осуществления родительская клетка и, в частности, родительские дрожжи содержат функциональное нарушение в одном или более продуктах гена, которые функционируют в аминокислотном или нуклеотидном биосинтетическом пути, таком как, например, продукты гена HIS3, LEU2, LYS1, LYS2, MET15, TRP1, ADE2 и URA3 в дрожжах, что делает родительскую клетку неспособной расти в среде без добавления одного или более питательных веществ (ауксотрофный фенотип). Затем ауксотрофный фенотип может быть сохранен путем трансформации родительской клетки с помощью хромосомной интеграции, кодирующей функциональную копию продукта нарушенного гена (в некоторых вариантах осуществления функциональная копия гена может происходить от близких видов, таких как Kluveromyces, Candida и т. д.), и полученная генетически модифицированная клетка может быть выбрана на основе потери ауксотрофного фенотипа родительской микробной клетки.
Для каждой из нуклеотидных последовательностей, содержащих промоторную последовательность, кодирующую последовательность (например, последовательность, кодирующую фермент) или последовательность терминатора, референсные последовательности описаны в настоящем документе. Настоящее описание также охватывает нуклеотидные последовательности, имеющие определенный процент нуклеотидной идентичности с референсной нуклеотидной последовательностью.
Для каждой из представляющих интерес аминокислотных последовательностей референсные последовательности описаны в настоящем документе. Настоящее описание также охватывает аминокислотные последовательности (например, ферментные аминокислотные последовательности), имеющие определенный процент аминокислотной идентичности с референсной аминокислотной последовательностью.
По очевидным причинам во всем настоящем описании конкретная нуклеотидная последовательность или конкретная аминокислотная последовательность, которая соответствует, соответственно, рассматриваемой нуклеотидной или аминокислотной идентичности, должна дополнительно приводить к получению белка (или фермента), который проявляет желаемую биологическую активность. В данном контексте «процент идентичности» между двумя нуклеотидными последовательностями или между двумя аминокислотными последовательностями определяют путем сравнения обеих оптимально выровненных последовательностей через окно сравнения.
Таким образом, часть нуклеотидной или аминокислотной последовательности в окне сравнения может включать добавления или делеции (например, «гэпы») по сравнению с референсной последовательностью (которая не включает эти добавления или эти делеции), чтобы получить оптимальное выравнивание между обеими последовательностями.
Термины «гомология последовательности», или «идентичность последовательности», или «гомология», или «идентичность» используются в настоящем документе взаимозаменяемо. Для целей настоящего изобретения здесь определено, что для определения процента гомологии последовательностей или идентичности последовательностей двух аминокислотных последовательностей или двух нуклеотидных последовательностей последовательности выравнивают для целей оптимального сравнения. Для оптимизации выравнивания между двумя последовательностями могут быть введены гэпы в любую из двух сравниваемых последовательностей. Такое выравнивание может быть осуществлено по всей длине сравниваемых последовательностей. Альтернативно, выравнивание может быть осуществлено на более короткой длине, например, на около 20, около 50, около 100 или более нуклеиновых кислот/оснований или аминокислот. Идентичность последовательности представляет собой процент идентичных совпадений между двумя последовательностями по зарегистрированной выровненной области.
Сравнение последовательностей и определение процента идентичности последовательностей между двумя последовательностями может быть выполнено с использованием математического алгоритма. Специалисту в данной области техники будет известно, что существует несколько различных компьютерных программ для выравнивания двух последовательностей и определения идентичности между двумя последовательностями (Kruskal, J. B. (1983) An overview of sequence comparison In D. Sankoff and J. B. Kruskal, (ed.), Time warps, string edits and macromolecules: the theory and practice of sequence comparison, pp. 1-44 Addison Wesley).
Процент идентичности последовательностей между двумя аминокислотными последовательностями или между двумя нуклеотидными последовательностями может быть определен с использованием алгоритма Нидлмана-Вунша для выравнивания двух последовательностей. (Needleman, S. B. and Wunsch, C. D. (1970) J. Mol. Biol. 48, 443-453). Как аминокислотные последовательности, так и нуклеотидные последовательности могут быть выровнены с помощью алгоритма. Алгоритм Нидлмана-Вунша был реализован в компьютерной программе NEEDLE.
Для целей изобретения использовали программу NEEDLE из программного обеспечения EMBOSS (версия 2.8.0 или выше, EMBOSS: The European Molecular Biology Open Software Suite (2000) Rice, P. LongdenJ. and Bleasby, A. Trends in Genetics 16, (6) pp276-277, http://emboss.bioinformatics.nl/). Для белковых последовательностей для матрицы замещения используют EBLOSUM62. Для нуклеотидной последовательности используют EDNAFULL. Необязательными используемыми параметрами являются штраф за открытие гэпа в размере 10 и штраф за продление гэпа в размере 0,5. Штраф за внесение концевого гэпа не добавляется. В разделе выходных данных было указано «Да» в ответ на вопрос «Краткая идентичность и сходство», а «SRS попарно» указано в качестве формата выравнивания выходных данных.
После выравнивания с помощью программы NEEDLE, как описано выше, процент идентичности последовательности между запрашиваемой последовательностью и последовательностью согласно изобретению рассчитывают следующим образом: Количество соответствующих положений в выравнивании, демонстрирующих идентичную аминокислоту или идентичный нуклеотид в обеих последовательностях, деленное на общую длину выравнивания после вычитания общего количества гэпов в выравнивании. Идентичность, определенная в настоящем документе, может быть получена из NEEDLE с использованием опции NOBRIEF и помечена в выходных данных программы как «самая длинная идентичность».
Сходство нуклеотидных и аминокислотных последовательностей, то есть процент идентичности последовательностей, можно определить с помощью выравнивания последовательностей с использованием нескольких других известных в данной области алгоритмов, предпочтительно с помощью математического алгоритма Карлина и Альтшуля (Karlin & Altschul (1993) Proc. Natl. Acad. Sci. USA 90: 5873-5877), с hmmalign (программное обеспечение HMMER, http://hmmer.wustl.edu/) или с алгоритмом CLUSTAL (Thompson, J. D., Higgins, D. G. & Gibson, T. J. (1994) Nucleic Acids Res. 22, 4673-80), которые доступны,Ошибка! Недопустимый объект гиперссылки. например, на https://www.ebi.ac.uk/Tools/msa/clustalo/, или программы GAP (математический алгоритм Университета Айовы) или математического алгоритма Майерса и Миллера (1989 - Cabios 4: 11-17) или Clone Manager 9. Используемые предпочтительные параметры являются параметрами по умолчанию, поскольку они установлены на https://www.ebi.ac.uk/Tools/msa/clustalo/.
Степень идентичности последовательностей (соответствие последовательностей) может быть рассчитана с использованием, например, BLAST, BLAT или BlastZ (или BlastX). Аналогичный алгоритм включен в программы BLASTN и BLASTP из Altschul et al (1990) J. Mol. Biol. 215, 403-410. Поиски полинуклеотидов BLAST выполняют с помощью программы BLASTN, балл = 100, длина представления = 12, для получения полинуклеотидных последовательностей, гомологичных тем нуклеиновым кислотам, которые кодируют соответствующий белок.
Поиски белка BLAST выполняют с помощью программы BLASTP, балл = 50, длина представления = 3, для получения аминокислотных последовательностей, гомологичных полипептиду SHC. Для получения выравниваний с гэпами для сравнительных целей используют Gapped BLAST, как описано в Altschul et al (1997) Nucleic Acids Res. 25, 3389-3402. При использовании программ BLAST и Gapped BLAST используются параметры по умолчанию для соответствующих программ. Анализ соответствия последовательностей может быть дополнен установленными методами картирования гомологичности, такими как Shuffle-LAGAN (Brudno M., Bioinformatics 2003b, 19 Suppl 1: 154-162) или случайные поля Маркова. Когда в настоящей заявке упоминаются проценты идентичности последовательностей, эти проценты рассчитывают по отношению к полной длине более длинной последовательности, если специально не указано иное.
В конкретных вариантах осуществления % идентичности между двумя последовательностями определяют с использованием CLUSTAL O (версия 1.2.4).
«Ферментацию» или «культивирование» обычно проводят в ферментаторах с подходящей средой для культивирования, адаптированной к культивируемой клетке, содержащей по меньшей мере один простой источник углерода и, при необходимости, сосубстраты.
Термин «ферментационная композиция» относится к композиции, которая содержит генетически модифицированные клетки-хозяева и продукты или метаболиты, продуцируемые генетически модифицированными клетками-хозяевами. Примером ферментационной композиции является цельноклеточный бульон, который может представлять собой все содержимое сосуда (например, колбы, планшета или ферментера), включая клетки, водную фазу и соединения, полученные из генетически модифицированных клеток-хозяев.
Термин «среда» относится к среде для культивирования, или культуральной среде, или ферментационной среде.
Для максимальной продукции гиалуроновой кислоты рекомбинантные клетки, используемые в качестве продуцирующих хозяев, предпочтительно имеют высокую скорость утилизации углеводов. Эти характеристики могут быть приданы с помощью мутагенеза и селекции, генной инженерии или могут быть естественными. Ферментационная среда, или «среда для культивирования», или «культуральная среда» для настоящих клеток может содержать по меньшей мере около 10 г/л глюкозы и/или сахарозы. Дополнительные углеродные субстраты могут включать, но не ограничиваются, моносахариды, такие как фруктоза, манноза, ксилоза и арабиноза; олигосахариды, такие как лактоза, мальтоза, галактоза или сахароза; полисахариды, такие как крахмал или целлюлоза или их смеси, и неочищенные смеси из возобновляемого сырья, такие как сывороточный пермеат, кукурузный раствор, патока из сахарной свеклы и ячменный солод. Другие углеродные субстраты могут включать глицерин, ацетат и/или этанол.
Следовательно, предполагается, что источник углерода, используемый в настоящем изобретении, может охватывать широкий спектр углеродсодержащих субстратов и будет ограничен только выбором клетки и, в частности, дрожжей.
Хотя предполагается, что все вышеупомянутые углеродные субстраты и их смеси подходят для настоящего изобретения, предпочтительными углеродными субстратами являются глюкоза, фруктоза и сахароза или их смеси с C5-сахарами, такими как ксилоза и/или арабиноза для клеток, и, в частности, дрожжей, модифицированные для использования C5-сахаров и, более конкретно, глюкозы.
Предпочтительными углеродными субстратами являются глюкоза или сахароза.
В дополнение к подходящему источнику углерода ферментационные среды могут содержать подходящие минералы, соли, кофакторы, буферы и другие компоненты, известные специалистам в данной области техники, подходящие для роста культур и активирования ферментативного пути, необходимого для получения целевого продукта.
Кроме того, могут быть рассмотрены дополнительные генетические модификации, подходящие для роста рекомбинантных клеток согласно изобретению.
Термин «аэробные условия» относится к концентрациям кислорода в среде для культивирования, достаточным для того, чтобы аэробная или факультативная анаэробная клетка, и, в частности, дрожжи, могла использовать дикислород в качестве конечного акцептора электронов.
«Микроаэробное условие» относится к среде для культивирования, в которой концентрация кислорода меньше, чем в воздухе, то есть концентрация кислорода до 6 % O2.
«Подходящая среда для культивирования» обозначает среду (например, стерильную жидкую среду), содержащую питательные вещества, необходимые или предпочтительные для поддержания и/или роста клетки, такие как источники углерода или углеродный субстрат, источники азота, например, пептон, дрожжевые экстракты, мясные экстракты, солодовые экстракты, мочевина, сульфат аммония, хлорид аммония, нитрат аммония и фосфат аммония; источники фосфора, например, монокалийфосфат или дикалийфосфат; микроэлементы (например, соли металлов), например, соли магния, соли кобальта и/или соли марганца; а также факторы роста, такие как аминокислоты, витамины, промоторы роста и тому подобное. Термин «углеродный источник», или «углеродный субстрат», или «источник углерода» в соответствии с настоящим изобретением обозначает любой источник углерода, который может быть использован специалистами в данной области техники для поддержания нормального роста клетки, включая гексозы (такие как глюкоза, галактоза или лактоза), пентозы, моносахариды, олигосахариды, дисахариды (такие как сахароза, целлобиоза или мальтоза), патоку, крахмал или его производные, целлюлозу, гемицеллюлозы и их комбинации.
Среды для культивирования, которые особенно подходят для получения рекомбинантных клеток по изобретению, и, в частности, рекомбинантных дрожжей по изобретению, более подробно описаны ниже в тексте.
В данном контексте термин «около» относится к разумному диапазону около значения, определенного специалистом в данной области техники. В некоторых вариантах осуществления термин «около» относится к ± одному, двум или трем стандартным отклонениям. В некоторых вариантах осуществления термин «около» относится к ± 5 %, 10%, 20 % или 25%. В некоторых вариантах осуществления термин «около» относится к ± 0,1, 0,2 или 0,3 логарифмическим единицам, например, единицам рН.
Общие признаки генетических модификаций, введенных согласно изобретению
- Все геномные модификации встраивают в рекомбинантные клетки и, в частности, в рекомбинантные дрожжи в соответствии с известными методами генной инженерии:
- Последовательные нуклеотидные последовательности, включенные в генную конструкцию, которая вводится в геном рекомбинантной клетки согласно изобретению, имеют следующую структуру:
Prom1-ORF1-term1-ORF2-gene2-term2 - …/… -Promn-ORFn-termn, где:
- Prom1 представляет собой последовательность, регулирующую экспрессию кодирующей последовательности ORF1,
- ORF1 представляет собой нуклеотидную последовательность, кодирующую целевой белок PROT1 и, в частности, целевой фермент PROT1,
- Term1 представляет собой последовательность терминатора транскрипции, которая опосредует терминацию транскрипции путем предоставления сигналов в только синтезированной мРНК, которые запускают процессы, которые высвобождают мРНК из транскрипционного комплекса, и
- «1», «2», …/… «n» может описывать или не описывать одну и ту же ORF (открытую рамку считывания), промотор или терминатор. Порядок нуклеотидных последовательностей не имеет значения. «n» представляет собой целое число, обычно находящееся в диапазоне от 5 до 20. Эти конструкции встраивают в одну из хромосом рекомбинантных клеток в контролируемом месте. В некоторых вариантах осуществления сайт встраивания не является существенным ни для функциональности встроенной конструкции, ни для жизнеспособности полученной генетически модифицированной клетки.
Как будет понятно специалистам в данной области техники, может быть предпочтительно модифицировать кодирующую последовательность для усиления ее экспрессии в конкретном хозяине. Генетический код является избыточными с 64 возможными кодонами, но большинство организмов обычно используют подмножество этих кодонов. Кодоны, которые чаще всего используются у вида, называются оптимальными кодонами, а те, которые не используются очень часто, классифицируются как редкие или малоиспользуемые кодоны. Кодоны могут быть замещены для отражения предпочтительной частоты использования кодонов хозяином в процессе, иногда называемом «оптимизацией кодонов» или «контролем неоднозначности кодонов видов». Оптимизация кодонов для других клеток-хозяев может быть легко определена с использованием таблиц частот использования кодонов или может быть выполнена с использованием коммерчески доступного программного обеспечения, такого как CodonOp (www.idtdna.com/CodonOptfrom) от Integrated DNA Technologies. Оптимизированные кодирующие последовательности, содержащие кодоны, предпочтительные для конкретного прокариотического или эукариотического хозяина (Murray et al, 1989, Nucl Acids Res. 17: 477-508), могут быть получены, например, для увеличения скорости трансляции или получения рекомбинантных РНК-транскриптов, обладающих желательными свойствами, такими как более длительный период полувыведения, по сравнению с транскриптами, полученными из неоптимизированной последовательности. Стоп-кодоны трансляции также могут быть модифицированы для отражения предпочтений хозяина. Например, типичными стоп-кодонами для S. cerevisiae и млекопитающих являются UAA и UGA, соответственно. Типичным стоп-кодоном для однодольных растений является UGA, тогда как насекомые и E. coli обычно используют UAA в качестве стоп-кодона (DalpHin et al, 1996, Nucl Acids Res. 24: 216-8).
- Когда рекомбинантная клетка представляет собой дрожжевую клетку, и, в частности, дрожжевую клетку Saccharomyces cerevisiae, нуклеотидные последовательности, введенные в геном дрожжей и происходящие из других организмов, отличных от Saccharomyces cerevisiae, как правило, «транскодированы» (как правило, «кодон-оптимизированы»), что означает, что эти нуклеотидные последовательности синтезированы с оптимальной частотой использования кодонов для экспрессии в S. cerevisiae. Нуклеотидная последовательность (и не белковая последовательность) некоторых нуклеотидных последовательностей из S. cerevisiae также была модифицирована («транскодирована») для минимизации рекомбинации с эндогенной копией указанного гена.
- Гены могут быть удалены с помощью стандартных процедур, используемых в клеточной генной инженерии. В некоторых вариантах осуществления гены, нацеленные на делецию, могут быть прерваны путем вставки одной из вышеописанных генных конструкций, или, альтернативно, гены, нацеленные на делецию, заменены коротким участком нуклеотида.
- Нуклеотидные последовательности можно сделать «индуцибельными или репрессируемыми» путем делеции эндогенной копии нуклеотидных последовательностей (при необходимости) и помещения новой копии ORF под контроль индуцибельного или репрессируемого промотора. Индуцибельный или репрессируемый промотор представляет собой промотор, активность которого модулируется или контролируется, т.е. либо повышается, либо снижается, при изменении условий окружающей среды или внешних раздражителей. Индукция или репрессия могут быть искусственно контролируемыми, что включает индукцию или репрессию абиотическими факторами, такими как химические соединения, не встречающиеся в природе в клетке, и, в частности, дрожжах, представляющих интерес, свет, уровни кислорода, тепло или холод. Список и последовательности индуцибельных или репрессируемых промоторов описаны в другом месте настоящего описания.
Рекомбинантные клетки согласно изобретению
Авторы изобретения разработали рекомбинантные клетки, в частности, рекомбинантные дрожжи, обладающие способностью продуцировать гиалуроновую кислоту.
Настоящее изобретение относится к рекомбинантным клеткам и, в частности, к рекомбинантным дрожжам, обладающим способностью продуцировать гиалуроновую кислоту, и где эта способность продуцировать гиалуроновую кислоту получена посредством множества изменений, которые были введены в их геном методами генной инженерии.
Настоящее изобретение относится к рекомбинантной дрожжевой клетке, продуцирующей гиалуроновую кислоту (HA), где рекомбинантная клетка содержит:
(a) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы;
(b) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы (UDP-GlcDH или HASB);
(c) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, где указанный полипептид, имеющий активность гиалуронидазы, содержит сигнал секреции, так что рекомбинантная дрожжевая клетка продуцирует гиалуроновую кислоту, в частности, имеющую желаемую молекулярную массу (HAMW), и
(d) (i) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутаминсинтетазы (GLN1); и/или
(ii) одну или более нарушенных эндогенных нуклеиновых кислот, кодирующих глутаматсинтазу (GLT1);
где указанная рекомбинантная дрожжевая клетка относится к роду Saccharomyces, или роду Candida, или роду Kluyveromyces, или роду Ogataea, или роду Yarrowia, или роду Debaryomyces, или роду Ashbya, и, в частности, выбрана из группы, состоящей из Saccharomyces cerevisiae, Saccharomyces boulardii, Saccharomyces bayanus, Saccharomyces paradoxus, Saccharomyces mikatae, Saccharomyces castelli, Candida albicans, Candida glabrata, Candida tropicalis, Kluyveromyces lactis, Kluyveromyces marxianus, Kluyveromyces polysporus, Kluyveromyces thermotolerens, Ogataea polymorpHa, Yarrowia lypolytica, Debaryomyces hansenii и Ashby gossypii, и предпочтительно представляет собой Saccharomyces cevisiae.
Настоящее изобретение дополнительно относится к рекомбинантной клетке-хозяину, продуцирующей гиалуроновую кислоту (HA), где рекомбинантная клетка-хозяин содержит:
(a) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы;
(b) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы (UDP-GlcDH или HASB);
(c) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, где указанный полипептид, имеющий активность гиалуронидазы, содержит сигнал секреции и якорный сигнал, так что клетка-хозяин продуцирует гиалуроновую кислоту, в частности, имеющую желаемую молекулярную массу (HAMW); и
(d) (i) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутаминсинтетазы (GLN1); и/или
(ii) одну или более нарушенных эндогенных нуклеиновых кислот, кодирующих глутаматсинтазу (GLT1).
Авторы изобретения обнаружили, что способность продуцировать гиалуроновую кислоту клетками, и, в частности, дрожжевыми клетками, может быть достигнута путем введения в геном этих клеток множества генетических изменений.
Продукция гиалуроновой кислоты клетками по изобретению и, в частности, дрожжевыми клетками по изобретению была достигнута путем оптимизации эндогенного метаболизма UDP-глюкозы и, необязательно, UDP-N-ацетилглюкозамина и направления последующего искусственно модифицированного метаболического пути в основном на продукцию гиалуроновой кислоты при одновременном поддержании оптимальной жизнеспособности полученных генетически модифицированных клеток.
Было определено, что продукция гиалуроновой кислоты рекомбинантными клетками согласно изобретению может быть увеличена путем увеличения превращения глюкозо-6-фосфата в последовательные промежуточные метаболиты (i) глюкозо-1-фосфат, UDP-глюкозу, UDP-глюкуронат и гиалуроновую кислоту и (ii) фруктозо-6-фосфат, глюкозамин-6-фосфат, N-ацетил-глюкозамин-6-фосфат, N-ацетил-глюкозамин-1-фосфат, UDP-N-ацетил-глюкозамин и гиалуроновую кислоту при сохранении метаболического баланса, обеспечивающего хорошую жизнеспособность полученных рекомбинантных клеток.
Действительно, для получения жизнеспособной рекомбинантной клетки согласно изобретению было протестировано множество различных конструкций для получения жизнеспособной и эффективной рекомбинантной клетки и, в частности, жизнеспособных рекомбинантных дрожжей. В частности, такие рекомбинантные дрожжи было трудно получить, поскольку временное накопление некоторых промежуточных продуктов, по-видимому, было токсичным для дрожжей.
Неожиданные технические трудности возникли при создании условий, подходящих для получения рекомбинантной клетки, способной продуцировать гиалуроновую кислоту и, в частности, продуцировать гиалуроновую кислоту с контролируемой молекулярной массой.
Под «контролируемой» молекулярной массой гиалуроновой кислоты согласно настоящему изобретению подразумевается, что по меньшей мере 80 %, в частности по меньшей мере 85 %, гиалуроновой кислоты, продуцируемой способом согласно настоящему изобретению, имеет молекулярную массу, находящуюся в определенном диапазоне молекулярной массы, посредством регулирования по меньшей мере одного параметра способа и/или рекомбинантной клетки согласно настоящему изобретению, такого как, например:
- природа и происхождение нуклеиновой кислоты, кодирующей гиалуронидазу рекомбинантной клетки,
- природа и происхождение промотора, контролирующего экспрессию нуклеиновой кислоты, кодирующей гиалуронидазу(-ы) рекомбинантной клетки,
- наличие якорного сигнала и/или сигнала секреции, связанного с кодируемой(-ыми) гиалуронидазой(-ами) рекомбинантной клетки,
- рН среды для культивирования в процессе стадии культивирования рекомбинантной клетки, и/или
- продолжительность культивирования рекомбинантной клетки.
Действительно, после долгих исследований и экспериментальных испытаний авторы изобретения обнаружили, что можно культивировать рекомбинантную клетку и, в частности, рекомбинантную дрожжевую клетку, более конкретно, рекомбинантную дрожжевую клетку Saccharomyces cerevisiae, способную продуцировать гиалуроновую кислоту с контролируемой молекулярной массой, контролируемой с использованием следующих параметров:
- выбора природы и происхождения нуклеотидных последовательностей, кодирующих полипептид, имеющий активность гиалуронидазы рекомбинантной клетки, в частности, рекомбинантных дрожжей, по изобретению; и/или
- природы и происхождения промотора, контролирующего экспрессию нуклеотидных последовательностей, кодирующих полипептид, имеющий активность гиалуронидазы рекомбинантной клетки, в частности, рекомбинантных дрожжей, по изобретению; и/или
- необязательного присутствия якорного сигнала, в дополнение к сигналу секреции, связанного с кодируемым полипептидом, имеющим активность гиалуронидазы рекомбинантной клетки, в частности, рекомбинантных дрожжей, согласно изобретению; и/или
- рН среды для культивирования в процессе стадии культивирования рекомбинантной клетки, в частности, рекомбинантной дрожжевой клетки, согласно изобретению; и/или
- продолжительность культивирования рекомбинантной клетки, в частности, рекомбинантной дрожжевой клетки, согласно изобретению.
Насколько известно авторам изобретателя, этого никогда не было достигнуто раньше.
Молекулярная масса гиалуроновой кислоты (HA) может находиться в диапазоне менее 50 кДа, предпочтительно в диапазоне от около 20 до около 50 кДа.
Альтернативно, молекулярная масса гиалуроновой кислоты (HA) может находиться в диапазоне более 50 кДа, предпочтительно в диапазоне от около 50 до около 250 кДа.
В другом альтернативном варианте молекулярная масса HA может находиться в диапазоне более 100 кДа, предпочтительно в диапазоне от около 100 до около 1500 кДа.
Нуклеиновая кислота, кодирующая полипептид, имеющий активность глутаминсинтетазы, может быть получена или происходит из Saccharomyces cerevisiae.
Нуклеиновая кислота, кодирующая полипептид, имеющий активность гиалуронидазы в рекомбинантной клетке согласно настоящему изобретению, может быть получена или происходит из по меньшей мере одного из Cupiennius salei, Loxosceles intermedia, Hirudo nipponia, Bothrops atrox или Tityus serrulatus.
Нуклеиновая кислота, кодирующая полипептид, имеющий активность гиалуронан-синтазы в рекомбинантной клетке согласно настоящему изобретению, может быть получена или происходит из по меньшей мере одной из Streptococcus zooepidemicus, вируса хлореллы PBCV1, вируса хлореллы CviKl, вируса хлореллы IL-5-2s1, вируса хлореллы CZ-2, вируса хлореллы CVG-1, Xenopus laevis или Pasteurella multocida и, в частности, получена или происходит из Streptococcus zooepidemicus, вируса хлореллы PBCV1, вируса хлореллы CviKl, вируса хлореллы IL-5-2s1, вируса хлореллы CZ-2, вируса хлореллы CVG-1 или Xenopus laevis.
Нуклеиновая кислота, кодирующая полипептид, имеющий активность UDP-глюкозодегидрогеназы в рекомбинантной клетке согласно настоящему изобретению, может быть получена или происходит из по меньшей мере одного из Arabidopsis thaliana, вируса хлореллы PBCV1 или Streptococcus zooepidemicus и, в частности, из Arabidopsis thaliana или вируса хлореллы PBCV1.
Рекомбинантная клетка согласно изобретению может содержать рекомбинантную нуклеиновую кислоту, кодирующую одну или более из:
(i) полипептида, имеющего активность глутамин-фруктозо-6-фосфатамидотрансферазы (GFA1); и/или
(ii) полипептида, имеющего активность UDP-N-ацетилглюкозаминпирофосфорилазы (QRI1).
Рекомбинантная клетка согласно изобретению может содержать по меньшей мере одну рекомбинантную нуклеиновую кислоту, кодирующую одну или более из:
(i) полипептида, имеющего активность фосфоглюкомутазы-1 (PGM1); и/или
(ii) полипептида, имеющего активность UTP-глюкозо-1-фосфат-уридилилтрансферазы (UGP1); и/или
(iii) полипептида, имеющего активность глюкозамин-6-фосфат-N-ацетилтрансферазы (GNA1); и/или
(iv) полипептида, имеющего активность фосфоацетилглюкозаминмутазы (PCM1).
Рекомбинантная дрожжевая клетка согласно изобретению может быть, в частности, выбрана из группы, состоящей из Saccharomyces cerevisiae, Saccharomyces boulardii, Saccharomyces bayanus, Saccharomyces paradoxus, Saccharomyces mikatae, Saccharomyces castelli, Candida albicans, Candida glabrata, Candida tropicalis, Kluyveromyces lactis, Kluyveromyces marxianus, Kluyveromyces polysporus, Kluyveromyces thermotolerens, Ogataea polymorpHa, Yarrowia lypolytica, Debaryomyces hansenii и Ashbya gossypii, и предпочтительно представляющая собой Saccharomyces cerevisiae.
Рекомбинантная клетка-хозяин согласно изобретению может относиться к порядку Saccharomycetales и, в частности, выбрана из группы, состоящей из Saccharomyces cerevisiae, Saccharomyces boulardii, Saccharomyces bayanus, Saccharomyces paradoxus, Saccharomyces mikatae, Saccharomyces castelli, Candida albicans, Candida glabrata, Candida tropicalis, Kluyveromyces lactis, Kluyveromyces marxianus, Kluyveromyces polysporus, Kluyveromyces thermotolerens, Ogataea polymorpHa, Yarrowia lypolytica, Debaryomyces hansenii и Ashbya gossypii, и предпочтительно представляет собой Saccharomyces cerevisiae.
Другой объект изобретения относится к способу продуцирования гиалуроновой кислоты (HA), имеющей желаемую молекулярную массу (HAMW), включающему:
(a) культивирование рекомбинантной клетки, как определено выше, то есть рекомбинантной дрожжевой клетки или рекомбинантной клетки-хозяина согласно настоящему изобретению, в среде для культивирования в течение времени, достаточного для продуцирования гиалуроновой кислоты (HA), имеющей желаемую молекулярную массу; и
(b) необязательно выделение или извлечение гиалуроновой кислоты (HA) из рекомбинантной клетки и/или из среды для культивирования.
В способе согласно изобретению HA может иметь молекулярную массу от около 20 до около 50 кДа и предпочтительно от 20 до 30 кДа.
В способе согласно изобретению HA может альтернативно иметь молекулярную массу от 30 до 50 кДа.
В способе согласно изобретению HA может альтернативно иметь молекулярную массу от около 50 до около 150 кДа.
В способе согласно изобретению HA может альтернативно иметь молекулярную массу от 150 до 1500 кДа.
В способе согласно изобретению нуклеиновая кислота, кодирующая полипептид, имеющий активность гиалуронидазы, может быть получена или происходит из Cupiennius salei, Loxosceles intermedia, Hirudo nipponia, Bothrops atrox или Tityus serrulatus.
В способе согласно изобретению нуклеиновая кислота, кодирующая полипептид, имеющий активность гиалуронан-синтазы, может быть получена или происходит из по меньшей мере одного из Streptococcus zooepidemicus, вируса хлореллы PBCV1, вируса хлореллы CviKl, вируса хлореллы IL-5-2s1, вируса хлореллы CZ-2, вируса хлореллы CVG-1, Xenopus laevis или Pasteurella multocida и, в частности, получена или происходит из по меньшей мере одного из Streptococcus zooepidemicus, вируса хлореллы PBCV1, вируса хлореллы CviKl, вируса хлореллы IL-5-2s1, вируса хлореллы CZ-2, вируса хлореллы CVG-1 или Xenopus laevis.
В способе согласно изобретению нуклеиновая кислота, кодирующая полипептид, имеющий активность UDP-глюкозодегидрогеназы, может быть получена или происходит из по меньшей мере одного из Arabidopsis thaliana, вируса хлореллы PBCV1 или Streptococcus zooepidemicus, и, в частности, может быть получена или происходит из Arabidopsis thaliana или вируса хлореллы PBCV1.
В способе согласно изобретению рекомбинантная клетка может содержать по меньшей мере одну рекомбинантную нуклеиновую кислоту, кодирующую одного или более из:
(i) полипептида, имеющего активность глутамин-фруктозо-6-фосфатамидотрансферазы (GFA1); и/или
(ii) полипептида, имеющего активность UDP-N-ацетилглюкозаминпирофосфорилазы (QRI1).
В способе согласно изобретению рекомбинантная клетка может содержать по меньшей мере одну рекомбинантную нуклеиновую кислоту, кодирующую одно или более из:
(i) полипептида, имеющего активность фосфоглюкомутазы-1 (PGM1);
(ii) полипептида, имеющего активность UTP-глюкозо-1-фосфат-уридилилтрансферазы (UGP1);
(iii) полипептида, имеющего активность глюкозамин-6-фосфат-N-ацетилтрансферазы (GNA1); и/или
(iv) полипептида, имеющего активность фосфоацетилглюкозаминмутазы (PCM1).
В способе согласно изобретению рекомбинантная клетка может быть членом рода Saccharomyces, и, в частности, представляет собой Saccharomyces cerevisiae.
В способе согласно изобретению молекулярная масса гиалуроновой кислоты может контролироваться временем ферментации.
В способе согласно изобретению время, достаточное для продуцирования гиалуроновой кислоты (HA), имеющей желаемую молекулярную массу, может представлять собой период от около 35 до около 50 часов, предпочтительно от около 40 до около 50 часов, предпочтительно около 48 часов.
В способе согласно изобретению молекулярная масса гиалуроновой кислоты может контролироваться посредством рН среды для культивирования.
В способе согласно изобретению молекулярную массу гиалуроновой кислоты может контролироваться посредством регулирования рН среды для культивирования в процессе стадии культивирования (а) способа согласно изобретению.
В способе согласно изобретению молекулярная масса гиалуроновой кислоты может контролироваться посредством удаления биомассы из среды для культивирования.
Способ согласно изобретению может быть осуществлен в промышленном масштабе, предпочтительно, где среда для культивирования составляет по меньшей мере около 100 л, более предпочтительно в диапазоне от около 1000 до около 3000 л, еще более предпочтительно около 10000 л или еще более предпочтительно около 100000 л или даже около 250000 л.
Другой объект изобретения относится к гиалуроновой кислоте (HA), полученной или получаемой из рекомбинантной клетки по изобретению или способом по изобретению.
Еще один объект изобретения относится к среде для культивирования, содержащей гиалуроновую кислоту (HA) согласно изобретению.
Настоящее изобретение дополнительно относится к композиции, содержащей гиалуроновую кислоту (HA) согласно изобретению.
Кроме того, настоящее изобретение относится к промышленному изделию, или потребительскому продукту, или расходному материалу, содержащему (i) HA, имеющую молекулярную массу в диапазоне более 100 кДа, предпочтительно в диапазоне от около 100 до около 1500 кДа, (ii) среду для культивирования согласно изобретению или (iii) композицию согласно изобретению.
Настоящее изобретение также относится к применению рекомбинантной клетки согласно изобретению для продуцирования гиалуроновой кислоты (HA), имеющей молекулярную массу в диапазоне от около 20 до около 50 кДа или от около 50 до около 1000 кДа.
Другой объект настоящего изобретения относится к способу продуцирования гиалуроновой кислоты, включающему стадии:
(a) культивирования рекомбинантных дрожжей согласно изобретению в среде для культивирования; и
(b) извлечения гиалуроновой кислоты из указанной среды для культивирования,
где гиалуроновая кислота, извлеченная на стадии (b), имеет молекулярную массу, контролируемую путем выбора:
- природы и происхождения нуклеиновой кислоты, кодирующей гиалуронидазу рекомбинантных дрожжей,
- природы и происхождения промотора, контролирующего экспрессию нуклеиновой кислоты, кодирующей гиалуронидазу(-ы) рекомбинантных дрожжей,
- наличия якорного сигнала и/или сигнала секреции, связанного с кодируемой(-ыми) гиалуронидазой(-ами) рекомбинантных дрожжей,
- рН среды для культивирования в процессе стадии культивирования рекомбинантных дрожжей, и/или
- продолжительности культивирования рекомбинантных дрожжей.
Более конкретно, изобретение относится к рекомбинантным дрожжам, продуцирующим гиалуроновую кислоту, где рекомбинантные дрожжи содержат:
(A) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутамин-фруктозо-6-фосфатамимидотрансферазы (GFA1);
(B) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы (QRI1);
(C) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы (UDP-GlcDH или HASB);
(D) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы (HASA); и
(E) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, где указанный полипептид, имеющий активность гиалуронидазы, содержит сигнал секреции, так что рекомбинантная дрожжевая клетка продуцирует гиалуроновую кислоту, в частности, имеющую желаемую молекулярную массу (HAMW),
указанные рекомбинантные дрожжи представляют собой Saccharomyces cerevisiae.
В конкретном варианте осуществления рекомбинантная клетка согласно изобретению и, в частности, рекомбинантные дрожжи согласно изобретению содержат одну рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глутаминсинтетазы (GLN1).
В конкретном варианте осуществления рекомбинантная клетка согласно изобретению и, в частности, рекомбинантные дрожжи согласно изобретению являются такими, что по меньшей мере одна, и, в частности, все ее эндогенные нуклеиновые кислоты, кодирующие глутаматсинтазу (GLT1), нарушены.
В конкретном варианте осуществления рекомбинантная клетка согласно изобретению и, в частности, рекомбинантные дрожжи согласно изобретению:
- содержит одну рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глутаминсинтетазы (GLN1), и, в частности, полипептид, имеющий активность глутаминсинтетазы (GLN1), полученную или происходящую из Saccharomyces cerevisiae; и
- является такой, что по меньшей мере одна, и, в частности, все ее эндогенные нуклеиновые кислоты, кодирующие глутаматсинтазу (GLT1), нарушены.
В конкретном варианте осуществления рекомбинантная клетка согласно изобретению и, в частности, рекомбинантные дрожжи согласно изобретению, содержат только одну рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы (GFA1).
В конкретном варианте осуществления рекомбинантная клетка согласно изобретению и, в частности, рекомбинантные дрожжи содержат от 5 до 10 рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы (QRI1).
В конкретном варианте осуществления рекомбинантная клетка согласно изобретению и, в частности, рекомбинантные дрожжи содержат от 3 до 7 рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы (UDP-GlcDH или HASB).
В другом варианте осуществления одна или более нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы (UDP-GlcDH или HASB), получена или происходит из по меньшей мере одного из Arabidopsis thaliana, вируса хлореллы PBCV1 или Streptococcus zooepidemicus, и, в частности, получена или происходит из Arabidopsis thaliana или вируса хлореллы PBCV1.
В конкретном варианте осуществления рекомбинантная клетка согласно изобретению и, в частности, рекомбинантные дрожжи содержат от 4 до 8 рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы (HASA).
В другом варианте осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующая полипептид, имеющий активность гиалуронан-синтазы (HASA), получена или происходит из по меньшей мере одной из Streptococcus zooepidemicus, вируса хлореллы PBCV1, вируса хлореллы CviKl, вируса хлореллы IL-5-2s1, вируса хлореллы CZ-2, вируса хлореллы CVG-1, Xenopus laevis или Pasteurella multocida и, в частности, получена или происходит из Streptococcus zooepidemicus, вируса хлореллы PBCV1, вируса хлореллы CviKl, вируса хлореллы IL-5-2s1, вируса хлореллы CZ-2, вируса хлореллы CVG-1 или Xenopus laevis.
В конкретном варианте осуществления рекомбинантная клетка согласно изобретению и, в частности, рекомбинантные дрожжи согласно изобретению содержат только одну рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность гиалуронидазы.
В другом варианте осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, получена или происходит из Cupiennius salei, Loxosceles intermedia, Hirudo nipponia, Bothrops atrox или Tityus serrulatus.
В другом варианте осуществления рекомбинантная клетка согласно изобретению и, в частности, рекомбинантная дрожжевая клетка могут содержать по меньшей мере одну рекомбинантную нуклеиновую кислоту, кодирующую одно или более из:
(A) полипептида, имеющего активность фосфоглюкомутазы-1 (PGM1); и/или
(B) полипептида, имеющего активность UTP-глюкозо-1-фосфат-уридилилтрансферазы (UGP1); и/или
(C) полипептида, имеющего активность глюкозамин-6-фосфат-N-ацетилтрансферазы (GNA1); и/или
(D) полипептида, имеющего активность фосфоацетилглюкозаминмутазы (PCM1).
В частности, рекомбинантная клетка согласно изобретению и, в частности, рекомбинантная дрожжевая клетка согласно изобретению содержит по меньшей мере две, в частности, по меньшей мере три и более конкретно все модификации, указанные выше.
В конкретном варианте осуществления нуклеиновая кислота, кодирующая полипептид, имеющий активность фосфоглюкомутазы-1 (PGM1), нуклеиновая кислота, кодирующая полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилилтрансферазы (UGP1), нуклеиновая кислота, кодирующая полипептид, имеющий активность глутамин-фруктозо-6-фосфат амидотрансферазы (GFA1), нуклеиновая кислота, кодирующая полипептид, имеющий активность глюкозамин-6-фосфат N-ацетилтрансферазы (GNA1), нуклеиновая кислота, кодирующая полипептид, имеющий активность фосфоацетилглюкозаминмутазы (PCM1), и нуклеиновая кислота, кодирующая полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы (QRI1), представляют собой нуклеиновые кислоты, происходящие или полученные из дрожжей, предпочтительно из Saccharomyces cerevisiae.
В конкретном варианте осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, определенный выше и содержащийся в рекомбинантной клетке согласно изобретению, и, в частности, содержащийся в рекомбинантных дрожжах согласно изобретению, находятся под контролем промотора, выбранного из группы, состоящей из pPDC1, pTDH3, pCCW12, pCCW12.Sm, pCCW12.sk, pCCW12.sba, pCCW12.sar, pTEF1, pENO2, pRPLA1, pNUP57 и pTEF3.
В конкретном варианте осуществления индуцибельные или репрессируемые промоторы, упомянутые в настоящем описании, выбраны из группы, состоящей из промоторов, индуцируемых или репрессируемых медью, или промоторов, индуцируемых или репрессируемых метионином, в частности, выбранных из группы, состоящей из pMET6, pMET25 и pSAM1.
Изобретение также относится к способу продуцирования гиалуроновой кислоты, как описано ранее, и включающему стадии:
(a) культивирования рекомбинантной клетки согласно изобретению и, в частности, рекомбинантных дрожжей, как определено в настоящем документе, в среде для культивирования; и
(b) извлечения гиалуроновой кислоты из указанной среды для культивирования,
где гиалуроновая кислота, извлеченная на стадии (b), имеет молекулярную массу, контролируемую путем выбора:
- природы и происхождения нуклеиновой кислоты, кодирующей гиалуронидазу рекомбинантной клетки согласно изобретению, и, в частности, рекомбинантных дрожжей согласно изобретению, и/или
- природы и происхождения промотора, контролирующего экспрессию нуклеиновой кислоты, кодирующей гиалуронидазу(-ы) рекомбинантной клетки согласно изобретению, и, в частности, рекомбинантных дрожжей, и/или
- наличия якорного сигнала и/или сигнала секреции, связанного с кодируемой(-ыми) гиалуронидазой(-ами) рекомбинантной клетки согласно изобретению, и, в частности, рекомбинантных дрожжей, и/или
- рН среды для культивирования в процессе стадии культивирования рекомбинантной клетки согласно изобретению и, в частности, рекомбинантных дрожжей; и/или
- продолжительности культивирования рекомбинантной клетки согласно изобретению и, в частности, рекомбинантных дрожжей.
Рекомбинантные нуклеиновые кислоты, кодирующие полипептид, имеющий активность гиалуронан-синтазы
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантные дрожжи согласно изобретению содержат одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы.
Полипептид, имеющий активность гиалуронан-синтазы, согласно изобретению означает полипептид, который превращает промежуточные метаболиты UDP-глюкоронат и UDP-N-ацетилглюкозамин (UDP-GlcNAc) в гиалуроновую кислоту ((β-D-1,3-GlcNAc-β-D-1,4-GlcA)n).
В варианте осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы, находятся под контролем индуцибельного или репрессируемого промотора, который является функциональным в рекомбинантных клетках согласно изобретению, таких как, например, индуцибельные или репрессируемые промоторы pCUP1 или pMET25.
Одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы, могут находиться под контролем промотора, выбранного из группы, состоящей из pCCW12, pCCW12.Sm, pTDH3-1.Sba и pTDH3.Sar.
Указанная одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы, могут происходить или быть получены из по меньшей мере одного из Streptococcus zooepidemicus (sz), вируса хлореллы PBCV1 (Vir), вируса хлореллы CviKl (Vir), вируса хлореллы IL-5-2s1 (Vir), вируса хлореллы CZ-2 (Vir), вируса хлореллы CVG-1 (Vir), Xenopus laevis (xl) или Pasteurella multocida (pm), и могут происходить или быть получены, в частности, из Streptococcus zooepidemicus, вируса хлореллы PBCV1, вируса хлореллы CviKl, вируса хлореллы IL-5-2s1, вируса хлореллы CZ-2, вируса хлореллы CVG-1 или Xenopus laevis, как показано в примерах в настоящем документе.
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантные дрожжи согласно изобретению, может содержать от 2 до 8, в частности, от 4 до 8 рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы (HASA). Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантные дрожжи согласно изобретению, может, например, содержать 2 или 6, и, в частности, 6 рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы (HASA).
В качестве примера, одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы, могут быть вставлены в ген JLP1, и/или в ген SAM3, и/или в ген TRP1, и/или в ген LYP1 рекомбинантной клетки и, в частности, рекомбинантных дрожжей, как показано в примерах в настоящем документе.
В варианте осуществления изобретения рекомбинантная клетка и, в частности, рекомбинантные дрожжи по изобретению содержат:
- от 2 до 8, в частности от 4 до 8 рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы (HASA);
- указанную одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы, происходящую или полученную из по меньшей мере одного из Streptococcus zooepidemicus (sz), вируса хлореллы PBCV1 (Vir), Xenopus laevis (xl) или Pasteurella multocida (pm), и происходящую или полученную из, в частности, по меньшей мере одного из Streptococcus zooepidemicus, вируса хлореллы PBCV1 или Xenopus laevis; и
- указанную одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы, находящуюся под контролем индуцибельного или репрессируемого промотора, который является функциональным в рекомбинантных клетках по изобретению, такого как, например, индуцибельные или репрессируемые промоторы pCUP или pMET25, и/или под контролем промотора, выбранного из группы, состоящей из pCCW12, pCCW12.Sm, pTDH3-1.Sba и pTDH3.Sar.
Рекомбинантные нуклеиновые кислоты, кодирующие полипептид, имеющий активность UDP-глюкозодегидрогеназы
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантные дрожжи согласно изобретению, содержит одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы (UDP-GlcDH или HASB).
Полипептид, имеющий активность UDP-глюкозодегидрогеназы (UDP-GlcDH или HASB), согласно изобретению означает полипептид, который превращает промежуточный метаболит уридиндифосфат глюкозу (UDP-глюкозу) в UDP-глюкуронат.
В варианте осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы (UDP-GlcDH или HASB), находятся под контролем индуцибельного или репрессируемого промотора, который является функциональным в рекомбинантных клетках согласно изобретению, таких как, например, индуцибельные или репрессируемые промоторы pMET25 или pMET6.
Одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы, могут находиться под контролем промотора, выбранного из группы, состоящей из pCCW12, в частности промоторов pCCW12.sk и pCCW12.sba; pTEF1.Sba и pTDH3.Sk.
Одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы, могут происходить или быть получены из по меньшей мере одного из Arabidopsis thaliana, вируса хлореллы PBCV1 или Streptococcus zooepidemicus, и, в частности, могут происходить или быть получены из Arabidopsis thaliana или вируса хлореллы PBCV1.
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантные дрожжи согласно изобретению, может содержать от 2 до 7, в частности, от 3 до 7 рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы. Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантные дрожжи согласно изобретению, может, например, содержать 2 или 5 рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы.
В качестве примера, одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы, могут быть вставлены в ген JLP1, и/или в ген TRP1, и/или в ген LYP1 рекомбинантной клетки и, в частности, рекомбинантных дрожжей, как показано в примерах в настоящем документе.
В варианте осуществления изобретения рекомбинантная клетка и, в частности, рекомбинантные дрожжи по изобретению содержат:
- от 2 до 7, и, в частности, от 3 до 7 рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы;
- указанную одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы, происходящую или полученную из по меньшей мере одного из Arabidopsis thaliana, вируса хлореллы PBCV1 или Streptococcus zooepidemicus, и происходящую или полученную, в частности, из Arabidopsis thaliana или вируса хлореллы PBCV1; и
- указанную одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы, находящуюся под контролем индуцибельного или репрессируемого промотора, который является функциональным в рекомбинантных клетках по изобретению, таких как, например, индуцибельные или репрессируемые промоторы pMET25 или pMET6, и/или под контролем промотора, выбранного из группы, состоящей из pCCW12, в частности, промоторов pCCW12.sk и pCCW12.sba; pTEF1.Sba и pTDH3.Sk.
Рекомбинантные нуклеиновые кислоты, кодирующие полипептид, имеющий активность гиалуронидазы
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантные дрожжи согласно изобретению, содержит одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы.
Полипептид, имеющий активность гиалуронидазы, согласно изобретению означает полипептид, который нарушает гиалуроновую кислоту, то есть превращает гиалуроновую кислоту с заданной молекулярной массой в гиалуроновую кислоту с более низкой молекулярной массой.
Как указано ранее, полипептиды, имеющие активность гиалуронидазы, согласно настоящему изобретению содержат сигнал секреции.
В одном варианте осуществления полипептид, имеющий активность гиалуронидазы, содержит как сигнал секреции, так и якорный сигнал.
В одном варианте осуществления указанная одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, находятся под контролем индуцибельного или репрессируемого промотора, который является функциональным в рекомбинантных клетках согласно настоящему изобретению.
Одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, могут находиться под контролем промотора, выбранного из группы, состоящей из pTEF1, pCCW12, pCCW12.sba, pCCW12.Sar, pPDC1, pTEF3, pTDH3, pNUP57, pCWP2 и pCCW10.ago.
Указанные одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, могут происходить или быть получены из по меньшей мере одного из Cupiennius salei (Csa), Loxosceles intermedia (Li), Hirudo nipponia (Hn), Bothrops atrox (Ba) или Tityus serrulatus (Ts), как показано в примерах в настоящем документе.
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантные дрожжи согласно изобретению, может содержать только одну рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность гиалуронидазы.
В качестве примера, одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, могут быть вставлены в ген JLP1 и/или в ген LYP1, как показано в примерах в настоящем документе.
В варианте осуществления изобретения рекомбинантная клетка и, в частности, рекомбинантные дрожжи по изобретению содержат:
- только одну рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность гиалуронидазы;
- указанную рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность гиалуронидазы, происходящую или полученную из Cupiennius salei (Csa), Loxosceles intermedia (Li), Hirudo nipponia (Hn), Bothrops atrox (Ba) или Tityus serrulatus (Ts);
- указанную рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность гиалуронидазы, содержащую либо (i) сигнал секреции и не содержащий якорного сигнала, либо (ii) сигнал секреции и якорный сигнал; и
- указанную рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность гиалуронидазы, находящуюся под контролем промотора, выбранного из группы, состоящей из pTEF1, pCCW12, pCCW12.sba, pCCW12.Sar, pPDC1, pTEF3, pTDH3, pNUP57, pCWP2 и pCCW10.ago.
Рекомбинантные нуклеиновые кислоты, кодирующие полипептид, имеющий активность глутаминсинтетазы
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантная дрожжевая клетка согласно изобретению, может содержать одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутаминсинтетазы.
Полипептид, имеющий активность глутаминсинтетазы, согласно изобретению означает полипептид, который превращает глутамат в глутамин при потреблении одного АТФ (аденозинтрифосфат) и одного NH4+.
В одном варианте осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутаминсинтетазы, находятся под контролем индуцибельного или репрессируемого промотора, который является функциональным в рекомбинантных клетках согласно настоящему изобретению.
Одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутаминсинтетазы, могут находиться под контролем промотора, выбранного из группы, состоящей из pTEF1 и pTEF1.Ago.
Указанные одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутаминсинтетазы, могут происходить или быть получены из Saccharomyces cerevisiae, как показано в примерах в настоящем документе.
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантная дрожжевая клетка, согласно изобретению может содержать только одну рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глутаминсинтетазы.
В качестве примера, одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутаминсинтетазы, могут быть вставлены в ген LYP1 или GLT1 рекомбинантной клетки и, в частности, рекомбинантной дрожжевой клетки, как показано в примерах в настоящем документе.
В варианте осуществления изобретения рекомбинантная клетка и, в частности, рекомбинантные дрожжи по изобретению содержат:
- только одну рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глутаминсинтетазы;
- указанную рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глутаминсинтетазы, происходящую или полученную из Saccharomyces cerevisiae; и
- указанную рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глутаминсинтетазы, находящуюся под контролем промотора, выбранного из группы, состоящей из pTEF1 и pTEF1.Ago.
В дополнительном варианте осуществления изобретения рекомбинантная клетка и, в частности, рекомбинантные дрожжи по изобретению содержат:
- только одну рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глутаминсинтазы;
- указанную рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глутаминсинтетазы, происходящую или полученную из Saccharomyces cerevisiae;
- указанную рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глутаминсинтетазы, находящуюся под контролем промотора, выбранного из группы, состоящей из pTEF1 и pTEF1.Ago; и
- указанную рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глутаминсинтетазы, встроенную в ген LYP1 или GLT1 рекомбинантной клетки и, в частности, рекомбинантной дрожжевой клетки.
Рекомбинантные нуклеиновые кислоты, кодирующие полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантная дрожжевая клетка согласно изобретению, может содержать одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы.
Полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы, согласно изобретению означает полипептид, который превращает фруктозо-6-фосфат в глюкозамин-6-фосфат.
В одном варианте осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы, находятся под контролем индуцибельного или репрессируемого промотора, который является функциональным в рекомбинантных клетках согласно настоящему изобретению.
Одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы, могут находиться под контролем промотора, выбранного из группы, состоящей из pTEF1 и pTEF1.Ago.
Указанные одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы, могут происходить или быть получены из Saccharomyces cerevisiae, как показано в примерах в настоящем документе.
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантная дрожжевая клетка согласно изобретению, может содержать одну рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы.
В качестве примера, одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы, могут быть вставлены в ген SAM3 рекомбинантной клетки и, в частности, рекомбинантной дрожжевой клетки, как показано в примерах в настоящем документе.
В варианте осуществления изобретения рекомбинантная клетка и, в частности, рекомбинантные дрожжи по изобретению содержат:
- только одну рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы;
- указанную рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы, происходящую или полученную из Saccharomyces cerevisiae; и
- указанную рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы, находящуюся под контролем промотора, выбранного из группы, состоящей из pTEF1 и pTEF1.Ago.
Рекомбинантные нуклеиновые кислоты, кодирующие полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантная дрожжевая клетка согласно изобретению, может содержать одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы.
Полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы, согласно изобретению означает полипептид, который может превращать N-ацетил-глюкозамин в UDP-N-ацетил-глюкозамин.
В варианте осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы, находятся под контролем индуцибельного или репрессируемого промотора, который является функциональным в рекомбинантных клетках согласно изобретению, таких как, например, индуцибельные или репрессируемые промоторы pMET6 или pCUP1.
Одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы, могут находиться под контролем промотора pTDH3.
Указанные одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы, могут происходить или быть получены из Saccharomyces cerevisiae, как показано в примерах в настоящем документе.
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантные дрожжи согласно изобретению, может содержать от 5 до 10 рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы. Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантная дрожжевая клетка согласно изобретению, может содержать 5, 7 или 8 рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы.
В качестве примера, одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы, могут быть вставлены в ген HIS3, и/или в ген JLP1, и/или в ген SAM3 рекомбинантной клетки и, в частности, рекомбинантных дрожжей, как показано в примерах в данном документе.
В варианте осуществления изобретения рекомбинантная клетка и, в частности, рекомбинантные дрожжи по изобретению содержат:
- от 5 до 10 рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы;
- указанную одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы, происходящую или полученную из Saccharomyces cerevisiae;
- указанную одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы, находящуюся под контролем индуцибельного или репрессируемого промотора, который является функциональным в рекомбинантных клетках по изобретению, таких как, например, индуцибельные или репрессируемые промоторы pMET6 или pCUP1 и/или под контролем промотора pTDH3.
Рекомбинантные нуклеиновые кислоты, кодирующие полипептид, имеющий активность фосфоглюкомутазы-1
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантная дрожжевая клетка согласно изобретению, может содержать одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоглюкомутазы-1 (PGM1).
Полипептид, имеющий активность фосфоглюкомутазы-1 (PGM1) согласно изобретению, означает полипептид, который превращает глюкозо-6-фосфат в промежуточный метаболит глюкозо-1-фосфат.
В варианте осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоглюкомутазы-1 (PGM1), находятся под контролем индуцибельного или репрессируемого промотора, который является функциональным в рекомбинантных клетках согласно изобретению, таких как, например, индуцибельные или репрессируемые промоторы.
Одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоглюкомутазы-1 (PGM1), могут находиться под контролем промотора pPDC1.
Одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоглюкомутазы-1 (PGM1), могут происходить или быть получены из Saccharomyces cerevisiae, как показано в примерах в настоящем документе.
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантная дрожжевая клетка согласно изобретению, может содержать только одну рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность фосфоглюкомутазы-1 (PGM1).
В качестве примера, одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоглюкомутазы-1, могут быть вставлены в ген SAM3 рекомбинантной клетки и, в частности, рекомбинантных дрожжей, как показано в примерах в настоящем документе.
В варианте осуществления изобретения рекомбинантная клетка и, в частности, рекомбинантные дрожжи по изобретению содержат:
- только одну рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность фосфоглюкомутазы-1;
- указанную рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность фосфоглюкомутазы-1, происходящую или полученную из Saccharomyces cerevisiae; и
- указанную рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность фосфоглюкомутазы-1, находящуюся под контролем промотора pPDC1.
Рекомбинантные нуклеиновые кислоты, кодирующие полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилилтрансферазы
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантная дрожжевая клетка согласно изобретению, содержит одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилилтрансферазы (UGP1).
Полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилилтрансферазы (UGP1), согласно изобретению означает полипептид, который превращает промежуточный метаболит глюкозо-1-фосфат в промежуточный метаболит UDP-глюкозу.
В варианте осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилтрансферазы, находятся под контролем индуцибельного или репрессируемого промотора, который является функциональным в рекомбинантных клетках согласно изобретению, таких как, например, индуцибельные или репрессируемые промоторы pSAM1 или pCUP1.
Одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилилтрансферазы, могут находиться под контролем промотора, выбранного из группы, состоящей из pPDC1 и pENO2.
Одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилилтрансферазы, могут происходить или быть получены из Saccharomyces cerevisiae, как показано в примерах в настоящем документе.
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантная дрожжевая клетка согласно изобретению, может содержать от 5 до 10 рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилилтрансферазы. Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантная дрожжевая клетка согласно изобретению, может содержать 5, 7 или 8 рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилилтрансферазы.
В качестве примера, одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий ген активности UTP-глюкозо-1-фосфат-уридилилтрансферазы, могут быть вставлены в ген HIS3, и/или в ген JLP1, и/или в ген SAM3 рекомбинантной клетки и, в частности, рекомбинантных дрожжей, как показано в примерах в данном документе.
В варианте осуществления изобретения рекомбинантная клетка и, в частности, рекомбинантные дрожжи по изобретению содержат:
- от 5 до 10 рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилилтрансферазы;
- указанную одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилилтрансферазы, происходящую или полученную из Saccharomyces cerevisiae; и
- указанную одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, находящуюся под контролем индуцибельного или репрессируемого промотора, который является функциональным в рекомбинантных клетках по изобретению, таких как, например, индуцибельные или репрессируемые промоторы pSAM1 или pCUP1 и/или под контролем промотора, выбранного из группы, состоящей из pPDC1 и pENO2.
Рекомбинантные нуклеиновые кислоты, кодирующие полипептид, имеющий активность глюкозамин-6-фосфат-N-ацетилтрансферазы
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантная дрожжевая клетка согласно изобретению, может содержать одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глюкозамин-6-фосфат-N-ацетилтрансферазы (GNA1).
Полипептид, имеющий активность в отношении глюкозамин-6-фосфат-N-ацетилтрансферазы (GNA1), согласно изобретению означает полипептид, который может превращать глюкозамин-6-фосфат в N-ацетил-глюкозамин-6-фосфат.
В одном варианте осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глюкозамин-6-фосфат-N-ацетилтрансферазы, находятся под контролем индуцибельного или репрессируемого промотора, который является функциональным в рекомбинантных клетках согласно настоящему изобретению.
Одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глюкозамин-6-фосфат-N-ацетилтрансферазы, могут находиться под контролем промотора pCWP2.
Указанные одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глюкозамин-6-фосфат-N-ацетилтрансферазы, могут происходить или быть получены из Saccharomyces cerevisiae, как показано в примерах в настоящем документе.
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантная дрожжевая клетка согласно изобретению, может содержать только одну рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глюкозамин-6-фосфат-N-ацетилтрансферазы.
В качестве примера, одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глюкозамин-6-фосфат-N-ацетилтрансферазы, могут быть вставлены в ген SAM3 рекомбинантной клетки и, в частности, рекомбинантных дрожжей, как показано в примерах в настоящем документе.
В варианте осуществления изобретения рекомбинантная клетка и, в частности, рекомбинантные дрожжи по изобретению содержат:
- только одну рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глюкозамин-6-фосфат-N-ацетилтрансферазы;
- указанную рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глюкозамин-6-фосфат-N-ацетилтрансферазы, происходящую или полученную из Saccharomyces cerevisiae; и
- указанную рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность глюкозамин-6-фосфат-N-ацетилтрансферазы, находящуюся под контролем промотора pCWP2.
Рекомбинантные нуклеиновые кислоты, кодирующие полипептид, имеющий активность фосфоацетилглюкозаминмутазы
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантная дрожжевая клетка согласно изобретению, может содержать одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоацетилглюкозаминмутазы (PCM1).
Полипептид, имеющий активность фосфоацетилглюкозаминмутазы (PCM1), согласно изобретению означает полипептид, который может превращать N-ацетилглюкозамин-6-фосфат в N-ацетилглюкозамин-1-фосфат.
В одном варианте осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоацетилглюкозаминмутазы, находятся под контролем индуцибельного или репрессируемого промотора, который является функциональным в рекомбинантных клетках согласно настоящему изобретению.
Одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоацетилглюкозаминмутазы, могут находиться под контролем промотора, выбранного из группы, состоящей из pTEF3 и pTEF1.
Указанные одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоацетилглюкозаминмутазы, могут происходить или быть получены из Saccharomyces cerevisiae, как показано в примерах в настоящем документе.
Рекомбинантная клетка согласно изобретению и, в частности, рекомбинантная дрожжевая клетка согласно изобретению, может содержать только одну рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность фосфоацетилглюкозаминмутазы.
В качестве примера, одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоацетилглюкозаминмутазы, могут быть вставлены в ген SAM3 рекомбинантной клетки и, в частности, рекомбинантных дрожжей, как показано в примерах в настоящем документе.
В варианте осуществления изобретения рекомбинантная клетка и, в частности, рекомбинантные дрожжи по изобретению содержат:
- только одну рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность фосфоацетилглюкозаминмутазы;
- указанную рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность фосфоацетилглюкозаминмутазы, происходящую или полученную из Saccharomyces cerevisiae; и
- указанную рекомбинантную нуклеиновую кислоту, кодирующую полипептид, имеющий активность фосфоацетилглюкозаминмутазы, находящуюся под контролем промотора, где промотор выбран из группы, состоящей из pTEF3 и pTEF1.
гиалуронан-синтаза (HASA)
Фермент гиалуронан-синтаза представляет собой белок, который описан в данной области техники для катализа превращения UDP-глюкуроната или UDP-N-ацетилглюкозы в гиалуроновую кислоту. Гиалуронан-синтаза, происходящая из Streptococcus zooepidemicus, вируса хлореллы PBCV1, Xenopus laevis или Pasteurella multocida, может быть названа HASA.
Способ, который осуществляют для измерения уровня активности полипептида, имеющего активность гиалуронан-синтазы, относится к общим знаниям специалиста в данной области техники.
В связи с этим специалист в данной области техники может предпочтительно ссылаться на способ колориметрического определения после обработки концентрированной серной кислотой и карбазолом, описанный в Bitter and Muir (Analytical Biochemistry, 4, 330-334, 1962).
Предпочтительный полипептид, имеющий активность гиалуронан-синтазы, в настоящем изобретении представляет собой фермент с шифром КФ (классификация ферментов) n 2.4.1.212.
Согласно предпочтительному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы, могут происходить или быть получены из организмов, предпочтительно выбранных из группы, состоящей из прокариотических организмов и эукариотических организмов. В некоторых вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы, могут происходить или быть получены из архебактерий. В некоторых вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы, могут происходить или быть получены из бактерий и, в частности, из Streptococcus zooepidemicus (Sz) или Pasteurella multocida (Pm), вируса хлореллы PBCV1 (Vir), вируса хлореллы CviKl (Vir), вируса хлореллы IL-5-2s1 (Vir), вируса хлореллы CZ-2 (Vir), вируса хлореллы CVG-1 (Vir) или Xenopus laevis (Xl).
Согласно еще одному предпочтительному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы, могут быть выбраны из группы, состоящей из нуклеотидных последовательностей, имеющих (i) по меньшей мере 65%, предпочтительно по меньшей мере 70%, предпочтительно по меньшей мере 80% нуклеотидную идентичность с нуклеотидной последовательностью, представленную как последовательность SEQ ID NO: 1 (Vir), SEQ ID NO: 2 (Vir), SEQ ID NO: 3 (Pm), SEQ ID NO: 4 (Pm), SEQ ID NO: 5 (Pm), SEQ ID NO: 6 (Xl), SEQ ID NO: 7 (sz), SEQ ID NO: 101 (Vir), SEQ ID NO: 102 (Vir), SEQ ID NO: 103 (Vir) или SEQ ID NO: 104 (Vir), и (ii) биологическую активность той же природы, что и нуклеотидная последовательность, имеющая, соответственно, нуклеотидную последовательность, представленную как последовательность SEQ ID NO: 1 (Vir), SEQ ID NO: 2 (Vir), SEQ ID NO: 3 (Pm), SEQ ID NO: 4 (Pm), SEQ ID NO: 5 (Pm), SEQ ID NO: 6 (Xl), SEQ ID NO: 7 (sz), SEQ ID NO: 101 (Vir), SEQ ID NO: 102 (Vir), SEQ ID NO: 103 (Vir) или SEQ ID NO: 104 (Vir).
Биологическая активность такой же природы в отношении этой последовательности, как объяснялось ранее, представляет собой способность кодировать полипептид, который превращает UDP-глюкуронат или UDP-N-ацетилглюкозу в гиалуроновую кислоту.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 65% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 70% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 80% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Для аминокислотной последовательности полипептида, имеющего активность гиалуронан-синтазы, происходящей из Streptococcus zooepidemicus, вируса хлореллы PBCV1, Xenopus laevis или Pasteurella multocida, специалист в данной области техники может ссылаться, соответственно, на номера доступа B4U0D4, Q84419, P13563, Q7BLV3, M1GZS8, M1H5V3, M1H2Q1 и M1HN86 в базе данных UniProt или на SEQ ID NO: 8 (Vir), SEQ ID NO: 9 (Pm), SEQ ID NO: 10 (Xl), SEQ ID NO:11 (Sz), SEQ ID NO: 105 (Vir), SEQ ID NO: 106 (Vir), SEQ ID NO: 107 (Vir) или SEQ ID NO: 108 (Vir), описанные в данном документе, в частности на SEQ ID NO: 8 (Vir), SEQ ID NO: 9 (Pm), SEQ ID NO: 10 (Xl), SEQ ID NO: 11 (Sz), SEQ ID NO: 105 (Vir), SEQ ID NO: 106 (Vir) или SEQ ID NO: 108 (Vir), и более конкретно на SEQ ID NO: 8 (Vir), SEQ ID NO: 9 (Pm), SEQ ID NO: 10 (Xl), SEQ ID NO: 11 (Sz).
Согласно другому конкретному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы, могут представлять собой нуклеиновую кислоту(-ы), кодирующую полипептид, имеющую аминокислотную последовательность, выбранную из группы, состоящей из последовательностей, имеющих по меньшей мере 50%, предпочтительно по меньшей мере 65%, предпочтительно по меньшей мере 80% аминокислотную идентичность с аминокислотной последовательностью, представленной как SEQ ID NO: 8 (Vir), SEQ ID NO: 9 (Pm) SEQ ID NO: 10 (Xl), SEQ ID NO: 11 (Sz), SEQ ID NO: 105 (Vir), SEQ ID NO: 106 (Vir), SEQ ID NO: 107 (Vir) или SEQ ID NO: 108 (Vir), а также биологической активностью той же природы, что и аминокислотная последовательность, представленная как SEQ ID NO: 8 (Vir), SEQ ID NO: 9 (Pm) SEQ ID NO: 10 (Xl), SEQ ID NO:11 (Sz), SEQ ID NO: 105 (Vir), SEQ ID NO: 106 (Vir), SEQ ID NO: 107 (Vir) или SEQ ID NO: 108 (Vir).
Биологическая активность той же природы в отношении этой последовательности является такой, как описано ранее, т.е. способность катализировать превращение UDP-глюкуроната или UDP-N-ацетилглюкозы в гиалуроновую кислоту.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 50% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 51%, 52%, 53%, 54%, 55%, 56%, 57%, 58%, 59%, 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 65% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 80% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как указано выше, уровень экспрессии одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы, в настоящем изобретении регулируется по меньшей мере одним промотором и по меньшей мере одним терминатором, например, как более подробно описано в настоящем документе, которые присутствуют в 5’- и 3’-положении, соответственно, одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы.
UDP-ГЛЮКОЗОДЕГИДРОГЕНАЗА (UDP-GlcDH или HASB)
UDP-глюкозодегидрогеназа представляет собой белок, который, как известно в данной области техники, катализирует превращение UDP-глюкозы в UDP-глюкуронат. UDP-глюкозодегидрогеназа, происходящая из генома Arabidopsis thaliana, вируса хлореллы PBCV1 или Streptococcus zooepidemicus, может называться HASB.
Способ, который осуществляют для измерения уровня активности полипептида, имеющего активность UDP-глюкозодегидрогеназы, относится к общим знаниям специалиста в данной области техники.
В этом отношении специалист в данной области техники может предпочтительно обратиться к способу, описанному в Oka and Jigami (FEBS Journal 273, 2645-2657, 2006).
Предпочтительный полипептид, имеющий активность UDP-глюкозодегидрогеназы, в настоящем описании представляет собой фермент, имеющий шифр КФ 1.1.1.22.
Согласно предпочтительному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы, могут происходить или быть получены из организмов, предпочтительно выбранных из группы, включающей прокариотические организмы и эукариотические организмы. В некоторых вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы, могут происходить или быть получены из архебактерий. В некоторых предпочтительных вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы, могут происходить или быть получены из дрожжей и, в частности, из Arabidopsis thaliana, вируса хлореллы PBCV1 или Streptococcus zooepidemicus haromyces.
Согласно еще одному предпочтительному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы, могут быть выбраны из группы, состоящей из нуклеотидных последовательностей, имеющих (i) по меньшей мере 65%, предпочтительно по меньшей мере 70%, предпочтительно по меньшей мере 80% нуклеотидную идентичность с нуклеиновой кислотой, представленной как последовательность SEQ ID NO: 12 (At), SEQ ID NO: 13 (Vir), SEQ ID NO: 14 (Vir) или SEQ ID NO: 15 (Sz), и (ii) биологическую активность той же природы, что и нуклеиновая кислота, представленной как последовательность SEQ ID NO: 12 (At), SEQ ID NO: 13 (Vir), SEQ ID NO: 14 (Vir) или SEQ ID NO: 15 (Sz). Нуклеиновые кислоты, представленные как последовательности SEQ ID NO: 12 (At), SEQ ID NO: 13 (Vir), SEQ ID NO: 14 (Vir) и SEQ ID NO: 15 (Sz), кодируют полипептид, имеющий активность UDP-глюкозодегидрогеназы, происходящей, соответственно, из Arabidopsis thaliana (At), вируса хлореллы PBCV1 (Vir) или Streptococcus zooepidemicus (Sz), которые также могут быть в совокупности названы HASB.
Биологическая активность такой же природы в отношении этой последовательности, как объяснялось ранее, представляет собой способность кодировать полипептид, который превращает UDP-глюкозу в UDP-глюкуронат.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 65% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 70% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанными референсными нуклеотидными последовательностями, а также биологическую активность той же природы, что и указанные референсные нуклеотидные последовательности.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 80% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанные референсные нуклеотидные последовательности.
Для аминокислотной последовательности полипептида, имеющего активность UDP-глюкозодегидрогеназы, из Arabidopsis thaliana, вируса хлореллы PBCV1 или Streptococcus zooepidemicus, специалист в данной области техники может ссылаться на номера доступа NP_173979.1, NP_048965 или KIS19289, соответственно, в базе данных UniProt, или на последовательности, представленные в SEQ ID NO: 16 (At), SEQ ID NO: 17 (Vir) и SEQ ID NO: 18 (Sz), описанные в настоящем документе.
Согласно другому конкретному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы, могут представлять собой нуклеиновую кислоту(-ы), кодирующую полипептид, имеющий аминокислотную последовательность, выбранную из группы, состоящей из последовательностей, имеющих по меньшей мере 55%, предпочтительно по меньшей мере 65%, предпочтительно по меньшей мере 80% аминокислотную идентичность с аминокислотной последовательностью SEQ ID NO: 16 (At), SEQ ID NO: 17 (Vir) и SEQ ID NO: 18 (Sz), а также биологической активностью той же природы, что и аминокислотная последовательность SEQ ID NO: 16 (At), SEQ ID NO: 17 (Vir) и SEQ ID NO: 18 (Sz).
Биологическая активность такой же природы в отношении этой последовательности является такой, как описано ранее, т.е. способность катализировать превращение UDP-глюкозы в UDP-глюкуронат.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 55% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 56%, 57%, 58%, 59%, 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 65% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 80% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как указано выше, уровень экспрессии одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы, в настоящем изобретении регулируется по меньшей мере одним промотором и по меньшей мере одним терминатором, например, как более подробно описано в настоящем документе, которые присутствуют в 5’- и 3’-положении, соответственно, одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы.
ГИАЛУРОНИДАЗА (HYAL)
Фермент гиалуронидаза представляет собой белок, который описан в данной области техники для катализа расщепления молекул гиалуроновой кислоты до более мелких молекул гиалуроновой кислоты. Гиалуронидаза, происходящая из Cupiennius salei, Loxosceles intermedia, Hirudo nipponia, Bothrops atrox, Tityus serrulatus или Vespa magnifica, может называться HYAL.
Полипептид, имеющий активность гиалуронидазы, согласно настоящему изобретению может обладать как сигналом секреции и якорным сигналом, или обладать сигналом секреции и не обладать якорным сигналом, или обладать сигналом секреции-якорным сигналом с двойной функцией секреции и закрепления. Когда кодируемый полипептид, имеющий активность гиалуронидазы, обладает как сигналом секреции, так и якорным сигналом, его можно назвать HYAL-31, как представлено в примерах. Когда кодированный полипептид, имеющий активность гиалуронидазы, обладает сигналом секреции и не имеет якорного сигнала, его можно назвать HYAL-3, как представлено в примерах.
Способ, который осуществляют для измерения уровня активности полипептида, имеющего активность гиалуронидазы, относится к общим знаниям специалиста в данной области техники.
В связи с этим специалист в данной области техники может предпочтительно контролировать молекулярную массу полученной гиалуроновой кислоты на агарозном геле.
Предпочтительный полипептид, имеющий активность гиалуронидазы, в настоящем описании представляет собой фермент с шифром КФ n 3.2.1.35.
Согласно предпочтительному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, могут происходить или быть получены из организмов, предпочтительно выбранных из группы, включающей прокариотические организмы и эукариотические организмы. В некоторых вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, могут происходить или быть получены из архебактерий. В некоторых вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, могут происходить или быть получены из организмов, предпочтительно выбранных из дрожжей. В некоторых других предпочтительных вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, могут происходить или быть получены из Cupiennius salei (Csa), Loxosceles intermedia (Li), Hirudo nipponia (Hn), Bothrops atrox (Ba), Tityus serrulatus (Ts) или Vespa magnifica (Vm), и, в частности, из Cupiennius salei (Csa), Loxosceles intermedia (Li), Hirudo nipponia (Hn), Bothrops atrox (Ba) и Tityus serrulatus (Ts).
Согласно еще одному предпочтительному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, могут быть выбраны из группы, состоящей из нуклеотидных последовательностей, имеющих по меньшей мере 65%, предпочтительно по меньшей мере 70%, предпочтительно по меньшей мере 80% нуклеотидную идентичность с нуклеиновой кислотой SEQ ID NO: 19 (Ba), SEQ ID NO: 25 (Li), SEQ ID NO: 21 (Csa), SEQ ID NO: 27 (Ts), SEQ ID NO: 23 (Hn) или SEQ ID NO: 29 (Vm), а также биологической активностью той же природы, что и нуклеиновая кислота SEQ ID NO: 19 (Ba), SEQ ID NO: 25 (Li), SEQ ID NO: 21 (Csa), SEQ ID NO: 27 (Ts), SEQ ID NO: 23 (Hn) или SEQ ID NO: 29 (Vm). Нуклеиновая кислота SEQ ID NO: 19 (Ba), SEQ ID NO: 25 (Li), SEQ ID NO: 21 (Csa), SEQ ID NO: 27 (Ts), SEQ ID NO: 23 (Hn) или SEQ ID NO: 29 (Vm) кодирует полипептид, имеющий активность гилуронидазы, содержит сигнал секреции и не содержит якорный сигнал и происходит или получена из Bothrops atrox, Loxosceles intermedia, Cupiennius salei, Tityus serrulatus, Hirudo nipponia или Vespa magnifica, соответственно.
Согласно другому предпочтительному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, могут быть выбраны из группы, состоящей из последовательностей нуклеиновых кислот, имеющих по меньшей мере 65%, предпочтительно по меньшей мере 70%, предпочтительно по меньшей мере 80% нуклеотидную идентичность с нуклеиновой кислотой SEQ ID NO: 22 (Csa), SEQ ID NO: 26 (Li), SEQ ID NO: 24 (Hn), SEQ ID NO: 20 (Ba), SEQ ID NO: 28 (Ts) или SEQ ID NO: 30 (Vm), а также биологическую активность той же природы, что и нуклеиновая кислота SEQ ID NO: 22 (Csa), SEQ ID NO: 26 (Li), SEQ ID NO: 24 (Hn), SEQ ID NO: 20 (Ba), SEQ ID NO: 28 (Ts) или SEQ ID NO: 30 (Vm). Нуклеиновая кислота SEQ ID NO: 22 (Csa), SEQ ID NO: 26 (Li), SEQ ID NO: 24 (Hn), SEQ ID NO: 20 (Ba) SEQ ID NO: 28 (Ts) или SEQ ID NO: 30 (Vm) кодирует полипептид, имеющий активность гилуронидазы, содержит сигнал секреции и якорный сигнал и происходит или получена из Cupiennius salei, Loxosceles intermedia, Hirudo nipponia, Bothrops atrox, Tityus serrulatus или Vespa magnifica, соответственно.
В конкретном варианте осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, могут быть выбраны из группы, состоящей из нуклеотидных последовательностей, (i) имеющих по меньшей мере 65%, предпочтительно по меньшей мере 70%, предпочтительно по меньшей мере 80% нуклеотидную идентичность с нуклеиновой кислотой SEQ ID NO: 19 (Ba), SEQ ID NO: 25 (Li), SEQ ID NO: 21 (Csa), SEQ ID NO: 27 (Ts) или SEQ ID NO: 23 (Hn) и (ii) имеющих биологическую активность той же природы, что и нуклеиновая кислота SEQ ID NO: 19 (Ba), SEQ ID NO: 25 (Li), SEQ ID NO: 21 (Csa), SEQ ID NO: 27 (Ts) или SEQ ID NO: 23 (Hn).
В конкретном варианте осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, могут быть выбраны из группы, состоящей из нуклеотидных последовательностей, имеющих (i) по меньшей мере 65%, предпочтительно по меньшей мере 70%, предпочтительно по меньшей мере 80% нуклеотидную идентичность с нуклеиновой кислотой SEQ ID NO: 22 (Csa), SEQ ID NO: 26 (Li), SEQ ID NO: 24 (Hn), SEQ ID NO: 20 (Ba) или SEQ ID NO: 28 (Ts) и (ii) имеющих биологическую активность той же природы, что и нуклеиновая кислота SEQ ID NO: 22 (Csa), SEQ ID NO: 26 (Li), SEQ ID NO: 24 (Hn), SEQ ID NO: 20 (Ba) или SEQ ID NO: 28 (Ts).
Биологическая активность такой же природы в отношении этой последовательности представляет собой, как объяснялось ранее, способность кодировать полипептид, который катализирует расщепление молекул гиалуроновой кислоты на более мелкие молекулы гиалуроновой кислоты.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 65% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 70% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 80% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Для аминокислотной последовательности одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, из Cupiennius salei, Loxosceles intermedia, Hirudo nipponia, Bothrops atrox или Tityus serrulatus специалист в данной области техники может ссылаться на номера доступа A0A0S4JYH2, R4J7Z9, X4Y2L4, A0A2H4Z8F4 или P85841, соответственно, в базе данных UniProt, или на SEQ ID NO: 33 (Csa), SEQ ID NO: 37 (Li), SEQ ID NO: 35 (Hn), SEQ ID NO: 31 (Ba), SEQ ID NO: 39 (Ts) или SEQ ID NO: 41 (Vm), описанные в настоящем документе.
Согласно другому конкретному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, могут представлять собой нуклеиновую кислоту(-ы), кодирующую полипептид, имеющую аминокислотную последовательность, выбранную из группы, состоящей из последовательностей, имеющих по меньшей мере 50%, предпочтительно по меньшей мере 65%, предпочтительно по меньшей мере 80% аминокислотную идентичность с аминокислотной последовательностью SEQ ID NO: 33 (Csa), SEQ ID NO: 37 (Li), SEQ ID NO: 35 (Hn), SEQ ID NO: 31 (Ba), SEQ ID NO: 39 (Ts) или SEQ ID NO: 41 (Vm), которые содержат сигнал секреции и не имеют якорного сигнала, а также биологическую активность той же природы, что и аминокислотная последовательность SEQ ID NO: 33 (Csa), SEQ ID NO: 37 (Li), SEQ ID NO: 35 (Hn), SEQ ID NO: 31 (Ba), SEQ ID NO: 39 (Ts) или SEQ ID NO: 41 (Vm).
Согласно другому конкретному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, могут представлять собой нуклеиновую кислоту(-ы), кодирующую полипептид, имеющую аминокислотную последовательность, выбранную из группы, состоящей из последовательностей, имеющих по меньшей мере 55%, предпочтительно по меньшей мере 65%, предпочтительно по меньшей мере 80% аминокислотную идентичность с аминокислотной последовательностью SEQ ID NO: 34 (Csa), SEQ ID NO: 38 (Li), SEQ ID NO: 36 (Hn), SEQ ID NO: 32 (Ba), SEQ ID NO: 40 (Ts) или SEQ ID NO: 42 (Vm), которые содержат сигнал секреции и якорный сигнал, а также биологическую активность того же характера, что и аминокислотная последовательность SEQ ID NO: 34 (Csa), SEQ ID NO: 38 (Li), SEQ ID NO: 36 (Hn), SEQ ID NO: 32 (Ba), SEQ ID NO: 40 (Ts) или SEQ ID NO: 42 (Vm).
В конкретном варианте осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, могут представлять собой нуклеиновую кислоту(-ы), кодирующую полипептид, имеющую аминокислотную последовательность, выбранную из группы, состоящей из последовательностей, имеющих по меньшей мере 55%, предпочтительно по меньшей мере 65%, предпочтительно по меньшей мере 80% аминокислотную идентичность с аминокислотной последовательностью SEQ ID NO: 33 (Csa), SEQ ID NO: 37 (Li), SEQ ID NO: 35 (Hn), SEQ ID NO: 31 (Ba) или SEQ ID NO: 39 (Ts), а также биологическую активность той же природы, что и аминокислотная последовательность SEQ ID NO: 33 (Csa), SEQ ID NO: 37 (Li), SEQ ID NO: 35 (Hn), SEQ ID NO: 31 (Ba) или SEQ ID NO: 39 (Ts).
В другом конкретном варианте осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, могут представлять собой нуклеиновую кислоту(-ы), кодирующую полипептид, имеющий аминокислотную последовательность, выбранную из группы, состоящей из последовательностей, имеющих по меньшей мере 55%, предпочтительно по меньшей мере 65%, предпочтительно по меньшей мере 80% аминокислотную идентичность с аминокислотной последовательностью SEQ ID NO: 34 (Csa), SEQ ID NO: 38 (Li), SEQ ID NO: 36 (Hn), SEQ ID NO: 32 (Ba) или SEQ ID NO: 40 (Ts), а также биологическую активность той же природы, что и аминокислотная последовательность SEQ ID NO: 34 (Csa), SEQ ID NO: 38 (Li), SEQ ID NO: 36 (Hn), SEQ ID NO: 32 (Ba) или SEQ ID NO: 40 (Ts).
Биологическая активность такой же природы в отношении этой последовательности является такой, как описано ранее, т.е. способность катализировать расщепление молекул гиалуроновой кислоты на более мелкие молекулы гиалуроновой кислоты.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 55% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 56%, 57%, 58%, 59%, 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 65% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 80% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как указано выше, уровень экспрессии одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, в настоящем изобретении регулируется по меньшей мере одним промотором и по меньшей мере одним терминатором, например, как более подробно описано в настоящем документе, которые присутствуют в 5’- и 3’-положении, соответственно, одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы.
ГЛЮТАМИНСИНТЕТАЗА (GLN1)
Фермент глутаминсинтетаза представляет собой белок, который описан в данной области техники для катализа превращения глутамата в глутамин. Глутаминсинтетаза, происходящая из Saccharomyces cerevisiae, может называться GLN1.
Способ, который осуществляют для измерения уровня активности полипептида, имеющего активность глутаминсинтетазы, относится к общим знаниям специалиста в данной области техники.
В этом отношении специалист в данной области техники может предпочтительно ссылаться на способ, описанный в Legrain et al. (1982) European Journal of Biochemistry 123, 611-616.
Предпочтительный полипептид, имеющий активность глутаминсинтетазы, в настоящем изобретении представляет собой фермент с шифром КФ n 6.3.1.2.
Согласно предпочтительному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутаминсинтетазы, могут происходить или быть получены из организмов, предпочтительно выбранных из группы, включающей прокариотические организмы и эукариотические организмы. В некоторых вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутаминсинтезы, могут происходить или быть получены из архебактерий. В некоторых вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутаминсинтетазы, могут происходить или быть получены из дрожжей, и, в частности, из Saccharomyces cerevisiae.
Согласно еще одному предпочтительному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутаминсинтетазы, могут быть выбраны из группы, состоящей из нуклеотидных последовательностей, имеющих (i) по меньшей мере 65%, предпочтительно по меньшей мере 70%, предпочтительно по меньшей мере 80% нуклеотидную идентичность с нуклеотидной последовательностью, представленной как последовательность SEQ ID NO: 96 (Sc), и (ii) биологическую активность той же природы, что и нуклеотидная последовательность, представленная как последовательность SEQ ID NO: 96 (Sc). Нуклеиновая кислота, представленная как последовательность SEQ ID NO: 96, кодирует полипептид, имеющий активность глутаминсинтетазы, происходящей из Saccharomyces cerevisiae, которая также может называться GLN1.
Биологическая активность такой же природы в отношении этой последовательности представляет собой, как объяснялось ранее, способность кодировать полипептид, который превращает глутамат в глутамин, в частности, путем потребления одного АТФ и одного NH4+.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 65% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 70% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 80% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Для аминокислотной последовательности полипептида, имеющего активность глутаминсинтетазы, происходящей из Saccharomyces cerevisiae, специалист в данной области техники может обратиться к регистрационному номеру P32288 в базе данных UniProt или к последовательности SEQ ID NO: 97, описанной в настоящем документе.
Согласно другому конкретному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутаминсинтетазы, могут представлять собой нуклеиновую кислоту(-ы), кодирующую полипептид, имеющую аминокислотную последовательность, выбранную из группы, состоящей из последовательностей, имеющих по меньшей мере 35%, предпочтительно по меньшей мере 65%, предпочтительно по меньшей мере 80% аминокислотную идентичность с аминокислотной последовательностью SEQ ID NO: 97, а также биологическую активность той же природы, что и аминокислотная последовательность SEQ ID NO: 97.
Биологическая активность такой же природы в отношении этой последовательности является такой, как описано ранее, т.е. способность катализировать превращение глутамата в глутамин.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 35% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 36%, 37%, 38%, 39%, 40% 41%, 42%, 43%, 44%, 45%, 46%, 47%, 48%, 49%, 50%, 51%, 52%, 53%, 54%, 55%, 56%, 57%, 58%, 59%, 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 65% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 80% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как указано выше, уровень экспрессии полипептида, имеющего активность глутаминсинтетазы, в настоящем изобретении регулируется по меньшей мере одним промотором и по меньшей мере одним терминатором, например, как более подробно описано в настоящем документе, которые присутствуют в 5’- и 3’-положении, соответственно, одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутаминсинтетазы.
ГЛУТАМАТСИНТАЗА (GLT1)
Фермент глутаматсинтаза представляет собой белок, который описан в данной области техники для катализа превращения глутамина в глутамат. Глутаматсинтаза, происходящая из Saccharomyces cerevisiae, может называться GLT1.
Способ, который осуществляют для измерения уровня активности полипептида, имеющего активность глутаматсинтазы, относится к общим знаниям специалиста в данной области техники.
В этом отношении специалист в данной области техники может предпочтительно ссылаться на способ, описанный в Roon et al. (1974) Journal of bacteriology 118, 89-95.
Предпочтительный полипептид, имеющий активность глутаматсинтазы, в настоящем изобретении представляет собой фермент с шифром КФ n EC 1.4.1.14 (SEQ ID NO: 98).
Для аминокислотной последовательности полипептида, имеющего активность глутаматсинтазы, происходящей из Saccharomyces cerevisiae, специалист в данной области техники может обратиться к регистрационному номеру Q12680 в базе данных UniProt или к последовательности SEQ ID NO: 99, описанной в настоящем документе.
Как указано выше, уровень экспрессии полипептида, имеющего активность глутаматсинтазы, может быть снижен в рекомбинантной клетке и, в частности, в рекомбинантных дрожжах, согласно изобретению по сравнению с указанной клеткой, и, в частности, дрожжами, в их нерекомбинированной форме, то есть по меньшей мере один эндогенный ген рекомбинантной клетки и, в частности, рекомбинантных дрожжей, нарушен.
ГЛУТАМИН-ФРУКТОЗА-6-ФОСФАТАМИДОТРАНСФЕРАЗА (GFA1)
Фермент глутамин-фруктозо-6-фосфатамидотрансфераза представляет собой белок, который описан в данной области техники для катализа превращения фруктозо-6-фосфата в глюкозамин-6-фосфат. Глутамин-фруктозо-6-фосфатамидотрансфераза, происходящая из Saccharomyces cerevisiae, может называться GFA1.
Способ, который осуществляют для измерения уровня активности полипептида, имеющего активность глутамин-фруктозо-6-фосфатамидотрансферазы, относится к общим знаниям специалиста в данной области техники.
В этом отношении специалист в данной области техники может предпочтительно ссылаться на способ, описанный в Shiga Shibatan and Hiroaki Kitazawa (Plant Biotechnology 26, 149-152, 2009).
Предпочтительный полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы, в настоящем изобретении представляет собой фермент с шифром КФ n EC 2.6.1.16.
Согласно предпочтительному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы, могут происходить или быть получены из организмов, предпочтительно выбранных из группы, включающей прокариотические организмы и эукариотические организмы. В некоторых вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы, могут происходить или быть получены из архебактерий. В некоторых вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы, могут происходить или быть получены из организмов, предпочтительно выбранных из Bacillus subtilis, и дрожжей. В некоторых других предпочтительных вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы, могут происходить или быть получены из дрожжей и, в частности, из Saccharomyces cerevisiae.
Согласно еще одному предпочтительному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы, могут быть выбраны из группы, состоящей из нуклеотидных последовательностей, имеющих (i) по меньшей мере 65%, предпочтительно по меньшей мере 70%, предпочтительно по меньшей мере 80% нуклеотидную идентичность с нуклеотидной последовательностью, представленной как последовательность SEQ ID NO: 47 (Sc), и (ii) биологическую активность той же природы, что и нуклеотидная последовательность, представленная как последовательность SEQ ID NO: 47 (Sc). Нуклеиновая кислота, представленная как последовательность SEQ ID NO: 47, кодирует полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы, происходящей из Saccharomyces cerevisiae, который также может называться GFA1.
Согласно еще одному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы, могут быть выбраны из группы, состоящей из нуклеотидных последовательностей, имеющих (i) по меньшей мере 65%, предпочтительно по меньшей мере 70%, предпочтительно по меньшей мере 80% нуклеотидную идентичность с нуклеотидной последовательностью, представленной как последовательность SEQ ID NO: 48 или SEQ ID NO: 49, и (ii) биологическую активность той же природы, что и нуклеотидная последовательность, представленная как последовательность SEQ ID NO: 48 или SEQ ID NO: 49. Нуклеотидная последовательность, представленная как последовательность SEQ ID NO: 48 или SEQ ID NO: 49, кодирует полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы, происходящей от вируса хлореллы PBCV1.
Биологическая активность такой же природы в отношении этой последовательности, как объяснялось ранее, представляет собой способность кодировать полипептид, который превращает фруктозо-6-фосфат в глюкозамин-6-фосфат.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 65% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 70% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 80% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Для аминокислотной последовательности полипептида, имеющего активность глутамин-фруктозо-6-фосфатамидотрансферазы, происходящей из Saccharomyces cerevisiae, специалист в данной области техники может обратиться к регистрационному номеру NP8012818 в базе данных UniProt или к последовательности SEQ ID NO: 50, описанной в настоящем документе.
Для аминокислотной последовательности полипептида, имеющего активность глутамин-фруктозо-6-фосфатамидотрансферазы, происходящей из вируса хлореллы PBCV1, специалист в данной области техники может также ссылаться на регистрационный номер NP_048448 в базе данных UniProt или на последовательность SEQ ID NO: 51, описанную в настоящем документе.
Согласно другому конкретному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы, могут представлять собой нуклеиновую кислоту(-ы), кодирующую полипептид, имеющую аминокислотную последовательность, выбранную из группы, состоящей из последовательностей, имеющих по меньшей мере 35%, предпочтительно по меньшей мере 65%, предпочтительно по меньшей мере 80% аминокислотную идентичность с аминокислотной последовательностью SEQ ID NO: 50 или SEQ ID NO: 51, а также биологическую активность той же природы, что и аминокислотная последовательность SEQ ID NO: 50 или SEQ ID NO: 51.
Биологическая активность такой же природы в отношении этой последовательности является такой, как описано ранее, т.е. способность катализировать превращение фруктозо-6-фосфата в глюкозамин-6-фосфат.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 35% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 36%, 37%, 38%, 39%, 40% 41%, 42%, 43%, 44%, 45%, 46%, 47%, 48%, 49%, 50%, 51%, 52%, 53%, 54%, 55%, 56%, 57%, 58%, 59%, 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 65% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 80% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как указано выше, уровень экспрессии полипептида, имеющего активность глутамин-фруктозо-6-фосфатамидотрансферазы, в настоящем изобретении регулируется по меньшей мере одним промотором и по меньшей мере одним терминатором, например, как более подробно описано в настоящем документе, которые присутствуют в 5’- и 3’-положении, соответственно, одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутамин-фруктозо-6-фосфатамидотрансферазы.
UDP-N-АЦЕТИЛГЛЮКОЗАМИНПИРОФОСФОРИЛАЗА (QRI1)
Фермент UDP-N-ацетилглюкозаминпирофосфорилаза представляет собой белок, который описан в данной области техники для катализа превращения N-ацетилглюкозамин-6-фосфата в UDP-N-ацетилглюкозу. UDP-N-ацетилглюкозаминпирофосфорилаза, происходящая из Saccharomyces cerevisiae, может называться QRI1.
Способ, который осуществляют для измерения уровня активности полипептида, имеющего активность UDP-N-ацетилглюкозаминпирофосфорилазы, относится к общим знаниям специалиста в данной области техники.
В этом отношении специалист в данной области техники может предпочтительно ссылаться на способ, описанный в Mio et al. (Journal of Biological Chemistry, Col. 273, No. 23, June 5, 1998, 14392-14397), за исключением того, что UDP-N-ацетил-глюкозамин обнаруживают с помощью ЖХ-МС/МС с использованием колонки Synergi RP Fusion.
Предпочтительный полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы, в настоящем изобретении представляет собой фермент с шифром КФ n 2.7.7.23.
Согласно предпочтительному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы, могут происходить или быть получены из организмов, предпочтительно выбранных из группы, состоящей из прокариотических организмов и эукариотических организмов. В некоторых вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы, могут происходить или быть получены из архебактерий. В некоторых вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы, могут происходить или быть получены из организмов, предпочтительно выбранных из Bacillus subtilis, и дрожжей. В некоторых других предпочтительных вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы, могут происходить или быть получены из дрожжей, и, в частности, из Saccharomyces cerevisiae.
Согласно еще одному предпочтительному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы, могут быть выбраны из группы, состоящей из нуклеотидных последовательностей, имеющих (i) по меньшей мере 65%, предпочтительно по меньшей мере 70%, предпочтительно по меньшей мере 80% нуклеотидную идентичность с нуклеотидной последовательностью, представленной как SEQ ID NO: 52, и (ii) биологическую активность той же природы, что и нуклеотидная последовательность, представленная как SEQ ID NO: 52. Нуклеотидная последовательность, представленная как SEQ ID NO: 52, кодирует полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы, происходящей из Saccharomyces cerevisiae, которая также может называться QRI1.
Биологическая активность такой же природы в отношении этой последовательности представляет собой, как объяснялось ранее, способность кодировать полипептид, который превращает N-ацетил-глюкозамин-6-фосфат в UDP-N-ацетил-глюкозу.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 65% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 70% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 80% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Для аминокислотной последовательности полипептида, имеющего активность UDP-N-ацетилглюкозаминпирофосфорилазы, происходящей из Saccharomyces cerevisiae, специалист в данной области техники может обратиться к регистрационному номеру NP_010180 в базе данных UniProt или к SEQ ID NO. 53, описанной в настоящем документе.
Согласно другому конкретному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы, могут представлять собой нуклеиновую кислоту(-ы), кодирующую полипептид, имеющую аминокислотную последовательность, выбранную из группы, состоящей из последовательностей, имеющих по меньшей мере 35%, предпочтительно по меньшей мере 45%, предпочтительно по меньшей мере 80% аминокислотную идентичность с аминокислотной последовательностью, представленной как последовательность SEQ ID NO. 53, а также биологическую активность той же природы, что и аминокислотная последовательность, представленная как последовательность SEQ ID NO. 53.
Биологическая активность такой же природы в отношении этой последовательности является такой, как описано ранее, т.е. способность катализировать превращение N-ацетил-глюкозамин-6-фосфата в UDP-N-ацетил-глюкозу.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 35% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 36%, 37%, 38%, 39%, 40% 41%, 42%, 43%, 44%, 45%, 46%, 47%, 48%, 49%, 50%, 51%, 52%, 53%, 54%, 55%, 56%, 57%, 58%, 59%, 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 45% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 46%, 47%, 48%, 49%, 50%, 51%, 52%, 53%, 54%, 55%, 56%, 57%, 58%, 59%, 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 80% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как указано выше, уровень экспрессии одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы, в настоящем изобретении регулируется по меньшей мере одним промотором и по меньшей мере одним терминатором, например, как более подробно описано в настоящем документе, которые присутствуют в 5’- и 3’-положении, соответственно, одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-N-ацетилглюкозаминпирофосфорилазы.
Фосфоглюкомутаза-1 (PGM1)
Фермент фосфоглюкомутаза-1 представляет собой белок, который описан в данной области техники для катализации превращения глюкозо-6-фосфата в глюкозо-1-фосфат. Фосфоглюкомутаза-1, происходящая из Saccharomyces cerevisiae, может называться PGM1.
Способ, который осуществляют для измерения уровня активности полипептида, имеющего активность фосфоглюкомутазы-1, относится к общим знаниям специалиста в данной области техники.
В этом отношении специалист в данной области техники может предпочтительно ссылаться на способ, описанный в Tiwari and Bhat (Biochemical and BiopHysical Research Communications 366, 340-345, 2008).
Предпочтительный полипептид, имеющий активность фосфоглюкомутазы-1 в настоящем изобретении, представляет собой фермент с шифром КФ n 5.4.2.2.
Согласно предпочтительному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоглюкомутазы-1, могут происходить или быть получены из организмов, предпочтительно выбранных из группы, состоящей из прокариотических организмов и эукариотических организмом. В некоторых вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоглюкомутазы-1, могут происходить или быть получены из архебактерий. В некоторых вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоглюкомутазы-1, могут происходить или быть получены из организмов, предпочтительно выбранных из бактерий. В предпочтительном варианте осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоглюкомутазы-1, могут происходить или быть получены из Saccharomyces cerevisiae.
Согласно варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоглюкомутазы-1, могут быть выбраны из группы, состоящей из нуклеотидных последовательностей, имеющих (i) по меньшей мере 80% нуклеотидную идентичность с нуклеотидной последовательностью, представленной как последовательность SEQ ID NO: 54, которая происходит из Saccharomyces cerevisiae, и (ii) биологическую активность той же природы, что и нуклеотидная последовательность, представленная как последовательность SEQ ID NO: 54.
Биологическая активность такой же природы в отношении этой последовательности, как объяснялось ранее, представляет собой способность кодировать полипептид, который превращает глюкозо-6-фосфат в глюкозо-1-фосфат.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 80% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Для аминокислотной последовательности пептида, имеющего активность фосфоглюкомутазы-1, из Saccharomyces cerevisiae, специалист в данной области техники может обратиться к регистрационному номеру NP33401 в базе данных UniProt или к SEQ ID NO: 55, описанной в настоящем документе.
Согласно другому конкретному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоглюкомутазы-1, могут представлять собой нуклеиновую кислоту(-ы), кодирующую полипептид, имеющий аминокислотную последовательность, выбранную из группы, состоящей из последовательностей, имеющих по меньшей мере 80% аминокислотную идентичность с аминокислотной последовательностью, представленной как последовательность SEQ ID NO: 55, а также биологическую активность той же природы, что и аминокислотная последовательность, представленная как последовательность SEQ ID NO: 55.
Биологическая активность такой же природы в отношении этой последовательности является такой, как описано ранее, т.е. способность катализировать превращение глюкозо-6-фосфата в глюкозо-1-фосфат.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 80% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как указано выше, уровень экспрессии одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоглюкомутазы-1, в настоящем изобретении регулируется по меньшей мере одним промотором и по меньшей мере одним терминатором, например, как более подробно описано в настоящем документе, которые присутствуют в 5’- и 3’-положении, соответственно, одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоглюкомутазы-1.
UTP-ГЛЮКОЗО-1-ФОСФАТ-УРИДИЛИЛТРАНСФЕРАЗА (UGP1)
Фермент UTP-глюкозо-1-фосфат-уридилилтрансфераза представляет собой белок, который описан в данной области техники для катализа превращения глюкозо-1-фосфата в UDP-глюкозу. UTP-глюкозо-1-фосфат-уридилилтрансфераза, происходящая из Saccharomyces cerevisiae, может называться UGP1.
Способ, который осуществляют для измерения уровня активности полипептида, имеющего активность UTP-глюкозо-1-фосфат-уридилилтрансферазы, относится к общим знаниям специалиста в данной области техники.
В этом отношении специалист в данной области техники может предпочтительно ссылаться на способ, описанный в Roeben (J. Mol. Biol 364, 551-560, 2006).
Предпочтительный полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилилтрансферазы, в настоящем изобретении представляет собой фермент с шифром КФ n 2.7.7.9.
Согласно предпочтительному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилилтрансферазы, могут происходить или быть получены из организмов, предпочтительно выбранных из группы, состоящей из прокариотических организмов и эукариотических организмов. В некоторых вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилилтрансферазы, могут происходить или быть получены из архебактерий. В некоторых вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилилтрансферазы, могут происходить или быть получены из организмов, предпочтительно выбранных из бактерий. В предпочтительном варианте осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилилтрансферазы, могут происходить или быть получены из Saccharomyces cerevisiae.
Согласно конкретному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилтрансферазы, могут быть выбраны из группы, состоящей из нуклеотидных последовательностей, имеющих (i) по меньшей мере 80% нуклеотидную идентичность с нуклеиновой кислотой, представленной как последовательность SEQ ID NO: 56, происходящей из Saccharomyces cerevisiae, и (ii) биологическую активность той же природы, что и нуклеиновая кислота, представленная как последовательность SEQ ID NO: 56.
Биологическая активность такой же природы в отношении этой последовательности, как объяснялось ранее, представляет собой способность кодировать полипептид, который превращает глюкозо-1-фосфат в UDP-глюкозу.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 80% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Для аминокислотной последовательности полипептида, имеющего активность UTP-глюкозо-1-фосфат-уридилилтрансферазы, происходящей из Saccharomyces cerevisiae, специалист в данной области техники может обратиться к регистрационному номеру NP_32861 в базе данных UniProt или к последовательности, представленной как последовательность SEQ ID NO: 57, описанная в настоящем документе.
Согласно другому конкретному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилилтрансферазы, могут представлять собой нуклеиновую кислоту(-ы), кодирующую полипептид, имеющую аминокислотную последовательность, выбранную из группы, состоящей из последовательностей, имеющих по меньшей мере 80% аминокислотную идентичность с аминокислотной последовательностью, представленной как SEQ ID NO: 57, а также биологическую активность той же природы, что и аминокислотная последовательность, представленная как SEQ ID NO: 57.
Биологическая активность такой же природы в отношении этой последовательности является такой, как описано ранее, т.е. способность катализировать превращение глюкозо-1-фосфата в UDP-глюкозу.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 80% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как указано выше, уровень экспрессии одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилилтрансферазы, в настоящем изобретении регулируется по меньшей мере одним промотором и по меньшей мере одним терминатором, например, как более подробно описано в настоящем документе, которые присутствуют в 5’- и 3’-положении, соответственно, одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UTP-глюкозо-1-фосфат-уридилилтрансферазы.
ГЛЮКОЗАМИН-6-ФОСФАТ-N-АЦЕТИЛТРАНСФЕРАЗА (GNA1)
Фермент глюкозамин-6-фосфат-N-ацетилтрансфераза представляет собой белок, который описан в данной области техники для катализа превращения глюкозамин-6-фосфата в N-ацетил-глюкозамин-6-фосфат. Глюкозамин-6-фосфат N-ацетилтрансфераза, происходящая из Saccharomyces cerevisiae, может называться GNA1.
Способ, который осуществляют для измерения уровня активности полипептида, имеющего активность глюкозамин-6-фосфат-N-ацетилтрансферазы, относится к общим знаниям специалиста в данной области техники.
В этом отношении специалист в данной области техники может предпочтительно ссылаться на способ, описанный в Li et al. (Anal. Biochem. 370, 142-146, 2007).
Предпочтительный полипептид, имеющий активность глюкозамин-6-фосфат-N-ацетилтрансферазы, в настоящем изобретении представляет собой фермент с шифром КФ n 2.3.1.4.
Согласно предпочтительному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глюкозамин-6-фосфат-N-ацетилтрансферазы, могут происходить или быть получены из организмов, предпочтительно выбранных из группы, состоящей из прокариотических организмов и эукариотических организмов. В некоторых предпочтительных вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глюкозамин-6-фосфат-N-ацетилтрансферазы, могут происходить или быть получены из дрожжей и, в частности, из Saccharomyces cerevisiae.
Согласно конкретному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глюкозамин-6-фосфат-N-ацетилтрансферазы, могут быть выбраны из группы, состоящей из нуклеотидных последовательностей, имеющих (i) по меньшей мере 80% нуклеотидную идентичность с нуклеотидной последовательностью, представленной как последовательность SEQ ID NO: 58, и (ii) биологическую активность той же природы, что и нуклеотидная последовательность, представленная как последовательность SEQ ID NO: 58. Нуклеотидная последовательность, представленная как последовательность SEQ ID NO: 58, кодирует полипептид, имеющий активность глюкозамин-6-фосфат-N-ацетилтрансферазы, происходящей из Saccharomyces cerevisiae, который также может называться GNA1.
Биологическая активность такой же природы в отношении этой последовательности, как объяснялось ранее, представляет собой способность кодировать полипептид, который превращает глюкозамин-6-фосфат в N-ацетил-глюкозамин-6-фосфат.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 80% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Для аминокислотной последовательности полипептида, имеющего активность глюкозамин-6-фосфат-N-ацетилтрансферазы, происходящей из Saccharomyces cerevisiae, специалист в данной области техники может обратиться к регистрационному номеру NP_116637 в базе данных UniProt или к SEQ ID NO. 59, описанной в настоящем документе.
Согласно другому конкретному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глюкозамин-6-фосфат-N-ацетилтрансферазы, могут представлять собой нуклеиновую кислоту(-ы), кодирующую полипептид, имеющую аминокислотную последовательность, выбранную из группы, состоящей из последовательностей, имеющих по меньшей мере 80% аминокислотную идентичность с аминокислотной последовательностью, представленной как SEQ ID NO: 59, а также биологическую активность той же природы, что и аминокислотная последовательность, представленная как SEQ ID NO: 59.
Биологическая активность такой же природы в отношении этой последовательности является такой, как описано ранее, т.е. способность катализировать превращение глюкозамин-6-фосфата в N-ацетил-глюкозамин-6-фосфат.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 80% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как указано выше, уровень экспрессии одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глюкозамин-6-фосфат-N-ацетилтрансферазы, в настоящем изобретении регулируется по меньшей мере одним промотором и по меньшей мере одним терминатором, например, как более подробно описано в настоящем документе, которые присутствуют в 5’- и 3’-положении, соответственно, одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глюкозамин-6-фосфат-N-ацетилтрансферазы.
ФОСФОАЦЕТИЛГЛЮКОЗАМИНАМУТАЗА (PCM1)
Фермент фосфоацетилглюкозаминмутаза представляет собой белок, который описан в данной области техники для катализа превращения N-ацетил-глюкозамин-6-фосфата в N-ацетил-глюкозамин-1-фосфат. Фосфоацетилглюкозаминмутаза, происходящая из Saccharomyces cerevisiae, может называться PCM1.
Способ, который осуществляют для измерения уровня активности полипептида, имеющего активность фосфоацетилглюкозаминмутазы, относится к общим знаниям специалиста в данной области техники.
В этом отношении специалист в данной области техники может предпочтительно ссылаться на способ, описанный в Bandini et al. (Molecular Microbiology 85(3), 513-534, 2012).
Предпочтительный полипептид, имеющий активность фосфоацетилглюкозаминмутазы, в настоящем изобретении представляет собой фермент с шифром КФ n 5.4.2.3.
Согласно предпочтительному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоацетилглюкозаминмутазы, могут происходить или быть получены из организмов, предпочтительно выбранных из группы, состоящей из прокариотических организмов и эукариотических организмов. В некоторых предпочтительных вариантах осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоацетилглюкозаминмутазы, могут происходить или быть получены из дрожжей, и, в частности, из Saccharomyces cerevisiae.
Согласно конкретному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоацетилглюкозаминмутазы, могут быть выбраны из группы, состоящей из нуклеотидных последовательностей, имеющих (i) по меньшей мере 80% нуклеотидную идентичность с нуклеотидной последовательностью, представленной как SEQ ID NO: 60, и (ii) биологическую активность той же природы, что и нуклеотидная последовательность, представленная как SEQ ID NO: 60. Нуклеиновая кислота, представленная как SEQ ID NO: 60, кодирует полипептид, имеющий активность фосфоацетилглюкозаминмутазы, происходящей из Saccharomyces, которая также может называться PCM1.
Биологическая активность такой же природы в отношении этой последовательности, как объяснялось ранее, представляет собой способность кодировать полипептид, который превращает N-ацетил-глюкозамин-6-фосфат в N-ацетил-глюкозамин-1-фосфат.
Как описано в настоящем документе, нуклеотидная последовательность, имеющая по меньшей мере 80% нуклеотидную идентичность с референсной нуклеотидной последовательностью, включает нуклеотидные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% нуклеотидную идентичность с указанной референсной нуклеотидной последовательностью, а также биологическую активность той же природы, что и указанная референсная нуклеотидная последовательность.
Для аминокислотной последовательности полипептида, имеющего активность фосфоацетилглюкозаминмутазы, происходящей из Saccharomyces cerevisiae, специалист в данной области техники может обратиться к регистрационному номеру NP_010856 в базе данных UniProt или к SEQ ID NO. 61, описанной в настоящем документе.
Согласно другому конкретному варианту осуществления одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоацетилглюкозаминмутазы, могут представлять собой нуклеиновую кислоту(-ы), кодирующую полипептид, имеющий аминокислотную последовательность, выбранную из группы, состоящей из последовательностей, имеющих по меньшей мере 80% аминокислотную идентичность с аминокислотной последовательностью, представленной как SEQ ID NO: 61, а также биологическую активность той же природы, что и аминокислотная последовательность, представленная как SEQ ID NO: 61.
Биологическая активность такой же природы в отношении этой последовательности является такой, как описано ранее, т.е. способность катализировать превращение N-ацетил-глюкозамин-6-фосфата в N-ацетил-глюкозамин-1-фосфат.
Как описано в настоящем документе, аминокислотная последовательность, имеющая по меньшей мере 80% аминокислотную идентичность с референсной аминокислотной последовательностью, включает аминокислотные последовательности, имеющие по меньшей мере 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% и 99% аминокислотную идентичность с указанной референсной аминокислотной последовательностью, а также биологическую активность той же природы, что и указанная референсная аминокислотная последовательность.
Как указано выше, уровень экспрессии одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоацетилглюкозаминмутазы, в настоящем изобретении регулируется по меньшей мере одним промотором и по меньшей мере одним терминатором, как более подробно описано в настоящем документе, которые присутствуют в 5’- и 3’-положении, соответственно, одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность фосфоацетилглюкозаминмутазы.
ПРОМОТОРЫ
Как описано в настоящем документе, экспрессия представляющих интерес генов, которые были генетически сконструированы для получения рекомбинантной клетки согласно изобретению, содержит соответствующие регуляторные последовательности, которые являются функциональными в рекомбинантных клетках согласно изобретению и, в частности, в рекомбинантных дрожжевых клетках согласно изобретению, включая, в частности, Saccharomyces cerevisiae.
Для желаемой экспрессии кодирующих последовательностей, представляющих интерес, могут быть использованы различные промоторы.
Промоторы согласно изобретению могут быть выбраны из группы, состоящей из следующих промоторов:
• pTDH3 (SEQ ID NO: 62),
• pTDH3.sk (SEQ ID NO: 63),
• pTDH3-1.Sba (SEQ ID NO: 64),
• pTDH3.Sar (SEQ ID NO: 65),
• pENO2 (SEQ ID NO: 66),
• pTEF3 (SEQ ID NO: 67),
• pTEF1 (SEQ ID NO: 68),
• pTEF1.ago (SEQ ID NO: 69),
• pTEF1.sba (SEQ ID NO: 70),
• pPDC1 (SEQ ID NO: 71),
• pCCW12 (SEQ ID NO: 72),
• pCCW12.Sm (SEQ ID NO: 73),
• pCCW12.sk (SEQ ID NO: 74),
• pCCW12.sba (SEQ ID NO: 75),
• pCCW12.sar (SEQ ID NO: 76),
• pNUP57 (SEQ ID NO: 77),
• pCCW10.ago (SEQ ID NO: 78),
• pCWP2 (SEQ ID NO: 79) и
• pRPLA1 (SEQ ID NO: 80).
Промоторы, более предпочтительно представляющие интерес в настоящем изобретении, могут быть выбраны из группы, состоящей из:
• pTDH3 (SEQ ID NO: 62),
• pTDH3.sk (SEQ ID NO: 63),
• pTDH3-1.Sba (SEQ ID NO: 64),
• pTDH3.Sar (SEQ ID NO: 65),
• pENO2 (SEQ ID NO: 66),
• pTEF3 (SEQ ID NO: 67),
• pTEF1 (SEQ ID NO: 68),
• pTEF1.ago (SEQ ID NO: 69),
• pTEF1.sba (SEQ ID NO: 70),
• pPDC1 (SEQ ID NO: 71),
• pCCW12 (SEQ ID NO: 72),
• pCCW12.Sm (SEQ ID NO: 73),
• pCCW12.sk (SEQ ID NO: 74),
• pCCW12.sba (SEQ ID NO: 75) и
• pCCW12.sar (SEQ ID NO: 76).
Указанные промоторы могут, в частности, быть выбраны из группы, состоящей из pTDH3, pTDH3-1.Sba, pTDH3.Sar, pENO2, pTEF3, pTEF1, pPDC1, pCCW12, pCCW12.Sm, pCCW12.sk, pCCW12.sba и pCCW12.sar.
Альтернативно, промоторы, представляющие интерес в настоящем изобретении, могут быть выбраны из группы, состоящей из:
• pNUP57 (SEQ ID NO: 77) и
• pCCW10.ago (SEQ ID NO: 78).
Другими промоторами, представляющими интерес в настоящем изобретении, могут быть:
• pCWP2 (SEQ ID NO: 79) и
• pRPLA1 (SEQ ID NO: 80).
Как упоминалось ранее, индуцибельные или репрессируемые промоторы представляют собой промоторы, активность которых контролируется наличием или отсутствием биотических или абиотических факторов, а также количеством указанного фактора. Соответственно, для некоторых промоторов их активность, в частности, будет индуцироваться и, таким образом, увеличиваться, когда количество данного фактора увеличивается или было увеличено, и, соответственно, активность этих же промоторов может быть репрессирована и, таким образом, снижена, когда количество указанного фактора уменьшается или было уменьшено. Количество указанного фактора(-ов) в среде для культивирования рекомбинантной дрожжевой клетки согласно изобретению, содержащей индуцибельные или репрессируемые промоторы, может быть определено и, таким образом, контролироваться специалистом в данной области техники.
Например, увеличение количества меди в среде для культивирования рекомбинантной дрожжевой клетки согласно изобретению, содержащей промотор pCUP-1, будет индуцировать и, таким образом, увеличивать транскрипцию гена под контролем этого промотора. Напротив, уменьшение количества меди в указанной среде для культивирования приведет к репрессии и, следовательно, к уменьшенной транскрипции гена под контролем этого промотора.
В другом примере увеличение количества метионина в среде для культивирования рекомбинантной дрожжевой клетки согласно изобретению, содержащей промотор pMET6, будет репрессировать и, таким образом, уменьшать транскрипцию гена под контролем этого промотора. Напротив, уменьшение количества метионина в указанной среде для культивирования приведет к индуцированной и, следовательно, повышенной транскрипции гена под контролем этого промотора.
По этой причине следующие промоторы упоминаются в настоящем тексте как индуцибельные или репрессируемые промоторы.
Согласно первому варианту осуществления индуцибельные или репрессируемые промоторы согласно изобретению могут быть выбраны из группы, содержащей промоторы, индуцируемые или репрессируемые медью, промоторы, индуцируемые или репрессируемые метионином, и промоторы, индуцируемые или репрессируемые треонином, и, в частности, представляют собой CUP1, являющийся индуцируемыми или репрессируемыми медью (SEQ ID NO: 81).
Согласно этому варианту осуществления индуцибельный или репрессируемый промотор согласно изобретению может, в частности, представлять собой pCUP1.
Таким образом, активность этих промоторов индуцируется посредством увеличения присутствия метионина, меди или треонина, как указано выше, и их активность уменьшается, то есть репрессируется, когда количество метионина, меди или треонина уменьшается.
Согласно второму варианту осуществления индуцибельные или репрессируемые промоторы согласно изобретению могут быть выбраны из группы, содержащей промоторы, индуцируемые или репрессируемые медью, промоторы, индуцируемые или репрессируемые лизином, и промоторы, индуцируемые или репрессируемые метионином, и, в частности, выбраны из группы, состоящей из:
• pMET6, являющийся индуцируемым или репрессируемым метионином (SEQ ID NO: 82),
• pMET25, являющийся индуцируемым или репрессируемым метионином (SEQ ID NO: 83), и
• pSAM1, являющийся индуцируемым или репрессируемым метионином (SEQ ID NO: 84).
Согласно этому конкретному варианту осуществления индуцибельный или репрессируемый промотор согласно изобретению может быть выбран из группы, состоящей из pMET6, pMET25 и pSAM1.
Таким образом, активность этих промоторов репрессируется посредством увеличения присутствия метионина, меди, лизина или глюкозы, как указано выше, и их активность увеличивается, то есть индуцируется, когда количество метионина, меди, лизина или глюкозы уменьшается.
В конкретном варианте осуществления индуцибельные или репрессируемые промоторы согласно изобретению могут быть выбраны из группы, содержащей промоторы, индуцируемые или репрессируемые медью, промоторы, индуцируемые или репрессируемые глюкозой, промоторы, индуцируемые или репрессируемые лизином, промоторы, индуцируемые или репрессируемые метионином, и промоторы, индуцируемые или репрессируемые треонином.
В более конкретном варианте осуществления индуцибельный или репрессируемый промотор согласно изобретению может быть выбран из группы, состоящей из pCUP1, pMET6, pSAM1 и pMET25.
Синтетические промоторы, как описано в Blazeck & Alper (2013) Biotechnol. J. 8 46-58, также можно использовать.
Промоторы согласно настоящему изобретению могут происходить из любого организма из класса Saccharomycetes и, в частности, могут происходить из организма, выбранного из группы, состоящей из по меньшей мере одного из Saccharomyces cerevisiae, Saccharomyces boulardii, Saccharomyces castelii, Saccharomyces bayanus, Saccharomyces arboricola, Saccharomyces kudriavzevii, Saccharomyces mikatae, Ashbya gossypii, Kluveromyces lactis, Pichia pastoris, Candida glabrata, Candida tropicalis, Debaryomyces castelii, Yarrowia lipolitica и Cyberlindnera jadinii.
Промоторы согласно настоящему изобретению предпочтительно могут происходить из организма, выбранного из группы, состоящей из Saccharomyces cerevisiae (sc), Saccharomyces mikatae (Sm), Saccharomyces kudriavzevii (sk), Saccharomyces bayanus (sba) и Saccharomyces arboricola (Sar).
ТЕРМИНАТОРЫ
Как описано в настоящем документе, экспрессия представляющих интерес генов, которые были генетически сконструированы для получения рекомбинантной клетки согласно изобретению, и, в частности, рекомбинантных дрожжей согласно изобретению, содержит соответствующие последовательности терминаторов транскрипции, которые являются функциональными в рекомбинантных клетках согласно изобретению, и, в частности, в рекомбинантных дрожжевых клетках согласно изобретению, в частности, в Saccharomyces cerevisiae.
Указанные терминаторы транскрипции, идентичные или различные, можно найти в литературе Yamanishi et al., (2013) ACS synthetic biology 2, 337-347.
Терминаторы, более предпочтительно представляющие интерес в настоящем изобретении, могут быть выбраны из группы, содержащей:
• tTPI1 из гена, кодирующего триозофосфатную изомеразу (SEQ ID NO: 85),
• tMET25 из гена, кодирующего O-ацетил гомосерин-O-ацетилсеринсульфгидрилазу (SEQ ID NO: 86),
• tDIT1 (SEQ ID NO: 87),
• tRPL3 (SEQ ID NO: 88),
• tRPL3.sm (SEQ ID NO: 89),
• tRPL3.sba (SEQ ID NO: 90),
• tRPL41B (SEQ ID NO: 91),
• tRPL15A (SEQ ID NO: 92),
• tRPL15A.sba (SEQ ID NO: 93),
• tIDP1 (SEQ ID NO: 94),
• tTEF1.sba (SEQ ID NO: 95) и
• tTDH3 (SEQ ID NO: 100).
В частности, указанный терминатор может быть выбран из группы, состоящей из tTPI1, tMET25, tDIT1, tRPL3, tRPL3.sm, tRPL3.sba, tRPL41B, tRPL15A, tRPL15A.sba, tIDP1, tTEF1.sba и tTDH3.
Терминаторы согласно настоящему изобретению могут происходить из любого организма из класса Saccharomycete https://en.wikipedia.org/wiki/Saccharomycetesи, в частности, могут происходить из организма, выбранного из группы, состоящей из Saccharomyces cerevisiae и Saccharomyces Bayanus.
РЕКОМБИНАНТНЫЕ КЛЕТКИ
Рекомбинантные клетки по изобретению могут быть выбраны из группы, состоящей из дрожжей и бактерий.
Рекомбинантные клетки согласно настоящему изобретению, такие как рекомбинантная клетка-хозяин согласно настоящему изобретению, предпочтительно представляют собой рекомбинантные дрожжевые клетки.
Как правило, дрожжи могут быстро расти и могут культивироваться при более высокой плотности по сравнению с бактериями и не требуют асептической среды в промышленных условиях. Кроме того, дрожжевые клетки могут быть легче отделены от среды для культивирования по сравнению с бактериальными клетками, что значительно упрощает процесс экстракции и очистки продукта.
Рекомбинантная клетка согласно настоящему изобретению и, в частности, рекомбинантная дрожжевая клетка согласно настоящему изобретению, предпочтительно представляет собой клетку Saccharomycetales.
Рекомбинантная клетка согласно настоящему изобретению и, в частности, рекомбинантные дрожжи согласно настоящему изобретению, могут, в частности, относится к роду Saccharomyces, или роду Candida, или роду Kluyveromyces, или роду Ogataea, или роду Yarrowia, или роду Debaryomyces, или роду Ashbya.
Рекомбинантная клетка согласно настоящему изобретению, относящаяся к роду Saccharomyces, может быть выбрана из группы, состоящей из Saccharomyces cerevisiae, Saccharomyces boulardii, Saccharomyces bayanus, Saccharomyces paradoxus, Saccharomyces mikatae, Saccharomyces castelli, Saccharomyces cariocanus, Saccharomyces kudriavzevii, Saccharomyces arboricolus, Saccharomyces pastorianus, Saccharomyces uvarum и Saccharomyces delbrueckii.
Рекомбинантная клетка по изобретению, относящаяся к роду Candida, может быть выбрана из группы, состоящей из Candida albicans, Candida glabrata, Candida tropicalis, Candida dubliniensis, Candida parapsilosis, Candida lusitaniae и Candida guilliermondii.
Рекомбинантная клетка по изобретению, относящаяся к роду Kluyveromyces, может быть выбрана из группы, состоящей из Kluyveromyces lactis, Kluyveromyces marxianus, Kluyveromyces polysporus, Kluyveromyces thermotoleren, Kluyveromyces dobzhanskii и Kluyveromyces wickerhamii.
Рекомбинантная клетка по изобретению, относящаяся к роду Ogataea, может быть выбрана из группы, состоящей из Ogataea polymorpHa, Ogataea histrianica, Ogataea deakii, Ogataea kolombanensis, Ogataea pHilodendra, Ogataea siamensis, Ogataea angusta, Ogataea parapolymorpHa, Ogataea minuta, Ogataea nonfermentans и Ogataea kodamae.
Рекомбинантная клетка по изобретению, относящаяся к роду Yarrowia, может быть выбрана из группы, состоящей из Yarrowia lypolytica, Yarrowia paropHonii, Yarrowia galli, Yarrowia oslonensis, Yarrowia alimentaria, Yarrowia hollandica и Yarrowia yakushimensis.
Рекомбинантная клетка по изобретению, относящаяся к роду Debaryomyces, может быть выбрана из группы, состоящей из Debaryomyces hansenii, Debaryomyces carsonii, Debaryomyces castellii, Debaryomyces marama, Debaryomyces occidentalis, Debaryomyces oviformis, Debaryomyces nepalensis, Debaryomyces coudertii, Debaryomyces udenii, Debaryomyces psychrosporus и Debaryomyces yamadae.
Рекомбинантная клетка по изобретению, относящаяся к роду Ashbya, может быть выбрана из группы, состоящей из Ashbya gossypii и Ashbya aceri.
Рекомбинантная клетка согласно изобретению, и в частности рекомбинантная дрожжевая клетка согласно изобретению, может быть, в частности, выбрана из группы, состоящей из Saccharomyces cerevisiae, Saccharomyces boulardii, Saccharomyces bayanus, Saccharomyces paradoxus, Saccharomyces mikatae, Saccharomyces castelli, Candida albicans, Candida glabrata, Candida tropicalis, Kluyveromyces lactis, Kluyveromyces marxianus, Kluyveromyces polysporus, Kluyveromyces thermotolerens, Ogataea polymorpHa, Yarrowia lypolytica, Debaryomyces hansenii и Ashbya gossypii, и предпочтительно представляющая собой Saccharomyces cerevisiae.
В конкретном варианте осуществления рекомбинантная дрожжевая клетка согласно изобретению относится к роду Saccharomyces, Kluyveromyces или Eremothecium, более конкретно относится к видам, выбранным из группы, состоящей из Saccharomyces cerevisiae, Kluyveromyces Marxianus, Ogataea polymorpHa и Ashbya gossypii.
В варианте осуществления рекомбинантная клетка-хозяин согласно настоящему изобретению представляет собой дрожжи, выбранные из порядка Saccharomycetales, в частности, из семейства Saccharomycetaceae, и, в частности, выбранные из группы, состоящей из Yarrowia lipolitica, Kluyveromyces Marxianus, Ogataea polymorpHa, Ashbya gossypii и Saccharomyces cerevisiae.
Рекомбинантная клетка согласно настоящему изобретению наиболее предпочтительно может представлять собой клетку Saccharomyces cerevisiae.
Как указано выше, рекомбинантная клетка согласно изобретению обладает способностью продуцировать гиалуроновую кислоту посредством вставки одной или более рекомбинантных нуклеиновых кислот согласно настоящему изобретению. В некоторых вариантах осуществления рекомбинантные дрожжи согласно изобретению обладают способностью продуцировать гиалуроновую кислоту, имеющую контролируемый размер (контролируемую молекулярную массу), путем вставки одной или более рекомбинантных нуклеиновых кислот согласно настоящему изобретению.
Способы, применяемые для вставки конкретной ДНК-конструкции в ген, относятся к общим знаниям специалиста в данной области техники. Связанный способ более подробно описан в настоящем документе после примеров.
Однако возникли неожиданные технические трудности, поскольку последствия встраивания ДНК-конструкций в геном клетки и, в частности, в геном дрожжей, например, в геном Saccharomyces cerevisiae, непредсказуемы. В частности, выживаемость клеток и, в частности, дрожжей и их способность расти и продуцировать желаемую гиалуроновую кислоту также непредсказуемы.
Для получения рекомбинантной клетки и, в частности, рекомбинантных дрожжей согласно изобретению авторами изобретения было протестировано множество различных конструкций с целью получения жизнеспособной и эффективной рекомбинантной клетки и, в частности, дрожжей.
УСЛОВИЯ КУЛЬТИВИРОВАНИЯ
Настоящее изобретение также относится к применению рекомбинантной клетки по изобретению для продуцирования гиалуроновой кислоты, в частности, гиалуроновой кислоты с контролируемой молекулярной массой.
Настоящее изобретение также относится к способу продуцирования гиалуроновой кислоты (HA), имеющей желаемую молекулярную массу (HAMW), включающему:
(a) культивирование рекомбинантной клетки согласно настоящему изобретению в среде для культивирования в течение времени, достаточного для получения гиалуроновой кислоты (HA), имеющей желаемую молекулярную массу; и
(b) необязательно выделение или извлечение гиалуроновой кислоты (HA) из рекомбинантной клетки и/или из среды для культивирования.
Как правило, клетки по изобретению и, в частности, дрожжи по изобретению выращивают при температуре в диапазоне от около 20 до около 37°С, предпочтительно при температуре в диапазоне от 27 до 34°С в подходящей среде для культивирования.
Подходящие питательные среды для клеток по изобретению и, в частности, для дрожжей по изобретению представляют собой обычные коммерчески полученные среды, такие как бульон, который содержит основу азотного агара для дрожжей, сульфат аммония и декстрозу в качестве источника углерода/энергии, или среда YPD (пептон декстроза дрожжей), смесь пептона, дрожжевого экстракта и декстрозы в оптимальных пропорциях для выращивания большинства. Также могут быть использованы другие определенные или синтетические питательные среды, и подходящая среда для роста конкретной клетки, и, в частности, дрожжей, будет известна специалисту в области микробиологии или науки о ферментации.
Конкретной средой, подходящей для данного изобретения, является среда SY, которая содержит следующие элементы:
KH2PO4: 100 мМ; MgSO4×7H2O: 2,8 мМ; K2SO4: 11,5 мМ; Na2SO4: 1,1 мМ; NaCl: 2,6 мМ; CaCl2×2H2O: 0,7 мМ; CuSO4×5H2O: 15 мкМ; KI: 6 мкМ; FeCl3: 30 мкМ; ZnSO4×7H2O: 61 мкМ; MnSO4×H2O: 25 мкМ; H2SO4: 110 мкМ; гемикальциевая соль пантотеновой кислоты: 42 мкМ; гидрохлорид тиамина: 59 мкМ; гидрохлорид пиридоксина: 49 мкМ; мио-инозитол (C6H12O6): 555 мкМ; никотиновая кислота (C6H5NO2): 29 мкМ; D-биотин: 0,82 мкМ; цитрат аммония трехосновный: 33 мкМ; и глюкоза или сахароза 2-30 %.
Источники углерода, которые могут быть использованы в среде для культивирования, включают фруктозу, маннозу, ксилозу и арабинозу; олигосахариды, такие как лактоза, мальтоза, галактоза или сахароза; полисахариды, такие как крахмал или целлюлоза или их смеси; и неочищенные смеси из возобновляемого сырья, такие как сывороточный пермеат, кукурузный раствор, патока из сахарной свеклы и ячменный солод.
Источники азота, которые могут быть включены в среду для культивирования, включают пептон, дрожжевые экстракты, мясные экстракты, солодовые экстракты, мочевину, сульфат аммония, хлорид аммония, нитрат аммония, фосфат аммония, цитрат аммония и их комбинации.
Среда для культивирования может дополнительно содержать микроэлементы (например, соли металлов), например, соли магния, соли кобальта и/или соли марганца; а также факторы роста, такие как аминокислоты, витамины, промоторы роста и тому подобное.
Примеры витаминов, которые могут быть включены, представляют собой пантотеновые кислоты гемикальций, гидрохлорид тиамина; гидрохлорид пиридоксина; мио-инозитол; никотиновую кислоту; D-биотин, фолиевую кислоту, пара-аминобензойную кислоту, рибофлавин.
Среда для культивирования согласно настоящему изобретению может дополнительно включать редкие элементы, такие как CuSO4×5H2O, KI, FeCl3, ZnSO4×7H2O, MnSO4×H2O или H2SO4, MgCl2, CaCl2, NaCl, K2HPO4, KH2PO4, ZnCl, H3BO3, MnSO4, Na2MoO4.
Термин «подходящая среда для культивирования» определен выше.
Примеры известных сред для культивирования для рекомбинантной клетки согласно настоящему изобретению известны специалисту в данной области техники и представлены в следующей публикации D. Burke et al., Methods in yeast Genetics - A Cold Spring Harbor Laboratory Course Manual (2000).
Подходящие диапазоны рН для ферментации могут составлять от рН 3,0 до рН 7,5, где рН от 4 до 6 является предпочтительным в качестве начального условия.
Как упоминалось в других разделах настоящего описания, значение рН среды для культивирования можно регулировать в процессе стадии культивирования способа согласно изобретению для модуляции активности полипептида, направленной на активность гиалуронидазы, которая будет влиять на молекулярную массу молекул гиалуроновой кислоты, продуцируемых рекомбинантной клеткой согласно изобретению, и, в частности, рекомбинантными дрожжами согласно изобретению.
В частности, рН среды для культивирования может быть изменен в соответствии с гиалуроновой кислотой, которая предназначена для продуцирования рекомбинантными дрожжами. Например, рН среды для культивирования может оставаться на уровне рН 4, 5,5 или 6 в течение времени культивирования.
В конкретном варианте осуществления значение рН среды для культивирования может изменяться или быть измененным в течение времени культивирования рекомбинантной клетки согласно изобретению, в частности, рекомбинантных дрожжей согласно изобретению. Как упоминалось ранее, Saccharomyces cerevisiae подкисляет среду, в которой она культивируется, и, таким образом, снижает рН своей среды для культивирования. Например, значение рН среды для культивирования может начинаться с 6, может быть снижено до 4, а затем доведено обратно до 6. В другом примере значение рН среды для культивирования может начинаться с 6, оставаться или поддерживаться на уровне 6, а затем может быть снижено до 4.
В конкретном варианте осуществления значение рН среды для культивирования может быть модулировано в процессе стадии культивирования (а) способа согласно настоящему изобретению таким образом, чтобы в конце стадии культивирования способа согласно настоящему изобретению значение рН среды для культивирования являлось таким же, как значение рН в начале указанной стадии культивирования (а).
В другом варианте осуществления рН среды для культивирования может оставаться неизменным в течение времени культивирования рекомбинантной клетки согласно изобретению и, в частности, рекомбинантной дрожжевой клетки согласно изобретению.
Указанное время культивирования рекомбинантной клетки согласно изобретению и, в частности, рекомбинантных дрожжей согласно изобретению, может варьироваться в зависимости от молекулярной массы гиалуроновой кислоты, представляющей интерес. Чем больше указанное время, тем ниже молекулярная масса гиалуроновой кислоты в данной среде для культивирования рекомбинантной клетки по изобретению и, в частности, рекомбинантной дрожжевой клетки по изобретению.
Время культивирования рекомбинантной клетки согласно настоящему изобретению и, в частности, рекомбинантной дрожжевой клетки согласно настоящему изобретению, может составлять от около 35 часов до около 50 часов, предпочтительно от около 40 часов до около 50 часов и, в частности, составляет около 48 часов.
Ферментация может проводиться в аэробных или микроаэробных условиях.
Количество продукта гиалуроновой кислоты в ферментационной среде может быть определено с использованием ряда способов, известных в данной области техники, например, высокоэффективной жидкостной хроматографии (ВЭЖХ) или газовой хроматографии (ГХ).
В настоящем способе может использоваться периодический способ ферментации. Классическая периодическая ферментация представляет собой замкнутую систему, в которой состав среды устанавливается в начале ферментации и не подвергается искусственным изменениям в процессе ферментации. Таким образом, в начале ферментации среду инокулируют желаемым организмом или организмами, и ферментации позволяют осуществляться без добавления чего-либо в систему. Однако, как правило, способ или система «периодической» ферментации является периодическим с точки зрения добавления источника углерода, и часто предпринимаются попытки контролировать такие факторы, как температура, рН и концентрация кислорода. В периодических системах состав метаболитов и биомассы системы постоянно изменяется до момента прекращения ферментации. В периодических культурах клетки переходят из статистической фазы задержки в логарифмическую фазу быстрого роста и, наконец, в стационарную фазу, где скорость роста уменьшается или останавливается. При отсутствии обработки клетки в стационарной фазе в конечном итоге погибнут. Клетки в логарифмической фазе обычно отвечают за основную часть производства конечного продукта или промежуточного продукта.
В настоящем изобретении также может быть использована система с подпиткой. Система с подпиткой аналогична типичной периодической системе, за исключением того, что субстрат источника углерода добавляется с приращениями по мере ферментации. Системы с подпиткой подходят, когда репрессия катаболитов (например, репрессия глюкозы) склонна ингибировать метаболизм клеток и когда желательно иметь ограниченное количество субстрата в среде. Измерение фактической концентрации субстрата в системах с подпиткой является сложным и поэтому оценивается на основе изменений измеряемых факторов, таких как рН, растворенный кислород и парциальное давление отходящих газов, таких как CO2.
Способы периодического культивирования и культивирования с подпиткой широко распространены и хорошо известны в данной области техники, и примеры можно найти в Biotechnology: A Textbook of Industrial Microbiology, Crueger, Crueger, and Brock, Second Edition (1989) Sinauer Associates, Inc., Sunderland, MA, или Deshpande, Mukund V., Appl. Biochem. Biotechnol., 36, 227, (1992). Хотя настоящее изобретение осуществляют в периодическом режиме, предполагается, что способ может быть адаптирован для непрерывной ферментации.
Непрерывная ферментация представляет собой открытую систему, в которой определенную ферментационную среду непрерывно добавляют в биореактор и одновременно удаляют равное количество кондиционированной среды для обработки. Непрерывная ферментация обычно поддерживает культуры при постоянной высокой плотности, где клетки в основном находятся в логарифмической фазе роста.
Непрерывная ферментация позволяет модулировать один фактор или любое количество факторов, которые влияют на рост клеток или концентрацию конечного продукта. Например, один способ будет поддерживать лимитирующее питательное вещество, такое как источник углерода или уровень азота, с фиксированной скоростью и позволять варьировать все другие параметры. В других системах ряд факторов, влияющих на рост, может непрерывно изменяться, в то время как концентрация клеток, измеренная по мутности среды, остается постоянной. Непрерывные системы стремятся поддерживать устойчивые условия роста, и, таким образом, потерю клеток из-за удаления среды нужно соотносить со скоростью роста клеток при ферментации. Способы модуляции питательных веществ и факторов роста для непрерывных процессов ферментации, а также методы максимизации скорости образования продукта хорошо известны в области промышленной микробиологии.
Предполагается, что настоящее изобретение может быть осуществлено с использованием периодических процессов, процессов с подпиткой или непрерывных процессов, и что любой известный способ ферментации будет подходящим. Кроме того, предполагается, что клетки могут быть иммобилизованы на субстрате в виде цельноклеточных катализаторов и подвергнуты условиям ферментации для продукции.
Чтобы еще улучшить продукцию гиалуроновой кислоты, конкретный вариант осуществления может состоять из культивирования рекомбинантных клеток согласно изобретению, в частности, рекомбинантных дрожжевых клеток согласно изобретению, в подходящей среде для культивирования, такой как вышеупомянутая, где указанная среда для культивирования содержит оптимальное количество источника углерода, особенно глюкозы или сахарозы.
В предпочтительных вариантах осуществления источник углерода, содержащийся в указанной оптимальной среде для культивирования, состоит из глюкозы и/или сахарозы. В предпочтительных вариантах осуществления указанная оптимальная среда для культивирования содержит 1 мас.% или более глюкозы и/или сахарозы, в частности, содержит 5 мас.% или более глюкозы и/или сахарозы, в частности, содержит 10 мас.% или более глюкозы и/или сахарозы, в частности, содержит 15 мас.% или более глюкозы и/или сахарозы. В предпочтительных вариантах осуществления указанная оптимальная среда для культивирования содержит не более 40 мас.% глюкозы, что включает не более 35 мас.% глюкозы.
В предпочтительном варианте осуществления способ согласно изобретению осуществляют в промышленном масштабе.
Более конкретно, среда для культивирования способа согласно изобретению может составлять по меньшей мере около 100 л, более предпочтительно в диапазоне от около 1000 до около 3000 л, еще более предпочтительно около 10000 л, еще более предпочтительно 100000 л или даже около 250000 л.
Изобретение также относится к способу продуцирования гиалуроновой кислоты, как описано ранее, включающему стадии:
(a) культивирования рекомбинантной клетки согласно настоящему изобретению в среде для культивирования и
(b) извлечения гиалуроновой кислоты из указанной среды для культивирования,
где гиалуроновая кислота, извлеченная на стадии (b), имеет молекулярную массу, контролируемую путем выбора:
- природы и происхождения одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, рекомбинантной клетки по изобретению и, в частности, рекомбинантных дрожжей по изобретению,
- природы и происхождения промотора, контролирующего экспрессию одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, рекомбинантной клетки по изобретению и, в частности, рекомбинантных дрожжей по изобретению,
- наличие или отсутствие якорного сигнала, связанного с одной или более рекомбинантными нуклеиновыми кислотами, кодирующими полипептид, имеющий активность гиалуронидазы, рекомбинантной клетки по изобретению и, в частности, рекомбинантных дрожжей по изобретению,
- рН среды для культивирования в процессе стадии культивирования рекомбинантной клетки согласно изобретению и, в частности, рекомбинантных дрожжей; и/или
- продолжительности культивирования рекомбинантной клетки по изобретению и, в частности, рекомбинантных дрожжей по изобретению.
Молекулярная масса гиалуроновой кислоты может представлять собой конкретную молекулярную массу или более предпочтительно конкретный диапазон молекулярных масс, такой как, например, менее 50 кДа, в диапазоне от около 20 до около 50 кДа, 50 кДа или более, в диапазоне от около 50 до около 150 кДа, в диапазоне от около 50 до около 250 кДа, 100 кДа или более, в диапазоне от около 100 до около 1500 кДа, в диапазоне от около 150 до около 1500 кДа, более 1000 кДа или более 1500 кДа.
Настоящее изобретение также относится к применению рекомбинантной клетки согласно изобретению и, в частности, рекомбинантной дрожжевой клетки согласно изобретению для продуцирования гиалуроновой кислоты (HA), имеющей молекулярную массу в диапазоне от около 20 до около 50 кДа или от около 50 до около 1000 кДа.
Одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, рекомбинантной клетки согласно изобретению могут, например, быть выбраны из тех, которые происходят или были получены из по меньшей мере одного из Cupiennius salei (Csa), Loxosceles intermedia (Li), Hirudo nipponia (Hn), Bothrops atrox (Ba), Tityus serrulatus (Ts) или Vespa magnifica (Vm), в частности, из по меньшей мере одного из Cupiennius salei (Csa), Loxosceles intermedia (Li ), Hirudo nipponia (Hn), Bothrops atrox (Ba) или Tityus serrulatus (Ts), более предпочтительно из тех из последовательностей, которые представлены как последовательности SEQ ID NO: 19 (Ba), SEQ ID NO: 25 (Li), SEQ ID NO: 21 (Csa), SEQ ID NO: 27 (Ts) или SEQ ID NO: 23 (Hn) (в присутствии сигнала секреции и в отсутствие якорного сигнала).
Одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, рекомбинантной клетки согласно изобретению могут, например, быть выбраны из тех, которые происходят или были получены из по меньшей мере одного из Cupiennius salei (Csa), Loxosceles intermedia (Li), Hirudo nipponia (Hn), Bothrops atrox (Ba), Tityus serrulatus (Ts) или Vespa magnifica (Vm), в частности, из Cupiennius salei (Csa), Loxosceles intermedia (Li), Hirudo nipponia (Hn), Bothrops atrox (Ba) или Tityus serrulatus (Ts), в частности, из последовательностей, представленных как последовательности SEQ ID NO: 22 (Csa), SEQ ID NO: 26 (Li), SEQ ID NO: 24 (Hn), SEQ ID NO: 20 (Ba) или SEQ ID NO: 28 (Ts) (в присутствии как сигнала секреции, так и якорного сигнала).
Одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, рекомбинантной клетки согласно изобретению могут, например, быть помещены под контроль промотора, выбранного из группы, состоящей из pTEF1, pCCW12, pCCW12.sba, pCCW12.Sar, pPDC1, pTEF3, pTDH3, pNUP57 и pCCW10.ago.
В частности, промоторы одной или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, рекомбинантной клетки согласно настоящему изобретению и, в частности, рекомбинантных дрожжей согласно настоящему изобретению могут происходить или быть получены из Saccharomyces Bayanus, Saccharomyces kudriavzevii, Saccharomyces mikatae, Saccharomyces arboricola или других сахаромицетов или Abishia gossypii.
Сигнал секреции согласно настоящему изобретению может, например, иметь:
- нуклеотидную последовательность, представленную как SEQ ID NO: 43; и/или
- аминокислотную последовательность, представленную как SEQ ID NO: 44.
Якорный сигнал согласно настоящему изобретению может, например, иметь:
- нуклеотидную последовательность, представленную как SEQ ID NO: 45; и/или
- аминокислотную последовательность, представленную как SEQ ID NO: 46.
Сигнал секреции может быть слит с полипептидом, имеющим активность гилуронидазы, путем создания химерной нуклеиновой кислоты, начиная с нуклеотидной последовательности, кодирующей сигнальный пептид, за которой следует рекомбинантная нуклеиновая кислота, кодирующая полипептид, имеющий активность гиалуронидазы, как определено ранее.
Сигнал секреции и якорный сигнал могут быть слиты с полипептидом, имеющим активность гилуронидазы, путем создания химерной нуклеиновой кислоты, начиная с нуклеотидной последовательности, кодирующей сигнальный пептид, за которой следует рекомбинантная нуклеиновая кислота, кодирующая полипептид, имеющий активность гиалуронидазы, как определено ранее, за которой следует нуклеотидная последовательность, кодирующая якорный сигнал.
Такие химерные нуклеотидные последовательности могут быть получены методами, известными специалисту в данной области техники, такими как химический синтез нуклеиновых кислот или любые рекомбинантные методы, такие как клонирование или ПЦР.
Изобретение также относится к способу, как описано ранее, для продуцирования гиалуроновой кислоты, имеющей молекулярную массу около 50 кДа или менее, и, в частности, менее 50 кДа, и около 20 кДа или более, где:
(a) рН среды выше 4 и, в частности, находится в диапазоне от около 5 до около 7;
(b) одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, встроенная в геном рекомбинантной клетки согласно изобретению, происходит или получена:
(i) из Tityus serrulatus, обладает сигналом секреции, но лишена якорного сигнала, и находится под контролем промотора, выбранного из группы, состоящей из pTDH3, pENO2, pTEF3, pTEF1, pPDC1, pCCW12, pCCW12.Sm, pCCW12.sk, pCCW12.sba, pCCW12.sar, pTDH3-1.Sba и pTDH3.Sar;
(ii) из Cupiennius salei, обладает сигналом секреции, но лишена якорного сигнала, и находится под контролем промотора, выбранного из группы, состоящей из pNUP57 и pCCW10.ago;
(iii) из Cupiennius salei, обладает сигналом секреции и якорным сигналом и находится под контролем промотора pCWP2;
(iv) из Loxosceles intermedia, обладает сигналом секреции, но лишена якорного сигнала, и находится под контролем промотора, выбранного из группы, состоящей из pTDH3, pENO2, pTEF3, pTEF1, pPDC1, pCCW12, pCCW12.Sm, pCCW12.sk, pCCW12.sba, pCCW12.sar, pTDH3-1.Sba и pTDH3.Sar; или
(v) из Hirudo nipponia, обладает сигналом секреции, но лишена якорного сигнала, и находится под контролем промотора, выбранного из группы, состоящей из pNUP57 и pCCW10.ago; или
(vi) из Hirudo nipponia, обладает как сигналом секреции, так и якорным сигналом и находится под контролем промотора, выбранного из группы, состоящей из pTDH3, pENO2, pTEF3, pTEF1, pPDC1, pCCW12, pCCW12.Sm, pCCW12.sk, pCCW12.sba, pCCW12.sar, pTDH3-1.Sba и pTDH3.Sar; и
(c) стадию извлечения гиалуроновой кислоты из среды для культивирования проводят примерно через 48 часов после начала культивирования рекомбинантной клетки согласно изобретению, в частности, рекомбинантной дрожжевой клетки согласно изобретению;
рекомбинантная клетка представляет собой, в частности, рекомбинантную дрожжевую клетку и, более конкретно, клетку Saccharomyces cerevisiae.
Изобретение также относится к способу, как описано ранее, для продуцирования гиалуроновой кислоты, имеющей молекулярную массу около 50 кДа или более и около 1000 кДа или менее, где:
(a) рН среды составляет от около 4 до около 6 и необязательно варьируется от около 6 до около 4 в процессе стадии культивирования рекомбинантной клетки, в частности, рекомбинантной дрожжевой клетки, согласно изобретению;
(b) одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, встроенная в геном рекомбинантной клетки согласно изобретению, происходит или получена:
(i) из Tityus serrulatus, обладает сигналом секреции, но лишена якорного сигнала, и находится под контролем промотора, выбранного из группы, состоящей из pTDH3, pENO2, pTEF3, pTEF1, pPDC1, pCCW12, pCCW12.Sm, pCCW12.sk, pCCW12.sba, pCCW12.sar, pTDH3-1.Sba и pTDH3.Sar;
(ii) из Tityus serrulatus, обладает как сигналом секреции, так и якорным сигналом и находится под контролем промотора, выбранного из группы, состоящей из pTDH3, pENO2, pTEF3, pTEF1, pPDC1, pCCW12, pCCW12.Sm, pCCW12.sk, pCCW12.sba, pCCW12.sar, pTDH3-1.Sba и pTDH3.Sar;
(iii) из Loxosceles intermedia, обладает как сигналом секреции, так и якорным сигналом и находится под контролем промотора, выбранного из группы, состоящей из pNUP57 и pCCW10.ago;
(iv) из Loxosceles intermedia, обладает сигналом секреции, но лишена якорного сигнала, и находится под контролем промотора, выбранного из группы, состоящей из pTDH3, pENO2, pTEF3, pTEF1, pPDC1, pCCW12, pCCW12.Sm, pCCW12.sk, pCCW12.sba, pCCW12.sar, pTDH3-1.Sba и pTDH3.Sar,
(v) из Cupiennius salei, обладает как сигналом секреции, так и якорным сигналом и находится под контролем промотора, выбранного из группы, состоящей из pNUP57 и pCCW10.ago;
(vi) из Cupiennius salei, обладает сигналом секреции, но лишена якорного сигнала, и находится под контролем промотора, выбранного из группы, состоящей из pNUP57 и pCCW10.ago; или
(vii) из Hirudo nipponia, обладает как сигналом секреции, так и якорным сигналом и находится под контролем промотора, выбранного из группы, состоящей из pTDH3, pENO2, pTEF3, pTEF1, pPDC1, pCCW12, pCCW12.Sm, pCCW12.sk, pCCW12.sba, pCCW12.sar, pTDH3-1.Sba и pTDH3.Sar; и
(c) стадию извлечения гиалуроновой кислоты из среды для культивирования проводят примерно через 48 часов после начала культивирования рекомбинантной клетки согласно изобретению, в частности, рекомбинантной дрожжевой клетки согласно изобретению;
рекомбинантная клетка представляет собой, в частности, рекомбинантную дрожжевую клетку и, более конкретно, клетку Saccharomyces cerevisiae.
Изобретение также относится к способу, как описано ранее, для продуцирования гиалуроновой кислоты, имеющей молекулярную массу более чем около 1000 кДа и, в частности, имеющей молекулярную массу от около 1000 до около 1,5 млн Да, где:
(a) рН среды составляет от около 4 до около 6 и необязательно варьируется от около 6 до около 4 в процессе стадии культивирования рекомбинантной клетки, в частности, рекомбинантных дрожжей, согласно изобретению;
(b) одна или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, встроенная в геном рекомбинантной клетки согласно изобретению, происходит или получена:
(i) из Tityus serrulatus, обладает сигналом секреции, но лишена якорного сигнала, и находится под контролем промотора, выбранного из группы, состоящей из pNUP57 и pCCW10.ago;
(ii) из Loxosceles intermedia, обладает сигналом секреции, но лишена якорного сигнала, и находится под контролем промотора, выбранного из группы, состоящей из pNUP57 и pCCW10.ago;
(iii) из Bothrops atrox, обладает сигналом секреции, но лишена якорного сигнала, и находится под контролем промотора, выбранного из группы, состоящей из pTDH3, pENO2, pTEF3, pTEF1, pPDC1, pCCW12, pCCW12.Sm, pCCW12.sk, pCCW12.sba, pCCW12.sar, pTDH3-1.Sba и pTDH3.Sar; или
(iv) из Bothrops atrox, обладает как сигналом секреции, так и якорным сигналом и находится под контролем промотора, выбранного из группы, состоящей из pTDH3, pENO2, pTEF3, pTEF1, pPDC1, pCCW12, pCCW12.Sm, pCCW12.sk, pCCW12.sba, pCCW12.sar, pTDH3-1.Sba и pTDH3.Sar;
и
(c) стадию извлечения гиалуроновой кислоты из среды для культивирования проводят примерно через 48 часов после начала культивирования рекомбинантной клетки согласно изобретению, в частности, рекомбинантной дрожжевой клетки согласно изобретению;
рекомбинантная клетка представляет собой, в частности, рекомбинантные дрожжи и, более конкретно, клетку Saccharomyces cerevisiae.
Другой аспект настоящего изобретения относится к гиалуроновой кислоте (HA), полученной или получаемой из рекомбинантной клетки по изобретению или способом по изобретению.
Дополнительный аспект изобретения представляет собой среду для культивирования, содержащую гиалуроновую кислоту по изобретению.
Изобретение дополнительно относится к композиции, содержащей гиалуроновую кислоту согласно изобретению.
Изобретение также относится к промышленному изделию, или потребительскому продукту, или расходному материалу, содержащему (i) гиалуроновую кислоту по изобретению, (ii) среду для культивирования, содержащую гиалуроновую кислоту по изобретению, или (iii) композицию, содержащую гиалуроновую кислоту по изобретению.
В частности, указанное промышленное изделие, или потребительский продукт, или расходный материал согласно изобретению может представлять собой косметический продукт, вкусо-ароматическое вещество, парфюмерный продукт, пищевой продукт, продукт питания, напиток, текстурант, фармацевтическую композицию, биологически активную добавку, нутрицевтик, чистящее средство и/или стоматологическую композицию и/или композицию для гигиены полости рта.
ОЧИСТКА ГИАЛУРОНОВОЙ КИСЛОТЫ
В соответствии с конкретным аспектом изобретения ферментативное получение гиалуроновой кислоты предпочтительно включает стадию извлечения гиалуроновой кислоты, полученной из среды для культивирования. Извлечение гиалуроновой кислоты из среды для культивирования является рутинной задачей для специалиста в данной области техники. Оно может быть достигнуто с помощью ряда методов, хорошо известных в данной области техники, включая, но не ограничиваясь, испарение через полупроницаемую мембрану, селективное осаждение, фильтрацию, центрифугирование, распылительную сушку, лиофилизацию или жидкостную экстракцию. Специалист в данной области знает, как адаптировать параметры каждого метода в зависимости от характеристик материала, подвергаемого извлечению.
Дрожжи в качестве модели клетки в настоящем изобретении предпочтительны тем, что синтезированная гиалуроновая кислота полностью выделяется за пределы клеток, что упрощает процесс очистки.
Удаление газа осуществляют отпарным газом, выбранным из гелия, аргона, диоксида углерода, водорода, азота или их смеси.
Жидкостная экстракция достигается с помощью органического растворителя в качестве гидрофобной фазы, такого как пентан, гексан, гептан или додекан. Также могут быть использованы восстановительные растворители.
Специалистам в данной области техники будет понятно, что из-за вырожденной природы генетического кода для кодирования данного фермента согласно настоящему изобретению могут быть использованы различные молекулы ДНК, отличающиеся своими нуклеотидными последовательностями. Нативная последовательность ДНК, кодирующая биосинтетические ферменты, описанные выше, упоминается в настоящем документе только для иллюстрации варианта осуществления настоящего изобретения, и настоящее изобретение включает молекулы ДНК любой последовательности, которые кодируют аминокислотные последовательности полипептидов и белков ферментов, используемых в способах по настоящему изобретению. Аналогичным образом, полипептид обычно может переносить одну или более аминокислотных замен, делеций и вставок в своей аминокислотной последовательности без потери или значительной потери желаемой активности. Настоящее изобретение включает такие полипептиды с аминокислотными последовательностями, отличными от специфических белков, описанных в настоящем документе, при условии, что модифицированные или вариантные полипептиды обладают ферментативной анаболической или катаболической активностью референсного полипептида. Кроме того, аминокислотные последовательности, кодируемые последовательностями ДНК, показанными в настоящем документе, просто иллюстрируют варианты осуществления настоящего изобретения.
В настоящем документе описаны специфические гены и белки, пригодные для применения в способах, композициях и организмах по настоящему изобретению; однако следует понимать, что абсолютная идентичность с такими генами не является необходимой. Например, изменения в конкретном гене или полинуклеотиде, содержащем последовательность, кодирующую полипептид или фермент, могут быть выполнены и подвергнуты скринингу на активность. Как правило, такие изменения включают консервативные мутации и молчащие мутации. Такие модифицированные или мутированные полинуклеотиды и полипептиды могут быть подвергнуты скринингу на экспрессию функционального фермента с использованием способов, известных в данной области техники.
Из-за присущей вырожденности генетического кода для клонирования и экспрессии полинуклеотидов, кодирующих такие ферменты, также могут быть использованы другие полинуклеотиды, которые кодируют по существу те же или функционально эквивалентные полипептиды.
Методики, известные специалистам в данной области техники, могут быть пригодны для идентификации дополнительных гомологичных генов и гомологичных ферментов. Как правило, аналогичные гены и/или аналогичные ферменты могут быть идентифицированы с помощью функционального анализа и будут иметь функциональное сходство.
Способы, известные специалистам в данной области техники, могут быть пригодны для идентификации аналогичных генов и аналогичных ферментов или любых генов, белков или ферментов пути биосинтеза, указанные способы могут включать, но не ограничиваются, клонирование гена с помощью ПЦР с использованием праймеров на основе опубликованной последовательности гена/фермента, представляющего интерес, или с помощью вырожденной ПЦР с использованием вырожденных праймеров, предназначенных для амплификации консервативной области среди представляющего интерес гена. Кроме того, специалист в данной области техники может использовать способы для идентификации гомологичных или аналогичных генов, белков или ферментов с функциональной гомологией или сходством. Способы включают изучение клетки или клеточной культуры на каталитическую активность фермента с помощью ферментных анализов in vitro на указанную активность (например, как описано в настоящем документе или в Kiritani, K., Branched-Chain Amino Acids Methods Enzymology, 1970), затем выделение фермента с указанной активностью путем очистки, определение белковой последовательности фермента с помощью таких методов, как расщепление по Эдману, конструирование праймеров ПЦР до вероятной нуклеотидной последовательности, амплификация указанной последовательности ДНК с помощью ПЦР и клонирование указанной нуклеотидной последовательности. Для идентификации гомологичных или подобных генов и/или гомологичных или подобных ферментов, аналогичных генов и/или аналогичных ферментов или белков способы также включают сравнение данных, касающихся гена-кандидата или гена-фермента, с базами данных, такими как BRENDA, KEGG или MetaCYC. Ген-кандидат или ген-фермент могут быть идентифицированы в вышеупомянутых базах данных в соответствии с изложенными в настоящем документе данными.
ПРОИЗВОДНЫЕ
Термин «гиалуроновая кислота (HA)», используемый в настоящем документе, также предназначен для охвата производных гиалуроновой кислоты, таких как, но не ограничиваясь, ацетилированная или сульфатированная гиалуроновая кислота, пригодная для применения в косметическом продукте, вкусо-ароматическом веществе, парфюмерном продукте, пищевом продукте, продукте питания, напитке, текстуранте, фармацевтической композиции, биологически активной добавке, нутрицевтике, чистящем средстве и/или стоматологической композиции и/или композиции для гигиены полости рта или их комбинациях.
Гиалуроновая кислота может быть получена в виде композиции.
СОСТАВЫ И ПРОДУКТЫ
Композиция по настоящему изобретению может быть включена в состав/продукт, такой как нутрицевтический, фармацевтический, ветеринарный, энологический или косметический состав/продукт.
Таким образом, в настоящем изобретении предложен состав, содержащий композицию по изобретению. Например, в настоящем изобретении может быть предложен косметический состав, содержащий композицию согласно изобретению.
В настоящем изобретении также предложен продукт, содержащий композицию по изобретению. Например, в настоящем изобретении может быть предложен косметический продукт, содержащий композицию согласно изобретению.
«Косметический продукт» означает любое вещество или смесь, предназначенную для контакта с внешними частями человеческого тела (эпидермис, волосяная система, ногти, губы и внешние половые органы) или с зубами и слизистыми оболочками полости рта исключительно или главным образом с целью их очистки, придания запаха, изменения их внешнего вида, их защиты, поддержания их в хорошем состоянии, коррекции запахов тела и/или их комбинаций.
Подразумевается, что «вещество» означает химический элемент и его соединения в естественном состоянии или полученные любым способом производства, включая любую добавку, необходимую для сохранения его стабильности, и любую примесь, полученную в результате используемого способа, но исключая любой растворитель, который может быть отделен, не влияя на стабильность вещества или изменяя его состав.
«Смесь» предназначена для обозначения смеси или раствора, состоящего из двух или более веществ.
Настоящее изобретение также относится к применению композиции по изобретению в нутрицевтическом, фармацевтическом, ветеринарном, энологическом или косметическом составе/продукте.
Такие составы или продукты далее упоминаются как «составы или продукты по изобретению».
Нутрицевтический, фармацевтический, ветеринарный, энологический или косметический состав/продукт может необязательно дополнительно содержать фармацевтические/ветеринарные/косметические (включая косметически активные) ингредиенты, такие как эксципиенты, носители и их смеси, в зависимости от обстоятельств.
«Косметические» или «косметические активные ингредиенты» означают любые и все природные, встречающиеся в природе, идентичные природным, синтетические, полученные синтетически, полученные биосинтетически, устойчивые, возобновляемые и/или биоразлагаемые соединения, ингредиенты, промежуточные продукты, молекулы, вещества, исходные материалы или продукты по отдельности или в составе смеси соединений, ингредиентов, промежуточных продуктов, молекул, веществ, исходных материалов или продуктов, смесей, композиций, составов (включая, но не ограничиваясь, увлажняющие средства для кожи, кремы, бальзамы, сыворотки, масла, косметику для лица, смываемые средства для волос, несмываемые средства для волос, красители для волос (включая но не ограничиваясь, натуральные красители для волос) и/или их комбинации), готовые продукты и родственные технологии, включая, но не ограничиваясь, компоненты, включенные, например, в косметический состав (такие как, но не ограничиваясь, натуральные красители, консерванты, эмульгаторы, антиоксиданты и тому подобное, которые, например, не обладают активностью на коже, волосах, коже головы и тому подобном, но играют роль в составе готового продукта), системы доставки, маркетинговые вспомогательные средства (такие как, например, окрашенные унисферы, применяемые к полупрозрачным составам) и способы получения чего-либо, относящегося к ним, пригодного для использования/используемого для/предназначенного для:
- нанесения путем втирания, обливания, разбрызгивания, распыления или иным образом непосредственно на или к телу человека или животного и/или путем приведения в контакт с различными внешними и/или поверхностными частями тела человека или животного (включая, но не ограничиваясь, кожу, волосы, волосы на теле, волосяную систему, кожу головы, ногти, губы, внешние половые органы, зубы, слизистую оболочку полости рта и/или носа и тому подобное) и/или непрямое нанесение на или к телу человека или животного, такое как, например, нанесение в составе ткани или нанесение на ткань как часть устройства доставки (такого как капсула) или системы доставки (такой как смеси или составы), нанесенной на ткань; и/или
- очищения, ухода, охлаждения, украшения, кондиционирования, обработки, успокаивания, текстурирования, повышения привлекательности, защиты, поддержания, улучшения, усиления, переделывания и/или изменения внешней части и/или поверхности тела человека или животного (такой как, но не ограничиваясь, кожа головы) или эстетического внешнего вида тела человека или животного; и/или с целью главным образом очистки или придания аромата, или защиты или поддержания в хорошем состоянии, или борьбы с запахом тела, или изменения внешнего вида, или исправления или восстановления состояния дисбаланса кожи, слизистой оболочки полости рта, кожи головы или волос путем обеспечения успокаивания, заживления, восстановления или оживления, увлажнения кожи или для облегчения, смазывания, увлажнения, тонуса, заживления, стерилизации, облегчения, коррекции и/или устранения состояний сухости, раздражения, травмы или усталости, и/или с целью коррекции нарушений пигментации или обеспечения нефармацевтического предотвращения и/или лечения перхоти, акне, раздражения и/или воспаления и тому подобного и/или восстановления баланса бактериальной флоры (например, микробиома) на поверхности кожи (например, например, путем повышения уровня полезной бактериальной флоры на поверхности кожи) и/или в целях поддержания тела человека или животного в хорошем состоянии для целей здоровья и/или благополучия и/или для улучшения внешнего вида тела человека или животного, например, путем улучшения внешнего вида продукта, нанесенного на человека или тело; и/или
- обеспечения косметической и/или дерматологической функции и/или преимущества с пользой для биологической активности (но без влияния на структуру или функцию организма). во избежание сомнений, косметический или косметический активный ингредиент или любая его часть также может квалифицироваться как функциональный ингредиент и/или нутрицевтик.
«Функциональный ингредиент» означает пищевой ингредиент или часть пищевого продукта, который обеспечивает лекарственные преимущества или пользу для здоровья, включая любое из следующего: каротиноид, пищевые волокна, жирные кислоты, сапонин, антиоксидант, флавоноид, изотиоцианат, фенол, полифенол (такой как ресвератрол), растительный стерол или станол (фитостеролы и фитостанолы), полиол, пребиотик, фитоэстроген, соевый белок, сульфиды/тиол, витамин, глюкозамин, консерванты, гидратационные агенты, пищевые гелеобразующие ингредиенты, пищевые гелевые смеси и гелевые композиции, длинноцепочечные первичные алифатические насыщенные спирты, красители, текстурирующие агенты, эмульгаторы и их комбинации.
«Нутрицевтик» означает любые и все природные, встречающиеся в природе, устойчивые, полученные синтетически и полученные биосинтетически соединения, смеси соединений, функциональные ингредиенты, молекулы, композиции, исходные материалы и промежуточные продукты (включая связанные с ними компоненты и устройства доставки (такие как капсулы), их системы доставки (такие как смеси или составы) и способы получения вышеуказанного), которые связаны со здоровьем и/или косметическими преимуществами, а также улучшением или поддержанием физических свойств тела человека. во избежание сомнений, нутрицевтики включают соединения, которые могут быть использованы в качестве добавок к пище или напитку, будь то твердый состав, капсула, таблетка, жидкий состав, раствор или суспензия.
Альтернативно, нутрицевтический, фармацевтический, ветеринарный, энологический или косметический состав/продукт может состоять или по существу состоять из композиции по изобретению.
Косметический состав/продукт может представлять собой антивозрастной состав.
В данном контексте ссылки на фармацевтически, ветеринарно или косметически приемлемые эксципиенты могут относиться к фармацевтически, ветеринарно или косметически приемлемым адъювантам, разбавителям и/или носителям, известным специалистам в данной области техники.
Под «фармацевтически/ветеринарно/косметически приемлемым» подразумевается, что дополнительные компоненты композиции, как правило, безопасны, нетоксичны и ни биологически, ни иным образом нежелательны. например, дополнительные компоненты могут быть, как правило, стерильными и апирогенными. Такие компоненты должны быть «приемлемыми» в том смысле, что они совместимы с композицией по настоящему изобретению и не вредны для ее реципиентов. таким образом, «фармацевтически приемлемые эксципиенты» включают любое соединение(-я), используемое(-ые) для формирования части состава, которое предназначено для действия только в качестве эксципиента, то есть не предназначено для проявления биологической активности.
Нутрицевтический, фармацевтический, ветеринарный, энологический или косметический состав/продукт может быть в форме жидкости или твердого вещества.
Жидкие лекарственные составы/продукты для перорального введения включают растворы, эмульсии, водные или масляные суспензии, сиропы и эликсиры.
Составы и продукты (например, фармацевтические, ветеринарные или косметические составы/продукты), описанные в настоящем документе, например, предназначенные для перорального введения, могут быть получены в соответствии со способами, известными специалистам в данной области техники, например, путем смешивания компонентов состава/продукта вместе.
Состав или продукт (например, фармацевтический, ветеринарный или косметический состав/продукт) может содержать один или более дополнительных ингредиентов, таких как фармацевтические ингредиенты и эксципиенты, такие как подсластители, ароматизаторы, красители и консерванты.
Состав или продукт (например, фармацевтический, ветеринарный или косметический состав/продукт) также может содержать один или более дополнительных активных ингредиентов, таких как косметические или фармацевтические активные ингредиенты, такие как гиалуроновая кислота, экстракт центеллы азиатской, пептиды, такие как matrixyl® и argireline®, и их смеси.
Состав или продукт согласно настоящему изобретению может содержать активный ингредиент(-ы) в смеси с нетоксичными фармацевтически приемлемыми эксципиентами (или ингредиентами). эти эксципиенты (или ингредиенты) могут быть, например, инертными разбавителями, такими как карбонат кальция, карбонат натрия, лактоза, фосфат кальция или фосфат натрия; гранулирующими и дезинтегрирующими агентами, например, кукурузным крахмалом, мальтодекстрином или альгиновой кислотой; связующими агентами, например, крахмалом, желатином или аравийской камедью; или смазывающими агентами, например, стеаратом магния, стеариновой кислотой, тальком и их смесями.
Жидкие составы или продукты (например, фармацевтические, ветеринарные или косметические составы/продукты) могут содержаться в капсуле, которая может быть без покрытия или с покрытием, как определено выше.
Подходящие фармацевтические или ветеринарные носители включают инертные твердые разбавители или наполнители, стерильные водные растворы и различные органические растворители. примерами жидких носителей являются сироп, арахисовое масло, оливковое масло, фосфолипиды, жирные кислоты, амины жирных кислот, полиоксиэтилен и вода.
Кроме того, носитель или разбавитель может включать любой материал с замедленным высвобождением, известный в данной области техники, такой как глицерилмоностеарат или глицерилдистеарат, отдельно или смешанный с воском.
Подходящие фармацевтические носители включают инертные стерильные водные растворы и различные органические растворители. примерами жидких носителей являются сироп, растительные масла, фосфолипиды, жирные кислоты, амины жирных кислот, полиоксиэтилен и вода. кроме того, носитель или разбавитель может включать любой материал с замедленным высвобождением, известный в данной области техники, такой как глицерилмоностеарат или глицерилдистеарат, отдельно или смешанный с воском.
Подходящие косметические носители обычно представляют собой носители, которые подходят для местного введения на внешнюю поверхность тела человека, такую как кожа, и/или волосы, и/или кожа головы.
Как правило, такие носители являются дерматологически приемлемыми.
Фраза «дерматологически приемлемый носитель» означает, что носитель подходит для местного нанесения на кератиновую ткань, обладает хорошими эстетическими свойствами, совместим с активными веществами в композиции и не вызывает каких-либо необоснованных проблем с безопасностью или токсичностью.
Носитель может быть в самых разнообразных формах. в некоторых случаях растворимость или диспергируемость компонентов (например, экстрактов, солнцезащитных активных, дополнительных компонентов) может определять форму и характер носителя. неограничивающие примеры включают простые растворы (например, водные или безводные), дисперсии, эмульсии и твердые формы (например, гели, стики, жидкотекучие твердые вещества или аморфные материалы).
Дерматологически приемлемый носитель может быть в форме эмульсии. эмульсия обычно может быть классифицирована как имеющая непрерывную водную фазу (например, масло в воде и вода в масле в воде) или непрерывную масляную фазу (например, вода в масле или масло в воде). масляная фаза по настоящему изобретению может содержать силиконовые масла, несиликоновые масла, такие как углеводородные масла, сложные эфиры, простые эфиры и тому подобное, и их смеси. водная фаза обычно содержит воду и водорастворимые ингредиенты (например, водорастворимые увлажняющие агенты, кондиционирующие агенты, антимикробные препараты, увлажнители и/или другие активные вещества для ухода за кожей). однако в некоторых случаях водная фаза может содержать компоненты, отличные от воды, включая, но не ограничиваясь, водорастворимые увлажняющие агенты, кондиционирующие агенты, антимикробные препараты, увлажнители и/или другие водорастворимые активные вещества для ухода за кожей. в некоторых случаях неводный компонент композиции содержит увлажнитель, такой как глицерин и/или другой полиол(-ы). эмульсии также могут содержать эмульгатор. эмульгаторы могут быть неионными, анионными или катионными.
Носитель может содержать один или более дерматологически приемлемых гидрофильных разбавителей. в данном контексте «разбавитель» включает материалы, в которых композиция по изобретению может быть диспергирована, растворена или иным образом включена. гидрофильные разбавители включают воду, органические гидрофильные разбавители, такие как низшие одновалентные спирты (например, c1-c4), и низкомолекулярные гликоли и полиолы, включая пропиленгликоль, полиэтиленгликоль, полипропиленгликоль, глицерин, бутиленгликоль, 1,2,4-бутантриол, сложные эфиры сорбитола, 1,2,6-гексантриол, этанол, изопропанол, сложные эфиры сорбитола, бутандиол, простой эфир пропанола, этоксилированные простые эфиры, пропоксилированные простые эфиры и их комбинации.
Косметический состав/продукт может необязательно содержать один или более дополнительных ингредиентов, обычно используемых в косметических композициях (например, красители, агенты для тонуса кожи, агенты против старения кожи, противовоспалительные агенты, солнцезащитные агенты, их комбинации и тому подобное), при условии, что дополнительные ингредиенты нежелательно не изменяют антигликирующие преимущества, обеспечиваемые композицией.
В некоторых случаях может быть желательным выбрать агенты для тонуса кожи, которые функционируют посредством различных биологических путей, чтобы активные вещества не мешали друг другу, что может снизить эффективность обоих агентов. Дополнительные ингредиенты, при включении в композицию, должны быть пригодны для применения в контакте с кожной тканью человека без чрезмерной токсичности, несовместимости, нестабильности, аллергической реакции и тому подобного.
Термин «носитель», используемый в данном документе, может также относиться к натуральному продукту или продукту, происходящему из природы, который был трансформирован или модифицирован таким образом, что он отличается от натурального продукта, из которого он произошел, такой как мальтодекстрин.
Количество композиции по изобретению, присутствующей в нутрицевтических, фармацевтических, ветеринарных, энологических или косметических составах или продуктах, будет варьироваться в зависимости от применения.
Как правило, количество композиции по настоящему изобретению, которое может присутствовать в нутрицевтических, фармацевтических, ветеринарных, энологических или косметических составах или продуктах, составляет от около 0,001 до около 50 мас.%, например, от около 0,01 до около 30 % или от около 1 до около 20 % нутрицевтических, фармацевтических, ветеринарных, энологических или косметических составов или продуктов, например, от около 0,01 до около 20 мас.%, или от около 0,1 до 10 мас.%, или от около 1 до около 5 мас.% состава или продукта.
Специалистам в данной области техники будет понятно, что из-за вырожденной природы генетического кода для кодирования данного фермента согласно настоящему изобретению могут быть использованы различные молекулы днк, отличающиеся своими нуклеотидными последовательностями. Нативная последовательность днк, кодирующая биосинтетические ферменты, описанные выше, упоминается в настоящем документе только для иллюстрации варианта осуществления настоящего изобретения, и настоящее изобретение включает молекулы днк любой последовательности, которые кодируют аминокислотные последовательности полипептидов и белков ферментов, используемых в способах по настоящему изобретению. Аналогичным образом, полипептид обычно может переносить одну или более аминокислотных замен, делеций и вставок в своей аминокислотной последовательности без потери или значительной потери желаемой активности. Настоящее изобретение включает такие полипептиды с аминокислотными последовательностями, отличными от специфических белков, описанных в настоящем документе, при условии, что модифицированные или вариантные полипептиды обладают ферментативной анаболической или катаболической активностью референсного полипептида. Кроме того, аминокислотные последовательности, кодируемые последовательностями днк, показанными в настоящем документе, просто иллюстрируют варианты осуществления настоящего изобретения.
В настоящем документе описаны специфические гены и белки, пригодные для применения в способах, композициях и организмах по настоящему изобретению; однако следует понимать, что абсолютная идентичность с такими генами не является необходимой. например, изменения в конкретном гене или полинуклеотиде, содержащем последовательность, кодирующую полипептид или фермент, могут быть выполнены и подвергнуты скринингу на активность. как правило, такие изменения включают консервативные мутации и молчащие мутации. Такие модифицированные или мутированные полинуклеотиды и полипептиды могут быть подвергнуты скринингу на экспрессию функционального фермента с использованием способов, известных в данной области техники.
Из-за присущей вырожденности генетического кода для клонирования и экспрессии полинуклеотидов, кодирующих такие ферменты, также могут быть использованы другие полинуклеотиды, которые кодируют по существу те же или функционально эквивалентные полипептиды.
Методики, известные специалистам в данной области техники, могут быть пригодны для идентификации дополнительных гомологичных генов и гомологичных ферментов. Как правило, аналогичные гены и/или аналогичные ферменты могут быть идентифицированы с помощью функционального анализа и будут иметь функциональное сходство.
Способы, известные специалистам в данной области техники, могут быть пригодны для идентификации аналогичных генов и аналогичных ферментов или любых генов, белков или ферментов пути биосинтеза, указанные способы могут включать, но не ограничиваются, клонирование гена с помощью пцр с использованием праймеров на основе опубликованной последовательности гена/фермента, представляющего интерес, или с помощью вырожденной пцр с использованием вырожденных праймеров, предназначенных для амплификации консервативной области среди представляющего интерес гена. кроме того, специалист в данной области техники может использовать методики для идентификации гомологичных или аналогичных генов, белков или ферментов с функциональной гомологией или сходством. методы включают изучение клетки или клеточной культуры на каталитическую активность фермента с помощью ферментных анализов in vitro на указанную активность (например, как описано в настоящем документе или в kiritani, k., branched-chain amino acids methods enzymology, 1970), затем выделение фермента с указанной активностью путем очистки, определение белковой последовательности фермента с помощью таких методов, как расщепление по эдману, конструирование праймеров ПЦР до вероятной нуклеотидной последовательности, амплификация указанной последовательности днк с помощью ПЦР и клонирование указанной нуклеотидной последовательности. для идентификации гомологичных или подобных генов и/или гомологичных или подобных ферментов, аналогичных генов и/или аналогичных ферментов или белков способы также включают сравнение данных, касающихся гена-кандидата или гена-фермента, с базами данных, такими как brenda, kegg или metacyc. ген-кандидат или ген-фермент могут быть идентифицированы в вышеупомянутых базах данных в соответствии с изложенными в настоящем документе данными.
Термины «от … до …» и «в диапазоне от... до...» следует понимать как включающие пределы, если не указано иное. в настоящем описании и следующей формуле изобретения, если из контекста не следует иное, слово «содержат» и такие вариации, как «содержит», «содержащий» и «имеет», следует понимать как подразумевающие включение указанного целого числа или стадии или группы целых чисел или стадий, но не исключение любого другого целого числа или стадии или группы целых чисел или стадий. термин «содержащий» также означает «включающий», а также «состоящий», например, композиция, «содержащая» x, может состоять исключительно из x или может включать что-то дополнительное, например, x + y. следует также отметить, что, как используется в настоящем описании и прилагаемой формуле изобретения, формы единственного числа включают ссылки на множественное число, если содержание явно не диктует иное. в качестве примера, ссылка на «ген» или «фермент» представляет собой ссылку на «один или более генов» или «один или более ферментов».
Следует понимать, что настоящее изобретение не ограничивается конкретными методиками, протоколами и реагентами, описанными в настоящем документе, поскольку они могут варьироваться. следует также отметить, что терминология, используемая в настоящем документе, предназначена только для описания конкретных вариантов осуществления и не предназначена для ограничения объема настоящего изобретения, который будет ограничен только прилагаемой формулой изобретения. если не указано иное, все технические и научные термины, используемые в настоящем документе, имеют те же значения, которые обычно понимаются специалистом в данной области техники. в соответствии с настоящим изобретением могут быть использованы общепринятые методы молекулярной биологии, микробиологии и рекомбинантной днк, которые находятся в пределах компетенции специалиста в данной области техники.
Это изобретение не ограничивается в своем применении деталями конструкции и расположением компонентов, изложенными в следующем описании или проиллюстрированными на фигурах. настоящее изобретение может быть реализовано другими вариантами осуществления и может быть реализовано на практике или осуществлено различными способами. кроме того, формулировки и терминология, используемые в настоящем документе, предназначены для описания и не должны рассматриваться как ограничивающие. предпочтительно термины, используемые в настоящем документе, определены, как описано в "a multilingual glossary of biotechnological terms: (iupac recommendations)", leuenberger, h.g.w, nagel, b. and kolbl, h. eds. (1995), helvetica chimica acta, ch-4010 basel, switzerland).
В тексте настоящего описания приведены ссылки на несколько документов. каждый из документов, цитируемых в настоящем документе (включая все патенты, патентные заявки, научные публикации, спецификации производителя, инструкции, представления последовательности регистрационных номеров genbank и т. д.), будь то указанные ранее или далее, полностью включен в настоящий документ посредством ссылки.
Следующие примеры и фигуры представлены в качестве иллюстрации и не подразумевают ограничение изобретения.
ПРИМЕРЫ
Пример 1: Протокол получения рекомбинантного штамма Saccharomyces cerevisiae согласно изобретению
Все далее реализованные рекомбинантные штаммы saccharomyces cerevisiae были сконструированы из стандартных штаммов с использованием стандартной процедуры молекулярной генетики дрожжей (Methods In Yeast Genetics - A Cold Spring Harbor Laboratory Course Manual (2000) by d. Burke, d. Dawson, t. Stearns cshl press).
Кластер следующих упомянутых генов интегрировали в рекомбинантные дрожжи сразу, используя способность дрожжей эффективно рекомбинировать свободные концы днк, которые имеют гомологию последовательностей.
Кроме того, для лучшего понимания следующих генотипов:
- jlp1, lyp1, sam3, his3, leu2, trp1 и ura3 являются сайтами встраивания.
- строчные буквы означают, что рассматриваемый ген неактивен, заглавные буквы отражают активный ген.
- «::»: после названия гена означает, что ген прерывается последующим (если вставлено более одного гена, они указаны в скобках []). прерывание гена сопутствует полной делеции кодирующей последовательности, но сохраняет промотор. следовательно, ген, за которым следует «::», неактивен и отмечен строчными буквами. если не указано, транскрипция вставленного гена контролируется промотором нарушенного гена.
- «gene.Kl» означает, что ген происходит из Kluyveromyces lactis.
Более конкретно, кодирующие последовательности, подлежащие клонированию, были искусственно синтезированы. для гетерологичных последовательностей (не дрожжевых) нуклеотидные последовательности модифицировали для получения синонимичной кодирующей последовательности с использованием частоты использования дрожжевого кодона. используя фермент рестрикции и классическую технологию клонирования, каждую синтетическую последовательность клонировали между промотором транскрипции и терминатором транскрипции. каждой промоторной последовательности предшествует последовательность от 50 до 200 нуклеотидов, гомологичная последовательности терминатора вышележащего гена. аналогично, за терминатором каждого гена (гена, содержащего промотор-кодирующая последовательность-терминатор) следуют последовательности, гомологичные непосредственно следующему гену. Таким образом, каждая единица, подлежащая интеграции, имеет от 50 до 200 нуклеотидов, перекрывающихся как с единицей выше по потоку, так и с единицей ниже по потоку. Для первой единицы промотору предшествуют от 50 до 200 нуклеотидов, гомологичных нуклеотиду дрожжевой хромосомы для локуса, в который он будет интегрирован. Аналогично, для последней единицы за терминатором следуют от 50 до 200 нуклеотидов, гомологичных нуклеотиду дрожжевой хромосомы для локуса, в который он будет интегрирован.
Затем каждую единицу амплифицируют пцр из конструкций плазмид с получением x единицы линейной днк, имеющей перекрывающиеся последовательности. по меньшей мере один из этих генов является ауксотрофным маркером для выбора события рекомбинации. все линейные фрагменты трансформируют в дрожжах сразу, и выбирают рекомбинантную дрожжевую клетку для ауксотрофии, связанной с используемым маркером. Затем целостность последовательности проверяют с помощью пцр и секвенирования.
Пример 2: Сравнительные примеры продуцирования гиалуроновой кислоты
1. Продукция гиалуроновой кислоты менее 50 кДа
A. Сначала получают три рекомбинантных штамма: YA5234-1, YA5235-1 и YA5302-2.
Соответственно, эти три штамма являются следующими:
YA5234-1: MAT-α, can1-100, his3::[pSAM1-UGP1- tRPL3-pMET6-QRI1-tIDP1-HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA2.Sz-tRPL41B, pCUP1-UGP1-tTPI1, pTDH3-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pCCW12.sba-HYAL-3.Ts-tRPL15A, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tDIT1, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF3-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[pMET6-HASB.Vir-tRPL3, pMET25-HASA-1.Vir-tIDP1- TRP1]x2
YA5235-1: MAT-α, can1-100, his3::[pSAM1-UGP1- tRPL3-pMET6-QRI1-tIDP1-HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA2.Sz-tRPL41B, pCUP1-UGP1-tTPI1, pTDH3-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pNUP57-HYAL-3.Csa-tRPL15A, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tDIT1, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF3-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[pMET6-HASB.Vir-tRPL3, pMET25-HASA-1.Vir-tIDP1- TRP1]x2
YA5302-2: MAT-α, can1-100, his3::[pSAM1-UGP1- tRPL3-pMET6-QRI1-tIDP1-HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA2.Sz-tRPL41B, pCUP1-UGP1-tRPL3, pCUP1-QRI1-tIDP1, pPDC1-UGP1-tTPI1, pTDH3-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pCCW12.Sba-HYAL-3.Li-tRPL15A, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tDIT1, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF3-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[pMET6-HASB.Vir-tRPL3, pMET25-HASA-1.Vir-tIDP1- TRP1]x2
HYAL-3 представляет собой нуклеотидную последовательность, кодирующую полипептид, имеющий активность гиалуронидазы, ассоциированную с сигналом секреции, но не якорным сигналом.
Все HASA, HASA-1, HASA-A, HASA2 и XHASA2 представляют собой нуклеиновую кислоту, кодирующую полипепид, имеющий активность гиалуронан-синтазы. Они отличаются друг от друга тем, что представляют собой различные перекодированные варианты нуклеотидной последовательности, кодирующей ферменты гиалуронан-синтазы. HASA-1 имеет последовательность SEQ ID NO: 1, HASA-A имеет последовательность SEQ ID NO: 2, HASA2 имеет последовательность SEQ ID NO: 7, и XHASA2 имеет последовательность SEQ ID NO: 6.
HASB и HASB-A представляют собой нуклеотидную последовательность, кодирующую полипептид, имеющий активность UDP-глюкозо-6-дегидрогеназы. Они отличаются друг от друга тем, что представляют собой различные перекодированные варианты нуклеотидной последовательности, кодирующей фермент. HASB.At имеет последовательность SEQ ID NO: 12, HASB.Vir имеет последовательность SEQ ID NO: 13, и HASB-A.Vir имеет последовательность SEQ ID NO: 14.
Все эти штаммы инкубировали в 25 мл среды SY, забуференной MES 0,1 M pH 5,5, в колбе Эрленмейера с дефлекторами в течение 48 часов при 28°C при энергичном перемешивании.
Среда SY содержит следующие элементы:
KH2PO4: 100 мм; MgSO4×7H2O: 2,8 мм; K2SO4: 11,5 мм; Na2SO4: 1,1 мм; NaCl: 2,6 мм; CaCl2×2H2O: 0,7 мм; CuSO4×5H2O: 15 мкм; KI: 6 мкм; FeCl3: 30 мкм; ZnSO4×7H2O: 61 мкм; MnSO4×H2O: 25 мкм; H2SO4: 110 мкм; гемикальциевая соль пантотеновой кислоты: 42 мкм; гидрохлорид тиамина: 59 мкм; гидрохлорид пиридоксина: 49 мкм; мио-инозитол (C6H12O6): 555 мкм; никотиновая кислота (C6H5NO2): 29 мкм; D-биотин: 0,82 мкм; цитрат аммония трехосновный: 33 мкм; и глюкоза или сахароза от 2 до 30 %.
Питательную среду извлекали через 48 часов и анализировали на содержание и качество гиалуроновой кислоты. Аликвоту среды загружали и пропускали через 0,5% агарозный гель, затем окрашивали «универсальным красителем» (Sigma Aldrich CAS номер 7423-31-6).
Количество гиалуроновой кислоты, присутствующей в среде, оценивали с помощью колориметрического определения после обработки концентрированной серной кислотой и карбазолом (Bitter and Muir (1962) analytical biochemistry 4, 330-334).
В иллюстративных целях агарозный гель, полученный после пропускания аликвоты супернатанта штамма YA5235-1 и окрашивания ее «универсальным красителем» (номер CAS 7423-31-6), представлен на фигуре 2A. Классически его вводят в гель бок о бок со стандартами молекулярной массы (мм) ha (слева направо мм 10 кДа, 20 кДа, 50 кДа и 300 кДа).
Количество, полученное с этими различными штаммами, составляет соответственно:
- YA5234-1: 2,4 г.л-1.
- YA5235-1: 4,5 г.л-1.
- YA5302-2: 3,7 г.л-1.
Для сравнения, нативный штамм дрожжей, например, штамм CC788-2D (Chérest et al. (2000) J Biol. Chem. 275: 14056-14063), не продуцирует гиалуроновую кислоту.
Из этого эксперимента следует, что рекомбинантный штамм, содержащий модификации согласно изобретению, продуцирует большее количество гиалуроновой кислоты при культивировании в тех же условиях по сравнению с другими рекомбинантными штаммами, не содержащими всех генетических модификаций согласно изобретению.
Кроме того, эти три штамма привели к получению через 48 часов гиалуроновой кислоты, имеющей молекулярную массу от 20 до 50 кДа.
B. Также были получены три других рекомбинантных штамма: YA5110-13 и YA5260-4.
Эти три штамма являются следующими:
YA5110-13: MAT-α, can1-100, his3::[pSAM1-UGP1-tRPL3, pMET6-QRI1-tIDP1-HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA2.Sz-tRPL41B, pCUP1-UGP1-tTPI1, pTDH3-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pNUP57-HYAL-3.Hn-tRPL15A, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tDIT1, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF3-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[pMET6-HASB.Vir-tRPL3, pMET25-HASA-1.Vir-tIDP1-TRP1]x2
YA5260-4: MAT-α, can1-100, his3::[pSAM1-UGP1-tRPL3-pMET6-QRI1-tIDP1- HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA2.Sz-tRPL41B, pCUP1-UGP1-tRPL3, pCUP1-QRI1-tIDP1, pPDC1-UGP1-tTPI1, pTDH3-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pTEF3-HYAL-31.Hn-tRPL15A, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tDIT1, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF3-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[pMET6-HASB.Vir-tRPL3, pMET25-HASA-1.Vir-tIDP1- TRP1]x2
YA5569: MAT-α, his3::[pSAM1-UGP1-tRPL3, pMET6-QRI1-tIDP1, HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA-1.Sz-tRPL41B, pCUP1-UGP1-tRPL3, pCUP1-QRI1-tIDP1, pPDC1-UGP1-tTPI1, pTDH3-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pCWP2-HYAL-31.Csa-tRPL15A, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tRPL41B, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1.Ago-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF1-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[tRPL3-HASB.Vir-pMET6, pMET25-HASA-1.Vir-tIDP1, TRP1]x2
HYAL-31 представляет собой нуклеотидную последовательность, кодирующую полипептид, имеющий активность гиалуронидазы, связанную как с сигналом секреции, так и с якорным сигналом.
Все HASA-1, HASA-A, HASA2 и XHASA2 представляют собой нуклеотидную последовательность, кодирующую полипептид, имеющий активность гиалуронан-синтазы. Они отличаются друг от друга тем, что представляют собой различные перекодированные варианты нуклеотидной последовательности, кодирующей фермент гиалуронан-синтазу. HASA-1 имеет последовательность SEQ ID NO: 1, HASA-A имеет последовательность SEQ ID NO: 2, HASA2 имеет последовательность SEQ ID NO: 7, и XHASA2 имеет последовательность SEQ ID NO: 6.
HASB и HASB-A представляют собой нуклеотидную последовательность, кодирующую полипептид, имеющий активность UDP-глюкозо-6-дегидрогеназы. Они отличаются друг от друга тем, что представляют собой различные перекодированные варианты нуклеотидной последовательности, кодирующей фермент. HASB.At имеет последовательность SEQ ID NO: 12, HASB.Vir имеет последовательность SEQ ID NO: 13, и HASB-A.Vir имеет последовательность SEQ ID NO: 14.
Штаммы инокулировали в 2 литрах вышеуказанной среды SY при pH 6 в 2% сахарозе и 500 мкМ CuSO4 в биореакторе. Затем их выращивали с подпиткой, добавляя 500 мкМ CuSO4 через 7 ч, 24 ч, 31 ч и от 130 до 175 г.л-1 сахарозы от 10 до 48 ч.
Для YA5110-13 рН поддерживали между 5,8 и 6,2 с использованием 15% H2SO4 и 10% NH4OH от t=31 ч.
Для YA5260-4 рН поддерживали между 5,8 и 6,2 с использованием 15% H2SO4 и 10% NH4OH на всем протяжении ферментации.
Для YA5569 рН поддерживали между 5,8 и 6,2 с использованием 15% H2SO4 и 10% NH4OH на всем протяжении ферментации.
Питательную среду извлекали через 48 часов и анализировали на содержание и качество гиалуроновой кислоты, как описано выше.
Количество гиалуроновой кислоты, полученное с помощью этих двух штаммов, составляет соответственно:
- YA5110-13: 23 г.л-1.
- YA5260-4: 16 г.л-1.
- YA5569: 32 г.л-1
В сравнении нативный штамм не продуцирует гиалуроновую кислоту.
Из этого эксперимента следует, что рекомбинантный штамм, содержащий модификации согласно изобретению, продуцирует большее количество гиалуроновой кислоты при культивировании в тех же условиях по сравнению с другими рекомбинантными штаммами, не содержащими всех генетических модификаций согласно изобретению.
Кроме того, гиалуроновая кислота, продуцируемая штаммами YA5110-13 и YA5260, имела молекулярную массу около 20 кДа, тогда как гиалуроновая кислота, продуцируемая YA5569, имела молекулярную массу от около 20 до 50 кДа.
Точно такой же эксперимент проводили с использованием этих трех рекомбинантных штаммов при замене сахарозы глюкозой. полученная гиалуроновая кислота имела такую же молекулярную массу около 20 кДа или от около 20 до около 50 кДа через 48 часов.
C. Другой рекомбинантный штамм 5672-29A был получен следующим образом:
5672-29A: MAT-α, his3::[pSAM1-UGP1-tRPL3, pMET6-QRI1-tIDP1, HIS3]x5, jlp1::[LEU2.Sba, pTEF1.Sba-HASB.Vir-tRPL3.Sm, pTDH3.Sk-HASB.Vir-tTEF1.Sba, pTDH3-1.Sba-HASA-1.Vir-tRPL3.Sba, pTDH3.Sar-HASA-1.Vir-tRPL15A.Sba, pTEF1-HYAL-31.Hn-tRPL15A], leu2, sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1.Ago-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF1-PCM1-tRPL41B, TRP1.Sba-loxP], trp1
HYAL-31 представляет собой гиалуронидазу, связанную с якорным сигналом.
1 HASA-1 представляет собой нуклеотидную последовательность, кодирующую полипептид, имеющий активность гиалуронан-синтазы. HASA-1 имеет последовательность SEQ ID NO: 1.
Штамм инокулировали в 25 мл указанной выше среды SY при pH 5,5, забуференной MES 0,1 M, в колбе Эрленмейера с дефлекторами при 28°C при энергичном перемешивании.
Питательную среду извлекали через 48 часов и анализировали на содержание и качество гиалуроновой кислоты, как описано выше.
Количество гиалуроновой кислоты, полученное с помощью штамма, составляло 3,7 г.л-1.
2. Получение гиалуроновой кислоты с молекулярной массой от 50 до 1000 кДа
A. Сначала получали три рекомбинантных штамма: YA5233-1, YA5359-10 и YA5381-1.
Соответственно, эти три штамма являются следующими:
YA5233-1: MAT-α, can1-100, his3::[pSAM1-UGP1-tRPL3-pMET6-QRI1-tIDP1-HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA2.Sz-tRPL41B, pCUP1-UGP1-tTPI1, pTDH3-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pTEF1-HYAL-3.Ts-tRPL15A, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tDIT1, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF3-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[pMET6-HASB.Vir-tRPL3, pMET25-HASA-1.Vir-tIDP1- TRP1]x2
YA5359-10: MAT-α, can1-100, his3::[pSAM1-UGP1-tRPL3-pMET6-QRI1-tIDP1-HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA2.Sz-tRPL41B, pCUP1-UGP1- tTPI1, pTDH3-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pCCW12.sba-HYAL-31.Ts-tRPL15A, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tDIT1, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF3-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[pMET6-HASB.Vir-tRPL3, pMET25-HASA-1.Vir-tIDP1- TRP1]x2
YA5381-1: MAT-α, can1-100, his3::[pSAM1-UGP1-tRPL3-pMET6-QRI1-tIDP1-HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA2.Sz-tRPL41B, pCUP1-UGP1- tTPI1, pTDH3-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pCCW12.Sar-HYAL2-31.Ts-tRPL15A, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tDIT1, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF3-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[pMET6-HASB.Vir-tRPL3, pMET25-HASA-1.Vir-tIDP1- TRP1]x2
HASA-1, HASA-A, HASA2 и XHASA2 определены ранее.
HASB и HASB-A определены ранее.
Все эти штаммы инкубировали в 25 мл указанной выше среды SY, забуференной MES 0,1 M pH 5,5, в колбе Эрленмейера с дефлекторами в течение 48 часов при 28°C при энергичном перемешивании.
Питательную среду извлекали через 48 часов и анализировали на содержание и качество гиалуроновой кислоты, как определено выше.
В иллюстративных целях агарозный гель, полученный после пропускания аликвоты супернатанта штамма YA5359-10, через 31 ч и через 48 ч и окрашивания его «универсальным красителем» (номер CAS 7423-31-6), представлен на фигуре 2B. Классически его вводят в гель бок о бок со стандартами молекулярной массы (мм) ha (слева направо мм 20 кДа, 50 кДа, от 60 до 120 кДа, 300 кДа и 750 кДа).
Количество, полученное с этими различными штаммами, составляет соответственно:
- YA5233-1: 3,1 г.л-1.
- YA5359-10: 3,4 г.л-1.
- YA5381-1: 3,0 г.л-1.
В сравнении нативный штамм не продуцирует гиалуроновую кислоту.
Из этого эксперимента следует, что рекомбинантный штамм, содержащий модификации согласно изобретению, продуцирует большее количество гиалуроновой кислоты при культивировании в тех же условиях по сравнению с другими рекомбинантными штаммами, не содержащими всех генетических модификаций согласно изобретению.
Кроме того, эти три штамма приводили к получению через 48 часов гиалуроновой кислоты, имеющей молекулярную массу, составляющую:
- для YA5233-1: от 50 до 500 кДа;
- для YA5359-10: от 100 до 750 кДа; и
- для YA5381-1: от 50 до 250 кДа.
B. Также были получены шесть других рекомбинантных штаммов: YA5262-16, YA5326-3, YA5300-15, YA5358-4, YA5264-1 и YA5331-6.
Эти шесть штаммов являются следующими:
YA5262-16: MAT-α, can1-100, his3::[pSAM1-UGP1-tRPL3-pMET6-QRI1-tIDP1-HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA2.Sz-tRPL41B, pCUP1-UGP1-tRPL3, pCUP1-QRI1-tIDP1, pPDC1-UGP1-tTPI1, pTDH3-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pCCW10.ago-HYAL-31.Hn-tRPL15A, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tDIT1, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF3-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[pMET6-HASB.Vir-tRPL3, pMET25-HASA-1.Vir-tIDP1- TRP1]x2
YA5326-3: MAT-α, can1-100, his3::[pSAM1-UGP1-tRPL3-pMET6-QRI1-tIDP1-HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA2.Sz-tRPL41B, pCUP1-UGP1-tTPI1, pTDH3-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pCCW10.ago-HYAL-31.Csa-tRPL15A, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tDIT1, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF3-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[pMET6-HASB.Vir-tRPL3, pMET25-HASA-1.Vir-tIDP1-TRP1]x2
YA5300-15: MAT-α, can1-100, his3::[pSAM1-UGP1-tRPL3-pMET6-QRI1-tIDP1-HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA2.Sz-tRPL41B, pCUP1-UGP1-tRPL3, pCUP1-QRI1-tIDP1, pPDC1-UGP1-tTPI1, pTDH3-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pTDH3-HYAL-3.Ts-tRPL15A, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tDIT1, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF3-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[pMET6-HASB.Vir-tRPL3, pMET25-HASA-1.Vir-tIDP1-TRP1]x2
YA5358-4: MAT-α, can1-100, his3::[pSAM1-UGP1-tRPL3-pMET6-QRI1-tIDP1-HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA2.Sz-tRPL41B, pCUP1-UGP1-tRPL3, pCUP1-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pCCW12.Sar-HYAL-31.Li-tRPL15A, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tDIT1, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF3-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[pMET6-HASB.Vir-tRPL3, pMET25-HASA-1.Vir-tIDP1- TRP1]x2
YA5264-1: MAT-α, can1-100, his3::[pSAM1-UGP1-tRPL3-pMET6-QRI1-tIDP1-HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA2.Sz-tRPL41B, pCUP1-UGP1-tTPI1, pTDH3-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pTDH3-HYAL-31.Ts-tRPL15A, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tDIT1, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF3-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[pMET6-HASB.Vir-tRPL3, pMET25-HASA-1.Vir-tIDP1-TRP1]x2
YA5331-6: MAT-α, can1-100, his3::[pSAM1-UGP1-tRPL3-pMET6-QRI1-tIDP1-HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA2.Sz-tRPL41B, pCUP1-UGP1-tRPL3, pCUP1-QRI1-tIDP1, pPDC1-UGP1-tTPI1, pTDH3-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pTEF3-HYAL-31.Li-tRPL15A, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tDIT1, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF3-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[pMET6-HASB.Vir-tRPL3, pMET25-HASA-1.Vir-tIDP1-TRP1]x2
HASA-1, HASA-A, HASA2 и XHASA2 определены ранее.
HASB и HASB-A определены ранее.
YA5262-16 инокулировали в 2 литрах вышеуказанной среды SY при pH 4 в 2% глюкозе в биореакторе, и pH поддерживали на уровне 4 на всем протяжении ферментации с использованием 15% H2SO4 и 10% NH4OH.
YA5326-3 был:
- инокулирован в 2 литрах вышеуказанной среды SY при pH 6 в 2% глюкозе в биореакторе, и pH поддерживали на уровне 6 на всем протяжении ферментации с использованием 15% H2SO4 и 10% NH4OH; или
- инокулирован в 2 литрах вышеуказанной среды SY при pH 6 в 2% сахарозе в биореакторе, и pH поддерживали при 6 до 34 ч и при pH 4 от 34 ч до 48 ч с помощью 15% H2SO4 и 10% NH4OH.
YA5300-15 был инокулирован в 2 литрах вышеуказанной среды SY при pH 6 в 2% сахарозе в биореакторе, и pH поддерживали на уровне 6 на всем протяжении ферментации с использованием 15% H2SO4 и 10% NH4OH.
YA5358-4 был инокулирован в 2 литрах вышеуказанной среды SY при pH 6 в 2% глюкозе в биореакторе, и pH поддерживали на уровне 6 на всем протяжении ферментации с использованием 15% H2SO4 и 10% NH4OH.
YA5264-1 был инокулирован в 2 литрах вышеуказанной среды sy при pH 6 в 2% сахарозе в биореакторе, и pH поддерживали на уровне 6 на всем протяжении ферментации с использованием 15% H2SO4 и 10% NH4OH.
YA5331-6 был инокулирован в 2 литрах вышеуказанной среды SY при pH 6 в 2% глюкозе в биореакторе, и pH поддерживали на уровне 6 на всем протяжении ферментации с использованием 15% H2SO4 и 10% NH4OH.
Питательную среду извлекали через 48 часов и анализировали на содержание и качество гиалуроновой кислоты, как описано выше.
Количество гиалуроновой кислоты, полученное с помощью этих двух штаммов, составляет соответственно:
- YA5262-16: 19 г.л-1;
- YA5326-3: соответственно 13 г.л-1 и 15 г.л-1;
- YA5300-15: 9 г.л-1;
- YA5358-4: 14 г.л-1;
- YA5264-1: 6 г.л-1; и
- YA5331-6: 9 г.л-1.
В сравнении нативный штамм не продуцирует гиалуроновую кислоту.
Из этого эксперимента следует, что рекомбинантный штамм, содержащий модификации согласно изобретению, продуцирует большее количество гиалуроновой кислоты при культивировании в тех же условиях по сравнению с другими рекомбинантными штаммами, не содержащими всех генетических модификаций согласно изобретению.
Кроме того, гиалуроновая кислота, продуцируемая этими штаммами через 48 часов, имела молекулярную массу:
- YA5262-16: 50 кДа;
- YA5326-3: соответственно 50 кДа или составляет от 50 до 250 кДа;
- YA5300-15: составляет от 100 до 1000 кДа;
- YA5358-4: составляет от 100 до 1000 кДа;
- YA5264-1: составляет от 100 до 1000 кДа; и
- YA5331-6: составляет от 100 до 1000 кДа.
Кроме того, ранее описанный рекомбинантный штамм YA5235-1 инокулировали в биореакторе при рН 6 в 2% сахарозе, и рн поддерживали при 6 до 34 ч и при 4 от 34 ч до 48 ч с помощью 15% H2SO4 и 10% NH4OH.
через 48 ч среда содержит 18 г.л-1 от 100 до 1000 кДа гиалуроновой кислоты.
тот же эксперимент проводили с использованием ya5235-1 при использовании глюкозы вместо сахарозы. полученная гиалуроновая кислота также имеет молекулярную массу от 100 до 1000 кДа.
Эти результаты показывают, что, в частности, регулирование рн в процессе ферментации, а также продукция гиалуронидазы, связанной с сигналом секреции или сигналом секреции и якорным сигналом, влияет или даже позволяет контролировать размер продуцируемого полимера гиалуроновой кислоты.
3. Получение гиалуроновой кислоты с молекулярной массой выше 1000 кДа
получали четыре рекомбинантных штамма: YA5232-1, YA5303-3, YA5374-4 и YA5382-1.
Соответственно, эти четыре штамма являются следующими:
YA5232-1: MAT-α, can1-100, his3::[pSAM1-UGP1-tRPL3-pMET6-QRI1-tIDP1-HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA2.Sz-tRPL41B, pCUP1-UGP1-tTPI1, pTDH3-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pNUP57-HYAL-3.Ts-tRPL15A, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tDIT1, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF3-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[pMET6-HASB.Vir-tRPL3, pMET25-HASA-1.Vir-tIDP1- TRP1]x2
YA5303-2: MAT-α, can1-100, his3::[pSAM1-UGP1-tRPL3-pMET6-QRI1-tIDP1-HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA2.Sz-tRPL41B, pCUP1-UGP1- tTPI1, pTDH3-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pNUP57-HYAL-3.Li-tRPL15A, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tDIT1, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF3-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[pMET6-HASB.Vir-tRPL3, pMET25-HASA-1.Vir-tIDP1-TRP1]x2
YA5374-3: MAT-α, can1-100, his3::[pSAM1-UGP1-tRPL3-pMET6-QRI1-tIDP1-HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA2.Sz-tRPL41B, pCUP1-UGP1- tTPI1, pTDH3-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pCCW12.Sar-HYAL-3.Ba-tRPL15A, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tDIT1, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF3-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[pMET6-HASB.Vir-tRPL3, pMET25-HASA-1.Vir-tIDP1-TRP1]x2
YA5382-1: MAT-α, can1-100, his3::[pSAM1-UGP1-tRPL3-pMET6-QRI1-tIDP1-HIS3]x5, jlp1::[LEU2.Kl, pCUP1-HASA2.Sz-tRPL41B, pCUP1-UGP1- tTPI1, pTDH3-QRI1-tMET25, pCCW12-HASB.At-tRPL15A], leu2, lyp1::[pTEF1-HYAL2-31.Ba-tRPL15A, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tDIT1, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF3-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[pMET6-HASB.Vir-tRPL3, pMET25-HASA-1.Vir-tIDP1-TRP1]x2
HASA-1, HASA-A, HASA2 и XHASA2 определены ранее.
HASB и HASB-A определены ранее.
Все эти штаммы инкубировали в 25 мл указанной выше среды SY, забуференной mes 0,1 m pH 5,5, в колбе Эрленмейера с дефлекторами в течение 48 часов при 28°C при энергичном перемешивании.
Питательную среду извлекали через 48 часов и анализировали на содержание и качество гиалуроновой кислоты, как определено выше.
Количество, полученное с этими различными штаммами, составляет соответственно:
- YA5232-1: 4 г.л-1.
- YA5303-3: 2,7 г.л-1.
- YA5374-3: 2,5 г.л-1.
- YA5382-1: 3,0 г.л-1.
В сравнении нативный штамм не продуцирует гиалуроновую кислоту.
Из этого эксперимента следует, что рекомбинантный штамм, содержащий модификации согласно изобретению, продуцирует большее количество гиалуроновой кислоты при культивировании в тех же условиях по сравнению с другими рекомбинантными штаммами, не содержащими всех генетических модификаций согласно изобретению.
Кроме того, эти четыре штамма приводили к получению через 48 часов гиалуроновой кислоты, имеющей молекулярную массу:
- для YA5232-1: более чем около 1000 кДа;
- для YA5303-3: около 1000 кДа;
- для YA5374-3: более чем около 1000 кДа; и
- для YA5382-1: более чем около 1000 кДа.
Пример 3: Сравнительные примеры продукции гиалуроновой кислоты
A. Получают пять следующих рекомбинантных штаммов:
YA5509: MAT-α, can1-100, his3::[tRPL3-UGP1-pSAM1, pMET6-QRI1-tIDP1, HIS3]x5, jlp1::[LEU2.Kl-RS, pCUP1-HASA.Sz-tRPL41B, pCUP1-UGP1-tTPI1, pTDH3-QRI1-tMET25, pCCW12-UGD1.At-tRPL15A], leu2, lyp1::[pCCW10.Ago-HYAL-31.Hn-tRPL15A, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tRPL41B, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl-RS, pPDC1-PGM1-tIDP1, pTEF1.Ago-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF1-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[tRPL3-HASB.Vir-pMET6, pMET25-HASA.Vir-tIDP1, TRP1]x2, ura3::[tRPL3-MHPF.Ec-pPDC1, pTDH3-GDH-21.Eca-tIDP1, URA3]x2
YA5789: MAT-α, can1-100, his3::[tRPL3-UGP1-pSAM1, pMET6-QRI1-tIDP1, HIS3]x5, jlp1::[LEU2.Kl-RS, pCUP1-HASA.Sz-tRPL41B, pCUP1-UGP1-tRPL3, pCUP1-QRI1-tIDP1, pPDC1-UGP1-tTPI1, pTDH3-QRI1-tMET25, pCCW12-UGD1.At-tRPL15A], leu2, lyp1::[tMET3.Sba-MET3.Sba-RS-pMET3.Sba, pCCW10.Ago-HYAL-31.Hn-tRPL15A, pTEF1.Ago-GLN1-tTDH3, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tRPL41B, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], met3::, sam3::[LEU2.Kl-RS, pPDC1-PGM1-tIDP1, pTEF1.Ago-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF1-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[tRPL3-HASB.Vir-pMET6, pMET25-HASA.Vir-tIDP1, TRP1]x2, ura3::[tRPL3-MHPF.Ec-pPDC1, pTDH3-GDH-21.Eca-tIDP1, URA3]x2
YA5790: MAT-α, can1-100, glt1::[MET3.Sba-RS, pCCW10.Ago-HYAL-31.Hn-tRPL15A, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tRPL41B, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba, pTEF1.Ago-GLN1-tTDH3], his3::[tRPL3-UGP1-pSAM1, pMET6-QRI1-tIDP1, HIS3]x5, jlp1::[LEU2.Kl-RS, pCUP1-HASA.Sz-tRPL41B, pCUP1-UGP1-tRPL3, pCUP1-QRI1-tIDP1, pPDC1-UGP1-tTPI1, pTDH3-QRI1-tMET25, pCCW12-UGD1.At-tRPL15A], leu2, met3::, sam3::[LEU2.Kl-RS, pPDC1-PGM1-tIDP1, pTEF1.Ago-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF1-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[tRPL3-HASB.Vir-pMET6, pMET25-HASA.Vir-tIDP1, TRP1]x2, ura3::[tRPL3-MHPF.Ec-pPDC1, pTDH3-GDH-21.Eca-tIDP1, URA3]x2
YA5806: MAT-α, can1-100, glt1::[MET3.Sba-RS, pCCW10.Ago-HYAL-31.Hn-tRPL15A, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tRPL41B, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], his3::[tRPL3-UGP1-pSAM1, pMET6-QRI1-tIDP1, HIS3]x5, jlp1::[LEU2.Kl-RS, pCUP1-HASA.Sz-tRPL41B, pCUP1-UGP1-tRPL3, pCUP1-QRI1-tIDP1, pPDC1-UGP1-tTPI1, pTDH3-QRI1-tMET25, pCCW12-UGD1.At-tRPL15A], leu2, met3::, sam3::[LEU2.Kl-RS, pPDC1-PGM1-tIDP1, pTEF1.Ago-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF1-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[tRPL3-HASB.Vir-pMET6, pMET25-HASA.Vir-tIDP1, TRP1]x2, ura3::[tRPL3-MHPF.Ec-pPDC1, pTDH3-GDH-21.Eca-tIDP1, URA3]x2
YA5658: MAT-α, can1-100, his3::[tRPL3-UGP1-pSAM1, pMET6-QRI1-tIDP1, HIS3]x5, jlp1::[LEU2.Kl-RS, pCUP1-HASA.Sz-tRPL41B, pCUP1-UGP1-tRPL3, pCUP1-QRI1-tIDP1, pPDC1-UGP1-tTPI1, pTDH3-QRI1-tMET25, pCCW12-UGD1.At-tRPL15A], leu2, lyp1::[pCCW10.Ago-HYAL-31.Hn-tRPL15A, pTEF1.Ago-GLN1-tTDH3, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sk-HASB-A.Vir-tTEF1.Sba, pCCW12-HASA-1.Vir-tRPL41B, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], sam3::[LEU2.Kl-RS, pPDC1-PGM1-tIDP1, pTEF1.Ago-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF1-PCM1-tIDP1, pCCW12-XHASA2.Xl-tRPL3, pTDH3-QRI1-tIDP1], trp1::[tRPL3-HASB.Vir-pMET6, pMET25-HASA.Vir-tIDP1, TRP1]x2, ura3::[tRPL3-MHPF.Ec-pPDC1, pTDH3-GDH-21.Eca-tIDP1, URA3]x2
HASA-1, HASA-A и XHASA2 определены ранее.
HASB и HASB-A определены ранее.
Все эти штаммы инкубировали в 25 мл указанной выше среды SY, забуференной MES 0,1 M pH 5,5, в колбе Эрленмейера с дефлекторами в течение 48 часов при 28 °C при энергичном перемешивании.
Питательную среду извлекали через 48 часов и анализировали на содержание и качество гиалуроновой кислоты, как определено выше.
Количество, полученное с этими различными штаммами, составляет соответственно:
- YA5509: 3,5 г.л-1.
- YA5789 (сверхэкспрессия GLN1): 5 г.л-1.
- YA5658 (сверхэкспрессия GNL1): 4,5 г.л-1.
- YA5806 (ΔGLT1): 4,5 г.л-1.
- YA5790 (сверхэкспрессия GNL1; ΔGLT1): 6,7 г.л-1.
В сравнении нативный штамм не продуцирует гиалуроновую кислоту.
В результате этого эксперимента в аналогичных условиях рекомбинантный штамм согласно изобретению продуцирует значительно больше гиалуроновой кислоты, когда либо gln1 сверхэкспрессируется, либо glt1 нарушен, по сравнению с другими рекомбинантными штаммами согласно изобретению, лишенными любой из этих двух модификаций (по сравнению с увеличенным выходом продукции на 27-32 % и 27 %).
Кроме того, рекомбинантный штамм согласно изобретению продуцирует еще больше гиалуроновой кислоты, когда gln1 сверхэкспрессируются, и glt1 нарушен, по сравнению с другими рекомбинантными штаммами согласно изобретению, содержащими только одну из этих двух модификаций или лишенными обеих (повышенный выход продукции на 48 % по сравнению с штаммом, не содержащим ни одной из этих двух модификаций).
B. Получают четыре следующих рекомбинантных штамма:
YA6178: MAT-α, glt1::[MET3.Sba, pTDH3-HYAL-31.Csa-tRPL15A, pTEF1.Ago-GLN1-tTDH3, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-A.Vir-tRPL15A.Sba], his3::[pSAM1-UGP1-tRPL3, pMET6-QRI1-tIDP1, HIS3]x3, jlp1::[LEU2.Sba-loxP, pTEF1.Sba-HASB.Vir-tRPL3.Sm, pTDH3.Sk-HASB-A.Vir-tTEF1.Sba, pTDH3-1.Sba-HASA-1.Vir-tRPL3.Sba, pTDH3.Sar-HASA-A.Vir-tRPL15A.Sba], leu2, met3Δ1, sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1.Ago-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF1-PCM1-tRPL41B, TRP1.Sba-loxP], trp1, ura3::[pPDC1-MHPF.Ec-tRPL3, pTDH3-GDH-21.Eca-tIDP1, URA3]x2
YA6179: MAT-α, glt1::[MET3.Sba, pTDH3-HYAL-31.Csa-tRPL15A, pTEF1.Ago-GLN1-tTDH3, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-2.Vir-tRPL15A.Sba], his3::[pSAM1-UGP1-tRPL3, pMET6-QRI1-tIDP1, HIS3]x3, jlp1::[LEU2.Sba-loxP, pTEF1.Sba-HASB.Vir-tRPL3.Sm, pTDH3.Sk-HASB-A.Vir-tTEF1.Sba, pTDH3-1.Sba-HASA-1.Vir-tRPL3.Sba, pTDH3.Sar-HASA-A.Vir-tRPL15A.Sba], leu2, met3Δ1, sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1.Ago-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF1-PCM1-tRPL41B, TRP1.Sba-loxP], trp1, ura3::[pPDC1-MHPF.Ec- tRPL3, pTDH3-GDH-21.Eca-tIDP1, URA3]x2
YA6180: MAT-α, glt1::[MET3.Sba, pTDH3-HYAL-31.Csa-tRPL15A, pTEF1.Ago-GLN1-tTDH3, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-3.Vir-tRPL15A.Sba], his3::[pSAM1-UGP1-tRPL3, pMET6-QRI1-tIDP1, HIS3]x3, jlp1::[LEU2.Sba-loxP, pTEF1.Sba-HASB.Vir-tRPL3.Sm, pTDH3.Sk-HASB-A.Vir-tTEF1.Sba, pTDH3-1.Sba-HASA-1.Vir-tRPL3.Sba, pTDH3.Sar-HASA-A.Vir-tRPL15A.Sba], leu2, met3Δ1, sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1.Ago-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF1-PCM1-tRPL41B, TRP1.Sba-loxP], trp1, ura3::[pPDC1-MHPF.Ec-tRPL3, pTDH3-GDH-21.Eca-tIDP1, URA3]x2
YA6181: MAT-α, glt1::[MET3.Sba, pTDH3-HYAL-31.Csa-tRPL15A, pTEF1.Ago-GLN1-tTDH3, pCCW12.Sba-HASB.vir-tRPL3, pCCW12.Sm-HASA-5.Vir-tRPL15A.Sba], his3::[pSAM1-UGP1-tRPL3, pMET6-QRI1-tIDP1, HIS3]x3, jlp1::[LEU2.Sba-loxP, pTEF1.Sba-HASB.Vir-tRPL3.Sm, pTDH3.Sk-HASB-A.Vir-tTEF1.Sba, pTDH3-1.Sba-HASA-1.Vir-tRPL3.Sba, pTDH3.Sar-HASA-A.Vir-tRPL15A.Sba], leu2, met3Δ1, sam3::[LEU2.Kl, pPDC1-PGM1-tIDP1, pTEF1.Ago-GFA1-tRPL15A, pENO2-UGP1-tRPL3, pCWP2-GNA1-tTPI1, pTEF1-PCM1-tRPL41B, TRP1.Sba-loxP], trp1, ura3::[pPDC1-MHPF.Ec- tRPL3, pTDH3-GDH-21.Eca-tIDP1, URA3]x2
HASA-1 и HASA-A определены ранее.
HASB и HASB-A определены ранее.
Все HASA-2, HASA-3 и HASA5 представляют собой нуклеотидную последовательность, кодирующую полипептид, имеющий активность гиалуронан-синтазы. Они отличаются друг от друга тем, что представляют собой различные перекодированные варианты нуклеотидной последовательности, кодирующей фермент гиалуронан-синтазу. HASA-2 имеет последовательность SEQ ID NO: 101, HASA-3 имеет последовательность SEQ ID NO: 102, и HASA-5 имеет последовательность SEQ ID NO: 104.
Все эти штаммы инкубировали в 25 мл указанной выше среды SY, забуференной MES 0,1 M pH 5,5, в колбе Эрленмейера с дефлекторами в течение 48 часов при 28°C при энергичном перемешивании.
Питательную среду извлекали через 48 часов и анализировали на содержание и качество гиалуроновой кислоты, как определено выше.
Количество, полученное с этими различными штаммами, составляет соответственно:
- YA6178: 6,3 г.л-1.
- YA6179: 5,9 г.л-1.
- YA6180: 5,2 г.л-1.
- YA6181: 6,4 г.л-1.
В сравнении нативный штамм не продуцирует гиалуроновую кислоту.
Кроме того, эти четыре штамма привели к получению через 48 часов гиалуроновой кислоты, имеющей молекулярную массу около 20 кДа.
ПОСЛЕДОВАТЕЛЬНОСТИ
SEQ ID NO: 1 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (Hasa), происходящую из вируса хлореллы PBCV-1
ATGGGTAAGAACATCATTATTATGGTTTCTTGGTACACTATTATTACATCCAATCTCATCGCAGTGGGTGGCGCCTCACTCATACTAGCCCCAGCTATTACGGGCTATGTCCTTCACTGGAACATTGCCCTTTCAACAATTTGGGGAGTGTCGGCCTACGGAATTTTCGTGTTTGGTTTCTTTCTTGCCCAGGTATTATTTAGTGAACTCAACCGGAAAAGGCTCCGGAAGTGGATTTCCCTCCGACCCAAAGGGTGGAATGATGTTAGGTTGGCTGTAATTATTGCCGGCTACCGTGAGGACCCGTATATGTTCCAAAAGTGTCTTGAAAGTGTGCGTGACTCAGACTATGGGAATGTAGCTAGACTAATATGCGTTATTGACGGCGATGAAGACGACGACATGAGGATGGCTGCAGTGTACAAGGCTATCTATAACGACAACATCAAGAAACCTGAGTTTGTCCTCTGTGAGAGTGACGATAAGGAGGGTGAGAGAATAGATAGCGATTTCAGCCGTGATATCTGCGTGCTGCAACCGCATCGCGGAAAGCGTGAATGTTTGTACACAGGGTTCCAATTGGCAAAGATGGACCCCTCAGTTAATGCCGTCGTCCTAATCGACAGTGACACTGTGTTAGAAAAGGACGCGATTCTCGAaGTAGTATACCCGCTGGCATGCGATCCAGAAATACAGGCTGTAGCAGGCGAATGCAAAATATGGAATACTGACACACTGTTGAGTTTGCTGGTAGCCTGGCGATATTACAGCGCATTTTGCGTAGAGCGTAGCGCCCAATCATTCTTCAGGACAGTACAATGCGTCGGAGGACCTCTCGGCGCCTACAAGATTGATATAATTAAGGAAATCAAGGACCCATGGATCAGCCAACGTTTCCTTGGCCAAAAGTGCACATACGGCGACGATAGACGACTCACTAATGAAATACTAATGAGGGGTAAGAAAGTAGTTTTCACCCCATTCGCTGTTGGCTGGTCCGACAGCCCGACGAACGTCTTCCGTTACATTGTACAGCAAACACGGTGGTCCAAGTCGTGGTGTAGGGAGATATGGTATACACTGTTTGCAGCATGGAAGCATGGACTTTCGGGCATTTGGCTCGCATTCGAGTGCTTATACCAGATTACTTATTTCTTCCTGGTGATTTACCTATTCTCCCGTTTGGCTGTTGAGGCTGACCCACGGGCGCAAACGGCCACCGTCATTGTTTCGACCACAGTTGCGCTTATTAAGTGCGGTTACTTTAGCTTCAGAGCTAAAGACATTAGGGCCTTCTATTTCGTCCTCTACACGTTCGTTTACTTCTTCTGCATGATTCCGGCACGAATAACTGCGATGATGACCCTGTGGGACATAGGTTGGGGAACCAGGGGAGGAAATGAGAAGCCTTCCGTAGGCACCAGAGTTGCTTTGTGGGCCAAGCAATATTTGATTGCTTACATGTGGTGGGCCGCTGTCGTCGGTGCTGGCGTGTACTCCATCGTTCATAATTGGATGTTTGACTGGAATTCACTTTCCTACAGGTTCGCACTGGTAGGCATCTGTTCGTATATAGTTTTCATTGTAATAGTGCTGGTAGTCTACTTTACAGGAAAGATCACGACCTGGAACTTCACGAAGCTACAGAAAGAATTGATCGAGGACCGCGTACTGTACGACGCAACGACCAATGCCCAGTCGGTATAA
SEQ ID NO: 2 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (HASA), происходящую из вируса хлореллы PBCV-1
ATGGGCAAGAATATTATTATCATGGTCAGTTGGTATACCATTATTACATCAAACCTAATTGCTGTCGGTGGAGCCTCACTAATCTTAGCTCCCGCGATTACGGGTTATGTGCTTCATTGGAATATTGCTTTATCCACTATTTGGGGTGTTAGCGCTTACGGCATCTTTGTGTTCGGTTTCTTCTTGGCTCAGGTGTTATTCTCTGAGCTAAACAGAAAGAGACTCAGAAAGTGGATTTCGCTGCGGCCGAAGGGATGGAACGATGTTCGGTTAGCGGTGATCATTGCCGGTTATCGTGAAGATCCTTATATGTTTCAGAAGTGTTTGGAATCTGTTCGAGACTCAGACTACGGTAACGTTGCTAGGCTGATCTGCGTAATCGATGGAGACGAAGATGACGATATGAGAATGGCCGCGGTTTATAAAGCCATCTATAACGATAACATTAAGAAGCCAGAGTTTGTTTTATGCGAATCGGATGACAAGGAGGGTGAGAGGATTGATTCTGACTTCTCGCGTGACATCTGTGTCCTGCAGCCCCACAGGGGAAAGCGAGAGTGCCTCTATACAGGATTCCAATTAGCTAAAATGGACCCAAGCGTTAATGCTGTCGTCCTTATCGATAGCGACACGGTGTTGGAAAAGGACGCAATATTGGAAGTAGTCTATCCACTCGCTTGTGATCCAGAGATCCAGGCCGTGGCTGGCGAGTGCAAGATTTGGAATACAGATACGCTTCTGTCATTACTGGTGGCGTGGCGTTATTATTCAGCATTCTGTGTGGAGAGGAGCGCACAATCGTTCTTTCGGACTGTACAATGCGTAGGCGGTCCACTAGGAGCATATAAAATTGACATAATCAAAGAGATAAAAGATCCTTGGATTTCGCAGAGATTCCTCGGTCAAAAGTGTACCTATGGGGACGACAGGCGGTTGACTAACGAGATTCTAATGAGAGGTAAGAAGGTGGTGTTCACTCCTTTTGCGGTAGGTTGGAGCGATTCGCCCACAAATGTATTCAGATACATTGTTCAACAAACAAGGTGGTCGAAATCGTGGTGCCGAGAAATATGGTACACGTTGTTCGCCGCATGGAAACACGGCTTGTCGGGTATATGGCTCGCTTTCGAGTGCCTTTATCAGATCACTTACTTCTTCCTGGTTATTTACTTGTTTTCAAGACTGGCAGTGGAAGCTGATCCAAGGGCTCAGACTGCTACTGTCATCGTTTCAACAACAGTGGCGCTAATAAAGTGTGGTTACTTCAGCTTTCGCGCGAAGGACATAAGAGCGTTTTACTTTGTTCTTTATACCTTTGTATATTTCTTCTGTATGATCCCGGCCCGGATAACAGCTATGATGACATTATGGGACATTGGTTGGGGCACCAGGGGTGGGAATGAGAAGCCGTCCGTAGGAACGAGAGTAGCGCTGTGGGCCAAGCAGTATCTTATCGCATACATGTGGTGGGCAGCTGTCGTCGGGGCAGGTGTATACAGCATAGTACATAACTGGATGTTTGACTGGAACTCACTCTCATATCGATTCGCATTGGTCGGGATCTGCTCTTACATCGTGTTTATTGTTATAGTCTTAGTAGTATATTTCACTGGAAAGATAACAACATGGAATTTCACTAAGCTTCAAAAGGAATTGATTGAAGACAGGGTGCTCTACGATGCGACAACTAATGCACAAAGCGTATAA
SEQ ID NO: 3 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (HASA), происходящую из Pasteurella multocida
ATGAACACCCTTTCCCAGGCAATTAAGGCTTATAATAGTAATGATTATCAACTAGCCCTCAAGCTGTTCGAAAAGTCGGCAGAAATCTACGGCAGAAAGATAGTTGAgTTCCAAATTACGAAGTGCAAGGAGAAACTTTCTGCGCACCCATCCGTTAACAGTGCGCATCTCTCGGTTAACAAAGAAGAGAAGGTGAATGTTTGCGACAGTCCATTAGACATAGCCACTCAATTATTGTTATCGAATGTGAAAAAACTCGTCCTTAGTGATAGCGAGAAAAATACACTAAAGAATAAATGGAAGTTGTTGACTGAAAAGAAGTCTGAGAACGCAGAGGTCCGGGCCGTAGCTTTAGTTCCCAAGGACTTTCCGAAAGATTTAGTGCTTGCGCCGTTACCAGACCATGTGAACGATTTTACGTGGTATAAGAAGCGGAAGAAACGCCTAGGAATCAAACCAGAACACCAACACGTTGGCCTCTCCATTATTGTGACAACGTTCAACCGTCCTGCCATCCTCAGCATCACCCTGGCTTGCCTCGTCAATCAAAAGACCCATTATCCTTTTGAGGTGATCGTGACCGACGATGGTTCTCAAGAGGATTTATCGCCTATAATCCGTCAATATGAGAACAAGCTAGACATCCGTTATGTTCGGCAAAAGGACAACGGTTTTCAGGCATCGGCCGCACGTAATATGGGCCTACGTCTAGCCAAATATGACTTCATTGGGCTCCTTGATTGTGATATGGCTCCCAACCCTTTGTGGGTACACTCATACGTTGCGGAACTATTAGAGGACGATGATTTGACCATAATAGGCCCCAGGAAGTACATTGACACGCAACACATAGATCCCAAGGATTTCCTTAATAACGCCTCTCTGTTAGAGTCGTTGCCAGAGGTTAAGACCAATAATTCCGTCGCGGCTAAGGGCGAGGGGACCGTATCTTTAGACTGGCGTTTGGAACAATTTGAGAAGACCGAGAACTTGAGGCTATCCGATAGCCCTTTCCGATTCTTCGCAGCTGGGAATGTGGCTTTCGCCAAGAAGTGGCTTAACAAGTCAGGATTCTTCGACGAGGAATTCAATCACTGGGGAGGTGAAGATGTAGAGTTCGGTTATCGTCTGTTTCGGTACGGTTCGTTCTTCAAAACTATAGACGGCATCATGGCCTATCATCAGGAACCGCCAGGTAAAGAAAACGAAACTGACAGAGAAGCGGGCAAGAACATTACCCTCGATATAATGAGGGAGAAGGTGCCTTACATCTACCGTAAACTCCTGCCTATAGAAGACAGTCATATCAACCGAGTACCATTGGTATCAATTTACATCCCGGCCTACAACTGTGCTAACTATATTCAAAGATGTGTTGATTCAGCTTTGAATCAAACGGTAGTTGATCTCGAAGTGTGCATTTGCAACGACGGTAGTACTGACAACACGCTGGAAGTTATTAACAAGCTGTATGGTAATAATCCGCGTGTGCGTATAATGTCTAAACCCAATGGCGGCATTGCGAGTGCATCCAACGCAGCGGTCAGCTTCGCAAAGGGTTATTACATAGGACAGTTGGACAGCGACGATTACTTAGAACCCGACGCAGTGGAGTTATGTCTCAAGGAATTTCTTAAGGATAAGACCCTTGCGTGCGTTTACACCACTAATCGTAACGTCAACCCAGATGGCTCTTTAATAGCCAATGGCTATAACTGGCCAGAGTTCAGTCGTGAGAAGTTGACTACGGCCATGATTGCTCATCACTTCCGGATGTTTACCATTCGTGCTTGGCATCTGACGGATGGGTTCAATGAGAAGATTGAGAACGCTGTTGACTACGACATGTTTCTCAAGCTCAGTGAAGTTGGTAAATTTAAGCATCTGAACAAAATATGTTATAATCGGGTGTTACACGGCGATAACACCTCAATCAAGAAgCTTGGCATACAAAAGAAGAATCATTTCGTAGTTGTCAATCAGTCTCTAAACCGCCAAGGTATAACTTATTATAACTACGATGAATTTGATGATCTCGATGAGAGTCGGAAATACATTTTCAACAAGACTGCAGAGTATCAAGAAGAGATAGATATTCTTAAAGATATTAAGATCATTCAGAACAAAGACGCCAAAATAGCTGTCTCCATTTTCTATCCGAACACTCTAAACGGGTTGGTGAAGAAGCTAAATAATATTATAGAGTATAATAAGAATATCTTCGTTATTGTACTTCATGTCGATAAGAATCACTTAACCCCAGACATCAAGAAGGAGATATTAGCCTTCTACCATAAGCATCAGGTGAACATCTTATTGAACAATGACATCTCCTACTATACATCAAATCGTCTGATTAAGACAGAAGCCCATTTGAGTAACATTAACAAGCTaAGTCAATTAAATCTTAACTGCGAATACATTATATTCGACAATCACGATTCCTTATTTGTGAAGAACGATTCCTATGCATACATGAAGAAGTATGATGTTGGAATGAACTTCTCTGCATTGACTCATGATTGGATTGAAAAGATAAACGCTCACCCGCCATTTAAGAAGCTgATCAAAACTTACTTCAATGACAATGATCTTAAGTCGATGAATGTAAAGGGTGCCTCCCAGGGAATGTTTATGACATACGCATTAGCCCACGAGTTATTGACGATCATCAAGGAGGTGATAACCTCTTGTCAATCCATTGACTCCGTCCCCGAATACAACACAGAAGATATTTGGTTTCAGTTTGCACTTTTAATTCTGGAAAAGAAGACCGGCCACGTATTCAACAAGACAAGCACTCTCACGTATATGCCATGGGAACGTAAACTGCAGTGGACGAATGAACAAATAGAGTCCGCAAAGAGGGGCGAAAACATTCCGGTAAACAAGTTCATCATTAACAGCATTACCCTTTAA
SEQ ID NO: 4 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (HASA), происходящую из Pasteurella multocida
ATGAACACCCTTTCCCAGGCAATTAAGGCTTATAATAGTAATGATTATCAACTAGCCCTCAAGCTGTTCGAAAAGTCGGCAGAAATCTACGGCAGAAAGATAGTTGAgTTCCAAATTACGAAGTGCAAGGAGAAACTTTCTGCGCACCCATCCGTTAACAGTGCGCATCTCTCGGTTAACAAAGAAGAGAAGGTGAATGTTTGCGACAGTCCATTAGACATAGCCACTCAATTATTGTTATCGAATGTGAAAAAACTCGTCCTTAGTGATAGCGAGAAAAATACACTAAAGAATAAATGGAAGTTGTTGACTGAAAAGAAGTCTGAGAACGCAGAGGTCCGGGCCGTAGCTTTAGTTCCCAAGGACTTTCCGAAAGATTTAGTGCTTGCGCCGTTACCAGACCATGTGAACGATTTTACGTGGTATAAGAAGCGGAAGAAACGCCTAGGAATCAAACCAGAACACCAACACGTTGGCCTCTCCATTATTGTGACAACGTTCAACCGTCCTGCCATCCTCAGCATCACCCTGGCTTGCCTCGTCAATCAAAAGACCCATTATCCTTTTGAGGTGATCGTGACCGACGATGGTTCTCAAGAGGATTTATCGCCTATAATCCGTCAATATGAGAACAAGCTAGACATCCGTTATGTTCGGCAAAAGGACAACGGTTTTCAGGCATCGGCCGCACGTAATATGGGCCTACGTCTAGCCAAATATGACTTCATTGGGCTCCTTGATTGTGATATGGCTCCCAACCCTTTGTGGGTACACTCATACGTTGCGGAACTATTAGAGGACGATGATTTGACCATAATAGGCCCCAGGAAGTACATTGACACGCAACACATAGATCCCAAGGATTTCCTTAATAACGCCTCTCTGTTAGAGTCGTTGCCAGAGGTTAAGACCAATAATTCCGTCGCGGCTAAGGGCGAGGGGACCGTATCTTTAGACTGGCGTTTGGAACAATTTGAGAAGACCGAGAACTTGAGGCTATCCGATAGCCCTTTCCGATTCTTCGCAGCTGGGAATGTGGCTTTCGCCAAGAAGTGGCTTAACAAGTCAGGATTCTTCGACGAGGAATTCAATCACTGGGGAGGTGAAGATGTAGAGTTCGGTTATCGTCTGTTTCGGTACGGTTCGTTCTTCAAAACTATAGACGGCATCATGGCCTATCATCAGGAACCGCCAGGTAAAGAAAACGAAACTGACAGAGAAGCGGGCAAGAACATTACCCTCGATATAATGAGGGAGAAGGTGCCTTACATCTACCGTAAACTCCTGCCTATAGAAGACAGTCATATCAACCGAGTACCATTGGTATCAATTTACATCCCGGCCTACAACTGTGCTAACTATATTCAAAGATGTGTTGATTCAGCTTTGAATCAAACGGTAGTTGATCTCGAAGTGTGCATTTGCAACGACGGTAGTACTGACAACACGCTGGAAGTTATTAACAAGCTGTATGGTAATAATCCGCGTGTGCGTATAATGTCTAAACCCAATGGCGGCATTGCGAGTGCATCCAACGCAGCGGTCAGCTTCGCAAAGGGTTATTACATAGGACAGTTGGACAGCGACGATTACTTAGAACCCGACGCAGTGGAGTTATGTCTCAAGGAATTTCTTAAGGATAAGACCCTTGCGTGCGTTTACACCACTAATCGTAACGTCAACCCAGATGGCTCTTTAATAGCCAATGGCTATAACTGGCCAGAGTTCAGTCGTGAGAAGTTGACTACGGCCATGATTGCTCATCACTTCCGGATGTTTACCATTCGTGCTTGGCATCTGACGGATGGGTTCAATGAGAAGATTGAGAACGCTGTTGACTACGACATGTTTCTCAAGCTCAGTGAAGTTGGTAAATTTAAGCATCTGAACAAAATATGTTATAATCGGGTGTTACACGGCGATAACACCTCAATCAAGAAgCTTGGCATACAAAAGAAGAATCATTTCGTAGTTGTCAATCAGTCTCTAAACCGCCAAGGTATAACTTATTATAACTACGATGAATTTGATGATCTCGATGAGAGTCGGAAATACATTTTCAACAAGACTGCAGAGTATCAAGAAGAGATAGATATTCTTAAAGATATTTAA
SEQ ID NO: 5 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (HASA), происходящую из Pasteurella multocida
ATGAACACCCTTTCCCAGGCAATTAAGGCTTATAATAGTAATGATTATCAACTAGCCCTCAAGCTGTTCGAAAAGTCGGCAGAAATCTACGGCAGAAAGATAGTTGAgTTCCAAATTACGAAGTGCAAGGAGAAACTTTCTGCGCACCCATCCGTTAACAGTGCGCATCTCTCGGTTAACAAAGAAGAGAAGGTGAATGTTTGCGACAGTCCATTAGACATAGCCACTCAATTATTGTTATCGAATGTGAAAAAACTCGTCCTTAGTGATAGCGAGAAAAATACACTAAAGAATAAATGGAAGTTGTTGACTGAAAAGAAGTCTGAGAACGCAGAGGTCCGGGCCGTAGCTTTAGTTCCCAAGGACTTTCCGAAAGATTTAGTGCTTGCGCCGTTACCAGACCATGTGAACGATTTTACGTGGTATAAGAAGCGGAAGAAACGCCTAGGAATCAAACCAGAACACCAACACGTTGGCCTCTCCATTATTGTGACAACGTTCAACCGTCCTGCCATCCTCAGCATCACCCTGGCTTGCCTCGTCAATCAAAAGACCCATTATCCTTTTGAGGTGATCGTGACCGACGATGGTTCTCAAGAGGATTTATCGCCTATAATCCGTCAATATGAGAACAAGCTAGACATCCGTTATGTTCGGCAAAAGGACAACGGTTTTCAGGCATCGGCCGCACGTAATATGGGCCTACGTCTAGCCAAATATGACTTCATTGGGCTCCTTGATTGTGATATGGCTCCCAACCCTTTGTGGGTACACTCATACGTTGCGGAACTATTAGAGGACGATGATTTGACCATAATAGGCCCCAGGAAGTACATTGACACGCAACACATAGATCCCAAGGATTTCCTTAATAACGCCTCTCTGTTAGAGTCGTTGCCAGAGGTTAAGACCAATAATTCCGTCGCGGCTAAGGGCGAGGGGACCGTATCTTTAGACTGGCGTTTGGAACAATTTGAGAAGACCGAGAACTTGAGGCTATCCGATAGCCCTTTCCGATTCTTCGCAGCTGGGAATGTGGCTTTCGCCAAGAAGTGGCTTAACAAGTCAGGATTCTTCGACGAGGAATTCAATCACTGGGGAGGTGAAGATGTAGAGTTCGGTTATCGTCTGTTTCGGTACGGTTCGTTCTTCAAAACTATAGACGGCATCATGGCCTATCATCAGGAACCGCCAGGTAAAGAAAACGAAACTGACAGAGAAGCGGGCAAGAACATTACCCTCGATATAATGAGGGAGAAGGTGCCTTACATCTACCGTAAACTCCTGCCTATAGAAGACAGTCATATCAACCGAGTACCATTGGTATCAATTTACATCCCGGCCTACAACTGTGCTAACTATATTCAAAGATGTGTTGATTCAGCTTTGAATCAAACGGTAGTTGATCTCGAAGTGTGCATTTGCAACGACGGTAGTACTGACAACACGCTGGAAGTTATTAACAAGCTGTATGGTAATAATCCGCGTGTGCGTATAATGTCTAAACCCAATGGCGGCATTGCGAGTGCATCCAACGCAGCGGTCAGCTTCGCAAAGGGTTATTACATAGGACAGTTGGACAGCGACGATTACTTAGAACCCGACGCAGTGGAGTTATGTCTCAAGGAATTTCTTAAGGATAAGACCCTTGCGTGCGTTTACACCACTAATCGTAACGTCAACCCAGATGGCTCTTTAATAGCCAATGGCTATAACTGGCCAGAGTTCAGTCGTGAGAAGTTGACTACGGCCATGATTGCTCATCACTTCCGGATGTTTACCATTCGTGCTTGGCATCTGACGGATGGGTTCAATGAGAAGATTGAGAACGCTGTTGACTACGACATGTTTCTCAAGCTCAGTGAAGTTGGTAAATTTAAGCATCTGAACAAAATATGTTATAATCGGGTGTTACACGGCGATAACACCTCAATCAAGAAGCTTGGCATACAAAAGAAGAATCATTTCGTAGTTGTCAATCAGTCTCTAAACCGCCAAGGTATAACTTATTATAACTACGATGAATTTGATGATCTCGATGAGAGTCGGAAATACATTTTCAACAAGACTGCAGAGTATCAAGAAGAGATAGATATTCTTAAAGATATTGGATCCGCCATTTCTCAAATCACTGACGGTCAAATCCAAGCTACTACCACTGCTACCACCGAAGCTACCACCACTGCTGCCCCATCTTCCACCGTTGAAACTGTTTCTCCATCCAGCACCGAAACTATCTCTCAACAAACTGAAAATGGTGCTGCTAAGGCCGCTGTCGGTATGGGTGCCGGTGCTCTAGCTGCTGCTGCTATGTTGTTATAA
SEQ ID NO: 6 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (HASA), происходящую из Xenopus laevis
ATGCACTGTGAACGATTTATTTGTATATTACGAATAATTGGTACGACTTTGTTCGGAGTAAGTCTGCTACTAGGGATATCCGCCGCTTATATCGTGGGATACCAATTCATTCAGACGGATAATTACTACTTTTCCTTCGGTCTCTACGGTGCTATTTTAGCTTTACATTTAATCATTCAGTCTCTCTTCGCATTCCTGGAGCATCGTAAGATGAAGCGGTCACTTGAAACCCCTATAAAATTAAACAAGAGCGTAGCATTGTGTATCGCTGCATACCAGGAAGACGAAGATTATCTTAGAAAATGTTTGCTTTCTGTGAAACGGCTCACATACCCCGGTATGAAGGTAATCATGGTGATAGATGGTAACTCTGATGACGATCTATACATGATGAACATATTCAGAGAGATCATGGGAAATGATAGCTGCGCCACCTATGTATGGAAGAATAATTTTCACATGAAGGGACCAAACGAGACCGACGAGACTCACCGCGAGTCCATGCAGCATGTAACACAGATGGTGCTTTCTAACAGAAATGTCTGTATCATGCAAAAGTGGAACGGGAAACGCGAGGTGATGTATACTGCATTCAAAGCGCTGGGTCGGTCGGTTGATTACGTCCAAGTGTGCGACTCAGATACAGTCCTTGATCCAGCAAGCTCGGTGGAGATGGTCAAGGTGTTGGAGGAAGACATTATGGTCGGAGGTGTAGGCGGAGACGTGCAGATACTCAATAAGTACGACTCCTGGATCAGTTTCTTGAGTTCGGTTCGTTATTGGATGGCTTTCAATATAGAACGAGCATGCCAATCATACTTTGGCTGTGTGCAGTGTATATCGGGGCCTCTGGGCATGTACAGAAACTCACTCTTACATGAGTTCATTGAAGACTGGTACAATCAAGAATTCCTCGGTTCCCAATGCTCTTTCGGTGATGATCGGCATTTGACTAATCGAGTACTATCATTGGGCTATGCTACTAAATACACTGCGCGCAGTAAGTGTCTGACAGAAACCCCCACAGAATATCTTAGATGGTTGAACCAACAAACCAGGTGGAGTAAGTCCTATTTCCGCGAGTGGTTGTACAACTCTTTGTGGTTCCACAAACACCATTTATGGATGACTTATGAAGCCGTAATTACGGGTTTCTTCCCCTTCTTCTTAATAGCGACGGTGATTCAGCTCTTCTATCGTGGTCGAATTTGGAATATCTTACTCTTTCTACTCACAGTTCAATTAGTTGGTCTAATAAAGTCGTCGTTTGCAAGTGCGTTGCGTGGAAACATCGTTATGGTCTTTATGAGTTTCTACAGTGTTTTATACATGAGTAGCTTGCTGCCAGCAAAGATGTTTGCAATCGCCACGATAAACAAGGCTGGATGGGGTACTAGTGGTAGAAAGACCATAGTTGTTAATTTTATTGGTTTAATCCCTATTACGGTATGGTTCACAATTTTACTAGGGGGAGTATGCTACACTATATGGCGGGAAACCAAGAAGCCGTTTAGCGAGTCTGAGAAGATCGTTCTTGCGGTCGGTGCTATATTGTATGCTTGTTATTGGGTCATGTTGCTTACAATGTATGTCAGTCTTGTCATGAAGTGCGGGCGCCGTAGGAAGGAACCACAGCACGACCTTGTTTTAGCATAA
SEQ ID NO: 7 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (HASA), происходящую из Streptococcus Zooepidemicus
ATGAGGACGTTAAAGAATCTTATCACTGTTGTAGCGTTCAGTATATTCTGGGTTTTGCTGATCTATGTAAATGTCTATCTTTTCGGTGCGAAGGGGTCTCTATCAATATATGGATTCTTGCTAATTGCGTATTTGCTTGTGAAGATGAGTCTTTCATTCTTCTATAAACCATTCAAAGGTCGAGCTGGTCAGTATAAAGTCGCAGCGATTATCCCTTCATACAACGAGGATGCAGAATCGCTGTTGGAAACCTTAAAATCTGTTCAACAACAAACCTATCCCCTTGCTGAAATTTATGTAGTTGATGATGGTTCCGCAGATGAAACCGGTATCAAGCGGATCGAGGATTATGTCAGGGATACAGGCGACTTAAGTTCAAATGTGATTGTGCATCGATCAGAAAAGAATCAAGGCAAGAGACACGCCCAAGCATGGGCATTTGAAAGATCTGATGCAGATGTATTTCTAACAGTCGATAGTGATACTTACATTTATCCGGACGCCCTTGAAGAGTTATTGAAAACCTTCAATGATCCGACAGTATTTGCCGCAACTGGCCACTTGAACGTTCGTAACAGGCAGACTAATCTATTGACCAGACTCACTGATATAAGATACGACAATGCTTTTGGCGTCGAACGTGCTGCTCAAAGTGTAACTGGTAATATACTGGTGTGTTCCGGGCCACTGTCCGTCTATCGCAGAGAAGTAGTAGTCCCGAACATTGACAGGTATATTAATCAGACTTTTCTGGGTATCCCCGTGTCAATTGGGGACGACCGGTGTTTAACGAACTACGCTACTGATTTGGGCAAGACTGTATATCAGTCGACGGCTAAATGTATTACAGACGTCCCAGATAAGATGTCGACTTACCTTAAACAGCAGAATAGATGGAATAAGTCATTCTTTAGAGAATCTATCATCAGCGTGAAGAAGATCATGAATAATCCATTCGTGGCGCTTTGGACCATTTTGGAGGTTTCCATGTTTATGATGCTTGTCTACTCTGTCGTTGATTTCTTTGTAGGTAACGTTCGAGAATTTGATTGGCTCAGAGTTCTTGCTTTCTTAGTTATCATCTTCATCGTTGCGCTATGCAGGAATATTCATTACATGCTAAAACATCCGCTTAGCTTCTTACTCAGCCCTTTCTACGGCGTTTTGCATCTCTTCGTTTTGCAGCCATTGAAGCTCTACTCCTTATTTACCATTCGAAACGCTGATTGGGGTACGCGCAAGAAACTATTAtaa
SEQ ID NO: 8 представляет собой аминокислотную последовательность гиалуронан-синтазы (HASA), происходящую из вируса хлореллы PBCV-1
MGKNIIIMVSWYTIITSNLIAVGGASLILAPAITGYVLHWNIALSTIWGVSAYGIFVFGFFLAQVLFSELNRKRLRKWISLRPKGWNDVRLAVIIAGYREDPYMFQKCLESVRDSDYGNVARLICVIDGDEDDDMRMAAVYKAIYNDNIKKPEFVLCESDDKEGERIDSDFSRDICVLQpHRGKRECLYTGFQLAKMDPSVNAVVLIDSDTVLEKDAILEVVYPLACDPEIQAVAGECKIWNTDTLLSLLVAWRYYSAFCVERSAQSFFRTVQCVGGPLGAYKIDIIKEIKDPWISQRFLGQKCTYGDDRRLTNEILMRGKKVVFTPFAVGWSDSPTNVFRYIVQQTRWSKSWCREIWYTLFAAWKHGLSGIWLAFECLYQITYFFLVIYLFSRLAVEADPRAQTATVIVSTTVALIKCGYFSFRAKDIRAFYFVLYTFVYFFCMIPARITAMMTLWDIGWGTRGGNEKPSVGTRVALWAKQYLIAYMWWAAVVGAGVYSIVHNWMFDWNSLSYRFALVGICSYIVFIVIVLVVYFTGKITTWNFTKLQKELIEDRVLYDATTNAQSV
SEQ ID NO: 9 представляет собой аминокислотную последовательность гиалуронан-синтазы (HASA), происходящую из Pasteurella multocida
MNTLSQAIKAYNSNDYQLALKLFEKSAEIYGRKIVEFQITKCKEKLSAHPSVNSAHLSVNKEEKVNVCDSPLDIATQLLLSNVKKLVLSDSEKNTLKNKWKLLTEKKSENAEVRAVALVPKDFPKDLVLAPLPDHVNDFTWYKKRKKRLGIKPEHQHVGLSIIVTTFNRPAILSITLACLVNQKTHYPFEVIVTDDGSQEDLSPIIRQYENKLDIRYVRQKDNGFQASAARNMGLRLAKYDFIGLLDCDMAPNPLWVHSYVAELLEDDDLTIIGPRKYIDTQHIDPKDFLNNASLLESLPEVKTNNSVAAKGEGTVSLDWRLEQFEKTENLRLSDSPFRFFAAGNVAFAKKWLNKSGFFDEEFNHWGGEDVEFGYRLFRYGSFFKTIDGIMAYHQEPPGKENETDREAGKNITLDIMREKVPYIYRKLLPIEDSHINRVPLVSIYIPAYNCANYIQRCVDSALNQTVVDLEVCICNDGSTDNTLEVINKLYGNNPRVRIMSKPNGGIASASNAAVSFAKGYYIGQLDSDDYLEPDAVELCLKEFLKDKTLACVYTTNRNVNPDGSLIANGYNWPEFSREKLTTAMIAHHFRMFTIRAWHLTDGFNEKIENAVDYDMFLKLSEVGKFKHLNKICYNRVLHGDNTSIKKLGIQKKNHFVVVNQSLNRQGITYYNYDEFDDLDESRKYIFNKTAEYQEEIDILKDIKIIQNKDAKIAVSIFYPNTLNGLVKKLNNIIEYNKNIFVIVLHVDKNHLTPDIKKEILAFYHKHQVNILLNNDISYYTSNRLIKTEAHLSNINKLSQLNLNCEYIIFDNHDSLFVKNDSYAYMKKYDVGMNFSALTHDWIEKINAHPPFKKLIKTYFNDNDLKSMNVKGASQGMFMTYALAHELLTIIKEVITSCQSIDSVPEYNTEDIWFQFALLILEKKTGHVFNKTSTLTYMPWERKLQWTNEQIESAKRGENIPVNKFIINSITL
SEQ ID NO: 10 представляет собой аминокислотную последовательность гиалуронан-синтазы (HASA), происходящую из Xenopus Laevis
MHCERFICILRIIGTTLFGVSLLLGISAAYIVGYQFIQTDNYYFSFGLYGAILALHLIIQSLFAFLEHRKMKRSLETPIKLNKSVALCIAAYQEDEDYLRKCLLSVKRLTYPGMKVIMVIDGNSDDDLYMMNIFREIMGNDSCATYVWKNNFHMKGPNETDETHRESMQHVTQMVLSNRNVCIMQKWNGKREVMYTAFKALGRSVDYVQVCDSDTVLDPASSVEMVKVLEEDIMVGGVGGDVQILNKYDSWISFLSSVRYWMAFNIERACQSYFGCVQCISGPLGMYRNSLLHEFIEDWYNQEFLGSQCSFGDDRHLTNRVLSLGYATKYTARSKCLTETPTEYLRWLNQQTRWSKSYFREWLYNSLWFHKHHLWMTYEAVITGFFPFFLIATVIQLFYRGRIWNILLFLLTVQLVGLIKSSFASALRGNIVMVFMSFYSVLYMSSLLPAKMFAIATINKAGWGTSGRKTIVVNFIGLIPITVWFTILLGGVCYTIWRETKKPFSESEKIVLAVGAILYACYWVMLLTMYVSLVMKCGRRRKEPQHDLVLA
SEQ ID NO: 11 представляет собой аминокислотную последовательность гиалуронан-синтазы (HASA), происходящую из Streptococcus Zooepidemicus
MRTLKNLITVVAFSIFWVLLIYVNVYLFGAKGSLSIYGFLLIAYLLVKMSLSFFYKPFKGRAGQYKVAAIIPSYNEDAESLLETLKSVQQQTYPLAEIYVVDDGSADETGIKRIEDYVRDTGDLSSNVIVHRSEKNQGKRHAQAWAFERSDADVFLTVDSDTYIYPDALEELLKTFNDPTVFAATGHLNVRNRQTNLLTRLTDIRYDNAFGVERAAQSVTGNILVCSGPLSVYRREVVVPNIDRYINQTFLGIPVSIGDDRCLTNYATDLGKTVYQSTAKCITDVPDKMSTYLKQQNRWNKSFFRESIISVKKIMNNPFVALWTILEVSMFMMLVYSVVDFFVGNVREFDWLRVLAFLVIIFIVALCRNIHYMLKHPLSFLLSPFYGVLHLFVLQPLKLYSLFTIRNADWGTRKKLL
SEQ ID NO: 12 представляет собой нуклеотидную последовательность udp-глюкозодегидрогеназы (HASB), происходящую из Arabidopsis Thaliana
ATGGTCAAAATATGCTGTATCGGGGCTGGATATGTCGGTGGGCCTACAATGGCCGTTATGGCCCTAAAGTGTCCAGAGATTGAAGTCGTGGTAGTTGATATATCGGAGCCACGAATTAACGCATGGAACTCAGACCGTCTACCAATTTATGAGCCAGGGTTAGAGGATGTCGTCAAACAGTGTAGAGGGAAGAATTTGTTCTTCTCTACAGATGTAGAGAAGCATGTATTTGAGTCAGATATAGTGTTTGTTTCGGTAAACACTCCTACGAAAACGCAGGGTCTGGGTGCAGGTAAAGCAGCAGATTTGACATATTGGGAGTCCGCTGCTCGCATGATAGCTGATGTGAGCAAATCGTCGAAAATCGTCGTTGAAAAGAGTACAGTACCAGTTCGTACAGCCGAGGCTATAGAAAAGATTTTAACGCACAATTCGAAGGGTATCGAATTCCAGATCTTATCAAATCCAGAATTCTTGGCCGAAGGGACGGCGATTAAAGACTTATATAACCCTGATAGAGTTCTAATCGGTGGCAGGGACACCGCTGCGGGACAAAAGGCCATTAAGGCGTTGCGTGACGTGTATGCCCACTGGGTTCCTGTTGAGCAAATAATCTGTACTAATTTATGGAGTGCCGAGCTATCAAAGTTGGCTGCGAACGCATTTCTAGCTCAAAGGATAAGTTCAGTAAACGCAATGTCAGCGCTTTGTGAGGCAACTGGTGCTGACGTAACCCAAGTCGCTCACGCCGTTGGAACCGACACTAGAATTGGACCGAAGTTTCTTAACGCATCCGTAGGCTTCGGCGGATCTTGCTTTCAGAAAGACATCCTGAATCTTATTTACATCTGCGAATGCAATGGTCTTCCAGAAGCAGCCAATTATTGGAAACAGGTAGTCAAGGTAAATGACTACCAAAAGATTAGGTTTGCTAATCGAGTCGTATCTTCTATGTTCAACACCGTCTCCGGTAAGAAAATTGCTATTTTGGGATTTGCGTTCAAGAAGGACACCGGCGACACGCGTGAAACTCCTGCCATAGATGTGTGTAATCGCCTCGTGGCTGATAAAGCAAAGCTGTCGATCTATGATCCGCAAGTATTAGAAGAGCAGATCCGCCGTGATCTGTCCATGGCCCGATTCGATTGGGACCATCCAGTCCCACTCCAGCAGATCAAAGCTGAAGGTATCTCCGAACAGGTTAACGTTGTGTCCGACGCCTACGAGGCTACGAAGGATGCTCATGGTTTATGTGTTTTAACCGAATGGGACGAATTCAAGTCACTTGATTTTAAGAAGATCTTTGATAATATGCAGAAACCCGCTTTCGTTTTCGACGGAAGAAACGTGGTCGACGCTGTGAAATTGAGAGAAATTGGATTCATAGTATATTCCATAGGTAAACCTCTGGATAGTTGGCTCAAGGATATGCCGGCTGTTGCATAA
SEQ ID NO: 13 представляет собой перекодированную нуклеотидную последовательность UDP-глюкозодегидрогеназы (HASB), происходящую из вируса хлореллы PBCV-1
ATGAGTAGAATTGCTGTCGTTGGATGCGGTTACGTGGGTACGGCCTGCGCCGTACTTTTGGCGCAGAAGAACGAAGTTATCGTTTTGGATATCTCGGAGGACCGGGTACAACTGATTAAGAATAAGAAGTCACCTATAGAAGATAAGGAAATCGAAGAATTCCTGGAGACGAAAGATTTGAATCTAACAGCGACGACGGATAAGGTGCTCGCCTATGAGAATGCTGAATTCGTTATAATAGCTACACCGACCGATTACGATGTCGTCACTAGATATTTCAACACTAAGTCTGTTGAAAATGTGATAGGCGATGTCATTAAGAACACTCAGACACACCCTACTATAGTGATCAAGAGTACTATTCCAATCGGTTTCGTGGATAAAGTTAGAGAACAGTTCGATTATCAAAATATTATCTTCTCGCCGGAATTCTTGAGAGAAGGACGAGCATTATATGATAATCTTTACCCCTCCCGTATCATCGTCGGTGATGACTCCCCAATTGCCTTAAAATTCGCGAATCTCTTGGTCGAGGGTAGCAAAACTCCACTAGCTCCCGTATTAACTATGGGTACGCGAGAGGCCGAAGCTGTAAAACTATTTTCAAATACATATTTGGCTATGAGAGTAGCATACTTCAATGAGCTAGACACATTTGCAATGTCCCATGGTATGAACGCAAAAGAGATTATCGACGGAGTCACACTAGAACCAAGGATAGGGCAGGGTTATTCGAATCCTTCATTTGGGTATGGAGCCTATTGTTTCCCAAAAGATACAAAGCAATTGTTGGCTAATTTTGAAGGGGTTCCACAAGATATTATTGGCGCAATCGTAGAGTCTAACGAAACTAGAAAGGAGGTTATTGTTTCTGAGGTCGAGAACAGATTTCCGACCACAGTTGGCGTATATAAGTTGGCTGCTAAAGCTGGTTCGGATAATTTCAGGTCTAGTGCGATAGTCGATATCATGGAAAGGTTGGCTAATAAGGGCTACCACATCAAAATATTTGAACCTACCGTTGAACAATTTGAGAATTTTGAGGTAGATAATAATCTCACAACTTTTGCAACCGAGTCTGATGTAATAATTGCGAACAGAGTTCCAGTCGAACATCGCATTCTGTTTGGGAAGAAGTTAATAACACGGGATGTCTATGGGGATAA
SEQ ID NO: 14 представляет собой перекодированную нуклеотидную последовательность UDP-глюкозодегидрогеназы (HASB), происходящую из вируса хлореллы PBCV-1
ATGTCACGAATCGCAGTAGTTGGCTGTGGGTACGTGGGAACCGCATGCGCTGTACTGCTGGCGCAAAAGAATGAGGTAATCGTTCTTGATATTAGTGAGGATAGGGTCCAACTAATCAAGAACAAGAAATCCCCGATCGAAGATAAGGAGATTGAAGAATTCTTGGAAACAAAAGACCTAAACTTAACTGCAACAACTGACAAAGTTTTAGCCTACGAAAACGCTGAGTTTGTGATTATAGCGACACCCACAGATTATGACGTAGTTACCAGATACTTTAACACGAAGTCCGTAGAGAACGTCATTGGAGATGTTATAAAGAATACTCAGACTCATCCTACGATAGTAATAAAGTCAACCATTCCCATAGGTTTCGTAGATAAGGTTAGGGAGCAATTCGATTACCAGAACATTATATTTTCGCCAGAATTTCTGAGAGAGGGTCGCGCCCTGTATGATAATCTATATCCATCACGGATTATAGTGGGCGATGACTCTCCGATTGCACTTAAGTTTGCTAATCTTTTAGTTGAGGGCTCCAAAACTCCGCTCGCCCCAGTACTTACGATGGGTACACGTGAGGCTGAAGCTGTCAAGCTGTTTTCAAACACATACCTTGCTATGCGAGTCGCATACTTTAACGAACTAGATACCTTTGCTATGTCGCACGGTATGAATGCTAAAGAAATCATAGATGGCGTAACGTTGGAGCCTCGGATAGGTCAAGGATATTCCAATCCATCTTTTGGCTACGGTGCGTATTGTTTCCCAAAGGACACGAAGCAATTATTAGCTAACTTTGAGGGTGTTCCGCAAGATATAATTGGGGCGATAGTAGAAAGCAATGAAACACGGAAGGAGGTAATCGTGAGTGAAGTGGAAAACCGATTCCCCACTACGGTCGGCGTTTACAAATTAGCCGCCAAGGCTGGTTCCGACAATTTCCGATCCAGCGCAATAGTAGATATTATGGAAAGATTAGCTAATAAGGGATACCACATTAAAATCTTTGAACCTACTGTCGAACAGTTCGAGAACTTCGAGGTTGATAATAACTTGACGACTTTCGCAACGGAGAGCGATGTAATTATTGCAAACCGCGTACCTGTGGAACATCGAATTTTGTTCGGAAAGAAGCTGATTACACGCGATGTATATGGCGATAACTAA
SEQ ID NO: 15 представляет собой перекодированную нуклеотидную последовательность UDP-глюкозодегидрогеназы (HASB), происходящую из Streptococcus Zooepidemicus
ATGAAGATATCGGTAGCGGGTTCGGGGTACGTGGGGTTATCCTTGTCAATCTTGCTTGCCCAACATAACGATGTGACTGTTGTAGATATAATCGACGAAAAGGTACGGCTAATTAACCAGGGCATATCTCCGATTAAGGATGCGGACATTGAGGAATATCTGAAGAATGCACCGTTGAATCTTACGGCTACACTAGACGGAGCTTCGGCTTATAGTAATGCTGATCTGATTATAATCGCAACGCCAACTAATTACGATTCAGAACGCAATTATTTCGACACCAGACACGTTGAAGAAGTAATTGAGCAAGTATTGGATTTAAATGCCTCCGCTACTATAATCATCAAGAGTACCATACCCTTGGGTTTTATTAAACACGTAAGAGAGAAATACCAAACAGACAGAATCATCTTTTCTCCAGAGTTCTTAAGAGAGTCAAAGGCATTGTACGATAACTTATACCCCTCTCGTATAATAGTCAGTTATGAGAAGGATGACTCTCCAAGAGTTATACAAGCAGCTAAGGCGTTCGCGGGTTTATTAAAAGAGGGGGCAAAGAGCAAGGATACCCCAGTTCTGTTTATGGGCTCTCAAGAAGCTGAAGCTGTCAAGCTGTTTGCTAATACTTTTCTCGCCATGAGGGTCAGTTACTTCAACGAGCTTGACACTTATAGCGAATCAAAAGGACTAGACGCCCAAAGAGTTATAGAAGGCGTCTGCCATGATCAAAGGATAGGTAATCATTACAATAATCCATCCTTCGGATATGGCGGTTATTGTTTACCCAAAGACTCAAAGCAACTTTTGGCTAATTATAGAGGCATACCTCAGTCTCTAATGTCTGCCATCGTTGAATCGAACAAGATCCGTAAGTCGTATTTAGCTGAACAAATATTAGATAGGGCTTCTTCACAAAAGCAGGCTGGTGTACCTTTAACCATAGGATTTTACCGTTTGATTATGAAGTCCAACTCCGATAACTTTAGAGAATCAGCCATTAAAGATATTATTGACATCATTAATGACTACGGTGTCAATATTGTCATTTATGAACCTATGTTGGGAGAAGACATTGGTTATAGAGTCGTTAAAGATTTGGAACAGTTTAAGAACGAAAGTACAATTATTGTTAGTAACAGGTTTGAAGATGATTTAGGTGATGTTATTGATAAAGTTTATACACGTGACGTCTTTGGTAG
SEQ ID NO: 16 представляет собой аминокислотную последовательность udp-глюкозодегидрогеназы (HASB), происходящую из Arabidopsis Thaliana
MVKICCIGAGYVGGPTMAVMALKCPEIEVVVVDISEPRINAWNSDRLPIYEPGLEDVVKQCRGKNLFFSTDVEKHVFESDIVFVSVNTPTKTQGLGAGKAADLTYWESAARMIADVSKSSKIVVEKSTVPVRTAEAIEKILTHNSKGIEFQILSNPEFLAEGTAIKDLYNPDRVLIGGRDTAAGQKAIKALRDVYAHWVPVEQIICTNLWSAELSKLAANAFLAQRISSVNAMSALCEATGADVTQVAHAVGTDTRIGPKFLNASVGFGGSCFQKDILNLIYICECNGLPEAANYWKQVVKVNDYQKIRFANRVVSSMFNTVSGKKIAILGFAFKKDTGDTRETPAIDVCNRLVADKAKLSIYDPQVLEEQIRRDLSMARFDWDHPVPLQQIKAEGISEQVNVVSDAYEATKDAHGLCVLTEWDEFKSLDFKKIFDNMQKPAFVFDGRNVVDAVKLREIGFIVYSIGKPLDSWLKDMPAVA
SEQ ID NO: 17 представляет собой аминокислотную последовательность UDP-глюкозодегидрогеназы (HASB), происходящую из вируса хлореллы PBCV1
MSRIAVVGCGYVGTACAVLLAQKNEVIVLDISEDRVQLIKNKKSPIEDKEIEEFLETKDLNLTATTDKVLAYENAEFVIIATPTDYDVVTRYFNTKSVENVIGDVIKNTQTHPTIVIKSTIPIGFVDKVREQFDYQNIIFSPEFLREGRALYDNLYPSRIIVGDDSPIALKFANLLVEGSKTPLAPVLTMGTREAEAVKLFSNTYLAMRVAYFNELDTFAMSHGMNAKEIIDGVTLEPRIGQGYSNPSFGYGAYCFPKDTKQLLANFEGVPQDIIGAIVESNETRKEVIVSEVENRFPTTVGVYKLAAKAGSDNFRSSAIVDIMERLANKGYHIKIFEPTVEQFENFEVDNNLTTFATESDVIIANRVPVEHRILFGKKLITRDVYGDN
SEQ ID NO: 18 представляет собой аминокислотную последовательность UDP-глюкозодегидрогеназы (HASB), происходящую из Streptococcus Zooepidemicus
MKISVAGSGYVGLSLSILLAQHNDVTVVDIIDEKVRLINQGISPIKDADIEEYLKNAPLNLTATLDGASAYSNADLIIIATPTNYDSERNYFDTRHVEEVIEQVLDLNASATIIIKSTIPLGFIKHVREKYQTDRIIFSPEFLRESKALYDNLYPSRIIVSYEKDDSPRVIQAAKAFAGLLKEGAKSKDTPVLFMGSQEAEAVKLFANTFLAMRVSYFNELDTYSESKGLDAQRVIEGVCHDQRIGNHYNNPSFGYGGYCLPKDSKQLLANYRGIPQSLMSAIVESNKIRKSYLAEQILDRASSQKQAGVPLTIGFYRLIMKSNSDNFRESAIKDIIDIINDYGVNIVIYEPMLGEDIGYRVVKDLEQFKNESTIIVSNRFEDDLGDVIDKVYTRDVFGRD
SEQ ID NO: 19 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Bothrops Atrox, с N-концевым сигналом секреции
ATGCAATTTAGCACAGTCGCATCAGTAGCCTTCGTTGCCTTGGCCAACTTCGTGGCAGCACCGATGTATCCGAACGAACCGTTCTTAGTCTTTTGGAACGCGCCTACAACTCAGTGTAGACTTCGATATAAGGTTGACCTTGATCTGAAGACATTCCATATCGTGACAAATGCTAATGACTCGCTGTCAGGATCGGCTGTCACGATTTTCTATCCCACGCACTTAGGGGTTTACCCACATATTGATGACAGGGGGCACTTCTTCAATGGCATCATACCCCAAAATGAATCCCTGGTAAAGCATTTAAACAAATCTAAATCAGATATTAATCGAATGATTCCCTTAAGAACATTCCACGGGCTGGGAGTCATAGACTGGGAAAACTGGCGGCCACAGTGGGATAGGAATTGGGGAAGTAAGAACGTTTATAGGAATAGATCAATCCAATTCGCGCGTGATCTCCACCCAGAGCTTAGTGAGGACAAGATTAAACGCTTGGCAAAACAGGAATTCGAGAAAGCTGCAAAGAGTTTTATGAGGGATACACTATTATTAGCCGAGGAGATGCGACCAGACGGCTACTGGGGATACTATCTGTACCCCGATTGTCACAATTACAATTATAAGACTAAGCCAGATCAGTACACAGGAGAGTGCCCTGACATCGAGATGTCACGTAACAATCAACTCTTGTGGCTTTGGCGGGATAGCACTGCCCTTTTCCCCAATATCTACTTAGAGACTATACTAAGAAGCTCTGACAATGCCCTGAAGTTTGTGCACCATAGGCTCAAGGAGGCAATGAGGATAGCCTCAATGGCTCGAAATGACTACGCGTTGCCTTTCTTTGTTTATGCTCGACCATTCTATGCCTATACCTTCGAACCATTGACTCAGGAAGACCTTGTGACTACGGTCGGAGAGACCGCGGACATGGGCGCCGCTGGGATCGTATTTTGGGGGAGTATGCAGTACGCAAGCACGGTTGAATCTTGCGGCAAAGTCAAGGACTACATGAATGGCCCACTGGGGCGTTACATTGTGAATGTTACAACTGCCGCCAAAATTTGCTCACGATTCTTGTGCAAACGTCATGGTAGGTGTGTAAGAAAGCACTCAGACTCCAATGCATTCCTTCACCTATTTCCCGATTCGTTTCGCATAATGGTGCACGGGAATGCAACCGAGAAGAAAGTTATAGTAAAGGGGAAGCTGGAATTAAAGAATCTTATATTCTTACGTAATAACTTTATGTGCCAGTGTTATCAAGGCTGGAAAGGTCTATATTGCGAGAAGCATTCGATAAAGGAAATTCGGAAAATCTAA
SEQ ID NO: 20 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Bothrops Atrox, с N-концевым сигналом секреции и с-концевым якорным сигналом
ATGCAATTTAGCACAGTCGCATCAGTAGCCTTCGTTGCCTTGGCCAACTTCGTGGCAGCACCGATGTATCCGAACGAACCGTTCTTAGTCTTTTGGAACGCGCCTACAACTCAGTGTAGACTTCGATATAAGGTTGACCTTGATCTGAAGACATTCCATATCGTGACAAATGCTAATGACTCGCTGTCAGGATCGGCTGTCACGATTTTCTATCCCACGCACTTAGGGGTTTACCCACATATTGATGACAGGGGGCACTTCTTCAATGGCATCATACCCCAAAATGAATCCCTGGTAAAGCATTTAAACAAATCTAAATCAGATATTAATCGAATGATTCCCTTAAGAACATTCCACGGGCTGGGAGTCATAGACTGGGAAAACTGGCGGCCACAGTGGGATAGGAATTGGGGAAGTAAGAACGTTTATAGGAATAGATCAATCCAATTCGCGCGTGATCTCCACCCAGAGCTTAGTGAGGACAAGATTAAACGCTTGGCAAAACAGGAATTCGAGAAAGCTGCAAAGAGTTTTATGAGGGATACACTATTATTAGCCGAGGAGATGCGACCAGACGGCTACTGGGGATACTATCTGTACCCCGATTGTCACAATTACAATTATAAGACTAAGCCAGATCAGTACACAGGAGAGTGCCCTGACATCGAGATGTCACGTAACAATCAACTCTTGTGGCTTTGGCGGGATAGCACTGCCCTTTTCCCCAATATCTACTTAGAGACTATACTAAGAAGCTCTGACAATGCCCTGAAGTTTGTGCACCATAGGCTCAAGGAGGCAATGAGGATAGCCTCAATGGCTCGAAATGACTACGCGTTGCCTTTCTTTGTTTATGCTCGACCATTCTATGCCTATACCTTCGAACCATTGACTCAGGAAGACCTTGTGACTACGGTCGGAGAGACCGCGGACATGGGCGCCGCTGGGATCGTATTTTGGGGGAGTATGCAGTACGCAAGCACGGTTGAATCTTGCGGCAAAGTCAAGGACTACATGAATGGCCCACTGGGGCGTTACATTGTGAATGTTACAACTGCCGCCAAAATTTGCTCACGATTCTTGTGCAAACGTCATGGTAGGTGTGTAAGAAAGCACTCAGACTCCAATGCATTCCTTCACCTATTTCCCGATTCGTTTCGCATAATGGTGCACGGGAATGCAACCGAGAAGAAAGTTATAGTAAAGGGGAAGCTGGAATTAAAGAATCTTATATTCTTACGTAATAACTTTATGTGCCAGTGTTATCAAGGCTGGAAAGGTCTATATTGCGAGAAGCATTCGATAAAGGAAATTCGGAAAATCGGATCCGCCATTTCTCAAATCACTGACGGTCAAATCCAAGCTACTACCACTGCTACCACCGAAGCTACCACCACTGCTGCCCCATCTTCCACCGTTGAAACTGTTTCTCCATCCAGCACCGAAACTATCTCTCAACAAACTGAAAATGGTGCTGCTAAGGCCGCTGTCGGTATGGGTGCCGGTGCTCTAGCTGCTGCTGCTATGTTGTTATAA
SEQ ID NO: 21 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Cupiennius Salei, с N-концевым сигналом секреции
ATGCAATTCAGCACTGTTGCATCAGTTGCATTTGTCGCCCTGGCGAATTTTGTAGCCGCGTTCAAGATTTACTGGAACGTCCCAACTTTTCAGTGCACGCATAACTACAAAATCGATTATGTCAAATTGTTGTCCACTTACGGGATACAGGTCAATGATGGCGGTAAGTTTCAAGGAAACCAAGTGACTATCTTTTATGAAACCCAGTTGGGTTTGTATCCACGAATCCTAAAATCTGGTAAAATGGAAAACGGCGGAATCCCTCAACGCGGTAACTTTGAGAAACACCTAGAAAAGGCAAGCACGGACCTCCAGAAAGTGATCCCTTGGAAAGAGTTTAGCGGATTAGGTGTGATAGATTGGGAGGCTTGGAGACCCACATGGGAATTTAACTGGGAACCGTTGAGGATATATCAAACCGAATCAATTAAGAGAGCTAAAGAACTACACCCTACCGCAAACGATTCCGCAGTAAAAGAAATTGCAGAGCGGCAATGGGAAGATTCAGCCAAGTTATACATGTTAGAAACACTGCGGCTGGCAAAGAAACTTCGACCTCAAGCGCCTTGGTGTTACTACTTATTTCCTGATTGCTATAATTACGTCGGAAAGAAACCAAAAGATTTCCAATGTAGTGCCTCGATACGTAAAGGTAACGATAAGCTAAGCTGGTTGTGGAAAGATTCTACGGCATTGTGTCCATCGATATACGTATATGAATCACAATTAGACAGGTATTCTTTTGAACAAAGGACATGGCGCGACAATGAGAAACTTCGGGAAGCGTTGCGTGTAGCCACGAGAACCTCTAAAATATACCCATACGTTAACTATTTCGATAAGGAGCTTATACCGGAGCAAGAAGTATGGAGAATGCTTGCGCAGGCAGCTGCTGTCGGTGGCAGTGGTGCGGTAATTTGGGGCTCATCTGCTGCAGTTGCATCTGAAGAGTTATGTAAATCTTTAAAACAGTATATTATTGAAACGCTTGGGCCGGCGGCAGAGAAGGTGGCTTGGCGTAGTGACTTATGCAGCAAAGAAATTTGTAATAATCAGGGTCGCTGCACATTCCCGGACGATGATTATGCAAACGCATGGAAATTATTTACAGATGATACTGTTAAGTTTTATGCTGGTAATATTACATGTAGGTGCTCCGAGAATTATTCTGGTCGTTTCTGCGAAAAGAAGAATTAA
SEQ ID NO: 22 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Cupiennius Salei, с N-концевым сигналом секреции и с-концевым якорным сигналом
ATGCAATTCAGCACTGTTGCATCAGTTGCATTTGTCGCCCTGGCGAATTTTGTAGCCGCGTTCAAGATTTACTGGAACGTCCCAACTTTTCAGTGCACGCATAACTACAAAATCGATTATGTCAAATTGTTGTCCACTTACGGGATACAGGTCAATGATGGCGGTAAGTTTCAAGGAAACCAAGTGACTATCTTTTATGAAACCCAGTTGGGTTTGTATCCACGAATCCTAAAATCTGGTAAAATGGAAAACGGCGGAATCCCTCAACGCGGTAACTTTGAGAAACACCTAGAAAAGGCAAGCACGGACCTCCAGAAAGTGATCCCTTGGAAAGAGTTTAGCGGATTAGGTGTGATAGATTGGGAGGCTTGGAGACCCACATGGGAATTTAACTGGGAACCGTTGAGGATATATCAAACCGAATCAATTAAGAGAGCTAAAGAACTACACCCTACCGCAAACGATTCCGCAGTAAAAGAAATTGCAGAGCGGCAATGGGAAGATTCAGCCAAGTTATACATGTTAGAAACACTGCGGCTGGCAAAGAAACTTCGACCTCAAGCGCCTTGGTGTTACTACTTATTTCCTGATTGCTATAATTACGTCGGAAAGAAACCAAAAGATTTCCAATGTAGTGCCTCGATACGTAAAGGTAACGATAAGCTAAGCTGGTTGTGGAAAGATTCTACGGCATTGTGTCCATCGATATACGTATATGAATCACAATTAGACAGGTATTCTTTTGAACAAAGGACATGGCGCGACAATGAGAAACTTCGGGAAGCGTTGCGTGTAGCCACGAGAACCTCTAAAATATACCCATACGTTAACTATTTCGATAAGGAGCTTATACCGGAGCAAGAAGTATGGAGAATGCTTGCGCAGGCAGCTGCTGTCGGTGGCAGTGGTGCGGTAATTTGGGGCTCATCTGCTGCAGTTGCATCTGAAGAGTTATGTAAATCTTTAAAACAGTATATTATTGAAACGCTTGGGCCGGCGGCAGAGAAGGTGGCTTGGCGTAGTGACTTATGCAGCAAAGAAATTTGTAATAATCAGGGTCGCTGCACATTCCCGGACGATGATTATGCAAACGCATGGAAATTATTTACAGATGATACTGTTAAGTTTTATGCTGGTAATATTACATGTAGGTGCTCCGAGAATTATTCTGGTCGTTTCTGCGAAAAGAAGAATGGATCCGCCATTTCTCAAATCACTGACGGTCAAATCCAAGCTACTACCACTGCTACCACCGAAGCTACCACCACTGCTGCCCCATCTTCCACCGTTGAAACTGTTTCTCCATCCAGCACCGAAACTATCTCTCAACAAACTGAAAATGGTGCTGCTAAGGCCGCTGTCGGTATGGGTGCCGGTGCTCTAGCTGCTGCTGCTATGTTGTTATAA
SEQ ID NO: 23 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Hirudo Nipponia, с N-концевым сигналом секреции
ATGCAATTCTCTACTGTCGCTTCCGTTGCTTTCGTCGCTTTGGCTAACTTTGTTGCCGCTATGAAGGAGATAGCAGTTACCATCGATGATAAGAATGTTATAGCGTCTGTCAGTGAAAGCTTCCATGGTGTGGCTTTCGACGCAAGCCTATTCTCACCTAAAGGGCTATGGTCGTTTGTTGACATTACTTCACCCAAGTTATTCAAGCTTCTGGAGGGACTCTCCCCTGGTTATTTCCGTGTCGGCGGCACATTTGCGAACTGGTTATTCTTCGACCTCGATGAAAACAACAAGTGGAAGGATTACTGGGCTTTTAAGGACAAGACTCCAGAGACCGCCACGATTACCCGACGGTGGCTCTTCAGGAAGCAAAACAACCTCAAGAAGGAAACCTTTGATGATTTGGTAAAGCTTACAAAGGGGTCCAAGATGCGGCTGCTATTTGATCTAAACGCAGAGGTCCGTACAGGATATGAGATAGGCAAGAAGATGACATCAACTTGGGACTCAAGCGAGGCAGAAAAGTTGTTCAAATATTGCGTTAGCAAGGGATATGGAGATAATATCGATTGGGAGTTAGGCAACGAACCTGATCACACGTCAGCACACAATTTGACAGAGAAGCAAGTAGGTGAAGATTTTAAGGCCCTACACAAGGTGTTGGAAAAGTATCCAACACTTAATAAAGGTAGCTTGGTTGGTCCAGACGTTGGGTGGATGGGAGTGTCGTACGTCAAGGGTCTGGCTGACGGGGCTGGAGATCATGTGACCGCTTTTACTCTACATCAGTATTATTTCGATGGAAATACGAGTGATGTTAGTACCTACTTGGATGCGACGTACTTTAAGAAGTTGCAACAGTTATTCGATAAGGTAAAAGACGTACTCAAGAATTCTCCACATAAGGACAAACCCTTGTGGCTAGGGGAAACCTCTTCCGGCTACAACAGTGGGACTAAAGATGTATCCGATAGATACGTGTCGGGGTTCTTGACGCTGGACAAGTTGGGGCTTTCGGCGGCAAATAACGTCAAGGTGGTCATCAGACAAACGATTTATAATGGTTACTATGGTTTGCTTGACAAGAATACTTTGGAGCCCAATCCGGACTACTGGCTGATGCACGTCCACAATTCCTTAGTTGGTAATACCGTTTTCAAGGTCGATGTCAGCGATCCCACAAACAAAGCCCGTGTTTACGCTCAGTGTACGAAGACCAATAGTAAACATACCCAGTCACGTTATTATAAGGGGTCCCTAACCATTTTCGCGTTGAATGTAGGTGATGAAGATGTTACACTCAAGATTGATCAATACAGTGGTAAGAAAATATACTCATATATTCTGACGCCTGAAGGCGGCCAGTTAACCTCTCAAAAGGTACTGCTTAACGGTAAAGAATTGAAGTTAGTGTCAGATCAACTTCCAGAACTTAACGCGGACGAAAGTAAAACATCCTTCACATTGTCTCCCAAAACTTTTGGATTCTTTGTGGTCTCGGATGCCAACGTTGAAGCTTGCAAGAAATAA
SEQ ID NO: 24 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Hirudo Nipponia, с N-концевым сигналом секреции и с-концевым якорным сигналом
ATGCAATTCTCTACTGTCGCTTCCGTTGCTTTCGTCGCTTTGGCTAACTTTGTTGCCGCTATGAAGGAGATAGCAGTTACCATCGATGATAAGAATGTTATAGCGTCTGTCAGTGAAAGCTTCCATGGTGTGGCTTTCGACGCAAGCCTATTCTCACCTAAAGGGCTATGGTCGTTTGTTGACATTACTTCACCCAAGTTATTCAAGCTTCTGGAGGGACTCTCCCCTGGTTATTTCCGTGTCGGCGGCACATTTGCGAACTGGTTATTCTTCGACCTCGATGAAAACAACAAGTGGAAGGATTACTGGGCTTTTAAGGACAAGACTCCAGAGACCGCCACGATTACCCGACGGTGGCTCTTCAGGAAGCAAAACAACCTCAAGAAGGAAACCTTTGATGATTTGGTAAAGCTTACAAAGGGGTCCAAGATGCGGCTGCTATTTGATCTAAACGCAGAGGTCCGTACAGGATATGAGATAGGCAAGAAGATGACATCAACTTGGGACTCAAGCGAGGCAGAAAAGTTGTTCAAATATTGCGTTAGCAAGGGATATGGAGATAATATCGATTGGGAGTTAGGCAACGAACCTGATCACACGTCAGCACACAATTTGACAGAGAAGCAAGTAGGTGAAGATTTTAAGGCCCTACACAAGGTGTTGGAAAAGTATCCAACACTTAATAAAGGTAGCTTGGTTGGTCCAGACGTTGGGTGGATGGGAGTGTCGTACGTCAAGGGTCTGGCTGACGGGGCTGGAGATCATGTGACCGCTTTTACTCTACATCAGTATTATTTCGATGGAAATACGAGTGATGTTAGTACCTACTTGGATGCGACGTACTTTAAGAAGTTGCAACAGTTATTCGATAAGGTAAAAGACGTACTCAAGAATTCTCCACATAAGGACAAACCCTTGTGGCTAGGGGAAACCTCTTCCGGCTACAACAGTGGGACTAAAGATGTATCCGATAGATACGTGTCGGGGTTCTTGACGCTGGACAAGTTGGGGCTTTCGGCGGCAAATAACGTCAAGGTGGTCATCAGACAAACGATTTATAATGGTTACTATGGTTTGCTTGACAAGAATACTTTGGAGCCCAATCCGGACTACTGGCTGATGCACGTCCACAATTCCTTAGTTGGTAATACCGTTTTCAAGGTCGATGTCAGCGATCCCACAAACAAAGCCCGTGTTTACGCTCAGTGTACGAAGACCAATAGTAAACATACCCAGTCACGTTATTATAAGGGGTCCCTAACCATTTTCGCGTTGAATGTAGGTGATGAAGATGTTACACTCAAGATTGATCAATACAGTGGTAAGAAAATATACTCATATATTCTGACGCCTGAAGGCGGCCAGTTAACCTCTCAAAAGGTACTGCTTAACGGTAAAGAATTGAAGTTAGTGTCAGATCAACTTCCAGAACTTAACGCGGACGAAAGTAAAACATCCTTCACATTGTCTCCCAAAACTTTTGGATTCTTTGTGGTCTCGGATGCCAACGTTGAAGCTTGCAAGAAAGGATCCGCCATTTCTCAAATCACTGACGGTCAAATCCAAGCTACTACCACTGCTACCACCGAAGCTACCACCACTGCTGCCCCATCTTCCACCGTTGAAACTGTTTCTCCATCCAGCACCGAAACTATCTCTCAACAAACTGAAAATGGTGCTGCTAAGGCCGCTGTCGGTATGGGTGCCGGTGCTCTAGCTGCTGCTGCTATGTTGTTATAA
SEQ ID NO: 25 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Loxosceles Intermedia, с N-концевым сигналом секреции
ATGCAGTTTTCAACCGTTGCGAGCGTCGCTTTTGTGGCTCTTGCTAATTTCGTTGCCGCCTTCGATGTCTTCTGGAATGTTCCGTCGCAGCAATGCAAGAAATATGGTATGAAATTCGTTCCGCTCTTAGAGCAATACTCTATCCTAGTCAACAAAGAAGACAATTTCAAGGGCGACAAAATAACGATCTTTTATGAGTCACAGCTCGGGCTTTACCCACATATTGGTGCAAACGACGAGTCGTTTAATGGCGGGATACCACAATTAGGTGACCTGAAAGCACACTTAGAAAAGTCAGCGGTTGATATACGACGTGATATTTTGGATAAGTCGGCGACTGGTCTAAGAATTATAGACTGGGAAGCATGGAGACCAATATGGGAATTCAACTGGTCTAGCCTACGAAAGTACCAAGATAAAATGAAGAAAGTCGTCCGCCAGTTTAACCCGACTGCTCATGAATCCACAGTGGCCAAACTAGCACATAATGAGTGGGAAAATAGTAGTAAGTCTTGGATGCTTTCTACATTGCAGTTGGGTAAGCAACTTCGTCCAAACTCTGTATGGTGCTATTATTTATTTCCCGACTGTTATAACTATGATGGCAACTCAGTCCAAGAATTTCAGTGTTCTGAAGCTATCCGTAAGGGGAACGATAGGTTGAAATGGTTGTGGGAAGAATCGACAGCTGTATGCCCATCTATCTACATAAAAGAAGGCCAACTGACCAATTATACCTTGCAAAAGAGAATCTGGTTTACCAATGGGAGATTACAGGAAGCCTTGAGAGTAGCTCAACCTAAAGCGCGTATTTATCCATACATAAATTACTCCATCAAACCCGGAATGATGGTGCCTGAAGTTGAGTTTTGGCGGTTAATCGCTCAGATAGCCTCGCTGGGTATGGATGGAGCAGTGATTTGGGGATCAAGTGCGAGTGTAGGCAGTAAGAATCATTGTGCGCAATTAATGAAGTACATTGCAGACGTATTGGGTCCTGCAACTTTGCGCATAAAAGAAAATGTAGCACGGTGCAGTAAACAGGCGTGCTCTGGTAGGGGTAGATGTACCTGGCCTAAAGATACCTCTGTTATTGCTTGGAAGTTCCTCGTTGAAAAGGAAGACTATGACTTTTATCTGGGTGATATAGAGTGTAAATGTGTTGAAGGCTACGAAGGTAGGTACTGTGAACAAAAGACTAAGTAA
SEQ ID NO: 26 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Loxosceles Intermedia, с N-концевым сигналом секреции и С-концевым якорным сигналом
ATGCAGTTTTCAACCGTTGCGAGCGTCGCTTTTGTGGCTCTTGCTAATTTCGTTGCCGCCTTCGATGTCTTCTGGAATGTTCCGTCGCAGCAATGCAAGAAATATGGTATGAAATTCGTTCCGCTCTTAGAGCAATACTCTATCCTAGTCAACAAAGAAGACAATTTCAAGGGCGACAAAATAACGATCTTTTATGAGTCACAGCTCGGGCTTTACCCACATATTGGTGCAAACGACGAGTCGTTTAATGGCGGGATACCACAATTAGGTGACCTGAAAGCACACTTAGAAAAGTCAGCGGTTGATATACGACGTGATATTTTGGATAAGTCGGCGACTGGTCTAAGAATTATAGACTGGGAAGCATGGAGACCAATATGGGAATTCAACTGGTCTAGCCTACGAAAGTACCAAGATAAAATGAAGAAAGTCGTCCGCCAGTTTAACCCGACTGCTCATGAATCCACAGTGGCCAAACTAGCACATAATGAGTGGGAAAATAGTAGTAAGTCTTGGATGCTTTCTACATTGCAGTTGGGTAAGCAACTTCGTCCAAACTCTGTATGGTGCTATTATTTATTTCCCGACTGTTATAACTATGATGGCAACTCAGTCCAAGAATTTCAGTGTTCTGAAGCTATCCGTAAGGGGAACGATAGGTTGAAATGGTTGTGGGAAGAATCGACAGCTGTATGCCCATCTATCTACATAAAAGAAGGCCAACTGACCAATTATACCTTGCAAAAGAGAATCTGGTTTACCAATGGGAGATTACAGGAAGCCTTGAGAGTAGCTCAACCTAAAGCGCGTATTTATCCATACATAAATTACTCCATCAAACCCGGAATGATGGTGCCTGAAGTTGAGTTTTGGCGGTTAATCGCTCAGATAGCCTCGCTGGGTATGGATGGAGCAGTGATTTGGGGATCAAGTGCGAGTGTAGGCAGTAAGAATCATTGTGCGCAATTAATGAAGTACATTGCAGACGTATTGGGTCCTGCAACTTTGCGCATAAAAGAAAATGTAGCACGGTGCAGTAAACAGGCGTGCTCTGGTAGGGGTAGATGTACCTGGCCTAAAGATACCTCTGTTATTGCTTGGAAGTTCCTCGTTGAAAAGGAAGACTATGACTTTTATCTGGGTGATATAGAGTGTAAATGTGTTGAAGGCTACGAAGGTAGGTACTGTGAACAAAAGACTAAGGGATCCGCCATTTCTCAAATCACTGACGGTCAAATCCAAGCTACTACCACTGCTACCACCGAAGCTACCACCACTGCTGCCCCATCTTCCACCGTTGAAACTGTTTCTCCATCCAGCACCGAAACTATCTCTCAACAAACTGAAAATGGTGCTGCTAAGGCCGCTGTCGGTATGGGTGCCGGTGCTCTAGCTGCTGCTGCTATGTTGTTATAA
SEQ ID NO: 27 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Tityus Serrulatus, с N-концевым сигналом секреции
ATGCAATTCTCTACTGTCGCTTCCGTTGCTTTCGTCGCTTTGGCTAACTTTGTTGCCGCTGCTGATTTTAAAGTTTACTGGGAAGTGCCTTCCTTCCTTTGTTCTAAACGTTTTAAAATTAATGTAACGGAAGTTTTAACAAGTCACGAGATTCTTGTCAATCAGGGTGAGAGTTTCAACGGTGACAAGATAGTAATCTTTTACGAAAACCAATTGGGGAAGTACCCGCATATTGACTCAAACAATGTGGAGATCAATGGAGGAATACTTCAAGTAGCCGATTTGGCGAAGCATTTGAAAGTAGCCAAGGATAATATCACTAAATTCGTCCCGAATCCTAATTTCAACGGTGTCGGAGTGATCGACTGGGAAGCTTGGCGGCCATCATGGGAATTTAACTGGGGTAAGTTAAAAGTATATAAAGAAAAGAGCATTGACTTGGTCAAGTCGAAACATCCGGAGTGGCCCTCCGACAGGGTTGAAAAGGTTGCTAAAGAGGAGTGGGAGGAGAGTGCCAAAGAATGGATGGTGAAGACCCTGAAGTTAGCACAGGAAATGCGACCGAACGCAGTTTGGTGCTATTATCTATTCCCTGACTGCTACAATTATTTCGGTAAGGATCAACCCTCTCAATTCAGCTGCTCGTCTCGAATTCAGAAGGAAAATTCTCGTCTTTCTTGGCTCTGGAATCAATCAACAGCCATTTGCCTAAGCATTTATATCCAGGAATCCCATGTTACCAAATATAATATGTCCCAGCGGACATGGTGGATCGATGCGAGATTAAGAGAAGCAATTCGAGTCAGCGAACACAGACCAAACATACCCATCTACCCTTACATTAATTATATTCTACCTGGAACTAATCAAACTGTACCAGCAATGGACTTTAAAAGGACACTGGGTCAAATAGCTAGCCTCGGCCTAGATGGTGCTTTGTTATGGGGATCTAGCTATCATGTTTTAACAGAATCTCAATGCAAAATCACTTCTGATTATGTGAAATCAGTGATTGCTCCTACCGTGGCTACTGTCGTTCTCAATACAAACAGATGCTCACAGATAATTTGTAAGGGTCGCGGCAACTGTGTTTGGCCTGAAGAACCATTTAGTTCTTGGAAATACTTAGTTGACCCCAAAATGCCAGTGTTCAAGCCAACCAACATCCACTGTAAATGTAAAGGTTACCTAGGTAGATACTGTGAGATCCCAAAGTAA
SEQ ID NO: 28 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Tityus Serrulatus, с N-концевым сигналом секреции и С-концевым якорным сигналом
ATGCAATTCTCTACTGTCGCTTCCGTTGCTTTCGTCGCTTTGGCTAACTTTGTTGCCGCTGCTGATTTTAAAGTTTACTGGGAAGTGCCTTCCTTCCTTTGTTCTAAACGTTTTAAAATTAATGTAACGGAAGTTTTAACAAGTCACGAGATTCTTGTCAATCAGGGTGAGAGTTTCAACGGTGACAAGATAGTAATCTTTTACGAAAACCAATTGGGGAAGTACCCGCATATTGACTCAAACAATGTGGAGATCAATGGAGGAATACTTCAAGTAGCCGATTTGGCGAAGCATTTGAAAGTAGCCAAGGATAATATCACTAAATTCGTCCCGAATCCTAATTTCAACGGTGTCGGAGTGATCGACTGGGAAGCTTGGCGGCCATCATGGGAATTTAACTGGGGTAAGTTAAAAGTATATAAAGAAAAGAGCATTGACTTGGTCAAGTCGAAACATCCGGAGTGGCCCTCCGACAGGGTTGAAAAGGTTGCTAAAGAGGAGTGGGAGGAGAGTGCCAAAGAATGGATGGTGAAGACCCTGAAGTTAGCACAGGAAATGCGACCGAACGCAGTTTGGTGCTATTATCTATTCCCTGACTGCTACAATTATTTCGGTAAGGATCAACCCTCTCAATTCAGCTGCTCGTCTCGAATTCAGAAGGAAAATTCTCGTCTTTCTTGGCTCTGGAATCAATCAACAGCCATTTGCCTAAGCATTTATATCCAGGAATCCCATGTTACCAAATATAATATGTCCCAGCGGACATGGTGGATCGATGCGAGATTAAGAGAAGCAATTCGAGTCAGCGAACACAGACCAAACATACCCATCTACCCTTACATTAATTATATTCTACCTGGAACTAATCAAACTGTACCAGCAATGGACTTTAAAAGGACACTGGGTCAAATAGCTAGCCTCGGCCTAGATGGTGCTTTGTTATGGGGATCTAGCTATCATGTTTTAACAGAATCTCAATGCAAAATCACTTCTGATTATGTGAAATCAGTGATTGCTCCTACCGTGGCTACTGTCGTTCTCAATACAAACAGATGCTCACAGATAATTTGTAAGGGTCGCGGCAACTGTGTTTGGCCTGAAGAACCATTTAGTTCTTGGAAATACTTAGTTGACCCCAAAATGCCAGTGTTCAAGCCAACCAACATCCACTGTAAATGTAAAGGTTACCTAGGTAGATACTGTGAGATCCCAAAGGGATCCGCCATTTCTCAAATCACTGACGGTCAAATCCAAGCTACTACCACTGCTACCACCGAAGCTACCACCACTGCTGCCCCATCTTCCACCGTTGAAACTGTTTCTCCATCCAGCACCGAAACTATCTCTCAACAAACTGAAAATGGTGCTGCTAAGGCCGCTGTCGGTATGGGTGCCGGTGCTCTAGCTGCTGCTGCTATGTTGTTATAA
SEQ ID NO: 29 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Vespa Magnifica, с N-концевым сигналом секреции
ATGCAATTTTCTACAGTGGCAAGTGTTGCATTCGTTGCACTAGCCAACTTTGTGGCGGCAGATAGCTGTGGGTCAAACTGCGAAAAGAGTGAGAGACCGAAAAGGGTCTTCAACATTTACTGGAACGTACCTACATTCATGTGTCACCAGTACGGACTATACTTTGACGAGGTCACGAATTTTAATATAAAGCACAACAGCAAAGACAATTTTCAAGGGGACAAGATCGCGATCTTTTATGACCCCGGGGAGTTTCCCGCTCTGCTGCCACTAAACTATGGTAAGTACAAGATCAGGAATGGTGGTGTTCCACAAGAGGGTAACATCACCATCCATCTGCAGAGATTCATAGAGTACCTAGATAAGACCTATCCGAACCGTAACTTTTCAGGCATCGGTGTGATCGATTTCGAGAGGTGGAGACCAATTTTCAGACAGAATTGGGGTAATATGAAGATTTACAAGAACTTCTCCATCGATCTTGTGCGTAAAGAGCATCCTTTCTGGAATAAGAAAATGATCGAGTTGGAAGCTTCTAAAAGATTCGAGAAATACGCCCGTCTGTTCATGGAAGAAACATTAAAGTTGGCTAAGAAAACTAGAAAACAGGCCGATTGGGGCTACTACGGTTACCCCTATTGCTTCAACATGTCTCCTACTAATTTCGTTCCTGACTGCGATGTCACAGCTAGGGATGAGAACAACGAGATGTCTTGGTTGTTTAACAACCAGAATGTCCTATTACCAAGTGTATACATTAGGAGAGAGCTAACTCCTGACCAGAGGATTGGGCTTGTACAGGGGAGAGTGAAGGAAGCTGTGAGAATTTCAAATAAACTGAAGCACTCACCTAAAGTCTTCAGCTATTGGTGGTATGTTTACCAAGACGAGACCAACACCTTCTTAACGGAGACCGACGTCAAGAAGACGTTTCAGGAGATTGTGATCAACGGTGGAGATGGGATTATAATCTGGGGTTCGTCCTCTGATGTAAACAGCTTGTCCAAGTGTACGAGGTTAAGGGAGTACCTATTGACAGTCTTGGGACCAATTGCTGTTAACGTGACTGAAGCAGTAAACTAA
SEQ ID NO: 30 представляет собой перекодированную нуклеотидную последовательность гиалуронидазы (HYAL), происходящую из Vespa Magnifica, с N-концевым сигналом секреции и С-концевым якорным сигналом
ATGCAATTTTCTACAGTGGCAAGTGTTGCATTCGTTGCACTAGCCAACTTTGTGGCGGCAGATAGCTGTGGGTCAAACTGCGAAAAGAGTGAGAGACCGAAAAGGGTCTTCAACATTTACTGGAACGTACCTACATTCATGTGTCACCAGTACGGACTATACTTTGACGAGGTCACGAATTTTAATATAAAGCACAACAGCAAAGACAATTTTCAAGGGGACAAGATCGCGATCTTTTATGACCCCGGGGAGTTTCCCGCTCTGCTGCCACTAAACTATGGTAAGTACAAGATCAGGAATGGTGGTGTTCCACAAGAGGGTAACATCACCATCCATCTGCAGAGATTCATAGAGTACCTAGATAAGACCTATCCGAACCGTAACTTTTCAGGCATCGGTGTGATCGATTTCGAGAGGTGGAGACCAATTTTCAGACAGAATTGGGGTAATATGAAGATTTACAAGAACTTCTCCATCGATCTTGTGCGTAAAGAGCATCCTTTCTGGAATAAGAAAATGATCGAGTTGGAAGCTTCTAAAAGATTCGAGAAATACGCCCGTCTGTTCATGGAAGAAACATTAAAGTTGGCTAAGAAAACTAGAAAACAGGCCGATTGGGGCTACTACGGTTACCCCTATTGCTTCAACATGTCTCCTACTAATTTCGTTCCTGACTGCGATGTCACAGCTAGGGATGAGAACAACGAGATGTCTTGGTTGTTTAACAACCAGAATGTCCTATTACCAAGTGTATACATTAGGAGAGAGCTAACTCCTGACCAGAGGATTGGGCTTGTACAGGGGAGAGTGAAGGAAGCTGTGAGAATTTCAAATAAACTGAAGCACTCACCTAAAGTCTTCAGCTATTGGTGGTATGTTTACCAAGACGAGACCAACACCTTCTTAACGGAGACCGACGTCAAGAAGACGTTTCAGGAGATTGTGATCAACGGTGGAGATGGGATTATAATCTGGGGTTCGTCCTCTGATGTAAACAGCTTGTCCAAGTGTACGAGGTTAAGGGAGTACCTATTGACAGTCTTGGGACCAATTGCTGTTAACGTGACTGAAGCAGTAAACGGATCCGCCATTTCTCAAATCACTGACGGTCAAATCCAAGCTACTACCACTGCTACCACCGAAGCTACCACCACTGCTGCCCCATCTTCCACCGTTGAAACTGTTTCTCCATCCAGCACCGAAACTATCTCTCAACAAACTGAAAATGGTGCTGCTAAGGCCGCTGTCGGTATGGGTGCCGGTGCTCTAGCTGCTGCTGCTATGTTGTTATAA
SEQ ID NO: 31 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Bothrops Atrox, с N-концевым сигналом секреции
MQFSTVASVAFVALANFVAAPMYPNEPFLVFWNAPTTQCRLRYKVDLDLKTFHIVTNANDSLSGSAVTIFYPTHLGVYpHIDDRGHFFNGIIPQNESLVKHLNKSKSDINRMIPLRTFHGLGVIDWENWRPQWDRNWGSKNVYRNRSIQFARDLHPELSEDKIKRLAKQEFEKAAKSFMRDTLLLAEEMRPDGYWGYYLYPDCHNYNYKTKPDQYTGECPDIEMSRNNQLLWLWRDSTALFPNIYLETILRSSDNALKFVHHRLKEAMRIASMARNDYALPFFVYARPFYAYTFEPLTQEDLVTTVGETADMGAAGIVFWGSMQYASTVESCGKVKDYMNGPLGRYIVNVTTAAKICSRFLCKRHGRCVRKHSDSNAFLHLFPDSFRIMVHGNATEKKVIVKGKLELKNLIFLRNNFMCQCYQGWKGLYCEKHSIKEIRKI
SEQ ID NO: 32 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Bothrops Atrox, с N-концевым сигналом секреции и С-концевым якорным сигналом
MQFSTVASVAFVALANFVAAPMYPNEPFLVFWNAPTTQCRLRYKVDLDLKTFHIVTNANDSLSGSAVTIFYPTHLGVYpHIDDRGHFFNGIIPQNESLVKHLNKSKSDINRMIPLRTFHGLGVIDWENWRPQWDRNWGSKNVYRNRSIQFARDLHPELSEDKIKRLAKQEFEKAAKSFMRDTLLLAEEMRPDGYWGYYLYPDCHNYNYKTKPDQYTGECPDIEMSRNNQLLWLWRDSTALFPNIYLETILRSSDNALKFVHHRLKEAMRIASMARNDYALPFFVYARPFYAYTFEPLTQEDLVTTVGETADMGAAGIVFWGSMQYASTVESCGKVKDYMNGPLGRYIVNVTTAAKICSRFLCKRHGRCVRKHSDSNAFLHLFPDSFRIMVHGNATEKKVIVKGKLELKNLIFLRNNFMCQCYQGWKGLYCEKHSIKEIRKIGSAISQITDGQIQATTTATTEATTTAAPSSTVETVSPSSTETISQQTENGAAKAAVGMGAGALAAAAMLL
SEQ ID NO: 33 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Cupiennius Salei, с N-концевым сигналом секреции
MQFSTVASVAFVALANFVAAFKIYWNVPTFQCTHNYKIDYVKLLSTYGIQVNDGGKFQGNQVTIFYETQLGLYPRILKSGKMENGGIPQRGNFEKHLEKASTDLQKVIPWKEFSGLGVIDWEAWRPTWEFNWEPLRIYQTESIKRAKELHPTANDSAVKEIAERQWEDSAKLYMLETLRLAKKLRPQAPWCYYLFPDCYNYVGKKPKDFQCSASIRKGNDKLSWLWKDSTALCPSIYVYESQLDRYSFEQRTWRDNEKLREALRVATRTSKIYPYVNYFDKELIPEQEVWRMLAQAAAVGGSGAVIWGSSAAVASEELCKSLKQYIIETLGPAAEKVAWRSDLCSKEICNNQGRCTFPDDDYANAWKLFTDDTVKFYAGNITCRCSENYSGRFCEKKN
SEQ ID NO: 34 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Cupiennius Salei, с N-концевым сигналом секреции и С-концевым якорным сигналом
MQFSTVASVAFVALANFVAAFKIYWNVPTFQCTHNYKIDYVKLLSTYGIQVNDGGKFQGNQVTIFYETQLGLYPRILKSGKMENGGIPQRGNFEKHLEKASTDLQKVIPWKEFSGLGVIDWEAWRPTWEFNWEPLRIYQTESIKRAKELHPTANDSAVKEIAERQWEDSAKLYMLETLRLAKKLRPQAPWCYYLFPDCYNYVGKKPKDFQCSASIRKGNDKLSWLWKDSTALCPSIYVYESQLDRYSFEQRTWRDNEKLREALRVATRTSKIYPYVNYFDKELIPEQEVWRMLAQAAAVGGSGAVIWGSSAAVASEELCKSLKQYIIETLGPAAEKVAWRSDLCSKEICNNQGRCTFPDDDYANAWKLFTDDTVKFYAGNITCRCSENYSGRFCEKKNGSAISQITDGQIQATTTATTEATTTAAPSSTVETVSPSSTETISQQTENGAAKAAVGMGAGALAAAAMLL
SEQ ID NO: 35 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Hirudo Nipponia, с N-концевым сигналом секреции
MQFSTVASVAFVALANFVAA~MKEIAVTIDDKNVIASVSESFHGVAFDASLFSPKGLWSFVDITSPKLFKLLEGLSPGYFRVGGTFANWLFFDLDENNKWKDYWAFKDKTPETATITRRWLFRKQNNLKKETFDDLVKLTKGSKMRLLFDLNAEVRTGYEIGKKMTSTWDSSEAEKLFKYCVSKGYGDNIDWELGNEPDHTSAHNLTEKQVGEDFKALHKVLEKYPTLNKGSLVGPDVGWMGVSYVKGLADGAGDHVTAFTLHQYYFDGNTSDVSTYLDATYFKKLQQLFDKVKDVLKNSpHKDKPLWLGETSSGYNSGTKDVSDRYVSGFLTLDKLGLSAANNVKVVIRQTIYNGYYGLLDKNTLEPNPDYWLMHVHNSLVGNTVFKVDVSDPTNKARVYAQCTKTNSKHTQSRYYKGSLTIFALNVGDEDVTLKIDQYSGKKIYSYILTPEGGQLTSQKVLLNGKELKLVSDQLPELNADESKTSFTLSPKTFGFFVVSDANVEACKKGSAISQITDGQIQATTTATTEATTTAAPSSTVETVSPSSTETISQQTENGAAKAAVGMGAGALAAAAMLL
SEQ ID NO: 36 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Hirudo Nipponia, с N-концевым сигналом секреции и С-концевым якорным сигналом
MQFSTVASVAFVALANFVAA~MKEIAVTIDDKNVIASVSESFHGVAFDASLFSPKGLWSFVDITSPKLFKLLEGLSPGYFRVGGTFANWLFFDLDENNKWKDYWAFKDKTPETATITRRWLFRKQNNLKKETFDDLVKLTKGSKMRLLFDLNAEVRTGYEIGKKMTSTWDSSEAEKLFKYCVSKGYGDNIDWELGNEPDHTSAHNLTEKQVGEDFKALHKVLEKYPTLNKGSLVGPDVGWMGVSYVKGLADGAGDHVTAFTLHQYYFDGNTSDVSTYLDATYFKKLQQLFDKVKDVLKNSpHKDKPLWLGETSSGYNSGTKDVSDRYVSGFLTLDKLGLSAANNVKVVIRQTIYNGYYGLLDKNTLEPNPDYWLMHVHNSLVGNTVFKVDVSDPTNKARVYAQCTKTNSKHTQSRYYKGSLTIFALNVGDEDVTLKIDQYSGKKIYSYILTPEGGQLTSQKVLLNGKELKLVSDQLPELNADESKTSFTLSPKTFGFFVVSDANVEACKK
SEQ ID NO: 37 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящей из Loxosceles Intermedia, с N-концевым сигналом секреции
MQFSTVASVAFVALANFVAAFDVFWNVPSQQCKKYGMKFVPLLEQYSILVNKEDNFKGDKITIFYESQLGLYpHIGANDESFNGGIPQLGDLKAHLEKSAVDIRRDILDKSATGLRIIDWEAWRPIWEFNWSSLRKYQDKMKKVVRQFNPTAHESTVAKLAHNEWENSSKSWMLSTLQLGKQLRPNSVWCYYLFPDCYNYDGNSVQEFQCSEAIRKGNDRLKWLWEESTAVCPSIYIKEGQLTNYTLQKRIWFTNGRLQEALRVAQPKARIYPYINYSIKPGMMVPEVEFWRLIAQIASLGMDGAVIWGSSASVGSKNHCAQLMKYIADVLGPATLRIKENVARCSKQACSGRGRCTWPKDTSVIAWKFLVEKEDYDFYLGDIECKCVEGYEGRYCEQKTK
SEQ ID NO: 38 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Loxosceles Intermedia, с N-концевым сигналом секреции и С-концевым якорным сигналом
MQFSTVASVAFVALANFVAAFDVFWNVPSQQCKKYGMKFVPLLEQYSILVNKEDNFKGDKITIFYESQLGLYpHIGANDESFNGGIPQLGDLKAHLEKSAVDIRRDILDKSATGLRIIDWEAWRPIWEFNWSSLRKYQDKMKKVVRQFNPTAHESTVAKLAHNEWENSSKSWMLSTLQLGKQLRPNSVWCYYLFPDCYNYDGNSVQEFQCSEAIRKGNDRLKWLWEESTAVCPSIYIKEGQLTNYTLQKRIWFTNGRLQEALRVAQPKARIYPYINYSIKPGMMVPEVEFWRLIAQIASLGMDGAVIWGSSASVGSKNHCAQLMKYIADVLGPATLRIKENVARCSKQACSGRGRCTWPKDTSVIAWKFLVEKEDYDFYLGDIECKCVEGYEGRYCEQKTKGSAISQITDGQIQATTTATTEATTTAAPSSTVETVSPSSTETISQQTENGAAKAAVGMGAGALAAAAMLL
SEQ ID NO: 39 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Tityus Serrulatus, с N-концевым сигналом секреции
MQFSTVASVAFVALANFVAAADFKVYWEVPSFLCSKRFKINVTEVLTSHEILVNQGESFNGDKIVIFYENQLGKYpHIDSNNVEINGGILQVADLAKHLKVAKDNITKFVPNPNFNGVGVIDWEAWRPSWEFNWGKLKVYKEKSIDLVKSKHPEWPSDRVEKVAKEEWEESAKEWMVKTLKLAQEMRPNAVWCYYLFPDCYNYFGKDQPSQFSCSSRIQKENSRLSWLWNQSTAICLSIYIQESHVTKYNMSQRTWWIDARLREAIRVSEHRPNIPIYPYINYILPGTNQTVPAMDFKRTLGQIASLGLDGALLWGSSYHVLTESQCKITSDYVKSVIAPTVATVVLNTNRCSQIICKGRGNCVWPEEPFSSWKYLVDPKMPVFKPTNIHCKCKGYLGRYCEIPK
SEQ ID NO: 40 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Tityus Serrulatus, с N-концевым сигналом секреции и С-концевым якорным сигналом
MQFSTVASVAFVALANFVAAADFKVYWEVPSFLCSKRFKINVTEVLTSHEILVNQGESFNGDKIVIFYENQLGKYpHIDSNNVEINGGILQVADLAKHLKVAKDNITKFVPNPNFNGVGVIDWEAWRPSWEFNWGKLKVYKEKSIDLVKSKHPEWPSDRVEKVAKEEWEESAKEWMVKTLKLAQEMRPNAVWCYYLFPDCYNYFGKDQPSQFSCSSRIQKENSRLSWLWNQSTAICLSIYIQESHVTKYNMSQRTWWIDARLREAIRVSEHRPNIPIYPYINYILPGTNQTVPAMDFKRTLGQIASLGLDGALLWGSSYHVLTESQCKITSDYVKSVIAPTVATVVLNTNRCSQIICKGRGNCVWPEEPFSSWKYLVDPKMPVFKPTNIHCKCKGYLGRYCEIPKGSAISQITDGQIQATTTATTEATTTAAPSSTVETVSPSSTETISQQTENGAAKAAVGMGAGALAAAAMLL
SEQ ID NO: 41 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Vespa Magnifica, с N-концевым сигналом секреции
MQFSTVASVAFVALANFVAADSCGSNCEKSERPKRVFNIYWNVPTFMCHQYGLYFDEVTNFNIKHNSKDNFQGDKIAIFYDPGEFPALLPLNYGKYKIRNGGVPQEGNITIHLQRFIEYLDKTYPNRNFSGIGVIDFERWRPIFRQNWGNMKIYKNFSIDLVRKEHPFWNKKMIELEASKRFEKYARLFMEETLKLAKKTRKQADWGYYGYPYCFNMSPTNFVPDCDVTARDENNEMSWLFNNQNVLLPSVYIRRELTPDQRIGLVQGRVKEAVRISNKLKHSPKVFSYWWYVYQDETNTFLTETDVKKTFQEIVINGGDGIIIWGSSSDVNSLSKCTRLREYLLTVLGPIAVNVTEAVN
SEQ ID NO: 42 представляет собой аминокислотную последовательность гиалуронидазы (HYAL), происходящую из Vespa Magnifica, с N-концевым сигналом секреции и С-концевым якорным сигналом
MQFSTVASVAFVALANFVAADSCGSNCEKSERPKRVFNIYWNVPTFMCHQYGLYFDEVTNFNIKHNSKDNFQGDKIAIFYDPGEFPALLPLNYGKYKIRNGGVPQEGNITIHLQRFIEYLDKTYPNRNFSGIGVIDFERWRPIFRQNWGNMKIYKNFSIDLVRKEHPFWNKKMIELEASKRFEKYARLFMEETLKLAKKTRKQADWGYYGYPYCFNMSPTNFVPDCDVTARDENNEMSWLFNNQNVLLPSVYIRRELTPDQRIGLVQGRVKEAVRISNKLKHSPKVFSYWWYVYQDETNTFLTETDVKKTFQEIVINGGDGIIIWGSSSDVNSLSKCTRLREYLLTVLGPIAVNVTEAVNAISQITDGQIQATTTATTEATTTAAPSSTVETVSPSSTETISQQTENGAAKAAVGMGAGALAAAAMLL
SEQ ID NO: 43 представляет собой нуклеотидную последовательность последовательности секреции, добавленной в 5’
ATGCAATTTAGCACAGTCGCATCAGTAGCCTTCGTTGCCTTGGCCAACTTCGTGGCAGCA
SEQ ID NO: 44 представляет собой аминокислотную последовательность последовательности секреции, добавленной в N-конце
MQFSTVASVAFVALANFVAA
SEQ ID NO: 45 представляет собой нуклеотидную последовательность якорной последовательности, добавленной в 3’
GGATCCGCCATTTCTCAAATCACTGACGGTCAAATCCAAGCTACTACCACTGCTACCACCGAAGCTACCACCACTGCTGCCCCATCTTCCACCGTTGAAACTGTTTCTCCATCCAGCACCGAAACTATCTCTCAACAAACTGAAAATGGTGCTGCTAAGGCCGCTGTCGGTATGGGTGCCGGTGCTCTAGCTGCTGCTGCTATGTTGTTATAA
SEQ ID NO: 46 представляет собой аминокислотную последовательность якорной последовательности, добавленной в C-конце
AISQITDGQIQATTTATTEATTTAAPSSTVETVSPSSTETISQQTENGAAKAAVGMGAGALAAAAMLL
SEQ ID NO: 47 представляет собой нуклеотидную последовательность глутамин-фруктозо-6-фосфатамидотрансферазы (GFA1), происходящую из Saccharomyces Cerevisiae
ATGTGTGGTATCTTTGGTTACTGCAATTATCTAGTGGAAAGATCCAGAGGAGAAATTATCGACACCTTAGTGGATGGTTTACAAAGATTAGAATATAGAGGCTATGATTCCACCGGTATTGCTATCGATGGTGACGAAGCTGATTCTACTTTCATCTATAAGCAAATCGGTAAAGTGAGTGCTTTGAAAGAGGAGATTACTAAGCAAAATCCGAACAGAGACGTTACTTTTGTCTCTCATTGTGGTATTGCGCATACTAGATGGGCTACTCACGGTCGACCAGAACAAGTTAACTGTCACCCTCAAAGATCTGACCCAGAAGACCAATTTGTGGTCGTTCATAATGGTATCATCACAAATTTTAGAGAACTGAAGACTCTTTTAATTAACAAAGGTTATAAATTCGAAAGTGATACCGATACCGAGTGTATTGCTAAACTATATTTGCATTTATACAATACAAATTTACAAAATGGGCATGACTTAGATTTCCACGAATTAACCAAGCTAGTTCTTTTAGAACTAGAAGGTTCATACGGGTTATTATGTAAATCTTGTCACTATCCTAATGAGGTTATCGCCACTAGAAAAGGGTCCCCTTTACTGATTGGTGTCAAATCTGAAAAAAAACTAAAAGTCGACTTCGTGGATGTGGAATTTCCCGAAGAAAACGCTGGTCAACCGGAAATTCCATTGAAATCTAACAACAAATCATTTGGCTTGGGCCCAAAGAAAGCTCGTGAATTTGAAGCTGGTTCCCAAAATGCCAATTTACTACCAATTGCCGCCAATGAATTTAACTTGAGACATTCTCAATCCAGGGCTTTCCTATCAGAAGATGGATCTCCAACACCGGTGGAATTTTTTGTTTCTTCGGATGCGGCATCTGTTGTTAAACATACCAAGAAGGTGCTATTTTTAGAAGATGACGATTTGGCTCATATTTACGATGGTGAGTTACATATTCATAGATCTAGAAGAGAAGTAGGCGCATCAATGACAAGGTCCATTCAAACTTTAGAGATGGAGTTAGCTCAGATCATGAAGGGCCCTTACGACCATTTTATGCAAAAGGAAATCTATGAGCAACCAGAATCTACTTTCAATACTATGAGAGGTAGAATCGACTATGAAAATAATAAAGTGATATTGGGTGGTTTAAAGGCATGGTTACCAGTTGTCAGAAGAGCACGGAGACTGATCATGATCGCATGCGGTACTTCTTATCATTCATGTTTGGCTACTCGTGCTATCTTCGAAGAATTATCAGATATCCCAGTTAGTGTGGAATTAGCGTCTGACTTTCTGGACAGAAAATGCCCTGTCTTCAGAGACGATGTATGCGTGTTTGTTTCACAAAGTGGTGAAACTGCGGATACCATGCTGGCTCTAAATTATTGTTTAGAAAGAGGAGCCTTAACTGTCGGAATTGTTAACAGTGTTGGTTCTTCTATCTCTCGTGTCACCCACTGTGGTGTTCATATTAACGCTGGTCCTGAAATTGGTGTTGCCTCTACAAAAGCTTATACTTCCCAGTATATTGCCTTAGTGATGTTTGCTCTATCGCTGTCAGATGACCGTGTATCGAAAATAGACAGAAGAATTGAAATCATTCAAGGCTTGAAGTTAATCCCGGGCCAAATTAAGCAGGTATTAAAGCTGGAACCAAGAATAAAAAAGCTCTGTGCGACTGAATTAAAGGATCAAAAATCTCTATTGTTATTGGGTAGAGGTTACCAATTTGCTGCTGCTCTGGAAGGTGCTTTGAAGATCAAAGAAATTTCTTATATGCATTCTGAAGGTGTTTTGGCAGGTGAGTTGAAGCACGGTGTCTTGGCCTTGGTGGACGAAAACTTGCCAATCATTGCTTTTGGTACCAGAGACTCTCTATTCCCTAAAGTAGTTTCCTCTATTGAGCAAGTTACTGTAAGAAAGGGCCATCCAATTATTATTTGTAACGAAAATGATGAAGTGTGGGCGCAAAAATCTAAATCAATCGACCTGCAAACCTTAGAAGTTCCACAAACTGTTGATTGTTTACAAGGTCTAATTAATATTATTCCATTACAACTAATGTCATATTGGTTGGCTGTTAATAAAGGGATTGATGTTGATTTTCCAAGAAACTTGGCTAAATCTGTTACCGTCGAATAA
SEQ ID NO: 48 представляет собой перекодированную нуклеотидную последовательность глутамин-фруктозо-6-фосфатамидотрансферазы (GFA1), происходящую из вируса хлореллы 1 (PBCV-1)
ATGTGCGGGATCTTCGGTGCTGTGTCGAACAATAATAGCATAGAAGTTTCCATCAAGGGTATACAGAAGCTAGAGTACCGCGGGTACGATTCGTGTGGAATAGCCTATACAGACGGAGGCGCCATTGAACGGATCAGGTCAATAGATGGGATCGACGACTTAAGGAAGAAAACAATAACAGAGTCTTCCCCGGTAGCTATCGCTCATTCAAGGTGGAGTACCACTGGGATTCCAAGTGTTGTGAACGCCCACCCGCACATCTCTCGGGGCACGTCTGGATGCGAGTCGCGCATTGCAGTCGTACACAATGGCATTATTGAAAATTACCAGCAGATCCGCAAGTACTTGATAAATCTTGGGTATACTTTCGATTCACAGACCGACACGGAAGTCATTGCTCATCTAATAGACTCGCAGTATAACGGGAACATCCTGCACACCGTCCAAATGGCAGTTAAGCACCTCAAAGGAAGCTACGCCATAGCAGTCATGTGCCATAAGGAGTCCGGGAAGATCGTGGTGGCAAAACAGAAGAGTCCGTTGGTATTGGGTATAGGAAGCGACGGAGCTTATTATATCGCATCGGACGTATTGGCTCTTCCCACTAACAAAGTGGTCTACATAAGTGACGGATTCTCTGCTGAGTTAAGTCCTGGATCGATGACTATCTATGATCTGGATGGCAATAAGGTAGAATACGAGGTGGAAGACGTTGAAATGGAGCAGACGTCGATGTCTTTAGATAACTTTGATCACTACATGATCAAAGAGATCAATGAACAGCCGATATCAATTCTCAATACTATTAAGAACAAAGGATTCTATGCAGAGATATTTGGTGATCTAGCACATGAAATATTTCAGAAGATCGACAATATATTGATTCTAGCCTGCGGAACTTCGTATCATGCAGGTCTCGTCGGGAAGCAATGGATAGAGACCATCTCACGCATCCCGGTGGATGTTCATATTGCAAGCGAGTATGAGCCGACAATTCCACGAGCCAATACACTTGTGATAACGATTAGTCAAAGCGGCGAGACTGCGGATACAATCGCAGCCCTTCAACGAGCGCAAAACGCAGGAATGATATACACTTTGTGTATCTGCAACAGCCCCAAGTCAACTCTAGTGCGCGAGTCGATAATGAAATACATAACCAAATGCGGTTCAGAAGTTTCTGTTGCCAGTACTAAAGCATTTACGTCGCAACTTGTGGTGTTGTATATGCTTGCGAACGTTCTTGCGAACAAAACTGATGATCTGCTAGGGGATCTTCCTCAAGCTATCGAGAGAGTAATCTGTCTTACTAATGACGAAATGAAGCGTTGGGCGGATGAAATTTGTACTGCCAAAAGTGCCATCTTCTTAGGGAGAGGACTGAACGCACCTGTAGCATTTGAGGGCGCGCTAAAGTTGAAGGAAATCTCATATATCCATGCCGAGGGTTTCCTCGGTGGAGAGTTGAAGCATGGGCCGCTGGCTTTGTTGGACGATAAGATCCCTGTAATCGTGACTGTTGCTGACCACGCTTATTTGGATCACATTAAGGCTAACATCGACGAGGTATTGGCACGAAACGTTACCGTATACGCGATCGTCGATCAGTATGTTAATATTGAACCACAGGAGCGACTGCATGTAGTAAAAGTGCCGTTTGTGAGTAAAGAGTTTTCTCCCATCATCCACACAATTCCGATGCAATTGTTATCGTATTATGTCGCGATCAAGCTGGGCAAGAACGTTGACAAGCCACGTAACCTGGCGAAAAGTGTTACAACATTCtaa
SEQ ID NO: 49 представляет собой перекодированную нуклеотидную последовательность глутамин-фруктозо-6-фосфатамидотрансферазы (GFA1), происходящую из вируса хлореллы 1 (PBCV-1)
ATGTGTGGCATCTTTGGAGCAGTGTCAAACAACAACTCTATCGAGGTGTCAATCAAGGGTATTCAGAAGCTAGAATATCGTGGGTATGATTCGTGCGGTATTGCGTATACAGATGGGGGTGCGATTGAGCGTATACGTTCTATTGACGGCATTGACGATCTGCGTAAGAAAACAATCACAGAATCATCACCAGTGGCCATTGCTCACTCGCGGTGGAGCACCACTGGAATTCCATCAGTGGTGAACGCACATCCTCATATTTCTCGCGGAACCAGTGGGTGTGAGTCTCGTATCGCGGTAGTCCACAACGGTATCATTGAAAACTATCAGCAGATCCGAAAATATCTCATCAATCTTGGTTATACGTTTGATAGTCAAACGGACACAGAGGTCATTGCGCATTTGATTGATTCTCAGTACAATGGGAATATCTTGCACACCGTCCAAATGGCTGTCAAGCACCTGAAGGGCTCTTATGCCATTGCAGTTATGTGTCATAAAGAGTCTGGTAAAATAGTCGTGGCGAAACAGAAGTCACCCCTCGTACTTGGAATCGGCTCAGATGGTGCTTACTACATCGCTTCGGACGTGCTGGCGCTGCCGACAAATAAAGTTGTTTATATTTCAGACGGTTTCTCCGCAGAACTATCTCCAGGGAGTATGACCATTTACGATCTTGATGGAAATAAAGTAGAATATGAAGTAGAGGACGTTGAAATGGAACAAACTAGTATGTCTCTCGATAACTTTGATCATTACATGATTAAGGAAATTAATGAGCAACCAATCAGTATTCTAAACACTATAAAAAATAAAGGGTTCTATGCAGAAATATTCGGTGATTTGGCTCATGAAATCTTCCAAAAAATAGACAACATCCTGATACTGGCTTGTGGTACAAGTTATCACGCCGGTCTTGTAGGAAAACAGTGGATAGAGACCATCTCtAGAATCCCCGTGGATGTTCACATCGCGAGTGAATACGAACCTACTATTCCGAGAGCGAACACATTGGTAATCACTATTTCACAGTCGGGTGAAACTGCGGACACGATAGCGGCTTTGCAACGGGCCCAAAACGCCGGGATGATTTATACATTGTGTATTTGCAATTCACCAAAGAGCACTCTTGTTCGTGAGAGCATTATGAAGTACATCACGAAATGTGGTTCTGAGGTGTCAGTGGCATCAACGAAGGCGTTTACTTCTCAGCTCGTAGTACTGTACATGCTGGCAAACGTATTGGCAAATAAAACCGATGATTTGCTGGGAGACCTCCCACAGGCAATAGAACGGGTAATTTGTTTGACAAATGACGAAATGAAACGATGGGCCGACGAAATTTGCACTGCGAAATCCGCGATCTTCCTGGGAAGAGGACTAAACGCACCAGTTGCCTTTGAGGGAGCGTTGAAGCTCAAAGAAATCTCTTACATTCATGCAGAGGGCTTCCTGGGAGGTGAGTTGAAACACGGCCCCCTCGCACTCCTTGATGACAAGATTCCTGTTATCGTAACCGTAGCAGATCATGCTTATTTGGACCATATCAAAGCAAATATCGACGAAGTGCTTGCGAGGAACGTTACGGTATACGCCATAGTAGACCAGTATGTGAACATCGAGCCCCAGGAACGCCTTCACGTCGTCAAGGTTCCGTTTGTATCCAAAGAATTTTCTCCGATAATTCACACTATCCCGATGCAACTGCTTTCGTATTACGTGGCAATTAAGCTTGGAAAGAACGTTGACAAACCAAGGAATCTTGCAAAATCCGTGACTACCTTTTAA
SEQ ID NO: 50 представляет собой аминокислотную последовательность глутамин-фруктозо-6-фосфатамидотрансферазы (GFA1), происходящую из Saccharomyces Cerevisiae
MCGIFGYCNYLVERSRGEIIDTLVDGLQRLEYRGYDSTGIAIDGDEADSTFIYKQIGKVSALKEEITKQNPNRDVTFVSHCGIAHTRWATHGRPEQVNCHPQRSDPEDQFVVVHNGIITNFRELKTLLINKGYKFESDTDTECIAKLYLHLYNTNLQNGHDLDFHELTKLVLLELEGSYGLLCKSCHYPNEVIATRKGSPLLIGVKSEKKLKVDFVDVEFPEENAGQPEIPLKSNNKSFGLGPKKAREFEAGSQNANLLPIAANEFNLRHSQSRAFLSEDGSPTPVEFFVSSDAASVVKHTKKVLFLEDDDLAHIYDGELHIHRSRREVGASMTRSIQTLEMELAQIMKGPYDHFMQKEIYEQPESTFNTMRGRIDYENNKVILGGLKAWLPVVRRARRLIMIACGTSYHSCLATRAIFEELSDIPVSVELASDFLDRKCPVFRDDVCVFVSQSGETADTMLALNYCLERGALTVGIVNSVGSSISRVTHCGVHINAGPEIGVASTKAYTSQYIALVMFALSLSDDRVSKIDRRIEIIQGLKLIPGQIKQVLKLEPRIKKLCATELKDQKSLLLLGRGYQFAAALEGALKIKEISYMHSEGVLAGELKHGVLALVDENLPIIAFGTRDSLFPKVVSSIEQVTARKGHPIIICNENDEVWAQKSKSIDLQTLEVPQTVDCLQGLINIIPLQLMSYWLAVNKGIDVDFPRNLAKSVTVE
SEQ ID NO: 51 представляет собой аминокислотную последовательность глутамин-фруктозо-6-фосфатамидотрансферазы (GFA1), происходящую из вируса хлореллы 1 (PBCV-1)
MCGIFGAVSNNNSIEVSIKGIQKLEYRGYDSCGIAYTDGGAIERIRSIDGIDDLRKKTITESSPVAIAHSRWSTTGIPSVVNAHpHISRGTSGCESRIAVVHNGIIENYQQIRKYLINLGYTFDSQTDTEVIAHLIDSQYNGNILHTVQMAVKHLKGSYAIAVMCHKESGKIVVAKQKSPLVLGIGSDGAYYIASDVLALPTNKVVYISDGFSAELSPGSMTIYDLDGNKVEYEVEDVEMEQTSMSLDNFDHYMIKEINEQPISILNTIKNKGFYAEIFGDLAHEIFQKIDNILILACGTSYHAGLVGKQWIETISRIPVDVHIASEYEPTIPRANTLVITISQSGETADTIAALQRAQNAGMIYTLCICNSPKSTLVRESIMKYITKCGSEVSVASTKAFTSQLVVLYMLANVLANKTDDLLGDLPQAIERVICLTNDEMKRWADEICTAKSAIFLGRGLNAPVAFEGALKLKEISYIHAEGFLGGELKHGPLALLDDKIPVIVTVADHAYLDHIKANIDEVLARNVTVYAIVDQYVNIEPQERLHVVKVPFVSKEFSPIIHTIPMQLLSYYVAIKLGKNVDKPRNLAKSVTTF
SEQ ID NO: 52 представляет собой нуклеотидную последовательность UDP-N-ацетилглюкозаминпирофосфорилазы (QRI1), происходящую из Saccharomyces Cerevisiae
ATGACTGACACAAAACAGCTATTCATTGAAGCCGGACAAAGTCAACTTTTCCACAATTGGGAAAGCTTGTCTCGCAAAGACCAAGAAGAATTGCTTTCAAACCTGGAGCAAATATCTTCCAAGAGGTCCCCTGCAAAACTACTGGAAGACTGTCAAAATGCTATTAAATTCTCACTAGCTAACTCTTCTAAGGATACTGGCGTCGAAATTTCACCATTGCCCCCTACTTCGTACGAGTCGCTTATTGGCAACAGTAAGAAAGAAAATGAATACTGGCGTTTAGGCCTTGAAGCTATTGGCAAGGGTGAAGTCGCAGTGATTTTAATGGCTGGCGGACAAGGTACGCGGTTAGGATCCTCTCAACCAAAGGGCTGTTACGACATTGGATTGCCTTCTAAGAAATCTCTTTTTCAAATTCAAGCTGAAAAGTTGATCAGGTTGCAAGATATGGTAAAGGACAAAAAGGTAGAAATTCCTTGGTATATTATGACATCAGGCCCCACTAGAGCGGCTACTGAGGCATACTTTCAAGAACACAATTATTTTGGCTTGAATAAAGAACAAATTACGTTCTTCAACCAGGGAACCCTGCCTGCCTTTGATTTAACCGGGAAGCATTTCCTAATGAAAGACCCAGTAAACCTATCTCAATCACCAGATGGAAATGGTGGACTCTACCGTGCCATCAAGGAAAACAAGTTGAACGAAGACTTTGATAGGAGAGGAATCAAGCATGTTTACATGTACTGTGTCGATAATGTCCTATCTAAAATCGCAGACCCTGTATTTATTGGTTTTGCCATCAAGCATGGCTTCGAACTGGCCACCAAAGCCGTTAGAAAGAGAGATGCGCATGAATCAGTTGGGTTAATTGCTACTAAAAACGAGAAACCATGTGTCATAGAATATTCTGAAATTTCCAATGAATTGGCTGAAGCAAAGGATAAAGATGGCTTATTAAAACTACGCGCAGGCAACATTGTAAATCATTATTACCTAGTGGATTTACTAAAACGTGATTTGGATCAGTGGTGTGAGAATATGCCATATCACATTGCGAAGAAGAAAATTCCAGCTTATGATAGTGTTACCGGCAAGTACACTAAGCCTACCGAACCAAACGGTATAAAATTAGAGCAATTCATATTTGATGTCTTTGACACTGTACCACTGAACAAGTTTGGGTGCTTAGAAGTAGATAGATGCAAAGAATTTTCACCTTTAAAAAACGGTCCTGGTTCTAAGAACGATAATCCTGAGACCAGCAGACTAGCATATTTGAAACTAGGAACCTCGTGGTTGGAAGATGCAGGCGCTATTGTAAAAGATGGGGTACTAGTCGAAGTTTCCAGCAAATTGAGTTATGCAGGTGAAAATCTATCCCAGTTCAAAGGTAAAGTCTTTGACAGAAGTGGTATAGTATTAGAAAAATAA
SEQ ID NO: 53 представляет собой аминокислотную последовательность UDP-N-ацетилглюкозаминпирофосфорилазы (QRI1), происходящую из Saccharomyces Cerevisiae
MTDTKQLFIEAGQSQLFHNWESLSRKDQEELLSNLEQISSKRSPAKLLEDCQNAIKFSLANSSKDTGVEISPLPPTSYESLIGNSKKENEYWRLGLEAIGKGEVAVILMAGGQGTRLGSSQPKGCYDIGLPSKKSLFQIQAEKLIRLQDMVKDKKVEIPWYIMTSGPTRAATEAYFQEHNYFGLNKEQITFFNQGTLPAFDLTGKHFLMKDPVNLSQSPDGNGGLYRAIKENKLNEDFDRRGIKHVYMYCVDNVLSKIADPVFIGFAIKHGFELATKAVRKRDAHESVGLIATKNEKPCVIEYSEISNELAEAKDKDGLLKLRAGNIVNHYYLVDLLKRDLDQWCENMPYHIAKKKIPAYDSVTGKYTKPTEPNGIKLEQFIFDVFDTVPLNKFGCLEVDRCKEFSPLKNGPGSKNDNPETSRLAYLKLGTSWLEDAGAIVKDGVLVEVSSKLSYAGENLSQFKGKVFDRSGIVLEK
SEQ ID NO: 54 представляет собой нуклеотидную последовательность фосфоглюкомутазы-1 (PGM1), происходящую из Saccharomyces Cerevisiae
ATGTCACTTCTAATAGATTCTGTACCAACAGTTGCTTATAAGGACCAAAAACCGGGTACTTCAGGTTTACGTAAGAAGACCAAGGTTTTCATGGATGAGCCTCATTATACTGAGAACTTCATTCAAGCAACAATGCAATCTATCCCTAATGGCTCAGAGGGAACCACTTTAGTTGTTGGAGGAGATGGTCGTTTCTACAACGATGTTATCATGAACAAGATTGCCGCAGTAGGTGCTGCAAACGGTGTCAGAAAGTTAGTCATTGGTCAAGGCGGTTTACTTTCAACACCAGCTGCTTCTCATATAATTAGAACATACGAGGAAAAGTGTACCGGTGGTGGTATCATATTAACTGCCTCACACAACCCAGGCGGTCCAGAGAATGATTTAGGTATCAAGTATAATTTACCTAATGGTGGGCCAGCTCCAGAGAGTGTCACTAACGCTATCTGGGAAGCGTCTAAAAAATTAACTCACTATAAAATTATAAAGAACTTCCCCAAGTTGAATTTGAACAAGCTTGGTAAAAACCAAAAATATGGCCCATTGTTAGTGGACATAATTGATCCTGCCAAAGCATACGTTCAATTTCTGAAGGAAATTTTTGATTTTGACTTAATTAAAAGCTTCTTAGCGAAACAGCGCAAAGACAAAGGGTGGAAGTTGTTGTTTGACTCCTTAAATGGTATTACAGGACCATATGGTAAGGCTATATTTGTTGATGAATTTGGTTTACCGGCAGAGGAAGTTCTTCAAAATTGGCACCCTTTACCTGATTTCGGCGGTTTACATCCCGATCCGAATCTAACCTATGCACGAACTCTTGTTGACAGGGTTGACCGCGAAAAAATTGCCTTTGGAGCAGCCTCCGATGGTGATGGTGATAGGAATATGATTTACGGTTATGGCCCTGCTTTCGTTTCGCCAGGTGATTCTGTTGCCATTATTGCCGAATATGCACCCGAAATTCCATACTTCGCCAAACAAGGTATTTATGGCTTGGCACGTTCATTTCCTACATCCTCAGCCATTGATCGTGTTGCAGCAAAAAAGGGATTAAGATGTTACGAAGTTCCAACCGGCTGGAAATTCTTCTGTGCCTTATTTGATGCTAAAAAGCTATCAATCTGTGGTGAAGAATCCTTCGGTACAGGTTCCAATCATATCAGAGAAAAGGACGGTCTATGGGCCATTATTGCTTGGTTAAATATCTTGGCTATCTACCATAGGCGTAACCCTGAAAAGGAAGCTTCGATCAAAACTATTCAGGACGAATTTTGGAACGAGTATGGCCGTACTTTCTTCACAAGATACGATTACGAACATATCGAATGCGAGCAGGCCGAAAAAGTTGTAGCTCTTTTGAGTGAATTTGTATCAAGGCCAAACGTTTGTGGCTCCCACTTCCCAGCTGATGAGTCTTTAACCGTTATCGATTGTGGTGATTTTTCGTATAGAGATCTAGATGGCTCCATCTCTGAAAATCAAGGCCTTTTCGTAAAGTTTTCGAATGGGACTAAATTTGTTTTGAGGTTATCCGGCACAGGCAGTTCTGGTGCAACAATAAGATTATACGTAGAAAAGTATACTGATAAAAAGGAGAACTATGGCCAAACAGCTGACGTCTTCTTGAAACCCGTCATCAACTCCATTGTAAAATTCTTAAGATTTAAAGAAATTTTAGGAACAGACGAACCAACAGTCCGCACATAG
SEQ ID NO: 55 представляет собой аминокислотную последовательность фосфоглюкомутазы-1 (PGM1), происходящую из Saccharomyces Cerevisiae
MSLLIDSVPTVAYKDQKPGTSGLRKKTKVFMDEpHYTENFIQATMQSIPNGSEGTTLVVGGDGRFYNDVIMNKIAAVGAANGVRKLVIGQGGLLSTPAASHIIRTYEEKCTGGGIILTASHNPGGPENDLGIKYNLPNGGPAPESVTNAIWEASKKLTHYKIIKNFPKLNLNKLGKNQKYGPLLVDIIDPAKAYVQFLKEIFDFDLIKSFLAKQRKDKGWKLLFDSLNGITGPYGKAIFVDEFGLPAEEVLQNWHPLPDFGGLHPDPNLTYARTLVDRVDREKIAFGAASDGDGDRNMIYGYGPAFVSPGDSVAIIAEYAPEIPYFAKQGIYGLARSFPTSSAIDRVAAKKGLRCYEVPTGWKFFCALFDAKKLSICGEESFGTGSNHIREKDGLWAIIAWLNILAIYHRRNPEKEASIKTIQDEFWNEYGRTFFTRYDYEHIECEQAEKVVALLSEFVSRPNVCGSHFPADESLTVIDCGDFSYRDLDGSISENQGLFVKFSNGTKFVLRLSGTGSSGATIRLYVEKYTDKKENYGQTADVFLKPVINSIVKFLRFKEILGTDEPTVRT
SEQ ID NO: 56 представляет собой нуклеотидную последовательность UTP-глюкозо-1-фосфат-уридилилтрансферазы (UGP1), происходящую из Saccharomyces Cerevisiae
ATGTCCACTAAGAAGCACACCAAAACACATTCCACTTATGCATTCGAGAGCAACACAAACAGCGTTGCTGCCTCACAAATGAGAAACGCCTTAAACAAGTTGGCGGACTCTAGTAAACTTGACGATGCTGCTCGCGCTAAGTTTGAGAACGAACTGGATTCGTTTTTCACGCTTTTCAGGAGATATTTGGTAGAGAAGTCTTCTAGAACCACCTTGGAATGGGACAAGATCAAGTCTCCCAACCCGGATGAAGTGGTTAAGTATGAAATTATTTCTCAGCAGCCCGAGAATGTCTCAAACCTTTCCAAATTGGCTGTTTTGAAGTTGAACGGTGGGCTGGGTACCTCCATGGGCTGCGTTGGCCCTAAATCTGTTATTGAAGTGAGAGAGGGAAACACCTTTTTGGATTTGTCTGTTCGTCAAATTGAATACTTGAACAGACAGTACGATAGCGACGTGCCATTGTTATTGATGAATTCTTTCAACACTGACAAGGATACGGAACACTTGATTAAGAAGTATTCCGCTAACAGAATCAGAATCAGATCTTTCAATCAATCCAGGTTCCCAAGAGTCTACAAGGATTCTTTATTGCCTGTCCCCACCGAATACGATTCTCCACTGGATGCTTGGTATCCACCAGGTCACGGTGATTTGTTTGAATCTTTACACGTATCTGGTGAACTGGATGCCTTAATTGCCCAAGGAAGAGAAATATTATTTGTTTCTAACGGTGACAACTTGGGTGCTACCGTCGACTTAAAAATTTTAAACCACATGATCGAGACTGGTGCCGAATATATAATGGAATTGACTGATAAGACCAGAGCCGATGTTAAAGGTGGTACTTTGATTTCTTACGATGGTCAAGTCCGTTTATTGGAAGTCGCCCAAGTTCCAAAAGAACACATTGACGAATTCAAAAATATCAGAAAGTTTACCAACTTCAACACGAATAACTTATGGATCAATCTGAAAGCAGTAAAGAGGTTGATCGAATCGAGCAATTTGGAGATGGAAATCATTCCAAACCAAAAAACTATAACAAGAGACGGTCATGAAATTAATGTCTTACAATTAGAAACCGCTTGTGGTGCTGCTATCAGGCATTTTGATGGTGCTCACGGTGTTGTCGTTCCAAGATCAAGATTCTTGCCTGTCAAGACCTGTTCCGATTTGTTGCTGGTTAAATCAGATCTATTCCGTCTGGAACACGGTTCTTTGAAGTTAGACCCATCCCGTTTTGGTCCAAACCCATTAATCAAGTTGGGCTCGCATTTCAAAAAGGTTTCTGGTTTTAACGCAAGAATCCCTCACATCCCAAAAATCGTCGAGCTAGATCATTTGACCATCACTGGTAACGTCTTTTTAGGTAAAGATGTCACTTTGAGGGGTACTGTCATCATCGTTTGCTCCGACGGTCATAAAATCGATATTCCAAACGGCTCCATATTGGAAAATGTTGTCGTTACTGGTAATTTGCAAATCTTGGAACATTGA
SEQ ID NO: 57 представляет собой аминокислотную последовательность UTP-глюкозо-1-фосфат-уридилилтрансферазы (UGP1), происходящую из Saccharomyces Cerevisiae
MSTKKHTKTHSTYAFESNTNSVAASQMRNALNKLADSSKLDDAARAKFENELDSFFTLFRRYLVEKSSRTTLEWDKIKSPNPDEVVKYEIISQQPENVSNLSKLAVLKLNGGLGTSMGCVGPKSVIEVREGNTFLDLSVRQIEYLNRQYDSDVPLLLMNSFNTDKDTEHLIKKYSANRIRIRSFNQSRFPRVYKDSLLPVPTEYDSPLDAWYPPGHGDLFESLHVSGELDALIAQGREILFVSNGDNLGATVDLKILNHMIETGAEYIMELTDKTRADVKGGTLISYDGQVRLLEVAQVPKEHIDEFKNIRKFTNFNTNNLWINLKAVKRLIESSNLEMEIIPNQKTITRDGHEINVLQLETACGAAIRHFDGAHGVVVPRSRFLPVKTCSDLLLVKSDLFRLEHGSLKLDPSRFGPNPLIKLGSHFKKVSGFNARIpHIPKIVELDHLTITGNVFLGKDVTLRGTVIIVCSDGHKIDIPNGSILENVVVTGNLQILEH
SEQ ID NO: 58 представляет собой нуклеотидную последовательность глюкозамин-6-фосфат-n-ацетилтрансферазы (GNA1), происходящую из Saccharomyces Cerevisiae
ATGAGCTTACCCGATGGATTTTATATAAGGCGAATGGAAGAGGGGGATTTGGAACAGGTCACTGAGACGCTAAAGGTTTTGACCACCGTGGGCACTATTACCCCCGAATCCTTCAGCAAACTCATAAAATACTGGAATGAAGCCACAGTATGGAATGATAACGAAGATAAAAAAATAATGCAATATAACCCCATGGTGATTGTGGACAAGCGCACCGAGACGGTTGCCGCTACGGGGAATATCATCATCGAAAGAAAGATCATTCATGAACTGGGGCTATGTGGCCACATCGAGGACATTGCAGTAAACTCCAAGTATCAGGGCCAAGGTTTGGGCAAGCTCTTGATTGATCAATTGGTAACTATCGGCTTTGACTACGGTTGTTATAAGATTATTTTAGATTGCGATGAGAAAAATGTCAAATTCTATGAAAAATGTGGGTTTAGCAACGCAGGCGTGGAAATGCAAATTAGAAAATAG
SEQ ID NO: 59 представляет собой аминокислотную последовательность глюкозамин-6-фосфат-n-ацетилтрансферазы (GNA1), происходящую из Saccharomyces Cerevisiae
MSLPDGFYIRRMEEGDLEQVTETLKVLTTVGTITPESFSKLIKYWNEATVWNDNEDKKIMQYNPMVIVDKRTETVAATGNIIIERKIIHELGLCGHIEDIAVNSKYQGQGLGKLLIDQLVTIGFDYGCYKIILDCDEKNVKFYEKCGFSNAGVEMQIRK
SEQ ID NO: 60 представляет собой нуклеотидную последовательность фосфоацетилглюкозаминмутазы (pcm1), происходящую из Saccharomyces Cerevisiae
ATGAAGGTTGATTACGAGCAATTGTGCAAACTCTACGATGACACGTGCCGCACAAAGAATGTGCAGTTCAGTTACGGTACGGCCGGATTCAGAACGCTGGCCAAGAATTTGGATACGGTGATGTTCAGTACTGGTATACTGGCGGTTCTCAGGTCGCTGAAGCTTCAGGGTCAGTATGTGGGGGTGATGATCACGGCGTCGCACAACCCATACCAGGACAACGGGGTCAAGATCGTGGAACCAGACGGATCGATGCTTTTGGCCACATGGGAGCCATATGCCATGCAGTTGGCCAATGCGGCCTCTTTTGCCACTAATTTTGAAGAATTTCGTGTTGAGTTGGCCAAGCTGATTGAACACGAAAAGATTGATTTGAATACAACCGTCGTGCCTCACATCGTGGTTGGGAGAGACTCTAGGGAAAGTAGTCCATACTTGCTGCGCTGCTTGACTTCCTCCATGGCCAGCGTCTTCCACGCGCAAGTTTTGGACCTAGGCTGTGTCACTACGCCTCAATTGCATTACATTACTGATTTGTCCAACAGGCGGAAACTGGAAGGAGACACAGCGCCAGTTGCCACAGAACAGGACTACTATTCGTTCTTTATAGGAGCCTTCAACGAGCTCTTCGCCACGTATCAGCTGGAGAAGAGGCTGTCTGTCCCAAAATTGTTCATAGACACAGCCAATGGTATCGGTGGTCCACAGTTGAAAAAACTACTGGCCTCCGAAGATTGGGACGTGCCAGCGGAGCAAGTTGAGGTAATCAACGACAGGTCCGATGTTCCAGAACTGTTGAATTTTGAATGCGGTGCGGATTATGTGAAGACTAACCAGAGATTACCCAAGGGTCTTTCTCCATCCTCGTTTGATTCGCTATATTGCTCCTTTGATGGTGACGCAGACAGGGTTGTGTTCTACTATGTCGACTCAGGATCAAAATTTCATTTGTTGGATGGTGACAAAATTTCCACTTTGTTTGCAAAGTTCTTGTCTAAACAACTAGAATTGGCACACCTAGAACATTCTTTGAAGATTGGTGTTGTGCAAACTGCCTATGCAAACGGCAGTTCCACCGCTTACATAAAAAATACGTTGCACTGTCCCGTGTCTTGCACTAAGACAGGTGTTAAACACTTGCATCATGAAGCTGCCACTCAGTACGATATTGGCATTTATTTCGAAGCAAATGGACATGGTACGATTATATTCAGCGAAAAATTTCATCGAACTATCAAATCTGAATTATCCAAGTCCAAGTTAAATGGTGATACGTTAGCTTTGAGAACTTTGAAGTGTTTCTCTGAATTGATTAATCAGACCGTGGGAGATGCTATTTCAGACATGCTTGCTGTCCTTGCTACTTTGGCGATTTTGAAAATGTCGCCAATGGATTGGGATGAAGAGTATACTGATTTGCCCAACAAGCTGGTTAAGTGCATCGTTCCTGATAGGTCAATTTTCCAAACCACGGACCAGGAAAGAAAATTGCTCAATCCAGTGGGGTTGCAAGACAAGATAGATCTTGTGGTAGCCAAGTATCCCATGGGAAGAAGCTTTGTCAGAGCCAGTGGTACGGAGGATGCGGTGAGGGTTTATGCGGAATGTAAGGACTCCTCTAAGTTAGGTCAATTTTGTGACGAAGTGGTGGAGCACGTTAAGGCATCTGCTTGA
SEQ ID NO: 61 представляет собой аминокислотную последовательность фосфоацетилглюкозаминмутазы (pcm1), происходящую из Saccharomyces Cerevisiae
MKVDYEQLCKLYDDTCRTKNVQFSYGTAGFRTLAKNLDTVMFSTGILAVLRSLKLQGQYVGVMITASHNPYQDNGVKIVEPDGSMLLATWEPYAMQLANAASFATNFEEFRVELAKLIEHEKIDLNTTVVpHIVVGRDSRESSPYLLRCLTSSMASVFHAQVLDLGCVTTPQLHYITDLSNRRKLEGDTAPVATEQDYYSFFIGAFNELFATYQLEKRLSVPKLFIDTANGIGGPQLKKLLASEDWDVPAEQVEVINDRSDVPELLNFECGADYVKTNQRLPKGLSPSSFDSLYCSFDGDADRVVFYYVDSGSKFHLLDGDKISTLFAKFLSKQLELAHLEHSLKIGVVQTAYANGSSTAYIKNTLHCPVSCTKTGVKHLHHEAATQYDIGIYFEANGHGTIIFSEKFHRTIKSELSKSKLNGDTLALRTLKCFSELINQTVGDAISDMLAVLATLAILKMSPMDWDEEYTDLPNKLVKCIVPDRSIFQTTDQERKLLNPVGLQDKIDLVVAKYPMGRSFVRASGTEDAVRVYAECKDSSKLGQFCDEVVEHVKASA
SEQ ID NO: 62 представляет собой нуклеотидную последовательность промотора pTDH3
CTGCTGTAACCCGTACATGCCCAAAATAGGGGGCGGGTTACACAGAATATATAACATCGTAGGTGTCTGGGTGAACAGTTTATTCCTGGCATCCACTAAATATAATGGAGCCCGCTTTTTAAGCTGGCATCCAGAAAAAAAAAGAATCCCAGCACCAAAATATTGTTTTCTTCACCAACCATCAGTTCATAGGTCCATTCTCTTAGCGCAACTACAGAGAACAGGGGCACAAACAGGCAAAAAACGGGCACAACCTCAATGGAGTGATGCAACCTGCCTGGAGTAAATGATGACACAAGGCAATTGACCCACGCATGTATCTATCTCATTTTCTTACACCTTCTATTACCTTCTGCTCTCTCTGATTTGGAAAAAGCTGAAAAAAAAGGTTGAAACCAGTTCCCTGAAATTATTCCCCTACTTGACTAATAAGTATATAAAGACGGTAGGTATTGATTGTAATTCTGTAAATCTATTTCTTAAACTTCTTAAATTCTACTTTTATAGTTAGTCTTTTTTTTAGTTTTAAAACACCAAGAACTTAGTTTCGAATAAACACACATAAACAAACAAA
SEQ ID NO: 63 представляет собой нуклеотидную последовательность промотора pTDH3.Sk
CAATTCATCGGCCCTTTTAGCGGCTACCCGCGCCATCTAAATGATAGGGCGGGTGACACTATGGTAAATCCCATAATTAGGTGTCTGGGTGAGTGGTTCTGATGCCGGCATCCACTAAATATATTGGAGCCCATTTTTTACGCGGGCTTCCAGAAAAAAAGAGAATCCCAGCACCAAAAGGTGGTTCTCTTCACCAACCATCAGATCATAGGTCCACAACCACACATAACAGGGGCACAAAAAGGCAAAAAACGGACATAACCTCAATGGAGTGATGCAAATTGACTGGAGCAAAAGCTGACACAAGGCATTGATTGACCTACGCATGTATCTGTATTCTTTTCTTACACCTTCTATTACCTTCTAACTCTTTGGGTTGGAAAAAACTGAAAAAAAAGGTTGGGACCTGGTTCCCCCAAGTTGTCCCCCTACTTGGTTATTAAATATATAAAGACAGCAAGTGTTGATTATAATCTTGTAAATCTATAGTTCTTAATCTATACTTCTATTTATATTTTAAATTAGTCTTTTTATTTCCAAGTCCCCAAGAACTTAGTTTCGAATAAACACACACAAATAAACACA
SEQ ID NO: 64 представляет собой нуклеотидную последовательность промотора pTDH3-1.sba
GCAGCGCTTCTTCCGCTCTAGTTTTTATAGTTATTATTACTACCACCTTAAAAATACGTAAATACTCAAAATAGTAGTGATATTCCCAACCTTATTCATCCAAGGCACATCATCATCATCAGCCATTCATCTTTCACCTGCCATTAGTAACCCGTCTTCTCATTGAGCGGGTTACGGCAGCCACAGGCCACATTCCGAATGTCTGGGTGAGCGGTCCCTTTTCCAGCATCCACTAAATATCTCCGATCCCGCTTTTTAATCTGGCTTCCTGAAAAAAAGAGAATCCCAGCACCAAAAAATGGCTCTCTTCACCAACCATCAGATCATAGGTCCCATTCTCTTACCGCAACCGTACAGAACAGGGGAAAACGGGTACAACCTCAATGGAGTGATGCAAACTGACTGGAGCAAAAAGCTGACACAAGGCAATCGACCTACGTGTCTGTCTATTTTCTCACACCTTCTATTACCTTCTAACTCTCTGGGTTGGAAAAAACTGAAAAAAAGGTTGAGACCAGTTTCCACAAATCATCCCCCTGTTTGATTAATAAATATATAAAGACGACAACTATCGATCATAAACTCATAAAACTATAACTCCTTTACACTTCTTATTTTATAGTTATTCTATTTTAATTCTTATTGATTTTAAAACCCCAAGAACTTAGTTTCGAAAACACACACACACAAACAATTAAAA
SEQ ID NO: 65 представляет собой нуклеотидную последовательность промотора pTDH3.Sar
GAGCTAAATATCAGCCCTTCGGGTCCTGCCTGCTACCCGGTCCTGTTCGAATAAAAACGCGGGTAACACGACCCAGTAACACCTGTCGTTGGGTGTCTGGGTCAGAAGTTCTGATACCGGCTTCCACTAAATAGATTGGGTTCCGCTCTTTACGCTGGCTTCCTGAAAAAAGAGATTCCGGGCACCAAAAAATTGGTCTCTTTGCCAACCATCAGATCATAGGTCCATTCTCTTACCATAACCACACAGGATAGGGGCACCACAGGCGAAAATGGGCACAAAATCTCAATGGAGTGATGCAAATTAGCTGGAACAAAAGCTGACACAAGGCAATTAACCTGCGCATGTATCCATCTCCTTTTCTTACACCTTCTCTTACGTTCTAACTGTTTGGGTTGGAAAAATTAAAAAAAAAAGGTTGAGACCAGTTTCCCCAAATCGTCCCCCTACTTGATTCATAAATATATAAAGACGACAACTATTGATTATAATCTTGTAAATCTATAACTCTTTACTTTCTCCTATTTATAATTTAACTTAATCTTTTTAGATTTAAAACCCCAAGAACTTAGTTTCGAACAAACACACACAAATAAACAAAA
SEQ ID NO: 66 представляет собой нуклеотидную последовательность промотора pENO2
CGCTCAGCATCTGCTTCTTCCCAAAGATGAACGCGGCGTTATGTCACTAACGACGTGCACCAACTTGCGGAAAGTGGAATCCCGTTCCAAAACTGGCATCCACTAATTGATACATCTACACACCGCACGCCTTTTTTCTGAAGCCCACTTTCGTGGACTTTGCCATATGCAAAATTCATGAAGTGTGATACCAAGTCAGCATACACCTCACTAGGGTAGTTTCTTTGGTTGTATTGATCATTTGGTTCATCGTGGTTCATTAATTTTTTTTCTCCATTGCTTTCTGGCTTTGATCTTACTATCATTTGGATTTTTGTCGAAGGTTGTAGAATTGTATGTGACAAGTGGCACCAAGCATATATAAAAAAAAAAAGCATTATCTTCCTACCAGAGTTGATTGTTAAAAACGTATTTATAGCAAACGCAATTGTAATTAATTCTTATTTTGTATCTTTTCTTCCCTTGTCTCAATCTTTTATTTTTATTTTATTTTTCTTTTCTTAGTTTCTTTCATAACACCAAGCAACTAATACTATAACATACAATAATA
SEQ ID NO: 67 представляет собой нуклеотидную последовательность промотора pTEF3
GGCTGATAATAGCGTATAAACAATGCATACTTTGTACGTTCAAAATACAATGCAGTAGATATATTTATGCATATTACATATAATACATATCACATAGGAAGCAACAGGCGCGTTGGACTTTTAATTTTCGAGGACCGCGAATCCTTACATCACACCCAATCCCCCACAAGTGATCCCCCACACACCATAGCTTCAAAATGTTTCTACTCCTTTTTTACTCTTCCAGATTTTCTCGGACTCCGCGCATCGCCGTACCACTTCAAAACACCCAAGCACAGCATACTAAATTTCCCCTCTTTCTTCCTCTAGGGTGTCGTTAATTACCCGTACTAAAGGTTTGGAAAAGAAAAAAGAGACCGCCTCGTTTCTTTTTCTTCGTCGAAAAAGGCAATAAAAATTTTTATCACGTTTCTTTTTCTTGAAAATTTTTTTTTTTGATTTTTTTCTCTTTCGATGACCTCCCATTGATATTTAAGTTAATAAACGGTCTTCAATTTCTCAAGTTTCAGTTTCATTTTTCTTGTTCTATTACAACTTTTTTTACTTCTTGCTCATTAGAAAGAAAGCATAGCAATCTAATCTAAGTTTTAATTACAAA
SEQ ID NO: 68 представляет собой нуклеотидную последовательность промотора pTEF1
GTTTAGCTTGCCTCGTCCCCGCCGGGTCACCCGGCCAGCGACATGGAGGCCCAGAATACCCTCCTTGACAGTCTTGACGTGCGCAGCTCAGGGGCATGATGTGACTGTCGCCCGTACATTTAGCCCATACATCCCCATGTATAATCATTTGCATCCATACATTTTGATGGCCGCACGGCGCGAAGCAAAAATTACGGCTCCTCGCTGCAGACCTGCGAGCAGGGAAACGCTCCCCTCACAGACGCGTTGAATTGTCCCCACGCCGCGCCCCTGTAGAGAAATATAAAAGGTTAGGATTTGCCACTGAGGTTCTTCTTTCATATACTTCCTTTTAAAATCTTGCTACGATACAGTTCTCACATCACATCCGAACATAAACAACC
SEQ ID NO: 69 представляет собой нуклеотидную последовательность промотора pTEF1.ago
GTTTAGCTTGCCTCGTCCCCGCCGGGTCACCCGGCCAGCGACATGGAGGCCCAGAATACCCTCCTTGACAGTCTTGACGTGCGCAGCTCAGGGGCATGATGTGACTGTCGCCCGTACATTTAGCCCATACATCCCCATGTATAATCATTTGCATCCATACATTTTGATGGCCGCACGGCGCGAAGCAAAAATTACGGCTCCTCGCTGCAGACCTGCGAGCAGGGAAACGCTCCCCTCACAGACGCGTTGAATTGTCCCCACGCCGCGCCCCTGTAGAGAAATATAAAAGGTTAGGATTTGCCACTGAGGTTCTTCTTTCATATACTTCCTTTTAAAATCTTGCTACGATACAGTTCTCACATCACATCCGAACATAAACAACC
SEQ ID NO: 70 представляет собой нуклеотидную последовательность промотора pTEF1.sba
CGCCAACAAACCTTCGAACACTTTAATTTTCGAGGACCGCAGATCCTCACATCACACCCACACCCAAGACTGCTTCCCCCACACACCCTGCATCTGTACACTTTCTTCTGCTCTGTTTTTCTCTCCGGCGTTCTCTCGGGTCGCCCGCATCGCCGCGCCGGCTGGAACCGCCCACGCACCGCATATTGCAAATCGCCTGCCCCCTCTTGCTCCTTTTTGAGGGCGCGCCGTTACCCGCGCCCAGGGTCCGGAAAAAGAAACAAGGCTCTACCGCGTTTCTTTTTCCTTGTCGAAAAAGGCAAAAATGAAAATTTTTATCACGTTTCTTTTTTTTTGAAAAATTTTTTTTTTGGTTTTTTTTCTTTCGATGGCCTCCCATTGATATTTAAGTTAATAAATGGTTTTCAGTTTTCAAGTTTCAGTTTGTGTTCTTCTTTGCTAACTTTCACTTACACCTCGAAAGAAAGTATAGCAATCTAATCTTAGTTTTAATTACAA
SEQ ID NO: 71 представляет собой нуклеотидную последовательность промотора pPDC1
TTATTTACCTATCTCTAAACTTCAACACCTTATATCATAACTAATATTTCTTGAGATAAGCACACTGCACCCATACCTTCCTTAAAAACGTAGCTTCCAGTTTTTGGTGGTTCCGGCTTCCTTCCCGATTCCGCCCGCTAAACGCATATTTTTGTTGCCTGGTGGCATTTGCAAAATGCATAACCTATGCATTTAAAAGATTATGTATGCTCTTCTGACTTTTCGTGTGATGAGGCTCGTGGAAAAAATGAATAATTTATGAATTTGAGAACAATTTTGTGTTGTTACGGTATTTTACTATGGAATAATCAATCAATTGAGGATTTTATGCAAATATCGTTTGAATATTTTTCCGACCCTTTGAGTACTTTTCTTCATAATTGCATAATATTGTCCGCTGCCCCTTTTTCTGTTAGACGGTGTCTTGATCTACTTGCTATCGTTCAACACCACCTTATTTTCTAACTATTTTTTTTTTAGCTCATTTGAATCAGCTTATGGTGATGGCACATTTTTGCATAAACCTAGCTGTCCTCGTTGAACATAGGAAAAAAAAATATATAAACAAGGCTCTTTCACTCTCCTTGCAATCAGATTTGGGTTTGTTCCCTTTATTTTCATATTTCTTGTCATATTCCTTTCTCAATTATTATTTTCTACTCATAACCTCACGCAAAATAACACAGTCAAATCAATCAAA
SEQ ID NO: 72 представляет собой нуклеотидную последовательность промотора pCCW12
aaccagggcaaagcaaaataaaagAAACTTAATACGTTATGCCGTAATGAAGGGCTACCAAAAACGATAATCTCAACTGTAAACAGGTACAATGCGGACCCTTTTGCCACAAAACATACATCATTCATTGCCGGAAAAAGAAAGAAGTGAAGACAGCAGTGCAGCCAGCCATGTTGCGCCAATCTAATTATAGATGCTGGTGCCCTGAGGATGTATCTGGAGCCAGCCATGGCATCATGCGCTACCGCCGGATGTAAAATCCGACACGCAAAAGAAAACCTTCGAGGTTGCGCACTTCGCCCACCCATGAACCACACGGTTAGTCCAAAAGGGGCAGTTCAGATTCCAGATGCGGGAATTAGCTTGCTGCCACCCTCACCTCACTAACGCTGCGGTGTGCGGATACTTCATGCTATTTATAGACGCGCGTGTCGGAATCAGCACGCGCAAGAACCAAATGGGAAAATCGGAATGGGTCCAGAACTGCTTTGAGTGCTGGCTATTGGCGTCTGATTTCCGTTTTGGGAATCCTTTGCCGCGCGCCCCTCTCAAAACTCCGCACAAGTCCCAGAAAGCGGGAAAGAAATAAAACGCCACCAAAAAAAAAAATAAAAGCCAATCCTCGAAGCGTGGGTGGTAGGCCCTGGATTATCCCGTACAAGTATTTCTCAGGAGTAAAAAAACCGTTTGTTTTGGAATTCCCCATTTCGCGGCCACCTACGCCGCTATCTTTGCAACAACTATCTGCGATAACTCAGCAAATTTTGCATATTCGTGTTGCAGTATTGCGATAATGGGAGTCTTACTTCCAACATAACGGCAGAAAGAAATGTGAGAAAATTTTGCATCCTTTGCCTCCGTTCAAGTATATAAAGTCGGCATGCTTGATAATCTTTCTTTCCATCCTACATTGTTCTAATTATTCTTATTCTCCTTTATTCTTTCCTAACATACCAAGAAATTAATCTTctgtcattcgcttaaacactatatcaata
SEQ ID NO: 73 представляет собой нуклеотидную последовательность промотора pCCW12.Sm
CGTTGTGCTGTAGTGAAGGAAGACTAAAAAGGATAATCACAGTTGTAAAGAGGTATAATGCGGACCCTTTTGCCACAAAACACACATCTTTCGTTTCCAAAATAAGAAAGAAGAAAGCAAAAAGATTAGCAGCCACGTTGCTGCGATCTAATTATAGACGGTGGCGTCATCATTCTCACCCAAGATTGTGTCTTGAACCTGCCACGGGTCCTGCGTTATCGCCGGATGTAAAACTAGACATGCAAAAAAAGGACCTTCCAGGTAGCGTGCTCCACACCACCCATGACCACCACAGTTAGTCCAAAAGAGGCAGCACCACTTCCCGATGGGGGAATTAGATTGCTGCCACCCTCACCTCACTAATGCTGCGGTGTGCGGATATGCCCTGCTATATATAGCTCCGCGTTTTTGAACCAGCACAGCGCGAGCACCAAAAAGGAAAATCGCATAGGCCCAGAACTGATTTCAGCACGGGCTATTGGCGTTGGGTTTCCGTTCTGGGAAACCTTCGCCGCGTCCCCCTCACAAACCTCCGCACAAGTTCGAGCAAGCGGGAAAAAACGAAAAACGCCATTAATACTAAATAAAGCAAATCCTCGAAGCGTGGGTGGCAAGCCCCTGGATTTTTCCGCACAAGTACTCTTCTCAGGAGTAAAAAAACCCGTTTGTTTTGGAATTCCCCATTTCGCGGCCATCTACGCCGGTATCTTCGCAATATCTATCAGCGATAACTCAGCAATTTTAATATTCGTGTTGCAGTGCTGCGATAGCGGGAGTCTTGTTTGTAACATAACGGCAGAAAGGAATGAGAGAAAATTTTCCATTCTTTGGCCTCCGTTCAAGTATATAAAGCCGGCATGCTTGGTAATCTTTCTCTCTCTTCTGTATTGTTTCTATAATACTTTTATCTTCTAATTATTTTCTGAAAAAACCAAGAAATTAATCTTCTGTCATTCGCTTAAACACTATATCAATA
SEQ ID NO: 74 представляет собой нуклеотидную последовательность промотора pCCW12.Sk
TGTAAAATCCTACACGCAAAAAACCTCTTGGGTTGCGCGTTTTCCACCACCCACGACCCGCACAATCAATCCAAAAGGGGCAACGCCAGTTCCCAATGCGGGAATTAGCTCCTCACCCCCCTCACCCGCTAACGCTGCGGTGTGCGGACACGCAGCAGTATTTATAGATCCTCGTGTTGGAACCAGCCCGCGTGAGCACCAAATTGGAAAGTCGCAATGGGCCCAGAACCGCTTTCAGTACTGGGCCATTGGCGTCTAGTTTCCGTTTTGAGCGTCCTTCGCCGCGTCTCTCTGTGAAATCCCCGCACAAGTCTGAGCAGGCAAAAAAAAAAAACGCCACCAAAAATAAATAAAGCCAATCCTCGAAGGATGAGTAGGAAAGGAAGCCCCTGGTTTTTTCCCGCACGAATATTTTTCAGGAGTGAAAAAATCCGTTTGTTTTGGAATTCCCCATTTCGCGCTCACCTACGCCGGTATCTTTGGAACAACTATCAGCGATAACTCAGCAAAATTTGCATATCCGTGCTGCAATAGTGCGATAGTGGGATTGGGAGTCTTGTTGCATCATAACGGCAGAAAGGAATGAATAAAAATTTTCCGTTCTTTGTCTCCGTTCAAGTATATAAAGTCGGCATGCTTGATTATCTTTTCTTCTCTTCTACTACATTTCTATTTCACTTTCTACTCTATTCTTCCCTGAAAAACCCAAGAAAATAATCTTCTGTCATTCGCTTAAACAATATATCAAAA
SEQ ID NO: 75 представляет собой нуклеотидную последовательность промотора pCCW12.Sba
ACCATGCCACGGTGCTGGCCCCACTTCCACCCACGACCCGCACGGTTGGCCCGAAAGGGGCAACACCAGTTCCCAATACGGAAATTAGTCCGCCACCACCCTCACCTCGCTAGAGCTGCGGTGTGCGGGCGTGCATCGCTATTTATAGACATGCCTGCTGGCGTCACCGCGCGCGAGCACCAAACAGGAAAATCGCACTGGGCCCAGAACCACGCTATGCGCTGGGCCGATGGCGTCCGGTTTCCCTTTGGGAGCCCCCTGCCACGTTCGCCTAACAAATCCCCGCACCGGCTTGAGAAAAAAGCGAAAAGCGAAAAAAAAAAATCAACGCCACCAAAATTAAAAAAAAAGAGCCATCCTCGAAGGGTGAATAGTAGCCCCTGACTTTTCCCGCACAGACAGACACCTTTCAGGAGTGAACAAAAAAGCAGTTTGTTTTGGAATTCCCCCATTTCGCGGTGGCCTGCGCAGGTATCTCTGCGTCAACTATCAGCGATAACTCAGCAAATTTTGCATATTCGTGTTGCGATACTACGATAATGGGAGTCTGTCGCCTAATAACGGCAACAAGGAATGAGAGAGAAAAATTTTCTTCATTCTCCAGCTCCCGTTCAAGTATATAAGGTCGGCATGGTCGATTGTCTTTCCTTCTCTTCAGTTACGTCTCTCTATTTACATTATTCTTATTTTTATTTAATAAAAACCCCAAGAAATTAATCTTCTGTCATTCGCTTAAACACTATATCAAAA
SEQ ID NO: 76 представляет собой нуклеотидную последовательность промотора pCCW12.Sar
AAAAAACAACCTTCTGCCAACCTGCGTGCTTCTCACCACCCATGACCCACACAATTGACCCGAATGGGGCAACTCCAGTTCCCAATACGGGAATTAACTCGCCACCATATTTACCGCGTTGAAGCTGTGGTGTGCGGACACTCCGTACTATTTATAGACCCACGCGGTGGAACCAGCACGCGCGCGCACTAAACAGGAAAATCGCATTGAGTCCAGAACCGCCACCAGCACTTGGCCATTGGCGTCTAATTTCCGTTTTCGGCGCCCCTCACCGCGTCCTTCTAACAAAGCGCGCACAAGCTTGAGCAAGTGAAAAGAAAATTAAAAATAAAAAACCGCCACCAAAACAAATAAAGCAATCTTCGAAGTGTGGGTTGGTGGGAAGCCCCTGGCTTTTCCCGCACCAGTCGTTTTCAGGAGTAAAAAAATACCCGTTTGTTTTGGAATTCCCCATTTCGCGGCGACCTGCGCCGGTATCTTTGCAACAACTATTTGCGATAACTCAGCAAAATTTGCATATTCGTGTTGGGATATTGCGATAGTGGGAGTCTTGTTGCATAATAACGGTAAAAAGAAGTGAAGGAAAAAAATTTGCATCCTTTAGTCTCAGTTCAAGTATATAAAGTCGGGATATTCAATTATCTTTCTTTCTCTTGCTCAAAGGTTTCTATATTTTTTTTATAGTATTTCTTTTGTTATAAAATACCAAGAAATTAATCTTCTGTCATTCGCTTAAATACTACATCAATA
SEQ ID NO: 77 представляет собой нуклеотидную последовательность промотора pNUP57
TCATCTGCGCAATGACTATCAAGACCTTCTGCAAGAATTTCAAATCTCACTGAAAATCTTGACCGAAAAGTGTCTTGAAAACCCATCAAGCCTGCAAAACCTATCTTTGACATTAGTCTCCATTATAAAAACGGCATAGTTGGGAGAAAACTTTCCATACTTCAATTGTGGACTGATATAAGTATTTTAGTTTTGCCCGCATGATCATCCCACATGGCTACAGCAGTTCTCTCATAGGAAAATAGTACAATAGCTACGTGATATAATCTAAATAATTGTTGCCAATGTGTAATTATATCATTTTGAACGTACGCGAAATGGATTATTTTCAAAAATTTTGTTTCTTGAAATGAGTAAAAGCAAAAGTCCAACTCTCCAAGTCGATGTAAACAACTTTTTGCCAAAGGGACTGAAAGACTAAATCGAGGATTATCCCGTTCAAACTATTCCAGAAACGCTCGTTAGTAACAAAAGACATACCTTGTTGACCAATTGATCAC
SEQ ID NO: 78 представляет собой нуклеотидную последовательность промотора pCCW10.ago
GGTACCACGGCAACCTCGTTCGCTGTTCATCCCCTTCGTCACACAGGACGTTGGATGCCGTAAGCAGCGTTGCTTTTGATCCTCagGATCGGCCGGGTAACCCGCGGCtGCTTCTATTTTAGTATTCATATCTCAAGCACATCCATTCCGGCCGTTTGGGGGCGCCGCCGCACTCGTGTCCATTCCTACCGTGGCACTTAGGGCTATCCTGTCGGAGCGCCCCGCCGACCGCCTTATCGGCACCAAAAGTAGAAGCCCCGGCCCCGCGTGGCTCAGACTCACCATCGGTGCTATTTACTTTTCGATCAGATCGCGGCGCGCGGTGGCCGGCATTTCCGGAAGCGGCCACGGAGCAGAGGTGGCGCATTCGAATCGCATACGTCTTCGCCACGCCGGAAAAAAAATTTTCGGCTATATAAGGAGAGGCGGCCGTCTTGCTGCAGGCAGTTTCACTTTCTCTAAAACCAAAGAACATCGATTTCTTTAGTCACTCGCTTCCTTACACCGAACTCGAGGCGGCCGC
SEQ ID NO: 79 представляет собой нуклеотидную последовательность промотора pCWP2
CTAGCCTCCCCTTTTTATTTTGTGCGGTCACCGCAAGGGACAAAGCTTTTCTTAGAAAACCGTCTGAGAAGCATAACGTACGCCATCCCCTAGACATATTAATAATGCTACAGATACTATGCTGCTCGTCTTTTTTTGACGACCCTTTTATTGCAATGTGCAACTAATGGCAAACAACCACATAGTATCACAGTATTACATTGCCTCCACCGATGCGGATGTTAGGGCGCCAAGTCTGTCATGAAGCATGTTCCTGTCATAATCTTGTATGCAAAATACCGCGTTCTGCGCCACTGATATGCTAGGCAGCAGCAACCTATGCAGAAGATTGCTTTTCCCACGCCTGTTTTACGTCTCCAGGGCACTTGAAACAATGCAGCGATCGCCGCCACAACACGCCAAAGAGAAGCGAAAGTGGGCCTGGGCGGCCTCAGTTTCGGCAGAGGTAAACAACACGAACTGAACTGCCTTAGCTCCGAAGGGCAATTCCACAGGCACTCCGCGGGGCCCGGCCAAGGCCCAAAAGGCGTGGAATATGCGCGTTTTGGGGCCATAACACCCAGTACCACGGCCGGAACGGGCCATATAATAAGTTTTTCACTCTCAAGAATGGTAAACGTAAATAGGAACATCCCACTACCCTAGAAATTGCGGAAATTTCGCGCTTATCATTAGAAAATCTGGAACCGTCCTTTTTCCTCTTTCTTGCATTTCCCTTTCCGTATTATTGCCATTCTTTAACTGCATTTGGGGAACCGTAGACCAAAAGCCAAACAGAGAAATGTAACGTTCTAAAAAAAAAACAACGAAAAAATTGAAAAATAAGATACAATAATCGTATATAAATCAGGCTTCTTGTTCATCATTTTCAATTCTCTTCTTGCCATCCCTTTTCCTATCTTTGTTCTTTTCTTCTCATAATCAAGAATAAATAACTTCATCA
SEQ ID NO: 80 представляет собой нуклеотидную последовательность промотора pRPLA1
TCAAGTTGGATACTGATCTGATCTCTCCGCCCTACTACCAGGGACCCTCATGATTACCGCTCGAATGCGACGTTTCCTGCCTCATAAAACTGGCTTGAAAATATTTATTCGCTGAACAGTAGCCTAGCTTATAAAAATTTCATTTAATTAATGTAATATGAAAACTCACATGCCTTCTGTTTCTAAAATTGTCACAGCAAGAAATAACATTACCATACGTGATCTTATTAAACTCTAGTATCTTGTCTAATACTTCATTTAAAAGAAGCCTTAACCCTGTAGCCTCATCTATGTCTGCTACATATCGTGAGGTACGAATATCGTAAGATGATACCACGCAACTTTGTAATGATTTTTTTTTTTTCATTTTTTAAAGAATGCCTTTACATGGTATTTGAAAAAAATATCTTTATAAAGTTTGCGATCTCTTCTGTTCTGAATAATTTTTAGTAAAAGAAATCAAAAGAATAAAGAAATAGTCCGCTTTGTCCAATACAACAGCTTAAACCGATTATCTCTAAAATAACAAGAAGAA
SEQ ID NO: 81 представляет собой нуклеотидную последовательность промотора pCUP1
CGGCAAACTTCAACGATTTCTATGATGCATTTTATAATTAGTAAGCCGATCCCATTACCGACATTTGGGCGCTATACGTGCATATGTTCATGTATGTATCTGTATTTAAAACACTTTTGTATTATTTTTCCTCATATATGTGTATAGGTTTATACGGATGATTTAATTATTACTTCACCACCCTTTATTTCAGGCTGATATCTTAGCCTTGTTACTAGTTAGAAAAAGACATTTTTGCTGTCAGTCACTGTCAAGAGATTCTTTTGCTGGCATTTCTTCTAGAAGCAAAAAGAGCGATGCGTCTTTTCCGCTGAACCGTTCCAGCAAAAAAGACTACCAACGCAATATGGATTGTCAGAATCATATAAAAGAGAAGCAAATAACTCCTTGTCTTGTATCAATTGCATTATAATATCTTCTTGTTAGTGCAATATCATATAGAAGTCATCGAAATAGATATTAAGAAAAACAAACTGTACAATCAATCAATCAATCATCACATAAA
SEQ ID NO: 82 представляет собой нуклеотидную последовательность промотора pMET6
CCACAGGAAATATTTCACGTGACTTACAAACAGAGTCGTACGTCAGGACCGGAGTCAGGTGAAAAAATGTGGGCCGGTAAAGGGAAAAAACCAGAAACGGGACTACTATCGAACTCGTTTAGTCGCGAACGTGCAAAAGGCCAATATTTTTCGCTAGAGTCATCGCAGTCATGGCAGCTCTTTCGCTCTATCTCCCGGTCGCAAAACTGTGGTAGTCATAGCTCGTTCTGCTCAATTGAGAACTGTGAATGTGAATATGGAACAAATGCGATAGATGCACTAATTTAAGGGAAGCTAGCTAGTTTTCCCAACTGCGAAAGAAAAAAAGGAAAGAAAAAAAAATTCTATATAAGTGATAGATATTTCCATCTTTACTAGCATTAGTTTCTCTTTTACGTATTCAATATTTTTGTTAAACTCTTCCTTTATCATAAAAAAGCAAGCATCTAAGAGCATTGACAACACTCTAAGAAACAAAATACCAATATAATTTCAAAGTACATATCAAAA
SEQ ID NO: 83 представляет собой нуклеотидную последовательность промотора pMET25
TTACATTATCAATCCTTGCGTTTCAGCTTCCACTAATTTAGATGACTATTTCTCATCATTTGCGTCATCTTCTAACACCGTATATGATAATATACTAGTAACGTAAATACTAGTTAGTAGATGATAGTTGATTTTTATTCCAACACTAAGAAATAATTTCGCCATTTCTTGAATGTATTTAAAGATATTTAATGCTATAATAGACATTTAAATCCAATTCTTCCAACATACAATGGGAGTTTGGCCGAGTGGTTTAAGGCGTCAGATTTAGGTGGATTTAACCTCTAAAATCTCTGATATCTTCGGATGCAAGGGTTCGAATCCCTTAGCTCTCATTATTTTTTGCTTTTTCTCTTGAGGTCACATGATCGCAAAATGGCAAATGGCACGTGAAGCTGTCGATATTGGGGAACTGTGGTGGTTGGCAAATGACTAATTAAGTTAGTCAAGGCGCCATCCTCATGAAAACTGTGTAACATAATAACCGAAGTGTCGAAAAGGTGGCACCTTGTCCAATTGAACACGCTCGATGAAAAAAATAAGATATATATAAGGTTAAGTAAAGCGTCTGTTAGAAAGGAAGTTTTTCCTTTTTCTTGCTCTCTTGTCTTTTCATCTACTATTTCCTTCGTGTAATACAGGGTCGTCAGATACATAGATACAATTCTATTACCCCCATCCATACA
SEQ ID NO: 84 представляет собой нуклеотидную последовательность промотора pSAM1
GAAACGGACGTAAGACGGAAATAGAATTTGAAGATAAAGTTATATATCACTACACACGAATACTTTCTTTTTTTTTTTTCACAGGAAAACTGTGGTGGCGCCCTTGCCTACTAGTGCATTTCTTTTTTCGGGTTCTTGTCTCGAcGAAATTTTAGCCTCATCGTAGTTTTTCACTCTGGTATCGATGAAAAAGGGAAGAGTAAAAAGTTTTCCGTTTAGTACTTAATGGGATTGGTTTGGGACGTATATATCGACTGGTGTTGTCTGTTATTCATCGTTGTTTTTCGGTTAGCTTCGAAAAAAAAATAGAGTAAAAACCAGGAATTTACCCTAAAAACAAGAAAAAATAAGATAAACGAAAAT
SEQ ID NO: 85 представляет собой нуклеотидную последовательность терминатора tTPI1
GATTAATATAATTATATAAAAATATTATCTTCTTTTCTTTATATCTAGTGTTATGTAAAATAAATTGATGACTACGGAAAGCTTTTTTATATTGTTTCTTTTTCATTCTGAGCCACTTAAATTTCGTGAATGTTCTTGTAAGGGACGGTAGATTTACAAGTGATACAACAAAAAGCAAGGCGCTTTTTCTAATAAAAAGAAGAAAAGCATTTAACAATTGAACACCTCTATATCAACGAAGAATATTACTTTGTCTCTAAATCCTTGTAAAATGTGTACGATCTCTATATGGGTTACTCA
SEQ ID NO: 86 представляет собой нуклеотидную последовательность терминатора tMET25
GTGTGCGTAATGAGTTGTAAAATTATGTATAAACCTACTTTCTCTCACAAGTACTATACTTTTATAAAACGAACTTTATTGAAATGAATATCCTTTTTTTCCCTTGTTACATGTCGTGACTCGTACTTTGAACCTAAATTGTTCTAACATCAAAGAACAGTGTTAATTCGCAGTCGAGAAGAAAAATATGGTGAACAAGACTCATCTACTTCATGAGACTACTTTACGCCTCCTATAAAGCTGTCACACTGGATAAATTTATTGTAGGACCAAGTTACAAAAGAGGATGATGGAGGTTT
SEQ ID NO: 87 представляет собой нуклеотидную последовательность терминатора tDIT1
TAAAGTAAGAGCGCTACATTGGTCTACCTTTTTGTTCTTTTACTTAAACATTAGTTAGTTCGTTTTCTTTTTCTCATTTTTTTATGTTTCCCCCCCAAAGTTCTGATTTTATAATATTTTATTTCACACAATTCCATTTAACAGAGGGGGAATAGATTCTTTAGCTTAGAAAATTAGTGATCAATATATATTTGCCTTTCTTTTCATCTTTTCAGTGATATTAATGGTTTCGAGACACTGCAATGGCCCTAGTTGTCTAAGAGGATAGATGTTACTGTCAAAGATGATATTTTGAATTTC
SEQ ID NO: 88 представляет собой нуклеотидную последовательность терминатора tRPL3
GAAGTTTTGTTAGAAAATAAATCATTTTTTAATTGAGCATTCTTATTCCTATTTTATTTAAATAGTTTTATGTATTGTTAGCTACATACAACAGTTTAAATCAAATTTTCTTTTTCCCAAGTCCAAAATGGAGGTTTATTTTGATGACCCGCATGCGATTATGTTTTGAAAGTATAAGACTACATACATGTACATATATTTAAACATGTAAACCCGTCCATTATATTGCTTACTTTCTTCTTTTTTGCCGTTTTGACTTGGACCTCTGGTTTGCTATTTCCTTACAATCTTTGCTACAAT
SEQ ID NO: 89 представляет собой нуклеотидную последовательность терминатора tRPL3.sm
GAAGTTTTTAAAGCATTTTTTAGACACTTCTCATTTTTCTAAGTTTTTTTAAAATAGTTTTATGTATTTACTACGTATCACAATTTGAAATAATTCATCTTCCCAAAAAACTAAGATTTTTATCCTTGTCACGATCCGTAACCAGTTTATAATATTTTAGAGCTTATACACGTACGTATACACACGTGTCGGTACATGAGAATTACGTTCAAAATTATTCACTTTTTTTTTCTCTGCCGTTTTACTTTTGAACTCTGTCTCGCTATTTCCTTACAATCTTCGCTACAATACCACTTGCCCTTGG
SEQ ID NO: 90 представляет собой нуклеотидную последовательность терминатора tRPL3.sba
GAAGTTTTCTGACAAAAACATAACGTTTTTTCCAATCATTTCTTATTTTTCCGGTTTATTTAAATAGTTTTTATGTACTATTATACGTATGACTATTTAACTTAAATTCTTCCTCCCAAGAAATCTCCCAAGTTTTTCATTATCATGGCATACACCACTATCAGTTACAAAATGGTAGCTCAACCATATATATATCTCTATATACACATATAAATGCAAACAGGTCCAAGTCACCGCTCACTGCAGTTTCTTTTGCCGTTTTGACTTCGATCTCTGCTTGGCTATTTTCTCACAATCCT
SEQ ID NO: 91 представляет собой нуклеотидную последовательность терминатора tRPL41B
GCGGATTGAGAGCAAATCGTTAAGTTCAGGTCAAGTAAAAATTGATTTCGAAAACTAATTTCTCTTATACAATCCTTTGATTGGACCGTCATCCTTTCGAATATAAGATTTTGTTAAGAATATTTTAGACAGAGATCTACTTTATATTTAATATCTAGATATTACATAATTTCCTCTCTAATAAAATATCATTAATAAAATAAAAATGAAGCGATTTGATTTTGTGTTGTCAACTTAGTTTGCCGCTATGCCTCTTGGGTAATGCTATTATTGAATCGAAGGGCTTTATTATATTACCCT
SEQ ID NO: 92 представляет собой нуклеотидную последовательность терминатора tRPL15A
GCTGGTTGATGGAAAATATAATTTTATTGGGCAAACTTTTGTTTATCTGATGTGTTTTATACTATTATCTTTTTAATTAATGATTCTATATACAAACCTGTATATTTTTTCTTTAACCAATTTTTTTTTTTATAGACCTAGAGCTGTACTTTTATTCTGCTATCAAGCAAACCCCTACCCCCTCTTCTCAATCCTCCCCTCAGGCAGAACTTATCTACCTGTATCAAGGAGCGGACGAGGGAGTCCTAATTGTTCTACGTATACCAATGCTAGCAGCTTACATAGGTGGTGGCACTACCA
SEQ ID NO: 93 представляет собой нуклеотидную последовательность терминатора tRPL15A.sba
GCTGGCTGATGAAAAATATAGTTCTGTTGGGCAAGCATTTGTTTACCTAGCATCTCTTTTATACTATTATTATCTTTATATTTGATGATTTTATATACAAGTTGTATACCTTTTCTTTAACCAATTTTTTTTTTTCTAATGGTGCACCTAGAAGTACATTTTTTCTCACCAATAGATAGTCAAGATACTCCCAGCCTCTATGGCGTTACCACGGAGCCGACAAGGGAAAGCTGCTTATCTTACATATGCAGATGCCAAGGCCCGTTACAGGCCGCCTTATTGATGTTTAGAAATAGCTTC
SEQ ID NO: 94 представляет собой нуклеотидную последовательность терминатора tIDP1
TCGAATTTACGTAGCCCAATCTACCACTTTTTTTTTTCATTTTTTAAAGTGTTATACTTAGTTATGCTCTAGGATAATGAACTACTTTTTTTTTTTTTTTTTTACTGTTATCATAAATATATATACCTTATTGTTGTTTGCAACCGTCGGTTAATTCCTTATCAAGGTTCCCCAAGTTCGGATCATTACCATCAATTTCCAACATTTTCATGAGTTCTTCTTCTTCATTACCGTGTTTTAGGGGGCTGTTCGCACTTCTAATAGGGCTATCACCAAGCTGTTCTAATTCGTCCAAAAGTT
SEQ ID NO: 95 представляет собой нуклеотидную последовательность терминатора tTEF1.sba
GGAGATTGATAGGACTTTTCTAGTTGCATATCTTTTATTTTTAAATCTTATCTATTAGTTAATTTTTTGTAATTTATCCTTATATATATAGTTTGGTTATTCTAAAACATCATTTCAGTATCTAAAACCTCTCTTATTCATTACCTTTTTATTTAATGGTTTTTGCTACAGGCAAAAATTTAATGGTTTTTGCTACAGGCAAAAATCCCGCCGTGGACTTATTCCACGTTAACTCGGTTACAGGGTCATGAACCATTTTGTCAATTATCGAAATAACTTCTTCAAAAGTCCCTCTTACTT
SEQ ID NO: 96 представляет собой нуклеотидную последовательность глутаминсинтетазы (gln1), происходящую из Saccharomyces Cerevisiae
ATGGCTGAAGCAAGCATCGAAAAGACTCAAATTTTACAAAAATATCTAGAACTGGACCAAAGAGGTAGAATAATTGCCGAATACGTTTGGATCGATGGTACTGGTAACTTACGTTCCAAAGGTAGAACTTTGAAGAAGAGAATCACATCCATTGACCAATTGCCAGAATGGAACTTCGACGGTTCTTCTACCAACCAAGCGCCAGGCCACGACTCTGACATCTATTTGAAACCCGTTGCTTACTACCCAGATCCCTTCAGGAGAGGTGACAACATTGTTGTCTTGGCCGCATGTTACAACAATGACGGTACTCCAAACAAGTTCAACCACAGACACGAAGCTGCCAAGCTATTTGCTGCTCATAAGGATGAAGAAATCTGGTTTGGTCTAGAACAAGAATACACTCTATTTGACATGTATGACGATGTTTACGGATGGCCAAAGGGTGGGTACCCAGCTCCACAAGGTCCTTACTACTGTGGTGTTGGTGCCGGTAAGGTTTATGCCAGAGACATGATCGAAGCTCACTACAGAGCTTGTTTGTATGCCGGATTAGAAATTTCTGGTATTAACGCTGAAGTCATGCCATCTCAATGGGAATTCCAAGTCGGTCCATGTACCGGTATTGACATGGGTGACCAATTATGGATGGCCAGATACTTTTTGCACAGAGTGGCAGAAGAGTTTGGTATCAAGATCTCATTCCATCCAAAGCCATTGAAGGGTGACTGGAACGGTGCCGGTTGTCACACTAACGTTTCCACCAAGGAAATGAGACAACCAGGTGGTATGAAATACATCGAACAAGCCATCGAGAAGTTATCCAAGAGACACGCTGAACACATTAAGTTGTACGGTAGCGATAACGACATGAGATTAACTGGTAGACATGAAACCGCTTCCATGACTGCCTTTTCTTCTGGTGTCGCCAACAGAGGTAGCTCAATTAGAATCCCAAGATCCGTCGCCAAGGAAGGTTACGGTTACTTTGAAGACCGTAGACCAGCTTCCAACATCGACCCATACTTGGTTACAGGTATCATGTGTGAAACTGTTTGCGGTGCTATTGACAATGCTGACATGACGAAGGAATTTGAAAGAGAATCTTCATAA
SEQ ID NO: 97 представляет собой аминокислотную последовательность глутаминсинтетазы (gln1), происходящую из Saccharomyces Cerevisiae
MAEASIEKTQILQKYLELDQRGRIIAEYVWIDGTGNLRSKGRTLKKRITSIDQLPEWNFDGSSTNQAPGHDSDIYLKPVAYYPDPFRRGDNIVVLAACYNNDGTPNKFNHRHEAAKLFAAHKDEEIWFGLEQEYTLFDMYDDVYGWPKGGYPAPQGPYYCGVGAGKVYARDMIEAHYRACLYAGLEISGINAEVMPSQWEFQVGPCTGIDMGDQLWMARYFLHRVAEEFGIKISFHPKPLKGDWNGAGCHTNVSTKEMRQPGGMKYIEQAIEKLSKRHAEHIKLYGSDNDMRLTGRHETASMTAFSSGVANRGSSIRIPRSVAKEGYGYFEDRRPASNIDPYLVTGIMCETVCGAIDNADMTKEFERESS
SEQ ID NO: 98 представляет собой нуклеотидную последовательность глутаматсинтазы (glt1), происходящую из Saccharomyces Cerevisiae
ATGCCAGTGTTGAAATCAGACAATTTCGATCCATTGGAAGAAGCTTACGAAGGTGGGACAATTCAAAACTATAACGATGAACACCATCTTCATAAATCTTGGGCAAATGTGATTCCGGACAAACGAGGACTTTACGACCCTGATTATGAACATGACGCTTGTGGTGTCGGTTTCGTAGCAAATAAGCATGGTGAACAGTCTCACAAGATTGTTACTGACGCTAGATATCTTTTAGTGAATATGACACATCGTGGTGCCGTCTCATCTGATGGGAACGGTGACGGTGCCGGTATTCTGCTAGGTATTCCTCACGAATTTATGAAAAGAGAATTCAAGTTAGATCTTGATCTAGACATACCTGAGATGGGCAAATACGCCGTAGGTAACGTCTTCTTCAAGAAGAACGAAAAAAATAACAAGAAAAATTTAATTAAGTGTCAGAAGATTTTCGAGGATTTAGCTGCATCCTTCAACTTATCCGTATTAGGTTGGAGAAACGTCCCCGTAGATTCTACTATTTTAGGAGACGTTGCATTATCTCGTGAACCTACTATTCTACAGCCATTATTGGTTCCATTGTATGATGAAAAACAACCGGAGTTTAATGAAACTAAATTTAGAACTCAATTGTATCTTTTAAGGAAGGAGGCCTCTCTTCAAATAGGACTGGAAAACTGGTTCTATGTTTGTTCCCTAAACAATACCACCATTGTTTACAAGGGTCAATTGACGCCAGCTCAAGTGTATAACTACTATCCCGACTTGACTAATGCGCATTTCAAATCCCACATGGCGTTGGTCCATTCAAGATTTTCCACTAATACTTTCCCCTCTTGGGATAGAGCTCAACCTTTACGTTGGCTAGCTCATAATGGTGAAATTAACACCTTAAGAGGTAACAAGAATTGGATGCGCTCCAGAGAAGGTGTGATGAATTCAGCAACTTTCAAAGATGAGTTAGACAAACTATACCCAATTATCGAAGAAGGTGGTTCTGATTCAGCTGCATTGGATAACGTTTTAGAACTATTGACTATTAATGGCACATTATCTCTACCTGAAGCTGTTATGATGATGGTTCCTGAAGCGTATCATAAGGATATGGATTCTGACCTAAAAGCATGGTACGACTGGGCTGCATGTCTGATGGAACCTTGGGATGGTCCAGCTTTGTTAACTTTCACTGATGGACGTTACTGTGGTGCTATATTGGATAGAAATGGTTTAAGACCTTGTCGTTATTACATCACTAGTGATGACAGAGTTATCTGTGCTTCAGAGGTAGGTGTCATTCCTATCGAAAATTCATTGGTTGTTCAAAAAGGTAAACTGAAGCCAGGTGATTTATTCCTAGTGGATACTCAATTGGGTGAAATGGTCGATACTAAAAAGTTAAAATCTCAAATCTCAAAAAGACAAGATTTTAAGTCTTGGTTATCCAAAGTCATCAAGTTAGACGACTTGTTATCAAAAACCGCTAATTTGGTTCCTAAAGAATTTATATCACAGGATTCATTGTCTTTGAAAGTTCAAAGTGACCCACGTCTATTGGCCAATGGTTATACCTTCGAACAAGTCACATTTCTGTTAACTCCAATGGCTTTAACAGGTAAAGAAGCTTTAGGTTCGATGGGTAACGATGCGCCACTGGCTTGTTTAAATGAAAATCCTGTCTTACTTTATGATTATTTCAGACAATTGTTTGCTCAAGTGACCAATCCTCCAATTGACCCAATTCGTGAAGCAAATGTTATGTCGTTAGAATGTTATGTCGGACCTCAAGGCAACCTTTTGGAAATGCATTCATCTCAATGTGATCGTTTATTATTGAAATCTCCTATTTTGCATTGGAATGAGTTCCAAGCTTTGAAAAACATTGAAGCTGCTTACCCATCATGGTCTGTAGCAGAAATTGATATCACATTCGACAAGAGTGAGGGTCTATTGGGCTATACCGACACAATTGATAAAATCACTAAGTTAGCGAGCGAAGCAATTGATGATGGTAAAAAGATCTTAATAATTACTGACAGGAAAATGGGTGCCAACCGTGTTTCCATCTCCTCTTTGATTGCAATTTCATGTATTCATCATCACCTAATCAGAAACAAGCAGCGTTCCCAAGTTGCTTTGATTTTGGAAACAGGTGAAGCCAGAGAAATTCACCATTTCTGTGTCCTACTAGGTTATGGTTGTGATGGTGTTTATCCATACTTAGCCATGGAAACTTTGGTCAGAATGAATAGAGAAGGTCTACTTCGTAATGTCAACAATGACAATGATACACTTGAGGAAGGGCAAATACTAGAAAATTACAAGCACGCTATTGATGCAGGTATCTTGAAGGTTATGTCTAAAATGGGTATCTCCACTCTAGCATCCTACAAAGGTGCTCAAATTTTTGAAGCCCTAGGTTTAGATAACTCTATTGTTGATTTGTGTTTCACAGGTACTTCTTCCAGAATTAGAGGTGTAACTTTCGAGTATTTGGCTCAAGATGCCTTTTCTTTACATGAGCGTGGTTATCCATCCAGACAAACCATTAGTAAATCTGTTAACTTACCAGAAAGTGGTGAATACCACTTTAGGGATGGTGGTTACAAACACGTCAACGAACCAACCGCAATTGCTTCGTTACAAGATACTGTCAGAAACAAAAATGATGTCTCTTGGCAATTATATGTAAAGAAGGAAATGGAAGCAATTAGAGACTGTACACTAAGAGGACTGTTAGAATTAGATTTTGAAAATTCTGTCAGTATCCCTCTAGAACAAGTTGAACCATGGACTGAAATTGCCAGAAGATTTGCGTCAGGTGCAATGTCTTATGGTTCTATTTCTATGGAAGCTCACTCTACATTGGCTATTGCCATGAATCGTTTAGGGGCCAAATCCAATTGTGGTGAAGGTGGTGAAGACGCAGAACGTTCTGCTGTTCAAGAAAACGGTGATACTATGAGATCTGCTATCAAACAAGTTGCTTCCGCTAGATTCGGTGTAACTTCATACTACTTGTCAGATGCTGATGAAATCCAAATTAAGATTGCTCAGGGTGCTAAGCCGGGTGAAGGTGGTGAACTACCAGCCCACAAAGTGTCTAAGGATATCGCAAAAACCAGGCACTCCACCCCTAATGTTGGGTTAATCTCTCCTCCTCCTCATCACGATATTTATTCCATTGAAGATTTGAAACAACTGATTTATGATTTGAAATGTGCTAATCCAAGAGCGGGAATTTCTGTAAAGTTGGTTTCCGAAGTTGGTGTTGGTATTGTTGCCTCTGGTGTAGCTAAGGCTAAAGCCGATCATATCTTAGTTTCTGGTCATGATGGTGGTACAGGTGCTGCAAGATGGACGAGTGTCAAATATGCGGGTTTGCCATGGGAATTAGGTCTAGCTGAAACTCACCAGACTTTAGTCTTGAATGATTTAAGACGTAATGTTGTTGTCCAAACCGATGGTCAATTGAGAACTGGGTTTGATATTGCTGTTGCAGTTTTATTAGGGGCAGAATCTTTTACCTTGGCAACAGTTCCATTAATTGCTATGGGTTGTGTTATGTTAAGAAGATGTCACTTGAACTCTTGTGCTGTTGGTATTGCCACACAAGATCCATATTTGAGAAGTAAGTTTAAGGGTCAGCCCGAACATGTTATCAACTTCTTCTATTACTTGATCCAAGATTTAAGACAAATCATGGCCAAGTTAGGATTCCGTACCATTGACGAAATGGTGGGTCATTCTGAAAAATTAAAGAAAAGGGACGACGTAAATGCCAAAGCCATAAATATCGATTTATCTCCTATTTTGACCCCAGCACATGTTATTCGTCCAGGTGTTCCAACCAAGTTCACTAAGAAACAAGACCACAAACTCCACACCCGTCTAGATAATAAGTTAATCGATGAGGCTGAAGTTACTTTGGATCGTGGCTTACCAGTGAATATTGACGCCTCTATAATCAATACTGATCGTGCACTCGGTTCTACTTTATCTTACAGAGTCTCGAAGAAATTTGGTGAAGATGGTTTGCCAAAGGACACCGTTGTCGTTAACATAGAAGGTTCAGCGGGTCAATCTTTTGGTGCTTTCCTAGCTTCTGGTATCACTTTTATCTTGAATGGTGATGCTAATGATTATGTTGGTAAAGGTTTATCCGGTGGTATTATTGTCATTAAACCACCAAAGGATTCTAAATTCAAGAGTGATGAAAATGTAATTGTTGGTAACACTTGTTTCTATGGTGCTACTTCTGGTACTGCATTCATTTCAGGTAGTGCCGGTGAGCGTTTCGGTGTCAGAAACTCTGGTGCCACCATCGTTGTTGAGAGAATTAAGGGTAACAATGCCTTTGAGTATATGACTGGTGGTCGTGCCATTGTCTTATCACAAATGGAATCCCTAAACGCCTTCTCTGGTGCTACTGGTGGTATTGCATACTGTTTAACTTCCGATTACGACGATTTTGTTGGAAAGATTAACAAAGATACTGTTGAGTTAGAATCATTATGTGACCCGGTCGAGATTGCGTTTGTTAAGAATTTGATCCAGGAGCATTGGAACTACACACAATCTGATCTAGCAGCCAGGATTCTCGGTAATTTCAACCATTATTTGAAAGATTTCGTTAAAGTCATTCCAACTGATTATAAGAAAGTTTTGTTGAAGGAGAAAGCAGAAGCTGCCAAGGCAAAGGCTAAGGCAACTTCAGAATACTTAAAGAAGTTTAGATCGAACCAAGAAGTTGATGACGAAGTCAATACTCTATTGATTGCTAATCAAAAAGCTAAAGAGCAAGAAAAAAAGAAGAGTATTACTATTTCAAATAAGGCCACTTTGAAGGAGCCTAAGGTTGTTGATTTAGAAGATGCAGTTCCAGATTCCAAACAGCTAGAGAAGAATAGCGAAAGGATTGAAAAAACACGTGGTTTTATGATCCACAAACGTCGTCATGAGACACACAGAGATCCAAGAACCAGAGTTAATGACTGGAAAGAATTTACTAACCCTATTACCAAGAAGGATGCCAAATATCAAACTGCGAGATGTATGGATTGTGGTACACCATTCTGTTTATCTGATACCGGTTGTCCCCTATCTAACATTATCCCCAAGTTTAATGAATTGTTATTCAAGAACCAATGGAAGTTGGCACTGGACAAATTGCTAGAGACAAACAATTTCCCAGAATTCACTGGAAGAGTATGTCCAGCACCCTGTGAGGGAGCTTGTACACTAGGTATTATTGAAGACCCAGTCGGCATAAAATCGGTTGAAAGAATTATCATTGACAATGCTTTCAAGGAAGGATGGATTAAGCCTTGTCCACCAAGTACACGCACTGGCTTTACAGTGGGTGTCATTGGTTCTGGTCCAGCAGGTTTAGCGTGTGCTGATATGTTGAACCGTGCCGGACATACGGTCACTGTTTATGAAAGATCCGACCGTTGTGGTGGGTTATTGATGTATGGTATTCCAAACATGAAGTTGGATAAGGCTATAGTGCAACGTCGTATTGATCTATTGAGTGCCGAAGGTATTGACTTTGTTACCAACACCGAAATTGGTAAAACCATAAGCATGGATGAGCTAAAGAACAAGCACAATGCAGTAGTGTATGCTATCGGTTCTACCATTCCACGTGACTTACCTATTAAGGGTCGTGAATTGAAGAATATTGATTTTGCCATGCAGTTGTTGGAATCTAACACAAAAGCTTTATTGAACAAAGATCTGGAAATCATTCGTGAAAAGATCCAAGGTAAGAAAGTAATTGTTGTCGGTGGTGGTGACACAGGTAACGATTGTTTAGGTACATCTGTAAGACACGGTGCAGCATCAGTTTTGAATTTCGAATTGTTGCCTGAGCCACCAGTGGAACGTGCCAAAGACAATCCATGGCCTCAATGGCCGCGTGTCATGAGAGTGGACTACGGTCATGCTGAAGTGAAAGAGCATTATGGTAGAGACCCTCGTGAATACTGCATCTTGTCCAAGGAATTTATCGGTAACGATGAGGGTGAAGTCACTGCCATCAGAACTGTGCGCGTAGAATGGAAGAAGTCACAAAGTGGCGTATGGCAAATGGTAGAAATTCCCAACAGTGAAGAGATCTTTGAAGCCGATATCATTTTGTTGTCTATGGGTTTCGTGGGTCCTGAATTGATCAATGGCAACGATAACGAAGTTAAGAAGACAAGACGTGGTACGATTGCCACACTCGACGACTCCTCATACTCTATTGATGGAGGAAAGACTTTTGCATGTGGTGACTGTAGAAGAGGGCAATCTTTGATTGTCTGGGCCATCCAAGAAGGTAGAAAATGTGCTGCCTCTGTCGATAAGTTCCTAATGGACGGCACTACGTATCTACCAAGTAATGGTGGTATCGTTCAACGTGATTACAAACTATTGAAAGAATTAGCTAGTCAAGTCTAA
SEQ ID NO: 99 представляет собой аминокислотную последовательность глутаматсинтазы (glt1), происходящую из Saccharomyces Cerevisiae
MPVLKSDNFDPLEEAYEGGTIQNYNDEHHLHKSWANVIPDKRGLYDPDYEHDACGVGFVANKHGEQSHKIVTDARYLLVNMTHRGAVSSDGNGDGAGILLGIpHEFMKREFKLDLDLDIPEMGKYAVGNVFFKKNEKNNKKNLIKCQKIFEDLAASFNLSVLGWRNVPVDSTILGDVALSREPTILQPLLVPLYDEKQPEFNETKFRTQLYLLRKEASLQIGLENWFYVCSLNNTTIVYKGQLTPAQVYNYYPDLTNAHFKSHMALVHSRFSTNTFPSWDRAQPLRWLAHNGEINTLRGNKNWMRSREGVMNSATFKDELDKLYPIIEEGGSDSAALDNVLELLTINGTLSLPEAVMMMVPEAYHKDMDSDLKAWYDWAACLMEPWDGPALLTFTDGRYCGAILDRNGLRPCRYYITSDDRVICASEVGVIPIENSLVVQKGKLKPGDLFLVDTQLGEMVDTKKLKSQISKRQDFKSWLSKVIKLDDLLSKTANLVPKEFISQDSLSLKVQSDPRLLANGYTFEQVTFLLTPMALTGKEALGSMGNDAPLACLNENPVLLYDYFRQLFAQVTNPPIDPIREANVMSLECYVGPQGNLLEMHSSQCDRLLLKSPILHWNEFQALKNIEAAYPSWSVAEIDITFDKSEGLLGYTDTIDKITKLASEAIDDGKKILIITDRKMGANRVSISSLIAISCIHHHLIRNKQRSQVALILETGEAREIHHFCVLLGYGCDGVYPYLAMETLVRMNREGLLRNVNNDNDTLEEGQILENYKHAIDAGILKVMSKMGISTLASYKGAQIFEALGLDNSIVDLCFTGTSSRIRGVTFEYLAQDAFSLHERGYPSRQTISKSVNLPESGEYHFRDGGYKHVNEPTAIASLQDTVRNKNDVSWQLYVKKEMEAIRDCTLRGLLELDFENSVSIPLEQVEPWTEIARRFASGAMSYGSISMEAHSTLAIAMNRLGAKSNCGEGGEDAERSAVQENGDTMRSAIKQVASARFGVTSYYLSDADEIQIKIAQGAKPGEGGELPAHKVSKDIAKTRHSTPNVGLISPPpHHDIYSIEDLKQLIYDLKCANPRAGISVKLVSEVGVGIVASGVAKAKADHILVSGHDGGTGAARWTSVKYAGLPWELGLAETHQTLVLNDLRRNVVVQTDGQLRTGFDIAVAVLLGAESFTLATVPLIAMGCVMLRRCHLNSCAVGIATQDPYLRSKFKGQPEHVINFFYYLIQDLRQIMAKLGFRTIDEMVGHSEKLKKRDDVNAKAINIDLSPILTPAHVIRPGVPTKFTKKQDHKLHTRLDNKLIDEAEVTLDRGLPVNIDASIINTDRALGSTLSYRVSKKFGEDGLPKDTVVVNIEGSAGQSFGAFLASGITFILNGDANDYVGKGLSGGIIVIKPPKDSKFKSDENVIVGNTCFYGATSGTAFISGSAGERFGVRNSGATIVVERIKGNNAFEYMTGGRAIVLSQMESLNAFSGATGGIAYCLTSDYDDFVGKINKDTVELESLCDPVEIAFVKNLIQEHWNYTQSDLAARILGNFNHYLKDFVKVIPTDYKKVLLKEKAEAAKAKAKATSEYLKKFRSNQEVDDEVNTLLIANQKAKEQEKKKSITISNKATLKEPKVVDLEDAVPDSKQLEKNSERIEKTRGFMIHKRRHETHRDPRTRVNDWKEFTNPITKKDAKYQTARCMDCGTPFCLSDTGCPLSNIIPKFNELLFKNQWKLALDKLLETNNFPEFTGRVCPAPCEGACTLGIIEDPVGIKSVERIIIDNAFKEGWIKPCPPSTRTGFTVGVIGSGPAGLACADMLNRAGHTVTVYERSDRCGGLLMYGIPNMKLDKAIVQRRIDLLSAEGIDFVTNTEIGKTISMDELKNKHNAVVYAIGSTIPRDLPIKGRELKNIDFAMQLLESNTKALLNKDLEIIREKIQGKKVIVVGGGDTGNDCLGTSVRHGAASVLNFELLPEPPVERAKDNPWPQWPRVMRVDYGHAEVKEHYGRDPREYCILSKEFIGNDEGEVTAIRTVRVEWKKSQSGVWQMVEIPNSEEIFEADIILLSMGFVGPELINGNDNEVKKTRRGTIATLDDSSYSIDGGKTFACGDCRRGQSLIVWAIQEGRKCAASVDKFLMDGTTYLPSNGGIVQRDYKLLKELASQV
SEQ ID NO: 100 представляет собой нуклеотидную последовательность терминатора tTDH3
GTGAATTTACTTTAAATCTTGCATTTAAATAAATTTTCTTTTTATAGCTTTATGACTTAGTTTCAATTTATATACTATTTTAATGACATTTTCGATTCATTGATTGAAAGCTTTGTGTTTTTTCTTGATGCGCTATTGCATTGTTCTTGTCTTTTTCGCCACATGTAATATCTGTAGTAGATACCTGATACATTGTGGATGCTGAGTGAAATTTTAGTTAATAATGGAGGCGCTCTTAATAATTTTGGGGATATTGGCTTTTTTTTTTAAAGTTTACAAATGAATTTTTTCCGCCAGGAT
SEQ ID NO: 101 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (hasa), происходящую из вируса хлореллы CviKl
ATGCTTTTCAGTTGTTTGTCCTTCGTGATCTGCCATCTTAGTTTTATTTTGCGTTATTACAAGAGGCTTCTAAAAGTGACGATGGGAAAGAACATTATAATAATGGTGAGTTGGTACACAATAATAACTTCCAACATCATCGCCGTCGGTGGGGCGTCTCTGATTTTGGCCCCAGCCATCACTGGATACATCTTGCACTGGAACATCGCCTTGTCAACCATCTGGGGAGTTTCCGCTTATGGGATATTCGTGTTCGGATTCTTCCTGGCTCAGGTTTTATTTAGTGAGCTAAATCGTAAAAGACTAAGAAAGTGGATTTCTCTAAGACCAAAGGGTTGGAACGACGTACGTCTGGCTGTCATCATAGCTGGTTACAGGGAAGACCCGTACATGTTTCAGAAATGCCTTGAGTCAGTAAGGGACTCTGACTATGGTAATGTCGCTCGTCTTATCTGTGTAATTGACGGAGATGAGGACGACGACATGAAGATGGCAGCCGTTTATAAGGCGATATATAATGACAATATCAAGAAGCCAGAGTTTGTGTTATGTGAGAGCGATGATAAGGAAGGCGAGAGAATTGACTCAGATTTTAGCAGGGACATCTGCGTCTTACAACCACACCGTGGCAAAAGGGAGTGCTTGTATACCGGCTTTCAGCTGGCCAAAATGGACCCGTCGGTAAACGCCGTTGTTCTTATTGACTCTGACACGGTCTTGGAAAAGGACGCAATCTTGGAAGTCGTGTATCCATTGGCCTGTGACCCGGAAATTCAAGCTGTCGCAGGAGAGTGCAAAATATGGAACACAGATACACTTTTGTCGTTGTTGGTGGCTTGGAGATATTATTCAGCCTTTTGCGTGGAGAGATCCGCCCAATCATTCTTTAGGACAGTCCAGTGTGTAGGTGGACCCTTGGGCGCCTACAAGATAGATATCATCAAAGAGATCAAAGATCCCTGGATCTCCCAACGTTTCTTAGGTCAGAAGTGCACCTACGGTGACGACCGTAGGTTAACAAATGAAATCTTAATGAGGGGTAAGAAGGTCGTCTTCACTCCTTTCGCAGTTGGCTGGAGTGACTCACCAACCAACGTGTTCAGGTACATCGTACAACAGACTAGGTGGAGTAAATCATGGTGCCGTGAGATATGGTACACTTTGTTTGCTGCGTGGAAGCACGGACTAAGCGGAATTTGGTTGGCATTTGAGTGCCTTTATCAGATTACGTACTTCTTCCTAGTCATATATTTATTTTCGAGACTAGCCGTTGAAGCTGACCCAAGAGCACAGACCGCAACAGTAATCGTGTCTACCACGGTAGCCCTGATTAAGTGTGGTTACTTCTCTTTTCGTGCGAAAGATATTCGTGCTTTCTACTTCGTCCTGTACACATTTGTCTACTTCTTCTGTATGATCCCAGCAAGGGTGACAGCCATGATGACACTTTGGGATATCGGCTGGGGCACGCGTGGCGGAAACGAGAAACCAAGTGTCGGCACTAGGGTCGCTCTGTGGGCTAAACAGTATTTGATAGCATACATGTGGTGGGCAGCAGTTGTTGGCGCTGGGGTATACTCCATTGTTCATAATTGGATGTTTGACTGGAACTCACTATCCTATAGGTTCGCACTTGTAGGTATATGCTCTTACATCGTATTCATCACAATCGTTCTAGTCATCTATTTCACAGGAAAGATTACCACATGGAATTTCACCAAATTACAGAAGGAGTTAATCAAGGATAGGGTCTTATACGATGCTTCCACTAACGCCCAGACTGTATAA
SEQ ID NO: 102 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (hasa), происходящую из вируса хлореллы IL-5-2s1
ATGGCTGCTTCATTCTATGTTATCTTCTTGTTCGTAATATGCCACCTGTCCTTCGTCTTATATCGTCAAGTTCTATACATAATTTTGGGTAGATACTGGAGTGTTAACAAGCTGACAATGATCTCTTGGTATACCATTATATCATCTAATCTAATCGCAATCGGTGGGGCTTCCCTTATTTTGGCACCGGCCATAACCGGCTACATTTTGCATTGGAACATAGCTCTAAGCACAATTTGGGGTGTGTCAGCCTATGGCATTTTCGTGTTCGGGTTCTTTCTTGCTCAGGTTTTGTTCAGTGAGCTTAACAGGAAGAGGTTGAGAAAATGGATCTCTTTGAGACCAGATAACTGGAACGCGGTGAGAGTTGCCGTGATAATCGCTGGTTACCGTGAAGACCCATACATGTTTCAAAAGTGTTTGGAATCGGTGAGAGACTCCGATTATGGTAACATTGCGAGGCTTATATGCGTTATAGATGGGGACGAAGATGACGACATGAAGATGGCAGATGTATACAAGGCTATTTACAATGACAATATAAAGAAGCCGGAAATTATCCTATGTGAGTCCGACGACAAAGAGGGAGAAAGGATAGACAGTGATTTTAGCCGTGATATTTGCGTGCTTCAGCCTCACAGAGGTAAGCGTGAATGTTTATATACTGGCTTTCAGTTAGCTAAAATGGACCCCTCTGTACACGCGGTTGTGCTTATTGACTCGGATACAGTTTTGGAGAAGGATGCCATCCTGGAAGTGGTCTACCCACTTGCTTGCGACCATGAGATTCAAGCAGTCGCAGGTGAATGCAAGATATGGAATACGGACACCTTATTATCCATATTAGTCGCCTGGCGTTACTACTCAGCTTTCTGCGTTGAGCGTAGCGCTCAGTCCTTCTTCCGTACTGTGCAATGCGTCGGCGGTCCGTTAGGGGCATACAAAATAGACATAATTAAAGAGATAAAGGAGCCGTGGATTTCACAAAGATTTCTGGGTCAGAAGTGTACGTACGGAGATGACAGAAGATTAACTAACGAAGTGTTGATGCGTGGAAAGAAAGTAGTCTTCACACCTTTTGCGGTAGGATGGAGCGACTCGCCTACTAATGTCTTCCGTTATATTGTGCAGCAGACGAGGTGGAGTAAGAGCTGGTGCAGGGAGATTTGGTATACACTGTTCGCGGCGTGGAAGCATGGGTTATCAGGCATTTGGTTGGCATTTGAGTGCTTGTATCAGATCACATACTTCTTTCTAGTGATATATCTGTTCAGTAGACTAGCAGTCGAGGCTGACCCGAGAGCGCAAACTGCAACGGTTATAGTCAGCACAATGGTTTCACTAATCAAGTGTGGATATTTCTCATTCCGTGCTAAGGACATTAGAGCGTTTTATTTCGTACTATATACTTTTGTGTACTTCTTTTGCATGATCCCAGCAAGAGTCACTGCTATGATGACCTTGTGGGATATTGGGTGGGGTACTAGGGGTGGAAACGTGAAACCATCGATCGGAACTAGGATCTCTTTGTGGGCTAAGCAGTACTTAATCGCGTACATGTGGTGGGCAGCTGTGATCGCCGCAGGAGTCTATAGTATAATACATAATTGGATGTTTGATTGGAACTCCTTGTCCTATCGTTTCGCGTTAATAGGCATCTGCTCGTATATCGTATTCATTGCCATTGTTATAGTGATATACTTCACAGGTAAGATCACCACTTGGAATTTTACCAAGCTACAGAAAGAGTTAATTGAAGATAGAGTCTTGCATGATGCCGATGTGGACATACAGAACGTATAA
SEQ ID NO: 103 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (HASA), происходящую из вируса хлореллы CZ-2
ATGACATCTTGGAGAACGATTGTGTCAGCTAACCTTTTCGCAGTTGGTGGGGCTCTTCTAATGTTAGCCCCAGCTATCGTGGGCTATGTATTTCAGTGGAATATAGGCGTGTCCGCAGTCTGGGGCATCTCCGTATACGGCGTCTTTGTGTTGGGATTTTATATCGCTCAAATCGTCTTCTCTGAGTTCAACAGGATGAGATTATCCGATTGGATAAGTCTTAGACCAGACAACTGGAACGCCACAAGGGTTGCGGTCATTATAGCTGGATACAGAGAAGATCCTTTTATGTTCAAGAAGTGCTTAGAGAGTGTGAGGGATTCGGAATACGGCAACGTAGCAAGGCTTATATGCGTAATTGACGGAGACGAAGAAGAGGACCTAAAGATGGCTGAGATTTACAAGCAGGTTTACAATGACAACGTGAAGAAACCAGGTGTAGTGTTATGCGAATCGGAGAACAAGAATGGATCGACTATAGATTCGGACGTATCTAAGAATATATGCATACTGCAACCCCACCGTGGGAAACGTGAGAGCCTATATACCGGTTTCCAATTGGCAAGCATGGACCCTTCCGTACATGCGGTTGTTCTTATAGATTCCGACACTGTATTAGAGAAGAATGCTATTCTTGAGGTCGTATACCCTCTATCTTGTGACCCCAACATTAAGGCCGTCGCCGGGGAGTGCAAGATATGGAATACAGACACCATCTTGTCCATGCTTGTCTCTTGGAGATACTTCTCTGCCTTCAATGTCGAGCGTGGAGCCCAGTCATTATGGAAGACTGTGCAATGCGTAGGCGGGCCACTTGGCGCATACACTATCGACATCATAAATGAAATTAAAGACCCGTGGATTACCCAGACATTCCTGGGCAACAAGTGCACTTATGGCGACGATAGACGTCTTACCAATGAGGTTTTAATGAGGGGCAAGAAGATTGTATACACTCCGTTTGCCGTCGGTTGGAGCGACAGTCCGACGAATGTCATGAGGTACATTGTGCAGCAAACTAGATGGAGTAAGTCATGGTGCAGAGAGATATGGTACACGTTAGGCAGTGCCTGGAAACATGGATTCTCCGGCATATACCTTGCGTTTGAGTGTATGTACCAGATAATGTACTTCTTCTTAGTCATGTACCTGTTTTCGTATATCGCAATAAAGGCAGACATCCGTGCTCAGACTGCAACTGTGTTGGTTTCTACTCTAGTCACCATAATAAAGAGCAGTTACCTAGCGCTGAGGGCCAAGAACCTGAAGGCTTTCTATTTCGTTCTGTATACCTATGTCTATTTCTTTTGCATGATACCTGCTAGGATTACCGCTATGTTTACAATGTTTGATATAGCTTGGGGTACACGTGGTGGTAATGCGAAAATGACAATCGGGGCTAGAGTTTGGCTGTGGGCGAAGCAGTTCTTAATAACTTATATGTGGTGGGCAGGAGTACTAGCGGCGGGAGTTTACAGTATAGTTGACAATTGGTACTTCGATTGGGCTGATATACAGTACAGGTTTGCATTGGTAGGTATTTGCTCGTATTTGGTCTTTGTCAGTATTGTACTGGTAATCTACTTGATCGGTAAGATAACAACGTGGAACTACACACCGCTACAGAAGGAACTTATTGAGGAGAGATACTTGCATAACGCCTCTGAGAATGCCCCGGAAGTTTAA
SEQ ID NO: 104 представляет собой перекодированную нуклеотидную последовательность гиалуронан-синтазы (hasa), происходящую из вируса хлореллы CVG-1
ATGACTTCTTGGCGTACAATTGTTTCTGCTAACTTGTTCGCAGTTGGTGGCGCCTTGTTGATGTTAGCTCCCGCGATAGCCGGTTATGTATTTAAATGGAACATAGGCGTTTCTGCCGTTTGGGGTATTTCAGTGTACGGGGTCTTCGTGCTTGGTTTCTATATTGCACAGGTAGTCTTCAGCGAGTTTAATAGGATGCAGCTGTCAGACTGGATCTCATTGAGACCCGACAACTGGAACGCCACCAGAGTAGCGGTAATTATTGCTGGTTACAGGGAAGACCCCTTTATGTTCAAGAAGTGCCTAGAATCTGTGAGAGACTCAGAATACGGGAACATAGCGAGGCTAATCTGTGTTATCGACGGCGATGAAGAGGAAGACCTTAAGATGGCTGAGATATACAAGCAAGTATACAACGACAACGTCAAGACCCCCGGTGTTGTGCTATGCGAGAATGAAAATAAGAATGGTAGCACCATTGACCCAGATTTTAGTAAGAACATCTGCATTCTGCAACCACACAGGGGCAAACGTGAATCTTTGTACACCGGATTCCAGATGGCTGGCATGGACCCATCAGTGCACGCAGTTGTACTTATAGACAGTGATACTGTTCTTGAAAAGAACGCTATCCTAGAGGTTGTGTACCCTCTATCTTGTGATCCAAATATCAAAGCTGTCGCGGGAGAGTGTAAAATCTGGAACACAGATACCATTTTGTCTATGCTAGTTTCATGGCGTTATTTCTCGGCTTTCAACGTGGAGAGAGGCGCACAGTCCCTTTGGAAAACAGTCCAGTGTGTCGGCGGGCCTTTGGGAGCATACACTATAGACATCATAAACGAGATAAAAGACCCCTGGATTACTCAGACATTCTTAGGAAACAAATGTACGTATGGTGACGACAGAAGGTTAACCAATGAAGTGCTTATGAGGGGAAAGAAGATTGTCTATACTCCCTTTGCTGTCGGTTGGTCCGATTCGCCCACAAACGTTATGAGGTACATCGTCCAGCAGACAAGGTGGTCTAAGAGCTGGTGCCGTGAGATTTGGTACACCTTGGGATCAGCATGGAAACATGGTTTCTCCGGAATCTACTTAGCGTTCGAGTGCATGTACCAGATTATGTATTTCTTTATTGTGATGTATTTGTTCAGTTACATTGCCATTAAAGCCAACATCAGGGCACAAGCAGCCACGGTATTGGTCAGTACGCTTGTCGCAGTAATCAAATCTAGTTATTTGGCATTAAGAGCGAAGAACCTAAAAGCTTTGTATTTCGTCCTGTATACCTACGTCTACTTCTTCTGCATGATTCCAGCTAGAATAACAGCGATGTTCACGATGTTCGATATTGCATGGGGTACTAGAGGCGGTAACGCAAAGATGACGATCGGTGCTAGAGTCTGGTTGTGGGCTAAACAATTCTTAATTACATACATGTGGTGGGTGGGAGTTTTGGCCGCTGGGGTCTACAGTATAGTCGATAACTGGTACTTCGACTGGGCGGACATCCAGTACAGATTCGCGCTAGTGGGGATTTGCAGTTACTTAGGTTTCGTTTCCATAATGCTGGTATTCTATCTGATTGGTAAAATAACTACGTGGAATTACACTCCTCTACAAAAGGAGCTGATTAAAGAGAGGTTACACGCCGCTAATGCAACAGAGGTCTAA
SEQ ID NO: 105 представляет собой аминокислотную последовательность гиалуронан-синтазы (hasa), происходящую из вируса хлореллы CviKl
MLFSCLSFVICHLSFILRYYKRLLKVTMGKNIIIMVSWYTIITSNIIAVGGASLILAPAITGYILHWNIALSTIWGVSAYGIFVFGFFLAQVLFSELNRKRLRKWISLRPKGWNDVRLAVIIAGYREDPYMFQKCLESVRDSDYGNVARLICVIDGDEDDDMKMAAVYKAIYNDNIKKPEFVLCESDDKEGERIDSDFSRDICVLQpHRGKRECLYTGFQLAKMDPSVNAVVLIDSDTVLEKDAILEVVYPLACDPEIQAVAGECKIWNTDTLLSLLVAWRYYSAFCVERSAQSFFRTVQCVGGPLGAYKIDIIKEIKDPWISQRFLGQKCTYGDDRRLTNEILMRGKKVVFTPFAVGWSDSPTNVFRYIVQQTRWSKSWCREIWYTLFAAWKHGLSGIWLAFECLYQITYFFLVIYLFSRLAVEADPRAQTATVIVSTTVALIKCGYFSFRAKDIRAFYFVLYTFVYFFCMIPARVTAMMTLWDIGWGTRGGNEKPSVGTRVALWAKQYLIAYMWWAAVVGAGVYSIVHNWMFDWNSLSYRFALVGICSYIVFITIVLVIYFTGKITTWNFTKLQKELIKDRVLYDASTNAQTV
SEQ ID NO: 106 представляет собой аминокислотную последовательность гиалуронан-синтазы (hasa), происходящую из вируса хлореллы IL-5-2s1
MAASFYVIFLFVICHLSFVLYRQVLYIILGRYWSVNKLTMISWYTIISSNLIAIGGASLILAPAITGYILHWNIALSTIWGVSAYGIFVFGFFLAQVLFSELNRKRLRKWISLRPDNWNAVRVAVIIAGYREDPYMFQKCLESVRDSDYGNIARLICVIDGDEDDDMKMADVYKAIYNDNIKKPEIILCESDDKEGERIDSDFSRDICVLQpHRGKRECLYTGFQLAKMDPSVHAVVLIDSDTVLEKDAILEVVYPLACDHEIQAVAGECKIWNTDTLLSILVAWRYYSAFCVERSAQSFFRTVQCVGGPLGAYKIDIIKEIKEPWISQRFLGQKCTYGDDRRLTNEVLMRGKKVVFTPFAVGWSDSPTNVFRYIVQQTRWSKSWCREIWYTLFAAWKHGLSGIWLAFECLYQITYFFLVIYLFSRLAVEADPRAQTATVIVSTMVSLIKCGYFSFRAKDIRAFYFVLYTFVYFFCMIPARVTAMMTLWDIGWGTRGGNVKPSIGTRISLWAKQYLIAYMWWAAVIAAGVYSIIHNWMFDWNSLSYRFALIGICSYIVFIAIVIVIYFTGKITTWNFTKLQKELIEDRVLHDADVDIQNV
SEQ ID NO: 107 представляет собой аминокислотную последовательность гиалуронан-синтазы (hasa), происходящую из вируса хлореллы CZ-2
MTSWRTIVSANLFAVGGALLMLAPAIVGYVFQWNIGVSAVWGISVYGVFVLGFYIAQIVFSEFNRMRLSDWISLRPDNWNATRVAVIIAGYREDPFMFKKCLESVRDSEYGNVARLICVIDGDEEEDLKMAEIYKQVYNDNVKKPGVVLCESENKNGSTIDSDVSKNICILQpHRGKRESLYTGFQLASMDPSVHAVVLIDSDTVLEKNAILEVVYPLSCDPNIKAVAGECKIWNTDTILSMLVSWRYFSAFNVERGAQSLWKTVQCVGGPLGAYTIDIINEIKDPWITQTFLGNKCTYGDDRRLTNEVLMRGKKIVYTPFAVGWSDSPTNVMRYIVQQTRWSKSWCREIWYTLGSAWKHGFSGIYLAFECMYQIMYFFLVMYLFSYIAIKADIRAQTATVLVSTLVTIIKSSYLALRAKNLKAFYFVLYTYVYFFCMIPARITAMFTMFDIAWGTRGGNAKMTIGARVWLWAKQFLITYMWWAGVLAAGVYSIVDNWYFDWADIQYRFALVGICSYLVFVSIVLVIYLIGKITTWNYTPLQKELIEERYLHNASENAPEV
SEQ ID NO: 108 представляет собой аминокислотную последовательность гиалуронан-синтазы (hasa), происходящую из вируса хлореллы CVG-1
MTSWRTIVSANLFAVGGALLMLAPAIAGYVFKWNIGVSAVWGISVYGVFVLGFYIAQVVFSEFNRMQLSDWISLRPDNWNATRVAVIIAGYREDPFMFKKCLESVRDSEYGNIARLICVIDGDEEEDLKMAEIYKQVYNDNVKTPGVVLCENENKNGSTIDPDFSKNICILQpHRGKRESLYTGFQMAGMDPSVHAVVLIDSDTVLEKNAILEVVYPLSCDPNIKAVAGECKIWNTDTILSMLVSWRYFSAFNVERGAQSLWKTVQCVGGPLGAYTIDIINEIKDPWITQTFLGNKCTYGDDRRLTNEVLMRGKKIVYTPFAVGWSDSPTNVMRYIVQQTRWSKSWCREIWYTLGSAWKHGFSGIYLAFECMYQIMYFFIVMYLFSYIAIKANIRAQAATVLVSTLVAVIKSSYLALRAKNLKALYFVLYTYVYFFCMIPARITAMFTMFDIAWGTRGGNAKMTIGARVWLWAKQFLITYMWWVGVLAAGVYSIVDNWYFDWADIQYRFALVGICSYLGFVSIMLVFYLIGKITTWNYTPLQKELIKERLHAANATEV
--->
ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> GIVAUDAN SA
<120> РЕКОМБИНАНТНЫЕ КЛЕТКИ, ПРОДУЦИРУЮЩИЕ ГИАЛУРОНОВУЮ КИСЛОТУ
<130> PR92297/MGG
<150> EP21306488.4
<151> 2021-10-26
<150> EP21166743.1
<151> 2021-04-01
<160> 108
<170> BiSSAP 1.3.6
<210> 1
<211> 1707
<212> ДНК
<213> Вирус хлореллы Paramecium bursaria 1
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы PBCV-1
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы PBCV-1
<400> 1
atgggtaaga acatcattat tatggtttct tggtacacta ttattacatc caatctcatc 60
gcagtgggtg gcgcctcact catactagcc ccagctatta cgggctatgt ccttcactgg 120
aacattgccc tttcaacaat ttggggagtg tcggcctacg gaattttcgt gtttggtttc 180
tttcttgccc aggtattatt tagtgaactc aaccggaaaa ggctccggaa gtggatttcc 240
ctccgaccca aagggtggaa tgatgttagg ttggctgtaa ttattgccgg ctaccgtgag 300
gacccgtata tgttccaaaa gtgtcttgaa agtgtgcgtg actcagacta tgggaatgta 360
gctagactaa tatgcgttat tgacggcgat gaagacgacg acatgaggat ggctgcagtg 420
tacaaggcta tctataacga caacatcaag aaacctgagt ttgtcctctg tgagagtgac 480
gataaggagg gtgagagaat agatagcgat ttcagccgtg atatctgcgt gctgcaaccg 540
catcgcggaa agcgtgaatg tttgtacaca gggttccaat tggcaaagat ggacccctca 600
gttaatgccg tcgtcctaat cgacagtgac actgtgttag aaaaggacgc gattctcgaa 660
gtagtatacc cgctggcatg cgatccagaa atacaggctg tagcaggcga atgcaaaata 720
tggaatactg acacactgtt gagtttgctg gtagcctggc gatattacag cgcattttgc 780
gtagagcgta gcgcccaatc attcttcagg acagtacaat gcgtcggagg acctctcggc 840
gcctacaaga ttgatataat taaggaaatc aaggacccat ggatcagcca acgtttcctt 900
ggccaaaagt gcacatacgg cgacgataga cgactcacta atgaaatact aatgaggggt 960
aagaaagtag ttttcacccc attcgctgtt ggctggtccg acagcccgac gaacgtcttc 1020
cgttacattg tacagcaaac acggtggtcc aagtcgtggt gtagggagat atggtataca 1080
ctgtttgcag catggaagca tggactttcg ggcatttggc tcgcattcga gtgcttatac 1140
cagattactt atttcttcct ggtgatttac ctattctccc gtttggctgt tgaggctgac 1200
ccacgggcgc aaacggccac cgtcattgtt tcgaccacag ttgcgcttat taagtgcggt 1260
tactttagct tcagagctaa agacattagg gccttctatt tcgtcctcta cacgttcgtt 1320
tacttcttct gcatgattcc ggcacgaata actgcgatga tgaccctgtg ggacataggt 1380
tggggaacca ggggaggaaa tgagaagcct tccgtaggca ccagagttgc tttgtgggcc 1440
aagcaatatt tgattgctta catgtggtgg gccgctgtcg tcggtgctgg cgtgtactcc 1500
atcgttcata attggatgtt tgactggaat tcactttcct acaggttcgc actggtaggc 1560
atctgttcgt atatagtttt cattgtaata gtgctggtag tctactttac aggaaagatc 1620
acgacctgga acttcacgaa gctacagaaa gaattgatcg aggaccgcgt actgtacgac 1680
gcaacgacca atgcccagtc ggtataa 1707
<210> 2
<211> 1707
<212> ДНК
<213> Вирус хлореллы Paramecium bursaria 1
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы PBCV-1
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы PBCV-1
<400> 2
atgggcaaga atattattat catggtcagt tggtatacca ttattacatc aaacctaatt 60
gctgtcggtg gagcctcact aatcttagct cccgcgatta cgggttatgt gcttcattgg 120
aatattgctt tatccactat ttggggtgtt agcgcttacg gcatctttgt gttcggtttc 180
ttcttggctc aggtgttatt ctctgagcta aacagaaaga gactcagaaa gtggatttcg 240
ctgcggccga agggatggaa cgatgttcgg ttagcggtga tcattgccgg ttatcgtgaa 300
gatccttata tgtttcagaa gtgtttggaa tctgttcgag actcagacta cggtaacgtt 360
gctaggctga tctgcgtaat cgatggagac gaagatgacg atatgagaat ggccgcggtt 420
tataaagcca tctataacga taacattaag aagccagagt ttgttttatg cgaatcggat 480
gacaaggagg gtgagaggat tgattctgac ttctcgcgtg acatctgtgt cctgcagccc 540
cacaggggaa agcgagagtg cctctataca ggattccaat tagctaaaat ggacccaagc 600
gttaatgctg tcgtccttat cgatagcgac acggtgttgg aaaaggacgc aatattggaa 660
gtagtctatc cactcgcttg tgatccagag atccaggccg tggctggcga gtgcaagatt 720
tggaatacag atacgcttct gtcattactg gtggcgtggc gttattattc agcattctgt 780
gtggagagga gcgcacaatc gttctttcgg actgtacaat gcgtaggcgg tccactagga 840
gcatataaaa ttgacataat caaagagata aaagatcctt ggatttcgca gagattcctc 900
ggtcaaaagt gtacctatgg ggacgacagg cggttgacta acgagattct aatgagaggt 960
aagaaggtgg tgttcactcc ttttgcggta ggttggagcg attcgcccac aaatgtattc 1020
agatacattg ttcaacaaac aaggtggtcg aaatcgtggt gccgagaaat atggtacacg 1080
ttgttcgccg catggaaaca cggcttgtcg ggtatatggc tcgctttcga gtgcctttat 1140
cagatcactt acttcttcct ggttatttac ttgttttcaa gactggcagt ggaagctgat 1200
ccaagggctc agactgctac tgtcatcgtt tcaacaacag tggcgctaat aaagtgtggt 1260
tacttcagct ttcgcgcgaa ggacataaga gcgttttact ttgttcttta tacctttgta 1320
tatttcttct gtatgatccc ggcccggata acagctatga tgacattatg ggacattggt 1380
tggggcacca ggggtgggaa tgagaagccg tccgtaggaa cgagagtagc gctgtgggcc 1440
aagcagtatc ttatcgcata catgtggtgg gcagctgtcg tcggggcagg tgtatacagc 1500
atagtacata actggatgtt tgactggaac tcactctcat atcgattcgc attggtcggg 1560
atctgctctt acatcgtgtt tattgttata gtcttagtag tatatttcac tggaaagata 1620
acaacatgga atttcactaa gcttcaaaag gaattgattg aagacagggt gctctacgat 1680
gcgacaacta atgcacaaag cgtataa 1707
<210> 3
<211> 2919
<212> ДНК
<213> Pasteurella multocida
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из Pasteurella multocida
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из Pasteurella multocida
<400> 3
atgaacaccc tttcccaggc aattaaggct tataatagta atgattatca actagccctc 60
aagctgttcg aaaagtcggc agaaatctac ggcagaaaga tagttgagtt ccaaattacg 120
aagtgcaagg agaaactttc tgcgcaccca tccgttaaca gtgcgcatct ctcggttaac 180
aaagaagaga aggtgaatgt ttgcgacagt ccattagaca tagccactca attattgtta 240
tcgaatgtga aaaaactcgt ccttagtgat agcgagaaaa atacactaaa gaataaatgg 300
aagttgttga ctgaaaagaa gtctgagaac gcagaggtcc gggccgtagc tttagttccc 360
aaggactttc cgaaagattt agtgcttgcg ccgttaccag accatgtgaa cgattttacg 420
tggtataaga agcggaagaa acgcctagga atcaaaccag aacaccaaca cgttggcctc 480
tccattattg tgacaacgtt caaccgtcct gccatcctca gcatcaccct ggcttgcctc 540
gtcaatcaaa agacccatta tccttttgag gtgatcgtga ccgacgatgg ttctcaagag 600
gatttatcgc ctataatccg tcaatatgag aacaagctag acatccgtta tgttcggcaa 660
aaggacaacg gttttcaggc atcggccgca cgtaatatgg gcctacgtct agccaaatat 720
gacttcattg ggctccttga ttgtgatatg gctcccaacc ctttgtgggt acactcatac 780
gttgcggaac tattagagga cgatgatttg accataatag gccccaggaa gtacattgac 840
acgcaacaca tagatcccaa ggatttcctt aataacgcct ctctgttaga gtcgttgcca 900
gaggttaaga ccaataattc cgtcgcggct aagggcgagg ggaccgtatc tttagactgg 960
cgtttggaac aatttgagaa gaccgagaac ttgaggctat ccgatagccc tttccgattc 1020
ttcgcagctg ggaatgtggc tttcgccaag aagtggctta acaagtcagg attcttcgac 1080
gaggaattca atcactgggg aggtgaagat gtagagttcg gttatcgtct gtttcggtac 1140
ggttcgttct tcaaaactat agacggcatc atggcctatc atcaggaacc gccaggtaaa 1200
gaaaacgaaa ctgacagaga agcgggcaag aacattaccc tcgatataat gagggagaag 1260
gtgccttaca tctaccgtaa actcctgcct atagaagaca gtcatatcaa ccgagtacca 1320
ttggtatcaa tttacatccc ggcctacaac tgtgctaact atattcaaag atgtgttgat 1380
tcagctttga atcaaacggt agttgatctc gaagtgtgca tttgcaacga cggtagtact 1440
gacaacacgc tggaagttat taacaagctg tatggtaata atccgcgtgt gcgtataatg 1500
tctaaaccca atggcggcat tgcgagtgca tccaacgcag cggtcagctt cgcaaagggt 1560
tattacatag gacagttgga cagcgacgat tacttagaac ccgacgcagt ggagttatgt 1620
ctcaaggaat ttcttaagga taagaccctt gcgtgcgttt acaccactaa tcgtaacgtc 1680
aacccagatg gctctttaat agccaatggc tataactggc cagagttcag tcgtgagaag 1740
ttgactacgg ccatgattgc tcatcacttc cggatgttta ccattcgtgc ttggcatctg 1800
acggatgggt tcaatgagaa gattgagaac gctgttgact acgacatgtt tctcaagctc 1860
agtgaagttg gtaaatttaa gcatctgaac aaaatatgtt ataatcgggt gttacacggc 1920
gataacacct caatcaagaa gcttggcata caaaagaaga atcatttcgt agttgtcaat 1980
cagtctctaa accgccaagg tataacttat tataactacg atgaatttga tgatctcgat 2040
gagagtcgga aatacatttt caacaagact gcagagtatc aagaagagat agatattctt 2100
aaagatatta agatcattca gaacaaagac gccaaaatag ctgtctccat tttctatccg 2160
aacactctaa acgggttggt gaagaagcta aataatatta tagagtataa taagaatatc 2220
ttcgttattg tacttcatgt cgataagaat cacttaaccc cagacatcaa gaaggagata 2280
ttagccttct accataagca tcaggtgaac atcttattga acaatgacat ctcctactat 2340
acatcaaatc gtctgattaa gacagaagcc catttgagta acattaacaa gctaagtcaa 2400
ttaaatctta actgcgaata cattatattc gacaatcacg attccttatt tgtgaagaac 2460
gattcctatg catacatgaa gaagtatgat gttggaatga acttctctgc attgactcat 2520
gattggattg aaaagataaa cgctcacccg ccatttaaga agctgatcaa aacttacttc 2580
aatgacaatg atcttaagtc gatgaatgta aagggtgcct cccagggaat gtttatgaca 2640
tacgcattag cccacgagtt attgacgatc atcaaggagg tgataacctc ttgtcaatcc 2700
attgactccg tccccgaata caacacagaa gatatttggt ttcagtttgc acttttaatt 2760
ctggaaaaga agaccggcca cgtattcaac aagacaagca ctctcacgta tatgccatgg 2820
gaacgtaaac tgcagtggac gaatgaacaa atagagtccg caaagagggg cgaaaacatt 2880
ccggtaaaca agttcatcat taacagcatt accctttaa 2919
<210> 4
<211> 2112
<212> ДНК
<213> Pasteurella multocida
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из Pasteurella multocida
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из Pasteurella multocida
<400> 4
atgaacaccc tttcccaggc aattaaggct tataatagta atgattatca actagccctc 60
aagctgttcg aaaagtcggc agaaatctac ggcagaaaga tagttgagtt ccaaattacg 120
aagtgcaagg agaaactttc tgcgcaccca tccgttaaca gtgcgcatct ctcggttaac 180
aaagaagaga aggtgaatgt ttgcgacagt ccattagaca tagccactca attattgtta 240
tcgaatgtga aaaaactcgt ccttagtgat agcgagaaaa atacactaaa gaataaatgg 300
aagttgttga ctgaaaagaa gtctgagaac gcagaggtcc gggccgtagc tttagttccc 360
aaggactttc cgaaagattt agtgcttgcg ccgttaccag accatgtgaa cgattttacg 420
tggtataaga agcggaagaa acgcctagga atcaaaccag aacaccaaca cgttggcctc 480
tccattattg tgacaacgtt caaccgtcct gccatcctca gcatcaccct ggcttgcctc 540
gtcaatcaaa agacccatta tccttttgag gtgatcgtga ccgacgatgg ttctcaagag 600
gatttatcgc ctataatccg tcaatatgag aacaagctag acatccgtta tgttcggcaa 660
aaggacaacg gttttcaggc atcggccgca cgtaatatgg gcctacgtct agccaaatat 720
gacttcattg ggctccttga ttgtgatatg gctcccaacc ctttgtgggt acactcatac 780
gttgcggaac tattagagga cgatgatttg accataatag gccccaggaa gtacattgac 840
acgcaacaca tagatcccaa ggatttcctt aataacgcct ctctgttaga gtcgttgcca 900
gaggttaaga ccaataattc cgtcgcggct aagggcgagg ggaccgtatc tttagactgg 960
cgtttggaac aatttgagaa gaccgagaac ttgaggctat ccgatagccc tttccgattc 1020
ttcgcagctg ggaatgtggc tttcgccaag aagtggctta acaagtcagg attcttcgac 1080
gaggaattca atcactgggg aggtgaagat gtagagttcg gttatcgtct gtttcggtac 1140
ggttcgttct tcaaaactat agacggcatc atggcctatc atcaggaacc gccaggtaaa 1200
gaaaacgaaa ctgacagaga agcgggcaag aacattaccc tcgatataat gagggagaag 1260
gtgccttaca tctaccgtaa actcctgcct atagaagaca gtcatatcaa ccgagtacca 1320
ttggtatcaa tttacatccc ggcctacaac tgtgctaact atattcaaag atgtgttgat 1380
tcagctttga atcaaacggt agttgatctc gaagtgtgca tttgcaacga cggtagtact 1440
gacaacacgc tggaagttat taacaagctg tatggtaata atccgcgtgt gcgtataatg 1500
tctaaaccca atggcggcat tgcgagtgca tccaacgcag cggtcagctt cgcaaagggt 1560
tattacatag gacagttgga cagcgacgat tacttagaac ccgacgcagt ggagttatgt 1620
ctcaaggaat ttcttaagga taagaccctt gcgtgcgttt acaccactaa tcgtaacgtc 1680
aacccagatg gctctttaat agccaatggc tataactggc cagagttcag tcgtgagaag 1740
ttgactacgg ccatgattgc tcatcacttc cggatgttta ccattcgtgc ttggcatctg 1800
acggatgggt tcaatgagaa gattgagaac gctgttgact acgacatgtt tctcaagctc 1860
agtgaagttg gtaaatttaa gcatctgaac aaaatatgtt ataatcgggt gttacacggc 1920
gataacacct caatcaagaa gcttggcata caaaagaaga atcatttcgt agttgtcaat 1980
cagtctctaa accgccaagg tataacttat tataactacg atgaatttga tgatctcgat 2040
gagagtcgga aatacatttt caacaagact gcagagtatc aagaagagat agatattctt 2100
aaagatattt aa 2112
<210> 5
<211> 2322
<212> ДНК
<213> Pasteurella multocida
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из Pasteurella multocida
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из Pasteurella multocida
<400> 5
atgaacaccc tttcccaggc aattaaggct tataatagta atgattatca actagccctc 60
aagctgttcg aaaagtcggc agaaatctac ggcagaaaga tagttgagtt ccaaattacg 120
aagtgcaagg agaaactttc tgcgcaccca tccgttaaca gtgcgcatct ctcggttaac 180
aaagaagaga aggtgaatgt ttgcgacagt ccattagaca tagccactca attattgtta 240
tcgaatgtga aaaaactcgt ccttagtgat agcgagaaaa atacactaaa gaataaatgg 300
aagttgttga ctgaaaagaa gtctgagaac gcagaggtcc gggccgtagc tttagttccc 360
aaggactttc cgaaagattt agtgcttgcg ccgttaccag accatgtgaa cgattttacg 420
tggtataaga agcggaagaa acgcctagga atcaaaccag aacaccaaca cgttggcctc 480
tccattattg tgacaacgtt caaccgtcct gccatcctca gcatcaccct ggcttgcctc 540
gtcaatcaaa agacccatta tccttttgag gtgatcgtga ccgacgatgg ttctcaagag 600
gatttatcgc ctataatccg tcaatatgag aacaagctag acatccgtta tgttcggcaa 660
aaggacaacg gttttcaggc atcggccgca cgtaatatgg gcctacgtct agccaaatat 720
gacttcattg ggctccttga ttgtgatatg gctcccaacc ctttgtgggt acactcatac 780
gttgcggaac tattagagga cgatgatttg accataatag gccccaggaa gtacattgac 840
acgcaacaca tagatcccaa ggatttcctt aataacgcct ctctgttaga gtcgttgcca 900
gaggttaaga ccaataattc cgtcgcggct aagggcgagg ggaccgtatc tttagactgg 960
cgtttggaac aatttgagaa gaccgagaac ttgaggctat ccgatagccc tttccgattc 1020
ttcgcagctg ggaatgtggc tttcgccaag aagtggctta acaagtcagg attcttcgac 1080
gaggaattca atcactgggg aggtgaagat gtagagttcg gttatcgtct gtttcggtac 1140
ggttcgttct tcaaaactat agacggcatc atggcctatc atcaggaacc gccaggtaaa 1200
gaaaacgaaa ctgacagaga agcgggcaag aacattaccc tcgatataat gagggagaag 1260
gtgccttaca tctaccgtaa actcctgcct atagaagaca gtcatatcaa ccgagtacca 1320
ttggtatcaa tttacatccc ggcctacaac tgtgctaact atattcaaag atgtgttgat 1380
tcagctttga atcaaacggt agttgatctc gaagtgtgca tttgcaacga cggtagtact 1440
gacaacacgc tggaagttat taacaagctg tatggtaata atccgcgtgt gcgtataatg 1500
tctaaaccca atggcggcat tgcgagtgca tccaacgcag cggtcagctt cgcaaagggt 1560
tattacatag gacagttgga cagcgacgat tacttagaac ccgacgcagt ggagttatgt 1620
ctcaaggaat ttcttaagga taagaccctt gcgtgcgttt acaccactaa tcgtaacgtc 1680
aacccagatg gctctttaat agccaatggc tataactggc cagagttcag tcgtgagaag 1740
ttgactacgg ccatgattgc tcatcacttc cggatgttta ccattcgtgc ttggcatctg 1800
acggatgggt tcaatgagaa gattgagaac gctgttgact acgacatgtt tctcaagctc 1860
agtgaagttg gtaaatttaa gcatctgaac aaaatatgtt ataatcgggt gttacacggc 1920
gataacacct caatcaagaa gcttggcata caaaagaaga atcatttcgt agttgtcaat 1980
cagtctctaa accgccaagg tataacttat tataactacg atgaatttga tgatctcgat 2040
gagagtcgga aatacatttt caacaagact gcagagtatc aagaagagat agatattctt 2100
aaagatattg gatccgccat ttctcaaatc actgacggtc aaatccaagc tactaccact 2160
gctaccaccg aagctaccac cactgctgcc ccatcttcca ccgttgaaac tgtttctcca 2220
tccagcaccg aaactatctc tcaacaaact gaaaatggtg ctgctaaggc cgctgtcggt 2280
atgggtgccg gtgctctagc tgctgctgct atgttgttat aa 2322
<210> 6
<211> 1656
<212> ДНК
<213> Xenopus laevis
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из Xenopus laevis
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из Xenopus laevis
<400> 6
atgcactgtg aacgatttat ttgtatatta cgaataattg gtacgacttt gttcggagta 60
agtctgctac tagggatatc cgccgcttat atcgtgggat accaattcat tcagacggat 120
aattactact tttccttcgg tctctacggt gctattttag ctttacattt aatcattcag 180
tctctcttcg cattcctgga gcatcgtaag atgaagcggt cacttgaaac ccctataaaa 240
ttaaacaaga gcgtagcatt gtgtatcgct gcataccagg aagacgaaga ttatcttaga 300
aaatgtttgc tttctgtgaa acggctcaca taccccggta tgaaggtaat catggtgata 360
gatggtaact ctgatgacga tctatacatg atgaacatat tcagagagat catgggaaat 420
gatagctgcg ccacctatgt atggaagaat aattttcaca tgaagggacc aaacgagacc 480
gacgagactc accgcgagtc catgcagcat gtaacacaga tggtgctttc taacagaaat 540
gtctgtatca tgcaaaagtg gaacgggaaa cgcgaggtga tgtatactgc attcaaagcg 600
ctgggtcggt cggttgatta cgtccaagtg tgcgactcag atacagtcct tgatccagca 660
agctcggtgg agatggtcaa ggtgttggag gaagacatta tggtcggagg tgtaggcgga 720
gacgtgcaga tactcaataa gtacgactcc tggatcagtt tcttgagttc ggttcgttat 780
tggatggctt tcaatataga acgagcatgc caatcatact ttggctgtgt gcagtgtata 840
tcggggcctc tgggcatgta cagaaactca ctcttacatg agttcattga agactggtac 900
aatcaagaat tcctcggttc ccaatgctct ttcggtgatg atcggcattt gactaatcga 960
gtactatcat tgggctatgc tactaaatac actgcgcgca gtaagtgtct gacagaaacc 1020
cccacagaat atcttagatg gttgaaccaa caaaccaggt ggagtaagtc ctatttccgc 1080
gagtggttgt acaactcttt gtggttccac aaacaccatt tatggatgac ttatgaagcc 1140
gtaattacgg gtttcttccc cttcttctta atagcgacgg tgattcagct cttctatcgt 1200
ggtcgaattt ggaatatctt actctttcta ctcacagttc aattagttgg tctaataaag 1260
tcgtcgtttg caagtgcgtt gcgtggaaac atcgttatgg tctttatgag tttctacagt 1320
gttttataca tgagtagctt gctgccagca aagatgtttg caatcgccac gataaacaag 1380
gctggatggg gtactagtgg tagaaagacc atagttgtta attttattgg tttaatccct 1440
attacggtat ggttcacaat tttactaggg ggagtatgct acactatatg gcgggaaacc 1500
aagaagccgt ttagcgagtc tgagaagatc gttcttgcgg tcggtgctat attgtatgct 1560
tgttattggg tcatgttgct tacaatgtat gtcagtcttg tcatgaagtg cgggcgccgt 1620
aggaaggaac cacagcacga ccttgtttta gcataa 1656
<210> 7
<211> 1254
<212> ДНК
<213> Streptococcus zooepidemicus
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из Streptococcus zooepidemicus
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из Streptococcus zooepidemicus
<400> 7
atgaggacgt taaagaatct tatcactgtt gtagcgttca gtatattctg ggttttgctg 60
atctatgtaa atgtctatct tttcggtgcg aaggggtctc tatcaatata tggattcttg 120
ctaattgcgt atttgcttgt gaagatgagt ctttcattct tctataaacc attcaaaggt 180
cgagctggtc agtataaagt cgcagcgatt atcccttcat acaacgagga tgcagaatcg 240
ctgttggaaa ccttaaaatc tgttcaacaa caaacctatc cccttgctga aatttatgta 300
gttgatgatg gttccgcaga tgaaaccggt atcaagcgga tcgaggatta tgtcagggat 360
acaggcgact taagttcaaa tgtgattgtg catcgatcag aaaagaatca aggcaagaga 420
cacgcccaag catgggcatt tgaaagatct gatgcagatg tatttctaac agtcgatagt 480
gatacttaca tttatccgga cgcccttgaa gagttattga aaaccttcaa tgatccgaca 540
gtatttgccg caactggcca cttgaacgtt cgtaacaggc agactaatct attgaccaga 600
ctcactgata taagatacga caatgctttt ggcgtcgaac gtgctgctca aagtgtaact 660
ggtaatatac tggtgtgttc cgggccactg tccgtctatc gcagagaagt agtagtcccg 720
aacattgaca ggtatattaa tcagactttt ctgggtatcc ccgtgtcaat tggggacgac 780
cggtgtttaa cgaactacgc tactgatttg ggcaagactg tatatcagtc gacggctaaa 840
tgtattacag acgtcccaga taagatgtcg acttacctta aacagcagaa tagatggaat 900
aagtcattct ttagagaatc tatcatcagc gtgaagaaga tcatgaataa tccattcgtg 960
gcgctttgga ccattttgga ggtttccatg tttatgatgc ttgtctactc tgtcgttgat 1020
ttctttgtag gtaacgttcg agaatttgat tggctcagag ttcttgcttt cttagttatc 1080
atcttcatcg ttgcgctatg caggaatatt cattacatgc taaaacatcc gcttagcttc 1140
ttactcagcc ctttctacgg cgttttgcat ctcttcgttt tgcagccatt gaagctctac 1200
tccttattta ccattcgaaa cgctgattgg ggtacgcgca agaaactatt ataa 1254
<210> 8
<211> 568
<212> БЕЛОК
<213> Вирус хлореллы Paramecium bursaria 1
<220>
<223> Аминокислотная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы PBCV-1
<220>
<223> Аминокислотная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы PBCV-1
<400> 8
Met Gly Lys Asn Ile Ile Ile Met Val Ser Trp Tyr Thr Ile Ile Thr
1 5 10 15
Ser Asn Leu Ile Ala Val Gly Gly Ala Ser Leu Ile Leu Ala Pro Ala
20 25 30
Ile Thr Gly Tyr Val Leu His Trp Asn Ile Ala Leu Ser Thr Ile Trp
35 40 45
Gly Val Ser Ala Tyr Gly Ile Phe Val Phe Gly Phe Phe Leu Ala Gln
50 55 60
Val Leu Phe Ser Glu Leu Asn Arg Lys Arg Leu Arg Lys Trp Ile Ser
65 70 75 80
Leu Arg Pro Lys Gly Trp Asn Asp Val Arg Leu Ala Val Ile Ile Ala
85 90 95
Gly Tyr Arg Glu Asp Pro Tyr Met Phe Gln Lys Cys Leu Glu Ser Val
100 105 110
Arg Asp Ser Asp Tyr Gly Asn Val Ala Arg Leu Ile Cys Val Ile Asp
115 120 125
Gly Asp Glu Asp Asp Asp Met Arg Met Ala Ala Val Tyr Lys Ala Ile
130 135 140
Tyr Asn Asp Asn Ile Lys Lys Pro Glu Phe Val Leu Cys Glu Ser Asp
145 150 155 160
Asp Lys Glu Gly Glu Arg Ile Asp Ser Asp Phe Ser Arg Asp Ile Cys
165 170 175
Val Leu Gln Pro His Arg Gly Lys Arg Glu Cys Leu Tyr Thr Gly Phe
180 185 190
Gln Leu Ala Lys Met Asp Pro Ser Val Asn Ala Val Val Leu Ile Asp
195 200 205
Ser Asp Thr Val Leu Glu Lys Asp Ala Ile Leu Glu Val Val Tyr Pro
210 215 220
Leu Ala Cys Asp Pro Glu Ile Gln Ala Val Ala Gly Glu Cys Lys Ile
225 230 235 240
Trp Asn Thr Asp Thr Leu Leu Ser Leu Leu Val Ala Trp Arg Tyr Tyr
245 250 255
Ser Ala Phe Cys Val Glu Arg Ser Ala Gln Ser Phe Phe Arg Thr Val
260 265 270
Gln Cys Val Gly Gly Pro Leu Gly Ala Tyr Lys Ile Asp Ile Ile Lys
275 280 285
Glu Ile Lys Asp Pro Trp Ile Ser Gln Arg Phe Leu Gly Gln Lys Cys
290 295 300
Thr Tyr Gly Asp Asp Arg Arg Leu Thr Asn Glu Ile Leu Met Arg Gly
305 310 315 320
Lys Lys Val Val Phe Thr Pro Phe Ala Val Gly Trp Ser Asp Ser Pro
325 330 335
Thr Asn Val Phe Arg Tyr Ile Val Gln Gln Thr Arg Trp Ser Lys Ser
340 345 350
Trp Cys Arg Glu Ile Trp Tyr Thr Leu Phe Ala Ala Trp Lys His Gly
355 360 365
Leu Ser Gly Ile Trp Leu Ala Phe Glu Cys Leu Tyr Gln Ile Thr Tyr
370 375 380
Phe Phe Leu Val Ile Tyr Leu Phe Ser Arg Leu Ala Val Glu Ala Asp
385 390 395 400
Pro Arg Ala Gln Thr Ala Thr Val Ile Val Ser Thr Thr Val Ala Leu
405 410 415
Ile Lys Cys Gly Tyr Phe Ser Phe Arg Ala Lys Asp Ile Arg Ala Phe
420 425 430
Tyr Phe Val Leu Tyr Thr Phe Val Tyr Phe Phe Cys Met Ile Pro Ala
435 440 445
Arg Ile Thr Ala Met Met Thr Leu Trp Asp Ile Gly Trp Gly Thr Arg
450 455 460
Gly Gly Asn Glu Lys Pro Ser Val Gly Thr Arg Val Ala Leu Trp Ala
465 470 475 480
Lys Gln Tyr Leu Ile Ala Tyr Met Trp Trp Ala Ala Val Val Gly Ala
485 490 495
Gly Val Tyr Ser Ile Val His Asn Trp Met Phe Asp Trp Asn Ser Leu
500 505 510
Ser Tyr Arg Phe Ala Leu Val Gly Ile Cys Ser Tyr Ile Val Phe Ile
515 520 525
Val Ile Val Leu Val Val Tyr Phe Thr Gly Lys Ile Thr Thr Trp Asn
530 535 540
Phe Thr Lys Leu Gln Lys Glu Leu Ile Glu Asp Arg Val Leu Tyr Asp
545 550 555 560
Ala Thr Thr Asn Ala Gln Ser Val
565
<210> 9
<211> 972
<212> БЕЛОК
<213> Pasteurella multocida
<220>
<223> Аминокислотная последовательность гиалуронан-синтазы (HASA),
происходящая из Pasteurella multocida
<220>
<223> Аминокислотная последовательность гиалуронан-синтазы (HASA),
происходящая из Pasteurella multocida
<400> 9
Met Asn Thr Leu Ser Gln Ala Ile Lys Ala Tyr Asn Ser Asn Asp Tyr
1 5 10 15
Gln Leu Ala Leu Lys Leu Phe Glu Lys Ser Ala Glu Ile Tyr Gly Arg
20 25 30
Lys Ile Val Glu Phe Gln Ile Thr Lys Cys Lys Glu Lys Leu Ser Ala
35 40 45
His Pro Ser Val Asn Ser Ala His Leu Ser Val Asn Lys Glu Glu Lys
50 55 60
Val Asn Val Cys Asp Ser Pro Leu Asp Ile Ala Thr Gln Leu Leu Leu
65 70 75 80
Ser Asn Val Lys Lys Leu Val Leu Ser Asp Ser Glu Lys Asn Thr Leu
85 90 95
Lys Asn Lys Trp Lys Leu Leu Thr Glu Lys Lys Ser Glu Asn Ala Glu
100 105 110
Val Arg Ala Val Ala Leu Val Pro Lys Asp Phe Pro Lys Asp Leu Val
115 120 125
Leu Ala Pro Leu Pro Asp His Val Asn Asp Phe Thr Trp Tyr Lys Lys
130 135 140
Arg Lys Lys Arg Leu Gly Ile Lys Pro Glu His Gln His Val Gly Leu
145 150 155 160
Ser Ile Ile Val Thr Thr Phe Asn Arg Pro Ala Ile Leu Ser Ile Thr
165 170 175
Leu Ala Cys Leu Val Asn Gln Lys Thr His Tyr Pro Phe Glu Val Ile
180 185 190
Val Thr Asp Asp Gly Ser Gln Glu Asp Leu Ser Pro Ile Ile Arg Gln
195 200 205
Tyr Glu Asn Lys Leu Asp Ile Arg Tyr Val Arg Gln Lys Asp Asn Gly
210 215 220
Phe Gln Ala Ser Ala Ala Arg Asn Met Gly Leu Arg Leu Ala Lys Tyr
225 230 235 240
Asp Phe Ile Gly Leu Leu Asp Cys Asp Met Ala Pro Asn Pro Leu Trp
245 250 255
Val His Ser Tyr Val Ala Glu Leu Leu Glu Asp Asp Asp Leu Thr Ile
260 265 270
Ile Gly Pro Arg Lys Tyr Ile Asp Thr Gln His Ile Asp Pro Lys Asp
275 280 285
Phe Leu Asn Asn Ala Ser Leu Leu Glu Ser Leu Pro Glu Val Lys Thr
290 295 300
Asn Asn Ser Val Ala Ala Lys Gly Glu Gly Thr Val Ser Leu Asp Trp
305 310 315 320
Arg Leu Glu Gln Phe Glu Lys Thr Glu Asn Leu Arg Leu Ser Asp Ser
325 330 335
Pro Phe Arg Phe Phe Ala Ala Gly Asn Val Ala Phe Ala Lys Lys Trp
340 345 350
Leu Asn Lys Ser Gly Phe Phe Asp Glu Glu Phe Asn His Trp Gly Gly
355 360 365
Glu Asp Val Glu Phe Gly Tyr Arg Leu Phe Arg Tyr Gly Ser Phe Phe
370 375 380
Lys Thr Ile Asp Gly Ile Met Ala Tyr His Gln Glu Pro Pro Gly Lys
385 390 395 400
Glu Asn Glu Thr Asp Arg Glu Ala Gly Lys Asn Ile Thr Leu Asp Ile
405 410 415
Met Arg Glu Lys Val Pro Tyr Ile Tyr Arg Lys Leu Leu Pro Ile Glu
420 425 430
Asp Ser His Ile Asn Arg Val Pro Leu Val Ser Ile Tyr Ile Pro Ala
435 440 445
Tyr Asn Cys Ala Asn Tyr Ile Gln Arg Cys Val Asp Ser Ala Leu Asn
450 455 460
Gln Thr Val Val Asp Leu Glu Val Cys Ile Cys Asn Asp Gly Ser Thr
465 470 475 480
Asp Asn Thr Leu Glu Val Ile Asn Lys Leu Tyr Gly Asn Asn Pro Arg
485 490 495
Val Arg Ile Met Ser Lys Pro Asn Gly Gly Ile Ala Ser Ala Ser Asn
500 505 510
Ala Ala Val Ser Phe Ala Lys Gly Tyr Tyr Ile Gly Gln Leu Asp Ser
515 520 525
Asp Asp Tyr Leu Glu Pro Asp Ala Val Glu Leu Cys Leu Lys Glu Phe
530 535 540
Leu Lys Asp Lys Thr Leu Ala Cys Val Tyr Thr Thr Asn Arg Asn Val
545 550 555 560
Asn Pro Asp Gly Ser Leu Ile Ala Asn Gly Tyr Asn Trp Pro Glu Phe
565 570 575
Ser Arg Glu Lys Leu Thr Thr Ala Met Ile Ala His His Phe Arg Met
580 585 590
Phe Thr Ile Arg Ala Trp His Leu Thr Asp Gly Phe Asn Glu Lys Ile
595 600 605
Glu Asn Ala Val Asp Tyr Asp Met Phe Leu Lys Leu Ser Glu Val Gly
610 615 620
Lys Phe Lys His Leu Asn Lys Ile Cys Tyr Asn Arg Val Leu His Gly
625 630 635 640
Asp Asn Thr Ser Ile Lys Lys Leu Gly Ile Gln Lys Lys Asn His Phe
645 650 655
Val Val Val Asn Gln Ser Leu Asn Arg Gln Gly Ile Thr Tyr Tyr Asn
660 665 670
Tyr Asp Glu Phe Asp Asp Leu Asp Glu Ser Arg Lys Tyr Ile Phe Asn
675 680 685
Lys Thr Ala Glu Tyr Gln Glu Glu Ile Asp Ile Leu Lys Asp Ile Lys
690 695 700
Ile Ile Gln Asn Lys Asp Ala Lys Ile Ala Val Ser Ile Phe Tyr Pro
705 710 715 720
Asn Thr Leu Asn Gly Leu Val Lys Lys Leu Asn Asn Ile Ile Glu Tyr
725 730 735
Asn Lys Asn Ile Phe Val Ile Val Leu His Val Asp Lys Asn His Leu
740 745 750
Thr Pro Asp Ile Lys Lys Glu Ile Leu Ala Phe Tyr His Lys His Gln
755 760 765
Val Asn Ile Leu Leu Asn Asn Asp Ile Ser Tyr Tyr Thr Ser Asn Arg
770 775 780
Leu Ile Lys Thr Glu Ala His Leu Ser Asn Ile Asn Lys Leu Ser Gln
785 790 795 800
Leu Asn Leu Asn Cys Glu Tyr Ile Ile Phe Asp Asn His Asp Ser Leu
805 810 815
Phe Val Lys Asn Asp Ser Tyr Ala Tyr Met Lys Lys Tyr Asp Val Gly
820 825 830
Met Asn Phe Ser Ala Leu Thr His Asp Trp Ile Glu Lys Ile Asn Ala
835 840 845
His Pro Pro Phe Lys Lys Leu Ile Lys Thr Tyr Phe Asn Asp Asn Asp
850 855 860
Leu Lys Ser Met Asn Val Lys Gly Ala Ser Gln Gly Met Phe Met Thr
865 870 875 880
Tyr Ala Leu Ala His Glu Leu Leu Thr Ile Ile Lys Glu Val Ile Thr
885 890 895
Ser Cys Gln Ser Ile Asp Ser Val Pro Glu Tyr Asn Thr Glu Asp Ile
900 905 910
Trp Phe Gln Phe Ala Leu Leu Ile Leu Glu Lys Lys Thr Gly His Val
915 920 925
Phe Asn Lys Thr Ser Thr Leu Thr Tyr Met Pro Trp Glu Arg Lys Leu
930 935 940
Gln Trp Thr Asn Glu Gln Ile Glu Ser Ala Lys Arg Gly Glu Asn Ile
945 950 955 960
Pro Val Asn Lys Phe Ile Ile Asn Ser Ile Thr Leu
965 970
<210> 10
<211> 551
<212> БЕЛОК
<213> Xenopus laevis
<220>
<223> Аминокислотная последовательность гиалуронан-синтазы (HASA),
происходящая из Xenopus laevis
<220>
<223> Аминокислотная последовательность гиалуронан-синтазы (HASA),
происходящая из Xenopus laevis
<400> 10
Met His Cys Glu Arg Phe Ile Cys Ile Leu Arg Ile Ile Gly Thr Thr
1 5 10 15
Leu Phe Gly Val Ser Leu Leu Leu Gly Ile Ser Ala Ala Tyr Ile Val
20 25 30
Gly Tyr Gln Phe Ile Gln Thr Asp Asn Tyr Tyr Phe Ser Phe Gly Leu
35 40 45
Tyr Gly Ala Ile Leu Ala Leu His Leu Ile Ile Gln Ser Leu Phe Ala
50 55 60
Phe Leu Glu His Arg Lys Met Lys Arg Ser Leu Glu Thr Pro Ile Lys
65 70 75 80
Leu Asn Lys Ser Val Ala Leu Cys Ile Ala Ala Tyr Gln Glu Asp Glu
85 90 95
Asp Tyr Leu Arg Lys Cys Leu Leu Ser Val Lys Arg Leu Thr Tyr Pro
100 105 110
Gly Met Lys Val Ile Met Val Ile Asp Gly Asn Ser Asp Asp Asp Leu
115 120 125
Tyr Met Met Asn Ile Phe Arg Glu Ile Met Gly Asn Asp Ser Cys Ala
130 135 140
Thr Tyr Val Trp Lys Asn Asn Phe His Met Lys Gly Pro Asn Glu Thr
145 150 155 160
Asp Glu Thr His Arg Glu Ser Met Gln His Val Thr Gln Met Val Leu
165 170 175
Ser Asn Arg Asn Val Cys Ile Met Gln Lys Trp Asn Gly Lys Arg Glu
180 185 190
Val Met Tyr Thr Ala Phe Lys Ala Leu Gly Arg Ser Val Asp Tyr Val
195 200 205
Gln Val Cys Asp Ser Asp Thr Val Leu Asp Pro Ala Ser Ser Val Glu
210 215 220
Met Val Lys Val Leu Glu Glu Asp Ile Met Val Gly Gly Val Gly Gly
225 230 235 240
Asp Val Gln Ile Leu Asn Lys Tyr Asp Ser Trp Ile Ser Phe Leu Ser
245 250 255
Ser Val Arg Tyr Trp Met Ala Phe Asn Ile Glu Arg Ala Cys Gln Ser
260 265 270
Tyr Phe Gly Cys Val Gln Cys Ile Ser Gly Pro Leu Gly Met Tyr Arg
275 280 285
Asn Ser Leu Leu His Glu Phe Ile Glu Asp Trp Tyr Asn Gln Glu Phe
290 295 300
Leu Gly Ser Gln Cys Ser Phe Gly Asp Asp Arg His Leu Thr Asn Arg
305 310 315 320
Val Leu Ser Leu Gly Tyr Ala Thr Lys Tyr Thr Ala Arg Ser Lys Cys
325 330 335
Leu Thr Glu Thr Pro Thr Glu Tyr Leu Arg Trp Leu Asn Gln Gln Thr
340 345 350
Arg Trp Ser Lys Ser Tyr Phe Arg Glu Trp Leu Tyr Asn Ser Leu Trp
355 360 365
Phe His Lys His His Leu Trp Met Thr Tyr Glu Ala Val Ile Thr Gly
370 375 380
Phe Phe Pro Phe Phe Leu Ile Ala Thr Val Ile Gln Leu Phe Tyr Arg
385 390 395 400
Gly Arg Ile Trp Asn Ile Leu Leu Phe Leu Leu Thr Val Gln Leu Val
405 410 415
Gly Leu Ile Lys Ser Ser Phe Ala Ser Ala Leu Arg Gly Asn Ile Val
420 425 430
Met Val Phe Met Ser Phe Tyr Ser Val Leu Tyr Met Ser Ser Leu Leu
435 440 445
Pro Ala Lys Met Phe Ala Ile Ala Thr Ile Asn Lys Ala Gly Trp Gly
450 455 460
Thr Ser Gly Arg Lys Thr Ile Val Val Asn Phe Ile Gly Leu Ile Pro
465 470 475 480
Ile Thr Val Trp Phe Thr Ile Leu Leu Gly Gly Val Cys Tyr Thr Ile
485 490 495
Trp Arg Glu Thr Lys Lys Pro Phe Ser Glu Ser Glu Lys Ile Val Leu
500 505 510
Ala Val Gly Ala Ile Leu Tyr Ala Cys Tyr Trp Val Met Leu Leu Thr
515 520 525
Met Tyr Val Ser Leu Val Met Lys Cys Gly Arg Arg Arg Lys Glu Pro
530 535 540
Gln His Asp Leu Val Leu Ala
545 550
<210> 11
<211> 417
<212> БЕЛОК
<213> Streptococcus zooepidemicus
<220>
<223> Аминокислотная последовательность гиалуронан-синтазы (HASA),
происходящая из Streptococcus zooepidemicus
<220>
<223> Аминокислотная последовательность гиалуронан-синтазы (HASA),
происходящая из Streptococcus zooepidemicus
<400> 11
Met Arg Thr Leu Lys Asn Leu Ile Thr Val Val Ala Phe Ser Ile Phe
1 5 10 15
Trp Val Leu Leu Ile Tyr Val Asn Val Tyr Leu Phe Gly Ala Lys Gly
20 25 30
Ser Leu Ser Ile Tyr Gly Phe Leu Leu Ile Ala Tyr Leu Leu Val Lys
35 40 45
Met Ser Leu Ser Phe Phe Tyr Lys Pro Phe Lys Gly Arg Ala Gly Gln
50 55 60
Tyr Lys Val Ala Ala Ile Ile Pro Ser Tyr Asn Glu Asp Ala Glu Ser
65 70 75 80
Leu Leu Glu Thr Leu Lys Ser Val Gln Gln Gln Thr Tyr Pro Leu Ala
85 90 95
Glu Ile Tyr Val Val Asp Asp Gly Ser Ala Asp Glu Thr Gly Ile Lys
100 105 110
Arg Ile Glu Asp Tyr Val Arg Asp Thr Gly Asp Leu Ser Ser Asn Val
115 120 125
Ile Val His Arg Ser Glu Lys Asn Gln Gly Lys Arg His Ala Gln Ala
130 135 140
Trp Ala Phe Glu Arg Ser Asp Ala Asp Val Phe Leu Thr Val Asp Ser
145 150 155 160
Asp Thr Tyr Ile Tyr Pro Asp Ala Leu Glu Glu Leu Leu Lys Thr Phe
165 170 175
Asn Asp Pro Thr Val Phe Ala Ala Thr Gly His Leu Asn Val Arg Asn
180 185 190
Arg Gln Thr Asn Leu Leu Thr Arg Leu Thr Asp Ile Arg Tyr Asp Asn
195 200 205
Ala Phe Gly Val Glu Arg Ala Ala Gln Ser Val Thr Gly Asn Ile Leu
210 215 220
Val Cys Ser Gly Pro Leu Ser Val Tyr Arg Arg Glu Val Val Val Pro
225 230 235 240
Asn Ile Asp Arg Tyr Ile Asn Gln Thr Phe Leu Gly Ile Pro Val Ser
245 250 255
Ile Gly Asp Asp Arg Cys Leu Thr Asn Tyr Ala Thr Asp Leu Gly Lys
260 265 270
Thr Val Tyr Gln Ser Thr Ala Lys Cys Ile Thr Asp Val Pro Asp Lys
275 280 285
Met Ser Thr Tyr Leu Lys Gln Gln Asn Arg Trp Asn Lys Ser Phe Phe
290 295 300
Arg Glu Ser Ile Ile Ser Val Lys Lys Ile Met Asn Asn Pro Phe Val
305 310 315 320
Ala Leu Trp Thr Ile Leu Glu Val Ser Met Phe Met Met Leu Val Tyr
325 330 335
Ser Val Val Asp Phe Phe Val Gly Asn Val Arg Glu Phe Asp Trp Leu
340 345 350
Arg Val Leu Ala Phe Leu Val Ile Ile Phe Ile Val Ala Leu Cys Arg
355 360 365
Asn Ile His Tyr Met Leu Lys His Pro Leu Ser Phe Leu Leu Ser Pro
370 375 380
Phe Tyr Gly Val Leu His Leu Phe Val Leu Gln Pro Leu Lys Leu Tyr
385 390 395 400
Ser Leu Phe Thr Ile Arg Asn Ala Asp Trp Gly Thr Arg Lys Lys Leu
405 410 415
Leu
<210> 12
<211> 1446
<212> ДНК
<213> Arabidopsis thaliana
<220>
<223> Нуклеотидная последовательность UDP-глюкозодегидрогеназы (HASB),
происходящая из Arabidopsis thaliana
<220>
<223> Нуклеотидная последовательность UDP-глюкозодегидрогеназы (HASB),
происходящая из Arabidopsis thaliana
<400> 12
atggtcaaaa tatgctgtat cggggctgga tatgtcggtg ggcctacaat ggccgttatg 60
gccctaaagt gtccagagat tgaagtcgtg gtagttgata tatcggagcc acgaattaac 120
gcatggaact cagaccgtct accaatttat gagccagggt tagaggatgt cgtcaaacag 180
tgtagaggga agaatttgtt cttctctaca gatgtagaga agcatgtatt tgagtcagat 240
atagtgtttg tttcggtaaa cactcctacg aaaacgcagg gtctgggtgc aggtaaagca 300
gcagatttga catattggga gtccgctgct cgcatgatag ctgatgtgag caaatcgtcg 360
aaaatcgtcg ttgaaaagag tacagtacca gttcgtacag ccgaggctat agaaaagatt 420
ttaacgcaca attcgaaggg tatcgaattc cagatcttat caaatccaga attcttggcc 480
gaagggacgg cgattaaaga cttatataac cctgatagag ttctaatcgg tggcagggac 540
accgctgcgg gacaaaaggc cattaaggcg ttgcgtgacg tgtatgccca ctgggttcct 600
gttgagcaaa taatctgtac taatttatgg agtgccgagc tatcaaagtt ggctgcgaac 660
gcatttctag ctcaaaggat aagttcagta aacgcaatgt cagcgctttg tgaggcaact 720
ggtgctgacg taacccaagt cgctcacgcc gttggaaccg acactagaat tggaccgaag 780
tttcttaacg catccgtagg cttcggcgga tcttgctttc agaaagacat cctgaatctt 840
atttacatct gcgaatgcaa tggtcttcca gaagcagcca attattggaa acaggtagtc 900
aaggtaaatg actaccaaaa gattaggttt gctaatcgag tcgtatcttc tatgttcaac 960
accgtctccg gtaagaaaat tgctattttg ggatttgcgt tcaagaagga caccggcgac 1020
acgcgtgaaa ctcctgccat agatgtgtgt aatcgcctcg tggctgataa agcaaagctg 1080
tcgatctatg atccgcaagt attagaagag cagatccgcc gtgatctgtc catggcccga 1140
ttcgattggg accatccagt cccactccag cagatcaaag ctgaaggtat ctccgaacag 1200
gttaacgttg tgtccgacgc ctacgaggct acgaaggatg ctcatggttt atgtgtttta 1260
accgaatggg acgaattcaa gtcacttgat tttaagaaga tctttgataa tatgcagaaa 1320
cccgctttcg ttttcgacgg aagaaacgtg gtcgacgctg tgaaattgag agaaattgga 1380
ttcatagtat attccatagg taaacctctg gatagttggc tcaaggatat gccggctgtt 1440
gcataa 1446
<210> 13
<211> 1166
<212> ДНК
<213> Вирус хлореллы Paramecium bursaria 1
<220>
<223> Перекодированная нуклеотидная последовательность UDP-глюкозодегидрогеназы
(HASB), происходящая из вируса хлореллы PBCV-1
<220>
<223> Перекодированная нуклеотидная последовательность UDP-глюкозодегидрогеназы
(HASB), происходящая из вируса хлореллы PBCV-1
<400> 13
atgagtagaa ttgctgtcgt tggatgcggt tacgtgggta cggcctgcgc cgtacttttg 60
gcgcagaaga acgaagttat cgttttggat atctcggagg accgggtaca actgattaag 120
aataagaagt cacctataga agataaggaa atcgaagaat tcctggagac gaaagatttg 180
aatctaacag cgacgacgga taaggtgctc gcctatgaga atgctgaatt cgttataata 240
gctacaccga ccgattacga tgtcgtcact agatatttca acactaagtc tgttgaaaat 300
gtgataggcg atgtcattaa gaacactcag acacacccta ctatagtgat caagagtact 360
attccaatcg gtttcgtgga taaagttaga gaacagttcg attatcaaaa tattatcttc 420
tcgccggaat tcttgagaga aggacgagca ttatatgata atctttaccc ctcccgtatc 480
atcgtcggtg atgactcccc aattgcctta aaattcgcga atctcttggt cgagggtagc 540
aaaactccac tagctcccgt attaactatg ggtacgcgag aggccgaagc tgtaaaacta 600
ttttcaaata catatttggc tatgagagta gcatacttca atgagctaga cacatttgca 660
atgtcccatg gtatgaacgc aaaagagatt atcgacggag tcacactaga accaaggata 720
gggcagggtt attcgaatcc ttcatttggg tatggagcct attgtttccc aaaagataca 780
aagcaattgt tggctaattt tgaaggggtt ccacaagata ttattggcgc aatcgtagag 840
tctaacgaaa ctagaaagga ggttattgtt tctgaggtcg agaacagatt tccgaccaca 900
gttggcgtat ataagttggc tgctaaagct ggttcggata atttcaggtc tagtgcgata 960
gtcgatatca tggaaaggtt ggctaataag ggctaccaca tcaaaatatt tgaacctacc 1020
gttgaacaat ttgagaattt tgaggtagat aataatctca caacttttgc aaccgagtct 1080
gatgtaataa ttgcgaacag agttccagtc gaacatcgca ttctgtttgg gaagaagtta 1140
ataacacggg atgtctatgg ggataa 1166
<210> 14
<211> 1170
<212> ДНК
<213> Вирус хлореллы Paramecium bursaria 1
<220>
<223> Перекодированная нуклеотидная последовательность UDP-глюкозодегидрогеназы
(HASB), происходящая из вируса хлореллы PBCV-1
<220>
<223> Перекодированная нуклеотидная последовательность UDP-глюкозодегидрогеназы
(HASB), происходящая из вируса хлореллы PBCV-1
<400> 14
atgtcacgaa tcgcagtagt tggctgtggg tacgtgggaa ccgcatgcgc tgtactgctg 60
gcgcaaaaga atgaggtaat cgttcttgat attagtgagg atagggtcca actaatcaag 120
aacaagaaat ccccgatcga agataaggag attgaagaat tcttggaaac aaaagaccta 180
aacttaactg caacaactga caaagtttta gcctacgaaa acgctgagtt tgtgattata 240
gcgacaccca cagattatga cgtagttacc agatacttta acacgaagtc cgtagagaac 300
gtcattggag atgttataaa gaatactcag actcatccta cgatagtaat aaagtcaacc 360
attcccatag gtttcgtaga taaggttagg gagcaattcg attaccagaa cattatattt 420
tcgccagaat ttctgagaga gggtcgcgcc ctgtatgata atctatatcc atcacggatt 480
atagtgggcg atgactctcc gattgcactt aagtttgcta atcttttagt tgagggctcc 540
aaaactccgc tcgccccagt acttacgatg ggtacacgtg aggctgaagc tgtcaagctg 600
ttttcaaaca cataccttgc tatgcgagtc gcatacttta acgaactaga tacctttgct 660
atgtcgcacg gtatgaatgc taaagaaatc atagatggcg taacgttgga gcctcggata 720
ggtcaaggat attccaatcc atcttttggc tacggtgcgt attgtttccc aaaggacacg 780
aagcaattat tagctaactt tgagggtgtt ccgcaagata taattggggc gatagtagaa 840
agcaatgaaa cacggaagga ggtaatcgtg agtgaagtgg aaaaccgatt ccccactacg 900
gtcggcgttt acaaattagc cgccaaggct ggttccgaca atttccgatc cagcgcaata 960
gtagatatta tggaaagatt agctaataag ggataccaca ttaaaatctt tgaacctact 1020
gtcgaacagt tcgagaactt cgaggttgat aataacttga cgactttcgc aacggagagc 1080
gatgtaatta ttgcaaaccg cgtacctgtg gaacatcgaa ttttgttcgg aaagaagctg 1140
attacacgcg atgtatatgg cgataactaa 1170
<210> 15
<211> 1199
<212> ДНК
<213> streptococcus zooepidemicus
<220>
<223> Перекодированная нуклеотидная последовательность UDP-глюкозодегидрогеназы
(HASB), происходящая из Streptococcus zooepidemicus
<220>
<223> Перекодированная нуклеотидная последовательность UDP-глюкозодегидрогеназы
(HASB), происходящая из Streptococcus zooepidemicus
<400> 15
atgaagatat cggtagcggg ttcggggtac gtggggttat ccttgtcaat cttgcttgcc 60
caacataacg atgtgactgt tgtagatata atcgacgaaa aggtacggct aattaaccag 120
ggcatatctc cgattaagga tgcggacatt gaggaatatc tgaagaatgc accgttgaat 180
cttacggcta cactagacgg agcttcggct tatagtaatg ctgatctgat tataatcgca 240
acgccaacta attacgattc agaacgcaat tatttcgaca ccagacacgt tgaagaagta 300
attgagcaag tattggattt aaatgcctcc gctactataa tcatcaagag taccataccc 360
ttgggtttta ttaaacacgt aagagagaaa taccaaacag acagaatcat cttttctcca 420
gagttcttaa gagagtcaaa ggcattgtac gataacttat acccctctcg tataatagtc 480
agttatgaga aggatgactc tccaagagtt atacaagcag ctaaggcgtt cgcgggttta 540
ttaaaagagg gggcaaagag caaggatacc ccagttctgt ttatgggctc tcaagaagct 600
gaagctgtca agctgtttgc taatactttt ctcgccatga gggtcagtta cttcaacgag 660
cttgacactt atagcgaatc aaaaggacta gacgcccaaa gagttataga aggcgtctgc 720
catgatcaaa ggataggtaa tcattacaat aatccatcct tcggatatgg cggttattgt 780
ttacccaaag actcaaagca acttttggct aattatagag gcatacctca gtctctaatg 840
tctgccatcg ttgaatcgaa caagatccgt aagtcgtatt tagctgaaca aatattagat 900
agggcttctt cacaaaagca ggctggtgta cctttaacca taggatttta ccgtttgatt 960
atgaagtcca actccgataa ctttagagaa tcagccatta aagatattat tgacatcatt 1020
aatgactacg gtgtcaatat tgtcatttat gaacctatgt tgggagaaga cattggttat 1080
agagtcgtta aagatttgga acagtttaag aacgaaagta caattattgt tagtaacagg 1140
tttgaagatg atttaggtga tgttattgat aaagtttata cacgtgacgt ctttggtag 1199
<210> 16
<211> 481
<212> БЕЛОК
<213> Arabidopsis thaliana
<220>
<223> Аминокислотная последовательность UDP-глюкозодегидрогеназы (HASB),
происходящая из Arabidopsis thaliana
<220>
<223> Аминокислотная последовательность UDP-глюкозодегидрогеназы (HASB),
происходящая из Arabidopsis thaliana
<400> 16
Met Val Lys Ile Cys Cys Ile Gly Ala Gly Tyr Val Gly Gly Pro Thr
1 5 10 15
Met Ala Val Met Ala Leu Lys Cys Pro Glu Ile Glu Val Val Val Val
20 25 30
Asp Ile Ser Glu Pro Arg Ile Asn Ala Trp Asn Ser Asp Arg Leu Pro
35 40 45
Ile Tyr Glu Pro Gly Leu Glu Asp Val Val Lys Gln Cys Arg Gly Lys
50 55 60
Asn Leu Phe Phe Ser Thr Asp Val Glu Lys His Val Phe Glu Ser Asp
65 70 75 80
Ile Val Phe Val Ser Val Asn Thr Pro Thr Lys Thr Gln Gly Leu Gly
85 90 95
Ala Gly Lys Ala Ala Asp Leu Thr Tyr Trp Glu Ser Ala Ala Arg Met
100 105 110
Ile Ala Asp Val Ser Lys Ser Ser Lys Ile Val Val Glu Lys Ser Thr
115 120 125
Val Pro Val Arg Thr Ala Glu Ala Ile Glu Lys Ile Leu Thr His Asn
130 135 140
Ser Lys Gly Ile Glu Phe Gln Ile Leu Ser Asn Pro Glu Phe Leu Ala
145 150 155 160
Glu Gly Thr Ala Ile Lys Asp Leu Tyr Asn Pro Asp Arg Val Leu Ile
165 170 175
Gly Gly Arg Asp Thr Ala Ala Gly Gln Lys Ala Ile Lys Ala Leu Arg
180 185 190
Asp Val Tyr Ala His Trp Val Pro Val Glu Gln Ile Ile Cys Thr Asn
195 200 205
Leu Trp Ser Ala Glu Leu Ser Lys Leu Ala Ala Asn Ala Phe Leu Ala
210 215 220
Gln Arg Ile Ser Ser Val Asn Ala Met Ser Ala Leu Cys Glu Ala Thr
225 230 235 240
Gly Ala Asp Val Thr Gln Val Ala His Ala Val Gly Thr Asp Thr Arg
245 250 255
Ile Gly Pro Lys Phe Leu Asn Ala Ser Val Gly Phe Gly Gly Ser Cys
260 265 270
Phe Gln Lys Asp Ile Leu Asn Leu Ile Tyr Ile Cys Glu Cys Asn Gly
275 280 285
Leu Pro Glu Ala Ala Asn Tyr Trp Lys Gln Val Val Lys Val Asn Asp
290 295 300
Tyr Gln Lys Ile Arg Phe Ala Asn Arg Val Val Ser Ser Met Phe Asn
305 310 315 320
Thr Val Ser Gly Lys Lys Ile Ala Ile Leu Gly Phe Ala Phe Lys Lys
325 330 335
Asp Thr Gly Asp Thr Arg Glu Thr Pro Ala Ile Asp Val Cys Asn Arg
340 345 350
Leu Val Ala Asp Lys Ala Lys Leu Ser Ile Tyr Asp Pro Gln Val Leu
355 360 365
Glu Glu Gln Ile Arg Arg Asp Leu Ser Met Ala Arg Phe Asp Trp Asp
370 375 380
His Pro Val Pro Leu Gln Gln Ile Lys Ala Glu Gly Ile Ser Glu Gln
385 390 395 400
Val Asn Val Val Ser Asp Ala Tyr Glu Ala Thr Lys Asp Ala His Gly
405 410 415
Leu Cys Val Leu Thr Glu Trp Asp Glu Phe Lys Ser Leu Asp Phe Lys
420 425 430
Lys Ile Phe Asp Asn Met Gln Lys Pro Ala Phe Val Phe Asp Gly Arg
435 440 445
Asn Val Val Asp Ala Val Lys Leu Arg Glu Ile Gly Phe Ile Val Tyr
450 455 460
Ser Ile Gly Lys Pro Leu Asp Ser Trp Leu Lys Asp Met Pro Ala Val
465 470 475 480
Ala
<210> 17
<211> 389
<212> БЕЛОК
<213> Вирус хлореллы Paramecium bursaria 1
<220>
<223> Аминокислотная последовательность UDP-глюкозодегидрогеназы (HASB),
происходящая из вируса хлореллы PBCV1
<220>
<223> Аминокислотная последовательность UDP-глюкозодегидрогеназы (HASB),
происходящая из вируса хлореллы PBCV1
<400> 17
Met Ser Arg Ile Ala Val Val Gly Cys Gly Tyr Val Gly Thr Ala Cys
1 5 10 15
Ala Val Leu Leu Ala Gln Lys Asn Glu Val Ile Val Leu Asp Ile Ser
20 25 30
Glu Asp Arg Val Gln Leu Ile Lys Asn Lys Lys Ser Pro Ile Glu Asp
35 40 45
Lys Glu Ile Glu Glu Phe Leu Glu Thr Lys Asp Leu Asn Leu Thr Ala
50 55 60
Thr Thr Asp Lys Val Leu Ala Tyr Glu Asn Ala Glu Phe Val Ile Ile
65 70 75 80
Ala Thr Pro Thr Asp Tyr Asp Val Val Thr Arg Tyr Phe Asn Thr Lys
85 90 95
Ser Val Glu Asn Val Ile Gly Asp Val Ile Lys Asn Thr Gln Thr His
100 105 110
Pro Thr Ile Val Ile Lys Ser Thr Ile Pro Ile Gly Phe Val Asp Lys
115 120 125
Val Arg Glu Gln Phe Asp Tyr Gln Asn Ile Ile Phe Ser Pro Glu Phe
130 135 140
Leu Arg Glu Gly Arg Ala Leu Tyr Asp Asn Leu Tyr Pro Ser Arg Ile
145 150 155 160
Ile Val Gly Asp Asp Ser Pro Ile Ala Leu Lys Phe Ala Asn Leu Leu
165 170 175
Val Glu Gly Ser Lys Thr Pro Leu Ala Pro Val Leu Thr Met Gly Thr
180 185 190
Arg Glu Ala Glu Ala Val Lys Leu Phe Ser Asn Thr Tyr Leu Ala Met
195 200 205
Arg Val Ala Tyr Phe Asn Glu Leu Asp Thr Phe Ala Met Ser His Gly
210 215 220
Met Asn Ala Lys Glu Ile Ile Asp Gly Val Thr Leu Glu Pro Arg Ile
225 230 235 240
Gly Gln Gly Tyr Ser Asn Pro Ser Phe Gly Tyr Gly Ala Tyr Cys Phe
245 250 255
Pro Lys Asp Thr Lys Gln Leu Leu Ala Asn Phe Glu Gly Val Pro Gln
260 265 270
Asp Ile Ile Gly Ala Ile Val Glu Ser Asn Glu Thr Arg Lys Glu Val
275 280 285
Ile Val Ser Glu Val Glu Asn Arg Phe Pro Thr Thr Val Gly Val Tyr
290 295 300
Lys Leu Ala Ala Lys Ala Gly Ser Asp Asn Phe Arg Ser Ser Ala Ile
305 310 315 320
Val Asp Ile Met Glu Arg Leu Ala Asn Lys Gly Tyr His Ile Lys Ile
325 330 335
Phe Glu Pro Thr Val Glu Gln Phe Glu Asn Phe Glu Val Asp Asn Asn
340 345 350
Leu Thr Thr Phe Ala Thr Glu Ser Asp Val Ile Ile Ala Asn Arg Val
355 360 365
Pro Val Glu His Arg Ile Leu Phe Gly Lys Lys Leu Ile Thr Arg Asp
370 375 380
Val Tyr Gly Asp Asn
385
<210> 18
<211> 401
<212> БЕЛОК
<213> Streptococcus zooepidemicus
<220>
<223> Аминокислотная последовательность UDP-глюкозодегидрогеназы (HASB),
происходящая из Streptococcus zooepidemicus
<220>
<223> Аминокислотная последовательность UDP-глюкозодегидрогеназы (HASB),
происходящая из Streptococcus zooepidemicus
<400> 18
Met Lys Ile Ser Val Ala Gly Ser Gly Tyr Val Gly Leu Ser Leu Ser
1 5 10 15
Ile Leu Leu Ala Gln His Asn Asp Val Thr Val Val Asp Ile Ile Asp
20 25 30
Glu Lys Val Arg Leu Ile Asn Gln Gly Ile Ser Pro Ile Lys Asp Ala
35 40 45
Asp Ile Glu Glu Tyr Leu Lys Asn Ala Pro Leu Asn Leu Thr Ala Thr
50 55 60
Leu Asp Gly Ala Ser Ala Tyr Ser Asn Ala Asp Leu Ile Ile Ile Ala
65 70 75 80
Thr Pro Thr Asn Tyr Asp Ser Glu Arg Asn Tyr Phe Asp Thr Arg His
85 90 95
Val Glu Glu Val Ile Glu Gln Val Leu Asp Leu Asn Ala Ser Ala Thr
100 105 110
Ile Ile Ile Lys Ser Thr Ile Pro Leu Gly Phe Ile Lys His Val Arg
115 120 125
Glu Lys Tyr Gln Thr Asp Arg Ile Ile Phe Ser Pro Glu Phe Leu Arg
130 135 140
Glu Ser Lys Ala Leu Tyr Asp Asn Leu Tyr Pro Ser Arg Ile Ile Val
145 150 155 160
Ser Tyr Glu Lys Asp Asp Ser Pro Arg Val Ile Gln Ala Ala Lys Ala
165 170 175
Phe Ala Gly Leu Leu Lys Glu Gly Ala Lys Ser Lys Asp Thr Pro Val
180 185 190
Leu Phe Met Gly Ser Gln Glu Ala Glu Ala Val Lys Leu Phe Ala Asn
195 200 205
Thr Phe Leu Ala Met Arg Val Ser Tyr Phe Asn Glu Leu Asp Thr Tyr
210 215 220
Ser Glu Ser Lys Gly Leu Asp Ala Gln Arg Val Ile Glu Gly Val Cys
225 230 235 240
His Asp Gln Arg Ile Gly Asn His Tyr Asn Asn Pro Ser Phe Gly Tyr
245 250 255
Gly Gly Tyr Cys Leu Pro Lys Asp Ser Lys Gln Leu Leu Ala Asn Tyr
260 265 270
Arg Gly Ile Pro Gln Ser Leu Met Ser Ala Ile Val Glu Ser Asn Lys
275 280 285
Ile Arg Lys Ser Tyr Leu Ala Glu Gln Ile Leu Asp Arg Ala Ser Ser
290 295 300
Gln Lys Gln Ala Gly Val Pro Leu Thr Ile Gly Phe Tyr Arg Leu Ile
305 310 315 320
Met Lys Ser Asn Ser Asp Asn Phe Arg Glu Ser Ala Ile Lys Asp Ile
325 330 335
Ile Asp Ile Ile Asn Asp Tyr Gly Val Asn Ile Val Ile Tyr Glu Pro
340 345 350
Met Leu Gly Glu Asp Ile Gly Tyr Arg Val Val Lys Asp Leu Glu Gln
355 360 365
Phe Lys Asn Glu Ser Thr Ile Ile Val Ser Asn Arg Phe Glu Asp Asp
370 375 380
Leu Gly Asp Val Ile Asp Lys Val Tyr Thr Arg Asp Val Phe Gly Arg
385 390 395 400
Asp
<210> 19
<211> 1326
<212> ДНК
<213> Bothrops atrox
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Bothrops atrox с N-концевым сигналом секреции
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Bothrops atrox с N-концевым сигналом секреции
<400> 19
atgcaattta gcacagtcgc atcagtagcc ttcgttgcct tggccaactt cgtggcagca 60
ccgatgtatc cgaacgaacc gttcttagtc ttttggaacg cgcctacaac tcagtgtaga 120
cttcgatata aggttgacct tgatctgaag acattccata tcgtgacaaa tgctaatgac 180
tcgctgtcag gatcggctgt cacgattttc tatcccacgc acttaggggt ttacccacat 240
attgatgaca gggggcactt cttcaatggc atcatacccc aaaatgaatc cctggtaaag 300
catttaaaca aatctaaatc agatattaat cgaatgattc ccttaagaac attccacggg 360
ctgggagtca tagactggga aaactggcgg ccacagtggg ataggaattg gggaagtaag 420
aacgtttata ggaatagatc aatccaattc gcgcgtgatc tccacccaga gcttagtgag 480
gacaagatta aacgcttggc aaaacaggaa ttcgagaaag ctgcaaagag ttttatgagg 540
gatacactat tattagccga ggagatgcga ccagacggct actggggata ctatctgtac 600
cccgattgtc acaattacaa ttataagact aagccagatc agtacacagg agagtgccct 660
gacatcgaga tgtcacgtaa caatcaactc ttgtggcttt ggcgggatag cactgccctt 720
ttccccaata tctacttaga gactatacta agaagctctg acaatgccct gaagtttgtg 780
caccataggc tcaaggaggc aatgaggata gcctcaatgg ctcgaaatga ctacgcgttg 840
cctttctttg tttatgctcg accattctat gcctatacct tcgaaccatt gactcaggaa 900
gaccttgtga ctacggtcgg agagaccgcg gacatgggcg ccgctgggat cgtattttgg 960
gggagtatgc agtacgcaag cacggttgaa tcttgcggca aagtcaagga ctacatgaat 1020
ggcccactgg ggcgttacat tgtgaatgtt acaactgccg ccaaaatttg ctcacgattc 1080
ttgtgcaaac gtcatggtag gtgtgtaaga aagcactcag actccaatgc attccttcac 1140
ctatttcccg attcgtttcg cataatggtg cacgggaatg caaccgagaa gaaagttata 1200
gtaaagggga agctggaatt aaagaatctt atattcttac gtaataactt tatgtgccag 1260
tgttatcaag gctggaaagg tctatattgc gagaagcatt cgataaagga aattcggaaa 1320
atctaa 1326
<210> 20
<211> 1537
<212> ДНК
<213> Bothrops atrox
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Bothrops atrox с N-концевым сигналом секреции и C-концевым
якорным сигналом
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Bothrops atrox с N-концевым сигналом секреции и C-концевым
якорным сигналом
<400> 20
atgcaattta gcacagtcgc atcagtagcc ttcgttgcct tggccaactt cgtggcagca 60
ccgatgtatc cgaacgaacc gttcttagtc ttttggaacg cgcctacaac tcagtgtaga 120
cttcgatata aggttgacct tgatctgaag acattccata tcgtgacaaa tgctaatgac 180
tcgctgtcag gatcggctgt cacgattttc tatcccacgc acttaggggt ttacccacat 240
attgatgaca gggggcactt cttcaatggc atcatacccc aaaatgaatc cctggtaaag 300
catttaaaca aatctaaatc agatattaat cgaatgattc ccttaagaac attccacggg 360
ctgggagtca tagactggga aaactggcgg ccacagtggg ataggaattg gggaagtaag 420
aacgtttata ggaatagatc aatccaattc gcgcgtgatc tccacccaga gcttagtgag 480
gacaagatta aacgcttggc aaaacaggaa ttcgagaaag ctgcaaagag ttttatgagg 540
gatacactat tattagccga ggagatgcga ccagacggct actggggata ctatctgtac 600
cccgattgtc acaattacaa ttataagact aagccagatc agtacacagg agagtgccct 660
gacatcgaga tgtcacgtaa caatcaactc ttgtggcttt ggcgggatag cactgccctt 720
ttccccaata tctacttaga gactatacta agaagctctg acaatgccct gaagtttgtg 780
caccataggc tcaaggaggc aatgaggata gcctcaatgg ctcgaaatga ctacgcgttg 840
cctttctttg tttatgctcg accattctat gcctatacct tcgaaccatt gactcaggaa 900
gaccttgtga ctacggtcgg agagaccgcg gacatgggcg ccgctgggat cgtattttgg 960
gggagtatgc agtacgcaag cacggttgaa tcttgcggca aagtcaagga ctacatgaat 1020
ggcccactgg ggcgttacat tgtgaatgtt acaactgccg ccaaaatttg ctcacgattc 1080
ttgtgcaaac gtcatggtag gtgtgtaaga aagcactcag actccaatgc attccttcac 1140
ctatttcccg attcgtttcg cataatggtg cacgggaatg caaccgagaa gaaagttata 1200
gtaaagggga agctggaatt aaagaatctt atattcttac gtaataactt tatgtgccag 1260
tgttatcaag gctggaaagg tctatattgc gagaagcatt cgataaagga aattcggaaa 1320
atcggatccg ccatttctca aatcactgac ggtcaaatcc aagctactac cactgctacc 1380
accgaagcta ccaccactgc tgccccatct tccaccgttg aaactgtttc tccatccagc 1440
accgaaacta tctctcaaca aactgaaaat ggtgctgcta aggccgctgt cggtatgggt 1500
gccggtgctc tagctgctgc tgctatgttg ttataaa 1537
<210> 21
<211> 1197
<212> ДНК
<213> Cupiennius salei
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Cupiennius salei с N-концевым сигналом секреции
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Cupiennius salei с N-концевым сигналом секреции
<400> 21
atgcaattca gcactgttgc atcagttgca tttgtcgccc tggcgaattt tgtagccgcg 60
ttcaagattt actggaacgt cccaactttt cagtgcacgc ataactacaa aatcgattat 120
gtcaaattgt tgtccactta cgggatacag gtcaatgatg gcggtaagtt tcaaggaaac 180
caagtgacta tcttttatga aacccagttg ggtttgtatc cacgaatcct aaaatctggt 240
aaaatggaaa acggcggaat ccctcaacgc ggtaactttg agaaacacct agaaaaggca 300
agcacggacc tccagaaagt gatcccttgg aaagagttta gcggattagg tgtgatagat 360
tgggaggctt ggagacccac atgggaattt aactgggaac cgttgaggat atatcaaacc 420
gaatcaatta agagagctaa agaactacac cctaccgcaa acgattccgc agtaaaagaa 480
attgcagagc ggcaatggga agattcagcc aagttataca tgttagaaac actgcggctg 540
gcaaagaaac ttcgacctca agcgccttgg tgttactact tatttcctga ttgctataat 600
tacgtcggaa agaaaccaaa agatttccaa tgtagtgcct cgatacgtaa aggtaacgat 660
aagctaagct ggttgtggaa agattctacg gcattgtgtc catcgatata cgtatatgaa 720
tcacaattag acaggtattc ttttgaacaa aggacatggc gcgacaatga gaaacttcgg 780
gaagcgttgc gtgtagccac gagaacctct aaaatatacc catacgttaa ctatttcgat 840
aaggagctta taccggagca agaagtatgg agaatgcttg cgcaggcagc tgctgtcggt 900
ggcagtggtg cggtaatttg gggctcatct gctgcagttg catctgaaga gttatgtaaa 960
tctttaaaac agtatattat tgaaacgctt gggccggcgg cagagaaggt ggcttggcgt 1020
agtgacttat gcagcaaaga aatttgtaat aatcagggtc gctgcacatt cccggacgat 1080
gattatgcaa acgcatggaa attatttaca gatgatactg ttaagtttta tgctggtaat 1140
attacatgta ggtgctccga gaattattct ggtcgtttct gcgaaaagaa gaattaa 1197
<210> 22
<211> 1407
<212> ДНК
<213> Cupiennius salei
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Cupiennius salei с N-концевым сигналом секреции и C-концевым
якорным сигналом
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Cupiennius salei с N-концевым сигналом секреции и C-концевым
якорным сигналом
<400> 22
atgcaattca gcactgttgc atcagttgca tttgtcgccc tggcgaattt tgtagccgcg 60
ttcaagattt actggaacgt cccaactttt cagtgcacgc ataactacaa aatcgattat 120
gtcaaattgt tgtccactta cgggatacag gtcaatgatg gcggtaagtt tcaaggaaac 180
caagtgacta tcttttatga aacccagttg ggtttgtatc cacgaatcct aaaatctggt 240
aaaatggaaa acggcggaat ccctcaacgc ggtaactttg agaaacacct agaaaaggca 300
agcacggacc tccagaaagt gatcccttgg aaagagttta gcggattagg tgtgatagat 360
tgggaggctt ggagacccac atgggaattt aactgggaac cgttgaggat atatcaaacc 420
gaatcaatta agagagctaa agaactacac cctaccgcaa acgattccgc agtaaaagaa 480
attgcagagc ggcaatggga agattcagcc aagttataca tgttagaaac actgcggctg 540
gcaaagaaac ttcgacctca agcgccttgg tgttactact tatttcctga ttgctataat 600
tacgtcggaa agaaaccaaa agatttccaa tgtagtgcct cgatacgtaa aggtaacgat 660
aagctaagct ggttgtggaa agattctacg gcattgtgtc catcgatata cgtatatgaa 720
tcacaattag acaggtattc ttttgaacaa aggacatggc gcgacaatga gaaacttcgg 780
gaagcgttgc gtgtagccac gagaacctct aaaatatacc catacgttaa ctatttcgat 840
aaggagctta taccggagca agaagtatgg agaatgcttg cgcaggcagc tgctgtcggt 900
ggcagtggtg cggtaatttg gggctcatct gctgcagttg catctgaaga gttatgtaaa 960
tctttaaaac agtatattat tgaaacgctt gggccggcgg cagagaaggt ggcttggcgt 1020
agtgacttat gcagcaaaga aatttgtaat aatcagggtc gctgcacatt cccggacgat 1080
gattatgcaa acgcatggaa attatttaca gatgatactg ttaagtttta tgctggtaat 1140
attacatgta ggtgctccga gaattattct ggtcgtttct gcgaaaagaa gaatggatcc 1200
gccatttctc aaatcactga cggtcaaatc caagctacta ccactgctac caccgaagct 1260
accaccactg ctgccccatc ttccaccgtt gaaactgttt ctccatccag caccgaaact 1320
atctctcaac aaactgaaaa tggtgctgct aaggccgctg tcggtatggg tgccggtgct 1380
ctagctgctg ctgctatgtt gttataa 1407
<210> 23
<211> 1530
<212> ДНК
<213> Hirudo nipponia
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Hirudo Nipponia с N-концевым сигналом секреции
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Hirudo Nipponia с N-концевым сигналом секреции
<400> 23
atgcaattct ctactgtcgc ttccgttgct ttcgtcgctt tggctaactt tgttgccgct 60
atgaaggaga tagcagttac catcgatgat aagaatgtta tagcgtctgt cagtgaaagc 120
ttccatggtg tggctttcga cgcaagccta ttctcaccta aagggctatg gtcgtttgtt 180
gacattactt cacccaagtt attcaagctt ctggagggac tctcccctgg ttatttccgt 240
gtcggcggca catttgcgaa ctggttattc ttcgacctcg atgaaaacaa caagtggaag 300
gattactggg cttttaagga caagactcca gagaccgcca cgattacccg acggtggctc 360
ttcaggaagc aaaacaacct caagaaggaa acctttgatg atttggtaaa gcttacaaag 420
gggtccaaga tgcggctgct atttgatcta aacgcagagg tccgtacagg atatgagata 480
ggcaagaaga tgacatcaac ttgggactca agcgaggcag aaaagttgtt caaatattgc 540
gttagcaagg gatatggaga taatatcgat tgggagttag gcaacgaacc tgatcacacg 600
tcagcacaca atttgacaga gaagcaagta ggtgaagatt ttaaggccct acacaaggtg 660
ttggaaaagt atccaacact taataaaggt agcttggttg gtccagacgt tgggtggatg 720
ggagtgtcgt acgtcaaggg tctggctgac ggggctggag atcatgtgac cgcttttact 780
ctacatcagt attatttcga tggaaatacg agtgatgtta gtacctactt ggatgcgacg 840
tactttaaga agttgcaaca gttattcgat aaggtaaaag acgtactcaa gaattctcca 900
cataaggaca aacccttgtg gctaggggaa acctcttccg gctacaacag tgggactaaa 960
gatgtatccg atagatacgt gtcggggttc ttgacgctgg acaagttggg gctttcggcg 1020
gcaaataacg tcaaggtggt catcagacaa acgatttata atggttacta tggtttgctt 1080
gacaagaata ctttggagcc caatccggac tactggctga tgcacgtcca caattcctta 1140
gttggtaata ccgttttcaa ggtcgatgtc agcgatccca caaacaaagc ccgtgtttac 1200
gctcagtgta cgaagaccaa tagtaaacat acccagtcac gttattataa ggggtcccta 1260
accattttcg cgttgaatgt aggtgatgaa gatgttacac tcaagattga tcaatacagt 1320
ggtaagaaaa tatactcata tattctgacg cctgaaggcg gccagttaac ctctcaaaag 1380
gtactgctta acggtaaaga attgaagtta gtgtcagatc aacttccaga acttaacgcg 1440
gacgaaagta aaacatcctt cacattgtct cccaaaactt ttggattctt tgtggtctcg 1500
gatgccaacg ttgaagcttg caagaaataa 1530
<210> 24
<211> 1740
<212> ДНК
<213> Hirudo nipponia
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Hirudo Nipponia с N-концевым сигналом секреции и C-концевым
якорным сигналом
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Hirudo Nipponia с N-концевым сигналом секреции и C-концевым
якорным сигналом
<400> 24
atgcaattct ctactgtcgc ttccgttgct ttcgtcgctt tggctaactt tgttgccgct 60
atgaaggaga tagcagttac catcgatgat aagaatgtta tagcgtctgt cagtgaaagc 120
ttccatggtg tggctttcga cgcaagccta ttctcaccta aagggctatg gtcgtttgtt 180
gacattactt cacccaagtt attcaagctt ctggagggac tctcccctgg ttatttccgt 240
gtcggcggca catttgcgaa ctggttattc ttcgacctcg atgaaaacaa caagtggaag 300
gattactggg cttttaagga caagactcca gagaccgcca cgattacccg acggtggctc 360
ttcaggaagc aaaacaacct caagaaggaa acctttgatg atttggtaaa gcttacaaag 420
gggtccaaga tgcggctgct atttgatcta aacgcagagg tccgtacagg atatgagata 480
ggcaagaaga tgacatcaac ttgggactca agcgaggcag aaaagttgtt caaatattgc 540
gttagcaagg gatatggaga taatatcgat tgggagttag gcaacgaacc tgatcacacg 600
tcagcacaca atttgacaga gaagcaagta ggtgaagatt ttaaggccct acacaaggtg 660
ttggaaaagt atccaacact taataaaggt agcttggttg gtccagacgt tgggtggatg 720
ggagtgtcgt acgtcaaggg tctggctgac ggggctggag atcatgtgac cgcttttact 780
ctacatcagt attatttcga tggaaatacg agtgatgtta gtacctactt ggatgcgacg 840
tactttaaga agttgcaaca gttattcgat aaggtaaaag acgtactcaa gaattctcca 900
cataaggaca aacccttgtg gctaggggaa acctcttccg gctacaacag tgggactaaa 960
gatgtatccg atagatacgt gtcggggttc ttgacgctgg acaagttggg gctttcggcg 1020
gcaaataacg tcaaggtggt catcagacaa acgatttata atggttacta tggtttgctt 1080
gacaagaata ctttggagcc caatccggac tactggctga tgcacgtcca caattcctta 1140
gttggtaata ccgttttcaa ggtcgatgtc agcgatccca caaacaaagc ccgtgtttac 1200
gctcagtgta cgaagaccaa tagtaaacat acccagtcac gttattataa ggggtcccta 1260
accattttcg cgttgaatgt aggtgatgaa gatgttacac tcaagattga tcaatacagt 1320
ggtaagaaaa tatactcata tattctgacg cctgaaggcg gccagttaac ctctcaaaag 1380
gtactgctta acggtaaaga attgaagtta gtgtcagatc aacttccaga acttaacgcg 1440
gacgaaagta aaacatcctt cacattgtct cccaaaactt ttggattctt tgtggtctcg 1500
gatgccaacg ttgaagcttg caagaaagga tccgccattt ctcaaatcac tgacggtcaa 1560
atccaagcta ctaccactgc taccaccgaa gctaccacca ctgctgcccc atcttccacc 1620
gttgaaactg tttctccatc cagcaccgaa actatctctc aacaaactga aaatggtgct 1680
gctaaggccg ctgtcggtat gggtgccggt gctctagctg ctgctgctat gttgttataa 1740
<210> 25
<211> 1206
<212> ДНК
<213> Loxosceles intermedia
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Loxosceles intermedia с N-концевым сигналом секреции
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Loxosceles intermedia с N-концевым сигналом секреции
<400> 25
atgcagtttt caaccgttgc gagcgtcgct tttgtggctc ttgctaattt cgttgccgcc 60
ttcgatgtct tctggaatgt tccgtcgcag caatgcaaga aatatggtat gaaattcgtt 120
ccgctcttag agcaatactc tatcctagtc aacaaagaag acaatttcaa gggcgacaaa 180
ataacgatct tttatgagtc acagctcggg ctttacccac atattggtgc aaacgacgag 240
tcgtttaatg gcgggatacc acaattaggt gacctgaaag cacacttaga aaagtcagcg 300
gttgatatac gacgtgatat tttggataag tcggcgactg gtctaagaat tatagactgg 360
gaagcatgga gaccaatatg ggaattcaac tggtctagcc tacgaaagta ccaagataaa 420
atgaagaaag tcgtccgcca gtttaacccg actgctcatg aatccacagt ggccaaacta 480
gcacataatg agtgggaaaa tagtagtaag tcttggatgc tttctacatt gcagttgggt 540
aagcaacttc gtccaaactc tgtatggtgc tattatttat ttcccgactg ttataactat 600
gatggcaact cagtccaaga atttcagtgt tctgaagcta tccgtaaggg gaacgatagg 660
ttgaaatggt tgtgggaaga atcgacagct gtatgcccat ctatctacat aaaagaaggc 720
caactgacca attatacctt gcaaaagaga atctggttta ccaatgggag attacaggaa 780
gccttgagag tagctcaacc taaagcgcgt atttatccat acataaatta ctccatcaaa 840
cccggaatga tggtgcctga agttgagttt tggcggttaa tcgctcagat agcctcgctg 900
ggtatggatg gagcagtgat ttggggatca agtgcgagtg taggcagtaa gaatcattgt 960
gcgcaattaa tgaagtacat tgcagacgta ttgggtcctg caactttgcg cataaaagaa 1020
aatgtagcac ggtgcagtaa acaggcgtgc tctggtaggg gtagatgtac ctggcctaaa 1080
gatacctctg ttattgcttg gaagttcctc gttgaaaagg aagactatga cttttatctg 1140
ggtgatatag agtgtaaatg tgttgaaggc tacgaaggta ggtactgtga acaaaagact 1200
aagtaa 1206
<210> 26
<211> 1416
<212> ДНК
<213> Loxosceles intermedia
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Loxosceles intermedia с N-концевым сигналом секреции и C-концевым
якорным сигналом
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Loxosceles intermedia с N-концевым сигналом секреции и C-концевым
якорным сигналом
<400> 26
atgcagtttt caaccgttgc gagcgtcgct tttgtggctc ttgctaattt cgttgccgcc 60
ttcgatgtct tctggaatgt tccgtcgcag caatgcaaga aatatggtat gaaattcgtt 120
ccgctcttag agcaatactc tatcctagtc aacaaagaag acaatttcaa gggcgacaaa 180
ataacgatct tttatgagtc acagctcggg ctttacccac atattggtgc aaacgacgag 240
tcgtttaatg gcgggatacc acaattaggt gacctgaaag cacacttaga aaagtcagcg 300
gttgatatac gacgtgatat tttggataag tcggcgactg gtctaagaat tatagactgg 360
gaagcatgga gaccaatatg ggaattcaac tggtctagcc tacgaaagta ccaagataaa 420
atgaagaaag tcgtccgcca gtttaacccg actgctcatg aatccacagt ggccaaacta 480
gcacataatg agtgggaaaa tagtagtaag tcttggatgc tttctacatt gcagttgggt 540
aagcaacttc gtccaaactc tgtatggtgc tattatttat ttcccgactg ttataactat 600
gatggcaact cagtccaaga atttcagtgt tctgaagcta tccgtaaggg gaacgatagg 660
ttgaaatggt tgtgggaaga atcgacagct gtatgcccat ctatctacat aaaagaaggc 720
caactgacca attatacctt gcaaaagaga atctggttta ccaatgggag attacaggaa 780
gccttgagag tagctcaacc taaagcgcgt atttatccat acataaatta ctccatcaaa 840
cccggaatga tggtgcctga agttgagttt tggcggttaa tcgctcagat agcctcgctg 900
ggtatggatg gagcagtgat ttggggatca agtgcgagtg taggcagtaa gaatcattgt 960
gcgcaattaa tgaagtacat tgcagacgta ttgggtcctg caactttgcg cataaaagaa 1020
aatgtagcac ggtgcagtaa acaggcgtgc tctggtaggg gtagatgtac ctggcctaaa 1080
gatacctctg ttattgcttg gaagttcctc gttgaaaagg aagactatga cttttatctg 1140
ggtgatatag agtgtaaatg tgttgaaggc tacgaaggta ggtactgtga acaaaagact 1200
aagggatccg ccatttctca aatcactgac ggtcaaatcc aagctactac cactgctacc 1260
accgaagcta ccaccactgc tgccccatct tccaccgttg aaactgtttc tccatccagc 1320
accgaaacta tctctcaaca aactgaaaat ggtgctgcta aggccgctgt cggtatgggt 1380
gccggtgctc tagctgctgc tgctatgttg ttataa 1416
<210> 27
<211> 1218
<212> ДНК
<213> Tityus serrulatus
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Tityus serrulatus с N-концевым сигналом секреции
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Tityus serrulatus с N-концевым сигналом секреции
<400> 27
atgcaattct ctactgtcgc ttccgttgct ttcgtcgctt tggctaactt tgttgccgct 60
gctgatttta aagtttactg ggaagtgcct tccttccttt gttctaaacg ttttaaaatt 120
aatgtaacgg aagttttaac aagtcacgag attcttgtca atcagggtga gagtttcaac 180
ggtgacaaga tagtaatctt ttacgaaaac caattgggga agtacccgca tattgactca 240
aacaatgtgg agatcaatgg aggaatactt caagtagccg atttggcgaa gcatttgaaa 300
gtagccaagg ataatatcac taaattcgtc ccgaatccta atttcaacgg tgtcggagtg 360
atcgactggg aagcttggcg gccatcatgg gaatttaact ggggtaagtt aaaagtatat 420
aaagaaaaga gcattgactt ggtcaagtcg aaacatccgg agtggccctc cgacagggtt 480
gaaaaggttg ctaaagagga gtgggaggag agtgccaaag aatggatggt gaagaccctg 540
aagttagcac aggaaatgcg accgaacgca gtttggtgct attatctatt ccctgactgc 600
tacaattatt tcggtaagga tcaaccctct caattcagct gctcgtctcg aattcagaag 660
gaaaattctc gtctttcttg gctctggaat caatcaacag ccatttgcct aagcatttat 720
atccaggaat cccatgttac caaatataat atgtcccagc ggacatggtg gatcgatgcg 780
agattaagag aagcaattcg agtcagcgaa cacagaccaa acatacccat ctacccttac 840
attaattata ttctacctgg aactaatcaa actgtaccag caatggactt taaaaggaca 900
ctgggtcaaa tagctagcct cggcctagat ggtgctttgt tatggggatc tagctatcat 960
gttttaacag aatctcaatg caaaatcact tctgattatg tgaaatcagt gattgctcct 1020
accgtggcta ctgtcgttct caatacaaac agatgctcac agataatttg taagggtcgc 1080
ggcaactgtg tttggcctga agaaccattt agttcttgga aatacttagt tgaccccaaa 1140
atgccagtgt tcaagccaac caacatccac tgtaaatgta aaggttacct aggtagatac 1200
tgtgagatcc caaagtaa 1218
<210> 28
<211> 1428
<212> ДНК
<213> Tityus serrulatus
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Tityus serrulatus с N-концевым сигналом секреции и C-концевым
якорным сигналом
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Tityus serrulatus с N-концевым сигналом секреции и C-концевым
якорным сигналом
<400> 28
atgcaattct ctactgtcgc ttccgttgct ttcgtcgctt tggctaactt tgttgccgct 60
gctgatttta aagtttactg ggaagtgcct tccttccttt gttctaaacg ttttaaaatt 120
aatgtaacgg aagttttaac aagtcacgag attcttgtca atcagggtga gagtttcaac 180
ggtgacaaga tagtaatctt ttacgaaaac caattgggga agtacccgca tattgactca 240
aacaatgtgg agatcaatgg aggaatactt caagtagccg atttggcgaa gcatttgaaa 300
gtagccaagg ataatatcac taaattcgtc ccgaatccta atttcaacgg tgtcggagtg 360
atcgactggg aagcttggcg gccatcatgg gaatttaact ggggtaagtt aaaagtatat 420
aaagaaaaga gcattgactt ggtcaagtcg aaacatccgg agtggccctc cgacagggtt 480
gaaaaggttg ctaaagagga gtgggaggag agtgccaaag aatggatggt gaagaccctg 540
aagttagcac aggaaatgcg accgaacgca gtttggtgct attatctatt ccctgactgc 600
tacaattatt tcggtaagga tcaaccctct caattcagct gctcgtctcg aattcagaag 660
gaaaattctc gtctttcttg gctctggaat caatcaacag ccatttgcct aagcatttat 720
atccaggaat cccatgttac caaatataat atgtcccagc ggacatggtg gatcgatgcg 780
agattaagag aagcaattcg agtcagcgaa cacagaccaa acatacccat ctacccttac 840
attaattata ttctacctgg aactaatcaa actgtaccag caatggactt taaaaggaca 900
ctgggtcaaa tagctagcct cggcctagat ggtgctttgt tatggggatc tagctatcat 960
gttttaacag aatctcaatg caaaatcact tctgattatg tgaaatcagt gattgctcct 1020
accgtggcta ctgtcgttct caatacaaac agatgctcac agataatttg taagggtcgc 1080
ggcaactgtg tttggcctga agaaccattt agttcttgga aatacttagt tgaccccaaa 1140
atgccagtgt tcaagccaac caacatccac tgtaaatgta aaggttacct aggtagatac 1200
tgtgagatcc caaagggatc cgccatttct caaatcactg acggtcaaat ccaagctact 1260
accactgcta ccaccgaagc taccaccact gctgccccat cttccaccgt tgaaactgtt 1320
tctccatcca gcaccgaaac tatctctcaa caaactgaaa atggtgctgc taaggccgct 1380
gtcggtatgg gtgccggtgc tctagctgct gctgctatgt tgttataa 1428
<210> 29
<211> 1083
<212> ДНК
<213> Vespa magnifica
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Vespa magnifica с N-концевым сигналом секреции
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Vespa magnifica с N-концевым сигналом секреции
<400> 29
atgcaatttt ctacagtggc aagtgttgca ttcgttgcac tagccaactt tgtggcggca 60
gatagctgtg ggtcaaactg cgaaaagagt gagagaccga aaagggtctt caacatttac 120
tggaacgtac ctacattcat gtgtcaccag tacggactat actttgacga ggtcacgaat 180
tttaatataa agcacaacag caaagacaat tttcaagggg acaagatcgc gatcttttat 240
gaccccgggg agtttcccgc tctgctgcca ctaaactatg gtaagtacaa gatcaggaat 300
ggtggtgttc cacaagaggg taacatcacc atccatctgc agagattcat agagtaccta 360
gataagacct atccgaaccg taacttttca ggcatcggtg tgatcgattt cgagaggtgg 420
agaccaattt tcagacagaa ttggggtaat atgaagattt acaagaactt ctccatcgat 480
cttgtgcgta aagagcatcc tttctggaat aagaaaatga tcgagttgga agcttctaaa 540
agattcgaga aatacgcccg tctgttcatg gaagaaacat taaagttggc taagaaaact 600
agaaaacagg ccgattgggg ctactacggt tacccctatt gcttcaacat gtctcctact 660
aatttcgttc ctgactgcga tgtcacagct agggatgaga acaacgagat gtcttggttg 720
tttaacaacc agaatgtcct attaccaagt gtatacatta ggagagagct aactcctgac 780
cagaggattg ggcttgtaca ggggagagtg aaggaagctg tgagaatttc aaataaactg 840
aagcactcac ctaaagtctt cagctattgg tggtatgttt accaagacga gaccaacacc 900
ttcttaacgg agaccgacgt caagaagacg tttcaggaga ttgtgatcaa cggtggagat 960
gggattataa tctggggttc gtcctctgat gtaaacagct tgtccaagtg tacgaggtta 1020
agggagtacc tattgacagt cttgggacca attgctgtta acgtgactga agcagtaaac 1080
taa 1083
<210> 30
<211> 1293
<212> ДНК
<213> Vespa magnifica
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Vespa magnifica с N-концевым сигналом секреции и C-концевым
якорным сигналом
<220>
<223> Перекодированная нуклеоитидная последовательность гиалуронидазы (HYAL),
происходящая из Vespa magnifica с N-концевым сигналом секреции и C-концевым
якорным сигналом
<400> 30
atgcaatttt ctacagtggc aagtgttgca ttcgttgcac tagccaactt tgtggcggca 60
gatagctgtg ggtcaaactg cgaaaagagt gagagaccga aaagggtctt caacatttac 120
tggaacgtac ctacattcat gtgtcaccag tacggactat actttgacga ggtcacgaat 180
tttaatataa agcacaacag caaagacaat tttcaagggg acaagatcgc gatcttttat 240
gaccccgggg agtttcccgc tctgctgcca ctaaactatg gtaagtacaa gatcaggaat 300
ggtggtgttc cacaagaggg taacatcacc atccatctgc agagattcat agagtaccta 360
gataagacct atccgaaccg taacttttca ggcatcggtg tgatcgattt cgagaggtgg 420
agaccaattt tcagacagaa ttggggtaat atgaagattt acaagaactt ctccatcgat 480
cttgtgcgta aagagcatcc tttctggaat aagaaaatga tcgagttgga agcttctaaa 540
agattcgaga aatacgcccg tctgttcatg gaagaaacat taaagttggc taagaaaact 600
agaaaacagg ccgattgggg ctactacggt tacccctatt gcttcaacat gtctcctact 660
aatttcgttc ctgactgcga tgtcacagct agggatgaga acaacgagat gtcttggttg 720
tttaacaacc agaatgtcct attaccaagt gtatacatta ggagagagct aactcctgac 780
cagaggattg ggcttgtaca ggggagagtg aaggaagctg tgagaatttc aaataaactg 840
aagcactcac ctaaagtctt cagctattgg tggtatgttt accaagacga gaccaacacc 900
ttcttaacgg agaccgacgt caagaagacg tttcaggaga ttgtgatcaa cggtggagat 960
gggattataa tctggggttc gtcctctgat gtaaacagct tgtccaagtg tacgaggtta 1020
agggagtacc tattgacagt cttgggacca attgctgtta acgtgactga agcagtaaac 1080
ggatccgcca tttctcaaat cactgacggt caaatccaag ctactaccac tgctaccacc 1140
gaagctacca ccactgctgc cccatcttcc accgttgaaa ctgtttctcc atccagcacc 1200
gaaactatct ctcaacaaac tgaaaatggt gctgctaagg ccgctgtcgg tatgggtgcc 1260
ggtgctctag ctgctgctgc tatgttgtta taa 1293
<210> 31
<211> 441
<212> БЕЛОК
<213> Bothrops atrox
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL),
происходящая из Bothrops atrox с N-концевым сигналом секреции
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL),
происходящая из Bothrops atrox с N-концевым сигналом секреции
<400> 31
Met Gln Phe Ser Thr Val Ala Ser Val Ala Phe Val Ala Leu Ala Asn
1 5 10 15
Phe Val Ala Ala Pro Met Tyr Pro Asn Glu Pro Phe Leu Val Phe Trp
20 25 30
Asn Ala Pro Thr Thr Gln Cys Arg Leu Arg Tyr Lys Val Asp Leu Asp
35 40 45
Leu Lys Thr Phe His Ile Val Thr Asn Ala Asn Asp Ser Leu Ser Gly
50 55 60
Ser Ala Val Thr Ile Phe Tyr Pro Thr His Leu Gly Val Tyr Pro His
65 70 75 80
Ile Asp Asp Arg Gly His Phe Phe Asn Gly Ile Ile Pro Gln Asn Glu
85 90 95
Ser Leu Val Lys His Leu Asn Lys Ser Lys Ser Asp Ile Asn Arg Met
100 105 110
Ile Pro Leu Arg Thr Phe His Gly Leu Gly Val Ile Asp Trp Glu Asn
115 120 125
Trp Arg Pro Gln Trp Asp Arg Asn Trp Gly Ser Lys Asn Val Tyr Arg
130 135 140
Asn Arg Ser Ile Gln Phe Ala Arg Asp Leu His Pro Glu Leu Ser Glu
145 150 155 160
Asp Lys Ile Lys Arg Leu Ala Lys Gln Glu Phe Glu Lys Ala Ala Lys
165 170 175
Ser Phe Met Arg Asp Thr Leu Leu Leu Ala Glu Glu Met Arg Pro Asp
180 185 190
Gly Tyr Trp Gly Tyr Tyr Leu Tyr Pro Asp Cys His Asn Tyr Asn Tyr
195 200 205
Lys Thr Lys Pro Asp Gln Tyr Thr Gly Glu Cys Pro Asp Ile Glu Met
210 215 220
Ser Arg Asn Asn Gln Leu Leu Trp Leu Trp Arg Asp Ser Thr Ala Leu
225 230 235 240
Phe Pro Asn Ile Tyr Leu Glu Thr Ile Leu Arg Ser Ser Asp Asn Ala
245 250 255
Leu Lys Phe Val His His Arg Leu Lys Glu Ala Met Arg Ile Ala Ser
260 265 270
Met Ala Arg Asn Asp Tyr Ala Leu Pro Phe Phe Val Tyr Ala Arg Pro
275 280 285
Phe Tyr Ala Tyr Thr Phe Glu Pro Leu Thr Gln Glu Asp Leu Val Thr
290 295 300
Thr Val Gly Glu Thr Ala Asp Met Gly Ala Ala Gly Ile Val Phe Trp
305 310 315 320
Gly Ser Met Gln Tyr Ala Ser Thr Val Glu Ser Cys Gly Lys Val Lys
325 330 335
Asp Tyr Met Asn Gly Pro Leu Gly Arg Tyr Ile Val Asn Val Thr Thr
340 345 350
Ala Ala Lys Ile Cys Ser Arg Phe Leu Cys Lys Arg His Gly Arg Cys
355 360 365
Val Arg Lys His Ser Asp Ser Asn Ala Phe Leu His Leu Phe Pro Asp
370 375 380
Ser Phe Arg Ile Met Val His Gly Asn Ala Thr Glu Lys Lys Val Ile
385 390 395 400
Val Lys Gly Lys Leu Glu Leu Lys Asn Leu Ile Phe Leu Arg Asn Asn
405 410 415
Phe Met Cys Gln Cys Tyr Gln Gly Trp Lys Gly Leu Tyr Cys Glu Lys
420 425 430
His Ser Ile Lys Glu Ile Arg Lys Ile
435 440
<210> 32
<211> 511
<212> БЕЛОК
<213> Bothrops atrox
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Bothrops atrox с N-концевым сигналом секреции и C-концевым якорным сигналом
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Bothrops atrox с N-концевым сигналом секреции и C-концевым якорным сигналом
<400> 32
Met Gln Phe Ser Thr Val Ala Ser Val Ala Phe Val Ala Leu Ala Asn
1 5 10 15
Phe Val Ala Ala Pro Met Tyr Pro Asn Glu Pro Phe Leu Val Phe Trp
20 25 30
Asn Ala Pro Thr Thr Gln Cys Arg Leu Arg Tyr Lys Val Asp Leu Asp
35 40 45
Leu Lys Thr Phe His Ile Val Thr Asn Ala Asn Asp Ser Leu Ser Gly
50 55 60
Ser Ala Val Thr Ile Phe Tyr Pro Thr His Leu Gly Val Tyr Pro His
65 70 75 80
Ile Asp Asp Arg Gly His Phe Phe Asn Gly Ile Ile Pro Gln Asn Glu
85 90 95
Ser Leu Val Lys His Leu Asn Lys Ser Lys Ser Asp Ile Asn Arg Met
100 105 110
Ile Pro Leu Arg Thr Phe His Gly Leu Gly Val Ile Asp Trp Glu Asn
115 120 125
Trp Arg Pro Gln Trp Asp Arg Asn Trp Gly Ser Lys Asn Val Tyr Arg
130 135 140
Asn Arg Ser Ile Gln Phe Ala Arg Asp Leu His Pro Glu Leu Ser Glu
145 150 155 160
Asp Lys Ile Lys Arg Leu Ala Lys Gln Glu Phe Glu Lys Ala Ala Lys
165 170 175
Ser Phe Met Arg Asp Thr Leu Leu Leu Ala Glu Glu Met Arg Pro Asp
180 185 190
Gly Tyr Trp Gly Tyr Tyr Leu Tyr Pro Asp Cys His Asn Tyr Asn Tyr
195 200 205
Lys Thr Lys Pro Asp Gln Tyr Thr Gly Glu Cys Pro Asp Ile Glu Met
210 215 220
Ser Arg Asn Asn Gln Leu Leu Trp Leu Trp Arg Asp Ser Thr Ala Leu
225 230 235 240
Phe Pro Asn Ile Tyr Leu Glu Thr Ile Leu Arg Ser Ser Asp Asn Ala
245 250 255
Leu Lys Phe Val His His Arg Leu Lys Glu Ala Met Arg Ile Ala Ser
260 265 270
Met Ala Arg Asn Asp Tyr Ala Leu Pro Phe Phe Val Tyr Ala Arg Pro
275 280 285
Phe Tyr Ala Tyr Thr Phe Glu Pro Leu Thr Gln Glu Asp Leu Val Thr
290 295 300
Thr Val Gly Glu Thr Ala Asp Met Gly Ala Ala Gly Ile Val Phe Trp
305 310 315 320
Gly Ser Met Gln Tyr Ala Ser Thr Val Glu Ser Cys Gly Lys Val Lys
325 330 335
Asp Tyr Met Asn Gly Pro Leu Gly Arg Tyr Ile Val Asn Val Thr Thr
340 345 350
Ala Ala Lys Ile Cys Ser Arg Phe Leu Cys Lys Arg His Gly Arg Cys
355 360 365
Val Arg Lys His Ser Asp Ser Asn Ala Phe Leu His Leu Phe Pro Asp
370 375 380
Ser Phe Arg Ile Met Val His Gly Asn Ala Thr Glu Lys Lys Val Ile
385 390 395 400
Val Lys Gly Lys Leu Glu Leu Lys Asn Leu Ile Phe Leu Arg Asn Asn
405 410 415
Phe Met Cys Gln Cys Tyr Gln Gly Trp Lys Gly Leu Tyr Cys Glu Lys
420 425 430
His Ser Ile Lys Glu Ile Arg Lys Ile Gly Ser Ala Ile Ser Gln Ile
435 440 445
Thr Asp Gly Gln Ile Gln Ala Thr Thr Thr Ala Thr Thr Glu Ala Thr
450 455 460
Thr Thr Ala Ala Pro Ser Ser Thr Val Glu Thr Val Ser Pro Ser Ser
465 470 475 480
Thr Glu Thr Ile Ser Gln Gln Thr Glu Asn Gly Ala Ala Lys Ala Ala
485 490 495
Val Gly Met Gly Ala Gly Ala Leu Ala Ala Ala Ala Met Leu Leu
500 505 510
<210> 33
<211> 398
<212> БЕЛОК
<213> Cupiennius salei
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Cupiennius salei с N-концевым сигналом секреции
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Cupiennius salei с N-концевым сигналом секреции
<400> 33
Met Gln Phe Ser Thr Val Ala Ser Val Ala Phe Val Ala Leu Ala Asn
1 5 10 15
Phe Val Ala Ala Phe Lys Ile Tyr Trp Asn Val Pro Thr Phe Gln Cys
20 25 30
Thr His Asn Tyr Lys Ile Asp Tyr Val Lys Leu Leu Ser Thr Tyr Gly
35 40 45
Ile Gln Val Asn Asp Gly Gly Lys Phe Gln Gly Asn Gln Val Thr Ile
50 55 60
Phe Tyr Glu Thr Gln Leu Gly Leu Tyr Pro Arg Ile Leu Lys Ser Gly
65 70 75 80
Lys Met Glu Asn Gly Gly Ile Pro Gln Arg Gly Asn Phe Glu Lys His
85 90 95
Leu Glu Lys Ala Ser Thr Asp Leu Gln Lys Val Ile Pro Trp Lys Glu
100 105 110
Phe Ser Gly Leu Gly Val Ile Asp Trp Glu Ala Trp Arg Pro Thr Trp
115 120 125
Glu Phe Asn Trp Glu Pro Leu Arg Ile Tyr Gln Thr Glu Ser Ile Lys
130 135 140
Arg Ala Lys Glu Leu His Pro Thr Ala Asn Asp Ser Ala Val Lys Glu
145 150 155 160
Ile Ala Glu Arg Gln Trp Glu Asp Ser Ala Lys Leu Tyr Met Leu Glu
165 170 175
Thr Leu Arg Leu Ala Lys Lys Leu Arg Pro Gln Ala Pro Trp Cys Tyr
180 185 190
Tyr Leu Phe Pro Asp Cys Tyr Asn Tyr Val Gly Lys Lys Pro Lys Asp
195 200 205
Phe Gln Cys Ser Ala Ser Ile Arg Lys Gly Asn Asp Lys Leu Ser Trp
210 215 220
Leu Trp Lys Asp Ser Thr Ala Leu Cys Pro Ser Ile Tyr Val Tyr Glu
225 230 235 240
Ser Gln Leu Asp Arg Tyr Ser Phe Glu Gln Arg Thr Trp Arg Asp Asn
245 250 255
Glu Lys Leu Arg Glu Ala Leu Arg Val Ala Thr Arg Thr Ser Lys Ile
260 265 270
Tyr Pro Tyr Val Asn Tyr Phe Asp Lys Glu Leu Ile Pro Glu Gln Glu
275 280 285
Val Trp Arg Met Leu Ala Gln Ala Ala Ala Val Gly Gly Ser Gly Ala
290 295 300
Val Ile Trp Gly Ser Ser Ala Ala Val Ala Ser Glu Glu Leu Cys Lys
305 310 315 320
Ser Leu Lys Gln Tyr Ile Ile Glu Thr Leu Gly Pro Ala Ala Glu Lys
325 330 335
Val Ala Trp Arg Ser Asp Leu Cys Ser Lys Glu Ile Cys Asn Asn Gln
340 345 350
Gly Arg Cys Thr Phe Pro Asp Asp Asp Tyr Ala Asn Ala Trp Lys Leu
355 360 365
Phe Thr Asp Asp Thr Val Lys Phe Tyr Ala Gly Asn Ile Thr Cys Arg
370 375 380
Cys Ser Glu Asn Tyr Ser Gly Arg Phe Cys Glu Lys Lys Asn
385 390 395
<210> 34
<211> 468
<212> БЕЛОК
<213> Cupiennius salei
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Cupiennius salei с N-концевым сигналом секреции и C-концевым якорным сигналом
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Cupiennius salei с N-концевым сигналом секреции и C-концевым якорным сигналом
<400> 34
Met Gln Phe Ser Thr Val Ala Ser Val Ala Phe Val Ala Leu Ala Asn
1 5 10 15
Phe Val Ala Ala Phe Lys Ile Tyr Trp Asn Val Pro Thr Phe Gln Cys
20 25 30
Thr His Asn Tyr Lys Ile Asp Tyr Val Lys Leu Leu Ser Thr Tyr Gly
35 40 45
Ile Gln Val Asn Asp Gly Gly Lys Phe Gln Gly Asn Gln Val Thr Ile
50 55 60
Phe Tyr Glu Thr Gln Leu Gly Leu Tyr Pro Arg Ile Leu Lys Ser Gly
65 70 75 80
Lys Met Glu Asn Gly Gly Ile Pro Gln Arg Gly Asn Phe Glu Lys His
85 90 95
Leu Glu Lys Ala Ser Thr Asp Leu Gln Lys Val Ile Pro Trp Lys Glu
100 105 110
Phe Ser Gly Leu Gly Val Ile Asp Trp Glu Ala Trp Arg Pro Thr Trp
115 120 125
Glu Phe Asn Trp Glu Pro Leu Arg Ile Tyr Gln Thr Glu Ser Ile Lys
130 135 140
Arg Ala Lys Glu Leu His Pro Thr Ala Asn Asp Ser Ala Val Lys Glu
145 150 155 160
Ile Ala Glu Arg Gln Trp Glu Asp Ser Ala Lys Leu Tyr Met Leu Glu
165 170 175
Thr Leu Arg Leu Ala Lys Lys Leu Arg Pro Gln Ala Pro Trp Cys Tyr
180 185 190
Tyr Leu Phe Pro Asp Cys Tyr Asn Tyr Val Gly Lys Lys Pro Lys Asp
195 200 205
Phe Gln Cys Ser Ala Ser Ile Arg Lys Gly Asn Asp Lys Leu Ser Trp
210 215 220
Leu Trp Lys Asp Ser Thr Ala Leu Cys Pro Ser Ile Tyr Val Tyr Glu
225 230 235 240
Ser Gln Leu Asp Arg Tyr Ser Phe Glu Gln Arg Thr Trp Arg Asp Asn
245 250 255
Glu Lys Leu Arg Glu Ala Leu Arg Val Ala Thr Arg Thr Ser Lys Ile
260 265 270
Tyr Pro Tyr Val Asn Tyr Phe Asp Lys Glu Leu Ile Pro Glu Gln Glu
275 280 285
Val Trp Arg Met Leu Ala Gln Ala Ala Ala Val Gly Gly Ser Gly Ala
290 295 300
Val Ile Trp Gly Ser Ser Ala Ala Val Ala Ser Glu Glu Leu Cys Lys
305 310 315 320
Ser Leu Lys Gln Tyr Ile Ile Glu Thr Leu Gly Pro Ala Ala Glu Lys
325 330 335
Val Ala Trp Arg Ser Asp Leu Cys Ser Lys Glu Ile Cys Asn Asn Gln
340 345 350
Gly Arg Cys Thr Phe Pro Asp Asp Asp Tyr Ala Asn Ala Trp Lys Leu
355 360 365
Phe Thr Asp Asp Thr Val Lys Phe Tyr Ala Gly Asn Ile Thr Cys Arg
370 375 380
Cys Ser Glu Asn Tyr Ser Gly Arg Phe Cys Glu Lys Lys Asn Gly Ser
385 390 395 400
Ala Ile Ser Gln Ile Thr Asp Gly Gln Ile Gln Ala Thr Thr Thr Ala
405 410 415
Thr Thr Glu Ala Thr Thr Thr Ala Ala Pro Ser Ser Thr Val Glu Thr
420 425 430
Val Ser Pro Ser Ser Thr Glu Thr Ile Ser Gln Gln Thr Glu Asn Gly
435 440 445
Ala Ala Lys Ala Ala Val Gly Met Gly Ala Gly Ala Leu Ala Ala Ala
450 455 460
Ala Met Leu Leu
465
<210> 35
<211> 579
<212> БЕЛОК
<213> Hirudo nipponia
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Hirudo Nipponia с N-концевым сигналом секреции
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Hirudo Nipponia с N-концевым сигналом секреции
<400> 35
Met Gln Phe Ser Thr Val Ala Ser Val Ala Phe Val Ala Leu Ala Asn
1 5 10 15
Phe Val Ala Ala Met Lys Glu Ile Ala Val Thr Ile Asp Asp Lys Asn
20 25 30
Val Ile Ala Ser Val Ser Glu Ser Phe His Gly Val Ala Phe Asp Ala
35 40 45
Ser Leu Phe Ser Pro Lys Gly Leu Trp Ser Phe Val Asp Ile Thr Ser
50 55 60
Pro Lys Leu Phe Lys Leu Leu Glu Gly Leu Ser Pro Gly Tyr Phe Arg
65 70 75 80
Val Gly Gly Thr Phe Ala Asn Trp Leu Phe Phe Asp Leu Asp Glu Asn
85 90 95
Asn Lys Trp Lys Asp Tyr Trp Ala Phe Lys Asp Lys Thr Pro Glu Thr
100 105 110
Ala Thr Ile Thr Arg Arg Trp Leu Phe Arg Lys Gln Asn Asn Leu Lys
115 120 125
Lys Glu Thr Phe Asp Asp Leu Val Lys Leu Thr Lys Gly Ser Lys Met
130 135 140
Arg Leu Leu Phe Asp Leu Asn Ala Glu Val Arg Thr Gly Tyr Glu Ile
145 150 155 160
Gly Lys Lys Met Thr Ser Thr Trp Asp Ser Ser Glu Ala Glu Lys Leu
165 170 175
Phe Lys Tyr Cys Val Ser Lys Gly Tyr Gly Asp Asn Ile Asp Trp Glu
180 185 190
Leu Gly Asn Glu Pro Asp His Thr Ser Ala His Asn Leu Thr Glu Lys
195 200 205
Gln Val Gly Glu Asp Phe Lys Ala Leu His Lys Val Leu Glu Lys Tyr
210 215 220
Pro Thr Leu Asn Lys Gly Ser Leu Val Gly Pro Asp Val Gly Trp Met
225 230 235 240
Gly Val Ser Tyr Val Lys Gly Leu Ala Asp Gly Ala Gly Asp His Val
245 250 255
Thr Ala Phe Thr Leu His Gln Tyr Tyr Phe Asp Gly Asn Thr Ser Asp
260 265 270
Val Ser Thr Tyr Leu Asp Ala Thr Tyr Phe Lys Lys Leu Gln Gln Leu
275 280 285
Phe Asp Lys Val Lys Asp Val Leu Lys Asn Ser Pro His Lys Asp Lys
290 295 300
Pro Leu Trp Leu Gly Glu Thr Ser Ser Gly Tyr Asn Ser Gly Thr Lys
305 310 315 320
Asp Val Ser Asp Arg Tyr Val Ser Gly Phe Leu Thr Leu Asp Lys Leu
325 330 335
Gly Leu Ser Ala Ala Asn Asn Val Lys Val Val Ile Arg Gln Thr Ile
340 345 350
Tyr Asn Gly Tyr Tyr Gly Leu Leu Asp Lys Asn Thr Leu Glu Pro Asn
355 360 365
Pro Asp Tyr Trp Leu Met His Val His Asn Ser Leu Val Gly Asn Thr
370 375 380
Val Phe Lys Val Asp Val Ser Asp Pro Thr Asn Lys Ala Arg Val Tyr
385 390 395 400
Ala Gln Cys Thr Lys Thr Asn Ser Lys His Thr Gln Ser Arg Tyr Tyr
405 410 415
Lys Gly Ser Leu Thr Ile Phe Ala Leu Asn Val Gly Asp Glu Asp Val
420 425 430
Thr Leu Lys Ile Asp Gln Tyr Ser Gly Lys Lys Ile Tyr Ser Tyr Ile
435 440 445
Leu Thr Pro Glu Gly Gly Gln Leu Thr Ser Gln Lys Val Leu Leu Asn
450 455 460
Gly Lys Glu Leu Lys Leu Val Ser Asp Gln Leu Pro Glu Leu Asn Ala
465 470 475 480
Asp Glu Ser Lys Thr Ser Phe Thr Leu Ser Pro Lys Thr Phe Gly Phe
485 490 495
Phe Val Val Ser Asp Ala Asn Val Glu Ala Cys Lys Lys Gly Ser Ala
500 505 510
Ile Ser Gln Ile Thr Asp Gly Gln Ile Gln Ala Thr Thr Thr Ala Thr
515 520 525
Thr Glu Ala Thr Thr Thr Ala Ala Pro Ser Ser Thr Val Glu Thr Val
530 535 540
Ser Pro Ser Ser Thr Glu Thr Ile Ser Gln Gln Thr Glu Asn Gly Ala
545 550 555 560
Ala Lys Ala Ala Val Gly Met Gly Ala Gly Ala Leu Ala Ala Ala Ala
565 570 575
Met Leu Leu
<210> 36
<211> 509
<212> БЕЛОК
<213> Hirudo nipponia
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Hirudo Nipponia с N-концевым сигналом секреции и C-концевым якорным сигналом
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Hirudo Nipponia с N-концевым сигналом секреции и C-концевым якорным сигналом
<400> 36
Met Gln Phe Ser Thr Val Ala Ser Val Ala Phe Val Ala Leu Ala Asn
1 5 10 15
Phe Val Ala Ala Met Lys Glu Ile Ala Val Thr Ile Asp Asp Lys Asn
20 25 30
Val Ile Ala Ser Val Ser Glu Ser Phe His Gly Val Ala Phe Asp Ala
35 40 45
Ser Leu Phe Ser Pro Lys Gly Leu Trp Ser Phe Val Asp Ile Thr Ser
50 55 60
Pro Lys Leu Phe Lys Leu Leu Glu Gly Leu Ser Pro Gly Tyr Phe Arg
65 70 75 80
Val Gly Gly Thr Phe Ala Asn Trp Leu Phe Phe Asp Leu Asp Glu Asn
85 90 95
Asn Lys Trp Lys Asp Tyr Trp Ala Phe Lys Asp Lys Thr Pro Glu Thr
100 105 110
Ala Thr Ile Thr Arg Arg Trp Leu Phe Arg Lys Gln Asn Asn Leu Lys
115 120 125
Lys Glu Thr Phe Asp Asp Leu Val Lys Leu Thr Lys Gly Ser Lys Met
130 135 140
Arg Leu Leu Phe Asp Leu Asn Ala Glu Val Arg Thr Gly Tyr Glu Ile
145 150 155 160
Gly Lys Lys Met Thr Ser Thr Trp Asp Ser Ser Glu Ala Glu Lys Leu
165 170 175
Phe Lys Tyr Cys Val Ser Lys Gly Tyr Gly Asp Asn Ile Asp Trp Glu
180 185 190
Leu Gly Asn Glu Pro Asp His Thr Ser Ala His Asn Leu Thr Glu Lys
195 200 205
Gln Val Gly Glu Asp Phe Lys Ala Leu His Lys Val Leu Glu Lys Tyr
210 215 220
Pro Thr Leu Asn Lys Gly Ser Leu Val Gly Pro Asp Val Gly Trp Met
225 230 235 240
Gly Val Ser Tyr Val Lys Gly Leu Ala Asp Gly Ala Gly Asp His Val
245 250 255
Thr Ala Phe Thr Leu His Gln Tyr Tyr Phe Asp Gly Asn Thr Ser Asp
260 265 270
Val Ser Thr Tyr Leu Asp Ala Thr Tyr Phe Lys Lys Leu Gln Gln Leu
275 280 285
Phe Asp Lys Val Lys Asp Val Leu Lys Asn Ser Pro His Lys Asp Lys
290 295 300
Pro Leu Trp Leu Gly Glu Thr Ser Ser Gly Tyr Asn Ser Gly Thr Lys
305 310 315 320
Asp Val Ser Asp Arg Tyr Val Ser Gly Phe Leu Thr Leu Asp Lys Leu
325 330 335
Gly Leu Ser Ala Ala Asn Asn Val Lys Val Val Ile Arg Gln Thr Ile
340 345 350
Tyr Asn Gly Tyr Tyr Gly Leu Leu Asp Lys Asn Thr Leu Glu Pro Asn
355 360 365
Pro Asp Tyr Trp Leu Met His Val His Asn Ser Leu Val Gly Asn Thr
370 375 380
Val Phe Lys Val Asp Val Ser Asp Pro Thr Asn Lys Ala Arg Val Tyr
385 390 395 400
Ala Gln Cys Thr Lys Thr Asn Ser Lys His Thr Gln Ser Arg Tyr Tyr
405 410 415
Lys Gly Ser Leu Thr Ile Phe Ala Leu Asn Val Gly Asp Glu Asp Val
420 425 430
Thr Leu Lys Ile Asp Gln Tyr Ser Gly Lys Lys Ile Tyr Ser Tyr Ile
435 440 445
Leu Thr Pro Glu Gly Gly Gln Leu Thr Ser Gln Lys Val Leu Leu Asn
450 455 460
Gly Lys Glu Leu Lys Leu Val Ser Asp Gln Leu Pro Glu Leu Asn Ala
465 470 475 480
Asp Glu Ser Lys Thr Ser Phe Thr Leu Ser Pro Lys Thr Phe Gly Phe
485 490 495
Phe Val Val Ser Asp Ala Asn Val Glu Ala Cys Lys Lys
500 505
<210> 37
<211> 401
<212> БЕЛОК
<213> Loxosceles intermedia
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Loxosceles intermedia с N-концевым сигналом секреции
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Loxosceles intermedia с N-концевым сигналом секреции
<400> 37
Met Gln Phe Ser Thr Val Ala Ser Val Ala Phe Val Ala Leu Ala Asn
1 5 10 15
Phe Val Ala Ala Phe Asp Val Phe Trp Asn Val Pro Ser Gln Gln Cys
20 25 30
Lys Lys Tyr Gly Met Lys Phe Val Pro Leu Leu Glu Gln Tyr Ser Ile
35 40 45
Leu Val Asn Lys Glu Asp Asn Phe Lys Gly Asp Lys Ile Thr Ile Phe
50 55 60
Tyr Glu Ser Gln Leu Gly Leu Tyr Pro His Ile Gly Ala Asn Asp Glu
65 70 75 80
Ser Phe Asn Gly Gly Ile Pro Gln Leu Gly Asp Leu Lys Ala His Leu
85 90 95
Glu Lys Ser Ala Val Asp Ile Arg Arg Asp Ile Leu Asp Lys Ser Ala
100 105 110
Thr Gly Leu Arg Ile Ile Asp Trp Glu Ala Trp Arg Pro Ile Trp Glu
115 120 125
Phe Asn Trp Ser Ser Leu Arg Lys Tyr Gln Asp Lys Met Lys Lys Val
130 135 140
Val Arg Gln Phe Asn Pro Thr Ala His Glu Ser Thr Val Ala Lys Leu
145 150 155 160
Ala His Asn Glu Trp Glu Asn Ser Ser Lys Ser Trp Met Leu Ser Thr
165 170 175
Leu Gln Leu Gly Lys Gln Leu Arg Pro Asn Ser Val Trp Cys Tyr Tyr
180 185 190
Leu Phe Pro Asp Cys Tyr Asn Tyr Asp Gly Asn Ser Val Gln Glu Phe
195 200 205
Gln Cys Ser Glu Ala Ile Arg Lys Gly Asn Asp Arg Leu Lys Trp Leu
210 215 220
Trp Glu Glu Ser Thr Ala Val Cys Pro Ser Ile Tyr Ile Lys Glu Gly
225 230 235 240
Gln Leu Thr Asn Tyr Thr Leu Gln Lys Arg Ile Trp Phe Thr Asn Gly
245 250 255
Arg Leu Gln Glu Ala Leu Arg Val Ala Gln Pro Lys Ala Arg Ile Tyr
260 265 270
Pro Tyr Ile Asn Tyr Ser Ile Lys Pro Gly Met Met Val Pro Glu Val
275 280 285
Glu Phe Trp Arg Leu Ile Ala Gln Ile Ala Ser Leu Gly Met Asp Gly
290 295 300
Ala Val Ile Trp Gly Ser Ser Ala Ser Val Gly Ser Lys Asn His Cys
305 310 315 320
Ala Gln Leu Met Lys Tyr Ile Ala Asp Val Leu Gly Pro Ala Thr Leu
325 330 335
Arg Ile Lys Glu Asn Val Ala Arg Cys Ser Lys Gln Ala Cys Ser Gly
340 345 350
Arg Gly Arg Cys Thr Trp Pro Lys Asp Thr Ser Val Ile Ala Trp Lys
355 360 365
Phe Leu Val Glu Lys Glu Asp Tyr Asp Phe Tyr Leu Gly Asp Ile Glu
370 375 380
Cys Lys Cys Val Glu Gly Tyr Glu Gly Arg Tyr Cys Glu Gln Lys Thr
385 390 395 400
Lys
<210> 38
<211> 471
<212> БЕЛОК
<213> Loxosceles intermedia
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Loxosceles intermedia с N-концевым сигналом секреции и C-концевым
якорным сигналом
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Loxosceles intermedia с N-концевым сигналом секреции и C-концевым
якорным сигналом
<400> 38
Met Gln Phe Ser Thr Val Ala Ser Val Ala Phe Val Ala Leu Ala Asn
1 5 10 15
Phe Val Ala Ala Phe Asp Val Phe Trp Asn Val Pro Ser Gln Gln Cys
20 25 30
Lys Lys Tyr Gly Met Lys Phe Val Pro Leu Leu Glu Gln Tyr Ser Ile
35 40 45
Leu Val Asn Lys Glu Asp Asn Phe Lys Gly Asp Lys Ile Thr Ile Phe
50 55 60
Tyr Glu Ser Gln Leu Gly Leu Tyr Pro His Ile Gly Ala Asn Asp Glu
65 70 75 80
Ser Phe Asn Gly Gly Ile Pro Gln Leu Gly Asp Leu Lys Ala His Leu
85 90 95
Glu Lys Ser Ala Val Asp Ile Arg Arg Asp Ile Leu Asp Lys Ser Ala
100 105 110
Thr Gly Leu Arg Ile Ile Asp Trp Glu Ala Trp Arg Pro Ile Trp Glu
115 120 125
Phe Asn Trp Ser Ser Leu Arg Lys Tyr Gln Asp Lys Met Lys Lys Val
130 135 140
Val Arg Gln Phe Asn Pro Thr Ala His Glu Ser Thr Val Ala Lys Leu
145 150 155 160
Ala His Asn Glu Trp Glu Asn Ser Ser Lys Ser Trp Met Leu Ser Thr
165 170 175
Leu Gln Leu Gly Lys Gln Leu Arg Pro Asn Ser Val Trp Cys Tyr Tyr
180 185 190
Leu Phe Pro Asp Cys Tyr Asn Tyr Asp Gly Asn Ser Val Gln Glu Phe
195 200 205
Gln Cys Ser Glu Ala Ile Arg Lys Gly Asn Asp Arg Leu Lys Trp Leu
210 215 220
Trp Glu Glu Ser Thr Ala Val Cys Pro Ser Ile Tyr Ile Lys Glu Gly
225 230 235 240
Gln Leu Thr Asn Tyr Thr Leu Gln Lys Arg Ile Trp Phe Thr Asn Gly
245 250 255
Arg Leu Gln Glu Ala Leu Arg Val Ala Gln Pro Lys Ala Arg Ile Tyr
260 265 270
Pro Tyr Ile Asn Tyr Ser Ile Lys Pro Gly Met Met Val Pro Glu Val
275 280 285
Glu Phe Trp Arg Leu Ile Ala Gln Ile Ala Ser Leu Gly Met Asp Gly
290 295 300
Ala Val Ile Trp Gly Ser Ser Ala Ser Val Gly Ser Lys Asn His Cys
305 310 315 320
Ala Gln Leu Met Lys Tyr Ile Ala Asp Val Leu Gly Pro Ala Thr Leu
325 330 335
Arg Ile Lys Glu Asn Val Ala Arg Cys Ser Lys Gln Ala Cys Ser Gly
340 345 350
Arg Gly Arg Cys Thr Trp Pro Lys Asp Thr Ser Val Ile Ala Trp Lys
355 360 365
Phe Leu Val Glu Lys Glu Asp Tyr Asp Phe Tyr Leu Gly Asp Ile Glu
370 375 380
Cys Lys Cys Val Glu Gly Tyr Glu Gly Arg Tyr Cys Glu Gln Lys Thr
385 390 395 400
Lys Gly Ser Ala Ile Ser Gln Ile Thr Asp Gly Gln Ile Gln Ala Thr
405 410 415
Thr Thr Ala Thr Thr Glu Ala Thr Thr Thr Ala Ala Pro Ser Ser Thr
420 425 430
Val Glu Thr Val Ser Pro Ser Ser Thr Glu Thr Ile Ser Gln Gln Thr
435 440 445
Glu Asn Gly Ala Ala Lys Ala Ala Val Gly Met Gly Ala Gly Ala Leu
450 455 460
Ala Ala Ala Ala Met Leu Leu
465 470
<210> 39
<211> 405
<212> БЕЛОК
<213> Tityus serrulatus
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL),
происходящая из Tityus serrulatus с N-концевым сигналом секреции
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL),
происходящая из Tityus serrulatus с N-концевым сигналом секреции
<400> 39
Met Gln Phe Ser Thr Val Ala Ser Val Ala Phe Val Ala Leu Ala Asn
1 5 10 15
Phe Val Ala Ala Ala Asp Phe Lys Val Tyr Trp Glu Val Pro Ser Phe
20 25 30
Leu Cys Ser Lys Arg Phe Lys Ile Asn Val Thr Glu Val Leu Thr Ser
35 40 45
His Glu Ile Leu Val Asn Gln Gly Glu Ser Phe Asn Gly Asp Lys Ile
50 55 60
Val Ile Phe Tyr Glu Asn Gln Leu Gly Lys Tyr Pro His Ile Asp Ser
65 70 75 80
Asn Asn Val Glu Ile Asn Gly Gly Ile Leu Gln Val Ala Asp Leu Ala
85 90 95
Lys His Leu Lys Val Ala Lys Asp Asn Ile Thr Lys Phe Val Pro Asn
100 105 110
Pro Asn Phe Asn Gly Val Gly Val Ile Asp Trp Glu Ala Trp Arg Pro
115 120 125
Ser Trp Glu Phe Asn Trp Gly Lys Leu Lys Val Tyr Lys Glu Lys Ser
130 135 140
Ile Asp Leu Val Lys Ser Lys His Pro Glu Trp Pro Ser Asp Arg Val
145 150 155 160
Glu Lys Val Ala Lys Glu Glu Trp Glu Glu Ser Ala Lys Glu Trp Met
165 170 175
Val Lys Thr Leu Lys Leu Ala Gln Glu Met Arg Pro Asn Ala Val Trp
180 185 190
Cys Tyr Tyr Leu Phe Pro Asp Cys Tyr Asn Tyr Phe Gly Lys Asp Gln
195 200 205
Pro Ser Gln Phe Ser Cys Ser Ser Arg Ile Gln Lys Glu Asn Ser Arg
210 215 220
Leu Ser Trp Leu Trp Asn Gln Ser Thr Ala Ile Cys Leu Ser Ile Tyr
225 230 235 240
Ile Gln Glu Ser His Val Thr Lys Tyr Asn Met Ser Gln Arg Thr Trp
245 250 255
Trp Ile Asp Ala Arg Leu Arg Glu Ala Ile Arg Val Ser Glu His Arg
260 265 270
Pro Asn Ile Pro Ile Tyr Pro Tyr Ile Asn Tyr Ile Leu Pro Gly Thr
275 280 285
Asn Gln Thr Val Pro Ala Met Asp Phe Lys Arg Thr Leu Gly Gln Ile
290 295 300
Ala Ser Leu Gly Leu Asp Gly Ala Leu Leu Trp Gly Ser Ser Tyr His
305 310 315 320
Val Leu Thr Glu Ser Gln Cys Lys Ile Thr Ser Asp Tyr Val Lys Ser
325 330 335
Val Ile Ala Pro Thr Val Ala Thr Val Val Leu Asn Thr Asn Arg Cys
340 345 350
Ser Gln Ile Ile Cys Lys Gly Arg Gly Asn Cys Val Trp Pro Glu Glu
355 360 365
Pro Phe Ser Ser Trp Lys Tyr Leu Val Asp Pro Lys Met Pro Val Phe
370 375 380
Lys Pro Thr Asn Ile His Cys Lys Cys Lys Gly Tyr Leu Gly Arg Tyr
385 390 395 400
Cys Glu Ile Pro Lys
405
<210> 40
<211> 475
<212> БЕЛОК
<213> Tityus serrulatus
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Tityus serrulatus с N-концевым сигналом секреции и C-концевым якорным сигналом
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Tityus serrulatus с N-концевым сигналом секреции и C-концевым якорным сигналом
<400> 40
Met Gln Phe Ser Thr Val Ala Ser Val Ala Phe Val Ala Leu Ala Asn
1 5 10 15
Phe Val Ala Ala Ala Asp Phe Lys Val Tyr Trp Glu Val Pro Ser Phe
20 25 30
Leu Cys Ser Lys Arg Phe Lys Ile Asn Val Thr Glu Val Leu Thr Ser
35 40 45
His Glu Ile Leu Val Asn Gln Gly Glu Ser Phe Asn Gly Asp Lys Ile
50 55 60
Val Ile Phe Tyr Glu Asn Gln Leu Gly Lys Tyr Pro His Ile Asp Ser
65 70 75 80
Asn Asn Val Glu Ile Asn Gly Gly Ile Leu Gln Val Ala Asp Leu Ala
85 90 95
Lys His Leu Lys Val Ala Lys Asp Asn Ile Thr Lys Phe Val Pro Asn
100 105 110
Pro Asn Phe Asn Gly Val Gly Val Ile Asp Trp Glu Ala Trp Arg Pro
115 120 125
Ser Trp Glu Phe Asn Trp Gly Lys Leu Lys Val Tyr Lys Glu Lys Ser
130 135 140
Ile Asp Leu Val Lys Ser Lys His Pro Glu Trp Pro Ser Asp Arg Val
145 150 155 160
Glu Lys Val Ala Lys Glu Glu Trp Glu Glu Ser Ala Lys Glu Trp Met
165 170 175
Val Lys Thr Leu Lys Leu Ala Gln Glu Met Arg Pro Asn Ala Val Trp
180 185 190
Cys Tyr Tyr Leu Phe Pro Asp Cys Tyr Asn Tyr Phe Gly Lys Asp Gln
195 200 205
Pro Ser Gln Phe Ser Cys Ser Ser Arg Ile Gln Lys Glu Asn Ser Arg
210 215 220
Leu Ser Trp Leu Trp Asn Gln Ser Thr Ala Ile Cys Leu Ser Ile Tyr
225 230 235 240
Ile Gln Glu Ser His Val Thr Lys Tyr Asn Met Ser Gln Arg Thr Trp
245 250 255
Trp Ile Asp Ala Arg Leu Arg Glu Ala Ile Arg Val Ser Glu His Arg
260 265 270
Pro Asn Ile Pro Ile Tyr Pro Tyr Ile Asn Tyr Ile Leu Pro Gly Thr
275 280 285
Asn Gln Thr Val Pro Ala Met Asp Phe Lys Arg Thr Leu Gly Gln Ile
290 295 300
Ala Ser Leu Gly Leu Asp Gly Ala Leu Leu Trp Gly Ser Ser Tyr His
305 310 315 320
Val Leu Thr Glu Ser Gln Cys Lys Ile Thr Ser Asp Tyr Val Lys Ser
325 330 335
Val Ile Ala Pro Thr Val Ala Thr Val Val Leu Asn Thr Asn Arg Cys
340 345 350
Ser Gln Ile Ile Cys Lys Gly Arg Gly Asn Cys Val Trp Pro Glu Glu
355 360 365
Pro Phe Ser Ser Trp Lys Tyr Leu Val Asp Pro Lys Met Pro Val Phe
370 375 380
Lys Pro Thr Asn Ile His Cys Lys Cys Lys Gly Tyr Leu Gly Arg Tyr
385 390 395 400
Cys Glu Ile Pro Lys Gly Ser Ala Ile Ser Gln Ile Thr Asp Gly Gln
405 410 415
Ile Gln Ala Thr Thr Thr Ala Thr Thr Glu Ala Thr Thr Thr Ala Ala
420 425 430
Pro Ser Ser Thr Val Glu Thr Val Ser Pro Ser Ser Thr Glu Thr Ile
435 440 445
Ser Gln Gln Thr Glu Asn Gly Ala Ala Lys Ala Ala Val Gly Met Gly
450 455 460
Ala Gly Ala Leu Ala Ala Ala Ala Met Leu Leu
465 470 475
<210> 41
<211> 360
<212> БЕЛОК
<213> Vespa magnifica
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Vespa magnifica с N-концевым сигналом секреции
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Vespa magnifica с N-концевым сигналом секреции
<400> 41
Met Gln Phe Ser Thr Val Ala Ser Val Ala Phe Val Ala Leu Ala Asn
1 5 10 15
Phe Val Ala Ala Asp Ser Cys Gly Ser Asn Cys Glu Lys Ser Glu Arg
20 25 30
Pro Lys Arg Val Phe Asn Ile Tyr Trp Asn Val Pro Thr Phe Met Cys
35 40 45
His Gln Tyr Gly Leu Tyr Phe Asp Glu Val Thr Asn Phe Asn Ile Lys
50 55 60
His Asn Ser Lys Asp Asn Phe Gln Gly Asp Lys Ile Ala Ile Phe Tyr
65 70 75 80
Asp Pro Gly Glu Phe Pro Ala Leu Leu Pro Leu Asn Tyr Gly Lys Tyr
85 90 95
Lys Ile Arg Asn Gly Gly Val Pro Gln Glu Gly Asn Ile Thr Ile His
100 105 110
Leu Gln Arg Phe Ile Glu Tyr Leu Asp Lys Thr Tyr Pro Asn Arg Asn
115 120 125
Phe Ser Gly Ile Gly Val Ile Asp Phe Glu Arg Trp Arg Pro Ile Phe
130 135 140
Arg Gln Asn Trp Gly Asn Met Lys Ile Tyr Lys Asn Phe Ser Ile Asp
145 150 155 160
Leu Val Arg Lys Glu His Pro Phe Trp Asn Lys Lys Met Ile Glu Leu
165 170 175
Glu Ala Ser Lys Arg Phe Glu Lys Tyr Ala Arg Leu Phe Met Glu Glu
180 185 190
Thr Leu Lys Leu Ala Lys Lys Thr Arg Lys Gln Ala Asp Trp Gly Tyr
195 200 205
Tyr Gly Tyr Pro Tyr Cys Phe Asn Met Ser Pro Thr Asn Phe Val Pro
210 215 220
Asp Cys Asp Val Thr Ala Arg Asp Glu Asn Asn Glu Met Ser Trp Leu
225 230 235 240
Phe Asn Asn Gln Asn Val Leu Leu Pro Ser Val Tyr Ile Arg Arg Glu
245 250 255
Leu Thr Pro Asp Gln Arg Ile Gly Leu Val Gln Gly Arg Val Lys Glu
260 265 270
Ala Val Arg Ile Ser Asn Lys Leu Lys His Ser Pro Lys Val Phe Ser
275 280 285
Tyr Trp Trp Tyr Val Tyr Gln Asp Glu Thr Asn Thr Phe Leu Thr Glu
290 295 300
Thr Asp Val Lys Lys Thr Phe Gln Glu Ile Val Ile Asn Gly Gly Asp
305 310 315 320
Gly Ile Ile Ile Trp Gly Ser Ser Ser Asp Val Asn Ser Leu Ser Lys
325 330 335
Cys Thr Arg Leu Arg Glu Tyr Leu Leu Thr Val Leu Gly Pro Ile Ala
340 345 350
Val Asn Val Thr Glu Ala Val Asn
355 360
<210> 42
<211> 428
<212> БЕЛОК
<213> Vespa magnifica
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Vespa magnifica с N-концевым сигналом секреции и C-концевым якорным сигналом
<220>
<223> Аминокислотная последовательность гиалуронидазы (HYAL), происходящая из
Vespa magnifica с N-концевым сигналом секреции и C-концевым якорным сигналом
<400> 42
Met Gln Phe Ser Thr Val Ala Ser Val Ala Phe Val Ala Leu Ala Asn
1 5 10 15
Phe Val Ala Ala Asp Ser Cys Gly Ser Asn Cys Glu Lys Ser Glu Arg
20 25 30
Pro Lys Arg Val Phe Asn Ile Tyr Trp Asn Val Pro Thr Phe Met Cys
35 40 45
His Gln Tyr Gly Leu Tyr Phe Asp Glu Val Thr Asn Phe Asn Ile Lys
50 55 60
His Asn Ser Lys Asp Asn Phe Gln Gly Asp Lys Ile Ala Ile Phe Tyr
65 70 75 80
Asp Pro Gly Glu Phe Pro Ala Leu Leu Pro Leu Asn Tyr Gly Lys Tyr
85 90 95
Lys Ile Arg Asn Gly Gly Val Pro Gln Glu Gly Asn Ile Thr Ile His
100 105 110
Leu Gln Arg Phe Ile Glu Tyr Leu Asp Lys Thr Tyr Pro Asn Arg Asn
115 120 125
Phe Ser Gly Ile Gly Val Ile Asp Phe Glu Arg Trp Arg Pro Ile Phe
130 135 140
Arg Gln Asn Trp Gly Asn Met Lys Ile Tyr Lys Asn Phe Ser Ile Asp
145 150 155 160
Leu Val Arg Lys Glu His Pro Phe Trp Asn Lys Lys Met Ile Glu Leu
165 170 175
Glu Ala Ser Lys Arg Phe Glu Lys Tyr Ala Arg Leu Phe Met Glu Glu
180 185 190
Thr Leu Lys Leu Ala Lys Lys Thr Arg Lys Gln Ala Asp Trp Gly Tyr
195 200 205
Tyr Gly Tyr Pro Tyr Cys Phe Asn Met Ser Pro Thr Asn Phe Val Pro
210 215 220
Asp Cys Asp Val Thr Ala Arg Asp Glu Asn Asn Glu Met Ser Trp Leu
225 230 235 240
Phe Asn Asn Gln Asn Val Leu Leu Pro Ser Val Tyr Ile Arg Arg Glu
245 250 255
Leu Thr Pro Asp Gln Arg Ile Gly Leu Val Gln Gly Arg Val Lys Glu
260 265 270
Ala Val Arg Ile Ser Asn Lys Leu Lys His Ser Pro Lys Val Phe Ser
275 280 285
Tyr Trp Trp Tyr Val Tyr Gln Asp Glu Thr Asn Thr Phe Leu Thr Glu
290 295 300
Thr Asp Val Lys Lys Thr Phe Gln Glu Ile Val Ile Asn Gly Gly Asp
305 310 315 320
Gly Ile Ile Ile Trp Gly Ser Ser Ser Asp Val Asn Ser Leu Ser Lys
325 330 335
Cys Thr Arg Leu Arg Glu Tyr Leu Leu Thr Val Leu Gly Pro Ile Ala
340 345 350
Val Asn Val Thr Glu Ala Val Asn Ala Ile Ser Gln Ile Thr Asp Gly
355 360 365
Gln Ile Gln Ala Thr Thr Thr Ala Thr Thr Glu Ala Thr Thr Thr Ala
370 375 380
Ala Pro Ser Ser Thr Val Glu Thr Val Ser Pro Ser Ser Thr Glu Thr
385 390 395 400
Ile Ser Gln Gln Thr Glu Asn Gly Ala Ala Lys Ala Ala Val Gly Met
405 410 415
Gly Ala Gly Ala Leu Ala Ala Ala Ala Met Leu Leu
420 425
<210> 43
<211> 60
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность последовательности сигнала секреции,
добавленного в N-конце
<220>
<223> Нуклеотидная последовательность последовательности сигнала секреции,
добавленного в N-конце
<400> 43
atgcaattta gcacagtcgc atcagtagcc ttcgttgcct tggccaactt cgtggcagca 60
<210> 44
<211> 20
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Аминоксилотная последовательность последовательности сигнала секреции,
добавленного в N-конце
<220>
<223> Аминоксилотная последовательность последовательности сигнала секреции,
добавленного в N-конце
<400> 44
Met Gln Phe Ser Thr Val Ala Ser Val Ala Phe Val Ala Leu Ala Asn
1 5 10 15
Phe Val Ala Ala
20
<210> 45
<211> 213
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность якорной последовательности, добавленной
в C-конце
<220>
<223> Нуклеотидная последовательность якорной последовательности, добавленной
в C-конце
<400> 45
ggatccgcca tttctcaaat cactgacggt caaatccaag ctactaccac tgctaccacc 60
gaagctacca ccactgctgc cccatcttcc accgttgaaa ctgtttctcc atccagcacc 120
gaaactatct ctcaacaaac tgaaaatggt gctgctaagg ccgctgtcgg tatgggtgcc 180
ggtgctctag ctgctgctgc tatgttgtta taa 213
<210> 46
<211> 68
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Аминоксилотная последовательность якорной последовательности, добавленной
в C-конце
<220>
<223> Аминоксилотная последовательность якорной последовательности, добавленной
в C-конце
<400> 46
Ala Ile Ser Gln Ile Thr Asp Gly Gln Ile Gln Ala Thr Thr Thr Ala
1 5 10 15
Thr Thr Glu Ala Thr Thr Thr Ala Ala Pro Ser Ser Thr Val Glu Thr
20 25 30
Val Ser Pro Ser Ser Thr Glu Thr Ile Ser Gln Gln Thr Glu Asn Gly
35 40 45
Ala Ala Lys Ala Ala Val Gly Met Gly Ala Gly Ala Leu Ala Ala Ala
50 55 60
Ala Met Leu Leu
65
<210> 47
<211> 2154
<212> ДНК
<213> Saccharomyces cerevisiae
<220>
<223> Нуклеотидная последовательность глутамин-фруктозо-6-фосфатамидотрансферазы
(GFA1), происходящая из Saccharomyces cerevisiae
<220>
<223> Нуклеотидная последовательность глутамин-фруктозо-6-фосфатамидотрансферазы
(GFA1), происходящая из Saccharomyces cerevisiae
<400> 47
atgtgtggta tctttggtta ctgcaattat ctagtggaaa gatccagagg agaaattatc 60
gacaccttag tggatggttt acaaagatta gaatatagag gctatgattc caccggtatt 120
gctatcgatg gtgacgaagc tgattctact ttcatctata agcaaatcgg taaagtgagt 180
gctttgaaag aggagattac taagcaaaat ccgaacagag acgttacttt tgtctctcat 240
tgtggtattg cgcatactag atgggctact cacggtcgac cagaacaagt taactgtcac 300
cctcaaagat ctgacccaga agaccaattt gtggtcgttc ataatggtat catcacaaat 360
tttagagaac tgaagactct tttaattaac aaaggttata aattcgaaag tgataccgat 420
accgagtgta ttgctaaact atatttgcat ttatacaata caaatttaca aaatgggcat 480
gacttagatt tccacgaatt aaccaagcta gttcttttag aactagaagg ttcatacggg 540
ttattatgta aatcttgtca ctatcctaat gaggttatcg ccactagaaa agggtcccct 600
ttactgattg gtgtcaaatc tgaaaaaaaa ctaaaagtcg acttcgtgga tgtggaattt 660
cccgaagaaa acgctggtca accggaaatt ccattgaaat ctaacaacaa atcatttggc 720
ttgggcccaa agaaagctcg tgaatttgaa gctggttccc aaaatgccaa tttactacca 780
attgccgcca atgaatttaa cttgagacat tctcaatcca gggctttcct atcagaagat 840
ggatctccaa caccggtgga attttttgtt tcttcggatg cggcatctgt tgttaaacat 900
accaagaagg tgctattttt agaagatgac gatttggctc atatttacga tggtgagtta 960
catattcata gatctagaag agaagtaggc gcatcaatga caaggtccat tcaaacttta 1020
gagatggagt tagctcagat catgaagggc ccttacgacc attttatgca aaaggaaatc 1080
tatgagcaac cagaatctac tttcaatact atgagaggta gaatcgacta tgaaaataat 1140
aaagtgatat tgggtggttt aaaggcatgg ttaccagttg tcagaagagc acggagactg 1200
atcatgatcg catgcggtac ttcttatcat tcatgtttgg ctactcgtgc tatcttcgaa 1260
gaattatcag atatcccagt tagtgtggaa ttagcgtctg actttctgga cagaaaatgc 1320
cctgtcttca gagacgatgt atgcgtgttt gtttcacaaa gtggtgaaac tgcggatacc 1380
atgctggctc taaattattg tttagaaaga ggagccttaa ctgtcggaat tgttaacagt 1440
gttggttctt ctatctctcg tgtcacccac tgtggtgttc atattaacgc tggtcctgaa 1500
attggtgttg cctctacaaa agcttatact tcccagtata ttgccttagt gatgtttgct 1560
ctatcgctgt cagatgaccg tgtatcgaaa atagacagaa gaattgaaat cattcaaggc 1620
ttgaagttaa tcccgggcca aattaagcag gtattaaagc tggaaccaag aataaaaaag 1680
ctctgtgcga ctgaattaaa ggatcaaaaa tctctattgt tattgggtag aggttaccaa 1740
tttgctgctg ctctggaagg tgctttgaag atcaaagaaa tttcttatat gcattctgaa 1800
ggtgttttgg caggtgagtt gaagcacggt gtcttggcct tggtggacga aaacttgcca 1860
atcattgctt ttggtaccag agactctcta ttccctaaag tagtttcctc tattgagcaa 1920
gttactgtaa gaaagggcca tccaattatt atttgtaacg aaaatgatga agtgtgggcg 1980
caaaaatcta aatcaatcga cctgcaaacc ttagaagttc cacaaactgt tgattgttta 2040
caaggtctaa ttaatattat tccattacaa ctaatgtcat attggttggc tgttaataaa 2100
gggattgatg ttgattttcc aagaaacttg gctaaatctg ttaccgtcga ataa 2154
<210> 48
<211> 1788
<212> ДНК
<213> Вирус хлореллы Paramecium bursaria 1
<220>
<223> Перекодированная нуклеотидная последовательность глутамин-фруктозо-6-
фосфатамидотрансферазы (GFA1), происходящая из вируса хлореллы 1 (PBCV-1)
<220>
<223> Перекодированная нуклеотидная последовательность глутамин-фруктозо-6-
фосфатамидотрансферазы (GFA1), происходящая из вируса хлореллы 1 (PBCV-1)
<400> 48
atgtgcggga tcttcggtgc tgtgtcgaac aataatagca tagaagtttc catcaagggt 60
atacagaagc tagagtaccg cgggtacgat tcgtgtggaa tagcctatac agacggaggc 120
gccattgaac ggatcaggtc aatagatggg atcgacgact taaggaagaa aacaataaca 180
gagtcttccc cggtagctat cgctcattca aggtggagta ccactgggat tccaagtgtt 240
gtgaacgccc acccgcacat ctctcggggc acgtctggat gcgagtcgcg cattgcagtc 300
gtacacaatg gcattattga aaattaccag cagatccgca agtacttgat aaatcttggg 360
tatactttcg attcacagac cgacacggaa gtcattgctc atctaataga ctcgcagtat 420
aacgggaaca tcctgcacac cgtccaaatg gcagttaagc acctcaaagg aagctacgcc 480
atagcagtca tgtgccataa ggagtccggg aagatcgtgg tggcaaaaca gaagagtccg 540
ttggtattgg gtataggaag cgacggagct tattatatcg catcggacgt attggctctt 600
cccactaaca aagtggtcta cataagtgac ggattctctg ctgagttaag tcctggatcg 660
atgactatct atgatctgga tggcaataag gtagaatacg aggtggaaga cgttgaaatg 720
gagcagacgt cgatgtcttt agataacttt gatcactaca tgatcaaaga gatcaatgaa 780
cagccgatat caattctcaa tactattaag aacaaaggat tctatgcaga gatatttggt 840
gatctagcac atgaaatatt tcagaagatc gacaatatat tgattctagc ctgcggaact 900
tcgtatcatg caggtctcgt cgggaagcaa tggatagaga ccatctcacg catcccggtg 960
gatgttcata ttgcaagcga gtatgagccg acaattccac gagccaatac acttgtgata 1020
acgattagtc aaagcggcga gactgcggat acaatcgcag cccttcaacg agcgcaaaac 1080
gcaggaatga tatacacttt gtgtatctgc aacagcccca agtcaactct agtgcgcgag 1140
tcgataatga aatacataac caaatgcggt tcagaagttt ctgttgccag tactaaagca 1200
tttacgtcgc aacttgtggt gttgtatatg cttgcgaacg ttcttgcgaa caaaactgat 1260
gatctgctag gggatcttcc tcaagctatc gagagagtaa tctgtcttac taatgacgaa 1320
atgaagcgtt gggcggatga aatttgtact gccaaaagtg ccatcttctt agggagagga 1380
ctgaacgcac ctgtagcatt tgagggcgcg ctaaagttga aggaaatctc atatatccat 1440
gccgagggtt tcctcggtgg agagttgaag catgggccgc tggctttgtt ggacgataag 1500
atccctgtaa tcgtgactgt tgctgaccac gcttatttgg atcacattaa ggctaacatc 1560
gacgaggtat tggcacgaaa cgttaccgta tacgcgatcg tcgatcagta tgttaatatt 1620
gaaccacagg agcgactgca tgtagtaaaa gtgccgtttg tgagtaaaga gttttctccc 1680
atcatccaca caattccgat gcaattgtta tcgtattatg tcgcgatcaa gctgggcaag 1740
aacgttgaca agccacgtaa cctggcgaaa agtgttacaa cattctaa 1788
<210> 49
<211> 1788
<212> ДНК
<213> Вирус хлореллы Paramecium bursaria 1
<220>
<223> Перекодированная нуклеотидная последовательность глутамин-фруктозо-6-
фосфатамидотрансферазы (GFA1), происходящая из вируса хлореллы 1 (PBCV-1)
<220>
<223> Перекодированная нуклеотидная последовательность глутамин-фруктозо-6-
фосфатамидотрансферазы (GFA1), происходящая из вируса хлореллы 1 (PBCV-1)
<400> 49
atgtgtggca tctttggagc agtgtcaaac aacaactcta tcgaggtgtc aatcaagggt 60
attcagaagc tagaatatcg tgggtatgat tcgtgcggta ttgcgtatac agatgggggt 120
gcgattgagc gtatacgttc tattgacggc attgacgatc tgcgtaagaa aacaatcaca 180
gaatcatcac cagtggccat tgctcactcg cggtggagca ccactggaat tccatcagtg 240
gtgaacgcac atcctcatat ttctcgcgga accagtgggt gtgagtctcg tatcgcggta 300
gtccacaacg gtatcattga aaactatcag cagatccgaa aatatctcat caatcttggt 360
tatacgtttg atagtcaaac ggacacagag gtcattgcgc atttgattga ttctcagtac 420
aatgggaata tcttgcacac cgtccaaatg gctgtcaagc acctgaaggg ctcttatgcc 480
attgcagtta tgtgtcataa agagtctggt aaaatagtcg tggcgaaaca gaagtcaccc 540
ctcgtacttg gaatcggctc agatggtgct tactacatcg cttcggacgt gctggcgctg 600
ccgacaaata aagttgttta tatttcagac ggtttctccg cagaactatc tccagggagt 660
atgaccattt acgatcttga tggaaataaa gtagaatatg aagtagagga cgttgaaatg 720
gaacaaacta gtatgtctct cgataacttt gatcattaca tgattaagga aattaatgag 780
caaccaatca gtattctaaa cactataaaa aataaagggt tctatgcaga aatattcggt 840
gatttggctc atgaaatctt ccaaaaaata gacaacatcc tgatactggc ttgtggtaca 900
agttatcacg ccggtcttgt aggaaaacag tggatagaga ccatctctag aatccccgtg 960
gatgttcaca tcgcgagtga atacgaacct actattccga gagcgaacac attggtaatc 1020
actatttcac agtcgggtga aactgcggac acgatagcgg ctttgcaacg ggcccaaaac 1080
gccgggatga tttatacatt gtgtatttgc aattcaccaa agagcactct tgttcgtgag 1140
agcattatga agtacatcac gaaatgtggt tctgaggtgt cagtggcatc aacgaaggcg 1200
tttacttctc agctcgtagt actgtacatg ctggcaaacg tattggcaaa taaaaccgat 1260
gatttgctgg gagacctccc acaggcaata gaacgggtaa tttgtttgac aaatgacgaa 1320
atgaaacgat gggccgacga aatttgcact gcgaaatccg cgatcttcct gggaagagga 1380
ctaaacgcac cagttgcctt tgagggagcg ttgaagctca aagaaatctc ttacattcat 1440
gcagagggct tcctgggagg tgagttgaaa cacggccccc tcgcactcct tgatgacaag 1500
attcctgtta tcgtaaccgt agcagatcat gcttatttgg accatatcaa agcaaatatc 1560
gacgaagtgc ttgcgaggaa cgttacggta tacgccatag tagaccagta tgtgaacatc 1620
gagccccagg aacgccttca cgtcgtcaag gttccgtttg tatccaaaga attttctccg 1680
ataattcaca ctatcccgat gcaactgctt tcgtattacg tggcaattaa gcttggaaag 1740
aacgttgaca aaccaaggaa tcttgcaaaa tccgtgacta ccttttaa 1788
<210> 50
<211> 717
<212> БЕЛОК
<213> Saccharomyces cerevisiae
<220>
<223> Аминокислотная последовательность глутамин-фруктозо-6-фосфатамидотрансферазы
(GFA1), происходящая из Saccharomyces cerevisiae
<220>
<223> Аминокислотная последовательность глутамин-фруктозо-6-фосфатамидотрансферазы
(GFA1), происходящая из Saccharomyces cerevisiae
<400> 50
Met Cys Gly Ile Phe Gly Tyr Cys Asn Tyr Leu Val Glu Arg Ser Arg
1 5 10 15
Gly Glu Ile Ile Asp Thr Leu Val Asp Gly Leu Gln Arg Leu Glu Tyr
20 25 30
Arg Gly Tyr Asp Ser Thr Gly Ile Ala Ile Asp Gly Asp Glu Ala Asp
35 40 45
Ser Thr Phe Ile Tyr Lys Gln Ile Gly Lys Val Ser Ala Leu Lys Glu
50 55 60
Glu Ile Thr Lys Gln Asn Pro Asn Arg Asp Val Thr Phe Val Ser His
65 70 75 80
Cys Gly Ile Ala His Thr Arg Trp Ala Thr His Gly Arg Pro Glu Gln
85 90 95
Val Asn Cys His Pro Gln Arg Ser Asp Pro Glu Asp Gln Phe Val Val
100 105 110
Val His Asn Gly Ile Ile Thr Asn Phe Arg Glu Leu Lys Thr Leu Leu
115 120 125
Ile Asn Lys Gly Tyr Lys Phe Glu Ser Asp Thr Asp Thr Glu Cys Ile
130 135 140
Ala Lys Leu Tyr Leu His Leu Tyr Asn Thr Asn Leu Gln Asn Gly His
145 150 155 160
Asp Leu Asp Phe His Glu Leu Thr Lys Leu Val Leu Leu Glu Leu Glu
165 170 175
Gly Ser Tyr Gly Leu Leu Cys Lys Ser Cys His Tyr Pro Asn Glu Val
180 185 190
Ile Ala Thr Arg Lys Gly Ser Pro Leu Leu Ile Gly Val Lys Ser Glu
195 200 205
Lys Lys Leu Lys Val Asp Phe Val Asp Val Glu Phe Pro Glu Glu Asn
210 215 220
Ala Gly Gln Pro Glu Ile Pro Leu Lys Ser Asn Asn Lys Ser Phe Gly
225 230 235 240
Leu Gly Pro Lys Lys Ala Arg Glu Phe Glu Ala Gly Ser Gln Asn Ala
245 250 255
Asn Leu Leu Pro Ile Ala Ala Asn Glu Phe Asn Leu Arg His Ser Gln
260 265 270
Ser Arg Ala Phe Leu Ser Glu Asp Gly Ser Pro Thr Pro Val Glu Phe
275 280 285
Phe Val Ser Ser Asp Ala Ala Ser Val Val Lys His Thr Lys Lys Val
290 295 300
Leu Phe Leu Glu Asp Asp Asp Leu Ala His Ile Tyr Asp Gly Glu Leu
305 310 315 320
His Ile His Arg Ser Arg Arg Glu Val Gly Ala Ser Met Thr Arg Ser
325 330 335
Ile Gln Thr Leu Glu Met Glu Leu Ala Gln Ile Met Lys Gly Pro Tyr
340 345 350
Asp His Phe Met Gln Lys Glu Ile Tyr Glu Gln Pro Glu Ser Thr Phe
355 360 365
Asn Thr Met Arg Gly Arg Ile Asp Tyr Glu Asn Asn Lys Val Ile Leu
370 375 380
Gly Gly Leu Lys Ala Trp Leu Pro Val Val Arg Arg Ala Arg Arg Leu
385 390 395 400
Ile Met Ile Ala Cys Gly Thr Ser Tyr His Ser Cys Leu Ala Thr Arg
405 410 415
Ala Ile Phe Glu Glu Leu Ser Asp Ile Pro Val Ser Val Glu Leu Ala
420 425 430
Ser Asp Phe Leu Asp Arg Lys Cys Pro Val Phe Arg Asp Asp Val Cys
435 440 445
Val Phe Val Ser Gln Ser Gly Glu Thr Ala Asp Thr Met Leu Ala Leu
450 455 460
Asn Tyr Cys Leu Glu Arg Gly Ala Leu Thr Val Gly Ile Val Asn Ser
465 470 475 480
Val Gly Ser Ser Ile Ser Arg Val Thr His Cys Gly Val His Ile Asn
485 490 495
Ala Gly Pro Glu Ile Gly Val Ala Ser Thr Lys Ala Tyr Thr Ser Gln
500 505 510
Tyr Ile Ala Leu Val Met Phe Ala Leu Ser Leu Ser Asp Asp Arg Val
515 520 525
Ser Lys Ile Asp Arg Arg Ile Glu Ile Ile Gln Gly Leu Lys Leu Ile
530 535 540
Pro Gly Gln Ile Lys Gln Val Leu Lys Leu Glu Pro Arg Ile Lys Lys
545 550 555 560
Leu Cys Ala Thr Glu Leu Lys Asp Gln Lys Ser Leu Leu Leu Leu Gly
565 570 575
Arg Gly Tyr Gln Phe Ala Ala Ala Leu Glu Gly Ala Leu Lys Ile Lys
580 585 590
Glu Ile Ser Tyr Met His Ser Glu Gly Val Leu Ala Gly Glu Leu Lys
595 600 605
His Gly Val Leu Ala Leu Val Asp Glu Asn Leu Pro Ile Ile Ala Phe
610 615 620
Gly Thr Arg Asp Ser Leu Phe Pro Lys Val Val Ser Ser Ile Glu Gln
625 630 635 640
Val Thr Ala Arg Lys Gly His Pro Ile Ile Ile Cys Asn Glu Asn Asp
645 650 655
Glu Val Trp Ala Gln Lys Ser Lys Ser Ile Asp Leu Gln Thr Leu Glu
660 665 670
Val Pro Gln Thr Val Asp Cys Leu Gln Gly Leu Ile Asn Ile Ile Pro
675 680 685
Leu Gln Leu Met Ser Tyr Trp Leu Ala Val Asn Lys Gly Ile Asp Val
690 695 700
Asp Phe Pro Arg Asn Leu Ala Lys Ser Val Thr Val Glu
705 710 715
<210> 51
<211> 595
<212> БЕЛОК
<213> Вирус хлореллы Paramecium bursaria 1
<220>
<223> Аминокислотная последовательность глутамин-фруктозо-6-фосфатамидотрансферазы
(GFA1), происходящая из Вируса хлореллы 1 (PBCV-1)
<220>
<223> Аминокислотная последовательность глутамин-фруктозо-6-фосфатамидотрансферазы
(GFA1), происходящая из Вируса хлореллы 1 (PBCV-1)
<400> 51
Met Cys Gly Ile Phe Gly Ala Val Ser Asn Asn Asn Ser Ile Glu Val
1 5 10 15
Ser Ile Lys Gly Ile Gln Lys Leu Glu Tyr Arg Gly Tyr Asp Ser Cys
20 25 30
Gly Ile Ala Tyr Thr Asp Gly Gly Ala Ile Glu Arg Ile Arg Ser Ile
35 40 45
Asp Gly Ile Asp Asp Leu Arg Lys Lys Thr Ile Thr Glu Ser Ser Pro
50 55 60
Val Ala Ile Ala His Ser Arg Trp Ser Thr Thr Gly Ile Pro Ser Val
65 70 75 80
Val Asn Ala His Pro His Ile Ser Arg Gly Thr Ser Gly Cys Glu Ser
85 90 95
Arg Ile Ala Val Val His Asn Gly Ile Ile Glu Asn Tyr Gln Gln Ile
100 105 110
Arg Lys Tyr Leu Ile Asn Leu Gly Tyr Thr Phe Asp Ser Gln Thr Asp
115 120 125
Thr Glu Val Ile Ala His Leu Ile Asp Ser Gln Tyr Asn Gly Asn Ile
130 135 140
Leu His Thr Val Gln Met Ala Val Lys His Leu Lys Gly Ser Tyr Ala
145 150 155 160
Ile Ala Val Met Cys His Lys Glu Ser Gly Lys Ile Val Val Ala Lys
165 170 175
Gln Lys Ser Pro Leu Val Leu Gly Ile Gly Ser Asp Gly Ala Tyr Tyr
180 185 190
Ile Ala Ser Asp Val Leu Ala Leu Pro Thr Asn Lys Val Val Tyr Ile
195 200 205
Ser Asp Gly Phe Ser Ala Glu Leu Ser Pro Gly Ser Met Thr Ile Tyr
210 215 220
Asp Leu Asp Gly Asn Lys Val Glu Tyr Glu Val Glu Asp Val Glu Met
225 230 235 240
Glu Gln Thr Ser Met Ser Leu Asp Asn Phe Asp His Tyr Met Ile Lys
245 250 255
Glu Ile Asn Glu Gln Pro Ile Ser Ile Leu Asn Thr Ile Lys Asn Lys
260 265 270
Gly Phe Tyr Ala Glu Ile Phe Gly Asp Leu Ala His Glu Ile Phe Gln
275 280 285
Lys Ile Asp Asn Ile Leu Ile Leu Ala Cys Gly Thr Ser Tyr His Ala
290 295 300
Gly Leu Val Gly Lys Gln Trp Ile Glu Thr Ile Ser Arg Ile Pro Val
305 310 315 320
Asp Val His Ile Ala Ser Glu Tyr Glu Pro Thr Ile Pro Arg Ala Asn
325 330 335
Thr Leu Val Ile Thr Ile Ser Gln Ser Gly Glu Thr Ala Asp Thr Ile
340 345 350
Ala Ala Leu Gln Arg Ala Gln Asn Ala Gly Met Ile Tyr Thr Leu Cys
355 360 365
Ile Cys Asn Ser Pro Lys Ser Thr Leu Val Arg Glu Ser Ile Met Lys
370 375 380
Tyr Ile Thr Lys Cys Gly Ser Glu Val Ser Val Ala Ser Thr Lys Ala
385 390 395 400
Phe Thr Ser Gln Leu Val Val Leu Tyr Met Leu Ala Asn Val Leu Ala
405 410 415
Asn Lys Thr Asp Asp Leu Leu Gly Asp Leu Pro Gln Ala Ile Glu Arg
420 425 430
Val Ile Cys Leu Thr Asn Asp Glu Met Lys Arg Trp Ala Asp Glu Ile
435 440 445
Cys Thr Ala Lys Ser Ala Ile Phe Leu Gly Arg Gly Leu Asn Ala Pro
450 455 460
Val Ala Phe Glu Gly Ala Leu Lys Leu Lys Glu Ile Ser Tyr Ile His
465 470 475 480
Ala Glu Gly Phe Leu Gly Gly Glu Leu Lys His Gly Pro Leu Ala Leu
485 490 495
Leu Asp Asp Lys Ile Pro Val Ile Val Thr Val Ala Asp His Ala Tyr
500 505 510
Leu Asp His Ile Lys Ala Asn Ile Asp Glu Val Leu Ala Arg Asn Val
515 520 525
Thr Val Tyr Ala Ile Val Asp Gln Tyr Val Asn Ile Glu Pro Gln Glu
530 535 540
Arg Leu His Val Val Lys Val Pro Phe Val Ser Lys Glu Phe Ser Pro
545 550 555 560
Ile Ile His Thr Ile Pro Met Gln Leu Leu Ser Tyr Tyr Val Ala Ile
565 570 575
Lys Leu Gly Lys Asn Val Asp Lys Pro Arg Asn Leu Ala Lys Ser Val
580 585 590
Thr Thr Phe
595
<210> 52
<211> 1434
<212> ДНК
<213> Saccharomyces cerevisiae
<220>
<223> Нуклеотидая последовательность UDP-N-ацетилглюкозаминпирофосфорилазы (QRI1),
происходящая из Saccharomyces cerevisiae
<220>
<223> Нуклеотидая последовательность UDP-N-ацетилглюкозаминпирофосфорилазы (QRI1),
происходящая из Saccharomyces cerevisiae
<400> 52
atgactgaca caaaacagct attcattgaa gccggacaaa gtcaactttt ccacaattgg 60
gaaagcttgt ctcgcaaaga ccaagaagaa ttgctttcaa acctggagca aatatcttcc 120
aagaggtccc ctgcaaaact actggaagac tgtcaaaatg ctattaaatt ctcactagct 180
aactcttcta aggatactgg cgtcgaaatt tcaccattgc cccctacttc gtacgagtcg 240
cttattggca acagtaagaa agaaaatgaa tactggcgtt taggccttga agctattggc 300
aagggtgaag tcgcagtgat tttaatggct ggcggacaag gtacgcggtt aggatcctct 360
caaccaaagg gctgttacga cattggattg ccttctaaga aatctctttt tcaaattcaa 420
gctgaaaagt tgatcaggtt gcaagatatg gtaaaggaca aaaaggtaga aattccttgg 480
tatattatga catcaggccc cactagagcg gctactgagg catactttca agaacacaat 540
tattttggct tgaataaaga acaaattacg ttcttcaacc agggaaccct gcctgccttt 600
gatttaaccg ggaagcattt cctaatgaaa gacccagtaa acctatctca atcaccagat 660
ggaaatggtg gactctaccg tgccatcaag gaaaacaagt tgaacgaaga ctttgatagg 720
agaggaatca agcatgttta catgtactgt gtcgataatg tcctatctaa aatcgcagac 780
cctgtattta ttggttttgc catcaagcat ggcttcgaac tggccaccaa agccgttaga 840
aagagagatg cgcatgaatc agttgggtta attgctacta aaaacgagaa accatgtgtc 900
atagaatatt ctgaaatttc caatgaattg gctgaagcaa aggataaaga tggcttatta 960
aaactacgcg caggcaacat tgtaaatcat tattacctag tggatttact aaaacgtgat 1020
ttggatcagt ggtgtgagaa tatgccatat cacattgcga agaagaaaat tccagcttat 1080
gatagtgtta ccggcaagta cactaagcct accgaaccaa acggtataaa attagagcaa 1140
ttcatatttg atgtctttga cactgtacca ctgaacaagt ttgggtgctt agaagtagat 1200
agatgcaaag aattttcacc tttaaaaaac ggtcctggtt ctaagaacga taatcctgag 1260
accagcagac tagcatattt gaaactagga acctcgtggt tggaagatgc aggcgctatt 1320
gtaaaagatg gggtactagt cgaagtttcc agcaaattga gttatgcagg tgaaaatcta 1380
tcccagttca aaggtaaagt ctttgacaga agtggtatag tattagaaaa ataa 1434
<210> 53
<211> 477
<212> БЕЛОК
<213> Saccharomyces cerevisiae
<220>
<223> Аминокислотная последовательность UDP-N-ацетилглюкозаминпирофосфорилазы
(QRI1), происходящая из Saccharomyces cerevisiae
<220>
<223> Аминокислотная последовательность UDP-N-ацетилглюкозаминпирофосфорилазы
(QRI1), происходящая из Saccharomyces cerevisiae
<400> 53
Met Thr Asp Thr Lys Gln Leu Phe Ile Glu Ala Gly Gln Ser Gln Leu
1 5 10 15
Phe His Asn Trp Glu Ser Leu Ser Arg Lys Asp Gln Glu Glu Leu Leu
20 25 30
Ser Asn Leu Glu Gln Ile Ser Ser Lys Arg Ser Pro Ala Lys Leu Leu
35 40 45
Glu Asp Cys Gln Asn Ala Ile Lys Phe Ser Leu Ala Asn Ser Ser Lys
50 55 60
Asp Thr Gly Val Glu Ile Ser Pro Leu Pro Pro Thr Ser Tyr Glu Ser
65 70 75 80
Leu Ile Gly Asn Ser Lys Lys Glu Asn Glu Tyr Trp Arg Leu Gly Leu
85 90 95
Glu Ala Ile Gly Lys Gly Glu Val Ala Val Ile Leu Met Ala Gly Gly
100 105 110
Gln Gly Thr Arg Leu Gly Ser Ser Gln Pro Lys Gly Cys Tyr Asp Ile
115 120 125
Gly Leu Pro Ser Lys Lys Ser Leu Phe Gln Ile Gln Ala Glu Lys Leu
130 135 140
Ile Arg Leu Gln Asp Met Val Lys Asp Lys Lys Val Glu Ile Pro Trp
145 150 155 160
Tyr Ile Met Thr Ser Gly Pro Thr Arg Ala Ala Thr Glu Ala Tyr Phe
165 170 175
Gln Glu His Asn Tyr Phe Gly Leu Asn Lys Glu Gln Ile Thr Phe Phe
180 185 190
Asn Gln Gly Thr Leu Pro Ala Phe Asp Leu Thr Gly Lys His Phe Leu
195 200 205
Met Lys Asp Pro Val Asn Leu Ser Gln Ser Pro Asp Gly Asn Gly Gly
210 215 220
Leu Tyr Arg Ala Ile Lys Glu Asn Lys Leu Asn Glu Asp Phe Asp Arg
225 230 235 240
Arg Gly Ile Lys His Val Tyr Met Tyr Cys Val Asp Asn Val Leu Ser
245 250 255
Lys Ile Ala Asp Pro Val Phe Ile Gly Phe Ala Ile Lys His Gly Phe
260 265 270
Glu Leu Ala Thr Lys Ala Val Arg Lys Arg Asp Ala His Glu Ser Val
275 280 285
Gly Leu Ile Ala Thr Lys Asn Glu Lys Pro Cys Val Ile Glu Tyr Ser
290 295 300
Glu Ile Ser Asn Glu Leu Ala Glu Ala Lys Asp Lys Asp Gly Leu Leu
305 310 315 320
Lys Leu Arg Ala Gly Asn Ile Val Asn His Tyr Tyr Leu Val Asp Leu
325 330 335
Leu Lys Arg Asp Leu Asp Gln Trp Cys Glu Asn Met Pro Tyr His Ile
340 345 350
Ala Lys Lys Lys Ile Pro Ala Tyr Asp Ser Val Thr Gly Lys Tyr Thr
355 360 365
Lys Pro Thr Glu Pro Asn Gly Ile Lys Leu Glu Gln Phe Ile Phe Asp
370 375 380
Val Phe Asp Thr Val Pro Leu Asn Lys Phe Gly Cys Leu Glu Val Asp
385 390 395 400
Arg Cys Lys Glu Phe Ser Pro Leu Lys Asn Gly Pro Gly Ser Lys Asn
405 410 415
Asp Asn Pro Glu Thr Ser Arg Leu Ala Tyr Leu Lys Leu Gly Thr Ser
420 425 430
Trp Leu Glu Asp Ala Gly Ala Ile Val Lys Asp Gly Val Leu Val Glu
435 440 445
Val Ser Ser Lys Leu Ser Tyr Ala Gly Glu Asn Leu Ser Gln Phe Lys
450 455 460
Gly Lys Val Phe Asp Arg Ser Gly Ile Val Leu Glu Lys
465 470 475
<210> 54
<211> 1713
<212> ДНК
<213> Saccharomyces cerevisiae
<220>
<223> Нуклеотидная последовательность фосфоглюкомутазы-1 (PGM1),
происходящая из Saccharomyces cerevisiae
<220>
<223> Нуклеотидная последовательность фосфоглюкомутазы-1 (PGM1),
происходящая из Saccharomyces cerevisiae
<400> 54
atgtcacttc taatagattc tgtaccaaca gttgcttata aggaccaaaa accgggtact 60
tcaggtttac gtaagaagac caaggttttc atggatgagc ctcattatac tgagaacttc 120
attcaagcaa caatgcaatc tatccctaat ggctcagagg gaaccacttt agttgttgga 180
ggagatggtc gtttctacaa cgatgttatc atgaacaaga ttgccgcagt aggtgctgca 240
aacggtgtca gaaagttagt cattggtcaa ggcggtttac tttcaacacc agctgcttct 300
catataatta gaacatacga ggaaaagtgt accggtggtg gtatcatatt aactgcctca 360
cacaacccag gcggtccaga gaatgattta ggtatcaagt ataatttacc taatggtggg 420
ccagctccag agagtgtcac taacgctatc tgggaagcgt ctaaaaaatt aactcactat 480
aaaattataa agaacttccc caagttgaat ttgaacaagc ttggtaaaaa ccaaaaatat 540
ggcccattgt tagtggacat aattgatcct gccaaagcat acgttcaatt tctgaaggaa 600
atttttgatt ttgacttaat taaaagcttc ttagcgaaac agcgcaaaga caaagggtgg 660
aagttgttgt ttgactcctt aaatggtatt acaggaccat atggtaaggc tatatttgtt 720
gatgaatttg gtttaccggc agaggaagtt cttcaaaatt ggcacccttt acctgatttc 780
ggcggtttac atcccgatcc gaatctaacc tatgcacgaa ctcttgttga cagggttgac 840
cgcgaaaaaa ttgcctttgg agcagcctcc gatggtgatg gtgataggaa tatgatttac 900
ggttatggcc ctgctttcgt ttcgccaggt gattctgttg ccattattgc cgaatatgca 960
cccgaaattc catacttcgc caaacaaggt atttatggct tggcacgttc atttcctaca 1020
tcctcagcca ttgatcgtgt tgcagcaaaa aagggattaa gatgttacga agttccaacc 1080
ggctggaaat tcttctgtgc cttatttgat gctaaaaagc tatcaatctg tggtgaagaa 1140
tccttcggta caggttccaa tcatatcaga gaaaaggacg gtctatgggc cattattgct 1200
tggttaaata tcttggctat ctaccatagg cgtaaccctg aaaaggaagc ttcgatcaaa 1260
actattcagg acgaattttg gaacgagtat ggccgtactt tcttcacaag atacgattac 1320
gaacatatcg aatgcgagca ggccgaaaaa gttgtagctc ttttgagtga atttgtatca 1380
aggccaaacg tttgtggctc ccacttccca gctgatgagt ctttaaccgt tatcgattgt 1440
ggtgattttt cgtatagaga tctagatggc tccatctctg aaaatcaagg ccttttcgta 1500
aagttttcga atgggactaa atttgttttg aggttatccg gcacaggcag ttctggtgca 1560
acaataagat tatacgtaga aaagtatact gataaaaagg agaactatgg ccaaacagct 1620
gacgtcttct tgaaacccgt catcaactcc attgtaaaat tcttaagatt taaagaaatt 1680
ttaggaacag acgaaccaac agtccgcaca tag 1713
<210> 55
<211> 570
<212> БЕЛОК
<213> Saccharomyces cerevisiae
<220>
<223> Аминокислотная последовательность фосфоглюкомутазы-1 (PGM1), происходящая из
Saccharomyces cerevisiae
<220>
<223> Аминокислотная последовательность фосфоглюкомутазы-1 (PGM1), происходящая из
Saccharomyces cerevisiae
<400> 55
Met Ser Leu Leu Ile Asp Ser Val Pro Thr Val Ala Tyr Lys Asp Gln
1 5 10 15
Lys Pro Gly Thr Ser Gly Leu Arg Lys Lys Thr Lys Val Phe Met Asp
20 25 30
Glu Pro His Tyr Thr Glu Asn Phe Ile Gln Ala Thr Met Gln Ser Ile
35 40 45
Pro Asn Gly Ser Glu Gly Thr Thr Leu Val Val Gly Gly Asp Gly Arg
50 55 60
Phe Tyr Asn Asp Val Ile Met Asn Lys Ile Ala Ala Val Gly Ala Ala
65 70 75 80
Asn Gly Val Arg Lys Leu Val Ile Gly Gln Gly Gly Leu Leu Ser Thr
85 90 95
Pro Ala Ala Ser His Ile Ile Arg Thr Tyr Glu Glu Lys Cys Thr Gly
100 105 110
Gly Gly Ile Ile Leu Thr Ala Ser His Asn Pro Gly Gly Pro Glu Asn
115 120 125
Asp Leu Gly Ile Lys Tyr Asn Leu Pro Asn Gly Gly Pro Ala Pro Glu
130 135 140
Ser Val Thr Asn Ala Ile Trp Glu Ala Ser Lys Lys Leu Thr His Tyr
145 150 155 160
Lys Ile Ile Lys Asn Phe Pro Lys Leu Asn Leu Asn Lys Leu Gly Lys
165 170 175
Asn Gln Lys Tyr Gly Pro Leu Leu Val Asp Ile Ile Asp Pro Ala Lys
180 185 190
Ala Tyr Val Gln Phe Leu Lys Glu Ile Phe Asp Phe Asp Leu Ile Lys
195 200 205
Ser Phe Leu Ala Lys Gln Arg Lys Asp Lys Gly Trp Lys Leu Leu Phe
210 215 220
Asp Ser Leu Asn Gly Ile Thr Gly Pro Tyr Gly Lys Ala Ile Phe Val
225 230 235 240
Asp Glu Phe Gly Leu Pro Ala Glu Glu Val Leu Gln Asn Trp His Pro
245 250 255
Leu Pro Asp Phe Gly Gly Leu His Pro Asp Pro Asn Leu Thr Tyr Ala
260 265 270
Arg Thr Leu Val Asp Arg Val Asp Arg Glu Lys Ile Ala Phe Gly Ala
275 280 285
Ala Ser Asp Gly Asp Gly Asp Arg Asn Met Ile Tyr Gly Tyr Gly Pro
290 295 300
Ala Phe Val Ser Pro Gly Asp Ser Val Ala Ile Ile Ala Glu Tyr Ala
305 310 315 320
Pro Glu Ile Pro Tyr Phe Ala Lys Gln Gly Ile Tyr Gly Leu Ala Arg
325 330 335
Ser Phe Pro Thr Ser Ser Ala Ile Asp Arg Val Ala Ala Lys Lys Gly
340 345 350
Leu Arg Cys Tyr Glu Val Pro Thr Gly Trp Lys Phe Phe Cys Ala Leu
355 360 365
Phe Asp Ala Lys Lys Leu Ser Ile Cys Gly Glu Glu Ser Phe Gly Thr
370 375 380
Gly Ser Asn His Ile Arg Glu Lys Asp Gly Leu Trp Ala Ile Ile Ala
385 390 395 400
Trp Leu Asn Ile Leu Ala Ile Tyr His Arg Arg Asn Pro Glu Lys Glu
405 410 415
Ala Ser Ile Lys Thr Ile Gln Asp Glu Phe Trp Asn Glu Tyr Gly Arg
420 425 430
Thr Phe Phe Thr Arg Tyr Asp Tyr Glu His Ile Glu Cys Glu Gln Ala
435 440 445
Glu Lys Val Val Ala Leu Leu Ser Glu Phe Val Ser Arg Pro Asn Val
450 455 460
Cys Gly Ser His Phe Pro Ala Asp Glu Ser Leu Thr Val Ile Asp Cys
465 470 475 480
Gly Asp Phe Ser Tyr Arg Asp Leu Asp Gly Ser Ile Ser Glu Asn Gln
485 490 495
Gly Leu Phe Val Lys Phe Ser Asn Gly Thr Lys Phe Val Leu Arg Leu
500 505 510
Ser Gly Thr Gly Ser Ser Gly Ala Thr Ile Arg Leu Tyr Val Glu Lys
515 520 525
Tyr Thr Asp Lys Lys Glu Asn Tyr Gly Gln Thr Ala Asp Val Phe Leu
530 535 540
Lys Pro Val Ile Asn Ser Ile Val Lys Phe Leu Arg Phe Lys Glu Ile
545 550 555 560
Leu Gly Thr Asp Glu Pro Thr Val Arg Thr
565 570
<210> 56
<211> 1500
<212> ДНК
<213> Saccharomyces cerevisiae
<220>
<223> Нуклеотидная последовательность UTP-глюкозо-1-фосфат-уридилилтрансферазы
(UGP1), происходящая из Saccharomyces cerevisiae
<220>
<223> Нуклеотидная последовательность UTP-глюкозо-1-фосфат-уридилилтрансферазы
(UGP1), происходящая из Saccharomyces cerevisiae
<400> 56
atgtccacta agaagcacac caaaacacat tccacttatg cattcgagag caacacaaac 60
agcgttgctg cctcacaaat gagaaacgcc ttaaacaagt tggcggactc tagtaaactt 120
gacgatgctg ctcgcgctaa gtttgagaac gaactggatt cgtttttcac gcttttcagg 180
agatatttgg tagagaagtc ttctagaacc accttggaat gggacaagat caagtctccc 240
aacccggatg aagtggttaa gtatgaaatt atttctcagc agcccgagaa tgtctcaaac 300
ctttccaaat tggctgtttt gaagttgaac ggtgggctgg gtacctccat gggctgcgtt 360
ggccctaaat ctgttattga agtgagagag ggaaacacct ttttggattt gtctgttcgt 420
caaattgaat acttgaacag acagtacgat agcgacgtgc cattgttatt gatgaattct 480
ttcaacactg acaaggatac ggaacacttg attaagaagt attccgctaa cagaatcaga 540
atcagatctt tcaatcaatc caggttccca agagtctaca aggattcttt attgcctgtc 600
cccaccgaat acgattctcc actggatgct tggtatccac caggtcacgg tgatttgttt 660
gaatctttac acgtatctgg tgaactggat gccttaattg cccaaggaag agaaatatta 720
tttgtttcta acggtgacaa cttgggtgct accgtcgact taaaaatttt aaaccacatg 780
atcgagactg gtgccgaata tataatggaa ttgactgata agaccagagc cgatgttaaa 840
ggtggtactt tgatttctta cgatggtcaa gtccgtttat tggaagtcgc ccaagttcca 900
aaagaacaca ttgacgaatt caaaaatatc agaaagttta ccaacttcaa cacgaataac 960
ttatggatca atctgaaagc agtaaagagg ttgatcgaat cgagcaattt ggagatggaa 1020
atcattccaa accaaaaaac tataacaaga gacggtcatg aaattaatgt cttacaatta 1080
gaaaccgctt gtggtgctgc tatcaggcat tttgatggtg ctcacggtgt tgtcgttcca 1140
agatcaagat tcttgcctgt caagacctgt tccgatttgt tgctggttaa atcagatcta 1200
ttccgtctgg aacacggttc tttgaagtta gacccatccc gttttggtcc aaacccatta 1260
atcaagttgg gctcgcattt caaaaaggtt tctggtttta acgcaagaat ccctcacatc 1320
ccaaaaatcg tcgagctaga tcatttgacc atcactggta acgtcttttt aggtaaagat 1380
gtcactttga ggggtactgt catcatcgtt tgctccgacg gtcataaaat cgatattcca 1440
aacggctcca tattggaaaa tgttgtcgtt actggtaatt tgcaaatctt ggaacattga 1500
<210> 57
<211> 499
<212> БЕЛОК
<213> Saccharomyces cerevisiae
<220>
<223> Аминокислотная последовательность UTP-глюкозо-1-фосфат-уридилилтрансферазы
(UGP1), происходящая из Saccharomyces cerevisiae
<220>
<223> Аминокислотная последовательность UTP-глюкозо-1-фосфат-уридилилтрансферазы
(UGP1), происходящая из Saccharomyces cerevisiae
<400> 57
Met Ser Thr Lys Lys His Thr Lys Thr His Ser Thr Tyr Ala Phe Glu
1 5 10 15
Ser Asn Thr Asn Ser Val Ala Ala Ser Gln Met Arg Asn Ala Leu Asn
20 25 30
Lys Leu Ala Asp Ser Ser Lys Leu Asp Asp Ala Ala Arg Ala Lys Phe
35 40 45
Glu Asn Glu Leu Asp Ser Phe Phe Thr Leu Phe Arg Arg Tyr Leu Val
50 55 60
Glu Lys Ser Ser Arg Thr Thr Leu Glu Trp Asp Lys Ile Lys Ser Pro
65 70 75 80
Asn Pro Asp Glu Val Val Lys Tyr Glu Ile Ile Ser Gln Gln Pro Glu
85 90 95
Asn Val Ser Asn Leu Ser Lys Leu Ala Val Leu Lys Leu Asn Gly Gly
100 105 110
Leu Gly Thr Ser Met Gly Cys Val Gly Pro Lys Ser Val Ile Glu Val
115 120 125
Arg Glu Gly Asn Thr Phe Leu Asp Leu Ser Val Arg Gln Ile Glu Tyr
130 135 140
Leu Asn Arg Gln Tyr Asp Ser Asp Val Pro Leu Leu Leu Met Asn Ser
145 150 155 160
Phe Asn Thr Asp Lys Asp Thr Glu His Leu Ile Lys Lys Tyr Ser Ala
165 170 175
Asn Arg Ile Arg Ile Arg Ser Phe Asn Gln Ser Arg Phe Pro Arg Val
180 185 190
Tyr Lys Asp Ser Leu Leu Pro Val Pro Thr Glu Tyr Asp Ser Pro Leu
195 200 205
Asp Ala Trp Tyr Pro Pro Gly His Gly Asp Leu Phe Glu Ser Leu His
210 215 220
Val Ser Gly Glu Leu Asp Ala Leu Ile Ala Gln Gly Arg Glu Ile Leu
225 230 235 240
Phe Val Ser Asn Gly Asp Asn Leu Gly Ala Thr Val Asp Leu Lys Ile
245 250 255
Leu Asn His Met Ile Glu Thr Gly Ala Glu Tyr Ile Met Glu Leu Thr
260 265 270
Asp Lys Thr Arg Ala Asp Val Lys Gly Gly Thr Leu Ile Ser Tyr Asp
275 280 285
Gly Gln Val Arg Leu Leu Glu Val Ala Gln Val Pro Lys Glu His Ile
290 295 300
Asp Glu Phe Lys Asn Ile Arg Lys Phe Thr Asn Phe Asn Thr Asn Asn
305 310 315 320
Leu Trp Ile Asn Leu Lys Ala Val Lys Arg Leu Ile Glu Ser Ser Asn
325 330 335
Leu Glu Met Glu Ile Ile Pro Asn Gln Lys Thr Ile Thr Arg Asp Gly
340 345 350
His Glu Ile Asn Val Leu Gln Leu Glu Thr Ala Cys Gly Ala Ala Ile
355 360 365
Arg His Phe Asp Gly Ala His Gly Val Val Val Pro Arg Ser Arg Phe
370 375 380
Leu Pro Val Lys Thr Cys Ser Asp Leu Leu Leu Val Lys Ser Asp Leu
385 390 395 400
Phe Arg Leu Glu His Gly Ser Leu Lys Leu Asp Pro Ser Arg Phe Gly
405 410 415
Pro Asn Pro Leu Ile Lys Leu Gly Ser His Phe Lys Lys Val Ser Gly
420 425 430
Phe Asn Ala Arg Ile Pro His Ile Pro Lys Ile Val Glu Leu Asp His
435 440 445
Leu Thr Ile Thr Gly Asn Val Phe Leu Gly Lys Asp Val Thr Leu Arg
450 455 460
Gly Thr Val Ile Ile Val Cys Ser Asp Gly His Lys Ile Asp Ile Pro
465 470 475 480
Asn Gly Ser Ile Leu Glu Asn Val Val Val Thr Gly Asn Leu Gln Ile
485 490 495
Leu Glu His
<210> 58
<211> 480
<212> ДНК
<213> Saccharomyces cerevisiae
<220>
<223> Нуклеотидная последовательность глюкозамин-6-фосфат-N-ацетилтрансферазы
(GNA1), происходящая из Saccharomyces cerevisiae
<220>
<223> Нуклеотидная последовательность глюкозамин-6-фосфат-N-ацетилтрансферазы
(GNA1), происходящая из Saccharomyces cerevisiae
<400> 58
atgagcttac ccgatggatt ttatataagg cgaatggaag agggggattt ggaacaggtc 60
actgagacgc taaaggtttt gaccaccgtg ggcactatta cccccgaatc cttcagcaaa 120
ctcataaaat actggaatga agccacagta tggaatgata acgaagataa aaaaataatg 180
caatataacc ccatggtgat tgtggacaag cgcaccgaga cggttgccgc tacggggaat 240
atcatcatcg aaagaaagat cattcatgaa ctggggctat gtggccacat cgaggacatt 300
gcagtaaact ccaagtatca gggccaaggt ttgggcaagc tcttgattga tcaattggta 360
actatcggct ttgactacgg ttgttataag attattttag attgcgatga gaaaaatgtc 420
aaattctatg aaaaatgtgg gtttagcaac gcaggcgtgg aaatgcaaat tagaaaatag 480
<210> 59
<211> 159
<212> БЕЛОК
<213> Saccharomyces cerevisiae
<220>
<223> Аминокислотная последовательность глюкозамин-6-фосфат-N-ацетилтрансферазы
(GNA1), происходящая из Saccharomyces cerevisiae
<220>
<223> Аминокислотная последовательность глюкозамин-6-фосфат-N-ацетилтрансферазы
(GNA1), происходящая из Saccharomyces cerevisiae
<400> 59
Met Ser Leu Pro Asp Gly Phe Tyr Ile Arg Arg Met Glu Glu Gly Asp
1 5 10 15
Leu Glu Gln Val Thr Glu Thr Leu Lys Val Leu Thr Thr Val Gly Thr
20 25 30
Ile Thr Pro Glu Ser Phe Ser Lys Leu Ile Lys Tyr Trp Asn Glu Ala
35 40 45
Thr Val Trp Asn Asp Asn Glu Asp Lys Lys Ile Met Gln Tyr Asn Pro
50 55 60
Met Val Ile Val Asp Lys Arg Thr Glu Thr Val Ala Ala Thr Gly Asn
65 70 75 80
Ile Ile Ile Glu Arg Lys Ile Ile His Glu Leu Gly Leu Cys Gly His
85 90 95
Ile Glu Asp Ile Ala Val Asn Ser Lys Tyr Gln Gly Gln Gly Leu Gly
100 105 110
Lys Leu Leu Ile Asp Gln Leu Val Thr Ile Gly Phe Asp Tyr Gly Cys
115 120 125
Tyr Lys Ile Ile Leu Asp Cys Asp Glu Lys Asn Val Lys Phe Tyr Glu
130 135 140
Lys Cys Gly Phe Ser Asn Ala Gly Val Glu Met Gln Ile Arg Lys
145 150 155
<210> 60
<211> 1674
<212> ДНК
<213> Saccharomyces cerevisiae
<220>
<223> Нуклеотидная последовательность фосфоацетилглюкозаминмутазы (PCM1),
происходящая из Saccharomyces cerevisiae
<220>
<223> Нуклеотидная последовательность фосфоацетилглюкозаминмутазы (PCM1),
происходящая из Saccharomyces cerevisiae
<400> 60
atgaaggttg attacgagca attgtgcaaa ctctacgatg acacgtgccg cacaaagaat 60
gtgcagttca gttacggtac ggccggattc agaacgctgg ccaagaattt ggatacggtg 120
atgttcagta ctggtatact ggcggttctc aggtcgctga agcttcaggg tcagtatgtg 180
ggggtgatga tcacggcgtc gcacaaccca taccaggaca acggggtcaa gatcgtggaa 240
ccagacggat cgatgctttt ggccacatgg gagccatatg ccatgcagtt ggccaatgcg 300
gcctcttttg ccactaattt tgaagaattt cgtgttgagt tggccaagct gattgaacac 360
gaaaagattg atttgaatac aaccgtcgtg cctcacatcg tggttgggag agactctagg 420
gaaagtagtc catacttgct gcgctgcttg acttcctcca tggccagcgt cttccacgcg 480
caagttttgg acctaggctg tgtcactacg cctcaattgc attacattac tgatttgtcc 540
aacaggcgga aactggaagg agacacagcg ccagttgcca cagaacagga ctactattcg 600
ttctttatag gagccttcaa cgagctcttc gccacgtatc agctggagaa gaggctgtct 660
gtcccaaaat tgttcataga cacagccaat ggtatcggtg gtccacagtt gaaaaaacta 720
ctggcctccg aagattggga cgtgccagcg gagcaagttg aggtaatcaa cgacaggtcc 780
gatgttccag aactgttgaa ttttgaatgc ggtgcggatt atgtgaagac taaccagaga 840
ttacccaagg gtctttctcc atcctcgttt gattcgctat attgctcctt tgatggtgac 900
gcagacaggg ttgtgttcta ctatgtcgac tcaggatcaa aatttcattt gttggatggt 960
gacaaaattt ccactttgtt tgcaaagttc ttgtctaaac aactagaatt ggcacaccta 1020
gaacattctt tgaagattgg tgttgtgcaa actgcctatg caaacggcag ttccaccgct 1080
tacataaaaa atacgttgca ctgtcccgtg tcttgcacta agacaggtgt taaacacttg 1140
catcatgaag ctgccactca gtacgatatt ggcatttatt tcgaagcaaa tggacatggt 1200
acgattatat tcagcgaaaa atttcatcga actatcaaat ctgaattatc caagtccaag 1260
ttaaatggtg atacgttagc tttgagaact ttgaagtgtt tctctgaatt gattaatcag 1320
accgtgggag atgctatttc agacatgctt gctgtccttg ctactttggc gattttgaaa 1380
atgtcgccaa tggattggga tgaagagtat actgatttgc ccaacaagct ggttaagtgc 1440
atcgttcctg ataggtcaat tttccaaacc acggaccagg aaagaaaatt gctcaatcca 1500
gtggggttgc aagacaagat agatcttgtg gtagccaagt atcccatggg aagaagcttt 1560
gtcagagcca gtggtacgga ggatgcggtg agggtttatg cggaatgtaa ggactcctct 1620
aagttaggtc aattttgtga cgaagtggtg gagcacgtta aggcatctgc ttga 1674
<210> 61
<211> 557
<212> БЕЛОК
<213> Saccharomyces cerevisiae
<220>
<223> Аминокислотная последовательность фосфоацетилглюкозаминмутазы (PCM1),
происходящая из Saccharomyces cerevisiae
<220>
<223> Аминокислотная последовательность фосфоацетилглюкозаминмутазы (PCM1),
происходящая из Saccharomyces cerevisiae
<400> 61
Met Lys Val Asp Tyr Glu Gln Leu Cys Lys Leu Tyr Asp Asp Thr Cys
1 5 10 15
Arg Thr Lys Asn Val Gln Phe Ser Tyr Gly Thr Ala Gly Phe Arg Thr
20 25 30
Leu Ala Lys Asn Leu Asp Thr Val Met Phe Ser Thr Gly Ile Leu Ala
35 40 45
Val Leu Arg Ser Leu Lys Leu Gln Gly Gln Tyr Val Gly Val Met Ile
50 55 60
Thr Ala Ser His Asn Pro Tyr Gln Asp Asn Gly Val Lys Ile Val Glu
65 70 75 80
Pro Asp Gly Ser Met Leu Leu Ala Thr Trp Glu Pro Tyr Ala Met Gln
85 90 95
Leu Ala Asn Ala Ala Ser Phe Ala Thr Asn Phe Glu Glu Phe Arg Val
100 105 110
Glu Leu Ala Lys Leu Ile Glu His Glu Lys Ile Asp Leu Asn Thr Thr
115 120 125
Val Val Pro His Ile Val Val Gly Arg Asp Ser Arg Glu Ser Ser Pro
130 135 140
Tyr Leu Leu Arg Cys Leu Thr Ser Ser Met Ala Ser Val Phe His Ala
145 150 155 160
Gln Val Leu Asp Leu Gly Cys Val Thr Thr Pro Gln Leu His Tyr Ile
165 170 175
Thr Asp Leu Ser Asn Arg Arg Lys Leu Glu Gly Asp Thr Ala Pro Val
180 185 190
Ala Thr Glu Gln Asp Tyr Tyr Ser Phe Phe Ile Gly Ala Phe Asn Glu
195 200 205
Leu Phe Ala Thr Tyr Gln Leu Glu Lys Arg Leu Ser Val Pro Lys Leu
210 215 220
Phe Ile Asp Thr Ala Asn Gly Ile Gly Gly Pro Gln Leu Lys Lys Leu
225 230 235 240
Leu Ala Ser Glu Asp Trp Asp Val Pro Ala Glu Gln Val Glu Val Ile
245 250 255
Asn Asp Arg Ser Asp Val Pro Glu Leu Leu Asn Phe Glu Cys Gly Ala
260 265 270
Asp Tyr Val Lys Thr Asn Gln Arg Leu Pro Lys Gly Leu Ser Pro Ser
275 280 285
Ser Phe Asp Ser Leu Tyr Cys Ser Phe Asp Gly Asp Ala Asp Arg Val
290 295 300
Val Phe Tyr Tyr Val Asp Ser Gly Ser Lys Phe His Leu Leu Asp Gly
305 310 315 320
Asp Lys Ile Ser Thr Leu Phe Ala Lys Phe Leu Ser Lys Gln Leu Glu
325 330 335
Leu Ala His Leu Glu His Ser Leu Lys Ile Gly Val Val Gln Thr Ala
340 345 350
Tyr Ala Asn Gly Ser Ser Thr Ala Tyr Ile Lys Asn Thr Leu His Cys
355 360 365
Pro Val Ser Cys Thr Lys Thr Gly Val Lys His Leu His His Glu Ala
370 375 380
Ala Thr Gln Tyr Asp Ile Gly Ile Tyr Phe Glu Ala Asn Gly His Gly
385 390 395 400
Thr Ile Ile Phe Ser Glu Lys Phe His Arg Thr Ile Lys Ser Glu Leu
405 410 415
Ser Lys Ser Lys Leu Asn Gly Asp Thr Leu Ala Leu Arg Thr Leu Lys
420 425 430
Cys Phe Ser Glu Leu Ile Asn Gln Thr Val Gly Asp Ala Ile Ser Asp
435 440 445
Met Leu Ala Val Leu Ala Thr Leu Ala Ile Leu Lys Met Ser Pro Met
450 455 460
Asp Trp Asp Glu Glu Tyr Thr Asp Leu Pro Asn Lys Leu Val Lys Cys
465 470 475 480
Ile Val Pro Asp Arg Ser Ile Phe Gln Thr Thr Asp Gln Glu Arg Lys
485 490 495
Leu Leu Asn Pro Val Gly Leu Gln Asp Lys Ile Asp Leu Val Val Ala
500 505 510
Lys Tyr Pro Met Gly Arg Ser Phe Val Arg Ala Ser Gly Thr Glu Asp
515 520 525
Ala Val Arg Val Tyr Ala Glu Cys Lys Asp Ser Ser Lys Leu Gly Gln
530 535 540
Phe Cys Asp Glu Val Val Glu His Val Lys Ala Ser Ala
545 550 555
<210> 62
<211> 574
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность промотора pTDH3
<220>
<223> Нуклеотидная последовательность промотора pTDH3
<400> 62
ctgctgtaac ccgtacatgc ccaaaatagg gggcgggtta cacagaatat ataacatcgt 60
aggtgtctgg gtgaacagtt tattcctggc atccactaaa tataatggag cccgcttttt 120
aagctggcat ccagaaaaaa aaagaatccc agcaccaaaa tattgttttc ttcaccaacc 180
atcagttcat aggtccattc tcttagcgca actacagaga acaggggcac aaacaggcaa 240
aaaacgggca caacctcaat ggagtgatgc aacctgcctg gagtaaatga tgacacaagg 300
caattgaccc acgcatgtat ctatctcatt ttcttacacc ttctattacc ttctgctctc 360
tctgatttgg aaaaagctga aaaaaaaggt tgaaaccagt tccctgaaat tattccccta 420
cttgactaat aagtatataa agacggtagg tattgattgt aattctgtaa atctatttct 480
taaacttctt aaattctact tttatagtta gtcttttttt tagttttaaa acaccaagaa 540
cttagtttcg aataaacaca cataaacaaa caaa 574
<210> 63
<211> 585
<212> ДНК
<213> Saccharomyces kudriavzevii
<220>
<223> Нуклеотидная последовательность промотора pTDH3.Sk
<220>
<223> Нуклеотидная последовательность промотора pTDH3.Sk
<400> 63
caattcatcg gcccttttag cggctacccg cgccatctaa atgatagggc gggtgacact 60
atggtaaatc ccataattag gtgtctgggt gagtggttct gatgccggca tccactaaat 120
atattggagc ccatttttta cgcgggcttc cagaaaaaaa gagaatccca gcaccaaaag 180
gtggttctct tcaccaacca tcagatcata ggtccacaac cacacataac aggggcacaa 240
aaaggcaaaa aacggacata acctcaatgg agtgatgcaa attgactgga gcaaaagctg 300
acacaaggca ttgattgacc tacgcatgta tctgtattct tttcttacac cttctattac 360
cttctaactc tttgggttgg aaaaaactga aaaaaaaggt tgggacctgg ttcccccaag 420
ttgtccccct acttggttat taaatatata aagacagcaa gtgttgatta taatcttgta 480
aatctatagt tcttaatcta tacttctatt tatattttaa attagtcttt ttatttccaa 540
gtccccaaga acttagtttc gaataaacac acacaaataa acaca 585
<210> 64
<211> 700
<212> ДНК
<213> Saccharomyces bayanus
<220>
<223> Нуклеотидная последовательность промотора pTDH3-1.sba
<220>
<223> Нуклеотидная последовательность промотора pTDH3-1.sba
<400> 64
gcagcgcttc ttccgctcta gtttttatag ttattattac taccacctta aaaatacgta 60
aatactcaaa atagtagtga tattcccaac cttattcatc caaggcacat catcatcatc 120
agccattcat ctttcacctg ccattagtaa cccgtcttct cattgagcgg gttacggcag 180
ccacaggcca cattccgaat gtctgggtga gcggtccctt ttccagcatc cactaaatat 240
ctccgatccc gctttttaat ctggcttcct gaaaaaaaga gaatcccagc accaaaaaat 300
ggctctcttc accaaccatc agatcatagg tcccattctc ttaccgcaac cgtacagaac 360
aggggaaaac gggtacaacc tcaatggagt gatgcaaact gactggagca aaaagctgac 420
acaaggcaat cgacctacgt gtctgtctat tttctcacac cttctattac cttctaactc 480
tctgggttgg aaaaaactga aaaaaaggtt gagaccagtt tccacaaatc atccccctgt 540
ttgattaata aatatataaa gacgacaact atcgatcata aactcataaa actataactc 600
ctttacactt cttattttat agttattcta ttttaattct tattgatttt aaaaccccaa 660
gaacttagtt tcgaaaacac acacacacaa acaattaaaa 700
<210> 65
<211> 602
<212> ДНК
<213> Saccharomyces arboricola
<220>
<223> Нуклеотидная последовательность промотора pTDH3.Sar
<220>
<223> Нуклеотидная последовательность промотора pTDH3.Sar
<400> 65
gagctaaata tcagcccttc gggtcctgcc tgctacccgg tcctgttcga ataaaaacgc 60
gggtaacacg acccagtaac acctgtcgtt gggtgtctgg gtcagaagtt ctgataccgg 120
cttccactaa atagattggg ttccgctctt tacgctggct tcctgaaaaa agagattccg 180
ggcaccaaaa aattggtctc tttgccaacc atcagatcat aggtccattc tcttaccata 240
accacacagg ataggggcac cacaggcgaa aatgggcaca aaatctcaat ggagtgatgc 300
aaattagctg gaacaaaagc tgacacaagg caattaacct gcgcatgtat ccatctcctt 360
ttcttacacc ttctcttacg ttctaactgt ttgggttgga aaaattaaaa aaaaaaggtt 420
gagaccagtt tccccaaatc gtccccctac ttgattcata aatatataaa gacgacaact 480
attgattata atcttgtaaa tctataactc tttactttct cctatttata atttaactta 540
atctttttag atttaaaacc ccaagaactt agtttcgaac aaacacacac aaataaacaa 600
aa 602
<210> 66
<211> 550
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность промотора pENO2
<220>
<223> Нуклеотидная последовательность промотора pENO2
<400> 66
cgctcagcat ctgcttcttc ccaaagatga acgcggcgtt atgtcactaa cgacgtgcac 60
caacttgcgg aaagtggaat cccgttccaa aactggcatc cactaattga tacatctaca 120
caccgcacgc cttttttctg aagcccactt tcgtggactt tgccatatgc aaaattcatg 180
aagtgtgata ccaagtcagc atacacctca ctagggtagt ttctttggtt gtattgatca 240
tttggttcat cgtggttcat taattttttt tctccattgc tttctggctt tgatcttact 300
atcatttgga tttttgtcga aggttgtaga attgtatgtg acaagtggca ccaagcatat 360
ataaaaaaaa aaagcattat cttcctacca gagttgattg ttaaaaacgt atttatagca 420
aacgcaattg taattaattc ttattttgta tcttttcttc ccttgtctca atcttttatt 480
tttattttat ttttcttttc ttagtttctt tcataacacc aagcaactaa tactataaca 540
tacaataata 550
<210> 67
<211> 598
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность промотора pTEF3
<220>
<223> Нуклеотидная последовательность промотора pTEF3
<400> 67
ggctgataat agcgtataaa caatgcatac tttgtacgtt caaaatacaa tgcagtagat 60
atatttatgc atattacata taatacatat cacataggaa gcaacaggcg cgttggactt 120
ttaattttcg aggaccgcga atccttacat cacacccaat cccccacaag tgatccccca 180
cacaccatag cttcaaaatg tttctactcc ttttttactc ttccagattt tctcggactc 240
cgcgcatcgc cgtaccactt caaaacaccc aagcacagca tactaaattt cccctctttc 300
ttcctctagg gtgtcgttaa ttacccgtac taaaggtttg gaaaagaaaa aagagaccgc 360
ctcgtttctt tttcttcgtc gaaaaaggca ataaaaattt ttatcacgtt tctttttctt 420
gaaaattttt ttttttgatt tttttctctt tcgatgacct cccattgata tttaagttaa 480
taaacggtct tcaatttctc aagtttcagt ttcatttttc ttgttctatt acaacttttt 540
ttacttcttg ctcattagaa agaaagcata gcaatctaat ctaagtttta attacaaa 598
<210> 68
<211> 383
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность промотора pTEF1
<220>
<223> Нуклеотидная последовательность промотора pTEF1
<400> 68
gtttagcttg cctcgtcccc gccgggtcac ccggccagcg acatggaggc ccagaatacc 60
ctccttgaca gtcttgacgt gcgcagctca ggggcatgat gtgactgtcg cccgtacatt 120
tagcccatac atccccatgt ataatcattt gcatccatac attttgatgg ccgcacggcg 180
cgaagcaaaa attacggctc ctcgctgcag acctgcgagc agggaaacgc tcccctcaca 240
gacgcgttga attgtcccca cgccgcgccc ctgtagagaa atataaaagg ttaggatttg 300
ccactgaggt tcttctttca tatacttcct tttaaaatct tgctacgata cagttctcac 360
atcacatccg aacataaaca acc 383
<210> 69
<211> 383
<212> ДНК
<213> Ashbya gossypii
<220>
<223> Нуклеотидная последовательность промотора pTEF1.ago
<220>
<223> Нуклеотидная последовательность промотора pTEF1.ago
<400> 69
gtttagcttg cctcgtcccc gccgggtcac ccggccagcg acatggaggc ccagaatacc 60
ctccttgaca gtcttgacgt gcgcagctca ggggcatgat gtgactgtcg cccgtacatt 120
tagcccatac atccccatgt ataatcattt gcatccatac attttgatgg ccgcacggcg 180
cgaagcaaaa attacggctc ctcgctgcag acctgcgagc agggaaacgc tcccctcaca 240
gacgcgttga attgtcccca cgccgcgccc ctgtagagaa atataaaagg ttaggatttg 300
ccactgaggt tcttctttca tatacttcct tttaaaatct tgctacgata cagttctcac 360
atcacatccg aacataaaca acc 383
<210> 70
<211> 498
<212> ДНК
<213> Saccharomyces bayanus
<220>
<223> Нуклеотидная последовательность промотора pTEF1.Sba
<220>
<223> Нуклеотидная последовательность промотора pTEF1.Sba
<400> 70
cgccaacaaa ccttcgaaca ctttaatttt cgaggaccgc agatcctcac atcacaccca 60
cacccaagac tgcttccccc acacaccctg catctgtaca ctttcttctg ctctgttttt 120
ctctccggcg ttctctcggg tcgcccgcat cgccgcgccg gctggaaccg cccacgcacc 180
gcatattgca aatcgcctgc cccctcttgc tcctttttga gggcgcgccg ttacccgcgc 240
ccagggtccg gaaaaagaaa caaggctcta ccgcgtttct ttttccttgt cgaaaaaggc 300
aaaaatgaaa atttttatca cgtttctttt tttttgaaaa attttttttt tggttttttt 360
tctttcgatg gcctcccatt gatatttaag ttaataaatg gttttcagtt ttcaagtttc 420
agtttgtgtt cttctttgct aactttcact tacacctcga aagaaagtat agcaatctaa 480
tcttagtttt aattacaa 498
<210> 71
<211> 76
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность промотора pPDC1
<220>
<223> Нуклеотидная последовательность промотора pPDC1
<400> 71
ttatttacct atctctaaac ttcaacacct tatatcataa ctaatatttc ttgagataag 60
cacactgcac ccatac 76
<210> 72
<211> 998
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность промотора pCCW12
<220>
<223> Нуклеотидная последовательность промотора pCCW12
<400> 72
aaccagggca aagcaaaata aaagaaactt aatacgttat gccgtaatga agggctacca 60
aaaacgataa tctcaactgt aaacaggtac aatgcggacc cttttgccac aaaacataca 120
tcattcattg ccggaaaaag aaagaagtga agacagcagt gcagccagcc atgttgcgcc 180
aatctaatta tagatgctgg tgccctgagg atgtatctgg agccagccat ggcatcatgc 240
gctaccgccg gatgtaaaat ccgacacgca aaagaaaacc ttcgaggttg cgcacttcgc 300
ccacccatga accacacggt tagtccaaaa ggggcagttc agattccaga tgcgggaatt 360
agcttgctgc caccctcacc tcactaacgc tgcggtgtgc ggatacttca tgctatttat 420
agacgcgcgt gtcggaatca gcacgcgcaa gaaccaaatg ggaaaatcgg aatgggtcca 480
gaactgcttt gagtgctggc tattggcgtc tgatttccgt tttgggaatc ctttgccgcg 540
cgcccctctc aaaactccgc acaagtccca gaaagcggga aagaaataaa acgccaccaa 600
aaaaaaaaat aaaagccaat cctcgaagcg tgggtggtag gccctggatt atcccgtaca 660
agtatttctc aggagtaaaa aaaccgtttg ttttggaatt ccccatttcg cggccaccta 720
cgccgctatc tttgcaacaa ctatctgcga taactcagca aattttgcat attcgtgttg 780
cagtattgcg ataatgggag tcttacttcc aacataacgg cagaaagaaa tgtgagaaaa 840
ttttgcatcc tttgcctccg ttcaagtata taaagtcggc atgcttgata atctttcttt 900
ccatcctaca ttgttctaat tattcttatt ctcctttatt ctttcctaac ataccaagaa 960
attaatcttc tgtcattcgc ttaaacacta tatcaata 998
<210> 73
<211> 976
<212> ДНК
<213> Saccharomyces mikatae
<220>
<223> Нуклеотидная последовательность промотора pCCW12.Sm
<220>
<223> Нуклеотидная последовательность промотора pCCW12.Sm
<400> 73
cgttgtgctg tagtgaagga agactaaaaa ggataatcac agttgtaaag aggtataatg 60
cggacccttt tgccacaaaa cacacatctt tcgtttccaa aataagaaag aagaaagcaa 120
aaagattagc agccacgttg ctgcgatcta attatagacg gtggcgtcat cattctcacc 180
caagattgtg tcttgaacct gccacgggtc ctgcgttatc gccggatgta aaactagaca 240
tgcaaaaaaa ggaccttcca ggtagcgtgc tccacaccac ccatgaccac cacagttagt 300
ccaaaagagg cagcaccact tcccgatggg ggaattagat tgctgccacc ctcacctcac 360
taatgctgcg gtgtgcggat atgccctgct atatatagct ccgcgttttt gaaccagcac 420
agcgcgagca ccaaaaagga aaatcgcata ggcccagaac tgatttcagc acgggctatt 480
ggcgttgggt ttccgttctg ggaaaccttc gccgcgtccc cctcacaaac ctccgcacaa 540
gttcgagcaa gcgggaaaaa acgaaaaacg ccattaatac taaataaagc aaatcctcga 600
agcgtgggtg gcaagcccct ggatttttcc gcacaagtac tcttctcagg agtaaaaaaa 660
cccgtttgtt ttggaattcc ccatttcgcg gccatctacg ccggtatctt cgcaatatct 720
atcagcgata actcagcaat tttaatattc gtgttgcagt gctgcgatag cgggagtctt 780
gtttgtaaca taacggcaga aaggaatgag agaaaatttt ccattctttg gcctccgttc 840
aagtatataa agccggcatg cttggtaatc tttctctctc ttctgtattg tttctataat 900
acttttatct tctaattatt ttctgaaaaa accaagaaat taatcttctg tcattcgctt 960
aaacactata tcaata 976
<210> 74
<211> 750
<212> ДНК
<213> Saccharomyces kudriavzevii
<220>
<223> Нуклеотидная последовательность промотора pCCW12.Sk
<220>
<223> Нуклеотидная последовательность промотора pCCW12.Sk
<400> 74
tgtaaaatcc tacacgcaaa aaacctcttg ggttgcgcgt tttccaccac ccacgacccg 60
cacaatcaat ccaaaagggg caacgccagt tcccaatgcg ggaattagct cctcaccccc 120
ctcacccgct aacgctgcgg tgtgcggaca cgcagcagta tttatagatc ctcgtgttgg 180
aaccagcccg cgtgagcacc aaattggaaa gtcgcaatgg gcccagaacc gctttcagta 240
ctgggccatt ggcgtctagt ttccgttttg agcgtccttc gccgcgtctc tctgtgaaat 300
ccccgcacaa gtctgagcag gcaaaaaaaa aaaacgccac caaaaataaa taaagccaat 360
cctcgaagga tgagtaggaa aggaagcccc tggttttttc ccgcacgaat atttttcagg 420
agtgaaaaaa tccgtttgtt ttggaattcc ccatttcgcg ctcacctacg ccggtatctt 480
tggaacaact atcagcgata actcagcaaa atttgcatat ccgtgctgca atagtgcgat 540
agtgggattg ggagtcttgt tgcatcataa cggcagaaag gaatgaataa aaattttccg 600
ttctttgtct ccgttcaagt atataaagtc ggcatgcttg attatctttt cttctcttct 660
actacatttc tatttcactt tctactctat tcttccctga aaaacccaag aaaataatct 720
tctgtcattc gcttaaacaa tatatcaaaa 750
<210> 75
<211> 750
<212> ДНК
<213> Saccharomyces bayanus
<220>
<223> Нуклеотидная последовательность промотора pCCW12.Sba
<220>
<223> Нуклеотидная последовательность промотора pCCW12.Sba
<400> 75
accatgccac ggtgctggcc ccacttccac ccacgacccg cacggttggc ccgaaagggg 60
caacaccagt tcccaatacg gaaattagtc cgccaccacc ctcacctcgc tagagctgcg 120
gtgtgcgggc gtgcatcgct atttatagac atgcctgctg gcgtcaccgc gcgcgagcac 180
caaacaggaa aatcgcactg ggcccagaac cacgctatgc gctgggccga tggcgtccgg 240
tttccctttg ggagccccct gccacgttcg cctaacaaat ccccgcaccg gcttgagaaa 300
aaagcgaaaa gcgaaaaaaa aaaatcaacg ccaccaaaat taaaaaaaaa gagccatcct 360
cgaagggtga atagtagccc ctgacttttc ccgcacagac agacaccttt caggagtgaa 420
caaaaaagca gtttgttttg gaattccccc atttcgcggt ggcctgcgca ggtatctctg 480
cgtcaactat cagcgataac tcagcaaatt ttgcatattc gtgttgcgat actacgataa 540
tgggagtctg tcgcctaata acggcaacaa ggaatgagag agaaaaattt tcttcattct 600
ccagctcccg ttcaagtata taaggtcggc atggtcgatt gtctttcctt ctcttcagtt 660
acgtctctct atttacatta ttcttatttt tatttaataa aaaccccaag aaattaatct 720
tctgtcattc gcttaaacac tatatcaaaa 750
<210> 76
<211> 750
<212> ДНК
<213> Saccharomyces arboricola
<220>
<223> Нуклеотидная последовательность промотора pCCW12.Sar
<220>
<223> Нуклеотидная последовательность промотора pCCW12.Sar
<400> 76
aaaaaacaac cttctgccaa cctgcgtgct tctcaccacc catgacccac acaattgacc 60
cgaatggggc aactccagtt cccaatacgg gaattaactc gccaccatat ttaccgcgtt 120
gaagctgtgg tgtgcggaca ctccgtacta tttatagacc cacgcggtgg aaccagcacg 180
cgcgcgcact aaacaggaaa atcgcattga gtccagaacc gccaccagca cttggccatt 240
ggcgtctaat ttccgttttc ggcgcccctc accgcgtcct tctaacaaag cgcgcacaag 300
cttgagcaag tgaaaagaaa attaaaaata aaaaaccgcc accaaaacaa ataaagcaat 360
cttcgaagtg tgggttggtg ggaagcccct ggcttttccc gcaccagtcg ttttcaggag 420
taaaaaaata cccgtttgtt ttggaattcc ccatttcgcg gcgacctgcg ccggtatctt 480
tgcaacaact atttgcgata actcagcaaa atttgcatat tcgtgttggg atattgcgat 540
agtgggagtc ttgttgcata ataacggtaa aaagaagtga aggaaaaaaa tttgcatcct 600
ttagtctcag ttcaagtata taaagtcggg atattcaatt atctttcttt ctcttgctca 660
aaggtttcta tatttttttt atagtatttc ttttgttata aaataccaag aaattaatct 720
tctgtcattc gcttaaatac tacatcaata 750
<210> 77
<211> 500
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность промотора pNUP57
<220>
<223> Нуклеотидная последовательность промотора pNUP57
<400> 77
tcatctgcgc aatgactatc aagaccttct gcaagaattt caaatctcac tgaaaatctt 60
gaccgaaaag tgtcttgaaa acccatcaag cctgcaaaac ctatctttga cattagtctc 120
cattataaaa acggcatagt tgggagaaaa ctttccatac ttcaattgtg gactgatata 180
agtattttag ttttgcccgc atgatcatcc cacatggcta cagcagttct ctcataggaa 240
aatagtacaa tagctacgtg atataatcta aataattgtt gccaatgtgt aattatatca 300
ttttgaacgt acgcgaaatg gattattttc aaaaattttg tttcttgaaa tgagtaaaag 360
caaaagtcca actctccaag tcgatgtaaa caactttttg ccaaagggac tgaaagacta 420
aatcgaggat tatcccgttc aaactattcc agaaacgctc gttagtaaca aaagacatac 480
cttgttgacc aattgatcac 500
<210> 78
<211> 523
<212> ДНК
<213> Ashbya gossypii
<220>
<223> Нуклеотидная последовательность промотора pCCW10.ago
<220>
<223> Нуклеотидная последовательность промотора pCCW10.ago
<400> 78
ggtaccacgg caacctcgtt cgctgttcat ccccttcgtc acacaggacg ttggatgccg 60
taagcagcgt tgcttttgat cctcaggatc ggccgggtaa cccgcggctg cttctatttt 120
agtattcata tctcaagcac atccattccg gccgtttggg ggcgccgccg cactcgtgtc 180
cattcctacc gtggcactta gggctatcct gtcggagcgc cccgccgacc gccttatcgg 240
caccaaaagt agaagccccg gccccgcgtg gctcagactc accatcggtg ctatttactt 300
ttcgatcaga tcgcggcgcg cggtggccgg catttccgga agcggccacg gagcagaggt 360
ggcgcattcg aatcgcatac gtcttcgcca cgccggaaaa aaaattttcg gctatataag 420
gagaggcggc cgtcttgctg caggcagttt cactttctct aaaaccaaag aacatcgatt 480
tctttagtca ctcgcttcct tacaccgaac tcgaggcggc cgc 523
<210> 79
<211> 943
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность промотора pCWP2
<220>
<223> Нуклеотидная последовательность промотора pCWP2
<400> 79
ctagcctccc ctttttattt tgtgcggtca ccgcaaggga caaagctttt cttagaaaac 60
cgtctgagaa gcataacgta cgccatcccc tagacatatt aataatgcta cagatactat 120
gctgctcgtc tttttttgac gaccctttta ttgcaatgtg caactaatgg caaacaacca 180
catagtatca cagtattaca ttgcctccac cgatgcggat gttagggcgc caagtctgtc 240
atgaagcatg ttcctgtcat aatcttgtat gcaaaatacc gcgttctgcg ccactgatat 300
gctaggcagc agcaacctat gcagaagatt gcttttccca cgcctgtttt acgtctccag 360
ggcacttgaa acaatgcagc gatcgccgcc acaacacgcc aaagagaagc gaaagtgggc 420
ctgggcggcc tcagtttcgg cagaggtaaa caacacgaac tgaactgcct tagctccgaa 480
gggcaattcc acaggcactc cgcggggccc ggccaaggcc caaaaggcgt ggaatatgcg 540
cgttttgggg ccataacacc cagtaccacg gccggaacgg gccatataat aagtttttca 600
ctctcaagaa tggtaaacgt aaataggaac atcccactac cctagaaatt gcggaaattt 660
cgcgcttatc attagaaaat ctggaaccgt cctttttcct ctttcttgca tttccctttc 720
cgtattattg ccattcttta actgcatttg gggaaccgta gaccaaaagc caaacagaga 780
aatgtaacgt tctaaaaaaa aaacaacgaa aaaattgaaa aataagatac aataatcgta 840
tataaatcag gcttcttgtt catcattttc aattctcttc ttgccatccc ttttcctatc 900
tttgttcttt tcttctcata atcaagaata aataacttca tca 943
<210> 80
<211> 535
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность промотора pRPLA1
<220>
<223> Нуклеотидная последовательность промотора pRPLA1
<400> 80
tcaagttgga tactgatctg atctctccgc cctactacca gggaccctca tgattaccgc 60
tcgaatgcga cgtttcctgc ctcataaaac tggcttgaaa atatttattc gctgaacagt 120
agcctagctt ataaaaattt catttaatta atgtaatatg aaaactcaca tgccttctgt 180
ttctaaaatt gtcacagcaa gaaataacat taccatacgt gatcttatta aactctagta 240
tcttgtctaa tacttcattt aaaagaagcc ttaaccctgt agcctcatct atgtctgcta 300
catatcgtga ggtacgaata tcgtaagatg ataccacgca actttgtaat gatttttttt 360
ttttcatttt ttaaagaatg cctttacatg gtatttgaaa aaaatatctt tataaagttt 420
gcgatctctt ctgttctgaa taatttttag taaaagaaat caaaagaata aagaaatagt 480
ccgctttgtc caatacaaca gcttaaaccg attatctcta aaataacaag aagaa 535
<210> 81
<211> 505
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность промотора pCUP1
<220>
<223> Нуклеотидная последовательность промотора pCUP1
<400> 81
cggcaaactt caacgatttc tatgatgcat tttataatta gtaagccgat cccattaccg 60
acatttgggc gctatacgtg catatgttca tgtatgtatc tgtatttaaa acacttttgt 120
attatttttc ctcatatatg tgtataggtt tatacggatg atttaattat tacttcacca 180
ccctttattt caggctgata tcttagcctt gttactagtt agaaaaagac atttttgctg 240
tcagtcactg tcaagagatt cttttgctgg catttcttct agaagcaaaa agagcgatgc 300
gtcttttccg ctgaaccgtt ccagcaaaaa agactaccaa cgcaatatgg attgtcagaa 360
tcatataaaa gagaagcaaa taactccttg tcttgtatca attgcattat aatatcttct 420
tgttagtgca atatcatata gaagtcatcg aaatagatat taagaaaaac aaactgtaca 480
atcaatcaat caatcatcac ataaa 505
<210> 82
<211> 510
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность промотора pMET6
<220>
<223> Нуклеотидная последовательность промотора pMET6
<400> 82
ccacaggaaa tatttcacgt gacttacaaa cagagtcgta cgtcaggacc ggagtcaggt 60
gaaaaaatgt gggccggtaa agggaaaaaa ccagaaacgg gactactatc gaactcgttt 120
agtcgcgaac gtgcaaaagg ccaatatttt tcgctagagt catcgcagtc atggcagctc 180
tttcgctcta tctcccggtc gcaaaactgt ggtagtcata gctcgttctg ctcaattgag 240
aactgtgaat gtgaatatgg aacaaatgcg atagatgcac taatttaagg gaagctagct 300
agttttccca actgcgaaag aaaaaaagga aagaaaaaaa aattctatat aagtgataga 360
tatttccatc tttactagca ttagtttctc ttttacgtat tcaatatttt tgttaaactc 420
ttcctttatc ataaaaaagc aagcatctaa gagcattgac aacactctaa gaaacaaaat 480
accaatataa tttcaaagta catatcaaaa 510
<210> 83
<211> 686
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность промотора pMET25
<220>
<223> Нуклеотидная последовательность промотора pMET25
<400> 83
ttacattatc aatccttgcg tttcagcttc cactaattta gatgactatt tctcatcatt 60
tgcgtcatct tctaacaccg tatatgataa tatactagta acgtaaatac tagttagtag 120
atgatagttg atttttattc caacactaag aaataatttc gccatttctt gaatgtattt 180
aaagatattt aatgctataa tagacattta aatccaattc ttccaacata caatgggagt 240
ttggccgagt ggtttaaggc gtcagattta ggtggattta acctctaaaa tctctgatat 300
cttcggatgc aagggttcga atcccttagc tctcattatt ttttgctttt tctcttgagg 360
tcacatgatc gcaaaatggc aaatggcacg tgaagctgtc gatattgggg aactgtggtg 420
gttggcaaat gactaattaa gttagtcaag gcgccatcct catgaaaact gtgtaacata 480
ataaccgaag tgtcgaaaag gtggcacctt gtccaattga acacgctcga tgaaaaaaat 540
aagatatata taaggttaag taaagcgtct gttagaaagg aagtttttcc tttttcttgc 600
tctcttgtct tttcatctac tatttccttc gtgtaataca gggtcgtcag atacatagat 660
acaattctat tacccccatc cataca 686
<210> 84
<211> 363
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность промотора pSAM1
<220>
<223> Нуклеотидная последовательность промотора pSAM1
<400> 84
gaaacggacg taagacggaa atagaatttg aagataaagt tatatatcac tacacacgaa 60
tactttcttt tttttttttc acaggaaaac tgtggtggcg cccttgccta ctagtgcatt 120
tcttttttcg ggttcttgtc tcgacgaaat tttagcctca tcgtagtttt tcactctggt 180
atcgatgaaa aagggaagag taaaaagttt tccgtttagt acttaatggg attggtttgg 240
gacgtatata tcgactggtg ttgtctgtta ttcatcgttg tttttcggtt agcttcgaaa 300
aaaaaataga gtaaaaacca ggaatttacc ctaaaaacaa gaaaaaataa gataaacgaa 360
aat 363
<210> 85
<211> 300
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность терминатора tTPI1
<220>
<223> Нуклеотидная последовательность терминатора tTPI1
<400> 85
gattaatata attatataaa aatattatct tcttttcttt atatctagtg ttatgtaaaa 60
taaattgatg actacggaaa gcttttttat attgtttctt tttcattctg agccacttaa 120
atttcgtgaa tgttcttgta agggacggta gatttacaag tgatacaaca aaaagcaagg 180
cgctttttct aataaaaaga agaaaagcat ttaacaattg aacacctcta tatcaacgaa 240
gaatattact ttgtctctaa atccttgtaa aatgtgtacg atctctatat gggttactca 300
<210> 86
<211> 299
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность терминатора tMET25
<220>
<223> Нуклеотидная последовательность терминатора tMET25
<400> 86
gtgtgcgtaa tgagttgtaa aattatgtat aaacctactt tctctcacaa gtactatact 60
tttataaaac gaactttatt gaaatgaata tccttttttt cccttgttac atgtcgtgac 120
tcgtactttg aacctaaatt gttctaacat caaagaacag tgttaattcg cagtcgagaa 180
gaaaaatatg gtgaacaaga ctcatctact tcatgagact actttacgcc tcctataaag 240
ctgtcacact ggataaattt attgtaggac caagttacaa aagaggatga tggaggttt 299
<210> 87
<211> 300
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность терминатора tDIT1
<220>
<223> Нуклеотидная последовательность терминатора tDIT1
<400> 87
taaagtaaga gcgctacatt ggtctacctt tttgttcttt tacttaaaca ttagttagtt 60
cgttttcttt ttctcatttt tttatgtttc ccccccaaag ttctgatttt ataatatttt 120
atttcacaca attccattta acagaggggg aatagattct ttagcttaga aaattagtga 180
tcaatatata tttgcctttc ttttcatctt ttcagtgata ttaatggttt cgagacactg 240
caatggccct agttgtctaa gaggatagat gttactgtca aagatgatat tttgaatttc 300
<210> 88
<211> 300
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность терминатора tRPL3
<220>
<223> Нуклеотидная последовательность терминатора tRPL3
<400> 88
gaagttttgt tagaaaataa atcatttttt aattgagcat tcttattcct attttattta 60
aatagtttta tgtattgtta gctacataca acagtttaaa tcaaattttc tttttcccaa 120
gtccaaaatg gaggtttatt ttgatgaccc gcatgcgatt atgttttgaa agtataagac 180
tacatacatg tacatatatt taaacatgta aacccgtcca ttatattgct tactttcttc 240
ttttttgccg ttttgacttg gacctctggt ttgctatttc cttacaatct ttgctacaat 300
<210> 89
<211> 304
<212> ДНК
<213> Saccharomyces mikatae
<220>
<223> Нуклеотидная последовательность терминатора tRPL3.sm
<220>
<223> Нуклеотидная последовательность терминатора tRPL3.sm
<400> 89
gaagttttta aagcattttt tagacacttc tcatttttct aagttttttt aaaatagttt 60
tatgtattta ctacgtatca caatttgaaa taattcatct tcccaaaaaa ctaagatttt 120
tatccttgtc acgatccgta accagtttat aatattttag agcttataca cgtacgtata 180
cacacgtgtc ggtacatgag aattacgttc aaaattattc actttttttt tctctgccgt 240
tttacttttg aactctgtct cgctatttcc ttacaatctt cgctacaata ccacttgccc 300
ttgg 304
<210> 90
<211> 299
<212> ДНК
<213> Saccharomyces bayanus
<220>
<223> Нуклеотидная последовательность терминатора tRPL3.sba
<220>
<223> Нуклеотидная последовательность терминатора tRPL3.sba
<400> 90
gaagttttct gacaaaaaca taacgttttt tccaatcatt tcttattttt ccggtttatt 60
taaatagttt ttatgtacta ttatacgtat gactatttaa cttaaattct tcctcccaag 120
aaatctccca agtttttcat tatcatggca tacaccacta tcagttacaa aatggtagct 180
caaccatata tatatctcta tatacacata taaatgcaaa caggtccaag tcaccgctca 240
ctgcagtttc ttttgccgtt ttgacttcga tctctgcttg gctattttct cacaatcct 299
<210> 91
<211> 300
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность терминатора tRPL41B
<220>
<223> Нуклеотидная последовательность терминатора tRPL41B
<400> 91
gcggattgag agcaaatcgt taagttcagg tcaagtaaaa attgatttcg aaaactaatt 60
tctcttatac aatcctttga ttggaccgtc atcctttcga atataagatt ttgttaagaa 120
tattttagac agagatctac tttatattta atatctagat attacataat ttcctctcta 180
ataaaatatc attaataaaa taaaaatgaa gcgatttgat tttgtgttgt caacttagtt 240
tgccgctatg cctcttgggt aatgctatta ttgaatcgaa gggctttatt atattaccct 300
<210> 92
<211> 300
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность терминатора tRPL15A
<220>
<223> Нуклеотидная последовательность терминатора tRPL15A
<400> 92
gctggttgat ggaaaatata attttattgg gcaaactttt gtttatctga tgtgttttat 60
actattatct ttttaattaa tgattctata tacaaacctg tatatttttt ctttaaccaa 120
tttttttttt tatagaccta gagctgtact tttattctgc tatcaagcaa acccctaccc 180
cctcttctca atcctcccct caggcagaac ttatctacct gtatcaagga gcggacgagg 240
gagtcctaat tgttctacgt ataccaatgc tagcagctta cataggtggt ggcactacca 300
<210> 93
<211> 300
<212> ДНК
<213> Saccharomyces bayanus
<220>
<223> Нуклеотидная последовательность терминатора tRPL15A.sba
<220>
<223> Нуклеотидная последовательность терминатора tRPL15A.sba
<400> 93
gctggctgat gaaaaatata gttctgttgg gcaagcattt gtttacctag catctctttt 60
atactattat tatctttata tttgatgatt ttatatacaa gttgtatacc ttttctttaa 120
ccaatttttt tttttctaat ggtgcaccta gaagtacatt ttttctcacc aatagatagt 180
caagatactc ccagcctcta tggcgttacc acggagccga caagggaaag ctgcttatct 240
tacatatgca gatgccaagg cccgttacag gccgccttat tgatgtttag aaatagcttc 300
<210> 94
<211> 300
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность терминатора tIDP1
<220>
<223> Нуклеотидная последовательность терминатора tIDP1
<400> 94
tcgaatttac gtagcccaat ctaccacttt tttttttcat tttttaaagt gttatactta 60
gttatgctct aggataatga actacttttt tttttttttt tttactgtta tcataaatat 120
atatacctta ttgttgtttg caaccgtcgg ttaattcctt atcaaggttc cccaagttcg 180
gatcattacc atcaatttcc aacattttca tgagttcttc ttcttcatta ccgtgtttta 240
gggggctgtt cgcacttcta atagggctat caccaagctg ttctaattcg tccaaaagtt 300
<210> 95
<211> 300
<212> ДНК
<213> Saccharomyces bayanus
<220>
<223> Нуклеотидная последовательность терминатора tTEF1.sba
<220>
<223> Нуклеотидная последовательность терминатора tTEF1.sba
<400> 95
ggagattgat aggacttttc tagttgcata tcttttattt ttaaatctta tctattagtt 60
aattttttgt aatttatcct tatatatata gtttggttat tctaaaacat catttcagta 120
tctaaaacct ctcttattca ttaccttttt atttaatggt ttttgctaca ggcaaaaatt 180
taatggtttt tgctacaggc aaaaatcccg ccgtggactt attccacgtt aactcggtta 240
cagggtcatg aaccattttg tcaattatcg aaataacttc ttcaaaagtc cctcttactt 300
<210> 96
<211> 1113
<212> ДНК
<213> Saccharomyces cerevisiae
<220>
<223> Нуклеотидная последовательность глутаминсинтетазы (GLN1)
<220>
<223> Нуклеотидная последовательность глутаминсинтетазы (GLN1)
<400> 96
atggctgaag caagcatcga aaagactcaa attttacaaa aatatctaga actggaccaa 60
agaggtagaa taattgccga atacgtttgg atcgatggta ctggtaactt acgttccaaa 120
ggtagaactt tgaagaagag aatcacatcc attgaccaat tgccagaatg gaacttcgac 180
ggttcttcta ccaaccaagc gccaggccac gactctgaca tctatttgaa acccgttgct 240
tactacccag atcccttcag gagaggtgac aacattgttg tcttggccgc atgttacaac 300
aatgacggta ctccaaacaa gttcaaccac agacacgaag ctgccaagct atttgctgct 360
cataaggatg aagaaatctg gtttggtcta gaacaagaat acactctatt tgacatgtat 420
gacgatgttt acggatggcc aaagggtggg tacccagctc cacaaggtcc ttactactgt 480
ggtgttggtg ccggtaaggt ttatgccaga gacatgatcg aagctcacta cagagcttgt 540
ttgtatgccg gattagaaat ttctggtatt aacgctgaag tcatgccatc tcaatgggaa 600
ttccaagtcg gtccatgtac cggtattgac atgggtgacc aattatggat ggccagatac 660
tttttgcaca gagtggcaga agagtttggt atcaagatct cattccatcc aaagccattg 720
aagggtgact ggaacggtgc cggttgtcac actaacgttt ccaccaagga aatgagacaa 780
ccaggtggta tgaaatacat cgaacaagcc atcgagaagt tatccaagag acacgctgaa 840
cacattaagt tgtacggtag cgataacgac atgagattaa ctggtagaca tgaaaccgct 900
tccatgactg ccttttcttc tggtgtcgcc aacagaggta gctcaattag aatcccaaga 960
tccgtcgcca aggaaggtta cggttacttt gaagaccgta gaccagcttc caacatcgac 1020
ccatacttgg ttacaggtat catgtgtgaa actgtttgcg gtgctattga caatgctgac 1080
atgacgaagg aatttgaaag agaatcttca taa 1113
<210> 97
<211> 370
<212> БЕЛОК
<213> Saccharomyces cerevisiae
<220>
<223> Аминокислотная последовательность глутаминсинтетазы (GLN1)
<220>
<223> Аминокислотная последовательность глутаминсинтетазы (GLN1)
<400> 97
Met Ala Glu Ala Ser Ile Glu Lys Thr Gln Ile Leu Gln Lys Tyr Leu
1 5 10 15
Glu Leu Asp Gln Arg Gly Arg Ile Ile Ala Glu Tyr Val Trp Ile Asp
20 25 30
Gly Thr Gly Asn Leu Arg Ser Lys Gly Arg Thr Leu Lys Lys Arg Ile
35 40 45
Thr Ser Ile Asp Gln Leu Pro Glu Trp Asn Phe Asp Gly Ser Ser Thr
50 55 60
Asn Gln Ala Pro Gly His Asp Ser Asp Ile Tyr Leu Lys Pro Val Ala
65 70 75 80
Tyr Tyr Pro Asp Pro Phe Arg Arg Gly Asp Asn Ile Val Val Leu Ala
85 90 95
Ala Cys Tyr Asn Asn Asp Gly Thr Pro Asn Lys Phe Asn His Arg His
100 105 110
Glu Ala Ala Lys Leu Phe Ala Ala His Lys Asp Glu Glu Ile Trp Phe
115 120 125
Gly Leu Glu Gln Glu Tyr Thr Leu Phe Asp Met Tyr Asp Asp Val Tyr
130 135 140
Gly Trp Pro Lys Gly Gly Tyr Pro Ala Pro Gln Gly Pro Tyr Tyr Cys
145 150 155 160
Gly Val Gly Ala Gly Lys Val Tyr Ala Arg Asp Met Ile Glu Ala His
165 170 175
Tyr Arg Ala Cys Leu Tyr Ala Gly Leu Glu Ile Ser Gly Ile Asn Ala
180 185 190
Glu Val Met Pro Ser Gln Trp Glu Phe Gln Val Gly Pro Cys Thr Gly
195 200 205
Ile Asp Met Gly Asp Gln Leu Trp Met Ala Arg Tyr Phe Leu His Arg
210 215 220
Val Ala Glu Glu Phe Gly Ile Lys Ile Ser Phe His Pro Lys Pro Leu
225 230 235 240
Lys Gly Asp Trp Asn Gly Ala Gly Cys His Thr Asn Val Ser Thr Lys
245 250 255
Glu Met Arg Gln Pro Gly Gly Met Lys Tyr Ile Glu Gln Ala Ile Glu
260 265 270
Lys Leu Ser Lys Arg His Ala Glu His Ile Lys Leu Tyr Gly Ser Asp
275 280 285
Asn Asp Met Arg Leu Thr Gly Arg His Glu Thr Ala Ser Met Thr Ala
290 295 300
Phe Ser Ser Gly Val Ala Asn Arg Gly Ser Ser Ile Arg Ile Pro Arg
305 310 315 320
Ser Val Ala Lys Glu Gly Tyr Gly Tyr Phe Glu Asp Arg Arg Pro Ala
325 330 335
Ser Asn Ile Asp Pro Tyr Leu Val Thr Gly Ile Met Cys Glu Thr Val
340 345 350
Cys Gly Ala Ile Asp Asn Ala Asp Met Thr Lys Glu Phe Glu Arg Glu
355 360 365
Ser Ser
370
<210> 98
<211> 6438
<212> ДНК
<213> Saccharomyces cerevisiae
<220>
<223> Нуклеотидная последовательность глутаматсинтазы (GLT1)
<220>
<223> Нуклеотидная последовательность глутаматсинтазы (GLT1)
<400> 98
atgccagtgt tgaaatcaga caatttcgat ccattggaag aagcttacga aggtgggaca 60
attcaaaact ataacgatga acaccatctt cataaatctt gggcaaatgt gattccggac 120
aaacgaggac tttacgaccc tgattatgaa catgacgctt gtggtgtcgg tttcgtagca 180
aataagcatg gtgaacagtc tcacaagatt gttactgacg ctagatatct tttagtgaat 240
atgacacatc gtggtgccgt ctcatctgat gggaacggtg acggtgccgg tattctgcta 300
ggtattcctc acgaatttat gaaaagagaa ttcaagttag atcttgatct agacatacct 360
gagatgggca aatacgccgt aggtaacgtc ttcttcaaga agaacgaaaa aaataacaag 420
aaaaatttaa ttaagtgtca gaagattttc gaggatttag ctgcatcctt caacttatcc 480
gtattaggtt ggagaaacgt ccccgtagat tctactattt taggagacgt tgcattatct 540
cgtgaaccta ctattctaca gccattattg gttccattgt atgatgaaaa acaaccggag 600
tttaatgaaa ctaaatttag aactcaattg tatcttttaa ggaaggaggc ctctcttcaa 660
ataggactgg aaaactggtt ctatgtttgt tccctaaaca ataccaccat tgtttacaag 720
ggtcaattga cgccagctca agtgtataac tactatcccg acttgactaa tgcgcatttc 780
aaatcccaca tggcgttggt ccattcaaga ttttccacta atactttccc ctcttgggat 840
agagctcaac ctttacgttg gctagctcat aatggtgaaa ttaacacctt aagaggtaac 900
aagaattgga tgcgctccag agaaggtgtg atgaattcag caactttcaa agatgagtta 960
gacaaactat acccaattat cgaagaaggt ggttctgatt cagctgcatt ggataacgtt 1020
ttagaactat tgactattaa tggcacatta tctctacctg aagctgttat gatgatggtt 1080
cctgaagcgt atcataagga tatggattct gacctaaaag catggtacga ctgggctgca 1140
tgtctgatgg aaccttggga tggtccagct ttgttaactt tcactgatgg acgttactgt 1200
ggtgctatat tggatagaaa tggtttaaga ccttgtcgtt attacatcac tagtgatgac 1260
agagttatct gtgcttcaga ggtaggtgtc attcctatcg aaaattcatt ggttgttcaa 1320
aaaggtaaac tgaagccagg tgatttattc ctagtggata ctcaattggg tgaaatggtc 1380
gatactaaaa agttaaaatc tcaaatctca aaaagacaag attttaagtc ttggttatcc 1440
aaagtcatca agttagacga cttgttatca aaaaccgcta atttggttcc taaagaattt 1500
atatcacagg attcattgtc tttgaaagtt caaagtgacc cacgtctatt ggccaatggt 1560
tataccttcg aacaagtcac atttctgtta actccaatgg ctttaacagg taaagaagct 1620
ttaggttcga tgggtaacga tgcgccactg gcttgtttaa atgaaaatcc tgtcttactt 1680
tatgattatt tcagacaatt gtttgctcaa gtgaccaatc ctccaattga cccaattcgt 1740
gaagcaaatg ttatgtcgtt agaatgttat gtcggacctc aaggcaacct tttggaaatg 1800
cattcatctc aatgtgatcg tttattattg aaatctccta ttttgcattg gaatgagttc 1860
caagctttga aaaacattga agctgcttac ccatcatggt ctgtagcaga aattgatatc 1920
acattcgaca agagtgaggg tctattgggc tataccgaca caattgataa aatcactaag 1980
ttagcgagcg aagcaattga tgatggtaaa aagatcttaa taattactga caggaaaatg 2040
ggtgccaacc gtgtttccat ctcctctttg attgcaattt catgtattca tcatcaccta 2100
atcagaaaca agcagcgttc ccaagttgct ttgattttgg aaacaggtga agccagagaa 2160
attcaccatt tctgtgtcct actaggttat ggttgtgatg gtgtttatcc atacttagcc 2220
atggaaactt tggtcagaat gaatagagaa ggtctacttc gtaatgtcaa caatgacaat 2280
gatacacttg aggaagggca aatactagaa aattacaagc acgctattga tgcaggtatc 2340
ttgaaggtta tgtctaaaat gggtatctcc actctagcat cctacaaagg tgctcaaatt 2400
tttgaagccc taggtttaga taactctatt gttgatttgt gtttcacagg tacttcttcc 2460
agaattagag gtgtaacttt cgagtatttg gctcaagatg ccttttcttt acatgagcgt 2520
ggttatccat ccagacaaac cattagtaaa tctgttaact taccagaaag tggtgaatac 2580
cactttaggg atggtggtta caaacacgtc aacgaaccaa ccgcaattgc ttcgttacaa 2640
gatactgtca gaaacaaaaa tgatgtctct tggcaattat atgtaaagaa ggaaatggaa 2700
gcaattagag actgtacact aagaggactg ttagaattag attttgaaaa ttctgtcagt 2760
atccctctag aacaagttga accatggact gaaattgcca gaagatttgc gtcaggtgca 2820
atgtcttatg gttctatttc tatggaagct cactctacat tggctattgc catgaatcgt 2880
ttaggggcca aatccaattg tggtgaaggt ggtgaagacg cagaacgttc tgctgttcaa 2940
gaaaacggtg atactatgag atctgctatc aaacaagttg cttccgctag attcggtgta 3000
acttcatact acttgtcaga tgctgatgaa atccaaatta agattgctca gggtgctaag 3060
ccgggtgaag gtggtgaact accagcccac aaagtgtcta aggatatcgc aaaaaccagg 3120
cactccaccc ctaatgttgg gttaatctct cctcctcctc atcacgatat ttattccatt 3180
gaagatttga aacaactgat ttatgatttg aaatgtgcta atccaagagc gggaatttct 3240
gtaaagttgg tttccgaagt tggtgttggt attgttgcct ctggtgtagc taaggctaaa 3300
gccgatcata tcttagtttc tggtcatgat ggtggtacag gtgctgcaag atggacgagt 3360
gtcaaatatg cgggtttgcc atgggaatta ggtctagctg aaactcacca gactttagtc 3420
ttgaatgatt taagacgtaa tgttgttgtc caaaccgatg gtcaattgag aactgggttt 3480
gatattgctg ttgcagtttt attaggggca gaatctttta ccttggcaac agttccatta 3540
attgctatgg gttgtgttat gttaagaaga tgtcacttga actcttgtgc tgttggtatt 3600
gccacacaag atccatattt gagaagtaag tttaagggtc agcccgaaca tgttatcaac 3660
ttcttctatt acttgatcca agatttaaga caaatcatgg ccaagttagg attccgtacc 3720
attgacgaaa tggtgggtca ttctgaaaaa ttaaagaaaa gggacgacgt aaatgccaaa 3780
gccataaata tcgatttatc tcctattttg accccagcac atgttattcg tccaggtgtt 3840
ccaaccaagt tcactaagaa acaagaccac aaactccaca cccgtctaga taataagtta 3900
atcgatgagg ctgaagttac tttggatcgt ggcttaccag tgaatattga cgcctctata 3960
atcaatactg atcgtgcact cggttctact ttatcttaca gagtctcgaa gaaatttggt 4020
gaagatggtt tgccaaagga caccgttgtc gttaacatag aaggttcagc gggtcaatct 4080
tttggtgctt tcctagcttc tggtatcact tttatcttga atggtgatgc taatgattat 4140
gttggtaaag gtttatccgg tggtattatt gtcattaaac caccaaagga ttctaaattc 4200
aagagtgatg aaaatgtaat tgttggtaac acttgtttct atggtgctac ttctggtact 4260
gcattcattt caggtagtgc cggtgagcgt ttcggtgtca gaaactctgg tgccaccatc 4320
gttgttgaga gaattaaggg taacaatgcc tttgagtata tgactggtgg tcgtgccatt 4380
gtcttatcac aaatggaatc cctaaacgcc ttctctggtg ctactggtgg tattgcatac 4440
tgtttaactt ccgattacga cgattttgtt ggaaagatta acaaagatac tgttgagtta 4500
gaatcattat gtgacccggt cgagattgcg tttgttaaga atttgatcca ggagcattgg 4560
aactacacac aatctgatct agcagccagg attctcggta atttcaacca ttatttgaaa 4620
gatttcgtta aagtcattcc aactgattat aagaaagttt tgttgaagga gaaagcagaa 4680
gctgccaagg caaaggctaa ggcaacttca gaatacttaa agaagtttag atcgaaccaa 4740
gaagttgatg acgaagtcaa tactctattg attgctaatc aaaaagctaa agagcaagaa 4800
aaaaagaaga gtattactat ttcaaataag gccactttga aggagcctaa ggttgttgat 4860
ttagaagatg cagttccaga ttccaaacag ctagagaaga atagcgaaag gattgaaaaa 4920
acacgtggtt ttatgatcca caaacgtcgt catgagacac acagagatcc aagaaccaga 4980
gttaatgact ggaaagaatt tactaaccct attaccaaga aggatgccaa atatcaaact 5040
gcgagatgta tggattgtgg tacaccattc tgtttatctg ataccggttg tcccctatct 5100
aacattatcc ccaagtttaa tgaattgtta ttcaagaacc aatggaagtt ggcactggac 5160
aaattgctag agacaaacaa tttcccagaa ttcactggaa gagtatgtcc agcaccctgt 5220
gagggagctt gtacactagg tattattgaa gacccagtcg gcataaaatc ggttgaaaga 5280
attatcattg acaatgcttt caaggaagga tggattaagc cttgtccacc aagtacacgc 5340
actggcttta cagtgggtgt cattggttct ggtccagcag gtttagcgtg tgctgatatg 5400
ttgaaccgtg ccggacatac ggtcactgtt tatgaaagat ccgaccgttg tggtgggtta 5460
ttgatgtatg gtattccaaa catgaagttg gataaggcta tagtgcaacg tcgtattgat 5520
ctattgagtg ccgaaggtat tgactttgtt accaacaccg aaattggtaa aaccataagc 5580
atggatgagc taaagaacaa gcacaatgca gtagtgtatg ctatcggttc taccattcca 5640
cgtgacttac ctattaaggg tcgtgaattg aagaatattg attttgccat gcagttgttg 5700
gaatctaaca caaaagcttt attgaacaaa gatctggaaa tcattcgtga aaagatccaa 5760
ggtaagaaag taattgttgt cggtggtggt gacacaggta acgattgttt aggtacatct 5820
gtaagacacg gtgcagcatc agttttgaat ttcgaattgt tgcctgagcc accagtggaa 5880
cgtgccaaag acaatccatg gcctcaatgg ccgcgtgtca tgagagtgga ctacggtcat 5940
gctgaagtga aagagcatta tggtagagac cctcgtgaat actgcatctt gtccaaggaa 6000
tttatcggta acgatgaggg tgaagtcact gccatcagaa ctgtgcgcgt agaatggaag 6060
aagtcacaaa gtggcgtatg gcaaatggta gaaattccca acagtgaaga gatctttgaa 6120
gccgatatca ttttgttgtc tatgggtttc gtgggtcctg aattgatcaa tggcaacgat 6180
aacgaagtta agaagacaag acgtggtacg attgccacac tcgacgactc ctcatactct 6240
attgatggag gaaagacttt tgcatgtggt gactgtagaa gagggcaatc tttgattgtc 6300
tgggccatcc aagaaggtag aaaatgtgct gcctctgtcg ataagttcct aatggacggc 6360
actacgtatc taccaagtaa tggtggtatc gttcaacgtg attacaaact attgaaagaa 6420
ttagctagtc aagtctaa 6438
<210> 99
<211> 2145
<212> БЕЛОК
<213> Saccharomyces cerevisiae
<220>
<223> Аминокислотная последовательность глутаматсинтазы (GLT1)
<220>
<223> Аминокислотная последовательность глутаматсинтазы (GLT1)
<400> 99
Met Pro Val Leu Lys Ser Asp Asn Phe Asp Pro Leu Glu Glu Ala Tyr
1 5 10 15
Glu Gly Gly Thr Ile Gln Asn Tyr Asn Asp Glu His His Leu His Lys
20 25 30
Ser Trp Ala Asn Val Ile Pro Asp Lys Arg Gly Leu Tyr Asp Pro Asp
35 40 45
Tyr Glu His Asp Ala Cys Gly Val Gly Phe Val Ala Asn Lys His Gly
50 55 60
Glu Gln Ser His Lys Ile Val Thr Asp Ala Arg Tyr Leu Leu Val Asn
65 70 75 80
Met Thr His Arg Gly Ala Val Ser Ser Asp Gly Asn Gly Asp Gly Ala
85 90 95
Gly Ile Leu Leu Gly Ile Pro His Glu Phe Met Lys Arg Glu Phe Lys
100 105 110
Leu Asp Leu Asp Leu Asp Ile Pro Glu Met Gly Lys Tyr Ala Val Gly
115 120 125
Asn Val Phe Phe Lys Lys Asn Glu Lys Asn Asn Lys Lys Asn Leu Ile
130 135 140
Lys Cys Gln Lys Ile Phe Glu Asp Leu Ala Ala Ser Phe Asn Leu Ser
145 150 155 160
Val Leu Gly Trp Arg Asn Val Pro Val Asp Ser Thr Ile Leu Gly Asp
165 170 175
Val Ala Leu Ser Arg Glu Pro Thr Ile Leu Gln Pro Leu Leu Val Pro
180 185 190
Leu Tyr Asp Glu Lys Gln Pro Glu Phe Asn Glu Thr Lys Phe Arg Thr
195 200 205
Gln Leu Tyr Leu Leu Arg Lys Glu Ala Ser Leu Gln Ile Gly Leu Glu
210 215 220
Asn Trp Phe Tyr Val Cys Ser Leu Asn Asn Thr Thr Ile Val Tyr Lys
225 230 235 240
Gly Gln Leu Thr Pro Ala Gln Val Tyr Asn Tyr Tyr Pro Asp Leu Thr
245 250 255
Asn Ala His Phe Lys Ser His Met Ala Leu Val His Ser Arg Phe Ser
260 265 270
Thr Asn Thr Phe Pro Ser Trp Asp Arg Ala Gln Pro Leu Arg Trp Leu
275 280 285
Ala His Asn Gly Glu Ile Asn Thr Leu Arg Gly Asn Lys Asn Trp Met
290 295 300
Arg Ser Arg Glu Gly Val Met Asn Ser Ala Thr Phe Lys Asp Glu Leu
305 310 315 320
Asp Lys Leu Tyr Pro Ile Ile Glu Glu Gly Gly Ser Asp Ser Ala Ala
325 330 335
Leu Asp Asn Val Leu Glu Leu Leu Thr Ile Asn Gly Thr Leu Ser Leu
340 345 350
Pro Glu Ala Val Met Met Met Val Pro Glu Ala Tyr His Lys Asp Met
355 360 365
Asp Ser Asp Leu Lys Ala Trp Tyr Asp Trp Ala Ala Cys Leu Met Glu
370 375 380
Pro Trp Asp Gly Pro Ala Leu Leu Thr Phe Thr Asp Gly Arg Tyr Cys
385 390 395 400
Gly Ala Ile Leu Asp Arg Asn Gly Leu Arg Pro Cys Arg Tyr Tyr Ile
405 410 415
Thr Ser Asp Asp Arg Val Ile Cys Ala Ser Glu Val Gly Val Ile Pro
420 425 430
Ile Glu Asn Ser Leu Val Val Gln Lys Gly Lys Leu Lys Pro Gly Asp
435 440 445
Leu Phe Leu Val Asp Thr Gln Leu Gly Glu Met Val Asp Thr Lys Lys
450 455 460
Leu Lys Ser Gln Ile Ser Lys Arg Gln Asp Phe Lys Ser Trp Leu Ser
465 470 475 480
Lys Val Ile Lys Leu Asp Asp Leu Leu Ser Lys Thr Ala Asn Leu Val
485 490 495
Pro Lys Glu Phe Ile Ser Gln Asp Ser Leu Ser Leu Lys Val Gln Ser
500 505 510
Asp Pro Arg Leu Leu Ala Asn Gly Tyr Thr Phe Glu Gln Val Thr Phe
515 520 525
Leu Leu Thr Pro Met Ala Leu Thr Gly Lys Glu Ala Leu Gly Ser Met
530 535 540
Gly Asn Asp Ala Pro Leu Ala Cys Leu Asn Glu Asn Pro Val Leu Leu
545 550 555 560
Tyr Asp Tyr Phe Arg Gln Leu Phe Ala Gln Val Thr Asn Pro Pro Ile
565 570 575
Asp Pro Ile Arg Glu Ala Asn Val Met Ser Leu Glu Cys Tyr Val Gly
580 585 590
Pro Gln Gly Asn Leu Leu Glu Met His Ser Ser Gln Cys Asp Arg Leu
595 600 605
Leu Leu Lys Ser Pro Ile Leu His Trp Asn Glu Phe Gln Ala Leu Lys
610 615 620
Asn Ile Glu Ala Ala Tyr Pro Ser Trp Ser Val Ala Glu Ile Asp Ile
625 630 635 640
Thr Phe Asp Lys Ser Glu Gly Leu Leu Gly Tyr Thr Asp Thr Ile Asp
645 650 655
Lys Ile Thr Lys Leu Ala Ser Glu Ala Ile Asp Asp Gly Lys Lys Ile
660 665 670
Leu Ile Ile Thr Asp Arg Lys Met Gly Ala Asn Arg Val Ser Ile Ser
675 680 685
Ser Leu Ile Ala Ile Ser Cys Ile His His His Leu Ile Arg Asn Lys
690 695 700
Gln Arg Ser Gln Val Ala Leu Ile Leu Glu Thr Gly Glu Ala Arg Glu
705 710 715 720
Ile His His Phe Cys Val Leu Leu Gly Tyr Gly Cys Asp Gly Val Tyr
725 730 735
Pro Tyr Leu Ala Met Glu Thr Leu Val Arg Met Asn Arg Glu Gly Leu
740 745 750
Leu Arg Asn Val Asn Asn Asp Asn Asp Thr Leu Glu Glu Gly Gln Ile
755 760 765
Leu Glu Asn Tyr Lys His Ala Ile Asp Ala Gly Ile Leu Lys Val Met
770 775 780
Ser Lys Met Gly Ile Ser Thr Leu Ala Ser Tyr Lys Gly Ala Gln Ile
785 790 795 800
Phe Glu Ala Leu Gly Leu Asp Asn Ser Ile Val Asp Leu Cys Phe Thr
805 810 815
Gly Thr Ser Ser Arg Ile Arg Gly Val Thr Phe Glu Tyr Leu Ala Gln
820 825 830
Asp Ala Phe Ser Leu His Glu Arg Gly Tyr Pro Ser Arg Gln Thr Ile
835 840 845
Ser Lys Ser Val Asn Leu Pro Glu Ser Gly Glu Tyr His Phe Arg Asp
850 855 860
Gly Gly Tyr Lys His Val Asn Glu Pro Thr Ala Ile Ala Ser Leu Gln
865 870 875 880
Asp Thr Val Arg Asn Lys Asn Asp Val Ser Trp Gln Leu Tyr Val Lys
885 890 895
Lys Glu Met Glu Ala Ile Arg Asp Cys Thr Leu Arg Gly Leu Leu Glu
900 905 910
Leu Asp Phe Glu Asn Ser Val Ser Ile Pro Leu Glu Gln Val Glu Pro
915 920 925
Trp Thr Glu Ile Ala Arg Arg Phe Ala Ser Gly Ala Met Ser Tyr Gly
930 935 940
Ser Ile Ser Met Glu Ala His Ser Thr Leu Ala Ile Ala Met Asn Arg
945 950 955 960
Leu Gly Ala Lys Ser Asn Cys Gly Glu Gly Gly Glu Asp Ala Glu Arg
965 970 975
Ser Ala Val Gln Glu Asn Gly Asp Thr Met Arg Ser Ala Ile Lys Gln
980 985 990
Val Ala Ser Ala Arg Phe Gly Val Thr Ser Tyr Tyr Leu Ser Asp Ala
995 1000 1005
Asp Glu Ile Gln Ile Lys Ile Ala Gln Gly Ala Lys Pro Gly Glu Gly
1010 1015 1020
Gly Glu Leu Pro Ala His Lys Val Ser Lys Asp Ile Ala Lys Thr Arg
1025 1030 1035 1040
His Ser Thr Pro Asn Val Gly Leu Ile Ser Pro Pro Pro His His Asp
1045 1050 1055
Ile Tyr Ser Ile Glu Asp Leu Lys Gln Leu Ile Tyr Asp Leu Lys Cys
1060 1065 1070
Ala Asn Pro Arg Ala Gly Ile Ser Val Lys Leu Val Ser Glu Val Gly
1075 1080 1085
Val Gly Ile Val Ala Ser Gly Val Ala Lys Ala Lys Ala Asp His Ile
1090 1095 1100
Leu Val Ser Gly His Asp Gly Gly Thr Gly Ala Ala Arg Trp Thr Ser
1105 1110 1115 1120
Val Lys Tyr Ala Gly Leu Pro Trp Glu Leu Gly Leu Ala Glu Thr His
1125 1130 1135
Gln Thr Leu Val Leu Asn Asp Leu Arg Arg Asn Val Val Val Gln Thr
1140 1145 1150
Asp Gly Gln Leu Arg Thr Gly Phe Asp Ile Ala Val Ala Val Leu Leu
1155 1160 1165
Gly Ala Glu Ser Phe Thr Leu Ala Thr Val Pro Leu Ile Ala Met Gly
1170 1175 1180
Cys Val Met Leu Arg Arg Cys His Leu Asn Ser Cys Ala Val Gly Ile
1185 1190 1195 1200
Ala Thr Gln Asp Pro Tyr Leu Arg Ser Lys Phe Lys Gly Gln Pro Glu
1205 1210 1215
His Val Ile Asn Phe Phe Tyr Tyr Leu Ile Gln Asp Leu Arg Gln Ile
1220 1225 1230
Met Ala Lys Leu Gly Phe Arg Thr Ile Asp Glu Met Val Gly His Ser
1235 1240 1245
Glu Lys Leu Lys Lys Arg Asp Asp Val Asn Ala Lys Ala Ile Asn Ile
1250 1255 1260
Asp Leu Ser Pro Ile Leu Thr Pro Ala His Val Ile Arg Pro Gly Val
1265 1270 1275 1280
Pro Thr Lys Phe Thr Lys Lys Gln Asp His Lys Leu His Thr Arg Leu
1285 1290 1295
Asp Asn Lys Leu Ile Asp Glu Ala Glu Val Thr Leu Asp Arg Gly Leu
1300 1305 1310
Pro Val Asn Ile Asp Ala Ser Ile Ile Asn Thr Asp Arg Ala Leu Gly
1315 1320 1325
Ser Thr Leu Ser Tyr Arg Val Ser Lys Lys Phe Gly Glu Asp Gly Leu
1330 1335 1340
Pro Lys Asp Thr Val Val Val Asn Ile Glu Gly Ser Ala Gly Gln Ser
1345 1350 1355 1360
Phe Gly Ala Phe Leu Ala Ser Gly Ile Thr Phe Ile Leu Asn Gly Asp
1365 1370 1375
Ala Asn Asp Tyr Val Gly Lys Gly Leu Ser Gly Gly Ile Ile Val Ile
1380 1385 1390
Lys Pro Pro Lys Asp Ser Lys Phe Lys Ser Asp Glu Asn Val Ile Val
1395 1400 1405
Gly Asn Thr Cys Phe Tyr Gly Ala Thr Ser Gly Thr Ala Phe Ile Ser
1410 1415 1420
Gly Ser Ala Gly Glu Arg Phe Gly Val Arg Asn Ser Gly Ala Thr Ile
1425 1430 1435 1440
Val Val Glu Arg Ile Lys Gly Asn Asn Ala Phe Glu Tyr Met Thr Gly
1445 1450 1455
Gly Arg Ala Ile Val Leu Ser Gln Met Glu Ser Leu Asn Ala Phe Ser
1460 1465 1470
Gly Ala Thr Gly Gly Ile Ala Tyr Cys Leu Thr Ser Asp Tyr Asp Asp
1475 1480 1485
Phe Val Gly Lys Ile Asn Lys Asp Thr Val Glu Leu Glu Ser Leu Cys
1490 1495 1500
Asp Pro Val Glu Ile Ala Phe Val Lys Asn Leu Ile Gln Glu His Trp
1505 1510 1515 1520
Asn Tyr Thr Gln Ser Asp Leu Ala Ala Arg Ile Leu Gly Asn Phe Asn
1525 1530 1535
His Tyr Leu Lys Asp Phe Val Lys Val Ile Pro Thr Asp Tyr Lys Lys
1540 1545 1550
Val Leu Leu Lys Glu Lys Ala Glu Ala Ala Lys Ala Lys Ala Lys Ala
1555 1560 1565
Thr Ser Glu Tyr Leu Lys Lys Phe Arg Ser Asn Gln Glu Val Asp Asp
1570 1575 1580
Glu Val Asn Thr Leu Leu Ile Ala Asn Gln Lys Ala Lys Glu Gln Glu
1585 1590 1595 1600
Lys Lys Lys Ser Ile Thr Ile Ser Asn Lys Ala Thr Leu Lys Glu Pro
1605 1610 1615
Lys Val Val Asp Leu Glu Asp Ala Val Pro Asp Ser Lys Gln Leu Glu
1620 1625 1630
Lys Asn Ser Glu Arg Ile Glu Lys Thr Arg Gly Phe Met Ile His Lys
1635 1640 1645
Arg Arg His Glu Thr His Arg Asp Pro Arg Thr Arg Val Asn Asp Trp
1650 1655 1660
Lys Glu Phe Thr Asn Pro Ile Thr Lys Lys Asp Ala Lys Tyr Gln Thr
1665 1670 1675 1680
Ala Arg Cys Met Asp Cys Gly Thr Pro Phe Cys Leu Ser Asp Thr Gly
1685 1690 1695
Cys Pro Leu Ser Asn Ile Ile Pro Lys Phe Asn Glu Leu Leu Phe Lys
1700 1705 1710
Asn Gln Trp Lys Leu Ala Leu Asp Lys Leu Leu Glu Thr Asn Asn Phe
1715 1720 1725
Pro Glu Phe Thr Gly Arg Val Cys Pro Ala Pro Cys Glu Gly Ala Cys
1730 1735 1740
Thr Leu Gly Ile Ile Glu Asp Pro Val Gly Ile Lys Ser Val Glu Arg
1745 1750 1755 1760
Ile Ile Ile Asp Asn Ala Phe Lys Glu Gly Trp Ile Lys Pro Cys Pro
1765 1770 1775
Pro Ser Thr Arg Thr Gly Phe Thr Val Gly Val Ile Gly Ser Gly Pro
1780 1785 1790
Ala Gly Leu Ala Cys Ala Asp Met Leu Asn Arg Ala Gly His Thr Val
1795 1800 1805
Thr Val Tyr Glu Arg Ser Asp Arg Cys Gly Gly Leu Leu Met Tyr Gly
1810 1815 1820
Ile Pro Asn Met Lys Leu Asp Lys Ala Ile Val Gln Arg Arg Ile Asp
1825 1830 1835 1840
Leu Leu Ser Ala Glu Gly Ile Asp Phe Val Thr Asn Thr Glu Ile Gly
1845 1850 1855
Lys Thr Ile Ser Met Asp Glu Leu Lys Asn Lys His Asn Ala Val Val
1860 1865 1870
Tyr Ala Ile Gly Ser Thr Ile Pro Arg Asp Leu Pro Ile Lys Gly Arg
1875 1880 1885
Glu Leu Lys Asn Ile Asp Phe Ala Met Gln Leu Leu Glu Ser Asn Thr
1890 1895 1900
Lys Ala Leu Leu Asn Lys Asp Leu Glu Ile Ile Arg Glu Lys Ile Gln
1905 1910 1915 1920
Gly Lys Lys Val Ile Val Val Gly Gly Gly Asp Thr Gly Asn Asp Cys
1925 1930 1935
Leu Gly Thr Ser Val Arg His Gly Ala Ala Ser Val Leu Asn Phe Glu
1940 1945 1950
Leu Leu Pro Glu Pro Pro Val Glu Arg Ala Lys Asp Asn Pro Trp Pro
1955 1960 1965
Gln Trp Pro Arg Val Met Arg Val Asp Tyr Gly His Ala Glu Val Lys
1970 1975 1980
Glu His Tyr Gly Arg Asp Pro Arg Glu Tyr Cys Ile Leu Ser Lys Glu
1985 1990 1995 2000
Phe Ile Gly Asn Asp Glu Gly Glu Val Thr Ala Ile Arg Thr Val Arg
2005 2010 2015
Val Glu Trp Lys Lys Ser Gln Ser Gly Val Trp Gln Met Val Glu Ile
2020 2025 2030
Pro Asn Ser Glu Glu Ile Phe Glu Ala Asp Ile Ile Leu Leu Ser Met
2035 2040 2045
Gly Phe Val Gly Pro Glu Leu Ile Asn Gly Asn Asp Asn Glu Val Lys
2050 2055 2060
Lys Thr Arg Arg Gly Thr Ile Ala Thr Leu Asp Asp Ser Ser Tyr Ser
2065 2070 2075 2080
Ile Asp Gly Gly Lys Thr Phe Ala Cys Gly Asp Cys Arg Arg Gly Gln
2085 2090 2095
Ser Leu Ile Val Trp Ala Ile Gln Glu Gly Arg Lys Cys Ala Ala Ser
2100 2105 2110
Val Asp Lys Phe Leu Met Asp Gly Thr Thr Tyr Leu Pro Ser Asn Gly
2115 2120 2125
Gly Ile Val Gln Arg Asp Tyr Lys Leu Leu Lys Glu Leu Ala Ser Gln
2130 2135 2140
Val
2145
<210> 100
<211> 300
<212> ДНК
<213> Saccharomyces cerevisiae
<220>
<223> Нуклеотидная последовательность терминатора tTDH3
<220>
<223> Нуклеотидная последовательность терминатора tTDH3
<400> 100
gtgaatttac tttaaatctt gcatttaaat aaattttctt tttatagctt tatgacttag 60
tttcaattta tatactattt taatgacatt ttcgattcat tgattgaaag ctttgtgttt 120
tttcttgatg cgctattgca ttgttcttgt ctttttcgcc acatgtaata tctgtagtag 180
atacctgata cattgtggat gctgagtgaa attttagtta ataatggagg cgctcttaat 240
aattttgggg atattggctt ttttttttaa agtttacaaa tgaatttttt ccgccaggat 300
<210> 101
<211> 1788
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы CviKI
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы CviKI
<400> 101
atgcttttca gttgtttgtc cttcgtgatc tgccatctta gttttatttt gcgttattac 60
aagaggcttc taaaagtgac gatgggaaag aacattataa taatggtgag ttggtacaca 120
ataataactt ccaacatcat cgccgtcggt ggggcgtctc tgattttggc cccagccatc 180
actggataca tcttgcactg gaacatcgcc ttgtcaacca tctggggagt ttccgcttat 240
gggatattcg tgttcggatt cttcctggct caggttttat ttagtgagct aaatcgtaaa 300
agactaagaa agtggatttc tctaagacca aagggttgga acgacgtacg tctggctgtc 360
atcatagctg gttacaggga agacccgtac atgtttcaga aatgccttga gtcagtaagg 420
gactctgact atggtaatgt cgctcgtctt atctgtgtaa ttgacggaga tgaggacgac 480
gacatgaaga tggcagccgt ttataaggcg atatataatg acaatatcaa gaagccagag 540
tttgtgttat gtgagagcga tgataaggaa ggcgagagaa ttgactcaga ttttagcagg 600
gacatctgcg tcttacaacc acaccgtggc aaaagggagt gcttgtatac cggctttcag 660
ctggccaaaa tggacccgtc ggtaaacgcc gttgttctta ttgactctga cacggtcttg 720
gaaaaggacg caatcttgga agtcgtgtat ccattggcct gtgacccgga aattcaagct 780
gtcgcaggag agtgcaaaat atggaacaca gatacacttt tgtcgttgtt ggtggcttgg 840
agatattatt cagccttttg cgtggagaga tccgcccaat cattctttag gacagtccag 900
tgtgtaggtg gacccttggg cgcctacaag atagatatca tcaaagagat caaagatccc 960
tggatctccc aacgtttctt aggtcagaag tgcacctacg gtgacgaccg taggttaaca 1020
aatgaaatct taatgagggg taagaaggtc gtcttcactc ctttcgcagt tggctggagt 1080
gactcaccaa ccaacgtgtt caggtacatc gtacaacaga ctaggtggag taaatcatgg 1140
tgccgtgaga tatggtacac tttgtttgct gcgtggaagc acggactaag cggaatttgg 1200
ttggcatttg agtgccttta tcagattacg tacttcttcc tagtcatata tttattttcg 1260
agactagccg ttgaagctga cccaagagca cagaccgcaa cagtaatcgt gtctaccacg 1320
gtagccctga ttaagtgtgg ttacttctct tttcgtgcga aagatattcg tgctttctac 1380
ttcgtcctgt acacatttgt ctacttcttc tgtatgatcc cagcaagggt gacagccatg 1440
atgacacttt gggatatcgg ctggggcacg cgtggcggaa acgagaaacc aagtgtcggc 1500
actagggtcg ctctgtgggc taaacagtat ttgatagcat acatgtggtg ggcagcagtt 1560
gttggcgctg gggtatactc cattgttcat aattggatgt ttgactggaa ctcactatcc 1620
tataggttcg cacttgtagg tatatgctct tacatcgtat tcatcacaat cgttctagtc 1680
atctatttca caggaaagat taccacatgg aatttcacca aattacagaa ggagttaatc 1740
aaggataggg tcttatacga tgcttccact aacgcccaga ctgtataa 1788
<210> 102
<211> 1803
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы IL-5-2s1
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы IL-5-2s1
<400> 102
atggctgctt cattctatgt tatcttcttg ttcgtaatat gccacctgtc cttcgtctta 60
tatcgtcaag ttctatacat aattttgggt agatactgga gtgttaacaa gctgacaatg 120
atctcttggt ataccattat atcatctaat ctaatcgcaa tcggtggggc ttcccttatt 180
ttggcaccgg ccataaccgg ctacattttg cattggaaca tagctctaag cacaatttgg 240
ggtgtgtcag cctatggcat tttcgtgttc gggttctttc ttgctcaggt tttgttcagt 300
gagcttaaca ggaagaggtt gagaaaatgg atctctttga gaccagataa ctggaacgcg 360
gtgagagttg ccgtgataat cgctggttac cgtgaagacc catacatgtt tcaaaagtgt 420
ttggaatcgg tgagagactc cgattatggt aacattgcga ggcttatatg cgttatagat 480
ggggacgaag atgacgacat gaagatggca gatgtataca aggctattta caatgacaat 540
ataaagaagc cggaaattat cctatgtgag tccgacgaca aagagggaga aaggatagac 600
agtgatttta gccgtgatat ttgcgtgctt cagcctcaca gaggtaagcg tgaatgttta 660
tatactggct ttcagttagc taaaatggac ccctctgtac acgcggttgt gcttattgac 720
tcggatacag ttttggagaa ggatgccatc ctggaagtgg tctacccact tgcttgcgac 780
catgagattc aagcagtcgc aggtgaatgc aagatatgga atacggacac cttattatcc 840
atattagtcg cctggcgtta ctactcagct ttctgcgttg agcgtagcgc tcagtccttc 900
ttccgtactg tgcaatgcgt cggcggtccg ttaggggcat acaaaataga cataattaaa 960
gagataaagg agccgtggat ttcacaaaga tttctgggtc agaagtgtac gtacggagat 1020
gacagaagat taactaacga agtgttgatg cgtggaaaga aagtagtctt cacacctttt 1080
gcggtaggat ggagcgactc gcctactaat gtcttccgtt atattgtgca gcagacgagg 1140
tggagtaaga gctggtgcag ggagatttgg tatacactgt tcgcggcgtg gaagcatggg 1200
ttatcaggca tttggttggc atttgagtgc ttgtatcaga tcacatactt ctttctagtg 1260
atatatctgt tcagtagact agcagtcgag gctgacccga gagcgcaaac tgcaacggtt 1320
atagtcagca caatggtttc actaatcaag tgtggatatt tctcattccg tgctaaggac 1380
attagagcgt tttatttcgt actatatact tttgtgtact tcttttgcat gatcccagca 1440
agagtcactg ctatgatgac cttgtgggat attgggtggg gtactagggg tggaaacgtg 1500
aaaccatcga tcggaactag gatctctttg tgggctaagc agtacttaat cgcgtacatg 1560
tggtgggcag ctgtgatcgc cgcaggagtc tatagtataa tacataattg gatgtttgat 1620
tggaactcct tgtcctatcg tttcgcgtta ataggcatct gctcgtatat cgtattcatt 1680
gccattgtta tagtgatata cttcacaggt aagatcacca cttggaattt taccaagcta 1740
cagaaagagt taattgaaga tagagtcttg catgatgccg atgtggacat acagaacgta 1800
taa 1803
<210> 103
<211> 1686
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы CZ-2
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы CZ-2
<400> 103
atgacatctt ggagaacgat tgtgtcagct aaccttttcg cagttggtgg ggctcttcta 60
atgttagccc cagctatcgt gggctatgta tttcagtgga atataggcgt gtccgcagtc 120
tggggcatct ccgtatacgg cgtctttgtg ttgggatttt atatcgctca aatcgtcttc 180
tctgagttca acaggatgag attatccgat tggataagtc ttagaccaga caactggaac 240
gccacaaggg ttgcggtcat tatagctgga tacagagaag atccttttat gttcaagaag 300
tgcttagaga gtgtgaggga ttcggaatac ggcaacgtag caaggcttat atgcgtaatt 360
gacggagacg aagaagagga cctaaagatg gctgagattt acaagcaggt ttacaatgac 420
aacgtgaaga aaccaggtgt agtgttatgc gaatcggaga acaagaatgg atcgactata 480
gattcggacg tatctaagaa tatatgcata ctgcaacccc accgtgggaa acgtgagagc 540
ctatataccg gtttccaatt ggcaagcatg gacccttccg tacatgcggt tgttcttata 600
gattccgaca ctgtattaga gaagaatgct attcttgagg tcgtataccc tctatcttgt 660
gaccccaaca ttaaggccgt cgccggggag tgcaagatat ggaatacaga caccatcttg 720
tccatgcttg tctcttggag atacttctct gccttcaatg tcgagcgtgg agcccagtca 780
ttatggaaga ctgtgcaatg cgtaggcggg ccacttggcg catacactat cgacatcata 840
aatgaaatta aagacccgtg gattacccag acattcctgg gcaacaagtg cacttatggc 900
gacgatagac gtcttaccaa tgaggtttta atgaggggca agaagattgt atacactccg 960
tttgccgtcg gttggagcga cagtccgacg aatgtcatga ggtacattgt gcagcaaact 1020
agatggagta agtcatggtg cagagagata tggtacacgt taggcagtgc ctggaaacat 1080
ggattctccg gcatatacct tgcgtttgag tgtatgtacc agataatgta cttcttctta 1140
gtcatgtacc tgttttcgta tatcgcaata aaggcagaca tccgtgctca gactgcaact 1200
gtgttggttt ctactctagt caccataata aagagcagtt acctagcgct gagggccaag 1260
aacctgaagg ctttctattt cgttctgtat acctatgtct atttcttttg catgatacct 1320
gctaggatta ccgctatgtt tacaatgttt gatatagctt ggggtacacg tggtggtaat 1380
gcgaaaatga caatcggggc tagagtttgg ctgtgggcga agcagttctt aataacttat 1440
atgtggtggg caggagtact agcggcggga gtttacagta tagttgacaa ttggtacttc 1500
gattgggctg atatacagta caggtttgca ttggtaggta tttgctcgta tttggtcttt 1560
gtcagtattg tactggtaat ctacttgatc ggtaagataa caacgtggaa ctacacaccg 1620
ctacagaagg aacttattga ggagagatac ttgcataacg cctctgagaa tgccccggaa 1680
gtttaa 1686
<210> 104
<211> 1677
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы CVG-1
<220>
<223> Перекодированная нуклеотидная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы CVG-1
<400> 104
atgacttctt ggcgtacaat tgtttctgct aacttgttcg cagttggtgg cgccttgttg 60
atgttagctc ccgcgatagc cggttatgta tttaaatgga acataggcgt ttctgccgtt 120
tggggtattt cagtgtacgg ggtcttcgtg cttggtttct atattgcaca ggtagtcttc 180
agcgagttta ataggatgca gctgtcagac tggatctcat tgagacccga caactggaac 240
gccaccagag tagcggtaat tattgctggt tacagggaag acccctttat gttcaagaag 300
tgcctagaat ctgtgagaga ctcagaatac gggaacatag cgaggctaat ctgtgttatc 360
gacggcgatg aagaggaaga ccttaagatg gctgagatat acaagcaagt atacaacgac 420
aacgtcaaga cccccggtgt tgtgctatgc gagaatgaaa ataagaatgg tagcaccatt 480
gacccagatt ttagtaagaa catctgcatt ctgcaaccac acaggggcaa acgtgaatct 540
ttgtacaccg gattccagat ggctggcatg gacccatcag tgcacgcagt tgtacttata 600
gacagtgata ctgttcttga aaagaacgct atcctagagg ttgtgtaccc tctatcttgt 660
gatccaaata tcaaagctgt cgcgggagag tgtaaaatct ggaacacaga taccattttg 720
tctatgctag tttcatggcg ttatttctcg gctttcaacg tggagagagg cgcacagtcc 780
ctttggaaaa cagtccagtg tgtcggcggg cctttgggag catacactat agacatcata 840
aacgagataa aagacccctg gattactcag acattcttag gaaacaaatg tacgtatggt 900
gacgacagaa ggttaaccaa tgaagtgctt atgaggggaa agaagattgt ctatactccc 960
tttgctgtcg gttggtccga ttcgcccaca aacgttatga ggtacatcgt ccagcagaca 1020
aggtggtcta agagctggtg ccgtgagatt tggtacacct tgggatcagc atggaaacat 1080
ggtttctccg gaatctactt agcgttcgag tgcatgtacc agattatgta tttctttatt 1140
gtgatgtatt tgttcagtta cattgccatt aaagccaaca tcagggcaca agcagccacg 1200
gtattggtca gtacgcttgt cgcagtaatc aaatctagtt atttggcatt aagagcgaag 1260
aacctaaaag ctttgtattt cgtcctgtat acctacgtct acttcttctg catgattcca 1320
gctagaataa cagcgatgtt cacgatgttc gatattgcat ggggtactag aggcggtaac 1380
gcaaagatga cgatcggtgc tagagtctgg ttgtgggcta aacaattctt aattacatac 1440
atgtggtggg tgggagtttt ggccgctggg gtctacagta tagtcgataa ctggtacttc 1500
gactgggcgg acatccagta cagattcgcg ctagtgggga tttgcagtta cttaggtttc 1560
gtttccataa tgctggtatt ctatctgatt ggtaaaataa ctacgtggaa ttacactcct 1620
ctacaaaagg agctgattaa agagaggtta cacgccgcta atgcaacaga ggtctaa 1677
<210> 105
<211> 595
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы CviKI
<220>
<223> Аминокислотная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы CviKI
<400> 105
Met Leu Phe Ser Cys Leu Ser Phe Val Ile Cys His Leu Ser Phe Ile
1 5 10 15
Leu Arg Tyr Tyr Lys Arg Leu Leu Lys Val Thr Met Gly Lys Asn Ile
20 25 30
Ile Ile Met Val Ser Trp Tyr Thr Ile Ile Thr Ser Asn Ile Ile Ala
35 40 45
Val Gly Gly Ala Ser Leu Ile Leu Ala Pro Ala Ile Thr Gly Tyr Ile
50 55 60
Leu His Trp Asn Ile Ala Leu Ser Thr Ile Trp Gly Val Ser Ala Tyr
65 70 75 80
Gly Ile Phe Val Phe Gly Phe Phe Leu Ala Gln Val Leu Phe Ser Glu
85 90 95
Leu Asn Arg Lys Arg Leu Arg Lys Trp Ile Ser Leu Arg Pro Lys Gly
100 105 110
Trp Asn Asp Val Arg Leu Ala Val Ile Ile Ala Gly Tyr Arg Glu Asp
115 120 125
Pro Tyr Met Phe Gln Lys Cys Leu Glu Ser Val Arg Asp Ser Asp Tyr
130 135 140
Gly Asn Val Ala Arg Leu Ile Cys Val Ile Asp Gly Asp Glu Asp Asp
145 150 155 160
Asp Met Lys Met Ala Ala Val Tyr Lys Ala Ile Tyr Asn Asp Asn Ile
165 170 175
Lys Lys Pro Glu Phe Val Leu Cys Glu Ser Asp Asp Lys Glu Gly Glu
180 185 190
Arg Ile Asp Ser Asp Phe Ser Arg Asp Ile Cys Val Leu Gln Pro His
195 200 205
Arg Gly Lys Arg Glu Cys Leu Tyr Thr Gly Phe Gln Leu Ala Lys Met
210 215 220
Asp Pro Ser Val Asn Ala Val Val Leu Ile Asp Ser Asp Thr Val Leu
225 230 235 240
Glu Lys Asp Ala Ile Leu Glu Val Val Tyr Pro Leu Ala Cys Asp Pro
245 250 255
Glu Ile Gln Ala Val Ala Gly Glu Cys Lys Ile Trp Asn Thr Asp Thr
260 265 270
Leu Leu Ser Leu Leu Val Ala Trp Arg Tyr Tyr Ser Ala Phe Cys Val
275 280 285
Glu Arg Ser Ala Gln Ser Phe Phe Arg Thr Val Gln Cys Val Gly Gly
290 295 300
Pro Leu Gly Ala Tyr Lys Ile Asp Ile Ile Lys Glu Ile Lys Asp Pro
305 310 315 320
Trp Ile Ser Gln Arg Phe Leu Gly Gln Lys Cys Thr Tyr Gly Asp Asp
325 330 335
Arg Arg Leu Thr Asn Glu Ile Leu Met Arg Gly Lys Lys Val Val Phe
340 345 350
Thr Pro Phe Ala Val Gly Trp Ser Asp Ser Pro Thr Asn Val Phe Arg
355 360 365
Tyr Ile Val Gln Gln Thr Arg Trp Ser Lys Ser Trp Cys Arg Glu Ile
370 375 380
Trp Tyr Thr Leu Phe Ala Ala Trp Lys His Gly Leu Ser Gly Ile Trp
385 390 395 400
Leu Ala Phe Glu Cys Leu Tyr Gln Ile Thr Tyr Phe Phe Leu Val Ile
405 410 415
Tyr Leu Phe Ser Arg Leu Ala Val Glu Ala Asp Pro Arg Ala Gln Thr
420 425 430
Ala Thr Val Ile Val Ser Thr Thr Val Ala Leu Ile Lys Cys Gly Tyr
435 440 445
Phe Ser Phe Arg Ala Lys Asp Ile Arg Ala Phe Tyr Phe Val Leu Tyr
450 455 460
Thr Phe Val Tyr Phe Phe Cys Met Ile Pro Ala Arg Val Thr Ala Met
465 470 475 480
Met Thr Leu Trp Asp Ile Gly Trp Gly Thr Arg Gly Gly Asn Glu Lys
485 490 495
Pro Ser Val Gly Thr Arg Val Ala Leu Trp Ala Lys Gln Tyr Leu Ile
500 505 510
Ala Tyr Met Trp Trp Ala Ala Val Val Gly Ala Gly Val Tyr Ser Ile
515 520 525
Val His Asn Trp Met Phe Asp Trp Asn Ser Leu Ser Tyr Arg Phe Ala
530 535 540
Leu Val Gly Ile Cys Ser Tyr Ile Val Phe Ile Thr Ile Val Leu Val
545 550 555 560
Ile Tyr Phe Thr Gly Lys Ile Thr Thr Trp Asn Phe Thr Lys Leu Gln
565 570 575
Lys Glu Leu Ile Lys Asp Arg Val Leu Tyr Asp Ala Ser Thr Asn Ala
580 585 590
Gln Thr Val
595
<210> 106
<211> 600
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы IL-5-2s1
<220>
<223> Аминокислотная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы IL-5-2s1
<400> 106
Met Ala Ala Ser Phe Tyr Val Ile Phe Leu Phe Val Ile Cys His Leu
1 5 10 15
Ser Phe Val Leu Tyr Arg Gln Val Leu Tyr Ile Ile Leu Gly Arg Tyr
20 25 30
Trp Ser Val Asn Lys Leu Thr Met Ile Ser Trp Tyr Thr Ile Ile Ser
35 40 45
Ser Asn Leu Ile Ala Ile Gly Gly Ala Ser Leu Ile Leu Ala Pro Ala
50 55 60
Ile Thr Gly Tyr Ile Leu His Trp Asn Ile Ala Leu Ser Thr Ile Trp
65 70 75 80
Gly Val Ser Ala Tyr Gly Ile Phe Val Phe Gly Phe Phe Leu Ala Gln
85 90 95
Val Leu Phe Ser Glu Leu Asn Arg Lys Arg Leu Arg Lys Trp Ile Ser
100 105 110
Leu Arg Pro Asp Asn Trp Asn Ala Val Arg Val Ala Val Ile Ile Ala
115 120 125
Gly Tyr Arg Glu Asp Pro Tyr Met Phe Gln Lys Cys Leu Glu Ser Val
130 135 140
Arg Asp Ser Asp Tyr Gly Asn Ile Ala Arg Leu Ile Cys Val Ile Asp
145 150 155 160
Gly Asp Glu Asp Asp Asp Met Lys Met Ala Asp Val Tyr Lys Ala Ile
165 170 175
Tyr Asn Asp Asn Ile Lys Lys Pro Glu Ile Ile Leu Cys Glu Ser Asp
180 185 190
Asp Lys Glu Gly Glu Arg Ile Asp Ser Asp Phe Ser Arg Asp Ile Cys
195 200 205
Val Leu Gln Pro His Arg Gly Lys Arg Glu Cys Leu Tyr Thr Gly Phe
210 215 220
Gln Leu Ala Lys Met Asp Pro Ser Val His Ala Val Val Leu Ile Asp
225 230 235 240
Ser Asp Thr Val Leu Glu Lys Asp Ala Ile Leu Glu Val Val Tyr Pro
245 250 255
Leu Ala Cys Asp His Glu Ile Gln Ala Val Ala Gly Glu Cys Lys Ile
260 265 270
Trp Asn Thr Asp Thr Leu Leu Ser Ile Leu Val Ala Trp Arg Tyr Tyr
275 280 285
Ser Ala Phe Cys Val Glu Arg Ser Ala Gln Ser Phe Phe Arg Thr Val
290 295 300
Gln Cys Val Gly Gly Pro Leu Gly Ala Tyr Lys Ile Asp Ile Ile Lys
305 310 315 320
Glu Ile Lys Glu Pro Trp Ile Ser Gln Arg Phe Leu Gly Gln Lys Cys
325 330 335
Thr Tyr Gly Asp Asp Arg Arg Leu Thr Asn Glu Val Leu Met Arg Gly
340 345 350
Lys Lys Val Val Phe Thr Pro Phe Ala Val Gly Trp Ser Asp Ser Pro
355 360 365
Thr Asn Val Phe Arg Tyr Ile Val Gln Gln Thr Arg Trp Ser Lys Ser
370 375 380
Trp Cys Arg Glu Ile Trp Tyr Thr Leu Phe Ala Ala Trp Lys His Gly
385 390 395 400
Leu Ser Gly Ile Trp Leu Ala Phe Glu Cys Leu Tyr Gln Ile Thr Tyr
405 410 415
Phe Phe Leu Val Ile Tyr Leu Phe Ser Arg Leu Ala Val Glu Ala Asp
420 425 430
Pro Arg Ala Gln Thr Ala Thr Val Ile Val Ser Thr Met Val Ser Leu
435 440 445
Ile Lys Cys Gly Tyr Phe Ser Phe Arg Ala Lys Asp Ile Arg Ala Phe
450 455 460
Tyr Phe Val Leu Tyr Thr Phe Val Tyr Phe Phe Cys Met Ile Pro Ala
465 470 475 480
Arg Val Thr Ala Met Met Thr Leu Trp Asp Ile Gly Trp Gly Thr Arg
485 490 495
Gly Gly Asn Val Lys Pro Ser Ile Gly Thr Arg Ile Ser Leu Trp Ala
500 505 510
Lys Gln Tyr Leu Ile Ala Tyr Met Trp Trp Ala Ala Val Ile Ala Ala
515 520 525
Gly Val Tyr Ser Ile Ile His Asn Trp Met Phe Asp Trp Asn Ser Leu
530 535 540
Ser Tyr Arg Phe Ala Leu Ile Gly Ile Cys Ser Tyr Ile Val Phe Ile
545 550 555 560
Ala Ile Val Ile Val Ile Tyr Phe Thr Gly Lys Ile Thr Thr Trp Asn
565 570 575
Phe Thr Lys Leu Gln Lys Glu Leu Ile Glu Asp Arg Val Leu His Asp
580 585 590
Ala Asp Val Asp Ile Gln Asn Val
595 600
<210> 107
<211> 561
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы CZ-2
<220>
<223> Аминокислотная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы CZ-2
<400> 107
Met Thr Ser Trp Arg Thr Ile Val Ser Ala Asn Leu Phe Ala Val Gly
1 5 10 15
Gly Ala Leu Leu Met Leu Ala Pro Ala Ile Val Gly Tyr Val Phe Gln
20 25 30
Trp Asn Ile Gly Val Ser Ala Val Trp Gly Ile Ser Val Tyr Gly Val
35 40 45
Phe Val Leu Gly Phe Tyr Ile Ala Gln Ile Val Phe Ser Glu Phe Asn
50 55 60
Arg Met Arg Leu Ser Asp Trp Ile Ser Leu Arg Pro Asp Asn Trp Asn
65 70 75 80
Ala Thr Arg Val Ala Val Ile Ile Ala Gly Tyr Arg Glu Asp Pro Phe
85 90 95
Met Phe Lys Lys Cys Leu Glu Ser Val Arg Asp Ser Glu Tyr Gly Asn
100 105 110
Val Ala Arg Leu Ile Cys Val Ile Asp Gly Asp Glu Glu Glu Asp Leu
115 120 125
Lys Met Ala Glu Ile Tyr Lys Gln Val Tyr Asn Asp Asn Val Lys Lys
130 135 140
Pro Gly Val Val Leu Cys Glu Ser Glu Asn Lys Asn Gly Ser Thr Ile
145 150 155 160
Asp Ser Asp Val Ser Lys Asn Ile Cys Ile Leu Gln Pro His Arg Gly
165 170 175
Lys Arg Glu Ser Leu Tyr Thr Gly Phe Gln Leu Ala Ser Met Asp Pro
180 185 190
Ser Val His Ala Val Val Leu Ile Asp Ser Asp Thr Val Leu Glu Lys
195 200 205
Asn Ala Ile Leu Glu Val Val Tyr Pro Leu Ser Cys Asp Pro Asn Ile
210 215 220
Lys Ala Val Ala Gly Glu Cys Lys Ile Trp Asn Thr Asp Thr Ile Leu
225 230 235 240
Ser Met Leu Val Ser Trp Arg Tyr Phe Ser Ala Phe Asn Val Glu Arg
245 250 255
Gly Ala Gln Ser Leu Trp Lys Thr Val Gln Cys Val Gly Gly Pro Leu
260 265 270
Gly Ala Tyr Thr Ile Asp Ile Ile Asn Glu Ile Lys Asp Pro Trp Ile
275 280 285
Thr Gln Thr Phe Leu Gly Asn Lys Cys Thr Tyr Gly Asp Asp Arg Arg
290 295 300
Leu Thr Asn Glu Val Leu Met Arg Gly Lys Lys Ile Val Tyr Thr Pro
305 310 315 320
Phe Ala Val Gly Trp Ser Asp Ser Pro Thr Asn Val Met Arg Tyr Ile
325 330 335
Val Gln Gln Thr Arg Trp Ser Lys Ser Trp Cys Arg Glu Ile Trp Tyr
340 345 350
Thr Leu Gly Ser Ala Trp Lys His Gly Phe Ser Gly Ile Tyr Leu Ala
355 360 365
Phe Glu Cys Met Tyr Gln Ile Met Tyr Phe Phe Leu Val Met Tyr Leu
370 375 380
Phe Ser Tyr Ile Ala Ile Lys Ala Asp Ile Arg Ala Gln Thr Ala Thr
385 390 395 400
Val Leu Val Ser Thr Leu Val Thr Ile Ile Lys Ser Ser Tyr Leu Ala
405 410 415
Leu Arg Ala Lys Asn Leu Lys Ala Phe Tyr Phe Val Leu Tyr Thr Tyr
420 425 430
Val Tyr Phe Phe Cys Met Ile Pro Ala Arg Ile Thr Ala Met Phe Thr
435 440 445
Met Phe Asp Ile Ala Trp Gly Thr Arg Gly Gly Asn Ala Lys Met Thr
450 455 460
Ile Gly Ala Arg Val Trp Leu Trp Ala Lys Gln Phe Leu Ile Thr Tyr
465 470 475 480
Met Trp Trp Ala Gly Val Leu Ala Ala Gly Val Tyr Ser Ile Val Asp
485 490 495
Asn Trp Tyr Phe Asp Trp Ala Asp Ile Gln Tyr Arg Phe Ala Leu Val
500 505 510
Gly Ile Cys Ser Tyr Leu Val Phe Val Ser Ile Val Leu Val Ile Tyr
515 520 525
Leu Ile Gly Lys Ile Thr Thr Trp Asn Tyr Thr Pro Leu Gln Lys Glu
530 535 540
Leu Ile Glu Glu Arg Tyr Leu His Asn Ala Ser Glu Asn Ala Pro Glu
545 550 555 560
Val
<210> 108
<211> 558
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы CVG-1
<220>
<223> Аминокислотная последовательность гиалуронан-синтазы (HASA),
происходящая из вируса хлореллы CVG-1
<400> 108
Met Thr Ser Trp Arg Thr Ile Val Ser Ala Asn Leu Phe Ala Val Gly
1 5 10 15
Gly Ala Leu Leu Met Leu Ala Pro Ala Ile Ala Gly Tyr Val Phe Lys
20 25 30
Trp Asn Ile Gly Val Ser Ala Val Trp Gly Ile Ser Val Tyr Gly Val
35 40 45
Phe Val Leu Gly Phe Tyr Ile Ala Gln Val Val Phe Ser Glu Phe Asn
50 55 60
Arg Met Gln Leu Ser Asp Trp Ile Ser Leu Arg Pro Asp Asn Trp Asn
65 70 75 80
Ala Thr Arg Val Ala Val Ile Ile Ala Gly Tyr Arg Glu Asp Pro Phe
85 90 95
Met Phe Lys Lys Cys Leu Glu Ser Val Arg Asp Ser Glu Tyr Gly Asn
100 105 110
Ile Ala Arg Leu Ile Cys Val Ile Asp Gly Asp Glu Glu Glu Asp Leu
115 120 125
Lys Met Ala Glu Ile Tyr Lys Gln Val Tyr Asn Asp Asn Val Lys Thr
130 135 140
Pro Gly Val Val Leu Cys Glu Asn Glu Asn Lys Asn Gly Ser Thr Ile
145 150 155 160
Asp Pro Asp Phe Ser Lys Asn Ile Cys Ile Leu Gln Pro His Arg Gly
165 170 175
Lys Arg Glu Ser Leu Tyr Thr Gly Phe Gln Met Ala Gly Met Asp Pro
180 185 190
Ser Val His Ala Val Val Leu Ile Asp Ser Asp Thr Val Leu Glu Lys
195 200 205
Asn Ala Ile Leu Glu Val Val Tyr Pro Leu Ser Cys Asp Pro Asn Ile
210 215 220
Lys Ala Val Ala Gly Glu Cys Lys Ile Trp Asn Thr Asp Thr Ile Leu
225 230 235 240
Ser Met Leu Val Ser Trp Arg Tyr Phe Ser Ala Phe Asn Val Glu Arg
245 250 255
Gly Ala Gln Ser Leu Trp Lys Thr Val Gln Cys Val Gly Gly Pro Leu
260 265 270
Gly Ala Tyr Thr Ile Asp Ile Ile Asn Glu Ile Lys Asp Pro Trp Ile
275 280 285
Thr Gln Thr Phe Leu Gly Asn Lys Cys Thr Tyr Gly Asp Asp Arg Arg
290 295 300
Leu Thr Asn Glu Val Leu Met Arg Gly Lys Lys Ile Val Tyr Thr Pro
305 310 315 320
Phe Ala Val Gly Trp Ser Asp Ser Pro Thr Asn Val Met Arg Tyr Ile
325 330 335
Val Gln Gln Thr Arg Trp Ser Lys Ser Trp Cys Arg Glu Ile Trp Tyr
340 345 350
Thr Leu Gly Ser Ala Trp Lys His Gly Phe Ser Gly Ile Tyr Leu Ala
355 360 365
Phe Glu Cys Met Tyr Gln Ile Met Tyr Phe Phe Ile Val Met Tyr Leu
370 375 380
Phe Ser Tyr Ile Ala Ile Lys Ala Asn Ile Arg Ala Gln Ala Ala Thr
385 390 395 400
Val Leu Val Ser Thr Leu Val Ala Val Ile Lys Ser Ser Tyr Leu Ala
405 410 415
Leu Arg Ala Lys Asn Leu Lys Ala Leu Tyr Phe Val Leu Tyr Thr Tyr
420 425 430
Val Tyr Phe Phe Cys Met Ile Pro Ala Arg Ile Thr Ala Met Phe Thr
435 440 445
Met Phe Asp Ile Ala Trp Gly Thr Arg Gly Gly Asn Ala Lys Met Thr
450 455 460
Ile Gly Ala Arg Val Trp Leu Trp Ala Lys Gln Phe Leu Ile Thr Tyr
465 470 475 480
Met Trp Trp Val Gly Val Leu Ala Ala Gly Val Tyr Ser Ile Val Asp
485 490 495
Asn Trp Tyr Phe Asp Trp Ala Asp Ile Gln Tyr Arg Phe Ala Leu Val
500 505 510
Gly Ile Cys Ser Tyr Leu Gly Phe Val Ser Ile Met Leu Val Phe Tyr
515 520 525
Leu Ile Gly Lys Ile Thr Thr Trp Asn Tyr Thr Pro Leu Gln Lys Glu
530 535 540
Leu Ile Lys Glu Arg Leu His Ala Ala Asn Ala Thr Glu Val
545 550 555
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| ДРОЖЖИ, ПРОДУЦИРУЮЩИЕ ЭКТОИН | 2018 |
|
RU2745157C1 |
| КОНСТРУКЦИИ ДНК-АНТИТЕЛ ДЛЯ ПРИМЕНЕНИЯ ПРОТИВ БОЛЕЗНИ ЛАЙМА | 2017 |
|
RU2813829C2 |
| НУКЛЕОТИДНАЯ ПОСЛЕДОВАТЕЛЬНОСТЬ, КОДИРУЮЩАЯ СЛИТЫЙ БЕЛОК, СОСТОЯЩИЙ ИЗ РАСТВОРИМОГО ВНЕКЛЕТОЧНОГО ФРАГМЕНТА ЧЕЛОВЕЧЕСКОГО Dll4 И КОНСТАНТНОЙ ЧАСТИ ТЯЖЕЛОЙ ЦЕПИ ЧЕЛОВЕЧЕСКОГО IgG4 | 2021 |
|
RU2787060C1 |
| T-КЛЕТОЧНЫЕ РЕЦЕПТОРЫ, РАСПОЗНАЮЩИЕ МУТАЦИЮ R175H ИЛИ Y220C В P53 | 2020 |
|
RU2830061C2 |
| Вакцина на основе AAV5 для индукции специфического иммунитета к вирусу SARS-CoV-2 и/или профилактики коронавирусной инфекции, вызванной SARS-CoV-2 | 2020 |
|
RU2760301C1 |
| БИСПЕЦИФИЧЕСКИЕ АНТИТЕЛА, СВЯЗЫВАЮЩИЕСЯ С TFR | 2019 |
|
RU2810756C2 |
| НОВЫЙ ПОЛИПЕПТИД И СПОСОБ ПОЛУЧЕНИЯ L-ЛЕЙЦИНА С ЕГО ИСПОЛЬЗОВАНИЕМ | 2021 |
|
RU2811433C1 |
| РЕКОМБИНАНТНОЕ ПОЛУЧЕНИЕ СТЕВИОЛ-ГЛИКОЗИДОВ | 2014 |
|
RU2741103C2 |
| Вакцина на основе AAV5 для индукции специфического иммунитета к вирусу SARS-CoV-2 и/или профилактики коронавирусной инфекции, вызванной SARS-CoV-2 | 2020 |
|
RU2783313C1 |
| Выделенный рекомбинантный вирус на основе вируса гриппа для индукции специфического иммунитета к вирусу гриппа и/или профилактики заболеваний, вызванных вирусом гриппа | 2021 |
|
RU2813150C2 |
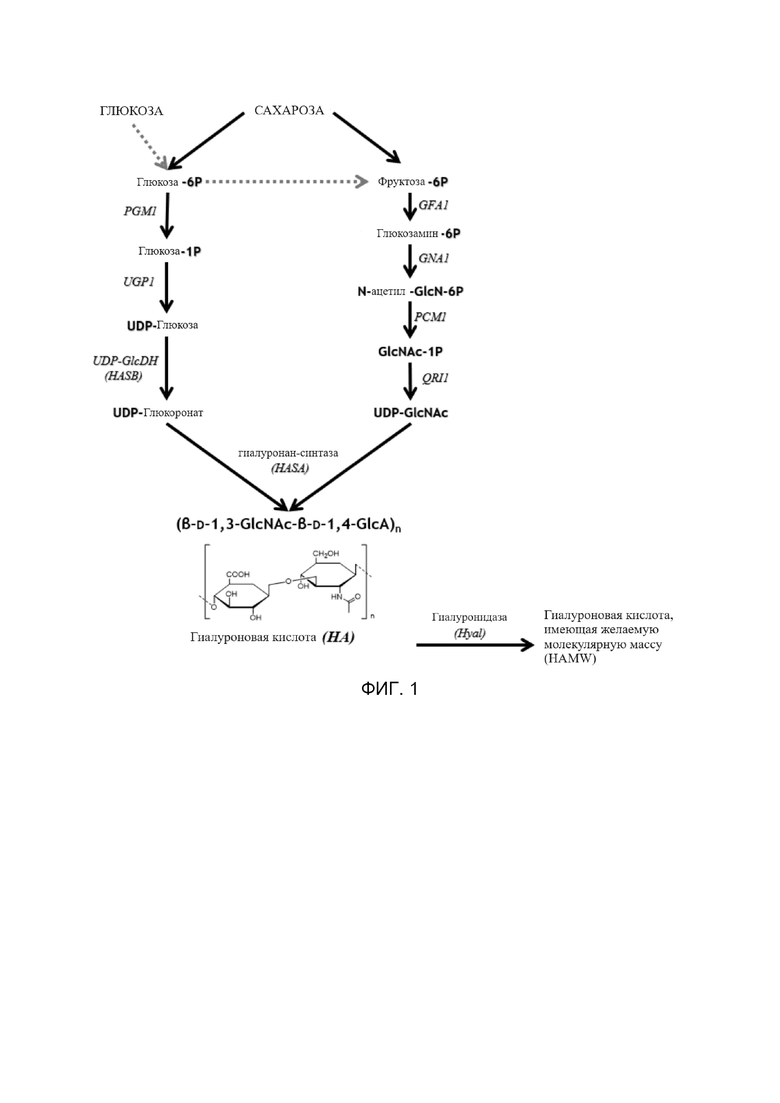
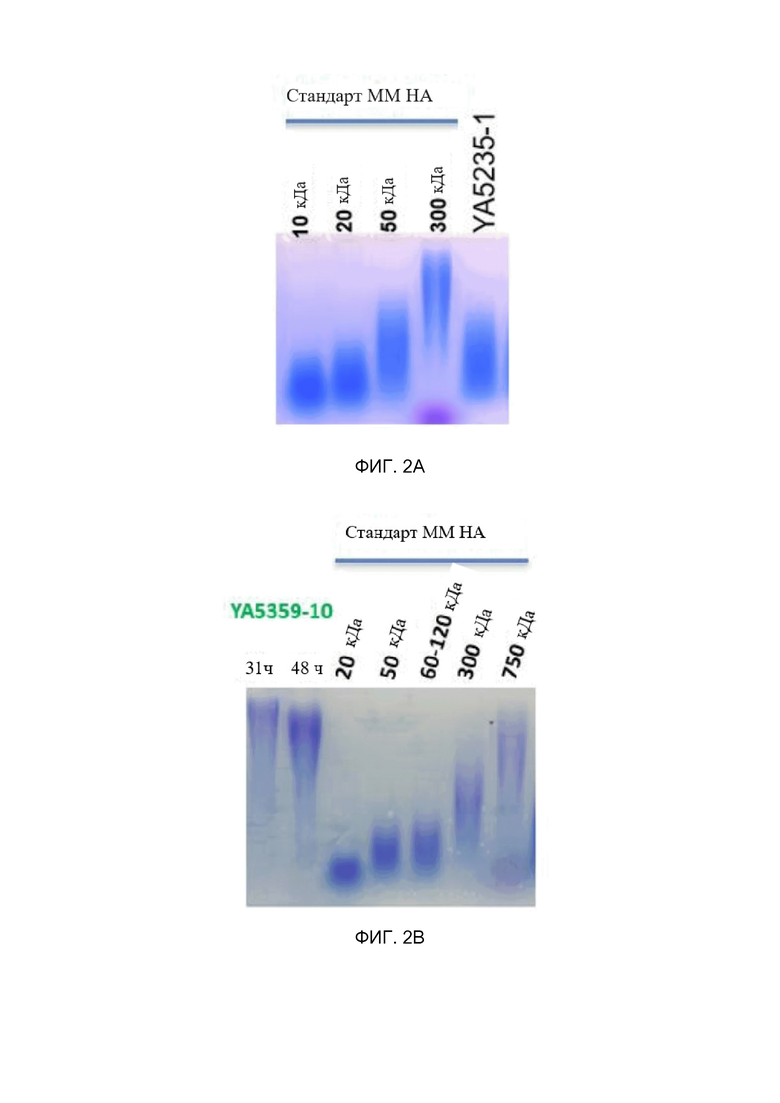
Изобретение относится к биотехнологии, в частности к биопродукции гиалуроновой кислоты. Предложена рекомбинантная клетка, содержащая множество модификаций, как описано в настоящем тексте. Настоящее изобретение дополнительно относится к способам, обеспечивающим биопродукцию гиалуроновой кислоты, имеющей контролируемую молекулярную массу, с использованием генетически модифицированных клеток по изобретению. Изобретение позволяет экономически эффективно получать большие количества безопасной для применения человеком гиалуроновой кислоты определенного и контролируемого размера. 5 н. и 21 з.п. ф-лы, 2 ил., 3 пр. 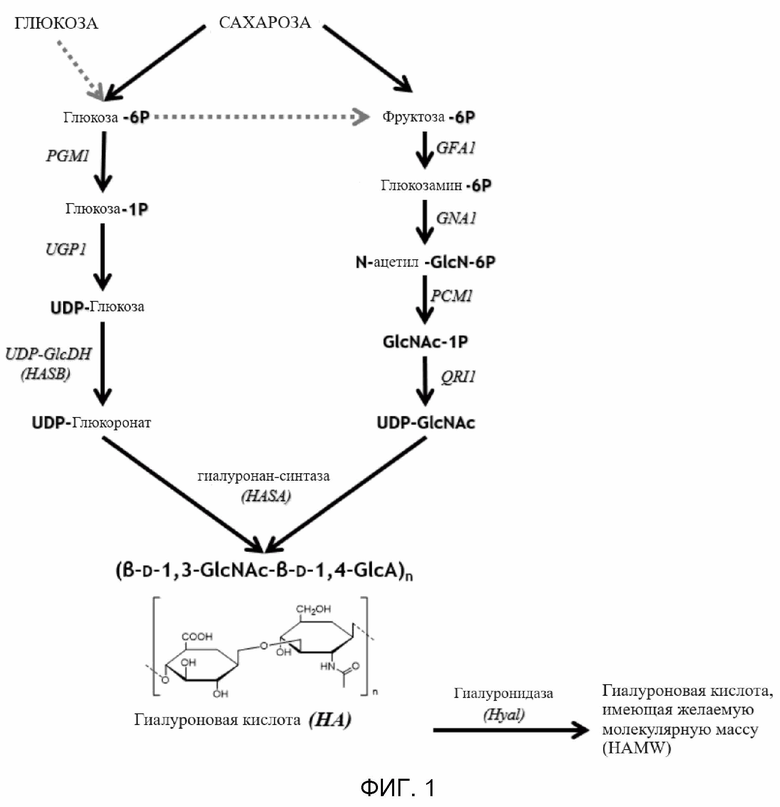
1. Рекомбинантная дрожжевая клетка, продуцирующая гиалуроновую кислоту (HA), где рекомбинантная клетка содержит:
(a) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы;
(b) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP (уридинтрифосфат)-глюкозодегидрогеназы (UDP-GlcDH или HASB);
(c) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, где указанный полипептид, имеющий активность гиалуронидазы, содержит сигнал секреции, так что рекомбинантная дрожжевая клетка продуцирует гиалуроновую кислоту, в частности, имеющую желаемую молекулярную массу (HAMW), и
(d) (i) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутаминсинтетазы (GLN1); и/или
(ii) одну или более нарушенных эндогенных нуклеиновых кислот, кодирующих глутаматсинтазу (GLT1), где указанные нарушенные нуклеиновые кислоты неспособны кодировать функциональную или полностью функциональную глутаматсинтазу;
где указанная рекомбинантная дрожжевая клетка относится к роду Saccharomyces, или роду Candida, или роду Kluyveromyces, или роду Ogataea, или роду Yarrowia, или роду Debaryomyces, или роду Ashbya.
2. Рекомбинантная клетка-хозяин, продуцирующая гиалуроновую кислоту (HA), где рекомбинантная клетка-хозяин содержит:
(a) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронан-синтазы;
(b) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность UDP-глюкозодегидрогеназы (UDP-GlcDH или HASB);
(c) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность гиалуронидазы, где указанный полипептид, имеющий активность гиалуронидазы, содержит сигнал секреции и якорный сигнал, так что клетка-хозяин продуцирует гиалуроновую кислоту, в частности, имеющую желаемую молекулярную массу (HAMW); и
(d) (i) одну или более рекомбинантных нуклеиновых кислот, кодирующих полипептид, имеющий активность глутаминсинтетазы (GLN1); и/или
(ii) одну или более нарушенных эндогенных нуклеиновых кислот, кодирующих глутаматсинтазу (GLT1), где указанные нарушенные нуклеиновые кислоты неспособны кодировать функциональную или полностью функциональную глутаматсинтазу.
3. Рекомбинантная клетка по п. 1 или 2, где молекулярная масса HA находится в диапазоне менее 50 кДа, предпочтительно в диапазоне от около 20 до около 50 кДа.
4. Рекомбинантная клетка по п. 1 или 2, где молекулярная масса HA находится в диапазоне более 50 кДа, предпочтительно в диапазоне от около 50 до около 250 кДа.
5. Рекомбинантная клетка по п. 1 или 2, где молекулярная масса HA находится в диапазоне более 100 кДа, предпочтительно в диапазоне от около 100 до около 1500 кДа.
6. Рекомбинантная клетка по любому из пп. 1-5, где нуклеиновая кислота, кодирующая полипептид, имеющий активность глутаминсинтетазы, получена или происходит из Saccharomyces cerevisiae.
7. Рекомбинантная клетка по любому из пп. 1-6, где нуклеиновая кислота, кодирующая полипептид, имеющий активность гиалуронидазы, получена или происходит из по меньшей мере одного из Cupiennius salei, Loxosceles intermedia, Hirudo nipponia, Bothrops atrox или Tityus serrulatus.
8. Рекомбинантная клетка по любому из пп. 1-7, где нуклеиновая кислота, кодирующая полипептид, имеющий активность гиалуронан-синтазы, получена или происходит из Streptococcus zooepidemicus, вируса хлореллы PBCV1, вируса хлореллы CviKl, вируса хлореллы IL-5-2s1, вируса хлореллы CZ-2, вируса хлореллы CVG-1, Xenopus laevis или Pasteurella multocida, в частности получена или происходит из по меньшей мере одного из Streptococcus zooepidemicus, вируса хлореллы PBCV1, вируса хлореллы CviKl, вируса хлореллы IL-5-2s1, вируса хлореллы CZ-2, вируса хлореллы CVG-1 или Xenopus laevis.
9. Рекомбинантная клетка по любому из пп. 1-8, где нуклеиновая кислота, кодирующая полипептид, имеющий активность UDP-глюкозодегидрогеназы, получена или происходит из по меньшей мере одного из Arabidopsis thaliana, вируса хлореллы PBCV1 или Streptococcus zooepidemicus, в частности из Arabidopsis thaliana или вируса хлореллы PBCV1.
10. Рекомбинантная клетка по любому из пп. 1-9, где рекомбинантная клетка содержит рекомбинантную нуклеиновую кислоту, кодирующую одно или более из:
(i) полипептида, имеющего активность глутамин-фруктозо-6-фосфатамидотрансферазы (GFA1); и/или
(ii) полипептида, имеющего активность UDP-N-ацетилглюкозаминпирофосфорилазы (QRI1).
11. Рекомбинантная клетка по любому из пп. 1-10, где рекомбинантная клетка содержит по меньшей мере одну рекомбинантную нуклеиновую кислоту, кодирующую одно или более из:
(i) полипептида, имеющего активность фосфоглюкомутазы-1 (PGM1); и/или
(ii) полипептида, имеющего активность UTP (уридинтрифосфат)-глюкозо-1-фосфат-уридилилтрансферазы (UGP1); и/или
(iii) полипептида, имеющего активность глюкозамин-6-фосфат-N-ацетилтрансферазы (GNA1); и/или
(iv) полипептида, имеющего активность фосфоацетилглюкозаминмутазы (PCM1).
12. Рекомбинантная дрожжевая клетка по любому из пп. 1 и 3-11, выбранная из группы, состоящей из Saccharomyces cerevisiae, Saccharomyces boulardii, Saccharomyces bayanus, Saccharomyces paradoxus, Saccharomyces mikatae, Saccharomyces castelli, Candida albicans, Candida glabrata, Candida tropicalis, Kluyveromyces lactis, Kluyveromyces marxianus, Kluyveromyces polysporus, Kluyveromyces thermotolerens, Ogataea polymorpha, Yarrowia lypolytica, Debaryomyces hansenii и Ashbya gossypii, и предпочтительно представляющая собой Saccharomyces cerevisiae.
13. Рекомбинантная клетка-хозяин по любому из пп. 2-11, относящаяся к порядку Saccharomycetales, и, в частности, выбранная из группы, состоящей из Saccharomyces cerevisiae, Saccharomyces boulardii, Saccharomyces bayanus, Saccharomyces paradoxus, Saccharomyces mikatae, Saccharomyces castelli, Candida albicans, Candida glabrata, Candida tropicalis, Kluyveromyces lactis, Kluyveromyces marxianus, Kluyveromyces polysporus, Kluyveromyces thermotolerens, Ogataea polymorpha, Yarrowia lypolytica, Debaryomyces hansenii и Ashbya gossypii, и предпочтительно представляющая собой Saccharomyces cerevisiae.
14. Способ продуцирования гиалуроновой кислоты (HA), имеющей желаемую молекулярную массу (HAMW), включающий:
(a) культивирование рекомбинантной клетки, как определено в любом из пп. 1-13, в среде для культивирования в течение времени, достаточного для продуцирования гиалуроновой кислоты (HA), имеющей желаемую молекулярную массу; и
(b) необязательно выделение или извлечение гиалуроновой кислоты (HA) из рекомбинантной клетки и/или из среды для культивирования.
15. Способ по п. 14, где HA имеет молекулярную массу от около 20 до около 50 кДа и предпочтительно от около 20 до около 30 кДа.
16. Способ по п. 15, где HA имеет молекулярную массу от около 30 до около 50 кДа.
17. Способ по п. 14, где молекулярная масса HA составляет от около 50 до около 150 кДа.
18. Способ по п. 14, где молекулярная масса HA составляет от около 150 до около 1500 кДа.
19. Способ по любому из пп. 14-18, где рекомбинантная клетка содержит по меньшей мере одну рекомбинантную нуклеиновую кислоту, кодирующую одно или более из:
(i) полипептида, имеющего активность глутамин-фруктозо-6-фосфатамидотрансферазы (GFA1); и/или
(ii) полипептида, имеющего активность UDP-N-ацетилглюкозаминпирофосфорилазы (QRI1).
20. Способ по любому из пп. 14-19, где рекомбинантная клетка содержит по меньшей мере одну рекомбинантную нуклеиновую кислоту, кодирующую одно или более из:
(i) полипептида, имеющего активность фосфоглюкомутазы-1 (PGM1);
(ii) полипептида, имеющего активность UTP-глюкозо-1-фосфат-уридилилтрансферазы (UGP1);
(iii) полипептида, имеющего активность глюкозамин-6-фосфат-N-ацетилтрансферазы (GNA1); и/или
(iv) полипептида, имеющего активность фосфоацетилглюкозаминмутазы (PCM1).
21. Способ по любому из пп. 14-20, где рекомбинантная клетка является членом рода Saccharomyces и, в частности, представляет собой Saccharomyces cerevisiae.
22. Способ по любому из пп. 14-21, где время, достаточное для продуцирования гиалуроновой кислоты (HA), имеющей желаемую молекулярную массу, представляет собой период от около 35 до около 50 часов, предпочтительно от около 40 до около 50 часов, предпочтительно около 48 часов.
23. Способ по любому из пп. 14-22, где молекулярную массу гиалуроновой кислоты контролируют путем регулирования pH среды для культивирования.
24. Способ по любому из пп. 14-23, где способ осуществляют в промышленном масштабе, предпочтительно, где среда для культивирования составляет по меньшей мере около 100 л, более предпочтительно в диапазоне от около 1000 до около 3000 л, еще более предпочтительно около 10000 л, еще более предпочтительно около 100000 л или даже около 250000 л.
25. Применение рекомбинантной клетки, как определено в любом из пп. 1-13, для продуцирования гиалуроновой кислоты (HA), имеющей молекулярную массу в диапазоне от около 20 до около 50 кДа или от около 50 до около 1000 кДа.
26. Способ продуцирования гиалуроновой кислоты, включающий стадии:
(a) культивирования рекомбинантных дрожжей, как определено в любом из пп. 1 и 3-12, в среде для культивирования; и
(b) извлечения гиалуроновой кислоты из указанной среды для культивирования,
где гиалуроновая кислота, извлеченная на стадии (b), имеет молекулярную массу, контролируемую путем выбора:
- природы и происхождения нуклеиновой кислоты, кодирующей гиалуронидазу, рекомбинантных дрожжей,
- природы и происхождения промотора, контролирующего экспрессию нуклеиновой кислоты, кодирующей гиалуронидазу(ы), рекомбинантных дрожжей,
- наличия якорного сигнала и/или сигнала секреции, связанного с кодируемой(ыми) гиалуронидазой(ами), рекомбинантных дрожжей,
- pH среды для культивирования в процессе стадии культивирования рекомбинантных дрожжей, и/или
- продолжительности культивирования рекомбинантных дрожжей.
| PubChem [Internet] | |||
| Bethesda (MD): National Library of Medicine (US), National Center for Biotechnology Information; 2004 | |||
| Оковка для разборных ящиков | 1930 |
|
SU24759A1 |
| EP 0002917337 A4, 01.06.2016 | |||
| Способ культивирования насекомых семейства Sarcophagidae в лабораторных условиях | 2022 |
|
RU2790682C1 |
| КОСМЕТИЧЕСКАЯ МАСКА | 2000 |
|
RU2191000C2 |
| GOMES A.M.V | |||
| et | |||

