[001] Настоящая технология относится к поисковым системам в целом и, в частности, к способам и системам для хранения множества документов, предназначенных для формирования поисковыми системами результатов поиска. Уровень техники
[002] Различные глобальные и локальные сети (например, сеть Интернет) обеспечивают пользователям доступ к огромному объему информации. Эта информация включает в себя множество контекстно-зависимых тем, таких как новости и текущие события, карты, информация о компаниях, финансовая информация и ресурсы, информация о дорожном движении, информация, касающаяся игр и развлечений, и т.д. Пользователи применяют разнообразные клиентские устройства (настольный компьютер, смартфон, планшет и т.д.) для получения доступа к богатому информационному содержимому (такому как изображения, аудиоматериалы, видеоматериалы, анимация и другой мультимедийный контент из таких сетей).
[003] Объем информации, доступной на различных Интернет-ресурсах, в течение последней пары лет растет экспоненциально. Для помощи типичному пользователю в поиске необходимой информации было разработано несколько решений. Одним из примеров таких решений является поисковая система. В качестве примера можно привести поисковые системы GOOGLE™, YANDEX™, YAHOO!™ и т.д. Пользователь может получать доступ к интерфейсу поисковой системы и отправлять поисковый запрос, связанный с информацией, которую требуется найти в сети Интернет. В ответ на поисковый запрос поисковая система выдает ранжированный список результатов поиска. Ранжированный список результатов поиска формируется на основе различных алгоритмов ранжирования конкретной поисковой системы, примененной пользователем для поиска. Общая цель таких алгоритмов ранжирования заключается в представлении наиболее релевантных результатов поиска в верхней части ранжированного списка, тогда как менее релевантные результаты поиска могут располагаться в ранжированном списке на менее заметных местах (т.е. наименее релевантные результаты поиска находятся в нижней части ранжированного списка).
[004] Следует отметить, что результаты поиска должны быть предоставлены в пределах приемлемого интервала времени после отправки запроса. Иными словами, не только предоставленные пользователю результаты поиска должны быть релевантными, но и время реакции должно быть достаточно малым, чтобы пользователь остался удовлетворенным сервисом, который обеспечивает поисковая система.
Раскрытие изобретения
[005] Целью настоящего изобретения является устранение по меньшей мере некоторых недостатков известных решений. Варианты осуществления настоящей технологии способны обеспечить и/или расширить арсенал подходов и/или способов достижения целей в настоящей технологии.
[006] Разработчики настоящей технологии установили, что если документы, предоставляемые пользователю поисковой системы в качестве результатов поиска, объединить в группы описанным здесь образом, то, например, может быть уменьшено время реакции на запрос, отправленный пользователем. В частности, объединение документов в группы таким особым образом позволяет быстрее определять релевантные запросу документы среди большого количества документов, которые могут быть предоставлены в качестве результатов поиска.
[007] Разработчики настоящей технологии также установили, что объединение документов в группы описанным здесь образом позволяет уменьшить количество серверов базы данных, к которым требуется обращаться для их получения. В частности, объединение документов в группы таким образом позволяет определять среди всех серверов базы данных подмножество серверов (или один сервер) базы данных, такое как подмножество целевых серверов (или один целевой сервер) базы данных, на которых хранятся документы и доступ к которым может потребоваться для получения документов. Это способствует не только уменьшению вычислительной мощности, выделяемой для операций по получению документов, но и к уменьшению количества запросов на доступ к серверам базы данных, хранящим документы.
[008] Разработчики настоящей технологии также установили, что описанное здесь хранение документов в группах в известном смысле позволяет «распределить» нагрузку (от запросов на доступ) на серверы базы данных, работающие в режиме высокой нагрузки, среди множества серверов базы данных. Например, распределение этой нагрузки позволяет ускорять операции, выполняемые сервером для предоставления релевантных документов по запросу, отправленному пользователем поисковой системы.
[009] Согласно первому аспекту настоящей технологии реализован способ хранения множества документов в системе базы данных. Система базы данных связана с сервером, выполняющим этот способ. Способ включает в себя получение сервером данных документа, связанных с соответствующими документами из множества документов. Способ включает в себя формирование сервером, использующим алгоритм машинного обучения (MLA, Machine Learning Algorithm), для каждого документа из множества документов вектора документа на основе данных этого документа. Алгоритм MLA обучен на основе обучающей пары документ-запрос, связанной с коэффициентом релевантности, указывающим на релевантность обучающего документа из обучающей пары обучающему запросу из этой обучающей пары. Нейронная сеть (NN, Neural Network) обучена формировать (а) вектор обучающего документа для обучающего документа и (б) вектор обучающего запроса для обучающего запроса так, чтобы значение близости друг к другу (а) вектора обучающего документа для обучающего документа и (б) вектора обучающего запроса для обучающего запроса представляло собой коэффициент релевантности. Способ включает в себя хранение сервером множества документов в виде групп документов в системе базы данных. Каждая группа документов связана с вектором группы. Группа документов содержит документы, связанные с векторами документов, пространственно близкими к вектору группы.
[0010] В некоторых вариантах осуществления способа алгоритм MLA представляет собой сеть NN.
[0011] В некоторых вариантах осуществления способа пространственная близость указывает на сходство друг с другом документов в группе документов.
[0012] В некоторых вариантах осуществления способа он дополнительно включает в себя определение сервером вектора группы для каждой группы документов на основе векторов документов, связанных со множеством документов.
[0013] В некоторых вариантах осуществления способа группы документов содержат группы, количество которых равно заранее заданному числу K.
[0014] В некоторых вариантах осуществления способа он дополнительно включает в себя группирование множества документов в группы документов.
[0015] В некоторых вариантах осуществления способа группирование включает в себя выполнение сервером алгоритма вида «K-средних» (K-means) для векторов документов, связанных со множеством документов, в результате чего определяются векторы группы и связанные с ними группы документов из множества документов.
[0016] В некоторых вариантах осуществления способа он дополнительно включает в себя:
- получение сервером от электронного устройства, связанного с сервером, текущего запроса на предоставление электронному устройству текущего документа, релевантного текущему запросу;
- получение сервером данных запроса, связанных с текущим запросом;
- формирование сервером, использующим алгоритм MLA, для текущего запроса вектора текущего запроса на основе данных запроса, связанных с текущим запросом;
- определение сервером среди векторов групп вектора группы, наиболее схожего с вектором текущего запроса и связанного с целевой группой документов; и
- обращение сервера к системе базы данных для получения документов из целевой группы документов.
[0017] В некоторых вариантах осуществления способа обращение к системе базы данных включает в себя отсутствие получения документов из других групп документов, отличных от целевой группы документов.
[0018] В некоторых вариантах осуществления способа система базы данных содержит базу данных, разделенную на множество сегментов. Хранение групп документов включает в себя хранение сервером групп документов в виде соответствующих сегментов базы данных в системе базы данных, каждый из которых связан с вектором группы.
[0019] В некоторых вариантах осуществления способа система базы данных содержит множество серверов базы данных. Хранение групп документов в виде сегментов включает в себя хранение сервером множества сегментов базы данных на множестве серверов базы данных в системе базы данных.
[0020] В некоторых вариантах осуществления способа сервер базы данных из множества серверов базы данных хранит несколько сегментов из множества сегментов.
[0021] В некоторых вариантах осуществления способа несколько серверов базы данных из множества серверов базы данных хранят один и тот же сегмент из множества сегментов.
[0022] В некоторых вариантах осуществления способа множество серверов базы данных физически расположены в нескольких географических точках.
[0023] В некоторых вариантах осуществления способа любые два сервера базы данных из множества серверов базы данных, географически близкие друг к другу, хранят сегменты, имеющие векторы групп, более схожие друг с другом, чем векторы групп сегментов, хранящихся на любых других двух серверах базы данных из множества серверов базы данных, географически более далеких друг от друга, чем указанные два сервера базы данных.
[0024] В некоторых вариантах осуществления способа он дополнительно включает в себя:
- получение сервером от электронного устройства, связанного с сервером, текущего запроса на предоставление электронному устройству текущего документа, релевантного текущему запросу;
- получение сервером данных запроса, связанных с текущим запросом;
- формирование сервером, использующим алгоритм MLA, для текущего запроса вектора текущего запроса на основе данных запроса, связанных с текущим запросом;
- определение сервером среди векторов групп вектора группы, наиболее схожего с вектором текущего запроса и связанного с целевым сегментом из множества сегментов; и
- обращение сервера к хранящему целевой сегмент целевому серверу базы данных из множества серверов базы данных для получения документов из целевого сегмента.
[0025] В некоторых вариантах осуществления способа обращение к целевому серверу базы данных включает в себя отсутствие обращение сервера к другим серверам базы данных в системе базы данных, отличным от целевого сервера базы данных.
[0026] В некоторых вариантах осуществления способа он дополнительно включает в себя определение целевого сервера базы данных на основе географического положения электронного устройства и множества серверов базы данных.
[0027] В некоторых вариантах осуществления способа алгоритм MLA представляет собой сеть NN, содержащую предназначенную для документа часть и предназначенную для запроса часть. Предназначенная для документа часть способна формировать вектор обучающего документа на основе данных документа, связанных с обучающим документом. Предназначенная для запроса часть способна формировать вектор обучающего запроса на основе данных запроса, связанных с обучающим запросом. Предназначенная для документа часть и предназначенная для запроса часть совместно обучены так, чтобы значение близости друг к другу (а) вектора обучающего документа и (б) вектора обучающего запроса представляло собой коэффициент релевантности.
[0028] Согласно второму аспекту настоящей технологии реализован сервер для хранения множества документов в системе базы данных, связанной с сервером. Сервер способен получать данные документа, связанные с соответствующими документами из множества документов. Сервер способен с использованием алгоритма MLA формировать для каждого документа из множества документов соответствующий вектор документа на основе данных документа. Сеть NN обучена на основе обучающей пары документ-запрос, связанной с коэффициентом релевантности, указывающим на релевантность обучающего документа из обучающей пары обучающему запросу из этой обучающей пары. Сеть NN обучена формировать (а) вектор обучающего документа для обучающего документа и (б) вектор обучающего запроса для обучающего запроса так, чтобы значение близости друг к другу (а) вектора обучающего документа для обучающего документа и (б) вектора обучающего запроса для обучающего запроса представляло собой коэффициент релевантности. Сервер способен хранить множество документов в виде групп документов в системе базы данных. Каждая группа документов связана с вектором группы. Группа документов содержит документы, связанные с векторами документов, пространственно близкими к вектору группы.
[0029] В некоторых вариантах осуществления сервера алгоритм MLA представляет собой сеть NN.
[0030] В некоторых вариантах осуществления сервера пространственная близость указывает на сходство друг с другом документов в группе документов.
[0031] В некоторых вариантах осуществления сервер способен определять для каждой группы документов вектор группы на основе векторов документов, связанных со множеством документов.
[0032] В некоторых вариантах осуществления сервера группы документов содержат группы, количество которых равно заранее заданному числу K.
[0033] В некоторых вариантах осуществления сервер способен объединять множество документов в группы документов.
[0034] В некоторых вариантах осуществления сервер, способный объединять в группы, способен выполнять алгоритм «K-средних» для векторов документов, связанных со множеством документов, в результате чего определяются векторы группы и связанные с ними группы документов из множества документов.
[0035] В некоторых вариантах осуществления сервер способен:
- получать от электронного устройства, связанного с сервером, текущий запрос на предоставление электронному устройству текущего документа, релевантного текущему запросу;
- получать данные запроса, связанные с текущим запросом;
- формировать с использованием алгоритма MLA для текущего запроса вектор текущего запроса на основе данных запроса, связанных с текущим запросом;
- определять среди векторов групп вектор группы, наиболее схожий с вектором текущего запроса и связанный с целевой группой документов; и
- обращаться к системе базы данных для получения документов из целевой группы документов.
[0036] В некоторых вариантах осуществления сервера он способен не получать документы из других групп документов, отличных от целевой группы документов, при обращении к системе базы данных.
[0037] В некоторых вариантах осуществления сервера система базы данных содержит базу данных, разделенную на множество сегментов. Сервер способен хранить группы документов в виде сегментов базы данных в системе базы данных, каждый из которых связан с вектором группы.
[0038] В некоторых вариантах осуществления сервера система базы данных содержит множество серверов базы данных. Сервер, способный хранить группы документов в виде сегментов, способен хранить множество сегментов базы данных на множестве серверов базы данных в системе базы данных.
[0039] В некоторых вариантах осуществления сервера сервер базы данных из множества серверов базы данных хранит несколько сегментов из множества сегментов.
[0040] В некоторых вариантах осуществления сервера несколько серверов базы данных из множества серверов базы данных хранят один и тот же сегмент из множества сегментов.
[0041] В некоторых вариантах осуществления сервера множество серверов базы данных физически расположены в нескольких географических точках.
[0042] В некоторых вариантах осуществления сервера любые два сервера базы данных из множества серверов базы данных, географически близкие друг к другу, хранят сегменты, имеющие векторы групп, более схожие друг с другом, чем векторы групп сегментов, хранящихся на любых других двух серверах базы данных из множества серверов базы данных, географически более далеких друг от друга, чем указанные два сервера базы данных.
[0043] В некоторых вариантах осуществления сервер способен:
- получать от электронного устройства, связанного с сервером, текущий запрос на предоставление электронному устройству текущего документа, релевантного текущему запросу;
- получать данные запроса, связанные с текущим запросом;
- формировать с использованием алгоритма MLA для текущего запроса вектор текущего запроса на основе данных запроса, связанных с текущим запросом;
- определять среди векторов групп вектор группы, наиболее схожий с вектором текущего запроса и связанный с целевым сегментом из множества сегментов; и
- обращаться к хранящему целевой сегмент целевому серверу базы данных из множества серверов базы данных для получения документов из целевого сегмента.
[0044] В некоторых вариантах осуществления сервера его способность обращаться к целевому серверу базы данных включает в себя способность не обращаться к другим серверам базы данных в системе базы данных, отличным от целевого сервера базы данных.
[0045] В некоторых вариантах осуществления сервера он способен определять целевой сервер базы данных на основе географического положения электронного устройства и множества серверов базы данных.
[0046] В некоторых вариантах осуществления сервера алгоритм MLA представляет собой сеть NN, содержащую предназначенную для документа часть и предназначенную для запроса часть. Предназначенная для документа часть способна формировать вектор обучающего документа на основе данных документа, связанных с обучающим документом. Предназначенная для запроса часть способна формировать вектор обучающего запроса на основе данных запроса, связанных с обучающим запросом. Предназначенная для документа часть и предназначенная для запроса часть совместно обучены так, чтобы значение близости друг к другу (а) вектора обучающего документа и (б) вектора обучающего запроса представляло собой коэффициент релевантности.
[0047] Согласно третьему аспекту настоящей технологии реализован способ получения документов для текущего запроса. Текущий запрос представляет собой запрос на предоставление электронному устройству, связанному с пользователем, документов, релевантных текущему запросу. Способ выполняется сервером, связанным с электронным устройством. Способ включает в себя получение сервером текущего запроса и данных запроса, связанных с текущим запросом. Способ включает в себя формирование сервером для текущего запроса вектора текущего запроса на основе данных запроса, связанных с текущим запросом. Способ включает в себя определение сервером среди векторов групп вектора группы, наиболее схожего с вектором текущего запроса. Векторы групп связаны с группами документов. Группы документов хранятся в системе базы данных, связанной с сервером. Наиболее схожий вектор группы связан с целевой группой документов. Способ включает в себя обращение сервера к системе базы данных для получения документов из целевой группы документов. Целевая группа документов содержит документы, связанные с векторами документов, пространственно близкими к наиболее схожему вектору группы.
[0048] В некоторых вариантах осуществления способа система базы данных содержит множество серверов базы данных, хранящих группы документов. Обращение к системе базы данных включает в себя обращение сервера только к серверу базы данных, хранящему целевую группу документов, из множества серверов базы данных.
[0049] Согласно четвертому аспекту настоящей технологии реализован сервер для получения документов для текущего запроса. Текущий запрос представляет собой запрос на предоставление электронному устройству, связанному с пользователем, документов, релевантных текущему запросу. Сервер связан с электронным устройством и способен получать текущий запрос. Сервер способен получать данные запроса, связанные с текущим запросом. Сервер способен формировать для текущего запроса вектор текущего запроса на основе данных запроса, связанных с текущим запросом. Сервер способен определять среди векторов групп наиболее схожий с вектором текущего запроса вектор группы. Векторы групп связаны с группами документов. Группы документов хранятся в системе базы данных, связанной с сервером. Наиболее схожий вектор группы связан с целевой группой документов. Сервер способен обращаться к системе базы данных для получения документов из целевой группы документов. Целевая группа документов содержит документы, связанные с векторами документов, пространственно близкими к наиболее схожему вектору группы.
[0050] В некоторых вариантах осуществления сервера система базы данных содержит множество серверов базы данных, хранящих группы документов. Сервер при обращении к системе базы данных способен из множества серверов базы данных обращаться только к серверу базы данных, хранящему целевую группу документов.
[0051] В контексте настоящего описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, от клиентских устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну компьютерную систему, что не существенно для настоящей технологии. В настоящем контексте выражение «сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая конкретная задача принимается, выполняется или запускается одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами). Это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или инициировать выполнение любой задачи или запроса либо результатов любых задач или запросов. Все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, причем в выражении «по меньшей мере один сервер» подразумеваются оба эти случая.
[0052] В контексте настоящего описания термин «клиентское устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения поставленной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры клиентских устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как клиентское устройство, также может функционировать как сервер для других клиентских устройств. Использование выражения «клиентское устройство» не исключает использования нескольких клиентских устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо результатов любых задач или запросов либо шагов любого описанного здесь способа.
[0053] В контексте настоящего описания термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерных аппаратных средств для хранения этих данных, их применения или обеспечения их использования иным способом. База данных может располагаться в тех же аппаратных средствах, где реализован процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо база данных может располагаться в отдельных аппаратных средствах, таких как специализированный сервер или множество серверов.
[0054] В контексте настоящего описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д., но не ограничивается ими.
[0055] В контексте настоящего описания выражение «компонент» включает в себя обозначение программного обеспечения (подходящего для определенных аппаратных средств), необходимого и достаточного для выполнения определенной функции или нескольких функций.
[0056] В контексте настоящего описания выражение «пригодный для использования в компьютере носитель информации» означает носители любого рода и вида, включая ОЗУ, ПЗУ, диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, твердотельные накопители, накопители на магнитных лентах и т.д.
[0057] В контексте настоящего описания числительные «первый» «второй», «третий» и т.д. используются лишь для указания различия между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, вида, хронологии, иерархии или классификации, в данном случае, серверов, а также что их использование (само по себе) не подразумевает наличие «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента в действительности могут быть одним и тем же элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - различные программные и/или аппаратные средства.
[0058] Каждый вариант осуществления настоящей технологии относится к по меньшей мере одной из вышеупомянутых целей и/или аспектов, но не обязательно ко всем ним. Должно быть понятно, что некоторые аспекты настоящей технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, явным образом здесь не упомянутым.
[0059] Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов осуществления настоящей технологии содержатся в дальнейшем описании, в приложенных чертежах и в формуле изобретения.
Краткое описание чертежей
[0060] Дальнейшее описание приведено для лучшего понимания настоящей технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
[0061] На фиг. 1 представлена схема системы, реализованной согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[0062] На фиг. 2 приведена схема соответствующей не имеющим ограничительного характера вариантам осуществления настоящей технологии системы базы данных, представленной на фиг. 1.
[0063] На фиг. 3 представлен соответствующий не имеющим ограничительного характера вариантам осуществления настоящей технологии контент, хранящийся в представленном на фиг. 1 репозитории данных поисковой системы.
[0064] На фиг. 4 представлен соответствующий не имеющим ограничительного характера вариантам осуществления настоящей технологии контент, хранящийся в рабочем репозитории, представленном на фиг. 1.
[0065] На фиг. 5 приведена схема соответствующей не имеющим ограничительного характера вариантам осуществления настоящей технологии итерации обучения нейронной сети сервера, представленного на фиг. 1.
[0066] На фиг. 6 приведена схема соответствующей не имеющим ограничительного характера вариантам осуществления настоящей технологии процедуры группирования сервером, представленным на фиг. 1, для объединения документов в группы.
[0067] На фиг. 7 приведена схема соответствующей не имеющим ограничительного характера вариантам осуществления настоящей технологии системы базы данных, представленной на фиг. 1.
[0068] На фиг. 8 приведена блок-схема соответствующего не имеющим ограничительного характера вариантам осуществления настоящей технологии способа хранения документов, выполняемого сервером, представленным на фиг. 1. Осуществление изобретения
[0069] Представленные в данном описании примеры и условный язык предназначены для обеспечения лучшего понимания принципов настоящей технологии, а не для ограничения ее объема до таких специально приведенных примеров и условий. Очевидно, что специалисты в данной области техники способны разработать различные способы и устройства, которые явно не описаны и не показаны, но реализуют принципы настоящей технологии в пределах ее существа и объема.
[0070] Кроме того, чтобы способствовать лучшему пониманию, последующее описание может содержать упрощенные варианты реализации настоящей технологии. Специалисту в данной области должно быть понятно, что различные варианты осуществления данной технологии могут быть значительно сложнее.
[0071] В некоторых случаях также приводятся полезные примеры модификаций настоящей технологии. Они способствуют пониманию, но также не определяют объема или границ данной технологии. Представленный перечень модификаций не является исчерпывающим и специалист в данной области может разработать другие модификации в пределах объема настоящей технологии. Кроме того, если в некоторых случаях модификации не описаны, это не означает, что они невозможны и/или что описание содержит единственно возможный вариант реализации того или иного элемента настоящей технологии.
[0072] Более того, описание принципов, аспектов и вариантов реализации настоящей технологии, а также их конкретные примеры, предназначены для охвата их структурных и функциональных эквивалентов, независимо от того, известны они в настоящее время или будут разработаны в будущем. Например, специалистам в данной области техники должно быть очевидно, что любые описанные структурные схемы соответствуют концептуальным представлениям иллюстративных принципиальных схем, реализующих принципы настоящей технологии. Также должно быть очевидно, что любые блок-схемы, схемы процессов, диаграммы изменения состояния, псевдокоды и т.п.соответствуют различным процессам, которые могут быть представлены на машиночитаемом физическом носителе информации и могут выполняться компьютером или процессором, независимо от того, показан такой компьютер или процессор явно или нет.
[0073] Функции различных элементов, показанных на чертежах, включая любой функциональный блок, обозначенный как «процессор» или «графический процессор», могут осуществляться с использованием специализированных аппаратных средств, а также аппаратных средств, способных выполнять соответствующее программное обеспечение. Если используется процессор, его функции могут выполняться одним выделенным процессором, одним совместно используемым процессором или множеством отдельных процессоров, некоторые из которых могут использоваться совместно. В некоторых вариантах осуществления настоящей технологии процессор может представлять собой процессор общего назначения, такой как центральный процессор (CPU), или специализированный процессор, такой как графический процессор (GPU). Кроме того, явное использование термина «процессор» или «контроллер» не должно трактоваться как указание исключительно на аппаратные средства, способные выполнять программное обеспечение, и может, помимо прочего, подразумевать аппаратные средства цифрового сигнального процессора (DSP), сетевой процессор, специализированную интегральную схему (ASIC), программируемую вентильную матрицу (FPGA), ПЗУ для хранения программного обеспечения, ОЗУ и энергонезависимое ЗУ. Также могут подразумеваться другие аппаратные средства, общего назначения и/или заказные.
[0074] Программные модули (или просто модули), реализация которых предполагается в виде программных средств, могут быть представлены в данном документе как любое сочетание элементов блок-схемы или других элементов, указывающих на выполнение шагов процесса и/или содержащих текстовое описание. Такие модули могут выполняться аппаратными средствами, показанными явно или предполагаемыми.
[0075] Учитывая вышеизложенные принципы, далее рассмотрены некоторые не имеющие ограничительного характера примеры, иллюстрирующие различные варианты реализации аспектов настоящей технологии.
[0076] На фиг. 1 представлена схема системы 100, пригодной для реализации вариантов осуществления настоящей технологии, не имеющих ограничительного характера. Очевидно, что система 100 приведена только для демонстрации варианта реализации настоящей технологии. Таким образом, дальнейшее описание системы представляет собой описание примеров, иллюстрирующих настоящую технологию.
[0077] В общем случае система 100 может быть использована для предоставления результатов поиска пользователю в ответ на отправленный им запрос. С этой целью система 100 содержит, помимо прочего, электронное устройство 102, связанное с пользователем 101, сервер 106, множество серверов 108 ресурсов и систему 150 базы данных. Например, пользователь 101 может с помощью электронного устройства 102 отправить запрос серверу 106, который в ответ может предоставить пользователю 101 результаты поиска. Сервер 106 формирует эти результаты поиска на основе информации, полученной, например, от множества серверов 108 ресурсов и хранящейся в системе 150 базы данных. Эти результаты поиска, предоставленные системой 100, могут быть релевантными отправленному запросу. Далее более подробно описаны некоторые функции элементов системы 100. Электронное устройство
[0078] Как упомянуто выше, система 100 содержит электронное устройство 102, связанное с пользователем 101. Электронное устройство 102 (или просто устройство 102) иногда может называться клиентским устройством, оконечным устройством или клиентским электронным устройством. Следует отметить, что связь электронного устройства 102 с пользователем 101 не означает необходимости предлагать или подразумевать какой-либо режим работы, например, вход в систему, регистрацию и т.п.
[0079] В контексте настоящего описания, если явно не указано другое, термин «электронное устройство» или «устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения поставленной задачи. Таким образом, некоторые не имеющие ограничительного характера примеры устройств 102 включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.д.), смартфоны, планшеты и т.п. Устройство 102 содержит известные в данной области техники аппаратные средства и/или прикладное программное обеспечение и/или встроенное программное обеспечение (либо их сочетание) для выполнения браузерного приложения (не показано).
[0080] В общем случае браузерное приложение обеспечивает пользователю 101 доступ к одному или нескольким веб-ресурсам. На реализацию браузерного приложения не накладывается каких-либо особых ограничений. Например, браузерное приложение, выполняемое устройством 102, может быть реализовано в виде браузера Yandex™. В частности, пользователь 101 может использовать браузерное приложение (а) для перехода на веб-сайт поисковой системы и (б) для отправки запроса, в ответ на который ему могут быть предоставлены релевантные результаты поиска.
[0081] Устройство 102 способно формировать запрос 180 в ответ на отправку запроса пользователем 101. Запрос 180 может представлять собой один или несколько пакетов данных, содержащих информацию, указывающую на запрос, отправленный пользователем 101. Устройство 102 также способно получать ответ 190. Ответ 190 может представлять собой один или несколько пакетов данных содержащих информацию, указывающую на результаты поиска, релевантные отправленному запросу, и машиночитаемые команды для демонстрации браузерным приложением этих результатов поиска пользователю 101. Формирование контента ответа 190 в ответ на отправленный запрос более подробно описано далее.
Сеть связи
[0082] Система 100 содержит сеть 110 связи. В не имеющем ограничительного характера примере в качестве сети 110 связи может использоваться сеть Интернет. В других не имеющих ограничительного характера примерах сеть 110 связи может быть реализована иначе, например, в виде любой глобальной сети связи, локальной сети связи, частной сети связи и т.п.На практике реализация сети 110 связи, на которую не накладывается каких-либо ограничений, может, среди прочего, зависеть от реализации других элементов системы 100.
[0083] Сеть 110 связи предназначена для обеспечения связи между по меньшей мере некоторыми компонентами системы 100, такими как устройство 102, множество серверов 108 ресурсов и сервер 106. Например, это означает, что множество серверов 108 ресурсов доступно устройству 102 через сеть 110 связи. В другом примере это означает, что множество серверов 108 ресурсов доступно серверу 106 через сеть 110 связи. В еще одном примере это означает, что сервер 106 доступен устройству 102 через сеть 110 связи.
[0084] Сеть 110 связи может быть использована для передачи пакетов данных между устройством 102, множеством серверов 108 ресурсов и сервером 106. Например, сеть 110 связи может быть использована для отправки запроса 180 устройством 102 серверу 106. В другом примере сеть 110 связи может быть использована для отправки ответа 190 сервером 106 устройству 102. Множество серверов ресурсов
[0085] Как упомянуто выше, множество серверов 108 ресурсов может быть доступно через сеть 110 связи. Множество серверов 108 ресурсов может быть реализовано в виде традиционных компьютерных серверов. В не имеющем ограничительного характера примере осуществления настоящей технологии сервер из множества серверов 108 ресурсов может быть реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™. Сервер из множества серверов 108 ресурсов также может быть реализован с использованием любых других подходящих аппаратных средств и/или прикладного программного обеспечения и/или встроенного программного обеспечения либо их сочетания.
[0086] Множество серверов 108 ресурсов способно содержать ресурсы (или веб-ресурсы), которые могут быть доступны устройству 102 и/или серверу 106. На вид ресурсов, расположенных на множестве серверов 108 ресурсов, не накладывается каких-либо ограничений. Тем не менее, в некоторых вариантах осуществления настоящей технологии эти ресурсы могут содержать электронные документы (или просто документы), представляющие собой веб-страницы.
[0087] Например, множество серверов 108 ресурсов может содержать веб-страницы, т.е. множество серверов 108 ресурсов может хранить документы, представляющие собой веб-страницы и доступные устройству 102 и/или серверу 106. Документ может быть составлен на языке разметки и может, среди прочего, содержать (а) контент веб-страницы и (б) машиночитаемые команды для отображения этой веб-страницы (содержащегося на ней контента).
[0088] Устройство 102 может обратиться к серверу из множества серверов 108 ресурсов с целью получения документа, хранящегося на этом сервере. Например, пользователь 101 может ввести веб-адрес, связанный с веб-страницей, в браузерном приложении устройства 102. В свою очередь, устройство 102 может обратиться к серверу ресурсов, содержащему эту веб-страницу, с целью получения документа, представляющего эту веб-страницу, для отображения контента веб-страницы с использованием браузерного приложения.
[0089] Сервер 106 может обратиться к серверу из множества серверов 108 ресурсов с целью получения документа, хранящегося на этом сервере ресурсов. Назначение сервера 106, осуществляющего доступ ко множеству серверов 108 ресурсов и получающего от них документы, более подробно описано далее. Сервер
[0090] Система 100 содержит сервер 106, который может быть реализован в виде традиционного компьютерного сервера. В примере осуществления настоящей технологии сервер 106 может быть реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™. Очевидно, что сервер 106 может быть реализован с использованием любых других подходящих аппаратных средств и/или прикладного программного обеспечения и/или встроенного программного обеспечения либо их сочетания. В представленном не имеющем ограничительного характера варианте осуществления настоящей технологии сервер 106 представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 106 могут быть распределены между несколькими серверами.
[0091] В общем случае сервер 106 управляется и/или администрируется поставщиком услуг поисковой системы (не показан), таким как оператор поисковой системы Yandex™. Сервер 106 может содержать поисковую систему для выполнения одного или нескольких поисков в ответ на запросы, отправленные пользователями поисковой системы.
[0092] Например, сервер 106 может получать от устройства 102 запрос 180, указывающий на запрос, отправленный пользователем 101. Сервер 106 в ответ на отправленный запрос может выполнять поиск с целью формирования результатов поиска, релевантных отправленному запросу. В результате сервер 106 может сформировать ответ 190, указывающий на результаты поиска, и может отправить ответ 190 устройству 102 для демонстрации результатов поиска пользователю 101 с использованием браузерного приложения.
[0093] Сформированные для отправленного запроса результаты поиска могут быть представлены в любом виде. В не имеющем ограничительного характера примере настоящей технологии результаты поиска, сформированные сервером 106, могут указывать на документы, релевантные отправленному запросу. Далее описано определение и получение сервером 106 документов, релевантных отправленному запросу.
[0094] Сервер 106 также способен выполнять приложение 120 обходчика. В общем случае приложение 120 обходчика используется сервером 106 для «посещения» ресурсов, доступных через сеть 110 связи, и их получения или загрузки для дальнейшего использования. Например, приложение 120 обходчика может быть использовано сервером 106 для доступа ко множеству серверов 108 ресурсов и для получения или загрузки документов, представляющих веб-страницы, размещенные на множестве серверов 108 ресурсов.
[0095] Предполагается, что приложение 120 обходчика может выполняться сервером 106 периодически с целью получения или загрузки документов, которые были обновлены и/или стали доступными через сеть 110 связи после предыдущего выполнения приложения 120 обходчика.
[0096] Сервер 106 также способен использовать нейронную сеть 130 (NN). В общем случае сеть NN состоит из группы взаимосвязанных искусственных «нейронов», обрабатывающих информацию с использованием коннекционного подхода к вычислениям. Сети NN используются для моделирования сложных взаимосвязей между входами и выходами (без фактической информации об этих взаимосвязях) или для поиска закономерностей в данных. Сети NN сначала адаптируются на этапе обучения, когда они обеспечиваются известным набором входных данных и информацией для адаптации сети NN с целью формирования надлежащих выходных данных (для ситуации, для которой выполняется попытка моделирования). На этапе обучения сеть NN адаптируется к изучаемой ситуации и изменяет свою структуру так, чтобы она была способна обеспечить адекватные предсказываемые выходные данные для входных данных в новой ситуации (на основе изученного). Таким образом, вместо попытки определения сложных статистических распределений или математических алгоритмов для некоторой ситуации, сеть NN пытается предоставить «интуитивный» ответ на основе «восприятия» этой ситуации.
[0097] Сети NN широко используются во многих случаях, когда важно лишь получить выходные данные на основе входных данных и менее важна или вовсе не важна информация о том, как получаются эти выходные данные. Например, сети NN широко используются для оптимизации распределения веб-трафика между серверами, а также при сравнении, обработке и кластеризации данных, включая фильтрацию, векторизацию и т.п.
[0098] В целом, можно сказать, что реализация сети 130 NN сервером 106 может быть разделена на два основных этапа: этап обучения и этап использования. Сначала сеть 130 NN обучается на этапе обучения. Затем на этапе использования, когда сети 130 NN известно, какие предполагаются входные данные и какие должны выдаваться выходные данные, сеть 130 NN используется сервером 106 с реальными данными.
[0099] Предполагается, что в некоторых вариантах осуществления настоящей технологии сеть 130 NN может быть реализована в виде полносвязной сети NN. Это означает, что слои нейронов сети 130 NN могут быть связаны так, чтобы каждый нейрон слоя был связан с каждым нейроном следующего слоя. Предполагается, что сеть 130 NN также может быть реализована в виде сети NN прямого распространения, в виде сети NN с архитектурой автокодировщика и т.п.
[00100] Сервер 106 может использовать сеть 130 NN с целью формирования векторов документов для документов, полученных приложением 120 обходчика. Предполагается, что векторы документов, сформированные для этих документов, могут быть использованы сервером 106 для эффективного хранения документов в системе 150 базы данных.
[00101] Сервер 106 также может использовать сеть 130 NN с целью формирования векторов запросов для запросов, отправленных серверу 106. Предполагается, что векторы запросов, сформированные для отправленных серверу 106 запросов, могут быть использованы сервером 106 для эффективного получения потенциально релевантных документов из системы 150 базы данных.
[00102] Далее более подробно описано осуществляемое сервером 106 обучение сети 130 NN и использование сети 130 NN для вышеупомянутого формирования векторов документов и векторов запросов. Перед описанием обучения и последующего использования сети 130 NN сервером 106 приведено описание системы 150 базы данных, репозитория 160 данных поисковой системы и рабочего репозитория 170. Система базы данных
[00103] На фиг. 2 представлена система 150 базы данных, связанная с сервером 106. В общем случае система 150 базы данных способна хранить большое количество документов, полученных приложением 120 обходчика. В частности, сервер 106 способен хранить это большое количество документов в системе 150 базы данных в группах, т.е. сервер 106 способен хранить документы в системе 150 базы данных в виде групп документов.
[00104] Кроме того, сервер 106 способен хранить группы документов в сочетании с соответствующими идентификаторами. Как более подробно описано далее, идентификатор для группы документов может представлять собой вектор, который сервер 106 способен сформировать на основе документов из данной группы документов.
[00105] Как описано далее, способ, используемый сервером 106 для определения групп документов и хранения их в системе 150 базы данных в сочетании с идентификаторами, позволяет повысить эффективность использования системы 150 базы данных во время выполнения операций по получению документов.
[00106] Предполагается, что в некоторых вариантах осуществления настоящей технологии система 150 базы данных может быть способной содержать базу 200 данных. В общем случае база 200 данных может представлять собой структурированный набор данных о документах и доступна серверу 106 для определения документов, потенциально релевантных отправленному запросу.
[00107] Предполагается, что система 150 базы данных может быть сформирована из множества 250 серверов базы данных, содержащих базу 200 данных. В представленном на фиг. 2 не имеющем ограничительного характера примере множество 250 серверов базы данных содержит первый сервер 252 базы данных, второй сервер 254 базы данных, третий сервер 256 базы данных и четвертый сервер 258 базы данных. Множество 250 серверов базы данных, образующее систему 150 базы данных, может быть связано с сервером 106, чтобы обеспечить серверу 106 доступ к базе 200 данных. Несмотря на то, что множество 250 серверов базы данных показано как содержащее лишь четыре сервера базы данных, предполагается, что множество 250 серверов базы данных, образующее систему 150 базы данных, может содержать другое количество серверов базы данных без выхода за границы настоящей технологии.
[00108] Предполагается, что множество 250 серверов базы данных может быть расположено в различных географических точках. В не имеющем ограничительного характера примере первый сервер 252 базы данных и второй сервер 254 базы данных могут располагаться рядом с первой географической точкой, а третий сервер 256 базы данных и четвертый сервер 258 базы данных могут располагаться рядом со второй географической точкой.
[00109] В некоторых вариантах осуществления настоящей технологии база 200 данных, содержащаяся в системе 150 базы данных, может быть «сегментированной», т.е. разделенной на множество 210 сегментов. Это означает, что структурированный набор данных, содержащийся в системе 150 базы данных, может быть разделен на разделы, каждый из которых соответствует сегменту из множества 210 сегментов.
[00110] Как показано на чертежах, база 200 данных может состоять из первого сегмента 212, второго сегмента 214, третьего сегмента 216 и четвертого сегмента 218. Например, каждый сегмент из числа первого сегмента 212, второго сегмента 214, третьего сегмента 216 и четвертого сегмента 218 может храниться в системе 150 базы данных в виде группы документов. Несмотря на то, что множество 210 сегментов показано как содержащее лишь четыре сегмента, предполагается, что множество 210 сегментов может содержать другое количество сегментов без выхода за границы настоящей технологии.
[00111] Сервер 106 может сформировать множество 210 сегментов (например, определить группы документов) базы 200 данных и хранить эти сегменты из множества 210 сегментов на соответствующих серверах базы данных из множества 250 серверов базы данных.
[00112] Сервер 106 также может отслеживать ранение конкретных сегментов из множества 210 сегментов на конкретных серверах базы данных из множества 250 серверов базы данных. С этой целью сервер 106 может хранить данные 140 соответствия (см. фиг. 1), указывающие на конкретные сегменты из множества 210 сегментов, хранящиеся на конкретных серверах базы данных из множества 250 серверов базы данных. Например, данные 140 соответствия могут содержать список идентификаторов групп документов (например, сегментов из множества 210 сегментов) и данные, указывающие на то, какой сервер из множества 250 серверов базы данных хранит группы документов, связанные с этими идентификаторами.
[00113] Следует еще раз отметить, что эти идентификаторы могут быть реализованы в виде векторов, сформированных сервером 106 на основе документов из соответствующих групп документов. Таким образом, запись в данных 140 соответствия может содержать (а) идентификатор в виде вектора для группы документов и (б) данные, идентифицирующие сервер базы данных из множества 250 серверов базы данных. Эта запись указывает на то, что группа документов, связанная с этим идентификатором, хранится на этом сервере базы данных.
[00114] Далее более подробно описано выполняемое сервером 106 (а) формирование множества 210 сегментов (например, определение групп документов) базы 200 данных и (б) определение конкретного сервера базы данных из множества 250 серверов базы данных для хранения конкретного сегмента.
[00115] Как описано выше, сервер 106 может использовать базу 200 данных, когда сервер 106 выполняет поиск релевантных документов в ответ на отправленный запрос. В общем случае во время использования базы 200 данных сервер 106 может быть способным:
- определять по меньшей мере один целевой сегмент (например, по меньшей мере одну целевую группу документов) из множества 210 сегментов базы 200 данных на основе отправленного запроса, при этом по меньшей мере один целевой сегмент содержит данные для определения документов, потенциально релевантных отправленному запросу;
- использовать данные 140 соответствия для определения по меньшей мере одного целевого сервера базы данных из множества 250 серверов базы данных, который содержит этот по меньшей мере один целевой сегмент; и
- осуществлять доступ к по меньшей мере одному целевому серверу базы данных с целью получения данных из по меньшей мере одного целевого сегмента.
[00116] Далее более подробно описано выполнение сервером 106 вышеупомянутых шагов при использовании базы 200 данных. Репозиторий данных поисковой системы
[00117] Как показано на фиг. 1, серверу 106 доступен репозиторий 160 данных поисковой системы. В общем случае репозиторий 160 данных поисковой системы способен хранить информацию, относящуюся к поисковой системе сервера 106. Несмотря на то, что репозиторий 160 данных поисковой системы показан на фиг. 1 в виде элемента, отдельного от системы 150 базы данных, предполагается, что репозиторий 160 данных поисковой системы может содержаться в системе 150 базы данных.
[00118] Например, репозиторий 160 данных поисковой системы может хранить информацию о поисках, ранее выполненных поисковой системой. В другом примере репозиторий 160 данных поисковой системы может хранить информацию о ранее отправленных серверу 106 запросах и о документах, которые могут быть предоставлены поисковой системой сервера 106 в качестве результатов поиска.
[00119] Предполагается, что репозиторий 160 данных поисковой системы может хранить данные запроса, связанные с соответствующими запросами. Данные запроса, связанные с запросом, могут быть различных видов и на них не накладывается каких-либо ограничений. Например, репозиторий 160 данных поисковой системы может хранить данные запроса для соответствующих запросов, в качестве неограничивающих примеров включая следующее:
- популярность запроса;
- частоту отправки запроса;
- количество «кликов», связанных с запросом;
- указания на другие отправленные запросы, связанные с запросом;
- указания на документы, связанные с запросом;
- другие статистические данные, связанные с запросом;
- текст, связанный с запросом;
- количество символов в запросе;
- другие текстовые данные, связанные с запросом;
- другие присущие запросу характеристики.
[00120] Репозиторий 160 данных поисковой системы также может хранить данные документа, связанные с соответствующими документами. Данные документа, связанные с документом, могут быть различных видов и на них не накладывается каких-либо ограничений. Например, репозиторий 160 данных поисковой системы может хранить данные документа для соответствующих документов, в качестве неограничивающих примеров включая следующее:
- популярность документа;
- коэффициент кликов для документа;
- время на «клик», связанное с документом;
- указания на другие документы, связанные с документом;
- указания на запросы, связанные с документом;
- другие статистические данные, связанные с документом;
- текст, связанный с документом;
- другие текстовые данные, связанные с документом;
- объем памяти, занимаемой документом;
- другие присущие документу характеристики.
[00121] Предполагается, что репозиторий 160 данных поисковой системы может также хранить информацию в виде пар запрос-документ. Например, репозиторий 160 данных поисковой системы может хранить большое количество пар запрос-документ, подобных паре 300 запрос-документ (см. фиг. 3). Пара 300 запрос-документ содержит запрос 302 и документ 304. Например, запрос 302 может представлять собой ранее отправленный серверу 106 запрос, а документ 304 может представлять собой документ, ранее предоставленный поисковой системой в ответ на запрос 302.
[00122] Как описано выше, репозиторий 160 данных поисковой системы может хранить данные запроса, связанные с запросами, и данные документа, связанные с документами. Например, репозиторий 160 данных поисковой системы может хранить запрос 302 в сочетании с данными 306 запроса и может хранить документ 304 в сочетании с данными 308 документа.
[00123] Также предполагается, что репозиторий 160 данных поисковой системы может хранить данные, указывающие на коэффициент релевантности для пары запрос-документ. Коэффициент релевантности для пары запрос-документ указывает на то, насколько документ из пары запрос-документ релевантен запросу из этой пары запрос-документ. Например, репозиторий 160 данных поисковой системы может хранить данные, указывающие на коэффициент 310 релевантности для пары 300 запрос-документ. Коэффициент 310 релевантности указывает на то, насколько документ 304 релевантен запросу 302.
[00124] На способ определения коэффициентов релевантности для пар запрос-документ не накладывается каких-либо ограничений. Например, коэффициенты релевантности могут быть по меньшей мере частично получены из данных о действиях пользователя, связанных с соответствующими парами запрос-документ. В другом примере коэффициенты релевантности могут быть оценены экспертами, в задачу которых входит оценка релевантности документа, предоставленного в ответ на полученный запрос.
[00125] Сервер 106 может использовать информацию, хранящуюся в репозитории 160 данных поисковой системы, в качестве обучающих данных для обучения сети 130 NN. Также предполагается, что сервер 106 может использовать информацию, хранящуюся в репозитории 160 данных поисковой системы, на этапе использования сети 130 NN. Далее более подробно описано использование сервером 106 информации, хранящейся в репозитории 160 данных поисковой системы. Рабочий репозиторий
[00126] Как показано на фиг. 1, серверу 106 доступен рабочий репозиторий 170. В общем случае рабочий репозиторий 170 может использоваться сервером 106 для временного или постоянного хранения информации, определенной или сформированной сервером 106 во время его работы, для последующего ее использования. Несмотря на то, что рабочий репозиторий 170 показан на фиг. 1 в виде элемента, отдельного от системы 150 базы данных, предполагается, что рабочий репозиторий 170 и/или репозиторий 160 данных поисковой системы может содержаться в системе 150 базы данных.
[00127] В представленном на фиг. 4 не имеющем ограничительного характера примере рабочий репозиторий 170 может использоваться сервером 106 для временного или постоянного хранения сформированных сетью NN данных 400, которые могут быть сформированы сетью 130 NN на этапе ее использования. Сформированные сетью NN данные 400 содержат вышеупомянутое множество 402 векторов документов, связанное со множеством 450 документов. Как описано далее, множество 402 векторов документов формируется сетью 130 NN на этапе использования сети 130 NN.
[00128] Например, во время работы сервера 106 он может использовать сеть 130 NN (см. фиг. 1) с целью формирования для каждого документа из множества 450 документов соответствующего вектора документа из множества 402 векторов документов. В результате сервер 106 может временно или постоянно хранить в рабочем репозитории 170 векторы документов в сочетании с документами, на основе которых они были сформированы сетью 130 NN.
[00129] Следует отметить, что множество 450 документов может содержать документы, полученные приложением 120 обходчика, и/или ранее предоставленные в качестве результатов поиска поисковой системой. В не имеющем ограничительного характера примере множество 450 документов может содержать все документы, которые потенциально могут быть предоставлены поисковой системой сервера 106 в качестве результатов поиска в ответ на отправленные запросы.
[00130] Предполагается, что информация, хранящаяся в рабочем репозитории 170, может быть использована сервером 106 для формирования множества 210 сегментов (например, для определения групп документов) базы 200 данных (см. фиг. 2). Также предполагается, что информация, хранящаяся в рабочем репозитории 170, может быть использована с целью формирования идентификаторов для групп документов. Также предполагается, что информация, хранящаяся в рабочем репозитории 170, может быть использована сервером 106 с целью определения конкретного сервера базы данных из множества 250 серверов базы данных для хранения конкретного сегмента из множества 210 сегментов (например, конкретной группы документов). В дальнейшем использование сервером 106 информации, временно или постоянно хранящейся в рабочем репозитории 170, для выполнения вышеупомянутых функций сервера 106 описано более подробно.
[00131] Далее описано обучение сервером 106 сети 130 NN на этапе ее обучения для формирования множества 402 векторов документов на этапе ее использования.
Этап обучения нейронной сети
[00132] На фиг. 5 представлена итерация обучения сети 130 NN. Несмотря на то, что на фиг. 5 представлена только одна итерация обучения сети NN, следует отметить, что сервер 106 может выполнять большое количество итераций обучения подобно тому, как сервер 106 выполняет итерацию обучения, представленную на фиг. 5, без выхода за границы настоящей технологии.
[00133] Следует отметить, что сеть 130 NN обучается на основе обучающей пары запрос-документ. В представленном на фиг. 5 не имеющем ограничительного характера примере сеть 130 NN обучается на основе пары 300 запрос-документ. Предполагается, что каждая итерация обучения сети 130 NN может быть выполнена на основе соответствующей пары запрос-документ, полученной сервером 106 из репозитория 160 данных поисковой системы.
[00134] Следует также отметить, что сервер 106 может выполнять множество моделей 132 векторизации запроса и множество моделей 134 векторизации документа (см. также фиг. 1). В общем случае модель векторизации, в известном смысле, способна преобразовывать первичные данные об элементе в векторную форму, представляющую эти первичные данные. Модель векторизации предназначена для получения первичных данных некоторого вида, обработки первичных данных этого вида и формирования соответствующего вектора для первичных данных этого вида.
[00135] На модели из множества моделей 132 векторизации запроса не накладывается каких-либо особых ограничений. Например, множество моделей 132 векторизации запроса может содержать первую модель векторизации запроса, способную получать текстовые данные, связанные с запросом, и формировать первый субвектор запроса, связанный с запросом и представляющий текстовые данные запроса. В другом примере множество моделей 132 векторизации запроса может содержать вторую модель векторизации запроса, способную получать статистические данные, связанные с запросом, и формировать второй субвектор запроса, связанный с запросом и представляющий статистические данные запроса (а также потенциально может выполнять конкатенацию этих первичных статистических данных для преобразования в векторную форму).
[00136] Аналогично, на модели из множества моделей 134 векторизации документа не накладывается каких-либо особых ограничений. Например, множество моделей 134 векторизации документа может содержать первую модель векторизации документа, способную получать текстовые данные, связанные с документом, и формировать первый субвектор документа, связанный с документом и представляющий текстовые данные документа. В другом примере множество моделей 134 векторизации документа может содержать вторую модель векторизации документа, способную получать статистические данные, связанные с документом, и формировать второй субвектор документа, связанный с документом и представляющий статистические данные документа (а также потенциально может выполнять конкатенацию этих первичных статистических данных для преобразования в векторную форму).
[00137] В некоторых вариантах осуществления изобретения множество моделей 132 векторизации запроса и множество моделей 134 векторизации документа также могут содержать по меньшей мере одну общую модель векторизации.
[00138] Следует отметить, что другие потенциальные модели векторизации также могут быть использованы в качестве части множества моделей 132 векторизации запроса и/или множества моделей 134 векторизации документа. Например, могут быть использованы следующие потенциальные модели векторизации: углубленные структурированные семантические модели (DSSM, Deep Structured Semantic Model), модели вида «мешок слов» (bag-of-words), модели вида word2vec, модели вида sent2vec и т.д. Таким образом, можно сказать, что для формирования субвекторов могут быть использованы различные способы векторизации.
[00139] Можно предположить, что множество моделей 132 векторизации запроса содержит три модели векторизации запроса, а множество моделей 134 векторизации документа содержит три модели векторизации документа (см. фиг. 5).
[00140] Сервер 106 может использовать данные 306 запроса, связанные с запросом 302, в качестве входных данных для множества моделей 132 векторизации запроса. В результате каждая модель из множества моделей 132 векторизации запроса выдает субвектор запроса на основе данных соответствующего вида в данных 306 запроса. Например, множество моделей 132 векторизации запроса выдает первый субвектор 521 запроса, второй субвектор 522 запроса и третий субвектор 523 запроса.
[00141] Кроме того, сервер 106 может использовать данные 308 документа, связанные с документом 304, в качестве входных данных для множества моделей 134 векторизации документа. В результате каждая модель из множества моделей 134 векторизации документа выдает субвектор документа на основе данных соответствующего вида в данных 308 запроса. Например, множество моделей 134 векторизации документа выдает первый субвектор 524 документа, второй субвектор 525 документа и третий субвектор 526 документа.
[00142] Следует отметить, что первый субвектор 521 запроса, второй субвектор 522 запроса, третий субвектор 523 запроса, первый субвектор 524 документа, второй субвектор 525 документа и третий субвектор 526 документа используются сервером 106 в качестве входных данных сети 130 NN во время итерации обучения сети 130 NN.
[00143] Таким образом, можно сказать, что сервер 106 может использовать множество моделей 132 векторизации запроса и множество моделей 134 векторизации документа, которые способны обрабатывать первичные данные, связанные с запросом из пары запрос-документ, и первичные данные, связанные с документом из пары запрос-документ, с целью формирования обучающих входных данных для сети 130 NN.
[00144] Также следует отметить, что сеть 130 NN содержит две части: предназначенную для запроса часть 502 и предназначенную для документа часть 504. Предназначенная для запроса часть 502 способна получать субвекторы, выданные множеством моделей 132 векторизации запроса. Иными словами, предназначенная для запроса часть 502 способна получать первый субвектор 521 запроса, второй субвектор 522 запроса и третий субвектор 523 запроса. Предназначенная для документа часть 504 способна получать субвекторы, выданные множеством моделей 134 векторизации документа. Иными словами, предназначенная для документа часть 504 способна получать первый субвектор 524 документа, второй субвектор 525 документа и третий субвектор 526 документа.
[00145] Предназначенная для запроса часть 502 способна формировать вектор 550 обучающего запроса, а предназначенная для документа часть 504 способна формировать вектор 560 обучающего документа. Вектор 550 обучающего запроса связан с запросом 302 и основан на данных 306 запроса, а вектор 560 обучающего документа связан с документом 304 и основан на данных 308 документа.
[00146] Когда вектор 550 обучающего запроса и вектор 560 обучающего документа сформированы предназначенной для запроса частью 502 и предназначенной для документа частью 504, соответственно, сервер 106 может определять значение 570 близости вектора 550 обучающего запроса и вектора 560 обучающего документа. Например, значение 570 близости может соответствовать векторному расстоянию между вектором 550 обучающего запроса и вектором 560 обучающего документа. Значение 570 близости может указывать на то, насколько пространственно близки друг к другу вектор 550 обучающего запроса и вектор 560 обучающего документа.
[00147] Например, векторное расстояние между векторами может соответствовать евклидову расстоянию между этими векторами. В другом примере векторное расстояние между векторами может соответствовать скалярному произведению этих векторов. Таким образом, предполагается, что векторное расстояние может соответствовать пространственной близости двух векторов в векторном пространстве без выхода за границы настоящей технологии.
[00148] Обучение сети 130 NN предназначено для адаптации сети 130 NN с целью формирования вектора запроса и вектора документа так, чтобы значение близости представляло собой коэффициент релевантности для обучающей пары запрос-документ. В этом случае цель обучения сети 130 NN заключается в адаптации сети 130 NN для формирования вектора 550 обучающего запроса и вектора 560 обучающего документа так, чтобы значение 570 близости представляло собой коэффициент 310 релевантности для пары 300 запрос-документ.
[00149] Для адаптации сети 130 NN с целью формирования вектора 550 обучающего запроса и вектора 560 обучающего документа так, чтобы значение 570 близости представляло собой коэффициент 310 релевантности для пары 300 запрос-документ, сервер 106 может сравнивать значение 570 близости с коэффициентом 310 релевантности. На основе результата этого сравнения сервер 106 может использовать различные способы обучения для корректировки связей между нейронами сети 130 NN и, следовательно, для адаптации сети 130 NN. Например, сервер 106 может использовать алгоритм обратного распространения для корректировки связей между нейронами сети 130 NN на основе ситуации, возникшей во время итерации обучения сети 130 NN.
[00150] В результате сеть 130 NN на этапе ее обучения адаптируется для (а) получения входных данных, основанных на данных запроса, связанных с запросом, и использования предназначенной для запроса части 502 для формирования вектора запроса, (б) получения входных данных, основанных на данных документа, связанных с документом, и использования предназначенной для документа части 504 для формирования вектора документа так, чтобы (в) близость вектора документа и вектора запроса друг к другу представляла собой релевантность собой документа запросу.
[00151] Как описано далее, поскольку близость вектора документа и вектора запроса друг к другу представляет собой релевантность документа запросу, то это означает, что чем пространственно ближе друг к другу вектор документа и вектор запроса, тем выше релевантность документа запросу. Также следует отметить, что поскольку близость вектора документа и вектора запроса друг к другу представляет собой релевантность документа запросу, то это означает, что чем пространственно дальше друг от друга вектор документа и вектор запроса, тем ниже релевантность документа запросу.
[00152] Следует отметить, что во время итерации обучения сети 130 NN предназначенная для запроса часть 502 и предназначенная для документа часть 504 обучаются совместно или одновременно, поскольку при необходимости связи между нейронами предназначенной для запроса части 502 и связи между нейронами предназначенной для документа части 504 корректируются совместно или одновременно на каждой итерации на основе результата сравнения значения близости (например, значения 570 близости) и коэффициента релевантности (например, коэффициента 310 релевантности).
[00153] В результате предназначенная для запроса часть 502 и предназначенная для документа часть 504 обучаются путем совместной или одновременной адаптации предназначенной для запроса части 502 и предназначенной для документа части 504 с целью формирования соответствующих векторов так, чтобы близость этих векторов друг к другу представляла собой коэффициент релевантности для пары запрос-документ, для которой были сформированы эти векторы.
[00154] Следует отметить, что несмотря на то, что предназначенная для запроса часть 502 и предназначенная для документа часть 504 обучаются совместно или одновременно, сервер 106 на этапе использования сети 130 NN использует предназначенную для запроса часть 502 отдельно от предназначенной для документа части 504. Далее описано применение сервером 106 сети 130 NN на этапе ее использования и, в частности, использование сервером 106 обученной предназначенной для документа части 504 и обученной предназначенной для запроса части 502. Этап использования нейронной сети
[00155] Как описано выше, этап использования сети 130 NN включает в себя использование сервером 106 предназначенной для документа части 504 и использование сервером 106 предназначенной для запроса части 502.
[00156] С одной стороны, сервер 106 может использовать предназначенную для документа часть 504 сети 130 NN для формирования множества 402 векторов документов для множества 450 документов (см. фиг. 4).
[00157] Каждый вектор из множества 402 векторов документов может быть сформирован предназначенной для документа частью 504 на основе данных документа, связанных с соответствующим документом из множества 450 документов. Каждый вектор из множества 402 векторов документов может быть сформирован предназначенной для документа частью 504 подобно тому, как предназначенная для документа часть 504 формирует вектор 560 обучающего документа (см. фиг. 5).
[00158] В результате сервер 106 может использовать обученную предназначенную для документа часть 504 сети 130 NN с целью формирования вектора из множества 402 векторов документов для соответствующего документа из множества 450 документов. Сервер 106 может временно или постоянно хранить сформированные сетью NN данные 400 в рабочем репозитории 170 для последующего их использования.
[00159] С другой стороны, сервер 106 может использовать предназначенную для запроса часть 502 сети 130 NN с целью формирования вектора запроса для отправленного серверу 106 запроса, в ответ на который сервер 106 должен предоставить результаты поиска.
[00160] Например, сервер 106 может получать запрос 180 (см. фиг. 1), указывающий на запрос, отправленный пользователем 101. Сервер 106 может получать из репозитория 160 данных поисковой системы данные запроса, связанные с запросом, отправленным пользователем 101. В результате сервер 106 может использовать обученную предназначенную для запроса часть 502 сети 130 NN для формирования вектора запроса для запроса, отправленного пользователем 101, на основе данных запроса, связанных с запросом, отправленным пользователем 101.
[00161] Предполагается, что данные запроса для запроса, отправленного пользователем 101, могут быть предварительно обработаны и сохранены в репозитории 160 данных поисковой системы до получения запроса 180. В других случаях эти данные запроса могут быть обработаны после получения запроса 180 и предоставлены серверу 106 для дальнейшего их использования. В других случаях данные запроса для запроса, отправленного пользователем 101, могут быть частично предварительно обработаны и сохранены в репозитории 160 данных поисковой системы до получения запроса 180 и частично обработаны после получения запроса 180 без выхода за границы настоящей технологии.
[00162] Следует еще раз отметить, что множество 450 документов может содержать очень большое количество документов. Поскольку множество 450 документов содержит документы, которые потенциально могут быть предоставлены поисковой системой в качестве результатов поиска, количество документов в множестве 450 документов может составлять тысячи, миллионы или даже миллиарды. Поэтому определение такого же количества значений близости сервером 106 для определения того, какие документы из множества документов потенциально наиболее релевантны запросу, отправленному пользователем 101, может потребовать неприемлемо большого количества времени.
[00163] Пользователь 101 предполагает, что время реакции для предоставления результатов поиска должно быть в пределах нескольких секунд с момента отправки им запроса. В то же время определение очень большого количества значений близости сервером 106 требует значительного времени и/или значительных компьютерных ресурсов, что может привести к неприемлемому времени реакции при предоставлении результатов поиска пользователю 101.
[00164] Разработчики настоящей технологии предложили способы и системы для группировки документов из множества 450 документов и хранения этих групп документов таким образом, чтобы уменьшить время реакции на запрос, отправленный пользователем 101. Иными словами, разработчики настоящей технологии предложили способы хранения множества 450 документов в виде групп документов таким образом, чтобы выбор документов с высокой вероятностью релевантности запросу, отправленному пользователем 101, требовал меньшего количества операций (например, меньшего количества сравнений векторов, меньшего количества определений значений близости), чем описано выше.
[00165] В общем случае предполагается, что сервер 106 может определять группы документов из множества 450 документов, каждая из которых связана с вектором группы так, чтобы документы в группе документов были связаны с векторами документов, близкими к вектору группы. Этот вектор группы может использоваться сервером 106 в качестве идентификатора для группы документов, как описано выше. Следует отметить, что документы, сгруппированные в соответствии с вектором группы, подобным или близким к вектору запроса, отправленного пользователем 101, имеют высокую вероятность релевантности запросу, отправленному пользователем 101.
[00166] Таким образом, вместо сравнения вектора запроса, отправленного пользователем 101, с каждым вектором из множества 402 векторов документов, сервер 106 может сравнивать вектор запроса, отправленного пользователем 101, с векторами групп, количество которых меньше количества векторов во множестве 402 векторов документов.
[00167] Далее описано определение сервером 106 групп документов из множества 450 документов и соответствующих векторов групп (например, идентификаторов). Группировка документов
[00168] На фиг. 6 представлен не имеющий ограничительного характера пример процедуры 600 группировки, которую сервер 106 может выполнять для объединения в группы множества 450 документов. С этой целью сервер 106 может использовать алгоритм 145 «K-средних».
[00169] В общем случае алгоритм 145 «K-средних» способен получать (а) множество 402 векторов документов и (б) значение 650 для К и в ответ способен выполнять группировку множества 402 векторов документов в К групп векторов документов. Можно сказать, что сервер 106 способен группировать документы из множества 450 документов в соответствии с тем, как множество 402 векторов документов сгруппировано в К групп векторов документов алгоритмом 145 «K-средних».
[00170] Кроме того, алгоритм 145 «K-средних» может выполняться сервером 106 с целью определения вектора группы для каждой группы из K групп векторов документов. Вектор группы может быть использован в качестве идентификатора для группы документов.
[00171] Следует отметить, что графическое представление 602 определения алгоритмом 145 «K-средних» K групп векторов документов и их соответствующих векторов групп приведено на фиг. 6 лишь для иллюстрации и что алгоритм 145 «K-средних» в действительности не предназначен для формирования или отображения графического представления 602. Кроме того, на графическом представлении 602 точки данных представляют векторы из множества 402 векторов документов и показаны как отображенные на основе их близости друг к другу. Следует также отметить, что графическое представление 602 в виде упрощенного двухмерного представления приведено лишь для иллюстрации. В действительности для точной иллюстрации множества 402 векторов документов, отображенного на основе близости этих векторов друг другу, необходимо многомерное представление.
[00172] Можно предположить, что значение К, введенное в алгоритм 145 «K-средних», равно 4. Это означает, что сервер 106, выполняющий алгоритм 145 «K-средних», способен сгруппировать множество 402 векторов документов в 4 группы векторов документов, каждая из которых связана с вектором группы.
[00173] Сервер 106, выполняющий алгоритм 145 «K-средних», может определить первую группу 610 векторов документов, связанную с первым вектором 620 группы, вторую группу 612 векторов документов, связанную со вторым вектором 622 группы, третью группу 614 векторов документов, связанную с третьим вектором 624 группы и четвертую группу 616 векторов документов, связанную с четвертым вектором 626 группы.
[00174] После определения сервером 106, выполняющим алгоритм 145 «K-средних», первой, второй, третьей и четвертой групп 610, 612, 614и616 векторов документов в сочетании с первым, вторым, третьим и четвертым векторами 620, 622, 624 и 626 групп, сервер 106 может сгруппировать документы из множества 450 документов в соответствии с тем, как множество 402 векторов документов было сгруппировано в первую, вторую, третью и четвертую группы 610, 612, 614 и 616 векторов документов. Затем сервер 106 может сопоставить группу документов с вектором группы, связанным с группой векторов документов.
[00175] Например, как показано на фиг. 6, первая группа 640 документов сопоставлена с первым вектором 620 группы, поскольку документы из первой группы 640 документов связаны с векторами документов из первой группы 610 векторов документов. Вторая группа 642 документов сопоставлена со вторым вектором 622 группы, поскольку документы из второй группы 642 документов связаны с векторами документов из второй группы 612 векторов документов. Третья группа 644 документов сопоставлена с третьим вектором 624 группы, поскольку документы из третьей группы 644 документов связаны с векторами документов из третьей группы 614 векторов документов. Четвертая группа 646 документов сопоставлена с четвертым вектором 626 группы, поскольку документы из четвертой группы 646 документов связаны с векторами документов из четвертой группы 616 векторов документов.
[00176] В некоторых вариантах осуществления настоящей технологии сервер 106 может выполнять процедуру дополнения группы для дополнения группы документов по меньшей мере одним документом, который в противном случае был бы включен в состав другой группы документов.
[00177] В качестве примера можно рассмотреть документ, связанный с вектором 630 документа, показанным на графическом представлении 602. Как описано выше, сервер 106 способен включить этот документ в состав четвертой группы 646 документов и сопоставить этот документ с четвертым вектором 626 группы. Действительно, как показано на графическом представлении 602, вектор 630 документа близко расположен к четвертому вектору 626 группы и входит в состав четвертой группы 616 векторов документов.
[00178] Тем не менее, как также показано на графическом представлении 602, вектор 630 документа близко расположен к третьему вектору 624 группы. Предполагается, что в некоторых вариантах осуществления настоящей технологии, если значение близости (например, векторное расстояние) третьего вектора 624 группы и вектора 630 документа друг к другу меньше заранее заданного порога, то сервер 106 может дополнить третью группу 644 документов документом, связанным с вектором 630 документа.
[00179] Таким образом, можно сказать, что в некоторых вариантах осуществления настоящей технологии группы документов, определенные сервером 106 из множества 450 документов, могут не быть взаимоисключающими. Это означает, что в некоторых вариантах осуществления настоящей технологии документ из множества 450 документов при группировке может быть включен в состав по меньшей мере одной группы документов и связан с по меньшей мере одним вектором группы.
[00180] Сервер 106 способен хранить первую группу 640 документов в сочетании с первым вектором 620 группы, вторую группу 642 документов в сочетании со вторым вектором 622 группы, третью группу 644 документов в сочетании с третьим вектором 624 группы и четвертую группу 646 документов в сочетании с четвертым вектором 626 группы.
[00181] В некоторых вариантах осуществления изобретения вместо хранения множества 402 векторов документов сервер 106 может хранить в системе 150 базы данных лишь векторы групп, связанные с соответствующими группами документов. В этом случае сервер 106 может хранить значительно меньшее количество векторов в системе 150 базы данных.
[00182] Таким образом, для получения документов с высокой вероятностью релевантности запросу, отправленному пользователем 101, сервер 106 может определять векторы групп, наиболее схожие с вектором запроса, отправленного пользователем 101. Затем сервер 106 может получать документы из группы документов, связанной с наиболее схожим вектором группы. Хранение сегментов на серверах базы данных
[00183] В некоторых вариантах осуществления изобретения, где система 150 базы данных содержит базу 200 данных, сервер 106 может хранить группы документов в виде сегментов базы 200 данных. Сервер 106 может хранить группы документов в виде сегментов базы 200 данных на множестве 250 серверов базы данных в системе 150 базы данных (см. фиг. 7).
[00184] В первом примере сервер 106 может хранить первую группу 640 документов в виде первого сегмента 212 на первом сервере 252 базы данных. Следует отметить, что первый сегмент 212 базы 200 данных хранится в сочетании с первым вектором 620 группы (например, с идентификатором для первого сегмента 212).
[00185] Во втором примере сервер 106 может хранить вторую группу 642 документов в виде второго сегмента 214 на третьем сервере 256 базы данных. Следует отметить, что второй сегмент 214 базы 200 данных хранится в сочетании со вторым вектором 622 группы (например, с идентификатором для второго сегмента 214).
[00186] Как описано выше, сервер 106 может отслеживать хранение конкретных сегментов базы 200 данных на конкретных серверах базы данных в системе 150 базы данных. Например, при хранении множества 210 сегментов на множестве 250 серверов базы данных сервер 106 может регистрировать и накапливать данные 140 соответствия, указывающие (а) на векторы групп, связанные со множеством 210 сегментов, и (б) на серверы базы данных, хранящие сегменты, связанные с соответствующими векторами групп.
[00187] В этом случае данные 140 соответствия могут, например, указывать на то, что (а) первый вектор 620 группы связан с первым сервером 252 базы данных и вторым сервером 254 базы данных, (б) второй вектор 622 группы связан с третьим сервером 256 базы данных, (в) третий вектор 624 группы связан с четвертым сервером 258 базы данных, (г) четвертый вектор 626 группы связан с четвертым сервером 258 базы данных.
[00188] Данные 140 соответствия могут быть использованы сервером 106 для доступа к системе 150 базы данных. В частности, сервер 106 может использовать данные 140 соответствия, чтобы обращаться лишь к некоторым серверам из множества 250 серверов базы данных и не обращаться к другим серверам из множества 250 серверов базы данных.
[00189] Например, при формировании сервером 106 вектора запроса для запроса, отправленного пользователем 101, сервер 106 может сравнивать этот вектор запроса с векторами групп, как описано выше, и определять вектор группы, наиболее схожий с вектором запроса. Наиболее схожий вектор группы связан с целевым сегментом из множества 210 сегментов, содержащим документы с высокой вероятностью релевантности запросу, отправленному пользователем 101.
[00190] После определения сервером 106 наиболее схожего вектора группы (который представляет собой идентификатор целевого сегмента) сервер 106 может просматривать данные 140 соответствия и определять целевой сервер базы данных, хранящий целевой сегмент. После определения целевого сервера базы данных из множества 250 серверов базы данных сервер 106 может обращаться к целевому серверу базы данных для получения документов из целевого сегмента.
[00191] Следует отметить, что при обращении к целевому серверу базы данных серверу 106 не требуется обращаться к другим серверам базы данных в системе 150 базы данных. Например, векторы групп, которые, исходя из результатов сравнения вектора запроса и соответствующих векторов групп, более далеки от вектора запроса, связаны с сегментами, которые с меньшей вероятностью содержат высокорелевантные документы для запроса, отправленного пользователем 101. Поэтому обращение к этим сегментам на других серверах базы данных может не потребоваться. В результате возможно уменьшение сетевого трафика и количества запросов на доступ к серверам базы данных в системе 150 базы данных.
[00192] Предполагается, что сервер 106 может дублировать сегмент базы 200 данных для хранения в системе 150 базы данных. Например, сервер 106 может дублировать первый сегмент 212 и хранить его на втором сервере 254 базы данных в сочетании с первым вектором 620 группы. Такое дублирование сегмента базы 200 данных может выполняться для выравнивания нагрузки на серверы базы данных, к которым сервер 106 часто обращается во время работы.
[00193] Например, первый вектор 620 группы может быть определен в качестве наиболее схожего вектора для большого количества векторов запросов, сформированных на основе запросов, отправленных поисковой системе сервера 106. В результате первый сегмент 212 может быть определен как целевой сегмент для этого большого количества запросов и, следовательно, серверу 106 очень много раз может потребоваться доступ к первому сегменту 212. Это означает, что серверу 106 очень много раз может потребоваться доступ к первому серверу 252 базы данных, содержащему первый сегмент 212. Это может привести к высокой нагрузке на первый сервер 252 базы данных, поскольку к нему часто обращается сервер 106.
[00194] Поэтому дублирование первого сегмента 212, к которому часто обращается сервер 106, и хранение дублирующей версии на другом сервере базы данных позволяет сбалансировать нагрузку на первый сервер 252 базы данных. Наличие копии первого сегмента 212 на втором сервере 254 базы данных позволяет перенаправлять часть запросов на доступ от сервера 106 с первого сервера 252 базы данных, на котором размещен первый сегмент 212, на второй сервер 254 базы данных, на котором размещена копия первого сегмента 212.
[00195] Предполагается, что сервер 106 может хранить несколько сегментов на общем сервере базы данных. Например, сервер 106 может хранить (а) третью группу 644 документов в виде третьего сегмента 216 на четвертом сервере 258 базы данных и (б) четвертую группу 646 документов в виде четвертого сегмента 218 на четвертом сервере 258 базы данных. Следует отметить, что третий сегмент 216 хранится в сочетании с третьим вектором 624 группы, а четвертый сегмент 218 хранится в сочетании с четвертым вектором 626 группы.
[00196] В некоторых случаях хранение нескольких сегментов на общем сервере базы данных может быть полезным, когда векторы групп, связанные с несколькими сегментами, близки друг к другу. Например, можно предположить, что вектор запроса, сформированный для запроса, отправленного пользователем 101, близок к третьему вектору 624 группы. При этом вектор запроса, сформированный для запроса, отправленного пользователем 101, также может быть близок к четвертому вектору 626 группы. В результате в некоторых вариантах осуществления настоящей технологии сервер 106 может определить несколько целевых сегментов и, следовательно, для получения документов серверу 106 может потребоваться доступ к нескольким сегментам.
[00197] В этом случае хранение нескольких сегментов на общем сервере базы данных на основе близости соответствующих векторов групп друг к другу может быть полезным, поскольку это позволяет уменьшить общее количество целевых серверов базы данных, к которым должен обращаться сервер 106. Например, в этом случае, поскольку третий сегмент 216, связанный с третьим вектором 624 группы, и четвертый сегмент 218, связанный с четвертым вектором 626 группы хранятся на четвертом сервере 258 базы данных, серверу 106 для доступа к третьему сегменту 216 и к четвертому сегменту 218 может потребоваться обращение только к одному серверу базы данных (к четвертому серверу 258 базы данных), а не к двум серверам базы данных, как в случае, когда третий сегмент 216 и четвертый сегмент 218 хранятся на разных серверах базы данных.
[00198] Предполагается, что после описанного выше получения документов из целевых сегментов эти документы могут быть использованы сервером 106 для формирования результатов поиска в ответ на запрос, отправленный пользователем 101. Например, документы, полученные таким образом из целевых сегментов, могут быть введены в алгоритмы ранжирования поисковой системы, что позволяет серверу 106 выбирать из полученных таким образом документов те документы, что должны быть предоставлены в качестве результатов поиска, и определять их порядок. Затем сервер 106 может сформировать ответ 190, содержащий информацию, указывающую на результаты поиска для запроса, отправленного пользователем 101.
[00199] В некоторых вариантах осуществления настоящей технологии сервер 106 способен выполнять представленный на фиг. 8 способ 800 хранения множества 450 документов в системе 150 базы данных. Способ 800 описан далее. Шаг 802: получение сервером данных документа, связанных с соответствующими документами из множества документов.
[00200] Способ начинается с шага 802, на котором сервер 106 может получать данные документа, связанные со множеством 450 документов. В не имеющем ограничительного характера примере настоящей технологии сервер 106 может получать данные документа для множества 450 документов из репозитория 160 данных поисковой системы. Шаг 804: формирование сервером, использующим алгоритм MLA, вектора документа на основе данных документа для каждого документа из множества документов.
[00201] Способ 800 продолжается на шаге 802, на котором сервер 106 может использовать алгоритм MLA (например, сеть 130 NN) на этапе использования для формирования множества 402 векторов документов, например, как показано на фиг. 4. Сеть 130 NN обучена до ее применения на этапе использования.
[00202] Например, на фиг. 5 представлена одна итерация этапа обучения сети 130 NN. Сеть 130 NN обучается на основе обучающей пары документ-запрос, связанной с коэффициентом релевантности. В этом случае обучающая пара документ-запрос, связанная с коэффициентом релевантности, представляет собой пару 300 запрос-документ, связанную с коэффициентом 310 релевантности. Как описано выше, коэффициент 310 релевантности указывает на релевантность документа 304 запросу 302.
[00203] Как описано выше, сеть 130 NN обучается так, чтобы значение 570 близости друг к другу вектора 560 документа и вектора 550 запроса представляло собой коэффициент 310 релевантности. Значение 570 близости может представлять собой векторное расстояние между вектором 560 документа и вектором 550 запроса. Иными словами, значение 570 близости может указывать на то, насколько пространственно близки или далеки друг от друга вектор 560 документа и вектор 550 запроса.
[00204] Для адаптации сети 130 NN с целью формирования вектора 550 обучающего запроса и вектора 560 обучающего документа так, чтобы значение 570 близости представляло собой коэффициент 310 релевантности для пары 300 запрос-документ, сервер 106 может сравнивать значение 570 близости с коэффициентом 310 релевантности. На основе результата этого сравнения сервер 106 может использовать различные способы обучения для корректировки связей между нейронами сети 130 NN и, следовательно, для адаптации сети 130 NN. Например, сервер 106 может использовать алгоритм обратного распространения для корректировки связей между нейронами сети 130 NN на основе ситуации, возникшей во время итерации обучения сети 130 NN. Шаг 806: хранение сервером множества документов в системе базы данных в виде групп документов, каждая из которых связана с вектором группы.
[00205] Способ 800 продолжается на шаге 806, на котором сервер 106 хранит множество 450 документов в виде групп документов в системе 150 базы данных. Каждая группа документов хранится сервером 106 в системе 150 базы данных в сочетании с вектором группы. Группа документов содержит документы, связанные с векторами документов, пространственно близкими к вектору группы.
[00206] Например, сервер 106 может сформировать вектор документа из множества 402 векторов документов для документа из множества 450 документов. На шаге 806 сервер 106 может хранить множество 450 документов в виде первой группы 640 документов, второй группы 642 документов, третьей группы 644 документов и четвертой группы 646 документов (см. фиг. 4).
[00207] Следует отметить, что первая группа 640 документов, вторая группа 642 документов, третья группа 644 документов и четвертая группа 646 документов связаны с первым вектором 620 группы, вторым вектором 622 группы, третьим вектором 624 группы и четвертым вектором 626 группы, соответственно.
[00208] В качестве примера можно рассмотреть первую группу 640 документов, связанную с первым вектором 620 группы. Первая группа 640 документов содержит документы из множества документов 450, связанные с соответствующими векторами документов из множества 402 векторов документов, пространственно близкими к первому вектору 620 группы.
[00209] Следует отметить, что пространственная близость друг к другу одного вектора документа, соответствующего одному документу из первой группы 640 документов, и другого вектора документа, соответствующего другому документу из первой группы 640 документов, указывает на сходство этих документов.
[00210] Предполагается, что сервер 106 может определять для каждой группы документов вектор группы на основе векторов документов, связанных со множеством 450 документов. Сервер 106 может группировать множество 450 документов в первую группу 640 документов, вторую группу 642 документов, третью группу 644 документов и четвертую группу 646 документов.
[00211] Например, для группирования множества 450 документов сервер 106 может выполнять алгоритм 145 «K-средних» для множества 402 векторов документов, связанных со множеством 450 документов и, таким образом, определять (а) первый вектор 620 группы, второй вектор 622 группы, третий вектор 624 группы и четвертый вектор 626 группы и, соответственно, связанные с ними (б) первую группу 640 документов, вторую группу 642 документов, третью группу 644 документов и четвертую группу 646 документов.
[00212] Как описано выше, предполагается, что группы документов могут содержать заранее заданное количество групп, равное К.
[00213] В некоторых вариантах осуществления изобретения сервер 106 может получать текущий запрос от устройства 102, связанного с сервером 106. Текущий запрос может представлять собой запрос, отправленный пользователем 101. Текущий запрос относится к предоставлению устройству 102 по меньшей мере одного текущего документа, релевантного текущему запросу.
[00214] Сервер 106 может получать данные запроса, связанные с текущим запросом. Например, сервер 106 может получать данные запроса из репозитория 160 данных поисковой системы. Как описано выше, сервер 106 может использовать предназначенную для запроса часть 502 сети 130 NN с целью формирования для текущего запроса вектора текущего запроса на основе данных запроса, связанных с текущим запросом.
[00215] Сервер 106 также может определять вектор группы, наиболее схожий с вектором текущего запроса из числа первого вектора 620 группы, второго вектора 622 группы, третьего вектора 624 группы и четвертого вектора 626 группы. Наиболее схожий вектор группы связан с целевой группой документов из числа первой группы 640 документов, второй группы 642 документов, третьей группы 644 документов и четвертой группы 646 документов.
[00216] Сервер 106 может использовать данные 140 соответствия для доступа к системе 150 базы данных с целью получения документов из целевой группы документов. Сервер 106 в ответ на текущий запрос может предоставлять устройству 102 по меньшей мере один документ из целевой группы документов.
[00217] Сервер 106 может при обращении к системе 150 базы данных не получать документы из других групп документов, отличных от целевой группы документов.
[00218] Предполагается, что система 150 базы данных может содержать базу 200 данных, разделенную на множество 210 сегментов (см. фиг. 2). В некоторых вариантах осуществления изобретения хранение групп документов сервером 106 может включать в себя хранение сервером 106 групп документов в виде сегментов базы 200 данных в системе 150 базы данных, каждый из которых связан с вектором группы.
[00219] В некоторых вариантах осуществления изобретения система 150 базы данных может содержать множество 250 серверов базы данных. Предполагается, что хранение сервером 106 групп документов в виде сегментов может включать в себя хранение множества 210 сегментов базы 200 данных на множестве 250 серверов базы данных в системе 150 базы данных.
[00220] В некоторых вариантах осуществления изобретения сервер базы данных из множества 250 серверов базы данных может хранить несколько сегментов из множества 210 сегментов. Например, четвертый сервер 258 базы данных может хранить третий сегмент 216, связанный с третьим вектором 624 группы, и четвертый сегмент 218, связанный с четвертым вектором 626 группы (см. фиг. 7).
[00221] В некоторых вариантах осуществления изобретения несколько серверов базы данных из множества 250 серверов базы данных могут хранить один и тот же сегмент из множества 210 сегментов. Например, первый сервер 252 базы данных и второй сервер 254 базы данных могут хранить первый сегмент 212 (в частности, первый сегмент 212 и копию первого сегмента 212, соответственно) в сочетании с первым вектором 620 группы.
[00222] В некоторых вариантах осуществления изобретения множество 250 серверов базы данных может быть физически расположено в нескольких географических точках. Предполагается, что сегменты, хранящиеся на соответствующих серверах из множества 250 серверов базы данных, могут быть выбраны сервером 106 для хранения на основе физического местоположения серверов из множества серверов 250 базы данных.
[00223] Например, любые два сервера базы данных из множества 250 серверов базы данных, географически близкие друг к другу, могут хранить сегменты из множества 210 сегментов, имеющие схожие друг с другом векторы групп. В другом примере любые два сервера базы данных из множества 250 серверов базы данных, географически далекие друг от друга, хранят сегменты из множества 210 сегментов, имеющие векторы групп, пространственно далекие друг от друга (по сравнению с другим вектором группы другого сегмента, хранящегося на сервере базы данных, географически близкого к одному из этих двух серверов базы данных).
[00224] В некоторых вариантах осуществления изобретения сервер 106 может получать текущий запрос и данные запроса, связанные с текущим запросом, и может определять для текущего запроса вектор текущего запроса, как описано выше. Сервер 106 может определять вектор группы, наиболее схожий с вектором текущего запроса, например, на основе данных 140 соответствия. Наиболее схожий вектор группы может быть связан с целевым сегментом из множества 210 сегментов. Сервер 106 может использовать данные 140 соответствия для обращения к целевому серверу базы данных из множества 250 серверов базы данных с целью получения документов из целевого сегмента. Целевой сервер базы данных хранит целевой сегмент.
[00225] В некоторых вариантах осуществления изобретения обращение к целевому серверу базы данных может включать в себя отсутствие обращения сервера 106 к другим серверам базы данных в системе 150 базы данных, отличным от целевого сервера базы данных.
[00226] В некоторых вариантах осуществления изобретения, где несколько серверов базы данных из множества 250 серверов базы данных хранят несколько реплик целевой базы данных, сервер 106 может определять целевой сервер базы данных на основе географического положения устройства 102 и множества 250 серверов базы данных. Например, устройство 102 может с использованием запроса 180 предоставлять серверу 106 информацию, указывающую на географическое положение устройства 102.
[00227] Сервер 106 может учитывать географическую близость устройства 102 к географическим точкам множества 250 серверов базы данных при определении целевого сервера базы данных. Например, если два сервера базы данных хранят общий сегмент, определенный в качестве целевого сегмента для доступа к нему и получения из него документов, то сервер 106 может выбирать для получения документов тот сервер из этих двух серверов базы данных, который географически ближе расположен к устройству 102.
[00228] Предполагается, что географическое положение множества 250 серверов базы данных может храниться сервером 106 в качестве части данных 140 соответствия.
[00229] Предполагается, что сеть 130 NN может содержать предназначенную для документа часть 504 и предназначенную для запроса часть 502 (см. фиг. 5). Предназначенная для документа часть 504 способна формировать вектор обучающего документа на основе данных документа, связанных с обучающим документом. Предназначенная для запроса часть 502 способна формировать вектор обучающего запроса на основе данных запроса, связанных с обучающим запросом. Предназначенная для документа часть 504 и предназначенная для запроса часть 502 совместно обучены так, чтобы значение близости друг к другу (а) вектора обучающего документа и (б) вектора обучающего запроса представляло собой коэффициент релевантности.
[00230] В некоторых вариантах осуществления настоящей технологии предполагается, что реализация сети 130 NN может отличаться от описанной выше. Например, несмотря на то, что сеть 130 NN описана как содержащая две части, предполагается, что сеть 130 NN может быть реализована в виде пары сетей NN, пригодных для обучения и использования, подобного описанному выше в отношении двух частей сети 130 NN.
[00231] В других вариантах осуществления настоящей технологии предполагается, что сеть 130 NN может быть обучена с использованием штрафных функций, отличных от описанных выше. Например, в некоторых вариантах осуществления настоящей технологии сеть 130 NN может быть адаптирована путем использования основанных на ранжировании штрафных функций. Для лучшей иллюстрации этого можно предположить, что для обучающего запроса доступен ранжированный список обучающих документов. В этом случае во время обучения предназначенная для запроса часть 502 может формировать вектор обучающего запроса для обучающего запроса подобно тому, как это описано выше. Кроме того, во время обучения предназначенная для документа часть 504 может формировать векторы обучающих документов для обучающих документов подобно тому, как описано выше. Кроме того, во время обучения может быть определено векторное расстояние между вектором обучающего запроса и каждым вектором обучающего документа. На основе этих векторных расстояний может быть сформирован основанный на расстояниях ранжированный список обучающих документов. Таким образом, можно сказать, что сервер 106 может иметь (а) ранжированный список обучающих документов и (б) основанный на расстояниях ранжированный список этих обучающих документов. В некоторых вариантах осуществления настоящей технологии штрафные функции, используемые сервером 106 для обучения сети 130 NN, могут быть основаны на разности между (а) рангами обучающих документов из ранжированного списка и (б) рангами обучающих документов из основанного на расстояниях ранжированного списка.
[00232] Кроме того, для выполнения по меньшей мере некоторых функций сети 130 NN вместо сети NN могут использоваться алгоритмы MLA других видов. В некоторых вариантах осуществления настоящей технологии для выполнения по меньшей мере некоторых функций сети 130 NN вместо нее могут использоваться алгоритмы MLA вида «линейная модель». Например, алгоритмы MLA «линейная модель» могут быть обучены с целью определения коэффициентов для субвекторов, которые после умножения на эти коэффициенты и конкатенации образуют векторы документов и векторы запросов.
[00233] Иными словами, для формирования вектора документа алгоритм MLA «линейная модель» может определять коэффициенты для субвекторов, сформированных на основе данных документа, связанных с документом, а затем эти субвекторы могут быть умножены на соответствующие коэффициенты и конкатенированы друг с другом для формирования вектора документа. Кроме того, для формирования вектора запроса другой алгоритм MLA «линейная модель» может определять коэффициенты для субвекторов, сформированных на основе данных запроса, связанных с запросом, а затем эти субвекторы могут быть умножены на соответствующие коэффициенты и конкатенированы друг с другом для формирования вектора запроса. Следует отметить, что такие алгоритмы MLA «линейная модель» могут быть обучены формировать соответствующие коэффициенты для субвекторов так, чтобы векторное расстояние между вектором документа и вектором запроса (которые сформированы путем конкатенации субвекторов, умноженных на соответствующие коэффициенты) представляло собой коэффициент релевантности для соответствующей пары документ-запрос.
[00234] Специалистам в данной области техники должно быть очевидно, что по меньшей некоторые варианты осуществления настоящей технологии преследуют цель расширения арсенала технических решений определенной технической проблемы, присущей традиционным системам рекомендации элементов цифрового контента -выбора и предоставления для демонстрации пользователям релевантных элементов цифрового контента.
[00235] Очевидно, что не все упомянутые в данном описании технические эффекты должны присутствовать в каждом варианте осуществления настоящей технологии. Например, возможны варианты осуществления настоящей технологии, когда пользователь не получает некоторые из этих технических эффектов, или другие варианты реализации, когда пользователь получает другие технические эффекты либо технический эффект отсутствует.
[00236] Для специалиста в данной области могут быть очевидными изменения и усовершенствования описанных выше вариантов осуществления настоящей технологии. Предшествующее описание приведено лишь в иллюстративных целях, а не для ограничения объема изобретения. Объем охраны настоящей технологии определяется исключительно объемом приложенной формулы изобретения.
[00237] Несмотря на то, что описанные выше варианты реализации приведены со ссылкой на конкретные шаги, выполняемые в определенном порядке, должно быть понятно, что эти шаги могут быть объединены, разделены или их порядок может быть изменен без выхода за границы настоящей технологии. Соответственно, порядок и группировка шагов не носят ограничительного характера для настоящей технологии.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ РАНЖИРОВАНИЮ ОБЪЕКТОВ | 2020 |
|
RU2782502C1 |
| Способы и серверы для ранжирования цифровых документов в ответ на запрос | 2020 |
|
RU2775815C2 |
| Способ и сервер для ранжирования цифровых документов в ответ на запрос | 2020 |
|
RU2818279C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ПРОВЕРКИ МЕДИАКОНТЕНТА | 2022 |
|
RU2815896C2 |
| СПОСОБ И СИСТЕМА ДЛЯ РАСШИРЕНИЯ ПОИСКОВЫХ ЗАПРОСОВ С ЦЕЛЬЮ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2018 |
|
RU2720905C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ НЕЙРОННОЙ СЕТИ ФОРМИРОВАНИЮ ТЕКСТОВОЙ ВЫХОДНОЙ ПОСЛЕДОВАТЕЛЬНОСТИ | 2020 |
|
RU2798362C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРИРОВАНИЯ ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТА | 2018 |
|
RU2733481C2 |
| СИСТЕМА И СПОСОБ ОБУЧЕНИЯ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2023 |
|
RU2832419C2 |
| СИСТЕМА И СПОСОБ ФОРМИРОВАНИЯ ОБУЧАЮЩЕГО НАБОРА ДЛЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2017 |
|
RU2711125C2 |
| Способ и сервер для формирования расширенного запроса | 2021 |
|
RU2813582C2 |
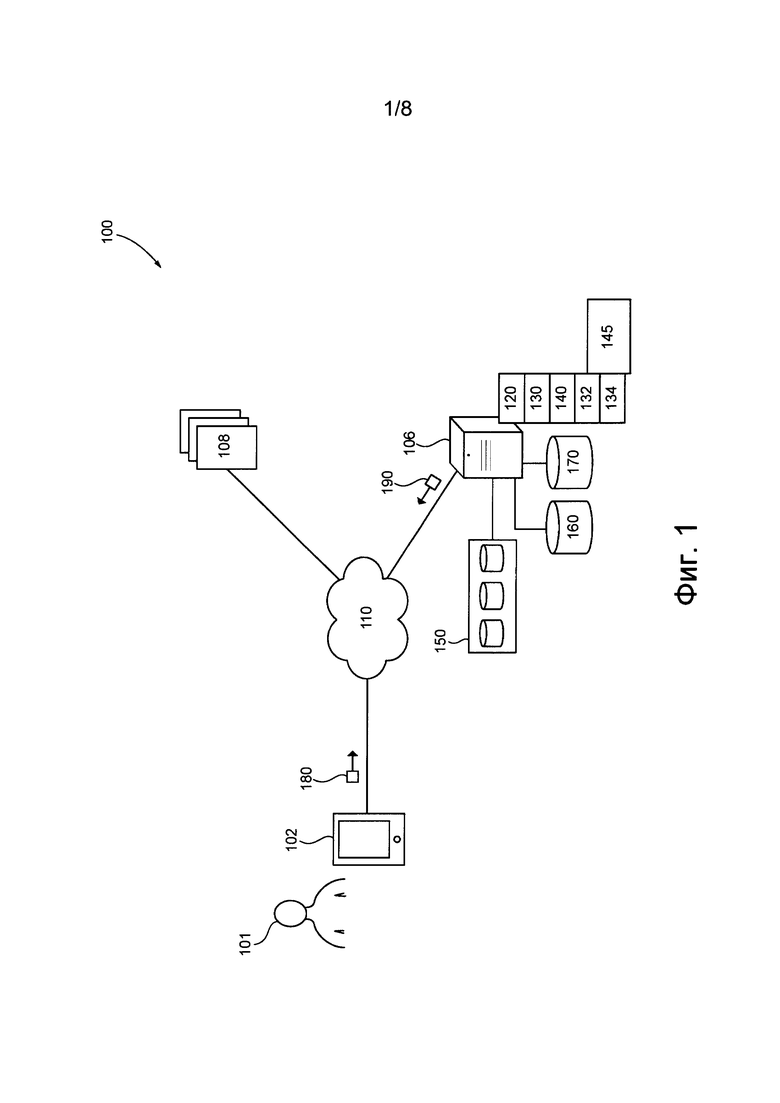
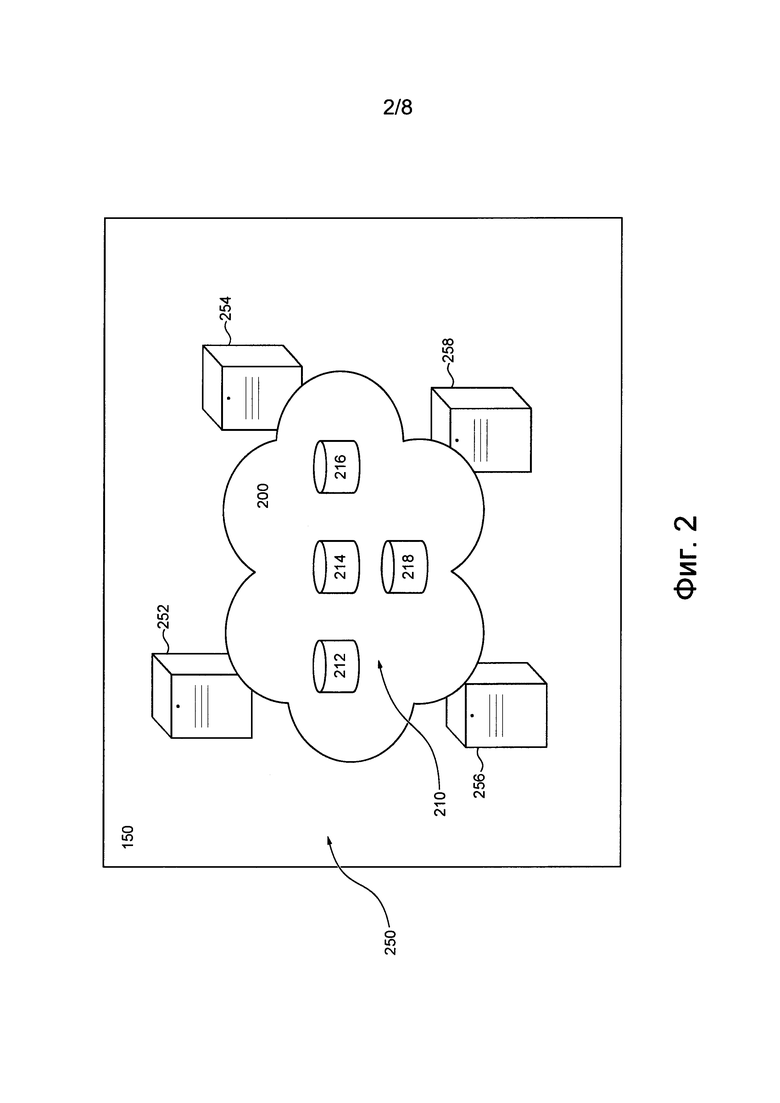
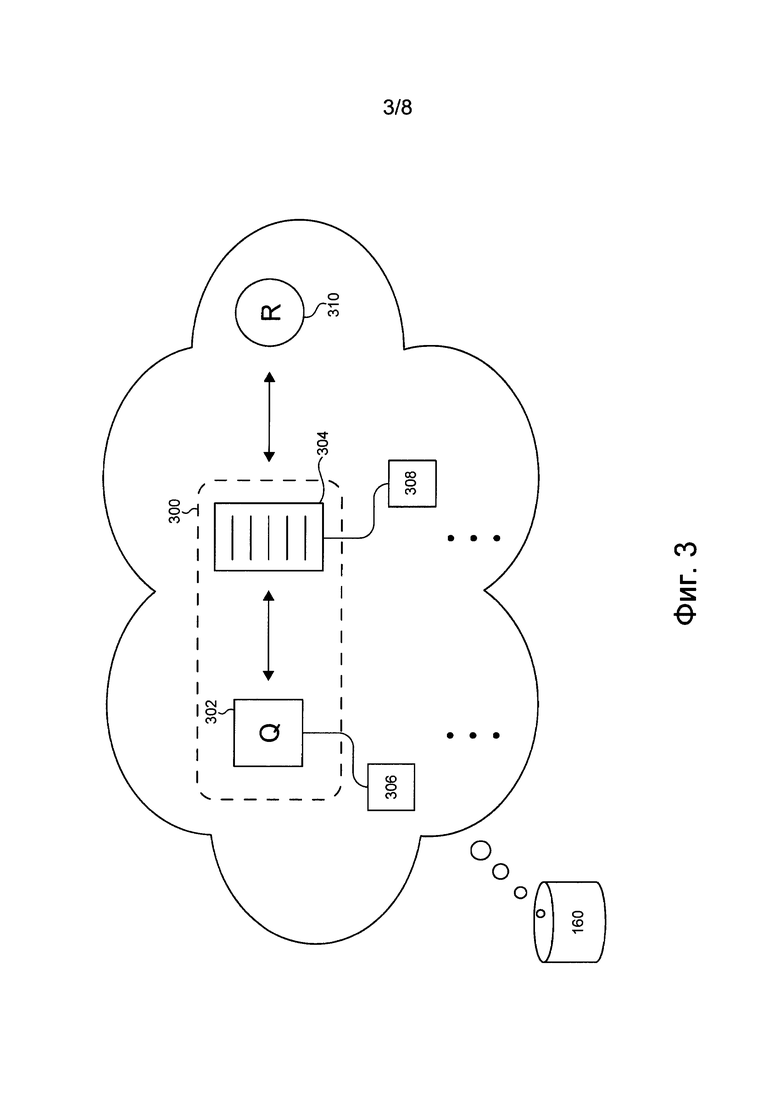
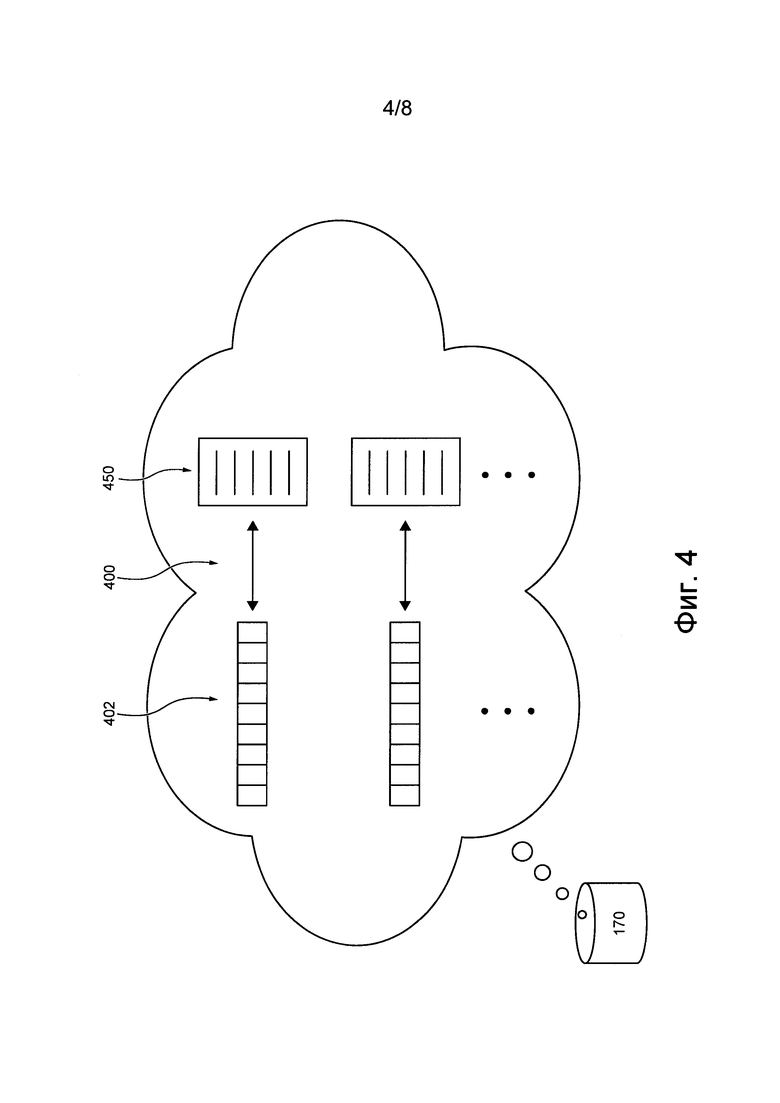
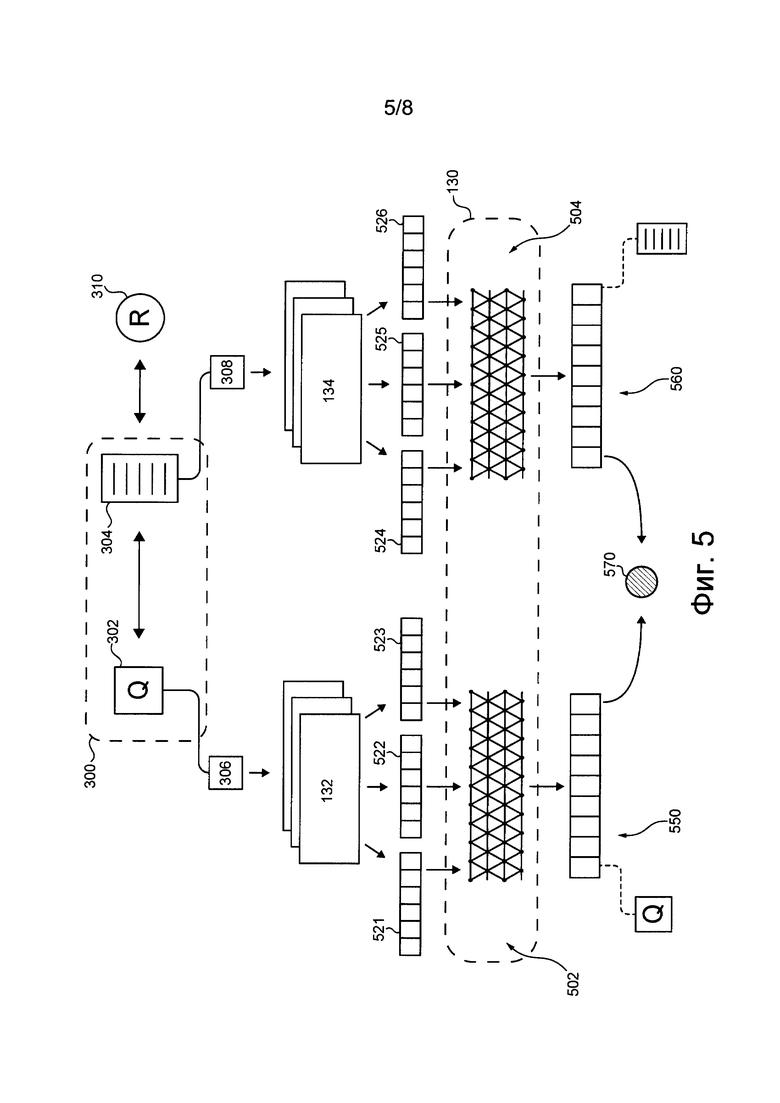
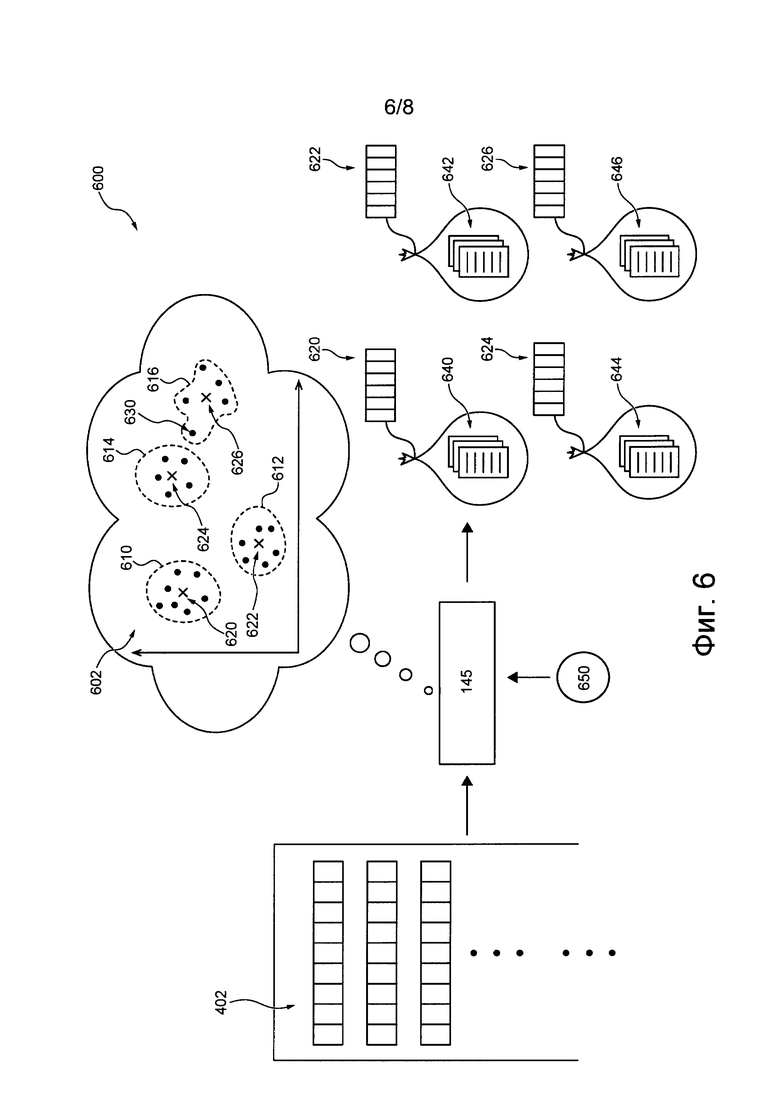
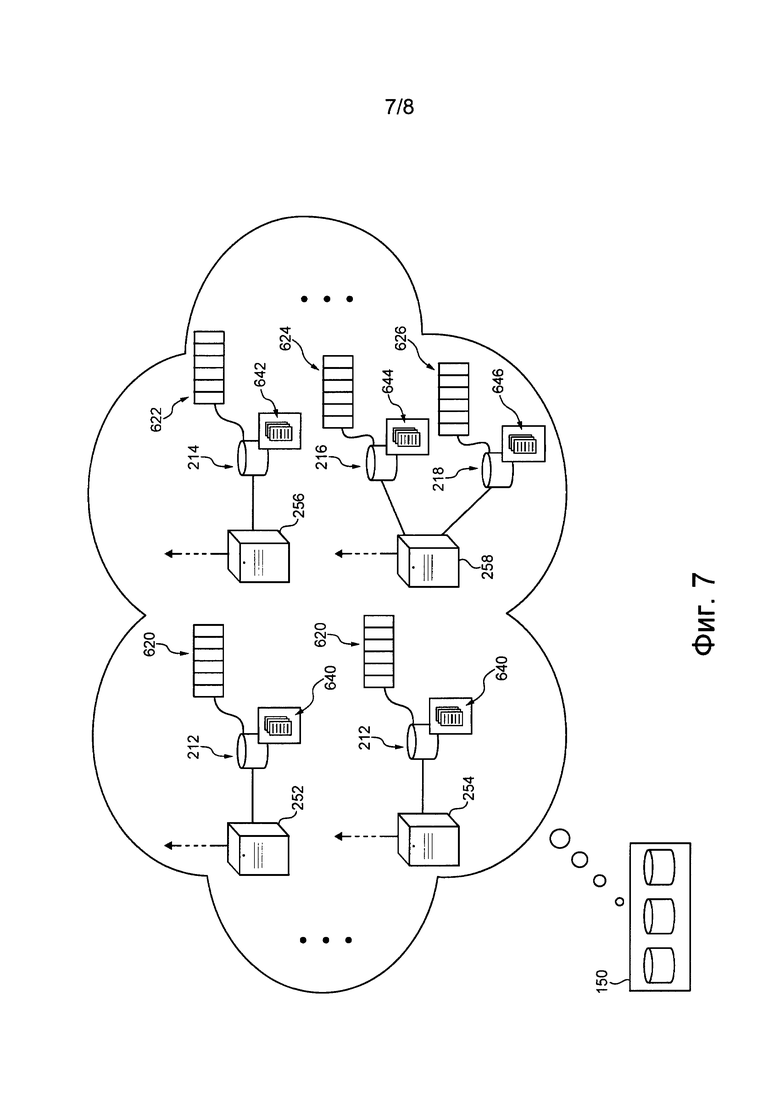
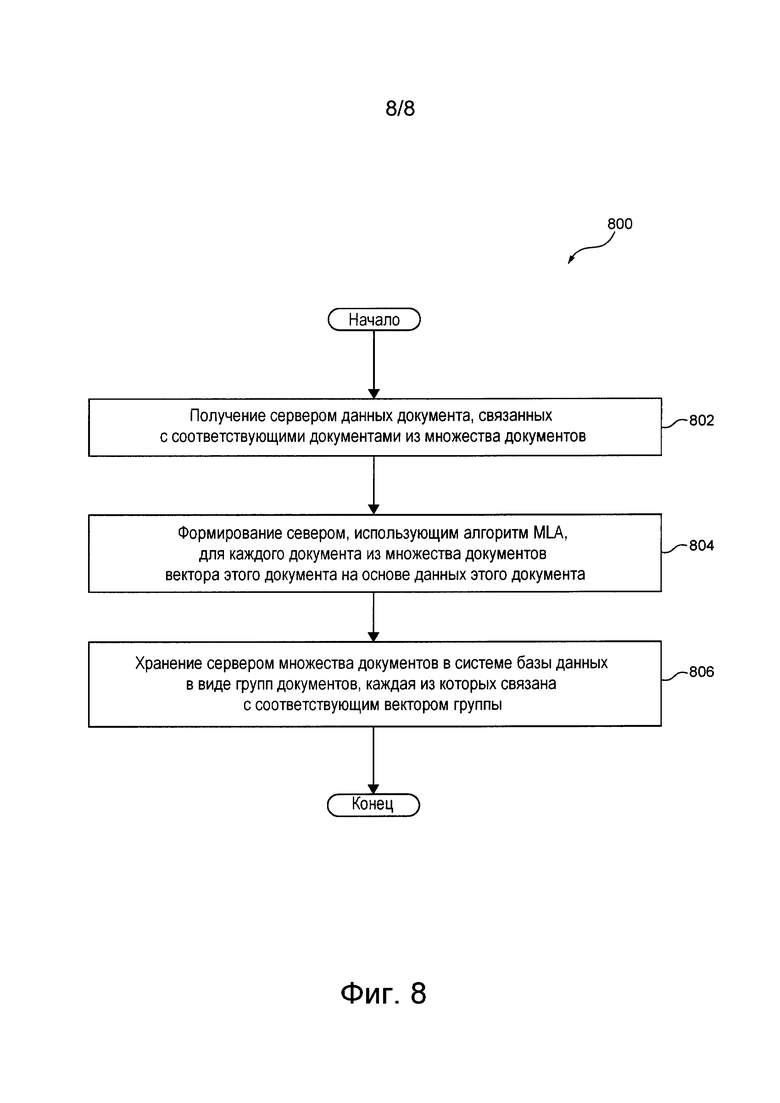
Группа изобретений относится к поисковым системам и может быть использована для хранения множества документов, предназначенных для формирования поисковыми системами результатов поиска. Техническим результатом является уменьшение времени реакции на запрос, отправленный пользователем, а также уменьшение количества серверов базы данных. Способ включает в себя получение данных документа, связанных с документами. Алгоритм машинного обучения используется для формирования для каждого документа вектора документа на основе данных документа. Способ также включает в себя хранение документов в виде групп документов в системе базы данных. Каждая группа документов связана с вектором группы. Группа документов содержит документы, связанные с векторами документов, пространственно близкими к вектору группы. 4 н. и 34 з.п. ф-лы, 8 ил.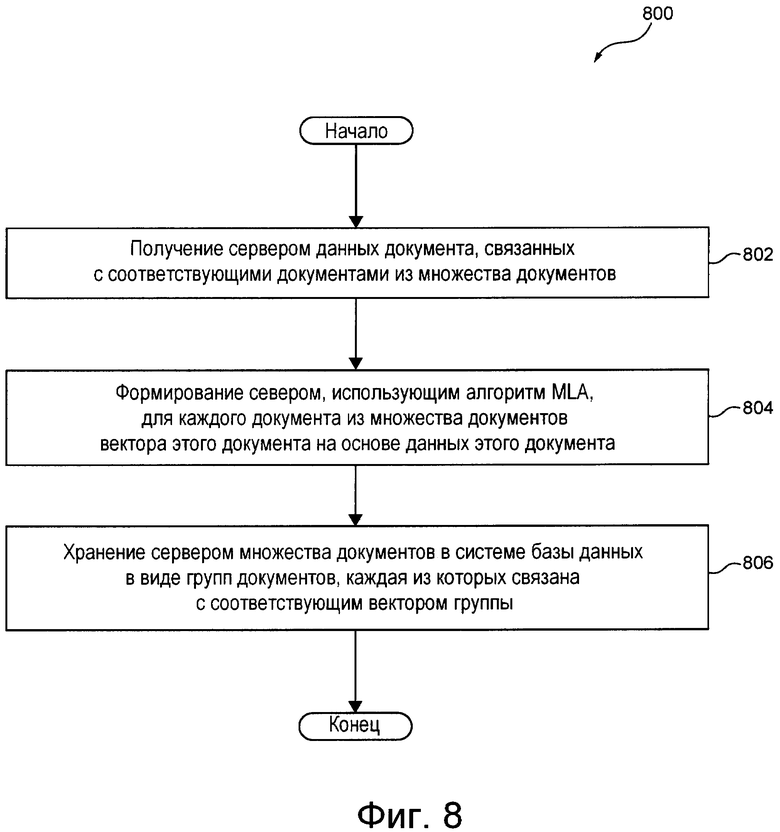
1. Способ хранения множества документов в связанной сервером системе базы данных, выполняемый сервером и включающий в себя:
- получение сервером данных документа, связанных с соответствующими документами из множества документов;
- формирование сервером, использующим алгоритм машинного обучения (MLA), вектора документа на основе данных документа для каждого документа из множества документов, при этом алгоритм MLA обучен на основе обучающей пары документ-запрос, связанной с коэффициентом релевантности, указывающим на релевантность обучающего документа из обучающей пары обучающему запросу из обучающей пары, формировать (а) вектор обучающего документа для обучающего документа и (б) вектор обучающего запроса для обучающего запроса так, чтобы значение близости друг к другу (а) вектора обучающего документа для обучающего документа и (б) вектора обучающего запроса для обучающего запроса представляло собой коэффициент релевантности;
- группирование множества документов в группы документов;
- хранение сервером множества документов в системе базы данных в виде групп документов, каждая из которых связана с вектором группы, при этом группа документов содержит документы, связанные с векторами документов, пространственно близкими к вектору группы.
2. Способ по п. 1, отличающийся тем, что пространственная близость указывает на сходство друг с другом документов в группе документов.
3. Способ по п. 1, отличающийся тем, что дополнительно включает в себя определение сервером вектора группы для каждой группы документов на основе векторов документов, связанных с множеством документов.
4. Способ по п. 1, отличающийся тем, что группы документов содержат группы, количество которых равно заранее заданному числу K.
5. Способ по п. 1, отличающийся тем, что группирование включает в себя выполнение сервером алгоритма «K-средних» для векторов документов, связанных с множеством документов, в результате чего определяются векторы групп и связанные с ними группы документов из множества документов.
6. Способ по п. 1, отличающийся тем, что он дополнительно включает в себя:
- получение сервером от электронного устройства, связанного с сервером, текущего запроса на предоставление электронному устройству текущего документа, релевантного текущему запросу;
- получение сервером данных запроса, связанных с текущим запросом;
- формирование сервером, использующим алгоритм MLA, для текущего запроса вектора текущего запроса на основе данных запроса, связанных с текущим запросом;
- определение сервером среди векторов групп вектора группы, наиболее схожего с вектором текущего запроса и связанного с целевой группой документов; и
- обращение сервера к системе базы данных для получения документов из целевой группы документов.
7. Способ по п. 6, отличающийся тем, что обращение к системе базы данных включает в себя отсутствие получения документов из других групп документов, отличных от целевой группы документов.
8. Способ по п. 1, отличающийся тем, что система базы данных содержит базу данных, разделенную на множество сегментов, а хранение групп документов включает в себя хранение сервером групп документов в виде сегментов базы данных в системе базы данных, каждый из которых связан с вектором группы.
9. Способ по п. 8, отличающийся тем, что система базы данных содержит множество серверов базы данных, а хранение групп документов в виде сегментов включает в себя хранение сервером множества сегментов базы данных на множестве серверов базы данных в системе базы данных.
10. Способ по п. 9, отличающийся тем, что сервер базы данных из множества серверов базы данных хранит несколько сегментов из множества сегментов.
11. Способ по п. 8, отличающийся тем, что несколько серверов базы данных из множества серверов базы данных хранят один и тот же сегмент из множества сегментов.
12. Способ по п. 8, отличающийся тем, что множество серверов базы данных физически расположены в нескольких географических точках.
13. Способ по п. 12, отличающийся тем, что любые два сервера базы данных из множества серверов базы данных, географически близкие друг к другу, хранят сегменты, имеющие векторы групп, более схожие друг с другом, чем векторы групп сегментов, хранящихся на любых других двух серверах базы данных из множества серверов базы данных, географически более далеких друг от друга, чем указанные два сервера базы данных.
14. Способ по п. 12, отличающийся тем, что дополнительно включает в себя:
- получение сервером от электронного устройства, связанного с сервером, текущего запроса на предоставление электронному устройству текущего документа, релевантного текущему запросу;
- получение сервером данных запроса, связанных с текущим запросом;
- формирование сервером, использующим алгоритм MLA, для текущего запроса вектора текущего запроса на основе данных запроса, связанных с текущим запросом;
- определение сервером среди векторов групп вектора группы, наиболее схожего с вектором текущего запроса и связанного с целевым сегментом из множества сегментов; и
- обращение сервера к хранящему целевой сегмент целевому серверу базы данных из множества серверов базы данных для получения документов из целевого сегмента.
15. Способ по п. 14, отличающийся тем, что обращение к целевому серверу базы данных включает в себя отсутствие обращения сервера к другим серверам базы данных в системе базы данных, отличным от целевого сервера базы данных.
16. Способ по п. 14, отличающийся тем, что дополнительно включает в себя определение целевого сервера базы данных на основе географического положения электронного устройства и множества серверов базы данных.
17. Способ по п. 1, отличающийся тем, что алгоритм MLA представляет собой нейронную сеть (NN), содержащую предназначенную для документа часть и предназначенную для запроса часть, при этом:
- предназначенная для документа часть способна формировать вектор обучающего документа на основе данных документа, связанных с обучающим документом;
- предназначенная для запроса часть способна формировать вектор обучающего запроса на основе данных запроса, связанных с обучающим запросом; и
- предназначенная для документа часть и предназначенная для запроса часть совместно обучены так, чтобы значение близости друг к другу (а) вектора обучающего документа и (б) вектора обучающего запроса представляло собой коэффициент релевантности.
18. Сервер для хранения множества документов в связанной с сервером системе базы данных, способный:
- получать данные документа, связанные с соответствующими документами из множества документов;
- формировать для каждого документа из множества документов вектор документа на основе данных документа с использованием алгоритма MLA, обученного на основе обучающей пары документ-запрос, связанной с коэффициентом релевантности, указывающим на релевантность обучающего документа из обучающей пары обучающему запросу из обучающей пары, формировать (а) вектор обучающего документа для обучающего документа и (б) вектор обучающего запроса для обучающего запроса так, чтобы значение близости друг к другу (а) вектора обучающего документа для обучающего документа и (б) вектора обучающего запроса для обучающего запроса представляло собой коэффициент релевантности;
- группировать документы в группы документов;
- хранить множество документов в системе базы данных в виде групп документов, каждая из которых связана с вектором группы, при этом группа документов содержит документы, связанные с векторами документов, пространственно близкими к вектору группы.
19. Сервер по п. 18, отличающийся тем, что пространственная близость указывает на сходство друг с другом документов в группе документов.
20. Сервер по п. 18, отличающийся тем, что он способен определять вектор группы для каждой группы документов на основе векторов документов, связанных с множеством документов.
21. Сервер по п. 18, отличающийся тем, что группы документов содержат группы, количество которых равно заранее заданному числу К.
22. Сервер по п. 18, отличающийся тем, что его способность группировать включает в себя способность выполнять алгоритм «K-средних» для векторов документов, связанных с множеством документов, и таким образом определять векторы групп и связанные с ними группы документов из множества документов.
23. Сервер по п. 18, отличающийся тем, что он способен:
- получать от электронного устройства, связанного с сервером, текущий запрос на предоставление электронному устройству текущего документа, релевантного текущему запросу;
- получать данные запроса, связанные с текущим запросом;
- формировать с использованием алгоритма MLA для текущего запроса вектор текущего запроса на основе данных запроса, связанных с текущим запросом;
- определять среди векторов групп вектор группы, наиболее схожий с вектором текущего запроса и связанный с целевой группой документов; и
- обращаться к системе базы данных для получения документов из целевой группы документов.
24. Сервер по п. 23, отличающийся тем, что способность сервера обращаться к системе базы данных включает в себя способность не получать документы из других групп документов, отличных от целевой группы документов.
25. Сервер по п. 18, отличающийся тем, что система базы данных содержит базу данных, разделенную на множество сегментов, а способность сервера хранить группы документов включает в себя способность хранить группы документов в виде сегментов базы данных в системе базы данных, каждый из которых связан с вектором группы.
26. Сервер по п. 25, отличающийся тем, что система базы данных содержит множество серверов базы данных, а способность сервера хранить группы документов в виде сегментов включает в себя способность хранить множество сегментов базы данных на множестве серверов базы данных в системе базы данных.
27. Сервер по п. 26, отличающийся тем, что сервер базы данных из множества серверов базы данных способен хранить несколько сегментов из множества сегментов.
28. Сервер по п. 25, отличающийся тем, что несколько серверов базы данных из множества серверов базы данных способны хранить один и тот же сегмент из множества сегментов.
29. Сервер по п. 25, отличающийся тем, что множество серверов базы данных физически расположены в нескольких географических точках.
30. Сервер по п. 29, отличающийся тем, что любые два сервера базы данных из множества серверов базы данных, географически близкие друг к другу, способны хранить сегменты, имеющие векторы групп, более схожие друг с другом, чем векторы групп сегментов, хранящихся на любых других двух серверах базы данных из множества серверов базы данных, географически более далеких друг от друга, чем указанные два сервера базы данных.
31. Сервер по п. 29, отличающийся тем, что он способен:
- получать от электронного устройства, связанного с сервером, текущий запрос на предоставление электронному устройству текущего документа, релевантного текущему запросу;
- получать данные запроса, связанные с текущим запросом;
- формировать с использованием алгоритма MLA для текущего запроса вектор текущего запроса на основе данных запроса, связанных с текущим запросом;
- определять среди векторов групп вектор группы, наиболее схожий с вектором текущего запроса и связанный с целевым сегментом из множества сегментов; и
- обращаться к хранящему целевой сегмент целевому серверу базы данных из множества серверов базы данных для получения документов из целевого сегмента.
32. Сервер по п. 31, отличающийся тем, что его способность обращаться к целевому серверу базы данных включает в себя способность не обращаться к другим серверам базы данных в системе базы данных, отличным от целевого сервера базы данных.
33. Сервер по п. 31, отличающийся тем, что он способен определять целевой сервер базы данных на основе географического положения электронного устройства и множества серверов базы данных.
34. Сервер по п. 18, отличающийся тем, что алгоритм MLA представляет собой сеть NN, содержащую предназначенную для документа часть и предназначенную для запроса часть, при этом:
- предназначенная для документа часть способна формировать вектор обучающего документа на основе данных документа, связанных с обучающим документом;
- предназначенная для запроса часть способна формировать вектор обучающего запроса на основе данных запроса, связанных с обучающим запросом; и
- предназначенная для документа часть и предназначенная для запроса часть совместно обучены так, чтобы значение близости друг к другу (а) вектора обучающего документа и (б) вектора обучающего запроса представляло собой коэффициент релевантности.
35. Способ получения документов для текущего запроса, предназначенного для предоставления электронному устройству, связанному с пользователем, документов, релевантных текущему запросу, выполняемый сервером, связанным с электронным устройством, и включающий в себя:
- получение сервером текущего запроса;
- получение сервером данных запроса, связанных с текущим запросом;
- формирование сервером для текущего запроса вектора текущего запроса на основе данных запроса, связанных с текущим запросом;
- определение сервером среди векторов групп вектора группы, наиболее схожего с вектором текущего запроса, при этом векторы групп связаны с группами документов, группы документов хранятся в системе базы данных, связанной с сервером, а наиболее схожий вектор группы связан с целевой группой документов; и
- обращение сервера к системе базы данных для получения документов из целевой группы документов, при этом целевая группа документов содержит документы, связанные с векторами документов, пространственно близкими к наиболее схожему вектору группы.
36. Способ по п. 35, отличающийся тем, что система базы данных содержит множество серверов базы данных, хранящих группы документов, а обращение к системе базы данных включает в себя обращение сервера только к хранящему целевую группу документов серверу базы данных из множества серверов базы данных.
37. Сервер для получения документов для текущего запроса, предназначенного для предоставления электронному устройству, связанному с пользователем, документов, релевантных текущему запросу, связанный с электронным устройством и способный:
- получать текущий запрос;
- получать данные запроса, связанные с текущим запросом;
- формировать для текущего запроса вектор текущего запроса на основе данных запроса, связанных с текущим запросом;
- определять среди векторов групп вектор группы, наиболее схожий с вектором текущего запроса, при этом векторы групп связаны с группами документов, группы документов хранятся в системе базы данных, связанной с сервером, а наиболее схожий вектор группы связан с целевой группой документов; и
- обращаться к системе базы данных для получения документов из целевой группы документов, при этом целевая группа документов содержит документы, связанные с векторами документов, пространственно близкими к наиболее схожему вектору группы.
38. Сервер по п. 37, отличающийся тем, что система базы данных содержит множество серверов базы данных, хранящих группы документов, а способность сервера обращаться к системе базы данных включает в себя способность обращаться только к хранящему целевую группу документов серверу базы данных из множества серверов базы данных.
| РАНЖИРАТОР РЕЗУЛЬТАТОВ ПОИСКА | 2014 |
|
RU2608886C2 |
| СПОСОБ СОЗДАНИЯ ОБУЧАЮЩЕГО ОБЪЕКТА ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2637883C1 |
| US 6189002 B1, 13.02.2001 | |||
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |

