ОБЛАСТЬ ТЕХНИКИ
Настоящее техническое решение относится к области вычислительной техники, в частности к компьютерно-реализуемым способам равномерного распределения данных при создании или формировании витрин данных на серверном оборудовании.
УРОВЕНЬ ТЕХНИКИ
Достоинствами применения витрин данных является физическое разделение данных между различными группами данных, а также относительная простота семантики данных в пределах одной витрины данных (Казакова И.А. «Хранилища и витрины данных в системах поддержки принятия решений», Мир современной науки). Чаще всего с помощью витрин данных анализируют данные и строят ML-модели. Также витрины могут использоваться в качестве мастер-данных, например, как справочники. Помимо этого, витрина данных может выступать периферическим узлом в сетях обмена данными между различными участниками. Типовой проект внедрения витрин состоит из технологической и прикладной частей.
Из уровня техники известен патент RU 2683690 C1, опубл. 01.04.2019. Решение характеризует способ автоматической генерации программного кода для корпоративного хранилища данных. Способ реализуется с помощью процессора и включает следующие шаги: - получают метаданные, описывающие настройку механизмов трансформации данных для их загрузки на уровень детального слоя хранилища данных и расчета витрин хранилища данных; - формируют по меньшей мере один шаблон обновления данных детального слоя хранилища данных и витрины данных хранилища данных; - осуществляют генерацию программного кода для загрузки данных в детальный слой хранилища данных и расчета витрин данных на основе полученных метаданных и сформированного шаблона обновления данных; - устанавливают сгенерированный на предыдущем шаге программный код на среду хранилища данных для выполнения загрузок; - осуществляют переиспользование метаданных для обновления детального слоя хранилища данных и витрин данных посредством внесения дельты изменений в вышеуказанный шаблон обновления данных в случае внесения изменений в постановку задачи или посредством переключения шаблонов обновления данных в случае смены типа реляционной базы данных для использования полученного шаблона обновления данных при последующей генерации программного кода.
Из уровня техники также известен патент RU 2795902 C1, опубл. 15.05.2023. Решение характеризует способ, который содержит следующие этапы: предварительно на кластере разворачивается ядро фреймворка; подготавливают правила генерации витрин данных, содержащие набор параметров преобразования данных, позволяющие автоматически определять типы данных в создаваемых таблицах генерируемой витрины данных; подготавливают правила оркестрации данных, содержащие декларативное описание: параметры расчета целевых таблиц и выполнения запросов внутри расчетов; параметры накопления данных в разрезе истории для каждой таблицы, списки ключевых полей, списки полей для сравнения и хеширования; параметры контекста выполнения; подготовленные на предыдущих шагах правила загружают в репозиторий; на основе загруженных в репозиторий правил автоматически генерируют и сохраняют в репозиторий дистрибутив витрины данных; сгенерированный и сохраненный дистрибутив витрины данных производит на основе декларативного описания: преобразование данных; вызывает процедуры накопления данных в разрезе истории; выполняет резервное копирование; выполняет процедуру восстановления процесса трансформации данных после сбоя.
Предлагаемое к рассмотрению техническое решение направлено на устранение недостатков современного уровня техники. Заявленное техническое решение реализовано для равномерного распределения данных при создании или формировании витрин данных и отличается от известных решений тем, что предложенное решение обеспечивает значительное уменьшение нагрузки на серверное оборудование/оборудование хранения данных, а также обеспечивает увеличение производительности серверного оборудования за счет равномерного распределения данных в файловой системе на серверном оборудовании.
Кроме того, заявленное техническое решение не требует наличия ни оркестратора, ни вычислительного кластера и не является его частью. При этом в уровне техники не было выявлено решений, обеспечивающих равномерное распределение данных при создании или формировании витрин данных на серверном оборудовании.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Технической проблемой, на решение которой направлено заявленное решение, является создание компьютерно-реализуемого способа равномерного распределения данных при формировании витрин данных на серверном оборудовании.
Технический результат заявленного объекта техники заключается в уменьшении нагрузки на серверное оборудование/оборудование хранения данных и в увеличении производительности серверного оборудования за счет равномерного распределения данных в файловой системе на оборудовании.
Заявленный технический результат достигается за счет реализации компьютерно-реализуемого способа равномерного распределения данных при формировании витрин данных на серверном оборудовании, включающего этапы, на которых: осуществляют выделение записываемой информации, которая характеризуется количеством строк и занимаемым объемом в файлах на диске в файловой системе на серверном оборудовании; определяют количество строк и размер витрины данных в байтах, который она занимает в файлах на диске в файловой системе на серверном оборудовании; перераспределяют строки из исходных файлов витрины данных, формируя новые файлы, каждый из которых содержит не более указанного количества строк, вычисленного согласно выражению, где максимальное количество строк на файл равно отношению суммы общего количества строк в витрине данных, умноженного на целевой размер блока в байтах каждого формируемого файла, и размера занятого витриной дискового пространства в байтах за вычетом единицы, к размеру занятого витриной дискового пространства в байтах, с отбрасыванием дробной части, при этом целевой размер в байтах каждого формируемого файла равен значению установленной константы для каждого отдельного соответствующего кластера; или перераспределяют строки из исходных файлов витрины данных, формируя новые файлы, причем значение количества формируемых файлов равно отношению суммы размера витрины данных в байтах, который она занимает в файлах на диске в файловой системе, и целевого размера в байтах каждого формируемого файла за вычетом единицы, к целевому размеру в байтах каждого формируемого файла, с отбрасыванием дробной части; на основе полученных значений количества строк в файле или количества файлов осуществляют равномерную запись полученных наборов строк на диски в файловой системе на серверном оборудовании.
В частном варианте реализации способа, распределение данных осуществляют в партицированых данных по файлам в подкаталогах витрины данных.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения. К заявке прилагаются следующие чертежи:
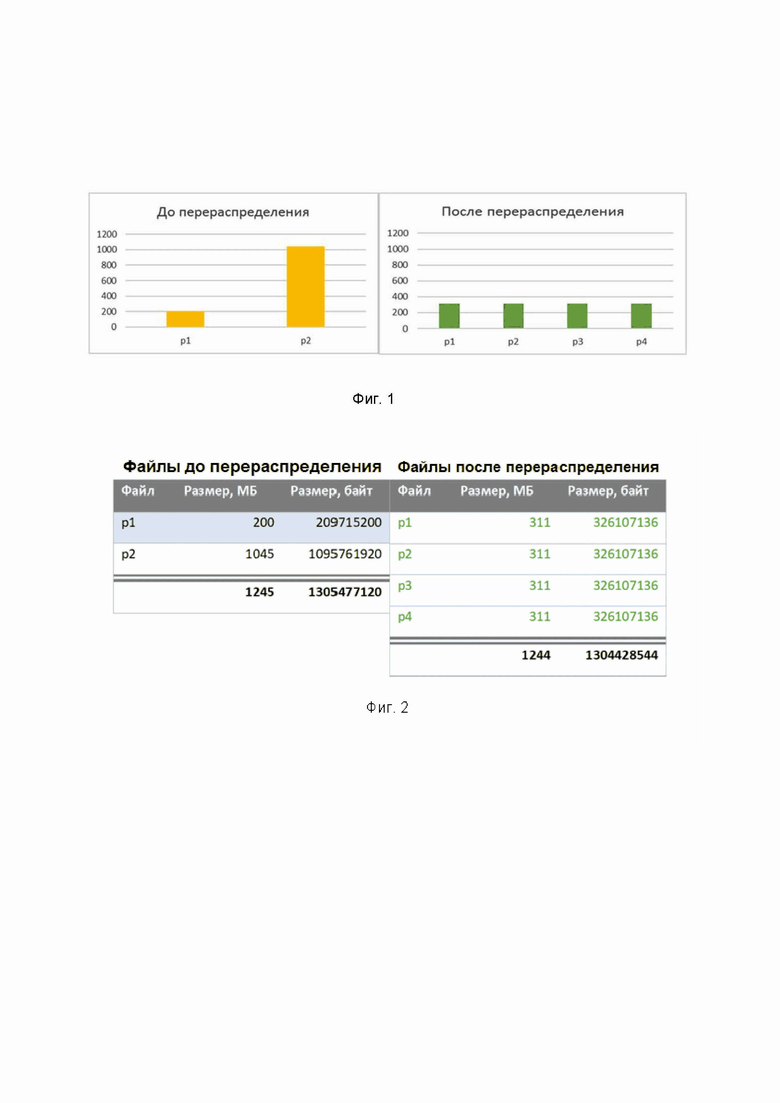
Фиг. 1 иллюстрирует результаты применения заявленного технического решения до и после распределения данных, с учетом вычисления количества строк в файле.
Фиг. 2 иллюстрирует объем файлов до и после распределения данных.
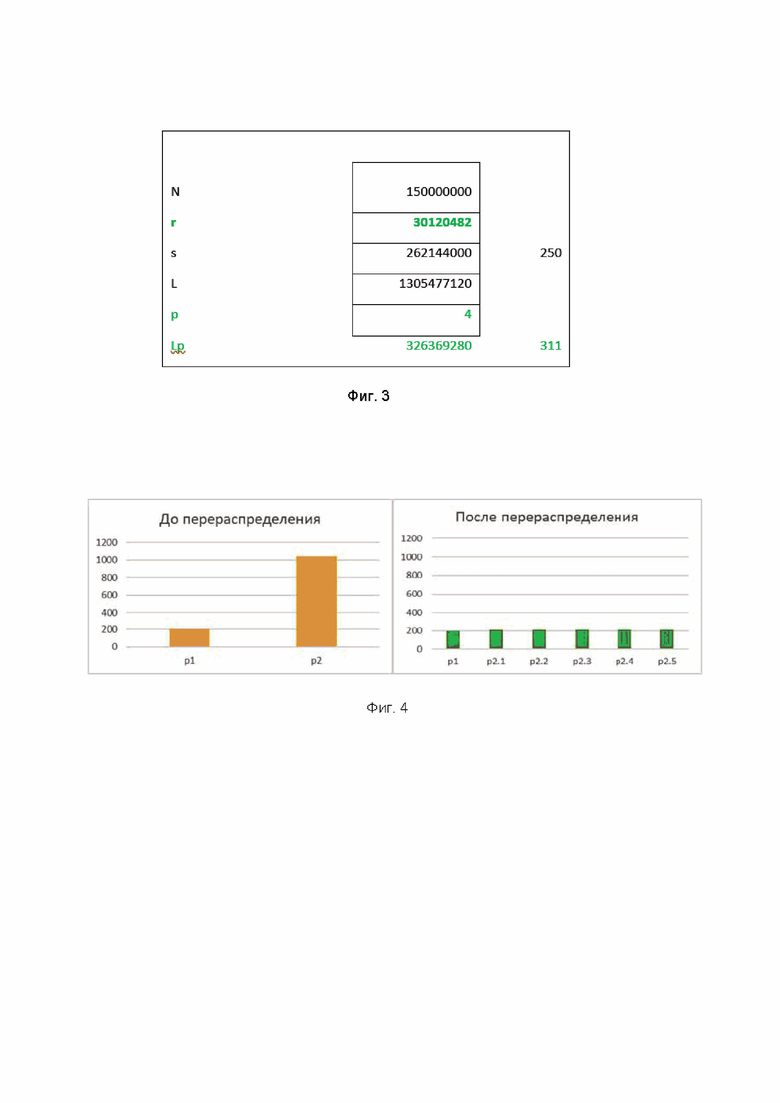
Фиг. 3 иллюстрирует пример полученного значения, необходимого для распределения данных, в результате вычисления количества строк в файле.
Фиг. 4 иллюстрирует результаты применения заявленного технического решения до и после распределения данных, с учетом вычисления количества файлов.
Фиг. 5 иллюстрирует объем файлов до и после распределения данных, с учетом расчёта количества файлов.
Фиг. 6 иллюстрирует пример полученного значения, необходимого для распределения данных, в результате вычисления количества файлов, в партицированых данных по файлам в подкаталогах витрины данных.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако квалифицированному в предметной области специалисту будет очевидно, каким образом можно использовать настоящее изобретение как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять излишне понимание особенностей настоящего изобретения.
Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
Витрина данных - это одна или несколько таблиц (отношений в реляционной модели), данные которых, хранятся в одном или нескольких файлах в машиночитаемом формате на одном или нескольких серверах под управлением системы баз данных. Настоящее техническое решение позволяет равномерно распределять любой тип данных.
Витрина данных может содержать несколько терабайт данных. Оптимальным способом хранения такой витрины считается сочетание процесса партицирования данных и минимизации количества файлов с одновременной максимизацией их объема. Процесс партицирования позволяет распределять строки витрины данных по файлам в каталогах файловой системы по выбранному столбцу. Чаще всего столбец партицирования содержит дату в формате строки. В решении может применяться функция партицирования, которая принимает на вход один или несколько столбцов витрины, распределяя строки данных по файлам в подкаталогах, используя значения в указанных столбцах партицирования для названий подкаталогов в файловой системе. Такое распределение позволяет автоматически исключать подкаталоги и файлы, строки из которых не считываются. Минимизация количества файлов витрины данных сокращает количество одновременно запускаемых потоков чтения. Как правило, вычислительный кластер используется множеством клиентов-приложений, каждое из которых может считывать строки из множества файлов. В файловой системе данные записываются и считываются блоками. Один файл может занимать один или несколько блоков. Часть неполного блока возвращается файловой системе. Каждый поток чтения блока данных занимает одно вычислительное ядро процессора. Поскольку количество ядер в кластере постоянно, то может возникать ситуация нехватки вычислительных ресурсов, при которой приложения не смогут работать в кластере. В современном уровне техники отсутствует функция минимизации количества записываемых файлов. Однако, на это можно повлиять, задав максимальное количество строк на файл. Также необходимо обеспечить, чтобы размер файлов был как можно ближе к размеру блока, но не превышал его. Чтобы вычислить максимальное количество строк на файл, необходимо узнать размер витрины в файловой системе и указать целевой размер файла.
В предпочтительном варианте реализации, кластером является один или несколько серверов локальной вычислительной сети, объединенных логически. Кластер характеризуется количеством ядер ЦПУ, объемом оперативной памяти и объемом системы долговременного хранения. Кластер содержит прикладное программное обеспечение, позволяющее, в частности, вычислять витрины данных, считывать блоки данных в оперативную память из системы хранения, записывать блоки данных из оперативной памяти в систему хранения. Значение размера блока устанавливается на весь кластер и на протяжении жизни кластера является константным параметром. Значение размера блока подбирается так, чтобы данные, считываемые из системы хранения, целиком умещались в оперативной памяти, но при этом количество запросов чтения блоков было минимальным. Например, если размер блока в кластере установлен в 4096 байт, то для чтения всего файла, размером 1048576000 байт из системы хранения потребуется 256 000 запросов, возможно, с передачей данных по сети. При этом, если прочитать тот же файл с установленным размером блока в 268435456, то потребуется всего 4 запроса чтения, при условии, что каждый сервер имеет не менее 268435456 байт доступной оперативной памяти.
Концептуально, любая система обработки информации, взаимодействующая с подсистемой ввода/вывода информации, опирается на понятие пропускной способности. Суть подобного взаимодействия заключается в том, чтобы на всем пути обработки информации обеспечить баланс производительности устройств ввода/вывода и обработки информации так, чтобы минимизировать количество простаивающих устройств обработки и максимизировать объем одновременно считываемой или записываемой информации.
Например, имея в распоряжении сервер с четырьмя процессорами, по четыре физических ядра на процессор в режиме гипервизора, фактически можно получить 32 логических обработчика, каждый из которых работает независимо и имеет собственный кэш в оперативной памяти. Если объем доступной оперативной памяти составляет 32 ГБ, то каждый обработчик получает 1 ГБ памяти, который сможет заполнить данными с диска за раз, не деградируя на прерываниях ввода/вывода при промахе кэша и дочитывании. Логично, что доступный объем меньше, потому что необходимо учитывать накладные расходы ядра операционной системы и на создание административного сеанса время от времени. Оптимальный объем ресурса памяти для одного обработчика считается от 256 МБ до 1 ГБ, что можно использовать при записи файлов на диски в распределенной файловой системе. Не стоит делать меньше, так как оперируя большим объемом данных в несколько петабайт, можно получить запредельно большое число маленьких файлов на дисках, что скажется на производительности процессов их чтения не в лучшую сторону, поскольку «позиционирование» на файл в файловой системе будет занимать значительное время, несмотря на применение хорошо зарекомендовавших себя подходов в организации хранения и позиционирования файлов.
Если попытаться параллельно считать некоторый или весь объем информации, хранящейся на диске в файлах, то скорость чтения будет равна скорости чтения самого большого файла. Если размер такого файла будет больше, чем выделенный кэш обработчика, то неизбежны задержки при чтении, а в некоторых случаях - и сброс данных на диски.
Настоящее техническое решение направлено на решение вышеупомянутых проблем и позволяет равномерно распределять данные при формировании витрин данных на серверном оборудовании. Равномерного распределения данных можно добиться путем качественного и эффективного перераспределения данных в файловой системе. Перераспределение данных в файловой системе - это результат записи перераспределенных данных, которые были загружены в процессе выделения записываемой информации из оперативной памяти в файловую систему. Перераспределение данных выполняется в оперативной памяти по представленным далее алгоритмам, посредством вызовов низкоуровневого API (например, DataFrame API Apache Spark). На техническом уровне перераспределение данных выполняется по алгоритмам низкоуровневого API в зависимости от расположения данных на серверах и настроек серверного кластера так, чтобы данные, объединяемые в одном файле, полностью оказались в оперативной памяти ровно одного сервера.
На начальном этапе, для обеспечения равномерного распределения данных, при формировании витрин данных на серверном оборудовании, необходимо выделить записываемую информацию, которая характеризуется количеством строк N и занимаемым объемом в файлах L на диске в файловой системе на серверном оборудовании. Выделение записываемой информации - это процесс загрузки данных в память и применение к ним преобразований (сокращение, проекция, соединение, объединение, сортировка, пересечение, исключение). Для таблиц подобные преобразования выполняются на языке SQL. Чтобы загрузить данные таблиц в память из файлов и применить к ним преобразования необходимо выполнить низкоуровневые вызовы API на одном или нескольких серверах. Также низкоуровневое API позволяет определить количество строк в таблицах и размер файлов, в которых хранятся данные таблиц. Таким образом, для реализации последующих этапов заявленного способа необходимо определить количество строк N и размер витрины L в байтах, который она занимает в файлах на диске в файловой системе на серверном оборудовании.
Перераспределить строки из исходных файлов витрины данных можно двумя альтернативными этапами. Первый этап, на котором осуществляется перераспределение строк из исходных файлов витрины данных, реализуется путем формирования новых файлов, каждый из которых содержит не более конкретного количества строк, вычисленного согласно выражению: r=(N*s+L-1)/L, где r - количество строк в файле, N - общее количество строк в витрине, L - размер витрины в байтах, который она занимает в файлах на диске в файловой системе, s - целевой размер в байтах каждого формируемого файла. На фигуре 3 проиллюстрирован конкретный пример с полученными результирующими значениями, необходимыми для равномерного распределения данных.
Другими словами, максимальное количество строк на файл равно отношению суммы общего количества строк в витрине данных, умноженного на целевой размер блока в байтах каждого формируемого файла, и размера занятого витриной дискового пространства в байтах за вычетом единицы, к размеру занятого витриной дискового пространства в байтах, с отбрасыванием дробной части. При этом целевой размер в байтах каждого формируемого файла равен значению установленной константы для каждого отдельного соответствующего кластера. Фигура 2 иллюстрирует файлы до и после распределения данных. В частном варианте реализации, целевой размер в байтах каждого формируемого файла может быть равен значению в 262144000.
Второй альтернативный этап применяется для очень больших витрин данных, так как позволяет перераспределить строки ровно в одном файле за раз, применяясь к каждому исходному файлу. В одном из вариантов реализации, под «очень большой» витриной данных подразумевается 1 терабайт данных и больше. В другом частном варианте реализации, это значение может начинаться от 1 петабайта и больше.
В этом случае строки перераспределяют из исходных файлов витрины данных, формируя новые файлы, причем значение количества новых формируемых файлов вычисляется согласно выражению: p=(L+s-1)/s, где p - количество файлов. На фигуре 6 проиллюстрирован конкретный пример с полученными результирующими значениями для равномерного распределения данных.
Другими словами, количество файлов, необходимых для качественного распределения данных, равно отношению суммы размера витрины данных в байтах и целевого размера в байтах каждого формируемого файла за вычетом единицы, к целевому размеру в байтах каждого формируемого файла, с отбрасыванием дробной части. Фигура 5 иллюстрирует файлы до и после распределения данных, с учетом расчёта количества файлов.
На финальном этапе, с учетом полученных значений количества строк в файле или количества файлов, осуществляют равномерную запись полученных наборов строк на диски в файловой системе на серверном оборудовании. Таким образом, каждый файл, записываемый в распределенной файловой системе, получает размер, немного меньший или немного больший конкретного значения байт, установленного в зависимости от константы для каждого отдельного соответствующего кластера. Допустимое отклонения от конкретного значения байт варьируется в диапазоне от -10% до +20%. Поскольку строки в витрине данных, как правило, разной длины, то и процент допустимого отклонения от целевого размера будет разным, и зависит от характера записываемых данных.
Фигура 1 иллюстрирует результаты применения заявленного технического решения до и после распределения данных, с учетом расчёта количества строк в файле. Фигура 4 иллюстрирует результаты применения заявленного технического решения до и после распределения данных с учетом расчёта количества файлов.
Данные созданной витрины записываются в один или несколько файлов, в один или несколько каталогов системы хранения, в минимально возможном количестве файлов и с максимально возможным размером каждого файла на основе размера блока данных как параметра.
Информация, записанная на диски в распределенной файловой системе подобным образом, может быть считана параллельно со скоростью считывания одного информационного блока (файла), содержащего рассчитанное количество строк.
Для реализации настоящего технического решения используются, по меньшей мере: одно или несколько вычислительных устройств; локальная и/или распределенная система хранения данных.
В частном варианте реализации изобретения, статистическая информация, касающаяся процесса расчета витрин данных и базы данных, для возможности восстановления работоспособности, накапливается в системе хранения. Данный процесс позволяет дополнительно увеличить производительность серверного оборудования за счет повышения отказоустойчивости. Восстановление работоспособности обеспечивается за счет «безопасного запуска», когда алгоритм работы способа продолжается с того же места, на котором он прекратился из-за непредвиденных обстоятельств. В данном случае, информация о прервавшем вычисления шаге и этапе сохраняется во встраиваемую базу данных. При следующем запуске сохраненное состояние и номер этапа считываются из сохраненной базы данных, а вычисления продолжатся с загруженного шага. Если в запросах используются сессионные представления, то в режиме с восстановлением они будут автоматически заменены на временные таблицы.
Вычисляемая витрина может содержать десятки и сотни терабайт данных, и процесс резервного копирования такой витрины сравним по сложности и временным затратам с ее полным пересчетом. Настоящее изобретение дополнительно позволяет не тратить вычислительные ресурсы на резервное копирование вычисляемой витрины данных, опираясь на систему хранения, поскольку контроль за типами и составом столбцов вычисляемой витрины данных основан на сравнении схем целевой таблицы витрины и промежуточной таблицы результатов вычислений. Процесс вычисления прерывается при несовпадении схем, что позволяет контролировать состав и типы данных столбцов вычисляемой витрины на соответствие бизнес-требованиям.
Несмотря на то, что изобретение описано со ссылкой на раскрываемые варианты воплощения, для специалистов в данной области должно быть очевидно, что конкретные, подробно описанные эксперименты приведены лишь в целях иллюстрирования настоящего изобретения и их не следует рассматривать как каким-либо образом ограничивающие объем изобретения. Должно быть понятно, что возможно осуществление различных модификаций без отступления от сути настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ФОРМИРОВАНИЯ ПАРТИЦИОНИРОВАННЫХ ВИТРИН ДАННЫХ, СОДЕРЖАЩИХ ГЕОДАННЫЕ, И ИХ ИСПОЛЬЗОВАНИЯ В ПРОЦЕССЕ ЭКСПЛУАТАЦИИ ХРАНИЛИЩА ДАННЫХ | 2023 |
|
RU2811359C1 |
| СПОСОБ И СИСТЕМА УПРАВЛЕНИЯ МЕТАДАННЫМИ В ВЫСОКОНАГРУЖЕННЫХ ОБЛАЧНЫХ СРЕДАХ | 2024 |
|
RU2829567C1 |
| Способ обработки данных в гибридном хранилище | 2023 |
|
RU2831216C1 |
| ДИНАМИЧЕСКОЕ ОПРЕДЕЛЕНИЕ СОВМЕСТИМОСТИ ФАЙЛОВЫХ СИСТЕМ В РЕАЛЬНОМ ВРЕМЕНИ | 2020 |
|
RU2808634C1 |
| СПОСОБ ПОСТРОЕНИЯ РАСПРЕДЕЛЕННОЙ ИНФОРМАЦИОННОЙ СИСТЕМЫ | 2018 |
|
RU2699683C1 |
| Способ записи информации на оптические диски однократной записи, организованные в гибридные структуры | 2024 |
|
RU2839304C1 |
| УСТРОЙСТВО ДЛЯ РЕДАКТИРОВАНИЯ, СПОСОБ РЕДАКТИРОВАНИЯ И НОСИТЕЛЬ ЗАПИСИ | 2000 |
|
RU2263954C2 |
| СПОСОБ И СИСТЕМА АВТОМАТИЗИРОВАННОЙ ГЕНЕРАЦИИ И ЗАПОЛНЕНИЯ ВИТРИН ДАННЫХ С ИСПОЛЬЗОВАНИЕМ ДЕКЛАРАТИВНОГО ОПИСАНИЯ | 2022 |
|
RU2795902C1 |
| ПРОЗРАЧНОЕ ВОССТАНОВЛЕНИЕ ПОСЛЕ ОТКАЗА | 2012 |
|
RU2595903C2 |
| СПОСОБ ЗАЩИТЫ ДОСТУПНОСТИ И КОНФИДЕНЦИАЛЬНОСТИ ХРАНИМЫХ ДАННЫХ И СИСТЕМА НАСТРАИВАЕМОЙ ЗАЩИТЫ ХРАНИМЫХ ДАННЫХ | 2014 |
|
RU2584755C2 |

Изобретение относится к способу равномерного распределения данных при формировании витрин данных на серверном оборудовании. Технический результат заключается в обеспечении равномерного распределения данных при формировании витрин данных на серверном оборудовании. Способ включает этапы, на которых: осуществляют выделение записываемой информации, которая характеризуется количеством строк и занимаемым объемом в файлах на диске в файловой системе на серверном оборудовании; определяют количество строк и размер витрины данных в байтах, который она занимает в файлах на диске в файловой системе на серверном оборудовании; перераспределяют строки из исходных файлов витрины данных, формируя новые файлы, каждый из которых содержит не более указанного количества строк, вычисленного согласно выражению, где максимальное количество строк на файл равно отношению суммы общего количества строк в витрине данных, умноженного на целевой размер блока в байтах каждого формируемого файла, и размера занятого витриной дискового пространства в байтах за вычетом единицы, к размеру занятого витриной дискового пространства в байтах, с отбрасыванием дробной части, при этом целевой размер в байтах каждого формируемого файла равен значению установленной константы для каждого отдельного соответствующего кластера; или перераспределяют строки из исходных файлов витрины данных, формируя новые файлы, причем значение количества формируемых файлов равно отношению суммы размера витрины данных в байтах, который она занимает в файлах на диске в файловой системе, и целевого размера в байтах каждого формируемого файла за вычетом единицы, к целевому размеру в байтах каждого формируемого файла, с отбрасыванием дробной части; на основе полученных значений количества строк в файле или количества файлов осуществляют равномерную запись полученных наборов строк на диски в файловой системе на серверном оборудовании. 1 з.п. ф-лы, 6 ил.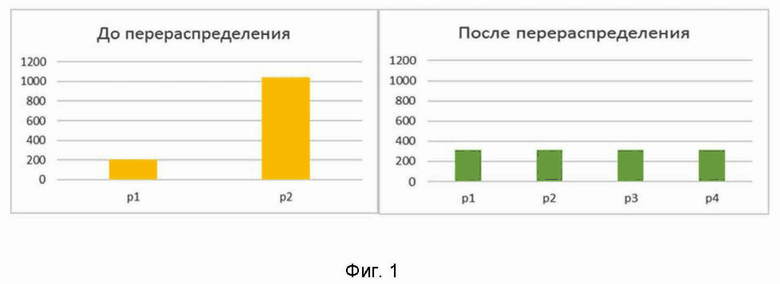
1. Способ равномерного распределения данных при формировании витрин данных на серверном оборудовании, включающий этапы, на которых: осуществляют выделение записываемой информации, которая характеризуется количеством строк и занимаемым объемом в файлах на диске в файловой системе на серверном оборудовании; определяют количество строк и размер витрины данных в байтах, который она занимает в файлах на диске в файловой системе на серверном оборудовании; перераспределяют строки из исходных файлов витрины данных, формируя новые файлы, каждый из которых содержит не более указанного количества строк, вычисленного согласно выражению, где максимальное количество строк на файл равно отношению суммы общего количества строк в витрине данных, умноженного на целевой размер блока в байтах каждого формируемого файла, и размера занятого витриной дискового пространства в байтах за вычетом единицы, к размеру занятого витриной дискового пространства в байтах, с отбрасыванием дробной части, при этом целевой размер в байтах каждого формируемого файла равен значению установленной константы для каждого отдельного соответствующего кластера; или перераспределяют строки из исходных файлов витрины данных, формируя новые файлы, причем значение количества формируемых файлов равно отношению суммы размера витрины данных в байтах, который она занимает в файлах на диске в файловой системе, и целевого размера в байтах каждого формируемого файла за вычетом единицы, к целевому размеру в байтах каждого формируемого файла, с отбрасыванием дробной части; на основе полученных значений количества строк в файле или количества файлов осуществляют равномерную запись полученных наборов строк на диски в файловой системе на серверном оборудовании.
2. Способ по п.1, характеризующийся тем, что распределение данных осуществляют в партицированых данных, по файлам в подкаталогах витрины данных.
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОЙ ГЕНЕРАЦИИ ПРОГРАММНОГО КОДА ДЛЯ КОРПОРАТИВНОГО ХРАНИЛИЩА ДАННЫХ | 2017 |
|
RU2683690C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЗИРОВАННОЙ ГЕНЕРАЦИИ И ЗАПОЛНЕНИЯ ВИТРИН ДАННЫХ С ИСПОЛЬЗОВАНИЕМ ДЕКЛАРАТИВНОГО ОПИСАНИЯ | 2022 |
|
RU2795902C1 |
| СПОСОБ И СИСТЕМА ФОРМИРОВАНИЯ ПАРТИЦИОНИРОВАННЫХ ВИТРИН ДАННЫХ, СОДЕРЖАЩИХ ГЕОДАННЫЕ, И ИХ ИСПОЛЬЗОВАНИЯ В ПРОЦЕССЕ ЭКСПЛУАТАЦИИ ХРАНИЛИЩА ДАННЫХ | 2023 |
|
RU2811359C1 |
| US 7970728 B2, 28.06.2011 | |||
| US 7840607 B2, 23.11.2010 | |||
| US 20090182718 A1, 16.07.2009 | |||
| US 20110295792 A1, 01.12.2011. | |||

