Ссылка на родственные заявки
[0001] Согласно настоящей заявке испрашивается приоритет в соответствии с предварительной заявкой на выдачу патента Китая №202110034450.2, поданной в Китайское национальное управление интеллектуальной собственности (Патентное ведомство Китая) 11 января 2021 г., которая ссылкой полностью включена в настоящий документ.
Область техники, к которой относится настоящее изобретение
[0002] Варианты осуществления настоящего раскрытия связаны с областью техники для разделения предложения на слова, и в частности, связаны со способом, устройством, вычислительным устройством и с носителем данных для разделения на слова, основанном на межъязыковой аугментации данных.
Предшествующий уровень техники настоящего изобретения
[0003] Благодаря развитию информационных технологий обычным требованием в информационную эру стало предоставление пользователю услуг поиска и службы рекомендаций. При предоставлении пользователям услуг поиска и службы рекомендаций необходимо выполнить надлежащее разделение предложений на слова. В традиционной задаче разделения предложения на слова для содержащих пробелы предложений на английском языке разделение на слова выполняется с помощью пробелов. Однако, в отличие от традиционной задачи разделения предложения на слова, пользователи в действительности не строго соблюдают правила грамматики с разделением слов пробелами, и часто вводят несколько слов слитно. Неправильное разделение предложения на слова влияет на последующие задачи, например, на выделение сущностей и семантическую классификацию. Следовательно, специальную модель разделения на слова необходимо обучить с помощью коммерческого сценария. Для обучения модели разделения на слова необходим большой объем языковых данных. Однако для некоторых стран и регионов с относительно бедными языковыми данными сложно получить ресурсы языковых данных на раннем этапе развития модели из-за недостаточных пользовательских данных и нехватки соответствующих ресурсов комментариев.
[0004] Соответствующие способы для разделения предложения на слова обычно классифицируются на словарный способ, который основан на вероятности и статистике, и на модельный способ, который основан на нейронной сети. Основная логика работы словарного способа заключается в получении достаточного числа слов и определения значений их частотности, и получения окончательного результата разделения на слова с помощью вычисления вероятностей появления различных комбинаций разделения на слова. Основная логика работы модельного способа заключается в использовании метода последовательной расстановки меток для вычисления глобальной оптимальной последовательности комбинаций с помощью вероятности перехода признаков, и преобразования последовательности в результат разделения на слова. Для обоих методов требуется достаточный набор обучающих языковых данных. Однако сложно получить обучающие языковые данные в регионах с низкими языковыми ресурсами. Популярное решение для регионов с низкими языковыми ресурсами заключается в использовании предоставленной компанией Google межъязыковой модели двунаправленных представлений кодировщика от трансформеров (multilingual bidirectional encoder representation from transformers - BERT) для разделения на слова. Модель предварительно обучается с помощью загруженного большого набора данных, и затем точно настраивается с помощью небольшого набора данных для каждого языка с низкими ресурсами (ЯНР). Модель BERT преобразует текст в векторы, которые вводятся в качестве признаков в последующую модель для предсказания. Однако, разделение на слова выполняется на тексте, преобразованном с помощью предварительно обученной предоставленной компанией Google модели BERT, а векторы также основаны на словах. Следовательно, эту модель нельзя непосредственно применить для задачи разделения на слова. Кроме того, предварительно обученная модель BERT обучается на основе формального лингвистического корпуса текстов (например, новости и публикации в блоге) и в нем мало уникального контекста, создаваемого в социальной экологии продукта.
Краткое раскрытие настоящего изобретения
[0005] Согласно вариантам осуществления настоящего раскрытия предложены способ, устройство, вычислительное устройство и носитель данных для разделения на слова с помощью межъязыковой аугментации данных, и используется лингвистический корпус текстов из региона языка с высокими ресурсами (ЯВР) в качестве средства для расширения и валидации для региона ЯНР с помощью разделения на слова ЯНР, и устранения несбалансированности языковых ресурсов.
[0006] Согласно первой особенности вариантов осуществления настоящего раскрытия, предложен способ для разделения на слова, основанный на межъязыковой аугментации данных, в котором предусмотрены следующие стадии:
[0007] получение множества групп данных ЯВР, и получение множества первых групп языковых данных для разделения на слова с помощью обработки множества групп данных ЯВР, причем множество первых групп языковых данных для разделения на слова образует первый лингвистический корпус для разделения на слова;
[0008] получение множества групп данных ЯНР, получение множества кандидатов для разделения на слова с помощью обработки данных ЯНР, и выбор вторых языковых данных для разделения на слова из множества кандидатов для разделения на слова на основании степени соответствия между каждым из кандидатов для разделения на слова и первым лингвистическим корпусом для разделения на слова;
[0009] получение модели разделения на слова с помощью обучения на основании вторых языковых данных для разделения на слова, и вывод множества результатов кандидата для разделения на слова с помощью ввода множества групп подлежащих разделению на слова данных в модель разделения на слова; и
[0010] выбор результата кандидата для разделения на слова с наибольшей степенью соответствия в качестве результата разделения на слова на основании степени соответствия между каждым из результатов кандидата для разделения на слова и первым лингвистическим корпусом для разделения на слова.
[0011] Согласно второй особенности вариантов осуществления настоящего раскрытия, предложено устройство для разделения на слова, основанное на межъязыковой аугментации данных, включающее в себя:
[0012] первый модуль получения, выполненный с возможностью получить множество групп данных ЯВР, и получить множество групп первых языковых данных для разделения на слова с помощью обработки множества групп данных ЯВР, причем множество групп первых языковых данных для разделения на слова образует первый лингвистический корпус для разделения на слова;
[0013] первый модуль получения, выполненный с возможностью получить множество групп данных ЯНР, получить множество кандидатов для разделения на слова с помощью обработки данных ЯНР, и выбрать вторые языковые данные для разделения на слова из множества кандидатов для разделения на слова на основании степени соответствия между каждым из кандидатов для разделения на слова и первым лингвистическим корпусом для разделения на слова;
[0014] модуль кандидата для разделения на слова, выполненный с возможностью получить модель разделения на слова с помощью обучения на основании вторых языковых данных для разделения на слова, и вывести множество результатов из кандидата для разделения на слова с помощью ввода множества групп подлежащих разделению на слова данных в модель разделения на слова; и
[0015] модуль определения разделения на слова, выполненный с возможностью выбрать результат кандидата для разделения на слова с наибольшей степенью соответствия в качестве результата разделения на слова на основании степени соответствия между каждым из результатов кандидата для разделения на слова и первым лингвистическим корпусом для разделения на слова.
[0016] Согласно третьей особенности вариантов осуществления настоящего раскрытия, предложено вычислительное устройство для разделения на слова, основанное на межъязыковой аугментации данных, включающее в себя память и один или несколько процессоров, причем
[0017] память выполнена с возможностью хранить одну или несколько программ; и
[0018] один или несколько процессоров после загрузки и выполнения одной или нескольких программ заставлены выполнять способ для разделения на слова с помощью межъязыковой аугментации данных согласно первой особенности.
[0019] Согласно четвертой особенности вариантов осуществления настоящего раскрытия, предложен носитель данных, на котором содержатся выполняемые компьютером команды. Выполняемые компьютером команды после их загрузки и выполнения процессором компьютера заставляют процессор компьютера выполнять способ для разделения на слова с помощью межъязыковой аугментации данных согласно первой особенности.
[0020] Согласно пятой особенности вариантов осуществления настоящего раскрытия, дополнительно предложена программа для разделения на слова, основанная на межъязыковой аугментации данных. Программа после ее загрузки и выполнения процессором заставляет процессор компьютера выполнять способ для разделения на слова с помощью межъязыковой аугментации данных согласно первой особенности.
[0021] Согласно вариантам осуществления настоящего раскрытия данные ЯВР получаются и обрабатываются для получения языковых данных для разделения на слова, и затем данные ЯНР получаются и обрабатываются для получения кандидата для разделения на слова. Кандидат для разделения на слова, который имеет высокую степень соответствия с языковыми данными для разделения на слова, выбирается в качестве языковых данных для разделения на слова из данных ЯНР из кандидата для разделения на слова на основании языковых данных для разделения на слова, полученных из данных ЯВР. Модель разделения на слова обучается с помощью языковых данных для разделения на слова языка с низкими ресурсами, так что результаты кандидата для разделения на слова можно автоматически вывести для данных ЯНР из этой модели. Результат кандидата для разделения на слова выбирается на основании степени соответствия между каждым из результатов кандидата для разделения на слова и языковыми данными для разделения на слова по данным ЯВР. Обучающие данные для модели из ЯНР автоматически расширяются и верифицируются с помощью использования языковых данных ЯВР, так что устраняется несбалансированность ресурсов языковых данных и ресурсов комментариев между разными языками, и предоставляется более простое и эффективное решение для многонационального продукта, чтобы быстрее проводить итерации модели разделения на слова на ЯНР. Кроме того, поскольку автоматически создаются обучающие языковые данные для ЯНР, при последующих обновлениях необходимо в основном поддерживать только ЯВР, и стоимость сопровождения снижается.
Краткое описание фигур
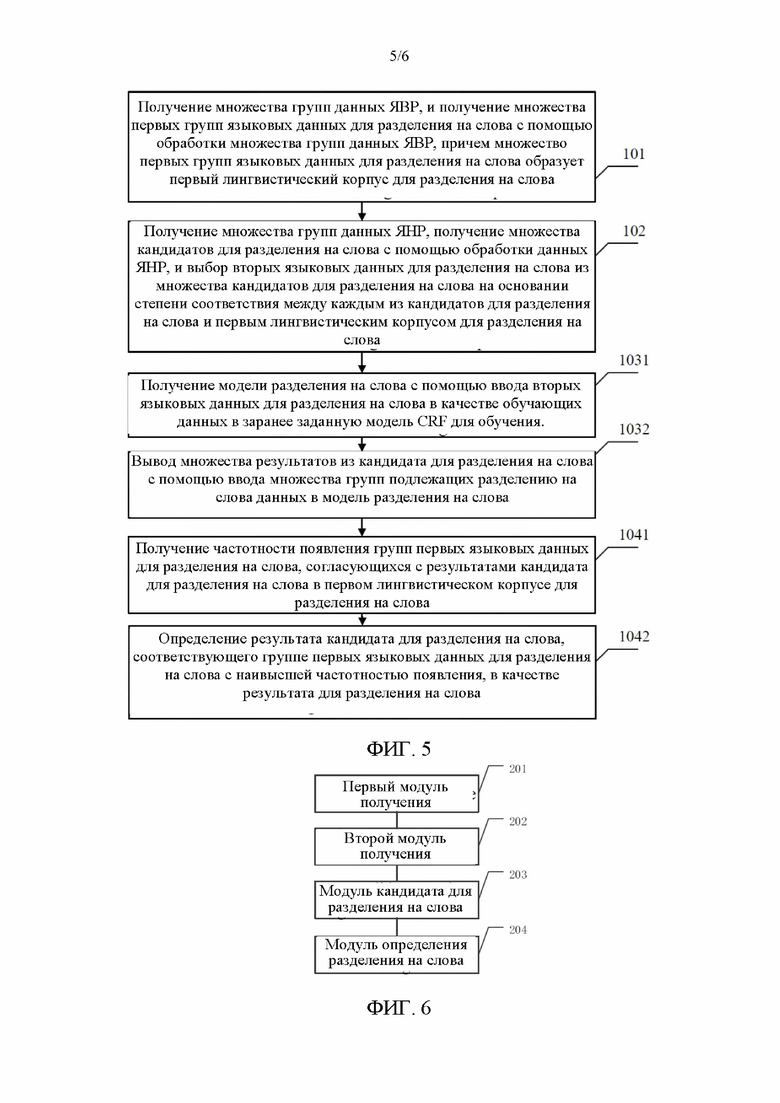
[0022] На фиг. 1 показана блок-схема алгоритма способа для разделения на слова на основании межъязыковой аугментации данных согласно некоторым вариантам осуществления настоящего раскрытия;
[0023] На фиг. 2 показана блок-схема алгоритма другого способа для разделения на слова на основании межъязыковой аугментации данных согласно некоторым вариантам осуществления настоящего раскрытия;
[0024] На фиг. 3 показана блок-схема алгоритма другого способа для разделения на слова на основании межъязыковой аугментации данных согласно некоторым вариантам осуществления настоящего раскрытия;
[0025] На фиг. 4 показана блок-схема алгоритма другого способа для разделения на слова на основании межъязыковой аугментации данных согласно некоторым вариантам осуществления настоящего раскрытия;
[0026] На фиг. 5 показана блок-схема алгоритма другого способа для разделения на слова на основании межъязыковой аугментации данных согласно некоторым вариантам осуществления настоящего раскрытия;
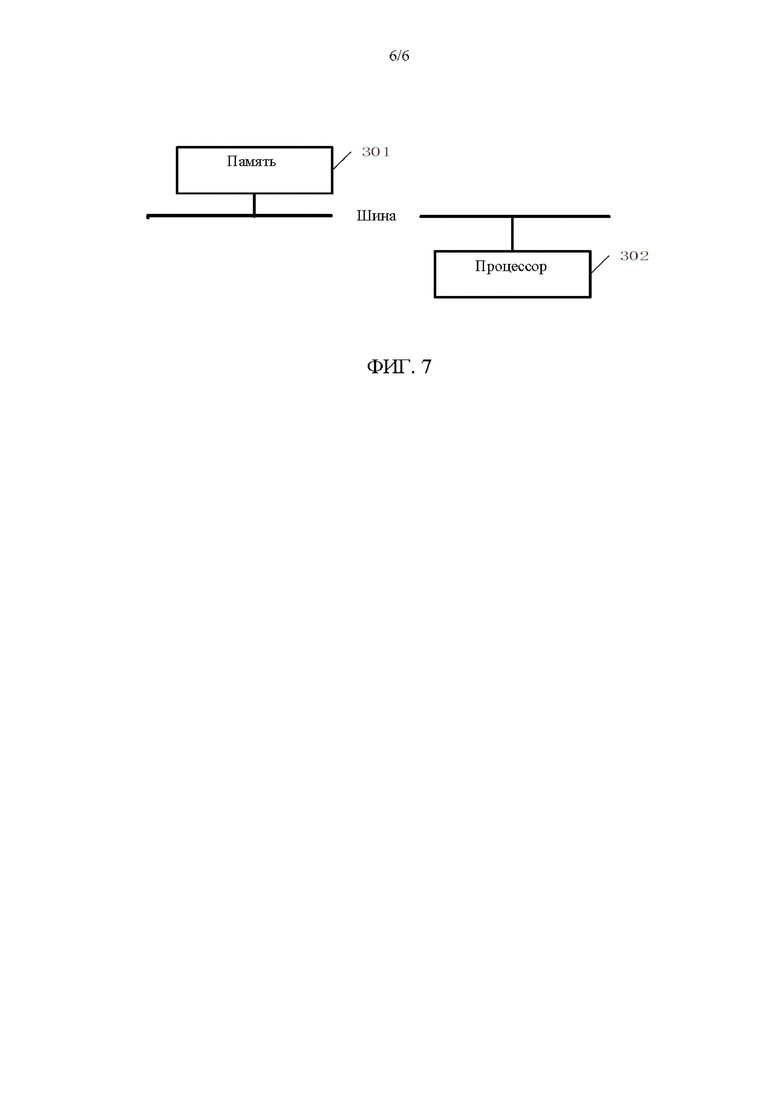
[0027] На фиг. 6 показана упрощенная блок-схема устройства для разделения на слова на основании межъязыковой аугментации данных согласно некоторым вариантам осуществления настоящего раскрытия; и
[0028] На фиг. 7 показана упрощенная блок-схема вычислительного устройства для разделения на слова на основании межъязыковой аугментации данных согласно некоторым вариантам осуществления настоящего раскрытия.
Подробное раскрытие настоящего изобретения
[0029] Для более понятного изложения цели, технических решений и преимуществ настоящего раскрытия конкретные варианты осуществления настоящего раскрытия подробно описаны ниже со ссылками на сопровождающие фигуры. Следует понимать, что описанные в настоящем документе конкретные варианты осуществления предназначены только для объяснения настоящего раскрытия, и не предназначены для ограничения настоящего раскрытия. Кроме того, следует также отметить, что для упрощения описания на сопровождающих фигурах показано только частичное содержание, относящееся к настоящему раскрытию, а не полное содержание. Перед переходом к подробным описаниям приведенных в качестве примера (иллюстративных) вариантов осуществления следует отметить, что некоторые приведенные в качестве примера (иллюстративные) варианты осуществления описаны как процессы или способы, представленные на блок-схемах. Хотя на блок-схеме операции (или этапы) показаны в виде последовательного процесса, многие операции могут быть выполнены параллельно, в многопоточном режиме или одновременно. Кроме того, порядок выполнения операций может быть изменен. Процесс может быть окончен после выполнения всех его операций, или он может дополнительно иметь другие этапы, не показанные на сопровождающей фигуре. Процесс может соответствовать способу, функции, процедуре, подпрограмме или тому подобному.
[0030] Согласно вариантам осуществления настоящего раскрытия предложены способ, устройство, вычислительное устройство и носитель данных для разделения на слова, основанном на межъязыковой аугментации данных. Согласно вариантам осуществления настоящего раскрытия, сначала получаются и обрабатываются данные ЯВР для получения языковых данных для разделения на слова, и затем данные ЯНР получаются и обрабатываются для получения кандидата для разделения на слова. Кандидат для разделения на слова, который имеет высокую степень соответствия с языковыми данными для разделения на слова, выбирается в качестве языковых данных для разделения на слова из данных ЯНР из кандидата для разделения на слова на основании языковых данных для разделения на слова, полученных из данных ЯВР. Модель разделения на слова обучается с помощью языковых данных для разделения на слова языка с низкими ресурсами, так что результаты кандидата для разделения на слова можно автоматически вывести для данных ЯНР из этой модели. Результат кандидата для разделения на слова выбирается на основании степени соответствия между каждым из результатов кандидата для разделения на слова и языковыми данными для разделения на слова по данным ЯВР.
[0031] Согласно вариантам осуществления настоящего раскрытия, модель разделения на слова и обучающие данные для разделения на слова в регионе с низкими ресурсами (в основном в регионе, в котором говорят на языке или диалекте национального меньшинства) автоматически создаются с помощью технологии машинного обучения. Конкретный способ предусматривает следующие стадии. Сначала пакет языковых данных для разделения на слова из ЯВР (например, английского языка) создается с использованием данных, естественным образом введенных пользователем, и выполняется полуавтоматическая верификация. Затем пакет языковых данных для разделения на слова для регионов с низкими ресурсами автоматически создается с использованием этого решения, и выполняется автоматическая верификации с использованием языковых данных из ЯВР. Наконец, модель разделения на слова для ЯНР обучается с использованием глобального словаря со словами с высокой частотностью. Согласно вариантам осуществления, обучающие данные для модели из ЯНР автоматически расширяются и верифицируются с помощью использования языковых данных ЯВР, так что устраняется несбалансированность ресурсов языковых данных и ресурсов комментариев между разными языками, и предоставляется более простое и более эффективное решение для многонационального продукта, чтобы быстрее проводить итерации модели разделения на слова на ЯНР. Кроме того, поскольку автоматически создаются обучающие языковые данные для ЯНР, при последующих обновлениях необходимо в основном поддерживать только ЯВР, и стоимость сопровождения снижается.
[0032] Подробные описания представлены ниже.
[0033] На фиг. 1 показана блок-схема алгоритма способа для разделения на слова на основании межъязыковой аугментации данных согласно некоторым вариантам осуществления настоящего раскрытия. Согласно некоторым вариантам осуществления настоящего раскрытия, основанный на межъязыковой аугментации данных способ для разделения на слова выполняется с помощью устройства для разделения на слова, основанном на межъязыковой аугментации данных. Устройство для разделения на слова, основанное на межъязыковой аугментации данных, реализуется с помощью аппаратуры и/или программного обеспечения, и встроено в вычислительное устройство.
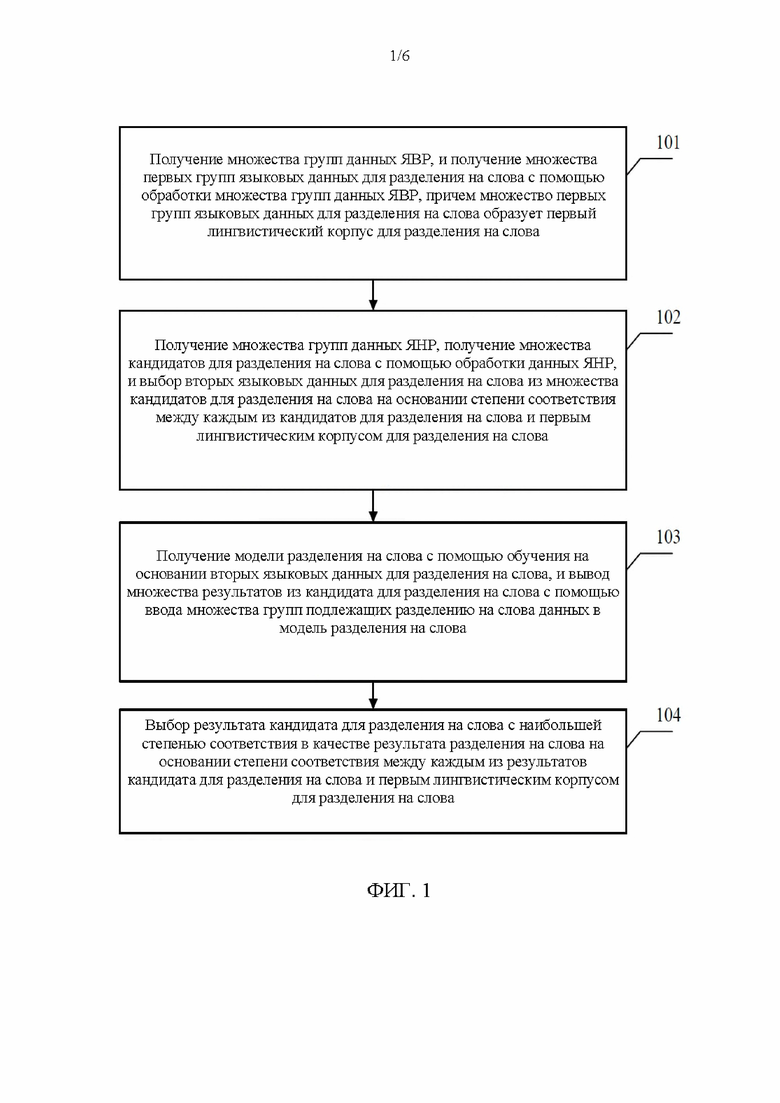
[0034] Далее для описания используется пример, в котором устройство для разделения на слова, основанное на межъязыковой аугментации данных, выполняет способ для разделения на слова, основанный на межъязыковой аугментации данных. Как показано на фиг. 1, основанный на межъязыковой аугментации данных способ для разделения на слова предусматривает следующие стадии:
[0035] На стадии 101 проводится получение и обработка множества групп данных ЯВР для получения множества групп первых языковых данных для разделения на слова, причем множество групп первых языковых данных для разделения на слова образует первый лингвистический корпус для разделения на слова.
[0036] Согласно некоторым вариантам осуществления настоящего раскрытия, ЯВР являются языками, имеющими много языковых данных и данных комментариев, и в общем случае это более широко используемые языки, например, английский и китайский. В отличие от ЯВР, ЯНР являются языками, для которых мало языковых данных и данных комментариев, и они обычно являются языками национальных меньшинств, например, испанский, немецкий, французский, вьетнамский и тайский, или различные диалекты, например, кантонский, хакка и чаошаньский.
[0037] Применение настоящего раскрытия основано на предположении, что данные различных языков для одного продукта имеют аналогичные распределения данных. Согласно фактическим сценариям применения, это предположение справедливо при использовании многих многонациональных продуктов, поскольку пользователи в различных странах используют тот же самый набор базовых услуг, например способы ввода и темы для сайта микроблогов Твиттер, и имеют аналогичные языковые экосистемы, например, некоторые популярные слова и укоренившиеся выражения.
[0038] Получение данных ЯВР заключается в получении естественным образом введенных пользователем данных в регионе ЯВР, например, данных поискового запроса пользователя или данных комментария пользователя. Согласно некоторым вариантам осуществления настоящего раскрытия, сценарий получения данных ЯВР заключается в следующем: при использовании видео-клиента, применяемого в стране ЯВР, получение данных комментария от зарегистрированного пользователя в видеоролике, воспроизводимом в видео-клиенте, или данных поискового запроса, когда пользователь проводит поиск в видеоролике, воспроизводимом в видео-клиенте. Можно легко понять, что такие данные комментария обычно представляют из себя абзац текста. Согласно некоторым вариантам осуществления, абзац содержит множество предложений, составленных из символов или слов, или текст абзаца составлен из символов или слов. Конечно, данные комментария могут альтернативно содержать другие синтаксические единицы, например, знаки эмоций. Данные поискового запроса часто содержит небольшое количество синтаксических единиц, и обычно отображаются ключевыми словами, включая имена, время и другие информационные выражения, обычно это фразы или короткие предложения. Согласно некоторым другим вариантам осуществления, сценарий получения данных ЯВР заключается в преобразовании речевой информации из короткого видеоролика в текст в качестве данных ЯВР, или в получении языковых данных из опубликованной диссертации с веб-сайта диссертаций в качестве данных ЯВР. Согласно некоторым другим вариантам осуществления, данные ЯВР являются различными языковыми данными, которые можно легко получить.
[0039] Согласно вариантам осуществления настоящего раскрытия, пакет данных ЯВР очищается и преобразуется для создания множества групп коротких предложений. Каждая группа коротких предложений содержит множество фраз, каждая из которых имеет одинаковое количество синтаксических единиц. Например, данные ЯВР «ваш счастливый день рождения» преобразуется в короткое предложение с 2 лингвистическими единицами, то есть, «ваш счастливый, счастливый день, день рождения». В этом коротком предложении «ваш счастливый», «счастливый день» и «день рождения» являются тремя фразами в наборе короткого предложения. В случае, когда «ваш счастливый день рождения» преобразуется в короткое предложение с 3 синтаксическими единицами, короткое предложение является предложением «ваш счастливый день, счастливый день рождения». В случае, когда «ваш счастливый день рождения» преобразуется в короткое предложение с 1 синтаксической единицей, короткое предложение является предложением «ваш, счастливый, день, рождения». «Ваш», «счастливый», «день» и «рождения» являются фразами в коротком предложении «ваш, счастливый, день, рождения». Согласно вариантам осуществления настоящего раскрытия, синтаксическая единица является соответствующим словом или символом на различных языках или в различных языковых сценариях. Например, в китайском языке предложение содержит множество иероглифов, и каждый иероглиф существует независимо в качестве синтаксической единицы. Например, в английском языке предложение содержит множество слов, и каждое слово существует независимо в качестве синтаксической единицы.
[0040] Полученные данные ЯВР обычно содержат абзацы или предложения. Абзац или предложение используется в качестве группы данных ЯВР. Каждая группа данных ЯВР обрабатывается для получения первых языковых данных для разделения на слова. Например, в англоязычных странах, полученные языковые данные из англоязычной страны являются данными ЯВР, поскольку английский язык используется как родной язык во многих странах, и английский язык является международным языком. Полученные данные ЯВР являются предложением, например, «ваш счастливый день рождения», или абзацем, например, «Сегодня хороший день. Я приготовил отменный обед». «Ваш счастливый день рождения» и «Сегодня хороший день. Я приготовил отменный обед» используются как различные группы данных ЯВР и обрабатываются для получения первых языковых данных для разделения на слова. Согласно настоящему раскрытию, нет никаких твердых правил для группирования данных ЯВР. Описанное в вариантах осуществления множество групп данных ЯВР олицетворяет, что каждое предложение или состоящий из множества предложений абзац может быть обработан в качестве независимой группы данных ЯВР для получения первых языковых данных для разделения на слова.
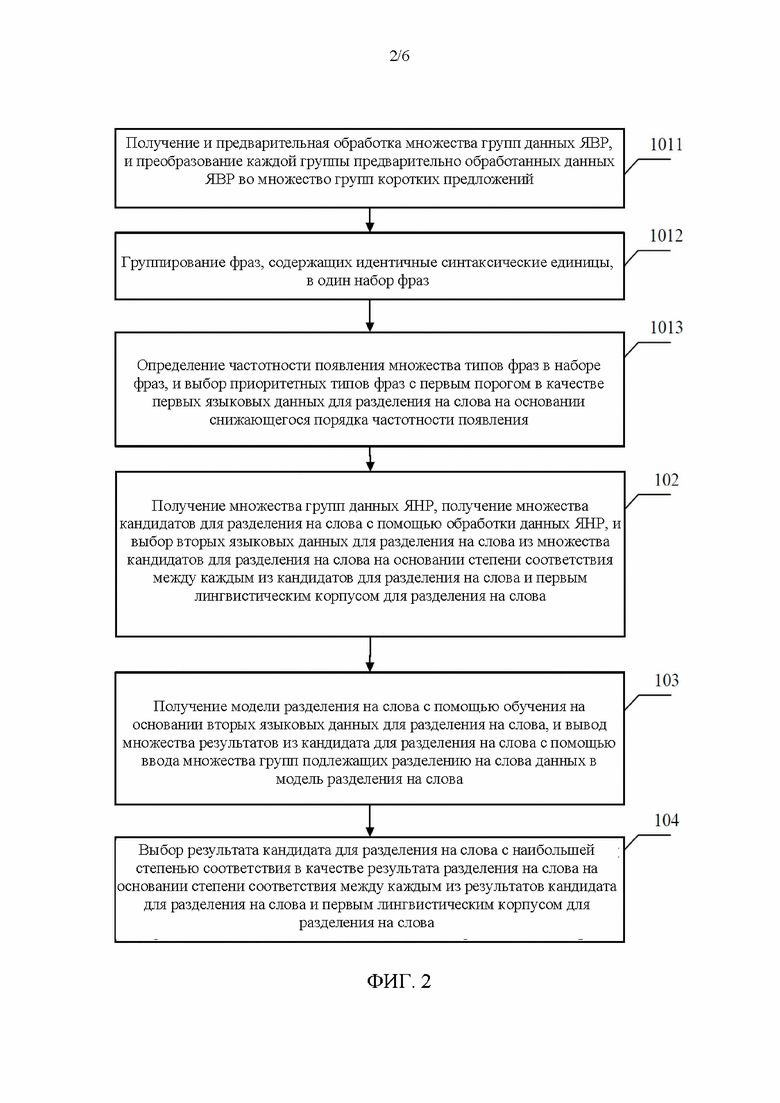
[0041] Согласно другому варианту осуществления, метод обработки каждой группы данных ЯВР для получения группы первых языковых данных для разделения на слова показан стадиями с 1011 по 1013 на фиг. 2. На стадии 1011 множество групп данных ЯВР получается и предварительно обрабатывается, и каждая группа предварительно обработанных данных ЯВР преобразуется во множество групп коротких предложений. Каждая группа коротких предложений содержит множество фраз, каждая из которых имеет одинаковое количество синтаксических единиц. На стадии 1012 фразы, содержащие идентичные синтаксические единицы, группируются в один набор фраз. Набор фраз содержит множество типов фраз. На стадии 1013 извлекается информация о частотности появления множества типов фраз в наборе фраз, и m приоритетных типов фраз выбираются в качестве первых языковых данных для разделения на слова на основании снижающегося порядка частотности появления.
[0042] Согласно некоторым вариантам осуществления, m является натуральным целым числом, например, 1, 2 или 3. Согласно решению вариантов осуществления значение m равно 3.
[0043] Согласно некоторым вариантам осуществления, предварительная обработка предусматривает следующие стадии: преобразование знака пунктуации в данных ЯВР на основании первого заранее заданного правила, и преобразование знака эмоций в данных ЯВР в синтаксическую единицу на основании второго заранее заданного правила. Во время предварительной обработки единообразные правила преобразования используется для преобразования некоторых специальных синтаксических единиц в данных ЯВР, включая знак пунктуации, знак эмоций и тому подобное. Например, в случае, когда данные ЯВР получены из данных комментария, и данные комментария содержат знак эмоций, знак эмоций может быть преобразован в синтаксическую единицу согласно значению знака эмоций, полученному с помощью распознавания значения. Например, знак эмоций, соответствующий значению «счастливый», является улыбающимся лицом (смайликом). В том случае, когда улыбающееся лицо присутствует в данных комментария, улыбающееся лицо преобразуется в синтаксическую единицу «счастливый». Получение значения знака эмоций и преобразование знака эмоций в синтаксическую единицу согласно значению является вторым заранее заданным правилом согласно вариантам осуществления настоящего раскрытия. Согласно другому варианту осуществления, второе заранее заданное правило может быть заранее задано для создания сопоставления между знаком эмоций и синтаксической единицей, и соответствующая синтаксическая единица может быть более прямо получена с помощью знака эмоций. Согласно еще одному другому варианту осуществления, метод предварительной обработки знака эмоций не обязательно является преобразованием, и знак эмоций может быть непосредственно удален. Аналогичным образом, преобразование знака пунктуации проводится на основании первого заранее заданного правила, например, знак точки используется для обозначения конца полного предложения, но в китайском и в английском языках используются разные обозначения знака точки. Первое заранее заданное правило дает знаку пунктуации унифицированное выражение.
[0044] Согласно некоторым вариантам осуществления, предполагается, что группой предварительно обработанных данных ЯВР является группа «цзинь тянь гэй пэн ю го шэн жи, чжу шэн жи гуай лэ» (сегодня день рождения моего друга, счастливого дня рождения моему другу). Данные ЯВР могут быть преобразованы во множество групп коротких предложений. Множество групп коротких предложений соответствует различным количествам следующих друг за другом синтаксических единиц. В случае, когда данные ЯВР преобразованы в короткое предложение с 2 следующими друг за другом синтаксическими единицами, коротким предложением является следующее предложение «цзинь тянь, тянь гэй, гэй пэн, пэн ю, ю го, го шэн, шэн жи, жи чжу, чжу шэн, шэн жи, жи гуай, гуай лэ». Аналогичным образом, может также быть получено короткое предложение с 3 следующими друг за другом синтаксическими единицами, это следующее предложение «цзинь тянь гэй, тянь гэй пэн, гэй пэн ю, пэн ю, ю го шэн, го шэн жи, шэн жи». Каждая группа коротких предложений содержит множество фраз. Например, «цзинь тянь гэй» и «гэй пэн ю» являются фразами, описанными в вариантах осуществления. Следует понимать, что фразы в каждой группе коротких предложений имеют одинаковое количество следующих друг за другом синтаксических единиц. В вышеупомянутых фразах, фразы, содержащие идентичные синтаксические единицы, группируются в набор фраз. Например, вышеупомянутые фразы, содержащие «шэн жи», могут быть сгруппированы в набор фраз. Следует отметить, что правило группирования в настоящем раскрытии определяет идентичные синтаксические единицы и идентичный порядок синтаксических единиц, но при этом пробелы между синтаксическими единицами не учитываются. Например, рассмотрим три коротких предложения «Ты (пробел) мне нравишься», «Ты мне (пробел) нравишься» и «Ты (пробел) мне (пробел) нравишься», в случае вышеупомянутых трех коротких предложений, если в них убрать пробелы, все предложения станут одинаковыми «Ты мне нравишься». Следовательно, строчка синтаксической единицы «Ты мне нравишься» определяется в качестве ключевого слова для группирования фраз в набор фраз. Набор фраз содержит множество типов фраз. Например, «Ты мне нравишься» определяется в качестве ключевого слова. Все фразы, которые могут стать ключевым словом после удаления пробелов, составляют набор фраз. Поскольку положения пробелов во фразах являются различными, фразы являются различными, хотя ключевое слово одно и то же. Другими словами, имеются различные типы фраз. Например, «Ты (пробел) мне нравишься» и «Ты мне (пробел) нравишься» являются двумя различными типами фраз. При этом предполагается, что в набор фраз входят следующие фразы: «Ты (пробел) мне нравишься», «Ты (пробел) мне нравишься», «Ты мне (пробел) нравишься» и «Ты (пробел) мне (пробел) нравишься». Можно осознать, что фраза «Ты (пробел) мне нравишься» появляется дважды, и поэтому ее частотность выше, чем у двух других типов фраз. Согласно варианту осуществления, m приоритетных типов фраз выбираются в качестве первых языковых данных для разделения на слова на основании снижающегося порядка частотности появления. Согласно варианту осуществления, значение m равно 3. Согласно другому варианту осуществления, m может принимать другое значение, например, 5 или 4. Это никак не ограничивается в настоящем раскрытии. В другом примере в набор фраз входят следующие фразы: «Ты (пробел) мне нравишься», «Ты (пробел) мне нравишься», «Ты мне (пробел) нравишься», «Ты (пробел) мне (пробел) нравишься» и «Ты (пробел) мне (пробел) нравишься». В том случае, когда значение m равно 2, фразы «Ты (пробел) мне нравишься» и «Ты (пробел) мне (пробел) нравишься» выбраны в качестве группы первых языковых данных для разделения на слова. Поскольку получено достаточное количество данных ЯВР, получено большое количество групп первых языковых данных для разделения на слова. Достаточное количество групп первых языковых данных для разделения на слова составляет лингвистический корпус, то есть первый лингвистический корпус для разделения на слова, описанный в настоящем раскрытии.
[0045] Согласно другим вариантам осуществления, выбор m приоритетных типов фраз в качестве первых языковых данных для разделения на слова на основании снижающегося порядка частотности появления, предусматривает следующие стадии: выбор m приоритетных типов фраз в качестве кандидата первых языковых данных для разделения на слова на основании снижающегося порядка частотности появления; случайный выбор фразы из набора фраз, и образование ключевого слова с помощью удаления всех пробелов из фразы; вывод предсказанных языковых данных для разделения на слова с помощью ввода ключевого слова в заранее заданную модель разделения на слова; и сравнение кандидата первых языковых данных для разделения на слова с предсказанными языковыми данными для разделения на слова, и после обнаружения, что кандидат первых языковых данных для разделения на слова является точно таким же, как предсказанные языковые данные для разделения на слова, определение кандидата первых языковых данных для разделения на слова в качестве первых языковых данных для разделения на слова; или после обнаружения, что кандидат первых языковых данных для разделения на слова является отличающимся от предсказанных языковых данных для разделения на слова, коррекция кандидата первых языковых данных для разделения на слова, и определение скорректированного кандидата первых языковых данных для разделения на слова в качестве первых языковых данных для разделения на слова.
[0046] Величина m имеет заранее заданное значение, и оно является натуральным целым числом. Например, значение m равно 2, 3 или 5, это никак не ограничивается в настоящем раскрытии. Во время предыдущих операций выполняется полуавтоматическая верификация для получения первых языковых данных для разделения на слова. Таким образом, m приоритетных типов фраз, выбранных на основании снижающегося порядка частотности появления, не непосредственно определяются в качестве первых языковых данных для разделения на слова и не включаются в первый лингвистический корпус для разделения на слова, а они определяются в качестве кандидата первых языковых данных для разделения на слова, и кандидат первых языковых данных для разделения на слова верифицируется. Способ верификации предусматривает случайный выбор фразы из набора фраз, и удаление всех пробелов из фразы для образования ключевого слова. Например, набор фраз, соответствующий четырем следующим друг за другом синтаксическим единицам ABCD, включает в себя фразы «А (пробел) ВС (пробел) D» и «А (пробел) BCD». Фраза "А (пробел) ВС D» случайным образом выбрана, и пробелы удаляются для образования ключевого слова ABCD. Ключевое слово ABCD вводится в заранее заданную модель для разделения на слова. Заранее заданная модель для разделения на слова является моделью для разделения на слова, которая была раскрыта и использовалась в известном уровне техники. Заранее заданная модель для разделения на слова выводит множество групп предсказанных языковых данных для разделения на слова для ключевого слова ABCD, например, выводит «А (пробел) ВС (пробел) D», «А (пробел) BCD» и «АВ (пробел) CD». Кандидат языковых данных для разбиения на слова сравнивается с предсказанными языковыми данными для разбиения на слова. Другими словами, «А (пробел) ВС (пробел) D» и «А (пробел) BCD» сравниваются с «А (пробел) ВС (пробел) D», «А (пробел) BCD» и «АВ (пробел) CD». Каждая фраза «А (пробел) ВС (пробел) D» и «А (пробел) BCD» имеет соответствующую группу предсказанных языковых данных для разбиения на слова. Фразы «А (пробел) ВС (пробел) D» и «А (пробел) BCD» определяются в качестве первых языковых данных для разбиения на слова. В другом случае, предполагается, что кандидатом первых языковых данных для разбиения на слова являются «А (пробел) ВС (пробел) D», «А (пробел) BCD» и «АВ (пробел) CD», а предсказанными языковыми данными для разбиения на слова являются «А (пробел) ВС (пробел) D» и «А (пробел) BCD». Можно осознать, что «АВ (пробел) CD» в кандидате первых языковых данных для разбиения на слова не соответствует группе предсказанных языковых данных для разбиения на слова. Следовательно, фраза «АВ (пробел) CD» не определяется в качестве первых языковых данных для разбиения на слова, а фразы «А (пробел) ВС (пробел) D» и «А (пробел) BCD» определяются в качестве первых языковых данных для разбиения на слова.
[0047] На стадии 102 множество групп данных ЯНР получаются и обрабатываются для получения множества кандидатов для разделения на слова, и вторые языковые данные для разделения на слова выбираются из множества кандидатов для разделения на слова на основании степени соответствия между каждым из кандидатов для разделения на слова и первым лингвистическим корпусом для разделения на слова.
[0048] Данные ЯНР существуют в связи с данными ЯВР. Как упоминалось выше, ЯВР являются языками, имеющими много языковых данных и данных комментариев, и в общем случае это более широко используемые языки. ЯНР являются языками, которые меньше используются, аудитория которых меньше, и в которых не хватает языковых данных.
[0049] Аналогичным образом, получение данных ЯНР заключается в получении данных поисковых запросов или данных комментариев пользователей из региона ЯНР. Сценарий получения данных ЯНР является точно таким же, как сценарий получения данных ЯВР. Например, когда видео-клиент применяется в стране ЯНР, проводится получение данных комментария от зарегистрированного пользователя в видеоролике, когда пользователь просматривает видеоролик с помощью видео-клиента, или данных поискового запроса, когда пользователь проводит поиск в видеоролике, воспроизводимом в видео-клиенте. Можно легко понять, что такие данные комментария обычно представляют из себя абзац текста. Согласно некоторым вариантам осуществления, абзац содержит множество предложений, составленных из символов или слов, или текст абзаца составлен из символов или слов. Конечно, данные комментария могут альтернативно содержать другие синтаксические единицы, например, знаки эмоций. Данные поискового запроса часто содержит небольшое количество синтаксических единиц, и обычно отображаются ключевыми словами, включая имена, время и другие информационные выражения, обычно это фразы или короткие предложения. Согласно некоторым другим вариантам осуществления, сценарий получения данных ЯНР заключается в преобразовании речевой информации из короткого видеоролика в текст в качестве данных ЯНР. Согласно некоторым другим вариантам осуществления, данные ЯНР являются различными языковыми данными, которые можно легко получить, например, субтитрами местных новостных передач.
[0050] Аналогичным образом, согласно вариантам осуществления настоящего раскрытия, полученные данные ЯНР можно очистить и преобразовать. Очистка и преобразование данных по существу является предварительной обработкой данных. Предварительно обработанные данные ЯНР затем обрабатываются для получения кандидата для разделения на слова. Согласно вариантам осуществления настоящего раскрытия, кандидат для разделения на слова предназначен для последующего выбора вторых языковых данных для разделения на слова, то есть языковых данных для разделения на слова, из данных ЯНР, из кандидата для разделения на слова.
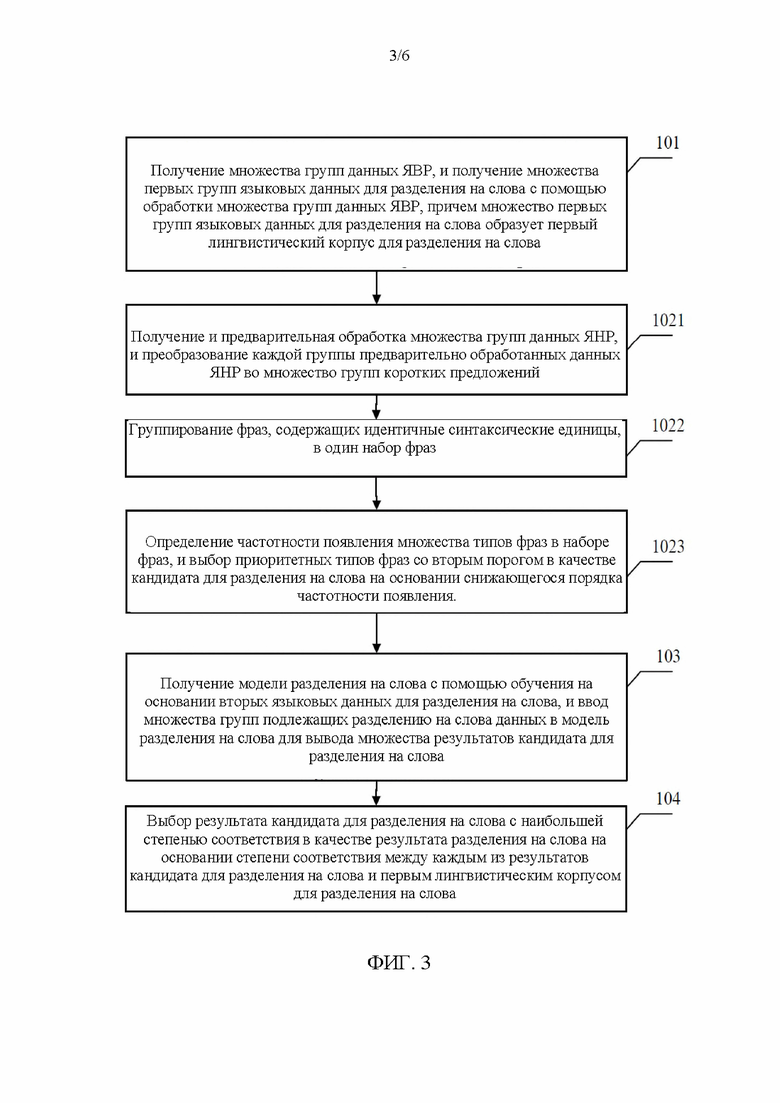
[0051] Согласно некоторым вариантам осуществления, стадия 102 дополнительно оптимизируется. Как показано стадиям с 1021 по 1023 на фиг. 3, множество групп данных ЯНР получаются и обрабатываются для получения множества кандидатов для разделения на слова, при этом предусмотрены следующие стадии: на стадии 1021 проводится получение и обработка множества групп данных ЯНР; предварительная обработка множества групп данных ЯНР; преобразование каждой группы предварительно обработанных данных ЯНР во множество групп фраз, причем каждая группа коротких предложений включает в себя множество фраз, каждая из которых имеет то же самое количество синтаксических единиц; на стадии 1022 проводится группирование фраз, содержащих идентичные синтаксические единицы, в один набор фраз, причем этот набор фраз содержит множество типов фраз; а на стадии 1023 проводится определение частотности появления множества типов фраз в наборе фраз, и выбор п приоритетных типов фраз в качестве кандидата для разделения на слова на основании снижающегося порядка частотности появления.
[0052] Согласно некоторым вариантам осуществления настоящего раскрытия, метод предварительной обработки данных ЯНР точно такой же, как метод предварительной обработки данных ЯВР, и он предусматривает следующие стадии: преобразование знака пунктуации в данных ЯНР на основании первого заранее заданного правила, и преобразование знака эмоций в данных ЯВР в синтаксическую единицу на основании второго заранее заданного правила. Во время предварительной обработки проводится преобразование специальных синтаксических единиц в полученных данных ЯНР, точно так же, как для данных ЯВР. Например, в случае, когда данные ЯНР получены из данных комментария, и данные комментария содержат знак эмоций, знак эмоций может быть преобразован в синтаксическую единицу согласно значению знака эмоций, полученному с помощью распознавания значения. Например, знак эмоций, соответствующий значению «счастливый», является улыбающимся лицом (смайликом). В том случае, когда улыбающееся лицо присутствует в данных комментария, улыбающееся лицо преобразуется в синтаксическую единицу «счастливый». Получение значения знака эмоций и преобразование знака эмоций в синтаксическую единицу согласно значению является вторым заранее заданным правилом согласно вариантам осуществления настоящего раскрытия. Согласно другому варианту осуществления, второе заранее заданное правило может быть заранее задано для создания сопоставления между знаком эмоций и синтаксической единицей, и соответствующая синтаксическая единица может быть более прямо получена с помощью знака эмоций. Согласно еще одному другому варианту осуществления, метод предварительной обработки знака эмоций не обязательно является преобразованием, и знак эмоций может быть непосредственно удален. Аналогичным образом, преобразование знака пунктуации проводится на основании первого заранее заданного правила, например, знак точки используется для обозначения конца полного предложения, но в китайском и в английском языках используются разные обозначения знака точки. Первое заранее заданное правило дает знаку пунктуации унифицированное выражение.
[0053] Согласно некоторым вариантам осуществления, метод преобразования предварительно обработанных данных ЯНР в короткие предложения точно такой же, как метод преобразования предварительно обработанных данных ЯВР в короткие предложения. Каждая группа коротких предложений содержит множество фраз, каждая из которых имеет одинаковое количество синтаксических единиц.
[0054] Например, данными ЯНР является строчка «ABCDEFADEGCABCD», причем каждая английская буква обозначает синтаксическую единицу. Согласно вариантам осуществления, синтаксической единицей является слово с существенным значением, исключая знаки, пробелы и тому подобное. Преобразование «ABCDEFADEGCABCD» во множество групп коротких предложений указывает, что «ABCDEFADEGCABCD» преобразуется в короткое предложение с 4 следующими друг за другом синтаксическими единицами, в короткое предложение с 3 следующими друг за другом синтаксическими единицами, и в короткое предложение с другим количеством следующих друг за другом синтаксических единиц. В данном случае «ABCDEFADEGCABCD» преобразуется в короткое предложение с 4 следующими друг за другом синтаксическими единицами: «ABCD, BCDE, CDEF, DEFA, EFAD, FADE, ADEG, DEGC, EGCA, GCAB, CABC, ABCD». Можно осознать, что группа коротких предложений содержит 12 фраз, и каждая фраза содержит 4 следующие друг за другом синтаксические единицы. Для упрощения понимания в показанном выше выражении данных ЯНР пробелы фактически удалены и показаны только синтаксические единицы. Однако на практике между двумя любыми синтаксическими единицами может быть пробел. На основании показанной выше группы фраз, фактически здесь представлено «АВ (ПРОБЕЛ) CDE FAD EGCABC (ПРОБЕЛ) D». В этом случае группой коротких предложений с 4 следующими друг за другом синтаксическими единицами является группа «АВ (пробел) CD, В (пробел) CDE, CDE (пробел) F, DE (пробел) FA, EFAD, FAD (пробел) Е, AD (пробел) EG, DEGC, EGCA, GCAB, CABC, ABC (пробел) D».
[0055] Согласно некоторым вариантам осуществления, фразы, содержащие идентичные синтаксические единицы, фактически группируются в набор фраз, и набор фраз содержит множество типов фраз. В приведенном выше примере фразы группируются в «АВ (пробел) CD, В (пробел) CDE, CDE (пробел) F, DE (пробел) FA, EFAD, FAD (пробел) Е, AD (пробел) EG, DEGC, EGCA, GCAB, CABC, ABC (пробел) D». Например, короткое предложение, составленное из существенных синтаксических единиц, после удаления пробела в «АВ (пробел) CD» превращается в «ABCD», короткое предложение, составленное из существенных синтаксических единиц, после удаления пробела в «В (пробел) CDE» превращается в «BCDE», и при этом очевидно, что синтаксические единицы не являются в точности теми же самыми. Легко определить, что в приведенной выше группе коротких предложений синтаксические единицы в «АВ (пробел) CD» и в «АВС (пробел) D» являются существенно идентичными. Следовательно, два коротких предложения группируются в набор фраз. Набор фраз содержит два типа фраз: «АВ (пробел) CD» и «АВС (пробел) D».
[0056] Определяется частотность появления множества типов фраз в наборе фраз, и n приоритетных типов фраз выбираются в качестве кандидата для разделения на слова, основанного на снижающемся порядке частотности появления. Например, в наборе фраз, содержащим «АВ (пробел) CD», есть только два типа фраз, и количество каждого из двух типов фраз равно 1. Другими словами, частотности появления «АВ (пробел) CD» и «АВС (пробел) D» идентичны в этом наборе фраз. Согласно другому варианту осуществления, например, в набор фраз входят следующие фразы: «АВ (пробел) CD», «АВС (пробел) D», «АВС (пробел) D», «АВС (пробел) D», «АВ (пробел) CD», «А (пробел) BCD» и «А (пробел) ВС (пробел) D». В этот набор фраз включено всего 7 фраз и в нем 4 типа фраз. Количество фраз «АВ (пробел) CD» равно 2, количество фраз «АВС (пробел) D» равно 3, количество фраз «А (пробел) BCD» равно 1, а количество фраз «А (пробел) ВС (пробел) D» равно 1. Следовательно, частотность появления фразы «АВС (ПРОБЕЛ) D» наивысшая в этом наборе фраз, а именно три фразы из семи, а частотность появления фразы «АВ (пробел) CD» стоит на втором месте, а именно два фразы из семи. При этом n приоритетных фраз выбраны в качестве кандидата для разделения на слова. Величина n может иметь точно такое значение, как т, или может отличаться от него. Величина n является натуральным целым числом. В случае, когда значение n равно 2, как в показанном выше примере, «АВС (пробел) D» и «АВ (пробел) CD» выбираются в качестве кандидата для разделения на слова.
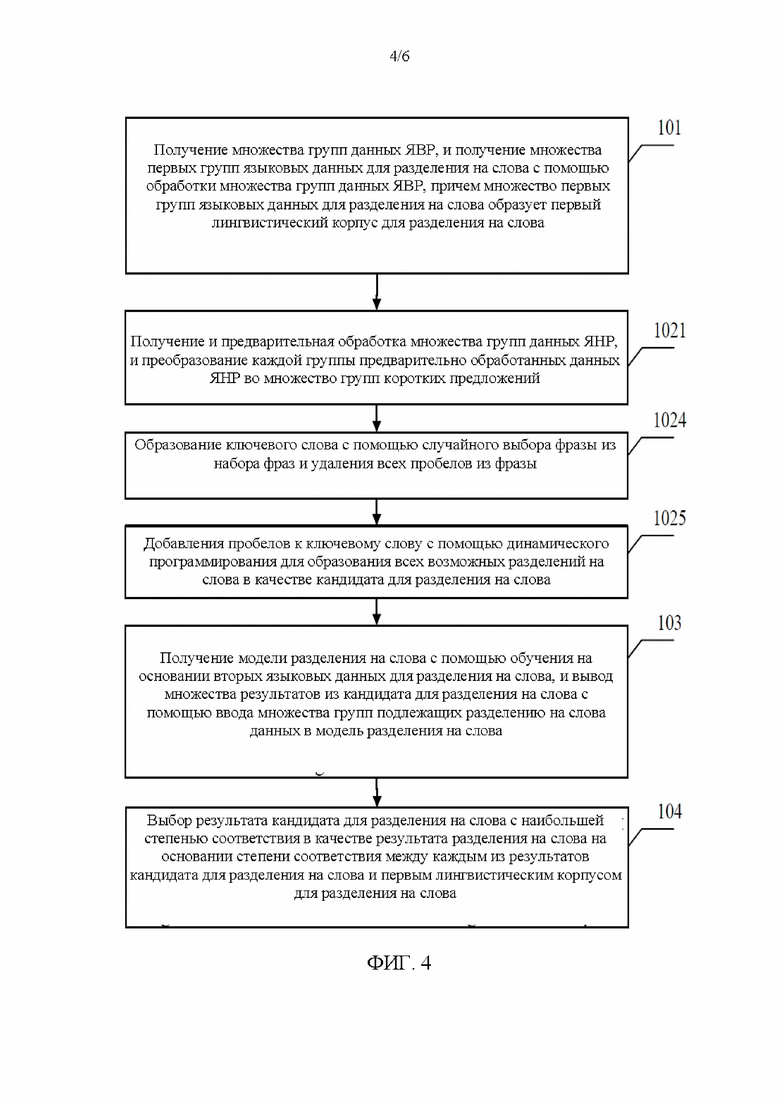
[0057] Принцип обработки данных ЯНР для получения множества кандидатов для разделения на слова по существу точно такой же, как принцип обработки данных ЯВР для получения первых языковых данных для разделения на слова. Согласно другому варианту реализации, стадия 102 также дополнительно оптимизируется. Как показано на фиг. 4, стадии 1022 и 1023 на фиг. 3 заменяются на стадии 1024 и 1025. На стадии 1024 все пробелы в каждой фразе удаляются для образования ключевого слова. На стадии 1025 пробелы добавляются к ключевому слову с помощью динамического программирования для образования всех возможных разделений на слова в качестве кандидата для разделения на слова.
[0058] Этот вариант осуществления является таким же, как вышеописанный вариант осуществления в том, что каждую группу предварительно обработанных данных ЯНР необходимо преобразовать во множество групп коротких предложений, и все пробелы в любой фразе удаляются для образования ключевого слова. Согласно вышеупомянутому варианту осуществления не заявляется, что для образования ключевого слова удаляются пробелы в любой фразе, но эта операция фактически выполняется. Это реализуется с помощью группирования фраз в одну группу коротких предложений, которые по существу образуют ключевое слово с помощью удаления пробелов из фраз, и при этом фразы, соответствующее одинаковому ключевому слову, группируются вместе. Согласно вариантам осуществления, образуется ключевое слово, но фразы не группируются на основании ключевого слова. В случае образования ключевого слова пробелы добавляются к ключевому слову с помощью динамического программирования для образования всех возможных разделений на слова в качестве кандидата для разделения на слова. Динамическое программирование является одним из основных методов программирования и часто используется при программировании. Например, ключевым словом является ABCD, и пробелы динамические добавляются для образования фраз «А (пробел) BCD», «АВ (пробел) CD», «АВС (пробел) D», «ABCD», «А (пробел) В (пробел) CD», «А (пробел) ВС (пробел) D», «АВ (пробел) С (пробел) D» и «А (пробел) В (пробел) С (пробел) D». Все фразы «А (пробел) BCD», «АВ (пробел) CD», «АВС (пробел) D», «ABCD», «А (пробел) В (пробел) CD», «А (пробел) ВС (пробел) D», «АВ (пробел) С (пробел) D» и «А (пробел) В (пробел) С (пробел) D» определяются в качестве кандидата для разделения на слова.
[0059] Согласно некоторым вариантам осуществления, процесс выбора вторых языковых данных для разделения на слова из множества кандидатов для разделения на слова на основании степени соответствия между каждым из кандидатов для разделения на слова и первым лингвистическим корпусом для разделения на слова предусматривает следующие стадии:
[0060] перевод множества кандидатов для разделения на слова во множество кандидатов для разделения на слова языка с высокими ресурсами, соответствующих данным ЯВР с помощью модели перевода; получение частотности появления группы первых языковых данных для разделения на слова, согласующейся с кандидатом для разделения на слова языка с высокими ресурсами в первом лингвистическом корпусе для разделения на слова; определение индекса частотности с помощью вычисления на основании вероятности перевода кандидата для разделения на слова во множество кандидатов для разделения на слова языка с высокими ресурсами и частотности появления группы первых языковых данных для разделения на слова, согласующейся с кандидатом для разделения на слова языка с высокими ресурсами в первом лингвистическом корпусе для разделения на слова; и определение кандидата для разделения на слова языка с высокими ресурсами, соответствующего группе первых языковых данных для разделения на слова с наивысшим индексом частотности, который определяется в качестве второго набора языковых данных для разделения на слова. Существует много способов для вычисления индекса частотности, это никак не ограничивается в настоящем раскрытии. Например, индекс частотности определяется с помощью сложения значений частотности появления и вероятности перевода.
[0061] Согласно вариантам осуществления, применяемая модель перевода является существующей и широко используемой в отрасли моделью, например, это может быть трансформер, рекуррентная нейронная сеть (RNN) кодер-декодер, или механизм внимания (Attention). Согласно вариантам осуществления, ЯНР преобразуются в ЯВР с помощью модели перевода. Модель перевода обычно реализуется в виде программного обеспечения для перевода, и содержится на веб-странице или на интеллектуальном терминале в качестве клиента. Модель перевода часто предоставляет пользователю интерактивный рабочий интерфейс для выполнения наглядного перевода. Например, кандидат для разделения на слова abed необходимо перевести в ABCD на ЯВР. Фразы abed и ABCD часто выражают одинаковое значение, но являются различными выражениями в двух разных языках. Например, «счастливый день рождения» можно перевести в «чжу ни шэн жи гуай лэ» или в «чжу ни шэн жи гай синь» на китайском языке. Результаты перевода по существу имеют то же самое значение, но слова, выражения и тому подобное являются другими. Различные результаты перевода, полученные с помощью модели перевода, соответствуют различным вероятностям перевода. Вероятности перевода и результаты перевода отображаются одновременно.
[0062] Согласно вышеупомянутым стадиям, поскольку получены достаточные данные ЯВР, был сформирован обширный первый лингвистический корпус для разделения на слова. Согласно вариантам осуществления, определяется частотность появления группы первых языковых данных для разделения на слова, которая точно такая же, как у полученного кандидата для разделения на слова языка с высокими ресурсами в первом лингвистическом корпусе для разделения на слова. Например, количество фраз ABCD в первом лингвистическом корпусе для разделения на слова равно 15, количество кандидатов для разделения на слова языка с высокими ресурсами ABCD в ЯВР, в который переведен abed из ЯНР, и которые согласованы с первым лингвистическим корпусом для разделения на слова, равно 15, и совпадающая частотность равна 15. Предположим, что в первом лингвистическом корпусе для разделения на слова имеется М фраз, причем М является натуральным целым числом. В этом случае, частотность появления ABCD равна 15/М. Предположим, что кандидат для разделения на слова языка с высокими ресурсами, в которой был переведен кандидат для разделения на слова, содержит фразы «А (пробел) BCD» и «АВС (пробел) D», 12 и 23 из которых соответственно согласованы с первым лингвистическим корпусом для разделения на слова. Очевидно, что частотность появления «АВС (пробел) D» выше, чем частотность появления «А (пробел) BCD». Следовательно, «А (пробел) BCD» определяется как вторые языковые данные для разделения на слова.
[0063] На стадии 103 проводится обучение на основании вторых языковых данных для разделения на слова для получения модели для разделения на слова, и множество групп подлежащих разделению на слова данных вводится в модель разделения на слова для вывода множества результатов кандидата для разделения на слова.
[0064] Согласно вариантам осуществления настоящего раскрытия, на стадии 103 проводится обучение на основании вторых языковых данных для разделения на слова для получения модели для разделения на слова, и множество групп подлежащих разделению на слова данных вводится в модель разделения на слова для вывода множества результатов кандидата для разделения на слова. Как показано на фиг. 5, стадия 103 предусматривает две подстадии. На стадии 1031 вторые языковые данные для разделения на слова вводятся в качестве обучающих данных в заранее заданную модель условных случайных полей (CRF) для обучения с целью получения модели разделения на слова. На стадии 1032 множество групп подлежащих разделению на слова данных вводится в модель разделения на слова для вывода множества результатов кандидата для разделения на слова.
[0065] Модель CRF является моделью условных случайных полей, в настоящем раскрытии модель CRF используется в качестве основания модели, и обучающие данные вводится в модель CRF для обучения модели. Полученные на предыдущей стадии вторые языковые данные для разделения на слова определяются в качестве обучающих данных. А в случае, когда проводится обучение модели для разделения на слова и вводятся подлежащие разделению на слова данные, множество результатов кандидата для разделения на слова может быть автоматически выведено. Количество результатов кандидата для разделения на слова может быть задано на основании фактической ситуации, например, 5. Конечно, количество может иметь другое значение, это никак не ограничивается в настоящем раскрытии. Следует отметить, что одной из целей настоящего раскрытия является предоставление удобства для регионов ЯНР с помощью ряда способов и ассоциирования ЯНР на основании ЯВР, что упрощает разделение на слова в ЯНР. Следовательно, согласно вариантам осуществления, подлежащие разделению на слова данные часто являются данными ЯНР.
[0066] На стадии 104 результат кандидата для разделения на слова с наибольшей степенью соответствия выбирается в качестве результата разделения на слова на основании степени соответствия между каждым из результатов кандидата для разделения на слова и первым лингвистическим корпусом для разделения на слова.
[0067] Согласно некоторым вариантам осуществления, как показано на фиг. 5, выбор результата кандидата для разделения на слова с наибольшей степенью соответствия в качестве результата разделения на слова на основании степени соответствия между каждым из результатов кандидата для разделения на слова и первым лингвистическим корпусом для разделения на слова предусматривает следующие стадии: на стадии 1041 проводится получение частотности появления групп первых языковых данных для разделения на слова, согласующихся с кандидатом для разделения на слова в первом лингвистическом корпусе для разделения на слова; и на стадии 1042 проводится определение результата кандидата для разделения на слова, соответствующего группе первых языковых данных для разделения на слова с наивысшей частотностью появления, в качестве результата для разделения на слова.
[0068] Окончательный результат для разделения на слова выбирается на основании частотности появления в первом лингвистическом корпусе для разделения на слова, используемой в качестве степени соответствия. Поскольку подлежащие разделению на слова данные могут быть данными ЯНР, соответствующие результаты кандидата для разделения на слова также являются данными ЯНР. В данном случае результаты кандидата для разделения на слова переводятся в ЯВР с помощью модели перевода. Первые языковые данные для разделения на слова, соответствующие переведенным результатам кандидата для разделения на слова в первом лингвистическом корпусе для разделения на слова, согласовываются, и определяются частотности появления. Результат кандидата для разделения на слова, соответствующий первым языковым данным для разделения на слова с наивысшей частотностью появления, определяется в качестве результата для разделения на слова.
[0069] Согласно другой особенности раскрытия, на фиг. 6 показано устройство для разделения на слова на основании межъязыковой аугментации данных согласно некоторым вариантам осуществления настоящего раскрытия. Как показано на фиг. 6, устройство для разделения на слова на основании межъязыковой аугментации данных содержит в своем составе: первый модуль 201 получения, второй модуль 202 получения, модуль 203 кандидата для разделения на слова и модуль 204 определения разделения на слова. Первый модуль 201 получения выполнен с возможностью получить множество групп данных ЯВР, и получить множество групп первых языковых данных для разделения на слова с помощью обработки множества групп данных ЯВР. Множество групп первых языковых данных для разделения на слова образует первый лингвистический корпус для разделения на слова. Второй модуль 202 получения выполнен с возможностью получить множество групп данных ЯНР, получить множество кандидатов для разделения на слова с помощью обработки данных ЯНР, и выбрать вторые языковые данные для разделения на слова из множества кандидатов для разделения на слова на основании степени соответствия между каждым из кандидатов для разделения на слова и первым лингвистическим корпусом для разделения на слова. Модуль 203 кандидата для разделения на слова выполнен с возможностью получить модель разделения на слова с помощью обучения на основании вторых языковых данных для разделения на слова, и вывести множество результатов кандидата для разделения на слова с помощью ввода множества групп подлежащих разделению на слова данных в модель разделения на слова. Модуль 204 определения разделения на слова выполнен с возможностью выбрать результат кандидата для разделения на слова с наибольшей степенью соответствия в качестве результата разделения на слова на основании степени соответствия между каждым из результатов кандидата для разделения на слова и первым лингвистическим корпусом для разделения на слова.
[0070] Согласно некоторым вариантам осуществления, в первом модуле 201 получения процесс получения множества групп первых языковых данных для разделения на слова с помощью обработки множества групп данных ЯВР предусматривает следующие стадии: предварительная обработка множества групп данных ЯВР; преобразование каждой группы предварительно обработанных данных ЯВР во множество групп коротких предложений, причем каждая группа коротких предложений включает в себя множество фраз, каждая из которых имеет то же самое количество синтаксических единиц, группирование фраз, содержащих идентичные синтаксические единицы, в один набор фраз, причем этот набор фраз содержит множество типов фраз; определение частотности появления множества типов фраз в наборе фраз; и выбор m приоритетных типов фраз в качестве первых языковых данных для разделения на слова на основании снижающегося порядка частотности появления.
[0071] Предварительная обработка предусматривает следующие стадии: преобразование знака пунктуации в данных ЯВР на основании первого заранее заданного правила, и преобразование знака эмоций в данных ЯВР в синтаксическую единицу на основании второго заранее заданного правила.
[0072] Выбор m приоритетных типов фраз в качестве первых языковых данных для разделения на слова на основании снижающегося порядка частотности появления предусматривает следующие стадии: выбор m приоритетных типов фраз в качестве кандидата первых языковых данных для разделения на слова на основании снижающегося порядка частотности появления; случайный выбор фразы из набора фраз, и образование ключевого слова с помощью удаления всех пробелов из фразы; вывод предсказанных языковых данных для разделения на слова с помощью ввода ключевого слова в заранее заданную модель разделения на слова; сравнение кандидата первых языковых данных для разделения на слова с предсказанными языковыми данными для разделения на слова, и после обнаружения, что кандидат первых языковых данных для разделения на слова является точно таким же, как предсказанные языковые данные для разделения на слова, определение кандидата первых языковых данных для разделения на слова в качестве первых языковых данных для разделения на слова; или после обнаружения, что кандидат первых языковых данных для разделения на слова является отличающимся от предсказанных языковых данных для разделения на слова, выбор первых языковых данных для разделения на слова из кандидата языковых данных для разделения на слова и предсказанных языковых данных для разделения на слова на основании заранее заданного правила выбора слов.
[0073] Во втором модуле 202 получения процесс получения множества кандидатов для разделения на слова с помощью обработки данных ЯНР предусматривает следующие стадии: предварительная обработка множества групп данных ЯНР; преобразование каждой группы предварительно обработанных данных ЯНР во множество групп коротких предложений, причем каждая группа коротких предложений включает в себя множество фраз, каждая из которых имеет то же самое количество синтаксических единиц; группирование фраз, содержащих идентичные синтаксические единицы, в один набор фраз, причем этот набор фраз содержит множество типов фраз; определение частотности появления множества типов фраз в наборе фраз, и выбор n приоритетных типов фраз в качестве кандидата для разделения на слова на основании снижающегося порядка частотности появления.
[0074] Предварительная обработка предусматривает следующие стадии: преобразование знака пунктуации в данных ЯНР на основании первого заранее заданного правила, и преобразование знака эмоций в данных ЯНР в синтаксическую единицу на основании второго заранее заданного правила.
[0075] Во втором модуле 202 получения процесс получения множества кандидатов для разделения на слова с помощью обработки данных ЯНР может предусматривать следующие стадии: предварительная обработка множества групп данных ЯНР; преобразование каждой группы предварительно обработанных данных ЯНР во множество групп коротких предложений, причем каждая группа коротких предложений включает в себя множество фраз, каждая из которых имеет то же самое количество синтаксических единиц; образование ключевого слова с помощью удаления всех пробелов из каждой фразы; и образование всех возможных разделений на слова в качестве кандидата для разделения на слова с помощью добавления пробелов в ключевое слово с помощью динамического программирования.
[0076] Выбор вторых языковых данных для разделения на слова из множества кандидатов для разделения на слова на основании степени соответствия между каждым из кандидатов для разделения на слова и первым лингвистическим корпусом для разделения на слова предусматривает следующие стадии: перевод множества кандидатов для разделения на слова во множество кандидатов для разделения на слова языка с высокими ресурсами, соответствующих данным ЯВР с помощью модели перевода; получение частотности появления группы первых языковых данных для разделения на слова, согласующейся с кандидатом для разделения на слова языка с высокими ресурсами в первом лингвистическом корпусе для разделения на слова; и определение кандидата для разделения на слова языка с высокими ресурсами, соответствующего группе первых языковых данных для разделения на слова с наивысшим индексом частотности в качестве второго набора языковых данных для разделения на слова.
[0077] Согласно некоторым вариантам осуществления, получение модели разделения на слова с помощью обучения на основании ввода вторых языковых данных для разделения на слова в качестве обучающих данных в заранее заданную модель CRF для обучения с целью получения модели разделения на слова. Выбор результата кандидата для разделения на слова с наибольшей степенью соответствия в качестве результата разделения на слова на основании степени соответствия между каждым из результатов кандидата для разделения на слова и первым лингвистическим корпусом для разделения на слова предусматривает следующие стадии: получение частотности появления групп первых языковых данных для разделения на слова, согласующихся с кандидатом для разделения на слова в первом лингвистическом корпусе для разделения на слова; и определение результата кандидата для разделения на слова, соответствующего группе первых языковых данных для разделения на слова с наивысшей частотностью появления, в качестве результата для разделения на слова.
[0078] Как показано на фиг. 7, согласно вариантам осуществления настоящего раскрытия, дополнительно предложено вычислительное устройство для разделения на слова, основанное на межъязыковой аугментации данных, включающее в себя память 301 и один или несколько процессоров 302. Память 301 выполнена с возможностью хранить одну или несколько программ. Один или несколько процессоров 302 после загрузки и выполнения одной или нескольких программ заставлены выполнять описанный в настоящем раскрытии способ для разделения на слова с помощью межъязыковой аугментации.
[0079] Согласно вариантам осуществления настоящего раскрытия, дополнительно предложен носитель данных, на котором содержатся выполняемые компьютером команды. Выполняемые компьютером команды после их загрузки и выполнения процессором компьютера заставляют процессор компьютера выполнять предложенный в вышеупомянутых вариантах осуществления способ для разделения на слова с помощью межъязыковой аугментации данных.
[0080] Конечно, что касается носителя данных, в котором хранятся выполняемые компьютером команды, предложенные согласно вариантам осуществления настоящего раскрытия, хранящиеся в носителе данных выполняемые компьютером команды не ограничены выполнением вышеупомянутого способа для разделения на слова с помощью межъязыковой аугментации данных, и могут дополнительно выполнять операции, относящиеся к предложенному согласно любому варианту осуществления настоящего раскрытия способу для разделения на слова с помощью межъязыковой аугментации данных.
[0081] Согласно вариантам осуществления настоящего раскрытия, дополнительно предложена программа для разделения на слова, основанная на межъязыковой аугментации данных. Когда эта программа загружена и выполняется, при этом выполняются операции, относящиеся к предложенному в вышеупомянутых вариантах осуществления способу для разделения на слова с помощью межъязыковой аугментации данных.
[0082] Вышеупомянутые варианты осуществления просто являются предпочтительными вариантами осуществления настоящего раскрытия и используемого технического принципа. Настоящее раскрытие не ограничено описанными в настоящем документе конкретными вариантами осуществления, и различные очевидные изменения, корректировки и замены могут быть выполнены специалистами в этой области техники, и они не выходят за пределы объема правовой охраны настоящего раскрытия. Следовательно, хотя настоящее раскрытие было подробно описано с использованием вышеупомянутых вариантов осуществления, настоящее раскрытие не ограничено вышеупомянутыми вариантами осуществления, и может также включать большое количество других эквивалентных вариантов осуществления, не выходя за пределы основного замысла настоящего раскрытия, и объем настоящего раскрытия определяется объемом приложенной формулы изобретения.
Изобретение относится к области автоматической обработки текста на естественном языке. Технический результат заключается в повышении точности разделения на слова текста на языке с низкими ресурсами. Технический результат достигается за счет того, что из множества групп данных языка с высокими ресурсами образуют первый лингвистический корпус; из множества групп данных языка с низкими ресурсами получают множество кандидатов для разделения на слова; выбирают вторые языковые данные для разделения на слова из множества кандидатов для разделения на слова на основании степени соответствия между каждым из кандидатов для разделения на слова и первым лингвистическим корпусом; обучают модель разделения на слова на основании вторых языковых данных для разделения на слова; вводят множество групп данных, подлежащих разделению на слова, в модель разделения на слова; и получают результат на основании степени соответствия между каждым из результатов кандидата для разделения на слова и первым лингвистическим корпусом для разделения на слова. 4 н. и 8 з.п. ф-лы, 7 ил.
1. Способ для разделения на слова, основанный на межъязыковой аугментации данных, выполняемой на сервере, предусматривает следующие стадии:
получение множества групп данных языка с высокими ресурсами (ЯВР), и получение множества групп первых языковых данных для разделения на слова с помощью обработки множества групп данных ЯВР, причем множество групп первых языковых данных для разделения на слова первого языка образует первый лингвистический корпус для разделения на слова;
получение множества групп данных языка с низкими ресурсами (ЯНР), получение множества кандидатов для разделения на слова с помощью обработки множества групп данных ЯНР, и выбор вторых языковых данных для разделения на слова из множества кандидатов для разделения на слова на основании степени соответствия между каждым из кандидатов для разделения на слова и первым лингвистическим корпусом для разделения на слова;
получение модели разделения на слова с помощью обучения на основании вторых языковых данных для разделения на слова, и вывод множества результатов кандидата для разделения на слова с помощью ввода множества групп подлежащих разделению на слова данных в модель разделения на слова; и
выбор результата кандидата для разделения на слова с наибольшей степенью соответствия в качестве результата разделения на слова на основании степени соответствия между каждым из результатов кандидата для разделения на слова и первым лингвистическим корпусом для разделения на слова.
2. Способ по п. 1, отличающийся тем, что получение множества групп первых языковых данных для разделения на слова с помощью обработки множества групп данных ЯВР предусматривает следующие стадии:
предварительная обработка множества групп данных ЯВР;
преобразование каждой группы предварительно обработанных данных ЯВР во множество групп коротких предложений, причем каждая группа коротких предложений включает в себя множество фраз, каждая из которых имеет то же самое количество синтаксических единиц;
группирование фраз, содержащих идентичные синтаксические единицы, в один набор фраз, причем набор фраз содержит множество типов фраз; и
определение частотности появления множества типов фраз в наборе фраз, и выбор m приоритетных типов фраз в качестве первых языковых данных для разделения на слова на основании снижающегося порядка частотности появления.
3. Способ по п. 2, отличающийся тем, что предварительная обработка групп данных ЯВР предусматривает следующие стадии: преобразование знаков пунктуации в данных ЯВР согласно первому заранее заданному правилу и/или преобразование знаков эмоций в данных ЯВР в синтаксические единицы согласно второму заранее заданному правилу.
4. Способ по п. 2, отличающийся тем, что выбор m приоритетных типов фраз в качестве первых языковых данных для разделения на слова на основании снижающегося порядка частотности появления предусматривает следующие стадии:
выбор m приоритетных типов фраз в качестве первых языковых данных для разделения на слова в снижающемся порядке частотности появления;
случайный выбор фразы из набора фраз, и образование ключевого слова с помощью удаления всех пробелов из фразы;
вывод предсказанных языковых данных для разделения на слова с помощью ввода ключевого слова в заранее заданную модель разделения на слова; и
сравнение кандидата первых языковых данных для разделения на слова с предсказанными языковыми данными для разделения на слова, и после обнаружения, что кандидат первых языковых данных для разделения на слова является точно таким же, как предсказанные языковые данные для разделения на слова, определение кандидата первых языковых данных для разделения на слова в качестве первых языковых данных для разделения на слова; или после обнаружения, что кандидат первых языковых данных для разделения на слова является отличающимся от предсказанных языковых данных для разделения на слова, коррекция кандидата первых языковых данных для разделения на слова, и определение скорректированного кандидата первых языковых данных для разделения на слова в качестве первых языковых данных для разделения на слова.
5. Способ по любому из пп. 1-4, отличающийся тем, что получение множества кандидатов для разделения на слова с помощью обработки данных ЯНР предусматривает следующие стадии:
предварительная обработка множества групп данных ЯНР;
преобразование каждой группы предварительно обработанных данных ЯНР во множество групп коротких предложений, причем каждая группа коротких предложений включает в себя множество фраз, каждая из которых имеет то же самое количество синтаксических единиц;
группирование фраз, содержащих идентичные синтаксические единицы, в один набор фраз, причем набор фраз содержит множество типов фраз; и
определение частотности появления множества типов фраз в наборе фраз, и выбор n приоритетных типов фраз в качестве кандидата для разделения на слова на основании снижающегося порядка частотности появления.
6. Способ по любому из пп. 1-4, отличающийся тем, что получение множества кандидатов для разделения на слова с помощью обработки данных ЯНР предусматривает следующие стадии:
предварительная обработка множества групп данных ЯНР;
преобразование каждой группы предварительно обработанных данных ЯНР во множество групп коротких предложений, причем каждая группа коротких предложений включает в себя множество фраз, каждая из которых имеет то же самое количество синтаксических единиц;
образование ключевого слова с помощью удаления всех пробелов из фразы; и
образование всех возможных разделений на слова в качестве кандидата для разделения на слова с помощью добавления пробелов к ключевому слову с помощью динамического программирования.
7. Способ по п. 5 или 6, отличающийся тем, что процесс выбора вторых языковых данных для разделения на слова из множества кандидатов для разделения на слова на основании степени соответствия между каждым из кандидатов для разделения на слова и первым лингвистическим корпусом для разделения на слова предусматривает следующие стадии:
перевод множества кандидатов для разделения на слова во множество кандидатов для разделения на слова языка с высокими ресурсами, соответствующих данным ЯВР с помощью модели перевода, причем каждый кандидат для разделения на слова языка с высокими ресурсами соответствует вероятности перевода, назначенной с помощью модели перевода;
получение частотности появления группы первых языковых данных для разделения на слова, согласующейся с кандидатом для разделения на слова языка с высокими ресурсами в первом лингвистическом корпусе для разделения на слова;
вычисление индекса частотности на основании вероятности перевода кандидата для разделения на слова языка с высокими ресурсами и частотности появления группы первых языковых данных для разделения на слова, согласующейся с кандидатом для разделения на слова языка с высокими ресурсами в первом лингвистическом корпусе для разделения на слова; и
определение кандидата для разделения на слова языка с высокими ресурсами, соответствующего группе первых языковых данных для разделения на слова с наивысшим индексом частотности в качестве второго набора языковых данных для разделения на слова.
8. Способ по любому из пп. 1-7, отличающийся тем, что получение модели разделения на слова с помощью обучения на основании вторых языковых данных для разделения на слова предусматривает следующую стадию:
получение модели разделения на слова с помощью ввода вторых языковых данных для разделения на слова в качестве обучающих данных в заранее заданную модель условных случайных полей (CRF) для обучения.
9. Способ по любому из пп. 1-8, отличающийся тем, что выбор результата кандидата для разделения на слова с наибольшей степенью соответствия в качестве результата разделения на слова на основании степени соответствия между каждым из результатов кандидата для разделения на слова и первым лингвистическим корпусом для разделения на слова предусматривает следующие стадии:
получение частотности появления групп первых языковых данных для разделения на слова, согласующихся с результатами кандидата для разделения на слова в первом лингвистическом корпусе для разделения на слова; и
определение результата кандидата для разделения на слова, соответствующего группе первых языковых данных для разделения на слова с наивысшей частотностью появления, в качестве результата для разделения на слова.
10. Устройство для разделения на слова, основанное на межъязыковой аугментации данных, включающее в себя:
первый модуль получения, выполненный с возможностью получить множество групп данных языка с высокими ресурсами (ЯВР), и получить множество групп первых языковых данных для разделения на слова с помощью обработки множества групп данных ЯВР, причем множество групп первых языковых данных для разделения на слова образует первый лингвистический корпус для разделения на слова;
второй модуль получения, выполненный с возможностью получить множество групп данных языка с низкими ресурсами (ЯНР), получить множество кандидатов для разделения на слова с помощью обработки данных ЯНР, и выбрать вторые языковые данные для разделения на слова из множества кандидатов для разделения на слова на основании степени соответствия между каждым из кандидатов для разделения на слова и первым лингвистическим корпусом для разделения на слова;
модуль кандидата для разделения на слова, выполненный с возможностью получить модель разделения на слова с помощью обучения на основании вторых языковых данных для разделения на слова, и вывести множество результатов из кандидата для разделения на слова с помощью ввода множества групп подлежащих разделению на слова данных в модель разделения на слова; и
модуль определения разделения на слова, выполненный с возможностью выбрать результат кандидата для разделения на слова с наибольшей степенью соответствия в качестве результата разделения на слова на основании степени соответствия между каждым из результатов кандидата для разделения на слова и первым лингвистическим корпусом для разделения на слова.
11. Вычислительное устройство для разделения на слова, основанное на межъязыковой аугментации данных, включающее в себя память и один или несколько процессоров; причем
память выполнена с возможностью хранить одну или несколько программ; и
один или несколько процессоров после загрузки и выполнения одной или нескольких программ заставлены выполнять способ для разделения на слова, основанный на межъязыковой аугментации данных, как определено в любом из пп. 1-9.
12. Носитель данных, на котором хранится одна или несколько выполняемых компьютером команд, причем одна или несколько выполняемых компьютером команд после их загрузки и выполнения процессором компьютера заставляют процессор компьютера выполнять способ для разделения на слова с помощью межъязыковой аугментации данных, как определено в любом из пп. 1-9.
| CN 111090727 A, 01.05.2020 | |||
| Токарный резец | 1924 |
|
SU2016A1 |
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| Автоматическое извлечение именованных сущностей из текста | 2014 |
|
RU2665239C2 |
| СИСТЕМА И МЕТОДИКА АВТОМАТИЧЕСКОГО ОБУЧЕНИЯ ЯЗЫКАМ НА ОСНОВЕ ЧАСТОТНОСТИ СИНТАКСИЧЕСКИХ МОДЕЛЕЙ | 2015 |
|
RU2632656C2 |

