Область техники
Изобретение относится к области информационных технологий, а более конкретно к системам и способам использования больших языковых моделей при мониторинге безопасности и реагировании на инциденты.
Уровень техники
В настоящий момент всё больше компаний используют центры мониторинга информационной безопасности (англ. Security Operations Center, SOC), что связано с растущим количеством информационных угроз, усложнением инфраструктуры компании, а также требованиями со стороны властей и регуляторов по защите данных пользователей от кражи или незаконного использования. В последние годы также вырос и средний размер ущерба от инцидента информационной безопасности (далее - инцидент), связанного с проникновением в инфраструктуру компании, который превысил 5 млн. долларов на 2022 год (Cost of a Data Breach 2022 Report (IBM)).
Специалисты SOC обрабатывают данные (так называемые артефакты, т.е. связанные с инцидентом документы и иные файлы), собранную с рабочих мест сотрудников, сетевых устройств и других объектов компьютерной инфраструктуры, чтобы как можно раньше обнаружить и остановить развитие возможного инцидента в атаку. Для мониторинга и сбора данных специалисты могут использовать SIEM (Security information and event management) решения и EDR (Endpoint detection and response) продукты, например Kaspersky Unified Monitoring and Analysis Platform, а также сетевые экраны и системы обнаружения вторжений (англ. Intrusion Prevention System, IPS), системы обнаружения аномального поведения пользователей (англ. User and Entity Behavior Analytics, UEBA).
Получив данные, которые могут указывать на возможный инцидент, специалисты SOC определяют, есть ли угроза, и если есть - каковы ее параметры, такие как тип (например, нежелательный контент, несанкционированный доступ, утечка информации) или источник (например, на каком компьютере была обнаружена шпионская программа). При обнаружении возможного инцидента принимаются меры по его устранению и минимизации ущерба.
Несмотря на то, что множество функций различных SIEM-решений автоматизировано, для корректного определения инцидента всё равно используется экспертиза специалиста в области компьютерной безопасности, что может приводить к пропуску возможных инцидентов, так как человек не всегда может иметь доступ к актуальной информации относительно самых последних инцидентов и связанных с ними артефактов. Увеличение количества источников информации, связанных с инцидентами, также не всегда помогает в решении проблемы, потому что требуется время на их добавление в SOC. Кроме того, самим специалистам может не всегда хватать времени и экспертизы для выделения и обработки важных артефактов, так как самих артефактов могут быть тысячи. Данная проблема особенно актуальна в случае APT-атаки (англ. Advanced Persistent Threat), когда паттерны инцидента могут быть неизвестны как специалистам SOC, так и SIEM-решениям.
Существуют различные автоматические системы для обработки информации по компьютерным инцидентам. Например, предлагаемая в патенте US8776241 технология служит для расследования инцидентов информационной безопасности. Ядро данной системы позволяет определять причины возникновения инцидента и применять соответствующие меры для исправления последствий и предотвращения появления данного инцидента в корпоративной сети. Эффективность данной системы также достигается благодаря возможности интерпретировать системные события и записи системных журналов в доступную и удобную форму. Система позволяет строить связи системных событий и хранить только необходимую информацию для определения лиц, виновных в нарушении политики безопасности, и выявления уязвимостей в инфраструктуре корпоративной сети, из-за которых инцидент безопасности мог произойти. Ключевой особенностью технологии является построение цепочек событий. Описание патента содержит несколько примеров построения данных цепочек. Среди них отслеживание событий в хронологическом порядке, когда события, зафиксированные в корпоративной сети, сортируются по времени и анализируются в заданном порядке. Другой способ составления цепочек основан на связях компьютеров и системных событий. Два компьютера считаются связанными, в том случае если на них зафиксированы события с одним объектом компьютерной системы, например с файлом или ссылкой.
Однако указанная система не может решить описанную выше проблему, связанную с недостатком времени и экспертизы со стороны как специалистов, так и информационных систем. Исследователи угроз часто публикуют результаты своих расследований (тактики, методы и процедуры злоумышленников) в Интернете в виде отчетов, презентаций, статей в блогах, твитов и другого контента. Проходит достаточно много времени, прежде чем эти знания систематизируются и применяются в рамках SOC-команд и SIEM-решений.
Таким образом, известные технологии имеют недостатки, препятствующие полноценному решению заявленной технической проблемы, поэтому возникает необходимость в заявленном изобретении.
Раскрытие сущности изобретения
Технический результат заключается в уменьшении времени сбора и повышении уровня обработки информации (артефактов) во время проведения расследования инцидента информационной безопасности.
В варианте реализации используется способ автоматического составления запросов и ответов к большой языковой модели по вопросам, связанным с компьютерной безопасностью, включающий этапы, на которых: получают входные данные от элементов центра мониторинга информационной безопасности; выделяют одну или несколько фраз из входных данных; составляют текстовый запрос из выделенных фраз; отправляют текстовый запрос к большой языковой модели; получают ответ от большой языковой модели; выделяют ключевые фразы из ответа от большой языковой модели.
В еще одном варианте реализации составляют текстовый запрос к большой языковой модели на естественном языке.
В другом варианте реализации выделяют ключевые фразы из ответа от большой языковой модели с использованием библиотек обработки естественного языка.
В еще одном варианте реализации выделяют ключевые фразы из ответа от большой языковой модели с использованием набора регулярных выражений.
В другом варианте реализации входные данные от элементов центра мониторинга информационной безопасности имеют формат JSON.
В еще одном варианте реализации входные данные от элементов центра мониторинга информационной безопасности имеют формат XML.
Краткое описание чертежей
Дополнительные цели, признаки и преимущества настоящего изобретения будут очевидными из прочтения последующего описания осуществления изобретения со ссылкой на прилагаемые чертежи, на которых:
На Фиг. 1 представлена схема работы настоящего изобретения.
Фиг. 2 отображает способ работы настоящего изобретения.
Фиг. 3 представляет пример компьютерной системы, с помощью которой может быть реализовано настоящее изобретение.
Осуществление изобретения
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Приведенное описание предназначено для помощи специалисту в области техники для исчерпывающего понимания изобретения, которое определяется только в объеме приложенной формулы.
Глоссарий
Центр мониторинга информационной безопасности (англ. Security Operations Center, SOC) - структурное подразделение организации, отвечающее за оперативный мониторинг IT-среды и предотвращение инцидентов информационной безопасности (далее - инцидентов). Специалисты SOC собирают и анализируют данные с различных объектов инфраструктуры организации и при обнаружении подозрительной активности принимают меры для предотвращения атаки. Для мониторинга и сбора данных используются такие элементы, как: SIEM-решения, EDR-продукты, NDR и аналогичные им (далее - элементы SOC). Кроме того, в рамках SOC используются также сервисы типа Threat Intelligence Platform https://encyclopedia.kaspersky.ru/glossary/threat-intelligence/.
SIEM (Security Information and Event Management) - класс программных продуктов, предназначенных для сбора и анализа информации о событиях безопасности. В задачи систем SIEM входит:
отслеживать в режиме реального времени сигналы тревоги, поступающие от сетевых устройств и приложений;
обрабатывать полученные данные и находить взаимосвязи между ними;
выявлять отклонения от нормального поведения контролируемых систем;
оповещать специалистов SOC об обнаруженных инцидентах.
EDR (Endpoint Detection & Response) - класс решений для обнаружения и изучения вредоносной активности на конечных точках: подключенных к сети рабочих станциях, серверах, устройствах Интернета вещей (англ. Internet of Things, IoT) и так далее.
Специалист SOC (ИБ-специалист, специалист информационной безопасности) - сотрудник, ответственный за сбор и анализ данных, связанных с инцидентами. Как правило, ИБ-специалисты работают в рамках SOC с продуктами уровня SIEM, EDR и иных средств сбора данных и отслеживания инцидентов.
Индикатор компрометации (англ. Indicator of Compromise, IoC) - в сфере компьютерной безопасности наблюдаемый в сети или на конкретном устройстве объект или активность, который с большой долей вероятности указывает на несанкционированный доступ к системе, что указывает и на компрометацию объекта или активности.
В качестве индикатора компрометации, например, выступают:
Необычные DNS-запросы.
Подозрительные файлы, приложения и процессы.
IP-адреса и домены, принадлежащие ботнетам или командным серверам вредоносного ПО.
Значительное количество обращений к учетной записи (попытка перебора паролей).
Подозрительная активность в учетных записях администраторов или привилегированных пользователей.
Неожиданное обновление ПО.
Установка неразрешенного (нелегитимного) ПО.
Передача данных через редко используемые порты.
Нетипичное для человека поведение на веб-сайте.
Сигнатура или хеш-сумма вредоносной программы.
Необычный размер HTML-ответов.
Несанкционированное изменение конфигурационных файлов, реестров или настроек устройства.
Большое количество неудачных попыток входа в систему.
Большая языковая модель (англ. LLM, large language model) - это языковая модель, состоящая из нейронной сети со множеством параметров (обычно миллиарды весовых коэффициентов и более), обученной на большом количестве текстов.
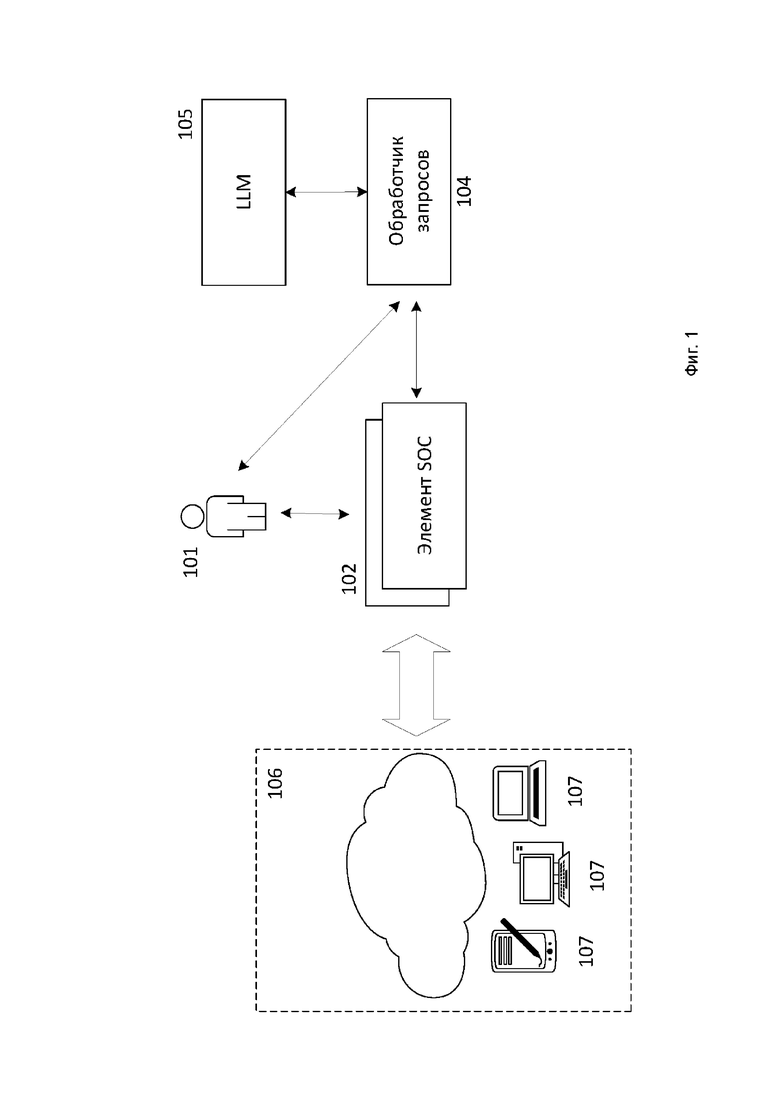
На Фиг. 1 представлена схема работы настоящего изобретения. ИБ-специалисты 101, элементы SOC 102 взаимодействуют с обученной большой языковой моделью (далее - LLM) 105 через обработчик запросов 104. Элементами SOC 102 являются SIEM-решения, EDR-продукты и аналогичные им. В одном из вариантов реализации ИБ-специалист 101 взаимодействует с LLM 105 через веб-интерфейс обработчика 104. Элементы SOC 102 собирают данные с конечных точек 107 инфраструктуры предприятия 106 для сбора и анализа информации о событиях безопасности. Примером конечных точек 107 являются компьютеры (хосты) и такие устройства как смартфоны, роутеры, IoT-устройства. В предпочтительном варианте реализации на конечных точках 107 установлены EDR-решения.
Инфраструктура предприятия 106 может также содержать и другие устройства, не отмеченные на Фиг. 1, а именно системы СКУД (системы контроля и управления доступом, англ. access control), SCADA (Supervisory Control And Data Acquisition, диспетчерское управление и сбор данных), блоки PLC (Programmable Logic Controller, программируемый контроллер) и другие программно-аппаратные системы современного предприятия.
В одном из вариантов реализации LLM 105 осуществляет работу на основании запросов на естественном языке. В этом случае обработчик 104 выполняет функции перевода запросов ввода-вывода от элементов SOC в необходимый для LLM формат ввода и наоборот (например, JSON/XML).
В еще одном из вариантов реализации LLM 105 дополнительно обучена на текстах, взятых из различных блогов, статей и публикаций, связанных с инцидентами информационной безопасности (например, DFIR Report) и исследованиями угроз (например, securelist.com).
Обработчик 104 также используется для хранения контекста, который используется при взаимодействии с LLM 105 в виде запросов-ответов для того, чтобы эффективность взаимодействия с LLM 105 была максимальной. Контекст включает все ранее сделанные запросы к LLM 105, а также полученные ответы.
В одном из вариантов реализации обработчик 104 реализован с использованием библиотек обработки естественного языка, такими как SpaCy, NTLK и другими. В еще одном варианте реализации обработчик 104 использует набор регулярных выражений для выделений элементов текста из полученных ответов от LLM 105. В качестве элемента текста используется токен (англ. token), N-грамма или лексема.
ИБ-специалисты 101 и элементы SOC 102 передают в обработчик 104 собранные с одного или нескольких устройств 107 данные о:
модулях, сконфигурированных для автоматического выполнения (автозапуск, англ. autorun);
запущенных процессах и их командных строках;
событиях из журналов операционной системы (далее - ОС): установки служб, запуски процессов, выполнения скриптов PowerShell и т.д.;
событиях из журналов приложений (антивируса, браузера или средства удаленного управления системой);
метаинформации по файлам (как процессам, там и файлам системы): имя, путь, хеш, метаинформацию из манифеста (оригинальное имя, описание, имя разработчика), информацию по цифровой подписи, строки из файла, отладочную информацию, имена секций, диззасемблированный/декомпилированный код точек входа в исполняемый файл (или экспортируемом DLL библиотекой функций), часть текстового-файла скрипта;
информации по исполнению файла (например, в эмуляторе или в виртуальной машине), которая включает журнал вызовов системных API-функций и их аргументы, а также дополнительную информацию, например, дескрипторы открытых файлов.
LLM 105 не может корректно принимать на вход подобные данные, поэтому обработчик 104 преобразует эти данные в запросы такого вида:
Является ли следующее имя службы Windows ‘$ServiceName’ со следующей строкой запуска ‘$Servicecmd’ индикатором компрометации?
Является какая-нибудь из следующих служб Windows c соответствующими командными строками индикатором компрометации?
[
{
“ServiceName”: “ServiceName1”,
“Servicecmd”: “Servicecmd1”
},
{
“ServiceName”: “ServiceName2”,
“Servicecmd”: “Servicecmd2”
},
]
Ответ от LLM 105 включает текстовое описание, которое может быть легко интерпретировано со стороны ИБ-специалиста 101. Пример ответа:
“Да, указанная комбинация запущенного процесса и командной строки может быть индикатором компрометации”.
Также LLM 105 предоставляет информацию к ответу, такую как, например:
“Метаданные были индикаторами компрометации, например, так: «командная строка пытается загрузить файл с внешнего сервера» или «она использует флаг -ep bypass, который приказывает PowerShell обойти стандартные проверки безопасности»”.
Обработчик 104 интерпретирует ответ от LLM 105, выделяя ключевые фразы. Примером такой фразы является ответ, включающий слова “да”, “yes”, который дают утвердительный ответ на изначальные запросы. Кроме того, для упрощения интерпретации ответа от LLM 105, обработчик 104 вставляет дополнительно следующий текст к запросу:
Твой ответ должен быть json объектом со следующей структурой:
{short_answer:”yes/no”,
long_answer_with description:full_text,
other_data_required_to_investigate_incident:full_text
}
При обнаружении подобных ключевых фраз обработчик 104:
передает сигнал тревоги (alert) в элементы SOC 102, а также ИБ-специалисту 101;
отправляет запрос на сбор дополнительных данных с одного из устройств 107, на которых были собраны первоначальные данные для запроса;
запускает (послужит триггером) для мер по реагированию (например, блокирует один или несколько хостов 107).
Таким образом, обработчик 104 работает с LLM 105 по шаблону “вопрос-ответ”, где в рамках запросов к LLM 105 использует ключевые фразы для составления вопросов, а при анализе ответов от LLM 105 опирается на поиск ключевых фраз для поиска утвердительного ответа на изначальный вопрос или определение необходимости дополнительных вопросов.
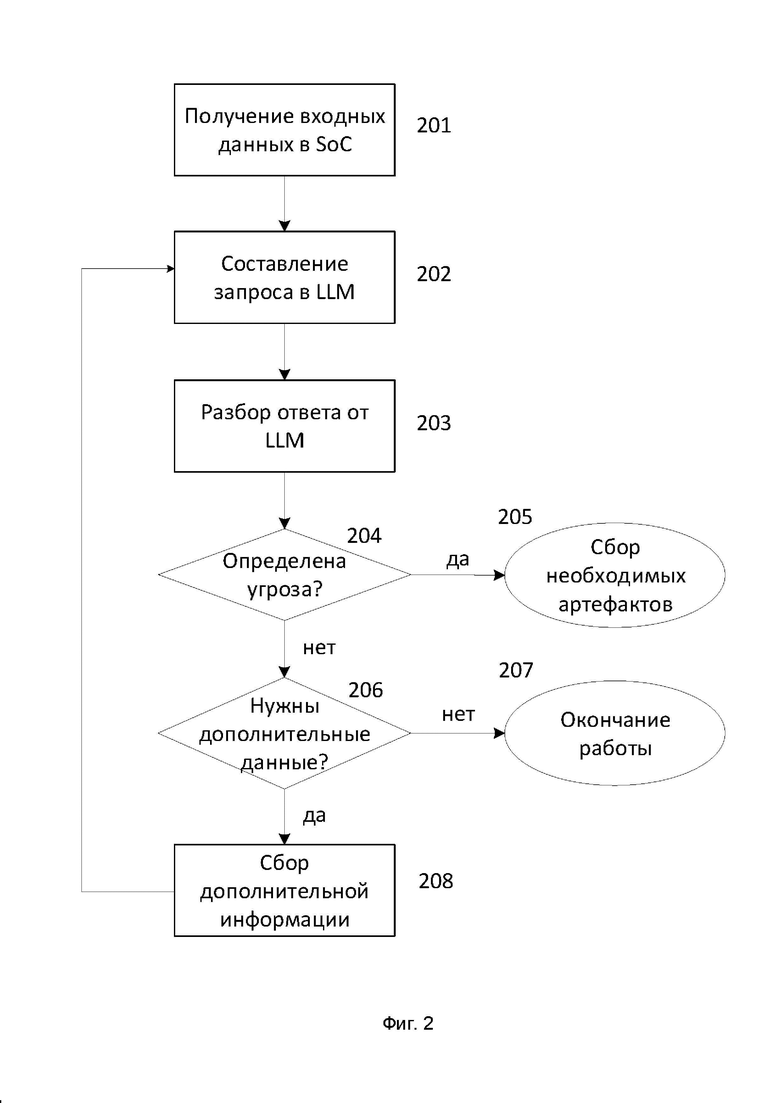
Фиг. 2 отображает способ работы настоящего изобретения.
На этапе 201 происходит получение входных данных в центр мониторинга информационной безопасности (SOC). Как правило, элементы SOC 102 собирают входные данные (примеры собираемых данных описаны выше) с конечных точек 107 инфраструктуры предприятия 106.
На этапе 202 происходит формирование запроса в LLM 105. Так как запросы к LLM 105 формируются на естественном языке, то обработчик 104 добавляет следующие ключевые фразы к входным данным:
“Is the combination of: ” - задается перечисление необходимых данных,
“is an indicator of compromise”, “is a threat”, “is an attack”, “is a cyber attack”, “is malicious action/file” - вопрос по угрозе,
“think it step by step” - требование дать ответ с разбивкой по шагам,
“is presence file on disk” - запрос по определенному файлу.
Указанные фразы хранятся как в самом обработчике 104 (например, в виде списка), так и в отдельной базе данных (не отображена на Фиг. 1).
Запросы, например, могут иметь вид:
Is the combination of process “C:\Users\User01\AppData\Local\Temp\dOlnolh.exe” and command line “ -EgUxRCdQ” is an indicator of compromise?
Согласно представленному запросу входными данными являются:
Данные о процессе и командной строке его запуска были получены от EDR, установленного на одном из хостов 107. Обработчик 104 перечисляет указанные объекты в запросе и добавляет указанные выше ключевые фразы для формирования запроса на естественном языке.
На этапе 203 обработчик 104 получает ответ от LLM 105 и анализирует его. Так как LLM 105 выдает ответ в виде текста на естественном языке, то обработчик 104 использует подключенные библиотеки обработки естественного языка, такие как SpaCy или NTLK, для выделения нужных терминов и фраз. Анализ включает выделение заранее известных фраз или элементов текста. В качестве элемента текста используется токен (англ. token), N-грамма или лексема. В одном из вариантов реализации выделение известных фраз реализуется с помощью регулярных выражений.
На этапе 204 определяют, была ли выделена угроза по результатам ответа от LLM 105. Критерием выделения угрозы является наличие в ответе определенных фраз. Один из вариантов реализации основан на поиске в ответе слов «yes», «да» и других утвердительных вариантов ответа. Другие ключевые фразы: «This could be an indicator of compromise» (это может быть индикатором компрометации), «This is suspicious behaviour» (подозрительное поведение). Если угроза выделена, то на этапе 205 происходит сбор необходимых артефактов с помощью элементов SOC 102 и дальнейший разбор инцидента / угрозы в рамках SOC с привлечением специалистов 101.
Если определенные фразы на этапе 204 не были определены, то переходят к этапу 206.
На этапе 206 определяют, нужны ли еще данные для LLM 105. Ключевыми фразами в таком случае являются: «should be further investigated» (продолжить исследование), «additional data required» (необходимы дополнительные данные), «necessary to analyze further» (необходимо провести дополнительный анализ) и другие аналогичные фразы. Указанные фразы хранятся как в самом обработчике 104 (например, в виде списка), так и в отдельной базе данных (не отображена на Фиг. 1). Дополнительно анализируется, какого типа информация требуется в зависимости от наличия следующих слов:
Endpoint, host, local - означает необходимость сбора информации с хостов 107.
Registry - требуется информация из реестра.
File - требуется информация о файловой активности.
Network - необходима информация о сетевой активности.
Process - требуется информация о процессах.
Autorun - требуется дополнительная информация о ключах автозапуска.
PowerShell - дополнительно требуется анализ скриптов PowerShell.
Кроме того, анализируется контекст, связанный с данными словами. Например, для слова «process» может быть определено уточнение «running process», что означает только запущенные процессы.
В том случае, если обработчик 104 не смог выделить, какие дополнительные данные могут быть необходимы, то работа способа завершается на этапе 207.
После определения необходимой дополнительной информации переходят к этапу 208.
На этапе 208 собирают на одном из элементов SOC 102 дополнительную информацию. Например, для сбора информации с одного из хостов 107 используется EDR-решение. Затем работа способа повторяется с этапа 202 уже с новыми собранными данными, пока способ не закончит свою работу либо на этапе 205, либо на этапе 207.
LLM 105 на Фиг. 1 можно дополнительно дообучать. На одном или нескольких целевых хостах 107 (это могут быть в том числе и виртуальные машины и объекта типа sandbox) происходит целенаправленное заражение известными примерами (сэмплами) вредоносных программ. Например, можно установить фреймворк PowerShell Empire и запустить несколько типовых вредоносных процедур. После этого выполняется способ по Фиг. 2 для выделения нужных запросов и ответов со стороны LLM 105.
Например, в ответ на запрос:
Is the following is indicator of compromise:
Launch String: “C:\Windows\System32\WindowsPowerShell\v1.0\powershell.exe” -NonI -W hidden -c “IEX ([Text.Encoding]::UNICODE.GetString([Convert]::FromBase64String((gp HKCU:\Software\Microsoft\Windows\CurrentVersion debug).debug)))”
LLM 105 выдает следующий ответ:
Yes, this could be an indicator of compromise. It is possible that the attacker has created a malicious task in the registry to launch PowerShell with a hidden flag and encoded base64 string. This code could potentially execute malicious commands on the system, such as installing malware or stealing data. In order to confirm if this indeed an indicator of compromise, it would be necessary to analyze script further and look for other clues that indicate malicious activity.
Данный ответ означает:
“Да, это может быть индикатором компрометации. Возможно, злоумышленник создал вредоносную задачу в реестре для запуска PowerShell со скрытым флагом и закодированной строкой base64. Этот код потенциально может выполнять вредоносные команды в системе, такие как установка вредоносного ПО или кража данных. Для того чтобы подтвердить, действительно ли это является индикатором компрометации, необходимо проанализировать сценарий дополнительно и осуществить поиск других признаков, указывающих на вредоносную активность.”
Выполнив несколько последовательных запросов к LLM 105 с различными параметрами, которые касаются вредоносной активности на хостах 107 и получив необходимые ответы, можно дополнить контекст, который будет использоваться при переобучении / дообучения LLM 105.
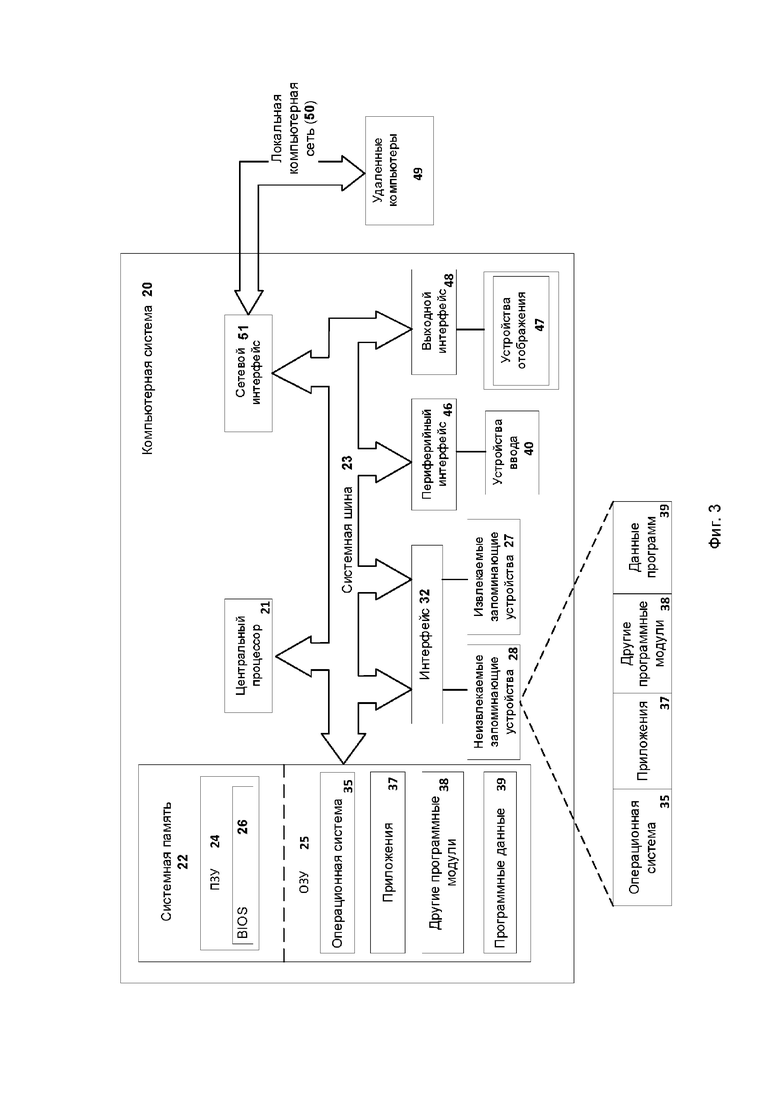
На Фиг. 3 представлена компьютерная система, на которой могут быть реализованы различные варианты систем и способов, раскрытых в настоящем документе. Компьютерная система 20 может представлять собой систему, сконфигурированную для реализации настоящего изобретения и может быть представлена в виде одного вычислительного устройства или в виде нескольких вычислительных устройств, например, настольного компьютера, портативного компьютера, ноутбука, сервера, мейнфрейма, встраиваемого устройства и других форм вычислительных устройств.
Как показано на Фиг. 3, компьютерная система 20 включает в себя: центральный процессор 21, системную память 22 и системную шину 23, которая связывает разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая в свою очередь память шины или контроллер памяти шины, периферийную шину и локальную шину, способную взаимодействовать с любой другой шинной архитектурой. Примерами шин являются: PCI, ISA, PCI-Express, HyperTransport™, InfiniBand™, Serial ATA, I2C и другие подходящие соединения между компонентами компьютерной системы 20. Центральный процессор 21 содержит один или несколько процессоров, имеющих одно или несколько ядер. Центральный процессор 21 исполняет один или несколько наборов машиночитаемых инструкций, реализующих способы, представленные в настоящем документе. Системная память 22 может быть любой памятью для хранения данных и/или компьютерных программ, исполняемых центральным процессором 21. Системная память может содержать как постоянное запоминающее устройство (ПЗУ) 24, так и память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) 26, содержит основные процедуры, которые обеспечивают передачу информации между элементами компьютерной системы 20, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Компьютерная система 20 включает в себя одно или несколько устройств хранения данных, таких как одно или несколько извлекаемых запоминающих устройств 27, одно или несколько неизвлекаемых запоминающих устройств 28, или комбинации извлекаемых и неизвлекаемых устройств. Одно или несколько извлекаемых запоминающих устройств 27 и/или неизвлекаемых запоминающих устройств 28 подключены к системной шине 23 через интерфейс 32. В одном из вариантов реализации извлекаемые запоминающие устройства 27 и соответствующие машиночитаемые носители информации представляют собой энергонезависимые модули для хранения компьютерных инструкций, структур данных, программных модулей и других данных компьютерной системы 20. Системная память 22, извлекаемые запоминающие устройства 27 и неизвлекаемые запоминающие устройства 28 могут использовать различные машиночитаемые носители информации. Примеры машиночитаемых носителей информации включают в себя машинную память, такую как кэш-память, SRAM, DRAM, ОЗУ не требующую конденсатора (Z-RAM), тиристорную память (T-RAM), eDRAM, EDO RAM, DDR RAM, EEPROM, NRAM, RRAM, SONOS, PRAM; флэш-память или другие технологии памяти, такие как твердотельные накопители (SSD) или флэш-накопители; магнитные кассеты, магнитные ленты и магнитные диски, такие как жесткие диски или дискеты; оптические носители, такие как компакт-диски (CD-ROM) или цифровые универсальные диски (DVD); и любые другие носители, которые могут быть использованы для хранения нужных данных и к которым может получить доступ компьютерная система 20.
Системная память 22, извлекаемые запоминающие устройства 27 и неизвлекаемые запоминающие устройства 28, содержащиеся в компьютерной системе 20 используются для хранения операционной системы 35, приложений 37, других программных модулей 38 и программных данных 39. Компьютерная система 20 включает в себя периферийный интерфейс 46 для передачи данных от устройств ввода 40, таких как клавиатура, мышь, стилус, игровой контроллер, устройство голосового ввода, устройство сенсорного ввода, или других периферийных устройств, таких как принтер или сканер через один или несколько портов ввода/вывода, таких как последовательный порт, параллельный порт, универсальная последовательная шина (USB) или другой периферийный интерфейс. Устройство отображения 47, такое как один или несколько мониторов, проекторов или встроенных дисплеев, также подключено к системной шине 23 через выходной интерфейс 48, такой как видеоадаптер. Помимо устройств отображения 47, компьютерная система 20 оснащена другими периферийными устройствами вывода (на Фиг. 3 не показаны), такими как динамики и другие аудиовизуальные устройства.
Компьютерная система 20 может работать в сетевом окружении, используя сетевое соединение с одним или несколькими удаленными компьютерами 49. Удаленный компьютер (или компьютеры) 49 является рабочим персональным компьютером или сервером, который содержит большинство или все упомянутые компоненты, отмеченные ранее при описании сущности компьютерной системы 20, представленной на Фиг. 3. В сетевом окружении также могут присутствовать и другие устройства, например, маршрутизаторы, сетевые станции или другие сетевые узлы. Компьютерная система 20 может включать один или несколько сетевых интерфейсов 51 или сетевых адаптеров для связи с удаленными компьютерами 49 через одну или несколько сетей, таких как локальная компьютерная сеть (LAN) 50, глобальная компьютерная сеть (WAN), интранет и Интернет. Примерами сетевого интерфейса 51 являются интерфейс Ethernet, интерфейс Frame Relay, интерфейс SONET и беспроводные интерфейсы.
Варианты раскрытия настоящего изобретения могут представлять собой систему, способ, или машиночитаемый носитель (или носитель) информации.
Машиночитаемый носитель информации является осязаемым устройством, которое сохраняет и хранит программный код в форме машиночитаемых инструкций или структур данных, к которым имеет доступ центральный процессор 21 компьютерной системы 20. Машиночитаемый носитель может быть электронным, магнитным, оптическим, электромагнитным, полупроводниковым запоминающим устройством или любой подходящей их комбинацией. В качестве примера, такой машиночитаемый носитель информации может включать в себя память с произвольным доступом (RAM), память только для чтения (ROM), EEPROM, портативный компакт-диск с памятью только для чтения (CD-ROM), цифровой универсальный диск (DVD), флэш-память, жесткий диск, портативную компьютерную дискету, карту памяти, дискету или даже механически закодированное устройство, такое как перфокарты или рельефные структуры с записанными на них инструкциями.
Система и способ настоящего изобретения, могут быть рассмотрены в терминах средств. Термин «средство», используемый в настоящем документе, относится к реальному устройству, компоненту или группе компонентов, реализованных с помощью аппаратного обеспечения, например, с помощью интегральной схемы, специфичной для конкретного приложения (ASIC) или FPGA, или в виде комбинации аппаратного и программного обеспечения, например, с помощью микропроцессорной системы и набора машиночитаемых инструкций для реализации функциональности средства, которые (в процессе выполнения) превращают микропроцессорную систему в устройство специального назначения. Средство также может быть реализовано в виде комбинации этих двух компонентов, при этом некоторые функции могут быть реализованы только аппаратным обеспечением, а другие функции - комбинацией аппаратного и программного обеспечения. В некоторых вариантах реализации, по крайней мере, часть, а в некоторых случаях и все средство может быть выполнено на центральном процессоре 21 компьютерной системы 20. Соответственно, каждое средство может быть реализовано в различных подходящих конфигурациях и не должно ограничиваться каким-либо конкретным вариантом реализации, приведенным в настоящем документе.
В заключение следует отметить, что приведенные в описании сведения являются примерами, которые не ограничивают объем настоящего изобретения, определенного формулой. Специалисту в данной области становится понятным, что при разработке любого реального варианта осуществления настоящего изобретения необходимо принять множество решений, специфических для конкретного варианта осуществления, для достижения конкретных целей, и эти конкретные цели будут разными для разных вариантов осуществления. Понятно, что такие усилия по разработке могут быть сложными и трудоемкими, но, тем не менее, они будут обычной инженерной задачей для тех, кто обладает обычными навыками в данной области, пользуясь настоящим раскрытием изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ применения больших языковых моделей при реагировании на инциденты информационной безопасности | 2023 |
|
RU2825972C1 |
| Способ комбинирования большой языковой модели и агента безопасности | 2023 |
|
RU2825975C1 |
| Способ корректировки параметров модели машинного обучения для определения ложных срабатываний и инцидентов информационной безопасности | 2020 |
|
RU2763115C1 |
| Способ обработки событий информационной безопасности перед передачей на анализ | 2020 |
|
RU2762528C1 |
| Система и способ корреляции событий для выявления инцидента информационной безопасности | 2019 |
|
RU2739864C1 |
| Способ выявления угроз информационной безопасности (варианты) | 2023 |
|
RU2802539C1 |
| Система и способ реагирования на инцидент информационной безопасности | 2023 |
|
RU2824732C1 |
| СИСТЕМА ИНТЕЛЛЕКТУАЛЬНОГО УПРАВЛЕНИЯ КИБЕРУГРОЗАМИ | 2019 |
|
RU2702269C1 |
| СПОСОБ И СИСТЕМА КИБЕРТРЕНИРОВОК | 2022 |
|
RU2808388C1 |
| Способ фильтрации событий для передачи на удаленное устройство | 2022 |
|
RU2813239C1 |
Настоящее изобретение относится к области информационных технологий, а более конкретно к способу использования больших языковых моделей при мониторинге безопасности и реагировании на инциденты. Технический результат заключается в уменьшении времени сбора и повышении уровня обработки информации (артефактов) во время проведения расследования инцидента информационной безопасности. Технический результат достигается тем, что получают входные данные от элементов центра мониторинга информационной безопасности; выделяют одну или несколько фраз из входных данных; составляют текстовый запрос из выделенных фраз; отправляют текстовый запрос к большой языковой модели; получают ответ от большой языковой модели от элементов центра мониторинга информационной безопасности; выделяют ключевые фразы из ответа от большой языковой модели. Выделяется возможная угроза на основании анализа ответа. 5 з.п. ф-лы, 3 ил.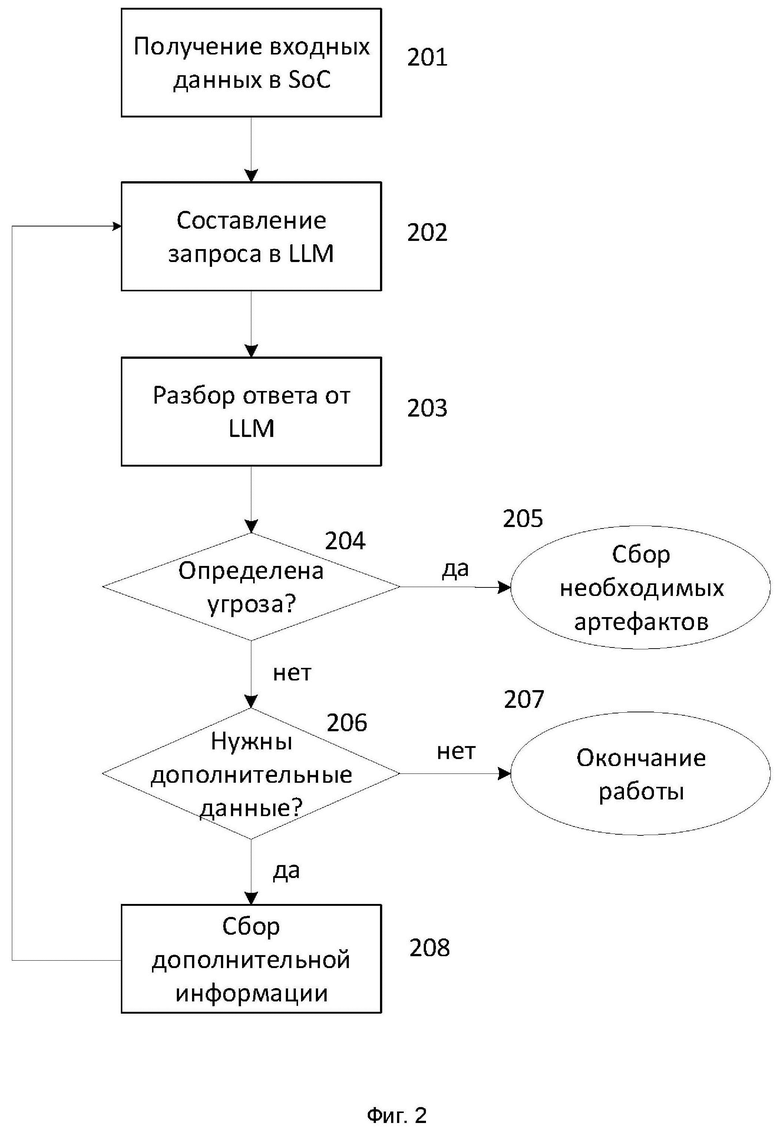
1. Реализуемый компьютером способ автоматического составления запросов и ответов к большой языковой модели по вопросам, связанным с компьютерной безопасностью, при этом способ осуществляется при помощи обработчика запросов и включает этапы, на которых:
а) получают входные данные от элементов центра мониторинга информационной безопасности;
б) формируют текстовый запрос на естественном языке к большой языковой модели, связанный с компьютерной безопасностью,
при этом:
• выделяют одну или несколько ключевых фраз к входным данным;
• составляют указанный текстовый запрос из выделенных фраз и входных данных;
• отправляют указанный текстовый запрос к большой языковой модели;
в) получают ответ от большой языковой модели и осуществляют его анализ, во время которого выделяют заранее известные фразы или элементы текста;
г) определяют наличие угрозы компьютерной безопасности на основании выделенных фраз или элементов текста,
при этом:
• если угроза определена, то происходит сбор необходимой информации в виде артефактов с помощью элементов центра мониторинга информационной безопасности;
• если угроза не определена, то определяют необходимость дополнительных данных путем повторения этапа б), при этом выделяют другие ключевые фразы.
2. Способ по п.1, в котором элементами текста являются по меньшей мере одно из: токен, N-грамма или лексема.
3. Способ по п.1, в котором выделяют известные фразы и элементы текста из ответа от большой языковой модели с использованием библиотек обработки естественного языка.
4. Способ по п.1, в котором выделяют известные фразы из ответа от большой языковой модели с использованием набора регулярных выражений.
5. Способ по п.1, в котором входные данные от элементов центра мониторинга информационной безопасности имеют формат JSON.
6. Способ по п.1, в котором входные данные от элементов центра мониторинга информационной безопасности имеют формат XML.
| Электромагнитный прерыватель | 1924 |
|
SU2023A1 |
| Печь-кухня, могущая работать, как самостоятельно, так и в комбинации с разного рода нагревательными приборами | 1921 |
|
SU10A1 |
| CN 114117002, 01.03.2022 | |||
| Способ обнаружения аномалии в поведении доверенного процесса и система для его реализации | 2022 |
|
RU2790329C1 |
| Воздухораспределительное устройство | 1961 |
|
SU148692A1 |

